Primers • Knowledge Distillation
- Overview
- Definition
- Classical Distillation Families
- Offline, Online, and Semi-Online Distillation
- On-Policy and Off-Policy Distillation
- Relationship Between Offline/Online and Off-Policy/On-Policy Distillation
- Off-Policy and On-Policy Distillation for Autoregressive LLMs
- Divergence Choice: Forward KL, Reverse KL, and JSD
- Self-Distillation and On-Policy Self-Distillation
- Distillation as Synthetic Data and Post-Training Infrastructure
- Distillation and Reinforcement Learning
- Multi-Domain Post-Training and Capability Consolidation
- Implementation View
- Primer Roadmap
- Foundations
- Teacher–Student Formulation
- Temperature Scaling and Soft Targets
- Token-Level Distillation in Autoregressive Models
- Divergence Choices and Their Effects
- Supervised Distillation and Sequence-Level Distillation
- Representation and Intermediate-Layer Distillation
- Distillation as Synthetic Data Generation
- Limitations of Classical Distillation
- Implementation Considerations
- Offline Distillation
- Online Distillation
- Core Definition
- Relationship to Offline, Off-Policy, and On-Policy Distillation
- Major Forms of Online Distillation
- Advantages of Online Distillation
- Limitations of Online Distillation
- Semi-Online and Hybrid Approaches
- Online Distillation in Modern LLM Training
- Implementation Pattern
- Online Distillation in the Broader Distillation Taxonomy
- Off-Policy Distillation
- Definition and Formal Objective
- Sources of Off-Policy Data
- Sequence-Level Distillation
- Logit Distillation
- Synthetic Data Pipelines
- Advantages of Off-Policy Distillation
- Limitations: Distribution Mismatch
- Behavioral Consequences
- Relationship to Reinforcement Learning
- Engineering and Systems Considerations
- When Off-Policy Distillation is Preferred
- On-Policy Distillation (OPD)
- Core Idea and Formal Objective
- Intuition: Learning from One’s Own Mistakes
- Generalized Knowledge Distillation (GKD)
- Choice of Divergence and Reward Interpretation
- Distillation and Reinforcement Learning
- Reinforcement Learning via Self-Distillation
- Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation
- Scaling Reasoning Efficiently via Relaxed On-Policy Distillation
- Self-Distilled RLVR
- Unifying Group-Relative and Self-Distillation Policy Optimization via Sample Routing
- OpenClaw-RL: Train Any Agent Simply by Talking
- Practical Failure Modes and Stabilization Recipes
- Practical Training Loop
- Self-Distillation (SD)
- Core Formulation
- Temporal Self-Distillation
- Ensemble and Multi-View Self-Distillation
- Contextual Self-Distillation
- On-Policy Self-Distillation (OPSD)
- Self-Distillation as Reinforcement Learning
- Reinforcement Learning via Self-Distillation
- Self-Distilled RLVR
- Aligning Language Models from User Interactions
- Self-Distillation in Agentic Systems
- Advantages of Self-Distillation
- Limitations and Failure Modes
- When Self-Distillation is Preferred
- Multi-Teacher Distillation
- Core Formulation
- Motivation: Capability Consolidation and the See-Saw Problem
- Multi-Teacher On-Policy Distillation (MOPD)
- Reverse KL and Advantage Interpretation
- Teacher Selection and Routing Strategies
- Multi-Teacher Distillation and Reinforcement Learning
- Engineering and Systems Design
- Advantages of Multi-Teacher Distillation
- Limitations and Challenges
- When Multi-Teacher Distillation is Preferred
- Comparative Analysis
- Implementation Patterns
- Canonical Distillation Dataflow
- Off-Policy Pipeline Architecture
- On-Policy Pipeline Architecture
- Generation Buffers and Asynchronous Execution
- Teacher Scoring Infrastructure
- Log-Probability Payload Design
- Full-Vocabulary Versus Top-k Approximation
- Tokenizer Compatibility and Alignment
- Stabilization Mechanisms
- Multi-Teacher Routing Infrastructure
- Self-Distillation Systems
- RL–Distillation Hybrid Systems
- Evaluation and Regression Monitoring
- Practical Design Defaults
- Decision Guide for Choosing a Distillation Method
- References
- Foundational distillation papers
- On-policy distillation and generalizations
- Self-distillation and privileged supervision
- Multi-teacher and capability consolidation
- Agentic and interaction-driven distillation
- Synthetic data and RLHF references
- Imitation learning and exposure bias
- Systems, tooling, and infrastructure
- Blogs and implementation guides
- Twitter / X threads and informal discussions
- Broader LLM training context
- Citation
Overview
Definition
-
Distillation is a training paradigm in which a student model is optimized to reproduce useful behavior from a teacher model, usually to obtain a model that is cheaper, faster, smaller, easier to deploy, or more specialized than the teacher. The canonical formulation was popularized in Distilling the Knowledge in a Neural Network by Hinton et al. (2015), which showed that a student can learn from the teacher’s softened output probabilities rather than only from hard labels.
-
At a high level, distillation replaces or augments ordinary supervised learning with a matching objective between teacher and student distributions. For a teacher distribution \(p_T\) and student distribution \(p_S^\theta\) over labels or next tokens, a standard token-level objective is:
\[\mathcal{L}_{KD}(\theta) =\mathbb{E}_{(x,y)} \left[ D\left( p_T(\cdot \mid x, y_{<t}) \,\Vert\, p_S^\theta(\cdot \mid x, y_{<t}) \right) \right]\]- where \(D\) is usually forward KL, reverse KL, Jensen-Shannon divergence, cross-entropy on sampled teacher outputs, or a task-specific hybrid. In language models, the conditioning context includes the prompt \(x\) and the partial output \(y_{<t}\), so distillation is fundamentally about matching next-token behavior under particular trajectories.
Classical Distillation Families
-
Classical distillation has several major families. Logit or soft-label distillation matches the teacher’s probability distribution directly, often with temperature scaling. Sequence-level distillation trains on full outputs generated by the teacher, as introduced for neural machine translation in Sequence-Level Knowledge Distillation by Kim and Rush (2016), where teacher-generated translations serve as simplified targets for the student. Representation distillation matches hidden states, attention maps, embeddings, or intermediate features, which is common in encoder models such as DistilBERT by Sanh et al. (2019), which combines language-modeling, distillation, and cosine-distance losses to compress BERT.
-
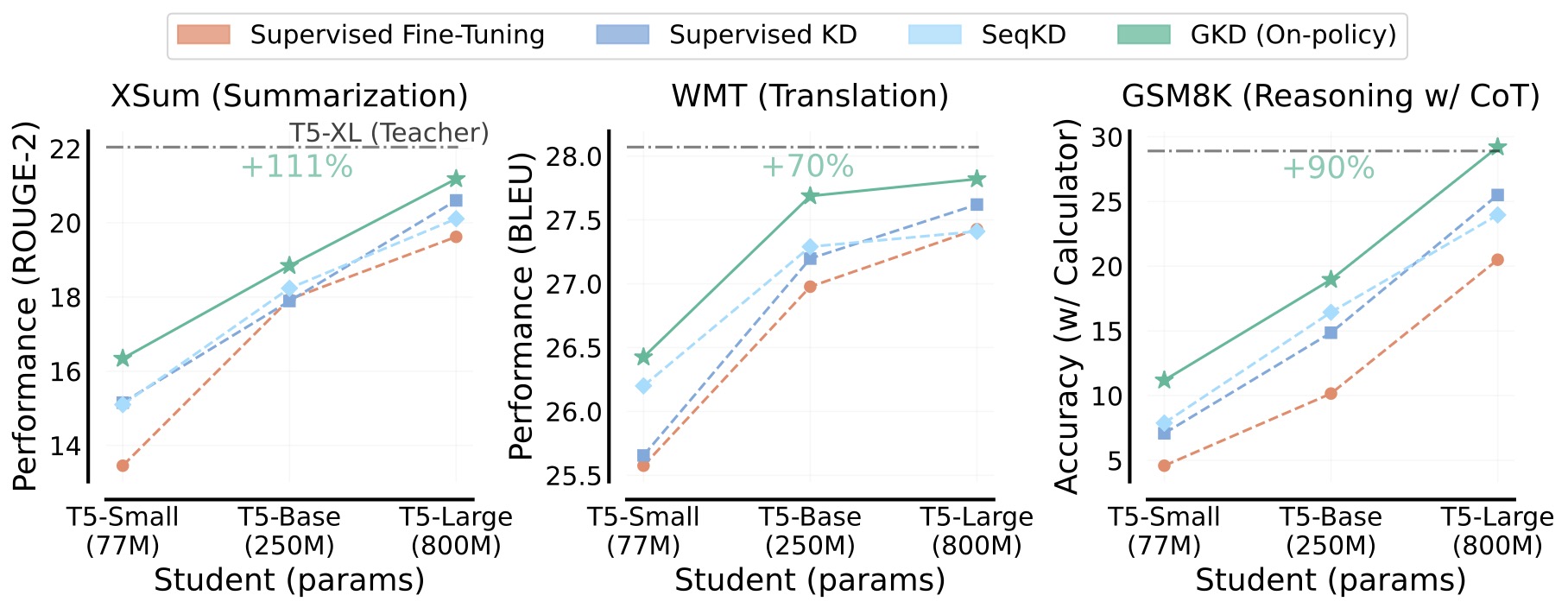
The following figure (source) shows an overview comparison of Generalized Knowledge Distillation with supervised fine-tuning, supervised KD, and sequence-level KD across summarization, translation, and reasoning tasks, emphasizing that on-policy GKD trains on student-generated outputs rather than only fixed target sequences.
Offline, Online, and Semi-Online Distillation
-
Distillation can also be categorized by whether the teacher is fixed or co-trained. Offline distillation uses a pretrained, frozen teacher and trains a student from stored or live teacher outputs; this is the standard teacher-student setting used by most classical KD systems. Online distillation trains multiple students, peers, or teacher-like supervisors simultaneously, so the teaching signal evolves during training rather than coming from a fixed teacher. Deep Mutual Learning by Zhang et al. (2017) is a canonical online distillation method in which peer networks learn collaboratively and teach each other throughout training. Co-distillation and online mutual learning therefore differ from ordinary offline KD not because they necessarily change the loss, but because the teacher distribution is non-stationary and coupled to the student’s optimization.
-
Semi-online distillation sits between offline and online regimes. One common form keeps a strong pretrained teacher but periodically adapts or updates an auxiliary teacher, supervisor, or student ensemble. Shadow Knowledge Distillation: Bridging Offline and Online Knowledge Transfer by Li et al. (2022) studies the empirical performance gap between offline and online distillation and attributes much of the benefit of online methods to reversed student-to-teacher transfer rather than only to simultaneous training.
On-Policy and Off-Policy Distillation
-
On-policy and off-policy distillation classify methods according to the source of the trajectories on which the distillation loss is computed, rather than according to whether the teacher is frozen or co-trained. This distinction is especially important for autoregressive language models, where each token changes the future contexts that the model will encounter during generation.
-
In off-policy distillation, the student is trained on sequences generated by an external source, such as a human-labeled dataset, teacher-generated completions, or another model’s rollouts. The student does not determine the contexts on which it is supervised. Classical supervised knowledge distillation, sequence-level distillation, and most synthetic-data pipelines fall into this category. Sequence-Level Knowledge Distillation by Kim and Rush (2016) and standard supervised KD as described in DistilBERT by Sanh et al. (2019) are canonical off-policy approaches.
-
In on-policy distillation, the student first samples its own trajectories and then receives dense teacher supervision along those exact rollouts. The training data distribution therefore evolves with the student. On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes by Agarwal et al. (2024) formalizes this idea as Generalized Knowledge Distillation (GKD), which treats distillation as an imitation-learning problem and trains on student-generated sequences rather than only fixed datasets.
-
The core GKD procedure samples a student trajectory with probability \(\lambda\) and otherwise falls back to dataset trajectories, then minimizes a divergence between teacher and student token distributions over the resulting sequences. This interpolates continuously between purely off-policy and purely on-policy training.
-
Formally, the on-policy objective can be written as:
-
The key advantage is that the student is trained in the same types of contexts it will encounter during inference, mitigating exposure bias and compounding errors. Thinking Machines Lab describes this as combining the on-policy relevance of reinforcement learning with the dense per-token supervision of distillation.
-
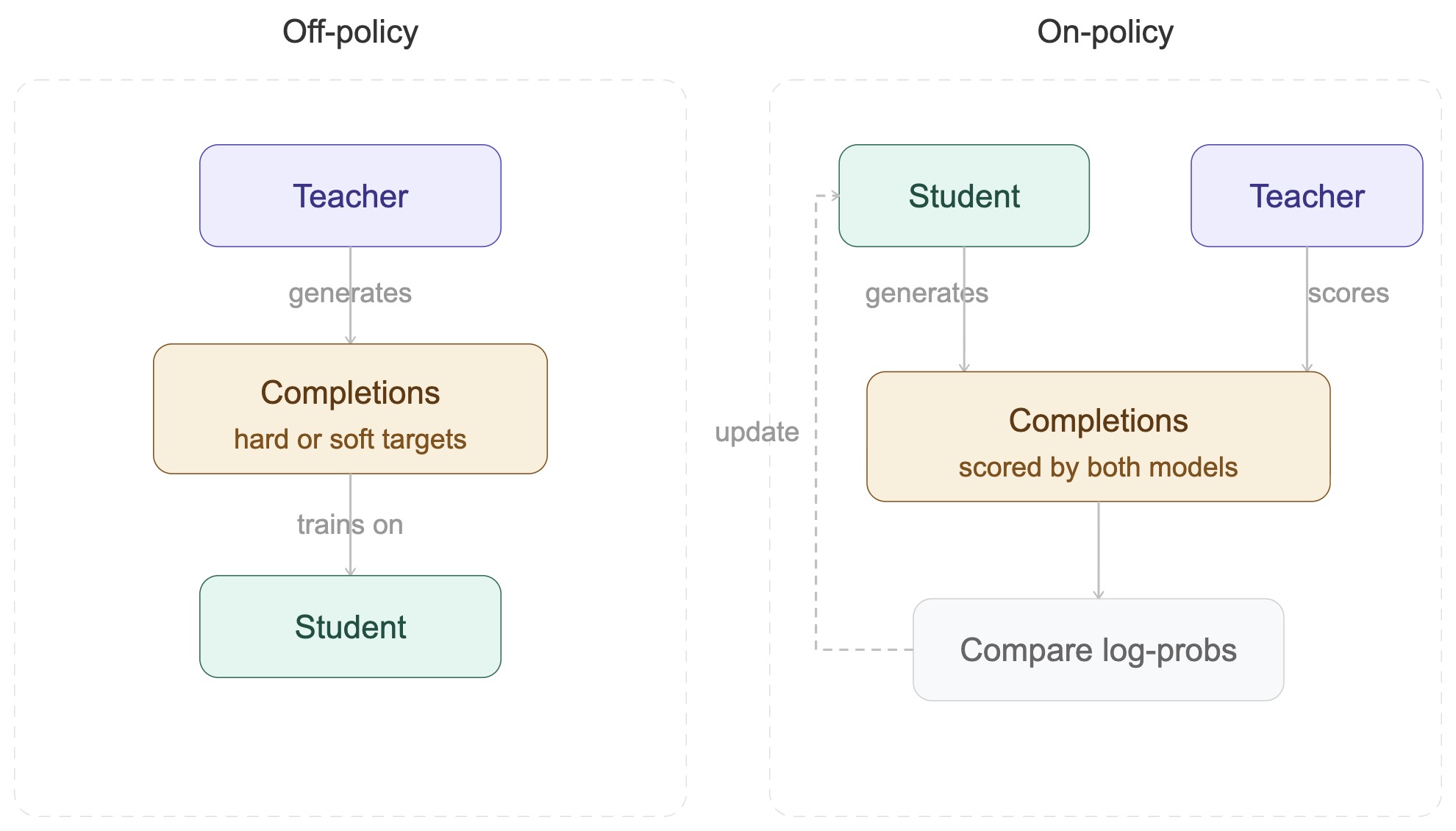
The following figure shows the distinction between off-policy and on-policy distillation: off-policy training uses teacher-generated completions, whereas on-policy training samples the student’s own rollouts and evaluates those exact rollouts with the teacher.

-
A useful intuition is provided by the chess analogy from Thinking Machines Lab. Off-policy distillation is like watching grandmaster games: the learner observes strong moves, but only in positions the expert encounters. On-policy distillation is like having a chess engine annotate every move in your own games, identifying precisely which moves were brilliant and which were blunders.
-
The following figure shows the chess analogy, illustrating how on-policy distillation provides move-by-move feedback on the student’s own trajectories.

-
From an implementation perspective, off-policy distillation is simpler because teacher outputs can be precomputed and reused. On-policy distillation is more computationally demanding because student rollouts and teacher evaluations must be generated repeatedly during training. However, it often delivers superior performance on long-horizon reasoning tasks because it teaches the student to recover from its own mistakes rather than only imitate ideal trajectories. Distilling 100B+ Models 40x Faster with TRL demonstrates practical infrastructure for large-scale OPD, including generation buffers, batched teacher queries, and compressed binary log-probability transfer to make 100B+ teachers tractable.
-
On-policy and off-policy are orthogonal to the offline/online distinction. A frozen teacher can be used in either regime, and multiple co-trained peers can still operate off-policy if they supervise each other on fixed datasets. In practice:
- Offline + Off-Policy: Classical teacher-student distillation with precomputed teacher outputs.
- Offline + On-Policy: Modern OPD with a frozen teacher scoring student rollouts.
- Online + Off-Policy: Deep Mutual Learning on shared minibatches.
- Online + On-Policy: Co-trained models supervising one another on their own generated trajectories.
-
This separation is conceptually important because most recent advances in LLM post-training, including Generalized Knowledge Distillation, On-Policy Self-Distillation, and Multi-Teacher On-Policy Distillation, use frozen teachers and are therefore offline in teacher update pattern while simultaneously on-policy in trajectory generation.
Relationship Between Offline/Online and Off-Policy/On-Policy Distillation
-
Offline and online distillation are related to, but distinct from, off-policy and on-policy distillation. Offline versus online describes the training-time relationship between teacher and student: frozen teacher versus concurrently trained teacher or peers. Off-policy versus on-policy describes the trajectory source: external data or teacher trajectories versus student-generated rollouts.
-
Thus, classical offline KD is usually off-policy, because the student trains on fixed human, dataset, or teacher trajectories. However, online distillation can still be off-policy if peers exchange predictions on fixed batches, and offline distillation can be on-policy if a frozen teacher scores rollouts generated by the current student. This is exactly the setup used in on-policy LLM distillation: the teacher can remain frozen, but the data distribution changes because trajectories are sampled from the student.
