NLP • LLM Context Length Extension
- Overview
- Advantages of Extended Context Length
- Background: Interpolation and how it increases context length
- Background: NTK, NTK-Aware, and Dynamic NTK
- Related Papers
- Extending Context Window of Large Language Models via Positional Interpolation
- YaRN: Efficient Context Window Extension of Large Language Models
- LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
- LongQLoRA: Efficient and Effective Method to Extend Context Length of Large Language Models
- MemGPT: Towards LLMs as Operating Systems
- LM-Infinite: Simple On-The-Fly Length Generalization for Large Language Models
- LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning
- In Search of Needles in a 11M Haystack: Recurrent Memory Finds What LLMs Miss
- Citation
Overview
- The increasing application of Large Language Models (LLMs) across sectors has highlighted a significant challenge: their predefined context lengths. This limitation impacts efficiency, especially when applications require the processing of extensive documents or large-scale conversations. While directly training LLMs on longer contexts is a potential solution, it is not always efficient and can be resource-intensive.
- This article will discuss various methods aimed at enhancing the context length of LLMs.
- Context length serves as a vital parameter determining the efficacy of LLMs. Achieving a context length of up to 100K is notable. The value of such an achievement, however, might be perceived differently with the progression of time and technology.
- One primary use-case for LLMs is to analyze a large set of custom data, such as company-specific documents or problem-related texts, and to answer queries specific to this dataset, rather than the generalized training data.
- Let’s take a look at existing Solutions to Address Context Length Limitations:
- Summarization & Chained Prompts: Current approaches often involve the use of sophisticated summarization methods coupled with chained prompts.
- Vector Databases: These are used to store embeddings of custom documents, which can then be queried based on similarity metrics.
- Fine-Tuning with Custom Data: This method, while effective, is not universally accessible due to restrictions on certain commercial LLMs and complexities with open-source LLMs.
- Customized LLMs: Developing smaller, data-centric LLMs is another solution, though it presents its own set of challenges.
Advantages of Extended Context Length
- An LLM with an expanded context length can offer more tailored and efficient interactions by processing user-specific data without the need for model recalibration. This on-the-fly learning approach, leveraging in-memory processing, has the potential to enhance accuracy, fluency, and creativity.
- Analogy for Context: Similar to how computer RAM retains the operational context of software applications, an extended context length allows an LLM to maintain and process a broader scope of user data.
- In this article, we aim to present a detailed examination of methods focused on increasing the context length, emphasizing their practical implications and benefits.
Background: Interpolation and how it increases context length
- What is interpolation at non-integer positions?
- Interpolation is a mathematical method to determine unknown values between two known values. In the context of the Llama 2 model, “interpolating at non-integer positions” refers to a technique where the positions of tokens (pieces of data or text) are adjusted to fit within the model’s original context window, even if the data extends beyond it.
- Instead of using whole numbers (integers) for positions, this method utilizes values between whole numbers (non-integers).
- Why do they do this?
- By using this interpolation method, Llama 2 can process text inputs that are much larger than its designed capacity or its original window size.
- What is the benefit?
- The advantage of this technique is that despite processing larger chunks of data, the model doesn’t suffer in performance. It can handle more data while still operating effectively.
- In simpler terms: Meta has used a clever method to let Llama 2 handle more data at once without slowing it down or reducing its effectiveness. They achieve this by adjusting the way data positions are calculated, using values between whole numbers.
- The image below by Damien Benveniste illustrates the interpolation concept in detail.
Extending Context Window of Large Language Models via Position Interpolation
- This paper introduces a technique called Position Interpolation (PI) to extend the context length of large language models (LLMs) like Llama without compromising their performance.
- LLMS use positional encodings, such as RoPE, to represent the order of tokens in a sequence. However, naively fine-tuning these models on longer contexts can be slow and ineffective, especially when extending the context length by a large factor (e.g., 8 times).
- The key insight behind PI is that extrapolating positional encodings beyond the trained range can result in unstable and out-of-distribution attention scores. Instead, PI interpolates between the trained integer steps to create smooth and stable positional encodings.
- To do this, PI downscales the positional indices before computing the positional encodings. For instance, if the original context length is 4096, PI rescales the indices from [0, 4096] to [0, 2048], matching the original length. This effectively interpolates the positional encodings between the original integer steps, reducing the maximum relative distance and making the attention scores more stable.
- During fine-tuning, the model adapts quickly to the interpolated positional encodings, which are more stable than extrapolated ones. The authors prove that the interpolated attention score has a much smaller upper bound than the extrapolated attention score, ensuring that the model’s behavior remains consistent and predictable.
- Experiments demonstrate that PI successfully extends models like Llama-7B to handle context lengths of up to 32768 with only 1000 training steps. Evaluations on various tasks, such as language modeling, question answering, and retrieval, confirm that the extended models effectively leverage long contexts without sacrificing performance on shorter contexts.
- Thus, Position Interpolation offers a simple yet effective way to extend the context length of LLMs like Llama. By downscaling positional indices and interpolating between trained integer steps, PI creates smooth and stable positional encodings, enabling models to adapt to longer contexts without losing stability or performance.
- The technique was originally proposed by u/emozilla on Reddit as “Dynamically Scaled RoPE further increases performance of long context Llama with zero fine-tuning” and allows us to scale out the context length of models without fine-tuning by dynamically interpolating RoPE to represent longer sequences while preserving performance.
- While it works well out of the box, performance can be further improved by additional fine-tuning. With RoPE scaling, companies can now easily extend open-source LLMs to the context lengths which work for their given use case.
- From the Reddit post:
- “When u/kaiokendev first posted about linearly interpolating RoPE for longer sequences, I (and a few others) had wondered if it was possible to pick the correct scale parameter dynamically based on the sequence length rather than having to settle for the fixed tradeoff of maximum sequence length vs. performance on shorter sequences. My idea was to use the exact position values for the first 2k context (after all, why mess with a good thing?) and then re-calculate the position vector for every new sequence length as the model generates token by token. Essentially, set scale to original model context length / current sequence length. This has the effect of slowly increasing scale as the sequence length increases.
- I did some experiments and found that this has very strong performance, much better than simple linear interpolation. When u/bloc97 posted his NTK-Aware method, it was much closer to this dynamic linear scaling in terms of performance. Compared to dynamic linear scaling, NTK-Aware has higher perplexity for shorter sequences, but better perplexity at the tail end of the sequence lengths. Unfortunately, it also suffers from catastrophic perplexity blowup, just like regular RoPE and static linear scaling.
- The main hyperparamter of NTK-Aware is \(\alpha\). Like static linear scaling, it represents a tradeoff between short/long sequence performance. So I thought, why not use the same dynamic scaling method with NTK-Aware? For Dynamic NTK, the scaling of \(\alpha\) is set to (\(\alpha\) * current sequence length / original model context length) - (\(\alpha\) - 1). The idea again is to dynamically scale the hyperparameter as the sequence length increases.
- This uses the same methodology as NTK-Aware (perplexity on GovReport test). You can check out all the code on GitHub.”
- Hugging Face Transformers now supports RoPE-scaling (rotary position embeddings) to extend the context length of large language models like Llama, GPT-NeoX, or Falcon.
- So in essence, RoPE scaling dynamically rescales relative position differences based on the input length, analogous to a rope stretching and contracting.
