Primers • Padding
- Overview: Why We Pad
- Fixed Padding (using Dataset Statistics)
- Dynamic Padding (using Per-batch Padding)
- Uniform Length Batching/Grouping by Length (using Per-Batch Padding after Sorting)
- References
- Citation
Overview: Why We Pad
- GPUs are much more efficient when we can give them multiple training samples to work on in parallel, so we give them a “batch” of samples.
- In order for the GPU to operate on a batch, however, all of the inputs need to be of the same length. Remember that a tensor has to be rectangular – you can’t have a ragged edge. (Generalize this to higher dimensions as needed.) But sequences are different lengths, as commonly seen in practice. To address this, we pad all of our input sequences to be a single fixed length. Padding is thus used to remove the ragged edge when sequences are different lengths.
- We also provide the model with an “attention mask” (or book-keep valid length) for each sample, which identifies the
[PAD]tokens and tells BERT to ignore them. - Batching the data differently can lead to different total lengths of batches (especially mixing inputs that distinctly differ in their sizes within the same minibatch) – as highlighted below – which can affect computational efficiency since computation on the padding tokens is useless.
- Side Note: It seems that the
[PAD]tokens may in fact have some small effect on accuracy of the model, as highlighted in Fine-Tuning and Evaluating BERT.
Fixed Padding (using Dataset Statistics)
-
Below are some example sentences from a French dataset that have been tokenized with a French BERT model called CamemBERT. For the sake of illustration, let’s say that our dataset only consists of these 12 sentences, and we’re dividing them into 3 batches of 4 samples each. 
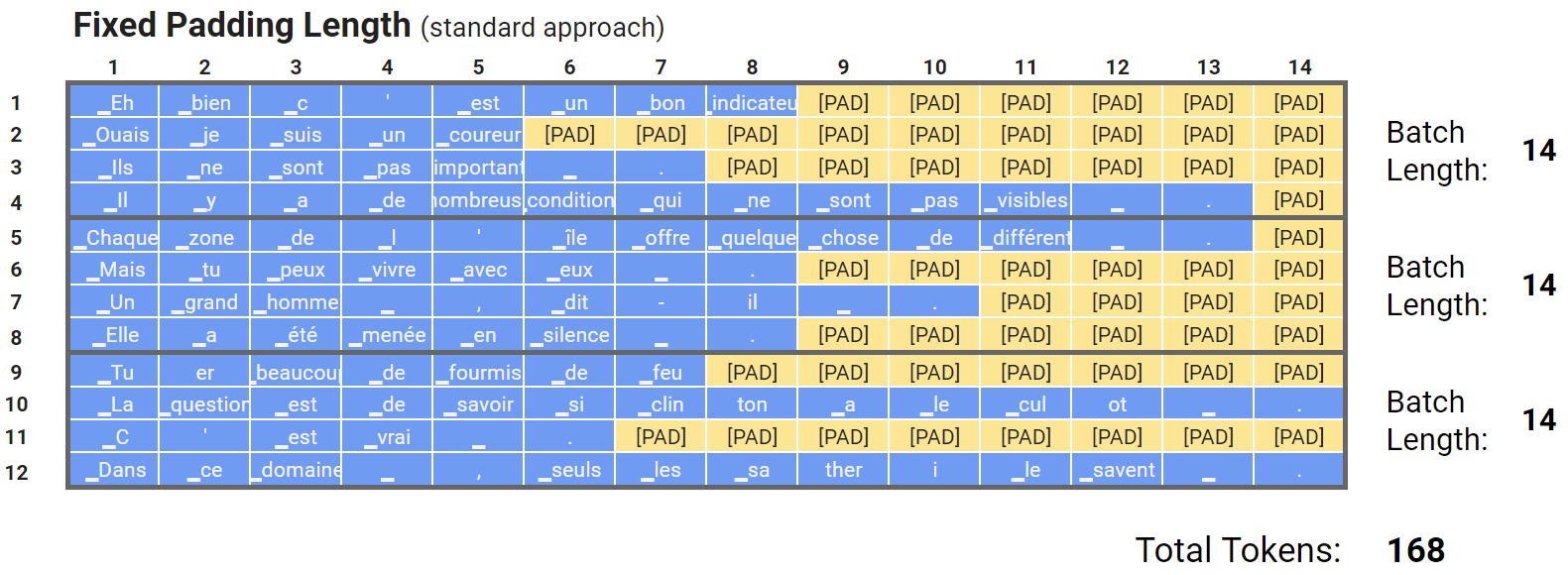
- In order to feed multiple samples into BERT at once, we are padding out all of the sentences to a length of 14 (to match the length of the longest sentence(s) in the dataset).
