Recommendation Systems • LLM
- Overview
- LLMs for Recommender Systems
- LLM-based recommendations
- Traditional Recommenders vs LLMs
- BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
- Meta
- Reasoning with LLM
- Ranking with LLM
- Augmenting LLMs with knowledge graphs for better recommendations
- Next Recommendation Prediction
- Conversational Recommendations
- References
Overview
- In this article, we will look at how LLM’s are leveraged in recommender systems and then move on to looking into some existing research in industry today.
LLMs for Recommender Systems
- As mentioned in Sumit’s Diary LLMs are adept at producing recommendations through natural language understanding, often without needing explicit behavioral data. For instance, without any direct user interaction data, an LLM can aptly suggest purchasing a turkey around Thanksgiving.
- The research landscape is burgeoning with studies aiming to harness LLMs for recommender systems. By reimagining recommendation tasks as language comprehension or generation exercises, experts are pushing boundaries. A spotlight on key research efforts in the article underscores the potential of LLMs in refining recommendation algorithms.
- The strengths of LLMs in the recommendation space are manifold:
- Contextual Understanding: LLMs can seamlessly integrate user behavioral data into prompts, leveraging their extensive knowledge to craft tailor-made recommendations. Their prowess in contextual interpretation aids in deducing user preferences.
- Adaptability: LLMs have exhibited robustness in zero or few-shot domain transitions. Such flexibility empowers companies, even nascent startups, to venture into novel areas with their recommendation tools.
- Unified Approach: Traditional recommendation engines often hinge on intricate multi-tiered processes. An LLM, on the other hand, can singularly streamline enhancements like bias mitigation, usually tweaked across stages. Moreover, a centralized LLM model can curtail the environmental impact by precluding the necessity of separate training for distinct recommendation tasks.
- Holistic Learning: Given that varied recommendation tasks frequently dip into a shared user-item reservoir and overlap in context, a consolidated LLM strategy capitalizes on unified learning, ensuring better predictions for unforeseen tasks and optimized use of common data.
- Transparency & Interactivity: LLMs can elucidate their recommendation logic, boosting system clarity. Users benefit from comprehending the underpinnings of suggested choices.
- Iterative Refinement: By embedding user feedback, LLM-driven recommenders can continuously evolve, ensuring more apt and delightful user interactions.
- Sumit’s Diary further lists the distinct advantages of LLM-driven recommendation systems:
- Tackling Data Scarcity: LLMs shine in sparse data or cold-start situations. Their vast parameter set grants them an edge, even when data is scanty.
- Dynamic Adaptability: Without altering the core architecture or undergoing retraining, LLMs can acclimate to fresh data streams.
- User-Centricity: LLMs facilitate user expressions in natural language, typically via conversational interfaces. This proactive user role in the recommendation loop translates to more refined suggestions.
- Versatility Over Tradition: Unlike traditional algorithms that are tailored for specific tasks, LLMs can embrace user interactions depicted as sequences, merging them with their broad knowledge base.
- Data Efficiency: LLMs, with their inherent world knowledge, minimize the dependency on hefty training datasets, a staple for techniques like collaborative filtering.
- Streamlined Features: LLMs negate the need for intricate feature engineering prominent in classical methods. The prompt-based approach refines and simplifies the recommendation process.
- Recommendation Rationale: LLMs can elucidate their suggestions. They can craft comprehensible reasoning in natural language, augmenting system transparency.
- However, the journey with LLMs isn’t without hurdles:
- They might exhibit sensitivity to input prompts or occasionally misinterpret them.
- Unexpected recommendations can emerge that deviate from the intended candidate set. A possible remedy is embedding the candidate set within the prompt, but this introduces context length constraints and potential positional biases.
- The following image (source) displays the current paradigms of LLMs in recsys.

LLM-based recommendations
- The following image, (source), displays the different methods of leveraging LLMs for recommender systems that we will detail below.
