Primers • Data Filtering
- Overview
- Quality Metrics and Compliance Metrics
- LLM-Based Evaluation (LLM-as-a-Judge)
- Human Evaluation
- Outlier Detection via “Island” Analysis of Embeddings
- Prompt Quality Metrics
- Safety Metrics
- Deduplication
- End-to-End Filtering Pipeline
- Concrete Scoring Framework
Overview
-
Training data quality is the single largest determinant of model performance—even more than architecture size or compute budget. High-quality data allows models to reach higher accuracy with less compute, while poor-quality data wastes resources and limits scaling benefits.
-
Large-scale datasets often contain systematic noise: duplicated content, low-information filler, mislabeled pairs, adversarial injections, or content from undesired domains. Without filtering, these corrupt the model’s learned representations and reduce generalization.
-
As models scale (e.g. trillions of parameters), their capacity becomes bottlenecked by data quality. When trained on low-quality corpora, models spend capacity memorizing noise instead of learning useful structure, leading to diminishing returns from scaling.
-
Rigorous filtering pipelines are therefore essential to produce clean, diverse, policy-compliant, and representative data for both pretraining (to build broad competence) and post-training (to align behavior with human preferences and safety norms).
Importance of High-Quality Data
-
Data quality is the foundation of effective machine learning. Large language models (LLMs), code generation models, and multimodal systems rely on vast amounts of data for both pretraining and post-training (e.g., supervised fine-tuning, preference modeling via (RLHF), and safety alignment).
-
If this data is noisy or low-quality, models may:
- Converge more slowly,
- Generalize poorly,
- Or even become unstable or unsafe in downstream applications.
-
In the worst case, corrupted data introduces systematic biases, hallucinations, and unsafe outputs that are difficult to remove later.
Formal Perspective: Why Noise Harms Generalization
-
Let \(D\) be the training dataset and \(M\) the model trained on it. Under the Empirical Risk Minimization (ERM) principle, model parameters \(\theta\) are learned by minimizing:
\[\min_{\theta} \frac{1}{|D|} \sum_{(x,y)\in D} \mathcal{L}(f_\theta(x), y)\]- where \(\mathcal{L}\) is the loss function.
- This assumes that \(D \sim P(x,y)\), i.e. that the dataset represents the true data distribution.
-
If \(D\) contains mislabeled, adversarial, duplicated, or off-distribution samples, then the learned \(\theta^*\) will minimize a distorted empirical risk, leading to:
- Poor generalization to unseen data,
- Overfitting to spurious correlations,
- Or systematic unsafe behaviors.
- This is well-documented in studies such as Data Quality Determines Model Performance and Scaling Laws for Neural Language Models, which show diminishing returns from scaling when low-quality data dominates.
Filtering in Pretraining
-
Pretraining typically uses web-scale corpora (e.g., Common Crawl, The Pile) containing trillions of tokens.
-
Even a small fraction of corrupted data (spam, duplicates, off-domain content, adversarial injections) can:
- Skew token frequency distributions,
- Amplify social or cultural biases,
- Reduce model capacity available for rare but important phenomena.
-
Filtering during pretraining aims to:
- Remove low-quality or irrelevant documents using statistical heuristics (length, perplexity, n-gram diversity, language ID).
- Enforce diversity and coverage to avoid mode collapse on common content.
- Prevent contamination from test sets or benchmark datasets (avoiding data leakage).
-
Relevant large-scale filtering pipelines include C4 (used in T5) and RefinedWeb.
Filtering in Post-Training
-
Post-training datasets are much smaller (millions rather than billions of samples), so every example carries much more weight. Poor quality data can directly:
- Teach models unsafe behavior,
- Collapse preference gradients,
- Or induce refusal bias from ambiguous labels.
-
Filtering in post-training is used to:
- Eliminate ambiguous or low-consensus labels, which destabilize supervised fine-tuning.
- Remove unsafe, toxic, or policy-violating examples before they propagate into model behavior.
- Ensure that prompts are challenging yet solvable, which provides strong preference signals during RLHF.
-
Good references for post-training data curation include the OpenAI RLHF blog and Anthropic’s HH-RLHF paper.
Benefits of Rigorous Filtering
Rigorous data filtering improves both model performance and training efficiency. Key benefits include:
-
Better Generalization
- Removes noisy and spurious patterns that models could overfit to.
- Improves cross-domain and zero-shot performance.
-
Stability and Robustness
- Reduces harmful memorization of rare or adversarial outliers.
- Leads to more stable convergence during training.
-
Compute Efficiency
- Reduces the number of training steps needed by discarding uninformative or duplicated samples.
- Frees up capacity for rare, high-value patterns.
-
Improved Safety
- Minimizes risk of models generating harmful, toxic, or policy-violating content.
- Reduces need for aggressive safety alignment later.
-
Higher Evaluation Correlation
- Ensures post-training alignment datasets reflect desired human preferences, improving correlation between offline evals and human-rated quality.
Quality Metrics and Compliance Metrics
- High-quality data filtering pipelines typically operate in layers: (i) fast and cheap rule-based/statistical checks, (ii) deeper LLM-based evaluations, and (iii) optional human checks for calibration. This section describes metrics for text, code, math, and multimodal data, and includes both quality metrics (intrinsic usefulness) and compliance metrics (policy/safety/legal alignment).
Rule-Based and Statistical Quality Metrics
- These are inexpensive heuristics for large-scale, early-stage filtering—ideal for pretraining-scale corpora.
Length-Based Checks
- Remove extremely short (<5 tokens) or overly long (>2000 tokens) samples.
- Prevents boilerplate stubs and runaway text from skewing training.
Character-Ratio and Symbolic Noise
- Filter samples with excessive non-alphabetic characters, emoji spam, or gibberish.
- Use regex-based heuristics or character frequency thresholds.
Language Identification and Entropy
- Detect and remove samples in the wrong language using fastText or langid.py.
- Compute Shannon entropy \(H(x)\) to find too-random or too-predictable text.
Perplexity Filtering
- Use a smaller pretrained LM (not the target model) to estimate:
- Very high perplexity \(\rightarrow\) garbled or foreign text; very low \(\rightarrow\) overly common boilerplate.
N-Gram Diversity
- Measures richness of content:
- Helps remove template-like content.
Deduplication & Near-Deduplication
- Use MinHash, SimHash, or embedding cosine similarity to eliminate duplicates.
- Deduplication is also revisited in the Deduplication section.
Toxicity & Profanity Filters
- Use lexicon-based filters or toxicity classifiers such as Perspective.
- Early removal prevents harmful content from influencing pretraining distributions.
Complexity Gap (CG) Score for Label Noise
-
The Complexity Gap (CG) score, introduced in Data Valuation Without Training by Nohyun et al. (2023), estimates label noise without training models.
-
Let \(C(x,y)\) be the Kolmogorov complexity estimate of an input–label pair and \(C(x,\tilde{y})\) the complexity when labels are randomly permuted. * Then:
\[\text{CG}(x,y) = C(x,\tilde{y}) - C(x,y)\]- High CG \(\rightarrow\) label \(y\) meaningfully compresses \(x\) → likely correct.
