Distilled • Facebook Messenger/WhatsApp
- Overview
- Design Goals/Requirements
- Scale Estimation and Performance/Capacity Requirements
- System APIs
- High Level System Design
- Data Model
- Detailed Component Design
- Messages Handling
- How will clients maintain an open connection with the server?
- How can the server keep track of all the opened connections to efficiently redirect messages to the users?
- What will happen when the server receives a message for a user who has gone offline?
- How many chat servers do we need?
- How do we know which server holds the connection to which user?
- How should the server process a ‘deliver message’ request?
- How does the messenger maintain the sequencing of the messages?
- Messages Handling
- Managing user’s status
- Data partitioning
- Cache
- Load balancing
- Fault tolerance and Replication#
- Extended Requirements
- Further Reading
Overview
- Facebook Messenger is a software application that provides text-based instant messaging services to its users. Messenger users can chat with their Facebook friends both from cell phones and Facebook’s website.
- Similar Services: Whatsapp.
Design Goals/Requirements
- Functional requirements:
- Messenger should support 1-1 conversations between users.
- Messenger should keep track of the online/offline statuses of its users.
- Messenger should support the persistent storage of chat history.
- Non-functional requirements:
- Minimum latency: Users should have a real-time chatting experience with minimum latency.
- High consistency: Our system should be highly consistent; users should see the same chat history on all their devices.
- Relatively high availability but not at the cost of consistency (due to CAP theorem): As we know from the CAP theorem, that we can have either high availability or high consistency, we can tolerate lower availability in the interest of consistency (but high availability is still desirable).
- Extended Requirements:
- Group Chats: Messenger should support multiple people talking to each other in a group.
- Push notifications: Messenger should be able to notify users of new messages when they are offline.
Scale Estimation and Performance/Capacity Requirements
- Some back-of-the-envelope calculations based on average numbers.
Traffic estimates
- Daily Active Users (DAUs): 1B.
- Number of messages each user send: 50.
- Total number of messages sent per day: 50 billion.
Storage estimates
- Message size: 100 bytes.
- Storage needed for one day worth of messages: 50 billion messages * 100 bytes = 5 TB/day.
- Storage needed to store five years of chat history: 5 TB * 365 days * 5 years ~= 9.1 PB.
- Besides chat messages, we also need to store users’ information, messages’ metadata (ID, Timestamp, etc.). Not to mention, the above calculation doesn’t take data compression and replication into consideration.
Bandwidth estimates
- Upload/download needed: 5 TB (per day) / 86400 sec (per day) ~= 58 MB/s
- Since each incoming message needs to go out to another user, we will need the same amount of bandwidth 25MB/s for both upload and download.
System APIs
- Once we have finalized the requirements, it’s always a good idea to define the system APIs. This should explicitly state what is expected from the system. These would be running as microservices on our application servers.
- We can have SOAP or REST APIs to expose the functionality of our service. The following could be the definition of the API for sending the message:
sendMessage(api_dev_key, user_id, addressed_user_id, chat_id)
- Parameters:
api_dev_key (string):The API developer key of a registered can be used to, among other things, throttle users based on their allocated quota.user_id (number):The ID of the author of the message (can also beauthor_id).addressed_user_id (number):The ID of the user whom the message is addressed to.chat_id (number):The ID of the chat session where this message needs to be linked to.timestamp (number):The timestamp of the message.
- We can have SOAP or REST APIs to expose the functionality of our service. The following could be the definition of the API for retrieving the message:
getMessage(api_dev_key, user_id, user_to_id, chat_id)
- Parameters:
api_dev_key (string):The API developer key of a registered can be used to, among other things, throttle users based on their allocated quota.user_id (number):The ID of the current user trying to retrieve the latest chat messages.chat_id (number):The ID of the chat session where this message needs to be linked to.timestamp (number):The timestamp of the message.
- Returns: (JSON) Returns a JSON object containing a list of messages, each having
author_id(the ID of the user whom the message is authored by),message_text(the contents of the message),timestamp(the timestamp of the message).
High Level System Design
- At a high level, we will need a chat server that will be the central piece orchestrating all the communications between users. When a user wants to send a message to another user, they will connect to the chat server and send the message to the server; the server then passes that message to the other user and also stores it in the database.
