aman.ai
exploring the art of artificial intelligence
one concept at a time
Distilled AI
Stanford CS230
Deep Learning
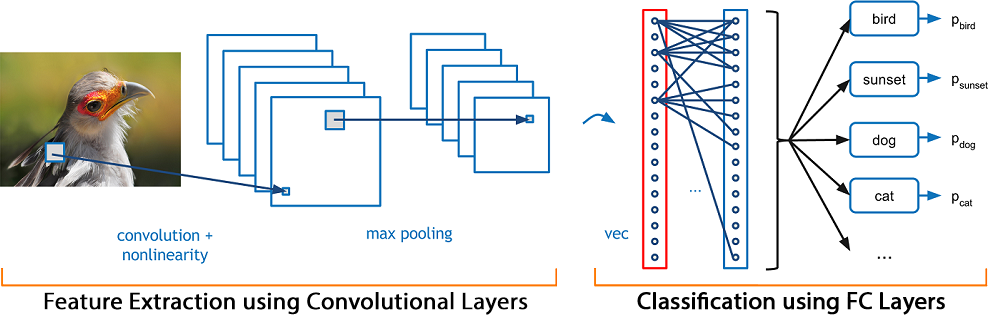
Stanford CS231n
Convolutional Neural Networks
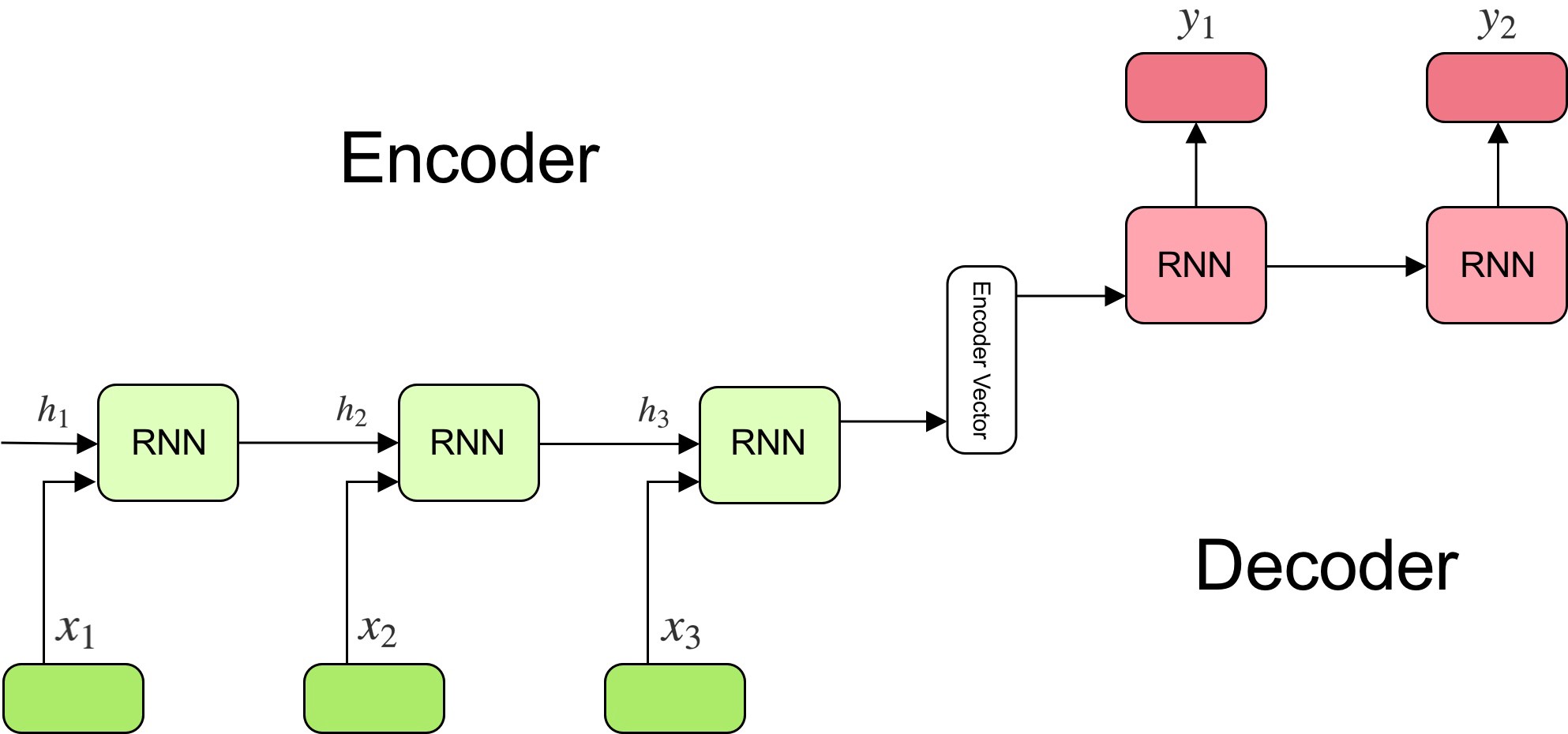
Stanford CS224n
Natural Language Processing

