Introduction
- The Generative Pre-trained Transformer (GPT) by OpenAI is a family of autoregressive language models.
- GPT utilizes the decoder architecture from the standard Transformer network (with a few engineering tweaks) as a independent unit. This is coupled with an unprecedented size of 2048 as the number of tokens as input and 175 billion parameters (requiring ~800 GB of storage).
- The training method is “generative pretraining”, meaning that it is trained to predict what the next token is. The model demonstrated strong few-shot learning on many text-based tasks.
- The end result is the ability to generate human-like text with swift response time and great accuracy. Owing to the GPT family of models having been exposed to a reasonably large dataset and number of parameters (175B), these language models require few or in some cases no examples to fine-tune the model (a process that is called “prompt-based” fine-tuning) to fit the downstream task. The quality of the text generated by GPT-3 is so high that it can be difficult to determine whether or not it was written by a human, which has both benefits and risks (source).
- Before GPT, language models (LMs) were typically trained on a large amount of accurately labelled data, which was hard to come by. These LMs offered great performance on the particular supervised task that they were trained to do, but were unable to be domain-adapted to other tasks easily.
- Microsoft announced on September 22, 2020, that it had licensed “exclusive” use of GPT-3; others can still use the public API to receive output, but only Microsoft has access to GPT-3’s underlying model.
- Let’s look below at each GPT1, GPT2, and GPT3 (with emphasis on GPT-3 as its more widely used today) and how they were able to make a dent in Natural Language Processing tasks.
- GPT-1 was released in 2018 by OpenAI. It contained 117 million parameters.
- Trained on an enormous BooksCorpus dataset, this generative language model was able to learn large range dependencies and acquire vast knowledge on a diverse corpus of contiguous text and long stretches.
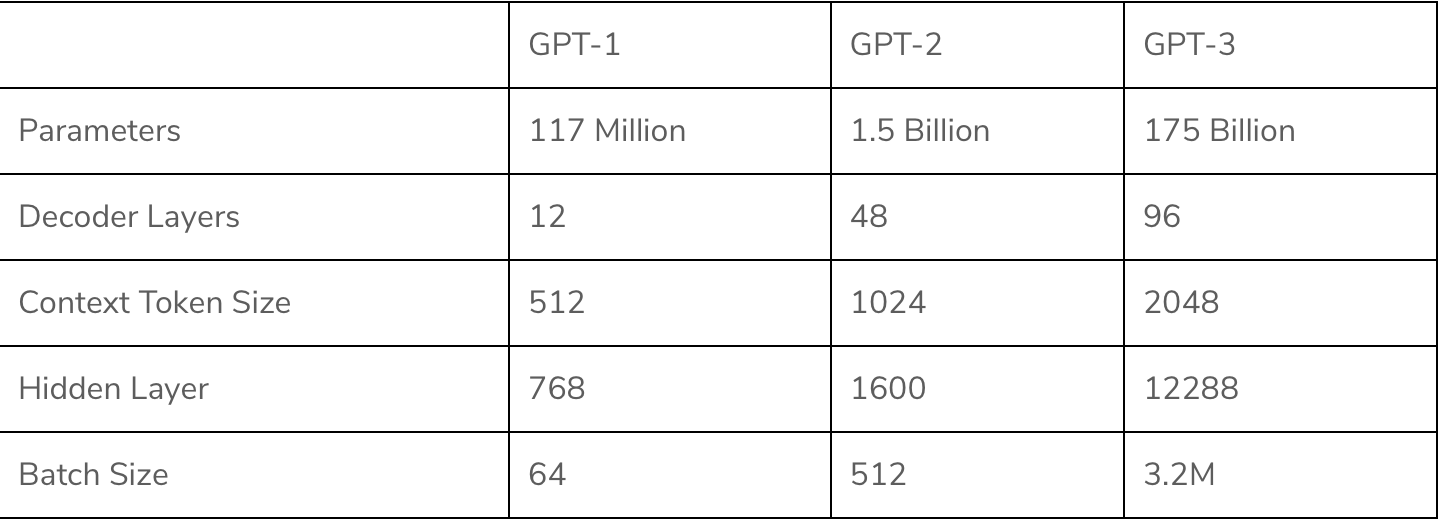
- GPT-1 uses the 12-layer decoder from the original transformer architecture that contains self attention.
- GPT was able to use transfer learning and thus, was able to perform many NLP tasks with very little fine-tuning.
