Primers • DeepSeek-V4
- Overview
- Architecture Overview
- Manifold-Constrained Hyper-Connections (mHC)
- Motivation: Reconsidering Residual Connectivity
- Core Insight: Residual Mixing as Geometric Constraint
- Why Doubly Stochastic Constraints Matter
- Sinkhorn Projection Implementation
- Full mHC Layer Structure
- Kernel-Level Implementation
- Why mHC Matters for DeepSeek-V4 Specifically
- Conceptual Interpretation: Learned Markov Mixing
- Broader Architectural Significance
- Hybrid Attention with Compressed Sparse Attention and Heavily Compressed Attention
- Compressed Sparse Attention
- The Lightning Indexer and FP4 QK Path
- Heavily Compressed Attention
- Why Two Attention Mechanisms Instead of One
- Efficiency Implications
- Heterogeneous KV Cache Architecture and Inference State Management
- Relation to DeepSeek Sparse Attention and Prior Efficient Attention
- Broader Architectural Significance
- Optimization Stack: Muon, FP4 Quantization-Aware Training, and Stability at Scale
- Post-Training Stack: Specialist Training, GRPO, and On-Policy Distillation
- Specialist Training as Capability Decomposition
- Reinforcement Learning with GRPO
- Why Specialist RL Before Unification
- Thinking Management and Persistent Reasoning Traces
- Unified Model Consolidation through On-Policy Distillation
- Why Reverse KL Is Interesting
- Specialist Models as Capability Teachers
- Efficient Infrastructure for RL and Distillation
- Why This Post-Training Stack Matters
- Agentic Capabilities and Long-Horizon Task Performance
- Agentic Reasoning as Trajectory Optimization
- Planning and Decomposition for Long-Horizon Tasks
- Code Agents and Programmatic Interaction
- Tool Use as Externalized Cognition
- Long-Horizon Memory and Context Persistence
- Agentic Benchmarking as a Different Regime
- Why Agentic Optimization May Matter Beyond Agents
- Benchmark Performance
- Limitations, Open Questions, and Future Architectures
- References
- DeepSeek architecture and system overviews
- Residual Scaling
- Sparse modeling and Mixture-of-Experts systems
- Long-context memory and efficient attention
- Optimization, scaling laws, and systems training
- Quantization and low-precision training
- Reinforcement learning and post-training alignment
- Reasoning and structured problem solving
- Agentic systems, tools, and long-horizon behavior
- Evaluation and benchmark frameworks
- Broader architectural and systems perspectives
- Citation
Overview
-
DeepSeek-V4-Pro is a preview series of sparse Mixture-of-Experts language models designed around efficient one-million-token context processing, with two main variants: DeepSeek-V4-Pro, a 1.6T-parameter model with 49B activated parameters per token, and DeepSeek-V4-Flash, a 284B-parameter model with 13B activated parameters per token. The release positions long-context inference as the core systems problem: not simply making the context window larger, but reducing the attention FLOPs and KV-cache growth that normally make ultra-long contexts impractical.
-
DeepSeek-V4 keeps the Transformer backbone introduced in Attention Is All You Need by Vaswani et al. (2017), which established scaled dot-product self-attention as the core sequence modeling primitive, but replaces the most expensive long-context pieces with a hybrid attention design that combines compression and sparsity. It also retains the DeepSeekMoE design from DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models by Dai et al. (2024), which improves parameter efficiency through fine-grained routed experts, and keeps Multi-Token Prediction ideas aligned with Better & Faster Large Language Models via Multi-token Prediction by Gloeckle et al. (2024), where auxiliary future-token heads improve sample efficiency and generation-oriented capability.
-
The high-level objective is to make long-horizon reasoning, agent workflows, codebase-scale editing, large-document analysis, and test-time scaling more practical. Vanilla attention has quadratic training-time complexity in sequence length and linear KV-cache growth during autoregressive inference, so a model that targets one-million-token use has to attack both computation and memory:
-
In full attention, every query token scores against all prior key tokens, making long-context decoding increasingly memory-bandwidth-bound and KV-cache-heavy. DeepSeek-V4’s central architectural claim is that long-context capability should be built into the model architecture, not treated only as an inference-engine optimization.
-
The following figure (source) shows benchmark performance of DeepSeek-V4-Pro-Max and its counterparts, plus the inference FLOPs and KV-cache size comparisons of DeepSeek-V4 series and DeepSeek-V3.2.
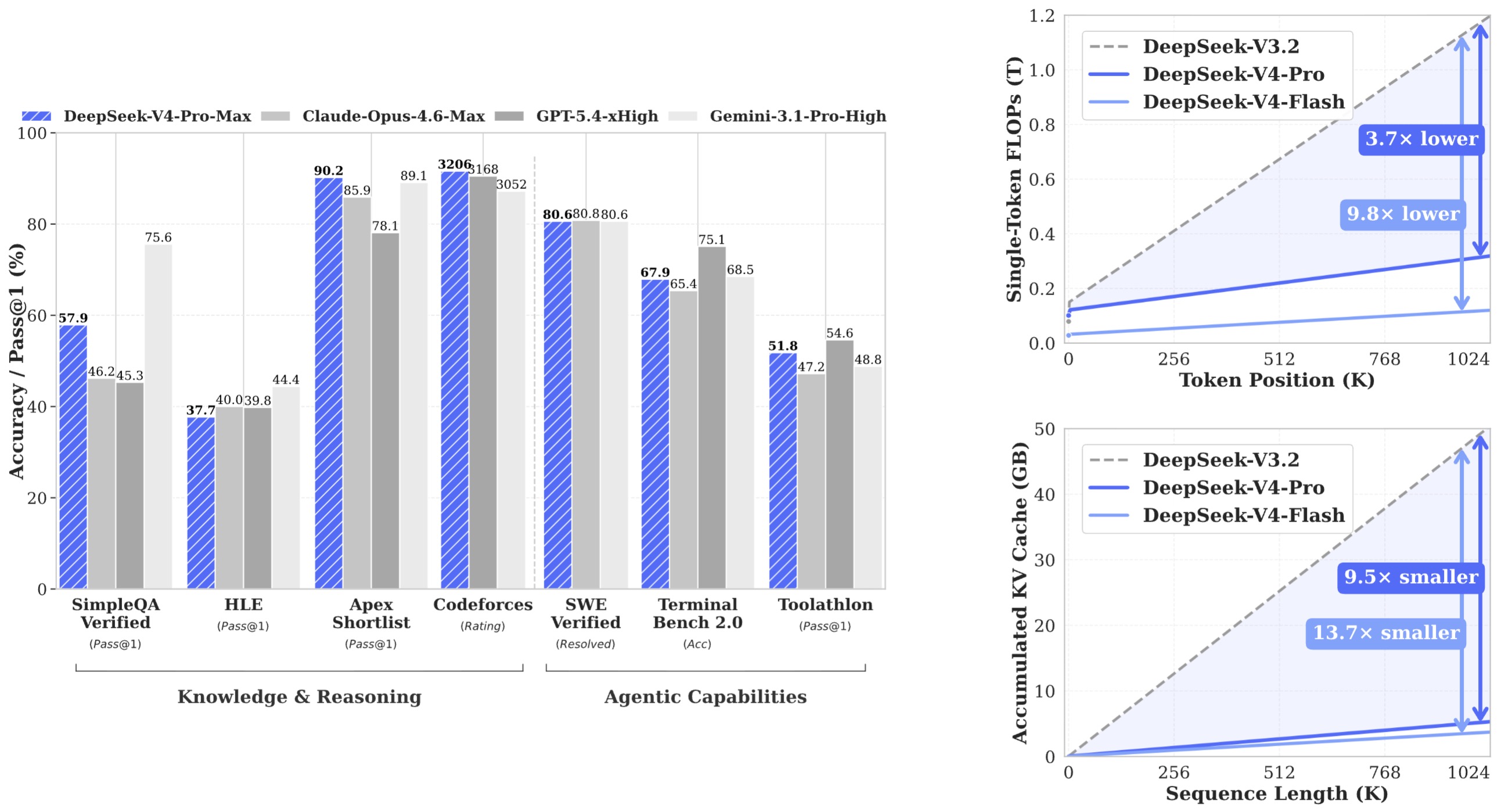
- At a one-million-token context, DeepSeek-V4-Pro is reported to use 27% of the single-token inference FLOPs and 10% of the KV cache of DeepSeek-V3.2, while DeepSeek-V4-Flash is reported to use 10% of the FLOPs and 7% of the KV cache, making Flash the more latency- and cost-oriented member of the pair.
Architecture Overview
-
DeepSeek-V4 follows the Transformer paradigm but introduces a set of tightly coupled architectural innovations that specifically target long-context efficiency, training stability at extreme scale, and parameter efficiency through sparse activation. The architecture integrates three primary innovations: hybrid attention (CSA + HCA), Manifold-Constrained Hyper-Connections (mHC), and optimized Mixture-of-Experts routing, all layered on top of a Multi-Token Prediction training framework.
-
At a high level, the model pipeline consists of token embeddings, stacked Transformer blocks with hybrid attention and MoE feed-forward layers, enhanced residual pathways via mHC, and dual objectives via standard language modeling loss and auxiliary multi-token prediction loss.
-
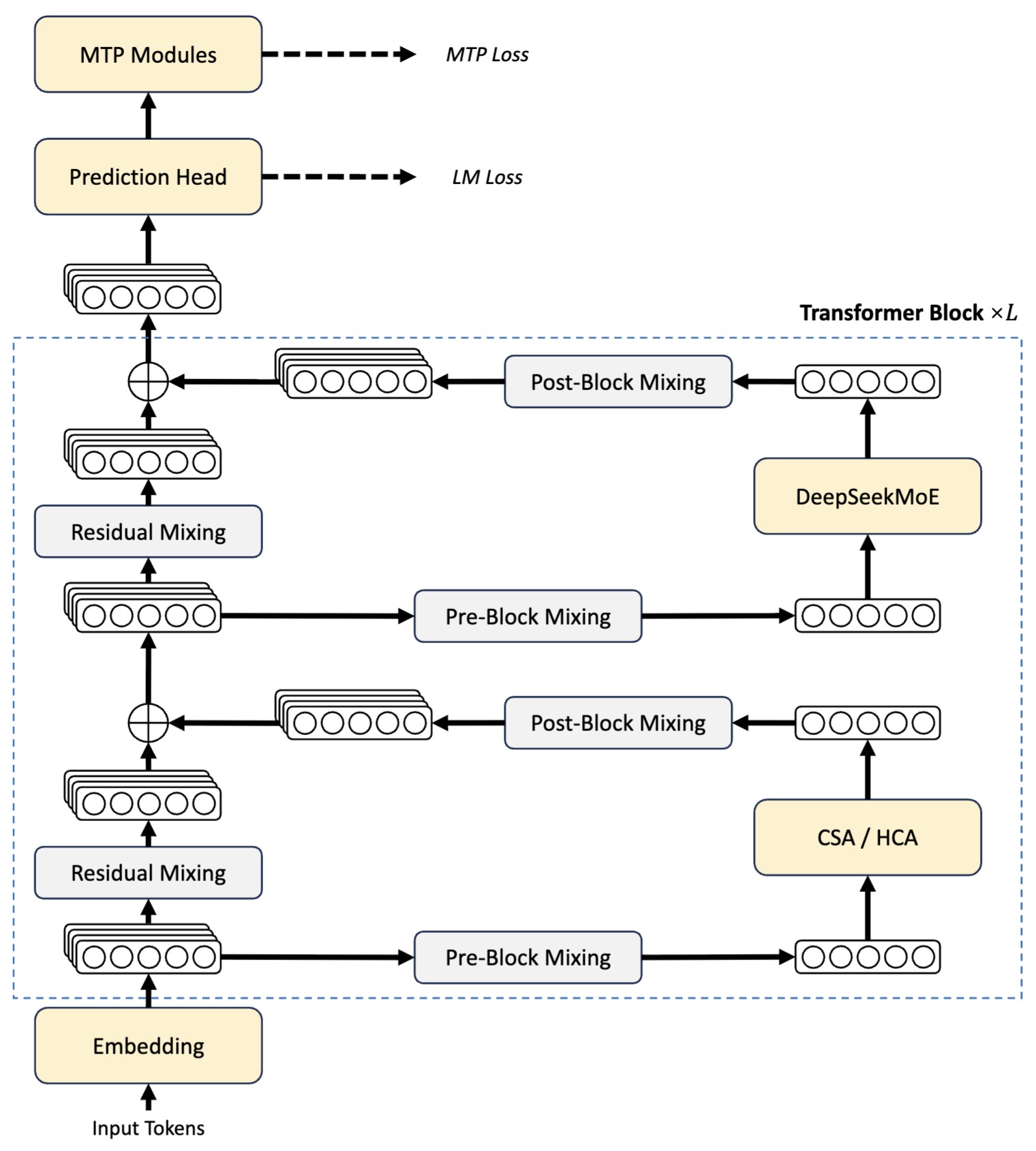
The following figure (source) shows the overall architecture of DeepSeek-V4 series, including hybrid CSA (Compressed Sparse Attention) and HCA (Heavily Compressed Attention) for attention layers, DeepSeekMoE for feed-forward layers, and strengthen conventional residual connections with mHC.
-
This architecture highlights three interacting subsystems:
- Attention subsystem (CSA + HCA) for scalable context processing
- Computation subsystem (DeepSeekMoE) for parameter-efficient scaling
- Signal propagation subsystem (mHC) for deep stability and expressivity
-
These components are not independent. Their co-design is critical. For example, compressed attention reduces memory pressure, which allows more aggressive MoE scaling, which in turn increases model capacity, which then requires more stable residual propagation through mHC.
Transformer Backbone with Sparse Activation
-
DeepSeek-V4 retains the standard Transformer structure introduced in Attention Is All You Need by Vaswani et al. (2017), which introduced modern self-attention scaling, but replaces dense feed-forward layers with routed expert layers following the DeepSeekMoE paradigm from DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models by Dai et al. (2024), where tokens are dynamically routed to a subset of experts.
-
For each token representation \(x\), the MoE layer computes:
\[y = \sum_{i \in \mathcal{E}(x)} g_i(x) \cdot \text{Expert}_i(x)\]-
where:
- \(\mathcal{E}(x)\) is the selected set of experts
- \(g_i(x)\) is the routing weight
- only a small subset of experts are active per token
-
-
This reduces per-token compute from \(O(N_{\text{experts}})\) to \(O(k)\), where \(k \ll N\), enabling trillion-parameter models with manageable compute budgets.
