Models • ChatGPT
- Overview
- Training ChatGPT
- Parameter count
- How would you detect ChatGPT-generated text?
- Related: InstructGPT
- Visual Summary
- Further Reading
- References
Overview
- The world has been enamored by ChatGPT’s extraordinary capabilities and has been trying to identify ChatGPT’s various use-cases.
- ChatGPT is a chat-bot released by OpenAI (with a focus on multi-round conversational dialogue as it’s mode of interaction) and has far out-shined its predecessor, GPT-3, in generating text.
- Recall that GPT used the decoder part of the Transformer architecture and was trained to do next word prediction. In doing so, it could often offer false or hurtful information as it was only trained to predict the next word by being trained from text on the internet.
- ChatGPT and its sibling model, InstructGPT, are both designed to fix that problem and be more aligned with its users via the use of RLHF.
- Below, we’ve broken down the internals of ChatGPT and InstructGPT; check out the primer on GPT if you’d like a refresher.
Training ChatGPT
- ChatGPT has been fine-tuned on with a combination of both Supervised Learning and Reinforcement Learning by using human feedback.
- Specifically, ChatGPT uses “Reinforcement Learning from Human Feedback (RLHF), which uses human feedback in the training loop to minimize harmful, untruthful, and/or biased outputs” (source: Assembly AI). This is accomplished by having AI trainers rank the responses from the model.
- ChatGPT’s dataset includes a wide variety of text from the internet, including articles, websites, books, and more.
