Primers • Reasoning in LLMs
- Overview
- Invoking reasoning in LLMs
- Prompting-Based Reasoning
- Decoding and Aggregation-Based Reasoning
- Search-Based Reasoning
- Tool-Augmented Reasoning
- Reinforcement Learning-Based Reasoning
- WebGPT
- DeepSeek-R1
- Reinforcement Learning for Tool-Integrated Reasoning
- Tool-Augmented Reward Modeling (Themis)
- Tool Learning with Foundation Models
- The “Aha” Moment and Emergent Reasoning
- Evaluation of reasoning using datasets
- GSM8K (grade-school math reasoning)
- MATH (competition-level mathematical reasoning)
- AIME and IMO: Mathematical Olympiad–Level Reasoning
- ARC and Science QA Benchmarks (ARC-AGI-1 and ARC-AGI-2)
- OpenThoughts3: Large-Scale Open Reasoning Dataset
- DROP and Numerical Reading-Comprehension Reasoning
- BIG-bench and BIG-bench Hard
- MMLU and AGIEval (Knowledge + Reasoning Exam Benchmarks)
- HELM and Holistic Multi-Metric Reasoning Evaluation
- Multimodal reasoning and factuality
- Summary of reasoning evaluation datasets and their interrelations
- Open challenges and future directions
- Bringing it together—end-to-end blueprints for reasoning systems (small, medium, large budgets)
- Failure analysis—diagnosing and fixing reasoning errors
- Further Reading
- References
- Citation
Overview
-
Large Language Models (LLMs) are sequence models that learn a conditional distribution over tokens. Given a context \(x_{<t}\), an LLM parameterized by \(\theta\) predicts the next token via:
\[p_\theta(x_t \mid x_{<t})=\mathrm{softmax}\left(f_\theta(x_{<t})\right)\] -
Reasoning, in this primer, is the process by which an LLM instantiates and manipulates intermediate structures to transform inputs into solutions that satisfy constraints beyond surface-level pattern completion. A useful abstraction is to introduce latent “thoughts” \(z\) and write:
\[p_\theta(y\mid x)=\sum_{z} p_\theta(y\mid x,z) p_\theta(z\mid x)\]- where \(z\) ranges over intermediate steps such as plans, subgoals, tool calls, or formal derivations. Externalizing \(z\) in the output (for example, step-by-step rationales) is one way we can probe, debug, and improve this process.
-
From an architectural standpoint, modern LLMs implement this computation with transformers introduced in Attention Is All You Need by Vaswani et al. (2017). Pretraining objectives and representations popularized by BERT by Devlin et al. (2018) helped establish bidirectional text understanding, while today’s generative LLMs typically use decoder-only transformers. Scaling trends such as power-law loss curves in Scaling Laws for Neural Language Models by Kaplan et al. (2020) and compute-optimal training in Training Compute-Optimal Large Language Models (“Chinchilla”) by Hoffmann et al. (2022) explain why larger, better-trained models often exhibit stronger reasoning—although how “reasoning” emerges remains an active debate, with claims of sharp emergent abilities in Emergent Abilities of Large Language Models by Wei et al. (2022) and counter-arguments that such “emergence” can be a metric artifact in Are Emergent Abilities of Large Language Models a Mirage? by Schaeffer et al. (2023).
-
A practical working definition that guides the rest of this primer is that reasoning in LLMs can be understood as learned, compositional computation over latent steps \(z\) that yields verifiable conclusions.
-
This definition is agnostic to whether steps are printed as Chain-of-Thought (CoT), searched over as a tree, executed as code, or kept internal.
What counts as “reasoning” for LLMs?
-
Deductive reasoning: Deriving logically necessary conclusions from premises, e.g., symbolic algebra, formal proofs, or rule application.
-
Inductive reasoning: Generalizing patterns from examples, e.g., few-shot extrapolation, schema induction, or pattern completion that yields testable hypotheses.
-
Abductive reasoning: Inferring the most plausible explanation for observations (hypothesis selection under uncertainty), common in diagnosis and root-cause analysis.
-
Procedural reasoning: Planning and multi-step control in which the model decomposes tasks, executes actions (possibly via tools), and revises plans.
-
These categories are not mutually exclusive; many benchmarks interleave them.
Interfaces that elicit reasoning
-
Researchers have discovered prompting and decoding interfaces that expose or amplify the latent steps \(z\).
-
Chain-of-thought (CoT): Providing or eliciting step-by-step rationales improves multi-step problem solving, as shown in Chain-of-Thought Prompting Elicits Reasoning in Large Language Models by Wei et al. (2022) and Zero-shot CoT (“Let’s think step by step”) in Large Language Models are Zero-Shot Reasoners by Kojima et al. (2022). Self-Consistency Improves CoT Reasoning in Language Models by Wang et al. (2022) samples multiple reasoning paths and marginalizes to a consensus.
-
Search over thoughts: Tree of Thoughts: Deliberate Problem Solving with Large Language Models by Yao et al. (2023) treats intermediate steps as nodes and performs lookahead/backtracking, bridging LLM inference with classic heuristic search.
-
Reasoning and acting: ReAct: Synergizing Reasoning and Acting in Language Models by Yao et al. (2022) interleaves reasoning traces with tool or environment actions, enabling information gathering and plan revision.
The role of scaling and the “aha” phenomenon
-
Scaling laws predict smoother loss improvements with model/data/compute, yet qualitative “jumps” in task performance are often reported. Two perspectives coexist:
-
Emergence view: Some abilities appear only beyond certain scales or training regimes, as argued by Wei et al. (2022).
-
Measurement view: Apparent discontinuities arise from metric non-linearities or data scarcity, per Schaeffer et al. (2023).
-
-
In either view, improved interfaces and training often turn tacit competence into explicit problem solving. For instance, RL specialized to reward intermediate solution quality, as in DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning by Guo et al. (2025), reports substantial gains on math and logic without supervised rationales, highlighting how credit assignment can shape useful latent computations.
A minimal mathematical lens
-
Training typically minimizes the expected negative log-likelihood (cross-entropy) \(\mathcal{L}(\theta)=\mathbb{E}_{x\sim \mathcal{D}}\left[-\sum_{t}\log p_\theta(x_t\mid x_{<t})\right]\).
-
Reasoning-oriented inference augments this with structure over \(z\):
-
CoT-style sampling: Sample \(z^{(k)}\sim p_\theta(z\mid x)\) and select \(\hat{y}\) by majority or confidence weighting \(\hat{y}=\arg\max_y \sum_{k} w \left(z^{(k)}\right), p_\theta(y\mid x,z^{(k)})\).
-
Search over thoughts: Define a scoring function \(s(z_{1:t})\) and expand nodes to maximize expected downstream reward, akin to beam/A* variants over textual states.
-
Reinforcement Learning for reasoning: Optimize \(\theta\) against a task reward \(R(y,z)\), shaping \(p_\theta(z\mid x)\) toward productive step structures rather than purely imitating text.
-
Invoking reasoning in LLMs
-
Reasoning in LLMs is not an automatic or always-on capability—it is typically invoked through specific interfaces or training strategies that elicit structured intermediate computation. In other words, while an LLM can always generate text, certain modes of interaction encourage it to perform reasoning-like processes internally or externally.
-
Invoking reasoning can be viewed as shaping the latent variable \(z\) in the generative formulation \(p_\theta(y \mid x)=\sum_z p_\theta(y \mid x,z)p_\theta(z \mid x)\), so that the model generates more useful or verifiable intermediate structures (the “thoughts” \(z\)) instead of directly producing the final answer \(y\).
-
At a top level, there are several paradigms (and methodologies per paradigm) to invoke reasoning:
-
Prompting-based: Purely contextual reasoning induction through examples and instructions within the prompt, without modifying model parameters or architecture.
- Chain-of-Thought (CoT) prompting: Encourages explicit step-by-step reasoning traces, guiding models to decompose complex problems into interpretable intermediate steps.
- Implicit reasoning via in-context composition: Induces structured reasoning by presenting compositional examples that demonstrate multi-step problem-solving directly within the input context.
-
Decoding and aggregation-based \(\rightarrow\) Ensemble reasoning through sampling and consensus.
- Decoding and aggregation-based reasoning: Samples diverse reasoning paths via stochastic decoding and aggregates results through voting, confidence scoring, or verifier-based consensus.
- Reflection and self-verification loops: Iteratively critiques, revises, and improves its own reasoning outputs using self-feedback, enhancing correctness and logical consistency.
-
Search-based \(\rightarrow\) Explicit reasoning exploration guided by evaluation.
- Tree-of-Thoughts (ToT) prompting/search: Expands reasoning as a branching search tree of partial thoughts, evaluating and pruning paths to find coherent solutions.
- Monte Carlo Tree Search (MCTS)-based reasoning: Conducts stochastic rollouts and value backpropagation to balance exploration and exploitation, refining reasoning through simulated decision trajectories.
-
Tool-augmented \(\rightarrow\) Hybrid symbolic–neural reasoning.
- ReAct frameworks: Integrates reasoning with environment actions, enabling models to think, act, and observe dynamically during problem-solving.
- Toolformer-based reasoning: Enables models to autonomously decide when and how to call external APIs or tools during inference, integrating symbolic computation, retrieval, or execution for improved factuality and reasoning precision.
-
RL-based \(\rightarrow\) Learning to reason through reward optimization.
- Reinforcement learning for reasoning (e.g., DeepSeek-R1): Optimizes reasoning strategies using reward feedback to align reasoning depth, accuracy, and efficiency across diverse tasks.
-
-
Each of these methods aims to transform a generic text generator into a compositional problem-solver, either through prompting, decoding, or training modification.
Methodologies for Invoking Reasoning in LLMs
- There are several overarching paradigms by which reasoning can be invoked in LLMs. Each family emphasizes a different mechanism—whether through prompting, decoding, exploration, tool use, or learning signals. Below, the principal methodologies are organized into five broad families.
Prompting-Based Reasoning
-
Prompting-based approaches induce reasoning by structuring the input context to make intermediate thinking explicit or implicitly compositional. These methods rely purely on contextual cues rather than architectural or training modifications. Examples below:
-
Chain-of-Thought (CoT) Prompting: Introduced by Wei et al. (2022), CoT explicitly elicits step-by-step reasoning traces, guiding the model to externalize intermediate computations before giving the final answer. Formally, the model predicts
\[\hat{y} = \arg\max_y \sum_z p_\theta(y, z | x)\]- where \(z\) denotes latent reasoning traces approximated through explicit textual reasoning.
-
Zero-Shot and Few-Shot CoT: As shown by Kojima et al. (2022), adding simple triggers like “Let’s think step by step” can induce reasoning behavior even without demonstrations, revealing latent reasoning priors in large models.
-
Implicit Reasoning via In-Context Composition: From Brown et al. (2020), LLMs can implicitly perform reasoning by inferring structured input–output mappings from few-shot examples. This process is latent, with reasoning occurring in attention dynamics rather than explicit text.
- Implicit composition thus shows that LLMs can internalize algorithmic reasoning even without producing verbalized steps.
-
Decoding and Aggregation-Based Reasoning
-
Decoding strategies strengthen reasoning robustness by sampling and aggregating multiple reasoning paths rather than trusting a single deterministic chain. They treat reasoning as probabilistic inference over latent cognitive trajectories. Examples below:
-
Self-Consistency Decoding: Wang et al. (2022) proposed sampling multiple reasoning chains and aggregating their final answers to approximate Bayesian marginalization:
\[\hat{y} = \arg\max_y \sum_{k=1}^{K} \mathbb{I}[y^{(k)} = y],\]- where \(y^{(k)}\) are outcomes from diverse reasoning samples. This approach reduces variance and enhances robustness on multi-step tasks.
-
Reflection and Self-Verification Loops: Frameworks such as Reflexion (Shinn et al. (2023)) and Self-Refine (Madaan et al. (2023)) introduce iterative critique–revise cycles, allowing models to assess and improve their reasoning traces:
\[x \xrightarrow{\text{reason}} (z, y) \xrightarrow{\text{reflect}} c \xrightarrow{\text{revise}} (z', y')\]- Each loop refines the reasoning toward correctness or coherence.
-
RCOT and Critic–Judge Systems: Zhang et al. (2024) and Zhou et al. (2023) formalized structured reflective reasoning where critic models evaluate reasoning traces. This improves factual accuracy and consistency through meta-evaluation.
-
Search-Based Reasoning
-
Search-based reasoning treats reasoning as explicit exploration through a structured search space. Instead of committing to one reasoning chain, the model maintains and expands a frontier of partial thoughts guided by learned or heuristic values. Examples below:
-
Tree-of-Thoughts (ToT) Prompting: Yao et al. (2023) generalized CoT into a search tree of reasoning steps, where partial “thoughts” are evaluated and expanded. This transforms reasoning from a linear chain to a controlled exploration process guided by heuristic value estimates.
-
Monte Carlo Tree Search (MCTS) and Value-Guided Variants: Building on Tree-of-Thoughts, these methods treat reasoning trajectories as nodes in a decision tree, using stochastic rollouts and value estimates \(V_\phi(z_{1:t})\) to select the most promising branches:
\[z_{t+1} \sim \pi_\theta(z_t | z_{<t}), \quad V_\phi(z_{1:t}) \approx \mathbb{E}[R | z_{1:t}]\]- This search-based framing bridges symbolic planning with neural reasoning and underlies deliberative reasoning systems that combine exploration, pruning, and value-guided selection.
-
Tool-Augmented and Interaction-Based Reasoning
-
This family connects internal reasoning with external information or computational tools, turning static text prediction into interactive cognition. Examples below:
-
ReAct Frameworks (Reason + Act): Yao et al. (2022) proposed alternating between internal “Thought” and external “Action” steps:
\[x \rightarrow \text{Thought}_1 \rightarrow \text{Action}_1 \rightarrow \text{Observation}_1 \rightarrow \cdots \rightarrow y\]- This structure enables reasoning intertwined with API calls, search, or tool execution.
-
Tool-Augmented Reasoning: Schick et al. (2023) (Toolformer) and Gao et al. (2022) (PAL) demonstrated that LLMs can autonomously learn to invoke external tools like Python interpreters or search engines, grounding reasoning in verifiable computation.
\[\pi_\theta(a_t | s_t) = \begin{cases} \text{generate thought } z_t & \text{if } a_t = \text{think},\\ \text{call tool } \mathcal{T}_i(s_t) & \text{if } a_t = \text{act} \end{cases}\] -
PAL (Program-Aided Language Models): Delegates subproblems to code snippets, merging natural-language reasoning with executable verification. This hybrid reasoning yields higher factuality and transparency.
-
Reflexion Agents: Shinn et al. (2023) extended ReAct-style systems with reflective feedback, enabling models to self-correct and improve during tool-based interactions.
-
Reinforcement Learning-Based Reasoning
-
Reinforcement Learning (RL) frames reasoning as policy optimization over reasoning trajectories, where models learn to maximize rewards reflecting correctness, efficiency, or verifiability. Examples below:
-
DeepSeek-R1 (Correctness-Guided Policy Optimization): Guo et al. (2025) introduced a RL framework for reasoning that eliminates the need for human-annotated rationales. Instead, the model learns directly from correctness-based feedback signals that are objectively verifiable. The optimization objective is defined as:
\[\mathcal{J}(\theta) = \mathbb{E}_{x, z, y \sim p \theta(\cdot|x)} [R(y, z)]\]-
Key Components:
-
Reward Structure:
-
The reward function integrates both correctness and computational efficiency:
\(R(y, z) = \mathbb{I}[\text{correct}(y)] - \lambda \text{cost}\)z\(\)
- where:
- \(\mathbb{I}[\text{correct}(y)]\) indicates whether the model’s answer \(y\) matches the ground truth, while \(\text{cost}\)z\(\) measures the resource usage (e.g., number of reasoning steps or token length) of the reasoning trace \(z\).
- The hyperparameter \(\lambda\) balances the trade-off between accuracy and efficiency.
- where:
-
-
Policy Learning without Rationales:
- Unlike earlier reasoning models that rely on process-level/step-level human supervision or rationalized trajectories, DeepSeek-R1 learns purely from outcome-level rewards.
- This shifts the training paradigm from imitating explanations to discovering effective reasoning trajectories through exploration and optimization.
-
Conciseness and Verifiability:
- By penalizing longer or redundant reasoning paths, the model learns to favor concise solutions.
- The reward design implicitly biases the policy toward interpretable and verifiable reasoning traces, improving robustness across mathematical and symbolic reasoning tasks.
-
Empirical Findings:
- DeepSeek-R1 demonstrates that outcome-based RL—when paired with reward shaping—can achieve reasoning quality comparable to process-supervised models.
- The study highlights that reinforcement-driven optimization can uncover reasoning strategies aligned with correctness and minimal computational cost, without explicit human process supervision.
-
-
-
Process vs. Outcome Supervision: Lightman et al. (2023) and OpenAI (2023) demonstrated that step-level (i.e., process-level) correctness rewards improve reliability and stability compared to outcome-level rewards.
-
Tool-Augmented RLHF: Nakano et al. (2021) extended RLHF to web-based environments.
-
In WebGPT, Nakano et al. implemented Reinforcement Learning with Human Feedback (RLHF)** over a browser-driven interface, where the model navigated and queried the web to retrieve supporting evidence before answering. Reward models trained on human preferences compared answers and their citations, encouraging factual accuracy and verifiability through policy optimization with proximal policy optimization (PPO). This demonstrated that verifiable, tool-grounded reasoning could be operationalized within an RL framework.
-
Building on that foundation, Themis (Li et al., 2024) proposed tool-augmented reward modeling, allowing reward models themselves to call external APIs—calculators, translators, or search engines—during preference evaluation. The hybrid loss function
- unifies pairwise ranking with autoregressive reasoning supervision. Themis improves factuality, arithmetic precision, and interpretability, showing +17.7 % accuracy gain on tool-based datasets and a 7.3 % TruthfulQA improvement over standard reward models.
-
-
Tool Learning with Foundation Models: Qin et al. (2024) surveyed tool-augmented reasoning as a general paradigm, viewing foundation models as controllers that plan subtasks, invoke APIs, and optimize through feedback loops. RL-based reasoning appears within a broader reasoning–action–observation–reward cycle, emphasizing transparency, adaptability, and safety.
-
Reflexion (Verbal RL): Shinn et al. (2023) interpreted reflection as verbal reinforcement learning, where self-generated critiques act as linguistic rewards guiding iterative improvement.
-
Prompting-Based Reasoning
- Prompting strategies elicit reasoning through the design of the input context rather than architectural or training changes. These methods rely on the model’s ability to externalize thought patterns when given structured cues.
Chain-of-Thought (CoT) prompting
-
The CoT methodology explicitly elicits step-by-step reasoning before producing an answer. Instead of directly predicting the output \(y\) from input \(x\), the model is guided to generate intermediate steps \(z_1, z_2, \ldots, z_k\) that form a coherent reasoning chain:
\[x \rightarrow z_1 \rightarrow z_2 \rightarrow \cdots \rightarrow z_k \rightarrow y\] - This approach was introduced in Chain-of-Thought Prompting Elicits Reasoning in Large Language Models by Wei et al. (2022). The key contribution of Wei et al. was to show that few-shot exemplars containing reasoning traces (〈input, reasoning, answer〉) dramatically improve reasoning performance. By providing examples of multi-step reasoning in the prompt, large models could successfully decompose problems into intermediate steps.
- In contrast, Large Language Models are Zero-Shot Reasoners by Kojima et al. (2022) later demonstrated that the same multi-step reasoning could be triggered even without exemplars—by simply appending the phrase “Let’s think step by step,” enabling zero-shot reasoning. While Wei et al. highlighted reasoning as an emergent property of scale through structured exemplars, Kojima et al. (2022) revealed that linguistic cues alone can unlock latent reasoning abilities already present in pretrained LLMs.
Mechanism
- Prompt-level induction: The prompt includes exemplars where the reasoning is explicit (Wei et al. (2022)).
- Latent structure exposure: The model learns to externalize intermediate computation as natural language.
-
Generalization: Even without supervision, the model generalizes to unseen reasoning tasks (as shown by Kojima et al. (2022)).
-
Formally, CoT modifies inference to condition on a reasoning trace \(z\):
\[\hat{y} = \arg\max_y \sum_z p_\theta(y, z \mid x)\]-
where:
- \(x\): the input question or problem statement presented to the model.
- \(y\): the final output or predicted answer generated by the model.
- \(z\): the intermediate reasoning trace, consisting of one or more steps \(z_1, z_2, \ldots, z_k\).
- \(p_\theta(y, z \mid x)\): the joint probability of producing a reasoning sequence \(z\) and final answer \(y\) given input \(x\), parameterized by model weights \(\theta\).
- \(\sum_z\): marginalization over all possible reasoning paths, representing the model’s implicit consideration of multiple reasoning trajectories.
- \(\arg\max_y\): selects the answer \(y\) with the highest overall likelihood after integrating over possible reasoning traces.
- \(\hat{y}\): the final selected output predicted by the model.
-
- When CoT prompting is used, the summation is approximated by sampling one or several \(z\) sequences explicitly.
Variants
- Zero-shot CoT: Introduced by Kojima et al. (2022), who found that simply prompting with “Let’s think step by step” elicits reasoning in the absence of any few-shot exemplars, proving that LLMs are zero-shot reasoners capable of multi-step inference without examples.
- Few-shot CoT: Proposed by Wei et al. (2022), which relies on a few explicit reasoning demonstrations in the prompt to teach structured decomposition of problems.