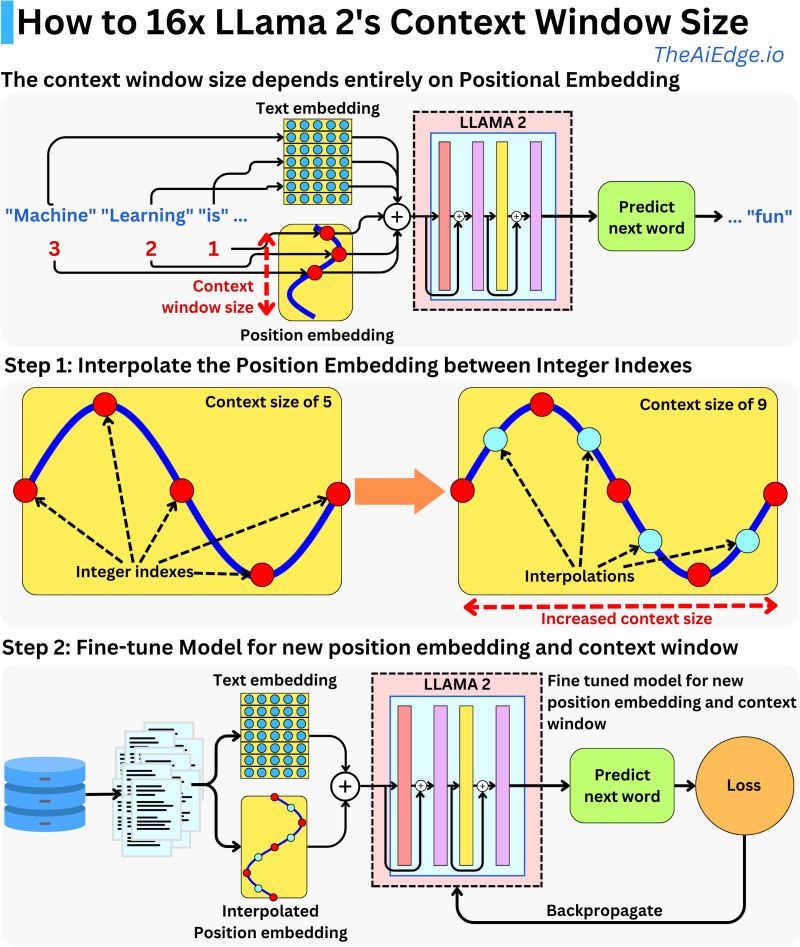
Deep Dive into how Llama 2’s context window increased
- Why Llama 2 is a Preferred Choice for Large Context Windows:
- Llama 2, despite initially appearing to have a smaller context window size (4096 tokens or approximately 3000 words) compared to models like ChatGPT, GPT-4, and Claude 2, offers significant advantages due to its open-source nature and the innovative use of Rotary Positional Embeddings (RoPE).
- Understanding the Typical Transformer Architecture:
- Most transformer models, including Llama 2, consist of:
- Embeddings: Used to encode the text input.
- Transformer Blocks: Execute the primary processing tasks.
- Prediction Head: Tailored to the learning task at hand.
- The context size, or the amount of text the model can consider at once, is defined by the size of the positional embedding, which combines with the text embedding matrix to encode text.
- Rotary Positional Embeddings (RoPE) in Llama 2:
- Llama 2 uses Rotary Positional Embeddings (RoPE), distinguishing it from models that use typical sine function encoding. This method modifies each attention layer in such a way that the computed attention between input tokens is solely dependent on their distance from each other, rather than their absolute positions in the sequence. This relative positioning allows for more flexible handling of context windows.
- Extending the Context Window with Interpolation:
- Meta, the developer of Llama 2, employs a technique to extend the context window by interpolating at non-integer positions, allowing the model to process text inputs much larger than its original window size, maintaining its performance level.
- Implementation:
- The practical implementation of extending the context window involves rescaling the integer positions, and a minor modification in the model’s code can accomplish this. Despite the model not being initially trained for extended position embedding, it can be fine-tuned to adapt to the new context window and can dynamically adjust to the user’s needs, especially when it’s used to fine-tune on private data.
- Llama 2’s approach to positional embeddings and its open-source nature make it a versatile choice for tasks requiring large context windows. With simple modifications and fine-tuning, it can adapt to varying needs while maintaining optimal performance, proving to be a highly flexible and efficient model. The research and methodology involved can be further explored in Chen et al. (2023).
Background: NTK, NTK-Aware, and Dynamic NTK
- Let’s go over how NTK and Dynamic NTK are associated with extending the context length in LLMs, enabling them to process and understand longer sequences of text.
NTK (Neural Tangent Kernel)
- NTK, or Neural Tangent Kernel, is a fundamental concept in machine learning and neural networks.
- It describes how neural networks, particularly deep neural networks, evolve during training under specific conditions.
- In technical terms, NTK is a kernel function that emerges in the infinite-width limit of neural networks, capturing their behavior during training.
- Researchers use NTK to understand neural network behavior, convergence speed, and the impact of architectural choices.
NTK-Aware Method
- Proposed in NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation. by
bloc97. - NTK-Aware addresses the challenge of extending the context window by preserving the model’s sensitivity to high-frequency components in the data.
- High-frequency components are crucial in language processing for capturing fine-grained details and nuances in text.
- The term “NTK” in “NTK-Aware” relates to the Neural Tangent Kernel, a theoretical framework describing how the output of a neural network changes in response to small changes in its parameters.
- When extending the context window, NTK-Aware adjusts the model to prevent the loss of sensitivity to high-frequency components. This may involve weight or architecture modifications to compensate for potential detail loss when processing longer sequences.
Dynamic NTK Method
- Dynamic NTK interpolation, a part of YaRN, dynamically adapts the model’s attention mechanism based on input sequence length.
- Instead of a fixed setting for extended contexts, the model adjusts its processing according to the actual sequence length.
- For shorter sequences near the training length, adjustments are minimal, but as sequence length increases, Dynamic NTK scales the adaptations.
- NTK-Aware focuses on specific adjustments to preserve high-frequency information in extended contexts, while Dynamic NTK offers flexibility and efficiency by tailoring adjustments to varying context sizes. Both methods enable language models to handle longer text sequences beyond their original training limits. Dynamic NTK mechanism thus interpolates frequencies unevenly, keeping high frequencies intact.
- Dynamic NTK interpolation is a key component of YaRN that empowers language models to handle extended context windows with improved efficiency and performance.
Related Papers
Extending Context Window of Large Language Models via Positional Interpolation
- This paper by Chen et al. from Meta AI in 2023 presents Position Interpolation (PI) that extends the context window sizes of RoPE-based pretrained LLMs such as LLaMA models to up to 32768 with minimal fine-tuning (within 1000 steps), while demonstrating strong empirical results on various tasks that require long context, including passkey retrieval, language modeling, and long document summarization from LLaMA 7B to 65B.
- Meanwhile, the extended model by Position Interpolation preserve quality relatively well on tasks within its original context window. To achieve this goal, Position Interpolation linearly down-scales the input position indices to match the original context window size, rather than extrapolating beyond the trained context length which may lead to catastrophically high attention scores that completely ruin the self-attention mechanism.
- They present a theoretical study which shows that the upper bound of interpolation is at least ∼600x smaller than that of extrapolation, further demonstrating its stability.
- Models extended via Position Interpolation retain its original architecture and can reuse most pre-existing optimization and infrastructure.
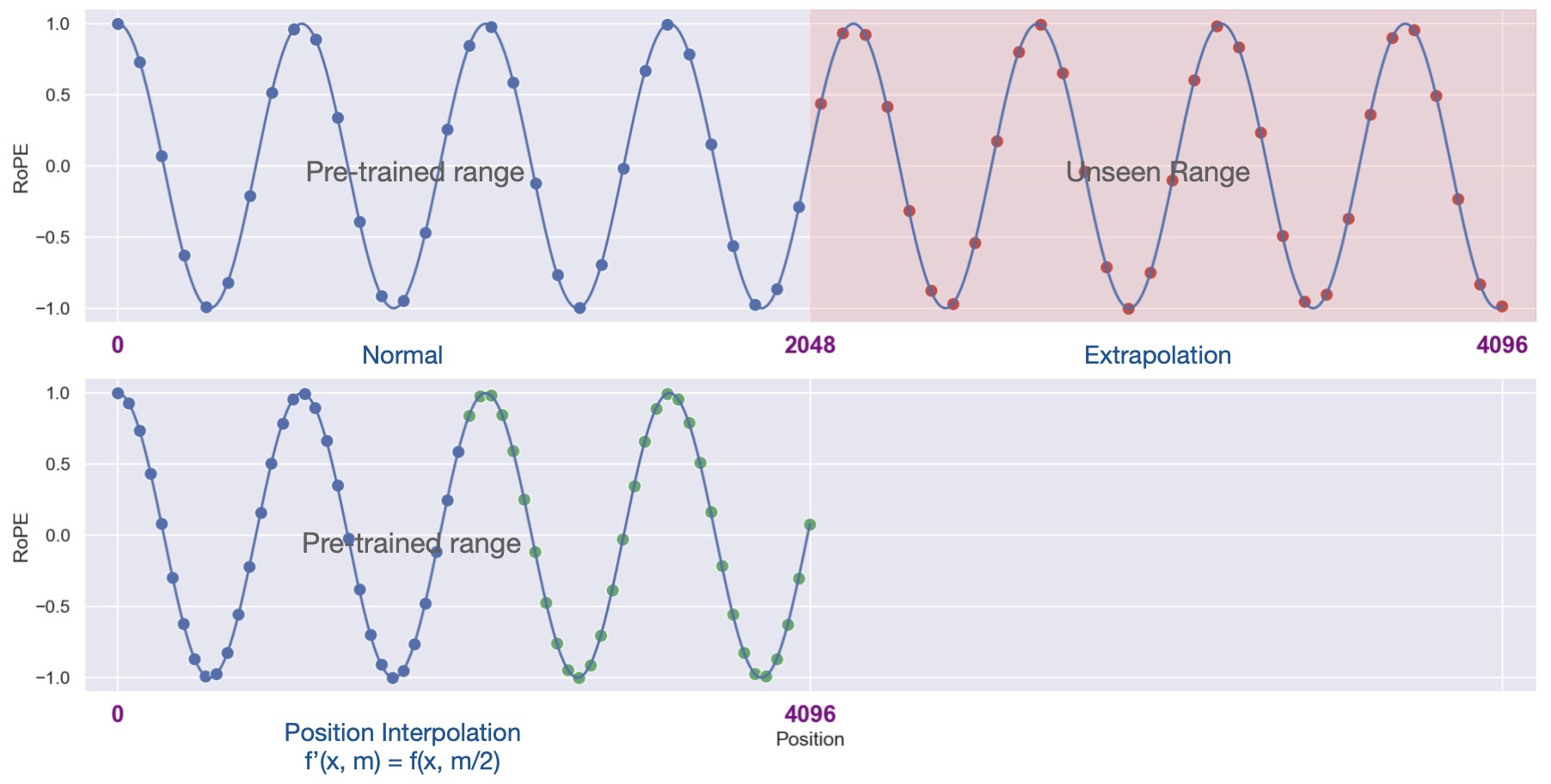
- The following figure from the paper illustrates the Position Interpolation method. Consider a Llama model pre-trained with a 2048 context window length. Upper left illustrates the normal usage of an LLM model: input position indices (blue dots) are within the pre-trained range. Upper right illustrates length extrapolation where models are required to operate unseen positions (red dots) up to 4096. Lower left illustrates Position Interpolation where we downscale the position indices (blue and green dots) themselves from [0, 4096] to [0, 2048] to force them to reside in the pretrained range.
