Key-Value DB
- Overview
- Understanding the Problem and Establishing Design Scope
- Single Server Key-Value Store
- Distributed Key-Value Store
- Classification of Key-Value Stores based on CAP Characteristics
- Real-world Distributed Systems
- CAP Trade-offs in Distributed Key-Value Stores
- System Components of a Key-Value Store
- Data Partitioning in a Key-Value Store
- Summary of Data Replication in a Key-Value Store
- Consistency in a Key-Value Store
- Summary of Handling Failures in a Key-Value Store
- Handling Temporary Failures in a Key-Value Store
- Handling Data Center Outage in a Key-Value Store
Overview
- A key-value store is a non-relational database that stores data as key-value pairs.
- Keys must be unique and can be plain text or hashed values.
- Values can be strings, lists, objects, or other data types.
- Key-value stores treat values as opaque objects.
- Common key-value store implementations include Amazon Dynamo, Memcached, and Redis.
- The goal is to design a key-value store that supports the following operations:
- put(key, value): Insert a value associated with a key.
- get(key): Retrieve the value associated with a key.
Understanding the Problem and Establishing Design Scope
- Designing a key-value store involves making tradeoffs between read, write, and memory usage.
- Consistency and availability are important factors to consider in the design.
- The key-value store should have the following characteristics:
- Small size for each key-value pair (less than 10 KB).
- Ability to store large data sets.
- High availability, ensuring quick response even during failures.
- Scalability to handle large amounts of data.
- Automatic scaling based on traffic.
- Tunable consistency, allowing flexibility in balancing consistency and performance.
- Low latency to minimize response time.
Single Server Key-Value Store
- Developing a key-value store that operates within a single server is relatively straightforward.
- A common approach is to use a hash table to store key-value pairs in memory.
- However, fitting all data in memory may not be feasible due to space constraints.
- Two optimizations can be employed to maximize data storage within a single server:
- Data compression techniques can be applied to reduce the space occupied by key-value pairs.
- Only frequently accessed data is stored in memory, while less frequently accessed data is stored on disk.
- Despite these optimizations, a single server has limited capacity and may quickly reach its limits.
- To support large-scale data storage, a distributed key-value store is required.
Distributed Key-Value Store
- A distributed key-value store, also known as a distributed hash table (DHT), distributes key-value pairs across multiple servers in a network.
- When designing a distributed system, it is important to consider the CAP theorem, which outlines the tradeoff between consistency, availability, and partition tolerance.
- The CAP theorem states that it is impossible for a distributed system to simultaneously provide all three guarantees: consistency, availability, and partition tolerance.
- Consistency refers to all clients seeing the same data at the same time, regardless of which node they connect to.
- Availability ensures that clients receive a response even if some nodes are down.
- Partition tolerance means the system continues to function despite communication failures between nodes.
- According to the CAP theorem, a distributed system must sacrifice one of the properties to achieve consistency and availability.
- The specific tradeoff made depends on the requirements and design goals of the key-value store.
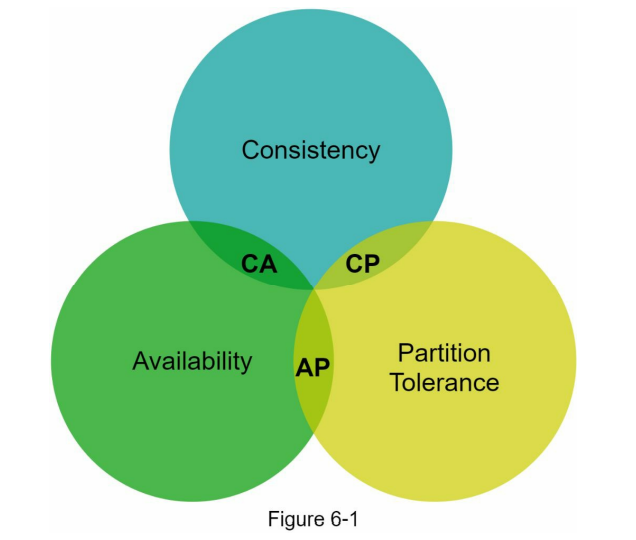
Classification of Key-Value Stores based on CAP Characteristics
- Key-value stores are classified into different categories based on the CAP characteristics they support.
- CP (consistency and partition tolerance) systems prioritize consistency and partition tolerance while sacrificing availability.
- AP (availability and partition tolerance) systems prioritize availability and partition tolerance while sacrificing consistency.
- CA (consistency and availability) systems aim to support both consistency and availability, but achieving partition tolerance becomes challenging in real-world applications.