- The right half of the image below, from the original transformer paper, “Attention Is All You Need”, represents the decoder model:
- GPT-2 was released in February 2019 by OpenAI and it used a larger dataset while also adding additional parameters to build a more robust language model.
- GPT-2 became 10 times larger than GPT-1 with 1.5 billion parameters and had 10 times the data compared to GPT-1.
- Write With Transformer is a webapp created and hosted by Hugging Face showcasing the generative capabilities of several models. GPT-2 is one of them and is available in five different sizes: small, medium, large, XL and a distilled version of the small checkpoint: distilgpt-2.
- GPT-2 is an unsupervised deep learning transformer-based language model created by OpenAI to help in predicting the next word or words in a sentence.
- Language tasks such as reading, summarizing, and translation can be learned by GPT-2 from raw text without using domain specific training data.
- GPT-3 is a massive language prediction and generation model developed by OpenAI capable of generating long sequences of the original text. GPT-3 became the OpenAI’s breakthrough AI language program.
- GPT-3 is able to generate paragraphs and texts to almost sound like a person has generated them instead.
- GPT-3 contains 175 billion parameters and is 100 times larger than GPT-2. Its trained on 500 billion word data set known as “Common Crawl”.
- GPT-3 is also able to write code snippets, like SQL queries, and perform other intelligent tasks. However, it is expensive and inconvenient to perform inference owing to its 175B-parameter size.
- GPT-3 eliminates the finetuning step that was needed for its predecessors as well as for encoder models such as BERT.
- GPT-3 is capable of responding to any text by generating a new piece of text that is both creative and appropriate to its context.
- Here is a working use case of GPT-3 you can try out: debuild.io where GPT will give you the code to build the application you define.
- Just like its predecessors, GPT-3 is an API served by OpenAI, lets look at the image below (source) to see a visual representation of how this black box works:

- The output here is generated by what GPT has learned during the training phase. GPT-3’s dataset was quite massive with 300 billion tokens or words that it was trained on.
- It was trained on only one specific task which was predicting the next word, and thus, is an unsupervised pre-trained model.
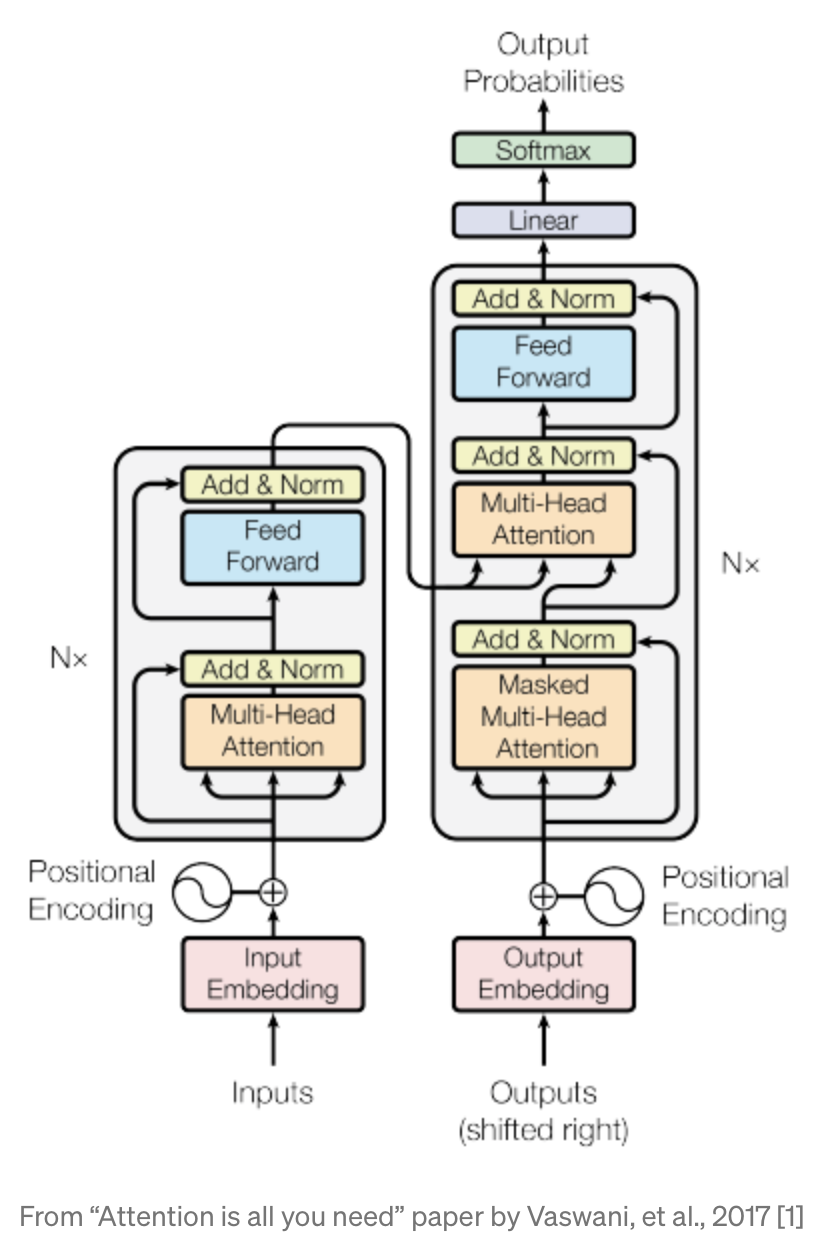
- In the image below (source), we can see what the training process looks like for GPT-3.
