Ad Click Aggregator
Overview
- 1 billion clicks per day
-
2 million ads
- up to a few minutes from end-to-end
- 0.1kB per click (mostly for metadata anlytics info)
- View count cant be counted twice -> can have impact on pay
Functional Requirements
- we should capture ad click events
- we should be able to query the ad click events, as a marketing analyst
- 1B clicks per day / 100k
- 10,000 TPS
- (We’ll say peak is 5X of avg.) up to 50,000 TPS
- Storage:
- 10,000 TPS avg. * 0.1 kiloByte per click -> 1,000 kB per second = 1MB per second
- 50,000 TPS avg. * 0.1 kB per click = 5MB per second
- How much storage for 1 year of data?
- 1MB per second * 100k seconds in a day * 365 days in a year
- 1MB * 100k * 365 = 36,500k MB per year = 36,500 GB = 36.5 TB
- 1MB per second * 100k seconds in a day * 365 days in a year
- How much storage for 10 years of data?
-
36.5 TB * 10 = 365 TB
- How many analytical page view per second?
-
100k MAU for analysts each views the anlytics page 10 times per day on average
- 100k DAU
- 10 times per day on average
- 100k * 10 -> the number of page views per day
- 1M pages views per day
-
1M / 100k = 10
- 10 TPS for analyst page views
Non-functional Requirements
- actual ad clicks and redirect should be pretty fast (low latency)
- high availability for the ad click events
- eventual consistency is good enough
High Level architecture
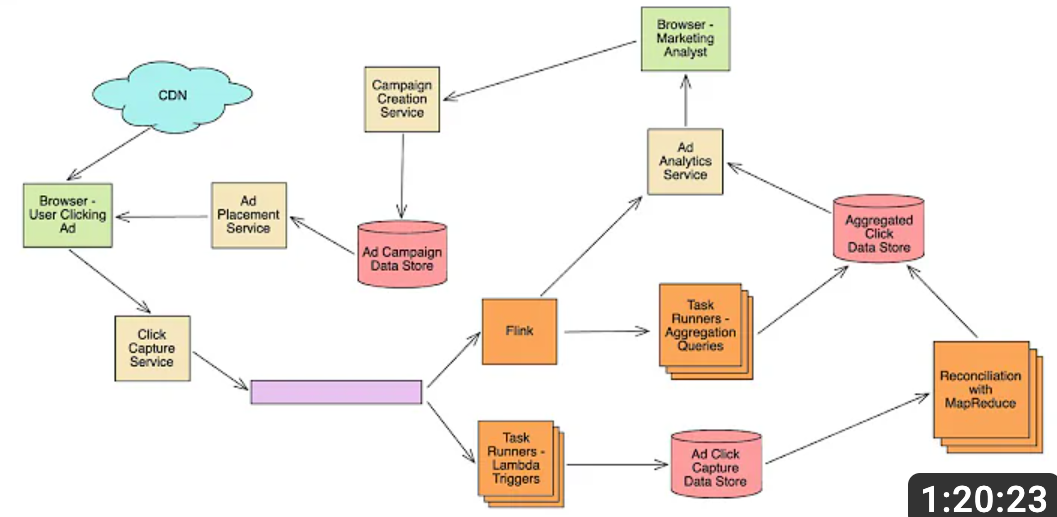
- Content Delivery Network (CDN): Serves ads to users’ browsers quickly. Examples include Akamai and Cloudflare.
- Purpose: CDNs are employed to distribute digital content globally, ensuring that users access data from the nearest server, reducing latency. In this context, it serves the ad content, so ads load quickly regardless of a user’s location.
- Data Example: Cached copies of static files such as HTML, CSS, images, and JavaScript that compose the ad.
- Browser User Clicking Ad: The interaction where users click on ads.
- Purpose: Represents the user’s interaction with an ad. Capturing this interaction is essential for analyzing user engagement with different ads.
- Data Example: Information related to the click, such as user agent, timestamp, ad ID, and coordinates.
- Click Capture Service: Captures click details using technologies like JavaScript.
- Purpose: Acts as a service endpoint that captures click events from users. This is vital for tracking which ads are being clicked on and by whom.