- This is the most common approach, and it’s certainly the simplest to implement, code-wise.
Cons of Fixed Padding
- Remember that irrespective of the size of the samples within each mini-batch, your model still runs to the length of our batch’s longest sequence.
- Fixed padding is inefficient because of the amount of work that needs to be done to process the sequences in our dataset (in this case, work worth 168 tokens). That might not be optimal; look at all that unnecessary work we did on the first batch! We’re wasting time on computation we never needed to do – computation work done on padding is thrown out anyway.
- This was obviously a toy example. For larger datasets the problem is more extreme – because the ratio between the longest and average sequence lengths in a batch can be larger.
Dynamic Padding (using Per-batch Padding)
- While the attention mask ensures that the
[PAD]tokens don’t influence BERT’s interpretation of the text, the[PAD]tokens are still fully included in all of the mathematical operations that BERT is performing. This means they do impact our speed for training and evaluation. - And although all of the samples within a batch need to be of the same length, BERT doesn’t care what length that is, and we can feed it batches of text with different maximum lengths!
-
(If you think about it, there’s nowhere in our code that we ever explicitly tell BERT what sequence length to expect from us. We pad our dataset to whatever length we want, and BERT processes it just fine). 
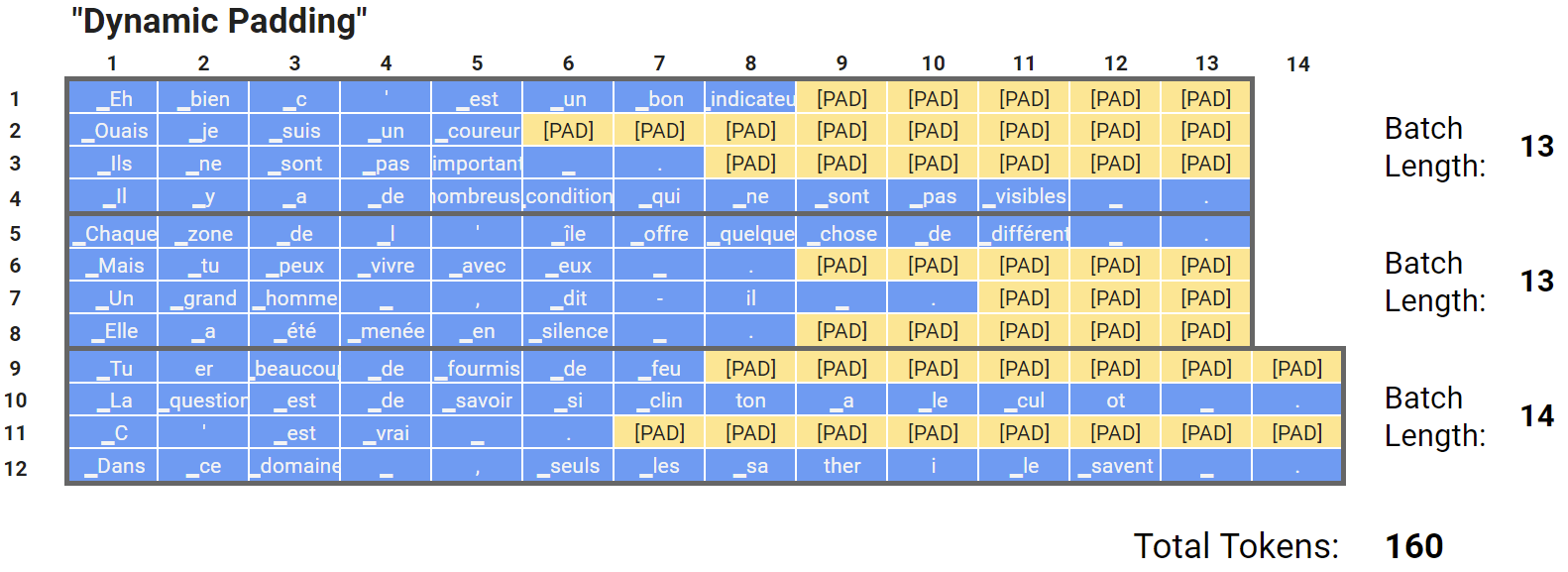
- So, if we’re willing to get more sophisticated with our code, we can customize our padding for each batch. This shouldn’t have any impact on our accuracy.
