Natural Language Processing • Neural Networks
- Overview
- Recurrent Neural Networks
- Long short term memory (LSTMs)
- Limitations of RNNs
- Deep Learning Classifiers
- Regularization
- Xavier Initialization
- Optimization Techniques
- Convolutional Neural Networks (CNNs)
- References
- Citation
Overview
- Neural networks, inspired by the human brain’s biological neurons, are at the heart of deep learning algorithms and form a subset of machine learning.
- They play a crucial role in financial services, aiding in tasks such as forecasting, marketing research, fraud detection, and risk assessment.
- These networks can have multiple processing layers, making them “deep” and thereby laying the foundation for deep learning algorithms.
Recurrent Neural Networks
- Recurrent Neural Networks (RNNs), a specialized type of neural networks, are specifically designed for dealing with sequence data. The term “recurrent” comes from the network’s ability to perform the same task for each element in the input sequence, with the output depending on the previous computations.
- The defining characteristic of RNNs is their “memory” — they can remember previous inputs due to their internal loops, and use this memory in current computations. This makes them particularly effective for tasks that involve sequential inputs, such as language modeling, where context and the order of inputs play a crucial role.
- The below slide (source) depicts the timesteps and innerworkings of RNN.
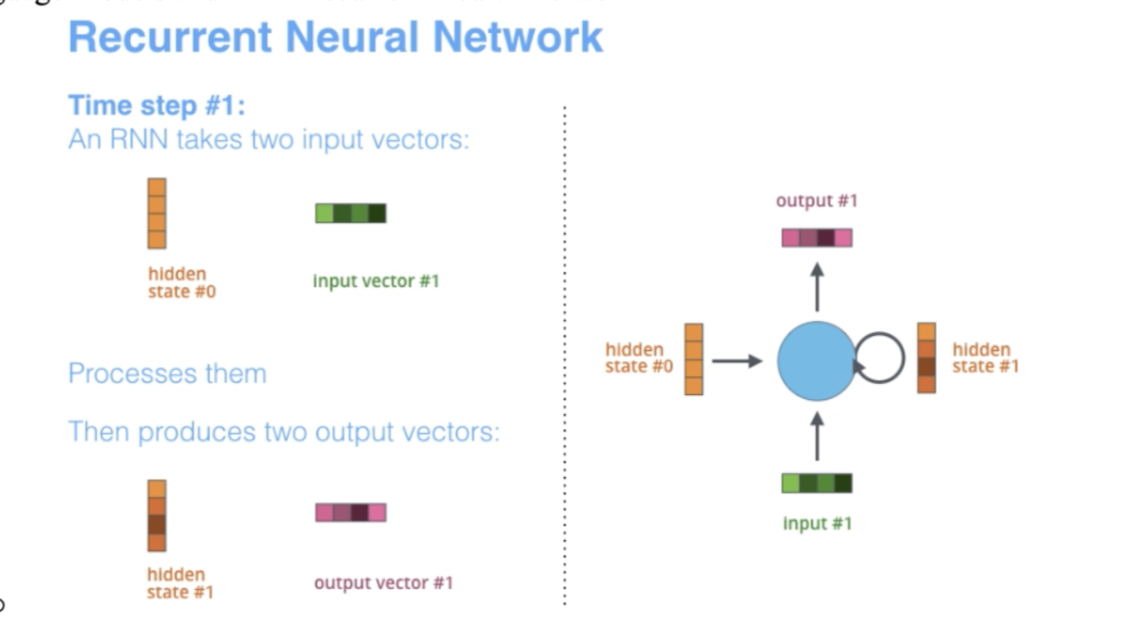
- RNNs shine in natural language processing (NLP) tasks, providing the ability to discern semantic nuances in a sequence. For example, they can differentiate between “dog” and “hot dog”, despite the shared word. The ability to handle varying lengths of input text — from single sentences to whole documents — further cements their usefulness in NLP. This flexibility, coupled with their ability to capture context over an unbounded range, often gives RNNs the edge over Convolutional Neural Networks (CNNs) in sequence modeling tasks.
- RNNs are also highly effective in tasks like machine translation where summarizing entire sentences into fixed vectors is required. They are then mapped back to a target sequence of variable length.
- Contrastingly, CNNs tend to focus more on extracting the most important n-grams from the text. While this can be adequate for certain classification tasks, CNNs generally lack the ability to capture the long-term dependencies and contextual subtleties that RNNs excel at.
