Primers • Speculative Decoding
- Background
- Core Techniques
- Comparative Analysis
- Implementation Deep Dive: How to Build Speculative Decoders
- Future Directions
- Takeaways
- Further Reading
- References
- Citation
Background
-
Large Language Models (LLMs), such as GPT-4, Llama, and T5, have demonstrated remarkable capabilities across natural language understanding, reasoning, and generation tasks. These models are generally trained using the next-token prediction paradigm—where, given a sequence of tokens, the model is optimized to predict the next token. Despite its effectiveness, this approach poses major inefficiencies, especially during inference.
-
Why is inference so slow?:
-
In an autoregressive LLM, generating a sequence of \(K\) tokens requires \(K\) sequential forward passes through the model. Each step uses the model’s prediction to compute the next input. This serial nature becomes the bottleneck during generation, as each token depends on the previous one and prevents parallelization.
-
The memory bandwidth bottleneck exacerbates the problem: the model parameters must be loaded from memory to the accelerator for every token generation step. As the model scales (e.g., hundreds of billions of parameters), so does the computational and memory cost of inference.
-
-
Motivation for Speculative Decoding:
-
To address the inference bottleneck in autoregressive LLMs, speculative decoding has emerged as a class of strategies aimed at accelerating generation without changing the model’s output distribution in a statistically significant way. Rather than predicting one token at a time, these approaches attempt to guess multiple future tokens in parallel and verify them efficiently. This general idea can be realized in several ways, with three of the most common methods listed below:
-
Speculative Decoding via Draft Models: A smaller, faster “draft model” generates a sequence of candidate tokens ahead of the main model. The full model then verifies these tokens in parallel, accepting correct predictions and only reverting to standard autoregressive decoding when a mismatch is detected. This approach can yield 2\(\times\)–6\(\times\) speedups in practice.
-
Tree-based Multi-Head Verification (Medusa): Instead of a separate draft model, the main model is equipped with multiple parallel “verification heads” that produce and check alternative token paths in a tree-like structure. This enables concurrent exploration of multiple continuation candidates, reducing the number of full forward passes needed.
-
Multi-token Prediction Heads (Self-Speculative Decoding): The model is augmented with additional output heads trained to predict several future tokens directly from the current hidden state. These predictions are verified internally, allowing the model to bypass multiple sequential steps without introducing an external model or branching search structure.
-
-
Across these methods, the key principle remains the same: perform more speculative work per forward pass, then verify correctness in parallel, thereby alleviating the strict serial nature of next-token generation.
-
-
Example Scenario:
- Suppose we want to generate 5 tokens. Traditional decoding would require 5 forward passes. With speculative decoding, a draft model might propose all 5 tokens in one shot. The target model then verifies this batch—accepting or correcting as needed. If, say, 4 tokens are accepted, only 2 forward passes were needed, resulting in 2.5\(\times\) speedup.
-
This optimization is particularly appealing for:
- Real-time applications (chatbots, code completion)
- Edge deployment scenarios
- High-load server environments
-
The following figure (source) offers a visual illustration of the non-speculative generation (left) compared to speculative generation (right).
Core Techniques
- Speculative decoding comes in multiple flavors, but the core idea is the same: use a lightweight method to guess several tokens, then verify them using the original (or “target”) model. We now explore the primary strategies, implementation patterns, and trade-offs.
Speculative Decoding via Draft Models
-
Introduced in Fast Inference from Transformers via Speculative Decoding by Leviathan et al. (2023).
-
Pipeline Overview:
- Drafting: Use a smaller (faster) model to generate \(\gamma\) speculative tokens.
- Verification: Run the large model to score all tokens up to \(\gamma\).
- Acceptance: Accept prefix tokens that match the large model’s top predictions.
- Fallback: If a token diverges, fall back to large model sampling for correction.
-
The following figure from the paper shows a technique illustrated in the case of unconditional language modeling. Each line represents one iteration of the algorithm. The green tokens are the suggestions made by the approximation model (here, a GPT-like Transformer decoder with 6M parameters trained on 1m1b with 8k tokens) that the target model (here, a GPT-like Transformer decoder with 97M parameters in the same setting) accepted, while the red and blue tokens are the rejected suggestions and their corrections, respectively. For example, in the first line the target model was run only once, and 5 tokens were generated.

-
Algorithm Summary (simplified from Leviathan et al.):
def speculative_decode(draft_model, target_model, prompt, gamma): draft_tokens = draft_model.generate(prompt, max_new_tokens=gamma) scores = target_model.score(prompt + draft_tokens) # accept up to the first mismatch n_accept = count_agreement(draft_tokens, scores) accepted = draft_tokens[:n_accept] # complete the next token from the target model next_token = target_model.sample(prompt + accepted) return accepted + [next_token] -
Advantages:
- Can be plugged into existing models without retraining.
