Primers • FlashAttention
- Motivation & Background
- FlashAttention‑1
- FlashAttention‑2
- FlashAttention‑3
- Comparative Analysis
- Accuracy Trade-offs, Practical Considerations, and Integration Guidance
- Performance Benchmarks, Code Integration Examples, and Tuning Tips
- Code Walkthroughs for Custom Head-Dimension & Long‑Sequence Optimization
- Best Practices/Recommendations
- Deep Dive into Softmax Streaming and I/O Complexity Analysis
- Integration with Modern Frameworks and Benchmark Scripts
- References
- Citation
Motivation & Background
-
Introduced in FlashAttention: Fast and Memory‑Efficient Exact Attention with IO‑Awareness by Dao et al. (2022), FlashAttention aims to dramatically speed up Transformer-style attention on GPUs while simultaneously reducing memory usage.
-
Standard self-attention scales poorly with sequence length \(N\), because it computes the full \(N \times N\) attention matrix and performs \(O(N^2 \cdot d)\) operations and memory storage. Especially on long-context models, both compute and memory usage balloon. Existing approximate methods (e.g., Linformer, Performer) often sacrifice accuracy or fail to deliver wall-clock improvements in practice due to GPU inefficiencies.
FlashAttention’s core insight is IO-awareness: recognizing that the primary performance bottleneck on GPUs is not floating-point operations (FLOPs), but data movement between high-bandwidth memory (HBM) and the on-chip cache (SRAM/registers). Rather than optimizing just the computation, FlashAttention restructures the memory access pattern. It tiles the attention computation into blocks that fit entirely in SRAM and processes them sequentially, drastically reducing expensive off-chip memory traffic. Crucially, it recomputes certain intermediate values (like softmax normalization constants) rather than storing them, which is cheaper than reading from HBM.
- The following figure (source) shows a comparison between standard attention and FlashAttention, showing how FlashAttention reduces memory reads/writes by fusing operations into fewer memory transactions.
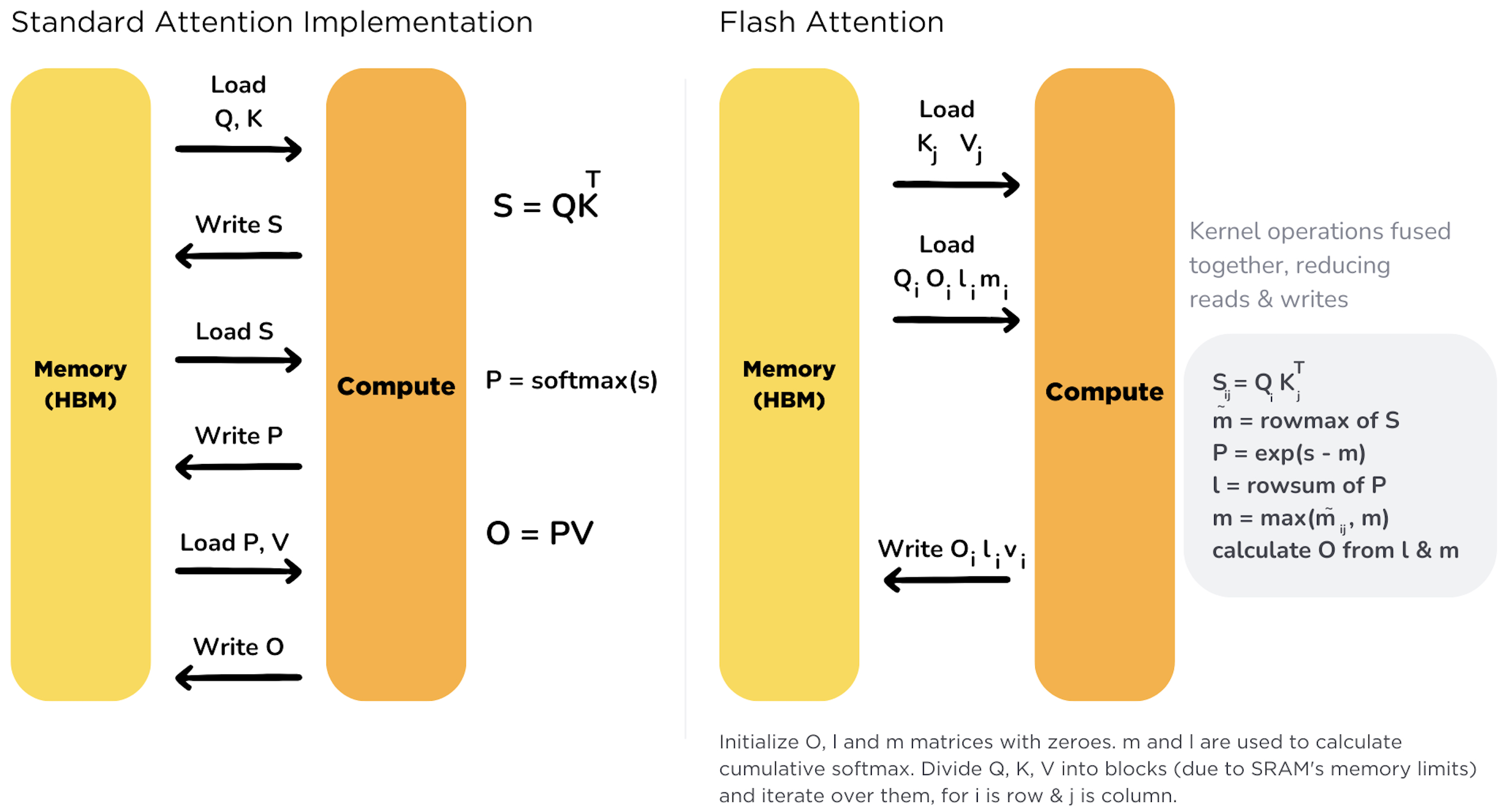
-
This design leads to exact attention results (unlike approximations) while achieving linear memory growth in \(N\), thanks to never materializing the full attention matrix. The implementation uses kernel fusion to combine operations like QKᵀ matmul, masking, softmax, and dropout into a single CUDA kernel, minimizing inter-kernel launch overhead and avoiding unnecessary memory round trips.
- Key benefits documented:
- Up to 3× speedup on GPT‑2 (seq = 1K),
- 15% end‑to‑end speedup on BERT‑large (seq=512) compared to MLPerf baselines,
- Ability to handle much longer contexts (1K–64K) with viable accuracy gains.
- Mathematically, given queries \(Q \in \mathbb{R}^{N \times d}\), keys \(K\) and values \(V\), FlashAttention splits into tile blocks of size \(B\) and loops:
- … but never materializes the full \(N \times N\) logits matrix. Instead it processes blocks of \(K, V\), accumulates partial results, and recomputes necessary maxima for numerically stable softmax. The I/O complexity is shown to be optimal for typical on‑chip cache sizes within constant factors.
