Distilled • Instagram
- Overview
- Design Goals/Requirements
- Scale Estimation and Performance/Capacity Requirements
- System APIs
- Data Model
- High Level System Design
- Detailed Component Design
- Reliability and Redundancy
- Data Sharding
- Ranking and News Feed Generation
- News Feed Creation with Sharded Data
- Cache and Load balancing
- Further Reading
Overview
- Instagram is a social networking service that enables its users to upload and share their photos and videos with other users. Instagram users can choose to share information either publicly or privately. Anything shared publicly can be seen by any other user, whereas privately shared content can only be accessed by the specified set of people. Instagram also enables its users to share through many other social networking platforms, such as Facebook, Twitter, Flickr, and Tumblr.
- We plan to design a simpler version of Instagram for this design problem, where a user can share photos and follow other users. The ‘News Feed’ for each user will consist of top photos of all the people the user follows.
- Let’s design a photo-sharing service like Instagram, where users can upload photos to share them with other users.
- Similar Services: Flickr, Picasa.
Design Goals/Requirements
-
Functional requirements:
- Users should be able to upload/download/view photos.
- Users can perform searches based on photo/video titles.
- Users can follow other users.
- The system should generate and display a user’s News Feed consisting of top photos from all the people the user follows.
- Non-functional requirements:
- Minimum latency: Our system should be able to generate any user’s newsfeed in real-time so the user does not experience any significant lag during newsfeed generation - maximum latency seen by the end user would be 200ms.
- High availability: The final design should be highly available because if Facebook’s news feed is down then it will be all over the news and we do not want that to happen since we are designing a highly available system.
- Eventual consistency (due to CAP theorem): As we know from the CAP theorem, that we can have either high availability or high consistency, thus we will aim for an eventually consistent system. Consistency can take a hit (in the interest of availability) if a user doesn’t see a photo for a while; it should be fine.
- High reliability: The system should be highly reliable; any uploaded photo or video should never be lost.
- Read-heavy service: Our system will be read heavy in nature as more users will be loading their news feed rather than posting photos, thus the number of read requests will be far greater than write requests. Our system should thus be able to retrieve photos quickly.
- Also, users can upload as many photos as they like; therefore, efficient management of storage should be a crucial factor in designing this system.
- Not in scope:
- Adding tags to photos, searching photos on tags, commenting on photos, tagging users to photos, who to follow, etc.
Scale Estimation and Performance/Capacity Requirements
- Adding tags to photos, searching photos on tags, commenting on photos, tagging users to photos, who to follow, etc.
- Some back-of-the-envelope calculations based on average numbers. using average numbers.
Traffic estimates
- Daily Active Users (DAUs): 1B (with 2B total users).
- Newsfeed requests: Each user fetching their timeline an average of five times a day, leading to 5B newsfeed requests per day or approximately 58K requests per second.
- Photos uploaded everyday: 10M (= 10M/86400 = ~116 photos/sec).
- Likes on each photo: 5.
- Each user follows 500 other users.
Storage estimates
- Average photo file size: 500 kB.
- Total storage needed for photos: 10M * 500 kB = 5TB.
- Total space required for 10 years: 5TB * 365 (days a year) * 10 (years) ~= 18.25PB
System APIs
- Once we have finalized the requirements, it’s always a good idea to define the system APIs. This should explicitly state what is expected from the system. These would be running as microservices on our application servers.
- We can have SOAP or REST APIs to expose the functionality of our service. The following could be the definition of the API for getting the newsfeed:
getUserFeed(api_dev_key, user_id, since_id, count, max_id, exclude_replies)
- Parameters:
api_dev_key (string):The API developer key of a registered can be used to, among other things, throttle users based on their allocated quota.user_id (number):The ID of the user for whom the system will generate the newsfeed.since_id (number):Optional; returns results with an ID higher than (that is, more recent than) the specified ID.count (number):Optional; specifies the number of feed items to try and retrieve up to a maximum of 200 per distinct request.max_id (number):Optional; returns results with an ID less than (that is, older than) or equal to the specified ID.exclude_replies(boolean):Optional; this parameter will prevent replies from appearing in the returned timeline.
- Returns: (JSON) Returns a JSON object containing a list of feed items.
Data Model
Defining the DB schema in the early stages of the interview would help to understand the data flow among various components and later would guide towards data partitioning.