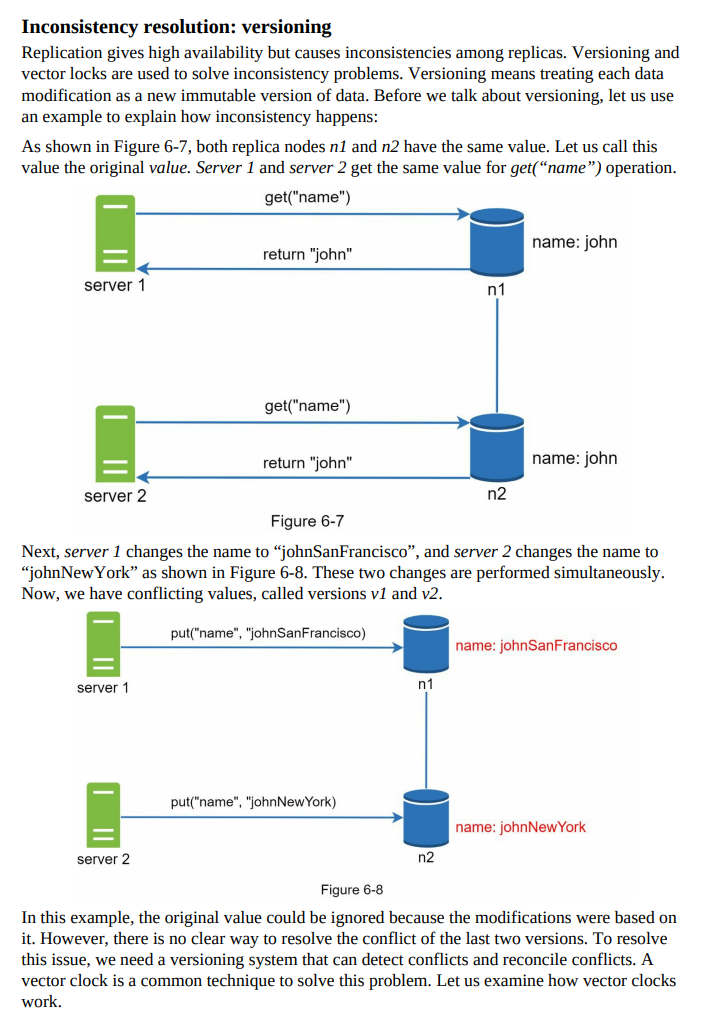
- In distributed systems, data is often replicated across multiple nodes to ensure fault tolerance and availability.
- In the ideal situation where there is no network partition, data written to one replica node is automatically replicated to other nodes, achieving both consistency and availability.
Real-world Distributed Systems
- In real-world distributed systems, network partitions are inevitable and can cause challenges in maintaining consistency and availability.
- When a network partition occurs, we are faced with a choice between consistency and availability.
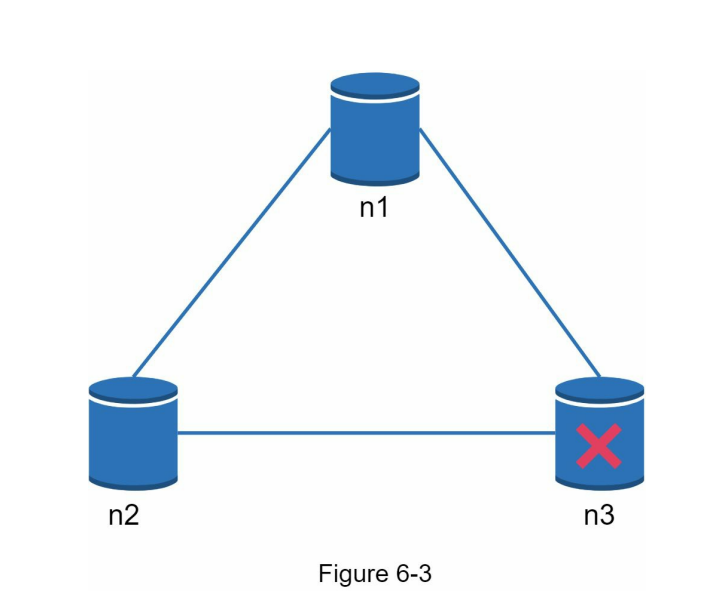
- In the scenario depicted in Figure 6-3, replica node n3 goes down and loses communication with nodes n1 and n2.
- If clients write data to nodes n1 or n2, the data cannot be propagated to node n3, resulting in inconsistent data.