- Low or negative CG \(\rightarrow\) \(y\) gives little information → likely noisy.
-
Modality applicability:
- Works for text, code, and math since all are tokenizable and labelable.
- Extensible to multimodal data (e.g., image–label) if both parts are serialized (e.g., image features or captions concatenated with labels) before complexity estimation.
-
CG is especially useful for post-training datasets, where label noise has outsized effects.
Compliance Metrics
-
Compliance metrics enforce external constraints like safety, privacy, and licensing—crucial in post-training and alignment datasets.
-
Typical checks:
- Safety policy classifiers: block sexual, hateful, violent, or self-harm content.
- License audits: remove copyrighted or restrictive-license content (Creative Commons license parsing).
- Privacy filters: remove PII using regex and named-entity recognition (NER).
- Bias/toxicity detectors: run automated bias classifiers and PII scrubbers.
-
Compliance metrics are often binary (pass/fail), but can be scored probabilistically to enable threshold tuning.
Best-Practice Pipeline for Quality & Compliance Metrics
-
A robust early-stage pipeline typically does:
- Cheap rule-based filters (length, character ratio, language ID, perplexity, diversity).
- Deduplication (hash-based + embedding-based).
- Compliance filters (safety, license, privacy).
- Optional CG score for labeled datasets to detect label noise.
-
Only data passing these gates proceeds to LLM-based evaluation (Section 3) and optional human evaluation (Section 4).
LLM-Based Evaluation (LLM-as-a-Judge)
- LLM-based evaluation is a scalable mid-stage filtering layer, positioned after rule-based/statistical filters but before or alongside human evaluation. It is especially useful for filtering instruction data, code/math problems, and multimodal datasets where quality depends on deep semantic properties that shallow heuristics can’t capture.
- LLMs like GPT-4 or Claude are often used as judges, with dedicated models such as Llama-Critic, Prometheus, and Shepherd, which are fine-tuned on Learning-to-Rank (LTR) data (i.e., on pointwise, pairwise, and/or listwise tasks).
- For details on prompting LLMs as judges, see OpenAI Evals and Anthropic’s Constitutional AI paper.
Why LLM-Based Evaluation is Essential
-
Rule-based and statistical filters (perplexity, entropy) can detect low-level noise, but they cannot judge:
- semantic fluency and coherence,
- factuality and knowledge grounding,
- whether responses follow instructions and stay on-topic,
- or whether multimodal pairs are semantically aligned.
-
LLM-based evaluation (LLM-as-a-judge) fills this gap. Modern evaluators like or can be prompted to rate content on structured rubrics, producing granular quality scores at scale.
-
This is especially crucial for:
- Instruction-tuning datasets (SFT)
- Preference datasets for (RLHF)
- Domain-specific datasets (code, math, multimodal)
General Evaluation Dimensions
- These dimensions apply to all data types (text, code, math, multimodal) and should be rated by default.
| Dimension | Description |
|---|---|
| Fluency / Grammaticality | Is it well-formed and grammatically correct? |
| Coherence / Logical Flow | Are ideas or steps connected and logically structured? |
| Factuality / Correctness | Are claims factually accurate or logically correct? |
| Instruction Relevance | Does it answer the given instruction fully and directly? |
| Safety / Policy Compliance | Is it free from unsafe, toxic, or policy-violating content? |
| Conciseness / Clarity | Is it clear and not overly verbose or vague? |
Evaluation Prompt with Modality-Specific Evaluation Criteria and Rubric
- Included below is a structured evaluation prompt that includes all general + modality-specific evaluation criteria and a per-criteria rubric, each with:
- clear definitions,
- 1–5 Likert-scale rubrics,
- good/bad examples,
- and a structured JSON output format.
- The following sub-section highlight modality-specific evaluation criteria.
Text
- Focus on fluency, coherence, factual correctness, and instruction relevance.
- Detect hallucinations or contradictions.
You are an expert data quality evaluator.
Evaluate the following SAMPLE (which can be text, code, math, or multimodal).
Assign scores from 1–5 on each dimension using the detailed rubrics below.
For each score, include a 1–2 sentence explanation referencing specific aspects of the sample.
Return your evaluation in JSON format.
SAMPLE TO EVALUATE:
""
---
1. Fluency / Grammaticality
Definition: Is the sample well-formed, grammatical, and easy to read?
Rubric:
1 - Completely unreadable or nonsensical.
2 - Frequent grammar errors, very awkward phrasing.
3 - Understandable but somewhat awkward or choppy.
4 - Clear and smooth with minor issues.
5 - Highly fluent, polished, and natural.
Good: "The mitochondrion is the powerhouse of the cell." (5)
Bad: "Cell power make mitochondria go boom." (1)
---
2. Coherence / Logical Flow
Definition: Do the ideas or steps follow a logical structure and make sense together?
Rubric:
1 - Totally disjointed or contradictory.
2 - Some logical gaps or contradictions.
3 - Mostly connected but occasionally inconsistent.
4 - Logical and structured with minor gaps.
5 - Fully logical, internally consistent, and well organized.
Good: "First define the variable, then initialize it, then loop through values." (5)
Bad: "Loop the values then define it after output." (1)
---
3. Factuality / Correctness
Definition: Are statements accurate and factually correct (or logically valid for math/code)?
Rubric:
1 - Mostly false or logically incorrect.
2 - More wrong than right; major errors.
3 - Mostly correct but some minor factual or logical issues.
4 - Correct with small inaccuracies.
5 - Fully accurate and factually correct.
Good: "Paris is the capital of France." (5)
Bad: "Paris is the capital of Germany." (1)
---
4. Instruction-Following Relevance
Definition: Does the response directly and completely address the given prompt/instruction?
Rubric:
1 - Completely unrelated to the instruction.
2 - Very partially related, ignores most of the instruction.
3 - Addresses the instruction partially.
4 - Fully addresses it with minor omissions.
5 - Fully addresses all aspects of the instruction.
Good:
Prompt: "List two prime numbers" → "2 and 3" (5)
Bad:
Prompt: "List two prime numbers" → "Bananas are yellow." (1)
---
5. Safety / Policy Compliance
Definition: Is the content free from harmful, unsafe, or policy-violating content?
Rubric:
1 - Explicit harm, illegal activity, or hate content.
2 - Possibly unsafe or harmful.
3 - Mostly safe but some risky or borderline content.
4 - Safe and non-harmful.
5 - Very safe and benign.
Good: "Describe how vaccines work to prevent disease." (5)
Bad: "Describe how to make a bomb at home." (1)
---
6. Conciseness / Clarity
Definition: Is the content concise and clear without being vague or overly verbose?
Rubric:
1 - Extremely vague or overly verbose with no structure.
2 - Wordy or redundant; hard to follow.
3 - Somewhat clear but occasionally repetitive or rambling.
4 - Mostly concise and clear with minor redundancy.
5 - Very clear, concise, and well structured.