- In summary, our system needs to handle the following use cases:
- Receive incoming messages and deliver outgoing messages.
- Store and retrieve messages from the database.
- Keep a record of which user is online or has gone offline, and notify all the relevant users about these status changes.
- In summary, our system needs to handle the following use cases:
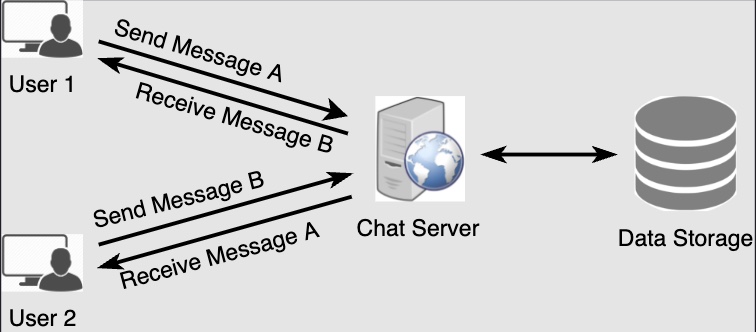
- The detailed workflow would look like this:
User-Asends a message toUser-Bthrough the chat server.- The server receives the message and sends an acknowledgment to
User-A. - The server stores the message in its database and sends the message to
User-B. User-Breceives the message and sends the acknowledgment to the server.- The server notifies
User-Athat the message has been delivered successfully toUser-B.
Data Model
Storing and retrieving the messages from the database
-
Whenever the chat server receives a new message, it needs to store it in the database. To do so, we have two options:
- Start a separate thread, which will work with the database to store the message.
- Send an asynchronous request to the database to store the message.
-
We have to keep certain things in mind while designing our database:
- How to efficiently work with the database connection pool.
- How to retry failed requests.
- Where to log those requests that failed even after some retries.
- How to retry these logged requests (that failed after the retry) when all the issues have been resolved.
Which storage system should we use?
-
We need to have a database that can support a very high rate of small updates and also fetch a range of records quickly. This is required because we have a huge number of small messages that need to be inserted in the database and, while querying, a user is mostly interested in sequentially accessing the messages.
-
We cannot use RDBMS like MySQL or NoSQL like MongoDB because we cannot afford to read/write a row from the database every time a user receives/sends a message. This will not only make the basic operations of our service run with high latency but also create a huge load on databases.
-
Both of our requirements can be easily met with a wide-column database solution like HBase. HBase is a column-oriented key-value NoSQL database that can store multiple values against one key into multiple columns. HBase is modeled after Google’s BigTable and runs on top of Hadoop Distributed File System (HDFS).
- The advantage of HBase is that it groups data together to store new data in a memory buffer and, once the buffer is full, it dumps the data to the disk. This way of storage not only helps to store a lot of small data quickly but also fetching rows by the key or scanning ranges of rows. HBase is also an efficient database to store variable-sized data, which is also required by our service.
How should clients efficiently fetch data from the server?
- Clients should paginate while fetching data from the server. Page size could be different for different clients, e.g., cell phones have smaller screens, so we need fewer messages/conversations in the viewport.
Detailed Component Design
-
Let’s try to build a simple solution first where everything runs on one server.
-
At the high level, our system needs to handle the following use cases:
- Receive incoming messages and deliver outgoing messages.
- Store and retrieve messages from the database.
- Keep a record of which user is online or has gone offline, and notify all the relevant users about these status changes.
-
Let’s talk about these scenarios one by one:
Messages Handling
-
How would we efficiently send/receive messages? To send messages, a user needs to connect to the server and post messages for the other users. To get a message from the server, the user has two options:
- “Pull” model or Fan-out-on-load: Users can periodically ask the server if there are any new messages for them.
- “Push” model or Fan-out-on-write: Users can keep a connection open with the server and can depend upon the server to notify them whenever there are new messages.
-
In the pull model approach, the server needs to keep track of messages that are still waiting to be delivered, and as soon as the receiving user connects to the server to ask for any new message, the server can return all the pending messages. To minimize latency for the user, they have to check the server quite frequently, and most of the time, they will be getting an empty response if there are no pending messages. This will waste a lot of resources and does not look like an efficient solution.