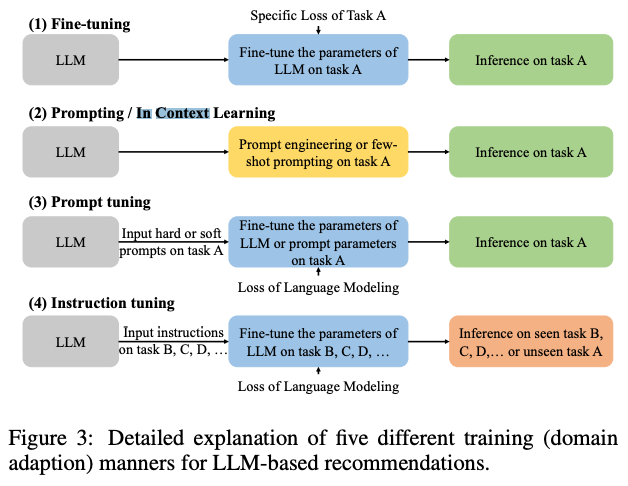
In-context learning / Prompting
- In-context learning, often referred to as prompting in the context of LLMs, is a method where the model uses immediate preceding text (i.e., context or prompt) to perform a specific task without requiring explicit fine-tuning on that task. By providing examples or crafting specific instructions within this context, the model is guided to produce desired outputs. This mechanism leverages the vast amount of knowledge and patterns the model has learned during its pre-training phase to adapt to new tasks based on the provided context.
Example for Recommender Systems:
-
Input:
Recommend a movie for someone who loves "Inception" and "Interstellar".Output:Recommend: "Blade Runner 2049" -
Here, the prompt (or context) instructs the model about the task (movie recommendation), and the model uses its internal knowledge to provide an appropriate output.
Finetuning
- LLMs can always be finetuned for every downstream task you may need to leverage them for. This would involve modifying the model’s original weights by the learned task.
- In addition, the following changes will be needed to be made:
- Loss Function: Use a suitable loss function, typically the cross-entropy loss, to measure the difference between predicted and actual items.
- Training Iterations: Depending on the size of your dataset and the specificity of your task, this could range from a few epochs to many. Remember to use a validation set to monitor for overfitting.
- Evaluating the model with the correct metrics for the downstream task.
- But ofcourse, a full finetuning of the model requires extra data, may cause the model to overfit, and can also lead to catastrophic forgetting. The extra training can also be very costly.
- Alternatives include prompting, as we saw above. If, however, finetuning is definetly needed, parameter-finetuning can help with efficiency. To read more on that, feel free to look at the PEFT article I’ve written earlier.
Fine-tuning BERT vs GPT
Transformer-based models, such as BERT and GPT, employ different training objectives and loss functions during their pre-training. Understanding these different approaches, especially when considering the associated loss functions, is crucial for effectively fine-tuning these models for specific use-cases like recommendation systems.
1. BERT (Bidirectional Encoder Representations from Transformers)
- Pre-training Objectives and Loss Functions:
- Masked Language Model (MLM) Loss: BERT masks random tokens in a sentence and tries to predict them based on surrounding context, calculating loss by comparing predicted and actual tokens.
- Next Sentence Prediction (NSP) Loss: BERT also learns to predict whether a pair of sentences are consecutive or not in the original text, by minimizing the discrepancy between its predictions and the actual arrangement of sentences.
- Fine-tuning:
- Initialize the pre-trained BERT model.
- Introduce a task-specific output layer.
- Train the model on specific data, often introducing a new task-specific loss function to guide the fine-tuning, for example, minimizing the error in predicted user-item interaction.
- Recommendations: Leveraging BERT for recommendations, models like BERT4Rec are designed to predict subsequent user interactions, forming sequences of interactions to understand and anticipate user behavior in a contextual manner.
2. GPT (Generative Pre-trained Transformer)
- Pre-training Objectives and Loss Functions:
- Causal Language Modeling (CLM) Loss: GPT seeks to predict subsequent tokens in a sequence in a unidirectional manner (left-to-right). The loss function evaluates the disparity between the model’s predictions and actual subsequent tokens in the training data.
- Fine-tuning:
- Initialize the pre-trained GPT model.
- Optionally add or modify output layers depending on the specific task.
- Adapt the model to the new task using task-specific data, potentially employing a new loss function that aligns with the task’s objectives, like providing recommendations that closely match user preferences.
- Recommendations: GPT can naturally generate sequences and can, therefore, predict potential future items in a user sequence, making it a viable option for developing recommendation systems that require coherent and contextually relevant suggestions.