Coursera Machine Learning Specialization
Supervised ML, Unsupervised ML, Advanced ML Algos

Recommendation Systems
Candidate Generation, Ranking, Retrieval, Code Deep-dive
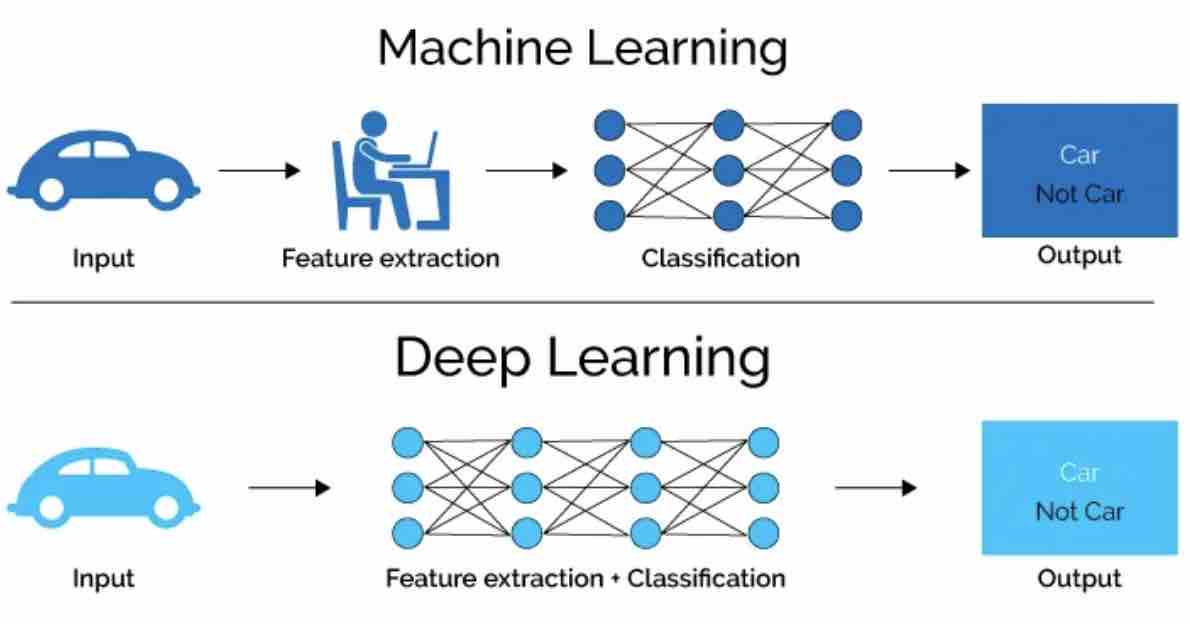
Coursera Deep Learning Specialization
Basics, Hyperparams, Structuring Projects, ConvNets, Sequential Models

