Primers • GPT-4o Native Image Generation
- Introduction
- Multimodal Input/Output Sequence Format in GPT-4o
- Image Representation and Latent Modeling
- Unified Transformer Architecture and Attention Patterns
- Training Objectives and Modality-Specific Loss Functions
- Diffusion Sampling and Row-by-Row Decoding with Rolling Diffusion
- Image Rendering, VAE Decoding, and Final Output Construction
- Integration with Text Generation and Modality Interleaving
- Architectural Scaling, Training Regimes, and Implementation Strategy
- Summary of Design Decisions and Forward-Looking Considerations
- Evaluation, Sample Quality, and Benchmark Comparisons
- References
Introduction
-
GPT-4o introduces a significant leap in multimodal generative modeling by enabling native image generation within a unified autoregressive decoding process. Unlike previous systems such as ChatGPT, which relied on discrete modality-specific APIs (e.g., calling a DALL·E model externally to generate an image), GPT-4o integrates image synthesis directly into its transformer backbone. It accomplishes this by representing images as sequences of continuous-valued latent patches, decoded using diffusion-based denoising, and interleaved naturally with text tokens within a single sequence of model outputs.
-
Previous image generation from systems like ChatGPT involved ChatGPT calling an image generation tool (DALL·E) on the user’s behalf. While this new Transfusion approach involves GPT-4o outputting an optional sequence of tokens for text, then a special token to signal the generation of an image (
<BOI>), followed by a sequence of ( n ) random image patches which are then filled in using diffusion, and finally a special token to signal the end of the image block (<EOI>). This interleaving of text tokens and image patches can be repeated as needed, supporting rich multimodal documents. These image patches are subsequently converted into a final image using either a simple linear layer or U-Net up blocks in conjunction with a Variational Autoencoder (VAE) decoder. -
This integration marks a paradigm shift in the design of large multimodal models: rather than viewing modalities as disjoint domains stitched together by toolchains, GPT-4o processes them as a unified token stream with modality-aware processing logic and a shared transformer core. Both text tokens and image patch embeddings are interpreted by the same sequence model, and the transition between modalities is handled inline, governed by special control tokens such as
<BOI>(Begin of Image) and<EOI>(End of Image). -
The architectural foundations of GPT-4o draw heavily on recent breakthroughs in multimodal modeling. Three particularly influential contributions include:
-
Chameleon (Meta, 2024): Chameleon explored early-fusion multimodal transformers that handle text and image data using a shared token vocabulary. Images are discretized into codebook indices via vector-quantized VAEs (VQ-VAEs), allowing them to be represented as sequences of discrete tokens just like text. While this approach simplifies integration, it introduces a significant information bottleneck due to the coarse granularity of quantized image tokens. All images were broken into discrete image tokens chosen from a vocabulary of fixed size, and the image token generation was also done from the same vocabulary. This discretization process may result in information loss and imposes constraints on representational expressiveness, which is one of the biggest drawbacks of the Chameleon architecture.
-
Transfusion (Zhou et al., 2024): Transfusion presents a novel transformer that is trained using both language modeling (for text) and denoising diffusion (for continuous image latent vectors). It demonstrates that a single transformer model can learn to predict text tokens autoregressively and generate image latents via denoising, within the same training regime. Unlike Chameleon which discretizes images, Transfusion preserves the full fidelity of image representations by modeling them in continuous latent space using pretrained VAEs, and applies denoising diffusion directly to those vectors without quantization. As a result, Transfusion significantly outperforms Chameleon, surpassing it in every combination of text-to-image, image-to-text, and mixed-modality generation tasks. Importantly, Transfusion introduces a hybrid attention masking strategy that allows for causal attention across the full sequence and bidirectional attention within image blocks, enabling rich image generation while preserving the left-to-right flow of text decoding.
-
Rolling Diffusion (Ruhe et al., 2024): Rolling Diffusion proposes a novel denoising strategy where image latents are generated row-by-row or block-by-block, rather than all at once. By reparameterizing the diffusion schedule locally within a sliding window of patches, this technique enables models to generate visual content in a streaming or sequential fashion, closely aligning with the causal nature of text generation. This innovation is particularly valuable for efficient image decoding in models like GPT-4o, where full-image generation in one shot would be prohibitively expensive or inflexible.
-
-
Together, these contributions provide the theoretical and empirical groundwork for GPT-4o’s design. From Transfusion, GPT-4o inherits the dual loss framework and unified transformer. From Chameleon, it borrows ideas for modality-agnostic tokenization and attention sharing (while avoiding its quantization drawbacks). And from Rolling Diffusion, it adopts the ability to generate images incrementally, improving both runtime efficiency and interactive applicability.
-
The remainder of this primer explores GPT-4o’s architecture, training objectives, attention patterns, image rendering pipeline, and decoding procedures in detail. Each section will reference architectural diagrams and implementation-specific insights drawn directly from the above papers.
Multimodal Input/Output Sequence Format in GPT-4o
- GPT-4o represents a unified generative modeling approach that outputs both natural language tokens and image content within a single autoregressive token stream. This fundamental design choice enables GPT-4o to process and generate interleaved multimodal documents without relying on external systems for image generation (unlike earlier models that delegated image synthesis to DALL·E-style modules).
Sequence Construction
- At training and inference time, data samples are formatted as interleaved sequences of discrete and continuous elements. These sequences are tokenized and presented to a single transformer model:
[Text tokens] ... <BOI> [Latent patch vectors] <EOI> ... [Text tokens]
-
Text tokens are standard discrete tokens derived from a Byte Pair Encoding (BPE) tokenizer, consistent with LLaMA-style implementations. Each token is an integer and mapped to a high-dimensional embedding vector.
-
<BOI>(Begin of Image) and<EOI>(End of Image) tokens act as boundary markers, explicitly identifying where the image content begins and ends in the token stream. -
Latent patch vectors represent image data, not as pixel arrays, but as compressed, continuous latent vectors in \(\mathbb{R}^d\), generated using a VAE or Latent Diffusion model.
-
This design enables GPT-4o to fluidly alternate between natural language and visual content generation without architectural context switching, similar to Transfusion’s token stream format. The following figure (source) offers a high-level illustration of the Transfusion architecture with an example showing the placement of text tokens, BOI, latent vectors, and EOI within a shared transformer input. Transfusion follows a single transformer perceives, processes, and produces data of every modality. Discrete (text) tokens are processed autoregressively and trained on the next token prediction objective. Continuous (image) vectors are processed together in parallel and trained on the diffusion objective. Marker BOI and EOI tokens separate the modalities.
![]()
Interleaved Token Semantics
- GPT-4o distinguishes between modalities using:
- Modality-specific positional encodings
- Modality markers (
<BOI>,<EOI>) - Attention masking (causal for text, bidirectional for image)
-
Each token (whether text or image) is embedded into a shared hidden representation space \(\mathbb{R}^d\) so that all subsequent transformer operations can proceed uniformly.