-
DeepSeek-V4 modifies earlier MoE routing in several important ways:
- Replaces sigmoid-based affinity scoring with \(\sqrt{\operatorname{Softplus}(\cdot)}\), improving gradient behavior
- Removes strict routing target limits to allow more flexible expert utilization
- Introduces sequence-wise balancing instead of global auxiliary loss-heavy balancing
- Incorporates hash-based routing in early layers, inspired by Hash Layers for Large Sparse Models by Roller et al. (2021), which reduces routing overhead through deterministic token-expert assignment in early layers
-
These changes reduce routing instability and improve throughput under large-scale distributed training.
Multi-Token Prediction Objective
-
DeepSeek-V4 continues the use of multi-token prediction (MTP), where the model predicts multiple future tokens at each step instead of only the next token. This idea builds on works like Better & Faster Large Language Models via Multi-token Prediction by Gloeckle et al. (2024), where auxiliary prediction heads improve training efficiency.
-
The total loss combines standard next-token loss and MTP loss:
\[\mathcal{L} = \mathcal{L}_{LM} + \lambda \mathcal{L}_{MTP}\]-
where:
\[\mathcal{L}_{LM} = -\mathbb{E}_{t} \log P(x_t | x_{<t})\] \[\mathcal{L}_{MTP} = -\mathbb{E}_{t,k} \log P(x_{t+k} | x_{<t})\]
-
-
This provides two benefits:
- Improves gradient signal density during training
- Aligns better with inference-time decoding where multiple tokens are generated sequentially
-
In large-scale regimes, this significantly accelerates convergence and improves long-horizon coherence.
DeepSeekMoE Design and Routing Mechanics
-
DeepSeek-V4 inherits the DeepSeekMoE design, which differs from earlier MoE architectures such as Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity by Fedus et al. (2021), where typically a single expert is activated per token.
-
DeepSeekMoE uses:
- fine-grained expert partitioning
- multiple experts per token
- shared experts for generalization
-
This hybrid routing balances specialization and robustness. Tokens can access both domain-specialized experts and shared experts, improving generalization across tasks.
-
The routing function is implicitly learned:
\[g(x) = \text{TopK}(\phi(x))\]- where \(\phi(x)\) is the routing network.
-
To avoid collapse where a few experts dominate, DeepSeek-V4 removes heavy auxiliary losses and instead introduces lighter sequence-level balancing, reducing training instability while maintaining load distribution.
-
Related sparse scaling ideas also connect to GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding by Lepikhin et al. (2020), which introduced large-scale expert sharding, and Outrageously Large Neural Networks by Shazeer et al. (2017), which established modern sparse MoE routing.
Design Philosophy: Co-Optimization for Long Context
-
The architecture is best understood not as isolated improvements but as a system-level co-design:
- attention compression reduces KV memory footprint
- reduced KV memory enables longer context and larger batch sizes
- MoE scaling increases capacity without increasing per-token compute
- mHC ensures stability as depth and width scale
- MTP improves training efficiency to support trillion-scale pretraining
-
This integrated design directly addresses the scaling bottlenecks identified in long-context LLMs.
Manifold-Constrained Hyper-Connections (mHC)
- Manifold-Constrained Hyper-Connections (mHC) constitute one of the most significant architectural innovations in DeepSeek-V4 because they modify a component even more foundational than attention or routing, namely the topology of residual signal propagation itself. Rather than treating residual connections as fixed identity shortcuts, mHC recasts residual propagation as a learnable structured dynamical system, while imposing geometric constraints that preserve stability at extreme scale.
- This section draws particularly on mHC: Manifold-Constrained Hyper-Connections by Xie et al. (2026), which develops the theoretical foundations, optimization framework, and systems implementation underlying the method.
Motivation: Reconsidering Residual Connectivity
-
Standard residual networks rely fundamentally on identity-preserving transport:
\[x_{l+1}=x_l + F(x_l;W_l)\]-
which recursively induces the telescoping form:
\[x_L = x_l + \sum_{i=l}^{L-1} F(x_i;W_i)\]- and thereby enables signal propagation across large depth.
-
-
The identity path acts as an implicit conservation mechanism for representations. This principle was foundational in Deep Residual Learning by He et al. (2015), where residual connections made the optimization of very deep networks feasible.
-
Hyper-Connections generalize this paradigm by expanding the residual stream into multiple interacting channels. Rather than a single residual pathway, one maintains:
\[X_l \in \mathbb{R}^{n_{hc}\times d}\]-
with propagation governed by:
\[X_{l+1} =B_l X_l +C_l F_l(A_l X_l)\]- where \(A_l\) performs pre-block mixing, \(B_l\) governs residual transport within the widened residual manifold, and \(C_l\) maps transformed features back into that expanded stream.
-
-
This formulation introduces an additional topological scaling axis without materially increasing the FLOPs of the inner computational block.
-
However, unconstrained residual mixing introduces serious instability as depth increases. Repeated compositions \(\prod_{i=1}^{L-l} B_{L-i}\) may induce spectral amplification, attenuation of signal norms, gradient collapse, or outright optimization divergence.
-
It is precisely this instability in residual topology scaling that mHC was designed to address.
Core Insight: Residual Mixing as Geometric Constraint
-
The central idea underlying mHC is that residual mixing should not be unconstrained.
-
Instead, residual mappings are projected onto a structured manifold in which identity-like conservation properties persist even under deep composition.
-
Specifically, residual mappings are constrained to lie in the Birkhoff polytope:
\[\mathcal M ={ M \in \mathbb R^{n\times n} : M1_n = 1_n, 1_n^T M =1_n^T, M \ge 0 }\]- which is the manifold of doubly stochastic matrices.
-
Because each row and column sums to one and all entries are nonnegative, each output residual stream becomes a convex mixture of input streams. Consequently, \(B_lX_l\) cannot arbitrarily amplify signal norms.
-
The mHC analysis establishes \(\| B_l \|_2 \le 1\) which implies the residual transformation is non-expansive. This constitutes the central stability property of the framework.
Why Doubly Stochastic Constraints Matter
-
The importance of this constraint arises through several interlocking consequences.
-
First, the mapping preserves mean signal statistics:
\[\frac1n \sum_i x_i =\frac1n \sum_i (B_lX_l)_i\]- which prevents uncontrolled drift in feature energy across depth.
-
Second, the manifold possesses closure under multiplication. If \(B_1,B_2 \in \mathcal M\) then \(B_1B_2 \in \mathcal M\) as well. Therefore even across arbitrarily many layers \(\prod_i B_i \in \mathcal M\), and the conservation property remains preserved under composition. This restores precisely the stability mechanism that unconstrained Hyper-Connections compromise.
-
Third, spectral stability follows directly. Because \(\rho(B_l)\le1\), the risks of vanishing and exploding propagation are substantially mitigated. This links mHC conceptually to earlier stability-oriented architectures such as Unitary Evolution Recurrent Neural Networks by Arjovsky et al. (2016), but extends those principles into Transformer residual topology.
-
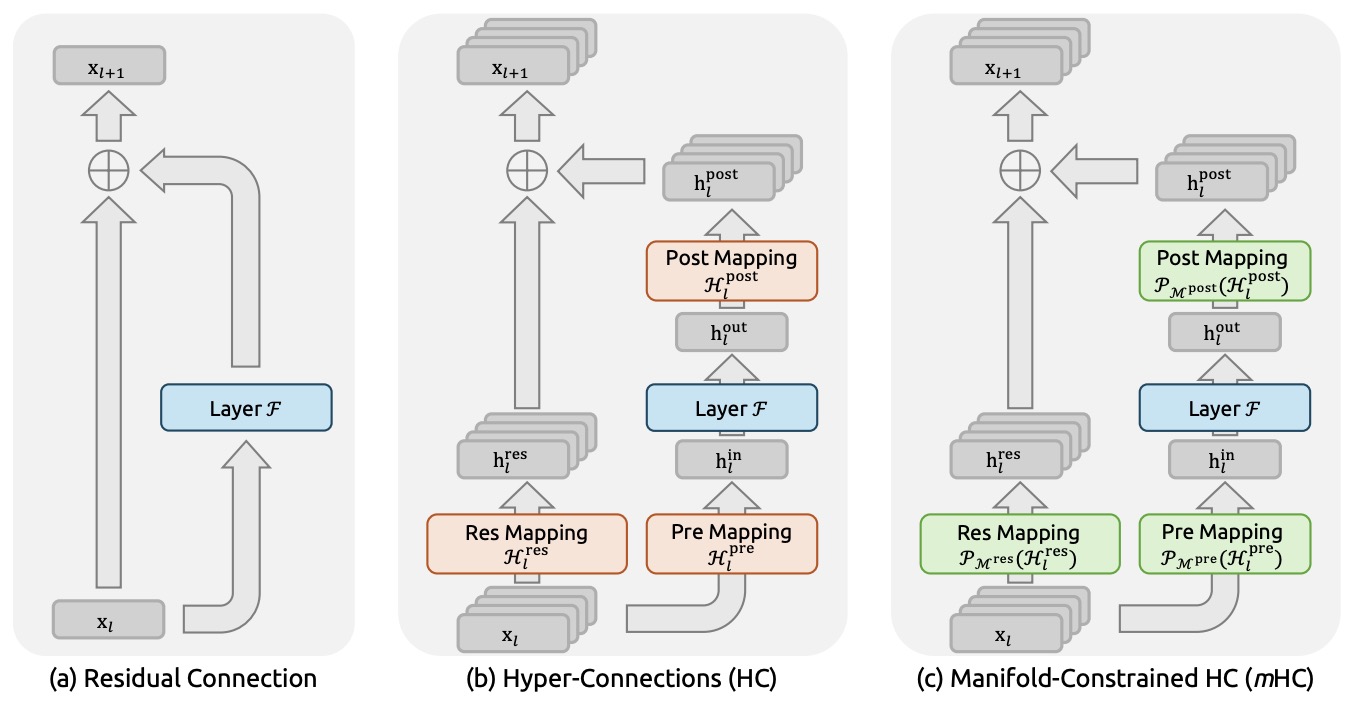
The following figure (source) shows the comparison among residual connections, unconstrained Hyper-Connections, and manifold-constrained Hyper-Connections. This figure is particularly important because it makes explicit that mHC is not merely a richer residual structure, but a geometrically constrained reformulation of residual topology itself.
Sinkhorn Projection Implementation
-
The practical challenge is how learnable residual mappings are maintained on the Birkhoff manifold during optimization.
-
The solution adopted is entropic Sinkhorn projection, based on Sinkhorn-Knopp by Sinkhorn and Knopp (1967).
-
Beginning with unconstrained logits
\[S_l\]- one first exponentiates:
-
and then iteratively normalizes rows and columns:
\[K \leftarrow \text{diag}(u)K\text{diag}(v)\]- until convergence yields:
-
This procedure is differentiable, which allows unconstrained optimization in parameter space while enforcing constrained signal propagation in function space.
-
As a consequence, learnability, geometric validity, and optimization stability are simultaneously maintained.
Parameterization Strategy
-
The mHC work emphasizes that manifold projection alone is insufficient; projection and parameterization must be co-designed.
-
The residual expansion factor \(n_{hc}\) is typically kept modest, often \(n_{hc}=4\), which increases topological richness while keeping additional compute overhead low.
-
The reported training overhead is approximately 6.7% at (n=4). This observation is important because many otherwise elegant architectural proposals become impractical once systems overhead is considered.
Full mHC Layer Structure
-
Under mHC, a Transformer block is restructured as follows:
-
The residual state is first represented as \(X_l\), which is transformed through pre-block mixing \(z_l=A_lX_l\).
-
The Transformer block then computes \(h_l=F_l(z_l)\), which is mapped back through \(u_l=C_l h_l\) and finally combined through constrained residual transport \(X_{l+1}=B_lX_l + u_l\) with \(B_l \in \mathcal M\). This inserts structured mixing before and after every Transformer block.
-
-
From a broader perspective, attention performs mixing over tokens, Mixture-of-Experts performs mixing over computation pathways, and mHC performs mixing over residual transport streams. These represent distinct axes of architectural mixing whose interaction is central to DeepSeek-V4’s scaling behavior.
Kernel-Level Implementation
-
An important strength of the mHC proposal is that it extends beyond mathematical formulation into systems realization. mHC incorporates fused kernels in which residual mixing and projection operations are combined, thereby reducing repeated memory traffic and alleviating bandwidth pressure.
-
Selective recomputation is then used in place of storing all widened residual streams explicitly. This reduces activation memory requirements and is conceptually related to checkpointing methods such as Training Deep Nets with Sublinear Memory Cost by Chen et al. (2016), though specialized to widened residual streams.
-
The implementation further overlaps expert communication, mHC communication, and compute inside the DualPipe scheduling framework inherited from DeepSeek systems infrastructure. This is particularly important because widened residual streams could otherwise become a communication bottleneck at scale.
Why mHC Matters for DeepSeek-V4 Specifically
-
mHC’s significance becomes particularly clear in the context of trillion-scale sparse models.
-
Mixture-of-Experts substantially increases representational capacity, while long-context attention introduces extremely deep dependency chains. Scaling both simultaneously without improving residual transport would introduce considerable fragility. Within this setting, mHC functions almost as a structural conditioner for the network as a whole.
-
mhC improves optimization conditioning, supports greater depth scalability, increases residual expressivity, and stabilizes long-horizon reasoning behavior. In that sense, it may be interpreted less as an isolated module and more as a scaling-oriented architectural mechanism.
Conceptual Interpretation: Learned Markov Mixing
- There is also a compelling alternative interpretation of mHC through the lens of stochastic operators. Each constrained residual matrix can be viewed as a Markov transition operator, because doubly stochastic matrices define stochastic kernels. Then residual propagation \(X_{l+1}=B_lX_l\) resembles controlled diffusion over residual streams. This links mHC conceptually to graph diffusion operators and spectral geometric methods. It also helps explain why the paper frames the contribution not merely as a residual modification, but as manifold-constrained topological design. That framing is considerably broader and potentially more consequential.
Broader Architectural Significance
-
Although attention innovations often dominate discourse around frontier model architectures, mHC may ultimately prove comparably significant because it operates at the level of signal transport itself rather than token interaction alone.
-
Historically, major advances in deep model scaling have often corresponded to the introduction of new architectural primitives. Residual networks established identity-preserving transport across depth. Transformers introduced attention as a scalable routing mechanism for representation learning. Mixture-of-Experts introduced sparse conditional computation as a new scaling axis for model capacity.
