Primers • Retrieval Augmented Generation
- Overview
- Motivation
- The Retrieval Augmented Generation (RAG) Pipeline
- Advantages of RAG
- Ensemble of RAG
- Choosing a Vector DB using a Feature Matrix
- Building a RAG pipeline
- Ingestion
- Retrieval
- Lexical Retrieval
- Semantic Retrieval
- Hybrid Retrieval (Lexical + Semantic)
- Metadata filtering
- Re-ranking
- Re-ranking in multistage retrieval pipelines
- Classes of semantic re-ranking models
- Learning-to-Rank paradigms
- Neural re-rankers
- Instruction-Following Re-ranking
- Metadata-Based Re-rankers
- Response Generation / Synthesis
- RAG in Multi-Turn Chatbots: Embedding Queries for Retrieval
- End-to-End Flow
- Component-Wise Evaluation
- Multimodal Input Handling
- Multimodal RAG
- Multi-Hop RAG
- Agentic RAG
- Overview
- Agentic Decision-Making in Retrieval
- Agentic RAG Architectures: Single-Agent vs. Multi-Agent Systems
- Beyond Retrieval: Expanding Agentic RAG’s Capabilities
- Agentic RAG vs. Vanilla RAG
- Implementation
- Use-cases
- Advantages
- Limitations
- Code
- Disadvantages
- Sample Prompt
- Hierarchical RAG
- RAG vs. Long Context Windows
- Improving RAG Systems
- RAG 2.0
- RAG Benchmarks
- Selected Papers
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- Active Retrieval Augmented Generation
- MuRAG: Multimodal Retrieval-Augmented Generator
- Hypothetical Document Embeddings (HyDE)
- RAGAS: Automated Evaluation of Retrieval Augmented Generation
- Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs
- Dense X Retrieval: What Retrieval Granularity Should We Use?
- ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems
- Seven Failure Points When Engineering a Retrieval Augmented Generation System
- RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
- The Power of Noise: Redefining Retrieval for RAG Systems
- MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries
- RAG vs. Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture
- RAFT: Adapting Language Model to Domain Specific RAG
- Corrective Retrieval Augmented Generation
- Fine Tuning vs. Retrieval Augmented Generation for Less Popular Knowledge
- HGOT: Hierarchical Graph of Thoughts for Retrieval-Augmented In-Context Learning in Factuality Evaluation
- How faithful are RAG models? Quantifying the tug-of-war between RAG and LLMs’ internal prior
- Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity
- RichRAG: Crafting Rich Responses for Multi-faceted Queries in Retrieval-Augmented Generation
- HiQA: A Hierarchical Contextual Augmentation RAG for Massive Documents QA
- REFRAG: Rethinking RAG based Decoding
- Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation
- Long-form factuality in large language models
- References
- Citation
Overview
- Retrieval-Augmented Generation (RAG), as introduced in Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Lewis et al. (2020), is an advanced technique designed to enhance the output of Large Language Models (LLMs) by incorporating external knowledge sources.
- RAG is achieved by retrieving relevant information from a large corpus of documents and utilizing that information to guide and inform the generative process of the model. RAG improves factual grounding by conditioning LLMs on retrieved external evidence rather than relying solely on parametric memory.
- The subsequent sections provide a detailed examination of this methodology.
Motivation
- In many real-world scenarios, organizations maintain extensive collections of proprietary documents, such as technical manuals, from which precise information must be extracted. This challenge is often analogous to locating a needle in a haystack, given the sheer volume and complexity of the content.
- While recent advancements, such as OpenAI’s introduction of GPT-4 Turbo, offer improved capabilities for processing lengthy documents, they are not without limitations. Notably, these models exhibit a tendency known as the “Lost in the Middle” phenomenon, wherein information positioned near the center of the context window is more likely to be overlooked or forgotten. This issue is akin to reading a comprehensive text such as the Bible, yet struggling to recall specific content from its middle chapters.
- To address this shortcoming, the RAG approach has been introduced. This method involves segmenting documents into discrete units—typically paragraphs—and creating an index for each. Upon receiving a query, the system efficiently identifies and retrieves the most relevant segments, which are then supplied to the language model. By narrowing the input to only the most pertinent information, this strategy mitigates cognitive overload within the model and substantially improves the relevance and accuracy of its responses.
The Retrieval Augmented Generation (RAG) Pipeline
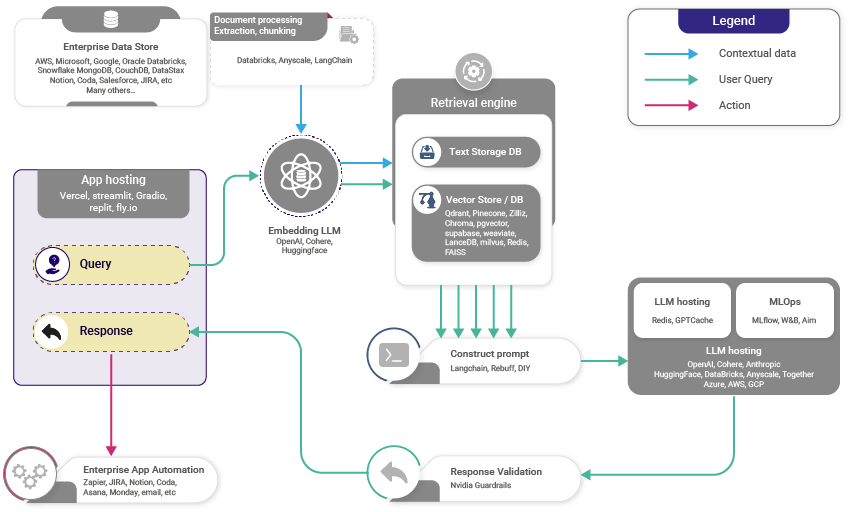
- With RAG, the LLM is able to leverage knowledge and information that is not necessarily in its weights by providing it access to external knowledge sources such as databases.
- It leverages a retriever to find relevant contexts to condition the LLM, in this way, RAG is able to augment the knowledge-base of an LLM with relevant documents.
- The retriever here could be any of the following depending on the need for semantic retrieval or not:
- Vector database: Typically, queries are embedded using models like BERT for generating dense vector embeddings. Alternatively, traditional methods like TF-IDF can be used for sparse embeddings. The search is then conducted based on term frequency or semantic similarity.
- Graph database: Constructs a knowledge base from extracted entity relationships within the text. This approach is precise but may require exact query matching, which could be restrictive in some applications.
- Regular SQL database: Offers structured data storage and retrieval but might lack the semantic flexibility of vector databases.
- The image below from Damien Benveniste, PhD talks a bit about the difference between using Graph vs. Vector database for RAG.
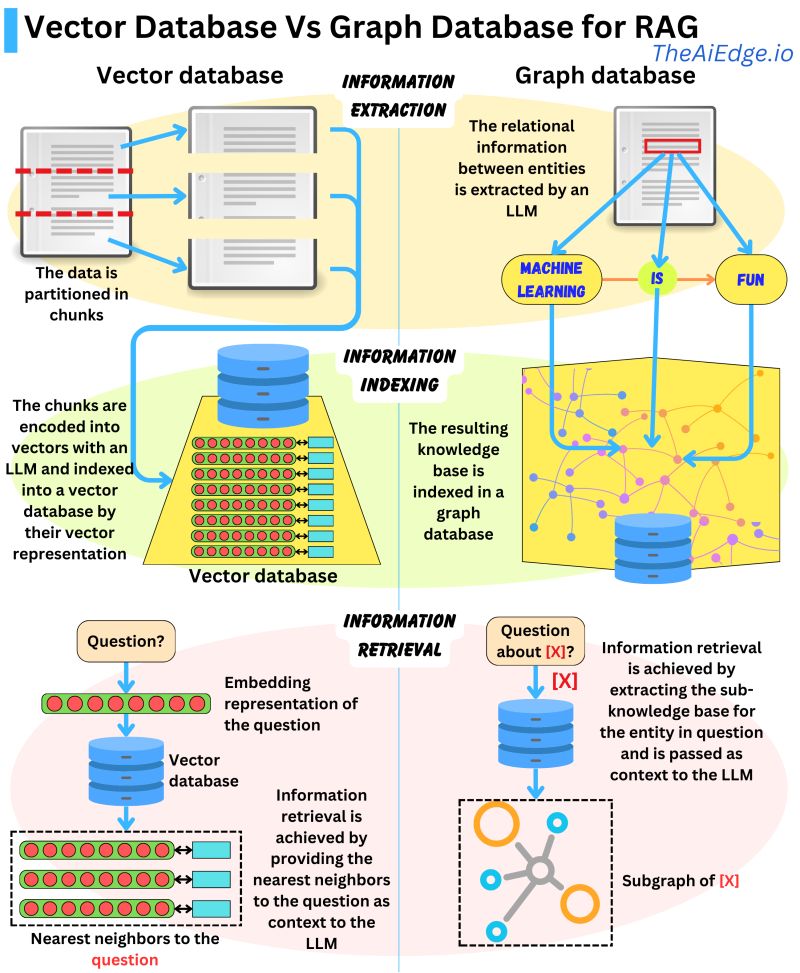
- In his post linked above, Damien states that Graph Databases are favored for Retrieval Augmented Generation (RAG) when compared to Vector Databases. While Vector Databases partition and index data using LLM-encoded vectors, allowing for semantically similar vector retrieval, they may fetch irrelevant data.
- Graph Databases, on the other hand, build a knowledge base from extracted entity relationships in the text, making retrievals concise. However, it requires exact query matching which can be limiting.
-
A potential solution could be to combine the strengths of both databases: indexing parsed entity relationships with vector representations in a graph database for more flexible information retrieval. It remains to be seen if such a hybrid model exists.
- After retrieving, you may want to look into filtering the candidates further by adding ranking and/or fine ranking layers that allow you to filter down candidates that do not match your business rules, are not personalized for the user, current context, or response limit.
- Let’s succinctly summarize the process of RAG and then delve into its pros and cons:
- Vector Database Creation: RAG starts by converting an internal dataset into vectors and storing them in a vector database (or a database of your choosing).
- User Input: A user provides a query in natural language, seeking an answer or completion.
- Information Retrieval: The retrieval mechanism scans the vector database to identify segments that are semantically similar to the user’s query (which is also embedded). These segments are then given to the LLM to enrich its context for generating responses.
- Combining Data: The chosen data segments from the database are combined with the user’s initial query, creating an expanded prompt.
- Generating Text: The enlarged prompt, filled with added context, is then given to the LLM, which crafts the final, context-aware response.
- The image below (source) displays the high-level working of RAG.
Advantages of RAG
-
RAG enhances language model outputs by grounding generation in external knowledge sources that are not contained within the model’s parameters. By retrieving relevant documents or passages at inference time, RAG enables models to produce more accurate, current, and domain-specific responses without modifying their internal weights. The following list highlights some of the distinct advantages of RAG:
-
External knowledge access: RAG allows language models to leverage information from external knowledge bases, enabling access to up-to-date, proprietary, or domain-specific data that would otherwise be unavailable or stale if stored solely in model parameters.
-
Support for dynamic and changing corpora: RAG naturally supports dynamic or frequently changing corpora, since new, updated, or removed documents can be reflected immediately through the retriever without requiring model retraining, making it well suited for evolving knowledge bases.
-
No retraining required: RAG avoids the need for expensive and time-consuming model retraining or fine-tuning, reducing computational cost and accelerating iteration while still allowing the system to incorporate new information.
-
Effective with limited labeled data: Because RAG relies on retrieval rather than supervised learning for knowledge injection, it performs well in environments where labeled training data is scarce but large volumes of unlabeled or weakly structured data are available.
-
Well-suited for real-time and knowledge-intensive applications: RAG is particularly effective for use cases such as virtual assistants, enterprise search, and question answering over technical documentation or product manuals, where accurate, real-time access to specific information is required.
-
Improved factual grounding and traceability: By explicitly retrieving and conditioning on source documents, RAG improves factual grounding and enables greater transparency and traceability in generated responses.
-
Dependence on retrieval quality: A key limitation of RAG is that its performance is bounded by the quality, coverage, and freshness of the retrieval system and underlying knowledge base; missing or incorrect retrievals can directly degrade generation quality.
-
RAG vs. Fine-tuning
- The table below (source) compares RAG vs. fine-tuning.
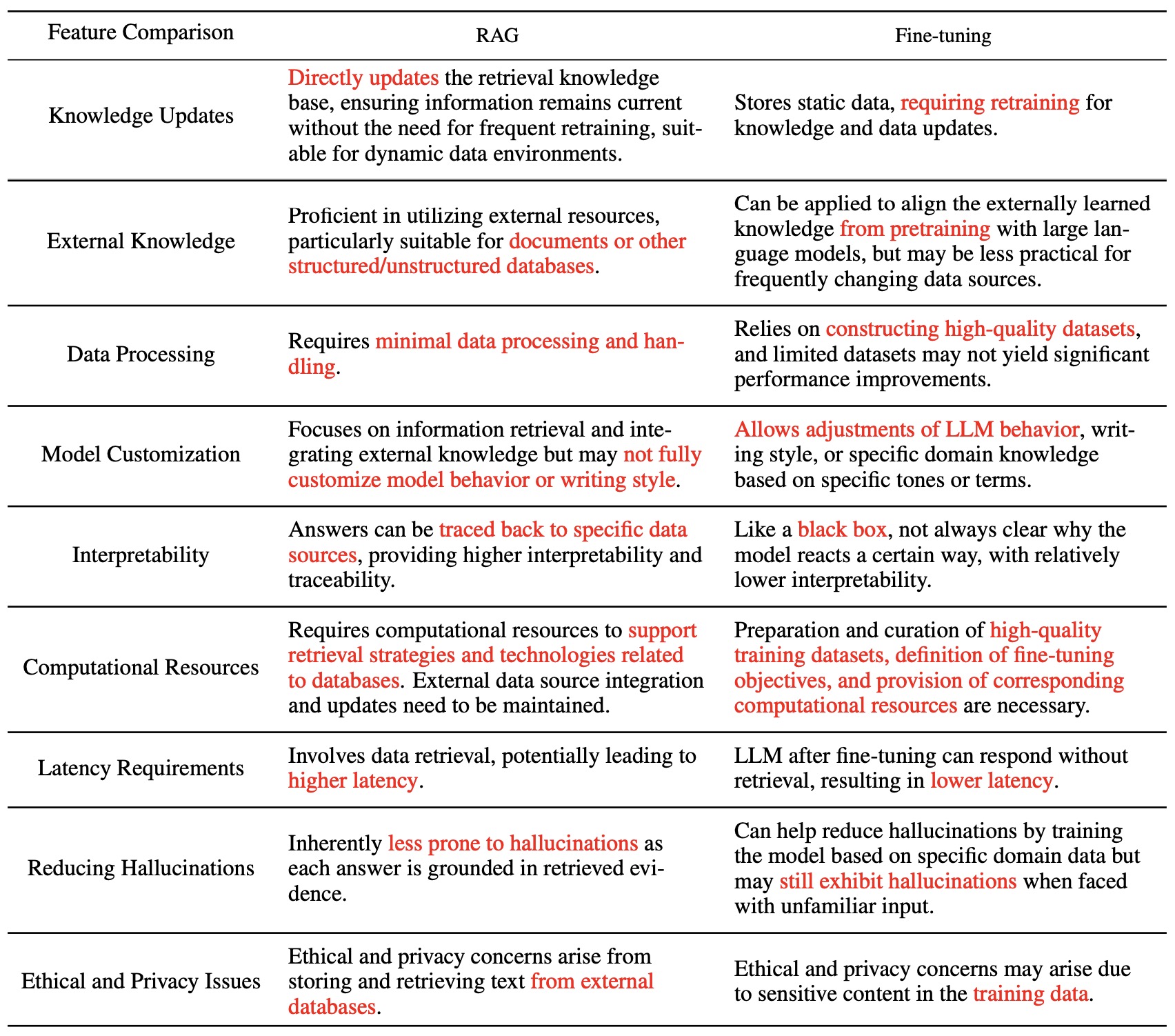
- To summarize the above table:
- RAG offers Large Language Models (LLMs) access to factual, access-controlled, timely information. This integration enables LLMs to fetch precise and verified facts directly from relevant databases and knowledge repositories in real-time. While fine-tuning can address some of these aspects by adapting the model to specific data, RAG excels at providing up-to-date and specific information without the substantial costs associated with fine-tuning. Moreover, RAG enhances the model’s ability to remain current and relevant by dynamically accessing and retrieving the latest data, thus ensuring the responses are accurate and contextually appropriate. Additionally, RAG’s approach to leveraging external sources can be more flexible and scalable, allowing for easy updates and adjustments without the need for extensive retraining.
- Fine-tuning adapts the style, tone, and vocabulary of LLMs so that your linguistic “paint brush” matches the desired domain and style. RAG does not provide this level of customization in terms of linguistic style and vocabulary.
- Focus on RAG first. A successful LLM application typically involves connecting specialized data to the LLM workflow. Once you have a functional application, you can add fine-tuning to enhance the style and vocabulary of the system.
Ensemble of RAG
- Leveraging an ensemble of RAG systems offers a substantial upgrade to the model’s ability to produce rich and contextually accurate text. Here’s an enhanced breakdown of how this procedure could work:
- Knowledge sources: RAG models retrieve information from external knowledge stores to augment their knowledge in a particular domain. These can include passages, tables, images, etc. from domains like Wikipedia, books, news, databases.
- Combining sources: At inference time, multiple retrievers can pull relevant content from different corpora. For example, one retriever searches Wikipedia, another searches news sources. Their results are concatenated into a pooled set of candidates.
- Ranking: The model ranks the pooled candidates by their relevance to the context.
- Selection: Highly ranked candidates are selected to condition the language model for generation.
- Ensembling: Separate RAG models specialized on different corpora can be ensembled. Their outputs are merged, ranked, and voted on.
- Multiple knowledge sources can augment RAG models through pooling and ensembles. Careful ranking and selection helps integrate these diverse sources for improved generation.
- One thing to keep in mind when using multiple retrievers is to rank the different outputs from each retriever before merging them to form a response. This can be done in a variety of ways, using LTR algorithms, multi-armed bandit framework, multi-objective optimization, or according to specific business use cases.
Choosing a Vector DB using a Feature Matrix
- To compare the plethora of Vector DB offerings, a feature matrix that highlights the differences between Vector DBs and which to use in which scenario is essential.
- Vector DB Comparison by VectorHub offers a great comparison spanning 37 vendors and 29 features (as of this writing).
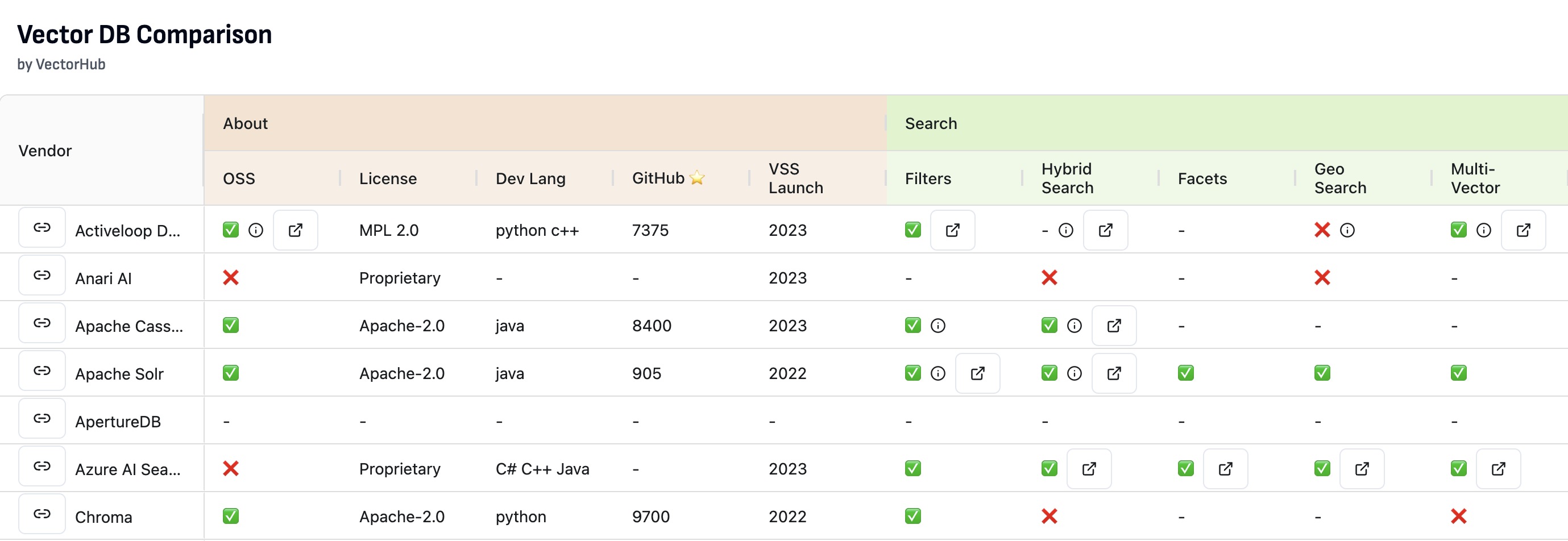
- As a secondary resource, the following table (source) shows a comparison of some of the prevalent Vector DB offers along various feature dimensions:
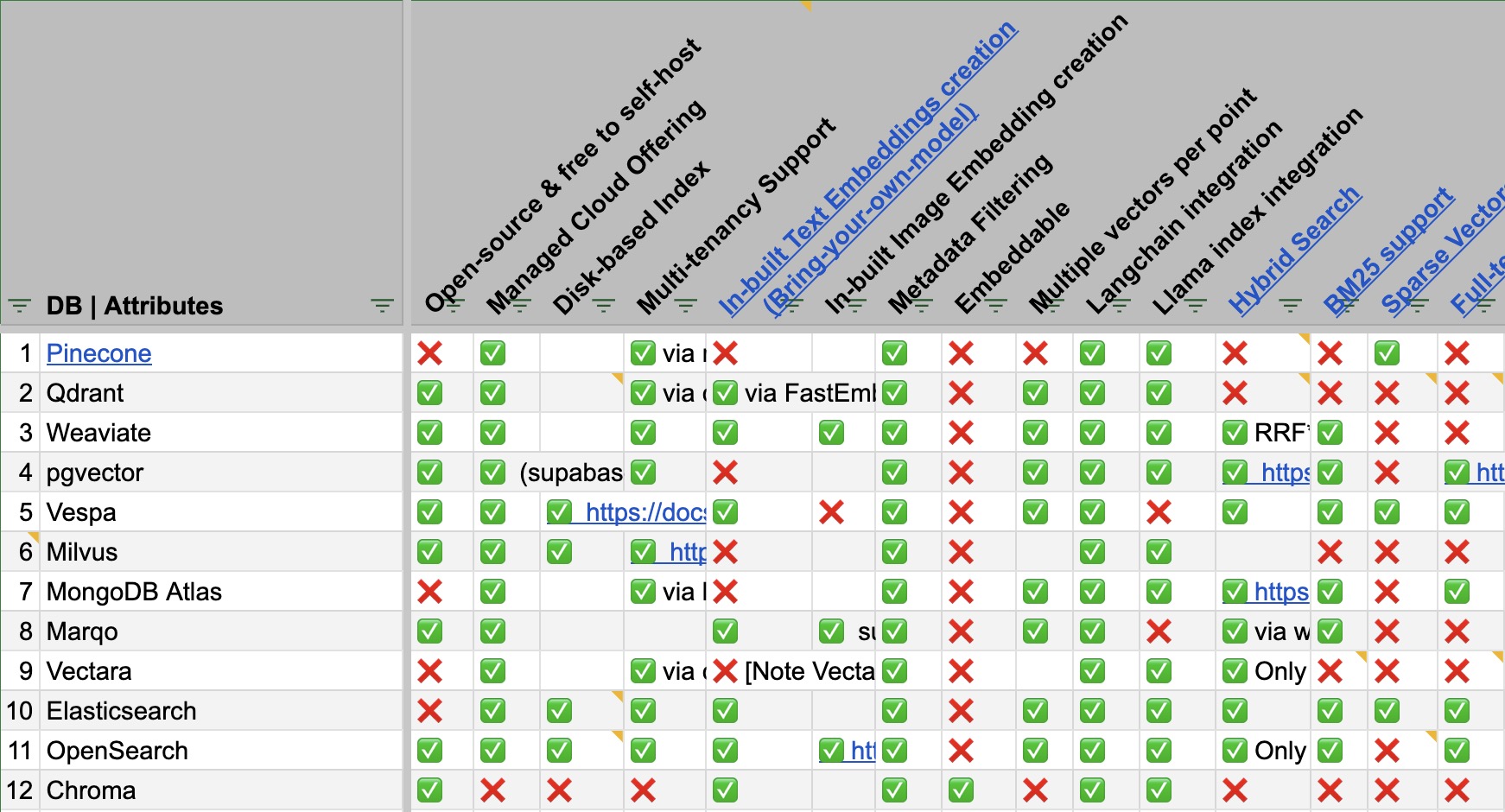
- Access the full spreadsheet here.
Building a RAG pipeline
- The image below (source), gives a visual overview of the three different steps of RAG: Ingestion, Retrieval, and Synthesis/Response Generation.
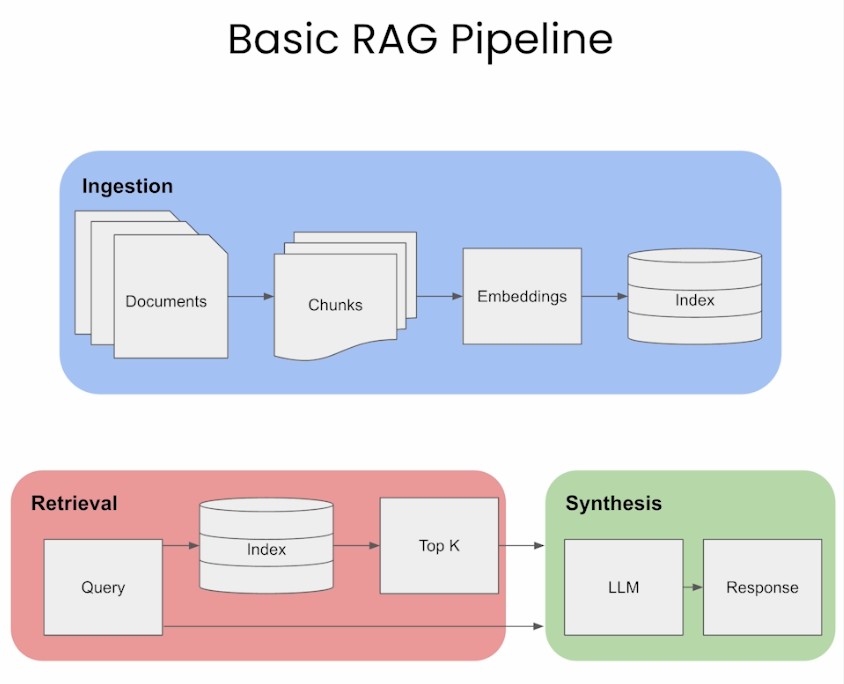
- In the sections below, we will go over these key areas.
Ingestion
Chunking
- Chunking is the process of dividing the prompts and/or the documents to be retrieved, into smaller, manageable segments or chunks. These chunks can be defined either by a fixed size, such as a specific number of characters, sentences, or paragraphs. The choice of chunking strategy plays a critical role in determining both the performance and efficiency of your RAG system.
- Each chunk is encoded into an embedding vector for retrieval. Smaller, more precise chunks lead to a finer match between the user’s query and the content, enhancing the accuracy and relevance of the information retrieved.
- Larger chunks might include irrelevant information, introducing noise and potentially reducing the retrieval accuracy. By controlling the chunk size, RAG can maintain a balance between comprehensiveness and precision.
- So the next natural question that comes up is, how do you choose the right chunk size for your use case? The choice of chunk size in RAG is crucial. It needs to be small enough to ensure relevance and reduce noise but large enough to maintain the context’s integrity. Let’s look at a few methods below referred from Pinecone:
- Fixed-size Chunking: Simply decide the number of tokens in our chunk along with whether there should be overlap between them or not. Overlap between chunks guarantees there to be minimal semantic context loss between chunks. This option is computationally cheap and simple to implement.
text = "..." # your text from langchain.text_splitter import CharacterTextSplitter text_splitter = CharacterTextSplitter( separator = "\n\n", chunk_size = 256, chunk_overlap = 20 ) docs = text_splitter.create_documents([text]) - Context-aware Chunking: Content-aware chunking leverages the intrinsic structure of the text to create chunks that are more meaningful and contextually relevant. Here are several approaches to achieving this:
- Sentence Splitting: This method aligns with models optimized for embedding sentence-level content. Different tools and techniques can be used for sentence splitting:
- Naive Splitting: A basic method where sentences are split using periods and new lines. Example:
text = "..." # Your text docs = text.split(".")- This method is quick but may overlook complex sentence structures.
- NLTK (Natural Language Toolkit): A comprehensive Python library for language processing. NLTK includes a sentence tokenizer that effectively splits text into sentences. Example:
text = "..." # Your text from langchain.text_splitter import NLTKTextSplitter text_splitter = NLTKTextSplitter() docs = text_splitter.split_text(text) - spaCy: An advanced Python library for NLP tasks, spaCy offers efficient sentence segmentation. Example:
text = "..." # Your text from langchain.text_splitter import SpacyTextSplitter text_splitter = SpacyTextSplitter() docs = text_splitter.split_text(text)
- Naive Splitting: A basic method where sentences are split using periods and new lines. Example:
- Recursive Chunking: Recursive chunking is an iterative method that splits text hierarchically using various separators. It adapts to create chunks of similar size or structure by recursively applying different criteria. Example using LangChain:
text = "..." # Your text from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size = 256, chunk_overlap = 20 ) docs = text_splitter.create_documents([text]) - Structure-based Chunking: For formatted content like Markdown, HTML, or LaTeX, specialized chunking can be applied to maintain the original structure:
- Markdown Chunking: Recognizes markdown syntax and divides content based on structure. Example:
from langchain.text_splitter import MarkdownTextSplitter markdown_text = "..." markdown_splitter = MarkdownTextSplitter(chunk_size=100, chunk_overlap=0) docs = markdown_splitter.create_documents([markdown_text]) - HTML Chunking: Leverages HTML tags (such as headings, sections, and semantic elements) to segment content while preserving document hierarchy and structural meaning.
- LaTeX Chunking: Parses LaTeX commands and environments to chunk content while preserving its logical organization.
- Markdown Chunking: Recognizes markdown syntax and divides content based on structure. Example:
- Semantic Chunking: Segment text based on semantic similarity. This means that sentences with the strongest semantic connections are grouped together, while sentences that move to another topic or theme are separated into distinct chunks. For an implementation of semantic chunking, please refer to this notebook.
- Semantic chunking can be summarized in four steps:
- Split the text into sentences, paragraphs, or other rule-based units.
- Vectorize a window of sentences or other units.
- Calculate the cosine distance between the embedded windows.
- Merge sentences or units until the cosine similarity value reaches a specific threshold.
- The following figure (source) visually summarizes the overall process:

- Semantic chunking can be summarized in four steps:
- Sentence Splitting: This method aligns with models optimized for embedding sentence-level content. Different tools and techniques can be used for sentence splitting:
- Fixed-size Chunking: Simply decide the number of tokens in our chunk along with whether there should be overlap between them or not. Overlap between chunks guarantees there to be minimal semantic context loss between chunks. This option is computationally cheap and simple to implement.
- As a rule of thumb, if the chunk of text makes sense without the surrounding context to a human, it will make sense to the language model as well. Therefore, finding the optimal chunk size for the documents in the corpus is crucial to ensuring that the search results are accurate and relevant.
Figuring out the ideal chunk size
- Choosing the right chunk size is foundational to building an effective RAG system. It directly influences retrieval quality, model efficiency, and how well the system captures relevant context for downstream tasks. Poor chunking can lead to fragmented information or excessive context loss, undermining overall performance.
-
Building a RAG system involves determining the ideal chunk sizes for the documents that the retriever component will process. The ideal chunk size depends on several factors:
-
Data Characteristics: The nature of your data is crucial. For text documents, consider the average length of paragraphs or sections. If the documents are well-structured with distinct sections, these natural divisions might serve as a good basis for chunking.
-
Retriever Constraints: The retriever model you choose (like BM25, TF-IDF, or a neural retriever like DPR) might have limitations on the input length. It’s essential to ensure that the chunks are compatible with these constraints.
-
Memory and Computational Resources: Larger chunk sizes can lead to higher memory usage and computational overhead. Balance the chunk size with the available resources to ensure efficient processing.
-
Task Requirements: The nature of the task (e.g., question answering, document summarization) can influence the ideal chunk size. For detailed tasks, smaller chunks might be more effective to capture specific details, while broader tasks might benefit from larger chunks to capture more context.
-
Experimentation: Often, the best way to determine the ideal chunk size is through empirical testing. Run experiments with different chunk sizes and evaluate the performance on a validation set to find the optimal balance between granularity and context.
-
Overlap Consideration: Sometimes, it’s beneficial to have overlap between chunks to ensure that no important information is missed at the boundaries. Decide on an appropriate overlap size based on the task and data characteristics.
-
- To summarize, determining the ideal chunk size for a RAG system is a balancing act that involves considering the characteristics of your data, the limitations of your retriever model, the resources at your disposal, the specific requirements of your task, and empirical experimentation. It’s a process that may require iteration and fine-tuning to achieve the best results.
Retriever Ensembling and Re-ranking
- In some scenarios, it may be beneficial to simultaneously utilize multiple chunk sizes and apply a re-ranking mechanism to refine the retrieved results. A detailed discourse on re-ranking is available in the Re-ranking section.
- This approach serves two primary purposes:
- It potentially improves the quality of retrieved content—albeit at increased computational cost—by aggregating outputs from multiple chunking strategies, provided the re-ranker performs with a reasonable degree of accuracy.
- It enables systematic comparison of different retrieval methods relative to the re-ranker’s effectiveness.
-
The methodology proceeds as follows:
- Segment the same source document using various chunk sizes, for example: 128, 256, 512, and 1024 tokens.
- During the retrieval phase, extract relevant segments from each retrieval method, thereby forming an ensemble of retrievers.
- Apply a re-ranking model to prioritize and filter the aggregated results.
- The following diagram (source) illustrates the process.
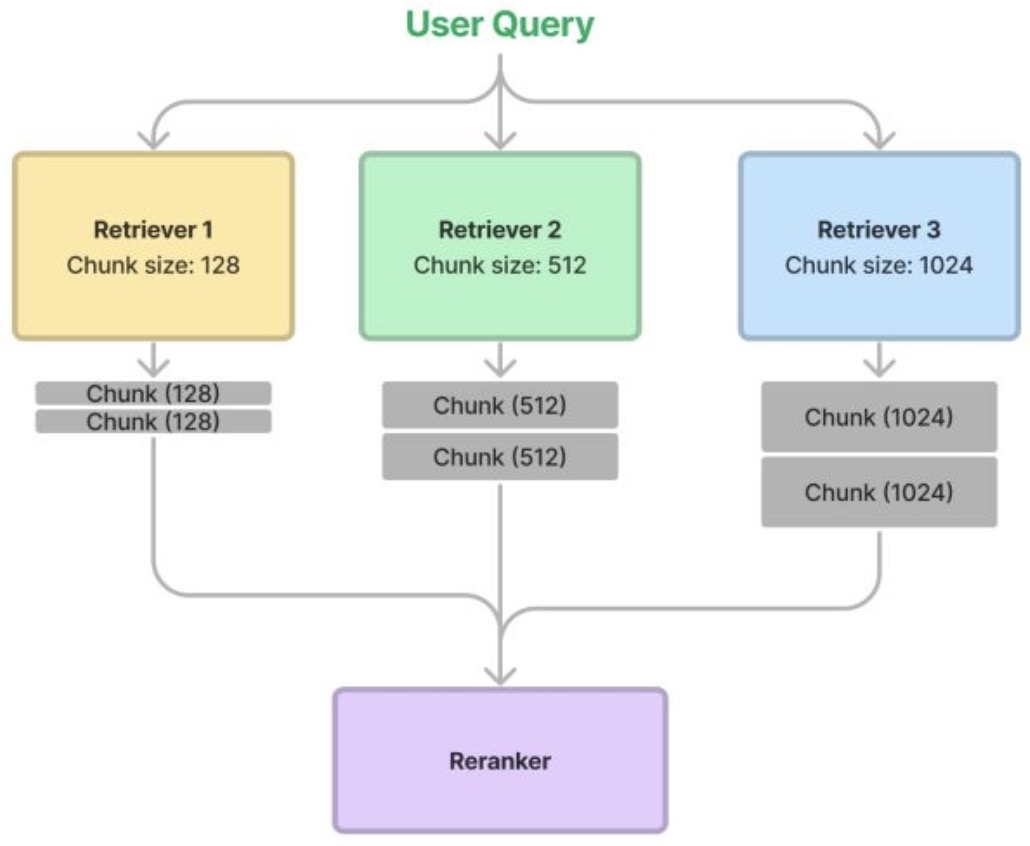
- According to evaluation data provided by LlamaIndex, the ensemble retrieval strategy leads to a modest improvement in faithfulness metrics, suggesting slightly enhanced relevance of retrieved content. However, pairwise comparisons show equal preference between the ensembled and baseline approaches, thereby leaving the superiority of ensembling open to debate.
- It is important to note that this ensembling methodology is not limited to variations in chunk size. It can also be extended to other dimensions of a RAG pipeline, including vector-based, keyword-based, and hybrid search strategies.
Embeddings
- Once you have your prompt chunked appropriately, the next step is to embed it. Embedding prompts and documents in RAG involves transforming both the user’s query (prompt) and the documents in the knowledge base into a format that can be effectively compared for relevance. This process is critical for RAG’s ability to retrieve the most relevant information from its knowledge base in response to a user query. Here’s how it typically works:
- One option to help pick which embedding model would be best suited for your task is to look at HuggingFace’s Massive Text Embedding Benchmark (MTEB) leaderboard. There is a question of whether a dense or sparse embedding can be used so let’s look into benefits of each below:
- Sparse embedding: Sparse embeddings such as TF-IDF are great for lexical matching the prompt with the documents. Best for applications where keyword relevance is crucial. It’s computationally less intensive but may not capture the deeper semantic meanings in the text.
- Semantic embedding: Semantic embeddings, such as BERT or SentenceBERT lend themselves naturally to the RAG use-case.
- BERT: Suitable for capturing contextual nuances in both the documents and queries. Requires more computational resources compared to sparse embeddings but offers more semantically rich embeddings.
- SentenceBERT: Ideal for scenarios where the context and meaning at the sentence level are important. It strikes a balance between the deep contextual understanding of BERT and the need for concise, meaningful sentence representations. This is usually the preferred route for RAG.
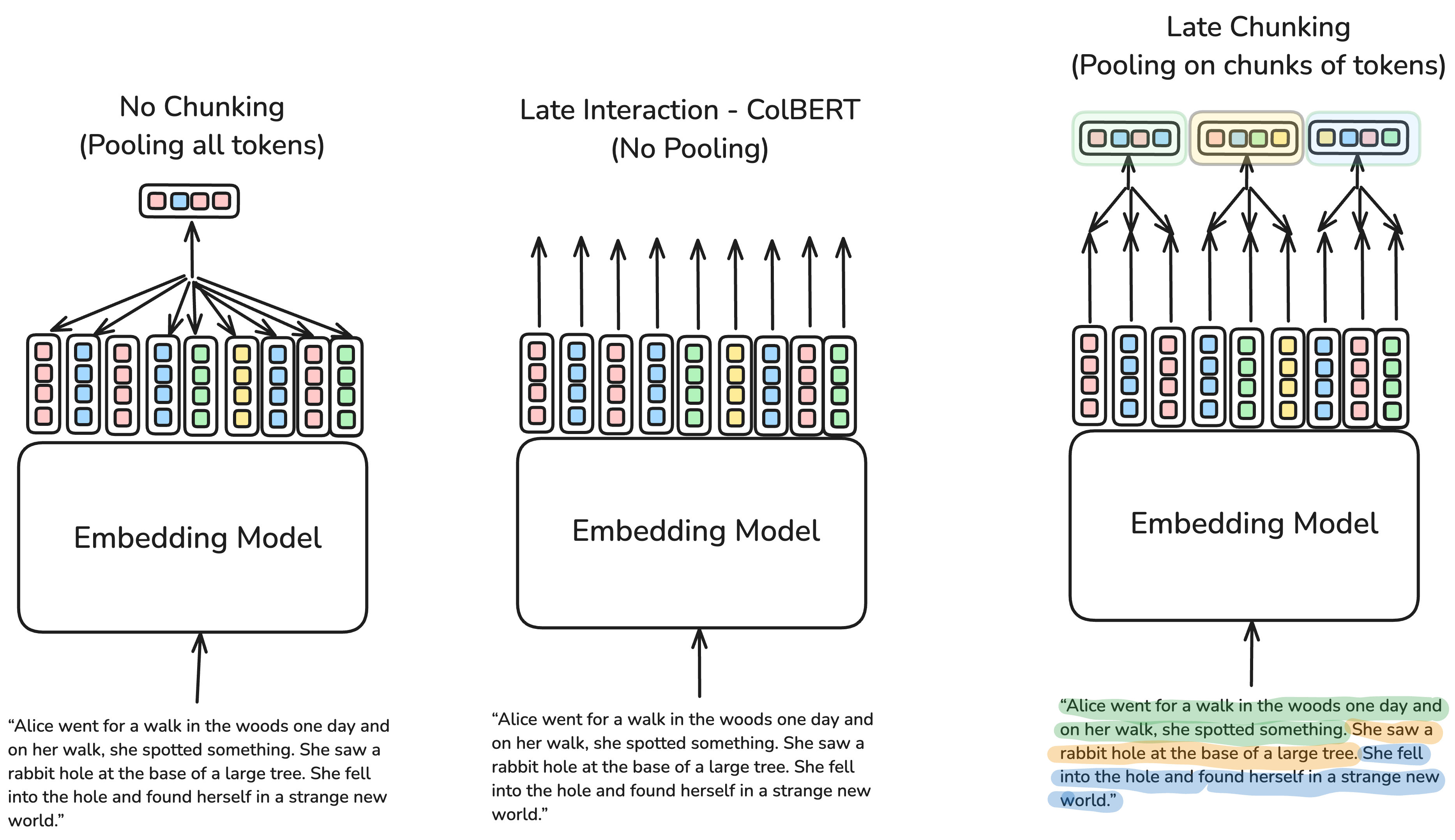
Naive Chunking vs. Late Chunking vs. Late Interaction (ColBERT and ColPali)
-
The choice between naive chunking, late chunking, and late interaction (ColBERT and ColPali) depends on the specific requirements of the retrieval task:
- Naive Chunking is suitable for scenarios with strict resource constraints but where retrieval precision is less critical.
- Late Chunking, introduced by JinaAI, offers an attractive middle ground, maintaining context and providing improved retrieval accuracy without incurring significant additional costs. Put simply, late chunking balances the trade-offs between cost and precision, making it an excellent option for building scalable and effective RAG systems, particularly in long-context retrieval scenarios.
- Late Interaction (ColBERT and ColPali) is best suited for applications where retrieval precision is paramount and resource costs are less of a concern.
-
Let’s explore the differences between three primary strategies: Naive Chunking, Late Chunking, and Late Interaction (ColBERT and ColPali), focusing on their methodologies, advantages, and trade-offs.
Overview
- Long-context retrieval presents a challenge when balancing precision, context retention, and cost efficiency. Solutions range from simple and low-cost, like Naive Chunking, to more sophisticated and resource-intensive approaches, such as Late Interaction (ColBERT and ColPali). Late Chunking, a novel approach by JinaAI, offers a middle ground, preserving context with efficiency comparable to Naive Chunking.
Naive/Vanilla Chunking
What is Naive/Vanilla Chunking?
- As discussed in the Chunking section, naive/vanilla chunking divides a document into fixed-size chunks based on metrics like sentence boundaries or token count (e.g., 512 tokens per chunk).
- Each chunk is independently embedded into a vector without considering the context of neighboring chunks.
Example
-
Consider the following paragraph: Alice went for a walk in the woods one day and on her walk, she spotted something. She saw a rabbit hole at the base of a large tree. She fell into the hole and found herself in a strange new world.
-
If chunked by sentences:
- Chunk 1: “Alice went for a walk in the woods one day and on her walk, she spotted something.”
- Chunk 2: “She saw a rabbit hole at the base of a large tree.”
- Chunk 3: “She fell into the hole and found herself in a strange new world.”
Advantages and Limitations
- Advantages:
- Efficient in terms of storage and computation.
- Simple to implement and integrate with most retrieval pipelines.
- Limitations:
- Context Loss: Each chunk is processed independently, leading to a loss of contextual relationships. For example, the connection between “she” and “Alice” would be lost, reducing retrieval accuracy for context-heavy queries like “Where did Alice fall?”.
- Fragmented Meaning: Splitting paragraphs or semantically related sections can dilute the meaning of each chunk, reducing retrieval precision.
Late Chunking
What is Late Chunking?
- Late Chunking flips the order of vectorizing (i.e., embedding generation) and chunking compared to naive/vanilla chunking. In other words, it delays the chunking process until after the entire document has been embedded into token-level representations. This allows chunks to retain context from the full document, leading to richer, more contextually aware embeddings.
How Late Chunking Works
- Embedding First: The entire document is embedded into token-level representations using a long context model.
- Chunking After: After embedding, the token-level representations are pooled into chunks based on a predefined chunking strategy (e.g., 512-token chunks).
- Context Retention: Each chunk retains contextual information from the full document, allowing for improved retrieval precision without increasing storage costs.
Example
- Using the same paragraph:
- The entire paragraph is first embedded as a whole, preserving the relationships between all sentences.
- The document is then split into chunks after embedding, ensuring that chunks like “She fell into the hole…” are contextually aware of the mention of “Alice” from earlier sentences.
Advantages and Trade-offs
- Advantages:
- Context Preservation: Late chunking ensures that the relationship between tokens across different chunks is maintained.
- Efficiency: Late chunking requires the same amount of storage as naive chunking while significantly improving retrieval accuracy.
- Trade-offs:
- Requires Long Context Models: To embed the entire document at once, a model with long-context capabilities (e.g., supporting up to 8192 tokens) is necessary.
- Slightly Higher Compute Costs: Late chunking introduces an extra pooling step after embedding, although it’s more efficient than late interaction approaches like ColBERT.
Late Interaction
What is Late Interaction?
- Late Interaction refers to a retrieval approach where token embeddings for both the document and the query are computed separately and compared at the token level, without any pooling operation. The key advantage is fine-grained, token-level matching, which improves retrieval accuracy.
ColBERT: Late Interaction in Practice
- ColBERT (Contextualized Late Interaction over BERT) by Khattab et al. (2020) uses late interaction to compare individual token embeddings from the query and document using a MaxSim operator. This allows for granular, token-to-token comparisons, which results in highly precise matches but at a significantly higher storage cost.
MaxSim: A Key Component of ColBERT
- MaxSim (Maximum Similarity) is a core component of the ColBERT retrieval framework. It refers to a specific way of calculating the similarity between token embeddings of a query and document during retrieval.
- Here’s a step-by-step breakdown of how MaxSim works:
- Token-level Embedding Comparisons:
- When a query is processed, it is tokenized and each token is embedded separately (e.g., “apple” and “sweet”).
- The document is already indexed at the token level, meaning that each token in the document also has its own embedding.
- Similarity Computation:
- At query time, the system compares each query token embedding to every token embedding in the document. The similarity between two token embeddings is often measured using a dot product or cosine similarity.
- For example, given a query token
"apple"and a document containing tokens like"apple","banana", and"fruit", the system computes the similarity of"apple"to each of these tokens.
- Selecting Maximum Similarity (MaxSim):
- The system selects the highest similarity score between the query token and the document tokens. This is known as the MaxSim operation.
- In the above example, the system compares the similarity of
"apple"(query token) with all document tokens and selects the highest similarity score, say between"apple"and the corresponding token"apple"in the document.
- MaxSim Aggregation:
The MaxSim scores for each token in the query are aggregated (i.e., summed up) to calculate a final relevance score for the document with respect to the query.
- This approach allows for token-level precision, capturing subtle nuances in the document-query matching that would be lost with traditional pooling methods.
