Natural Language Processing • Tokenizer
- Overview
- Motivation
- Tokenization: The Specifics
- Sub-word Tokenization
- WordPiece
- Byte Pair Encoding (BPE)
- Unigram Sub-word Tokenization
- SentencePiece
- Summary
- Comparative Analysis
- Use-cases
- Tiktoken
- References
Overview
- This section delineates the importance of tokenization in Natural Language Processing (NLP) and elucidates its role in enabling machines to comprehend language. Teaching machines to understand language is a multifaceted endeavor aimed at equipping them with the ability to read and interpret the meaning embedded within texts.
- To aid machines in learning language, it is essential to segment text into smaller units known as tokens, which are subsequently processed. Tokenization, the procedure of breaking down text into these tokens, serves as the foundational input for language models.
- Although the extent of semantic comprehension achieved by these models is not entirely elucidated, it is posited that they acquire syntactic knowledge at lower levels of the neural network and task-specific semantic understanding at higher levels. This perspective is supported by ongoing research and literature in the field (source).
- Furthermore, instead of representing text as a continuous string, it can be transformed into a vector or list comprising its constituent vocabulary words. This process, known as tokenization, converts each vocabulary word in a text into an individual token, thereby facilitating a structured approach to language processing by machines.
Motivation
- Language models do not perceive text as human beings, but rather as a sequence of numbers, known as tokens. Tokenization is a method utilized for this conversion of text into tokens. It possesses several advantageous properties:
- Tokenizers are reversible and lossless, enabling the transformation of tokens back into the original text without any loss of information.
- Tokenizers can process words that they haven’t been seen before (i.e., text that was not included in the data used to build the tokenizer’s vocabulary). By breaking down words and building a vast vocabulary at the sub-word level, tokenizers can handle rare words or new word combinations. In other words, tokenizers aid in allowing the model to recognize common sub-words. For example, “ing” is a frequent subword in English. Thus, BPE often divides “encoding” into tokens such as “encod” and “ing” rather than, for instance, “enc” and “oding”. This repeated exposure to the “ing” token in various contexts assists models in generalizing and enhancing their understanding of grammar.
- Tokenizers effectively compresses text: typically, the sequence of tokens is shorter than the original text in bytes. On average, each token corresponds to approximately four bytes (thus, offering a 4x compression factor).
Tokenization: The Specifics
- Let’s dive deeper on how tokenization works.
- To start off, there are many ways and options to tokenize text. You can tokenize by removing spaces, adding a split character between words or simply break the input sequence into separate words.
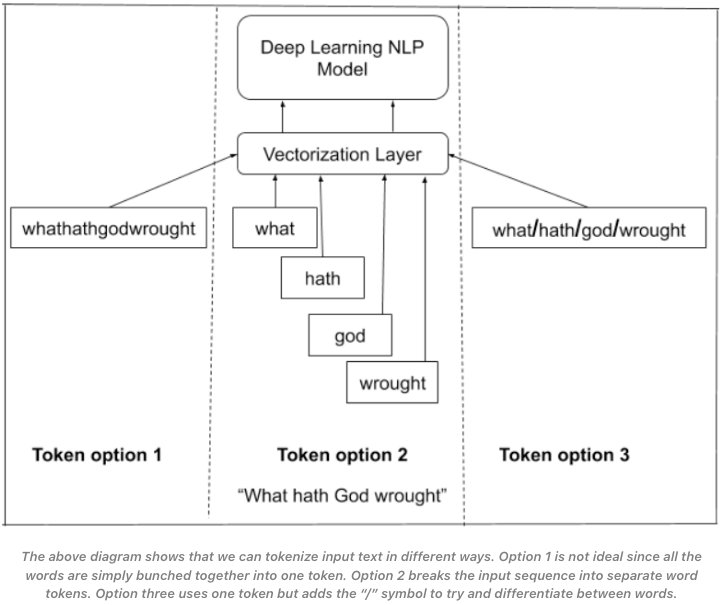
- This can be visualized by the image above (source).
