NLP • Hallucination Detection and Mitigation
- Overview
- Strategies for Hallucination Mitigation
- Prompting-Based Techniques
- Model
- Post-Response Generation Techniques
- Post-Response Generation
- Related Papers
- References
Overview
- Hallucination in Large Language Models (LLMs) refers to instances where an AI model produces text that, while often grammatically correct and plausible, is not grounded in the provided input or may be factually inaccurate. This phenomenon is particularly prevalent in systems like GPT-3 and GPT-4, where generated content might deviate from or contradict the input.
-
Understanding the causes of hallucination is crucial:
-
Insufficient Training Data: Models lacking exposure to diverse data during training may fail to establish accurate correlations between inputs and appropriate outputs, leading to hallucinated content.
-
Model Overfitting: Overfitting to training data can cause models to produce outputs that mirror the training set but misalign with new or different inputs.
-
Inadequate Supervision: Without proper guidance, models might rely excessively on internal logic, resulting in outputs that appear to “hallucinate.”
-
Knowledge Cutoff: LLMs like ChatGPT have a knowledge cutoff date and thus are unaware of information beyond that point. Consequently, they may provide outdated or irrelevant responses.
-
- The presence of hallucination in AI-generated content underscores the need for continuous refinement to enhance the reliability of AI systems in practical scenarios. Simultaneously, it opens avenues for pioneering research in artificial intelligence and natural language processing domains.
Strategies for Hallucination Mitigation
-
Addressing hallucinations in LLMs requires a multifaceted approach, incorporating techniques at various stages of the generation process:
-
Prompting-Based: Methods like Chain-of-Verification (CoVe) enable models to self-verify outputs during generation.
-
Model-Based: Approaches such as active detection and mitigation leverage model internals to identify and correct hallucinations in real-time.
-
Post-Response Generation: Techniques like Retrieval-Augmented Generation (RAG), SelfCheckGPT, FActScore, and G-Eval assess and enhance the factual accuracy of generated content after its creation.
-
-
By integrating these strategies, developers and researchers can enhance the reliability and factual accuracy of LLM outputs, fostering greater trust and utility in AI-generated content.
Prompting-Based Techniques
- Prompting-based techniques involve guiding the model’s behavior during the input phase to reduce the likelihood of hallucinations. These methods leverage structured prompts or strategies that encourage the model to generate more accurate and verifiable outputs.
Retrieval-Augmented Generation (RAG)
-
Proposed by: Lewis et al. in Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks and Shuster et al. in Retrieval Augmentation Reduces Hallucination in Conversation
-
Classification: Mitigation
-
Description:
- Retrieval-Augmented Generation (RAG) is a technique designed to enhance the factual accuracy of Large Language Models (LLMs) by integrating external knowledge sources into the generation process. Traditional LLMs generate responses based solely on their pre-trained knowledge, which can lead to hallucinations—instances where the model produces plausible but incorrect or fabricated information. RAG addresses this limitation by retrieving relevant documents from an external corpus and conditioning the generation process on this retrieved information.
-
Retrieval-Augmented Generation represents a significant advancement in mitigating hallucinations in LLMs by grounding their outputs in external, verifiable information. By combining retrieval mechanisms with generative models, RAG enhances the factual accuracy, adaptability, and transparency of AI systems, making them more reliable for real-world applications.
- The RAG architecture comprises two main components:
- Retriever: Given a user query, the retriever searches an external knowledge base to find documents relevant to the query. This is typically achieved using dense vector representations and similarity search techniques.
- Generator: The generator, often a sequence-to-sequence model like BART, takes the retrieved documents and the original query as input to produce a response that is grounded in the retrieved information.
- By incorporating up-to-date and context-specific information at inference time, RAG enables LLMs to generate more accurate and relevant responses without the need for retraining on new data.
-
Implementation Details:
-
Indexing: The external knowledge base is preprocessed, and documents are converted into vector embeddings using models like DPR (Dense Passage Retrieval). These embeddings are stored in a vector database for efficient retrieval.
-
Retrieval: At inference time, the retriever computes the similarity between the query and the document embeddings to fetch the top-k relevant documents.
-
Generation: The generator receives the concatenated retrieved documents and the original query to produce a response. This process ensures that the generated output is informed by the most relevant external information.
-
-
Impact:
- The integration of RAG has demonstrated significant improvements in reducing hallucinations across various applications:
- Enhanced Accuracy: By grounding responses in retrieved documents, RAG reduces the likelihood of generating incorrect information.
- Domain Adaptability: RAG allows LLMs to access domain-specific knowledge bases, making them more adaptable to specialized fields without extensive retraining.
- Transparency: Since responses are based on retrieved documents, it’s possible to trace back the information to its source, enhancing the transparency and trustworthiness of the model’s outputs.
- The integration of RAG has demonstrated significant improvements in reducing hallucinations across various applications:
-
Challenges and Considerations:
-
While RAG offers substantial benefits, it also introduces certain challenges:
-
Retrieval Quality: The effectiveness of RAG heavily depends on the quality and relevance of the retrieved documents. Poor retrieval can lead to inadequate or misleading responses.
-
Computational Overhead: The retrieval process adds computational complexity and latency to the response generation pipeline.
-
Integration Complexity: Implementing RAG requires maintaining an up-to-date and comprehensive external knowledge base, which can be resource-intensive.
