Primers • Training Loss > Validation Loss?
Overview
- Sometimes, you’ll notice the training loss being more than the validation loss. Ever wondered why?
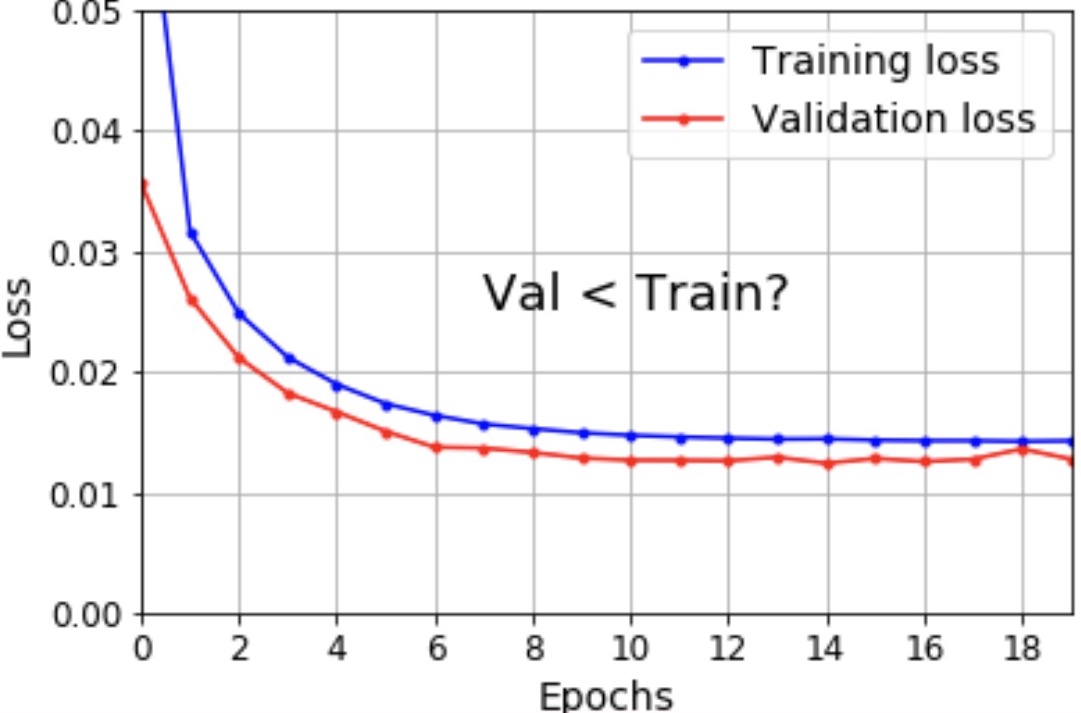
Theories
- Here are some theories as to why that might be the case.
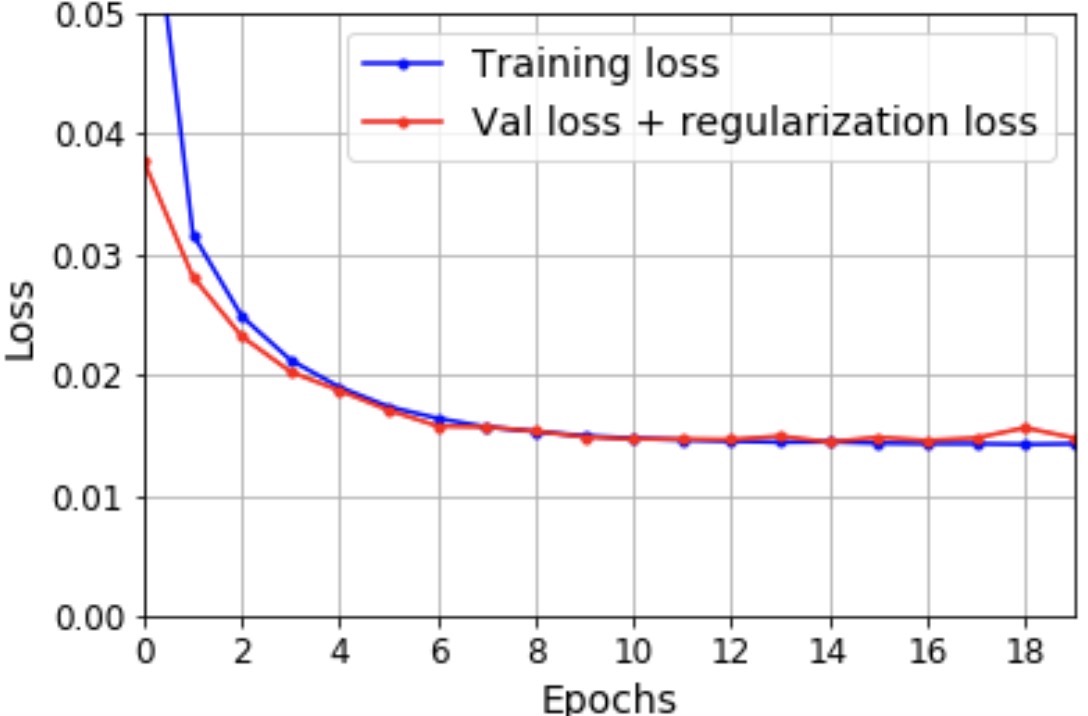
- Regularization: The most common reason is regularization (e.g., dropout), since it applies during training, but not during validation and testing. If we add the regularization loss to the validation loss, here’s how things look:
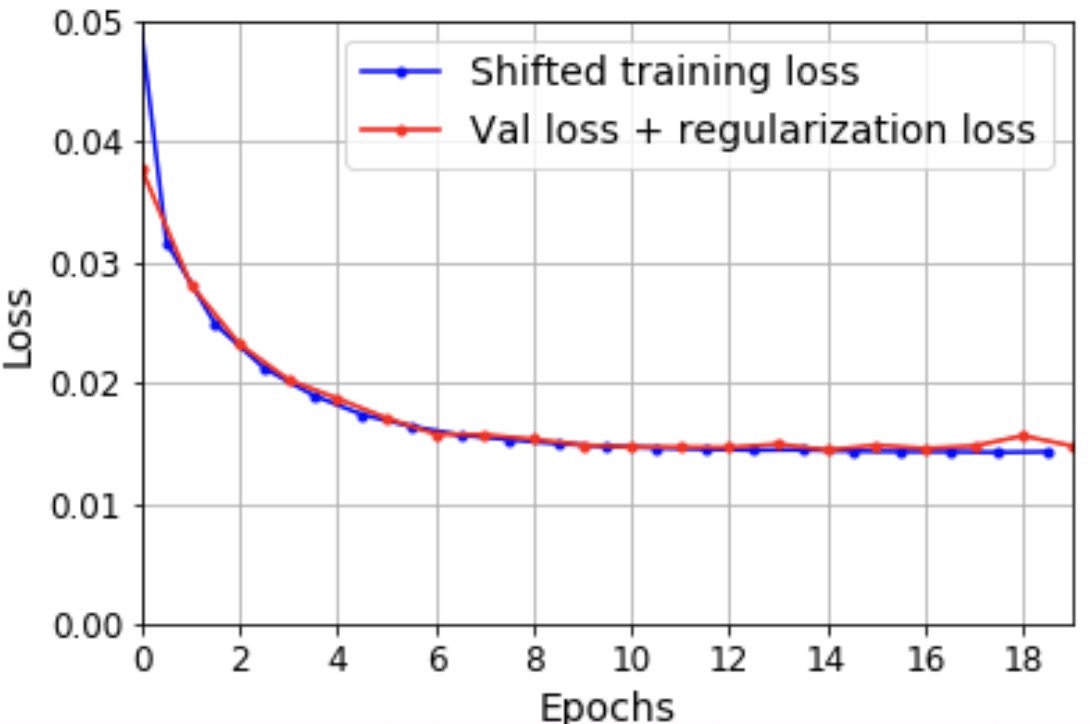
- Epoch delta between training and validation loss: The training loss is measured during each epoch, while the validation loss is measured after each epoch, so on average the training loss is measured half an epoch earlier. If we shift the training loss by half an epoch to the left (where it should be), things look much different:
-
Easier validation set: Perhaps, the validation set is easier than the training set! This can happen by chance if the validation set is too small, or if it wasn’t properly sampled (e.g., too many easy classes).
-
Data leaks: It might also be possible that the training set leaked into the validation set.
- Data augmentation: Using data augmentation during training might also cause this.
- As an example, suppose that the augmentation algorithm involves randomly cropping the images, and 10% of the time, the resulting cropped image misses the main object in the image. Classifying the training images will be more difficult than classifying the validation images.
- Another common case is when the augmentation algorithm involves many transformations, and the resulting images have more diversity (in lighting, rotation, scale, etc.) than the validation images. Again, the training images would be harder to classify than the validation images.
- To validate this theory, using the same augmentation procedure (as used in training) for validation to compare the training and validation losses, would make sense.
- However, make sure to not do this if you’re using early stopping or comparing different models, since in these cases, you are really only interested in the test performance, not the train performance.
- Note that even if the validation loss is close to the train loss, your model may still be overfitting.
Remedies
- Account for the regularization loss when comparing training and validation losses.
- Shift the training loss by half an epoch.
- Make sure the validation set is large enough.
- Sample the validation set from the same distribution as train, without leaks.
References
- Aurélien Geron’s Twitter for the great inputs.
Citation
If you found our work useful, please cite it as:
@article{Chadha2020DistilledTrainingLossValidationLoss,
title = {Training Loss > Validation Loss?},
author = {Chadha, Aman},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}