-
Viewed within that progression, mHC may be interpreted as introducing another primitive: topology-constrained residual scaling, in which expressivity is increased not through unconstrained connectivity, but through geometrically regulated connectivity that preserves optimization stability.
-
If this principle generalizes beyond the DeepSeek stack, its implications may extend well beyond a single model family and influence broader architectural design for ultra-deep and long-context sequence models.
-
Notably, what makes mHC especially compelling is not only the architectural proposal itself, but the fact that it is accompanied by a rare synthesis of mathematical characterization, optimization machinery, and hardware-conscious systems implementation. Architectural ideas that simultaneously span those three levels are uncommon, and historically those are often the ideas that exert the greatest long-term influence.
-
The next section can proceed to DeepSeek-V4’s Hybrid Attention architecture, including Compressed Sparse Attention, Heavily Compressed Attention, FP4 QK paths, and million-token inference mechanics.
Hybrid Attention with Compressed Sparse Attention and Heavily Compressed Attention
-
If mHC addresses stability along the depth dimension, the hybrid attention architecture in DeepSeek-V4 addresses the complementary scaling problem along the sequence dimension. This subsystem is arguably the core systems innovation behind DeepSeek-V4’s one-million-token context capability, because it directly attacks the two principal bottlenecks that make ultra-long-context inference prohibitively expensive: the quadratic growth of attention computation and the linear growth of key-value cache memory.
-
Conventional Transformer attention scales poorly with sequence length because every query token attends against the full prefix: \(\text{Attention}(Q,K,V)=\operatorname{softmax}\left(\frac{QK^\top}{\sqrt d}\right)V\) which implies computational complexity \(O(n^2d)\) for sequence length (n). Although this quadratic form was acceptable for moderate contexts, it becomes increasingly prohibitive at million-token scale because autoregressive inference becomes dominated not only by FLOPs, but also by memory movement through increasingly large KV caches.
-
DeepSeek-V4 addresses this not through a single efficient attention approximation, but through a hybrid architecture in which two distinct compressed attention mechanisms solve different aspects of the long-context problem.
-
The central design philosophy is decomposition. Rather than forcing a single mechanism to balance long-range coverage, compression fidelity, and compute efficiency simultaneously, DeepSeek-V4 separates those objectives into two complementary subsystems. Compressed Sparse Attention (CSA) handles high-resolution retrieval over compressed history, while Heavily Compressed Attention (HCA) provides more aggressive compression with dense reasoning over a reduced latent representation.
-
Attention Is All You Need by Vaswani et al. (2017) established dense attention as the foundational primitive, while Longformer by Beltagy et al. (2020) introduced sparse local-global attention, Performer by Choromanski et al. (2020) developed kernelized linear attention approximations, and FlashAttention by Dao et al. (2022) showed that IO-aware kernels can substantially improve practical efficiency. DeepSeek-V4 can be interpreted as extending this trajectory toward a systems-oriented compressed attention hierarchy, with additional systems-level context available in DeepSeek-V4 Preview Release and DeepSeek-V4 Technical Overview.
Compressed Sparse Attention
-
Compressed Sparse Attention is designed around a key observation: for long-context inference, the model does not require full-resolution access to all historical tokens at all times, but it does require accurate retrieval over relevant portions of long-range context. CSA therefore compresses the KV cache along the sequence dimension before sparse attention is applied, so the model attends over an indexed compressed memory rather than the entire raw token history.
-
If original keys and values are \(K,V \in \mathbb R^{n \times d},\) CSA forms compressed representations \(K_c,V_c\) with \(K_c=C_K(K),\quad V_c=C_V(V),\) where (C_K) and (C_V) denote learned or structured compression operators. Attention then becomes \(\text{CSA}(Q,K_c,V_c)=\text{SparseAttn}(Q,K_c,V_c)\), rather than dense attention over full-resolution history.
-
The key subtlety is that CSA is not merely sparse attention. It is compressed sparse attention, meaning that sparsity operates over compressed memory rather than raw token neighborhoods. This makes the mechanism closer to retrieval over structured memory than conventional attention over a flat prefix.
-
The compression layer substantially reduces effective attention scope, while sparse retrieval preserves access to globally relevant content. This changes the scaling profile from \(O(n^2)\rightarrow O(nk),\) where (k) is the sparse retrieval budget, with compression further reducing constant factors. This mechanism is one of the principal contributors to the reduction in single-token inference FLOPs.
-
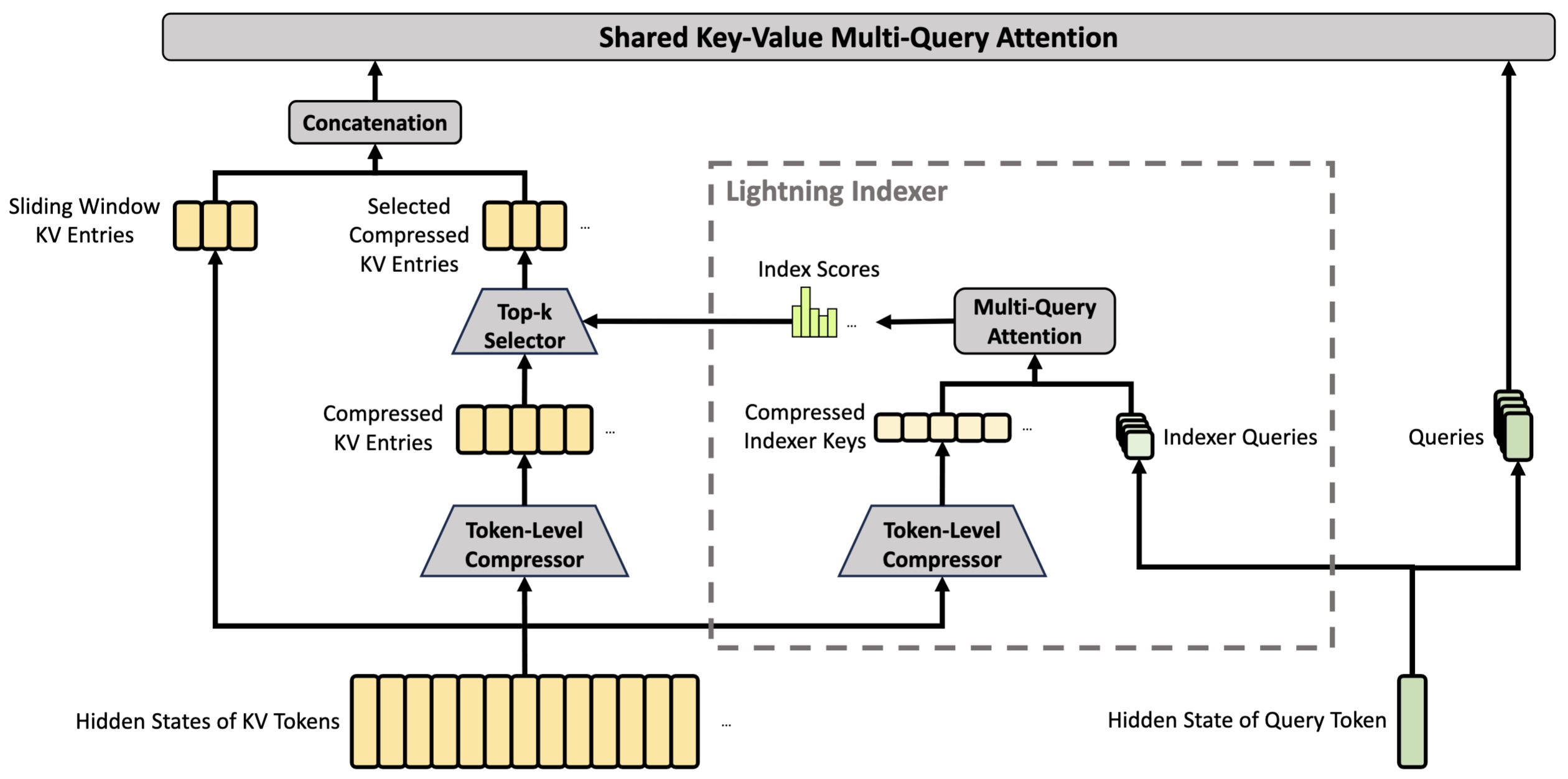
The following figure (source) shows the CSA mechanism. CSA compresses the number of KV entries to \(\frac{1}{m}\) times, and then applies DeepSeek Sparse Attention for further acceleration. Additionally, a small set of sliding window KV entries is combined with the selected compressed KV entries to enhance local fine-grained dependencies.
The Lightning Indexer and FP4 QK Path
-
One particularly notable implementation detail is the lightning indexer associated with CSA. Long-context efficiency is constrained not only by algorithmic complexity, but also by memory bandwidth and data movement. DeepSeek-V4 therefore applies FP4 precision not only to routed expert parameters, but also to the QK path used inside the CSA indexer.
-
Rather than storing and processing those components in higher precision, query-key pathways in the indexer remain in FP4 through storage and compute. This matters because similarity computation often dominates compressed retrieval systems. If similarity scoring is \(s_{ij}=q_i^\top k_j,\) then lowering precision directly reduces storage bandwidth, cache traffic, and index lookup cost.
-
This is an important systems point because many efficient-attention methods reduce arithmetic while remaining memory-bound. DeepSeek-V4 explicitly targets both arithmetic and memory movement, which helps explain why the attention design and quantization strategy are tightly coupled rather than separate optimizations.
-
This precision-aware retrieval design can be viewed as complementary to IO-aware optimization ideas from FlashAttention-2 by Dao et al. (2023), though applied in a compressed sparse retrieval regime rather than conventional dense attention.
Heavily Compressed Attention
-
Where CSA preserves compressed but structured sparse retrieval, HCA pushes compression much further. Its purpose is distinct: rather than acting as an indexed retrieval layer, HCA forms a much smaller latent compressed representation while retaining dense attention over that compressed state.
-
If aggressive compression maps \(K,V\rightarrow \tilde K,\tilde V\) with \(m \ll n,\) then dense attention operates over \(\tilde K,\tilde V\in\mathbb R^{m\times d}\) via \(\text{HCA}(Q,\tilde K,\tilde V)=\operatorname{softmax}\left(\frac{Q\tilde K^\top}{\sqrt d}\right)\tilde V,\) but now over a drastically smaller latent sequence.
-
Unlike CSA, which uses sparsity after compression, HCA retains dense attention but makes density affordable through much stronger compression. This is a fundamentally different operating point: CSA optimizes retrieval fidelity, whereas HCA optimizes maximal efficiency. Their coexistence is therefore deliberate rather than redundant.
-
The following figure (source) shows the core architectures of HCA. HCA performs heavier compression, where the KV entries of \(m^{\prime}(\gg m)\) tokens will be consolidated into one. Also, DeepSeek-V4 additionally introduces a small set of sliding window KV entries to enhance local fine-grained dependencies.
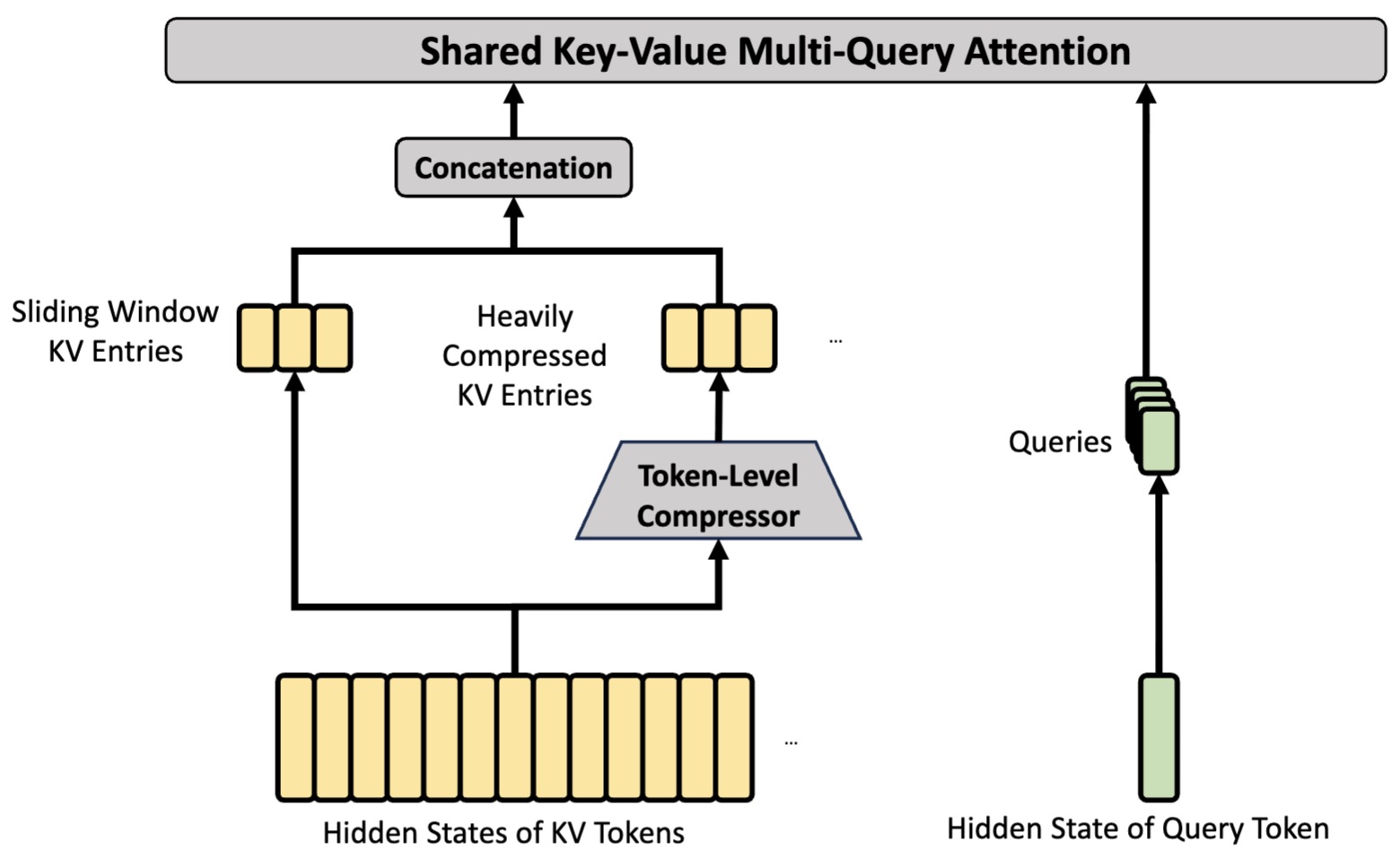
-
The architecture can therefore be viewed as hierarchical memory processing. CSA handles relatively fine-grained long-range retrieval, while HCA provides much coarser but extremely efficient compressed global context. This layered design is one of the more novel aspects of the system.