- One of the more challenging tasks in NLP — natural language generation — is another area where RNNs prove their mettle. Conditioned on textual or visual data, deep Long Short-Term Memory (LSTM) networks, a type of RNN, have been shown to generate task-specific text in machine translation, image captioning, and more. In these cases, the RNN acts as a decoder.
- A typical RNN maintains a hidden layer over time, feeding its outputs back into the network for subsequent predictions. This iterative process, illustrated below (source), helps the network to learn complex patterns over the course of a sequence
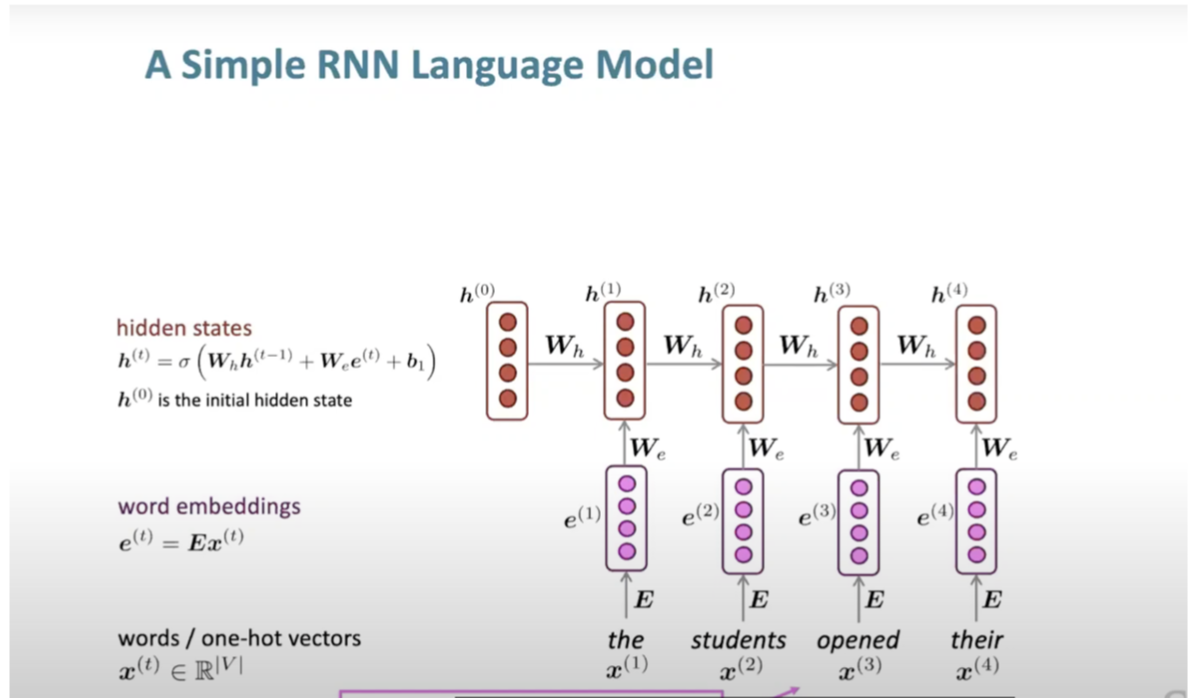
Training a Recurrent Neural Network (RNN) Language Model
-
Here’s a streamlined overview of the process involved in training an RNN language model:
- Initially, you need a large text corpus, a common prerequisite for most NLP applications.
- Feed this corpus into your RNN language model, calculating the output distribution at each step.
- Evaluate the performance of your model by measuring the cross-entropy loss.
- Average this measurement to determine the overall loss for the entire training set.
-
In practice, the corpus is typically divided into smaller sections to facilitate computation of the loss on manageable data chunks.
-
Specific steps in the training process include:
- Implementing backpropagation and updating parameters accordingly.
- Computing the loss and backpropagating it through the network.
- Executing backpropagation over timesteps, which involves summing gradients as you proceed. This process is known as “backpropagation through time.”
Generating Text with an RNN
- Generating text with an RNN involves a recursive process where the sampled output from one step is used as the input for the next step. Key points in this process include:
- Utilizing the softmax function as the final layer in the network to generate probabilities for the output.
- Using a special symbol to indicate the beginning of a sequence.
- Implementing another special symbol to signify the end of a sequence.
Long short term memory (LSTMs)
- Two primary issues with Recurrent Neural Networks (RNNs) are the problems of vanishing and exploding gradients:
- Vanishing Gradient Problem: This issue arises when the model fails to learn from distant information to use it for future predictions.
