Primers • DeepSeek Janus-Pro
- Introduction
- Technical Architecture of Janus-Pro
- Detailed Pipeline Stages of Janus-Pro
- Why Janus-Pro Is Better Than DALL-E and Other SOTA Models
- References
Introduction
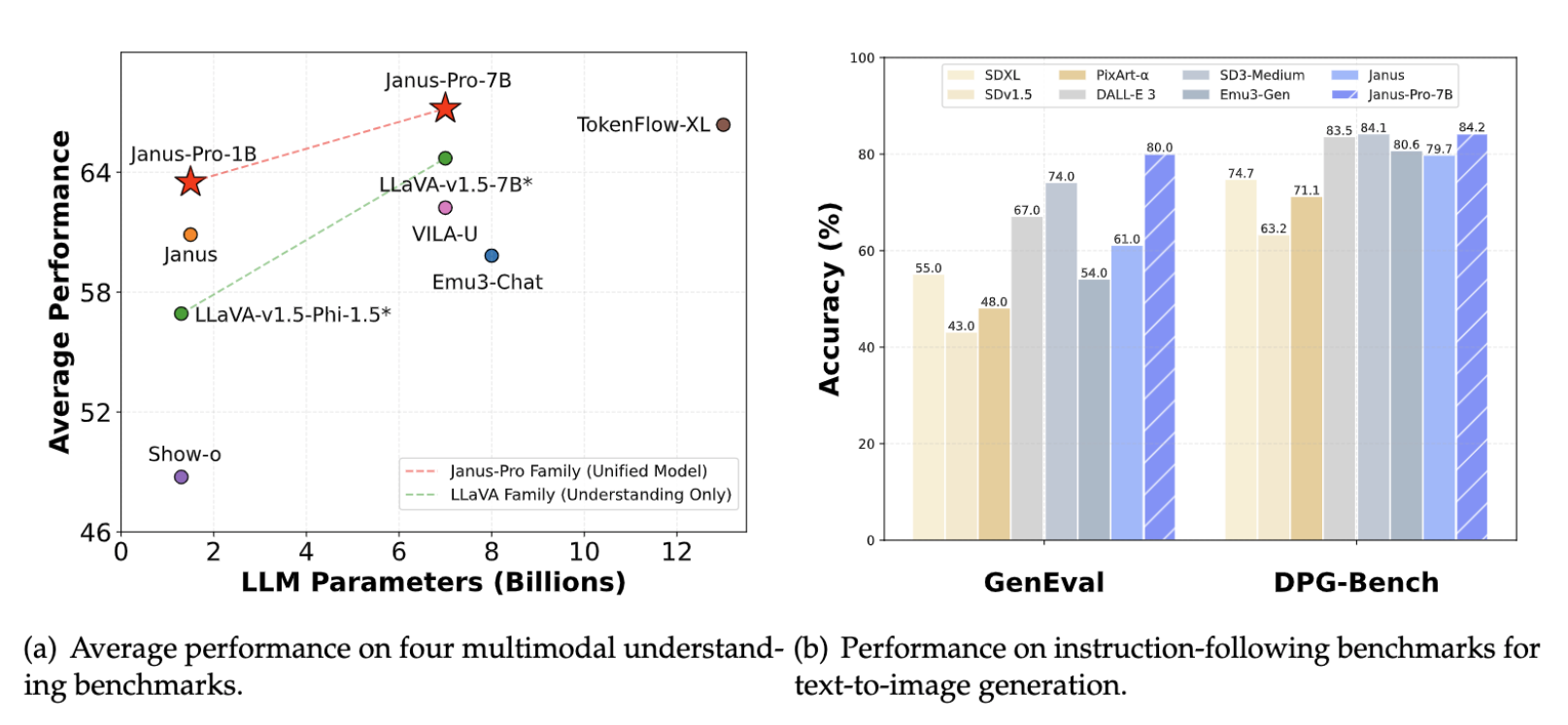
- Multimodal artificial intelligence, which integrates vision and language tasks, has advanced rapidly. Janus-Pro is a cutting-edge framework that builds on its predecessor, Janus, through key innovations like decoupled visual encoders for understanding and generation, an optimized three-stage training pipeline, and a robust architecture leveraging synthetic data. These improvements enable Janus-Pro to surpass current SOTA models in performance metrics like GenEval accuracy (80%) and DPG-Bench (84.19), offering unparalleled scalability and efficiency.