- Multi-CoT aggregation: Proposed in Self-Consistency Improves Chain of Thought Reasoning in Language Models by Wang et al. (2022), combines multiple reasoning traces to improve robustness and consistency. By sampling diverse reasoning paths and aggregating their outcomes—through majority voting, confidence weighting, or entailment-based filtering—this approach mitigates random errors in individual chains and enhances overall answer reliability, particularly on complex or ambiguous reasoning tasks. A detailed discourse on this topic is available in the Decoding and Aggregation-Based Reasoning section.
Advantages
- Readable, auditable reasoning process.
- Enables interpretability and debugging.
- Boosts performance on tasks requiring intermediate computation.
Limitations
- Prone to verbosity and “overthinking.”
- Can expose internal biases and hallucinations in intermediate steps.
- Sensitive to prompt wording and length.
Implicit Reasoning via In-Context Composition
- Implicit reasoning via in-context composition refers to the ability of LLMs to perform structured reasoning without being explicitly instructed to reason step-by-step. Instead of producing overt “thoughts” or intermediate rationales, the model implicitly composes reasoning patterns from the examples, instructions, and latent structure provided in the prompt.
- This phenomenon underlies few-shot learning and in-context learning (ICL), first formalized in Language Models are Few-Shot Learners by Brown et al. (2020).
- In short, implicit reasoning through in-context composition reveals that LLMs can simulate reasoning procedures internally—demonstrating that reasoning is not only something models can “say,” but also something they can do silently.
Core Idea
- During in-context learning, an LLM observes examples of input–output pairs in the prompt:
Example 1: x₁ → y₁
Example 2: x₂ → y₂
...
Query: xₙ → ?
-
Although no parameter updates occur, the model constructs an internal algorithm that maps inputs to outputs based on patterns in the examples. This implicit mechanism acts as a temporary reasoning program embedded within the attention dynamics of the transformer.
-
Mathematically, the model approximates:
\[p_\theta(y_n | x_n, \mathcal{C}) = f_\theta(x_n; \mathcal{C})\]- where the context \(\mathcal{C} = {(x_i, y_i)}_{i=1}^{n-1}\) acts as a soft prompt encoding the reasoning structure.
Mechanism
-
Pattern induction The attention mechanism identifies regularities across examples in the prompt (e.g., logical rules, transformations, or operations).
-
Implicit composition The model learns to simulate an algorithm consistent with those examples without explicit symbolic representation.
-
Generalization When applied to the query, the model executes the induced procedure on-the-fly, effectively performing reasoning within the hidden activations rather than the output text.
Evidence of Implicit Reasoning
-
Several studies show that LLMs can encode algorithmic reasoning purely through in-context composition:
- Transformers as Meta-Learners by von Oswald et al. (2023): demonstrates that transformers approximate gradient descent in activation space, effectively learning “how to learn” from examples.
-
Rethinking In-Context Learning as Implicit Bayesian Inference by Xie et al. (2022): formalizes ICL as a Bayesian posterior update over latent hypotheses \(h\), as follows:
\[p(h|x_{1:n}, y_{1:n}) \propto p(h)\prod_i p(y_i|x_i, h)\] - What Learning Algorithms Can Transformers Implement? by Akyürek et al. (2023): shows that transformers can instantiate implicit gradient-based learners and execute reasoning-like adaptations.
-
These findings imply that reasoning does not necessarily require explicit verbalization—it can occur within the model’s hidden computation.
Examples
- In-context arithmetic reasoning (e.g., “2 + 3 = 5, 4 + 5 = 9, 6 + 7 = ?”) where the model infers the pattern without showing intermediate steps.
- Logical pattern induction (e.g., mapping “A\(\rightarrow\)B, B\(\rightarrow\)C, therefore A\(\rightarrow\)C”) purely from example structure.
- Code pattern imitation: reproducing unseen programming functions after seeing analogous examples in the context.
Advantages
- Efficiency: No need for verbose intermediate reasoning.
- Speed: Faster inference due to single-pass computation.
- Adaptivity: Learns task-specific reasoning patterns dynamically from the prompt.
Limitations
- Opacity: Reasoning is latent and not interpretable.
- Fragility: Sensitive to prompt order, formatting, and example selection.
- Limited generalization: Implicit algorithms often fail outside the statistical range of given examples.
Relationship to Explicit Reasoning
- Implicit reasoning complements explicit reasoning (like CoT) along a spectrum:
| Type | Reasoning Representation | Interpretability | Example |
|---|---|---|---|
| Explicit | Textual steps visible in output | High | “Let’s think step by step” |
| Implicit | Reasoning internal to activations | Low | Few-shot induction, analogy |
- Recent work (Learning to Reason with Language Models by Zelikman et al. (2022)) suggests that both can coexist: explicit reasoning can teach the model to develop implicit reasoning circuits that persist even when steps are hidden.
Decoding and Aggregation-Based Reasoning
-
Decoding and aggregation-based reasoning conceptualizes reasoning as a process of exploring multiple candidate reasoning trajectories during decoding and aggregating their outcomes to reach a consensus answer. Rather than committing to a single deterministic reasoning chain, these methods embrace stochastic diversity—sampling multiple reasoning paths via temperature-controlled decoding or beam search—and then consolidate the results through majority voting, weighted aggregation, or external verification (say with a different model, e.g., another LLM as a judge).
-
The central premise is that LLMs encode a distribution over many plausible reasoning paths; by sampling and marginalizing across this space, one can recover more reliable and consistent conclusions. This approach bridges statistical ensembling and reasoning robustness, effectively reducing variance and mitigating local hallucinations.
-
Representative methods in this family include Self-Consistency Decoding by Wang et al. (2022), Majority-Vote CoT, Verifier-Guided Decoding by Lightman et al. (2023), Weighted Self-Consistency, and Mixture-of-Reasoners / Ensemble CoT strategies. Together, they embody an ensemble-based philosophy of reasoning—achieving reliability not through a single flawless chain, but through statistical agreement among many plausible reasoning hypotheses.
Self-Consistency Decoding
-
Self-Consistency Decoding builds upon CoT prompting by introducing stochastic reasoning diversity—instead of generating a single reasoning chain, the model samples multiple independent reasoning paths and aggregates their final answers to reach a more reliable conclusion.
-
This method was proposed in Self-Consistency Improves Chain-of-Thought Reasoning in Language Models by Wang et al. (2022).
Core Idea
-
LLMs can produce many plausible reasoning paths \(z^{(1)}, z^{(2)}, \ldots, z^{(K)}\) for the same input \(x\). Each path ends with a potential answer \(y^{(k)}\). Rather than trusting the first decoded path (which may be incorrect due to randomness or local bias), the model aggregates across samples to find the most self-consistent answer.
-
Formally, this can be written as:
\[\hat{y} = \arg\max_{y} \sum_{k=1}^{K} \mathbb{I}[y^{(k)} = y]\]-
where:
- \(\hat{y}\): the final predicted answer obtained by selecting the most frequently occurring outcome among sampled reasoning paths.
- \(y\): a candidate answer being evaluated for consistency across reasoning trajectories.
- \(y^{(k)}\): the final output generated from the \(k^{th}\) reasoning chain \(z^{(k)}\).
- \(K\): the total number of sampled reasoning paths (i.e., the number of independent reasoning attempts by the model).
- \(\mathbb{I}[y^{(k)} = y]\): an indicator function that equals 1 if the answer from the \(k^{th}\) reasoning path matches \(y\), and 0 otherwise.
- \(\sum_{k=1}^{K} \mathbb{I}[y^{(k)} = y]\): counts how many times each candidate answer \(y\) appears across all reasoning samples.
- \(\arg\max_{y}\): selects the answer \(y\) that occurs most frequently (the mode) among the \(K\) generated reasoning paths, ensuring self-consistency through aggregation.
-
-
In practice, \(K\) ranges from 5 to 50 samples depending on model size and task complexity.
Mechanism
-
Sampling phase: Use temperature sampling (e.g., \(T = 0.7\)) to generate diverse reasoning traces \(z^{(k)}\).
-
Aggregation phase: Extract the final answers \(y^{(k)}\) and perform majority voting or probabilistic marginalization.
-
Selection phase: Choose the most frequent answer (or a weighted consensus based on log-probabilities).
- This implicitly integrates over multiple latent reasoning variables \(z\), approximating the marginalization in
Intuition
-
Different reasoning paths represent samples from the model’s internal “belief distribution” over possible reasoning chains. Self-Consistency acts as a Bayesian marginalization step, improving robustness to local hallucinations and premature reasoning collapses.
-
Empirically, the method yields substantial gains on multi-step arithmetic and logic benchmarks such as GSM8K, MultiArith, and StrategyQA.
Advantages
- Reduces the variance and brittleness of individual CoT runs.
- Encourages exploration of diverse reasoning paths.
- Significantly improves accuracy on reasoning tasks without changing model parameters.
Limitations
- Computationally expensive (requires many samples).
- Inefficient for tasks where answers are non-discrete or continuous.
- Aggregation may fail if reasoning errors are systematic across samples.
Reflection and Self-Verification Loops
-
Reflection and self-verification methods extend reasoning by allowing a model to analyze, critique, and improve its own outputs. Rather than generating a single reasoning trace and final answer, the model iteratively reviews its reasoning, identifies potential errors, and either revises the reasoning or re-generates the answer.
-
This meta-cognitive process—analogous to human self-checking—is central to recent efforts to make reasoning both more reliable and more factual.
-
A key paper introducing this paradigm is Reflexion: Language Agents with Verbal Reinforcement Learning by Shinn et al. (2023), and Self-Refine: Iterative Refinement with Self-Feedback by Madaan et al. (2023).
Core Idea
-
Reflection frameworks conceptualize reasoning as an iterative loop between generation, evaluation, and revision. A single pass through the LLM may produce a reasoning chain \(z\) and output \(y\), but the model can further reflect on its own reasoning by generating a self-critique \(c\) that identifies flaws or inconsistencies.
-
This process can be formalized as:
- Each iteration ideally brings the reasoning trace closer to correctness or coherence.
Mechanism
-
Initial reasoning phase: The model generates a reasoning chain and provisional answer.
-
Reflection phase: The model (or a secondary evaluator) reviews the reasoning for logical, factual, or procedural errors. Example prompt: “Examine the above reasoning carefully. Identify mistakes or unsupported steps, and propose corrections.”
-
Revision phase: The model generates a new reasoning chain incorporating the critique. Optionally, feedback can be looped over multiple rounds.
-
Termination: The loop ends when a confidence threshold or reflection limit is reached.
Theoretical Framing
-
Reflection can be viewed as approximate gradient descent in the space of reasoning traces, where the model updates its “beliefs” about a solution through internal self-assessment.
-
Given an initial reasoning trace \(z^{(0)}\), the update rule can be seen as:
\[z^{(t+1)} = \text{Refine}\big(z^{(t)}, \text{Critique}(z^{(t)})\big)\]- where Critique is an operator producing feedback and Refine modifies the reasoning accordingly.
-
This closely parallels iterative inference in classical optimization and meta-learning frameworks.
Variants
- Reflexion (Shinn et al. (2023)): Uses verbal reinforcement (self-generated critique and reward).
- Self-Refine (Madaan et al. (2023)): Separates roles into task solver, feedback provider, and reviser.
- Critic–Judge systems (Zhou et al. (2023)): Introduces a secondary “critic” model to evaluate and score reasoning traces.
- RCOT (Reflective Chain-of-Thought) (Zhang et al. (2024)): Adds structured self-correction within CoT reasoning.
Advantages
- Improves factual correctness and logical soundness of reasoning chains.
- Encourages interpretable, auditable reasoning corrections.
- Can operate with minimal supervision—feedback is model-generated.
Limitations
- Computationally expensive due to iterative passes.
- Susceptible to feedback loops—reflections may amplify minor errors.
- Quality of reflection depends heavily on prompt design and model calibration.
Relationship to RL and CoT
-
Reflection complements RL and CoT:
- Like RL, it provides a feedback signal, but in natural language form rather than scalar rewards.
- Like CoT, it operates at the level of reasoning traces, but introduces a meta-layer of critique.
-
This synergy is foundational in modern autonomous reasoning agents that continuously self-improve through reflection cycles.
Search-Based Reasoning
-
Search-based reasoning extends CoT and Tree-of-Thought paradigms by formalizing reasoning as an explicit search or planning process through a structured state space of partial thoughts. Rather than producing a single reasoning trajectory, the model dynamically explores multiple hypotheses, evaluates their promise, and selectively expands the most promising reasoning branches. This approach transforms reasoning from sequence generation into strategic exploration—closer to the deliberative search processes in classical AI.
-
The key insight behind search-based reasoning is that complex reasoning tasks (e.g., mathematical proofs, algorithmic puzzles, or multi-hop reasoning) often require exploring alternative reasoning directions, pruning dead-ends, and backtracking—capabilities absent from purely linear text generation.
-
This family includes Tree-of-Thoughts (ToT) by Yao et al. (2023), Monte Carlo Tree Search (MCTS)-augmented reasoning, value-guided search frameworks, and hybrid plan–execute–evaluate reasoning systems that embed search within or atop language model inference.
Tree-of-Thoughts (ToT) Prompting
-
Tree-of-Thoughts (ToT) generalizes CoT prompting into a structured search process over multiple reasoning paths. Instead of committing to a single linear reasoning chain, ToT explores a branching search tree where each node corresponds to a partial “thought,” and branches represent possible continuations of reasoning.
-
This approach was introduced in Tree of Thoughts: Deliberate Problem Solving with Large Language Models by Yao et al. (2023).
Core Idea
-
CoT prompting treats reasoning as a single sampled trajectory:
\[x \rightarrow z_1 \rightarrow z_2 \rightarrow \cdots \rightarrow z_T \rightarrow y\]- while ToT treats reasoning as an exploration problem over multiple possible continuations at each step:
-
The model explicitly evaluates partial thoughts \(z_{1:t}\) using a heuristic function or value model, guiding the expansion toward promising reasoning directions.
Mechanism
- Thought generation:
- The model generates candidate continuations for the current thought, e.g., \(z_t^{(1)}, z_t^{(2)}, \ldots, z_t^{(b)}\)
- Evaluation:
- Each partial reasoning sequence \(z_{1:t}\) is scored by the model itself or a learned value function \(V_\phi(z_{1:t})\), estimating expected success.
- Search algorithm:
- Employs strategies such as breadth-first search (BFS), depth-first search (DFS), or Monte Carlo Tree Search (MCTS) to explore reasoning paths selectively.
- Selection:
- The final answer is derived from the highest-valued complete reasoning path or an ensemble of top candidates.
-
Mathematically, this resembles a policy/value formulation:
\[z_{t+1} \sim \pi_\theta(z_t \mid z_{1:t}) \quad \text{and} \quad V_\phi(z_{1:t}) \approx \mathbb{E}[R \mid z_{1:t}]\]- where \(R\) is a reward for a correct or high-quality final output.
Example
-
For a math problem such as “Find the smallest integer satisfying …”, the ToT procedure may branch into:
- Thought A: Try algebraic manipulation.
- Thought B: Try substitution.
- Thought C: Try bounding argument.
-
The model evaluates which partial derivation yields progress and prunes unpromising branches, effectively performing deliberate reasoning.
Advantages
- Encourages exploration over multiple reasoning directions, avoiding early commitment to incorrect logic.
- Enables planning and backtracking, crucial for complex reasoning.
- Integrates well with external evaluators or reward functions.
Limitations
- Computationally expensive: exponential search space mitigated only by pruning heuristics.
- Requires a reliable evaluation function to score partial reasoning.
- Harder to parallelize and tune compared to CoT or Self-Consistency.
Relation to Other Methods
-
Tree-of-Thoughts bridges the gap between:
- CoT (single deterministic reasoning chain), and
- Search-based reasoning in classical AI (state-space exploration, planning).
-
In this sense, it operationalizes the idea that reasoning should be deliberative, not merely associative.
Monte Carlo Tree Search (MCTS)-based Reasoning
Core Idea
-
Monte Carlo Tree Search (MCTS)-based reasoning refines search-based reasoning by using stochastic simulations to balance exploration and exploitation over the reasoning space. Each node in the search tree represents a partial reasoning trace \(z_{1:t} = (z_1, z_2, \ldots, z_t)\), and edges represent possible next reasoning steps \(z_{t+1}\). Unlike simple breadth-first or depth-first traversal, MCTS uses probabilistic sampling to explore promising reasoning branches while still allocating some computation to less-visited ones, ensuring a balance between discovering new reasoning paths and refining strong candidates.
-
Formally, reasoning unfolds as a growing search tree \(\mathcal{T}\):
\[\mathcal{T} = { z_{1:t} \mid z_{1:t-1} \in \mathcal{T},\ z_t \in \text{Expand}(z_{1:t-1}) }\]- where the Expand step is guided by the LLM’s conditional distribution \(p_\theta(z_t \mid z_{1:t-1}, x)\), and the evaluation function \(V_\phi(z_{1:t})\) estimates how promising each partial reasoning sequence is.
-
MCTS then uses simulated rollouts—partial reasoning trajectories extended to completion—to estimate downstream rewards, which are backpropagated through the tree to update value and visit counts. The algorithm repeatedly selects nodes using an upper-confidence bound (UCB) criterion that trades off exploration and exploitation:
\[a^* = \arg\max_a \left( Q(s, a) + c \sqrt{\frac{\log N(s)}{N(s, a) + 1}} \right)\]- where \(Q(s, a)\) is the average reward for taking reasoning step \(a\) in state \(s\), \(N(s, a)\) the number of visits, and \(c\) a temperature constant controlling exploration.
-
This process continues until reasoning trajectories reach terminal states—complete solutions \(y\)—and the highest-valued trace or ensemble of top traces is selected as the model’s output.
Mechanism
-
Selection: From the root node, traverse the tree by selecting the child that maximizes the UCB criterion, balancing high-value and underexplored reasoning branches.
-
Expansion: When an underexplored node is reached, the model generates several possible next reasoning steps \(z_t^{(1)}, z_t^{(2)}, \ldots, z_t^{(b)} \sim p_\theta(z_t \mid z_{1:t-1}, x)\), forming new branches for exploration.
-
Simulation (Rollout): The model continues reasoning (deterministically or stochastically) until reaching a terminal output \(y\), producing a full reasoning chain \(z_{1:T}\).
-
Evaluation: The resulting trace is scored via a value estimator \(V_\phi(z_{1:T})\) or a domain-specific verifier (e.g., math correctness, code execution success).
-
Backpropagation: The value score is propagated upward, updating \(Q(s, a)\) and visit counts \(N(s, a)\) along the path, gradually refining the search policy.
-
Selection of Final Output: After sufficient iterations, the reasoning path with the highest cumulative value (or visit count) is chosen as the final answer.
Theoretical Framing
-
MCTS-based reasoning can be interpreted as an approximate Bayesian inference mechanism, marginalizing over reasoning paths by repeated stochastic sampling and value-based weighting. It formalizes reasoning as a policy–value system:
\[z_{t+1} \sim \pi_\theta(z_t \mid z_{1:t}, x), \quad V_\phi(z_{1:t}) \approx \mathbb{E}[R \mid z_{1:t}]\]- where \(\pi_\theta\) is the reasoning policy and \(V_\phi\) the expected reward estimator.
-
This structure directly parallels AlphaZero-style planning in RL: reasoning steps are “moves,” the value function measures progress toward correctness, and search iterations improve reasoning through self-guided exploration.
Example: Mathematical Problem Solving
-
Consider a geometry proof question. A linear CoT might pursue a single argument, but an MCTS-based reasoner could simulate multiple reasoning directions:
- Branch A: Attempt to derive relations via similar triangles.
- Branch B: Substitute coordinates and apply algebraic constraints.
- Branch C: Explore symmetry arguments for simplification.
-
Each branch is evaluated through rollouts—checking consistency or partial correctness—and promising directions are expanded further, while unproductive branches are pruned. Over multiple iterations, the search converges on the most coherent reasoning trace, yielding deliberate and explainable reasoning rather than heuristic guessing.
Variants and Extensions
- LLM-MCTS (Yao et al. (2024)): Combines MCTS with Tree-of-Thought reasoning, using the LLM both for expansion and value estimation.
- Verifier-Guided MCTS: Integrates external verifiers to provide precise reward signals at rollout, improving pruning accuracy.
- Value-Guided MCTS: Employs a trained value model \(V_\phi\) (similar to process reward models) to estimate reasoning quality before rollout.
- Hybrid Planning Frameworks: Combine symbolic planners (A*, BFS) with MCTS exploration to scale reasoning in code, logic, or multi-agent environments.
Advantages
- Balances exploration and exploitation, avoiding premature convergence.
- Can discover nonlinear, multi-path reasoning solutions.
- Scales naturally to complex reasoning where evaluating partial progress is feasible.
- Compatible with verifier-guided or reward-shaped supervision, enabling hybrid reasoning pipelines.
Limitations
- High computational cost: repeated rollouts and evaluations are expensive.
- Value-model sensitivity: incorrect scoring can misdirect exploration.
- Context window saturation: maintaining multiple partial traces taxes memory.
- Diminishing returns: excessive exploration may not improve accuracy proportionally.
Relationship to Other Reasoning Methods
- MCTS generalizes Tree-of-Thoughts (ToT) by adding quantitative evaluation and stochastic rollouts, bridging symbolic search and probabilistic reasoning.
- It operationalizes planning in reasoning space, complementing RL-based reasoning (which learns heuristics) and Self-Consistency decoding (which averages independent samples rather than guided rollouts).
