Primers • Padding and Packing
Overview
- In the context of training sequential models, such as those that consume text, audio, or time series, the concepts of padding and packing address the challenge of varying sequence lengths in a dataset.
Padding
Motivation: The Necessity of Padding
- GPUs operate with greater efficiency when processing multiple training samples in parallel, hence the use of batching when training models, especially deep models.
- To facilitate GPU operations on a batch, all inputs must be of uniform length, as tensors need to be rectangular without irregular edges. However, in practical applications, sequences often vary in length. Padding is used to standardize input sequences to a fixed length, thereby eliminating any irregularities.
- An “attention mask” is provided for each sample to identify
[PAD]tokens and instruct BERT to disregard them. - Varying the batching method can result in different total lengths for batches, particularly when combining inputs of significantly different sizes within the same minibatch. This variation can affect computational efficiency since processing padding tokens is redundant.
- Note: It has been observed that
[PAD]tokens might have a minor effect on the model’s accuracy, as discussed in Fine-Tuning and Evaluating BERT.
Fixed Padding (Utilizing Dataset Statistics)
-
Below are example sentences from a French dataset tokenized with a French BERT model, CamemBERT. For illustration, consider a dataset consisting of 12 sentences divided into 3 batches of 4 samples each. 
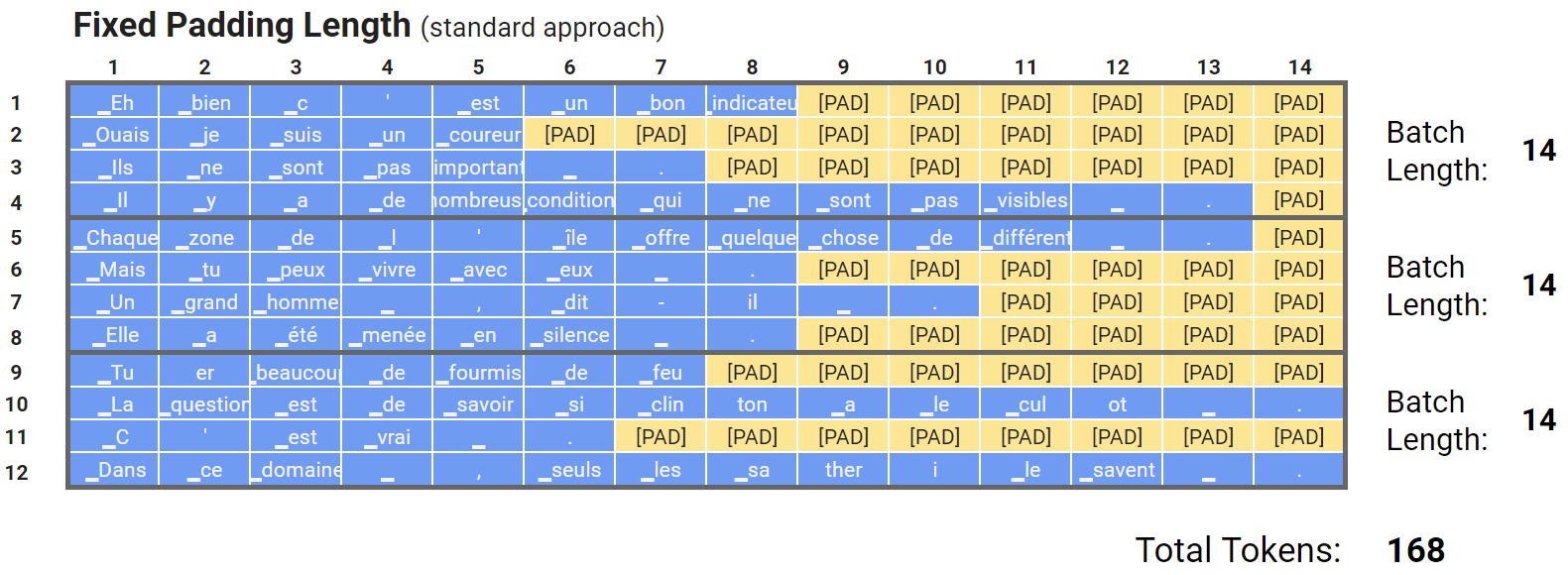
- To feed multiple samples into BERT simultaneously, all sentences are padded to a length of 14, matching the longest sentence in the dataset.