- Janus-Pro’s innovative architecture, optimized training strategy, and balanced focus on understanding and generation tasks make it superior to models like DALL-E and Stable Diffusion. By addressing their limitations—such as noisy datasets, inefficient training, and lack of task decoupling—Janus-Pro not only outperforms them in benchmarks but also demonstrates versatility across real-world applications.
- Janus-Pro is open-source and its code and models are available for public use on GitHub, enabling researchers and developers to explore and build upon its architecture and innovations.
- The figure below from the original paper shows Janus Pro’s performance as compared with other multimodal models.
Technical Architecture of Janus-Pro
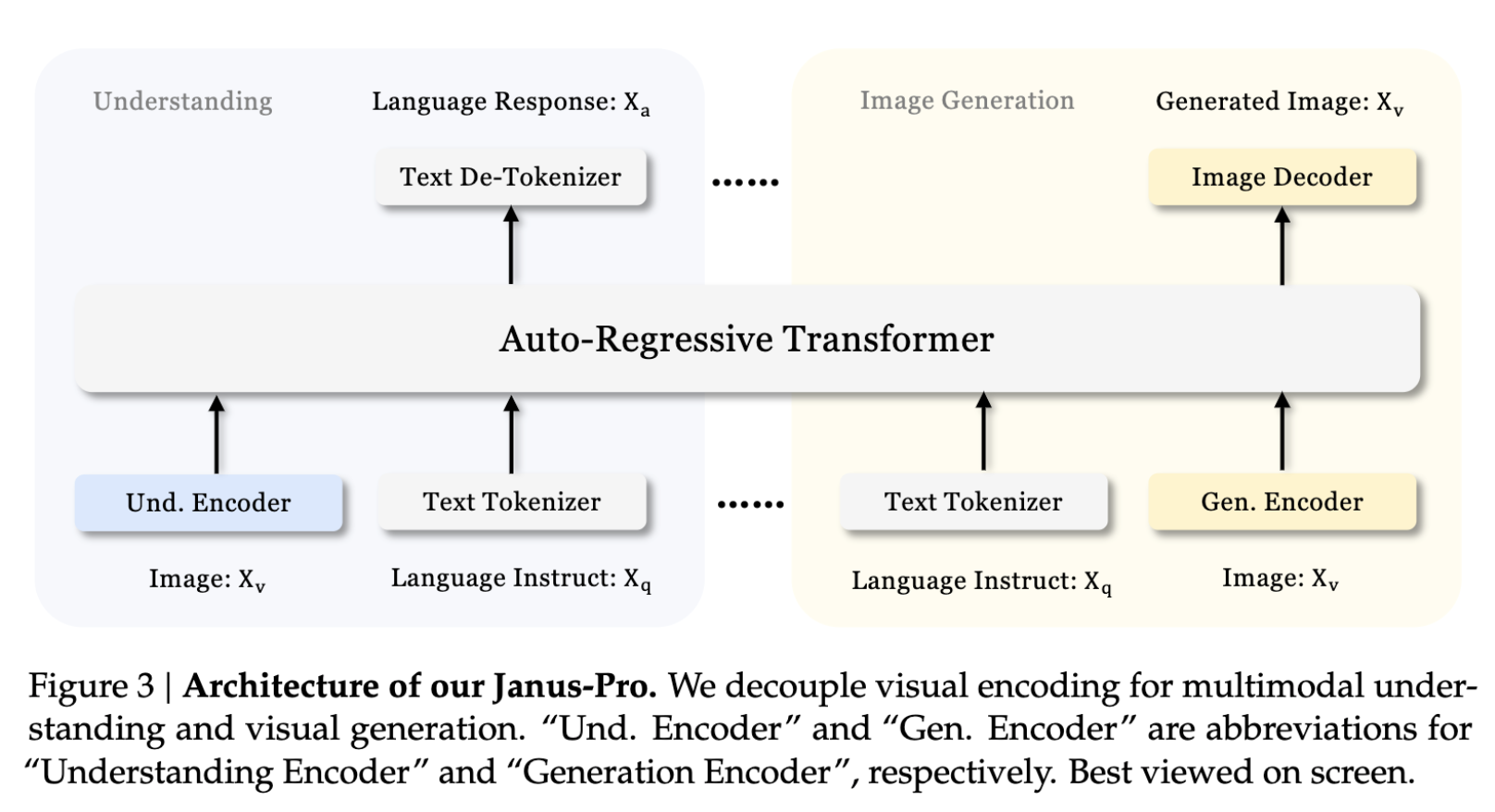
- The architecture of Janus-Pro (shown below) retains the core philosophy of decoupling visual encoding for multimodal understanding and generation tasks, an approach that sets it apart from traditional unified architectures. Below is an overview of its core components:
Decoupled Visual Encoding
-
Janus-Pro employs independent encoding strategies tailored for its two primary tasks:
- Understanding Encoder: Utilizes the SigLIP encoder, a high-performance visual encoder that extracts detailed semantic features from images and maps them into a 1-D sequence compatible with the language model.