- This background establishes the rationale: attention is memory‑bound; FlashAttention removes the bound by reordering computation; yields real speed and memory improvements with no approximation.
FlashAttention‑1
-
FlashAttention‑1 employs an I/O‑aware attention algorithm optimized for GPU memory hierarchy, targeting the true bottleneck in transformer workloads: memory bandwidth rather than pure computation (FLOPs).
-
The figure below from the paper shows: (Left) FlashAttention uses tiling to prevent materialization of the large \(N \times N\) attention matrix (dotted box) on (relatively) slow GPU HBM. In the outer loop (red arrows), FlashAttention loops through blocks of the \(K\) and \(V\) matrices and loads them to fast on-chip SRAM. In each block, FlashAttention loops over blocks of \(Q\) matrix (blue arrows), loading them to SRAM, and writing the output of the attention computation back to HBM. Right: Speedup over the PyTorch implementation of attention on GPT-2. FlashAttention does not read and write the large \(N \times N\) attention matrix to HBM, resulting in a 7.6× speedup on the attention computation.
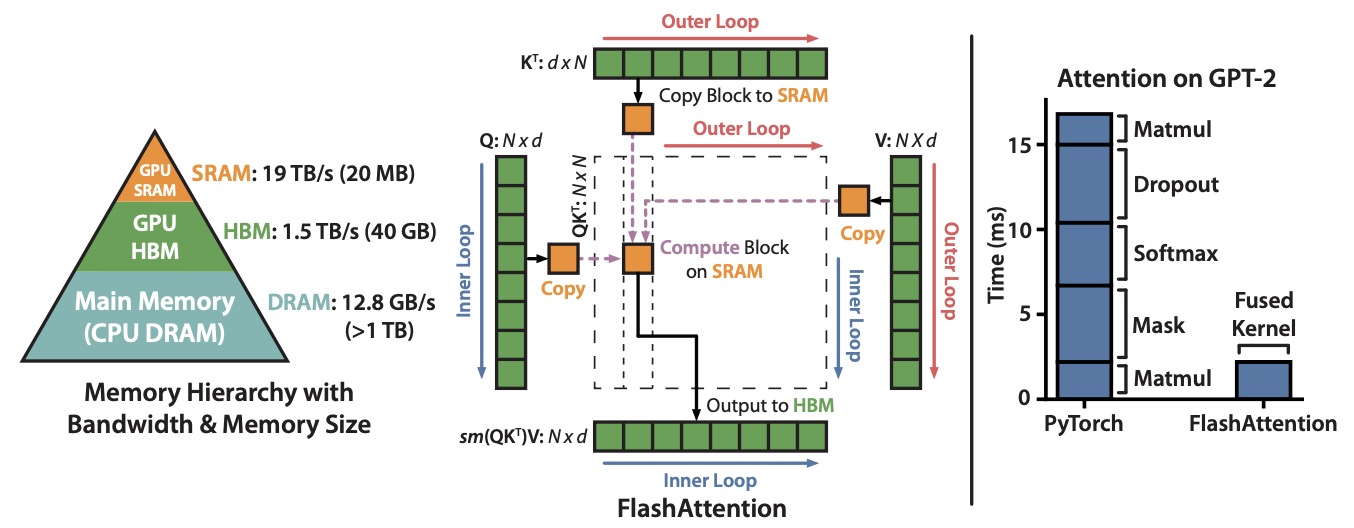
CUDA kernel fusion
-
A single fused kernel handles all stages: \(QK^T\), mask, softmax, dropout, and final multiply by \(V\). This eliminates repeated reads/writes between GPU HBM and SRAM that occur when separating stages.
-
This kernel fusion not only reduces inter-stage memory traffic but also eliminates kernel launch overhead, which is non-negligible in high-frequency, short-duration GPU operations. As noted in community discussions, launching multiple kernels individually incurs scheduling and memory synchronization costs, which FlashAttention’s fusion avoids.
-
Tensors \(Q, K, V\) are partitioned into small fixed-size blocks that fit into on-chip SRAM or registers. A block of \(K, V\) is loaded once; loops iterate over corresponding \(Q\) blocks.
Tiling and recomputation strategy
- Attention calculation is expressed as:
-
… but the algorithm avoids materializing the full \(N \times N\) matrix. Instead, it breaks the computation into tiles of size \(B\). For each block of queries \(Q_{i}\) and key-value \(K_{j}, V_{j}\), it computes partial attention contributions.
-
As described in blog explanations, these tiles are sized so they fit entirely within a single Streaming Multiprocessor’s shared memory (SRAM). This ensures efficient compute on GPU warps and avoids uncoalesced memory accesses.
-
To handle numerical stability of softmax without storing all logits, it recomputes per-block max and sum for normalization. Intermediate maxima and scaling factors (like cumulative \(m_i\), \(l_i\)) are merged across tiles as:
- … with streaming updates across blocks to form the final output. This limits memory to \(O(N \cdot d)\) instead of \(O(N^2)\). According to the Medium explanation, this recomputation is cheaper than storing full logits, thanks to the high arithmetic intensity of GPUs and the low cost of on-chip computation compared to HBM I/O.
I/O analysis
-
Standard attention requires \(O(N^2)\) reads/writes to HBM (compute and softmax across full matrix). In contrast, FlashAttention performs only \(O(N \cdot d)\) accesses, asymptotically optimal within constant factors for realistic SRAM sizes.
-
As clarified on Reddit, this does not reduce theoretical time complexity, but it dramatically reduces practical runtime by targeting the memory bottleneck—the true limiting factor on GPU workloads. One commenter summarized: “It’s faster because GPUs are memory bottlenecked, not because it has better time complexity.”
GPU memory hierarchy exploitation
-
Blocks are sized so \(B \times d\) fits in on-chip SRAM (e.g. 128–256 KB per SM). Each streaming multiprocessor processes local tiles entirely within onboard SRAM and registers before writing back to HBM.
-
The Medium blog emphasizes that FlashAttention’s memory access pattern is carefully optimized to be GPU-friendly: row-major loading, coalesced access, and tight loop tiling. This results in high bandwidth utilization and reduced memory stalls.
-
By reducing trips between SRAM and HBM, FlashAttention becomes memory-bandwidth–bound less often and thus achieves wall‑clock speedups.
Performance observations
-
Benchmarks show 3× speed on GPT-2 with sequence length 1K, and 15% end‑to‑end speedup on BERT-large with seq = 512 compared to MLPerf baseline implementations.