- This approach is the most common and straightforward to implement.
Disadvantages of Fixed Padding
- The model processes up to the length of the longest sequence in each mini-batch, regardless of the sample sizes within the batch.
- Fixed padding is inefficient due to the extra computational work required to process the sequences, exemplified by the unnecessary processing of 168 tokens in the example. This results in wasted computational effort on padding.
- This inefficiency becomes more pronounced with larger datasets, where the ratio between the longest and average sequence lengths in a batch can be significantly larger.
Dynamic Padding (Per-Batch Padding)
- Despite the attention mask ensuring that
[PAD]tokens do not influence BERT’s interpretation of the text, these tokens are still included in all mathematical operations, impacting training and evaluation speed. - Although samples within a batch must be of the same length, BERT can handle batches of varying maximum lengths.
-
BERT does not require explicit instructions regarding sequence length; it processes batches of any length without issue. 
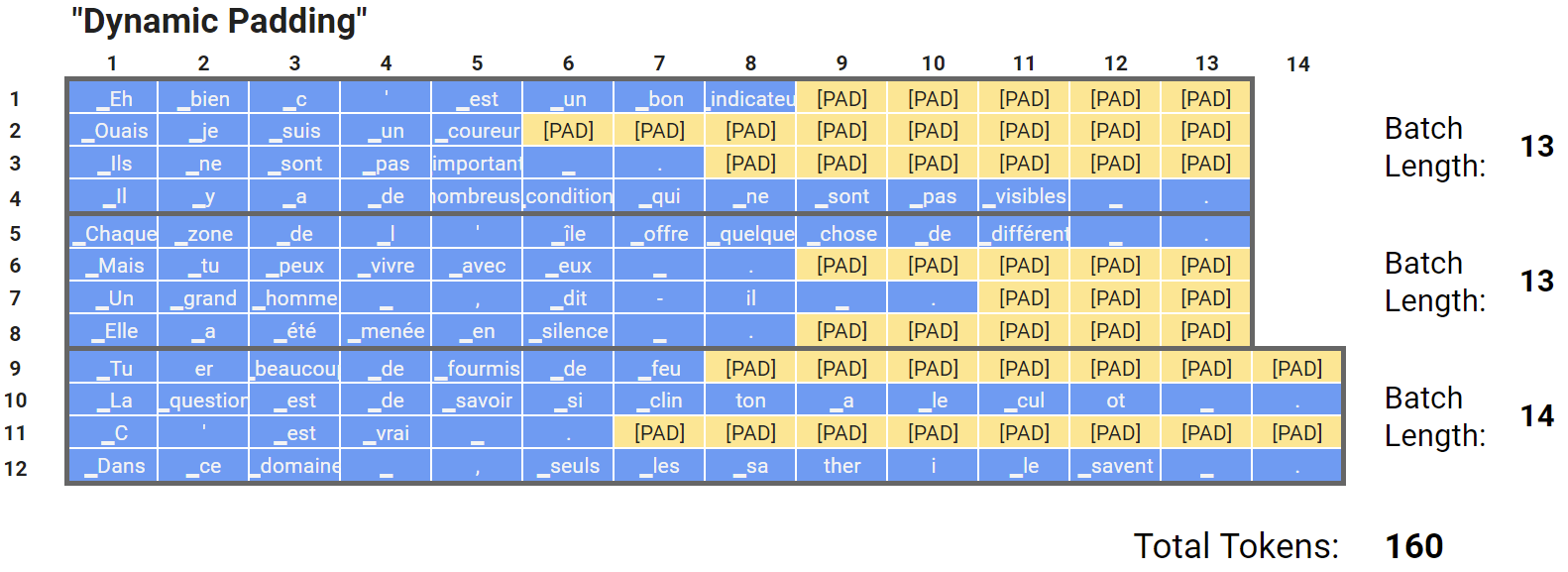
- By using more sophisticated code, we can customize padding for each batch without affecting accuracy.
Disadvantages of Dynamic Padding
- While dynamic padding reduces unnecessary computation (processing 160 tokens instead of 168), it is still constrained by the longest sequence in the batch, which may be much longer than the average sequence length.