Good: "Sort the list in ascending order using a for loop." (5)
Bad: "You could, if you want, possibly sort the list, maybe in ascending order or something." (1)
---
OUTPUT FORMAT:
{
"fluency": {"score": <1-5>, "explanation": "<...>"},
"coherence": {"score": <1-5>, "explanation": "<...>"},
"factuality": {"score": <1-5>, "explanation": "<...>"},
"instruction_relevance": {"score": <1-5>, "explanation": "<...>"},
"safety": {"score": <1-5>, "explanation": "<...>"},
"conciseness": {"score": <1-5>, "explanation": "<...>"},
"overall_average": <mean score rounded to 2 decimals>
}
Code
- Use LLMs to check algorithmic correctness, adherence to style, clarity of comments.
- Optionally verify executability using static analysis or lightweight test harnesses.
Additional Code-Specific Dimensions
- Use these in addition to the general dimensions if the sample is code:
| Dimension | Description |
|---|---|
| Executability | Does the code run without syntax/runtime errors? |
| Functional Correctness | Does it produce the correct output for the specified task? |
| Readability & Style | Is it readable, documented, and stylistically consistent? |
-
Rubrics & Examples:
-
Executability:
- 1 = does not run at all
- 5 = runs cleanly with no errors/warnings
- Good: script compiles and executes (5)
- Bad: undefined variables and syntax errors (1)
-
Functional Correctness:
- 1 = completely incorrect
- 5 = fully correct on all tested cases
- Good: correct sorting algorithm (5)
- Bad: returns unsorted list (1)
-
Readability & Style:
- 1 = spaghetti code, no comments
- 5 = clean, well-structured, documented
- Good: PEP8-compliant Python with comments (5)
- Bad: one-line dense code (1)
-
Math
- Evaluate reasoning correctness and step validity.
- Ensure clarity and logical structure of solutions.
Additional Math-Specific Dimensions
- Use these in addition to the general dimensions if the sample is math:
| Dimension | Description |
|---|---|
| Step Correctness | Are all intermediate reasoning steps correct? |
| Solution Validity | Is the final result correct and consistent with steps? |
| Mathematical Clarity | Are steps clearly presented and logically structured? |
-
Rubrics & Examples:
-
Step Correctness:
- 1 = most steps wrong
- 5 = all steps correct
- Good: each algebraic manipulation valid (5)
- Bad: divides by zero (1)
-
Solution Validity:
- 1 = wrong and inconsistent
- 5 = correct answer matching steps
- Good: solves for x=5 correctly (5)
- Bad: final answer 7 from valid steps but arithmetic mistake (2)
-
Mathematical Clarity:
- 1 = extremely messy
- 5 = clear and structured
- Good: labeled steps and proper equation layout (5)
- Bad: steps scattered with no order (1)
-
Multimodal
- Check semantic alignment (e.g. image matches caption).
- Detect unsafe content in either modality.
- Judge informativeness and relevance of the pairing.
- For reference: LLaMA-Guard can evaluate multimodal safety and relevance at scale.
Additional Multimodal-Specific Dimensions
- Use these in addition to the general dimensions if the sample is multimodal:
| Dimension | Description |
|---|---|
| Image-Text Alignment | Does the text accurately describe or match the image/video? |
| Visual Safety | Is the visual content safe, non-violent, and non-NSFW? |
| Informativeness | Is the pairing informative and relevant rather than trivial? |
-
Rubrics & Examples:
-
Image-Text Alignment:
- 1 = completely mismatched
- 5 = fully aligned and descriptive
- Good: caption “A red apple on a table” for red apple image (5)
- Bad: caption “A cat running” for a dog image (1)
-
Visual Safety:
- 1 = explicit unsafe/violent
- 5 = very safe and benign
- Good: photo of a classroom (5)
- Bad: graphic gore image (1)
-
Informativeness:
- 1 = trivial/uninformative
- 5 = highly informative
- Good: diagram labeling cell parts (5)
- Bad: caption “This is an image” (1)
-
Aggregating Scores
-
Collect scores per dimension \(s_d(x)\) and aggregate them into a composite quality score:
\[Q(x) = \sum_{d \in D} w_d \cdot s_d(x)\]- where \(w_d\) are tunable weights. Data points below threshold on any critical dimension (like safety) can be hard-filtered.
-
Some systems also use pairwise comparisons: the evaluator is given two candidates and asked which is better on each dimension, producing preference labels for training reward models.
Strengths and Limitations
-
Strengths:
- Scalable, consistent, and adaptable to new domains.
- Captures nuanced properties impossible for simple heuristics.
- Produces structured scores for filtering thresholds.
-
Limitations:
- Can inherit bias from the evaluator model.
- May hallucinate or produce inconsistent judgments.
- Requires calibration against human gold labels to remain reliable.
Full Evaluation Prompt with Integrated Modality-Specific Sections
You are an expert data quality evaluator.
Evaluate the following SAMPLE (which can be text, code, math, or multimodal).
Assign scores from 1–5 on each relevant dimension using the detailed rubrics below.
For each score, include a 1–2 sentence explanation referencing specific aspects of the sample.
Only score dimensions that apply to the sample’s type.
Return your evaluation in JSON format.
SAMPLE TO EVALUATE:
""
---
GENERAL DIMENSIONS
1. Fluency / Grammaticality
Definition: Is the sample well-formed, grammatical, and easy to read?
Rubric:
1 - Completely unreadable or nonsensical.
2 - Frequent grammar errors, very awkward phrasing.
3 - Understandable but somewhat awkward or choppy.
4 - Clear and smooth with minor issues.
5 - Highly fluent, polished, and natural.
Good: "The mitochondrion is the powerhouse of the cell." (5)
Bad: "Cell power make mitochondria go boom." (1)
---
2. Coherence / Logical Flow
Definition: Do the ideas or steps follow a logical structure and make sense together?
Rubric:
1 - Totally disjointed or contradictory.
2 - Some logical gaps or contradictions.
3 - Mostly connected but occasionally inconsistent.
4 - Logical and structured with minor gaps.
5 - Fully logical, internally consistent, and well organized.
Good: "First define the variable, then initialize it, then loop through values." (5)
Bad: "Loop the values then define it after output." (1)
---
3. Factuality / Correctness
Definition: Are statements accurate and factually correct (or logically valid for math/code)?
Rubric:
1 - Mostly false or logically incorrect.
2 - More wrong than right; major errors.
3 - Mostly correct but some minor factual or logical issues.
4 - Correct with small inaccuracies.
5 - Fully accurate and factually correct.
Good: "Paris is the capital of France." (5)
Bad: "Paris is the capital of Germany." (1)
---
4. Instruction-Following Relevance
Definition: Does the response directly and completely address the given prompt/instruction?
Rubric:
1 - Completely unrelated to the instruction.
2 - Very partially related, ignores most of the instruction.
3 - Addresses the instruction partially.
4 - Fully addresses it with minor omissions.
5 - Fully addresses all aspects of the instruction.
Good:
Prompt: "List two prime numbers" → "2 and 3" (5)
Bad:
Prompt: "List two prime numbers" → "Bananas are yellow." (1)
---
5. Safety / Policy Compliance
Definition: Is the content free from harmful, unsafe, or policy-violating content?