YaRN: Efficient Context Window Extension of Large Language Models
- This paper by Peng et al. from Nous Research, EleutherAI, and the University of Geneva, proposes Yet Another RoPE extensioN method (YaRN) to efficiently extend the context window of transformer-based language models using Rotary Position Embeddings (RoPE).
- The authors address the limitation of transformer-based language models, specifically their inability to generalize beyond the sequence length they were trained on. YaRN demonstrates a compute-efficient way to extend the context window of such models, requiring significantly fewer tokens and training steps compared to previous methods.
- YaRN enables Llama models to effectively utilize and extrapolate to context lengths much longer than their original pre-training would allow. This method surpasses previous state-of-the-art approaches in context window extension.
- The paper details various technical aspects of YaRN, including its capability to extrapolate beyond the limited context of a fine-tuning dataset. The models fine-tuned using YaRN have been reproduced online, supporting context lengths up to 128k.
- YaRN introduces an innovative technique known as “Dynamic NTK” (Neural Tangents Kernel) interpolation, which modifies the attention mechanism of the model. This dynamic scaling allows the model to handle longer contexts without extensive retraining. By doing so, YaRN surpasses previous approaches in context window extension and significantly reduces the computational resources required. Put simply, Dynamic NTK is designed to address the challenge of extending the context window of transformer-based language models using Rotary Position Embeddings (RoPE). It achieves this by dynamically scaling the attention mechanism of the model, allowing it to efficiently process longer text sequences without requiring extensive retraining.
- Dynamic NTK interpolation modifies the traditional attention mechanism to adapt to extended contexts, ensuring that the model can effectively utilize and extrapolate to context lengths much longer than its original pre-training would allow. This dynamic scaling approach optimizes the use of available resources and computational power.
- Dynamic NTK interpolation is a key component of YaRN that empowers language models to handle extended context windows with improved efficiency and performance, making it a valuable advancement in the field of large language models.
- Additionally, YaRN incorporates a temperature parameter that affects the perplexity across different data samples and token positions within the extended context window. Adjusting this temperature parameter modifies the attention mechanism, enhancing the model’s ability to handle extended context lengths efficiently.
- Extensive experiments demonstrate YaRN’s efficacy. For instance, it achieves context window extension of language models with RoPE as the position embedding, using only about 0.1% of the original pre-training corpus, a significant reduction in computational resources.
- The following figure from the paper illustrates that evaluations focus on several aspects, such as perplexity scores of fine-tuned models with extended context windows, the passkey retrieval task, and performance on standardized LLM benchmarks. YaRN models show strong performance across all contexts, effectively extending the context window of Llama 2 models to 128k. The following figure from the paper illustrates the sliding window perplexity (S = 256) of ten 128k Proof-pile documents truncated to evaluation context window size.
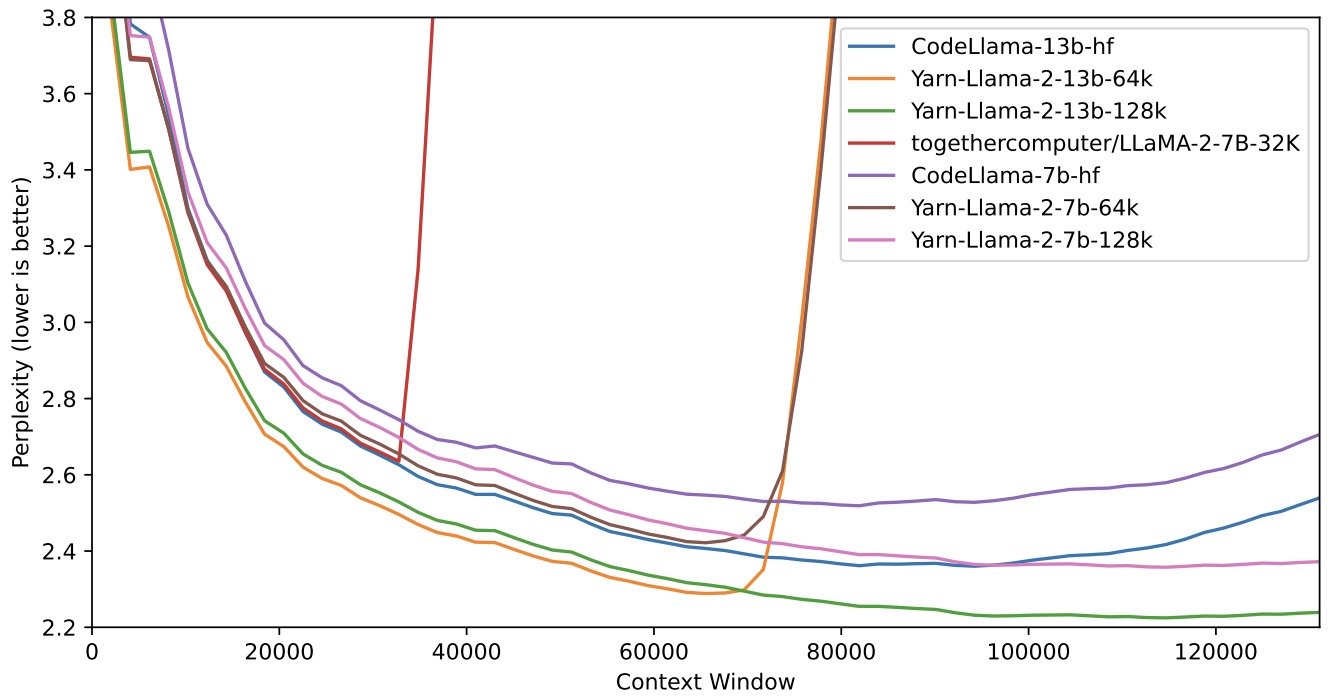
- The paper concludes that YaRN improves upon all existing RoPE interpolation methods and acts as a highly efficient drop-in replacement. It preserves the original abilities of fine-tuned models while attending to very large context sizes and allows for efficient extrapolation and transfer learning under compute-constrained scenarios.
- The research illustrates YaRN as a significant advancement in extending the context window of large language models, offering a more compute-efficient approach with broad implications for model training and performance.
- Code
LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
- This paper by Chen et al. from CUHK and MIT presents LongLoRA, an efficient fine-tuning approach that extends the context sizes of pre-trained large language models (LLMs) during fine-tuning, with limited computation cost.
- Typically, training LLMs with long context sizes is computationally expensive, requiring extensive training hours and GPU resources. For example, training on the context length of 8192 needs 16x computational costs in self-attention layers as that of 2048.
