Rate Limiter Engineering Design
- Overview
- Step 1: Understand the problem, establish design
- Step 2: Propose high level design and get buy in
- Step 3 design deep dive
- Step 4 - Wrap Up
Overview
- In this article, we will take the framework from earlier and leverage it to design a rate limiter.
- In network systems, a rate limiter is employed to regulate the rate of traffic transmitted by clients or services. Specifically in the context of HTTP, a rate limiter imposes restrictions on the number of client requests permitted within a specified timeframe. If the count of API requests surpasses the defined threshold set by the rate limiter, any excess calls are blocked. Here are a few examples of rate limiting scenarios:
- Users can only create a maximum of 2 posts per second.
- A maximum of 10 accounts can be created per day from the same IP address.
- Rewards can be claimed no more than 5 times per week from the same device.
- Prior to diving into the design process, it is important to understand the advantages of implementing an API rate limiter:
- Prevention of resource starvation resulting from potential Denial of Service (DoS) attacks. Nearly all major tech companies enforce some form of rate limiting on their APIs. For instance, Twitter limits tweets to 300 per 3 hours, while Google Docs APIs have default limits of 300 read requests per user every 60 seconds. By employing a rate limiter, excess calls that could lead to DoS attacks, intentional or unintentional, can be effectively blocked.
- Cost reduction. Restricting excessive requests translates to fewer servers required and the ability to allocate more resources to high-priority APIs. This aspect is particularly crucial for companies utilizing paid third-party APIs. For example, external APIs such as credit checks, payment processing, and health record retrieval are charged on a per-call basis. Limiting the number of calls becomes essential to minimize costs.
- Prevention of server overload. A rate limiter plays a vital role in mitigating server load by filtering out excessive requests caused by bots or user misbehavior. This safeguards servers from unnecessary strain.
Step 1: Understand the problem, establish design
- To design a rate limiter system, it is crucial to establish the problem’s scope and requirements. In an interview scenario between an interviewer and a candidate, the following discussions take place:
- The type of rate limiter to be designed is clarified as a server-side API rate limiter.
- The rate limiter should be able to throttle API requests based on various factors such as IP, user ID, or other properties.
- The system needs to handle a large number of requests and operate in a distributed environment.
- The decision to implement the rate limiter as a separate service or within application code is left to the candidate.
- It is necessary to inform users who are throttled by the rate limiter.
- The requirements for the system are summarized as follows:
- Accurate limitation of excessive requests.
- Low latency to avoid slowing down HTTP response time.
- Efficient utilization of memory.
- Support for distributed rate limiting across multiple servers or processes.
- Clear exception handling to inform users when their requests are throttled.
- High fault tolerance to ensure that issues with the rate limiter do not impact the entire system.
Step 2: Propose high level design and get buy in
- When deciding where to implement a rate limiter in a basic client and server communication model, there are two options to consider:
- Client-side implementation:
- Implementing the rate limiter on the client-side is generally not recommended due to potential vulnerabilities. Malicious actors can forge client requests, undermining the effectiveness of rate limiting measures.
- Lack of control over the client implementation further complicates the enforcement of rate limiting.
