Read List
- Read List
- Course Notes
- Stanford CS231n Notes
- Stanford CS224n Notes
- Stanford CS230 Section Notes
- Stanford CS229 Notes
- Stanford CS236 Notes
- Stanford CS329s Notes
- Stanford CS324 Notes
- Stanford CS131 Notes
- CMU 11-777 Slides
- CMU 11-877 Slides
- MIT Lecture Notes on Artificial Intelligence
- NLP Course by Yandex
- Hugging Face Deep Reinforcement Learning Course
- Hugging Face Transformers Course
- Hugging Face Diffusion Models Course
- Hugging Face Audio Course
- Hugging Face NLP Course
- LLM101n: Let’s build a Storyteller
- Books
- Deep Learning by Ian Goodfellow, Yoshua Bengio and Aaron Courville
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow by Aurelien Geron
- Pattern Recognition and Machine Learning by Christopher Bishop
- Reinforcement Learning: An Introduction by Richard Sutton and Andrew Barto
- Speech and Language Processing by Dan Jurafsky and James Martin
- The Machine Learning Engineering Book by Andriy Burkov
- The Hundred-Page Machine Learning Book by Andriy Burkov
- Machine Learning Interviews Book by Chip Huyen
- Machine Learning Systems Design by Chip Huyen
- Deep Learning Interviews: Hundreds of fully solved job interview questions from a wide range of key topics in AI
- Top 100 NLP Questions
- Dive into Deep Learning
- Mathematics for Machine Learning
- Foundations of Machine Learning
- Probabilistic Machine Learning: An Introduction
- Python for Computational Science and Engineering
- Concise Machine Learning
- Probability and Statistics - The Science of Uncertainty
- Introduction to Theoretical Computer Science
- Computer Vision
- “Intro to Deep Learning” Course of the Hebrew University of Jerusalem
- The Cartoon Guide To Statistics
- Bayes’ Theorem: A Visual Introduction for Beginners
- Deep learning Book by Shelly Sheynin
- Synthetic Data for Deep Learning
- Interpretable Machine Learning: A Guide for Making Black Box Models Explainable
- Modern Deep Learning Techniques Applied to Natural Language Processing
- Fixing All Gemma Bugs
- You can now train a 70b language model at home
- OPT-175B Logbook
- GPT in 60 Lines of NumPy
- Newsletters
- Interactive visualizations
- Blogs
- Company Blogs
- Meta AI Blog
- Amazon Science Blog
- Apple Machine Learning Blog
- OpenAI Blog
- Google AI Blog
- Google DeepMind Blog
- Microsoft Research Blog
- NVIDIA Generative AI Blog
- Cohere Blog
- Meta Engineering Blog
- Instagram Engineering Blog
- Uber Engineering Blog
- Netflix Tech Blog
- Airbnb Engineering Blog
- Twitter Engineering Blog
- Engineering at Quora Blog
- Yelp Engineering Blog
- LinkedIn Engineering Blog
- Spotify Engineering Blog
- Salesforce Developer Blog
- Github Engineering Blog
- Pinterest Engineering Blog
- Mixedbread Blog
- Personal blogs
- Eugene Yan’s Blog
- Christopher Olah’s Blog
- Lilian Weng’s Blog
- Andrej Karpathy’s Blog
- Jay Alammar’s Blog
- Chip Huyen’s Blog
- Aman Arora’s Blog
- A Lazy Data Science Guide
- Yi Tay’s blog
- The GenAI Guide
- David Batista’s Blog
- Kevin Zakka’s Blog
- Adit Deshpande’s Blog
- Lavanya’s Blog
- Distill.pub
- Query Understanding by Daniel Tunkelang
- Interconnects by Nathan Lambert
- Company Blogs
- Github repositories
- Awesome Deep Vision
- Awesome NLP
- Awesome GPT-3
- Awesome MLOps: References and Articles
- Awesome MLOps: Tools
- Awesome Multimodal Large Language Models
- Applied ML
- 100 Must-Read NLP Papers
- Neural Net Drawing Libraries
- Acceptance Rate for Major AI Conferences
- Reading List for Topics in Multimodal Machine Learning by Paul Liang
- Anti-hype LLM reading list
- System Design 101
- Web Resources
- Articles and Blog Posts
- AI
- Brief Intro to Deep Learning with a Digit Classification Example by Andrej Karpathy
- What I learned from looking at 200 machine learning tools by Chip Huyen
- Real-time machine learning: challenges and solutions
- Data Distribution Shifts and Monitoring
- 10 Techniques to deal with Imbalanced Classes in Machine Learning
- Deep learning model compression by Rachit Singh
- Machine Learning Crash Course by Google
- What is MLOps? Machine Learning Operations Explained by Harshit Tyagi
- Understanding BigBird’s block sparse attention
- CenterNet, Explained
- Checklist — Behavioral Testing of NLP Models
- Google Research: Themes from 2021 and Beyond
- SOTAWHAT - A script to keep track of state-of-the-art AI research by Chip Huyen
- The Unreasonable Syntactic Expressivity of RNNs by John Hewitt
- A Detailed Understanding of Convolutional Neural Networks by MarkTechPost
- A Design Analysis of Cloud-based Microservices Architecture at Netflix by Cao Duc Nguyen
- How Netflix works: the (hugely simplified) complex stuff that happens every time you hit Play by Mayukh Nair
- Autoregressive Models in Deep Learning — A Brief Survey by George Ho
- Artificial intelligence is helping old video games Look like new
- A detailed example of how to generate your data in parallel with PyTorch
- How to train your deep learning models in a distributed fashion
- MIT Deep Learning Basics: Introduction and Overview with TensorFlow
- A Glimpse into the Future of AI by Mohamed El-Geish
- A brief timeline of NLP from Bag of Words to the Transformer family
- The Annotated Transformer
- A vision to make AI systems learn and reason like animals and humans
- Generative Flow Networks Tutorial
- Machine Learning FAQ
- HuggingFace: Leveraging Pre-trained Language Model Checkpoints for Encoder-Decoder Models
- Stitch Fix: Algorithms Tour
- NVIDIA: How to Build a Winning Recommendation System, Parts 1-3
- Glossary of Deep Learning: Word Embedding
- wevi: word embedding visual inspector
- IBM: What are foundation models?
- Practicing ML in a Non-ML Job
- Emil’s Story as a Self-Taught AI Researcher
- Overview of Active Learning for Deep Learning
- A Visual Notebook to Using BERT for the First Time
- Best Practices for Deploying Language Models
- First Principles of Computer Vision
- AI/ML Cheatsheets for Stanford/MIT Courses
- Interpretable Machine Learning: A Guide for Making Black Box Models Explainable
- List of datasets for machine-learning research
- It’s Time to Stop Being “Data-Driven” (And Start Being Data-Informed)
- Principles for data driven organizations
- Pretrain, Prompt, Predict
- Why Scientific Studies Are So Often Wrong: The Streetlight Effect
- Google “We Have No Moat, And Neither Does OpenAI”
- The New New Moats
- Recommender Systems: Lessons From Building and Deployment
- How to Run LLMs Locally
- Edge AI Just Got Faster
- lyft2vec — Embeddings at Lyft
- Injecting GPT-4’s reasoning into recommendation algorithms
- RTutor: Chat with your data in dozens of human languages!
- Google’s Jigsaw was trying to fight toxic speech with AI. Then the AI started talking
- Llama from scratch (or how to implement a paper without crying)
- Deep Learning Tuning Playbook
- Knowledge sharing memo for IDEFICS, an open-source reproduction of Flamingo (A VLM model by DeepMind)
- Inside Amazon’s Artificial Intelligence Flywheel
- The Ultra-Scale Playbook: Training LLMs on GPU Clusters
- Making Deep Learning Go Brrrr From First Principles
- How to Scale Your Model
- Defeating Nondeterminism in LLM Inference
- Miscellaneous
- A Survival Guide to a PhD by Andrej Karpathy
- Doing well in your courses by Andrej Karpathy
- Planning paper writing by Devi Parikh
- On time management by Devi Parikh
- Managing the organized chaos that is software development by Mohamed El-Geish
- Reacting to Corrective Feedback by Mohamed El-Geish
- Learning from Hundreds of Resumes and Tens of Interviews in a Few Weeks by Mohamed El-Geish
- Up and Down the Ladder of Abstraction by Bret Victor
- Excel Formulae Bible
- LeetCode: General Backtracking Questions/Solutions
- LeetCode: Dynamic Programming Patterns
- TopCoder: Dynamic Programming Patterns
- A Step by Step Guide to Dynamic Programming
- Grokking LeetCode: A Smarter Way to Prepare for Coding Interviews
- Google Cloud Developer’s Visual Notes
- Python for Interviewing: An Overview of the Core Data Structures
- Shipping to Production by The Pragmatic Engineer
- What Is Canary Testing? A Detailed Explanation
- Super Study Guide: Algorithms & Data Structures
- Regular Expression Generator from Natural Language using Artificial Intelligence
- New Programming Jargon
- The AI Hierarchy of Needs
- An Alternative to Statistical Significance for Making Decisions with Experiments
- Slime Mold
- What I Wish Someone Had Told Me
- AI
Read List
- A curated set of books, newsletters, blogs, Github repos, and other web resources I’d recommend to build intuition around AI concepts.
Course Notes
Stanford CS231n Notes
- Notes that accompany the Stanford class CS231n: Convolutional Neural Networks for Visual Recognition.

Stanford CS224n Notes
- Notes that accompany the Stanford class CS224n: Natural Language Processing with Deep Learning.
Stanford CS230 Section Notes
- Notes that accompany the Stanford class CS230: Deep Learning.
Stanford CS229 Notes
- Notes that accompany the Stanford class CS229: Machine Learning.

Stanford CS236 Notes
- Notes that accompany the Stanford class CS236: Deep Generative Models.

Stanford CS329s Notes
- Notes that accompany the Stanford class CS329s: Machine Learning Systems Design.

Stanford CS324 Notes
- Notes that accompany the Stanford class CS324: Advances in Foundation Models (formerly, CS324: Large Language Models).

Stanford CS131 Notes
- Notes that accompany the Stanford class CS131 Computer Vision: Foundations and Applications. Also, github with TeX source.

CMU 11-777 Slides
- Slides that accompany the CMU class 11-777 Multimodal Machine Learning.

CMU 11-877 Slides
- Slides that accompany the CMU class 11-877 Advanced Topics in Multimodal Machine Learning.

MIT Lecture Notes on Artificial Intelligence
- Notes that accompany MIT’s 6.034 Artificial Intelligence.
NLP Course by Yandex
- Natural Language Processing course taught at the Yandex School of Data Analysis (YSDA) by Lena Voita, a Research Scientist at Facebook AI Research.

Hugging Face Deep Reinforcement Learning Course
- This repository contains the Deep Reinforcement Learning Course by Hugging Face by Thomas Simonini and Omar Sanseviero.
- You’ll learn about Deep Q-Learning, Policy Gradient, Actor-Critic Methods, Proximal Policy Optimization, and more!

Hugging Face Transformers Course
- A course by Hugging Face on applying Transformers to various tasks in natural language processing and beyond.

Hugging Face Diffusion Models Course
- This repository contains the Diffusion Models course by Hugging Face.

Hugging Face Audio Course
- This course by Hugging Face explores how transformers can be applied to audio data.
- You’ll learn how to use transformers to tackle a range of audio-related tasks. Whether you are interested in speech recognition, audio classification, or generating speech from text (text-to-speech), this course has you covered.

Hugging Face NLP Course
- This course by Hugging Face explores NLP using libraries from the Hugging Face ecosystem – 🤗 Transformers, 🤗 Datasets, 🤗 Tokenizers, and 🤗 Accelerate -— as well as the Hugging Face Hub.