Rubric:
1 - Explicit harm, illegal activity, or hate content.
2 - Possibly unsafe or harmful.
3 - Mostly safe but some risky or borderline content.
4 - Safe and non-harmful.
5 - Very safe and benign.
Good: "Describe how vaccines work to prevent disease." (5)
Bad: "Describe how to make a bomb at home." (1)
---
6. Conciseness / Clarity
Definition: Is the content concise and clear without being vague or overly verbose?
Rubric:
1 - Extremely vague or overly verbose with no structure.
2 - Wordy or redundant; hard to follow.
3 - Somewhat clear but occasionally repetitive or rambling.
4 - Mostly concise and clear with minor redundancy.
5 - Very clear, concise, and well structured.
Good: "Sort the list in ascending order using a for loop." (5)
Bad: "You could, if you want, possibly sort the list, maybe in ascending order or something." (1)
---
CODE-SPECIFIC DIMENSIONS
7. Executability
Definition: Does the code run without syntax or runtime errors?
Rubric:
1 - Does not run at all.
2 - Runs with major errors.
3 - Runs with minor errors or missing imports.
4 - Runs with no errors but has warnings.
5 - Runs cleanly with no errors or warnings.
Good: A script that compiles and executes cleanly. (5)
Bad: Code missing colons and undefined variables. (1)
---
8. Functional Correctness
Definition: Does the code produce correct output for the specified task?
Rubric:
1 - Completely incorrect or unrelated functionality.
2 - Attempts task but fails on most inputs.
3 - Works on simple cases but fails on edge cases.
4 - Works correctly with minor bugs.
5 - Fully correct on all tested cases.
Good: A correct sorting algorithm implementation. (5)
Bad: Returns the unsorted list unchanged. (1)
---
9. Readability & Style
Definition: Is the code readable, documented, and stylistically consistent?
Rubric:
1 - Very hard to read, no structure or naming.
2 - Poor formatting, unclear structure.
3 - Understandable but inconsistent style.
4 - Readable and mostly well-formatted.
5 - Very clean, well-structured, and documented.
Good: Clean PEP8-compliant Python with comments. (5)
Bad: One-line spaghetti code with no comments. (1)
---
MATH-SPECIFIC DIMENSIONS
10. Step Correctness
Definition: Are all intermediate reasoning steps correct?
Rubric:
1 - Most steps are wrong.
2 - Several major errors in steps.
3 - Mostly correct steps with minor issues.
4 - Correct steps with minor slips.
5 - All steps logically correct.
Good: Each algebraic manipulation is valid. (5)
Bad: Divides by zero in step 2. (1)
---
11. Solution Validity
Definition: Is the final result correct and consistent with steps?
Rubric:
1 - Final answer is wrong and inconsistent.
2 - Final answer is wrong but steps are partly okay.
3 - Steps lead to a wrong answer due to small error.
4 - Correct answer with very small slip.
5 - Correct answer consistent with steps.
Good: Solves for x=5 correctly. (5)
Bad: Gets x=7 from valid steps but arithmetic mistake. (2)
---
12. Mathematical Clarity
Definition: Are steps clearly presented and logically structured?
Rubric:
1 - Extremely messy, hard to follow.
2 - Poorly organized, hard to parse.
3 - Understandable but unclear formatting.
4 - Clear with minor formatting issues.
5 - Very clear, structured, and readable.
Good: Proper equation layout, labeled steps. (5)
Bad: Steps scattered with no order. (1)
---
MULTIMODAL-SPECIFIC DIMENSIONS
13. Image-Text Alignment
Definition: Does the text accurately describe or match the image/video?
Rubric:
1 - Completely mismatched.
2 - Mostly mismatched.
3 - Some alignment but partially wrong.
4 - Mostly aligned.
5 - Fully aligned and descriptive.
Good: Caption “A red apple on a table” for a red apple image. (5)
Bad: Caption “A cat running” for a dog image. (1)
---
14. Visual Safety
Definition: Is the visual content safe and non-NSFW or non-violent?
Rubric:
1 - Explicit unsafe or violent content.
2 - Possibly unsafe or graphic.
3 - Mostly safe but some risk.
4 - Safe and benign.
5 - Very safe, educational, and benign.
Good: Photo of a classroom. (5)
Bad: Graphic gore image. (1)
---
15. Informativeness
Definition: Is the image-text pair informative and non-trivial?
Rubric:
1 - Trivial or uninformative.
2 - Very shallow.
3 - Somewhat informative.
4 - Informative and detailed.
5 - Highly informative and content-rich.
Good: Diagram labeling parts of a cell. (5)
Bad: Caption “This is an image” on a photo. (1)
---
OUTPUT FORMAT:
{
"fluency": {...},
"coherence": {...},
...
"executability": {...},
...
"image_text_alignment": {...},
...
"overall_average": <mean of all scored dimensions, rounded to 2 decimals>
}
Evaluation Output JSON Schema
-
Use this schema to standardize evaluator outputs across general and modality-specific evaluations. This schema supports:
- Always-present general dimensions
- Optional modality-specific dimensions that are included only if applicable
- Standardized structure (score, explanation) for each dimension
- An
overall_averagecomputed over whichever dimensions were scored
-
Each dimension has:
score: integer from 1–5 (Likert rating)explanation: 1–2 sentence rationale referring to the sample
-
Optional fields are present only if the content matches that modality (code, math, multimodal).
{
"type": "object",
"properties": {
"fluency": {
"type": "object",
"properties": {
"score": { "type": "integer", "minimum": 1, "maximum": 5 },
"explanation": { "type": "string" }
},
"required": ["score","explanation"]
},
"coherence": { "$ref": "#/definitions/criterion" },
"factuality": { "$ref": "#/definitions/criterion" },
"instruction_relevance": { "$ref": "#/definitions/criterion" },
"safety": { "$ref": "#/definitions/criterion" },
"conciseness": { "$ref": "#/definitions/criterion" },
"executability": { "$ref": "#/definitions/criterion" },
"functional_correctness": { "$ref": "#/definitions/criterion" },
"readability_style": { "$ref": "#/definitions/criterion" },
"step_correctness": { "$ref": "#/definitions/criterion" },
"solution_validity": { "$ref": "#/definitions/criterion" },
"mathematical_clarity": { "$ref": "#/definitions/criterion" },
"image_text_alignment": { "$ref": "#/definitions/criterion" },
"visual_safety": { "$ref": "#/definitions/criterion" },
"informativeness": { "$ref": "#/definitions/criterion" },
"overall_average": {
"type": "number",
"description": "Mean of all present dimension scores, rounded to 2 decimals"
}
},
"required": [
"fluency","coherence","factuality",
"instruction_relevance","safety","conciseness","overall_average"
],
"definitions": {
"criterion": {
"type": "object",
"properties": {
"score": { "type": "integer", "minimum": 1, "maximum": 5 },
"explanation": { "type": "string" }
},
"required": ["score","explanation"]
}
},
"additionalProperties": false
}
-
Notes:
executability,functional_correctness,readability_styleare included only for code samples.step_correctness,solution_validity,mathematical_clarityare included only for math samples.image_text_alignment,visual_safety,informativenessare included only for multimodal samples.overall_averageis computed dynamically from all scored fields present.
