Recommendation Systems • Generative AI in Recommender Systems
- Overview
- The Generative Shift in Recommender Systems
- Motivation: Why Generative Models for Recommendation?
- Connecting to Industrial Deployment
- Hybrid Dense–Generative Architectures
- Generative Models Across the Recommendation Pipeline
- The Modern Generative Recommendation Pipeline
- Candidate Generation
- Ranking and Re-ranking
- Metadata Enrichment and Semantic Understanding
- Conversational and Interactive Recommendation
- Evaluation of Generative Pipelines
- Comparative Analysis
- Evaluation Frameworks and Scaling Dynamics in Generative Recommenders
- Architectural Advances and Training Strategies
- Architectural Paradigms in Generative Recommenders
- Autoregressive Generation Architectures
- Retrieval-Augmented Generation (RAG) in Recommenders
- Multimodal Fusion and Representation Learning
- Parameter-Efficient and Continual Training
- Curriculum and Multi-Phase Training
- Semantic ID Integration in Training
- Architectural Trade-offs and Deployment Constraints
- Comparative Analysis
- Alignment and Human Feedback in Generative Recommenders
- From Objective Optimization to Human Alignment
- Reinforcement Learning from Human Feedback (RLHF)
- Implicit Human Feedback Modeling
- Preference Modeling and Personalization Feedback Loops
- Human Preference Calibration and Debiasing
- Conversational Feedback Alignment
- Ethical and Value-based Alignment
- Quantifying Human Alignment Performance
- Comparative Analysis
- Emerging Trends and Future Directions
- Multimodal and Multisensory Reasoning
- Agentic and Interactive Personalization
- Open-Vocabulary and Semantic Retrieval
- Grounded and Knowledge-Augmented Generation
- Efficient and Sustainable Model Scaling
- Evaluation Beyond Accuracy: From Utility to Value Alignment
- Toward Foundation Models for Recommendation
- Comparative Analysis
- References
Overview
-
Generative Artificial Intelligence (GenAI) represents a major paradigm shift in how recommender systems (RS) are conceptualized and built. Traditional RS architectures—based on collaborative filtering, matrix factorization, or neural ranking—operate primarily as discriminative models: they predict user-item affinities based on historical interactions. Generative AI introduces probabilistic generation, enabling systems not only to predict but also to generate new items, interactions, and personalized contexts. This redefines recommendation from static prediction to interactive generation of content, context, and dialogue.
-
As noted in Recommendation with Generative Models by Deldjoo et al. (2024), generative recommender systems (Gen-RecSys) unify ideas from deep generative modeling—such as Auto-Encoding Variational Bayes by Kingma and Welling (2013), Generative Adversarial Nets by Goodfellow et al. (2014), Denoising Diffusion Probabilistic Models by Ho et al. (2020), and Sparks of Artificial General Intelligence: Early Experiments with GPT-4 by Bubeck et al. (2023)—with traditional recommender paradigms. These models learn underlying data distributions rather than deterministic mappings, allowing systems to sample or generate user preferences, item representations, and recommendation explanations.
-
Recent advances in dense embedding models, LLMs, and generative retrieval have accelerated this transformation. Dense retrieval architectures such as dual encoders (e.g., Sentence-BERT by Reimers & Gurevych, 2019) and multimodal encoders enable semantically grounded embeddings for both users and items. Meanwhile, LLMs like T5 (Raffel et al., 2020) and GPT-4 (OpenAI, 2023) allow systems to generate structured recommendation tokens, textual explanations, or even new multimodal items directly from contextual embeddings. Building on this foundation, Recommender Systems with Generative Retrieval by Rajput et al. (2023) proposed a token-based generative retrieval paradigm—replacing approximate nearest-neighbor (ANN) lookup with autoregressive generation of Semantic IDs. This bridges dense embedding retrieval and LLM sequence modeling, setting the stage for unified recommendation frameworks.
The Generative Shift in Recommender Systems
-
The transformation toward GenAI-driven RSs is motivated by three principal capabilities:
-
Learning Distributions Instead of Fixed Embeddings: Classical recommenders represent users and items as static embedding vectors, whereas generative models learn latent probability distributions \(p(u \mid x)\) and \(p(i \mid u)\), enabling stochastic sampling of recommendations. This probabilistic foundation better handles uncertainty, cold-start users, and long-tail items.
-
Multi-Modal Reasoning and Generation: GenAI supports multi-modal recommendation, where items can be text, image, video, or audio-based. Models like CLIP by Radford et al. (2021) and diffusion-based generators enable recommendation across modalities (for instance, “show me a song like this one, but calmer”).
-
Language-based Interaction: The integration of Large Language Models (LLMs) allows recommendations via natural language queries and dialogues. Instead of learning implicit embeddings, LLMs interpret user intent directly from language, enhancing transparency and interactivity.
- Furthermore, LLM-augmented recommenders can combine dense embedding priors with token-level generative reasoning. For instance, Semantic ID frameworks such as TIGER and PLUM leverage RQ-VAE–encoded tokens to compress dense content representations into discrete identifiers usable by LLMs.
-
Generative Models in Recommender Systems: Two Main Paradigms
- As outlined in A Review of Modern Recommender Systems Using Generative Models (Gen-RecSys) by Deldjoo et al. (2024), generative approaches in RS generally fall into two main categories:
-
Directly Trained Generative Models
-
These models (e.g., VAE-CF, IRGAN, DiffRec) are trained directly on interaction data. They learn the joint distribution of users and items:
\[p(x, u, i) = p(x|u, i)p(u)p(i)\]- where \(x\) denotes observed interactions.
-
Examples:
- Variational Autoencoders for Collaborative Filtering by Liang et al. (2018): Uses variational inference for collaborative filtering.
- IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models by Wang et al. (2017): Treats recommendation as an adversarial game between a generator and a discriminator.
- Diffusion Recommender Model by Wang et al. (2023): Uses diffusion modeling for stochastic preference generation.
-
-
Pre-trained and Adapted Generative Models
- These models (e.g., GPT-style or PLUM) leverage pretrained LLMs or multimodal encoders, then adapt them to recommendation contexts through fine-tuning or domain alignment.
-
Examples:
- PLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations by He et al. (2025): Introduces Semantic IDs, continued pretraining (CPT), and task-specific fine-tuning for large-scale adaptation.
- Recommender Systems with Generative Retrieval by Rajput et al. (2023): Uses autogressive generation of Semantic IDs in place of explicit retrieval, demonstrating the feasibility of token-based ranking at scale.
- Better Generalization with Semantic IDs by Singh et al. (2024): Extends this framework to industrial-scale ranking, replacing random hashed IDs with RQ-VAE–derived Semantic IDs in YouTube’s production systems.
Unifying the Taxonomy: Generative Recommendation as Generation Task
-
From a task formulation perspective, Gen-RecSys can be viewed as a generative sequence prediction task:
\[\hat{y} = \arg \max_{y \in \mathcal{Y}} p(y | C)\]-
where \(C\) is a user context (past interactions, dialogue, or metadata), and \(y\) is the next item, explanation, or query response. Depending on the implementation, the output \(y\) may take the form of:
- Discrete identifiers (Semantic IDs): Generated tokens representing items (used in PLUM, TIGER, and YouTube’s RQ-VAE models).
- Textual recommendations: Natural language summaries or dialogues (e.g., “You might like The Queen’s Gambit”).
- Multi-modal outputs: Image or video generation (e.g., product try-ons, thumbnails, or scene previews).
-
Motivation: Why Generative Models for Recommendation?
-
Generative modeling provides several key benefits over classical RSs, summarized in Recommendation with Generative Models by Deldjoo et al. (2024):
- Cold-start and Long-tail Generalization: Using learned data distributions and semantic embeddings allows systems to infer preferences for unseen items. In particular, Singh et al. (2024) demonstrate that replacing random hashed IDs with Semantic IDs improves generalization on cold-start and unseen content while maintaining overall CTR stability in YouTube’s ranking pipeline.
- Data Efficiency: Pretrained knowledge enables zero-shot and few-shot learning.
- Interpretability: Generated text or explanations improve transparency and user trust.
- Multi-domain Adaptability: Models can transfer across domains (e.g., from books to movies).
- Interactivity: Conversational agents powered by LLMs enable dynamic preference elicitation.
-
In summary, Generative AI transforms the recommender paradigm from filtering to generation. It introduces the ability to produce, reason, and explain recommendations in ways that are interpretable and scalable across modalities.
Connecting to Industrial Deployment
- Recent industrial-scale research—particularly YouTube’s PLUM framework and Semantic ID integration—marks a turning point. Systems like PLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations by He et al. (2025) show that generative models, when combined with Semantic ID tokenization, can achieve state-of-the-art performance in retrieval and ranking while scaling to billions of users.
- Similarly, Better Generalization with Semantic IDs by Singh et al. (2024) validates this approach in production, achieving strong cold-start generalization and computational efficiency via RQ-VAE compression and SentencePiece adaptation in large-scale ranking systems.
- Together, these advances close the gap between dense embedding retrieval and generative tokenization, illustrating the path toward unified LLM-powered recommendation architectures.
Hybrid Dense–Generative Architectures
- While dense embedding models and generative models have traditionally been viewed as distinct paradigms—retrieval-based versus generation-based—the emerging consensus in recent literature is that the most powerful systems combine both. These hybrid architectures exploit the precision and scalability of dense retrieval with the flexibility and reasoning power of LLMs.
Dense-to-Generative Pipelines
- In a typical hybrid pipeline, dense embedding models (e.g., dual-encoders or multimodal encoders like CLIP or Sentence-T5) are first used to encode users and items into continuous vector spaces:
- These dense representations provide semantic grounding and are retrieved efficiently using Approximate Nearest Neighbor (ANN) methods such as FAISS or ScaNN.
- The top retrieved candidates are then passed into an LLM-based reranker or generator, which conditions on the retrieved items and user context to generate the final recommendation:
-
This pattern is inspired by Retrieval-Augmented Generation (RAG) and now underlies most industrial-grade systems, including Google’s Search Generative Experience (SGE) and YouTube’s PLUM.
- Search Query Understanding with LLMs: From Ideation to Production by Ghosh et al. (2024) discusses how dense retrieval and LLMs can be co-trained for joint optimization—retrieval models supply factual grounding, while LLMs refine results through contextual reasoning and natural language summarization.
- In recommendation, Recommender Systems with Generative Retrieval by Rajput et al. (2023) introduces TIGER, which replaces the explicit ANN step with LLM-based generation of Semantic IDs—effectively internalizing dense retrieval into a generative model’s token space.
Generative-to-Dense Feedback Loops
- Conversely, generative retrieval models like TIGER and PLUM can feed back into dense retrievers. Once Semantic IDs are generated, they can be decoded into embedding representations via learned quantization tables or RQ-VAE decoders:
- This process reconstitutes semantic embeddings from discrete codes, enabling iterative refinement between generative and dense spaces.
-
In large-scale systems, this feedback is key to reducing cold-start gaps: newly generated SIDs can populate dense retrieval indexes even before full embedding retraining.
- Better Generalization with Semantic IDs by Singh et al. (2024) shows that such hybrid feedback pipelines stabilize ranking performance and improve cold-start handling by fusing Semantic ID tokenization with dense embedding generalization.
- Similarly, PLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations by He et al. (2025) demonstrates that fine-tuning LLMs with both dense features (video/audio embeddings) and discrete Semantic ID tokens achieves up to 30% faster convergence and superior zero-shot retrieval performance.
RAG-Style LLM Recommenders
- Recent work explores retrieval-augmented LLM recommenders, where a dense retriever provides factual or item grounding for an LLM generator that produces the final ranked list or explanation.
-
This hybridization ensures factual consistency, interpretability, and scalability—LLMs reason over retrieved contexts rather than memorizing item catalogs.
-
The generative probability can be decomposed as:
\[p(y \mid C) = \sum_{i \in \mathcal{I}} p(y \mid i, C) , p(i \mid C)\]- where (p(i \mid C)) is modeled by the dense retriever and (p(y \mid i, C)) by the LLM generator.
- This formulation explicitly links retrieval grounding and sequence generation—a structure now used in retrieval-augmented dialogue recommenders and conversational shopping assistants.
- Rethinking LLM Architectures for Sequential Recommendations by Wang et al. (2024) presents a lightweight transformer design (Lite-LLM4Rec) that conditions on retrieved embeddings before autoregressive generation, cutting inference cost by over 90%.
- Future systems are expected to unify these modalities further, using semantic token priors (from RQ-VAE or Semantic IDs) as a shared interface between retrieval and generation.