-
It includes text from a wide range of sources and covers a diverse range of topics, in order to provide me with a broad understanding of language and the ability to generate text on a wide range of topics.
- Below, the diagram from OpenAI (source) shows a high level overview of how ChatGPT is trained.
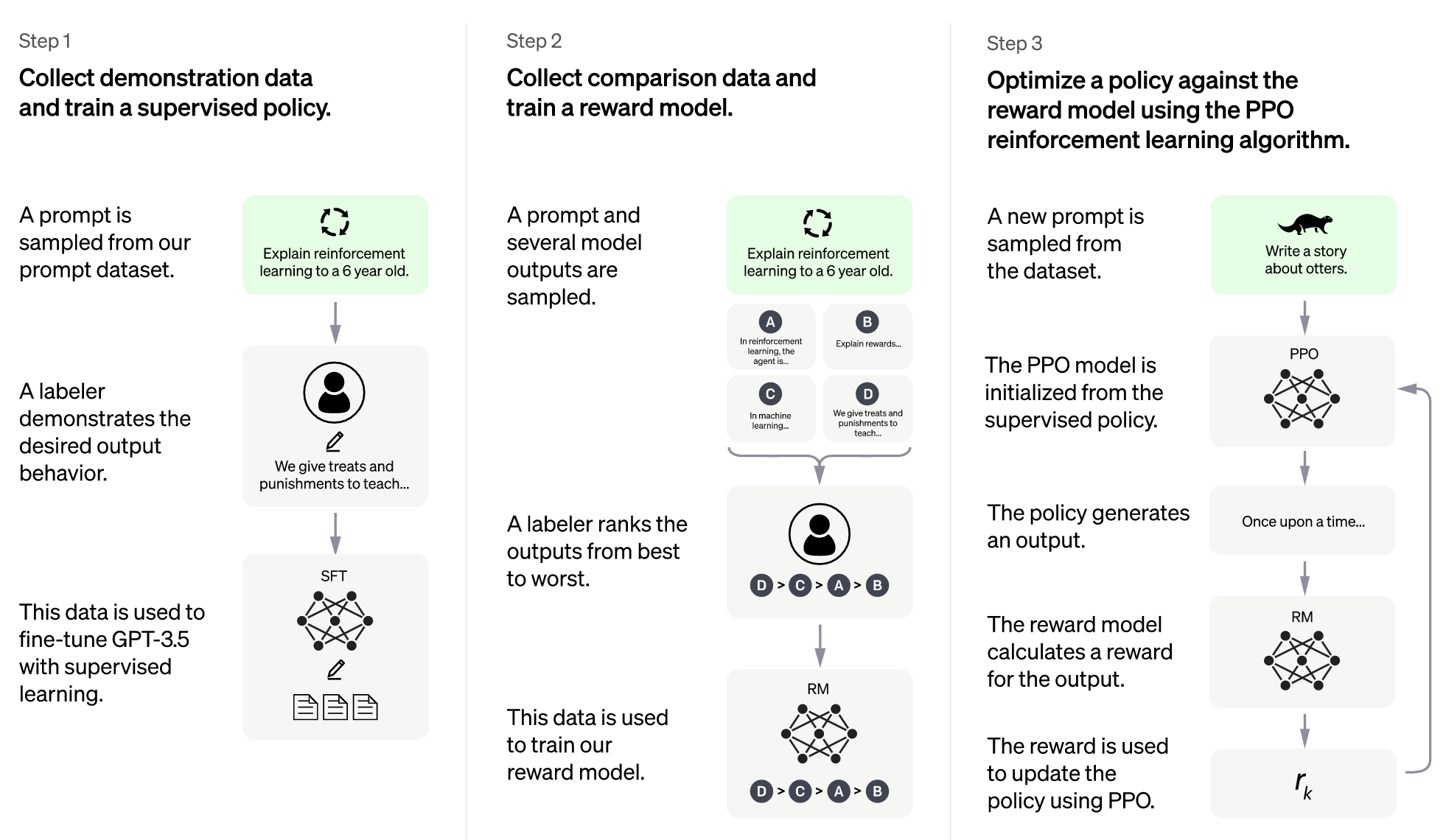
- “Once ChatGPT has been trained, it can be used to generate text by starting with a given prompt and then generating the next word in the sequence, based on the patterns it has learned from the training data. The generated text can be fed back into ChatGPT as input, allowing it to generate further text, and so on, effectively creating a conversation.” OpenAI
- Lastly, if you ask ChatGPT itself how it works internally, here’s what it has to say:
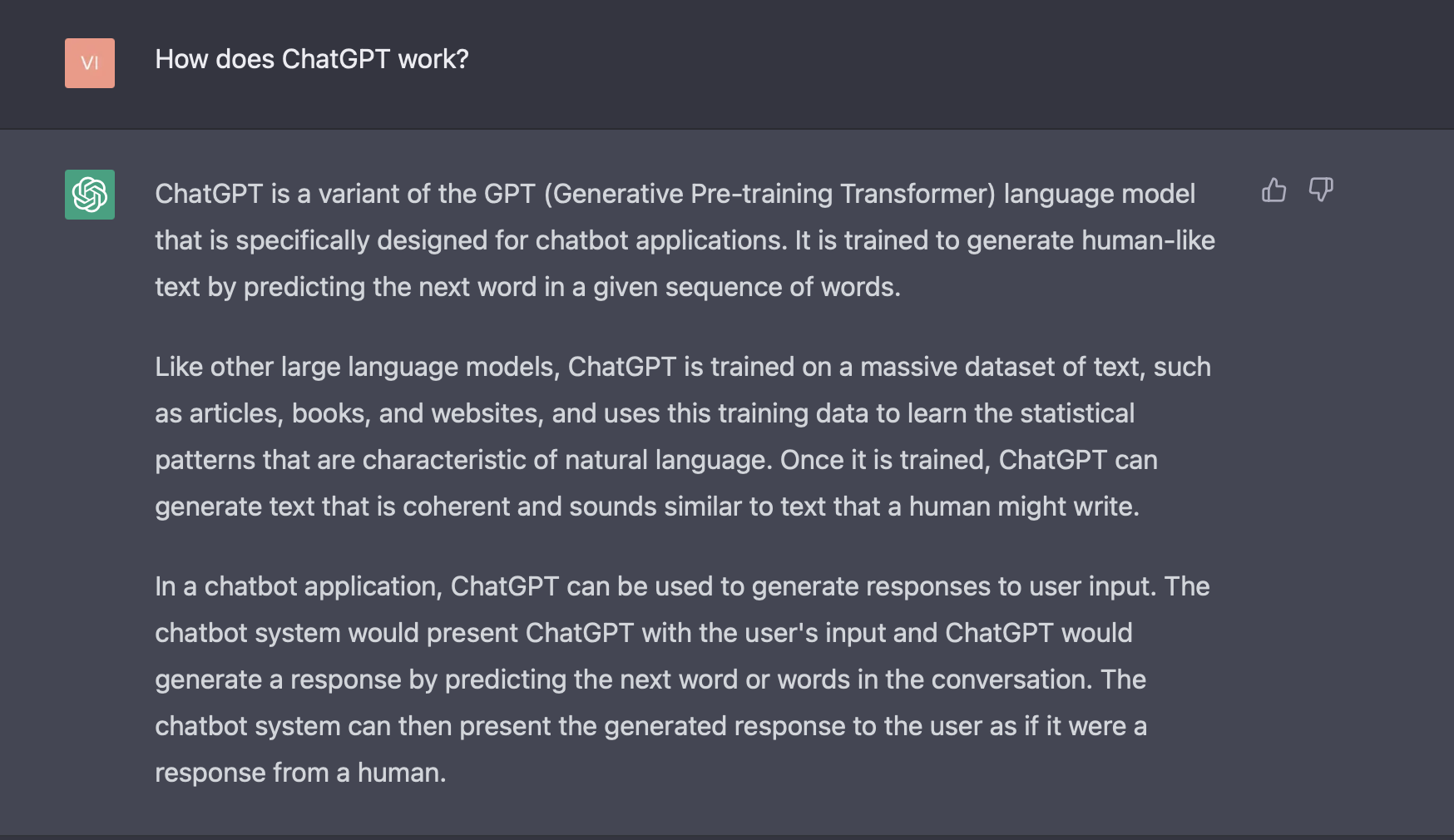
- ChatGPT is able to perform a multitude of tasks from debugging code, making an itinerary for your travel, writing a short story or poem, to coming up with recipes of your favorite meals.
- Since there isn’t a publication available on ChatGPT as of yet, we will look at details from its sibling model, InstructGPT, below. However, note that ChatGPT is finetuned from a model in the GPT-3.5 series, which finished training in early 2022 (source), while InstructGPT was finetuned on GPT-3.
Parameter count
- This Microsoft paper (likely accidentally) confirmed previous rumors that ChatGPT-3.5 is 20B parameters. Given its fast inference speed, this seems well-aligned. OpenAI did an excellent job distilling and compressing the model.
