Primers • Claude Code
- Overview
- Architecture
- Overview
- Agent Loop
- Execution Harness
- Role and Responsibilities
- Action Parsing and Dispatch
- Permission and Safety Enforcement
- Tool Execution and Environment Interaction
- Observation Capture and Reintegration
- Security Architecture
- Error Handling and Recovery
- Scheduling and Background Execution
- Remote and Distributed Execution
- Integration with State and Context
- Implications
- Tool System
- Context Manager
- Command System
- State and Persistence
- State Model
- Dual Memory Architecture
- Memory Hierarchy and Retrieval Strategy
- Retrieval Budgets and Context Efficiency
- Session History
- Persistence Mechanisms
- Cost and Usage Tracking
- State Management Architecture
- Background Consolidation and AutoDream
- Concurrency and Locking
- Remote and Distributed State
- Integration with Context
- Implications
- File-Based Memory
- Memory as Persistent Context
- The
CLAUDE.mdHierarchy - Directory Walking and Lazy Loading
- Rules as Scoped Memory
- Imports and Composition
- Auto Memory
- Memory and Commands
- Interaction with Compaction
- File-Based Retrieval versus Vector Retrieval
- Why Markdown Matters
- Practical Design Pattern
- Memory Failures, Context Rot, and Recovery
- Memory Failures, Context Rot, and Recovery
- Commands and Usage Patterns
- Workflows and Patterns
- Evaluation and Debugging
- Customization and Integration
- References
- Claude Code documentation and product resources
- Anthropic engineering and agent design
- Claude Code architecture analyses and deep dives
- Practitioner guides and workflows
- Talks, interviews, and practitioner insights
- Community posts and social media insights
- Core language model and transformer foundations
- Tool use, reasoning, and agent frameworks
- Memory, context, and long-horizon reasoning
- Iterative improvement and self-reflection
- Agent architectures and long-horizon systems
- Reinforcement learning and decision systems
- Citation
Overview
- Claude Code represents a transition from assistive code generation toward fully agentic software development, where a language model operates as an active participant in the software lifecycle rather than a passive tool. It integrates large language models, tool execution, and long-context reasoning into a cohesive system that runs locally and interacts directly with a developer’s environment. This shift is not merely incremental but architectural, redefining how software is specified, generated, and validated.
From Autocomplete to Agents
-
The evolution of AI-assisted programming began with sequence modeling advances such as Attention Is All You Need by Vaswani et al. (2017), which introduced the transformer architecture and enabled scalable attention over sequences. This was followed by contextual representation models like BERT by Devlin et al. (2018), which improved bidirectional understanding, and generative systems like GPT-3 by Brown et al. (2020), which demonstrated strong few-shot learning for code and natural language tasks.
-
Claude Code extends these capabilities into the domain of agentic execution. Instead of producing isolated outputs, the system operates in iterative loops of reasoning and action, similar to frameworks such as ReAct by Yao et al. (2022), which interleave reasoning traces with tool usage. This paradigm enables the model to plan multi-step workflows, execute commands, observe results, and refine its approach dynamically.
-
This transition is also reflected in modern product design. As discussed in Using Claude Code: session management and 1M context, the emphasis has shifted from single-turn interactions to long-running sessions where the model accumulates knowledge and adapts over time.
Local Agent Model
-
A defining feature of Claude Code is that it operates directly on the user’s machine rather than as a purely cloud-hosted interface. This design aligns with the notion of a persistent agent embedded within the developer’s workflow. The system has access to local files, can execute shell commands, and interacts with development tools in real time.
-
This local-first architecture provides several advantages. It enables tighter integration with project state, reduces latency in iterative workflows, and allows the model to act on real artifacts rather than abstractions. The uploaded materials describe this as a system that effectively “lives” on the computer and interacts continuously with its environment.
-
From a systems perspective, this can be viewed as an instance of embodied AI, where the model’s capabilities are extended through its ability to act within an environment. This idea resonates with broader trends in agent design, as explored in Toolformer by Schick et al. (2023), which demonstrates how models can learn to invoke tools to enhance their capabilities.
Context as State
-
Claude Code’s behavior is governed by its context window, which includes system prompts, conversation history, tool calls, outputs, and file contents. The Anthropic documentation defines the context window as everything the model can “see” when generating its next response in Using Claude Code: session management and 1M context.
-
This can be formalized as:
- The introduction of a 1M token context window represents a major increase in capacity, enabling the model to process entire codebases or long interaction histories. As discussed in Why Claude’s 1M context length is a big deal, this scale enables workflows that were previously infeasible, such as reasoning over full repositories in a single session.
Context Limits
- Despite this capacity, performance degrades as context grows due to the nature of attention. As more tokens are added, attention becomes diffuse, reducing focus on relevant information. This phenomenon, known as context rot, is explicitly discussed in Anthropic’s guide, where increasing context can “distract from the current task” in long sessions (refer Using Claude Code: session management and 1M context).
The Agentic Execution Loop
- Claude Code operates through a continuous loop of reasoning, action, and observation. At each step, the model evaluates the current state, decides on an action such as editing code or invoking a tool, and incorporates the resulting output into its context. This can be formalized as:
-
This formulation parallels reinforcement learning frameworks such as Deep Q-Networks by Mnih et al. (2015), where agents update their state based on interactions with an environment. In Claude Code, however, the policy is encoded in the pretrained model and refined through prompt engineering and system design rather than explicit reward optimization.
-
The effectiveness of this loop depends heavily on the surrounding infrastructure. As discussed in Building Claude Code, the “harness” around the model, including context management, tool integration, and system prompts, is as important as the model itself in enabling reliable agentic behavior.
System Architecture
-
Claude Code can be understood as a layered system where the language model interacts with a structured execution environment. The core components include the model responsible for reasoning and generation, the tooling layer that enables interaction with files and external systems, the context manager that governs what information is visible at each step, and the execution harness that orchestrates the entire process.
-
As illustrated in the diagram on page 1, the context window aggregates multiple sources of information into a single sequence that the model attends over, with a hard cutoff at the maximum token limit.
Commands and Interaction
-
Claude Code exposes commands as structured controls over the agent’s state, not merely as shortcuts. The official Commands - Claude Code Docs explains that commands manage permissions, clear or compact context, switch models, run workflows, and orchestrate tasks.
-
Core commands directly reshape the session.
/clearstarts with empty context,/compactsummarizes history while preserving continuity,/rewindremoves later turns and returns to an earlier checkpoint, and/resumerestores prior sessions. Workflow commands extend this control plane:/planseparates design from execution,/agentsmanages sub-agent configurations, and/batchdecomposes large changes into parallel work units.
Pro Tips and Patterns
-
Effective use of Claude Code depends on context engineering rather than prompt engineering alone. Practical guidance from A Guide to Claude Code 2.0 and Here are 50+ slash commands in Claude Code emphasizes keeping context lean, initializing projects with
/init, using/compactproactively, separating planning from execution with/plan, and relying on build or test validation loops. -
A productive workflow is to start in plan mode, approve or revise the plan, execute changes, inspect
/diff, run tests, then compact only the useful session state. For large refactors,/batchis preferable because it decomposes work into isolated agent tasks instead of overloading one context window.
Implications
- The integration of long-context reasoning, tool execution, and structured commands transforms programming into a supervisory activity. Developers increasingly define intent, guide workflows, and validate outputs rather than writing code line by line.
Architecture
Overview
-
Claude Code’s architecture is best understood as a system where the language model is only a small component embedded within a much larger deterministic infrastructure. While the model performs reasoning, the majority of system behavior emerges from orchestration layers including context management, permission enforcement, tool routing, and execution control. A detailed architectural analysis in shows that only a small fraction of the system corresponds to model-driven logic, with the overwhelming majority implemented as structured systems that govern reliability, safety, and scalability.
-
This reflects a broader shift in agent design: as model capabilities converge, the harness becomes the primary differentiator. This observation is explicitly articulated in the design-space analysis in , which notes that Claude Code adopts a minimal scaffolding approach where the model performs reasoning while the harness enforces boundaries.
-
At a system level, Claude Code decomposes into a pipeline of interacting components:
- User and interface layer (CLI, IDE, SDK)
- Agent loop (central reasoning-execution cycle)
- Permission system (safety and approval)
- Tool layer (actions and environment interaction)
- State and persistence layer (memory and session storage)
- Execution environment (local or remote runtime)
-
The following figure (source) shows the end-to-end architecture Claude Code agent pipeline from user input through interfaces, the agent loop, permission system, tools, execution environment, and state persistence. The system operates as a closed loop where actions produce observations that feed back into subsequent reasoning. This architecture closely mirrors agent frameworks such as ReAct by Yao et al. (2022), where reasoning and acting are interleaved, but extends it with production-grade infrastructure for safety, persistence, and extensibility.
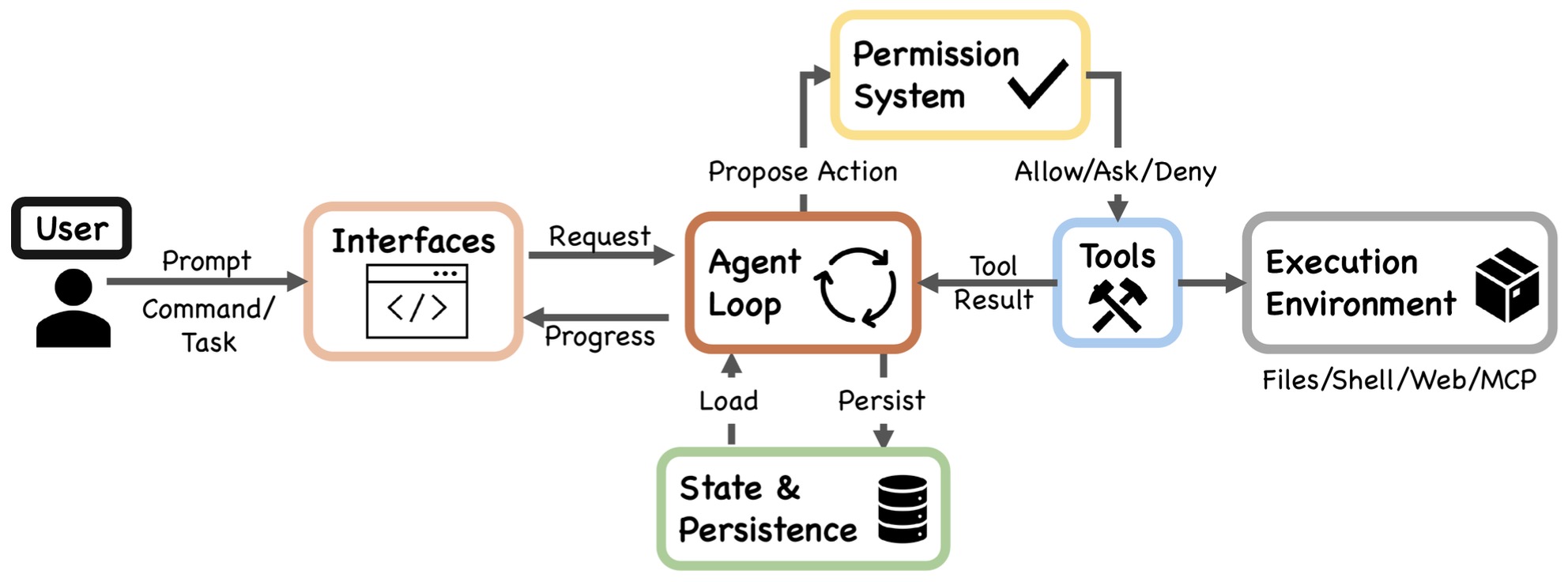
- The following figure (source) shows Claude Code’s layered architecture, including surface, core, safety/action, backend, and state layers.
