Problem statement
- Build a machine learning model to predict if an ad will be clicked.
- For the sake of simplicity, we will not focus on the cascade of classifiers that is commonly used in AdTech.

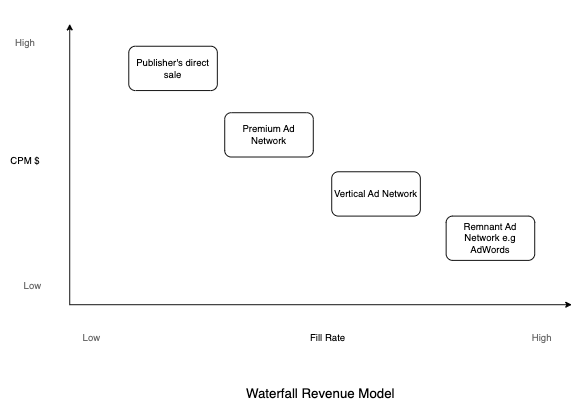
- Let’s understand the ad serving background before moving forward. The ad request goes through a waterfall model where publishers try to sell its inventory through direct sales with high CPM (Cost Per Million). If it is unable to do so, the publishers pass the impression to other networks until it is sold.
Metrics
- During the training phase, we can focus on machine learning metrics instead of revenue metrics or CTR metrics. Below are the two metrics:
- Offline metrics
- Normalized Cross-Entropy (NCE): NCE is the predictive logloss divided by the cross-entropy of the background CTR. This way NCE is insensitive to background CTR. This is the NCE formula
\(N C E=\frac{\left.-\frac{1}{N} \sum_{i=1}^n\left(\frac{1+y_i}{2} \log \left(p_i\right)\right)+\frac{1-y_i}{2} \log \left(1-p_i\right)\right)}{-(p * \log (p)+(1-p) * \log (1-p))}\)
- Online metrics
- Revenue Lift: Percentage of revenue changes over a period of time. Upon deployment, a new model is deployed on a small percentage of traffic. The key decision is to balance between percentage traffic and the duration of the A/B testing phase.
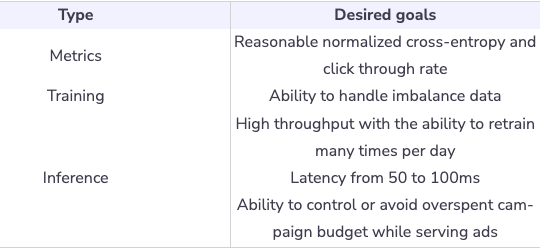
Requirements
- Training
- Imbalance data: The Click Through Rate (CTR) is very small in practice (1%-2%), which makes supervised training difficult. We need a way to train the model that can handle highly imbalanced data.
- Retraining frequency: The ability to retrain models many times within one day to capture the data distribution shift in the production environment.
- Train/validation data split: To simulate a production system, the training data and validation data is partitioned by time.
- Inference
- Serving: Low latency (50ms - 100ms) for ad prediction.
- Latency: Ad requests go through a waterfall model, therefore, recommendation latency for ML model needs to be fast.
- Overspent: If the ad serving model repeatedly serves the same ads, it might end up over-spending the campaign budget and publishers lose money.
Feature engineering

Training data
- Before building any ML models we need to collect training data. The goal here is to collect data across different types of posts while simultaneously improving the user experience. As you recall from the previous lesson about the waterfall model, we can collect a lot of data about ad clicks. We can use this data for training the Ad Click model.
- We can start to use data for training by selecting a period of data: last month, last six months, etc. In practice, we want to find a balance between training time and model accuracy. We also downsample the negative data to handle the imbalanced data.
Model Selection
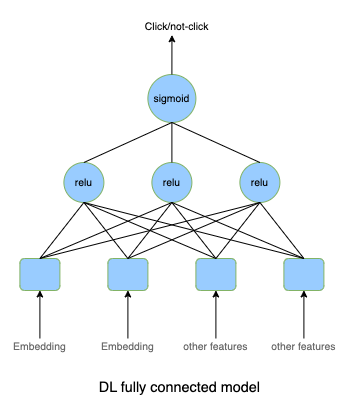
- We can use deep learning in distributed settings. We can start with fully connected layers with the Sigmoid activation function applied to the final layer. Because the CTR is usually very small (less than 1%), we would need to resample the training data set to make the data less imbalanced. It’s important to leave the validation and test sets intact to have accurate estimations about model performance.
Evaluation
- One approach is to split the data into training data and validation data. Another approach is to replay evaluation to avoid biased offline evaluation. Assume the training data we have up until time
t.
- We use test data from time
t+1 and reorder their ranking based on our model during inference. If there is an accurate click prediction, we record a match. The total match will be considered as total clicks.
- During evaluation, we will also evaluate how big our training data set should be and how frequently we need to retrain the model among many other hyperparameters.
Calculation and estimation
- Assumptions
- 40K ad requests per second or 100 billion ad requests per month
- Each observation (record) has hundreds of features, and it takes 500 bytes to store.
- Data size
- Data: historical ad click data includes [user, ads, click_or_not].
- With an estimated 1% CTR, it has 1 billion clicked ads. We can start with 1 month of data for training and validation. Within a month we have \(100 * 10^{12} * 500=5 * 10^{16}\) bytes or 50 PB. One way to make it more manageable is to downsample the data, i.e., keep only 1%-10% or use 1 week of data for training data and use the next day for validation data.