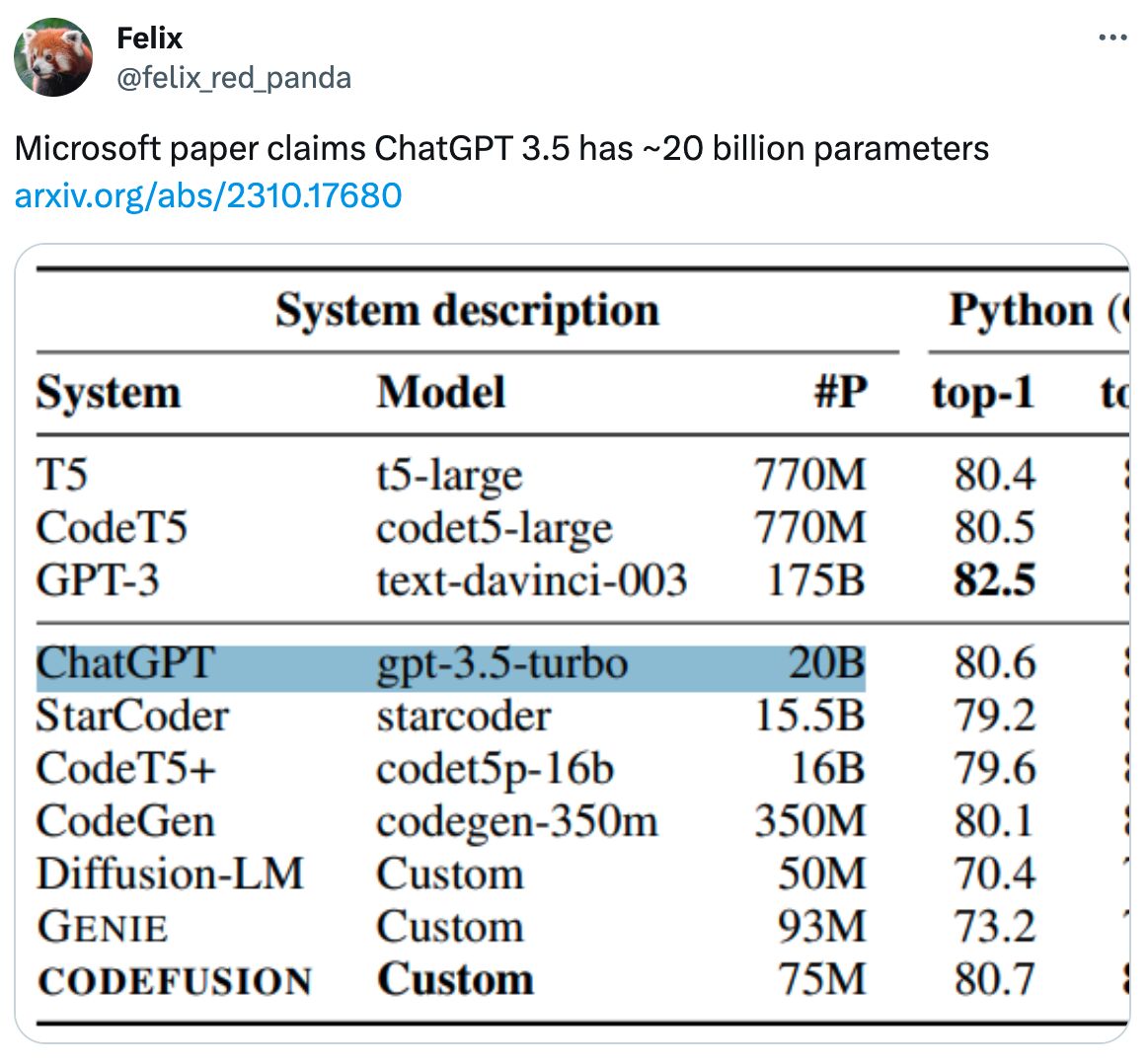
- However, note that model parameters ultimately don’t matter nearly as much as the data quality and diversity, which most of the efforts are dedicated to at big LLM teams.
How would you detect ChatGPT-generated text?
- After learning about ChatGPT and seeing its vast use cases, the next question on everyone’s mind usually is, how would you be able to detect if a content is generated by ChatGPT or a human?
- Let’s look at a few methods:
- Watermarking: A Watermark for Large Language Models
- “In the paper “A Watermark for Large Language Models” , the authors propose a relatively simple method. The idea is that the creators of the LLM would add a “watermark” signal to any generated text passage, such that the meaning and quality of the passage is not altered by the signal, the signal can easily be detected without needing any access to the LLM that generated it, and the signal cannot be easily removed by simple modifications to the text” (source: Prof. Melanie Mitchell)
- Watermarking by an LLM would have it unnoticeably generate a secret signal in the text that would help it identify where the text came from.
- OpenAI’s watermarking is a cryptography-based approach to the problem.
- DetectGPT by Eric Mitchell et al.:
- “DetectGPT relies on generating the (log-)probabilities of the text. If an LLM produces text, each token has a conditional probability of appearing based on the previous tokens. Multiply all these conditional probabilities (or effectively, sum up the log probabilities) to obtain the (joint) probability for the text.