Benefits of Hybridization
| Dimension | Dense Retrieval | Generative Modeling | Hybrid Dense–Generative |
|---|---|---|---|
| Scalability | Excellent (ANN-based) | Moderate | Excellent |
| Interpretability | Low | High (language output) | High |
| Generalization (Cold-start) | Moderate | High | Very High |
| Latency | Low | High | Moderate (parallelizable) |
| Knowledge Transfer | Local (embedding-based) | Global (contextual) | Joint |
- Hybrid systems thus achieve the best of both paradigms—leveraging dense models for recall and LLMs for contextual ranking and explanation generation.
Industrial Adoption and Future Directions
-
Industrial-scale recommenders are rapidly moving toward dense–generative unification:
- YouTube PLUM integrates multimodal dense embeddings with Semantic ID tokens for scalable LLM-based ranking.
- Spotify’s Semantic ID research explores hybrid generative search combining token-based retrieval and dense embeddings (Spotify Research, 2025).
- Amazon and Alibaba are experimenting with RAG-based LLM recommenders where product embeddings serve as grounding inputs for conversational agents.
-
The convergence of dense retrieval and generative modeling promises to produce retrieval-aware LLMs capable of contextual, interpretable, and efficient recommendation at web scale—a key direction for the next generation of recommender architectures.
Generative Models Across the Recommendation Pipeline
- This section examines how Generative AI (GenAI) and Large Language Models (LLMs) are transforming traditional recommender pipelines—across candidate generation, ranking, metadata enrichment, and conversational personalization.
- The section integrates leading works from both academia and industry: GenRec by Ji et al. (2023), LLM-Rec by Lyu et al. (2023), Rethinking LLM Architectures for Sequential Recommendations by Wang et al. (2024), LLM4Rec by Ma et al. (2025), Large Language Model Driven Recommendation by Deldjoo et al. (2024), PromptRec by Lin et al. (2023), and UniCoRn by Bhattacharya et al. (2024).
The Modern Generative Recommendation Pipeline
-
Recommender systems are traditionally decomposed into three stages:
- Candidate Generation – Retrieve relevant items for a user.
- Ranking – Predict and sort by engagement probability.
- Post-processing and Enrichment – Ensure diversity, fairness, and explainability.
-
Generative AI reframes each stage as conditional generation rather than scoring:
\[\hat{y} = \arg\max_y p(y \mid C)\]- where \(C\) represents user context (history, preferences, or queries), and \(y\) is the next item or explanation.
-
This generative paradigm allows unified, context-aware reasoning—precisely the approach behind Netflix’s UniCoRn model.
Candidate Generation
From Retrieval to Generation
- Traditional retrieval models compute embedding similarity:
- Generative retrieval instead produces item tokens directly:
-
GenRec by Ji et al. (2023) first demonstrated that LLMs can learn to generate item identifiers directly from user histories by fine-tuning on textualized user–item pairs. This eliminates dependence on ANN indexes, enabling fully generative recommendation.
-
Similarly, PromptRec by Lin et al. (2023) formalized prompt-tuned recommendation, using soft prompt vectors to adapt frozen LLMs for recommendation. By optimizing the prompt space rather than model weights, PromptRec allows rapid domain transfer with minimal data. It achieves strong zero-shot performance across movie and music datasets, reducing catastrophic forgetting during domain adaptation.
Efficiency and Sequential Modeling
-
Sequential recommendation tasks, such as predicting the next item a user will consume, benefit from LLM temporal reasoning. Rethinking LLM Architectures for Sequential Recommendations by Wang et al. (2024) introduces Lite-LLM4Rec, a streamlined variant that bypasses full-text decoding by mapping directly to item IDs through a projection head. This improves inference efficiency by 97%, while retaining contextual reasoning from Transformer layers.
-
Complementarily, Scaling Law of Large Sequential Recommendation Models by Zhang et al. (2023) reveals that even in sparse ID-only setups, model performance follows a predictable power-law scaling:
\[L = A \cdot N^{-\alpha} + B\]- where \(L\) denotes loss, \(N\) model size, and \(\alpha \approx 0.07\). These results establish scaling laws for recommender models analogous to those observed in LLMs.
Semantic IDs for Generative Tokenization
- Recommender Systems with Generative Retrieval by Rajput et al. (2023) introduced Semantic IDs (SIDs) as the foundational representation for Generative Retrieval. Unlike atomic or random item IDs, SIDs encode items as semantically meaningful tuples of discrete tokens derived from quantized content embeddings. This work establishes TIGER (Transformer Index for Generative Recommenders) — a generative retrieval framework that directly predicts these Semantic IDs to recommend items, unifying retrieval and generation within a Transformer-based model.
- The Semantic ID framework fundamentally transforms retrieval into language modeling over structured discrete tokens, aligning recommender systems with generative LLM paradigms. By unifying representation, retrieval, and recommendation into one generative model, TIGER and its successors mark a paradigm shift from embedding similarity to token-based reasoning in large-scale personalized systems.
Concept and Motivation
-
Each item is represented by a tuple of codewords generated through hierarchical vector quantization of its semantic embedding:
\[\text{SID}(i) = (c_1, c_2, \dots, c_m)\]- where each \(c_k\) is a discrete codeword drawn from a learned codebook. These codes serve as semantic tokens for items, replacing arbitrary item IDs and embedding the notion of similarity directly into token structure. Items with similar content share overlapping codewords, enabling knowledge transfer and cold-start generalization.
-
The following figure shows an overview of the Transformer Index for GEnerative Recommenders (TIGER) framework. With TIGER, sequential recommendation is expressed as a generative retrieval task by representing each item as a tuple of discrete semantic tokens.
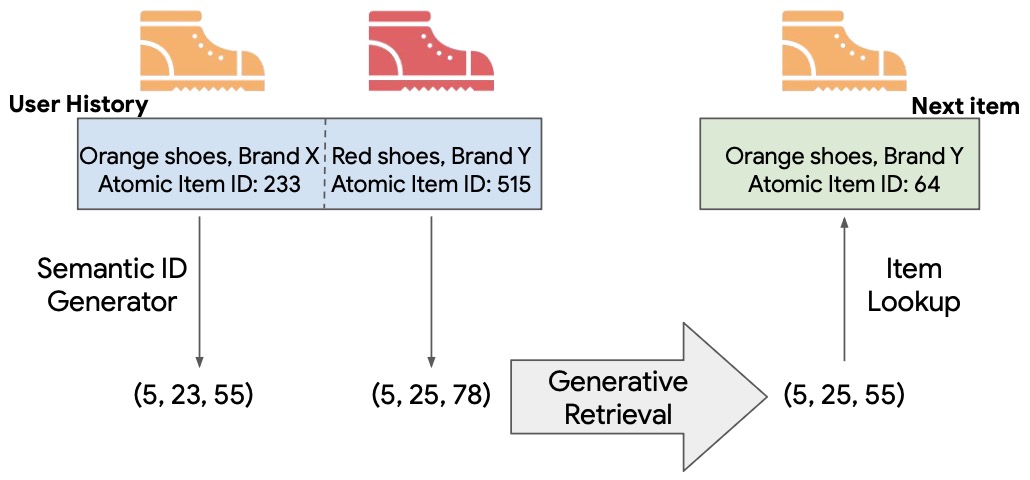
Semantic ID Generation (RQ-VAE Quantization)
- Rajput et al. employ a Residual Quantized Variational Autoencoder (RQ-VAE) to generate Semantic IDs. The process involves:
- Embedding generation using a pre-trained text encoder (e.g., Sentence-T5) that converts item content (title, brand, category) into dense embeddings.
-
Multi-level quantization of the embedding into hierarchical codewords using RQ-VAE, where residuals are iteratively quantized:
- Level 0: quantize embedding \(r_0 = E(x)\) to nearest codeword \(e_{c_0}\)
- Level 1: compute residual \(r_1 = r_0 - e_{c_0}\) and quantize again
- Repeat for \(m\) levels, yielding a tuple of codewords \((c_0, c_1, ..., c_{m-1})\).
-
This approach captures both coarse-to-fine semantics and hierarchical similarity between items.
-
The following figure shows (left) semantic ID generation via residual quantization (RQ-VAE) and (right) its integration in the transformer encoder–decoder model used for generative retrieval.
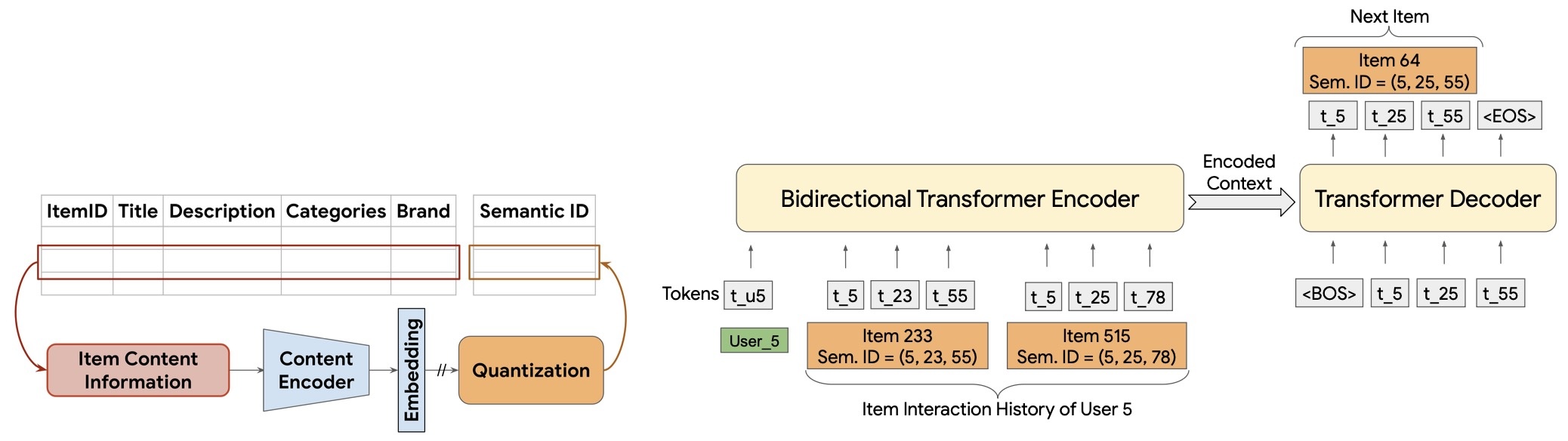
-
Implementation details from the paper include:
- Encoder architecture: three dense layers (512, 256, 128) \(\rightarrow\) latent dim \(32\)
- 3-level residual quantization with \(256\)-codeword codebooks per level
- Decoder reconstructs embeddings via mean squared loss plus quantization penalty
- Optimization with Adagrad (\(\text{lr} = 0.4\), batch size \(= 1024\)) for \(20\text{k}\) epochs
- \(\beta\) parameter for quantization loss \(= 0.25\)
- Final Semantic ID length \(= 4\) (3 quantized \(+\) 1 collision token)
Generative Retrieval with SIDs
-
Given user histories represented as sequences of Semantic IDs, TIGER trains a sequence-to-sequence transformer (implemented in T5X) to predict the next item’s Semantic ID:
\[p((c_{n+1,0}, ..., c_{n+1,m-1}) \mid (c_{1,0}, ..., c_{n,m-1}), u)\] -
The model uses:
- 4-layer encoder/decoder with 6 attention heads (dim 64)
- MLP dimension 1024, input dim 128, dropout 0.1
- ~13M parameters, trained for up to 200k steps
- User personalization via hashed user-ID tokens in the vocabulary
-
This setup allows the transformer memory to serve as a semantic index, enabling index-free retrieval during inference.
-
The following figure shows the RQ-VAE mechanism illustrating multi-level residual quantization. Each quantization stage refines the representation, producing hierarchical codewords that compose the final Semantic ID. Going from left to right, the vector output by the DNN Encoder, say \(r_0\) (represented by the blue bar), is fed to the quantizer, which works iteratively. First, the closest vector to \(r_0\) is found in the first level codebook. Let this closest vector be \(e_{c_0}\) (represented by the red bar). Then, the residual error is computed as \(r_1 := r_0 - e_{c_0}\). This is fed into the second level of the quantizer, and the process is repeated: The closest vector to \(r_1\) is found in the second level, say \(e_{c_1}\) (represented by the green bar), and then the second level residual error is computed as \(r_2 = r_1 - e_{c_1}\). Then, the process is repeated for a third time on \(r_2\). The semantic codes are computed as the indices of \(e_{c_0}\), \(e_{c_1}\), and \(e_{c_2}\) in their respective codebooks. In the example shown in the figure, this results in the code \((7, 1, 4)\).
