Introduction
- Google’s conversational AI, Bard is designed to help its customers with information retrieval by the use of NLP.
- Bard, which is a lightweight version of LaMDA, will be updating Google’s search to display a synthesized version of the answer you’re searching for.
- LaMDA (Language Model for Dialogue Applications), which is built on Transformers, was trained on dialogue in order to better understand the nuances of language.
- The model can engage in more open-ended, dynamic conversations with users and respond to more complex queries.
- Google envisions that LaMDA could be used in a variety of applications, including customer service, language translation, and voice assistants.
- As the blog states, LaMDA was built on Towards a Human-like Open-Domain Chatbot.
- In this article, we will dissect the technicalities of Meena, the predecessor to Bard, until more research is made publicly available for Bard.
- Meena is a 2.6 billion parameter neural conversational model that has been trained end-to-end by Google Research’s Brain Team.
- The Chatbot Meena is able to hold sensible conversations and this is because it was evaluated through a human metric called Sensibleness and Specificity Average (SSA).
Metric: Sensibleness and Specificity Average (SSA)
- SSA is designed to measure how sensible and specific Meena’s responses are in the context of a given conversation.
- SSA measures the extent to which the language model produces sensible and specific responses to prompts.
- To compute SSA, a set of prompts is given to the language model, and the generated responses are evaluated by human judges.
- Each response is given a score between 0 and 1, representing its sensibleness and specificity.
- Sensibleness refers to the degree to which the response is coherent and grammatically correct, while specificity refers to the degree to which the response is relevant and informative.
- The average of the sensibleness and specificity scores for all responses is then calculated to obtain the SSA score.
- A higher SSA score indicates that the language model produces more sensible and specific responses.
- A quick note here about perplexity, which is a commonly used metric to evaluate language models,while perplexity is a useful metric for evaluating the quality of language models for tasks such as machine translation or text generation, it is not always a reliable measure of overall language model performance.
- SSA is a metric that is specifically designed to evaluate the quality of generated text.
- It provides a more direct measure of the language model’s ability to produce coherent and relevant responses to prompts.
Training
- “The training objective is to minimize perplexity, the uncertainty of predicting the next token (in this case, the next word in a conversation). At its heart lies the Evolved Transformer seq2seq architecture, a Transformer architecture discovered by evolutionary neural architecture search to improve perplexity.” Google AI
- The data Meena used to train on was mined and filtered from public domain social media conversations.
- The conversations with multiple speakers are stored in a tree structure where the root of the tree is the first message and the replies are the child nodes.
- “The Meena model has 2.6 billion parameters and is trained on 341 GB of text, filtered from public domain social media conversations.
- Compared to an existing state-of-the-art generative model, OpenAI GPT-2, Meena has 1.7x greater model capacity and was trained on 8.5x more data.” Google AI
Architecture
- Meena’s architecture includes: an Evolved Transformer (ET) seq2seq model with 2.6B parameters with 1 ET encoder block and 13 ET decoder blocks as shown below.
