Primers • Agents
- Overview
- The “Agentic AI Moment”
- The Agentic Workflow
- Workflows vs. Agents
- The Agent Framework
- Agentic Design Patterns
- Reflection
- Function/Tool/API Calling
- Planning
- Multi-agent Collaboration
- Implementation
- Agentic Workflow Patterns
- Single-Agent vs. Multi-Agent Systems
- Why this distinction matters
- Conceptual definitions
- Visual overview
- Architectural comparison
- Core tradeoffs
- When single-agent systems are usually better
- When multi-agent systems become competitive
- Architecture selection guidance
- Key takeaways
- Case Study: Cursor’s Multi-Agentic System
- Agent Harness as the Coordination Layer
- Dynamic Context Discovery
- Retrieval and Semantic Search
- Specialized Agent Models for Software Engineering
- Sandboxing for Secure Execution
- From Single-Agent Coding to Multi-Agent Coding
- Multi-Agent Optimization
- Agentic Code Review
- Cloud Agents and Durable Execution
- Productivity Impact
- Design Principles
- Training and Evals
- Runtime
- Review
- Coordination
- Outlook
- Agent Harness as the Coordination Layer
- Model Context Protocol (MCP)
- Overview
- Why MCP?
- General Architecture
- How MCP Works
- MCP vs. API
- Security, Updates, and Authentication
- Getting Started with MCP: High-Level Steps
- Use-Cases of MCP in Real-World Development Scenarios
- Automating Feature Development from Ticket to Implementation
- Intelligent Ticket and Task Management
- Automated Communication with Relevant Stakeholders
- Smart Staging, Commit Messages, and PR Creation
- Automated Debugging and Console Log Access
- Integration with Personal Task Management Tools
- Automated Project Announcements
- MCP Servers List
- Agent2Agent (A2A) Protocol
- Agentic Retrieval-Augmented Generation (RAG)
- How Agentic RAG Works
- Agentic Decision-Making in Retrieval
- Agentic RAG Architectures: Single-Agent vs. Multi-Agent Systems
- Beyond Retrieval: Expanding Agentic RAG’s Capabilities
- Agentic RAG vs. Vanilla RAG: Key Differences
- Implementing Agentic RAG: Key Approaches
- Enterprise-driven Adoption
- Benefits
- Limitations
- Code
- Disadvantages of Agentic RAG
- Summary
- Reinforcement Learning for Agents
- Benchmarks
- Common Use-cases
- Case Studies
- Frameworks/Libraries
- Example Flow Chart for an LLM Agent: Handling a Customer Inquiry
- Use Cases
- Build your own LLM Agent
- Responsible AI Agents
- Related Papers
- Reflection
- Tool Calling
- Planning
- Multi-Agent Collaboration
- ChatDev: Communicative Agents for Software Development
- AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
- APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets
- AutoAgents: A Framework for Automatic Agent Generation
- MetaGPT: Meta Programming for Multi-Agent Collaborative Framework
- Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models
- OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning
- Further Reading
- References
- Citation
Overview
- AI agents are autonomous systems that combine the decision-making and action-oriented capabilities of autonomous frameworks with the natural language processing and comprehension strengths of Large Language Models (LLMs). The LLM serves as the “brain” within an agent, interpreting language, generating responses, and planning tasks, while the agent framework enables the execution of these tasks within a defined environment. Together, they allow agents to engage in goal-oriented workflows, where LLMs contribute strategic insights, problem-solving, and adaptability to achieve outcomes with minimal human intervention.
- AI agents leverage LLMs as central reasoning engines, which facilitate real-time decision-making, task prioritization, and dynamic adaptation. In practice, an AI agent operates through a cycle: the LLM analyzes incoming information, formulates an actionable plan, and collaborates with a series of modular systems—such as APIs, web tools, or embedded sensors—to execute specific steps. Throughout this process, the LLM can maintain context and iterate, adjusting actions based on feedback from the agent’s environment or outcomes from previous steps. This integrated system enables AI agents to tackle complex, multi-phase tasks with increasing sophistication, driving innovation across sectors like finance, software engineering, and scientific discovery.
The “Agentic AI Moment”
- Many people experienced a pivotal “AI moment” with the release of ChatGPT—a time when the system’s capabilities exceeded their expectations. This phenomenon, often called the “ChatGPT moment,” encapsulates interactions where the AI’s performance went beyond anticipated limits, demonstrating remarkable competence, creativity, or problem-solving ability.
- Analogous to the “ChatGPT moment,” agents have had an “Agentic AI moment”—an instance where an AI system exhibits unexpected autonomy and resourcefulness. One notable example (source) involves an AI agent developed for online research. During a live demonstration, the agent encountered a rate-limiting error while accessing its primary web search tool. Instead of failing, the agent seamlessly adapted by switching to a secondary tool—a Wikipedia search feature—to complete the task effectively. This unplanned pivot showcased the agent’s ability to adjust independently to unforeseen circumstances, a hallmark of agentic planning and adaptive problem-solving that highlights the emerging potential of AI agents in complex, real-world applications.
The Agentic Workflow
- Most current applications of large language models (LLMs) operate in zero-shot mode, where the model generates responses token by token without revisiting or refining its initial output. This approach is akin to asking someone to write an essay in one continuous attempt without making any corrections. While LLMs perform remarkably well under these constraints, an agentic, iterative workflow often leads to higher-quality results.
-
A typical agentic workflow involves an LLM following a structured, multi-step process. Depending on the task, some or all of the following steps may be included:
- Planning an outline for the task
- Assessing whether additional research or web searches are needed
- Drafting an initial response
- Reviewing and identifying weak or irrelevant sections
- Revising based on detected areas for improvement
- This structured, human-like refinement process enables AI agents to produce more robust and nuanced outputs compared to a single-pass approach.
Workflows vs. Agents
- The term “agent” can have multiple interpretations. Some define agents as fully autonomous systems capable of operating independently over extended periods, using various tools to complete complex tasks. Others see them as prescriptive systems that follow predefined workflows.
-
Per Anthropic, categorize both under agentic systems but distinguish between two key architectures:
- Workflows: Systems where LLMs and tools are orchestrated through predefined code paths to complete tasks.
- Agents: Systems where LLMs dynamically direct their own processes, deciding how to use tools and manage tasks autonomously.
- By leveraging these agentic approaches, AI systems can move beyond single-shot responses, refining their outputs iteratively and intelligently.
The Agent Framework
- The Agent Framework provides a structured and modular design for organizing the core components of an AI agent. This setup allows for effective, adaptive interactions by combining critical components, each with defined roles that contribute to seamless task performance.
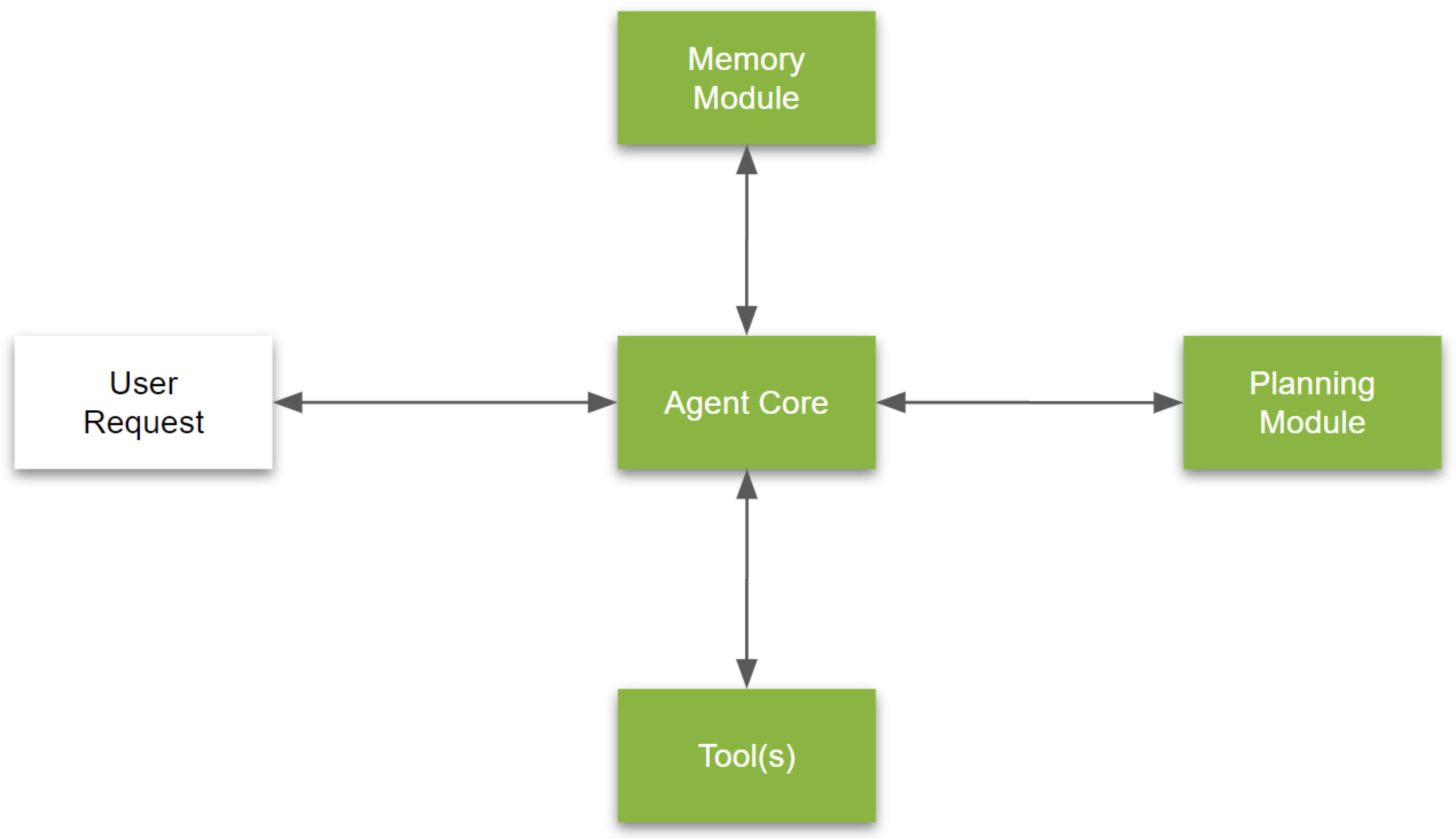
- The image above (source) illustrates the architecture of a typical end-to-end agent pipeline. Below, we explore each component in detail to understand the technical workings of an AI agent.
Agent Core (LLM)
-
At the heart of the agent, the Agent Core functions as the primary decision-making engine, where OpenAI’s GPT-4 is employed to handle high-level reasoning and dynamic task management. This component includes:
- Decision-Making Engine: Analyzes input data, memory, and goals to generate suitable responses.
- Goal Management System: Continuously updates the agent’s objectives based on task progression.
- Integration Bus: Manages the flow of information between memory, tools, and planning modules, ensuring cohesive data exchange.
-
The Agent Core uses the LLM’s capabilities to complete tasks, generate new tasks as needed, and dynamically adjust priorities based on the evolving task context.
Memory Modules
-
Memory is a fundamental part of the framework, with a vector databases (such as Pinecone, Weaviate, Chroma, etc.) providing robust storage and retrieval mechanisms for task-related data. The memory modules enhance the agent’s context-awareness and task relevance through:
- Short-term Memory (STM): Manages temporary data for immediate task requirements, stored in volatile structures like stacks or queues to support quick access and frequent clearing.
- Long-term Memory (LTM): Uses vector databases for persistent storage of historical interactions, enabling the agent to reference past conversations or data over extended periods. Semantic similarity-based retrieval is employed to enhance relevance, factoring in recency and importance for efficient access.
Tools
-
Tools empower the agent with specialized capabilities to execute tasks precisely, often leveraging the LangChain framework for structured workflows. Tools include:
- Executable Workflows: Defined within LangChain, providing structured, data-aware task handling.
- APIs: Facilitate secure access to both internal and external data sources, enriching the agent’s functional range.
- Middleware: Supports data exchange between the core and tools, handling formatting, error-checking, and ensuring security.
-
LangChain’s integration enables the agent to dynamically interact with its environment, providing flexibility and adaptability across diverse tasks.
Planning Module
- For complex problem-solving, the Planning Module enables structured approaches like task decomposition and reflection to guide the agent in optimizing solutions. The Task Management system within this module utilizes a deque data structure to autonomously generate, manage, and prioritize tasks. It adjusts priorities in real-time as tasks are completed and new tasks are generated, ensuring goal-aligned task progression.
- In summary, the LLM Agent Framework combines an LLM’s advanced language capabilities with a vector database’s efficient memory system and an agentic framework’s responsive tooling. These integrated components create a cohesive, powerful AI agent capable of adaptive, real-time decision-making and dynamic task execution across complex applications.
Agentic Design Patterns
- Agentic design patterns empower AI models to transcend static interactions, enabling dynamic decision-making, self-assessment, and iterative improvement. These patterns establish structured workflows that allow AI to actively refine its outputs, incorporate new tools, and even collaborate with other AI agents to complete complex tasks. By leveraging agentic patterns, language models evolve from simple, one-step responders to adaptable, reliable, and contextually aware systems, enhancing their application across various domains.
- A well-defined categorization of agentic design patterns is crucial for developing robust and efficient AI agents. By organizing these patterns into a clear framework, developers and researchers can better understand how to structure AI workflows, optimize performance, and ensure that agents are equipped to handle complex, dynamic tasks.
-
Below is a practical framework for classifying the most common agentic design patterns across various applications:
-
Reflection: The agent evaluates its work, identifying areas for improvement and refining its outputs based on this assessment. This process enables continuous improvement, ultimately leading to a more robust and accurate final output.
-
Tool Use: Agents are equipped with specific tools, such as web search or code execution capabilities, to gather necessary information, take actions, or process complex data in real time as part of their tasks.
-
Planning: The agent constructs and follows a comprehensive, step-by-step plan to achieve its objectives. This process may involve outlining, researching, drafting, and revising phases, as is often required in complex writing or coding tasks.
-
Multi-agent Collaboration: Multiple agents collaborate, each taking on distinct roles and contributing unique expertise to solve complex tasks by breaking them down into smaller, more manageable sub-tasks. This approach mirrors human teamwork, where roles like software engineer and QA specialist contribute to different aspects of a project.
-
-
These agentic design patterns represent diverse methodologies through which AI agents can optimize task performance, refine outputs, and dynamically adapt workflows. For those exploring multi-agent systems (MAS), frameworks such as AutoGen, Crew AI, and LangGraph offer robust platforms for designing and deploying multi-agent solutions. Additionally, open-source projects such as ChatDev simulate a virtual software company operated by AI agents, provide developers with accessible tools to experiment with MAS.
- A detailed overview of agentic design patterns is available in our Agentic Design Patterns primer.
Reflection
Overview
-
To boost the effectiveness of LLMs, a pivotal approach is the incorporation of a reflective mechanism within their workflows. Reflection is a method by which LLMs improve their output quality through self-evaluation and iterative refinement. By implementing this approach, an LLM can autonomously recognize gaps in its output, adjust based on feedback, and ultimately deliver responses that are more precise, efficient, and contextually aligned with user needs. This structured, iterative process transforms the typical query-response interaction into a dynamic cycle of continuous improvement.
-
Reflection represents a relatively straightforward type of agentic workflow, yet it has proven to significantly enhance LLM output quality across diverse applications. By encouraging models to reflect on their performance, refine their responses, and utilize external tools for self-assessment, this design pattern enables models to deliver accurate, efficient, and contextually relevant results. This iterative process not only strengthens an LLM’s ability to produce high-quality outputs but also imbues it with a form of adaptability, allowing it to better meet complex, evolving requirements.
-
The integration of Reflection into agentic workflows is transformative, rendering LLMs more adaptable, self-aware, and capable of handling complex tasks autonomously. As a foundational design pattern, Reflection holds substantial promise for enhancing the efficacy and reliability of LLM-based applications. This approach highlights the growing capacity of these models to function as intelligent, self-improving agents, poised to meet the demands of increasingly sophisticated tasks with minimal human intervention.
Reflection Workflow: Step-by-Step Process
Initial Output Generation
- In a typical task, such as writing code, the LLM is first prompted to generate an initial response aimed at accomplishing a specific goal (e.g., completing “task X”). This response may serve as a draft that will later be subjected to further scrutiny.
Self-Evaluation and Constructive Feedback
-
After producing an initial output, the LLM can be guided to assess its response. For instance, in the case of code generation, it may be prompted with:
“Here’s code intended for task X: [previously generated code].
Check the code carefully for correctness, style, and efficiency, and provide constructive criticism for improvement.” -
This self-critique phase enables the LLM to recognize any flaws in its work. It can identify issues related to correctness, efficiency, and stylistic quality, thus facilitating the detection of areas needing refinement.
Revision Based on Feedback
-
Once the LLM generates feedback on its own output, the agentic workflow proceeds by prompting the model to integrate this feedback into a revised response. In this stage, the context given to the model includes both the original output and the constructive criticism it produced. The LLM then generates a refined version that reflects the improvements suggested during self-reflection.
-
This cycle of criticism and rewriting can be repeated multiple times, resulting in iterative enhancements that significantly elevate the quality of the final output.
Beyond Self-Reflection: Integrating Additional Tools
-
Reflection can be further augmented by equipping the LLM with tools that enable it to evaluate its own output quantitatively. For instance:
- Code Evaluation: The model can run its code through unit tests to verify accuracy, using test cases to ensure correct results.
- Text Validation: The LLM can leverage internet searches or external databases to fact-check and verify textual content.
-
When errors or inaccuracies are detected through these tools, the LLM can reflect on the discrepancies, producing additional feedback and proposing ways to improve the output. This tool-supported reflection enables the LLM to refine its responses even further, effectively combining self-critique with external validation.
Multi-Agent Framework for Enhanced Reflection
- To optimize the Reflection process, a multi-agent framework can be utilized. In this configuration, two distinct agents are employed:
- Output Generation Agent: Primarily responsible for producing responses aimed at achieving the designated task effectively.
- Critique Agent: Tasked with critically evaluating the output of the first agent, offering constructive feedback to enhance its quality.
- Through this dialogue between agents, the LLM achieves improved results, as the two agents collaboratively identify and rectify weaknesses in the output. This cooperative approach introduces a second level of reflection, allowing the LLM to gain insights that a single-agent setup might miss.
Example of Reflection: Multi-Agent Framework for Iterative Code Improvement
-
In the context of Reflection, one effective implementation involves a multi-agent interaction where two agents—a Coder Agent and a Critic Agent—collaborate to refine code through iterative feedback and revisions, emphasizing the synergy between generation and critique. Example below:
-
Initial Task and Code Generation: The process begins with a prompt given to the Coder Agent, instructing it to “write code for {task}.” The Coder Agent generates an initial version of the code, labeled here as
do_task(x). -
Critique and Error Identification: The Critic Agent then reviews the initial code. In this case, it identifies a specific issue, stating, “There’s a bug on line 5. Fix it by…” and offers a constructive suggestion for improvement. This feedback allows the Coder Agent to understand where the code falls short.
-
Code Revision: Based on the Critic Agent’s feedback, the Coder Agent revises its code, producing an updated version,
do_task_v2(x). This revised code aims to address the issues highlighted in the first critique. -
Further Testing and Feedback: The Critic Agent assesses the new version, testing it further (such as through unit tests). Here, it notes that “It failed Unit Test 3” and advises a further change, indicating that additional refinements are necessary for accuracy.
-
Final Iteration: The Coder Agent, with this additional guidance, creates yet another iteration of the code—
do_task_v3(x). This repeated process of critique and revision continues until the code meets the desired standards for functionality and efficiency.
-
-
This example highlights the iterative nature of Reflection within a multi-agent framework. By engaging a Coder Agent focused on output generation and a Critic Agent dedicated to providing structured feedback, the system harnesses a continuous improvement loop. This interaction enables large language models to autonomously detect errors, refine logic, and improve their responses.
-
The multi-agent setup exemplifies how Reflection can be operationalized to produce high-quality, reliable results. This structured approach not only enhances the LLM’s output but also mirrors human collaborative workflows, where constructive feedback leads to better solutions through repeated refinement.
Function/Tool/API Calling
- The advent of Tool Use in LLMs represents a pivotal design pattern in agentic AI workflows, enabling LLMs to perform a diverse range of tasks beyond text generation. Tool Use refers to the capability of an LLM to utilize specific functions—such as executing code, conducting web searches, or interacting with productivity tools—within its responses, effectively expanding its utility far beyond conventional, language-based outputs. This approach allows LLMs to tackle more complex queries and execute multifaceted tasks by selectively invoking various external tools. From answering specific questions to performing calculations, the use of function calls empowers LLMs to provide highly accurate and contextually informed responses.
- A foundational example of Tool Use is seen in scenarios where users request information not available in the model’s pre-existing training data. For instance, if a user asks, “What is the best coffee maker according to reviewers?”, a model equipped with Tool Use may initiate a web search, fetching up-to-date information by generating a command string such as
{tool: web-search, query: "coffee maker reviews"}. Upon processing, the model retrieves relevant pages, synthesizes the data, and delivers an informed response. This dynamic response mechanism emerged from early realizations that traditional transformer-based language models, reliant solely on pre-trained knowledge, were inherently limited. By integrating a web search tool, developers enabled the model to access and incorporate fresh information into its output, a capability now widely adopted across various LLMs in consumer-facing applications. - Moreover, Tool Use enables LLMs to handle calculations and other tasks requiring precision that text generation alone cannot achieve. For example, when a user asks, “If I invest $100 at compound 7% interest for 12 years, what do I have at the end?”, an LLM could respond by executing a Python command like
100 * (1+0.07)**12. The LLM generates a string such as{tool: python-interpreter, code: "100 * (1+0.07)**12"}, and then the calculation tool processes this command to deliver an accurate answer. This illustrates how Tool Use facilitates complex mathematical reasoning within conversational AI systems. - The scope of Tool Use, however, extends well beyond web searches or basic calculations. As the technology has evolved, developers have implemented a wide array of functions, enabling LLMs to interface with multiple external resources. These functions may include accessing specialized databases, interacting with productivity tools like email and calendar applications, generating or interpreting images, and engaging with multiple data sources such as Search (via Google/Bing Search APIs), Wikipedia, and academic repositories like arXiv.
- Systems now prompt LLMs with detailed descriptions of available functions, specifying their capabilities and parameters. With these cues, an LLM can autonomously select the appropriate function to fulfill the user’s request. In settings where hundreds of tools are accessible, developers often employ heuristics to streamline function selection, prioritizing the tools most relevant to the current context—a strategy analogous to the subset selection techniques used in retrieval-augmented generation (RAG) systems.
- The development of large multimodal models (LMMs) such as LLaVa, GPT-4V, and Gemini marked another milestone in Tool Use. Prior to these models, LLMs could not process or manipulate images directly, and any image-related tasks had to be offloaded to specific computer vision functions, such as object recognition or scene analysis. The introduction of GPT-4’s function-calling capabilities in 2023 further advanced Tool Use by establishing a more general-purpose function interface, laying the groundwork for a versatile, multimodal AI ecosystem where models seamlessly integrate text, image, and other data types. This new functionality has subsequently led to a proliferation of LLMs designed to exploit Tool Use, broadening the range of applications and enhancing overall adaptability.
- For instance, below is a prompt from SmolLM2 for function calling, where the model is prompted to choose relevant functions based on specific user inquiries is as follows. The prompt template guides SmolLM2 in structuring its function calls precisely and prompts it to assess the relevance and sufficiency of available parameters before executing a function.
You are an expert in composing functions. You are given a question and a set of possible functions.
Based on the question, you will need to make one or more function/tool calls to achieve the purpose.
If none of the functions can be used, point it out and refuse to answer.
If the given question lacks the parameters required by the function, also point it out.
You have access to the following tools:
<tools></tools>
The output MUST strictly adhere to the following format, and NO other text MUST be included.
The example format is as follows. Please make sure the parameter type is correct. If no function call is needed, please make the tool calls an empty list '[]'.
<tool_call>[
{"name": "func_name1", "arguments": {"argument1": "value1", "argument2": "value2"}},
(more tool calls as required)
]</tool_call>
- The evolution of Tool Use and function-calling capabilities in LLMs demonstrates the significant strides taken toward realizing general-purpose, agentic AI workflows. By enabling LLMs to autonomously utilize specialized tools across various contexts, developers have transformed these models from static text generators into dynamic, multifunctional systems capable of addressing a vast array of user needs. As the field advances, we can expect further innovations that expand the breadth and depth of Tool Use, pushing the boundaries of what LLMs can achieve in an integrated, agentic environment.