-
-
Chain-of-Verification (CoVe)
-
Proposed by: Dhuliawala et al. Chain-of-Verification Reduces Hallucination in Large Language Models
-
Classification: Detection & Mitigation
-
Description:
-
The Chain-of-Verification (CoVe) method addresses the issue of hallucinations—plausible yet incorrect information—in LLM outputs. CoVe introduces a structured, multi-step process that encourages the model to self-verify its responses, thereby enhancing factual accuracy.
-
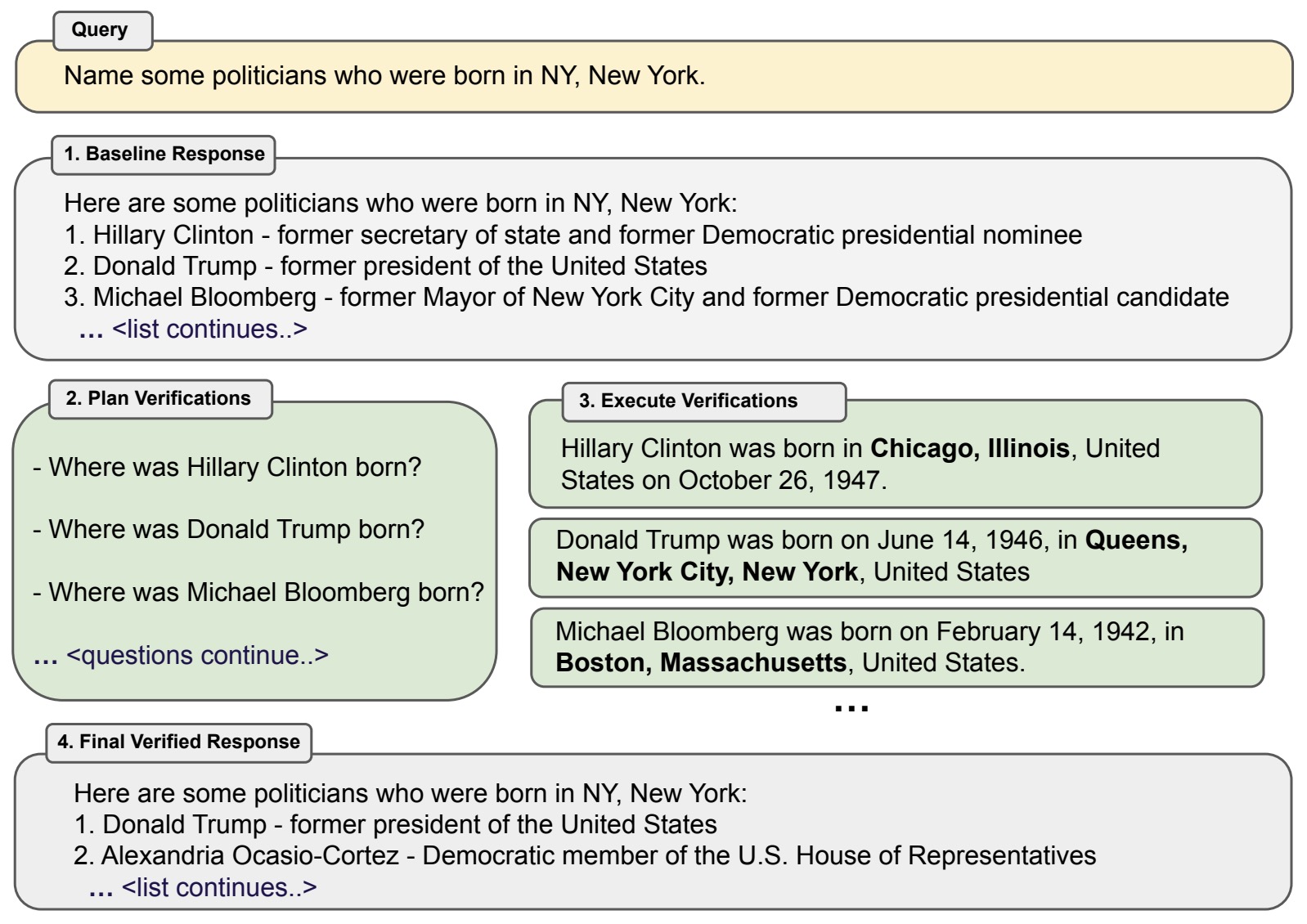
CoVe Process:
-
Baseline Response Generation: The LLM generates an initial response to a given query. This response may contain inaccuracies or hallucinations.
-
Verification Planning: Based on the initial response, the LLM formulates a set of verification questions aimed at fact-checking specific claims made in the baseline response.
-
Independent Verification Execution: Each verification question is answered independently by the LLM, without access to the initial response, to prevent bias and ensure objectivity.
-
Final Response Generation: The LLM synthesizes the answers to the verification questions to produce a revised, fact-checked final response.
-
-
This methodology is illustrated in the following diagram from the original paper:
-
CoVe Variants:
-
The authors explore several variants of the CoVe method to assess the impact of different attention mechanisms and prompt structures:
-
Joint CoVe: Combines the planning and answering of verification questions in a single prompt. While efficient, this approach allows the model to attend to the initial (possibly incorrect) response, increasing the risk of repeating hallucinations.
-
Two-Step CoVe: Separates the planning and answering stages into distinct prompts. This reduces the model’s exposure to the initial response during verification but still allows attention across all question-answer pairs, which may lead to some cross-contamination.