-
A useful taxonomy is therefore two-dimensional:
| Axis | Main options | What it determines |
|---|---|---|
| Teacher update pattern | Offline, online, semi-online | Whether the teacher is frozen, co-trained, or partially adapted |
| Trajectory source | Off-policy, on-policy | Whether sequences come from datasets/teachers or from the student |
| Target type | Hard, soft, feature, preference, reward-like | Whether supervision is tokens, logits, hidden states, preferences, or dense advantages |
| Teacher identity | External, self, multi-teacher, peer ensemble | Whether knowledge comes from another model, the same model, several models, or co-learners |
Off-Policy and On-Policy Distillation for Autoregressive LLMs
-
For autoregressive LLMs, the most important modern distinction is not only what is matched, but where the trajectories come from. Off-policy distillation trains the student on trajectories produced by a teacher, a dataset, or another external policy. On-policy distillation trains the student on its own rollouts and asks the teacher to score the student’s actual visited states.
-
This distinction is central because autoregressive errors compound: a student that deviates early at inference may enter contexts it never saw during fixed-dataset distillation. On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes by Agarwal et al. (2024) formalizes this as Generalized Knowledge Distillation, using teacher feedback on student-generated sequences to reduce train-inference mismatch.
-
The following figure (source) shows the distinction between off-policy and on-policy distillation: off-policy training uses teacher-generated completions, whereas on-policy training samples the student’s own rollouts and evaluates those exact rollouts with the teacher.
Divergence Choice: Forward KL, Reverse KL, and JSD
-
The loss direction matters. Forward KL,
\[D_{KL}(p_T \,\Vert\, p_S) =\sum_x p_T(x)\log\frac{p_T(x)}{p_S(x)}\]- is teacher-weighted and tends to be mean-seeking, penalizing the student for missing teacher modes. Reverse KL,
- is student-weighted and tends to be mode-seeking, penalizing tokens the student actually proposes when the teacher assigns them low probability. The TRL writeup Distilling 100B+ Models 40x Faster with TRL highlights this engineering distinction because top-\(k\) approximations differ depending on whether top tokens are selected from the teacher or the student.
-
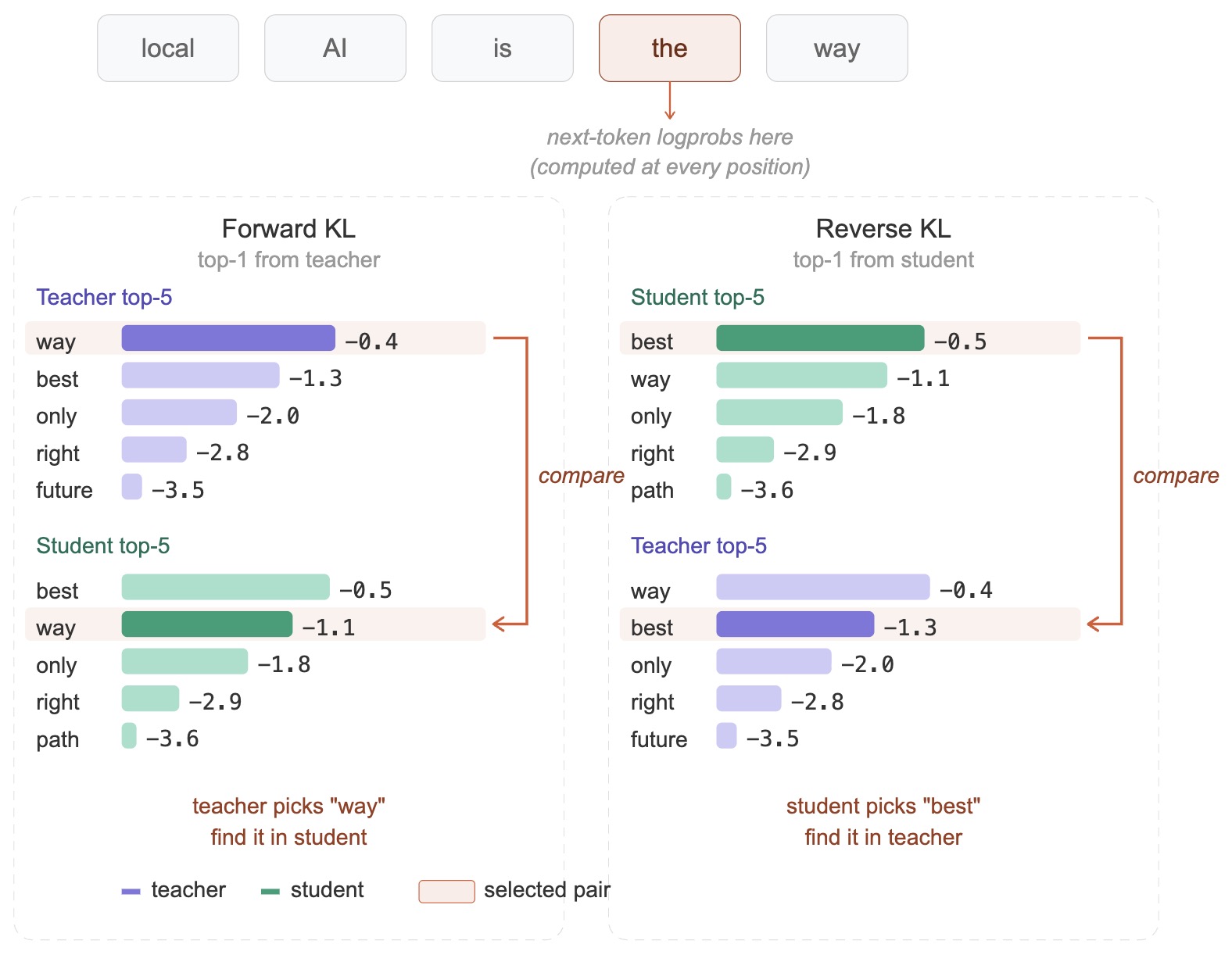
The following figure shows forward KL and reverse KL, including their different weighting behavior and their mean-seeking versus mode-seeking tendencies.
Self-Distillation and On-Policy Self-Distillation
-
Self-distillation is a related family in which the teacher is not a separate larger model. In older usage, it can mean training a model from its own predictions, from earlier checkpoints, or from an ensemble of itself. In newer LLM reasoning work, self-distillation can be on-policy and context-conditioned: Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models by Zhao et al. (2026) uses one model as both student and teacher, where the teacher view receives privileged information such as a verified solution while the student view sees only the problem.
-
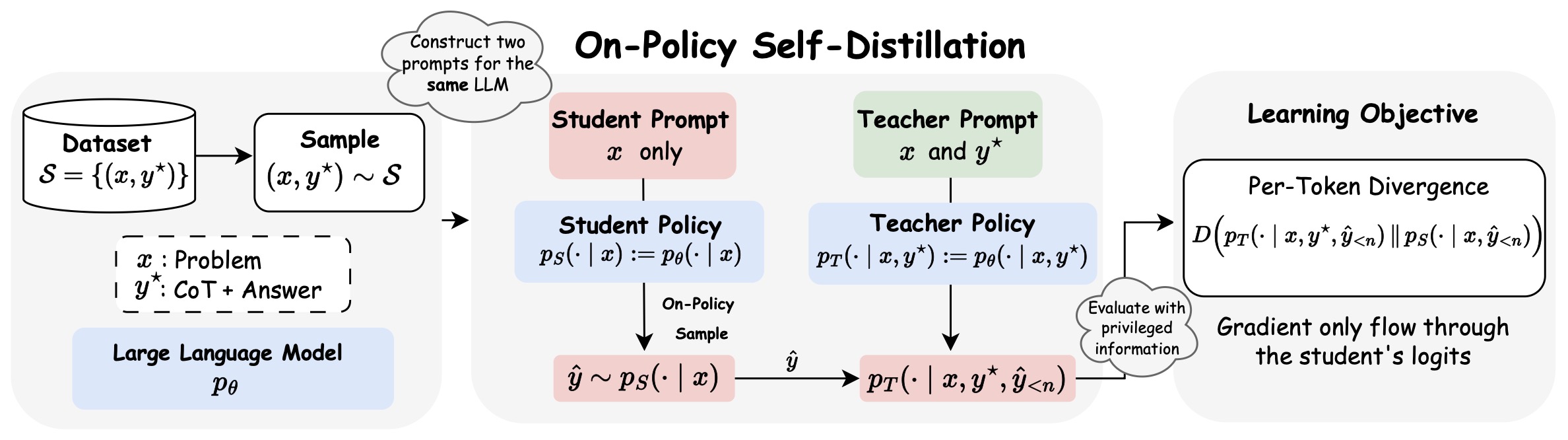
The following figure shows On-Policy Self-Distillation (OPSD), where the same model defines a student policy conditioned only on the problem and a teacher policy conditioned on privileged solution information. Given a reasoning dataset \(\mathcal{S}=\left\{\left(x_i, y_i^{\star}\right)\right\}_{i=1}^N\), we instantiate two policies from the same LLM: a student policy \(p_S(\cdot \mid x)\) and a teacher policy \(p_T\left(\cdot \mid x, y^{\star}\right)\). The student generates an on-policy response \(\hat{y} \sim p_S(\cdot \mid x)\). Both policies then evaluate this trajectory to produce next-token distributions \(p_S\left(\cdot \mid x, \hat{y}_{<n}\right)\) and \(p_T\left(\cdot \mid x, y^{\star}, \hat{y}_{<n}\right)\) at each step \(n\). The learning objective minimizes the per-token divergence \(D\left(p_T \,\Vert\, p_S\right)\) along the student’s rollout. The divergence here can be forward KL, reverse KL or JSD. Crucially, gradients backpropagate only through the student’s logits, allowing the model to self-distill.
Distillation as Synthetic Data and Post-Training Infrastructure
- A newer way to understand distillation is as part of the broader synthetic-data and post-training toolkit. The RLHF Book’s chapter Synthetic Data describes distillation as both a data engine, where stronger models generate completions, critiques, preferences, or filters, and a skill-transfer method, where a stronger model’s capabilities are transferred into a weaker model. The same chapter frames the path from offline KD to on-policy distillation as a move from static teacher-generated data toward student-sampled trajectories with dense teacher feedback.
Distillation and Reinforcement Learning
-
This connection also clarifies why distillation and reinforcement learning are now tightly linked. RL with verifiable rewards provides on-policy training but usually sparse scalar feedback, while OPD provides dense token-level feedback over on-policy trajectories. The RLHF Book expresses this bridge by treating the OPD token-level signal as an advantage-like term:
\[A_t^{\mathrm{OPD}} =\log \pi_T(a_t \mid s_t) - \log \pi_\theta(a_t \mid s_t)\]- where sampled tokens that the teacher rates above the student receive positive advantage, and sampled tokens the teacher rates below the student receive negative advantage.
-
Recent papers make this RL–distillation connection more explicit. Reinforcement Learning via Self-Distillation by Hübotter et al. (2026) introduces Self-Distillation Policy Optimization, which converts rich textual feedback such as runtime errors or judge comments into dense learning signals without an external teacher. Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation by Yang et al. (2026) argues that OPD is a special case of dense KL-constrained RL and generalizes it with a flexible reference model and reward scaling. Scaling Reasoning Efficiently via Relaxed On-Policy Distillation by Ko et al. (2026) interprets teacher–student log-likelihood ratios as token rewards and introduces relaxed OPD techniques for stability.
-
The relationship between distillation and RL is especially important for reasoning, coding, and agentic systems. Self-Distilled RLVR by Yang et al. (2026) argues that privileged self-distillation alone can leak information and destabilize long training, so it uses self-distillation to determine fine-grained update magnitudes while retaining RLVR for update direction. Unifying Group-Relative and Self-Distillation Policy Optimization via Sample Routing by Li et al. (2026) routes correct samples to GRPO-style reward-aligned RL and failed samples to self-distillation correction, combining sparse correctness signals with dense token-level supervision. OpenClaw-RL: Train Any Agent Simply by Talking by Wang et al. (2026) extends this idea to agent interactions, using next-state signals such as user replies, tool outputs, terminal states, and GUI changes as both scalar feedback and hindsight-guided OPD supervision.
Multi-Domain Post-Training and Capability Consolidation
- In multi-domain post-training, distillation also functions as a capability consolidation tool after or during RL. Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation by Yang et al. (2026) uses multi-domain OPD from the strongest intermediate teacher models to recover benchmark regressions and sustain gains after broader Cascade RL.
- Aligning Language Models from User Interactions by Kleine Buening et al. (2026) uses user follow-up messages as hindsight context for self-distillation, updating the model toward the behavior it would have produced after seeing the user’s correction or clarification. Informal discussion around this trend also appears in Cameron R. Wolfe’s X posts on multi-teacher OPD and the utility of combining specialist teachers, including this MOPD discussion thread.
Implementation View
-
In implementation terms, modern LLM distillation usually requires four decisions: the source of trajectories, the teacher signal, the divergence or surrogate loss, and the systems design for computing log-probabilities. The Thinking Machines post On-Policy Distillation frames on-policy distillation as combining the relevance of RL with the dense per-token signal of distillation: the student samples its own trajectories, while the teacher provides token-level feedback rather than a sparse sequence-level reward.
-
The following figure shows an intuitive chess analogy for on-policy distillation: rather than merely observing expert games or receiving only win/loss feedback, the learner receives dense move-level feedback on its own play.

Primer Roadmap
- The rest of the primer covers the major types of distillation in detail: classical soft-label distillation, hard-label and sequence-level distillation, representation and attention distillation, task-specific versus task-agnostic distillation, offline and online distillation, off-policy distillation, on-policy distillation, self-distillation, on-policy self-distillation, multi-teacher on-policy distillation, and the newer RL–distillation hybrid family that treats teacher log-probability gaps, hindsight feedback, or self-teacher contexts as dense policy-optimization signals.
Foundations
- Classical knowledge distillation establishes the core teacher–student framework that underlies all subsequent variants, including offline distillation, online distillation, off-policy distillation, on-policy distillation, self-distillation, and modern reinforcement learning hybrids. The central insight is that a model can learn not only from hard labels, but from the richer probability distribution produced by a stronger teacher or peer model. This section introduces the mathematical foundations, temperature scaling, divergence choices, early extensions, and the distinction between fixed-teacher and co-trained-teacher settings that made distillation a general-purpose model compression and capability transfer technique.
Teacher–Student Formulation
-
The classical formulation of distillation considers two models: a teacher \(p_T\), typically large and high-performing, and a student \(p_S^\theta\), typically smaller or more efficient. The objective is to transfer the teacher’s behavior into the student while reducing computational cost or improving specialization.
-
This paradigm was formalized in Distilling the Knowledge in a Neural Network by Hinton et al. (2015), which introduced the idea that the teacher’s soft output probabilities encode richer information than hard labels, revealing inter-class similarities. The student is trained to match these soft distributions rather than only the argmax class.
-
In the original classical setting, the teacher is usually fixed before the student is trained. This corresponds to offline distillation: the teacher distribution is stationary, and the student learns from a stable reference model.
-
Online distillation relaxes this assumption. In methods such as Deep Mutual Learning by Zhang et al. (2017), multiple peer models learn collaboratively and teach one another during training, so there may be no single pretrained superior teacher and no fixed teacher distribution.
-
For classification or token prediction, the core offline teacher–student loss is typically:
\[\mathcal{L}_{KD}(\theta) =\mathbb{E}_{x \sim \mathcal{D}} \left[ D\left( p_T(\cdot \mid x) ,\Vert, p_S^\theta(\cdot \mid x) \right) \right]\]- where \(D\) is a divergence, most commonly forward KL.
-
For online or mutual distillation, the same form can be generalized by replacing the single frozen teacher \(p_T\) with one or more evolving peers \(p_j^{\theta_j}\):
\[\mathcal{L}_{i}(\theta_i) =\mathcal{L}_{\text{task}}(\theta_i) +\lambda \sum_{j\neq i} D\left( p_j^{\theta_j}(\cdot \mid x) ,\Vert, p_i^{\theta_i}(\cdot \mid x) \right)\]- where model \(i\) learns from peer models \(j\) while also updating its own parameters. This captures the essential shift from one-way offline transfer to reciprocal online transfer.
-
In practice, distillation is often combined with supervised learning:
\[\mathcal{L}(\theta) =\alpha \mathcal{L}_{CE}(\theta) +(1 - \alpha)\mathcal{L}_{KD}(\theta)\]- where \(\mathcal{L}_{CE}\) is cross-entropy with ground-truth labels and \(\alpha\) balances teacher imitation and label supervision.
Temperature Scaling and Soft Targets
- A central idea in classical distillation is temperature scaling. The teacher logits \(z_i\) are softened using a temperature \(T > 1\):
-
Higher temperatures produce smoother distributions, making low-probability classes more visible. This helps the student learn nuanced relationships that are otherwise hidden in one-hot labels.
-
The distillation loss then becomes:
-
The factor \(T^2\) ensures gradient magnitudes remain stable when scaling logits.
-
In offline distillation, temperature is typically applied to a frozen teacher’s logits. In online distillation, temperature may be applied to each peer model’s logits before exchanging predictions, helping prevent mutual learning from collapsing too quickly into overconfident agreement.
-
Implementation detail: in large vocabulary settings such as LLMs, computing full softmax distributions is expensive. In practice, systems often approximate the loss using top-\(k\) tokens from either the teacher or student distribution, depending on whether forward or reverse KL is used.
Token-Level Distillation in Autoregressive Models
- For language models, distillation is applied at the token level. Given an input sequence \(x\) and generated tokens \(y = (y_1, \dots, y_n)\), both teacher and student define conditional distributions:
- The distillation objective aggregates per-token divergence:
-
This formulation is explicitly described in On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes by Agarwal et al. (2024), where distillation is framed as minimizing divergence between teacher and student token distributions along sequences.
-
Offline token-level distillation usually evaluates the teacher and student on a fixed sequence distribution, such as human-written outputs, teacher-generated outputs, or cached synthetic data. This is simple and stable, but it can create a gap between training prefixes and inference prefixes.
-
Online token-level distillation allows the supervising distribution to change during training. In peer-learning settings, each model may provide token-level probabilities to other models on shared batches; in more advanced LLM systems, periodically refreshed checkpoints or peer models can serve as evolving teachers.
-
A key implication is that the quality of training depends heavily on the distribution of prefixes \(y_{<t}\) encountered during training, which motivates the distinction between off-policy and on-policy methods discussed later.
Divergence Choices and Their Effects
-
Different divergences induce different behaviors in the student:
-
Forward KL:
\[D_{KL}(p_T ,\Vert, p_S)\]- This penalizes the student for assigning low probability to tokens the teacher considers likely. It leads to mean-seeking behavior, encouraging coverage of all teacher modes.
-
Reverse KL:
\[D_{KL}(p_S ,\Vert, p_T)\]- This penalizes tokens the student produces that the teacher considers unlikely. It leads to mode-seeking behavior, focusing on dominant modes.
-
Jensen-Shannon Divergence (JSD):
\[D_{JSD}(p_T ,\Vert, p_S) =\beta D_{KL}\left(p_T ,\Vert, m\right) +(1 - \beta) D_{KL}\left(p_S ,\Vert, m\right)\]- where \(m = \beta p_T + (1 - \beta)p_S\). JSD interpolates between forward and reverse KL and is bounded, which can improve stability.
-
-
Practical insight: forward KL is often used in classical supervised KD, while reverse KL is frequently used in on-policy distillation because it aligns naturally with sampling from the student distribution.