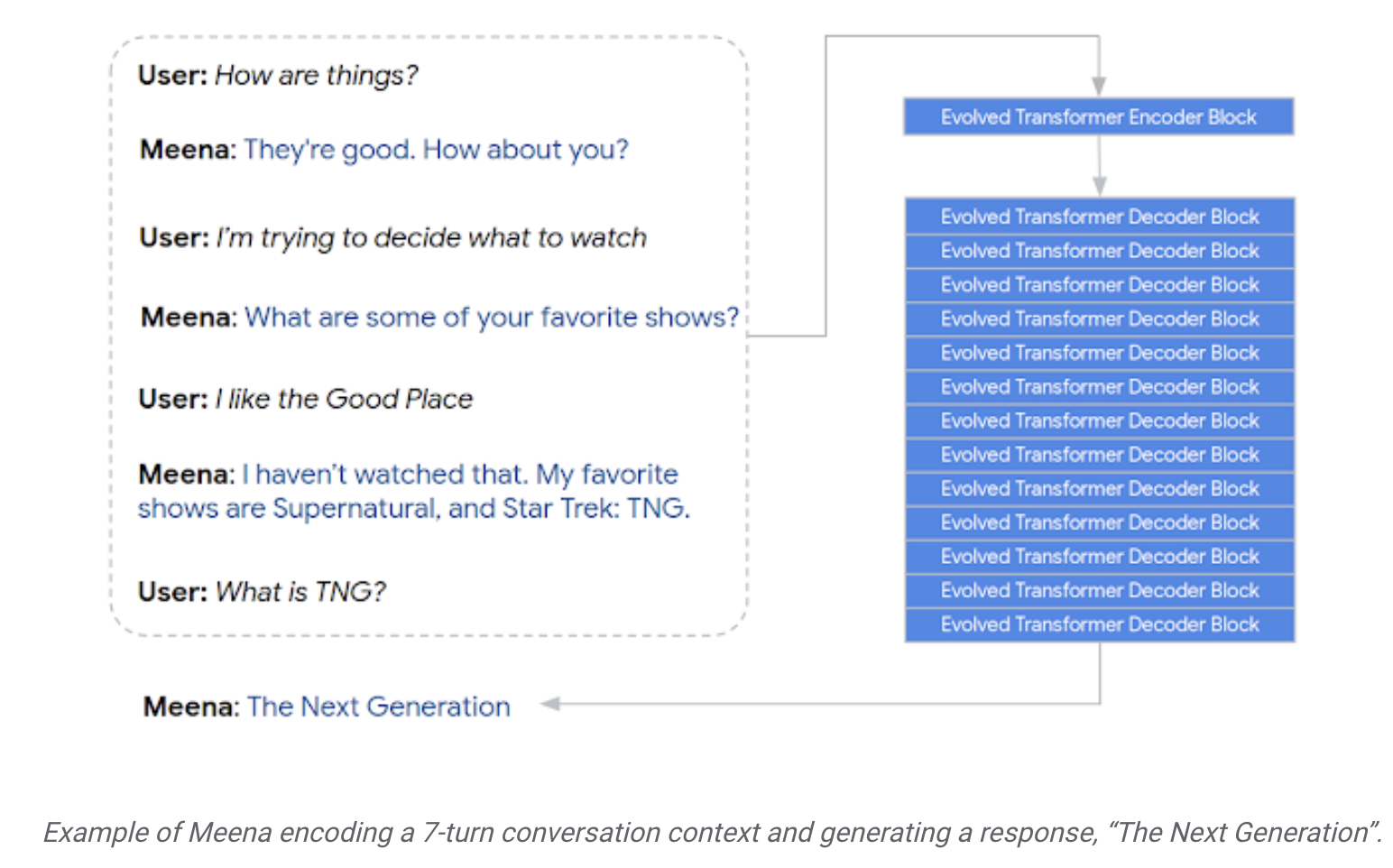
- The “Evolved Transformer” (ET) is a neural architecture that combines evolutionary algorithms and the Transformer architecture for automatic neural architecture search.
- The encoder, per usual, encodes the contextual meaning of the conversation while the decoder works on a sensible response.
- “Through tuning the hyper-parameters, we discovered that a more powerful decoder was the key to higher conversational quality.” Google AI
- For decoding in particular, the paper found that a model with sufficiently low perplexity can achieve diverse and high-quality responses using a simple sample-and-rank decoding strategy.
- In this strategy, they sampled N independent candidate responses using random sampling with a temperature T, and selected the candidate response with the highest probability as the final output.
- The temperature T is a hyper-parameter that regulates the probability distribution of the next token during decoding.