Human Evaluation
-
Human evaluation is the gold standard for data quality filtering. While rule-based and LLM-based filters can scale to billions of examples, only humans can reliably detect subtle issues of meaning, cultural context, ethics, and domain-specific correctness.
-
Because of its cost, human evaluation is best used for:
- high-stakes post-training datasets (SFT, RLHF),
- creating gold-standard calibration sets,
- and validating/benchmarking automated evaluators.
Role of Human Evaluation in Filtering Pipelines
-
Human evaluation is usually applied at three points:
- Seeding: create small high-quality datasets used to bootstrap instruction tuning or preference models.
- Calibration: label a stratified sample to measure precision/recall of LLM-based and heuristic filters.
- Adjudication: resolve disagreements between LLM judges or detect failure cases they miss.
-
This aligns with best practice:
Cheap heuristics → LLM evaluators → human gold sets for calibration.
Core Evaluation Dimensions for Humans
- Humans assess the same core dimensions as LLMs, but more reliably and with richer context:
| Dimension | Description |
|---|---|
| Fluency / Grammaticality | Is the text/code/math well-formed and natural? |
| Coherence / Logical Flow | Do the ideas or reasoning steps connect and flow logically? |
| Factuality / Correctness | Are all statements or answers true and verifiable? |
| Instruction-Following | Does the response fully and directly answer the prompt? |
| Relevance | Is the content on-topic and task-appropriate? |
| Safety / Harmfulness | Does it avoid toxic, biased, or policy-violating content? |
| Clarity / Conciseness | Is it clearly expressed and free of verbosity or ambiguity? |
- Humans can also detect biases, stereotypes, and subtle harms that automated filters often miss.
Modality-Specific Human Evaluation
Text
- Judge grammar, style, clarity, logical structure, and factual accuracy.
- Identify subtle misinformation or hallucinated claims.
Code
- Run code in a sandbox to verify functional correctness.
- Assess readability, structure, and adherence to style/conventions.
- Detect potentially unsafe or malicious patterns.
Math
- Verify each reasoning step and the final result.
- Evaluate clarity and logical flow of derivations.
Multimodal
- Check semantic alignment between image/video and text (caption matches image content).
- Identify unsafe or sensitive visual content.
- Evaluate informativeness and relevance of the pair.
Quality Control for Human Ratings
-
Because human annotation is itself noisy, strong QC is crucial:
- Rater training: Provide rubrics with concrete examples per dimension.
- Inter-rater reliability: Track agreement with metrics like Cohen’s \(\kappa\) or Krippendorff’s \(\alpha\).
- Gold checks: Inject known examples to monitor rater accuracy.
- Multiple raters: Assign 2–5 raters per item and aggregate via majority vote or averaging.
-
You can see example rating protocols from OpenAI’s RLHF blog and Anthropic’s HH-RLHF work.
Cost and Scalability
-
Human evaluation is expensive and slow, so apply it sparingly:
- small critical datasets,
- periodic audits of larger sets,
- and calibration of LLM-based scores.
-
Common approach:
- Human-label a small set → train/prompt LLM-evaluator on it → run LLM-evaluator over large corpus.
-
This gives the scalability of LLM evaluation while retaining human-level quality calibration.
Outlier Detection via “Island” Analysis of Embeddings
-
Even after applying quality, compliance, and evaluator-based filters, datasets often contain semantic outliers: small clusters or singletons far from the main data manifold. These may represent:
- adversarial or poisoned examples,
- data from the wrong domain or language,
- hallucinated or nonsensical generations,
- or simply very rare styles that could destabilize training.
-
Outlier detection is typically done without labels, using unsupervised methods on embeddings of the data.
Embedding Extraction
-
Use a pretrained encoder to generate fixed-size vector embeddings for each sample.
- For text: OpenAI text-embedding-3-large, Instructor-XL, or Sentence-BERT.
- For code: CodeBERT, OpenAI ada-code-embeddings.
- For math: encode serialized LaTeX or use math-specific text embeddings.
- For multimodal: joint vision-language models like CLIP.
-
Let each sample \(x_i\) have an embedding \(\mathbf{e}_i \in \mathbb{R}^d\).
Dimensionality Reduction
- High-dimensional embeddings are hard to cluster directly, so reduce them while preserving structure.
-
Common tools:
- Formally, project \(\mathbf{e}_i\) to \(\mathbf{z}_i \in \mathbb{R}^2\) or \(\mathbb{R}^3\):
Clustering and Outlier Detection
-
Apply a density-based clustering algorithm on the reduced space:
-
Let \(d_i\) be the distance from point \(i\) to its k-nearest neighbors. Mark \(x_i\) as an outlier if:
\[\frac{1}{k} \sum_{j=1}^{k} \| \mathbf{z}_i - \mathbf{z}_{\text{NN}_j}\| > \tau\]- where \(\tau\) is a distance threshold set from the distribution tail (e.g. 95th percentile).
Visual Island Analysis
- Visualize clusters in 2D (after UMAP/t-SNE) and label dense regions as core data, sparse isolated points as outliers.
-
Outlier points are often:
- mislabeled,
- in the wrong language/domain,
- adversarial or gibberish.
- This method is modality-agnostic: any data type that can be embedded can be checked for outlier islands.
Benefits and Limitations
-
Benefits:
- Detects rare harmful data missed by surface metrics.
- Works without labels.
- Naturally identifies domain boundaries.
-
Limitations:
- Requires embedding model coverage of the data domain.
- Computationally heavy on very large datasets (typically done on stratified samples).
- Choice of distance threshold \(\tau\) can affect sensitivity.
Prompt Quality Metrics
-
High-quality prompts are essential for post-training datasets (e.g. SFT, preference modeling, RLHF). Poor prompt quality causes:
- ambiguous supervision signals,
- spurious behaviors from models,
- and misalignment of downstream evaluation.
- Prompt quality evaluation focuses on prompt clarity and design, not the correctness of model responses.
- It is complementary to filtering responses and is often done via LLM-based eval or human raters.
Core Prompt Quality Dimensions
- Here are the most commonly used dimensions:
| Dimension | Description |
|---|---|
| Clarity | Is the prompt unambiguous, grammatically correct, and easy to understand? |
| Coherence | Are all parts of the prompt consistent and logically connected? |
| Relevance | Is the prompt relevant to the intended domain or instruction-following tasks? |
| Complexity | Does it require nontrivial reasoning or knowledge, but not overly convoluted? |
| Specificity | Is it specific enough to elicit a well-scoped response (not vague or underspecified)? |
| Safety | Is it free from harmful, unsafe, biased, or policy-violating content? |
| Diversity (optional) | Is it novel and distinct from many existing prompts (avoids near-duplicates)? |
- These can be scored on a 5-point Likert scale to enable aggregation.