-
Generation Encoder: Leverages a VQ tokenizer that converts images into discrete IDs, enabling stable image decoding and efficient learning of pixel dependencies.
- By separating these two encoders, Janus-Pro mitigates the conflicts typically observed in unified multimodal models, where the same visual representation is used for drastically different tasks. This leads to optimized task-specific performance.
Autoregressive Transformer Core
- At the heart of Janus-Pro is a unified autoregressive transformer that processes multimodal feature sequences. These sequences, formed by concatenating text and image features, flow seamlessly through the model to generate outputs for either task.
Multi-Stage Training Pipeline
-
Janus-Pro employs a three-stage training strategy:
- Stage I: Training adaptors and image decoders focuses on aligning image features with text through robust pixel dependency modeling. Using fixed LLM parameters, this stage employs ImageNet to map simple categories (e.g., ‘sunflower’) into meaningful representations. Extended training ensures stable feature alignment, improving subsequent multimodal learning and generation stability.
- Stage II: Unified pretraining leverages a mix of high-quality text-to-image datasets and synthetic aesthetic data at a 1:1 ratio. These datasets include diverse prompts and scenarios to train the model for intricate multimodal generation tasks. Synthetic data, curated using advanced prompt engineering (e.g., MidJourney datasets), ensures faster convergence and eliminates inconsistencies found in real-world datasets. The unified autoregressive model is trained exclusively on dense prompts, enhancing the model’s ability to process and align complex visual and textual instructions. This approach optimizes the training pipeline, enabling Janus-Pro to surpass inefficiencies observed in earlier models, including DALL-E 3.
- Stage III: Fine-tuning is performed across multimodal (5 parts), text-only (1 part), and image-to-text (4 parts) datasets, ensuring balanced performance across diverse tasks. Loss functions include cross-entropy for text-to-text and multimodal alignment tasks, and reconstruction loss for image generation tasks, which optimizes visual fidelity while preserving textual alignment. Additionally, advanced datasets such as MEME understanding, chart comprehension, and multimodal dialogue benchmarks are incorporated, enhancing the model’s ability to handle nuanced real-world challenges.
Detailed Pipeline Stages of Janus-Pro
- The Janus-Pro pipeline is carefully designed in three optimized stages to maximize performance and overcome the limitations of previous models, including Janus and others like DALL-E 3. Each stage is pivotal in ensuring superior multimodal understanding and text-to-image generation capabilities.
Stage I: Initial Adaptation and Image Head Training
-
This stage focuses on initializing and stabilizing the visual encoding processes.
- Goals:
- Train adaptors that map image and text features into a unified latent space compatible with the language model.
- Stabilize the image generation process using fixed LLM parameters.
- Techniques:
- Uses ImageNet for category-driven pixel dependency modeling. For example, category names like “sunflower” are used to guide the model in generating simple yet semantically correct images.
- Extends training iterations compared to Janus, ensuring the adaptors and image decoder learn robust feature mappings.
- Why it’s Better:
- Previous models, such as DALL-E 3, struggled with noise in early image generation stages due to less rigorous initial training. Janus-Pro eliminates this problem by prolonging Stage I, leading to better stabilization in later stages.
Stage II: Unified Pretraining with Dense Descriptive Prompts
-
This stage is the backbone of Janus-Pro’s superior multimodal capabilities.
- Goals:
- Train the unified autoregressive model with both text and image data.
- Eliminate inefficiencies by focusing exclusively on dense text-to-image data rather than splitting it across multiple datasets.
- Techniques:
- Incorporates high-quality synthetic aesthetic data alongside real-world data in a 1:1 ratio. The synthetic data is generated using robust prompt engineering tools (e.g., MidJourney prompts) to enhance training diversity and quality.
- Synthetic data ensures faster convergence, as it avoids the noise and inconsistencies common in real-world datasets.
- Introduces a redesigned learning schedule:
- Real-world data is phased out in favor of descriptive prompts, allowing the model to specialize in rich semantic generation tasks.
- Text-only training is minimized, keeping the model focused on multimodal learning.
