Primers • Looped Transformers
- Overview
- Architecture
- Training
- Stability
- Scaling Laws
- Reasoning
- Generalization
- Test-Time Compute
- Staircase and Ladder Attention
- Implementations
- Open Questions
- Looped Transformers vs. RLMs
- References
- Citation
Overview
-
Looped transformers scale neural networks by reusing the same transformer block, or a small stack of blocks, multiple times during a single forward pass. Instead of assigning a distinct set of parameters to every layer in a deep stack, a looped model repeatedly applies shared parameters to refine the hidden state. This increases effective depth while keeping parameter count fixed, making compute a runtime resource rather than a static architectural choice.
-
The core promise is straightforward: a compact model can spend more computation on difficult inputs while keeping stored weights relatively small. Looped transformers therefore offer a way to scale reasoning depth without proportionally scaling parameter count. They reuse weights across depth, increase computation through recurrence, and perform iterative latent refinement before producing output.
-
The core motivation is that many reasoning and algorithmic tasks require substantial depth, but not necessarily a proportional increase in unique parameters. A model may need to think longer rather than know more. Reasoning with Latent Thoughts: On the Power of Looped Transformers by Saunshi et al. (2025) demonstrates that a \(k\)-layer transformer block looped \(L\) times can behave similarly to a (kL)-layer transformer on reasoning tasks, showing that depth can sometimes matter more than unique parameters.
Research Lineage
-
This architectural idea has emerged across several related lines of work:
- Looped Transformers as Programmable Computers by Giannou et al. (2023) shows that a fixed set of transformer layers placed in a loop can emulate general-purpose computers, memory edits, branches, function calls, and iterative algorithms.
- Looped Transformers Are Better at Learning Learning Algorithms by Yang et al. (2024) demonstrates that parameter sharing helps transformers naturally implement iterative optimization procedures with far fewer parameters.
- Scaling up Test-Time Compute with Latent Reasoning by Geiping et al. (2025) shows that recurrent-depth language models improve when given additional recurrence at inference time, enabling latent-space reasoning without explicit chain-of-thought.
- Scaling Latent Reasoning via Looped Language Models by Zhu et al. (2025) introduces Ouro, a looped language model family that combines latent iteration, learned depth allocation, and large-scale pretraining.
- Parcae: Scaling Laws for Stable Looped Language Models by Prairie et al. (2026) develops stability theory and scaling laws for looped architectures.
- Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers by Kohli et al. (2026) shows that looping enables systematic generalization and depth extrapolation that conventional transformers struggle to achieve.
-
Together, these works suggest that looped transformers define a scaling axis orthogonal to parameter count and data size.
Core Mechanism
-
A standard transformer applies a sequence of distinct layer functions:
\[h_{i+1}=f_{\theta_i}(h_i)\]- where each layer has its own parameters \(\theta_i\).
-
A looped transformer instead reuses the same function repeatedly:
\[h_{t+1}=f_{\theta}(h_t,x), \quad t=0,1,\dots,L-1\]- where \(h_0\) is the initial token representation, \(x\) is the input, \(L\) is the number of loop iterations, and \(\theta\) is shared across every iteration. The final representation \(h_L\) is passed to the language modeling head to predict the next token.
-
If the recurrent block contains \(k\) transformer layers and is executed \(L\) times, the model has effective depth:
-
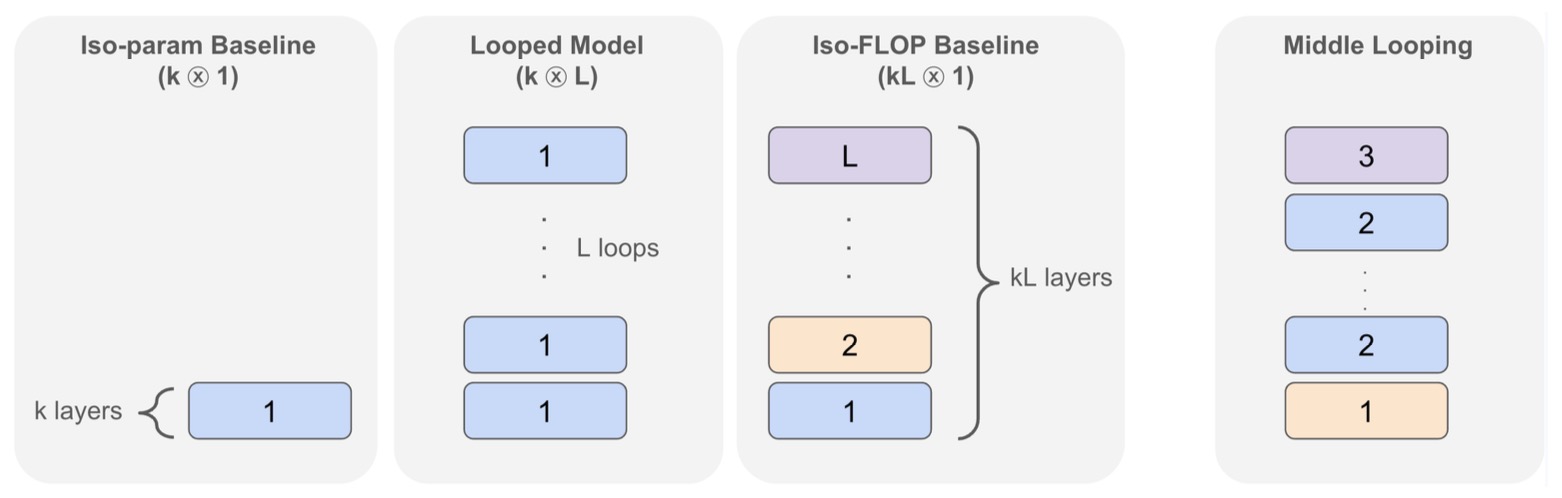
This is why a compact model can behave like a much deeper one while storing far fewer parameters. This structure is often written as \(k \otimes L\), meaning a \(k\)-layer block looped \(L\) times.
-
The following figure (source) shows the simple architecture-agnostic looping mechanism where a \(k\)-layer block looped \(L\) times, written as \(k \otimes L\), matches the effective depth of a \(kL\)-layer non-looped model while using far fewer distinct parameters.
Why It Matters
-
Looping separates two quantities that standard transformers usually conflate:
- Parameters: what the model can store.
- Computation: how much processing the model performs on a specific input.
-
FAIR’s Which one is more important: more parameters or more computation? frames this distinction directly, arguing that compute and parameter count should be treated as separate design axes. This is central to looped transformers: parameter count remains fixed, while FLOPs grow with the number of loops.
-
As a result:
- Parameter efficiency comes from reusing the same block instead of storing many unique layers.
- Runtime depth control allows more loops to be run for harder inputs.
- Latent reasoning refines hidden states internally without emitting intermediate tokens.
- Algorithmic structure lets the model resemble iterative procedures such as search, optimization, and multi-hop composition.
- Deployment efficiency improves because memory footprint remains much smaller than an equally deep non-looped model.
-
This is especially attractive for inference, where parameter storage, memory bandwidth, and activation movement often dominate deployment cost.
Latent Reasoning
-
Recent reasoning systems often improve performance by generating longer chain-of-thought outputs. That approach externalizes reasoning into text, which increases sequence length, latency, and context usage.
-
Looped transformers provide a different route: they reason internally in continuous latent space. Instead of producing intermediate tokens, the model repeatedly refines its hidden state:
-
Each loop acts like another internal computation step before the model emits the next token. Scaling up Test-Time Compute with Latent Reasoning by Geiping et al. (2025) demonstrates that recurrent-depth language models can improve at inference time by running additional loops, effectively increasing reasoning compute without generating longer chain-of-thought text.
-
The following figure (source) shows a visualization of the architecture. Each block consists of a number of sub-layers. The blue prelude block embeds the inputs into latent space, where the green shared recurrent block is a block of layers that is repeated to compute the final latent state, which is decoded by the layers of the red coda block.
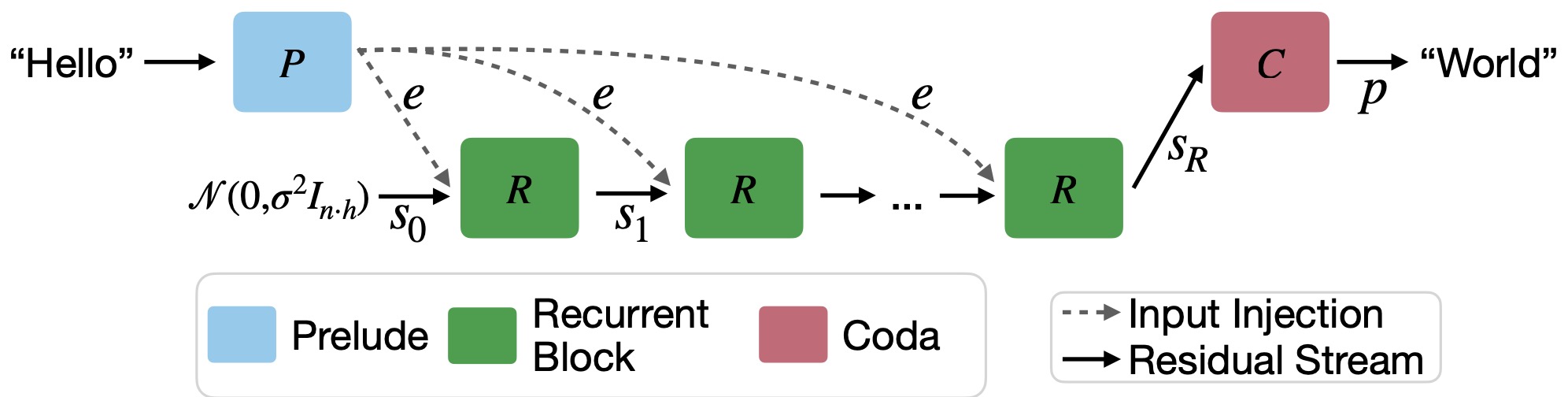
-
Unlike chain-of-thought, these intermediate states are never decoded into text. This enables more compact reasoning, non-linguistic internal search, better compute efficiency, and reasoning trajectories that do not need to be human-readable. Training Large Language Models to Reason in a Continuous Latent Space by Hao et al. (2025) introduces Coconut, showing that continuous latent states can encode multiple possible reasoning branches rather than committing immediately to a single text-token path.
-
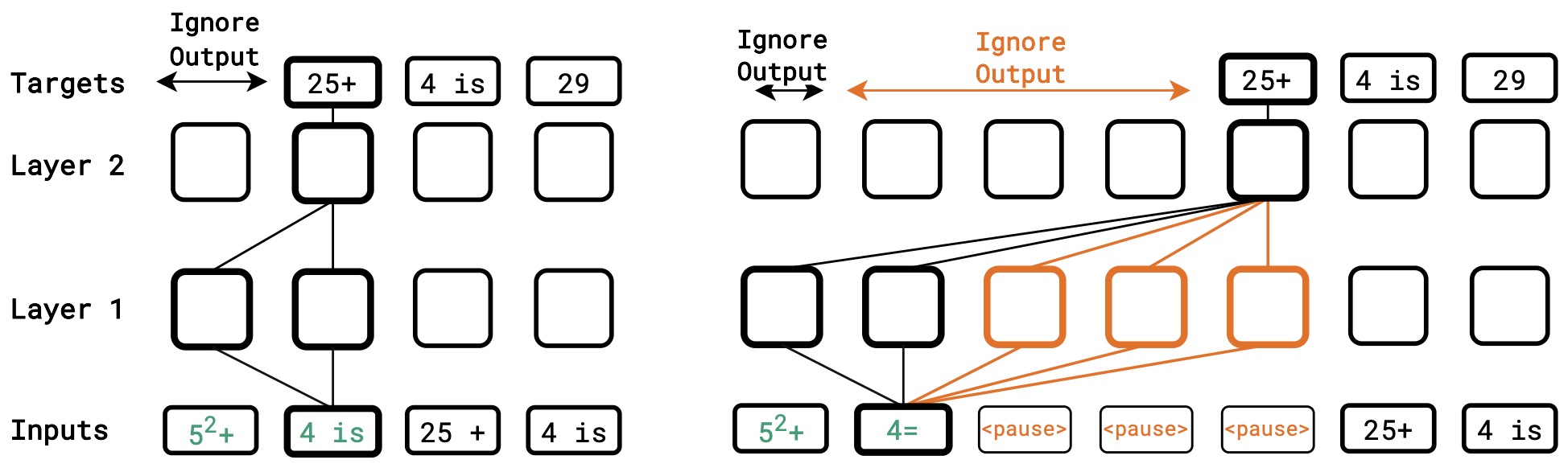
The following figure (source) shows (left) standard inference and finetuning and (right) pause-inference and pause-finetuning for a decoder-only model on a downstream task, where the model attends to the full prefix before generating the target answer. Rounded squares denote Transformer operations consisting of self-attention and MLP layers in a 2-layer Transformer. “Ignore Output” means that the corresponding output token is not extracted during inference, is not fed back autoregressively, and is not backpropagated through during finetuning. The connecting lines show selected computational pathways from the prefix token “4 is” to the output token “25+”. In the standard setting, output extraction begins immediately after the final prefix token; in the pause setting, manually inserted
<pause>tokens delay output extraction and create additional colored computational pathways between the prefix and the target answer.
Iterative Computation
-
Many hard tasks are naturally iterative: multi-hop retrieval, graph search, gradient descent, constraint propagation, planning, and dynamic programming all involve repeated updates to an internal state.
-
Looped transformers match this structure directly:
\[h_{t+1}=\mathcal{A}_{\theta}(h_t)\]- where \(\mathcal{A}_{\theta}\) is a learned update rule. The recurrent block becomes one computational step, and looping becomes the control mechanism that repeatedly executes that step.
-
Looped Transformers Are Better at Learning Learning Algorithms by Yang et al. (2024) shows that looped models learn iterative solvers for regression and optimization tasks with less than 10% of the parameters required by comparable standard transformers. Looped Transformers as Programmable Computers by Giannou et al. (2023) extends this view by showing that a shallow transformer in a loop can simulate a small instruction-set computer.