-
Factored CoVe: Each verification question is answered in complete isolation, with no access to the initial response or other verification answers. This strict separation minimizes the risk of propagating errors and has been shown to be the most effective variant in reducing hallucinations.
-
Factor+Revise: Builds upon Factored CoVe by introducing an additional revision step. The model cross-checks the original response against the independently obtained verification answers to identify and correct inconsistencies.
-
-
-
Impact:
-
Empirical evaluations demonstrate that CoVe significantly reduces hallucination rates across various tasks, including list-based questions from Wikidata, closed-book MultiSpanQA, and long-form text generation. Notably, the Factored CoVe variant achieves the highest performance gains, highlighting the importance of independent verification in mitigating false information.
-
Furthermore, the study finds that verification questions are often answered more accurately than the initial claims in the baseline response, underscoring the effectiveness of prompting LLMs to critically assess their outputs.
-
In summary, CoVe enhances the factual reliability of LLM-generated content by incorporating a self-verification mechanism that systematically identifies and corrects potential inaccuracies.
-
Model
- Model-based techniques focus on integrating mechanisms within the model’s architecture or training process to detect and mitigate hallucinations. These approaches often involve real-time analysis of the model’s outputs and confidence levels to ensure factual consistency.
Active Detection and Mitigation via Low-Confidence Validation
-
Proposed by: Varshney et al. in A Stitch in Time Saves Nine: Detecting and Mitigating Hallucinations of LLMs by Actively Validating Low-Confidence Generation
-
Classification: Detection & Mitigation
-
Description: This approach actively detects and mitigates hallucinations during the generation process by:
-
Detection: Identifying low-confidence elements in the generated text based on model uncertainty metrics.
-
Validation: Generating specific validation questions targeting these low-confidence elements.
-
Mitigation: Using the answers to the validation questions to correct any detected hallucinations in the text.
-
-
Impact: The method achieves a detection recall of approximately 88% and successfully mitigates 57.6% of the correctly detected hallucinations. Notably, it does not introduce new hallucinations even in cases of false positives.
Post-Response Generation Techniques
Decoding by Contrasting Layers (DoLa)
-
Proposed by: Chuang et al. in DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models
-
Classification: Mitigation
-
Description:
-
DoLa introduces a novel decoding strategy aimed at reducing hallucinations in large language models (LLMs) without requiring additional training or external retrieval mechanisms. The core idea is to leverage the observation that factual knowledge in LLMs is predominantly encoded in the later (mature) layers of the transformer architecture, while earlier (premature) layers capture more general linguistic patterns.
-
Key Components:
-
Dynamic Premature Layer Selection: For each token during generation, DoLa dynamically selects a premature layer by identifying which earlier layer’s output distribution is most divergent from the mature layer’s distribution. This divergence is quantified using the Jensen-Shannon Divergence (JSD), a symmetric measure of dissimilarity between two probability distributions.
-
Contrastive Decoding: Once the appropriate premature layer is selected, DoLa computes the next token’s probability distribution by contrasting the logit outputs of the mature layer with those of the chosen premature layer. Specifically, it subtracts the log probabilities of the premature layer from those of the mature layer, effectively amplifying the factual content while suppressing generic linguistic patterns.
-
Adaptive Mechanism: The dynamic selection allows DoLa to adapt to the complexity of the token being generated. For straightforward tokens with similar distributions across layers (low JSD), earlier layers might be selected. Conversely, for tokens requiring intricate real-world knowledge, layers closer to the mature layer are chosen to enhance factual accuracy.
-
-
Illustrative Example:
- In a scenario where the model is prompted with “What is the capital of Washington State?”, earlier layers might assign higher probabilities to “Seattle” due to its prominence, while the mature layer correctly identifies “Olympia” as the capital. DoLa’s contrastive approach ensures that the factual answer “Olympia” is favored in the final output.
-
-
Impact:
-
Empirical evaluations demonstrate that DoLa significantly enhances the factuality of LLM outputs across various tasks:
-
TruthfulQA: DoLa improved the performance of LLaMA family models by 12–17% absolute points, indicating a substantial reduction in hallucinated content.
-
Open-Ended Generation: In tasks requiring open-ended responses, DoLa generated more informative and factually accurate outputs, receiving better ratings from evaluators, including GPT-4.
-
Efficiency: Despite its benefits, DoLa introduces only a minimal computational overhead during inference, making it a practical solution for enhancing LLM reliability without significant performance trade-offs.
-
-
-
DoLa’s innovative approach of dynamically contrasting transformer layers during decoding offers a lightweight yet effective mechanism to mitigate hallucinations in LLMs, enhancing their reliability in generating factual content.
Post-Response Generation
- Post-response generation techniques are applied after the model has produced an output, aiming to assess and enhance the factual accuracy of the content. These methods include verification against external knowledge bases and consistency checks to identify and correct potential hallucinations.
SelfCheckGPT
-
Proposed by: Manakul et al. in SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
-
Classification: Detection
-
Description:
-
SelfCheckGPT is a sampling-based approach designed to detect hallucinations without requiring access to external databases or model internals. The methodology involves:
-
Sampling: Generating multiple stochastic responses for a given prompt using the same LLM.
-
Consistency Checking: Assessing the consistency across these samples. Consistent outputs suggest factual accuracy, while divergence indicates potential hallucinations.