-
Despite being continuous vectors, image patch latents are handled similarly to token embeddings: they are added to position embeddings and passed into the transformer as sequence elements.
-
This idea is rooted in the early-fusion formulation presented in the Chameleon architecture, a family of mixed-modal foundation models capable of generating and reasoning with mixed sequences of arbitrarily interleaved textual and image content.
- Chameleon demonstrated the feasibility of uniformly tokenizing all modalities. GPT-4o inherits this idea but adapts it to continuous embeddings (from VAE-encoded image patches) rather than discretized tokens.
Patch Representation and Emission
-
In the image generation phase, GPT-4o autoregressively emits:
<BOI>token — switches the model into image-generation mode- Sequence of latent vectors — sampled using a diffusion process
<EOI>token — signals image is complete and resumes text mode
-
Each latent vector corresponds to a patch from a latent image space, typically derived from a pretrained VAE trained on high-resolution images:
- \(n\): number of patches (e.g., for a 16 \(\times\) 16 grid, \(n = 256\))
-
\(d\): embedding dimension (e.g., \(d = 32\))
- This latent sequence is processed just like text tokens in the transformer, with the difference that during training, a diffusion-based denoising objective is applied instead of a next-token prediction loss. The following figure (source) illustrates the Transfusion architecture’s image-to-latent encoding and decoding pathway including the following steps: (i) VAE encoding, (ii) latent patchification (grid slicing), (iii) Optional linear projection or U-Net down blocks, and (iv) output latents used in transformer.
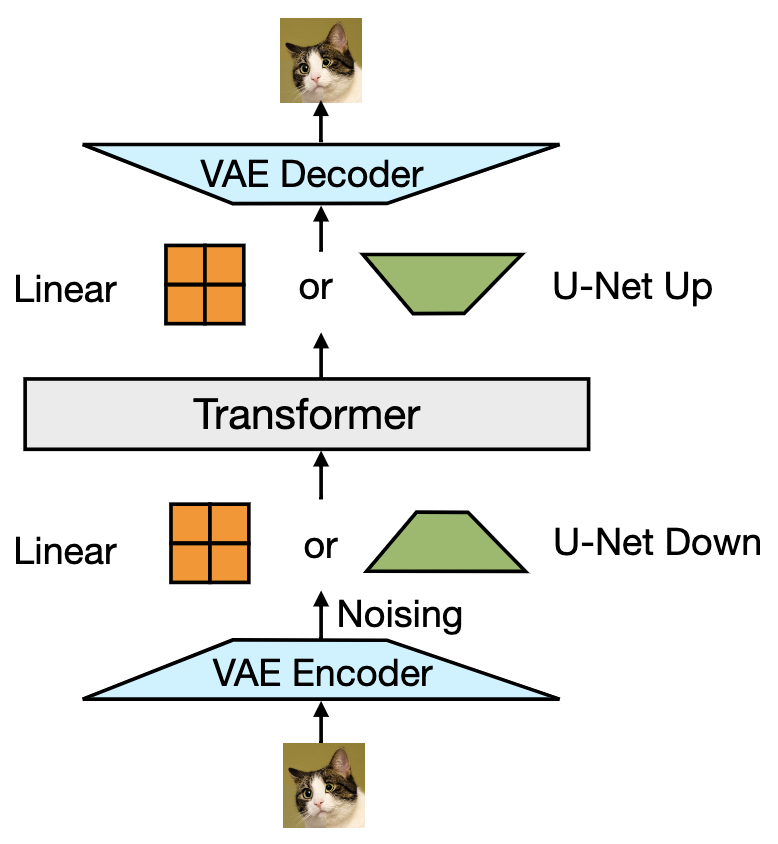
Example Input/Output Patterns
- GPT-4o handles diverse multimodal prompt configurations:
- Text → Image:
"Draw a steampunk elephant" → `<BOI>` [image latents] `<EOI>` - Image → Text:
`<BOI>` [image latents] `<EOI>` → "This is a steampunk elephant." - Image + Text → Image:
`<BOI>` [image latents] `<EOI>` "Now show it in space" → `<BOI>` [new image] `<EOI>` - Fully interleaved documents:
"Here’s a diagram:" `<BOI>` [image] `<EOI>` "This represents the core architecture."
- By embedding image and text elements into a shared sequence, GPT-4o is capable of:
- Contextually grounded image generation
- Visual question answering
- Captioning
- Multimodal dialogue
- Fully interleaved generation
- This kind of seamless interaction is foundational to future interactive AI agents, and GPT-4o offers one of the first viable blueprints for such unified modality handling.
Image Representation and Latent Modeling
- GPT-4o relies on latent-space representations for image generation, avoiding direct generation in pixel space (which is computationally expensive) or discrete image token generation (which is lossy, as seen in Chameleon). Instead, it draws directly from the latent diffusion modeling framework, using continuous patch embeddings derived from a pretrained VAE.
- This section details how image data is processed, encoded, and decoded using VAE architectures, referencing design elements from both the Transfusion and Rolling Diffusion papers.
Latent Space Encoding via VAE
-
The core mechanism for representing image data in GPT-4o is a variational autoencoder, trained to compress and reconstruct image patches in a continuous latent space.
-
At training and inference time, each image is converted into a sequence of latent vectors via the encoder:
\[z = \text{VAE}_{\text{enc}}(x), \quad \text{with } z \in \mathbb{R}^{n \times d}\]- where:
- \(x \in \mathbb{R}^{H \times W \times 3}\): original RGB image (e.g., 256×256).
- \(z\): latent encoding of the image.
- \(n\): number of latent tokens (e.g., 256 for a 16×16 grid).
- \(d\): dimensionality of each latent vector (e.g., 8, 16, or 32 depending on compression).
- where:
-
After generation, the latent representation is decoded back into pixel space using the decoder:
\[\hat{x} = \text{VAE}_{\text{dec}}(z)\]- where:
- \(\hat{x}\): reconstructed image.
- \(\text{VAE}_{\text{dec}}\): decoder (typically a U-Net or CNN-based upsampler).
- where:
-
This architecture is compatible with the Latent Diffusion Models (LDM) described by Rombach et al. (2022), and reused in both Transfusion and Rolling Diffusion.
Patchification Process
-
The latent space is structured by dividing the compressed VAE output into a regular spatial grid of patches. For example:
- A 256×256 image → compressed to a 32×32 latent grid by the encoder
- Each 2×2 region of the latent space is flattened into one vector (via patchification)
- Resulting in 256 patch vectors of dimension \(d\)
-
These vectors are flattened left-to-right, top-to-bottom to produce a 1D sequence:
- Patch embedding options:
- Simple linear layer (low compute cost, used during scaling)
- U-Net Down Blocks (used in Transfusion for better local structure retention)
-
The image patch vectors are then treated as continuous tokens and passed into the shared Transformer sequence model.
- Implementation Notes (from Transfusion):
- Add learned positional embeddings or use RoPE (rotary positional encoding).