-
Conceptually, HCA has affinities with memory-compression ideas explored in Compressive Transformer by Rae et al. (2019), where compressed memories extend context horizons, though DeepSeek-V4 integrates compression directly into the main attention hierarchy rather than treating it as an auxiliary memory pathway.
Why Two Attention Mechanisms Instead of One
-
A natural question is why both mechanisms are needed. The answer is that long-context processing has conflicting objectives that are difficult to satisfy within a single operator. High-fidelity retrieval requires relatively conservative compression and structured sparsity, whereas extreme efficiency benefits from aggressive compression.
-
Trying to optimize both simultaneously inside one mechanism generally forces poor tradeoffs. DeepSeek-V4 instead separates the problem into complementary attention pathways. This is analogous in spirit to hierarchical memory systems in computer architecture, where different levels serve different latency and capacity regimes.
-
Viewed through that lens, CSA behaves like a structured retrieval cache, while HCA behaves more like compressed long-term memory. This layered interpretation aligns with broader hierarchical retrieval perspectives in agentic systems and long-context architectures, including MemGPT by Packer et al. (2023), where memory is explicitly treated as a hierarchy rather than a flat context window.
Efficiency Implications
-
This design directly drives the reported scaling improvements. At one million tokens, DeepSeek-V4-Pro uses roughly 27% of the single-token inference FLOPs of DeepSeek-V3.2 and roughly 10% of its KV cache, while DeepSeek-V4-Flash reduces those further still.
-
These gains are not attributable to sparsity alone. They emerge from the combined effect of compression, sparse retrieval, compressed dense attention, precision reduction, and specialized KV-cache management. This is important because many efficient-attention proposals optimize asymptotics while underestimating systems overheads.
-
The reported efficiency behavior is discussed further in DeepSeek API Documentation: Long Context and DeepSeek-V4 Technical Overview, both of which emphasize architectural and systems co-design rather than isolated algorithmic tricks.
Heterogeneous KV Cache Architecture and Inference State Management
-
Hybrid attention introduces a systems challenge beyond compressed retrieval itself: the model no longer maintains a uniform KV memory structure across layers. Because CSA, HCA, and Sliding Window Attention produce KV entries with different compression ratios, update rules, and eviction policies, inference requires a heterogeneous cache abstraction rather than conventional paged KV memory.
-
Long-context efficiency therefore depends not only on reducing attention FLOPs, but also on organizing memory movement efficiently under irregular cache geometries. The architecture partitions memory into a classical KV cache for CSA and HCA, alongside a state cache for sliding-window states and tokens awaiting compression.
-
This separation permits each request to maintain fixed-size cache blocks while supporting layer-specific storage semantics, reducing fragmentation while preserving compatibility with high-performance attention kernels. Particularly important is the treatment of “unready-for-compression” tokens as persistent sequence state, which elevates what would otherwise be transient buffering into a first-class inference primitive.
-
The following figure (source) shows the heterogeneous KV cache layout for DeepSeek-V4, illustrating the classical KV cache for CSA/HCA alongside the state cache used for sliding-window attention and pending compression states.
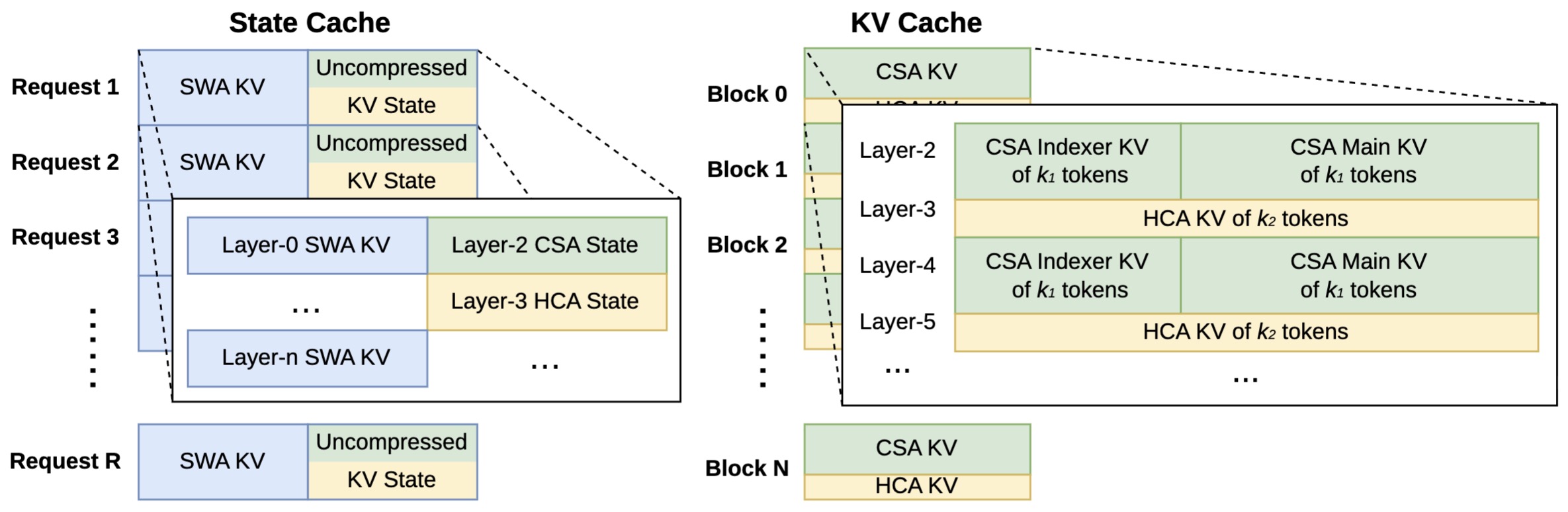
- Conceptually, this memory design can be viewed as the inference counterpart to hybrid attention itself: just as CSA and HCA partition attention computation according to information granularity, the KV layout partitions memory according to persistence and update dynamics. This coupling between architectural compression and cache-system organization is one reason the model sustains efficient million-token inference while avoiding the breakdowns that conventional homogeneous KV management would induce.
Relation to DeepSeek Sparse Attention and Prior Efficient Attention
-
Although CSA and HCA are new components, they also sit within a broader lineage. Sparse attention traces back through work such as Sparse Transformers by Child et al. (2019), where structured sparsity reduced long-range cost.
-
Compression-based approaches connect conceptually to latent-attention and memory-compression methods such as Compressive Transformer by Rae et al. (2019). DeepSeek-V4 differs in that it does not merely approximate standard attention; instead, it reorganizes long-context attention into a layered compressed retrieval architecture.
-
This distinction matters because the design is closer to changing the memory hierarchy than modifying one operator. The broader systems perspective is also echoed in work such as PagedAttention / vLLM by Kwon et al. (2023), which reframes inference memory management itself as part of model serving architecture.
Broader Architectural Significance
-
Hybrid attention in DeepSeek-V4 is significant not merely because it extends context windows, but because it reframes long-context scaling as a memory hierarchy problem rather than solely an attention approximation problem. That shift is subtle but consequential, because it changes the design target from “one better attention operator” to a layered system of operators specialized for different compression and retrieval regimes.
-
Historically, attention research often sought a single better attention mechanism. DeepSeek-V4 instead treats attention as a composite system whose subcomponents operate at different levels of memory granularity. That perspective may prove more scalable as models move toward longer contexts, more agentic workflows, and more persistent task states.
-
Just as mHC introduced topology-constrained residual scaling, hybrid CSA-HCA may represent an analogous architectural primitive for long-context memory scaling. Both innovations reflect the same deeper design philosophy: scaling emerges not from enlarging conventional primitives indefinitely, but from reorganizing those primitives structurally.
Optimization Stack: Muon, FP4 Quantization-Aware Training, and Stability at Scale
-
If the hybrid attention architecture in DeepSeek-V4 solves the efficiency problem of million-token context processing, the optimization stack addresses an equally difficult problem: how to train such a system stably and efficiently at trillion-parameter scale. In DeepSeek-V4, optimization is not treated as a secondary implementation detail, but rather as an architectural component in its own right. The Muon optimizer, FP4 quantization-aware training, and large-scale systems co-design are best understood as mutually reinforcing components of one optimization stack rather than isolated techniques.
-
This perspective reflects a broader trend in frontier models, namely that scaling limits increasingly emerge not only from model architecture, but from optimizer dynamics, numerical precision, and distributed training efficiency. In that sense, DeepSeek-V4 extends a trajectory that includes optimizer-centered scaling work such as Adam: A Method for Stochastic Optimization by Kingma and Ba (2014), LAMB by You et al. (2019), and more recent optimizer redesign efforts underlying frontier-scale training.
Why Optimization Becomes a Primary Bottleneck
-
At trillion-scale sparse model training, optimization instability does not usually arise from one single source. It emerges from the interaction of routing dynamics, very large batch sizes, precision compression, residual depth, and long-context attention. These interactions create failure modes that do not appear in smaller-scale dense models.
-
Gradient noise scales differently in sparse conditional computation, routing creates expert imbalance dynamics, and million-token attention introduces numerical sensitivities absent at conventional context lengths. In such settings, simply scaling familiar optimizers often becomes inadequate. This is precisely the motivation for introducing Muon into DeepSeek-V4.
-
The broader challenge resembles observations in scaling-law analyses such as Scaling Laws for Neural Language Models by Kaplan et al. (2020), where optimization and architecture increasingly co-determine achievable scaling.
Muon Optimizer
-
One of the major changes in DeepSeek-V4 relative to earlier generations is adoption of Muon as the primary optimizer. The motivations are faster convergence and improved training stability.
-
Conceptually, Muon can be understood as an optimizer designed to improve conditioning and scaling behavior at extreme training scale. Whereas Adam-type methods maintain first- and second-moment statistics:
\[m_t =\beta_1m_{t-1} +(1-\beta_1)g_t\] \[v_t =\beta_2v_{t-1} +(1-\beta_2)g_t^2\]-
with updates:
\[\theta_{t+1} =\theta_t \eta \frac{\hat m_t}{\sqrt{\hat v_t}+\epsilon}\]
-
-
Muon modifies this paradigm with geometry-aware preconditioning mechanisms designed for improved large-scale conditioning. While much of the practical benefit is empirical, the motivation is fundamentally about more stable optimization trajectories.
-
This places Muon in conversation with optimizer geometry ideas seen in Shampoo by Gupta et al. (2018), where structured second-order preconditioning improves conditioning, and newer large-scale optimizer developments discussed in Muon by Jordan et al. (2024).
-
One way to interpret Muon is as attacking optimizer inefficiency that emerges once architecture itself has been scaled aggressively. If mHC stabilizes residual transport and hybrid attention stabilizes long-context computation, Muon contributes analogous stabilization in optimization space.
-
That symmetry is noteworthy. Each major DeepSeek-V4 innovation can be read as solving instability in a different domain: signal transport, sequence memory, and optimization dynamics.
Efficient Implementation of Muon
-
DeepSeek-V4 does not merely adopt Muon algorithmically, but redesigns infrastructure around it. Hybrid ZeRO-style strategies and cost-effective Muon implementations reduce optimizer overhead.
-
This matters because optimizer sophistication often creates unacceptable systems cost. Many theoretically appealing optimizers fail because they do not scale operationally. DeepSeek-V4 appears unusually attentive to this gap.
-
This emphasis echoes broader practical lessons from systems-oriented optimizer scaling efforts such as ZeRO by Rajbhandari et al. (2020), where optimizer-state partitioning became essential to extreme-scale training.
FP4 Quantization-Aware Training
-
A second major optimization innovation is the use of FP4 quantization-aware training. This is notable because FP4 appears not merely as an inference compression trick, but as part of training itself.
-
Two principal uses stand out: FP4 is used for routed expert parameters, and it is also used in the QK path inside the CSA indexer. This is significant because it targets two major memory-movement bottlenecks simultaneously: sparse expert parameter access and long-context retrieval computation.
-
In quantized training, weights can be represented approximately as \(W_q = Q(W)\), where \(Q(\cdot)\) is the quantization operator.
-
Training then effectively optimizes under constrained precision \(\mathcal L(\theta) \rightarrow \mathcal L(Q(\theta))\) rather than in full precision. That introduces nontrivial optimization challenges, because quantization noise interacts with gradient updates. Quantization-aware training seeks to make the optimization process robust to those effects.
-
Conceptually this extends ideas seen in Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference by Jacob et al. (2018), but at a far more aggressive precision regime.
-
The interesting point is that FP4 here is not framed only as memory reduction. It is framed as a systems-level scaling mechanism. Potential future hardware gains beyond present implementations suggest the optimization stack anticipates hardware evolution rather than only current accelerators. This is a subtle but important distinction. It suggests the design is partially hardware-forward-looking.
Quantization as Optimization Co-Design
- What is especially important is that quantization is not treated independently from optimizer dynamics. Lower precision introduces gradient noise and numerical perturbations. The optimizer must tolerate those. This is one reason Muon and FP4 are better understood jointly: one reduces optimization fragility, while the other reduces precision and memory costs. Together they make a more aggressive operating regime feasible. That co-design perspective is often underappreciated. It also resonates with broader low-precision frontier efforts such as QLoRA by Dettmers et al. (2023), though DeepSeek-V4 applies low precision much deeper into core pretraining infrastructure.
Stability Mitigation During Pretraining
-
Training instability is treated as an expected scaling phenomenon rather than an anomaly.
-
Several DeepSeek-V4 innovations can be understood through that lens. mHC mitigates instability in residual transport. Muon improves optimizer conditioning. FP4 quantization-aware training controls low-precision noise. Hybrid attention reduces extreme sequence-scale computational stresses.
-
Together these do not merely improve efficiency. They enlarge the stable operating region of the training system. That may be the deeper story.
-
This perspective also aligns with emerging views in scaling work such as DeepNet by Wang et al. (2022), which framed stability-preserving architectural scaling as central to ultra-deep Transformer training.
Distributed Systems Co-Design
-
Optimization in DeepSeek-V4 also extends into distributed systems. Fused MoE kernels overlap compute, communication, and memory access, contextual parallelism manages compressed attention, and tensor-level checkpointing supports fine-grained recomputation.