-
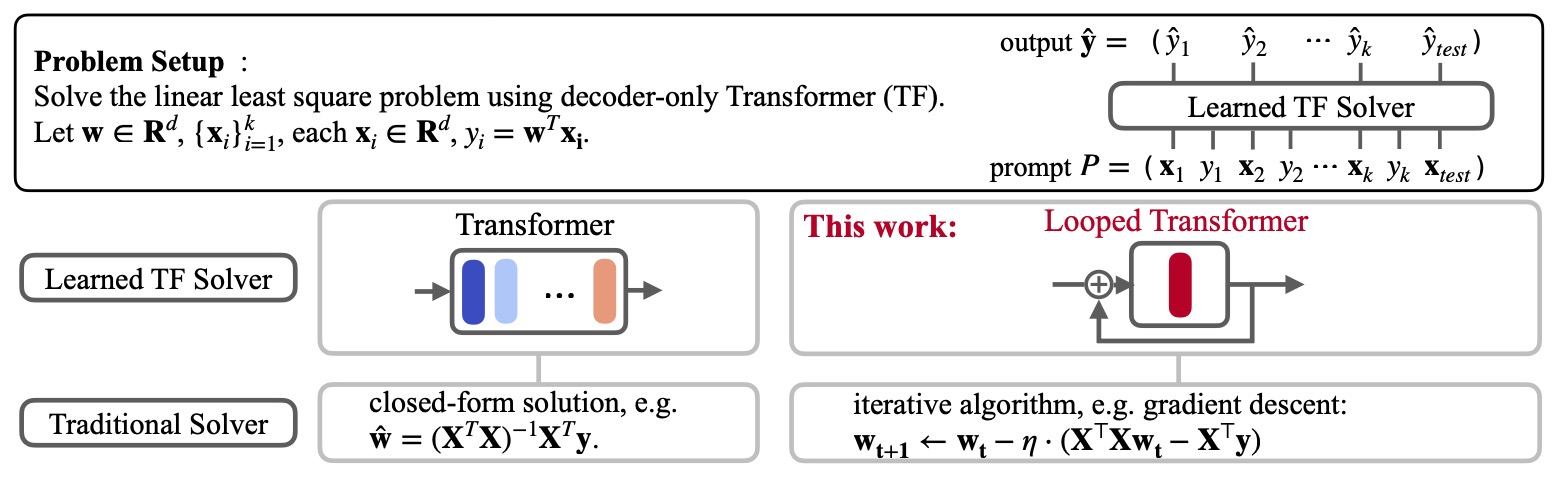
The following figure (source) shows how a transformer can be trained to learn an iterative learning algorithm for in-context linear regression, contrasting a learned transformer solver with an iterative gradient-descent-style solver. They consider the task of training a transformer to solve linear regression in context. The provided prompt \(\left(\boldsymbol{x}_1, y_1, \boldsymbol{x}_2, y_2, \cdots, \boldsymbol{x}_k, y_k, \boldsymbol{x}_{\text {test }}\right)\) is fed into a decoder transformer. The objective is to reduce the squared loss between the predicted \(\hat{y}_{\text {test }}\) based on this prompt, and the target value \(f\left(\boldsymbol{x}_{\text {test }}\right)\). What Can Transformers Learn In-Context? A Case Study of Simple Function Classes by Garg et al. (2022) demonstrated that a decoder transformer can learn to solve linear regression, which potentially involves learning the approximation of the least squares solution. In this study, we aim to train a transformer to learn iterative learning algorithms. Their goal is to achieve performance on par with standard transformers but with fewer paramtters. To this end, we introduce the looped transformer architecture and its accompanying training methodology.
- The following figure (source) shows a looped transformer architecture, where the input sequence stores the commands, memory where the data is read/written from, and a scratchpad where intermediate results are stored. The input is processed by the network and the output is used as the new input, allowing the network to iteratively update an implicit state and perform complex computations.
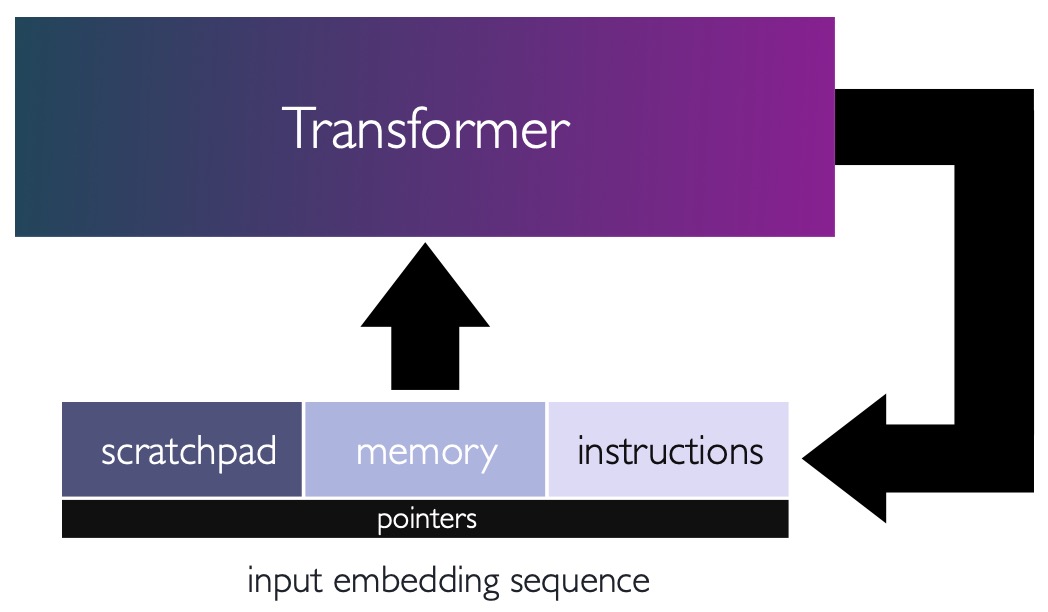
Knowledge Use
-
A recurring lesson is that looped transformers often improve knowledge manipulation more than knowledge storage. Modern language models already store large amounts of information; the harder problem is combining facts, rules, and latent features in unfamiliar ways.
-
Scaling Latent Reasoning via Looped Language Models by Zhu et al. (2025) reports that Ouro models trained on up to 7.7 trillion tokens achieve performance competitive with larger non-looped models, with evidence that the advantage comes from stronger knowledge composition rather than simply greater memorization.
-
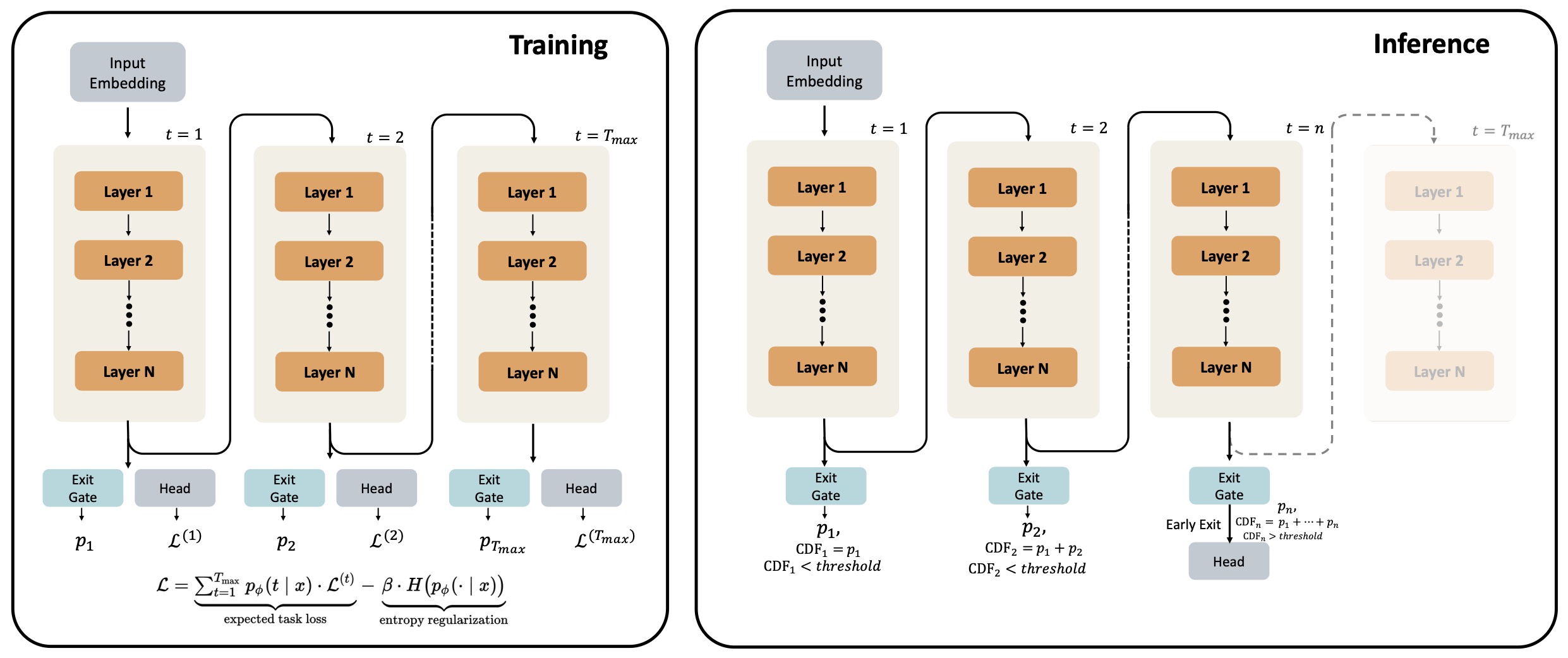
The following figure (source) shows an overview of the parameter-shared Looped Language Model (LoopLM) architecture. Left (Training): During training, the model applies a stack of \(N\) layers repeatedly for \(T_{max}\) recurrent steps. At each recurrent step \(l\), an exit gate predicts the probability \(p_l\) of exiting, and a language modeling head \(L_l\) computes the lanugage modeling loss. Right (Inference): At inference time, the model can exit early based on the accumulated exit probability.
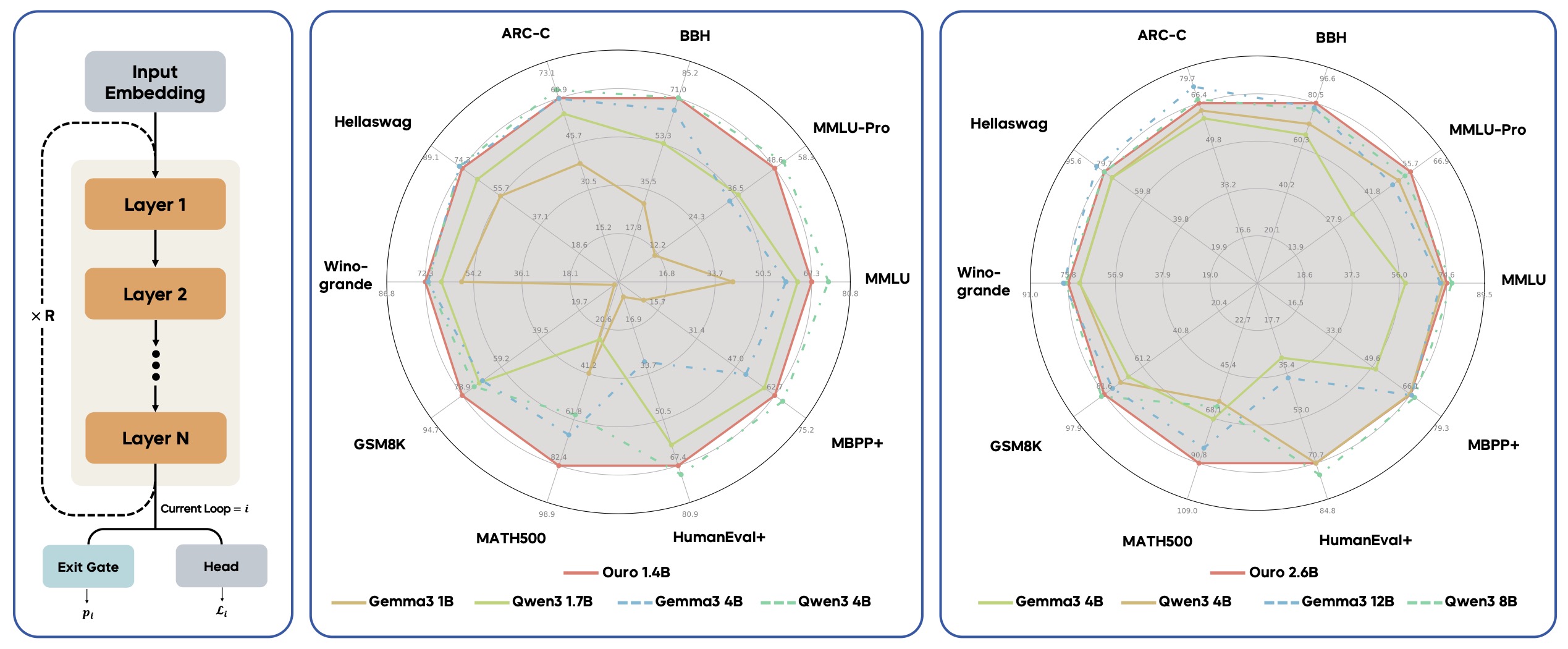
- The following figure (source) benchmark comparisons for Ouro. (Left) The parameter-shared looped architecture. (Middle & Right) Radar plots comparing the Ouro 1.4B and 2.6B models, both with 4 recurrent steps (red), against individual transformer baselines. Ouro demonstrates strong performance comparable to or exceeding much larger baselines.
- This makes looped transformers especially relevant for compositional reasoning: the model can repeatedly retrieve, transform, and combine internal information before committing to an output token.
Architecture
-
Looped transformers usually preserve the outer shape of a decoder-only language model while changing the depth structure. Instead of a long stack of unique layers, the model is commonly divided into three regions:
- Prelude: non-looped layers that prepare token representations.
- Recurrent core: one or more shared transformer blocks applied repeatedly.
- Coda: non-looped layers that convert the final recurrent state into logits.