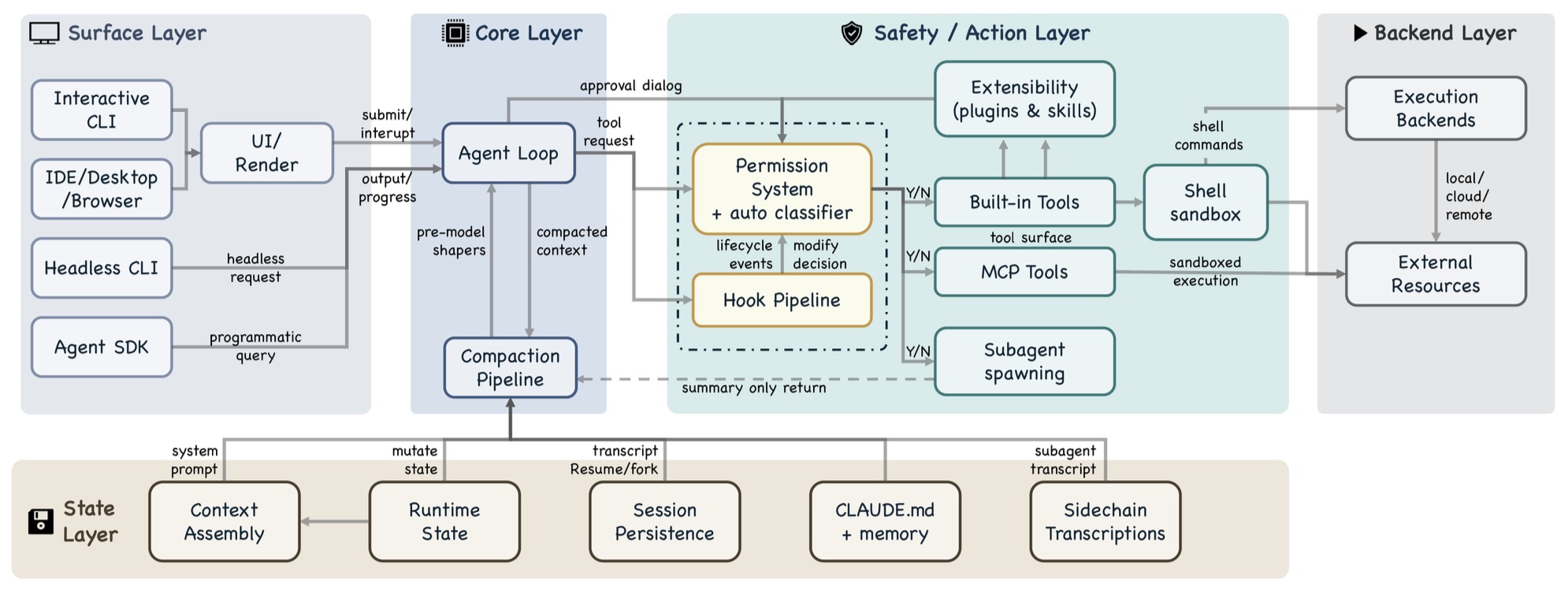
- A key implication is that Claude Code is not a monolithic model-driven system but a composition of interacting subsystems, each responsible for a specific aspect of agent behavior. The remainder of this section examines these subsystems in detail.
Agent Loop
-
The agent loop is the central execution engine of Claude Code, responsible for orchestrating the continuous cycle of reasoning, action, and observation. Unlike traditional request-response systems, Claude Code operates as a persistent process where each iteration builds on accumulated state, enabling long-horizon tasks and adaptive behavior.
-
At its core, the agent loop is implemented as a query orchestration engine that manages conversation state, tool execution, and streaming outputs. A detailed breakdown in Claude Code — Source Code Documentation & Analysis describes this component as the “conversation loop orchestrator,” responsible for maintaining message history, dispatching tool calls, and handling retries and streaming.
Execution Cycle
-
Each iteration of the loop follows a structured pipeline:
- Context assembly from system prompts, history, and environment
- Model inference to produce the next action or response
- Tool invocation if required
- Observation capture from tool outputs
- Context update with new information
-
This cycle repeats until the task is complete. Conceptually, this can be expressed as:
- This formulation aligns closely with agent frameworks such as ReAct by Yao et al. (2022), which demonstrate that interleaving reasoning and acting improves performance on multi-step tasks by grounding decisions in external feedback.
Query Engine Implementation
-
The agent loop is concretely implemented through a central query engine module. According to Claude Code — Source Code Documentation & Analysis, this module handles several critical responsibilities in a single execution path.
-
It maintains structured message histories across roles such as user, assistant, system, and tool outputs, ensuring that all interactions are encoded into context. It supports real-time streaming of tokens, allowing partial outputs to be rendered while the model continues generating. It orchestrates tool calls by parsing model outputs, dispatching the appropriate tool, and reinserting results into the loop. It also implements retry logic with exponential backoff to handle API errors and rate limits.
-
An important optimization is prompt caching, where repeated portions of context are reused across iterations to reduce token usage and latency. This reflects techniques explored in retrieval-augmented systems such as RETRO by Borgeaud et al. (2022), where cached or retrieved context improves efficiency and scalability.
Streaming and Interleaving
-
A distinguishing feature of the agent loop is its support for streaming and interleaved execution. Rather than waiting for the model to complete a full response, the system processes tokens incrementally. When the model emits a tool call, execution is paused, the tool is invoked, and the result is injected back into the context before generation continues.
-
This creates a fine-grained interleaving between reasoning and acting. The design guide in Dive into Claude Code highlights that this interleaving is critical for responsiveness and correctness, as it allows the model to adapt mid-generation based on new information.
Auto-Compaction within the Loop
-
The agent loop is tightly integrated with context management through automatic compaction. When the context window approaches its limit, the system triggers a summarization step that compresses earlier interactions into a shorter representation.
-
As described in Using Claude Code: session management and 1M context, this compaction process allows the loop to continue operating beyond the nominal context limit, effectively extending the usable horizon of the system.
-
Internally, compaction is implemented as a secondary model invocation that produces a structured summary of prior interactions. This design mirrors hierarchical memory approaches, where detailed short-term information is periodically consolidated into abstract representations.
Tool-Oriented Control Flow
-
Control flow in the agent loop is largely determined by tool usage. When the model decides to invoke a tool, it effectively transfers control to the execution environment. The loop then resumes once the tool returns a result.
-
This pattern can be interpreted as a form of dynamic program synthesis, where the model generates a sequence of actions that are executed externally. Research such as Toolformer by Schick et al. (2023) shows that models can learn to decide when and how to call tools, and Claude Code operationalizes this capability in a production setting.
Error Handling and Retry Logic
-
Robustness in the agent loop is achieved through explicit error handling mechanisms. The query engine detects failures such as API errors, tool execution failures, or permission denials, and applies retry strategies with backoff.
-
This ensures that transient failures do not terminate the session. It also allows the model to adapt its strategy based on observed errors, incorporating failure signals into subsequent reasoning.
Cost and Usage Tracking
-
Another important aspect of the agent loop is cost tracking. The system monitors token usage across input, output, and cached segments, and computes associated costs based on model pricing.
-
This information is used both for user feedback and for internal optimization, such as deciding when to compact context or reuse cached prompts. The documentation in Claude Code — Source Code Documentation & Analysis notes that cost tracking is integrated directly into the query engine, making it part of the core execution path.
Multi-Interface Consistency
-
The same agent loop underlies all interfaces, including CLI, SDK, and IDE integrations. This unified design ensures that behavior is consistent regardless of how the system is accessed.
-
The architectural guide Dive into Claude Code emphasizes that this single-loop design simplifies reasoning about system behavior and reduces duplication across interfaces.
Implications
-
The agent loop transforms Claude Code from a static model into a dynamic system capable of sustained interaction. By integrating reasoning, action, and feedback into a single pipeline, it enables complex workflows such as iterative debugging, multi-step refactoring, and full application development.
-
At the same time, the loop introduces new challenges. Errors can propagate through context, tool misuse can lead to incorrect state updates, and compaction can discard critical information. Managing these tradeoffs is central to effective system design and usage.
Execution Harness
-
The execution harness is the layer that transforms the language model’s outputs into concrete actions within the user’s environment. While the agent loop determines what to do, the harness determines how those decisions are realized, enforcing structure, safety, and determinism. In practice, this layer is responsible for bridging probabilistic model outputs with deterministic system execution.
-
As emphasized in Claude Code — Source Code Documentation & Analysis, the harness sits at the boundary between reasoning and execution, coordinating tools, permissions, and system state while maintaining a consistent control flow across all interactions.
Role and Responsibilities
-
The execution harness performs several tightly coupled functions. It parses model outputs into structured actions, routes these actions to the appropriate tools, enforces permission constraints, executes commands in the environment, and captures outputs as observations. These observations are then reinjected into the context, closing the loop.
-
Unlike traditional interpreters, the harness must operate under uncertainty, since model outputs are not guaranteed to be valid or safe. This necessitates extensive validation and control logic.
-
This design reflects a broader trend in agent systems where reliability is achieved through structured orchestration rather than model guarantees alone, as discussed in Build Your Own AI Agent: A Design Space Guide.
Action Parsing and Dispatch
-
When the model produces an output, the harness must determine whether it represents plain text, a tool invocation, or a sequence of actions. This involves parsing structured patterns embedded in the model’s response.
-
Internally, tool calls are represented in a structured format, often validated against JSON schemas before execution. This ensures that inputs conform to expected types and constraints. The documentation describes each tool as having a schema-defined interface, enabling consistent validation and dispatch (Claude Code — Source Code Documentation & Analysis).
-
Once validated, the harness routes the action to the appropriate tool module, initiating execution.
Permission and Safety Enforcement
-
A critical function of the execution harness is enforcing safety constraints. Every action passes through a permission system that determines whether it can be executed automatically, requires user approval, or must be denied.
-
This permission model typically operates in modes such as allow, ask, or deny, providing granular control over potentially sensitive operations such as file modification or shell execution. The command documentation Commands - Claude Code Docs highlights that permission settings can be adjusted dynamically, allowing users to control the level of autonomy granted to the agent.
-
This layer ensures that even if the model proposes unsafe or unintended actions, they are intercepted before execution.
Tool Execution and Environment Interaction
-
Once an action is approved, the harness executes it within the appropriate environment. This may involve invoking shell commands, reading or writing files, or interacting with external services.
-
Execution is typically sandboxed to prevent unintended side effects. For example, shell commands may be run with timeouts, restricted environments, or validation checks. This reflects principles from secure execution systems, where isolation and validation are used to mitigate risk.
-
The harness also captures outputs in a structured format, ensuring that results can be interpreted and reused by the model.
Observation Capture and Reintegration
-
After execution, the harness captures the result of the action and converts it into a form suitable for inclusion in the context. This may involve formatting outputs, truncating large results, or summarizing information.
-
These observations are appended to the context:
- This step is critical because it determines how the model perceives the consequences of its actions. Poorly formatted or overly verbose outputs can degrade performance, while concise and structured observations improve reasoning.
Security Architecture
-
The execution harness incorporates a multi-layered security system, particularly for shell command execution. A detailed analysis in Comprehensive Analysis of Claude Code describes a validation pipeline that parses commands into abstract syntax trees and applies multiple validators before execution.
-
This approach aligns with secure parsing techniques, where commands are analyzed structurally rather than treated as raw strings. Research in program analysis and secure execution supports this approach, as it reduces the risk of injection and unintended behavior.