-
If we go with the push model approach, where all the active users keep a connection open with the server, then as soon as the server receives a message, it can immediately pass the message to the intended user. This way, the server does not need to keep track of the pending messages, and we will have minimum latency, as the messages are delivered instantly on the opened connection.
How will clients maintain an open connection with the server?
- We can use HTTP Long Polling or WebSockets. In long polling, clients can request information from the server with the expectation that the server may not respond immediately. If the server has no new data for the client when the poll is received, instead of sending an empty response, the server holds the request open and waits for response information to become available. Once it does have new information, the server immediately sends the response to the client, completing the open request. Upon receipt of the server response, the client can immediately issue another server request for future updates. This gives a lot of improvements in latencies, throughputs, and performance. However, the long polling request can timeout or receive a disconnect from the server; in that case, the client has to open a new request.
How can the server keep track of all the opened connections to efficiently redirect messages to the users?
- The server can maintain a hash table, where “key” would be the
UserIDand “value” would be the connection object. So whenever the server receives a message for a user, it looks up that user in the hash table to find the connection object and sends the message on the open request.
What will happen when the server receives a message for a user who has gone offline?
- If the receiver has disconnected, the server can notify the sender about the delivery failure. However, if it is a temporary disconnect, e.g., the receiver’s long-poll request just timed out, then we should expect a reconnect from the user. In that case, we can ask the sender to retry sending the message.
- This retry could be embedded in the client’s logic so that users don’t have to retype the message. The server can also store the message for a while and retry sending it once the receiver reconnects.
- The obvious last resort is to simply send a Push Notification to the user if they’re offline.
How many chat servers do we need?
- Let’s plan for 500 million connections at any time. Assuming a modern server can handle 50K concurrent connections at any time, we would need 10K such servers.
How do we know which server holds the connection to which user?
- We can introduce a software load balancer in front of our chat servers; that can map each
UserIDto a server to redirect the request.
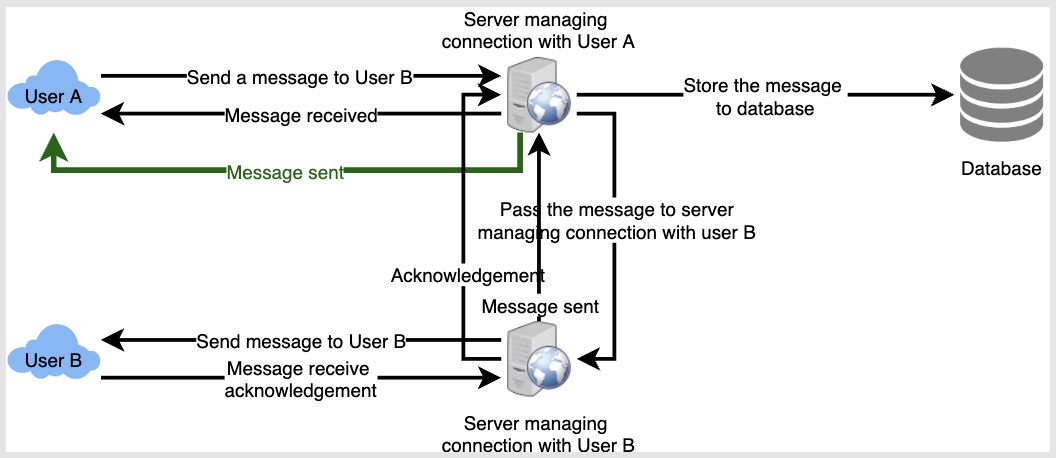
How should the server process a ‘deliver message’ request?
-
The server needs to do the following things upon receiving a new message: 1) Store the message in the database, 2) Send the message to the receiver, and 3) Send an acknowledgment to the sender.
-
The chat server will first find the server that holds the connection for the receiver and pass the message to that server to send it to the receiver. The chat server can then send the acknowledgment to the sender; we don’t need to wait to store the message in the database (this can happen in the background). Storing the message is discussed in the next section.
How does the messenger maintain the sequencing of the messages?
-
We can store a timestamp with each message, which is the time when the server receives the message. However, this will still not ensure the correct ordering of messages for clients. The scenario where the server timestamp cannot determine the exact order of messages would look like this:
- User-1 sends a message
M1to the server for User-2. - The server receives
M1atT1. - Meanwhile, User-2 sends a message
M2to the server for User-1. - The server receives the message
M2atT2, such thatT2>T1. - The server sends the message
M1to User-2 andM2to User-1.