-
A typical computation is:
-
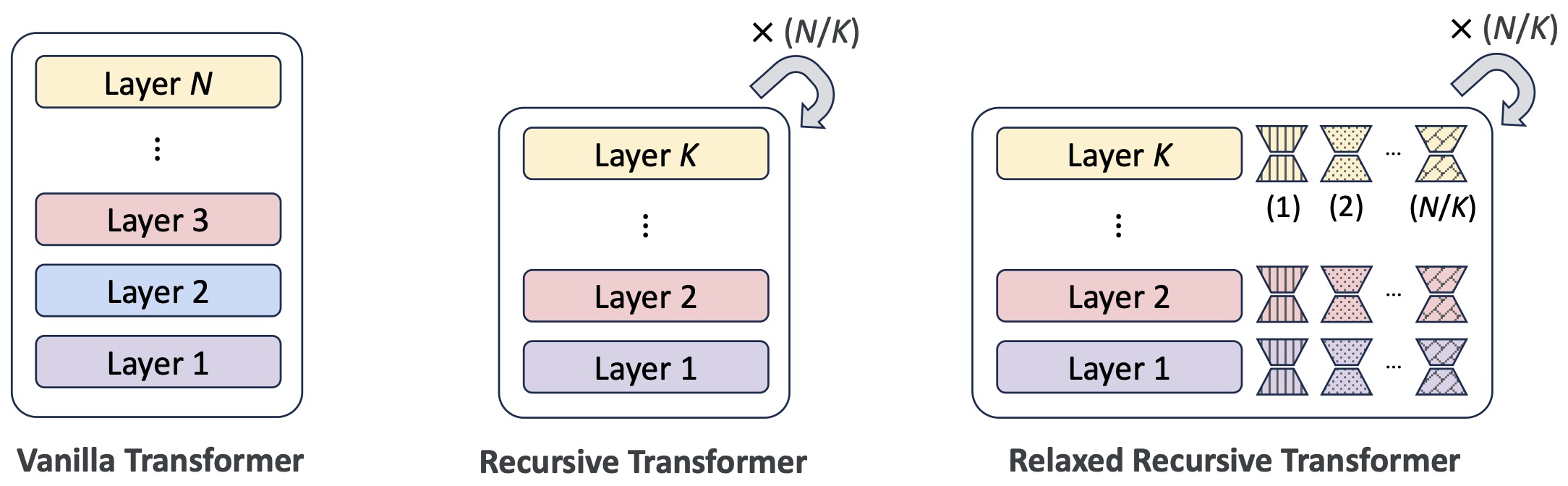
Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA by Bae et al. (2025) uses this recursive-block view to convert pretrained transformers into smaller recursive models, then relaxes strict weight tying with layer-wise LoRA adapters.
-
The following figure (source) shows the conversion from a vanilla \(N\)-layer Transformer to a Recursive Transformer with \(\frac{N}{K}\) blocks of \(K\) shared layers, and then to a Relaxed Recursive Transformer with layer-specific LoRA modules.
Shared Core
- The recurrent core is typically a standard transformer block or stack. In a residual formulation, one loop step can be written as:
- In implementation, this means the same module object is called repeatedly inside a loop:
for step in range(num_loops):
hidden_states = recurrent_block(
hidden_states,
attention_mask=attention_mask
)
- The key detail is that
recurrent_blockhas one shared set of weights. Gradients from all loop steps accumulate into the same parameters during backpropagation.
Effective Depth
- If the recurrent core contains \(k\) layers and is executed for \(L\) loops, the effective depth is:
- This allows a compact model to behave like a much deeper one while storing far fewer parameters. Looped Transformers Are Better at Learning Learning Algorithms by Yang et al. (2024) shows that repeated structure is especially useful for learning iterative algorithms such as regression solvers.
Weight Tying
-
The defining implementation choice is how aggressively weights are tied.
-
Strict tying uses the exact same attention, MLP, normalization, and projection weights at every loop step:
-
Relaxed tying adds small step-specific adapters:
\[\theta_t=\theta+\Delta\theta_t\]- where \(\Delta\theta_t\) is often low-rank. Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA by Bae et al. (2025) uses LoRA modules to preserve most memory savings while recovering performance lost from strict parameter sharing.
Loop Count
-
Loop count can be fixed, sampled, or learned.
-
A fixed-depth setup uses the same loop count during training and inference:
- A test-time scaling setup trains on one depth or a range of depths, then increases recurrence during inference:
-
Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers by Kohli et al. (2026) shows that increasing recurrence at inference time can unlock depth extrapolation on multi-hop reasoning tasks.
-
The following figure (source) shows the recurrent-depth model architecture where a shared transformer block is repeated \(R\) times before layer normalization and the language-model head. The embedding layer and language model head (LM Head) have tied weights. In their experiments, they use a simple looped transformer similar to Reasoning with Latent Thoughts: On the Power of Looped Transformers Saunshi et al. (2025) without design elements such as input injection, gated halting, and middle looping.

- A learned early-exit setup predicts whether each token or sequence needs more computation. Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation by Bae et al. (2025) introduces token-level routing so different tokens can receive different recursion depths.
Output Heads
- Most looped language models apply the language modeling head only after the final loop:
- Adaptive-depth models may attach auxiliary heads at intermediate loops:
- These intermediate predictions can support early exit, depth supervision, confidence-based routing, or learned compute allocation. Scaling Latent Reasoning via Looped Language Models by Zhu et al. (2025) uses an exit mechanism so computation can be allocated dynamically rather than uniformly.
Training
-
Training looped transformers requires more than tying weights and repeatedly calling the same block. Because the same parameters are reused across many iterations, the model is optimized through a deeper computational graph than its parameter count suggests, and training must teach the recurrent block to refine representations progressively rather than solve the prediction problem in one static pass.
-
The training objective is usually the standard autoregressive language modeling loss:
\[\mathcal{L}_{\text{LM}} =-\sum_{t=1}^{T} \log p(x_t \mid x_{<t})\]- where the probability distribution is computed from the final recurrent state after \(L\) loop iterations. Even though the loss is familiar, recurrence changes the optimization dynamics because every loop contributes gradients to the same shared weights.
Depth Sampling
-
A central training decision is whether to use a fixed loop count or sample loop counts during training. If a model is always trained with the same recurrence depth, it may become brittle when evaluated with fewer or more loops. A more flexible approach samples the number of iterations:
\[L \sim p(L)\]- where \(p(L)\) may be uniform over a bounded range, biased toward shorter depths early in training, or gradually expanded as the model stabilizes.
-
This teaches the model to produce useful representations after a small number of iterations while still benefiting from additional computation when more loops are available. Scaling up Test-Time Compute with Latent Reasoning by Geiping et al. (2025) uses recurrent-depth training so the model can exploit increased inference-time recurrence for latent reasoning. Parcae: Scaling Laws for Stable Looped Language Models by Prairie et al. (2026) studies this compute axis systematically and shows that loop count can follow predictable scaling behavior when training is stable.
Progressive Refinement
- The recurrent block is best understood as a learned refinement operator. Rather than treating each layer as a different stage of processing, the same function is applied repeatedly so that the hidden state becomes progressively more useful:
-
Ideally, each iteration reduces prediction error or improves the internal representation:
\[\mathcal{E}(h_{t+1}) \leq \mathcal{E}(h_t)\]- where \(\mathcal{E}\) denotes an implicit task error. This is why looped transformers naturally resemble iterative procedures such as gradient descent, graph search, message passing, and constraint propagation. Looped Transformers Are Better at Learning Learning Algorithms by Yang et al. (2024) shows that looped architectures are particularly effective at learning iterative optimization behavior with far fewer parameters than standard transformers.
Multi-Step Supervision
- Some looped models apply loss only after the final iteration:
-
This keeps the training objective simple and encourages the final state to be maximally predictive. Other recipes attach auxiliary prediction heads to intermediate loop states and train with a weighted sum:
\[\mathcal{L} =\sum_{t=1}^{L} w_t \mathcal{L}_t\]- where \(\mathcal{L}_t\) is the language modeling loss after loop \(t\). Intermediate supervision can improve gradient flow, make early exits more reliable, and encourage every recurrence step to produce a meaningful refinement rather than relying only on the final iteration.
-
Scaling Latent Reasoning via Looped Language Models by Zhu et al. (2025) combines recurrent pretraining with learned depth allocation, so the model is trained not only to predict tokens but also to decide how much latent computation is useful.
Exit and Routing Losses
-
When a looped model supports early exit or token-level adaptive depth, training usually adds objectives that make computation allocation learnable. A simple form penalizes excessive recurrence:
\[\mathcal{L} =\mathcal{L}_{\text{LM}} + \lambda \mathbb{E}[L]\]-
where \(\mathbb{E}[L]\) is the expected number of recurrent steps. Entropy regularization may also be used so the routing mechanism does not collapse into always exiting early or always using maximum depth:
\[\mathcal{L} =\mathcal{L}_{\text{LM}} - \beta H(p)\]
-
-
Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation by Bae et al. (2025) extends adaptive computation to the token level, allowing different tokens in the same sequence to receive different recursion depths.
Uptraining from Existing Models
- A practical way to build looped transformers is to convert an existing pretrained transformer into a recursive model. Suppose the original model contains layers \(\theta_1,\dots,\theta_N\). A shared recurrent block can be initialized by selecting representative layers, averaging compatible layers, or compressing several layers into a smaller repeated block:
- After tying the layers, the model is uptrained so it can adapt to repeated use of the same block. This avoids training from scratch and makes looped architectures more practical for modern language models. Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA by Bae et al. (2025) shows that pretrained transformers can be converted into recursive models and then improved with layer-wise LoRA adapters that partially relax strict weight tying.
Depth Curriculum
-
Training often benefits from gradually increasing recurrence depth. Early in training, short loops reduce instability and help the block learn basic transformations; later, longer loops teach the model to sustain useful computation across many applications of the same weights.
-
A simple schedule is:
\[L_{\max}(s) =\min(L_{\text{target}}, L_0 + ks)\]- where \(s\) is the training step, \(L_0\) is the initial loop budget, and \(k\) controls how quickly the maximum depth grows. Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers by Kohli et al. (2026) shows that training strategy strongly affects whether recurrent-depth transformers can extrapolate to deeper multi-hop reasoning than they saw during training.
Inference Scaling
- A defining advantage of looped transformers is that inference-time compute can be increased after training by running more loop iterations:
-
Performance often improves with additional loops before saturating. A useful empirical shape is:
\(\epsilon\)L\(\approx \epsilon_\infty + A e^{-kL}\)
- where \(\epsilon(L)\) is error after \(L\) loops, \(\epsilon_\infty\) is the asymptotic error, and \(A e^{-kL}\) captures diminishing returns. Parcae: Scaling Laws for Stable Looped Language Models by Prairie et al. (2026) characterizes this behavior and treats looping as a predictable compute-scaling axis.
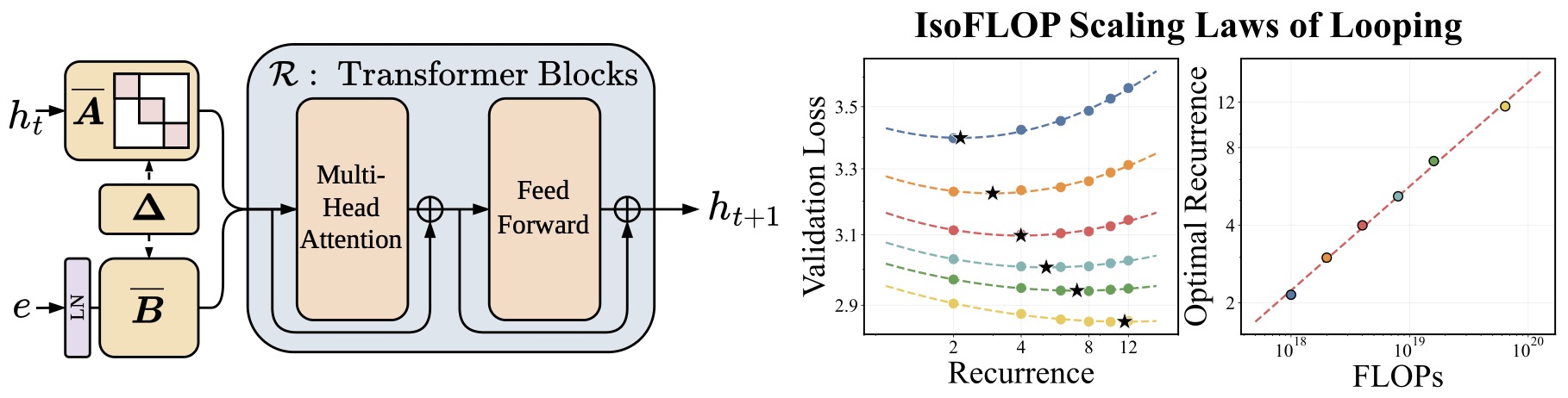
-
The following figure shows Parcae stabilizing recurrent dynamics and establishing looping as a scaling axis for increased computation. (Left) Parcae constrains the spectral norm of \(A\) and normalizes the input injection, stabilizing the residual stream \(h_t\) across loops. (Right) We observe looping to be an orthogonal axis of scaling compute which follows a power law.
Training Setup
-
In implementation, looped models usually require careful choices around recurrence depth, normalization, optimization, and memory management. Loop counts during training commonly span a modest range and may be increased at inference; the shared recurrent core is often a small stack of transformer layers rather than a single layer; normalization is usually placed before attention and feed-forward sublayers to stabilize repeated application; gradient clipping is commonly needed because the unrolled graph can amplify updates; the learning rate is often set more conservatively than for a comparable non-looped model; mixed precision is typically used as in standard LLM training; and activation checkpointing becomes important because activation memory grows with the number of unrolled iterations unless recomputation is used.
-
The broader training philosophy is that a looped transformer learns a reusable computational step. Instead of learning a fixed sequence of specialized layers, it learns a transformation that can be applied repeatedly to move an internal state closer to a useful answer.
Stability
- Stability is one of the hardest practical problems in looped transformers. Reusing the same block many times can amplify small errors, cause residual states to grow uncontrollably, or produce loss spikes during training. A looped transformer is therefore not just a transformer with shared weights; it is a dynamical system whose behavior depends on what repeated application of the same transformation does to the residual stream.