-
Moreover, it enables context lengths up to 64K (e.g. Path-X and Path-256 tasks) with stronger downstream performance, which would otherwise exceed memory constraints.
-
Importantly, this performance improvement holds without any approximation—FlashAttention computes the exact same result as standard attention, just with dramatically lower overhead.
Summary
-
FlashAttention‑1 centers around a fused CUDA kernel combining all stages of attention.
-
It partitions \(Q, K, V\) into SRAM-sized tiles, recomputes necessary normalization for softmax to avoid full \(N^2\) storage, and accumulates partial results efficiently.
-
This IO-centric design achieves lower memory traffic and faster runtime than naive or approximate alternatives, while preserving exact attention results.
-
Its practical optimizations—tiling, kernel fusion, recomputation, and warp-efficient softmax—make it the first attention algorithm to fully align with the GPU’s memory architecture for real-world performance gains.
FlashAttention‑2
-
Introduced in FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning by Dao et al., FlashAttention‑2 builds upon the original version by optimizing work partitioning and parallelism to approach high GPU utilization.
-
The following figure from the paper shows that FlashAttention-2 parallelize the workers (thread blocks) in the forward pass (left) where each worker takes care of a block of rows of the attention matrix. In the backward pass (right), each worker takes care of a block of columns of the attention matrix.
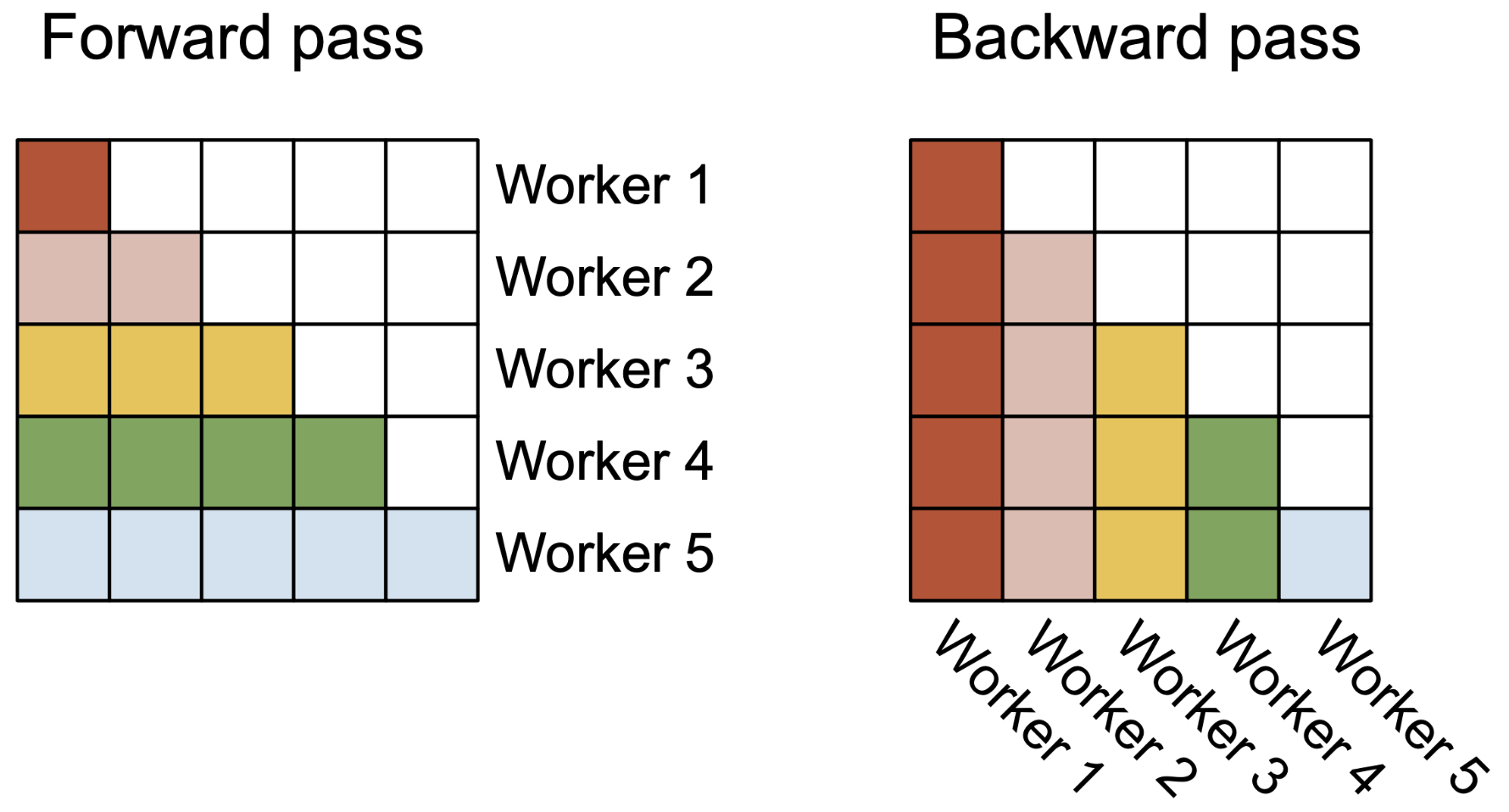
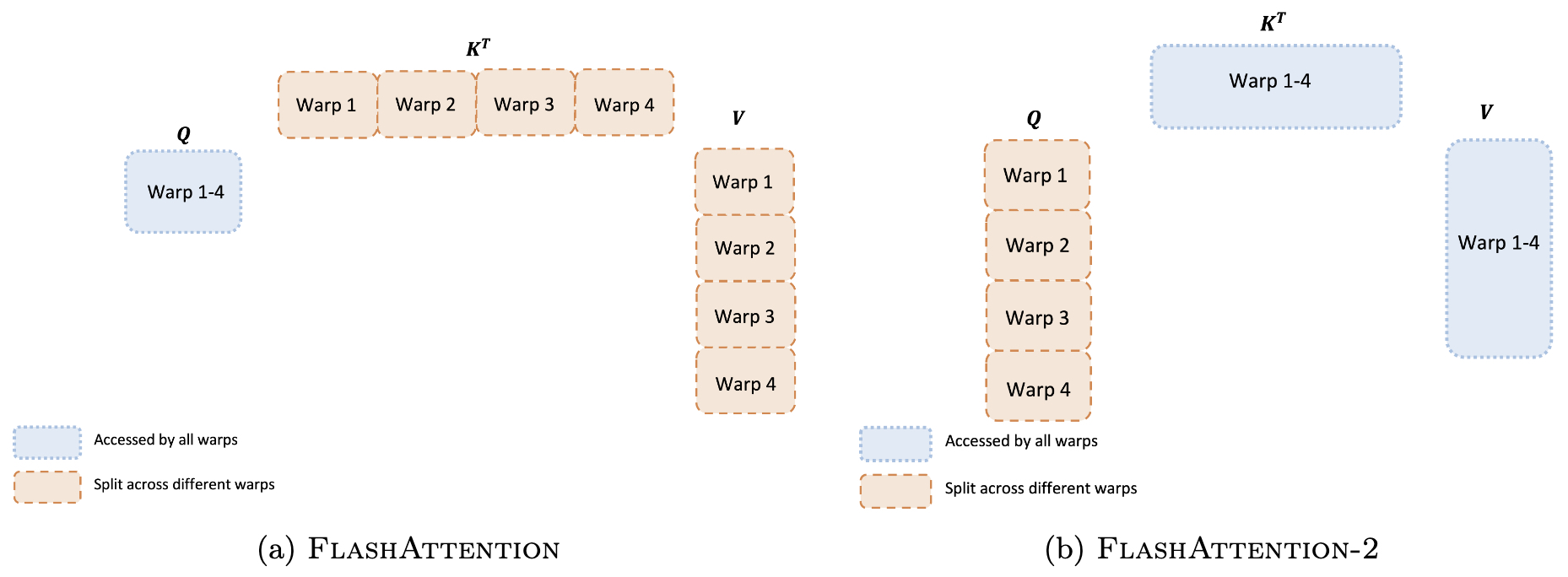
- The following figure from the paper shows work partitioning between different warps in the forward pass in FlashAttention-2.
