Designing a Unique ID Generator in Distributed Systems
- Overview
- Step 1 Understand the problem and establish design scope
- Step 2 - Propose high-level design and get buy-in
- Step 3 - Design deep dive
- Sequence number
- Step 4 - Wrap up
Overview
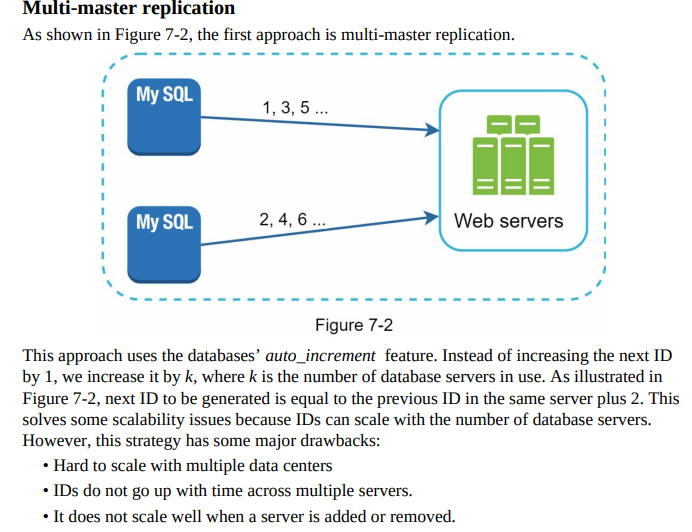
- Auto_increment, which is commonly used for generating unique IDs in traditional databases, is not suitable for a distributed environment.
- Generating unique IDs across multiple databases in a distributed system with minimal delay is challenging.
- A distributed unique ID generator should be designed to handle the scale and distribution of the system.
- Consistency and uniqueness of generated IDs must be ensured across multiple nodes.
- Consider using algorithms specifically designed for distributed environments, such as UUID or snowflake, for generating unique IDs.
- The ID generator should be scalable and able to handle high loads and concurrent requests.
- It is important to handle potential issues such as network partitions, node failures, and data center outages when designing the ID generator.
- Replication and synchronization mechanisms should be implemented to ensure consistency and availability of the ID generator across distributed nodes.
- The ID generator should be designed to be fault-tolerant, resilient, and highly available.
- Consider incorporating distributed consensus protocols or coordination services, such as ZooKeeper or etcd, to coordinate the ID generation process across distributed nodes.
- Thorough testing and monitoring should be performed to validate the performance, scalability, and reliability of the unique ID generator in a distributed system.
Step 1 Understand the problem and establish design scope
- Clarify the characteristics of unique IDs, such as uniqueness and sortability.
- Determine the incrementing pattern of IDs, considering time-based increments.
- Verify the data type requirement, ensuring that IDs only contain numerical values.
- Establish the length requirement for IDs, which should fit into 64 bits.
- Discuss the scale of the system, aiming to generate over 10,000 unique IDs per second.
- Summarize the requirements: unique IDs, numerical values, 64-bit length, ordered by date, and high throughput of 10,000 IDs per second.
Step 2 - Propose high-level design and get buy-in
- Multiple options can be used to generate unique IDs in distributed systems. The options we considered are: • Multi-master replication • Universally unique identifier (UUID) • Ticket server • Twitter snowflake approach
UUID
- UUID (Universally Unique Identifier) is a 128-bit number used to identify information in computer systems.
- UUIDs have a very low probability of collision, making them suitable for generating unique IDs.
- UUIDs can be generated independently without coordination between servers.
- Example of a UUID: 09c93e62-50b4-468d-bf8a-c07e1040bfb2.
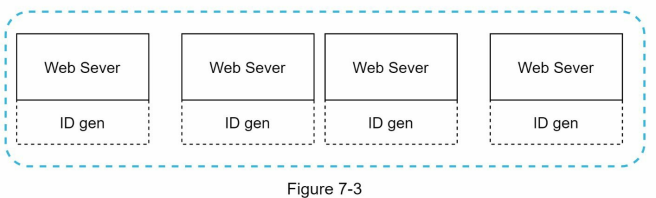
- UUIDs design is depicted in Figure 7-3.
- In this design, each web server contains an ID generator, and a web server is responsible for generating IDs independently. Pros: • Generating UUID is simple. No coordination between servers is needed so there will not be any synchronization issues. • The system is easy to scale because each web server is responsible for generating IDs they consume. ID generator can easily scale with web servers. Cons: • IDs are 128 bits long, but our requirement is 64 bits. • IDs do not go up with time. • IDs could be non-numeric.
Ticket Server
- Ticket servers are another interesting way to generate unique IDs. Flicker developed ticket servers to generate distributed primary keys [2]. It is worth mentioning how the system works
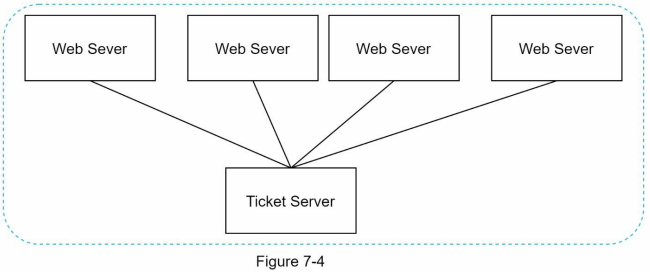
- The idea is to use a centralized auto_increment feature in a single database server called the Ticket Server.
- This approach provides numeric IDs.
- It is easy to implement and suitable for small to medium-scale applications.
- However, a major drawback is the single point of failure. If the Ticket Server goes down, all systems relying on it will face issues.
