Primers • Diffusion LLMs
- Overview
- Denoising Dynamics
- Reinforcement Learning (RL) Mismatch
- LLaDA Family
- Sampling and Inference
- Reasoning and Planning
- Preference Alignment
- Scaling and Context
- Multimodal dLLMs
- Failure Modes
- dLLMs in Practice
- References
- Citation
Overview
Definition
-
A diffusion Large Language Model (dLLM), also commonly referred to as a Large Language Diffusion Model (LLDM) or Diffusion Language Model (DLM), or in some contexts a Discrete Diffusion Model (DDM) when emphasizing the underlying discrete-state formulation, is a language model that generates text by iterative denoising rather than by committing to the next token one step at a time. In the current mainstream formulation for text, the model starts from a sequence in which many or all response positions are replaced by a special mask token, then repeatedly predicts masked positions and selectively keeps or re-mask tokens until a clean sequence emerges. This family is usually instantiated as masked diffusion language modeling, which has so far been the most practically successful discrete diffusion recipe for language, building on earlier discrete-state diffusion work such as Structured Denoising Diffusion Models in Discrete State-Spaces by Austin et al. (2021), which introduced absorbing-mask style corruption for discrete data, and A Continuous Time Framework for Discrete Denoising Models by Campbell et al. (2022), which provided a continuous-time probabilistic foundation for discrete denoising.
-
What makes this important is that it breaks the long-standing assumption that strong language modeling must be tied to left-to-right autoregression. The large-scale evidence is now hard to ignore: LLaDA, introduced in Large Language Diffusion Models by Nie et al. (2025), showed that a diffusion model trained from scratch at 8B parameters can be competitive with similarly sized autoregressive baselines on broad benchmarks, while Dream 7B: Diffusion Large Language Models by Ye et al. (2025) showed that AR-initialized diffusion models can become especially strong on planning-style tasks and support flexible generation orders.
-
Taken together, these results suggest that the main point of diffusion LLMs is not merely faster or more parallel decoding. The deeper shift is that language generation is reformulated as iterative probabilistic refinement: the model repeatedly revises a partially observed sequence until it becomes coherent, instead of making an irreversible left-to-right commitment at each token.
Autoregressive vs. diffusion
-
The cleanest way to see the difference is to compare the factorization assumptions.
-
An autoregressive LLM defines:
\[p_\theta(x)=\prod_{i=1}^{L} p_\theta(x_i \mid x_{<i})\]- which makes exact sequence likelihoods and token-level policy gradients natural, but also hard-codes a left-to-right generation order. This next-token view is inherited from the standard Transformer language-modeling paradigm established by Attention Is All You Need by Vaswani et al. (2017), and later scaled into modern LLM training pipelines.
-
A masked diffusion LLM instead defines a forward corruption process that replaces tokens with a mask symbol, and learns a reverse process that reconstructs them. In LLaDA-style masked diffusion, if \(x_0\) is the clean sequence and \(x_t\) is its corrupted version at noise level \(t\in[0,1]\), each token is independently masked with probability \(t\):
\[q_t(x_t \mid x_0)=\prod_{i=1}^{L} q_t(x_t^i \mid x_0^i), \qquad q_t(x_t^i \mid x_0^i)= \begin{cases} 1-t, & x_t^i=x_0^i\\ t, & x_t^i=\texttt{[MASK]} \end{cases}\] -
This is the core forward process used in large masked DLMs.
-
So the real change is not just parallel decoding. It is a change in what the model treats as primitive. Autoregressive models treat the next token as primitive; diffusion models treat denoising a corrupted whole as primitive. That shift matters because it gives the model access to bidirectional context at every denoising step, much more like a generative version of the bidirectional conditioning that made BERT by Devlin et al. (2018) so effective for representation learning, except here the objective is genuinely generative rather than purely masked-token pretraining.
Training objective
- For masked DLMs, the standard training loss is a masked cross-entropy over corrupted inputs. In the LLaDA formulation, one representative form is:
-
Intuitively, the model samples a corruption level \(t\), masks tokens accordingly, and is penalized only on the masked positions. The \(frac{1}{t}\) weighting corrects for the fact that different noise levels expose different numbers of masked positions. A key theoretical point is that this objective is not merely heuristic masking; it is linked to a variational likelihood bound, so training remains tied to maximum-likelihood-style generative modeling rather than ad hoc reconstruction. That theoretical simplification and clarification is central in Simplified and Generalized Masked Diffusion for Discrete Data by Shi et al. (2024), which shows that the continuous-time variational objective reduces to a weighted integral of cross-entropy losses, and in Simple and Effective Masked Diffusion Language Models by Sahoo et al. (2024), which turns that view into a strong practical recipe for language modeling.
-
A useful way to summarize the objective is:
- Masked language modeling gives the local prediction task
- The diffusion formulation supplies the global generative semantics
- The ELBO view explains why this is more than BERT with sampling
Generation process
-
At inference time, a masked diffusion LLM typically begins with a prompt plus a fully masked response region. At each denoising step, it predicts all masked positions simultaneously, then keeps some predictions and re-masks others. In LLaDA, low-confidence remasking is used in practice: tokens with lower confidence are more likely to be masked again, which creates an annealed coarse-to-fine refinement process.
-
The following figure (source) shows an overview of LLaDA: (a) Pre-training. LLaDA is trained on text with random masks applied independently to all tokens at the same ratio \(t \sim U[0,1]\). (b) SFT. Only response tokens are possibly masked. (c) Sampling. LLaDA simulates a diffusion process from \(t=1\) (fully masked) to \(t=0\) (unmasked), predicting all masks simultaneously at each step with flexible remask strategies.
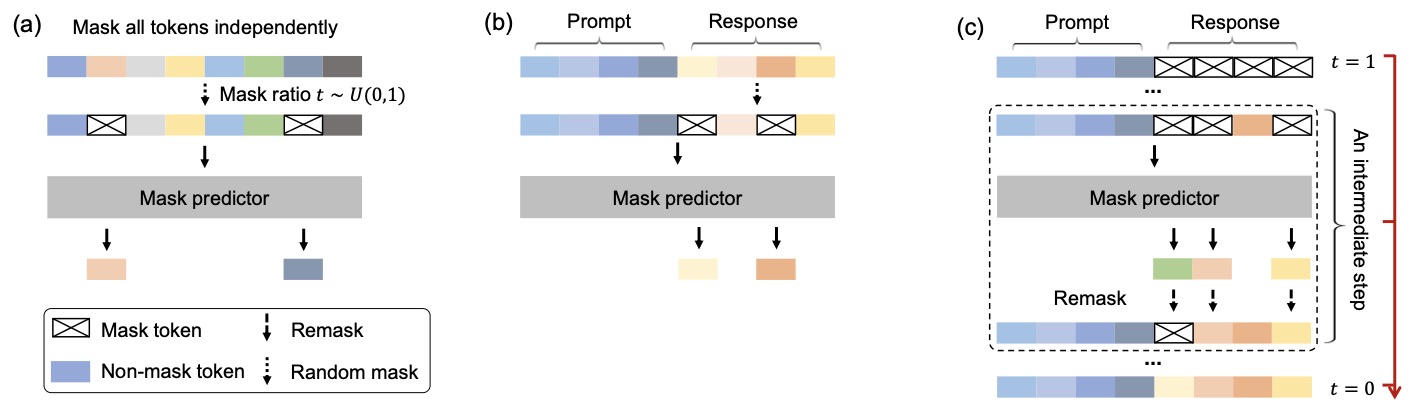
-
This generation process has three immediate consequences:
-
First, there is no fixed generation order. High-confidence content can appear early anywhere in the sequence, while difficult spans are deferred. Dream 7B: Diffusion Large Language Models by Ye et al. (2025) is particularly explicit about treating arbitrary-order generation and planning flexibility as first-class advantages of the diffusion formulation.
-
Second, every intermediate denoising state is a full sequence, albeit a noisy one. This is very different from autoregressive generation, where mid-generation you only have a prefix. This property later becomes crucial for reinforcement learning, because intermediate states can be evaluated globally.
-
Third, generation quality and speed are naturally tradeable through the number of denoising steps and the remasking schedule. This creates flexible inference regimes unavailable to standard autoregressive decoding.
-
Advantages
-
The strongest case for diffusion LLMs is not that they dominate autoregressive models everywhere today. It is that they change the constraint set.
-
They offer bidirectional conditioning during generation, which is structurally attractive for infilling, editing, and global consistency. They remove the hard commitment to left-to-right order. They expose new forms of inference flexibility, including arbitrary-order and blockwise decoding.
-
They also appear promising for long-context modeling. UltraLLaDA: Scaling the Context Length to 128K for Diffusion Large Language Models by He et al. (2025) shows that diffusion-aware positional extensions enable stable scaling to 128K tokens, while LLaDA2.0: Scaling Up Diffusion Language Models to 100B by Bie et al. (2025) demonstrates frontier-scale diffusion LLMs with competitive performance.
-
A subtler motivation is that autoregressive LLMs have known directional blind spots. The Reversal Curse: LLMs trained on “A is B” fail to learn “B is A” by Berglund et al. (2023) shows a concrete failure mode of left-to-right training, and diffusion models offer a structurally different inductive bias.
Limitations
- The biggest conceptual cost of diffusion LLMs is likelihood. In autoregressive models, exact sequence log-probability is cheap:
-
In diffusion LLMs, there is no equally cheap factorization. In practice, people rely on ELBO-style surrogates or approximations. This is one of the defining technical tensions of the area.
-
This issue motivates a large portion of recent work. LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models by Zhu et al. (2025) analyzes variance in ELBO-based preference optimization, Principled RL for Diffusion LLMs Emerges from a Sequence-level Perspective by Ou et al. (2025) proposes sequence-level RL using ELBO surrogates, and Improving Reasoning for Diffusion Language Models via Group Diffusion Policy Optimization by Rojas et al. (2025) introduces lower-variance estimators for RL training.
-
The right mental model is:
A diffusion LLM is a different generative object with a different training signal, decoding geometry, and post-training problem, not just a parallelized autoregressive model.
Denoising Dynamics
Forward process
-
The defining object in a diffusion LLM is the forward corruption process, which converts a clean sequence \(y\) into progressively noisier versions \(y_t\). In masked diffusion for language, this noise is discrete and implemented through masking rather than Gaussian perturbations.
-
Formally, each token is independently replaced with a mask token with probability \(t\), giving:
-
This formulation, used in LLaDA and related masked diffusion models, creates a continuum of partially observed sequences indexed by \(t\in[0,1]\), where \(t=1\) corresponds to a fully masked sequence and \(t=0\) corresponds to the clean data.
-
What is subtle but important is that this corruption is not just noise injection. It defines a tractable latent-variable model over sequences, where \(y_t\) acts as a noisy latent state connecting the observed data to the model’s predictions.
Reverse process
- The model learns a reverse process that reconstructs the original tokens from corrupted inputs. At each noise level \(t\), a Transformer predicts a distribution over vocabulary tokens for every masked position:
-
Unlike autoregressive models, this prediction is fully bidirectional. Every token attends to every other token regardless of position, which fundamentally changes the geometry of inference.
-
In practice, generation proceeds through a discretized sequence of timesteps \(t_1 > t_2 > \dots > t_T\), where at each step the model:
- Predicts token distributions at masked positions
- Selects a subset of predictions to keep
- Re-masks uncertain tokens
-
This creates a stochastic iterative refinement process rather than a single forward pass.
Iterative refinement
-
A key emergent property of this setup is coarse-to-fine generation.
-
Early in the denoising process, when most tokens are masked, the model is forced to rely heavily on global context and priors, producing rough semantic structure. Later steps refine local details as more tokens become available.
-
This behavior is closely tied to what Reinforcing the Diffusion Chain of Lateral Thought by Huang et al. (2025) calls lateral reasoning: intermediate states need not be grammatical or even locally consistent, but they can still be globally informative.
-
The following figure (source) illustrates a comparison between CoT and DCoLT. (a) A typical CoT performs vertical thinking by following an auto-regressive convention that generates responses token by token from left to right in a linear way. (b) DCoLT performs lateral thinking that generates the responses in a non-linear way without following the auto-regressive order; moreover, at each step, it can generate multiple tokens at chosen positions. We focus on the lateral thinking in this paper by reinforcing the chain of such lateral thought as an entirety in DLMs.
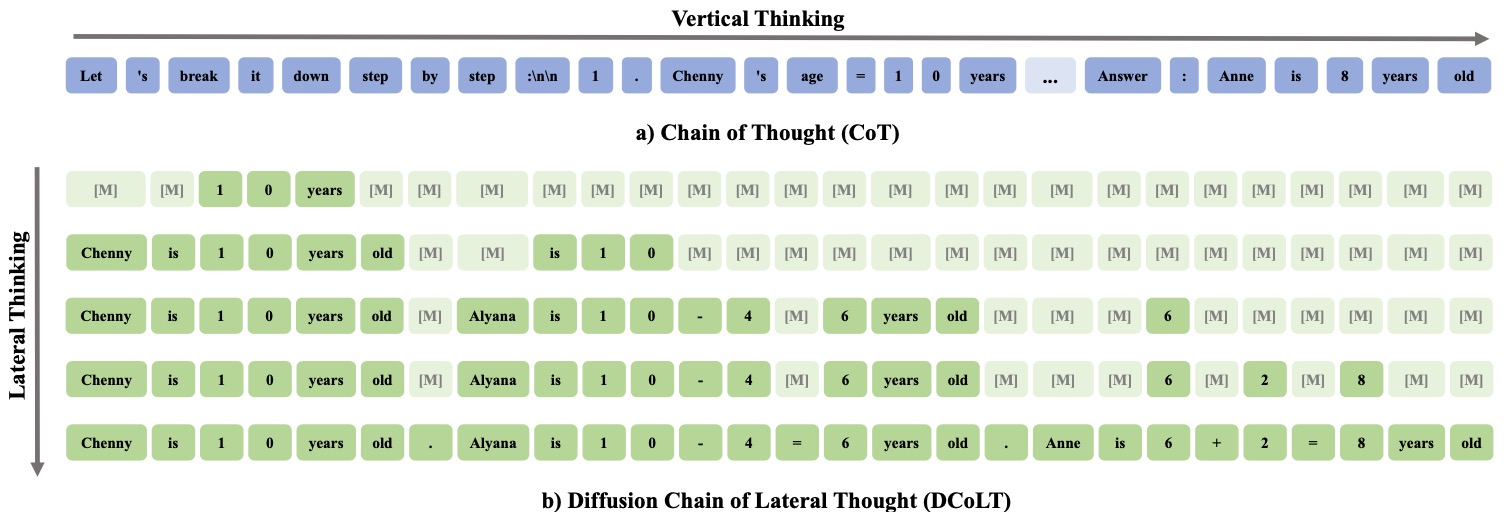
- This figure illustrates a crucial conceptual shift. Autoregressive reasoning proceeds as a linear chain, while diffusion reasoning evolves as a sequence of global states that can be revised non-locally.
ELBO formulation
-
Because exact likelihood is intractable, diffusion LLMs are trained using a variational lower bound.
-
A standard form of the ELBO objective is:
-
This connects directly to the masked cross-entropy loss discussed earlier. The ELBO interpretation is important because it preserves the probabilistic semantics of training, ensuring that the model is still optimizing a likelihood-based objective rather than a purely heuristic reconstruction loss.
-
Recent work such as LLaDA 1.5 by Zhu et al. (2025) emphasizes that this ELBO introduces nested expectations over both timestep \(t\) and corrupted samples (y_t), which later becomes a major source of variance in post-training optimization.
Confidence and remasking
-
A practical but critical design choice in diffusion LLMs is how to decide which tokens to keep at each step.
-
Most implementations use a confidence-based rule. After predicting token distributions, the model computes confidence scores (often maximum probability or entropy-based), and only the most confident tokens are fixed, while the rest are re-masked for future refinement.
-
This creates a dynamic schedule where easy tokens are resolved early, while hard tokens remain flexible longer.
-
This mechanism is central to performance. In fact, Reinforcing the Diffusion Chain of Lateral Thought by Huang et al. (2025) shows that the order in which tokens are unmasked can itself be learned as a policy, using ranking models such as Plackett–Luce to decide which tokens to reveal at each step.