Tool Calling Examples: Web Search and Code Execution
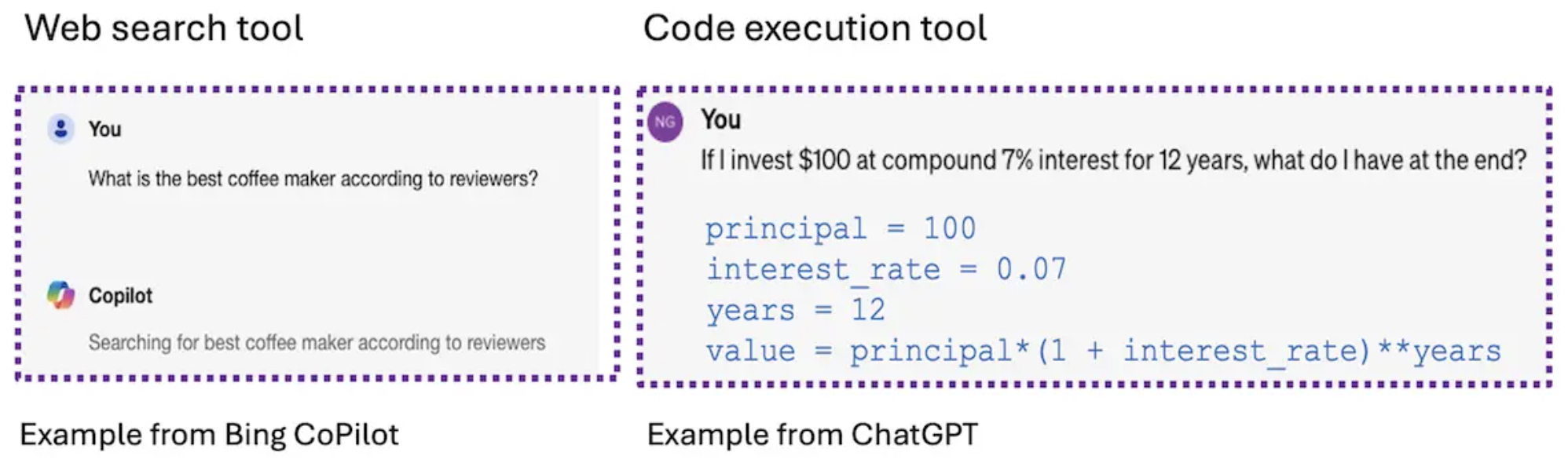
- LLMs can leverage tools such as web search to provide current product recommendations and code execution to handle complex calculations, showcasing their adeptness at choosing and using the right tools based on user input.
- The image below (source) showcases practical examples of tool calling in LLMs, highlighting two specific tools: a web search tool and a code execution tool. In the left panel, an example from Bing Copilot illustrates how an LLM can utilize a web search tool. When a user asks, “What is the best coffee maker according to reviewers?”, the model initiates a web search to gather relevant information from current online reviews. This allows the LLM to provide an informed answer based on up-to-date data.
- The right panel demonstrates an example from ChatGPT using a code execution tool. When a user asks, “If I invest $100 at compound 7% interest for 12 years, what do I have at the end?”, the LLM responds by generating a Python command to calculate the compounded interest. The code snippet,
principal = 100; interest_rate = 0.07; years = 12; value = principal * (1 + interest_rate) ** years, is executed, providing an accurate financial calculation rather than relying solely on text-based reasoning. - These examples illustrate the model’s ability to identify and select the appropriate tool based on the user’s query, further demonstrating the flexibility and enhanced capabilities of Tool Use in agentic LLM workflows.
Function Calling Datasets
Hermes Function-Calling V1
- The Hermes Function-Calling V1 dataset is designed for training language models to perform structured function calls and return structured outputs based on natural language instructions.
- It includes function-calling conversations, json-mode samples, agentic json-mode, and structured extraction examples, showcasing various scenarios where AI agents interpret queries and execute relevant function calls.
- The Hermes Function-Calling Standard enables language models to execute API calls based on user requests, improving AI’s practical utility by allowing direct API interactions.
Glaive Function Calling V2
- The Glaive Function Calling (52K) and Glaive Function Calling v2 (113K) are datasets generated through Glaive for the task of function calling, in the following format:
SYSTEM: You are an helpful assistant who has access to the following functions to help the user, you can use the functions if needed-
{
JSON function definiton
}
USER: user message
ASSISTANT: assistant message
Function call invocations are formatted as-
ASSISTANT: <functioncall> {json function call}
Response to the function call is formatted as-
FUNCTION RESPONSE: {json function response}
- There are also samples which do not have any function invocations, multiple invocations and samples with no functions presented and invoked to keep the data balanced.
Salesforce’s xlam-function-calling-60k
- Salesforce’s xlam-function-calling-60k contains 60,000 data samples collected by APIGen, an automated data generation pipeline designed to produce verifiable high-quality datasets for function-calling applications. Each data in our dataset is verified through three hierarchical stages: format checking, actual function executions, and semantic verification, ensuring its reliability and correctness.
- Also, xLAM-1b-fc-r and xLAM-7b-fc-r.
JSON Data Format for Query and Answers
- This JSON data format is used to represent a query along with the available tools and the corresponding answers. Here’s a description of the JSON format which consists of the following key-value pairs: ```
-
query (string): The query or problem statement.
-
tools (array): An array of available tools that can be used to solve the query.
-
Each tool is represented as an object with the following properties:
-
name (string): The name of the tool.
-
description (string): A brief description of what the tool does.
-
parameters (object): An object representing the parameters required by the tool.
-
Each parameter is represented as a key-value pair, where the key is the parameter name and the value is an object with the following properties:
-
type (string): The data type of the parameter (e.g., “int”, “float”, “list”).
-
description (string): A brief description of the parameter.
-
required (boolean): Indicates whether the parameter is required or optional.
-
-
-
-
-
answers (array): An array of answers corresponding to the query.
-
Each answer is represented as an object with the following properties:
-
name (string): The name of the tool used to generate the answer.
-
arguments (object): An object representing the arguments passed to the tool to generate the answer.
- Each argument is represented as a key-value pair, where the key is the parameter name and the value is the corresponding value. ```
-
-
- Note that they format the query, tools, and answers as a string, but you can easily recover each entry to the JSON object via
json.loads(...).
Example
- Here’s an example JSON data:
{
"query": "Find the sum of all the multiples of 3 and 5 between 1 and 1000. Also find the product of the first five prime numbers.",
"tools": [
{
"name": "math_toolkit.sum_of_multiples",
"description": "Find the sum of all multiples of specified numbers within a specified range.",
"parameters": {
"lower_limit": {
"type": "int",
"description": "The start of the range (inclusive).",
"required": true
},
"upper_limit": {
"type": "int",
"description": "The end of the range (inclusive).",
"required": true
},
"multiples": {
"type": "list",
"description": "The numbers to find multiples of.",
"required": true
}
}
},
{
"name": "math_toolkit.product_of_primes",
"description": "Find the product of the first n prime numbers.",
"parameters": {
"count": {
"type": "int",
"description": "The number of prime numbers to multiply together.",
"required": true
}
}
}
],
"answers": [
{
"name": "math_toolkit.sum_of_multiples",
"arguments": {
"lower_limit": 1,
"upper_limit": 1000,
"multiples": [3, 5]
}
},
{
"name": "math_toolkit.product_of_primes",
"arguments": {
"count": 5
}
}
]
}
- In this example, the query asks to find the sum of multiples of 3 and 5 between 1 and 1000, and also find the product of the first five prime numbers. The available tools are
math_toolkit.sum_of_multiplesandmath_toolkit.product_of_primes, along with their parameter descriptions. The answers array provides the specific tool and arguments used to generate each answer.
Synth-APIGen-v0.1
- A dataset of 50k samples by Argilla.
Example
- This example demonstrates the use of the
complex_to_polarfunction, which is designed to convert complex numbers into their polar coordinate representations. The input query requests conversions for two specific complex numbers,3 + 4jand1 - 2j, showcasing how the function can be called with different arguments to obtain their polar forms.
{
"func_name": "complex_to_polar",
"func_desc": "Converts a complex number to its polar coordinate representation.",
"tools": "[{\"type\":\"function\",\"function\":{\"name\":\"complex_to_polar\",\"description\":\"Converts a complex number to its polar coordinate representation.\",\"parameters\":{\"type\":\"object\",\"properties\":{\"complex_number\":{\"type\":\"object\",\"description\":\"A complex number in the form of `real + imaginary * 1j`.\"}},\"required\":[\"complex_number\"]}}}]",
"query": "I'd like to convert the complex number 3 + 4j and 1 - 2j to polar coordinates.",
"answers": "[{\"name\": \"complex_to_polar\", \"arguments\": {\"complex_number\": \"3 + 4j\"}}, {\"name\": \"complex_to_polar\", \"arguments\": {\"complex_number\": \"1 - 2j\"}}]",
"model_name": "meta-llama/Meta-Llama-3.1-70B-Instruct",
"hash_id": "f873783c04bbddd9d79f47287fa3b6705b3eaea0e5bc126fba91366f7b8b07e9",
}
],
"category": "E-commerce Platforms",
"subcategory": "Kayak",
"task": "Flight Search"
}
Evaluation
- To ensure that Tool Use capabilities meet the demands of diverse real-world scenarios, it is crucial to evaluate the function-calling performance of LLMs rigorously. This evaluation encompasses assessing model performance across both Python and non-Python programming environments, with a focus on how effectively the model can execute functions, select the appropriate tools, and discern when a function is necessary within a conversational context. An essential aspect of this evaluation is testing the model’s ability to invoke functions accurately based on user prompts and determine whether certain functions are applicable or needed.
- This structured evaluation methodology enables a holistic understanding of the model’s function-calling performance, combining both syntactic accuracy and real-world execution fidelity. By examining the model’s ability to navigate various programming contexts and detect relevance in function invocation, this approach underscores the practical reliability of LLMs in diverse applications.
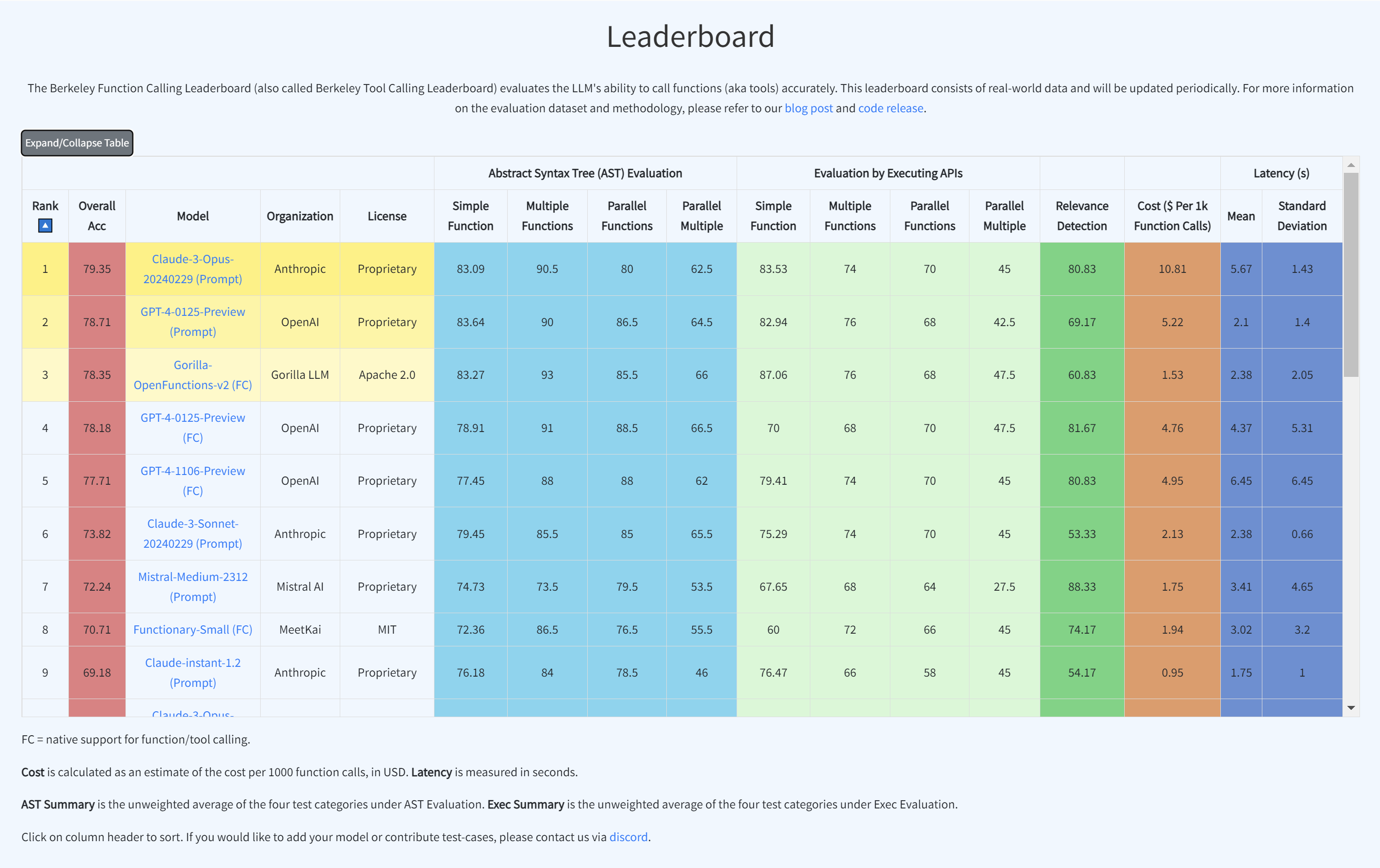
Berkeley Function-Calling Leaderboard
- Berkeley Function-Calling Leaderboard (BFCL) assesses the function-calling capabilities of various LLMs. It consists of 2,000 question-function-answer pairs across multiple programming languages (Python, Java, JavaScript, REST API, SQL).
- The evaluation covers complex use cases, including simple, multiple, and parallel function calls, requiring the selection and simultaneous execution of functions.
- BFCL tests function relevance detection to see how models handle irrelevant functions, expecting them to return an error message.
- Both proprietary and open-source models perform similarly in simple scenarios, but GPT-series models excel in more complex function-calling tasks.
- The Gorilla OpenFunctions dataset has expanded from 100 to 2,000 data points, increasing diversity and complexity in evaluations. The dataset includes functions from varied fields such as Mathematics, Sports, Finance, and more, covering 40 sub-domains.
- Evaluations are divided into Python (simple, multiple, parallel, parallel multiple functions) and Non-Python (chatting capability, function relevance, REST API, SQL, Java, JavaScript) categories.
- Python evaluations cover scenarios from single function calls to complex parallel multiple function calls.
- Non-Python evaluations test models on general-purpose chat, relevance detection, and specific API and language scenarios.
- Function relevance detection is a key focus, evaluating whether models avoid using irrelevant functions and highlighting their potential for hallucination.
- REST API testing involves real-world GET requests with parameters in URLs and headers, assessing models’ ability to generate executable API calls.
- SQL evaluation includes basic SQL queries, while Java and JavaScript testing focus on language-specific function-calling abilities.
- BFCL uses AST evaluation to check syntax and structural accuracy, and executable evaluation to verify real-world function execution.
- AST evaluation ensures function matching, parameter consistency, and type/value accuracy.
- Executable function evaluation runs generated functions to verify response accuracy and consistency, particularly for REST APIs.
- The evaluation approach requires complete matching of model outputs to expected results; partial matches are considered failures.
- Ongoing development includes continuous updates and community feedback to refine evaluation methods, especially for SQL and chat capabilities.
Python Evaluation
- Inspired by the Berkeley Function-Calling Leaderboard and APIGen, the evaluation framework can be organized by function type (simple, multiple, parallel, parallel multiple) or evaluation method (AST or execution of APIs). This categorization helps in comparing model performances on standard function-calling scenarios and assessing their accuracy and efficiency. By structuring the evaluation in this way, it provides a comprehensive view of how well the model performs across different types of function calls and under varying conditions. More on the section on Evaluation Methods.
- The Python evaluation categories, listed below, assess the model’s ability to handle single and multiple function calls, both sequentially and in parallel. These tests simulate realistic scenarios where the model must interpret user queries, select appropriate functions, and execute them accurately, mimicking real-world applications. By testing these different scenarios, the evaluation can highlight the model’s proficiency in using Python-based function calls under varying degrees of complexity and concurrency.
-
Simple Function: In this category, the evaluation involves a single, straightforward function call. The user provides a JSON function document, and the model is expected to invoke only one function call. This test examines the model’s ability to handle the most common and basic type of function call correctly.
-
Parallel Function: This evaluation scenario requires the model to make multiple function calls in parallel in response to a single user query. The model must identify how many function calls are necessary and initiate them simultaneously, regardless of the complexity or length of the user query.
-
Multiple Function: This category involves scenarios where the user input can be matched to one function call out of two to four available JSON function documentations. The model must accurately select the most appropriate function to call based on the given context.
-
Parallel Multiple Function: This is a complex evaluation combining both parallel and multiple function categories. The model is presented with multiple function documentations, and each relevant function may need to be invoked zero or more times in parallel.
- As mentioned earlier, each Python evaluation category includes both Abstract Syntax Tree (AST) and executable evaluations. A significant limitation of AST evaluation is the variety of methods available to construct function calls that achieve the same result, leading to challenges in consistency and accuracy. In these cases, executable evaluations provide a more reliable alternative by directly running the code to verify outcomes, allowing for precise and practical validation of functionality across different coding approaches.
Non-Python Evaluation
- The non-Python evaluation categories, listed below, test the model’s ability to handle diverse scenarios involving conversation, relevance detection, and the use of different programming languages and technologies. These evaluations provide insights into the model’s adaptability to various contexts beyond Python. By including these diverse categories, the evaluation aims to ensure that the model is versatile and capable of handling various use cases, making it applicable in a broad range of applications.
-
Chatting Capability: This category evaluates the model’s general conversational abilities without invoking functions. The goal is to see if the model can maintain coherent dialogue and recognize when function calls are unnecessary. This is distinct from function relevance detection, which involves determining the suitability of invoking any provided functions.
-
Function Relevance Detection: This tests whether the model can discern when none of the provided functions are relevant. The ideal outcome is that the model refrains from making any function calls, demonstrating an understanding of when it lacks the required function information or user instruction.
-
REST API: This evaluation focuses on the model’s ability to generate and execute realistic REST API calls using Python’s requests library. It tests the model’s understanding of GET requests, including path and query parameters, and its ability to generate calls that match real-world API documentation.
-
SQL: This category assesses the model’s ability to construct simple SQL queries using custom
sql.executefunctions. The evaluation is limited to basic SQL operations like SELECT, INSERT, UPDATE, DELETE, and CREATE, testing whether the model can generalize function-calling capabilities beyond Python. -
Java + JavaScript: Despite the uniformity in function-calling formats across languages, this evaluation examines how well the model adapts to language-specific types and syntax, such as Java’s HashMap. It includes examples that test the model’s handling of Java and JavaScript, emphasizing the need for language-specific adaptations.
Evaluation Methods
-
Two primary methods are used to evaluate model performance:
-
Abstract Syntax Tree (AST) Evaluation: AST evaluation involves parsing the model-generated function calls to check their structure against expected outputs. It verifies the function name, parameter presence, and type correctness. AST evaluation is ideal for cases where execution isn’t feasible due to language constraints or when the result cannot be easily executed.
- Simple Function AST Evaluation
- The AST evaluation process focuses on comparing a single model output function against its function doc and possible answers. Here is a flow chart (source) that shows the step-by-step evaluation process.
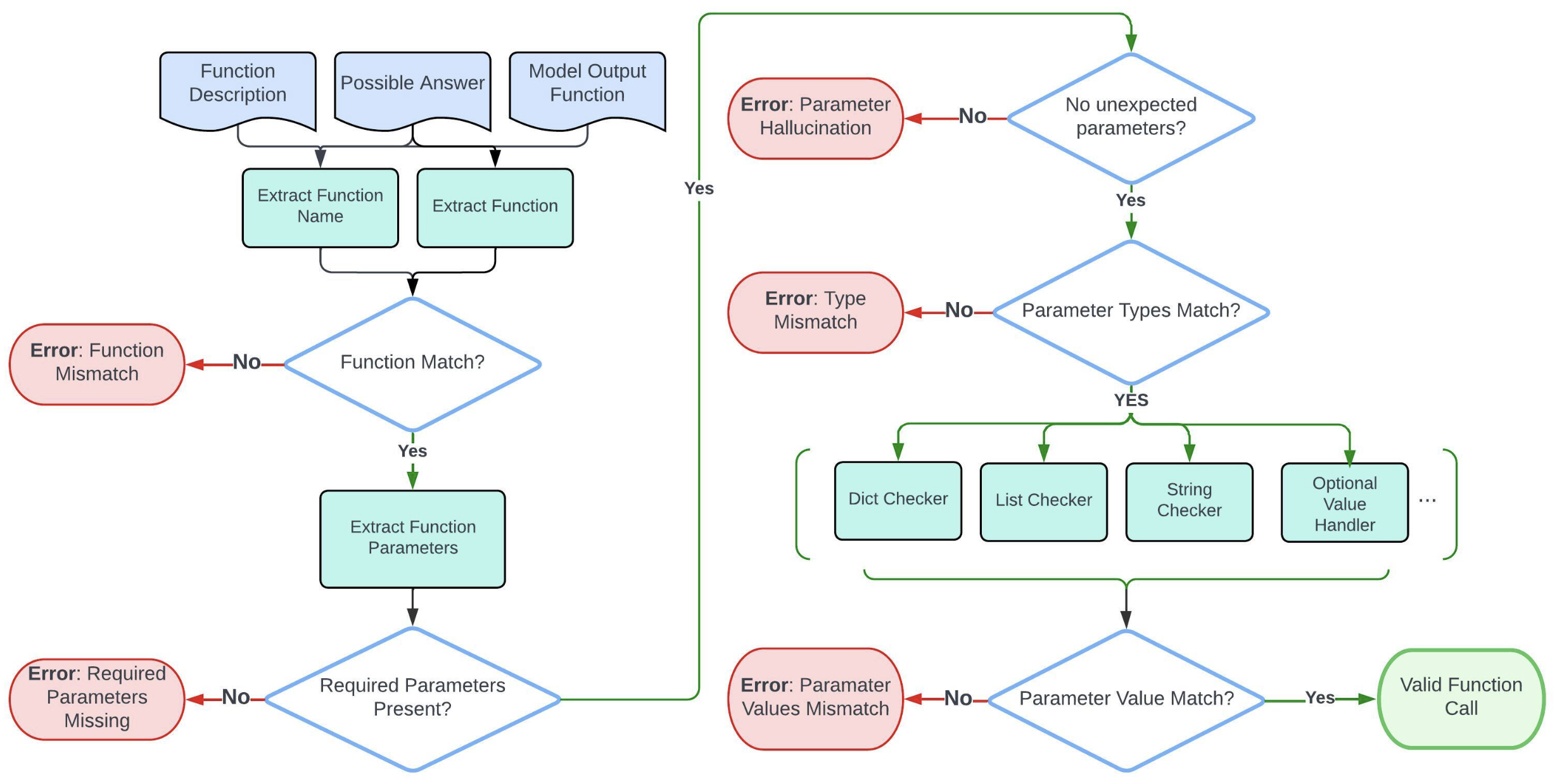
- Multiple/Parallel/Parallel-Multiple Functions AST Evaluation
- The multiple, parallel, or parallel-multiple function AST evaluation process extends the idea in the simple function evaluation to support multiple model outputs and possible answers.
- The evaluation process first associates each possible answer with its function doc. Then it iterates over the model outputs and calls the simple function evaluation on each function (which takes in one model output, one possible answer, and one function doc).
- The order of model outputs relative to possible answers is not required. A model output can match with any possible answer.
- The evaluation process first associates each possible answer with its function doc. Then it iterates over the model outputs and calls the simple function evaluation on each function (which takes in one model output, one possible answer, and one function doc).
- The evaluation employs an all-or-nothing approach to evaluation. Failure to find a match across all model outputs for any given possible answer results in a failed evaluation.
- The multiple, parallel, or parallel-multiple function AST evaluation process extends the idea in the simple function evaluation to support multiple model outputs and possible answers.
- Simple Function AST Evaluation
-
Executable Function Evaluation: This metric assesses the model by executing the function calls it generates and comparing the outputs against expected results. This evaluation is crucial for testing real-world applicability, focusing on whether the function calls run successfully, produce the correct types of responses, and maintain structural consistency in their outputs.
-
-
The combination of AST and executable evaluations ensures a comprehensive assessment, providing insights into both the syntactic and functional correctness of the model’s output.
Inference Example Output with XML and JSON
-
Typical function calling datasets uses a combination of both XML and JSON elements (cf. inference output sample below), as detailed below.