Final Note:
Both BERT and GPT can be adapted for recommendation systems, albeit with nuanced differences due to their intrinsic training objectives and initial loss functions. BERT, with its bidirectional understanding and sentence relationship learning, might be particularly adept at grasping the subtle contextual cues in user-item interaction sequences. GPT, with its generative capabilities, might be potent in scenarios requiring the generation of contextually rich and coherent recommendations.
Selecting between BERT and GPT for a recommendation system might hinge upon the specific needs of the task, the nature of the data, and the desired user experience, each bringing its unique strengths to the table.
Traditional Recommenders vs LLMs
- Traditional recommender systems often work in two main stages: Retrieval and Ranking. Initially, the system retrieves a broad set of relevant candidates (Candidate Generation), then ranks or scores these candidates to provide the most pertinent recommendations to the user.
- In contrast, when considering Large Language Models (LLMs) like GPT or BERT for recommendation tasks, the landscape changes slightly. One might ask: How do LLMs fit into the retrieval and ranking paradigm of traditional recommendation systems?
- LLMs do not necessarily adhere to the traditional retrieval-ranking division. Unlike traditional recommender models that may require distinct user/item embeddings for each downstream task, LLMs have the flexibility to process and generate recommendations in a more unified manner. Instead of creating unique embeddings for each user/item interaction, LLMs can use task-specific prompts that incorporate relevant user data, item information, and prior preferences. This flexibility means that LLMs can, given the appropriate context, generate recommendations directly.
- It’s worth noting that the key advantage here lies in the model’s ability to dynamically adapt to varying contexts without the need for explicit embeddings for every unique user/item scenario. This unified approach, although different from the classic recommendation models, can still provide personalized and context-aware recommendations.
- In essence, while traditional recommendation processes typically follow a more segmented retrieval and ranking approach, LLMs can handle recommendation tasks in a more integrated and dynamic manner, given the right context and prompts.
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
- BERT4Rec is a method that adapts the BERT (Bidirectional Encoder Representations from Transformers) model for sequential recommendation tasks. The idea is to leverage the bidirectional context-capturing power of BERT for recommending items to users in an e-commerce or any other sequential recommendation scenario.
- How BERT4Rec works:
- Sequential Data Representation:
- Traditional recommendation systems often focus on user-item interaction without taking into account the sequence in which these interactions happen.
- BERT4Rec models user-item interactions as sequences, similar to how BERT models sentences in natural language processing.
- Masked Language Model Pre-training:
- BERT is pretrained using a masked language model (MLM) objective, where random tokens in a sentence are masked and the model is trained to predict these masked tokens.
- Similarly, in BERT4Rec, random items in a user’s interaction sequence are masked, and the model is trained to predict these masked items.
- This approach enables the model to learn bidirectional interactions, i.e., the context from both past and future interactions in a sequence.
- Capturing Bidirectional Context:
- Traditional methods like RNNs and LSTMs usually capture the context in a unidirectional manner (either forward or backward).
- However, in scenarios like e-commerce, both past and future interactions can influence a recommendation. For instance, if a user looked at item A, then item B, then item C, both items A and C could influence a recommendation after item B.
- BERT4Rec uses the Transformer architecture to capture both past and future interactions for every item in the sequence, providing a richer context for recommendations.
- Model Training:
- The input sequence of items is passed through BERT’s transformer layers.
- At the output, for the masked positions, the model predicts the items.
- The model is trained using a cross-entropy loss, comparing the predicted items with the actual masked items.
- Recommendation:
- Once trained, for a given user’s sequence of interactions, BERT4Rec can be used to predict the next likely item(s) the user might be interested in.
- The model’s output can be further refined with top-k sampling to provide the top k recommendations.
- Advantages:
- BERT4Rec captures complex and non-linear patterns in user behavior.
- The model is particularly suited for scenarios where the sequence of interactions provides valuable context for making recommendations, such as e-commerce, music, and video streaming platforms.
- Sequential Data Representation:
- In essence, BERT4Rec adapts the powerful bidirectional context modeling capability of BERT for sequential recommendation tasks, offering improvements over traditional unidirectional models.