- As we stated earlier, we use one of these options as a way to split the larger text into a smaller unit, a token, to serve as input to the model.
- Additionally, in order for the model to learn relationships between words in a sequence of text, we need to represent it as a vector.
- We do this in lieu or hard coding grammatical rules within our system as the complexity for this would be exponential since it would change per language.
- Instead, with vector representation, the model has encoded meaning in any dimension of this vector.
Sub-word Tokenization
- Sub-word tokenization is a method used to break words down into smaller sub-tokens. It is based on the concept that many words in a language share common prefixes or suffixes, and by breaking words into smaller units, we can handle rare and out-of-vocabulary words more effectively.
- By employing sub-word tokenization, we can better handle out-of-vocabulary words (OOV) by combining one or more common words. For example, “anyplace” can be broken down into “any” and “place”. This approach not only aids in handling OOV words but also reduces the model size and improves efficiency.
- Tokenizers are specifically designed to address the challenge of out-of-vocabulary (OOV) words by breaking down words into smaller units. This enables the model to handle a broader range of vocabulary.
- There are several algorithms available for performing sub-word tokenization, each with its own strengths and characteristics. These algorithms offer different strategies for breaking down words into sub-tokens, and their selection depends on the specific requirements and goals of the NLP task at hand.
Per OpenAI’s Tokenizer Platform page, a helpful rule of thumb is that one token generally corresponds to ~4 characters of text for common English text. This translates to roughly \({\frac{3}{4}}^{th}\) of a word (so 100 tokens ~= 75 words).
WordPiece
- Initial Inventory: WordPiece starts with an inventory of all individual characters in the text.
- Build Language Model: A language model is created using this initial inventory.
- New Word Unit Creation: The algorithm iteratively creates new word units by combining existing units in the inventory. The selection criterion for the new word unit is based on which combination most increases the likelihood of the training data when added to the model.
- Iterative Process: This process continues until reaching a predefined number of word units or the likelihood increase falls below a certain threshold.
Example
- To illustrate the process of WordPiece tokenization, consider a simple sentence “she walked. he is a dog walker. i walk” and see how the algorithm constructs the vocabulary and tokenizes the text step-by-step.
- Initial Inventory:
- WordPiece starts with individual characters as the initial inventory: ‘s’, ‘h’, ‘e’, ‘ ‘, ‘w’, ‘a’, ‘l’, ‘k’, ‘d’, ‘.’, ‘i’, ‘o’, ‘g’, ‘r’
- Building the Vocabulary:
- First Iteration:
- Suppose the most significant likelihood increase comes from combining ‘w’ and ‘a’ to form ‘wa’.
- New Inventory: ‘s’, ‘h’, ‘e’, ‘ ‘, ‘wa’, ‘l’, ‘k’, ‘d’, ‘.’, ‘i’, ‘o’, ‘g’, ‘r’
- Second Iteration:
- Next, the combination ‘l’ and ‘k’ gives a good likelihood boost, forming ‘lk’.
- New Inventory: ‘s’, ‘h’, ‘e’, ‘ ‘, ‘wa’, ‘lk’, ‘d’, ‘.’, ‘i’, ‘o’, ‘g’, ‘r’
- Third Iteration:
- Let’s say combining ‘wa’ and ‘lk’ into ‘walk’ is the next most beneficial addition.
- New Inventory: ‘s’, ‘h’, ‘e’, ‘ ‘, ‘walk’, ‘d’, ‘.’, ‘i’, ‘o’, ‘g’, ‘r’
- Further Iterations:
- The process continues, adding more combinations like ‘er’, ‘ed’, etc., based on what increases the likelihood the most.
- First Iteration:
- Tokenizing the Text:
- “she walked. he is a dog walker. i walk”
- With the current state of the vocabulary, the algorithm would tokenize the text as follows:
- ‘she’, ‘walk’, ‘ed’, ‘.’, ‘he’, ‘is’, ‘a’, ‘dog’, ‘walk’, ‘er’, ‘.’, ‘i’, ‘walk’
- Here, words like ‘she’, ‘he’, ‘is’, ‘a’, ‘dog’, ‘i’ remain as they are since they’re either already in the initial inventory or don’t present a combination that increases likelihood significantly.
