Recommendation Systems • Cold Start
- Overview
- Item/Product Cold Start
- User/Visitor Cold Start
- Community / Marketplace Cold Start
- Hybrid recommender system
- Knowledge-based systems
- Active learning
- Context-aware systems
- Feature Hashing Trick
- References
Overview
- The cold start problem occurs when the recommendations, predictions, or other personalized services receives a new user and is unsure about what items to recommend to them since there is little or no historical data available on them. Similarly, it also exists when a new item is added and the system is unsure of which user to recommend that item to.
- Netflix, for example, has the cold start problem occurring when a new user signs up and there is no information available about their movie preferences or viewing history. Similarly, when a new item is added to Netflix, there may be no data available on how users have interacted with it, making it difficult to provide relevant recommendations. All three categories of cold-start (new community, new item, and new user) have in common the lack of user interactions and presents some commonalities in the strategies available to address them.
- Below, we will look at both, the user and item cold start problem.
Item/Product Cold Start
- When a new product is added to a web store or fresh content is uploaded to a media platform, it initially remains unknown with zero interactions or ratings, rendering it practically invisible to the recommendation system. This is referred to as product or item cold start, even though it may be relevant to some or many users.
- Classified sites and news platforms are hit the hardest by this phenomenon. Fresh items on these platforms are typically in high demand, but their value deteriorates rapidly. Breaking news from yesterday becomes stale news today, and vintage bikes put up for sale last week may already be sold.
- In addition, marketplaces also face item cold start issues when the same product is offered by different sellers under different product IDs. Since the personalization engine views these as distinct items, user interactions and ratings for one product won’t affect how its duplicates are recommended.
- On e-commerce sites, a cold start item belongs to the long-tail of products, which are low-hype goods that sell only a few each month, but their sheer volume still generates significant traffic. As a result of low demand, it takes a long time for these products to accumulate enough user interactions to be recognized by the recommendation system, thus making them cold start items.
- Item/product cold start constitutes a problem mainly for collaborative filtering algorithms due to the fact that they rely on the item’s interactions to make recommendations. However, it can be addressed using content-based filtering as indicated below.
Content-based filtering
- Content-based filtering is an algorithm that recommends items based on their features such as text, metadata, and tags. These algorithms are thus much less prone to the new item problem since they choose which items to recommend based on the feature the items possesses; even if no interactions for a new item exist, its features will allow for a recommendation to be made.
- To generate item embeddings using the item’s description, these algorithm adopt techniques such as, Term Frequency-Inverse Document Frequency (TF-IDF), Best Matching 25 (BM25), Word2Vec, BERT, or SBERT to represent item features and cosine similarity to measure the similarity between items. The scikit-learn library provides an implementation of TF-IDF Vectorizer.
- Use cases:
- Spotify uses content-based filtering to recommend songs to its users. The algorithm analyzes the features/metadata of a user’s favorite songs, such as tempo, genre, and mood, and recommends other songs with similar features.
- Netflix uses content-based filtering to recommend TV shows and movies to its users. The algorithm analyzes the metadata of each title, such as genre, cast, and plot summary, and recommends titles with similar metadata to the user.
- Optimizing for serendipity is also another way to recommend long-tail items to the user which, in turn, alleviates the cold start problem.
User/Visitor Cold Start
- When a website encounters new visitors without known behavior or preferences (affinity towards a particular class of products, prior in-domain browsing history, etc.), it can be difficult to create a personalized experience for them due to the absence of data typically used for generating recommendations. This is known as the user or visitor cold start problem.
- Not only first-time users of a website, but even returning visitors can confuse recommendation systems if their behavior and preferences change from one session to the next.
- Classified sites and video sharing platforms are often faced with this issue. For instance, a user may be interested in comparing and searching for hiking boots for a while, but once they make a purchase, they may switch to something completely unrelated, such as art supplies. In such cases, their browsing history won’t be helpful in predicting their next choice due to their session-based behavior. As another example, users might be interested in DIY videos over the span of a couple of months, but might exhibit a change of interest, showing affinity towards food recipes next.
- In a broader context, some level of user cold start will always exist as long as online consumers continue to explore new topics and trends, and their lifestyle, circumstances, and needs continue to evolve.