- We feed words into our model.
- We expect an output.
- We then check if the output matches the expected output.
- If not, we calculate the error or loss and update the model and ask for a new prediction.
- Thus, the next time it comes across this example, it knows what the output should look like.
- This is the general loop used in supervised training, nothing out of the ordinary, lets look below.
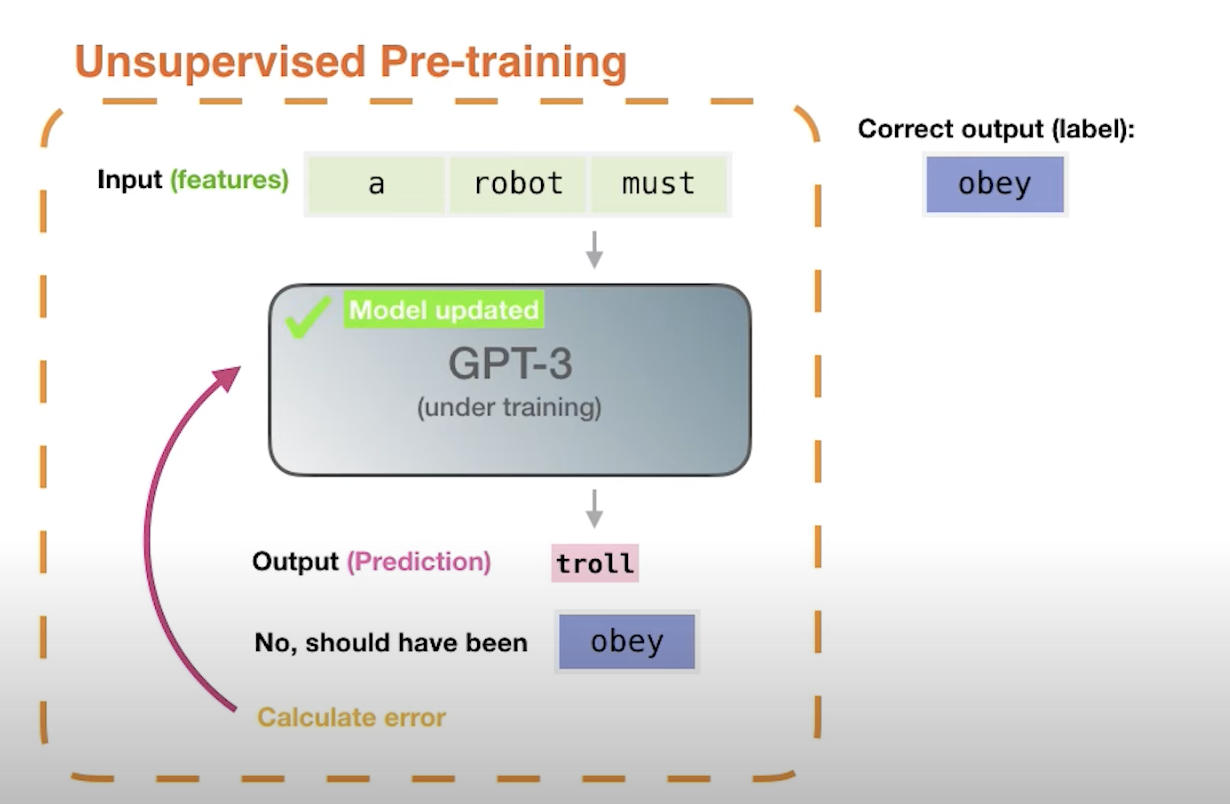
- Let’s visualize another way of looking at the model in the figure below (source).