-
XML Structure: Elements like
<|im_start|>,<tool_call>, and<tool_response>resemble XML-like tags, which help demarcate different parts of the communication. -
Dictionary/JSON Structure: Within the
<tool_call>and<tool_response>tags, the data for the function arguments and the stock fundamentals is formatted as Python-style dictionaries (or JSON-like key-value pairs), such as{'symbol': 'TSLA'}and{"name": "get_stock_fundamentals", "content": {'symbol': 'TSLA', 'company_name': 'Tesla, Inc.' ...}}.
-
-
This combination provides an XML-like structure for message flow and JSON for data representation, allowing for structured, nested data representation and demarcation of sections.
-
Here’s an example of the inference output from Hermes Function-Calling V1:
<|im_start|>user
Fetch the stock fundamentals data for Tesla (TSLA)<|im_end|>
<|im_start|>assistant
<tool_call>
{'arguments': {'symbol': 'TSLA'}, 'name': 'get_stock_fundamentals'}
</tool_call><|im_end|>
<|im_start|>tool
<tool_response>
{"name": "get_stock_fundamentals", "content": {'symbol': 'TSLA', 'company_name': 'Tesla, Inc.', 'sector': 'Consumer Cyclical', 'industry': 'Auto Manufacturers', 'market_cap': 611384164352, 'pe_ratio': 49.604652, 'pb_ratio': 9.762013, 'dividend_yield': None, 'eps': 4.3, 'beta': 2.427, '52_week_high': 299.29, '52_week_low': 152.37}}
</tool_response>
<|im_end|>
JSON/Structured Outputs
- Once a model is trained on a system prompt that asks for JSON-based structured outputs (below), the model should respond with only a JSON object response, based on the specific JSON schema provided.
<|im_start|>system
You are a helpful assistant that answers in JSON. Here's the JSON schema you must adhere to:\n<schema>\n{schema}\n</schema><|im_end|>
-
The schema can be made from a pydantic object using (e.g., a standalone script available is here from Hermes Function-Calling V1).
-
As an example from Hermes Function-Calling V1:
{
"id": "753d8365-0e54-43b1-9514-3f9b819fd31c",
"conversations": [
{
"from": "system",
"value": "You are a function calling AI model. You are provided with function signatures within <tools> </tools> XML tags. You may call one or more functions to assist with the user query. Don't make assumptions about what values to plug into functions.\n<tools>\n[{'type': 'function', 'function': {'name': 'search_flights', 'description': 'Searches for flights based on departure and destination cities, dates, class, and other preferences.', 'parameters': {'type': 'object', 'properties': {'departure_city': {'type': 'string', 'description': 'The city from which the flight will depart.'}, 'destination_city': {'type': 'string', 'description': 'The destination city for the flight.'}, 'departure_date': {'type': 'string', 'description': 'The departure date for the flight.', 'format': 'date'}, 'return_date': {'type': 'string', 'description': 'The return date for the flight.', 'format': 'date'}, 'class': {'type': 'string', 'description': 'The class of the flight ticket.', 'enum': ['economy', 'business', 'first']}, 'flexible_cancellation': {'type': 'boolean', 'description': 'Indicates if the search should filter for flights with flexible cancellation policies.'}}, 'required': ['departure_city', 'destination_city', 'departure_date', 'return_date', 'class']}}}]\n</tools>\nFor each function call return a json object with function name and arguments within <tool_call> </tool_call> tags with the following schema:\n<tool_call>\n{'arguments': <args-dict>, 'name': <function-name>}\n</tool_call>\n"
},
{
"from": "human",
"value": "I'm planning a kayaking trip and looking to book flights from Los Angeles to Auckland. My departure is scheduled for July 10th, 2023, and I intend to return on July 24th, 2023. I would prefer to travel in economy class and would also like the option to have flexible cancellation policies for the tickets due to the uncertain nature of outdoor activities. Could you please search for flights that meet these criteria and provide me with the available options?"
},
{
"from": "gpt",
"value": "<tool_call>\n{'arguments': {'departure_city': 'Los Angeles', 'destination_city': 'Auckland', 'departure_date': '2023-07-10', 'return_date': '2023-07-24', 'class': 'economy', 'flexible_cancellation': True}, 'name': 'search_flights'}\n</tool_call>\n"
},
{
"from": "tool",
"value": "<tool_response>\n{\"name\": \"search_flights\", \"content\": {\"flights\": [{\"flight_number\": \"AA118\", \"airline\": \"American Airlines\", \"departure_airport\": \"LAX\", \"departure_city\": \"Los Angeles\", \"departure_date\": \"2023-07-10T08:00:00Z\", \"departure_terminal\": \"4\", \"arrival_airport\": \"AKL\", \"arrival_city\": \"Auckland\", \"arrival_date\": \"2023-07-11T14:25:00Z\", \"arrival_terminal\": \"I\", \"duration\": \"17h 25m\", \"class\": \"Economy\", \"price\": \"$950\", \"flexible_cancellation\": true}, {\"flight_number\": \"UA796\", \"airline\": \"United Airlines\", \"departure_airport\": \"LAX\", \"departure_city\": \"Los Angeles\", \"departure_date\": \"2023-07-10T11:30:00Z\", \"departure_terminal\": \"7\", \"arrival_airport\": \"AKL\", \"arrival_city\": \"Auckland\", \"arrival_date\": \"2023-07-11T18:30:00Z\", \"arrival_terminal\": \"I\", \"duration\": \"16h 0m\", \"class\": \"Economy\", \"price\": \"$975\", \"flexible_cancellation\": true}, {\"flight_number\": \"NZ6\", \"airline\": \"Air New Zealand\", \"departure_airport\": \"LAX\", \"departure_city\": \"Los Angeles\", \"departure_date\": \"2023-07-10T21:00:00Z\", \"departure_terminal\": \"B\", \"arrival_airport\": \"AKL\", \"arrival_city\": \"Auckland\", \"arrival_date\": \"2023-07-12T05:20:00Z\", \"arrival_terminal\": \"I\", \"duration\": \"13h 20m\", \"class\": \"Economy\", \"price\": \"$1020\", \"flexible_cancellation\": true}], \"return_flights\": [{\"flight_number\": \"AA117\", \"airline\": \"American Airlines\", \"departure_airport\": \"AKL\", \"departure_city\": \"Auckland\", \"departure_date\": \"2023-07-24T14:10:00Z\", \"departure_terminal\": \"I\", \"arrival_airport\": \"LAX\", \"arrival_city\": \"Los Angeles\", \"arrival_date\": \"2023-07-24T06:00:00Z\", \"arrival_terminal\": \"4\", \"duration\": \"12h 50m\", \"class\": \"Economy\", \"price\": \"$950\", \"flexible_cancellation\": true}, {\"flight_number\": \"UA797\", \"airline\": \"United Airlines\", \"departure_airport\": \"AKL\", \"departure_city\": \"Auckland\", \"departure_date\": \"2023-07-24T19:15:00Z\", \"departure_terminal\": \"I\", \"arrival_airport\": \"LAX\", \"arrival_city\": \"Los Angeles\", \"arrival_date\": \"2023-07-24T10:15:00Z\", \"arrival_terminal\": \"7\", \"duration\": \"11h 0m\", \"class\": \"Economy\", \"price\": \"$975\", \"flexible_cancellation\": true}, {\"flight_number\": \"NZ5\", \"airline\": \"Air New Zealand\", \"departure_airport\": \"AKL\", \"departure_city\": \"Auckland\", \"departure_date\": \"2023-07-24T19:30:00Z\", \"departure_terminal\": \"I\", \"arrival_airport\": \"LAX\", \"arrival_city\": \"Los Angeles\", \"arrival_date\": \"2023-07-24T10:30:00Z\", \"arrival_terminal\": \"B\", \"duration\": \"12h 0m\", \"class\": \"Economy\", \"price\": \"$1020\", \"flexible_cancellation\": true}]}}\n</tool_response>\n"
},
{
"from": "gpt",
"value": "Here are the available flight options with flexible cancellation policies for your kayaking trip from Los Angeles to Auckland:\n\n**Outbound Flights (Los Angeles to Auckland):**\n1. **American Airlines AA118**\n - Departure: July 10, 2023, 8:00 AM from LAX Terminal 4\n - Arrival: July 11, 2023, 2:25 PM at AKL Terminal I\n - Duration: 17h 25m\n - Price: $950\n\n2. **United Airlines UA796**\n - Departure: July 10, 2023, 11:30 AM from LAX Terminal 7\n - Arrival: July 11, 2023, 6:30 PM at AKL Terminal I\n - Duration: 16h 0m\n - Price: $975\n\n3. **Air New Zealand NZ6**\n - Departure: July 10, 2023, 9:00 PM from LAX Terminal B\n - Arrival: July 12, 2023, 5:20 AM at AKL Terminal I\n - Duration: 13h 20m\n - Price: $1020\n\n**Return Flights (Auckland to Los Angeles):**\n1. **American Airlines AA117**\n - Departure: July 24, 2023, 2:10 PM from AKL Terminal I\n - Arrival: July 24, 2023, 6:00 AM at LAX Terminal 4\n - Duration: 12h 50m\n - Price: $950\n\n2. **United Airlines UA797**\n - Departure: July 24, 2023, 7:15 PM from AKL Terminal I\n - Arrival: July 24, 2023, 10:15 AM at LAX Terminal 7\n - Duration: 11h 0m\n - Price: $975\n\n3. **Air New Zealand NZ5**\n - Departure: July 24, 2023, 7:30 PM from AKL Terminal I\n - Arrival: July 24, 2023, 10:30 AM at LAX Terminal B\n - Duration: 12h 0m\n - Price: $1020\n\nAll the listed prices are in economy class with flexible cancellation policies. Please review the options and let me know if you would like to proceed with booking any of these flights or if you need further assistance."
}
],
"category": "E-commerce Platforms",
"subcategory": "Kayak",
"task": "Flight Search"
}
Gorilla OpenFunctions-v2 LLM
-
Overview:
- State-of-the-Art Performance: Gorilla OpenFunctions-v2 is an open-source Large Language Model (LLM) that offers advanced function-calling capabilities, comparable to GPT-4.
- Extended Chat Completion: Extends LLM chat completion with the ability to generate executable API calls from natural language instructions and relevant API contexts.
-
Key Features:
- Multi-Function Support:
- Allows selection from multiple available functions based on user instructions, offering flexibility and adaptability within a single prompt.
- Parallel Function Calling:
- Supports executing the same function multiple times with different parameter values, streamlining workflows needing simultaneous function calls.
- Combined Multi & Parallel Functionality:
- Executes both multi-function and parallel function calls in one chat completion call, handling complex API call scenarios in a single prompt for efficient, high-capability outputs.
- Expanded Data Type Support:
- Enhanced compatibility with diverse programming languages by supporting extensive data types:
- Python: Supports
string,number,boolean,list,tuple,dict, andAny. - Java: Includes support for
byte,short,int,float,double,long,boolean,char, and complex types likeArrayList,Set,HashMap, andStack. - JavaScript: Covers
String,Number,BigInt,Boolean,Array,Date,dict (object), andAny.
- Python: Supports
- Extending beyond typical JSON schema limits, this feature allows users to leverage OpenFunctions-v2 in a straightforward plug-and-play fashion without intricate data handling or reliance on string literals.
- Enhanced compatibility with diverse programming languages by supporting extensive data types:
- Function Relevance Detection:
- Minimizes irrelevant function calls by detecting whether the user’s prompt is conversational or function-oriented.
- If no function is relevant, the model raises an “Error” message with additional guidance, helping refine requests and reducing hallucinations.
- Enhanced RESTful API Capabilities:
- Specially trained to handle RESTful API calls, Gorilla OpenFunctions-v2 optimizes interactions with widely-used services, such as Slack and PayPal.
- This high-quality support for REST API execution boosts compatibility across a broad range of applications and services.
- Pioneering Open-Source Model with Seamless Integration:
- As the first open-source model to support multi-language, multi-function, and parallel function calls, Gorilla OpenFunctions-v2 stands at the forefront of function calling in LLMs.
- Integrates effortlessly into diverse applications, making it a seamless drop-in replacement that requires minimal setup.
- Broad Application Compatibility:
- Gorilla OpenFunctions-v2’s versatility supports a wide range of platforms, from social media like Instagram to delivery and utility services such as Google Calendar, Stripe, and DoorDash.
- Its adaptability makes it a top choice for developers aiming to expand functional capabilities across multiple sectors with ease.
- Multi-Function Support:
-
The figure below (source) highlights some of the key features of OpenFunctions-v2:

Example
- The example below demonstrates function calling, where the LLM interprets a natural language prompt to generate an API request. Given the user’s request for weather data at specific coordinates, the model formulates an API call with precise parameters, enabling automated data retrieval.
"User": "Can you fetch me the weather data for the coordinates
37.8651 N, 119.5383 W, including the hourly forecast for temperature,
wind speed, and precipitation for the next 10 days?"
"Function":
{
...
"parameters":
{
"type": "object",
"properties":
{
"url":
{
"type": "string",
"description": "The API endpoint for fetching weather
data from the Open-Meteo API for the given latitude
and longitude, default
https://api.open-meteo.com/v1/forecast"
}
...
}
}
}
"GPT-4 output":
{
"name": "requests.get",
"parameters": {
"params":
{
"latitude": "37.8651",
"longitude": "-119.5383",
"forecast_days": 10
},
}
}
Best Practices, Guidelines, and Limitations
- Per Anthropic, when using tools with Claude, it’s important to follow best practices, understand limitations, and optimize tool design to ensure effective interactions.
Choosing the Right Model for Tool Use
- Claude 3 Opus is best for complex tool use, as it can handle multiple tools simultaneously and detect missing arguments. It will ask for clarification when necessary.
- Claude 3 Haiku is better suited for simple tool use but defaults to using tools more frequently—even when unnecessary. It will also infer missing parameters rather than asking for clarification.
Tool Usage Limits
- Handling large toolsets
- Claude can accurately select from over 250+ tools, as long as the user query includes all required parameters.
- This limit applies regardless of tool complexity. Complex tools typically have numerous parameters or deeply nested schemas.
- Optimizing tool complexity
- Claude performs better with simpler tools.
- To improve accuracy, avoid deeply nested JSON objects and reduce the number of required inputs.
Sequential vs. Parallel Tool Execution
- Claude generally prefers sequential tool execution—using one tool at a time, analyzing the output, and then deciding on the next step.
- While parallel tool use is possible, it may lead to:
- Missing dependencies (e.g., filling in placeholder values for parameters that depend on previous outputs).
- Unnecessary tool invocations.
- Best practice: Design workflows that encourage sequential tool execution to improve accuracy.
Error Handling and Retries
- If Claude’s tool request is invalid, returning an error response will often prompt it to retry with missing parameters filled in.
- However, after 2-3 failed attempts, Claude may stop retrying and instead return an apology message.
Designing Effective Tool Interfaces
- Tools are an essential part of agentic systems, enabling Claude to interact with external services and APIs. However, tools should be carefully designed, just like prompts, to ensure clarity and usability. By thoughtfully designing your tools, you can reduce errors, improve model accuracy, and create more efficient agent workflows, per the below guidelines per Anthropic’s blog on building effective agents.
Choosing the Right Tool Format
- The way tools are structured can significantly impact Claude’s accuracy. Some formats are harder for an LLM to generate correctly than others:
- Diff vs. Full Rewrite:
- Writing a diff requires pre-determining line changes, which is error-prone.
- A full rewrite avoids this complexity.
- Markdown vs. JSON for structured output:
- JSON requires escaping newlines and quotes, increasing error risks.
- Markdown is often easier for Claude to handle accurately.
Best Practices for Tool Design
- Give the model enough tokens to “think” before committing to an output.
- Stick to familiar formats that naturally occur in publicly available text (e.g., Markdown over escaped JSON).
- Minimize formatting overhead—avoid requiring Claude to track line counts or escape large text blocks.
Improving Tool Usability
- Make tool descriptions intuitive—think like a human: Would a developer immediately understand how to use this tool?
- Refine parameter names and descriptions—write them as if documenting an API for a junior developer.
- Test extensively—run real-world inputs in a sandbox environment to uncover edge cases and refine accordingly.
- Poka-yoke (mistake-proof) your tools.
- Example: Instead of using relative file paths, require absolute paths to avoid errors when switching directories.
Planning
- Planning is a foundational design pattern that empowers an AI system, typically a LLM, to autonomously determine a sequence of actions or steps needed to accomplish complex tasks. Through this dynamic decision-making process, the AI breaks down broad objectives into smaller, manageable steps, executing them in a structured sequence to produce coherent, often intricate outputs. This document delves into the importance of Planning in agentic AI design, illustrating its function with examples and examining its current capabilities alongside its limitations.
- As a transformative design pattern, Planning grants LLMs the ability to autonomously devise and execute plans/strategies for completing tasks. Although current implementations can still exhibit unpredictability, Planning can empower an AI agent with enhanced creative problem-solving capability that enables it to navigate tasks in unforeseen, innovative ways.
- The power of Planning lies in its flexibility and adaptability. When effectively implemented, Planning enables an AI to respond to unforeseen conditions, make informed decisions about task progression, and select tools best suited to each step. This autonomy, however, introduces unpredictability in the agent’s behavior and outcomes.
Overview
- Planning in agentic AI refers to the AI’s ability to autonomously design a task plan, selecting the steps necessary to achieve a given goal. Unlike more deterministic processes, Planning involves a level of adaptability, allowing the AI to adjust its approach based on available tools, task requirements, and unforeseen constraints.
- For example, if an AI agent is tasked with conducting online research on a specific topic, it can independently generate a series of subtasks. These might include identifying key subtopics, gathering relevant information from reputable sources, synthesizing findings, and compiling the research into a cohesive report. Through Planning, the agent does not simply execute pre-programmed instructions but rather determines the optimal sequence of actions to meet the objective.
Example
-
Agentic Planning becomes especially critical when tasks are multifaceted and cannot be completed in a single step. In such cases, an LLM-driven agent dynamically designs a sequence of steps to accomplish the overarching goal. An example from the HuggingGPT paper illustrates this approach: if the objective is to render a picture of a girl in the same pose as a boy in an initial image, the AI might decompose the task as follows:
- Step 1: Detect the pose in the initial picture of the boy using a pose-detection tool, producing a temporary output file (e.g.,
temp1). - Step 2: Use a pose-to-image tool to generate an image of a girl in the detected pose from
temp1, yielding the final output.
- Step 1: Detect the pose in the initial picture of the boy using a pose-detection tool, producing a temporary output file (e.g.,
- In this structured format, the AI specifies each action step, defining the tool to use, the input file, and the expected output. This process then triggers software that invokes the necessary tools in the designated sequence to complete the task successfully. The agent’s autonomous Planning ability facilitates this multi-step workflow, demonstrating its capacity to tackle intricate, non-linear tasks.
- The following figure (source) offers a visual overview of the above process:

Planning vs. Deterministic Approaches
- Planning is not required in every agentic workflow. For simpler tasks or those that follow a predefined sequence, a deterministic, step-by-step approach may suffice. For instance, if an agent is programmed to reflect on and revise its output a fixed number of times, it can execute this series of steps without needing adaptive planning.
- However, for complex or open-ended tasks where it is difficult to predefine the necessary sequence, Planning allows the AI to dynamically decide on the appropriate steps. This adaptive approach is especially valuable for tasks that may involve unexpected challenges or require the agent to select from a range of tools and methods to reach the best outcome.
Multi-agent Collaboration
Background
- Multi-agent collaboration has emerged as a pivotal AI design pattern for executing complex tasks by breaking them down into manageable subtasks. By assigning these subtasks to specialized agents—each acting as a software engineer, product manager, designer, QA engineer, etc.—multi-agent collaboration mirrors the structure of a well-coordinated team, where each agent performs specific, designated roles. These agents, whether built by prompting a single LLM in various ways or by employing multiple LLMs, can carry out their assigned tasks with tailored capabilities. For instance, prompting an LLM to act as a “software engineer” by instructing it to “write clear, efficient code” enables it to focus solely on that aspect, thereby honing its output to the requirements of the software engineering subtask.
- This approach has strong parallels in multi-threading, where complex programs are divided across multiple processors or threads to be executed concurrently, improving efficiency and performance. The agentic model thus offers a divide-and-conquer structure that enables AI systems to manage intricate workflows by breaking them into smaller, role-based actions.
Motivation
-
The adoption of MAS in AI is driven by several key factors:
-
Demonstrated Effectiveness: The multi-agent approach has consistently produced positive results across various projects. Ablation studies, such as those presented in the AutoGen paper, have confirmed that MAS often yield superior performance compared to single-agent configurations for complex tasks. The multi-agent structure allows each agent to focus narrowly on a specific subtask, which is conducive to better performance than attempting to accomplish the entire task in a monolithic approach.
-
Enhanced Task Focus and Optimization: Despite recent advancements allowing some LLMs to accept extensive input contexts (e.g., Gemini 1.5 Pro with 1 million tokens), a multi-agent system still holds distinct advantages. Each agent can be directed to focus on one isolated subtask at a time, enhancing its ability to execute that task with precision. By setting tailored expectations—such as prioritizing code clarity for a “software engineer” agent over scalability or security—developers can optimize the output of each subtask according to specific project requirements.
-
Decomposition of Complex Tasks: Beyond immediate efficiency gains, MAS offers a powerful conceptual framework for managing complex tasks by breaking them down into smaller, more manageable subtasks. This design pattern enables developers to simplify workflows while simultaneously enhancing communication and task alignment among agents. Much like a manager in a company would assign tasks to specialized employees to address different facets of a project, MAS uses this human organizational structure as a blueprint for assigning AI tasks.
-
-
This design abstraction supports developers in “hiring” agents for distinct roles and assigning tasks according to their “specializations,” with each agent independently executing its workflow, utilizing memory to track interactions, and potentially collaborating with other agents as necessary. Multi-agent workflows can involve dynamic elements like planning and tool use, enabling agents to respond adaptively and collectively in complex scenarios through interconnected calls and message passing.
Implementation
-
While managing human teams has inherent challenges, applying similar organizational strategies to multi-agent AI systems is not only manageable but also offers low-risk flexibility; any issues in an AI agent’s performance are easily rectified. Emerging frameworks such as AutoGen, CrewAI, and LangGraph provide robust platforms for developing and implementing MAS tailored to diverse applications. Additionally, open-source projects like ChatDev allow developers to experiment with multi-agent setups in a virtual “software company” environment, offering valuable insights into the collaborative potential of AI agents. Such tools represent the leading edge of multi-agent technology, providing a foundation for AI-driven task decomposition and collaboration.
-
In summary, multi-agent collaboration is a compelling and effective AI design pattern that leverages agent specialization, task decomposition, and focused prompting to enable more efficient handling of complex tasks. As multi-agent frameworks continue to advance, they are likely to become foundational in AI-driven workflows, providing developers with both the structure and flexibility to tackle increasingly sophisticated projects.
Agentic Workflow Patterns
- This section examines common patterns observed in the development of agentic systems, beginning with the fundamental component—augmented LLMs—and progressively increasing in complexity, from structured workflows to autonomous agents.
- Each of these patterns enhances the efficiency and effectiveness of agentic systems by structuring tasks in a way that optimally leverages LLM capabilities.
Prompt Chaining
- Prompt chaining involves decomposing a task into a sequence of steps, where each LLM call processes the output of the preceding step. Programmatic validation mechanisms (referred to as “gates”) may be applied at intermediate stages to ensure procedural accuracy.
- Optimal Use Cases:
- This workflow is beneficial when a task can be clearly divided into structured subtasks. It prioritizes improved accuracy over latency by simplifying each LLM call.
- Examples:
- Generating marketing copy and subsequently translating it into another language.
- Creating an outline for a document, verifying its adherence to specific criteria, and then generating the final document based on the outline.
Routing
-
Routing involves classifying an input and directing it to an appropriate specialized task. This approach facilitates the separation of concerns and enables more precise prompts. Without routing, optimizing for one input type may degrade performance for others.
- Optimal Use Cases:
- Routing is effective for tasks with distinct categories that require specialized handling. Classification can be performed by either an LLM or a traditional classification model.
- Examples:
- Categorizing customer service queries (e.g., general inquiries, refund requests, technical support) and routing them to appropriate downstream processes.
- Assigning simple queries to lightweight models (e.g., Claude 3.5 Haiku) while directing complex queries to more capable models (e.g., Claude 3.5 Sonnet) to balance efficiency and cost.
Parallelization
- Parallelization entails multiple LLM instances working on a task simultaneously, with results aggregated programmatically. It manifests in two key forms:
- Sectioning: Dividing a task into independent subtasks that can be processed in parallel.
- Voting: Running the same task multiple times to obtain diverse outputs.
- Optimal Use Cases:
- Parallelization is advantageous when tasks can be effectively subdivided to enhance speed or when multiple perspectives improve reliability.