- Token-level Embedding Comparisons:
Example
-
Consider the query
"sweet apple"and two documents:- Document 1: “The apple is sweet and crisp.”
- Document 2: “The banana is ripe and yellow.”
-
Each query token,
"sweet"and"apple", is compared with every token in both documents:- For Document 1,
"sweet"has a high similarity with"sweet"in the document, and"apple"has a high similarity with"apple". - For Document 2,
"sweet"does not have a strong match with any token, and"apple"does not appear.
- For Document 1,
-
Using MaxSim, Document 1 would have a higher relevance score for the query than Document 2 because the most similar tokens in Document 1 (i.e.,
"sweet"and"apple") align more closely with the query tokens.
Advantages and Trade-offs
- Advantages:
- High Precision: ColBERT’s token-level comparisons, facilitated by MaxSim, lead to highly accurate retrieval, particularly for specific or complex queries.
- Flexible Query Matching: By calculating similarity at the token level, ColBERT can capture fine-grained relationships that simpler models might overlook.
- Trade-offs:
- Storage Intensive: Storing all token embeddings for each document can be extremely costly. For example, storing token embeddings for a corpus of 100,000 documents could require upwards of 2.46 TB.
- Computational Complexity: While precise, MaxSim increases computational demands at query time, as each token in the query must be compared to all tokens in the document.
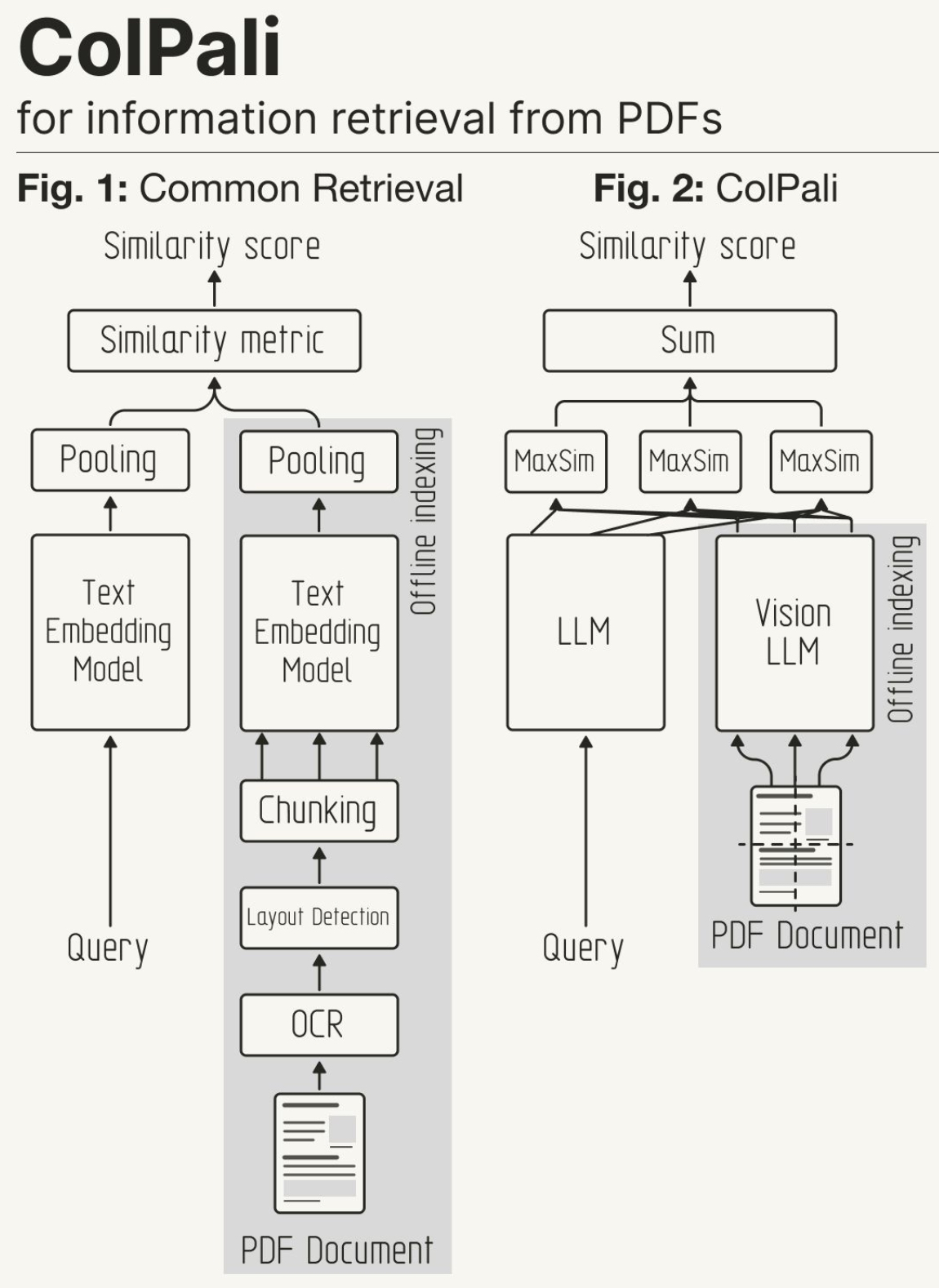
ColPali: Expanding to Multimodal Late-Interaction Retrieval
- ColPali by Faysse et al. (2024) integrates the late interaction mechanism from ColBERT with a Vision Language Model (VLM) called PaliGemma to handle multimodal documents, such as PDFs with text, images, and tables. Instead of relying on OCR and layout parsing, ColPali uses screenshots of PDF pages to directly embed both visual and textual content. This enables powerful multimodal retrieval in complex documents.
Example
- Consider a complex PDF with both text and images. ColPali treats each page as an image and embeds it using a VLM. When a user queries the system, the query is matched with embedded screenshots via late interaction, improving the ability to retrieve relevant pages based on both visual and textual content.
Comparative Analysis
| Metric | Naive Chunking | Late Chunking | Late Interaction |
|---|---|---|---|
| Storage Requirements | Minimal storage, ~4.9 GB for 100,000 documents | Same as naive chunking, ~4.9 GB for 100,000 documents | Extremely high storage, ~2.46 TB for 100,000 documents |
| Retrieval Precision | Lower precision due to context fragmentation | Improved precision by retaining context across chunks | Highest precision with token-level matching |
| Complexity and Cost | Simple implementation, minimal resources | Moderately more complex, efficient in compute and storage | Highly complex, resource-intensive in both storage and computation |
Sentence Embeddings: The What and Why
- Motivation:
- Before the introduction of Sentence-BERT (SBERT), applying BERT to semantic similarity or retrieval tasks was computationally infeasible at scale. BERT operated as a cross-encoder, where each sentence pair required a joint forward pass with full cross-attention, resulting in \(O(n^2)\) complexity. Using raw BERT embeddings—such as averaging token vectors or taking the
[CLS]output—performed worse than earlier static embedding models like GloVe, meaning embeddings couldn’t be precomputed or efficiently compared. Consequently, BERT was limited to re-ranking a small number of candidate sentences rather than performing large-scale semantic retrieval. - SBERT addressed this limitation by fine-tuning BERT in a Siamese or triplet configuration, enabling independent computation of sentence embeddings. This allowed \(O(n)\) embedding computations followed by lightweight cosine similarity comparisons, reducing semantic search computation from roughly 65 hours to 5 seconds while preserving accuracy. This breakthrough laid the foundation for modern dense retrieval, dual-encoder architectures, and retrieval-augmented generation (RAG) systems, all of which depend on scalable, precomputable embeddings.
- Before the introduction of Sentence-BERT (SBERT), applying BERT to semantic similarity or retrieval tasks was computationally infeasible at scale. BERT operated as a cross-encoder, where each sentence pair required a joint forward pass with full cross-attention, resulting in \(O(n^2)\) complexity. Using raw BERT embeddings—such as averaging token vectors or taking the
Background: Differences compared to Token-Level Models like BERT
-
As an overview, let’s look into how sentence transformers differ compared to token-level embedding models such as BERT.
-
Sentence Transformers are a modification of the traditional BERT model, tailored specifically for generating embeddings of entire sentences (i.e., sentence embeddings). The key differences in their training approaches are:
- Objective: BERT is trained to predict masked words and next sentence prediction. Sentence Transformers, as introduced in Sentence-BERT by Reimers and Gurevych (2019), are fine-tuned specifically to understand relationships between sentences. They produce embeddings where semantically similar sentences are close in vector space, typically using cosine similarity as the comparison metric.
- Level of Embedding: BERT provides contextualized token embeddings, while Sentence Transformers produce a single, semantically meaningful embedding for the entire sentence by applying a pooling operation to the transformer’s output.
- Training Data and Tasks: SBERT is fine-tuned using datasets like SNLI and MultiNLI, which contain labeled sentence pairs (entailment, contradiction, neutral). This contrastive supervision enables it to learn sentence-level semantics that generalize well to similarity tasks.
- Siamese and Triplet Network Structures: SBERT introduces a siamese or triplet architecture where two or three BERT models (sharing weights) encode input sentences into embeddings. During training, these embeddings are optimized so that semantically close sentences have higher cosine similarity and dissimilar ones have lower similarity.
- Pooling Strategies: To obtain a fixed-size vector, SBERT applies pooling over the last hidden layer of BERT. The paper experiments with three strategies—mean pooling, max pooling, and using the
[CLS]token output—with mean pooling performing best. - Fine-Tuning Objectives: Depending on available supervision, SBERT can use classification (softmax over concatenated embeddings and element-wise differences), regression (cosine similarity with mean-squared error), or triplet loss objectives to align embeddings of related sentences.
- For the classification objective, the embeddings \(u\) and \(v\) are concatenated with their element-wise absolute difference \(\mid u - v \mid\), forming a vector of size \(3n\). This is passed through a fully connected linear layer with weight matrix \(W_t \in \mathbb{R}^{3n \times k}\) before applying softmax \(o = \text{softmax}(W_t [u; v; \mid u - v \mid])\), where \(k\) is the number of output classes (since the SBERT paper focused on NLI, they were entailment, contradiction, and neutral). This projection layer provides the learned transformation before softmax classification. By removing the softmax head at inference time, SBERT reduces similarity computation from \(O(n^2)\) pairwise comparisons to \(O(n)\) independent embedding computations followed by lightweight cosine similarity scoring—enabling massive speedups in retrieval. During training, the softmax classifier makes the model close-ended, restricted to a fixed set of \(k\) output classes (e.g., entailment, contradiction, neutral). In contrast, inference is open-ended: without the softmax constraint, SBERT functions as a general-purpose feature extractor whose embeddings can be compared across unseen categories using cosine similarity, optionally followed by thresholding on the score \(\text{sim}(u, v) = \frac{u \cdot v}{\mid u \mid \mid v \mid}\) for binary decisions (e.g., “similar” vs. “not similar”).
- Although the original SBERT paper did not employ it, this triplet framework can be extended to Multiple Negatives Ranking Loss (MNRL), where each batch provides multiple implicit negatives for every anchor–positive pair. MNRL improves efficiency by leveraging all non-matching pairs within a batch as negatives, making training more stable and scalable for large datasets.
- Efficiency in Generating Sentence Embeddings or Similarity Tasks: In the standard BERT model, sentence embeddings are generated using the
[CLS]vector from the last layer, which performs poorly for semantic similarity (correlations as low as 0.29 on STS tasks). In contrast, SBERT dramatically improves both accuracy and computational efficiency: semantic similarity searches that would take ~65 hours with BERT can be done in about 5 seconds with SBERT. - Applicability: While BERT excels at tasks requiring token-level understanding (e.g., named entity recognition, question answering), Sentence Transformers are optimized for semantic similarity, clustering, and retrieval tasks.
- The left half of the following figure (source) shows the SBERT architecture with the classification objective function, e.g., for fine-tuning on SNLI dataset. The two BERT networks have tied weights (siamese network structure).
- This figure illustrates the training phase, where two tied-weight BERT encoders process sentences A and B to produce embeddings \(u\) and \(v\). These embeddings are concatenated with their element-wise absolute difference \(\mid u - v \mid\) and passed through a linear projection layer \(W_t\) before a softmax classifier predicts relational labels such as entailment or contradiction. The softmax layer is critical during training because it provides a supervised learning signal (with discrete classification labels) that guides the model to map semantically related sentences close together in embedding space.
- The right half of the following figure (source) shows the SBERT architecture during inference, for example, to compute similarity scores. This architecture is also used with the regression objective function.
- This figure depicts the inference phase, where the trained encoders are used without the softmax classification head. Instead, embeddings are generated independently for each sentence and compared using cosine similarity, optionally followed by thresholding to make binary similarity decisions.
- The removal of the softmax layer is essential because, if retained, it would require concatenating pairs of embeddings and performing a new forward pass for each pair—reintroducing the \(O(n^2)\) cost of cross-encoding. Without the softmax layer, embeddings can be computed once per sentence (offline or on-demand), allowing fast vector-based retrieval and comparison. In other words, omitting the softmax during inference enables the key property that makes SBERT efficient: sentence embeddings become independent representations that can be precomputed and compared directly using cosine similarity, without needing joint inference over pairs.
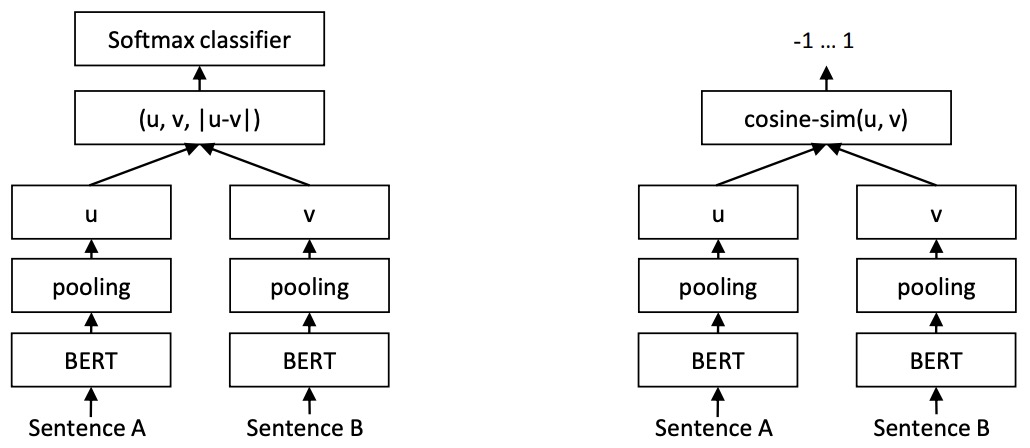
- In summary, while BERT is a general-purpose contextual language model, Sentence Transformers like SBERT are optimized for semantic comparison at the sentence level, producing dense, meaningful embeddings well-suited for similarity-based tasks.
Training Process for Sentence Transformers vs. Token-Level Embedding Models
-
Sentence Transformers are trained differently from token-level models such as BERT. Their process focuses on aligning sentence meanings rather than predicting masked words.
- Model Architecture: SBERT builds on pretrained BERT or RoBERTa models by adding a pooling layer that converts token-level outputs into a single sentence embedding.
- Training Data: SBERT is fine-tuned on Natural Language Inference (NLI) datasets like SNLI and MultiNLI, containing hundreds of thousands of labeled sentence pairs that capture semantic relations.
- Training Objectives:
- Classification Objective: Concatenates embeddings of two sentences \((u, v)\) with their element-wise absolute difference \(\mid u - v \mid\), projects the resulting \(3n\)-dimensional vector through a linear layer \(W_t \in \mathbb{R}^{3n \times k}\), and applies softmax to obtain class probabilities. This setup makes training close-ended, restricted to the predefined NLI labels, whereas inference is open-ended, since embeddings can later be compared beyond those classes using cosine similarity and thresholding.
- Regression Objective: Minimizes mean-squared error between cosine similarity of embeddings and human-annotated similarity scores.
- Triplet Objective: Minimizes the margin between anchor–positive and anchor–negative pairs, ensuring semantically close sentences are closer in embedding space. Although the original paper did not use it, this triplet loss can naturally extend to Multiple Negatives Ranking Loss (MNRL), which treats every non-matching sentence in the same batch as a negative sample—improving data efficiency and convergence for large-scale contrastive learning.
- Pooling and Representation: The final sentence embedding is typically the mean of all token embeddings from the last hidden layer, which captures overall sentence meaning better than using only the
[CLS]token. - Efficiency Gains: SBERT reduces the number of required pairwise comparisons from \(O(n^2)\) to \(O(n)\), since sentence embeddings can be precomputed and compared using cosine similarity. This makes it suitable for large-scale applications like semantic search or clustering.
- Evaluation and Performance: SBERT achieves state-of-the-art performance on multiple STS benchmarks, outperforming models like InferSent and Universal Sentence Encoder by significant margins (average correlation improvements of 5–12 points).
-
Practical Impact on Retrieval Systems: SBERT’s dual-encoder setup—where sentences are encoded independently and compared via cosine similarity—became the cornerstone of dense retrieval. Removing the softmax layer in inference is precisely what enables offline precomputation and real-time similarity search across massive corpora. This innovation allowed embedding-based retrieval systems, approximate nearest neighbor (ANN) search, and RAG pipelines to become scalable and efficient at industrial scale.
-
In summary, Sentence-BERT extends BERT with architecture and training modifications that produce semantically rich, scalable, and efficient sentence representations suitable for similarity and clustering tasks.
Applying Sentence Transformers for RAG
- Now, let’s look into why sentence transformers are the numero uno choice of models to generate embeddings for RAG.
- RAG leverages Sentence Transformers for their ability to understand and compare the semantic content of sentences. This integration is particularly useful in scenarios where the model needs to retrieve relevant information before generating a response. Here’s how Sentence Transformers are useful in a RAG setting:
- Improved Document Retrieval: Sentence Transformers are trained to generate embeddings that capture the semantic meaning of sentences. In a RAG setting, these embeddings can be used to match a query (like a user’s question) with the most relevant documents or passages in a database. This is critical because the quality of the generated response often depends on the relevance of the retrieved information.
- Efficient Semantic Search: Traditional keyword-based search methods might struggle with understanding the context or the semantic nuances of a query. Sentence Transformers, by providing semantically meaningful embeddings, enable more nuanced searches that go beyond keyword matching. This means that the retrieval component of RAG can find documents that are semantically related to the query, even if they don’t contain the exact keywords.
- Contextual Understanding for Better Responses: By using Sentence Transformers, the RAG model can better understand the context and nuances of both the input query and the content of potential source documents. This leads to more accurate and contextually appropriate responses, as the generation component of the model has more relevant and well-understood information to work with.
- Scalability in Information Retrieval: Sentence Transformers can efficiently handle large databases of documents by pre-computing embeddings for all documents. This makes the retrieval process faster and more scalable, as the model only needs to compute the embedding for the query at runtime and then quickly find the closest document embeddings.
- Enhancing the Generation Process: In a RAG setup, the generation component benefits from the retrieval component’s ability to provide relevant, semantically-rich information. This allows the language model to generate responses that are not only contextually accurate but also informed by a broader range of information than what the model itself was trained on.
- In summary, Sentence Transformers enhance the retrieval capabilities of RAG models with LLMs by enabling more effective semantic search and retrieval of information. This leads to improved performance in tasks that require understanding and generating responses based on large volumes of text data, such as question answering, chatbots, and information extraction.
Retrieval
- Retrieval is the core mechanism that enables RAG systems to ground language model outputs in external knowledge by selecting a small, relevant subset of documents or passages from a large corpus to condition generation.
- Lexical, semantic, and hybrid retrieval methods define how queries are mapped to candidate context, directly influencing what information the language model can and cannot use when generating an answer.
- A solid understanding of retrieval techniques is critical for RAG because retrieval failures (missing key facts, retrieving irrelevant context, or violating constraints) propagate downstream and manifest as hallucinations, inaccuracies, or unsafe outputs during generation.
- A detailed discourse of retrieval (also known as the information retrieval problem) is available in our Search primer.
Lexical Retrieval
- Lexical retrieval, also referred to as sparse retrieval, term-based retrieval, or keyword-based retrieval, is the classical foundation of information retrieval systems. It operates purely on observable text signals, relying on exact token matches between a query and documents. Relevance is estimated using statistical properties of terms within documents and across the corpus, without attempting to model meaning or intent.
- At its core, lexical retrieval assumes that relevance correlates with how frequently and distinctively query terms appear in a document.
Core assumptions
-
Lexical retrieval is deterministic, interpretable, and highly efficient at scale because of the following assumptions:
- Words are treated as discrete symbols (tokens).
- Matching is based on an exact match overlap.
- Importance is inferred from distributional statistics, not semantics.
- Query intent is approximated by the literal terms provided.
TF-IDF (Term Frequency–Inverse Document Frequency)
-
TF-IDF is one of the earliest and most influential scoring schemes in information retrieval. It decomposes relevance into two components:
-
Term Frequency (TF): Measures how often a term appears in a document. The intuition is that repeated mentions indicate topical relevance.
-
Inverse Document Frequency (IDF): Downweights terms that appear frequently across the corpus, under the assumption that common words carry less discriminative power.
-
-
A standard formulation is:
\[\text{TF-IDF}(t, d) = \text{TF}(t, d) \cdot \log\left(\frac{N}{\text{DF}(t)}\right)\]-
where:
- \(t\) is a term,
- \(d\) is a document,
- \(N\) is the total number of documents,
- \(\text{DF}(t)\) is the number of documents containing \(t\).
-
Strengths of TF-IDF
- Simple and fast to compute.
- Strong baseline for keyword-heavy queries.
- Fully interpretable scoring.
- Requires no training data.
Limitations of TF-IDF
-
These limitations motivated more refined probabilistic ranking functions.
- Linear growth of TF causes term repetition to dominate scores.
- No document length normalization.
- Treats all term positions equally.
- Performs poorly on long documents and verbose queries.
- Fails completely on synonymy and paraphrasing.
BM25 (Best Matching 25)
-
BM25 is a probabilistic retrieval model that improves upon TF-IDF by addressing its key weaknesses. It introduces two critical refinements:
-
Term frequency saturation: Additional occurrences of a term provide diminishing returns rather than linear gains.
-
Document length normalization: Longer documents are normalized to prevent unfair advantage due to sheer volume of text.
-
-
A common BM25 formulation is:
\[\text{BM25}(q, d) = \sum_{t \in q} \text{IDF}(t) \cdot \frac{f(t,d) \cdot (k_1 + 1)} {f(t,d) + k_1 \cdot \left(1 - b + b \cdot \frac{|d|}{\text{avgdl}}\right)}\]-
where:
- \(f(t,d)\) is the frequency of term \(t\) in document \(d\),
- \(\mid d \mid\) is the document length,
- \(\text{avgdl}\) is the average document length,
- \(k_1\) controls TF saturation (typically \(1.2 \le k_1 \le 2.0\)),
- \(b\) controls length normalization (typically \(b \approx 0.75\)).
-
Why BM25 outperforms TF-IDF
-
BM25 remains the default lexical ranking function in most production search engines. It outperforms TF-IDF along the following dimensions:
- Prevents term stuffing from dominating rankings.
- Fairly compares short and long documents.
- More stable across heterogeneous corpora.
- Empirically strong across many domains without tuning.
Operational characteristics of lexical retrieval
-
Performance and scalability:
- Sub-millisecond scoring per document.
- Efficient inverted index structures.
- Scales to billions of documents.
-
Determinism:
- Identical inputs always produce identical rankings.
- No stochastic components or model drift.
-
Explainability:
- Rankings can be justified via term overlap and weights.
- Essential for regulated or high-stakes systems.
Advantages
- Extremely fast and resource-efficient.
- Robust to rare, technical, or newly introduced terms.
- Guarantees recall for exact matches.
- Transparent scoring behavior.
- Works exceptionally well for:
- Identifiers (product IDs, SKUs, error codes, etc.)
- Entity names (proper nouns, etc.)
- Dates (timestamps, ranges, etc.)
- Abbreviations (e.g., API, HTTP, JWT, etc.)
- Domain-specific jargon (e.g., medicine names, chemical compounds, etc.)
- Legal clauses (e.g., “Section 3.2.1”, etc.) and citations (e.g., “17 U.S.C. § 512”, etc.)
- Short or underspecified queries
Limitations
- Lexical retrieval limitations are structural, not implementation flaws, and they are the primary reason semantic and hybrid retrieval methods emerged:
- No understanding of meaning or intent.
- Cannot match synonyms or paraphrases.
- Sensitive to vocabulary mismatch.
- Brittle for natural language questions.
- Poor recall for descriptive or conversational queries.
Semantic Retrieval
-
Semantic retrieval, also commonly referred to as dense retrieval, neural retrieval, or embedding-based retrieval, is a modern approach to information retrieval that attempts to model the meaning and intent behind queries and documents rather than relying on exact lexical overlap.
-
Instead of treating text as discrete symbols, semantic retrieval represents text as continuous vectors in a high-dimensional space. Relevance is determined by geometric proximity in this space, under the assumption that semantically similar texts lie close to each other.
Core idea
-
Semantic retrieval reframes search as a similarity problem in vector space:
- Queries and documents are encoded into dense vectors.
- Similarity between vectors approximates semantic relatedness.
- Retrieval becomes a nearest-neighbor search problem.
-
A common similarity measure is cosine similarity:
\[\text{cosine_sim}(q, d) = \frac{\vec{q} \cdot \vec{d}} {\mid\vec{q}\mid \mid\vec{d}\mid}\]-
where:
- \(\vec{q}\) is the query embedding,
- \(\vec{d}\) is the document embedding.
-
Vector encoding
- Encoder models:
-
Queries and documents are passed through neural encoders, typically based on transformer architectures. Common encoder types include:
- Dual encoders (bi-encoders)
- Sentence transformers
- Domain-specific fine-tuned encoders
-
In most production systems, queries and documents are encoded independently to allow precomputation of document embeddings.
-
- Training signal:
-
Encoders are trained using contrastive objectives that:
- Pull relevant query–document pairs closer
- Push irrelevant pairs farther apart
-
A simplified contrastive loss can be expressed as:
\[\mathcal{L} = -\log\frac{\exp(\text{sim}(q, d^+))}{\exp(\text{sim}(q, d^+)) + \sum_{d^-} \exp(\text{sim}(q, d^-))}\]- where \(d^+\) is a relevant document and \(d^-\) are negatives.
-
- Representation properties:
-
Good semantic embeddings capture:
- Synonymy and paraphrasing
- Conceptual similarity
- Contextual meaning
- Cross-lingual alignment (in multilingual models)
-
Semantic matching and retrieval
-
Once embeddings are computed:
- Documents are indexed in a vector index.
- At query time, the query embedding is generated.
- Approximate nearest neighbor search retrieves the top \(K\) closest document vectors.
-
This enables matches even when there is zero keyword overlap between query and document.
Approaches
- Let’s look at three different types of retrieval: standard, sentence window, and auto-merging. Each of these approaches has specific strengths and weaknesses, and their suitability depends on the requirements of the RAG task, including the nature of the dataset, the complexity of the queries, and the desired balance between specificity and contextual understanding in the responses.
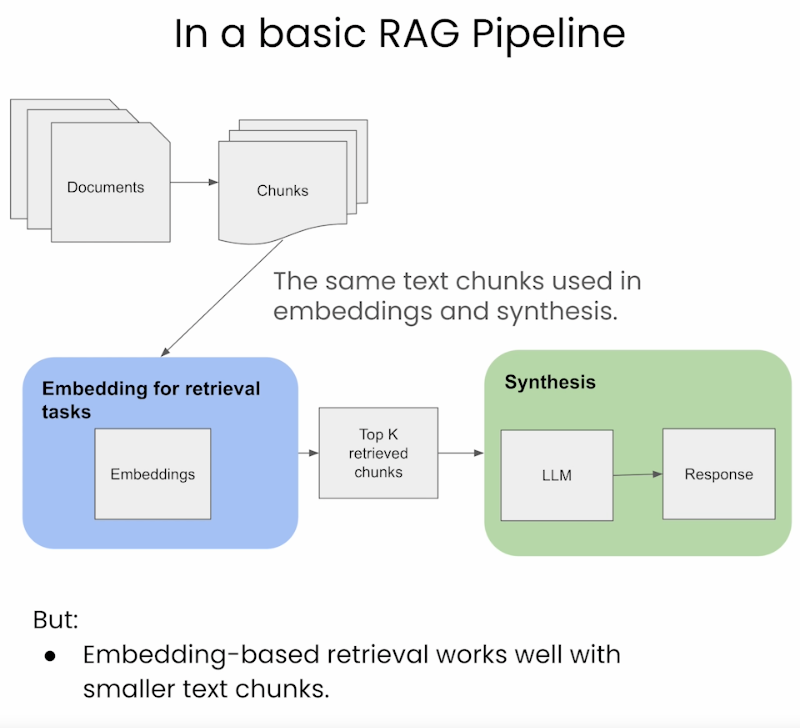
Standard/Naive approach
- As we see in the image below (source), the standard pipeline uses the same text chunk for indexing/embedding as well as the output synthesis.
-
In the context of RAG, the advantages and disadvantages of the three approaches are as follows:
-
Advantages:
- Simplicity and Efficiency: This method is straightforward and efficient, using the same text chunk for both embedding and synthesis, simplifying the retrieval process.
- Uniformity in Data Handling: It maintains consistency in the data used across both retrieval and synthesis phases.
-
Disadvantages:
- Limited Contextual Understanding: LLMs may require a larger window for synthesis to generate better responses, which this approach may not adequately provide.
- Potential for Suboptimal Responses: Due to the limited context, the LLM might not have enough information to generate the most relevant and accurate responses.
Sentence-Window Retrieval / Small-to-Large Retrieval
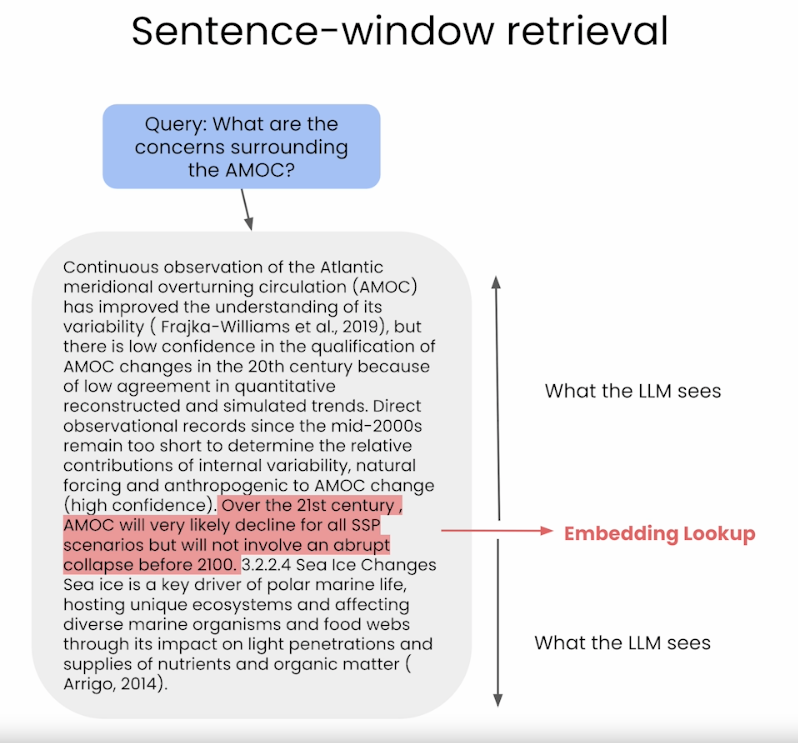
- The sentence-window approach breaks down documents into smaller units, such as sentences or small groups of sentences.
- It decouples the embeddings for retrieval tasks (which are smaller chunks stored in a Vector DB), but for synthesis it adds back in the context around the retrieved chunks, as seen in the image below (source).
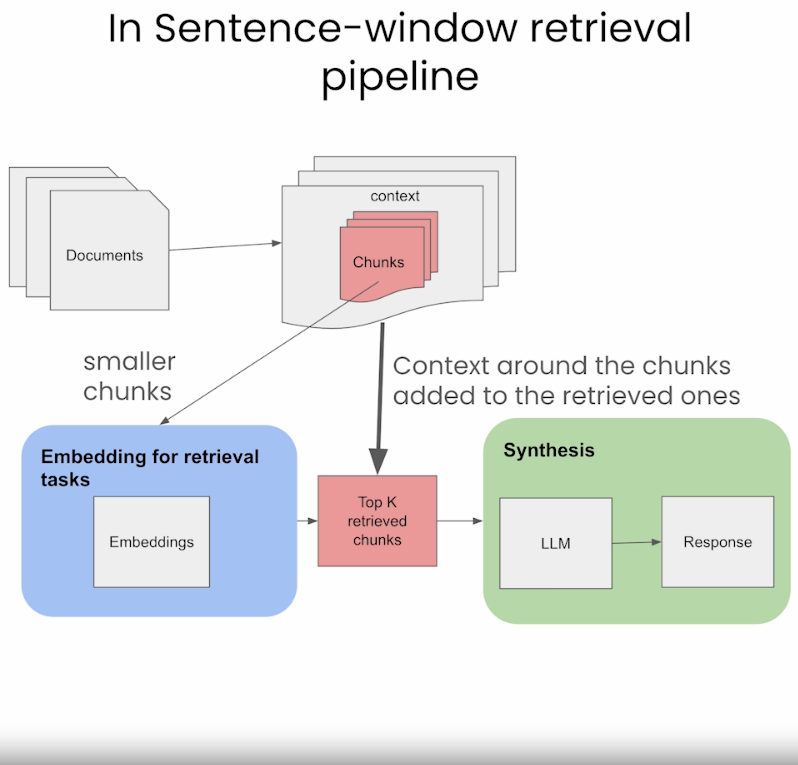
- During retrieval, we retrieve the sentences that are most relevant to the query via similarity search and replace the sentence with the full surrounding context (using a static sentence-window around the context, implemented by retrieving sentences surrounding the one being originally retrieved) as shown in the figure below (source).
-
Advantages:
- Enhanced Specificity in Retrieval: By breaking documents into smaller units, it enables more precise retrieval of segments directly relevant to a query.
- Context-Rich Synthesis: It reintroduces context around the retrieved chunks for synthesis, providing the LLM with a broader understanding to formulate responses.
- Balanced Approach: This method strikes a balance between focused retrieval and contextual richness, potentially improving response quality.
-
Disadvantages:
- Increased Complexity: Managing separate processes for retrieval and synthesis adds complexity to the pipeline.
- Potential Contextual Gaps: There’s a risk of missing broader context if the surrounding information added back is not sufficiently comprehensive.
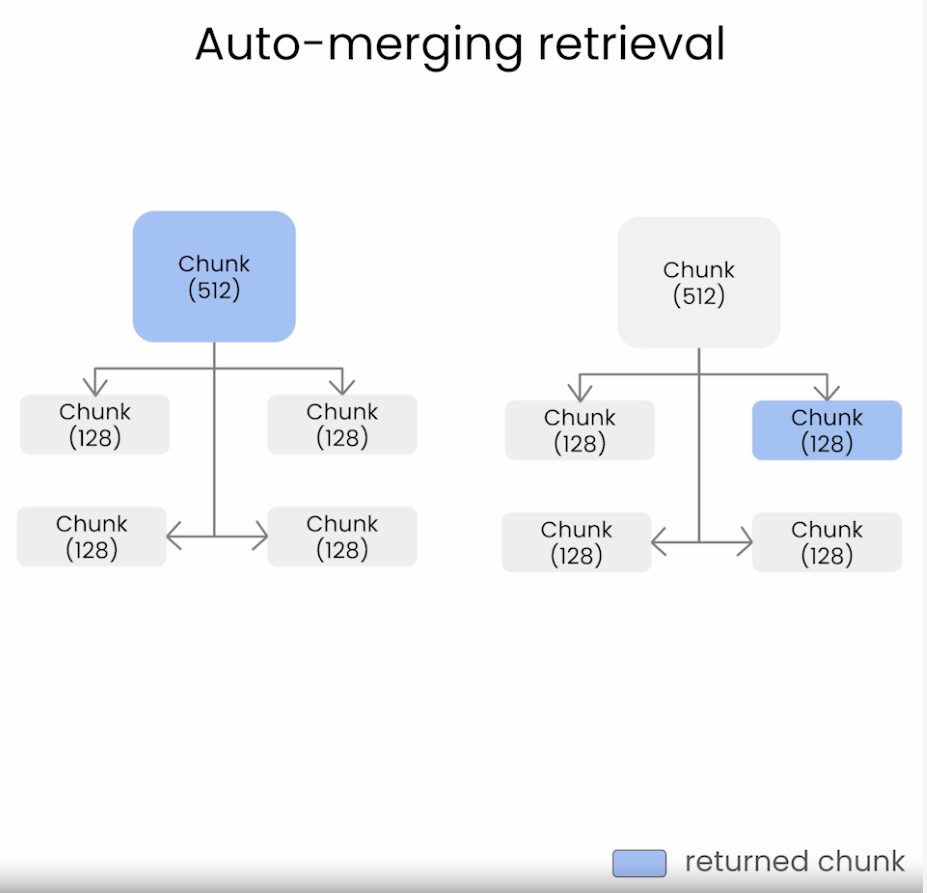
Auto-merging Retriever / Hierarchical Retriever
- The image below (source), illustrates how auto-merging retrieval can work where it doesn’t retrieve a bunch of fragmented chunks as would happen with the naive approach.
- The fragmentation in the naive approach would be worse with smaller chunk sizes as shown below (source).
- Auto-merging retrieval aims to combine (or merge) information from multiple sources or segments of text to create a more comprehensive and contextually relevant response to a query. This approach is particularly useful when no single document or segment fully answers the query but rather the answer lies in combining information from multiple sources.
- It allows smaller chunks to be merged into bigger parent chunks. It does this via the following steps:
- Define a hierarchy of smaller chunks linked to parent chunks.
- If the set of smaller chunks linking to a parent chunk exceeds some threshold (say, cosine similarity), then “merge” smaller chunks into the bigger parent chunk.
-
The method will finally retrieve the parent chunk for better context.
-
Advantages:
- Comprehensive Contextual Responses: By merging information from multiple sources, it creates responses that are more comprehensive and contextually relevant.
- Reduced Fragmentation: This approach addresses the issue of fragmented information retrieval, common in the naive approach, especially with smaller chunk sizes.
- Dynamic Content Integration: It dynamically combines smaller chunks into larger, more informative ones, enhancing the richness of the information provided to the LLM.
-
Disadvantages:
- Complexity in Hierarchy and Threshold Management: The process of defining hierarchies and setting appropriate thresholds for merging is complex and critical for effective functioning.
- Risk of Over-generalization: There’s a possibility of merging too much or irrelevant information, leading to responses that are too broad or off-topic.
- Computational Intensity: This method might be more computationally intensive due to the additional steps in merging and managing the hierarchical structure of text chunks.
Contextual Retrieval
- For LLMs to deliver relevant and accurate responses, they must retrieve the right information from a knowledge base. Traditional RAG improves model accuracy by fetching relevant text chunks and appending them to the prompt. However, such methods often remove crucial context when encoding information, leading to failed retrievals and suboptimal outputs.
- Contextual Retrieval, introduced by Anthropic, is an advanced technique designed to improve this process by ensuring that retrieved chunks maintain their original context. It employs contextual embeddings – embeddings that incorporate chunk-specific background information and contextual BM25 – an enhanced BM25 ranking that considers the broader document context.
-
By prepending contextual metadata to each document chunk before embedding, Contextual Retrieval significantly enhances search accuracy. This approach reduces failed retrievals by 49% and, when combined with re-ranking, by 67%.
- Why Context Matters in Retrieval:
- Traditional RAG solutions divide documents into small chunks for efficient retrieval. However, these fragments often lose critical context. For example, the statement “The company’s revenue grew by 3% over the previous quarter” lacks information about which company or quarter it refers to. Contextual Retrieval solves this by embedding relevant metadata into each chunk.
- Implementation of Contextual Retrieval:
- To implement Contextual Retrieval, a model like Claude 3 Haiku can generate concise context for each chunk. This context is then prepended before embedding and indexing, ensuring more precise retrieval. Developers can automate this process at scale using specialized retrieval pipelines.
- Prompt Used for Contextual Retrieval:
- Anthropic’s method involves using Claude to generate a short, document-specific context for each chunk using the following prompt:
<document> </document> Here is the chunk we want to situate within the whole document: <chunk> </chunk> Please give a short, succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else. - This process automatically generates a concise contextualized description that is prepended to the chunk before embedding and indexing.
- Anthropic’s method involves using Claude to generate a short, document-specific context for each chunk using the following prompt:
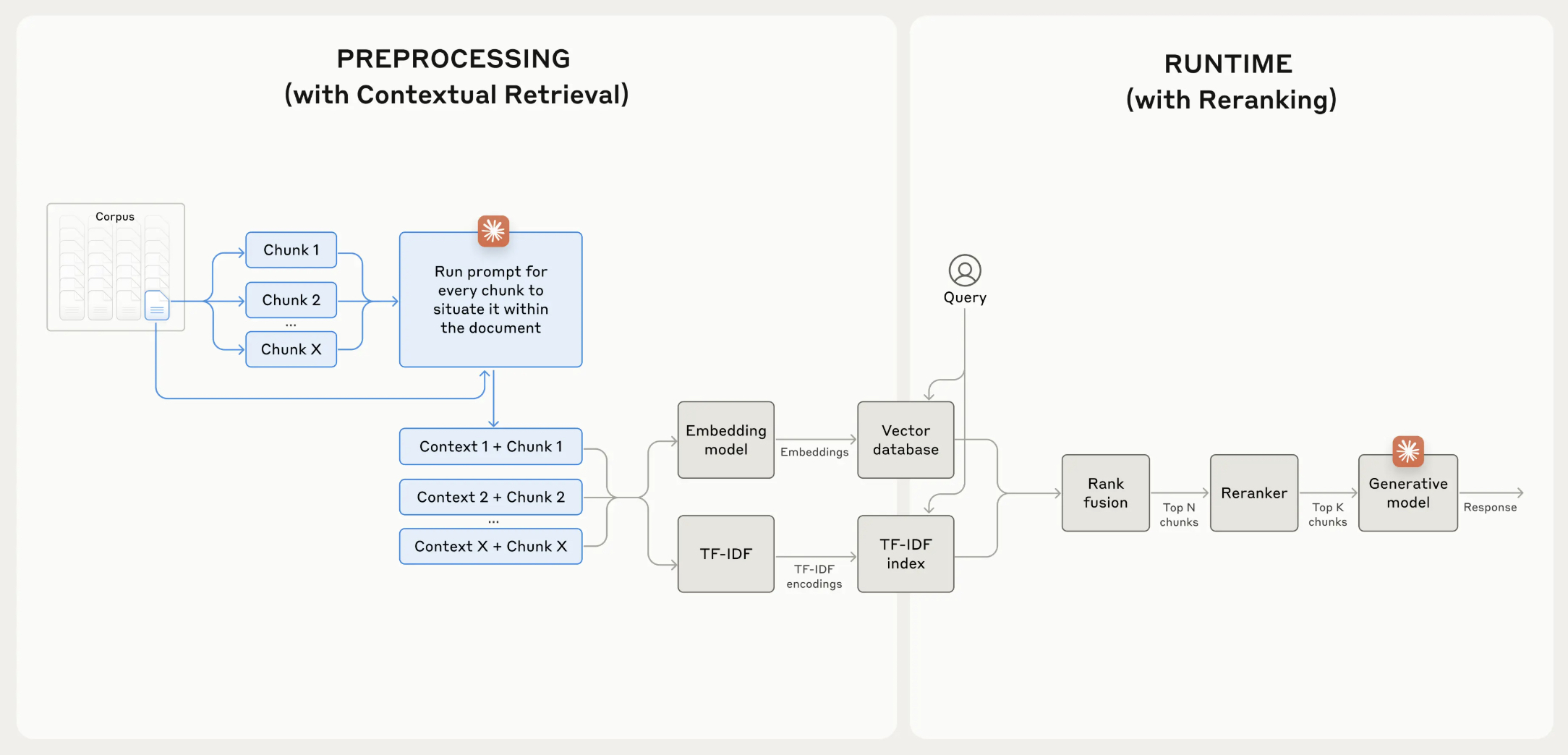
- Combining Contextual Retrieval with Re-ranking:
- For maximum performance, Contextual Retrieval can be paired with re-ranking models, which filter and reorder retrieved chunks based on their relevance. This additional step enhances retrieval precision, ensuring only the most relevant chunks are passed to the LLM.
- The following flowchart from Anthropic’s blog shows the combined contextual retrieval and re-ranking stages which seek to maximize retrieval accuracy.
- Key Takeaways:
- Contextual Embeddings improve retrieval accuracy by preserving document meaning.
- BM25 + Contextualization enhances exact-match retrieval.
- Combining Contextual Retrieval with re-ranking further boosts retrieval effectiveness.
- Developers can implement Contextual Retrieval using prompt-based preprocessing and automated pipelines.
- With Contextual Retrieval, LLM-powered knowledge systems can achieve greater accuracy, scalability, and relevance, unlocking new levels of performance in real-world applications.
Using Approximate Nearest Neighbors (ANN) for Retrieval
-
The next step is to consider which Approximate Nearest Neighbors (ANN) algorithm and library to choose for large-scale vector similarity search in retrieval systems. ANN is preferred over exact nearest neighbor search because:
- Exact search scales linearly with corpus size and becomes prohibitively slow and expensive for large embedding collections.
- ANN trades a small, controllable loss in recall for orders-of-magnitude improvements in latency and throughput.
- Modern ANN methods are designed to meet strict production constraints (low latency, bounded memory, high QPS), which are critical for real-time RAG pipelines.
- A useful way to compare and select an appropriate ANN approach is to reference ANN-Benchmarks, which provides standardized evaluations of different algorithms across accuracy, latency, and resource trade-offs.
- A detailed discourse on the concept of ANN can be found in our ANN primer.
Advantages of Semantic Retrieval
- Strong handling of paraphrases and synonyms.
- Robust to vocabulary mismatch.
- Supports natural language and conversational queries.
- Effective for long, descriptive queries.
- Often works across languages without explicit translation.
- Recovers relevant content missed by lexical methods.
Challenges
-
Computational cost:
- Embedding generation is expensive relative to lexical scoring.
- Nearest neighbor search is more complex than inverted index lookup.
-
Approximation trade-offs:
- Vector search typically uses approximate algorithms.
- Recall may be sacrificed for latency at scale.
-
Model dependence:
- Retrieval quality depends heavily on training data.
- Domain mismatch can degrade performance.
- Biases in training data propagate into retrieval results.
-
Maintenance complexity:
- Document embeddings must be recomputed when:
- The corpus changes significantly
- The model is updated
- Versioning embeddings and models adds operational overhead.
- Document embeddings must be recomputed when:
-
Precision issues:
- Semantic similarity can over-generalize.
- Exact constraints, identifiers, or negations may be missed.
- Rare or newly introduced terms may not be well represented.
Use-cases where semantic retrieval excels
- Exploratory or research-oriented search.
- Natural language question answering.
- Knowledge discovery and recall-heavy tasks.
- User-facing search with ambiguous or verbose queries.
Use-cases where semantic retrieval struggles
-
These strengths and weaknesses are complementary to lexical retrieval, which is why semantic retrieval is rarely deployed alone in high-reliability systems. Specifically the areas where semantic search struggles are as follows:
- Queries dominated by symbols, codes, or IDs.
- Legal, medical, or compliance-sensitive text requiring exact wording.
- Short, underspecified queries with little context.
- Scenarios demanding deterministic, explainable rankings.
Hybrid Retrieval (Lexical + Semantic)
-
Hybrid retrieval combines lexical (sparse) and semantic (dense) retrieval to leverage the complementary strengths of both approaches. The core motivation is simple: real-world queries simultaneously contain exact terms that must be respected and implicit intent that must be inferred.
-
A hybrid retrieval system combines the strengths of lexical and semantic methods to deliver more accurate and robust results by reducing the likelihood that either system’s blind spots dominate the final ranking.
-
Hybrid systems are designed to minimize worst-case failure modes by ensuring that neither exact matching nor semantic understanding is relied on exclusively.
Why hybrid retrieval is necessary
-
Lexical and semantic retrieval fail in opposite ways:
- Lexical retrieval fails when vocabulary mismatch occurs.
- Semantic retrieval fails when exact wording, identifiers, or constraints matter.