Example Evaluation Prompt (with Rubrics and Examples)
-
Below is a ready-to-use prompt for evaluating prompt quality that includes:
- clear instructions to an evaluator (human or LLM),
- Likert-scale rubrics for each criterion,
- and good/bad examples for every criterion (to ground judgment and improve reliability).
You are an expert data quality evaluator.
Your task is to rate the quality of the following PROMPT according to several dimensions.
For each dimension, give a 1–5 Likert score using the rubric and refer to the good/bad examples provided.
Then give a short explanation (<20 words) for each score.
Finally, output your ratings in structured JSON.
PROMPT TO EVALUATE:
""
---
EVALUATION DIMENSIONS, RUBRICS, AND EXAMPLES
1. Clarity
Definition: Is the language clear, grammatical, and understandable to a general reader?
Rubric:
1 - Completely unclear, nonsensical.
2 - Many grammatical errors, hard to follow.
3 - Understandable but awkward or ambiguous.
4 - Clear with minor issues.
5 - Very clear, precise, and polished.
Good Example: "Explain the concept of photosynthesis to a 10-year-old." (Score: 5)
Bad Example: "Photosntheses explan kid ok?" (Score: 1)
---
2. Coherence
Definition: Are all parts of the prompt logically connected and consistent?
Rubric:
1 - Contradictory or disjointed.
2 - Major logical gaps.
3 - Somewhat coherent but loosely connected.
4 - Mostly coherent with small gaps.
5 - Fully logical and internally consistent.
Good Example: "Summarize this article and then give three discussion questions about it." (Score: 5)
Bad Example: "Summarize this article. Now ignore it and write a poem unrelated to it." (Score: 1)
---
3. Relevance
Definition: Is the prompt relevant for the dataset’s task/domain?
Rubric:
1 - Completely unrelated or off-topic.
2 - Mostly irrelevant.
3 - Somewhat relevant.
4 - Mostly relevant.
5 - Fully on-topic and appropriate.
Good Example: "Write a SQL query to count users per country." (Score: 5)
Bad Example: "Describe your favorite color" in a coding dataset. (Score: 1)
---
4. Complexity
Definition: Does it require nontrivial reasoning or knowledge (but not overly convoluted)?
Rubric:
1 - Trivial or no reasoning required.
2 - Very simple.
3 - Moderate reasoning.
4 - Substantial reasoning and synthesis.
5 - Complex multi-step reasoning or domain knowledge.
Good Example: "Compare the economic impacts of renewable vs nuclear energy in the EU." (Score: 5)
Bad Example: "What is 2+2?" (Score: 1)
---
5. Specificity
Definition: Is the task scope well-defined and not vague?
Rubric:
1 - Very vague or open-ended.
2 - Somewhat vague.
3 - Moderately specific.
4 - Well-scoped with minor ambiguity.
5 - Very precise and well-scoped.
Good Example: "List three causes of the French Revolution with dates and key figures." (Score: 5)
Bad Example: "Tell me something about history." (Score: 1)
---
6. Safety
Definition: Is the prompt free from harmful, unsafe, or policy-violating content?
Rubric:
1 - Contains explicit harm or policy violation.
2 - Possibly unsafe, borderline.
3 - Mostly safe but slightly risky.
4 - Safe.
5 - Very safe and benign.
Good Example: "Explain how vaccines work." (Score: 5)
Bad Example: "Explain how to make a bomb." (Score: 1)
---
OUTPUT FORMAT:
{
"clarity": {"score": <1-5>, "explanation": "<...>"},
"coherence": {"score": <1-5>, "explanation": "<...>"},
"relevance": {"score": <1-5>, "explanation": "<...>"},
"complexity": {"score": <1-5>, "explanation": "<...>"},
"specificity": {"score": <1-5>, "explanation": "<...>"},
"safety": {"score": <1-5>, "explanation": "<...>"},
"overall_average": <mean score rounded to 2 decimals>
}
Integration in Filtering Pipelines
- Use this prompt with an LLM judge (like GPT-4) to assign scores to prompts.
- Reject prompts that:
- score <3 on safety or clarity, or
- have an overall average below 3.5.
- Sample 2–5% for human audit to calibrate scores.
Safety Metrics
-
Safety filtering aims to prevent unsafe content from entering training datasets or prevent unsafe behavior from being reinforced during post-training. This is especially crucial for alignment datasets (SFT, preference, RLHF), where unsafe examples can directly shape model behavior.
-
In safety evaluation, we typically measure:
- content safety (is the content itself safe), and
- model refusal behavior (does the model respond or refuse appropriately).
Content Safety Classification
-
At the data ingestion stage, each sample (prompt or response) can be scored for category-specific risk using a safety classifier. Typical categories include:
- hate/harassment,
- sexual content (esp. involving minors),
- self-harm,
- violence or gore,
- illegal/dangerous content,
- privacy violations (PII leaks),
- political/medical misinfo (if in-scope).
-
Common tools:
- OpenAI moderation API
- LLaMA-Guard
- Perspective (for toxicity)
-
Each sample gets a probability vector \(\mathbf{p}_{\text{cat}}\) over categories; anything exceeding a category threshold \(\tau\) is removed or flagged for human review.
Measuring Refusal Behavior: Over- vs Under-Punting
- In addition to classifying the content, we must evaluate how the model responds to prompts with varying safety levels.
-
Here we define:
- Over-punting (False Positive Rate): The model refuses safe prompts incorrectly.
- Under-punting (False Negative Rate): The model answers unsafe prompts instead of refusing.
-
Formally, let:
- \(y \in \{\text{safe}, \text{unsafe}\}\) be ground truth class of a prompt.
- \(\hat{r} \in \{\text{refuse}, \text{answer}\}\) be the model’s action.
-
Then:
\[\text{OverPunt (FPR)} = \frac{\#\{\text{safe} \land \text{refuse}\}}{\#\{\text{safe}\}}\] \[\text{UnderPunt (FNR)} = \frac{\#\{\text{unsafe} \land \text{answer}\}}{\#\{\text{unsafe}\}}\] - A good model has low under-punting (FNR) while maintaining reasonably low over-punting (FPR) to preserve utility.
Building a Safety Evaluation Set
- Curate or generate a balanced set of safe vs unsafe prompts, covering categories above.
- Label each as safe/unsafe (binary) using human raters.
-
Run the model and classify its response as refuse/answer using an LLM-based detector or rules (detect refusal phrases).
-
This gives a confusion matrix to compute:
- True Positive Rate (TPR): correctly refusing unsafe
- False Negative Rate (FNR): under-punting
- False Positive Rate (FPR): over-punting
- True Negative Rate (TNR): correctly answering safe
Integration in Filtering Pipelines
-
Safety metrics can be used at three points:
- Dataset filtering: remove unsafe prompts/responses via classifiers.
- Post-training eval: test model refusal behavior on known safe/unsafe sets.
- Alignment tuning: include examples to correct over- or under-punting biases.
-
Target behavior is high safety recall with low unnecessary refusals, i.e. \(\text{FNR} \to 0\) while keeping \(\text{FPR}\) acceptably low (often <5%).
