Distilled • Live Commenting
- Overview
- Design Goals/Requirements
- Scale Estimation and Performance/Capacity Requirements
- System APIs
- High Level System Design
- Detailed Component Design
- Data Model
- Further Reading
Overview
- Live commenting relates to the active real-time feed of comments that we see at the bottom of each post, while we are passively scrolling across the Facebook News Feed.
- Don’t get confused that this question is related in any way to Live Videos.
Design Goals/Requirements
- Functional requirements:
- Enable real-time commenting on the posts
- This means that the users should be able to see the new comments in real-time for the posts that are visible in front of their screen.
- Since users are continuously scrolling the news feed, the posts that are visible in their view change very frequently.
- Non-functional requirements:
- Minimum latency: Users should have a real-time chatting experience with minimum latency.
- High consistency: Our system should be highly consistent; users should see the same chat history on all their devices.
- Relatively high availability but not at the cost of consistency (due to CAP theorem): As we know from the CAP theorem, that we can have either high availability or high consistency, we can tolerate lower availability in the interest of consistency (but high availability is still desirable).
- Read-heavy service: Our service should support a heavy read load. There will be a lot of read requests compared to adding comments.
Scale Estimation and Performance/Capacity Requirements
- Number of pieces of content that receive comments per minute: 100 million.
- In that same minute, users submit around a million comments that need to get routed to the correct viewers, which is ~17K comments/sec.
System APIs
- Once we have finalized the requirements, it’s always a good idea to define the system APIs. This should explicitly state what is expected from the system. These would be running as microservices on our application servers.
- We can have SOAP or REST APIs to expose the functionality of our service. The following could be the definition of the API for fetching live comments:
getCommentsLive(user_id, post_id, comment_id, timestamp, api_dev_key)
- Parameters:
user_id (number):The ID of the user for whom the system will send live comments.post_id (number):The ID of the post that is in active view.timestamp (number):The current timestamp to send comments with timestamps associated greater than the current time – can also optionally send the ID (if the ID is encoded based on the timestamp) of the latest comment to fetch comments greater than this ID).api_dev_key (string):The API developer key of a registered can be used to, among other things, throttle users based on their allocated quota.
- Returns: (JSON) Returns a JSON object containing a list of comments with their respective
comment_poster_id(the ID of the user who has posted the comment),comment_id(the ID of the comment),timestamp(the timestamp of the comment) etc.
High Level System Design
-
The process of pushing a comment to all the viewers is called fanout. By analogy, the push approach is called fanout-on-write, while the pull approach is called fanout-on-load. Let’s discuss different options for publishing comments to users.
- “Pull” model or Fan-out-on-load:
- This method involves keeping all the recent comment data in memory so that users can pull it from the server whenever they need it.
- Clients can pull the feed data on a regular basis or manually whenever they need it.
- Possible issues with this approach are:
- New data might not be shown to the users until they issue a pull request.
- It’s hard to find the right pull cadence, as most of the times, a pull requests will result in an empty response if there is no new data, causing a waste of resources.
- “Push” model or Fan-out-on-write:
- For a push system, once a user has published a post, we can immediately push this post to all the followers, thereby being more real-time than the pull model.
- The advantage is that when fetching the live comments, you don’t need to go through the current post’s available comments and get updates for each of them. It significantly reduces read operations. To efficiently handle this, users have to maintain a Long Poll request with the server for receiving the updates.
- A possible problem with this approach is the celebrity-user issue: when a user has millions of followers (i.e., a celebrity-user), their posts typically receive several thousands to millions of comments which several million to billion people are viewing, the server has to push updates to a lot of people.
- A hybrid approach here would be a problem since some posts would have live comments while others wouldn’t. This would lead to our users not knowing what to expect from each post.
- “Pull” model or Fan-out-on-load:
Detailed Component Design

Pushing vs. Pulling Data
- Pull/Poll-based approach: For every page that had comment-able content, the page would periodically send a request to check whether new comments had arrived. By increasing the polling frequency, we could approximate a real-time feel. Unfortunately, simple experimentation led us to quickly conclude that this approach would not scale.