Coursera Natural Language Specialization
Classification Models, Vector Space Models, Sequence Models, Attention Models

Multimodal Machine Learning
Representations, Fusion Techniques, Co-learning
Research
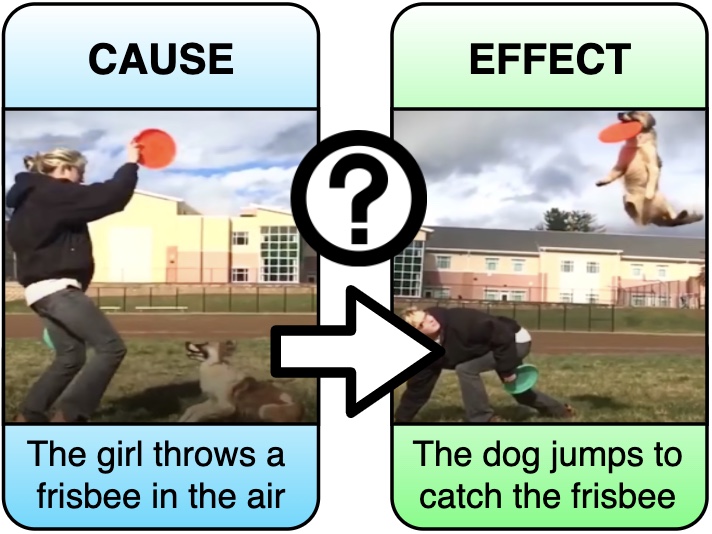
iReason
Multimodal commonsense reasoning using videos and NLP
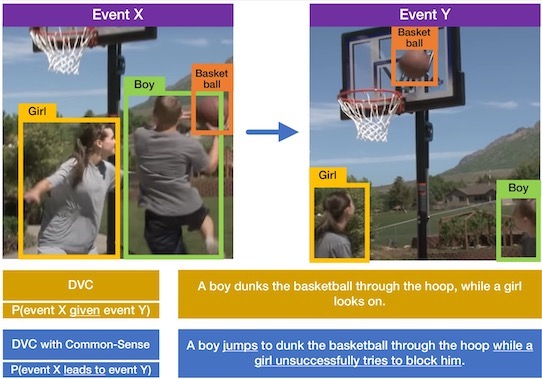
iPerceive
Closing the gap between man and machine