- Conversely, if data is written to node n3 but not yet propagated to nodes n1 and n2, nodes n1 and n2 would have stale data.
- These scenarios highlight the trade-off between consistency and availability in distributed systems during network partitions.
CAP Trade-offs in Distributed Key-Value Stores
- When choosing consistency over availability (CP system), write operations to nodes n1 and n2 must be blocked to prevent data inconsistency among the servers. This can result in unavailability of the system.
- Systems with high consistency requirements, such as bank systems, prioritize maintaining the most up-to-date and consistent data. Inconsistencies due to network partitions can lead to errors being returned until consistency is restored.
- On the other hand, when choosing availability over consistency (AP system), the system continues accepting reads, even if it may return stale data. Write operations are accepted by nodes n1 and n2, and data synchronization with node n3 occurs when the network partition is resolved.
- The choice between CP and AP depends on the specific use case and requirements of the distributed key-value store. It is essential to discuss and determine the appropriate CAP guarantees with your interviewer when designing the system.
System Components of a Key-Value Store
- Data partition: Dividing the key-value pairs across multiple nodes in a distributed system. Different techniques, such as consistent hashing, can be used for efficient data partitioning.
- Data replication: Storing multiple copies of data on different nodes to ensure availability and fault tolerance. Replication strategies, such as consistent hashing with virtual nodes, are commonly used.
- Consistency: Ensuring that data replicas are consistent and up-to-date. Various consistency models, such as eventual consistency and strong consistency, can be implemented based on the requirements of the key-value store.
- Inconsistency resolution: Handling conflicts and resolving inconsistencies that may arise due to concurrent updates or network partitions. Techniques like vector clocks or conflict resolution algorithms can be employed.
- Handling failures: Implementing mechanisms to detect and handle node failures, such as through heartbeat messages or failure detection algorithms. Failure recovery and data resynchronization are crucial aspects of maintaining system availability.
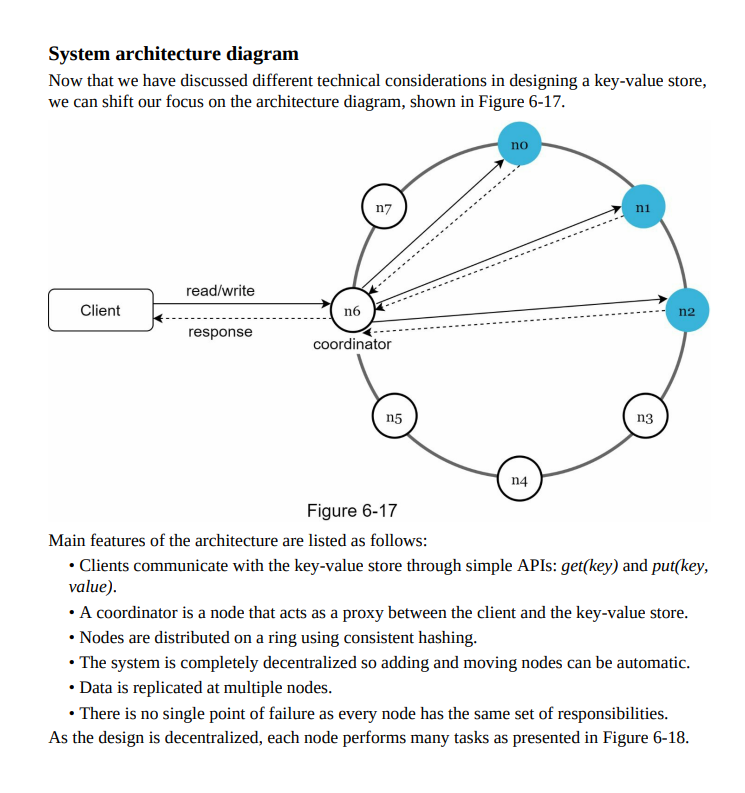
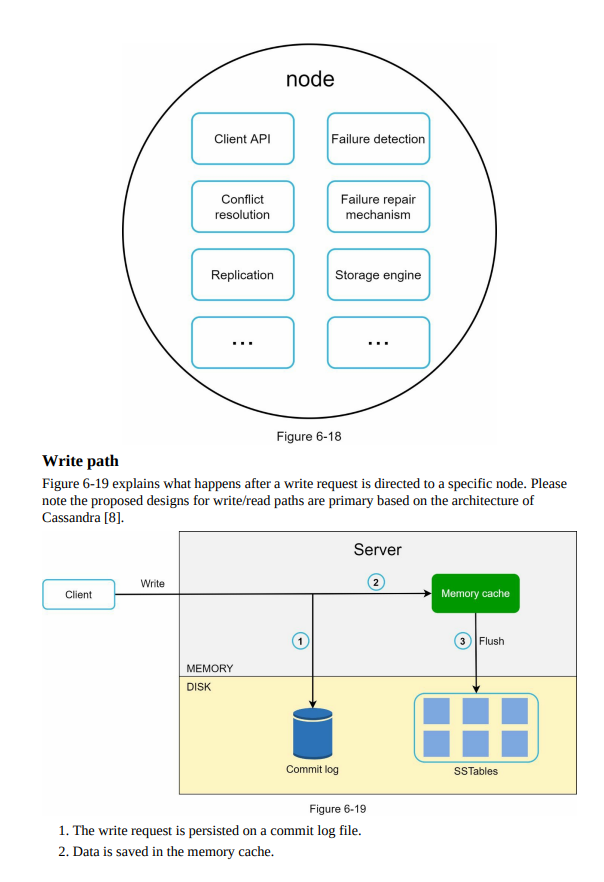
- System architecture diagram: Visual representation of the key-value store’s components and their interactions, including nodes, data partitions, replication, and communication channels.