- Cons of this approach: Because humans are so sensitive to latency in real-time communications, creating a truly serendipitous commenting experience requires comments to arrive as quickly as humanly and electronically possible. In a poll-based approach this would mean a polling interval of less than five seconds (and that would still feel slow!), which would very easily overload our servers.
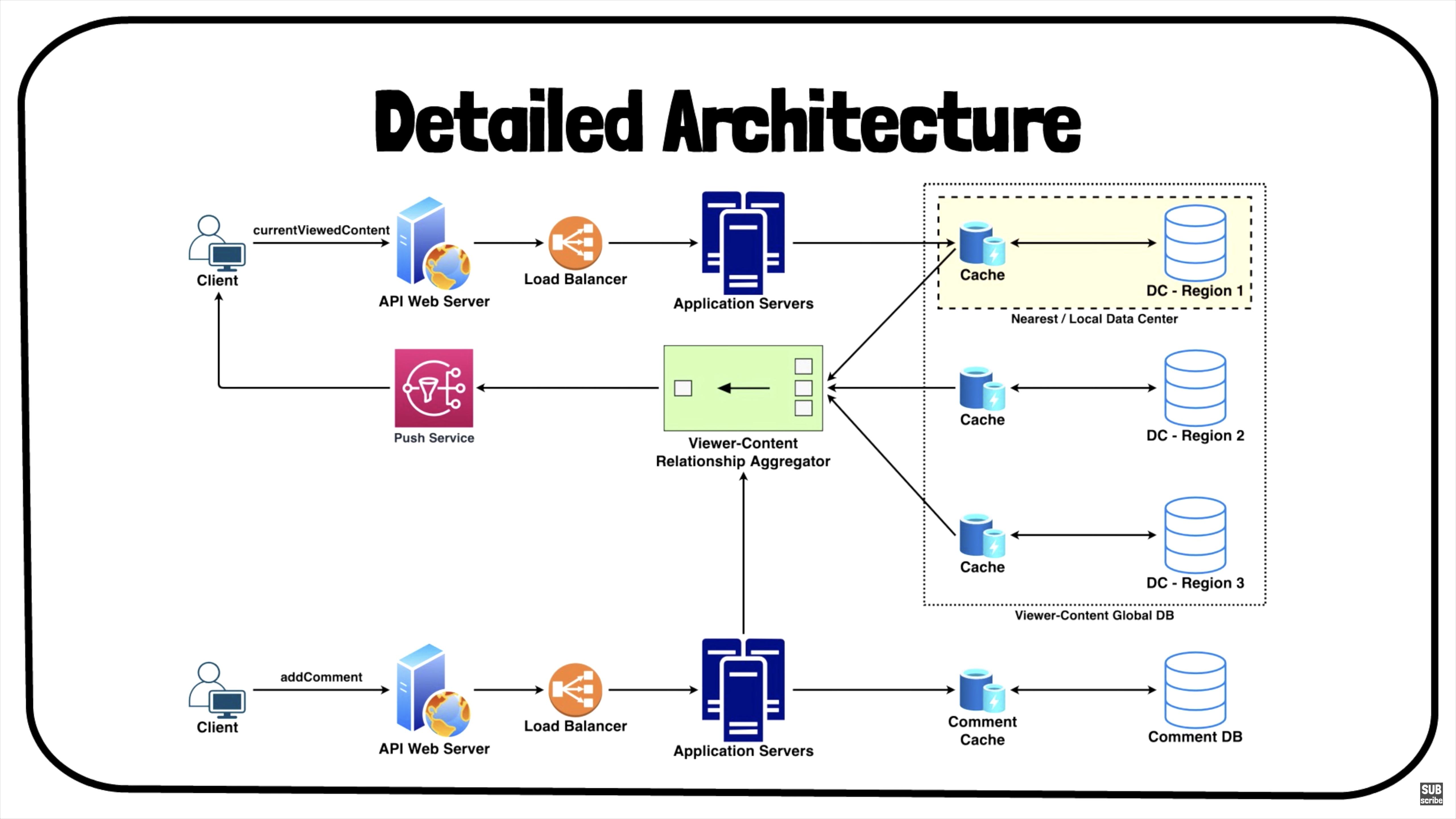
- Push-based approach: A push-based approach was more relevant to the task. To be able to push information about comments to viewers, we need to know who may be viewing the piece of content that each new comment pertains to. Because we serve 100 million pieces of content per minute, we needed a system that could keep track of this “who’s looking at what” information (i.e., viewer-to-content associations, discussed later), but also handle the incredible rate at which this information changed.