-
In offline distillation, divergence selection primarily controls how the student approximates a fixed teacher. In online distillation, divergence selection also affects training dynamics among co-evolving models: overly strong agreement losses can reduce diversity too early, while weaker or temperature-smoothed agreement can preserve complementary learning signals for longer.
Supervised Distillation and Sequence-Level Distillation
-
Two important classical variants are widely used:
-
Supervised (logit-level) distillation:
\[\mathcal{L}_{SD} =\mathbb{E}_{(x,y)} \left[ D_{KL}\big(p_T ,\Vert, p_S\big)(y \mid x) \right]\]- This provides dense supervision at every token, leveraging the full distribution rather than only correct labels.
-
Sequence-level distillation:
-
Introduced in Sequence-Level Knowledge Distillation by Kim and Rush (2016), this replaces ground-truth outputs with teacher-generated sequences. The student is trained via standard likelihood:
\[\mathcal{L}_{SeqKD} =\mathbb{E}_{x} \left[-\log p_S(y_T \mid x) \right]\]- where \(y_T \sim p_T(\cdot \mid x)\).
-
This simplifies the target distribution, often making learning easier but discarding distributional richness.
-
-
-
Both supervised logit-level distillation and sequence-level distillation are most commonly implemented as offline methods: a frozen teacher labels fixed data or generates synthetic targets, and the student is trained afterward.
-
Online versions are possible when teacher outputs are generated by co-trained peers or periodically refreshed teachers rather than by a static teacher. In such cases, the same supervised or sequence-level objective can be used, but the source distribution evolves during optimization.
Representation and Intermediate-Layer Distillation
-
Classical distillation need not operate solely on output probabilities. Representation distillation aligns hidden states, attention maps, and embeddings.
-
DistilBERT: a distilled version of BERT by Sanh et al. (2019) combines three losses:
-
DistilBERT loss components: masked language modeling loss, distillation loss on softened logits, cosine embedding loss on hidden representations.
-
This multi-objective approach preserves both output behavior and internal representations, demonstrating that distillation can transfer structural knowledge in addition to token probabilities.
-
-
Subsequent work has extended this principle to:
- Representation-alignment targets: attention map matching, value and key projection matching, layer-wise feature regression, contrastive representation alignment.
-
These techniques are especially useful when the student architecture differs substantially from the teacher.
-
In offline representation distillation, the teacher’s hidden states can be cached or computed live from a frozen teacher. In online representation distillation, peers may align intermediate representations during co-training, but this is more architecture-sensitive because hidden-state dimensions, layer counts, and attention structures must be compatible or projected into a shared space.
Distillation as Synthetic Data Generation
-
A complementary perspective, emphasized in the RLHF Book chapter Synthetic Data, is that distillation is also a structured data-generation process. A teacher can produce:
-
Synthetic supervision artifacts: answers, chain-of-thought traces, critiques, preference labels, filtered examples.
-
The student then trains on these outputs either as hard targets or as soft distributions.
-
-
This viewpoint broadens distillation from model compression to a general capability-transfer mechanism. In modern LLM pipelines, generating high-quality synthetic reasoning traces often precedes more advanced on-policy or reinforcement learning stages.
-
In offline synthetic-data distillation, the generated examples are usually fixed before student training or regenerated in separate rounds. In online synthetic-data distillation, examples, critiques, or peer labels may evolve as teachers, students, or self-improvement loops change during training.
Limitations of Classical Distillation
-
Despite its effectiveness, classical distillation suffers from several structural limitations:
-
Distribution mismatch: The student is trained on fixed trajectories, such as ground-truth or teacher-generated sequences, but at inference it generates its own tokens. Errors compound because it encounters states not seen during training. This issue is highlighted in imitation learning literature and explicitly discussed in On-Policy Distillation of Language Models.
-
Teacher bias and mode collapse: Forward KL encourages the student to cover all teacher modes, sometimes leading to overly smooth or low-confidence outputs.
-
Capacity mismatch: If the student cannot represent the teacher distribution, minimizing forward KL may produce unrealistic samples or unstable behavior.
-
Data inefficiency: Off-policy distillation may waste training effort on trajectories the student would never generate, reducing practical efficiency.
-
Teacher staleness in offline KD: A frozen teacher cannot adapt to the student’s changing failure modes, which can limit the usefulness of teacher feedback late in training.
-
Non-stationarity in online KD: A co-trained or evolving teacher can provide fresher supervision, but the target distribution changes over time, making optimization and reproducibility harder. Deep Mutual Learning by Zhang et al. (2017) shows that collaboratively trained peers can outperform a static-teacher setup, but the method also shifts distillation from a simple one-way transfer problem into a coupled multi-model optimization problem.
-
Implementation Considerations
-
In modern LLM systems, classical distillation requires careful engineering:
-
Log-probability extraction: The teacher must provide token-level log-probabilities. This is often done via a separate inference server, for example vLLM-based systems, with batched requests and compressed logprob transmission.
-
Top-\(k\) approximation: Full-vocabulary KL is expensive. Approximations using top-\(k\) tokens reduce memory and bandwidth requirements, especially for large vocabularies of roughly \(100{,}000\) tokens or more.
-
Batching and caching: Efficient pipelines buffer student generations and batch teacher evaluations to amortize cost, enabling distillation even from 100B+ models at scale.
-
Hybrid objectives: Many systems combine supervised fine-tuning, distillation, and reinforcement learning signals in a single pipeline.
-
Offline execution pattern: Offline KD usually separates teacher inference from student optimization. Teacher completions, logits, hidden states, or labels can be precomputed, cached, audited, and reused across multiple student runs.
-
Online execution pattern: Online KD requires coordination among multiple co-trained models or periodically refreshed teachers. This adds communication overhead, synchronization complexity, and non-stationary targets, but it can provide more adaptive supervision.
-
Semi-online compromise: Semi-online systems periodically refresh teacher checkpoints or add shadow teachers while preserving some stability of offline KD. Shadow Knowledge Distillation: Bridging Offline and Online Knowledge Transfer by Li et al. (2022) studies this intermediate regime and frames it as a bridge between static offline transfer and fully online knowledge exchange.
-
Offline Distillation
-
Offline distillation is the classical and historically dominant form of knowledge distillation. In offline distillation, the teacher model is trained beforehand and then frozen. The student is subsequently optimized to imitate this fixed teacher using either precomputed teacher outputs or teacher evaluations generated during training. Because the teacher does not change, the supervision signal is stationary, which makes offline distillation stable, reproducible, and comparatively simple to implement.
-
Most of the literature traditionally referred to as “knowledge distillation” implicitly assumes an offline setting. Distilling the Knowledge in a Neural Network by Hinton et al. (2015) is the canonical example: a pretrained ensemble or large model produces softened probability distributions that supervise a smaller student. DistilBERT by Sanh et al. (2019) similarly uses a frozen BERT teacher to train a compact transformer.
Core Definition
-
Let \(p_T\) denote a pretrained teacher and \(p_S^\theta\) the student. Offline distillation optimizes:
\[\mathcal{L}_{\text{offline}}(\theta) =\mathbb{E}_{(x,y)\sim\mathcal{D}} \left[ D\left( p_T(\cdot \mid x, y_{<t}) \,\Vert\, p_S^\theta(\cdot \mid x, y_{<t}) \right) \right]\]- where:
- \(\mathcal{D}\) is a fixed dataset.
- \(p_T\) is frozen throughout training.
- \(D\) is typically forward KL, reverse KL, JSD, or cross-entropy.
- where:
-
The defining property is that the teacher parameters remain constant:
\[\nabla_\phi \mathcal{L}_{\text{offline}} = 0\]- where \(\phi\) denotes teacher parameters.
Relationship to Off-Policy and On-Policy Distillation
-
Offline distillation and off-policy distillation are closely related but not identical concepts.
- Offline vs. online describes whether the teacher is frozen or co-trained.
- Off-policy vs. on-policy describes where trajectories come from.
-
Most offline distillation is also off-policy, because the student trains on fixed human or teacher-generated sequences. However, offline distillation can also be on-policy if a frozen teacher evaluates rollouts generated by the current student. This is precisely the setup used in many modern on-policy LLM distillation methods, including On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes by Agarwal et al. (2024), where the teacher remains fixed but the trajectory distribution changes over time.
-
Thus, “offline” refers to teacher dynamics, while “on-policy” refers to data dynamics.
Common Forms of Offline Distillation
-
Offline distillation encompasses many of the most widely used distillation approaches:
-
Soft-Label Distillation: The teacher provides full probability distributions over classes or tokens, often softened with temperature scaling.
-
Sequence-Level Distillation: The teacher generates complete outputs that become training targets, as introduced in Sequence-Level Knowledge Distillation by Kim and Rush (2016).
-
Representation Distillation: The student matches hidden states, embeddings, attention maps, or intermediate activations.
-
Preference and Reward Distillation: The teacher provides rankings, scalar rewards, or critiques rather than direct logits.
-
Precomputed vs. Live Teacher Querying: Offline distillation does not require that teacher outputs be fully precomputed.
-
Precomputed offline distillation: Teacher outputs are generated once and stored.
-
Live offline distillation: The frozen teacher is queried during training, but its parameters remain unchanged.
-
Both are considered offline because the teacher itself is static.
-
-
Advantages of Offline Distillation
-
Stability: The target distribution does not change during training.
-
Reproducibility: Repeated runs see identical teacher behavior.
-
Engineering simplicity: Teacher and student optimization are decoupled.
-
Caching efficiency: Teacher outputs can be stored and reused.
-
Scalability: Large teachers can supervise many student experiments.
Limitations of Offline Distillation
-
Teacher staleness: The teacher cannot adapt to the student’s evolving weaknesses.
-
Potential distribution mismatch: If training trajectories are fixed, the student may not learn to recover from its own mistakes.
-
Storage requirements: Precomputing token-level distributions can be expensive.
-
Capability ceiling: The student is fundamentally bounded by the teacher’s performance and biases.
Semi-Online Variants
- Some systems partially relax the static-teacher assumption by periodically updating a teacher snapshot or ensemble. Shadow Knowledge Distillation: Bridging Offline and Online Knowledge Transfer by Li et al. (2022) studies this intermediate regime and argues that part of the online distillation advantage comes from reversed student-to-teacher transfer rather than only from simultaneous training.
Offline Distillation in Modern LLM Training
-
In contemporary LLM pipelines, offline distillation is widely used for compressing frontier models into smaller deployable models, generating synthetic instruction and reasoning datasets, transferring capabilities after RL or alignment, and creating baseline models before on-policy fine-tuning.
-
The RLHF Book chapter Synthetic Data presents offline distillation as the first stage in a progression from static synthetic data generation to fully on-policy distillation and RL-integrated post-training.
Implementation Pattern
-
Select or train the teacher model: Begin with a strong model, ensemble, specialist checkpoint, or post-RL model whose behavior should be transferred into the student. In most offline settings, this teacher is already trained before the distillation run begins.
-
Freeze the teacher parameters: Keep the teacher fixed throughout student training. This ensures that the supervision distribution remains stationary and that repeated student runs can be compared cleanly.
-
Generate or query teacher outputs: Use the teacher to produce hard targets, soft probabilities, hidden-state targets, critiques, preferences, or reward-like annotations. These outputs may be generated once before training or queried live during student optimization.
-
Store targets or log-probabilities when useful: For large-scale systems, cache teacher completions, token IDs, top-\(k\) log-probabilities, embeddings, or preference labels so they can be reused across multiple student runs. Full-vocabulary logits are usually expensive, so practical systems often store compressed targets.
-
Train the student to match the teacher: Optimize the student with the appropriate matching loss, such as cross-entropy on teacher-generated tokens, KL divergence on teacher probabilities, MSE on hidden states, or a hybrid objective combining supervised and distillation losses.
-
Evaluate, diagnose, and iterate: Measure the student against task benchmarks, teacher agreement, latency, memory footprint, and regression suites. If the student underperforms, iterate by improving the teacher data, changing the divergence, adjusting temperature, increasing top-\(k\) coverage, or introducing on-policy rollouts.
Online Distillation
-
Online distillation generalizes the teacher-student paradigm by allowing the teacher signal to evolve during training rather than remain fixed. Instead of relying exclusively on a pretrained, frozen teacher, online distillation trains multiple models simultaneously and enables them to exchange knowledge throughout optimization. The supervision distribution is therefore non-stationary and adapts as the participating models improve.
-
The core motivation is that a fixed teacher may become stale relative to the student’s changing weaknesses and strengths. By allowing teachers and students to co-evolve, online distillation can provide more adaptive supervision, improve generalization, and in some cases outperform both conventional offline distillation and independently trained models.
-
The canonical example is Deep Mutual Learning by Zhang et al. (2017), which trains peer networks jointly and minimizes KL divergence between their predictive distributions. Each model acts simultaneously as both student and teacher, and all participants improve through reciprocal supervision. More recent approaches such as co-distillation and peer learning extend this idea to larger ensembles and distributed training systems.
Core Definition
-
Suppose there are \(K\) models with parameters \({\theta_k}_{k=1}^K\). For model \(i\), the online distillation objective can be written as:
\[\mathcal{L}_i(\theta_i) =\mathcal{L}_{\text{task}}(\theta_i) +\lambda \sum_{j \neq i} D\left( p_j(\cdot \mid x) \,\Vert\, p_i(\cdot \mid x) \right)\]-
where:
- \(\mathcal{L}_{\text{task}}\) is the primary supervised or reinforcement learning objective,
- \(D\) is a divergence such as KL or JSD,
- \(\lambda\) controls the strength of mutual supervision,
- all models update concurrently.
-
-
Unlike offline distillation, the teacher distributions \(p_j\) evolve throughout training:
\[\nabla_{\theta_j} \mathcal{L}_j \neq 0\]- for all participating models.
Relationship to Offline, Off-Policy, and On-Policy Distillation
-
Online versus offline describes whether the teacher changes during training. Off-policy versus on-policy describes where the training trajectories originate.
-
This yields four conceptually distinct combinations:
- Offline + Off-Policy: Classical KD using a frozen teacher and fixed teacher or dataset trajectories.
- Offline + On-Policy: Modern OPD, where a frozen teacher scores student-generated rollouts.
- Online + Off-Policy: Peer models exchange predictions on a fixed dataset or minibatch stream.
- Online + On-Policy: Multiple co-evolving models generate and score their own trajectories, potentially sharing rollouts and dense feedback.
-
Most historical online distillation methods are online and off-policy because they operate on shared minibatches. Emerging RL and LLM systems increasingly explore online and on-policy hybrids, where co-trained models evaluate trajectories sampled from their current policies.
Major Forms of Online Distillation
-
Mutual Learning: Each model teaches every other model, as in Deep Mutual Learning.
-
Co-Distillation: Large-scale training jobs periodically exchange predictions or checkpoints to improve convergence and robustness.
-
Peer Ensembles: Multiple comparable models learn jointly and average or vote on predictions during training.
-
Adaptive Teacher Distillation: A stronger model is periodically updated and continues to supervise one or more students.
-
Population-Based Distillation: A population of models with different objectives or hyperparameters exchanges knowledge during training.
Advantages of Online Distillation
-
Adaptive supervision: The teaching signal evolves with the models and can address newly emerging failure modes.
-
Improved generalization: Peer learning often reduces overconfidence and improves calibration.
-
No need for a single superior teacher: Comparable models can still benefit from teaching one another.
-
Regularization effects: Mutual agreement acts as a strong inductive bias.
-
Compatibility with distributed systems: Large training clusters can exchange logits or checkpoint summaries during optimization.
Limitations of Online Distillation
-
Higher system complexity: Multiple models must be trained simultaneously or synchronized periodically.
-
Non-stationary targets: The supervision distribution changes over time, which can complicate optimization.
-
Risk of consensus errors: If all participants share similar biases, they may reinforce incorrect behavior.
-
Compute overhead: Training several models jointly can be significantly more expensive than using a single frozen teacher.
Semi-Online and Hybrid Approaches
-
Many practical systems combine offline and online strategies:
-
Checkpoint refresh: A frozen teacher is periodically replaced by the latest strong checkpoint.
-
Teacher ensembles: A static teacher is supplemented with co-trained peers.
-
Shadow teachers: * Auxiliary teachers are updated asynchronously to provide fresher supervision.
-
-
Shadow Knowledge Distillation: Bridging Offline and Online Knowledge Transfer by Li et al. (2022) analyzes these intermediate approaches and shows that reversed student-to-teacher transfer contributes significantly to online distillation’s effectiveness.
Online Distillation in Modern LLM Training
-
Although most frontier LLM distillation remains offline, online principles appear increasingly often in:
- Multi-agent self-improvement systems,
- Self-play and debate frameworks,
- Checkpoint-based teacher refresh pipelines,
- Distributed co-training,
- Self-distillation with periodically updated teacher snapshots.
-
In large-scale post-training, a model may be supervised by:
- Specialist checkpoints trained on different domains,
- Recent versions of itself,
- Peer models in a shared optimization loop.
-
This blurs the boundary between online distillation, self-distillation, and multi-teacher distillation.
Implementation Pattern
-
Initialize multiple models or peers: Start with two or more models, which may differ in architecture, initialization, objective, or specialization.
-
Train each model on the primary objective: Each participant optimizes its own supervised, RL, or hybrid loss.
-
Exchange predictive distributions: At each step or periodically, models compute logits, hidden states, or critiques that are shared with other participants.
-
Compute mutual distillation losses: Each model matches one or more peer distributions using KL divergence, JSD, or related objectives.
-
Update all models concurrently: Gradients are applied to every participant, so each model acts as both teacher and student.
-
Synchronize or refresh when needed: In distributed systems, communication may occur asynchronously or at checkpoint boundaries rather than every minibatch.
-
Evaluate both individual and ensemble performance: Assess whether joint learning improves standalone models, ensemble behavior, and calibration.
Online Distillation in the Broader Distillation Taxonomy
-
Online distillation occupies the teacher-update axis of the distillation taxonomy. It complements rather than replaces distinctions such as:
- Off-policy versus on-policy,
- Single-teacher versus multi-teacher,
- External-teacher versus self-distillation,
- Supervised versus RL-integrated training.
-
Conceptually, online distillation is best understood as adaptive teacher evolution, while on-policy distillation is best understood as adaptive trajectory generation. Modern systems increasingly combine both.
Off-Policy Distillation
- Off-policy distillation is the classical and still most widely used form of distillation. The student is trained on trajectories generated by an external source, such as human-labeled datasets, teacher-generated completions, synthetic reasoning traces, or curated corpora, rather than on trajectories sampled from the student itself. This makes off-policy distillation simple, stable, and highly scalable, but also introduces the train–inference mismatch that motivates later on-policy methods.
Definition and Formal Objective
- Given a dataset of input-output pairs \(\mathcal{D} = {(x, y)}\), where outputs \(y\) may come from humans, a teacher model, or synthetic data pipelines, the student minimizes a divergence between teacher and student token distributions:
- This is the standard supervised distillation objective described in Distilling the Knowledge in a Neural Network by Hinton et al. (2015) and generalized to autoregressive sequence models in On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes by Agarwal et al. (2024).
Sources of Off-Policy Data
-
Off-policy data can be obtained from several sources:
-
Human-labeled datasets provide expert-written instruction responses, translations, preference annotations, and curated reasoning traces that serve as direct supervision targets.