-
These are not peripheral engineering details. At this scale they become part of optimization itself. The traditional distinction between “optimizer” and “systems layer” becomes increasingly artificial. DeepSeek-V4 reflects that convergence.
-
This convergence is also evident in broader systems work such as Megatron-LM by Shoeybi et al. (2019) and PaLM by Chowdhery et al. (2022), where parallelism strategy and optimization increasingly co-evolve.
Batch-Invariant Deterministic Kernels
-
A particularly unusual detail is emphasis on deterministic and batch-invariant kernels. This is easy to overlook, but potentially significant.
-
Bitwise reproducibility is often treated as secondary in large-scale training. DeepSeek-V4 appears to elevate it as infrastructure. That matters for debugging, stability analysis, and long-horizon distributed training reliability.
-
At trillion-scale, such issues cease to be peripheral. They become part of model development feasibility.
Optimization as an Architectural Layer
-
One of the most interesting conceptual implications of DeepSeek-V4 is that optimization begins to resemble an architectural layer rather than a separate concern.
-
Traditionally one speaks of model architecture, then optimizer, then infrastructure. DeepSeek-V4 increasingly collapses those boundaries. mHC, Muon, FP4, fused kernels, contextual parallelism, and KV-cache systems are all interdependent.
-
This suggests a broader shift. At frontier scale, architecture may increasingly mean architecture-plus-optimization-plus-systems as one co-designed object. That is a stronger claim than most model papers make, but DeepSeek-V4 arguably points in that direction.
-
The DeepSeek team has hinted at this framing in DeepSeek Research Updates and related engineering notes accompanying releases, where systems and model design are often discussed as inseparable.
Broader Significance
-
The Muon plus FP4 stack is significant not merely because it improves training efficiency, but because it reflects a different philosophy of scaling.
-
Rather than assume architecture scales first and optimization follows, DeepSeek-V4 treats optimizer geometry, numerical precision, and distributed execution as primary ingredients of capability scaling. Historically, major leaps in model scale have often followed advances in optimization as much as architecture.
-
Backpropagation itself was one such leap. Adam was another. Large-scale optimizer-state partitioning was another. Muon plus low-precision optimizer-aware training may plausibly belong in that lineage.
-
Whether Muon itself becomes broadly adopted remains uncertain. But the broader lesson, that optimizer and numerical design are now frontier architectural concerns, is likely durable.
-
The next section can proceed to DeepSeek-V4’s post-training stack, including specialist training, GRPO, and on-policy distillation.
Post-Training Stack: Specialist Training, GRPO, and On-Policy Distillation
-
If the pretraining stack in DeepSeek-V4 is designed to produce a highly capable general-purpose foundation model, the post-training stack is designed to specialize, consolidate, and amplify those capabilities through structured adaptation. A central feature of this stage is that post-training is not framed as a single alignment step, but rather as a multi-stage optimization system involving domain-specialized expert formation, reinforcement learning, and unified capability consolidation. This design reflects a broader shift in frontier models away from monolithic instruction tuning toward modular capability cultivation.
-
More fundamentally, this post-training architecture mirrors a recurring design philosophy already visible throughout DeepSeek-V4. Rather than scaling through monolithic mechanisms, difficult problems are decomposed, optimized independently, and then reintegrated through structured synthesis. mHC applies this principle to residual topology, hybrid attention applies it to long-context memory, and the post-training stack applies it to capability formation itself. That recurring pattern is important because it suggests a coherent systems philosophy rather than isolated innovations.
-
Conceptually, the post-training stack can be understood as separating capability acquisition from capability integration. Rather than forcing a single model to jointly learn all specialized behaviors through one optimization process, DeepSeek-V4 first develops specialized expert policies and only afterward consolidates those competencies into a unified model. This decomposition is one of the more distinctive features of the system.
-
The following figure shows the overall post-training pipeline, including specialist training, reinforcement learning, and unified on-policy distillation.
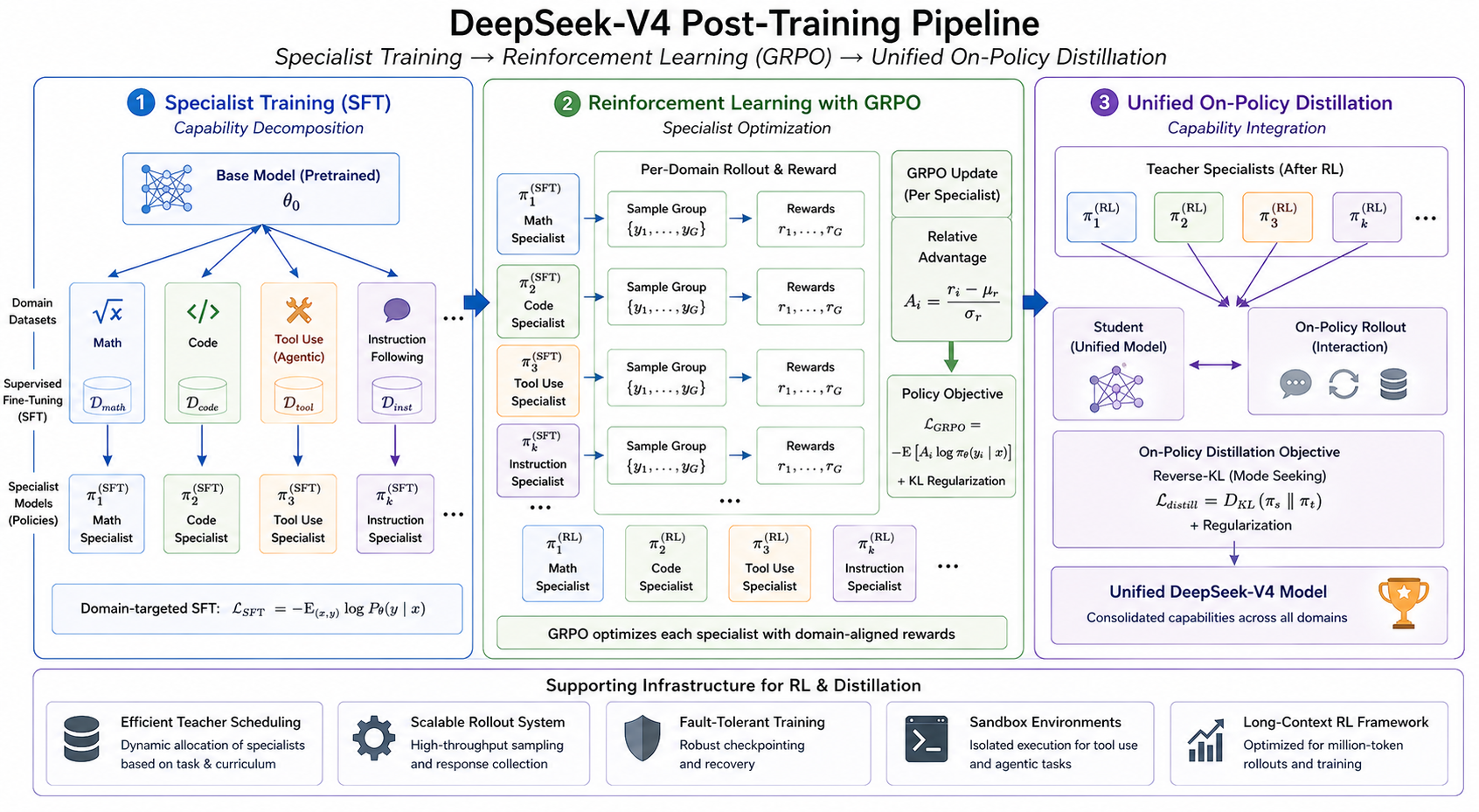
- This staged design has conceptual affinities with expert specialization and policy distillation work such as Policy Distillation by Rusu et al. (2015), while also intersecting modern alignment paradigms that increasingly separate capability learning from alignment optimization.
Specialist Training as Capability Decomposition
-
A foundational idea in the DeepSeek-V4 post-training stack is that certain domains, particularly mathematics, coding, agentic tool use, and instruction following, benefit from independent specialist optimization before unification. Rather than directly optimize a general-purpose assistant over a mixed objective spanning all these domains, specialist models are trained separately so each domain can develop under its own reward structure and data curriculum.
-
This begins with domain-targeted supervised fine-tuning. Given base parameters \(\theta_0\) each specialist model initializes from \(\theta_s \leftarrow \theta_0\) and then optimizes over domain-specific supervised data \(\mathcal L_{SFT}=-\mathbb E_{(x,y)}\log P_\theta(y \mid x)\).
-
This stage establishes the foundational behaviors of each specialist before reinforcement learning. This approach is related in spirit to specialization phenomena observed in InstructGPT by Ouyang et al. (2022), though here specialization is made explicit as a system design principle rather than an emergent byproduct.
-
The motivation is partly optimization-theoretic. Multi-domain objectives can interfere, especially when reward signals differ substantially across domains. Decomposition reduces that interference. One may view this stage as inducing a collection of domain-conditioned policies \({\pi_1,\pi_2,\dots,\pi_k}\), rather than forcing all domains into one policy immediately. That perspective becomes important later during consolidation.
Reinforcement Learning with GRPO
-
Following supervised specialist development, reinforcement learning is applied using Group Relative Policy Optimization (GRPO), introduced in DeepSeekMath by Shao et al. (2024) and extended in later DeepSeek reasoning systems.
-
GRPO can be viewed as a variant of policy optimization that replaces some dependence on learned value baselines with relative comparisons among groups of sampled outputs. Given sampled responses \({y_1,\dots,y_G}\) with rewards \({r_1,\dots,r_G}\) relative advantages can be formed through group normalization:
\[A_i=\frac{r_i-\mu_r}{\sigma_r}\]- where, \(\mu_r=\frac1G\sum_i r_i\).
-
The policy objective becomes \(\mathcal L_{GRPO}=-\mathbb E\left[A_i\log\pi_\theta(y_i \| x)\right]\) subject to regularization, often including KL constraints.
-
This retains the broader policy-optimization flavor of methods such as Proximal Policy Optimization by Schulman et al. (2017), while using relative group structure to improve stability and reward efficiency.
-
One important implication is that reward optimization becomes domain-specific. Mathematical correctness, code execution success, tool-use competence, and instruction-following behavior can each be optimized against domain-aligned reward signals, rather than forcing one reward structure across all tasks. This is a subtle but important departure from simpler RLHF formulations.
Why Specialist RL Before Unification
-
An immediate question is why reinforcement learning is applied before consolidation rather than after. The answer appears to be that specialization itself benefits from relatively unconstrained optimization. If one attempted unified RL across all domains from the outset, reward tradeoffs and interference would likely suppress specialist peak performance.
-
By allowing each specialist policy to be independently optimized, one can more effectively reach domain-level frontiers before integration. Conceptually, this resembles training specialists to local optima before constructing a broader ensemble-like unified policy. There are analogies here to modular and mixture-style learning, although implemented through post-training rather than architectural routing.
-
By allowing each specialist policy to be independently optimized, one can more effectively reach domain-level frontiers before integration. Conceptually, this resembles training specialists to local optima before constructing a broader ensemble-like unified policy. There are analogies here to modular and mixture-style learning, although implemented through post-training rather than architectural routing.
Thinking Management and Persistent Reasoning Traces
-
An important extension of specialist reinforcement learning in DeepSeek-V4 is that reasoning is not treated purely as token generation behavior, but as something whose persistence across interaction turns can itself be managed architecturally. This is significant because once reasoning traces become part of the model’s effective computational substrate, their lifecycle across dialogue turns becomes part of the post-training design space rather than merely an inference heuristic.
-
The DeepSeek-V4 paper introduces a differentiated thinking management strategy that separates tool-calling scenarios from ordinary conversational interaction. In tool-use settings, reasoning traces are preserved across turns, allowing cumulative chains of thought to persist through multi-step agent trajectories. In ordinary conversational settings, prior reasoning traces are discarded at each new user turn, preserving efficiency and avoiding unnecessary context growth. This bifurcation is conceptually important because it treats reasoning persistence as conditional memory management rather than a fixed global policy.
-
Rather than assuming one universal treatment for chain-of-thought traces, the model applies different persistence rules depending on whether reasoning is supporting long-horizon agent execution or ordinary dialogue. The following figure (source) illustrates this distinction.
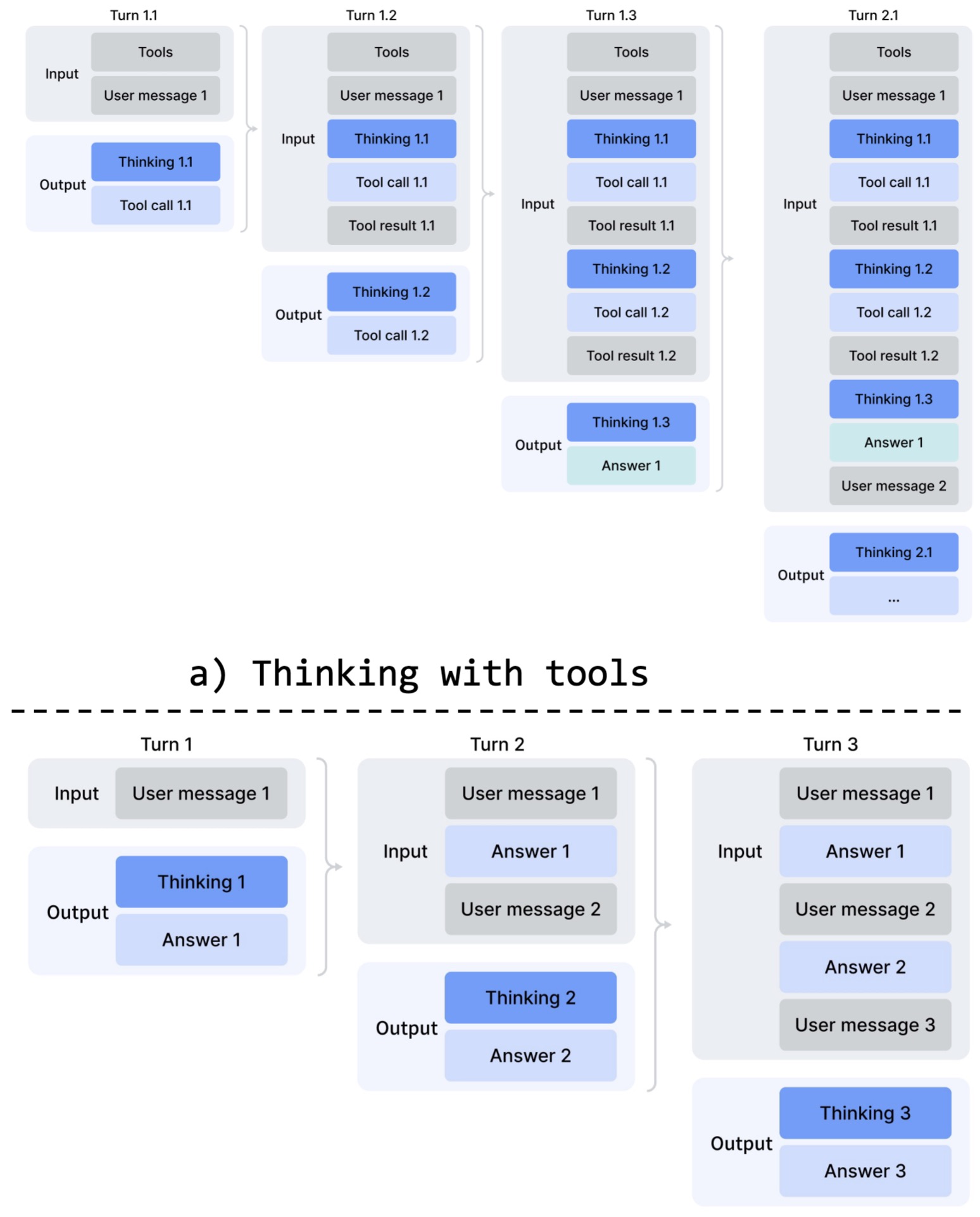
-
In tool-calling mode, reasoning traces survive across user turns and tool invocations, effectively supporting a cumulative reasoning state over trajectories. This can be viewed as extending optimization beyond token-level policy learning into trajectory-level state management. For agentic workflows, this matters because preserving intermediate reasoning across tool interactions can materially improve long-horizon competence.