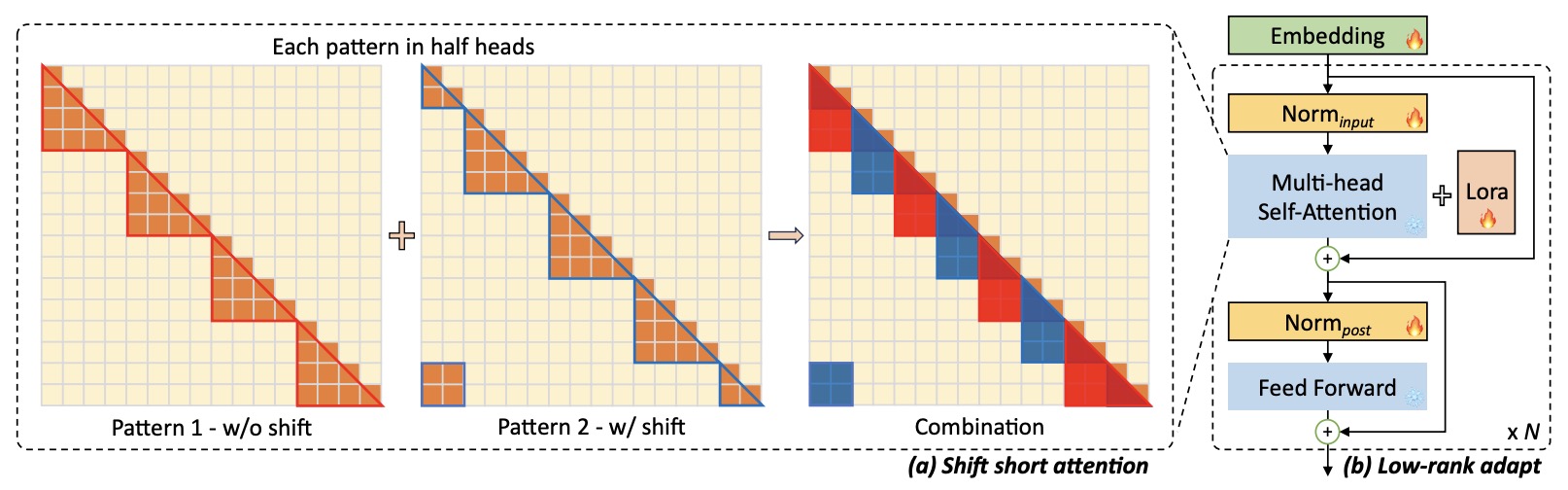
- LongLoRA speeds up the context extension of LLMs in two aspects. On the one hand, although dense global attention is needed during inference, fine-tuning the model can be effectively and efficiently done by sparse local attention. The proposed shift short attention ($$S^2$-attention) effectively enables context extension, leading to non-trivial computation savings with similar performance to fine-tuning with vanilla attention. Particularly, it can be implemented with only two lines of code in training, while being optional in inference.
- $$S^2$-attention splits the context into groups and only attends within each group. Tokens are shifted between groups in different heads to enable information flow. This approximates full attention but is much more efficient.
- On the other hand, they revisit the parameter-efficient fine-tuning regime for context expansion. Notably, they find that LoRA for context extension works well under the premise of trainable embedding and normalization. LongLoRA demonstrates strong empirical results on various tasks on Llama 2 models from 7B/13B to 70B.
- LongLoRA adopts Llama 2 7B from 4k context to 100k, or Llama 2 70B to 32k on a single 8x A100 machine. LongLoRA extends models’ context while retaining their original architectures, and is compatible with most existing techniques, like FlashAttention-2.
- In addition, to make LongLoRA practical, they collect a dataset, LongQA, for supervised fine-tuning. It contains more than 3k long context question-answer pairs.
- In summary, the key ideas are:
- Shift Short Attention (S2-Attn): During fine-tuning, standard full self-attention is very costly for long contexts. S2-Attn approximates the full attention using short sparse attention within groups of tokens. It splits the sequence into groups, computes attention in each group, and shifts the groups in half the heads to allow information flow. This is inspired by Swin Transformers. S2-Attn enables efficient training while allowing full attention at inference.
- Improved LoRA: Original LoRA only adapts attention weights. For long contexts, the gap to full fine-tuning is large. LongLoRA shows embedding and normalization layers are key. Though small, making them trainable bridges the gap.
- Compatibility with optimizations like FlashAttention-2: As S2-Attn resembles pre-training attention, optimizations like FlashAttention-2 still work at both train and inference. But many efficient attention mechanisms have large gaps to pre-training attention, making fine-tuning infeasible.
- Evaluation: LongLoRA extends the context of Llama 2 7B to 100k tokens, 13B to 64k tokens, and 70B to 32k tokens on one 8x A100 machine. It achieves strong perplexity compared to full fine-tuning baselines, while being much more efficient. For example, for Llama 2 7B with 32k context, LongLoRA reduces training time from 52 GPU hours to 24 hours.
- The following table from the paper illustrates an overview of LongLoRA designs. LongLoRA introduces shift short attention during finetuning. The trained model can retain its original standard self-attention during inference. In addition to plain LoRA weights, LongLoRA additionally makes embedding and normalization layers trainable, which is essential to long context learning, but takes up only a small proportion of parameters.
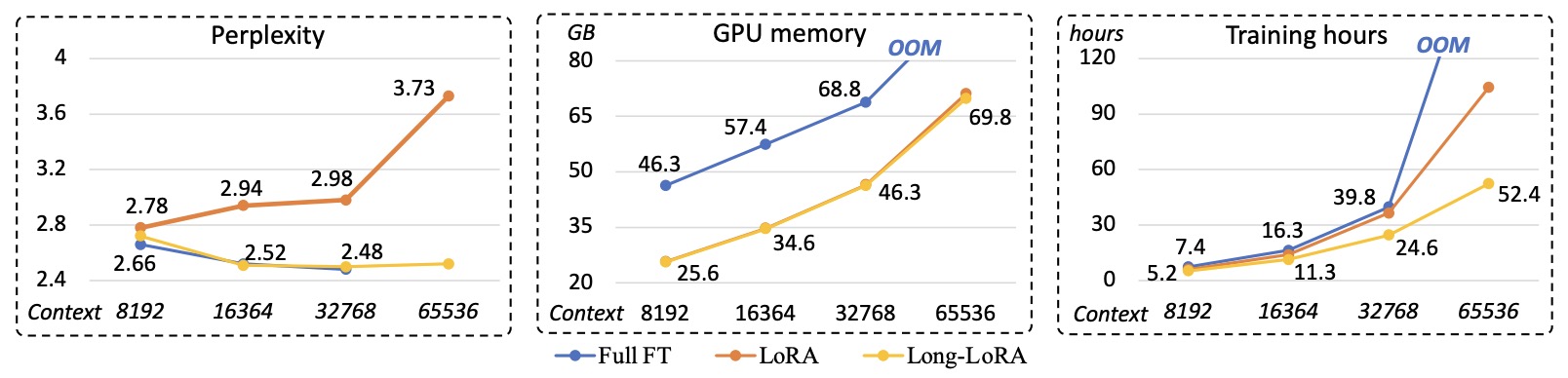
- The following table from the paper shows a performance and efficiency comparison between full fine-tuning, plain LoRA, and our LongLoRA. They fine-tune LLaMA2 7B on various context lengths, with FlashAttention-2 and DeepSpeed stage 2. Perplexity is evaluated on the Proof-pile test set. Plain LoRA baseline spends limited GPU memory cost, but its perplexity gets worse as the context length increases. LongLoRA achieves comparable performance to full fine-tuning while the computational cost is much less.
- Code.
LongQLoRA: Efficient and Effective Method to Extend Context Length of Large Language Models
- This paper by Yang from SYSU China introduces LongQLoRA, a novel method to extend the context length of large language models, particularly focusing on LLaMA2 models. The key innovation of LongQLoRA is its combination of Position Interpolation, QLoRA, and Shift Short Attention from LongLoRA to increase context lengths efficiently with limited resources.
- LongQLoRA was tested on LLaMA2 7B and 13B models, successfully extending their context length from 4096 to 8192, and even up to 12k tokens, using just a single 32GB V100 GPU and a mere 1000 fine-tuning steps. This performance was compared with other methods like LongLoRA and MPT-7B-8K, showing that LongQLoRA achieves competitive, if not superior, performance.
- The paper detailed the implementation of LongQLoRA, emphasizing its efficient fine-tuning method, which leverages quantization and low-rank adapter weights. Specifically, it sets the LoRA rank to 64 and adds these weights to all layers without training word embeddings and normalization layers. This approach significantly reduces the GPU memory footprint, enabling performance enhancements on resource-limited settings.