-
An important implementation detail is the use of multiple parsing strategies to detect inconsistencies and edge cases, highlighting the complexity of safely executing model-generated commands.
Error Handling and Recovery
-
The harness includes robust error handling mechanisms to ensure that failures do not disrupt the overall workflow. When an action fails, the harness captures the error and returns it to the model as an observation.
-
The model can then adapt its strategy based on this feedback, attempting alternative approaches or correcting mistakes. This creates a feedback-driven recovery mechanism, where errors become part of the reasoning process.
-
The query engine integrates retry logic with backoff strategies, allowing transient failures to be retried automatically, as described in Claude Code — Source Code Documentation & Analysis.
Scheduling and Background Execution
-
Beyond immediate execution, the harness supports scheduling and background tasks. Emerging features described in analyses such as Comprehensive Analysis of Claude Code indicate the presence of daemon-like capabilities, where tasks can be triggered based on time or external events.
-
This includes periodic execution, webhook-driven triggers, and background memory consolidation. These capabilities extend the agent loop beyond interactive sessions, enabling continuous operation.
Remote and Distributed Execution
-
The harness is also designed to support remote execution. Certain operations, such as complex planning, may be offloaded to remote model instances, with results integrated back into the local session.
-
This hybrid architecture balances local responsiveness with scalable computation, allowing the system to handle tasks that exceed local resource constraints.
Integration with State and Context
-
The execution harness is tightly coupled with the context manager. Every action and observation modifies the context, and the harness is responsible for ensuring that these updates are consistent and meaningful.
-
This integration ensures that the system maintains a coherent representation of the task across iterations, enabling long-horizon reasoning.
Implications
-
The execution harness is the backbone of Claude Code’s reliability. By enforcing structure, safety, and consistency, it enables the system to operate effectively despite the inherent uncertainty of model outputs.
-
It also highlights a key principle of agent design: intelligence emerges not only from the model but from the interaction between the model and its execution environment. The harness is where this interaction is formalized, making it one of the most critical components of the system.
Tool System
-
The tool system is the mechanism through which Claude Code interacts with the external world. While the language model generates intentions and the execution harness enforces structure, the tool layer provides the concrete capabilities that allow the agent to read, write, execute, and observe. In effect, tools extend the model’s capabilities beyond text generation into real-world computation.
-
A detailed architectural breakdown in Claude Code — Source Code Documentation & Analysis describes the tool system as a modular registry of over forty tools spanning file operations, shell execution, web access, and agent coordination. This modularity is critical, as it allows new capabilities to be added without modifying the core agent loop.
Tool Abstraction
-
Each tool in Claude Code is implemented as a self-contained module with a well-defined interface. Tools are defined by a schema specifying their inputs, outputs, and constraints. This schema-driven design ensures that all tool interactions are structured and validated before execution.
-
Formally, a tool can be represented as:
\[y = T(x; \theta)\]- where \(x\) is the structured input, \(y\) is the output, and \(\theta\) represents tool-specific parameters such as permissions or execution settings.
-
This abstraction aligns with research on tool-augmented models such as Toolformer by Schick et al. (2023), which shows that models can learn to invoke tools as part of reasoning. Claude Code extends this by enforcing strict schemas and validation layers around each tool.
Tool Registry and Discovery
-
The system maintains a centralized tool registry that enumerates all available tools. According to Claude Code — Source Code Documentation & Analysis, this registry includes more than forty tools grouped by functionality, including file manipulation, code execution, web access, and agent management.
-
The registry serves multiple purposes. It allows the model to discover available capabilities, enables the harness to route tool calls efficiently, and provides a consistent interface for validation and execution.
-
Dynamic tool discovery is also supported, particularly in environments where additional tools are loaded via external protocols such as MCP. This allows the system to extend its capabilities at runtime.
File System Tools
-
File system tools form the foundation of Claude Code’s interaction with codebases. These tools allow the agent to read files, write new files, edit existing files, and search across directories.
-
Examples include file reading with line ranges, writing or overwriting files, performing precise string-based edits, and searching for patterns using glob or regex-based queries. These tools enable the agent to navigate and manipulate large codebases efficiently.
-
The design of these tools emphasizes precision and safety. For example, edit operations are typically constrained to exact string replacements rather than arbitrary modifications, reducing the risk of unintended changes.
Execution Tools
-
Execution tools allow Claude Code to run code and commands within the environment. The most prominent example is the shell execution tool, which enables the agent to run commands with timeouts and validation.
-
This capability transforms the agent from a static generator into an interactive system capable of testing, building, and debugging code. It also introduces significant complexity, as executing arbitrary commands requires careful validation and sandboxing.
-
The system’s approach to command execution reflects principles from secure systems design, where inputs are validated, execution is constrained, and outputs are monitored for anomalies.
Web and Retrieval Tools
-
Claude Code includes tools for accessing external information, such as fetching web content and performing searches. These tools allow the agent to augment its knowledge with up-to-date or domain-specific information.
-
This capability is conceptually related to retrieval-augmented generation methods such as RETRO by Borgeaud et al. (2022), where external data sources are used to improve model performance.
-
In practice, web tools enable workflows such as documentation lookup, API exploration, and debugging based on external resources.
Agent and Task Tools
-
A distinctive feature of Claude Code is its support for agent-level tools that enable task decomposition and parallel execution. Tools such as agent spawning allow the system to create sub-agents, each operating in its own context.
-
These tools enable a hierarchical execution model:
-
where each subtask is handled by a separate agent. This approach improves scalability and reduces context interference, as each agent operates with a clean context.
-
The command system integrates with these tools, allowing users to orchestrate multi-agent workflows through commands such as
/batchand/agents(cf. Commands - Claude Code Docs).
Tool Lifecycle
-
The lifecycle of a tool invocation follows a structured sequence. First, the model generates a tool call with structured arguments. Next, the harness validates the input against the tool’s schema. If the input passes validation and permissions are satisfied, the tool is executed. Finally, the output is captured and reintegrated into the context.
-
This lifecycle ensures consistency and reliability across all tool interactions. It also provides multiple points for validation and control, reducing the risk of errors.
Permission Integration
-
Tools are tightly integrated with the permission system. Each tool defines its own permission requirements, which are evaluated before execution. This allows fine-grained control over what actions the agent can perform.
-
For example, file modification tools may require explicit approval, while read-only operations may be allowed automatically. This integration ensures that tool usage aligns with user preferences and safety constraints.
Error Handling and Feedback
-
When a tool invocation fails, the system captures the error and returns it to the model as part of the context. This allows the model to adapt its behavior based on observed failures.
-
For example, if a file edit fails due to a mismatch, the model can attempt a different approach. This feedback loop is essential for robust performance, as it allows the agent to recover from errors dynamically.
Extensibility and MCP Integration
-
Claude Code’s tool system is designed to be extensible through protocols such as the Model Context Protocol (MCP). MCP allows external services to expose tools that can be invoked by the agent, effectively expanding its capabilities beyond the local environment.
-
The documentation highlights that MCP integration enables server-side tools, allowing the agent to interact with databases, APIs, and other external systems in a structured way (cf. Claude Code — Source Code Documentation & Analysis).
-
This extensibility is a key architectural feature, as it allows the system to evolve without modifying the core codebase.
Advanced Capabilities
-
Emerging analyses such as Comprehensive Analysis of Claude Code suggest the presence of advanced internal tools, including those for background execution, notifications, and integration with external systems. While not all of these are exposed in public builds, they indicate the direction of future development.
-
These capabilities point toward a more autonomous agent model, where the system can operate continuously and interact with external systems without direct user intervention.
Implications
-
The tool system is what enables Claude Code to function as a practical coding agent. By providing structured, validated access to external capabilities, it allows the model to act on its decisions and observe the results.
-
At the same time, it introduces complexity in terms of validation, permissions, and error handling. Designing and managing this system is a central challenge in building reliable agentic systems.
Context Manager
-
The context manager is the subsystem responsible for constructing, maintaining, and transforming the sequence of tokens that defines Claude Code’s working memory. While the agent loop governs execution and the tool system enables action, the context manager determines what the model knows at each step. In practice, it is the most critical component for enabling long-horizon reasoning.
-
A detailed architectural breakdown in Claude Code — Source Code Documentation & Analysis describes this layer as a combination of context builders, history managers, and compaction services that collectively assemble the model’s input at each iteration.
Context Construction
-
At each step of the agent loop, the context manager constructs a unified sequence that includes system instructions, user inputs, assistant responses, tool calls, and tool outputs. This sequence is dynamically rebuilt for every model invocation.
-
The construction process is handled by dedicated modules that merge multiple sources of information. These include project-level configuration files such as
CLAUDE.md, environment metadata such as operating system and shell details, and runtime state such as the current working directory and git status. -
This process is described in Claude Code — Source Code Documentation & Analysis, which notes that the context builder merges global, user, and project-level configuration into a single system prompt, ensuring that the model has a consistent view of its environment.
-
This layered composition can be expressed as:
\[C = C_{\text{system}} \cup C_{\text{project}} \cup C_{\text{session}} \cup C_{\text{tools}}\]- where each component contributes a distinct type of information.
Context Caching
-
To improve efficiency, the context manager employs caching strategies that reuse portions of the context across iterations. Static components such as tool definitions and system instructions are often cached, while dynamic components such as user inputs and tool outputs are recomputed.
-
An implementation detail described in Comprehensive Analysis of Claude Code highlights the presence of a prompt cache boundary, where the context is split into globally cacheable and session-specific segments. Everything before this boundary, such as tool definitions and core instructions, is reused across sessions, while everything after it is unique to the current interaction.
-
This design reduces token usage and latency, particularly in large-scale deployments where repeated context would otherwise be costly.
Context Window Constraints
-
The context manager must operate within a fixed token limit. This constraint defines the maximum amount of information that can be presented to the model at any given time.
-
As discussed in Using Claude Code: session management and 1M context, this limit can reach up to one million tokens, enabling large-scale reasoning but also introducing challenges related to information overload.
-
The following figure (source) shows how the context window is bounded and how different components contribute to it. Specifically, it shows the composition of the context window, including system prompts, conversation history, tool outputs, and file reads within a fixed token limit.
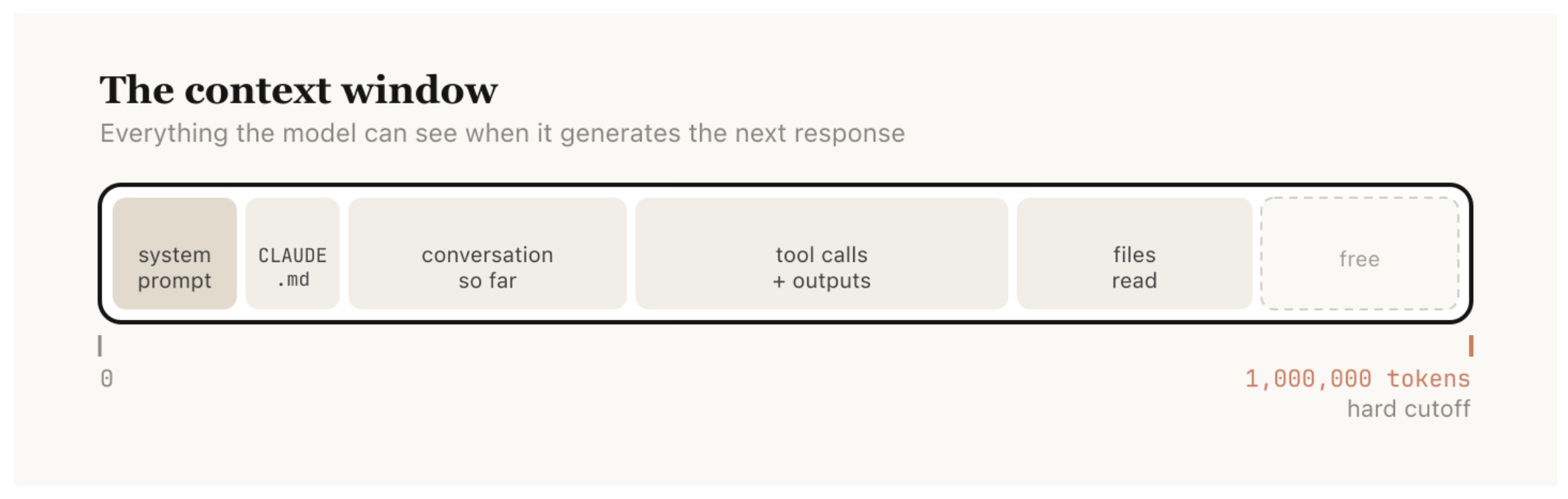
- This diagram illustrates that all information must fit within a single sequence, making prioritization and pruning essential.