- Collaborative filtering algorithms are the most affected in the new user case as without interactions, no inference can be made about the user’s preferences.
Demographic or User-to-User
- Demographic-based recommendations refer to a type of recommendation approach that uses demographic information about users to make personalized recommendations. Demographic-based recommendations filtering is a recommender system approach that classifies users based on their demographic information and provides recommendations accordingly. This technique involves creating user profiles by categorizing users into stereotypical descriptions or groups that represent certain demographic features or characteristics, such as age, nationality, gender, location, and other relevant characteristics.
- Here’s how demographic-based recommendations work:
- User Profiling: The first step is to create user profiles by collecting demographic information. Users are categorized based on their demographic attributes, creating segments or groups with similar characteristics. These segments can represent different customer segments or target audiences.
- Cumulative/Aggregate Behavior Analysis: Once the user profiles are established, the system analyzes the cumulative buying behavior or preferences of users within each demographic segment. This involves tracking the past interactions, purchases, or ratings of users in each segment.
- Recommendation Generation: When a new user with limited or no interaction history is encountered, demographic-based recommendations come into play. The system identifies the category or segment the user belongs to based on their demographic information. Then, it applies the cumulative buying preferences or behaviors of previous users within that segment to the new user. The system recommends items or services that were popular or well-received among users in that segment.
- People-to-People Correlations: Demographic-based techniques often establish “people-to-people” correlations by grouping users with similar demographic characteristics. This grouping allows the system to identify patterns and preferences specific to each segment, leveraging the collective behavior of users within those segments. Put simply, the process involves creating categories or segments of users with similar demographic characteristics and then tracking the cumulative buying behavior or preferences of users within each category.
- Unlike collaborative filtering or content-based techniques, demographic-based recommendations do not require a history of user ratings or item interactions. Instead, they rely on demographic information to create user profiles and make recommendations based on the preferences of users within similar demographic segments.
- While demographic filtering creates correlations between users, similar to collaborative techniques, it differs in terms of the data used. Demographic filtering relies on dissimilar data, specifically demographic information, to establish “people-to-people” correlations. Unlike collaborative filtering or content-based techniques that require a history of user ratings or item features, demographic filtering focuses on demographic characteristics to make recommendations.
- Demographic filtering can be useful in situations where user preferences or behavior patterns are strongly influenced by demographic factors such as age, gender, location, or other demographic attributes. By leveraging this information, the recommender system can tailor recommendations to users with similar demographic profiles, even in the absence of explicit user ratings or item features.
- Also, if no demographic features are present or their quality is too poor, a common strategy is to offer them non-personalized recommendations. This means that they could be recommended simply the most popular items (cf. Popular section below) either globally or for their specific geographical region or language.
Survey
- An onboarding survey when a user joins the platform helps gather relevant data to understand their preferences, behavior and characteristics (topics of interest, likes/dislikes, etc.) to build an initial user profile, a technique called preference elicitation. This can serve to generate an initial embedding for the user.
- Note that this information is acquired during the registration process, either by asking the user to input the data themselves, or by leveraging data already available, e.g., their social media accounts.
- A threshold has to be found between the length of the user registration process (which if too long might lead to too many users to abandon it), and the amount of initial data required for the recommender to work properly.
- The construction of the user’s profile may also be automated by integrating information from other user activities, such as browsing histories or social media platforms. If, for example, a user has been reading information about a particular music artist from a media portal, then the associated recommender system would automatically propose that artist’s releases when the user visits the music store.
- Companies like Spotify and Netflix often do this after the user registers and asks them to pick some of their favorite artists and genres. From there on, the model can start serving the most popular items on that list and learn from their future explicit and implicit interactions.
- As an example MovieLens, a web-based recommender system for movies, asks the user to rate some movies as a part of the registration. While preference elicitation strategy are a simple and effective way to deal with new users, the additional requirements during the registration will make the process more time-consuming for the user. Moreover, the quality of the obtained preferences might not be ideal as the user could rate items he/she has seen months or years ago or the provided ratings could be almost random if the user provided them without paying attention just to complete the registration quickly.