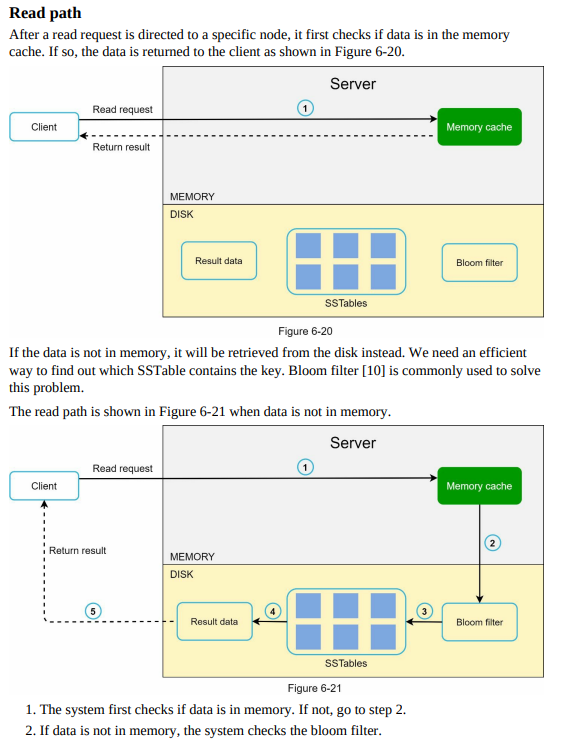
- Write path: The process of storing new key-value pairs or updating existing ones in the distributed system. It involves data partitioning, replication, consistency enforcement, and synchronization across nodes.
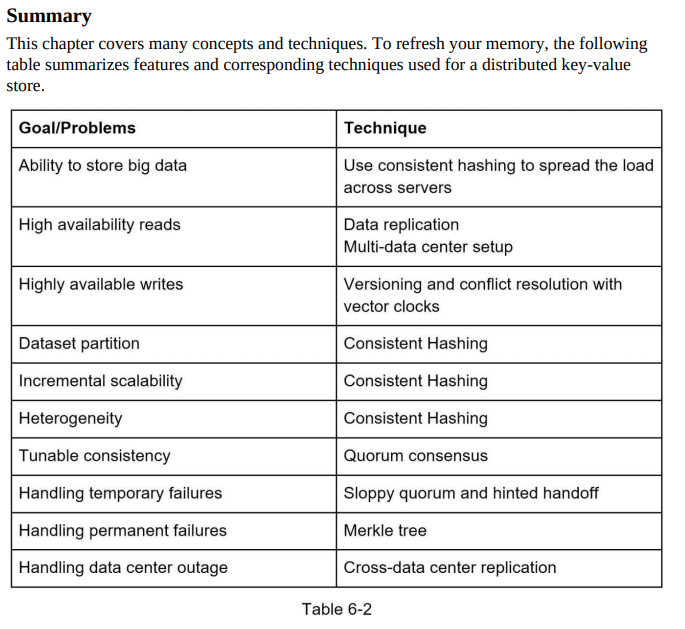
- Read path: Retrieving the value associated with a given key from the key-value store. It requires determining the appropriate node or replica to read from and ensuring data consistency during the retrieval process.
- The concepts discussed in this section draw inspiration from the design principles of key-value store systems like Dynamo, Cassandra, and BigTable.