-
This highlights an important point that does not exist in autoregressive models: the generation order is a learnable object.
Continuous vs. discrete time
-
There are two main formulations of diffusion LLMs:
-
Discrete-time models, such as LLaDA, operate with a finite sequence of timesteps and explicit masking ratios. These are currently the most practical and widely used.
-
Continuous-time models define a stochastic process over time and often use score-based formulations. These are more theoretically elegant and connect directly to classical diffusion modeling, but are less commonly used at scale in language.
-
-
The distinction matters mainly for training and theoretical analysis. In practice, most large-scale systems today use discrete masked diffusion due to simplicity and efficiency.
Key implications
-
The denoising process gives diffusion LLMs several structural properties that shape how these models are trained, optimized, and used in practice. Specifics below:
-
First, intermediate states are meaningful objects. Every \(y_t\) is a full sequence rather than a partial prefix, which means intermediate denoising states can themselves be evaluated, constrained, or used for credit assignment during optimization. This is one reason diffusion models are especially interesting for reinforcement learning and structured reasoning.
-
Second, uncertainty is explicit. The mask distribution and token confidence scores provide a native notion of uncertainty at each denoising step, which naturally supports adaptive remasking, confidence-aware decoding, and more principled control over generation.
-
Third, generation is inherently multi-step. Rather than producing a response through a single irreversible trajectory, diffusion models define a sequence of latent refinement states. This makes generation resemble trajectory optimization, which is central to how recent work formulates planning, sequence-level RL, and denoising-based reasoning in dLLMs.
-
-
Taken together, these properties are what make diffusion LLMs both powerful and challenging for post-training. They provide richer optimization signals than left-to-right models, but they also require rethinking standard assumptions behind likelihood estimation, policy optimization, and credit assignment.
Reinforcement Learning (RL) Mismatch
Why AR RL breaks
-
Reinforcement learning for autoregressive LLMs is built around a very specific probabilistic structure: the policy emits a token at position \(k\), the model exposes the conditional probability \(\pi_\theta(y_k \mid x, y_{<k})\), and the sequence likelihood factorizes exactly as:
\[\pi_\theta(y \mid x)=\prod_{k=1}^{L}\pi_\theta(y_k \mid x, y_{<k})\] -
That factorization is what makes PPO-, GRPO-, and DPO-style updates feel natural in the autoregressive world, because token-level importance ratios and token-level KL penalties are directly available. By contrast, diffusion LLMs generate by iterative denoising over the whole response, so the token-level left-to-right conditionals that these RL objectives assume are no longer the model’s native objects. This incompatibility is stated explicitly in Principled RL for Diffusion LLMs Emerges from a Sequence-Level Perspective by Ou et al. (2025), which argues that standard autoregressive RL objectives fundamentally mismatch non-autoregressive denoising, and in Improving Reasoning for Diffusion Language Models via Group Diffusion Policy Optimization by Rojas et al. (2025), which frames intractable likelihood as the main obstacle to RL fine-tuning for DLMs.
-
The deeper issue is that a diffusion model does not naturally expose one clean probability for “the response that was sampled” in the same cheap way an autoregressive model does. Instead, what it exposes most naturally is a denoising process over latent noisy states \(y_t\), and the exact sequence log-likelihood \(\log \pi_\theta(y\mid x)\) is typically intractable. In practice, one works with a lower bound or a surrogate, most commonly the ELBO. This is the central technical reason why it is easy to transplant reward functions from AR LLMs into dLLMs, but not easy to transplant the optimization objective itself.
The likelihood problem
- For diffusion LLMs, the common tractable proxy is the sequence-level ELBO:
-
This quantity is not the exact log-likelihood, but it is a principled surrogate arising from the diffusion formulation itself. The problem for RL is that policy-gradient style methods need likelihood ratios, and replacing exact log-likelihoods with Monte Carlo estimates of ELBOs injects both bias and variance into optimization. LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models by Zhu et al. (2025) makes this point especially clearly: once preference optimization is written in terms of ELBO-based estimators, the quality of learning becomes tightly controlled by estimator variance, not just by reward quality.
-
This distinction is easy to underappreciate if you come from AR post-training. In an autoregressive model, “compute the log-probability of the sampled answer” is routine. In a diffusion model, that same step becomes a nontrivial estimation problem. That is why so much of the dLLM RL literature is really about probability estimation under a denoising model, even when the papers are framed as RL papers.
Mean-field workarounds
-
The first class of solutions tried to preserve the token-level spirit of autoregressive RL by approximating diffusion likelihoods with token-local surrogates. The attraction is obvious: token-level methods are cheaper, easier to batch, and closer to existing GRPO-style codebases.
-
But this convenience comes at a cost. Improving Reasoning for Diffusion Language Models via Group Diffusion Policy Optimization by Rojas et al. (2025) argues that one-step unmasking style token-level likelihood estimates, used in prior diffusion RL methods, are computationally appealing but severely biased; the paper’s motivation is explicitly to move away from that approximation toward lower-variance sequence-level estimation. Likewise, Principled RL for Diffusion LLMs Emerges from a Sequence-Level Perspective by Ou et al. (2025) treats mean-field and tokenwise surrogates as heuristic patches that do not truly respect how dLLMs generate.
-
The conceptual problem with mean-field approximations is that they smuggle autoregressive thinking back into a model class whose main advantage is precisely that generation is holistic, order-agnostic, and globally revisable. Once you force the objective back into token-local pieces, you often lose the very global coupling that diffusion generation was giving you for free.
Trajectory-level view
-
A different line of work treats the denoising chain itself as the action trajectory. This is the most natural perspective if you think of diffusion generation as a sequence of latent decisions rather than as a single opaque sampler.
-
Reinforcing the Diffusion Chain of Lateral Thought with Diffusion Language Models by Huang et al. (2025) takes exactly this view. Its DCoLT framework interprets each intermediate reverse-diffusion step as a latent “thinking” action and optimizes the whole denoising trajectory using outcome-based RL. For LLaDA-like masked diffusion, the paper goes one step further and argues that the unmasking order is itself part of the policy, modeling it with a Plackett-Luce ranking distribution so that selecting which tokens to reveal becomes a learnable RL decision rather than a fixed heuristic.
-
This trajectory-centric view is attractive because it matches the phenomenology of diffusion generation. Intermediate states are meaningful, uncertainty is spatially distributed across the sequence, and late steps can revise early structure. In other words, the policy is not just “which answer do I output,” but also “how do I traverse the denoising path that leads to that answer.” The cost is that this space is large and optimization can become expensive, especially if one tries to reason over full latent trajectories rather than compressed sequence-level surrogates.
Sequence-level turn
-
The most principled response to the RL mismatch has been to stop pretending that dLLMs are token-action models at all, and instead treat the entire generated sequence as one action. That is the central move in Principled RL for Diffusion LLMs Emerges from a Sequence-Level Perspective by Ou et al. (2025), which proposes ELBO-based Sequence-level Policy Optimization, or ESPO. The key idea is simple but important: if the model’s native object is a distribution over whole sequences mediated by denoising, then the policy objective should also live at the sequence level, with the ELBO serving as a tractable proxy for the sequence likelihood.
-
In this view, the policy ratio is no longer built from tokenwise factors but from sequence-level scores. A stylized importance ratio takes the form:
\[r(y,x) =\exp\left( \mathcal{L}_\theta(y\mid x)-\mathcal{L}_{\theta_{\mathrm{old}}}(y\mid x) \right)\]- or a normalized variant of it. ESPO then adds stabilizers such as per-token normalization of ELBO ratios and robust KL estimation to keep training numerically well behaved at scale. The result is not merely a better estimator, but a cleaner definition of what the RL action actually is in a diffusion language model.
-
The reason this matters so much is philosophical as well as technical. Sequence-level RL accepts that diffusion models are not broken autoregressive models. They are a different kind of policy.
Variance reduction
-
Once you adopt ELBO-based sequence scores, the next problem is variance. The ELBO is an expectation over timesteps and masked samples, so naive Monte Carlo estimation can be noisy enough to destabilize RL or preference optimization.
-
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models by Zhu et al. (2025) studies this systematically in the preference-optimization setting. The paper shows that both the bias and variance of the preference optimization loss and gradient are governed by the variance of the score estimator, then proposes unbiased ways to reduce that variance, including improved budget allocation across timesteps and antithetic sampling between policy and reference estimates. These changes are not cosmetic. They are the main reason LLaDA 1.5 improves consistently over the SFT-only LLaDA baseline on math, code, and alignment benchmarks.
-
Improving Reasoning for Diffusion Language Models via Group Diffusion Policy Optimization by Rojas et al. (2025) makes a closely related point from the RL side. It decomposes the variance sources in ELBO estimation and introduces semi-deterministic Monte Carlo schemes to reduce variance under tight evaluation budgets, with empirical gains over diffu-GRPO-style baselines on reasoning and coding tasks.
-
So, in the current dLLM post-training literature, variance reduction is not an implementation detail. It is part of the algorithmic core.
Viewpoint Synthesis
-
A useful way to synthesize the field is that three viewpoints are now coexisting:
-
One viewpoint tries to preserve token-level RL through approximations. It is simple and often cheap, but tends to be biased and conceptually mismatched.
-
A second viewpoint treats the denoising chain as the real RL trajectory. It is conceptually rich and aligns well with the iterative nature of diffusion, but can be expensive and complex.
-
A third viewpoint, which is increasingly becoming the most principled default, treats the whole sequence as the action and uses ELBO-based sequence scores plus variance-control machinery. This is currently the cleanest answer to the question of how RL should be formulated for diffusion LLMs.
-
-
The broad lesson is that diffusion LLM post-training is forcing the community to revisit a hidden assumption from autoregressive RL: that the token is the natural unit of action. For dLLMs, that assumption is often wrong.
LLaDA Family
Why this family matters
- The LLaDA line is the clearest view we currently have of how diffusion LLMs evolved from a proof of concept into a post-trainable and then frontier-scale deployable family.
- Large Language Diffusion Models by Nie et al. (2025) established that a masked diffusion Transformer trained from scratch could reach 8B scale and remain competitive with similarly sized AR models; LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models by Zhu et al. (2025) showed that alignment for such models is mainly a likelihood-estimation and variance-control problem; and LLaDA2.0: Scaling Up Diffusion Language Models to 100B by Bie et al. (2025) turned the family into a staged AR-to-diffusion conversion pipeline with block diffusion, MoE scaling, and inference-oriented engineering.
LLaDA 1.0
Architecture
-
At its core, LLaDA is a masked diffusion language model built on a Transformer encoder rather than an autoregressive decoder. The model takes a partially masked sequence \(x_t\) and predicts all masked tokens simultaneously using bidirectional attention. Architecturally, the paper states that LLaDA closely follows the LLaMA design language, using RMSNorm, RoPE, and SwiGLU, but replacing the autoregressive causal decoder view with a mask-prediction encoder view. For the 8B model specifically, the paper reports 32 layers, model width 4096, 32 attention heads, vocabulary size {126,464}, FFN dimension {12,288}, 32 key/value heads, and about 8.02B total parameters, with 6.98B non-embedding parameters. This is important because it means LLaDA’s novelty is not a radically exotic backbone; it is a different probabilistic formulation wrapped around a mostly familiar Transformer architecture.
-
The training objective stays close to the masked diffusion ELBO surrogate:
\[\mathcal{L}(\theta) =-\mathbb{E}_{t,x_0,x_t} \left[ \frac{1}{t} \sum_{i=1}^{L} \mathbf{1}[x_t^i=\texttt{[MASK]}] \log p_\theta(x_0^i\mid x_t) \right]\]- where, \(t\sim U[0,1]\), and each token is independently masked with probability \(t\). This uniform-in-\(t\) masking schedule is one of the defining ingredients of LLaDA’s pretraining formulation, and it is what gives the model a continuous family of corruption levels rather than a single masked-language-modeling regime.
-
That figure captures the full original LLaDA recipe unusually well. In pretraining, all tokens may be independently masked at a shared ratio \(t\). In supervised fine-tuning, masking is restricted to response tokens so the prompt remains fixed conditioning context. In sampling, generation starts from a fully masked response and iteratively denoises toward (t=0), with remasking used to defer low-confidence positions. This makes LLaDA a full-sequence denoiser rather than a left-to-right next-token predictor.
LLaDA training pipeline
-
The original LLaDA paper is architecturally interesting not only because of the model, but because of the pipeline discipline. It uses the familiar pretrain then SFT recipe, but adapts both stages to diffusion. Pretraining masks the entire training text at a sampled ratio. SFT masks only the response side, which preserves instruction-following semantics under a diffusion loss. The 8B model was pretrained from scratch on 2.3T tokens and then SFTed on 4.5M instruction pairs, which made it one of the first serious demonstrations that a diffusion language model could be scaled in the same broad recipe class as mainstream LLMs.
-
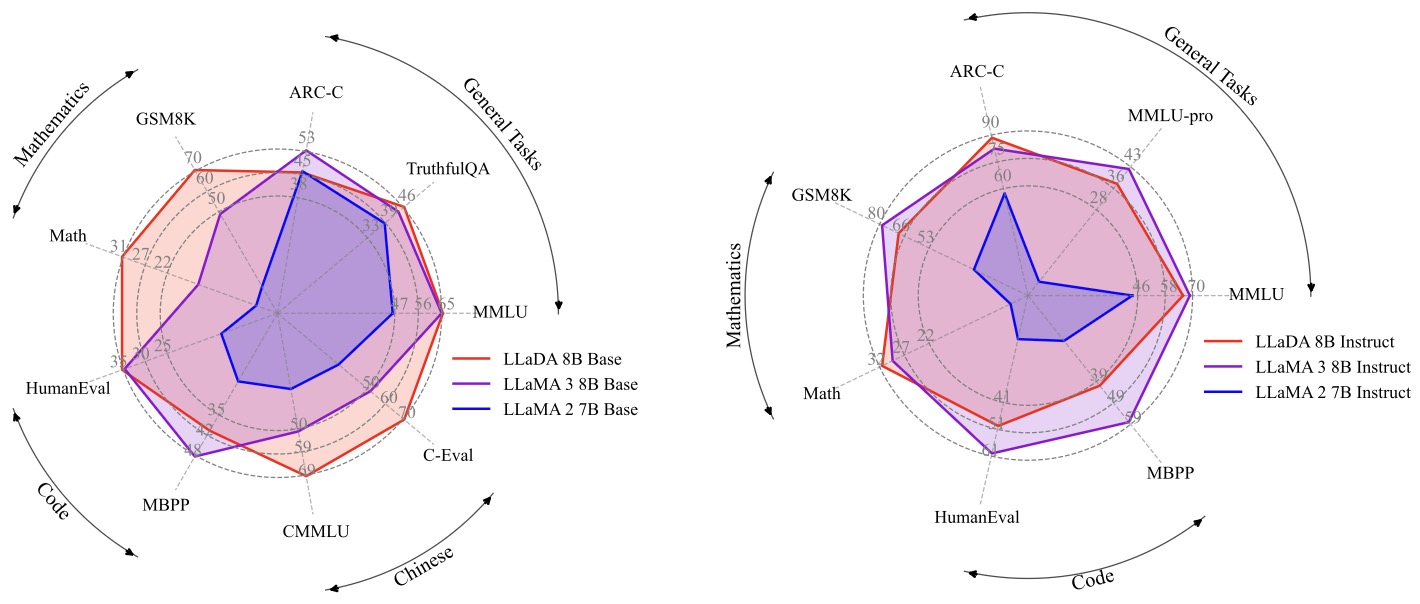
The following figure (source) shows zero/few-shot benchmark performance of LLaDA. LLaDA is scaled to 8B parameters from scratch and observe competitive zero/few-shot performance compared with strong autoregressive LLMs.
-
This benchmark figure matters architecturally because it validates the design choice to keep the backbone close to LLaMA while changing the generative mechanism. The paper reports that LLaDA 8B Base is competitive with LLaMA 3 8B Base on broad zero- and few-shot tasks, and that the instruct-tuned model also becomes broadly usable, which suggests that the mask-predictor architecture plus diffusion sampling is not merely a specialized infilling system but a genuine general-purpose LLM alternative.
