Distilled • Status/Posts Search
- Overview
- Design Goals/Requirements
- Scale Estimation and Performance/Capacity Requirements
- System APIs
- High Level System Design
- Data Model
- Detailed Component Design
- Fault Tolerance
- Caching
- Load Balancing
- Ranking
Overview
- Design a service that can store and search statues/posts/tweets on social networking services. For e.g., Twitter users can update their status whenever they like. Each status (called a tweet) consists of plain text and our goal is to design a system that allows searching over all the user tweets.
- Similarly, facebook provides a search bar at the top of its page to enable its users to search posts statuses videos and other forms of content posted by their friends and the pages they follow.
- Similar Problems: Facebook status/posts search, Twitter tweet search, LinkedIn post search.
Design Goals/Requirements
- Functional requirements:
- Develop the back-end of a system that will enable users to search the statuses that their friends and the pages they follow have posted on facebook.
- We can consider that these statuses will only contain text for this particular question.
- Non-functional requirements:
- Minimum latency: Our system should be able to search status of their followed friends and pages in real-time so the user does not experience any significant lag during the process.
- High availability: The final design should be highly available.
- Eventual consistency (due to CAP theorem): As we know from the CAP theorem, that we can have either high availability or high consistency, thus we will aim for an eventually consistent system.
- Read-heavy service: Our system will be read heavy in nature as more users will be searching on Facebook rather than posting statuses, thus the number of read requests will be far greater than write requests.
Scale Estimation and Performance/Capacity Requirements
- Some back-of-the-envelope calculations based on average numbers.
Traffic estimates
- For Facebook:
- Daily Active Users (DAUs): 2 billion.
- Number of searches per user per day: 5.
- Total number of searches per day: 2B*5 = 10 billion.
- Number of statuses updated per day (assuming every user updates their status everyday): 2 billion.
- Average size of a status: 300 bytes.
- For Twitter:
- Daily Active Users (DAUs): 200 million.
- Number of tweets per day: 400 million.
- Average size of a tweet: 300 bytes.
- Total number of searches per day: 500M.
- Word-join method: The search query will consist of multiple words combined with AND/OR.
Storage estimates
- Since we have 2 billion new posts/statuses every day and each post on average is 300 bytes, the total storage we need, will be: 2B * 300 => 600GB/day.
- Total storage needed per second: 600GB / 24hours / 3600sec ~= 6.9MB/second.
System APIs
- Once we have finalized the requirements, it’s always a good idea to define the system APIs. This should explicitly state what is expected from the system. These would be running as microservices on our application servers.
- We can have SOAP or REST APIs to expose the functionality of our service.
-
The following could be the definition of a read API to fetch the search results for a particular query:
search(user_id, search_terms, maximum_results_to_return, sort, page_token)- Parameters:
user_id (string): The user ID (or API developer keyapi_dev_key) of a registered account. This will be used to, among other things, throttle users based on their allocated quota.search_terms (string): A string containing the search terms.maximum_results_to_return (number): Number of posts to return.sort (number): Optional sort mode: Latest first (0 - default), Best matched (1), Most liked (2).page_token (string): This token will specify a page in the result set that should be returned.
- Returns (JSON): A JSON containing information about a list of posts matching the search query. Each result entry can have the user ID & name, post text, post ID, creation time, number of likes, etc.
- Parameters:
-
The following could be the definition of a write API to post new statuses and store them in our database:
postStatus(user_id, search_terms, maximum_results_to_return, sort, page_token)- Parameters:
user_id (string): The user ID (or API developer keyapi_dev_key) of a registered account. This will be used to, among other things, throttle users based on their allocated quota.status_contents (string): A string containing the status contents.timestamp (number): The timestamp of the status.
- Returns None
- Parameters:
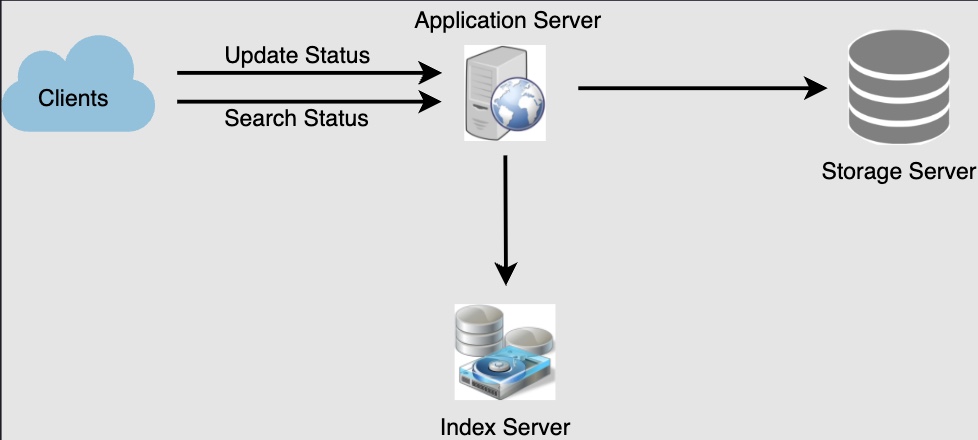
High Level System Design
- At a high level, we will need to:
- Store all the posts in a database.