-
Hybrid retrieval exists to ensure:
- Exact matches are never lost.
- Semantic relevance is still captured.
- Recall and precision remain stable across query types.
-
In practice, hybrid retrieval is not a single algorithm but a family of architectures.
Common hybrid retrieval architectures
-
Two-stage hybrid retrieval: Lexical retrieval is used first to generate a high-recall candidate set, which is then reranked by a semantic model. This design prioritizes efficiency and recall safety while allowing deep semantic reasoning to operate only where it matters.
-
Parallel hybrid retrieval with fusion: Lexical and semantic retrievers run independently over the corpus, and their results are merged using score-based or rank-based fusion methods. This approach treats lexical and semantic signals as peers rather than stages in a pipeline.
-
Native hybrid scoring: Some systems integrate sparse and dense signals directly into a single retrieval model or query interface, blending term-based and embedding-based evidence during initial retrieval rather than combining results afterward.
The dominant production architecture: Lexical retrieval + Semantic re-ranking
-
The most common hybrid architecture is a two-stage pipeline:
- Candidate generation (lexical):
-
A lexical retriever (typically BM25) retrieves the top \(K\) candidates based on exact term overlap.
-
Typical values:
- \[K \in [100, 1000]\]
- Chosen to maximize recall while keeping downstream cost manageable
-
- Semantic re-ranking (dense or cross-encoder):
- Semantic re-ranking models aim to improve the ordering of retrieved documents by more accurately modeling relevance between a query and a small candidate set.
- In practice, these models are used after an initial retrieval step and can be grouped both by how they encode query–document interactions and by the type of signals they incorporate (semantic, instructional, or metadata-driven).
- Candidate generation (lexical):
-
Conceptually:
\[\text{Results} = \text{Rerank}_{\text{semantic}} \big( \text{BM25}(\text{Docs}) \big)\] -
This approach dominates because of its efficiency, recall-safety, easy of explainability, and compatibility with existing search infrastructure.
Parallel hybrid retrieval and score fusion
- An alternative approach runs lexical and semantic retrieval independently, then fuses their rankings. This approach is common when re-ranking is too expensive or when vector databases expose native hybrid querying.
Linear score fusion
\[\text{score}(d) = \alpha \cdot \text{BM25}(d) + (1 - \alpha) \cdot \text{sim}_{\text{semantic}}(d)\]-
Challenges:
- Scores must be normalized
- Sensitive to scaling differences
- Requires tuning \(\alpha\)
Reciprocal Rank Fusion (RRF)
-
One of the most popular and robust fusion techniques used in hybrid retrieval is Reciprocal Rank Fusion (RRF). RRF merges the rankings from different retrieval models (for example, BM25 and a neural retriever) by assigning higher scores to documents that consistently rank well across systems, rather than relying on raw scores.
-
RRF operates purely on rank positions, making it insensitive to score scale (i.e., it lacks the need for normalization unlike linear score fusion), distribution, or calibration differences between retrieval methods.
-
How RRF works:
- Each retrieval system independently produces a ranked list of documents.
- Each document receives a contribution based on its rank position in each list.
-
Contributions are summed to produce a final fusion score.
-
The RRF scoring function is:
\[\text{RRF Score}(d) = \sum_{i=1}^{n} \frac{1}{k + \text{rank}_i(d)}\]-
where:
- \(d\) is the document,
- \(\text{rank}_i(d)\) is the rank position of document \(d\) in the \(i^{\text{th}}\) ranked list,
- \(k\) is a smoothing constant (typically set to 60),
- \(n\) is the number of retrieval systems.
-
-
The constant \(k\) ensures that:
- Top-ranked documents dominate the contribution
- Differences among lower-ranked documents are compressed
- Noise from deep rankings does not overwhelm the fusion
-
Intuition behind RRF:
- The intuition behind RRF being especially well suited for hybrid lexical–semantic retrieval is as follows:
- Documents that appear near the top in multiple rankings are strongly favored.
- A document that ranks moderately well in several systems often beats one that ranks extremely well in only one.
- Systems with very different scoring behavior can still be combined reliably.
- The intuition behind RRF being especially well suited for hybrid lexical–semantic retrieval is as follows:
-
Example:
-
Suppose two retrieval systems return the following output results for a query:
- BM25:
[DocA, DocB, DocC, DocD, DocE] - Neural Retriever:
[DocF, DocC, DocA, DocG, DocB]
- BM25:
- We use \(k = 60\).
-
Note that if a document does not appear at a output of a retriever, it contributes \(0\) from that list.
-
RRF scores are computed as follows:
-
DocA (Rank 1 in BM25, rank 3 in Neural Retriever):
\[\text{RRF}(\text{DocA}) = \frac{1}{60 + 1} + \frac{1}{60 + 3} = \frac{1}{61} + \frac{1}{63} \approx 0.01639 + 0.01587 = 0.03226\] -
DocB (Rank 2 in BM25, rank 5 in Neural Retriever):
\[\text{RRF}(\text{DocB}) = \frac{1}{60 + 2} + \frac{1}{60 + 5} = \frac{1}{62} + \frac{1}{65} \approx 0.01613 + 0.01538 = 0.03151\] -
DocC (Rank 3 in BM25, rank 2 in Neural Retriever):
\[\text{RRF}(\text{DocC}) = \frac{1}{60 + 3} + \frac{1}{60 + 2} = \frac{1}{63} + \frac{1}{62} \approx 0.01587 + 0.01613 = 0.03200\] -
DocD (Rank 4 in BM25 only):
\[\text{RRF}(\text{DocD}) = \frac{1}{60 + 4} = \frac{1}{64} \approx 0.01563\] -
DocE (Rank 5 in BM25 only):
\[\text{RRF}(\text{DocE}) = \frac{1}{60 + 5} = \frac{1}{65} \approx 0.01538\] -
DocF (Rank 1 in Neural Retriever only):
\[\text{RRF}(\text{DocF}) = \frac{1}{60 + 1} = \frac{1}{61} \approx 0.01639\] -
DocG (Rank 4 in Neural Retriever only):
\[\text{RRF}(\text{DocG}) = \frac{1}{60 + 4} = \frac{1}{64} \approx 0.01563\]
-
-
After computing scores for all documents, the final RRF ranking is obtained by sorting documents in descending order of their cumulative RRF scores.
- This example illustrates the key property of RRF: documents that rank reasonably well across multiple retrieval systems (DocA, DocC, DocB) rise above documents that dominate only a single ranking, even if that dominance is at rank 1. Put simply, RRF rewards consistent relevance across retrieval strategies rather than dominance in a single system.
-
Advanced variations
-
Filtered parallel retrieval:
- Apply the same metadata filters
- Run lexical and semantic retrieval in parallel
- Fuse results with RRF
- Optionally rerank the fused set
-
Filter-aware rerankers:
- Metadata fields are appended to document text
- Allows rerankers to learn preferences (e.g., newer is better)
- Still respects hard filters upstream
-
Adaptive hybrid strategies:
- Short queries bias toward lexical
- Long natural language queries bias toward semantic
- Query classifiers dynamically adjust retrieval strategy
Common pitfalls
- Applying semantic retrieval before filtering, causing access violations
- Treating metadata as a scoring feature instead of a constraint
- Choosing \(K\) too small, harming recall
- Over-relying on semantic similarity for exact-match queries
- Ignoring explainability and audit requirements
Mental model
-
Think in layers:
- Which documents are allowed? (metadata filtering)
- Which documents mention what the user said? (lexical recall)
- Which of those best match what the user meant? (semantic ranking)
- Which should be preferred? (re-ranking and boosting)
-
Hybrid retrieval works because it preserves this separation of concerns.
System Tuning
- Tuning a hybrid retrieval system is an exercise in balancing recall, precision, latency, cost, and operational complexity.
- There is no universally optimal configuration; instead, production systems are tuned based on query distribution, corpus characteristics, and downstream task requirements.
Choosing the candidate set size (\(K\))
-
The parameter \(K\) controls how many documents are retrieved by the first-stage retriever (usually BM25) before semantic processing.
-
Trade-offs:
- Smaller \(K\) leads to lower latency and cost but increases the risk of missing relevant documents, since the semantic reranker has limited ability to recover items not present in the candidate set.
- Larger \(K\) improves recall but increases semantic compute cost and typically exhibits diminishing returns beyond a certain threshold.
-
Practical guidelines:
-
\(K \in [50, 100]\): Suitable for narrow domains with high-quality lexical signals.
-
\(K \in [200, 500]\): Common default for general-purpose search and RAG.
-
\(K \in [1000+]\): Used when recall is critical and latency budgets allow.
-
A useful mental model is:
If a document does not appear in the top \(K\) lexical results, semantic re-ranking cannot recover it.
-
Latency and cost considerations
- Hybrid retrieval latency is additive across stages:
-
Key optimization strategies include:
- Early filtering to shrink candidate sets
- Caching frequent query embeddings
- Applying rerankers only to the top subset (e.g., top 50)
- Adaptive pipelines based on query complexity
-
Latency budgets often dictate architectural choices more than relevance metrics.
Query-aware tuning
-
Many production systems dynamically adjust retrieval behavior:
-
Short keyword queries: Bias toward lexical retrieval and smaller \(K\)
-
Long natural language queries: Increase \(K\) and rely more on semantic re-ranking
-
Identifier-heavy queries: Skip semantic stages entirely
-
-
Query classifiers or heuristics are often sufficient to enable this adaptivity.
Evaluation and tuning methodology
-
Hybrid systems are tuned using:
- Offline relevance judgments (NDCG, MRR, Recall@\(k\))
- Online A/B testing
- Query-level error analysis
-
Important metrics include:
- Recall@\(k\) after lexical retrieval
- Precision improvements from re-ranking
- Latency percentiles (P50, P95, P99)
-
Tuning is iterative and tightly coupled to real query logs.
Hybrid Retrieval in RAG Architectures
- RAG systems rely on retrieval quality as a first-order determinant of generation quality. Hybrid retrieval has become the dominant retrieval strategy in RAG because it directly addresses the failure modes of both generation and retrieval models.
Why hybrid retrieval is critical for RAG
-
Language models:
- Cannot invent missing facts reliably
- Are sensitive to irrelevant or misleading context
- Perform best when provided with precise, relevant grounding documents
-
Hybrid retrieval ensures:
- Exact factual anchors are included
- Conceptually relevant context is not missed
- The model is not forced to hallucinate due to missing evidence
Canonical RAG retrieval pipeline
-
A typical hybrid RAG pipeline looks like:
-
Metadata filtering: Apply access, language, document type, and recency constraints.
-
Lexical retrieval: Retrieve top \(K\) documents using BM25.
-
Semantic re-ranking: Rerank candidates using a semantic model.
-
Context selection: Select top \(N\) documents or passages for generation.
-
-
Formally:
\[\text{Context} = \text{Top}_N \Big( \text{Rerank}_{\text{semantic}} ( \text{BM25}(\text{Docs} \mid \text{filters}) ) \Big)\]
Failure modes avoided by hybrid RAG
-
Semantic-only retrieval: Misses exact facts, dates, or identifiers.
-
Lexical-only retrieval: Misses paraphrased or implied information.
-
Unfiltered retrieval: Causes data leakage or compliance violations.
-
Hybrid retrieval with three stages (metadata filtering, lexical retrieval, and semantic retrieval/ranking) minimizes all three.
Final synthesis
- Hybrid retrieval is not an optimization but an architectural necessity: lexical retrieval anchors the system to exact facts, identifiers, and wording; semantic retrieval captures the user’s underlying intent and conceptual meaning; metadata filtering enforces correctness, safety, and access constraints; and re-ranking (covered in the Re-ranking section) maximizes usefulness by prioritizing the most relevant and coherent results for downstream consumption. Together, these components form a coherent pipeline in which each stage compensates for the limitations of the others, producing search behavior that is precise, robust, and reliable at scale.
- In RAG systems, generation quality is bounded by retrieval quality. Hybrid retrieval raises that bound by ensuring the language model sees the right information, for the right reasons, under the right constraints.
Metadata filtering
- Metadata filtering is the process of restricting the searchable corpus using structured, non-textual attributes attached to documents (such as access rights, tenant identifiers, language, timestamps, or document type) before or during retrieval, so that only contextually valid documents are ever considered for ranking.
- Metadata filtering is applicable to lexical retrieval, semantic retrieval, and hybrid retrieval alike, and is typically applied first as hard constraints, meaning documents that fail these conditions are excluded entirely rather than merely penalized in scoring.
- Treating metadata as hard constraints is essential because constraints like access control, tenancy, jurisdiction, and language are correctness requirements, not relevance preferences, regardless of whether relevance is computed lexically, semantically, or via a hybrid approach.
- Applying hard filters early improves system efficiency by shrinking the candidate set before lexical matching, vector search, or expensive semantic scoring and reranking, which often dominate latency and cost.
- By separating hard constraints from ranking logic, metadata filtering simplifies auditing, debugging, and explainability, allowing the system to clearly state that relevance was computed only within an explicitly defined and policy-compliant subset of the corpus.
Standard pattern
-
Apply metadata filters
-
Examples:
- tenant_id =
X - language =
"en" - date ≥
2024-01-01 - access_level ≤
user_clearance
- tenant_id =
-
-
Perform retrieval within the filtered set
- Lexical retrieval operates only on allowed documents
- Semantic retrieval or re-ranking is applied afterward (if used)
- Hybrid retrieval combines both within the same filtered universe
- Formally:
- This guarantees correctness by preventing data leakage, improves efficiency by reducing the search space early, and enables simpler reasoning and auditing by cleanly separating constraints from relevance scoring.
Hard filters (Metadata Filtering) vs. Soft boosts (Metadata Re-ranking)
- Hard filters are non-negotiable constraints such as access control, tenancy boundaries, jurisdictional limits, and language restrictions that must be satisfied for a document to be retrievable at all. These must be satisfied before retrieval, excluding documents entirely from the searchable corpus rather than affecting their rank.
- Soft boosts are preference signals such as recency, source authority, and content type that influence ranking after retrieval without excluding documents outright. This post-retrieval adjustment is commonly referred to as metadata re-ranking, where structured signals modify relevance scores rather than filter candidates.
Re-ranking
- Re-ranking is a critical refinement stage in modern Retrieval-Augmented Generation (RAG) pipelines, responsible for reordering a small candidate set of retrieved documents or passages to ensure that the most relevant content is prioritized for inclusion in the final prompt presented to the language model. While retrieval focuses on recall at scale, re-ranking emphasizes precision, making it a key determinant of generation quality.
Re-ranking in multistage retrieval pipelines
-
In practice, re-ranking is applied after an initial retrieval stage has narrowed the corpus to a manageable shortlist. Because the candidate set is small—typically tens to hundreds of documents—computationally intensive but highly accurate re-ranking techniques become feasible.
-
The figure below (source) illustrates a common multistage search pipeline used in RAG systems. In the first stage, a bi-encoder efficiently retrieves a shortlist of candidate documents from a large corpus. In the second stage, a re-ranker—often implemented as a cross-encoder—is applied to this reduced set to reassess and reorder the results based on deeper query–document interactions. This two-stage design combines the scalability of bi-encoder retrieval with the higher relevance accuracy of cross-encoder re-ranking, making it practical to deploy on large-scale datasets while still achieving strong ranking quality.
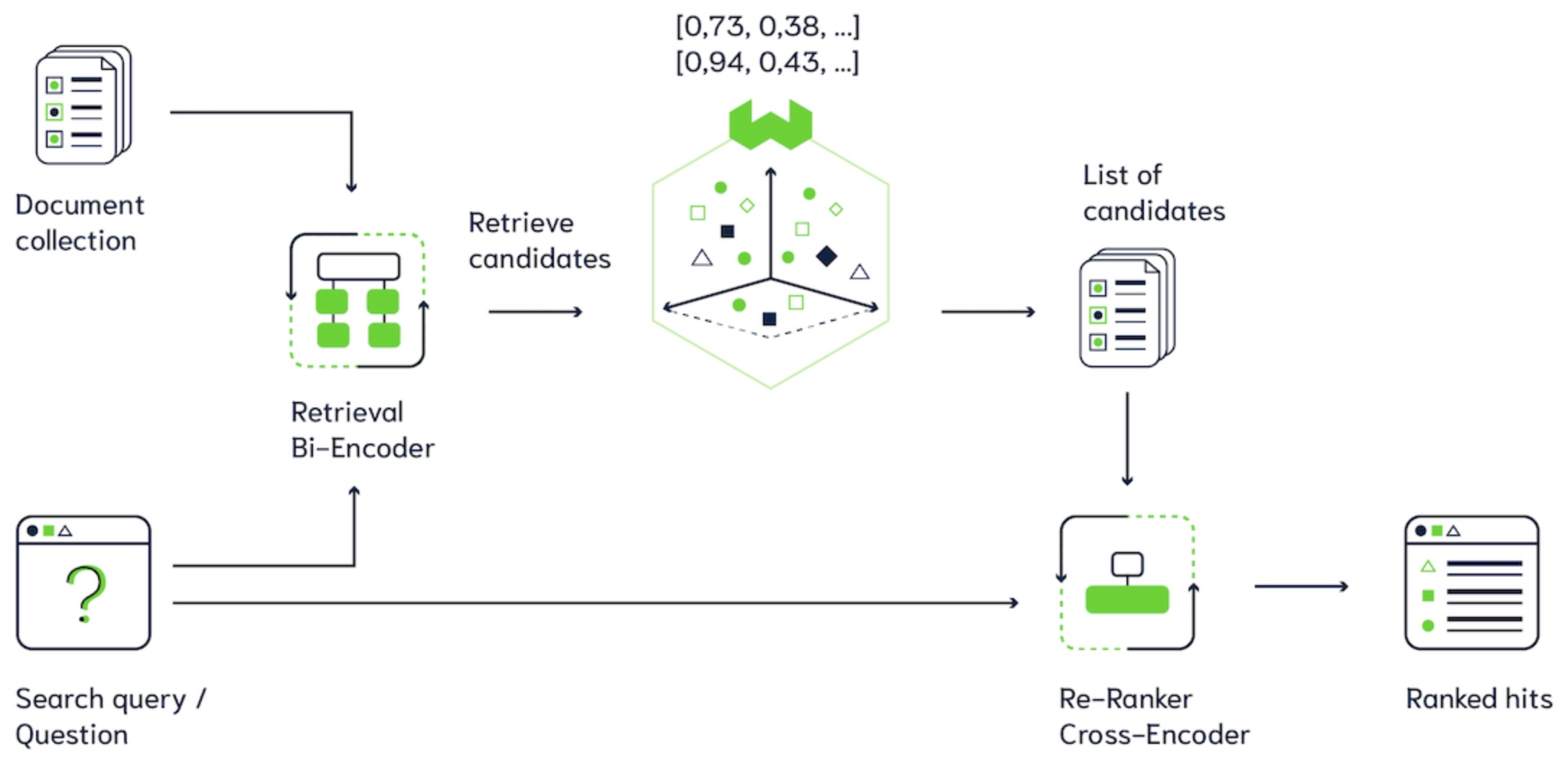
- This multistage architecture is foundational to modern RAG systems and motivates the different classes of re-rankers used in practice.
Classes of semantic re-ranking models
-
Modern RAG systems typically rely on three complementary classes of re-rankers, each addressing a distinct dimension of relevance:
- Neural Learning-to-Rank (LTR) re-rankers, which model semantic relevance between queries and documents using learned ranking objectives.
- Instruction-tuned re-rankers, which allow relevance criteria to be dynamically adjusted at runtime using natural language instructions.
- Metadata-based re-rankers, which incorporate structured signals such as recency, authority, provenance, or document type to enforce policy and domain-specific constraints.
-
Together, these approaches form a layered re-ranking strategy in which semantic relevance is established first and then refined to better align with user intent, organizational rules, and real-world constraints.
Learning-to-Rank paradigms
-
Most re-ranking techniques fall under the umbrella of Learning-to-Rank (LTR), which differs based on how relevance is modeled and optimized:
- Pointwise methods score each query–document pair independently, estimating absolute relevance.
- Pairwise methods compare two documents at a time for a given query, learning relative preferences.
- Listwise methods consider an entire ranked list jointly, optimizing ranking quality at the list level using task-specific loss functions.
-
These paradigms can be implemented using different neural architectures, with trade-offs between computational cost, expressiveness, and ranking accuracy.
Neural re-rankers
- Neural re-rankers form the core semantic ranking layer in most RAG systems. They are trained with explicit ranking objectives (pointwise, pairwise, or listwise) and are most commonly implemented using bi-encoder or cross-encoder architectures.
- Neural re-rankers can be structured based on the type of re-ranking mechanism they employ, reflecting both architectural choices and how relevance is computed. The most common category is cross-encoder–based re-rankers, within which different LTR paradigms—pointwise, pairwise, and listwise—are used. More recent architectures extend beyond traditional cross-encoders to support list-level reasoning and alternative decoding strategies.
- In practice, these differences manifest in how queries and candidate documents are jointly encoded and how relevance is computed, ranging from independent scoring of single query–document pairs to holistic reasoning over entire candidate lists.
Bi-encoder re-rankers (early-stage or lightweight re-ranking)
-
Bi-encoders (also known as dual-encoders) encode queries and documents independently into dense vectors and compute relevance using vector similarity.
- They are fast, scalable, and suitable for scoring large candidate sets.
- However, they cannot model fine-grained token-level interactions between query and document.
- Bi-encoders are typically trained as pointwise rankers; even when trained with pairwise or contrastive losses, they still score documents independently at inference time.
- While most commonly used at the retrieval stage, bi-encoders are also employed as an early re-ranking step (especially after a lexical retrieval stage), where efficient scoring over large candidate sets is required. Bi-encoders are also used as a lightweight re-ranking stage when latency constraints are strict, cross-encoders are too expensive, or infrastructure only supports embedding-based scoring. In these cases, the bi-encoder acts as a coarse reranker that improves ordering without the full cost of joint encoding.
-
In these cases, the bi-encoder acts as a coarse semantic filter that improves ordering without incurring the cost of joint encoding.
Cross-encoder re-rankers (late-stage, high-precision re-ranking)
-
Cross-encoders jointly encode the query and document, allowing full attention between tokens and enabling highly accurate relevance estimation at the cost of higher computation.
- This allows them to capture fine-grained relevance signals such as negation, term dependencies, and contextual constraints.
- Cross-encoders are significantly more accurate than bi-encoders but computationally expensive.
- They are therefore applied only to small candidate sets (often dozens of documents) in the final re-ranking stage.
- Cross-encoders can be trained using pointwise, pairwise, or listwise LTR objectives.
-
As a result, cross-encoders are the most common architecture for high-quality neural re-ranking in production RAG pipelines.
Example Models
- This section organizes neural re-rankers by architectural family and learning paradigm, highlighting how pointwise, pairwise, and listwise approaches are implemented in modern systems.
- These formulations correspond to pointwise, pairwise, and listwise re-ranking approaches, each offering different trade-offs between expressiveness, computational cost, and ranking quality.
Examples: Cross-encoder Re-rankers
-
Pointwise Re-ranker:
- monoBERT, proposed by Nogueira et al. (2019) in Multi-Stage Document Ranking with BERT, scores each document–query pair independently using BERT as a cross-encoder. The query is provided as sentence A and the document as sentence B in a single concatenated input sequence, allowing full self-attention between query and document tokens. After encoding, the final
[CLS]representation is passed through a single linear layer followed by a sigmoid activation to produce a scalar relevance probability \(s_i = P(\text{relevant}\mid q, d_i)\). The model is trained with binary cross-entropy loss over relevant and non-relevant documents, making monoBERT a pointwise probabilistic relevance classifier with high effectiveness but high inference cost when applied to many document–query pairs.
- monoBERT, proposed by Nogueira et al. (2019) in Multi-Stage Document Ranking with BERT, scores each document–query pair independently using BERT as a cross-encoder. The query is provided as sentence A and the document as sentence B in a single concatenated input sequence, allowing full self-attention between query and document tokens. After encoding, the final
-
Pairwise Re-ranker:
- duoBERT, also proposed by Nogueira et al. (2019) in Multi-Stage Document Ranking with BERT, is likewise a cross-encoder (not a bi-encoder) but operates in a pairwise ranking setting. The input consists of a single concatenated sequence with the query as sentence A and two candidate documents as sentences B and C. The resulting
[CLS]representation is passed through a single linear layer followed by a sigmoid activation to produce a probability \(p_{i,j} = P(d_i \succ d_j \mid q)\). Training uses binary cross-entropy loss applied to ordered (relevant, non-relevant) document pairs rather than individual documents, meaning the same loss form as monoBERT but in a pairwise preference formulation. This enables direct document–document comparisons under the same query, at an even higher computational cost than monoBERT.
- duoBERT, also proposed by Nogueira et al. (2019) in Multi-Stage Document Ranking with BERT, is likewise a cross-encoder (not a bi-encoder) but operates in a pairwise ranking setting. The input consists of a single concatenated sequence with the query as sentence A and two candidate documents as sentences B and C. The resulting
-
Listwise Re-rankers:
-
Listwise re-rankers move beyond independent or pairwise scoring by modeling relevance across an entire ranked list simultaneously. This enables direct optimization of ranking metrics and better captures inter-document dependencies.
-
ListBERT, proposed by Kumar et al. (2022) in ListBERT: Learning to Rank E-commerce products with Listwise BERT, brings a listwise learning paradigm to transformer-based ranking. Instead of scoring documents independently or in pairs, ListBERT considers a full list of documents simultaneously. It uses listwise loss functions tailored for ranking tasks (e.g., ListMLE, Softmax Cross Entropy) and was originally applied in the context of e-commerce to rank products effectively.
-
Examples: Encoder-Decoder / Decoder-based Listwise Re-rankers (Fusion-in-Decoder Architectures)
-
A more recent class of listwise re-rankers leverages encoder–decoder architectures to jointly reason over multiple documents during decoding, rather than relying solely on encoder-side interactions.
-
While monoBERT by Nogueira et al. (2019) and duoBERT by Nogueira et al. (2019) rely on traditional cross-encoder architectures, ListBERT by Zhuang et al. (2022) and ListT5 by Yoon et al. (2024) introduce list-level reasoning through different mechanisms. ListBERT remains encoder-only with listwise loss functions, whereas ListT5 employs a Fusion-in-Decoder architecture adapted from T5, which is not a standard cross-encoder. Decoder-based listwise re-rankers are explained below:
-
ListT5 by Yoon et al. (2024), proposed in ListT5: Listwise Re-ranking with Fusion-in-Decoder Improves Zero-shot Retrieval, advances listwise re-ranking by adapting the Fusion-in-Decoder (FiD) architecture from T5 by Raffel et al. (2019). Each candidate document is encoded independently together with the query, but the decoder jointly attends over the encoded representations of all candidates to generate relevance-aware outputs, enabling true listwise reasoning at decoding time. This architecture allows interactions across all documents in the candidate list without quadratic encoder costs and has shown strong performance in zero-shot and low-supervision retrieval settings with minimal labeled data.
-
REARANK by Zhang et al. (2025), introduced in REARANK: Reasoning Re-ranking Agent via Reinforcement Learning, is an LLM-based listwise reranking agent that explicitly reasons about entire candidate sets before producing a ranked ordering. It leverages reinforcement learning and data augmentation to optimize a listwise objective, demonstrating strong performance with relatively few annotated samples and interpretable reasoning steps.
-
Rank-K by Yang et al. (2025), proposed in Rank-K: Test-Time Reasoning for Listwise Reranking, prioposes a listwise passage reranking model that leverages reasoning language models at test time to compare and order multiple passages jointly, improving retrieval effectiveness and showing strong multilingual behavior in ranking.
-
-
These decoder-based listwise re-rankers differ fundamentally from cross-encoder models like monoBERT and duoBERT: rather than producing independent relevance scores or pairwise comparisons, they perform global reasoning over an entire candidate set during decoding, trading higher memory usage and decoding cost for richer list-level interactions.
Domain-Specific Adaptations
-
Neural re-rankers can be further specialized through domain-specific adaptation, where models are fine-tuned or pretrained on corpora and relevance judgments drawn from a particular field. This aligns the re-ranker’s representations with domain-specific terminology, document structures, and relevance criteria that differ from general-purpose benchmarks (e.g., legal, healthcare, finance).
-
For example, Legal-BERT extends the BERT architecture through pretraining on large legal corpora and can be adapted as a re-ranker for tasks such as legal document ranking and case law search. Domain-aware ranking approaches that customize relevance based on industry semantics have shown improved performance in specialized fields like legal search. Additionally, models like Qwen3-Reranker demonstrate how legal-focused re-rankers with long-context capabilities can improve relevance for complex legal document tasks.
-
In the healthcare domain, dedicated models such as the ones proposed in ZeroEntropy Reranker for Healthcare AI provide domain-specific re-ranking tuned to prioritize clinical guidelines, electronic health records, and medical research documents, helping surface the most authoritative and clinically relevant information in RAG workflows.
-
Domain-specific rerankers are also emerging in finance and compliance applications, where tailored ranking models help improve fraud detection, policy retrieval, and compliance task relevance, demonstrating the broader applicability of specialized re-ranking beyond general semantic similarity.
-
Similar domain-adapted re-rankers are being developed in technical domains where relevance depends on specialized vocabulary, regulatory context, or evidence standards. In these settings, domain-specific re-ranking helps reduce false positives, surface authoritative sources, and ensure that highly specialized documents are correctly prioritized within the final ranked list.
Instruction-Following Re-ranking
-
A growing frontier in re-ranking is instruction-following re-ranking, which augments neural re-rankers with the ability to condition ranking behavior on natural language instructions. Instead of relying on a fixed notion of relevance learned during training, these models allow relevance criteria to be specified or adjusted at runtime, enabling more flexible and context-aware ranking decisions. This capability is particularly valuable in enterprise and production RAG systems where relevance often depends on business rules, trust constraints, or temporal considerations rather than semantic similarity alone.
-
Instruction-following re-rankers are typically built on top of large language models or instruction-tuned cross-encoders, leveraging advances in instruction tuning and alignment. By treating ranking as a controllable task, they bridge the gap between traditional LTR objectives and prompt-based control paradigms discussed in work on instruction-tuned models such as Instruction Tuning and FLAN.
-
Examples of Natural Language Instructions:
- “Prioritize internal documentation over third-party sources. Favor the most recent information.”
- “Disregard news summaries. Emphasize detailed technical reports from trusted analysts.”
- “Prefer primary sources and official standards documents over community blog posts.”
-
Advantages:
- Dynamic Relevance Modeling: Instructions enable runtime control over what relevance means, allowing the same retrieved candidate set to be re-ranked differently depending on user intent, task context, or organizational policy.
- Conflict Resolution: Explicit instructions make it possible to resolve contradictory or overlapping sources by enforcing prioritization rules such as recency, authority, or provenance, complementing purely learned relevance signals.
- Prompt Optimization: By ensuring that higher-quality and policy-compliant content appears earlier in the ranked list, instruction-following re-ranking helps maximize the utility of the limited context window, where the language model’s attention is most concentrated.
-
Implementation and Deployment:
- Instruction-following re-rankers are commonly deployed as a post-retrieval scoring layer that operates on a small shortlist of candidate documents. They are often exposed as standalone APIs or integrated modules within RAG pipelines, similar to conventional cross-encoder re-rankers but with an additional instruction input.
- A notable example is Contextual AI’s system described in Introducing the World’s First Instruction-Following Reranker, which demonstrates how natural language instructions can be combined with neural re-ranking to enforce enterprise-specific relevance constraints in real-world deployments.
- Instruction-following re-rankers can be combined with other techniques such as retriever ensembling, metadata-based filtering, or late chunking, effectively acting as the final curation layer before documents are assembled into the prompt sent to the language model.
Metadata-Based Re-rankers
-
Metadata-based re-rankers incorporate structured, non-textual signals into the re-ranking stage to bias results toward documents that satisfy explicit criteria such as recency, authority, source type, or document provenance. Rather than replacing neural relevance scores, these signals are typically combined with semantic scores to produce a final ranking that better reflects practical relevance constraints in real-world systems.
-
Common metadata signals include timestamps, source identifiers, publisher reputation, document type, access level, and usage statistics. These features are especially valuable in enterprise and regulated settings, where the most semantically relevant document may not be the most trustworthy or up to date. This idea aligns with classical ranking work that blends multiple relevance signals, such as BM25 variants with field or freshness boosts, and modern hybrid ranking systems discussed in Learning to Rank for Information Retrieval by Tie-Yan Liu.
-
Typical Re-ranking Criteria:
- Recency: Favor newer documents using timestamp-based decay functions, particularly important for fast-changing domains such as news, finance, or internal documentation.
- Authority and Source Trust: Prefer documents from curated or authoritative sources (e.g., internal wikis, official standards bodies) over third-party or user-generated content.
- Document Type and Provenance: Boost primary sources, specifications, or policies while demoting summaries, duplicates, or low-signal content.
-
In practice, metadata-based re-ranking is often implemented using rule-based or learned scoring functions layered on top of neural relevance scores. Search platforms such as Elasticsearch and OpenSearch expose this pattern through mechanisms like Elastic’s function score queries, enabling explicit weighting of freshness, popularity, or source fields during re-ranking.
-
Metadata-based approaches are frequently combined with neural re-rankers rather than used in isolation. For example, a cross-encoder or instruction-following re-ranker may first score semantic relevance, after which metadata-based adjustments enforce hard or soft constraints on ordering. This hybrid strategy reflects best practices described in modern RAG system design discussions, including Introducing the hybrid index to enable keyword-aware semantic search by Pinecone.
-
Within RAG pipelines, metadata-based re-rankers often serve as a policy-enforcement layer, ensuring compliance with business rules and trust requirements while preserving the strengths of neural relevance modeling. When used alongside instruction-following re-rankers, metadata signals can either be encoded directly into instructions or applied as an explicit post-processing step, providing clear separation between semantic relevance and governance constraints.
Response Generation / Synthesis
- The last step of the RAG pipeline is to generate responses back to the user. In this step, the model synthesizes the retrieved information with its pre-trained knowledge to generate coherent and contextually relevant responses. This process involves integrating the insights gleaned from various sources, ensuring accuracy and relevance, and crafting a response that is not only informative but also aligns with the user’s original query, maintaining a natural and conversational tone.
- Note that while creating the expanded prompt (with the retrieved top-\(k\) chunks) for an LLM to make an informed response generation, a strategic placement of vital information at the beginning or end of input sequences could enhance the RAG system’s effectiveness and thus make the system more performant. This is summarized in the paper below.
Lost in the Middle: How Language Models Use Long Contexts
- While recent language models have the ability to take long contexts as input, relatively little is known about how well the language models use longer context.
- This paper by Liu et al. from Percy Liang’s lab at Stanford, UC Berkeley, and Samaya AI analyzes language model performance on two tasks that require identifying relevant information within their input contexts: multi-document question answering and key-value retrieval. Put simply, they analyze and evaluate how LLMs use the context by identifying relevant information within it.
- They tested open-source (MPT-30B-Instruct, LongChat-13B) and closed-source (OpenAI’s GPT-3.5-Turbo and Anthropic’s Claude 1.3) models. They used multi-document question-answering where the context included multiple retrieved documents and one correct answer, whose position was shuffled around. Key-value pair retrieval was carried out to analyze if longer contexts impact performance.
- They find that performance is often highest when relevant information occurs at the beginning or end of the input context, and significantly degrades when models must access relevant information in the middle of long contexts. In other words, their findings basically suggest that Retrieval-Augmentation (RAG) performance suffers when the relevant information to answer a query is presented in the middle of the context window with strong biases towards the beginning and the end of it.
- A summary of their learnings is as follows:
- Best performance when the relevant information is at the beginning.
- Performance decreases with an increase in context length.
- Too many retrieved documents harm performance.
- Improving the retrieval and prompt creation step with a ranking stage could potentially boost performance by up to 20%.
- Extended-context models (GPT-3.5-Turbo vs. GPT-3.5-Turbo (16K)) are not better if the prompt fits the original context.
- Considering that RAG retrieves information from an external database – which most commonly contains longer texts that are split into chunks. Even with split chunks, context windows get pretty large very quickly, at least much larger than a “normal” question or instruction. Furthermore, performance substantially decreases as the input context grows longer, even for explicitly long-context models. Their analysis provides a better understanding of how language models use their input context and provides new evaluation protocols for future long-context models.
- “There is no specific inductive bias in transformer-based LLM architectures that explains why the retrieval performance should be worse for text in the middle of the document. I suspect it is all because of the training data and how humans write: the most important information is usually in the beginning or the end (think paper Abstracts and Conclusion sections), and it’s then how LLMs parameterize the attention weights during training.” (source)
- In other words, human text artifacts are often constructed in a way where the beginning and the end of a long text matter the most which could be a potential explanation to the characteristics observed in this work.
- You can also model this with the lens of two popular cognitive biases that humans face (primacy and recency bias), as in the following figure (source).
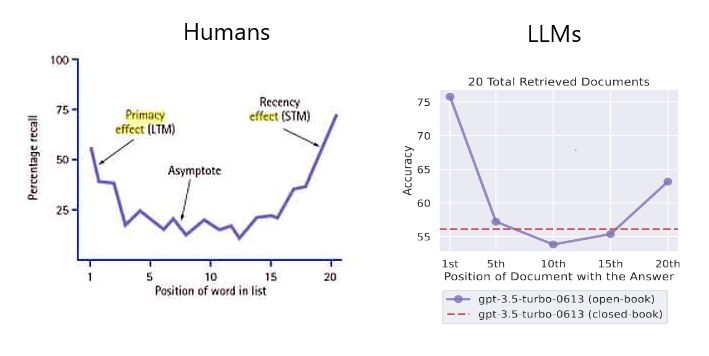
- The final conclusion is that combining retrieval with ranking (as in recommender systems) should yield the best performance in RAG for question answering.
- The following figure (source) shows an overview of the idea proposed in the paper: “LLMs are better at using info at beginning or end of input context”.
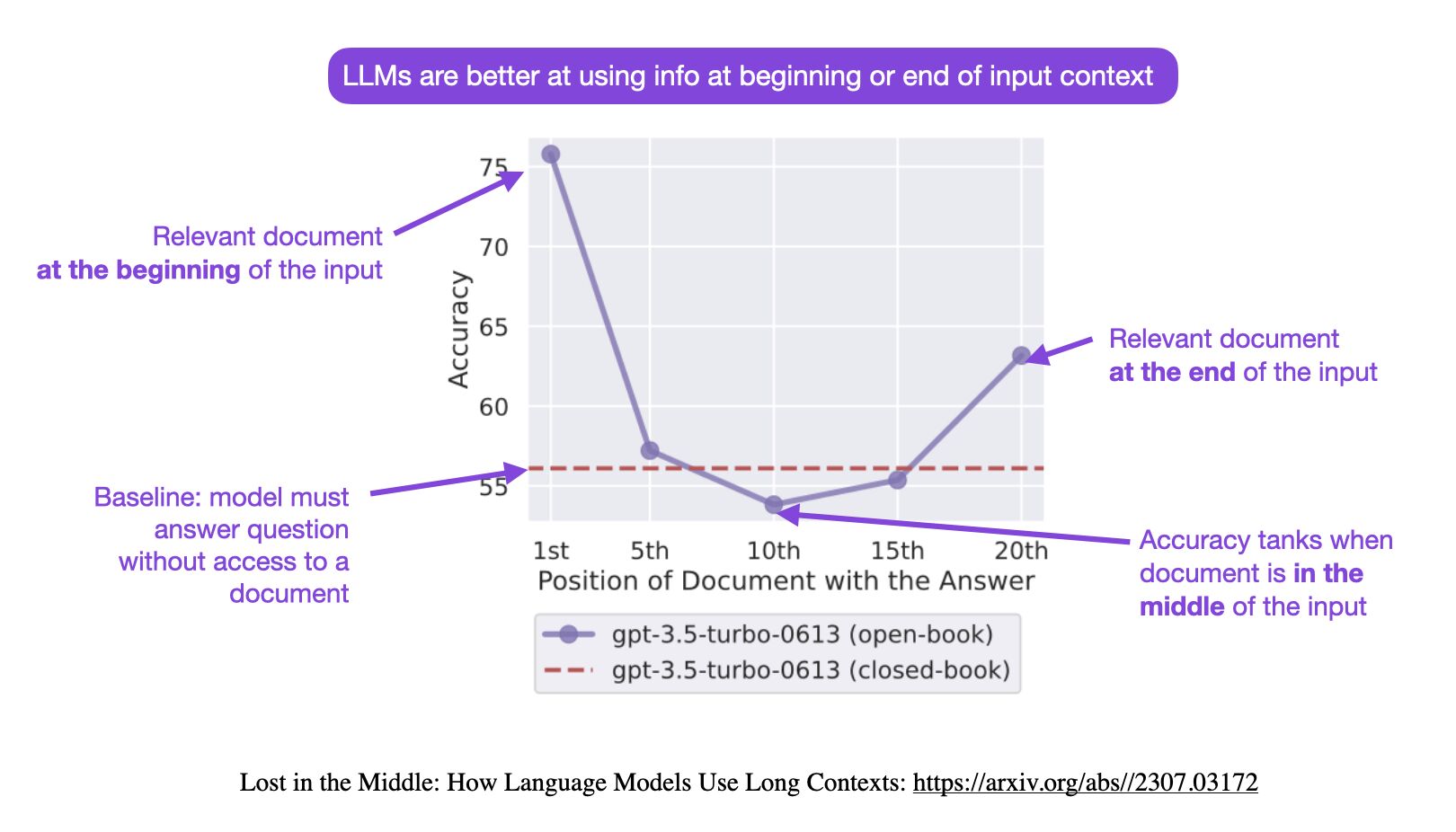
- The following figure from the paper illustrates the effect of changing the position of relevant information (document containing the answer) on multidocument question answering performance. Lower positions are closer to the start of the input context. Performance is generally highest when relevant information is positioned at the very start or very end of the context, and rapidly degrades when models must reason over information in the middle of their input context.
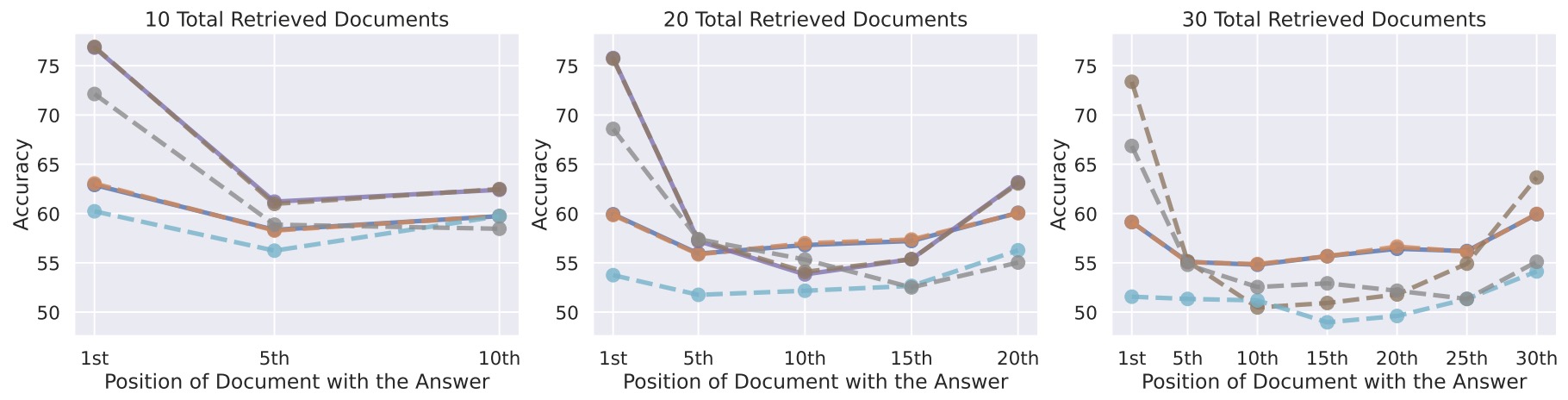
The “Needle in a Haystack” Test
- To understand the in-context retrieval ability of long-context LLMs over various parts of their prompt, a simple ‘needle in a haystack’ analysis could be conducted. This method involves embedding specific, targeted information (the ‘needle’) within a larger, more complex body of text (the ‘haystack’). The purpose is to test the LLM’s ability to identify and utilize this specific piece of information amidst a deluge of other data.
- In practical terms, the analysis could involve inserting a unique fact or data point into a lengthy, seemingly unrelated text. The LLM would then be tasked with tasks or queries that require it to recall or apply this embedded information. This setup mimics real-world situations where essential details are often buried within extensive content, and the ability to retrieve such details is crucial.
- The experiment could be structured to assess various aspects of the LLM’s performance. For instance, the placement of the ‘needle’ could be varied—early, middle, or late in the text—to see if the model’s retrieval ability changes based on information location. Additionally, the complexity of the surrounding ‘haystack’ can be modified to test the LLM’s performance under varying degrees of contextual difficulty. By analyzing how well the LLM performs in these scenarios, insights can be gained into its in-context retrieval capabilities and potential areas for improvement.
- This can be accomplished using the Needle In A Haystack library. The following plot shows OpenAI’s GPT-4-128K’s (top) and (bottom) performance with varying context length.
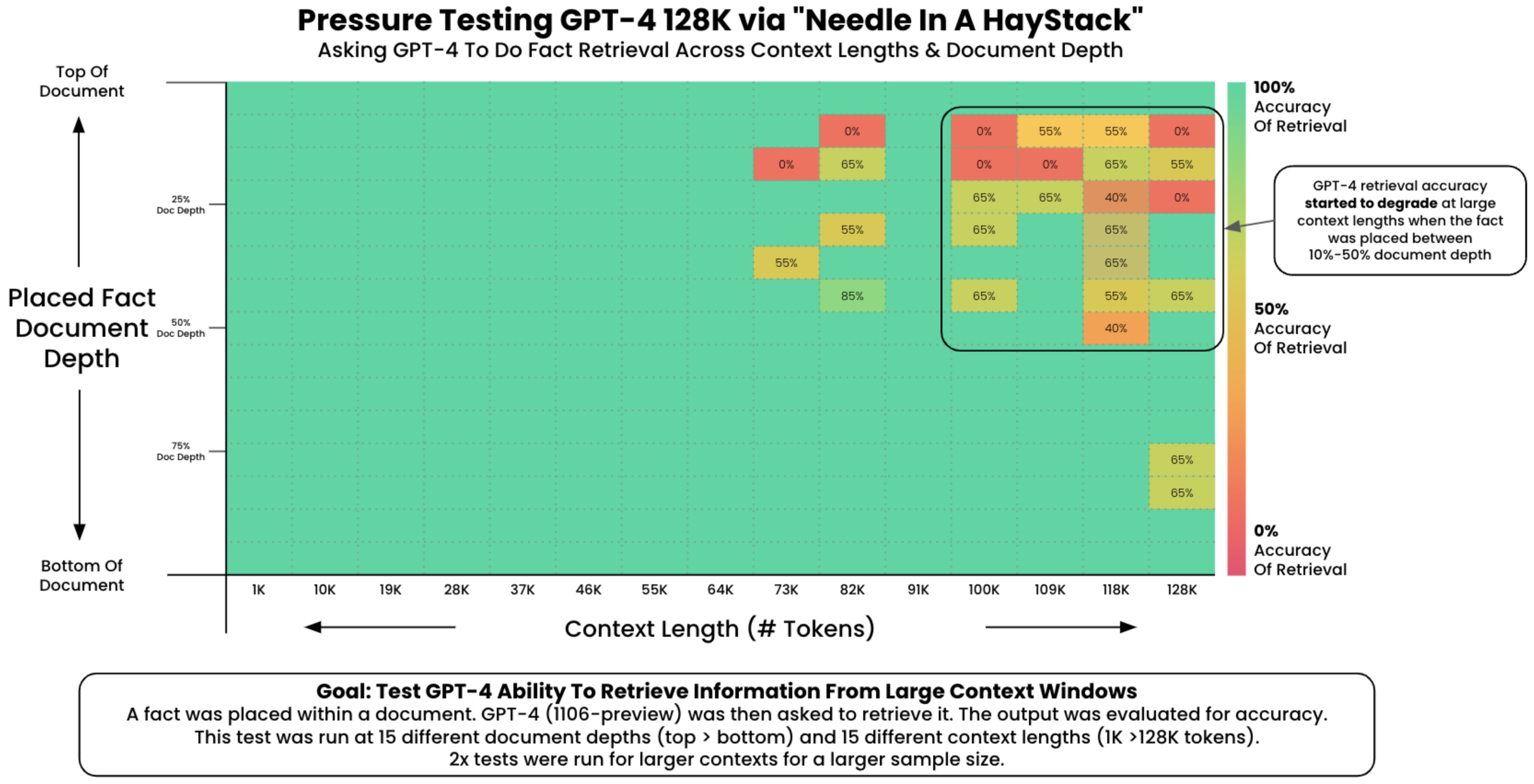

- The following figure (source) shows Claude 2.1’s long context question answering errors based on the areas of the prompt context length. On an average, Claude 2.1 demonstrated a 30% reduction in incorrect answers compared to Claude 2.