- Add timestep embeddings during diffusion training.
- Normalize latent values (LayerNorm or RMSNorm before transformer input).
Advantages Over Discretized Representations
-
Chameleon, a contemporaneous model from Meta, uses vector-quantized VAE (VQ-VAE) to compress images into discrete codebook indices. This approach allows uniform token handling across modalities but introduces quantization artifacts and information bottlenecks.
-
Chameleon quantizes images into discrete tokens introduces an upper bound on fidelity, particularly for images with fine-grained detail or high-frequency textures.
- In contrast, GPT-4o (via Transfusion-style training) retains full continuous latent space precision, resulting in:
- Higher image fidelity
- Lower FID scores (as shown in Transfusion’s MS-COCO evaluations)
- Better conditioning on prompt embeddings (improved CLIP scores)
- Moreover, continuous latents simplify image loss computation using denoising score-matching, without needing to manage a large discrete vocabulary (e.g., 8192 tokens as in Chameleon).
Conditioning and Patch Context Handling
- Within the transformer, each latent vector can:
- Attend to earlier tokens (text or image)
- Attend bidirectionally to other patches within the same image block (defined by
<BOI>and<EOI>markers)
-
This behavior is controlled by a custom attention mask:
- Causal attention globally (maintaining autoregressive property)
- Fully bidirectional within a
<BOI>–<EOI>block
-
This strategy allows intra-image coherence while preserving the left-to-right generation constraint across modalities.
- The following figure (source) visualizes the causal + intra-image attention mask.
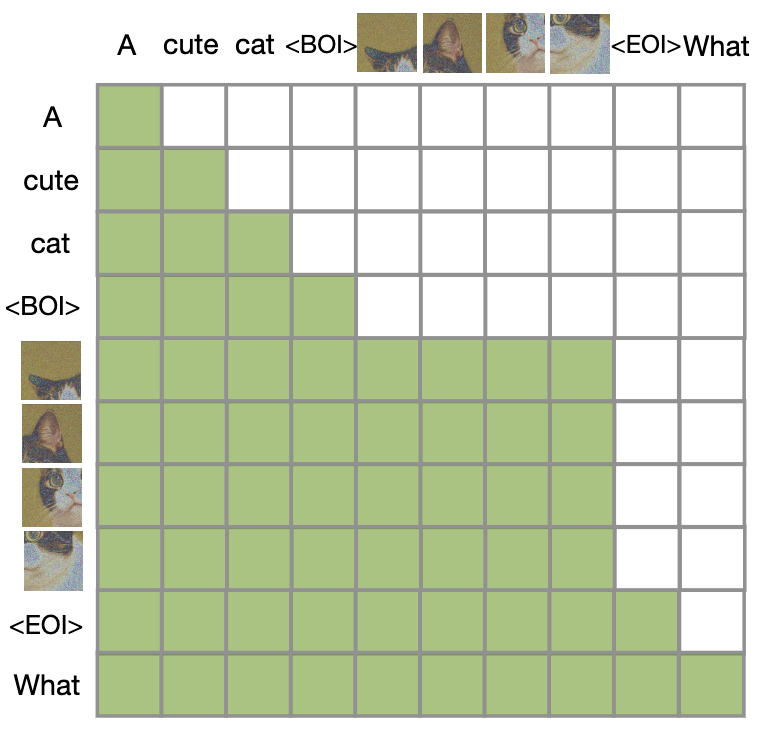
Latent Format and Token Emission Strategy
-
During inference, GPT-4o samples the image patch sequence in its latent form, one diffusion trajectory at a time, and reconstructs the final image via the VAE decoder.
-
To simplify implementation:
- Patch length \(n\) is fixed per image (e.g., 256).
- Patch dimensionality \(d\) is shared with transformer hidden size.
- An optional learnable BOS (beginning-of-sample) latent may be emitted first to stabilize generation.
- Diffusion operates on all \(n\) patches simultaneously or in rolling windows (discussed in Section 4).
Unified Transformer Architecture and Attention Patterns
- The core of GPT-4o’s image and text generation capabilities lies in its use of a single, shared Transformer architecture to model sequences of interleaved modalities. This section describes how GPT-4o structures its Transformer to support text autoregression, intra-image denoising, and seamless modality transitions — all within the same attention backbone.
- The design builds directly on the Transfusion architecture, enhanced by lessons from Chameleon and architectural stabilization strategies discussed in both.
Modality-Agnostic Input Pipeline
- All input elements — whether discrete text tokens or continuous image patches — are transformed into a shared embedding space of dimensionality \(d\), typically aligned with the model’s hidden size (e.g., 2048 or 4096).
Input projection layers:
- Text tokens: Mapped via a token embedding table.
- Image patches: Projected using one of two techniques:
- A simple linear layer: suitable for low-compute regimes.
- U-Net Down Blocks: extract local spatial structure more effectively, as used in Transfusion’s higher-quality configurations.
- The projected vectors are then augmented with:
- Rotary positional embeddings (RoPE): for spatial and temporal alignment.
- Timestep embeddings: when used in diffusion training to condition each vector on its noise level.
- These embeddings are added before the Transformer layers and ensure that each token — regardless of modality — is given context-aware encoding.
Transformer Backbone Design
-
GPT-4o likely uses a variant of the LLaMA-2-style transformer, sharing the following traits with Transfusion and Chameleon:
- LayerNorm variant: RMSNorm for stability and scale-insensitive layer normalization.
- Activation: SwiGLU (gated linear units with Swish) for increased model expressivity.
- Attention head scaling: high-dimensional queries and keys, enabling large context ranges.
- Key architectural choice: parameter sharing across modalities
- All attention and feedforward layers are shared between modalities.
- Only the input/output projections differ between text and image.
- This design dramatically simplifies multimodal modeling by not requiring separate encoders or decoders for different modalities, unlike previous approaches (e.g., Flamingo, DALL·E Mini).
Hybrid Attention Masking
-
A cornerstone of GPT-4o’s unified modeling is the hybrid attention mask used during training and inference. This approach enables:
- Causal attention for language modeling.
- Bidirectional attention within image blocks to support diffusion-style denoising.
- Strict autoregressive masking across modality boundaries, preserving sequence integrity.
Explanation
- Text tokens (left side) follow strict left-to-right causal attention.
- Image patches (middle) attend to each other freely within a BOI–EOI block.
- Cross-modal edges (text-to-image) are causal — image patches can condition on prior text, but not vice versa.
- This setup is critical to training a Transformer that can smoothly switch between next-token prediction and denoising objectives without loss of modality context.
Integration of Modality Markers and Position Awareness
- GPT-4o uses special tokens to delineate modalities:
<BOI>and<EOI>tokens signal the start and end of image blocks.- These markers are embedded and fed into the Transformer like regular tokens, allowing the model to learn boundary-aware generation behaviors.
- Each token also receives a positional encoding:
- RoPE embeddings: applied per-token across the full sequence.