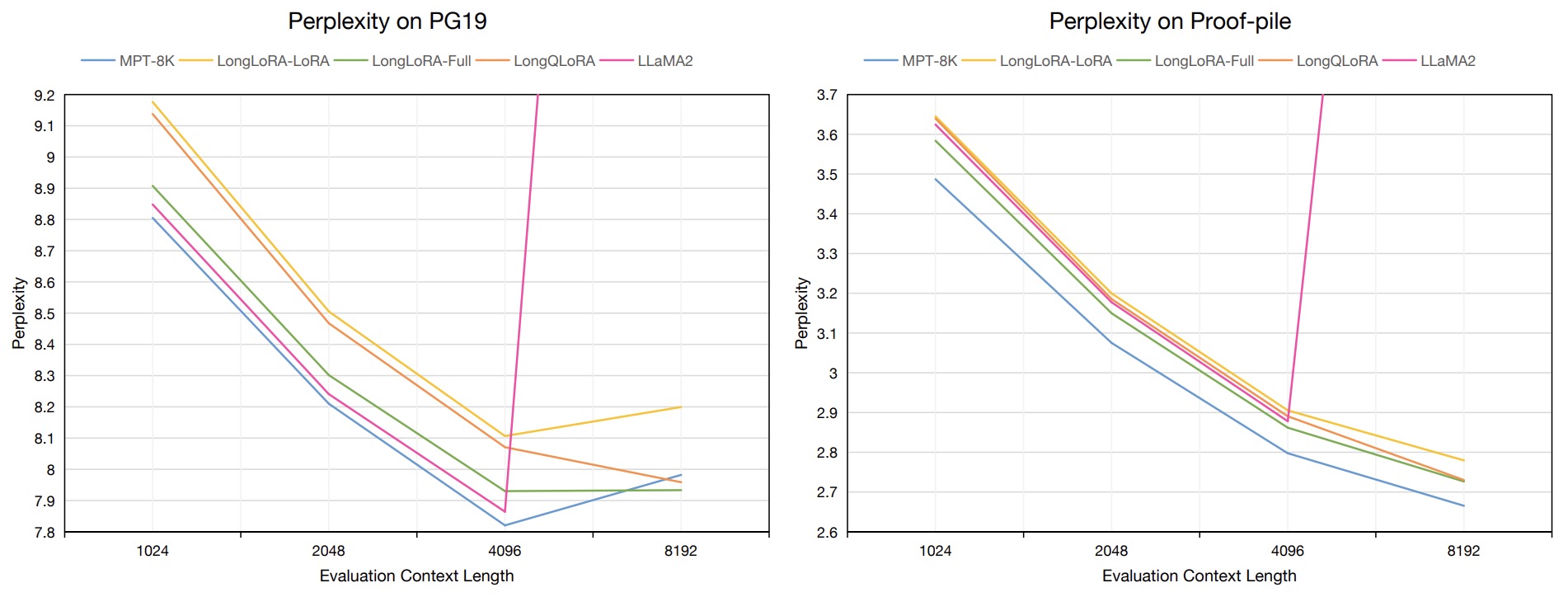
- The figure below from the original paper shows the evaluation perplexity of 7B models on PG19 validation and Proof-pile test datasets in evaluation context length from 1024 to 8192. All models are quantized to 4-bit in inference. LongQLoRA is finetuned based on LLaMA2-7B for 1000 steps with RedPajama dataset on a single V100 GPU. ‘LongLoRA-Full’ and ‘LongLoRA-LoRA’ mean LLaMA2-7B published by LongLoRA with full finetuning and LoRA finetuning respectively. MPT-7B-8K are better than LLaMA2, LongLoRA and LongQLoRA in context length from 1024 to 4096. LLaMA2-7B has very poor performance beyond the pre-defined context length of 8192. LongQLoRA outperforms LongLoRA-LoRA on both datasets in context length from 1024 to 8192. In context length of 8192, LongQLoRA is extremely close to LongLoRA-Full on Proof-pile test dataset, even better than MPT-7B-8K on PG19 validation dataset.
- Ablation studies were conducted to analyze the effects of LoRA rank, fine-tuning steps, and attention patterns in inference. These studies demonstrated the robustness and effectiveness of LongQLoRA across various settings and tasks.
- The authors also collected and built a long instruction dataset of 39k data points, focusing on tasks like book summarization and Natural Questions, to test LongQLoRA’s performance in both long and short context generation tasks.
- The results showed that LongQLoRA outperforms LongLoRA in several key metrics and closely matches the performance of more resource-intensive models like MPT-7B-8K. The model, training data, and code are publicly available for further research, emphasizing the paper’s contribution to the field of efficient language model training and context length extension.
MemGPT: Towards LLMs as Operating Systems
- This paper by Packer et al. from UC Berkeley introduces MemGPT, a groundbreaking system that revolutionizes the capabilities of large language models (LLMs) by enabling them to handle contexts beyond their standard limited windows. Drawing inspiration from traditional operating systems’ hierarchical memory systems, MemGPT manages different memory tiers within LLMs to provide extended context capabilities.
- The innovative MemGPT system allows LLMs to have virtually unlimited memory, mirroring the functionality of operating systems in managing memory hierarchies. This approach enables the LLMs to handle much larger contexts than their inherent limits would usually permit. The virtual context management technique, similar to virtual memory paging in operating systems, allows for effective data movement between fast and slow memory tiers, giving the appearance of a larger memory resource.
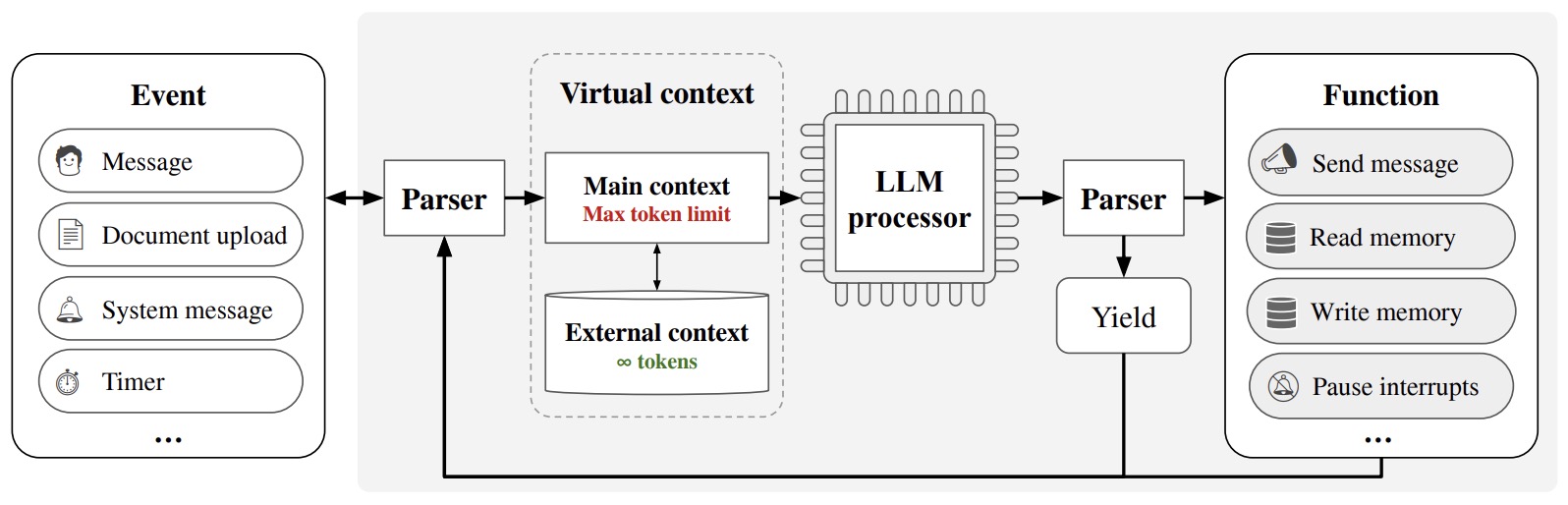
- MemGPT consists of two primary memory types: main context (analogous to OS main memory/RAM) and external context (similar to OS disk memory). The main context is the standard context window for LLMs, while external context refers to out-of-context storage. The system’s architecture enables intelligent management of data between these contexts. The LLM processor is equipped with function calls, which help manage its own memory, akin to an operating system’s management of physical and virtual memory.
- The following figure from the paper illustrates that in MemGPT (components shaded), a fixed-context LLM is augmented with a hierarchical memory system and functions that let it manage its own memory. The LLM processor takes main context (analogous to OS main memory/RAM) as input, and outputs text interpreted by a parser, resulting either in a yield or a function call. MemGPT uses functions to move data between main context and external context (analogous to OS disk memory). When the processor generates a function call, it can request control ahead of time to chain together functions. When yielding, the processor is paused until the next external event (e.g., a user message or scheduled interrupt).