- User-1 sends a message
-
So User-1 will see
M1first and thenM2, whereas User-2 will seeM2first and thenM1. -
To resolve this, we need to keep a sequence number with every message for each client. This sequence number will determine the exact ordering of messages for EACH user. With this solution, both clients will see a different view of the message sequence, but this view will be consistent for them on all devices.
Managing user’s status
-
We need to keep track of user’s online/offline status and notify all the relevant users whenever a status change happens. Since we are maintaining a connection object on the server for all active users, we can easily figure out the user’s current status from this. With 500M active users at any time, if we have to broadcast each status change to all the relevant active users, it will consume a lot of resources. We can do the following optimization around this:
- Whenever a client starts the app, it can pull the current status of all users in their friends’ list.
- Whenever a user sends a message to another user that has gone offline, we can send a failure to the sender and update the status on the client.
- Whenever a user comes online, the server can always broadcast that status with a delay of a few seconds (by batching updates from people) to see if the user does not go offline immediately.
- Clients can pull the status from the server about those users that are being shown on the user’s viewport. This should not be a frequent operation, as the server is broadcasting the online status of users and we can live with the stale offline status of users for a while.
- Whenever the client starts a new chat with another user, we can pull the status at that time.
-
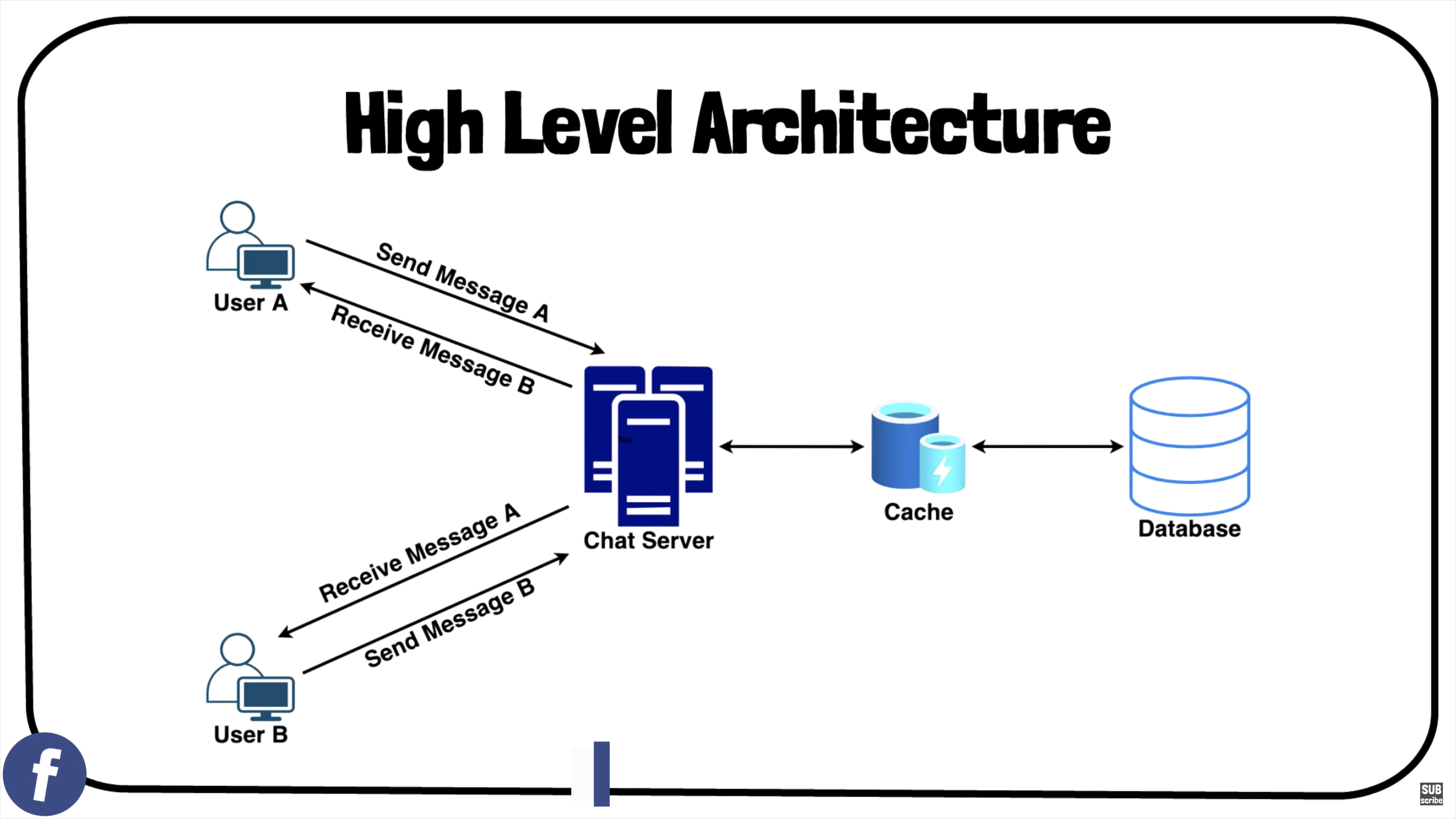
The following diagram shows the detailed component design for Facebook messenger:
- Design Summary:
- Clients will open a connection to the chat server to send a message; the server will then pass it to the requested user.