- Server-side implementation:
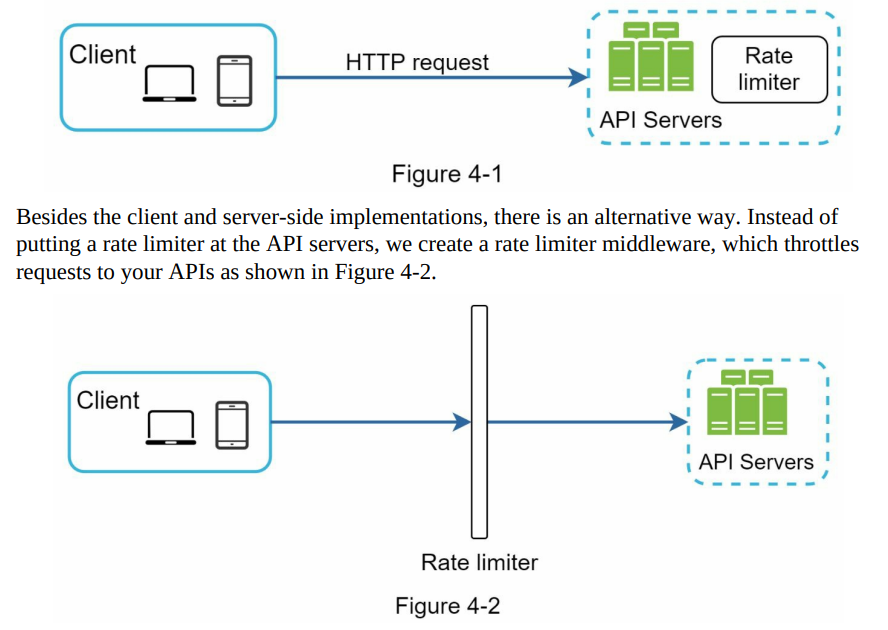
- Figure 4-1 illustrates a rate limiter placed on the server-side.
- Implementing the rate limiter on the server-side is a more reliable approach, allowing for better control and enforcement of rate limiting measures.
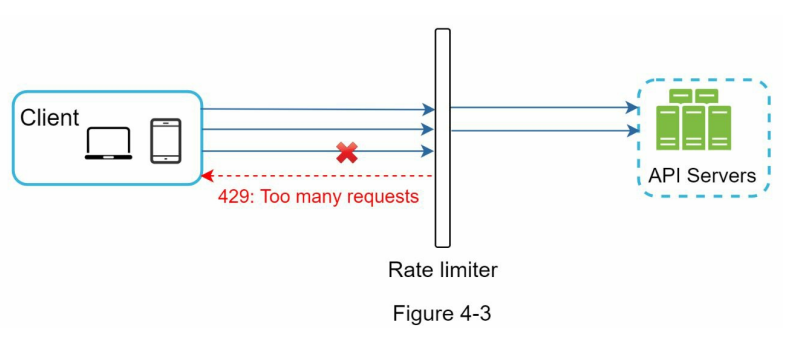
- To illustrate how rate limiting functions in this design, consider the following example (Figure 4-3):
- The API allows a maximum of 2 requests per second.
- Within a second, a client sends 3 requests to the server.
- The first two requests are successfully routed to the API servers.
- However, the rate limiter middleware detects the third request and throttles it.
- The rate limiter returns an HTTP status code 429, indicating that the user has exceeded the allowed number of requests.
- When implementing rate limiting in cloud microservices, the API gateway plays a crucial role, providing various functionalities such as rate limiting, SSL termination, authentication, IP whitelisting, and serving static content.
-
When deciding where to implement the rate limiter, considerations should be made based on your company’s technology stack, engineering resources, priorities, and goals. Here are some general guidelines:
- Evaluate your current technology stack, ensuring that your programming language is efficient for server-side rate limiting implementation.
- Choose a rate limiting algorithm that aligns with your business requirements. Server-side implementation offers more flexibility in algorithm selection, but third-party gateways may have limitations.
- If you already utilize microservice architecture with an API gateway for authentication, IP whitelisting, etc., it’s suitable to incorporate the rate limiter into the API gateway.
- Developing a custom rate limiting service requires time and resources. If you lack engineering resources, opting for a commercial API gateway is a more practical option.
- Algorithms for rate limiting:
- Rate limiting can utilize various algorithms, each with its own advantages and disadvantages.
- Understanding these algorithms at a high level helps in selecting the appropriate one(s) for specific use cases.
- Popular rate limiting algorithms include:
- Token bucket
- Leaking bucket
- Fixed window counter
- Sliding window log
- Sliding window counter
- Token bucket algorithm:
- The token bucket algorithm is widely used for rate limiting and is favored by internet companies like Amazon and Stripe.
- The algorithm functions as follows:
- A token bucket is a container with a predefined capacity.
- Tokens are added to the bucket at a predetermined rate periodically.
- When the bucket is full, no additional tokens are added.