- Each word goes through its own track and the model has a context window of say 2048 tokens. Thus the input and output have to fit within this range. Note, there are ways to expand and adjust this number but we will use this number for now.
- Each token is only processed in its own parallel “track”. Looking at it even deeper. Each token/word is a vector on its own, so when we process a word, we process a vector.
- This vector will then go through many layers of Transformer Decoders (GPT-3 has 96 layers), which are all stacked one on top of another as shown in the figure below (source).
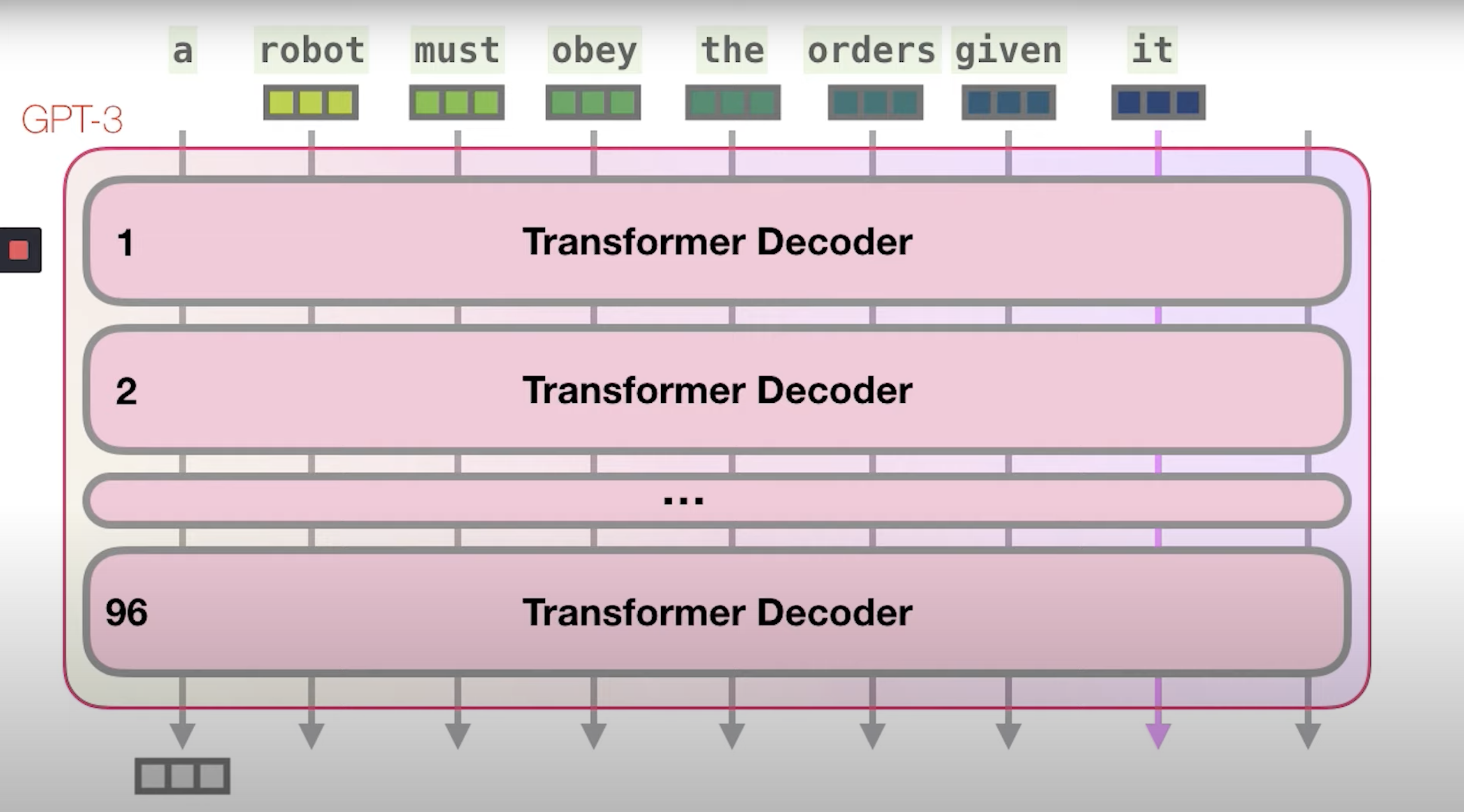
- The last token is the response or the next word prediction from the model.
GPT-4
References