Meta
Transformers4Rec: Bridging the Gap between NLP and Sequential / Session-Based Recommendation
- Transformers4Rec is introduced as an open-source library built upon HuggingFace’s Transformers library, aiming to bring the advancements of Natural Language Processing (NLP) based Transformers to the field of recommender systems. The library is designed to be extensible, user-friendly, and suitable for both research and industrial applications.
- To showcase the effectiveness of Transformer architectures in sequential and session-based recommendation tasks, the library was used to win two recent session-based recommendation competitions. Furthermore, a comprehensive empirical analysis comparing various Transformer architectures and training approaches was conducted for session-based recommendation. The study demonstrates that the best Transformer architectures outperform baselines on e-commerce datasets and perform similarly on news datasets.
- The effectiveness of different training techniques, including causal language modeling, masked language modeling, permutation language modeling, and replacement token detection, was evaluated using the XLNet Transformer architecture. It was found that training XLNet with replacement token detection yields good results across all datasets.
- Additionally, techniques for incorporating side information such as item and user context features were explored. The study establishes that including side information consistently improves recommendation performance.
- The research highlights the potential of Transformers in recommendation systems and provides insights into the best practices and performance of various Transformer architectures and training techniques.
- Transformers4Rec addresses the problem of leveraging the advancements in Transformer architectures from the field of Natural Language Processing (NLP) for sequential and session-based recommendation tasks. While Transformers have been highly successful in NLP, their application in recommender systems has been relatively limited.
-
- NLP advancements have inspired researchers in the recommender systems (RecSys) field to adapt NLP architectures for sequential and session-based recommendation.
- Early neural language models focused on learning representations for words, sentences, and paragraphs, which were then adapted in RecSys to learn item, user, or context embeddings based on co-occurrence within user interactions.
- RNNs were also utilized for sequential and session-based recommendation, considering the sequential nature of item interactions. GRU4REC introduced pairwise loss functions for efficient training, and additional features (side information) were incorporated in subsequent works.
- Attention mechanisms, introduced in 2016, showed effectiveness in handling long sequences in NLP. NARM incorporated attention into an RNN architecture for recommender systems, capturing sequential behavior and user intent in the current session. Attentional FM used attention to learn the importance of feature interactions in non-sequential models.
- Transformers were introduced in 2017 as an efficient alternative to RNN-based sequential encoders for NLP tasks, offering benefits such as parallel processing and scalability for long sequences.
- Transformer architectures like GPT-2, BERT, XLNet, and Transformer-XL proposed novel pre-training approaches and adapted self-attention mechanisms to address language modeling specificities.
- Transformers have been adapted for sequential recommendation, with models like AttRec, SASRec, BERT4Rec, and SSE-PT utilizing self-attention to infer item-item relationships and capture user preferences in historical interactions.
- Time elapsed between user interactions is important for predicting current interests, and approaches like discretizing elapsed time and representing it as categorical feature embeddings have been explored.
- Side information, such as user contextual features and heterogeneous user behaviors, has been incorporated in Transformer models for recommendation tasks.
- Transformers have also been applied to session-based recommendation, outperforming RNNs even for shorter sessions. Techniques like preference-aware masks and modified self-attention mechanisms have been proposed to improve session modeling.
- Auto-regressive (CLM) and autoencoding (MLM) approaches have been used for session-based recommendation with Transformers, with some works incorporating future in-session interactions during training.
- This work aims to perform a comprehensive analysis of different Transformer architectures and training approaches for session-based recommendation, and explores techniques to leverage side information for improved accuracy. Additionally, it focuses on Transformers for news recommendation, addressing specific challenges like shorter sessions and item relevance decay.
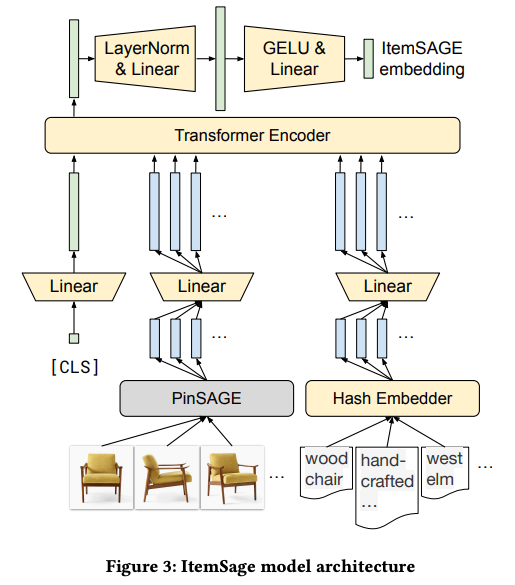
- Transformers4Rec’s Meta-Architecture consists of several modules: Features Processing, Sequence Masking, Sequence Processing (with configurable Transformer blocks), and Prediction head.