- Without batching by length, computation on padding tokens remains wasteful. Grouping sequences by length can minimize this waste.
Uniform Length Batching/Grouping by Length (Per-Batch Padding after Sorting)
-
To enhance efficiency, we can sort the dataset by length before creating batches. 
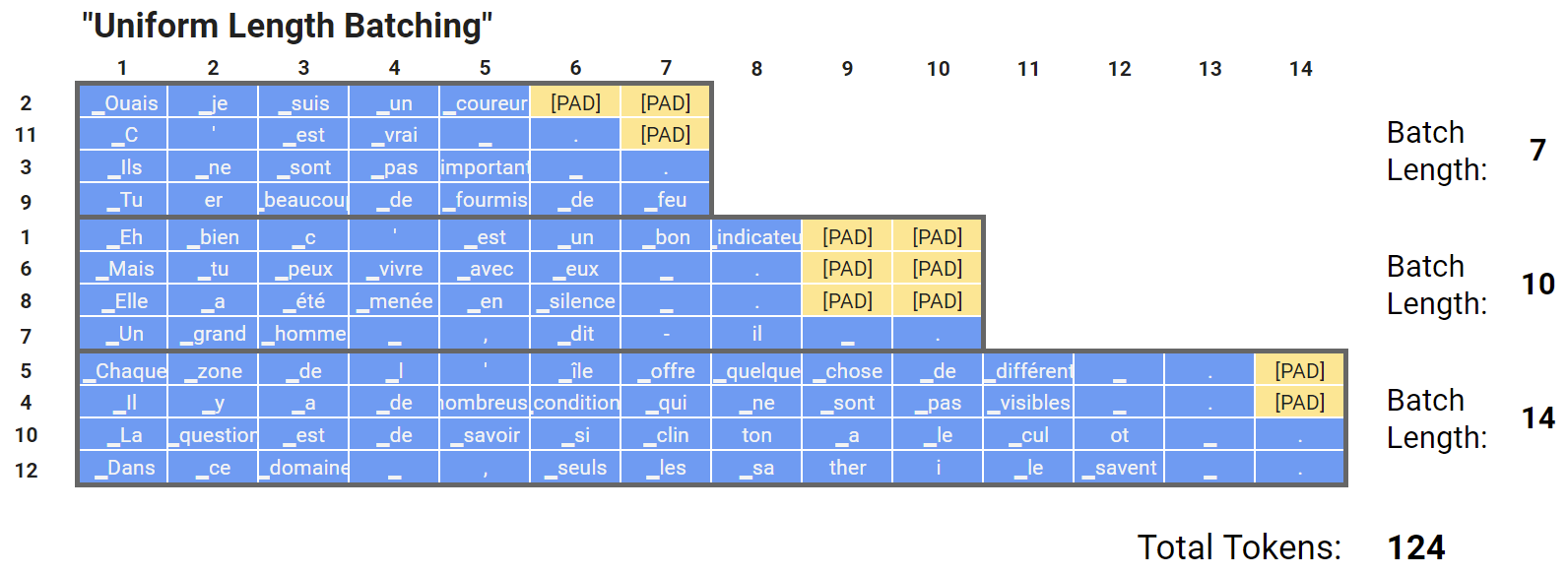
- Sorting by length before padding reduces the ratio between the longest and average sequence lengths within a batch, improving computational efficiency.
- For more details, refer to Michael’s experiments on “Weights and Biases” here, which indicate that this technique does not adversely impact performance.
- Note: In the above illustration, batches are selected sequentially, but in practice, they are selected randomly to introduce variability in the training data order.
Summary
-
Definition:
- Padding involves adding extra tokens (usually zeros or a specific
[PAD]token) to the sequences in a dataset so that all sequences in a batch have the same length. This ensures that the data can be processed in a uniform, rectangular tensor.
- Padding involves adding extra tokens (usually zeros or a specific
Applications:
- Standardizing Input Lengths:
- Padding is primarily used to standardize the lengths of sequences in a batch, making it possible for GPUs to process data in parallel efficiently.