Compaction Mechanism
-
When the context approaches its limit, the context manager triggers compaction, a process that summarizes earlier interactions into a shorter representation.
-
Internally, compaction is implemented as a secondary model invocation that produces a structured summary of the conversation. This summary replaces detailed history, reducing token usage while preserving high-level information.
-
The summarization process follows explicit instructions to capture user intent, prior actions, and key results. As described in Comprehensive Analysis of Claude Code, the summarizer uses internal reasoning steps to generate a high-quality summary, which is then stripped of intermediate reasoning before being inserted into the context.
-
This can be expressed as:
\[C' = f_{\text{compress}}(C)\]- where \(f_{\text{compress}}\) is a lossy transformation.
Limitations of Summarization
-
While compaction extends the effective horizon of the system, it introduces inherent limitations. Because summarization is lossy, some information is inevitably discarded. More importantly, the system does not distinguish between different sources of instructions when summarizing.
-
An analysis in Comprehensive Analysis of Claude Code highlights that instructions originating from user input and those embedded in files are treated equivalently during summarization. This means that potentially untrusted content can persist in compressed form, influencing future behavior.
-
This limitation reflects a broader challenge in memory-augmented systems, where compression trades off fidelity for efficiency.
History Management
-
The context manager maintains a structured history of interactions, including messages from different roles. This history is used to reconstruct context at each step and to support operations such as rewind and session branching.
-
The history system also tracks metadata such as timestamps, tool usage, and session boundaries. This information is used to support advanced features such as session resumption and branching workflows.
Auto-Compaction and Failure Handling
-
Compaction is often triggered automatically when the context reaches a threshold. However, this process is not always reliable. Observations from Comprehensive Analysis of Claude Code indicate that repeated compaction failures can occur, requiring safeguards such as retry limits to prevent excessive resource usage.
-
This highlights the complexity of managing large context windows in practice, where even auxiliary processes such as summarization can introduce failure modes.
Memory Consolidation
-
Beyond immediate compaction, the context manager supports longer-term memory consolidation. Emerging features described in Comprehensive Analysis of Claude Code include background processes that periodically summarize accumulated sessions into persistent memory.
-
These processes are triggered based on conditions such as elapsed time and session count, and use locking mechanisms to ensure consistency. This design resembles hierarchical memory systems, where short-term interactions are periodically consolidated into long-term representations.
Integration with Agent Loop
-
The context manager is tightly integrated with the agent loop. Every iteration depends on the current context, and every action modifies it. This bidirectional dependency makes context management central to the system’s operation.
-
The agent loop relies on the context manager to provide a coherent view of the task, while the context manager relies on the agent loop to generate new information. This coupling ensures that reasoning and memory evolve together.
Implications
-
The context manager defines the effective intelligence of Claude Code. While the model provides reasoning capability, it is the context that determines what information is available for reasoning.
-
This makes context engineering a central challenge. Efficient context construction enables long-horizon tasks, while poor context management leads to degraded performance and failure modes.
-
More broadly, the design of the context manager illustrates a key principle of agent systems: memory is not just storage but a dynamic process that must be actively managed to support reasoning and action.
Command System
-
The command system is the primary interface through which users exert structured control over Claude Code’s behavior. While natural language prompts guide high-level intent, commands provide deterministic hooks into the system, enabling precise manipulation of context, execution flow, permissions, and workflows. In practice, the command system serves as a control plane layered on top of the agent loop.
-
A comprehensive breakdown in Claude Code — Source Code Documentation & Analysis describes the command system as a registry of over one hundred slash commands, each implemented as a modular unit that integrates with the core architecture. This system enables users to transition from passive prompting to active orchestration.
Command Abstraction
-
Commands in Claude Code are implemented as structured modules with defined inputs, execution logic, and side effects. Each command encapsulates a specific operation, such as modifying context, triggering workflows, or interacting with the environment.
-
Conceptually, a command can be modeled as a transformation over system state:
\[S_{t+1} = \mathcal{C}(S_t, \text{args})\]- where \(S_t\) includes context, permissions, and execution state, and \(\mathcal{C}\) is the command function.
-
This abstraction allows commands to operate at a higher level than individual tool calls. While tools perform atomic actions, commands orchestrate sequences of actions and state transitions.
Command Registry and Modular Design
-
The command system is organized as a centralized registry, where each command is defined as an independent module. According to Claude Code — Source Code Documentation & Analysis, the codebase includes more than one hundred command modules, each responsible for a specific workflow or control operation.
-
This modular design enables extensibility and maintainability. New commands can be added without modifying the core system, and existing commands can be updated independently.
-
The registry also supports dynamic discovery, allowing the system to enumerate available commands and provide contextual suggestions to users.
Categories of Commands
-
Commands in Claude Code span several functional categories. These include session management commands that control context state, workflow commands that orchestrate multi-step tasks, tool-related commands that interact with the tool system, and system commands that manage configuration and permissions.
-
Session management commands such as
/clear,/compact,/rewind, and/resumedirectly manipulate the context. Workflow commands such as/plan,/batch, and/agentsenable structured task execution and decomposition. System commands such as/initand/configinitialize and configure the environment. -
The official documentation Commands - Claude Code Docs explains that these commands are designed to control permissions, manage sessions, and execute complex workflows in a structured manner.
Integration with Agent Loop
-
Commands are deeply integrated with the agent loop. When a command is invoked, it modifies the state of the system before the next iteration of the loop. For example,
/compacttriggers a compaction operation in the context manager, while/batchinitiates parallel task execution through the agent system. -
This integration ensures that commands are not external utilities but first-class components of the execution pipeline. Each command effectively reshapes the context or execution state, influencing all subsequent reasoning.
Workflow Orchestration
-
One of the most powerful aspects of the command system is its ability to orchestrate workflows. Commands can trigger multi-step processes that involve planning, execution, validation, and iteration.
-
For example, the
/plancommand initiates a planning phase where the model generates a structured approach without making changes. The/batchcommand decomposes a task into subtasks and executes them in parallel using sub-agents. The/agentscommand provides direct control over agent spawning and coordination. -
These capabilities align with hierarchical task decomposition strategies in AI, where complex problems are broken into smaller units. Research such as ReAct by Yao et al. (2022) demonstrates the effectiveness of interleaving reasoning and acting, and Claude Code extends this by allowing explicit orchestration through commands.
Context Manipulation Commands
-
Commands that manipulate context are particularly important, as they directly affect the model’s memory. The
/clearcommand resets the context entirely,/rewindtruncates it to a previous state, and/compactsummarizes it to reduce size. -
These operations correspond to transformations over the context sequence:
- The Anthropic guide Using Claude Code: session management and 1M context emphasizes that managing context is essential for maintaining performance in long sessions.
Multi-Agent Coordination
-
Commands also play a central role in coordinating multiple agents. The
/batchand/agentscommands enable parallel execution of tasks, where each sub-agent operates in its own context and returns results to the main session. -
This can be expressed as:
- Each subtask is handled independently, reducing context interference and improving scalability. The integration of commands with the agent system allows users to control this process explicitly.
Command Execution Lifecycle
-
The lifecycle of a command invocation follows a structured sequence. First, the command is parsed and validated against its schema. Next, it executes its logic, which may involve modifying context, invoking tools, or spawning agents. Finally, the resulting state changes are applied, and the agent loop resumes.
-
This lifecycle ensures that commands operate predictably and integrate seamlessly with the rest of the system.
Extensibility and Customization
-
The command system is designed to be extensible. Users and developers can define custom commands or extend existing ones through plugins and skill systems.
-
According to Claude Code — Source Code Documentation & Analysis, the architecture includes a plugin and skill system that allows user-defined extensions. This enables customization of workflows and integration with domain-specific tools.
Advanced Features
-
Advanced command features include batch execution, parallel processing, and integration with external systems through protocols such as MCP. These features enable the system to handle complex workflows that go beyond simple sequential execution.
-
Emerging analyses such as Comprehensive Analysis of Claude Code suggest additional capabilities such as background task scheduling and autonomous operation modes, indicating that the command system may evolve toward more autonomous control structures.
Implications
-
The command system transforms Claude Code from a conversational interface into a programmable environment. By providing structured control over context, execution, and workflows, it enables users to orchestrate complex tasks with precision.
-
It also highlights a key principle of agent design: effective control requires explicit mechanisms for manipulating state. Commands provide these mechanisms, making them a central component of the system’s architecture.
State and Persistence
-
The state and persistence layer governs how Claude Code maintains continuity across interactions, sessions, and long-running workflows. While the context manager handles short-term working memory within a single context window, the state layer extends this into durable representations that survive across iterations, sessions, and even background processes. This layer is essential for enabling Claude Code to function as a persistent agent rather than a stateless assistant.
-
A detailed architectural analysis in Claude Code — Source Code Documentation & Analysis describes this subsystem as a combination of session history management, state stores, cost tracking, and persistence utilities that together maintain a consistent view of the system over time. The memory architecture is further explored in Claude Code Memory Explained, which emphasizes that much of Claude Code’s practical effectiveness derives from its ability to reconstruct relevant knowledge from disk rather than relying solely on the model’s internal parameters.
State Model
-
State in Claude Code is distributed across multiple layers rather than centralized in a single structure. It includes in-memory session state, persisted history, configuration state, and external environment state.
-
This can be conceptualized as:
-
Session state includes active context and recent interactions, persistent state includes saved histories and configuration files, environment state includes file system and runtime conditions, and metadata includes cost tracking and usage statistics.
-
This distributed model allows the system to scale across different scopes of operation while maintaining flexibility. The core design principle is that memory serves as a retrieval-oriented index rather than a passive storage dump. Persisted information is continuously curated, deduplicated, and summarized so that only high-value information is surfaced to the model.
Dual Memory Architecture
-
Claude Code employs two complementary memory systems.
-
The first consists of user-authored
CLAUDE.mdfiles, which encode coding standards, project conventions, architectural guidance, and workflow preferences. These files are automatically discovered and merged from multiple scopes, including machine-wide, user-level, and project-local directories, as described in Claude Code — Source Code Documentation & Analysis. -
The second consists of automatically generated memory maintained by Claude itself. This includes build commands, debugging procedures, architectural decisions, and operational lessons that are not readily inferable from the source tree alone. These memories capture tacit knowledge accumulated across sessions and serve as a project-specific institutional memory.
-
Together, these systems combine explicit human guidance with machine-generated operational knowledge, allowing Claude Code to maintain continuity across long-term development efforts.
Memory Hierarchy and Retrieval Strategy
-
Rather than loading all stored information into context, Claude Code uses a bandwidth-aware retrieval architecture designed to minimize context pollution.