LLM101n: Let’s build a Storyteller
- This course by Andrej Karpathy builds a Storyteller AI Large Language Model. Hand in hand, you’ll be able create, refine and illustrate little stories with the AI. The course builds everything end-to-end from basics to a functioning web app similar to ChatGPT, from scratch in Python, C and CUDA, and with minimal computer science prerequisites.

Books
Deep Learning by Ian Goodfellow, Yoshua Bengio and Aaron Courville
- Intended to help students and practitioners enter the field of machine learning in general and deep learning in particular.

Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow by Aurelien Geron
- Gain an intuitive understanding of the concepts and tools for building intelligent systems using a range of techniques, starting with simple linear regression and progressing to deep neural networks.

Pattern Recognition and Machine Learning by Christopher Bishop
- The first textbook on pattern recognition to present approximate inference algorithms that enable fast approximate answers in situations where exact answers are not feasible.

Reinforcement Learning: An Introduction by Richard Sutton and Andrew Barto
- One of the most widely used textbooks on reinforcement learning. Covers Markov decision processes and reinforcement learning.
- Book page

Speech and Language Processing by Dan Jurafsky and James Martin
- The first of its kind to thoroughly cover language technology – at all levels and with all modern technologies – this book takes an empirical approach to the subject, based on applying statistical and other machine-learning algorithms to large corporations. The newest 3rd edition covers transformers, BERT, and fine-tuning etc.

The Machine Learning Engineering Book by Andriy Burkov
- For data analysts who lean towards a machine learning engineering role, and machine learning engineers alike who want to bring more structure to their work.

The Hundred-Page Machine Learning Book by Andriy Burkov
- All you need to know about machine learning in a hundred pages.

Machine Learning Interviews Book by Chip Huyen
- A book on machine learning interviews by Chip Huyen, Stanford Lecturer and Snorkel AI. Blog post.

Machine Learning Systems Design by Chip Huyen
- This booklet covers four main steps of designing a machine learning system:
- Project setup
- Data pipeline
- Modeling: selecting, training, and debugging
- Serving: testing, deploying, and maintaining
- It comes with links to practical resources that explain each aspect in more details. It also suggests case studies written by machine learning engineers at major tech companies who have deployed machine learning systems to solve real-world problems.
- At the end, the booklet contains 27 open-ended machine learning systems design questions that might come up in machine learning interviews. The answers for these questions are in the book Machine Learning Interviews.
Deep Learning Interviews: Hundreds of fully solved job interview questions from a wide range of key topics in AI
- A book on deep learning interviews by Shlomo Kashani and Amir Ivry. The book provides hundreds of questions and their solutions covering some core topics of deep learning:
- Logistic regression
- Probabilistic programming and Bayesian inference
- Deep learning math (calculus, algorithmic differentiation)
- Neural network ensembles
- Convolutional Neural Networks (CNNs)
- Job interview questions
- A good resource for students preparing for a job interview in the domain of deep learning or folks who are looking for a concise summary of DL topics.
- The PDF version of the book is available for free online. A hard copy version of the book is available for purchase online.

Top 100 NLP Questions
- Great material for preparing for an NLP job interview by Steve Nouri.

Dive into Deep Learning
- Interactive deep learning book from folks at Amazon, CMU, ETH Zürich, and Google with code, math, and discussions.

Mathematics for Machine Learning
- Learn the mathematical concepts behind ML. This book by Deisenroth, Faisal, and Ong is not intended to cover advanced machine learning techniques but instead aims to provide the necessary mathematical skills to read those other books.

Foundations of Machine Learning
- Another mathematical foundations building book by Mohri, Rostamizadeh, and Talwalkar from NYU.

Probabilistic Machine Learning: An Introduction
- A detailed introduction to machine learning (including deep learning) from Kevin Murphy from UBC and Google, through the unifying lens of probabilistic modeling and Bayesian decision theory. This book covers mathematical background (including linear algebra and optimization), basic supervised learning (including linear and logistic regression and deep neural networks), as well as more advanced topics (including transfer learning and unsupervised learning).

Python for Computational Science and Engineering
- Great walk-through of core ideas relevant to Computational Engineering and Scientific Computing using Python by Hans Fangohr, University of Southampton.

Concise Machine Learning
- This report by Jonathan Shewchuk contains lecture notes for UC Berkeley’s introductory class on Machine Learning.

Probability and Statistics - The Science of Uncertainty
- This text by Michael Evans and Jeffrey Rosenthal from UofT is an introductory text on probability and statistics, targeting students who have studied one year of calculus at the university level and are seeking an introduction to probability and statistics with mathematical content.

Introduction to Theoretical Computer Science
- A textbook in preparation for an introductory undergraduate course on theoretical computer science by Boaz Barak, Harvard.

Computer Vision
- This text by Christoph Rasche, Polytechnic University of Bucharest, is a dense introduction to the field of computer vision. It covers all three approaches, the classical engineering approach based on contours and regions; the local-features approach; and the Deep Learning approach.

“Intro to Deep Learning” Course of the Hebrew University of Jerusalem
- These notes composed by Hadar Sharvit cover a wide range of Deep Learning topics in a really well-written and accessible way. The linked Github repository also contains course exercises.

The Cartoon Guide To Statistics
- Do you want to learn statistics in an fun and interesting way? The Cartoon Guide to Statistics covers all the central ideas of modern statistics: the summary and display of data, probability in gambling and medicine, random variables, Bernoulli Trails, the Central Limit Theorem, hypothesis testing, confidence interval estimation, and much more—all explained in simple, clear, and yes, funny illustrations.

Bayes’ Theorem: A Visual Introduction for Beginners
- The Bayes’ theorem, named after the 18th-century British mathematician Thomas Bayes, is a mathematical formula for figuring out the conditional probability of an event. In essence, Bayes’ theorem calculates a probability of an event based upon prior knowledge of the conditions that may affect it. Bayes’ theorem forms the basis of a statistical inference approach called Bayesian inference. This intro by Dan Morris is a great way to get a grasp of this incredible piece of math!

Deep learning Book by Shelly Sheynin
- Covers the principles of deep learning, motivation, explanations, state-of-the-art papers for the various tasks and architectures: data pre-processing, weight initialization, activation functions, loss functions, optimization, regularization, convolutional neural networks, object detection, semantic segmentation, generative models, denoising, super resolution, style transfer and style manipulation, inpainting, self supervised learning, vision transformers, OCR, multi-modal.

Synthetic Data for Deep Learning
- Great survey on synthetic data generation paper by Sergey Nikolenko from Synthesis.ai and Steklov Institute of Mathematics at St. Petersburg, Russia.
- Synthetic data is an increasingly popular tool for training deep learning models, especially in computer vision but also in other areas. This work attempts to provide a comprehensive survey of the various directions in the development and application of synthetic data. The discussion centers around synthetic datasets for basic computer vision problems, both low-level (e.g., optical flow estimation) and high-level (e.g., semantic segmentation), synthetic environments and datasets for outdoor and urban scenes (autonomous driving), indoor scenes (indoor navigation), aerial navigation, simulation environments for robotics, applications of synthetic data outside computer vision (in neural programming, bioinformatics, NLP, etc.). Further, the synthetic-to-real domain adaptation problem is discussed that inevitably arises in applications of synthetic data, including syntheticto-real refinement with GAN-based models and domain adaptation at the feature/model level without explicit data transformations. Finally, privacy-related applications of synthetic data are discussed including generating synthetic datasets with differential privacy guarantees.

Interpretable Machine Learning: A Guide for Making Black Box Models Explainable
- This book by Christoph Molnar will enable you to select and correctly apply the interpretation method that is most suitable for your machine learning project.

Modern Deep Learning Techniques Applied to Natural Language Processing
- This project contains an overview of recent trends in deep learning based natural language processing (NLP). It covers the theoretical descriptions and implementation details behind deep learning models, such as recurrent neural networks (RNNs), convolutional neural networks (CNNs), and reinforcement learning, used to solve various NLP tasks and applications. The overview also contains a summary of state of the art results for NLP tasks such as machine translation, question answering, and dialogue systems.

Fixing All Gemma Bugs
- Daniel and Michael from Unsloth identified and fixed several bugs in Google Gemma, including issues with token addition, mathematical inaccuracies, and precision problems in machine learning models.

You can now train a 70b language model at home
- Answer.AI details an open source system, based on FSDP and QLoRA, that can train a 70b model on two consumer 24GB gaming GPUs.
OPT-175B Logbook
- OPT-175B logbook covering a series of notes written to summarize the process and communicate some of the challenges Meta faced along the way while training the model.
- Related: Chronicles of OPT development

GPT in 60 Lines of NumPy
- The blog post from implements picoGPT and flexes some of the benefits of JAX: (i) trivial to port Numpy using
jax.numpy, (ii) get gradients, and (iii) batch withjax.vmap. It also inferences GPT-2 checkpoints.
Newsletters
The Batch by deeplearning.ai
- The Batch is a weekly newsletter from deeplearning.ai which presents the most important AI events and perspective in a curated, easy-to-read report for engineers, and business leaders.
- Every Wednesday, The Batch highlights a mix of the most practical research papers, industry-shaping applications, and high-impact business news.

True Positive Weekly by Andriy Burkov
- The most important artificial intelligence and machine learning links of the week.
The Gradient by the Stanford Artificial Intelligence Laboratory (SAIL)
- The Gradient is a digital magazine that aims to be a place for discussion about research and trends in artificial intelligence and machine learning.

Hugging Face Newsletter
- Latest updates on NLP readings, research, and more!

Papers with Code Newsletter
- Stay informed on the latest trending ML papers with code, research developments, libraries, methods, and datasets.

Import AI
- A weekly newsletter about artificial intelligence based on detailed analysis of cutting-edge research by Jack Clark, a co-founder of Anthropic, an AI safety and research company.

The AiEdge Newsletter
- The AiEdge Newsletter by Damien Benveniste, ex-Team Lead at Meta seeks to explain complex ML topics in simple terms by breaking them down into nuggets and offering practical wisdom from the field. The highlight of this newsletter is that it addresses subjects that tend to be less mainstream and not found in typical textbooks.

Interactive visualizations
ConvNetJS: Deep Learning in your Browser
- ConvNetJS is a Javascript library for training neural networks entirely in your browser. Open a tab and you’re training. No software requirements, no compilers, no installations, no GPUs, no sweat.

Deeplearning.ai Notes
- Notes that supplement the Coursera Deep Learning Specialization. With interactive visualizations, these tutorials will help you build intuition about foundational deep learning concepts.

OpenAI Microscope
- OpenAI Microscope is a collection of visualizations of every significant layer and neuron of eight vision “model organisms” which are often studied in interpretability. Microscope makes it easier to analyze the features that form inside these neural networks.

Seeing Theory
- A visual introduction to probability and statistics. Also, includes a textbook called “Seeing Theory”.