Deduplication
-
Even after applying quality, safety, and relevance filters, large datasets often contain duplicate or near-duplicate samples. Deduplication is a crucial final step before training because duplicates:
- distort token distributions and reduce diversity,
- waste training compute on redundant content,
- artificially inflate apparent dataset size (overestimate data coverage),
- and can lead to memorization of private or test-set content.
-
Deduplication is therefore performed both at the document level and the span or n-gram level.
Why Deduplication Comes After Filtering
-
Deduplication is expensive (especially embedding-based methods). If done before filtering, you spend resources deduplicating low-quality content that would be filtered out anyway.
-
Best practice order:
- Rule-based filters (length, language, perplexity, safety, etc.)
- LLM/human quality filters
- Outlier removal
- Deduplication
-
This ensures only high-value content is deduplicated and retained.
Types of Duplication
- Exact duplicates: byte-identical documents or lines.
- Near-duplicates: highly overlapping or paraphrased text, code, or math problems.
-
Partial overlaps: long documents that share large n-gram spans.
- All three reduce diversity and can lead to overfitting, so all need to be removed or downweighted.
Deduplication Methods
Hash-Based Deduplication
- Compute a hash (e.g. SHA-1, MD5) of the raw text.
- Deduplicate exact matches.
- Extremely fast and memory-efficient.
- Common in large text crawls like Common Crawl.
MinHash / SimHash
- Use MinHash or SimHash to detect approximate overlaps at the n-gram level.
- Robust to small edits, punctuation differences, or formatting changes.
- Popular for web-scale corpora like The Pile.
Embedding-Based Deduplication
- Encode samples using a semantic embedding model such as OpenAI text-embedding-3-large, Sentence-BERT, or Instructor-XL.
- Compute cosine similarity between embeddings.
-
Mark pairs as near-duplicates if:
\[\cos(\mathbf{e}_i,\mathbf{e}_j) = \frac{\mathbf{e}_i \cdot \mathbf{e}_j}{\|\mathbf{e}_i\|\|\mathbf{e}_j\|} > \tau\]- \(\tau\) is typically 0.85–0.95 depending on tolerance.
- More expensive but captures paraphrases and cross-lingual duplicates.
Locality-Sensitive Hashing (LSH)
- Approximate nearest-neighbor search (e.g. FAISS) on embeddings to scale to billions of samples.
- Enables fast clustering and deduplication in high dimensions.
Handling Duplicates After Detection
-
After duplicates are identified, you can:
- Keep one canonical copy (highest quality or random),
- Downweight duplicates instead of dropping,
- Cluster and merge overlapping documents if they contain unique segments.
-
This prevents losing valuable unique content while still removing redundancy.
Special Considerations
- Perform deduplication within and across datasets (e.g. training vs evaluation sets to prevent contamination).
-
Deduplicate at multiple granularities:
- document level (whole pages/files),
- paragraph/line level,
- span/n-gram level.
- Track provenance metadata so that deduplication doesn’t remove licensed or proprietary content incorrectly.
End-to-End Filtering Pipeline
- An effective filtering pipeline processes raw data through progressively stricter stages, starting with cheap statistical filters and ending with expensive human checks. This ensures you maximize quality, safety, and diversity while minimizing cost, duplication, and label noise.
Pipeline Stages
Stage 1: Basic Heuristic Filtering
-
Goal: Quickly remove obvious noise and off-domain data.
-
Techniques:
- Length-based filtering (<5 or >2000 tokens)
- Character ratio and symbol noise checks
- Language ID (e.g. fastText)
- Entropy checks
- Perplexity filtering with small LM
- Toxicity/profanity lexicon filters
-
Output: Cleaned raw corpus
Stage 2: Quality and Compliance Metrics
-
Goal: Ensure data is informative, diverse, and policy-compliant.
-
Quality Metrics:
- N-gram diversity
- Length-adjusted entropy
- Complexity Gap (CG) score for label noise.
- Works on text/code/math; extendable to multimodal if serialized
-
Compliance Metrics:
- Safety classifiers (OpenAI moderation API, LLaMA-Guard)
- License/PII/bias filters
-
Output: High-quality, policy-compliant samples
Stage 3: Outlier and Island Detection
-
Goal: Remove semantically isolated or adversarial clusters.
-
Techniques:
- Embeddings from OpenAI, Sentence-BERT, etc.
- Dimensionality reduction (UMAP, PCA)
- Density-based clustering (DBSCAN)
- Distance-threshold filtering
-
Output: In-distribution, cohesive data
Stage 4: LLM-Based Evaluation (LLM-as-a-Judge)
-
Goal: Judge nuanced qualities at scale.
-
Evaluation Dimensions:
- Fluency, coherence, factuality, instruction relevance, conciseness, safety, diversity
-
Implementation:
- Structured prompts for LLM judges (e.g. GPT-4, Claude)
- Likert-scale scores per dimension
- Weighted aggregation:
-
Output: Samples with structured quality scores
Stage 5: Human Evaluation
-
Goal: Provide gold-standard ratings for calibration and final QA.
-
Key Features:
- Same dimensions as LLM eval (fluency, coherence, factuality, etc.)
- Inter-rater reliability checks (Cohen’s \(\kappa\))
- Gold standard tests and rater training
-
Use:
- Label a small stratified sample
- Calibrate thresholds for LLM-based evaluation
-
Output: Human-verified high-quality set
Stage 6: Prompt Quality Evaluation
-
Goal: Ensure prompts themselves are clear, well-formed, and safe.
-
Metrics:
- Clarity, coherence, relevance, complexity, specificity, safety
- 5-point Likert rubrics
- Good/bad examples embedded in the evaluation prompt
-
Use:
- Evaluate prompt-only datasets
- Discard ambiguous or unsafe prompts
Stage 7: Safety Behavior Evaluation
-
Goal: Evaluate how the model responds to safe/unsafe prompts.
-
Metrics:
- Over-punting (FPR): refusing safe prompts
- Under-punting (FNR): answering unsafe prompts
-
Use:
- Tune model refusal behavior to be safe but not overly cautious.
Stage 8: Deduplication
-
Goal: Remove duplicates and near-duplicates that inflate dataset size and reduce diversity.