- We need to store data about users, their uploaded photos, and the people they follow. The Photo table will store all data related to a photo; we need to have an index on (PhotoID, CreationDate) since we need to fetch recent photos first.

-
A straightforward approach for storing the above schema would be to use an RDBMS like MySQL since we require joins. But relational databases come with their challenges, especially when we need to scale them. For details, please take a look at SQL vs. NoSQL.
-
We can store photos in a distributed file storage like HDFS or S3.
-
We can store the above schema in a distributed key-value store to enjoy the benefits offered by NoSQL. All the metadata related to photos can go to a table where the ‘key’ would be the ‘PhotoID’ and the ‘value’ would be an object containing PhotoLocation, UserLocation, CreationTimestamp, etc.
-
NoSQL stores, in general, always maintain a certain number of replicas to offer reliability. Also, in such data stores, deletes don’t get applied instantly; data is retained for certain days (to support undeleting) before getting removed from the system permanently.
Storage Estimates
- Let’s estimate how much data will be going into each table and how much total storage we will need for 10 years.
User
- Assuming each “int” and “dateTime” is four bytes, each row in the User’s table will be of 68 bytes:
- UserID (4 bytes) + Name (20 bytes) + Email (32 bytes) + DateOfBirth (4 bytes) + CreationDate (4 bytes) + LastLogin (4 bytes) = 68 bytes
- If we have 500 million users, we will need 32GB of total storage: 500 million * 68 ~= 32GB
Photo
- Each row in Photo’s table will be of 284 bytes:
- PhotoID (4 bytes) + UserID (4 bytes) + PhotoPath (256 bytes) + PhotoLatitude (4 bytes) + PhotoLongitude(4 bytes) + UserLatitude (4 bytes) + UserLongitude (4 bytes) + CreationDate (4 bytes) = 284 bytes
- If 2M new photos get uploaded every day, we will need 0.5GB of storage for one day:
- 2M * 284 bytes ~= 0.5GB per day
- For 10 years, we will need 1.88TB of storage.
UserFollow
- Each row in the UserFollow table will consist of 8 bytes. If we have 500 million users and on average each user follows 500 users. We would need 1.82TB of storage for the UserFollow table:
- 500 million users * 500 followers * 8 bytes ~= 1.82TB
Total space required
- For all tables for 10 years will be 32GB + 1.88TB + 1.82TB ~= 3.7TB.
Caveats
- Keep in mind the above calculations do not include scaling of users and followers for the span of 10 years.
High Level System Design
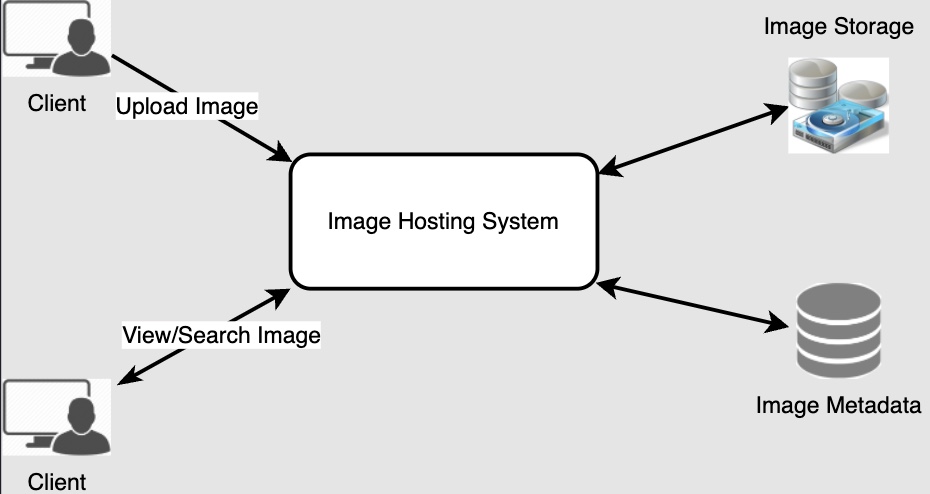
- At a high-level, we need to support two scenarios, one to upload photos and the other to view/search photos. Our service would need some object storage servers to store photos and some database servers to store metadata information about the photos.