- One of the key features of MemGPT is its capability to easily connect to external data sources. This feature enhances the system’s flexibility and utility in various applications. Furthermore, MemGPT comes with built-in support for LanceDB (YC W22), providing scalable semantic search via archival storage. This integration significantly boosts MemGPT’s ability to retrieve and process large amounts of data efficiently.
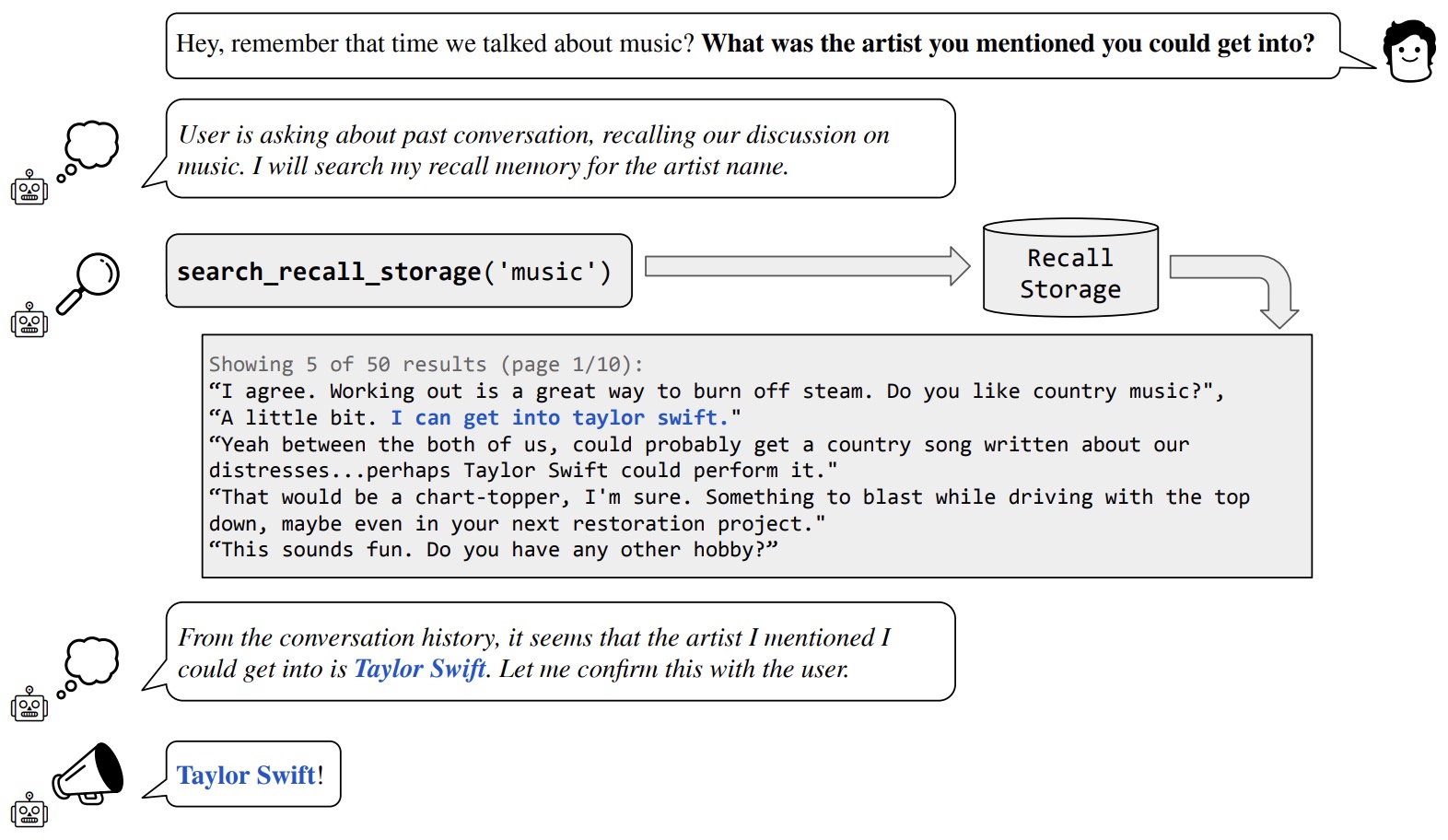
- The following figure from the paper illustrates the deep memory retrieval task. In the example shown, the user asks a question that can only be answered using information from a prior session (no longer in-context). Even though the answer is not immediately answerable using the in-context information, MemGPT can search through its recall storage containing prior conversations to retrieve the answer.
- The paper evaluates MemGPT’s performance in two critical domains: document analysis and conversational agents. In document analysis, MemGPT exceeds the capabilities of traditional LLMs by analyzing large documents that surpass the underlying LLM’s context window. For conversational agents, MemGPT demonstrates its effectiveness in maintaining long-term interactions with enhanced coherence and personalization, resulting in more natural and engaging dialogues.
- MemGPT’s versatility is further highlighted by its compatibility with many LLMs out of the box and the option to plug it into a custom LLM server. This feature ensures that MemGPT can be widely adopted and integrated into various existing LLM frameworks, enhancing their capabilities.
- Despite its pioneering approach and capabilities, the paper also notes limitations, such as reliance on specialized GPT-4 models for function calling and the proprietary nature of these models.
- Overall, MemGPT’s innovative approach, inspired by operating system techniques, represents a significant advancement in LLM capabilities. It opens new avenues for future research and applications, particularly in domains requiring massive or unbounded contexts and in integrating different memory tier technologies. The system’s ability to manage its own memory and connect to external sources, along with LanceDB support, positions MemGPT as a versatile and powerful tool in the realm of artificial intelligence.
- Code; Blog
LM-Infinite: Simple On-The-Fly Length Generalization for Large Language Models
- This paper by Han et al. from University of Illinois Urbana-Champaign and Meta, presents LM-Infinite, a method for enabling large language models (LLMs) to generate longer texts without retraining or additional parameters.
- LM-Infinite addresses the issue of LLMs’ length generalization failures, particularly on unseen sequence lengths. The authors identify three out-of-distribution (OOD) factors contributing to this problem: (1) unseen distances, (2) unseen number of tokens, and (3) implicitly encoded absolute position. The figure below from the paper shows a diagnosis of three OOD factors in LLMs.
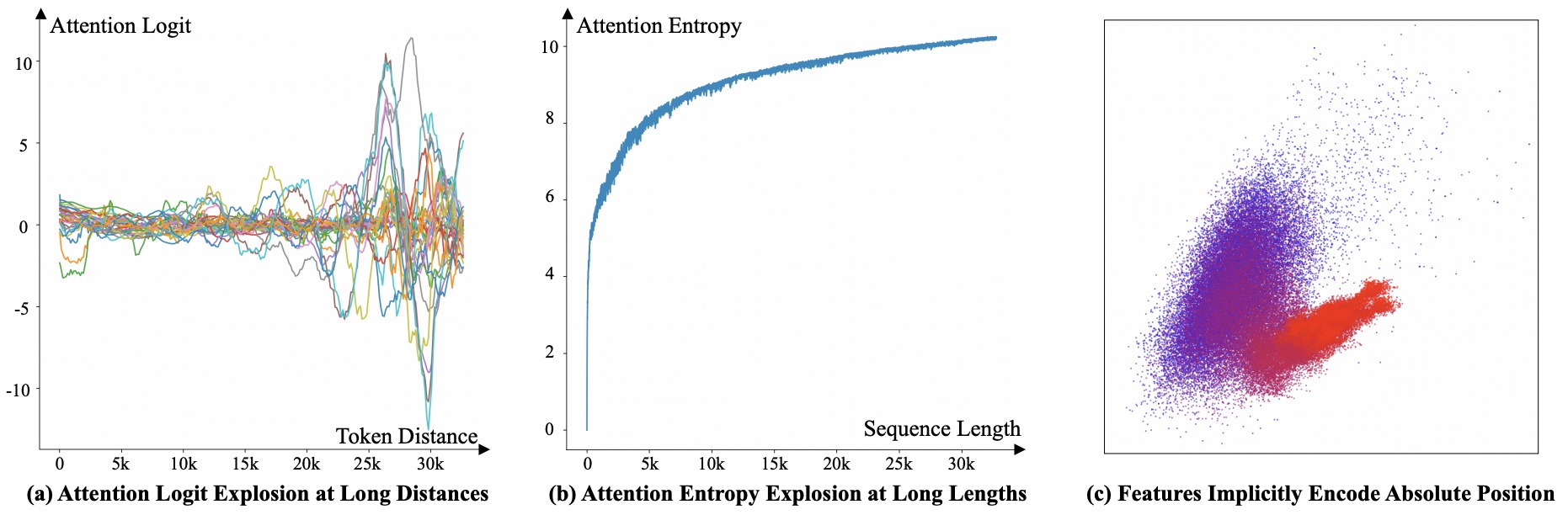
- The proposed solution, LM-Infinite, introduces a \(\Lambda\)-shaped attention mask and a distance limit during attention. This method is computationally efficient, requiring only \(O(n)\) time and space, and is compatible with various LLMs using relative-position encoding methods.