- ‘walked’ is broken down into ‘walk’ and ‘ed’, ‘walker’ into ‘walk’ and ‘er’, as these subwords (‘walk’, ‘ed’, ‘er’) are present in the expanded inventory.
- “she walked. he is a dog walker. i walk”
- Note:
- In a real-world scenario, the WordPiece algorithm would perform many more iterations, and the decision to combine tokens depends on complex statistical properties of the training data.
- The examples given are simplified and serve to illustrate the process. The actual tokens generated would depend on the specific training corpus and the parameters set for the vocabulary size and likelihood thresholds.
Byte Pair Encoding (BPE)
- Initial Inventory: Similar to WordPiece, Byte Pair Encoding (BPE) begins with all individual characters in the language.
- Frequency-Based Merges: Instead of using likelihood to guide its merges, BPE iteratively combines the most frequently occurring pairs of units in the current inventory.
- Fixed Number of Merges: This process is repeated for a predetermined number of merges.
Example
- Consider the input text: “she walked. he is a dog walker. i walk”. The steps that BPE follows for tokenization are as below:
- BPE Merges:
- First Merge: If ‘w’ and ‘a’ are the most frequent pair, they merge to form ‘wa’.
- Second Merge: Then, if ‘l’ and ‘k’ frequently occur together, they merge to form ‘lk’.
- Third Merge: Next, ‘wa’ and ‘lk’ might merge to form ‘walk’.
- Vocabulary: At this stage, the vocabulary includes all individual characters, plus ‘wa’, ‘lk’, and ‘walk’.
- Handling Rare/Out-of-Vocabulary (OOV) Words
- Subword Segmentation: Any word not in the vocabulary is broken down into subword units based on the vocabulary.
- Example: For a rare word like ‘walking’, if ‘walking’ is not in the vocabulary but ‘walk’ and ‘ing’ are, it gets segmented into ‘walk’ and ‘ing’.
- Benefits
- Common Subwords: This method ensures that words with common roots or morphemes, like ‘walked’, ‘walker’, ‘walks’, are represented using common subwords (e.g., ‘walk@@’). This helps the model to better understand and process these variations, as ‘walk@@’ would appear more frequently in the training data.
Unigram Sub-word Tokenization
- The algorithm starts by defining a vocabulary of the most frequent words and represent the remaining words as a combination of the vocabulary words.
- Then it iteratively splits the most probable word into smaller parts until a certain number of sub-words is reached.
- Unigram: A fully probabilistic model which does not use frequency occurrences. Instead, it trains a LM using a probabilistic model, removing the token which improves the overall likelihood the least and then starting over until it reaches the final token limit. (source)
SentencePiece
- Unsegmented Text Input: Unlike WordPiece and BPE, which typically operate on pre-tokenized or pre-segmented text (like words), SentencePiece works directly on raw, unsegmented text (including spaces). This approach allows it to model the text and spaces as equal citizens, essentially learning to tokenize from scratch without any assumption about word boundaries.
- Initial Inventory: SentencePiece starts with an inventory of individual characters, including spaces, from the text. This means every character, punctuation mark, and space is treated as a separate token initially.
- No Pre-defined Word Boundaries: Since it operates on raw text, there are no pre-existing word boundaries. SentencePiece learns subword units and tokenizes the text without relying on pre-defined tokenization rules, making it particularly useful for languages where word boundaries are not clear.
Example
- Applying SentencePiece to the input text “she walked. he is a dog walker. i walk” would involve the following steps:
Vocabulary Building
- Unsegmented Text Input:
- SentencePiece would take the raw, unsegmented text as input, treating each character (including spaces and punctuation) as a distinct symbol.