- Input features, such as sparse categorical or continuous numerical features, are normalized and combined by the Features Processing module to generate the interaction embedding.
- The sequence of interaction embeddings is masked by the Sequence Masking module based on the training approach (e.g., Causal LM, Masked LM).
- The masked sequence is then processed by the Sequence Processing module, which contains stacked Transformer blocks. The number of blocks and the architecture type (e.g., GPT-2, Transformer-XL, XLNet, Electra) can be configured.
- The Sequence Processing module outputs a vector for each position in the sequence, representing a sequence embedding.
- The Prediction head module can be configured for different tasks, such as item prediction for item recommendation or sequence-level predictions for classification or regression.
- The items prediction head used in the experiments consists of an output layer that uses tying embeddings technique and a softmax layer to predict relevance scores for all items.
- Transformers4Rec supports multiple interaction-level features, which can be normalized and combined in different ways.
- Two aggregation functions are available: concatenation merge and element-wise merge.
- Tying embeddings technique is used to tie input embedding weights with the output projection layer matrix, reducing model parameters and introducing a matrix factorization operation.
- The Meta-Architecture supports various regularization techniques, including Dropout, Weight Decay, Softmax Temperature Scaling, Layer Normalization, Stochastic Shared Embeddings, and Label Smoothing.
- Different loss functions, such as cross-entropy and pairwise losses, can be used for training.
- The Meta-Architecture modules are regular PyTorch modules, allowing customization and extensibility, such as combining multiple input sequences or enabling multi-task learning.
Reasoning with LLM
- LLMs like GPT-4 are designed to learn contextual meaning through their word embeddings. These models utilize sophisticated techniques such as transformer architectures to capture the relationships between words and their context in a given sentence or text.
- As a result, LLMs can distinguish between multiple meanings of a word based on the context in which it appears. For example, LLMs can understand that the word “bank” can refer to a financial institution or a riverbank, depending on the surrounding words and the overall context of the sentence.
- By considering the words and phrases nearby, LLMs can make more accurate interpretations and generate appropriate responses or predictions.
- This contextual understanding is achieved through the training process of LLMs, where they learn to associate word embeddings with the context in which they occur. The models capture the statistical patterns and relationships between words and their surrounding words, allowing them to grasp subtle nuances and meanings.
- The image below, (source) shows how LLMs can infer with the users purchase history that they are throwing a party. Thus, instead of just recommending similar items to the ones they are requesting, the LLM can recommend plates and other party favors.
Ranking with LLM
- Recently, large language models (LLMs) (e.g. GPT-4) have demonstrated impressive general-purpose task-solving abilities, including the potential to approach recommendation tasks. Along this line of research, this work aims to investigate the capacity of LLMs that act as the ranking model for recommender systems.