-
This scalability figure is especially revealing. The paper compares LLaDA and matched AR baselines across growing FLOP budgets and finds that LLaDA tracks AR scaling behavior reasonably well across tasks such as MMLU, ARC-C, CMMLU, PIQA, GSM8K, and HumanEval. In primer terms, this is the first evidence that the LLaDA architecture is not just workable at one scale point, but is a scalable family.
Sampling in LLaDA
- LLaDA’s inference design is just as important as its training design. The paper highlights low-confidence remasking, where the model re-masks the least confident predicted tokens at intermediate steps, creating an annealed coarse-to-fine decoder. It also reports that the same pretrained model can support diffusion sampling, semi-autoregressive sampling, and even block diffusion style sampling without retraining, although full diffusion sampling gave the best results in the original study. This flexibility is a major architectural virtue of the LLaDA formulation: generation order is not hard-coded into the model definition.
LLaDA 1.5
Architecture
-
LLaDA 1.5 is not a new base architecture in the sense of changing the backbone. It keeps the original LLaDA 8B Instruct model architecture and changes the post-training algorithm. That detail matters. The point of LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models by Zhu et al. (2025) is that once you already have an 8B diffusion LM with a LLaMA-like Transformer encoder backbone, the hard part becomes alignment under intractable likelihoods. The paper therefore uses LLaDA 8B Instruct as the base policy and reference family, then builds a DPO-style preference optimization framework around ELBO-based likelihood surrogates.
-
The core scoring object is an ELBO-derived preference score rather than an exact log-likelihood. If \(\hat{\mathcal{L}}_\theta\) denotes a Monte Carlo ELBO estimate, the preference score has the DPO-like structure:
-
The technical issue is that this score is noisy because each ELBO term is itself estimated over timesteps and masked samples. LLaDA 1.5’s architectural contribution, in the broader system sense, is therefore a variance-aware alignment layer on top of the base LLaDA model rather than a new denoising backbone.
-
The paper’s three key variance-reduction moves are straightforward but decisive: increase the Monte Carlo budget, allocate it across timesteps more intelligently, and use antithetic sampling between policy and reference ELBO estimates. In symbols, if the budget is \(n=n_t n_{y_t}\), LLaDA 1.5 argues that better allocation over timesteps and paired antithetic noise reduce the variance of the estimator without changing its expectation. This is why LLaDA 1.5 should be read as an alignment architecture, not just an algorithmic tweak. It changes what the post-training stack for diffusion LLMs has to look like.
-
This figure is the cleanest summary of what LLaDA 1.5 changed. The left panel shows consistent gains over the SFT-only LLaDA baseline on alignment, math, and code tasks. The right panel shows that after preference optimization, the model remains mathematically competitive with both diffusion and autoregressive peers. In other words, the backbone stayed the same, but the post-training stack became materially better.
Training Stack
- The training setup makes the design evolution concrete. The paper trains for one epoch on 350K preference pairs, initializes the reference policy from LLaDA Instruct, uses AdamW, and mixes the DPO-style preference loss with a small weighted MDM SFT loss to stabilize optimization. It also notes that multiple diffusion sampling strategies remain relevant at evaluation time, including diffusion sampling, diffusion semi-autoregressive sampling, and low-confidence remasking, with task-specific choice of the best sampler. This means LLaDA 1.5 does not collapse the diffusion model back into a single fixed decoding path after alignment; instead, it preserves the flexible sampling character of the original model while making the aligned policy more stable to train.
LLaDA2.0
Architecture
-
LLaDA2.0 is the biggest architectural jump in the family. The key move is to stop training a diffusion LM from scratch and instead convert a strong AR model into a diffusion LM through a staged transformation pipeline. LLaDA2.0: Scaling Up Diffusion Language Models to 100B by Bie et al. (2025) explicitly frames this around knowledge inheritance, progressive adaptation, and efficiency-aware design. The resulting family includes LLaDA2.0-mini at 16B total parameters and LLaDA2.0-flash at 100B total parameters, both as instruction-tuned MoE variants.
-
Architecturally, the most important idea is block diffusion. Instead of denoising isolated masked tokens only, the model is trained to denoise contiguous spans, which better matches efficient parallel decoding and allows the inference engine to exploit structures closer to blockwise AR execution. The training paradigm is organized into three stages: continual pretraining from AR to masked diffusion LM, block diffusion pretraining, and post-training with SFT and DPO. The paper calls the block-size schedule warmup, stable, and decay, or WSD: first progressively increase block size, then run large-scale full-sequence diffusion, then return to compact block diffusion.
-
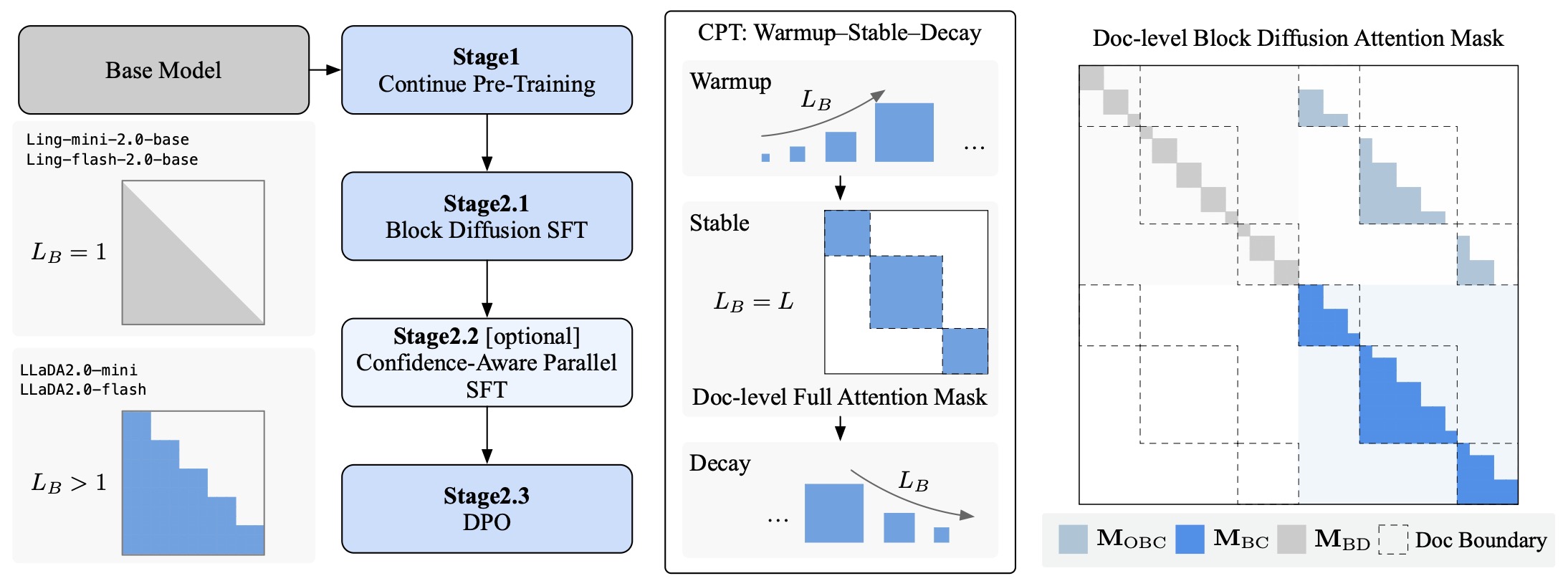
The following figure (source) shows a schematic of the progressive training framework for transforming an AR model into a MDLM. Continual Pre-Training Stage facilitates the Warmup-Stable-Decay strategies by scheduling block size \(L_B\) enables smooth, stable, and effective attention mask adaptation. Post-training Stage facilitates the same block diffusion configuration conducting the instruction SFT, Confidence-Aware Parallel SFT, and DPO. The right panel illustrates the document-level block diffusion attention mask,which enables an efficient, vectorized forward pass by constructing a single input sequence from multiple noisy and clean examples, such as \(\left[\boldsymbol{x}_{\text {noisy } 1}, \ldots, \boldsymbol{x}_{\text {clean } 1}, \ldots\right]\). The forward pass then employs a combination of block-diagonal (\(\mathbf{M}_{\mathrm{BD}}\)), offset block-causal (\(\mathbf{M}_{\mathrm{OBC}}\)), and block-causal (\(\mathbf{M}_{\mathrm{BC}}\)) masks.
-
This figure is the architectural heart of LLaDA2.0. It shows how the family moves from a base AR model through continual pretraining into masked diffusion, then into block diffusion, and then into post-training stages that include instruction SFT, confidence-aware parallel SFT, and DPO. It also illustrates the document-level block diffusion attention mask, which mixes block-diagonal, offset block-causal, and block-causal masking patterns so that multiple noisy and clean examples can be packed into one efficient forward pass. This is where LLaDA2.0 stops being just a modeling paper and becomes a systems-and-training paper as well.
-
Another key change in LLaDA2.0 is that it is designed for efficient inference infrastructure. The paper states that the block-diffusion execution pattern enables KV-cache reuse and allows the inference engine to benefit from optimizations originally developed for AR serving. It reports throughput gains over similarly sized AR baselines, especially for the confidence-aware parallel variant. So the architectural story is no longer only about probabilistic elegance; it is about making diffusion LLMs competitive in real deployment regimes.
-
The following figure (source) shows LLaDA2.0-flash main results. This figure is relevant to decoding because it reflects the end result of that efficiency-oriented redesign. The reported quality at 100B scale suggests that blockwise, parallel, deployment-aware diffusion inference can remain competitive on mainstream tasks rather than only on niche infilling-style workloads.
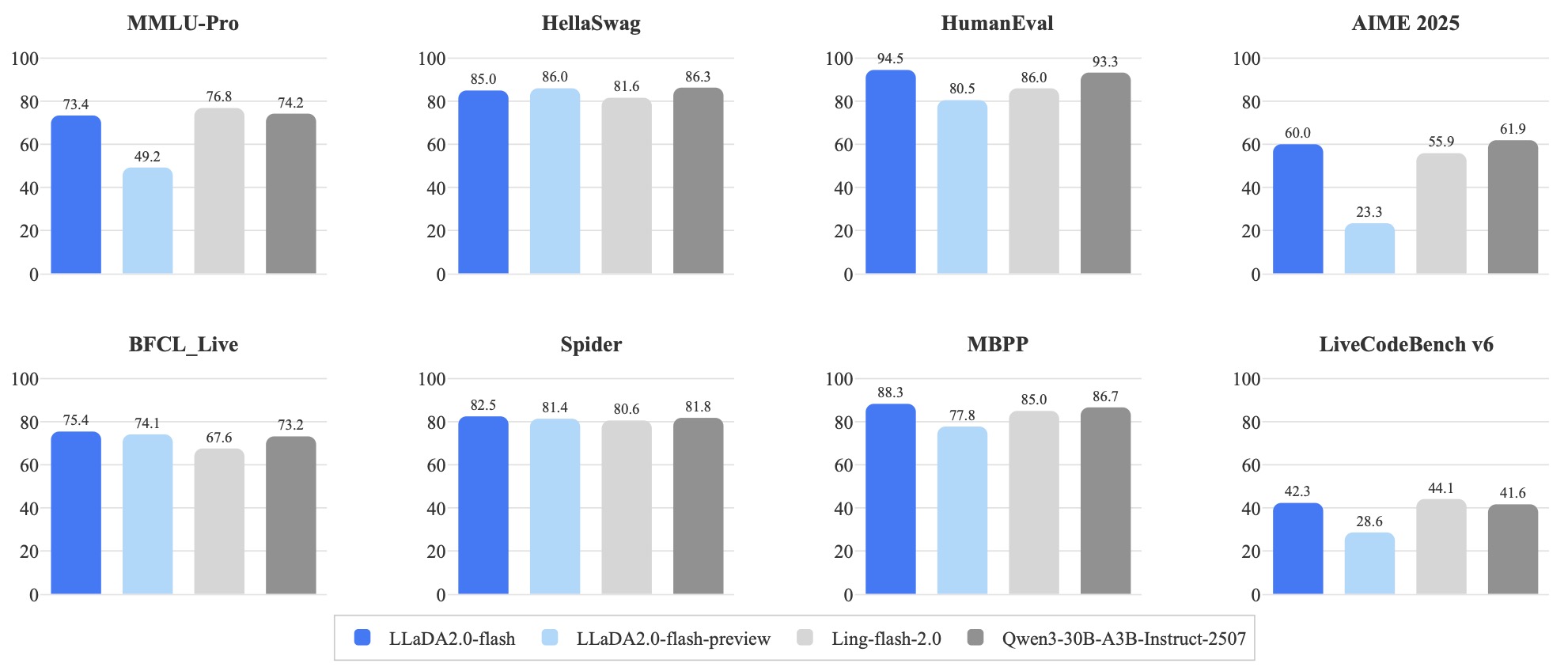
- This result figure matters because it shows where the family lands after all the architectural changes. LLaDA2.0-flash is reported as competitive on broad benchmarks and notably strong on code, math, and tool-use style tasks, which is exactly where one would expect a globally revisable, blockwise diffusion architecture to have room to shine.
LLaDA2.0-Uni
Overview
-
LLaDA2.0-Uni extends the LLaDA family from text-only diffusion language modeling into unified multimodal understanding and generation. The key idea in LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model by Bie et al. (2026) is that text and images can be handled by the same diffusion backbone if images are first converted into semantic discrete tokens rather than treated as continuous embeddings or reconstruction-oriented VQ tokens.
-
This changes the LLaDA story from “diffusion can be an alternative to autoregressive language modeling” to “diffusion can be the shared substrate for multimodal foundation models.” LLaDA2.0-Uni keeps the family’s core commitments, namely discrete masking, iterative denoising, block-wise decoding, and bidirectional context, but extends them to semantic image tokens. The result is a unified model that can answer questions about images, generate images, edit images from single or multiple references, and produce interleaved text-image outputs within one diffusion-native framework.
-
This makes LLaDA2.0-Uni a natural continuation of the family: LLaDA established masked diffusion as a viable language-modeling paradigm, LLaDA 1.5 made diffusion-native preference optimization practical through variance reduction, LLaDA2.0 scaled the recipe through AR-to-diffusion conversion, MoE scaling, and block diffusion, and LLaDA2.0-Uni asks whether the same discrete diffusion recipe can unify image understanding, image generation, image editing, and interleaved image-text reasoning.
-
The following figure (source) shows the benchmark performance of LLaDA2.0-Uni across multimodal understanding, image generation, and image editing benchmarks, comparing it against other unified and multimodal systems to position the model as a diffusion-native alternative for both perception and generation.