- Scale
- Supports 100 million users
High level design
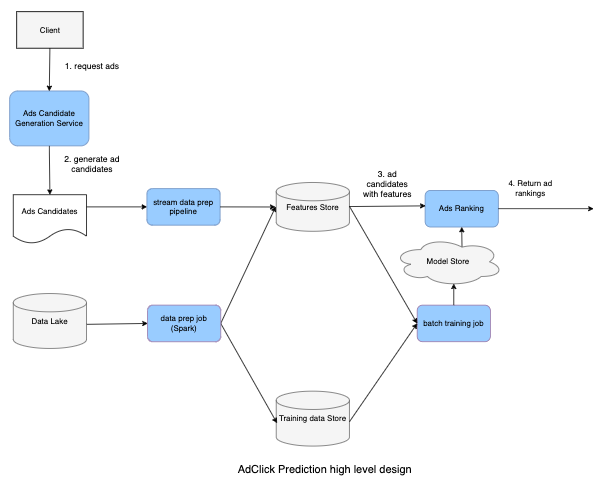
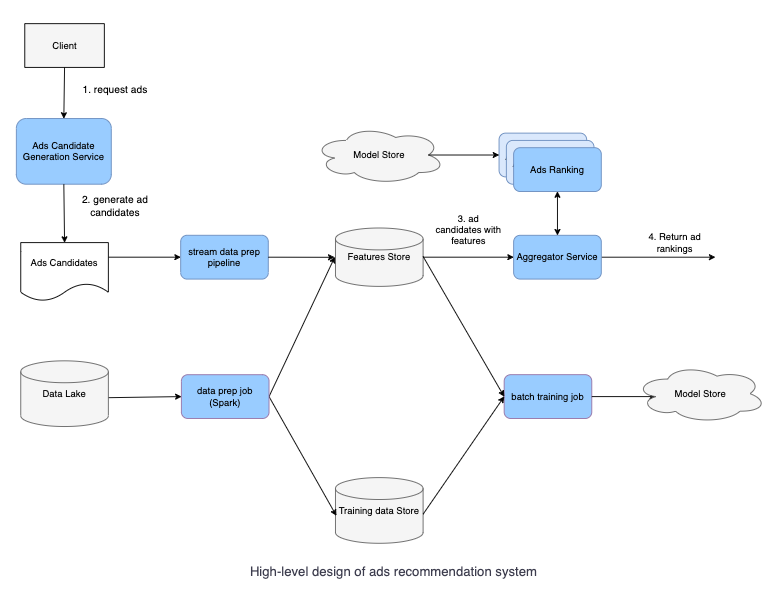
- Data lake: Store data that is collected from multiple sources, i.e., logs data or event-driven data (Kafka)
- Batch data prep: Collections of ETL (Extract, Transform, and Load) jobs that store data in Training data Store.
- Batch training jobs organize scheduled jobs as well as on-demand jobs to retrain new models based on training data storage.
- Model Store: Distributed storage like S3 to store models.
- Ad Candidates: Set of Ad candidates provided by upstream services (refer back to waterfall model).
- Stream data prep pipeline: Processes online features and stores features in key-value storage for low latency down-stream processing.
- Model Serving: Standalone service that loads different models and provides Ad Click probability.
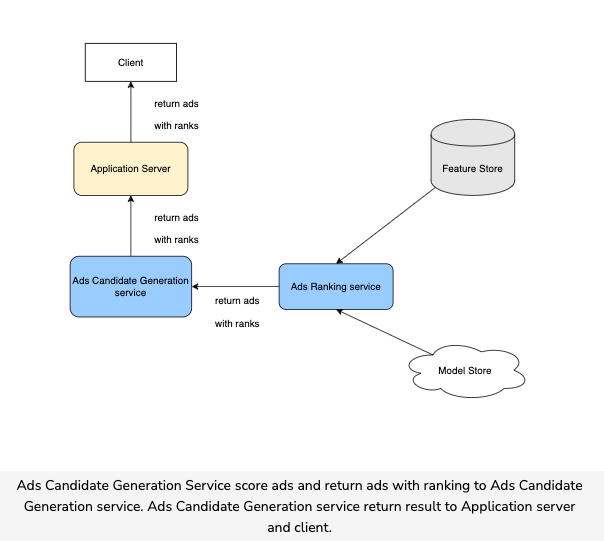
- User visits the homepage and sends an Ad request to the Candidate Generation Service. Candidate Generation Service generates a list of Ads Candidates and sends them to the Aggregator Service.
- The Aggregator Service splits the list of candidates and sends it to the Ad Ranking workers to score.
- Ad Ranking Service gets the latest model from Model Repos, gets the correct features from the Feature Store, produces ad scores, then returns the list of ads with scores to the Aggregator Service.
- The Aggregator Service selects top K ads (For example, k = 10, 100, etc.) and returns to upstream services.
Scale the design
- Given a latency requirement of 50ms-100ms for a large volume of Ad Candidates (50k-100k), if we partition one serving instance per request we might not achieve Service Level Agreement (SLA). For this, we scale out Model Serving and put Aggregator Service to spread the load for Model Serving components.
- One common pattern is to have the Aggregator Service. It distributes the candidate list to multiple serving instances and collects results. Read more about it here.
- We first learned to choose Normalize Entropy as the metric for the Ad Click Prediction Model.
- We learn how to apply the Aggregator Service to achieve low latency and overcome imbalance workloads.
- To scale the system and reduce latency, we can use kube-flow so that Ad Generation services can directly communicate with Ad Ranking services.