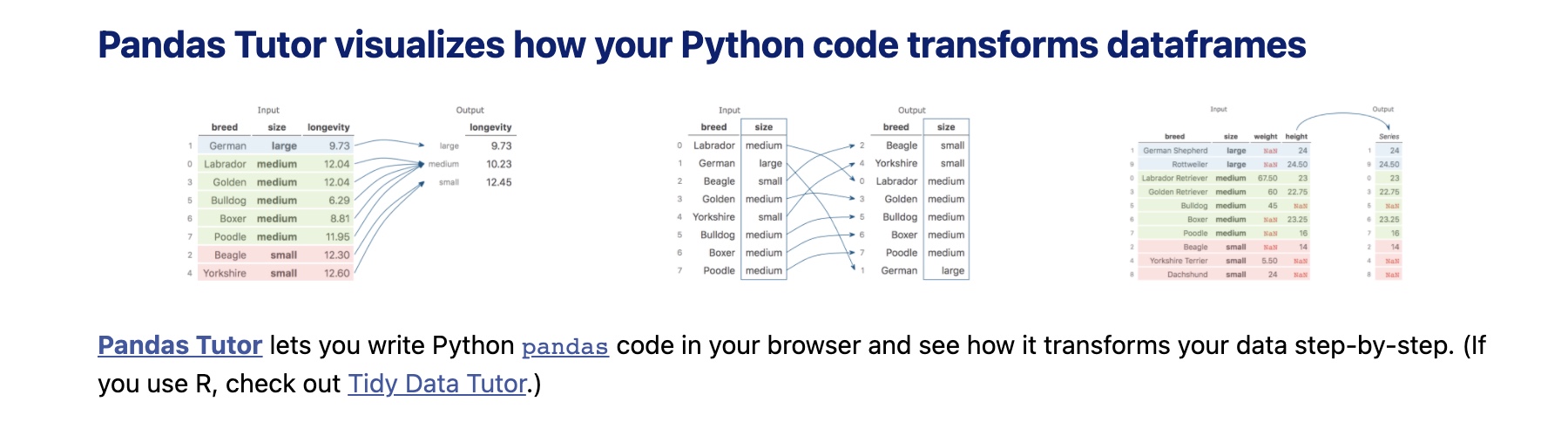
Pandas Tutor
- Pandas Tutor lets you write Python pandas code in your browser and see how it transforms your data step-by-step.
A visual introduction to machine learning
- A visual introduction to machine learning by Stephanie Yee and Tony Chu, offers a way to learn machine learning through interactive visualization. The visualizations are stunning, and the explanation is intuitive.

MLU-Explain by Amazon
- Machine Learning University (MLU) is an education initiative from Amazon designed to teach machine learning theory and practical application. As part of that goal, MLU-Explain exists to teach core machine learning concepts through visual essays in a fun, informative, and accessible manner.

Matrix Multiplication
- An interactive matrix multiplication calculator for educational purposes.
LLM Visualization
– This interactive LLM visualization that you can play with in your browser is hands down the best interactive experience with an LLM.

Blogs
Company Blogs
Meta AI Blog
- The official AI Research blog of Meta AI.
- Recommended articles:
- Self-supervised learning: The dark matter of intelligence
- How AI is getting better at detecting hate speech
- Training AI to detect hate speech in the real world
- Multiscale Vision Transformers: A hierarchical architecture for representing image and video information
- XLM-R: State-of-the-art cross-lingual understanding through self-supervision
- Speechless? Here’s how AI learns to finish your sentences
- Advances in multimodal understanding research at Meta AI
- Advances toward ubiquitous neural information retrieval
- M Now Offers Suggestions to Make Your Messenger Experience More Useful, Seamless and Delightful
- Introducing the Facebook Field Guide to Machine Learning video series
- New AI advancements drive Meta’s ads system performance and efficiency
- Using AI to Translate Speech For a Primarily Oral Language
- Meta’s new AI-powered speech translation system for Hokkien pioneers a new approach for an unwritten language
- Preserving the World’s Language Diversity Through AI
- Bringing the world closer together with a foundational multimodal model for speech translation
Amazon Science Blog
- The official AI Research blog of Amazon Science.
- Recommended articles:
- “Ambient intelligence” will accelerate advances in general AI
- Alexa at five: looking back, looking forward
- Alexa: The science must go on
- New method improves knowledge-graph-based question answering
- On-device speech processing makes Alexa faster, lower-bandwidth
- Improving question-answering models that use data from tables
- How Prime Video uses machine learning to ensure video quality
- Using computer vision to weed out product catalogue errors
- New Alexa feature enables natural, multiparty interactions
- The science behind visual ID
- Alexa unveils new speech recognition, text-to-speech technologies
Apple Machine Learning Blog
- The official AI Research blog of Apple.
- Recommended articles:
OpenAI Blog
- The official AI Research blog of OpenAI.
- Recommended articles:
- GPT-4
- Introducing ChatGPT
- Our approach to alignment research
- Aligning language models to follow instructions
- Learning from human preferences
- Learning to summarize with human feedback
- Fine-tuning GPT-2 from human preferences
- Proximal Policy Optimization
- A hazard analysis framework for code synthesis large language models
- How should AI systems behave, and who should decide?
- Efficient training of language models to fill in the middle
- Reinforcement Learning from Human Feedback
- Teaching with AI
- Related: GPT-4 Developer Livestream
Google AI Blog
- The official AI Research blog of Google.
- Recommended articles:
Google DeepMind Blog
- The official AI Research blog of Google DeepMind.
- Recommended articles:
Microsoft Research Blog
- The official AI Research blog of Microsoft.
NVIDIA Generative AI Blog
- The official AI Research blog of NVIDIA.
Cohere Blog
- The official AI Research blog of Cohere.
- Recommended articles:
- Generative AI with Cohere: Part 1 - Model Prompting
- Generative AI with Cohere: Part 2 - Use Case Ideation
- Generative AI with Cohere: Part 3 - The Generate Endpoint
- Generative AI with Cohere: Part 4 - Creating Custom Models
- Generative AI with Cohere: Part 5 - Chaining Prompts
- Tips and Tricks to Build Chatbots With Large Language Models (LLMs)
- What Are Word and Sentence Embeddings?
- What is Similarity Between Sentences?
- What Is Attention in Language Models?
- Introducing Cohere Summarize Beta: A New Endpoint for Text Summarization
- What’s the big deal with Generative AI? Is it the future or the present?
Meta Engineering Blog
- The Facebook Engineering Blog offers a highly technical digest on what’s going on in the software engineering world. From developer tools and popular platforms to infrastructure and artificial intelligence, the Facebook Engineering blog covers a wide range of topics and gives insights into how Facebook solves large-scale technical challenges.
- Recommended article:
Instagram Engineering Blog
- The Instagram Engineering blog is mostly specific to Instagram services, there are some posts that cover more broadly implemented topics.
- Recommended article:
Uber Engineering Blog
- Uber Engineering may be a little bit different from the other tech communities on this list, given that its service is felt more “in the real world” than strictly online. It can result in some interesting posts on the team’s blog, describing logistic issues from a tech perspective. They also have an interesting “Profiles in Coding” section, where you can read about the engineers, not just the software.
- Recommended articles:
Netflix Tech Blog
- Netflix is undoubtedly one of the most popular streaming services. A lot of different technical processes are going on under the hood: great UI and UX experience, a huge and uninterrupted movie database, and – the most exciting – a machine-learning model that powers movie recommendations. From the Netflix Tech blog, you’ll learn about all these topics in-depth. It’s always helpful to know how a seamless client service experience was achieved, and this blog covers that.
- Recommended articles:
- Decision Making at Netflix
- What is an A/B Test?
- Interpreting A/B test results: false positives and statistical significance
- Interpreting A/B test results: false negatives and power
- Building confidence in a decision
- Experimentation is a major focus of Data Science across Netflix
- Computational Causal Inference at Netflix
- It’s All A/Bout Testing: The Netflix Experimentation Platform
- A Survey of Causal Inference Applications at Netflix
- A/B Testing and Beyond: Improving the Netflix Streaming Experience with Experimentation and Data Science
- Quasi Experimentation at Netflix
Airbnb Engineering Blog
- Airbnb is a prominent startup success story, so their engineering blog is definitely worth checking out. It could be more technical, but soft skills are also important in the world of tech. They also have a Fintech section; the insights from the payments team are generally useful.
Twitter Engineering Blog
- Each social media platform has its own technical issues, and Twitter is not an exception. Still, as one of the most active social media platforms, it has to run as smoothly as possible. This blog shares how the Twitter engineering team tackles problems, but some posts are more broadly useful.
- Recommended article:
Engineering at Quora Blog
- Quora is a question-and-answer website – ask any question you’ve ever wondered about, and another user will respond.
- What was exciting to learn was that the Quora team builds Quora from the ground up, from backend infrastructure to ranking algorithms to frontend abstractions. The Engineering at Quora blog is fully devoted to the issues the team faces on both the front- and backend.
Yelp Engineering Blog
- Yelp is a crowd-sourced local business review and social networking resource. Its engineering blog is a great source of knowledge for those who want to learn more about Yelp functionality and some of Yelp’s troubleshooting methods. However, it also raises some rather broad questions about general machine learning, discusses hackathons, cloud, and API issues.
LinkedIn Engineering Blog
- LinkedIn is a unique professional social network, with a rather diverse blog. It contains a wide range of content, from the expected LinkedIn website-related problem-solving topics to more general concepts, all polished and deeply detailed.
Spotify Engineering Blog
- The Spotify blog offers an engaging and easy writing style along with a wide range of topics. Most of them are related to Spotify and all the magic behind one of the most popular music apps. But still, it covers a lot of general cloud, API, and machine-learning subjects, and videos and podcasts break up the more standard blog posts.
Salesforce Developer Blog
- The Salesforce Developer blog is devoted to backend and testing topics. Many large companies use Salesforce, so it’s vital to stay up to date with all the new products and tools it releases. If you’re not already using Salesforce, remember that learning new technologies broadens your mind personally and professionally.
Github Engineering Blog
- As you’re likely aware, GitHub is one of the most popular hosting sites for software development and version control using Git. Their blog has a special section for engineering posts which covers mostly GitHub workflow topics and related issues, however, since GitHub is broadly implemented in many tech companies, it can be considered as a generally useful blog.
Pinterest Engineering Blog
- Pinterest, the first visual discovery engine, is a creative website, and their blog lives up to the theme. You’ll find a lot of articles on architecture and infrastructure, design, and UX, as well as insights into what it’s like to work for Pinterest.
Mixedbread Blog
- Mixedbread.ai details their embeddings and reranking models, going over the thought process behind key design decisions.
- Recommended articles:

Personal blogs
Eugene Yan’s Blog
- Senior Scientist at Amazon who writes on ideas in machine learning, RecSys, and LLMs.
- Some of Eugene’s famous blog posts:
- System Design for Recommendations and Search
- Real-time Machine Learning For Recommendations
- Building a Strong Baseline Recommender in PyTorch, on a Laptop
- Beating the Baseline Recommender with Graph & NLP in Pytorch
- Bandits for Recommender Systems
- Serendipity: Accuracy’s Unpopular Best Friend in Recommenders
- Design Patterns in Machine Learning Code and Systems
- More Design Patterns For Machine Learning Systems
- Feature Stores: A Hierarchy of Needs
- Patterns for Personalization in Recommendations and Search
- Some Intuition on Attention and the Transformer
- Patterns for Building LLM-based Systems & Products
- How to Match LLM Patterns to Problems
- Search: Query Matching via Lexical, Graph, and Embedding Methods
- Writing Robust Tests for Data & Machine Learning Pipelines
- How to Write Data Labeling/Annotation Guidelines
- Experimenting with LLMs to Research, Reflect, and Plan
- Evaluation & Hallucination Detection for Abstractive Summaries

Christopher Olah’s Blog
- OpenAI machine learning researcher who likes to understand things clearly, and explain them well.
- Author of the wildly popular “Understanding LSTM Networks” post.

Lilian Weng’s Blog
- Robotics researcher @ OpenAI documenting her learning notes.

Andrej Karpathy’s Blog
- Thoughts on AI/ML from the Sr. Director of AI at Tesla.
- Author of the popular The Unreasonable Effectiveness of Recurrent Neural Networks, Deep Reinforcement Learning: Pong from Pixels, A Recipe for Training Neural Networks, and The state of Computer Vision and AI: we are really, really far away posts.
- Also, check out Karpathy’s Medium, where some of his more interesting posts are Yes you should understand backprop, Software 2.0, and AlphaGo, in context.

Jay Alammar’s Blog
- Blog posts that focus on visualizing machine learning one concept at a time.
- Some of Jay’s famous blog posts:
- Finding the Words to Say: Hidden State Visualizations for Language Models.
- Interfaces for Explaining Transformer Language Models.
- How GPT3 Works - Visualizations and Animations.
- The Illustrated Transformer.
- The Illustrated BERT, ELMo, and co..
- Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention).
- Visual and Interactive Guide to the Basics of Neural Networks.
- The Illustrated Retrieval Transformer.