-
In contrast, ordinary conversational interaction preserves the earlier DeepSeek strategy in which reasoning traces are dropped once a new user message arrives. This avoids uncontrolled context growth while reserving persistent reasoning only for settings where it contributes measurable value.
-
This mechanism complements the broader post-training decomposition philosophy. Specialist RL shapes domain reasoning policies, while thinking management governs how those policies unfold over interaction horizons. Together they suggest that DeepSeek-V4 treats reasoning not solely as an emergent behavior to be elicited, but increasingly as a managed computational object.
-
This perspective also reframes the
... structures discussed earlier. Rather than functioning merely as response formatting conventions, they participate in structured control over reasoning persistence. That subtle shift is one of the conceptual novelties of the V4 post-training stack. -
A further implication is that the unified model consolidation stage is not merely distilling specialist outputs, but consolidating specialist competence already embedded in differentiated reasoning-control regimes. That makes the transition into on-policy distillation stronger: what is being unified is not only what specialists know, but how they sustain reasoning over time.
Unified Model Consolidation through On-Policy Distillation
-
Once specialists have been developed, DeepSeek-V4 introduces a second major stage: unified model consolidation through on-policy distillation. This is one of the most distinctive aspects of the full pipeline.
-
The motivation is straightforward. Maintaining isolated specialists may maximize domain performance, but it fragments capabilities across separate policies. The objective of OPD is therefore not to replace specialist optimization, but to compress and merge those specialized competencies into a single coherent model while preserving much of their frontier-level behavior. Put simply, rather than simply ensemble specialists or continue multi-domain RL jointly, a unified student model is trained to absorb the behaviors of specialized teacher models. Student policy \(\pi_s\) learns from teacher policies \({\pi_1,\dots,\pi_k}\) through distillation.
-
The optimization is described in terms of reverse-KL-oriented learning \(\mathcal L_{distill}=D_{KL}(\pi_s\Vert\pi_t)\) or equivalent on-policy formulations.
-
This places it conceptually near distillation traditions beginning with Distilling the Knowledge in a Neural Network by Hinton et al. (2015), but extended into policy-level on-policy consolidation. The “on-policy” part matters. Rather than distilling only static teacher trajectories, student rollouts participate in the learning process, making this closer to interactive policy consolidation.
-
The following figure shows the on-policy distillation stage used to unify specialist policies into a single model.
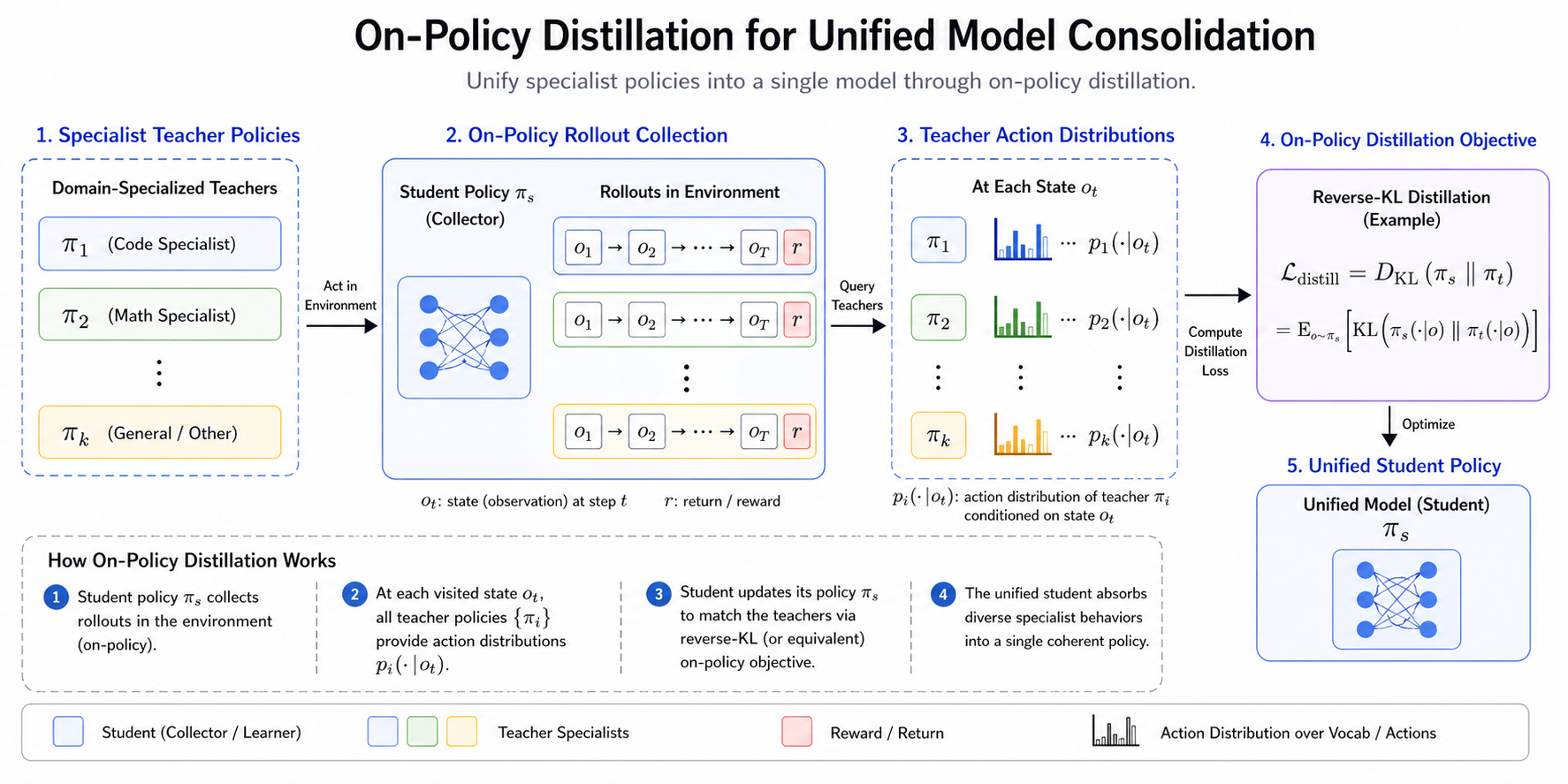
- This is a more dynamic formulation than classical distillation, and likely part of why the pipeline is positioned as capability integration rather than simply compression.
Why Reverse KL Is Interesting
-
The use of reverse-KL-style objectives is notable. Forward KL tends to encourage mode covering, whereas reverse KL tends toward mode seeking. That distinction matters.
-
In specialist consolidation, one often wants coherent high-quality behaviors rather than averaging incompatible behaviors across teachers. That makes reverse-KL particularly interesting in this context.
-
It also links to broader discussions in policy optimization and preference learning, including Direct Preference Optimization by Rafailov et al. (2023), where divergence geometry strongly shapes learned behavior. This is one of those design decisions that may have larger consequences than it first appears.
Specialist Models as Capability Teachers
-
A useful interpretation is that the specialist models function not merely as fine-tuned checkpoints, but as capability teachers. That framing changes how one views the system.
-
The unified model is not simply post-trained. It is synthesized. It inherits structured expertise through teacher-guided capability composition.
-
That is a different conception of alignment pipelines. Instead of alignment as behavior correction layered atop a model, this approaches alignment and capability formation through staged policy synthesis. That framing is unusual and important.
Efficient Infrastructure for RL and Distillation
-
The post-training stack also includes infrastructure innovations that support these algorithms at scale, including efficient teacher scheduling, fault-tolerant rollout systems, and scalable reinforcement learning frameworks for long-context settings.
-
These are not peripheral engineering details. In long-horizon RL settings, rollout infrastructure often becomes a major bottleneck. Treating it as part of algorithm design rather than post hoc engineering is increasingly necessary.
-
This mirrors broader lessons from large-scale RL systems such as SEED RL by Espeholt et al. (2019), where infrastructure and policy learning are deeply coupled.
Agentic Optimization and Sandbox Infrastructure
-
A particularly notable component is dedicated infrastructure for agentic tasks, including sandbox environments used during optimization.
-
This matters because agent capabilities often require interactive execution environments rather than static preference optimization. Once interaction loops become part of the target behavior, training environments become part of the learning problem.
-
This increasingly resembles reinforcement-learning systems for embodied or interactive agents rather than classical language-model post-training. That may prove an important long-term direction.
-
This trajectory also connects conceptually to tool-use and agent-training work such as Toolformer by Schick et al. (2023) and ReAct by Yao et al. (2023), though DeepSeek-V4 pushes further into agentic post-training infrastructure.
Why This Post-Training Stack Matters
-
The broader significance of this stack is not merely that it improves alignment or benchmark performance. It changes the structure of capability development.
-
Rather than one model learning everything through a single training objective, the process becomes specialization, optimization, and consolidation. That decomposition may scale better.
-
Historically, many post-training pipelines have largely been refinements of supervised tuning plus preference optimization. This architecture is more structured. It looks closer to modular capability engineering. That may matter as models become increasingly agentic and multi-domain.
Agentic Capabilities and Long-Horizon Task Performance
-
One of the defining ambitions of DeepSeek-V4 is not merely to improve static reasoning benchmarks, but to optimize for agentic competence over long-horizon tasks. This introduces a qualitatively different capability target. Traditional language-model evaluation often focuses on next-token prediction quality or bounded reasoning tasks, whereas agentic performance requires iterative planning, tool interaction, environment feedback integration, and sustained execution over extended trajectories. In DeepSeek-V4, these are treated as first-class optimization targets rather than emergent side effects.
-
More fundamentally, this emphasis reflects the same broader architectural philosophy visible throughout the system. Rather than assuming long-horizon agency emerges solely from scale, DeepSeek-V4 approaches agency through decomposition into planning, execution, memory, and tool-use subsystems that are strengthened separately and then integrated. This mirrors the structural pattern already seen in residual topology, long-context memory, and post-training capability synthesis, and suggests that agency itself is treated as a structured systems problem rather than a monolithic emergent behavior.
-
Conceptually, this framing places DeepSeek-V4 closer to emerging agent systems than conventional instruction-following language models. It also connects to a growing body of work suggesting that sustained autonomous task execution may require architectural and training modifications beyond simply scaling next-token prediction. Relevant foundations include ReAct by Yao et al. (2023), which interleaves reasoning and action, Toolformer by Schick et al. (2023), which integrates tool use into training, and Generative Agents by Park et al. (2023), which emphasizes memory-driven autonomous behavior.
Agentic Reasoning as Trajectory Optimization
-
A useful perspective is to treat agentic behavior not as single-step prediction but as trajectory optimization. Instead of optimizing token predictions \(P(x_t \| x_{<t})\), one increasingly optimizes policies over action trajectories \(\tau=(s_1,a_1,s_2,a_2,\dots,s_T)\) with objective \(\max_\pi\mathbb E_{\tau\sim\pi}[R(\tau)]\).
-
This shift is profound because the optimization target changes from local prediction quality to long-horizon return. That framing aligns agentic behavior much more closely with reinforcement learning than classical supervised language modeling. It also explains why GRPO and sandbox optimization play an important role in the broader DeepSeek-V4 stack.
-
In practical terms, model quality increasingly depends on planning persistence, recovery from failed intermediate actions, and adaptive strategy revision rather than isolated response quality.
Planning and Decomposition for Long-Horizon Tasks
-
A recurring challenge in long-horizon tasks is compounding error. Small planning mistakes early in a trajectory can cascade into large downstream failures. DeepSeek-V4 appears to address this partly through explicit decomposition pressures introduced during optimization. Rather than encouraging purely implicit chain-of-thought expansion, the model is optimized toward structured multistep problem decomposition.
-
This aligns with reasoning paradigms explored in Tree of Thoughts by Yao et al. (2023), where branching search improves problem solving, and Least-to-Most Prompting by Zhou et al. (2022), where decomposition improves compositional reasoning.
-
Conceptually, if a task can be decomposed into subgoals \(G={g_1,g_2,\dots,g_n}\), then planning becomes a policy over subgoal selection \(\pi(g_t \| s_t)\)
-
This converts long-horizon reasoning into hierarchical control. That matters because hierarchical control often scales better than flat policies for extended trajectories.
-
The following figure (source) shows hierarchical planning and task decomposition in DeepSeek-V4 agentic execution.