- In case the bucket is already full, any extra tokens overflow and are discarded.
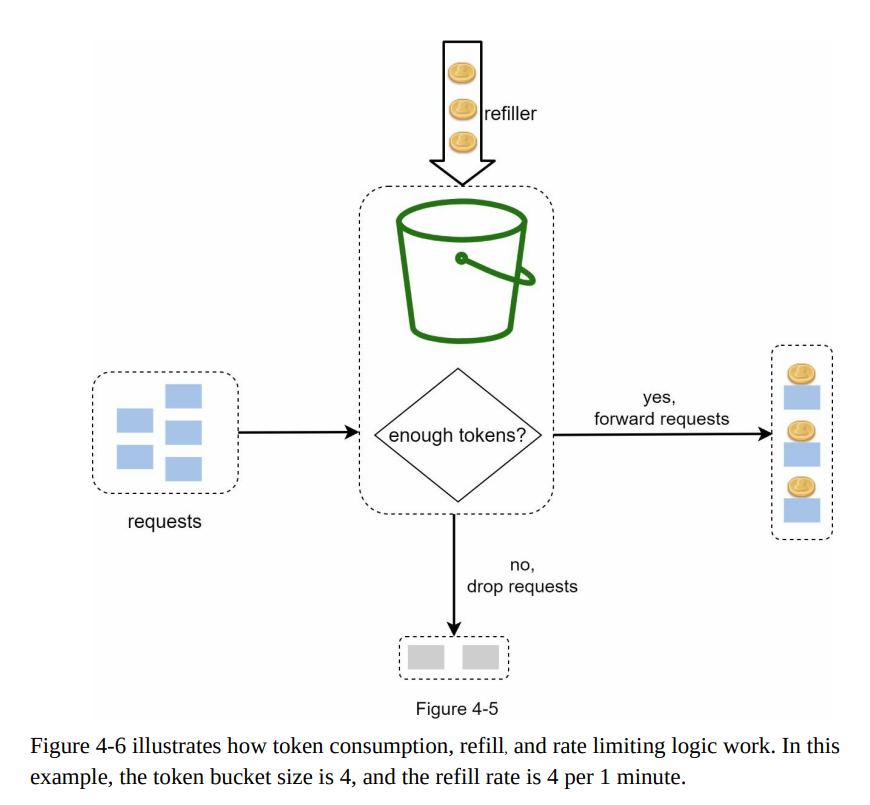
- Token bucket algorithm:
- The algorithm requires two parameters: bucket size (maximum number of tokens) and refill rate (tokens added per second).
- The number of buckets needed varies based on rate-limiting rules:
- Different API endpoints often require separate buckets for specific limitations (e.g., posting, adding friends, liking posts).
- Throttling based on IP addresses requires a bucket for each IP address.
- A global bucket shared by all requests may be suitable for a maximum request limit.
- Pros:
- Easy to implement.
- Memory efficient.
- Allows bursts of traffic as long as tokens are available.
- Cons:
- Tuning bucket size and refill rate can be challenging.
- Leaking bucket algorithm:
- Similar to the token bucket algorithm but with requests processed at a fixed rate.
- Typically implemented with a first-in-first-out (FIFO) queue.
- Algorithm steps:
- Upon request arrival, check if the queue is full. If not, add the request to the queue.
- If the queue is full, drop the request.
- Requests are processed from the queue at regular intervals.
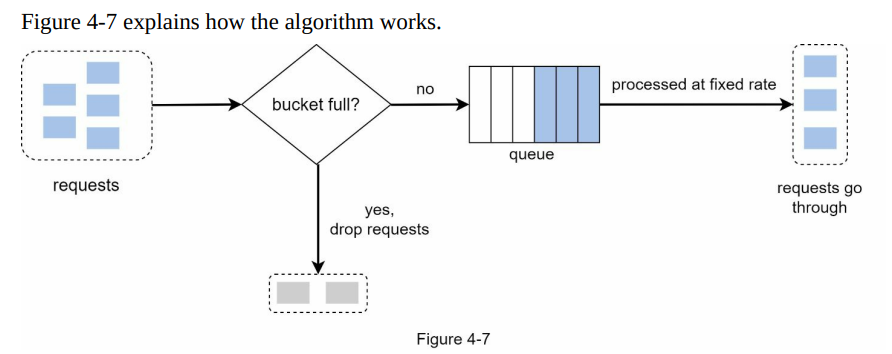
-
Leaking bucket algorithm:
- Takes two parameters: bucket size (equal to queue size) and outflow rate (requests processed at a fixed rate).