- Attention Mechanisms:
- Models like BERT use attention mechanisms that require fixed input sizes. Padding helps create uniform input lengths, and an attention mask is used to inform the model which tokens are padding and should be ignored.
- Implementation Simplicity:
- Padding is straightforward to implement, requiring minimal changes to the existing data processing pipeline. It’s a simple yet effective way to handle variable-length sequences.
- Batch Processing:
- Padding is highly compatible with batch processing, allowing for significant speedups when using hardware accelerators like GPUs and TPUs.
-
Advantages:
- Ease of Implementation: Simple to add padding tokens to sequences.
- Compatibility: Works well with most neural network frameworks and libraries.
- Efficiency: Facilitates parallel processing of data batches.
-
Disadvantages:
- Computational Inefficiency: Padding can lead to unnecessary computations on padding tokens, particularly if the difference in sequence lengths is large.
- Memory Overhead: Extra memory is required to store padding tokens, which can be significant in large datasets with high variance in sequence lengths.
- Potential Impact on Model Performance: Although attention masks mitigate this, there can still be minor effects on model performance due to padding tokens.
Packing
Motivation: The Problem with Padding
- Training sequence models such as Transformers, Recurrent Neural Networks (RNNs) (and its variants such as LSTMs and GRUs) with variable-length sequences can be challenging due to the need to batch sequences of different lengths. When training such models, sequences of varying lengths are typically padded to the length of the longest sequence in the batch. This padding results in unnecessary computations, especially when sequences are of significantly different lengths.
- Consider a batch of sequences with lengths
[4, 6, 8, 5, 4, 3, 7, 8]. If we pad all sequences to the maximum length (8), we will have:
[[a1, a2, a3, a4, 0, 0, 0, 0],
[b1, b2, b3, b4, b5, b6, 0, 0],
[c1, c2, c3, c4, c5, c6, c7, c8],
[d1, d2, d3, d4, d5, 0, 0, 0],
[e1, e2, e3, e4, 0, 0, 0, 0],
[f1, f2, f3, 0, 0, 0, 0, 0],
[g1, g2, g3, g4, g5, g6, g7, 0],
[h1, h2, h3, h4, h5, h6, h7, h8]]
- This padding results in 64 computations (8x8), but only 45 are necessary, leading to inefficiency.
- Let’s explore how to handle such scenarios efficiently using PyTorch’s
pack_padded_sequencefunction to save computational resources and training time.
Solution: Packing Sequences
- PyTorch provides the
pack_padded_sequencefunction to address this inefficiency. Packing sequences helps sequence models skip the padding and only process the relevant data, saving computation.
Code Example
import torch
import torch.nn.utils.rnn as rnn_utils
# Example sequences
sequences = [torch.tensor([1, 2, 3]), torch.tensor([3, 4])]
padded_sequences = rnn_utils.pad_sequence(sequences, batch_first=True)
print(padded_sequences)
# Output:
# tensor([[1, 2, 3],
# [3, 4, 0]])
packed_sequences = rnn_utils.pack_padded_sequence(padded_sequences, batch_first=True, lengths=[3, 2])
print(packed_sequences)
# Output:
# PackedSequence(data=tensor([1, 3, 2, 4, 3]), batch_sizes=tensor([2, 2, 1]))
Explanation
- To understand the packing process, consider the following:
- Original Sequences:
[[1, 2, 3], [3, 4]] - Padded Sequences:
[[1, 2, 3], [3, 4, 0]] - Packed Sequences: A
PackedSequenceobject with:data: [1, 3, 2, 4, 3]batch_sizes: [2, 2, 1]
Benefits of Packing
Reduced Computation
-
Consider the computational savings in a simple example. With padding, the operations required are:
- Multiplications: \(6 \times 9 = 54\)
- Additions: \(6 \times 8 = 48\)
-
With packing, the actual necessary operations are:
- Multiplications: 32
- Additions: 26
Efficiency
- The use of
pack_padded_sequencesignificantly reduces the number of operations, leading to faster training times and lower resource consumption.