-
Teacher-generated synthetic data is produced by stronger models that generate answers, chain-of-thought traces, critiques, or tool-use demonstrations intended to transfer specific capabilities.
-
Filtered synthetic corpora are created by generating multiple candidate outputs and retaining only those that score highly under verifiers, reward models, or additional teacher models.
-
Historical model outputs can be relabeled and refined using stronger models, allowing prior checkpoints or production logs to become training data for newer students.
-
-
The RLHF Book chapter Synthetic Data emphasizes that most modern post-training pipelines rely heavily on large-scale synthetic data generation before any reinforcement learning or on-policy distillation stage.
Sequence-Level Distillation
-
Sequence-level distillation is the most common off-policy method for LLMs.
-
Introduced in Sequence-Level Knowledge Distillation by Kim and Rush (2016), it trains the student on full teacher-generated outputs:
\[\mathcal{L}_{\text{SeqKD}} =\mathbb{E}_{x} \left[ - \log p_S(y_T \mid x) \right]\]-
where:
\[y_T \sim p_T(\cdot \mid x)\]
-
-
This approach often simplifies the target distribution by replacing multiple valid outputs with one teacher-selected response, which can make optimization substantially easier.
Logit Distillation
- In logit or soft-label distillation, the student matches the teacher’s full next-token distribution.
-
Compared with sequence-level distillation, this preserves uncertainty information, token similarities, and alternative plausible continuations.
-
This approach is especially effective when the teacher is much stronger and when the student has sufficient capacity to approximate the teacher distribution.
Synthetic Data Pipelines
-
A major modern use of off-policy distillation is as the final consumer of synthetic data pipelines.
-
A typical workflow proceeds through several stages:
-
Prompts are collected from benchmark datasets, user interactions, or automatically generated prompt sets designed to cover the target domains.
-
A strong teacher model generates one or more candidate completions for each prompt, often including intermediate reasoning traces or tool-use steps.
-
Reward models, verifiers, or additional teacher models evaluate the generated outputs to estimate correctness, helpfulness, and consistency.
-
The highest-quality outputs are selected, reranked, or filtered to remove low-confidence or incorrect examples.
-
The resulting dataset is stored as a reusable synthetic corpus that may include completions, chain-of-thought traces, verifier scores, and teacher log-probabilities.
-
The student model is trained on this curated dataset using sequence-level distillation, logit matching, or a hybrid objective.
-
-
Synthetic datasets may contain a wide range of artifacts, including:
-
Detailed chain-of-thought traces that expose intermediate reasoning steps and allow the student to imitate structured problem solving.
-
Verified code solutions that transfer programming ability while ensuring that generated programs pass unit tests or execution checks.
-
Critiques and revisions that teach the student how to diagnose and improve its own responses.
-
Tool-use transcripts that demonstrate how to call APIs, interpret outputs, and incorporate retrieved information into subsequent reasoning.
-
Preference annotations that encode relative quality judgments and can later support alignment or ranking objectives.
-
-
The RLHF Book highlights that this synthetic-data-to-distillation pipeline remains the dominant method for transferring capabilities from frontier models into smaller and more deployable students.
Advantages of Off-Policy Distillation
-
The training procedure is operationally simple because it closely resembles standard supervised fine-tuning on a fixed dataset.
-
Optimization is highly stable and reproducible because the same precomputed examples can be reused across runs.
-
Teacher inference is amortized efficiently, since outputs and log-probabilities are generated once and consumed many times.
-
The approach scales naturally to very large datasets and distributed training systems.
-
It integrates seamlessly with synthetic data generation pipelines that create specialized corpora for reasoning, coding, and instruction following.
Limitations: Distribution Mismatch
-
The central weakness of off-policy distillation is that the student is trained on trajectories it did not generate.
-
During inference, the student samples:
\[\hat{y} \sim p_S(\cdot \mid x)\]- which may diverge from teacher-generated sequences. Because each token conditions on previous tokens, small errors compound over long trajectories.
-
This problem is explicitly analyzed in On-Policy Distillation of Language Models and motivates Generalized Knowledge Distillation.
-
The Thinking Machines article On-Policy Distillation compares this to learning chess solely by watching grandmasters: one sees excellent play but not the board states produced by one’s own mistakes.
Behavioral Consequences
-
Off-policy students often exhibit:
-
Strong performance when their generated prefixes remain close to the trajectories seen during training.
-
Limited ability to recover from early mistakes that push generation into unfamiliar contexts.
-
Increased exposure bias, especially in long-horizon reasoning and agentic tasks.
-
Stylistic imitation of the teacher without fully reproducing the teacher’s underlying reasoning competence.
-
Overconfident predictions when trained primarily on single deterministic targets rather than full probability distributions.
-
Relationship to Reinforcement Learning
- Off-policy distillation and reinforcement learning differ in both trajectory source and feedback density, as indicated in the table below:
| Method | Trajectory source | Reward density |
|---|---|---|
| Off-policy KD | Teacher or dataset | Dense token-level |
| RLHF / RLVR | Student | Sparse sequence-level |
| On-policy distillation | Student | Dense token-level |
-
As a result, off-policy distillation is highly sample-efficient but less robust than on-policy approaches.
-
Many modern pipelines therefore follow a staged progression:
- Synthetic data is generated and filtered to create high-quality off-policy supervision.
- The student is trained through off-policy distillation to absorb the teacher’s broad capabilities.
- Reinforcement learning is applied to refine behaviors that are difficult to specify directly in the dataset.
- On-policy distillation is used to transfer the benefits of RL into a smaller or more efficient model.
-
The RLHF Book explicitly presents this progression as the “path to on-policy distillation.”
Engineering and Systems Considerations
-
Off-policy systems are operationally straightforward:
-
Teacher inference can be performed asynchronously and at large batch sizes, maximizing accelerator utilization.
-
Training examples may store token IDs, reasoning traces, verifier scores, and optionally top-\(k\) log-probabilities for later reuse.
-
The resulting synthetic datasets can be reused across many experiments and across multiple student architectures.
-
Student training proceeds independently and does not require synchronous communication with the teacher.
-
-
The primary costs arise from generating synthetic data, storing large corpora, and maintaining the filtering and verification infrastructure that ensures data quality.
When Off-Policy Distillation is Preferred
-
Off-policy distillation is the best choice when:
-
Simplicity and stability are more important than exact train–inference matching.
-
Large synthetic datasets are already available or can be generated economically.
-
Teacher inference can be amortized offline and reused across many experiments.
-
The student is unlikely to diverge substantially from the training distribution during deployment.
-
The primary goal is broad capability transfer rather than maximal robustness to self-generated errors.
-
-
It remains the dominant starting point for most practical distillation pipelines, even when more advanced on-policy or reinforcement learning stages are planned later.
On-Policy Distillation (OPD)
- On-policy distillation addresses the central limitation of off-policy methods by training the student on trajectories it actually generates, rather than on fixed datasets curated by humans or sampled from a teacher. By shifting supervision onto the student’s own state distribution, on-policy distillation substantially reduces exposure bias and compounding errors in autoregressive models. Conceptually, it combines the on-policy relevance of reinforcement learning with the dense, token-level feedback of knowledge distillation, and has emerged as one of the most important post-training primitives for reasoning models and capability transfer in modern LLM pipelines.
Core Idea and Formal Objective
- In on-policy distillation, the student first generates a rollout:
- The teacher then evaluates the exact same trajectory by assigning next-token probabilities conditioned on the student’s prefixes. The student is updated to reduce the divergence between its own token distributions and the teacher’s token distributions along this rollout:
- This formulation was introduced in On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes by Agarwal et al. (2024), which frames distillation as an imitation learning problem in the style of DAGGER and demonstrates substantial gains over conventional supervised and sequence-level KD across summarization, translation, and mathematical reasoning.
Intuition: Learning from One’s Own Mistakes
-
The key advantage of on-policy distillation is that the student receives feedback precisely in the contexts it is most likely to encounter at inference time.
-
The Thinking Machines article On-Policy Distillation presents an intuitive analogy to chess. Instead of only observing expert games, or receiving a single win-or-loss signal after playing a full game, the student receives move-by-move evaluations of its own choices. This makes it possible to identify and correct the specific decisions that caused the rollout to go off track.
-
The following figure (source) shows a chess.com-style visualization in which each move in the learner’s own game is graded from blunder to brilliant, illustrating how on-policy distillation provides dense, token-level feedback over self-generated trajectories.
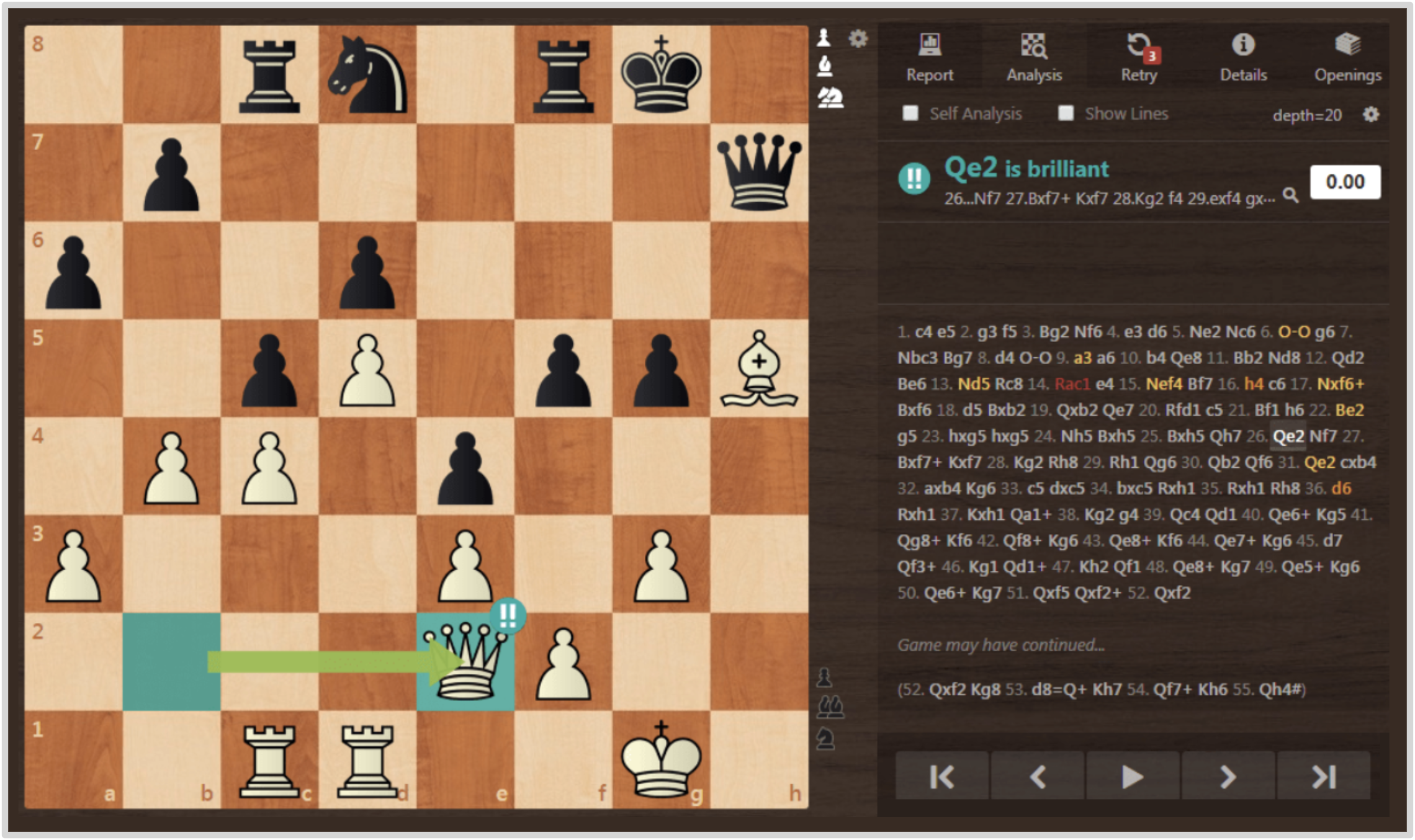
Generalized Knowledge Distillation (GKD)
-
Agarwal et al. introduce Generalized Knowledge Distillation (GKD), which unifies several forms of distillation under a single framework. At each training step, the algorithm may either:
-
Sample a trajectory from the student and obtain teacher supervision along that rollout.
-
Draw a trajectory from a fixed dataset, thereby mixing in traditional off-policy examples.
-
-
This mixture is controlled by a parameter \(\lambda \in [0,1]\), which specifies the fraction of training examples that are student-generated.
-
When \(\lambda = 0\), GKD reduces to standard supervised distillation. When \(\lambda = 1\), all training occurs on student-generated trajectories. Intermediate values provide a practical curriculum that combines the stability of offline supervision with the robustness benefits of on-policy training.
-
The following figure (source) shows that on-policy Generalized Knowledge Distillation significantly outperforms supervised fine-tuning, supervised KD, and sequence-level KD across summarization, translation, and mathematical reasoning tasks.
Choice of Divergence and Reward Interpretation
- Although forward KL remains theoretically valid, reverse KL is particularly well suited to on-policy training because the rollout is sampled from the student distribution. Under reverse KL, the student is penalized only for tokens it actually assigns probability to and that the teacher considers unlikely.
- This objective is naturally interpreted as a dense per-token reward:
-
Tokens that the teacher rates more highly than the student receive positive advantage, while tokens that the teacher considers worse than the student receive negative advantage. The multi-teacher OPD article Multi-Teacher On-Policy Distillation: A New Post-Training Primitive emphasizes that this makes reverse KL a particularly natural replacement for the advantage term in GRPO-style reinforcement learning.
-
The Hugging Face TRL writeup Distilling 100B+ Models 40x Faster with TRL similarly notes that reverse KL aligns cleanly with student-generated trajectories and requires only the teacher’s log-probabilities on sampled tokens rather than full-vocabulary distributions.
Distillation and Reinforcement Learning
-
One of the most important modern insights is that on-policy distillation can be understood as a dense, KL-constrained form of policy optimization.
-
The RLHF Book chapter Synthetic Data describes on-policy distillation as the natural progression after synthetic data generation and reinforcement learning. Reinforcement learning supplies on-policy trajectories but typically only sparse sequence-level rewards, whereas on-policy distillation provides token-level guidance from a stronger teacher over those same trajectories. Recent work strengthens this connection.
Reinforcement Learning via Self-Distillation
-
Reinforcement Learning via Self-Distillation by Hübotter et al. (2026) converts textual critiques, execution errors, and other rich feedback into dense token-level updates, showing that self-distillation can serve as a general policy optimization mechanism.
-
Implementation details:
-
The method constructs a teacher distribution conditioned on the original trajectory and a natural-language feedback string that explains what went wrong or how to improve.
-
Student trajectories are replayed under this feedback-augmented teacher context, allowing each token to receive targeted corrective supervision.
-
The same base model can be used as both student and teacher, eliminating the need for a separate external model.
-
The approach is particularly effective for coding and reasoning tasks where runtime errors and verifier messages provide highly informative textual signals.
-
-
The following figure (source) shows a comparison of RLVR and RLRF settings. In Reinforcement Learning with Verifiable Rewards (RLVR), the agent learns from a scalar reward \(r\), which often acts as an information bottleneck by masking the underlying environment state. In contrast, Reinforcement Learning with Rich Feedback (RLRF) utilizes tokenized feedback. In other words, in the core self-distillation policy optimization setup, in which textual feedback is transformed into a dense teacher signal over the original student rollout. This provides a significantly richer signal than a scalar reward, as the feedback can encapsulate both the reward as well as detailed observations of the state (such as runtime errors from a code environment or feedback from an LLM judge).
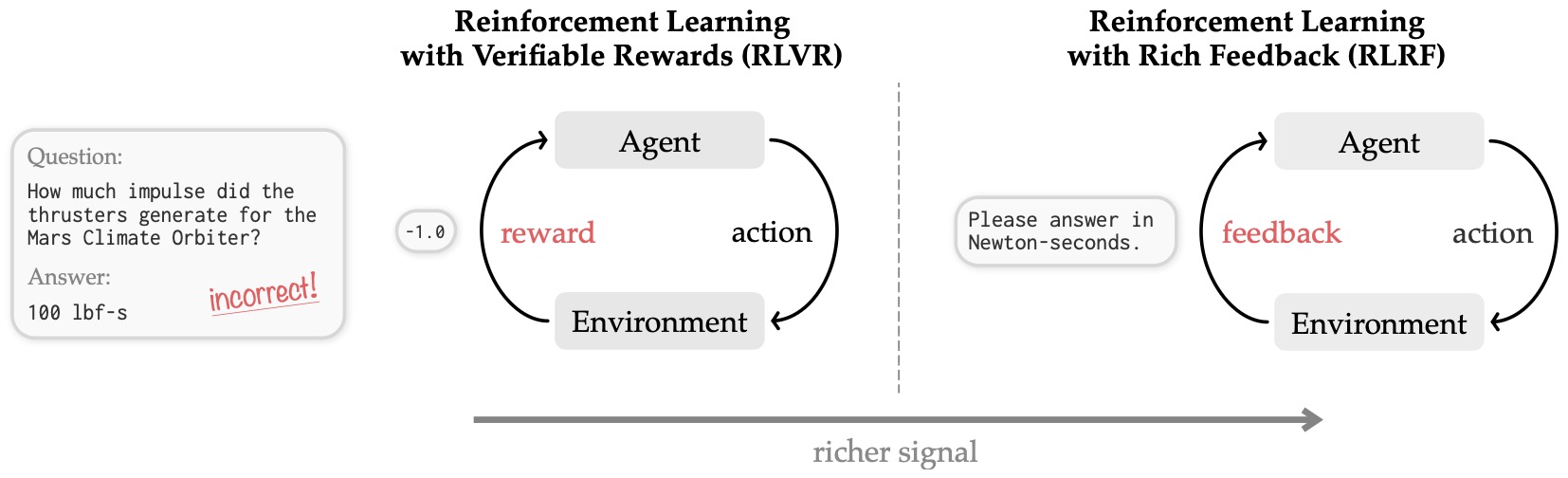
Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation
-
Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation by Yang et al. (2026) introduces ExOPD (i.e., extrapolation OPD), which generalizes OPD by combining teacher imitation with explicit reward extrapolation, allowing the student to exceed the teacher rather than merely match it.
-
Implementation details:
-
A reference teacher policy provides dense token-level supervision, while an external reward signal estimates how much better or worse the current trajectory is than the teacher baseline.
-
The distillation loss is reweighted by reward-derived scaling factors so that trajectories outperforming the teacher receive amplified updates.
-
The framework supports interchangeable reference models, including external teachers, self-teachers, or moving-average checkpoints.
-
This design decouples “who provides dense supervision” from “who defines the ultimate objective,” enabling teacher-guided exploration beyond teacher quality.
-
-
The following figure (source) shows the empirical effectiveness of ExOPD compared with off-policy distillation (SFT), standard OPD, and the weight-extrapolation method ExPO introduced in Model Extrapolation Expedites Alignment by Zheng et al. (2025) in multi-teacher and strong-to-weak distillation settings, with results averaged over 4 math reasoning and 3 code generation benchmarks. In multi-domain expert merging, ExOPD is the only method that yields a unified student that consistently outperforms all domain teachers; in strong-to-weak distillation, ExOPD significantly improves over standard OPD, with reward correction further boosting performance.