- Conceptually, MCTS moves LLM reasoning closer to explicit deliberation and decision-making, marking a key step from narrative reasoning toward search-based intelligence.
Tool-Augmented Reasoning
-
Tool-Augmented Reasoning extends an LLM’s capabilities beyond internal text-based inference by integrating external computational and retrieval tools into its reasoning process. Rather than relying solely on its learned parameters, a tool-augmented model can decide when to think and when to act—delegating parts of the reasoning process to verifiable, executable systems such as Python interpreters, search engines, databases, or APIs.
-
This paradigm effectively transforms an LLM into a reasoning orchestrator, coordinating multiple symbolic or functional modules to perform grounded, verifiable, and compositional reasoning. The LLM maintains the high-level reasoning flow in natural language but defers specific sub-tasks—such as numerical calculation, factual lookup, or logical evaluation—to specialized external systems.
-
The formalism for tool-augmented reasoning can be expressed as a hybrid reasoning policy:
\[\pi_\theta(a_t \mid s_t) = \begin{cases} \text{generate reasoning step } z_t, & \text{if } a_t = \text{think}, \\ \text{invoke tool } \mathcal{T}_i(s_t), & \text{if } a_t = \text{act} \end{cases}\]- where \(s_t\) is the current reasoning state, and \(\mathcal{T}_i\) denotes a callable external tool.
-
This formulation underpins several reasoning systems that merge symbolic and neural components, including ReAct (Yao et al. (2022)), Toolformer (Schick et al. (2023)), PAL (Gao et al. (2022)), and Gorilla (Patil et al. (2023)). Together, these systems exemplify the shift from static reasoning models toward interactive and compositional reasoning frameworks that can interface with the external world.
ReAct: Reason and Act Framework
Core Idea
-
ReAct (Reason + Act) introduces a structured reasoning framework in which language models interleave internal reasoning (“thoughts”) with external actions (“acts”). Rather than producing a single reasoning chain internally, the model alternates between cognitive reasoning steps and environment interactions, enabling active exploration, retrieval, and verification.
-
This concept was formalized in ReAct: Synergizing Reasoning and Acting in Language Models by Yao et al. (2022), where an LLM engages in iterative cycles of thinking, acting, and observing, following the trajectory:
- Each thought is an internal deliberation; each action interacts with an external environment (e.g., a search query or calculator call); and each observation provides feedback that informs the next reasoning step.
Mechanism
- Prompt Structure:
- The model is trained or prompted to alternate explicitly between “Thought:” and “Action:” stages.
- Example:
Thought: I should verify this fact. Action: search("When was the Theory of Relativity proposed?") Observation: 1905. Thought: That confirms Einstein’s 1905 paper. - Execution and Feedback:
- Each “Action” triggers a system-level call (search, API, or computation). The resulting observation is appended to the prompt context, grounding the model’s next reasoning step.
- Iterative Reasoning Loop:
-
This continues until the model converges on a final conclusion or the task’s stopping condition is met.
-
Formally, the reasoning trajectory is:
\[\tau = (x, {(t_i, a_i, o_i)}_{i=1}^T, y)\]- where \(t_i\) are reasoning traces, \(a_i\) are actions, and \(o_i\) are observations.
-
Theoretical Framing
-
ReAct operationalizes reasoning as a policy over both thoughts and actions:
\[\pi_\theta(t_i, a_i \mid s_i)\]- where \(s_i\) is the model’s current state (context + prior outputs).
-
This allows the model to perform goal-directed reasoning, selectively gathering new information, evaluating results, and iteratively refining its understanding—essentially turning passive inference into interactive cognition.
Advantages
- Enables active information acquisition, reducing dependence on memorized knowledge.
- Produces interpretable reasoning traces with explicit thought–action–observation sequences.
- Scales naturally to multi-step, real-world tasks involving dynamic environments.
Limitations
- Requires reliable execution infrastructure for handling tool calls and feedback.
- Susceptible to looping behaviors if not properly constrained.
- Context windows can become crowded with intermediate observations.
Extensions
- Reflexion (Shinn et al. (2023)): Adds self-evaluation and verbal RL to the ReAct cycle.
- AutoGPT / LangChain Agents (2023–2024): Build upon ReAct’s iterative structure to enable multi-step autonomous task execution and planning.
Toolformer and Self-Supervised Tool Learning
Core Idea
-
Toolformer: Language Models Can Teach Themselves to Use Tools by Schick et al. (2023) introduced a paradigm shift in self-supervised tool-augmented reasoning, where the model autonomously learns when and how to call external tools—without explicit supervision or hand-crafted prompts. Unlike ReAct, which depends on prompting and external orchestration, Toolformer integrates tool usage directly into the model’s generative policy, turning tool invocation into a learned reasoning behavior rather than a manually structured loop.
-
The central insight of Toolformer is that language models can self-label their own tool-use data: by inserting API calls into text and evaluating whether the resulting completion improves likelihood under the model’s own distribution. Through this mechanism, the model discovers not just how to use a tool, but when its invocation enhances reasoning performance.
-
This process transforms the model from a passive generator into an autonomous reasoning-controller that dynamically invokes external functions as part of its internal reasoning process.
Mechanism
- Candidate Tool Identification:
- The model is exposed to a set of tools—e.g., calculator, Wikipedia search, translation API, or question-answering module.
- Self-Supervised Data Generation:
- Toolformer uses the base LLM to generate potential API calls within text (e.g.,
call("calculate(3*7)")) and then evaluates whether including the resulting API output improves the log-likelihood of the original completion.
- Toolformer uses the base LLM to generate potential API calls within text (e.g.,
- Filtering and Fine-Tuning:
- Only API calls that improve model likelihood are retained. The model is then fine-tuned on these augmented examples, learning to integrate tools naturally during inference.
- Inference-Time Behavior:
-
During generation, the model autonomously decides when to invoke a tool. Tool outputs are inserted inline and directly influence subsequent reasoning steps.
-
Formally, the tool-augmented generation process is modeled as:
\[p(y|x) = \sum_{\mathcal{T}} p_\theta(y, \mathcal{T}(x))\]- where the model implicitly marginalizes over possible tool calls \(\mathcal{T}\) to produce the most likely reasoning continuation.
-
Theoretical Framing
-
Toolformer operationalizes compositional reasoning through differentiable decision-making over discrete actions (tool invocations). Each tool call acts as a functional composition step within the model’s reasoning trace, turning the sequence generation process into a form of neurosymbolic program synthesis.
-
By learning tool invocation autonomously, Toolformer bridges the gap between in-context reasoning and procedural reasoning, internalizing the interface between language and computation.
Representative Systems
- Toolformer (Schick et al. (2023)): The foundational framework for self-supervised tool usage across multiple APIs.
- PAL (Program-Aided Language Models) (Gao et al. (2022)): Delegates structured reasoning to Python execution, using LLMs to generate executable programs rather than answers directly.
- Gorilla (Patil et al. (2023)): Extends the concept to large-scale API access, enabling natural-language-to-API mapping for thousands of real-world endpoints.
- LLM-Augmented Reasoning (LLM-AR) (Paranjape et al. (2023)): Integrates tool selection and programmatic reasoning within retrieval-augmented inference pipelines.
- ToolBench (Huang et al. (2023)): Provides a benchmark for evaluating tool-use generalization and the efficiency of learned tool invocation.
Advantages
- Autonomous learning: No human annotation required for tool-use examples.
- Improved factuality: External tools provide non-parametric computation and verifiable results.
- Composable reasoning: Tool invocation integrates seamlessly into text generation.
- Scalable: Supports continual integration of new tools through additional fine-tuning on newly self-labeled tool-use data, without modifying the model’s architecture.
Limitations
- Requires reliable APIs and error-tolerant execution infrastructure.
- Self-supervised signal can bias toward frequent or high-likelihood calls, underusing rare but useful tools.
- Tool call latency and context-length constraints can affect real-time reasoning.
Relationship to ReAct and RL
- While ReAct structures reasoning via explicit prompts and environment interaction, Toolformer internalizes the decision to use tools via training-time self-supervision.
- RL methods, such as DeepSeek-R1, can complement Toolformer by learning optimal tool invocation policies via reward feedback rather than likelihood improvement.
Reinforcement Learning-Based Reasoning
- RL approaches frame reasoning as policy optimization over reasoning trajectories. The model learns to generate structured, verifiable chains that maximize explicit or implicit rewards.
- RL for reasoning treats reasoning as a goal-directed policy optimization problem, where the model learns to produce multi-step reasoning traces that maximize a task-specific reward. Rather than relying only on imitation of reasoning traces (as in supervised fine-tuning or CoT), this approach uses reward signals—explicit or implicit—to guide models toward useful intermediate reasoning behaviors.
- Emerging agentic reasoning paradigms extend this RL framing to encompass tool-integrated, interactive, and judgmental reasoning. Recent systems such as ToRL, ReTool, and SimpleTIR demonstrate how reinforcement learning enables LLMs to act as autonomous agents that reason through iterative tool use—executing, verifying, and refining their own outputs via external environments (e.g., code interpreters or search engines). This tool-integrated reasoning (TIR) broadens the feasible reasoning space beyond text-only models by breaking the “invisible leash” that constrains standard RL within the model’s pretraining distribution, as formally analyzed in Understanding Tool-Integrated Reasoning. Furthermore, reinforcement-trained reasoning extends beyond task-solving to include LLM-as-judge and reward-model architectures, where models evaluate or shape reasoning quality through learned, hierarchical feedback loops—constituting early forms of reasoning beyond general-purpose LLMs.
WebGPT
- The paper WebGPT: Browser-assisted Question-answering with Human Feedback by Nakano et al. (2021) represents one of the earliest large-scale implementations of reinforcement learning from human feedback (RLHF) for reasoning. It extends LLMs beyond static text reasoning by introducing a controlled web-browsing interface, enabling them to search, navigate, and cite external information sources while answering questions.
- By combining human preference modeling with interactive tool use, WebGPT laid the foundation for verifiable, tool-augmented reasoning systems.
Core Idea
- WebGPT extends the RL-style reasoning paradigm by equipping an LLM with a controlled web-browser interface: the model can query, click, scroll, and quote webpages in a simulated browsing environment (OpenAI).
- It then uses human feedback (via a reward model trained on pairwise comparisons) to select its best answers. In this way, the model’s reasoning trajectories include external information retrieval and verification steps, making reasoning more grounded and verifiable.
Mechanism
- The model begins with imitation learning (behavior cloning) on human browsing demonstrations, learning to execute search \(\rightarrow\) navigate \(\rightarrow\) quote chains.
- Next, a separate reward model is trained to predict human preference among answer–reference pairs. Answers are harvested via browsing and then compared.
- Finally, the policy is refined via rejection sampling (and optionally RL) with respect to that reward model: the top-ranked answers by the reward model are selected.
-
Browsing environment: At each time step \(t\) the model is given browser state \(s_t\), chooses an action \(a_t \in {\text{Search}, \text{Click}, \text{Scroll}, \text{Quote}}\), and obtains the next state \(s_{t+1}\). After \(T\) steps, it produces answer \(y\) with supporting references \(z\). The reward model assigns \(R(y,z)\). The training objective is to increase the probability of trajectories leading to high \(R\).
\[\mathcal{J}(\theta) = \mathbb{E}_{(x, (z,y) \sim \pi \theta(\cdot|x))} [R(y,z)]\]- where \(x\) is the question and \(z\) is the set of quoted references.
- Use of citations: The model is required to produce citations so that humans can verify factual accuracy.
- The following figure (source) shows the text-based browsing interface used in WebGPT, where a language model interacts with the environment via commands such as “search,” “scroll,” or “quote” to collect references during question answering.
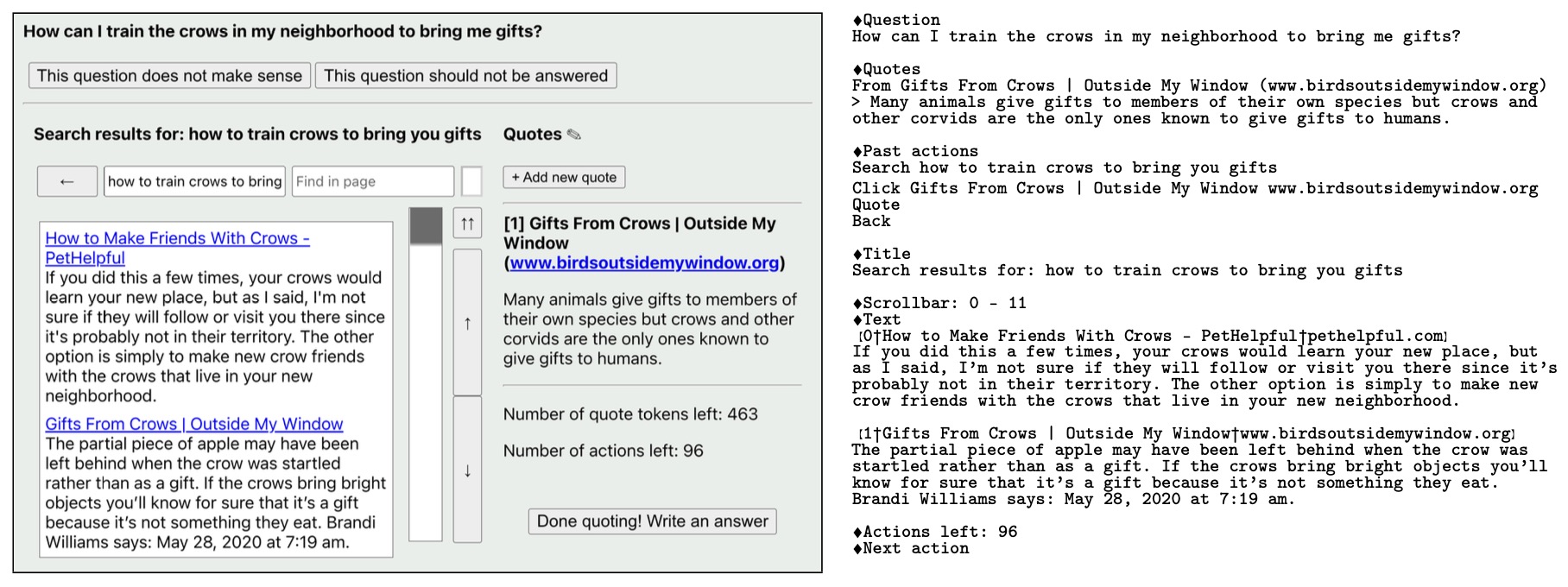
Implementation Details
- The base model is a fine-tuned version of GPT-3 (various sizes).
- Demonstration dataset: approximately 6K human browsing demonstrations collected via the browsing interface.
- Pairwise comparisons: approximately 21.5K human preference labels comparing two model‐generated answers (with references) to train the reward model.
- The browsing actions are limited to a text-browser interface (e.g., using the Bing Web Search API) to avoid full web access risks.
- In evaluation, the best model’s answers were preferred 56 % of the time to human demonstrators and 69 % of the time to the highest-voted Reddit answer on the ELI5 dataset.
Significance for RL-Based Reasoning
-
WebGPT advances RL-based reasoning in several ways:
- It moves beyond static, text-only reasoning chains to include interactive retrieval and verification, thus more closely approximating real-world reasoning.
- It operationalizes the notion of verifiable reasoning trajectories by requiring citations and human-preferenced ranking.
- It shows that LLMs can improve reasoning (in this case long-form QA) via reward-driven optimization of interactive reasoning policies, not just via next-token prediction.
Limitations and Considerations
- The browsing environment is constrained (text‐only, limited actions) and may still not fully capture open-web complexity.
- The reward model remains human-preference based and can inherit biases or noise.
- Credit assignment across long browsing trajectories remains challenging (a general RL-reasoning issue).
- Scalability: Collecting demonstrations and preference data is expensive; deployment in open domains still faces reliability issues.
DeepSeek-R1
- The most prominent example of RL for reasoning is DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning by Guo et al. (2025).
Core Idea
-
DeepSeek-R1 applies RL to improve reasoning performance without supervised rationales. The model learns to generate intermediate steps that lead to verifiably correct outcomes, using a reinforcement signal that rewards correct or efficient reasoning trajectories.
-
Formally, for a given problem \(x\), reasoning trace \(z\), and final answer \(y\),
\(R(y, z) = \mathbb{I}[\text{correct}(y)] - \lambda , \text{cost}\)z\(\)
- … and the objective is to maximize the expected reward:
- The model parameters are updated using RL methods such as policy gradient or Proximal Policy Optimization (PPO), as used in RLHF by Christiano et al. (2017) and its language-model applications in InstructGPT by Ouyang et al. (2022).
Mechanism
- Base model:
- Start with a pretrained LLM capable of multi-step reasoning (e.g., instruction-tuned).
-
Reward design:
- Outcome-based rewards: correctness of final answer.
- Process-based rewards: alignment with logical or stylistic reasoning norms.
- Efficiency penalties: shorter, more coherent chains get higher reward.
- Policy optimization:
- Update the model parameters \(\theta\) to maximize expected reward using policy-gradient methods.
-
The gradient estimate is:
\[\nabla_\theta \mathcal{J}(\theta) = \mathbb{E}[(R - b)\nabla_\theta \log p_\theta(y,z|x)]\]- where \(b\) is a baseline to reduce variance.
- Iterative refinement: Feedback from reward models, verification models, or external evaluators is used to shape the model’s reasoning distribution.
DeepSeek-R1 Highlights
- No human-annotated rationales: The system learns reasoning emergently through reward shaping.
- Curriculum design: Rewards evolve from simple tasks (e.g., arithmetic) to complex reasoning (e.g., proofs, logical deduction).
- Outcome: Demonstrated significant improvements on mathematical and logic benchmarks, outperforming supervised CoT-trained baselines.
Theoretical Framing
- Reasoning is formalized as sequential decision-making with hidden intermediate states:
- The RL agent (the LLM) learns to compose “thoughts” that maximize expected cumulative reward, rather than likelihood of training text. This bridges text prediction and deliberate reasoning via credit assignment.
Advantages
- Encourages reasoning structures that generalize beyond training distributions.
- Does not require labeled step-by-step data.
- Enables automated self-improvement through reward feedback.
Limitations
- Reward specification is delicate—poorly designed rewards can lead to reasoning shortcuts or gaming behavior.
- High computational cost due to exploration and rollouts.
- Credit assignment remains challenging for long reasoning chains.
Related Work
- Reflexion by Shinn et al. (2023): integrates self-reflective RL to iteratively improve reasoning quality.
- Constitutional AI by Bai et al. (2022): replaces human feedback with rule-based evaluators to align reasoning.
- Tool-Augmented RLHF by Nakano et al. (2021): incorporates tool usage (e.g., code execution) into reward computation.
- In summary, RL-based reasoning represents a shift from pattern completion to goal-directed optimization, allowing models to discover reasoning patterns that are not explicitly demonstrated in the data.
DeepSeek-R1: Practical takeaways and design patterns
-
DeepSeek-R1 reframed “reasoning” as a policy-optimization problem: start from a capable base model, define reward signals that prefer verifiable reasoning, and use RL to shape the latent steps \(z\) so that correct, readable chains become high-probability trajectories. The core lesson is operational: if you can score intermediate or final products reliably, you can push an LLM from pattern completion toward deliberate computation. For context on the method and results, see DeepSeek-R1 by Guo et al. (2025).
-
What DeepSeek-R1 actually optimizes:
-
At a high level, R1 maximizes expected reward over sampled chains:
\[\mathcal{J}(\theta)=\mathbb{E}_{x\sim\mathcal{D},z,y\sim p_\theta(\cdot\mid x)}\big[R(y,z)\big]\]-
where \(R\) blends correctness checks (exact answer, executable solver success), parsimony/format constraints, and sometimes readability penalties. In practice, implementations report variants of PPO/GRPO–style policy gradients:
\[\nabla_\theta\mathcal{J}(\theta)\approx \mathbb{E}\big[(R-b),\nabla_\theta\log p_\theta(y,z\mid x)\big]\]- … with a baseline \(b\) for variance reduction. R1 also uses staged training (e.g., cold-start data before RL) to stabilize exploration and improve “readability” of chains. See the paper for the multi-stage schedule and comparisons to o1-style models.
-
-
-
Why process supervision still matters:
- Even when you train only on outcome rewards, a verified step signal improves stability and sample efficiency. A practical alternative or complement is process reward modeling (PRM): label or auto-label whether each step is correct, then reward step sequences. This was shown to beat outcome-only supervision on MATH in Let’s Verify Step by Step by Lightman et al. (2023) and the accompanying OpenAI report by OpenAI (2023).
-
A minimal R1-style recipe you can reproduce:
- Collect tasks with verifiable end states (GSM8K, AIME, MATH). Build an automatic checker \(V\) that returns 1 when answers or traces pass.
- Train a small verifier or PRM if you can: \(V(z_t)\in[0,1]\) for each step. Use it either as reward shaping \(\sum_t V(z_t)\) or as a filter at decode time.
- Warm-start with supervised or distilled rationales to avoid unreadable chains; then switch to RL for exploration.
- Optimize a composite reward \(R=\lambda_1\text{Correct}(y)+\lambda_2\sum_{t}\text{StepOK}(z_t)-\lambda_3\text{Length}(z)-\lambda_4\text{FormatViolations}(z)\), tuning \(\lambda_i\) for your domain.
- During inference, marginalize over latent thoughts with a small self-consistency budget \(K\) and pick via verifier-guided selection—per Self-Consistency by Wang et al. (2022).