- Shopify uses leaky buckets for rate-limiting.
- Pros:
- Memory efficient due to limited queue size.
- Suitable for use cases requiring a stable outflow rate.
- Cons:
- Burst of traffic can fill up the queue, potentially leading to rate limiting of recent requests.
- Requires proper tuning of parameters.
-
Fixed window counter algorithm:
- Divides the timeline into fixed time windows with a counter assigned to each window.
- Each request increments the counter, and new requests are dropped if the counter reaches the threshold.
- Pros:
- Memory efficient.
- Easy to understand.
- Quota resets at the end of each time window, suitable for certain use cases.
- Cons:
- Traffic spikes at window edges can allow more requests than the allowed quota.
-
Sliding window log algorithm:
- Addresses the issue of the fixed window counter algorithm allowing more requests at window edges.
- Tracks request timestamps in a cache (e.g., Redis sorted sets).
- Outdated timestamps are removed, and the timestamp of a new request is added.
- If the log size is within the allowed count, the request is accepted; otherwise, it is rejected.
High level design
- Rate limiting algorithms require a counter to track the number of requests from a user or IP address.
- Counters should not be stored in a database due to slow disk access.
- In-memory cache is preferred for its speed and support for time-based expiration.
- Redis is a popular choice for implementing rate limiting.
- Redis offers commands like INCR to increase the counter and EXPIRE to set a timeout for automatic counter deletion.
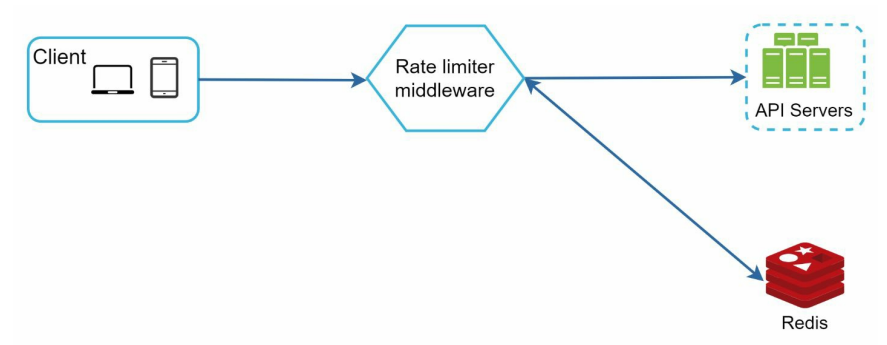
- The client sends a request to rate limiting middleware.
- Rate limiting middleware fetches the counter from the corresponding bucket in Redis and checks if the limit is reached or not.
- If the limit is reached, the request is rejected.
- If the limit is not reached, the request is sent to API servers. Meanwhile, the system increments the counter and saves it back to Redis.
Step 3 design deep dive
-
Summary:
- The high-level design in Figure 4-12 raises questions about rate limiting rules and handling rate-limited requests.
- Rate limiting rules define limits for specific domains and descriptors, stored in configuration files.
- When a request exceeds the rate limit, a HTTP response code 429 (too many requests) is returned to the client.
- Rate-limited requests can be enqueued for later processing, especially during system overload.
- Clients receive rate limiter headers in the HTTP response, including X-Ratelimit-Remaining (remaining allowed requests), X-Ratelimit-Limit (maximum calls per time window), and X-Ratelimit-Retry-After (time to wait before making another request without being throttled).

Rate limiter headers
- To inform clients about rate limiting, rate limiter headers are included in the HTTP response. These headers provide important information:
- X-Ratelimit-Remaining: Indicates the number of remaining allowed requests within the current time window.