- Requires no architectural changes to the large model.
- Fully preserves output distribution.
-
Challenges:
- Maintaining a separate draft model increases system complexity.
- Distribution mismatch between draft and target models can reduce acceptance rate.
- Memory and compute pressure if both models are large.
Tree-based Multi-Head Verification (Medusa)
-
Medusa, introduced in Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads by Cai et al. (2024), improves over basic multi-head speculative decoding by using tree attention.
-
The following image from the blog (source) shows the performance of Medusa on Vicuna-7b.
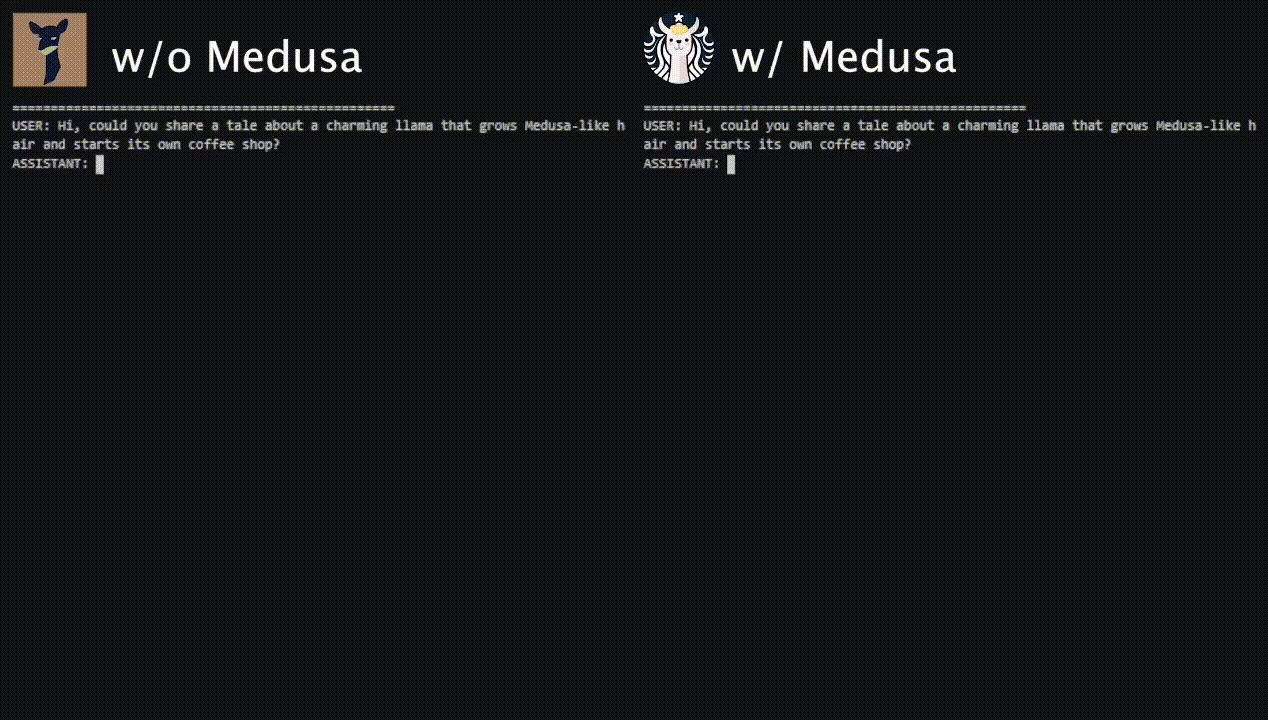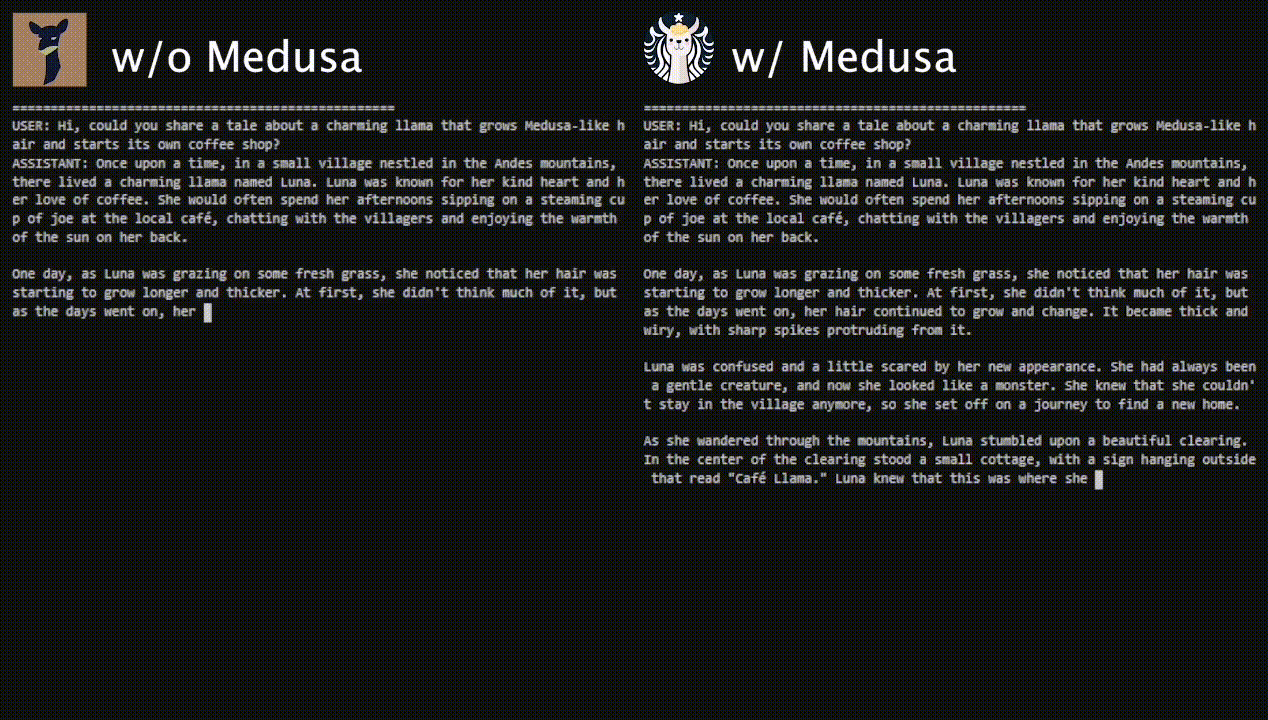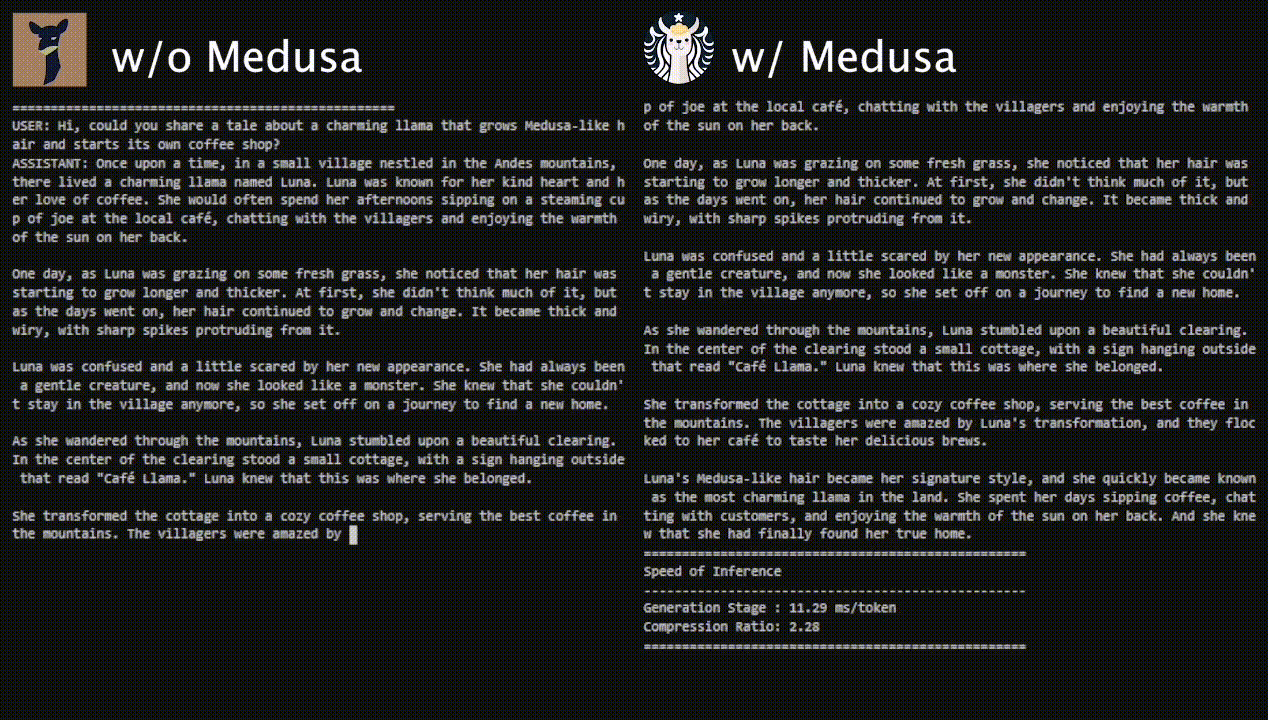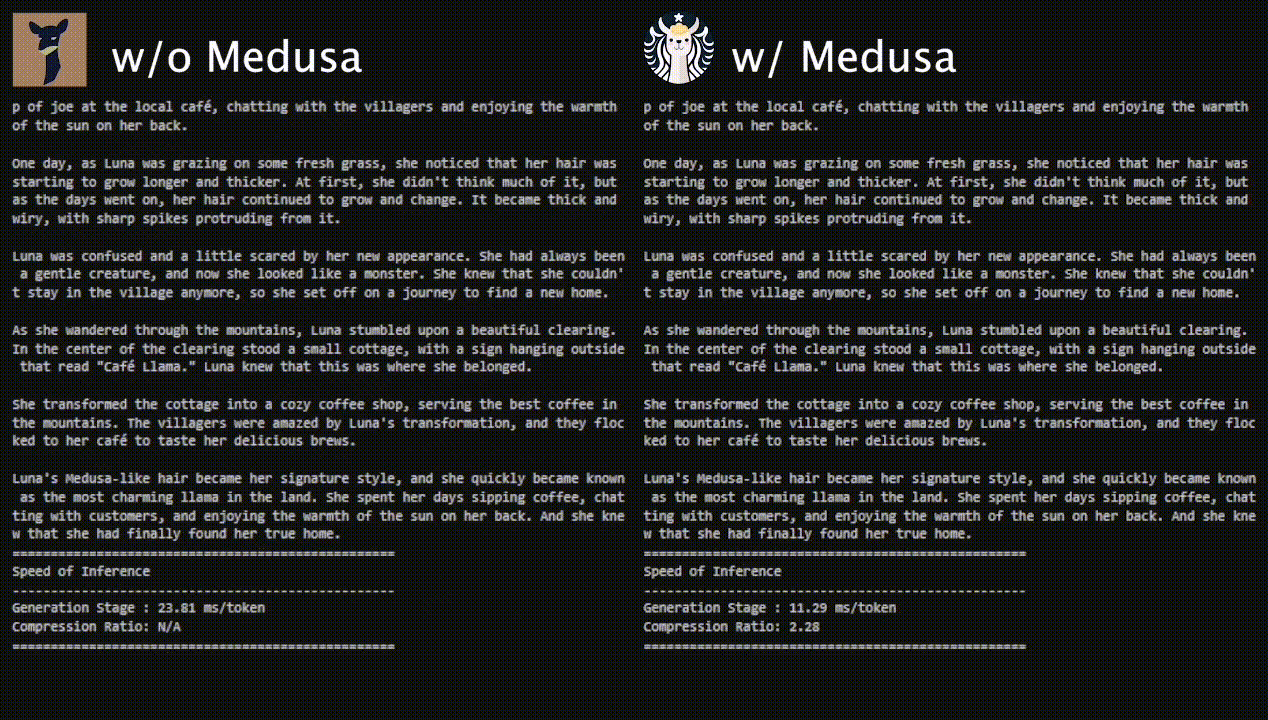
-
Core Features:
- Medusa Heads: Each predicts \(k+1\) tokens into the future from the last hidden state.
- Candidate Assembly: The top-k outputs from each head are combined to form speculative trees.
- Tree Attention: A custom attention mask ensures tokens attend only to predecessors in their path.
-
Acceptance Schemes: Two options:
- Rejection Sampling (match base model)
- Typical Acceptance (heuristic, faster)
-
Benefits:
- Higher speedups (~2.3–2.8\(\times\) in production) with minimal quality drop.
- Easy integration into existing models without retraining (Medusa-1) or with joint training (Medusa-2).
- Suitable for batch size = 1, which aligns with real-world use (e.g., chat).
-
Implementation Details:
\[p_{k_{t}} = \text{softmax}(W_{2_{k}} * (\text{SiLU}(W_{1_{k}} * h_t) + h_t))\]- where \(W_{1_{k}}\) is initialized to 0 and \(W_{2_{k}}\) is a clone of the base model’s LM head.
Multi-token Prediction Heads (Self-Speculative Decoding)
- Introduced in Better & Faster Large Language Models via Multi-token Prediction by Gloeckle et al. (2024).
- Instead of using a separate draft model, a recent trend is to build speculative capabilities directly into the main model. This is where multi-token prediction heads come in.