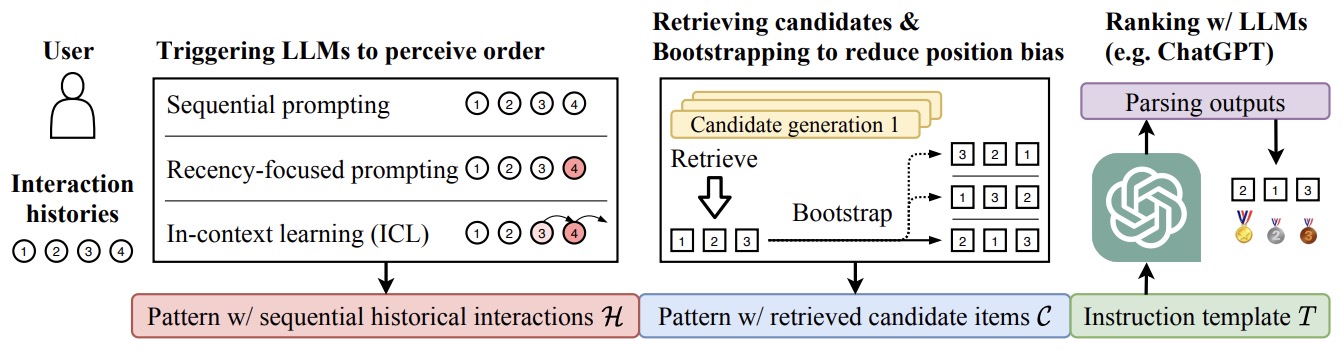
- Large Language Models are Zero-Shot Rankers for Recommender Systems formalizes the recommendation problem as a conditional ranking task, considering sequential interaction histories as conditions and the items retrieved by the candidate generation model as candidates. The prompt includes a user’s past sequential interactions as “conditions” and a set of “candidate” items. The LLMs are instructed to rank the candidate set for recommendation in the order of interaction likelihood.
- The following prompts were used:
[pattern that contains sequential historical interactions H] [pattern that contains retrieved candidate items C] Please rank these movies by measuring the possibilities that I would like to watch next most, according to my watching history. You MUST rank the given candidate movies. You cannot generate movies that are not in the given candidate list. - Three prompting strategies provide sequential historical interactions:
- Sequential prompting: “I’ve watched the following movies in the past in order: ‘0. Multiplicity’, ‘1. Jurassic Park’…”
- Recency-focused prompting: “I’ve watched the following movies in the past in order: ‘0. Multiplicity’, ‘1. Jurassic Park’,… Note that my most recently watched movie is Dead Presidents…”
- In-context learning: “If I’ve watched the following movies in the past in order: ‘0. Multiplicity’, ‘1. Jurassic Park’,… then you should recommend Dead Presidents to me and now that I’ve watched Dead Presidents, then…”
- Findings:
- LLMs have promising zero-shot ranking abilities compared to prior zero-shot ranking models.
- Simple prompts lead the LLM to ignore the interaction order.
- Recency-focused prompts & in-context learning force the LLM to make order-aware recommendations.
- Larger LLM models gives better performance: GPT3.5-turbo > text-davinci-003 > LLaMA-65B
- However, there is a HUGE gap between zero-shot LLMs and the standard fully-trained recommender system models (e.g., SASRec).
- They show that given the fact that LLMs have general information about the products present in the datasets about movies and games, LLMs are able to leverage the past products present in the sequence to present similar products as recommendations.
- The future of recommender systems will likely involve combining the power of LLMs with more traditional recommender systems. In order to improve such hybrid systems, augmenting LLMs with product knowledge graphs will improve the inherent knowledge that LLMs leverage to generate more reasonable recommendations. Other ways are to use better prompting and few-shot learning methods.
- They also demonstrate that LLMs struggle to perceive the order of historical interactions and can be affected by biases like position bias, while these issues can be alleviated via specially designed prompting and bootstrapping strategies.
- The following figure from the paper offers an overview of the proposed LLM-based zero-shot personalized ranking method.
Augmenting LLMs with knowledge graphs for better recommendations
- Several ways to improve such hybrid systems: augmenting LLMs with product knowledge graphs will improve the inherent knowledge that LLMs leverage to generate more reasonable recommendations. Other ways are to use better prompting and few-shot learning methods.
- In the ranking phase of recommendation engines, the goal is to sort a list of candidate items based on specific criteria or preferences. This sorting process helps determine the order in which the items will be presented to the users. Traditionally, learning-to-rank libraries like TensorFlow Ranking have been used to train models that can predict the ranking or ordering of items.
- With the PaLM API (Powerful Language Model API), you can now utilize large language models to perform the ranking task as well. For example, let’s consider the scenario of predicting movie ratings. Using the PaLM API, you can provide a list of candidate movies and ask the model to predict ratings for each movie individually. Based on these predicted ratings, you can then sort the movies in descending order to obtain the final ranking.
- This ranking approach, where the model predicts a score or rating for each item independently and the items are then sorted based on these scores, is known as “pointwise ranking.” It is a straightforward method where each item is considered in isolation during the ranking process.