Example Scenario
- Coming back to the original example in Motivation: the Problem with Padding, consider the six sequences with variable lengths, used as the batch size hyperparameter. These sequences need to be padded to the maximum length in the batch, which is 9 in this example.
padded_sequences = [
[a1, a2, a3, a4, a5, a6, a7, a8, a9],
[b1, b2, b3, b4, b5, 0, 0, 0, 0],
[c1, c2, c3, 0, 0, 0, 0, 0, 0],
[d1, d2, d3, d4, 0, 0, 0, 0, 0],
[e1, e2, 0, 0, 0, 0, 0, 0, 0],
[f1, f2, f3, f4, f5, f6, 0, 0, 0]
]
- This is visually depicted below (source):
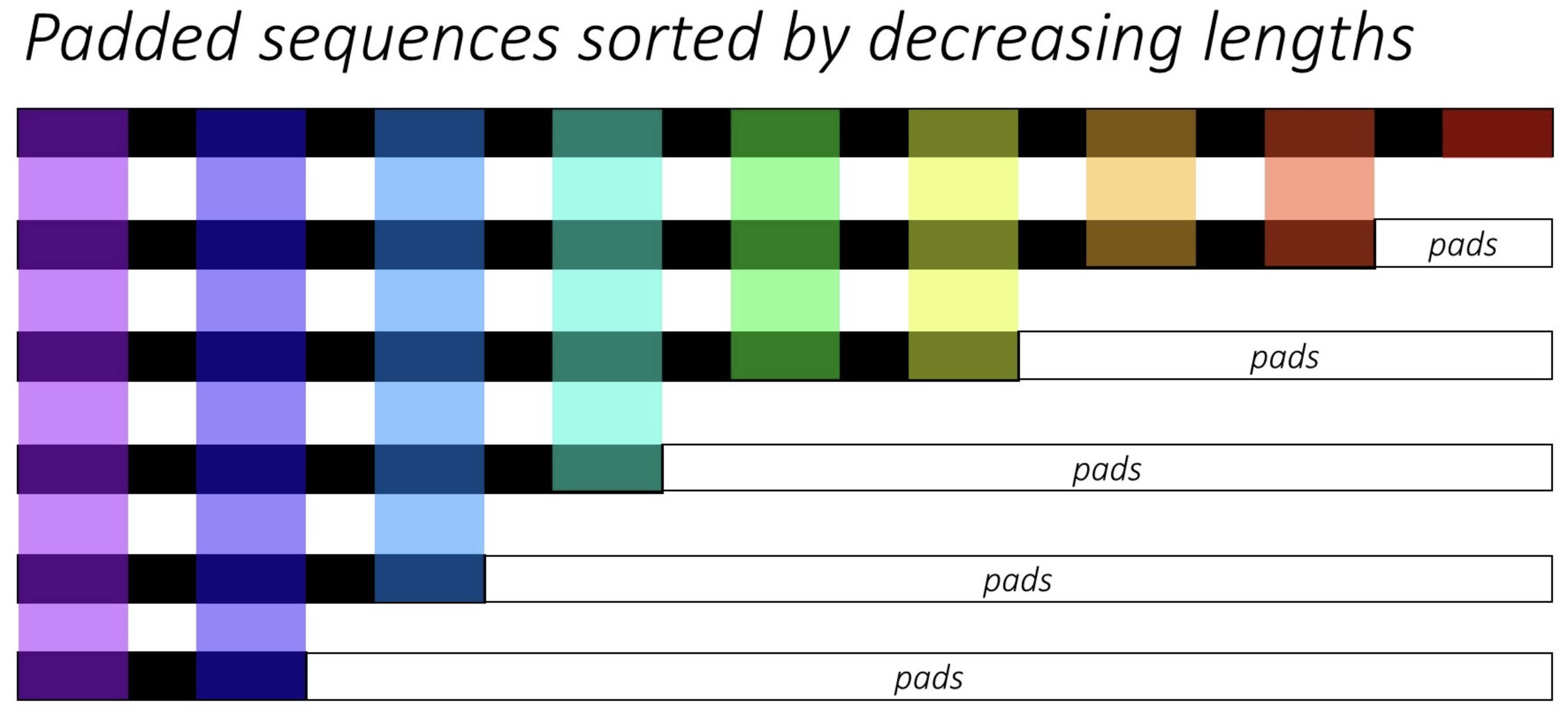
-
To perform matrix multiplication with a weight matrix \(W\) of shape (9, 3), we need to perform the following operations with padded sequences:
- Multiplications: \(6 \times 9 = 54\)
- Additions: \(6 \times 8 = 48\)
-
However, many of these computations are unnecessary due to zero-padding. The actual required computations are:
- Multiplications: 32
- Additions: 26
-
The savings in this simple example are significant: 22 multiplications and 22 additions
-
These savings are even more pronounced in large-scale applications, highlighting the efficiency of using
pack_padded_sequence.