-
Design patterns that travel well beyond R1:
-
Reward the thing you can check: If you can compile problems to executable checks, outcome-only RL is often enough to induce useful structure; add PRM when you need reliability. Evidence: process supervision consistently outperforms outcome supervision on math reasoning.
-
Stage your training: Short supervised warm-ups (few curated traces) can prevent RL from converging on unreadable or language-mixed chains before formatting penalties kick in. DeepSeek-R1 explicitly reports multi-stage training to address readability and stability.
-
Keep decoding and training consistent: If you will use verifier-guided selection at inference, train with that verifier “in the loop” (e.g., as a reward or rejection sampler) to reduce train–test mismatch.
-
Prefer execution and tools over narration where possible: Program-aided solving (e.g., Python) shrinks the search space and makes rewards less noisy; combine with ReAct-style tool calls when tasks need retrieval or computation, as in ReAct by Yao et al. (2022).
-
Budget your “thinking.: Use a small \(K\) for self-consistency, then select with \(V\). You approximate \(\hat{y}=\arg\max_y \sum_{k=1}^{K}\mathbb{I} \big[y^{(k)}=y\big]\), without exploding cost—again following Wang et al. (2022).
-
-
Operational pitfalls and guardrails:
-
Reward hacking and shortcutting: If the checker can be gamed (format cues, guessable ranges), the policy will exploit it. Rotate perturbations and adversarial seeds; log chains alongside rewards. DeepSeek-R1 notes emergent but sometimes messy behaviors under pure RL.
-
Over-deliberation and cost blow-ups: RL-trained reasoners may produce unnecessarily long chains. Penalize chain length and add early-stop verifiers; at inference, cap steps and prune with a threshold on \(V\).
-
Verification bottlenecks: Human step labels do not scale. Borrow from PRM800K and template-based auto-labeling when feasible, and fall back to outcome-only rewards with strong executors; see Lightman et al. (2023).
-
-
Where R1 fits in the broader landscape:
- R1-style RL sits between explicit prompting methods (CoT, self-consistency) and full agentic loops (ReAct/tools). It supplies a training-time force that makes those inference-time interfaces work more reliably: prompts elicit better chains, verifiers select more often-correct ones, and tools ground intermediate steps. That combination—policy shaping + marginalization + verification—is, to date, the most reliable way to turn text generators into auditable reasoners. For the primary R1 paper, see Guo et al. (2025); for process supervision foundations, see Lightman et al. (2023) and OpenAI’s report by OpenAI (2023).
Reinforcement Learning for Tool-Integrated Reasoning
- Tool-Integrated Reasoning (TIR) marks a paradigm shift in how LLMs perform complex reasoning tasks. Instead of relying solely on text-based inference, TIR enables models to invoke external tools—such as code interpreters, APIs, databases, or symbolic solvers—within their reasoning trajectories.
-
Through this mechanism, models alternate between linguistic reasoning and computational execution, forming a hybrid cognitive process that grounds natural language thought in verifiable computation. Formally, a TIR process can be expressed as:
\[s_t = {r_1, c_1, o_1, \ldots, r_t, c_t, o_t},\]- where \(r_t\) is a reasoning step, \(c_t\) a tool command, and \(o_t = I(c_t)\) the corresponding output from an interpreter \(I\).
-
This framework establishes a closed loop of reason → act → verify, significantly reducing hallucination and enabling models to achieve self-correction through external validation.
-
- Tool-Integrated Reinforcement Learning (TIRL) extends this paradigm by introducing reinforcement learning (RL) into the TIR loop. In TIRL, models are not merely taught to use tools—they learn when and how to use them optimally through trial, feedback, and reward.
-
The integration of RL allows the model to optimize over both symbolic actions (tool invocations) and linguistic reasoning steps, guided by reward functions that capture correctness, efficiency, and interpretability:
\[J(\theta) = \mathbb{E}_{\pi_\theta} \left[\sum_{t=0}^{T} \gamma^t r(s_t, a_t, o_t)\right]\]- where the policy \(\pi_\theta(a_t \mid s_t)\) produces both reasoning and tool actions.
-
This combination yields models capable of adaptive computation—deciding dynamically whether to reason internally or delegate computation externally for optimal task success.
-
-
This section surveys three recent and complementary frameworks that embody the TIRL paradigm:
- ToRL by Li et al. (2025): introduces Tool-Oriented Reinforcement Learning for code-augmented mathematical reasoning, coupling RL with symbolic execution for error correction and precision.
- ReTool by Feng et al. (2025): establishes a two-phase RL pipeline where LLMs interleave reasoning with real-time code execution, optimizing outcome-based rewards for verifiable solutions.
- TIR-Judge by Xu et al. (2025): extends the TIRL concept to evaluation agents, training LLM-based judges that reason, execute verification code, and learn reward functions for truthful, consistent assessment.
- Together, TIR and TIRL form the backbone of next-generation agentic intelligence—where reasoning is no longer passive text generation, but an interactive, executable, and self-optimizing process grounded in real-world feedback.
Tool-Integrated Reinforcement Learning (ToRL)
-
The Tool-Integrated Reinforcement Learning (ToRL) framework by Li et al. (2025) directly scales reinforcement learning from base models—without supervised fine-tuning—to autonomously acquire computational tool usage.
-
Unlike earlier Tool-Integrated Reasoning (TIR) approaches such as MathCoder by Wang et al. (2023) or ToRA by Gou et al. (2023), ToRL does not rely on distilled tool trajectories. Instead, the model learns tool strategies through reward-driven exploration from scratch.
Core Idea
-
ToRL enables unrestricted RL exploration with embedded interpreters (e.g., Python) for solving mathematical reasoning problems. Through repeated interaction between analytical reasoning and code execution, the model learns to balance symbolic reasoning with computational accuracy.
-
ToRL employs GRPO, setting the rollout batch size to 128 and generating 16 samples per problem.
-
In ToRL, this formulation allows the model to optimize end-to-end tool-use behavior purely through reinforcement signals, without explicit imitation of tool trajectories. It further supports exploration-driven learning, where even incorrect executions can contribute useful gradient signals toward improving reasoning-tool coordination.
-
The following figure (source) shows an example of CoT and TIR solution of the problem. TIR enables the model to write code and call an interpreter to obtain the output of the executed code, and then perform further reasoning based on the execution results.

Dataset and Training Pipeline
- ToRL constructs a 28k-instance dataset from MATH, NuminaMATH, and DeepScaleR, filtering for verifiable numerical tasks and excluding open-ended proofs.
- Training is performed directly on Qwen2.5-Math base models (1.5B, 7B), without prior fine-tuning. The RL loop enables exploration of tool-use trajectories, guided solely by outcome-based rewards.
Emergent Behaviors
-
ToRL demonstrates several self-organizing cognitive behaviors:
- Code usage evolution: the share of tasks solved via code rises as RL progresses.
- Self-regulation: the model autonomously detects and avoids ineffective code patterns.
- Analytical–computational adaptation: dynamically alternates between symbolic reasoning and code execution.
-
These capabilities emerge without explicit demonstrations—driven purely by reward feedback.
Results
- ToRL-7B achieves 43.3% accuracy on AIME24—surpassing RL baselines by 14% and SFT-based tool models by 17%.
Significance
- ToRL pioneers tool integration in large-scale RL from scratch, showing that emergent metacognitive capabilities (reflection, verification) can arise naturally from outcome-based training, bridging analytical and computational reasoning.
Reinforcement Learning for Strategic Tool Use (ReTool)
- ReTool by Feng et al. (2025) extends the RL paradigm by explicitly embedding tool execution into the rollout process. It introduces an interleaved reasoning and code execution framework for dynamic tool invocation and reflection.
Overview
-
ReTool is designed around two phases:
- Cold-start Supervised Fine-Tuning (SFT): constructing synthetic “code-augmented reasoning” traces using dual-verification pipelines.
- Reinforcement Learning (RL): refining the model’s policy to discover optimal tool-use strategies through outcome-based reward optimization.
Methodology
-
ReTool’s training integrates real-time code interpreter feedback within the PPO objective:
\[J_{PPO}(\theta) = \mathbb{E}_{(q,a) \sim D} \left[ \min \left( \frac{\pi_\theta(o_t | q, o_{<t}; CI)}{\pi_{\theta_{\text{old}}}(o_t | q, o_{<t}; CI)} \hat{A}_t, \text{clip}\left(\frac{\pi_\theta}{\pi_{\theta_{\text{old}}}}, 1-\epsilon, 1+\epsilon\right)\hat{A}_t \right) \right]\]-
where:
- \(\pi_\theta(o_t \mid q, o_{<t}; CI)\) denotes the policy model conditioned on the code interpreter (CI) state, which dynamically integrates executable code feedback during reasoning rollouts.
- \(\pi_{\theta_{\text{old}}}\) is the reference (behavior) policy from the previous iteration, used for importance sampling to stabilize learning.
- \(\hat{A}_t\) is the advantage estimate, representing how much better an action performed compared to the baseline at time step \(t\).
- \(\epsilon\) is a clipping parameter that limits policy updates to prevent destructive policy shifts (as introduced in Proximal Policy Optimization by Schulman et al. (2017)).
- The min operator enforces conservative updates by taking the smaller of the unclipped and clipped surrogate objectives.
- The expectation \(\mathbb{E}_{(q,a) \sim D}\) is taken over sampled question–answer pairs from the training dataset \(D\), reflecting the model’s distribution of reasoning trajectories.
- The conditioning on CI allows real-time interpreter feedback to influence token-level decision probabilities, enabling the model to learn when and how to invoke code execution within multi-turn reasoning rollouts.
-
-
The reward function is outcome-driven. It helps the model autonomously learn when and how to invoke tools through outcome-based reinforcement without human priors. It is expressed as:
\[R(a, \hat{a}) = \begin{cases} 1 & \text{if } a = \hat{a}, \\ -1 & \text{otherwise} \end{cases}\]-
Where:
- \(a\) denotes the predicted answer produced by the policy model.
- \(\hat{a}\) represents the ground-truth or reference answer derived from the supervised dataset or external evaluation function.
- A reward of 1 indicates that the model’s predicted outcome matches the correct solution, signifying successful reasoning or problem-solving.
- A reward of -1 penalizes incorrect outcomes, incentivizing the model to refine tool invocation and reasoning strategies during training.
- This rule-based accuracy reward is used in ReTool: Reinforcement Learning for Strategic Tool Use in LLMs by Feng et al. (2025)
-
This design minimizes reward hacking and fosters exploration diversity.
-
-
The following figure (source) shows text-based RL training process and ReTool’s RL training process.
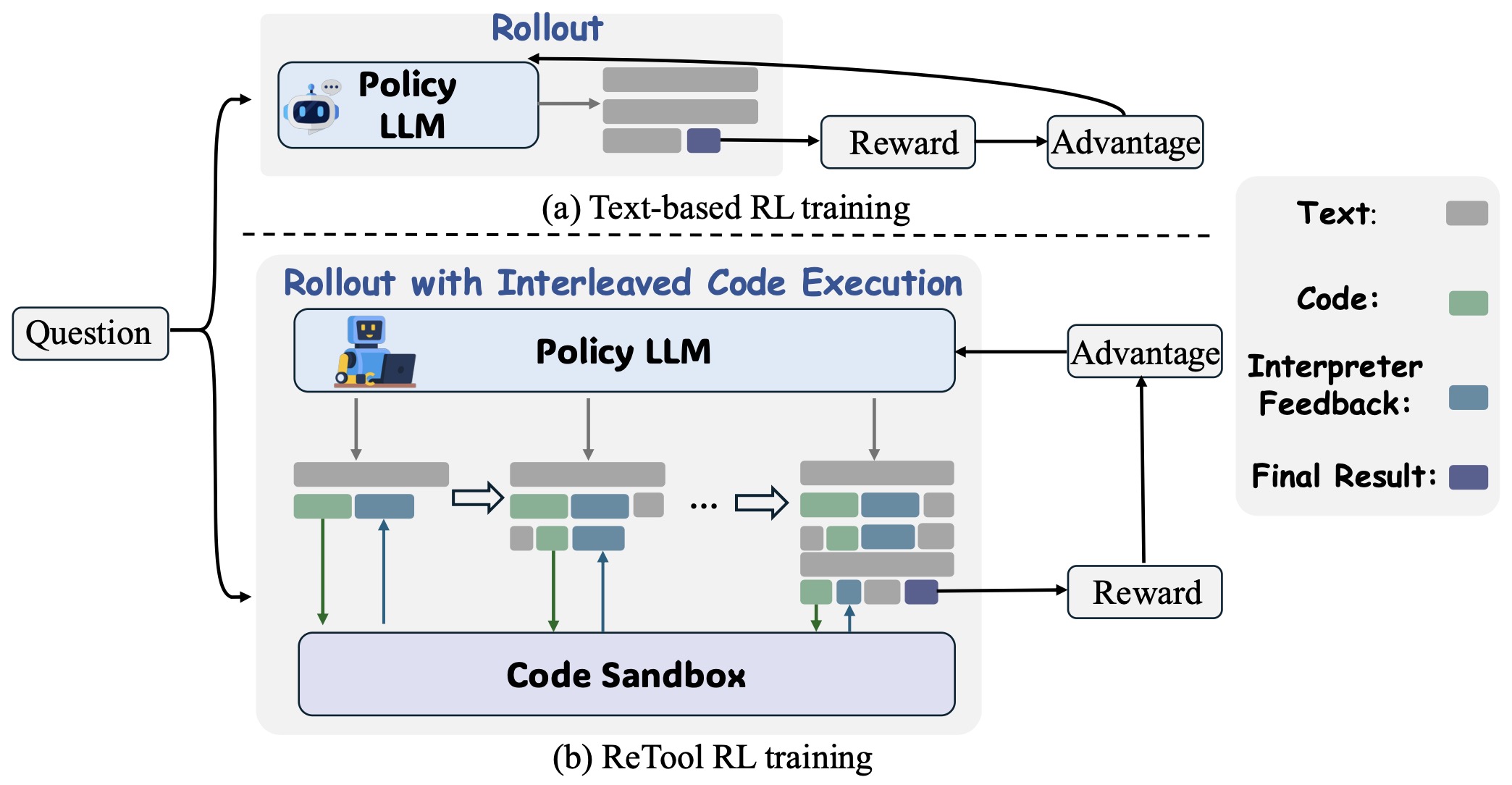
Emergent Behaviors
-
ReTool exhibits strategic learning of code usage, such as:
- Adaptive timing of tool invocation.
- Code self-correction—detecting and repairing tool errors mid-reasoning.
- Efficiency emergence, with response lengths reduced by ~40% after training.
Results
- ReTool-32B achieves 67% accuracy on AIME2024 in just 400 training steps—outperforming text-only RL baselines (40% at 1080 steps) and surpassing OpenAI’s o1-preview by 27.9%.
Impact
- ReTool establishes that dynamic interleaving of reasoning and code execution during RL leads to emergent meta-reasoning and adaptive tool use—key traits for future agentic reasoning systems.
Tool-Integrated Reinforcement Learning for LLM Judges (TIR-Judge)
- TIR-Judge by Xu et al. (2025) extends tool-augmented RL beyond reasoning tasks to evaluation and alignment. It trains LLM-based judges that can autonomously verify, compute, and reason during the evaluation of model responses.
Concept and Framework
-
TIR-Judge builds an RL pipeline for agentic evaluators, allowing LLM judges to:
- Generate natural-language reasoning.
- Produce code snippets for verification.
- Execute them within a sandbox.
- Incorporate results into final judgment.
-
Each judgment trajectory is represented as:
\[s_k = {r_1, c_1, o_1, \dots, r_k, c_k, o_k}\]- where \(r_i\) is the reasoning step, \(c_i\) the generated code, and \(o_i = I(c_i)\) the interpreter output.
Training
-
TIR-Judge employs an iterative RL pipeline combining pairwise, pointwise, and listwise judgments—spanning both verifiable (math, code) and non-verifiable (dialogue, safety) domains.
-
Two variants are explored:
- TIR-Judge-Distill, which uses small distillation-based initialization.
- TIR-Judge-Zero, trained purely via RL without any distillation data. Here is your text with added citations:
-
TIR-Judge adopts Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO) (an improved variant of GRPO) for training the LLM judge \(J\) parameterized by \(\pi_\theta\). Given a prompt-answer pair \((q, a)\), they first sample a group of \(G\) rollouts \({s_i}_{i=1}^G)\) from the current policy \(\pi_{\theta_{\text{old}}})\). Each rollout \(s_i\) is assigned a scalar reward \(R_i = R(s_i, a)\) with access to the oracle answer \(a\). The policy \(\pi_\theta\) is then updated with the following clipped policy gradient objective:
\[\mathcal J(\theta) = \mathbb E_{(q,a)\sim \mathcal D,{s_i}_{i=1}^G\sim\pi_{\theta_{\text{old}}}(\cdot\mid q)}\Bigg[\frac1{\sum_{i=1}^G |s_i|} \sum_{i=1}^G \sum_{t=1}^{|s_i|} \Big(\min\big(r_{i,t}(\theta),\widehat A_{i,t},\mathrm{clip}(r_{i,t}(\theta),1-\varepsilon_{\text{low}},1+\varepsilon_{\text{high}}),\widehat A_{i,t}\big)\\ -\beta D_{\rm KL}\big(\pi_\theta ,\Vert, \pi_{\rm ref}\big)\Big)\Bigg]\\ \quad\text{s.t. }0<\mid{s_i:\text{is_equivalent}(a,s_i)}\mid<G\]- where:
- \(r_{i,t}(\theta) = \frac{\pi_\theta(s_{i,t}\mid q, s_{i,<t})}{\pi_{\theta_{\rm old}}(s_{i,t}\mid q, s_{i,<t})}\) is the token-level importance weight, and
- \(\widehat A_{i,t} = \frac{R_i - \operatorname{mean}({R_i}_{i=1}^G)}{\operatorname{std}({R_i}_{i=1}^G)}\) is the token-level advantage
- The hyperparameters \(\varepsilon_{\text {low}}\) and \(\varepsilon_{\text{high}}\) control the clipping range for importance weights, while \(\beta\) regulates the KL-divergence penalty to stabilize training.
- where:
Results
- On seven public benchmarks, TIR-Judge surpasses reasoning-only judges by 6.4% (pointwise) and 7.7% (pairwise), and achieves 96% of Claude-Opus-4’s performance with only 8B parameters.
- The following figure (source) shows the TIR-Judge RL framework and training variants (TIR-Judge-Zero and Distill).
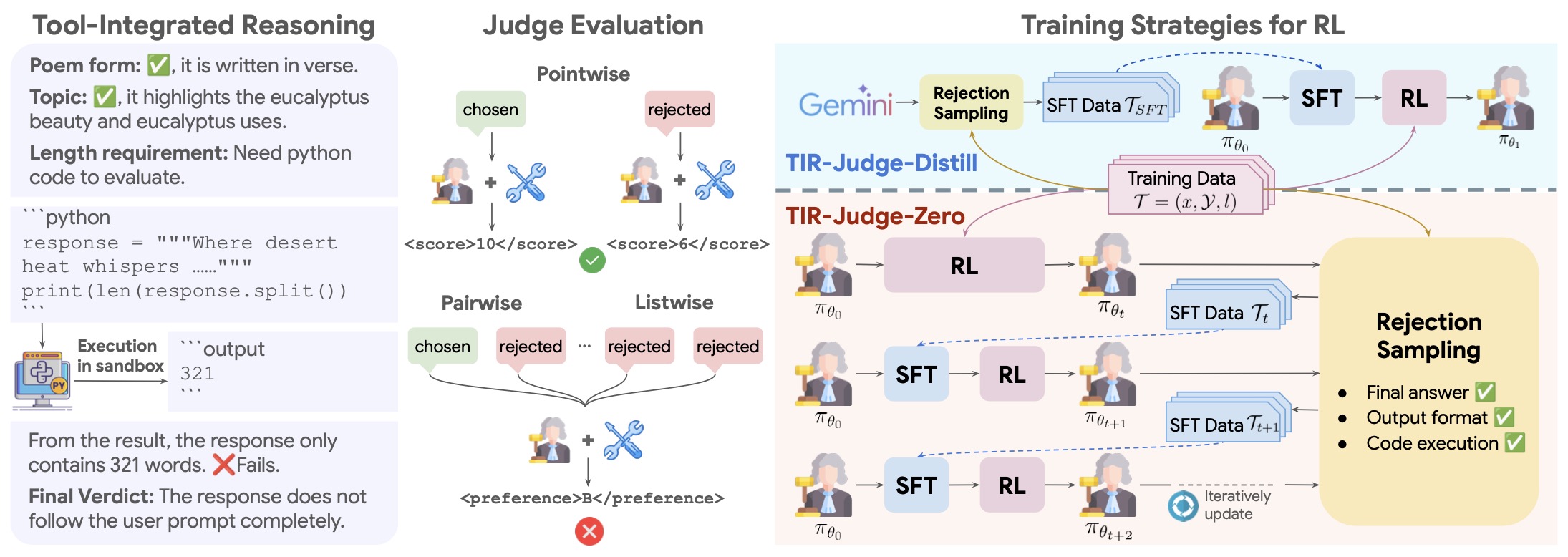
Key Insight
- TIR-Judge demonstrates that reinforcement learning can endow LLM judges with agentic verification abilities—evaluating not only by textual reasoning but by executing verifiable logic to test correctness.
- This closes the feedback loop in RLHF pipelines, enabling both reasoners and evaluators to become tool-augmented and self-improving.