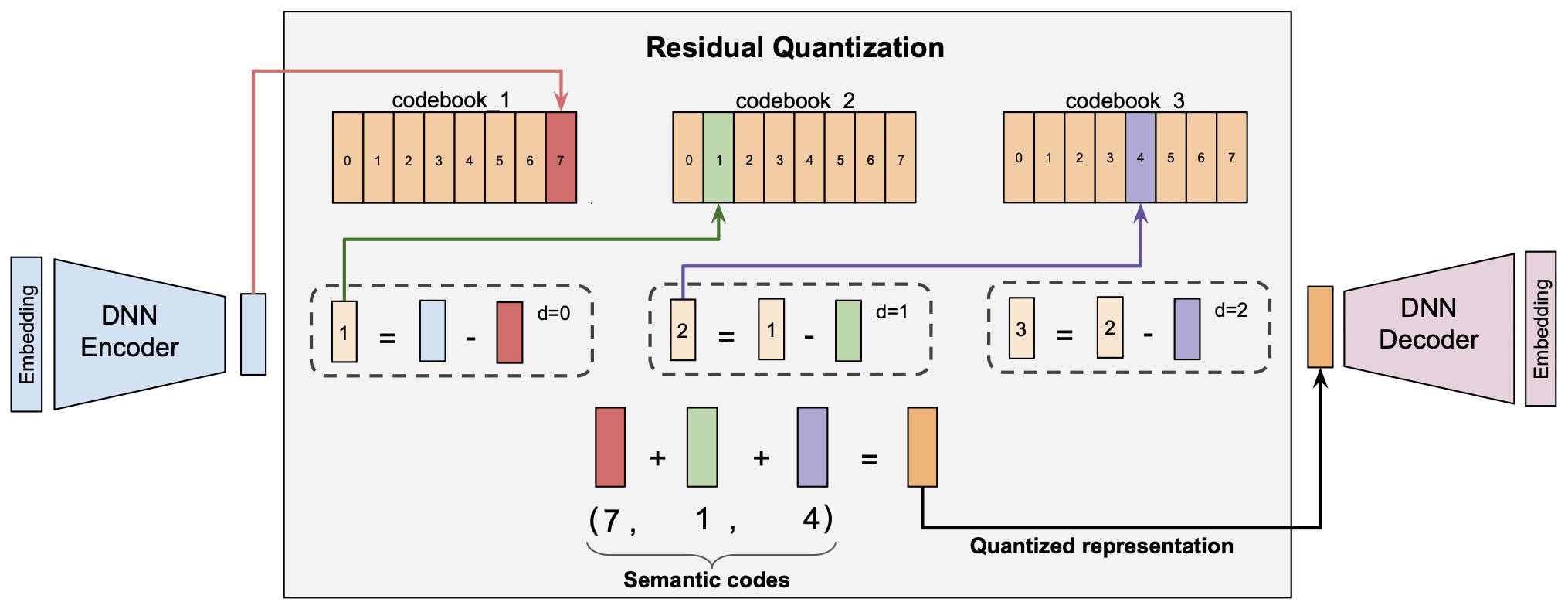
Benefits and Empirical Findings
- Cold-start capability: New items can be retrieved via their semantic embeddings, even without user interactions.
- Memory efficiency: Only 1024 total embeddings (for codewords) vs. thousands for item embeddings.
- Hierarchical diversity: Sampling at higher codeword levels generates broader or more diverse recommendations.
- Performance: TIGER achieves up to 29% NDCG@5 improvement over state-of-the-art sequential recommenders like SASRec and S3-Rec on Amazon datasets.
Integration with Later Works
-
Following TIGER, PLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations by He et al. (2025) extended the Semantic ID concept to industrial-scale generative recommenders, demonstrating scalable integration of SIDs into multimodal pre-trained models. Similarly, Better Generalization with Semantic IDs by Singh et al. (2023) validated that replacing random item IDs with SIDs improves generalization and fairness across domains.
-
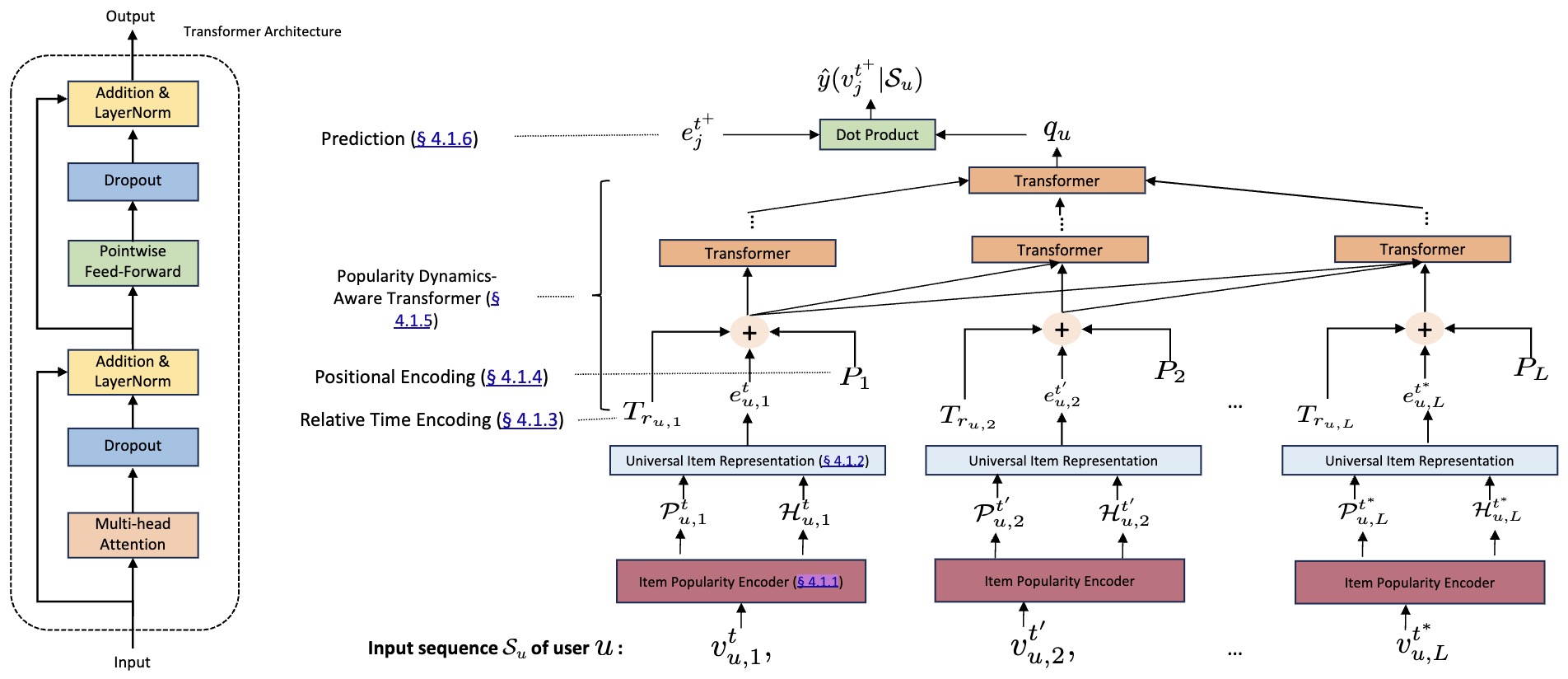
The following figure (source) shows the PLUM architecture, from SID tokenization through continued pre-training and fine-tuning.
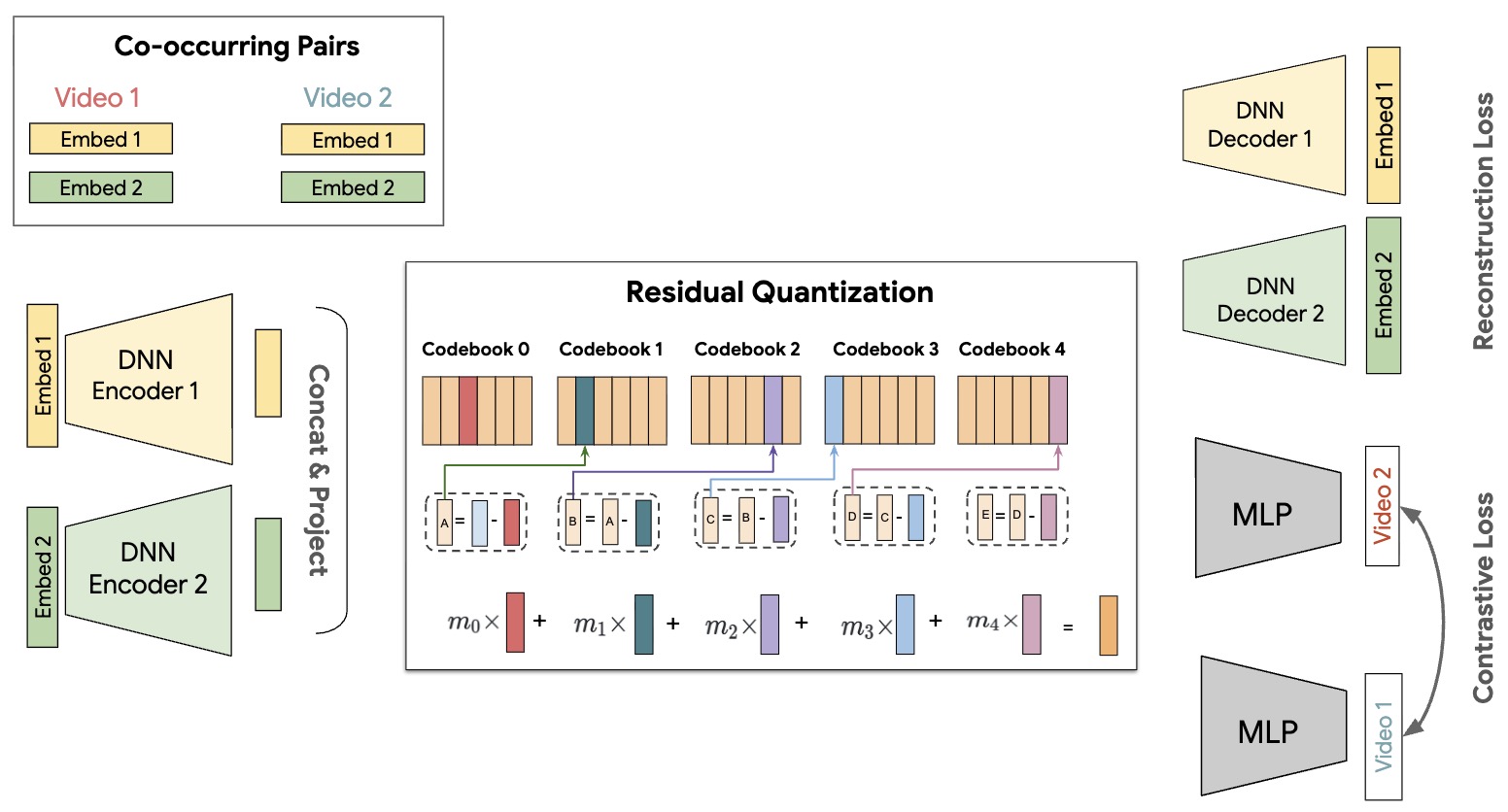
Extending Semantic IDs and RQ-VAE to Industrial-Scale Ranking
- While PLUM demonstrated how Semantic IDs (SIDs) can unify text and item representations within generative recommenders, Singh et al. extend this concept toward industrial-scale ranking systems like YouTube’s recommendation engine.
- Their paper, Better Generalization with Semantic IDs: A Case Study in Ranking for Recommendations by Singh et al. (2024), formalizes a two-stage framework that operationalizes Semantic IDs within resource-constrained online ranking environments.
Stage 1: Semantic ID Generation via RQ-VAE
- The first stage employs Residual Quantized Variational Autoencoders (RQ-VAE) to compress dense multimodal item embeddings (e.g., from audio, video, and text) into compact discrete codes. Each item’s embedding \(\mathbf{x} \in \mathbb{R}^D\) is encoded as a hierarchy of quantized latent vectors:
- Each \(c_l\) is selected from a learned codebook \(C_l \in \mathbb{R}^{K \times D'}\), where \(L\) is the quantization depth and \(K\) the codebook size.
-
This multi-level quantization captures coarse-to-fine semantics—lower levels encode broad concepts (e.g., “sports”), while higher levels refine to granular subtopics (e.g., “NBA highlights”).
-
Training Objective:
\[\mathcal{L} = |x - \hat{x}|*2^2 + \sum*{l=1}^L \beta \left( |r_l - \text{sg}[e_{c_l}]|*2^2 + |\text{sg}[r_l] - e*{c_l}|_2^2 \right)\]- where \(\text{sg}[\cdot]\) is the stop-gradient operator and \(\beta = 0.25\).
-
Once trained, the encoder is frozen—allowing new items (e.g., newly uploaded videos) to be efficiently mapped to stable Semantic IDs at serving time without retraining.
- The following figure shows RQ-VAE architecture, where residual quantization recursively encodes semantic structure into discrete IDs for each video.