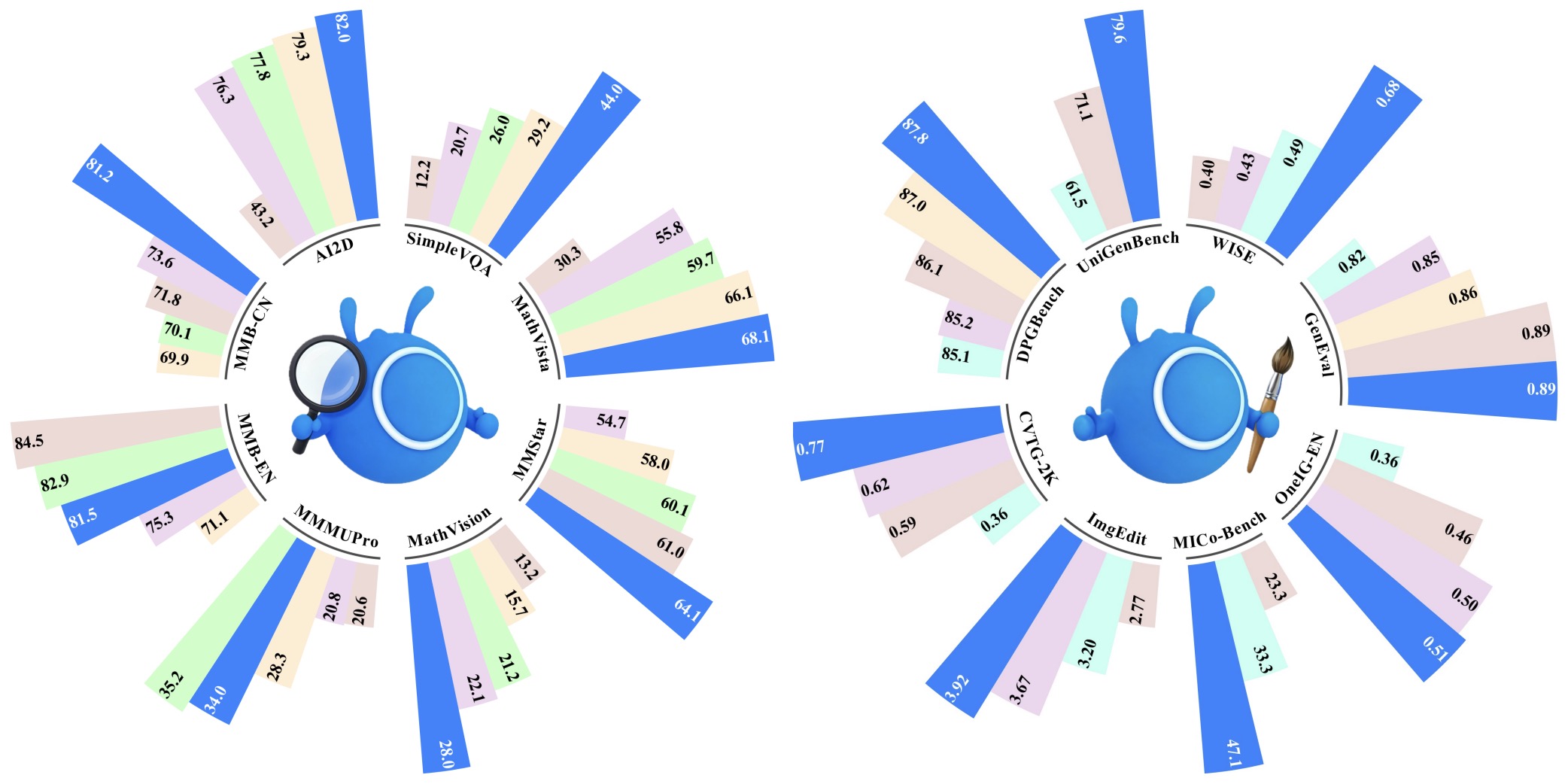
Motivation
-
Earlier multimodal diffusion LLMs already showed that unified diffusion is possible. MMaDA: Multimodal Large Diffusion Language Models by Yang et al. (2025) introduced a modality-agnostic diffusion foundation model for text reasoning, multimodal understanding, and text-to-image generation. Lumina-DiMOO: An Omni Diffusion Large Language Model for Multi-Modal Generation and Understanding by Xin et al. (2025) pushed fully discrete diffusion for multimodal generation and understanding. However, LLaDA2.0-Uni argues that these systems still face three architectural bottlenecks: reconstruction-style VQ tokenizers lose semantic information needed for visual understanding, excessive image compression hurts generation fidelity, and unconstrained full-bidirectional attention can be unreliable for text.
-
The model also contrasts with hybrid unified systems such as LLaDA-o: An Effective and Length-Adaptive Omni Diffusion Model by You et al. (2026), which decouples discrete masked diffusion for language and continuous diffusion for visual generation, and Emerging Properties in Unified Multimodal Pretraining by Deng et al. (2025), which introduces BAGEL as a decoder-only unified multimodal model trained on large interleaved multimodal data. LLaDA2.0-Uni instead tries to keep the central modeling substrate discrete: the dLLM backbone denoises both text tokens and semantic image tokens, while a separate diffusion decoder is used only after the semantic image-token plan has been generated.
Architecture
-
LLaDA2.0-Uni has three main components:
- A semantic discrete visual tokenizer, SigLIP-VQ, which maps images into discrete semantic tokens.
- A 16B MoE diffusion LLM backbone based on LLaDA2.0.
- A diffusion decoder that reconstructs generated semantic image tokens into pixels.
-
The tokenizer builds on SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features by Tschannen et al. (2025), which improves semantic understanding, localization, dense features, multilingual behavior, and multi-resolution support for vision-language encoders. In LLaDA2.0-Uni, this matters because visual tokens are not just reconstruction codes; they are the symbolic interface through which the dLLM reasons about charts, documents, objects, edited regions, and generated scenes.
-
A compact abstraction is:
\[z_v = Q(f_{\text{SigLIP2}}(I))\]- where \(I\) is the input image, \(f_{\text{SigLIP2}}(\cdot)\) extracts dense semantic visual features, and \(Q(\cdot)\) maps those features into a discrete codebook. LLaDA2.0-Uni then appends these visual tokens to the text vocabulary, along with special tokens for resolution and multimodal control.
-
The resulting unified vocabulary can be written as:
-
This is the architectural move that makes the model a true LLaDA-family extension: images become denoisable discrete symbols rather than side-channel embeddings.
-
The following figure (source) shows the architecture overview of LLaDA2.0-Uni: multimodal inputs are converted by the text tokenizer and SigLIP-VQ tokenizer into text tokens, image tokens, special tokens, and mask tokens; LLaDA2.0-mini performs modality-agnostic masked diffusion over the unified sequence; and outputs are decoded either through a text detokenizer or through a diffusion decoder for image generation and editing.
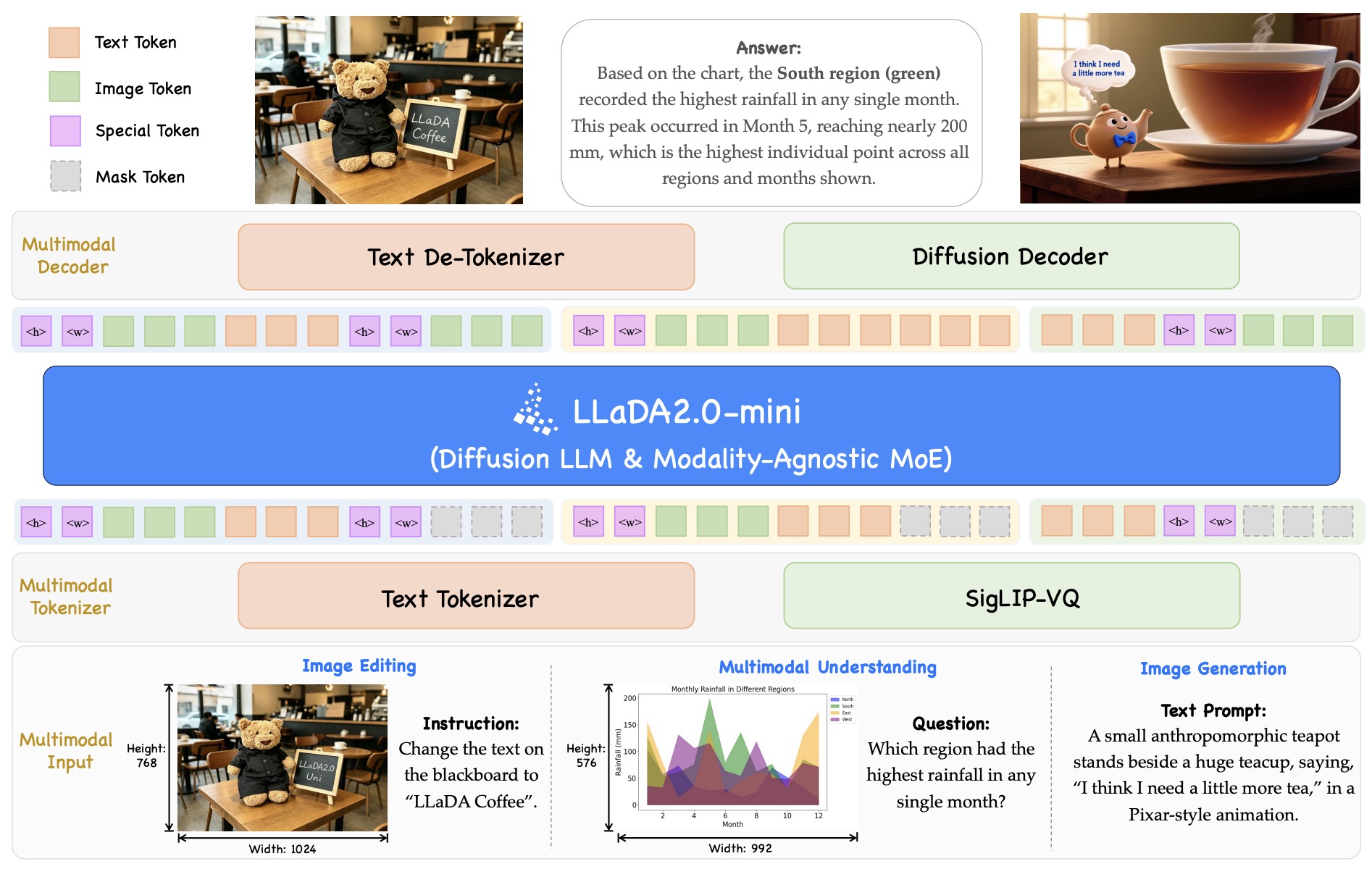
Objective
- The backbone is trained with the same basic masked diffusion logic as earlier LLaDA-family models, but over a multimodal token sequence. If \(x_0\) is the clean text-image sequence and \(x_t\) is the corrupted sequence, the objective is:
- The difference from text-only LLaDA is that \(x_0^i\) may now be a text token, an image token, or a special multimodal token. This avoids the usual hybrid design in which an autoregressive LLM models text while a separate diffusion model handles images under a different loss. The model instead has one discrete denoising objective for the shared semantic sequence.
Attention and Resolution
-
Although fully bidirectional attention is attractive for diffusion sampling, LLaDA2.0-Uni uses block-wise attention for stability. This is aligned with Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models by Arriola et al. (2025), which studies block diffusion as a middle ground between autoregressive decoding and fully parallel diffusion. In LLaDA2.0-Uni, block-wise attention helps preserve the benefits of parallel denoising while avoiding the degradation that can come from unconstrained full bidirectionality.
-
For image resolution, LLaDA2.0-Uni keeps the LLM-style 1D RoPE setup rather than switching the whole backbone to specialized 2D image positional encoding. It represents spatial information with explicit height and width tokens before the flattened visual-token sequence:
- This keeps the model close to the LLaDA text backbone while letting it support arbitrary image resolutions through tokenized size metadata.
Decoder
-
Because SigLIP-VQ tokens are optimized for semantic understanding, they cannot be decoded like standard reconstruction-trained VQ-VAE tokens. LLaDA2.0-Uni therefore adds a dedicated diffusion decoder built on Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer by Cai et al. (2025), a 6B image-generation model designed for efficient high-quality synthesis.
-
The decoder can be summarized as:
\[\hat{I}=D_{\phi}(z_v)\]- where \(z_v\) is the generated semantic visual-token sequence and \(D_{\phi}\) is the diffusion decoder. The important distinction is that the dLLM first produces a semantic visual plan in token space, and the decoder then turns that plan into pixels. The paper further distills the decoder from a 50-step classifier-free-guidance process into an 8-step CFG-free process, so multimodal generation inherits both diffusion-token parallelism and few-step image decoding.
Design evolution
-
The most straightforward way to understand the LLaDA family is to see each generation as solving a different bottleneck:
-
LLaDA solved the base modeling question: Large Language Diffusion Models by Nie et al. (2025) showed that a LLaMA-like Transformer trained with a masked diffusion objective and iterative remasking can become a real general-purpose LLM.
-
LLaDA 1.5 solved the alignment question: LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models by Zhu et al. (2025) showed that preference optimization for dLLMs needs diffusion-native likelihood estimation and variance reduction, with VRPO making ELBO-based alignment statistically practical.
-
LLaDA2.0 solved the scaling-and-deployment question: LLaDA2.0: Scaling Up Diffusion Language Models to 100B by Bie et al. (2025) showed that AR-to-diffusion conversion, block diffusion, MoE scaling, and efficiency-oriented training can turn diffusion LLMs into a 100B-class deployable family.
-
LLaDA2.0-Uni solved the multimodal unification question: LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model by Bie et al. (2026) showed that the same discrete diffusion recipe can support multimodal understanding, image generation, editing, and interleaved reasoning when images are represented as semantic discrete tokens.
-
-
In that sense, the LLaDA family is not just a sequence of similarly named models. It is the clearest case study of diffusion LLMs maturing from viability, to post-training, to scale and serving, to unified multimodal modeling.
Sampling and Inference
Native decoding modes
-
A useful way to think about LLaDA-family inference is that the model architecture stays mostly fixed while the decoding policy changes substantially. In the original Large Language Diffusion Models by Nie et al. (2025), the same pretrained model supports standard diffusion decoding, semi-autoregressive decoding, and block-style decoding variants, with the main difference being how many masked positions are updated per step and how aggressively uncertain predictions are re-masked. This is one of the family’s most important practical properties: decoding policy is a first-class design dimension, not just a low-level sampler setting.
-
The original full diffusion mode starts from a fully masked response region and updates many or all masked positions at each step. Semi-autoregressive variants instead partition the response into chunks and denoise chunkwise, trading some of the model’s global flexibility for more controlled generation. Later LLaDA-family work keeps this basic picture but increasingly engineers the decoding path around efficiency and deployment constraints rather than purely around probabilistic neatness.
-
This figure is still the cleanest visual summary of the family’s inference semantics: start from a masked response, predict all masked positions in parallel, keep confident ones, and re-mask uncertain ones as the noise level decreases. It is the decoding loop that turns a masked-token predictor into a generative language model.
Confidence-based remasking
-
The key algorithmic idea in early LLaDA inference is low-confidence remasking. After each denoising step, the model scores predicted tokens by confidence, keeps the more reliable ones, and re-masks the less reliable ones for later refinement. This produces a coarse-to-fine decoding dynamic in which global structure appears early and brittle local details are deferred. The original LLaDA paper explicitly presents this remasking logic as a central part of sampling rather than as a minor heuristic, because it determines both output quality and the number of useful denoising steps.
-
A good mental model is that remasking creates a dynamic trust region over token positions. Easy positions become fixed early, while hard positions remain revisable. In autoregressive decoding, earlier mistakes are usually irrevocable; in diffusion decoding, confidence-based remasking makes revision native to the generation process. That is a major reason diffusion models are attractive for tasks like infilling, editing, and globally constrained generation.
Speed-quality tradeoffs
-
Because diffusion generation runs for multiple denoising steps, inference quality depends strongly on how many steps you allow and how aggressively you freeze predictions. More steps usually improve refinement and consistency, but increase latency. Fewer steps improve throughput, but force the model to commit earlier and can leave hard positions under-optimized. This tradeoff is a recurring theme across the LLaDA family, from the original 8B model through LLaDA2.0’s deployment-oriented block diffusion variants.
-
In primer terms, diffusion LLM inference exposes a richer control surface than AR decoding. You are not just choosing temperature or top-\(p\); you are also choosing the denoising schedule, the reveal policy, the remasking rule, and often the structural unit of generation, whether tokenwise, chunkwise, or blockwise. That richer control space is one of the family’s strengths, but it also means benchmarking must always be read together with the chosen decoding setup.
LLaDA 1.5 decoding
-
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models by Zhu et al. (2025) does not mainly redesign the backbone, but it does matter for inference because alignment changes which decoding policies become effective. The paper keeps diffusion-native sampling in play and evaluates multiple samplers, including standard diffusion decoding and semi-autoregressive variants, while showing that better post-training makes those samplers materially more useful on reasoning, code, and alignment tasks. The main lesson is that for dLLMs, sampler quality and policy alignment are tightly coupled.
-
This coupling appears because the sampler determines which latent denoising paths are actually realized at test time, while preference optimization shapes which completed sequences the model prefers. If ELBO-based preference optimization is noisy, the model may not assign stable relative preference across candidate denoising outcomes; once variance is reduced, the same decoder can more reliably steer toward better final sequences. In that sense, LLaDA 1.5 improves inference indirectly by improving the statistical quality of post-training.
-
This figure is relevant to inference even though it is usually read as an alignment figure. The gains over the SFT-only baseline imply that the same diffusion decoding machinery becomes much more effective once the model’s sequence preferences are learned with lower-variance ELBO estimators.