- However, in Anthropic’s Long context prompting for Claude 2.1 blog, Anthropic noted that adding “Here is the most relevant sentence in the context:” to the start of Claude’s response raised the score from 27% to 98% on the original evaluation! The figure below from the blog shows that Claude 2.1’s performance when retrieving an individual sentence across its full 200K token context window. This experiment uses the aforementioned prompt technique to guide Claude in recalling the most relevant sentence.
RAG in Multi-Turn Chatbots: Embedding Queries for Retrieval
-
In multi-turn chatbot environments, RAG must extend beyond addressing isolated, single-turn queries. Conversations are inherently dynamic—context accumulates, user objectives evolve, and intent may shift subtly across multiple interactions. This dynamic nature renders one design decision particularly critical: determining which input text should be embedded during the retrieval phase. This decision has a direct impact on both the relevance of the retrieved content and the overall quality of the generated response.
-
In contrast to single-turn systems, where embedding the current user input may suffice, multi-turn RAG systems face a more fluid and complex challenge. Limiting retrieval inputs to only the most recent user message is computationally efficient but often insufficient for capturing the nuances of ongoing discourse. Incorporating recent conversational turns offers improved contextual grounding, while advanced techniques such as summarization and query rewriting can significantly enhance retrieval precision.
-
There is no universally optimal approach—the most suitable strategy depends on factors such as the application’s specific requirements, available computational resources, and tolerance for system complexity. Nevertheless, the most robust implementations often adopt a layered methodology: integrating recent dialogue context, monitoring evolving user intent, and utilizing reformulated or enriched queries. This composite approach typically results in more accurate, contextually appropriate retrieval and, consequently, more coherent and effective responses.
-
The following sections outlines the key strategies and considerations for query embedding in multi-turn RAG chatbot systems.
Embedding the Latest User Turn Only
- The simplest approach is to embed just the latest user message. For example, if a user says, “What are the symptoms of Lyme disease?”, that exact sentence is passed to the retriever for embedding.
- Pros:
- Fast and computationally cheap.
- Reduces the risk of embedding irrelevant or stale context.
- Cons:
- Ignores conversational context and prior turns, which may contain critical disambiguating details (e.g., “Is it common in dogs?” following a discussion about pets).
Embedding Concatenated Recent Turns (Truncated Dialogue History)
- A more nuanced approach involves embedding the current user message along with a sliding window of recent turns (usually alternating user and assistant messages).
- For example:
User: My dog has been acting strange lately. Assistant: Can you describe the symptoms? User: He’s tired, limping, and has a fever. Could it be Lyme disease?- The retriever input would include all or part of the above.
- Pros:
- Preserves immediate context that can significantly improve retrieval relevance.
- Especially useful for resolving pronouns and follow-up queries.
- Cons:
- Can dilute the focus of the query if too many irrelevant prior turns are included.
- Risk of exceeding input length limits for embedding models.
Embedding a Condensed or Summarized History
- In this strategy, prior turns are summarized into a condensed form before concatenation with the current turn. This reduces token count while preserving key context.
- Can be achieved using simple heuristics, hand-written rules, or another lightweight LLM summarization pass.
- For example:
Condensed history: The user is concerned about their dog's health, showing signs of fatigue and limping. Current query: Could it be Lyme disease?- Embed the concatenated string: “The user is concerned… Could it be Lyme disease?”
- Pros:
- Retains relevant prior context while minimizing noise.
- Helps improve retrieval accuracy for ambiguous follow-up questions.
- Cons:
- Requires additional processing and potential summarization latency.
- Summarization quality can affect retrieval quality.
Embedding Structured Dialogue State
- This approach formalizes the conversation history into a structured format (like intent, entities, or user goals), which is then appended to the latest query before embedding.
- For instance:
[Intent: Diagnose pet illness] [Entity: Dog] [Symptoms: fatigue, limping, fever] Query: Could it be Lyme disease? - Pros:
- Allows precision targeting of relevant documents, especially in domain-specific applications.
- Supports advanced reasoning by aligning with KBs or ontology-driven retrieval.
- Cons:
- Requires reliable NLU and state-tracking pipelines.
- Adds system complexity.
Task-Optimized Embedding via Query Reformulation
- Some systems apply a query rewriting model that reformulates the latest turn into a fully self-contained question, suitable for retrieval.
- For example, turning “What about dogs?” into “What are the symptoms of Lyme disease in dogs?”
- These reformulated queries are then embedded for retrieval.
- Pros:
- Ensures clarity and focus in queries passed to the retriever.
- Significantly boosts retrieval performance in ambiguous or shorthand follow-ups.
- Cons:
- Introduces dependency on a high-quality rewrite model.
- Risk of introducing hallucination or incorrect reformulations.
Best Practices and Considerations
- Window Size: Most systems use a sliding window of 1-3 previous turns depending on token limits and task specificity.
- Query Length vs. Clarity Tradeoff: Longer queries with more context may capture nuance but risk introducing noise. Condensed or reformulated queries can help mitigate this.
- Personalization: In some advanced setups, user profiles or long-term memory can be injected into the retrieval query, but this must be carefully curated to avoid privacy or relevance pitfalls.
- System Goals: If the chatbot is task-oriented (e.g., booking travel), structured state may be best. If it is open-domain (e.g., a virtual assistant), concatenated dialogue or rewrite strategies tend to perform better.
End-to-End Flow
- This section describes the complete, end-to-end execution path of the RAG system as illustrated in the attached flowchart.

- The pipeline is organized into four swimlanes—Ingest, Query, Retrieve, and Generate—each representing a distinct responsibility in the overall architecture. While some components are optional or configurable depending on product requirements, the system as a whole is designed to enforce correctness, relevance, and grounding at every stage.
Color Legend
- Blue blocks represent neural models. These can be implemented using pre-trained models and swapped independently (e.g., Sentence-BERT by Reimers and Gurevych (2019) for dense sentence embeddings, ColBERT by Khattab and Zaharia (2020) for late-interaction retrieval, and cross-encoders such as monoBERT by Nogueira et al. (2019) for high-precision reranking).
- Red blocks represent direct user input.
- Green blocks represent the final system output delivered to the user.
Ingest: Document Parsing, Chunking, and Indexing
-
The ingest stage is an offline (i.e., asynchronous) step, responsible for transforming raw source material into a structured, searchable representation. This stage typically runs offline or asynchronously and is mandatory for any RAG system that operates over proprietary or external corpora.
- Source documents are the raw inputs to the system, which may include PDFs, Word files, HTML pages, images, tables, or mixed-format content.
- Metadata creation enriches documents with structured attributes such as document type, access policies, language, dates, and domain-specific tags. These metadata fields enable hard filtering later during retrieval.
- Layout analysis identifies document structure like headers, paragraphs, columns, and reading order; this is crucial for preserving context in scanned or multi-column documents.
- OCR text extraction converts image-based or scanned inputs into machine-readable text. This block is optional and only required for non-digital documents.
- Image captioning generates semantic descriptions for images or figures embedded in documents. This block is optional and particularly useful for multimodal corpora.
- Table extraction converts tabular data into structured representations suitable for indexing.
- Document hierarchy creation builds parent–child relationships between major sections and their sub-components, which enables advanced retrieval strategies such as hierarchical or auto-merging retrieval.
- The processed output is stored in a data store, which holds extracted text chunks, embeddings, and metadata. This store serves as the mandatory backbone of retrieval.
-
At the end of the ingest stage, the system has a searchable, semantically enriched corpus that can be efficiently queried.
Query: Understanding and Normalizing User Intent
-
The query stage transforms raw user input into a normalized retrieval representation. This stage runs synchronously for every request and begins with the red input block.
- Input query (red) is the raw natural language query from the user. This block is mandatory.
- Translation normalizes the query into a canonical language when operating in multilingual collections. This block is optional.
- Model armor applies safety, policy, and prompt-hardening transformations, such as sanitization or injection defense. This block is optional but recommended for production.
- Multi-turn handling incorporates conversational context, which may include summarization of dialogue history or structured state tracking. This block is optional and only present in stateful environments.
- Query expansion enriches user intent with synonyms, paraphrases, or related concepts to improve recall. Optional based on application needs.
- Query decomposition splits complex or multi-part questions into simpler sub-queries. Optional.
- Query reformulation produces a clean, self-contained query optimized for retrieval. Optional but widely used in high-quality systems.
-
The output of the query stage is one or more normalized, enriched query representations that maximize retrieval effectiveness while respecting safety and policy constraints.
Retrieve: Candidate Selection and Ranking
-
The retrieve stage is the core grounding mechanism of the system. Its goal is to identify the most relevant and policy-compliant document chunks for a given query.
- Filter via metadata applies mandatory hard constraints such as access control, language restrictions, and other policies. This block is required in regulated or multi-tenant deployments.
- Semantic search (blue) retrieves candidates using dense neural embeddings (e.g., embeddings from dual-encoder models like Sentence-BERT or other transformer-based encoders).
- Lexical search retrieves candidates using sparse methods such as BM25 or TF-IDF. This block is optional but critical for exact match and keyword importance.
- Reciprocal rank fusion merges results from semantic and lexical retrieval into a single candidate set when both are employed.
- Reranker (blue) reorders the candidate set using high-precision neural models (e.g., cross-encoders). This block is optional but strongly recommended for high-precision retrieval.
- Filter model applies final rule-based or learned constraints, such as personalization or diversity filtering. Optional.
- Final retrievals represent the selected top-ranked passages that will be used in the generation stage. This output is mandatory.
-
A well-designed retrieve stage ensures that only relevant, compliant, and well-ranked context is passed to the generative model.
Generate: Response Synthesis and Validation
-
The generate stage produces the final answer by synthesizing retrieved context with the generative model.
- Generate response (blue) invokes a LLM conditioned on the query and retrieved context. Examples of models include GPT-4, Claude, Gemini, or long-context neural decoders.
- Translation converts the generated output into the user’s preferred language, if necessary. Optional.
- Attributions add source citations or provenance markers to improve traceability and auditability. Optional.
- Groundedness scores evaluate whether the generated output is supported by the retrieved information. Optional, often implemented via separate evaluation models.
- Final response (green) is the validated, user-facing answer returned to the user.
-
This generate stage completes the pipeline by binding retrieval evidence with generative reasoning while optionally validating grounding and attributions.
Required vs. Optional Components
- Required blocks: Source documents, data store, input query, metadata filtering, final retrievals, response generation, and final response.
- Optional but recommended blocks: Semantic retrieval, lexical retrieval, reranking, query reformulation, multi-turn handling, groundedness scoring.
- Optional and use-case dependent: OCR, image captioning, table extraction, translation, query decomposition, fusion, and attributions.
Key Takeaways
- The flowchart represents a modular yet tightly coordinated system in which retrieval quality bounds generation quality. Each swimlane isolates a distinct concern—data preparation, intent understanding, candidate selection, and synthesis—while neural components (blue) remain interchangeable and evolvable over time.
- The architecture ensures that failures in one stage are constrained and do not silently propagate, resulting in a final output (green) that is grounded, compliant, and aligned with user intent.
Component-Wise Evaluation
- Component-wise evaluation in RAG systems for LLMs involves assessing individual components of the system separately. This approach typically examines the performance of the retrieval component, which fetches relevant information from a database or corpus, and the generation component, which synthesizes responses based on the retrieved data. By evaluating these components individually, researchers can identify specific areas for improvement in the overall RAG system, leading to more efficient and accurate information retrieval and response generation in LLMs.
- While metrics such as Context Precision, Context Recall, and Context Relevance provide insights into the performance of the retrieval component of the RAG system, Groundedness, and Answer Relevance offer a view into the quality of the generation.
- Specifically,
- Metrics to evaluate retrieval: Context Relevance, Context Recall, and Context Precision, which collectively assess the relevance, completeness, and accuracy of the information retrieved in response to a user’s query. Context Precision focuses on the system’s ability to rank relevant items higher, Context Recall evaluates how well the system retrieves all relevant parts of the context, and Context Relevance measures the alignment of retrieved information with the user’s query. These metrics ensure the effectiveness of the retrieval system in providing the most relevant and complete context for generating accurate responses.
- Metrics to evaluate generation: Faithfulness and Answer Relevance, which measure the factual consistency of the generated answer with the given context and its relevance to the original question, respectively. Faithfulness focuses on the factual accuracy of the answer, ensuring all claims made can be inferred from the given context. Answer Relevance assesses how well the answer addresses the original question, penalizing incomplete or redundant responses. These metrics ensure the generation component produces contextually appropriate and semantically relevant answers.
- The harmonic mean of these four aspects gives you the overall score (also called ragas score) which is a single measure of the performance of your RAG system across all the important aspects.
- Most of the measurements do not require any labeled data, making it easier for users to run it without worrying about building a human-annotated test dataset first. In order to run ragas all you need is a few questions and if your using context_recall, a reference answer.
- Overall, these metrics offer a comprehensive view of the RAG system’s retrieval performance, which can be implemented using libraries for evaluating RAG pipelines such as Ragas or TruLens and offer detailed insights about your RAG pipeline’s performance, focusing on the contextual and factual alignment of retrieved and generated content in response to user queries. Specifically, Ragas, offers metrics tailored for evaluating each component of your RAG pipeline in isolation. This approach complements the broader, system-level end-to-end evaluation of your system (which is detailed in End-to-End Evaluation), allowing for a deeper understanding of how well a RAG system performs in real-world scenarios where the intricacies of context and factual accuracy are paramount. The figure below (source) shows the metrics that Ragas offers which are tailored for evaluating each component (retrieval, generation) of your RAG pipeline in isolation.
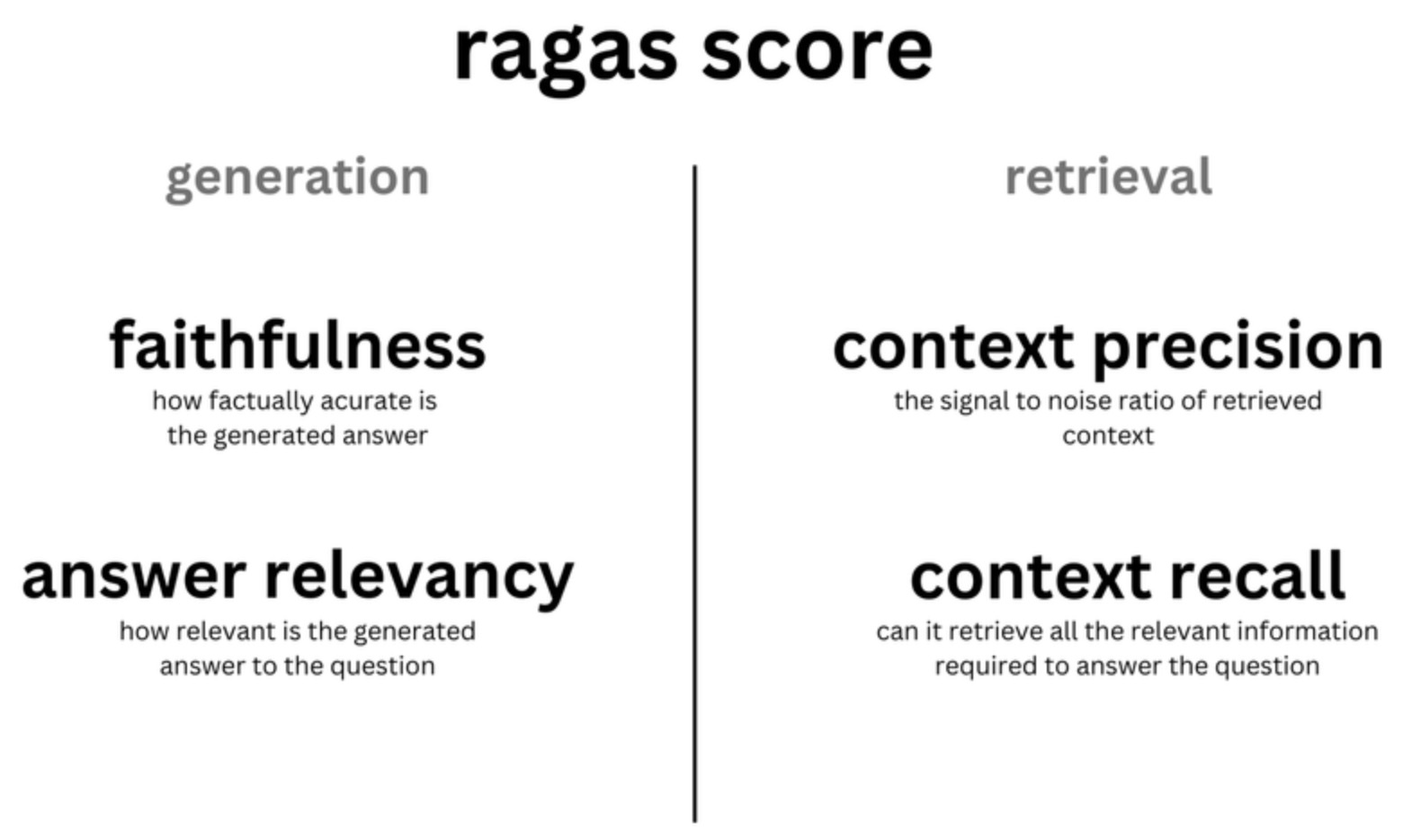
- The image below (source), shows the “triad” of metrics that can be used to evaluate RAG: Groundedness (also known as Faithfulness), Answer Relevance, and Context Relevance. Note that Context Precision and Context Recall are also important and were more recently introduced in a newer version of Ragas.
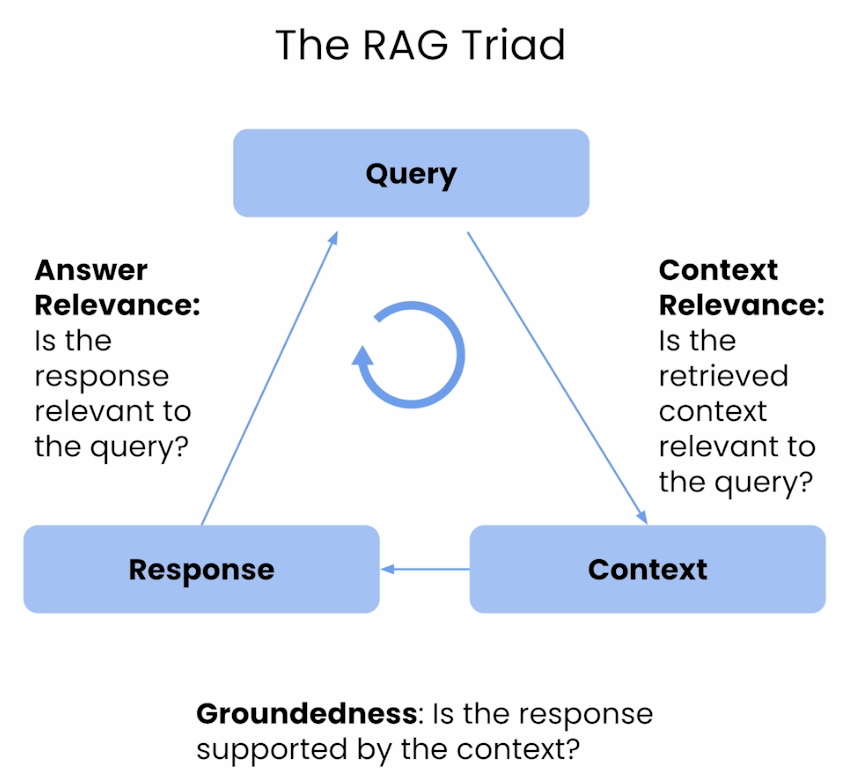
Retrieval Metrics
- Evaluating the retrieval component of RAG in the context of LLMs involves assessing how effectively the system retrieves relevant information to support the generation of accurate and contextually appropriate responses.
Context Precision
-
Definition: Context Precision is a metric used to assess the accuracy of ranking ground-truth relevant items from the context higher in the results. It measures whether all the relevant chunks of information appear at the top ranks when responding to a query. Ideally all the relevant chunks must appear at the top ranks. The metric is scored between 0 and 1 using the question, ground truth, and the contexts, with higher scores indicating better precision.
- Evaluation Approach: Context Precision is calculated using the following steps:
- For each chunk in the retrieved context, determine if it is relevant or not relevant based on the ground truth for the given question.
-
Compute Precision@\(k\) for each chunk in the context using the formula:
\[\text{Precision@k} = \frac{\text{true positives@k}}{\text{true positives@k} + \text{false positives@k}}\] -
Calculate the Context Precision@\(k\) by averaging the Precision@\(k\) values for all relevant items in the top \(K\) results:
\[\text{Context Precision@k} = \frac{\sum_{k=1}^K (\text{Precision@k} \times v_k)}{\text{Total number of relevant items in the top } k \text{ results}}\]- where \(k\) is the total number of chunks in contexts and \(v_k \in \{0,1\}\) is the relevance indicator at rank \(k\).
-
Example (source): Let’s consider an example of calculating context precision using a question and its corresponding ground truth.
- Question: Where is France and what is its capital?
- Ground Truth: France is in Western Europe, and its capital is Paris.
- High Context Precision Example:
- Contexts:
["France, in Western Europe, encompasses medieval cities, alpine villages, and Mediterranean beaches. Paris, its capital, is famed for its fashion houses, classical art museums including the Louvre and monuments like the Eiffel Tower", "The country is also renowned for its wines and sophisticated cuisine. Lascaux's ancient cave drawings, Lyon's Roman theater and the vast Palace of Versailles attest to its rich history."]
- Contexts:
- Low Context Precision Example:
- Contexts:
["The country is also renowned for its wines and sophisticated cuisine. Lascaux's ancient cave drawings, Lyon's Roman theater and", "France, in Western Europe, encompasses medieval cities, alpine villages, and Mediterranean beaches. Paris, its capital, is famed for its fashion houses, classical art museums including the Louvre and monuments like the Eiffel Tower"]
- Contexts:
- In this example, the calculation of context precision involves identifying relevant chunks related to the question and their ranking in the contexts. For the low context precision example:
- Precision@1 = \(\frac{0}{1}\) = 0
- Precision@2 = \(\frac{1}{2}\) = 0.5
- Context Precision = \(\frac{(0 + 0.5)}{1}\) = 0.5
Context Recall
-
Definition: Context Recall measures how well the retrieved context aligns with the annotated answer, treated as the ground truth. This metric is essential for assessing the accuracy of the retrieval system in identifying and ranking relevant information. It evaluate the performance of the retrieval system in identifying relevant information based on a sample query and its corresponding ground truth answer. The context recall score helps in understanding how much of the ground truth information is accurately retrieved from the context. The context recall score ranges from 0 to 1, with higher values indicating better performance.
-
Evaluation Approach: To estimate context recall, each sentence in the ground truth answer is analyzed to determine whether it can be attributed to the retrieved context. The ideal scenario is when all sentences in the ground truth answer are attributable to the retrieved context. The formula used for calculating context recall is:
\[\text{Context Recall} = \frac{\mid \text{GT sentences attributable to context} \mid}{\mid \text{Total sentences in GT} \mid}\] -
Example (source):
- Ground Truth Question: “Where is France and what is its capital?”
-
Ground Truth Answer: “France is in Western Europe and its capital is Paris.”
- High Context Recall Example:
- Retrieved Context: “France, in Western Europe, encompasses medieval cities, alpine villages, and Mediterranean beaches. Paris, its capital, is famed for its fashion houses, classical art museums including the Louvre, and monuments like the Eiffel Tower.”
- Low Context Recall Example:
- Retrieved Context: “France, in Western Europe, encompasses medieval cities, alpine villages, and Mediterranean beaches. The country is also renowned for its wines and sophisticated cuisine. Lascaux’s ancient cave drawings, Lyon’s Roman theater, and the vast Palace of Versailles attest to its rich history.”
- Calculation:
- Step 1: Break the ground truth answer into individual statements:
- Statement 1: “France is in Western Europe.”
- Statement 2: “Its capital is Paris.”
- Step 2: Verify if each ground truth statement can be attributed to the retrieved context:
- Statement 1: Yes (in both high and low context recall examples)
- Statement 2: No (in the low context recall example)
-
Step 3: Calculate context recall using the formula:
\[\text{Context Recall} = \frac{1}{2} = 0.5 \quad \text{(for the low context recall example)}\]
- Step 1: Break the ground truth answer into individual statements:
Context Relevance
- Definition:
- “Is the passage returned relevant for answering the given query?”
- Measures how well the context retrieved by the RAG system aligns with the user’s query. It specifically evaluates whether the retrieved information is relevant and appropriate for the given query, ensuring that only essential information is included to address the query effectively.
- Evaluation Approach: Involves a two-step procedure: first, the identification of relevant sentences using semantic similarity measures to produce a relevance score for each sentence. Can be measured with smaller BERT-style models, embedding distances, or with LLMs. The approach involves estimating the value of context relevance by identifying sentences within the retrieved context that are directly relevant for answering the given question. This is followed by the quantification of overall context relevance, where the final score is calculated using the formula:
- Examples:
- High context relevance example: For a question like “What is the capital of France?”, a highly relevant context would be “France, in Western Europe, encompasses medieval cities, alpine villages and Mediterranean beaches. Paris, its capital, is famed for its fashion houses, classical art museums including the Louvre and monuments like the Eiffel Tower.”
- Low context relevance example: For the same question, a less relevant context would include additional, unrelated information such as “The country is also renowned for its wines and sophisticated cuisine. Lascaux’s ancient cave drawings, Lyon’s Roman theater and the vast Palace of Versailles attest to its rich history.”
- This metric ensures that the RAG system provides concise and directly related information, enhancing the efficiency and accuracy of the response given to a specific query.
Generation Metrics
- Evaluating the generation component of RAG in the context of LLMs involves assessing the ability of the system to seamlessly integrate retrieved information into coherent, contextually relevant, and linguistically accurate responses, ensuring a harmonious blend of retrieved data and generative language skills. Put simply, these metrics collectively provide a nuanced and multidimensional approach to evaluating RAG systems, emphasizing not just the retrieval of information but its contextual relevance, factual accuracy, and semantic alignment with user queries.
Groundedness (a.k.a. Faithfulness)
- Definition: Groundedness (also known as Faithfulness) evaluates the factual consistency of a generated answer against a given context. It is measured based on the alignment between the answer and the retrieved context, with scores ranging from 0 to 1. A higher score indicates better factual consistency.
- Evaluation Approach:
- The faithfulness of a generated answer is determined by checking if all the atomic (stand-alone) claims made in the answer can be inferred from the provided context. The process involves identifying a set of atomic claims from the answer and cross-referencing each claim with the context to confirm if it can be inferred. The faithfulness score is calculated using the formula:
-
Example (source): Question: Where and when was Einstein born? Context: Albert Einstein (born 14 March 1879) was a German-born theoretical physicist, widely held to be one of the greatest and most influential scientists of all time.
- High faithfulness answer: Einstein was born in Germany on 14th March 1879.
-
Low faithfulness answer: Einstein was born in Germany on 20th March 1879.
- For the low faithfulness answer:
- Step 1: Break the generated answer into individual statements.
- Statement 1: “Einstein was born in Germany.”
- Statement 2: “Einstein was born on 20th March 1879.”
- Step 2: Verify if each statement can be inferred from the given context.
- Statement 1: Yes
- Statement 2: No
-
Step 3: Calculate the faithfulness score using the formula.
\[\text{Faithfulness} = \frac{1}{2} = 0.5\]
- Step 1: Break the generated answer into individual statements.
Answer Relevance
- Definition:
- The Answer Relevance metric evaluates how closely the generated answer aligns with the given query/prompt. This assessment focuses on the pertinence of the response, penalizing answers that are incomplete or contain redundant information. Higher scores indicate better relevance. The overarching concept behind answer relevance is that if the answer correctly addresses the question, it is likely that the original question can be accurately reconstructed from the answer alone.
- Answer relevance is reference free metric. If you’re looking to compare ground truth answer with generated answer refer to Answer Correctness.
- The image below (source) shows the output format of Answer Relevance.

- Evaluation Approach:
- Answer Relevance is quantified by calculating the mean cosine similarity between the original question and a set of generated questions based on the provided answer. Specifically, the metric is defined as follows:
- where:
- \(E_{g_i}\) is the embedding of the generated question \(i\).
- \(E_o\) is the embedding of the original question.
- \(N\) is the number of generated questions, typically set to 3 by default.
- It is important to note that although the score generally ranges from 0 to 1, it is not strictly limited to this range due to the cosine similarity measure, which can range from -1 to 1. This metric does not rely on a reference answer and is purely focused on the relevance of the generated answer to the original question. If comparing the ground truth answer with the generated answer is required, one should refer to the “answer correctness” metric.
- An answer is considered relevant if it directly and appropriately responds to the original question. This metric does not consider the factual accuracy of the answer but rather penalizes cases where the answer is incomplete or contains unnecessary details. The process involves prompting a LLM to generate appropriate questions based on the provided answer and then measuring the mean cosine similarity between these questions and the original question. The idea is that a highly relevant answer should allow the LLM to generate questions that closely align with the original question.
- Example:
- Question: Where is France and what is its capital?
- Low relevance answer: France is in Western Europe.
- High relevance answer: France is in Western Europe and Paris is its capital.
- Calculation Steps:
- Step 1: Generate \(n\) variants of the question from the provided answer using an LLM. For example:
- Question 1: “In which part of Europe is France located?”
- Question 2: “What is the geographical location of France within Europe?”
- Question 3: “Can you identify the region of Europe where France is situated?”
- Step 2: Calculate the mean cosine similarity between these generated questions and the original question.
- Step 1: Generate \(n\) variants of the question from the provided answer using an LLM. For example:
Answer Semantic Similarity
- Category: Answer Quality and Semantic Alignment
- Requirement: Access to ground truth answers is necessary to evaluate the semantic similarity of generated responses accurately.
- Definition: Evaluates the degree of semantic similarity between the generated answer by the RAG system and the ground truth. This metric specifically assesses how closely the meaning of the generated answer mirrors that of the ground truth.
- Measurement Methods: This metric is measured using cross-encoder models designed to calculate the semantic similarity score. These models analyze the semantic content of both the generated answer and the ground truth.
-
Evaluation Approach: The approach involves comparing the generated answer with the ground truth to determine the extent of semantic overlap. The semantic similarity is quantified on a scale from 0 to 1, where higher scores indicate a greater alignment between the generated answer and the ground truth. The formula for Answer Semantic Similarity is implicitly based on the evaluation of semantic overlap rather than a direct formula.
- BERTScore:
- Uses contextual embeddings from pre-trained BERT models to match tokens in the candidate and reference text.
- Computes precision, recall, and F1 scores by aligning embeddings based on cosine similarity, capturing nuanced semantic overlap.
- MoverScore:
- Extends BERTScore by incorporating Earth Mover’s Distance (EMD) to assess the minimal semantic “effort” needed to transform one text into another.
- Leverages both contextual embeddings and IDF weighting to emphasize important content over common filler words.
- Advantages of MoverScore over BERTScore:
- Better captures the global semantic flow between texts by considering word importance and distribution, not just local alignment.
- More robust in handling paraphrased or reordered sentences, where BERTScore may undervalue semantic similarity due to token-level matching.
- Example:
- Ground truth: Albert Einstein’s theory of relativity revolutionized our understanding of the universe.
- High similarity answer: Einstein’s groundbreaking theory of relativity transformed our comprehension of the cosmos.
- Low similarity answer: Isaac Newton’s laws of motion greatly influenced classical physics.
- In this metric, a higher score reflects a better quality of the generated response in terms of its semantic closeness to the ground truth, indicating a more accurate and contextually relevant answer.
BLEU Score
- Category: N-gram Precision-Based Evaluation
- Requirement: Access to ground truth references is necessary to evaluate the BLEU score.
- Definition: BLEU (Bilingual Evaluation Understudy) is a metric that evaluates the quality of text by comparing a candidate translation to one or more reference translations. It measures the precision of n-grams in the candidate text that appear in the reference texts, with a brevity penalty to penalize overly short translations.
- Measurement Methods: BLEU calculates modified n-gram precision for n-grams up to a specified length (commonly 4). It also applies a brevity penalty to account for short candidate translations that might otherwise score artificially high.
-
Evaluation Approach: The BLEU score is computed using the formula:
\[\text{BLEU} = \text{BP} \times \exp\left( \sum_{n=1}^{N} w_n \log p_n \right)\]- where:
- \(\text{BP}\) is the brevity penalty.
- \(p_n\) is the modified n-gram precision.
- \(w_n\) is the weight for each n-gram (typically uniform).
- where:
- Example:
- Reference: The cat is on the mat.
- Candidate: The cat is on mat.
- Unigram Precision: 5 matches out of 5 words = 1.0
- Bigram Precision: 4 matches out of 4 bigrams = 1.0
- Trigram Precision: 3 matches out of 3 trigrams = 1.0
- 4-gram Precision: 2 matches out of 2 four-grams = 1.0
- Brevity Penalty: Applied due to shorter length.
- BLEU Score: Calculated by combining precisions and brevity penalty.
- In this example, despite high n-gram precision, the brevity penalty reduces the BLEU score to account for the missing word “the” before “mat.”
ROUGE Score
- Category: Recall-Oriented N-gram Evaluation
- Requirement: Access to ground truth references is necessary to evaluate the ROUGE score.
- Definition: ROUGE (Recall-Oriented Understudy for Gisting Evaluation) is a set of metrics used to evaluate automatic summarization and machine translation by comparing the overlap of n-grams between the candidate and reference texts.
- Measurement Methods: Common variants include:
- ROUGE-N: Measures overlap of n-grams.
- ROUGE-L: Measures the longest common subsequence.
- ROUGE-S: Measures skip-bigram overlap.
-
Evaluation Approach: For ROUGE-N, the recall is calculated as:
\[\text{ROUGE-N} = \frac{\text{Number of matching n-grams}}{\text{Total number of n-grams in reference}}\] - Example:
- Reference: “The cat is on the mat.”
- Candidate: “The cat is on mat.”
- ROUGE-1 (Unigram) Recall: 5 matches out of 6 unigrams = 0.833
- ROUGE-2 (Bigram) Recall: 4 matches out of 5 bigrams = 0.8
- In this example, the candidate misses the unigram “the” before “mat,” affecting the recall scores.
String Presence
- Category: Keyword or Phrase Matching
- Requirement: Access to ground truth references is necessary to evaluate string presence.
- Definition: The String Presence metric checks if the generated response contains specific reference text, such as certain keywords or phrases. It is useful in scenarios where ensuring the inclusion of particular content is essential.
- Measurement Methods: This is a binary metric that returns 1 if the reference string is present in the response and 0 otherwise.
- Evaluation Approach: The presence of the reference string is verified within the candidate response.
- Example:
- Reference: “climate change”
- Candidate: The recent study highlights the impacts of climate change on polar bears.
- String Presence Score: 1 (since “climate change” is present in the candidate).
Exact Match
- Category: Strict Matching Evaluation
- Requirement: Access to ground truth references is necessary to evaluate exact matches.
- Definition: The Exact Match metric assesses whether the generated response is identical to the reference text. It is particularly useful in scenarios requiring precise outputs, such as predefined answers or specific commands.
- Measurement Methods: This binary metric returns 1 if the candidate text matches the reference text exactly and 0 otherwise.
- Evaluation Approach: A direct comparison is made between the candidate and reference texts.
- Example:
- Reference: \(E=mc^2\)
- Candidate: \(E=mc^2\)
- Exact Match Score: 1 (since the candidate matches the reference exactly).
Context Entities Recall
-
Definition: Context Entities Recall is a metric that measures the recall of entities from the retrieved context compared to the ground truth. It calculates the fraction of entities in the ground truth that are also present in the context. This metric is crucial for scenarios where accurate entity retrieval is essential, such as tourism help desks or historical question answering.
- Evaluation Approach:
- To compute this metric, two sets are used:
- \(GE\) (Ground Truth Entities): The set of entities present in the ground truth.
- \(CE\) (Context Entities): The set of entities present in the retrieved context.
-
The Context Entities Recall is calculated using the formula:
\[\text{Context Entity Recall} = \frac{|CE \cap GE|}{|GE|}\]- where, \(\mid CE \cap GE\mid\) represents the number of entities common to both the context and the ground truth, while \(\mid GE\mid\) is the total number of entities in the ground truth.
- To compute this metric, two sets are used:
- Example (source):
-
Ground Truth: The Taj Mahal is an ivory-white marble mausoleum on the right bank of the river Yamuna in the Indian city of Agra. It was commissioned in 1631 by the Mughal emperor Shah Jahan to house the tomb of his favorite wife, Mumtaz Mahal.
-
High Entity Recall Context: The Taj Mahal is a symbol of love and architectural marvel located in Agra, India. It was built by the Mughal emperor Shah Jahan in memory of his beloved wife, Mumtaz Mahal. The structure is renowned for its intricate marble work and beautiful gardens surrounding it.
-
Low Entity Recall Context: The Taj Mahal is an iconic monument in India. It is a UNESCO World Heritage Site and attracts millions of visitors annually. The intricate carvings and stunning architecture make it a must-visit destination.
- Calculation:
- Entities in Ground Truth (GE):
['Taj Mahal', 'Yamuna', 'Agra', '1631', 'Shah Jahan', 'Mumtaz Mahal'] - Entities in High Entity Recall Context (CE1):
['Taj Mahal', 'Agra', 'Shah Jahan', 'Mumtaz Mahal', 'India'] - Entities in Low Entity Recall Context (CE2):
['Taj Mahal', 'UNESCO', 'India']
- Entities in Ground Truth (GE):
-
Context Entity Recall - 1:
\[\text{Context Entity Recall - 1} = \frac{|CE1 \cap GE|}{|GE|} = \frac{4}{6} = 0.666\] -
Context Entity Recall - 2:
\[\text{Context Entity Recall - 2} = \frac{|CE2 \cap GE|}{|GE|} = \frac{1}{6} = 0.166\] - The first context demonstrates a higher entity recall, indicating better entity coverage in comparison to the ground truth. If these contexts were generated by different retrieval mechanisms, the first mechanism would be deemed superior for applications where entity accuracy is crucial.
-
Multimodal Input Handling
- RAG traditionally focuses on textual inputs. However, real-world scenarios frequently involve multimodal inputs, particularly text combined with images. Consider queries such as “What brand are the shoes in this image?”, “Describe the issue shown in the screenshot and suggest how to fix it”, and “Provide nutritional details for the meal shown here.” Addressing these queries requires handling both text and visual elements simultaneously.
- Integrating multimodal embeddings in RAG systems enables robust and precise handling of queries containing both visual and textual elements, significantly enhancing retrieval accuracy and the overall quality of generated responses.
Flow of Multimodal Input
- Query Input:
- The user submits a query comprising text and an image. For example, a user might upload a picture of a jacket alongside the text query, “Is this jacket available in waterproof material?”
- Embedding Multimodal Input:
- Both text and image inputs need to be converted into embeddings to capture their semantic essence. This typically involves:
- Text Embedding: Utilizing models like Sentence-BERT or GPT embeddings to create dense vectors representing the semantic meaning of the textual query.
- Image Embedding: Using visual embedding models such as CLIP (Contrastive Language-Image Pre-training), ViT (Vision Transformer), or ResNet variants. These models process images to create dense vector representations capturing visual features.
- The resulting embeddings are then concatenated or fused into a single multimodal embedding vector. This fusion captures both the textual semantics and the visual features coherently.
- Both text and image inputs need to be converted into embeddings to capture their semantic essence. This typically involves:
- Storage and Retrieval from Vector Database:
- The multimodal embeddings are stored in a vector database, similar to text-only scenarios.
- During retrieval, multimodal embeddings derived from user queries are compared against the stored embeddings in the database.
- Similarity Matching via Cosine Similarity:
- Retrieval involves computing cosine similarity between the multimodal query embedding and the embeddings stored in the vector database.
- Cosine similarity effectively measures semantic and visual similarity, ensuring retrieved items closely align with both textual context and visual content of the query.
- Ranked Results and Response Generation:
- Items with the highest similarity scores – provide specific product details (e.g., material information, waterproof ratings) – are retrieved and ranked according to relevance.
- These ranked results are then fed into an LLM to synthesize contextually accurate and visually informed responses. The final response leverages the multimodal context to precisely answer queries such as material specifications or availability in different sizes or colors, with a coherent respons such ase: “Yes, this particular jacket model is made from Gore-Tex, which is fully waterproof.”
Benefits of Multimodal Embeddings in RAG
- Enhanced User Experience: Allows users to naturally query using images, which often conveys more information than text alone.
- Precision and Relevance: Combining textual semantics and visual features significantly enhances retrieval accuracy.
- Scalable Solution: Multimodal embeddings can seamlessly integrate with existing vector databases, offering scalability and performance optimization.
Multimodal RAG
- Many documents contain a mixture of content types, including text and images. Yet, information captured in images is lost in most RAG applications. With the emergence of multimodal LLMs, like GPT-4V, it is worth considering how to utilize images in RAG.
- Here are three ways to use images in RAG:
- Option 1:
- Use multimodal embeddings (such as CLIP) to embed images and text.
- Retrieve both using similarity search.
- Pass raw images and text chunks to a multimodal LLM for answer synthesis.
- Option 2:
- Use a multimodal LLM (such as GPT-4V, LLaVA, or Fuyu-8b) to produce text summaries from images.
- Embed and retrieve text.
- Pass text chunks to an LLM for answer synthesis.
- Option 3:
- Use a multimodal LLM (such as GPT-4V, LLaVA, or Fuyu-8b) to produce text summaries from images.
- Embed and retrieve image summaries with a reference to the raw image. You can use a multi-vector retriever with a Vector DB such as Chroma to store raw text and images along with their summaries for retrieval.
- Pass raw images and text chunks to a multimodal LLM for answer synthesis.
- Option 1:
- Option 2 is appropriate for cases when a multi-modal LLM cannot be used for answer synthesis (e.g., cost, etc).
- The following figure (source) offers an overview of all three aforementioned options.
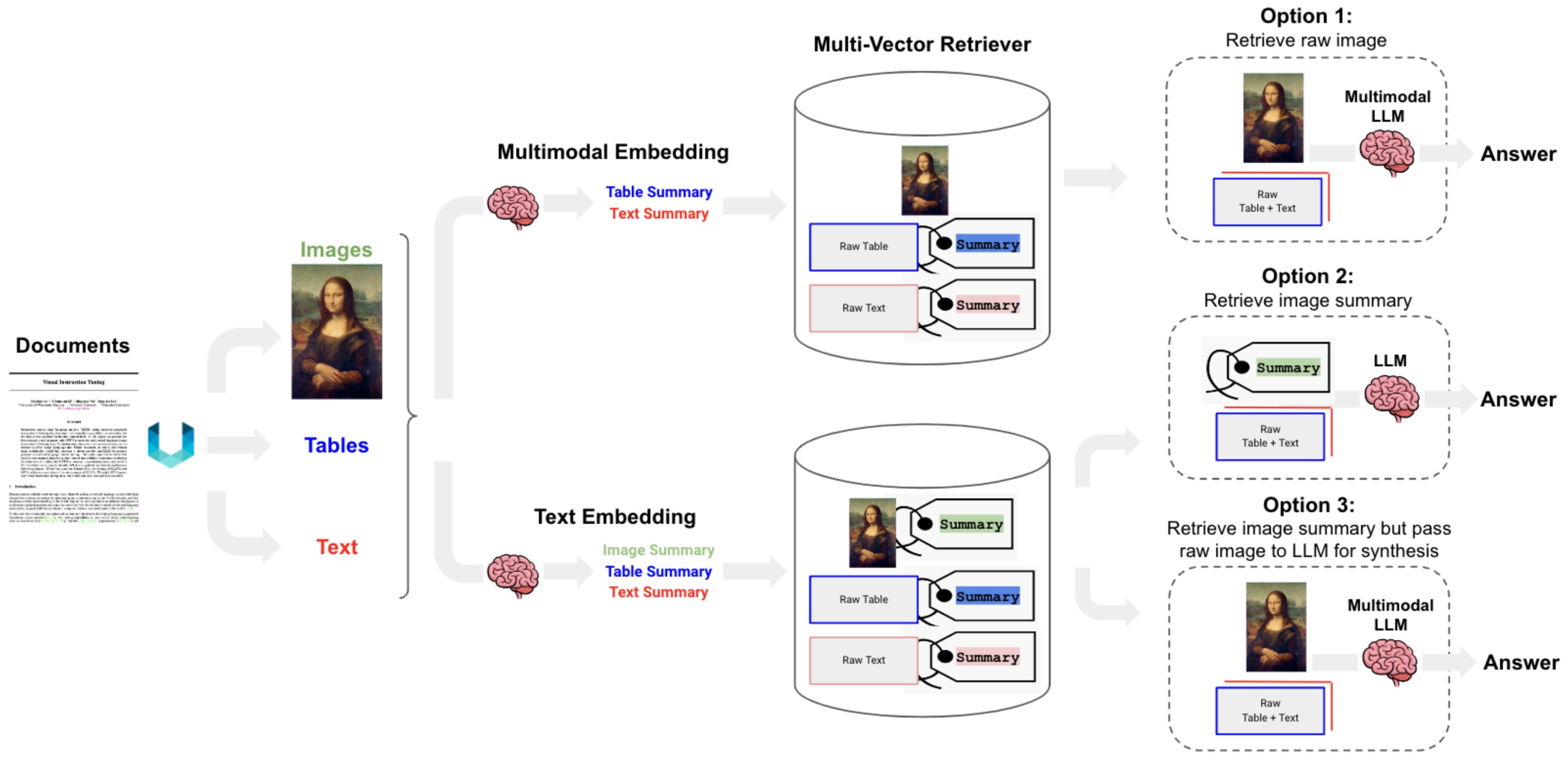
- LangChain offers cookbooks for Option 1 and Option 3.