- Examples:
- Sectioning:
- Implementing safeguards where one LLM processes user queries while another screens for inappropriate content.
- Automating model performance evaluations by assigning different evaluation criteria to separate LLM calls.
- Voting:
- Conducting code reviews for security vulnerabilities, with multiple prompts assessing different aspects of the code.
- Evaluating content for appropriateness by using multiple assessments to balance false positives and negatives.
- Sectioning:
Orchestrator-Workers
-
This workflow features a central LLM that dynamically decomposes tasks, assigns them to worker LLMs, and synthesizes their results.
- Optimal Use Cases:
- This approach is suited for complex tasks where the required subtasks are not predefined but must be determined dynamically. Unlike parallelization, which follows a fixed structure, this workflow offers greater adaptability.
- Examples:
- Software development tools that implement complex modifications across multiple files.
- Research tasks requiring information retrieval and synthesis from diverse sources.
Evaluator-Optimizer
-
In this iterative workflow, one LLM generates responses while another evaluates and refines them in a continuous loop.
- Optimal Use Cases:
- This pattern is particularly effective when clear evaluation criteria exist and iterative refinement adds measurable value. It is most beneficial when:
- Human feedback has been shown to enhance LLM-generated outputs.
- The LLM itself is capable of providing constructive feedback.
- This pattern is particularly effective when clear evaluation criteria exist and iterative refinement adds measurable value. It is most beneficial when:
- Examples:
- Literary translation, where an evaluator LLM can provide nuanced critiques that improve translation quality.
- Complex search tasks requiring iterative refinement, where an evaluator assesses whether additional searches are necessary to obtain comprehensive information.
Single-Agent vs. Multi-Agent Systems
Why this distinction matters
Budget-aware comparison
- A useful primer on agentic systems should separate two ideas that are often conflated: reasoning quality and compute expenditure. A large share of the apparent advantage of MAS comes from comparing architectures that do not actually spend the same reasoning budget.
- Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026) makes this point especially clearly: under matched thinking-token budgets on multi-hop reasoning tasks, SAS often matches or outperforms MAS, suggesting that many reported gains from orchestration are better explained by additional test-time computation or context effects than by inherent architectural superiority.
System-level scaling perspective
- This distinction becomes even more important when combined with system-level evidence from Towards a Science of Scaling Agent Systems by Kim et al. (2025), which shows that architecture-task alignment matters more than simply adding more agents.
- The paper further demonstrates that coordination can either improve performance significantly or degrade it depending on how well the coordination pattern matches the task, reinforcing that multi-agent gains are conditional rather than universal.
Unified reasoning vs. distributed orchestration
- At a broader engineering level, the single-agent versus multi-agent distinction reflects a deeper tradeoff between unified reasoning and distributed orchestration. A single-agent system preserves a coherent internal reasoning trajectory over the full task state, which often makes it simpler, more maintainable, and more compute-efficient.
- A multi-agent system externalizes reasoning into multiple interacting components, which can be powerful when the task genuinely benefits from decomposition, specialization, verification, or parallel search, but also introduces communication overhead, message compression, orchestration complexity, and new failure modes.
Real-world applicability
- This explains why MAS is particularly useful in practice for complex workflows with multiple stages, tasks requiring diverse expertise, large-scale automation pipelines, and collaborative problem-solving environments.
- These characteristics naturally arise in domains such as software engineering, research and analysis, business process automation, and simulation or modeling, where multiple reasoning paths or roles must be coordinated, meaning success depends on structural alignment between the task and the coordination pattern.
Design principle
- This budget-aware framing is also consistent with Reasoning in Token Economies: Budget-Aware Evaluation of LLM Reasoning Strategies by Wang et al. (2024), which shows in one line that many complex reasoning strategies lose much of their claimed advantage once compute is normalized.
- Taken together, these works suggest a disciplined design principle: begin with a single coherent reasoning process, and only introduce additional agents when decomposition, modularity, verification, or parallel exploration provides a clear architectural benefit.
Conceptual definitions
Single-agent systems
-
Single-agent systems (SAS) solve the task within one model call over a unified context, where the model sees the full problem state and performs one continuous internal reasoning trajectory before emitting a final answer.
-
In the attached paper, this corresponds to allocating the entire thinking-token budget \(B\) to a single reasoning process, without externalizing intermediate steps or fragmenting the reasoning path.
-
This unified setup aligns closely with the idea of preserving full information flow throughout reasoning, which is one of the key advantages highlighted in Towards a Science of Scaling Agent Systems by Kim et al. (2025), where SAS maximize context integration by maintaining a single coherent memory stream.
-
Because all reasoning occurs within one locus, there is effectively no communication overhead, no need for message passing, and no risk of information loss due to serialization, making SAS both information-efficient and structurally simple.
Multi-agent systems
-
Multi-agent systems distribute reasoning across multiple model calls, often structured as planners, workers, critics, or aggregators that operate on different parts of the task.
-
Each component operates on partial views and communicates via generated messages, effectively transforming the original context \(C\) into intermediate representations \(M = g(C)\) that must be shared and reconciled.
-
Put simply, SAS keeps reasoning latent and unified, while MAS externalizes reasoning into explicit communication channels, introducing both structure and overhead.
-
This externalization is central to the coordination tradeoffs described in Towards a Science of Scaling Agent Systems by Kim et al. (2025), where MAS incurs a coordination tax due to message passing, synchronization, and context compression across agents.
Information flow and representation
-
The key conceptual difference between SAS and MAS lies in how information is represented and propagated through the system. In SAS, the full context \(C\) is directly available to the reasoning process at every step, enabling consistent access to all prior information.
-
In MAS, the context is repeatedly transformed into intermediate messages \(M\), which are necessarily lossy representations of the original state and can introduce fragmentation or divergence across agents.
-
This difference explains why SAS tends to perform well on tightly coupled reasoning tasks, where maintaining a consistent global state is critical, while MAS can be advantageous in settings where decomposition, specialization, or parallel exploration outweigh the cost of information loss.
-
It also directly connects to the broader architectural insight that coordination is not free: every additional agent introduces a boundary where information must be compressed, transmitted, and reconstructed, which fundamentally changes the dynamics of reasoning.
Visual overview
Architectural intuition
- The following figure shows a simplified comparison between single-agent and multi-agent LLM architectures under a fixed thinking token budget, emphasizing how information flows through the system and how compute is allocated.
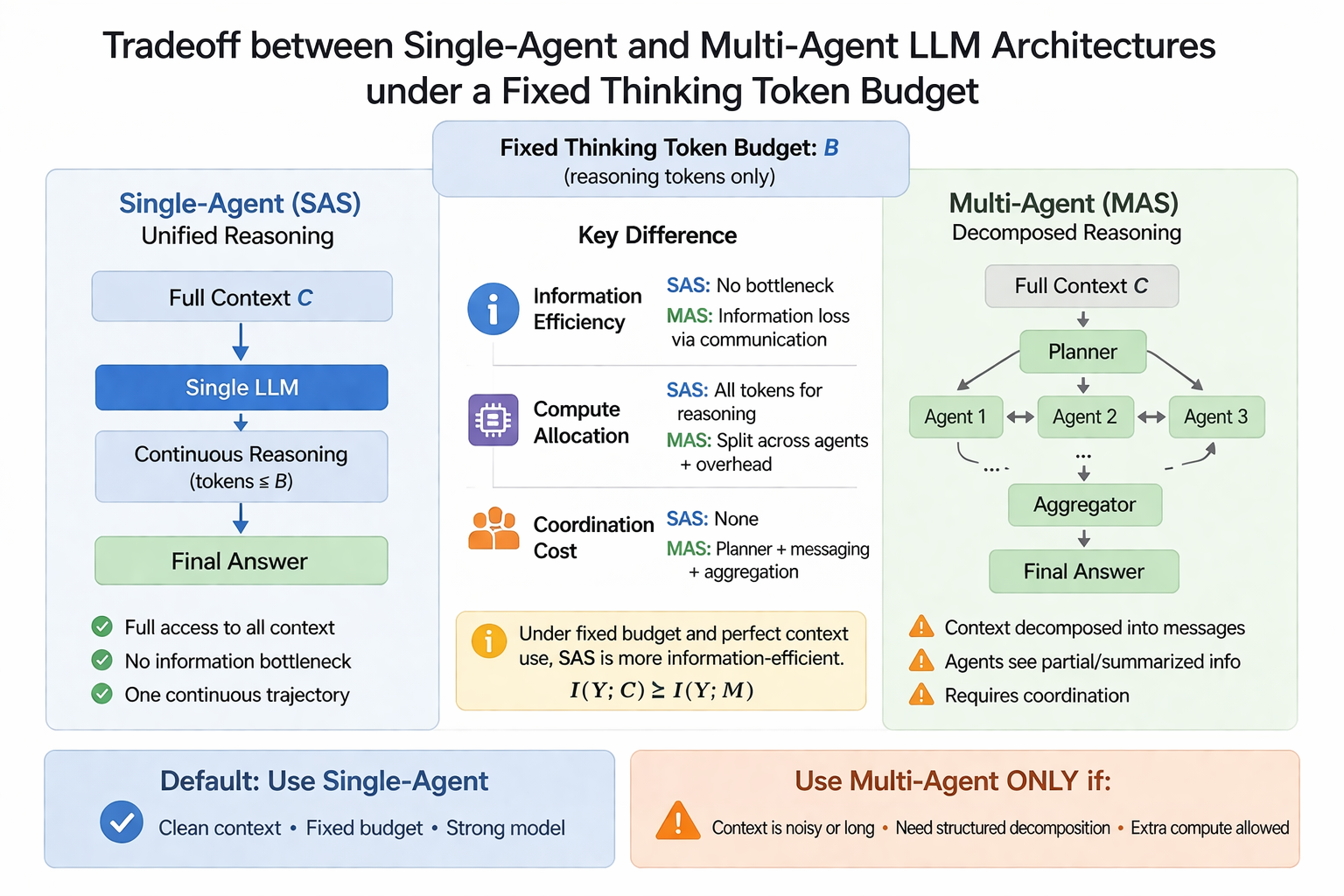
- In a single-agent setup, the full context is processed within a single reasoning trajectory, while in a multi-agent setup, that same context is split, transformed, and communicated across multiple interacting components.
Information flow differences
-
In the single-agent case, the model operates over a unified context \(C\), preserving all information internally and allowing each reasoning step to access the full history without any need for serialization or message passing.
-
In contrast, MAS transforms the context into intermediate messages \(M = g(C)\), which are passed between agents and can introduce compression, abstraction, or loss of detail at each step.
-
This distinction is closely related to the information bottleneck highlighted in both Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026) and Towards a Science of Scaling Agent Systems by Kim et al. (2025), where message passing reduces the effective information available for downstream reasoning.
-
In practical terms, every additional communication step in MAS introduces a transformation that can distort or omit useful signals, while SAS retains them natively.
Compute splitting and coordination
-
The figure also highlights how a fixed thinking-token budget \(B\) is used differently across architectures. In SAS, the entire budget is devoted to a single reasoning trajectory, maximizing depth and coherence.
-
In MAS, the same budget must be divided across multiple agents and coordination steps, reducing the effective reasoning depth available to each component.
-
This directly connects to the budget-controlled findings of Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026), which show that many MAS’ gains disappear when compute is normalized, and to the coordination overhead observed in Towards a Science of Scaling Agent Systems](https://arxiv.org/abs/2512.08296) by Kim et al. (2025), where additional agents introduce synchronization costs and increased total reasoning steps.
-
The visual intuition is that MAS trade depth for breadth, enabling parallel exploration or specialization at the cost of fragmentation and coordination complexity.
Architectural implication
- The key takeaway from this visual comparison is that architectural differences are not just about how many agents are used, but about how information and compute are structured across the system.
- SAS prioritizes coherence, depth, and simplicity, while MAS prioritize structure, modularity, and potential parallelism, making the choice between them fundamentally a question of how the task benefits from these tradeoffs.
Architectural comparison
Single-agent systems
Unified reasoning and context preservation
-
In a single-agent setup, the model has direct access to the full task context and spends the entire reasoning budget on one continuous chain of deliberation, allowing it to build and refine an internal representation without interruption.
-
This design is not only information-efficient but also structurally coherent, since all reasoning occurs within a shared latent space rather than being externalized into intermediate artifacts.
-
A key practical advantage is preservation of context. Because there is no need to serialize intermediate reasoning into messages, the system avoids context fragmentation and information loss.
-
In contrast, MAS must repeatedly summarize or transform intermediate outputs, which introduces subtle distortions and aligns with the information bottleneck described in Towards a Science of Scaling Agent Systems by Kim et al. (2025), where communication inherently compresses context.
Simplicity, maintainability, and flexibility
-
This unified reasoning structure also leads to improved simplicity and maintainability. A single-agent system requires fewer prompts, fewer coordination rules, and less orchestration logic, reducing both engineering overhead and system brittleness.
-
MAS, by comparison, introduce additional layers such as role definitions, routing policies, and aggregation mechanisms, each of which can fail independently and increase long-term maintenance complexity.
-
Another advantage is flexibility in problem solving. A well-configured single agent can dynamically shift strategies, tools, or reasoning styles within a single trajectory, adapting fluidly to task requirements.
-
This adaptability becomes especially important in real-world scenarios where tasks are not cleanly decomposable and require interleaving multiple capabilities such as retrieval, planning, and execution.
Scaling with modern LLM capabilities
-
Finally, advances in modern LLMs make SAS increasingly capable even for complex workflows. Longer context windows, improved reasoning capabilities, and better prompting techniques allow many tasks that previously required decomposition to be handled within a single coherent process.
-
This reinforces the empirical observation from Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026) that SAS is not only simpler but often more efficient under fixed compute budgets.
-
These observations are also consistent with Reasoning in Token Economies: Budget-Aware Evaluation of LLM Reasoning Strategies by Wang et al. (2024), which shows that many complex reasoning pipelines lose their advantage once compute is controlled.
-
Together with Towards a Science of Scaling Agent Systems by Kim et al. (2025), these results highlight that coordination overhead can offset the benefits of orchestration when the task does not require decomposition.
Multi-agent systems
Structured decomposition and coordination
-
In a multi-agent setup, the reasoning process is decomposed into interacting roles such as planners, workers, critics, or aggregators, each responsible for a subset of the overall task.
-
Towards a Science of Scaling Agent Systems by Kim et al. (2026) evaluates several such configurations, including sequential decomposition, subtask-parallel execution, role specialization, debate, and ensemble-style aggregation, all operating under a shared global token budget \(B\). This decomposition introduces structure, which can be beneficial in certain regimes. Parallel agents can explore different reasoning paths simultaneously, while specialized roles can focus on distinct aspects of the problem.
-
Put simply, MAS trades unified access for structured coordination, enabling breadth and modularity at the cost of coherence.
Real-world applicability and task alignment
-
These strengths are particularly relevant in real-world settings such as complex workflows with multiple stages, tasks requiring diverse expertise, and large-scale automation pipelines, where different components naturally operate on different parts of the problem. This is why MAS are increasingly used in domains like software engineering, research and analysis, business process automation, and simulation, where decomposition aligns with the underlying task structure.
-
This observation directly aligns with the architecture-task alignment principle from Towards a Science of Scaling Agent Systems by Kim et al. (2025), which shows that MAS succeeds when the task is inherently decomposable and fail when coordination is artificially imposed.
-
In practical terms, MAS work best when it mirrors real organizational structures where different roles contribute distinct, parallelizable value.
Coordination cost and failure modes
-
However, this structure comes at a cost. Each agent operates on partial or transformed context, and communication between agents introduces both overhead and opportunities for error.
-
The scaling analysis in Towards a Science of Scaling Agent Systems by Kim et al. (2025) shows that this coordination tax can dominate performance, especially in tasks that are sequential or tightly coupled.
-
MAS also tends to be more brittle from an engineering standpoint. Failures can arise not only from model reasoning errors but also from orchestration issues such as misaligned roles, incorrect aggregation, or communication breakdowns. This aligns with the findings of Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026), which highlights patterns such as over-exploration and incoherence in MAS compared to more focused reasoning in SAS.
-
The benefits of MAS are therefore highly context-dependent. For example, Improving Factuality and Reasoning in Language Models through Multiagent Debate by Du et al. (2023) shows that structured debate can improve reasoning in certain settings.
-
At the same time, real-world systems such as How we built our multi-agent research system demonstrate that multi-agent pipelines are most effective in open-ended exploration tasks where parallelism and role separation provide clear advantages.
Core tradeoffs
Information efficiency
Information bottleneck and message passing
- The central theoretical result from the attached paper is that MAS introduce an information bottleneck. Let \(Y\) denote the correct answer, \(C\) the full context, and \(M = g(C)\) the messages passed between agents.
- Then the following relationship holds due to the Data Processing Inequality:
- This inequality formalizes the idea that any transformation of the original context into intermediate messages cannot increase the information available about the correct answer.
- In practical terms, every step of message passing risks discarding useful signal, especially when intermediate outputs are summarized, abstracted, or truncated.
Entropy and uncertainty implications
- An equivalent formulation in terms of conditional entropy is:
- This means that conditioning on messages leaves more uncertainty about the correct answer than conditioning on the full context.
- In other words, MAS operates on noisier or less complete representations of the problem compared to SAS.
Practical impact on reasoning quality
-
The intuition behind context fragmentation can be formalized as: MAS must compress and transmit information, while SAS retains it natively within a unified reasoning process. This directly explains why SAS tends to perform better on tightly coupled reasoning tasks, while MAS can struggle when critical dependencies are lost across communication boundaries.
-
This observation also aligns with Towards a Science of Scaling Agent Systems by Kim et al. (2025), which describes how information fragmentation across agents increases coordination overhead and reduces effective reasoning quality.
-
Put simply, MAS introduces structural information loss, while SAS preserves full context fidelity.
Compute allocation
Token budget distribution
-
Another key tradeoff is how reasoning tokens are allocated. In SAS, the entire budget \(B\) is used for a single reasoning trajectory, maximizing depth and coherence.
-
In MAS, the same budget must be divided across multiple agents and coordination steps, reducing the effective reasoning depth available to each component. This split can be expressed conceptually as distributing \(B\) across agents and communication rounds, where each agent operates under a smaller effective budget than the single-agent baseline.
-
As a result, MAS often sacrifices depth of reasoning in exchange for breadth or parallelism.
Compute normalization and misleading gains
-
This creates an important confound: many reported gains from MAS arise because they implicitly use more compute rather than better structure.
-
When compute is normalized, as emphasized in both Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026) and Reasoning in Token Economies by Wang et al. (2024), these gains often disappear. This reinforces that fair comparisons must control for total reasoning tokens rather than number of agents.
-
Under equal budgets, SAS frequently matches or outperforms MAS because it uses all available compute for coherent reasoning rather than coordination.
Scaling and coordination overhead
- Beyond token splitting, MAS also introduces additional computational overhead due to coordination. The scaling analysis in Towards a Science of Scaling Agent Systems by Kim et al. (2025) presents a scaling law that shows that total reasoning steps grow superlinearly with the number of agents:
- The following table (source) shows architectural comparison of agent methods with objective complexity metrics.
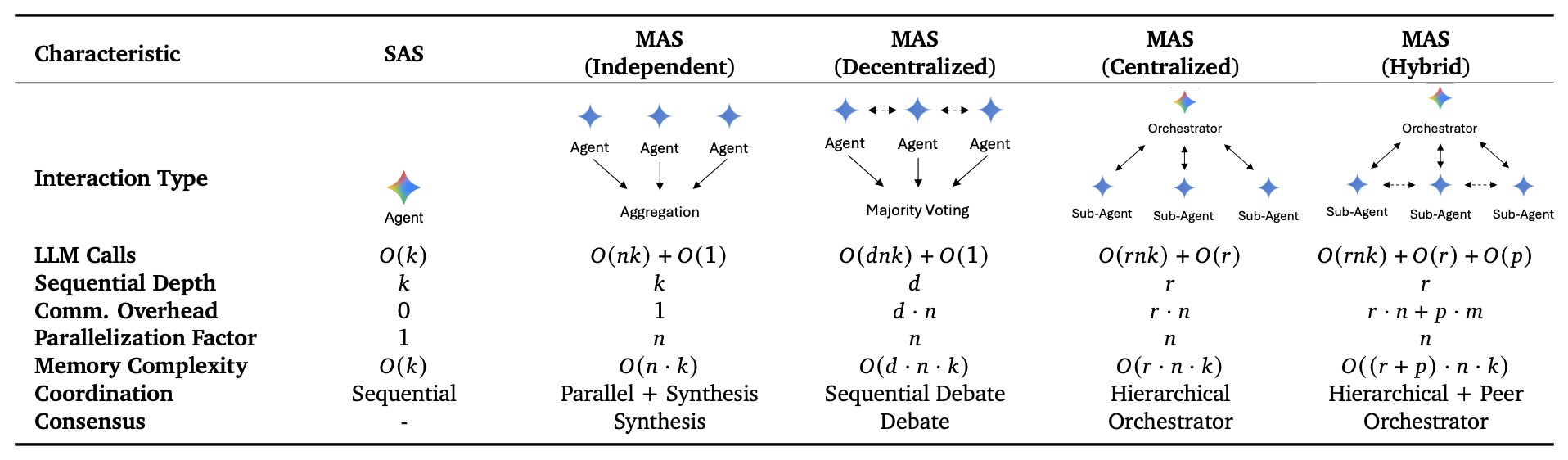
- This means that adding agents increases not just parallel work but also coordination cost, including synchronization, message passing, and aggregation. In practice, this can lead to higher latency and compute usage even when individual agents are operating on smaller budgets.
Coordination cost and failure modes
Coordination overhead and system complexity
-
MAS introduces additional layers of coordination, including planning, communication, and aggregation, each of which adds complexity to the system. These layers create overhead not present in SAS, both in terms of computation and engineering complexity.
-
The scaling results from Towards a Science of Scaling Agent Systems by Kim et al. (2025) quantify this overhead, showing that coordination can dominate performance costs, especially in hybrid or highly interactive architectures.
-
In one line, MAS trades reasoning simplicity for orchestration complexity.
Error propagation and amplification
-
These coordination layers also introduce new failure modes such as drift between agents, loss of critical information, or incorrect aggregation of intermediate results.
-
Errors are not isolated but can propagate across agents, leading to amplified failures in the final output.
-
Towards a Science of Scaling Agent Systems by Kim et al. (2026) reports that independent MAS can amplify trace-level errors by up to \(17.2\times\), while centralized systems reduce this to \(4.4\times\), highlighting how architecture choice directly affects reliability. This shows that coordination is not only a performance concern but also a safety and robustness concern.
Exploration vs. coherence tradeoff
-
The analysis in Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026) highlights patterns such as over-exploration in MAS versus more precise reasoning in SAS.
-
Put simply, MAS can broaden the search space but also increase the risk of incoherence or divergence across reasoning paths. This creates a fundamental tradeoff: MAS enables diversity and parallel exploration, while SAS maintains coherence and consistency.
-
The optimal choice depends on whether the task benefits more from exploring multiple hypotheses or from maintaining a tightly integrated reasoning trajectory.
When single-agent systems are usually better
Clean context and fixed budgets
Performance under equal compute
-
The empirical results in the attached paper show that under matched thinking-token budgets, SAS consistently matches or outperforms MAS across multiple models and datasets, including FRAMES and MuSiQue. This reinforces the central finding from Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026), where equal-budget comparisons remove the apparent advantage of orchestration. This result is particularly important because it isolates architecture from compute, showing that gains attributed to MAS are often driven by additional tokens rather than better reasoning structure.
-
Put simply, when compute is controlled, unified reasoning tends to dominate distributed coordination for many reasoning-heavy tasks.
Efficiency and coherence advantages
-
Because SAS preserves full context, avoids communication overhead, and uses all tokens for a single reasoning trajectory, it provides a strong baseline that many MAS fail to surpass. This efficiency is both computational and informational, since no intermediate compression or message passing is required. This aligns with the scaling insights from Towards a Science of Scaling Agent Systems by Kim et al. (2025), which show that coordination overhead can outweigh benefits when the task does not require decomposition.
-
In practice, SAS is often the most efficient choice when the problem can be solved through a coherent reasoning process over a well-defined context.
Strong base models
Diminishing returns from coordination
-
As model capability increases, the benefits of orchestration tend to diminish. Stronger models are better able to internally organize reasoning, reducing the need for explicit decomposition into multiple agents. This is consistent with the capability-saturation effect described in Towards a Science of Scaling Agent Systems by Kim et al. (2025), where coordination gains decrease as single-agent performance improves.
-
The paper identifies a practical threshold where tasks with sufficiently high single-agent baseline performance experience diminishing or even negative returns from additional agents. This reflects the idea that once a model can solve most of the task internally, coordination overhead becomes a net cost rather than a benefit.