iSeeBetter
Pushing the limits of video super resolution
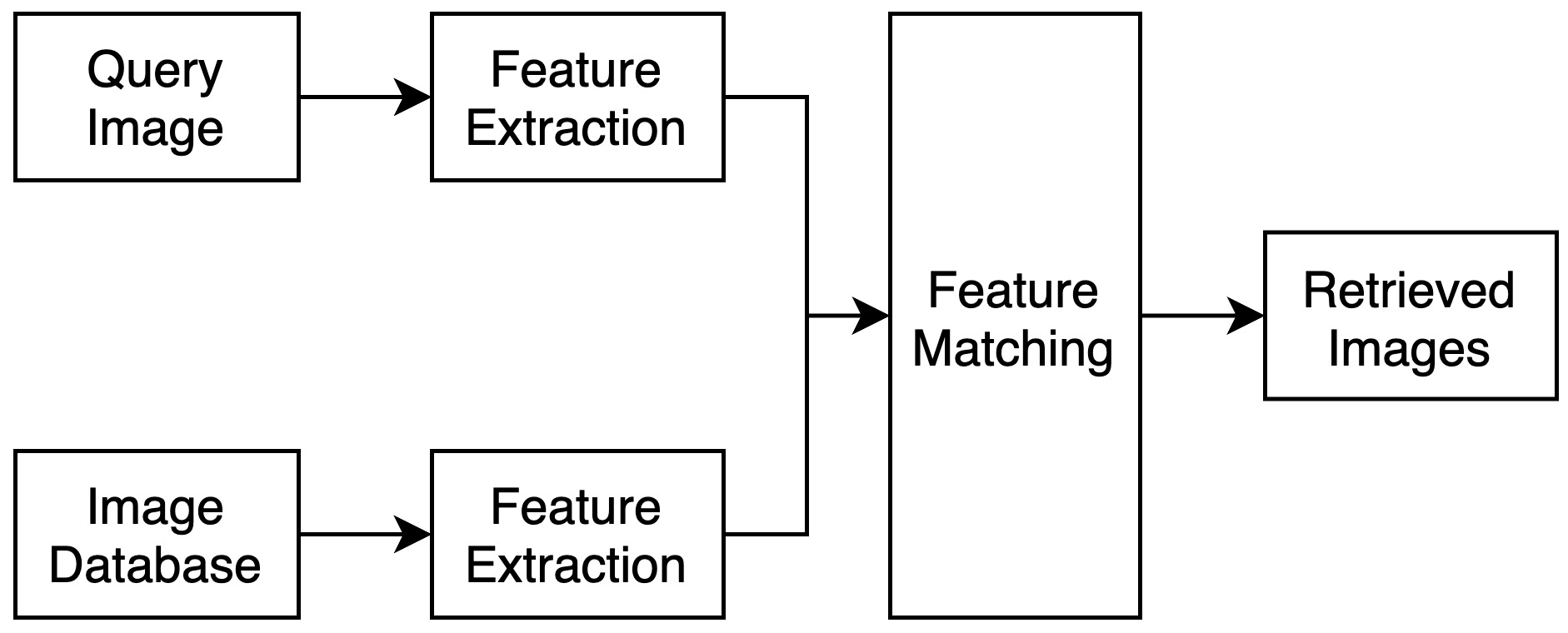
Content Based
Image Retrieval
Comparative study of feature extraction techniques

Face Recognition
Using the discrete cosine
transform

Dual Layer Video
Encryption
Using the RSA algorithm
Primers

AI Fundamentals
Concepts, Definitions, Terms
Graph Studio
Plots for common functions