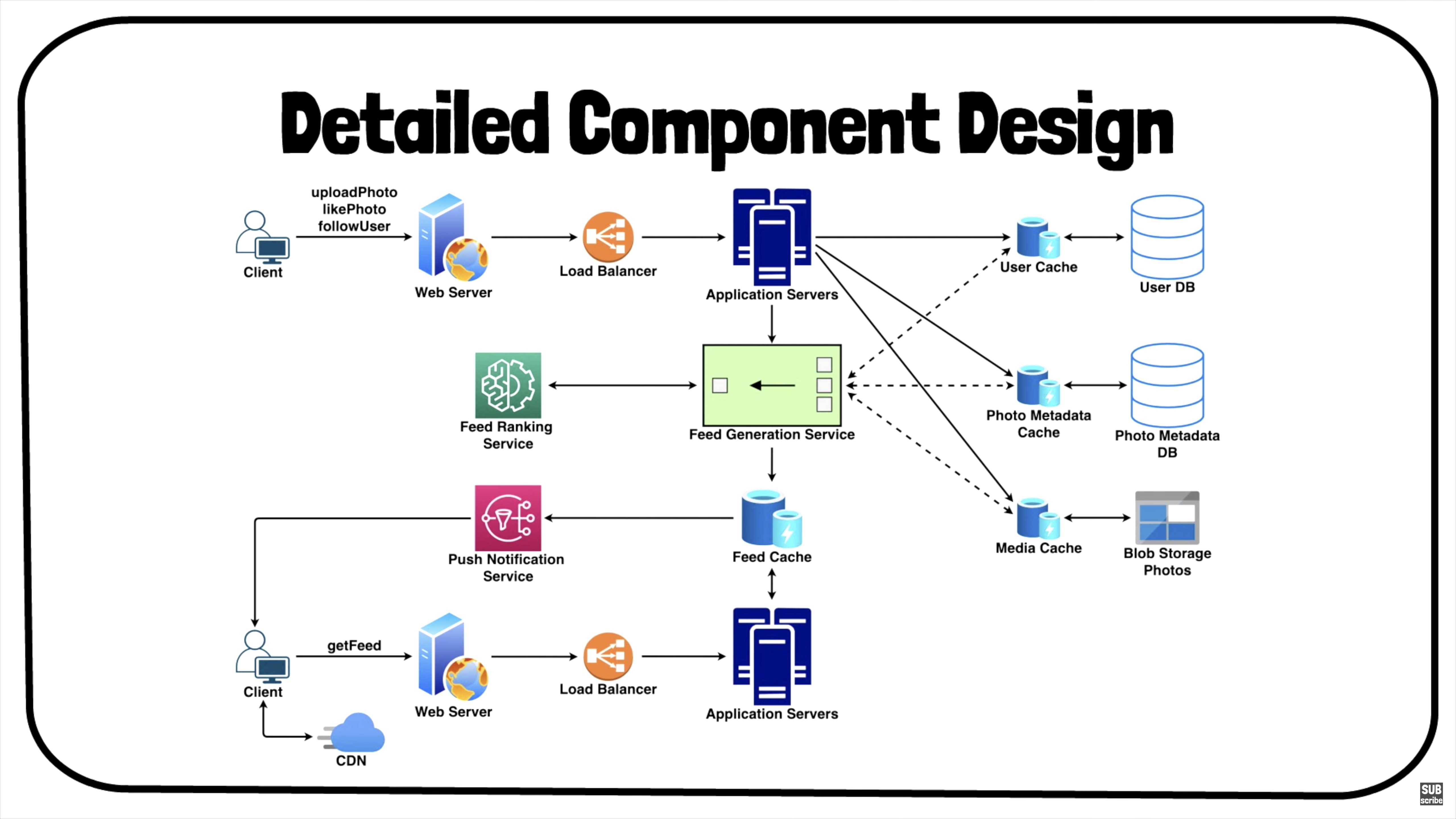
Detailed Component Design
-
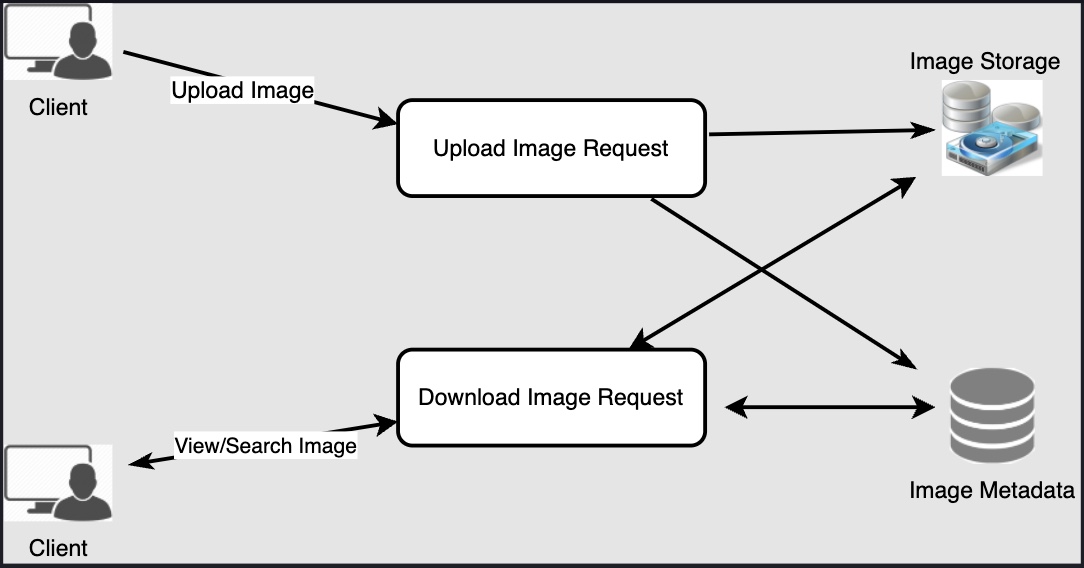
Photo uploads (or writes) can be slow as they have to go to the disk, whereas reads will be faster, especially if they are being served from cache.
-
Uploading users can consume all the available connections, as uploading is a slow process. This means that ‘reads’ cannot be served if the system gets busy with all the ‘write’ requests. We should keep in mind that web servers have a connection limit before designing our system. If we assume that a web server can have a maximum of 500 connections at any time, then it can’t have more than 500 concurrent uploads or reads.