- The following figure from Sebastian Raschka summarizes FlashAttention-2:
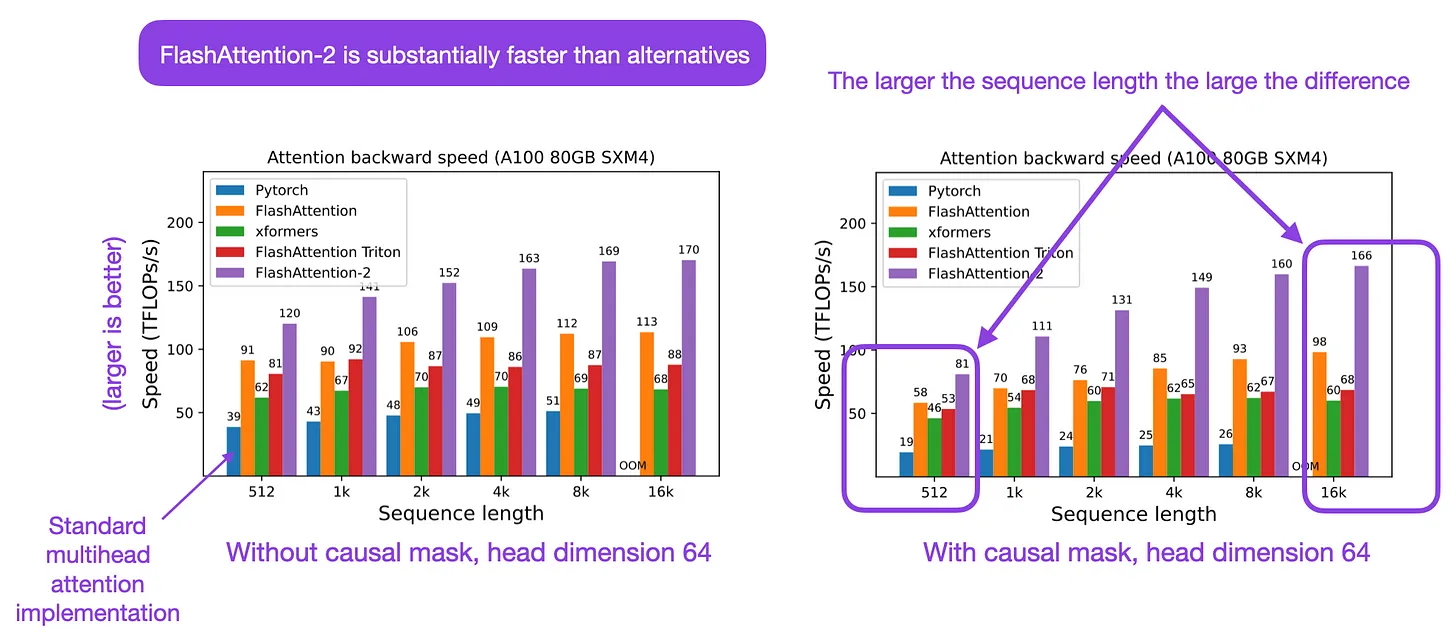
Architectural Enhancements
- Fewer non‑matmul FLOPs:
- FlashAttention‑2 rewrites elements of the softmax normalization to reduce non‑matrix‑multiply workloads (e.g. divisions, exponentials, masking operations), since non‑matmul FLOPs are much costlier on GPUs (up to 16× slower than Tensor-Core GEMMs).
- It reorders the online softmax updates, avoiding unnecessary rescaling during intermediate blocks. Only the final output is scaled once, reducing overhead substantially.
- Better parallelism across dimensions:
- Unlike FlashAttention‑1, which parallelizes mainly over batch size and attention heads, FlashAttention‑2 adds parallelism over sequence length.
- Each attention head’s computation can now be split across multiple thread blocks, improving occupancy even with long sequence and small batch regimes.
- Work partitioning between warps
- Within each thread block (e.g. 4–8 warps), FlashAttention‑2 carefully partitions tasks per warp to minimize shared memory synchronization.
- This reduces intra-block communication and avoids redundant shared memory reads and writes.
Performance Metrics
- On A100 GPUs, FlashAttention‑2 achieves ~2× speedup over FlashAttention‑1, reaching effective throughput of 50–73% of theoretical peak GFLOPs/S (~230 TFLOPs/s for FP16/BF16).
- During end-to-end training of GPT-style models, it sustains ~225 TFLOPs/s per A100 GPU (~72% FLOPs utilization).
- Memory use remains linear in sequence length (\(O(N \cdot d)\)), and backward pass also benefits from reduced I/O and better tiling, giving 2–4× backward speedup over naive implementations.
Implementation Details
- Integration with CUTLASS / CuTe:
- FlashAttention‑2 is implemented using NVIDIA’s CUTLASS 3.x and CuTe libraries, allowing for high-performance fused kernels built atop Tensor-Core primitives.
- As a rewrite from scratch, it significantly reduces overhead compared to custom CUDA implementations used in FlashAttention‑1.
- Bidirectional computation support:
- Similar tiling and normalization techniques are used in the backward pass, although it involves more intermediate values inside SRAM registers and requires careful bookkeeping (e.g. storing log-sum-exp values, but not raw max and sum separately).