- The figure below from the paper illustrates an overview of multi-token prediction. (Top) During training, the model predicts 4 future tokens at once, by means of a shared trunk and 4 dedicated output heads. During inference, we employ only the next-token output head. Optionally, the other three heads may be used to speed-up inference time. (Bottom) Multi-token prediction improves pass@1 on the MBPP code task, significantly so as model size increases. Error bars are confidence intervals of 90% computed with bootstrapping over dataset samples.

-
Architecture:
- A shared transformer trunk encodes context.
- Multiple decoder heads (1 per future token) make independent predictions.
- The first head is the standard next-token predictor; others predict \(2^{nd}, 3^{rd}, \dots n^{th}\) tokens.
-
Each head is trained with a cross-entropy loss on its respective position:
\[L_n = - Σ_t Σ_{i=1}^{n} log P( x_{t+i} | z_{1:t} )\]- where \(z_{1:t}\) is the shared latent context and each \(P(x_{t+i})\) is computed via its dedicated head.
-
Memory Optimization:
-
Instead of materializing all logits for all \(n\) heads, training sequentially processes each head to reduce GPU memory:
- Compute forward and backward for head 1
- Free logits, move to head 2
- Accumulate gradients on shared trunk
-
This reduces peak memory from \(O(nV + d)\) to \(O(V + d)\), with no speed tradeoff.
-
-
Advantages:
- No need for separate draft model.
- Unified architecture (easier to deploy, quantize, and train).
- Compatible with speculative decoding methods like blockwise parallelism or Medusa.
-
Drawbacks:
- Requires modifying the model during pretraining.
- Gains only materialize at scale (7B+ models).
- Finetuning these models may require care to preserve alignment.
Comparative Analysis
- In this section, we systematically compare the key speculative decoding strategies discussed earlier—draft model-based decoding, multi-token prediction heads, and Medusa. We’ll explore trade-offs across performance, ease of integration, training requirements, and deployment complexity.
Comparison Table
| Criteria | Draft Model (Leviathan et al., Nov 2022) |
Medusa Tree‑Attention (Cai et al., Jan 2024) |
Multi‑Token Prediction Heads (Gloeckle et al., Apr 2024) |
|---|---|---|---|
| Model changes required | None | Optional (Medusa‑1) / joint (Medusa‑2) | Yes (requires modifying output heads during pre-training) |
| Training cost | Low (can use off-the-shelf models as draft and target models) | Moderate (fine‑tune extra heads) | High (requires pre-training) |
| Inference speedup (observed) | \(\sim 2\times\text{–}3\times\) | \(\sim 2.2\times\text{–}3.6\times\) (typically \(2.3\times\text{–}2.8\times\)) | \(\sim 3\times\) (4‑token), up to \(\sim 6\times\) (8‑token draft window) |
| Output quality | Identical to base model | High (rejection + typical acceptance schemes) | Matches next‑token head |
| Deployment ease | Moderate (dual‑model system) | High (single model with extra heads) | High (single model if integrated from pretraining) |
| Memory overhead (training) | High (two model states / KV‑cache) | Low (single trunk + small head layers) | Efficient (\(O(V + d)\) peak memory) |
| Batch‑size friendliness | High | Optimized for batch size = 1 | High |
| Implementation maturity | Widely used since 2022 (T5, GPT) | Early adoption in LLMs like Vicuna, Zephyr | DeepSeek V3 |
When to Use Each Technique
-
Draft Model (Leviathan-style speculative decoding):
- Ideal when you can’t modify or retrain the base model.
- Suitable for legacy systems or commercial APIs.
- Offers “plug-and-play” inference acceleration with minimal integration overhead.
- Best when a strong, compact draft model is already available.
-
Medusa (Cai et al., 2024):
- Ideal for single-user interactive settings (e.g., chatbots).
- Offers fine-grained control via Medusa-1 (frozen backbone) or Medusa-2 (joint fine-tuning).
- Introduces tree attention to optimize speculative token verification.
- Can outperform others when output diversity or control is key.
-
Multi-token Prediction Heads (Gloeckle et al., 2024):
- Recommended during full model pretraining.
- Best for institutions training models from scratch or at scale.
- Enables self-speculative decoding with minimal architectural footprint.
- Very efficient for longer inputs or batch decoding workloads.
Implementation Details
-
Draft-based Implementation:
- Ensure the draft model is close enough in distribution to the main model; divergence kills speedup.
- Batch speculative runs and base model verifications.
- Use caching (KV cache reuse) to reduce redundant computations.
-
Multi-token Heads Implementation:
- Train with n-token loss: each head predicts future token i.
- Use gradient checkpointing or staggered backprop to control memory.
- At inference, use blockwise or greedy speculative decoding.