-
-
This approach leverages the premise that if an LLM has accurate knowledge about a topic, its responses will be consistent across multiple generations. In contrast, hallucinated content will result in varied and contradictory outputs.
-
-
Impact:
- SelfCheckGPT effectively detects hallucinations at both sentence and passage levels. It outperforms several baselines in sentence-level hallucination detection and passage-level factuality assessment, providing a valuable tool for evaluating the reliability of LLM outputs.
FActScore
-
Proposed by: Min et al. in FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation
-
Classification: Detection
-
Description:
-
FActScore offers a fine-grained evaluation of factual precision by:
-
Decomposition: Breaking down long-form text into a series of atomic facts, each representing a singular, verifiable statement.
-
Verification: Assessing each atomic fact against a reliable knowledge source to determine its factual accuracy.
-
Scoring: Computing the percentage of atomic facts supported by the knowledge source to derive the FActScore.
-
-
This method allows for a nuanced assessment of an LLM’s output, identifying specific areas where factual inaccuracies occur.
-
-
Impact:
- FActScore reveals that even advanced models like ChatGPT achieve only 58% factual precision, highlighting the prevalence of hallucinations in long-form text generation. The introduction of an automated model that estimates FActScore with less than a 2% error rate facilitates scalable evaluations, making it a practical tool for benchmarking LLMs.
G-Eval
-
Proposed by: Wang et al. in G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
-
Classification: Detection
-
Description:
-
G-Eval is a framework that employs large language models with chain-of-thought (CoT) prompting and a form-filling paradigm to assess the quality of NLG outputs. The evaluation process includes:
-
Task Introduction and Evaluation Criteria: Providing the LLM with the context of the task and the specific criteria for evaluation.
-
Chain-of-Thought Generation: Prompting the LLM to generate a detailed reasoning process (CoT) that leads to the evaluation decision.
-
Form-Filling: Using the CoT to fill out an evaluation form that scores various aspects such as coherence, factual consistency, relevance, and grammaticality.
-
-
This approach aligns the evaluation process more closely with human judgment by making the reasoning behind scores explicit.
-
-
Impact:
- G-Eval demonstrates a strong correlation with human judgments, outperforming traditional automatic metrics like BLEU and ROUGE. By providing a more human-aligned evaluation of NLG outputs, G-Eval serves as a valuable tool for assessing and improving the quality of LLM-generated text.
MixAlign: Interactive Question-Knowledge Alignment
-
Proposed by: Zhang et al. in Mitigating Language Model Hallucination with Interactive Question-Knowledge Alignment
-
Classification: Detection & Mitigation
-
Description:
-
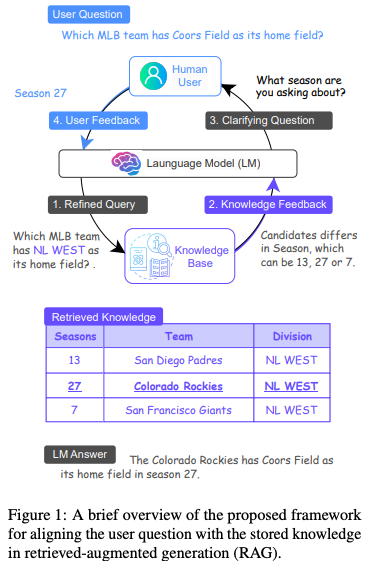
MixAlign addresses the challenge of hallucinations in large language models (LLMs) by focusing on the misalignment between user queries and the structure of external knowledge bases. Recognizing that users may pose questions that don’t directly correspond to the stored information, MixAlign introduces a two-pronged approach:
-
Model-Based Question-Knowledge Alignment: The system first employs an LLM to automatically refine the user’s question, aligning it with the schema of the knowledge base. This involves identifying and substituting attribute values to match the knowledge base’s structure, facilitating accurate retrieval of relevant information.
-
Human-Assisted Question-Knowledge Alignment: If ambiguities persist after the initial refinement—such as multiple candidate answers differing in specific attributes—the system engages the user through clarifying questions. For instance, if the ambiguity revolves around the “season” attribute, the system might ask, “Which season are you referring to?” The user’s response then guides the LLM to generate a more precise and contextually appropriate answer.
-
-
This interactive framework ensures that the LLM’s outputs are grounded in accurate and relevant information, effectively mitigating the risk of hallucinations.
-
-
Impact:
- Empirical evaluations demonstrate that MixAlign significantly enhances the alignment between user queries and knowledge bases, leading to improved accuracy in LLM responses. Specifically, the framework achieved up to a 22.2% improvement in model performance and a 27.1% reduction in hallucinations compared to baseline methods. These results underscore the efficacy of incorporating human-in-the-loop strategies to address the limitations of automated systems in handling ambiguous or misaligned queries.
Human-in-the-loop
- In general, employing human reviewers to validate the LLMs output can help mitigate the impact of hallucination and improve the overall quality and reliability of the generated text.
Related Papers
FACTSCORE: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation
- This paper by Min et al. from UW, University of Massachusetts Amherst, Allen Institute for AI, and Meta AI focuses on evaluating the factual accuracy of long-form text generated by large language models (LMs).
- The paper introduces FACTSCORE, a novel evaluation method that measures the factual precision of text generated by LMs. It breaks down a generation into atomic facts and calculates the percentage of these facts supported by a reliable knowledge source. This method is particularly necessary since text generations often contain a mix of supported and unsupported information, making binary judgments of quality inadequate.