- Another of the possible techniques is to apply active learning (machine learning). The main goal of active learning is to guide the user in the preference elicitation process in order to ask him to rate only the items that for the recommender point of view will be the most informative ones. This is done by analysing the available data and estimating the usefulness of the data points (e.g., ratings, interactions). As an example, say that we want to build two clusters from a certain cloud of points. As soon as we have identified two points each belonging to a different cluster, which is the next most informative point? If we take a point close to one we already know we can expect that it will likely belong to the same cluster. If we choose a point which is in between the two clusters, knowing which cluster it belongs to will help us in finding where the boundary is, allowing to classify many other points with just a few observations (source).
Popular
- A fallback approach in recommender systems for handling new or inactive users is to recommend popular items with broad appeal or high popularity among the user base, rather than personalized recommendations based on their preferences. Here are some key points about this strategy:
- Threshold for Active vs. Inactive Users: Recommender systems often define a threshold that distinguishes between active and inactive users based on their level of engagement or activity. Typically, the system is trained to learn the preferences of active users, while inactive users are considered less reliable indicators of personal preferences.
- Popular Retrieval for Inactive Users: If a user is classified as inactive or falls below the activity threshold, the recommender system can temporarily switch to a popular retrieval model. This means that the system serves the user the most popular items that have been well-received or frequently chosen by other users. These popular items are generally expected to have a broad appeal and are a safe choice for users with unknown or limited preferences.
- Transition to Personalized Recommendations: As the new user or inactive user engages more with the system and their preferences become more apparent, the recommender system gradually transitions from popular retrieval recommendations to personalized recommendations. This transition occurs when there is sufficient data available to infer the user’s preferences and provide more targeted recommendations.
- By initially serving popular items to new or inactive users, the recommender system can provide a satisfactory user experience while gathering data to better understand the user’s preferences. This approach allows the system to gradually tailor recommendations to each user as their engagement and preferences are learned over time.
The Harry Potter Effect
- From Harry Potter effect:
- Recommender systems that are biased towards generally popular items exhibit the so-called Harry Potter effect.
- (Almost) everybody likes Harry Potter. So most automated procedures will find out which items are generally popular, and recommend those to the users. While it is generally correct that users often like globally popular items, recommending them is usually not interesting.
- To avoid the Harry Potter effect, you can either filter out very popular items, or multiply the predicted rating by a factor that is lower the more globally popular an item is; in other words, items can be filtered or weighted down based on their global popularity.
- Specifically, when computing recommendations (for example movies) we can compare movie similarity to recommend to the user similar movies to the one they’ve seen. The problem, when we have an item which is liked by everyone, it “covers” any other subset of the data, and thus it will have the greatest similarity to all other items. For example, the movie Tarzan was watched 10 times. Harry Potter was watched 1,000,000 times. Every single time a viewer watched Tarzan, they watched also Harry Potter. So Harry Potter is the most similar movie to Tarzan (and to all the other movies as well).
- To prevent this Harry Potter effect, we normalize by the total number of ratings in the data. Thus, if we had an overlap of 10 watches of Tarzan with Harry Potter, we divide it to 1,000,000 occurrences of Harry Potter ratings, and thus diminish the “Harry Potter” effect.
Community / Marketplace Cold Start
- The new community problem, or systemic bootstrapping, refers to the startup of the system, when virtually no information the recommender can rely upon is present. This case presents the disadvantages of both the new user and the new item case, as all items and users are new. Due to this some of the techniques developed to deal with those two cases are not applicable to the system bootstrapping.
- If we have trends data from launches to other similar communities/marketplaces (say, an earlier launch in a different geographical area), perhaps we can try employing those. However, if this is a brand new marketplace being launched, we may want to invest in early adopter programs (in the same vein as Canary testing which is commonly done in software testing) that will enable interactions with the product and yield data and feedback. To this end, we can employ a four-stage testing process for changes, consisting of:
- Testing by dedicated, internal testers (QA employees).
- Further testing on a crowdtesting platform (volunteering employees).
- “Dogfooding,” which involves having employees use the product in their daily work.
- Beta testing, which involves releasing the product to a small group of product end users.
Hybrid recommender system
- The main idea to alleviate the cold-start problem is to rely on hybrid recommenders, in order to mitigate the disadvantages of one technique or model by combining it with another. In other words, hybrid recommender systems combine two or more recommendation techniques to provide more accurate recommendations.