Chip Huyen’s Blog
- Stanford alum who created and taught the courses CS 329S: Machine Learning Systems Design writing on AI/ML topics.
- Author of the popular A survivor’s guide to Artificial Intelligence courses at Stanford, What I learned from looking at 200 machine learning tools, and SOTAWHAT - A script to keep track of state-of-the-art AI research posts.

Aman Arora’s Blog
- Aman Arora’s blog on computer vision and NLP related articles.

A Lazy Data Science Guide
- Mohit Mayank’s guide book on data science for busy and equally lazy Data Scientists!

Yi Tay’s blog
- The blog post from Yi Tay, co-founder and chief scientist, Reka AI and ex-research scientist at Google Brain, discusses his experience training large language and multimodal models outside of a major tech company, highlighting the unpredictable quality of computing hardware, challenges in infrastructure, and adaptations in code and model scaling strategies.
- It emphasizes the “hardware lottery” in acquiring compute resources, the need for custom solutions for efficient training, and the pragmatic approach to model development in a startup environment.
- Notable articles:

The GenAI Guide
- Ravin Kumar’s GenAI guide that offers a guided tour of the fundamentals, the minimal set of resources needed to get a working understanding, and deep-dives into libraries, topics and papers.

David Batista’s Blog
- NLP researcher writing on topics that deal with transforming natural language into structured data.

Kevin Zakka’s Blog
- First-year Computer Science Masters student at Stanford University writes on his experiences with AI/ML.
Adit Deshpande’s Blog
- UCLA CS ‘19 grad writes on AI/ML.
Lavanya’s Blog
- Author of the well-recommended Best Practices for Picking a Machine Learning Model and A Whirlwind Tour of Machine Learning Models.

Distill.pub
- A modern medium for presenting research that showcases AI/ML concepts in clear, dynamic and vivid form.

Query Understanding by Daniel Tunkelang
- Join Daniel Tunkelang on his journey from characters to words to phrases, and ultimately to meaning. A perfect companion to decipher the art of query understanding and the role it plays in the search process.

Interconnects by Nathan Lambert
- Nathan Lambert’s blog covering important ideas in AI and how they integrate with society.

Github repositories
Awesome Deep Vision
- A curated list of deep learning resources for computer vision.

Awesome NLP
- A curated list of resources dedicated to NLP.

Awesome GPT-3
- A list of awesome demos and articles about the OpenAI GPT-3 API.
Awesome MLOps: References and Articles
- A list of references for machine learning operations (MLOps).
Awesome MLOps: Tools
- A list of tools for machine learning operations (MLOps).

Awesome Multimodal Large Language Models
- A curated list of multimodal LLM resources.
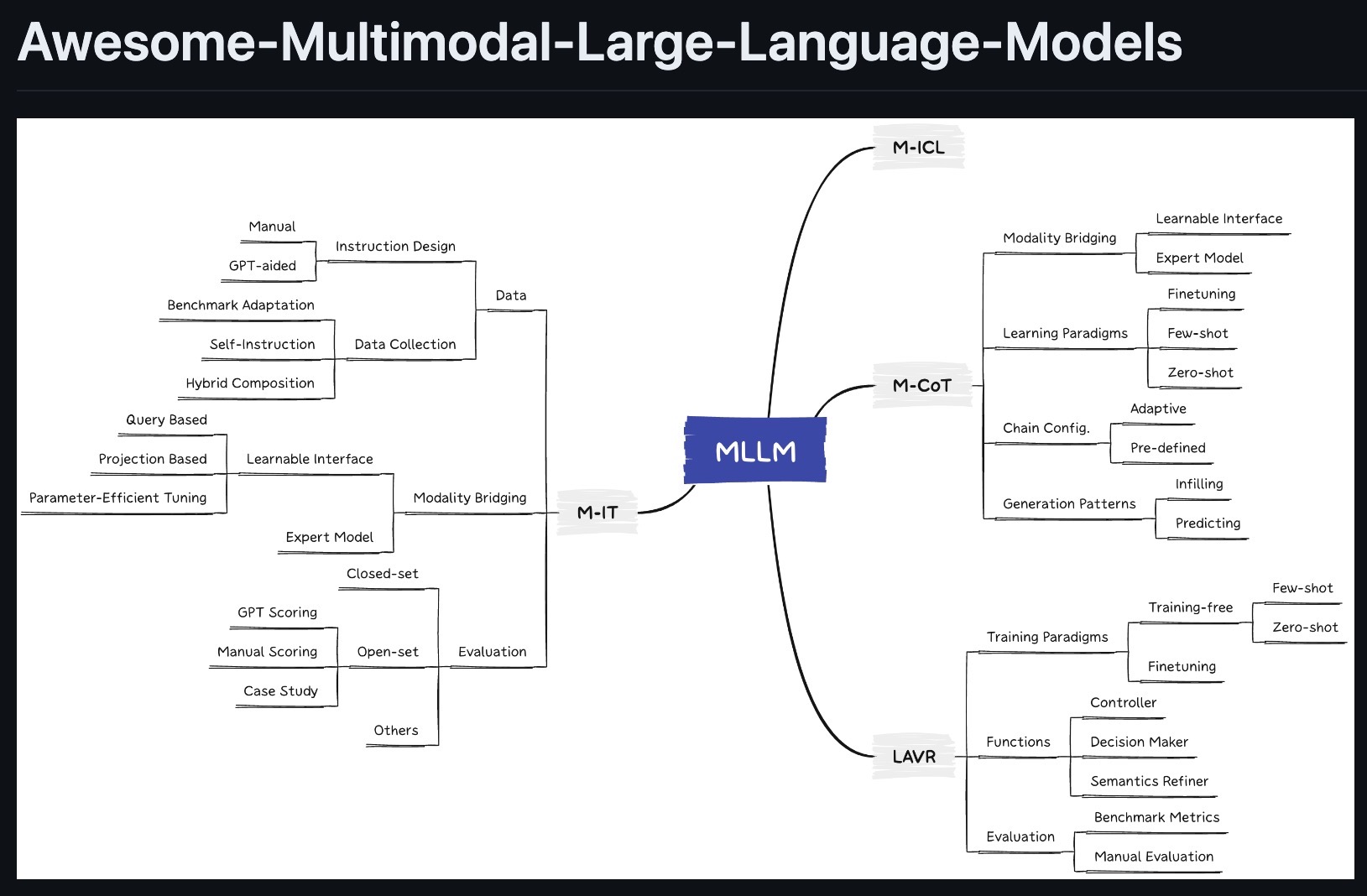
Applied ML
- Curated papers, articles, and blogs on data science & machine learning in production by Eugene Yan.

100 Must-Read NLP Papers
- A list of 100 important NLP papers that students and researchers working in the field should read.
Neural Net Drawing Libraries
- PlotNeuralNet generates LaTeX code for drawing neural networks for publications and presentations.
- NN-SVG generates SVGs for neural net architecture schematics.
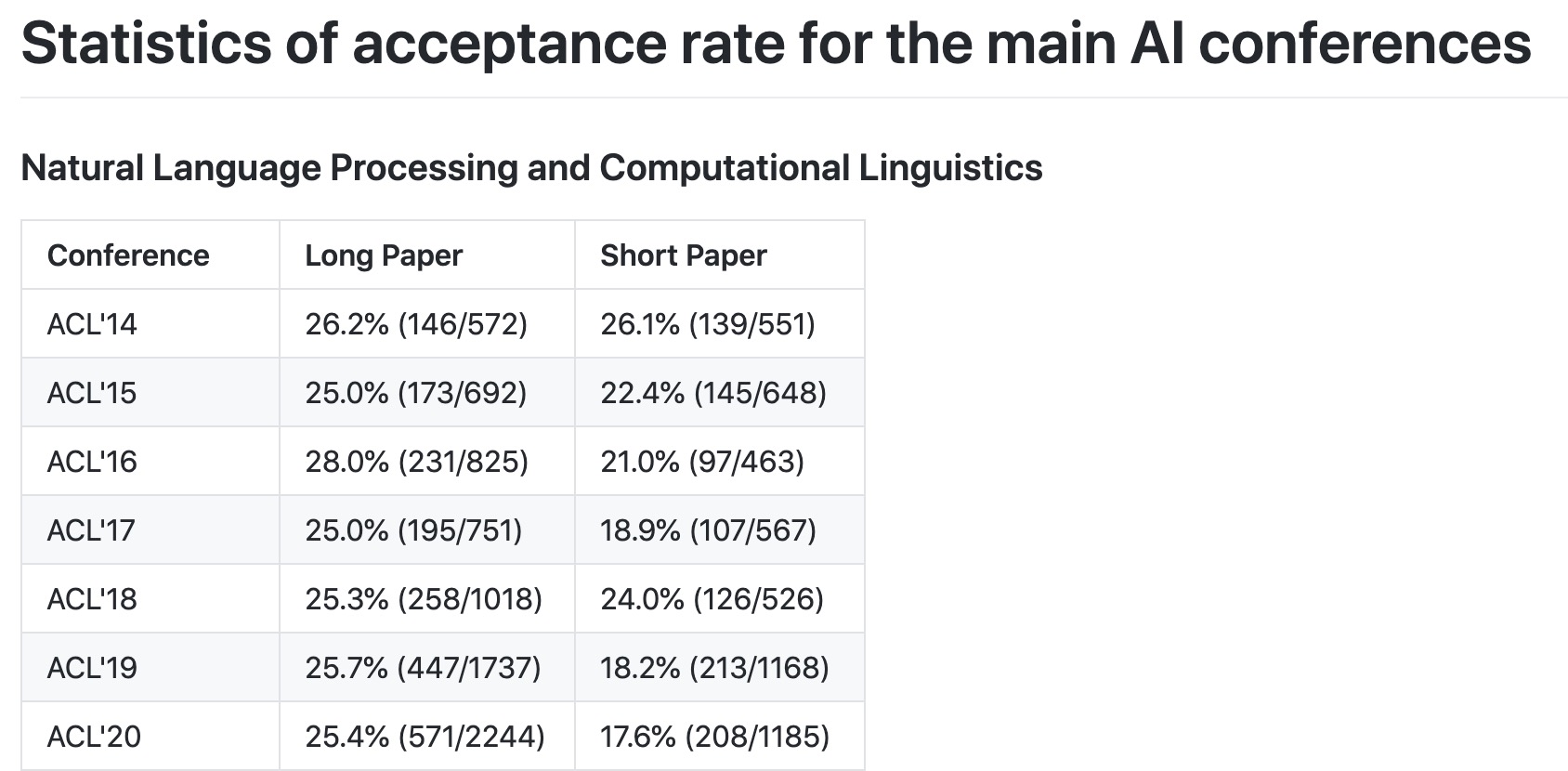
Acceptance Rate for Major AI Conferences
- Statistics of acceptance rate for the major AI conferences.
Reading List for Topics in Multimodal Machine Learning by Paul Liang
- Reading list for the CMU class 11-777 Multimodal Machine Learning.

Anti-hype LLM reading list
- Curated set of links to good explanations of how LLMs work.

System Design 101
- System Design tidbits to help you prepare for system design interviews by explaining complex systems using visuals and simple terms.

Web Resources
AI
PapersWithCode State-of-the-Art
- The latest AI/ML papers, with code and leaderboards comparing implementations in several Computer Vision and NLP sub-tasks.
AI Conference Deadlines
- Countdowns to top CV/NLP/ML/Robotics/AI conference deadlines.
arxiv-sanity
- A much lighter-weight arxiv-sanity from-scratch re-write. Periodically polls arxiv API for new papers. Then allows users to tag papers of interest, and recommends new papers for each tag based on SVMs over tfidf features of paper abstracts. Allows one to search, rank, sort, slice and dice these results in a pretty web UI.
- Lastly, arxiv-sanity-lite can send you daily emails with recommendations of new papers based on your tags. Curate your tags, track recent papers in your area, and don’t miss out!

alphaXiv
- alphaXiv is a forum for anyone to comment directly on top of arXiv papers.
ar5iv
- ar5iv serves arXiv articles as responsive web pages.
- Replace the “X” of arXiv in any article link to the “5” of ar5iv and be redirected to a corresponding ar5iv page.

labml.ai
- Find trending research papers easily to see the most popular papers on Twitter.

labml.ai: Paper Implementations
- A collection of simple PyTorch implementations of popular papers documented with explanations, which the website renders as side-by-side formatted notes.