-
Medusa Implementation:
-
Add feedforward speculative heads:
\[p_{k_{t}} = \text{softmax}(W_{2_{k}} @ (\text{SiLU}(W_{1_{k}} @ h_t) + h_t))\] - For tree attention, modify attention masks to ensure tokens only see ancestors.
- Use typical acceptance scheme to boost accepted token length without complex sampling.
-
Empirical Results Snapshot
-
From Better & Faster Large Language Models via Multi-token Prediction by Gloeckle et al. (2024), using 4-token prediction on a 7B model:
- 3\(\times\) faster inference.
- +4% higher pass@1 on HumanEval (code generation).
- Optimal token prediction window (\(n\)) varies: 4 is best for natural language, 8 for byte-level models.
-
From Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads by Cai et al. (2024), Medusa on Vicuna-7B:
- 2.3–2.8\(\times\) speedup.
- Quality preserved via training schemes (especially Medusa-2).
- Compatible with quantized backbones (QLoRA).
Key Takeaways
- Speed vs Simplicity: Draft-based methods are simpler but less efficient long-term. Integrated heads unlock better scaling.
- Training Budget Matters: If you’re training from scratch, invest in multi-token or Medusa heads.
- Serving Constraints: For distributed serving or edge deployment, Medusa-1 or next-token heads provide clean integration.
Implementation Deep Dive: How to Build Speculative Decoders
- This section focuses on the nuts and bolts of implementing speculative decoding. We cover architecture layouts, essential training routines, memory-saving tricks, and reference code patterns for each of the three major approaches.
Draft Model-Based Speculative Decoding
-
This method involves using two models:
- Target model: The large, accurate LLM whose output must be preserved.
- Draft model: A smaller model trained to approximate the target model’s predictions.
-
Architecture Overview:
- The following figure from the paper shows the workflow of draft model-based speculative decoding: proposal, parallel verification, selective acceptance. In the case of unconditional language modeling, each line represents one iteration of the algorithm. The green tokens are the suggestions made by the approximation model (here, a GPT-like Transformer decoder with 6M parameters trained on lm1b with 8k tokens) that the target model (here, a GPT-like Transformer decoder with 97M parameters in the same setting) accepted, while the red and blue tokens are the rejected suggestions and their corrections, respectively. For example, in the first line the target model was run only once, and 5 tokens were generated.
-
Each decoding step proceeds as follows:
- Generate a speculative prefix of \(\gamma\) tokens using the draft model (e.g., \(\gamma\) = 4).
- Run the target model in parallel to verify each token.
- Accept matching tokens; reject mismatches and resume standard decoding from there.
-
Key Implementation Elements:
-
Speculative Sampling: Uses rejection sampling to ensure distributional equivalence:
def accept_token(p_large, p_draft, x): if p_draft[x] <= p_large[x]: return True else: accept_prob = p_large[x] / p_draft[x] return random.random() < accept_prob -
Parallel Verification: Run \(\gamma\) + 1 parallel forward passes of the target model:
with torch.no_grad(): logits = target_model(prefix + draft_tokens) verified_probs = softmax(logits) -
Fallback Correction: If a token is rejected, sample again from an adjusted distribution:
residual = torch.clamp(p_large - p_draft, min=0) residual /= residual.sum() next_token = torch.multinomial(residual, num_samples=1)
-
-
Optimization Tip: Cache activations across reused prefixes to avoid redundant computation.
Medusa: Tree Attention + Parallel Heads
-
Medusa extends multi-token decoding with a novel attention mechanism that verifies multiple speculative paths simultaneously.
-
Architecture Overview:
- The following figure from the paper shows the proposed tree attention in Medusa: parallel candidates from multiple heads form branches that are verified simultaneously.