- Exploding Gradient Problem: This occurs when the gradient becomes excessively large, resulting in an overly significant update step during Stochastic Gradient Descent. This can lead to inaccurate updates as the step size becomes too large. A common solution for this problem is “gradient clipping”, where the step is kept in the same direction but its size is reduced.
- LSTMs introduce a solution to these problems by deviating from the traditional RNN structure. Instead of a single hidden vector present in RNNs, LSTMs build two hidden states: the hidden state and the cell state.
- The cell state is responsible for storing long-term information.
-
LSTMs have the ability to read, erase, and write from this cell, which is controlled by “gates”. These gates are also vectors that can be either open (1) or closed (0).
-
The following slides, sourced from Stanford CS224n course, illustrate LSTMs and their functionality:
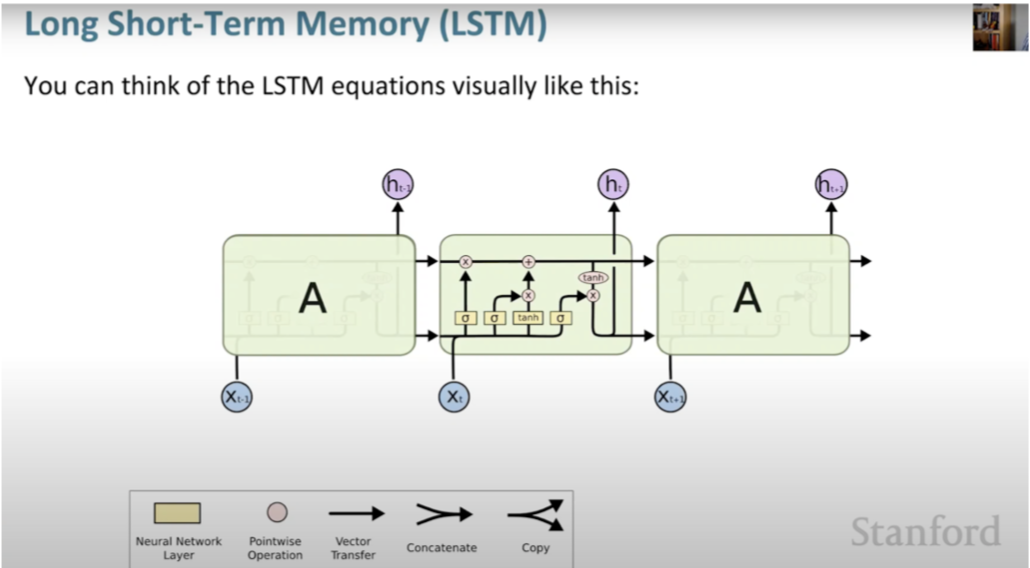
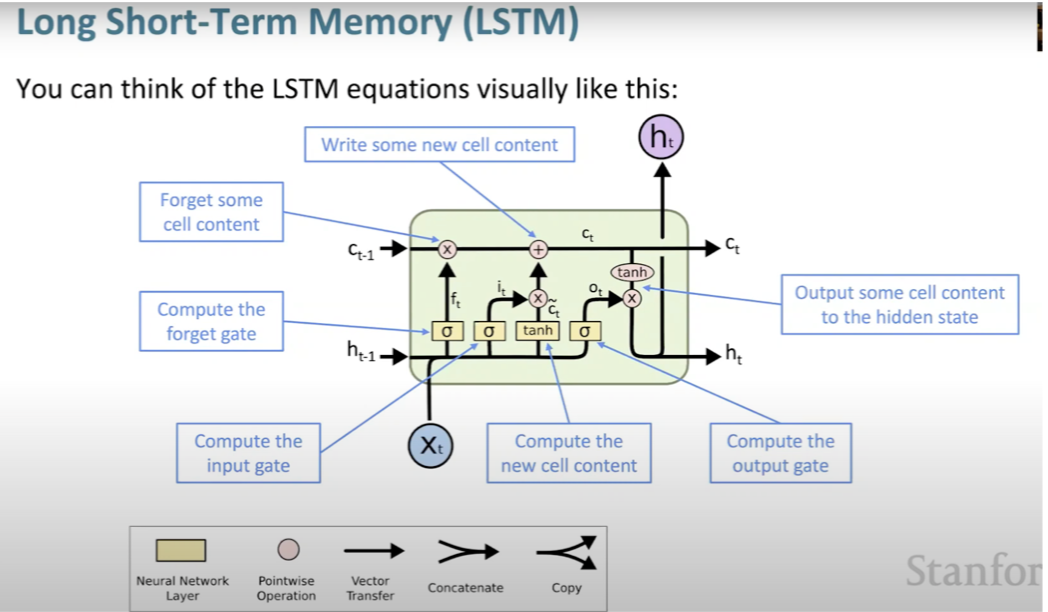
- LSTMs enhance the ability of RNNs to retain information over many timesteps, effectively managing long-distance dependencies. The gates are also learned via backpropagation.