Visual Explanation
- The
pack_padded_sequencefunction can be visually illustrated as follows using color-coding (source):
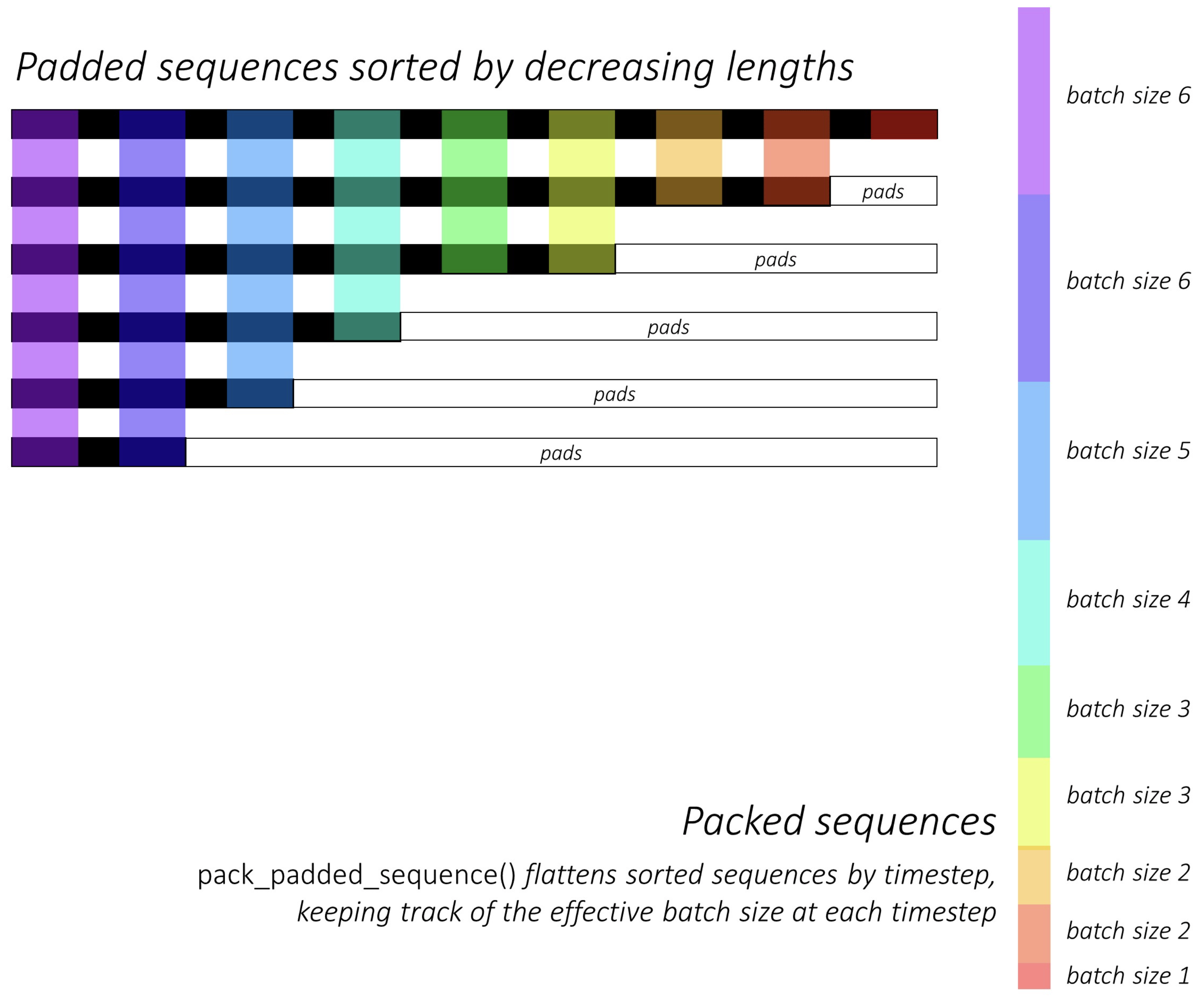
- As a result of using
pack_padded_sequence(), we will get a tuple of tensors containing (i) the flattened (along axis-1, in the above figure) sequences , (ii) the corresponding batch sizes,tensor([6, 6, 5, 4, 3, 3, 2, 2, 1])for the above example. - This packed data can then be passed to loss functions like
CrossEntropy()for efficient calculations.