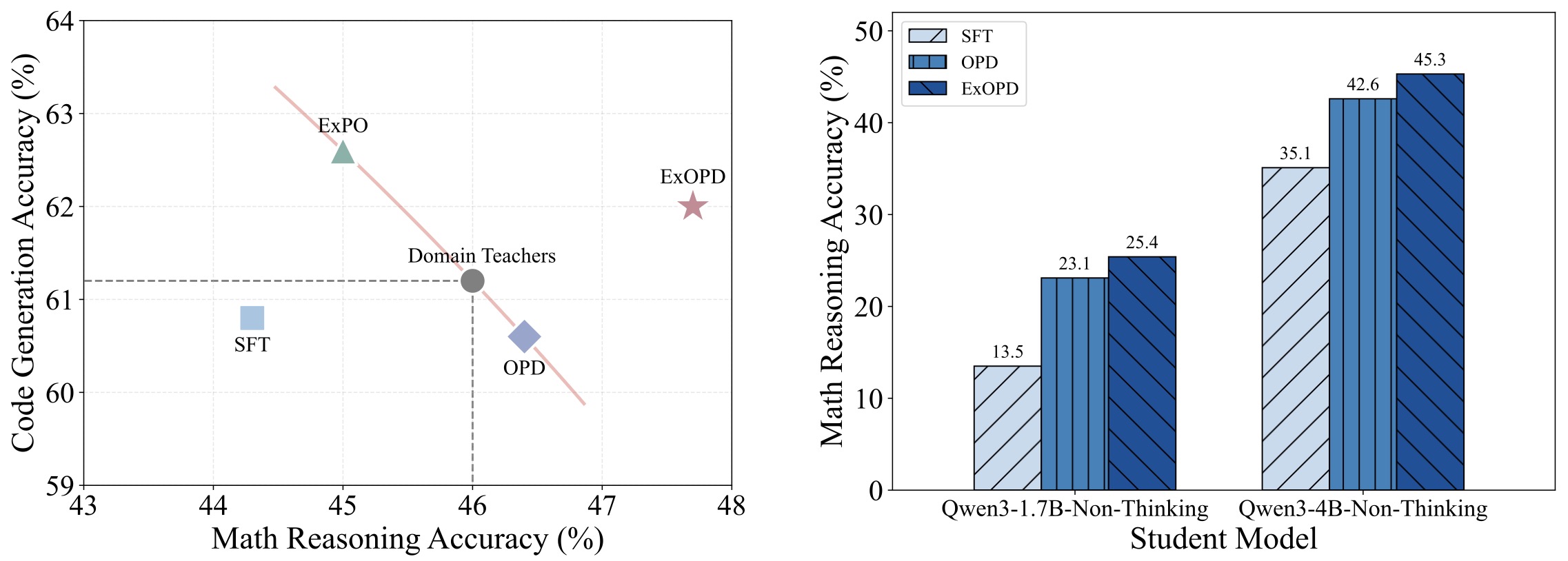
Scaling Reasoning Efficiently via Relaxed On-Policy Distillation
-
Scaling Reasoning Efficiently via Relaxed On-Policy Distillation by Ko et al. (2026) introduces REOPOLD, a relaxed on-policy distillation method designed to reduce over-imitation, improve stability, and scale reasoning training more efficiently.
-
Implementation details:
-
Token-level teacher–student log-likelihood ratios are treated as dense rewards, similar to reverse-KL advantages.
-
The authors relax strict imitation by clipping or tempering overly strong penalties on low-value tokens.
-
Partial rollouts and truncated reasoning traces are used to reduce compute while preserving the most informative supervision.
-
The approach is designed specifically for reasoning tasks where exact teacher imitation may be unnecessarily restrictive.
-
-
The following figure (source) shows an illustration of REOPOLD. While standard on-policy distillation often introduces instability and inefficiency by forcing the student to mimic the teacher excessively, REOPOLD fosters a more stable and effective learning environment. By establishing a formal connection between distillation and RL via a stop-gradient operation, REOPOLD uses teacher signals temperately and selectively. This filters out potentially harmful signals and prevents the student from deviating excessively from its original distribution.
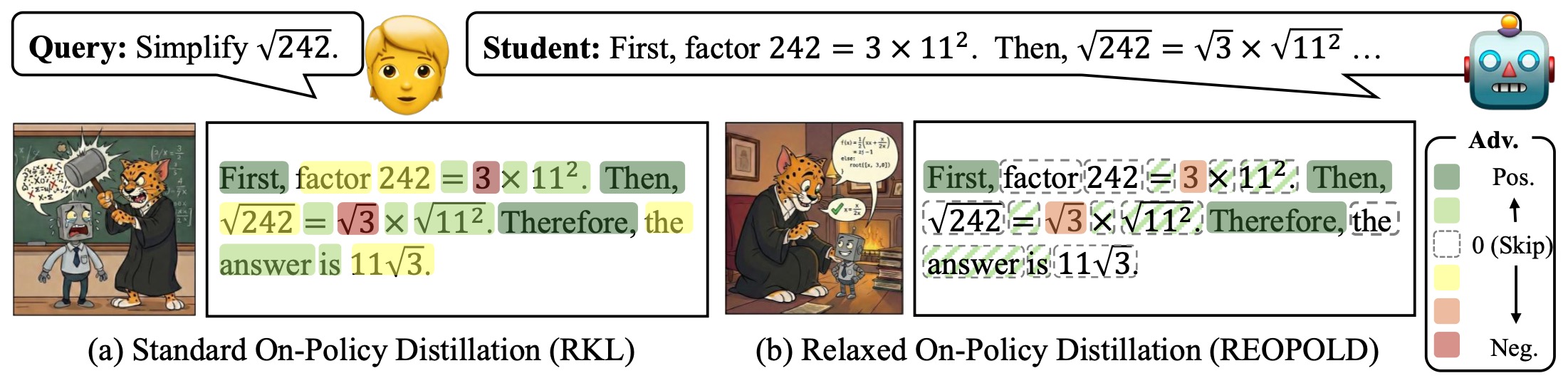
Self-Distilled RLVR
-
Self-Distilled RLVR by Yang et al. (2026) introduces RLSD, which combines reinforcement learning with verifiable rewards and privileged self-distillation, using self-distillation to modulate update magnitudes while preserving RL-derived update directions.
-
Implementation details:
-
A self-teacher receives privileged information such as the correct answer or verified reasoning trace.
-
Reinforcement learning determines which direction the policy should move based on correctness signals.
-
Self-distillation scales the magnitude of token-level updates according to how strongly the privileged teacher prefers alternative continuations.
-
This separation reduces information leakage while preserving the exploration and objective fidelity of RLVR.
-
-
The following figure (source) shows an overview of RLSD, with a hybrid design in which RLVR provides update directions and self-distillation provides fine-grained step sizes.
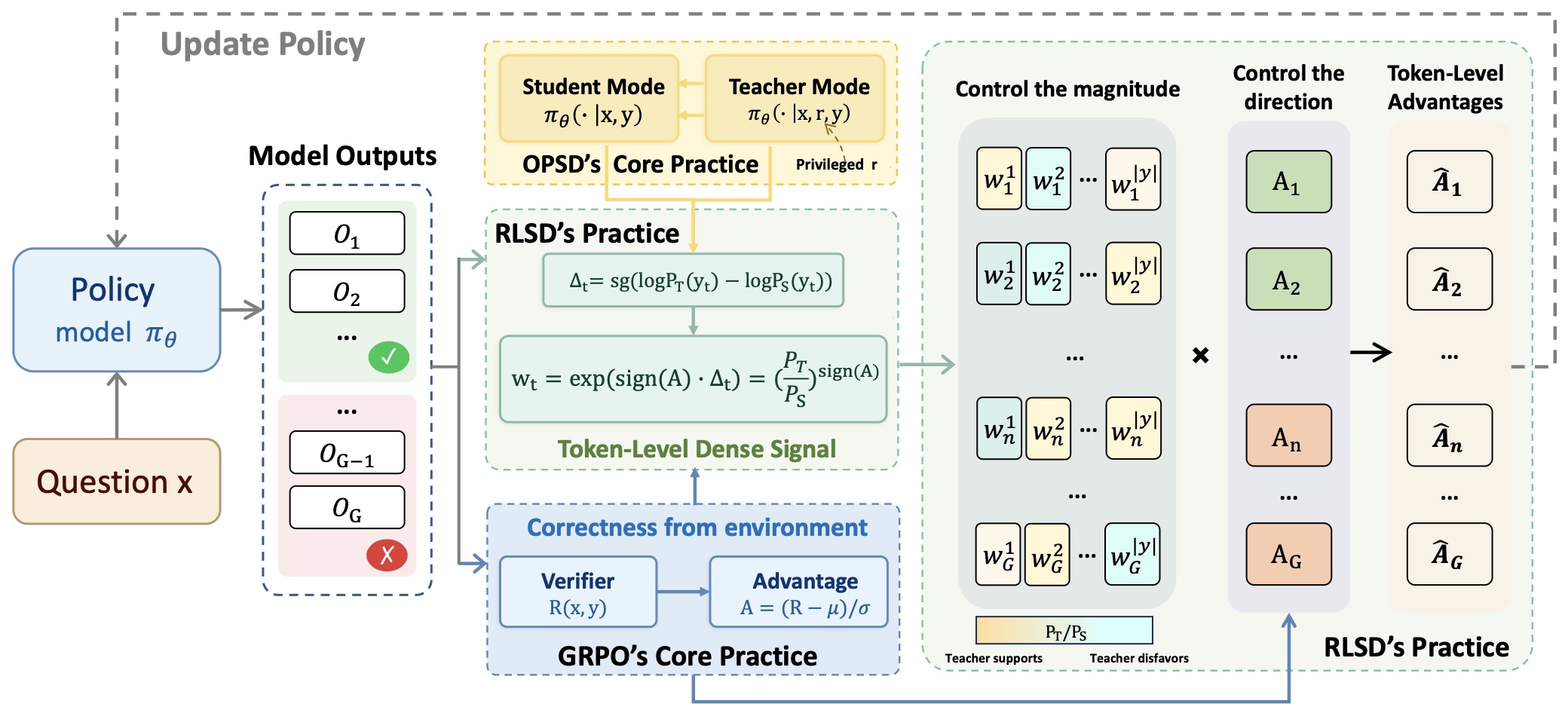
Unifying Group-Relative and Self-Distillation Policy Optimization via Sample Routing
-
Unifying Group-Relative and Self-Distillation Policy Optimization via Sample Routing by Li et al. (2026) introduces SRPO, a sample-routing framework that combines GRPO-style reinforcement learning on successful rollouts with self-distillation-based correction on failed rollouts.
-
Implementation details:
-
Correct samples are optimized using standard group-relative policy optimization.
-
Incorrect samples are replayed under a privileged teacher context and corrected using dense token-level self-distillation.
-
Routing decisions are based on verifier outcomes or reward thresholds.
-
The hybrid design preserves efficient RL updates on successful trajectories while extracting richer supervision from failures.
-
-
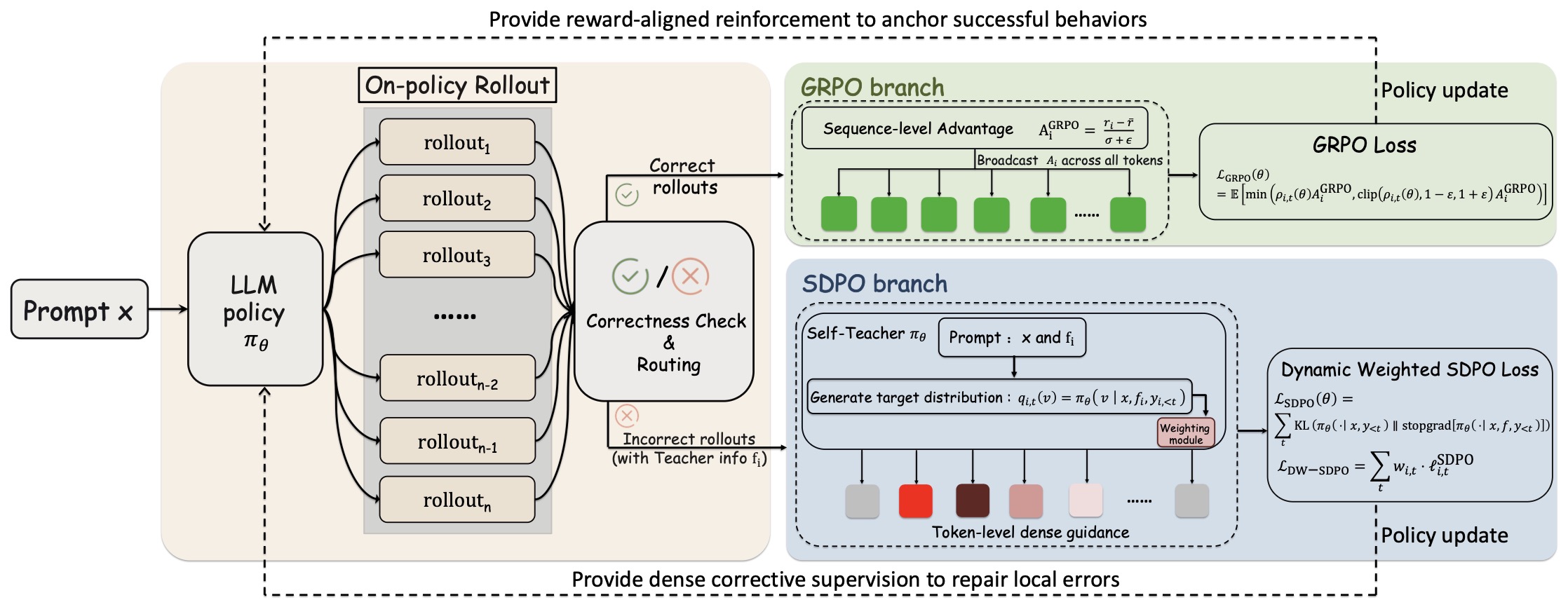
The following figure ([source])](https://arxiv.org/abs/2604.02288)) shows an overview of SRPO. Given a prompt \(x\), the policy \(\pi_\theta\) generates a group of on-policy rollouts. A correctness check routes each rollout to one of two branches: correct samples are sent to the GRPO branch, where group-relative advantages provide a reward-aligned policy update; incorrect samples with available teacher information are sent to the SDPO branch, where a feedback-conditioned self-teacher produces logit-level distillation targets via \(KL(P \,\Vert\, \operatorname{stopgrad}(Q))\) for dense corrective supervision.
OpenClaw-RL: Train Any Agent Simply by Talking
-
OpenClaw-RL: Train Any Agent Simply by Talking by Wang et al. (2026) extends the RL–distillation connection to interactive agents, treating user messages, tool outputs, and environment transitions as hindsight supervision.
-
Implementation details:
-
The agent’s original trajectory is replayed together with subsequent user or environment feedback.
-
A hindsight-conditioned teacher evaluates how the model would have acted if it had observed the later information earlier.
-
Tool outputs, GUI changes, and terminal states are converted into dense correction signals.
-
The same framework supports conversational agents, coding agents, and embodied control systems.
-
-
The following figure ([source])](https://arxiv.org/abs/2603.10165)) shows an overview of the OpenClaw-RL infrastructure. Interaction streams come from two agent types: Personal Agents (conversational, single-user), hostedonpersonaldevices, and General Agents (terminal, GUI, SWE, and tool-call agents), hosted on cloud services. The collected samples flow into our RL server built on the asynchronous slime framework, which consists of four decoupled components: (1) the environment server, (2) PRM/Judge for reward computation, (3) Megatron for policy training, and (4) SGLang for policy serving. These components support graceful weight updates and enable training with any agentic framework. The environment for personal agents is simply the users’ personal devices, which connect to the RL server over HTTP with confidential API keys. The environments for general agents are hosted on cloud services to enable scalable parallelization.
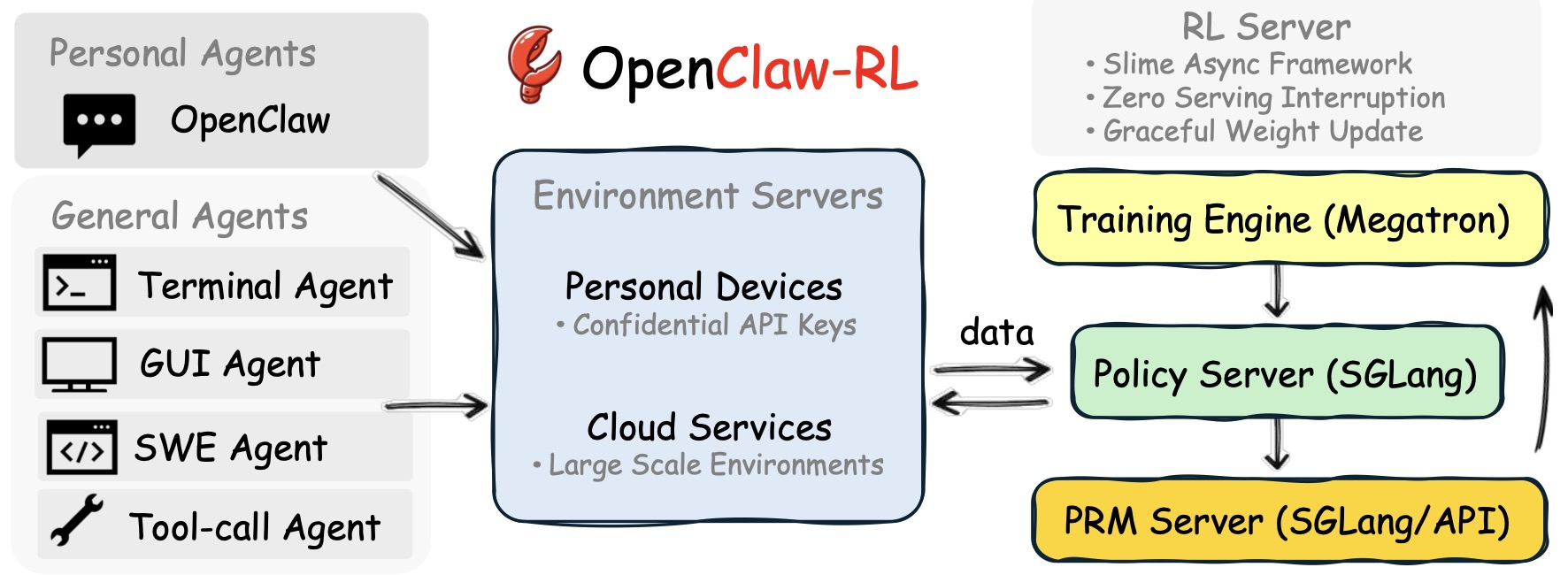
- The following figure ([source])](https://arxiv.org/abs/2603.10165)) shows how you can optimize your OpenClaw simply by using it. They provide a simulation result here.