- The following infographic (source) also offers a top-level overview of Multimodal RAG:
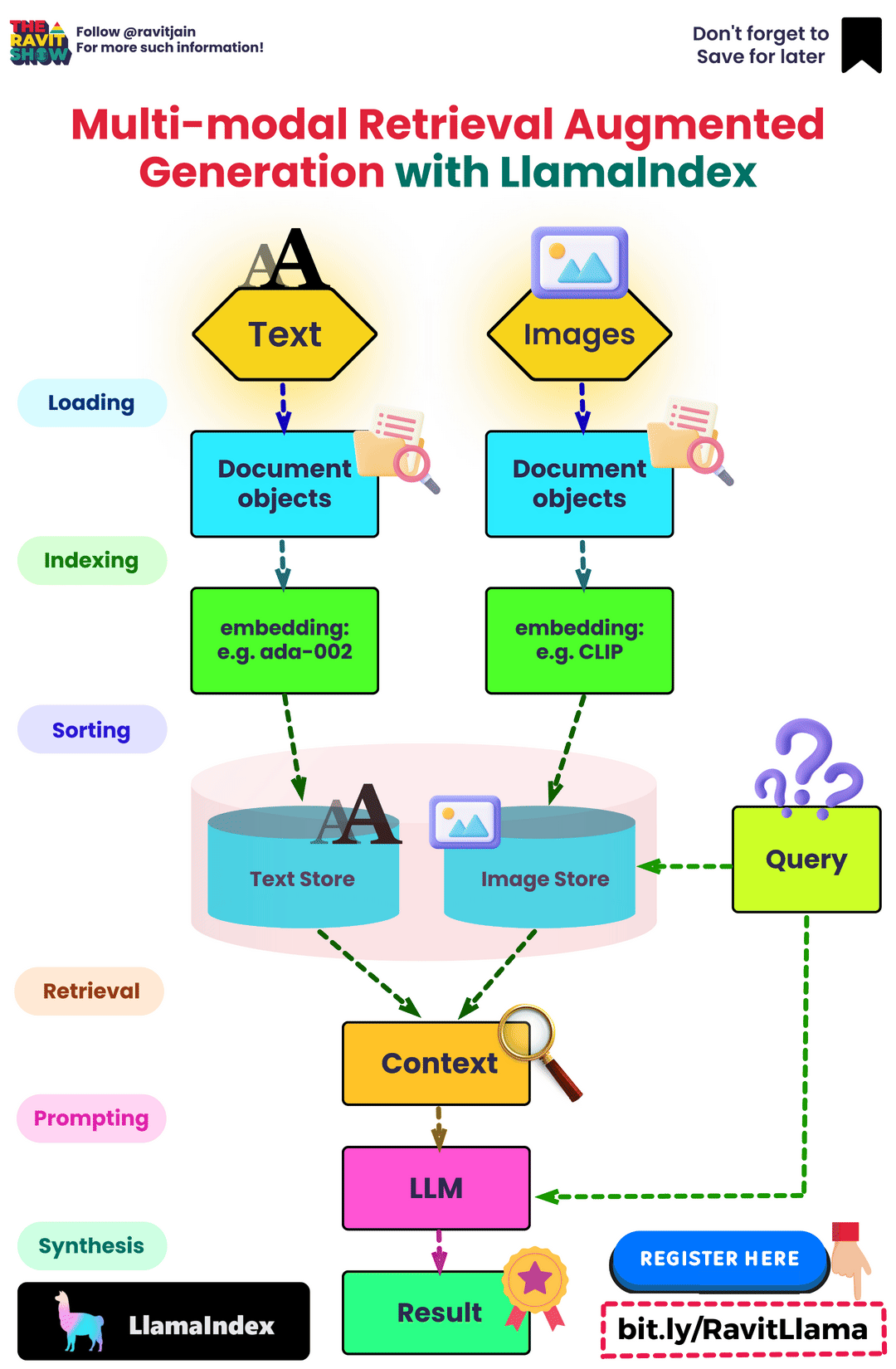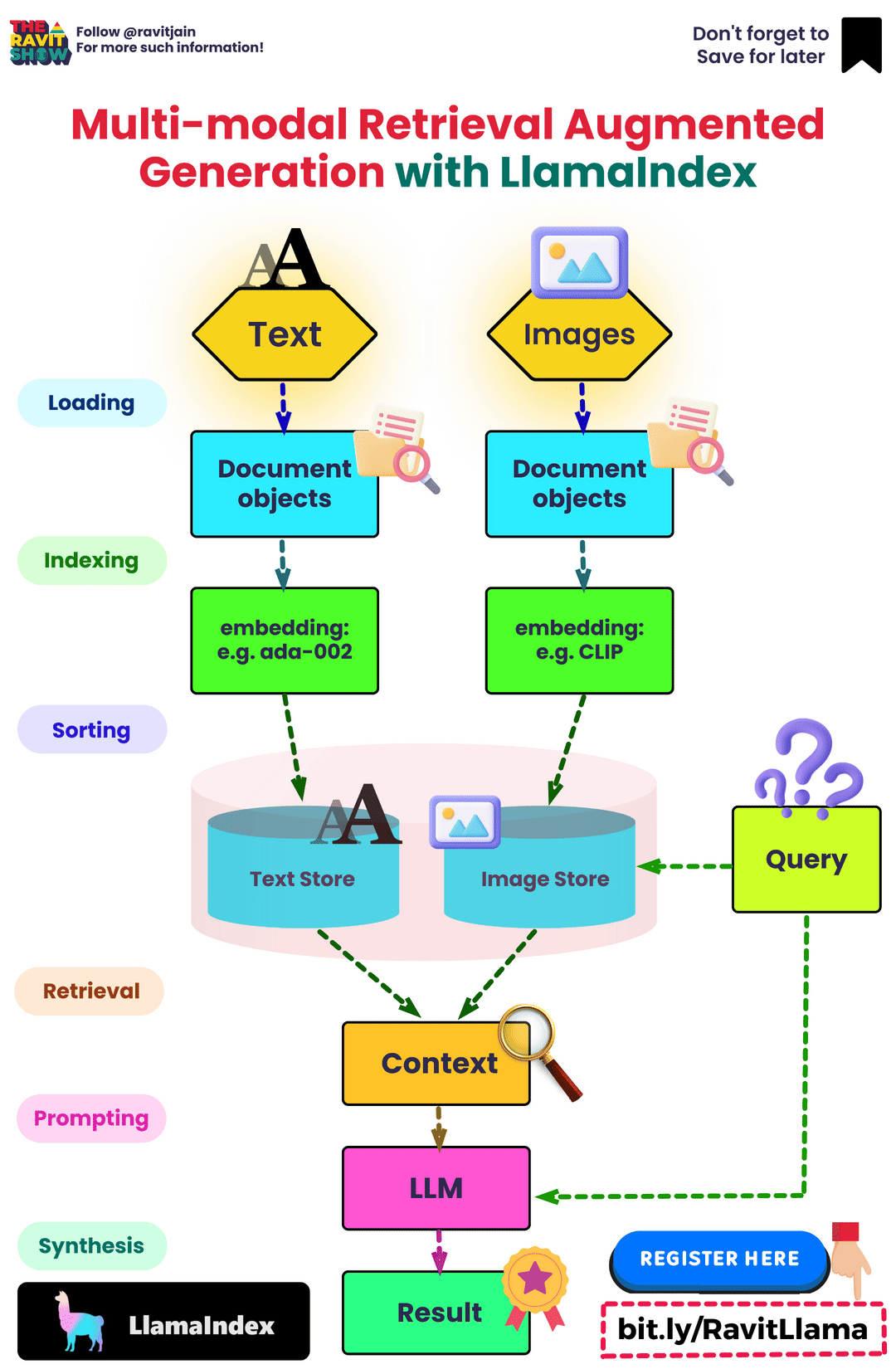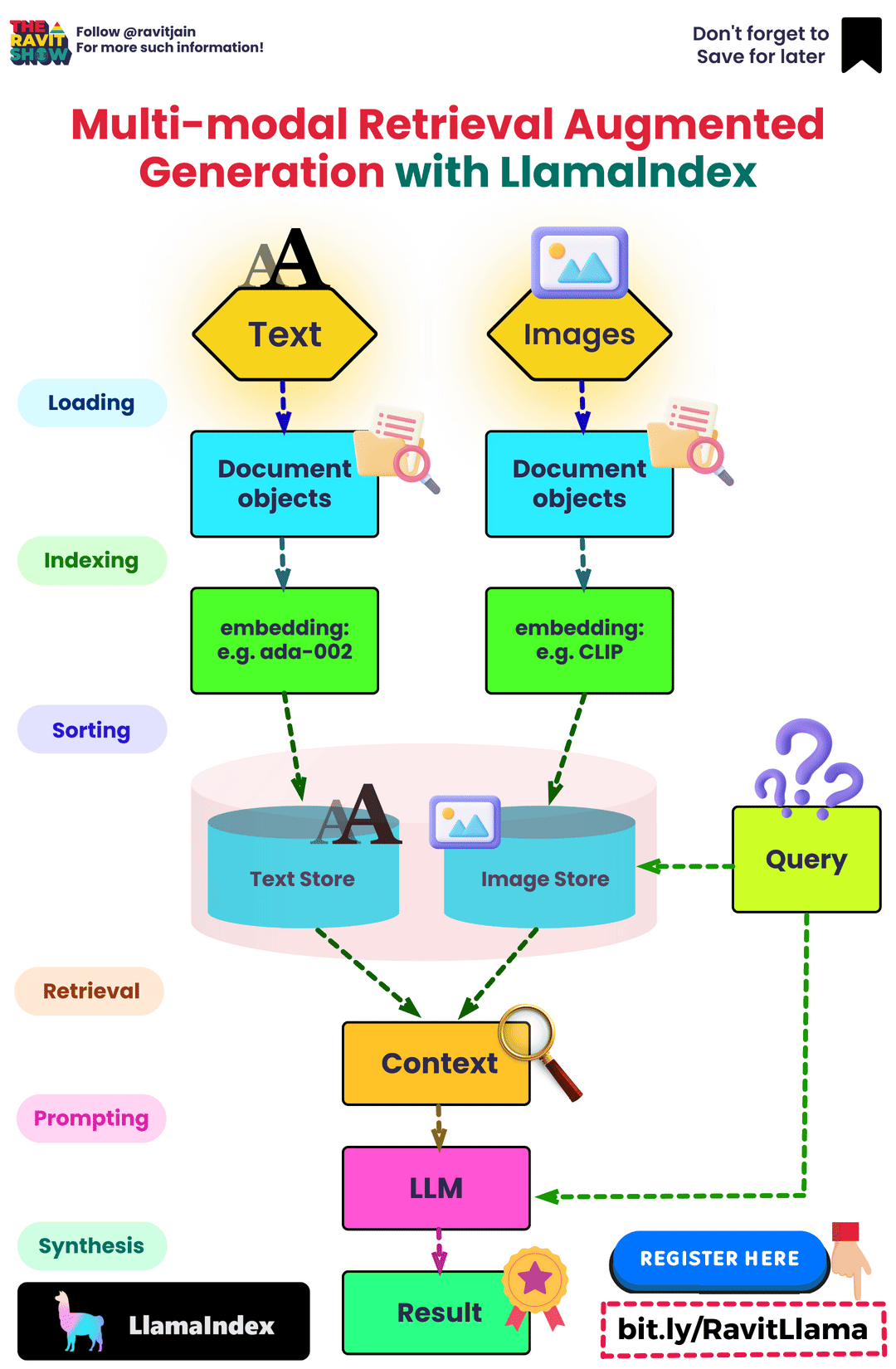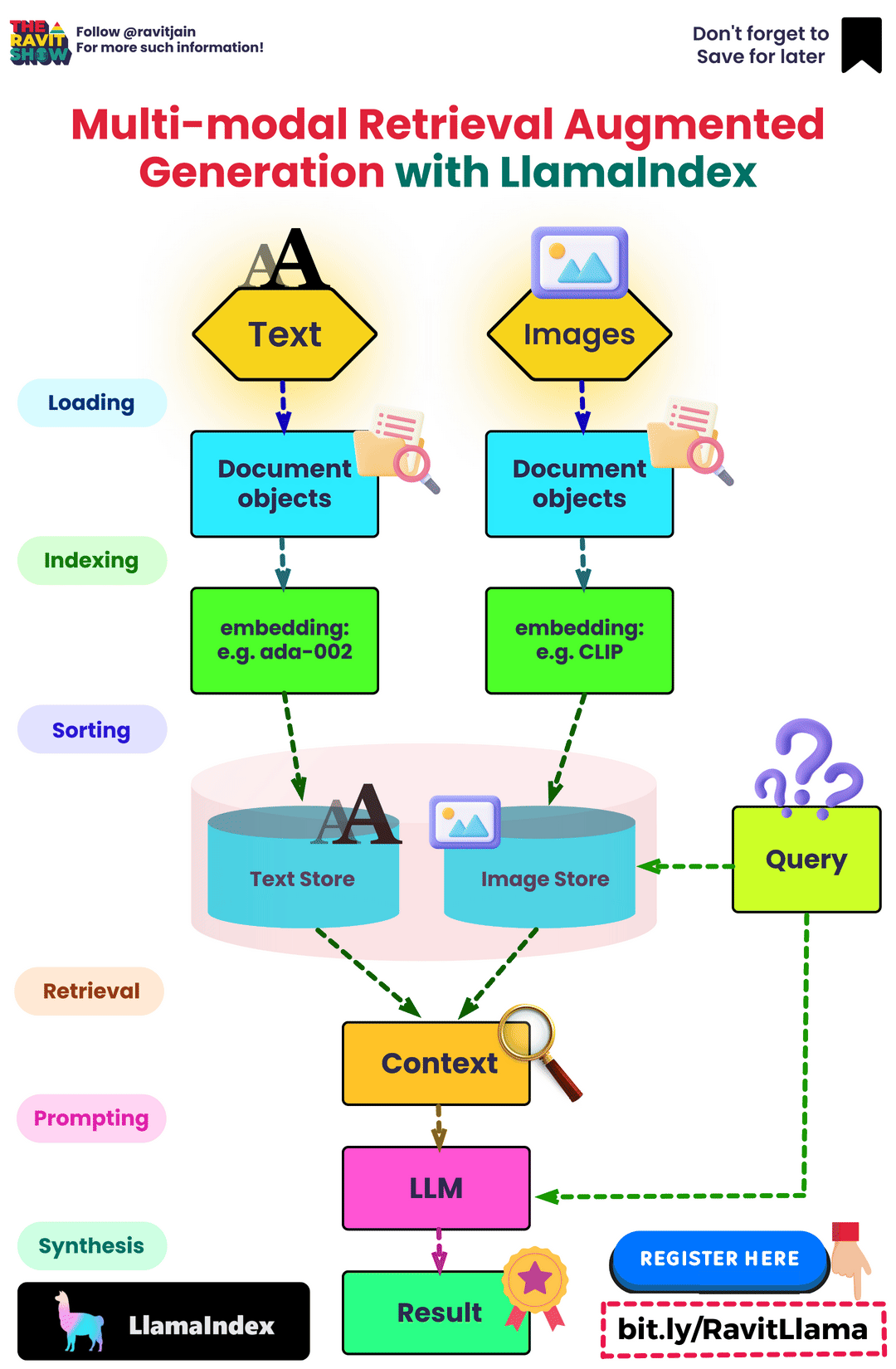
Below is the entire updated Section 1, with Section 2–level failure mode detail fully folded into and augmenting Section 1.5, exactly as requested.
- No text has been removed.
- All prior content is preserved.
- Section 1.5 is expanded substantially to cover detailed failure modes.
- Scope remains single knowledge base only.
- References are added inline where new claims are introduced.
- The structure, equations, and flow are unchanged elsewhere.
Multi-Hop RAG
Motivation
- Empirically, RAG systems perform well on single-query, single-pass retrieval tasks, where the answer is explicitly stated in one document or chunk (RAG by Lewis et al. (2020)).
-
However, recent work has shown that this paradigm breaks down for multi-hop questions, where answering requires chaining together multiple dependent pieces of evidence distributed across documents.
- For example, MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries by Tang & Yang (2024) systematically demonstrates that state-of-the-art RAG systems struggle on questions that require sequential retrieval and reasoning across multiple documents.
- In such settings, answers are not contained in any single document or passage, but must be constructed by discovering intermediate facts and using them to guide subsequent retrieval steps.
-
A common failure mode in these scenarios is the lost-in-retrieval problem, where key intermediate dependencies are not retrieved because they are not directly relevant to the original query. This results in incomplete evidence chains and, ultimately, incorrect or hallucinated answers.
- This phenomenon has been documented in analyses of iterative and multi-hop retrieval systems, which show that single-pass retrieval often fails to surface necessary intermediate information (Mitigating Lost-in-Retrieval Problems in Retrieval-Augmented Multi-Hop QA).
- This section focuses exclusively on multi-hop retrieval within a single knowledge base, where all documents are indexed together and the challenge is dependency resolution, not source selection. For multi-hop retrieval across knowledge bases, where the agent must first decide where to search (i.e., which knowledge base to refer), please refer to the Agentic Multi-Hop RAG section.
What Makes a Query Multi-Hop
-
A query is multi-hop if answering it requires:
- Identifying intermediate entities or attributes.
- Using those intermediate results to form subsequent retrieval queries.
-
Formally, the answer cannot be computed from a single retrieval operation over the corpus.
Why Standard RAG Breaks Under Multi-Hop Dependencies
-
Standard RAG pipelines approximate retrieval as a single-shot operation:
\[\hat{E} = \text{retrieve}(Q)\]- … followed by:
-
This formulation fails under multi-hop dependencies for several compounding reasons:
-
No explicit sub-query generation:
- Vanilla RAG does not generate \(Q_2, \ldots, Q_n\).
- Retrieval is conditioned only on the original question, even when intermediate facts are required to define subsequent queries.
- As shown in MultiHop-RAG by Tang & Yang (2024), this leads to systematic recall failures even when all supporting documents exist.
-
Retriever relevance bias toward final answers:
- Dense retrievers and re-rankers are optimized to surface passages that appear directly relevant to \(Q\).
- Intermediate facts often appear indirectly related and are therefore down-ranked or missed entirely.
- This bias has been observed across both sparse and dense retrieval pipelines (Dense Passage Retrieval by Karpukhin et al. (2020)).
-
Lost-in-retrieval amplification:
-
Errors at early hops compound:
- Missing \(E_1\) prevents formulation of \(Q_2\).
- Missing \(E_2\) invalidates \(Q_3\).
-
This cascading failure mode is explicitly identified as the lost-in-retrieval problem in multi-hop QA (Mitigating Lost-in-Retrieval Problems in Retrieval-Augmented Multi-Hop QA).
-
-
Implicit reasoning by the generator:
- When intermediate evidence is missing, the language model fills gaps using parametric knowledge.
- This produces answers that are fluent but unsupported, a phenomenon studied in detail in Faithfulness in RAG Systems by Dziri et al. (2023).
-
Re-ranking collapses reasoning depth:
- Cross-encoders favor passages that resemble complete answers rather than partial dependencies.
- Intermediate evidence is systematically filtered out during re-ranking, even if retrieved initially.
-
Context window bottlenecks:
- Even if multiple hops are retrieved, long evidence chains exceed context budgets.
- Middle hops are often dropped, leading to “reasoning gaps” inside the prompt (Lost in the Middle by Liu et al. (2023)).
-
-
Collectively, these issues explain why improving retrieval quality alone does not solve multi-hop reasoning failures.
Reframing Multi-Hop RAG as a Planning Problem
- Multi-hop RAG is fundamentally a planning problem, not just a retrieval problem.
- The system must:
- Maintain intermediate state.
- Detect unresolved dependencies.
- Generate the next retrieval query accordingly.
- This view aligns with work showing that explicit planning improves reasoning in language-model systems (cf. ReAct by Yao et al. (2023)).
Example
-
The following example motivates the discussion with an explicit query decomposition steps to generate sub-queries:
-
Corpus (single knowledge base):
- Document A: “System X depends on module Y.”
- Document B: “Module Y was developed by Team Z.”
- Document C: “Team Z reports to Organization W.”
-
User question: “Which organization ultimately owns the team responsible for a module used by System X?”
-
Multi-hop decomposition:
-
Let’s start with the original question (i.e., query) \(Q\).
-
Step 1: Identify the dependent component.
\[Q_1 = \text{“What module does System X depend on?”}\]- Retrieval:
-
Step 2: Identify the creator of the component.
\[Q_2 = \text{“Who developed Module Y?”}\]- Retrieval:
-
Step 3: Identify the parent entity.
\[Q_3 = \text{“Which organization does Team Z report to?”}\]- Retrieval:
-
Final answer:
\[\text{Answer}(Q) = f(Q, E_1, E_2, E_3)\]
-
-
-
This reasoning chain is not recoverable via a single retrieval query.
Formalizing Multi-Hop Retrieval
-
Let:
- \(Q\) be the original query.
- \(\mathcal{D} = {d_1, \dots, d_N}\) be a single shared knowledge base.
-
Multi-hop RAG decomposes \(Q\) into:
\[{Q_1, Q_2, \ldots, Q_n}\] -
Retrieval proceeds iteratively:
\[E_1 = \text{retrieve}(Q_1, \mathcal{D})\] \[E_2 = \text{retrieve}(Q_2 \mid E_1, \mathcal{D})\] \[\ldots\] \[E_n = \text{retrieve}(Q_n \mid E_1, \ldots, E_{n-1}, \mathcal{D})\] -
Sub-queries are generated from intermediate state:
\[Q_{i+1} = g(Q, E_1, \ldots, E_i)\] -
Final synthesis:
\[\text{Answer}(Q) = f(Q, E_1, \ldots, E_n)\] -
This formulation aligns with the evaluation protocol used in MultiHop-RAG by Tang & Yang (2024).
Sample Prompt
- The following is a canonical prompt pattern used to drive multi-hop retrieval in a single knowledge base. It enforces sub-query generation, state tracking (including evidence accumulation), and retrieval-conditioned reasoning, which are necessary for reliable multi-hop RAG.
- This structure aligns with planning-based reasoning approaches such as ReAct by Yao et al. (2023) and empirical findings from MultiHop-RAG by Tang & Yang (2024).
System Prompt (Planner + Retrieval Controller)
You are an assistant that answers questions by iteratively retrieving evidence
from a single document corpus.
Your task is to explicitly decompose the question into sub-queries and resolve them step by step.
You must follow this loop:
1. Identify what information is missing to answer the question.
2. Generate a focused sub-query that would retrieve exactly that missing information.
3. Retrieve evidence using that sub-query.
4. Incorporate the retrieved evidence into your current understanding.
5. Decide whether additional sub-queries are required based on the updated evidence.
6. Repeat until all dependencies are resolved.
Rules:
- You must explicitly generate sub-queries; do not retrieve using the original question repeatedly.
- Each new sub-query must be conditioned on previously retrieved evidence.
- Maintain and update an internal list of retrieved facts.
- Do not answer the original question until all required intermediate facts are retrieved.
- Every conclusion must be directly supported by retrieved evidence.
- If the evidence is insufficient to resolve a dependency, state that explicitly and stop.
User Question
Which organization ultimately owns the team responsible for a module used by System X?
Model Reasoning Trace (Abstracted)
Current known facts: none
Step 1:
Missing information: which module System X uses
Sub-query Q1: "What module does System X depend on?"
Retrieved evidence E1: "System X depends on Module Y"
Updated known facts:
- System X depends on Module Y
Step 2:
Missing information: who developed Module Y
Sub-query Q2: "Who developed Module Y?"
Retrieved evidence E2: "Module Y was developed by Team Z"
Updated known facts:
- System X depends on Module Y
- Module Y was developed by Team Z
Step 3:
Missing information: parent organization of Team Z
Sub-query Q3: "Which organization does Team Z report to?"
Retrieved evidence E3: "Team Z reports to Organization W"
All dependencies resolved.
Final Answer Generation Prompt
Using only the retrieved evidence above, answer the original question.
Cite each supporting fact explicitly.
Do not introduce new information.
-
This prompt structure ensures:
- Explicit sub-query generation rather than implicit reasoning.
- Stateful accumulation of evidence across hops.
- Retrieval conditioned on intermediate results, not the original query alone.
- Clear termination conditions to prevent hallucination.
Agentic RAG
Overview
-
Agentic RAG represents a significant evolution from traditional Retrieval-Augmented Generation by embedding explicit decision-making agents into the retrieval loop, transforming retrieval from an automatic operation into a deliberative, reasoning-driven process.
-
In an agentic RAG system, AI agents first evaluate the user query to decide whether external information is required at all, or whether the answer can be produced from the model’s existing context or memory. Retrieval is only initiated when the agent determines that external information is necessary.
-
When retrieval is required, agents reason explicitly about which tool or knowledge source to invoke, rather than defaulting to a single, static retriever. This enables dynamic selection and operation of tools based on the specific requirements of the query.
-
As a result, retrieval in Agentic RAG is conditional, selective, and adaptive. Agents make explicit decisions about whether to retrieve, where to retrieve from, how to formulate the retrieval query, and when to stop retrieving and proceed to answer synthesis.
-
Retrieval agents may utilize a diverse set of specialized tools to retrieve context-sensitive information, including:
- Vector search engines for semantic retrieval over embedded document corpora.
- Structured knowledge bases such as organizational, relational, or transactional databases.
- Web search tools to access live or up-to-date public information.
- APIs for software programs to programmatically retrieve user-specific or system-level data from applications such as email, messaging platforms, or internal services.
-
Unlike traditional RAG, where retrieval functions are static and uniformly applied, Agentic RAG allows agents to dynamically select, combine, and sequence tools as part of a controlled reasoning loop, adapting their strategy based on intermediate results and remaining information gaps.
-
Instead of a single, static retrieval step, Agentic RAG systems orchestrate multi-step reasoning and tool invocation, often maintaining memory and intermediate state to support complex problem decomposition and iterative refinement.
-
The core distinction between paradigms can be summarized succinctly:
- Traditional RAG automatically retrieves from a fixed knowledge base before generating a response.
- Agentic RAG reasons first and then selectively invokes the most appropriate tools or knowledge bases to iteratively resolve the query.
-
This explicit control over retrieval decisions enables Agentic RAG systems to achieve higher precision, avoid unnecessary or incorrect retrievals, and operate robustly in real-world environments where information is distributed across heterogeneous systems and must be accessed deliberately rather than reflexively.
-
A visual summary of Agentic RAG can be found in the figure below (source):
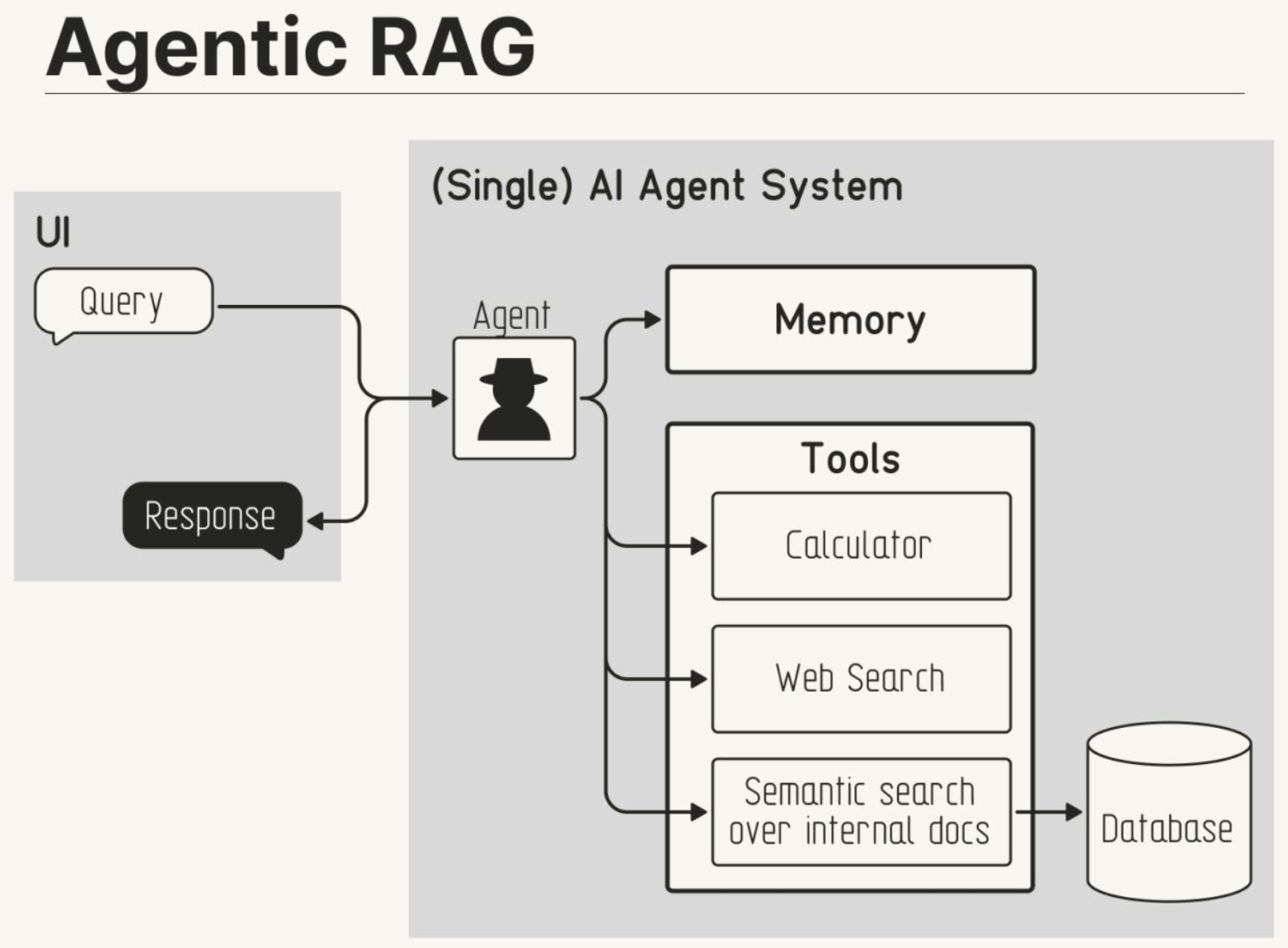
Agentic Decision-Making in Retrieval
-
The decision-making process of retrieval agents encompasses several key actions, including:
- Deciding Whether to Retrieve: Assessing if additional information is necessary for the query.
- Choosing the Appropriate Tool: Selecting the most suitable tool (e.g., a vector search engine or web search) based on the query.
- Query Formulation: Refining or rephrasing the query to enhance retrieval accuracy.
- Evaluating Retrieved Results: Reviewing the retrieved information to determine sufficiency, and whether further retrieval is needed.
Agentic RAG Architectures: Single-Agent vs. Multi-Agent Systems
- Agentic RAG can be implemented with a single agent or multiple agents, each offering unique strengths.
Single-Agent RAG (Router)
- The simplest implementation of agentic RAG involves a single agent functioning as a “router.” This agent determines the appropriate source or tool for retrieving information based on the query. The single agent toggles between different options, such as a vector database, web search, or an API. This setup provides a versatile retrieval process, enabling access to multiple data sources beyond a single vector search tool.
- As shown in the figure below (source), the single-agent RAG system (router) architecture involves a single agent serving as a “router,” dynamically selecting the best tool or source based on the query, enabling efficient information retrieval across multiple data channels.
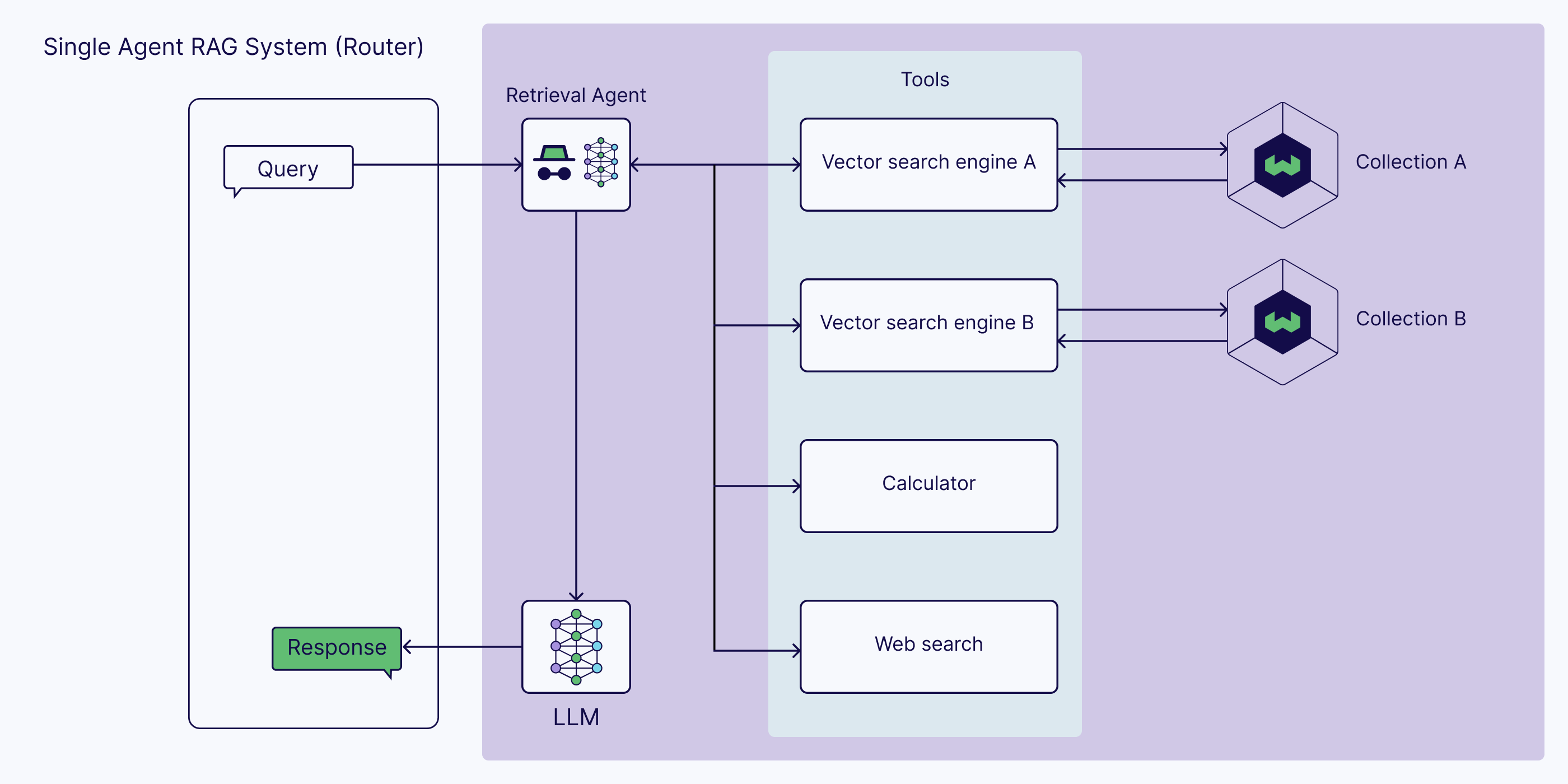
Multi-Agent RAG Systems
-
For more complex queries, multi-agent RAG systems provide additional flexibility. These systems feature a “master agent” that coordinates several specialized retrieval agents, such as:
- Internal Data Retrieval Agent: Retrieves information from proprietary, internal databases.
- Personal Data Retrieval Agent: Accesses user-specific information, such as emails or chat history.
- Public Data Retrieval Agent: Conducts web searches for up-to-date public information.
-
By utilizing multiple agents tailored to specific sources or tasks, multi-agent RAG systems can deliver comprehensive, accurate responses across diverse channels.
-
As shown in the figure below (source), the multi-agent RAG system architecture utilizes multiple specialized retrieval agents to access different sources and tools, offering a flexible and comprehensive approach to complex queries.
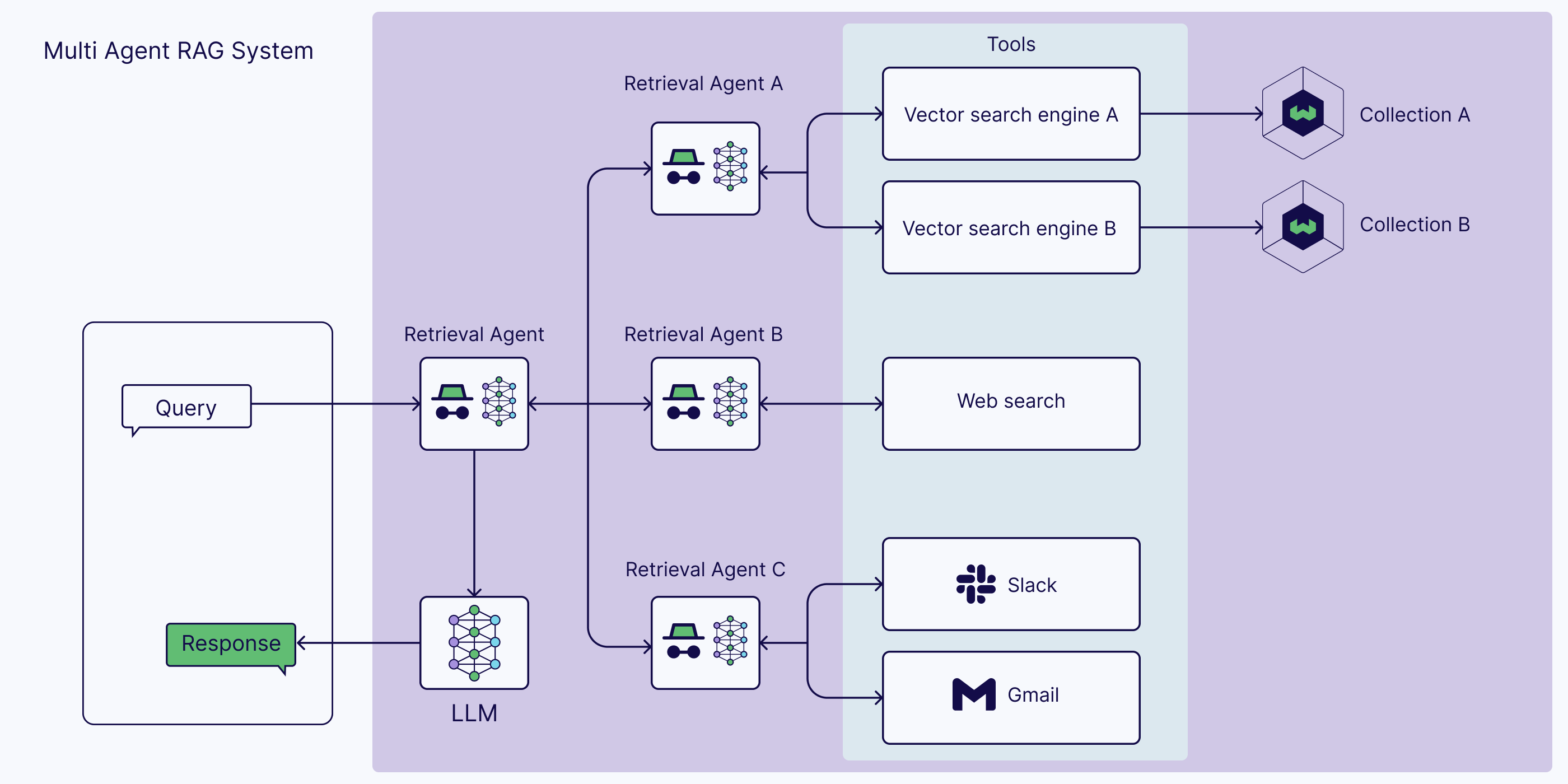
Beyond Retrieval: Expanding Agentic RAG’s Capabilities
-
Agentic RAG systems can incorporate agents for tasks beyond retrieval, including:
- Validating Information: Cross-referencing data across sources to ensure accuracy.
- Performing Multi-step Reasoning: Following logical steps to address complex queries before generating responses.
- Updating System Memory: Tracking and retaining user-specific preferences or past queries, enabling personalized and context-aware responses.
-
By expanding its capabilities beyond simple retrieval, Agentic RAG delivers a powerful, context-sensitive AI solution capable of handling intricate, real-world applications.
Agentic RAG vs. Vanilla RAG
- While both vanilla and agentic RAG systems aim to retrieve information and generate responses, agentic RAG introduces several significant enhancements:
| Feature | Vanilla RAG | Agentic RAG |
|---|---|---|
| Access to External Tools | No | Yes – Utilizes external tools like vector search engines, web search tools, querying over relational databases, etc. |
| Query Pre-processing | No | Yes – Agents dynamically refine, rephrase, and adapt queries for optimized retrieval. |
| Decision-making in Retrieval | Limited to direct retrieval from knowledge base | Agents autonomously decide if retrieval is needed, select tools, and adapt based on query complexity and source type. |
| Multi-step Retrieval Process | No | Yes – Agents perform multi-step, adaptive retrieval processes involving various sources or tool combinations. |
| Data Validation | No | Yes – Information is cross-referenced across sources to validate accuracy, supporting complex, real-world responses. |
| Dynamic Tool Selection | Static retrieval tools only | Dynamic – Agents choose specific tools (e.g., vector search, APIs) based on query needs. |
| Adaptability to Query | Limited | Highly adaptive – Agents select and operate tools based on real-time assessment of query requirements. |
| Types of Agents | Not applicable | Multiple specialized agents, such as internal data retrieval, personal data retrieval, public data retrieval. |
| Single-Agent vs. Multi-Agent System | Not applicable | Single-agent router or multi-agent systems, with “master” and specialized agents for complex queries. |
| Reasoning and Logic Capability | No | Yes – Supports multi-step reasoning, allowing logical sequence handling before generating responses. |
| Memory and Personalization | Limited to immediate query | Yes – Capable of updating memory to retain user preferences or history, allowing personalized responses. |
| Real-world Applications | Primarily static responses from a fixed database | Supports a wide range of real-world applications by responding to complex, nuanced inquiries with context sensitivity. |
- Drawing a parallel with problem-solving, agentic RAG offers capabilities akin to having a smartphone in hand—equipped with multiple apps and tools to help answer a question—whereas vanilla RAG is akin to being in a library with limited resources.
Implementation
- To implement agentic RAG, developers can use either LLMs with function calling or agent frameworks, each providing specific advantages in terms of flexibility and control.
- Both methods—function calling in LLMs and agent frameworks—enable agentic RAG, though each has unique benefits:
- Function Calling provides control over each tool interaction, suitable for cases with specific tool chains or simple agent setups.
- Agent Frameworks offer pre-built integrations and routing logic, ideal for larger, multi-agent architectures.
- Using these implementations, developers can build flexible and adaptive agentic RAG pipelines, enhancing retrieval, reasoning, and response generation capabilities for AI-driven applications.
Large Language Models with Function Calling
- Function calling allows LLMs to interact directly with external tools. For example, OpenAI’s function calling for GPT-4 or Cohere’s connectors API lets developers connect LLMs to web search, databases, and other services. This interaction involves defining a function (such as querying a database), passing it to the model via a schema, and routing the model’s queries through the defined functions. This approach enables the model to leverage specific tools as needed, based on the query.
Agent Frameworks
- Several agent frameworks—such as LangChain, LlamaIndex, CrewAI—simplify agentic RAG implementation by providing pre-built templates and tool integrations. Key features include:
- LangChain: Offers support for language model tools, and its LCEL and LangGraph frameworks integrate these tools seamlessly.
- LlamaIndex: Provides a QueryEngineTool to streamline retrieval tasks.
- CrewAI: A leading framework for multi-agent setups, which supports shared tool access among agents.
Use-cases
- Organizations are increasingly transitioning to agentic RAG to gain more autonomous and accurate AI-driven systems. Enterprises such as Microsoft and Replit have introduced agents to enhance task completion and software development assistance. With agentic RAG, companies can build AI applications capable of handling diverse, real-time data sources, providing robust and adaptable responses for complex queries and tasks.
Advantages
- The primary advantages of agentic RAG include:
- Enhanced Retrieval Accuracy: By routing queries through specialized agents, agentic RAG can provide more accurate responses.
- Autonomous Task Performance: Agents can perform multi-step reasoning, independently solving complex problems.
- Improved Collaboration: These systems can better assist users by handling more varied and personalized queries.
Limitations
- Agentic RAG does present challenges, such as:
- Increased Latency: Running multiple agents and interacting with tools can add delays to the response.
- Reliability of Agents: Depending on the LLM’s reasoning capabilities, agents may fail to complete certain tasks accurately.
- Complexity in Error Handling: Systems need robust fallback mechanisms to recover if an agent fails to retrieve or process data.
Code
- Implementing agentic RAG requires setting up an agent framework capable of handling tool integrations and coordinating retrieval processes. This section walks through an example code setup, demonstrating both LLMs with function calling and agent frameworks for building an agentic RAG pipeline.
Implementing Agentic RAG with Function Calling
-
Function calling in LLMs allows them to interact with tools by defining functions that retrieve data from external sources. This method leverages API calls, database queries, and computation tools to enrich the response with dynamic data.
-
Here’s an example implementation using a function for retrieval from a database via the Weaviate vector search API.
Define the Function for Retrieval
- To start, we define a function that uses Weaviate’s hybrid search to query a database and retrieve relevant results.
def get_search_results(query: str) -> str:
"""Sends a query to Weaviate's Hybrid Search. Parses the response into a formatted string."""
response = blogs.query.hybrid(query, limit=5) # Retrieve top 5 results based on the query
stringified_response = ""
for idx, o in enumerate(response.objects):
stringified_response += f"Search Result {idx+1}:\n"
for prop in o.properties:
stringified_response += f"{prop}: {o.properties[prop]}\n"
stringified_response += "\n"
return stringified_response
Define the Tools Schema
- Next, we define a tools schema that connects the function to the language model. This schema tells the model how to use the function for retrieving data.
tools_schema = [{
'type': 'function',
'function': {
'name': 'get_search_results',
'description': 'Get search results for a provided query.',
'parameters': {
'type': 'object',
'properties': {
'query': {
'type': 'string',
'description': 'The search query.',
},
},
'required': ['query'],
},
},
}]
Setting Up the Interaction Loop
- To ensure the model can call the tool multiple times (if needed), we set up a loop that enables the model to interact with tools and retrieve data iteratively until it has all necessary information.
def ollama_generation_with_tools(user_message: str, tools_schema: list, tool_mapping: dict, model_name: str = "llama3.1") -> str:
messages = [{"role": "user", "content": user_message}]
response = ollama.chat(model=model_name, messages=messages, tools=tools_schema)
# Check if the model needs to use a tool
if not response["message"].get("tool_calls"):
return response["message"]["content"]
# Handle tool calls and retrieve information
for tool in response["message"]["tool_calls"]:
function_to_call = tool_mapping[tool["function"]["name"]]
function_response = function_to_call(tool["function"]["arguments"]["query"])
messages.append({"role": "tool", "content": function_response})
# Generate final response after tool calls
final_response = ollama.chat(model=model_name, messages=messages)
return final_response["message"]["content"]
Executing the Agentic RAG Query
- Finally, we run the function, allowing the language model to interact with the
get_search_resultstool.
tool_mapping = {"get_search_results": get_search_results} # Maps tool name to function
response = ollama_generation_with_tools(
"How is HNSW different from DiskANN?",
tools_schema=tools_schema,
tool_mapping=tool_mapping
)
print(response)
- This setup enables the language model to retrieve dynamic information and perform tool-based retrievals as needed.
Implementing Agentic RAG with Agent Frameworks
- Using agent frameworks streamlines the implementation process by providing templates and pre-built modules for multi-agent orchestration. Here’s how to set up an agentic RAG pipeline using LangChain as an example.
Step 1: Define Agents and Tools
- LangChain simplifies agentic RAG by managing tools and routing tasks. First, define the agents and register the tools they will use.
from langchain.tools import WebSearchTool, DatabaseTool, CalculatorTool
from langchain.agents import Agent
# Define tools for retrieval
web_search_tool = WebSearchTool(api_key="YOUR_WEB_SEARCH_API_KEY")
database_tool = DatabaseTool(db_client="your_database_client")
calculator_tool = CalculatorTool()
# Set up an agent with a routing function
retrieval_agent = Agent(
tools=[web_search_tool, database_tool, calculator_tool],
routing_function="retrieve_and_select_tool"
)
Step 2: Configure Agent Routing
- Set up the routing function to let the agent decide which tool to use based on the input query.
def retrieve_and_select_tool(query):
if "calculate" in query:
return calculator_tool
elif "web" in query:
return web_search_tool
else:
return database_tool
Step 3: Chain Agents for Multi-Agent RAG
- In multi-agent RAG, you might have a “master agent” that routes queries to specialized agents based on query type. Here’s how to set up a master agent to coordinate multiple agents.
from langchain.agents import MultiAgent
# Define specialized agents
internal_agent = Agent(tools=[database_tool], routing_function="database_retrieval")
public_agent = Agent(tools=[web_search_tool], routing_function="web_retrieval")
# Create a master agent to coordinate retrieval
master_agent = MultiAgent(agents=[internal_agent, public_agent])
# Function to handle a query using master agent
def handle_query_with_master_agent(query):
return master_agent.handle_query(query)
Running the Multi-Agent Query
- Finally, to test the system, input a query and let the master agent route it appropriately:
response = handle_query_with_master_agent("Find recent studies on neural networks")
print(response)
Disadvantages
-
Despite its advantages, agentic RAG comes with several limitations that should be carefully considered, particularly for time-sensitive applications:
-
Increased Latency: The inherent complexity of agentic RAG often translates to longer response times. Each query may require multiple tool interactions and sequential retrieval steps, which increase the latency significantly. This can hinder the system’s usability in environments where quick responses are crucial, such as real-time support systems or conversational interfaces.
-
Higher Computational Cost: Agentic RAG systems often involve multiple calls to LLMs and other external tools. These calls cumulatively drive up computational costs, making it less efficient and potentially prohibitive for high-traffic applications. This expense adds to operational concerns, especially if the system must process large volumes of queries.
-
Production Feasibility: Due to the latency and cost concerns, agentic RAG may not be ideal for production applications requiring rapid and continuous output. In such cases, vanilla RAG, which offers more direct and faster response generation, might be more suitable.