- In terms of implementation, LM-Infinite uses a sliding window approach with a \(\Lambda\)-shaped mask for attention calculation. It allows for longer sequence handling by dynamically adjusting the window size based on token distances. The model also incorporates a novel truncation scheme to handle tokens outside the attention window, which are summarized and reused to maintain context relevance without significant computational overhead. The figure below from the paper shows: (a) LM-Infinite is a plug-and-play solution for various LLMs, consisting of a \(\Lambda\)-shaped mask and a distance constraint during attention. (b) A conceptual model for understanding how relative position encoding works.
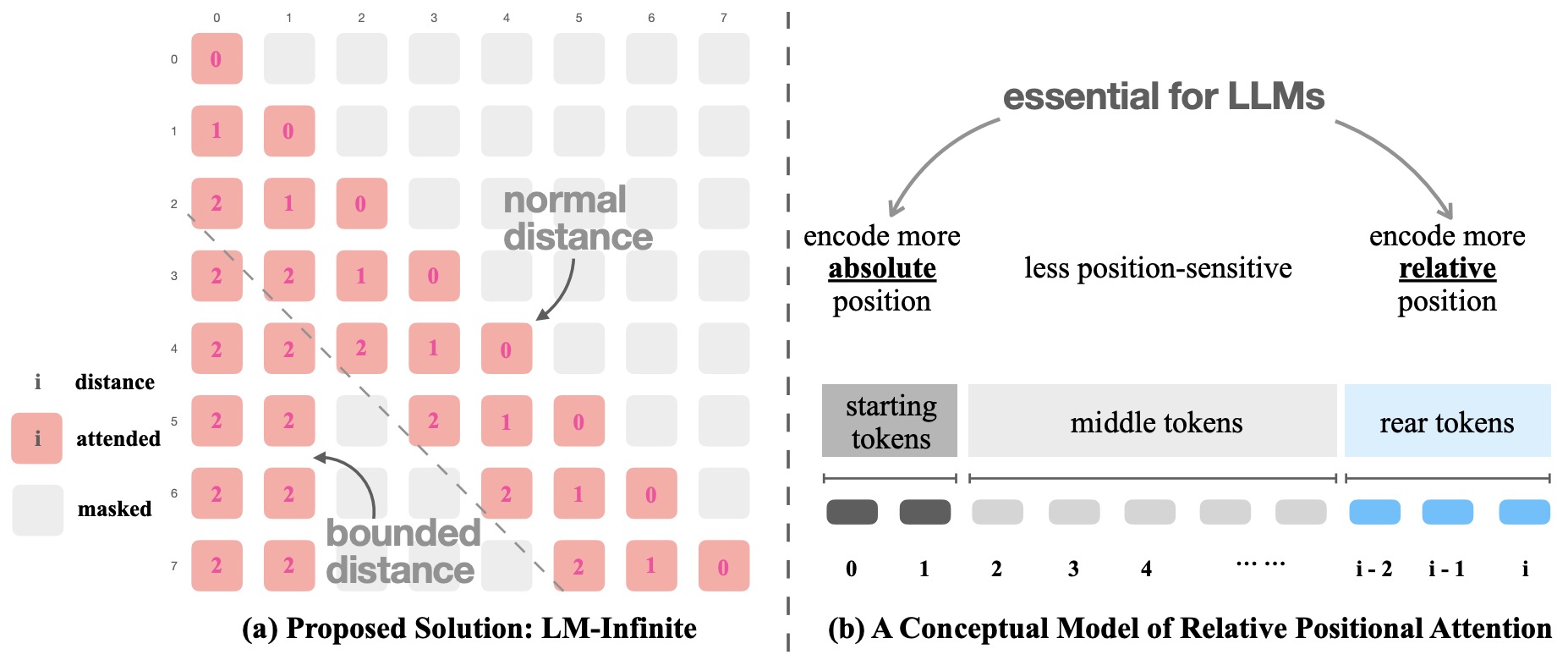
- An overview of LM-Infinite is illustrated in the figure above. This simple solution consists of two components: a \(\Lambda\)–shaped attention mask and a distance limit. As visualized in the figure, the \(\Lambda\)-shaped attention mask has two branches: a global branch on the left and a local branch on the right. The global branch allows each token to attend to the starting \(n_{\text {global }}\) tokens if they appear before the current token. The local branch allows each token to attend to preceding tokens within \(n_{\text {local }}\) distance. Any other tokens outside these two branches are ignored during attention. Here they heuristically set \(n_{\text {local }}=L_{\text {pretrain }}\) as equal to the training length limit. This choice includes the “comfort zone” of LLMs in attention. The selection of \(n_{\text {global }}\) has less effect on model performance, and they find that the range \([10,100]\) is generally okay. Note that \(n_{\text {global }}=0\) will lead to immediate quality degradation. This design is based on the OOD factors 2 and 3 above, where they aim to control the number of tokens to be attended to, while also ensuring the inclusion of starting tokens. Theoretically, LM-Infinite can access information from a context as long as \(n_{\text {layer }} L_{\text {pretrain }}\), because each deeper layer allows the attention to span \(L_{\text {pretrain }}\) farther than the layer above.
- The distance limit involves bounding the “effective distance” \(d$ within\)L_{\text {pretrain }}$. This only affects tokens that are in the global branch. In specific, recall that in relative positional encoding, the attention logit is originally calculated as \(w(\mathbf{q}, \mathbf{k}, d)$, where\)d$ is the distance between two tokens. Now they modify it as $$w\left(\mathbf{q}, \mathbf{k}, \min \left(d, L_{\text {pretrain }}\right)\right)$. This design is motivated by the OOD factor 1 and ensures that LLMs are not exposed to distances unseen during pre-training.
- LM-Infinite demonstrates consistent text generation fluency and quality for lengths up to 128k tokens on the ArXiv and OpenWebText2 datasets, achieving 2.72x decoding speedup without parameter updates.
- Evaluation includes experiments on ArXiv and OpenWebText2 corpora with models like LLaMA, Llama-2, MPT-7B, and GPT-J. LM-Infinite shows comparable or superior performance to LLMs fine-tuned on long sequences in terms of perplexity and BLEU/ROUGE metrics.
- The paper suggests that LM-Infinite can extend task-solving ability to longer sequences than training samples and offers potential for future work in understanding information in the masked-out attention region.
LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning
- This paper by Jin et al. addresses the limitation of Large Language Models (LLMs) in managing long context sequences, particularly due to their training on fixed-length sequences. This results in unpredictable behavior and performance degradation when LLMs encounter long input sequences during inference. The authors propose that LLMs inherently possess the ability to handle long contexts without requiring fine-tuning.
- Their core contributions are as follows:
- Self-Extend Method: The paper introduces ‘Self-Extend’, a method aimed at leveraging the intrinsic long context capabilities of LLMs. Self-Extend uses a FLOOR operation to map unseen large relative positions (encountered during inference) to known positions from the training phase. This approach is designed to address the positional out-of-distribution issue, allowing LLMs to process longer texts coherently without additional fine-tuning.
- Bi-Level Attention Information: Self-Extend constructs bi-level attention - group level and neighbor level. Group level attention is for tokens with long distances, employing the FLOOR operation on positions. Neighbor level attention targets nearby tokens without any modifications. This design aims to retain the relative ordering of information in extended texts.
- The figure below from the paper shows the attention score matrix (the matrix before Softmax operation) of the proposed Self-Extend while a sequence of length 10 is input to a LLM with pretraining context window (\(L\)) of length 7. The number is the relative distance between the corresponding query and key tokens. Self-Extend has two kinds of attention mechanism: for neighbor tokens within the neighbor window (\(w_n\), in this figure, it’s 4), it adapts the normal self-attention in transformers; for tokens out of the window, it adapts the values from the grouped attention. The group size (\(G\)) is set to 2. After the two parts merge, the same as the normal attention, the softmax operation is applied to the attention value matrix and gets the attention weight matrix.