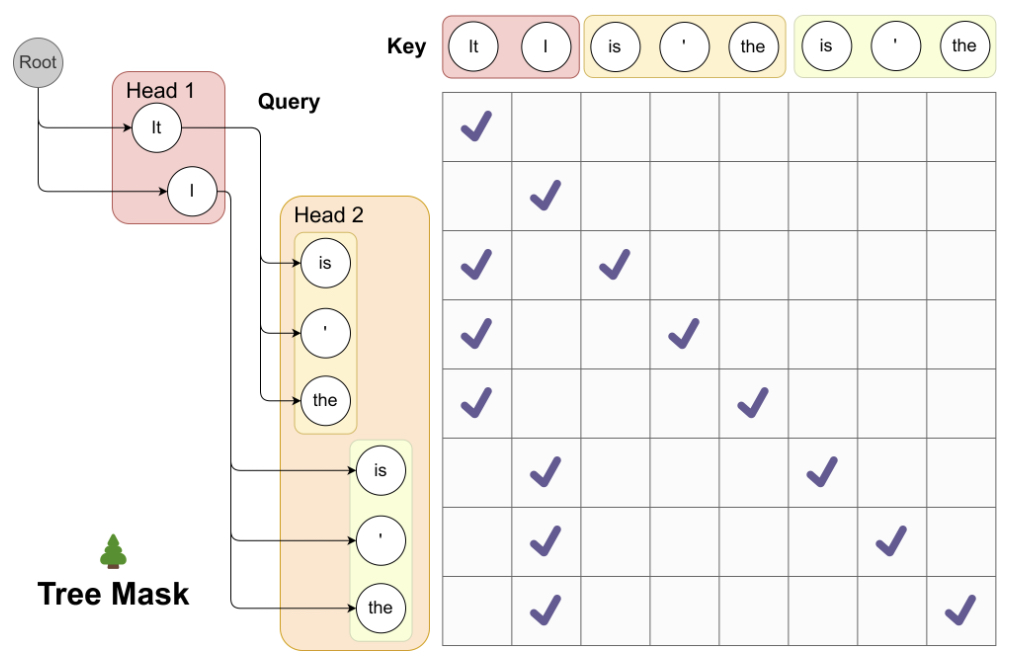
- Multiple lightweight Medusa heads project from the last hidden state.
- Each head proposes tokens at future positions (\(t+1\), \(t+2\), \(\dots\), \(t+K\)).
- Tree-structured attention masks control information flow to ensure correctness.
-
Medusa Head Definition:
def medusa_head(h_t, W1_k, W2_k): ff_out = F.silu(W1_k @ h_t) + h_t return softmax(W2_k @ ff_out) -
- \(W_{1_{k}}\) is initialized as zero, \(W_{2_{k}}\) cloned from LM head.
-
Tree Attention Implementation:
- Construct Cartesian product of top-k predictions from each head.
- Use attention mask that only allows intra-branch communication.
- Modify positional encodings for tree-based candidate verification.
-
Candidate Verification:
# Assume 2 heads with top-2 and top-3 predictions # Generate 6 branches, verify each in parallel mask = build_tree_attention_mask(branch_structure) attention_output = transformer_with_mask(input_ids, mask) -
Acceptance Strategy:
- Rejection sampling ensures fidelity.
- Typical acceptance (heuristic cutoff on deviation from target) boosts speed.
Multi-Token Prediction Heads
-
This approach modifies the LLM architecture to predict \(n\) future tokens at once during training.
-
Architecture Overview:
- The following figure from the paper shows the implementation structure of multi-token prediction: one trunk, multiple future-predicting heads, and staged loss computation.
- A shared transformer trunk generates a hidden state.
- \(n\) lightweight output heads decode tokens \(t+1\) to \(t+n\).
-
Model Structure:
# Trunk z = transformer_trunk(x) # Heads logits = [head_i(z) for i in range(n)] outputs = [softmax(logit) for logit in logits]-
Each head minimizes its own cross-entropy loss:
loss = sum([F.cross_entropy(logits[i], target[i]) for i in range(n)])
-
-
Memory-Efficient Training:
-
Sequential gradient computation for each head reduces memory:
for head in heads: output = head(z) loss = F.cross_entropy(output, target) loss.backward(retain_graph=True)
Inference Options:
- Use the next-token head for traditional generation.
- Use the other heads to propose speculative sequences for greedy decoding (e.g., blockwise).
-
Future Directions
- The field is still rapidly evolving. What began with speculative sampling is now branching into hybrid pipelines, adaptive acceptance, and tree-structured reasoning paths. With integration into quantized and edge-deployable models, speculative decoding is becoming not just an optimization—but a design paradigm for future LLM systems.
- The core techniques of speculative decoding have opened the door to a range of optimization opportunities for LLM inference. In this section, we explore emerging variants, hybrid models, and promising research directions that could further accelerate decoding while maintaining output fidelity.
Hybrid Approaches: Combining Draft + Head
-
Some systems now combine draft models with multi-token or Medusa heads to maximize acceptance rates and throughput.
-
Motivation:
- Use a draft model for a long speculative prefix.
- Use Medusa or multi-token heads to verify batches of predictions instead of verifying token-by-token.
-
Example Pipeline:
- Draft model proposes \(\gamma\) tokens.
- Medusa-style heads are used within the large model to validate candidate branches.
- Longest valid candidate is accepted.
-
Advantages:
- Combines high-quality approximation from draft with structural verification efficiency.
- Supports deeper pipelines (e.g., hierarchical draft-check loops).
- Naturally extensible to distributed and batched decoding.
Integration with Quantization & Pruning
-
Speculative decoding can synergize with model compression techniques:
- Quantized Models (e.g., QLoRA, GPTQ):
- Medusa heads can be trained/fine-tuned atop a frozen quantized model. Even the trunk used in multi-token prediction can be quantized (as in Medusa-1).