Comparative Analysis
| Framework | Focus | Training Style | Emergent Behavior | Key Results |
|---|---|---|---|---|
| ToRL | Tool integration during RL | GRPO | Self-regulated code use, reflection | +14% on AIME24 |
| ReTool | Strategic tool-use via interleaved code | PPO with outcome reward | Code self-correction, adaptive timing | +27.9% vs o1-preview |
| TIR-Judge | Tool-augmented evaluation | DAPO (an improved variant of GRPO) | Agentic verification, multi-domain generalization | 6.4–7.7% gains over text-only judges |
Theoretical Framing
-
All three frameworks share a reinforcement-based objective augmented with tool-conditioned state transitions:
\[p_\theta(c_{1:T}, o_{1:T} | x) = \prod_{t=1}^{T} p_\theta(a_t | x, c_{<t}, o_{<t}) p(o_t | a_t)\]- where \(a_t\) represents either reasoning or tool action and \(o_t\) its observation.
-
This formalism generalizes the Themis-style hybrid objective by integrating action-conditioned reasoning trajectories into the reward model.
Conceptual Implication
- The synthesis of ToRL, ReTool, and TIR-Judge underscores the transition from reactive reasoning to agentic reasoning—where LLMs not only reason about outputs but interact with tools to verify and improve them.
- These approaches redefine RLHF as Tool-Integrated Reinforcement Learning for Reasoning and Evaluation (TIRL²E)—a unified path toward verifiable, self-correcting AI systems.
Tool-Augmented Reward Modeling (Themis)
- The paper Tool-Augmented Reward Modeling (Themis) by Li et al. (2024) introduces an RLHF-based framework that directly enhances reasoning through external tool usage during the reward modeling process. The key idea is to allow reward models (RMs) to access external tools—such as search engines, calculators, and code interpreters—while evaluating responses, thereby grounding the reasoning process in factual and computational evidence.
- In summary, Themis operationalizes the idea that reasoning should be rewardable—transforming RLHF from passive alignment into active, evidence-grounded reasoning optimization.
Process
-
The training of the Themis reward model relies on supervised fine-tuning (SFT) rather than direct reinforcement learning. The RM is trained using supervised imitation of high-quality reasoning traces that demonstrate tool use and reward inference. This SFT stage helps the model learn to invoke tools, interpret results, and assign scores grounded in external evidence.
-
Importantly, reinforcement learning is not used to optimize the reward model itself—Themis remains an SFT-trained verifier that provides reward signals for downstream policy optimization (which can use RLHF or PPO).
-
The supervised fine-tuning loss integrates multiple components:
- A ranking loss over preference pairs to train the reward model,
- A reasoning loss to predict intermediate tool-use steps,
- An observation and rationale loss to improve interpretability:
where
- \(L_{\text{RM}}\) is the preference-based ranking loss,
- \(L_{\text{tool}}(t)\) models tool selection accuracy,
- \(L_{\text{obs}}(t)\) aligns model predictions with observed tool outputs, and
- \(L_{\text{rationale}}\) encourages the generation of coherent explanations for reward assignments.
-
This design enables Themis to be interpretable and verifiable without the instability of RL-based reward training. The authors note that RLHF or PPO can later be used to fine-tune the policy against the SFT-trained Themis RM—but not vice versa.
-
The following figure (source) shows illustrates the pipeline of (a) Vanilla reward models (RMs); (b) Tool-augmented RMs, namely Themis; (c) RL via proximal policy optimization (PPO) on above RMs; (d) Examples of single or multiple tool use process in the proposed approach.

Core Idea
-
Conventional reward models in RLHF predict human preferences solely based on static textual input. Themis instead models reasoning as a tool-augmented sequential decision process. Given a prompt \(x\) and model response \(y\), the reward model performs a multi-step reasoning trajectory \(c_{1:T} = (a_1, o_1, \dots, a_T, o_T)\), where each \(a_t\) is an action (thought or tool invocation) and \(o_t\) is the resulting observation.
-
The overall reward is represented as:
\[r_\theta(x, y, c_{1:T})\] -
… and optimized through a hybrid objective combining ranking and autoregressive reasoning losses:
\[L_{\text{total}} = L_{\text{RM}} + \alpha \sum_{t=1}^{T} (L_{\text{tool}}(t) + \beta L_{\text{obs}}(t)) + \omega L_{\text{rationale}}\] -
This enables the RM to learn both what to reward and how to reason about rewards using external evidence.
Mechanism
- Thought Generation: The RM decides whether external information is required.
- Tool Invocation: It dynamically selects a tool (e.g., Google, Calculator, Translator) and provides input arguments.
- Observation: The model processes the tool’s output.
- Rationale and Reward: It integrates the observations into a coherent rationale and outputs a scalar reward signal.
- This sequence creates a transparent reward pipeline, with interpretable reasoning traces linking tool use to reward assignment—enhancing trustworthiness and debuggability.
Implementation
- Themis uses Vicuna-7B as the backbone and is fine-tuned via SFT on the Tool-Augmented Reward Dataset (TARA)—a 15k-instance corpus combining seven tool APIs and human-annotated rationales.
- The dataset construction pipeline includes: (i) collecting QA pairs, (ii) building a ToolBank with APIs like Calculator, Weather, and WikiSearch, (iii) generating multi-agent tool-use trajectories via GPT-4 simulations, and (iv) filtering noise.
- In experiments, policies trained with Themis-based RMs outperform standard RMs by 17.7% in preference ranking and achieve a 32% win rate in human evaluations.
Theoretical Framing
-
Themis formalizes the reward inference as a reasoning trajectory:
\[p_\theta(c_{1:T} | x, y) = \prod_{t=1}^{T} p_\theta(a_t | x, y, c_{<t}) , p_\theta(o_t | a_t)\] -
The scalar reward \(r_\theta\) is derived from the terminal state \(s_T\) of this trajectory. The training objective encourages consistent ranking between correct and incorrect outputs via a contrastive loss:
\[L_{\text{RM}} = -\mathbb{E}_{(x, y_w, y_l) \sim D} [\log \sigma(r_\theta(x, y_w) - r_\theta(x, y_l))]\]
Conceptual Significance
- Themis reframes RLHF as interactive reasoning optimization: RMs are no longer passive preference predictors but active verifiers that reason and validate before rewarding.
- This bridges the gap between verbal reasoning and procedural verification, grounding alignment in externally verifiable evidence rather than subjective preference scores.
Related Work
- ReAct by Yao et al. (2022): integrates reasoning and action for tool use.
- Chain-of-Thought by Wei et al. (2022): scaffolds step-by-step reasoning.
- InstructGPT by Ouyang et al. (2022): establishes RLHF’s preference-based optimization paradigm.
- Themis extends these by adding tool-augmented reasoning and interpretable reward generation—a move toward verifiable and grounded alignment.
Tool Learning with Foundation Models
- The paper Tool Learning with Foundation Models by Qin et al. (2024) provides a comprehensive survey of how large foundation models acquire, use, and reason with tools—situating RL within a broader tool-augmented reasoning paradigm. It systematically maps out how reinforcement-based optimization interacts with external APIs, environments, and feedback mechanisms to enable verifiable reasoning and decision-making across domains.
Core Idea
-
Tool learning expands the scope of reasoning beyond static text generation to interactive environments, where a foundation model acts as a controller that plans, executes, and refines multi-step tool usage. In this formulation, the model transitions between reasoning (thought generation) and acting (tool invocation), with each action influenced by rewards or feedback signals derived from tool outcomes or human evaluation.
-
Formally, tool learning is modeled as a closed feedback loop:
\[\text{Reason} \rightarrow \text{Act (via tools)} \rightarrow \text{Observe} \rightarrow \text{Reward} \rightarrow \text{Refine}\]- which aligns conceptually with RL-based reasoning frameworks like Themis by Li et al. (2024) and DeepSeek-R1 by Guo et al. (2025).
- This structure transforms reasoning from an open-loop (text-only) system into a closed cognitive loop where every inference can be externally verified.
- The following figure shows (source) the conceptual overview of tool learning with foundation models, where models dynamically decide when and how to invoke tools such as web search and other APIs to solve complex problems.
Mechanism and Architecture
-
Qin et al. describe tool learning as a three-layer cognitive stack integrated into the foundation model framework:
- Planning Layer:
- Generates high-level reasoning plans or subgoals based on input context.
- Example: “To answer this, I should retrieve relevant information and perform a computation.”
- Tool Invocation Layer:
- Translates plans into executable tool calls—e.g., invoking a Python interpreter, SQL engine, search API, or code execution module.
- This layer operationalizes action selection, analogous to a policy in RL.
- Feedback and Adaptation Layer:
- Aggregates results, evaluates correctness, and provides reinforcement signals to refine the next cycle of planning.
- The reward function combines correctness, efficiency, and tool-use cost:
- Planning Layer:
-
This structure mirrors RL’s goal of policy optimization over reasoning trajectories, but within a modular, interpretable agentic architecture.
Implementation and Evaluation
-
The survey compiles empirical frameworks where RL-based reasoning interacts with tool environments:
- ReAct framework (Yao et al., 2022) couples reasoning steps with external actions (e.g., web search, calculators).
- Toolformer (Schick et al., 2023) fine-tunes LLMs to decide when to use APIs by self-generating tool-usage data.
- CodeRL (Le et al., 2022) applies RL to improve code reasoning and debugging performance.
- Themis (Li et al., 2024) explicitly integrates tool interactions into reward modeling for verifiable reasoning.
- AutoGPT and related systems (Torant et al., 2023) demonstrate autonomous chaining of reasoning–action loops in open environments.
-
Collectively, these systems embody what Qin et al. term “tool-augmented cognition”, where reasoning policies emerge from interaction, reflection, and correction rather than static imitation.
Theoretical Framing
-
The survey situates tool learning within the RL framework by drawing analogies between policy optimization and reasoning adaptation. Given an environment \(E\) with a set of tools \(\mathcal{T}\), a model \(\pi_\theta\) optimizes:
\[\mathcal{J}(\theta) = \mathbb{E}_{(x, a, r, s') \sim \mathcal{T}} \big[ R(x, a, s') \big],\]- where \(a\) corresponds to the tool action, and \(s'\) represents the post-tool reasoning state.
-
The loop parallels model-based RL, where tools serve as environment transitions and reasoning traces serve as trajectories.
-
This reframing positions LLMs as general-purpose policy optimizers over heterogeneous environments—bridging symbolic reasoning, API orchestration, and human feedback alignment.
Challenges and Open Problems
-
Qin et al. identify key challenges in tool-integrated RL for reasoning:
- Credit Assignment: Determining which tool interaction contributed most to final success.
- Exploration Efficiency: Balancing costly tool calls with information gain.
- Reward Design: Developing automatic, verifiable scoring mechanisms (e.g., verifiers, critics, self-evaluators).
- Safety and Trustworthiness: Ensuring reliable, interpretable tool use, especially in high-stakes domains like healthcare or finance.
- Generalization: Training models that can adapt to unseen tools or APIs without re-optimization.
Conceptual Significance
-
By synthesizing over 200 papers across AI, NLP, and robotics, Tool Learning with Foundation Models establishes tool-augmented reasoning as a unifying theme linking RL, reasoning, and alignment. The framework clarifies how reinforcement signals, tool feedback, and self-reflection together create grounded intelligence—where reasoning is both goal-driven and externally verifiable.
-
In the context of RL-based reasoning, the paper serves as a bridge between empirical advances like Themis and theoretical RL control principles, emphasizing that tools are not add-ons but core operators in the reasoning policy loop.
The “Aha” Moment and Emergent Reasoning
-
The “Aha” moment in LLMs marks a qualitative shift from pattern completion to goal-directed reasoning. In the context of DeepSeek-R1 (Guo et al. (2025)), this phenomenon is not a mere artifact of scale—it is the point at which the model learns to structure its internal search process around verifiable outcomes, producing reasoning traces that reflect deliberate, compositional thought rather than stochastic association.
-
This emergence parallels the human experience of insight: a sudden realization that reorganizes how subproblems are represented and solved. For LLMs, it signals the formation of stable latent reasoning circuits—internal pathways that consistently transform a complex question into decomposed, verifiable subgoals.
The DeepSeek-R1 Perspective
-
DeepSeek-R1 conceptualizes the “Aha” moment as a policy-level transition in the reasoning dynamics of the model. During early RL training, the model’s outputs are dominated by shallow heuristics—locally coherent but globally inconsistent reasoning chains. As reinforcement updates accumulate, the model begins to exploit verifiable reward structure: it learns that structured reasoning trajectories yield higher expected reward.
-
Formally, given a problem input \(x\), the model samples reasoning traces \(z\) leading to outcomes \(y\), maximizing
-
Initially, reward gradients are sparse—most reasoning attempts fail verification. But once the model discovers an internal representation \(h\) that decomposes the problem space (e.g., through implicit subgoal inference), reward signals align with coherent reasoning structure, triggering a phase transition in \(p_\theta(z \mid x)\).
-
Empirically, DeepSeek-R1 observed that this transition is abrupt yet self-stabilizing: the model begins to reuse and generalize reasoning motifs across unseen domains, much like a human suddenly “figures out” a new way of thinking about problems.
What Triggers the “Aha” Transition?
-
The DeepSeek-R1 findings suggest that the transition arises from the interaction between reinforcement feedback and latent compositionality. Three components drive this behavior:
- Sparse but verifiable rewards: Correct answers yield discrete, high-signal updates that privilege reasoning chains aligned with ground truth.
- Exploration pressure: The RL policy must explore sufficiently diverse reasoning paths before discovering stable, high-reward substructures.
- Representation reuse: Once a reasoning schema is found (e.g., arithmetic decomposition, symbolic manipulation), the model internalizes it as a reusable reasoning primitive.
-
These factors produce a self-organizing dynamic: reward gradients reshape the latent geometry of the model’s activations until symbolic structure becomes an attractor state—effectively, the model learns how to think rather than what to say.
Relating the Aha Moment to Emergent Reasoning
-
DeepSeek-R1 reframes emergence not as a scaling accident, but as an optimization-driven restructuring of cognition within the model. What appears as a sudden “Aha” is, in fact, a threshold phenomenon in representation alignment—when internal circuits that previously encoded diffuse associations crystallize into task-general reasoning routines.
-
This view aligns with the idea of representational phase transitions: as the model’s policy distribution becomes increasingly aligned with verifiable reward signals, latent subspaces reorganize to encode causal and compositional relations explicitly. At that point, the model exhibits stable reasoning behavior across mathematically verifiable tasks (AIME, MATH, GSM8K), a hallmark of emergent reasoning.
Why It Matters
- Understanding the “Aha” moment through the lens of DeepSeek-R1 clarifies that emergence is trainable, not mysterious. It arises when a model’s optimization incentives begin to reward internal structure over surface coherence. Once this shift occurs, the model moves beyond imitation of training data and begins to search, plan, and verify—the minimal ingredients of genuine reasoning.
Evaluation of reasoning using datasets
-
Evaluating reasoning in LLMs is about much more than accuracy on a single test set. Practical evaluation should balance outcome correctness, process quality, and robustness under different elicitation interfaces (e.g., CoT, self-consistency, search). In short, we want to know not only whether a model is right, but whether it got there via steps we can verify, and whether those steps still work when the interface changes.
-
Mathematically, many reasoning probes can be framed as estimating success under diverse latent traces \(z\):
- and contrasting this with thresholded outcome metrics such as exact match:
-
Because EM is thresholded, small likelihood gains can produce large apparent “jumps,” so pairing EM with smooth metrics (log-probability, Brier score, ECE) helps avoid mirage-like emergence claims. Background on these issues appears in Emergent Abilities of Large Language Models by Wei et al. (2022) and Are Emergent Abilities of Large Language Models a Mirage? by Schaeffer et al. (2023).
-
Representative benchmark families target complementary facets of reasoning. Grade-school and competition math emphasize multi-step derivations with programmatic verifiers (GSM8K by Cobbe et al. (2021); MATH by Hendrycks et al. (2021)). Mixed-task suites stress out-of-distribution and compositional behavior (BIG-bench by Srivastava et al. (2022); BIG-Bench Hard by Suzgun et al. (2022); MMLU by Hendrycks et al. (2020)). Science and reading-comprehension datasets probe discrete reasoning over text (ARC by Clark et al. (2018); DROP by Dua et al. (2019)). Broader evaluation frameworks like HELM by Liang et al. (2022) encourage multi-metric reporting that includes calibration and robustness, not just accuracy.
-
For process-aware evaluation, verifiers and critics score intermediate steps, not just final answers. For example, Training Verifiers to Solve Math Word Problems by Cobbe et al. (2021) introduced GSM8K alongside a verifier that selects among candidate solutions; later work formalized process supervision where step-level rewards or labels improve reliability (Let’s Verify Step by Step by Lightman et al. (2023)). These approaches help disentangle “good narratives” from genuinely correct reasoning.
-
Multimodal evaluation extends this logic to vision-language settings, where models must ground textual reasoning in images, charts, or documents. Recent surveys (e.g., VHELM by Lee et al. (2024)) consolidate tasks across perception, knowledge, and visual reasoning and push for standardized prompting and metrics. The same cautions apply: verify intermediate computations, test multiple interfaces, and report calibration in addition to accuracy.
GSM8K (grade-school math reasoning)
-
GSM8K by Cobbe et al. (2021) is a curated benchmark of 8.5K grade-school arithmetic word problems designed to probe multi-step reasoning with simple operations. The official repository summarizes a split of 7.5K training problems and 1K test problems, with solutions that typically require 2–8 steps (see dataset card). GSM8K is often used to detect “aha”-style thresholding because exact-match performance can jump sharply when models begin to reliably compose intermediate steps.
- Why it’s reasoning-centric:
- Problems are crafted to be solvable by a bright middle-schooler yet require composing several elementary operations. The target is not retrieval but stepwise manipulation (counting, unit arithmetic, proportional reasoning). This favors methods that surface or verify intermediate traces.
- Evaluation protocol:
- Given a problem x, the model produces a reasoning trace \(z\) and final answer \(y\). Exact match is computed as \(\text{EM}=\frac{1}{N}\sum_{i=1}^N \mathbb{I}[y_i=y_i^\star]\). Because \(\text{EM}\) is thresholded, small gains in \(p_\theta(y^\star\mid x)\) can yield large apparent jumps. Many evaluations now pair EM with verifier selection: sample K candidate solutions \({(z^{(k)},y^{(k)})}_{k=1}^K\) and choose \(k^\star=\arg\max_k V \left(z^{(k)},y^{(k)}\right),\qquad \hat{y}=y^{(k^\star)}\), where \(V\) is a trained verifier as introduced with GSM8K by Cobbe et al. (2021). This turns evaluation into a two-stage generate–verify pipeline. Process supervision work such as Let’s Verify Step by Step by Lightman et al. (2023) further scores intermediate steps, not just outcomes.
- Interfaces that matter on GSM8K:
- CoT prompting and self-consistency are especially effective. Self-Consistency Improves CoT Reasoning by Wang et al. (2022) showed large gains on GSM8K by sampling diverse chains and marginalizing answers, effectively approximating \(\hat{y}=\arg\max_y \sum_{k=1}^{K}\mathbb{I} \left[y^{(k)}=y\right]\).
-
Common pitfalls and controls:
- Overfitting to surface templates: vary paraphrases and numerical spans.
- Interface confounds: report with and without CoT and self-consistency.
- Verifier over-reliance: ensure the verifier isn’t shortcutting via superficial cues; ablate with randomized chains.
- Report smooth metrics (log-prob, Brier/ECE) alongside EM to avoid “mirage” emergence effects.
- What to report for reproducibility:
- Decoding temperatures and sample count \(K\), prompt format (few-shot exemplars and formatting), normalization rules for numeric answers, verifier architecture and training data, and any process-level scoring.
- Where feasible, release prompts, sampled chains, and verifier decision logs to enable step-level auditing.
MATH (competition-level mathematical reasoning)
- The MATH dataset by Hendrycks et al. (2021) extends arithmetic reasoning into formal mathematics. It contains roughly 12,500 problems across algebra, geometry, probability, number theory, and calculus—ranging from high school to early undergraduate difficulty. Each problem is paired with a detailed step-by-step solution written in natural language and LaTeX, enabling explicit reasoning evaluation.
Purpose and Design
-
Where GSM8K tests arithmetic composition, MATH evaluates symbolic and abstract reasoning that requires structured derivations. Problems are sourced from math competitions (AMC, AIME, Olympiad-level) and rewritten to include human-readable reasoning steps.
-
Each sample \((x, z^\star, y^\star)\) includes:
- Problem text \(x\)
- Step-by-step reasoning \(z^\star = (z_1, \ldots, z_T)\)
- Final answer \(y^\star\)
-
This supports supervision or verification at the process level rather than only on final outcomes.
Evaluation Protocol
- Models generate reasoning chains \(z\) and final answers \(y\).
- Evaluation includes:
-
Exact-match accuracy:
\[\text{EM} = \frac{1}{N}\sum_{i}\mathbb{I}[y_i = y_i^\star]\]- Here, numeric normalization and symbolic equivalence checking (e.g.,
sympy.simplify) are required because answers may differ syntactically but be mathematically identical.
- Here, numeric normalization and symbolic equivalence checking (e.g.,
- Verifier-based scoring:
- Separate verifiers or math solvers can re-execute each reasoning chain to confirm correctness.
- The “solver check” procedure detects inconsistent or hallucinated intermediate results.
- Step-level agreement:
- Compare generated reasoning steps \(z_t\) against gold steps \(z_t^\star\), useful for process supervision or reward model training.