Block diffusion decoding
-
The biggest inference shift arrives in LLaDA2.0: Scaling Up Diffusion Language Models to 100B by Bie et al. (2025). LLaDA2.0 moves from a mostly token-level masked diffusion view toward block diffusion as a deployment-oriented decoding abstraction. Instead of revealing arbitrary isolated tokens only, the model can denoise contiguous spans, which maps better onto efficient parallel execution and makes reuse of AR-style serving optimizations more plausible. The paper explicitly frames this around knowledge inheritance, progressive adaptation, and efficiency-aware design.
-
In practical terms, block diffusion changes inference in two ways. First, it reduces the overhead of purely positionwise iterative updates by operating on larger structural units. Second, it makes the generation path more compatible with cache reuse and serving backends that were originally optimized for autoregressive workloads. LLaDA2.0 therefore treats decoding not just as probabilistic inference but as a systems problem.
-
This figure matters here because it shows that block diffusion is not only a training trick. It is the bridge between diffusion modeling and efficient inference. The blockwise attention structure, the warmup-stable-decay schedule, and the post-training stages are all organized around making diffusion decoding more scalable in practice.
SPRINT acceleration
-
LLaDA2.0-Uni introduces SPRINT, Sparse Prefix Retention with Inference-time Non-uniform Token Unmasking, as a training-free acceleration method for multimodal block diffusion. The motivation is that block-wise diffusion decoding still requires \(B \times T\) forward passes for \(B\) generated blocks and \(T\) denoising steps, so parallel token prediction alone does not remove all inference cost.
-
SPRINT reduces cost in two ways. First, Sparse Prefix Retention prunes the prefix KV cache once per generated block, so later denoising steps attend to a shorter effective prefix. Each prefix token is scored by a mixture of key-norm importance and model confidence:
\[s_i = \alpha \cdot \bar{I}_i + (1-\alpha)\cdot c_i\]- where \(\bar{I}_i\) is mean-normalized key-norm importance, \(c_i=\max_v p_\theta(v\mid x_t)\) is top-1 token confidence, and LLaDA2.0-Uni uses \(\alpha=0.5\). The pruning is modality-aware: text tokens and image tokens use separate keep ratios because image tokens are often spatially redundant, while text tokens may carry instructions, constraints, or reasoning chains.
-
Second, Non-uniform Token Unmasking replaces a fixed denoising schedule with confidence-adaptive acceptance. Rather than unmasking a fixed number of tokens per step, the sampler accepts masked positions whose confidence exceeds a threshold:
- A minimum number of accepted tokens is enforced at each step so decoding always terminates. This makes SPRINT more than a generic speed trick: in multimodal diffusion, the sampler becomes a modality-aware compute-allocation policy, deciding which prefix tokens to retain and which masked outputs are reliable enough to commit early.
Parallel serving gains
-
One of the central claims of LLaDA2.0 is that preserving parallel decoding can translate into real serving advantages at scale. The paper reports that its 16B and 100B-class models are optimized for practical deployment and emphasizes throughput and efficiency benefits alongside benchmark quality. This is a meaningful shift from the original LLaDA paper, where inference flexibility was already present but deployment economics were not yet the main story.
-
The broader implication is that diffusion LLMs may become most compelling not when they mimic AR decoding exactly, but when they exploit structural parallelism that AR models do not have. LLaDA2.0’s confidence-aware parallel variants are interesting precisely because they operationalize that idea: use diffusion’s revisability where it helps, but package it into a serving pattern that remains cache-friendly and high-throughput.
Long-context inference
-
Long-context decoding is another place where LLaDA-family inference differs from AR assumptions. UltraLLaDA: Scaling the Context Length to 128K for Diffusion Large Language Models by He et al. (2025) studies how to extend LLaDA-style models to 128K context without retraining from scratch and argues that diffusion-specific RoPE extension plus appropriate masking strategies materially improves long-context behavior. The motivation is notable: unlike AR models, diffusion LLMs do not simply catastrophically fail beyond trained context length, but can exhibit a more local-perception style degradation, where recent segments dominate and distant context is underused.
-
This matters for inference because long-context generation is not just about increasing the window size. It is also about ensuring that the denoising process continues to allocate attention and uncertainty across distant positions in a stable way. UltraLLaDA’s contribution is therefore partly architectural and partly inferential: it adapts positional scaling to diffusion’s probabilistic dynamics so that denoising remains meaningful over far longer sequences.
-
The following figure (source) shows long-context benchmark performance of UltraLLaDA: NIAH evaluation up to 128K context-length. UltraLLaDA can find all of the needles within the context window 8–32× longer than that LongLLaDA can handle.
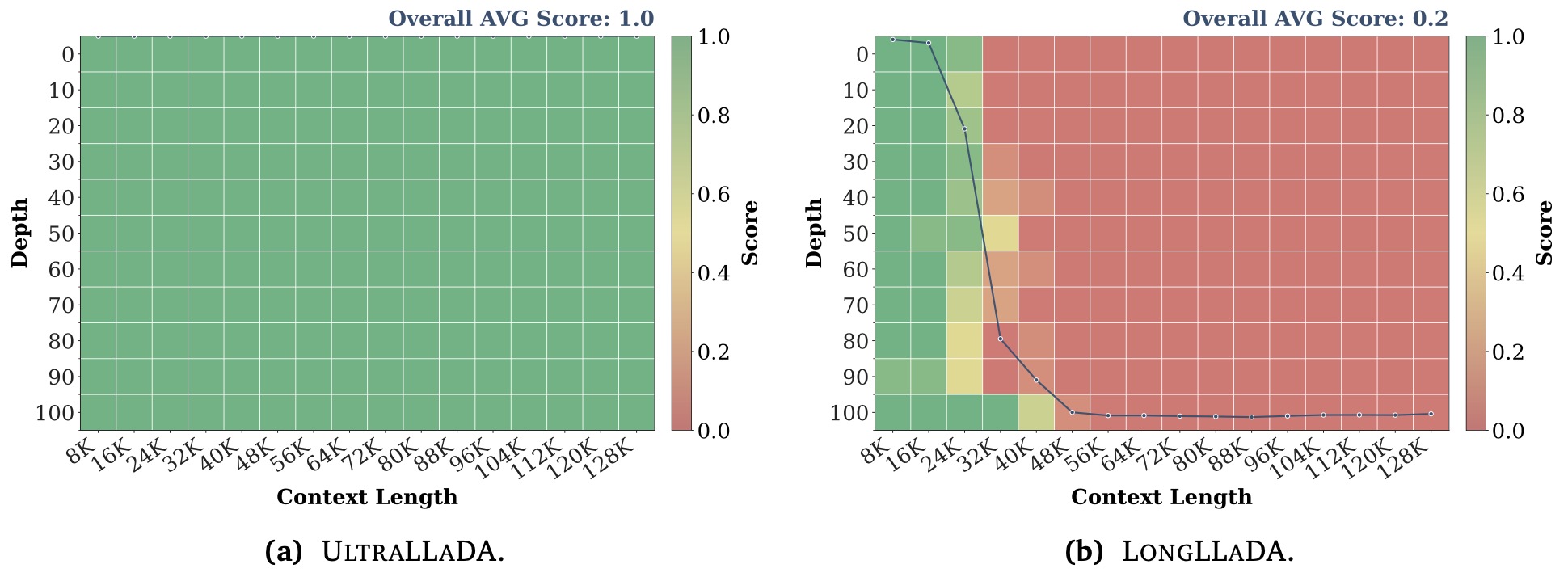
- This kind of figure is important in a primer because it highlights that diffusion inference has its own failure modes. The issue is often not abrupt collapse, but under-utilization of remote context, which requires different fixes than standard AR long-context extrapolation.
Choosing a decoder
-
Across the LLaDA family, the practical decoder choice depends on what you want to optimize. If you want maximal global revisability and are less constrained by latency, fuller diffusion decoding with more denoising steps remains attractive. If you want better deployment efficiency, chunked or block diffusion variants become more appealing. If you want long-context handling, positional extension and masking strategy become part of the decoder design itself rather than merely part of training. These tradeoffs are exactly why LLaDA-family papers spend so much effort on sampling policy and post-training details rather than treating generation as fixed.
-
The high-level lesson is that diffusion LLM inference is best understood as policy design over a denoising process. The model gives you a denoiser; the decoder decides how that denoiser is used.
Reasoning and Planning
Why reasoning changes
-
Reasoning in diffusion LLMs should not be understood as ordinary chain-of-thought with a different decoder. Autoregressive chain-of-thought is fundamentally linear: each intermediate token becomes part of the fixed prefix that conditions the next token. Diffusion reasoning is different because the model repeatedly revises a whole latent answer state, allowing partial ideas, equations, answer fragments, and later corrections to coexist before the final response is resolved.
-
Reinforcing the Diffusion Chain of Lateral Thought with Diffusion Language Models by Huang et al. (2025) formalizes this distinction by treating intermediate denoising steps as latent thinking actions rather than natural-language rationales.
Lateral thought
- The lateral-thought view says that a denoising trajectory is itself a reasoning object. If \(y_t\) is the partially denoised response at timestep \(t\), then the model’s reasoning path is not just the final answer \(y_0\), but the full chain:
-
DCoLT uses this chain as the unit of reinforcement learning. Instead of supervising every intermediate step with a process reward, it applies an outcome reward to the final answer and backpropagates credit through the denoising trajectory. In the continuous-time setting, the model’s score function defines a probabilistic policy over token updates; in the LLaDA-style masked setting, the unmasking order becomes part of the policy itself. Reinforcing the Diffusion Chain of Lateral Thought with Diffusion Language Models by Huang et al. (2025) reports that DCoLT improves LLaDA on GSM8K, MATH, MBPP, and HumanEval by optimizing this denoising trajectory directly.
-
A compact way to write the trajectory objective is:
\[\max_\theta ; \mathbb{E}_{\tau \sim \pi_\theta} \left[ R(y_0) \right], \quad \tau=(y_T,y_{T-1},\ldots,y_0)\]- where \(R(y_0)\) is an outcome reward such as answer correctness. The important shift is that \(\tau\), not a left-to-right token prefix, is the reasoning substrate.
Unmasking as policy
-
In masked diffusion, deciding what to reveal is almost as important as deciding what token to place there. This is a uniquely diffusion-specific reasoning issue. Autoregressive models have a fixed action order: position (1), then position (2), then position (3). LLaDA-style models must decide which masked positions should become reliable first.
-
DCoLT treats that reveal order as learnable. For LLaDA, it introduces an Unmasking Policy Module based on the Plackett-Luce ranking model, so masked positions receive ranking scores and the model selects which positions to unmask at each step. This is a meaningful architectural and algorithmic distinction: the reasoning policy includes both token choice and position choice. Reinforcing the Diffusion Chain of Lateral Thought with Diffusion Language Models by Huang et al. (2025) specifically identifies unmasking order as essential for optimizing RL actions in discrete-time masked diffusion.
-
The Plackett-Luce probability for selecting an ordered subset can be written as:
\[P(i_1,\ldots,i_K) =\prod_{k=1}^{K} \frac{\exp(s_{i_k})} {\sum_{j\in \mathcal{M}\setminus {i_1,\ldots,i_{k-1}}}\exp(s_j)}\]- where \(s_i\) is the score for masked position \(i\), and \(\mathcal{M}\) is the set of currently masked positions. In reasoning terms, this gives the model a trainable way to decide whether to solve the equation first, place the final answer first, fill in an explanation skeleton first, or defer uncertain details.
-
This matters because reveal order becomes part of the learned reasoning strategy itself. The model can decide whether to resolve equations first, sketch answer structure first, or defer uncertain spans until later denoising steps.
-
The following figure (source) illustrates the LLaDOU architecture, showing how the Unmask Policy Module predicts ordered token unmasking and integrates with LLaDA blocks for diffusion-based reasoning. Specifically, LLaDOU first predicts the token set to unmask \(\mathcal{U}_n\) according to the ranking score \(h_{\theta, n}\) by the UPM, and then samples those unmasked tokens in \(\mathcal{U}_n\) by LLaDA blocks. The figure makes explicit that the action in diffusion reasoning is richer than token selection alone. At each denoising step, the model jointly decides what content to generate and where latent uncertainty should be resolved next. That is a substantially different notion of reasoning policy from left-to-right chain-of-thought.
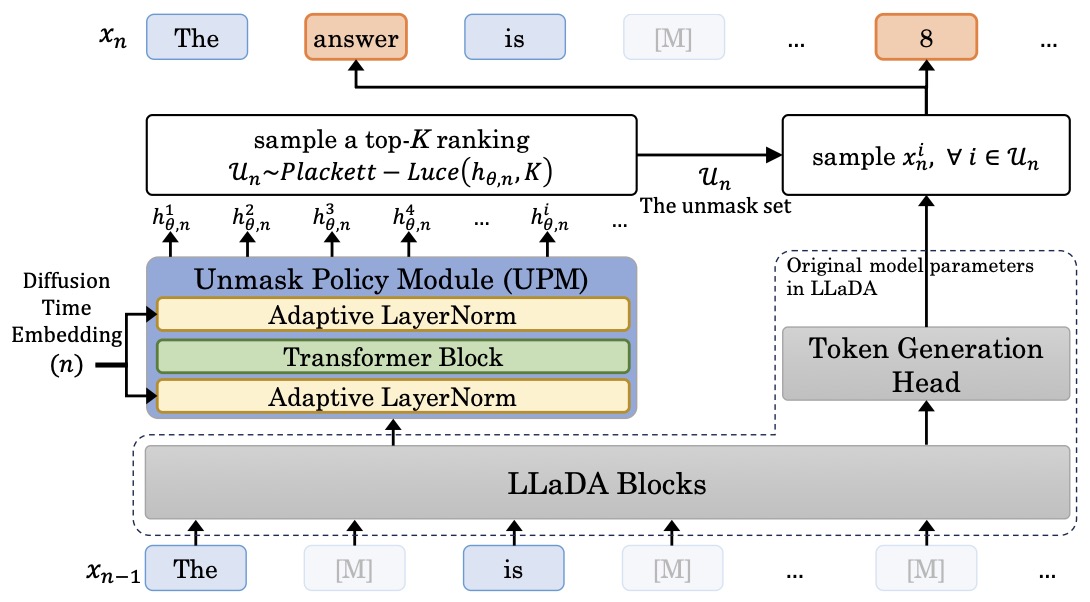
- Conceptually, this elevates the denoising trajectory into a structured control process. Rather than treating unmasking as a heuristic scheduling rule, LLaDOU treats it as part of the optimization target itself, which is why it serves as a bridge between diffusion generation and diffusion-native reinforcement learning.
d1 and diffu-GRPO
-
The first major wave of dLLM reasoning work tried to adapt the successful AR reasoning-RL recipe to masked diffusion. d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning by Zhao et al. (2025) combines masked SFT with diffu-GRPO, a critic-free policy-gradient method adapted from GRPO for masked diffusion models. The paper’s recipe is important because it established that pretrained diffusion LLMs can be post-trained into stronger reasoning models rather than remaining only general-purpose denoisers.
-
The central approximation in diffu-GRPO is to make token-level policy optimization computationally feasible for dLLMs, even though exact autoregressive token likelihoods do not exist. This helped demonstrate early gains, but later work argued that the approximation is biased. Improving Reasoning for Diffusion Language Models via Group Diffusion Policy Optimization by Rojas et al. (2025) explicitly frames one-step unmasking likelihood estimation as computationally efficient but severely biased, motivating more principled ELBO-based sequence likelihood estimation.
-
So d1 is best understood as the first strong practical bridge: it showed reasoning RL can work for diffusion LLMs, while also exposing why the token-level bridge is mathematically fragile.
Group Diffusion Policy Optimization (GDPO)
-
GDPO moves the reasoning story toward sequence-level likelihood estimation. Improving Reasoning for Diffusion Language Models via Group Diffusion Policy Optimization by Rojas et al. (2025) introduces Group Diffusion Policy Optimization, which uses ELBO-based sequence likelihood surrogates and semi-deterministic Monte Carlo schemes to reduce estimator variance under limited compute. The goal is to retain the group-relative advantages of GRPO while replacing biased token-level estimates with lower-variance diffusion-native sequence estimates.