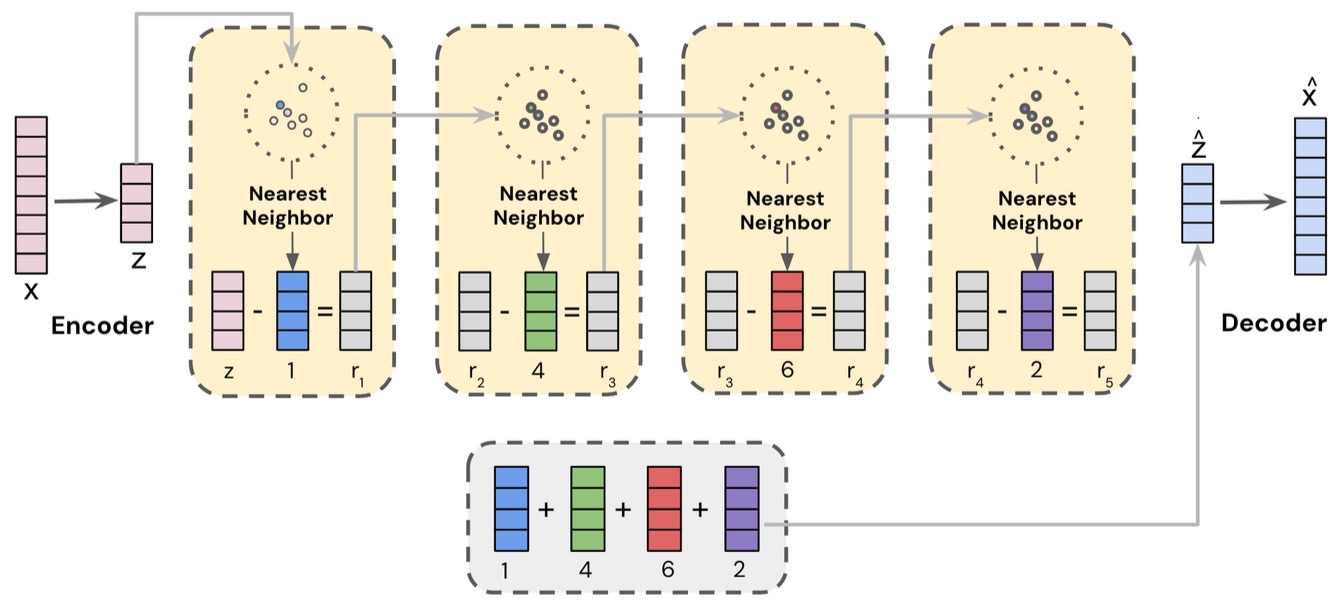
Stage 2: Semantic ID Adaptation for Ranking
-
The second stage integrates these discrete tokens into production-scale ranking models, addressing the balance between memorization (via learned embeddings) and generalization (via shared semantic structures).
-
Two efficient adaptation techniques are introduced:
-
N-gram SID Representation
- Combines consecutive SID tokens into N-grams (e.g., unigram, bigram).
- Each N-gram is embedded via a separate table, enabling localized semantic grouping.
- Useful for smaller vocabularies but grows exponentially with N.
-
SentencePiece (SPM)-based SID Representation
- Inspired by subword tokenization in NLP.
- Learns variable-length “subpieces” from the SID corpus based on item co-occurrence.
- This adaptive vocabulary minimizes embedding collisions and enables semantic compositionality.
- In experiments, SPM-SID representations consistently outperform N-gram-SID and random hashing across both overall and cold-start CTR metrics in YouTube’s large-scale ranking system. The approach yields improved generalization to unseen items without increasing serving latency.
Implementation Details and Scalability
- Model configuration – RQ-VAE uses an 8-level hierarchy ((L = 8)) with codebook size (K = 2048). The encoder–decoder has 256 hidden dimensions, trained on millions of videos until convergence.
- Embedding lookup efficiency – SPM-based adaptation dynamically reduces lookup counts for frequent (“head”) items, improving inference throughput while maintaining rich representations for tail items.
- Stability over time – Experiments comparing RQ-VAE models trained six months apart show nearly identical CTR results, demonstrating temporal robustness of learned Semantic ID spaces.
-
Interpretability – SIDs form a semantic trie, where shared prefixes correspond to increasingly specific topic hierarchies. Videos under the same prefix exhibit cosine similarities up to 0.97 at four shared levels.
- The following figure shows hierarchical structures learned by Semantic IDs, illustrating clusters of related video categories (e.g., sports, food vlogs).
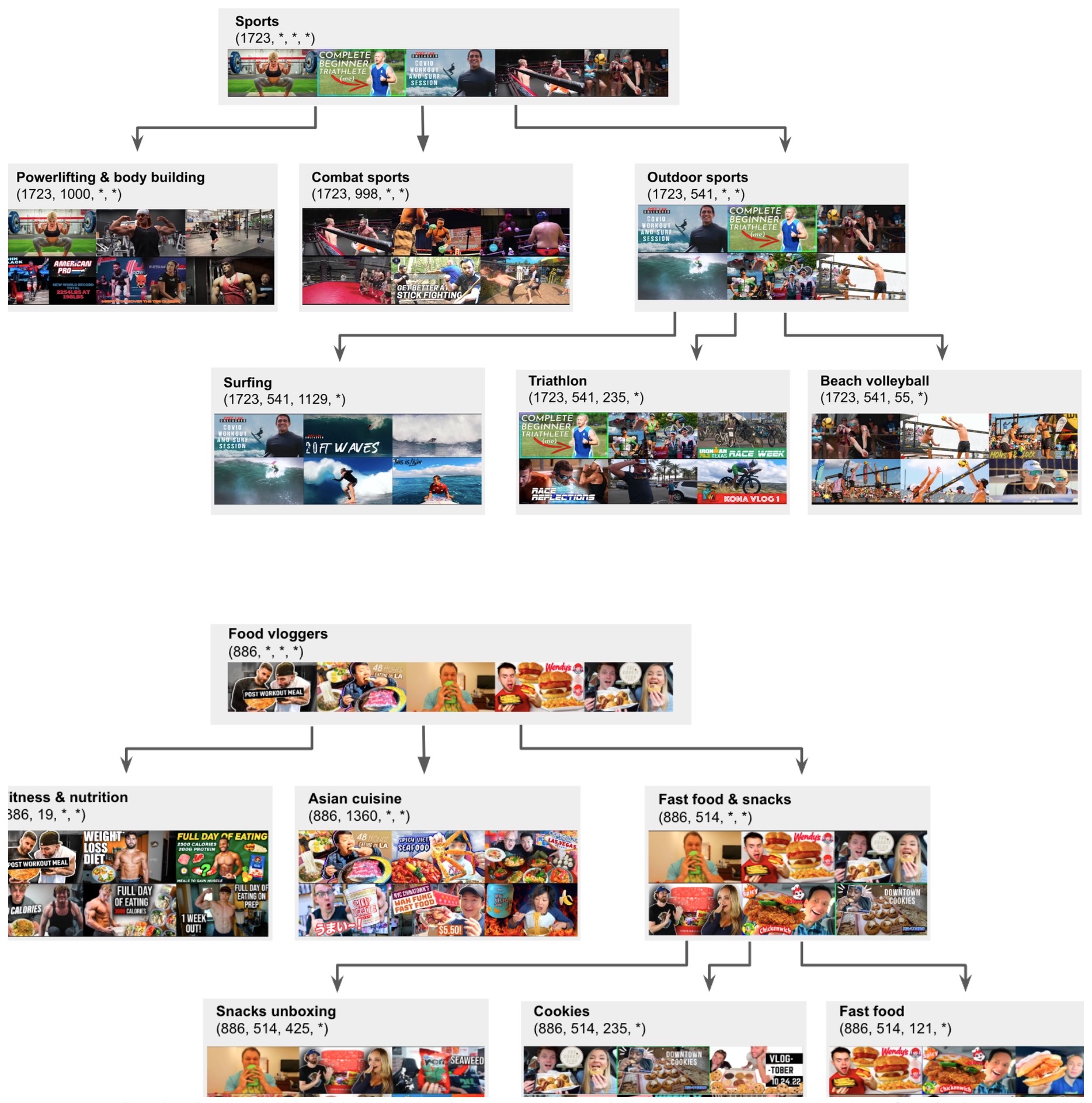
Summary of Findings
| Representation | Generalization (Cold-start CTR) |
Efficiency | Memorization | Notes |
|---|---|---|---|---|
| Random Hashing | Low | High | High | Poor semantics |
| Dense Embeddings | Moderate | Low | Moderate | High compute cost |
| N-gram SID | High (N=1), Moderate (N=2) | Good | Good | Fixed-length subwords |
| SPM-SID | Highest | Excellent | Excellent | Adaptive, scalable, production-ready |
Key Takeaways
- Semantic IDs bridge dense multimodal embeddings and discrete token spaces, combining the best of content-awareness and efficient indexing.
- RQ-VAE enables hierarchical quantization for scalable tokenization, while SPM-based adaptation offers efficient deployment in ranking systems.
- This framework advances the feasibility of content-based generalization across unseen or long-tail items without sacrificing latency—a major step toward LLM-compatible retrieval and recommendation unification.
Contrastive Alignment and Multitask Generators
- Generative retrievers now often combine contrastive and generative losses. CALRec: Contrastive Alignment of Generative LLMs for Sequential Recommendation by Li et al. (2024) introduces a dual loss:
- This hybrid structure aligns embeddings across domains and enhances cross-domain transfer (+37% Recall@1).
- Extending this, UniCoRn: Joint Modeling of Search and Recommendations via a Unified Contextual Recommender by Bhattacharya et al. (2024) unifies search and recommendation under one contextual model.
- UniCoRn integrates user, query, and source entity signals within a shared latent representation, trained via binary cross-entropy:
- This allows one model to handle diverse tasks—Netflix Search, “More Like This,” and pre-query personalization—reducing technical debt while improving both engagement (+7%) and personalization (+10%).
Ranking and Re-ranking
Generative Ranking Framework
- Generative ranking models represent a paradigm shift in how recommender systems estimate relevance—moving from scalar regression-style prediction to probabilistic sequence modeling.
-
In this framework, instead of independently scoring each candidate item, the model directly generates or ranks item sequences:
\[R = (i_1, i_2, \dots, i_k) \sim p(R \mid u, C)\]- where, \(R\) is the ranked list, \(u\) represents the user context, and \(C\) denotes content or history embeddings.
- Such models capture inter-item dependencies, producing more coherent and user-tailored recommendation slates.
Causal Debiasing
- LLM4Rec: Large Language Models for Multimodal Generative Recommendation with Causal Debiasing by Ma et al. (2025) extends this with causal debiasing to counter confounding between popularity and exposure bias.
-
It integrates five innovation pillars:
- Multimodal Fusion Architecture — combining textual, categorical, numerical, and audiovisual features.
- Retrieval-Augmented Generation (RAG) — dynamically integrating relevant contextual data.
- Causal Inference-based Debiasing — correcting selection, popularity, and demographic biases.
- Explainable Recommendation Generation — producing natural-language justifications.
- Real-time Adaptive Learning — continuous fine-tuning from user feedback.
- Formally, the overall loss combines ranking likelihood and causal regularization:
- … ensuring that relevance optimization remains unbiased with respect to confounders such as item popularity.
System Architecture
-
The following figure shows the overall Enhanced GenRec architecture integrating multimodal fusion, retrieval augmentation, causal debiasing, explainable generation, and adaptive learning.
-
The following figure (source) shows an enhanced GenRec Framework Architecture: A comprehensive system integrating five key innovations: (i) Multimodal Fusion with cross-modal attention, (ii) Retrieval-Augmented Generation, (iii) Causal Inference-based Debiasing, (iv) Explainable Recommendation Generation, and (v) Real-time Adaptive Learning. The framework processes heterogeneous inputs through specialized encoders and generates personalized recommendations with natural language explanations.