Interfaces and Findings
- CoT prompting significantly improves performance compared to direct-answer prompting, confirming that explicit intermediate steps help symbolic reasoning.
- Self-consistency decoding (sampling multiple CoT paths and voting) further stabilizes results, as shown by Wang et al. (2022).
-
Process-supervised fine-tuning—training on correct intermediate steps—yields more interpretable and verifiable reasoning chains (see Lightman et al. (2023)).
- Recent improvements, including RL fine-tuning (e.g., DeepSeek-R1 by Guo et al. (2025)), demonstrate that unsupervised reward shaping can further enhance reasoning without explicit step labels.
Advantages
- Explicit reasoning labels make it ideal for process-level evaluation and training.
- Covers a broad range of reasoning types—from algebraic manipulation to geometric proof sketching.
- Provides a benchmark for assessing symbolic and logical generalization.
Limitations
- Heavy reliance on domain-specific knowledge; general LLMs may fail without fine-tuning.
- Sensitive to formatting, LaTeX parsing, and equivalence evaluation.
- High variance due to the compositional nature of mathematical syntax.
Relation to GSM8K
| Aspect | GSM8K | MATH |
|---|---|---|
| Domain | Everyday arithmetic | Competition mathematics |
| Solution style | Natural language steps | Formal math derivations |
| Difficulty | Grade-school | High school to college |
| Step annotation | Implicit | Explicit (LaTeX and text) |
| Evaluation | Numeric EM, verifier | Symbolic EM, reasoning trace verification |
Recommended Reporting
- Report both accuracy and step-consistency metrics.
- Include per-topic breakdowns (algebra, geometry, etc.).
- Use symbolic equivalence checks for fairness.
- Where applicable, publish verifier logs and intermediate derivations for transparency.
AIME and IMO: Mathematical Olympiad–Level Reasoning
- One of the strongest indicators of genuine mathematical reasoning in LLMs comes from their performance on advanced competition problems such as the AIME (American Invitational Mathematics Examination) and IMO (International Mathematical Olympiad).
- These benchmarks probe not just computation but deep multi-step logical synthesis, often requiring extended reasoning chains, proof sketches, and symbolic manipulation far beyond typical arithmetic datasets such as GSM8K or MATH.
- In short, AIME and IMO tasks form the “upper bound” of reasoning evaluation—where models can no longer rely on patterns and must genuinely reason, often through symbolic, multi-turn computation.
AIME Dataset (OpenAI’s AIME and AIME24 Benchmarks)
- The AIME benchmark originated from OpenAI’s evaluations of mathematical reasoning competence in GPT models, with early references appearing in OpenAI’s technical system card for GPT-4 (2023) and follow-up analyses by the research community.
-
Recently, curated versions such as AIME24, AIME’23, and AIME’25 test sets have been used to track reasoning evolution in frontier models including GPT-4, DeepSeek-R1, and Claude 3 Opus.
-
Structure:
- 15 competition-grade problems per year.
- Each problem has an integer answer between 0 and 999.
- Questions cover algebra, number theory, geometry, and combinatorics.
- Each problem requires 3–10 reasoning steps—often with nested sub-problems.
-
Example: “How many positive integers (n) satisfy (n^2 + 12n - 2007 = k^2) for some integer (k)?”
-
Solving this requires:
- Completing the square: (n^2 + 12n = k^2 + 2007).
- Reformulating as a Diophantine condition.
- Identifying integer constraints and counting solutions.
Why AIME Is a “Pure” Reasoning Benchmark
- AIME problems are deliberately non-retrievable—they do not rely on memorized facts but on algebraic and logical construction.
- This means models cannot rely on pattern recognition alone; instead, they must generate intermediate transformations such as:
-
Then solve for integer factors of 2043, reasoning about parity and divisibility.
-
Thus, performance on AIME directly reflects the model’s symbolic abstraction ability, logical completeness, and numerical stability in long reasoning chains.
Evaluation Methodology
- Accuracy is measured as the percentage of correct integer answers across 15 problems:
- Given the discrete numeric range, random guessing yields only 0.1 % expected accuracy.
-
Hence, even modest accuracy (20–40 %) represents nontrivial reasoning ability.
- Modern evaluations also include CoT verification, where models must show step-by-step derivations.
- For example, DeepSeek-R1 (Guo et al. (2025)) achieved strong results on AIME’24 and AIME’25 using unsupervised reinforcement fine-tuning that directly optimized for reasoning correctness without labeled solutions.
IMO-Style Problems and Datasets
-
The International Mathematical Olympiad (IMO) represents the highest level of pre-college mathematical reasoning. Each annual IMO features six proof-based problems over two days, requiring creative, multi-lemma arguments rather than formulaic manipulation. While no official IMO benchmark exists for open LLM evaluation, several datasets have emerged that capture this flavor:
-
MiniF2F by Zheng et al. (2021):
- 488 formalized math competition problems, including AIME, AMC, and IMO-like tasks.
- Formulated for theorem provers such as Lean and Isabelle.
- Used to test formal reasoning and theorem-proving capabilities.
-
IMO Grand Challenge (OpenAI Formal Mathematics Dataset 2022–2024):
- Informal and formal versions of IMO-level problems released for research on formal reasoning.
- Evaluates both natural-language reasoning and formal proof synthesis.
- Models must convert text statements into symbolic proof steps.
-
ProofNet and LeanDojo (Polu et al. (2022); Zheng et al. (2023)):
- Contain IMO-like formal proofs represented in Lean.
- Allow objective scoring of proof correctness.
-
-
These datasets bridge mathematical language understanding and formal symbolic reasoning, advancing LLMs from numeric manipulation to verifiable theorem-level reasoning.
AIME and IMO in Modern Reasoning Research
- AIME as performance baseline: Many reasoning-focused models (e.g., DeepSeek-R1, OpenAI’s o1, and OpenMath) report AIME’24 accuracy as their headline metric, reflecting pure reasoning improvement.
- IMO as reasoning frontier: Proof-oriented tasks from IMO data drive progress toward formal reasoning alignment—where LLMs are trained to generate coherent proof steps verified by theorem provers.
- Bridging informal and formal reasoning: The MiniF2F and LeanDojo datasets link natural language reasoning to symbolic proof checking, a key step toward automated theorem discovery.
Comparative Summary
| Benchmark | Domain | Problem Type | Evaluation | Reasoning Depth | Typical Use |
|---|---|---|---|---|---|
| GSM8K | Grade-school | Arithmetic | EM, verifier | 2–6 steps | Introductory reasoning |
| MATH | High school/college | Symbolic | EM + symbolic equivalence | 4–8 steps | Formal algebraic reasoning |
| AIME | Olympiad-level | Integer/symbolic | Numeric EM | 5–10 steps | High-level logical synthesis |
| IMO / MiniF2F | Olympiad/formal | Proof synthesis | Theorem verification | 10+ steps | Formal and creative reasoning |
Why AIME and IMO Matter for Reasoning Evaluation
- They minimize retrieval bias: Success depends on symbolic reasoning, not memorization.
- They require compositional thinking: Multi-step reasoning chains must stay coherent under symbolic constraints.
- They connect to formal verification: Proof datasets allow automated correctness checks.
- They expose limits of scaling: Even frontier models (GPT-4, DeepSeek-R1, Claude 3 Opus) plateau at 30–50 % accuracy, far below expert humans.
ARC and Science QA Benchmarks (ARC-AGI-1 and ARC-AGI-2)
- The Abstraction and Reasoning Corpus (ARC) is one of the most enduring benchmarks for scientific reasoning in language models. It was first introduced as ARC-AGI-1 by Clark et al. (2018), and later extended as ARC-AGI-2 by Clark et al. (2023).
- The two stages collectively trace the field’s progress from information-retrieval-based question answering to reasoning-centric problem solving.
ARC-AGI-1 (Original ARC Challenge)
Dataset Overview
- ARC-AGI-1 consists of 7,787 grade-school science questions drawn from standardized exams in the United States, divided into an Easy Set (requiring factual recall) and a Challenge Set (requiring reasoning, causality, and multi-hop inference).
- Each item is multiple-choice with 3–5 answer options.
Why it matters for reasoning
- Unlike reading-comprehension tasks such as SQuAD, ARC’s Challenge questions cannot be solved by surface matching; they require the model to combine multiple scientific facts to reach the answer.
- For instance: “Why does placing a metal spoon in hot water make the handle warm?”
- Answering requires the latent inference chain: metal conducts heat \(\rightarrow\) heat flows along the spoon \(\rightarrow\) handle warms.
Evaluation
- Performance is computed as plain accuracy:
- However, modern setups also log reasoning traces \(z\) and check whether the final selected option follows a coherent causal explanation.
Key baselines
- *IR and PMI systems** (2018–2019): retrieval + heuristics.
- Transformer baselines (BERT, RoBERTa)—e.g., BERT by Devlin et al. (2018)—achieved large gains but still trailed human performance.
- CoT prompting (2022 onward) improved Challenge-set accuracy sharply, showing that explicit reasoning helps even with multiple-choice formats.
ARC-AGI-2 (The Abstraction and Generalization Intelligence benchmark)
Motivation
- By 2023, large models surpassed 90 % on the original ARC Challenge, largely through pattern matching and memorization.
- To push beyond this, Clark et al. (2023) introduced ARC-AGI-2, built to evaluate systematic generalization and abstraction rather than recall.
Design
- ARC-AGI-2 redefines each task family as a visual–symbolic reasoning problem. Problems resemble simple “concept games” expressed as grid transformations or symbolic relations; they test the model’s ability to infer rules and apply them to new instances.
- This format inherits the design of the original “Abstraction and Reasoning Corpus” (ARC) by Chollet (2019) but formalizes it into a fixed AGI-style benchmark suite.
Dataset composition
- 400 training, 200 validation, and 400 test tasks.
- Each task contains 2–5 input-output example pairs and a novel test case to solve.
- Inputs and outputs are small colored grids (e.g., 10×10 arrays).
- Tasks involve transformations such as symmetry, counting, pattern extension, or logical composition.
Why it matters
- ARC-AGI-2 tests for compositional generalization: models must discover and apply a hidden transformation rule from few examples, with no overlap between training and test transformations.
- It is explicitly designed to resist memorization and to reward algorithmic reasoning.
Evaluation
- Performance is the fraction of tasks for which all output grids exactly match ground truth:
- Since each task has a single correct transformation, partial credit is not given.
- Some studies additionally compute object-level F1 for graded evaluation.
Comparative insights: ARC vs. ARC-AGI-2
| Property | ARC-AGI-1 | ARC-AGI-2 |
|---|---|---|
| Domain | Textual grade-school science | Visual-symbolic abstraction |
| Input format | Multiple-choice text | Grid-based pattern transformations |
| Knowledge dependence | Requires external science facts | Minimal; focuses on reasoning rule induction |
| Evaluation metric | Accuracy on discrete choices | Exact grid-match (task success) |
| Reasoning type | Multi-hop causal inference | Program induction / rule synthesis |
| Typical LLM interface | CoT or retrieval-augmented QA | Program-generation or symbolic-executor integration |
Empirical trends
- CoT and retrieval-augmented prompting lifted ARC-AGI-1 accuracy above 80 % on recent frontier models.
- ARC-AGI-2 remains unsolved; even advanced models (GPT-4, Gemini 1.5 Pro, Claude 3 Opus) perform below 20 %, highlighting a continuing gap in compositional abstraction.
Practical evaluation guidance
- For ARC-AGI-1, report separate Easy vs. Challenge accuracies and check reasoning trace consistency.
- For ARC-AGI-2, pair symbolic executors (e.g., Python grid interpreters) with LLMs and report both per-task accuracy and per-object F1.
- Control for contamination: ARC-AGI-2 tasks are meant to be unseen; verify models were not fine-tuned on similar puzzles.
- Visualize rule inference: Output transformation code or step reasoning to make results interpretable.
OpenThoughts3: Large-Scale Open Reasoning Dataset
- The OpenThoughts3 dataset (Gokaslan et al. (2025)) represents a new milestone in open-source reasoning evaluation. It builds on the OpenThoughts2-1M dataset, scaling the pipeline to 1.2 million question–response pairs and systematically optimizing every stage of data generation and filtering to improve reasoning quality across math, code, and science domains.
Design and Pipeline
- OpenThoughts3 introduces a fully controlled, ablation-driven data construction pipeline designed to isolate and improve each component contributing to reasoning performance. The pipeline comprises six major stages:
- Question sourcing: Questions are drawn from both existing high-quality repositories (e.g., OpenR1-Math, AutoMathText, CodeFeedback) and newly generated datasets.
- Question mixing: Top-performing question sources are combined to enhance diversity.
- Filtering questions: FastText and LLM-based filters remove ambiguous or malformed inputs.
- Answer generation: Multiple candidate answers are produced per question using teacher models.
- Answer verification: Low-quality or inconsistent answers are filtered using LLM-based verification or majority consensus.
- Teacher selection: The best-performing teacher model is chosen empirically through small-scale fine-tuning trials.
- This pipeline allows reproducible scaling and quality control at each stage. Experiments with controlled subsets of 31,600 examples were used to evaluate each design decision before scaling up to the full dataset.
Evaluation Framework
-
OpenThoughts3 evaluates reasoning performance across eight standardized benchmarks, spanning multiple domains:
- Math: AIME24, AMC23, MATH500
- Code: CodeElo, CodeForces, LiveCodeBench (05/23–05/24)
-
Science: GPQA Diamond, JEEBench
- Each model trained on OpenThoughts3 is scored by average accuracy across these benchmarks, with decontamination procedures ensuring that no overlapping samples remain between training and test data. Evaluation uses the Evalchemy framework, with consistent metrics for accuracy, calibration, and robustness.
Results and Scaling Behavior
- OpenThoughts3 outperforms prior supervised fine-tuning (SFT) reasoning datasets—including AM, Nemotron Nano, and LIMO—when all models are fine-tuned from Qwen-2.5-7B-Instruct. Scaling analyses (from 1K to 1M samples) demonstrate that OpenThoughts3 achieves higher asymptotic performance and stronger data efficiency, particularly on AIME 2025, LiveCodeBench, and GPQA Diamond, where it improves accuracy by 15–20 percentage points over comparable datasets.
Model Progression and Impact
- Successive generations of models trained on OpenThoughts datasets—Bespoke-Stratos, OpenThinker, OpenThinker2, and OpenThinker3—illustrate consistent gains across reasoning domains:
| Model | AIME24 | AIME25 | GPQA-D | LiveCodeBench |
|---|---|---|---|---|
| Bespoke-Stratos-7B | 14.3 | 12.7 | 31.8 | 27.4 |
| OpenThinker-7B | 29.3 | 25.3 | 44.1 | 38.8 |
| OpenThinker2-7B | 60.7 | 38.7 | 47.0 | 56.3 |
| OpenThinker3-7B | 69.0 | 53.3 | 53.7 | 64.5 |
- The dataset’s public availability and transparent pipeline make it a cornerstone for open benchmarking of reasoning in LLMs. It also serves as a model for reproducible dataset design, providing controlled ablations and fully open access to both data and evaluation scripts through openthoughts.ai.
Summary
- Scope: 1.2M verified reasoning examples across math, code, and science
- Evaluation: Multi-domain, process-aware, and decontaminated benchmarking
- Teacher Model: QwQ-32B
- Performance: 53 % on AIME 2025, 51 % on LiveCodeBench, 54 % on GPQA Diamond
-
Release: Fully open dataset and training scripts
- OpenThoughts3 thus establishes a reproducible, open baseline for evaluating reasoning capabilities, enabling community-wide comparisons and accelerating transparent progress in reasoning-focused LLM development.
DROP and Numerical Reading-Comprehension Reasoning
- The DROP dataset (Discrete Reasoning Over Paragraphs) was introduced by Dua et al. (2019) as a benchmark to test reading comprehension that goes beyond span extraction and requires numerical, logical, and discrete reasoning grounded in text.
- It remains a canonical benchmark for assessing textual reasoning with numbers and has influenced numerous architectures and evaluation methods that integrate symbolic or programmatic reasoning into LLMs.
Dataset Overview
- Source: Passages drawn from Wikipedia.
- Scale: ~96,000 question–answer pairs.
- Format: Each instance consists of a paragraph and a question requiring counting, addition/subtraction, sorting, or comparison.
-
Answer types: integers, dates, or text spans that must be computed, not just extracted.
- Example:
- Paragraph: “The Lakers scored 30 points in the first quarter, 27 in the second, and 33 in the third.”
- Question: “How many points did they score in the first three quarters?”
- Answer: 90.
- A standard span-based model (like BERT QA) fails here because the answer does not appear verbatim in the paragraph—it must be derived.
Motivation and Reasoning Focus
- DROP was created to probe whether language models can perform discrete reasoning operations—arithmetic, comparison, and logic—over textual contexts.
- It shifts evaluation from “pattern recognition” to programmatic inference, where solving a question entails recovering the latent computational procedure:
- Here, Extract identifies relevant numbers and entities, while Compute performs arithmetic or comparison.
Evaluation Metrics
-
Exact Match (EM):
\[\text{EM} = \frac{1}{N}\sum_i \mathbb{I}[y_i = y_i^\star]\]- This metric is strict—minor numeric formatting differences cause failure.
- F1 (Token-level Overlap):
- Measures partial overlap for non-numeric answers (e.g., names, events).
- Programmatic Evaluation (Optional):
- Later models include execution-based scoring where answers are verified via symbolic solvers.
- Rationale Correctness:
- Optional metric where model-generated reasoning chains are compared against gold reasoning traces.
Baselines and Key Results
- BERT + span extraction (2019 baseline): ~33 F1 on dev set—failed on arithmetic.
- NumNet and NAQANet by Dua et al. (2019): introduced neural modules for number reasoning (addition, counting).
- T5, GPT-3, GPT-4 family models (2020–2024): surpassed 90 F1 using CoT and tool-augmented reasoning (calling calculators or parsers).
- ReAct frameworks (see Yao et al. (2022)): used reasoning + acting loops to dynamically extract, compute, and verify numeric answers.
Reasoning Interfaces and Enhancements
- CoT + Numeric Parsing
- LLMs produce structured reasoning steps such as:
Let's add the points: 30 + 27 + 33 = 90. The answer is 90.- Evaluation then checks whether intermediate steps correspond to correct operations.
- Tool-Augmented Solvers
- Toolformer (Schick et al. (2023)) and PAL (Gao et al. (2022)) approaches delegate computation to external interpreters (Python), converting reasoning into verifiable program traces.
- Process Verification
- Verifier-based checks, inspired by GSM8K’s verification setup (Cobbe et al. (2021)), score the consistency between the reasoning chain and the numerical result.
Dataset Extensions and Successors
- QASC (Khot et al. (2020)): tests multi-hop science reasoning with facts, complementing DROP’s numerical focus.
- MathQA-NL (Amini et al. (2019)): converts math word problems into natural language arithmetic reasoning tasks.
- NumGLUE (Lin et al. (2022)): provides broader numeric reasoning tasks across diverse NLP settings.
Key Insights from DROP
- Discrete reasoning is bottlenecked by arithmetic grounding, not linguistic comprehension.
- Tool augmentation consistently boosts performance by externalizing computation.
- Self-verification (reflection) improves robustness to arithmetic hallucinations.
- Evaluation beyond accuracy—including reasoning trace validity—is essential for judging genuine reasoning.
BIG-bench and BIG-bench Hard
-
The Beyond the Imitation Game Benchmark (BIG-bench), introduced by Srivastava et al. (2022), is a large-scale collaborative benchmark suite for evaluating general reasoning and knowledge in LLMs. It comprises over 200 diverse tasks contributed by more than 400 researchers, covering linguistic reasoning, commonsense, symbolic manipulation, arithmetic, logical deduction, and social intelligence.
-
The follow-up subset BIG-bench Hard (BBH) by Suzgun et al. (2022) isolates tasks where small and medium models fail but large models succeed, revealing sharp thresholds in reasoning performance.
Purpose and Structure
-
BIG-bench’s goal is to measure emergent capabilities—behaviors that appear only once models cross certain scale or training thresholds. Each task consists of an input prompt, model-generated completion, and ground-truth reference, with metrics varying by task type (accuracy, BLEU, likelihood, etc.).
-
Task families include:
- Symbolic and logical reasoning: arithmetic, boolean algebra, sorting, and pattern completion.
- Commonsense reasoning: physical causality, temporal logic, and counterfactual inference.
- Language understanding: ambiguity resolution, analogies, and narrative reasoning.
- Social and ethical reasoning: moral dilemmas, intent recognition, sarcasm detection.
BIG-bench Hard (BBH)
Motivation
-
In the original BIG-bench, task difficulty varied widely. To better analyze “emergence,” Suzgun et al. (2022) selected 23 particularly challenging tasks where:
- Small models (e.g., GPT-2 XL, 1.5B) performed at chance, but
- Larger models (e.g., PaLM 62B, 540B) showed steep accuracy gains.
-
These are called BIG-bench Hard tasks.
-
Examples of BBH tasks:
- Logical deduction and implication.
- Dyck language (balanced parentheses) recognition.
- Object counting and list manipulation.
- Strategy and planning puzzles.
- Hyperbaton (syntactic inversion) understanding.
Evaluation and Analysis
- Performance on BIG-bench and BBH is typically reported as accuracy or exact-match correctness.
-
Researchers also track performance curves over model scale to detect emergent “aha” transitions:
\[\text{Acc}_s = f(\text{params}_s)\]- where \(f\) shows near-flat trends for small models and steep rises once model capacity exceeds a critical threshold.