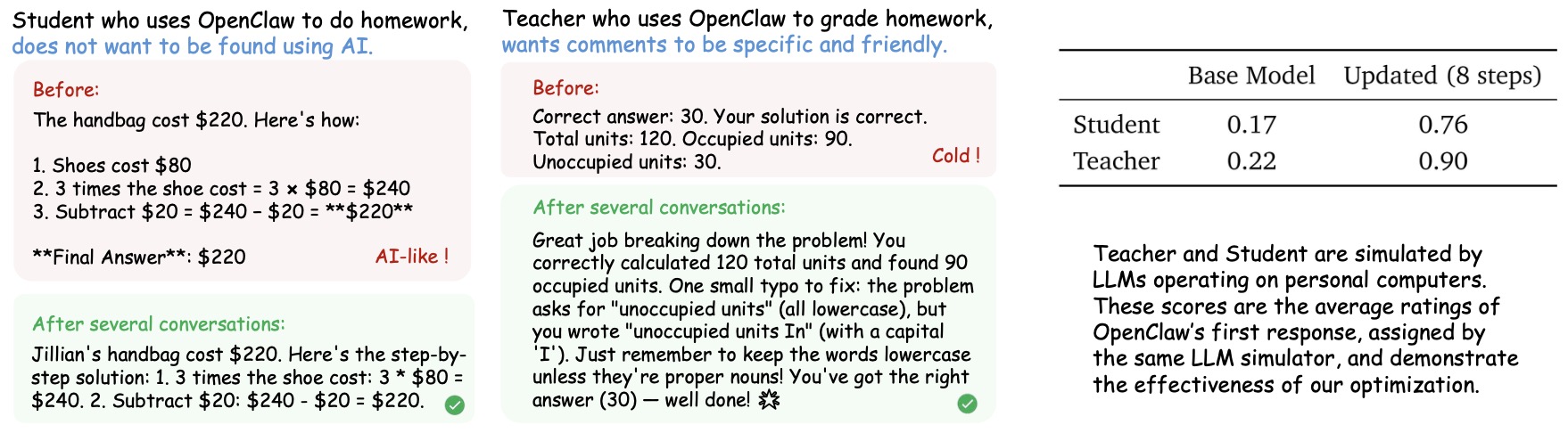
- The following figure ([source])](https://arxiv.org/abs/2603.10165)) shows an overview of the method. For personal agents, we support both binary-reward optimization and on-policy distillation training. In their experiments, they find that their combination yields significant performance gains. For general agentic RL, in addition to standard RLVR, they provide integrated step-wise rewards and a simple but effective standardization approach (Wang et al., 2026).
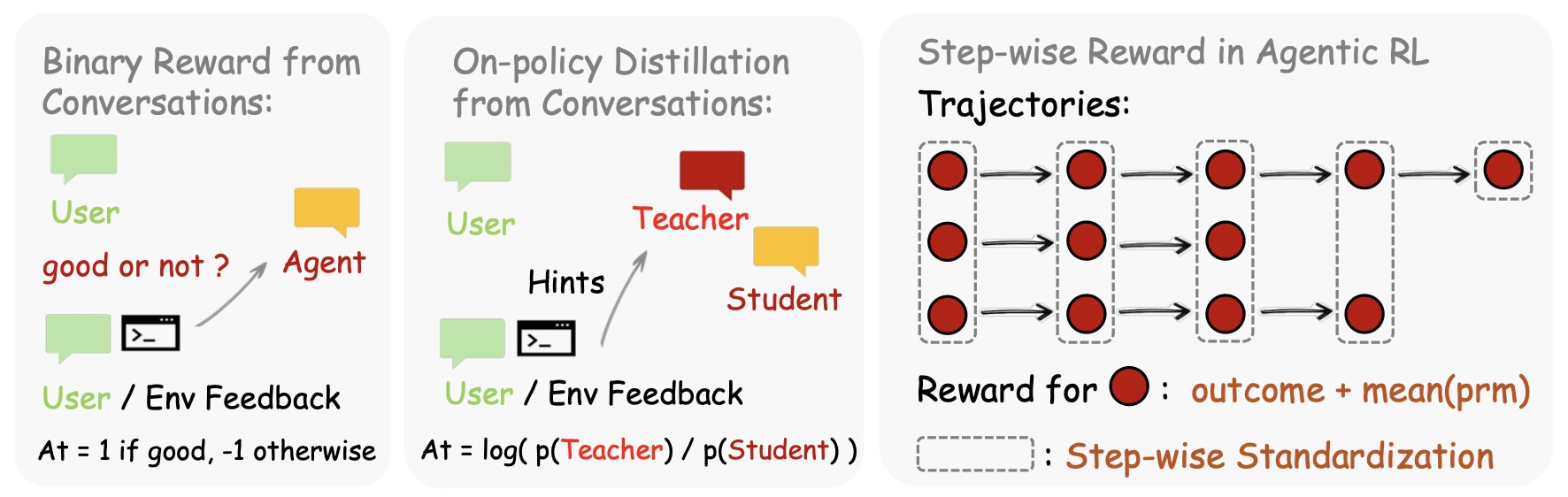
- Together, these methods establish that on-policy distillation is not simply an alternative to reinforcement learning, but a general dense supervision framework that can replace, augment, or stabilize policy-gradient methods while preserving the on-policy nature of learning.
Practical Failure Modes and Stabilization Recipes
- OPD should be viewed less as full-vocabulary distribution matching and more as a fragile communication protocol between teacher and student through a small set of locally plausible next-token choices.
- Qwen3, GLM-5, and MiMo use OPD in post-training, while also emphasizing that practical OPD can be more brittle than SFT or RL when teacher–student local token preferences stop overlapping. This interpretation aligns with three recent papers.
Thinking-Pattern Compatibility and Token Overlap
-
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe by Li et al. (2026) finds that OPD success depends on compatible teacher–student thinking patterns and on progressive alignment over a small shared set of high-probability tokens, which can carry roughly 97% to 99% of probability mass.
-
Implementation details:
-
Use an off-policy cold start before OPD so the student’s reasoning style and local token menus are closer to the teacher’s.
-
Select prompts that are aligned with the teacher’s reasoning style, rather than assuming benchmark superiority alone makes a teacher useful.
-
Monitor overlap among high-probability teacher and student tokens at student-visited prefixes, because benchmark accuracy alone does not indicate whether token-level supervision will be useful.
-
Avoid using a teacher that pulls an RL-improved student backward toward older reasoning patterns, even if that teacher is larger or stronger on aggregate benchmarks.
-
Track teacher continuation advantage as rollout prefixes lengthen, because the thread reports that useful teacher advantage can drop sharply on long student-generated prefixes.
-
-
The following figure ([source])](https://arxiv.org/abs/2603.10165)) shows an overview of the method. JustRL-1.5B is obtained by applying RL to DeepSeek-Distill-1.5B (DS1.5B), and Skywork-OR1-Math-7B (SW-7B) by applying RL to DeepSeek-Distill-7B (DS-7B)
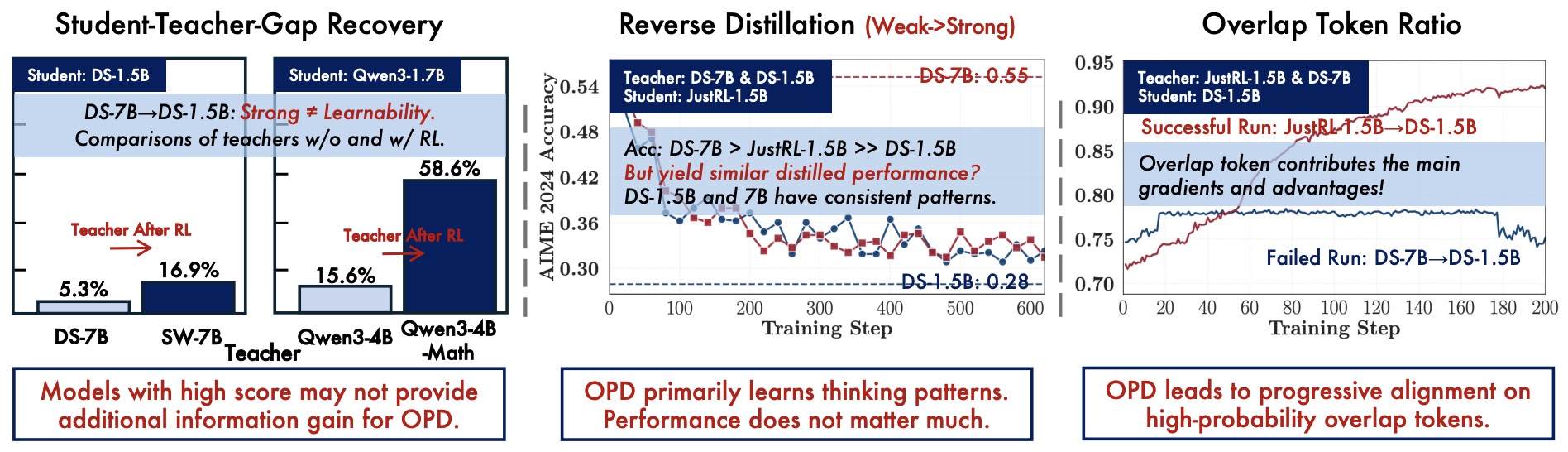
- The following figure ([source])](https://arxiv.org/abs/2603.10165)) presents a systematic study of OPD training dynamics, progressing from empirical conditions through token-level mechanism to practical recipe.

Length Inflation and Repetition Collapse
-
Demystifying OPD: Length Inflation and Stabilization Strategies for Large Language Models by Luo et al. (2026) identifies abrupt length inflation, repetition saturation, and truncation collapse as a major OPD failure mode; it proposes StableOPD, combining a reference-based divergence constraint with rollout mixture distillation.
-
Implementation details:
-
Track average rollout length, truncation rate, and repetition rate during training rather than relying only on validation accuracy.
-
Add a reference-based divergence constraint so the student cannot drift too quickly into repetitive or degenerate prefixes.
-
Mix on-policy rollouts with cleaner reference trajectories, preventing the training distribution from becoming dominated by self-generated repetitive garbage.
-
Treat repeated tokens as high-risk training examples because the teacher may assign them high local probability once the prefix has already become repetitive.
-
Stop or downweight updates from truncation-dominated batches, since they can bias gradients and accelerate collapse.
-
Sampled-Token OPD and Local Support Matching
-
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes by Fu et al. (2026) argues that sampled-token OPD is attractive because token-level feedback has much better worst-case variance scaling than sequence-level reverse KL, but it is biased and fragile because it observes only one sampled token rather than the teacher’s local support.
-
Implementation details:
-
Replace single sampled-token supervision with teacher top-\(K\) local support matching, where both teacher and student probabilities are renormalized over the teacher’s plausible next-token set.
-
Use top-\(p\) rollout sampling to reduce the chance that student rollouts drift into extremely low-probability prefixes where teacher guidance becomes unreliable.
-
Mask special tokens and tokenizer artifacts to avoid fake disagreements caused by token boundary mismatches.
-
Prefer truncated reverse KL over one-token log-ratio updates when teacher top-\(K\) logits are affordable.
-
Evaluate not only downstream metrics but also whether per-token advantages combine into coherent gradient directions rather than canceling across positions.
-
Practical Training Loop
-
A typical on-policy distillation training loop proceeds through the following stages.
-
Prompts are sampled from a task dataset or a synthetic prompt pool, ensuring that training covers the domains where teacher feedback is most valuable.
-
The student generates one or more rollouts while recording token identities, attention masks, and per-token student log-probabilities.
-
Each rollout is sent to the teacher, which computes token-level log-probabilities conditioned on the student’s exact prefixes.
-
A divergence or advantage-like loss is computed at every token, converting teacher–student discrepancies into dense learning signals.
-
Optional clipping, masking, and token weighting are applied to suppress unstable or low-value updates.
-
Gradients are propagated only through the student network, while the teacher remains fixed.
-
-
Because the teacher does not need to generate its own trajectory, but only evaluate the student’s rollout, teacher inference is substantially cheaper than full rollout generation.
Self-Distillation (SD)
-
Self-distillation extends the distillation paradigm by removing the strict requirement for a separate, larger teacher model. Instead, the student learns from a teacher signal derived from itself, either across time, across contexts, across checkpoints, across roles, or across different conditioning views of the same underlying model. This makes distillation more scalable and flexible, reducing infrastructure complexity while preserving many of the advantages of dense teacher supervision.
-
At a high level, self-distillation addresses two practical constraints:
- The cost or unavailability of strong external teachers
- The desire to refine a model using its own knowledge, structure, and evolving behavior
-
Rather than relying on an independent teacher, the model can generate supervisory signals from earlier checkpoints, alternative views of the same input, or teacher and student policies instantiated from the same base model.
-
In modern LLM training, self-distillation has evolved beyond a simple compression technique into a broader framework for iterative self-improvement, reasoning refinement, and reinforcement-learning-style policy optimization. Modern variants often combine self-distillation with on-policy training, allowing models to improve by learning from their own outputs while still benefiting from the stabilizing effects of teacher-style supervision.
-
Common forms of self-distillation include:
- Checkpoint-based self-distillation: a later student model learns from outputs produced by earlier or averaged checkpoints.
- View- or context-based self-distillation: the same model produces different supervisory signals under different prompts, contexts, augmentations, or conditioning views.
Core Formulation
-
In self-distillation, both the student and teacher are derived from the same base model. Let:
-
\(p_S^\theta\) denote the student policy.
-
\(p_T^\phi\) denote the teacher policy, which may correspond to an earlier checkpoint, an ensemble, or the same model under privileged conditioning.
-
-
The general training objective remains:
- The key distinction is not the loss itself, but the construction of the teacher signal.
Temporal Self-Distillation
- One of the earliest forms of self-distillation uses an earlier checkpoint of the same model as the teacher:
-
The student is trained to remain close to a historical version of itself while continuing to improve on new data.
-
This approach is useful because:
-
Earlier checkpoints often preserve capabilities that may otherwise degrade during later fine-tuning or RL stages.
-
Historical teachers stabilize optimization by preventing abrupt distributional shifts.
-
Training becomes more sample-efficient because no external teacher model is required.
-
Temporal self-distillation is widely used in large-scale post-training pipelines, especially when alternating between supervised fine-tuning and reinforcement learning.
-
Ensemble and Multi-View Self-Distillation
-
Another common variant constructs the teacher from multiple views or predictions of the same model.
-
The teacher distribution may be:
\[p_T =\frac{1}{K} \sum_{k=1}^{K} p_S^{\theta_k}\]-
where the ensemble members may differ in:
-
Prompt templates used during inference.
-
Sampling temperatures or decoding strategies.
-
Checkpoints or adapters applied to the same base model.
-
Retrieved context or auxiliary information.
-
This ensemble-style formulation often produces smoother and more robust supervision signals than any single view alone.
-
-
Contextual Self-Distillation
-
Modern reasoning-oriented self-distillation usually relies on contextual asymmetry rather than architectural asymmetry.
-
The student sees only the original task:
\[p_S(\cdot \mid x)\]- while the teacher receives privileged information:
-
where \(y^\star\) may include:
-
Verified solutions.
-
Ground-truth reasoning traces.
-
Runtime feedback.
-
Tool outputs.
-
User corrections.
-
-
This creates a stronger teacher signal without introducing a separate external model.
On-Policy Self-Distillation (OPSD)
-
The most important modern form of self-distillation is On-Policy Self-Distillation, introduced in Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models by Zhao et al. (2026).
-
In OPSD:
-
The student generates trajectories from the original problem context.
-
The teacher evaluates those same trajectories while additionally observing privileged solution information.
-
The student is updated using dense token-level divergences along its own rollout.
-
-
The resulting objective is:
- The following figure shows On-Policy Self-Distillation (OPSD), where the same model defines a student policy conditioned only on the problem and a teacher policy conditioned on privileged solution information. Given a reasoning dataset \(\mathcal{S}=\left\{\left(x_i, y_i^{\star}\right)\right\}_{i=1}^N\), we instantiate two policies from the same LLM: a student policy \(p_S(\cdot \mid x)\) and a teacher policy \(p_T\left(\cdot \mid x, y^{\star}\right)\). The student generates an on-policy response \(\hat{y} \sim p_S(\cdot \mid x)\). Both policies then evaluate this trajectory to produce next-token distributions \(p_S\left(\cdot \mid x, \hat{y}_{<n}\right)\) and \(p_T\left(\cdot \mid x, y^{\star}, \hat{y}_{<n}\right)\) at each step \(n\). The learning objective minimizes the per-token divergence \(D\left(p_T \,\Vert\, p_S\right)\) along the student’s rollout. The divergence here can be forward KL, reverse KL or JSD. Crucially, gradients backpropagate only through the student’s logits, allowing the model to self-distill.
-
The OPSD paper argues that models are often substantially better at evaluating or rationalizing a correct answer than generating the answer from scratch. By conditioning the teacher on verified solutions, the model effectively supervises itself from a privileged perspective.
-
Implementation details from the OPSD paper include:
-
The student rollout is generated first, and the teacher only scores the resulting trajectory rather than generating an independent completion.
-
The teacher context concatenates the original prompt with privileged solution information, creating an asymmetric supervision channel.
-
Reverse KL, forward KL, and Jensen–Shannon divergence are all evaluated experimentally, with reverse KL often performing best in practice.
-
Pointwise KL clipping is introduced to prevent stylistic tokens from dominating reasoning updates.
-
Separate weighting schemes are applied to reasoning tokens versus formatting or filler tokens.
-
Self-Distillation as Reinforcement Learning
-
Recent work increasingly treats self-distillation as a form of policy optimization rather than merely a compression technique.
-
The central idea is that the teacher defines a dense token-level improvement signal:
\[A_t =\log p_T(y_t) - \log p_S(y_t)\]- which behaves similarly to an RL advantage estimate.
-
This perspective enables self-distillation to integrate naturally into PPO-, GRPO-, and RLVR-style training loops.
Reinforcement Learning via Self-Distillation
-
Reinforcement Learning via Self-Distillation by Hübotter et al. (2026) formalizes this connection by converting textual feedback into dense token-level supervision.
-
The framework operates by:
-
Generating a trajectory from the student policy.
-
Obtaining textual critiques, runtime errors, or verifier feedback.
-
Conditioning the teacher on both the original trajectory and the feedback signal.
-
Replaying the trajectory under the teacher context to compute token-level corrections.
-
-
The following figure (source) shows a comparison of RLVR and RLRF settings. In Reinforcement Learning with Verifiable Rewards (RLVR), the agent learns from a scalar reward \(r\), which often acts as an information bottleneck by masking the underlying environment state. In contrast, Reinforcement Learning with Rich Feedback (RLRF) utilizes tokenized feedback. In other words, in the core self-distillation policy optimization setup, in which textual feedback is transformed into a dense teacher signal over the original student rollout. This provides a significantly richer signal than a scalar reward, as the feedback can encapsulate both the reward as well as detailed observations of the state (such as runtime errors from a code environment or feedback from an LLM judge).
-
Key implementation details include:
-
Runtime execution errors are converted directly into corrective teacher contexts for coding tasks.
-
The same model can simultaneously instantiate both the student and teacher views, reducing infrastructure requirements.