- FACTSCORE addresses two key ideas: using atomic facts as units for evaluation and assessing factual precision based on a specific knowledge source. It defines an atomic fact as a short sentence containing a single piece of information. This approach allows for a more fine-grained evaluation of factual precision than previous methods. The paper uses people biographies as a basis for evaluation due to their objective nature and covers diverse nationalities, professions, and rarity levels.
- The following image from the paper shows an overview of FACTSCORE, a fraction of atomic facts (pieces of information) supported by a given knowledge source. FACTSCORE allows a more fine-grained evaluation of factual precision, e.g., in the figure, the top model gets a score of 66.7% and the bottom model gets 10.0%, whereas prior work would assign 0.0 to both. FACTSCORE can either be based on human evaluation, or be automated, which allows evaluation of a large set of LMs with no human efforts.
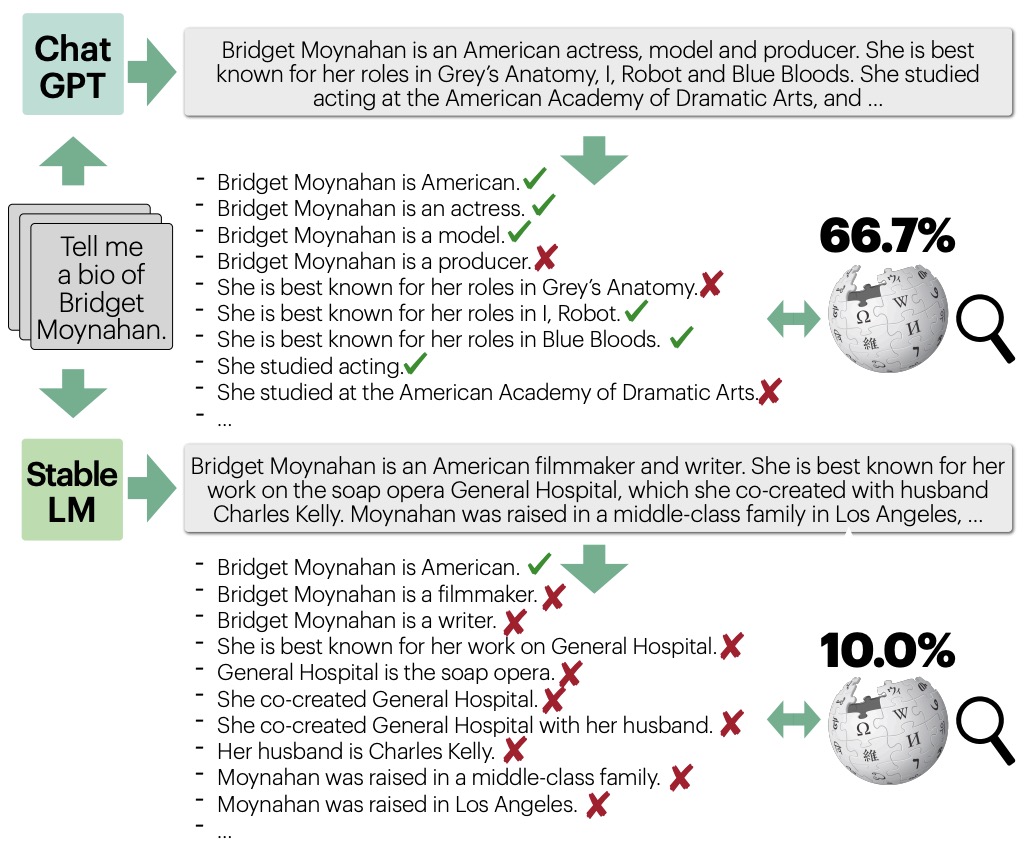
- Their automated estimator of FACTSCORE first breaks a generation into a series of atomic facts and then validates each against the given knowledge source. They use LLAMA 7B trained on Super Natural Instructions and ChatGPT as an LMEVAL, and Generalizable T5-based Retrievers for passage retrieval.
- The paper evaluates three state-of-the-art commercial LMs: InstructGPT, ChatGPT, and PerplexityAI. These models struggle with factual precision errors, with FACTSCOREs of 42%, 58%, and 71%, respectively. The study highlights that the factual precision of these LMs significantly drops with the rarity of the entities discussed in the text.
- To address the time-consuming and costly nature of human evaluation, the authors propose an automated model to estimate FACTSCORE. This model decomposes text into atomic facts and validates each against a knowledge source, closely approximating FACTSCORE with less than a 2% error rate. It allows the evaluation of a large set of new LMs without manual human effort.
- The paper also showcases the application of this automated estimator by evaluating 12 recently released LMs, offering insights into their factual accuracy. This approach could have cost $65K if evaluated by humans, highlighting the cost-effectiveness of the automated method.
- Finally, the paper suggests future work to enhance FACTSCORE, including considering other aspects of factuality such as recall (coverage of factual information), improving the estimator for better approximation of factual precision, and leveraging FACTSCORE to correct model generations.
- Overall, FACTSCORE represents a significant advancement in evaluating the factual precision of text generated by LMs, providing a detailed and cost-effective method for assessing the accuracy of long-form text.