-
To reduce metric artifacts, Schaeffer et al. (2023) recommend supplementing discrete accuracy with smoother calibration or log-likelihood metrics.
-
Metrics typically used:
- Accuracy (binary/categorical tasks).
- BLEU or F1 (generation tasks).
- Calibration Error (ECE).
- Agreement with reasoning verifiers (for CoT versions).
Findings and Emergent Patterns
- Emergence with scale: Several tasks (e.g., logical deduction, hyperbaton) show abrupt accuracy jumps once model scale passes tens of billions of parameters.
- Prompting sensitivity: CoT and self-consistency often unlock previously latent competence.
- Task diversity: Certain reasoning domains (symbolic or mathematical) scale predictably, while others (commonsense, ethics) show flat curves.
- Interface effect: Some improvements reflect reasoning elicitation rather than new model structure—highlighting the importance of consistent evaluation.
BIG-bench as a Meta-Evaluation Platform
-
BIG-bench is not a single dataset but an evaluation framework:
- Tasks are JSON-based and standardized for easy replication.
- Each model’s results are published via the BIG-bench leaderboard.
- Later extensions (e.g., HELM by Liang et al. (2022)) adopt its multi-metric design philosophy.
Key Insights
- Reasoning as a function of scale: BBH tasks provide the cleanest empirical evidence of emergent reasoning, complementing the theoretical analyses of Wei et al. (2022).
- Variance across domains: Some reasoning abilities (e.g., symbolic manipulation) are more predictable under scaling than others (commonsense or analogical reasoning).
- Need for mixed metrics: Threshold metrics exaggerate “emergence” and should be balanced with probabilistic scores.
- Prompting and sampling matter: CoT and self-consistency often unlock hidden performance, showing that reasoning can be elicited rather than learned.
Relation to Other Benchmarks
| Benchmark | Focus | Reasoning Type | Metric |
|---|---|---|---|
| GSM8K | Multi-step arithmetic | Quantitative | EM, verifier accuracy |
| MATH | Symbolic derivation | Algebraic/logical | Symbolic EM |
| DROP | Numerical text reasoning | Discrete arithmetic | EM, F1 |
| BIG-bench | General reasoning (200+ tasks) | Mixed | Accuracy, calibration |
| BBH | Emergent reasoning subset | Symbolic, logical | Accuracy |
MMLU and AGIEval (Knowledge + Reasoning Exam Benchmarks)
- The Massive Multitask Language Understanding (MMLU) benchmark, introduced by Hendrycks et al. (2020), and the more recent AGIEval benchmark by Zhong et al. (2023), both measure broad general knowledge across disciplines such as science, law, history, and mathematics.
- However, they differ substantially in what kind of reasoning they test—and it’s important to distinguish factual recall from genuine reasoning ability when interpreting results.
- MMLU is a superb general-knowledge diagnostic but not a robust reasoning test. It measures what a model knows, not how it thinks. AGIEval fills that gap by reintroducing structured logical reasoning under exam-like constraints, making it a better choice when evaluating actual cognitive reasoning ability rather than recall.
MMLU: Strengths and Limitations
Overview
- MMLU consists of 15,908 multiple-choice questions drawn from 57 academic subjects spanning four difficulty levels: elementary, high school, college, and professional.
- Each question has four answer options and one correct answer.
- It was designed to evaluate broad world knowledge and academic competence—from U.S. history to physics to philosophy.
What it measures
- Despite being widely reported as a reasoning benchmark, MMLU primarily tests factual recall and concept recognition rather than multi-step reasoning.
- Many questions take the form: “Which of the following best describes the function of mitochondria?”*
- Such questions require retrieving a known fact rather than performing compositional inference or deduction.
- A smaller subset—particularly in mathematics, logic, and formal reasoning subdomains—do require actual reasoning, but these represent a minority.
- Formally, models solve most MMLU items by maximizing \(\hat{y} = \arg\max_y p_\theta(y\mid x)\), without needing to construct latent reasoning chains \(z\).
- The evaluation does not assess reasoning steps, explanations, or causal understanding.
Empirical pattern
-
Performance correlates strongly with model pretraining breadth and instruction-tuning, not with explicit reasoning training:
- GPT-4, Claude 3, and Gemini 1.5 Pro all exceed 85 % accuracy, approaching or surpassing average human expert performance.
- Smaller models (≤13B parameters) exhibit smooth scaling without discontinuous “aha” jumps.
- Reasoning-centric techniques (e.g., CoT prompting) yield only minor improvements—confirming that most tasks do not require stepwise inference.
-
Thus, MMLU is a great measure of factual competence and transfer learning, but a weak measure of true reasoning.
AGIEval: Toward Cognitive and Reasoning Exams
Overview
- AGIEval, introduced by Zhong et al. (2023), repositions evaluation around human standardized exams—SAT, LSAT, GRE, Gaokao, and CPA—to test not just recall but logical, linguistic, and numerical reasoning.
Dataset composition
- ~5,000 exam-style multiple-choice questions.
- Sources include real standardized tests with verified solutions.
- Domains: reading comprehension, logical reasoning, quantitative problem solving, and language understanding.
Why it matters
- AGIEval questions are structurally different from MMLU’s academic facts:
- They often require multi-step reasoning over text, e.g., drawing inferences, identifying assumptions, or evaluating argument strength.
-
Many items cannot be solved by simple lookup or pattern matching.
-
For instance:
“If all A are B, and some B are not C, which of the following must be true?”
- This demands deductive reasoning—something MMLU largely omits.
Evaluation metric
- Standard accuracy:
- Optionally augmented by process-based scoring for models that generate reasoning traces before selecting an answer (e.g., “Let’s think step by step”).
Empirical findings
- Models that use CoT prompting perform significantly better on AGIEval (up to +15 %), indicating real reasoning benefit.
- Human-level reasoning (90 %+) is not yet achieved even by frontier models; top systems like GPT-4 and Claude 3 remain around 70–80 %.
- Results on AGIEval correlate more closely with reasoning-heavy benchmarks like BBH and ARC-AGI-2 than with MMLU.
Comparative Analysis
| Benchmark | Scope | Reasoning Type | Nature of Difficulty | Primary Strength | Primary Weakness |
|---|---|---|---|---|---|
| MMLU | 57 subjects | Mostly factual, some conceptual reasoning | Wide domain coverage | Measures knowledge breadth and domain recall | Weak process reasoning, high data overlap risk |
| AGIEval | Human exams (SAT, LSAT, etc.) | Deductive, verbal, and quantitative reasoning | Deep text comprehension | Stronger reasoning discrimination | Smaller scale, limited public data |
HELM and Holistic Multi-Metric Reasoning Evaluation
- The Holistic Evaluation of Language Models (HELM) framework by Liang et al. (2022) proposes a new philosophy for evaluating reasoning in LLMs: rather than relying on single-number accuracy, it measures breadth, robustness, and calibration across many dimensions.
- HELM is not just a benchmark suite—it is an evaluation paradigm for reasoning systems that balances factuality, robustness, and process quality.
- In summary, HELM shifts reasoning evaluation from “Did the model get it right?” to “How, how confidently, and under what conditions did it get it right?”. It represents a new generation of reasoning benchmarks designed for robustness, transparency, and multi-dimensional competence rather than single-metric performance.
Motivation
- Prior benchmarks (like MMLU, GSM8K, or BIG-bench) tend to isolate narrow skills—either factual recall or specific reasoning patterns—and use coarse metrics such as exact match or accuracy.
-
HELM argues that such single-dimensional evaluations are incomplete and sometimes misleading, because real reasoning quality depends on trade-offs among multiple axes:
- Accuracy: Does the model produce the correct output?
- Calibration: Does the model know what it doesn’t know?
- Robustness: Is reasoning stable under paraphrase, perturbation, or prompt variation?
- Fairness and bias: Does reasoning remain consistent across demographic contexts?
- Efficiency: How much computation or prompting is required?
- Transparency: Can we interpret and reproduce the reasoning process?
-
This multidimensional framing turns reasoning evaluation into a Pareto optimization problem:
\[\text{Model quality} = \text{Pareto}(A, R, C, F, E, T)\]- where \((A, R, C, F, E, T)\) correspond to the six axes above.
Structure of HELM
- HELM integrates over 40 datasets covering reasoning, knowledge, and generative tasks.
-
Its reasoning-oriented subsets include:
- GSM8K (mathematical reasoning).
- DROP (numerical reasoning).
- BoolQ (yes/no logical reasoning).
- HellaSwag (commonsense reasoning).
- ARC-Challenge (science reasoning).
- BBH (emergent reasoning).
- For each dataset, HELM reports a consistent set of 12 metrics, not just accuracy. This enables a full performance “profile” for each model.
Key Evaluation Dimensions for Reasoning
-
Process fidelity Does the model’s reasoning trace (if produced) align with valid logical steps? Process supervision (as in Lightman et al. (2023)) can be embedded into HELM evaluation pipelines.
-
Factual consistency Measures alignment between reasoning steps and external knowledge sources—important for fact-based reasoning tasks. Derived from factuality literature (see Min et al. (2023)).
-
Calibration of confidence Uses metrics like Expected Calibration Error (ECE) or Brier score to test whether probability estimates match correctness likelihood. For reasoning, this checks whether the model’s “confidence” reflects reasoning soundness.
-
Robustness and generalization Evaluates whether reasoning quality persists under paraphrasing or domain shifts—e.g., testing multiple phrasings of GSM8K or DROP problems.
-
Efficiency and scalability Tracks compute usage per query and sensitivity to sampling parameters (temperature, top-k). Helps reveal when reasoning improvements depend on costly inference techniques (e.g., self-consistency with 50 samples).
HELM as Meta-Evaluation Infrastructure
-
HELM is modular and extensible:
- Provides a standard API for adding reasoning tasks.
- Normalizes metrics across datasets, allowing meaningful comparison of reasoning vs. recall performance.
- Exposes Pareto frontiers—plots showing trade-offs among metrics (e.g., accuracy vs. calibration).
- Example:
- A model that is 2 % less accurate but 30 % better calibrated may be preferable for safety-critical reasoning.
- Open evaluation dashboards are maintained at https://crfm.stanford.edu/helm, where recent LLMs (GPT-4, Claude 3, Gemini, Llama 3) are compared under identical metrics and contexts.
Insights from HELM on Reasoning Evaluation
- Reasoning quality is multidimensional: Pure accuracy hides calibration or brittleness problems.
- Bigger isn’t always better: Some smaller, specialized models show higher process fidelity despite lower overall accuracy.
- Process metrics matter: Explicit reasoning supervision yields better calibration and factual consistency scores even when raw accuracy changes little.
- Benchmark unification helps generalization: Comparing performance across multiple reasoning datasets reveals consistent failure modes (e.g., arithmetic carry errors, logic reversals).
Tabular Summary
| Property | Description |
|---|---|
| Goal | Unified, multi-metric evaluation of LLM reasoning and knowledge |
| Key Metrics | Accuracy, calibration, robustness, fairness, efficiency, transparency |
| Core Idea | Reasoning should be judged holistically, not just by EM or accuracy |
| Representative Paper | HELM: Holistic Evaluation of Language Models by Liang et al. (2022) |
Multimodal reasoning and factuality
- Multimodal reasoning asks an LLM to integrate symbols from different channels—pixels, text, diagrams, charts—into a coherent computation. A practical lens is to treat visual evidence \(v\) as additional latent structure alongside textual thoughts \(z\):
- Strong systems learn when to attend to pixels versus text, how to ground numbers and entities visually, and how to verify intermediate steps with tools (e.g., OCR, symbolic math). Below is an overview of core model families, reasoning interfaces, and evaluation datasets, with factuality concerns specific to the vision–language setting.
Architectural families
-
Encoder–LLM adapters: Vision features flow into a frozen or lightly tuned LLM through learned adapters/gates. Representative examples include Flamingo by Alayrac et al. (2022). These models handle interleaved image–text streams and support few-shot visual learning.
-
End-to-end LVLMs with visual instruction tuning: LLaVA scales a vision encoder + LLM via curated “visual instruction” data to unlock step-by-step multimodal dialogue; see Visual Instruction Tuning (LLaVA) by Liu et al. (2023) and the LLaVA project page).
-
Embodied multimodal models: PaLM-E projects continuous robot/vision observations into a language space to support grounded planning and question answering, demonstrating cross-modal transfer from VL tasks to real-world control by Driess et al. (2023) (Project page).
Reasoning interfaces
-
Multimodal CoT: Extend textual CoT with visual grounding: first generate a rationale that references detected objects/regions, then infer the answer. Multimodal CoT by Zhang et al. (2023) (OpenReview: https://openreview.net/forum?id=gDlsMWost9) formalizes a two-stage pipeline: rationale generation followed by answer inference.
-
Tool-augmented visual reasoning: For charts, documents, and math-in-images, models benefit from OCR, table parsers, and Python execution. This effectively computes:
\[\hat{y}=\arg\max_y \sum_{z}, V \big(z,\text{OCR}(v),\text{Exec}(\cdot)\big),p_\theta(z\mid x,v)\]- where \(V\) is a verifier combining visual extraction with symbolic checks.
Evaluation datasets (breadth to depth)
-
General science, images + text: ScienceQA couples images with short curricula and annotated explanations, enabling process-aware scoring; see Learn to Explain: Multimodal Reasoning via Thought Chains for ScienceQA by Lu et al. (2022) and the project page. LLaVA-style visual instruction tuning reports large gains on this set.
-
Reading text in images (OCR-centric QA): TextVQA targets questions that depend on reading text in the scene—classic failure mode for purely semantic vision models; see Towards VQA Models That Can Read by Singh et al. (2019) and dataset hub).
-
Charts and data graphics: ChartQA evaluates numerical and logical reasoning over plots, where correctness hinges on faithful extraction and computation by Masry et al. (2022). Recent extensions like ChartQA-X add stepwise explanations.
-
Math in visual contexts: MathVista aggregates 28 sources and introduces new subsets (IQTest, FunctionQA, PaperQA) to probe diagram/math reasoning with images by Lu et al. (2023). It’s a strong stress test for multimodal CoT + tools.
-
Documents and forms (DocVQA family): DocVQA tasks require layout-aware reasoning (reading, aligning fields, aggregating numbers); canonical overviews appear in early DocVQA work by Mathew et al. (2021) and successors (surveyed across the DocVQA track). Note: exact subsets vary; evaluation typically combines span accuracy with structure-aware metrics.
Multimodal factuality: common failure modes and checks
-
Hallucinated perception: Models assert objects/text that are not present. Mitigation: require OCR/string citations from the image (evidence-required prompting) and penalize unsupported claims in the rationale.
-
Numeracy and unit grounding: Chart/diagram answers drift when units or scales are misread. Mitigation: explicit extraction–compute pipelines (ChartQA/MathVista style) and execution-based verification.
-
Visual–text consistency: Rationales must cite specific regions or tokens; require a verifier that re-reads the referenced region or re-parses the figure. ScienceQA’s annotated explanations are useful here.
-
Robustness to rendering/quality: Performance can collapse under low-resolution, skewed scans, or font variations—especially for OCR-heavy tasks (TextVQA, DocVQA). Reporting should include perturbation tests and confidence–accuracy calibration.
Takeaways
- Multimodal reasoning benefits most from explicit grounding and tools: CoT alone is often insufficient when numbers or text must be read from images.
- Evaluation should pair outcome accuracy with process fidelity: require models to show which pixels/strings support each step and verify with OCR/symbolic checks.
- Benchmarks like ScienceQA, TextVQA, ChartQA, and MathVista collectively surface perception, grounding, and computation—three pillars of multimodal factuality.
Summary of reasoning evaluation datasets and their interrelations
- Having surveyed the major reasoning benchmarks individually, this section consolidates them into a structured map of reasoning evaluation—covering mathematical, scientific, linguistic, multimodal, and factual reasoning. The goal is to highlight the complementary nature of datasets and clarify which reasoning dimensions each one probes.
Taxonomy of reasoning datasets
-
We can group reasoning benchmarks along two orthogonal axes:
- Reasoning type: arithmetic, symbolic, causal, commonsense, multimodal, etc.
- Evaluation focus: process vs. outcome, factual vs. abstract, single vs. multi-modal input
-
The resulting taxonomy looks as follows:
| Tier | Dataset | Domain | Reasoning Type | Input Modality | Eval Type | Process Evaluation | Level |
|---|---|---|---|---|---|---|---|
| 1 | GSM8K (Cobbe et al. (2021)) | Arithmetic | Quantitative, multi-step | Text | Exact Match, verifier | Yes | Grade-school |
| 2 | MATH (Hendrycks et al. (2021)) | Algebraic, symbolic | Formal derivation | Text, LaTeX | Symbolic equivalence | Yes | High school–college |
| 3 | AIME (OpenAI (2023)); Guo et al. (2025) | Olympiad math | Logical synthesis | Text | Numeric EM | Partial (trace) | Olympiad |
| 4 | IMO / MiniF2F (Zheng et al. (2021)) | Formal math | Proof reasoning | Text + Formal | Theorem check | Full | Olympiad/formal |
| 5 | DROP (Dua et al. (2019)) | Reading + arithmetic | Discrete reasoning | Text | EM, F1 | Optional | Middle/high school |
| 6 | ARC-AGI-1 (Clark et al. (2018)) | Science QA | Causal/multi-hop | Text | Accuracy | Partial | K–12 |
| 7 | ARC-AGI-2 (Clark et al. (2023)) | Abstract reasoning | Symbolic induction | Grid images | Task accuracy | Implicit | AGI-level abstraction |
| 8 | BIG-bench (Srivastava et al. (2022)) | Multi-domain | Logical, analogical, commonsense | Text | Accuracy | Limited | General |
| 9 | BIG-bench Hard (Suzgun et al. (2022)) | Subset (hard tasks) | Symbolic logic | Text | Accuracy | Some | Emergent reasoning |
| 10 | MMLU (Hendrycks et al. (2020)) | Academic exams | Knowledge recall | Text | Accuracy | No | Factual |
| 11 | AGIEval (Zhong et al. (2023)) | Human exams | Deductive, linguistic, numerical | Text | Accuracy | Some | Reasoning-heavy |
| 12 | HELM (Liang et al. (2022)) | Multi-domain | Holistic reasoning + factuality | Mixed | Multi-metric (12 metrics) | Yes | Meta-eval |
| 13 | ScienceQA (Lu et al. (2022)) | Visual science | Multimodal + causal | Image + text | EM, rationale F1 | Yes | Multimodal reasoning |
| 14 | ChartQA (Masry et al. (2022)) | Charts and graphs | Quantitative visual reasoning | Image + text | EM | Partial | Multimodal numeric |
| 15 | MathVista (Lu et al. (2023)) | Diagram math | Symbolic visual | Image + text | Accuracy, process check | Yes | Multimodal symbolic |
| 16 | TextVQA (Singh et al. (2019)) | OCR-based QA | Perceptual reasoning | Image | Accuracy | No | Visual perception |
| 17 | FEVER (Thorne et al. (2018)) | Fact verification | Factual consistency | Text | Accuracy, entailment | No | Factual verification |
| 18 | SciFact (Wadden et al. (2020)) | Science claims | Factual + causal | Text | Accuracy, entailment | Some | Research reasoning |
Conceptual clusters
-
Reasoning datasets cluster naturally into five meta-domains:
-
Quantitative reasoning: GSM8K, MATH, AIME, IMO, DROP, NumGLUE.
- Evaluates symbolic arithmetic and algebraic reasoning.
- Process-verifiable with numeric or symbolic solvers.
-
Causal and commonsense reasoning: ARC, ScienceQA, ATOMIC, AGIEval.
- Tests everyday and scientific causal inference.
- Often factual but requires multi-hop logic.
-
Abstract and algorithmic reasoning: ARC-AGI-2, BIG-bench Hard.
- Measures rule discovery and compositional generalization.
- Evaluates systematic reasoning beyond retrieval.
-
Multimodal reasoning: ScienceQA, ChartQA, MathVista, TextVQA.
- Combines perception with reasoning over visual/text inputs.
- Central for factual grounding and cross-modal coherence.
-
Factual reasoning and calibration: MMLU, HELM, FEVER, SciFact.
- Tests whether reasoning aligns with external truth.
- Important for assessing faithfulness and factual grounding.
-
Process vs. outcome alignment
- Reasoning benchmarks differ not only in difficulty but in whether they evaluate process fidelity or merely final correctness.
Here is your table formatted according to the specified style:
| Evaluation Dimension | Process-aware | Outcome-only |
|---|---|---|
| Step validation | GSM8K, MATH, ScienceQA, HELM | MMLU, AGIEval |
| Verifier presence | GSM8K, DeepSeek-R1, PAL tasks | ARC-AGI-1, ARC-AGI-2 |
| Multi-modal alignment | ScienceQA, ChartQA, MathVista | TextVQA |
| Factual trace scoring | FEVER, SciFact, HELM | None (factual EM only) |
- A general trend emerges: datasets built after 2022 increasingly support process-level scoring, allowing reasoning verification rather than answer-only grading.
Complementarity in reasoning diagnostics
-
Different benchmarks expose different weaknesses:
- GSM8K \(\rightarrow\) Arithmetic chain stability.
- DROP \(\rightarrow\) Numeric grounding errors.
- MATH \(\rightarrow\) Symbolic generalization.
- AGIEval \(\rightarrow\) Deductive reasoning under linguistic ambiguity.
- ARC-AGI-2 \(\rightarrow\) Compositional abstraction.
- ChartQA / MathVista \(\rightarrow\) Grounded multimodal computation.