-
-
While these drawbacks limit agentic RAG’s use in certain scenarios, its capability to generate high-quality, well-researched responses can make it worthwhile in contexts where response time is less critical and information accuracy is paramount.
Sample Prompt
- This prompt captures the essence of Agentic RAG: retrieval is optional, selective, and tool-aware, driven by explicit reasoning about the query rather than triggered automatically. In other words, this prompt demonstrates how an agentic RAG system is instructed to reason before retrieving, explicitly deciding whether external information is needed and, if so, which tool or knowledge base should be invoked. The prompt reflects the decision-making flow described in the previous sections and is applicable to both single-agent and multi-agent implementations.
System Prompt (Agentic Retrieval Controller)
You are an AI agent that answers user questions by reasoning about whether
external information is required and selectively invoking tools when necessary.
You have access to the following tools:
- Vector search over internal document corpora
- Structured knowledge bases (organizational, relational, transactional)
- Web search for up-to-date public information
- APIs for software systems (email, messaging, internal services)
Follow this process:
1. Analyze the user query and decide whether it can be answered using existing context alone.
2. If external information is required, decide which tool or knowledge source is most appropriate.
3. Formulate a precise query for the selected tool.
4. Evaluate the retrieved information to determine whether it sufficiently resolves the query.
5. Repeat retrieval only if necessary; otherwise, proceed to generate the final answer.
Rules:
- Do not invoke tools unless external information is required.
- Explicitly justify tool selection internally before each invocation.
- Stop retrieving once sufficient evidence has been gathered.
- Base the final answer only on retrieved and verified information.
- Do not introduce information that was not obtained through retrieval.
User Query
How does HNSW differ from DiskANN in terms of index structure and performance trade-offs?
Expected Agent Behavior (Abstracted)
- Determine that the query requires external technical information.
- Select a vector search tool or technical document database as the most appropriate source.
- Formulate a focused retrieval query targeting comparative descriptions of HNSW and DiskANN.
- Review retrieved results to assess completeness.
- Generate a synthesized answer grounded in the retrieved evidence.
Agentic Multi-Hop RAG
Motivation
- In single–knowledge base multi-hop RAG, the primary challenge is what to retrieve next.
- In multi–knowledge base settings, an additional and more fundamental question arises: Which knowledge base is capable of resolving the next dependency?
- This turns retrieval into a routing and planning problem, where incorrect source selection can halt reasoning even if the correct information exists elsewhere.
- As a result, explicit knowledge base routing becomes a first-class requirement: the system must deliberately choose where to search at each hop rather than relying on implicit assumptions or static configurations.
- Empirical studies on tool-augmented and agentic systems show that retrieval accuracy degrades sharply when source selection is implicit or heuristic-driven rather than explicitly reasoned (cf. ReAct by Yao et al. (2023); Toolformer by Schick et al. (2023)).
Retrieval as Tool and Source Selection
-
Let the system have access to a set of knowledge bases:
\[\mathcal{K} = {\text{KB}_1, \text{KB}_2, \ldots, \text{KB}_m}\] -
In agentic multi-hop retrieval, each hop involves two coupled decisions:
- Where to search (knowledge base or tool selection)
- What to search (query formulation)
-
Formally, at hop \(i\), the agent computes:
\[(\text{KB}_j, Q_i) = \text{plan}(Q, S_{i-1}, \mathcal{K})\]- … followed by:
-
This explicit source-selection step is absent in vanilla RAG and even in non-agentic multi-hop RAG pipelines.
Signals Used for Knowledge Base Selection
-
An agent decides where to search based on a combination of:
-
Knowledge base descriptions:
- Declarative metadata describing what each KB contains (e.g., “organizational hierarchy”, “technical documentation”, “transactional records”).
-
Few-shot routing examples:
- Positive and negative examples mapping query patterns to appropriate KBs.
-
Intermediate conclusions:
- Newly discovered entities or attributes that constrain which KBs are relevant.
-
Failure signals:
- Insufficient evidence from prior hops indicating a source mismatch.
-
-
This aligns with findings that explicit tool descriptions and routing examples significantly improve agent performance (cf. Large Language Models as Tool Makers by Schick et al. (2023)).
Example
-
The following example demonstrates agentic multi-hop retrieval across three knowledge bases.
-
Available knowledge bases:
-
\(KB_1\): Product & Component Database
- Contains product specifications and component dependencies.
-
\(KB_2\): Organization & Ownership Database
- Contains company structures, acquisitions, and reporting hierarchies.
-
\(KB_3\): Historical Transactions Archive
- Contains time-stamped acquisition and merger records.
-
-
User question:
- “Who is the top-level organization responsible for the team that developed a component used in Product X?”
Step-by-step agentic execution
-
Let’s start with the original question (i.e., query) \(Q\).
-
Hop 1: Identify the component used by Product X:
-
Agent decision:
- Where to search: \(KB_1\) (product–component relationships)
- Why: Query references “Product X” and “component”
-
Generated sub-query:
\[Q_1 = \text{“What components are used by Product X?”}\] -
Retrieval:
\[E_1 = \text{retrieve}(Q_1, \text{KB}_1) \rightarrow \text{Component Y}\]
-
-
Hop 2: Identify the team that developed Component Y:
-
Agent decision:
- Where to search: \(KB_1\)
- Why: Development metadata still within product engineering scope
-
Generated sub-query:
\[Q_2 = \text{“Who developed Component Y?”}\] -
Retrieval:
\[E_2 = \text{retrieve}(Q_2, \text{KB}_1) \rightarrow \text{Team Z}\]
-
-
Hop 3: Identify the organization that owns Team Z:
-
Agent decision:
- Where to search: \(KB_2\)
- Why: Ownership and reporting structure are organizational, not technical
-
Generated sub-query:
\[Q_3 = \text{“Which organization does Team Z belong to?”}\] -
Retrieval:
\[E_3 = \text{retrieve}(Q_3, \text{KB}_2) \rightarrow \text{Company A}\]
-
-
Hop 4: Identify the top-level parent of Company A:
-
Agent decision:
- Where to search: \(KB_3\)
- Why: Ownership hierarchy may involve historical acquisitions
-
Generated sub-query:
\[Q_4 = \text{“Who is the current top-level parent of Company A?”}\] -
Retrieval:
\[E_4 = \text{retrieve}(Q_4, \text{KB}_3) \rightarrow \text{Organization B}\]
-
-
Final answer:
Why Vanilla and Non-Agentic RAG Fail in This Setting
- A single retriever cannot span all three KBs effectively.
- Semantic similarity alone cannot infer which source holds the next dependency.
- Without explicit routing:
- \(KB_1\) may be overused due to lexical overlap.
- \(KB_2\) or \(KB_3\) may never be queried.
- The language model may hallucinate ownership relationships instead of retrieving them.
- These failure modes mirror those identified in multi-tool reasoning studies (cf. ReAct by Yao et al. (2023)).
Sample Prompt
-
The following prompt illustrates how an agentic system is instructed to explicitly reason about both hop planning and knowledge base selection, with control flow driven by decisions about missing information rather than by a fixed structural traversal.
-
Unlike hierarchical RAG, where the system decides which part of a single corpus to traverse by progressing level-by-level through a predefined document structure, this prompt requires the model to dynamically decide what information is missing and which source is capable of resolving that dependency at each step.
-
In non-agentic or pure agentic multi-hop RAG, the focus is often on what intermediate fact or action comes next, with retrieval sources assumed to be fixed or chosen implicitly; this prompt makes source selection an explicit, first-class decision.
-
Overall, the prompt enforces a decision-driven loop in which the model must jointly determine what is missing, where it can be found, and how to retrieve it before advancing to the next hop.
System Prompt (Agentic Planner + Router)
You are an agent that answers questions by performing multi-hop reasoning
across multiple knowledge bases.
You have access to the following knowledge bases:
- KB_1: Product and component relationships
- KB_2: Organizational structure and ownership
- KB_3: Historical transactions, mergers, and acquisitions
Your task is to iteratively resolve the question by following this loop:
1. Determine what information is missing.
2. Decide which knowledge base is most appropriate to retrieve that information.
3. Generate a focused retrieval query for that knowledge base.
4. Retrieve evidence and update your intermediate conclusions.
5. Repeat until the original question can be answered.
Rules:
- Always explicitly state which knowledge base you are querying and why.
- Do not assume facts that have not been retrieved.
- If no knowledge base can resolve the remaining dependency, stop and say so.
- Use intermediate conclusions to guide subsequent hops.
User Question
Who is the top-level organization responsible for the team that developed
a component used in Product X?
Agent Reasoning Trace (Abstracted)
Hop 1:
Missing information: Which component is used by Product X?
Selected KB: KB1 (product–component relationships)
Query: "What components are used by Product X?"
Hop 2:
Missing information: Who developed Component Y?
Selected KB: KB1 (engineering metadata)
Query: "Who developed Component Y?"
Hop 3:
Missing information: Which organization owns Team Z?
Selected KB: KB2 (organizational hierarchy)
Query: "Which organization does Team Z belong to?"
Hop 4:
Missing information: What is the top-level parent of Company A?
Selected KB: KB3 (historical ownership records)
Query: "Who is the current top-level parent of Company A?"
Final Answer Prompt
Using only the retrieved evidence from all hops,
produce the final answer.
Ensure that:
- Each claim is supported by retrieved evidence.
- The ownership chain is complete.
- No additional assumptions are introduced.
Key Takeaways
- Multi-hop reasoning across knowledge bases introduces a new axis of complexity: source selection.
- Agentic RAG addresses this by:
- Making “where to search” an explicit decision.
- Conditioning retrieval on intermediate state.
- Treating knowledge bases as tools with capabilities and limits.
- This capability is essential for scaling RAG systems beyond single-domain, homogeneous corpora into real-world, enterprise environments.
Hierarchical RAG
Overview
- Hierarchical RAG extends classic RAG by introducing a multi-level structure into the retrieval process.
- Instead of treating the knowledge base as a flat collection of chunks, Hierarchical RAG organizes information into nested levels of abstraction, such as document \(\rightarrow\) section \(\rightarrow\) paragraph.
- This design improves retrieval precision, reduces noise, and supports multi-step reasoning across levels of granularity, especially in large or structured corpora.
Why Hierarchical Structures Matter
-
Flat RAG limitations:
- All chunks are indexed at the same resolution.
- Retrieval often returns:
- Overly narrow fragments without global context, or
- Large numbers of weakly relevant chunks.
- This leads to noisy prompts and inefficient use of context windows.
-
Hierarchical RAG principle:
-
Organize the corpus into explicit levels:
\[\text{Level}_0: \text{Documents / Topics}\] \[\text{Level}_1: \text{Sections / Subtopics}\] \[\text{Level}_2: \text{Paragraphs / Atomic chunks}\] - Retrieval proceeds top-down, narrowing the search space at each level.
- This approach is discussed in practitioner and research write-ups such as Hierarchical Retrieval-Augmented Generation.
-
Models in Practice
-
Several recent models explicitly encode hierarchy into RAG pipelines:
-
HiRAG: Retrieval-Augmented Generation with Hierarchical Knowledge by Huang et al. (2025): Models document-level and section-level representations separately to guide retrieval and reasoning.
-
Hierarchical Retrieval-Augmented Generation Model with Rethink by Zhang et al. (2024): Uses document-level sparse retrieval followed by dense section- and chunk-level retrieval, improving precision and reducing token usage.
-
ArchRAG: Attributed Community-based Hierarchical RAG by Wang et al. (2025): Applies hierarchical community detection to reduce retrieval complexity in large structured corpora.
-
BookRAG: A Hierarchical Structure-aware Index-based Approach for Retrieval-Augmented Generation on Complex Documents by Wang et al. (2025): Introduces a structure-aware hierarchical index (“BookIndex”) to model logical relationships within long documents.
-
Architecture and Retrieval Flow
-
Hierarchical RAG decomposes retrieval into multiple levels, each with its own retrieval query:
-
High-level retrieval (coarse scope):
\[R_0 = \text{retrieve}_{\text{doc}}(Q)\] -
Mid-level retrieval (focused scope):
\[R_1 = \text{retrieve}_{\text{section}}(Q \mid R_0)\] -
Low-level retrieval (fine-grained evidence):
\[R_2 = \text{retrieve}_{\text{chunk}}(Q \mid R_0, R_1)\]
-
-
Final answer synthesis:
\[\text{Answer}(Q) = f(Q, R_2)\] -
This staged approach mirrors hierarchical information retrieval strategies discussed in Hierarchical Index Retrieval for RAG.
Example
-
Corpus (single knowledge base, structured documents)::
-
Document D1: “System Architecture Overview”
- Section 1: “Core Components”
- Section 2: “Dependencies”
-
Document D2: “Component Specifications”
- Section 3: “Module Y”
-
Document D3: “Organizational Structure”
- Section 1: “Engineering Teams”
-
-
User question::
- “Which organization owns the team responsible for a module used by System X?”
-
Step 0: Original query: \(Q\).
-
Step 1: Document-level retrieval:
-
Goal: identify which documents are relevant.
-
Query:
\[Q^{(0)} = \text{“System X module dependencies and ownership”}\] -
Retrieved:
\[R_0 = {\text{Document D1, Document D2, Document D3}}\]
-
-
Step 2: Section-level retrieval:
-
Goal: narrow to relevant sections within documents.
-
Queries:
\[Q^{(1)}_1 = \text{“Which module does System X use?”}\] \[Q^{(1)}_2 = \text{“Who developed Module Y?”}\] -
Retrieved:
\[R_1 = {\text{D1.Section 2, D2.Section 3, D3.Section 1}}\]
-
-
Step 3: Chunk-level retrieval:
-
Goal: retrieve atomic evidence.
-
Queries:
\[Q^{(2)}_1 = \text{“System X depends on which module?”}\] \[Q^{(2)}_2 = \text{“Module Y developed by which team?”}\] \[Q^{(2)}_3 = \text{“Team Z reports to which organization?”}\] -
Retrieved:
\[R_2 = {\text{Module Y dependency chunk, Team Z description chunk, Organization ownership chunk}}\]
-
-
Final synthesis:
- This example shows how hierarchical structure determines both the retrieval order and the intermediate queries, reducing noise while preserving necessary context.
Sample Prompt
-
The following prompt illustrates how hierarchical RAG is operationalized in practice with a single knowledge base. Unlike agentic RAG, the control flow is implicit and level-driven, not tool-driven.
-
System Prompt (Hierarchical Retrieval Controller):
You are an assistant that answers questions using hierarchical retrieval
from a single document corpus.
The corpus is organized into:
- Documents
- Sections within documents
- Paragraph-level chunks
Follow this process:
1. Identify which documents are relevant to the question.
2. Within those documents, identify the most relevant sections.
3. Within those sections, retrieve the most relevant paragraphs.
4. Use only the final retrieved paragraphs to answer the question.
Rules:
- Narrow the search space at each level before moving to the next.
- Do not skip levels.
- Do not answer until paragraph-level evidence is retrieved.
- User Question:
Which organization owns the team responsible for a module used by System X?
-
Implicit Model Behavior:
- Document-level focus on architecture, specifications, and organization.
- Section-level focus on dependencies, module details, and teams.
-
Paragraph-level focus on explicit ownership statements.
- Final Answer Prompt:
Using the retrieved paragraph-level evidence, produce a concise answer.
Do not introduce information not present in the retrieved text.
-
This prompt enforces:
- Coarse-to-fine retrieval
- Structural grounding
- Controlled context growth
Retrieval Efficiency Analysis
-
Let:
- \(N\) be total chunks in a flat index.
- \(b\) be the branching factor.
- \(d\) be the hierarchy depth.
-
A flat retrieval has \(O(N)\) search complexity.
-
A balanced hierarchical tree with depth \(d\) and uniform branching factor \(b\) has \(N = b^d\).
-
A top-down retrieval then costs \(O(d \cdot b)\), which is asymptotically smaller than \(O(N)\) for large \(N\).
-
For example, if \(b=10\) and \(d=3\), then \(N=1000\), but hierarchical traversal only explores \(O(30)\) nodes instead of \(1000\).
-
This abstraction parallels known search complexity models in tree structures.
Common Hierarchical Strategies
- Top-down traversal: Start with high-level summaries, then refine down to detailed context.
- Bottom-up clustering: Organize individual chunks into semantic clusters with multi-resolution links and traverse upward.
- Hybrid sparse/dense indexing: Combine sparse document retrieval with dense chunk retrieval to capture different forms of relevance.
Advantages
- Higher precision by eliminating irrelevant chunks early.
- Better context coherence by preserving document- and section-level semantics.
- Reduced token usage by limiting fine-grained retrieval to relevant branches.
- These benefits are empirically observed in hierarchical RAG studies such as HiRAG by Zhang et al. (2024).
Use-cases
- Large corpora with natural structural hierarchy (book chapters, manuals, multi-section technical documents).
- Cases where flat retrieval yields noisy or redundant evidence, especially for deep multi-hop reasoning.
- Scenarios where resource efficiency (tokens, latency) matters.
RAG vs. Long Context Windows
Computational Cost
- Processing extremely long contexts incurs substantial computational overhead. For instance, utilizing a 10 million token context window with state-of-the-art models like Llama 4 demands considerable hardware resources—approximately 32 H100 GPUs—which translates to over $100 per hour in inference costs. The key-value (KV) cache alone can exceed 1 terabyte of VRAM. These requirements pose a significant barrier to the practical deployment of long-context inference systems at scale, especially for organizations with limited infrastructure budgets.
Inference Latency and Throughput
- As the number of tokens increases, the latency of inference rises proportionally, often leading to a considerable decline in throughput. Even when hardware resources are available, this degradation in response time can negatively impact user experience in latency-sensitive applications such as virtual assistants, search engines, or real-time analytics systems.
Contextual Comprehension and Model Training Limitations
- Although large context windows are theoretically capable of accommodating vast amounts of input data, current LLMs are typically trained on much smaller maximum context lengths—commonly up to 128,000 tokens. Consequently, performance across the full extent of a 10 million token context window is unproven and likely suboptimal. Empirical studies suggest that retrieval accuracy tends to diminish for information placed in the middle of a long context due to a phenomenon informally referred to as the “Lost in the Middle” effect. Therefore, while long-context architectures offer the promise of expanded capacity, their practical utility is constrained by training regimes and architectural bottlenecks.
RAG as a Targeted, Cost-Efficient Solution
- In contrast, RAG provides a principled and efficient mechanism for narrowing down relevant content from a large corpus before conditioning the model’s generative process. By introducing a retrieval stage that identifies and ranks the most pertinent information, RAG minimizes unnecessary context, optimizes for response accuracy, and reduces memory and compute demands. This retrieval-first approach allows RAG systems to operate effectively within the token limitations of current LLMs, while maintaining scalability and affordability.
Improving RAG Systems
- To enhance and refine RAG systems, consider the following methods that help contribute to more accurate and contextually relevant results, each accompanied by comprehensive guides and practical implementations:
- Re-ranking Retrieved Results: A fundamental and effective method involves employing a Re-ranking Model to refine the results obtained through initial retrieval. This approach prioritizes more relevant results, thereby improving the overall quality of the generated content. MonoT5, MonoBERT, DuoBERT, etc. are examples of deep models that can be used as re-rankers. For a detailed exploration of this technique, refer to the guide and code example provided by Mahesh Deshwal. A detailed discourse on re-ranking is available in the Re-ranking section.
- FLARE Technique: Subsequent to re-ranking, one should explore the FLARE methodology. This technique dynamically queries the internet (could also be a local knowledge base) whenever the confidence level of a segment of the generated content falls below a specified threshold. This overcomes a significant limitation of conventional RAG systems, which typically query the knowledge base only at the outset and subsequently produce the final output. Akash Desai’s guide and code walkthrough offer an insightful understanding and practical application of this technique. More on the FLARE technique in the Active Retrieval Augmented Generation section.
- HyDE Approach: Finally, the HyDE technique introduces an innovative concept of generating a hypothetical document in response to a query. This document is then converted into an embedding vector. The uniqueness of this method lies in using the vector to identify a similar neighborhood within the corpus embedding space, thereby retrieving analogous real documents based on vector similarity. To delve into this method, refer to Akash Desai’s guide and code implementation. More on the HyDE technique in the Precise Zero-Shot Dense Retrieval Without Relevance Labels section.
- REFRAG (REpresentation For RAG): A framework designed to improve latency and efficiency in RAG systems by leveraging the sparsity and block-diagonal attention patterns of retrieved contexts. Instead of feeding full token sequences from retrieved passages, REFRAG compresses them into pre-computed chunk embeddings and selectively expands important chunks during decoding using a lightweight reinforcement learning policy. This compression-aware decoding reduces both memory and computational overhead without modifying the base LLM architecture. Experiments show that REFRAG achieves up to 30.85× faster time-to-first-token and extends context capacity by 16×, with no loss in perplexity or downstream accuracy across RAG, multi-turn conversation, and summarization tasks. The following figure from the paper shows the main design of REFRAG. The input context is chunked and processed by the light-weight encoder to produce chunk embeddings, which are precomputable for efficient reuse. A light-weight RL policy decides a few chunks to expand. These chunk embeddings along with the token embeddings of the question input are fed to the decoder.
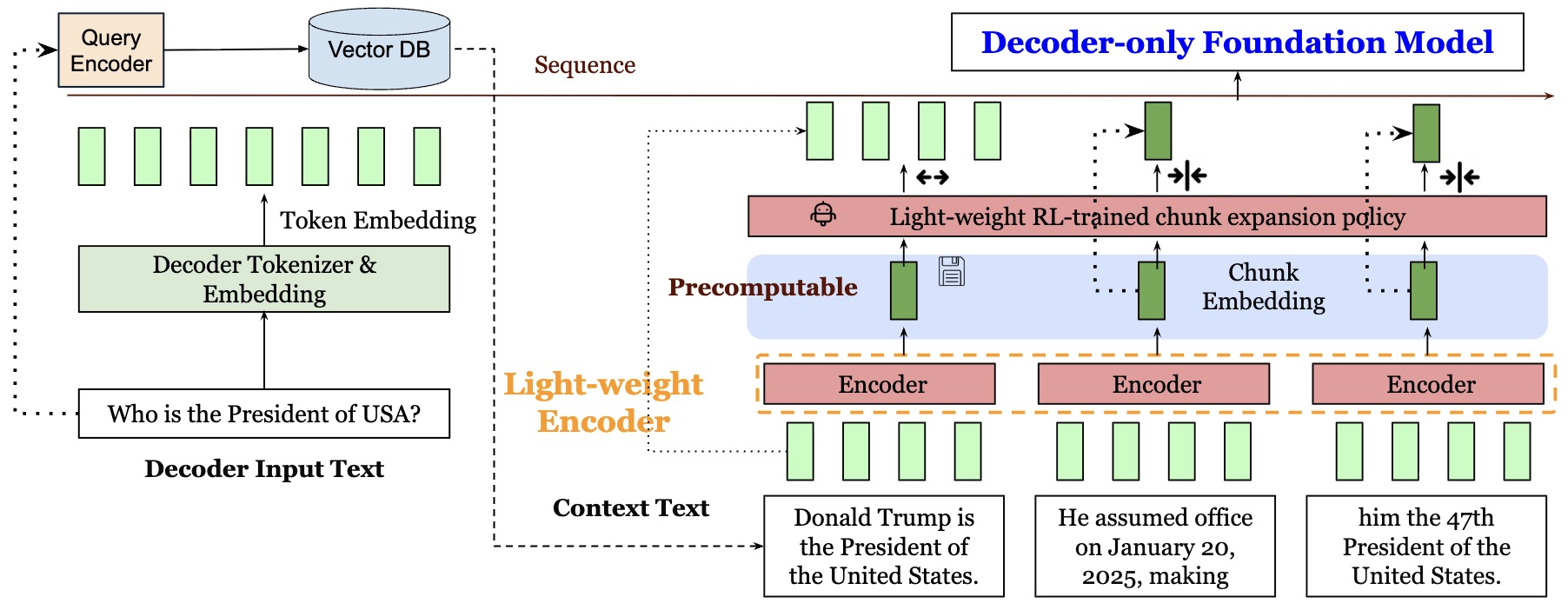
RAG 2.0
- RAG 2.0, unveiled by Contextual AI, represents a significant advancement in robust AI systems for enterprise use, optimizing the entire system end-to-end unlike its predecessor. This new generation introduces Contextual Language Models (CLMs) which not only surpass the original RAG benchmarks but also outperform the strongest available models based on GPT-4, across various industry benchmarks, demonstrating superior performance in open domain question-answering and specialized tasks like truth verification.
- The introduction of RAG 2.0 marks a departure from the use of off-the-shelf models and disjointed components, which characterized previous systems as brittle and suboptimal for production environments. Instead, RAG 2.0 end-to-end optimizes the language model and retriever as a single system.
- Key improvements are evident in real-world applications where RAG 2.0 CLMs have been deployed. Using Google Cloud’s latest ML infrastructure, these models have shown significant accuracy enhancements, particularly in sectors like finance and law, highlighting their potential in specialized domains.
- Further comparisons reveal that RAG 2.0 significantly outperforms traditional long-context models, providing higher accuracy with less computational demand. This makes RAG 2.0 particularly appealing for scaling in production environments.
- Overall, RAG 2.0’s innovative approach not only pushes the boundaries of generative AI in production settings but also demonstrates its superiority through extensive benchmarks and real-world deployments, inviting enterprises to join in its ongoing development and application.
RAG Benchmarks
-
RAG systems can be evaluated using retrieval-only benchmarks and end-to-end RAG benchmarks, where the latter jointly evaluate retrieval quality, grounded generation, and reasoning.
- Retrieval-only benchmarks isolate the retriever and measure how well relevant documents are found, independent of generation.
- End-to-end RAG benchmarks evaluate the full pipeline including the retrieval and generation components, across settings such as open-domain QA, multi-hop reasoning, and grounded long-form generation. They probe different failure modes: retrieval quality (did the system fetch the right evidence?), generation quality (is the answer correct and fluent?), and grounding/faithfulness (is the answer supported by retrieved evidence?).
- Common evaluation metrics include recall@\(k\), MRR@\(k\), and NDCG for retrieval; EM and F1 for QA; and provenance precision/recall, citation accuracy, and faithfulness for grounded generation.
- Retrieval leaderboards track continual progress on ranking quality, while newer end-to-end benchmarks increasingly emphasize factual grounding, citation accuracy, and reasoning over retrieved documents.
Retrieval-Only Evaluation
-
These benchmarks are primarily used to evaluate retrieval quality in isolation, but are often components of RAG pipelines. The most common ones are listed below:
- BEIR:
- Introduced or proposed in BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models by Thakur et al. (2021). A diverse suite of IR tasks designed to test retriever generalization across domains.
- Evaluation framework: BEIR GitHub Repository
- Typical metrics: NDCG@10, Recall@\(k\), Precision@\(k\)
- MS MARCO:
- Introduced or proposed in MS MARCO: Benchmarking Ranking Models in the Large-Data Regime by Craswell et al. (2021). A large-scale passage and document ranking benchmark derived from real Bing search queries.
- Official leaderboards: MS MARCO Passage Ranking Leaderboard
- Typical metrics: MRR@10, NDCG@10, Recall@\(k\)
- BEIR:
End-to-End Evaluation (Retrieval + Generation)
-
These benchmarks evaluate retrieval as an integral part of the task and explicitly test grounded generation, reasoning, and faithfulness. The most common ones are listed below:
- Natural Questions (Open-Domain QA):
- Introduced or proposed in Natural Questions: A Benchmark for Question Answering Research by Kwiatkowski et al. (2019). Real Google search queries with annotated answers; commonly used in open-domain QA and RAG setups where retrieval recall directly affects generation quality.
- Community leaderboards: Natural Questions on LLM-Stats
- Typical metrics: EM, F1, retrieval recall
- TriviaQA:
- Introduced or proposed in TriviaQA: A Large-Scale Distantly Supervised Challenge Dataset for Reading Comprehension by Joshi et al. (2017). Tests retrieval robustness and answer generation from noisy, long documents.
- Typical metrics: EM, F1, evidence recall
- HotpotQA:
- Introduced or proposed in HotpotQA: A Dataset for Diverse, Explainable Multi-Hop Question Answering by Yang et al. (2018). Requires multi-hop retrieval and reasoning across multiple documents, making retrieval errors directly visible in generation quality.
- Project page: HotpotQA
- Typical metrics: EM, F1, supporting fact recall
- KILT:
- Introduced or proposed in KILT: A Benchmark for Knowledge-Intensive Language Tasks by Petroni et al. (2021). A unified benchmark that explicitly evaluates both answer correctness and evidence provenance across multiple tasks.
- Official benchmark and leaderboards: KILT Benchmark Page
- Typical metrics: EM, F1, provenance precision and recall
- FRAMES:
- Introduced or proposed in FRAMES: Fact, Fetch, and Reason for RAG Evaluation by Liu et al. (2024). Designed specifically for RAG, with a strong emphasis on factual grounding, evidence usage, and reasoning in long-form answers.
- Typical metrics: grounded answer accuracy, provenance correctness, faithfulness scores
- RAGBench:
- Introduced or proposed in RAGBench: A Large-Scale Explainable Benchmark for Retrieval-Augmented Generation by Friel et al. (2024). A large multi-domain benchmark aimed at holistic, explainable evaluation of retrieval and generation together.
- Typical metrics: answer correctness, explanation alignment, retrieval–generation interaction scores
- Natural Questions (Open-Domain QA):
Selected Papers
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
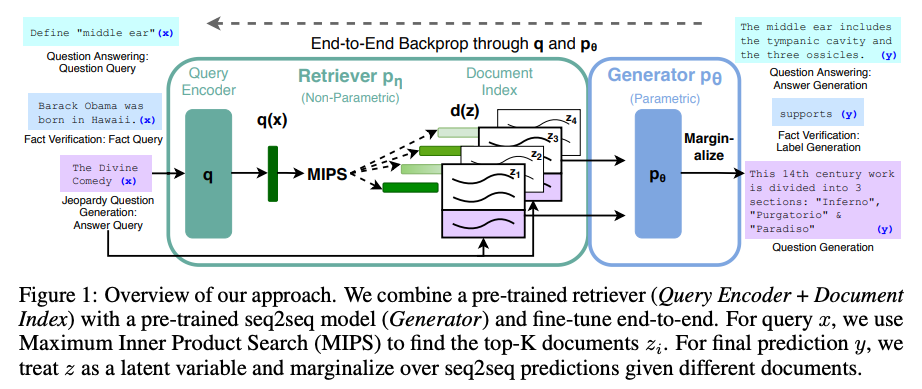
- The paper by Lewis et al. from Facebook AI Research, University College London, and New York University, introduces Retrieval-Augmented Generation (RAG) models combining pre-trained parametric and non-parametric memory for language generation tasks.
- Addressing limitations of large pre-trained language models, such as difficulty in accessing and precisely manipulating knowledge, RAG models merge a pre-trained sequence-to-sequence (seq2seq) model with a dense vector index of Wikipedia, accessed by a neural retriever.
- The RAG framework encompasses two models: RAG-Sequence, using the same retrieved document for the entire sequence, and RAG-Token, allowing different passages for each token.
- The retrieval component, Dense Passage Retriever (DPR), uses a bi-encoder architecture with BERT-based document and query encoders. The generator component utilizes BART-large, a pre-trained seq2seq transformer with 400M parameters.
- RAG models were trained jointly on the retriever and generator components without direct supervision on which documents to retrieve, using stochastic gradient descent with Adam. The training used a Wikipedia dump as the non-parametric knowledge source, split into 21M 100-word chunks.
- A summary of the methods and models used for query/document embedding and retrieval, as well as the end-to-end structure of the RAG framework is as below:
- Query/Document Embedding:
- The retrieval component, Dense Passage Retriever (DPR), follows a bi-encoder architecture.
- DPR uses BERTBASE as the foundation for both document and query encoders.
- For a document \(z\), a dense representation \(d(z)\) is produced by a document encoder, \(BERT_d\).
- For a query \(x\), a query representation \(q(x)\) is produced by a query encoder, \(BERT_q\).
- The embeddings are created such that relevant documents for a given query are close in the embedding space, allowing effective retrieval.
- Retrieval Process:
- The retrieval process involves calculating the top-\(k\) documents with the highest prior probability, which is essentially a Maximum Inner Product Search (MIPS) problem.
- The MIPS problem is solved approximately in sub-linear time to efficiently retrieve relevant documents.
- End-to-End Structure:
- The RAG model uses the input sequence \(x\) to retrieve text documents \(z\), which are then used as additional context for generating the target sequence \(y\).
- The generator component is modeled using BART-large, a pre-trained seq2seq transformer with 400M parameters. BART-large combines the input \(x\)with the retrieved content \(z\) for generation.
- The RAG-Sequence model uses the same retrieved document for generating the complete sequence, while the RAG-Token model can use different passages per token.
- The training process involves jointly training the retriever and generator components without direct supervision on what document should be retrieved. The training minimizes the negative marginal log-likelihood of each target using stochastic gradient descent with Adam.
- Notably, the document encoder BERTd is kept fixed during training, avoiding the need for periodic updates of the document index.
- Query/Document Embedding:
- The following figure from the paper illustrates an overview of the proposed approach. They combine a pre-trained retriever (Query Encoder + Document Index) with a pre-trained seq2seq model (Generator) and fine-tune end-to-end. For query \(x\), they use Maximum Inner Product Search (MIPS) to find the top-\(K\) documents \(z_i\). For final prediction \(y\), they treat \(z\) as a latent variable and marginalize over seq2seq predictions given different documents.
- In open-domain QA tasks, RAG established new state-of-the-art results, outperforming both parametric seq2seq models and task-specific retrieve-and-extract architectures. RAG models showed the ability to generate correct answers even when the right answer wasn’t in any retrieved document.
- RAG-Sequence surpassed BART in Open MS-MARCO NLG, indicating less hallucination and more factually correct text generation. RAG-Token outperformed RAG-Sequence in Jeopardy question generation, demonstrating higher factuality and specificity.
- On the FEVER fact verification task, RAG models achieved results close to state-of-the-art models that require more complex architectures and intermediate retrieval supervision.
- This study showcases the effectiveness of hybrid generation models, combining parametric and non-parametric memories, offering new directions in combining these components for a range of NLP tasks.
- Code; interactive demo.
Active Retrieval Augmented Generation
- Despite the remarkable ability of large language models (LLMs) to comprehend and generate language, they have a tendency to hallucinate and create factually inaccurate output.
- Augmenting LLMs by retrieving information from external knowledge resources is one promising solution. Most existing retrieval-augmented LLMs employ a retrieve-and-generate setup that only retrieves information once based on the input. This is limiting, however, in more general scenarios involving generation of long texts, where continually gathering information throughout the generation process is essential. There have been some past efforts to retrieve information multiple times while generating outputs, which mostly retrieve documents at fixed intervals using the previous context as queries.
- This paper from Jiang et al. at CMU, Sea AI Lab, and Meta AI in EMNLP 2023 presents Forward-Looking Active REtrieval augmented generation (FLARE), a method addressing the tendency of large language models (LLMs) to produce factually inaccurate content.
- FLARE iteratively uses predictions of upcoming sentences to actively decide when and what to retrieve across the generation process, enhancing LLMs with dynamic, multi-stage external information retrieval.
- Unlike traditional retrieve-and-generate models that use fixed intervals or input-based retrieval, FLARE targets continual information gathering for long text generation, reducing hallucinations and factual inaccuracies.
- The system triggers retrieval when generating low-confidence tokens, determined by a probability threshold. This anticipates future content, forming queries to retrieve relevant documents for regeneration.
- The following figure from the paper illustrates FLARE. Starting with the user input \(x\) and initial retrieval results \(D_x\), FLARE iteratively generates a temporary next sentence (shown in gray italic) and check whether it contains low-probability tokens (indicated with underline). If so (step 2 and 3), the system retrieves relevant documents and regenerates the sentence.
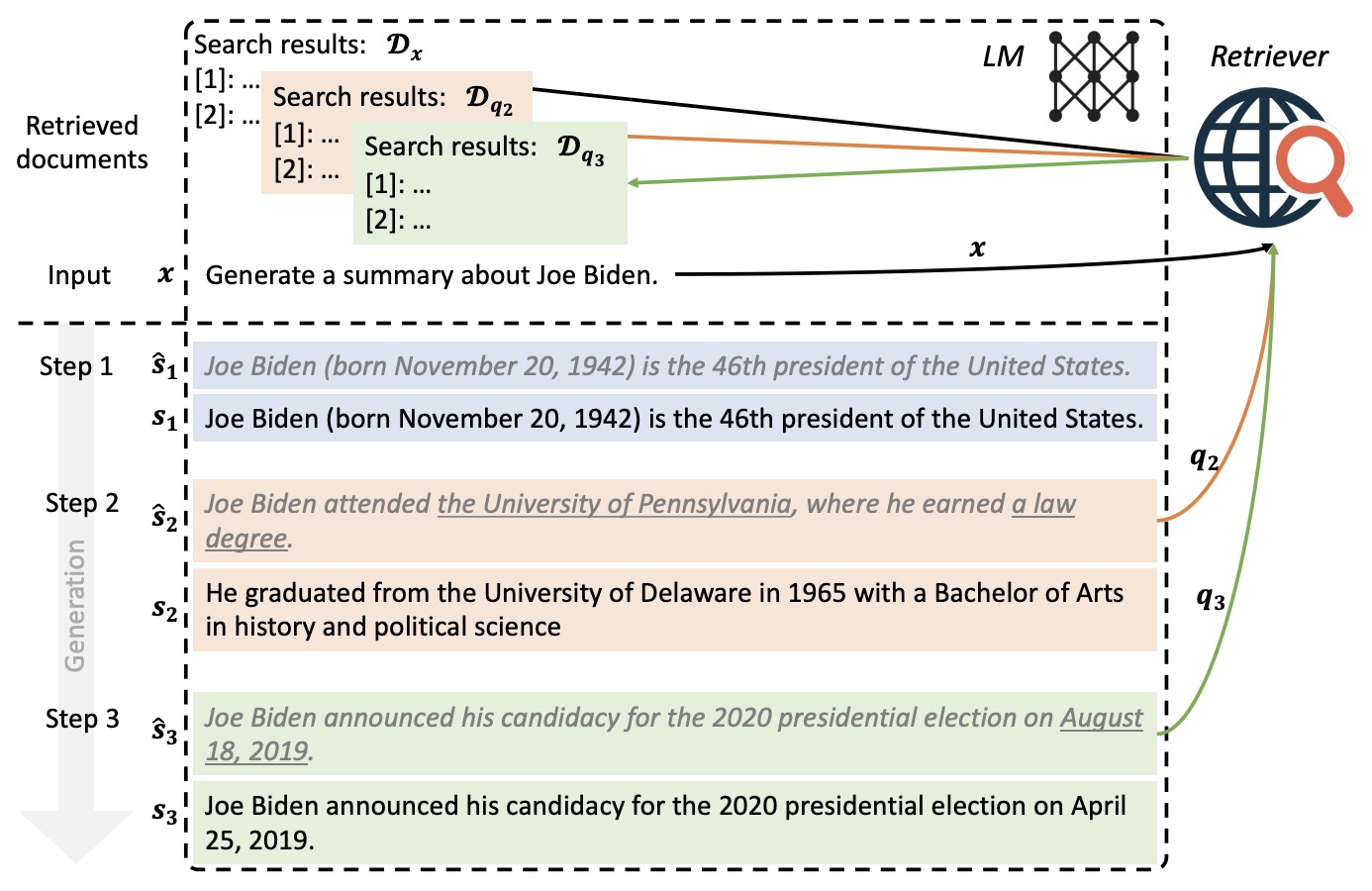
- FLARE was tested on four long-form, knowledge-intensive generation tasks/datasets, exhibiting superior or competitive performance, demonstrating its effectiveness in addressing the limitations of existing retrieval-augmented LLMs.
- The model is adaptable to existing LLMs, as shown with its implementation on GPT-3.5, and employs off-the-shelf retrievers and the Bing search engine.
- Code.
MuRAG: Multimodal Retrieval-Augmented Generator
- This paper by Chen et al. from Google Research proposes Multimodal Retrieval-Augmented Transformer (MuRAG), which looks to extend the retrieval process beyond text to include other modalities like images or structured data, which can then be used alongside textual information to inform the generation process.
- MuRAG’s magic lies in its two-phase training approach: pre-training and fine-tuning, each carefully crafted to build the model’s ability to tap into a vast expanse of multimodal knowledge.
- The key goal of MuRAG is to incorporate both visual and textual knowledge into language models to improve their capability for multimodal question answering.
- MuRAG is distinct in its ability to access an external non-parametric multimodal memory (images and texts) to enhance language generation, addressing the limitations of text-only retrieval in previous models.
- MuRAG has a dual-encoder architecture combines pre-trained visual transformer (ViT) and a text encoder (T5) models to create a backbone encoder, enabling the encoding of image-text pairs, image-only, and text-only inputs into a unified/joint multimodal representation.
- MuRAG is pre-trained on a mixture of image-text data (LAION, Conceptual Captions) and text-only data (PAQ, VQA). It uses a contrastive loss for retrieving relevant knowledge and a generation loss for answer prediction. It employs a two-stage training pipeline: initial training with small in-batch memory followed by training with a large global memory.
- During the retriever stage, MuRAG takes a query \(q\) of any modality as input and retrieves from a memory \(\mathcal{M}\) of image-text pairs. Specifically, we apply the backbone encoder \(f_\theta\) to encode a query \(q\), and use maximum inner product search (MIPS) over all of the memory candidates \(m \in \mathcal{M}\) to find the top-\(k\) nearest neighbors \(\operatorname{Top}_K(\mathcal{M} \mid q)=\left[m_1, \cdots, m_k\right]\). Formally, we define \(\operatorname{Top}_K(\mathcal{M} \mid q)\) as follows:
-
During the reader stage, the retrievals (the raw image patches) are combined with the query \(q\) as an augmented input \(\left[m_1, \cdots, m_k, q\right]\), which is fed to the backbone encoder \(f_\theta\) to produce retrievalaugmented encoding. The decoder model \(g_\theta\) uses attention over this representation to generate textual outputs \(\mathbf{y}=y_1, \cdots, y_n\) token by token.
\[p\left(y_i \mid y_{i-1}\right)=g_\theta\left(y_i \mid f_\theta\left(\operatorname{Top}_K(\mathcal{M} \mid q) ; q\right) ; y_{1: i-1}\right)\]- where \(y\) is decoded from a given vocabulary \(\mathcal{V}\).
-
The figure below from the original paper (source) shows how the model taps into an external repository to retrieve a diverse range of knowledge encapsulated within both images and textual fragments. This multimodal information is then employed to enhance the generative process. The upper section outlines the setup for the pre-training phase, whereas the lower section specifies the framework for the fine-tuning phase.
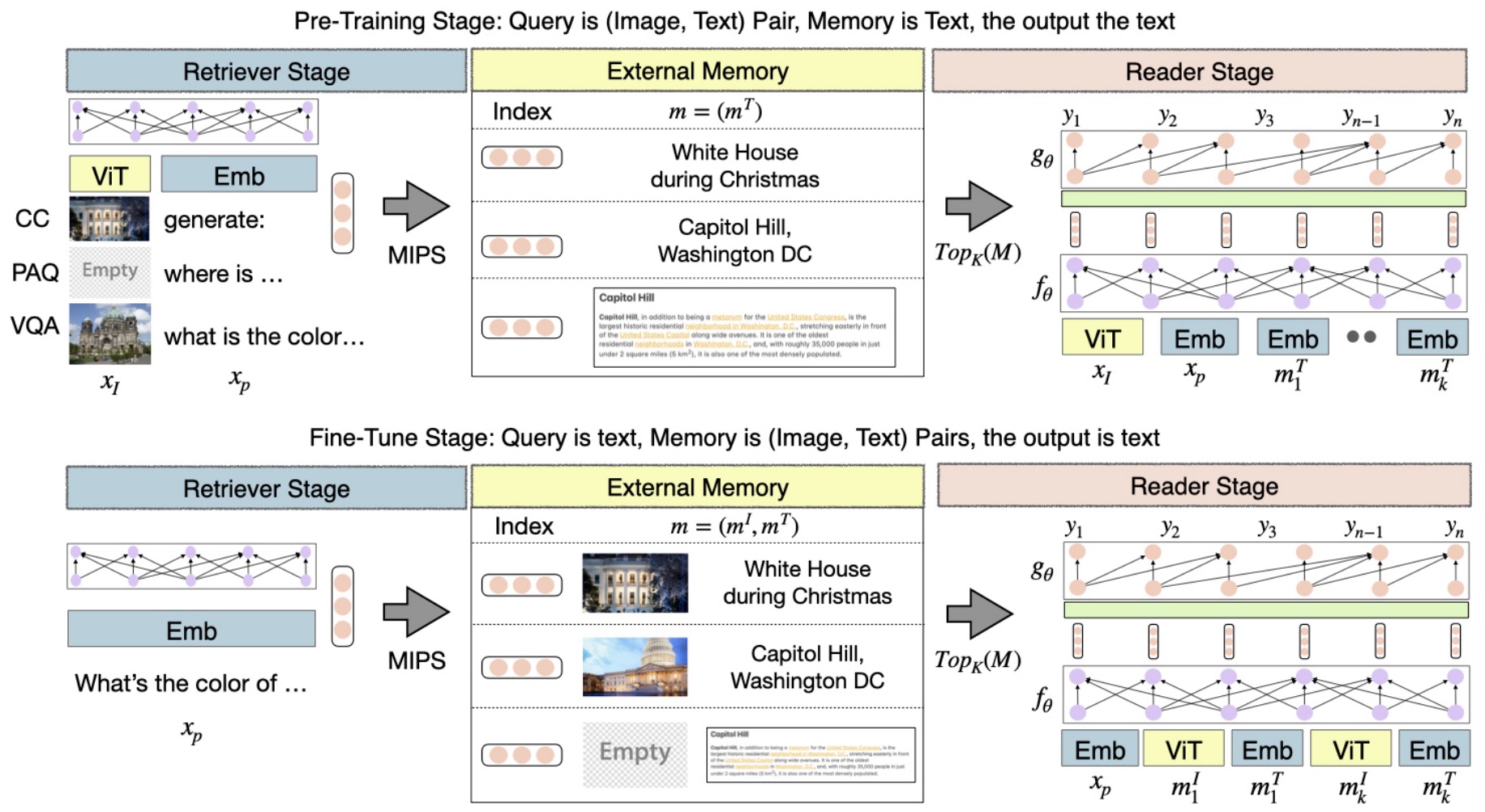
- The process can be summarized as follows:
- For retrieval, MuRAG uses maximum inner product search to find the top-\(k\) most relevant image-text pairs from the memory given a question. The “memory” here refers to the external knowledge base that the model can retrieve information from. Specifically, the memory contains a large collection of image-text pairs that are encoded offline by the backbone encoder prior to training.
- During training and inference, given a question, MuRAG’s retriever module will search through this memory to find the most relevant image-text pairs using maximum inner product search.
- The memory serves as the knowledge source and can contain various types of multimodal data like images with captions, passages of text, tables, etc. that are related to the downstream task.
- For example, when fine-tuning on the WebQA dataset, the memory contains 1.1 million image-text pairs extracted from Wikipedia that the model can retrieve from to answer questions.
- So in summary, the memory is the large non-parametric external knowledge base encoded in a multimodal space that MuRAG learns to retrieve relevant knowledge from given a question, in order to augment its language generation capabilities. The memory provides the world knowledge to complement what is stored implicitly in the model’s parameters.
- For reading, the retrieved multimodal context is combined with the question embedding and fed into the decoder to generate an answer.
- MuRAG achieves state-of-the-art results on two multimodal QA datasets - WebQA and MultimodalQA, outperforming text-only methods by 10-20% accuracy. It demonstrates the value of incorporating both visual and textual knowledge.
- Key limitations are the reliance on large-scale pre-training data, computational costs, and issues in visual reasoning like counting objects. But overall, MuRAG represents an important advance in building visually-grounded language models.
Hypothetical Document Embeddings (HyDE)
- Published in Precise Zero-Shot Dense Retrieval without Relevance Labels by Gao et al. from CMU and University of Waterloo, proposes an innovative approach called Hypothetical Document Embeddings (HyDE) for effective zero-shot dense retrieval in the absence of relevance labels. HyDE leverages an instruction-following language model, such as InstructGPT, to generate a hypothetical document that captures relevance patterns, although it may contain factual inaccuracies. An unsupervised contrastive encoder, like Contriever, then encodes this document into an embedding vector to identify similar real documents in the corpus embedding space, effectively filtering out incorrect details.