- DetectGPT then perturbs the text: if the probability of the new text is noticeably lower than the original one it is AI-generated. Otherwise, if it’s approximately the same, it’s human-generated.
- e.g., consider the 2 sentences below
- original input: “This sentence is generated by an AI or human” => log-proba 1
- perturbed: “This writing is created by a an AI or person” => log-proba 2
- If log-proba 2 < log-proba 1 -> AI-generated
- If log-proba 2 ~ log-proba 1 -> human-generated
- Limitation: Requires access to the (log-)probabilities of the texts. This involves using a specific LLM model, which may not be representative of the AI model used to generate the text in question.” Sebastian Raschka
- AI Classifier by OpenAI:
- As stated by OpenAI, “The AI Text Classifier is a fine-tuned GPT model that predicts how likely it is that a piece of text was generated by AI from a variety of sources, such as ChatGPT.”
- The training dataset here consists of both human and AI generated text and the model assigns probability from very unlikely, unlikely, or unclear if the text is AI-generated.
- GPTZero:
- “GPTZero computes perplexity values. The perplexity is related to the log-probability of the text mentioned for DetectGPT above. The perplexity is the exponent of the negative log-probability. So, the lower the perplexity, the less random the text. Large language models learn to maximize the text probability, which means minimizing the negative log-probability, which in turn means minimizing the perplexity.
- GPTZero then assumes the lower perplexity are more likely generated by an AI.