Results
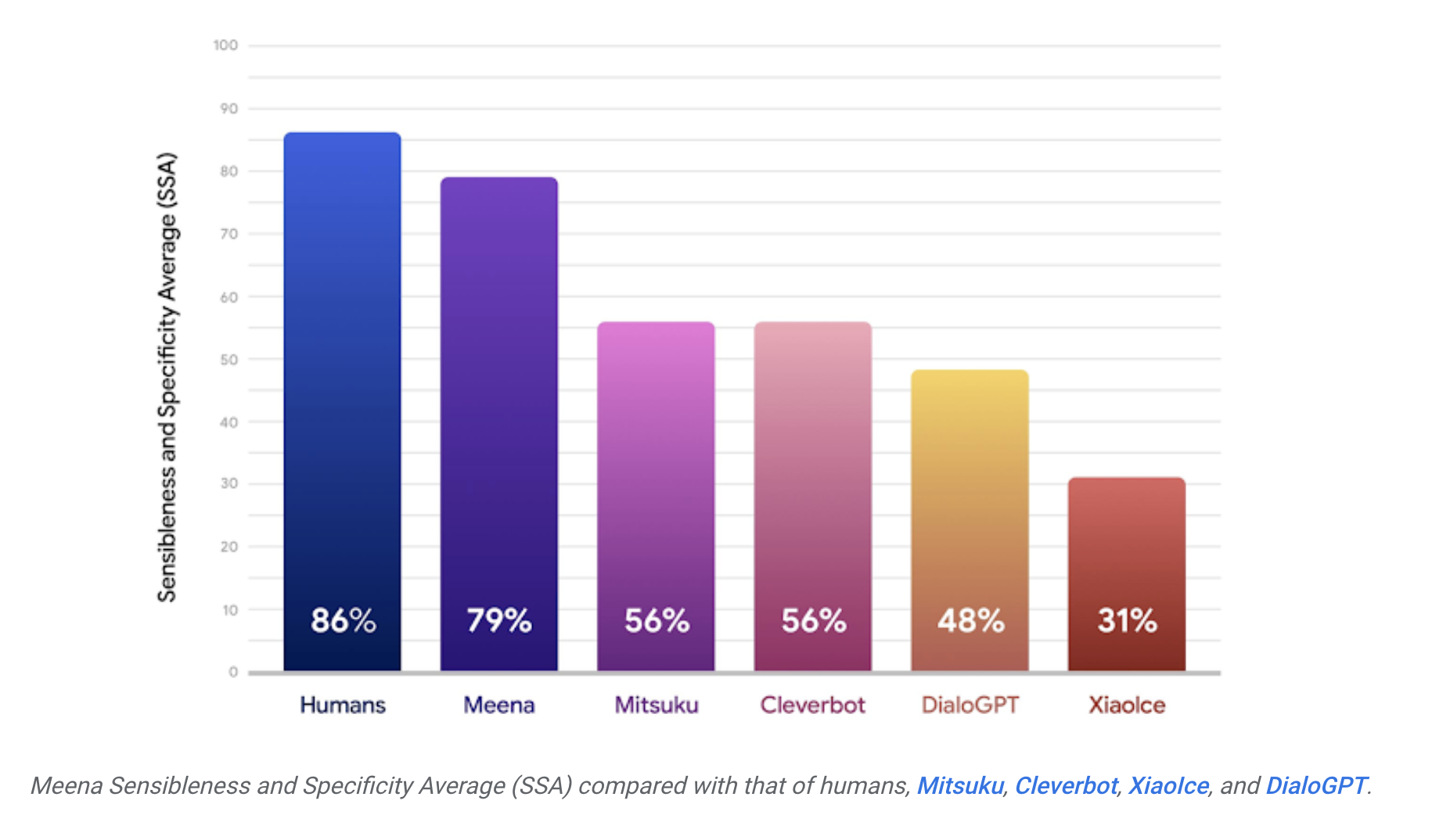
- Meena was able to achieve a perplexity of 10.2 (smaller is better) and that translates to an SSA score of 72% compared to 86% SSA achieved by the average person.
- The full version of Meena a filtering mechanism and tuned decoding had further advances the SSA score to 79%.
References