Primers • BigBird
- Background: Transformers
- Enter BigBird
- BigBird: Transformers for Longer Sequences
- References
- Citation
Background: Transformers
- The phenomenal success of Google’s BERT and other natural language processing (NLP) models based on transformers isn’t accidental. Behind all the SOTA performances lies transformers’ innovative self-attention mechanism, which enables networks to capture contextual information from an entire text sequence.
- However, the memory and computational requirements of self-attention grow quadratically with sequence length, making it very expensive to use transformer-based models for processing long sequences.
Enter BigBird
- To alleviate the quadratic dependency of transformers, a team of researchers from Google Research recently proposed a new sparse attention mechanism dubbed BigBird.
- In their paper Big Bird: Transformers for Longer Sequences, the team demonstrates that despite being a sparse attention mechanism, BigBird preserves all known theoretical properties of quadratic full attention models.
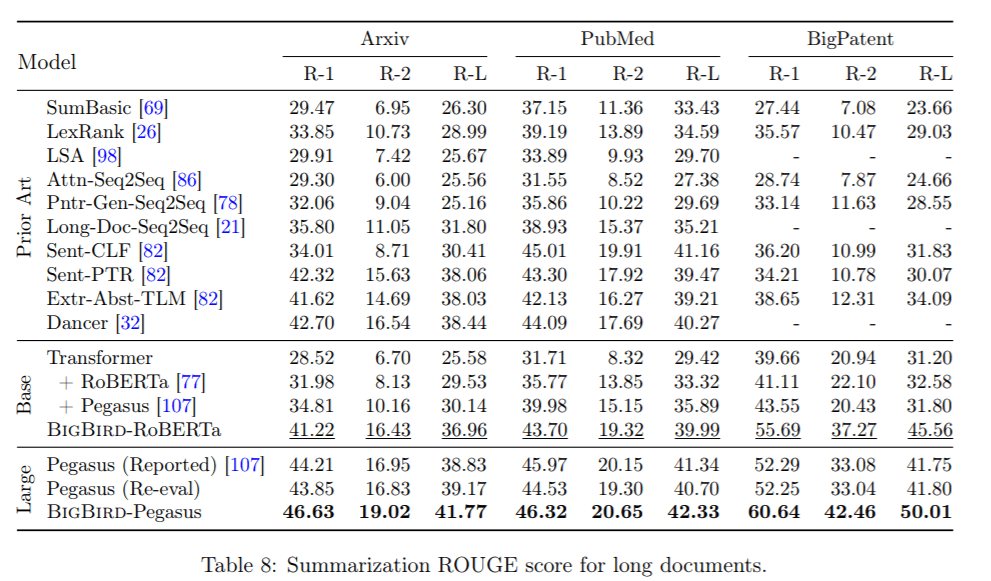
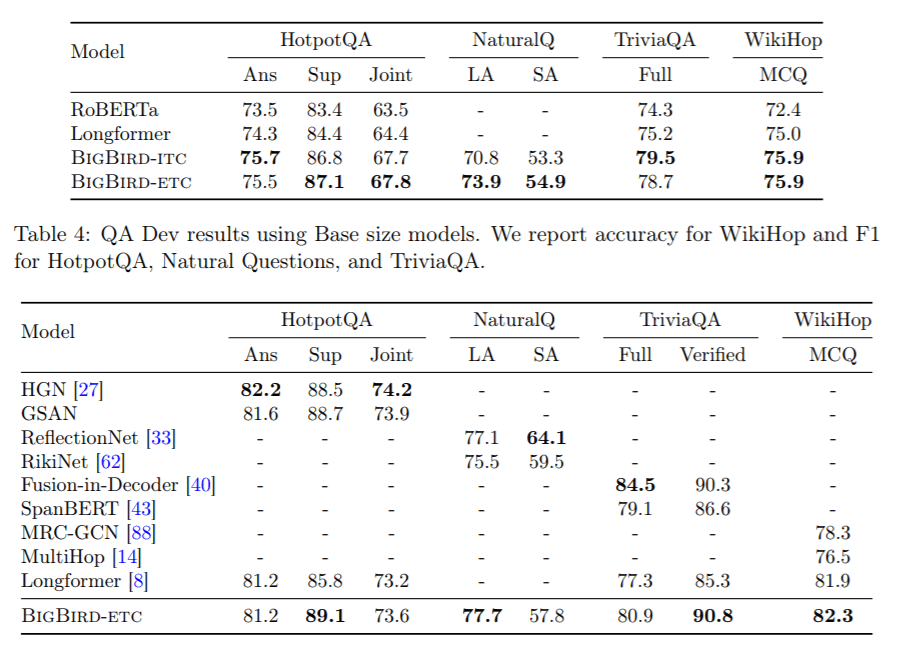
- In experiments, BigBird is shown to dramatically improve performance across long-context NLP tasks, producing SOTA results in question answering and summarization.
BigBird: Transformers for Longer Sequences
-
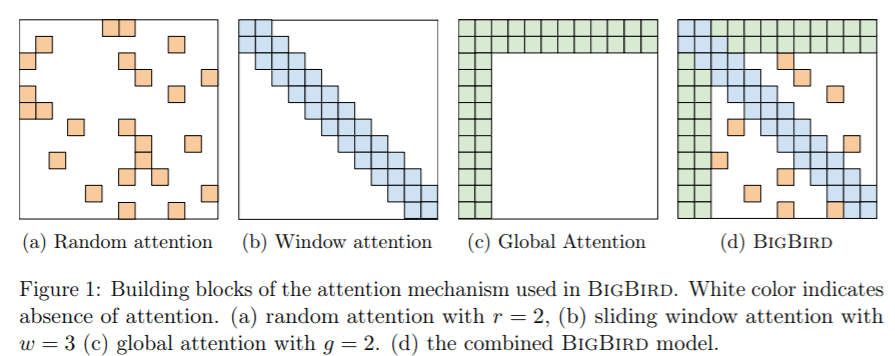
The researchers designed BigBird to satisfy all known theoretical properties of full transformers, building three main components into the model:
- A set of \(g\) global tokens that attend to all parts of a sequence.
- For each query \(q_i\), a set of \(r\) random keys that each query will attend to.
- A block of local neighbors \(w\) so that each node attends on their local structure.
-
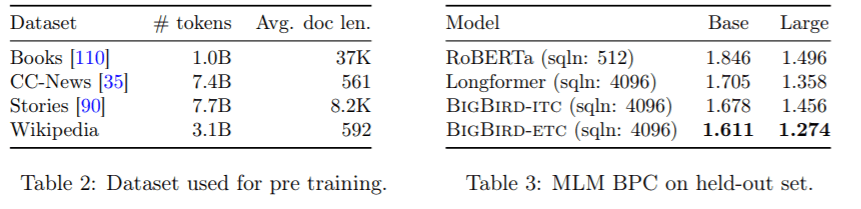
These innovations enable BigBird to handle sequences up to eight times longer than what was previously possible using standard hardware.
- Additionally, inspired by the capability of BigBird to handle long contexts, the team introduced a novel application of attention-based models for extracting contextual representations of genomics sequences like DNA. In experiments, BigBird proved to be beneficial in processing the longer input sequences and also delivered improved performance on downstream tasks such as promoter-region and chromatin profile prediction.
References
Citation
If you found our work useful, please cite it as:
@article{Chadha2020DistilledBigBird,
title = {BigBird},
author = {Chadha, Aman},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}