Dynamics
-
A useful abstraction writes the recurrent update as:
\[h_{t+1} =A h_t + B e + R(h_t,e)\]- where \(h_t\) is the residual state at loop step \(t\), \(e\) is the input embedding or conditioning signal, \(A\) controls how much of the previous residual state is retained, \(B\) controls how strongly the input is injected at each step, and \(R(h_t,e)\) represents nonlinear transformer operations such as attention and the MLP.
-
Parcae: Scaling Laws for Stable Looped Language Models by Prairie et al. (2026) uses this dynamical-systems view to explain why looped models can become unstable, identifying large spectral norms in injection parameters as a major source of residual explosion.
Residual Growth
- If the recurrent transformation expands hidden states, then repeated looping magnifies the expansion. In a simplified linear system:
- the state after \(L\) loops is:
-
If the spectral radius of \(A\) exceeds 1, then the norm of \(h_L\) can grow exponentially with \(L\). This is the core mathematical reason looped architectures are more fragile than ordinary feed-forward transformer stacks: the same unstable transformation is applied repeatedly rather than only once.
-
A stable looped model should keep the recurrent update contractive or at least norm-controlled:
\[\rho(A) \leq 1\]- where \(\rho(A)\) is the spectral radius. In practice, exact spectral control over the full nonlinear transformer is difficult, so implementations use normalization, residual scaling, careful initialization, and constrained parameterizations.
Normalization
-
Normalization is central because the same block sees its own outputs repeatedly. Pre-norm transformers are usually preferred because they normalize the input to each attention and MLP operation before the update is applied. A simplified pre-norm recurrent block can be written as:
\[h_{t+1} =h_t +\alpha F_\theta(\text{Norm}(h_t))\]- where \(\alpha\) is a residual scale. Smaller \(\alpha\) can prevent each loop from making overly large updates, while normalization keeps the input distribution to the shared block more consistent across loop iterations.
-
Post-norm can sometimes damp the final output of a block, but repeated post-norm architectures may still suffer from unstable intermediate dynamics. Parcae: Scaling Laws for Stable Looped Language Models by Prairie et al. (2026) specifically motivates stabilizing the residual stream rather than relying only on ordinary transformer normalization.
Injection
-
A subtle issue in looped models is whether the original input is injected once or repeatedly. If the input is only used to initialize (h_0), then later loops may drift away from the original prompt. If the input is injected at every step, the model receives persistent conditioning, but the repeated injection can destabilize the residual stream if its magnitude is uncontrolled.
-
The recurrent update with input injection is:
- Stable architectures therefore need to control both the memory term \(A h_t\) and the injection term \(B e\). Parcae: Scaling Laws for Stable Looped Language Models by Prairie et al. (2026) proposes constraining injection parameters through a negative diagonal parameterization and discretization, which is designed to prevent repeated input injection from causing residual explosion.
Loss Spikes
-
Loss spikes can arise when stochastic depth training exposes the model to loop counts it is not yet stable under. A model may perform well at \(L=4\) but become unstable at \(L=16\), and if training randomly samples \(L=16\), the resulting gradient can be large enough to destabilize the shared weights for all depths.
-
This is why depth curricula, gradient clipping, conservative learning rates, and activation norm monitoring are more important in looped transformers than in ordinary transformers. The repeated block must remain useful not only for the depths used in the current batch, but also for the range of depths expected at inference.
Overthinking
-
More recurrence is not always better. A looped model may improve for several iterations and then degrade if additional loops push the representation away from the correct answer. This failure mode is often called overthinking.
-
In qualitative terms, the model first refines its answer, then begins to overwrite or distort useful information. Formally, accuracy as a function of loop count may rise and then fall rather than monotonically saturate:
\(\text{Acc}(L+1) < \text{Acc}\)L\(\)
- for sufficiently large \(L\). Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers by Kohli et al. (2026) identifies overthinking as a limitation of recurrent-depth transformers, especially when recurrence is pushed far beyond the training regime.
Stabilization
-
A stable implementation typically treats recurrence as a controlled iterative process. The residual update should be small enough to avoid explosion, normalization should keep hidden-state statistics consistent across loops, input injection should be bounded, and the training distribution over loop counts should expose the model gradually to deeper computation.
-
A practical recurrent block often resembles:
\[h_{t+1} =h_t +\alpha_t F_\theta(\text{RMSNorm}(h_t))\]- where \(\alpha_t\) may be fixed, learned, or scheduled. The purpose of \(\alpha_t\) is to make each loop behave like a refinement step rather than a full independent layer. This design aligns looped transformers more closely with stable iterative algorithms, where each update is controlled to avoid divergence.
Scaling Laws
-
One of the most important developments in looped transformers is the discovery that recurrence follows predictable scaling laws. Just as conventional language models obey power laws relating loss to parameters, data, and training FLOPs, looped transformers reveal that increasing recurrence depth forms an additional and largely orthogonal axis of scaling. This means that model quality can be improved by allocating more computation to repeated applications of a fixed parameter set, without increasing the number of stored weights.
-
Parcae: Scaling Laws for Stable Looped Language Models by Prairie et al. (2026) provides the most systematic treatment of this phenomenon, deriving empirical laws for both training-time and inference-time scaling in stable looped language models.
Compute Axis
-
Traditional scaling laws treat model performance as a function of parameter count \(N\), dataset size \(D\), and total training compute \(C\). In standard transformers, increasing compute usually implies increasing parameters or training on more data. Looped transformers introduce a new factor, recurrence depth \(L\), which increases FLOPs while keeping parameter count fixed:
\[C \propto N D L\]- where \(N\) is the number of unique parameters,\(D\) is the amount of training data, and \(L\) is the average number of recurrent steps.
-
This decoupling makes it possible to ask a new question: given a fixed parameter budget, how should compute be divided between additional data and additional looping? Parcae: Scaling Laws for Stable Looped Language Models by Prairie et al. (2026) shows that optimal performance is achieved by increasing both data and recurrence together rather than relying exclusively on one or the other.
Effective Depth
- A looped model with \(k\) shared layers executed \(L\) times has effective depth:
-
Empirically, many reasoning and language modeling tasks depend more strongly on effective depth than on the number of distinct parameter sets. Reasoning with Latent Thoughts: On the Power of Looped Transformers by Saunshi et al. (2025) shows that looped and non-looped models often align when compared at equal effective depth, suggesting that recurrent computation can substitute for explicit stacking.
-
This observation is especially significant for reasoning tasks, where multi-step compositional computation appears to be the limiting factor rather than raw memorization capacity.
Training Scaling
-
When recurrence is treated as a variable rather than a fixed architectural choice, training loss follows predictable power-law behavior analogous to standard scaling laws:
\[\mathcal{L}(C) \approx a C^{-b} + c\]- where \(C\) includes FLOPs contributed by recurrent iterations.
-
The implication is that looping behaves as a first-class scaling mechanism rather than an architectural curiosity. Additional recurrence can be traded against increased model size or additional data while preserving predictable improvements. Parcae: Scaling Laws for Stable Looped Language Models by Prairie et al. (2026) demonstrates that stable looped models obey smooth and predictable loss curves as recurrence and data are scaled jointly.
Inference Scaling
- Looped transformers are especially notable because recurrence can be increased after training. If a model was trained on a range of loop counts, inference can use larger values:
-
Performance typically improves with diminishing returns, following a saturating exponential:
\[\epsilon(L) \approx \epsilon_\infty +A e^{-kL}\]- where \(\epsilon(L)\) is the task error after \(L\) loops.
-
This behavior closely parallels the scaling of chain-of-thought reasoning, except that the additional computation occurs entirely in latent space rather than through token generation. Scaling up Test-Time Compute with Latent Reasoning by Geiping et al. (2025) shows dramatic benchmark improvements when inference-time recurrence is increased, particularly on tasks such as GSM8K and ARC Challenge.
Compute Allocation
-
An important consequence of recurrence-based scaling is that computation can be allocated dynamically rather than uniformly. Some inputs may converge after only a few iterations, while others benefit from substantially more depth. Learned exit mechanisms and routing modules therefore turn recurrence into a per-input or per-token compute budget.
-
Scaling Latent Reasoning via Looped Language Models by Zhu et al. (2025) uses entropy-regularized exit probabilities to allocate computation adaptively across examples. Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation by Bae et al. (2025) generalizes this idea by allowing individual tokens to stop recurring at different depths.
-
This adaptive strategy effectively replaces the fixed-depth assumption of standard transformers with a learned, input-dependent computational schedule.
Parameter Efficiency
-
Because recurrence increases FLOPs without increasing stored weights, looped transformers occupy a favorable point on the trade-off between memory footprint and computational power. A smaller model with additional recurrence can often match a much larger standard transformer.
-
Scaling Latent Reasoning via Looped Language Models by Zhu et al. (2025) reports that Ouro models with 1.4B and 2.6B parameters perform competitively with models several times larger, while Parcae: Scaling Laws for Stable Looped Language Models by Prairie et al. (2026) shows that a 1.3B looped model achieves up to 87.5% of the quality of a transformer twice its size.
Scaling Interpretation
- The broader interpretation is that model quality depends on three largely independent resources:
-
Looped transformers expose computation as a directly controllable variable. Instead of increasing parameters to obtain deeper reasoning, one can increase recurrence to perform additional internal computation. This viewpoint echoes FAIR’s Which one is more important: more parameters or more computation?, which argued that parameter count and compute should be considered distinct resources in model design.
-
The practical consequence is that looped transformers create a new Pareto frontier. They allow models to trade latency for reasoning quality, memory for compute, and static depth for adaptive iterative processing, making recurrence a fundamental scaling mechanism rather than a niche architectural technique.
Reasoning
- One of the most compelling properties of looped transformers is their ability to perform multi-step reasoning entirely within the residual stream. Rather than emitting intermediate natural-language tokens as chain-of-thought, the model repeatedly updates a latent representation until it converges to a state from which the answer can be decoded. This turns reasoning into an internal iterative computation rather than an explicit textual process.
Latent Thoughts
- In conventional language models, additional reasoning is often achieved by generating more tokens, thereby extending the computational graph through the sequence dimension. Looped transformers instead extend the graph through recurrent depth:
-
Each hidden state can be interpreted as a latent thought, an intermediate representation that refines the model’s understanding of the problem. Reasoning with Latent Thoughts: On the Power of Looped Transformers by Saunshi et al. (2025) proves that a looped model can simulate \(T\) steps of chain-of-thought using \(T\) recurrent iterations, providing a theoretical connection between textual reasoning and latent iterative computation.
-
The following figure (source) shows: (Left) how chain-of-thought reasoning can be viewed as a looped process, where each iteration produces one new thought token. Specifically, chain-of-thought reasoning can be viewed as a looped model, where each iteration produces one new thoughts token. The new tokens are highlighted in red. (Right) A looped model simulates this reasoning internally through recurrent latent updates. Specifically, a looped model can instead generate multiple latent thoughts in parallel and, in theory, can simulate CoT reasoning my masking the updates appropriately
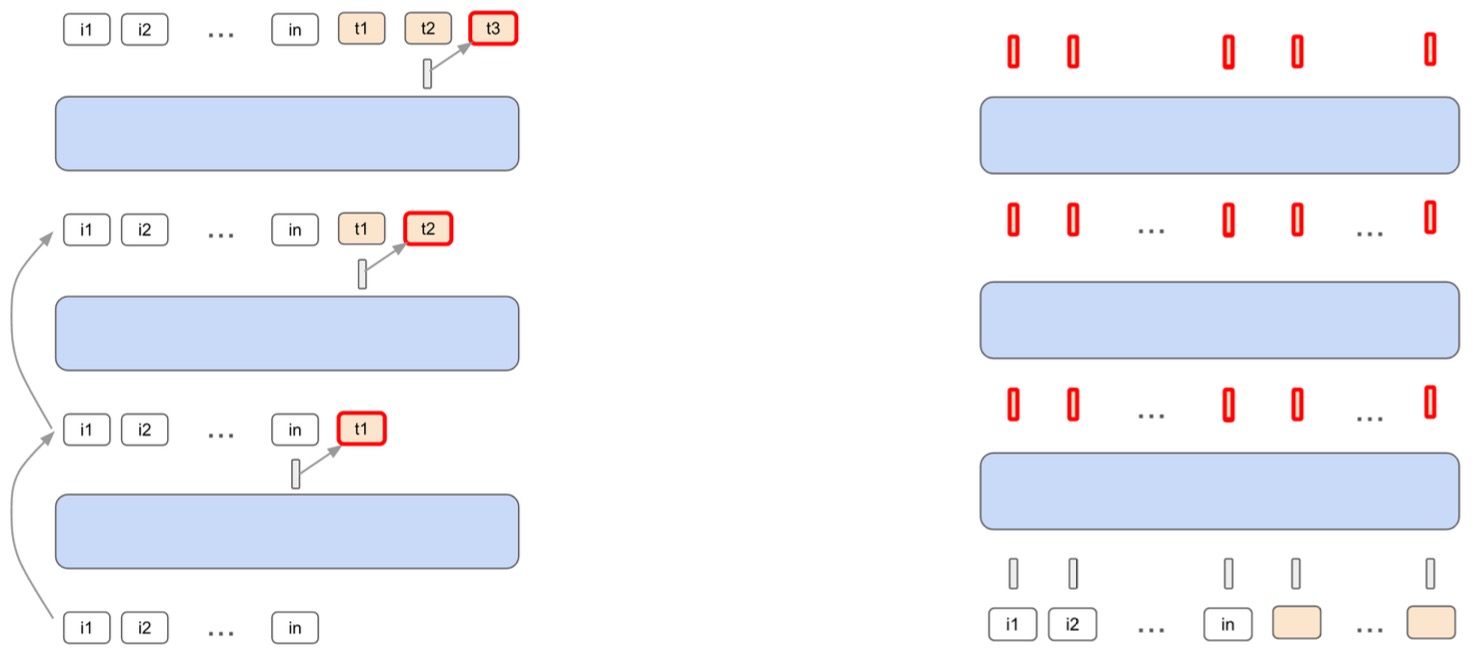
- Scaling up Test-Time Compute with Latent Reasoning by Geiping et al. (2025) demonstrates that these latent thoughts can be scaled at inference time by simply increasing the recurrence count, yielding substantial gains on mathematical and commonsense reasoning benchmarks.