- The effectiveness of Self-Extend was evaluated on popular LLMs like Llama-2, Mistral, and SOLAR across a variety of tasks, including language modeling, synthetic long context tasks, and real-world long context tasks. The results showed significant improvements in long context understanding, often surpassing fine-tuning-based methods.
- Performance was analyzed along the following dimensions:
- Language Modeling: Self-Extend was evaluated for language modeling on the PG19 dataset, which comprises long books. It effectively maintained low perplexity outside the pretraining context window for models like Llama-2-chat and Mistral.
- Synthetic Long Context Tasks: The method was assessed using the passkey retrieval task, testing the LLMs’ ability to recognize information throughout the entire length of a long text sequence.
- Real Long Context Tasks: The evaluation included benchmarks such as Longbench and L-Eval. Results showed notable performance improvements across different datasets. Self-Extend was found to perform comparably or better than several fine-tuned models, with some exceptions attributed to the specific characteristics of certain datasets.
- The paper concludes that Self-Extend, which is effective during inference without needing fine-tuning, can achieve performance on par with or superior to learning-based methods. This represents a significant advancement in enhancing the natural and efficient handling of longer contexts by LLMs.
In Search of Needles in a 11M Haystack: Recurrent Memory Finds What LLMs Miss
- This paper by Kuratov et al. from AIRI, MIPT, and London Institute for Mathematical Sciences addresses the challenge of processing long documents using generative transformer models. The authors introduce BABILong, a new benchmark designed to assess the capabilities of models in extracting and processing distributed facts within extensive texts. This benchmark aims to simulate real-world scenarios where essential information is interspersed with large amounts of irrelevant data, making it a suitable test for long-context processing.
- The authors developed BABILong by extending the bAbI tasks to include much longer contexts, using the PG19 dataset as background text. This benchmark allows the evaluation of models on document lengths up to millions of tokens, far exceeding the typical lengths used in existing benchmarks.
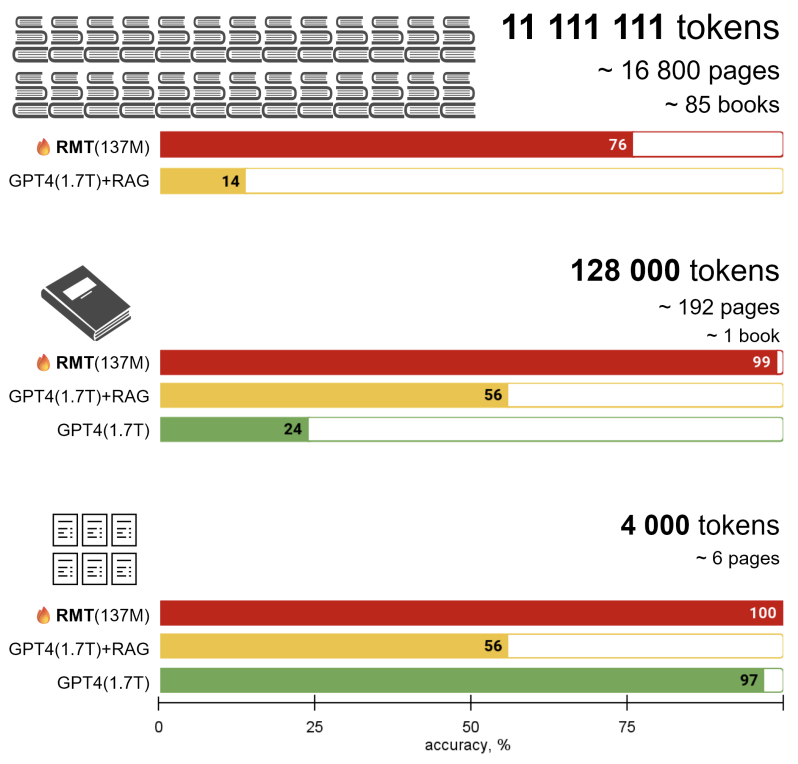
- The paper evaluates GPT-4 and RAG (Retrieval-Augmented Generation) on the BABILong tasks. Results show that these models can effectively handle sequences up to 104 elements but struggle with longer contexts. Specifically, GPT-4 and RAG were unable to maintain accuracy as context length increased, demonstrating a significant drop in performance for longer inputs.
- The figure below from the paper illustrates the fact that the memory augmented transformer answers questions about facts hidden in very long texts when retrieval augmented generation fails. We create a new BABILong dataset by randomly distributing simple episodic facts inside book corpus. Common RAG method fails to answer questions because order of facts matters. GPT-4 LLM effectively uses only fraction of the context and falls short for a full 128K window. Small LM (GPT-2) augmented with recurrent memory and fine-tuned for the task generalise well up to record 11M tokens. The parameter count for GPT-4 is based on public discussions.
- The figure below from the paper illustrates an example generation for BABILong dataset. Statements relevant for the question from a bAbILong sample are hidden inside a larger irrelevant texts from PG19.

- To address the limitations of existing models, the authors propose fine-tuning GPT-2 with recurrent memory augmentations. This approach allows the model to handle tasks involving up to 11 million tokens. The recurrent memory transformer (RMT) extends the context size by segmenting sequences and processing them recurrently, resulting in linear scaling with input size.
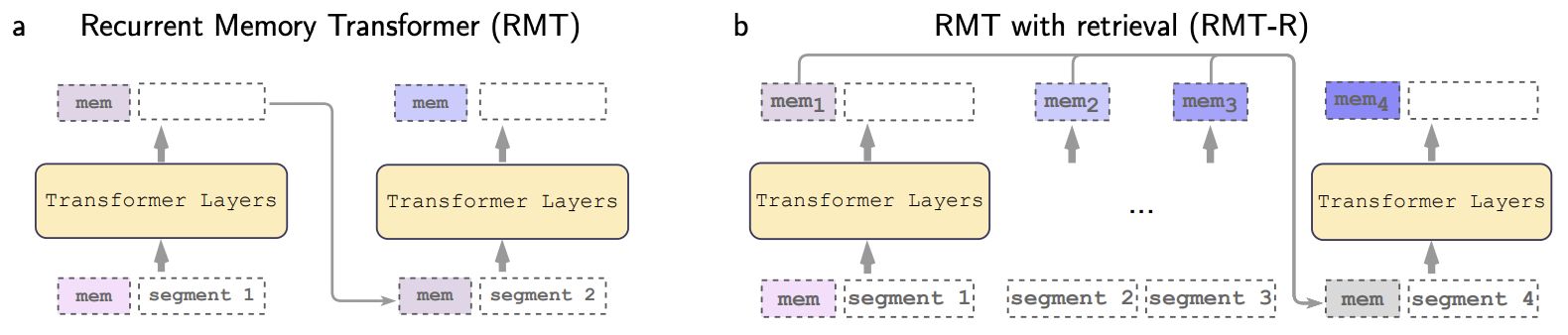
- The RMT uses memory tokens processed alongside segment tokens to retain information from previous segments. Each memory state consists of multiple memory tokens, allowing different views of past inputs. The model updates its memory state at each step, enabling it to maintain relevant information over long contexts. Additionally, the authors implemented self-retrieval for RMT, which involves cross-attention between all past states and the current memory state.
- The figure below from the paper illustrates the Recurrent Memory Transformer with self-retrieval from memory. (a) Recurrent memory transformer encodes information from the current segment to the memory vectors
[mem]. Memory vectors from the previous segment are passed over to the next segment and updated. (b) With self-retrieval it processes each segment sequentially and collects the corresponding memory states. Here, while processing segment 4, the model can retrieve from previous states from segments 1-3. This overcomes the memory bottleneck that can occur in purely recurrent models, similar to attention in RNNs.
- The authors used a curriculum training strategy for RMT and RMT-R (RMT with self-retrieval), starting with short sequences and gradually introducing longer ones. The models were trained on sequences up to 16k tokens and evaluated on sequences up to 10 million tokens. The results showed that both RMT and RMT-R significantly outperformed GPT-4 on long-context tasks, maintaining high performance even for extremely long sequences.
- The paper provides an analysis of memory states and attention patterns, showing that RMT effectively stores and retrieves relevant facts from memory. The visualizations demonstrate how the model updates its memory when encountering new facts and retrieves them when needed to answer questions.
- Overall, the proposed recurrent memory transformer demonstrates a substantial improvement in processing long sequences, setting a new record for input size handled by a neural network model. The approach highlights the potential of recurrent memory mechanisms to enhance the capabilities of language models in handling extensive contexts, paving the way for future research and development in this area.
- Code
Citation
@article{Chadha2020DistilledContextLengthExtension,
title = {LLM Context Length Extension},
author = {Chadha, Aman and Jain, Vinija},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}