Summary
- Architectural improvements:
- Reduces non-matmul operations
- Parallelism expanded across sequence-length dimension
- Optimized warp-level work partitioning
- Performance improvements:
- ~2× speedup over FlashAttention‑1
- ~225 TFLOPs/s sustained on A100 GPUs (~72% utilization)
- Enhanced backward pass performance
FlashAttention‑3
- Introduced in FlashAttention‑3: Fast and Accurate Attention with Asynchrony and Low-precision by Shah et al., FlashAttention‑3 targets Hopper‑class GPUs (e.g. NVIDIA H100) and leverages asynchronous execution and FP8 quantization to unlock dramatic speedups and accuracy improvements.
Architectural Innovations
- Asynchrony and pipelined overlap:
- The algorithm exploits hardware asynchrony on Hopper GPUs by assigning warp‑specialized roles: some warps perform matrix multiplications (GEMMs) using new WGMMA instructions, while others concurrently execute softmax and scaling, using ping‑pong scheduling between warp groups to hide memory and compute latency.
- Block‑wise GEMM and softmax operations are interleaved so that while one block is undergoing matrix multiplication, a previous block is performing softmax, maximizing concurrent utilization of Tensor Cores and Tensor Memory Accelerator (TMA).
- The following figure from the paper shows ping‑pong scheduling for 2 warpgroups to overlap softmax and GEMMs: the softmax of one warpgroup should be scheduled when the GEMMs of another warpgroup are running. The same color denotes the same iteration.

- The following figure from the paper shows 2-stage WGMMA-softmax pipelining.
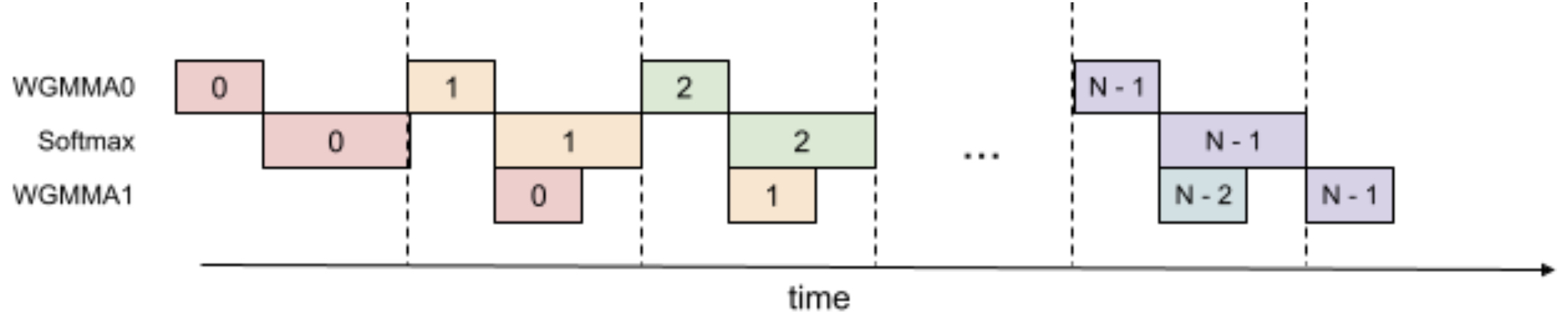
- Low‑precision support (FP8 and BF16):
- FlashAttention‑3 introduces block quantization and incoherent processing to make low‑precision (FP8) usable with low error. Instead of uniform per‑tensor scaling, block‑wise quantization plus outlier handling yields accuracy that is 2.6× better (in terms of RMSE) than baseline FP8 attention implementations.
- In FP16/BF16 mode, FlashAttention‑3 reaches up to ~740 TFLOPs/s (~75% of H100 peak), while in FP8 mode (e4m3 or e5m2), speeds reach ~1.2 PFLOPs/s—over 1.3× higher than FP16 throughput.
Performance Summary
- Forward pass:
- FlashAttention‑3 delivers ~1.5–2.0× speedup over FlashAttention‑2 in FP16/BF16 mode, and ~1.5 × in the backward pass (1.5‑1.75×).
- Peak throughput reported: ~840TFLOPs/s (forward) at ~85% utilization in BF16, ~1.3PFLOPs/s in FP8 mode. These numbers significantly outperform FlashAttention‑2 which tops ~230TFLOPs/s on A100.
- Backward pass:
- Backward-side speedups range from ~1.5× to ~1.75× over FlashAttention‑2, leveraging similar asynchrony and quantization-aware recomputation strategies.
- Accuracy & numerical stability:
- FP16 performance matches FlashAttention‑2 accuracy, since intermediate rescaling is done in FP32.
- FP8 mode achieves 2.6× lower RMSE than a standard FP8 baseline thanks to incoherent block quantization and dynamic range handling.
Implementation Highlights
- Uses Hopper-specific instructions: WGMMA (Warpgroup Matrix Multiply Accumulate) and TMA (Tensor Memory Accelerator) for high throughput FP16/BF16/FP8 GEMMs under fine-grained overlap scheduling.
- Scheduling design decouples GEMM and softmax roles across warp‑groups with ping‑pong execution, minimizing idle cycles and synchronisation stalls.
- Maintains linear memory (\(O(N \cdot d)\)) by streaming and recomputing per‑block normalization factors without storing full attention matrices.
Summary
- FlashAttention‑3 fully exploits Hopper hardware features (asynchrony, TMA, low‑precision support).
- Achieves ~1.5–2.0x speedups over FlashAttention‑2 and up to 1.3PFLOPs/s using FP8, with much improved numerical error.
- Combines warp‑specialization, pipelined overlap, and block quantization for superior architectural and performance gains.
Comparative Analysis
Overview
- FlashAttention‑1 pioneered the IO‑aware fused attention kernel with tiling and streaming softmax normalization.
- FlashAttention‑2 rearchitected the work distribution and reduced non‑matmul overheads.
- FlashAttention‑3 adopts Hopper‑GPU asynchrony and FP8 quantization techniques to unlock peak GPU performance.
Architectural Differences
-
FlashAttention‑1:
- Uses a single fused CUDA kernel per head/layer combining \(QK^T\), mask, softmax, dropout, and output multiplication to minimize HBM‑SRAM transfers.
- Tiles Q, K, V into SRAM‑sized blocks; recomputes per‑block softmax normalization for numerical stability.
- Parallelism primarily over batch and heads; limited use of sequence‑length concurrency.
- I/O‐optimal design—provably requires \(O(N \cdot d)\) memory traffic lower bound for practical SRAM sizes.