Continuous Thought
-
The broader idea that reasoning need not be expressed in language is explored in Training Large Language Models to Reason in a Continuous Latent Space by Hao et al. (2025), which introduces Chain of Continuous Thought (Coconut). Instead of decoding an intermediate token, Coconut feeds the final hidden state back into the model as the next input embedding, allowing the model to reason directly in continuous space.
-
Although Coconut does not use parameter tying in the same way as looped transformers, it reinforces the same conceptual claim: the most efficient reasoning process may be one that never leaves latent space.
Implicit Composition
-
Modern language models already store vast amounts of factual knowledge in their parameters, but they often struggle to combine that knowledge in novel ways. Looped transformers appear especially effective at this composition problem because repeated applications of the same block act like iterative retrieval and synthesis.
-
Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers by Kohli et al. (2026) studies implicit multi-hop reasoning, where models must answer questions in a single forward pass without explicit chain-of-thought. The authors show that recurrent-depth transformers can systematically combine facts that were never observed together during training, while standard transformers frequently fail.
-
For example, a model may retrieve:
- “The performer of Imagine is John Lennon.”
- “The spouse of John Lennon is Yoko Ono.”
-
By iteratively refining the hidden state, the model composes these facts internally and predicts the final answer without ever verbalizing the intermediate steps.
Systematic Generalization
-
Systematic generalization refers to the ability to recombine learned rules and facts in previously unseen configurations. In looped transformers, this capability emerges because each recurrent step applies the same transformation, encouraging the model to reuse a common reasoning procedure rather than memorize depth-specific templates.
-
Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers by Kohli et al. (2026) shows that out-of-distribution performance emerges through a three-stage grokking process. Models first memorize training examples, then generalize within the training distribution, and finally exhibit a sudden jump in systematic generalization to unseen compositions.
-
This result suggests that recurrence encourages the emergence of reusable computational rules rather than isolated associations.
Depth Extrapolation
-
Depth extrapolation is the ability to solve problems requiring more reasoning steps than were encountered during training. Because looped transformers can execute the same block arbitrarily many times, they naturally support this form of generalization.
-
If a model is trained with recurrence depth (L_{\text{train}}), then inference can use:
-
Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers by Kohli et al. (2026) reports that models trained on 20-hop reasoning tasks can generalize successfully to 30-hop questions by increasing recurrence depth at inference time.
-
This property is rare in conventional transformers, whose fixed architectural depth constrains the number of implicit reasoning steps available within a single forward pass.
Search Dynamics
-
Repeated refinement enables hidden states to represent multiple competing hypotheses before converging toward a final answer. Training Large Language Models to Reason in a Continuous Latent Space by Hao et al. (2025) argues that continuous latent states can encode several alternative reasoning branches simultaneously, effectively supporting breadth-first search in latent space.
-
In looped transformers, a similar phenomenon can occur when early iterations maintain uncertainty and later iterations progressively sharpen the representation. This makes recurrence analogous to iterative search, where each loop narrows the set of plausible solutions.
Reasoning and Memorization
-
A recurring theme across looped transformer research is the distinction between storing knowledge and manipulating knowledge. Parameters determine what information is encoded, while recurrence determines how deeply that information can be combined.
-
Scaling Latent Reasoning via Looped Language Models by Zhu et al. (2025) provides controlled experiments showing that looped models do not primarily benefit from larger knowledge capacity. Instead, they gain from stronger knowledge manipulation, producing reasoning traces that align more closely with correct final answers than conventional chain-of-thought.
Inference-Time Thinking
-
One of the most practical consequences of latent reasoning is that computation can be scaled at inference without retraining. For difficult questions, the model can simply run more recurrent steps, devoting additional computation to internal reasoning before generating the next token.
-
Scaling up Test-Time Compute with Latent Reasoning by Geiping et al. (2025) shows that more recurrence can dramatically improve performance, especially on tasks such as GSM8K that require substantial multi-step reasoning.
Conceptual Shift
-
Looped transformers suggest a different model of intelligence. Instead of viewing a language model as a static function that maps prompts directly to outputs, they frame it as an iterative computational process that repeatedly transforms an internal state until sufficient reasoning has occurred.
-
In this view, each recurrent step is analogous to one cycle of thought. Knowledge remains encoded in the parameters, but reasoning emerges from the repeated application of a learned computational operator. This turns inference into a controllable thinking process, where additional compute corresponds directly to additional latent reasoning depth.
Generalization
- A defining feature of looped transformers is that they improve not only raw benchmark performance but also the ability to generalize beyond the exact patterns seen during training. Conventional transformers often store large amounts of knowledge yet struggle to recombine that knowledge compositionally or to solve tasks requiring deeper reasoning chains than were represented in the training distribution. By repeatedly applying the same transformation, looped transformers encourage the emergence of reusable computational procedures that can be deployed in novel settings.
Systematic Composition
-
Systematic generalization refers to the ability to combine known facts, rules, or operators in previously unseen ways. In a standard transformer, different layers specialize to different representational roles, and the model may memorize shallow associations rather than learn a reusable reasoning mechanism. In a looped transformer, every recurrent step applies the same block, forcing the model to reuse a common update rule across all stages of reasoning.
-
Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers by Kohli et al. (2026) demonstrates that recurrent-depth transformers can solve out-of-distribution multi-hop tasks where models must compose facts that were never combined during training.
-
If the hidden state contains a partial reasoning result (h_t), each recurrent application can be viewed as a composition operator:
- Because the same operator is reused, the model learns a general transformation rather than a depth-specific lookup table.
Depth Extrapolation
-
Depth extrapolation is the ability to solve problems requiring more reasoning steps than were encountered during training. This is one of the most striking properties of looped transformers.
-
Suppose a model is trained on problems requiring up to \(k\) latent reasoning steps. At inference, the same recurrent block can be applied for more than \(k\) iterations:
-
If the recurrent operator implements a stable reasoning procedure, the model can continue composing information beyond its training horizon.
-
Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers by Kohli et al. (2026) shows that models trained on 20-hop reasoning can successfully answer 30-hop questions by simply increasing recurrence depth at test time.
-
This property closely resembles how an algorithm trained to perform one iteration of an update rule can be run repeatedly until convergence.
Grokking Dynamics
-
Systematic generalization in looped transformers often emerges abruptly rather than gradually. During training, the model first memorizes the training set, then generalizes within the training distribution, and finally undergoes a sharp transition to strong out-of-distribution performance.
-
The following figure (source) shows recurrent-depth model accuracy curves across training epochs and wall-clock time, illustrating the emergence of systematic generalization through training. The left panel plots test OOD accuracy for models trained with \(R \in {1,2,4,8}\) against training epochs, with curves smoothed by a 100-epoch rolling mean and shading indicating standard deviation. The middle panel plots test OOD accuracy for the same models against training wall-clock time in hours. The right panel focuses on the \(R=4\) model and compares accuracy on training, ID test, and OOD test examples across training epochs.
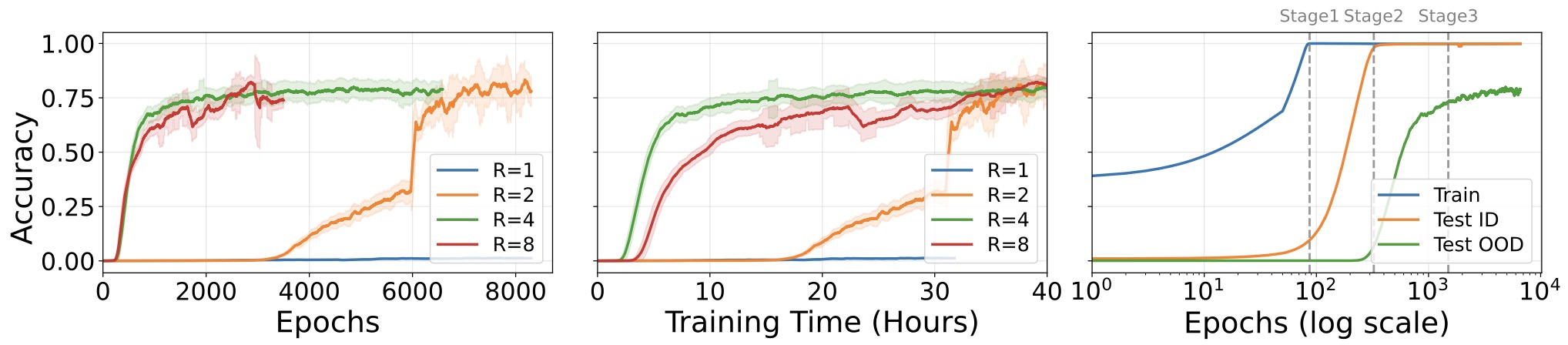
-
Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers by Kohli et al. (2026) identifies this as a three-stage grokking process, supported by mechanistic analysis of how internal representations evolve.
-
This behavior suggests that the recurrent block eventually discovers a compact algorithmic rule that can be applied repeatedly rather than relying on memorized templates.
Algorithmic Transfer
-
Looped transformers are naturally aligned with algorithmic tasks because iterative algorithms already consist of repeated applications of a common update rule. Once the model learns this update, it can transfer the procedure to larger or more complex instances.
-
Looped Transformers Are Better at Learning Learning Algorithms by Yang et al. (2024) shows that looped models excel at in-context regression and other tasks where the optimal solution is iterative, effectively internalizing learning algorithms with a small number of shared parameters.
-
Looped Transformers as Programmable Computers by Giannou et al. (2023) extends this argument by demonstrating that looped transformers can emulate function calls, conditional branches, and memory manipulation, enabling general-purpose computation.
Knowledge Composition
-
Modern language models often contain the facts needed to answer complex questions but fail to chain those facts together. Looped transformers improve this by repeatedly retrieving, transforming, and integrating parametric knowledge.
-
Scaling Latent Reasoning via Looped Language Models by Zhu et al. (2025) provides controlled experiments showing that looped models outperform much larger baselines primarily through superior knowledge manipulation rather than increased memorization.
-
This result reinforces the idea that generalization depends critically on the model’s ability to iteratively compose stored information.
Overthinking Limits
- Generalization is not unbounded. If the recurrent operator is applied too many times, the hidden state may drift away from the correct solution, causing accuracy to decline:
\(\text{Acc}(L+1) < \text{Acc}\)L\(\)
-
for sufficiently large \(L\).
-
This phenomenon, often called overthinking, places a practical limit on how far recurrence can be extended without additional safeguards. Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers by Kohli et al. (2026) identifies overthinking as a central limitation when extrapolating far beyond the training regime.
Generalization View
-
The broader lesson is that looped transformers transform depth from a fixed architectural constant into a reusable computational process. Because the same transformation is applied repeatedly, the model is encouraged to learn general-purpose reasoning procedures rather than collections of specialized layer behaviors.
-
This leads to two unusually strong forms of extrapolation: systematic composition, where the model recombines knowledge in new ways, and depth extrapolation, where it continues reasoning beyond the depths seen during training. Together, these properties suggest that recurrence is not merely a parameter-sharing trick but a mechanism for inducing more algorithmic and compositional forms of intelligence.
Test-Time Compute
- One of the most consequential properties of looped transformers is that they can consume more computation at inference time without changing their parameters. This makes reasoning depth a runtime decision rather than a fixed architectural constant. A model can therefore devote additional internal computation to difficult problems simply by executing more recurrent iterations before predicting the next token.
Runtime Depth
-
In a conventional transformer, the number of sequential transformations is fixed by the architecture. A 48-layer model always performs 48 layers of computation per token. In a looped transformer, the recurrent block can be executed for any number of iterations:
\[h_{t+1} =f_\theta(h_t,x) \quad t = 0,\dots,L-1\]- where \(L\) is selected at inference time. Increasing \(L\) increases effective depth and computational cost while leaving parameter count unchanged.
-
Scaling up Test-Time Compute with Latent Reasoning by Geiping et al. (2025) demonstrates that a recurrent-depth language model can continue improving on reasoning benchmarks as recurrence depth is increased far beyond its nominal parameter size.
Latent Scaling
-
The core intuition is that the model “thinks longer” internally rather than generating longer intermediate text. Each additional iteration refines the hidden state, allowing more retrieval, composition, and search to occur before the output is produced.
-
The following figure shows how benchmark accuracy increases as recurrence depth grows.
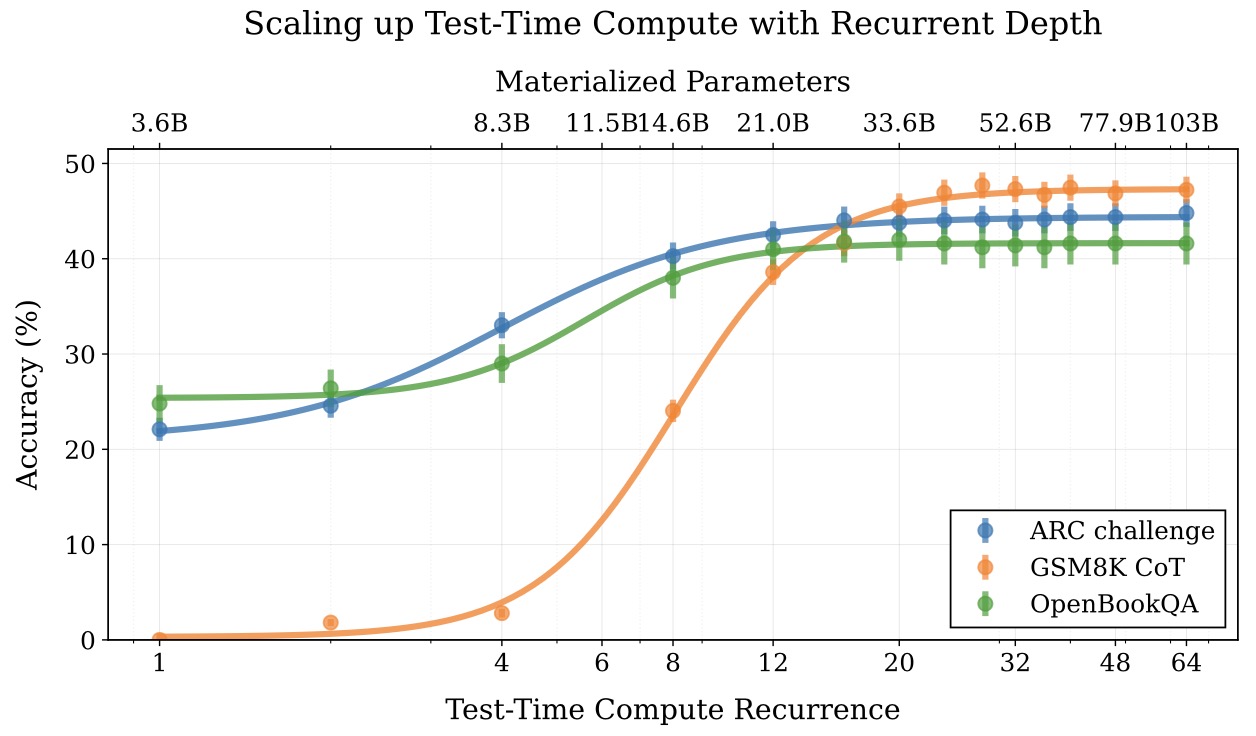
- In Scaling up Test-Time Compute with Latent Reasoning by Geiping et al. (2025), a 3.5B recurrent-depth model reaches a computational footprint equivalent to tens of billions of effective parameters when recurrence is increased at inference time, with especially large gains on arithmetic and multi-step reasoning tasks.