- Why it’s Better:
- Models like DALL-E 3 and SD3-Medium rely heavily on real-world data, which often contains inconsistencies. Janus-Pro’s use of synthetic data eliminates this issue, producing more stable and aesthetically pleasing outputs.
Stage III: Fine-Tuning Across Multimodal, Text-Only, and Visual Data
-
The final stage polishes the model’s understanding and generation capabilities.
- Goals:
- Enhance performance on specialized multimodal tasks like visual question answering, detailed text-to-image alignment, and multimodal conversation.
- Fine-tune the model for both instruction-following (e.g., text-to-image tasks) and creative generation tasks.
- Techniques:
- Adjusts the data ratio between multimodal data, pure text data, and text-to-image data to 5:1:4.
- This ensures a balance between multimodal understanding and generation tasks, unlike DALL-E 3, which leans more toward visual generation.
- Involves supervised fine-tuning on expanded datasets such as MEME understanding, chart comprehension, and conversational AI benchmarks.
- Adjusts the data ratio between multimodal data, pure text data, and text-to-image data to 5:1:4.
- Why it’s Better:
- Fine-tuning across a diverse dataset makes Janus-Pro more versatile in real-world tasks, such as creating instructional graphics or handling multimodal dialogues—areas where DALL-E struggles.
Why Janus-Pro Is Better Than DALL-E and Other SOTA Models
Decoupled Architecture for Better Task Specialization
- Janus-Pro Advantage:
- By using separate encoders for multimodal understanding and generation, Janus-Pro avoids the performance conflicts seen in unified encoder architectures (e.g., DALL-E 3 and Stable Diffusion models).
- This results in stronger semantic understanding for tasks like visual question answering and a more coherent generation for text-to-image prompts.
- Competitors’ Limitation:
- DALL-E 3 and others use a single visual encoder, which must simultaneously process inputs for understanding and generation, leading to compromises in both.
Superior Text-to-Image Instruction Following
- Janus-Pro Advantage:
- On the GenEval benchmark, which tests alignment between dense prompts and generated outputs, Janus-Pro scores 80% overall accuracy, surpassing DALL-E 3 (67%) and SD3-Medium (74%).
- Its use of synthetic aesthetic data and descriptive prompts enables better semantic alignment with intricate instructions, resulting in coherent, high-quality images.
- Competitors’ Limitation:
- DALL-E 3’s reliance on real-world data and inconsistent text-to-image mappings often results in less precise and aesthetically inconsistent outputs.
Stability and Scalability in Visual Generation
- Janus-Pro Advantage:
- Achieves unparalleled stability in image generation, with fewer issues like mismatched object positioning or color inaccuracies.
- Scales seamlessly to larger parameter sizes (7B model), improving performance without requiring significantly larger computational resources.
- Competitors’ Limitation:
- DALL-E 3 and similar models struggle with object consistency in dense scenes (e.g., handling multiple objects or understanding spatial relationships). Janus-Pro excels in these areas, as seen in its performance on the DPG-Bench (Dense Prompt Graph Benchmark), where it scores 84.19, outperforming DALL-E 3 (83.50).
Synthetic Data Utilization for Enhanced Quality
- Janus-Pro Advantage:
- By incorporating 72 million synthetic aesthetic samples, Janus-Pro achieves faster training convergence and improved output quality.
- These samples eliminate real-world noise, ensuring images are more detailed, vibrant, and aesthetically pleasing.
- Competitors’ Limitation:
- Real-world data used by DALL-E 3 and others often contains low-quality samples, resulting in unstable image generation and a reliance on heavy post-processing to improve aesthetics.
Advanced Fine-Tuning and Dataset Scaling
- Janus-Pro Advantage:
- Includes multimodal datasets for document understanding, table recognition, and multimodal conversations, making it more versatile than visual generation-focused models like DALL-E.
- Expanded datasets (e.g., 90M for multimodal understanding) give Janus-Pro superior performance on real-world applications.
- Competitors’ Limitation:
- Competitors like DALL-E are narrowly focused on creative text-to-image tasks and often underperform in multimodal understanding or cross-domain tasks.
Efficient Training Strategy
- Janus-Pro Advantage:
- Redesigning Stage II training to focus exclusively on dense descriptive prompts reduces computational inefficiencies by 20%-30%, making Janus-Pro both faster and cheaper to train.
- Competitors’ Limitation:
- DALL-E and Stable Diffusion models rely on computationally expensive diffusion techniques and often require extensive training on category-based labels, which are less effective for complex instructions.