- Initial Inventory: ‘s’, ‘h’, ‘e’, ‘ ‘, ‘w’, ‘a’, ‘l’, ‘k’, ‘d’, ‘.’, ‘i’, ‘o’, ‘g’, ‘r’
- First Iteration:
- The algorithm might begin by combining frequent pairs of characters, including spaces, based on statistical frequency.
- New Inventory Example: ‘s’, ‘h’, ‘e’, ‘ ‘, ‘w’, ‘a’, ‘l’, ‘k’, ‘d’, ‘.’, ‘i’, ‘o’, ‘g’, ‘r’, ‘e ‘, ‘ w’, ‘wa’
- Subsequent Iterations:
- The process continues, combining characters and character sequences into longer subword units based on frequency and context (which will in turn, maximize the likelihood of the text data), without any pre-existing notions of word boundaries. The goal is to find the optimal way to split the text into subword units that best represent the training data. For instance, ‘w’, ‘a’, ‘l’, ‘k’ might combine to form ‘walk’, ‘he’ might become a unit, and so on.
- New Inventory Example: ‘s’, ‘h’, ‘e’, ‘ ‘, ‘walk’, ‘d’, ‘.’, ‘i’, ‘o’, ‘g’, ‘r’, ‘she’, ‘ed’, ‘he’, ‘ is’
- Until Vocabulary Size is Reached:
- This iterative process of combining continues until a predefined vocabulary size is reached. The size of the vocabulary is a hyperparameter that can be adjusted depending on the desired granularity and model capacity.
Tokenizing the Text
- Final Tokenization: Once the vocabulary is established, SentencePiece tokenizes the text based on the learned subword units. For the example sentence, the tokenization might look like this:
- Original: “she walked. he is a dog walker. i walk”
- Tokenized: [‘she’, ‘walk’, ‘ed’, ‘.’, ‘he’, ‘ is’, ‘a’, ‘ dog’, ‘ walk’, ‘er’, ‘.’, ‘i’, ‘ walk’]
- Notice how punctuation and spaces are treated as tokens (e.g., ‘ed’, ‘is’, ‘walk’).
Handling Rare/Out-of-Vocabulary (OOV) Words
- Robust to Rare/Out-of-Vocabulary (OOV) Words: SentencePiece, like WordPiece and BPE, is designed to handle OOV words by breaking them down into subword units that are in the vocabulary. This flexibility allows it to effectively manage rare words, ensuring that even if a whole word is not in the vocabulary, its components will be. SentencePiece’s method of working with raw text makes it particularly adept at capturing nuanced subword patterns, including handling variations in spacing and punctuation. This capability enhances its robustness in multilingual contexts and languages with complex orthography.
Benefits
- No Need for Pre-tokenization: SentencePiece eliminates the need for language-specific pre-tokenization. This makes it particularly useful for languages (such as Japanese, Chinese, Thai, and Vietnamese) where word boundaries are not clear or in multilingual contexts.
- Uniform Treatment of Characters: By treating spaces and other characters equally, SentencePiece can capture a broader range of linguistic patterns, which is beneficial for modeling diverse languages and text types.
- In summary, SentencePiece offers a unique approach to tokenization by working directly on raw text and treating all characters, including spaces, on an equal footing. This method is particularly beneficial for languages with complex word structures and for multilingual models.
Summary
- Below is a summary of the aforementioned tokenization techniques.
Unigram Subword Tokenization
- It starts with a set of words, and then iteratively splits the most probable word into smaller parts.
- It assigns a probability to the newly created subwords based on their frequency in the text.
- It is less popular compare to other subword tokenization methods like BPE or SentencePiece.
- It has been reported to have good performance in some NLP tasks such as language modeling and text-to-speech.
BPE
- How It Works: BPE is a data compression technique that has been adapted for use in NLP. It starts with a base vocabulary of individual characters and iteratively merges the most frequent pair of tokens to form new, longer tokens. This process continues for a specified number of merge operations.