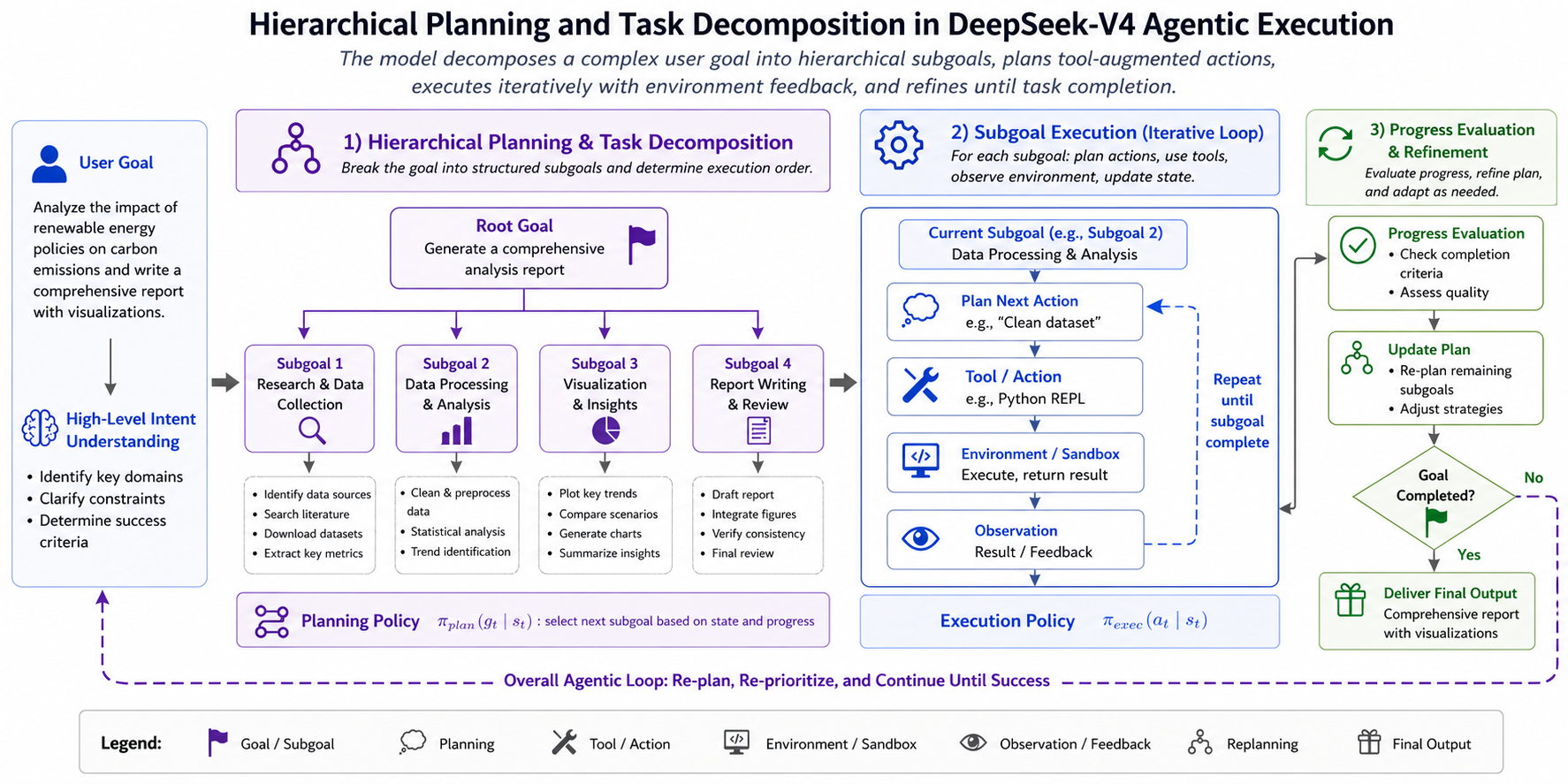
- One broader implication is that reasoning ability increasingly overlaps with planning architecture rather than being solely an emergent statistical property.
Code Agents and Programmatic Interaction
-
Code is especially important in this framework because code environments provide unusually rich feedback signals. Execution succeeds or fails, tests pass or fail, and intermediate state can be inspected. This makes coding a natural substrate for agent optimization.
-
DeepSeek-V4 places substantial emphasis on coding agents and agentic coding benchmarks. Rather than viewing coding merely as text generation, the model increasingly treats code synthesis as interactive search over program states.
-
A code-generation trajectory may be represented as iterative refinement:
\[p_0 \rightarrow p_1 \rightarrow \dots \rightarrow p_T\]- where each step incorporates execution feedback.
-
That resembles search-and-repair dynamics more than one-pass generation. This connects naturally to systems like AlphaCode by Li et al. (2022), where candidate generation and filtering improve coding performance, and Code as Policies by Liang et al. (2022), where executable programs become policy representations.
-
What is distinctive in DeepSeek-V4 is that coding appears treated not only as a benchmark domain, but as an optimization environment for broader agent competence. That is a stronger claim.
Tool Use as Externalized Cognition
-
A central principle in agentic systems is that intelligence need not reside entirely in internal model computation. Some computation can be externalized through tools. DeepSeek-V4 appears strongly aligned with this principle.
-
A tool call can be represented as an action \(a_t \in \mathcal A_{tool}\) embedded within a broader policy. The model then reasons not only over tokens but over possible computation pathways involving tools. This reframes tool use not as augmentation, but as part of cognition. That framing increasingly appears in work such as Toolformer by Schick et al. (2023) and MRKL Systems by Karpas et al. (2022), where modular external tools become integral to reasoning systems.
-
Within this perspective, some model capability is shifted from parametric memory toward adaptive tool orchestration. That may be especially important for scaling beyond purely parametric intelligence.
Long-Horizon Memory and Context Persistence
-
Long-horizon agents require memory not only in the conventional context-window sense, but as persistent task-state management. This is where DeepSeek-V4’s million-token context and hybrid attention architecture become particularly relevant to agency.
-
Long-context memory is not merely useful for document understanding. It becomes part of agent infrastructure. An agent maintaining latent task state \(m_t\) over time can be viewed as evolving under \(m_{t+1}=f(m_t,o_t,a_t)\), where observations and actions continuously update task memory. That perspective links long-context models to partially observable control systems. It also explains why memory scaling and agentic scaling are closely coupled. This has conceptual overlap with memory-oriented systems such as MemGPT by Packer et al. (2023), where memory management itself becomes part of the agent architecture.
Error Recovery and Self-Correction
-
A defining property of strong agents is not merely solving tasks when everything proceeds correctly, but recovering when execution deviates. This introduces a different competence criterion.
-
Recovery can be modeled as policy adaptation after failed transitions \(\pi(a_t \| s_t,e_t)\) conditioned on execution feedback \(e_t\). This begins to look closer to closed-loop control than static generation. It is increasingly believed that such recovery behaviors are crucial for robust autonomous systems. This also connects conceptually to self-correction and iterative refinement work such as Self-Refine by Madaan et al. (2023), though DeepSeek-V4 pushes these ideas into longer agentic trajectories.
Agentic Benchmarking as a Different Regime
-
An important point is that agentic evaluation is not simply harder benchmarks. It is often a different regime. Traditional benchmarks emphasize endpoint correctness, whereas agentic benchmarks evaluate trajectory competence.
-
Success may depend on planning efficiency, tool invocation timing, robustness to failure, and sustained coherence over many steps. These are qualitatively different metrics. This is partly why agentic coding benchmarks have become increasingly prominent. They probe something closer to autonomous competence, which is distinct from static reasoning tests.
Why Agentic Optimization May Matter Beyond Agents
-
There is a broader conceptual possibility here. Optimization for long-horizon agency may improve general reasoning even outside explicit agent tasks. Planning, decomposition, error recovery, and tool orchestration may be fairly general cognitive skills.
-
If so, agent optimization may improve more than agents. It may shape general intelligence. That possibility is increasingly discussed in frontier model development and is one reason agentic optimization has attracted so much interest. DeepSeek-V4 appears aligned with that view.
-
The emphasis on agentic capability is significant because it shifts the capability target itself. Rather than optimizing increasingly stronger passive models, the target becomes interactive systems capable of sustained autonomous problem solving.
-
Historically, language models were often evaluated as predictors, whereas agentic systems are increasingly evaluated as actors. That shift may prove as important as scaling itself. DeepSeek-V4 is notable partly because it appears designed with that shift explicitly in mind.
Benchmark Performance
-
A central question for any frontier model is not merely whether its architectural innovations are elegant, but whether they translate into measurable gains across reasoning, coding, long-context understanding, and agentic performance. In DeepSeek-V4, benchmarking is best interpreted not as a detached evaluation layer, but as the empirical surface through which the consequences of the architecture become visible. This is especially important because many of the innovations discussed earlier, including mHC, hybrid attention, and structured post-training, make claims not only about efficiency but about capability scaling.
-
More fundamentally, the evaluation philosophy reflects a broader shift in how frontier intelligence may need to be assessed. Static benchmark suites increasingly appear insufficient, and capability is becoming difficult to summarize through single aggregate scores. Reasoning, agency, long-context memory, efficiency, and robustness are increasingly treated as interacting dimensions rather than separable metrics. This multidimensional framing is significant because it suggests evaluation itself is becoming part of frontier architectural thinking. That perspective mirrors the same decomposition principle present throughout the model design, where intelligence is evaluated across partially distinct axes including mathematical reasoning, coding, factual knowledge, agentic task execution, and long-context robustness, rather than reduced to a monolithic scalar.
-
The following figure (source) shows representative benchmark performance of DeepSeek-V4-Pro and DeepSeek-V4-Flash across reasoning, coding, and general capability evaluations.
- This multidimensional evaluation philosophy aligns with broader concerns in capability assessment discussed in Beyond the Imitation Game Benchmark (BIG-bench) by Srivastava et al. (2022), where broad capability evaluation is emphasized over narrow task metrics, and in Holistic Evaluation of Language Models (HELM) by Liang et al. (2022), which argues that frontier models require multi-axis evaluation rather than single-score summaries.
Mathematical and Symbolic Reasoning
-
One area where DeepSeek-V4 is positioned strongly is mathematical and symbolic reasoning. These benchmarks are particularly important because they stress multi-step compositional reasoning rather than pattern recall, and performance in this regime often correlates with improvements in latent reasoning organization rather than superficial memorization. Tasks in this family often approximate optimization over reasoning trajectories:
\[r=(s_1,s_2,\dots,s_T)\]- where correctness depends not merely on the final answer but on maintaining coherent intermediate inference. This is partly why reasoning-oriented benchmarks have become so influential, since they probe structured cognition more than language modeling per se.
-
Relevant evaluations often relate conceptually to datasets such as GSM8K by Cobbe et al. (2021), which targets grade-school mathematical reasoning, and MATH by Hendrycks et al. (2021), which probes advanced symbolic reasoning. DeepSeek-V4’s reported strength in this domain is particularly notable because improvements here plausibly reflect interactions among multiple earlier innovations. mHC potentially improves long-chain reasoning stability, GRPO improves reasoning policy optimization, and specialist-to-unified distillation may improve reasoning consolidation. That interaction matters because benchmark gains may be emergent consequences of co-designed subsystems rather than any single component.
Coding Performance
-
Coding has become one of the most revealing frontier capability domains because it couples reasoning, precision, planning, and external verification. DeepSeek-V4 places unusual emphasis on coding not only as a benchmark but as a central capability axis. Program synthesis can be viewed as constrained search over programs
\[p^* =\arg\max_{p\in\mathcal P} P(p|x)\]- subject to correctness constraints \(C(p)=1\).
-
This makes coding substantially different from unconstrained text generation, and it is therefore unsurprising that coding benchmarks often surface distinctions that broader benchmarks miss. DeepSeek-V4 is positioned particularly strongly in agentic coding evaluations, which may be even more significant than classical code generation metrics, because these evaluations increasingly resemble interactive software engineering rather than prompt-response generation. This places DeepSeek-V4 in dialogue with coding-focused frontier systems shaped by ideas from AlphaCode by Li et al. (2022) and newer agentic coding paradigms emerging around iterative autonomous software tasks.
-
One notable point is that coding performance here appears linked not merely to stronger code priors, but to the broader agent stack discussed previously. That distinction may matter more over time than raw pass@k improvements, because it suggests coding performance partly reflects general advances in interactive policy competence.
Agentic Benchmarking
- Static benchmark performance, while important, is increasingly insufficient for frontier positioning. Agentic benchmarks probe a different regime in which success depends on long-horizon planning, tool sequencing, execution robustness, and trajectory coherence. This is better viewed as policy evaluation than conventional task evaluation. One can model success over task trajectories as:
-
This differs fundamentally from single-instance accuracy, because models can perform similarly on static tasks while differing substantially in trajectory competence. This is one reason agentic coding and tool-use benchmarks have become increasingly influential, since they probe something closer to autonomous competence than traditional static reasoning tests.
-
The rise of these evaluations also reflects a conceptual shift echoed in systems influenced by ReAct by Yao et al. (2023) and SWE-bench by Jimenez et al. (2023), where autonomous task completion becomes a primary metric. DeepSeek-V4’s positioning in this regime is arguably one of its most strategically important claims precisely because trajectory competence may prove more consequential than conventional benchmark leadership.
Long-Context Evaluations
-
Because one-million-token context is one of the defining claims of the model, long-context evaluation deserves separate treatment. Traditional reasoning benchmarks often under-measure this dimension, because long-context capability is not simply the ability to ingest longer sequences, but concerns retrieval fidelity, reasoning persistence, and degradation resistance as context length grows.
-
One useful way to formalize long-context robustness is through retrieval accuracy as a function of context length, denoted \(A(n)\). In an ideal long-context model, one seeks behavior where \(\frac{dA}{dn} \approx 0\) even as \(n\) becomes very large, implying that retrieval fidelity degrades minimally as context expands. This framing captures the central challenge of long-context scaling and connects naturally to stress-testing paradigms explored in Lost in the Middle by Liu et al. (2023), which demonstrated that retrieval failures can emerge subtly and non-uniformly over long sequences, motivating increasingly rigorous long-range evaluation methodologies.
-
DeepSeek-V4’s claims here are especially significant because they couple efficiency gains with robustness claims, which is a harder combination. This is precisely where the hybrid attention architecture should, in principle, manifest empirically, making these evaluations particularly important as partial validation of the long-context architectural claims.
World Knowledge and General Capability
-
Another axis emphasized in DeepSeek-V4 positioning concerns broad world knowledge and general-assistant capability. While often treated as less exciting than reasoning or coding, these remain important because many deployment settings depend on broad-domain competence. These evaluations often reflect both pretraining quality and post-training consolidation. They can be viewed as measuring effective approximation over broad task distributions \(\mathbb E_{x\sim D}[\ell(f_\theta(x))]\).
-
That broad-distribution view is useful because it emphasizes that general capability is partly about robustness across heterogeneous task families rather than isolated benchmark excellence. This aligns with benchmark ecosystems shaped by efforts like MMLU by Hendrycks et al. (2020), which remains one of the standard broad knowledge evaluations.