-
Teacher supervision is applied only to tokens causally related to the detected failure.
-
The method supports free-form textual critiques rather than requiring scalar rewards.
-
The framework is compatible with online rollout generation and asynchronous replay buffers.
-
Self-Distilled RLVR
-
Self-Distilled RLVR by Yang et al. (2026) combines self-distillation with reinforcement learning using verifiable rewards.
-
Rather than replacing RL, self-distillation modulates update magnitudes while RL determines the optimization direction.
-
The following figure (source) shows an overview of RLSD, with a hybrid design in which RLVR provides update directions and self-distillation provides fine-grained step sizes.
-
Implementation details include:
-
A privileged teacher policy observes verified answers or reasoning traces unavailable to the student.
-
RLVR computes trajectory-level correctness rewards that determine the sign of policy updates.
-
Self-distillation scales token-level update magnitudes according to teacher confidence.
-
The approach explicitly separates “where to move” from “how strongly to move.”
-
Information leakage is reduced because RL still determines the underlying optimization direction.
-
Aligning Language Models from User Interactions
-
Aligning Language Models from User Interactions by Kleine Buening et al. (2026) extends self-distillation into conversational alignment.
-
Instead of using verified answers, the teacher is conditioned on hindsight interaction information, such as user corrections or clarifications.
-
The system operates by:
-
Recording the original assistant response.
-
Observing the subsequent user interaction.
-
Reconstructing how the assistant should ideally have responded had it known the future interaction.
-
Distilling this hindsight policy into the original model.
-
-
The following figure (source) shows the hindsight self-distillation process driven by user follow-up interactions, i.e., direct learning from user interactions via self-distillation. From multi-turn user conversations, we obtain several interactions \((x, y, o)\) that consist of the conversation history \(x\), the model’s response \(y\), and the subsequent user message \(o\). By conditioning on the user’s follow-up, we form the hindsight policy and compare it to the original policy, producing token-level advantages that reinforce or penalize parts of the model’s original response. In this example, the user’s follow-up requests a more direct answer, leading to penalizing filler tokens and reinforcing the answer.

-
Implementation details include:
-
Future user messages are treated as privileged hindsight information.
-
The same interaction trace can support both RL-style preference learning and dense token-level distillation.
-
Teacher conditioning includes conversation continuation context unavailable during the original generation.
-
The framework naturally leverages production interaction logs without requiring manual labeling.
-
Dense hindsight supervision improves correction behavior and conversational adaptability.
-
Self-Distillation in Agentic Systems
-
Self-distillation is particularly powerful in agents because interaction trajectories naturally produce rich hindsight signals.
-
OpenClaw-RL: Train Any Agent Simply by Talking by Wang et al. (2026) extends self-distillation to interactive environments where tool outputs, GUI transitions, user replies, environment state changes – all become forms of dense feedback.
-
The following figure ([source])](https://arxiv.org/abs/2603.10165)) shows an overview of the OpenClaw-RL infrastructure. Interaction streams come from two agent types: Personal Agents (conversational, single-user), hostedonpersonaldevices, and General Agents (terminal, GUI, SWE, and tool-call agents), hosted on cloud services. The collected samples flow into our RL server built on the asynchronous slime framework, which consists of four decoupled components: (1) the environment server, (2) PRM/Judge for reward computation, (3) Megatron for policy training, and (4) SGLang for policy serving. These components support graceful weight updates and enable training with any agentic framework. The environment for personal agents is simply the users’ personal devices, which connect to the RL server over HTTP with confidential API keys. The environments for general agents are hosted on cloud services to enable scalable parallelization.
- The following figure ([source])](https://arxiv.org/abs/2603.10165)) shows how you can optimize your OpenClaw simply by using it. They provide a simulation result here.
- The following figure ([source])](https://arxiv.org/abs/2603.10165)) shows an overview of the method. For personal agents, we support both binary-reward optimization and on-policy distillation training. In their experiments, they find that their combination yields significant performance gains. For general agentic RL, in addition to standard RLVR, they provide integrated step-wise rewards and a simple but effective standardization approach (Wang et al., 2026).
-
Implementation details include:
-
Agent trajectories are replayed after observing downstream environment changes.
-
A hindsight-conditioned teacher evaluates what actions would have been preferable given later observations.
-
Tool outputs are transformed into token-level corrective supervision.
-
The framework supports asynchronous interaction logs collected from real deployments.
-
The same architecture applies to conversational agents, coding agents, and embodied systems.
-
Advantages of Self-Distillation
-
Self-distillation provides several major advantages:
-
It removes or reduces dependence on expensive external teacher models.
-
It enables continual self-improvement using interaction traces, runtime feedback, and privileged contexts.
-
It integrates naturally with reinforcement learning and hindsight supervision.
-
It can preserve capabilities across post-training stages without introducing new architectures.
-
It substantially simplifies deployment infrastructure because teacher and student share the same backbone.
-
Limitations and Failure Modes
-
Despite its advantages, self-distillation introduces unique risks:
-
The student may reinforce its own errors if the privileged teacher signal is weak or noisy.
-
Self-teachers cannot easily exceed the model family’s inherent capability ceiling without external rewards or search.
-
Incorrect privileged information can destabilize training more severely than ordinary supervised errors.
-
Careless rollout replay can lead to information leakage, especially in reasoning tasks.
-
Dense self-distillation objectives may over-regularize stylistic behavior unless carefully clipped or masked.
-
When Self-Distillation is Preferred
-
Self-distillation is especially useful when:
-
External frontier teachers are unavailable or prohibitively expensive.
-
The model already contains latent capability that can be unlocked through hindsight conditioning or privileged evaluation.
-
Interaction traces, tool outputs, or verifier signals are available as dense feedback sources.
-
Reinforcement learning alone is too sparse or unstable.
-
Continuous online adaptation is required in production systems.
-
-
Modern self-distillation methods increasingly blur the line between supervised learning, reinforcement learning, and iterative self-improvement, making self-distillation one of the most rapidly evolving areas in post-training research.
Multi-Teacher Distillation
- Multi-teacher distillation generalizes the standard teacher–student paradigm by allowing a single student model to learn from multiple teacher models, checkpoints, or policy variants simultaneously. This approach is especially valuable when different teachers specialize in different capabilities, domains, or stages of post-training. Rather than compressing one monolithic model, the student aggregates complementary strengths across reasoning, coding, alignment, safety, instruction following, and tool use. In modern LLM pipelines, multi-teacher distillation has become a powerful mechanism for capability consolidation, regression recovery, and post-RL stabilization, particularly when combined with on-policy training.
Core Formulation
-
Suppose there are \(K\) teacher models \({p_{T_k}}_{k=1}^{K}\). The student minimizes an aggregated divergence objective:
\[\mathcal{L}(\theta) =\mathbb{E}_{x, y} \left[ \sum_{k=1}^{K} w_k(x, y) D\left( p_{T_k}(\cdot \mid x, y_{<t}) \,\Vert\, p_S^\theta(\cdot \mid x, y_{<t}) \right) \right]\]- where \(w_k(x, y)\) determines the contribution of each teacher.
-
These weights may be:
-
Fixed constants that assign equal influence to all teachers.
-
Domain-specific routing scores based on prompt classification.
-
Confidence-based weights derived from entropy, verifier scores, or reward estimates.
-
Outputs of a learned gating model that dynamically selects the most relevant teachers.
-
-
The fundamental principle is that no single teacher needs to be globally optimal; each teacher can supervise the student in the regions where it is strongest.
Motivation: Capability Consolidation and the See-Saw Problem
-
Sequential post-training often improves one capability while degrading others. For example:
-
Reinforcement learning on mathematical reasoning can reduce writing quality or conversational helpfulness.
-
Safety alignment may suppress creative or exploratory behavior.
-
Coding fine-tuning can harm general instruction-following performance.
-
-
The multi-teacher on-policy distillation article Multi-Teacher On-Policy Distillation: A New Post-Training Primitive describes this as the “see-saw problem,” where gains in one domain cause regressions in another.
-
Multi-teacher distillation mitigates this by exposing the student to specialized teachers that preserve each domain’s strongest behaviors.
Multi-Teacher On-Policy Distillation (MOPD)
-
The most influential modern variant is Multi-Teacher On-Policy Distillation (MOPD), in which the student generates its own rollouts and multiple teachers score the same trajectory.
-
The following figure (source) shows the MOPD framework, where several specialized teachers supervise a single student across the student’s own trajectories.
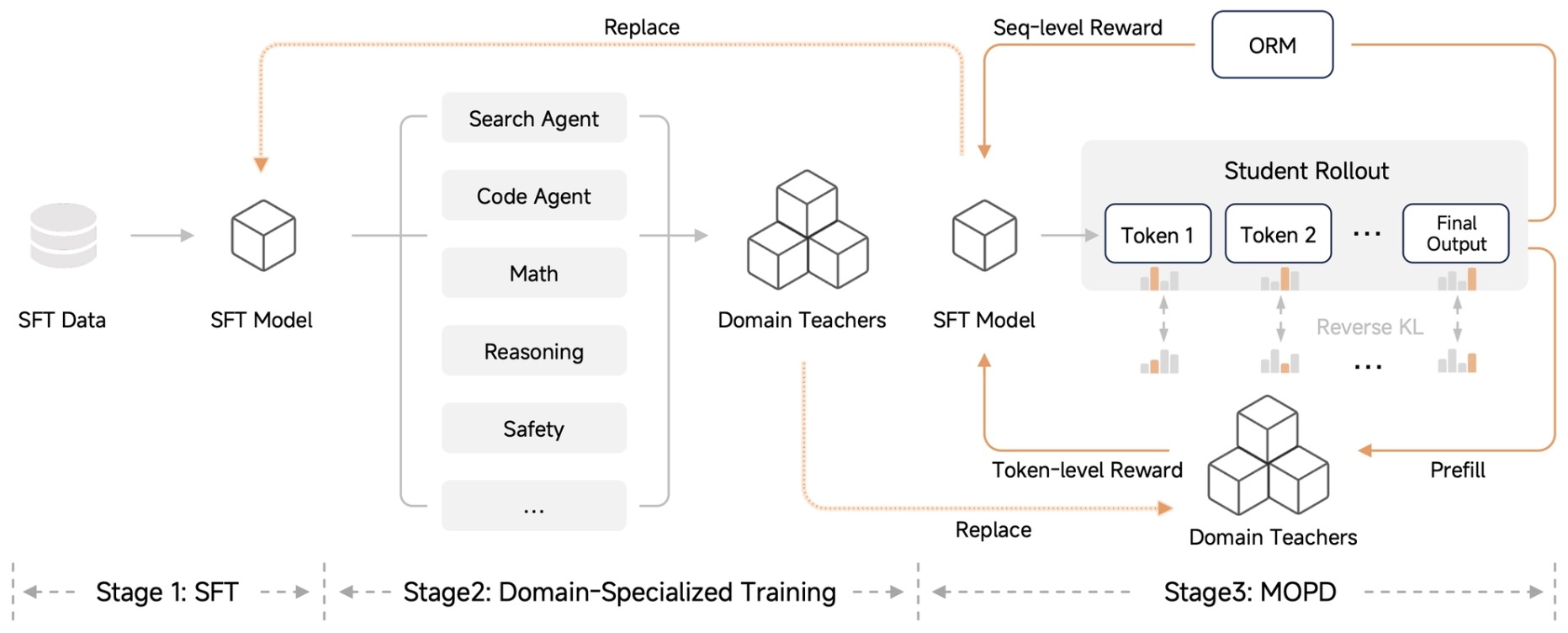
- The resulting objective can be written as:
- Because all teachers evaluate the same student-generated rollout, the student learns how each specialist would improve its own behavior in the states it actually visits.
Reverse KL and Advantage Interpretation
-
As with single-teacher on-policy distillation, reverse KL is particularly natural in multi-teacher settings.
-
For each teacher, the token-level improvement signal is:
- The aggregated update becomes:
- This formulation allows each teacher to contribute a dense advantage estimate, which can be inserted directly into GRPO- or PPO-style policy optimization loops.
Teacher Selection and Routing Strategies
-
One of the most important design choices is how to determine which teachers should supervise each prompt or trajectory.
-
Common routing strategies include:
-
Domain-based routing, where a math teacher supervises mathematical prompts, a coding teacher supervises programming tasks, and a general assistant teacher handles broad conversational prompts.
-
Checkpoint-based routing, where earlier supervised checkpoints preserve instruction-following behavior and later RL checkpoints provide specialized reasoning capabilities.
-
Confidence-based routing, where teachers with lower entropy or stronger verifier scores are weighted more heavily.
-
Mixture routing, where several teachers contribute simultaneously according to normalized weights.
-
Historical self-teachers, where earlier versions of the student are included to stabilize optimization and preserve prior capabilities.
-
Multi-Teacher Distillation and Reinforcement Learning
- Multi-teacher distillation is increasingly used as a post-RL consolidation mechanism.
Nemotron-Cascade 2
-
Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation by Yang et al. (2026) combines broad Cascade RL with subsequent multi-domain on-policy distillation from the strongest intermediate models.
-
Implementation details include:
-
Multiple intermediate checkpoints from different RL stages are retained as specialist teachers.
-
Student rollouts are scored by the most capable teacher for each domain.
-
Distillation is used to recover benchmark regressions that appear after aggressive RL.
-
Multi-domain OPD consolidates gains from mathematics, coding, and general instruction-following into a single model.
-
The method substantially improves capability retention while reducing the instability associated with long RL schedules.
-
-
The following figure (source) shows the Cascade RL and multi-domain OPD pipeline used to consolidate specialized capabilities.
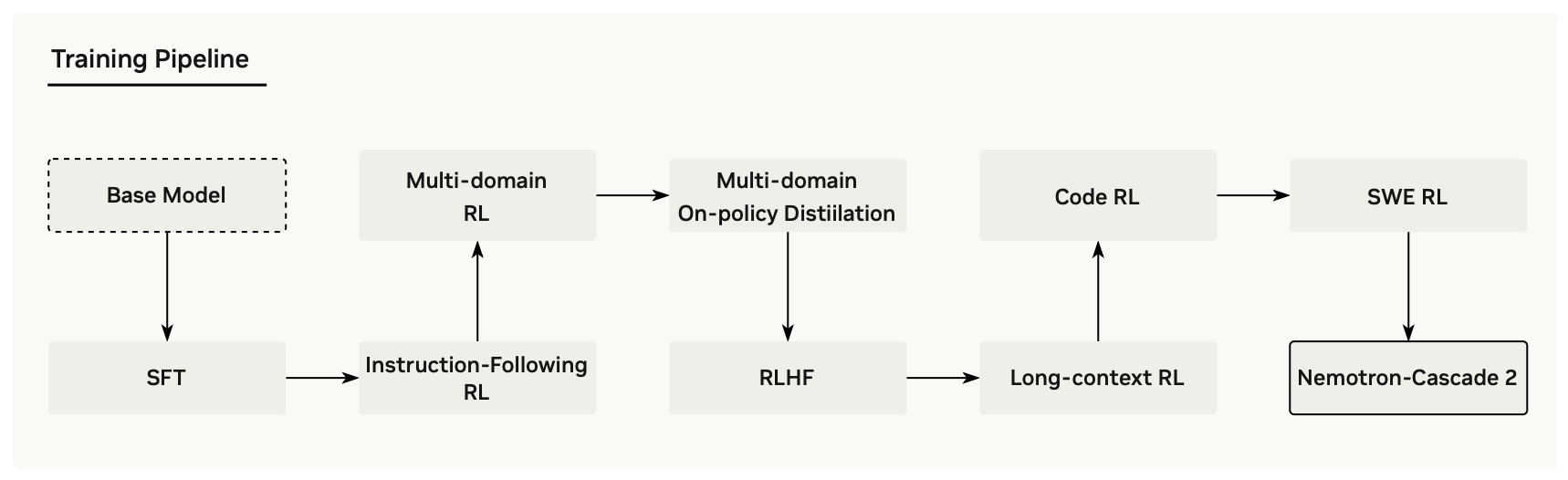
Multi-Teacher OPD in Practice
-
The article Multi-Teacher On-Policy Distillation: A New Post-Training Primitive and Cameron R. Wolfe’s X thread Multi-teacher on-policy distillation discussion emphasize several practical implementation patterns. Implementation details include:
-
Specialized teachers can be selected from supervised, RL, or domain-adapted checkpoints.
-
Earlier checkpoints are often included explicitly to prevent catastrophic forgetting.
-
Reverse KL enables each teacher to provide a token-level advantage estimate over the student rollout.
-
Teacher requests are scheduled dynamically to balance latency and accelerator utilization.
-
Capability regressions can be repaired without rerunning expensive RL training from scratch.
-
Engineering and Systems Design
-
Multi-teacher systems introduce significant infrastructure requirements:
-
Multiple teacher servers must be hosted and queried efficiently, often using vLLM-based inference clusters.
-
Routing logic determines which teachers should score each prompt or rollout.
-
Teacher log-probabilities from different models must be aligned and aggregated.
-
Tokenizer compatibility is highly desirable to avoid expensive retokenization and sequence alignment.
-
Fault tolerance and asynchronous scheduling are essential when dozens of teachers are involved.
-
-
The implementation complexity is higher than single-teacher distillation, but the resulting gains in capability preservation and modularity are often substantial.
Advantages of Multi-Teacher Distillation
-
Multi-teacher distillation offers several distinctive benefits:
-
It enables a single student to absorb complementary strengths from multiple specialized models.
-
It mitigates catastrophic forgetting and post-training regressions.
-
It provides a modular way to integrate new capabilities without retraining from scratch.
-
It supports efficient consolidation of RL-derived improvements.
-
It allows practitioners to reuse valuable intermediate checkpoints as lasting sources of supervision.
-
Limitations and Challenges
-
Despite its power, multi-teacher distillation introduces additional challenges:
-
Teacher signals may conflict, requiring careful weighting or routing.
-
Infrastructure costs increase significantly as the number of teachers grows.
-
Routing policies may become complex and task-dependent.
-
Poorly balanced weights can dilute specialization or destabilize optimization.
-
Cross-tokenizer alignment becomes difficult when teachers use incompatible vocabularies.
-
When Multi-Teacher Distillation is Preferred
-
Multi-teacher distillation is particularly effective when:
-
Different models excel in different domains and no single teacher dominates universally.
-
Sequential post-training has introduced regressions that must be repaired.
-
Multiple RL or supervised checkpoints contain complementary capabilities.
-
The goal is to consolidate broad performance into a single deployable model.
-
The available infrastructure can support multiple teacher inference services.
-
-
Multi-teacher distillation represents one of the most powerful modern post-training strategies, enabling practitioners to transform a collection of specialized models and checkpoints into a single unified student that retains the strongest behaviors of each.
Comparative Analysis
- Distillation methods can be understood along four primary axes: the source of trajectories, the origin of the teacher signal, the density and type of supervision, and the computational and systems complexity required to deploy them. Examining all methods through these dimensions makes it easier to determine which technique is appropriate for a particular training regime and how different methods can be composed within a larger post-training pipeline.