-
A concise
MEMORY.mdfile is loaded first and serves as an index rather than a complete knowledge base. This file is intentionally constrained to remain compact, typically on the order of a few hundred lines, and contains pointers to more detailed topic-specific files. -
Topic files are stored as focused Markdown documents covering specific architectural areas, workflows, or recurring issues. When a new user request arrives, a lightweight retrieval process selects the most relevant files and injects only those into context.
-
Historical transcripts are retained as structured JSON logs and are not loaded directly. Instead, they are searched selectively using targeted retrieval tools when specific historical details are required.
-
This layered approach ensures that memory is treated as a retrieval substrate rather than an indiscriminate archive.
-
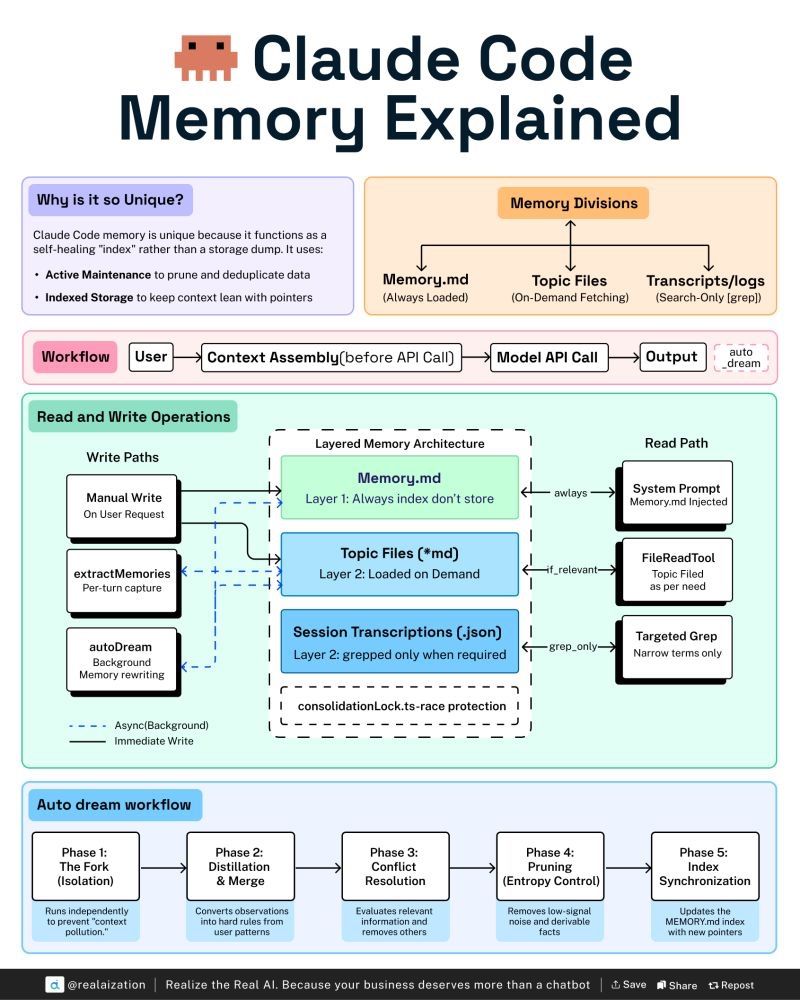
The following figure (source) shows Claude Code’s layered memory architecture and the read and write paths through the system.
MEMORY.mdacts as an always-loaded index, where topic files are loaded on demand, transcripts are searched selectively, and background processes consolidate and prune long-term memory.
Retrieval Budgets and Context Efficiency
-
A central design principle of Claude Code is that memory is constrained by explicit retrieval budgets. Rather than maximizing recall, the system maximizes relevance under strict token limits.
-
The retrieval workflow begins with the index file, which provides compact pointers to relevant information. A lightweight model-assisted side query then identifies a small set of topic files to load, typically selecting only the most relevant documents. Each selected file is truncated to a bounded size, and overall retrieval is governed by both per-turn and session-level budgets.
-
This approach reflects principles from retrieval-augmented generation systems such as RETRO by Borgeaud et al. (2022), which improve performance by retrieving only targeted external knowledge rather than loading large corpora wholesale.
-
The result is a memory system in which context pollution is constrained by architecture rather than left to chance.
Session History
-
Session history is the primary mechanism for maintaining continuity within a single interaction. It records all messages exchanged between the user, the assistant, and tools, along with associated metadata.
-
The history system supports operations such as appending new messages, truncating history during rewind operations, and reconstructing context for subsequent iterations. According to Claude Code — Source Code Documentation & Analysis, this history is stored in structured formats that distinguish between different message roles.
-
This structure enables precise reconstruction of context and supports advanced features such as branching and session resumption.
Persistence Mechanisms
-
Persistent state is stored across sessions to enable long-term continuity. This includes configuration files such as
CLAUDE.md, indexed memory files, cached context segments, and saved session data. -
The system uses file-based persistence for many of these components, leveraging the local file system for storage. This design aligns with the local-first architecture of Claude Code, ensuring that state is accessible, inspectable, and directly controllable by the user.
-
An important implementation detail is the use of memory directories that are automatically discovered and incorporated into the retrieval pipeline. This allows the agent to maintain project-specific knowledge without requiring explicit reinitialization.
Cost and Usage Tracking
-
The state layer includes a dedicated subsystem for tracking cost and usage metrics. According to Claude Code — Source Code Documentation & Analysis, this subsystem monitors token usage across input, output, and cached segments, and computes associated costs based on model pricing.
-
This information is stored as part of session metadata and is used for both user feedback and internal optimization. For example, cost data can inform decisions about when to compact context, retrieve additional memory, or reuse cached prompts.
State Management Architecture
-
Internally, state is managed using patterns similar to modern frontend state management systems. The architecture described in Claude Code — Source Code Documentation & Analysis references a Zustand-style store combined with React context, providing a reactive and modular approach to state updates.
-
This design allows different components of the system to subscribe to state changes and react accordingly. The UI layer updates in real time as new messages are added, while the agent loop and context manager consume updated state during subsequent iterations.
Background Consolidation and AutoDream
-
Beyond immediate state updates, Claude Code includes background processes that continuously refine long-term memory. The most notable of these is AutoDream, a memory consolidation system described in Comprehensive Analysis of Claude Code and illustrated in Claude Code Memory Explained.
-
AutoDream is triggered when sufficient time and interaction volume have accumulated, commonly after approximately twenty-four hours and multiple completed sessions. It operates as a forked sub-agent that performs a multi-stage consolidation pipeline:
- Isolation, where memory processing occurs independently from the active session
- Distillation and merge, where recurring observations are converted into generalized patterns
- Conflict resolution, where contradictory facts are reconciled
- Pruning, where low-signal and stale information is removed
- Index synchronization, where
MEMORY.mdis updated with new pointers
-
This process resembles biological sleep, in which episodic experiences are consolidated into abstract long-term memory.
Concurrency and Locking
-
Managing state in a concurrent environment requires careful coordination. Claude Code employs file-based locks to prevent simultaneous consolidation processes from interfering with one another.
-
As described in Comprehensive Analysis of Claude Code, lock files encode both process ownership and timestamps, allowing stale processes to be detected and previous state to be restored if consolidation fails.
-
These mechanisms are essential for maintaining consistency in systems that support parallel agents and asynchronous background tasks.
Remote and Distributed State
-
While most state is local, Claude Code also supports remote and distributed state through integrations with external services, remote sessions, and cloud-hosted tools.
-
The architecture documented in Claude Code — Source Code Documentation & Analysis includes dedicated modules for remote session handling and server-side integrations, enabling hybrid workflows that combine local persistence with remote computation.
Integration with Context
-
The state and persistence layer is tightly coupled with the context manager. Persistent memories, session histories, and configuration files are selectively retrieved and incorporated into the active context.
-
This design reflects a key principle: memory is a hint rather than an immutable source of truth. Persisted information guides the model but remains subject to reinterpretation and revision as new evidence emerges.
Implications
-
The state and persistence layer enables Claude Code to operate as a continuous system rather than a series of isolated interactions. By combining user-authored guidance, machine-generated memory, indexed retrieval, and background consolidation, it supports long-running workflows while preserving context efficiency.
-
More broadly, this design demonstrates that scalable agentic systems depend as much on disciplined memory architecture as on model intelligence. Claude Code’s effectiveness arises not from storing everything, but from continuously curating and reconstructing only the information most relevant to the task at hand.
-
Add this section immediately after “Context Engineering and Session Management” and before “Commands and Usage Patterns.” It is conceptually part of context engineering, but it also explains why
/memory,/init,/compact, rules, subagents, and session persistence behave the way they do.
File-Based Memory
- Claude Code’s memory design is deliberately file-centered: durable knowledge is stored as readable project files, rules, local notes, and auto-generated markdown rather than only as opaque embeddings. This makes memory auditable, editable, versionable, and easy to reason about. The design aligns with a broader lesson from Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems by Liu et al. (2026): in production coding agents, much of the intelligence comes from the deterministic harness around the model, including context assembly, memory loading, permissions, and recovery logic.
Memory as Persistent Context
-
Claude Code treats memory as persistent context rather than hard configuration. Each new session starts with a fresh context window, so cross-session continuity must be reconstructed from durable state. Claude Code provides two primary mechanisms:
CLAUDE.mdfiles written by humans, and auto memory written by Claude as it learns recurring project facts, debugging insights, coding conventions, and workflow preferences. How Claude remembers your project states that both memory systems are loaded at the start of every conversation, but they remain guidance rather than enforcement. -
A useful abstraction is:
\[C_0 = S + M_{\text{human}} + M_{\text{auto}} + E\]- where \(C_0\) is the initial session context, \(S\) is the system and tool scaffolding, \(M_{\text{human}}\) is human-authored project memory such as
CLAUDE.md, \(M_{\text{auto}}\) is Claude-authored auto memory, and \(E\) is environment context such as working directory, shell, platform, git state, and permissions.
- where \(C_0\) is the initial session context, \(S\) is the system and tool scaffolding, \(M_{\text{human}}\) is human-authored project memory such as
The CLAUDE.md Hierarchy
-
CLAUDE.mdis the main file-based memory primitive. It stores persistent instructions such as build commands, test workflows, project architecture, style conventions, security rules, and recurring constraints. Claude Code can load managed organization instructions, user-level instructions, project instructions, and local personal instructions, with project-specific content appearing later in context than broader instructions. How Claude remembers your project lists managed policy files,~/.claude/CLAUDE.md,./CLAUDE.md,./.claude/CLAUDE.md, and./CLAUDE.local.mdas separate scopes. -
This hierarchy gives Claude Code a layered memory model. Organization memory can encode compliance and security expectations; user memory can encode personal workflow preferences; project memory can encode repository architecture; local memory can encode private sandbox details or machine-specific setup. The system therefore separates shared team knowledge from personal notes without requiring a database.
Directory Walking and Lazy Loading
-
Claude Code discovers memory by walking from the current working directory upward through the filesystem, loading
CLAUDE.mdandCLAUDE.local.mdfiles it finds along the path. Files closer to the working directory are read later, which means more local instructions are more salient in the assembled context. Claude Code also discoversCLAUDE.mdfiles in subdirectories, but it does not necessarily load all of them at startup; nested files can load on demand when Claude reads files in those subdirectories. How Claude remembers your project describes this as directory-based discovery with subdirectory instructions included when relevant files are accessed. -
This design reduces startup context bloat in large monorepos. Instead of injecting every team’s rules into every task, Claude can defer path-specific instructions until the task touches that part of the repository.