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
- The quality of texts generated by natural language generation (NLG) systems is hard to measure automatically. Conventional reference-based metrics, such as BLEU and ROUGE, have been shown to have relatively low correlation with human judgments, especially for tasks that require creativity and diversity. Recent studies suggest using large language models (LLMs) as reference-free metrics for NLG evaluation, which have the benefit of being applicable to new tasks that lack human references. However, these LLM-based evaluators still have lower human correspondence than medium-size neural evaluators.
- This paper by Liu et al. from presents G-Eval, a framework of using large language models with chain-of-thoughts (CoT) and a form-filling paradigm, to assess the quality of NLG outputs.
- The following table from the paper illustrates the overall framework of G-Eval. We first input Task Introduction and Evaluation Criteria to the LLM, and ask it to generate a CoT of detailed Evaluation Steps. Then we use the prompt along with the generated CoT to evaluate the NLG outputs in a form-filling paradigm. Finally, we use the probability-weighted summation of the output scores as the final score.
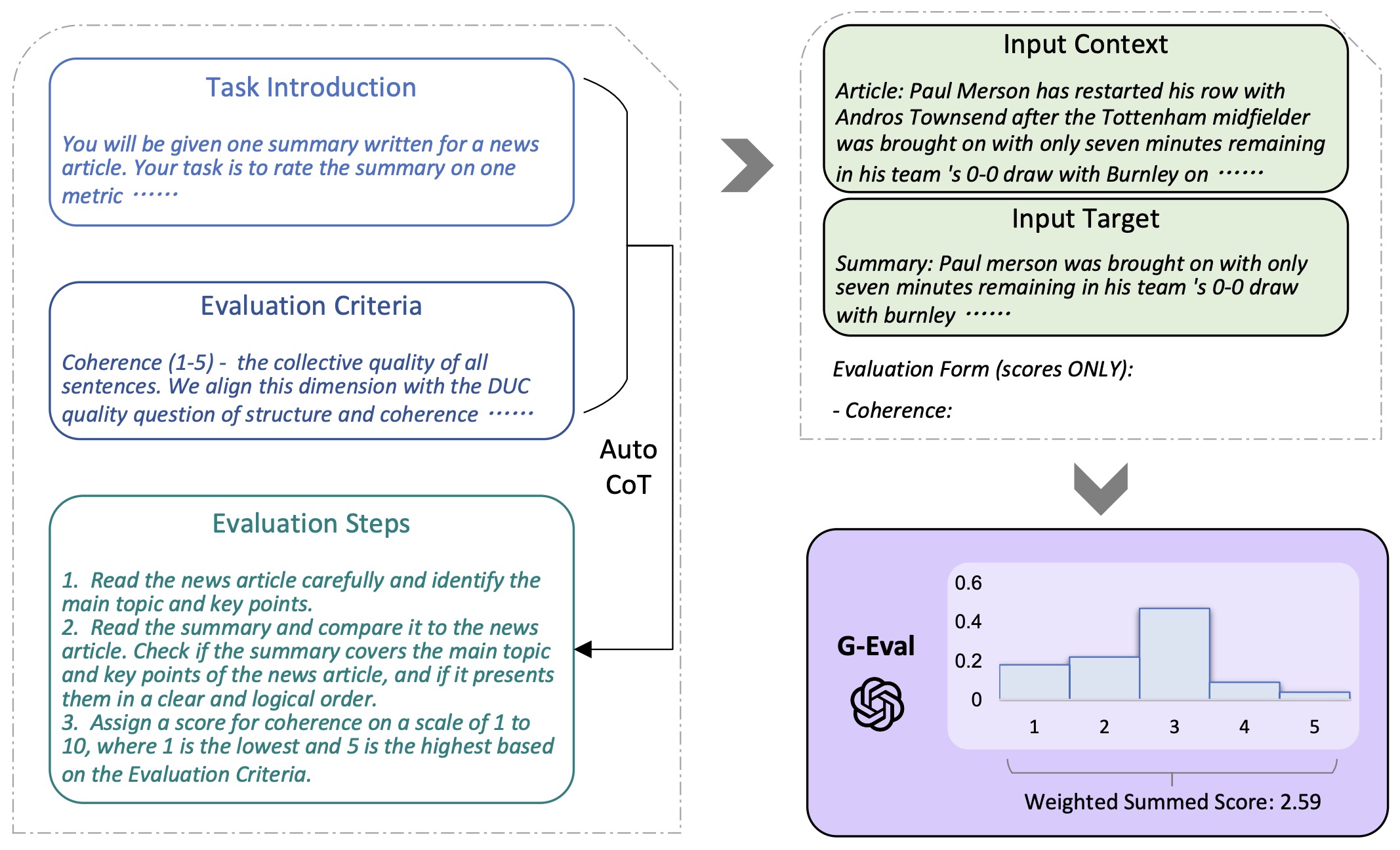
- They experiment with two generation tasks, text summarization and dialogue generation. They show that G-Eval with GPT-4 as the backbone model achieves a Spearman correlation of 0.514 with human on summarization task, outperforming all previous methods by a large margin.
- They also propose preliminary analysis on the behavior of LLM-based evaluators, and highlight the potential issue of LLM-based evaluators having a bias towards the LLM-generated texts.