- For image blocks, these are structured in row-major order (left-to-right, top-to-bottom).
- When diffusion is active, timestep encodings are added to image latents, supporting noise-conditioning.
- This approach aligns with Transfusion’s positional encoding strategy, which conditions patch vectors not only on their location but also on their position in the diffusion timeline.
Attention Implementation Details
- To implement the hybrid mask effectively:
- A binary attention mask is generated at runtime, based on the sequence of modality tokens.
- This mask is injected into the standard self-attention mechanism before softmax:
\(\text{Attention}(Q, K, V) = \text{softmax}( \frac{QK^T}{\sqrt{d_k}} + M ) V\)
- where \(M\) is the attention mask with entries:
- 0 for permitted attention
- \(-\infty\) for masked positions
- where \(M\) is the attention mask with entries:
-
To support intra-image bidirectionality, patches within the same image block are identified and grouped. Within each group, bidirectional attention is allowed.
- This is straightforward to implement using sliding window logic and token tagging during data preprocessing.
Training Objectives and Modality-Specific Loss Functions
-
A critical innovation in GPT-4o is the use of multiple loss functions applied within a shared Transformer model, tailored to the modality of the output token. Specifically:
- Discrete text tokens are trained using a language modeling (LM) objective.
- Continuous image patch vectors are trained using a denoising diffusion probabilistic model (DDPM) loss.
-
This dual-objective training recipe, first formalized in the Transfusion architecture, allows GPT-4o to optimize the correct learning signal for each modality while sharing the same transformer weights and input sequence stream.
Combined Loss Function
-
GPT-4o’s total loss is computed as a simple linear combination of the language modeling loss and diffusion loss:
\[\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{LM}} + \lambda \cdot \mathcal{L}_{\text{DDPM}}\]- where:
- \(\mathcal{L}_{\text{LM}}\): language modeling loss for discrete tokens.
- \(\mathcal{L}_{\text{DDPM}}\): denoising score-matching loss for image patches.
- \(\lambda\): weighting coefficient to balance the two losses (often tuned via validation or set to 1.0).
- where:
- This allows simultaneous optimization of:
- Left-to-right token prediction (for all textual elements)
- Latent vector denoising (for image patch reconstruction)
- This is consistent with Transfusion’s central idea: “combining a discrete distribution loss with a continuous distribution loss to optimize the same model.”
Language Modeling Loss (Text Tokens)
-
The LM loss used for text is standard autoregressive next-token prediction:
\[\mathcal{L}_{\text{LM}} = \mathbb{E}_{y}[-\log P_\theta(y_i | y_{<i})]\]- where:
- \(y\): a sequence of discrete tokens (e.g., from a BPE tokenizer).
- \(y_i\): the token to predict at position \(i\).
- \(y_{<i}\): the prefix up to, but not including, \(i\).
- \(P_\theta\): the model’s predicted probability distribution, parameterized by \(\theta\).
- \(\mathbb{E}_y\): the expectation over the training corpus.
- where:
-
This loss is computed per-token, and gradients are backpropagated only through tokens that belong to the text domain.
Diffusion Objective for Image Patches
- GPT-4o uses denoising score matching for learning to generate image patch latents. This is done using a DDPM loss following the formulation from Ho et al. (2020) and adopted in Transfusion and Rolling Diffusion.
Forward Diffusion Process
-
The forward process gradually adds Gaussian noise to a clean latent vector:
\[x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon\]- where:
- \(x_0\): clean latent image patch.
- \(x_t\): noisy version of \(x_0\) at timestep \(t\).
- \(\bar{\alpha}_t = \prod_{s=1}^{t}(1 - \beta_s)\): cumulative product of the noise schedule.
- \(\epsilon \sim \mathcal{N}(0, I)\): sampled Gaussian noise.
- where:
-
This process is implemented efficiently using the closed-form reparameterization trick that allows sampling \(x_t\) in a single step from \(x_0\).
Reverse Denoising Loss
-
The model learns to predict the noise added to each patch via a regression loss:
\[\mathcal{L}_{\text{DDPM}} = \mathbb{E}_{x_0, t, \epsilon} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c) \|^2 \right]\]- where:
- \(x_t\): the noised patch latent at timestep \(t\).
- \(\epsilon\): the actual Gaussian noise added to \(x_0\).
- \(\epsilon_\theta(x_t, t, c)\): model’s prediction of the noise, conditioned on:
- \(t\): diffusion step.
- \(c\): optional context (e.g., text prompt or prior image patches).
- \(\| \cdot \|^2\): squared L2 loss.
- where:
-
This loss is computed per image, i.e., across all patches in a given BOI–EOI block, rather than per patch token.
Visualizing the Forward and Reverse Diffusion Process
- The following figure (source) illustrates the forward (noising) and reverse (denoising) trajectories used in image patch training.
![]()
- These trajectories are applied in latent space using the VAE-compressed patch representations, allowing for highly efficient image generation.
Noise Schedule and Timestep Sampling
-
Transfusion and Rolling Diffusion both use cosine noise schedules or linear beta schedules to determine \(\beta_t\), which controls how much noise is added at each step.
-
Common schedule:
\[\bar{\alpha}_t = \cos^2 \left( \frac{t}{T} \cdot \frac{\pi}{2} \right)\]- At early steps (low \(t\)), noise is minimal → easier samples.
- At later steps (high \(t\)), noise increases → training becomes more challenging.
-
Timestep sampling is typically uniform or importance-weighted during training.
Training Considerations
- Gradient accumulation is used to manage large batches.
- Mixed-precision (bf16 or fp16) training improves memory efficiency.
- Modality-specific loss masking ensures that:
- No LM loss is applied on latent vectors.
- No DDPM loss is applied on text tokens.
- Each batch may contain:
- Pure text-only sequences.
- Text+image sequences.
- Image→text (captioning) samples.
- Fully interleaved documents.
Diffusion-Specific Training Behavior
- During diffusion training:
- The Transformer conditions on the sequence up to the current patch (text or earlier patches).
- The patch tokens themselves are noisy latents corresponding to time \(t\).
- The model predicts noise vectors \(\epsilon\), rather than predicting the patch directly.
- Additional training details:
- The timestep \(t\) is uniformly sampled during training.
- A sinusoidal or learnable embedding of \(t\) is added to the patch embedding.
- Teacher forcing is used: the target for each patch is the actual noise \(\epsilon\) added during the forward step.
Training Stability and Loss Balancing
- Chameleon’s findings with regarding to training stability were:
- Modality mismatch in entropy can cause training instability.
- To stabilize training across text and image losses, Chameleon uses:
- Query-Key Normalization (QK-Norm)
- z-loss regularization to prevent logit drift
- Dropout after attention and MLP layers
- In GPT-4o, which avoids discretization, many of these issues are naturally mitigated by:
- Lower entropy in continuous patch outputs (no softmax required)
- Separate loss paths for text (cross-entropy) and images (regression)
- However, hyperparameter tuning (especially for \(\lambda\)) remains critical, as over-weighting the image loss can reduce text fluency, and vice versa.