Write Locally, Read Globally
-
We would need to store millions of one-to-one, viewer-to-content associations in a database. Up until this point, Facebook engineering had built up infrastructure optimized for many more reads than writes. But now we had flipped the game. Every page load now requires multiple writes (one for each piece of content being displayed). Each write of a comment requires a read (to figure out the recipients of an update). We realized that we were building something that was fundamentally backwards from most of our other systems.
-
At Facebook, traditionally, writes are applied to one database and asynchronously replicated to databases across all regions. This makes sense as the write rate is normally much lower than the read rate (users consume content much more than they produce). A good way to think of this approach is “read locally, write globally”.
- Because of our unique situation, we settled on the completely opposite approach: “write locally, read globally.” This meant deploying distributed storage tiers that only handled writes locally, then less frequently collecting information from across all of our data centers to produce the final result. For example, when a user loads his News Feed through a request to our data center in Virginia, the system writes to a storage tier in the same data center, recording the fact that the user is now viewing certain pieces of content so that we can push them new comments.
- When someone enters a comment, we fetch the viewership information from all of our data centers across the country, combine the information (using aggregator servers), then push the updates out. In practice, this means we have to perform multiple cross-country reads for every comment produced. But it works because our commenting rate is significantly lower than our viewing rate. Reading globally saves us from having to replicate a high volume of writes across data centers, saving expensive, long-distance bandwidth. The flip approach – “write globally, read locally” – would be disadvantageous in this case owing to having to push a ton of writes to every data center (to make sure all of the servers have consistent data) and reading from one of them at runtime.
Data Model
Implementation of the Index
- Our index would be a big distributed hash table (using an in-memory data structure store, say Redis), where ‘key’ would be the viewer/user ID and ‘value’ will be a list of content/postIDs of all the posts that the viewer/user is actively looking at.
Storage estimates
- To represent the userIDs of 10B Facebook users, we will need 2^34 indexes, i.e., 34 bits = ~5 bytes.
- To represent the postIDs that each online Facebook user is active on, we will need 2^37 indexes (assuming there are 1T posts), i.e., 40 bits = 5 bytes.
- Per user (of which there are 1B DAUs), 5 bytes of userID for each online user and 10 posts per user (which would be 5*10 = 50 bytes). So total of 55 bytes per user.
- Assuming a total of a 1M new users active every second, 55 * 1M = 55 MB. This ofcouse, does not include removal of data from users logging off.
Which storage system should we use?
-
We need to have a database that can support a very high rate of small updates and also fetch a range of records quickly. This is required because we have a huge number of small post ID updates that need to be inserted in the database and, while querying, a user is mostly interested in sequentially accessing the post IDs.
-
We cannot use RDBMS like MySQL or NoSQL like MongoDB because we cannot afford to read/write a row from the database every time a user receives/sends a message. This will not only make the basic operations of our service run with high latency but also create a huge load on databases.
-
Both of our requirements can be easily met with a wide-column database solution like HBase. HBase is a column-oriented key-value NoSQL database that can store multiple values against one key into multiple columns. HBase is modeled after Google’s BigTable and runs on top of Hadoop Distributed File System (HDFS).
- The advantage of HBase is that it groups data together to store new data in a memory buffer and, once the buffer is full, it dumps the data to the disk. This way of storage not only helps to store a lot of small data quickly but also fetching rows by the key or scanning ranges of rows. HBase is also an efficient database to store variable-sized data, which is also required by our service.