Rules as Scoped Memory
-
For larger projects,
.claude/rules/provides a more modular form of memory. Rules are markdown files that can be scoped to file paths or subdirectories, allowing frontend, backend, security, testing, and API conventions to load only when relevant. How Claude remembers your project recommends rules when instruction files become large or when guidance applies only to specific parts of a repository. -
This turns memory loading into a relevance problem:
\[M_{\text{loaded}} = {m_i \in M : \text{scope}(m_i) \cap \text{task_files} \neq \emptyset}\]- where \(M_{\text{loaded}}\) is the subset of memory injected into context, \(m_i\) is an individual memory file or rule, and \(\text{task_files}\) is the set of files the session is working with.
Imports and Composition
-
CLAUDE.mdfiles can import additional files using@path/to/filesyntax. This allows memory to be composed from existing documents such asREADME.md,package.json, internal workflow guides, orAGENTS.md. How Claude remembers your project notes that imports are expanded into context at launch, support relative and absolute paths, and can recurse up to five hops. -
This is powerful but not free. Imports improve maintainability, but they do not reduce token usage if they are loaded at startup. A large imported document still consumes context. Therefore, imports should be used for authoritative, always-relevant guidance, while task-specific procedures are better encoded as skills or scoped rules.
Auto Memory
-
Auto memory lets Claude write notes for future sessions without the user manually editing
CLAUDE.md. It records durable project learnings such as build commands, architecture notes, debugging discoveries, style preferences, and workflow habits. How Claude remembers your project states that auto memory is loaded into every session, while only the first 200 lines or 25KB ofMEMORY.mdare loaded at startup. -
Auto memory is useful because much of what improves future agent performance is discovered during work rather than known upfront. For example, after repeatedly discovering that integration tests require Redis, Claude can persist that fact so future sessions do not re-discover it. What Is Claude Code Auto-Memory? How Your AI Agent Learns From Its Own Mistakes frames auto memory as a way for the agent to accumulate project-specific knowledge across sessions without manual updates. ([MindStudio][3])
-
A representative auto-memory item might be:
## Testing
- API integration tests require local Redis on port 6379.
- Use `pnpm test:api -- --runInBand` for flaky auth tests.
- The benefit is continuity; the risk is stale or incorrect knowledge. Because auto memory is plain markdown, the user can audit, edit, or delete it using
/memory.
Memory and Commands
-
The
/initcommand creates or improves a projectCLAUDE.mdby inspecting the repository and proposing build commands, test instructions, and conventions. How Claude remembers your project describes/initas a way to generate a starting project memory file, with newer interactive flows that can also set up skills and hooks. -
The
/memorycommand is the operational interface for file-based memory. It lists loadedCLAUDE.md,CLAUDE.local.md, and rules files; lets users toggle auto memory; and opens the auto memory folder for inspection. This makes memory not only persistent, but inspectable. If Claude ignores a convention,/memoryis the first debugging tool: it verifies whether the relevant file actually entered the context.
Interaction with Compaction
-
File-based memory is also important because it survives compaction differently from conversational instructions. If a rule is only stated in chat, it may be compressed, weakened, or lost during
/compact. If the same rule is written into project memory, Claude Code can re-read it from disk and re-inject it after compaction. How Claude remembers your project states that project-rootCLAUDE.mdsurvives compaction by being re-read from disk, while nestedCLAUDE.mdfiles reload when Claude next reads files in those directories. -
This suggests a practical rule: if an instruction should govern many future turns, it belongs in file memory rather than only in conversation.
File-Based Retrieval versus Vector Retrieval
-
Claude Code’s memory design reflects a broader tradeoff between file-based and vector-based memory. Vector memory represents text as embeddings and retrieves by semantic similarity; file-based memory stores readable artifacts and retrieves by path, scope, grep, rules, or explicit loading. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Lewis et al. (2020) established the modern RAG pattern of retrieving external knowledge for generation, while Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) shows that lexical search can outperform vector retrieval in several agentic long-memory settings, and that harness design and file-based result delivery materially affect end-to-end accuracy.
-
The retrieval contrast can be written as:
- Vector memory is strong when a query is paraphrased or semantically implicit. File-based memory is strong when the answer depends on exact commands, paths, conventions, timestamps, or versioned project facts. Coding agents often need the latter: “run
pnpm typecheckbefore committing,” “auth middleware lives insrc/server/auth,” or “do not log refresh tokens.”
Why Markdown Matters
-
Markdown is not an incidental storage format. It makes memory inspectable by both humans and models. Humans can review diffs, commit changes, delete stale entries, and reason about scope. Models can parse headings, bullets, code blocks, and file references. This is why
CLAUDE.md,.claude/rules/*.md, imported markdown files, andMEMORY.mdform a coherent memory substrate rather than a collection of unrelated features. -
The practical effect is that memory becomes part of the repository’s operational interface. A well-maintained
CLAUDE.mdis similar to a living engineering handbook, but optimized for an agent that must act inside the codebase.
Practical Design Pattern
- A strong Claude Code memory setup uses a small project
CLAUDE.mdfor always-relevant repository facts,.claude/rules/for scoped conventions,CLAUDE.local.mdfor private personal settings, auto memory for discovered recurring facts, and hooks for actions that must happen deterministically. This creates a layered memory system:
- For example, a project might use:
# CLAUDE.md
## Project commands
- Use `pnpm`, not `npm`.
- Run `pnpm typecheck` and `pnpm test` before finalizing changes.
## Architecture
- API routes live in `src/server/routes`.
- Database migrations live in `db/migrations`.
## Security
- Never log access tokens, refresh tokens, or raw authorization headers.
- Then
.claude/rules/security.mdcan add path-scoped security instructions for authentication files, while a hook can enforce that tests run before commit. The memory file guides behavior; the hook enforces procedure.
Memory Failures, Context Rot, and Recovery
-
Claude Code’s file-based memory system improves continuity and long-horizon reasoning, but it also introduces systems problems such as stale context, conflicting instructions, excessive memory growth, retrieval noise, and degraded reasoning under long histories. Memory is therefore not only an asset, but also a source of entropy that must be actively managed.
-
This mirrors a broader result in long-context agent research. Lost in the Middle: How Language Models Use Long Contexts by Liu et al. (2024) shows that model performance degrades when relevant information is buried within large contexts, while MemGPT: Towards LLMs as Operating Systems by Packer et al. (2023) frames long-horizon agents as systems that need explicit memory-management policies similar to paging and virtual memory in operating systems.
Memory Failures, Context Rot, and Recovery
-
Claude Code’s file-based memory system improves continuity and long-horizon reasoning, but it also introduces a central tradeoff: the same persistence that helps the agent remember useful project knowledge can also preserve stale facts, conflicting instructions, excessive context, retrieval noise, and unsafe assumptions. Memory is therefore not only an asset, but also a source of entropy that must be actively managed.
-
This mirrors broader findings in long-context agent research. Lost in the Middle: How Language Models Use Long Contexts by Liu et al. (2024) shows that model performance degrades when relevant information is buried inside large contexts, while MemGPT: Towards LLMs as Operating Systems by Packer et al. (2023) frames long-horizon agents as systems that need explicit memory-management policies similar to paging and virtual memory in operating systems.
-
In Claude Code, these risks appear in several practical forms. Large memory files consume context and reduce adherence; conflicting user, project, and local instructions can produce unstable behavior; stale auto memory can preserve outdated implementation facts; imported files can inject too much irrelevant context; and file content can accidentally be treated as more authoritative than it should be. How Claude remembers your project recommends keeping
CLAUDE.mdconcise, using specific instructions, checking for conflicts, and moving procedural workflows into hooks or skills when they must execute reliably. -
The most important boundary is that memory is context, not enforcement. A memory instruction saying “never run destructive commands” can guide the model, but it is weaker than a deny rule that blocks destructive commands. Sensitive behavioral requirements should therefore be backed by deterministic mechanisms such as permissions, hooks, managed settings, or infrastructure controls. This distinction captures Claude Code’s broader harness philosophy: the model reasons, but the harness enforces.
Context Rot
-
As sessions grow, the model accumulates tool outputs, failed attempts, logs, diffs, prior plans, and temporary instructions. Much of this information becomes irrelevant, but it still occupies context tokens and influences reasoning. Claude Code documentation describes this as context pressure, and broader long-context discussions often describe the same effect as context rot.
-
A useful abstraction is:
\[C_t = R_t + N_t\]-
where \(C_t\) is total context at time \(t\), \(R_t\) is relevant information, and \(N_t\) is irrelevant or stale information. Over time:
\[\frac{N_t}{C_t} \uparrow\]- which reduces effective reasoning quality.
-
-
This becomes especially problematic in coding agents because irrelevant context is often syntactically plausible. Old stack traces, abandoned architectures, obsolete implementation plans, and stale instructions may all appear related to the current task even when they should no longer influence the solution.
Stale Memory
-
A memory entry may remain syntactically valid but become semantically outdated. For example, a project memory file might continue to say that the repository uses Prisma even after the project has migrated to Drizzle or raw SQL. Claude may then repeatedly propose incorrect abstractions, test commands, or data-access patterns.
-
This is especially dangerous because file-based memory persists without automatic invalidation. A stale rule can survive many sessions, compactions, and restarts unless it is manually edited, superseded, or removed.
Conflicts
-
Layered memory systems can contain contradictions. A user-level memory file might prefer
npm, while a project-level memory file might requirepnpm. Since Claude Code merges memory into context rather than treating it as a formal policy language, conflicting instructions can produce unstable behavior. -
Claude Code partially mitigates this through scope and ordering: project-specific memory can be more relevant than broad user memory, and local files can be closer to the task than global files. However, this is not the same as deterministic conflict resolution. Persistent contradictions should be removed rather than left for the model to reconcile.
Memory Bloat
-
Large memory files reduce effective context bandwidth. If the memory payload dominates the task-specific context, the model spends attention on persistent instructions rather than the current work.
-
This can be represented as:
\[|M| \gg |T|\]- where \(\mid M \mid\) is memory size and \(\mid T \mid\) is task-relevant context size. When this happens, reasoning becomes dominated by durable context rather than current evidence.
-
How Claude remembers your project recommends keeping memory concise and warns that excessive memory growth can degrade adherence and increase token usage.
Retrieval Noise
-
File-based memory retrieval is often lexical, path-based, or scope-based rather than semantic. This makes it deterministic and inspectable, but also brittle. Useful memory may fail to activate when a query uses different phrasing, while irrelevant memory may activate because it contains overlapping keywords.
-
Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) shows that grep-style retrieval can outperform vector retrieval in several long-memory agent settings, but also shows that retrieval effectiveness depends strongly on harness design, result presentation, and surrounding context noise.
-
The retrieval process can be approximated as:
- Unlike vector retrieval, lexical retrieval does not naturally resolve paraphrases or implicit meaning. This is why file-based memory is strongest when the relevant facts are explicit, such as commands, paths, test names, API names, and architectural rules.
Overfitting
-
Claude may over-prioritize persistent instructions relative to local context. For example, a memory rule that says to prefer a repository pattern may cause Claude to introduce unnecessary abstractions even when the current task calls for a small procedural change.
-
This resembles over-regularization in optimization:
\[\mathcal{L}_{\text{effective}} =\mathcal{L}_{\text{task}} +\lambda \mathcal{L}_{\text{memory}}\]- where excessive memory weighting causes the model to optimize for historical conventions rather than the immediate user intent.
Auto-Memory Drift
-
Auto memory introduces another class of failure: learned misconceptions. Claude may infer a recurring rule from a narrow case and then preserve it as a general project fact. For example, it may record that Redis is required for tests when only one integration test suite depends on Redis.