Alignment with modern LLM trends
-
Advances in modern LLMs, including longer context windows and improved reasoning abilities, further reinforce this trend by making SAS more capable across a wide range of tasks.
-
Many workflows that previously required explicit decomposition can now be handled within a single reasoning trajectory, reducing the need for multi-agent orchestration. This trend also connects to broader findings in the literature that stronger base models reduce the marginal value of additional structure unless the task inherently requires it.
-
Put simply, as models improve, the default shifts increasingly toward SAS unless there is a clear structural reason to introduce MAS.
Tasks requiring global coherence
Sequential and tightly coupled tasks
-
Single-agent systems are particularly well-suited for tasks that require maintaining a consistent global state across multiple reasoning steps, such as sequential planning, constrained execution, or tightly coupled workflows.
-
In these settings, splitting reasoning across agents can fragment state and introduce inconsistencies.
-
The scaling analysis in Towards a Science of Scaling Agent Systems by Kim et al. (2025) shows that MAS can significantly degrade performance on sequential planning tasks, with large negative relative changes compared to single-agent baselines. This highlights that coordination is especially costly when reasoning steps are interdependent.
Avoiding context fragmentation
-
Because SAS operates over a unified context, it avoids the need to repeatedly serialize and reconstruct intermediate state, preserving consistency across the entire reasoning trajectory. This is critical for tasks where small errors or omissions can cascade into larger failures.
-
In contrast, MAS introduces boundaries where information must be compressed and transmitted, increasing the risk of losing important dependencies.
-
Put simply, SAS excels when coherence matters more than parallelism, making it the preferred choice for tightly integrated reasoning problems.
When multi-agent systems become competitive
Context degradation and noisy inputs
Limits of context utilization
-
A key nuance is that SAS assumes effective utilization of context, but in practice this assumption can break down due to long contexts, noise, distractors, or irrelevant information.
-
As context grows, models may fail to attend to the most relevant parts, reducing the effective information available for reasoning. Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026) models noisy inputs as \(\tilde{C}_\alpha\) where increasing \(\alpha\) corresponds to greater corruption or noise in the input.
-
As degradation increases, the available information decreases:
- This implies that the effectiveness of a single-agent system depends critically on its ability to utilize context efficiently, which is not guaranteed in long or noisy inputs.
Decomposition as filtering
-
In such regimes, a well-structured MAS can act as a filtering mechanism, breaking the problem into smaller subcontexts that are easier to process.
-
By distributing reasoning across agents, the system can isolate relevant signals and reduce the impact of noise or distraction. This connects directly to Lost in the Middle: How Language Models Use Long Contexts by Liu et al. (2023), which shows in one line that models often underutilize long contexts, and to Context Rot: How Increasing Input Tokens Impacts LLM Performance, which highlights performance degradation as context length grows.
-
Put simply, MAS can recover structure when raw context becomes too large or noisy for a single reasoning process.
Interaction with scaling behavior
- This also aligns with findings from Towards a Science of Scaling Agent Systems by Kim et al. (2025), where coordination can be beneficial in tasks involving partial observability, iterative information gathering, or high-entropy environments.
- In these cases, the ability to distribute reasoning across agents can compensate for limitations in context utilization.
Parallel search, specialization, and verification
Parallel exploration and diversity
-
MAS becomes advantageous when tasks benefit from exploring multiple reasoning paths in parallel, allowing different agents to pursue distinct hypotheses or strategies. This is particularly useful in open-ended or high-uncertainty tasks where no single reasoning trajectory is guaranteed to succeed.
-
Debate-style systems, for example, allow agents to challenge each other’s conclusions, surfacing alternative perspectives and improving robustness.
-
Improving Factuality and Reasoning in Language Models through Multiagent Debate by Du et al. (2023) shows in one line that structured debate can improve reasoning in certain settings.
Role specialization and modularity
-
MAS also enables role specialization, where different agents focus on distinct aspects of a task such as planning, execution, verification, or aggregation. This modularity can improve performance when tasks naturally decompose into separable components. This aligns with real-world system design, where complex workflows often involve multiple specialized roles working together.
-
In domains such as software engineering, research pipelines, and business automation, this mirrors how tasks are organized across teams and systems.
Verification and error correction
-
Another advantage of MAS is the ability to introduce explicit verification layers, where outputs from one agent are checked or refined by another.
-
Centralized architectures, in particular, can act as validation bottlenecks that reduce error propagation.
-
The scaling analysis in Towards a Science of Scaling Agent Systems by Kim et al. (2025) shows that centralized coordination significantly reduces error amplification compared to independent systems.
-
In one line, MAS can improve robustness when it introduces structured validation rather than uncoordinated parallelism.
Task structure and decomposability
Alignment with decomposable workflows
-
MAS is most effective when the task itself is inherently decomposable into semi-independent subproblems that can be solved in parallel or in loosely coupled stages. This includes workflows such as multi-stage analysis, distributed data processing, and collaborative problem-solving. These conditions are common in real-world applications such as software engineering pipelines, research and analysis, business process automation, and simulation environments.
-
In such settings, MAS aligns naturally with the structure of the work, making coordination beneficial rather than costly.
Architecture-task alignment principle
- This observation directly reflects the central finding from Towards a Science of Scaling Agent Systems by Kim et al. (2025), which shows that architecture-task alignment determines whether MAS succeeds or fails.
- Tasks that are decomposable benefit from coordination, while tasks that are sequential or tightly coupled tend to degrade under multi-agent architectures.
Limits of applicability
-
However, even in these favorable conditions, MAS is not universally superior. Gains depend heavily on implementation details, coordination mechanisms, and the specific structure of the task.
-
Put simply, MAS is most effective when decomposition is intrinsic to the problem rather than imposed by the system designer. This reinforces the broader design principle that MAS should be used selectively, as a targeted tool for handling complexity, noise, or structured exploration, rather than as a default architectural choice.
Architecture selection guidance
From heuristics to principled design
-
The combined evidence from Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026) and Towards a Science of Scaling Agent Systems by Kim et al. (2025) shifts architecture selection from heuristic design to principled reasoning.
-
Instead of assuming that more agents improve performance, these works show that architecture choice must be grounded in measurable tradeoffs involving information flow, compute allocation, coordination cost, and task structure.
-
Put simply, SAS maximizes information retention and reasoning coherence, while MAS introduces structure that can either help or harm depending on how it interacts with the task. This reframing emphasizes that architecture is not a matter of scaling complexity, but of aligning system structure with problem requirements.
Key Takeaways
-
At the highest level, the distinction between SAS and MAS can be understood as a tradeoff between coherence and coordination.
-
SAS emphasizes unified reasoning over a complete context, while MAS emphasizes modularity, parallelism, and structured interaction. This tradeoff manifests across all dimensions discussed earlier, including information efficiency, compute usage, error propagation, and system complexity.
-
Put simply, SAS prioritizes depth and consistency, while MAS prioritizes breadth and structure, and the correct choice depends on which dimension the task benefits from most.
Default design strategy
Start with a single-agent baseline
-
The strongest general recommendation is to begin with a single-agent system, since it provides a simpler, more maintainable, and often more efficient baseline.
-
By preserving full context, avoiding coordination overhead, and allocating the entire reasoning budget \(B\) to a single trajectory, SAS establishes a strong reference point for both performance and system design. This recommendation is directly supported by Tran et al. (2026), which shows that under equal compute budgets, SAS frequently matches or outperforms MAS on multi-hop reasoning tasks. It is further reinforced by Reasoning in Token Economies by Wang et al. (2024), which demonstrates that many complex reasoning pipelines lose their advantage once compute is normalized.
Treat multi-agent systems as a deliberate escalation
-
Rather than treating MAS as the default path to scaling, they should be introduced only when there is clear evidence that decomposition or coordination provides value. This reflects the architecture-task alignment principle from Kim et al. (2025), which shows that coordination can either help or harm depending on how well it matches the task.
-
Put simply, SAS should be the default for coherent reasoning, while MAS should be viewed as a targeted tool for handling complexity, noise, or structured workflows. This framing encourages disciplined system design by requiring explicit justification for additional architectural complexity.
Decision boundaries and escalation criteria
When single-agent systems dominate
-
Single-agent systems dominate in regimes where context is clean, reasoning is tightly coupled, and compute is constrained.
-
These include sequential planning, constrained execution, and tasks requiring global consistency across multiple steps.
-
Empirical results from Tran et al. (2026) show that under equal token budgets, SAS often outperforms MAS on multi-hop reasoning tasks.
-
Similarly, Kim et al. (2025) shows that when single-agent baseline performance is already high, additional coordination tends to yield diminishing or negative returns.
When multi-agent systems become beneficial
-
MAS become beneficial when tasks are inherently decomposable, require parallel exploration, or benefit from role specialization and verification.
-
These conditions arise in complex workflows, large-scale automation pipelines, collaborative problem-solving environments, and domains such as software engineering, research and analysis, business process automation, and simulation.
-
The architecture-task alignment principle from Kim et al. (2025) shows that MAS can produce significant gains when coordination matches task structure.
-
Put simply, MAS works best when decomposition is intrinsic to the problem rather than imposed by the system designer.
Boundary conditions and transitions
-
There is no sharp boundary between SAS and MAS, but rather a transition region where effectiveness depends on context quality, model capability, and task structure.
-
For example, as context becomes noisier or longer, MAS may become more competitive by filtering and structuring information across agents.
-
Conversely, as model capability increases, the need for explicit coordination decreases, shifting the optimal design toward SAS. This dynamic interplay highlights that architecture selection is not static but evolves with both task requirements and advances in model capabilities.
When to escalate to multi-agent systems in practice
Indicators for decomposition and structure
-
MAS should be introduced when tasks involve multiple independent or semi-independent components that can be processed in parallel or in loosely coupled stages. This includes scenarios with complex workflows, diverse expertise requirements, or pipelines that naturally map to multiple interacting roles. These conditions align with real-world systems such as software engineering pipelines, research workflows, business automation systems, and simulation environments.
-
In such settings, MAS mirrors the structure of the task, making coordination beneficial rather than wasteful.
Handling noise, scale, and context limitations
-
MAS is also appropriate when SAS struggles with long, noisy, or partially observable contexts where effective utilization of information breaks down.
-
By decomposing the problem, MAS can filter, restructure, or isolate relevant signals, improving robustness in degraded environments. This aligns with the earlier context degradation analysis, where breaking tasks into smaller subcontexts can recover useful information.
-
In one line, MAS acts as a structured filtering mechanism when raw context becomes too complex for unified reasoning.
Need for verification, robustness, and safety
-
Another important indicator for MAS is the need for explicit verification, validation, or redundancy in reasoning.
-
Multi-agent architectures can introduce critics, reviewers, or centralized aggregators that reduce error propagation and improve reliability.
-
The findings from Kim et al. (2025) show that centralized coordination significantly reduces error amplification compared to independent systems. This makes MAS particularly valuable in high-stakes or safety-critical workflows where correctness and robustness are more important than efficiency.
Integration with broader agentic patterns
Relationship to other design patterns
-
MAS should not be viewed in isolation but as one component within a broader set of agentic design patterns, including prompt chaining, routing, planning, tool use, and reflection.
-
In many cases, improvements attributed to MAS can instead be achieved by strengthening these underlying patterns within a single-agent system.
-
Prompt chaining exposes structure, routing enables specialization, planning organizes long-horizon reasoning, tool use connects to external systems, and reflection improves output quality.
-
Only when these patterns reveal a genuine need for multiple interacting roles should MAS be introduced.
Architecture as composition, not hierarchy
-
This perspective reframes architecture selection as a compositional problem rather than a linear progression from simple to complex systems.
-
SAS and MAS are alternative configurations that should be selected based on task requirements rather than viewed as stages in system maturity. This aligns with the broader architectural shift described in the primer, where intelligence emerges from structured interaction between components rather than from a single model invocation.
-
In one line, MAS is one possible composition of patterns, not the endpoint of system design.
Key takeaways
Architecture as a function of task structure
-
The central lesson is that architecture should be treated as a function of task structure rather than a fixed design choice.
-
The goal is to select the configuration that best aligns reasoning structure with the properties of the problem. This perspective integrates all prior observations, including information bottlenecks, compute allocation, coordination costs, and real-world applicability.
-
Put simply, the optimal architecture is the one that aligns system design with task structure.
Coordination as a scarce resource
-
Coordination is a scarce and expensive resource that introduces both capability and risk.
-
Every additional agent adds communication overhead, potential information loss, and new failure modes that must be justified by corresponding gains. This reinforces the principle that simplicity should be preferred unless complexity provides measurable benefits.
-
In practice, the most effective systems are those that use the simplest architecture capable of solving the problem reliably.
Design principle
-
Taken together, the evidence suggests a clear hierarchy of design decisions: begin with a single-agent system, strengthen internal structure through patterns such as planning, routing, and tool use, and only then introduce multi-agent coordination when the task demands it. This disciplined approach ensures that complexity is added incrementally and only when it provides real value.
-
Put simply, SAS is the default foundation, MAS is the specialized extension, and architecture selection is the process of deciding when to transition between them.
Case Study: Cursor’s Multi-Agentic System
-
Cursor’s multi-agentic system is a production-oriented architecture for software engineering in which planning, retrieval, editing, execution, review, and long-running orchestration are handled by a coordinated system of agents rather than by a single model response. Continually improving our agent harness describes the harness as the layer that turns a model into a usable software agent through context design, tool design, evals, and model-specific adaptation; Towards self-driving codebases shows how this layer scales from one agent to a planner-worker hierarchy for large codebases; and Speeding up GPU kernels by 38% with a multi-agent system demonstrates the same pattern on measurable optimization problems where agents iterate against benchmark feedback.
-
This system follows the broader trajectory of agentic AI research: ReAct by Yao et al. (2023) introduces the interleaving of reasoning and acting that underlies tool-using coding agents; AutoGen by Wu et al. (2023) frames multi-agent applications as configurable conversations among agents, tools, and humans; Reflexion by Shinn et al. (2023) shows how verbal feedback and episodic memory can improve agent behavior over repeated attempts; and SWE-bench by Jimenez et al. (2023) motivates repository-level evaluation because realistic software tasks require multi-file context, tool use, and executable validation.
Agent Harness as the Coordination Layer
-
The agent harness is the coordination layer that determines what the model can see, what actions it can take, how tool results are represented, when context is summarized, how failures are surfaced, and how the system evaluates whether an agentic change improves the developer experience. Continually improving our agent harness focuses on how Cursor iterates on harness changes with offline evals, online metrics, regression repair, and model-specific customization.
-
In this framing, a model is not the full agent. The model supplies a policy over language and actions, while the harness supplies the action space, state representation, environmental feedback, and operational constraints. This distinction matters because the same model can behave differently when paired with different prompt formats, tool schemas, edit mechanisms, context layouts, and failure-recovery strategies.
-
A simplified harness-level objective can be written as:
\[J(\theta)=\mathbb{E}_{\tau \sim \pi_\theta} \left[ R_{\mathrm{task}}(\tau) -\lambda_{\mathrm{lat}} C_{\mathrm{latency}}(\tau) -\lambda_{\mathrm{tok}} C_{\mathrm{tokens}}(\tau) -\lambda_{\mathrm{err}} C_{\mathrm{errors}}(\tau) -\lambda_{\mathrm{claim}} C_{\mathrm{unsupported}}(\tau) \right]\]- where, \(R_{\mathrm{task}}(\tau)\) rewards successful task completion, while the penalty terms capture latency, token use, tool failures, and unsupported claims. Composer: Building a fast frontier model with RL describes reinforcement learning that trains an agent model to use Cursor’s tools efficiently, minimize unnecessary responses, and avoid claims without evidence; Continually improving our agent harness describes the complementary systems process for measuring whether harness changes improve speed, intelligence, and efficiency.
-
The following figure (source) shows how dynamic context lets the model decide when to pull additional information into the context window, such as past conversations, active terminal sessions, or relevant tools.
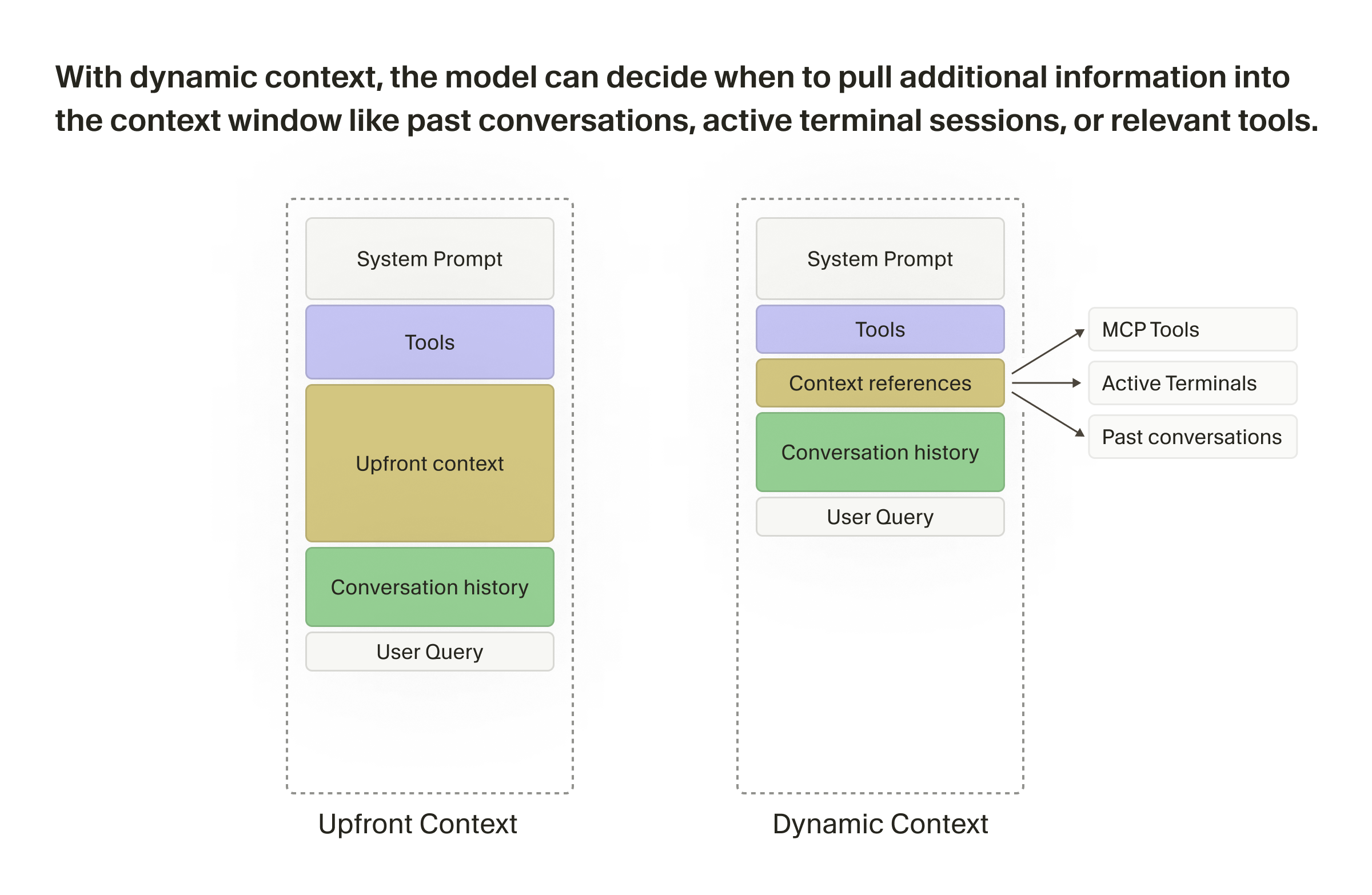
Dynamic Context Discovery
-
Dynamic context discovery is a context-engineering pattern in which the agent receives less static context upfront and retrieves the relevant details as the trajectory unfolds. Dynamic context discovery explains how Cursor represents long tool outputs, chat history, skills, MCP tool descriptions, and terminal sessions as files that the agent can search or inspect only when needed.
-
This pattern reduces context-window pressure because large observations are kept outside the prompt until they are relevant. Instead of truncating long terminal outputs or MCP responses, the system can write them to files and allow the agent to inspect the tail, grep for terms, or read additional ranges.
-
Dynamic context discovery also improves long-horizon reliability. When summarization compresses a long chat into a shorter state, information can be lost; exposing the full history as searchable files allows the agent to recover details that were omitted from the summary.
-
This approach can be understood as retrieval-augmented agent state:
\[s_t = \left(x_t,\; m_t,\; \operatorname{Retrieve}(q_t, \mathcal{D})\right)\]- where, \(x_t\) is the immediate user and system context, \(m_t\) is the agent’s working memory or summary, \(\mathcal{D}\) is the externalized context store, and \(\operatorname{Retrieve}(q_t, \mathcal{D})\) supplies only the documents or traces relevant to the current query \(q_t\).
Retrieval and Semantic Search
-
Codebase understanding is partly a retrieval problem. A coding agent must locate the right abstractions, call sites, invariants, tests, configuration files, and prior implementation patterns before making changes. Improving agent with semantic search reports that semantic search improves coding-agent performance by retrieving relevant code from natural-language queries, especially in large repositories where lexical search may miss the relevant files.
-
Semantic search complements exact tools such as
grep. Exact search works well when the agent knows the symbol, string, or file name; semantic search is more useful when the agent knows the intent, such as “where do we handle authentication?” or “where is this request validated?” -
Cursor trains its retrieval model from agent traces. When an agent searches, opens files, and eventually finds the right code, the trace reveals which files would have been useful earlier; an LLM can rank those useful targets, and the embedding model can be trained to align similarity scores with those rankings. Improving agent with semantic search describes this feedback loop as a way to train retrieval on how agents actually solve software tasks rather than on generic code similarity alone.
Specialized Agent Models for Software Engineering
-
Specialized coding-agent models can be trained directly inside the tool environment in which they will be deployed. Composer: Building a fast frontier model with RL introduces Composer as a mixture-of-experts model trained for software-engineering intelligence and speed with access to production search, file-editing, terminal, and semantic-search tools.
-
This is important because tool use is part of the task distribution. An agent that must edit files, run tests, inspect compiler errors, search across a repository, and recover from failed commands should be trained on trajectories that include those actions.
-
A generic policy-gradient view of this setting is:
\[\nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \nabla_\theta \log \pi_\theta(a_t \mid s_t) \left(R(\tau)-b(s_t)\right) \right]\]- where \(a_t\) can be a text response, file edit, search query, terminal command, or plan update; \(s_t\) includes the current conversation, repository state, retrieved context, and tool observations; and \(R(\tau)\) measures whether the software task was completed correctly, efficiently, and in a style consistent with the codebase. Composer: Building a fast frontier model with RL is especially relevant here because it emphasizes training on real-world software challenges with Cursor’s agent tools in the loop.
Sandboxing for Secure Execution
-
Tool-using coding agents become substantially more powerful when they can run terminal commands, install dependencies, execute tests, and inspect failures, but these capabilities require security boundaries. Implementing a secure sandbox for local agents explains how Cursor lets agents run freely inside a controlled environment while requesting approval for actions outside the sandbox, most commonly internet access.
-
Sandboxing reduces approval fatigue because safe local commands can proceed without repeated user intervention, while higher-risk operations still cross an explicit boundary. This matters for multi-agent workflows because manual approvals become a throughput bottleneck when several agents are running in parallel.
-
The execution environment is therefore part of the agent architecture. The agent’s ability to validate its own work depends on whether it can run the same builds, tests, package managers, and scripts a human developer would use.
From Single-Agent Coding to Multi-Agent Coding
-
Single agents are effective for focused tasks, but large projects require decomposition, ownership, and synchronization. Scaling long-running autonomous coding describes early experiments with hundreds of concurrent agents, showing that flat coordination through shared files and locks caused bottlenecks, brittle state updates, and risk-averse behavior.
-
A more scalable pattern is hierarchical role separation. Towards self-driving codebases describes a system in which a root planner owns the full goal, subplanners recursively own scoped parts of the project, and workers complete bounded implementation tasks in isolated repository copies.
-
The key design shift is from continuous global coordination to structured handoffs. Workers do not need to coordinate with every other worker; instead, they return completed work, deviations, findings, blockers, and concerns to the planner layer, which maintains broader project state.
-
The following figure (source) shows a planner-worker hierarchy in which work fans out through planners and subplanners, while completed work and feedback return through structured handoffs.