Conclusion
- Using
pack_padded_sequencein PyTorch optimizes sequence model training by reducing unnecessary computations associated with padding. This approach leads to faster training times and more efficient use of computational resources, especially in large-scale applications. - By understanding and implementing these techniques, practitioners can achieve more efficient training processes and potentially significant cost and time savings.
- For further reading and detailed implementation, refer to the PyTorch documentation for
pack_padded_sequence.
Summary
-
Definition:
- Packing, often referred to as packing sequences or sequence packing, involves organizing data in a way that minimizes padding by grouping sequences of similar lengths together. This technique aims to reduce the amount of padding required within each batch.
-
Applications:
- Dynamic Batching:
- Packing sequences into batches of similar lengths reduces the need for excessive padding, thus optimizing computational efficiency.
- Efficiency in Model Training:
- By minimizing padding, packing ensures that the model spends more computational resources on actual data rather than padding tokens, improving training efficiency.
- Memory Utilization:
- Packing sequences effectively reduces memory overhead by decreasing the number of padding tokens required, which is particularly beneficial in large-scale datasets.
- Dynamic Batching:
-
Advantages:
- Computational Efficiency: Reduces the number of unnecessary computations on padding tokens, leading to faster training times.
- Better Resource Utilization: Improves memory and computational resource utilization by minimizing padding.
- Enhanced Performance: Can lead to better model performance by focusing more on actual data rather than padding tokens.
-
Disadvantages:
- Complexity in Implementation: Requires more sophisticated data preprocessing and batch management techniques.
- Variable Batch Sizes: Batches might have varying numbers of sequences, depending on how they are grouped, which can complicate some aspects of training.
- Randomization Challenges: Ensuring randomness in training data order while maintaining efficient packing can be challenging.
Comparative Analysis: Padding and Packing
| Aspect | Padding | Packing |
|---|---|---|
| Efficiency | Simple but potentially inefficient due to extra computations on padding tokens. | More efficient by minimizing the number of padding tokens, leading to faster and more resource-efficient training. |
| Implementation Complexity | Easier to implement, requiring minimal changes to existing data pipelines. | More complex, requiring advanced data preprocessing and dynamic batching techniques. |
| Memory Utilization | Higher memory overhead due to additional padding tokens. | More efficient memory usage by reducing the need for padding. |
| Model Performance | Slight potential impact on model performance due to the presence of padding tokens, though mitigated by attention masks. | Potentially better model performance as it reduces the influence of padding tokens on training. |
| Flexibility | Provides uniform batch sizes, which can simplify training dynamics. | Results in variable batch sizes, which can introduce additional complexity but also offers more flexibility in handling different sequence lengths. |
Conclusion
- The choice between padding and packing depends on the specific requirements and constraints of the model training process. Padding is easier to implement and provides uniform batch sizes, making it suitable for simpler or smaller-scale projects. Packing, on the other hand, offers greater efficiency and better resource utilization, making it more suitable for large-scale projects where computational and memory resources are critical.
- In practice, a hybrid approach can also be beneficial, where initial padding is used for ease of implementation, followed by gradual integration of packing techniques as the project scales and the need for efficiency becomes more pronounced.
References
- Smart Batching Tutorial - Speed Up BERT Training
- Why shouldn’t you mix variable size inputs in the same minibatch?
- Why do we “pack” the sequences in PyTorch?
Citation
If you found our work useful, please cite it as:
@article{Chadha2020DistilledPaddingPacking,
title = {Padding and Packing},
author = {Chadha, Aman},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}