Diffusion Sampling and Row-by-Row Decoding with Rolling Diffusion
-
At inference time, GPT-4o must efficiently convert generated image patch latents into full high-fidelity images. While standard diffusion models typically denoise all image latents in parallel across multiple timesteps, GPT-4o likely adopts the Rolling Diffusion strategy to enable streamed, row-by-row decoding that scales more effectively for long, multimodal sequences and supports causal generation patterns.
-
Rolling Diffusion introduces a method for performing sequential denoising over spatial dimensions by reparameterizing diffusion time as a function of patch location. GPT-4o can incorporate this technique to match its autoregressive constraint while still benefiting from the high fidelity of diffusion-based image synthesis.
Motivation for Rolling Diffusion
-
The traditional DDPM sampling procedure expects to denoise an entire latent grid \(z \in \mathbb{R}^{n \times d}\) in parallel across all patches at every timestep \(t \in \{T, T-1, ..., 1\}\). While effective for static image generation, this method is incompatible with:
- Autoregressive token emission (GPT-4o generates patch tokens one-at-a-time or in segments).
- Streaming generation (e.g., real-time interleaved image + text outputs).
- Memory constraints (sampling all latents at every step is expensive for long sequences).
-
To address these constraints, Rolling Diffusion proposes a local, position-aware reparameterization of the diffusion schedule, allowing for sequential (e.g., row-wise or patch-wise) generation.
Local Time Reparameterization
-
In Rolling Diffusion, the noise schedule is made spatially dependent. Instead of a global timestep \(t\) being applied uniformly across all patches, a position-adjusted local timestep \(t_k\) is computed for each patch \(k\):
\[t_k = \frac{k + t}{W}\]- where:
- \(k\): index of the patch in the current image sequence.
- \(W\): total number of patches in a denoising window (e.g., a row).
- \(t\): global diffusion timestep.
- \(t_k\): adjusted timestep for patch \(k\) — later patches receive more noise.
- where:
-
This creates a rolling schedule, where denoising sweeps over the image spatially, producing cleaner outputs as we progress.
-
The following figure (source) visualizes the global rolling diffusion process and its local time reparameterizatiod in Rolling Diffusion. The global diffusion denoising time \(t\) (vertical axis) is mapped to a local time \(t_{k}\) for a frame \(k\) (horizontal axis). The local time is then used to compute the diffusion parameters \(α_{tk}\) and \(σ_{tk}\) . On the right, we show how the same local schedule can be applied to each sequence of frames based on the frame index \(w\). The nontrivial part of sampling the generative process only occurs in the sliding window as it gets shifted over the sequence.
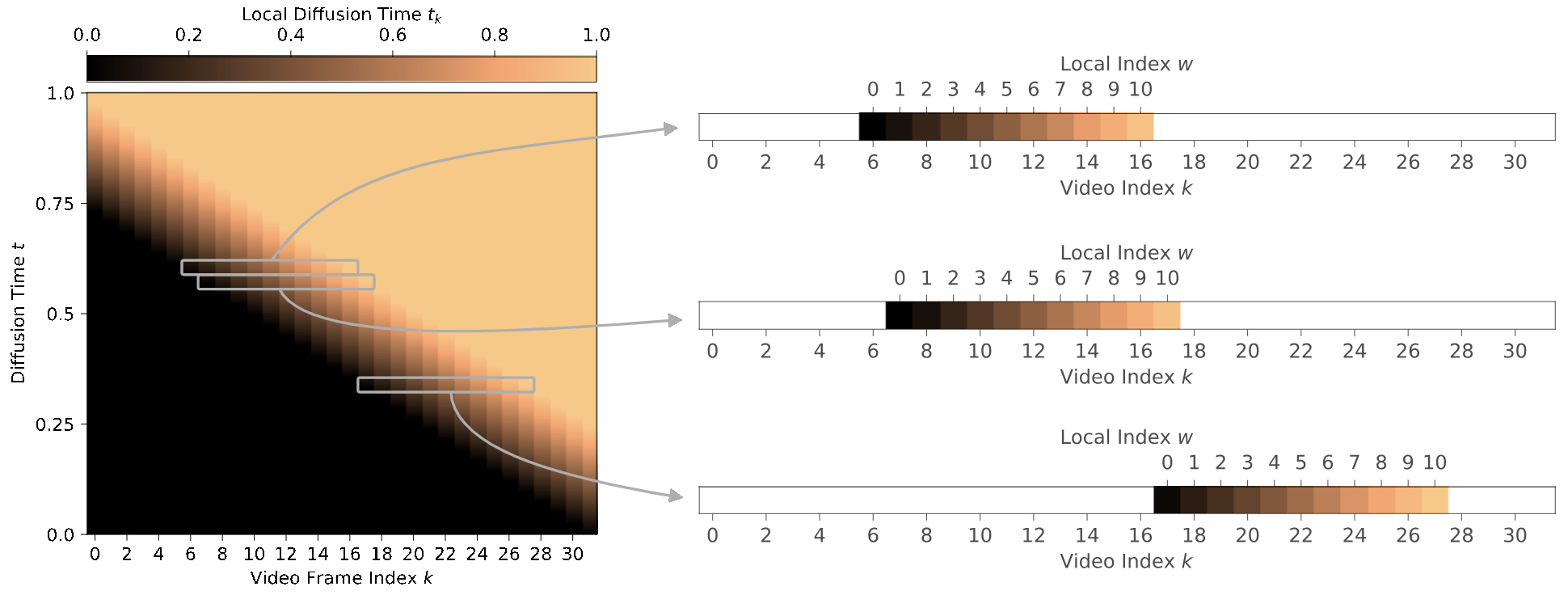
- This strategy enables the model to denoise and emit patches incrementally, staying in line with GPT-4o’s autoregressive framework.
Reverse Process with Rolling Denoising
-
The reverse step in Rolling Diffusion is a modification of the standard DDPM reverse equation, adapted to patch-wise sequential generation. For a given patch \(x_t^k\), the denoised value is computed as:
\[x_{t_k - 1}^k = \frac{1}{\sqrt{\alpha_{t_k}}} \left(x_{t_k}^k - \frac{1 - \alpha_{t_k}}{\sqrt{1 - \bar{\alpha}_{t_k}}} \epsilon_\theta(x_{t_k}^k, t_k)\right) + \sigma_{t_k} z\]- where:
- \(x_{t_k}^k\): current noisy latent patch at local time \(t_k\).
- \(\alpha_{t_k}, \bar{\alpha}_{t_k}\): noise schedule parameters for local time \(t_k\).
- \(\epsilon_\theta(\cdot)\): model’s predicted noise for patch \(k\) at that timestep.
- \(\sigma_{t_k}\): scale of Gaussian noise reintroduced at that step.
- \(z \sim \mathcal{N}(0, I)\): noise sampled per step.