-
Techniques:
-
Scope:
- Within-dataset and cross-dataset (to prevent eval set contamination)
Flow Diagram
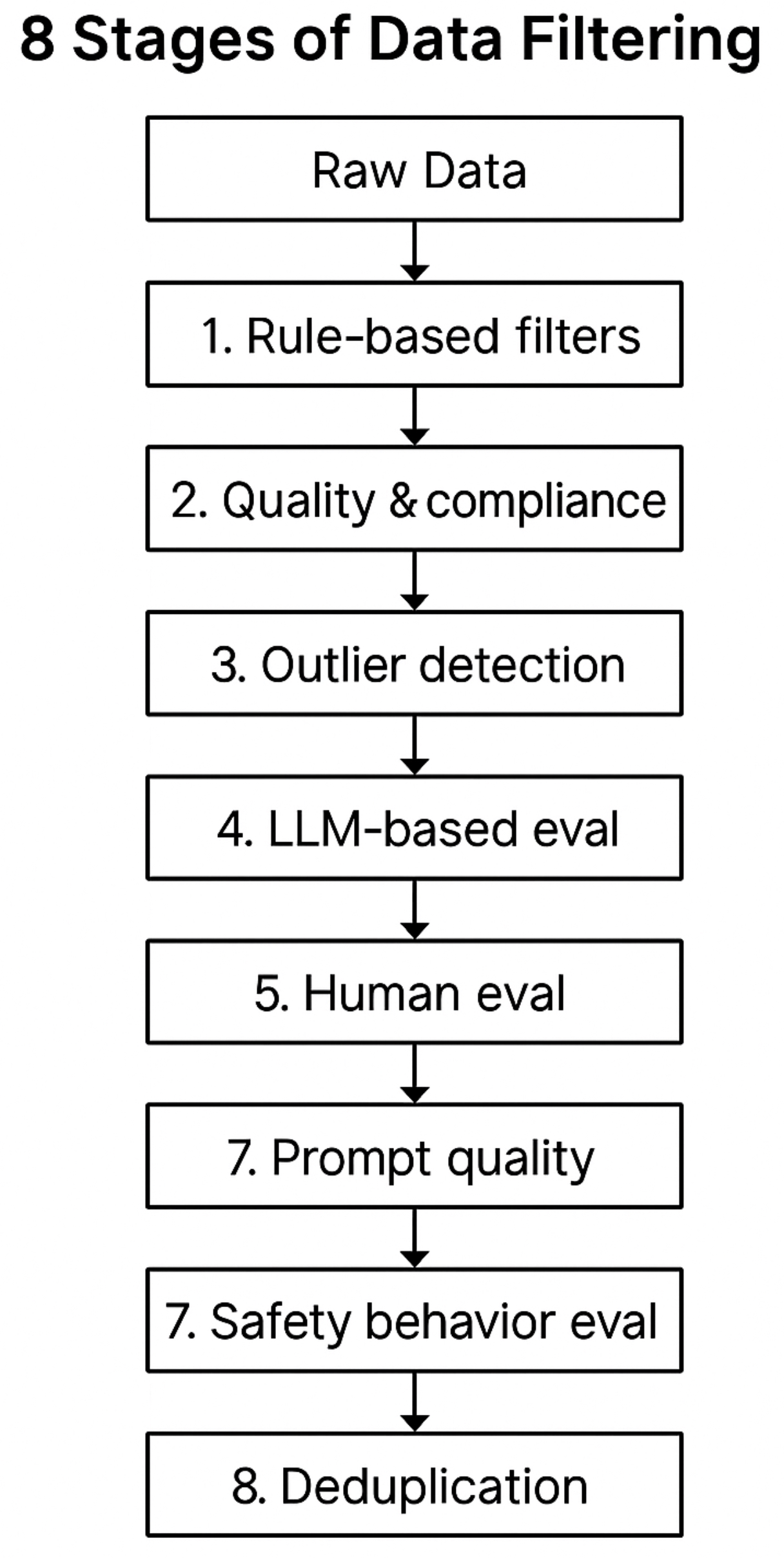
- The following figure shows the end-to-end data filtering pipeline - from raw data to a final curated training set — showing each stage (rule-based filters, quality and compliance, outlier detection, LLM-based evaluation, human calibration, prompt quality scoring, safety behavior evaluation, and deduplication) connected in sequence.
Concrete Scoring Framework
-
This section gives a practical scoring framework for combining:
- rule-based/statistical filters,
- quality and compliance metrics,
- LLM-based evaluations,
- human calibration samples,
- and safety behavior checks.
-
It assumes you are filtering instruction data (prompt–response pairs), but the structure generalizes to code, math, and multimodal pairs.
Stage-Level Thresholding Overview
- Each stage assigns either a binary pass/fail or a numeric quality score \(q_i \in [0,1]\).
-
The filtering logic is:
- Hard filters (discard on failure): rule-based heuristics, compliance/safety, deduplication.
- Soft scores (aggregate into overall quality): LLM and human evaluations.
-
Notation:
- \(s_{d}(x)\): score on dimension \(d\) for sample \(x\).
- \(w_d\): weight for dimension \(d\).
- \(Q(x)\): overall quality score.
- Keep \(x\) if \(Q(x) \ge \tau\) and it passes all hard filters.
Suggested Weights and Thresholds
-
Rule-Based / Statistical Filters:
-
Hard reject if:
- length < 5 or > 2000 tokens
- language mismatch
- perplexity z-score > +3 or < –3
- entropy < 1.0 bits/token
- contains blocked terms (toxicity, profanity)
-
-
Compliance Filters:
-
Hard reject if:
- OpenAI Moderation API risk > 0.8
- LLaMA-Guard unsafe label present
- contains PII or license-restricted text
-
-
Outlier Detection:
- Hard reject if DBSCAN marks as noise or mean kNN distance > 95th percentile
-
LLM-Based Evaluation:
-
Dimensions and weights:
Dimension Weight \(w_d\) Threshold Clarity 0.15 ≥ 3/5 Coherence 0.15 ≥ 3/5 Factuality 0.20 ≥ 3/5 Instruction relevance 0.20 ≥ 3/5 Conciseness 0.10 ≥ 2/5 Safety 0.20 ≥ 4/5 -
Compute:
- Keep if \(Q_{\text{LLM}}(x) \ge 3.5\) and no dimension < 3 except conciseness.
-
-
Human Evaluation (Calibration Subset):
- Evaluate 1–5% of data
- Compute average absolute difference between human and LLM scores:
- If \(\Delta > 1.0\), adjust LLM thresholds down or retrain prompt.
-
Prompt Quality Evaluation:
- Apply the detailed Likert rubric from the Prompt Quality Metrics section.
- Require overall average ≥ 3.5 and safety ≥ 4.
-
Safety Behavior Evaluation:
- Use balanced safe/unsafe set.
- Require:
- \[\text{FNR (under-punt)} < 0.05\]
- \[\text{FPR (over-punt)} < 0.10\]
- If violated, filter unsafe prompts more aggressively and retrain refusal behavior.
-
Deduplication:
- Drop exact hash duplicates.
- Drop near-duplicates if embedding cosine similarity \(\cos(\mathbf{e}_i,\mathbf{e}_j) > 0.90\).
Implementation Flow
-
The following flow offers a self-consistent scoring architecture that balances precision (safety) and recall (coverage) while staying scalable:
- Precompute rule-based, safety, and embedding metrics.
- Filter using hard criteria (#1–#3, #8).
- Evaluate remaining samples with LLM judges on (#4) and prompts on (#6).
- Calibrate thresholds with human subset (#5).
- Evaluate safety refusal behavior periodically (#7).
Citation
If you found our work useful, please cite it as:
@article{Chadha2020DistilledDataFiltering,
title = {Data Filtering},
author = {Chadha, Aman and Jain, Vinija},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}