-
To handle this bottleneck, we can split reads and writes into separate services. We will have dedicated servers for reads and different servers for writes to ensure that uploads don’t hog the system.
-
Separating photos’ read and write requests will also allow us to scale and optimize each of these operations independently.
Reliability and Redundancy
-
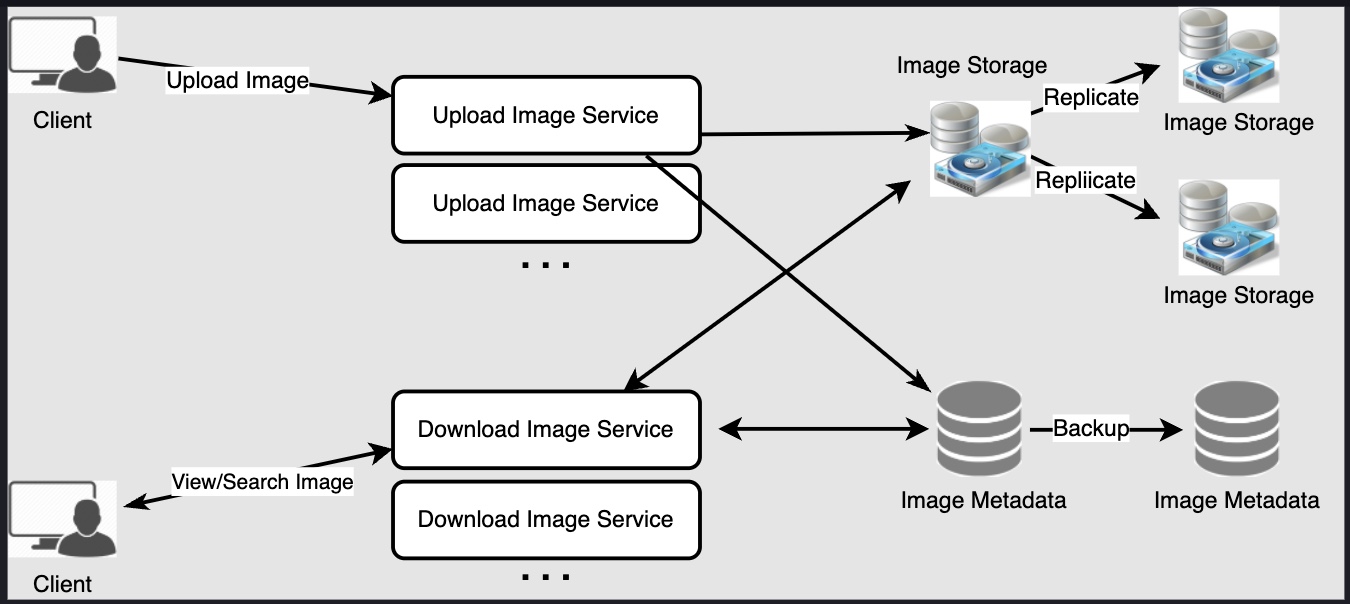
Losing files is not an option for our service. Therefore, we will store multiple copies of each file so that if one storage server dies, we can retrieve the photo from the other copy present on a different storage server.