42Papers
- Cutting-edge Computer Science and AI Papers.

Made With ML
- Offers two courses:
- Foundations: Learn the foundations of machine learning through intuitive explanations, clean code and visualizations.
- MLOps: Learn how to combine machine learning with software engineering to build production-grade applications.
Paper Digest
- Paper Digest is an AI-Powered Research Platform to stay current with the latest tech trends in AI, offering top-level highlights of arXived papers.

The Linked Open Data Cloud
- A repository of linked datasets that have been published in the Linked Data format.

ANN-Benchmarks
- ANN-Benchmarks is a benchmarking repository for approximate nearest neighbor algorithms (such as FAISS, ScaNN, ANNOY, PGVector, etc.) search that spans various commonplace datasets, distance measures, and algorithms.

Connected Papers
- Connected Papers is a visual tool that helps researchers find relevant papers by creating graphs based on paper similarity, not just citations.
- It uses Co-citation and Bibliographic Coupling as metrics, arranges papers in a Force Directed Graph for visual clustering, and is linked to the Semantic Scholar Paper Corpus.

There’s An AI For That (TAAFT)
- There’s An AI For That (TAAFT) is the leading AI aggregator, with a database of AI tools and tasks.

Smithery
- Smithery is a platform to help developers find and ship agentic services that follow the Model Context Protocols (MCP) specification.
- Smithery’s mission is to make agentic services accessible and accelerate the development of agentic AI.

Top Lean AI Native Companies Leaderboard
- Tracks the rise of ultra-lean, AI-native startups aiming for billion-dollar outcomes with minimal headcount, inspired by the idea of a “1-person unicorn” (or a “AI Solopreneur”).
Misc
Regular-Expressions.info
- A great Regular Expressions (RegEx) reference.

SQLBolt
- SQLBolt offers a series of interactive lessons and exercises designed to help you quickly learn SQL right in your browser.

Metacademy
- Metacademy is built around an interconnected web of concepts, each one annotated with a short description, a set of learning goals, a (very rough) time estimate, and pointers to learning resources.
- The concepts are arranged in a prerequisite graph, which is used to generate a learning plan for a concept.

Articles and Blog Posts
AI
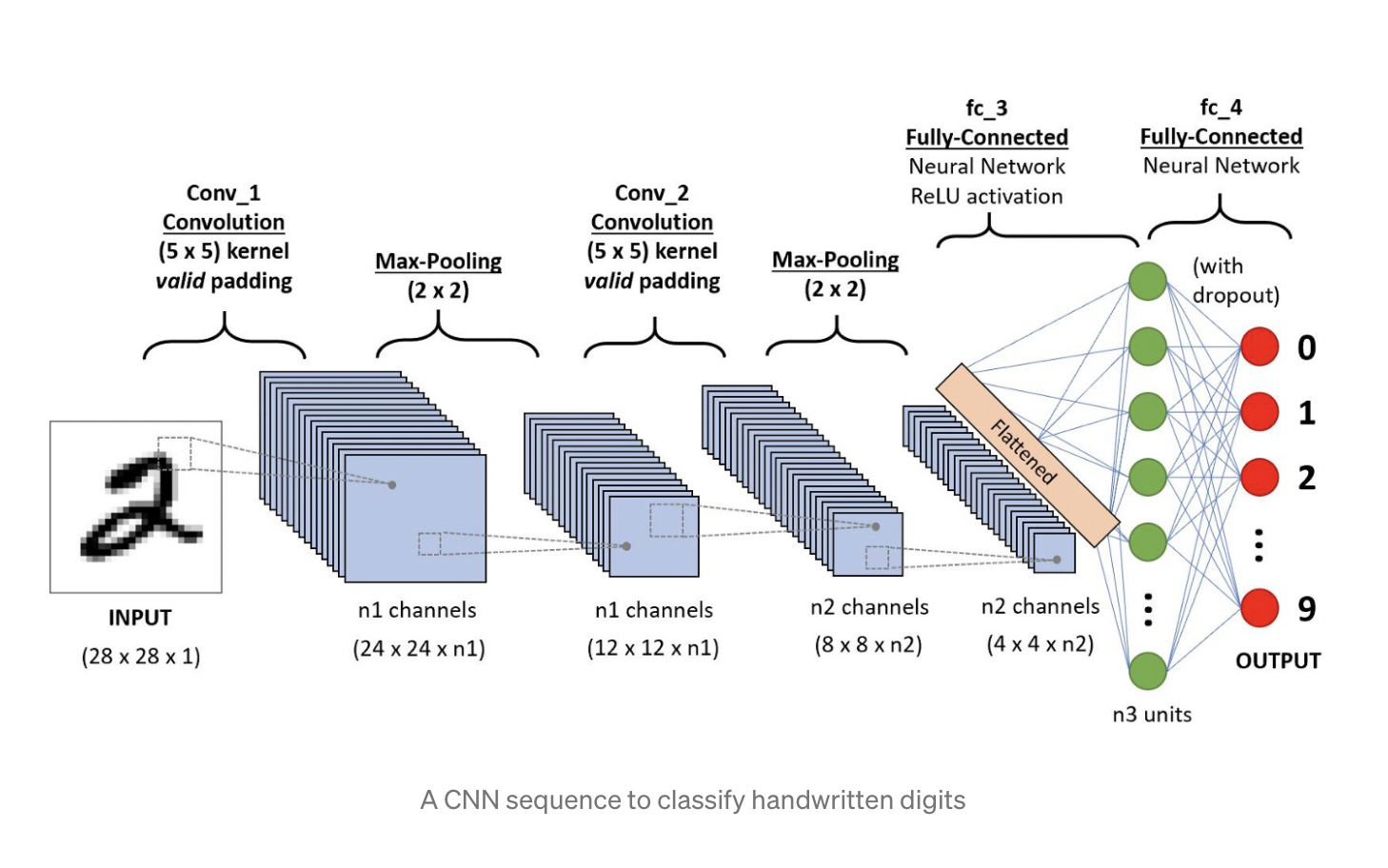
Brief Intro to Deep Learning with a Digit Classification Example by Andrej Karpathy
- Karpathy explains deep learning in layman terms using a digit classification example.
What I learned from looking at 200 machine learning tools by Chip Huyen
- A survey of the current state of machine learning tooling by Chip Huyen, Stanford Lecturer and Snorkel AI.

Real-time machine learning: challenges and solutions
- A synopsis of discussions with ~30 companies in different industries about their challenges with real-time machine learning by Chip Huyen, Stanford Lecturer and Snorkel AI.
- This post outlines the solutions for (1) online prediction and (2) continual learning, with step-by-step use cases, considerations, and technologies required for each level.

Data Distribution Shifts and Monitoring
- Deploying a model isn’t the end of the process. A model’s performance can degrade over time in production. Once a model has been deployed, we have to continually monitor its performance to detect data distribution shifts as well as deploy updates to fix these issues. This post outlines (i) common causes of machine learning failures in production, (ii) the types of data distribution shifts, and (iii) monitoring and observability metrics and tools.

10 Techniques to deal with Imbalanced Classes in Machine Learning
- A quick read by Analytics Vidhya on dealing with Imbalanced Classes in ML.

Deep learning model compression by Rachit Singh
- On quantization, pruning, DeepSpeed, and knowledge distillation.

Machine Learning Crash Course by Google
- A self-study guide by Google for aspiring machine learning practitioners. Machine Learning Crash Course features a series of lessons with video lectures, real-world case studies, and hands-on practice exercises.

What is MLOps? Machine Learning Operations Explained by Harshit Tyagi
- Machine learning operations (MLOps) explained.

Understanding BigBird’s block sparse attention
- Understanding BigBird’s block sparse attention and how it can handle sequence lengths of up to 4096 through.

CenterNet, Explained
- CenterNet is an anchorless object detection architecture. As such, this structure has an important advantage in that it replaces the classical NMS (Non Maximum Suppression) step during post-processing. This mechanism enables faster inference. Read more about the CenterNet architecture in this post.

Checklist — Behavioral Testing of NLP Models
- ML systems can run to completion without throwing any errors (indicating functional correctness) but can still produce incorrect outputs (indicating behavioral issues). Thus, it is important to test the behavioral aspects of your model to make sure it works as you expected. Read more on Checklist, an NLP testing framework.

Google Research: Themes from 2021 and Beyond
- This article from Jeff Dean, head of Google Research summarizes the areas in ML that are poised to go through exciting advances over the next several years.

SOTAWHAT - A script to keep track of state-of-the-art AI research by Chip Huyen
- A tool that returns the summary of the latest SOTA research by Chip Huyen, Stanford Lecturer and Snorkel AI.

The Unreasonable Syntactic Expressivity of RNNs by John Hewitt
- A second look at Karpathy’s post on The Unreasonable Effectiveness of Recurrent Neural Networks in the era of large pre-trained transformers.

A Detailed Understanding of Convolutional Neural Networks by MarkTechPost
- A great overview of CNNs!
A Design Analysis of Cloud-based Microservices Architecture at Netflix by Cao Duc Nguyen
- A comprehensive system design analysis of microservices architecture at Netflix to power its global video streaming services.
- What happens inside the Microservices Architecture at Netflix when you click the Play button:
- Client sends a play request to the backend running on AWS. The request is handled by AWS elastic load balancer (ELB).
- AWS ELB will forward that request to API Gateway Service running on AWS EC2 instances. That component, named Zuul, is built by the Netflix team to allow dynamic routing, traffic monitoring and security, etc.
- Application API component is the core business logic, in this scenario, the forwarded request from API Gateway Service is handled by Play API.
- Play API will call a microservice or a sequence of microservices to fulfill the request.
- Microservices are mostly stateless small programs, to control its cascading failure and enable resilience. Each microservice is isolated from the caller processes by Hystrix.
- Microservices can save to or get data from a data store during its process.
- Microservices can send events for tracking user activities or other data to the stream processing pipeline for either real-time processing of personalized recommendations.
- The data coming out of the stream processing pipeline can be persistent to other data stores such as AWS S3, Hadoop HDFS, Cassandra, etc.

How Netflix works: the (hugely simplified) complex stuff that happens every time you hit Play by Mayukh Nair
- How Netflix works, in layman terms.

Autoregressive Models in Deep Learning — A Brief Survey by George Ho
- Discourse on deep autoregressive models which are sequence models, yet feed-forward (i.e., not recurrent); generative models, yet supervised. This post offers some observations on how autoregressive models are a compelling alternative to RNNs for sequential data, and GANs for generation tasks.

Artificial intelligence is helping old video games Look like new
- Using AI super resolution models as the perfect tool to improve the graphics of classic games.

A detailed example of how to generate your data in parallel with PyTorch
- A tutorial on setting up a PyTorch Dataset using
torch.utils.data.Datasetand using PyTorch’s Dataloader class to fetch your data on multiple cores in real time and feed it right away to your deep learning model.

How to train your deep learning models in a distributed fashion
- Using distributed training on Azure ML using Horovod. Training process from Jupyter notebooks to Distributed ML. Concepts of data parallelism and model parallelism, centralized and de-centralized training, synchronous and asynchronous updates.
MIT Deep Learning Basics: Introduction and Overview with TensorFlow
- This blog post from Lex Fridman provides an overview of deep learning in seven architectural paradigms with links to TensorFlow tutorials for each. It accompanies the Deep Learning Basics lecture as part of MIT course 6.S094.