Performance Curves
-
Performance usually improves with additional loops before approaching a plateau. A common empirical model is:
\(\epsilon\)L\(\approx \epsilon_\infty + A e^{-kL}\)
- where (\epsilon\(L\)) is the error after \(L\) loops, (\epsilon_\infty) is the asymptotic error, and (A e^{-kL}) captures diminishing returns.
-
Parcae: Scaling Laws for Stable Looped Language Models by Prairie et al. (2026) shows that this saturating behavior is highly predictable, making recurrence depth a controllable and quantifiable source of additional capability.
Adaptive Depth
-
The most powerful use of test-time compute is not to apply the same number of loops to every example, but to allocate computation dynamically based on problem difficulty.
-
If an exit mechanism estimates the probability that the current state is sufficient, computation can stop once a confidence threshold is reached:
\[\text{stop if } p_{\text{exit}}(h_t) > \tau\]- where \(\tau\) is a predetermined threshold.
-
Scaling Latent Reasoning via Looped Language Models by Zhu et al. (2025) incorporates an exit gate that allows simple examples to terminate after fewer loops while reserving deeper recurrence for harder inputs.
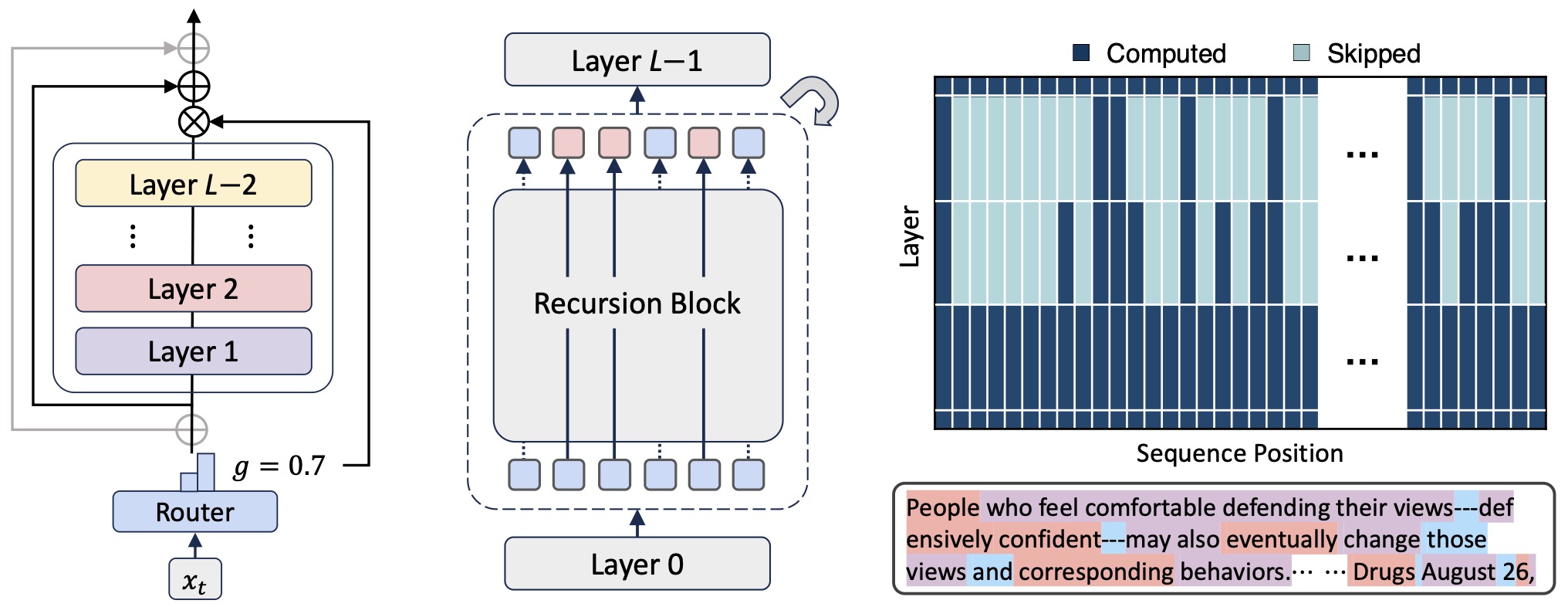
Token Routing
-
Some architectures refine adaptive depth further by allowing different tokens in the same sequence to receive different amounts of recurrent computation.
-
Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation by Bae et al. (2025) introduces lightweight routers that determine which tokens continue to participate in each recursion step. Tokens that have already converged are skipped, reducing both attention cost and key-value cache requirements.
-
This creates a token-specific depth function:
\[L_i =g(x_i)\]- where \(L_i\) is the number of recursions allocated to token \(i\).
-
The following figure (source) shows an overview of Mixture-of-Recursions (MoR). The left panel shows a recursion step made of a fixed stack of layers and a router that decides whether each token should continue through the block or exit. The middle panel shows the full model structure, where the shared recursion step is applied up to \(N_r\) times for each token depending on the router decision. The right panel shows an example token-wise routing pattern, where dark blue cells indicate active computation, light gray cells indicate skipped computation, and the colored labels below the sequence indicate whether each subword token uses \(1\), \(2\), or \(3\) recursion steps, shown as pink for \(1\), light blue for \(2\), and peach for \(3\), to predict the next token.
Latency Tradeoffs
-
Because parameter memory remains fixed, looped transformers convert memory costs into latency costs. Running more loops increases sequential computation and wall-clock time, but avoids storing a much larger model.
-
This introduces a flexible deployment trade-off. A system can:
- Use fewer loops for low-latency applications.
- Increase loops for difficult reasoning tasks.
- Terminate early when confidence is high.
- Scale computation according to available hardware budget.
-
The resulting model behaves similarly to an anytime algorithm, producing progressively better internal states as more compute becomes available.
Training Mismatch
-
To benefit from test-time scaling, the model must be trained so that additional loops remain productive. If the recurrent operator is optimized only for a fixed depth, increasing recurrence at inference may cause overthinking or instability.
-
Common strategies include stochastic depth sampling, multi-step supervision, and curricula over loop count. These techniques ensure that each additional iteration tends to refine rather than degrade the hidden state.
-
Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers by Kohli et al. (2026) shows that training choices strongly affect how well recurrent-depth transformers extrapolate to deeper reasoning chains.
Compute Economics
-
Test-time recurrence fundamentally changes the economics of scaling. Instead of deploying a larger model for all requests, one can deploy a compact looped model and selectively allocate more computation only when needed.
-
If model capability is viewed as a function of parameters \(N\) and inference compute \(C_{\text{test}}\),
\[\text{Capability} =f(N, C_{\text{test}})\]- then looped transformers expose \(C_{\text{test}}\) as a first-class control variable. This allows a single model to operate across a wide range of latency and quality targets, from fast responses with minimal recurrence to deep latent reasoning with substantially larger compute budgets.
-
In practical terms, looped transformers transform inference from a fixed-cost operation into an adaptive thinking process whose depth can be tuned continuously according to the complexity of the problem.
Staircase and Ladder Attention
-
Several years before looped language models became a major focus in large-scale pretraining, researchers at FAIR explored a closely related idea: increasing computation by repeatedly reusing the same transformer parameters. Their work on staircase attention and its simplified variant, ladder attention, introduced a family of recurrent attention architectures that explicitly decoupled parameter count from computation and anticipated many of the core ideas that now underpin looped transformers.
-
Staircase Attention for Recurrent Processing of Sequences by Ju et al. (2021) presents a recurrent attention mechanism that processes a sequence over multiple steps, combining recurrence over sequence positions with recurrence in depth. The accompanying FAIR article Which one is more important: more parameters or more computation? frames the broader motivation, arguing that model size and computation should be treated as distinct resources rather than inseparable aspects of a single architecture.
Staircase Processing
-
In staircase attention, computation unfolds over repeated processing steps. Each step contains two conceptual phases. A backward phase re-encodes the tokens processed so far, allowing the model to revise its understanding of prior context, and a forward phase incorporates new tokens from the input stream. This creates a staggered pattern of computation in which hidden states are refined repeatedly while new information is gradually introduced.
-
If \(h_t\) denotes the hidden state after processing step \(t\), the update can be abstractly written as:
\[h_{t+1} =f_\theta(h_t, x_{\leq t})\]- where the same parameters \(\theta\) are reused across all steps. This formulation is structurally similar to modern recurrent-depth transformers, differing mainly in how sequence progression and recurrent refinement are interleaved.
-
The following figure (source) shows staircase, ladder, and standard attention-style recurrent processing layouts, where repeated shared-weight computation trades additional compute for stronger modeling power. Specifically, the proposed staircase-family recurrent attention layouts are shown, where each outlined row is a parallel computation and rows are computed recurrently from bottom to top using shared weights. In the Staircase model, each time step introduces one new input chunk while recurrently processing a fixed number of previous chunks. In Cached Staircase, the final output state is cached and later included within the attention span after a fixed amount of recurrent processing. In Global Cached Staircase, all previous chunks are cached and attended in the final chunk. In the Ladder model, the full sequence is fed in without chunking and the same transformer computation is repeated a fixed number of times, making it the closest variant to modern looped transformers.
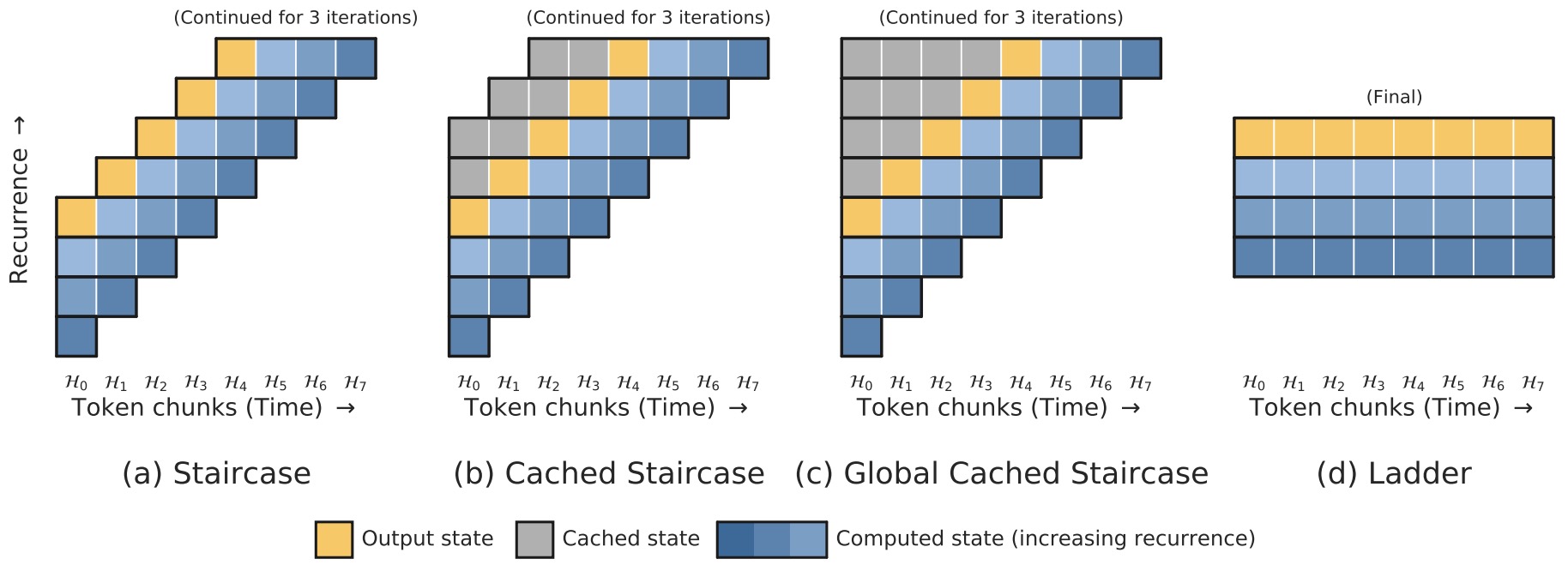
Ladder Variant
- The ladder variant is the most direct conceptual precursor to looped transformers. In ladder attention, the forward step is effectively removed, so the same transformer is applied repeatedly to an already available sequence. The sequence remains fixed, while only the hidden representation evolves:
-
This is precisely the computational pattern used in contemporary looped language models. Each recurrent step acts as another round of latent refinement, and the total amount of computation can be increased simply by executing more iterations.
-
The authors explicitly describe ladder attention as repeating the transformer with shared weights, making it an early and remarkably clear articulation of the looped-transformer paradigm.
Parameters and Compute
-
The key insight of staircase and ladder attention is that parameter count and computation should be treated independently. A model with a fixed number of parameters can be made substantially more powerful by performing more recurrent processing steps.