-
This same principle also applies to other components of the system. If we want to have high availability of the system, we need to have multiple replicas of services running in the system so that even if a few services die down, the system remains available and running. Redundancy removes the single point of failure in the system.
-
If only one instance of a service is required to run at any point, we can run a redundant secondary copy of the service that is not serving any traffic, but it can take control after the failover when the primary has a problem.
-
Creating redundancy in a system can remove single points of failure and provide a backup or spare functionality if needed in a crisis. For example, if there are two instances of the same service running in production and one fails or degrades, the system can failover to the healthy copy. Failover can happen automatically or require manual intervention.
Data Sharding
- Let’s discuss different schemes for metadata sharding:
Partitioning based on UserID
-
Let’s assume we shard based on the ‘UserID’ so that we can keep all photos of a user on the same shard. If one DB shard is 1TB, we will need four shards to store 3.7TB of data. Let’s assume, for better performance and scalability, we keep 10 shards.
-
So we’ll find the shard number by UserID % 10 and then store the data there. To uniquely identify any photo in our system, we can append the shard number with each PhotoID.
-
How can we generate PhotoIDs? Each DB shard can have its own auto-increment sequence for PhotoIDs, and since we will append ShardID with each PhotoID, it will make it unique throughout our system.
-
What are the different issues with this partitioning scheme?
- How would we handle hot users? Several people follow such hot users, and a lot of other people see any photo they upload.
- Some users will have a lot of photos compared to others, thus making a non-uniform distribution of storage.
- What if we cannot store all pictures of a user on one shard? If we distribute photos of a user onto multiple shards, will it cause higher latencies?
- Storing all photos of a user on one shard can cause issues like unavailability of all of the user’s data if that shard is down or higher latency if it is serving high load etc.
Partitioning based on PhotoID
- If we can generate unique PhotoIDs first and then find a shard number through “PhotoID % 10”, the above problems will have been solved. We would not need to append ShardID with PhotoID in this case, as PhotoID will itself be unique throughout the system.
How can we generate PhotoIDs?
- Here, we cannot have an auto-incrementing sequence in each shard to define PhotoID because we need to know PhotoID first to find the shard where it will be stored. One solution could be that we dedicate a separate database instance to generate auto-incrementing IDs. If our PhotoID can fit into 64 bits, we can define a table containing only a 64 bit ID field. So whenever we would like to add a photo in our system, we can insert a new row in this table and take that ID to be our PhotoID of the new photo.
Wouldn’t this key generating DB be a single point of failure?
- Yes, it would be. A workaround for that could be to define two such databases, one generating even-numbered IDs and the other odd-numbered. For MySQL, the following script can define such sequences:
KeyGeneratingServer1:
auto-increment-increment = 2
auto-increment-offset = 1
KeyGeneratingServer2:
auto-increment-increment = 2
auto-increment-offset = 2
-
We can put a load balancer in front of both of these databases to round-robin between them and to deal with downtime. Both these servers could be out of sync, with one generating more keys than the other, but this will not cause any issue in our system. We can extend this design by defining separate ID tables for Users, Photo-Comments, or other objects present in our system.
-
Alternately, we can implement a ‘key’ generation scheme similar to what we have discussed in Designing a URL Shortening service like TinyURL.
How can we plan for the future growth of our system?