- X-Ratelimit-Limit: Specifies the maximum number of calls the client can make per time window.
- X-Ratelimit-Retry-After: Specifies the number of seconds the client needs to wait before making another request without being throttled.
- When a user exceeds the rate limit, the server responds with a 429 “too many requests” error and includes the X-Ratelimit-Retry-After header, indicating the duration the client should wait before making a new request. These headers enable clients to understand their rate limit status and adjust their request behavior accordingly.
Detailed Design
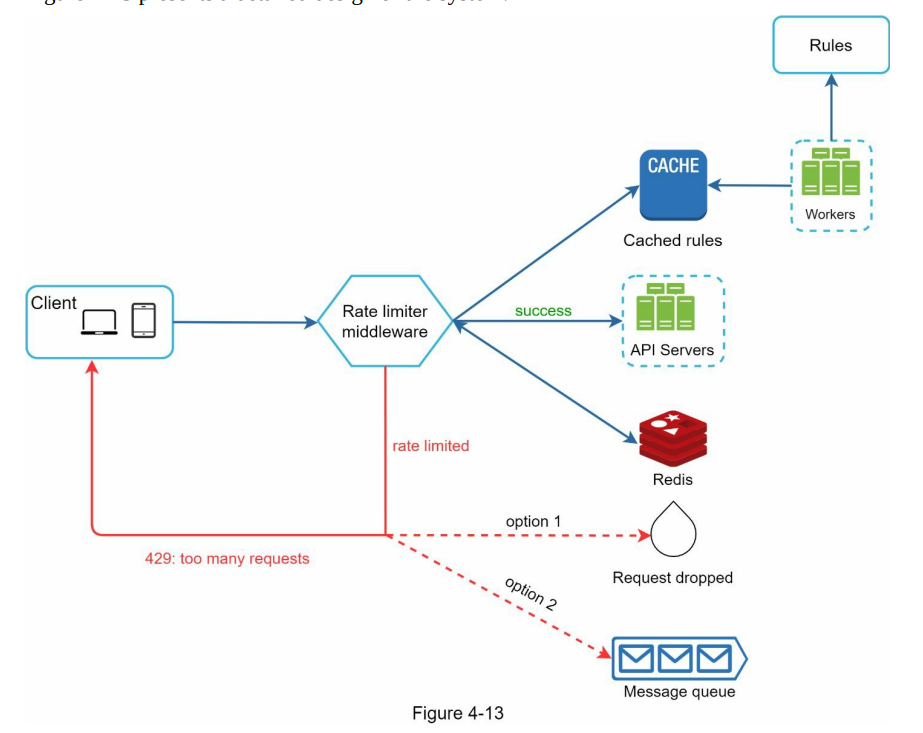
- Rules are stored on the disk. Workers frequently pull rules from the disk and store them in the cache.
- When a client sends a request to the server, the request is sent to the rate limiter middleware first.
- Rate limiter middleware loads rules from the cache. It fetches counters and last request timestamp from Redis cache. Based on the response, the rate limiter decides:
- if the request is not rate limited, it is forwarded to API servers.