- Code
Aligning Large Multimodal Models with Factually Augmented RLHF
- This paper by Sun et al. from UC Berkeley, CMU, UIUC, UW–Madison, UMass Amherst, MSR, MIT-IBM Watson AI Lab addresses the issue of multimodal misalignment in large multimodal models (LMMs), which can lead to hallucinations—generating textual outputs not grounded in multimodal context. To mitigate this, the authors propose adapting Reinforcement Learning from Human Feedback (RLHF) to vision-language alignment and introducing Factually Augmented RLHF (Fact-RLHF).
- The proposed method involves several key steps:
- Multimodal Supervised Fine-Tuning (SFT): The initial stage involves fine-tuning a vision encoder and a pre-trained large language model (LLM) on an instruction-following demonstration dataset to create a supervised fine-tuned model (πSFT).
- Multimodal Preference Modeling: This stage trains a reward model to score responses based on human annotations. The reward model uses pairwise comparison data to learn to prefer less hallucinated responses. The training employs a cross-entropy loss function to adjust the model’s preferences.
- Reinforcement Learning: The policy model is fine-tuned using Proximal Policy Optimization (PPO) to maximize the reward signal from the preference model. A KL penalty is applied to prevent over-optimization and reward hacking.
- Factually Augmented RLHF (Fact-RLHF): To enhance the reward model, it is augmented with factual information such as image captions and ground-truth multi-choice options. This addition helps the reward model avoid being misled by hallucinations that are not grounded in the actual image content.
- Enhancing Training Data: The authors improve the training data by augmenting GPT-4-generated vision instruction data with existing high-quality human-annotated image-text pairs. This includes data from VQA-v2, A-OKVQA, and Flickr30k, converted into suitable formats for vision-language tasks.
- MMHAL-BENCH: To evaluate the proposed approach, the authors develop a new benchmark, MMHAL-BENCH, focusing on penalizing hallucinations. This benchmark covers various types of questions that often lead to hallucinations in LMMs, such as object attributes, adversarial objects, comparisons, counting, spatial relations, and environment descriptions.
- The figure below from the paper illustrates that hallucination may occur during the Supervised Fine-Tuning (SFT) phase of LMM training and how Factually Augmented RLHF alleviates the issue of limited capacity in the reward model which is initialized from the SFT model.
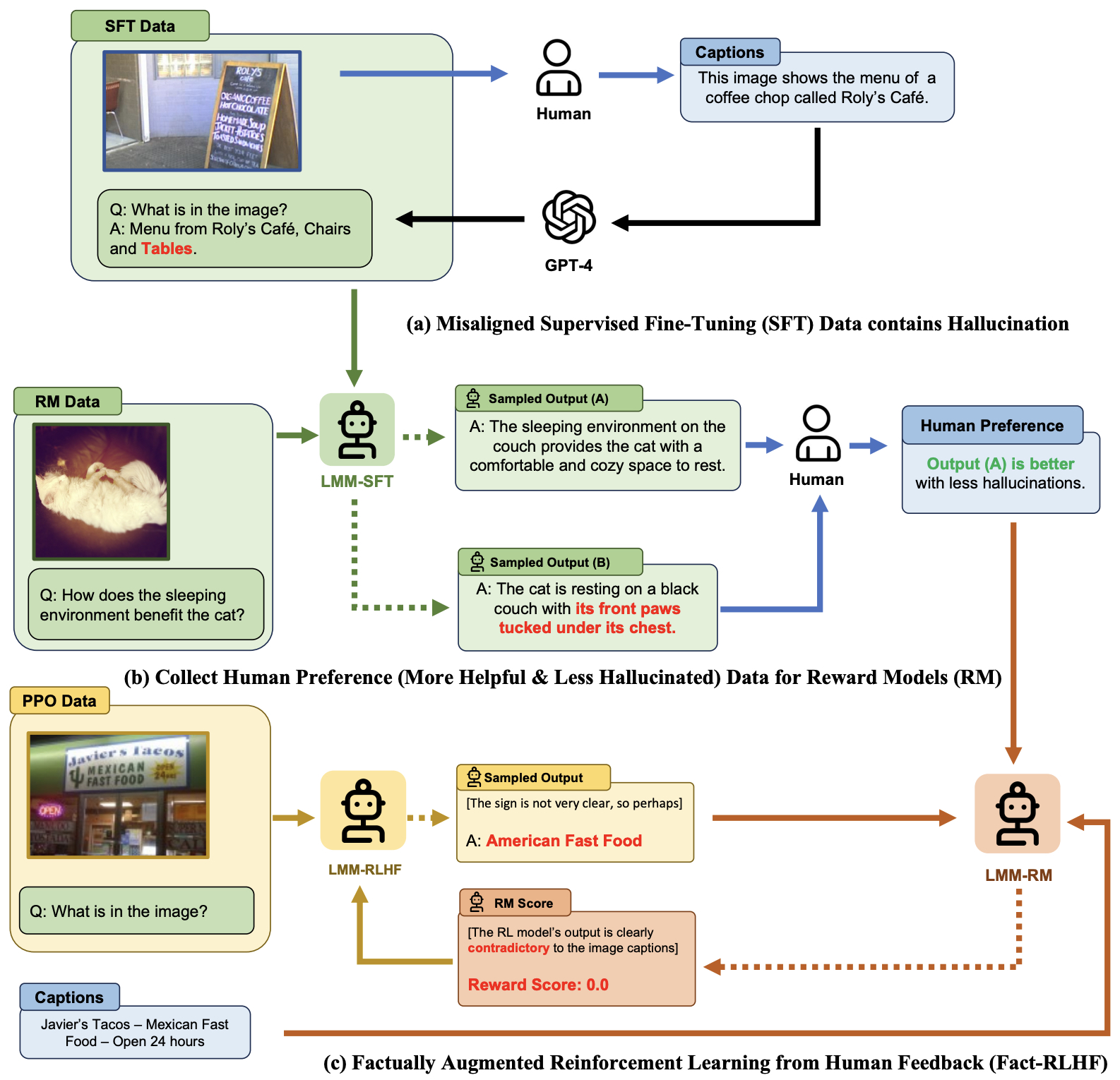
- The implementation of Fact-RLHF shows significant improvements:
- Improved Alignment: LLaVA-RLHF, the model trained with Fact-RLHF, achieves 94% of the performance level of text-only GPT-4 on the LLaVA-Bench dataset, compared to 87% by previous best methods.