-
Because auto memory accumulates inferred knowledge, it should be treated as heuristic state rather than verified configuration. It is useful precisely because it learns, but that same property means it must be audited.
Privacy Risks
-
Memory files can unintentionally contain secrets, credentials, internal URLs, private customer identifiers, or operational details. Since memory is automatically injected into future sessions, sensitive content can persist beyond the original task and appear in contexts where it is unnecessary.
-
The safer design is to treat memory as non-secret configuration. Sensitive policies should be enforced through permissions, hooks, managed settings, secret managers, or infrastructure controls rather than stored as plain-text guidance.
Fragmentation
-
Large agentic workflows fragment attention across many artifacts: shell outputs, code diffs, memory files, logs, stack traces, tool outputs, prior plans, and historical corrections. Lost in the Middle by Liu et al. (2024) shows that models often struggle to consistently use relevant information when it is buried among distractors.
-
This creates a practical challenge for coding agents:
- As the signal-to-noise ratio decreases, agent reliability declines.
Compaction
-
Claude Code’s
/compactcommand functions like garbage collection for the active conversation. Instead of preserving the full conversational trace, Claude rewrites the session into a distilled representation. -
This can be modeled as:
\[C_{\text{compressed}} =f(C_{\text{full}})\]- where \(f\) attempts to preserve salient state while discarding irrelevant material.
-
However, compaction is lossy. Details not preserved in the compacted summary may disappear from the active context. This is why durable instructions belong in file memory rather than only in chat history. If a rule should govern many future turns, it should live in
CLAUDE.md,.claude/rules/, or another durable memory file.
Rewind
-
A recurring best practice is preferring
/rewindover repeatedly correcting bad trajectories. Once incorrect assumptions enter context, they can continue influencing future reasoning even after the user states that they are wrong. -
For example, if Claude begins implementing a repository abstraction that the project does not want, the cleaner recovery path is to rewind to the point before the abstraction entered context and then restate the intended constraint. This removes the incorrect branch entirely rather than layering corrective instructions on top of polluted context.
Scoped Memory
-
.claude/rules/mitigates memory overload by restricting instructions to relevant files and directories. Instead of globally loading every frontend, backend, infrastructure, security, and database convention into every task, Claude Code can activate only the subset that applies to the files being inspected or modified. -
For example, frontend component rules should activate when Claude is working inside the UI layer, backend API rules should activate when the task touches server routes, infrastructure rules should activate when deployment manifests or environment configuration are involved, security rules should activate when authentication, authorization, secrets, or data exposure are relevant, and database rules should activate when migrations, schemas, query builders, or transactional behavior are in scope.
-
This acts as conditional memory activation:
\[M_{\text{active}} ={m_i : \text{scope}(m_i) \cap F \neq \emptyset}\]- where \(F\) is the current working file set.
-
This improves context efficiency in large repositories because Claude receives the memory that is most relevant to the current task rather than a monolithic rulebook.
Progressive Disclosure
-
One of the strongest properties of file-based memory is progressive disclosure. Instead of eagerly loading every artifact into context, Claude Code can reference paths, summaries, or filenames first, then expand only when needed.
-
The same principle appears in file-based retrieval architectures discussed in Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026), where retrieval results are written to files and selectively accessed later rather than injected inline into the prompt.
-
This decouples storage size from context-window size. The file system can hold far more information than the active model context, and the agent can choose what to read when the task requires it.
Best Practices
-
A stable Claude Code memory system depends on several practices. Project memory should remain concise and high-signal, with only durable repository facts and always-relevant constraints placed in
CLAUDE.md. Scoped instructions should move into.claude/rules/so frontend, backend, infrastructure, security, and database guidance activates only when relevant. Auto memory should be reviewed periodically because it can preserve useful discoveries as well as incorrect generalizations. Durable conventions should be written into files rather than left only in chat, because chat history may be compacted or discarded. Deterministic behaviors should be implemented with hooks and permissions rather than informal memory instructions. Long sessions should use/compactbefore context becomes unwieldy, and failed reasoning paths should be handled with/rewindrather than repeated corrections. Secrets, credentials, and sensitive operational details should not be stored in memory files. -
Together, these practices turn memory management into systems engineering rather than prompt writing.
Hybrid Memory
-
Modern agentic systems increasingly combine file-based memory with semantic retrieval layers.
-
A generalized architecture is:
-
Working context handles immediate reasoning, file memory stores authoritative project state, semantic retrieval handles large-scale recall, and summarization compresses long histories.
-
Claude Code is strongly biased toward the file-memory side of this design space because software engineering benefits heavily from transparency, determinism, editability, and versionability.
Coding Fit
-
Coding environments differ from open-ended conversational systems because many of the most important facts are explicit and structured. Build commands, file paths, APIs, coding conventions, dependency relationships, architectural constraints, migration procedures, and security policies are naturally represented as markdown files, rules, repository documents, and git-tracked history.
-
As a result, Claude Code’s memory system reflects a broader architectural insight: software engineering agents often benefit more from deterministic, inspectable memory than from purely semantic memory retrieval systems.
Commands and Usage Patterns
- Claude Code’s command system is the operational interface for controlling the agent. Commands determine how the session is shaped, how memory is managed, how permissions are granted, how work is reviewed, and how repetitive workflows become reusable. In practice, mastery of Claude Code depends less on knowing every command and more on knowing which command changes the agent’s state at the right moment. The official Claude Code commands reference describes commands as session-level controls for switching models, managing permissions, clearing context, and running workflows; the broader Claude Code overview frames Claude Code as an agentic tool that reads codebases, edits files, runs commands, and integrates with development tools.
Command Semantics
-
A Claude Code command is recognized only when it appears at the start of a message. Typing
/shows available commands, and typing letters after/filters the list. Text after the command name is interpreted as an argument, which means/compact preserve API constraints and database migration detailsis not a normal chat message but an instruction to the compaction mechanism. Availability can vary by platform, plan, and environment, so commands such as/desktopor/upgrademay not appear for all users. -
The distinction between built-in commands and skills is important. Built-in commands are implemented directly by the CLI, while skills are prompt-driven workflows that Claude can invoke through the same command interface. This means
/diffbehaves like a native interface action, whereas commands such as/batch,/loop,/debug, and/simplifybehave more like structured agent workflows.
Session Control
-
The most important commands for daily use are
/clear,/compact,/context,/rewind,/branch,/resume, and/rename. These commands govern the lifecycle of a session and should be treated as memory-management tools rather than convenience shortcuts. Anthropic’s Using Claude Code: session management and 1M context explains that session quality depends heavily on context management, especially when deciding whether to continue, rewind, compact, clear, or delegate to subagents. -
/clearstarts a new conversation with empty context while keeping the previous session available through/resume; it is appropriate when beginning a genuinely new task./compact [instructions]summarizes the conversation so far and replaces prior history with that summary; it is appropriate when the task is still ongoing but the session contains stale exploration, debugging output, or irrelevant intermediate attempts./contextvisualizes current context usage and provides optimization suggestions for memory bloat or context-heavy tools. -
Example:
/compact preserve the auth middleware constraints, the database schema, and the failing test names; drop the discarded JWT refresh-token approach
-
/rewindis the corrective command to use when Claude has taken a wrong path. It allows the user to return to an earlier point, drop subsequent failed reasoning from the context, and re-prompt from a cleaner state. This is often better than saying “that did not work” because the failed attempt itself otherwise remains in context and can continue influencing the model. -
Example:
/rewind
- Then:
* Do not use the repository abstraction. The auth module exposes only validateSession and refreshSession. Implement the middleware using those two functions and add tests for expired cookies.
Planning and Execution
-
/plan [description]enters plan mode directly and optionally starts the session with a task description. Plan mode is useful for architectural work, risky migrations, and ambiguous features because it makes the model articulate the approach before editing files. This aligns with Anthropic’s broader agent-design guidance in Building Effective AI Agents, which emphasizes simple, composable patterns over unnecessary framework complexity. -
Example:
/plan migrate the billing webhook handler from Express middleware to the new Fastify plugin architecture
- A practical execution pattern is to enter plan mode, request an implementation plan, review the plan, permit edits, run tests, review the diff, and then ask for cleanup.
Memory and Config
-
/initinitializes a project with aCLAUDE.mdguide file, and/memoryopens persistent memory files. These define architecture, constraints, and workflows. -
Example
CLAUDE.md:
Use pnpm.
Run pnpm test before completion.
API routes in src/server/routes.
Never log tokens.
- The pro tips emphasize starting from the project root and keeping memory concise to avoid context bloat .
Review and Security
-
/diffshows changes and/security-reviewscans for vulnerabilities. These are essential checkpoints. -
Example:
/diff
/security-review
Model and Effort Control
-
/model,/effort, and/fastadjust reasoning depth and performance. Higher effort is useful for complex reasoning; lower effort is sufficient for simple edits . -
Example:
/effort high
Permissions and Automation
/permissionscontrols tool access, and/hooksenables automation such as running tests after edits.
Subagents and Batch
-
Subagents isolate context for subtasks, while
/batchhandles large-scale parallel changes across a codebase. -
Example:
/batch migrate UI components to a new design system
Custom Commands and Skills
-
Custom commands and skills allow reusable workflows.
-
Example:
/pr
- for generating a pull request summary.
Workflows and Patterns
- Claude Code is most effective when used through structured workflows rather than isolated prompts. The system is designed around iterative loops of planning, execution, validation, and refinement, and the highest leverage comes from composing commands, context management, and validation into repeatable patterns. The shift is from issuing instructions to orchestrating a process, where the developer defines intent, constraints, and evaluation criteria while the agent performs implementation.
The Inner Loop
-
The dominant workflow in Claude Code follows a consistent loop: inspect the codebase, plan the approach, execute changes, validate results, review outputs, and iterate. This loop reflects the broader transition described in The future of agentic coding with Claude Code, where coding moves from direct text manipulation to delegating tasks to an agent that performs edits and refinement autonomously .
-
This loop can be formalized as:
-
Each stage is explicit in Claude Code. Planning corresponds to
/planor plan mode, execution corresponds to file edits and tool calls, validation corresponds to tests and builds, and review corresponds to/diffor manual inspection. -
Example:
/plan implement OAuth login with Google and GitHub providers
- Followed by:
Implement backend routes first, then frontend integration. Add tests for token validation and error states.
- Then:
pnpm test
/diff
/security-review
Plan First
-
A consistent high-quality pattern is separating planning from execution. The pro tips emphasize starting in plan mode and verifying assumptions before edits .
-
Example:
/plan refactor the payment retry logic to ensure idempotency
- Then:
Proceed with implementation. Prioritize correctness.
- This reduces cascading errors and aligns with structured reasoning approaches like ReAct by Yao et al. (2022), where reasoning precedes action.
Validation Loops
-
Validation is the core feedback mechanism. Without it, the agent cannot reliably converge to correct solutions. Strong validation loops include builds, tests, linting, and runtime checks .
-
Example:
pnpm typecheck && pnpm test
- If failures occur:
Fix the failing tests without weakening assertions.
- This creates a feedback system analogous to minimizing a loss:
Steering the Agent
-
Users should actively steer the agent rather than passively waiting for completion. Interrupting early prevents wasted computation and incorrect context buildup .
-
Example:
Stop. Do not introduce a new abstraction. Extend the existing module.
Branching Strategies
-
Branching allows exploration of multiple approaches without contaminating context.
-
Example:
/branch redis-queue
Implement using Redis.
- Then:
/branch postgres-queue
Implement using Postgres.
- Each branch evolves independently, enabling comparison.
Subagent Decomposition
-
Subagents isolate subtasks and reduce context overload.
-
Example:
Use a subagent to analyze the authentication module and summarize token lifecycle.