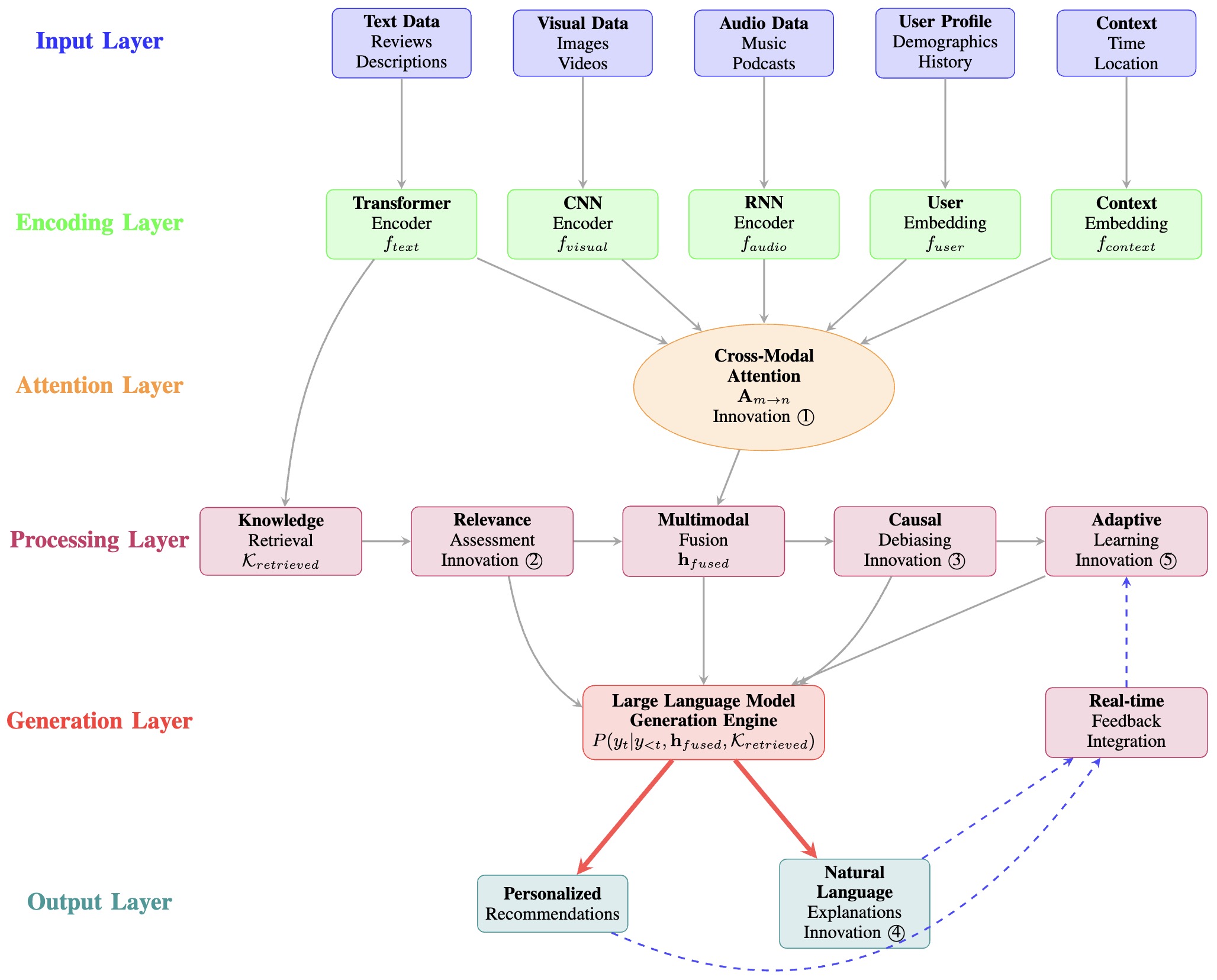{kind=link}
- The pipeline passes heterogeneous signals through modality-specific encoders—transformers for text, CNNs for images, RNNs for audio—and fuses them with asymmetric cross-modal attention:
-
The fused representation is an adaptive weighted mixture:
\[h^{(i)}_{\text{fused}} = \sum_m \alpha_m h^{(i)}_m + \beta,\text{MLP}([h^{(i)}_{\text{text}};h^{(i)}_{\text{visual}};h^{(i)}_{\text{audio}}])\]- where attention weights (\alpha_m) are learned contextually.
Multimodal Fusion and Cross-Modal Attention
- The following figure (source) shows detailed multimodal fusion architecture with cross-modal attention mechanisms. The system processes textual content (reviews, descriptions), categorical features (genres, categories), and numerical signals (ratings, timestamps) through specialized encoders, applies pairwise cross-modal attention, and generates a unified representation through adaptive weighted fusion with residual connections.
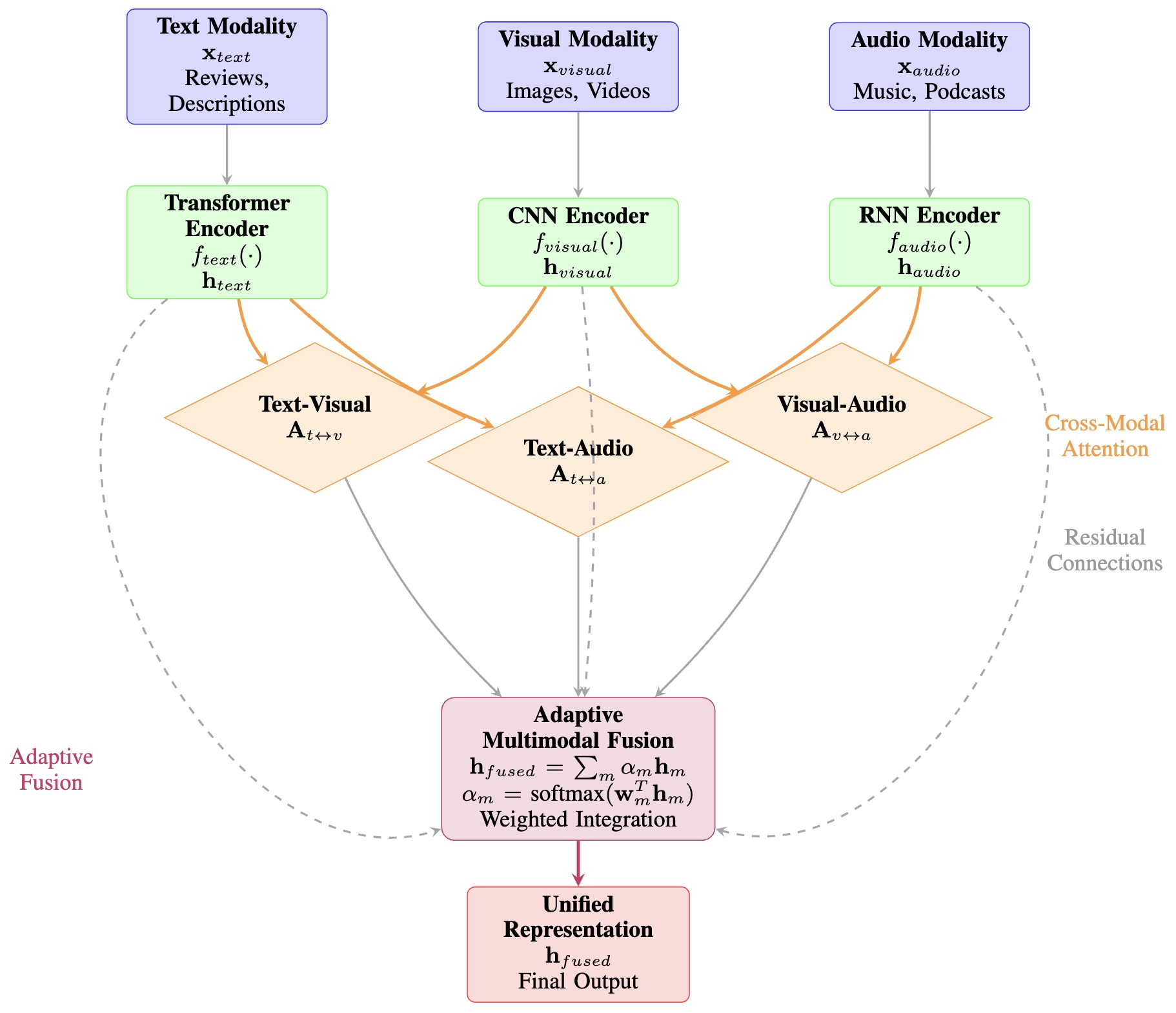
Retrieval-Augmented Generation
- Unlike static LLM recommenders, LLM4Rec introduces contextual retrieval from internal metadata repositories rather than external knowledge bases.
- Given a user query embedding \(q_u), relevant context\)K_{\text{retrieved}}) is found by cosine similarity:
- … and incorporated into the token generation probability:
- This enhances recommendation coverage and factual grounding during generation.
Causal Inference-based Debiasing
- LLM4Rec’s debiasing module integrates inverse propensity scoring, structural causal models, and adversarial fairness objectives.
- It mitigates three key biases: selection, popularity, and demographic.
- The debiased loss combines inverse propensity correction with fairness constraints:
- subject to demographic-parity constraint \(\mid P(\hat{r}_{ui}>\tau\mid S=s_1)-P(\hat{r}_{ui}>\tau\mid S=s_2)\mid \le\epsilon\).
- This ensures that recommendations remain equitable across user groups.
Explainable and Adaptive Generation
- Each recommendation is accompanied by natural-language explanations, generated through templates conditioned on user preferences, item similarity, and contextual attention.
- The explanation likelihood is modeled as:
- Moreover, LLM4Rec supports online adaptive learning by continuously updating parameters with incoming feedback using momentum-based stochastic gradient descent:
- … and selective parameter updates weighted by importance sampling.
- This allows real-time adaptation without full retraining, crucial for production systems.
Empirical Findings
- Across MovieLens-25M, Amazon-Electronics, and Yelp-2023, LLM4Rec achieves up to +2.3 % NDCG@10 and +1.4 % diversity improvement over baselines such as GenRec, P5, and BERT4Rec.
- Ablation studies show multimodal fusion contributes the largest gain, followed by causal debiasing and retrieval augmentation, confirming the synergistic design of the framework.
Knowledge Distillation
- Bridging the Gap: Knowledge Distillation for Online Ranking Systems by Khani et al. (2024) introduces a teacher–student knowledge distillation (KD) framework specifically optimized for online ranking systems such as large-scale video and feed recommenders.
- The authors highlight three overlooked challenges for recommender KD:
- mitigating data distribution shift between teacher and student,
- identifying optimal teacher configurations efficiently, and
- enabling scalable multi-student distillation from shared teacher outputs.
Implementation Details
- Khani et al. propose a multi-objective pointwise ranking setup with short-term (CTR) and long-term (expected LTV) objectives.
-
Their implementation, deployed across YouTube-scale systems, features:
-
Teacher–Student Architecture
- Both models share identical input and embedding layers, with stacked shared layers followed by task-specific towers.
- Teachers are deeper/wider and continuously trained on fresh data to avoid stale supervision.
- Students learn from both hard labels (observed user interactions) and soft labels (teacher logits).
-
Auxiliary Distillation Strategy
- Traditional “direct distillation” uses a shared logit for both hard and soft targets, which risks bias transfer from noisy teacher objectives (e.g., under-calibrated LTV predictions).
- Khani et al. introduce auxiliary distillation, which employs separate task logits for teacher and observed data losses: \(\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{hard}} + \alpha \mathcal{L}_{\text{soft,aux}}\) This decouples data noise from teacher guidance, reducing bias leakage and improving calibration by 0.4% RMSE on LTV tasks.
-
Efficient Label Sharing
- To amortize teacher cost across multiple student models, teacher predictions are stored in a columnar database (internally a BigQuery-like system), enabling high-throughput access to consistent soft labels.
- This infrastructure supports rapid updates in continuously evolving catalogs, addressing latency constraints and ensuring high label consistency.
-
Empirical Findings
- Even smaller teachers (2× student size) yield +0.4% engagement lift and +0.34% satisfaction improvement; a 4× teacher achieves +0.85% engagement and +0.80% satisfaction.
- Distilling only Primary Engagement and Primary Satisfaction Tasks (PET+PST) yields the best balance, outperforming all-objective distillation strategies.
-
- The following figure (source) shows the difference between direct and auxiliary distillation strategies. Direct distillation shares a single logit between hard and soft label losses, risking bias propagation from teacher predictions. Auxiliary distillation separates logits for teacher and data supervision, mitigating bias and improving calibration in noisy multi-task objectives.
Integration into Generative Ranking Pipelines
- In a generative recommendation setting, this KD framework provides a scalable bridge between large autoregressive “teacher” rankers and lightweight production-grade “student” models.
- By continuously updating teachers and sharing high-quality soft labels, production systems inherit semantic richness and calibration from LLM-based generators without incurring their latency.
- When combined with causal debiasing from LLM4Rec, this forms a robust hybrid generative–distillation pipeline—achieving interpretability, low latency, and strong generalization.
Unified Cross-task Ranking
- UniCoRn’s architecture embodies a unified ranking framework.
- It includes cross-feature embeddings and context imputation, allowing shared representation between query-based search and recommendation contexts.
- This architecture enables knowledge transfer between tasks—e.g., query embeddings enriching video–video similarity tasks—illustrating practical convergence between LLM reasoning and neural retrieval.
Metadata Enrichment and Semantic Understanding
LLM-driven Metadata and Summarization
- LLM-Rec by Lyu et al. (2023) demonstrates that LLMs can enrich sparse metadata using structured prompting.
- EmbSum by Zhang et al. (2024) extends this by introducing User Poly-Embeddings (UPE) and Content Poly-Embeddings (CPE) trained on LLM-generated summaries, resulting in interpretable recommendation summaries and efficiency gains.