A Glimpse into the Future of AI by Mohamed El-Geish
- “How did AI get here? What’s its growth trajectory like?” by Mohamed El-Geish, Director of AI, Cisco.

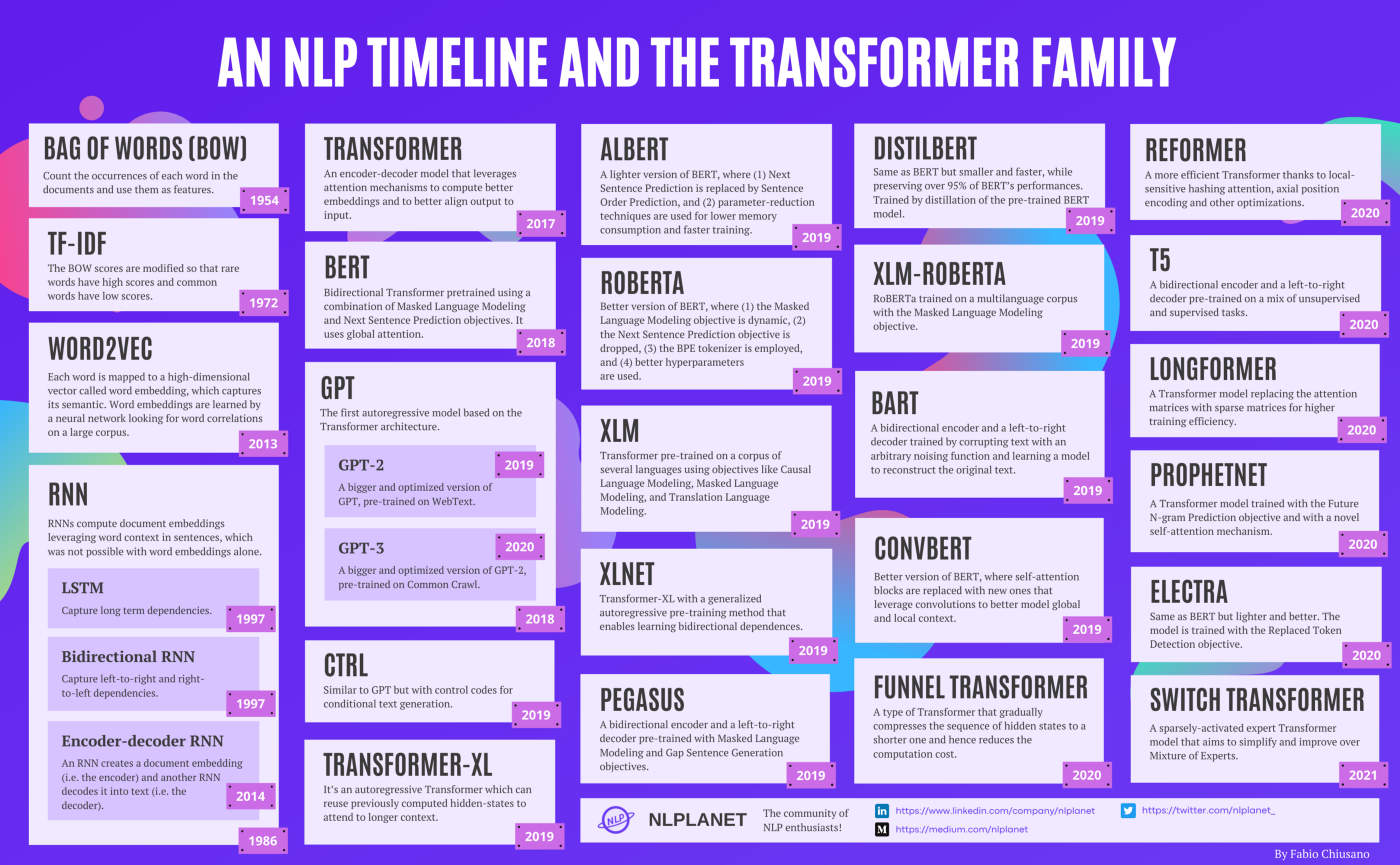
A brief timeline of NLP from Bag of Words to the Transformer family
- A brief timeline of NLP models from the traditional methods (BOW, TF-IDF, Word2Vec, etc.) to the Transformer family (BERT, GPT, RoBERTa, XLM, Reformer, ELECTRA, T5, etc.) from Fabio Chiusano.
The Annotated Transformer
- This article by Alexander Rush from Harvard presents an “annotated” version of the original Transformers paper in the form of a line-by-line implementation.
![]()
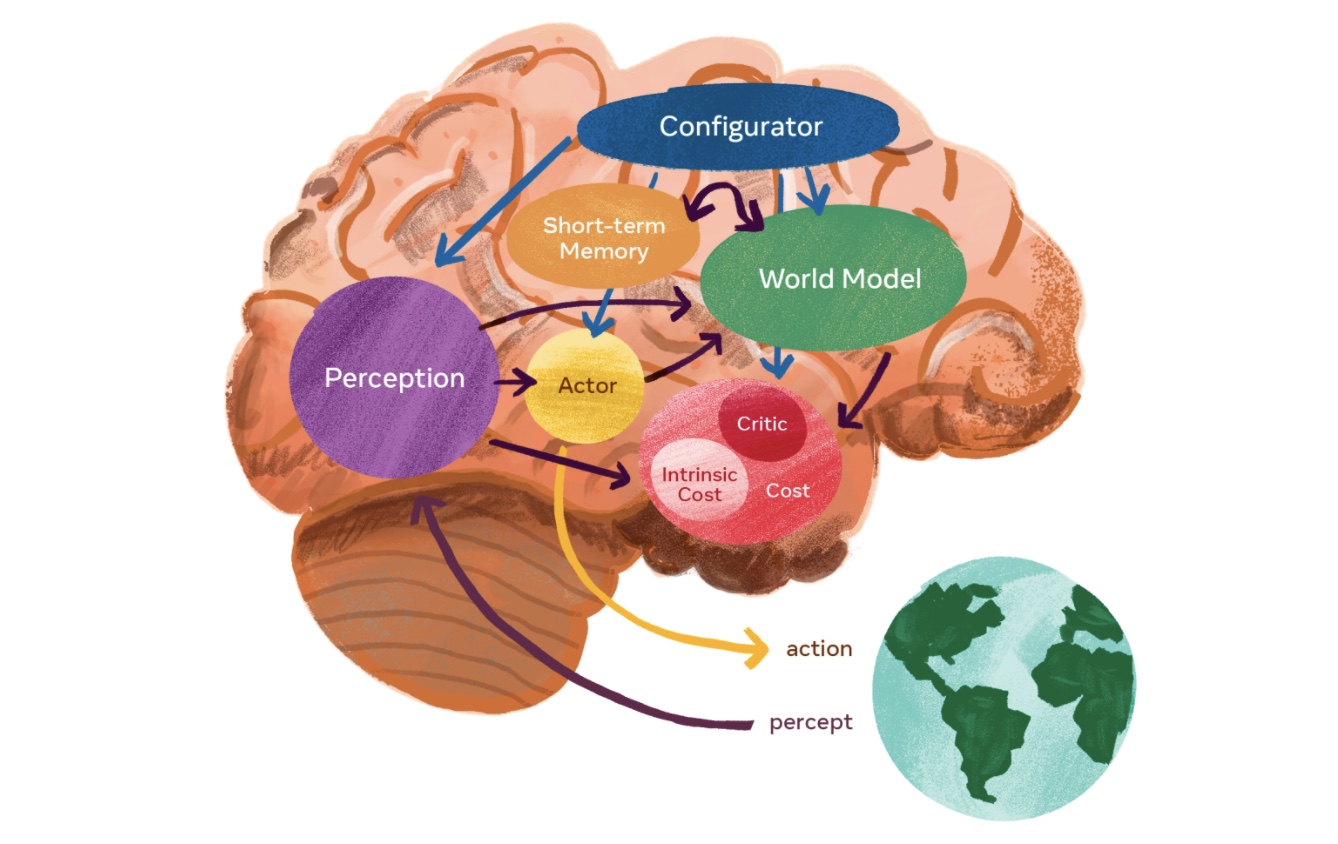
A vision to make AI systems learn and reason like animals and humans
- In this article, Yann LeCun, Chief Scientist at Meta, proposes a modular, configurable architecture for autonomous intelligence that would allow machines to learn world models in a self-supervised fashion and then use those models to predict, reason, and plan.
- Video: A Path Towards Autonomous AI at Baidu by Yann LeCun, Chief AI Scientist at Meta
- Summary:
- Autonomous AI requires predictive world models.
- World models must be able to perform multimodal predictions.
- Solution: Joint Embedding Predictive Architecture (JEPA).
- JEPA makes prediction in representation space, and can choose to ignore irrelevant or hard-to-predict details.
- JEPA can be trained non-contrastively by (1) making the representations of inputs maximally informative, (2) making the representations predictable from each other, (3) regularizing latent variables necessary for prediction.
- JEPAs can be stacked to make long-term/long-range predictions in more abstract representation spaces.
- Hierarchical JEPAs can be used for hierarchical planning.
Generative Flow Networks Tutorial
- Generative Flow Networks (GFlowNets) are a new research direction proposed by Yoshua Bengio. A GFlowNet is a trained stochastic policy or generative model, trained such that it samples objects $x$ through a sequence of constructive steps, with probability proportional to $R(x)$, where $R$ is some given non-negative integrable reward function. They live somewhere at the intersection of reinforcement learning, deep generative models and energy-based probabilistic modelling.
- Bengio’s technical talk at MILA; Discussion about GFlowNets, causality and consciousness providing a window on upcoming developments of GFlowNets aimed at bridging the gap between SOTA AI and human intelligence.
- First paper on GFlowNets published in NeurIPS 2021; blog entry.

Machine Learning FAQ
- Answers to frequently asked ML questions from Sebastian Raschka, Assistant Professor of Statistics, University of Wisconsin-Madison.

HuggingFace: Leveraging Pre-trained Language Model Checkpoints for Encoder-Decoder Models
- With the HuggingFace Encoder-Decoder class, you no longer need to stick to pre-built encoder-decoder models like BART or T5, but can instead build your own Encoder-Decoder architecture by doing a mix-and-match with the encoder and decoder model of your choice (similar to stacking legos!), say BERT-GPT2. This is called “warm-starting” encoder-decoder models.

Stitch Fix: Algorithms Tour
- The algorithms and recommendation models StitchFix uses under-the-hood to carry out their style selection processes.

NVIDIA: How to Build a Winning Recommendation System, Parts 1-3
- A three-part series that gives an overview of the NVIDIA team’s first-place solution for the booking.com challenge. This first post gives an overview of recommender system concepts. The second post will discuss deep learning for recommender systems. The third post will discuss the winning solution, the steps involved, and also what made a difference in the outcome.