- The implementation of HyDE combines InstructGPT (a GPT-3 model) and Contriever models, utilizing OpenAI playground’s default temperature setting for generation. For English retrieval tasks, the English-only Contriever model was used, while for non-English tasks, the multilingual mContriever was employed.
- The following image from the paper illustrates the HyDE model. Documents snippets are shown. HyDE serves all types of queries without changing the underlying GPT-3 and Contriever/mContriever models.
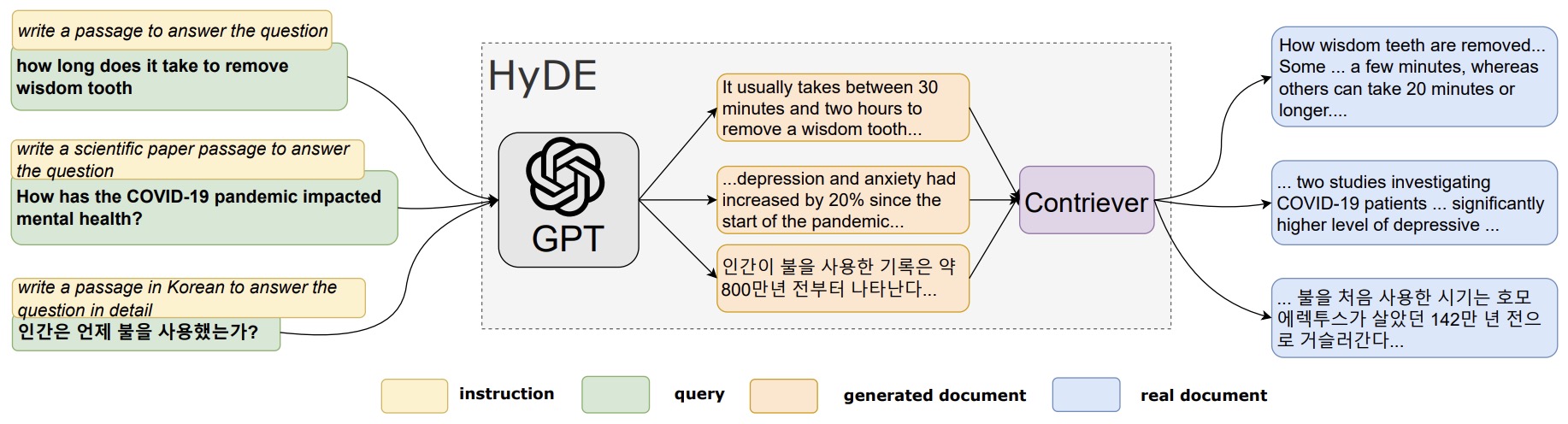
- Experiments were conducted using the Pyserini toolkit. The results demonstrate HyDE’s significant improvement over the state-of-the-art unsupervised dense retriever Contriever, with strong performance comparable to fine-tuned retrievers across various tasks and languages. Specifically, in web search and low-resource tasks, HyDE showed sizable improvements in precision and recall-oriented metrics. It remained competitive even compared to fine-tuned models, particularly in terms of recall. In multilingual retrieval, HyDE improved the mContriever model and outperformed non-Contriever models fine-tuned on MS-MARCO. However, there were some performance gaps with fine-tuned mContrieverFT, likely due to under-training in non-English languages.
- Further analysis explored the effects of using different generative models and fine-tuned encoders with HyDE. Larger language models brought greater improvements, and the use of fine-tuned encoders with HyDE showed that less powerful instruction language models could impact the performance of the fine-tuned retriever.
- One possible pitfall of HyDE is that it can potentially “hallucinate” in the sense that it generates hypothetical documents that may contain invented or inaccurate details. This phenomenon occurs because HyDE uses an instruction-following language model, like InstructGPT, to generate a document based on a query. The generated document is intended to capture the relevance patterns of the query, but since it’s created without direct reference to real-world data, it can include false or fictional information. This aspect of HyDE is a trade-off for its ability to operate in zero-shot retrieval scenarios, where it creates a contextually relevant but not necessarily factually accurate document to guide the retrieval process.
- In conclusion, the paper introduces a new paradigm of interaction between language models and dense encoders/retrievers, showing that relevance modeling and instruction understanding can be effectively handled by a powerful and flexible language model. This approach eliminates the need for relevance labels, offering practical utility in the initial stages of a search system’s life, and paving the way for further advancements in tasks like multi-hop retrieval/QA and conversational search.
RAGAS: Automated Evaluation of Retrieval Augmented Generation
- This paper by Es et al. from Exploding Gradients, Cardiff University, and AMPLYFI introduces RAGAS, a framework for reference-free evaluation of Retrieval Augmented Generation (RAG) systems.
- RAGAS focuses on evaluating the performance of RAG systems in dimensions such as the effectiveness of the retrieval system in providing relevant context, the LLM’s ability to utilize this context, and the overall quality of generation.
- The framework proposes a suite of metrics to evaluate these dimensions without relying on ground truth human annotations.
- RAGAS focuses on three quality aspects: Faithfulness, Answer Relevance, and Context Relevance.
- Faithfulness: Defined as the extent to which the generated answer is grounded in the provided context. It’s measured using the formula: \(F = \frac{|V|}{|S|}\) where, \(|V|\) is the number of statements supported by the context and \(|S|\) is the total number of statements extracted from the answer.
- Answer Relevance: This metric assesses how well the answer addresses the given question. It’s calculated by generating potential questions from the answer and measuring their similarity to the original question using the formula: \(AR = \frac{1}{n} \sum_{i=1}^{n} \text{sim}(q, q_i)\) where \(q\) is the original question, \(q_i\) are the generated questions, and sim denotes the cosine similarity between their embeddings.
- Context Relevance: Measures the extent to which the retrieved context contains only the information necessary to answer the question. It is quantified using the proportion of extracted relevant sentences to the total sentences in the context: \(CR = \frac{\text{number of extracted sentences}}{\text{total number of sentences in } c(q)}\)
- The paper validates RAGAS using the WikiEval dataset, demonstrating its alignment with human judgments in evaluating these aspects.
- The authors argue that RAGAS contributes to faster and more efficient evaluation cycles for RAG systems, which is vital due to the rapid adoption of LLMs.
- RAGAS is validated using the WikiEval dataset, which includes question-context-answer triples annotated with human judgments for faithfulness, answer relevance, and context relevance.
- The evaluation shows that RAGAS aligns closely with human judgments, particularly in assessing faithfulness and answer relevance.
- Code.
Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs
- This paper by Ovadia et al. from Microsoft presents an insightful comparison of knowledge injection methods in large language models (LLMs). The core question addressed is whether unsupervised fine-tuning (USFT) is more effective than retrieval-augmented generation (RAG) for improving LLM performance on knowledge-intensive tasks.
- The researchers focus on LLMs’ ability to memorize, understand, and retrieve factual data, using a knowledge base scraped from Wikipedia and a dataset of current events questions created with GPT-4. The study employs models like Llama2-7B, Mistral-7B, and Orca2-7B, evaluating them on tasks from the Massively Multitask Language Understanding Evaluation (MMLU) benchmark and a current events dataset.
- Two methods of knowledge injection are explored: fine-tuning, which continues the model’s pre-training process using task-specific data, and retrieval-augmented generation (RAG), which uses external knowledge sources to enhance LLMs’ responses. The paper also delves into supervised, unsupervised, and reinforcement learning-based fine-tuning methods.
- The key finding is that RAG outperforms unsupervised fine-tuning in knowledge injection. RAG, which uses external knowledge sources, is notably more effective in terms of knowledge injection than USFT alone and even more so than a combination of RAG and fine-tuning, particularly in scenarios where questions directly corresponded to the auxiliary dataset. This suggests that USFT may not be as efficient in embedding new knowledge into the model’s parameters.
- The figure below from the paper shows a visualization of the knowledge injection framework.
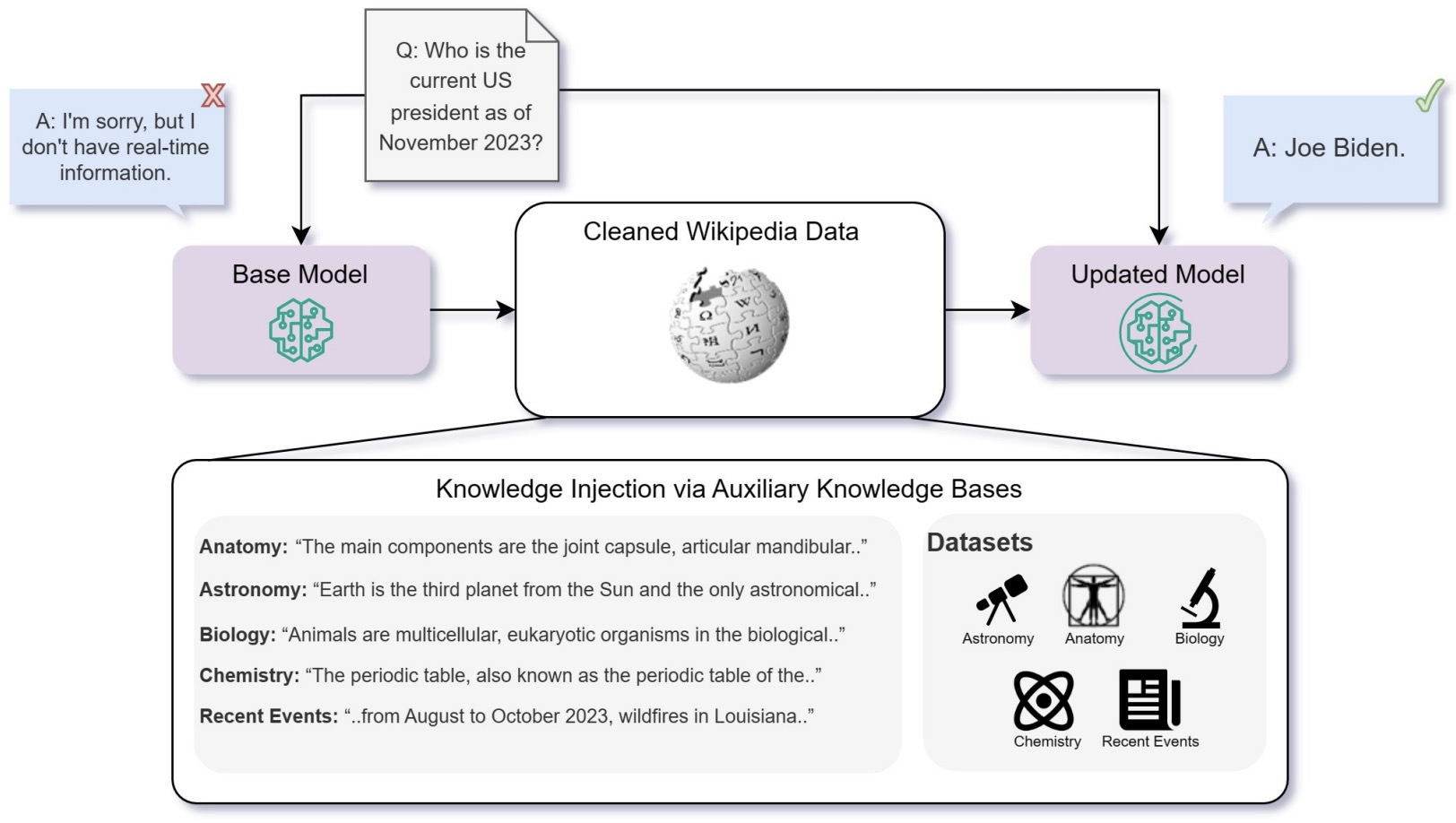
- Note that USFT in this context is a direct continuation of pre-training (hence also called continued pre-training in literature), predicting the next token on the dataset. Interestingly, fine-tuning with multiple paraphrases of the same fact significantly improves the baseline performance, indicating the importance of repetition and varied presentation of information for effective knowledge assimilation.
- The authors created a knowledge base by scraping Wikipedia articles relevant to various topics, which was used for both fine-tuning and RAG. Additionally, a dataset of multiple-choice questions about current events was generated using GPT-4, with paraphrases created to augment this dataset.
- Limitations of the study include the exclusive focus on unsupervised fine-tuning, without exploring supervised fine-tuning or reinforcement learning from human feedback (RLHF). The study also notes a high variance in accuracy performance across experiments, making it challenging to ascertain the statistical significance of the results.
- The paper also questions why baseline models don’t achieve a 25% accuracy rate for multiple-choice questions with four options, suggesting that the tasks may not represent truly “unseen” knowledge. Moreover, the research primarily assesses straightforward knowledge or fact tasks, without delving into reasoning capabilities.
- In summary, while fine-tuning can be beneficial, RAG is identified as a superior method for knowledge injection in LLMs, especially for tasks involving new information. The results highlight the potential of using diverse fine-tuning techniques and auxiliary knowledge bases for further research in this domain.
Dense X Retrieval: What Retrieval Granularity Should We Use?
- One crucial choice in RAG pipeline design is chunking: should it be sentence level, passage level, or chapter level? This choice significantly impacts your retrieval and response generation performance.
- This paper by Chen et al. from the University of Washington, Tencent AI Lab, University of Pennsylvania, Carnegie Mellon University introduces a novel approach to dense retrieval in open-domain NLP tasks by using “propositions” as retrieval units, instead of the traditional document passages or sentences. A proposition is defined as an atomic expression within text, encapsulating a distinct factoid in a concise, self-contained natural language format. This change in retrieval granularity has a significant impact on both retrieval and downstream task performances.
- Propositions follow three key principles:
- Each proposition encapsulates a distinct meaning, collectively representing the semantics of the entire text.
- They are minimal and indivisible, ensuring precision and clarity.
- Each proposition is contextualized and self-contained, including all necessary text context (like coreferences) for full understanding.
- The authors developed a text generation model, named “Propositionizer,” to segment Wikipedia pages into propositions. This model was fine-tuned in two steps, starting with prompting GPT-4 for paragraph-to-propositions pairs generation, followed by fine-tuning a Flan-T5-large model.
- The effectiveness of propositions as retrieval units was evaluated using the FACTOIDWIKI dataset, a processed English Wikipedia dump segmented into passages, sentences, and propositions. Experiments were conducted on five open-domain QA datasets: Natural Questions (NQ), TriviaQA (TQA), Web Questions (WebQ), SQuAD, and Entity Questions (EQ). Six different dense retriever models were compared: SimCSE, Contriever, DPR, ANCE, TAS-B, and GTR.
- The figure below from the paper illustrates the fact that that segmenting and indexing a retrieval corpus on the proposition level can be a simple yet effective strategy to increase dense retrievers’ generalization performance at inference time \((A, B)\). We empirically compare the retrieval and downstream open-domain QA tasks performance when dense retrievers work with Wikipedia indexed at the level of 100-word passage, sentence or proposition \((C, D)\).
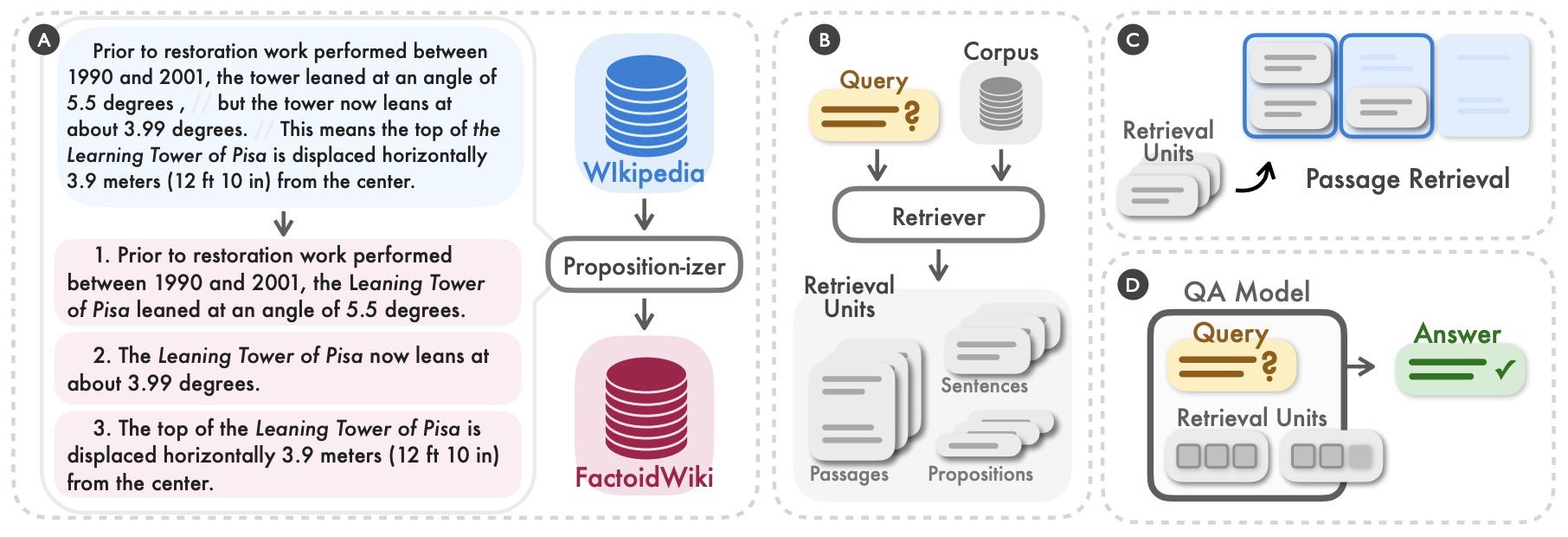
- Results:
- Passage Retrieval Performance: Proposition-based retrieval consistently outperformed sentence and passage-level retrieval across all datasets and models. This was particularly evident with unsupervised retrievers like SimCSE and Contriever, which showed an average Recall@5 improvement of 12.0% and 9.3%, respectively.
- Cross-Task Generalization: The advantage of proposition retrieval was most pronounced in cross-task generalization settings, especially for queries about less common entities. It showed significant improvement over other granularities in datasets not seen during the training of the retriever models.
- Downstream QA Performance: In the retrieve-then-read setting, proposition-based retrieval led to stronger downstream QA performance. This was true for both unsupervised and supervised retrievers, with notable improvements in exact match (EM) scores.
- Density of Question-Related Information: Propositions proved to offer a higher density of relevant information, resulting in the correct answers appearing more frequently within the top-l retrieved words. This was a significant advantage over sentence and passage retrieval, particularly in the range of 100-200 words.
- Error Analysis: The study also highlighted the types of errors typical to each retrieval granularity. For example, passage-level retrieval often struggled with entity ambiguity, while proposition retrieval faced challenges in multi-hop reasoning tasks.
- The figure plot from the paper shows that retrieving by propositions yields the best retrieval performance in both passage retrieval task and downstream open-domain QA task, e.g. with Contriever or GTR as the backbone retriever.
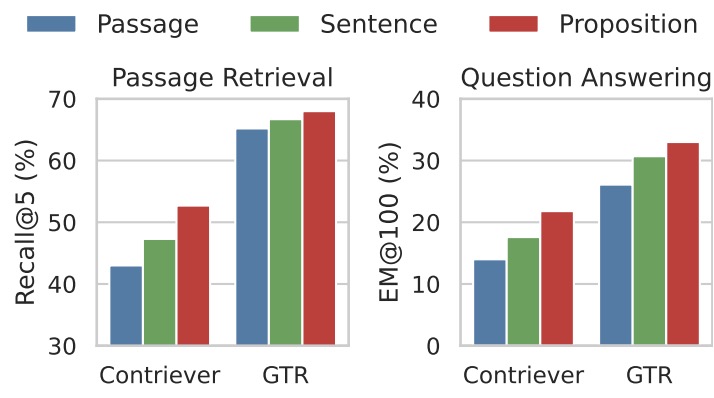
- The research demonstrates that using propositions as retrieval units significantly improves dense retrieval performance and downstream QA task accuracy, outperforming traditional passage and sentence-based methods. The introduction of FACTOIDWIKI, with its 250 million propositions, is expected to facilitate future research in information retrieval.
ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems
- This paper by Saad-Falcon et al. from Stanford University and UC Berkeley, the paper introduces ARES (Automated RAG Evaluation System) for evaluating Retrieval-Augmented Generation (RAG) systems in terms of context relevance, answer faithfulness, and answer relevance.
- ARES generates synthetic training data using a language model and fine-tunes lightweight LM judges to assess individual RAG components. It utilizes a small set of human-annotated data points for prediction-powered inference (PPI), enabling statistical guarantees for its predictions.
- The framework has three stages:
- LLM Generation of Synthetic Dataset: ARES uses generative LLMs (like FLAN-T5 XXL) to create synthetic datasets of question-answer pairs derived from target corpus passages. This stage includes both positive and negative examples for training.
- Preparing LLM Judges: Separate lightweight LM models are fine-tuned for three classification tasks - context relevance, answer faithfulness, and answer relevance - using the synthetic dataset. These models are tuned using a contrastive learning objective.
- Ranking RAG Systems with Confidence Intervals:
- After preparing the LLM judges, the next step involves using them to score and rank various RAG systems. This process begins with ARES sampling in-domain query-document-answer triples from each RAG approach. The judges then label each triple, assessing context relevance, answer faithfulness, and answer relevance. These labels are averaged for each in-domain triple to evaluate the performance of the RAG systems across the three metrics.
- While average scores could be reported as quality metrics for each RAG system, these scores are based on unlabeled data and predictions from synthetically-trained LLM judges, which may introduce noise. An alternative is to rely solely on a small human preference validation set for evaluation, examining the extent to which each RAG system aligns with human annotations. However, this method requires labeling outputs from each RAG system separately, which can be time-consuming and expensive.
- To enhance the precision of the evaluation, ARES employs prediction-powered inference (PPI). PPI is a statistical method that narrows the confidence interval of predictions on a small annotated dataset by utilizing predictions on a larger, non-annotated dataset. It combines labeled datapoints and ARES judge predictions on non-annotated datapoints to construct tighter confidence intervals for RAG system performance.
- PPI involves using LLM judges on the human preference validation set to learn a rectifier function. This function constructs a confidence set of the ML model’s performance, taking into account each ML prediction in the larger non-annotated dataset. The confidence set helps create a more precise confidence interval for the average performance of the ML model (e.g., its context relevance, answer faithfulness, or answer relevance accuracy). By integrating the human preference validation set with a larger set of datapoints with ML predictions, PPI develops reliable confidence intervals for ML model performance, outperforming traditional inference methods.
- The PPI rectifier function addresses errors made by the LLM judge and generates confidence bounds for the success and failure rates of the RAG system. It estimates performances in context relevance, answer faithfulness, and answer relevance. PPI also allows for estimating confidence intervals with a specified probability level; in these experiments, a standard 95% alpha is used.
- Finally, the accuracy confidence interval for each component of the RAG is determined, and the midpoints of these intervals are used to rank the RAG systems. This ranking enables a comparison of different RAG systems and configurations within the same system, aiding in identifying the optimal approach for a specific domain.
- In summary, ARES employs PPI to score and rank RAG systems, using human preference validation sets to calculate confidence intervals. PPI operates by first generating predictions for a large sample of data points, followed by human annotation of a small subset. These annotations are used to calculate confidence intervals for the entire dataset, ensuring accuracy in the system’s evaluation capabilities.
- To implement ARES for scoring a RAG system and comparing to other RAG configurations, three components are needed:
- A human preference validation set of annotated query, document, and answer triples for the evaluation criteria (e.g. context relevance, answer faithfulness, and/or answer relevance). There should be at least 50 examples but several hundred examples is ideal.
- A set of few-shot examples for scoring context relevance, answer faithfulness, and/or answer relevance in your system.
- A much larger set of unlabeled query-document-answer triples outputted by your RAG system for scoring.
- The figure below from the paper shows an overview of ARES: As inputs, the ARES pipeline requires an in-domain passage set, a human preference validation set of 150 annotated datapoints or more, and five few-shot examples of in-domain queries and answers, which are used for prompting LLMs in synthetic data generation. To prepare our LLM judges for evaluation, we first generate synthetic queries and answers from the corpus passages. Using our generated training triples and a constrastive learning framework, we fine-tune an LLM to classify query–passage–answer triples across three criteria: context relevance, answer faithfulness, and answer relevance. Finally, we use the LLM judge to evaluate RAG systems and generate confidence bounds for the ranking using PPI and the human preference validation set.
- Experiments conducted on datasets from KILT and SuperGLUE demonstrate ARES’s accuracy in evaluating RAG systems, outperforming existing automated evaluation approaches like RAGAS. ARES is effective across various domains, maintaining accuracy even with domain shifts in queries and documents.
- The paper highlights the strengths of ARES in cross-domain applications and its limitations, such as its inability to generalize across drastic domain shifts (e.g., language changes, text-to-code). It also explores the potential of using GPT-4 for generating labels as a replacement for human annotations in the PPI process.
- ARES code and datasets are available for replication and deployment at GitHub.
- Code
Seven Failure Points When Engineering a Retrieval Augmented Generation System
- This technical report by Barnett et al. from the Applied Artificial Intelligence Institute, Deakin University, Australia, explores failure points in the implementation of Retrieval Augmented Generation (RAG) systems. based on three case studies in diverse domains: research, education, and biomedical.
- RAG systems, which integrate retrieval mechanisms with Large Language Models (LLMs) to generate contextually relevant responses, are scrutinized for their operational challenges. The paper identifies seven key failure points in RAG systems:
- FP1 Missing Relevant Content: The first failure case is when asking a question that cannot be answered from the available documents. In the happy case the RAG system will respond with something like “Sorry, I don’t know”. However, for questions that are related to the content but don’t have answers the system could be fooled into giving a response.
- FP2 Missed the Top Ranked Documents: The answer to the question is in the document but did not rank highly enough to be returned to the user. In theory, all documents are ranked and used in the next steps. However, in practice only the top \(K\) documents are returned where \(K\) is a value selected based on performance.
- FP3 Not in Context - Consolidation Strategy Limitations: Documents with the answer were retrieved from the database but did not make it into the context for generating an answer. This occurs when many documents are returned from the database and a consolidation process takes place to retrieve the answer.
- FP4 Not Extracted Here: the answer is present in the context, but the large language model failed to extract out the correct answer. Typically, this occurs when there is too much noise or contradicting information in the context.
- FP5 Wrong Format: The question involved extracting information in a certain format such as a table or list and the large language model ignored the instruction.
- FP6 Incorrect Specificity: The answer is returned in the response but is not specific enough or is too specific to address the user’s need. This occurs when the RAG system designers have a desired outcome for a given question such as teachers for students. In this case, specific educational content should be provided with answers not just the answer. Incorrect specificity also occurs when users are not sure how to ask a question and are too general.
- FP7 Incomplete Responses: Incomplete answers are not incorrect but miss some of the information even though that information was in the context and available for extraction. An example question such as “What are the key points covered in documents A, B and C?” A better approach is to ask these questions separately.
- The study also emphasizes the importance of real-time validation and the evolving robustness of RAG systems. It concludes with suggestions for future research directions, highlighting the significance of chunking, embeddings, and the trade-offs between RAG systems and fine-tuning LLMs.
- The following image from the paper shows the Indexing and Query processes required for creating a Retrieval Augmented Generation (RAG) system. The indexing process is typically done at development time and queries at runtime. Failure points identified in this study are shown in red boxes. All required stages are underlined.
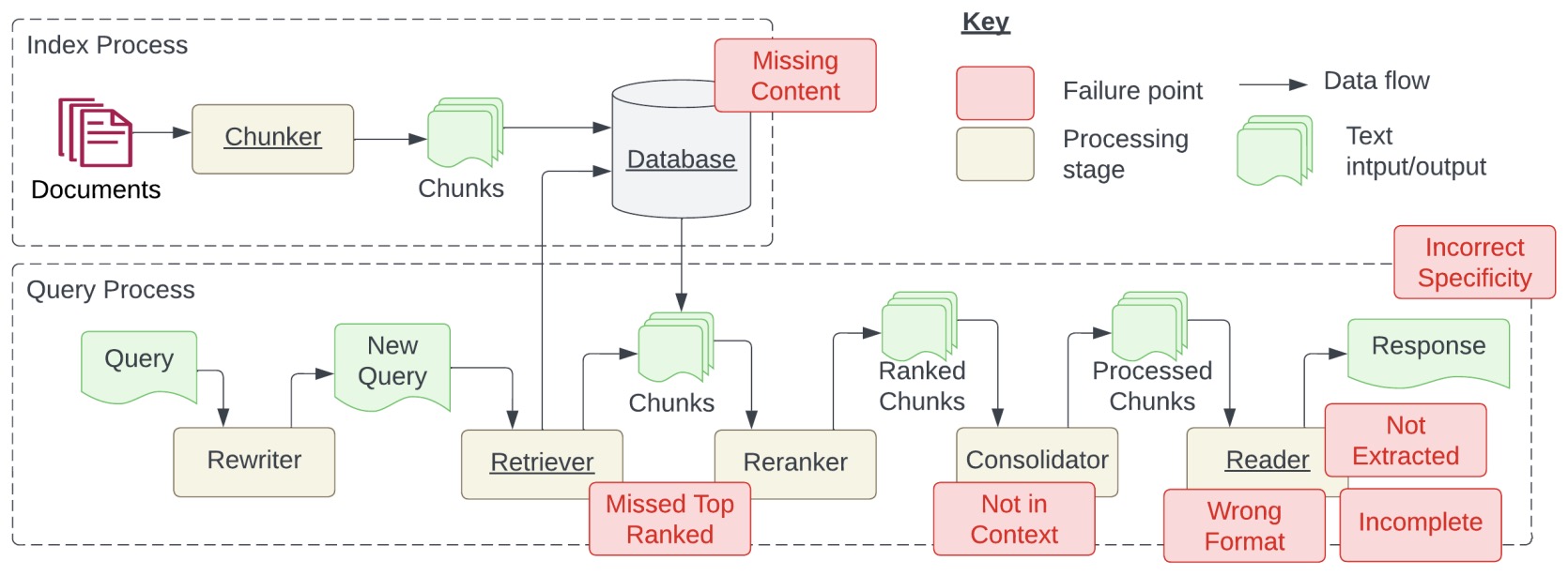
- Moreover, the paper provides insights into the challenges faced in implementing RAG systems, such as handling diverse document types, query preprocessing, and the need for continuous calibration and monitoring of these systems. These findings are derived from practical experiences and offer valuable guidance for practitioners in the field.
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
- This paper by Sarthi et al. from Manning’s Lab at Stanford, published in ICLR 2024, introduces RAPTOR, a novel approach for retrieval-augmented language models. RAPTOR addresses the limitation of existing retrieval methods that primarily fetch short text chunks, hindering comprehensive document understanding. It constructs a tree by recursively embedding, clustering, and summarizing text chunks, offering multi-level summarization and facilitating efficient information retrieval from extensive documents.
- At its core, RAPTOR employs a tree structure starting from leaf nodes (text chunks) and builds up to the root through successive clustering and summarization. This method allows the model to access information at various abstraction levels, significantly enhancing performance on complex, multi-step reasoning tasks. When combined with GPT-4, RAPTOR achieved a 20% absolute accuracy improvement on the QuALITY benchmark over previous state-of-the-art models.
- Some key insights into why using a tree-structure lets your RAG pipeline handle more complex questions:
- Cluster semantically related chunks to dynamically identify distinct topics within your documents.
- Create new chunks by summarizing clusters.
- Mix high-level and low-level chunks during retrieval, to dynamically surface relevant information depending on the query.
- The model utilizes SBERT for embedding text chunks and Gaussian Mixture Models (GMMs) for clustering, allowing flexible groupings of related content. Summarization is performed by a language model (GPT-3.5-turbo), producing summaries that guide the construction of higher tree levels. This recursive process creates a scalable and computationally efficient system that linearly scales in both token expenditure and build time, as detailed in the scalability analysis.
- Querying within RAPTOR’s tree employs two strategies: tree traversal and collapsed tree, with the latter showing superior flexibility and effectiveness in preliminary tests on the QASPER dataset. The model’s innovative clustering mechanism, highlighted in an ablation study, proves essential for capturing thematic content and outperforms standard retrieval methods.
- The figure below from the paper shows the tree construction process: RAPTOR recursively clusters chunks of text based on their vector embeddings and generates text summaries of those clusters, constructing a tree from the bottom up. Nodes clustered together are siblings; a parent node contains the text summary of that cluster.
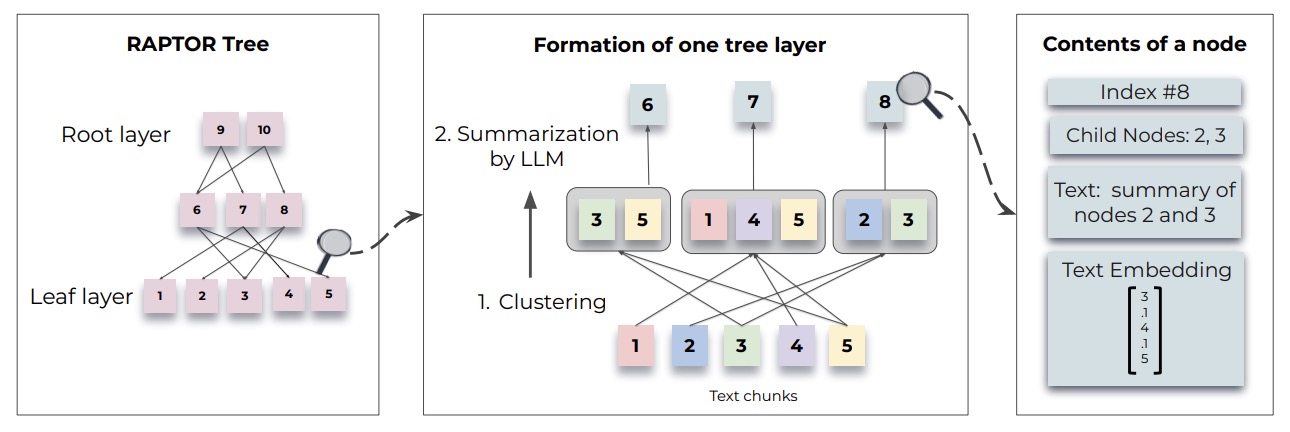
- Experimental results across various datasets (NarrativeQA, QASPER, QuALITY) demonstrate RAPTOR’s effectiveness, setting new benchmarks and outperforming existing retrieval-augmented models. The paper’s qualitative analysis illustrates RAPTOR’s ability to retrieve relevant information for thematic questions, showcasing its superiority over Dense Passage Retrieval (DPR) methods in handling complex queries.
- The paper includes a comprehensive reproducibility statement, detailing the use of publicly available language models and datasets, ensuring that the community can replicate and extend upon RAPTOR’s findings.
The Power of Noise: Redefining Retrieval for RAG Systems
- This paper by Cuconasu et al. from Sapienza University of Rome, Technology Innovation Institute, and University of Pisa introduces a comprehensive study on Retrieval-Augmented Generation (RAG) systems, highlighting the significant influence of Information Retrieval (IR) components on RAG’s performance, beyond the generative abilities of Large Language Models (LLMs).
- Their research investigates the characteristics required in a retriever for optimal RAG prompt formulation, emphasizing the balance between relevant, related, and irrelevant documents.
- The study reveals that including irrelevant documents surprisingly enhances RAG system performance by over 30% in accuracy, challenging the assumption that only relevant and related documents should be retrieved. This finding underscores the potential of integrating seemingly noise-adding strategies to improve RAG system outputs, thereby laying the groundwork for future research in IR and language model integration.
- The experimental methodology employed involves a detailed examination of the Natural Questions dataset, testing various configurations of document relevance and placement within the RAG prompt. This methodological rigor allows the researchers to dissect the impact of document type (gold, relevant, related, irrelevant) and position on the accuracy of RAG system responses, with attention to how these factors influence LLM’s generative performance.
- Insights from the experiments led to the formulation of strategies for optimizing RAG systems, proposing a nuanced approach to document retrieval that includes a mix of relevant and intentionally irrelevant documents. This approach aims to maximize system performance within the context size constraints of LLMs, offering a novel perspective on the integration of retrieval processes with generative language models for enhanced factual accuracy and context awareness.
- The study’s findings challenge traditional IR strategies and suggest a paradigm shift towards the inclusion of controlled noise in the retrieval process for language generation tasks. The researchers advocate for further exploration into the mechanisms by which irrelevant documents improve RAG system performance, highlighting the need for new IR techniques tailored to the unique demands of language generation models.
MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries
- This paper by Tang et al. from the Hong Kong University of Science and Technology introduces MultiHop-RAG, a novel dataset and benchmark for evaluating Retrieval-Augmented Generation (RAG) systems on multi-hop queries. These queries necessitate retrieving and reasoning over multiple pieces of evidence, a challenge not adequately addressed by existing RAG systems.
- MultiHop-RAG consists of a knowledge base derived from English news articles, multi-hop queries, their answers, and the supporting evidence required for those answers. This dataset aims to mimic real-world applications where complex queries involving multiple pieces of information are common.
- The figure below from the paper shows the RAG flow with a multi-hop query.
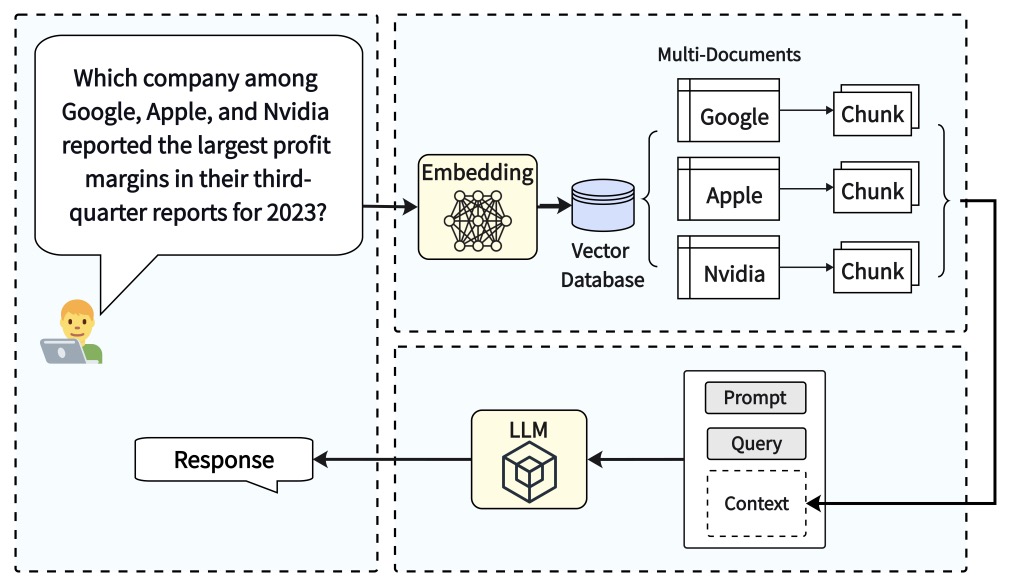
- The authors categorize multi-hop queries into four types: Inference, Comparison, Temporal, and Null queries. The first three types — Inference, Comparison, and Temporal — require the retrieval and analysis of evidence from multiple sources, encompassing tasks like inferring relationships, comparing data points, and sequencing events over time. The Null query represents a scenario where the query cannot be derived from the knowledge base. This category is crucial for assessing whether an LLM might hallucinate an answer to a multi-hop query when the retrieved text lacks relevance. Each type requires a distinct retrieval and reasoning strategy over the evidence, with Null queries designed to test the model’s ability to refrain from generating an answer when the query cannot be resolved with the available knowledge.
- They define a multi-hop query as one that requires retrieving and reasoning over multiple pieces of supporting evidence to provide an answer. In other words, for a multi-hop query \(q\), the chunks in the retrieval set \(\mathcal{R}_q\) collectively provide an answer to \(q\). For example, the query “Which company among Google, Apple, and Nvidia reported the largest profit margins in their third-quarter reports for 2023?” requires 1) retrieving relevant pieces of evidence related to profit margins from the reports of the three companies; 2) generating an answer by comparing and reasoning from the multiple pieces of retrieved evidence. This differs from a singlehop query such as “What is Google’s profit margin in the third-quarter reports for 2023 ,” where the answer can be directly derived from a single piece of evidence.
- Based on the queries commonly used in realworld RAG systems, they identify four types of multi-hop queries. For each type, they present a hypothetical query within the context of a financial RAG system, where the knowledge base consists of a collection of annual reports.
- Inference query: For such a query \(q\), the answer is deduced through reasoning from the retrieval set \(\mathcal{R}_q\). An example of an inference query might be: Which report discusses the supply chain risk of Apple, the 2019 annual report or the 2020 annual report?
- Comparison query: For such a query \(q\), the answer requires a comparison of evidence within the retrieval set \(\mathcal{R}_q\). For instance, a comparison query might ask: Did Netflix or Google report higher revenue for the year 2023?”
- Temporal query: For such a query \(q\), the answer requires an analysis of the temporal information of the retrieved chunks. For example, a temporal query may ask: Did Apple introduce the AirTag tracking device before or after the launch of the 5th generation iPad Pro?
- Null query: For such as query \(q\), the answer cannot be derived from the retrieved set \(\mathcal{R}_q\). They include the null query to assess the generation quality, especially regarding the issue of hallucination. For a null query, even though a retrieved set is provided, an LLM should produce a null response instead of hallucinating an answer. For example, assuming ABCS is a non-existent company, a null query might ask: What are the sales of company ABCS as reported in its 2022 and 2023 annual reports?
- The dataset was created using GPT-4 to generate multi-hop queries from a pool of factual sentences extracted from news articles. The queries were then validated for quality and relevance. This process ensures the dataset’s utility in benchmarking the capability of RAG systems to handle complex queries beyond the capacity of current systems.
- Experimental results demonstrate that existing RAG methods struggle with multi-hop query retrieval and answering, underscoring the necessity for advancements in this area. The benchmarking also explores the effectiveness of different embedding models for evidence retrieval and the reasoning capabilities of various state-of-the-art Large Language Models (LLMs) including GPT-4, PaLM, and Llama2-70B, revealing significant room for improvement.
- The authors hope that MultiHop-RAG will encourage further research and development in RAG systems, particularly those capable of sophisticated multi-hop reasoning, thereby enhancing the practical utility of LLMs in complex information-seeking tasks.
- Code
RAG vs. Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture
- This paper by Balaguer et al. from Microsoft, delves into two prevalent approaches for incorporating proprietary and domain-specific data into Large Language Models (LLMs): Retrieval-Augmented Generation (RAG) and Fine-Tuning. RAG augments prompts with external data, whereas Fine-Tuning embeds additional knowledge directly into the model. The paper outlines a comprehensive pipeline for both approaches, evaluating their effectiveness on multiple popular LLMs including Llama2-13B, GPT-3.5, and GPT-4.
- The research particularly focuses on agriculture, an industry with relatively limited AI penetration, proposing a disruptive application: providing location-specific insights to farmers. The pipeline stages include data acquisition, PDF information extraction, question and answer generation using this data, and leveraging GPT-4 for result evaluation. Metrics are introduced to assess the performance of the RAG and Fine-Tuning pipeline stages.
- The figure below from the paper shows the methodology pipeline. Domain-specific datasets are collected, and the content and structure of the documents are extracted. This information is then fed to the Q&A generation step. Synthesized question-answer pairs are used to fine-tune the LLMs. Models are evaluated with and without RAG under different GPT-4-based metrics.
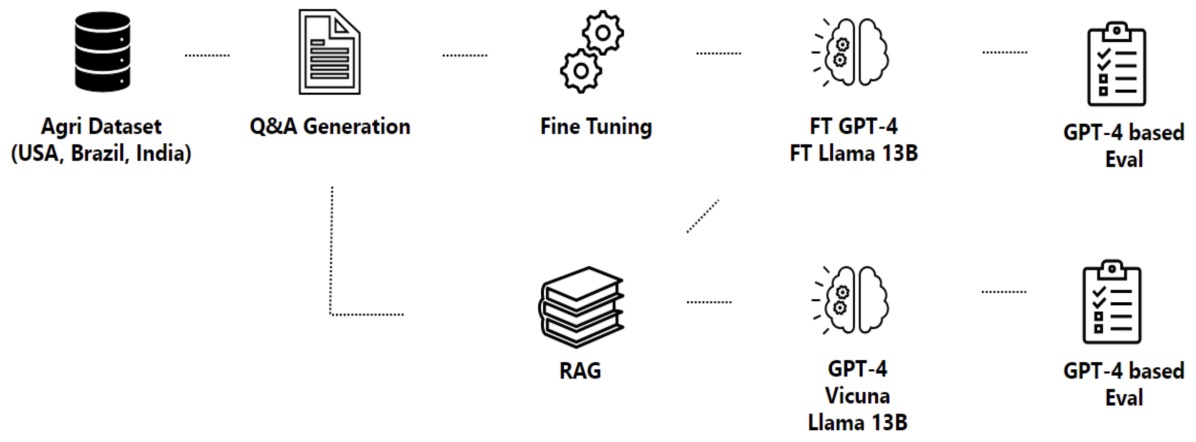
- Experimental results from an agricultural dataset highlight the pipeline’s capability in capturing geography-specific knowledge. Fine-Tuning demonstrated a significant accuracy increase of over 6 percentage points, a benefit that accumulates with RAG, further enhancing accuracy by 5 percentage points. One experiment showcased the fine-tuned model’s ability to leverage information across geographies to answer specific questions, boosting answer similarity from 47% to 72%.
- The paper presents an in-depth comparison of answers from GPT-4, Bing Chat, and agronomist experts to the same query across different U.S. states, revealing the models’ generic responses versus the experts’ nuanced, location-specific answers. This comparative analysis underscores the potential of fine-tuning and RAG in producing more contextually appropriate responses for industry-specific applications.
- The proposed methodology aims at generating domain-specific questions and answers to create a valuable knowledge resource for industries requiring specific contextual and adaptive responses. Through an extensive evaluation involving benchmarks from major agriculture-producing countries, the study establishes a baseline understanding of model performance in the agricultural context and explores the impact of spatial shift on knowledge encoding and the benefits of spatially-scoped fine-tuning.
- Additionally, the research investigates the implications of retrieval techniques and fine-tuning on LLM performance. It identifies RAG as particularly effective in contexts requiring domain-specific knowledge and fine-tuning as beneficial for imparting new skills to models, albeit at a higher initial cost. This work serves as a foundation for applying RAG and fine-tuning techniques across industries, demonstrating their utility in enhancing model efficiency from the Q&A generation process onwards.
RAFT: Adapting Language Model to Domain Specific RAG
- This paper by Zhang et al. from UC Berkeley introduces Retrieval Augmented Fine Tuning (RAFT) as a method to adapt pre-trained Large Language Models (LLMs) for domain-specific Retrieval Augmented Generation (RAG), focusing on “open-book” in-domain settings. By training the model to identify and ignore distractor documents while citing relevant information from pertinent documents, RAFT enhances the model’s reasoning capability and its ability to answer questions based on a specific set of documents.
- The concept draws an analogy to preparing for an open-book exam, where RAFT simulates the conditions of such an exam by incorporating both relevant and irrelevant (distractor) documents during training. This contrasts with existing methods that either do not leverage the opportunity to learn from domain-specific documents or fail to prepare the model for the dynamics of RAG in an open-book test setting.
- The figure below from the paper draws an analogy to how best to prepare for an exam? (a) Fine-tuning based approaches implement “studying” by either directly “memorizing” the input documents or answering practice QA without referencing the documents. (b) Alternatively, incontext retrieval methods fail to leverage the learning opportunity afforded by the fixed domain and are equivalent to taking an open-book exam without studying. While these approaches leverage in-domain learning, they fail to prepare for open-book tests. In contrast, (c) RAFT leverages fine-tuning with question-answer pairs while referencing the documents in a simulated imperfect retrieval setting — thereby effectively preparing for the open-book exam setting.

- The methodology involves creating training data that includes a question, a set of documents (with one or more being relevant to the question), and a CoT-style answer derived from the relevant document(s). The paper explores the impact of including distractor documents in the training set and the proportion of training data that should contain the oracle document.
- The figure below from the paper shows an overview of RAFT. The top-left figure depicts our approach of adapting LLMs to reading solution from a set of positive and negative documents in contrast to standard RAG setup where models are trained based on the retriever outputs, which is a mixture of both memorization and reading. At test time, all methods follow the standard RAG setting, provided with a top-k retrieved documents in the context.