- All the active users will keep a connection open with the server to receive messages.
- Whenever a new message arrives, the chat server will push it to the receiving user on the long poll request.
- Messages can be stored in HBase, which supports quick small updates and range-based searches.
- The servers can broadcast the online status of a user to other relevant users.
- Clients can pull status updates for users who are visible in the client’s viewport on a less frequent basis.
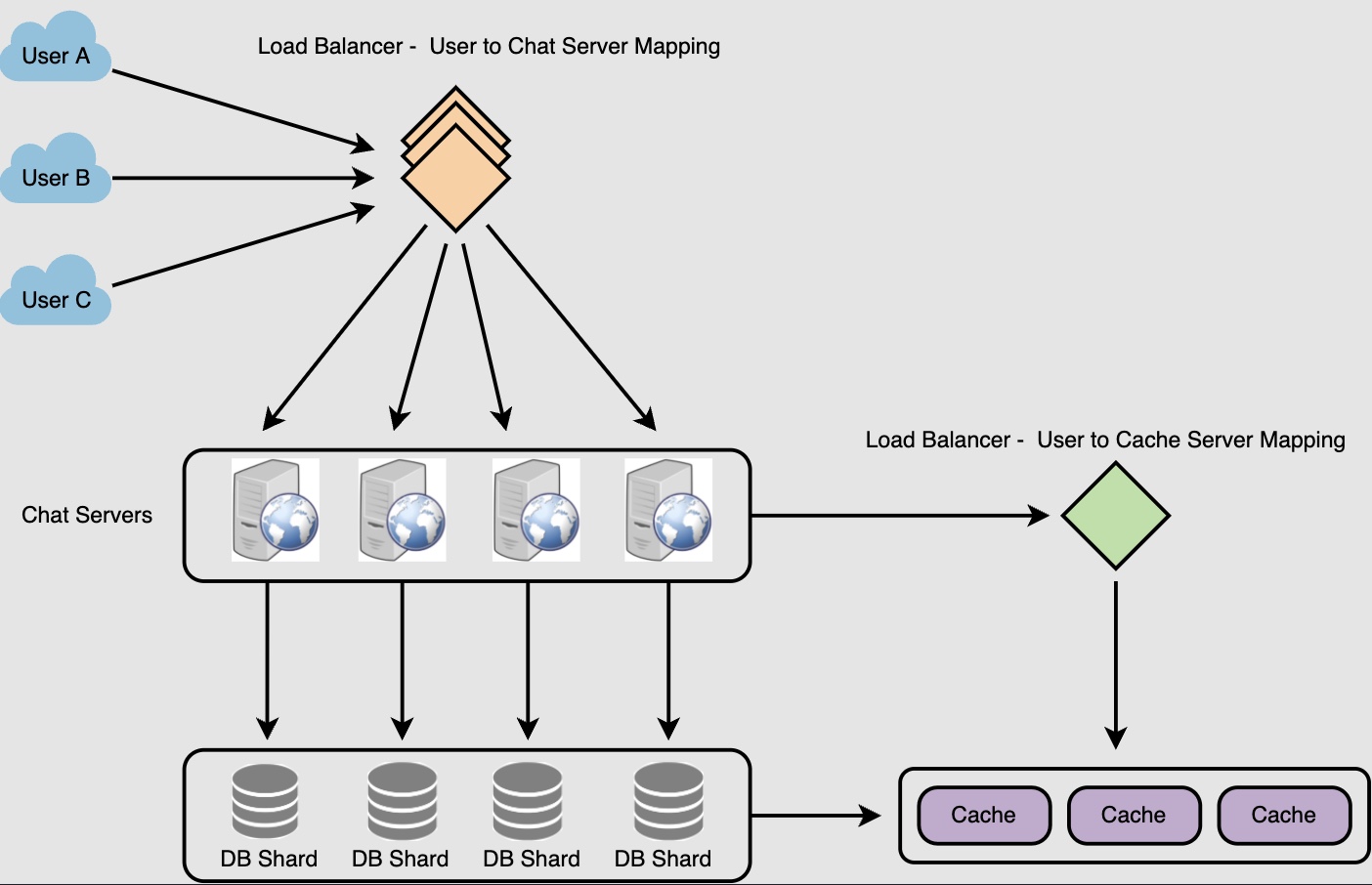
Data partitioning
- Since we will be storing a lot of data (3.6PB for five years), we need to distribute it onto multiple database servers. So, what will be our partitioning scheme?
Partitioning based on MessageID
- If we store different messages of a user on separate database shards, fetching a range of messages of a chat would be very slow, so we should not adopt this scheme.
Partitioning based on UserID
-
Let’s assume we partition based on the hash of the UserID so that we can keep all messages of a user on the same database. If one DB shard is 4TB, we will have “
3.6PB/4TB ~= 900” shards for five years. For simplicity, let’s assume we keep 1K shards. So we will find the shard number byhash(UserID) % 1000and then store/retrieve the data from there. This partitioning scheme will also be very quick to fetch chat history for any user. -
In the beginning, we can start with fewer database servers with multiple shards residing on one physical server. Since we can have multiple database instances on a server, we can easily store multiple partitions on a single server. Our hash function needs to understand this logical partitioning scheme so that it can map multiple logical partitions on one physical server.
-
Since we will store an unlimited history of messages, we can start with a large number of logical partitions that will be mapped to fewer physical servers. Then, as our storage demand increases, we can add more physical servers to distribute our logical partitions.
Cache
- We can cache a few recent messages (say last 15) in a few recent conversations that are visible in a user’s viewport (say last 5). Since we decided to store all of the user’s messages on one shard, the cache for a user should entirely reside on one machine too.
Load balancing