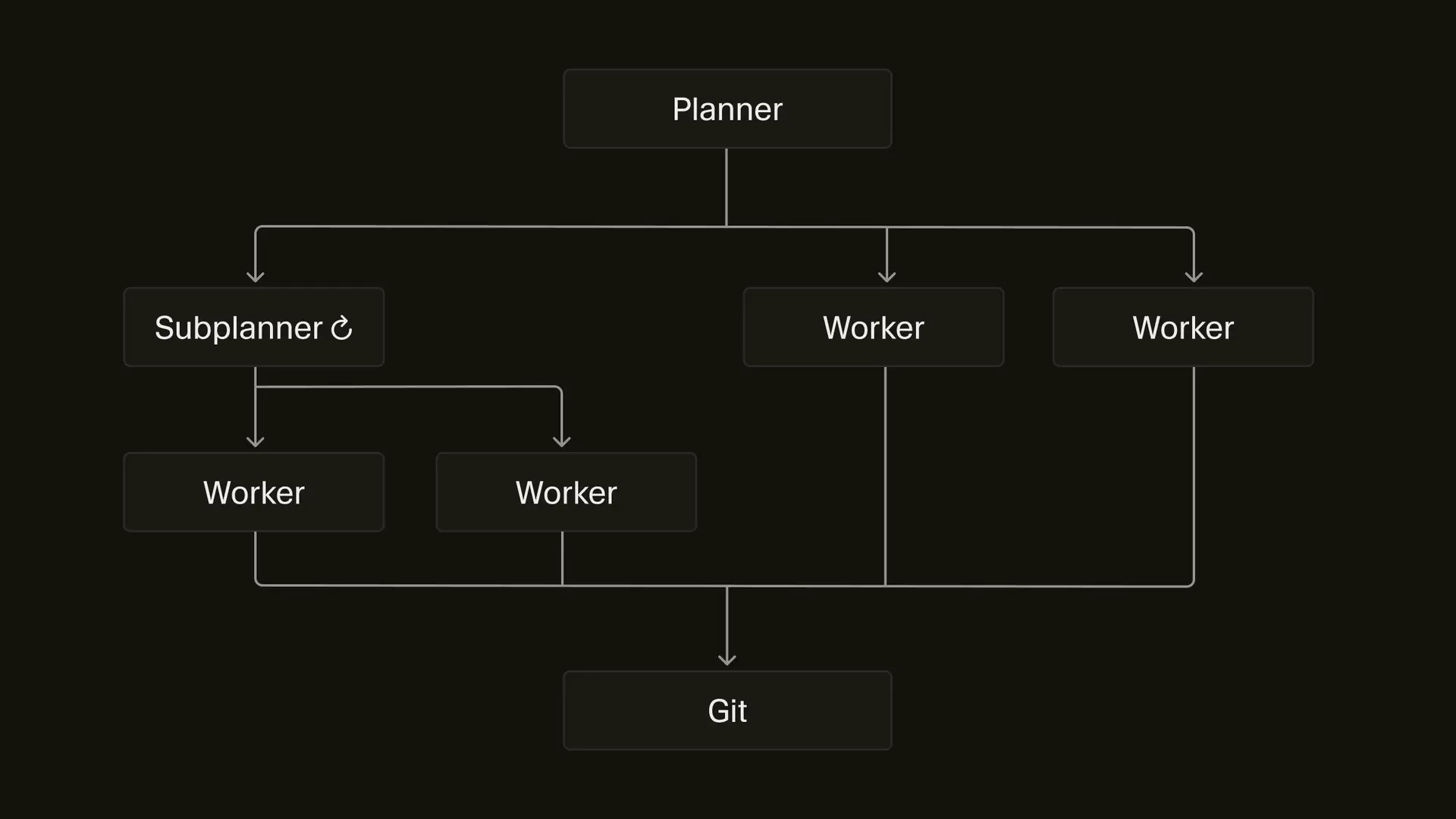
- This architecture treats multi-agent coding as a distributed-systems problem. Locks, stale state, merge conflicts, branch freshness, build artifacts, test latency, and worker isolation can dominate performance once the system scales beyond a few agents.
Multi-Agent Optimization
-
Multi-agent systems are especially useful when a task has a measurable objective and many plausible solution paths. Speeding up GPU kernels by 38% with a multi-agent system describes a system that optimized CUDA kernels for NVIDIA Blackwell GPUs by repeatedly generating, compiling, benchmarking, debugging, and improving candidate implementations.
-
Kernel optimization is a strong testbed for agent systems because correctness is automatically checkable and performance is directly measurable. The objective is not to imitate a reference answer, but to discover faster implementations under validity constraints.
-
A natural aggregate metric is geometric mean speedup:
\[S_{\mathrm{geo}}= \exp\left( \frac{1}{n} \sum_{i=1}^{n} \log \frac{ T^{\mathrm{baseline}}_{i} }{ T^{\mathrm{agent}}_{i} } \right)\]- where, \(T^{\mathrm{baseline}}_{i}\) is the runtime of the baseline kernel for task \(i\), and \(T^{\mathrm{agent}}_{i}\) is the runtime of the agent-generated kernel. The geometric mean is appropriate because speedups are multiplicative and should not be dominated by a few extreme wins.
-
The following figure (source) shows the optimization loop in which agents use benchmark feedback to iteratively improve kernel implementations.
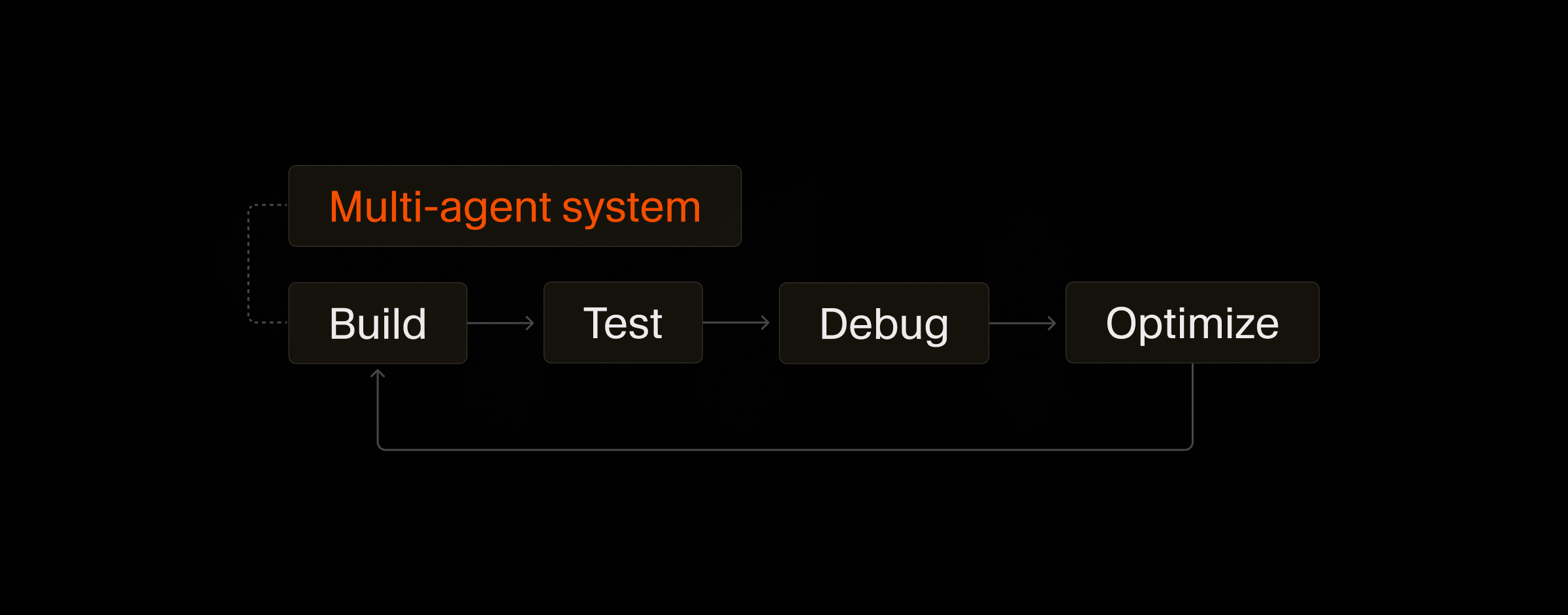
Agentic Code Review
-
Code review is another natural place for agentic decomposition. Building a better Bugbot describes a pull-request review agent that finds logic bugs, performance issues, and security vulnerabilities using multiple bug-finding passes, clustering, majority voting, validator models, filtering, and deduplication.
-
The multi-pass design functions like an ensemble of reviewers. Different diff orderings nudge the model toward different reasoning paths; when several passes independently identify the same issue, the system treats that agreement as stronger evidence that the finding is real.
-
Bugbot’s metric is not merely whether it produces comments, but whether developers resolve the flagged issues. Building a better Bugbot is useful here because it frames review-agent quality as a hill-climbing problem over production outcomes, including resolution rate and false-positive control.
-
The following figure (source) shows the improvement curve for Bugbot, where newer versions catch more real bugs without a comparable rise in false positives.
Cloud Agents and Durable Execution
-
Cloud agents extend local agents by giving them dedicated machines, dependencies, network access, durable state, and the ability to run unattended. What we’ve learned building cloud agents argues that the development environment is the product because cloud-agent quality depends heavily on reconstructing the same environment a human developer would rely on locally.
-
Durable execution is central to long-running work. Agents need to survive restarts, hibernate and resume machines, preserve repository state, continue after transient infrastructure failures, and allow humans to intervene without corrupting the task trajectory.
-
Cloud-agent infrastructure therefore resembles an operating layer for autonomous software workers: it manages machines, credentials, checkpoints, execution logs, environment setup, isolation, and handoff between human and agent control.
Productivity Impact
-
Coding agents change the distribution of developer work rather than simply accelerating isolated code generation. The productivity impact of coding agents reports that organizations merged more pull requests after Cursor’s agent became the default and highlights that experienced developers appear more likely to use agents for planned, higher-leverage tasks.
-
Better models can also expand the frontier of what developers attempt. Better AI models enable more ambitious work studies Cursor usage across companies and finds that stronger models are associated with increased usage and a later shift toward higher-complexity tasks.
-
This is consistent with a Jevons-like effect in software engineering: as agentic coding becomes more efficient, total demand for AI-assisted work can rise because previously uneconomical tasks become feasible.
Design Principles
-
Treat the harness as the product surface: the model’s intelligence is only useful when paired with the right tools, prompts, context representations, execution boundaries, and evaluation loops. Continually improving our agent harness is relevant because it shows that harness iteration can make the same model more useful in practice.
-
Prefer role structure over flat collaboration: planners should own goals, subplanners should own scoped decomposition, and workers should own bounded execution. Towards self-driving codebases is relevant because it shows how hierarchy reduced coordination failures in long-running multi-agent coding.
-
Make context dynamic: externalize logs, histories, tool descriptions, and skills as searchable artifacts rather than forcing all context into the prompt. Dynamic context discovery is relevant because it explains how on-demand context can reduce token use and preserve recoverability.
-
Give agents verifiable signals: tests, linters, benchmarks, type checks, review comments, and runtime errors provide feedback that agents can use to improve their next action. Best practices for coding with agents is relevant because it emphasizes that agents perform better when tasks have clear validation signals.
-
Use task-specific metrics: retrieval should optimize answer accuracy and code retention, review should optimize resolved findings, optimization should measure valid speedups, and long-running coding should measure throughput, freshness, and convergence. Improving agent with semantic search, Building a better Bugbot, and Speeding up GPU kernels by 38% with a multi-agent system each define different evaluation targets for different agentic subsystems.
-
The emerging pattern is a software factory built from specialized agents: one plans, one searches, one edits, one tests, one reviews, one debugs, and one optimizes. The harness decides which agent acts, what context it receives, which tools it can use, and how its output is integrated.
Training and Evals
- Agentic coding systems improve through a feedback loop that connects model training, harness design, production telemetry, offline benchmarks, and human review. Composer: Building a fast frontier model with RL describes training a software-engineering model inside realistic development environments with file editing, terminal commands, semantic search, and codebase tools; Continually improving our agent harness describes the parallel process of improving the harness around each model through experiments, evals, and real usage signals.
Training
-
A coding model is most useful when its training distribution resembles its deployment distribution. In agentic software engineering, this means the model should learn not only to emit code, but also to search, inspect files, edit safely, run tests, interpret failures, revise patches, and decide when to stop. Composer: Building a fast frontier model with RL is relevant because it trains Composer with the same categories of tools used inside Cursor’s production agent harness.
-
The policy can be modeled as a distribution over mixed actions:
\[a_t \in \{\text{respond},\text{plan},\text{search},\text{read},\text{edit},\text{run},\text{test},\text{summarize}\}\] \[\pi_\theta(a_t \mid s_t)\]- where \(s_t\) includes the user request, repository state, retrieved context, prior tool observations, and current plan. The model’s goal is not simply to maximize next-token likelihood, but to choose a sequence of actions that solves a software task under cost, latency, correctness, and safety constraints.
-
A general reinforcement-learning objective for software agents can be written as:
-
In this objective, \(R_{\mathrm{correct}}\) rewards correct task completion, \(R_{\mathrm{style}}\) rewards adherence to codebase conventions, \(R_{\mathrm{eff}}\) rewards efficient tool use and useful parallelism, while the cost terms penalize latency, token use, and unsafe or unsupported behavior. Composer: Building a fast frontier model with RL is relevant because it explicitly emphasizes efficient tool use, parallelism, low-latency interactivity, and minimizing unsupported claims.
-
This training setup is related to Deep Reinforcement Learning from Human Preferences by Christiano et al. (2017), which learns reward models from comparisons over agent behavior; Training language models to follow instructions with human feedback by Ouyang et al. (2022), which applies RLHF to align language models with user intent; and Direct Preference Optimization by Rafailov et al. (2023), which replaces explicit RLHF policy optimization with a direct preference loss.
-
A preference-training objective can be written as the DPO loss:
\[\mathcal{L}_{\mathrm{DPO}}(\pi_\theta;\pi_{\mathrm{ref}}) = -\mathbb{E}_{(x,y_w,y_l)} \left[ \log \sigma \left( \beta \log \frac{\pi_\theta(y_w \mid x)}{\pi_{\mathrm{ref}}(y_w \mid x)} - \beta \log \frac{\pi_\theta(y_l \mid x)}{\pi_{\mathrm{ref}}(y_l \mid x)} \right) \right]\]- where \(y_w\) is the preferred trajectory or response, \(y_l\) is the dispreferred one, \(\pi_{\mathrm{ref}}\) is the reference model, and \(\beta\) controls the strength of the preference update. For coding agents, preferences can reflect whether a patch compiles, passes tests, preserves style, minimizes unnecessary edits, and uses tools efficiently.
-
The following figure (source) shows Composer as a frontier coding model trained for fast agentic use with production search, editing, terminal, and semantic-search tools, whose software engineering ability improves with RL training.
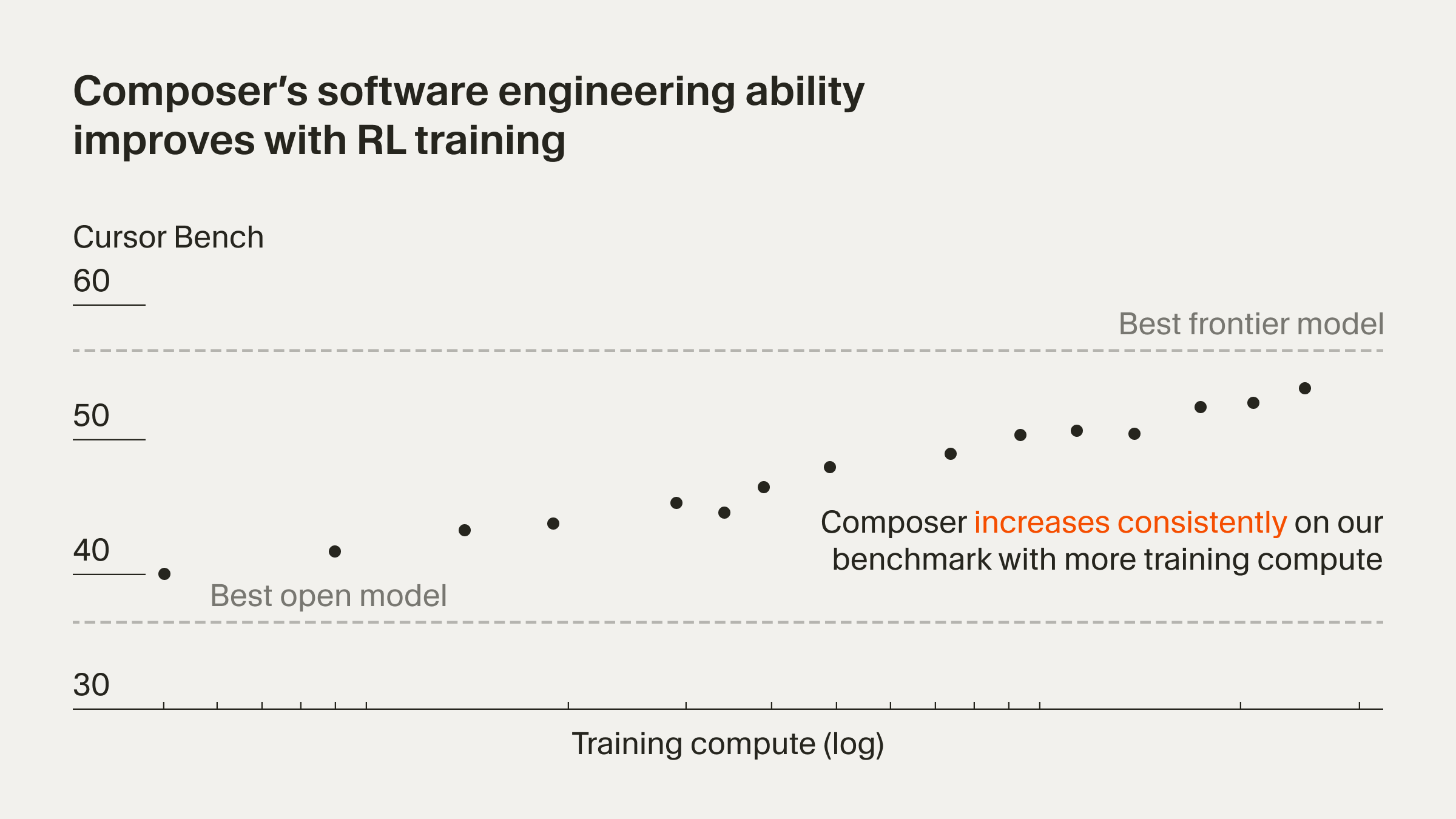
Trace Learning
-
Agent traces are a rich source of supervision because they contain the intermediate searches, file reads, edits, test failures, retries, and final outcomes that reveal how software tasks are actually solved. Improving agent with semantic search describes using agent sessions as training data for retrieval, where the system infers which code segments would have been useful earlier in the trajectory.
-
Trace learning is especially useful for training retrieval and tool-use behavior. If an agent eventually opens a file that resolves the task, the earlier search queries and missed retrieval opportunities can be converted into supervision for a retrieval model.
-
A retrieval model can be trained with a ranking loss over relevant and irrelevant code chunks:
\[\mathcal{L}_{\mathrm{rank}} = -\log \frac{ \exp(\operatorname{sim}(q,c^+)/\tau) }{ \exp(\operatorname{sim}(q,c^+)/\tau) + \sum_{c^- \in \mathcal{N}} \exp(\operatorname{sim}(q,c^-)/\tau) }\]- where \(q\) is the agent’s search query or latent information need, \(c^+\) is a code chunk judged useful, \(\mathcal{N}\) is a set of negative chunks, \(\operatorname{sim}\) is the embedding similarity function, and \(\tau\) is a temperature parameter. This objective encourages the retrieval model to rank useful implementation context above superficially similar but irrelevant code.
-
This approach is related to Dense Passage Retrieval by Karpukhin et al. (2020), which trains dense retrievers with contrastive supervision for question answering, and to Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Lewis et al. (2020), which combines retrieval with generation so that downstream answers are grounded in retrieved evidence.
Offline Evals
-
Offline evals provide a repeatable way to detect regressions before releasing a model or harness change. Continually improving our agent harness is relevant because it describes using offline benchmarks to assess harness changes before relying on noisier production signals.
-
For coding agents, offline evals should measure behavior at the repository level rather than only at the function-completion level. SWE-bench by Jimenez et al. (2023) is relevant because it evaluates whether models can resolve real GitHub issues through codebase edits, which better matches the multi-file, tool-using nature of agentic coding than isolated code-generation tests.
-
A repository-level eval can be formalized as:
\[\operatorname{PassRate} = \frac{1}{N} \sum_{i=1}^{N} \mathbb{1} \left[ \operatorname{Tests}(P_i(\tau_i))=\mathrm{pass} \right]\]- where \(P_i(\tau_i)\) is the patch produced by the agent trajectory \(\tau_i\) for task \(i\), and the indicator returns 1 only if the resulting repository passes the task’s validation suite.
-
Offline evals should also measure non-binary qualities that matter in production: edit minimality, idiomatic use of existing abstractions, test coverage, latency, tool-call count, context-window pressure, and frequency of unsupported claims. Composer: Building a fast frontier model with RL is relevant because it evaluates usefulness to software developers rather than only raw code correctness.
Online Evals
-
Online evals measure whether agent changes improve real developer workflows. The productivity impact of coding agents is relevant because it studies organizational outcomes such as pull-request throughput, revert rate, and developer behavior after agent usage increased.
-
Online metrics can be divided into immediate interaction metrics and downstream software metrics. Immediate metrics include acceptance rate, follow-up rate, task abandonment, latency, tool interruptions, and user edits after agent output. Downstream metrics include code retention, pull-request merge rate, revert rate, bugfix rate, review comments, and test failure frequency.
-
A simple code-retention metric can be written as:
\[\operatorname{Retention}(k) = \frac{ \sum_{j=1}^{M} \operatorname{LinesKept}_{j}(k) }{ \sum_{j=1}^{M} \operatorname{LinesGenerated}_{j} }\]- where, \(\operatorname{LinesKept}_{j}(k)\) is the number of agent-generated lines from interaction \(j\) that remain after \(k\) days or commits, and \(\operatorname{LinesGenerated}_{j}\) is the original number of generated lines. This metric is useful because code that remains in the repository is more likely to have matched developer intent and codebase constraints.
-
Online metrics require careful interpretation. A lower acceptance rate can indicate worse generations, but it can also indicate that users are asking the agent to attempt more ambitious tasks. Better AI models enable more ambitious work is relevant because it argues that better models can shift developers toward higher-complexity work rather than merely increasing the volume of simple tasks.
-
The following figure (source) shows the measured productivity effect of coding agents, including changes in pull-request throughput after agent usage became central to the workflow.
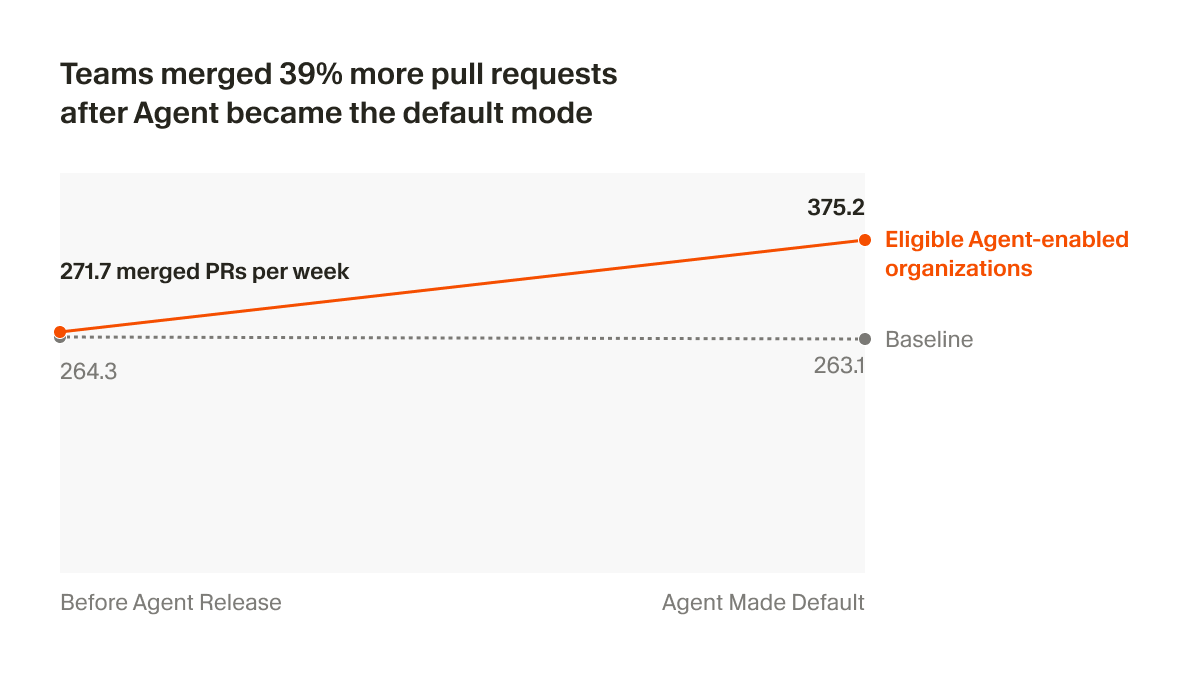
Review Evals
-
Review agents require different metrics from implementation agents. A review agent can look active by producing many comments, but the useful signal is whether the comments identify real issues that developers actually resolve. Building a better Bugbot is relevant because it uses resolution rate as a production metric for review-agent quality.