-
If a shared block contains \(N\) parameters and is executed \(L\) times, the effective computation scales approximately as:
\[C \propto N L\]- while the number of stored parameters remains \(N\).
-
This is exactly the principle that later became central to looped transformers, latent reasoning models, and adaptive test-time compute. The FAIR article Which one is more important: more parameters or more computation? articulates this argument directly and positions recurrent computation as an independent design dimension for deep learning systems.
Language Modeling Results
-
Ju et al. (2021) show that staircase attention yields lower perplexity than standard transformers of the same size and solves nonlinear state-tracking tasks that fixed-depth transformers struggle with. These results were an early empirical indication that repeated computation over the same parameters can unlock stronger reasoning and memory capabilities without requiring larger models.
-
In retrospect, these findings foreshadow the later success of recurrent-depth language models such as Huginn, Ouro, and Parcae, which scale this same principle to billions of parameters and trillions of tokens.
Relation to Looped Transformers
-
The connection between ladder attention and looped transformers is direct. Both architectures:
- Reuse the same parameters across multiple iterations
- Increase effective depth without increasing parameter count
- Enable test-time scaling by running more iterations
- Support latent reasoning rather than explicit chain-of-thought
- Expose computation as a runtime-adjustable resource
-
The main difference is historical emphasis. Staircase attention was introduced as a general recurrent attention mechanism for sequence modeling, while modern looped transformers focus specifically on reasoning, latent thought, and large-scale language modeling.
Historical Significance
-
The importance of staircase and ladder attention is that they established, as early as 2021, the core conceptual foundation that now drives much of the excitement around looped transformers. The architecture demonstrated that a transformer need not be a fixed stack of unique layers. Instead, it can be viewed as a reusable computational operator that is invoked repeatedly to refine an internal state.
-
This framing anticipated several major trends:
- Latent-space reasoning
- Adaptive inference depth
- Parameter-efficient scaling
- Separation of memory capacity from computational depth
-
As later work such as Scaling up Test-Time Compute with Latent Reasoning by Geiping et al. (2025) and Scaling Latent Reasoning via Looped Language Models by Zhu et al. (2025) demonstrates, this design principle has evolved into one of the most promising architectural directions for building models that can allocate additional internal computation to increasingly complex reasoning tasks.
Implementations
- Looped transformers are straightforward to implement because they preserve the internal structure of standard transformer blocks. The principal change is architectural rather than algorithmic: instead of instantiating a long stack of distinct modules, the model instantiates a smaller shared block and invokes it repeatedly inside a loop. This means that most existing transformer codebases can be adapted with relatively small modifications, making looped architectures practical both for research and for large-scale production systems.
Minimal Recurrence
- The simplest implementation wraps a standard transformer block in a Python loop:
class LoopedTransformer(nn.Module):
def __init__(self, block, num_loops):
super().__init__()
self.block = block # shared transformer block
self.num_loops = num_loops
def forward(self, x, attn_mask=None):
h = x
for _ in range(self.num_loops):
h = self.block(h, attn_mask)
return h
-
The critical detail is that
self.blockis a single module instance. Every recurrence step uses the same parameters, and gradients from all iterations accumulate into the shared weights during backpropagation. -
If the block contains \(k\) transformer layers and is executed \(L\) times, the effective depth becomes:
- This is the core implementation pattern underlying most modern looped architectures.
Prelude and Coda
- In large language models, the recurrent block is often surrounded by non-shared layers that specialize the beginning and end of computation:
def forward(tokens):
h = embed(tokens)
h = prelude(h)
for _ in range(num_loops):
h = recurrent_core(h)
h = coda(h)
return lm_head(h)
-
This pattern appears explicitly in Scaling Latent Reasoning via Looped Language Models by Zhu et al. (2025), where the model consists of an embedding layer, optional prelude layers, a recurrent core, an exit mechanism, and a language modeling head.
-
The following figure (source) shows an overview of the parameter-shared Looped Language Model (LoopLM) architecture. Left (Training): During training, the model applies a stack of \(N\) layers repeatedly for \(T_{max}\) recurrent steps. At each recurrent step \(l\), an exit gate predicts the probability \(p_l\) of exiting, and a language modeling head \(L_l\) computes the lanugage modeling loss. Right (Inference): At inference time, the model can exit early based on the accumulated exit probability.

Relaxed Sharing
-
Strict parameter tying maximizes compression but may reduce representational flexibility. A common compromise adds lightweight, loop-specific adapters to the shared block:
\[\theta_t =\theta + \Delta \theta_t\]- where \(\Delta \theta_t\) is typically a low-rank LoRA update.
-
In code, each loop can activate its own adapter while keeping the main weights shared. Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA by Bae et al. (2025) shows that this approach recovers much of the performance of untied models while preserving most of the parameter savings.
Adaptive Exits
- To avoid using unnecessary computation, many implementations attach a small exit head that predicts whether further recurrence is needed:
for step in range(max_loops):
h = recurrent_core(h)
exit_prob = exit_head(h)
if exit_prob.mean() > threshold:
break
-
The stopping rule can be applied at the sequence level, token level, or batch element level.
-
Scaling Latent Reasoning via Looped Language Models by Zhu et al. (2025) uses an entropy-regularized exit gate to allocate computation dynamically across examples.
Token Routing
-
A more granular design routes individual tokens rather than entire sequences. At each loop, a lightweight router determines which tokens continue participating in computation and which are skipped.
-
Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation by Bae et al. (2025) implements this strategy so that only active tokens incur attention and key-value cache costs, significantly improving throughput.
-
Conceptually, each token receives its own depth assignment:
\[L_i = g(x_i)\]- where \(L_i\) is the number of recursions allocated to token \(i\).
Key-Value Caching
-
During autoregressive generation, each loop can either compute fresh key-value projections or reuse previously computed values.
-
The most direct implementation recomputes keys and values at every recurrence, preserving full flexibility but increasing cost. Some architectures share key-value tensors across loops to reduce memory and bandwidth requirements. Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation by Bae et al. (2025) introduces a KV-sharing variant that reuses the first recursion’s cache.
-
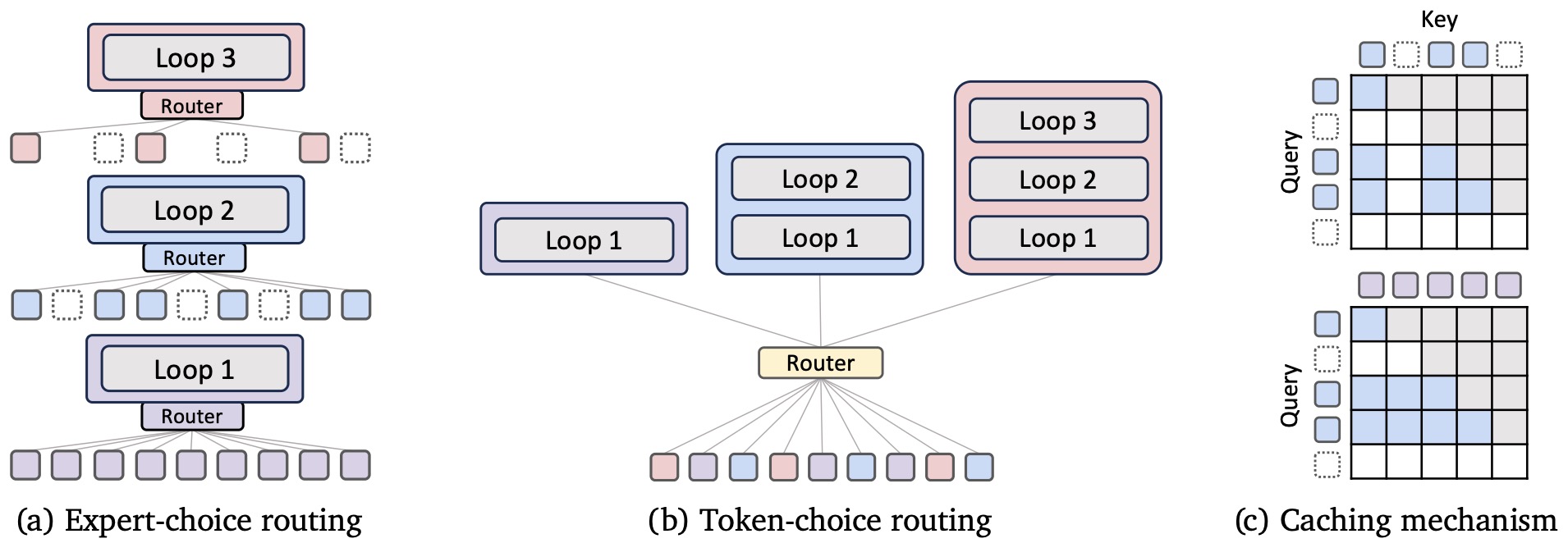
The following figure (source) shows the architectural components of Mixture-of-Recursions (MoR), including expert-choice routing, token-choice routing, and the caching mechanism for recursive token computation (i.e., recursive key-value caching). In expert-choice routing, a router selects the top-\(k\) tokens at each recursion step to continue computing, progressively narrowing the active token set as depth increases. In token-choice routing, each token receives a fixed recursion step assignment at the outset through a single routing decision, which defines its full compute path through the model. In the KV caching panels, each square in the matrix indicates whether a token row attends to another token’s cached key column: in recursion-wise KV caching, shown in blue, only the keys of currently selected non-dropped tokens are cached at each recursion step and attention is restricted to those entries; in recursive KV sharing, shown in purple, all keys of previous tokens are cached at the first recursion step and then shared across subsequent recursion steps for attention.
Memory and Checkpointing
- Although parameter memory is reduced, activation memory grows with the number of unrolled iterations. Training deep recurrence therefore benefits from activation checkpointing:
for _ in range(num_loops):
h = checkpoint(recurrent_core, h)
- Checkpointing recomputes activations during the backward pass and is often essential when loop counts become large.
Conversion from Pretrained Models
-
Existing transformers can be converted into recursive models by grouping layers into a shared block and reusing that block repeatedly. A simplified procedure is:
- Select a subset of layers.
- Tie their weights.
- Initialize a recurrent core.
- Uptrain on additional data.
- Optionally add LoRA adapters.
-
This approach allows strong recursive models to be built from existing checkpoints rather than trained from scratch. Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA by Bae et al. (2025) demonstrates recursive conversions of Gemma and related models.
Open Implementations
-
Several open-source implementations make looped architectures accessible:
- Ouro Project Page provides pretrained looped language models and evaluation results.
- recurrent-pretraining contains the Huginn recurrent-depth training code released alongside Geiping et al. (2025).
- OpenMythos is a community implementation inspired by speculative reconstructions of Claude Mythos and combines recurrent depth with Mixture-of-Experts and configurable attention.
-
These projects demonstrate that looped transformers can be integrated into conventional PyTorch and distributed-training pipelines with relatively modest engineering effort.
Engineering View
-
From an engineering perspective, looped transformers are appealing because they reuse well-understood components. The innovation lies in how those components are scheduled. A standard transformer can be reinterpreted as a reusable computational operator, and recurrence turns that operator into an iterative refinement engine.
-
This makes looped architectures unusually practical: they inherit the mature tooling, kernels, and optimization strategies developed for conventional transformers, while adding the ability to scale computation dynamically, compress parameters, and perform latent reasoning through repeated application of a shared block.
Open Questions
- Looped transformers have rapidly evolved from a theoretical curiosity into a serious architectural alternative for large-scale language models, but many of their most important properties remain only partially understood. The current literature establishes that recurrence can improve reasoning, parameter efficiency, and adaptive inference, yet several foundational questions remain open regarding optimization, expressivity, interpretability, and deployment.
Optimal Sharing
- One of the central design questions is how much parameter sharing should be enforced. At one extreme, strict tying uses exactly the same weights at every iteration:
- At the other extreme, every layer has independent parameters as in a conventional transformer. Between these endpoints lie partially shared models, such as relaxed recursive transformers with loop-specific LoRA updates:
- Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA by Bae et al. (2025) demonstrates that small low-rank adaptations can recover much of the performance lost under strict tying. The broader unresolved question is what degree of sharing best balances compression, generalization, and optimization.
Learned Halting
-
Although adaptive computation is one of the most attractive features of looped transformers, robust halting remains an open challenge. Exit mechanisms must detect when the hidden state contains sufficient information while avoiding premature stopping and unnecessary extra computation.
-
A typical stopping rule takes the form:
\[\text{stop if } p_{\text{exit}}(h_t) > \tau\]- where \(p_{\text{exit}}\) is predicted by a lightweight classifier.
-
Scaling Latent Reasoning via Looped Language Models by Zhu et al. (2025) and Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation by Bae et al. (2025) show promising results, but reliable and interpretable computation allocation remains an active research area.
Mechanistic Understanding
-
Why does recurrence improve reasoning so dramatically? Existing evidence suggests that looping encourages iterative retrieval, search, and composition, but the precise circuits responsible for these behaviors are not yet fully understood.
-
Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers by Kohli et al. (2026) offers early mechanistic analyses linking recurrence to systematic generalization and grokking, but a comprehensive theory of latent reasoning remains an open problem.
-
Important unanswered questions include whether different loops correspond to distinct reasoning phases, whether convergence can be diagnosed directly from hidden states, and how recurrent dynamics differ across tasks.
Convergence Criteria
-
Most current systems specify a fixed maximum loop count or rely on learned exit probabilities. A more principled approach would detect whether the recurrent state has converged.
-
One simple criterion is:
\[|h_{t+1} - h_t| < \varepsilon\]- where \(\varepsilon\) is a convergence threshold.
-
However, hidden-state stability does not necessarily imply that the model has reached the correct answer. Designing reliable convergence diagnostics that correlate with task success remains an open challenge with direct implications for adaptive inference.
Overthinking
-
Additional recurrence often improves performance up to a point, after which accuracy may decline as the model overwrites useful representations:
\(\text{Acc}(L+1) < \text{Acc}\)L\(\)
- for sufficiently large \(L\).
-
This overthinking phenomenon, highlighted in Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers by Kohli et al. (2026), suggests that recurrent operators may not always converge toward a stable fixed point. Understanding why overthinking occurs and how to prevent it is essential for reliable test-time scaling.