- All three categories of cold-start (new community, new item, and new user) have the lack of user interactions in common and present some commonalities in the strategies available to address them.
A common strategy when dealing with new items is to employ a hybrid system which can couple a collaborative filtering recommender for warm items, with a content-based filtering recommender for cold-items. While the two algorithms can be combined in different ways, the main drawback of this method is related to the poor recommendation quality often exhibited by content-based recommenders in scenarios where it is difficult to provide a comprehensive description of the item’s characteristics.
- The Apache Mahout library provides an implementation of this algorithm.
- Use cases:
- Goodreads uses a hybrid recommender system to recommend books to its users. The system combines content-based filtering and collaborative filtering. When a user signs up, the system asks for their favorite genres and authors, which are used as content-based features. The system also analyzes the user’s reading history and identifies similar users based on their historical reading patterns, which are used as collaborative features. The system combines these two sets of features to make recommendations to the user.
- Yelp uses a hybrid recommender system to recommend businesses to its users. The system combines content-based filtering, collaborative filtering, and contextual recommendations. When a user searches for a restaurant, the system considers the user’s location, search history, and preferred cuisine as contextual features. The system also analyzes the user’s historical check-ins and reviews, as well as the check-ins and reviews of other users with similar preferences, as collaborative features. The system also analyzes the restaurant’s metadata, such as price, ratings, and cuisine, as content-based features. The system combines these three sets of features to make recommendations to the user.
Knowledge-based systems
- Knowledge-based systems use domain knowledge to recommend items or content to users.
- This approach is useful when there is little or no historical user data. For instance, in a music recommendation system, domain knowledge about genres, artists, and music features can be used to make recommendations.
- Expert systems and rule-based systems are examples of knowledge-based systems.
- Use cases:
- IBM’s Watson, an AI system that uses natural language processing and machine learning to reveal insights from large amounts of unstructured data.
- Wolfram Alpha, a computational knowledge engine that provides answers to factual queries by computing answers from structured data.
Active learning
- Active learning is a technique that involves selecting a set of representative items for users and asking them to provide feedback. It can be clubbed with survey technique as mentioned earlier.
- This feedback is then used to improve the accuracy of the recommendations.
- This technique is suitable for cold start problems when there is insufficient historical data. Active learning can be implemented using various machine learning algorithms such as decision trees or neural networks.
- Use cases:
- Google’s Cloud AutoML, a suite of machine learning products that automate the process of training and deploying custom models for various use cases, such as image recognition, natural language processing, and translation.
- Microsoft’s Azure Machine Learning, a cloud-based service that enables data scientists to create and deploy machine learning models
Context-aware systems
- Context-aware systems consider contextual factors such as time, location, and user behavior to make recommendations.
- This method can be useful when user data is scarce or the recommendation problem is complex.
- For instance, in a restaurant recommendation system, contextual factors such as cuisine, price, and location can be considered to make personalized recommendations. Context-aware systems can be implemented using machine learning algorithms such as decision trees or rule-based systems.
- Use cases:
- Google Maps, a mapping service that uses contextual data such as traffic conditions and real-time updates to provide personalized directions to users.
- Spotify’s Discover Weekly, a music recommendation system that analyzes a user’s listening history, preferences, and current context to create a personalized playlist.