- Reduced Hallucinations: On MMHAL-BENCH, LLaVA-RLHF outperforms other baselines by 60%, showing a substantial reduction in hallucinated responses.
- Enhanced Performance: The model also sets new performance benchmarks on MMBench and POPE datasets, demonstrating improved general capabilities and alignment with human preferences.
- Overall, the paper highlights the effectiveness of integrating factual augmentation in RLHF to address multimodal misalignment, thereby reducing hallucinations and enhancing the reliability of large multimodal models. The authors have open-sourced their code, model, and data for further research and development in this area.
- Code
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models
- Microsoft’s research introduces a novel method called Decoding by Contrasting Layers (DoLa), aiming to mitigate hallucinations in large language models (LLMs) without necessitating additional training or retrieval. This technique rests upon the understanding that factual knowledge in LLMs is predominantly encoded within the latter or more mature layers of a transformer architecture.
- During the process of text generation, DoLa does not rely on a static selection of a premature layer (an earlier layer in the transformer architecture) for contrasting. Instead, it actively selects the premature layer suited for each token’s decoding. The way DoLa determines this layer is by calculating the Jensen-Shannon divergence (JSD) between the output distribution of the premature layer and that of the mature layer, which is the final layer in the architecture. JSD serves as a measure of dissimilarity between two probability distributions. The underlying logic is to select a premature layer that exhibits the maximum JSD when juxtaposed with the mature layer, effectively maximizing the contrast between the factual knowledge and linguistic tendencies encapsulated in these layers.
-
Here’s a closer examination of its functionality:
- For every token being decoded, DoLa dynamically picks a premature layer by identifying which layer’s output distribution is the most distinct (in terms of JSD) from the mature layer’s distribution.
- A higher JSD indicates more pronounced differences between the factual and linguistic content encoded in the two layers.
- The premature layer embodies more fundamental linguistic patterns, while the mature layer is more representative of factual knowledge.
- DoLa then calculates the next token’s probability distribution by contrasting the logit outputs of the mature layer and the chosen premature layer. Specifically, this involves subtracting the log probabilities of the premature layer from those of the mature layer.
- As a result, the generated probability distribution accentuates factual information while diminishing mere linguistic patterns.
- This method is versatile. For tokens that are relatively simple and where the distributions between layers are alike (manifested by a lower JSD), early layers might be selected as the premature layer. Conversely, for tokens necessitating intricate real-world knowledge, a higher premature layer might be selected to enhance the contrast with the mature layer.
- In empirical terms, when DoLa was tested across various tasks like multiple choice QA, open-ended QA, and text generation, the method showcased noticeable improvements in factuality and truthfulness, surpassing traditional decoding and other contrastive decoding techniques. Additionally, DoLa introduces only a minimal computational overhead during the inference phase, making it a lightweight yet effective approach.
-
In essence, DoLa offers a dynamic method of contrasting knowledge encoded in transformer layers to minimize hallucinations, and its ability to adaptively choose the appropriate premature layer for each token is central to its efficacy.
- The method employed by DoLa, as described, involves contrasting the outputs between a “premature” layer and a “mature” layer. The mature layer, typically the final layer in the model, is believed to encode more of the factual knowledge, while the premature layers, being earlier in the network, contain more basic linguistic patterns.
-
The reason for dynamically picking a premature layer (as opposed to the mature layer) lies in the very objective of the method:
- Contrast Mechanism: By contrasting the outputs of two layers (premature and mature), DoLa aims to amplify the factual information encoded in the mature layer while de-emphasizing the basic linguistic patterns in the premature layer.
- Dynamic Adaptability: While the mature layer remains consistent (as it’s always the final layer), choosing a premature layer dynamically provides adaptability. For different tokens or contexts, the distinction between the mature layer and a particular premature layer might be more pronounced, leading to a higher Jensen-Shannon divergence. By selecting different premature layers for different tokens, DoLa can better maximize this distinction.
- Highlighting Factual Information: The mature layer’s outputs are already expected to be more factual. The value in choosing the premature layer is in contrasting it with the mature layer. This emphasizes the factual content in the mature layer’s outputs even further.
- Flexibility: The range of possible outputs from premature layers provides a spectrum of linguistic patterns. By having the flexibility to select from this spectrum, DoLa can adaptively contrast different types of linguistic patterns against the factual knowledge in the mature layer, depending on the context.
- In essence, the mature layer acts as a consistent reference point, while the choice of premature layer allows the model to adaptively emphasize factual content over linguistic patterns, thereby aiming to reduce hallucinations and improve the factual accuracy of the generated content.