- Pruned Heads:
- Lightweight speculative heads use <0.1% of model parameters. This makes them ideal candidates for post-training head-specific pruning or low-rank approximations.
- Shared KV Caches:
- As seen in IBM’s PyTorch implementation, speculative tokens and trunk outputs can reuse the same attention cache with minimal overhead by adapting the paged attention kernel.
- Quantized Models (e.g., QLoRA, GPTQ):
Speculative Decoding for Byte-Level Model
-
Recent experiments show that speculative decoding is especially effective for byte-level tokenization models.
-
Why?
- Byte-level tokenizers (e.g., Tiktoken with vocab size 256) produce longer sequences for the same semantic content.
- This increases the number of decoding steps per input and exacerbates autoregressive latency.
-
Findings from Better & Faster Large Language Models via Multi-token Prediction by Gloeckle et al. (2024):
- 8-byte prediction outperforms single-token next prediction by 67% on MBPP pass@1.
- Inference speedup of 6.4\(\times\), fully amortizing byte-level overhead.
Beyond Decoding: Speculative Sampling for Diverse Output
-
While initial work focused on greedy or top-\(k\) decoding, speculative techniques are being extended to support:
- Diverse sampling (via top-\(p\) or temperature-controlled typical decoding)
- Beam search variants (speculative beam candidates + top-scoring path verification)
- Stochastic acceptance (accept “close enough” tokens under Wasserstein distance or KL threshold)
-
This makes speculative decoding viable for tasks requiring diversity, such as story generation, summarization, and open-ended Q\&A.
Future Research Directions
-
Several open questions and promising directions remain:
-
Speculative Training: Can models be explicitly trained to improve speculative token acceptance rates (e.g., contrastive token alignment)? This would unify training and decoding under a shared goal.
-
Reinforcement-Tuned Speculators: How can RLHF-style alignment guide draft model predictions or head outputs for better human preference alignment?
-
Adaptive Drafting: Can models dynamically adjust the speculative prefix length based on uncertainty, entropy, or input complexity?
-
Token-Free Decoding: Recent proposals like “latent decoding” (generating hidden states directly) could be paired with speculative strategies to push inference latency even lower.
-
Takeaways
- Speculative decoding represents a pivotal advancement in making LLM inference faster, more efficient, and more scalable—without compromising model accuracy or requiring massive retraining. In this primer, we’ve explored the conceptual underpinnings, design patterns, and technical implementations behind speculative decoding.
-
While hybrid speculative models (e.g., Medusa + draft) offer a path to greater speed and flexibility, future systems will likely feature dynamic, train-time-aware speculative inference pipelines tailored to use case and device constraints.
- Takeaways:
-
Autoregressive inference is inherently sequential, but speculative decoding introduces parallelism by “guessing” future tokens and verifying them.
-
Three main strategies dominate:
- Draft model decoding: Uses a separate small model for speculative suggestions.
- Multi-token prediction heads: Built into the model at pretraining time, allowing for native speculative output.
- Medusa: Enhances multi-head prediction with tree attention and flexible acceptance schemes.
-
Speedups are real and measurable:
- 2–3\(\times\) (draft models),
- 3–6\(\times\) (multi-token heads),
- 2.3–2.8\(\times\) (Medusa in real-world batch-1 usage).
-
Memory-efficient implementations are critical to unlocking the full benefits of speculative decoding, especially when dealing with large vocabularies and long sequences.
-
Use-case dependent:
- Draft models excel in low-latency deployment pipelines.
- Medusa is great for chatbots and single-user scenarios.
- Multi-token heads are most effective when trained from scratch.
-
Further Reading
- The Hitchhiker’s Guide to Speculative Decoding (PyTorch blog)
- An Optimal Lossy Variant of Speculative Decoding (Mentored Decoding)
- Speculative Decoding in vLLM: Overview & Integration
- Looking back at speculative decoding (Google Research blog)
- Speculative Decoding for Faster LLMs (Medium article)
- How Speculative Decoding Boosts vLLM Performance by up to 2.8\(\times\)
References
- Fast Inference from Transformers via Speculative Decoding
- MEDUSA: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
- Better & Faster Large Language Models via Multi-token Prediction
- Accelerating Large Language Model Decoding with Speculative Sampling
- DistillSpec: Improving Speculative Decoding via Knowledge Distillation
- Speculative Streaming: Fast LLM Inference without Auxiliary Models
- Recurrent Drafter for Fast Speculative Decoding in Large LLMs
Citation
If you found our work useful, please cite it as:
@article{Chadha2020DistilledSpeculativeDecoding,
title = {speculative-decoding},
author = {Chadha, Aman},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}