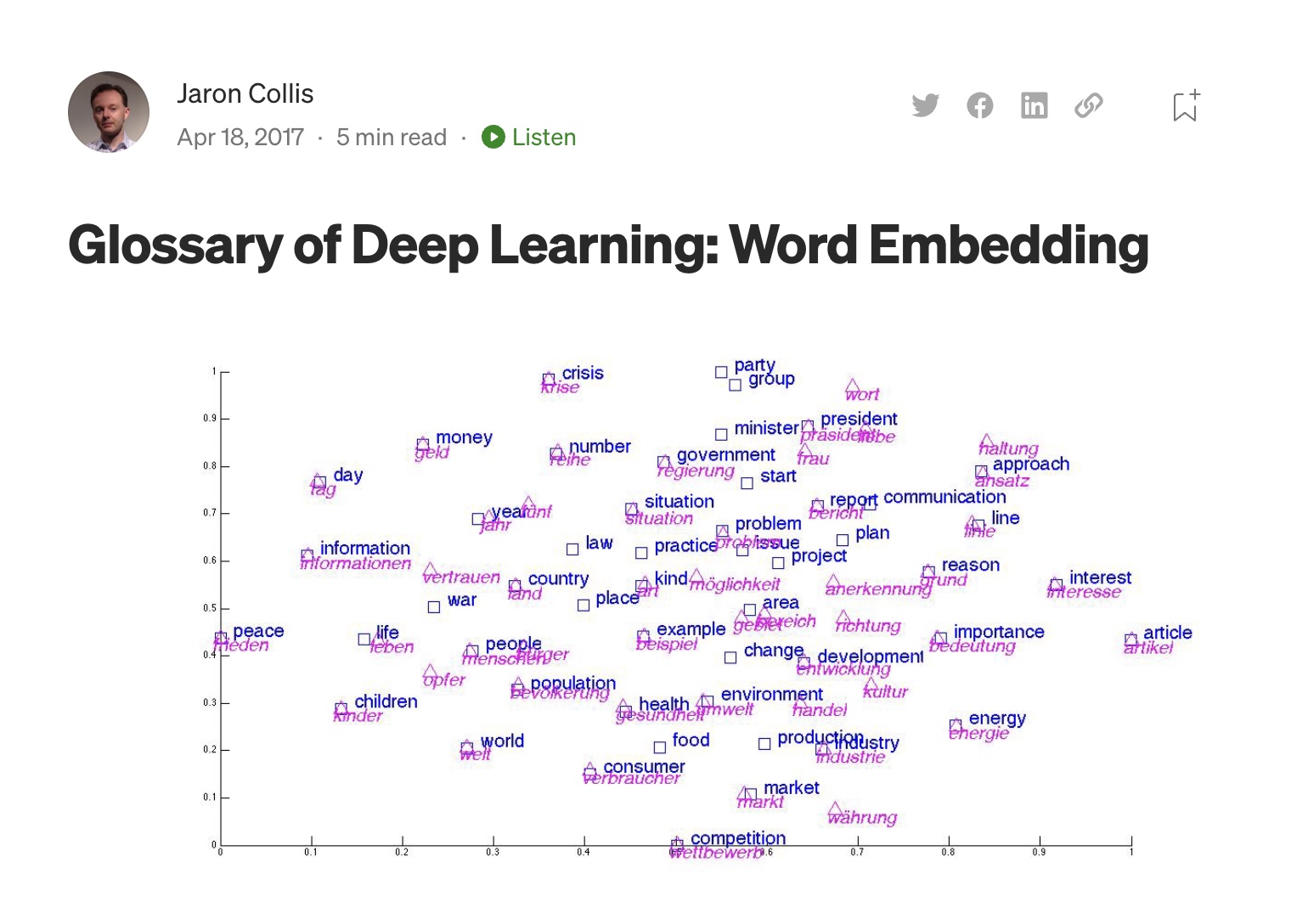
Glossary of Deep Learning: Word Embedding
- This post goes over the motivation of building word embeddings, which are low-dimensional vector representations from a corpus of text, which preserve the contextual similarity of words. It also offers a walkthrough of generating word embeddings with word2vec.
 )
)
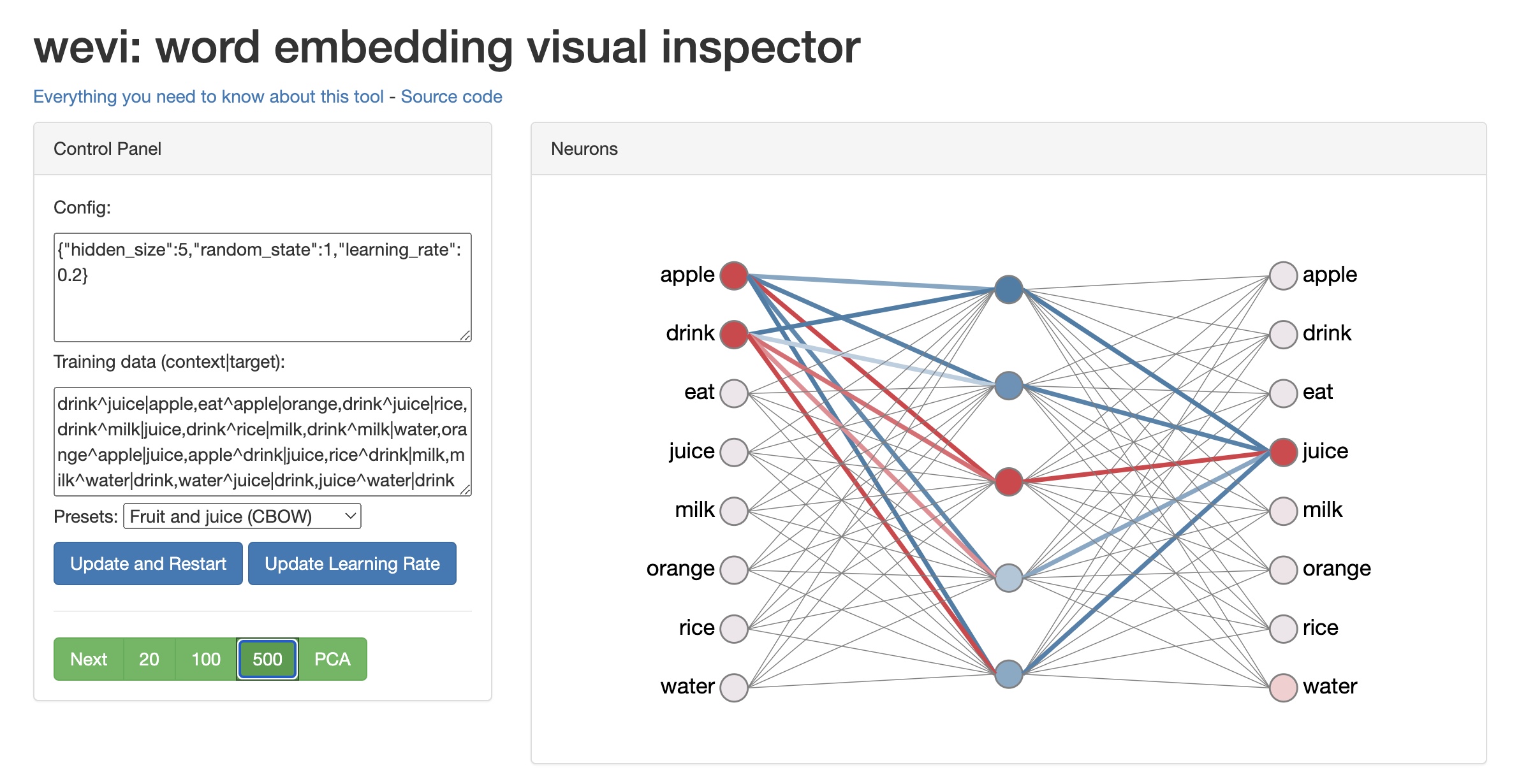
wevi: word embedding visual inspector
- A very neat visual demo by Xin Rong that shows how word embeddings are trained.
- Accompanying talk
IBM: What are foundation models?
- This article from IBM goes over the idea of foundation models which are models trained on a relatively large amount of unlabeled data and fine-tuned/transfer-learned/adapted to the downstream application, thereby replacing task-specific models. Foundation models is a term first popularized by the Stanford Institute for Human-Centered Artificial Intelligence.
- This paradigm has a host of benefits including: (i) instead of requiring a large, well-labelled dataset for the specific task, foundation models need a great amount unlabeled data and only a limited set of unlabeled data to fine-tune it for different downstream tasks thereby reducing the labeled data requirements dramatically, (ii) since a foundation model can be shared for different downstream tasks, we can save on the resources needed to train task-specific models owing to the knowledge transfer that foundation models bring about (training a relatively large model with billions of parameters roughly has roughly the same carbon footprint as running five cars over their lifetime), and (iii) democratizing AI research by making it much easier for small businesses to deploy AI in a wider range of mission-critical situations owing to the reduced data labeling requirements.

Practicing ML in a Non-ML Job
- Tips from Sayak Paul, ML Engineer at Carted, to help navigate the process of building a foundation in ML to eventually be able to pick it up as a potential career option.
- Some of the top-level tips he mentions are: (i) find solace in uncertainty, (ii) overwhelm and courage to learn, and (ii) learn, apply, (demo), and repeat.

Emil’s Story as a Self-Taught AI Researcher
- Emil Wallner is an “internet-taught” ML Researcher working as a resident at Google. This article offers an interview that follows his hero’s journey, self-taught approach to education, experience with AI, and path to Google.

Overview of Active Learning for Deep Learning
- This article by Jacob Gildenblat offers a fantastic overview of classical active learning, and then go over several papers that focus on active learning for deep learning.

A Visual Notebook to Using BERT for the First Time
- This Jupyter notebook by Jay Alammar offers a great intro to using a pre-trained BERT model to carry out sentiment classification using the Stanford Sentiment Treebank (SST2) dataset.

Best Practices for Deploying Language Models
- A preliminary set of best practices applicable to any organization developing or deploying large language models by Cohere, OpenAI, and AI21 Labs.

First Principles of Computer Vision
- A set of monographs on the First Principles of Computer Vision by Shree Nayar, Professor, Computer Science, Columbia University covering Camera and Imaging, Features and Boundaries, 3D Reconstruction I, 3D Reconstruction II, and Visual Perception.
- Accompanying videos: 150 videos of First Principles of Computer Vision and YouTube link.

AI/ML Cheatsheets for Stanford/MIT Courses
- These cheatsheets by Afshine Amidi and Shervine Amidi are easy-to-digest study guides highlighting the important points of some popular AI/ML courses at MIT/Stanford.
Interpretable Machine Learning: A Guide for Making Black Box Models Explainable
- This book by Christoph Molnar explores the concepts of interpretability in the context of ML and DL models. The book covers simple, interpretable models such as decision trees, decision rules and linear regression.
- The book also focuses on model-agnostic methods for interpreting black box models such as feature importance and accumulated local effects, and explaining individual predictions with SHapley Additive exPlanations (SHAP) values and Local Interpretable Model-agnostic Explanations (LIME).

List of datasets for machine-learning research
- This Wikipedia page includes a list of publicly available datasets for image, text, sound, signal, physical, biological data, etc.
- For each dataset, along with it’s name, the following metadata is included: a brief description, preprocessing done, number of instances, format, default task, date of creation, paper reference, creator name.

It’s Time to Stop Being “Data-Driven” (And Start Being Data-Informed)
- This post by Scuba Analytics argues that being data driven can harm organizations in some cases, but being data informed instead is the way to go.

Principles for data driven organizations
- This post by Xavier Amatriain champions being data-driven as a value that needs to permeate through the organization and work regardless of who is in the room making decisions; it has to be part of the culture and easily accessible at everyone’s fingertips.

Pretrain, Prompt, Predict
- This website offers a great summary of trends in prompt-based research.

Why Scientific Studies Are So Often Wrong: The Streetlight Effect
- This article by Discover Magazine talks about the streetlight effect and offers examples from economics, drug discovery, and randomized controlled trials in medicine.

Google “We Have No Moat, And Neither Does OpenAI”
- This article by Dylan Patel and Afzal Ahmad reports on a leaked internal Google document that claims Open Source AI will outcompete Google and OpenAI.

The New New Moats
- This article by Jerry Chen at Greylock partners explains why Systems of Intelligence are still the next defensible business model.

Recommender Systems: Lessons From Building and Deployment
- This article by Dhruvil Karani discusses practical considerations while building a recommender system right from dataset creation to model training to offline evaluation to A/B testing.

How to Run LLMs Locally
- This article by Thomas Capelle offers an overview of using llama.cpp which uses the GGML library to run LLMs locally.
- Related: LM Studio and GPT4All.