-
if the request is rate limited, the rate limiter returns 429 too many requests error to the client. In the meantime, the request is either dropped or forwarded to the queue
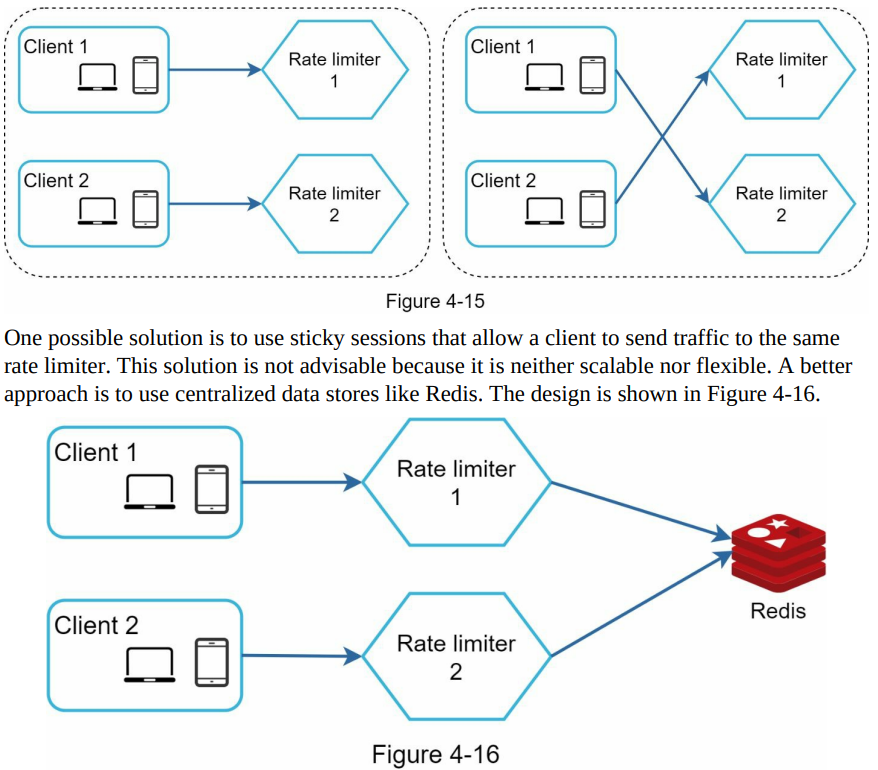
- Building a rate limiter for a distributed environment is more challenging compared to a single server environment.
- Two main challenges arise: race condition and synchronization issue.
- In a highly concurrent environment, race conditions can occur during the rate limiting process.
- Race conditions arise when multiple threads or servers simultaneously read the counter value, check if it exceeds the threshold, and increment the counter in Redis.
- These race conditions can lead to incorrect rate limiting decisions and inconsistent counter values.
- Synchronization mechanisms and techniques are necessary to address race conditions and ensure proper rate limiting functionality in a distributed environment.
- Race conditions can occur in a distributed environment when multiple threads or servers concurrently read and write the counter value.
- Locks can be used to solve race conditions, but they can significantly slow down the system.
- Two common strategies to address race conditions in a distributed environment are Lua scripts and sorted sets data structure in Redis.
- Synchronization is necessary when multiple rate limiter servers are used to handle traffic from different clients.
- Without synchronization, rate limiter servers may lack necessary data about clients, leading to improper rate limiting.
- Synchronization mechanisms need to be implemented to ensure consistent data across rate limiter servers in a distributed environment.
Performance optimization
- Implementing a multi-data center setup is important for optimizing the performance of a rate limiter, as it reduces latency for users located far from the data center.
- Cloud service providers often have geographically distributed edge servers that automatically route traffic to the nearest server, improving latency.
- Synchronizing data with an eventual consistency model is recommended for performance optimization. This model ensures consistency over time but allows for temporary inconsistencies during synchronization processes.
- Referring to the “Consistency” section in “Chapter 6: Design a Key-value Store” can provide further understanding of the eventual consistency model.
Monitoring
- Monitoring the rate limiter is crucial to ensure its effectiveness.
- Gathering analytics data helps evaluate the effectiveness of the rate limiting algorithm and rules.
- If rate limiting rules are too strict and valid requests are being dropped, adjustments may be needed to relax the rules.
- In cases of sudden increases in traffic, such as flash sales, the rate limiter may need to be adapted to support burst traffic.
- The token bucket algorithm is suitable for handling burst traffic situations.
Step 4 - Wrap Up
- The chapter covers different rate limiting algorithms: Token bucket, Leaking bucket, Fixed window, Sliding window log, Sliding window counter.
- The system architecture, rate limiter in a distributed environment, performance optimization, and monitoring are discussed.
- Additional talking points include hard vs soft rate limiting, rate limiting at different levels (application, IP), and best practices for clients to avoid being rate limited.
- The OSI model and its 7 layers are mentioned.
- Congratulatory message for reaching the end of the chapter.