- Bi-directional and multi-layer RNNs are used in tasks like sentiment classification. These methods combine the results of a backward RNN and a forward RNN. However, this is only applicable if the entire input sequence is available. A powerful pre-trained contextual representation system built on bidirectionality is BERT.
Limitations of RNNs
- RNNs do have several drawbacks. One of these is their linear interaction distance, encoding linear locality. While it is true that nearby words often affect each other’s meaning, RNNs require \(O(sequence\,length)\) steps for distant word pairs to interact, leading to a lack of parallelizability. Both the forward and backward passes have %%O(sequence\,length)5% non-parallelizable operations, which hampers training on large datasets.
- An alternative could be the use of word windows, which aggregates local contexts through 1D convolution. This reduces the number of unparallelizable operations as it does not increase with sequence length. However, this approach struggles with long-distance dependencies. Stacking word window layers could allow interaction between more distant words.
Deep Learning Classifiers
- Deep learning classifiers differ from traditional methods as they are non-linear classifiers. While softmax classifiers assign classes based on inputs via probability, traditional machine learning classifiers like Naive Bayes, SVM, logistic regression, and softmax classifier, are less powerful as they provide only linear decision boundaries, which may not be helpful for complex problems.
- In contrast, neural classifiers offer more power through their non-linear boundaries. Although the top layer still uses a softmax classifier (which is a linear classifier), beneath it are other layers of neural networks. These are considered simple feed forward multi-class classifiers such as k-Nearest Neighbors, Decision Trees, Naive Bayes, Random Forest, and Gradient Boosting.
Regularization
- When constructing neural networks with large parameters, regularization of the loss function is required. A full loss function includes regularization over all parameters. For example, L2 regularization ensures parameters are non-zero only if they are useful. This helps to prevent overfitting when there are many features and ensures that models generalize well with larger models.
Dropout
- Dropout is a regularization technique used to mitigate overfitting. It prevents complex co-adaptations on training data. Internally, during training, for each batch, 50% of the input for each neuron in the model is dropped. However, during testing, all model weights are retained. Dropout is a strong regularizer capable of learning a feature-dependent regularization.
Xavier Initialization
- Initializing neural network parameters or weights should not start from zero to avoid symmetries. Therefore, random values are preferred, and this is where Xavier initialization comes into play. It provides a good starting point for the iterative optimization of neural networks by assigning suitable initial random weights.
Optimization Techniques
- Though plain Stochastic Gradient Descent (SGD) is often sufficient for training neural networks, it does require careful tuning of learning rates. It’s essential to use a learning rate that is not too large (as it can cause model divergence) and not too small (as it may cause the training process to be excessively slow). One common strategy is to halve the learning rate after each epoch. Additionally, to avoid processing the data in the same order each time, it is recommended to shuffle the data during training.
Convolutional Neural Networks (CNNs)
- The core idea behind Convolutional Neural Networks (CNNs) is to compute vectors for every word of a certain length, or in other words, to compute vectors based on subsequences of words. This approach arose from the need for an effective feature function that could extract higher-level features from words or n-grams. These abstract features could then be used for various NLP tasks such as sentiment analysis, summarization, machine translation, and question answering (QA). Due to their effectiveness in computer vision tasks, CNNs became a popular choice in these scenarios.
- The following slides, sourced from Stanford CS224n course, illustrate this.