- HELM \(\rightarrow\) Multi-metric reasoning balance (accuracy vs. calibration).
-
Comprehensive reasoning evaluation therefore requires cross-benchmark triangulation, where performance consistency across clusters (e.g., math + causal + factual) signals genuine general reasoning ability rather than domain memorization.
Evolutionary timeline of reasoning datasets
| Period | Representative Datasets | Evaluation Trend |
|---|---|---|
| 2018–2019 | FEVER, DROP, ARC-AGI-1 | Simple factual or numerical reasoning |
| 2020–2021 | MMLU, MATH, SciFact | Broader academic reasoning; factual grounding |
| 2022 | BIG-bench, BBH, ScienceQA | Emergence and multimodality |
| 2023 | ARC-AGI-2, AGIEval, ChartQA | Abstraction and exam-level reasoning |
| 2024–2025 | MathVista, DeepSeek-R1 evals, AIME24, HELM 2.0 | Process-level and verifier-based evaluation |
Takeaways
- No single dataset fully captures “reasoning ability.”
- Process-level evaluation (verifier-based) is key for distinguishing reasoning from memorization.
- Factual and multimodal reasoning datasets highlight grounding and calibration as equally important dimensions.
- Emergent models (DeepSeek-R1, o1) show consistent gains across process-verifiable datasets—suggesting genuine reasoning generalization, not just surface recall.
- Future benchmarks will likely blend structured multimodal reasoning (MathVista-style) with holistic factual calibration (HELM-style).
Open challenges and future directions
-
Reasoning with LLMs has progressed from prompt tricks to trained policies with verifiers and tools, yet several core problems remain unresolved. Below are the most pressing research directions, each tied to concrete technical hurdles and representative papers.
-
Data quality, contamination, and measurement artifacts:
- Benchmarks can overstate progress if train/eval leakage or near-duplicates creep in, and thresholded metrics can manufacture “emergence.” Robust pipelines need aggressive deduplication, contamination audits, and smooth metrics (log-probability, Brier/ECE) alongside exact match. Deduplication reduces spurious gains as shown in Deduplicating Training Data Makes Language Models Better by Lee et al. (2021/2022); “mirage” emergence warns against overinterpreting cliffs in accuracy by Schaeffer et al. (2023).
-
From outcome accuracy to process fidelity at scale:
- We still lack scalable, low-cost ways to label and score intermediate steps. Process supervision (step-level rewards) outperforms final-answer rewards but is expensive to collect. A central agenda is bootstrapping verifiers and critics that generalize across tasks. Let’s Verify Step by Step by Lightman et al. (2023) and its companion report show sizable gains from process rewards; future work must automate step labeling and verification.
-
Stable credit assignment for long-horizon reasoning:
- Policy-gradient signals become sparse and high-variance as chains lengthen. Practical objectives combine outcome reward, step rewards, and parsimony penalties:
- Recent reasoning-RL systems (e.g., DeepSeek-R1 by Guo et al. (2025)) highlight training instabilities and the need for stronger variance reduction, curriculum schedules, and verifier shaping.
-
Grounded factuality via retrieval and editing:
- Parametric memory drifts; factual grounding demands retrieval that is updatable, precise, and uncertainty-aware. Retrieval-enhanced training and inference (RETRO by Borgeaud et al. (2021); Atlas by Izacard et al. (2022)) remain pillars, but integrating them with CoT and verifiers is under-explored. When knowledge is wrong, targeted causal edits (ROME/CounterFact by Meng et al. (2022)) open a path to consistent belief repair, yet large-scale, persistent editing with guarantees is still open.
-
Program-of-Thought and execution-first reasoning:
- Moving heavy computation out of the model and into tools reduces hallucinations and increases verifiability, but raises planner–executor alignment issues. Program-of-Thought Prompting by Chen et al. (2022) and follow-ups show strong math/finance gains when the model writes code that an external interpreter executes; robust abstractions for error propagation, partial credit, and debugging remain open problems.
-
Interface pathologies: overthinking, loops, and search collapse:
- Reasoning interfaces can induce failure modes like endless reflections, non-terminating searches, or degraded accuracy at higher “deliberation” budgets. Emerging reports discuss “overthinking” and coordination frameworks for multi-agent/compound inference; engineering reliable halting, pruning, and verifier-guided expansion at scale is an unsolved systems problem. See over-deliberation discussions in recent industry reports and news coverage.
-
Mechanistic understanding of reasoning representations:
- We lack consensus on what internal circuits implement algorithmic behavior. Induction heads offer a mechanistic account of in-context sequence copying by Olsson et al. (2022), and sparse-autoencoder work on monosemantic features suggests progress toward disentangling concept subspaces (Decomposing Language Models With Dictionary Learning by Elhage et al. (2023/2024); Scaling Monosemanticity by Nanda et al. (2024)). Extending these analyses to multi-step arithmetic, formal logic, and tool orchestration is a key scientific challenge.
-
Multimodal grounding and verifiable perception-to-reasoning:
- For charts, documents, and diagrams, factual errors often originate in perception (OCR, scale reading). Research must close the loop between perception and symbolic checks: cite the pixels/strings used, verify with OCR/table parsers, and execute numeric steps. Surveys and datasets like ChartQA by Masry et al. (2022), MathVista by Lu et al. (2023), and ScienceQA by Lu et al. (2022) point to evaluation designs where every step is grounded and checkable.
-
Holistic evaluation and governance:
- Reasoning quality is multidimensional—accuracy, calibration, robustness, and transparency must be reported together to avoid brittle systems optimized for one metric. HELM by Liang et al. (2022) is a template for multi-metric, cross-benchmark reporting; extending it with process fidelity and verifier agreement would better reflect real reliability.
-
Toward continually updatable, auditable reasoning systems:
- Production deployments need traceable reasoning artifacts, versioned prompts, reproducible seeds/temperatures, and auditable tool calls. Retrieval corpora and verifiers must be refreshable without catastrophic drift, ideally with automated regression tests spanning GSM8K, MATH, DROP, ARC-AGI-2, and multimodal suites.
-
A research synthesis:
- Many challenges rhyme: better verifiers reduce RL variance; stronger retrieval reduces hallucinated premises; mechanistic insight informs curriculum and interface design; execution-first approaches simplify verification but demand robust planners. A plausible near-term stack is retrieval-grounded, tool-augmented generation with verifier-guided decoding and process rewards—evaluated holistically and audited end-to-end.
- For comprehensive state-of-the-field perspectives, see Reasoning with Large Language Models, a Survey by Zhu et al. (2024) and recent surveys on RAG by Gao et al. (2024).
Bringing it together—end-to-end blueprints for reasoning systems (small, medium, large budgets)
-
This section distills the earlier material into three concrete, reproducible stacks for building auditable reasoning systems. Each blueprint includes data, training, inference, verification, and reporting. Citations point to canonical components: ReAct by Yao et al. (2022), PAL by Gao et al. (2022), Toolformer by Schick et al. (2023), Let’s Verify Step by Step by Lightman et al. (2023), and DeepSeek-R1 by Guo et al. (2025).
-
Small-budget blueprint (days, a few GPUs, no human labels):
-
Goal: get robust math/logic performance with verifiable answers using only open data and automated checks.
-
Data and tasks: Pick verifiable datasets: GSM8K, AIME (numeric), subsets of MATH with executable solutions. Build a checker \(V\) that accepts a final answer or reruns simple calculations (e.g., with PAL-style code). See PAL by Gao et al. (2022).
-
Base model and prompting: Start with a competent instruction model. Use few-shot CoT and a minimal ReAct scaffold for tool calls (calculator/Python), per Yao et al. (2022). Optionally teach tool usage with a tiny Toolformer-style corpus by Schick et al. (2023).
- Inference-time marginalization: Sample (K\in{5,10}) chains at temperature (T\approx 0.7); select with majority vote or a lightweight verifier:
\(\hat{y}=\arg\max_y \sum_{k=1}^{K}\mathbb{I}[y^{(k)}=y].\)
- If using a verifier \(V\), pick \(k^\star=\arg\max_k V(z^{(k)},y^{(k)})\). This is the self-consistency pattern supported by Lightman et al. (2023).
-
Tool-augmented execution: Adopt PAL-style execution: model writes small code snippets; a sandbox executes them; the result is fed back into the trace. This reduces arithmetic hallucinations (PAL by Gao et al. (2022)).
- Reporting: Always report exact-match plus smooth metrics (log-prob/Brier), sample budget \(K\), and failure analyses. Keep seeds and prompts fixed for reproducibility.
-
-
Deliverable: a lean, verifiable pipeline that often matches much larger models on GSM8K/AIME via execution and marginalization, without any supervised rationale data.
-
-
Medium-budget blueprint (weeks, modest RL, limited labeling):
- Goal: add process supervision and lightweight RL to stabilize reasoning chains and reduce variance.
-
Data and weak step labels: Collect a few thousand step-level labels on difficult subsets (e.g., MATH proof-y problems). Where human labels are scarce, auto-label with program checks (arithmetic steps, unit conversions). Use these to train a Process Reward Model (PRM) \(V_{\phi}(z_t)\in[0,1]\) as in Lightman et al. (2023).
-
RL objective with process shaping: Optimize a composite reward for sampled traces \(z\) and answer \(y\): \(R=\lambda_1\text{Correct}(y)+\lambda_2\sum_{t}\text{StepOK}_\phi(z_t)-\lambda_3\text{Length}\)z\(.\) Apply a PPO/GRPO-style update to maximize \(\mathbb{E}[R]\). Even small \(\lambda_2\) stabilizes learning.
-
Interface alignment: During training, alternate between CoT-only and ReAct+PAL rollouts so the policy learns both narration and execution. Keep the inference interface identical to the training distribution to reduce mismatch.
-
Decoding with verifier guidance: At inference, use \(K\in{10,20}\) and select via \(V_\phi\) rather than pure majority vote; this yields accuracy gains at lower \(K\) versus vanilla self-consistency.
-
Reporting and audits: Release PRM calibration curves, ablations for \(\lambda_i\), and PRM agreement with human judges on a held-out set.
- Deliverable: a reasoner whose chains are shorter, more correct, and less brittle than the small-budget stack, with modest added compute.
-
Large-budget blueprint (months, full RL for reasoning, multi-stage training):
-
Goal: train an RL-shaped reasoner in the spirit of DeepSeek-R1 that discovers efficient latent computation without step labels. See Guo et al. (2025).
- ** Multi-stage schedule**:
- Stage A (readability/cold start): brief supervised tuning on tidy rationales to avoid unreadable chains.
- Stage B (outcome-only RL): scale rollouts on verifiable tasks (GSM8K, AIME, portions of MATH), reward only final correctness plus formatting penalties.
- Stage C (process shaping at scale): introduce a PRM or auto-checkers for partial shaping; anneal \(\lambda_2\) to favor concise, valid steps.
- ** Reward and exploration**:
- Use a clipped policy-gradient objective; include entropy regularization early, then anneal. Penalize degenerate formats and excessively long traces. Practical reward:
- ** Tooling and orchestration**:
- Adopt ReAct for retrieval and environment actions Yao et al. (2022), PAL for execution Gao et al. (2022), and optionally Toolformer-style self-supervised tool-use expansion Schick et al. (2023).
- ** Inference-time budget and routing**:
- Route problems by hardness: cheap single-chain for easy items; for hard items, use (K\in{16,32,64}) with verifier ranking and early stopping once top-1 confidence crosses a threshold. This controls cost while preserving accuracy.
- ** Governance and evaluation**:
- Report exact-match and verifier agreement; publish chain samples; include calibration (ECE), cost per query, and robustness to paraphrases. Track progress on AIME and difficult subsets of MATH; for frontier claims, include AGIEval and ARC-AGI-2 slices.
- ** Multi-stage schedule**:
-
Deliverable: an RL-shaped model that exhibits the “aha” stabilization of coherent chains reported by Guo et al. (2025), with auditable traces and strong results on process-verifiable math/logic.
-
-
Common pitfalls and guardrails:
-
Reward hacking: If the checker leaks format cues (e.g., always “Answer: ___”), policies will exploit it. Randomize formats; adversarially perturb prompts; log rewards and traces.
-
Over-deliberation: Longer chains are not always better. Add a penalty \(-\lambda_3\text{Length}\)z\(\), set hard step caps, and prefer verifier-guided early stopping.
-
Train–test interface mismatch: If you will decode with tools/verifiers, include them during training rollouts; otherwise, improvements may evaporate at inference.
-
Contamination and measurement: Audit training/eval overlap and report smooth metrics in addition to accuracy to avoid “mirage” emergence.
-
-
Minimal shopping list:
- Papers and patterns to implement now: ReAct by Yao et al. (2022), PAL by Gao et al. (2022), Toolformer by Schick et al. (2023), PRM via Let’s Verify Step by Step by Lightman et al. (2023), and RL shaping per DeepSeek-R1 by Guo et al. (2025).
Failure analysis—diagnosing and fixing reasoning errors
-
Reasoning failures rarely stem from a single cause. They are usually mixtures of misread premises, brittle decoding, missing knowledge, arithmetic slips, or unfaithful chains. This section gives a practical taxonomy, diagnostic tests, and fixes you can apply systematically.
-
A practical taxonomy of reasoning failures:
-
Premise errors (factually wrong inputs or retrieved evidence): Typical sign: the chain is logical but starts from a false statement. Use targeted fact-check prompts or retrieval with citations; score truthfulness with TruthfulQA-style probes by Lin et al. (2021).
-
Computational slips (arithmetic/logic mistakes): Look for off-by-one, sign errors, unit mismatches. Prefer execution-first steps (e.g., write-and-run code) rather than verbal math.
-
Unfaithful CoT (the narrative doesn’t reflect the model’s actual decision path): Detect by intervening on steps and seeing whether the answer changes; see Measuring Faithfulness in CoT Reasoning by Lanham et al. (2023) and Faithful CoT Reasoning by Lyu et al. (2023).
-
Hallucinated specifics (spurious names, dates, citations): Black-box detection via answer self-disagreement (sample multiple continuations and compare); SelfCheckGPT by Manakul et al. (2023).
-
Interface pathologies (overthinking, loops, search collapse): Symptoms: very long chains with worse accuracy, repeated tool calls, or circular reflections. Use stricter halting and verifier gating.
-
-
Minimal diagnostic protocol (fast triage):
-
Given an input \(x\), run this four-pass check:
-
Pass A: Direct answer and calibrated confidence: Record log-probability of the chosen answer or an external calibration proxy (e.g., temperature-scaled vote share).
-
Pass B: Diverse chains (self-consistency): Sample \(k\) chains; compute answer plurality and chain variance. Large disagreement signals fragile reasoning.
-
Pass C: Fact-check the premises: For each factual claim \(c_j\) in the chain, check entailment against retrieved evidence or a truthfulness probe set (TruthfulQA) by Lin et al. (2021).
-
Pass D: Self-contradiction test:
-
Run SelfCheckGPT-style resampling; if paraphrased prompts or mutated questions flip key claims, flag as hallucination risk by Manakul et al. (2023).
-
A quick quantitative signal is the “consistency gap”:
\[\Delta_{\text{cons}} = 1 - \max_y \frac{1}{K}\sum_{k=1}^{K}\mathbb{I} \left[y^{(k)}=y\right]\]- where large \(\Delta_{\text{cons}}\) indicates unstable latent thoughts.
-
-
-
-
Root-cause drills:
-
Premise errors \(\rightarrow\) add retrieval and cite: Adopt retrieval-augmented generation (RAG) and require citations for each premise; see the RAG survey by Gao et al. (2023/2024). Pair retrieval with a verifier that checks whether each step is supported by evidence.
-
Unfaithful CoT \(\rightarrow\) intervene and re-evaluate: Apply counterfactual edits to the rationale (swap a correct substep with a wrong one) and watch if the answer changes; procedures in Lanham et al. (2023) and Lyu et al. (2023).
-
Hallucinated specifics \(\rightarrow\) self-agreement and metamorphic tests: Use SelfCheckGPT variance as a black-box detector; add metamorphic prompt mutations (rephrase, reorder facts). For a recent metamorphic variant, see MetaQA by — (2025).
-
Missing knowledge \(\rightarrow\) store and reuse working: Attach rationale memory to RAG so successful chains are retrieved next time; ARM-RAG by Melz et al. (2023).
-
-
Fixes that usually work (in the right order):
-
Shorten and execute: Prefer program-aided steps for math/logic; compute intermediate values with a tool rather than narrating them.
-
Gate with a verifier: Train a lightweight verifier \(v\) (or process reward model) to score steps; reject or resample chains below a threshold \(\tau\). This turns decoding into search-with-checks.
-
Add retrieval with citations: Require each factual step (z_t) to cite evidence; reject chains with unsupported claims. Retrieval summaries should be kept short and source-linked (RAG survey by Gao et al. (2023/2024)).
-
Calibrate confidence: Estimate confidence from vote share over (K) chains or from verifier scores. Report answers only when (p(\text{correct})) exceeds a threshold.
-
-
Instrumentation and metrics you should log:
-
Let \(z=(z_1,\dots,z_T)\) be a chain.
-
Process factuality: \(\text{PF}\)z\(=\frac{1}{T}\sum_{t=1}^{T}\mathbb{I}[z_t\ \text{is supported/true}]\). Compute via evidence entailment or symbolic checks; unfaithfulness tests follow Lanham et al. (2023).
-
Self-agreement and premise stability: Track variation across resamples and under prompt mutations; SelfCheckGPT by Manakul et al. (2023).
-
Truthfulness under adversarial prompts: Evaluate on a truthfulness set (e.g., TruthfulQA) to detect systematic falsehoods by Lin et al. (2021).
-
-
Cookbook: from symptom to fix:
-
The model gives confident but wrong facts: Action: enable retrieval + citation; reject answers lacking corroboration. Add TruthfulQA-style adversarial questions to regression tests by Lin et al. (2021).
-
Chains look fine but answers flip on minor prompt edits: Action: run SelfCheckGPT; if unstable, increase K, add verifier gating, or force execution for fragile steps by Manakul et al. (2023).
-
Long, meandering chains with lower accuracy: Action: add length penalties, early stopping once verifier confidence crosses \(\tau\); prune repeated tool calls.
-
Correct premises, wrong algebra: Action: switch to program-of-thought/execution-first; verify each numeric step.
-
-
Takeaway:
- Failure analysis works best when you make errors observable. That means shorter, tool-executed steps; retrieval with citations; verifier scores; and consistency checks. Together, these turn opaque failures into actionable bugs—so you can fix the right thing, in the right order.
Further Reading
- ARC Prize: Advancing Human-Level Reasoning in AI
- DeepSeek Project Overview
- OpenAI Research Blog: Reasoning in GPT Models
- Anthropic Research: Constitutional AI and Reasoning Safety
- Google DeepMind Blog: Towards AGI-Level Reasoning
- Microsoft Research: Tool-Use and Reasoning in Language Models
- Meta AI Blog: Advances in Multimodal Reasoning
- Stanford Center for Research on Foundation Models (CRFM)
- Berkeley Artificial Intelligence Research (BAIR) Blog: Scaling and Reasoning
- EleutherAI Research Forum
- ARC-AGI Benchmark Leaderboard
- Hugging Face Leaderboards: Reasoning and Math Tasks
- Papers with Code: Reasoning Benchmarks
- LangChain Documentation: Building ReAct and Tool-Augmented Agents
- AutoGPT GitHub Repository
- OpenDevin: Open Source Framework for Reasoning Agents
- DeepSeek-R1 Technical Overview and Benchmarks
- LLM-MCTS Implementations and Tutorials
- ToolBench Dataset and API Hub
- PAL (Program-Aided Language Models) Repository
References
Prompting-Based and Decoding–Aggregation Reasoning
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- Self-Consistency Improves Chain-of-Thought Reasoning in Language Models
- From Sparse to Rich Reasoning: The “Aha Moment” in LLMs
- Faithful Reasoning Using Large Language Models
- Reasoning Benchmarks: Survey and Analysis
Search-Based Reasoning
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models
- A Survey of Monte Carlo Tree Search Methods
- Reasoning with Language Models is Planning with World Models (RAP)
- Critic–Judge: Evaluating Reasoning Chains with Critique Models
Reflection and Self-Verification
- Reflexion: Language Agents with Verbal Reinforcement Learning
- Self-Refine: Iterative Refinement with Self-Feedback
- RCOT: Reflective Chain-of-Thought Learning
Tool-Augmented and Interaction-Based Reasoning
- Toolformer: Language Models Can Teach Themselves to Use Tools
- ReAct: Synergizing Reasoning and Acting in Language Models
- Program-Aided Language Models (PAL): Improving Reasoning with Code Execution
- Gorilla: Large Language Model Connected with Massive APIs
- LLM-Augmented Reasoning: Integrating Tool Use in Language Models
- ToolBench: Benchmarking Large Language Models for Tool Learning
Reinforcement Learning and Policy-Based Reasoning
- DeepSeek-R1: Encouraging Reasoning in LLMs via Reinforcement Learning
- Beyond the Imitation Game: Quantifying and Improving LLM Reasoning
Benchmark and Evaluation Datasets
- MMLU: Measuring Massive Multitask Language Understanding
- ARC-AGI: Evaluating Reasoning and Abstraction in Artificial General Intelligence
- AIME-Level Mathematical Reasoning in Large Language Models
- IMO-AGI: Benchmarking Mathematical Olympiad-Level Reasoning in Language Models
Citation
@article{Chadha2020DistilledReasoningInLLMs,
title = {Reasoning in LLMs},
author = {Chadha, Aman and Jain, Vinija},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}