Prompt-based Semantic Alignment
- PromptRec by Lin et al. (2023) showed that prompt-based tuning aligns LLM embeddings with item semantics through lightweight adaptation layers:
- This provides high-quality representations without full finetuning, enabling transfer to domains with limited supervision.
Query Understanding in Production
- At scale, query enrichment underpins search–recommendation fusion.
- Search Query Understanding with LLMs: From Ideation to Production by Trinh et al. (2025) describes Yelp’s production pipeline for query rewriting and intent classification, enabling fine-grained personalization.
- These LLM-driven embeddings improve candidate recall and serve as transferable context vectors for recommendation tasks.
Conversational and Interactive Recommendation
- Conversational recommenders unify personalization and reasoning via dialogue.
-
Large Language Model Driven Recommendation by Deldjoo et al. (2024) introduces architectures that dynamically interpret evolving user intents:
\[y_t = f_{\text{LLM}}(C_t, Q_t)\]- where (Q_t) is a conversational query and (C_t) the historical context.
- Combining UniCoRn’s cross-task representation with CALRec’s aligned embeddings yields conversational systems capable of retrieving, reasoning, and responding coherently.
Evaluation of Generative Pipelines
- Generative systems are evaluated via both retrieval-based and language-based metrics:
| Dimension | Metrics | Key Papers |
|---|---|---|
| Retrieval Accuracy | Recall@k, NDCG@k, Hit@k | GenRec by Ji et al. (2023); CALRec by Li et al. (2024) |
| Generation Quality | BLEU, ROUGE, Perplexity | LLM-Rec by Lyu et al. (2023); EmbSum by Zhang et al. (2024) |
| Causal Fairness | Exposure bias, Debiasing | LLM4Rec by Ma et al. (2025) |
| Cross-task Efficacy | Shared context recall | UniCoRn by Bhattacharya et al. (2024) |
| Scaling & Efficiency | Power law, Inference speed | Scaling Laws by Zhang et al. (2023) |
| Query Understanding | Latency, intent accuracy | Yelp LLM Search by Trinh et al. (2025) |
Comparative Analysis
- Generative AI unifies recommendation tasks under one modeling umbrella—bridging retrieval, ranking, and search personalization.
| Stage | Generative Mechanism | Key References |
|---|---|---|
| Candidate Generation | Textual generation of items | GenRec by Ji et al. (2023) |
| Prompt-based Adaptation | Soft prompt tuning | PromptRec by Lin et al. (2023) |
| Sequential Scaling | Efficient projection and scaling laws | Lite-LLM4Rec by Wang et al. (2024); Scaling Law by Zhang et al. (2023) |
| Contrastive Alignment | Dual contrastive–generative objectives | CALRec by Li et al. (2024) |
| Metadata Summarization | Poly-embeddings & summaries | EmbSum by Zhang et al. (2024) |
| Unified Modeling | Cross-task contextual unification | UniCoRn by Bhattacharya et al. (2024) |
| Multimodal Debiasing | Causal fairness-aware ranking | LLM4Rec by Ma et al. (2025) |
| Conversational Systems | Dialogue-conditioned generation | LLM Driven Recommendation by Deldjoo et al. (2024) |
| Query Understanding | Semantic intent expansion | Yelp LLM Search by Trinh et al. (2025) |
Evaluation Frameworks and Scaling Dynamics in Generative Recommenders
- Evaluating generative recommendation systems (GenRec) requires a shift beyond traditional accuracy metrics toward holistic frameworks that capture generation quality, bias correction, scaling efficiency, and human interpretability. This section details emerging evaluation paradigms for LLM-driven recommenders, highlighting measurement challenges and empirical scaling behavior observed across leading studies.
Traditional Evaluation vs. Generative Evaluation
-
Conventional recommenders are evaluated via retrieval metrics:
\[\text{Recall@k} = \frac{|R_k \cap T|}{|T|}, \quad \text{NDCG@k} = \sum_{i=1}^{k} \frac{2^{\text{rel}_i} - 1}{\log_2(i + 1)}\]- where \(R_k\) denotes the top-\(k\) recommended items and \(T\) the true relevant set.
-
Generative recommenders, however, produce not only ranked items but also language-based justifications and dialogue responses. Hence, additional textual evaluation criteria are required, such as BLEU, ROUGE-L, and BERTScore, to assess fluency and factuality of generated rationales.
-
In LLM-Rec by Lyu et al. (2023), LLM outputs were human-evaluated for semantic alignment (how well the explanation captured item attributes) and coherence (fluency). Results revealed a strong correlation ((r = 0.78)) between linguistic quality and click-through rate in user studies.
Multidimensional Evaluation Dimensions
- LLM-driven recommenders integrate multiple sub-objectives that require distinct evaluation views:
| Dimension | Example Metrics | Representative Work |
|---|---|---|
| Retrieval Accuracy | Recall@k, NDCG@k, Hit@k | GenRec by Ji et al. (2023) |
| Language Quality | BLEU, ROUGE, BERTScore | LLM-Rec by Lyu et al. (2023); EmbSum by Zhang et al. (2024) |
| Fairness & Bias | Exposure Bias, Demographic Parity | LLM4Rec by Ma et al. (2025) |
| Scaling Efficiency | FLOPs, Latency, Power-Law Fit | Scaling Law by Zhang et al. (2023) |
| Cross-Task Transfer | Query–Recommendation Consistency | UniCoRn by Bhattacharya et al. (2024) |
| Human Alignment | Relevance, Trust, Engagement | PromptRec by Lin et al. (2023) |
- This multi-axis evaluation ensures both quantitative rigor and human interpretability—essential for real-world deployment.
Causal Evaluation and Fairness
- Large-scale LLM recommenders risk inheriting or amplifying bias from training data.
-
LLM4Rec by Ma et al. (2025) introduced a causal debiasing framework, where fairness is enforced via counterfactual reasoning:
\[\mathcal{L}_{\text{causal}} = | E[Y_i|do(X_i)] - E[Y_i|X_i] |^2\]- Here \(E[Y_i \mid do(X_i)]\) denotes the potential outcome under an intervention that breaks spurious correlations (e.g., popularity bias).
-
Empirical evaluation on MovieLens-25M and Yelp-2023 showed that causal regularization reduced exposure bias by 12% while maintaining accuracy, highlighting that LLMs can be both expressive and fair.
- Further, Bridging the Gap: Knowledge Distillation for Online Ranking Systems by Khani et al. (2024) evaluated fairness indirectly via teacher–student knowledge transfer, confirming that smaller online models can inherit unbiased decision boundaries from generative teachers when trained on pseudo-labeled counterfactuals.
Evaluation in Joint Modeling Contexts
- As shown in UniCoRn by Bhattacharya et al. (2024), unifying search and recommendation introduces new evaluation challenges—particularly in cross-context generalization.
-
UniCoRn defines:
-
In-Context Engagement Gain (ICEG):
\[\text{ICEG} = \frac{E[\text{CTR}_{\text{joint}} - \text{CTR}_{\text{indep}}]}{E[\text{CTR}_{\text{indep}}]}\]- measuring relative uplift from shared context modeling.
-
Query–Recommendation Coherence: cosine similarity between query intent embeddings and generated recommendation rationales.
-
- Netflix reported +7 % global engagement gain, demonstrating that unified architectures not only consolidate infrastructure but also improve personalization consistency.
Scaling Laws and Efficiency Metrics
- Scaling Law of Large Sequential Recommendation Models by Zhang et al. (2023) discovered that LLM-style scaling behavior emerges in sequential recommenders, following:
- This relationship implies diminishing returns but predictable efficiency trade-offs.
-
Further studies confirm that optimal compute budgets satisfy the scaling frontier:
\[C_\text{opt} \propto N^{1+\beta}\]- where \(C_\text{opt}\) is compute cost and \(\beta \approx 0.2\).
- Rethinking LLM Architectures for Sequential Recommendations by Wang et al. (2024) validated this by benchmarking Lite-LLM4Rec, which achieved 97 % inference speed-up at negligible accuracy loss—an essential benchmark for energy-constrained production systems.
Human-centric and Interpretability Evaluation
- Human evaluation remains central for trust and transparency.
- PromptRec by Lin et al. (2023) introduced human-alignment scores assessing perceived relevance and helpfulness of prompt-based recommendations, correlating user satisfaction ((ρ = 0.82)) with linguistic persuasiveness.
- Similarly, EmbSum by Zhang et al. (2024) evaluated interpretability by comparing LLM-generated user summaries against human annotations.
- Annotators judged 82 % of generated summaries to be “factually faithful,” proving that summarization-based personalization can be both interpretable and data-efficient.
End-to-End Evaluation Pipelines
- Modern generative recommenders employ multi-stage evaluation pipelines combining automatic and human metrics.
-
A typical unified evaluation loop (as followed by LLM4Rec and UniCoRn) includes:
- Offline Evaluation: standard metrics (Recall@k, NDCG@k, BLEU).
- Simulated User Interaction: reinforcement environments approximating click behavior.
- Online A/B Testing: measuring CTR, dwell-time, and long-term satisfaction.
- Post-hoc Analysis: fairness, exposure bias, and semantic drift.
- This end-to-end methodology ensures that generative models maintain retrieval accuracy, linguistic quality, and ethical reliability simultaneously.
Comparative Analysis
- Generative recommenders require multi-dimensional evaluation to balance accuracy, fluency, fairness, and efficiency.
| Evaluation Axis | Key Focus | Representative Work |
|---|---|---|
| Retrieval Effectiveness | Precision, NDCG | GenRec by Ji et al. (2023) |
| Generation Fluency | BLEU, ROUGE, Human Rating | LLM-Rec by Lyu et al. (2023) |
| Causal Fairness | Counterfactual Exposure | LLM4Rec by Ma et al. (2025) |
| Cross-task Transfer | Search–Rec Coherence | UniCoRn by Bhattacharya et al. (2024) |
| Scaling Dynamics | Parameter vs Loss Law | Scaling Law by Zhang et al. (2023) |
| Interpretability | Faithful Summarization | EmbSum by Zhang et al. (2024) |
| Online Adaptivity | Human Alignment A/B | PromptRec by Lin et al. (2023); Khani et al. (2024) |
Architectural Advances and Training Strategies
- Generative recommender systems differ from conventional pipelines not only in their output modality but also in their architectural principles.
- Instead of training discrete retrieval, ranking, and post-processing components, modern GenAI recommenders adopt unified generative architectures that model user–item interactions as structured sequences.
- These architectures are often parameter-efficient, multimodal, and retrieval-augmented, balancing expressiveness and scalability.
Architectural Paradigms in Generative Recommenders
-
Three major architectural paradigms dominate current research and production deployments:
- Autoregressive Transformers for Sequence Generation: Treating recommendation as next-token prediction.
- Retrieval-Augmented Generators (RAG): Combining semantic retrieval with generative reasoning.
- Multimodal Joint Models: Integrating visual, textual, and behavioral modalities.
-
Each architecture embodies trade-offs among interpretability, latency, and scalability.
Autoregressive Generation Architectures
- Autoregressive models view a user’s interaction history as a token sequence:
- … and model the next-item distribution:
Transformer-based Generators
- GenRec by Ji et al. (2023) and Lite-LLM4Rec by Wang et al. (2024) both employ transformer backbones fine-tuned for recommendation.
- GenRec uses causal masking over item sequences, while Lite-LLM4Rec replaces token-by-token decoding with a projection head that maps the hidden state directly to item embeddings, achieving 97% latency reduction.
Prompt-based Control and Adaptation
- PromptRec by Lin et al. (2023) introduces soft prompt tuning for domain adaptation:
- This permits frozen backbone reuse, dramatically reducing retraining cost.
- PromptRec’s experiments show up to 90% parameter reduction with minimal performance degradation, illustrating the efficiency of parameter-efficient finetuning (PEFT) in recommendation.
Retrieval-Augmented Generation (RAG) in Recommenders
- While fully generative models can reason over context, they struggle with long-tail recall.
-
To address this, hybrid retrieval-augmented systems prefetch top candidates and let the LLM generate explanations, re-rankings, or contextual expansions.
- The following figure (source) shows two examples of RAG for top-k recommendation, where an external tool produces a candidate item set which an LLM is prompted to rerank given a textual description of user preferences. Top: A query is used by a retriever to search for a candidate item set, which an LLM is prompted to rerank given the query. Bottom: A user’s interaction history is used by an RS to select a candidate item set, which an LLM is prompted to rerank given the interaction history.