-
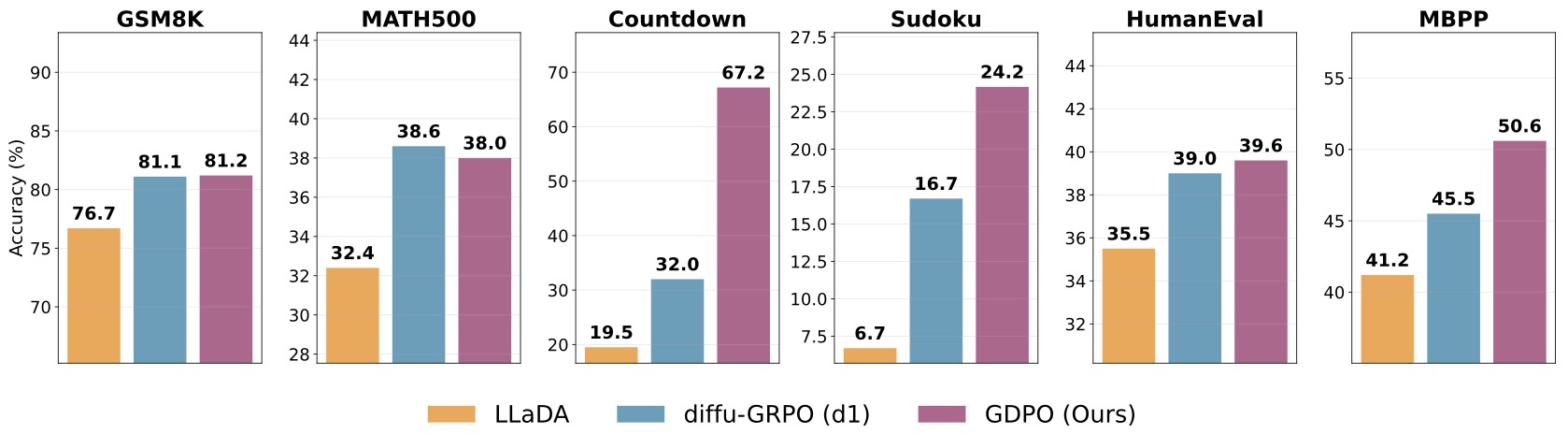
The following figure (source) shows that across reasoning, planning and coding tasks GDPO significantly outperforms the baseline (LLaDA) and other RL methods (diffu-GRPO). The figure is important because it shows the practical payoff of aligning the objective with the model class. GDPO improves over LLaDA and diffu-GRPO on reasoning, planning, and coding benchmarks, including tasks like Countdown and Sudoku where global consistency matters. That pattern supports the broader thesis that diffusion LLMs become more compelling when their post-training algorithms respect sequence-level denoising rather than forcing token-level AR structure.
ELBO-based Sequence-level Policy Optimization (ESPO)
-
ELBO-based Sequence-level Policy Optimization (ESPO) takes the sequence-level view even more directly. Principled RL for Diffusion LLMs Emerges from a Sequence-Level Perspective by Ou et al. (2025) treats the entire generated sequence as a single action and uses the ELBO as a tractable proxy for the sequence log-likelihood. This is conceptually clean because it avoids pretending that the diffusion model naturally emits left-to-right token actions.
-
A stylized ESPO-style ratio is:
\[r_\theta(y\mid x) =\exp\left( \frac{1}{L} \left[ \mathcal{L}_\theta(y\mid x) -\mathcal{L}_{\theta_{\mathrm{old}}}(y\mid x) \right] \right)\]- where the \(\frac{1}{L}\) normalization reflects the need to stabilize sequence-level likelihood ratios across different response lengths. The paper also emphasizes robust KL estimation, because naive KL penalties become unstable when based on noisy ELBO estimates. Principled RL for Diffusion LLMs Emerges from a Sequence-Level Perspective by Ou et al. (2025) reports especially large gains on planning-style tasks such as Countdown, where global sequence consistency is crucial.
-
The key lesson is that ESPO reframes diffusion RL around the correct action space. For AR models, the action can naturally be a token. For dLLMs, the action is often better understood as a completed sequence sampled through a denoising process.
Planning tasks
-
Planning tasks expose the difference between left-to-right commitment and global revision. In a task like Countdown, a model must select numbers and operations that satisfy a final constraint; in Sudoku-like tasks, local decisions must remain globally consistent. These tasks punish early irreversible mistakes, which makes them a natural testbed for diffusion-style refinement. GDPO reports particularly strong gains on Countdown and Sudoku, while ESPO reports dramatic improvements on Countdown relative to token-level baselines.
-
The reason is not that diffusion automatically reasons better. It is that its generation process makes a different kind of search available. A denoising model can initially sketch partial structure across the whole output and then refine incompatible parts. That does not solve planning by itself, but it gives RL a more suitable substrate to optimize.
Code generation
-
Code is another natural domain for diffusion reasoning because correctness depends on long-range consistency: variable names, function signatures, indentation, imports, control flow, and test-passing behavior must all line up. DCoLT reports improvements on MBPP and HumanEval by reinforcing the denoising trajectory, and GDPO also reports gains on HumanEval and MBPP by replacing biased token-level approximations with lower-variance sequence-level estimation.
-
In code, the diffusion advantage is easiest to interpret as global repair. A model that can revise later and earlier spans jointly is structurally well suited to fill in missing variables, adjust a return statement after seeing a loop body, or correct a helper function after the final usage pattern becomes clearer. The challenge is still optimization: without good likelihood surrogates or stable RL estimators, that structural advantage does not automatically translate into better benchmark scores.
Math reasoning
-
Math sits between language and planning. It often benefits from stepwise explanation, but it also requires final-answer consistency and sometimes nonlocal correction. The early d1 recipe showed that masked SFT plus diffu-GRPO can improve diffusion models on mathematical reasoning; DCoLT then showed that optimizing the denoising trajectory can further improve GSM8K and MATH; GDPO and ESPO pushed the field toward more principled sequence-level optimization.
-
The important distinction is that diffusion math reasoning need not produce its internal “scratchpad” in the same order as the final answer. Intermediate denoising states may contain answer fragments, partial equations, and unresolved spans that are not valid natural language yet. That is exactly the kind of intermediate representation that AR chain-of-thought hides, because AR models must serialize every intermediate thought into readable text.
Open questions
-
The reasoning evidence is promising, but the field is still young. We do not yet know when lateral denoising trajectories are genuinely better than AR chain-of-thought, when they are merely different, or when they make optimization harder. Current results suggest that diffusion reasoning is strongest when the task rewards global consistency, revision, or flexible ordering, but the advantage is not universal.
-
The next major open issue is credit assignment. If a final answer is correct, which denoising step deserved credit? Which unmasking decision mattered? Which intermediate state introduced the useful structure? DCoLT, GDPO, and ESPO answer this in different ways: trajectory-level RL, lower-variance ELBO-based group optimization, and sequence-level policy optimization. The long-term winner may combine all three.
-
The practical takeaway is simple: diffusion LLMs do not replace reasoning methods; they change the space in which reasoning methods operate.
Preference Alignment
Alignment problem
-
Preference alignment for diffusion LLMs starts from the same goal as alignment for autoregressive LLMs: make the model prefer better answers over worse ones. The difficulty is that most alignment methods assume cheap access to sequence log-probabilities, while diffusion LLMs only expose tractable likelihood surrogates.
-
In standard DPO, introduced in Direct Preference Optimization by Rafailov et al. (2023), the model is trained from preference pairs \((y_w,y_l)\), where \(y_w\) is preferred over \(y_l\). The autoregressive DPO objective depends on the policy-reference log-ratio:
- For diffusion LLMs, \(\log \pi_\theta(y\mid x)\) is not cheaply available, so the natural substitution is an ELBO estimate:
- This turns preference optimization into an estimator problem. The optimization target may look DPO-like, but the quantities inside it are noisy Monte Carlo estimates over diffusion timesteps and masked samples.
ELBO preference score
- The diffusion preference score used in LLaDA-style alignment can be written as:
-
The corresponding preference loss is:
\[\mathcal{L}_{\mathrm{pref}}(\theta) =-\mathbb{E}_{(x,y_w,y_l)} \left[ \log \sigma(s_\theta(x,y_w,y_l)) \right]\]- where \(\sigma(\cdot)\) is the sigmoid function.
-
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models by Zhu et al. (2025) is the central paper here because it identifies the main obstacle: the score \(s_\theta\) is built from four ELBO terms, and each term is estimated through nested sampling. This makes naive diffusion DPO unstable unless the score estimator variance is controlled.
Variance bottleneck
- The ELBO for a response is:
- A Monte Carlo estimate has the form:
- The issue is that DPO-style losses are nonlinear in the score. Even if \(\widehat{\mathcal{L}}_\theta\) is an unbiased estimator of \(\mathcal{L}_\theta\), the loss built from \(\log\sigma(\widehat{s}_\theta)\) can still become biased and high-variance. LLaDA 1.5’s key theoretical message is that both preference-loss bias and gradient variance are governed by score-estimator variance.
Variance-Reduced Preference Optimization (VRPO)
-
Variance-Reduced Preference Optimization, or VRPO, is LLaDA 1.5’s answer to this problem. It keeps the DPO-style preference objective but changes how ELBO scores are estimated.
-
The first idea is budget allocation. Instead of spending Monte Carlo samples naively, VRPO allocates samples across diffusion timesteps so the estimator covers the denoising trajectory more effectively. This matters because different timesteps contribute differently to uncertainty: very high-mask and low-mask regimes can have very different variance profiles.
-
The second idea is antithetic sampling. Rather than independently estimating policy and reference ELBOs, VRPO pairs their noise sources so that fluctuations cancel when computing the policy-reference difference. Since the preference score depends on differences of ELBOs, correlated estimation can reduce variance without changing the expected score.
-
A simplified antithetic score estimate can be thought of as:
\[\widehat{\Delta}(y) =\widehat{\mathcal{L}}_\theta(y;\epsilon) -\widehat{\mathcal{L}}_{\mathrm{ref}}(y;\epsilon')\]- where \(\epsilon\) and \(\epsilon'\) are paired so that estimator noise partially cancels in the difference.
-
The third idea is preserving an auxiliary masked-diffusion SFT term during preference training:
-
This keeps the model anchored to the diffusion language-modeling objective while preference optimization changes its ranking behavior.
-
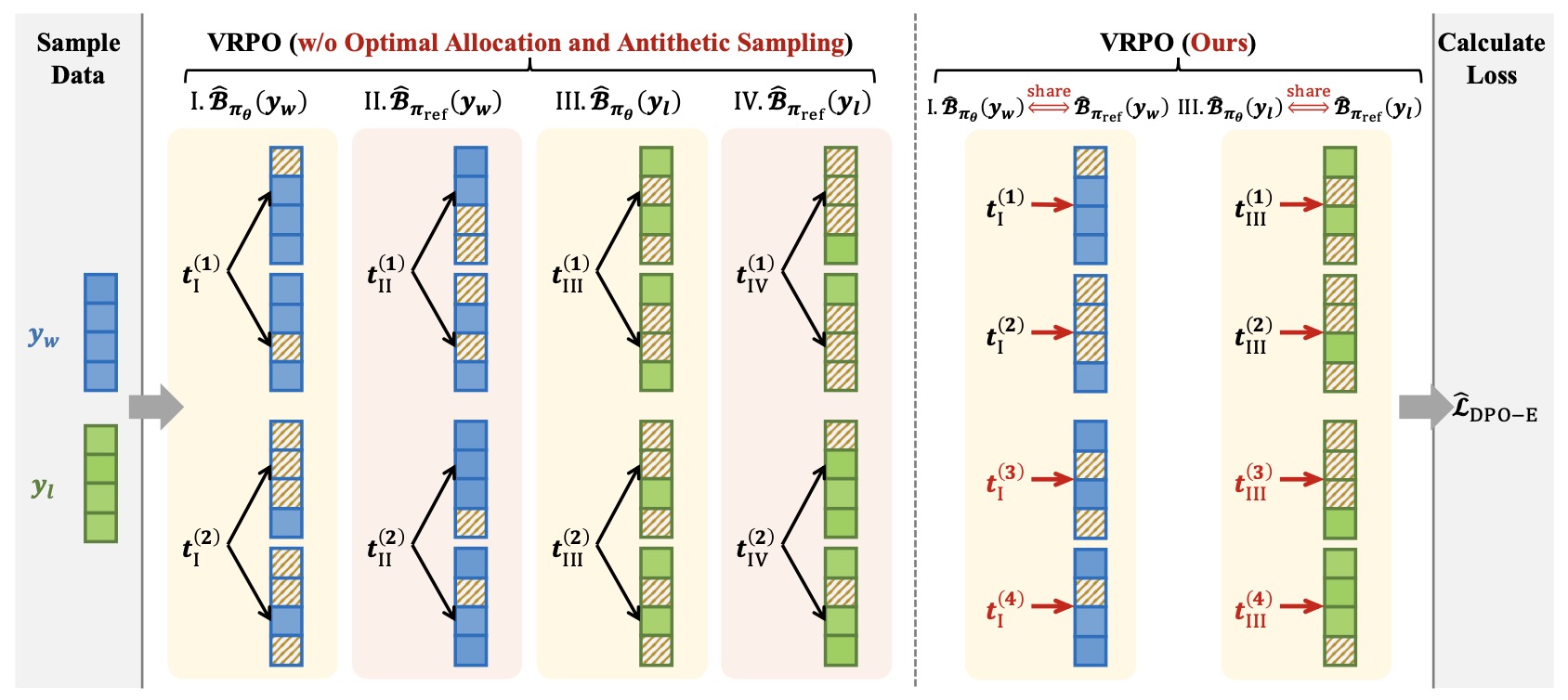
The following figure (source) illustrates what VRPO changes algorithmically, contrasting standard ELBO estimation with optimal budget allocation and antithetic variance reduction. It compares VRPO (right) with VRPO without optimal allocation and antithetic sampling (left). VRPO allocates the sampling budget across timesteps to sample only one masked data per timestep (indicated by red arrows) and shares Monte Carlo samples between paired ELBOs (highlighted with the red annotations above the blocks). The figure clarifies that VRPO is not “just DPO for diffusion,” but a statistical redesign of the likelihood-estimation layer underlying preference optimization.
LLaDA 1.5 Benchmark Performance
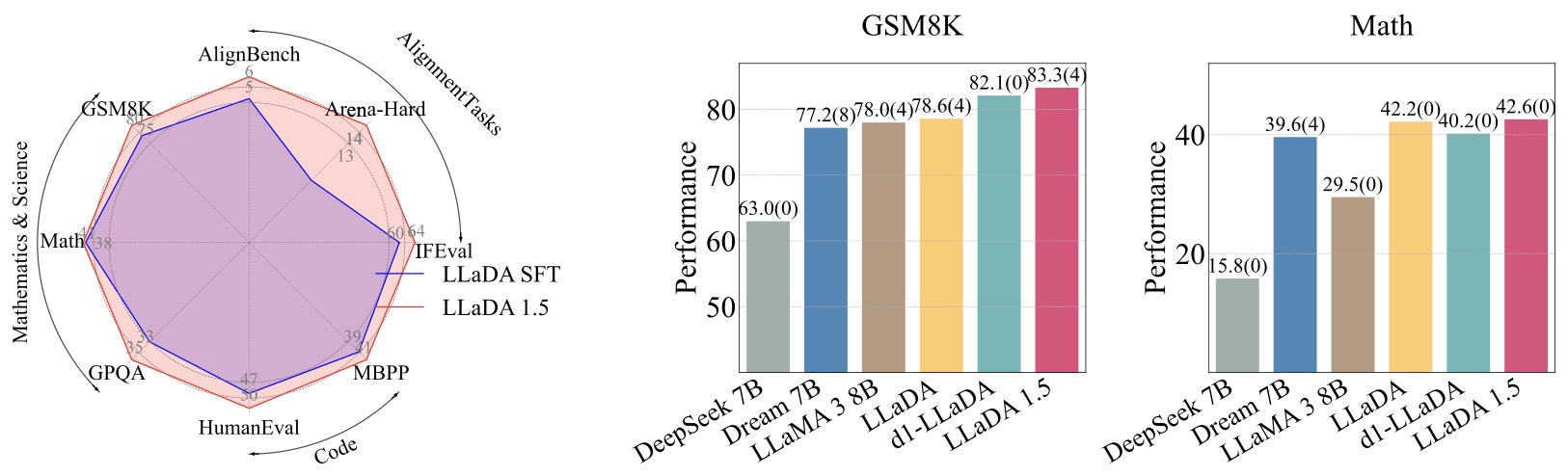
- The following figure (source) shows LLaDA 1.5’s benchmark results. The left panel shows that LLaDA 1.5 improves LLaDA consistently and significantly on various benchmarks. The right panel demonstrates that LLaDA 1.5 has a highly competitive mathematical performance compared to strong language MDMs and ARMs.