Tabular Comparison
- The following table summarizes the major families of distillation covered in this primer.
| Method | Trajectory source | Teacher source | Supervision signal | Primary advantage | Primary limitation |
|---|---|---|---|---|---|
| Soft-label knowledge distillation | Fixed dataset | External teacher | Dense token probabilities | Rich probabilistic supervision | Suffers from train–inference mismatch |
| Sequence-level distillation | Teacher-generated outputs | External teacher | Hard teacher sequences | Simple and highly scalable | Discards uncertainty information |
| Off-policy distillation | Dataset or teacher outputs | External teacher | Dense or hard targets | Stable and inexpensive | Does not train on student states |
| On-policy distillation | Student-generated rollouts | External teacher | Dense token-level divergences | Greatly improves robustness | Requires online teacher scoring |
| Temporal self-distillation | Fixed or mixed trajectories | Earlier checkpoint | Dense self-supervision | Preserves prior capabilities | Limited by historical model quality |
| Contextual self-distillation | Student-generated rollouts | Same model with privileged context | Dense token-level divergences | Eliminates external teacher dependence | Requires privileged information |
| On-policy self-distillation | Student-generated rollouts | Same model under privileged conditioning | Dense token-level divergences | Combines self-improvement with on-policy learning | Vulnerable to information leakage |
| Multi-teacher distillation | Fixed or student-generated trajectories | Multiple specialized teachers | Aggregated dense supervision | Consolidates complementary capabilities | Introduces routing and systems complexity |
| Multi-teacher on-policy distillation | Student-generated rollouts | Multiple specialized teachers | Dense multi-source token feedback | Powerful post-training consolidation | Highest infrastructure cost |
Trajectory Source
-
The most important distinction in modern LLM distillation is where the trajectories originate:
-
Off-policy methods rely on fixed sequences drawn from human annotations, teacher-generated synthetic data, or historical logs. These methods are straightforward and computationally efficient because all supervision can be precomputed and reused.
-
On-policy methods generate trajectories directly from the student and obtain feedback along the exact states the student visits. This significantly reduces exposure bias and better matches inference-time behavior.
-
Hybrid methods such as Generalized Knowledge Distillation interpolate between the two regimes using a mixture coefficient that gradually increases the proportion of student-generated data.
-
-
In practice, many successful training pipelines begin with off-policy synthetic data and later transition to on-policy training once the student becomes sufficiently capable.
Teacher Source
-
Another critical distinction is the origin of the teacher:
-
External teacher models are most common in classical distillation and are often substantially larger or stronger than the student.
-
Internal teachers arise in self-distillation, where the teacher is an earlier checkpoint, an ensemble of views, or the same model under privileged conditioning.
-
Multiple teachers are used when capabilities are distributed across specialists, RL checkpoints, or domain-adapted models.
-
-
The choice depends on infrastructure constraints, teacher availability, and whether privileged information can be supplied.
Supervision Density
-
Distillation methods differ significantly in the granularity of feedback:
-
Hard-label sequence distillation provides a single target token at each position.
-
Soft-label distillation provides full next-token probability distributions.
-
On-policy and self-distillation convert teacher–student log-probability differences into dense token-level advantages.
-
Reinforcement learning typically provides sparse trajectory-level rewards, which distillation can augment with fine-grained guidance.
-
-
Dense supervision is generally more sample-efficient, especially for long reasoning and agentic trajectories.
Reinforcement Learning Integration
-
Distillation increasingly serves as a complement to reinforcement learning:
-
Off-policy distillation is often used before RL to transfer broad capabilities from synthetic data.
-
On-policy distillation can replace policy-gradient advantages with token-level teacher feedback.
-
Self-distillation converts critiques, runtime errors, or hindsight information into dense update signals.
-
Multi-teacher distillation consolidates capabilities acquired during different RL stages.
-
-
The resulting view is that distillation and RL are no longer separate paradigms; instead, they occupy different points on a continuum of policy optimization techniques.
Comparison by Systems Complexity
-
The engineering burden varies substantially across methods:
-
Off-policy distillation is the simplest because teacher outputs can be precomputed offline.
-
On-policy distillation requires real-time interaction between student rollouts and teacher scoring services.
-
Self-distillation reduces infrastructure requirements by reusing the same model as both teacher and student.
-
Multi-teacher distillation introduces routing, scheduling, and aggregation complexity.
-
-
The systems cost should be considered alongside algorithmic benefits when selecting a method.
Practical Selection Heuristics
-
The following heuristics provide a concise decision framework:
-
Use off-policy distillation when stability, simplicity, and low operational cost are the highest priorities.
-
Use on-policy distillation when robustness to self-generated errors and long-horizon reasoning quality are critical.
-
Use self-distillation when external teachers are unavailable or when privileged information can strengthen the model’s own supervision.
-
Use multi-teacher distillation when capabilities are distributed across multiple specialized checkpoints or models.
-
Use RL–distillation hybrids when sparse correctness rewards need to be complemented with dense token-level feedback.
-
Common Training Progressions
-
Many state-of-the-art pipelines follow a staged progression rather than relying on a single method.
- Frontier models generate large volumes of synthetic data.
- Students are trained using off-policy distillation.
- Reinforcement learning improves targeted behaviors.
- On-policy distillation transfers RL-acquired capabilities more efficiently.
- Self-distillation and multi-teacher distillation consolidate improvements and recover regressions.
-
This progression, highlighted in the RLHF Book and numerous recent papers, reflects the increasingly unified view of synthetic data generation, reinforcement learning, and distillation as components of a single post-training stack.
Implementation Patterns
- Large-scale distillation is best understood as a distributed systems problem built around a teacher–student dataflow architecture. The fundamental challenge is to generate trajectories, obtain teacher evaluations, align tokenization, compute dense losses, and update the student efficiently at scale. The exact implementation differs depending on whether supervision is off-policy, on-policy, self-generated, or aggregated across multiple teachers, but the same architectural principles recur throughout modern post-training pipelines.
Canonical Distillation Dataflow
-
A production distillation system typically contains five major components:
-
A prompt source supplies instruction datasets, benchmark prompts, synthetic curricula, or production interaction logs that define the distribution of tasks to be learned.
-
A rollout engine generates student trajectories when training is on-policy, or streams precomputed examples when training is off-policy.
-
One or more teacher scoring services evaluate each trajectory and return token-level log-probabilities or other structured supervision signals.
-
A loss computation stage converts teacher–student discrepancies into divergences, advantage-like rewards, or hybrid objectives.
-
A training orchestrator manages batching, buffering, distributed optimization, evaluation, and checkpointing.
-
-
The Hugging Face article Distilling 100B+ Models 40x Faster with TRL emphasizes that throughput, communication efficiency, and logprob compression are often more important than the specific choice of divergence once models reach frontier scale.
Off-Policy Pipeline Architecture
-
Off-policy systems are architecturally straightforward because all teacher outputs can be generated in advance.
-
The workflow proceeds as follows:
-
Prompts are collected from curated datasets or synthetic generation pipelines.
-
One or more teacher models generate target responses and optional token-level distributions.
-
Verifiers, reward models, or filters select the highest-quality examples.
-
The resulting dataset is stored for repeated use.
-
The student is trained using cross-entropy, KL divergence, or a hybrid objective.
-
-
This design maximizes reproducibility and enables the same synthetic corpus to be reused across multiple experiments.
On-Policy Pipeline Architecture
-
On-policy systems introduce a closed feedback loop between student and teacher. The workflow proceeds as follows:
-
Prompts are sampled from a training dataset or curriculum.
-
The student generates one or more trajectories while recording token-level log-probabilities.
-
The generated trajectories are transmitted to the teacher scoring service.
-
The teacher computes token-level probabilities along the exact student prefixes.
-
A divergence or advantage-like loss is computed.
-
Gradients are propagated through the student only.
-
-
This architecture directly aligns training with the student’s inference distribution.
Generation Buffers and Asynchronous Execution
-
Teacher scoring is often more expensive than student updates, especially when the teacher contains hundreds of billions of parameters. Modern systems therefore decouple rollout generation from optimization:
-
Generation buffers maintain a queue of recently sampled trajectories.
-
Separate worker processes generate rollouts continuously.
-
Teacher requests are batched asynchronously to maximize accelerator utilization.
-
The trainer consumes scored trajectories whenever sufficient data accumulates.
-
-
The Hugging Face TRL implementation uses this design to achieve large throughput improvements when distilling from 100B+ teachers.
Teacher Scoring Infrastructure
-
Teacher scoring is typically served through optimized inference engines such as vLLM: Easy, Fast, and Cheap LLM Serving by Kwon et al. (2023).
-
Common implementation patterns include:
-
Hosting teachers on dedicated GPU clusters independent of student training.
-
Aggregating many trajectories into large scoring batches.
-
Returning only the log-probabilities required by the chosen loss.
-
Compressing outputs using binary encoding or top-\(k\) truncation.
-
Scheduling requests across multiple teachers when using MOPD.
-
Log-Probability Payload Design
-
The format of teacher outputs depends on the divergence objective:
-
Forward KL often requires top-\(k\) teacher distributions.
-
Reverse KL typically requires only the teacher’s log-probability for the student-sampled token.
-
Jensen–Shannon divergence may require partial distributions from both student and teacher.
-
Hybrid RL–distillation methods may also request token-level rewards, verifier signals, or routing metadata.
-
-
Careful payload design can reduce communication costs by orders of magnitude.
Full-Vocabulary Versus Top-k Approximation
- Exact forward KL requires evaluating all vocabulary entries:
-
For vocabularies exceeding 100,000 tokens, transmitting full distributions is often impractical.
-
Approximation strategies include:
-
Teacher top-\(k\) truncation, which retains only the most probable teacher tokens.
-
Student top-\(k\) truncation, which focuses on tokens most relevant under reverse KL.
-
Sampled-token scoring, which evaluates only the tokens actually generated by the student.
-
Mixed schemes that use exact probabilities for selected tokens and renormalized approximations elsewhere.
-
Tokenizer Compatibility and Alignment
-
Shared tokenization substantially simplifies implementation.
-
When teacher and student use the same tokenizer, token IDs align directly. When tokenizers differ, systems must detokenize text, retokenize under each model, and reconcile token boundaries, which introduces both complexity and approximation error.
-
For this reason, many practical distillation pipelines preferentially use teachers that share tokenizer lineage with the student.
Stabilization Mechanisms
-
Modern distillation systems include numerous safeguards.
-
Padding masks exclude non-semantic positions.
-
End-of-sequence masks prevent updates after generation termination.
-
Pointwise KL clipping limits unstable token-level divergences.
-
Token weighting emphasizes reasoning steps over formatting tokens.
-
Train–inference mismatch masks suppress tokens where serving and training engines disagree substantially.
-
-
These mechanisms are particularly important in reasoning and self-distillation settings.
Multi-Teacher Routing Infrastructure
-
Multi-teacher systems require additional orchestration.
-
Domain classifiers may assign prompts to specialized teachers.
-
Confidence-based weighting can emphasize teachers with lower entropy or stronger verifier scores.
-
Earlier checkpoints may be included to preserve previously acquired capabilities.
-
Aggregators combine teacher scores into a unified supervision signal.
-
Scheduling systems balance latency across heterogeneous teacher clusters.
-
Self-Distillation Systems
-
Self-distillation reduces infrastructure complexity by instantiating teacher and student from the same model under different contexts.
-
The workflow proceeds as follows:
-
A student prompt is constructed using only the original task.
-
A teacher prompt augments the task with privileged information such as verified answers or user feedback.
-
The student generates a rollout.
-
The same model scores that rollout under the privileged teacher context.
-
Gradients flow only through the student representation.
-
-
This design eliminates external teacher serving while preserving dense supervision.
RL–Distillation Hybrid Systems
-
Hybrid systems integrate scalar rewards with token-level teacher guidance.
-
Reinforcement learning determines trajectory-level improvement directions.
-
Distillation refines token-level update magnitudes.
-
Sample routing dispatches successful and failed trajectories to different objectives.
-
Hindsight feedback converts future observations into privileged teacher context.
-
Reward extrapolation enables students to surpass their teachers.
-
-
These designs increasingly dominate reasoning and agentic training pipelines.
Evaluation and Regression Monitoring
-
Distillation systems must be evaluated across both target and non-target domains. A robust evaluation suite typically measures:
-
Task-specific metrics such as accuracy, pass@k, or verifier success.
-
Behavioral metrics such as helpfulness, refusal calibration, and verbosity.
-
Distributional metrics such as KL divergence, entropy, and teacher disagreement.
-
Regression benchmarks that detect degradation in previously strong domains.
-
Systems metrics such as throughput, latency, and teacher utilization.
-
Practical Design Defaults
-
For most projects, an effective progression is:
- Begin with sequence-level or soft-label off-policy distillation.
- Introduce token-level teacher probabilities.
- Transition gradually to on-policy training.
- Add self-distillation when privileged context becomes available.
- Use multi-teacher distillation to consolidate specialized capabilities.
- Integrate RL–distillation hybrids when sparse rewards need dense token-level refinement.
-
This progression mirrors the increasingly unified post-training stack described throughout this primer, where synthetic data generation, reinforcement learning, and distillation operate as complementary components of a single scalable training system.
Decision Guide for Choosing a Distillation Method
- Selecting a distillation strategy is primarily a question of balancing teacher availability, desired robustness, engineering complexity, and the nature of the available supervision. In practice, most successful post-training pipelines begin with simple off-policy methods and progressively introduce on-policy, self-distillation, or multi-teacher techniques as the need for robustness and capability consolidation increases.
Choose Off-Policy Distillation When
-
You have access to a large corpus of high-quality human or synthetic examples and want the simplest, most stable training setup.
-
Teacher outputs can be generated offline and reused across many experiments, allowing inference cost to be amortized efficiently.
-
The student is expected to remain close to the training distribution and strong recovery from self-generated mistakes is not a primary concern.
-
You want a robust baseline before introducing more sophisticated on-policy or reinforcement learning stages.
Choose On-Policy Distillation When
-
Long reasoning chains, coding tasks, or agentic workflows are sensitive to compounding errors.
-
The student must learn how to recover from the exact mistakes it is likely to make during deployment.
-
Dense token-level supervision is preferred over sparse scalar rewards.
-
You want to transfer capabilities acquired through reinforcement learning into a smaller or more efficient model.
Choose Self-Distillation When
-
External teacher models are unavailable, too expensive, or operationally inconvenient.
-
The model already contains latent capability that can be unlocked using privileged information, hindsight context, or textual feedback.
-
Interaction traces, runtime errors, or user corrections can be used as rich internal supervision signals.
-
You want continual self-improvement without maintaining separate teacher infrastructure.
Choose On-Policy Self-Distillation When
-
Verified solutions, reference answers, or privileged reasoning traces are available.
-
The model is better at evaluating correct solutions than generating them from scratch.
-
You want the benefits of on-policy learning and dense supervision without relying on an external frontier teacher.
-
The task involves mathematical reasoning, coding, or other domains with reliable correctness signals.
Choose Multi-Teacher Distillation When
-
Different models or checkpoints specialize in complementary capabilities such as reasoning, coding, alignment, and safety.
-
Sequential post-training has introduced regressions that must be repaired.
-
You want to consolidate multiple specialized models into a single deployable student.
-
Your infrastructure can support routing and serving multiple teacher models efficiently.
Choose RL–Distillation Hybrids When
-
Sparse correctness rewards are available but insufficient on their own to provide fine-grained guidance.
-
You want reinforcement learning to determine update directions while distillation refines token-level update magnitudes.
-
Hindsight information, textual critiques, or verifier outputs can be converted into dense supervision.
-
The objective is to exceed teacher performance rather than merely imitate it.
Recommended Practical Progression
-
For most real-world projects, the following sequence is an effective default:
- Start with off-policy sequence-level or soft-label distillation to establish a stable baseline.
- Introduce token-level teacher probabilities for richer supervision.
- Transition gradually to on-policy distillation once the student is sufficiently capable.
- Use self-distillation when privileged context or hindsight feedback becomes available.
- Apply multi-teacher distillation to consolidate complementary capabilities and recover regressions.
- Integrate RL–distillation hybrids when sparse rewards need dense token-level refinement.
Key Takeaways
- If simplicity and low cost are paramount, begin with off-policy distillation.
- If robustness to self-generated errors is critical, adopt on-policy distillation.
- If no external teacher is available, use self-distillation.
- If verified answers or privileged solutions are available, prefer on-policy self-distillation.
- If capabilities are distributed across specialists, use multi-teacher distillation.
- If sparse rewards need dense corrective guidance, combine reinforcement learning with distillation.
References
Foundational distillation papers
- Distilling the Knowledge in a Neural Network by Hinton et al. (2015)
- Sequence-Level Knowledge Distillation by Kim and Rush (2016)
- DistilBERT: a distilled version of BERT by Sanh et al. (2019)
On-policy distillation and generalizations
- On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes by Agarwal et al. (2024)
- Rethinking On-Policy Distillation of Large Language Models by Li et al. (2026)
- Scaling Reasoning Efficiently via Relaxed On-Policy Distillation by Ko et al. (2026)
- Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation by Yang et al. (2026)
Self-distillation and privileged supervision
- Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models by Zhao et al. (2026)
- Reinforcement Learning via Self-Distillation by Hübotter et al. (2026)
- Self-Distilled RLVR by Yang et al. (2026)
- Aligning Language Models from User Interactions by Kleine Buening et al. (2026)
Multi-teacher and capability consolidation
- Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation by Yang et al. (2026)
- Unifying Group-Relative and Self-Distillation Policy Optimization via Sample Routing by Li et al. (2026)
Agentic and interaction-driven distillation
- OpenClaw-RL: Train Any Agent Simply by Talking by Wang et al. (2026)
Synthetic data and RLHF references
- The RLHF Book, Chapter 12: Synthetic Data
- The Path to On-Policy Distillation
- Training language models to follow instructions with human feedback by Ouyang et al. (2022)
- Deep Reinforcement Learning from Human Preferences by Christiano et al. (2017)
Imitation learning and exposure bias
- Imitation Learning and Structured Prediction Can Reduce Exposure Bias by Ross and Bagnell (2010)
- A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning by Ross et al. (2011)
Systems, tooling, and infrastructure
- Distilling 100B+ Models 40x Faster with TRL
- On-Policy Distillation (Hugging Face H4 demo)
- TRL Distillation Trainer Space
- vLLM: Easy, Fast, and Cheap LLM Serving by Kwon et al. (2023)
- DeepSpeed: System Optimizations for Large-Scale Training by Rasley et al. (2020)
Blogs and implementation guides
- On-Policy Distillation by Thinking Machines Lab
- Connectionism: Thinking Machines Research Blog
- Multi-Teacher On-Policy Distillation: A New Post-Training Primitive by Yumo Xu
Twitter / X threads and informal discussions
- Multi-teacher on-policy distillation discussion by Cameron R. Wolfe
- Follow-up thread on multi-teacher on-policy distillation and post-training by Cameron R. Wolfe
- On-policy distillation announcement thread by Kevin Lu
Broader LLM training context
- Scaling Laws for Neural Language Models by Kaplan et al. (2020)
- Language Models are Few-Shot Learners by Brown et al. (2020)
Citation
If you found our work useful, please cite it as:
@article{Chadha2020DistilledDistillation}
title = {Distillation},
author = {Chadha, Aman and Jain, Vinija},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}