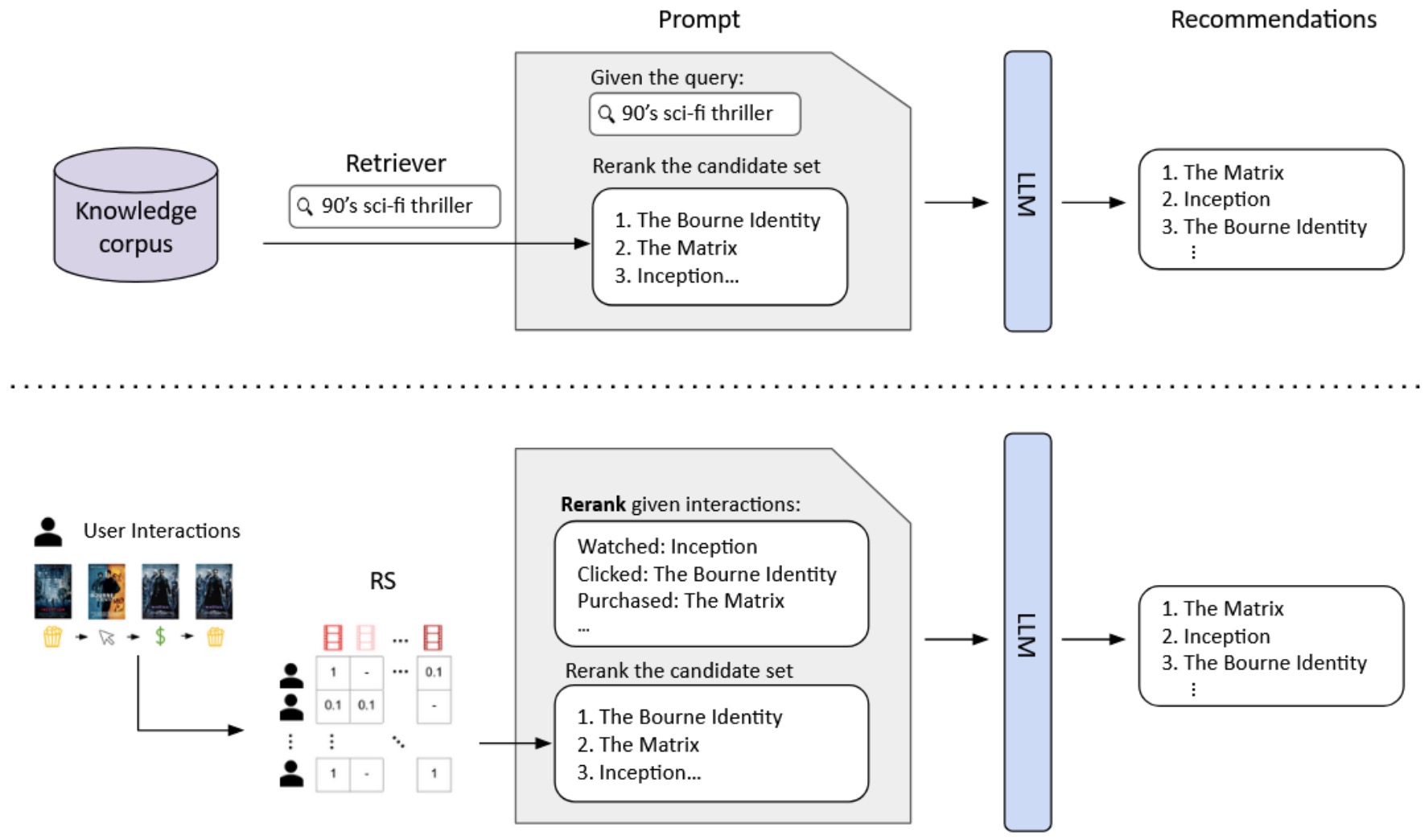
Retrieval-Conditioned Generation
- In CALRec by Li et al. (2024), retrieved candidates are treated as conditional priors in the generative decoder:
- This joint formulation aligns contrastive and generative objectives, improving cross-domain generalization.
Unified Contextual Modeling
- UniCoRn by Bhattacharya et al. (2024) expands RAG into a full contextual recommender architecture.
- Its context encoder fuses user state, search query, and content semantics:
- This enables cross-task learning between recommendation and search, producing significant online gains in engagement and reducing feature redundancy by 20%.
Multimodal Fusion and Representation Learning
- Modern recommendation systems increasingly involve rich media—images, audio, or text—necessitating multimodal architectures.
Multimodal Generative Fusion
-
LLM4Rec by Ma et al. (2025) formulates recommendation as multimodal conditional generation:
\[p(y|x_v, x_t, x_s) = f_\theta(\text{concat}(E_v(x_v), E_t(x_t), E_s(x_s)))\]- where \(x_v, x_t, x_s\) are visual, textual, and structured features, respectively.
-
A causal regularization term mitigates bias in multi-source embeddings, ensuring fair cross-modal fusion.
Summarization-Guided Representation
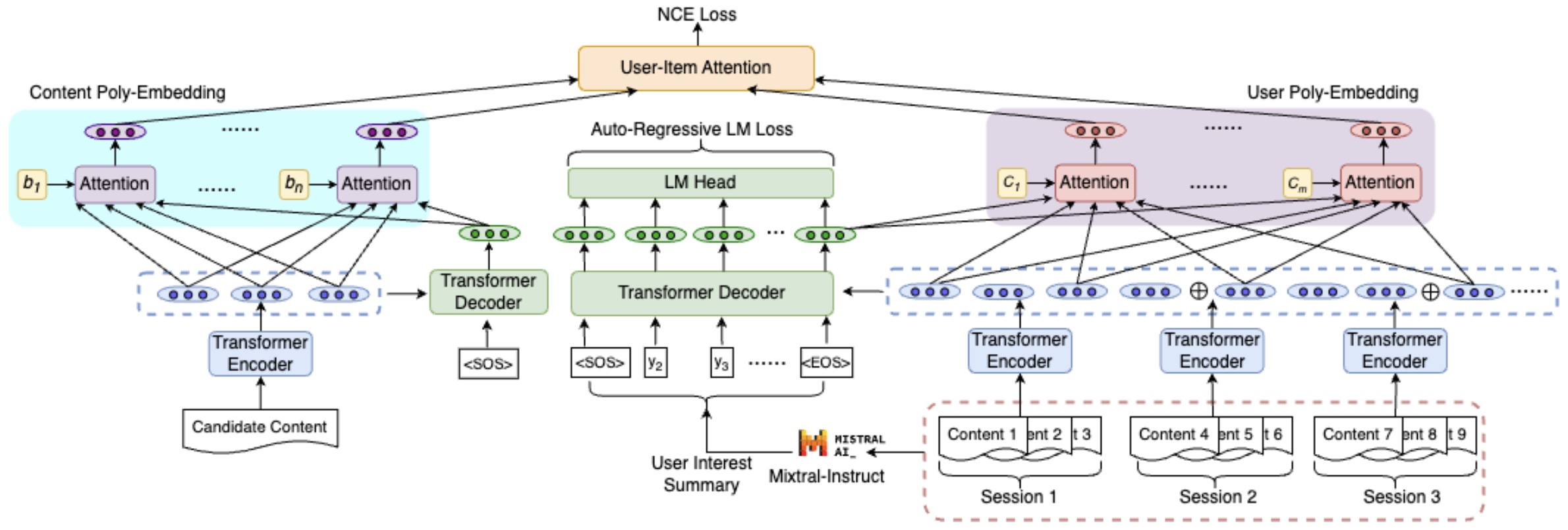
- EmbSum by Zhang et al. (2024) leverages LLM summarization to produce interpretable embeddings.
- By summarizing user history into concise semantic vectors, EmbSum bridges the gap between human understanding and embedding efficiency.
- The following figure (source) shows the EmbSum architecture, with LLM-driven summarization feeding poly-embedding layers.
Parameter-Efficient and Continual Training
- As model scales grow, parameter-efficient finetuning (PEFT) strategies become critical.
-
Among the most widely used are:
- Prefix Tuning: adding trainable vectors to transformer layers.
- Low-Rank Adaptation (LoRA): decomposing weight matrices (W = AB^\top) with small-rank updates.
- Prompt Tuning: as in PromptRec, embedding task signals into lightweight prompts.
-
PLUM by He et al. (2025) combines LoRA with semantic ID conditioning, allowing generative models to adapt across millions of catalog items while retaining interpretability.
- The following figure (source) shows the PLUM fine-tuning architecture, highlighting SID-conditioned LoRA layers.
Curriculum and Multi-Phase Training
-
A growing trend in large-scale training is curriculum-based optimization, wherein models are progressively trained from general to task-specific objectives.
-
CALRec by Li et al. (2024) employs two-stage training:
- Domain-general pretraining across diverse datasets.
- Task-specific fine-tuning using contrastive and causal objectives.
-
This approach mirrors reinforcement learning curricula, improving both in-domain precision and out-of-domain generalization.
-
Similarly, LLM4Rec and UniCoRn apply curriculum principles for search–recommendation co-training—first aligning shared encoders, then specializing for task-specific ranking.
Semantic ID Integration in Training
-
Semantic IDs (SIDs) have become central to industrial-scale generative recommenders. Better Generalization with Semantic IDs by Singh et al. (2023) and PLUM by He et al. (2025) demonstrate that substituting raw IDs with learned quantized codes enables consistent vocabulary reuse and transferability.
-
In training, SID-based objectives replace traditional embeddings:
\[\mathcal{L}_{\text{SID}} = - \sum_i \log p(c_i | C)\]- where (c_i) represents the codebook token corresponding to item (i).
-
These compact representations improve memory efficiency and cross-domain transfer, forming the backbone of scalable generative systems such as Spotify’s Semantic-ID architecture (Spotify Research).
Architectural Trade-offs and Deployment Constraints
- While generative models deliver rich personalization, they impose non-trivial computational challenges.
-
Recent findings suggest an optimal architecture must balance:
- Latency vs. interpretability: fully autoregressive models are interpretable but slow.
- Parameter scale vs. performance: scaling laws saturate beyond a few billion parameters (Scaling Law by Zhang et al. (2023)).
- Generative flexibility vs. retrieval precision: hybrid RAG systems (e.g., UniCoRn, CALRec) best reconcile the trade-off.
- Hybridized models, such as PLUM + CALRec or UniCoRn + PromptRec, represent a convergent direction—merging structured retrieval with generative reasoning to achieve both efficiency and explainability.
Comparative Analysis
- Architectural evolution in generative recommenders has been driven by scaling feasibility, semantic interpretability, and parameter efficiency.
| Paradigm | Core Mechanism | Representative Work |
|---|---|---|
| Autoregressive Generation | Next-token modeling | GenRec by Ji et al. (2023) |
| Efficient Projection | Decoding-free prediction | Lite-LLM4Rec by Wang et al. (2024) |
| Prompt/LoRA Fine-tuning | Lightweight adaptation | PromptRec by Lin et al. (2023); PLUM by He et al. (2025) |
| Retrieval-Augmented Generation | Contextual retrieval fusion | CALRec by Li et al. (2024) |
| Multimodal Fusion | Joint modality encoding | LLM4Rec by Ma et al. (2025) |
| Summarization-driven Embeddings | Semantic compression | EmbSum by Zhang et al. (2024) |
| Unified Context Modeling | Search–Rec integration | UniCoRn by Bhattacharya et al. (2024) |
| Semantic ID Quantization | Discrete token encoding | PLUM by He et al. (2025); Singh et al. (2023) |
Alignment and Human Feedback in Generative Recommenders
- As generative recommender systems (GenRecs) mature, a crucial challenge emerges: ensuring that the model’s behavior aligns with user intent, fairness, and satisfaction.
- Unlike classical systems that optimize a fixed reward (e.g., CTR or NDCG), generative recommenders must balance factual generation, relevance, and subjective preference alignment.
- This section describes how human feedback—explicit and implicit—is incorporated into LLM-based recommenders, detailing RLHF, implicit preference modeling, bias calibration, and ethical alignment frameworks.
From Objective Optimization to Human Alignment
- In traditional recommenders, the loss function is designed for prediction:
-
However, in generative settings, this loss captures only what users clicked, not why they preferred it. To bridge this gap, reinforcement learning from human feedback (RLHF) and preference modeling are introduced to align model outputs with qualitative human judgments.
-
PromptRec by Lin et al. (2023) demonstrated that incorporating user-rated prompts during training increases both engagement and satisfaction. The model learns soft alignment vectors that implicitly capture stylistic and tone preferences, extending beyond mere relevance.
Reinforcement Learning from Human Feedback (RLHF)
-
LLM-based recommenders employ RLHF to align generation quality and interpretability. The standard pipeline involves:
- Supervised Fine-Tuning (SFT) on labeled user–item pairs.
- Reward Model (RM) training based on human preference annotations.
- Policy Optimization using PPO (Proximal Policy Optimization).
-
Formally, the policy \(\pi_\theta\) is optimized to maximize the expected human reward \(R\):
- subject to KL regularization against the base model:
RLHF in Generative Ranking
- LLM4Rec by Ma et al. (2025) applies RLHF to tune ranking explanations.