-
This figure summarizes why LLaDA 1.5 matters. It shows that variance-reduced preference optimization improves the SFT-only LLaDA baseline across alignment, math, and code benchmarks, while keeping the model competitive with other strong diffusion and autoregressive models.
-
The important primer-level takeaway is that LLaDA 1.5 is not primarily about inventing a new denoising backbone. It shows that diffusion LLM alignment needs its own statistical machinery. Once exact likelihood is replaced by an ELBO estimate, variance control becomes part of the alignment algorithm.
DPO vs. VRPO
-
DPO and VRPO have the same broad preference-learning shape, but they differ in what the probability object means.
-
In AR DPO, the log-probability is exact and cheap:
- In VRPO, the log-probability is replaced by a diffusion ELBO estimate:
-
That substitution changes everything. The main challenge is no longer just choosing good preference data or a good value of \(\beta\). It is also designing an estimator whose variance is low enough that the preference signal remains meaningful.
-
This is why LLaDA 1.5 by Zhu et al. (2025) should be read as a bridge between alignment and probabilistic estimation. It brings DPO into diffusion LLMs by rebuilding the likelihood-estimation layer underneath it.
Alignment lessons
-
The broader lesson is that diffusion LLM alignment should be sequence-aware. Since the model generates through a denoising process, preference optimization should compare complete candidate responses using sequence-level scores rather than forcing tokenwise autoregressive structure.
-
This does not mean token-level feedback is useless. It means token-level feedback is not the natural probability geometry of the model. Preference optimization works best when it respects the model’s native object: a whole response reconstructed through a latent denoising chain.
-
The practical implication is that future diffusion alignment methods will likely combine three ingredients: ELBO-style sequence scoring, variance reduction, and diffusion-native decoding policies. LLaDA 1.5 is the first strong example of that recipe.
Scaling and Context
Scaling question
-
Scaling diffusion LLMs has two separate meanings. One is parameter and compute scaling: can masked diffusion models grow from research-scale models into frontier-scale LLMs? The other is context scaling: can the denoising process remain stable when the prompt grows from a few thousand tokens to 32K, 64K, or 128K?
-
The answer so far is cautiously positive. Large Language Diffusion Models by Nie et al. (2025) established the 8B trained-from-scratch proof point, UltraLLaDA: Scaling the Context Length to 128K for Diffusion Large Language Models by He et al. (2025) showed that LLaDA-style models can be post-trained to 128K context, and LLaDA2.0: Scaling Up Diffusion Language Models to 100B by Bie et al. (2025) pushed the family toward 100B total parameters through AR-to-diffusion conversion.
-
LLaDA2.0-Uni extends the LLaDA2.0 scaling path from text-only MoE diffusion language models into unified multimodal MoE diffusion models by using LLaDA2.0-mini as a 16B backbone, expanding its vocabulary with SigLIP-VQ visual tokens, and training text and image tokens under one block-level masked diffusion objective.
Compute scaling
-
The original LLaDA result matters because it showed that masked diffusion is not limited to small denoising models. LLaDA 8B was trained from scratch using a Transformer backbone similar to LLaMA, but with bidirectional masked-token prediction and iterative diffusion sampling instead of next-token prediction. The important scaling result is not merely benchmark competitiveness; it is that the same broad pretrain and SFT pipeline used for AR LLMs can be adapted to diffusion without collapsing.
-
The key lesson from this figure is that diffusion scaling is plausible when the model is trained as a proper generative model rather than as a small masked-LM variant. LLaDA’s evidence suggests that the generative principle, not the autoregressive factorization alone, can support broad LLM capabilities.
Long-context failure modes
-
Long-context diffusion has a different failure profile from long-context autoregression. AR models often suffer sharp degradation when positional embeddings are extrapolated too far, because every next-token prediction depends on a long causal history. Diffusion models can be more stable in perplexity under longer contexts, but they may develop local perception: the model attends mostly to recent segments and underuses distant information.
-
UltraLLaDA by He et al. (2025) frames this as the core problem for 128K diffusion LLMs: extending the window is not enough; the denoising process must continue to use remote context effectively.
Rotary Positional Embeddings (RoPE) adaptation
-
Most modern LLMs use Rotary Positional Embeddings (RoPE), to encode relative position. Standard long-context extension methods often stretch or rescale RoPE, but diffusion LLMs create an extra complication: the model repeatedly predicts masked spans under different corruption levels, so positional behavior interacts with the probabilistic denoising process.
-
UltraLLaDA introduces a diffusion-aware NTK-style RoPE extension. The core idea is to adapt positional scaling to the diffusion setting rather than directly reuse AR extrapolation. This allows the model to scale to 128K tokens through efficient post-training rather than full retraining from scratch.
-
The long-context objective remains diffusion-style:
\[\mathcal{L}_{\mathrm{long}}(\theta) =-\mathbb{E}_{t,y,y_t} \left[ \frac{1}{t} \sum_{i=1}^{L} \mathbf{1}[y_t^i=\texttt{[MASK]}] \log p_\theta(y^i\mid y_t,x) \right]\]- but now \(L\) can be very large, so masking strategy, positional extrapolation, and memory efficiency become central training variables.
Masking strategies
-
UltraLLaDA also shows that masking strategy matters for long-context adaptation. Uniformly masking across a very long document may not produce stable recall of distant information. More structured strategies can encourage the model to connect far-apart evidence with response spans.
-
The practical lesson is that long-context diffusion training is not just “increase context length and continue training.” It requires choosing where masks appear, how much corruption to apply, and how to preserve optimization stability across long sequences.
-
This figure is useful because it distinguishes context length from context use. A model can technically accept 128K tokens while still failing to retrieve or reason over distant content. UltraLLaDA’s contribution is aimed at that second problem.
AR conversion
-
LLaDA2.0 approaches scaling from a different direction. Instead of training a large diffusion LLM from scratch, it converts a pretrained autoregressive model into a masked diffusion language model. This matters because the cost of training a 100B-class model from scratch is enormous, while AR checkpoints already contain large amounts of linguistic and world knowledge.
-
The conversion recipe is staged. The model first inherits knowledge from the AR checkpoint, then progressively adapts to masked diffusion, then moves into block diffusion and post-training. This is a practical scaling strategy: preserve what AR pretraining already learned, but change the generation mechanism.
Block scaling
-
The central LLaDA2.0 scaling device is block diffusion. Rather than denoising arbitrary isolated tokens only, the model learns to denoise contiguous blocks. This gives diffusion a structure closer to efficient serving, because blocks can be parallelized while still preserving some sequential organization.
-
This figure shows the scaling recipe: AR initialization, continual pretraining into masked diffusion, block diffusion adaptation, and post-training with SFT and DPO. The key architectural idea is that block diffusion gives a bridge between fully parallel masked denoising and deployable large-model inference.
Frontier scale
-
LLaDA2.0 reports 16B and 100B total-parameter variants, including instruction-tuned MoE models intended for deployment. The important shift is that diffusion LLM scaling is no longer just a question of whether the objective works; it is also about whether the model can be served efficiently, aligned effectively, and benchmarked against strong AR systems.
-
This figure is relevant because it shows the outcome of combining AR knowledge inheritance, block diffusion, and post-training. LLaDA2.0’s significance is not only that it is larger than earlier dLLMs, but that it points to a plausible industrial recipe for scaling them.
Scaling Patterns
-
Recent work has made the broad contours of diffusion LLM scaling substantially clearer, particularly around how scalability, context extension, alignment, and deployment fit together as a coherent progression. This progression can be understood through four complementary developments:
-
LLaDA showed that diffusion LLMs can function as scalable base models. Large Language Diffusion Models by Nie et al. (2025) provided one of the first strong demonstrations that masked diffusion language modeling can scale with broadly similar recipes and capability trends to autoregressive LLMs.
-
LLaDA 1.5 showed that scaling diffusion models is inseparable from solving post-training. LLaDA 1.5 by Zhu et al. (2025) established that alignment for dLLMs is fundamentally tied to likelihood estimation and variance reduction, making statistical efficiency part of the scaling story.
-
UltraLLaDA showed that scaling is not only about parameters, but also about context. UltraLLaDA by He et al. (2025) demonstrated that long-context extension to 128K tokens is feasible when positional scaling and masking strategies are adapted to diffusion-specific dynamics.
-
LLaDA2.0 showed that frontier-scale deployment may be most practical through adaptation rather than retraining from scratch. LLaDA2.0 by Bie et al. (2025) combined AR initialization, block diffusion, and efficiency-aware post-training into a plausible path toward 100B-class diffusion systems.
-
-
Taken together, these developments suggest that the central theme in diffusion LLM scaling is not replacement of the autoregressive ecosystem, but structured adaptation of it. Diffusion models increasingly reuse AR backbones, checkpoints, serving ideas, and alignment machinery, while modifying the components that conflict with iterative denoising generation.
Multimodal dLLMs
Why multimodal fits
-
Diffusion LLMs are naturally attractive for multimodal modeling because their generation process is already non-autoregressive, bidirectional, and compatible with partial conditioning. In text-only dLLMs, the model reconstructs masked text from visible text; in multimodal dLLMs, the same denoising idea can condition on image embeddings, visual tokens, or other modality-specific features while reconstructing language or other discrete outputs.
-
This matters because multimodal tasks often require global alignment rather than left-to-right continuation. A model may need to inspect an image, locate multiple objects, compare spatial relations, and then generate an answer whose later words depend on earlier visual grounding. Diffusion’s ability to revise the whole response makes it structurally appealing for these settings. LLaDA-V: Large Language Diffusion Models with Visual Instruction Tuning by You et al. (2025) makes this case by extending LLaDA into a purely diffusion-based multimodal LLM with a vision encoder and connector, while LaViDa: A Large Diffusion Language Model for Multimodal Understanding by Li et al. (2025) builds diffusion-based VLMs for visual reasoning with parallel decoding and bidirectional context.
LLaDA-V
-
LLaDA-V is the most direct multimodal extension of the LLaDA family. It keeps LLaDA as the language diffusion backbone, adds a vision encoder, and uses an MLP connector to project visual features into the language embedding space. The resulting model conditions masked diffusion generation on visual features, rather than using the standard autoregressive “image tokens plus next-token decoding” pipeline used by many VLMs. LLaDA-V by You et al. (2025) reports that this architecture is competitive with autoregressive multimodal baselines and stronger than earlier diffusion MLLMs, despite being built on a language backbone that is not always stronger on pure text.
-
A simplified conditioning view is:
\[p_\theta(y^i \mid y_t, x, v)\]- where \(v\) denotes visual embeddings, \(x\) is the textual prompt, and \(y_t\) is the masked response state. The key change from text-only LLaDA is not the denoising loss itself, but the conditioning context used by the denoiser.
-
The diffusion training objective becomes:
- This objective says: given the image and prompt, reconstruct the masked response tokens. That makes LLaDA-V a visual instruction-tuned masked diffusion model rather than an AR captioning-style model.
Visual grounding
-
The important conceptual advantage of multimodal diffusion is that visual grounding can influence all response positions at every denoising step. In an autoregressive VLM, the model must serialize visual interpretation into a token prefix. In a diffusion VLM, the model can repeatedly revise the entire answer under the same visual context.
-
For example, if the final answer depends on a spatial relation such as “the red cup is behind the laptop,” the model does not need to commit to “red” before resolving “behind” or “laptop.” It can leave uncertain spans masked until enough global visual-language consistency emerges. This is the same coarse-to-fine logic as text-only dLLMs, but visual features make the benefit more obvious.
-
LaViDa by Li et al. (2025) emphasizes exactly these multimodal advantages: parallel decoding, bidirectional reasoning, and controllable generation through infilling-style mechanisms.
LaViDa
-
LaViDa is another important branch because it treats diffusion as a general VLM foundation rather than only as a LLaDA extension. The model equips a discrete diffusion language model with a vision encoder and jointly fine-tunes the combined system for multimodal instruction following. LaViDa by Li et al. (2025) reports competitive multimodal benchmark performance while highlighting speed, controllability, and bidirectional context as core benefits.
-
The architectural pattern is now becoming standard for diffusion VLMs:
- This resembles AR VLMs superficially, but the decoding semantics differ. The language model is not asked to produce the next answer token from a causal prefix; it is asked to reconstruct a partially masked answer conditioned on both the image and the text prompt.
Unified generation
-
Multimodal diffusion becomes especially interesting when the model is not limited to visual understanding. Since diffusion already originated as a powerful image generation paradigm, there is a natural long-term path toward unified models that denoise across text, image, audio, and action spaces.
-
That said, current LLaDA-style multimodal systems are mostly language-output models conditioned on images. They are closer to “diffusion VLMs” than full unified text-image generators. The important future direction is to make the denoising state itself multimodal:
\[z_t = (y_t, m_t, a_t,\ldots)\]-
where \(y_t\) might be text tokens, \(m_t\) visual tokens, and \(a_t\) audio or action tokens. A truly unified diffusion model would learn:
\[p_\theta(z_0 \mid z_t, c)\]- where \(c\) is any available conditioning context.
-
-
This is where diffusion has a conceptual edge over AR modeling: it is naturally compatible with partially observed structured objects, not only left-to-right strings.
LLaDA2.0-Uni
-
LLaDA2.0-Uni is the strongest LLaDA-family example of semantic-token multimodal diffusion. It keeps the LLaDA-style masked diffusion backbone while extending the token space to image understanding, image generation, editing, and interleaved image-text reasoning.
-
The key design choice is to represent images as semantic discrete tokens rather than reconstruction-only VQ tokens or continuous side-channel embeddings. This lets text and image tokens share one denoising objective:
\[\mathcal{L}_{\text{uni}}(\theta) = - \mathbb{E}_{t,x_0,x_t} \left[ \frac{1}{t} \sum_i \mathbf{1}[x_t^i=\texttt{[MASK]}] \log p_\theta(x_0^i \mid x_t) \right]\]- where \(x_0^i\) can be a text token, image token, or special multimodal token.
-
This makes LLaDA2.0-Uni different from earlier multimodal diffusion systems such as MMaDA and Lumina-DiMOO, which the paper argues are limited by reconstruction-oriented tokenizers, excessive image compression, and less stable fully bidirectional text modeling. It also differs from hybrid unified models such as BAGEL, because the dLLM backbone itself denoises both text and semantic image tokens while a diffusion decoder is used only for final pixel reconstruction.
Speed and control
-
Diffusion multimodal models inherit the speed-control tradeoff of text dLLMs. They can generate many tokens in parallel, but may need multiple denoising steps. For multimodal tasks, the payoff is that intermediate answer states can be globally revised under visual evidence.
-
This is useful for constrained answering, editing, and refinement. If a user asks a model to “answer in exactly three words” or “change only the object description,” a diffusion model can treat constraints as global conditions over the whole response. This is harder for AR models because constraints must be maintained through irreversible left-to-right continuation.
-
Commercial diffusion LLM work also points to speed as a key deployment motivation. Introducing Mercury, the World’s First Commercial-Scale Diffusion Large Language Model claims very high token throughput for diffusion text generation, and Introducing Mercury 2 frames diffusion as a path to fast reasoning-oriented language models. These are text-focused systems, but the same systems argument matters for multimodal assistants where latency is often user-visible.
Open challenges
-
The main open problem is that multimodal diffusion alignment is even harder than text-only diffusion alignment. The model must align visual grounding, textual helpfulness, factual correctness, and denoising stability at once. If the ELBO estimator is noisy in text-only preference optimization, the multimodal version adds another source of variance: the visual conditioning pathway.
-
Another challenge is evaluation. A diffusion VLM might produce a better globally revised answer, but standard benchmarks often score only the final string. That makes it difficult to tell whether the denoising trajectory itself is helping. Future evaluations may need to inspect revision behavior, visual grounding over intermediate states, and controllability under partial constraints.