-
What appears notable in DeepSeek-V4 is the attempt to pair strong specialist reasoning with broad general capability, which historically has sometimes involved tradeoffs. Reducing those tradeoffs may be one of the less discussed but important achievements.
Pro and Flash as Distinct Frontier Points
-
An especially interesting aspect of DeepSeek-V4 evaluation is that Pro and Flash represent not merely larger and smaller variants, but two different points on a capability-efficiency frontier. One can think of an implicit Pareto frontier \((C,E)\) over capability and efficiency.
-
DeepSeek-V4-Pro appears positioned toward maximal capability, whereas DeepSeek-V4-Flash appears positioned toward a stronger efficiency-capability balance. That is not simply model scaling, but productized frontier tradeoff design, and that may become increasingly important as frontier models diversify. This framing also reflects a broader industry trend toward capability-specialized model families rather than single flagship models.
Positioning Relative to Frontier Models
-
An important question is where DeepSeek-V4 sits relative to other frontier systems. Its strongest claims appear less about dominating every benchmark and more about unusual joint performance across open-model reasoning, million-token context, agentic coding, and efficiency. That combination is relatively unusual because many systems excel on one or two of those axes, whereas fewer push all simultaneously.
-
That is partly why the model is often positioned through multidimensional comparison rather than single benchmark leadership. Conceptually, this resembles moving the Pareto frontier rather than maximizing a single objective, and that is often a stronger claim.
What Benchmark Results Suggest About the Architecture
-
One useful way to interpret the evaluation results is not merely as outcomes but as evidence about the architecture. Strong long-context results support the hybrid attention thesis, strong reasoning supports parts of the mHC and post-training story, and strong agentic coding performance supports the specialist-plus-agent-training stack.
-
Viewed this way, benchmarks become partial empirical validation of architectural hypotheses. That interpretation is often more informative than leaderboard comparisons because it shifts attention from “who scores highest” toward “which architectural ideas appear to work,” which is arguably the more scientifically interesting question.
Limitations, Open Questions, and Future Architectures
-
If the preceding sections have emphasized DeepSeek-V4’s architectural innovations and empirical strengths, an equally important part of a technical assessment concerns what remains unresolved. Frontier architectures often matter as much for the questions they open as for the problems they solve. DeepSeek-V4 is no exception. Many of its most ambitious contributions, including manifold-constrained residual topology, layered compressed attention, optimizer-architecture co-design, and structured capability synthesis, also introduce unresolved theoretical and practical questions whose significance may extend beyond this model family.
-
More fundamentally, many of these open questions follow the same structural pattern seen throughout the system: scaling gains arise through decomposition and added structure, but additional structure can itself introduce complexity, brittleness, and interpretability challenges. This tension between structured scaling and structural overhead may be one of the central questions for future frontier architectures. One reason these questions matter is that frontier model progress increasingly depends less on enlarging known components and more on deciding which new primitives genuinely generalize, and historically that is often where long-term architectural trajectories are determined.
Open Questions Around mHC
-
One major question concerns whether mHC represents a broadly general residual primitive or a scaling-specific mechanism whose benefits are concentrated at extreme depth. The geometric constraints imposed through doubly stochastic mixing produce compelling stability properties, but they also raise questions about whether constrained residual transport limits certain forms of expressivity. In principle, constraining \(B_l \in \mathcal M\) stabilizes composition through \(\rho(B_l)\le1\), but there may exist a tradeoff between spectral stability and representational freedom. This tension resembles broader tradeoffs often encountered when explicit structure is imposed for optimization reasons.
-
A natural question is whether future work might relax hard manifold constraints into softer regularized objectives such as
\[\mathcal L =\mathcal L_{task} +\lambda \mathcal R(B_l)\]- where residual geometry is encouraged rather than enforced. Such formulations may preserve some stability while allowing richer dynamics. This relates conceptually to longstanding questions in geometry-aware learning and constrained optimization explored in areas influenced by Shampoo by Gupta et al. (2018) and manifold optimization traditions more broadly.
-
A second open question concerns whether residual topology scaling could become its own broader scaling axis analogous to parameter count, context length, or sparsity. If so, mHC may represent an early instance of a broader architectural category rather than a single mechanism. That possibility matters because it would elevate residual topology from an implementation technique into a potentially fundamental scaling primitive.
Open Questions in Hybrid Attention
-
The hybrid CSA-HCA design raises equally significant questions. Its central claim is that layered compressed attention can scale long-context reasoning more effectively than monolithic attention mechanisms. That may prove correct, but compressed memory hierarchies introduce possible information-loss tradeoffs that are not yet fully characterized.
-
Compression can be thought of as inducing approximation \((K,V) \rightarrow (\tilde K,\tilde V)\) with reconstruction loss \(\mathcal L_{comp}\).
-
A persistent open question is how such compression error interacts with reasoning over very long dependency chains, because small retrieval distortions may accumulate in ways current evaluations do not fully expose. This resembles broader concerns raised by work such as Lost in the Middle by Liu et al. (2023), where long-context retrieval weaknesses were shown to be subtle and highly distribution dependent.
-
A deeper question concerns whether future context scaling will continue through increasingly sophisticated compressed attention hierarchies, or whether entirely different memory paradigms may ultimately supersede context-window scaling itself. Retrieval-augmented persistent memory systems, external memory architectures, and agent-managed memory may all compete with this trajectory. That may ultimately be a deeper question than whether one attention mechanism outperforms another, because it concerns the long-term substrate of memory scaling itself.
Limits of Optimizer-Architecture Co-Design
-
The optimization stack raises another important class of questions. Muon, FP4 training, and systems-level co-design appear powerful, but they also illustrate a broader trend in which architectural progress increasingly depends on tightly coupled optimization machinery. That can improve capability, but may also reduce portability and reproducibility. Historically, highly specialized optimization stacks sometimes prove harder to generalize than the architectures they support, which raises a natural question of whether such optimizer-architecture couplings represent enduring architectural advances or partially contingent engineering solutions tied to a particular scaling regime.
-
Low-precision training also raises unresolved questions about optimization limits under extreme quantization. One can imagine effective optimization under quantized parameters \(\theta_q=Q(\theta)\), becoming unstable beyond some precision threshold \(p^*\).
-
Whether FP4 approaches remain scalable as models and reasoning depth continue to grow is not yet obvious. This connects to broader open questions in low-precision scaling explored in work such as QLoRA by Dettmers et al. (2023), though the frontier pretraining setting introduces additional uncertainties.
Questions Around Structured Capability Synthesis
-
The post-training stack introduces another important set of questions. The specialist-then-distill paradigm is compelling, but it raises unresolved issues concerning capability composition itself. When multiple specialist policies are consolidated, what precisely is preserved, what is averaged, and what may be lost?
-
Distillation often implicitly assumes a compressible teacher manifold. That assumption may fail. If specialists represent policies \({\pi_1,\dots,\pi_k}\), the unified student \(\pi_s\) may not preserve all desirable modes.
-
This is fundamentally a capability geometry question. The reverse-KL formulation partly addresses this, but it may not eliminate deeper issues of interference during consolidation. These concerns intersect broader questions about model merging, policy composition, and modular capability integration. They also connect conceptually to discussions around Policy Distillation by Rusu et al. (2015) and more recent alignment-oriented policy synthesis work.
-
Whether structured capability synthesis scales indefinitely remains an open question, particularly if future models rely on increasingly heterogeneous specialist capability pools.
Agentic Capability Remains an Unresolved Frontier
-
Perhaps the largest open question concerns agency itself. Current agentic evaluations are still relatively early, and long-horizon autonomous competence remains difficult to define, measure, and optimize robustly. That is partly because agency involves open-ended interaction rather than bounded task distributions.
-
One may write long-horizon objective optimization as \(\max_\pi\mathbb E[R(\tau)]\) but specifying \(R(\tau)\) well for general-purpose autonomous behavior is itself unresolved. That problem may be at least as hard as scaling the models, which is one reason work such as ReAct by Yao et al. (2023) and Generative Agents by Park et al. (2023) is often viewed less as solved methods than as early explorations.
-
DeepSeek-V4 advances this frontier, but it does not close it. The open question is much larger, involving not merely stronger agents, but the unresolved foundations of how general-purpose agency should be represented and optimized.
Interpretability and Structural Complexity
-
A broader concern cutting across all these innovations is interpretability. As architecture incorporates constrained residual manifolds, layered compressed memory systems, sparse specialists, reinforcement-trained specialists, and agentic subsystems, the system may become more capable but also harder to reason about mechanistically. There may be a tension between structured capability and interpretability complexity, and that possibility deserves emphasis.
-
Historically, many scaling innovations have increased opacity faster than understanding. DeepSeek-V4 may intensify that pattern unless interpretability methods advance correspondingly. This intersects growing mechanistic interpretability directions, though current tools may lag the architectural complexity involved.
-
A serious open question is whether future architectural progress will increasingly need interpretability constraints as part of design itself rather than post hoc analysis. That possibility feels increasingly plausible precisely because structural sophistication may otherwise outpace controllability.
Possible Implications for Future Architectures
-
Despite these uncertainties, DeepSeek-V4 may suggest several broader architectural directions. One implication is that future scaling may rely less on enlarging homogeneous primitives and more on introducing structured interacting primitives. Residual topology, memory hierarchy, optimizer geometry, and capability synthesis may all represent examples of that trend. This would represent a shift from scale-through-uniformity toward scale-through-structured-composition, which would constitute a major architectural transition.
-
A second implication concerns co-design. DeepSeek-V4 repeatedly blurs boundaries among model architecture, optimization, inference systems, and post-training. That may not be incidental. It may be where frontier design is moving, particularly because the historical separation among these layers may increasingly become artificial.
-
A third implication concerns whether future frontier models may become more modular internally, not only through MoE sparsity, but through broader structured specialization across memory, reasoning, and agency. If so, some future systems may look less like scaled monolithic Transformers and more like integrated cognitive systems composed of interacting modules. That possibility is increasingly taken seriously as models move toward more heterogeneous internal organization.
References
DeepSeek architecture and system overviews
- DeepSeek-V4 Technical Overview
- DeepSeek API Documentation
- DeepSeek Long Context Guide
- DeepSeek Research Repository
- DeepSeekMath by Shao et al. (2024)
- DeepSeek-V3 Technical Report by DeepSeek-AI et al. (2024)
- DeepSeek-V4 System Card and Release Materials
Residual Scaling
- Deep Residual Learning for Image Recognition by He et al. (2015)
- DeepNet: Scaling Transformers to 1,000 Layers by Wang et al. (2022)
- Unitary Evolution Recurrent Neural Networks by Arjovsky et al. (2016)
- mHC: Manifold-Constrained Hyper-Connections by Xie et al. (2026)
Sparse modeling and Mixture-of-Experts systems
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer by Shazeer et al. (2017)
- Switch Transformers by Fedus et al. (2021)
- GShard: Scaling Giant Models with Conditional Computation by Lepikhin et al. (2020)
- Mixtral of Experts by Jiang et al. (2024)
- Pathways by Barham et al. (2022)
Long-context memory and efficient attention
- Longformer by Beltagy et al. (2020)
- Performer by Choromanski et al. (2020)
- FlashAttention by Dao et al. (2022)
- FlashAttention-2 by Dao et al. (2023)
- Sparse Transformers by Child et al. (2019)
- Compressive Transformer by Rae et al. (2019)
- Lost in the Middle by Liu et al. (2023)
- PagedAttention / vLLM by Kwon et al. (2023)
- MemGPT: Towards LLMs as Operating Systems by Packer et al. (2023)
Optimization, scaling laws, and systems training
- Adam: A Method for Stochastic Optimization by Kingma and Ba (2014)
- LAMB by You et al. (2019)
- Shampoo by Gupta et al. (2018)
- Muon by Jordan et al. (2024)
- Scaling Laws for Neural Language Models by Kaplan et al. (2020)
- ZeRO by Rajbhandari et al. (2020)
- Megatron-LM by Shoeybi et al. (2019)
- PaLM by Chowdhery et al. (2022)
- Training Deep Nets with Sublinear Memory Cost by Chen et al. (2016)
Quantization and low-precision training
- Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference by Jacob et al. (2018)
- QLoRA by Dettmers et al. (2023)
- LLM.int8() by Dettmers et al. (2022)
- SmoothQuant by Xiao et al. (2022)
- FP8 Formats for Deep Learning by Micikevicius et al. (2022)
Reinforcement learning and post-training alignment
- Proximal Policy Optimization by Schulman et al. (2017)
- Policy Distillation by Rusu et al. (2015)
- Distilling the Knowledge in a Neural Network by Hinton et al. (2015)
- InstructGPT by Ouyang et al. (2022)
- Direct Preference Optimization by Rafailov et al. (2023)
- SEED RL by Espeholt et al. (2019)
Reasoning and structured problem solving
- Chain-of-Thought Prompting by Wei et al. (2022)
- Tree of Thoughts by Yao et al. (2023)
- Least-to-Most Prompting by Zhou et al. (2022)
- Self-Refine by Madaan et al. (2023)
- Reflexion by Shinn et al. (2023)
- GSM8K by Cobbe et al. (2021)
- MATH by Hendrycks et al. (2021)
Agentic systems, tools, and long-horizon behavior
- ReAct: Synergizing Reasoning and Acting in Language Models by Yao et al. (2023)
- Toolformer by Schick et al. (2023)
- MRKL Systems by Karpas et al. (2022)
- Generative Agents by Park et al. (2023)
- Voyager by Wang et al. (2023)
- Code as Policies by Liang et al. (2022)
- AlphaCode by Li et al. (2022)
- SWE-bench by Jimenez et al. (2023)
Evaluation and benchmark frameworks
- BIG-bench by Srivastava et al. (2022)
- HELM by Liang et al. (2022)
- MMLU by Hendrycks et al. (2020)
- Beyond Accuracy in LLM Evaluation
- DeepSeek Benchmarking Notes
Broader architectural and systems perspectives
- Pathways: Asynchronous Distributed Dataflow for ML by Barham et al. (2022)
- Building Effective AI Agents
- Writing Effective Tools for AI Agents
- Effective Context Engineering for AI Agents
- Effective Harnesses for Long-Running Agents
- Demystifying Evals for AI Agents
Citation
If you found our work useful, please cite it as:
@article{Chadha2020DistilledDeepSeekV4,
title = {DeepSeek-V4},
author = {Chadha, Aman and Jain, Vinija},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}