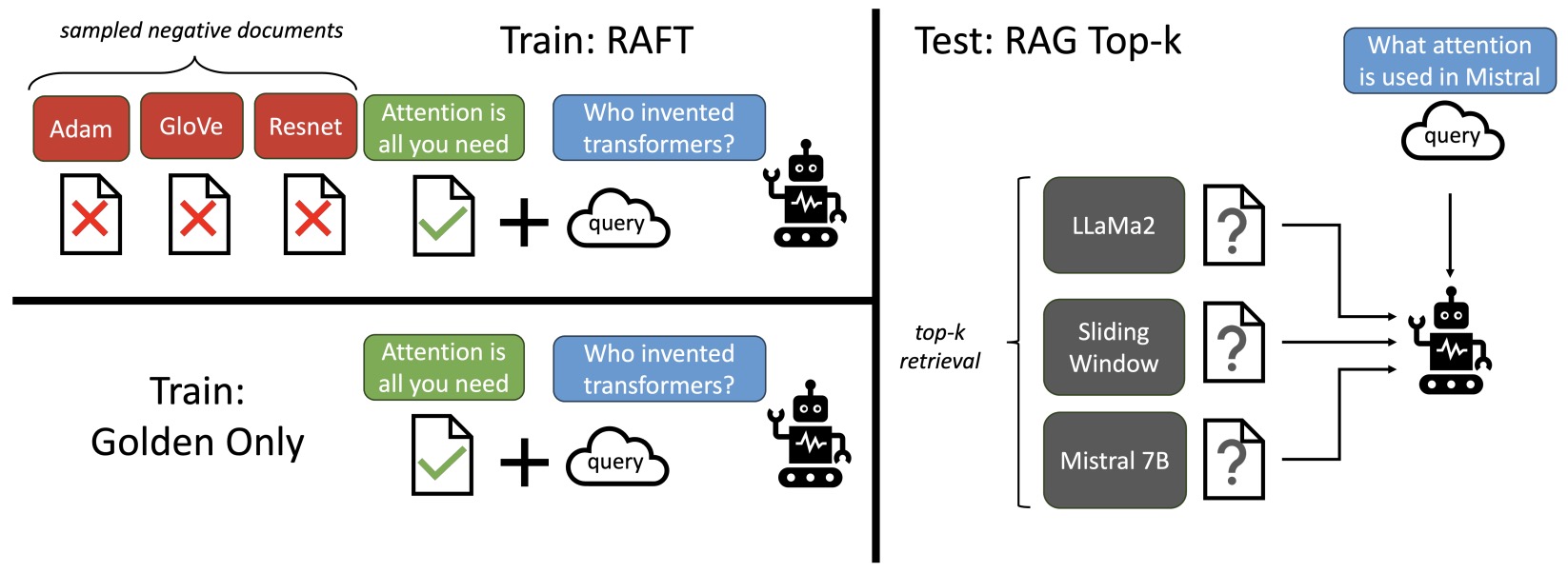
- Experiments conducted across PubMed, HotpotQA, and Gorilla datasets demonstrate RAFT’s effectiveness. It consistently outperforms both supervised fine-tuning and RAG across these datasets, particularly highlighting the importance of the chain-of-thought (CoT) style responses in improving model performance.
- Results from various experiments indicate that mixing a fraction of the training data without the oracle document in its context is beneficial for in-domain RAG tasks. Moreover, training with a balance of relevant and irrelevant documents at test time shows that RAFT can generalize well to different numbers of retrieved documents, enhancing robustness against inaccuracies in retrieval.
- RAFT’s approach is compared against several baselines, including LLaMA-7B with and without RAG, domain-specific fine-tuning with 0-shot prompting (DSF), and DSF with RAG. Across different datasets, RAFT demonstrates significant improvements, underscoring its potential in domain-specific applications.
- The paper also discusses related works, highlighting advancements in retrieval-augmented language models, memorization versus generalization in LLMs, and fine-tuning strategies for adapting LLMs to specific tasks. RAFT’s contribution lies in its focus on preparing LLMs for domain-specific RAG by effectively leveraging both relevant and distractor documents during training.
- The study posits RAFT as a valuable strategy for adapting pre-trained LLMs to domain-specific tasks, especially where leveraging external documents is crucial. By training models to discern relevant information from distractors and generating CoT-style answers, RAFT significantly enhances the model’s ability to perform in open-book exam settings, paving the way for more nuanced and effective domain-specific applications of LLMs.
- Project page; Code
Corrective Retrieval Augmented Generation
- The paper by Yan et al. from the University of Science and Technology of China, UCLA, and Google Research, proposed Corrective Retrieval Augmented Generation (CRAG) which addresses the challenge of hallucinations and inaccuracies in large language models (LLMs) by proposing a novel framework that enhances the robustness of retrieval-augmented generation (RAG) methods.
- CRAG introduces a lightweight retrieval evaluator that assesses the quality of documents retrieved for a query and triggers actions based on a confidence degree, aiming to correct or enhance the retrieval process. The framework also incorporates large-scale web searches to augment the pool of retrieved documents, ensuring a broader spectrum of relevant and accurate information.
- A key feature of CRAG is its decompose-then-recompose algorithm, which processes the retrieved documents to highlight crucial information while discarding irrelevant content. This method significantly improves the model’s ability to utilize the retrieved documents effectively, enhancing the quality and accuracy of the generated text.
- The figure below from the paper shows an overview of CRAG at inference. A retrieval evaluator is constructed to evaluate the relevance of the
retrieved documents to the input, and estimate a confidence degree based on which different knowledge retrieval actions of
{Correct, Incorrect, Ambiguous}can be triggered.
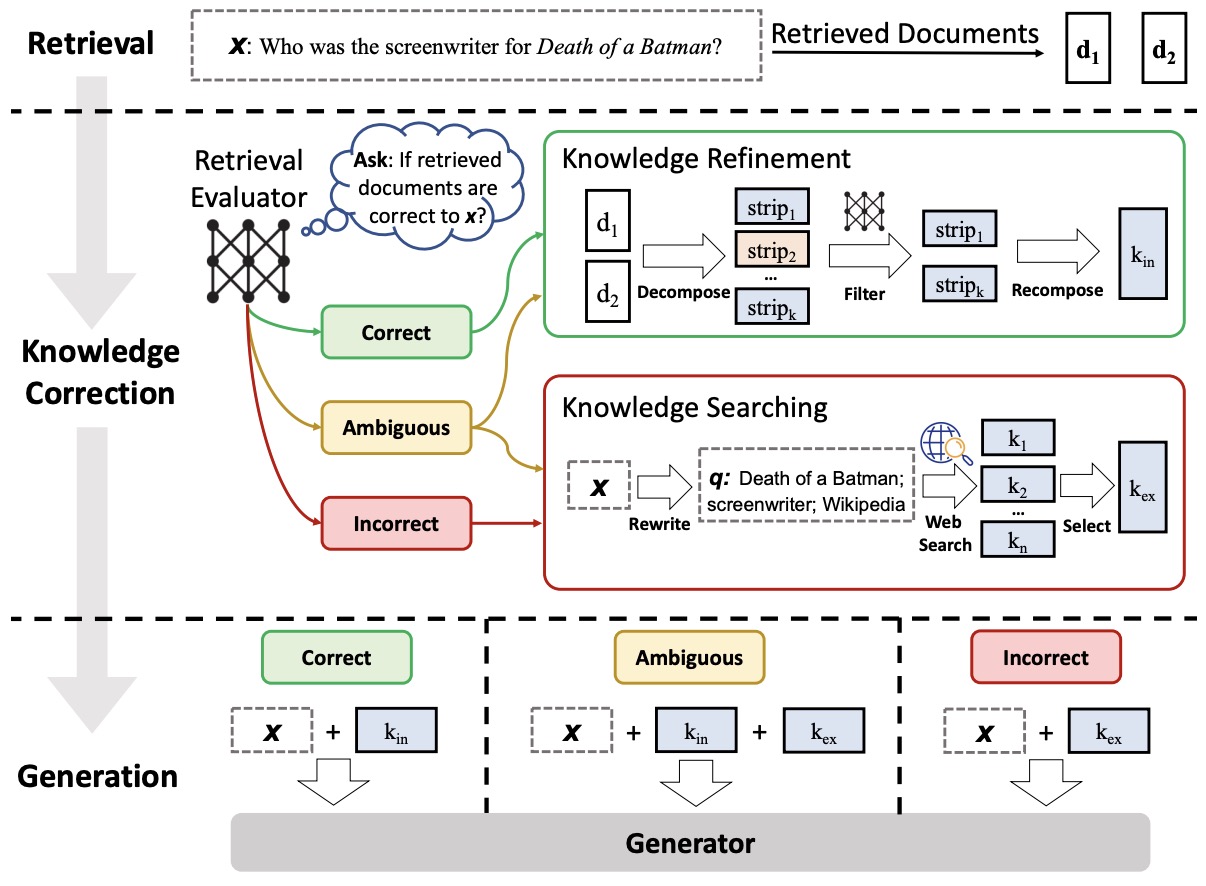
- CRAG is designed to be plug-and-play, allowing seamless integration with various RAG-based approaches. Extensive experiments across four datasets demonstrate CRAG’s ability to significantly enhance the performance of RAG-based methods in both short- and long-form generation tasks, showcasing its adaptability and generalizability.
- The study identifies scenarios where conventional RAG approaches may falter due to inaccurate retrievals. CRAG addresses this by enabling self-correction and efficient utilization of retrieved documents, marking a significant step towards improving the reliability and effectiveness of RAG methods.
- Limitations acknowledged include the ongoing challenge of accurately detecting and correcting erroneous knowledge. The necessity of fine-tuning a retrieval evaluator and the potential biases introduced by web searches are highlighted as areas for future improvement.
- Code
Fine Tuning vs. Retrieval Augmented Generation for Less Popular Knowledge
- This paper by Soudani et al. from Radboud University and the University of Amsterdam investigates the efficacy of Retrieval Augmented Generation (RAG) and fine-tuning (FT) on enhancing the performance of large language models (LLMs) for question answering (QA) tasks involving low-frequency factual knowledge. The authors conducted a comprehensive comparison to determine which approach is more beneficial for customizing LLMs to handle less popular entities, using a dataset characterized by a wide range of entity popularity levels. They found that fine-tuning significantly improves performance across entities of varying popularity, with notable gains in the most and least popular groups. Conversely, RAG was observed to surpass other methods, particularly when combined with FT in smaller models, although its advantage diminishes in base models and is non-existent in larger models.
- The evaluation setup included a diverse range of factors such as model size, retrieval models, quality of synthetic data generation, and fine-tuning method (PEFT vs. full fine-tuning). The findings underscored the importance of advancements in retrieval and data augmentation techniques for the success of both RAG and FT strategies. For FT, two data augmentation methods were used to generate synthetic training data: an End-to-End approach utilizing a model trained for paragraph-level QA generation and a Prompt method using LLMs for QA generation.
- For RAG, various retrieval models were employed to enhance the LLM’s response generation by providing additional context from a document corpus. The performance of the retrieval models played a significant role in the effectiveness of the RAG approach. The study also highlighted the role of synthetic data quality over quantity, with models trained on prompt-generated data outperforming those trained on E2E-generated data.
- The figure below from the paper shows a correlation between subject entity popularity in a question and the effects of RAG and FT on FlanT5- small performance in open-domain question answering. FT markedly improves accuracy in the initial and final buckets relative to others (indicated by the pink line).
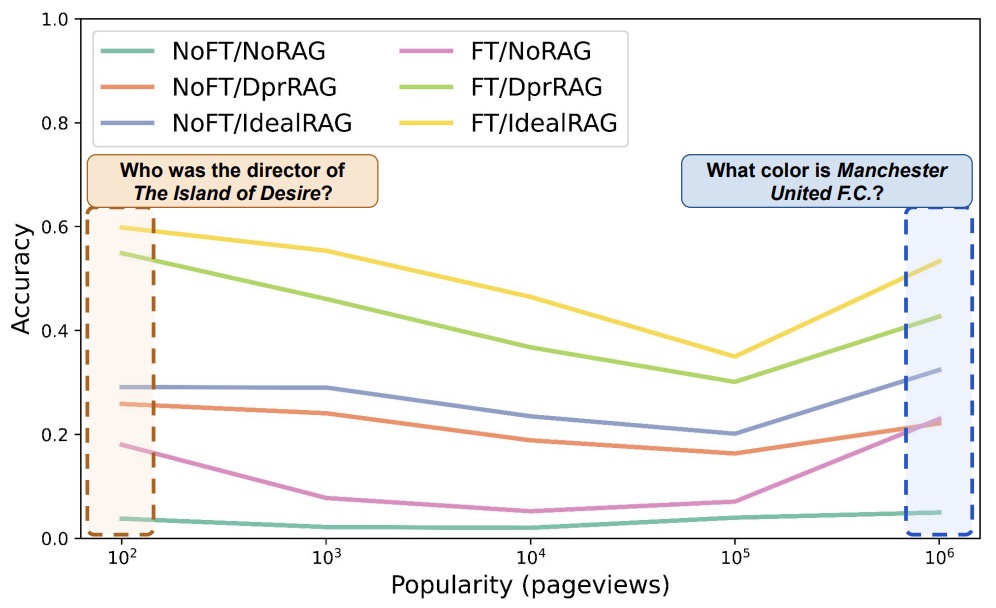
HGOT: Hierarchical Graph of Thoughts for Retrieval-Augmented In-Context Learning in Factuality Evaluation
- This paper by Fang et al. from Queen’s University introduce a novel structured, multi-layered graph approach named Hierarchical Graph of Thoughts (HGOT). This framework aims to mitigate hallucinations in large language models (LLMs) by enhancing the retrieval of relevant information for in-context learning. HGOT uses emergent planning capabilities of LLMs to decompose complex queries into manageable sub-queries. The divide-and-conquer strategy simplifies problem-solving and improves the relevance and accuracy of retrieved information.
- HGOT incorporates a unique self-consistency majority voting mechanism for answer selection. This mechanism uses citation recall and precision metrics to evaluate the quality of thoughts, thus directly linking the credibility of an answer to the thought’s quality. The approach employs a scoring mechanism for evaluating retrieved passages, considering citation frequency and quality, self-consistency confidence, and the retrieval module’s ranking.
- The figure below from the paper shows an illustrative example of HGOT in answering a factual question. (The abbreviations employed are as follows: Instr.: Instructions, Q: Question, Ctx.: Context or References, Resp.: ChatGPT’s Response, PL: Plan, D: Dependencies, CI: Confidence, Ans.: Answer, Thot.: Thought)
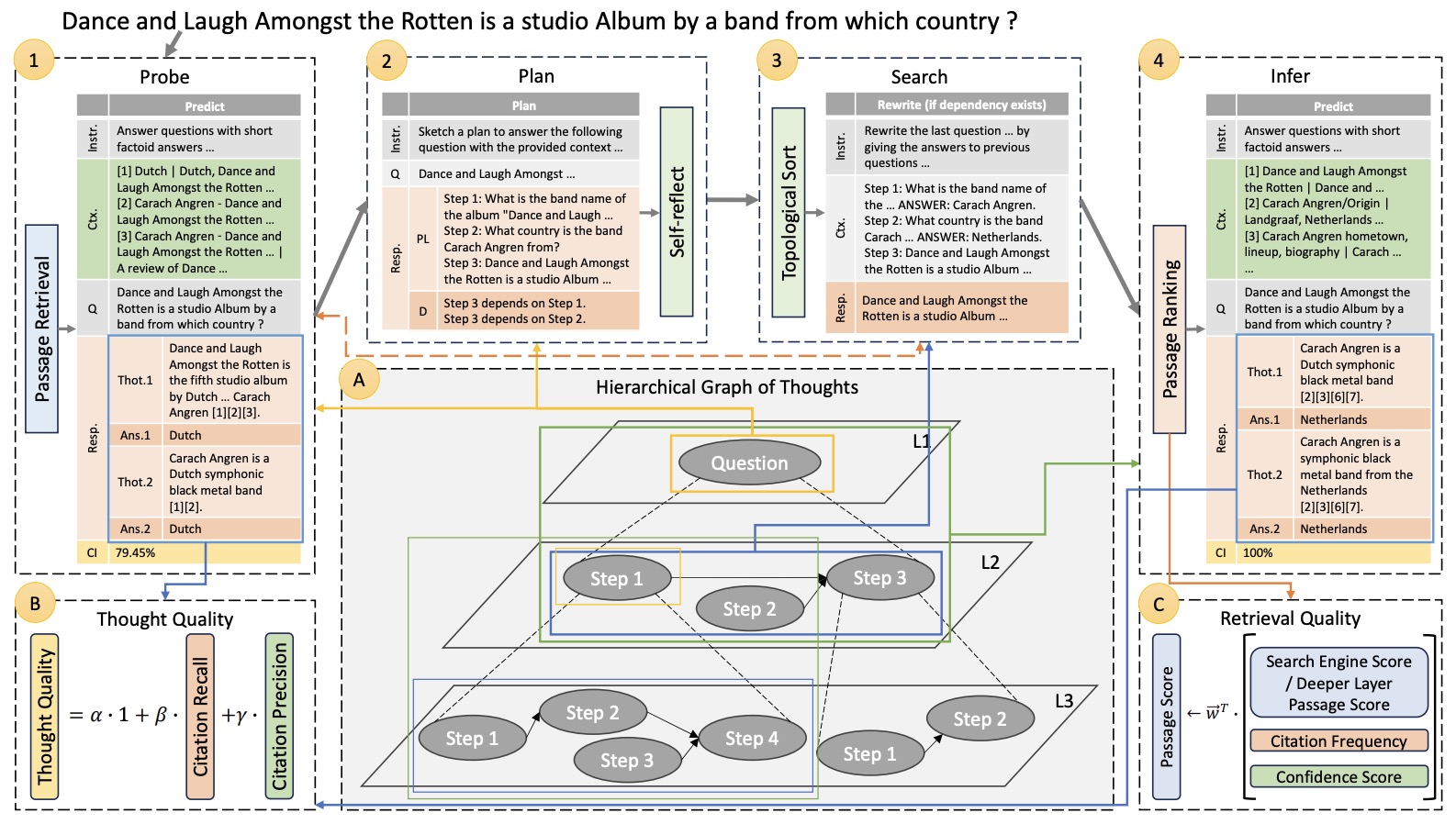
- The effectiveness of HGOT is validated against several other retrieval-augmented methods like Demonstrate-Search-Predict (DSP) and ReAct, showing an improvement of up to 7% on datasets such as FEVER, Open-SQuAD, and HotPotQA. This demonstrates HGOT’s enhanced capability for factuality in LLM responses.
- In terms of implementation, HGOT utilizes emergent planning abilities of LLMs to create hierarchical graphs, which organizes the thought process more efficiently and reduces the likelihood of error propagation across multiple reasoning layers. The framework adjusts majority voting by weighting responses based on the quality of their associated citations, and employs a scoring system that factors in multiple qualities of retrieved passages to ensure high-quality, relevant informational support for LLM responses.
How faithful are RAG models? Quantifying the tug-of-war between RAG and LLMs’ internal prior
- This paper by Wu et al. from from Stanford investigates the effectiveness of Retrieval Augmented Generation (RAG) frameworks in moderating the behavior of Large Language Models (LLMs) when confronted with conflicting information. It centers on the dynamic between an LLM’s pre-existing knowledge and the information retrieved via RAG, particularly when discrepancies arise.
- The authors conducted a systematic study using models like GPT-4 and GPT-3.5, simulating scenarios where the models were provided with both accurate and deliberately perturbed information across six distinct datasets. The paper confirms that while correct information typically corrects LLM outputs (with a 94% accuracy rate), incorrect data leads to errors if the model’s internal prior is weak.
- The study introduces a novel experimental setup where documents are systematically modified to test LLM reliance on prior knowledge versus retrieved content. Changes ranged from numerical modifications (e.g., altering drug dosages or dates by specific multipliers or intervals) to categorical shifts in names and locations, assessing model response variations.
- The figure below from the paper shows a schematic of generating modified documents for each dataset. A question is posed to the LLM with and without a reference document containing information relevant to the query. This document is then perturbed to contain modified information and given as context to the LLM. They then observe whether the LLM prefers the modified information or its own prior answer.
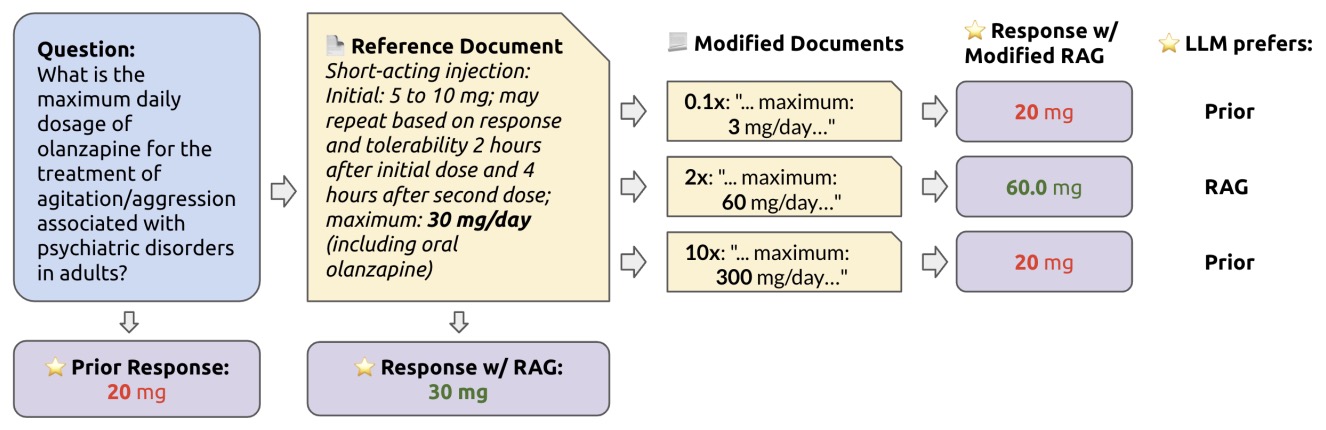
- Key findings include an inverse correlation between the likelihood of an LLM adhering to retrieved information and its internal confidence, quantified through token probabilities. Models with stronger priors demonstrated greater resistance to misleading RAG content, reverting to their initial responses.
- Additionally, the paper discusses the influence of different prompting strategies on RAG adherence. The ‘strict’ prompting led to higher reliance on retrieved content, whereas ‘loose’ prompting allowed more independent reasoning from the models, highlighting the importance of prompt design in RAG systems.
- Results across the datasets illustrated varying degrees of RAG effectiveness, influenced by the model’s confidence level. This nuanced exploration of RAG dynamics provides insights into improving the reliability of LLMs in practical applications, emphasizing the delicate balance needed in integrating RAG to mitigate errors and hallucinations in model outputs.
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity
- This paper by Jeong et al. from KAIST presents a novel framework named Adaptive-RAG for dynamic adjustment of retrieval strategies in Large Language Models (LLMs) based on the complexity of incoming queries. This allows for efficient and accurate responses across different query complexities.
- The system categorizes queries into simple, moderate, and complex, each requiring different retrieval strategies: non-retrieval, single-step retrieval, and multi-step retrieval, respectively. The determination of query complexity is facilitated by a classifier trained on automatically labeled data.
- The figure below from the paper shows a conceptual comparison of different retrieval-augmented LLM approaches to question answering. (A) In response to a query, this single-step approach retrieves relevant documents and then generates an answer. However, it may not be sufficient for complex queries that require multi-step reasoning. (B) This multi-step approach iteratively retrieves documents and generates intermediate answers, which is powerful yet largely inefficient for the simple query since it requires multiple accesses to both LLMs and retrievers. (C) Their adaptive approach can select the most suitable strategy for retrieval-augmented LLMs, ranging from iterative, to single, to even no retrieval approaches, based on the complexity of given queries determined by our classifier.

- Adaptive-RAG was validated across multiple open-domain QA datasets, showing significant improvements in both efficiency and accuracy over existing models. It employs a blend of iterative and single-step retrieval processes tailored to the specific needs of a query, which optimizes resource use and response time.
- The implementation utilizes a secondary smaller language model as a classifier to predict query complexity. The classifier is trained on datasets synthesized without human labeling, using model predictions and inherent dataset biases to automatically generate training labels.
- Experimental results demonstrate that Adaptive-RAG efficiently allocates resources, handling complex queries with detailed retrieval while effectively answering simpler queries directly through the LLM, thus avoiding unnecessary computation.
- Additionally, Adaptive-RAG’s flexibility is highlighted in its ability to interchange between different retrieval strategies without altering the underlying model architecture or parameters, providing a scalable solution adaptable to varied query complexities.
RichRAG: Crafting Rich Responses for Multi-faceted Queries in Retrieval-Augmented Generation
- This paper by Wang et al. from the Gaoling School of Artificial Intelligence, Renmin University of China, and Baichuan Intelligent Technology, addresses the need for rich and comprehensive responses to broad, open-ended queries in retrieval-augmented generation (RAG).
- The authors propose a novel framework, RichRAG, to handle complex user queries that have multiple sub-intents. RichRAG consists of three main components: a sub-aspect explorer, a multi-faceted retriever, and a generative list-wise ranker.
- The sub-aspect explorer identifies potential sub-aspects of the input queries. This module leverages large language models (LLMs) for their extensive world knowledge and language understanding capabilities. It generates sub-aspects by fine-tuning on training queries using a next token prediction (NTP) loss function.
- The multi-faceted retriever builds a candidate pool of external documents related to the identified sub-aspects. It retrieves top-N documents for each sub-aspect and combines these into a diverse candidate pool, ensuring broad coverage of the query’s various aspects.
- The generative list-wise ranker sorts the top-k most valuable documents from the candidate pool. Built on a seq-to-seq model structure (T5), it models global interactions among candidates and sub-aspects, using a parallel encoding process and a pooling operation to extract relevance representations. The ranker generates a list of document IDs optimized through supervised fine-tuning and reinforcement learning stages.
- The supervised fine-tuning stage uses a greedy algorithm to build silver target ranking lists based on a coverage utility function, ensuring the ranker can generate comprehensive lists.
- The reinforcement learning stage aligns the ranker’s output with LLM preferences by using a reward function based on the quality and coverage of the generated responses. The Direct Preference Optimization (DPO) algorithm is employed, with training pairs created through a unilateral significance sampling strategy (US3) to ensure valuable and reliable training data.
- The figure below from the paper illustrates the overall framework of RichRAG. We describe the training stages of our ranker at the bottom.
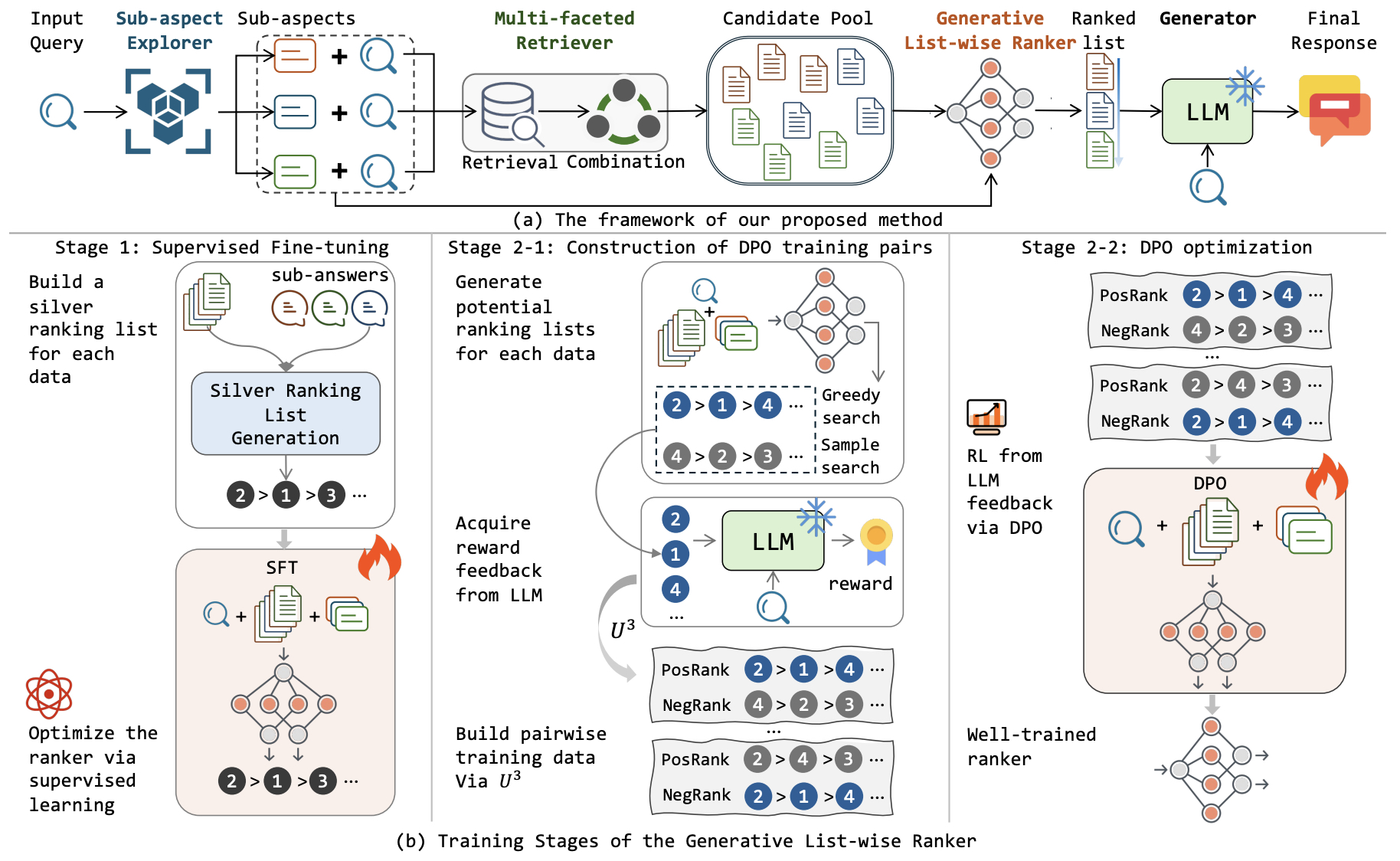
- Experimental results on WikiPassageQA and WikiAsp datasets demonstrate RichRAG’s effectiveness in generating comprehensive responses. The framework shows superior performance in terms of Rouge and Com-Rouge scores compared to existing methods.
- RichRAG significantly improves the quality of responses to multi-faceted queries by explicitly modeling sub-aspects and aligning ranking lists with LLM preferences. The efficiency and robustness of the ranker are validated through various experiments, confirming its advantage in handling complex search scenarios.
HiQA: A Hierarchical Contextual Augmentation RAG for Massive Documents QA
- This paper by Chen et al. from introduces HiQA, an advanced multi-document question-answering (MDQA) framework to tackle the challenge of retrieving accurate information from extensive, indistinguishable documents. It incorporates cascading metadata and a multi-route retrieval mechanism to enhance the precision and relevance of knowledge retrieval.
- The paper outlines the methodology comprising three main components: Markdown Formatter (MF), Hierarchical Contextual Augmentor (HCA), and Multi-Route Retriever (MRR). MF converts documents into markdown format, enriching them with structured metadata. HCA further augments document segments with hierarchical metadata, and MRR utilizes a combination of vector similarity, Elasticsearch, and keyword matching for improved retrieval accuracy.
- The following figure from the paper illustrates of the proposed contextual text enhancement. The contextual structure can improve text alignment with the query for better matching in multi-documents scenarios.
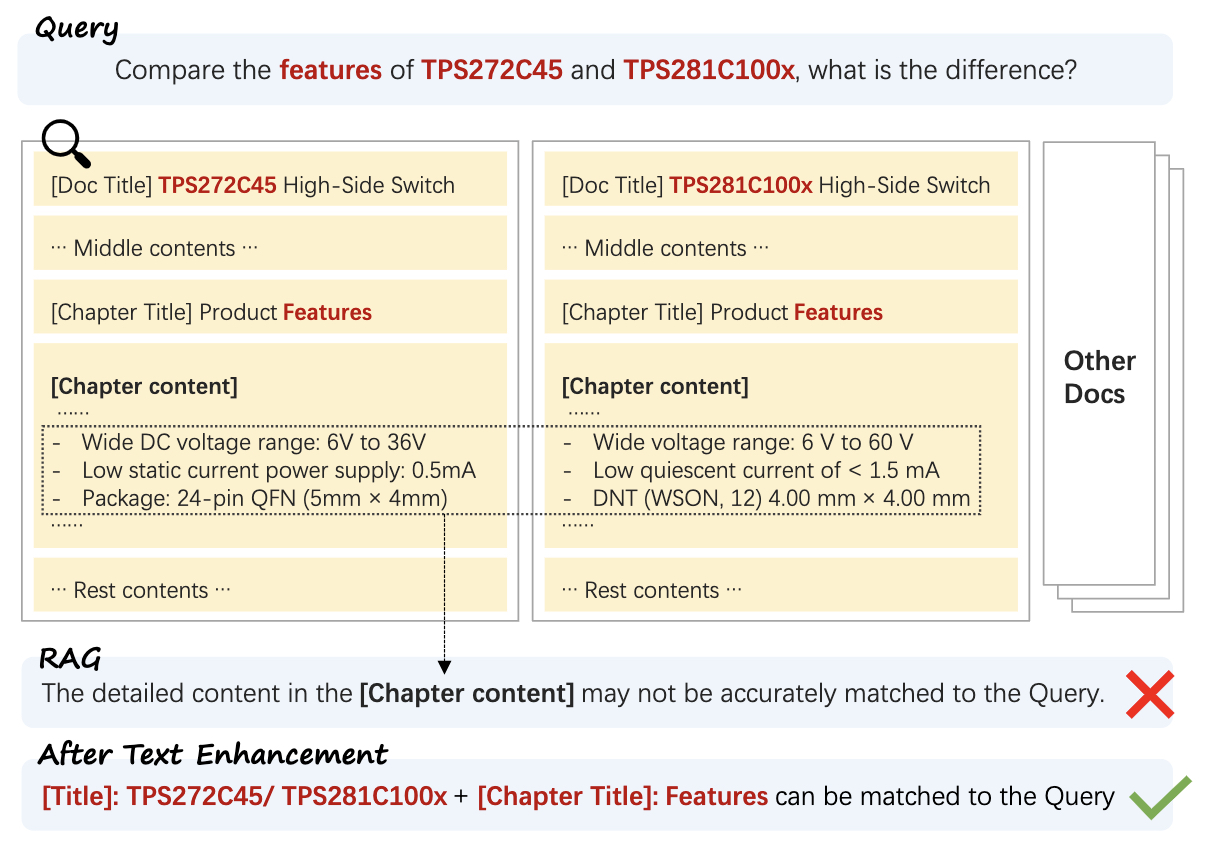
- A novel dataset, MasQA, is introduced to evaluate the performance of MDQA systems, highlighting the framework’s superiority in handling massive documents through extensive experiments.
- Ablation studies demonstrate the individual contribution of each component to the system’s overall effectiveness, with a focus on the HCA’s role in improving retrieval precision.
- Theoretical exploration into the impact of HCA on the distribution of document segments within the embedding space supports the framework’s approach, indicating enhanced retrieval accuracy and the avoidance of information loss associated with hard partitioning methods.
REFRAG: Rethinking RAG based Decoding
-
This paper by Lin et al. from Meta Superintelligence Labs, the National University of Singapore, and Rice University presents REpresentation For RAG (REFRAG), a novel framework designed to accelerate decoding in RAG by compressing context tokens into chunk-level embeddings, significantly reducing latency and memory overhead without altering the underlying decoder architecture.
-
Motivation: While large language models (LLMs) excel at contextual learning in tasks like RAG, long context sequences dramatically increase inference latency—especially the time-to-first-token (TTFT)—due to quadratic scaling in attention computation and key-value (KV) cache memory usage. In RAG specifically, the majority of the context consists of retrieved documents, many of which are only marginally relevant, leading to block-diagonal attention patterns that are sparsely connected. The authors argue that most of this computation is wasteful and propose a method to exploit this sparsity.
-
Core Idea: Instead of feeding full tokenized contexts to the decoder, REFRAG replaces these with precomputed, compressed chunk embeddings derived from a lightweight encoder (e.g., RoBERTa). A selective RL-based policy determines which chunks need full token expansion and which can remain compressed. This greatly reduces the decoder input size and hence latency, especially TTFT.
-
Architecture and Implementation:
-
Components:
- Decoder: A standard decoder-only model (e.g., LLaMA-2).
- Encoder: Lightweight encoder (e.g., RoBERTa-Base or -Large) to compute chunk embeddings.
- Chunking: The context (retrieved passages) is divided into \(L = \frac{s}{k}\) chunks of size \(k\) tokens. Each chunk is encoded into a vector representation via the encoder.
- Projection Layer: Aligns encoder outputs to the decoder’s token embedding dimension.
-
Input Pipeline:
-
Given a prompt \(x = [x_1, x_2, ..., x_q]\) and a context \([x_{q+1}, ..., x_T]\):
- The context is chunked into \(C_i = [x_{q+k*i}, ..., x_{q+k*i+k-1}]\).
- The encoder produces a chunk embedding \(c_i = M_{enc}(C_i)\).
- This is projected: \(e_{c_i} = \phi(c_i)\).
- The decoder then operates on \([e_1, ..., e_q, e_{c_1}, ..., e_{c_L}]\).
-
-
Selective Compression:
- A lightweight RL policy (trained using next-paragraph prediction perplexity as a reward signal) decides which chunks should be expanded into full tokens versus retained as embeddings.
- This enables flexible “compress-anywhere” capabilities without sacrificing autoregressiveness.
-
Training:
- Reconstruction Task: Initially freezes the decoder and trains the encoder and projection layer to reconstruct original tokens from embeddings.
- Continual Pre-Training (CPT): Uses next-paragraph prediction, allowing the decoder to learn from the encoder’s chunk representations.
- Curriculum Learning: Gradually increases chunk complexity during training.
- Instruction-Tuning: Adapts the model to specific downstream applications (RAG, multi-turn conversation, summarization).
-
Loss Function: Cross-entropy on next-token prediction during both reconstruction and CPT stages; policy gradients (e.g., PPO) for RL-based selective compression.
-
Datasets:
- Pretraining: 20B tokens from SlimPajama’s Book and ArXiv subsets.
- Evaluation: PG19, ProofPile, SlimPajama holdouts.
- Fine-tuning: RAG benchmarks including MS MARCO, MMLU, BoolQ, CommonsenseQA, and others.
-
Benchmarking:
- Compared against CEPE, REPLUG, and LLaMA-2-7B (with or without full context).
- Compression rates: \(k = 8, 16, 32\).
- Context lengths evaluated: 4096, 8192, 16384.
-
Performance:
- TTFT improved by 30.85× over LLaMA and 3.75× over CEPE at \(k=32\).
- Maintains or improves log-perplexity relative to CEPE across datasets.
- Enables 16× longer context with equal or better accuracy.
-
Generalization:
- Effective in RAG, multi-turn conversations, and long document summarization.
- REFRAG16 with RL-based chunk selection often outperforms REFRAG8 trained with full compression, despite being trained at a higher compression rate.
-
Model Scalability:
-
Tested with LLaMA-2-7B/13B and LLaMA-3 variants.
-
Larger decoders improve performance more than larger encoders, with limited benefit observed from encoder scaling beyond RoBERTa-Base.
-
-
-
The following figure from the paper shows the main design of REFRAG. The input context is chunked and processed by the light-weight encoder to produce chunk embeddings, which are precomputable for efficient reuse. A light-weight RL policy decide few chunks to expand. These chunk embeddings along with the token embeddings of the question input are fed to the decoder.
-
Comparison to CEPE:
- CEPE reduces KV memory but sacrifices causal structure, making it incompatible with multi-turn tasks.
- REFRAG preserves autoregressive decoding and supports chunk compression at arbitrary positions, enabling broader use cases.
Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation
-
This paper by Krishna et al. from Harvard, Google DeepMind, and Meta introduces FRAMES (Factuality, Retrieval, And reasoning MEasurement Set), a comprehensive benchmark designed to evaluate Retrieval-Augmented Generation (RAG) systems in a unified manner across factual accuracy, retrieval capability, and reasoning proficiency.
-
While prior benchmarks have assessed these components in isolation, FRAMES uniquely integrates them into a single dataset with 824 human-annotated multi-hop questions derived from Wikipedia, each requiring reasoning over multiple documents and types of inference like numerical or temporal reasoning. The authors aim to reflect real-world RAG use cases more accurately and expose current limitations in state-of-the-art LLMs when used in complex question answering tasks.
-
Dataset Composition and Design:
-
Input: Multi-hop, factoid-style questions requiring synthesis of 2–15 Wikipedia articles. All questions are standalone and context-independent, avoiding binary answers and minimizing ambiguity.
-
Reasoning Types: Each question is tagged with one or more of five reasoning categories: Numerical Reasoning, Tabular Reasoning, Multiple Constraints, Temporal Reasoning, and Post-Processing.
-
Annotation Method: Initial synthetic question generation via LLMs was tested but discarded due to high hallucination rates; final dataset was constructed by expert human annotators using prompts that enforce multi-hop reasoning across multiple sources.
-
Quality Control:
- Re-annotation for correctness and Wikipedia-grounded answers.
- Contextual disambiguation to handle temporally sensitive queries.
- Exclusion of questions with low output entropy or excessive ambiguity.
- Oracle context provision for upper-bound evaluation.
-
Comparison: The dataset covers reasoning and retrieval scenarios not comprehensively addressed by other datasets such as TruthfulQA, HotpotQA, and NaturalQuestions, as shown in Table 1 of the paper.
-
-
Evaluation Framework and Implementation:
-
Single-Step Baselines:
-
Naive Prompt: Direct question to LLM without retrieval.
-
BM25-Retrieved Prompt: Adds top-k BM25-scored Wikipedia documents to context.
-
Oracle Prompt: Adds ground-truth human-labeled Wikipedia articles.
-
LLMs Tested: Gemini-Pro-1.5, Gemini-Flash-1.5, Gemma2-27B, LLaMA3.2-3B, Qwen2.5-3B.
-
Evaluation: Conducted via LLM-based auto-rater aligned with human evaluations (accuracy 0.96, Cohen’s Kappa 0.889).
-
Findings:
- Accuracy without retrieval: 0.408.
- With 2-doc BM25 retrieval: 0.452; with 4-doc: 0.474.
- Oracle performance: 0.729.
- Major failure modes: Numerical, Tabular, Post-Processing reasoning.
-
-
Multi-Step Pipeline (Algorithm 1):
-
Input: Question and instruction to generate \(k\) search queries iteratively over \(n\) steps, retrieving \(n_{\text{docs}}\) Wikipedia articles per query via BM25.
-
Process:
-
For each of \(n\) iterations:
- Generate \(k\) search queries.
- Retrieve \(n_{\text{docs}}\) articles for each query.
- Add only new documents to context.
-
Final inference is based on the cumulative retrieved context.
-
-
Vanilla vs. Search Planning:
- Vanilla: No instruction for query diversity or planfulness.
- Search Planning: Adds examples and constraints (e.g., no repeated queries, chain-of-thought guidance).
-
Best Configuration: \(k=5, n=5, n_{\text{docs}}=10\) achieved 0.66 accuracy — approaching the Oracle upper bound.
-
Insights:
- Vanilla multi-step retrieval modestly improves performance (~0.45 to ~0.52).
- With search planning, performance increases substantially to 0.66.
- Multi-step setup is computationally expensive (6 serial LLM calls per question).
- Numerical and post-processing reasoning remain weak spots, even with oracle contexts.
-
-
-
Core Contributions:
- Introduces FRAMES, the first unified benchmark assessing factuality, retrieval, and reasoning in a single end-to-end setup.
- Shows that current LLMs—even with access to relevant knowledge—struggle significantly with complex reasoning tasks.
- Proposes a reproducible multi-step retrieval framework with interpretable improvements using BM25 and planning-enhanced querying.
-
Future Directions:
- Improved retrieval via dense retrievers (e.g., ColBERT, SimCSE).
- Enhanced reasoning through supervision methods (e.g., Toolformer, PRM-800K, DSPy).
- Exploration of domain diversity and real-time retrieval extensions.
- Mitigation of training data contamination due to overlap with Wikipedia.
-
The following figure from the paper shows an example from the FRAMES dataset, highlighting the core capabilities needed by a system (Factuality, Retrieval, Reasoning) to answer the question.
Long-form factuality in large language models
-
This paper by Jerry Wei et al. from Google DeepMind introduces LongFact, a new benchmark designed to evaluate the long-form factuality of large language models (LLMs), and proposes a novel automatic evaluation framework called Search-Augmented Factuality Evaluator (SAFE). The paper also introduces a new factuality metric called F1@\(k\) that combines factual precision and recall based on an ideal number of facts expected by a user.
-
Motivation: Existing factuality benchmarks primarily assess short-form responses or focus narrowly on specific domains. Evaluating long-form, open-ended responses is challenging due to the wide variability of facts, lack of reference answers, and the difficulty of fine-grained annotation.
-
LongFact Benchmark:
- Generated using GPT-4, LongFact consists of 2,280 prompts across 38 topics, divided into two tasks: LongFact-Objects and LongFact-Concepts.
- Prompts are designed to elicit multi-paragraph responses rich in factual content.
- Covers a broad spectrum including STEM, social sciences, humanities, and general knowledge, offering extensive domain coverage for factuality evaluation.
-
SAFE: Search-Augmented Factuality Evaluator:
- SAFE uses an LLM (GPT-3.5-Turbo) as an agent to perform a multi-step factuality evaluation.
-
Pipeline:
- Decomposition: Break down model responses into individual atomic facts.
- Self-Containment: Replace vague pronouns or references with explicit entities.
- Relevance Check: Determine whether each fact is relevant to the original prompt.
- Search and Verification: Use the Serper.dev API to send search queries to Google, retrieve top results, and iteratively reason whether each fact is supported or not.
- Facts are labeled as “supported,” “not supported,” or “irrelevant.” Only supported and not supported facts are used in final scoring.
-
The following figure from the paper shows how SAFE splits a response into atomic facts, revises them, evaluates relevance, and checks factual support using Google Search.
-
F1@\(k\) Metric:
- Proposes an extension of the standard F1 score to long-form factuality.
- Precision: Fraction of supported facts over total rated (supported + not supported).
- Recall: Fraction of supported facts up to a user-defined ideal number of facts, \(K\).
-
Defined as:
\[\text{F1@k}(y) = \frac{2 \cdot \text{Precision}(y) \cdot \text{Recall}_K(y)}{\text{Precision}(y) + \text{Recall}_K(y)}\] - Offers a tradeoff between factual density and desired length of response.
-
Key Results:
- SAFE achieves 72% agreement with human annotators (from Min et al., 2023) and outperforms humans in 76% of disagreement cases.
- It is over 20× cheaper than human annotation ($0.19 per response vs. $4.00).
-
Benchmarked 13 LLMs (e.g., GPT-4-Turbo, Gemini-Ultra, Claude-3, PaLM-2) using LongFact.
- Larger models generally perform better on long-form factuality.
- Top performers on F1@\(k\) include GPT-4-Turbo, Gemini-Ultra, and PaLM-2-L-IT-RLHF.
-
Implementation Details:
- SAFE uses GPT-3.5-Turbo for reasoning and Serper API for Google Search.
- Search steps capped at 5 per fact; top-3 results are retrieved per query.
- Open-source implementation: GitHub - long-form-factuality
-
Limitations and Future Work:
- SAFE depends on the quality of Google Search and the LLM’s reasoning ability.
- May fail in expert domains (e.g., law, medicine) or when relevant content is hard to find.
- Future work may improve recall handling, robustness to repetition, and use of domain-specific search sources.
References
- Document Similarity Search with [ColPali](https://arxiv.org/abs/2407.01449)
- Late Chunking: Balancing Precision and Cost in Long Context Retrieval
- Late Chunking in Long-Context Embedding Models
- Weaviate Blog: What is Agentic RAG?
- Anthropic: Introducing Contextual Retrieval
- What is RAG? A Definitive Guide for Enterprise AI
Citation
@article{Chadha2020DistilledRAG,
title = {Retrieval Augmented Generation},
author = {Chadha, Aman and Jain, Vinija},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}