-
The key takeaway is that multimodal diffusion LLMs are not just AR VLMs with a different sampler. They replace causal answer construction with conditional denoising, which may be a better fit for tasks where visual evidence, global constraints, and answer revision interact.
Failure Modes
Likelihood gap
-
The most important limitation of diffusion LLMs is still the lack of cheap exact likelihood. Autoregressive models expose:
\[\log p_\theta(y\mid x)=\sum_{i=1}^{L}\log p_\theta(y_i\mid x,y_{<i})\]- which makes training diagnostics, perplexity evaluation, RL ratios, KL penalties, and preference optimization straightforward.
-
Diffusion LLMs instead rely on ELBO-style surrogates:
\[\log p_\theta(y\mid x)\gtrsim \mathcal{L}_\theta(y\mid x)\]- where \(\mathcal{L}_\theta\) must often be estimated through noisy sampling over timesteps and masked states. LLaDA 1.5 by Zhu et al. (2025) and Principled RL for Diffusion LLMs by Ou et al. (2025) both treat this as the core post-training bottleneck.
Estimator variance
-
Once likelihood is replaced by an ELBO estimate, variance becomes a first-order problem. A noisy estimator can corrupt preference comparisons, destabilize policy ratios, and make KL penalties unreliable.
-
A typical estimator has the form:
- The issue is not only that this estimate is noisy. It is that downstream losses are nonlinear functions of it. For example, preference optimization uses \(\log\sigma(\widehat{s}_\theta)\), so unbiased ELBO estimates can still produce biased gradients after passing through the preference loss. LLaDA 1.5 by Zhu et al. (2025) addresses this with VRPO, while GDPO by Rojas et al. (2025) reduces ELBO variance using semi-deterministic Monte Carlo schemes.
Sampler dependence
-
Diffusion LLM quality depends heavily on the sampler. The same model can behave differently under full diffusion decoding, semi-autoregressive decoding, block diffusion, low-confidence remasking, or confidence-aware parallel decoding.
-
This creates a benchmarking challenge: a reported score is often a property of both the model and the sampler. In AR models, decoding choices also matter, but the underlying generation order is fixed. In dLLMs, the reveal order, remasking rule, number of denoising steps, and block size can all materially change performance.
-
This figure is useful here because it shows how much of the model’s behavior is determined by sampling policy. The denoiser predicts masked tokens, but the sampler decides which predictions become part of the next state.
Latency tradeoff
-
Diffusion LLMs can update many tokens in parallel, but they often need multiple denoising passes. This creates a speed tradeoff rather than a simple speed advantage.
-
If the model uses too many steps, latency can be high. If it uses too few, quality may drop because uncertain tokens are fixed too early. LLaDA2.0 addresses this through block diffusion and confidence-aware parallel decoding, but the broader issue remains: diffusion inference is a schedule-design problem, not just a forward-pass problem. LLaDA2.0 by Bie et al. (2025) is important because it treats inference efficiency as part of the architecture rather than an afterthought.
-
The relevance of this figure is that quality and efficiency must be read together. LLaDA2.0’s contribution is not only stronger benchmark performance, but a more deployable diffusion inference design.
Context underuse
-
Long-context diffusion models can fail differently from AR models. Rather than collapsing outright beyond the trained context window, they may exhibit local perception: the model technically accepts long context but relies disproportionately on recent or local spans.
-
UltraLLaDA by He et al. (2025) identifies this as a major obstacle for 128K-token diffusion LLMs and proposes diffusion-aware positional extension plus masking strategy changes to improve long-range recall.
-
The key lesson is that context length is not the same as context use. A diffusion LLM may need explicit positional and masking adaptations to retrieve distant information reliably.
Alignment fragility
-
Alignment is harder in dLLMs because the model’s probability geometry is less directly observable. In AR models, DPO and PPO can use exact sequence or token log-probabilities. In dLLMs, alignment relies on surrogates, and those surrogates are affected by estimator variance, sampler choice, and response length.
-
This means preference optimization can become fragile unless the algorithm explicitly accounts for diffusion structure. LLaDA 1.5’s VRPO is one answer, ESPO is another, and GDPO is a third. Their common message is that alignment cannot simply import AR objectives unchanged.
Evaluation ambiguity
-
Diffusion LLMs generate through intermediate states, but most benchmarks score only the final answer. This hides many of the model’s distinctive behaviors.
-
A dLLM might revise a wrong intermediate state into a correct answer, or it might pass through a useful partial plan that never appears in the final output. Standard benchmarks cannot tell whether the denoising trajectory helped. This is especially limiting for reasoning, planning, and multimodal tasks, where the model’s advantage may lie in revision dynamics rather than final-token probabilities.
Weak AR compatibility
-
Another limitation is ecosystem compatibility. Much of today’s LLM tooling assumes autoregression: KV-cache serving, next-token streaming, token-level logprobs, speculative decoding, perplexity comparisons, and many RLHF pipelines.
-
Diffusion LLMs can reuse some of this infrastructure, especially through block diffusion and AR-to-diffusion conversion, but they do not fit it naturally. LLaDA2.0’s block diffusion design is important precisely because it tries to recover compatibility with serving ideas built for AR models.
When AR wins
-
Autoregressive models still have major advantages. They are simple to train, simple to evaluate, easy to stream, and deeply optimized in existing inference stacks. Their exact likelihood factorization remains extremely useful for alignment, safety filtering, reward modeling, and diagnostics.
-
For tasks where left-to-right continuation is natural and latency must be minimized through streaming, AR models may remain the better default. Diffusion LLMs are most compelling when global revision, bidirectional context, infilling, blockwise parallelism, or long-range consistency are central.
Key takeaway
- The failure modes of diffusion LLMs mostly come from the same source as their strengths: they are not left-to-right models. That gives them bidirectional denoising, flexible generation order, and global revision, but it also removes cheap exact likelihoods, complicates alignment, and makes inference depend on sampler design.
dLLMs in Practice
When to use dLLMs
-
The strongest case for diffusion LLMs today is not “replace autoregressive LLMs everywhere,” but use them where their structure matters.
-
They are especially compelling when the task benefits from global revision, flexible generation order, bidirectional conditioning, or structured infilling. Reasoning problems with constraint satisfaction, code generation with long-range consistency, editing-heavy workflows, long-form revision, retrieval-intensive synthesis, and multimodal grounding all fit this pattern. Results from GDPO by Rojas et al. (2025), ESPO by Ou et al. (2025), and Reinforcing the Diffusion Chain of Lateral Thought by Huang et al. (2025) repeatedly show that dLLMs tend to look strongest precisely when global consistency matters. (arxiv.org)
-
For hands-on multimodal dLLM experimentation, LLaDA2.0-Uni is available through LLaDA2.0-Uni: Understanding and Generation the World and inclusionAI/LLaDA2.0-Uni, with examples for image understanding, text-to-image generation, image editing, and SPRINT-accelerated inference.
-
By contrast, if your workload is dominated by simple left-to-right continuation, ultra-low-latency streaming, or mature production serving stacks, autoregressive models may still be the better default.
-
A useful heuristic is:
- Use AR when sequential commitment is natural
- Consider diffusion when revision is intrinsic
-
That is not a theorem, but it matches much of the current evidence.
How to evaluate
-
One recurring mistake in evaluating diffusion LLMs is treating the model and the sampler as separable after the fact. They are not.
-
A dLLM should often be thought of as:
-
Changing denoising steps, remasking policy, block size, or reveal order can materially change results. This means benchmark comparisons should ideally specify \((\theta, S, T)\), where \(\theta\) is model parameters, \(S\) is the sampling policy, and \(T\) is the denoising schedule.
-
This is one reason the LLaDA papers spend so much effort discussing decoding strategies rather than reporting only model checkpoints. The decoding policy is part of the system.
-
A second evaluation lesson is that final-answer metrics alone may understate what diffusion models contribute. For planning or reasoning tasks, intermediate revision behavior may be as important as endpoint accuracy, but today’s benchmarks rarely capture that.
Practical recipe
-
If one were building with diffusion LLMs today, a practical recipe emerging from the literature would look something like this.
-
Start with a strong pretrained base. The field increasingly suggests conversion from strong AR checkpoints may often be more practical than training diffusion models from scratch, a major message of LLaDA2.0 by Bie et al. (2025).
-
Use diffusion-native post-training. For preference alignment, the strongest current lesson is not to naively port AR DPO or PPO, but to use sequence-level or variance-aware methods such as VRPO, GDPO, or ESPO.
-
Treat decoding as an optimization object. Low-confidence remasking, block diffusion, and denoising schedule choice often matter almost as much as the base model.
-
If long context matters, treat positional scaling and masking strategy as part of the model design itself, as UltraLLaDA argues.
-
This is strikingly different from the usual LLM recipe, where people often focus overwhelmingly on the base model and under-emphasize the generation algorithm.
Future directions
-
Several research directions appear particularly significant for the future development of diffusion LLMs. Current work suggests that progress is likely to be shaped less by a single breakthrough than by advances across a set of closely related open problems. Some of the most important emerging directions include:
-
Sequence-level reinforcement learning may become the default formulation for diffusion post-training. There is a strong conceptual case for treating the denoising-generated sequence, rather than individual tokens, as the natural action space, though this framework is still in an early stage of development.
-
Denoising trajectories themselves may evolve into trainable reasoning objects, rather than serving only as latent sampling paths. DCoLT points in this direction, but the broader question of learning to reason through structured denoising trajectories remains largely unresolved.
-
Block diffusion may emerge for diffusion LLMs in a role analogous to causal decoding in autoregressive models: a practical default abstraction balancing modeling flexibility with deployment efficiency. LLaDA2.0 presents one of the strongest current arguments for this possibility.
-
Unified multimodal diffusion language modeling remains a major frontier. If a common denoising framework can support language, vision, action, and tool use within a shared generative process, it could become one of the strongest long-term motivations for the paradigm.
-
LLaDA2.0-Uni makes this frontier more concrete by showing that semantic discrete visual tokens can let a LLaDA-style diffusion backbone support image understanding, image generation, image editing, and interleaved image-text reasoning within one unified denoising framework.
-
-
Taken together, these directions suggest that future progress in diffusion LLMs may depend as much on identifying the right abstractions for generation, reasoning, and optimization as on further scaling alone.
Lessons from LLaDA
-
The evolution of the LLaDA family makes the broader development of diffusion LLMs unusually clear, because each generation addresses a distinct bottleneck in turning diffusion language modeling into a scalable and practical paradigm. This progression can be understood through three major advances:
-
LLaDA showed that diffusion can support general-purpose language modeling at scale. Large Language Diffusion Models by Nie et al. (2025) provided one of the first strong demonstrations that masked diffusion language modeling can operate as a viable large-scale foundation model.
-
LLaDA 1.5 showed that alignment for diffusion LLMs is fundamentally a statistical estimation problem, not merely a straightforward extension of RLHF. LLaDA 1.5 by Zhu et al. (2025) made variance reduction and likelihood-surrogate estimation central components of diffusion post-training.
-
LLaDA2.0 showed that the path to frontier-scale deployment may be evolutionary rather than revolutionary, inheriting from autoregressive models while changing the underlying generative mechanism. LLaDA2.0 by Bie et al. (2025) framed AR-to-diffusion conversion, block diffusion, and efficiency-aware training as a practical scaling strategy.
-
-
It is fitting that this figure appears near the end of the primer, because it captures a broader direction emerging in the field: not diffusion versus autoregression, but increasingly hybrid systems that inherit from one paradigm while rethinking the foundations of the other.
References
Foundational diffusion papers
- Deep Unsupervised Learning using Nonequilibrium Thermodynamics by Sohl-Dickstein et al. (2015)
- Denoising Diffusion Probabilistic Models by Ho et al. (2020)
- Structured Denoising Diffusion Models in Discrete State-Spaces by Austin et al. (2021)
- A Continuous Time Framework for Discrete Denoising Models by Campbell et al. (2022)
- Simple and Effective Masked Diffusion Language Models by Sahoo et al. (2024)
- Simplified and Generalized Masked Diffusion for Discrete Data by Shi et al. (2024)
Diffusion language model foundations
- Large Language Diffusion Models by Nie et al. (2025)
- Dream 7B: Diffusion Large Language Models by Ye et al. (2025)
- LLaDA2.0: Scaling Up Diffusion Language Models to 100B by Bie et al. (2025)
- UltraLLaDA: Scaling the Context Length to 128K for Diffusion Large Language Models by He et al. (2025)
- Zhuokai Zhao’s dLLM post on X
Reinforcement learning for dLLMs
- d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning by Zhao et al. (2025)
- Reinforcing the Diffusion Chain of Lateral Thought with Diffusion Language Models by Huang et al. (2025)
- Improving Reasoning for Diffusion Language Models via Group Diffusion Policy Optimization by Rojas et al. (2025)
- Principled RL for Diffusion LLMs Emerges from a Sequence-Level Perspective by Ou et al. (2025)
Preference optimization and alignment
- Direct Preference Optimization by Rafailov et al. (2023)
- LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models by Zhu et al. (2025)
- Proximal Policy Optimization Algorithms by Schulman et al. (2017)
- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models by Shao et al. (2024)
Reasoning and planning
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models by Wei et al. (2022)
- The Reversal Curse: LLMs trained on “A is B” fail to learn “B is A” by Berglund et al. (2023)
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models by Yao et al. (2023)
- Language Models are Zero-Shot Planners by Huang et al. (2022)
Long context and scaling
- RoFormer: Enhanced Transformer with Rotary Position Embedding by Su et al. (2021)
- Scaling Laws for Neural Language Models by Kaplan et al. (2020)
- Training Compute-Optimal Large Language Models by Hoffmann et al. (2022)
Multimodal diffusion LLMs
- LLaDA-V: Large Language Diffusion Models with Visual Instruction Tuning by You et al. (2025)
- LaViDa: A Large Diffusion Language Model for Multimodal Understanding by Li et al. (2025)
- Flamingo: a Visual Language Model for Few-Shot Learning by Alayrac et al. (2022)
-
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models by Li et al. (2023)
-
LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model by Bie et al. (2026): extends the LLaDA family into unified multimodal understanding, image generation, image editing, and interleaved image-text reasoning through semantic discrete visual tokens, a 16B MoE dLLM backbone, and a diffusion decoder.
-
MMaDA: Multimodal Large Diffusion Language Models by Yang et al. (2025): proposes a modality-agnostic diffusion foundation model for language reasoning, multimodal understanding, and text-to-image generation.
-
Lumina-DiMOO: An Omni Diffusion Large Language Model for Multi-Modal Generation and Understanding by Xin et al. (2025): explores fully discrete diffusion for multimodal generation and understanding.
-
LLaDA-o: An Effective and Length-Adaptive Omni Diffusion Model by You et al. (2026): uses discrete masked diffusion for language and continuous diffusion for visual generation in an omni-modal setting.
-
Emerging Properties in Unified Multimodal Pretraining by Deng et al. (2025): introduces BAGEL, a decoder-only unified multimodal model trained on large-scale interleaved multimodal data.
-
SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features by Tschannen et al. (2025): provides the vision-language encoder foundation used by LLaDA2.0-Uni’s SigLIP-VQ semantic tokenizer.
- Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer by Cai et al. (2025): provides the image-generation backbone used by LLaDA2.0-Uni’s diffusion decoder.
Related diffusion RL foundations
- Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning by Wang et al. (2022)
- Diffusion Policy: Visuomotor Policy Learning via Action Diffusion by Chi et al. (2023)
- DPPO: Diffusion Policy Policy Optimization by Ren et al. (2024)
- Diffusion-QL: Reinforcement Learning via Diffusion Models by Wang et al. (2022)
Systems and inference directions
- Introducing Mercury, the World’s First Commercial-Scale Diffusion Large Language Model
- Introducing Mercury 2
- Closing the knowledge gap with diffusion language models
- Transformers are SSMs: Generalized Models and Inference Perspectives by Dao and Gu (2024)
Citation
If you found our work useful, please cite it as:
@article{Chadha2020DistilledDiffusionLLMs,
title = {Diffusion LLMs},
author = {Chadha, Aman and Jain, Vinija},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}