Edge AI Just Got Faster
- This article by Justine offers an overview of modifying llama.cpp to load weights using mmap() instead of C++ standard I/O. That enabled loading LLaMA 100x faster using half as much memory.

lyft2vec — Embeddings at Lyft
- This article by Javen Xu discusses how Lyft uses graph learning methods to generate embeddings.
- Their training algorithm extends from the Pytorch BigGraph package. The goal of training is to learn a \(d\)-dimensional embedding vectors for each entity (i.e. node) such that the calculated similarity between any two entities reflects their relationship. For example, two entities that are very close in the space would have a more positive similarity score than two distant entities.

Injecting GPT-4’s reasoning into recommendation algorithms
- This article by Peter Gostev talks about injecting reasoning into recommendations using GPT-4.

RTutor: Chat with your data in dozens of human languages!
- RTutor uses OpenAI’s powerful large language model to translate natural language into R code, which is then executed.
Google’s Jigsaw was trying to fight toxic speech with AI. Then the AI started talking
- OpenAI, Anthropic, and others are using Jigsaw’s Perspective – designed to moderate toxic human speech – to evaluate their large language models. What could go wrong?

Llama from scratch (or how to implement a paper without crying)
- A neat scaled-down implementation of Llama (from scratch) by Brian Kitano. It’s well explained and broken down into the main components using PyTorch code.

Deep Learning Tuning Playbook
- Notes from Google for maximizing the performance of deep learning models via tricks in the hyperparameter optimization (HPO) process. They also touch on other aspects of deep learning training, such as pipeline implementation and optimization, but our treatment of those aspects is not intended to be complete.

Knowledge sharing memo for IDEFICS, an open-source reproduction of Flamingo (A VLM model by DeepMind)
- Notes/lessons by HuggingFace on training IDEFICS, which is an 80 billion parameter model of DeepMind’s Flamingo VLM model. They highlight the mistakes they’ve made and remaining open questions. Using an auxiliary Z-loss, Atlas for data filtering, and BF16 loss values were particularly enlightening.
- Related: Older knowledge memo which focused on lessons learned from stabilizing training at medium scale.

Inside Amazon’s Artificial Intelligence Flywheel
- This article explores Amazon’s integration of artificial intelligence across its divisions, enhancing services like Alexa and Amazon Web Services through machine learning and deep learning advancements.

The Ultra-Scale Playbook: Training LLMs on GPU Clusters
- This book explores scaling LLM training from one to thousands of GPUs, distilling 4,000+ experiments on up to 512 GPUs into practical theory, code, and benchmarks covering memory profiling, activation recomputation, gradient accumulation, ZeRO/FSDP, data/tensor/pipeline/context/expert parallelism, communication–compute overlap, kernel fusion/FlashAttention, mixed/FP8 precision, and tactics to pick high-throughput, memory-fit configurations.

Making Deep Learning Go Brrrr From First Principles
- This blogpost explores how reasoning from first principles about compute, memory bandwidth, and overhead can guide effective optimizations to make deep learning models run efficiently, instead of relying on ad-hoc performance tricks.

How to Scale Your Model
- This book explores how to efficiently scale Transformer models across TPUs and GPUs by analyzing compute, memory, and communication limits, choosing parallelism strategies, and understanding hardware to optimize training and inference at massive scale.
Defeating Nondeterminism in LLM Inference
- This blogpost explores how LLM inference nondeterminism largely stems from lack of batch invariance (not just floating-point non-associativity or concurrency), and shows that making RMSNorm, matmul, and attention batch-invariant—using fixed-size Split-KV and consistent tiling—yields bitwise-reproducible outputs at temperature 0 with manageable performance costs, enabling true on-policy RL.

Miscellaneous
A Survival Guide to a PhD by Andrej Karpathy
- Advice from Karpathy on how one can traverse the PhD experience.

Doing well in your courses by Andrej Karpathy
- Advice from Karpathy for younger students on how to do well in their undergrad/grad courses.

Planning paper writing by Devi Parikh
- Planning paper writing by Devi Parikh, Associate Professor at Georgia Tech, Research Scientist at FAIR.

On time management by Devi Parikh
- Calendar. Not to-do lists. by Devi Parikh, Associate Professor at Georgia Tech, Research Scientist at FAIR.

Managing the organized chaos that is software development by Mohamed El-Geish
- How to go about planning the software development process by Mohamed El-Geish, Director of AI, Cisco.

Reacting to Corrective Feedback by Mohamed El-Geish
- Internalizing feedback the right way by Mohamed El-Geish, Director of AI, Cisco.

Learning from Hundreds of Resumes and Tens of Interviews in a Few Weeks by Mohamed El-Geish
- Building effective organizations and hiring people with the right skillset and cultural fit by Mohamed El-Geish, Director of AI, Cisco.
Up and Down the Ladder of Abstraction by Bret Victor
- Designing creative systems by Bret Victor, UI expert.

Excel Formulae Bible
- Excel is powerful for data analysis on smaller datasets. This Excel Formulae Bible from eforexcel is great summary of some useful Excel formulae.

LeetCode: General Backtracking Questions/Solutions
- Solutions to frequently asked backtracking questions on LeetCode.
![]()
LeetCode: Dynamic Programming Patterns
- Dynamic programming patterns that can be found in different problems from LeetCode.

TopCoder: Dynamic Programming Patterns
- Dynamic programming patterns that can be found in different problems from LeetCode.

A Step by Step Guide to Dynamic Programming
- Basic strategies to identify dynamic programming patterns in interviews and solve them.
- Related: also, check this Quora post.

Grokking LeetCode: A Smarter Way to Prepare for Coding Interviews
- The underlying problem-solving patterns for solving standard LeetCode problems.

Google Cloud Developer’s Visual Notes
- Infographics by Priyanka Vergadia that describe every product in the Google Cloud family in the visual sketchnote format to grasp the capability of the tools quickly and easily.

Python for Interviewing: An Overview of the Core Data Structures
- Must-know data structures with their time complexities and Python-specific caveats to kill your interview!
- Related: Time complexities for common Python operations involving lists, deque, set and dict.
Shipping to Production by The Pragmatic Engineer
- In this article, Gergely Orosz from The Pragmatic Engineer talks about the best practices for shipping your code to production in a way that is fast and reliable by adopting the concepts of canary testing, feature flags and staged rollouts.

What Is Canary Testing? A Detailed Explanation
- Canary testing (also known as canary release or canary deployment) is a powerful way of testing new features and new functionality in production with minimal impact to users in a live production environment.

Super Study Guide: Algorithms & Data Structures
- This book by Afshine Amidi and Shervine Amidi is a concise and illustrated guide for anyone who wants to brush up on their data structures and algorithm fundamentals in the context of coding interviews or computer science classes.
- It is divided into 4 parts:
- Foundations: main types of algorithms and related mathematical concepts
- Data structures: arrays, strings, queues, stacks, hash tables, linked lists and associated theorems and tricks
- Graphs and trees: graph concepts and graph traversal algorithms along with important types of trees
- Sorting and search: common, efficient sorting and search algorithms

Regular Expression Generator from Natural Language using Artificial Intelligence
- RegEx is difficult to write and comprehend to the average human reader because of its complex patterns. This website uses GPT-3 to generate regular expressions from plain English.

New Programming Jargon
- A list of new programming terms that have taken off in local circles (i.e. have heard others repeat it).

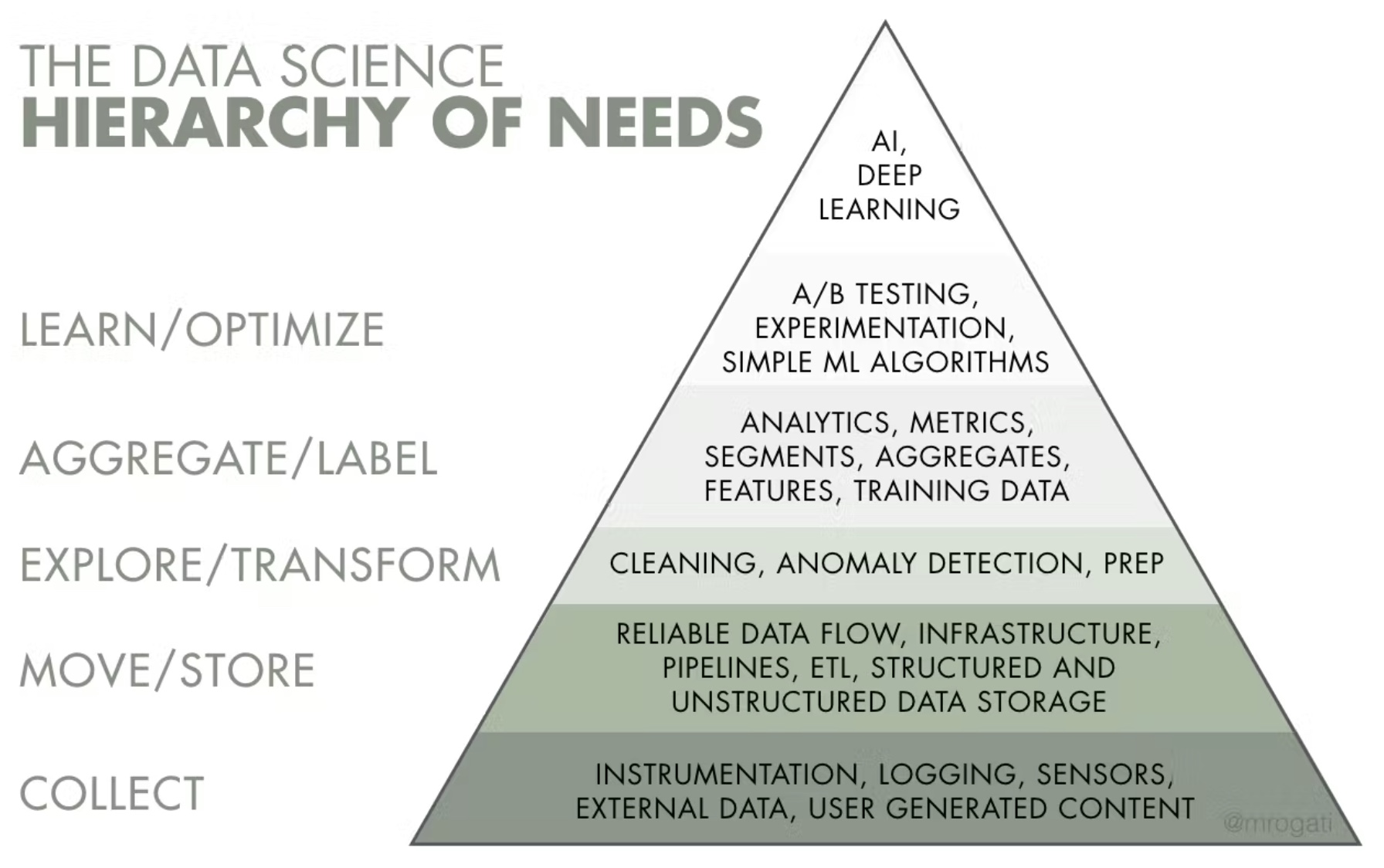
The AI Hierarchy of Needs
- AI as a pyramid of needs going from data collection at the bottom of the pyramid to ETL, analytics, and metrics in the middle to A/B testing and deep learning at the top.
An Alternative to Statistical Significance for Making Decisions with Experiments
- Null Hypothesis Statistical Testing (NHST) or more commonly known as statistical significance (stat sig.) has been the preferred to make decisions using experimentation. However, there are alternative approaches which are rapidly gaining adoption such as Expected Utility (EU). This article compares NHST with EU.

Slime Mold
- An approachable presentation by Alex Komoroske, done in an emoji style, showing why even when everyone is competent and collaborative, you can still get hurricane-force coordination headwinds.

What I Wish Someone Had Told Me
- Pearls of wisdom from Sam Altman, CEO of OpenAI.