Multimodal Recurrence
-
Most current looped models focus on text, but recurrence is equally applicable to multimodal architectures. Vision transformers, audio models, and multimodal agents could all benefit from adaptive iterative processing, particularly for planning and perception tasks that naturally require repeated refinement.
-
The success of iterative recycling in systems such as AlphaFold has strengthened interest in applying looped architectures to domains beyond language, but large-scale multimodal evidence remains limited.
Hardware Scheduling
-
Looped transformers change the computational profile of inference. They reduce parameter memory but increase sequential depth, and adaptive routing introduces irregular workloads where different tokens and examples require different numbers of iterations.
-
This raises systems-level questions about:
- How to batch examples with different loop counts
- How to share key-value caches across recursions
- How to schedule dynamic exits efficiently
- How to optimize for memory-bandwidth-limited hardware
-
Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation by Bae et al. (2025) and Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA by Bae et al. (2025) begin to address these questions, but substantial engineering opportunities remain.
Scaling Limits
-
Current evidence shows that recurrence can substitute for large amounts of explicit depth, but it remains unclear how far this substitution extends. Open questions include whether looped architectures can dominate standard transformers at frontier scale, whether recurrence remains advantageous as models approach trillions of parameters, and how much training data is required to fully exploit deeper latent computation.
-
Parcae: Scaling Laws for Stable Looped Language Models by Prairie et al. (2026) provides the first systematic scaling laws, but much larger-scale experiments will be needed to determine the ultimate limits of recurrence-based scaling.
Architectural Outlook
-
The most significant open question is whether recurrence will become a core component of future frontier models. Recent public speculation around architectures such as Claude Mythos reflects a growing belief that adaptive latent computation may be a key ingredient in next-generation reasoning systems.
-
Regardless of any specific commercial implementation, the research trajectory is increasingly clear. Looped transformers provide a principled way to separate memory from computation, to allocate depth dynamically, and to reason internally in latent space. Whether as a replacement for fixed-depth transformers or as a component within larger hybrid systems, recurrence appears poised to play a central role in the next phase of language model architecture.
Looped Transformers vs. RLMs
Core Difference
-
Looped transformers and Recursive Language Models both use the word “recursive,” but they refer to different levels of the stack.
-
A looped transformer changes the model architecture. Instead of stacking many distinct transformer layers, it reuses the same layer block multiple times inside a single forward pass. The recursion happens in the hidden states of the neural network.
-
An RLM changes the inference scaffold. It can wrap an ordinary language model, place the long prompt in an external environment, and let the model inspect, decompose, and recursively call models over selected snippets. The recursion happens in the system’s control flow.
-
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach by Geiping et al. (2025) studies models that scale test-time compute by iterating a recurrent block in latent space, while Recursive Language Models by Zhang et al. (2025) studies an inference strategy that treats prompts as external environment state and lets the model recursively call itself over programmatically selected snippets.
Where Recursion Lives
-
In a looped transformer, recursion is internal. The same parameters are applied repeatedly to the model’s activations. The model “thinks longer” before producing a token, but the thinking is latent and hidden inside the forward pass.
-
In an RLM, recursion is external. The root model writes code, receives observations, calls child models, stores variables, and eventually returns a final answer. The model “thinks longer” by running a trajectory through an environment.
-
A looped transformer looks like this at inference time:
hidden = embed(tokens)
for i in range(num_loops):
hidden = shared_transformer_block(hidden)
logits = lm_head(hidden)
- An RLM looks like this:
context = load_long_prompt()
env = PythonREPL({"context": context})
for step in range(max_steps):
action = root_model(query, history)
observation = env.execute(action)
history.append((action, observation))
if action_returns_final(action):
return resolve_final(action, env)
- Reasoning with Latent Thoughts: On the Power of Looped Transformers by Saunshi et al. (2025) argues that looped models can generate implicit latent thoughts and simulate multi-step reasoning through repeated loops, while RLMs make the intermediate process explicit as code execution, observations, recursive calls, and stored variables.
Main Goal
-
Looped transformers primarily target parameter-efficient depth and latent reasoning. They try to get the benefits of deeper models without storing a distinct set of weights for every layer. This makes them attractive when reasoning needs more depth than parameter count.
-
RLMs primarily target long-context control. They try to make a model useful over contexts that are too large, too dense, or too structured to pass directly through the model window. This makes them attractive when the bottleneck is not just reasoning depth, but access to a massive prompt or corpus.
-
Looped Transformers Are Better at Learning Learning Algorithms by Yang et al. (2024) shows that looped transformers can match standard transformers on in-context data-fitting problems with far fewer parameters, emphasizing iterative algorithm learning. Recursive Language Models by Zhang et al. (2025) shows that RLMs can handle inputs far beyond model context windows by loading the prompt into a REPL environment and letting the model inspect and decompose it.
Compute
-
Looped transformers separate parameters from compute. A model can keep the same parameter count while applying the same block more times. More loops mean more computation per token, but not necessarily more parameters.
-
RLMs also separate parameters from compute, but at the system level. The same base model can be called multiple times over different subproblems. More recursive calls mean more computation per query, but not necessarily a larger model.
-
The difference is what the extra compute operates on. In a looped transformer, extra compute refines hidden states. In an RLM, extra compute explores an external context, launches child calls, aggregates results, and verifies answers.
-
Scaling Latent Reasoning via Looped Language Models by Zhu et al. (2025) presents Ouro models that build reasoning into pretraining through iterative latent computation and learned depth allocation, while RLMs use runtime decomposition over an external prompt rather than modifying the transformer block itself.
Context
-
Looped transformers do not automatically solve long-context access. They may reason better within a given context window, but the input still has to be represented inside the model’s sequence. If the prompt is millions of tokens, a looped transformer still needs some mechanism for retrieval, memory, compression, chunking, or external access.
-
RLMs are built around this problem. The prompt is not fully placed into the model window. It is stored as an object in the environment, such as a string, dictionary of documents, repository file map, or paper collection. The model decides which slices to inspect and which subcontexts to pass to child calls.
-
This is the cleanest practical distinction:
-
Looped transformers increase effective depth.
-
RLMs increase effective context reach.
-
-
The following figure shows an RLM treating the prompt as part of the environment. It loads the input prompt as a variable inside a Python REPL environment \(\mathcal{E}\) and writes code to peek into, decompose, and invoke itself recursively over programmatic snippets of the variable.
Visibility
-
Looped transformer reasoning is latent. The intermediate states are hidden vectors, so the user and developer do not naturally see a readable decomposition. This can be useful because the model is not forced to verbalize every step, but it makes debugging and provenance harder.
-
RLM reasoning is inspectable. The trajectory contains actions, observations, child prompts, child outputs, variables, and finalization calls. This makes debugging easier, and it makes it possible to audit whether the model searched the right region, called children on the right documents, or grounded the final answer in evidence.
-
Training Large Language Models to Reason in a Continuous Latent Space by Hao et al. (2024) motivates latent-space reasoning by arguing that natural language is not always the best medium for reasoning, while RLMs choose the opposite tradeoff: they expose reasoning as an environment trajectory so that context management can be inspected, logged, and controlled.
Training
-
Looped transformers usually require architectural training or conversion. The model must learn to use repeated blocks productively, and training can be unstable if residual states explode or loop depth is mishandled.
-
RLMs can be used without retraining if the underlying model can follow instructions, write code, and call tools. However, training can make RLMs much better by teaching models when to inspect, when to recurse, when to batch calls, and when to stop.
-
Parcae: Scaling Laws For Stable Looped Language Models by Prairie et al. (2026) studies instability in looped architectures and proposes a stable looped design based on constraining injection parameters, while RLM training focuses on action-policy quality rather than hidden-state stability.
-
Reinforcing Recursive Language Models by Kim and Ahmad (2026) trains small models to behave as native RLMs by optimizing parent and child behavior under a shared policy, targeting recursive control decisions rather than the internal recurrence of a transformer block.
Adaptivity
-
Looped transformers can be fixed-depth or adaptive-depth. In fixed-depth looping, every token receives the same number of loops. In adaptive-depth looping, the model learns how much computation to spend per token or per example.
-
RLMs are naturally adaptive at the task level. The root model can decide to search once for a simple lookup, call children over many documents for evidence selection, or construct a large map-reduce plan for dense aggregation. The adaptivity is not just “how many loops?” but “which operations should be run over which parts of the context?”
-
Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation by Bae et al. (2025) adds token-level routing to recursive transformers so different tokens can receive different recursion depths, while RLMs route computation over environment objects such as documents, files, rows, spans, and child prompts.
Memory
-
Looped transformers reuse weights, but the model’s memory is still mostly hidden activations and KV cache. They are architectural memory savers because fewer unique layers need to be stored.
-
RLMs use external memory explicitly. The environment stores the long prompt, intermediate variables, candidate sets, child outputs, evidence spans, and final artifacts. The root model’s context window becomes a controller over this external memory rather than the place where all information must reside.
-
Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA by Bae et al. (2025) compresses standard transformers into recursive transformers by sharing blocks and relaxing them with depth-wise LoRA, while RLMs can wrap an existing model without changing its weights and use the REPL as persistent external memory.
Failure Modes
-
Looped transformers can fail through architectural and optimization issues: residual explosion, loss spikes, overthinking from too many recurrence steps, poor depth extrapolation, or failure to learn useful latent iteration.
-
RLMs fail through systems and policy issues: poor search terms, bad chunking, excessive child calls, observation flooding, unsupported aggregation, or returning a final answer that does not match the evidence stored in variables.
-
Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers by Kohli et al. (2026) reports that recurrent-depth transformers can generalize to deeper multi-hop reasoning by increasing inference-time recurrence, but also identifies overthinking when excessive recurrence degrades predictions.
Relationship
-
Looped transformers and RLMs are not competitors in a strict sense. They are complementary.
-
A looped transformer can be used as the base model inside an RLM. In that setup, the looped model provides stronger latent reasoning per call, while the RLM scaffold provides external context control.
root_model = LoopedTransformer(num_loops=8)
child_model = LoopedTransformer(num_loops=4)
rlm = RLM(
root_model=root_model,
child_model=child_model,
environment=PythonREPL(),
)
-
This hybrid would combine two forms of test-time compute: internal compute from repeated latent loops, external compute from recursive environment interaction.
-
A concise way to remember the distinction is: Looped transformers make one model call deeper, while RLMs make one task into a recursive computation.
Tabular Summary
| Dimension | Looped Transformer | Recursive Language Model |
|---|---|---|
| Level | Architecture | Inference scaffold |
| Recursion | Repeated neural blocks | Recursive model calls and environment actions |
| Main benefit | More effective depth with fewer parameters | More effective context reach and task decomposition |
| State | Hidden activations and KV cache | REPL variables, external context, child outputs |
| Reasoning | Latent, mostly invisible | Explicit, logged trajectory |
| Training need | Usually requires architectural training or conversion | Can be prompted, but improves with SFT or RL |
| Best for | Latent reasoning, parameter-efficient depth, adaptive compute | Long-context QA, evidence selection, codebases, dense aggregation |
| Failure mode | Instability, overthinking, bad loop depth | Bad decomposition, over-recursion, observation flooding |
| Complementarity | Can serve as root or child model | Can wrap looped or non-looped models |
- The practical takeaway is that looped transformers ask, “How can the model think longer inside a forward pass?” RLMs ask, “How can the model control a computation over context that is too large or complex to read all at once?”
References
Looped and recurrent-depth models
- Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach by Geiping et al. (2025); Huginn model; recurrent-pretraining code
- Scaling Latent Reasoning via Looped Language Models by Zhu et al. (2025); Ouro project page
- Parcae: Scaling Laws For Stable Looped Language Models by Prairie et al. (2026); Parcae code
- Reasoning with Latent Thoughts: On the Power of Looped Transformers by Saunshi et al. (2025)
- Looped Transformers are Better at Learning Learning Algorithms by Yang et al. (2024); looped transformer code
- Looped Transformers as Programmable Computers by Giannou et al. (2023); PMLR page
- Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers by Kohli et al. (2026); Loop-Think-Generalize code
- Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA by Bae et al. (2024)
- Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation by Bae et al. (2025); Mixture-of-Recursions code
- Think before you speak: Training Language Models With Pause Tokens by Goyal et al. (2023); OpenReview page
Precursors to Looped Transformers
- Staircase Attention for Recurrent Processing of Sequences by Ju et al. (2021); Meta AI publication page
- Which one is more important: more parameters or more computation? by FAIR, an article introducing staircase attention and hash layers as ways to decouple parameters from computation
RLM core
- Recursive Language Models by Zhang et al. (2025); Recursive Language Models blog; RLM code; RLM minimal code
- Reinforcing Recursive Language Models by Kim and Ahmad (2026); SkyRL code
Parameter sharing and recursive transformers
- Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA by Bae et al. (2025)
Latent reasoning
- Training Large Language Models to Reason in a Continuous Latent Space by Hao et al. (2025)
- Think Before You Speak: Training Language Models with Pause Tokens by Goyal et al. (2024)
Open-source implementations
- OpenMythos, a community-built theoretical reconstruction of Anthropic’s rumored Mythos architecture
- Meet OpenMythos: An Open-Source PyTorch Reconstruction of Claude Mythos Where 770M Parameters Match a 1.3B Transformer by MarkTechPost
Discussions and commentary
- On the Looped Transformers Controversy by Chris Hayduk, a discussion of why looped transformers are a plausible architectural ingredient in frontier reasoning models
- Claude Mythos is suspected of being a Looped transformer (LT) by Yuekun Yao, summarizing how looped transformers enable systematic generalization and depth extrapolation
- it’s a looped transformer (lt) by Sigrid Jin, a concise overview of the generalization advantages of looped transformers
- Training Large Language Models to Reason in a Continuous Latent Space by Hao et al. (2024); Coconut code
Related work
- Hash Layers for Large Sparse Models by Roller et al. (2021), a complementary approach that increases effective parameter capacity without increasing computation
Citation
If you found our work useful, please cite it as:
@article{Chadha2020DistilledLoopedTransformers,
title = {Looped Transformers},
author = {Chadha, Aman and Jain, Vinija},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}