- Build an index that can keep track of which word appears in which post. This index will help us quickly find posts that the users are trying to search for.
Data Model
Index
- What should our index look like? Since our post queries will consist of words, let’s build the index that can tell us which word comes in which post object.
Size of the Index
- Let’s first estimate how big our index will be. If we want to build an index for all the English words and some famous nouns like people names, city names, etc., and if we assume that we have around 300K English words and 200K nouns, then we will have 500k total words in our index. Let’s assume that the average length of a word is five characters.
- If we are keeping our index in memory, we need 2.5MB of memory to store all the words: 500K * 5 => 2.5MB.
- Let’s assume that we want to keep the index in memory for all the posts from only the past five years, which would be 3.6T as calculated above. To index 3.6T posts, we’ll need 2^46 indexes, which implies 46 bits for the index, which in turn means 6 bytes.
- Given that each PostID will need 6 bytes, the amount of memory we’ll need to store all the
PostID: 3.6T * 6 => 21.6 TB.
- Given that each PostID will need 6 bytes, the amount of memory we’ll need to store all the
Implementation of the Index
- Our index would be a big distributed hash table (using an in-memory data structure store, say Redis), where ‘key’ would be the word and ‘value’ will be a list of
PostIDsof all posts that contain that word.
- Assuming on average we have 40 words in each post and since we will not be indexing stop words (such as prepositions and common words) such as ‘the’, ‘an’, ‘and’ etc., let’s assume we will have around 15 words in each post that need to be indexed. This means each PostID will be stored 15 times in our index.
- So total memory we will need to store our index: (21.6T * 15) + 2.5MB ~= 324 TB.
- Assuming a high-end server has 128GB of memory, we would need 324000/128 = 2531 such servers to hold our index.
Detailed Component Design
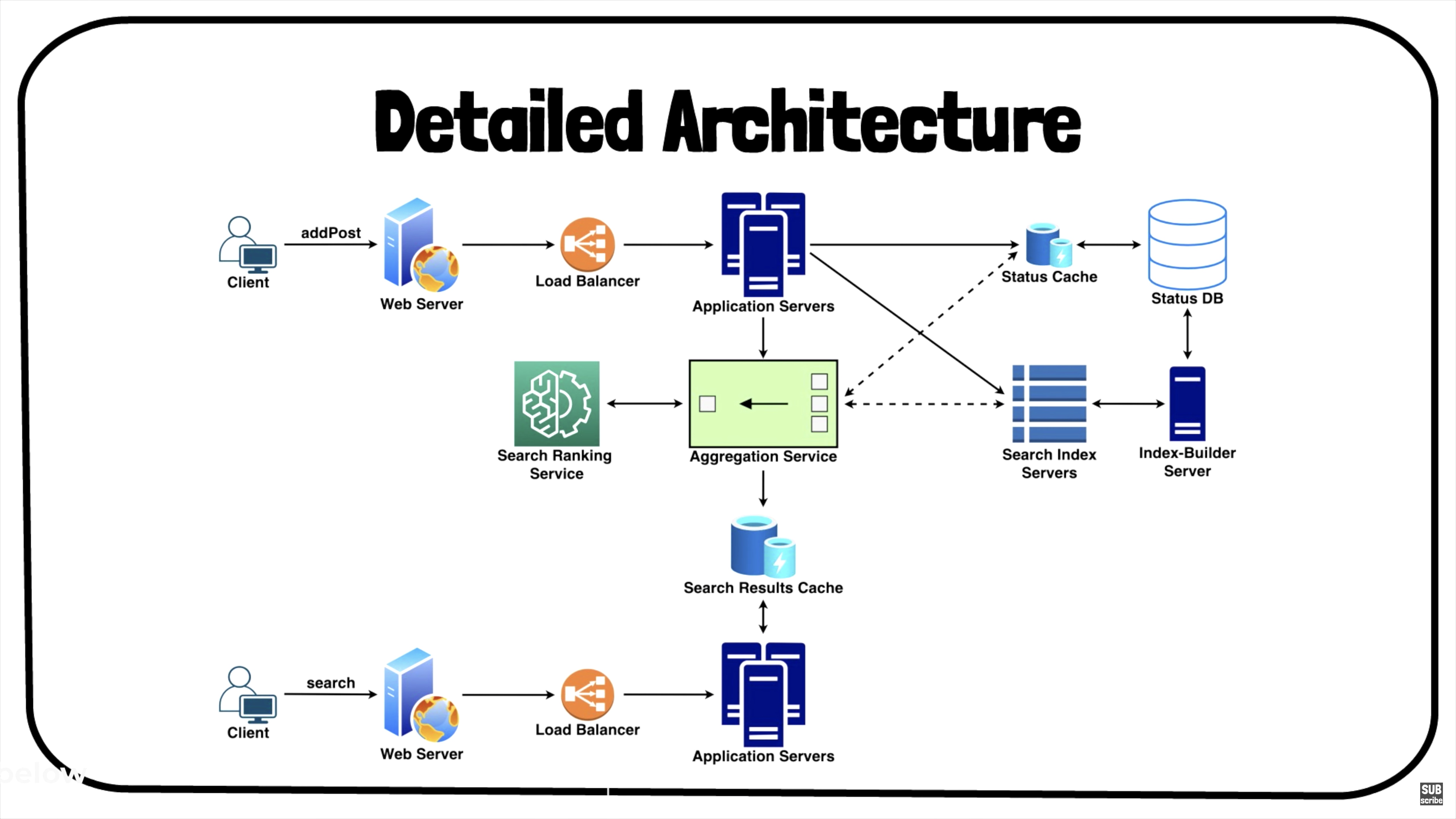
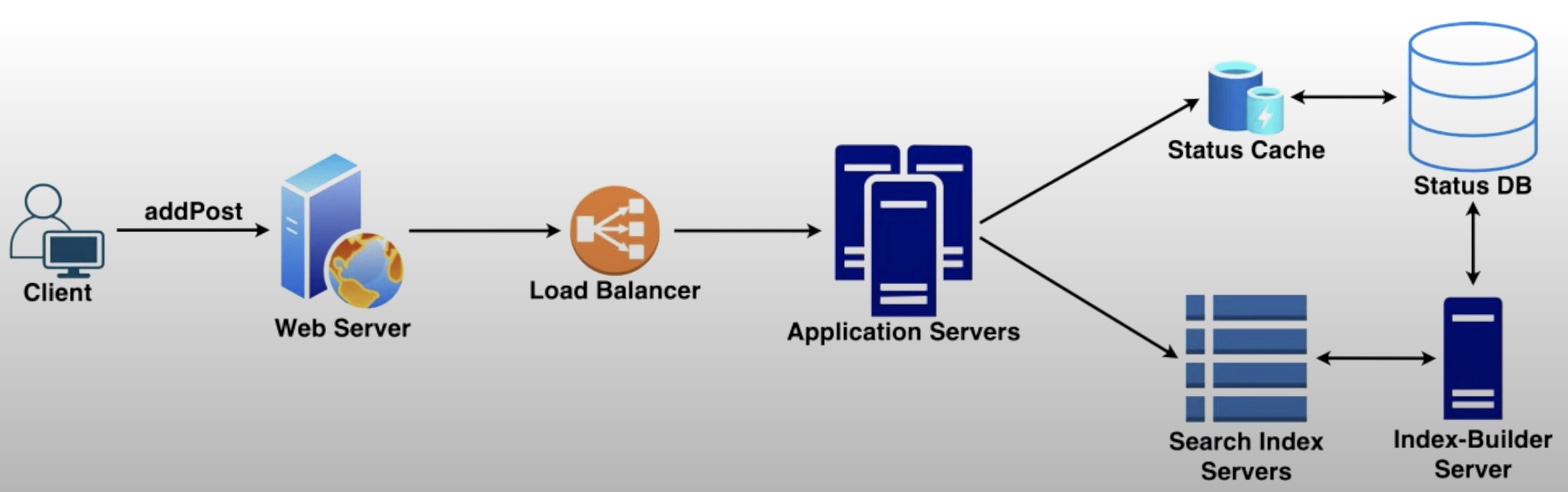
- A more detailed version of the architecture with
addPostalong withsearchis as follows:
- It includes various components, such as:
- Centralized servers to aggregate results (if sharding based on PostID).