Feature Hashing Trick
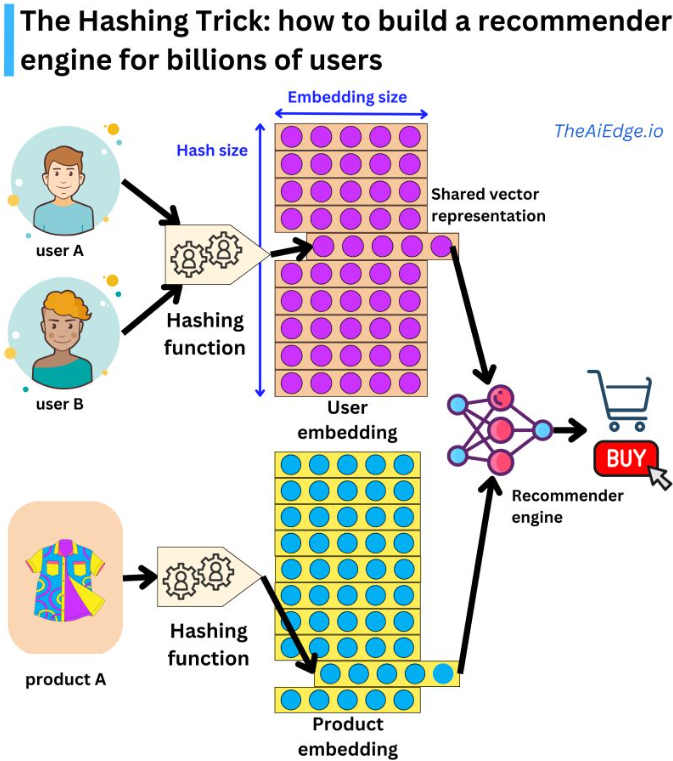
- This technique is inspired from Damien Benveniste’s post (source) and Feature Hashing for Large Scale Multitask Learning, and it also helps in memory conservation as well as the cold start problem. The hashing trick can be used to encode user and item features for matrix factorization.
- First, let’s see how it helps with memory conservation:
- Say you were to design a recommender model to display ads to users. A naive implementation could include a recommender engine with user and ads embeddings along with assigning a vector to each category seen during training, and an unknown vector for all categories not seen during training.
- While this could work for NLP, for recommender systems where you can have hundreds of new users daily, the number of unknown vectors could exponentially increase!
- Hashing trick is a way to handle this problem by assigning multiple users (or categories of sparse variables) to the same latent representation.
- This is done by a hashing function by having a hash-sized hyperparameter you can control the dimension of the embedding matrix and the resulting degree of hashing collision.
- Say you were to design a recommender model to display ads to users. A naive implementation could include a recommender engine with user and ads embeddings along with assigning a vector to each category seen during training, and an unknown vector for all categories not seen during training.
- The hashing trick is a method used in machine learning to reduce the dimensionality of feature vectors. It works by mapping each feature to a fixed-length vector of integers using a hash function.
- The hashing trick can be used to address the cold start problem by allowing the system to handle new or unknown features without requiring retraining of the model.
- Let’s take a deeper look at how it can help with the cold start problem via collaborative filtering:
- As stated earlier, the hashing trick is a technique used in machine learning for dimensionality reduction and feature engineering, where high-dimensional input vectors are mapped to a lower-dimensional space using a hash function.
- In collaborative filtering, the input data typically consists of a large number of high-dimensional sparse feature vectors that represent the user-item interactions. These feature vectors can be very large and computationally expensive to process, especially when dealing with large-scale datasets.
- To address this issue, the hashing trick can be applied to map the high-dimensional feature vectors to a lower-dimensional space with a fixed number of dimensions. The resulting lower-dimensional feature vectors can then be used as inputs to the collaborative filtering algorithm, which can be more computationally efficient to process.
- For example, in a user-item rating matrix, the high-dimensional feature vector for each user can include data such as their past ratings, demographic information, and behavioral data. By applying the hashing trick to these feature vectors, they can be mapped to a lower-dimensional space, reducing the computational complexity of the collaborative filtering algorithm.
- One advantage of using the hashing trick in collaborative filtering is that it can preserve the sparsity of the input data, which is important for many collaborative filtering algorithms. Additionally, the resulting lower-dimensional feature vectors can be more efficiently processed and stored, improving the overall performance of the recommendation system.
- The hashing trick is not limited to these two use-cases however, it can also help with personalization or in cases where the input data is high-dimensional and sparse, and where computational efficiency and storage constraints are a concern.
- “But wait, are we not going to decrease predictive performance by conflating different user behaviors? In practice the effect is marginal. Keep in mind that a typical recommender engine will be able to ingest hundreds of sparse and dense variables, so the hashing collision happening in one variable will be different from another one, and the content-based information will allow for high levels of personalization. But there are ways to improve on this trick. For example, at Meta they suggested a method to learn hashing functions to group users with similar behaviors. They also proposed a way to use multiple embedding matrices to efficiently map users to unique vector representations. This last one is somewhat reminiscent of the way a pair (token, index) is uniquely encoded in a Transformer by using the position embedding trick.
- The hashing trick is heavily used in typical recommender system settings but not widely known outside that community.