-
FlashAttention‑2:
- Introduces parallelism across sequence‐length dimension by splitting head computations over multiple thread blocks.
- Reduces non‑GEMM FLOPs by delaying softmax scaling operations—to eliminate redundant normalization across blocks.
- Implemented using CUTLASS and CuTe, targeting improved occupancy and thread‑block coordination.
- Enhanced warp‐group partitioning to reduce shared memory sync overhead.
-
FlashAttention‑3:
- Designed for NVIDIA Hopper (H100) hardware, using warp specialization and asynchronous scheduling: some warps perform WGMMA GEMMs, others perform softmax/scaling, overlapping computation.
- Pipeline GEMM and softmax per block in ping‑pong fashion across warp groups to maximize utilization of Tensor Cores and Tensor Memory Accelerator (TMA).
- Introduces block-wise FP8 quantization with incoherent processing and dynamic outlier handling to minimize numerical error.
- Leverages Hopper’s WGMMA and TMA instructions to sustain high throughput in both low-precision and standard FP16/BF16 modes.
Performance Comparison
| Version | Target GPU | Forward Speedup | Peak Throughput | Backward Speedup | Numerical Accuracy (Low‑prec) |
|---|---|---|---|---|---|
| FlashAttention‑1 | Ampere / A100 | ~3× over PyTorch on GPT‑2 (seq=1K) | ~30–50% utilization | ~ similar to baseline | Full FP16/BF16 accuracy; exact attention |
| FlashAttention‑2 | Ampere / A100 | ~2× over v1 | ~225TFLOPs/s (~72%) | ~2–4× over naive backward | Same full precision accuracy |
| FlashAttention‑3 | Hopper / H100 | ~1.5–2× over v2 (FP16) | ~740TFLOPs/s (~75% BF16); ~1.2–1.3PFLOPs/s (FP8) | ~1.5–1.75× over v2 | FP8 RMSE ~2.6× lower than baseline FP8; full precision accuracy preserved. |
Algorithmic & I/O Differences
- All versions maintain I/O-optimal behavior: FlashAttention‑1 achieves \(O(N \cdot d)\) data movement and is provably asymptotically optimal for typical SRAM sizes.
- FlashAttention‑2 maintains the same I/O characteristics, but reduces extra computation overhead by reducing normalization passes.
- FlashAttention‑3 retains I/O efficiency while introducing asynchronous overlap and low-precision formats to reduce HBM bandwidth use and maximize on-chip computation.
Summary
-
FlashAttention‑1 introduced an I/O-aware fused GPU kernel combining \(QK^T\), mask, softmax, and value multiplication. Using tiling and streaming softmax normalization, it reduces memory traffic from \(O(N^2)\) to \(O(N \cdot d)\), enabling exact attention with faster throughput on Ampere and earlier GPUs. Delivered ~3× speedup on GPT‑2 and ~15% on BERT‑large.
-
FlashAttention‑2 introduced parallelism over sequence length, optimized work partitioning across warps, and reduction of non-matmul FLOPs. Achieved ~2× speedup over v1, up to ~225 TFLOPs/s and ~72% FLOPs utilization on A100 GPUs; supports head dimensions up to 256.
-
FlashAttention‑3 exploited Hopper‑specific (H100) features—low‑precision support, warp-specialization, asynchronous pipelined GEMM-softmax execution, and block-wise FP8 quantization with incoherent processing. Achieved ~1.5–2× speedup over v2 in FP16/BF16 (~740 TFLOPs/s, ~75% utilization) and ~1.2 PFLOPs/s in FP8 mode, with ~2.6× lower numerical error than baseline FP8.
Accuracy Trade-offs, Practical Considerations, and Integration Guidance
Accuracy and Numerical Stability
-
All versions preserve full FP16/BF16 accuracy because intermediate normalization (softmax reduction) is computed in FP32 to avoid precision loss. None introduce approximation in the attention calculation itself.
-
FlashAttention‑3 extends this to low-precision FP8 operation by using block-wise quantization and incoherent processing to dramatically reduce quantization error. It achieves about 2.6× lower RMSE compared to baseline FP8 attention implementations.
Practical Hardware Compatibility
-
FlashAttention‑1 works on Ampere (e.g. A100), Ada, and earlier GPUs; it’s CPU-and-CUDA compatible and only requires standard CUDA/CUTLASS or Triton backends. Offers significant benefits for long-sequence attention workloads.
-
FlashAttention‑2 supports the same GPUs but is optimized further via CUTLASS 3.x and CuTe, requiring GPU compute capabilities Ampere or later for BF16 support.
-
FlashAttention‑3 requires Hopper architecture GPUs (e.g. H100, H800) and CUDA version ≥12.3 (ideally ≥12.8). Only one version currently supports FP8 forward and partial backward.
Integration & API Details
-
FlashAttention is available as a PyTorch C++/CUDA extension via
flash_attn_interfaceor via Triton. Typical usage replaces standardscaled_dot_product_attentionin PyTorch or in frameworks like DeepSpeed/Megatron. -
For FlashAttention‑2 and 3, the library exposes optimized kernels and automatically dispatches based on GPU architecture and precision flags (e.g. FP16 vs FP8). Some pipeline frameworks like Triton or CUDA Graphs may require manual configuration for optimal low‑latency inference.
Resource & Memory Usage
-
All versions maintain linear memory usage, \(O(N \cdot d)\), compared to \(O(N^2)\) of naive attention, enabling context lengths up to 64K or more with full precision.
-
GPU shared memory/register usage is tightly tuned. In FlashAttention‑3, large tile sizes and async overlap are enabled by Hopper’s TMA and WGMMA, though register pressure may increase and limit maximum head-dim or batch size.
When to Use Which Version
-
If you’re on Ampere-class GPUs or doing training/inference with FP16/BF16 and want a robust, well-tested solution: FlashAttention‑2 is the safe and high-performance default.
-
If you need full compatibility with older GPUs or have simpler integration needs, FlashAttention‑1 still provides excellent memory savings and speedups without hardware-specific dependencies.
-
If you have access to Hopper GPUs and want maximal throughput (especially with FP8), FlashAttention‑3 is the best choice—but be aware of hardware and software requirements. Quantization accuracy is excellent, but backward support in FP8 may be limited in early releases.
Performance Benchmarks, Code Integration Examples, and Tuning Tips
Performance Benchmarks
FlashAttention‑2 (Ampere / A100)
- On an NVIDIA A100 GPU, FlashAttention‑2 reaches forward‑pass throughput up to 230TFLOPs/s, about 50–73% of theoretical peak FP16/BF16 performance. Backward pass performance hits up to 63% of peak, significantly improving on v1. End-to-end training throughput for GPT-style models reaches about 225TFLOPs/s per A100 GPU, achieving roughly 72% model FLOPs utilization. It provides ~2× speedup over FlashAttention‑1, and up to 3–9× speedup over naïve PyTorch attention in benchmarks.