- Databases for storing the search index.
- Application servers to run system APIs as microservices.
- Search ranking service.
- Caches for fast retrieval.
- Load balancers to distribute load as evenly as possible, and ensure crashed servers are taken out of the load distribution loop.
Storage for Posts/Statuses/Tweets
-
We need to store 600GB of new data every day. Given this huge amount of data, we need to come up with a data partitioning scheme that will be efficiently distributing the data onto multiple servers. If we plan for next five years, we will need the following storage: 600GB * 365days * 5years ~= 1PB.
-
If we never want to be more than 80% full at any time, we approximately will need 1.2PB of total storage. Let’s assume that we want to keep an extra copy of all posts for fault tolerance; then, our total storage requirement will be 2.4PB. If we assume a modern server can store up to 8TB of data, we would need 300 such servers to hold all of the required data for the next five years.
-
Let’s start with a simplistic design where we store the posts in a MySQL database. We can assume that we store the posts in a table having two columns, PostID and PostText. Let’s assume we partition our data based on PostID. If our
PostIDare unique system-wide, we can define a hash function that can map a PostID to a storage server where we can store that post object.
How can we create system-wide unique PostID?
-
If we’re getting 2B new posts each day, then the number of post objects we can expect in five years would be 2B * 365 days * 5 years => 3.6 trillion.
-
This means we would need a five bytes number to identify
PostIDuniquely. Let’s assume we have a service that can generate a unique PostID whenever we need to store an object (the PostID discussed here will be similar to TweetID discussed in Designing Twitter). We can feed the PostID to our hash function to find the storage server and store our post object there.
Sharding
- We can partition our data based on two criteria:
Sharding based on Words
-
While building our index, we will iterate through all the words of a post and calculate the hash of each word to find the server where it would be indexed. To find all posts containing a specific word we have to query only the server which contains this word.
-
We have a couple of issues with this approach:
- What if a word becomes hot? Then there will be a lot of queries on the server holding that word. This high load will affect the performance of our service.
- Over time, some words can end up storing a lot of
PostIDcompared to others, therefore, maintaining a uniform distribution of words while posts are growing is quite tricky. To recover from these situations we either have to repartition our data or use Consistent Hashing.
Sharding based on PostID
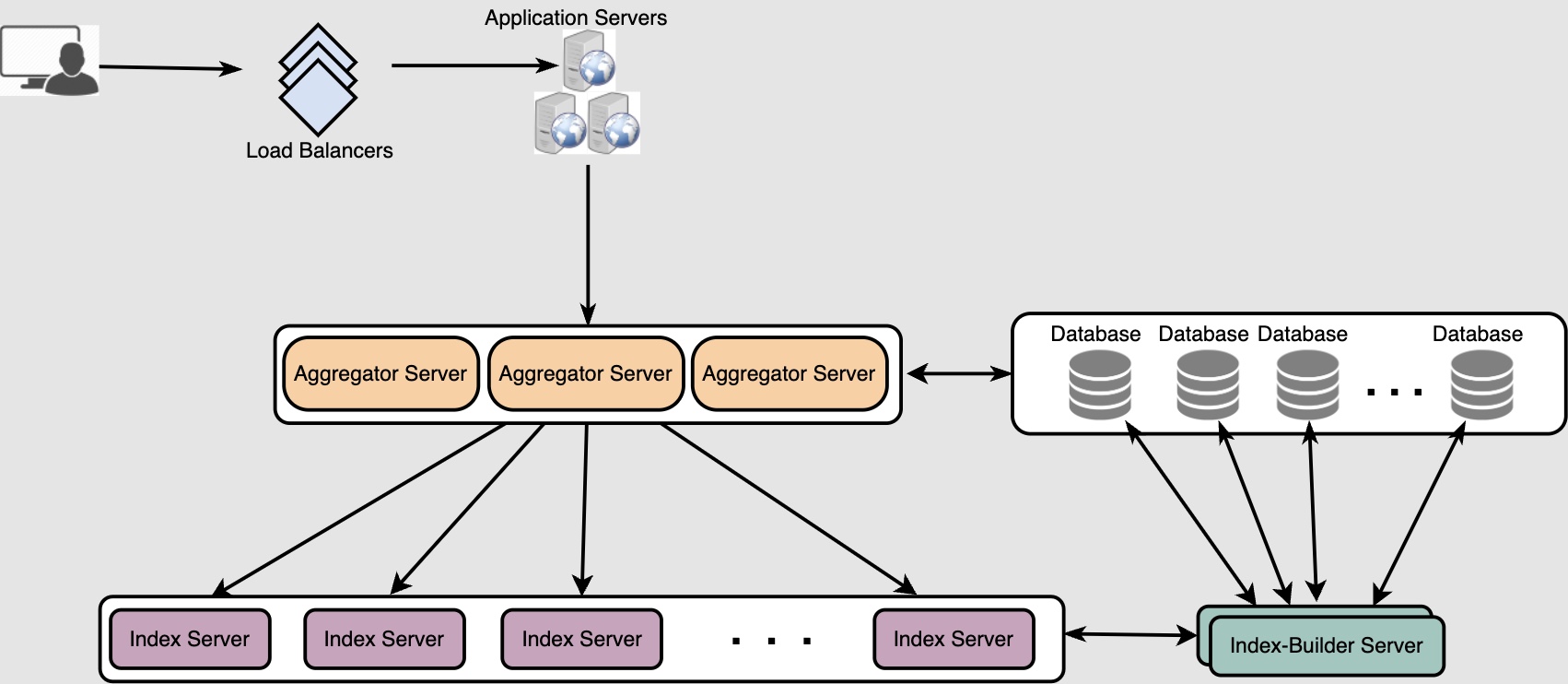
- While storing, we will pass the PostID to our hash function to find the server and index all the words of the post corresponding to the PostID on that server.
- While querying for a particular word, we have to query all the servers, and each server will return a set of
PostID. The downside is that we’ll need a centralized server will aggregate these results to return them to the user.
Fault Tolerance
- What will happen when an index server dies? We can have a secondary replica of each server and if the primary server dies, you can simply failover to the secondary. Both primary and secondary servers will have the same copy of the index.
What if both primary and secondary servers die at the same time?