- Limitations: see DetectGPT above. Furthermore, GPTZero only approximates the perplexity values by using a linear model.” Sebastian Raschka
- Watermarking: A Watermark for Large Language Models
Related: InstructGPT
- Paper: Training language models to follow instructions with human feedback by Ouyang et al.
- InstructGPT was also trained with RLHF much like ChatGPT in order to have the language model align with the user’s intent and you can learn more about the algorithm below.
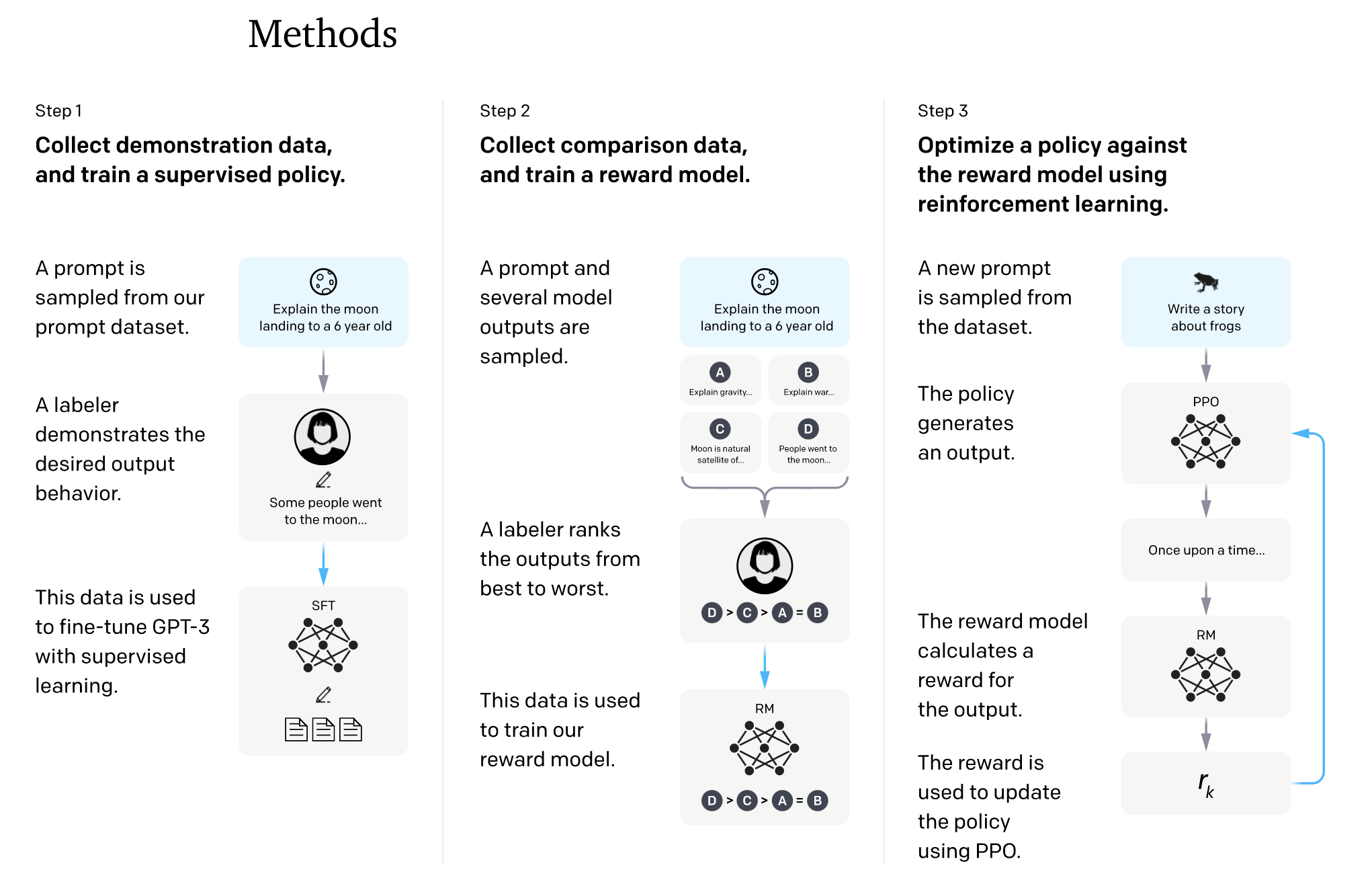
- InstructGPT’s training can be broken down into 3 steps:
- Supervised Learning:
- In this step, GPT-3 is fine-tuned with supervised learning based on human annotations that carry out instruction tuning.