- Data Example: JSON object containing essential click information such as ad ID, user ID, and the time of the click.
- Kafka: Acts as a message broker to transport click data, ensuring fault tolerance and scalability.
- Purpose: Apache Kafka is a distributed streaming platform used here to temporarily hold click events, decoupling the capture and processing systems. This ensures that processing can be scaled independently and that click events are not lost.
- Data Example: A partitioned and replicated topic containing click event messages.
- Kafka to Flink:
- Real-Time Stream Processing: Kafka provides a stream of click data that Flink can process in real-time. Flink’s ability to handle large-scale data streams makes it a natural fit for processing this data.
-
Aggregation and Analysis: Flink may be used to perform complex aggregations, filtering, and analysis on the click data, transforming raw click information into meaningful insights.
- Kafka to Task Runners - Lambda Triggers:
- Event-Driven Processing: Lambda triggers are designed to react to events. In this context, each ad click event captured in Kafka might trigger specific Lambda functions.
- Scalable Microservices: Lambda functions can provide a scalable way to handle individual or micro-batched tasks. These tasks might include additional data enrichment, transformation, or integration with other services.
-
Flexibility and Customization: Lambda triggers can execute custom logic and might be used to route specific click events to various downstream services, providing a flexible processing layer.
- Why Both Connections?
- Parallel Processing Paths: The architecture might require two distinct processing paths: one for real-time analysis and aggregation (via Flink) and another for more granular, event-driven tasks (via Lambda). Kafka’s ability to support multiple consumers allows it to feed both of these paths simultaneously.
- Optimization for Different Needs: Flink might be focused on bulk, real-time processing, analytics, and reporting, while Lambda handles specific, more nuanced tasks, like individual record transformations or notifications. This separation of concerns allows each component to be optimized for its specific role.
-
Redundancy and Robustness: Having multiple pathways for processing can increase the system’s robustness and flexibility, allowing it to accommodate various business logic and processing requirements without a single point of failure.
- Kafka’s connections to both Flink and Lambda triggers represent a strategic division of labor within the ad click aggregator system. By routing click events to both real-time analytics and event-driven microservices, the system can achieve a powerful combination of insights and flexibility, tailored to the diverse needs of an ad analytics platform.
- Task Runners - Lambda Trigger: Utilizes AWS Lambda to perform event-driven processing on incoming data.
- Purpose: These are stateless functions that are triggered to process click events. Utilizing Lambda functions allows parallel processing, making it scalable and cost-effective.
- Data Example: Individual click events that are processed and transformed as needed.
- Flink outputs to both task runners for aggregation queries and an ad analytics service for a number of reasons:
- Task Runners for Aggregation Queries:
- Purpose: Task runners might be used to handle more specific or complex aggregation queries that require custom processing, or batch processing that is different from Flink’s real-time stream processing.
- Technology Example: This could be implemented using serverless computing platforms like AWS Lambda.
- Advantages: Utilizing task runners enables parallel processing and scalability, allowing complex queries to be run efficiently without overloading the main Flink processing system. - Purpose: Executes custom aggregation queries on click data, providing flexibility in how data is analyzed and presented.
- Data Example: SQL-like queries that aggregate click data by different attributes, such as by ad ID or user demographic.
- Ad Analytics Service:
- Purpose: The ad analytics service likely represents a specialized application or module focused on analyzing the aggregated click data, generating insights, visualizations, and reports for marketing analysts.
- Technology Example: This might include tools like Tableau or a custom analytics dashboard.
- Advantages: Directly feeding processed data into an analytics service streamlines the process of analyzing ad performance. This can improve decision-making for marketing strategies, ad campaign optimizations, and more.
-
Why Both Connections?
- Separation of Duties: By having distinct output connections to task runners and an analytics service, Flink can segregate different types of processing and analysis. Task runners might handle complex, heavy-duty aggregation while the ad analytics service focuses on presenting insights in an understandable format.
- Efficiency and Flexibility: This design allows the system to efficiently distribute the right data to the right parts of the system without unnecessary duplication or complexity. It allows for flexible architecture, where different components can be modified or replaced without affecting the others.