- We have to allocate a new server and rebuild the same index on it. How can we do that? We don’t know what words/posts were kept on this server.
- If we were sharding based on the post object, the brute-force solution would be to iterate through the whole database and filter
PostIDusing our hash function to figure out all the required posts that would be stored on this server. This would not only be inefficient, but note that during the time when the server was being rebuilt, we would not be able to serve any query from it, thus missing some posts that should have been seen by the user – thereby, impacting uptime/availability.
How can we efficiently retrieve a mapping between posts and the index server?
- We have to build a reverse index that will map an the index server to the
PostIDit contains. Our Index-Builder server can hold this information. - We will need to build a Hashtable where the ‘key’ will be the index server number and the ‘value’ will be a HashSet containing all the
PostIDbeing kept at that index server. - Notice that we are keeping all the
PostIDin a HashSet; this will enable us to add/remove posts from our index quickly. So now, whenever an index server has to rebuild itself, it can simply ask the Index-Builder server for all the posts it needs to store and then fetch those posts to build the index. This approach will surely be fast. - We should also have a replica of the Index-Builder server for fault tolerance.
What happens if an application server?
- You can maintain a secondary application server and failover to the secondary if the primary fails.
Caching
- To deal with hot posts we can introduce a cache in front of our database. Assume 20% of posts are hot posts. We can use Memcached, which can store all such hot posts in memory.
- Application servers, before hitting the aggregators, can quickly check if the cache has that post. Based on clients’ usage patterns, we can adjust how many cache servers we need. For cache eviction policy, Least Recently Used (LRU) seems suitable for our system.
Load Balancing
- We can add a load balancing layer at two places in our system between:
- Clients and Web servers, and,
- Application servers and Aggregators.
- Initially, a simple Round Robin approach can be adopted; that distributes incoming requests equally among backend servers. This LB is simple to implement and does not introduce any overhead. Another benefit of this approach is LB will take dead servers out of the rotation and will stop sending any traffic to it.
- A problem with Round Robin LB is it won’t take server load into consideration. If a server is overloaded or slow or has crashed, the LB will not stop sending new requests to that server. To handle this, a more intelligent LB solution can be placed that periodically polls/queries the backend server about their load and adjust traffic based on that.
Ranking
- How about if we want to rank the search results by social graph distance, popularity, relevance, etc? Let’s assume we want to rank posts by popularity, like how many likes or comments a post is getting, etc.
- In such a case, our ranking algorithm can calculate a ‘popularity number’ (based on the number of likes, etc.) and store it with the index.
- Each partition can sort the results based on this popularity number before returning results to the aggregator server. The aggregator server combines all these results, sorts them based on the popularity number, and sends the top results to the user.