- Advantages: BPE is effective in handling rare or unknown words, as it can decompose them into subword units that it has seen during training. It also strikes a balance between the number of tokens (length of the input sequence) and the size of the vocabulary.
- Use in NLP: BPE is widely used in models like GPT-2 and GPT-3.
WordPiece
- How It Works: WordPiece is similar to BPE but differs slightly in its approach to creating new tokens. Instead of just merging the most frequent pairs, WordPiece looks at the likelihood of the entire vocabulary and adds the token that increases the likelihood of the data the most.
- Advantages: This method often leads to a more efficient segmentation of words into subwords compared to BPE. It’s particularly good at handling words not seen during training.
- Use in NLP: WordPiece is used in models like BERT and Google’s neural machine translation system.
SentencePiece
- How It Works: SentencePiece is a tokenization method that does not rely on pre-tokenized text. It can directly process raw text (including spaces and special characters) into tokens. SentencePiece can be trained to use either the BPE or unigram language model methodologies.
- Advantages: One of the key benefits of SentencePiece is its ability to handle multiple languages and scripts without needing pre-tokenization or language-specific logic. This makes it particularly useful for multilingual models.
- Use in NLP: SentencePiece is used in models like ALBERT and T5.
Comparative Analysis
-
WordPiece, BPE, and SentencePiece are all subword tokenization methods, each with distinct mechanisms and specific use-cases. Here’s a comparative analysis of the aforementioned algorithms.
-
WordPiece starts by splitting words into characters, then incrementally combines these into more frequent subwords. This process is driven by a likelihood maximization criterion, where the algorithm seeks to maximize the likelihood of the training data under the model. It’s particularly effective in languages with rich morphology, as it efficiently handles rare or unknown words by breaking them down into recognizable subword units, reducing vocabulary size and improving model performance, especially in languages with rich morphology. WordPiece is widely used in models like BERT and other Transformer-based architectures, where handling a diverse vocabulary efficiently is crucial.
-
BPE, initially developed for data compression, works by iteratively merging the most frequent pairs of bytes (or characters) in the training corpus. Starting from individual characters, BPE creates a fixed-size vocabulary of the most common character sequences, including both whole words and subword units. The primary difference between BPE and WordPiece is in their merging criteria: BPE strictly follows frequency counts for merging pairs, while WordPiece considers the overall likelihood of the data, leading to potentially different segmentations for the same text. BPE is simpler and less flexible but effective in reducing vocabulary size and handling out-of-vocabulary words. BPE’s approach is more straightforward and somewhat less flexible compared to WordPiece, as it does not directly optimize for any specific language modeling objectives. However, BPE’s simplicity has made it popular in various language models due to its effectiveness in reducing vocabulary size and handling out-of-vocabulary words by splitting them into known subword units. It’s commonly used in models like GPT and OpenAI’s language models, where a straightforward yet robust tokenization is needed, especially for languages with straightforward morphological structures.
-
SentencePiece, distinct from both, tokenizes directly from raw text without needing pre-tokenized words, treating the input as a raw byte stream. This approach is especially effective for languages without clear word boundaries, such as Japanese or Chinese. SentencePiece is highly versatile and language-agnostic, suitable for multilingual models or models that need to handle a wide range of languages and scripts. Its ability to tokenize from raw bytes makes it ideal for scenarios where language-specific preprocessing is either impractical or impossible.
-
In summary, while all three sub-word tokenization methods aim to reduce vocabulary size and handle rare words by breaking them into subwords, WordPiece optimizes for language modeling likelihood, whereas BPE follows a simpler frequency-based merging strategy. WordPiece and BPE focus on word-level decomposition and are suited for models dealing with languages having clear word boundaries and rich morphologies, SentencePiece offers a more universal solution. Its byte-level approach accommodates various scripts and languages, including those without space-delimited words, making it invaluable in multilingual or script-diverse contexts. Each of these tokenization methods is tailored to specific model architectures and linguistic scenarios, reflecting the diversity and complexity of language processing challenges.