- We can have a large number of logical partitions to accommodate future data growth, such that in the beginning, multiple logical partitions reside on a single physical database server. Since each database server can have multiple database instances running on it, we can have separate databases for each logical partition on any server.
- So whenever we feel that a particular database server has a lot of data, we can migrate some logical partitions from it to another server. We can maintain a config file (or a separate database) that can map our logical partitions to database servers; this will enable us to move partitions around easily.
- Whenever we want to move a partition, we only have to update the config file to announce the change.
Ranking and News Feed Generation
Feed generation
- To create the News Feed for any given user, we need to fetch the latest, most popular, and relevant photos of the people the user follows.
Feed generation
- Let’s take the simple case of the newsfeed generation service fetching most recent posts from all the users and entities that Jack follows; the query would look like this:
(SELECT FeedItemID FROM FeedItem WHERE UserID in (
SELECT EntityOrFriendID FROM UserFollow WHERE UserID = <current_user_id> and type = 0(user))
)
UNION
(SELECT FeedItemID FROM FeedItem WHERE EntityID in (
SELECT EntityOrFriendID FROM UserFollow WHERE UserID = <current_user_id> and type = 1(entity))
)
ORDER BY CreationDate DESC
LIMIT 100
-
For simplicity, let’s assume we need to fetch the top 100 photos for a user’s News Feed. Our application server will first get a list of people the user follows and then fetch metadata info of each user’s latest 100 photos. In the final step, the server will submit all these photos to our ranking algorithm, which will determine the top 100 photos (based on recency, likeness, etc.) and return them to the user.
-
Here are issues with this design for the feed generation service:
- We generate the timeline when a user loads their page. This would be quite slow and have a high latency since we have to query multiple tables and perform sorting/merging/ranking on the results.
- Crazy slow for users with a lot of friends/followers as we have to perform sorting/merging/ranking of a huge number of posts.
- For live updates, each status update will result in feed updates for all followers. This could result in high backlogs in our Newsfeed Generation Service.
- For live updates, the server pushing (or notifying about) newer posts to users could lead to very heavy loads, especially for people or pages that have a lot of followers.
-
To improve the efficiency, we can pre-generate the timeline and store it in a memory (preferable, for fast processing – using, say Redis) or a separate table.
Offline generation for newsfeed
-
We can have dedicated servers that are continuously generating users’ newsfeed and storing them in memory for fast processing or in a
UserNewsFeedtable. So, whenever a user requests for the new posts for their feed, we can simply serve it from the pre-generated, stored location. Using this scheme, user’s newsfeed is not compiled on load, but rather on a regular basis and returned to users whenever they request for it. -
Whenever these servers need to generate the feed for a user, they will first query to see what was the last time the feed was generated for that user. Then, new feed data would be generated from that time onwards. We can store this data in a hash table where the “key” would be UserID and “value” would be a STRUCT like this:
Struct {
LinkedHashMap<FeedItemID, FeedItem> FeedItems;
DateTime lastGenerated;
}
- We can store
FeedItemIDsin a data structure similar to Linked HashMap or TreeMap, which can allow us to not only jump to any feed item but also iterate through the map easily. Whenever users want to fetch more feed items, they can send the lastFeedItemIDthey currently see in their newsfeed, we can then jump to thatFeedItemIDin our hash-map and return next batch/page of feed items from there.
How many feed items should we store in memory for a user’s feed?
- Initially, we can decide to store 500 feed items per user, but this number can be adjusted later based on the usage pattern.
- For example, if we assume that one page of a user’s feed has 20 posts and most of the users never browse more than ten pages of their feed, we can decide to store only 200 posts per user.
- For any user who wants to see more posts (more than what is stored in memory), we can always query backend servers.
Should we generate (and keep in memory) newsfeeds for all users?
- There will be a lot of users that don’t log-in frequently. Here are a few things we can do to handle this:
- A more straightforward approach could be, to use an LRU based cache that can remove users from memory that haven’t accessed their newsfeed for a long time.
- A smarter solution can be to run ML-based models to predict the login pattern of users to pre-generate their newsfeed, for e.g., at what time of the day a user is active and which days of the week does a user access their newsfeed? etc.
- Let’s now discuss some solutions to our “live updates” problems in the following section.
Feed publishing (Fanout)
-
The process of pushing news feeds post to all the followers is called fanout. By analogy, the push approach is called fanout-on-write, while the pull approach is called fanout-on-load. Let’s discuss different options for publishing feed data to users.