FlashAttention‑3 (Hopper / H100)
- On NVIDIA H100 GPUs, FP16/BF16 mode hits ~740TFLOPs/s (~75% utilization) and FP8 mode approaches ~1.2PFLOPs/s, delivering 1.5–2× speedups over FlashAttention‑2. FP8 operation also achieves ~2.6× lower numerical error (RMSE) compared to baseline FP8 attention implementations.
Comparative Summary
- For Ampere/A100, FlashAttention‑2 delivers around 2× performance gain over v1.
- On Hopper/H100, FlashAttention‑3 boosts FP16 throughput by 1.5–2× and FP8 performance to 1.2PFLOPs/s, with high accuracy.
- Across versions, attention performance grows from ~50TFLOPs/s in v1 to over 1PFLOP/s in v3 when using FP8.
Integration & Code Examples
Installing FlashAttention (v1 & v2)
pip install flash-attn
- This provides both FlashAttention‑1 and ‑2 implementations in the official
flash-attnPyPI package (v2.x series).
PyTorch Usage Pattern
import torch
from flash_attn.flash_attn_interface import flash_attn_forward
# Inputs: Q, K, V as [batch, seq, heads, head_dim] FP16/BF16
output = flash_attn_forward(Q, K, V, causal=True, dropout_p=0.0)
- This replaces the typical
F.scaled_dot_product_attentionand is generally integrated into DeepSpeed, Megatron-LM, or custom PyTorch modules.
FlashAttention‑3 / FP8 usage
- As of v3 beta, FlashAttention‑3 supports FP16/BF16 forward/backward and FP8 forward on Hopper GPUs. Kernel selection will dispatch automatically if running on H100s.
- When using FP8 (
e4m3,e5m2), ensure CUDA ≥12.3 and appropriate hardware for full benefits.
Tuning Tips & Best Practices
-
Choose version based on GPU:
- Use FlashAttention‑2 on Ampere-Class (A100 etc.) for stable high performance with FP16/BF16.
- Use FlashAttention‑3 on Hopper/H100 for FP8-enabled maximal throughput.
-
Sequence length vs head dimension tuning: Block sizes are architected around head-dim and shared-memory capacity. Very small or large head dimensions might reduce efficiency due to register/shared-space constraints—especially in FlashAttention‑3.
-
Batch size considerations: For best per-GPU throughput, maintain sufficient token-level parallelism per GPU—e.g. batching multiple sequences of length ≥512 ensures high thread occupancy.
-
Causal masking: Both FlashAttention‑2 and ‑3 support causal masks. Performance remains high across masked and unmasked scenarios, with only minor overhead differences.
-
Mixed-precision strategies: For inference where FP8 is supported, use FP8 mode in FlashAttention‑3 to maximize throughput while maintaining near-FP16 accuracy. If FP8 backward is not yet stable, use BF16 for training.
-
Library integration: FlashAttention auto-detects GPU architecture and dispatches the appropriate kernel. For frameworks like Triton, CUDA Graphs, or DeepSpeed, ensure FP8 pipeline is enabled manually if needed and tests pass.
Code Walkthroughs for Custom Head-Dimension & Long‑Sequence Optimization
Supporting Larger Head Dimensions
-
FlashAttention‑2 extended support to larger head dimensions (up to 256), enabling compatibility with models like GPT‑J, CodeGen, and Stable Diffusion 1.x. In practice, use of head dimensions beyond 128 is now supported and optimized.
-
In PyTorch, when defining a custom transformer layer:
import torch
from flash_attn.flash_attn_interface import flash_attn_forward
head_dim = 192 # any value up to 256
Q = torch.randn(batch_size, seq_len, num_heads, head_dim, device=device, dtype=torch.float16)
...
output = flash_attn_forward(Q, K, V, causal=True)
- The FlashAttention kernels automatically adjust tiling strategy internally based on
head_dim. For v2, larger dims translate into larger tile sizes to better utilize shared memory and registers, while also maintaining occupancy on Ampere/A100 GPUs.
Long-Sequence Handling (e.g. 64K Context)
-
FlashAttention is designed to scale linearly in memory with sequence length, \(O(N \cdot d)\), enabling efficient usage even with 64K tokens.
-
For long-sequence inference or training:
seq_len = 65536
Q = torch.randn(1, seq_len, num_heads, head_dim, device=device, dtype=torch.bfloat16)
...
output = flash_attn_forward(Q, K, V, causal=True)
- The kernel streams tiles of \(Q\), \(K\), and \(V\) that fit into on-chip SRAM. It recomputes block-wise normalization using max–sum streaming to avoid full \(N \times N\) matrix materialization.
- This design ensures constant memory beyond per-token/load requirements—even at tens of thousands of tokens.
- FlashAttention‑3 further maximizes throughput on Hopper GPUs with long sequences via asynchronous pipelining and FP8 support.
Performance Tips for Long Context
- Larger tile sizes can improve throughput, but be mindful: they raise shared memory and register pressure. For sequences of 16K–64K tokens, default tile sizes are tested to balance occupancy and register use.
- Validation logs from users report practical throughput of FlashAttention‑3 in FP16/BF16 approaching 740 TFLOPs/s on H100 with long sequences; FP8 mode achieves ~1.2 PFLOPs/s with controlled RMSE (~2.6× lower than baseline FP8).
- For head-dimension tuning, stay within supported limits (≤ 256) to ensure kernel dispatch is optimized; backward support for dropout and FP8 may be constrained for
head_dim=256 on consumer GPUs.
Best Practices/Recommendations
-
Use FlashAttention‑2 on Ampere-class GPUs (like A100) for stable and well-tested performance with FP16/BF16 training or inference.
-
Choose FlashAttention‑3 if using Hopper-class GPUs and FP8 is supported (CUDA ≥ 12.3), for maximum throughput. It provides significant speed gains (~1.2 PFLOPs/s) with strong numerical fidelity.
-
Stick with FlashAttention‑1 if compatibility with older GPUs or simplicity is essential. It still offers substantial speed and memory savings without advanced hardware dependencies.
-
For long-context scenarios (e.g., inference on 64K token sequences) FlashAttention methods scale linearly in memory and support tiling-based streaming to remain performant. FP8 mode (on v3/Hopper) further reduces memory bandwidth use.
-
Head dimensions beyond 128 (up to 256) are supported and optimized in v2 and v3, but may introduce register/shared-memory pressure. Benchmark for your specific variant.