- This prevents intermediate noise from polluting the main context.
Batch Workflows
-
For large changes,
/batchdecomposes work and executes it in parallel. -
Example:
/batch migrate REST APIs to GraphQL
- Claude analyzes, splits tasks, and runs agents in parallel.
Continuous Automation
-
Commands like
/loopenable continuous workflows. -
Example:
/loop 10m check CI status and summarize failures
- This allows ongoing monitoring and response.
End-to-End Example
/clear
/init
/plan add email verification
Proceed with implementation
pnpm test
/diff
/security-review
Summarize changes for PR
Emergent Patterns
-
Effective usage follows consistent patterns. Start from project root, keep memory concise, plan before execution, interrupt early, prefer rewind over patching, use validation loops aggressively, delegate to subagents, and encode workflows into commands.
-
These patterns define context-first programming, where shaping the environment matters more than writing code directly.
Evaluation and Debugging
-
Claude Code’s effectiveness depends on its ability to produce correct, secure, and maintainable outputs under uncertainty. Reliability is not guaranteed by the model itself but emerges from structured evaluation, strong validation loops, and systematic debugging. The system should be treated as an iterative optimizer guided by feedback rather than a deterministic generator.
-
Anthropic’s broader guidance in Building Effective AI Agents emphasizes that simple workflows with strong feedback loops outperform complex but weakly validated systems. This principle is central to evaluating and debugging Claude Code outputs.
Reliability as Feedback
- Claude Code operates as a feedback-driven system where outputs are continuously evaluated against constraints. Reliability can be modeled as minimizing a composite error:
- The objective is to iteratively reduce ( \mathcal{L} ) through validation and correction. Unlike traditional development, where correctness is enforced during implementation, Claude Code relies on external signals such as test results and runtime behavior.
Validation Design
-
Strong validation loops provide clear, actionable signals. The most effective loops are deterministic and automated, including builds, type checks, tests, and linting. The pro tips emphasize that improving validation loops significantly improves agent performance .
-
Example:
pnpm typecheck && pnpm test && pnpm lint
- If failures occur:
Fix the failing tests without weakening assertions.
-
This creates a closed-loop system where the agent converges toward correctness.
-
From a control perspective:
\[\text{Output}_{t+1} = \text{Output}_t - \eta \nabla \mathcal{L}\]- where updates are guided by validation feedback.
Debugging Tools
- Claude Code provides structured debugging commands that transform debugging into a guided process.
/debug [description] enables debug logging and runs troubleshooting workflows.
- Example:
/debug tests hang after pnpm test
-
/diffreveals changes and helps identify where issues were introduced. -
Example:
/diff
Review changes related to authentication.
-
/doctordiagnoses installation and environment issues. -
These tools provide visibility into system state, which is essential for debugging.
Common Failure Modes
-
Claude Code exhibits distinct failure modes:
-
Hallucinated APIs where non-existent functions are introduced, over-generalization where unnecessary abstractions are created, context contamination where outdated information affects reasoning, and partial correctness where outputs pass some tests but fail edge cases.
-
These failures highlight the importance of strong validation and context control.
Debugging Strategies
-
Effective debugging relies on structured approaches.
-
Isolating the failure narrows scope:
Focus only on failing test "refresh token expiry".
- Reproducing issues ensures clarity:
Write a minimal reproduction test.
- Hypothesis-driven debugging improves accuracy:
Hypothesis: retry logic causes duplicate requests. Verify.
- This approach mirrors scientific reasoning and reduces incorrect fixes.
Security Evaluation
-
Security is enforced through invariants and analysis. The
/security-reviewcommand identifies vulnerabilities such as injection risks and improper authentication. -
Example:
/security-review
- Security constraints can be expressed as:
- Permissions and hooks further enforce trust boundaries by restricting unsafe actions.
Redundancy and Verification
-
Reliability improves with redundancy. Multiple validation methods such as tests, static analysis, and manual review increase confidence. Running alternative approaches or branches can also validate correctness.
-
This is analogous to ensemble methods where multiple evaluations improve accuracy.
Human Oversight
-
Human review remains essential. Developers evaluate outputs, catch subtle issues, and guide the agent. Even with automation, reviewing code remains a bottleneck .
-
Human oversight is critical for architecture, security, and edge cases.
Example Debug Workflow
pnpm test
/diff
/debug token refresh fails
Focus on failing test
Fix race condition
pnpm test
/security-review
- This structured workflow ensures systematic debugging and validation.
Reliability Implications
- Claude Code shifts responsibility from generation to system design. Reliability depends on validation loops, constraints, and context management rather than model capability alone. Developers must design systems that guide the agent toward correct outcomes.
Customization and Integration
-
Claude Code becomes significantly more powerful when extended beyond default usage into a programmable system tailored to a project or organization. Rather than acting as a static assistant, it functions as an extensible agent platform where memory, commands, tools, and integrations can be composed into higher-level systems. The developer’s role shifts toward designing this environment.
-
Anthropic’s Writing effective tools for AI agents emphasizes that agent performance depends heavily on how tools and interfaces are designed. Claude Code’s extensibility mechanisms are precisely where this design occurs.
Extensibility Layers
-
Claude Code exposes several composable layers: persistent memory through
CLAUDE.md, reusable workflows through custom commands, structured multi-step behaviors through skills, automation via hooks, external capabilities via MCP servers, and integrations with systems such as GitHub and IDEs. These layers combine to form a modular system, where complex behavior emerges from simple components. -
This mirrors classical modular system design:
- The effectiveness of the system depends not only on components but on how they interact.
Persistent Memory
-
The
CLAUDE.mdfile defines project-specific knowledge and acts as a persistent system prompt. It encodes architecture, constraints, workflows, and conventions. -
The pro tips emphasize keeping this file concise to avoid context bloat and degraded performance .
-
Example:
# Architecture
Backend: Fastify + PostgreSQL
Frontend: Next.js
# Commands
pnpm dev
pnpm test
# Constraints
All writes must be idempotent.
Never log tokens.
- This ensures consistent behavior across sessions.
Custom Commands
-
Custom commands encapsulate repeated prompts into reusable abstractions stored in
.claude/commands/or global directories. -
Example:
Review authentication changes.
Focus on:
- token handling
- session logic
- input validation
- Usage:
/review-auth
- These commands reduce repetition and enforce consistency.
Skills
-
Skills extend commands into structured workflows with defined steps, permissions, and optional automation.
-
Example:
Run tests, build project, deploy to staging, verify health checks.
-
Skills can specify allowed tools and execution order, making them suitable for complex processes like deployment or audits.
-
This aligns with tool-augmented agent research such as Toolformer by Schick et al. (2023), where structured tool usage improves performance.
Hooks and Automation
-
Hooks allow automatic execution of actions before or after events. They can enforce policies or trigger workflows.
-
Example:
{
"event": "after_edit",
"command": "pnpm test"
}
- Another example:
{
"event": "before_command",
"condition": "command.includes('rm -rf')",
"action": "deny"
}
- Hooks act as a policy layer, ensuring consistent behavior.
MCP and External Tools
-
MCP servers connect Claude Code to external systems such as APIs, databases, and internal tools. These extend the agent’s capabilities beyond the local environment.
-
Effective tools should be narrowly scoped, deterministic, and efficient in output size. Poorly designed tools increase ambiguity and degrade performance.
-
Example tool:
{
"name": "get_failed_ci_runs",
"description": "Fetch recent failed CI runs",
"output": ["id", "status", "error_summary"]
}
- This is preferable to generic APIs because it encodes intent.
Development Integration
-
Claude Code integrates with development systems such as GitHub, CI/CD pipelines, and IDEs. Commands like
/autofix-prallow the agent to monitor pull requests and fix issues automatically . -
Example:
/autofix-pr fix lint and type errors
- This creates continuous feedback loops between the agent and external systems.
Team Workflows
-
At the organizational level, teams can standardize workflows using shared memory files, commands, and skills. This ensures consistency and reduces onboarding friction.
-
Example:
/review-pr
- which enforces consistent review criteria across projects.
End-to-End Integration
- A complete workflow might involve implementing changes, validating locally, reviewing with
/diff, scanning with/security-review, and using/autofix-prfor CI fixes. Hooks enforce policies, while commands and skills standardize behavior.
System Design Perspective
-
Extensibility transforms Claude Code into a system design problem. Developers must define memory structures, workflows, validation loops, permissions, and integrations. Effectiveness depends on orchestration rather than raw model capability.
-
This reflects a broader trend in AI systems where performance is determined by how components are composed and controlled.
References
Claude Code documentation and product resources
- Claude Code Overview
- Claude Code Commands
- Claude Code Hooks
- Claude Code Skills
- Claude Code Memory Management
- Using Claude Code: session management and 1M context
- Introducing Claude Opus 4.7
Anthropic engineering and agent design
- Building Effective AI Agents
- Writing effective tools for AI agents
- Effective context engineering for AI agents
- Effective harnesses for long-running agents
- Demystifying evals for AI agents
- Code execution with MCP: building more efficient AI agents
- Introducing advanced tool use on the Claude Developer Platform
Claude Code architecture analyses and deep dives
- Claude Code — Source Code Documentation & Analysis
- Dive into Claude Code
- Build Your Own AI Agent: A Design Space Guide
- Comprehensive Analysis of Claude Code Source Leak
Practitioner guides and workflows
- A Guide to Claude Code 2.0 and getting better at using coding agents (Detailed practitioner workflow covering commands, sub-agents, hooks, MCP, and context engineering) ([sankalp’s blog][1])
Talks, interviews, and practitioner insights
- The future of agentic coding with Claude Code
- Building Claude Code (talk)
- Claude Code engineering workflow discussion
Community posts and social media insights
- Andrej Karpathy on feeling behind as a programmer amid agentic coding shifts
- Boris Cherny on 100% of his Claude Code contributions being written by Claude Code
- Lenny Rachitsky sharing Boris Cherny’s “100% of my code is written by Claude Code” interview clip
- Chaofan Shou on the Claude Code source map leak
- Shruti Mishra on the Claude Code source leak aftermath
- Context management pattern that improved Claude Code workflows
Core language model and transformer foundations
- Attention Is All You Need by Vaswani et al. (2017)
- BERT: Pre-training of Deep Bidirectional Transformers by Devlin et al. (2018)
- Language Models are Few-Shot Learners by Brown et al. (2020)
Tool use, reasoning, and agent frameworks
- ReAct: Synergizing Reasoning and Acting in Language Models by Yao et al. (2022)
- Toolformer: Language Models Can Teach Themselves to Use Tools by Schick et al. (2023)
- Gorilla: Large Language Model Connected with Massive APIs by Patil et al. (2023)
Memory, context, and long-horizon reasoning
- Neural Turing Machines by Graves et al. (2014)
- RETRO: Improving Language Models with Retrieval by Borgeaud et al. (2022)
- MemGPT: Towards LLMs as Operating Systems by Packer et al. (2023)
Iterative improvement and self-reflection
- Reflexion: Language Agents with Verbal Reinforcement Learning by Shinn et al. (2023)
- Self-Refine: Iterative Refinement with Self-Feedback by Madaan et al. (2023)
Agent architectures and long-horizon systems
- Generative Agents: Interactive Simulacra of Human Behavior by Park et al. (2023)
- Voyager: An Open-Ended Embodied Agent with LLMs by Wang et al. (2023)
Reinforcement learning and decision systems
- Human-level control through deep reinforcement learning by Mnih et al. (2015)
Citation
If you found our work useful, please cite it as:
@article{Chadha2020DistilledClaudeCode,
title = {Claude Code},
author = {Chadha, Aman and Jain, Vinija},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}