- We will need a load balancer in front of our chat servers that can map each UserID to a server that holds the connection for the user and then direct the request to that server. Similarly, we would need a load balancer for our cache servers.
Fault tolerance and Replication#
What will happen when a chat server fails?
-
Our chat servers are holding connections with the users. If a server goes down, should we devise a mechanism to transfer those connections to some other server? It’s extremely hard to failover TCP connections to other servers; an easier approach can be to have clients automatically reconnect if the connection is lost.
-
Should we store multiple copies of user messages? We cannot store only one copy of the user’s data because if the server holding the data crashes or is down permanently, we don’t have any mechanism to recover that data. For this, either we have to store multiple copies of the data on different servers or use techniques like Reed-Solomon encoding to distribute and replicate it.
Extended Requirements
Group chat
-
We can have separate group-chat objects in our system that can be stored on the chat servers. A group-chat object is identified by
GroupChatIDand will also maintain a list of people who are part of that chat. Our load balancer can direct each group chat message based onGroupChatID, and the server handling that group chat can iterate through all the users of the chat to find the server handling the connection of each user to deliver the message. -
In databases, we can store all the group chats in a separate table partitioned based on
GroupChatID.
Push notifications
-
In our current design, users can only send messages to online users; if the receiving user is offline, we send a failure to the sending user. Push notifications will enable our system to send messages to offline users.
-
For Push notifications, each user can opt-in from their device (or a web browser) to get notifications whenever there is a new message or event. Each manufacturer maintains a set of servers that handles pushing these notifications to the user.
-
To have push notifications in our system, we would need to set up a Notification server, which will take the messages for offline users and send them to the manufacturer’s push notification server, which will then send them to the user’s device.