- Essentially, InstructGPT starts with a set of labeled data that demonstrates the desired outcome and behavior from the model which is used to fine-tune GPT-3 with supervised learning.
- Reward Model:
- Here, a dataset is collected of rankings of several output options (could be outputs from the same model or could even be outputs from a larger model based on which the KL divergence of the model being trained vs. the larger model could be minimized) and the labeler ranks them from best to worst. A reward model is trained with this data as part of this step.
- Combining the two:
- Finally, the model generates an output to a new prompt it receives from the dataset. Then reinforcement learning is used by deploying proximal policy optimization by calculating the reward for the output and the policy is hence updated.
- We can visually understand the process by looking at the image below from OpenAI’s Training language models to follow instructions with human feedback
- Here is the improvement of performance by InstructGPT over its predecessors:
- “The resulting InstructGPT models are much better at following instructions than GPT-3. They also make up facts less often, and show small decreases in toxic output generation. Our labelers prefer outputs from our 1.3B InstructGPT model over outputs from a 175B GPT-3 model, despite having more than 100x fewer parameters.” OpenAI
- It is to be noted that InstructGPT can still make simple mistakes, however fine-tuning with human feedback has still enabled it to align with human intent (with a focus on enhancing trust and safety).
- It is important to note that the fine-tuning process proposed in the paper isn’t without its challenges. First, we need a significant volume of demonstration data. For instance, in the InstructGPT paper, they used 13k instruction-output samples for supervised fine-tuning, 33k output comparisons for reward modeling, and 31k prompts without human labels as input for RLHF. Second, fine-tuning comes with an alignment tax “negative transfer” – the process can lead to lower performance on certain critical tasks. (There’s no free lunch after all.) The same InstructGPT paper found that RLHF led to performance regressions (relative to the GPT-3 base model) on public NLP tasks like SQuAD, HellaSwag, and WMT 2015 French to English. A potential workaround is to have several smaller, specialized models that excel at narrow tasks.
Visual Summary
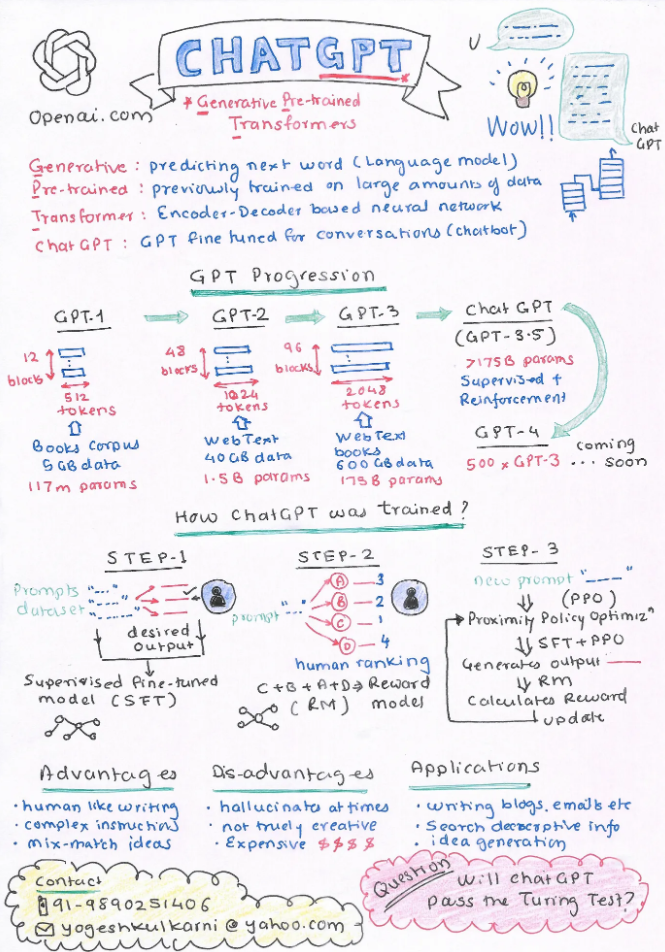
- The image above is provided by Yogesh Kulkarni.