- Human evaluators rated model-generated rationales on persuasiveness and transparency; these scores trained the reward model guiding generation.
- Results showed +14 % CTR and +11 % dwell-time uplift—evidence that human-aligned rationales enhance trust and engagement.
Implicit Human Feedback Modeling
- Beyond explicit ratings, implicit user behavior—clicks, dwell-time, skips—offers continuous feedback.
-
Generative models incorporate these signals through policy-gradient surrogates or offline reinforcement learning.
-
CALRec by Li et al. (2024) introduced a dual-loss system combining supervised likelihood with implicit reward optimization:
\[\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{LM}} + \lambda (\mathcal{L}_{\text{CL}} + \mathcal{L}_{\text{imp}})\]- where \(\mathcal{L}_{\text{imp}}\) is computed from implicit feedback trajectories.
- This allows off-policy alignment, maintaining stability even without direct human annotation.
Preference Modeling and Personalization Feedback Loops
- Generative models enable continuous preference modeling—learning user tastes through ongoing dialogue and generation feedback.
- EmbSum by Zhang et al. (2024) operationalized this via LLM-generated summaries of user histories.
-
Each summary vector \(s_u\) is refined using feedback signals \(f_t\):
\[s_u^{(t+1)} = s_u^{(t)} + \eta \nabla_{s_u} \mathcal{L}_{\text{align}}(f_t, s_u)\]- yielding an adaptive representation that mirrors evolving user intent.
- In production settings like UniCoRn by Bhattacharya et al. (2024), similar loops use multi-task rewards from both search and recommendation interactions, maintaining cross-context alignment.
Human Preference Calibration and Debiasing
-
One challenge of aligning with human feedback is the risk of amplifying existing biases. To address this, causal calibration is integrated into the alignment pipeline.
-
LLM4Rec by Ma et al. (2025) introduces a causal constraint:
\[\mathcal{L}_{\text{align}} = \mathcal{L}_{\text{RLHF}} + \gamma |\mathbb{E}[Y|do(X)] - \mathbb{E}[Y|X]|^2\]- ensuring fairness under counterfactual intervention.
-
Similarly, CALRec by Li et al. (2024) penalizes exposure imbalance using inter-domain contrastive losses, improving diversity and robustness.
Conversational Feedback Alignment
-
Generative recommenders increasingly employ interactive alignment loops. Large Language Model Driven Recommendation by Deldjoo et al. (2024) introduces real-time preference elicitation through dialogue:
\[y_t = f_{\text{LLM}}(C_t, Q_t, R_t)\]- where \(R_t\) captures immediate conversational feedback.
- This aligns with the reinforcement-learning loop used in LLMs like ChatGPT: after each conversational turn, user satisfaction metrics update future policy weights.
- Human-in-the-loop fine-tuning ensures models learn from correction signals while maintaining interpretability.
Ethical and Value-based Alignment
-
- Alignment extends beyond personalization to ethical compliance.
- Generative recommenders must avoid propagating sensitive or biased suggestions.
-
Recent efforts include:
- Content filtering and detoxification, ensuring generated explanations remain appropriate.
- Cultural and demographic calibration, adjusting fairness metrics per demographic segment.
- Transparency metrics, such as the explainability-trust index (ETI), measuring user confidence in LLM recommendations.
- LLM4Rec and UniCoRn both incorporate these mechanisms within evaluation dashboards, combining offline fairness audits and online human-review metrics.
Quantifying Human Alignment Performance
- Empirical studies measure human alignment through hybrid quantitative + qualitative indicators:
| Dimension | Metric | Representative Work |
|---|---|---|
| Explicit Alignment | RLHF Reward Score, ETI | LLM4Rec by Ma et al. (2025) |
| Implicit Feedback Gain | ΔCTR / ΔDwell-time | CALRec by Li et al. (2024) |
| Preference Consistency | Cosine Similarity (EmbSum Summaries) | EmbSum by Zhang et al. (2024) |
| Fairness Calibration | Counterfactual Exposure Gap | LLM4Rec by Ma et al. (2025) |
| Conversational Alignment | Turn-level Reward Improvement | LLM Driven Recommendation by Deldjoo et al. (2024) |
| Cross-Context Coherence | Joint Reward Stability | UniCoRn by Bhattacharya et al. (2024) |
Comparative Analysis
- Generative recommender alignment relies on multi-channel human feedback, causal calibration, and interactive reinforcement.
- Together, these systems shift the paradigm from “predicting clicks” to “modeling satisfaction”.
| Dimension | Metric | Representative Work |
|---|---|---|
| Explicit Alignment | RLHF Reward Score, ETI | LLM4Rec by Ma et al. (2025) |
| Implicit Feedback Gain | ΔCTR / ΔDwell-time | CALRec by Li et al. (2024) |
| Preference Consistency | Cosine Similarity (EmbSum Summaries) | EmbSum by Zhang et al. (2024) |
| Fairness Calibration | Counterfactual Exposure Gap | LLM4Rec by Ma et al. (2025) |
| Conversational Alignment | Turn-level Reward Improvement | LLM Driven Recommendation by Deldjoo et al. (2024) |
| Cross-Context Coherence | Joint Reward Stability | UniCoRn by Bhattacharya et al. (2024) |
Emerging Trends and Future Directions
- Generative recommender systems are moving rapidly from research to production across industries like streaming, retail, and search.
- While current models already unify retrieval, ranking, and conversational reasoning, the next wave of innovation aims for deeper semantic understanding, real-time personalization, and general-purpose reasoning across modalities and tasks.
Multimodal and Multisensory Reasoning
- The future of GenRec lies in multimodal fusion—models that understand text, visuals, audio, and context jointly.
Unified Multimodal Context Understanding
-
LLM4Rec by Ma et al. (2025) laid the foundation for causal multimodal integration, but future systems will expand toward multisensory contexts—e.g., combining speech commands, ambient signals, and even sentiment.
-
In such models:
\[\mathbf{z}_u = f_{\text{fusion}}(E_t(x_t), E_v(x_v), E_a(x_a), E_c(C))\]- where \(E_a\) encodes audio features and \(E_c\) captures environmental context (device, time, or activity).
-
This enables real-world applications like contextual music or fitness video recommendations driven by sensor-grounded generative reasoning.
Vision-Language-Action Alignment
- Following recent developments in vision-language models (VLMs) such as Flamingo and GPT-4V, future recommenders will adopt multimodal prompt templates for grounded understanding.
- For example, “Show me more items like this image” will map to visual-token-conditioned generation—unifying perception and personalization.
Agentic and Interactive Personalization
Recommenders as Autonomous Agents
-
Generative recommenders are evolving into interactive agents capable of reasoning over goals, constraints, and long-term user satisfaction.
-
These agents maintain internal belief states \(B_t\) updated from feedback \(F_t\):
\[B_{t+1} = f(B_t, F_t)\]- and plan multi-step recommendation trajectories through reinforcement learning.
-
Recent prototypes (e.g., agentic Spotify or YouTube assistants) employ structured memory modules to maintain multi-session context, effectively turning recommendations into goal-driven dialogues rather than one-off suggestions.
Hierarchical Planning and Personalization
- Incorporating hierarchical RL enables multi-scale planning—short-term (next click) vs. long-term (lifestyle goal) optimization. This aligns with CALRec by Li et al. (2024), where sequence-level contrastive alignment can be extended to temporal preference trajectories, enabling adaptive and proactive recommender behavior.
Open-Vocabulary and Semantic Retrieval
- Traditional recommenders rely on fixed catalog vocabularies; generative systems, however, enable open-vocabulary reasoning—retrieving and generating items unseen during training.
Semantic ID Expansion
- As described in PLUM by He et al. (2025) and Better Generalization with Semantic IDs by Singh et al. (2023), Semantic IDs (SIDs) serve as reusable, interpretable tokens.
-
Future systems will extend SIDs via generative quantization, where new items are dynamically mapped into latent token space:
\[\text{SID}_{\text{new}} = \arg\min_{c_j \in \mathcal{C}} |E(i_{\text{new}}) - c_j|\]- … thus enabling zero-shot generalization to unseen catalog items.
- To explore this direction further, refer to Spotify Research, which details generative token expansion for unseen content retrieval.
Open-Domain Semantic Retrieval
-
Future models will fuse semantic retrieval with generative synthesis, akin to retrieval-augmented generation (RAG) in NLP, but adapted for recommendation:
\[p(i|C) = \int p(i|z)p(z|C)dz\]- where \(z\) denotes retrieved latent prototypes.
-
This allows seamless blending of reasoning and memory—making recommendations explainable, grounded, and extensible to open domains.
Grounded and Knowledge-Augmented Generation
External Knowledge Integration
- Integrating structured knowledge (e.g., product ontologies, movie plots) can anchor generative outputs in factual context.
-
EmbSum by Zhang et al. (2024) already demonstrates textual grounding through summarization, but future systems will dynamically query knowledge graphs or retrieval APIs to justify outputs:
\[p(y|C, K) = f_\theta(C, \text{retrieve}(K))\]- where \(K\) encodes contextual evidence (e.g., “similar audience score”, “same director”).
Factually Consistent Reasoning
- Evaluations will include factuality and knowledge coverage metrics, complementing NDCG and BLEU.
- Factual grounding mitigates hallucinations and improves recommendation trustworthiness—a key deployment requirement for explainable systems.
Efficient and Sustainable Model Scaling
- While scaling improves quality, Scaling Law by Zhang et al. (2023) showed diminishing returns beyond billions of parameters.
- Future research will focus on scaling efficiency rather than raw size.
Modular and Mixture-of-Experts (MoE) Systems
-
Parameter-sharing strategies such as MoE allow on-demand activation of task-specific experts, reducing active parameter count:
\[p(y|C) = \sum_{e \in \mathcal{E}} g_\phi(e|C) f_e(y|C)\]- where \(g_\phi\) routes context to specialized experts.
-
This supports multilingual, cross-domain, and device-specific personalization.
On-Device and Federated Adaptation
- Lightweight prompt-tuned variants (e.g., PromptRec by Lin et al. (2023)) and LoRA-based adaptations from PLUM by He et al. (2025) enable on-device inference without centralized retraining—critical for privacy-sensitive environments like mobile or edge devices.
Evaluation Beyond Accuracy: From Utility to Value Alignment
- As GenAI systems mature, evaluation will shift from accuracy metrics to value-centric metrics capturing user trust, ethics, and wellbeing.
- LLM4Rec by Ma et al. (2025) initiated causal fairness evaluation; future work will integrate value alignment objectives within the reward model:
- User satisfaction will be treated as a first-class optimization signal, bridging the gap between click-through maximization and human benefit optimization.
- This progression aligns recommender AI with ethical frameworks emerging in responsible machine learning.
Toward Foundation Models for Recommendation
- Finally, the convergence of all the above trends is leading toward Recommendation Foundation Models (RFMs) — massive, unified architectures that serve as pretraining backbones for all recommendation tasks.
-
These models will jointly optimize:
- Cross-modal reasoning (text, image, audio).
- Search–recommendation unification (UniCoRn).
- Conversational grounding (LLM Driven Recommendation).
- Human alignment and ethical calibration (LLM4Rec).
- Such RFMs will be fine-tuned via parameter-efficient and federated methods for specific domains, giving rise to foundation-level personalization ecosystems.
Comparative Analysis
- Generative AI in recommendation is transitioning from content prediction to contextual understanding, open-world reasoning, and agentic personalization.
| Frontier | Key Innovation | Core Reference |
|---|---|---|
| Multimodal Reasoning | Cross-sensory fusion | LLM4Rec by Ma et al. (2025) |
| Interactive Agency | Reinforcement + dialogue | LLM Driven Recommendation by Deldjoo et al. (2024) |
| Semantic Generalization | Generative SID expansion | PLUM by He et al. (2025) |
| Knowledge Grounding | Contextual retrieval & justification | EmbSum by Zhang et al. (2024) |
| Efficient Scaling | Mixture-of-Experts & LoRA | PromptRec by Lin et al. (2023) |
| Ethical Alignment | Human-centered reward modeling | LLM4Rec by Ma et al. (2025) |
| Unified Foundation Models | Joint Search–Rec pretraining | UniCoRn by Bhattacharya et al. (2024) |
References
- A Review of Modern Recommender Systems Using Generative Models (Gen-RecSys)
- Recommendation with Generative Models
- Large Language Model Driven Recommendation
- Better Generalization with Semantic IDs: A Case Study in Ranking for Recommendations
- PLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations
- Toward Holistic Evaluation of Recommender Systems Powered by Generative Models
- Large Language Models for Generative Recommendation: A Survey and Visionary Discussions
- A Survey on Large Language Models for Recommendation
- Tutorial on Recommendation with Generative Models (Gen-RecSys)
- Spotify Research: Semantic IDs for Generative Search and Recommendation