- Granularity: BPE and WordPiece focus on subword units, while SentencePiece includes spaces and other non-text symbols in its vocabulary, allowing it to tokenize raw text directly.
- Handling of Rare Words: All three methods are effective in handling rare or unknown words by breaking them down into subword units.
- Training Data Dependency: BPE and WordPiece rely more heavily on the specifics of the training data, while SentencePiece’s ability to tokenize raw text makes it more flexible and adaptable to various languages and scripts.
- Use Cases: The choice of tokenization method depends on the specific requirements of the language model and the nature of the text it will process. For example, SentencePiece’s ability to handle raw text without pre-processing makes it a good choice for models dealing with diverse languages and scripts.
Use-cases
WordPiece
-
Some models that utilize WordPiece include:
-
BERT (Bidirectional Encoder Representations from Transformers): Developed by Google, BERT uses WordPiece for tokenization, enabling it to effectively handle a wide range of linguistic structures and vocabularies.
-
RoBERTa (Robustly Optimized BERT Approach): As an optimized version of BERT, RoBERTa also employs WordPiece encoding. It’s designed for more robust performance on natural language processing tasks.
-
DistilBERT: This is a smaller, faster, and lighter version of BERT that retains most of its performance. DistilBERT uses WordPiece for its tokenization.
-
ERNIE (Enhanced Representation through kNowledge Integration): Developed by Baidu, ERNIE is a language model that builds on the BERT architecture and uses WordPiece encoding.
-
-
WordPiece is chosen in these models due to its efficiency in handling a large vocabulary by breaking down words into smaller, manageable sub-words or tokens. This method allows for better handling of rare words and morphological variations in different languages.
BPE
-
Some models that employ BPE include:
-
Llama: Llama, developed by Meta AI, use BPE for their tokenization, allowing it to handle diverse linguistic structures effectively. Recent Llama models (3 and 3.1) (source).
-
GPT Series (up until GPT-2): Developed by OpenAI, the GPT models also use BPE, enabling efficient management of a vast range of vocabulary and linguistic structures. OpenAI’s tokenizer for GPT-3.5 and GPT-4 can be found here. Recent GPT models (GPT-3 and GPT-4 series models, including GPT-4-turbo and GPT-4o) use tiktoken.
-
XLNet: A transformer-based model that surpasses BERT in some benchmarks, XLNet utilizes BPE for its tokenization process.
-
Fairseq’s RoBERTa: While the original RoBERTa model from Facebook AI uses BPE, variations in implementations across different platforms might use different tokenization methods.
-
BART (Bidirectional and Auto-Regressive Transformers): Created by Facebook AI, BART, which combines features of auto-regressive models like GPT and auto-encoding models like BERT, uses BPE for tokenization.
-
-
BPE is chosen in these models due to its ability to effectively handle a diverse set of languages and scripts, and its efficiency in managing a large and complex vocabulary, which is particularly useful in generative tasks.
SentencePiece
-
Notable models utilizing SentencePiece encoding include:
- Llama 2: Llama 2 uses SentencePiece for tokenization (source).
- T5 (Text-to-Text Transfer Transformer): Developed by Google, T5 uses SentencePiece for its text processing, enabling it to handle a wide range of languages and tasks effectively.
- mT5: As an extension of T5, mT5 (multilingual T5) is specifically designed for multilingual capabilities, employing SentencePiece to process text across multiple languages.
- ALBERT (A Lite BERT): This model, a lighter version of BERT (Bidirectional Encoder Representations from Transformers), uses SentencePiece. It’s optimized for efficiency and lower memory consumption.
- XLNet: An advanced transformer model that surpasses BERT in some respects, XLNet also uses SentencePiece for tokenization.
-
SentencePiece is favored in these models for its versatility and efficiency in dealing with various languages, including those with non-Latin scripts, and for its ability to tokenize raw text directly without the need for pre-tokenization.
Tiktoken
- tiktoken is a fast BPE-based tokeniser developed by OpenAI. It is used by Llama 3 and 3.1.