- To mitigate this, multiple ticket servers can be set up, but this introduces new challenges such as data synchronization.
Twitter’s approach

- Twitter’s unique ID generation system called “snowflake” is an approach that can meet our requirements.
- In the snowflake approach, the ID is divided into different sections.
- The layout of a 64-bit ID consists of the following sections:
- Sign bit: 1 bit, always set to 0 for future use.
- Timestamp: 41 bits representing milliseconds since the epoch (Twitter snowflake default epoch is Nov 04, 2010).
- Datacenter ID: 5 bits, allowing for 32 datacenters.
- Machine ID: 5 bits, allowing for 32 machines per datacenter.
- Sequence number: 12 bits, incremented by 1 for each ID generated on a machine/process, reset to 0 every millisecond.
- The snowflake approach provides a distributed and scalable solution for generating unique IDs.
Step 3 - Design deep dive
Summary: The chosen approach for the unique ID generator in distributed systems is based on the Twitter snowflake ID generator. It utilizes a 64-bit ID format divided into different sections, including a timestamp, datacenter ID, machine ID, and sequence number. This design ensures uniqueness, ordering by time, and scalability in a distributed environment.
Bullets:
- The unique ID generator is based on the Twitter snowflake ID generator approach.
- The ID format is 64 bits long and divided into several sections.
- The timestamp section occupies 41 bits and represents milliseconds since a defined epoch.
- Datacenter ID and machine ID sections identify the source of the ID within the distributed system.
- The datacenter ID is 5 bits long, allowing up to 32 datacenters.
- The machine ID is 5 bits long, allowing up to 32 machines per datacenter.
- The sequence number section is 12 bits long and increments for each generated ID within a machine/process.
- The sequence number resets to 0 every millisecond to ensure uniqueness within that time interval.
- The design provides distributed and scalable ID generation for the distributed system.
- The generated IDs are numeric and can be easily used for various purposes.
- Summary:
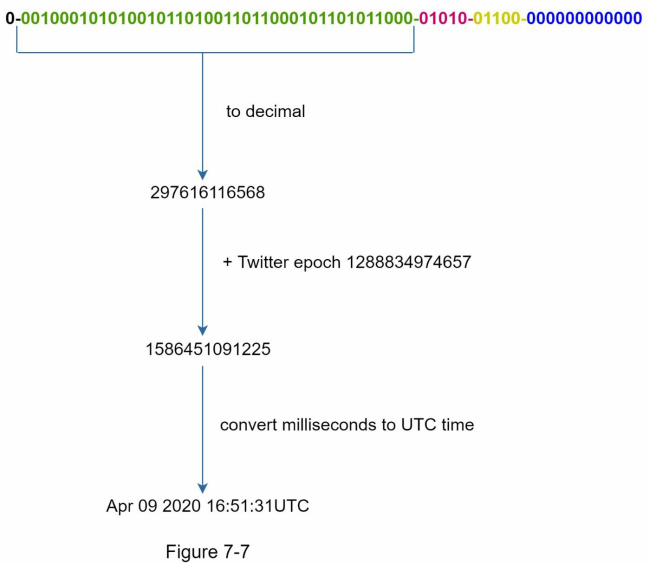
- In the unique ID generator design based on the Twitter snowflake approach, datacenter IDs and machine IDs are chosen during startup and remain fixed. Changes to these values must be carefully reviewed to avoid ID conflicts. The timestamp section, occupying 41 bits, is crucial for ordering IDs by time. Binary representation can be converted to UTC, allowing for sorting, and vice versa.
- Bullets:
- Datacenter IDs and machine IDs are selected during system startup and should not be changed without careful consideration to avoid ID conflicts.
- The timestamp section, consisting of 41 bits, plays a significant role in the ID generator design.
- The timestamp allows for the sorting of IDs based on time.
- Binary representation can be converted to UTC time using a conversion method.
- UTC time can also be converted back to binary representation.
- The timestamp ensures that generated IDs can be ordered chronologically.
- Ordering by time enables efficient retrieval and analysis of data based on ID timestamps.
- The 41-bit timestamp section in the ID generator can represent a maximum timestamp of 2^41 - 1, which is equivalent to approximately 69 years in milliseconds.
- This allows the ID generator to function for 69 years before reaching the maximum timestamp value.
- Setting a custom epoch time close to the current date helps delay the potential overflow of the timestamp section.
- After 69 years, a new epoch time will be needed, or alternative techniques must be adopted to migrate IDs and continue generating unique IDs.
Sequence number
- Sequence number is 12 bits, which give us 2 ^ 12 = 4096 combinations.
- This field is 0 unless more than one ID is generated in a millisecond on the same server. In theory, a machine can support a maximum of 4096 new IDs per millisecond.
Step 4 - Wrap up
In this chapter, we discussed different approaches to design a unique ID generator: multimaster replication, UUID, ticket server, and Twitter snowflake-like unique ID generator. We settle on snowflake as it supports all our use cases and is scalable in a distributed environment. If there is extra time at the end of the interview, here are a few additional talking points: • Clock synchronization. In our design, we assume ID generation servers have the same clock. This assumption might not be true when a server is running on multiple cores. The same challenge exists in multi-machine scenarios. Solutions to clock synchronization are out of the scope of this book; however, it is important to understand the problem exists. Network Time Protocol is the most popular solution to this problem. For interested readers, refer to the reference material [4]. • Section length tuning. For example, fewer sequence numbers but more timestamp bits are effective for low concurrency and long-term applications. • High availability. Since an ID generator is a mission-critical system, it must be highly available.