NumPy
Numerical processing in Python
Matplotlib
Plotting data in Python

Pandas
Data analysis in Python

Python 3
Basics to advanced

PyTorch
Torch building blocks

TensorFlow
TF2 basics
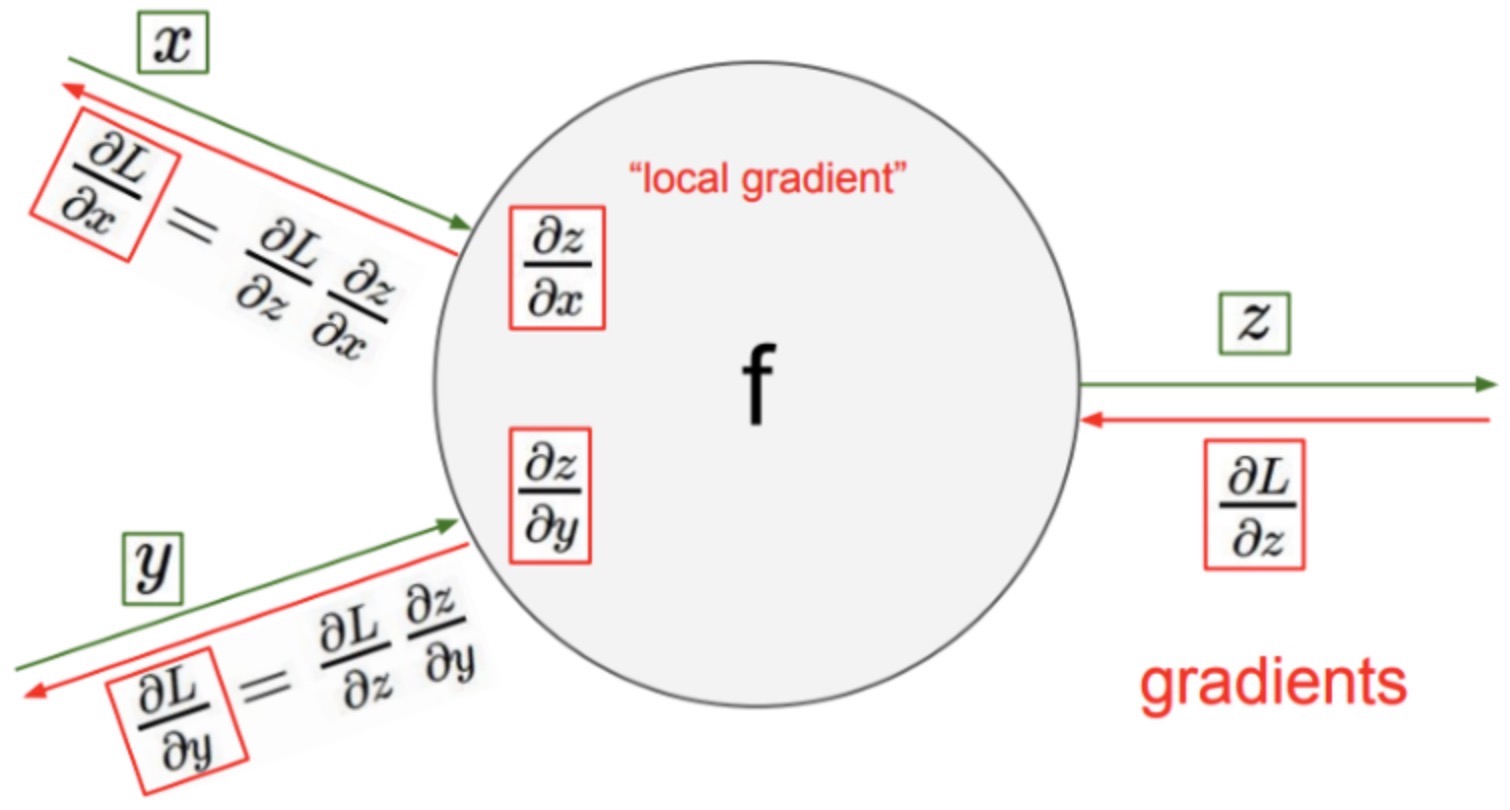
Backprop Guide
Partial gradient derivations for common layers/loss functions

Math
Linear algebra, differential calculus, distributions
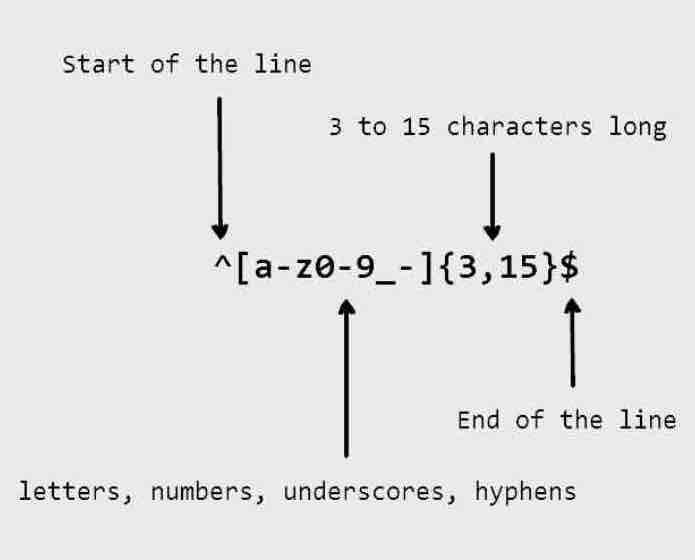
Regular Expressions Cheatsheet
Mine data easily with RegEx