- where:
-
Only a subset of patches (e.g., the current row) is denoised at each step. Previously denoised patches can be cached and fed as context to subsequent steps, allowing generation to proceed efficiently and causally.
Loss Function for Windowed Denoising
-
During training, a corresponding localized loss function is used. The model learns to predict noise for only the patches in the current window:
\[\mathcal{L}_{\text{win}, \theta} = \sum_{k \in \text{win}(t)} a(t_k) \left\| x_0^k - \hat{x}_0^k \right\|^2\]- where:
- \(\text{win}(t)\): the window of patches being denoised at time \(t\).
- \(a(t_k)\): time-dependent weighting function (e.g., based on signal-to-noise ratio).
- \(x_0^k\): the original clean patch.
- \(\hat{x}_0^k\): reconstruction from model prediction at local time \(t_k\).
- where:
-
This loss ensures the model focuses on the most relevant patches per step, keeping memory and compute cost bounded.
-
The following figure (source) illustrates the patchwise rolling denoising trajectory across a spatial image grid.

Application in GPT-4o
-
For GPT-4o, this decoding strategy offers key advantages:
- Autoregressive compatibility: Image patch latents can be denoised and emitted progressively, matching the causal output loop used for text.
- Streaming images: Patches can be rendered in order (e.g., row-by-row), enabling real-time visualization.
- Low memory footprint: Only a small working set of patches needs to be active at any timestep.
-
In practice, GPT-4o may emit an entire image patch block after denoising it through a rolling window and follow it immediately with an
<EOI>token. The decoder (a VAE) then reconstructs the final image from these denoised latents. -
This technique bridges the gap between diffusion model fidelity and language model autoregressiveness, which is essential for GPT-4o’s seamless multimodal output behavior.
Image Rendering, VAE Decoding, and Final Output Construction
- Once GPT-4o has generated the full sequence of image patch latents via its Transformer and diffusion mechanism, the model must decode these latent vectors back into a viewable RGB image. This is handled by a VAE decoder, a lightweight, trainable module that transforms low-dimensional continuous vectors into pixel-level outputs.
- This final rendering step is crucial for preserving image fidelity while maintaining the compactness and speed of latent-space generation. GPT-4o appears to follow the Transfusion decoder architecture, optionally incorporating elements from Rolling Diffusion to support structured decoding and temporal conditioning.
Patch Sequence to Latent Grid Reconstruction
-
During inference, the generated image latents take the form:
\[[z_1, z_2, \ldots, z_n] \in \mathbb{R}^{n \times d}\]- where:
- \(n\): total number of patches (e.g., 256 for 16×16 grid)
- \(d\): latent dimensionality (e.g., 8, 16, 32)
- where:
-
These vectors are arranged into a 2D grid, respecting the original spatial layout (top-to-bottom, left-to-right). This patch grid corresponds to the output size of the VAE encoder and serves as input to the decoder.
-
The process likely follows the same flow as in Transfusion which utilizes the VAE encoder and decoder stack used to convert raw images into latent patch tokens and reconstruct them into RGB space, as indicated above.
VAE Decoder Architecture
-
The decoder architecture used in GPT-4o, as suggested in the Transfusion paper, is a lightweight convolutional U-Net-style upsampler. It transforms the compact latent representation into a high-resolution image by progressively upsampling the spatial dimensions.
- Key components:
- Residual blocks: for nonlinear transformation at each resolution level.
- Transposed convolutions or upsampling layers: to increase resolution step-by-step.
- Group norm or layer norm: to stabilize training.
- Tanh output layer: to clamp output pixel values to \([-1, 1]\).
- Optional additions:
- Timestep embedding conditioning (used in diffusion guidance)
- Cross-attention from prompt tokens (used in conditional generation settings)
Note: In higher-fidelity settings, the decoder can include U-Net Up Blocks trained jointly with the Transformer, as done in the 7B Transfusion model.
Post-Processing and Image Reconstruction
- The final output of the decoder is a 3-channel image tensor:
- Typically with \(H = W = 256\), depending on the training resolution.
- The image tensor is post-processed as follows:
- De-normalized from \([-1, 1]\) to \([0, 255]\)
- Optionally converted from
float32touint8 - Converted to standard formats (e.g., PNG, JPEG) for rendering or output
- This step is generally handled outside the transformer loop and is purely feedforward — it does not influence subsequent text or image token generation.
Image Completion and the <EOI> Token
-
The end of an image block is marked by the generation of the special
<EOI>token:- Signals the termination of image patch generation.
- Tells the decoding pipeline to finalize the image rendering process.
- Triggers a switch back into language modeling mode in the autoregressive loop.
- The presence of
<EOI>ensures the image is fully delimited in the sequence, allowing for:- Clear boundaries for downstream token processing.
- Multimodal alternation: image → text → image → etc.
- This enables GPT-4o to support rich multimodal document generation, including captioned illustrations, inline graphics in essays, or visual dialogue.
Training Considerations for the Decoder
-
The decoder is usually pretrained before GPT-4o training, then frozen during Transformer training to reduce complexity and ensure latent consistency. Transfusion converts images to and from latent representations using a pretrained VAE, and then into patch representations with either a simple linear layer or U-Net down blocks.
-
However, in large-scale setups (e.g., 7B models trained on 2T tokens), joint fine-tuning of the decoder (especially U-Net blocks) has been shown to improve visual fidelity and compression robustness. GPT-4o likely adopts a hybrid regime:
- Pretrain the decoder on reconstruction loss.
- Fine-tune with frozen weights for initial scaling.
- Unfreeze for high-fidelity final-stage training.
Integration with Text Generation and Modality Interleaving
- One of GPT-4o’s defining capabilities is its ability to fluidly interleave text and image generation within a single autoregressive sequence. Unlike systems that bolt image generation onto a language model via tool use (e.g., DALL·E via API calls), GPT-4o treats image output as native to the model, making text and image generation indistinguishable from the perspective of the transformer.
- This section describes how modality interleaving is achieved, how control tokens like
<BOI>and<EOI>are used to guide generation modes, and how causal context is preserved across transitions.
Text and Image Blocks in the Token Stream
- GPT-4o generates output one token at a time. The stream can switch modalities at any position. For example:
["A majestic mountain."] → `<BOI>` [latent image patches] `<EOI>` → ["It’s located in the Himalayas."]
- Each mode (text vs. image) is identified in the token sequence using modality markers:
<BOI>(Begin of Image): triggers image generation.<EOI>(End of Image): signals end of image patch output.- Everything in between is treated as continuous latent vectors.
- Everything before/after is discrete tokens from the language model vocabulary.
- The process of how sequences are constructed with interleaved modalities using BOI and EOI tokens likely follows the proposal in the Transfusion architecture. The model learns to recognize modality boundaries and adapt its behavior accordingly.
Mode Switching During Generation
- GPT-4o dynamically switches between two operational modes:
Text Mode (Language Modeling)
- Activated when generating text tokens.
- Uses a causal transformer with next-token prediction.