- (Client) “Pull” model or Fan-out-on-load:
- This method involves keeping all the recent feed data in memory so that users can pull it from the server whenever they need it.
- Clients can pull the feed data on a regular basis or manually whenever they need it.
- Possible issues with this approach are:
- Data can become stale unless a pull request is issued. In other words, new data might not be shown to the users until they issue a pull request.
- It’s hard to find the right pull cadence, as most of the times, a pull requests will result in an empty response if there is no new data, causing a waste of resources.
- (Server) “Push” model or Fan-out-on-write:
- For a push system, once a user has published a post, we can immediately push this post to all the followers, thereby being more real-time than the pull model.
- The advantage is that when fetching the feed, you don’t need to go through your friend’s list and get feeds for each of them. It significantly reduces read operations. To efficiently handle this, users have to maintain a Long Poll request with the server for receiving the updates.
- A possible problem with this approach is the celebrity user issue: when a user has millions of followers (i.e., a celebrity-user), the server has to push updates to a lot of people.
- Hybrid model (push+pull model):
- An alternate method to handle feed data could be to use a hybrid approach, i.e., to do a combination of fan-out-on-write and fan-out-on-load.
- Specifically, we can stop pushing posts from users with a high number of followers (a celebrity user) and only push data for those users who have a few hundred (or thousand) followers.
- For celebrity users, we can let the followers pull the updates.
- Since the push operation can be extremely costly for users who have a lot of friends or followers, by disabling fanout for them, we can save a huge number of resources. Another alternate approach could be that, once a user publishes a post, we can limit the fanout to only her online friends.
- Thus, to get benefits from both the approaches, a combination of ‘push to notify’ and ‘pull for serving’ end-users is a great way to go. Purely a push or pull model is less versatile.
- Another approach could be that the server pushes updates to all the users not more than a certain frequency and letting users with a lot of updates to pull data regularly.
- (Client) “Pull” model or Fan-out-on-load:
-
For a detailed discussion about News-Feed generation, take a look at Designing Facebook’s Newsfeed.
News Feed Creation with Sharded Data
-
One of the most important requirements to create the News Feed for any given user is to fetch the latest photos from all people the user follows. For this, we need to have a mechanism to sort photos on their time of creation. To efficiently do this, we can make photo creation time part of the PhotoID. As we will have a primary index on PhotoID, it will be quite quick to find the latest PhotoIDs.
-
We can use epoch time for this. Let’s say our PhotoID will have two parts; the first part will be representing epoch time, and the second part will be an auto-incrementing sequence. So to make a new PhotoID, we can take the current epoch time and append an auto-incrementing ID from our key-generating DB. We can figure out the shard number from this PhotoID (with a simple hashing function such as PhotoID % 10) and store the photo there.
-
What could be the size of our PhotoID? Let’s say our epoch time starts today, then the number of bits needed to store the number of seconds for the next 50 years would be 86400 sec/day * 365 (days a year) * 50 (years) => 1.6 billion seconds.
-
We would need 31 bits to store this number. Since, on average, we are expecting 23 new photos per second, we can allocate 9 additional bits to store the auto-incremented sequence. So every second, we can store (2^9 => 512) new photos. We are allocating 9 bits for the sequence number which is more than what we require; we are doing this to get a full byte number (as 40 bits = ~5 bytes). We can reset our auto-incrementing sequence every second.
-
We will discuss this technique under ‘Data Sharding’ in Designing Twitter.
Cache and Load balancing
-
Our service would need a massive-scale photo delivery system to serve globally distributed users. Our service should push its content closer to the user using a large number of geographically distributed photo cache servers and use CDNs (for details, see Caching).
-
We can introduce a cache for metadata servers to cache hot database rows. We can use Memcache to cache the data, and Application servers before hitting the database can quickly check if the cache has desired rows. Least Recently Used (LRU) can be a reasonable cache eviction policy for our system. Under this policy, we discard the least recently viewed row first.
-
How can we build a more intelligent cache? If we go with the eighty-twenty rule, i.e., 20% of daily read volume for photos is generating 80% of the traffic, which means that certain photos are so popular that most people read them. This dictates that we can try caching 20% of the daily read volume of photos and metadata.