Deep Dive into Softmax Streaming and I/O Complexity Analysis
Softmax Normalization via Streaming Tiling
- FlashAttention‑1 employs online softmax normalization, processing tiles of queries \(Q_i\) and key‑value pair blocks \(K_j\), \(V_j\) sequentially.
- For each query block, the algorithm transforms \(O=\operatorname{softmax}\left(\frac{Q K^{\top}}{\sqrt{d}}\right) V\) by iteratively computing \(m_i=\max _j s_{i j}, \quad \ell_i=\sum_j \exp \left(s_{i j}-m_i\right)\) and updating output incrementally: streaming normalized contributions from each tile.
- This scheme avoids storing the full \(N \times N\) logits matrix and reduces memory overhead to \(O(N \cdot d)\), enabling contexts of up to 64K tokens. It also matches theoretical lower bounds for memory traffic given typical SRAM sizes.
I/O Complexity: Optimal Traffic Reduction
- Standard attention requires \(O(N^2)\) reads and writes to HBM (higher-latency global memory), including full logs and softmax intermediate storage.
- FlashAttention’s online approach ensures only \(O(N \cdot d)\) total traffic by streaming blocks that fit into SRAM, recomputing any softmax normalization factors on-the-fly rather than buffering large intermediate matrices.
- FlashAttention‑2 and ‑3 retain this I/O-optimal model, further enhancing compute throughput without affecting asymptotic memory usage.
FlashAttention‑2: Block-Parallel Hardware Tiling (Figure 1)
- FlashAttention‑2 arranges queries and key-value blocks in a block-parallel fashion: a block of query vectors is locally loaded per thread block, with key/value streamed block-wise to update per-query softmax state and output contributions. This parallel hardware structure eliminates sequential dependencies across blocks and supports query-level concurrency.
FlashAttention‑3: Ping‑Pong Scheduling and Overlapping of GEMM & Softmax
- FlashAttention‑3 introduces ping‑pong scheduling across two or more warp-groups: while one warpgroup executes GEMM for dot-product (Tensor Core usage), another group performs softmax/exponential operations using the multifunction unit. Synchronization barriers (e.g.
bar.sync) orchestrate this overlap across iterations to maximize effective utilization of both compute units. - Additionally, within a single warpgroup, intra-warpgroup pipelining allows parts of softmax to execute concurrently with GEMM, raising throughput further. This two-stage pipelining helps push FP16 forward performance from ~570 TFLOPs/s to ~640 TFLOPs/s (ex: seq_len = 8K, head_dim = 128).
Theoretical and Practical Impacts
- By aligning algorithmic tiling with GPU memory architecture, FlashAttention (all versions) achieves I/O-optimal behavior, dramatically reducing latency and memory bandwidth requirements as sequence length increases.
- FlashAttention‑2’s block-parallel tiling removes sequential dependencies, improving latency and occupancy across head and batch dimensions.
- FlashAttention‑3’s warp specialization and asynchronous overlap further minimize idle compute phases and merge slow non‑matmul softmax operations into periods where GEMMs are active.
Integration with Modern Frameworks and Benchmark Scripts
Framework Support & Installation
- The
flash-attnlibrary (v2 and above) provides seamless integration via a PyTorch C++/CUDA extension (flash_attn_interface), compatible with PyTorch 2.2+ and GPU architectures Ampere, Ada, and Hopper. - FlashAttention‑3 requires an H100/H800 GPU and CUDA ≥ 12.3 (12.8 recommended) for full FP8 support.
High-Level Integration
PyTorch (DeepSpeed, Megatron-LM, Hugging Face)
- Typical replacement code:
from flash_attn.flash_attn_interface import flash_attn_forward
# Q, K, V shaped [batch, seq_len, heads, head_dim], dtype FP16/BF16
O = flash_attn_forward(Q, K, V, causal=True, dropout_p=0.0)
- Automatically dispatches appropriate kernel version (v2 or v3) based on available GPU and precision.
- DeepSpeed and Megatron-LM often integrate FlashAttention as a drop-in replacement for standard scaled dot‑product attention.
Triton & xFormers Backends
- Trident implementations (e.g., in Triton language) provide alternative fused kernels and can be up to 1.3–1.5× slower than FlashAttention‑2 in forward pass.
- xFormers and Triton vary in API compatibility; official FlashAttention‑2 implementation is recommended for max speed.
Benchmark Script Examples
- Typically users benchmark with a script like:
python bench_attention.py \
--seq-len 4096 \
--batch-size 8 \
--num-heads 16 \
--head-dim 128 \
--use-causal \
--dtype fp16
-
Special flags such as
--use-flash-attn, or environment variablesUSE_FLASH_ATTN=1, activate the FlashAttention kernel rather than default PyTorch attention. -
Benchmark outputs from FlashAttention‑2 show:
- End-to-end GPT training throughput up to 225 TFLOPs/s per A100 GPU (∼72% FLOPs utilization).
- Forward+backward combined performance of 1.7–3.0× faster than FlashAttention‑1 and up to 9× faster than PyTorch baseline depending on config, with consistent speedups across head-dimensions 64 and 128.
-
For FlashAttention‑3 benchmarks:
- FP16/BF16 mode: ~740 TFLOPs/s (~75% utilization) on H100. FP8 mode: nearly 1.2–1.3 PFLOPs/s, with quantization error ~2.6× lower than baseline FP8.
Automated Dispatch & Precision Handling
- At runtime, FlashAttention inspects hardware IDs to decide between v2 (Ampere) and v3 (Hopper) kernels.
- For FP8 support (FlashAttention‑3), users may need to opt into an experimental API flag (e.g.
precision='fp8') or dependency on a nightly version. - If backward pass support in FP8 is still maturing, workflows can fallback to BF16 or FP16 for gradient computation.
Deployment and Inference Readiness
- FlashAttention can also serve in inference contexts within frameworks like Hugging Face — kernel dispatch handles causal masking efficiently.
- NVIDIA’s FlashInfer builds on FlashAttention‑3 to optimize KV-cache-aware inference, reducing inter-token latency by 29–69% compared to standard backends.
References
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
- FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
- The I/O Complexity of Attention, or How Optimal is Flash Attention?
- FlashInfer: Low-Latency Generative Inference with FlashAttention
- Online Pseudo-average Shifting Attention (PASA) for Robust Low-precision LLM Inference
- FlashAttention-3 blog post
- FlashAttention-2 paper site
- FlashAttention GitHub repository
- FlashAttention PyPI package
- The Evolution of FlashAttention: Revolutionizing Transformer Efficiency (Medium article)
Citation
If you found our work useful, please cite it as:
@article{Chadha2020DistilledFlashAttention,
title = {FlashAttention},
author = {Chadha, Aman},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}