- Continues until
<BOI>is generated or the sequence ends.
Image Mode (Diffusion Sampling)
- Activated when
<BOI>is emitted. - The model stops predicting from a vocabulary and begins predicting continuous latent vectors.
- These vectors are initialized as Gaussian noise and refined via diffusion over a fixed number of steps \(T\).
-
Ends when
<EOI>is generated. - This switching behavior is governed by a decoding algorithm that alternates between LM and DDPM decoding based on token type, likely similar to Transfusion’s decoding algorithm which switches between two modes: LM and diffusion. Once the diffusion process has ended, they append an EOI token to the predicted image and switch back to LM mode.
Causal Context Preservation
-
GPT-4o ensures that text and image blocks are causally conditioned on all preceding content, whether textual or visual.
- Examples:
- Text following an image can reference or describe it.
- An image generated after text is conditioned on the preceding caption.
- Each image block is self-contained: patch latents can attend bidirectionally to each other but only causally to tokens or images that came before it.
- This is implemented through carefully crafted attention masks, as discussed in sec3.
Prompt-Image Conditioning (Text → Image)
- When generating an image from a prompt:
- The text prompt (tokens before
<BOI>) is encoded using standard transformer self-attention. - The image patch generation is conditioned on these tokens via cross-attention and contextual embeddings.
- During diffusion, the image patch latents attend to the prior text but not to future tokens.
- The text prompt (tokens before
- This setup allows GPT-4o to:
- Translate rich textual descriptions into images.
- Preserve alignment between prompt and image content.
- Achieve strong CLIP alignment and FID scores, as shown in Transfusion benchmarks.
Captioning (Image → Text)
- When generating text from an image:
- The model first decodes image patches between
<BOI>and<EOI>. - These continuous patch vectors are processed and embedded into the transformer’s sequence.
- The next set of tokens is predicted autoregressively, using both the prior text and the embedded image as context.
- The model first decodes image patches between
- This approach allows GPT-4o to perform tasks such as:
- Descriptive captioning
- Scene understanding
- Visual question answering
- The following figure (source) shows examples of multimodal prompts and outputs generated by the Transfusion model, demonstrating text-to-image and image-to-text switching.
![]()
- GPT-4o likely uses a similar decoding structure, with image tokens generated via latent diffusion and text tokens sampled autoregressively.
Multimodal Documents and Interleaved Outputs
- GPT-4o can produce long-form documents with alternating modalities, such as:
["Here’s the blueprint:"] → `<BOI>` [Image 1] `<EOI>` → ["Let’s annotate it."] → `<BOI>` [Image 2] `<EOI>` → ["These two diagrams are connected."]
-
The autoregressive transformer handles the entire sequence uniformly, switching losses and decoding behavior based on token type. The use of shared embedding dimensions and positional encodings ensures continuity across modalities.
-
This makes GPT-4o one of the first models capable of natively authoring mixed-media content without needing external rendering calls or modality-specific submodels.
Architectural Scaling, Training Regimes, and Implementation Strategy
- The success of GPT-4o’s native multimodal generation hinges not only on its model design but also on scalable training, modality-balanced data sampling, and careful loss orchestration across discrete and continuous domains. The techniques described in both the Transfusion and Chameleon papers offer a glimpse into how GPT-4o might have been trained at scale to support both text and image generation in a unified Transformer.
Model Scaling and Configuration
-
GPT-4o likely follows a Transformer architecture family similar to what is presented in Transfusion Section 4.1, with models ranging from hundreds of millions to multiple billions of parameters. These configurations balance depth, width, and attention granularity for scalable multimodal modeling.
-
The following figure (source) lists the model sizes and layer configurations used in Transfusion’s experimental suite, which GPT-4o’s variants likely resemble.
![]()
| Parameter Count | Layers | Embedding Dim | Attention Heads |
|---|---|---|---|
| 0.16B | 16 | 768 | 12 |
| 0.37B | 24 | 1024 | 16 |
| 0.76B | 24 | 1536 | 24 |
| 1.4B | 24 | 2048 | 16 |
| 7B | 32 | 4096 | 32 |
- These architectures are LLaMA-style transformers with the following enhancements:
- SwiGLU activation (nonlinearity with gating)
- RoPE (rotary positional encoding) for long-range sequence coherence
- RMSNorm or LayerNorm pre-norm configurations
- Modality-shared attention and MLP layers
Training Data: Multimodal Sampling Strategy
-
GPT-4o is likely trained on a mixture of text and image-caption pairs, maintaining balance across modalities for every batch. Transfusion samples 0.5T tokens (patches) from two datasets at a 1:1 token ratio. For text, it uses the LLaMA 2 tokenizer and corpus. For images, it uses 380M Shutterstock images and captions, with each image resized to 256×256 resolution.
- To achieve 2T tokens total (as in the final 7B model), Transfusion also:
- Includes additional public image-caption datasets (e.g., CC12M)
- Upsamples images of people to improve diversity
- Uses 1T text tokens + ~1T image patches over 3.5B image-caption pairs
- This aligns with GPT-4o’s capability to handle high-quality images and a broad range of visual concepts.
Training Objectives and Scheduling
- As detailed in earlier sections, GPT-4o uses:
- Language modeling loss for discrete tokens
- Diffusion loss for continuous image patches
- These are combined with a scalar \(\lambda\) to control balance. In Transfusion, this was statically set, but in practice could be:
- Scheduled dynamically (e.g., curriculum-based)
- Modality-dependent (e.g., based on image size or patch count)
- GPT-4o likely employs a curriculum-based warmup where early training emphasizes text (to stabilize generation) and gradually incorporates image diffusion.
Optimizer and Hyperparameter Choices
-
Implementation parameters drawn from Transfusion and Chameleon include:
- Optimizer: AdamW
- Learning rate: 1e-4 with cosine decay
- Weight decay: 0.1
- Gradient clipping: 1.0 (global norm)
- Batch size: 1M tokens per batch (including both modalities)
- Dropout: 0.1 after attention and MLP layers
- Precision: bfloat16 or mixed-precision (depending on TPU/GPU setup)
-
Regularization and stabilization strategies used in GPT-4o may include:
- z-loss: prevents logit drift in softmax vocab predictions (used in Chameleon)
- Query-Key Normalization (QK-Norm): stabilizes attention variance between text and image blocks
- DropToken augmentation: probabilistically masking tokens to improve robustness
Discretization Ablation and Transfusion Superiority
- The following figure (source) compares the performance of Transfusion (continuous latents) vs. Chameleon (discrete tokens) on MS-COCO in terms of FID and CLIP scores.
![]()
- Findings relevant to GPT-4o:
- Transfusion achieves 2× better FID with less than 1/3 the compute.
- Transfusion outperforms Chameleon on text-to-image and image-to-text tasks.
- Discretization in Chameleon introduces a fidelity bottleneck that GPT-4o avoids by operating on continuous latents.
- Thus, GPT-4o’s use of native VAE-based latent patch generation offers significant quality advantages and better scaling.
