Overview
Hashing Trick
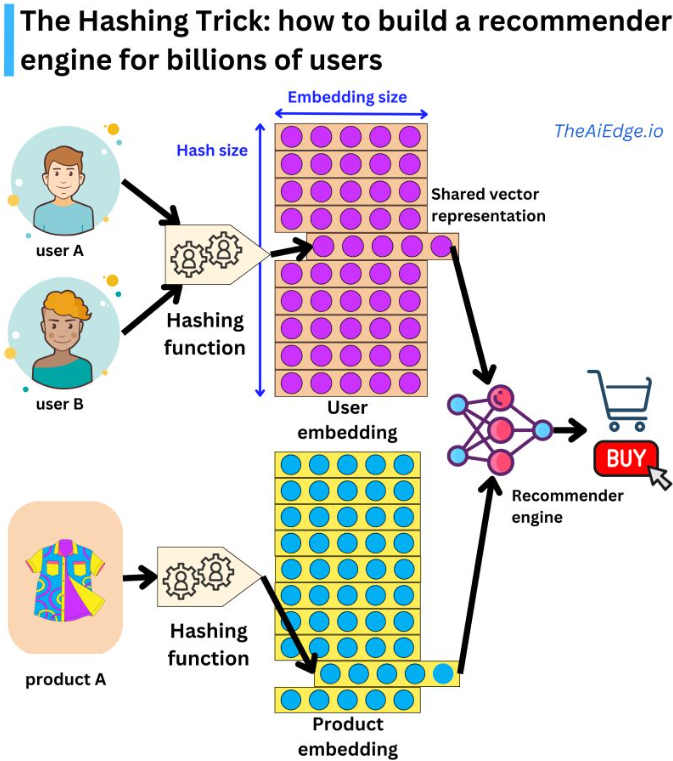
- Say you were to design a recommender model to display ads to users. A naive implementation could include a recommender engine with user and Ads embeddings along with assigning a vector to each category seen during training, and an unknown vector for all categories not seen during training.
- While this could work for NLP, for recommender systems where you can have hundreds of new users daily, the unknown category could exponentially increase!
- Hashing trick is a way to handle this problem by assigning multiple users (or categories of sparse variables) to the same latent representation.
- This is done by a hashing function by having a hash-sized hyperparameter you can control the dimension of the embedding matrix and the resulting degree of hashing collision.
- “But wait, are we not going to decrease predictive performance by conflating different user behaviors? In practice the effect is marginal. Keep in mind that a typical recommender engine will be able to ingest hundreds of sparse and dense variables, so the hashing collision happening in one variable will be different from another one, and the content-based information will allow for high levels of personalization. But there are ways to improve on this trick. For example, at Meta they suggested a method to learn hashing functions to group users with similar behaviors (https://lnkd.in/d4_JCNwu). They also proposed a way to use multiple embedding matrices to efficiently map users to unique vector representations (https://lnkd.in/diH4RSgH). This last one is somewhat reminiscent of the way a pair (token, index) is uniquely encoded in a Transformer by using the position embedding trick.
- The hashing trick is heavily used in typical recommender system settings but not widely known outside that community!” (source)