-
Real-time and Batch Processing Coordination: Flink can provide real-time stream processing and send data to task runners that might handle batch processing. This dual approach ensures that both real-time and batch processing needs are met, maximizing the value extracted from the data.
- Flink outputs to both task runners and the ad analytics service to accommodate diverse processing and analysis needs within the ad click aggregator system. This division ensures that the system can efficiently handle both complex aggregations and sophisticated analytics, providing valuable insights and actions based on ad click data.
- Ad Click Capture Data Store: Stores raw click data with databases like Apache Cassandra.
- Purpose: This is the database that stores all the raw click data. Having this information allows for historical analysis and raw data retrieval.
- Data Example: Structured data stored in tables with relationships representing the captured click information.
- Flink: Provides real-time stream processing to aggregate and filter click data.
- Purpose: Apache Flink is used for real-time stream processing. Within this system, it’s used for continuous computation, analysis, and aggregation of click streams. Flink enables real-time insights into ad performance, which is vital in a fast-paced advertising environment where quick adjustments to campaigns might be needed.
- Data Example: Streams of click events being analyzed and aggregated to provide statistics like click-through rate per ad.
- Reconciliation with MapReduce: Processes raw data using Apache Hadoop’s MapReduce for aggregation.
- Purpose: This component is used to deduplicate and reconcile click data, essential for accurate analytics.
- Data Example: Processing key-value pairs, where keys are identifiers like user_id, and values are click events.
- Aggregated Click Data Store: Utilizes data warehousing technologies like Amazon Redshift to store aggregated data.
- Purpose: This data store holds summarized click statistics. Aggregated data provides quicker access for reporting and analytics.
- Data Example: Summarized tables with counts, averages, etc., related to ad clicks.
- Ad Analytics Service: Derives insights using analytics platforms like Google Analytics.
- Purpose: A service that allows for visualizing and analyzing click data, providing insights and trends essential for marketing decision-making.
- Data Example: Charts, graphs, and other visual representations of ad performance.
- Browser Marketing Analyst: Analysts view insights to make decisions on campaigns.
- Purpose: Represents the human interaction with the system, where a marketing analyst can view analytics, gain insights, and make informed decisions.
- Data Example: Queries and interactions with various analytics and campaign management interfaces.
- Campaign Creation Service: Utilizes platforms like Adobe Campaign to create and manage new campaigns.
- Purpose: Enables the creation and management of advertising campaigns, allowing marketers to set targeting rules, budget, etc.
- Data Example: Detailed campaign configurations, including targeting parameters, budget allocation, and scheduling.
- Ad Campaign Data Store: Stores campaign details using SQL databases like MySQL.
- Purpose: Persistent storage for all campaign-related data, facilitating tracking and management of various ad campaigns.
- Data Example: Tables containing campaign metadata like campaign name, status, targeting rules, etc.
- Ad Placement Service: Places ads using Ad Servers like DoubleClick.
- Purpose: Responsible for placing ads on various websites or platforms based on the rules set in the campaigns, ensuring that ads are seen by the targeted audience.
- Data Example: Rulesets for where and when to place ads, including targeting parameters and frequency caps.
- Browser User Clicking Ad: The cycle continues with new ads.
Advantages and Technologies:
- Scalability: Systems like Kafka, Lambda, and distributed databases offer excellent scalability, handling large amounts of data.
- Real-time Processing: With Kafka and Flink, the architecture supports real-time processing, allowing immediate insights.
- Fault Tolerance: Technologies like Kafka and Hadoop provide robust fault tolerance, ensuring data integrity.
- Efficiency and Performance: Utilizing Flink for stream processing can increase efficiency and reduce latency compared to traditional batch processing.
- Complexity: The complexity of this system is in balancing various technologies to optimize for real-time processing, scalability, and fault tolerance.
Comparison to Alternatives:
- Versus Traditional Batch Processing: This architecture emphasizes real-time, event-driven processing, providing faster insights and reactions to user behavior.
- Versus Simpler Architectures: While a more streamlined design might be more manageable, this comprehensive system is designed to provide robust scalability, real-time insights, and fault tolerance, key for large-scale ad click processing.