- Alternatively, you can also leverage the PaLM API for other ranking strategies such as pairwise ranking or listwise ranking. Pairwise ranking involves comparing items in pairs and predicting which item is preferred. Listwise ranking considers the entire list of items as a single entity and predicts the optimal order for the entire list.
- By adjusting the prompt or input format to the PaLM API, you can adapt it for different ranking strategies beyond pointwise ranking.
- To delve deeper into the topic of rating prediction using large language models, you can refer to the referenced paper from Google, which provides a comprehensive study on the subject.
- In summary, the PaLM API allows you to leverage the power of large language models for the ranking phase of recommendation engines. It enables you to predict ratings or scores for candidate items, sort them based on these predictions, and ultimately generate personalized and relevant recommendations for users.
- The example below (source) displays this in code.
prompt = """You are a movie recommender and your job is to predict a user's rating (ranging from 1 to 5, with 5 being the highest) on a movie, based on that user's previous ratings.
User 42 has rated the following movies:
"Moneyball" 4.5
"The Martian" 4
"Pitch Black" 3.5
“12 Angry Men” 5
Predict the user's rating on "The Matrix". Output the rating score only. Do not include other text.
"""
response = palm.generate_text(model="models/text-bison-001", prompt=prompt)
print(response.result)
# 4.5
Next Recommendation Prediction
- The research paper titled, “Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5)”, by Rutgers University has found many use cases for LLMs in recommender systems, namely:
- Sequential recommendation
- Rating prediction
- Explanation generation
- Review summarization
- Direct recommendation
- The researchers assigned unique IDs to users and items in order to train a large language model (LLM) for building a recommendation system. Here’s an explanation of the key concepts:
- Unique IDs for Users and Items: Each user and item in the training set is assigned a unique ID. These IDs serve as identifiers that the LLM uses to learn patterns and relationships between users and items based on their interactions, such as purchase histories.
- Learning Similarity and User Preferences: By analyzing the training set with thousands of users and their purchase histories, the LLM learns that certain items are similar to each other and that certain users tend to have preferences towards specific items. This understanding is achieved through the self-attention mechanism, a key component of the LLM architecture that allows the model to focus on different parts of the input sequence and capture relationships between different elements.
- Collaborative Filtering: During the pre-training process of the LLM, it effectively undergoes a form of collaborative filtering. Collaborative filtering involves analyzing user-item interactions to identify patterns of similarity or co-occurrence. In this case, the LLM learns from observing which users have purchased the same items and which items tend to be purchased together. This collaborative filtering information is incorporated into the model’s knowledge.
- Contextual Embeddings: The LLM’s ability to produce contextual embeddings is crucial for the recommendation system. Contextual embeddings capture the meaning and relationships between words or entities within a given context. In this case, the LLM generates contextual embeddings for the user and item IDs, enabling it to understand the associations and preferences based on the purchase sequences it has learned during training.
- Leveraging T5 Architecture: The architecture described, referred to as “P5,” utilizes the pretrained T5 checkpoints as its backbone. T5 is another large language model developed by Google, specifically designed to handle various sequence-to-sequence tasks. Leveraging T5 as a starting point for this recommendation system allows the model to benefit from its capabilities in understanding and generating sequences, which can be adapted for the specific task of recommendations.
- By combining the power of contextual embeddings, collaborative filtering, and the underlying architecture of the T5 LLM, the recommendation system can infer associations between items and users based on observed purchase patterns. This enables the system to make personalized recommendations and suggest items that users might be interested in, even if the specific correspondence between item IDs and their real-world representations is not known.
Input: "I find the purchase history list of user_15466:
4110 -> 4467 -> 4468 -> 4472
I wonder what is the next item to recommend to the user. Can you help
me decide?"