Summary of Design Decisions and Forward-Looking Considerations
- GPT-4o’s native image generation capabilities represent a major advancement in multimodal foundation models. This section recaps the design choices that enable such functionality and outlines how these ideas can naturally extend beyond static images to richer modalities, including video, audio, and fully interactive visual dialogue.
Unified Modality Architecture
- GPT-4o is built on a single transformer backbone that processes and generates:
- Discrete text tokens via autoregressive language modeling.
- Continuous image latents via diffusion-based denoising.
- Modality switch tokens (
<BOI>,<EOI>) for toggling modes.
- This architecture eliminates the need for modality-specific submodules (e.g., separate encoders for text and vision), and instead relies on:
- Shared attention and MLP blocks.
- Modality-specific projection layers at input/output boundaries.
- A unified token stream, processed in the same way regardless of content.
- This unified design facilitates seamless interleaving of text and images, supporting applications like:
- Image captioning and generation.
- Multimodal dialogue (e.g., ask–show–explain).
- Structured document synthesis (e.g., scientific reports with figures).
Diffusion as the Bridge for Continuous Generation
-
GPT-4o adopts latent-space diffusion (inspired by Transfusion and Rolling Diffusion) rather than pixel-space generation or discrete-token prediction for images.
- Key benefits:
- Higher fidelity: avoids quantization artifacts found in Chameleon-style VQ-VAEs.
- Lower compute: denoising small patch sequences in latent space is cheaper than pixel-level modeling.
- Scalability: enables partial image generation (e.g., streaming rows), real-time visualization, and flexible conditioning.
- Rolling Diffusion adds further optimizations by enabling windowed denoising and row-wise patch rollout, aligning perfectly with GPT-4o’s causal transformer nature.
Comparison to Chameleon: Design Tradeoffs
-
Chameleon takes a different approach: it discretizes all inputs, including images, into a shared token vocabulary. While elegant in its simplicity, this introduces performance tradeoffs.
-
The following figure (source) shows an example of a mixed-modality sequence generated by Chameleon, highlighting its early-fusion token strategy.
- In contrast, GPT-4o:
- Preserves image fidelity by avoiding quantization.
- Uses separate objectives (LM + DDPM) for each modality, improving specialization.
- Adds complexity (e.g., diffusion decoder, special scheduling), but yields significantly better results.
- The Transfusion vs. Chameleon benchmarks in Section 8 demonstrate this tradeoff clearly: Transfusion (and by extension, GPT-4o) achieves lower FID, higher CLIP, and better sample quality at a fraction of the compute cost.
Extensibility to Future Modalities
- The architecture of GPT-4o is modality-general. The principles underpinning its design extend naturally to other types of data:
Video
- Frame sequences could be encoded as patch-latent stacks (spatial × temporal).
- Rolling Diffusion already proposes local time reparameterization, which can extend to temporal denoising over time windows.
- A special
<BOV>(Begin of Video) /<EOV>(End of Video) token could delimit video segments.
Audio
- Spectrograms or compressed audio latents can be modeled as 2D or 1D patch sequences.
- A transformer trained with autoregressive audio modeling (or diffusion in latent audio space) could be interleaved similarly.
3D and Scene Graphs
- With continuous patch embeddings, the model could handle voxels, mesh descriptors, or point clouds.
- Scenes can be represented in latent blocks similar to image rows.
GPT-4o as a Foundation for Future Multimodal Interfaces
- By tightly integrating continuous and discrete modalities in a single model with a flexible generation schedule, GPT-4o opens the door to:
- Visual conversational agents: fluent alternation between showing and telling.
- Interactive UIs: generating forms, diagrams, buttons, and text inline.
- Multimodal programming assistants: generating UI previews alongside code.
- Multimodal retrieval and synthesis: combining structured and unstructured inputs in a cohesive output.
- Its design demonstrates that multimodal intelligence doesn’t require stitching separate models together — it can emerge from co-trained, loss-specialized Transformers with unified autoregressive behavior.
Evaluation, Sample Quality, and Benchmark Comparisons
- To assess the effectiveness of GPT-4o’s image generation capabilities, we must examine how similar architectures — notably Transfusion and Chameleon — are evaluated on standard benchmarks. This section outlines the key metrics used, presents comparative performance results, and discusses sample quality in the context of multimodal generative tasks.
Evaluation Metrics for Image Quality and Prompt Alignment
- The two most commonly used metrics for evaluating generated images in research literature are:
FID (Fréchet Inception Distance)
- Measures the distributional distance between generated images and real ones.
- Lower is better.
- Evaluated using InceptionNet features extracted from real vs. generated images.
CLIP Score
- Measures semantic alignment between a prompt and generated image.
- Higher is better.
-
Computed as cosine similarity between CLIP embeddings of image and prompt.
- Additional metrics sometimes used:
- IS (Inception Score): assesses realism and diversity.
- Rec (Reconstruction error): for conditional generation.
- Human preference studies: for qualitative evaluations.
Transfusion Benchmark Performance
-
Transfusion conducted comprehensive evaluations on MS-COCO and other standard datasets, using the above metrics.
-
The following figure (source) summarizes Transfusion’s performance in terms of FID and CLIP across multiple model sizes.
![]()
- Key results:
- Transfusion achieves significantly lower FID than Chameleon and TokenT5.
- CLIP scores are highly competitive, often within 1–2% of DALL·E-2-style models.
- Latent-space generation outperforms discrete-token-based generation in every modality pair (text → image, image → text, mixed).
- These findings support GPT-4o’s use of continuous latent modeling and validate the choice of diffusion over discrete token generation.
Chameleon Performance Snapshot
-
Chameleon also provides evaluation metrics, with a focus on token-level performance across mixed-modality tasks.
-
The following figure (source) shows Chameleon’s mixed-modality prompt evaluation interface, which combines image and text inputs/outputs for qualitative inspection.
- Despite its simplicity and elegant early-fusion architecture, Chameleon’s discrete tokenization bottleneck reduces image fidelity:
- FID lags behind continuous-latent systems.
- CLIP alignment drops for high-resolution prompts with subtle details.
- Qualitative outputs exhibit blocky or aliased textures.
Implications for GPT-4o Evaluation
- GPT-4o likely exceeds the performance of Transfusion in production settings, for several reasons:
- More diverse training data: potentially 10× larger corpora.
- Better CLIP alignment: via joint training or distillation with ViT-G or similar.
- Optimized VAE + transformer co-training: for tighter compression-reconstruction fidelity.
- In-the-loop human evaluation: as used in OpenAI model alignment protocols.
- Furthermore, GPT-4o could support interactive sampling metrics:
- Generation speed vs. quality tradeoffs.
- Streaming patch visualizations.
- Row-wise FID or CLIP at intermediate decoding stages.
- These capabilities would place GPT-4o in a different regime of evaluation: less about pure realism, and more about pragmatic coherence, prompt control, and user-alignment.