Cons of Dynamic Padding
- While dynamic padding is better than fixed padding (we’re processing 160 tokens instead of 168), computation is still bounded by the longest sequence in the batch (which could be way longer than the average sequence size in terms of the number of tokens).
- Without batching by length, you perform wasteful computation on the padding tokens whose results you ignore anyway. To minimize wasted computation, we group by length as delineated below.
Uniform Length Batching/Grouping by Length (using Per-Batch Padding after Sorting)
-
We can go a step further, and sort our dataset by length before creating the batches, to be even more efficient. 
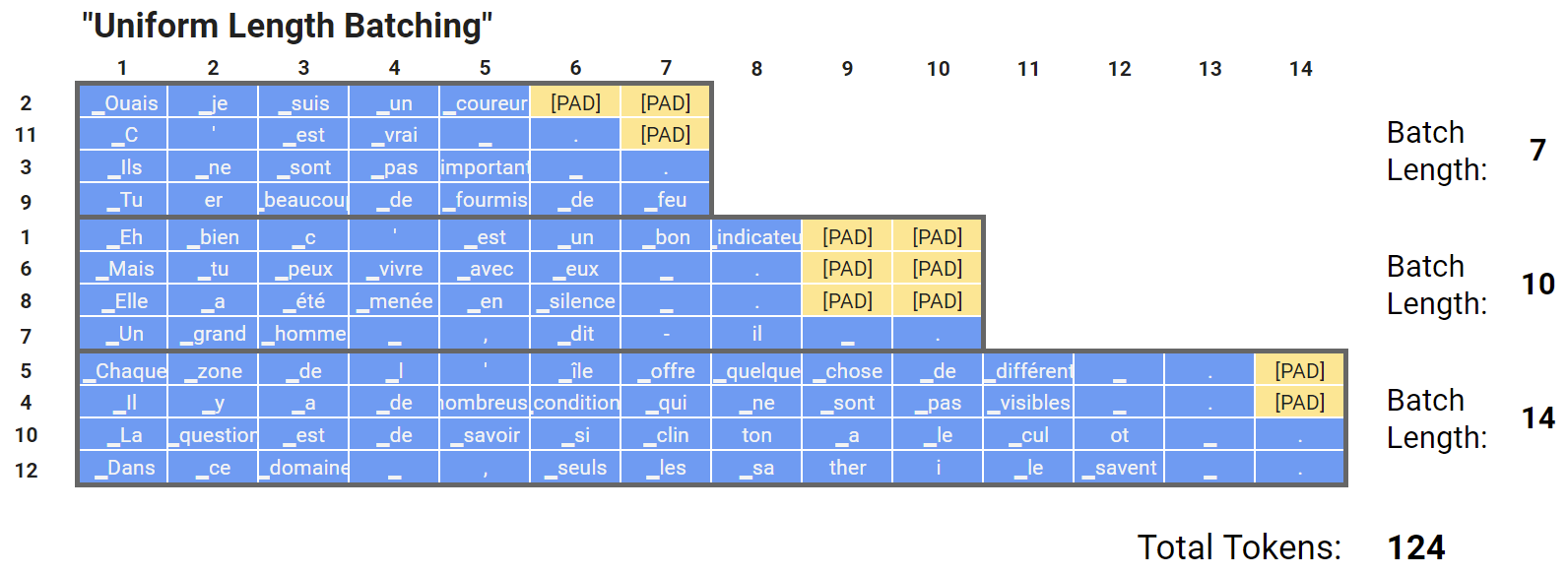
- Sorting by length before padding ensures the ratio between the longest and average sequence lengths in a batch would be much smaller than the without sorting, thus improving computation efficiency.
- Check out Michael’s experiments on “Weights and Biases” here that offer the intuition that this technique shouldn’t adversely impact performance.
- Note: In the above illustration above, we’ve selected the batches in sequence, but we’ll actually be selecting them more randomly, to allow for more randomness to the order of the training data.
References
- Smart Batching Tutorial - Speed Up BERT Training
- Why shouldn’t you mix variable size inputs in the same minibatch?
Citation
If you found our work useful, please cite it as:
@article{Chadha2020DistilledPadding,
title = {Padding},
author = {Chadha, Aman},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}