-
A review-agent resolution metric can be written as:
-
This metric must be balanced against recall. A very conservative review agent may have a high resolution rate but miss many important bugs. A more complete evaluation should track resolved findings, false positives, duplicate reports, severity, and whether the issue would have escaped into production.
-
Bugbot’s multi-pass architecture can be viewed as an ensemble estimator. If \(K\) independent passes inspect a pull request and \(v_i(b) \in \{0,1\}\) indicates whether pass \(i\) flags bug \(b\), a majority filter accepts the finding when:
-
The threshold \(m\) trades recall against precision. A higher threshold suppresses one-off hallucinated findings, while a lower threshold catches more rare or subtle issues.
-
The following figure (source) shows Bugbot’s production improvement curve over 11 versions, plotting resolution rate against average bugs per run. Higher-resolution findings become the optimization target for review-agent iteration.
Optimization Evals
-
Some agent tasks have measurable scalar objectives rather than human preference labels. Speeding up GPU kernels by 38% with a multi-agent system is relevant because it evaluates a multi-agent system through valid runtime improvements on CUDA kernel benchmarks.
-
Optimization evals are attractive because they create a closed feedback loop: generate candidate, compile, run correctness checks, benchmark speed, inspect failures, and repeat. This resembles black-box optimization with a language-model policy.
-
For a set of benchmark tasks, geometric mean speedup is:
\[S_{\mathrm{geo}} = \exp \left( \frac{1}{N} \sum_{i=1}^{N} \log \frac{ T^{\mathrm{base}}_i }{ T^{\mathrm{agent}}_i } \right)\]- where \(T^{\mathrm{base}}_i\) is baseline runtime and \(T^{\mathrm{agent}}_i\) is agent-produced runtime. The geometric mean is appropriate because speedups are multiplicative and should reflect broad improvement across the task set.
-
The same structure generalizes beyond kernels. In software engineering, scalar feedback can come from benchmark latency, memory use, bundle size, test runtime, static-analysis warnings, type-checking failures, coverage, or production incident rates.
Drift
-
Agent systems can regress even when the underlying model improves. A new model may call tools differently, overuse summaries, ignore existing abstractions, produce longer edits, or fail under a previously successful prompt format. Continually improving our agent harness is relevant because it frames harness evolution as continuous regression detection and repair.
-
Drift can be monitored by comparing a new model-harness pair \(h_{\mathrm{new}}\) against a baseline \(h_{\mathrm{base}}\) over a suite of evals:
-
For a metric \(M\) where higher is better, positive \(\Delta M\) indicates improvement. For cost metrics such as latency, tool errors, or token use, the sign should be inverted or tracked separately.
-
A robust release process should include task-level regression analysis. Average gains can hide concentrated failures on important workflows such as large refactors, test repair, migration edits, dependency upgrades, or code review.
Lessons
-
Train inside the deployment harness. Tool use, file editing, retrieval, terminal execution, and summarization are part of the agent’s action space, so they should appear in training and evals. Composer: Building a fast frontier model with RL is relevant because it trains the model with production-like agent tools.
-
Use traces as supervision. Search sessions, opened files, failed tests, accepted edits, and retained code provide training signals that are more specific to software engineering than generic text corpora. Improving agent with semantic search is relevant because it uses agent trajectories to improve retrieval.
-
Evaluate at the repository level. Single-function benchmarks miss the core difficulty of agentic coding, which is coordinating changes across files, tests, build systems, and existing abstractions. SWE-bench by Jimenez et al. (2023) is relevant because it evaluates real issue resolution in existing repositories.
-
Optimize for downstream outcomes. Review agents should optimize for resolved bugs, retrieval should optimize for useful context, implementation agents should optimize for retained correct code, and long-running agents should optimize for progress without excessive synchronization. Building a better Bugbot, Improving agent with semantic search, and Towards self-driving codebases each define a different production signal for a different agent subsystem.
-
Treat evaluation as continuous. Agentic systems are coupled systems, so model upgrades, tool changes, prompt changes, context policies, and infrastructure changes should be evaluated together rather than in isolation.
Runtime
- A multi-agent coding system depends on the quality of its runtime: agents must edit files quickly, execute commands safely, preserve state across long trajectories, recover from failures, and validate work in environments that match the developer’s repository. Editing Files at 1000 Tokens per Second explains why low-latency edit application is necessary for interactive coding flow; Implementing a secure sandbox for local agents explains how safe command execution reduces interruptions; and What we’ve learned building cloud agents explains why cloud agents require a durable operating layer around dedicated development environments.
Edits
-
File editing is a core action in software agents, but large edits are difficult for general-purpose models because they require preserving unchanged code, applying localized intent, avoiding syntax errors, and returning results quickly enough to keep developers in flow. Editing Files at 1000 Tokens per Second describes Cursor’s fast-apply model, which separates high-level planning from low-latency application of edits to the current file.
-
A useful decomposition is:
-
The planner can be a frontier model that reasons about the requested change, while the apply model is optimized for the narrower task of transforming the existing file according to the proposed edit.
-
Full-file rewriting is often more robust than emitting textual diffs because the model can preserve global file structure while applying a local transformation. The cost is that the model must generate many tokens, so latency becomes the bottleneck.
-
The following figure (source) shows a toy example of a change we want to ‘apply’, specifically a fast-apply interaction where a proposed change is applied to a file instead of being manually copied across a larger class.
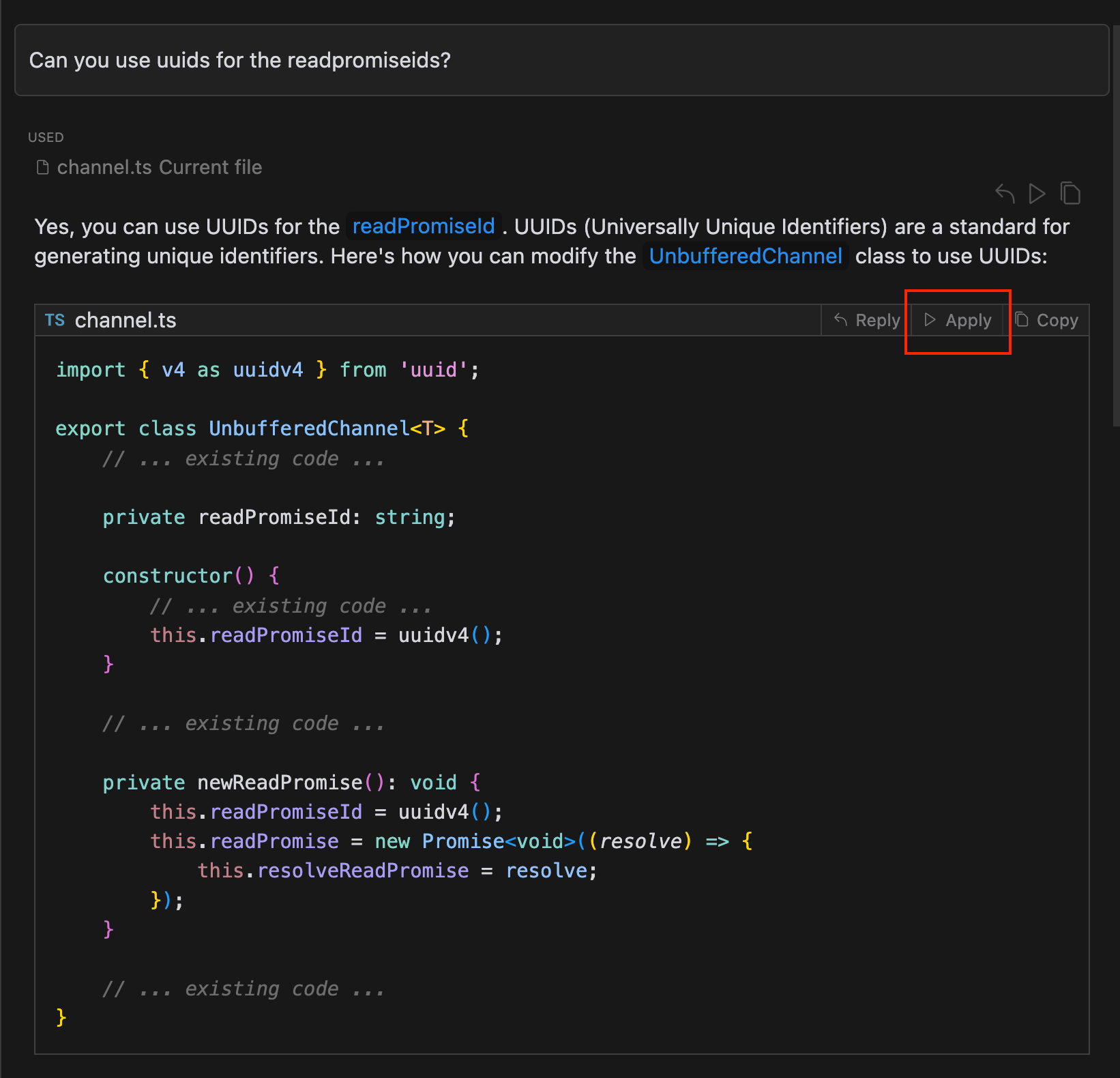
Decoding
-
Speculative editing adapts speculative decoding to code edits. Editing Files at 1000 Tokens per Second describes a speculative-decoding variant tailored for code edits, enabling fast full-file application while preserving accuracy.
-
The general idea is that a cheaper draft process proposes several future tokens, and a stronger verifier accepts or rejects them. Fast Inference from Transformers via Speculative Decoding by Leviathan et al. (2023) introduces speculative decoding as a way to accelerate autoregressive transformer inference without changing the target model’s output distribution; Accelerating Large Language Model Decoding with Speculative Sampling by Chen et al. (2023) presents a related rejection-sampling method that scores draft continuations in parallel.
-
If the draft model proposes \(k\) tokens and the verifier accepts \(A\) of them on average per verification step, the approximate speedup can be modeled as:
\[\operatorname{Speedup} \approx \frac{ k \cdot C_{\mathrm{target}} }{ C_{\mathrm{draft}}(k)+C_{\mathrm{verify}}(k) } \cdot \mathbb{E}\left[\frac{A}{k}\right]\]- where \(C_{\mathrm{target}}\) is the per-token cost of ordinary target-model decoding, \(C_{\mathrm{draft}}(k)\) is the cost of drafting \(k\) tokens, \(C_{\mathrm{verify}}(k)\) is the cost of verifying them, and \(\mathbb{E}[A/k]\) is the expected acceptance ratio.
-
In code-editing workloads, acceptance can be high because much of the file remains unchanged or follows predictable local structure. This makes speculative editing especially useful for apply-style transformations.
Tools
-
The runtime must expose tools as reliable, inspectable actions rather than as opaque side effects. Toolformer by Schick et al. (2023) shows that language models can be trained to decide when and how to call external tools, and coding agents extend this idea to repository search, file reads, file edits, terminal commands, test execution, package management, and build systems.
-
A coding-agent tool interface can be represented as:
\[o_{t+1} = \mathcal{E}(s_t, a_t)\]- where \(a_t\) is a tool action chosen by the agent, \(s_t\) is the current environment state, \(\mathcal{E}\) is the execution environment, and \(o_{t+1}\) is the observation returned to the model. A robust runtime must ensure that \(o_{t+1}\) is compact, relevant, and recoverable.
-
Tool observations should preserve enough detail for debugging but avoid flooding the context window. This connects runtime design to context design: long terminal outputs, build logs, and tool responses should be externalized into files or traces that the agent can inspect selectively.
Shell
-
Terminal access lets agents validate assumptions rather than merely claim correctness. Agents can run tests, invoke type checkers, inspect package errors, query the repository, and reproduce failures.
-
Command execution should be treated as a high-value feedback channel. A failed test supplies localized evidence about what went wrong; a compiler error supplies structured information about syntax or type violations; a benchmark result supplies a scalar objective for optimization.
-
A basic execution loop is:
- This loop is closely related to Voyager by Wang et al. (2023), which uses execution feedback and self-verification to build reusable skills over long-horizon tasks; in coding agents, the analogous skills are repository-specific procedures such as running a test subset, fixing a lint class, or applying a migration pattern.
Sandbox
-
Sandboxing gives agents freedom inside a controlled boundary while preserving user control over higher-risk operations. Implementing a secure sandbox for local agents explains that sandboxed agents can run commands inside a restricted environment and request approval when they need to step outside it, most commonly for internet access.
-
This design reduces the interruption cost of agentic workflows. Without sandboxing, each command may require approval, which serializes the workflow and becomes especially costly when multiple agents run in parallel.
-
A sandbox policy can be represented as a permission function:
\[\operatorname{Allow}(a_t, s_t) = \begin{cases} 1, & a_t \in \mathcal{A}_{\mathrm{safe}}(s_t) \\ 0, & a_t \in \mathcal{A}_{\mathrm{blocked}}(s_t) \\ \operatorname{AskUser}(a_t), & a_t \in \mathcal{A}_{\mathrm{escalate}}(s_t) \end{cases}\]- where safe actions execute automatically, blocked actions are denied, and escalation actions require explicit approval. The important property is that the boundary is visible to both the system and the user.
-
Platform-specific implementations may differ, but the design goal is stable: agents should be able to run ordinary local development commands, while network access, filesystem escape, credential exposure, and destructive actions remain constrained.
Cloud
-
Cloud agents generalize local agents by giving each agent a dedicated machine with its own repository checkout, dependencies, network configuration, and execution state. What we’ve learned building cloud agents argues that cloud agents are not just local agents moved to servers, but require an operating layer for long-running autonomous work.
-
The development environment is a central part of the product. If dependencies are missing, credentials are unavailable, tests cannot run, or the build system differs from local development, the agent may make poor decisions even when the model itself is capable.
-
Environment quality can be viewed as a multiplier on model capability:
\[Q_{\mathrm{agent}} = Q_{\mathrm{model}} \cdot Q_{\mathrm{context}} \cdot Q_{\mathrm{env}} \cdot Q_{\mathrm{tools}}\]- where a weak environment term \(Q_{\mathrm{env}}\) can dominate the final outcome, because the agent cannot verify work, inspect runtime failures, or use project-specific tooling correctly.
Durability
-
Long-running agents require durable execution. A task may span hours or days, involve many tool calls, survive transient infrastructure failures, and need human intervention without losing trajectory state.
-
Durable execution separates the conversation, the machine, and the repository state:
-
A robust system should checkpoint these states independently. The conversation stores intent and decisions; the repository stores code changes; the machine stores runtime environment and installed dependencies; checkpoints allow rollback, resume, and branch comparison.
-
What we’ve learned building cloud agents is relevant here because it emphasizes VM lifecycle, decoupling agents and machines from conversation state, and self-healing environments as core infrastructure for cloud agents.
Handoff
-
Runtime systems should support smooth transitions between human and agent control. A developer may assign a task to a cloud agent, inspect progress later, intervene in the branch, redirect the plan, or take over the final review.
-
Handoffs should include enough state for the next actor, human or agent, to continue safely:
- Structured handoffs are also useful in multi-agent systems, where workers return concise summaries to planners and planners decide whether to spawn more work, integrate changes, or repair regressions.
Latency
-
Latency is not merely a performance metric; it changes how developers use agents. Fast edits keep coding interactive, while slow edits push the agent into a background-worker mode.
-
A useful latency budget separates model thinking, context retrieval, tool execution, edit application, and validation:
- Different product modes optimize different terms. Interactive editing emphasizes low \(T_{\mathrm{apply}}\) and low \(T_{\mathrm{reason}}\); background agents tolerate higher latency but need stronger durability and validation; multi-agent optimization emphasizes throughput across many parallel trajectories.
Key Takeaways
-
Make edits fast enough for flow. Editing Files at 1000 Tokens per Second is relevant because it frames edit application as a specialized low-latency model problem rather than a generic chat-completion problem.
-
Put execution inside boundaries. Implementing a secure sandbox for local agents is relevant because it shows how restricted command execution can reduce interruptions while preserving approval boundaries.
-
Treat the environment as part of the agent. What we’ve learned building cloud agents is relevant because it argues that cloud-agent quality depends on reconstructing the development environment, not only on improving model intelligence.
-
Preserve state across long trajectories. Long-running agents need checkpoints, resumable machines, recoverable logs, and structured handoffs so that progress survives interruptions and human intervention.
-
Optimize runtime by mode. Interactive agents need fast local feedback; cloud agents need durable execution; multi-agent systems need isolation, branch management, and throughput; optimization agents need benchmark loops and reliable measurement.
Review
- Review is a natural specialization point in a multi-agent coding system because implementation and verification have different objectives. An implementation agent optimizes for completing a requested change, while a review agent optimizes for identifying hidden defects, unsafe assumptions, performance regressions, security issues, and violations of codebase-specific invariants. Building a better Bugbot describes Bugbot as a code-review agent that analyzes pull requests for logic bugs, performance issues, and security vulnerabilities before production; Bugbot now self-improves with learned rules explains how feedback from live review can be converted into learned rules that improve future reviews.
Goal
-
The goal of an agentic reviewer is not to maximize the number of comments. It is to maximize the number of real, actionable defects caught before merge while minimizing false positives and reviewer fatigue. This makes review-agent optimization different from generation-agent optimization: the review agent must be skeptical, precise, and grounded in repository context.
-
A review agent receives a code change \(\Delta\), repository context \(\mathcal{R}\), project rules \(\mathcal{G}\), and optional execution signals \(\mathcal{E}\), then produces a set of findings:
- Each finding \(f_i \in F\) should include the suspected defect, affected code location, reasoning, expected failure mode, and a concrete fix direction. A finding without a reproducible mechanism or code-grounded explanation should be filtered because it increases review noise.
Passes
-
Multi-pass review improves coverage by making several independent attempts to inspect the same change. Building a better Bugbot is relevant because it describes running multiple bug-finding passes with different diff orderings, then clustering and voting on the resulting findings.
-
The value of randomized or reordered passes is diversity. A model that sees the same diff in a different order may attend to different dependencies, edge cases, or control-flow paths. This is similar to ensemble reasoning: each pass is an imperfect detector, but agreement among passes can raise confidence.
-
If \(K\) review passes inspect a candidate bug \(b\), and \(v_i(b) \in \{0,1\}\) indicates whether pass \(i\) flagged it, then a simple voting rule is:
-
The threshold \(m\) controls the precision-recall tradeoff. A higher threshold reduces one-off hallucinations but can miss subtle bugs that only one pass discovers. A lower threshold improves recall but increases false-positive risk.
-
The following figure (source) shows the Bugbot dashboard used to track production review outcomes, including PRs reviewed, issues resolved, users, and hours saved over time.
Clustering
-
Multiple review passes may describe the same underlying bug in different words. Clustering converts redundant findings into canonical issue buckets so that the final review is concise rather than repetitive.
-
A clustering function groups candidate findings by semantic similarity, code location, and failure mechanism:
- For each bucket \(B_j \in \mathcal{B}\), the system can synthesize a single finding:
- The merged finding should preserve the strongest evidence across passes: the clearest reproduction path, the most precise affected lines, and the most actionable fix.
Validation
-
A validator model provides a second layer of review over the reviewer’s findings. Building a better Bugbot is relevant because it describes running Bugbot results through a validator model to catch false positives after majority voting and filtering.
-
Validation is important because the first-stage reviewer is optimized for discovering possible bugs, while the validator can be optimized for rejecting weak claims. This separation mirrors a prosecutor-defender pattern: one agent proposes defects, another demands stronger evidence.
-
A validator can estimate:
- The system can then surface only findings above a confidence threshold:
- The threshold \(\tau\) should depend on the product context. A high-stakes security review may accept more false positives for higher recall, while a default pull-request review may require stronger confidence to avoid noisy comments.
Rules
-
General-purpose review is insufficient for production codebases because many important bugs depend on local invariants: unsafe migrations, internal API misuse, domain-specific security constraints, performance-sensitive call paths, or conventions that are not obvious from the diff alone. Building a better Bugbot explains that Bugbot rules let teams encode codebase-specific invariants without hardcoding them into the system; Bugbot now self-improves with learned rules describes turning live feedback into learned rules that customize future Bugbot runs.
-
A rule can be represented as an instruction or detector over repository context:
-
The review policy can combine model judgment with explicit rules:
\[\operatorname{Score}(f_i) = \alpha \cdot p_{\mathrm{model}}(f_i) + \beta \cdot p_{\mathrm{rule}}(f_i) + \gamma \cdot p_{\mathrm{history}}(f_i)\]- where \(p_{\mathrm{model}}\) captures general reasoning, \(p_{\mathrm{rule}}\) captures rule-based relevance, and \(p_{\mathrm{history}}\) captures whether similar findings were resolved or dismissed in prior reviews.
Learning
-
Review agents can learn from production feedback. A dismissed comment, resolved comment, edited fix, repeated false positive, or user-authored rule all provide supervision about what the codebase considers important.
-
A useful feedback tuple is:
\[z = \left( f_i, \Delta, \mathcal{R}, y, u \right)\]- where \(f_i\) is the finding, \(\Delta\) is the reviewed change, \(\mathcal{R}\) is repository context, \(y\) is the outcome label, and \(u\) is optional human feedback. Outcomes may include resolved, ignored, dismissed as false positive, duplicate, not actionable, or fixed independently.
-
Learned rules can be viewed as compressed memory from prior reviews:
- This turns review from a stateless inference task into an adaptive process where the system becomes more aligned with a team’s codebase and preferences over time.
Metrics
-
Review-agent quality should be measured with outcome-based metrics. PlanetScale protects production reliability with Bugbot is relevant because it highlights resolution rate as a practical metric for whether Bugbot comments lead to addressed issues in production pull requests.
-
Resolution rate measures the fraction of surfaced findings that are addressed before merge:
- Precision estimates how many surfaced findings were real issues:
- Recall estimates how many real issues the review agent caught:
- In practice, recall is harder to measure because missed defects are often unknown until tests fail, users report bugs, incidents occur, or humans identify the issue later. This makes proxy metrics important: post-merge bugfixes, reverted pull requests, production incidents, test failures, and human review comments can all serve as delayed signals.
Triage
-
Not all findings should be treated equally. A review agent should prioritize defects by severity, confidence, affected surface area, exploitability, and fix difficulty.
-
A simple severity score can be written as:
- Security and correctness bugs should usually outrank style suggestions. Performance regressions should be prioritized when they affect hot paths, large loops, database queries, GPU kernels, or user-visible latency. Migration and data-corruption bugs should be prioritized when they are difficult to reverse.
Context
-
Review agents need more than the diff. They often need call sites, tests, type definitions, schema definitions, feature flags, migration history, dependency versions, and prior patterns in the repository.
-
Retrieval should therefore be review-aware. The agent should retrieve context that helps answer specific defect questions, such as whether a function can receive null input, whether a migration is backward-compatible, whether a permission check is consistently applied, or whether a changed API has external callers.
-
Review-specific retrieval can be represented as:
\[C_f = \operatorname{Retrieve} \left( q_f, \mathcal{R} \right)\]- where \(q_f\) is a query generated from a suspected finding, and \(C_f\) is the supporting or refuting context. A finding should become stronger when retrieved context confirms the failure path and weaker when context shows the code is safe.
Security
-
Security review benefits from agentic workflows because many vulnerabilities require tracing data flow across files. A review agent can inspect where input enters the system, where it is validated, how it is transformed, and where it reaches a sensitive sink.
-
A simplified taint-style analysis can be written as:
-
The review agent should flag paths where untrusted data reaches a sensitive sink without adequate validation or escaping. This is especially relevant for authentication, authorization, SQL queries, shell commands, file paths, secrets, deserialization, and cross-site scripting surfaces.
-
Agentic security review should still be grounded in executable and static signals where available. Type checks, tests, static analyzers, dependency scanners, and policy engines provide evidence that can reduce speculative findings.
Human Loop
-
Human feedback remains essential because review quality is partly subjective and codebase-specific. A finding can be technically correct but unhelpful if it is too speculative, low severity, already known, or inconsistent with the team’s preferred tradeoffs.
-
The best human-review loop is not manual micromanagement of every model step, but high-signal correction: dismissing false positives, resolving true positives, adding rules, editing findings, and marking recurring issue categories.