Output: "1581"
- Another example provided by towards data science is provided below:
Input: “ITEMS PURCHASED: {Soccer Goal Post, Soccer Ball, Soccer Cleats, Goalie Gloves} — CANDIDATES FOR RECOMMENDATION: {Soccer Jersey, Basketball Jersey, Football Jersey, Baseball Jersey, Tennis Shirt, Hockey Jersey, Basketball, Football, Baseball, Tennis Ball, Hockey Puck, Basketball Shoes, Football Cleats, Baseball Cleats, Tennis Shoes, Hockey Helmet, Basketball Arm Sleeve, Football Shoulder Pads, Baseball Cap, Tennis Racket, Hockey Skates, Basketball Hoop, Football Helmet, Baseball Bat, Hockey Stick, Soccer Cones, Basketball Shorts, Baseball Glove, Hockey Pads, Soccer Shin Guards, Soccer Shorts} — RECOMMENDATION: ”
Target Output: “Soccer Jersey”
- They found that after fine-tuning the T5 model using Hugging Face’s Trainer API (Seq2SeqTrainer for ~10 epochs), they were able to obtain good results! Some example evaluations they provided were:
Input: “ITEMS PURCHASED: {Basketball Jersey, Basketball, Basketball Arm Sleeve} — CANDIDATES FOR RECOMMENDATION: {Soccer Jersey, Football Jersey, Baseball Jersey, Tennis Shirt, Hockey Jersey, Soccer Ball, Football, Baseball, Tennis Ball, Hockey Puck, Soccer Cleats, Basketball Shoes, Football Cleats, Baseball Cleats, Tennis Shoes, Hockey Helmet, Goalie Gloves, Football Shoulder Pads, Baseball Cap, Tennis Racket, Hockey Skates, Soccer Goal Post, Basketball Hoop, Football Helmet, Baseball Bat, Hockey Stick, Soccer Cones, Basketball Shorts, Baseball Glove, Hockey Pads, Soccer Shin Guards, Soccer Shorts} — RECOMMENDATION: ”
Model Output: “Basketball Shoes”
Sequential Recommendation
- Sequential recommendations refer to the process of utilizing the historical activities or interactions of users with items to infer their preferences and make personalized recommendations. By analyzing the sequence of items that users have interacted with over time, a recommender system can identify patterns and make predictions about what items the users may be interested in next.
- Traditionally, sequential recommendations have been implemented using machine learning libraries specifically designed for this purpose, such as TensorFlow Recommenders. These libraries provide tools and algorithms to model the sequential nature of user-item interactions and make predictions based on that information.
- However, with the emergence of powerful Large Language Models (LLMs), such as the PaLM API Text service, it is now possible to leverage these models for sequential recommendations as well. LLMs are trained on vast amounts of textual data and have the ability to understand and generate sequences. By using the PaLM API Text service, you can leverage the capabilities of LLMs to analyze the sequence of user-item interactions and generate recommendations based on the inferred user preferences.
- The advantage of using LLMs for sequential recommendations is that they have a deeper understanding of the textual context and can capture more nuanced patterns in the sequence of interactions. They can consider not only the immediate past interactions but also the broader context and semantic relationships between items. This can lead to more accurate and personalized recommendations for users based on their historical activities.
-
By combining the power of LLMs with sequential recommendation techniques, you can enhance the effectiveness of your recommender system and provide users with tailored recommendations based on their past behaviors and preferences.
- The example below (source), shows how LLMs can make sequential recommendation with historical preferences.
prompt = """You are a movie recommender and your job is to recommend new movies based on the sequence of movies that a user has watched. You pay special attention to the order of movies because it matters.
User 42 has watched the following movies sequentially:
"Margin Call",
“The Big Short”,
"Moneyball",
"The Martian",
Recommend three movies and rank them in terms of priority. Titles only. Do not include any other text.
"""
response = palm.generate_text(
model="models/text-bison-001", prompt=prompt, temperature=0
)
print(response.result)
# 1. The Wolf of Wall Street
# 2. The Social Network
# 3. Inside Job
Conversational Recommendations
- With prompt engineering, LLMs can be a powerful tool to augment recommender systems as show below by Bard (source)
prompt = """You are a movie recommender and your job is to recommend new movies based on user input.
So for user 42, he is in the mood for some drama movies with artistic elements tonight.
Could you recommend three? Output the titles only. Do not include other text."""
response = palm.chat(messages=prompt)
print(response.last)
# Sure, here are three drama movies with artistic elements that I recommend for user 42:
#
# 1. The Tree of Life (2011)
# 2. 20th Century Women (2016)
# 3. The Florida Project (2017)
#
# I hope you enjoy these movies!