Data Partitioning in a Key-Value Store
- Data partitioning is essential for storing large data sets across multiple servers in a key-value store.
- The primary challenges in data partitioning are distributing data evenly and minimizing data movement when nodes are added or removed.
- Consistent hashing is a commonly used technique to address these challenges.
- In consistent hashing, servers are placed on a hash ring, and keys are hashed onto the same ring.
- The key is stored on the first server encountered while moving in the clockwise direction on the ring.
- This approach ensures that each key is assigned to a specific server, enabling efficient retrieval and distribution of data.
Summary of Data Replication in a Key-Value Store
- Data replication is essential for achieving high availability and reliability in a key-value store.
- Replication involves creating copies of data and storing them on multiple servers.
- Asynchronous replication is commonly used, where data is replicated to N servers, where N is a configurable parameter.
- The servers for replication are chosen by walking clockwise from the position where a key is mapped on the hash ring and selecting the first N servers encountered.
- This approach ensures that multiple copies of the data are stored on different servers, improving fault tolerance and data availability.
Consistency in a Key-Value Store
- Consistency ensures that data remains synchronized across replicas in a distributed key-value store.
- Quorum consensus is commonly used to achieve consistency for both read and write operations.
- N represents the number of replicas in the system.
- W denotes the size of the write quorum. For a write operation to be successful, it must receive acknowledgments from at least W replicas.
- R denotes the size of the read quorum. For a read operation to be successful, it must wait for responses from at least R replicas.
- The specific values of W and R can be configured based on system requirements and desired consistency guarantees.
- By using quorum consensus, the key-value store ensures that data updates are propagated to a sufficient number of replicas, guaranteeing consistency during read and write operations.
- Note: The actual values of W and R, as well as the specific quorum-based consistency model used, can vary depending on the implementation and requirements of the key-value store system.
Summary of Handling Failures in a Key-Value Store
- Failures are common in large distributed systems, and it is crucial to handle them effectively.
- Failure detection is an essential component in handling failures. It involves identifying when a server or node is no longer functioning properly.
- In a distributed system, relying on a single source of information to detect failures is insufficient. It is recommended to have at least two independent sources of information.
- All-to-all multicasting is a straightforward approach for failure detection but can be inefficient in large systems.
- Gossip protocol is a decentralized failure detection method commonly used. It operates by each node maintaining a membership list with member IDs and heartbeat counters.
- Nodes periodically send heartbeats to random nodes, which propagate to other nodes in the system. Heartbeat information is used to update the membership list.
- If a node’s heartbeat has not increased for a predefined period, it is considered offline or failed.
Note: Failure detection is just one aspect of handling failures in a key-value store. The actual failure resolution strategies may vary depending on the specific system design and requirements.
Handling Temporary Failures in a Key-Value Store
- Temporary failures can occur in a distributed key-value store due to network or server issues.
- In the strict quorum approach, both read and write operations may be blocked when failures are detected.
- To improve availability, a technique called “sloppy quorum” is used. Instead of enforcing the quorum requirement, the system selects the first W healthy servers for writes and the first R healthy servers for reads on the hash ring. Offline servers are ignored.
- When a server is unavailable, another server temporarily handles the requests. This allows the system to continue serving read and write operations despite the failure.
- To achieve data consistency, a process called hinted handoff is used. When the unavailable server comes back online, the changes made on the temporary server are pushed back to the original server.
- In the example shown in Figure 6-12, if server s2 is unavailable, reads and writes will be handled by server s3 temporarily. Once s2 is back online, s3 will hand the data back to s2 to maintain consistency.
Note: Handling temporary failures requires careful coordination and synchronization between servers to ensure data consistency and availability during the failure and recovery processes.
Handling Data Center Outage in a Key-Value Store
- Data center outages can occur due to various reasons such as power outage, network outage, or natural disasters.
- To ensure continuous availability and accessibility of data, it is important to replicate data across multiple data centers.
- Replicating data across multiple data centers enables users to access data even if one or more data centers are completely offline.
- During a data center outage, requests can be routed to the available data centers, ensuring uninterrupted access to the key-value store.
- Replication across data centers helps in distributing the load and reducing latency by serving requests from the nearest or least congested data center.
- Replication strategies, such as synchronous or asynchronous replication, can be employed to ensure data consistency and durability across data centers.
- Handling data center outage requires proper failover mechanisms, network routing strategies, and synchronization protocols to ensure seamless operation and recovery of the key-value store.
Note: Handling data center outages involves careful planning, redundancy, and disaster recovery strategies to minimize downtime and ensure data availability across different geographic locations.