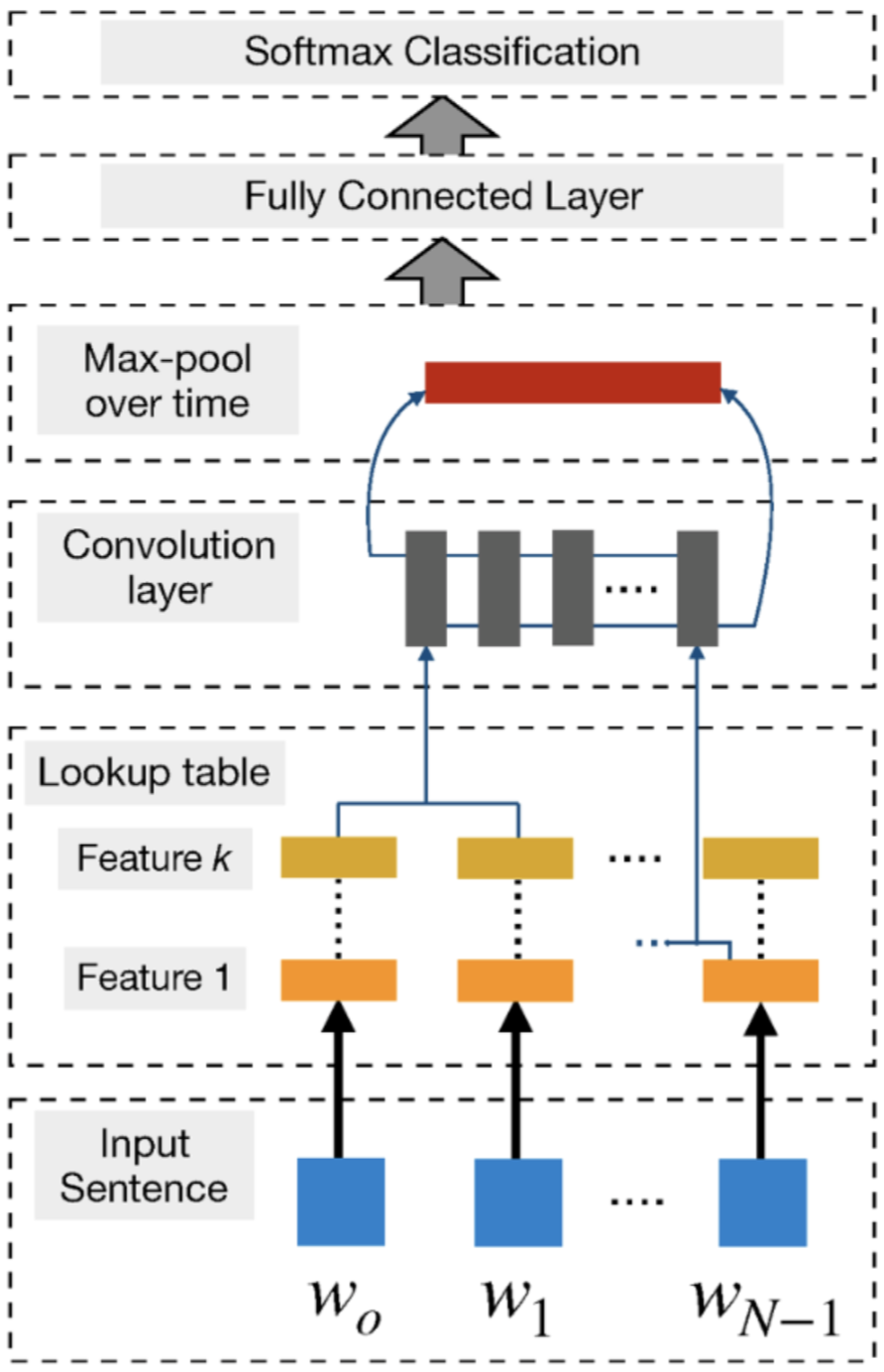
- CNNs have the capability to extract significant n-gram features from the input sentence to create an informative latent semantic representation of the sentence for downstream tasks. In a CNN, numerous convolutional filters or kernels (typically hundreds), of different widths, slide over the entire word embedding matrix, each extracting a specific n-gram pattern.
- A convolution layer is usually followed by a max-pooling strategy for two main reasons:
- Max pooling provides a fixed-length output which is generally required for classification. Thus, regardless of the size of the filters, max pooling always maps the input to a fixed dimension of outputs.
- It reduces the output’s dimensionality while preserving the most important n-gram features across the whole sentence. This is done in a translation invariant manner where each filter can extract a particular feature (e.g., negations) from anywhere in the sentence and incorporate it into the final sentence representation.
References
- Named Entity Recognition with NLTK and SpaCy
- What is named entity recognition (NER) and how can I use it?
- Dependency Parsing in Natural Language Processing with Examples
Citation
- If you found our work useful, please cite it as:
@article{Chadha2021Distilled,
title = {Neural Nets},
author = {Jain, Vinija and Chadha, Aman},
journal = {Distilled Notes for Stanford CS224n: Natural Language Processing with Deep Learning},
year = {2021},
note = {\url{https://aman.ai}}
}