-
The review system should preserve this feedback as structured data:
- This feedback can improve future review through learned rules, retrieval tuning, validation thresholds, and prompt updates.
Key Takeaways
-
Separate discovery from validation. One component should search broadly for possible bugs, while another should reject weak or unsupported findings.
-
Use ensembles for fragile reasoning. Multiple passes, different diff orderings, and majority voting reduce the chance that a single brittle reasoning path dominates the result.
-
Optimize for resolved findings, not comment volume. Building a better Bugbot is relevant because it treats review-agent quality as a hill-climbing process over resolution rate and false-positive control.
-
Encode local invariants. Bugbot now self-improves with learned rules is relevant because it turns live review feedback into repository-specific rules that shape future reviews.
-
Retrieve before asserting. Review findings should be grounded in codebase context, not only in the changed diff.
-
Keep comments actionable. Each surfaced finding should explain the failure mode, identify the affected code, and suggest a concrete direction for repair.
-
Use humans as teachers. Dismissals, fixes, and rule edits should become training or configuration signals rather than ephemeral review interactions.
Coordination
-
Long-horizon coding requires coordination because large software goals contain ambiguous decomposition, shared state, overlapping files, build dependencies, and delayed validation signals. Scaling long-running autonomous coding describes experiments with hundreds of concurrent agents on one project, focusing on coordination failures, planner-worker decomposition, and week-scale execution. ([Cursor][1])
-
This direction extends earlier multi-agent software-engineering work: ChatDev by Qian et al. (2023) frames software development as communication among specialized agents across design, coding, and testing, while MetaGPT by Hong et al. (2023) introduces standardized operating procedures and role specialization to reduce inconsistency in multi-agent collaboration. ([arXiv][2])
Scope
-
A single agent can solve a bounded task when the relevant files, tests, and acceptance criteria fit within one trajectory. Larger projects break this assumption because no single trajectory can reliably preserve global context, implement all subsystems, and validate every interaction. Towards self-driving codebases describes a browser-building experiment in which thousands of agents were orchestrated through a dedicated harness to explore the limits of autonomous codebase-scale work. ([Cursor][3])
-
The coordination problem can be formalized as assigning a project goal \(G\) to a set of agents \(\mathcal{A}={a_1,\ldots,a_n}\) over a task graph \(\mathcal{T}\):
- Here, each node \(v \in V\) is a task, each edge \(e \in E\) is a dependency, and the assignment function maps tasks to agents. The core systems problem is to maximize useful parallel progress while minimizing duplicated work, stale assumptions, merge conflicts, and global synchronization overhead.
Flatness
-
Flat coordination gives every agent equal status and asks agents to negotiate work through shared state. Scaling long-running autonomous coding describes an early design in which agents read a shared coordination file, claimed tasks, and used locks to avoid duplicate work, but the system became brittle and slow when agents held locks too long, forgot to release them, or waited behind other agents. ([Cursor][1])
-
A flat system can be represented as:
-
This design is simple, but it forces agents to reason about both local implementation and global coordination. The result is often conservative behavior: agents select small safe tasks, avoid unclear work, and fail to take end-to-end ownership of difficult subsystems.
-
The following figure (source) shows a flat self-coordination design in which agents coordinate through a shared state channel, exposing the synchronization bottleneck that appears when many workers must coordinate as peers.
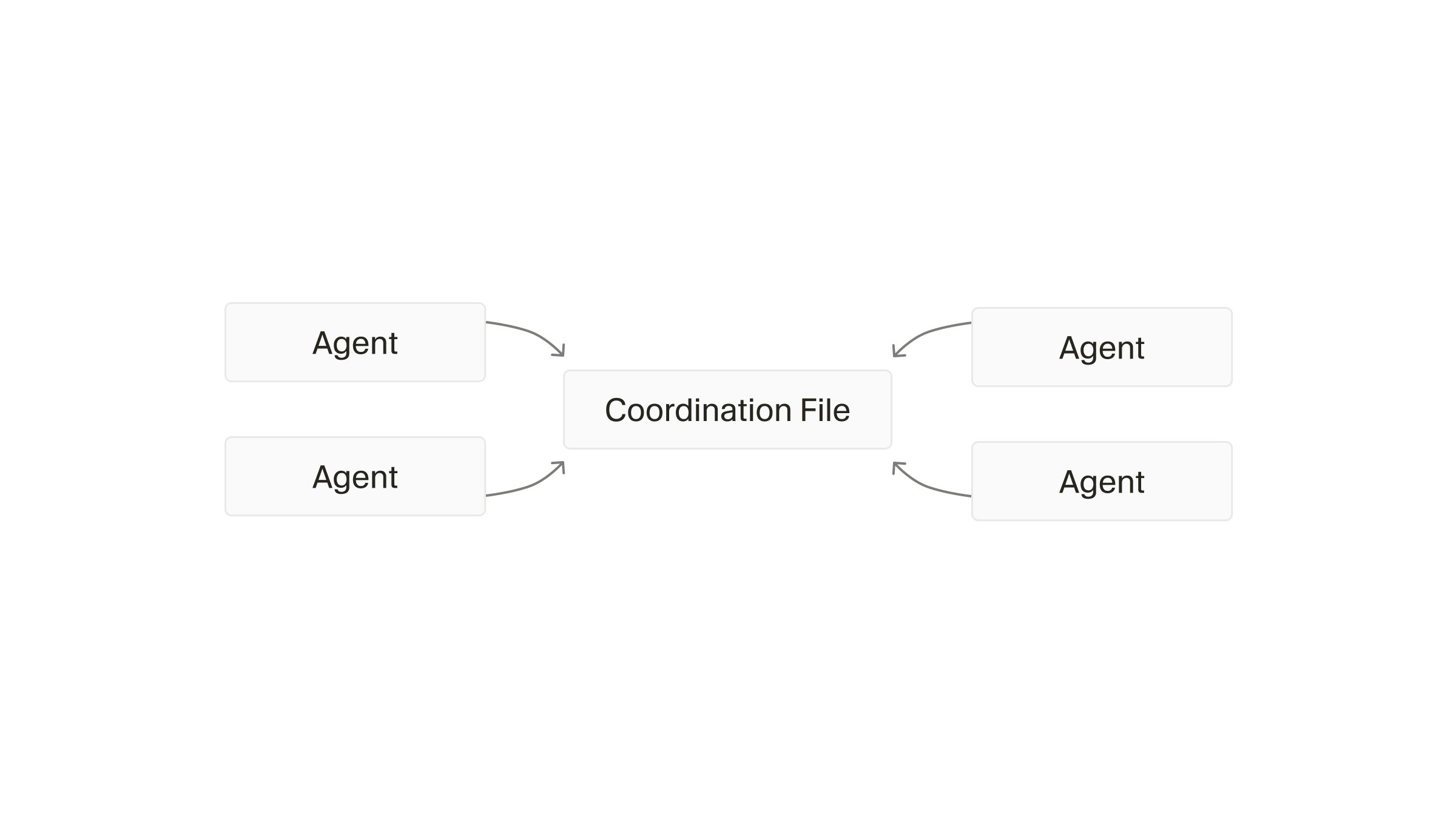
Roles
-
Hierarchical coordination separates planning from execution. Towards self-driving codebases describes a system where a root planner owns the overall goal, subplanners recursively decompose parts of the work, and workers complete bounded implementation tasks in isolated environments. ([Cursor][3])
-
The hierarchy can be written as:
-
Here, \(P_i\) denotes a planner or subplanner, and \(W_j\) denotes a worker. Planners preserve project intent and dependency structure, while workers focus on implementation without needing to track the entire project.
-
This resembles the role-based design in MetaGPT by Hong et al. (2023), where software tasks are decomposed through structured roles and standardized operating procedures to reduce cascading inconsistency across agents. ([arXiv][4])
Handoffs
-
Structured handoffs replace continuous global chatter. A worker should return a compact artifact that explains what changed, which tests ran, which assumptions were made, which problems remain, and which follow-up tasks are suggested. Towards self-driving codebases highlights handoffs as a way to let information propagate upward without forcing every worker to coordinate with every other worker. ([Cursor][3])
-
A handoff object can be represented as:
-
Here, \(g\) is the assigned goal, \(\Delta\) is the patch or artifact, \(r\) is the validation record, \(b\) is the blocker set, \(q\) is the open-question set, and \(n\) is the recommended next-step set.
-
Handoffs are also the point where memory becomes operational. A planner does not need full transcripts from every worker; it needs distilled state that is accurate enough to update the task graph and spawn the next unit of work.
Freshness
-
Freshness is the problem of ensuring that agents work against a current view of the codebase. In a multi-agent system, one worker may modify an abstraction while another worker is implementing against an older version of it. Towards self-driving codebases discusses branch freshness and synchronization as recurring bottlenecks in long-running autonomous coding. ([Cursor][3])
-
A simple freshness score for worker \(i\) can be modeled as:
-
Here, \(\Delta_i(t)\) measures how far the worker’s branch or context has drifted from the current integration branch at time \(t\), and \(\lambda\) controls how quickly stale context should reduce confidence.
-
Freshness management should avoid both extremes. Merging constantly creates synchronization overhead; merging rarely increases stale work and conflict risk.
Conflicts
-
Merge conflicts are not merely Git errors. They are symptoms of overlapping intent, stale assumptions, or insufficient decomposition. Scaling long-running autonomous coding is relevant because it shows that coordination overhead can collapse effective throughput when many agents compete for shared state or overlapping code regions. ([Cursor][1])
-
Let \(C_{ij}\) denote the conflict probability between agents \(i\) and \(j\). A coordination policy should reduce expected conflict cost:
- The system can reduce \(P(C_{ij}=1)\) by assigning disjoint files, separating interface work from implementation work, sequencing dependent tasks, and giving planners responsibility for cross-cutting changes.
Throughput
-
Throughput is the rate at which valid useful work lands in the codebase, not the raw number of tokens, commits, or agents. Towards self-driving codebases is relevant because it describes high-throughput autonomous coding as a systems problem involving planning, worker isolation, branch management, validation, and integration. ([Cursor][3])
-
A useful throughput objective is:
- A more realistic version subtracts rework, conflict cost, and validation failures:
- This distinction matters because a multi-agent system can appear productive while generating large amounts of low-quality work that later requires cleanup.
Governance
-
Long-running agents need stopping rules. Without them, agents may continue refining low-value details, repeatedly repair the same failing tests, or declare success prematurely.
-
A judge or supervisor can decide whether to continue, stop, merge, retry, or replan:
-
Here, \(G\) is the original goal, \(S_t\) is current project state, \(V_t\) is validation evidence, and \(H_{1:t}\) is the sequence of handoffs. The decision \(d_t\) can take values such as continue, spawn worker, request human input, run integration, or stop.
-
This form of supervision is related to AutoGen by Wu et al. (2023), which models multi-agent applications as conversations among agents, tools, and humans, with configurable coordination patterns for task completion.
Failure Modes
-
Long-horizon multi-agent coding introduces failure modes that do not appear in single-turn generation: stale branches, duplicate work, lock contention, risk-averse task selection, fragmented ownership, premature success claims, integration debt, and pathological loops.
-
These failures can be grouped as:
-
State failures include stale context and conflicting branches. Planning failures include poor decomposition and unclear ownership. Execution failures include broken builds and invalid patches. Integration failures include merge conflicts, inconsistent abstractions, and untested interactions.
-
Scaling long-running autonomous coding is relevant here because it documents how apparently small coordination choices, such as locks and shared files, can create systemic bottlenecks once agent count rises. ([Cursor][1])
Key Takeaways
-
Use hierarchy for large goals. Planners should own intent and decomposition, while workers should own bounded implementation.
-
Prefer handoffs over chatter. Coordination should move through concise structured artifacts, not unbounded peer-to-peer conversation.
-
Optimize net throughput. The goal is not to maximize agent count, commits, or generated code, but to maximize useful validated work merged per unit time.
-
Treat freshness as a first-class metric. Branch age, context drift, and dependency changes should influence whether work continues, rebases, or restarts.
-
Reserve global reasoning for planners. Workers should not need to understand the full project unless their task requires it.
-
Validate continuously. Tests, builds, type checks, benchmarks, and review agents should supply feedback before integration debt accumulates.
-
Expect coordination to dominate at scale. Once hundreds of agents operate concurrently, bottlenecks shift from model reasoning to distributed-systems concerns such as locks, state freshness, branch isolation, and integration policy.
Outlook
- Cursor’s multi-agentic system points toward a broader design pattern for software engineering: models become specialized workers, the harness becomes the operating layer, and the codebase becomes a continuously updated environment in which agents plan, retrieve, edit, test, review, and integrate work. Continually improving our agent harness shows that the harness determines how models use tools and context; Towards self-driving codebases shows how hierarchical planners and workers can scale autonomous coding; and What we’ve learned building cloud agents shows that durable development environments are central to long-running agent reliability.
Architecture
- The final architecture is best understood as a layered system:
-
The model supplies reasoning and action selection; the harness supplies prompts, tools, context policy, safety policy, and orchestration; the runtime supplies execution, isolation, persistence, and validation; the codebase supplies the evolving environment; and evaluation supplies the feedback required to improve the system over time.
-
Composer: Building a fast frontier model with RL is relevant here because it treats tool use, semantic search, terminal execution, and efficient action selection as part of the model’s training environment rather than as external add-ons.
-
Dynamic context discovery is relevant because it shifts the architecture from static prompt stuffing toward on-demand retrieval of logs, history, skills, terminal sessions, and tool descriptions.
-
Improving agent with semantic search is relevant because it shows that codebase understanding depends on retrieval systems trained from actual agent traces, not only on generic code embeddings.
-
The following figure (source) shows a final multi-agent coding architecture in which planners, workers, validation, integration, and feedback loops operate as a coordinated system for codebase-scale autonomy.
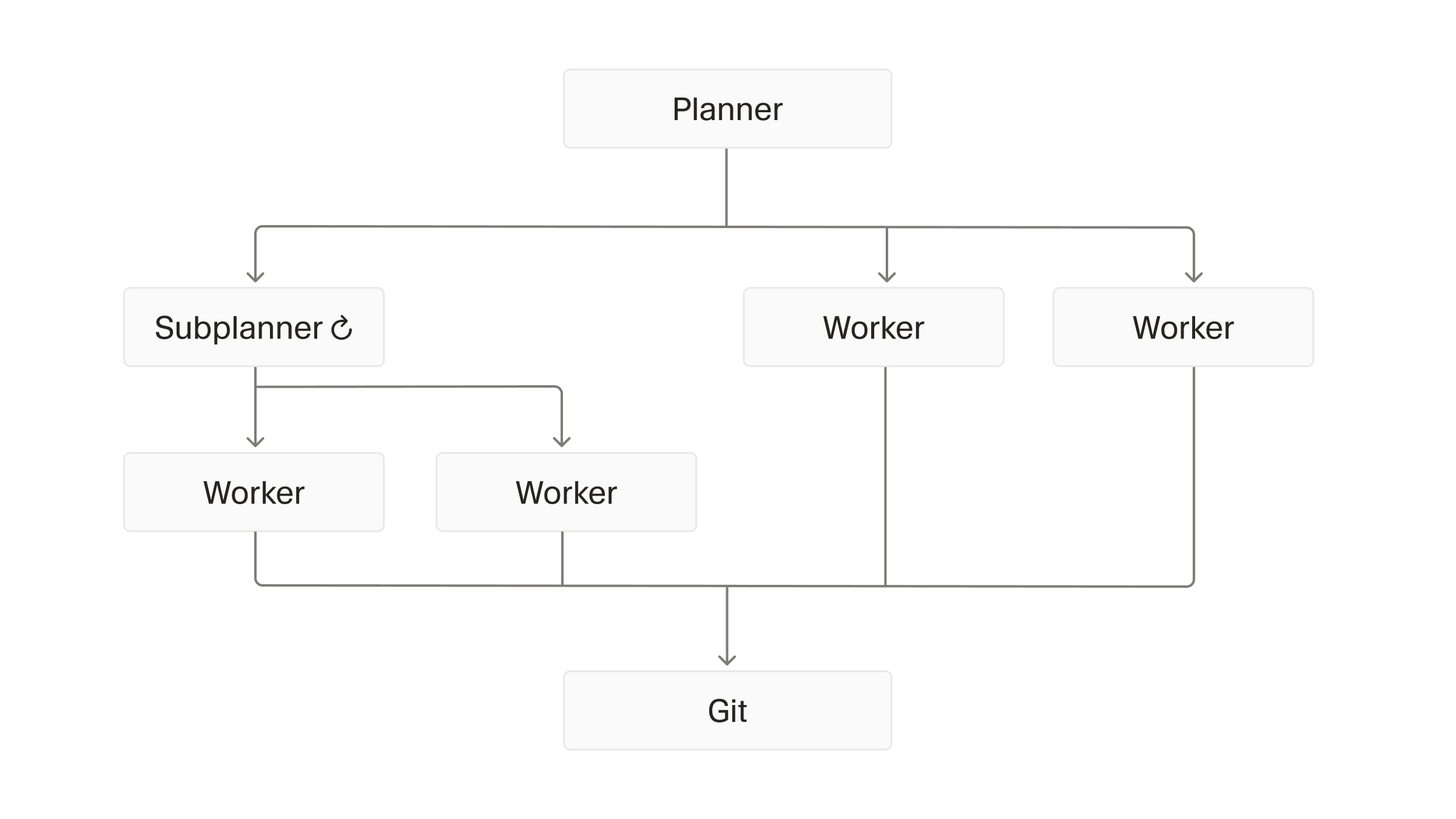
Autonomy
-
Autonomy should be treated as a spectrum rather than a binary property. A local interactive agent may propose edits while the developer remains in tight control; a background cloud agent may implement a scoped task asynchronously; a multi-agent system may decompose a large goal into many worker tasks; and a self-driving codebase system may continuously plan, implement, validate, and repair work over long horizons.
-
This can be represented as increasing scope over time:
\[A = f \left( H,\; C,\; T,\; E,\; V \right)\]- where \(A\) is the effective autonomy level, \(H\) is harness quality, \(C\) is context quality, \(T\) is tool reliability, \(E\) is environment fidelity, and \(V\) is validation strength. A system should only increase autonomy when the surrounding infrastructure can support it.
-
Scaling long-running autonomous coding is relevant because it shows that autonomy fails without coordination mechanisms, role separation, and state management.
-
Implementing a secure sandbox for local agents is relevant because autonomy requires safety boundaries that let agents act without requiring approval for every low-risk command.
-
What we’ve learned building cloud agents is relevant because unattended autonomy depends on durable machines, persistent state, environment reconstruction, and self-healing execution.
Evaluation
-
Evaluation becomes the central control mechanism for multi-agentic coding systems. Without strong evaluation, agents may generate large volumes of code that look productive but fail to compile, violate local conventions, duplicate work, or introduce hidden defects.
-
The evaluation stack should combine task completion, code quality, review quality, runtime behavior, and downstream repository outcomes:
\[M_{\mathrm{total}} = w_1M_{\mathrm{correct}} + w_2M_{\mathrm{style}} + w_3M_{\mathrm{retention}} + w_4M_{\mathrm{review}} + w_5M_{\mathrm{latency}} - w_6M_{\mathrm{rework}}\]- where correctness, style, retention, review usefulness, and latency are balanced against rework and invalid output. The weights should depend on the task mode: interactive edits emphasize latency, review emphasizes precision, optimization emphasizes benchmark improvement, and long-running coding emphasizes net merged progress.
-
Building a better Bugbot is relevant because it treats code review as a measurable hill-climbing process over resolved findings and false-positive control.
-
The productivity impact of coding agents is relevant because it connects agent use to organizational metrics such as pull-request throughput and downstream development behavior.
-
Better AI models enable more ambitious work is relevant because it shows that model improvements can change the complexity distribution of developer tasks, so evaluation must account for changing task ambition rather than only simple acceptance rates.
Economics
-
The economic impact of agentic coding is likely to come from expanding the feasible scope of software work, not only from accelerating existing tasks. As agentic systems reduce the cost of planning, implementation, review, refactoring, testing, and optimization, developers can attempt larger changes and maintain more complex systems.
-
This effect can be expressed as a demand expansion relationship:
\[\Delta W_{\mathrm{total}} = \Delta W_{\mathrm{accelerated}} + \Delta W_{\mathrm{new}}\]-
where \(\Delta W_{\mathrm{accelerated}}\) is work that was already being done faster, while \(\Delta W_{\mathrm{new}}\) is work that becomes feasible because the agentic system lowers cost, latency, or coordination burden.
-
Better AI models enable more ambitious work is relevant because it describes a shift toward higher-complexity usage after stronger coding models become available.
-
-
Speeding up GPU kernels by 38% with a multi-agent system is relevant because it shows the economic value of agents on long-tail optimization problems that are valuable but expensive for scarce human experts to address manually.
Risks
-
The main risks are not limited to model hallucination. Multi-agent coding systems can fail through stale context, unsafe commands, misleading validation, duplicated work, excessive synchronization, brittle prompts, overconfident review comments, hidden integration debt, and silent environment mismatch.
-
These risks can be grouped as:
-
Model risk includes incorrect reasoning and unsupported claims. Context risk includes missing or stale repository information. Tool risk includes unreliable search, edits, or terminal output. Runtime risk includes unsafe execution or mismatched environments. Coordination risk includes duplicated work and merge conflicts. Evaluation risk includes false confidence from incomplete tests or weak metrics.
-
Continually improving our agent harness is relevant because it frames harness changes as measurable interventions that can introduce both improvements and regressions.
-
Implementing a secure sandbox for local agents is relevant because safety is a runtime property, not only a model-alignment property.
-
Towards self-driving codebases is relevant because it documents how coordination, integration, and throughput become dominant constraints at high agent counts.
Research
-
Several research directions remain central to the next generation of multi-agent coding systems.
-
First, agents need better long-horizon memory. Dynamic context discovery and searchable history are early steps, but agents still need mechanisms for preserving project intent, design rationale, unresolved tradeoffs, and cross-agent dependencies over days or weeks.
-
Second, agents need stronger verification. Unit tests, type checks, linters, benchmarks, review agents, static analysis, runtime traces, and human feedback should be combined into a layered validation system.
-
Third, agents need better coordination policies. The system must decide when to spawn agents, when to merge work, when to rebase, when to stop, when to ask for help, and when to discard a trajectory.
-
Fourth, agents need better task-specific models. A fast edit-application model, a codebase retriever, a review validator, a planner, and an optimization worker may each require different training data and evaluation signals.
-
ReAct by Yao et al. (2023) remains foundational because it connects reasoning with actions in an environment.
-
AutoGen by Wu et al. (2023) remains relevant because it formalizes multi-agent interaction patterns among agents, tools, and humans.
-
SWE-bench by Jimenez et al. (2023) remains important because repository-level issue resolution is closer to real software work than isolated code-generation tasks.
-
MetaGPT by Hong et al. (2023) remains relevant because role specialization and standardized procedures reduce ambiguity in multi-agent software workflows.
-
Toolformer by Schick et al. (2023) remains relevant because tool-use decisions are a core part of agent competence.
Key Takeaways
-
Build the harness as the control plane. The harness should manage tools, prompts, retrieval, state, safety, evaluation, and model-specific adaptation.
-
Train agents in the environments they will use. File edits, terminal commands, search, tests, and failure recovery should be part of the training distribution.
-
Keep context recoverable rather than always visible. Long logs, histories, tool schemas, and terminal sessions should be searchable external memory.
-
Separate planning from execution. Planners should preserve intent and dependencies, while workers should focus on bounded deliverables.
-
Prefer verification over confidence. Tests, benchmarks, type checks, review agents, and runtime evidence should ground agent claims.
-
Optimize for net useful work. Agent count, token volume, and commit count are secondary to retained, validated, maintainable code.
-
Treat safety as a systems property. Sandboxing, permission boundaries, credential handling, audit logs, and human escalation should be part of the runtime.
-
Measure each subsystem by its own outcome. Retrieval should improve useful context, editing should improve fast and correct application, review should improve resolved findings, optimization should improve valid benchmark performance, and orchestration should improve merged progress.
-
The central lesson is that multi-agentic coding is not a single model capability. It is an integrated software system in which models, harnesses, retrieval, tools, runtime environments, evaluation, and human feedback co-evolve into a new development workflow.
Model Context Protocol (MCP)
Overview
-
The Model Context Protocol (MCP) is an open protocol designed to standardize how applications provide context to LLMs. Think of MCP as the AI equivalent of a USB-C port: just as USB-C creates a standardized way for devices to connect with various peripherals, MCP provides a uniform approach to integrating AI models with different data sources and tools.
-
The following figure (source) illustrates MCP’s client-server architecture: A standardized bridge connecting AI applications with local and remote data sources akin to how a USB-C port enables seamless connectivity between multiple peripherals without requiring separate adapters.
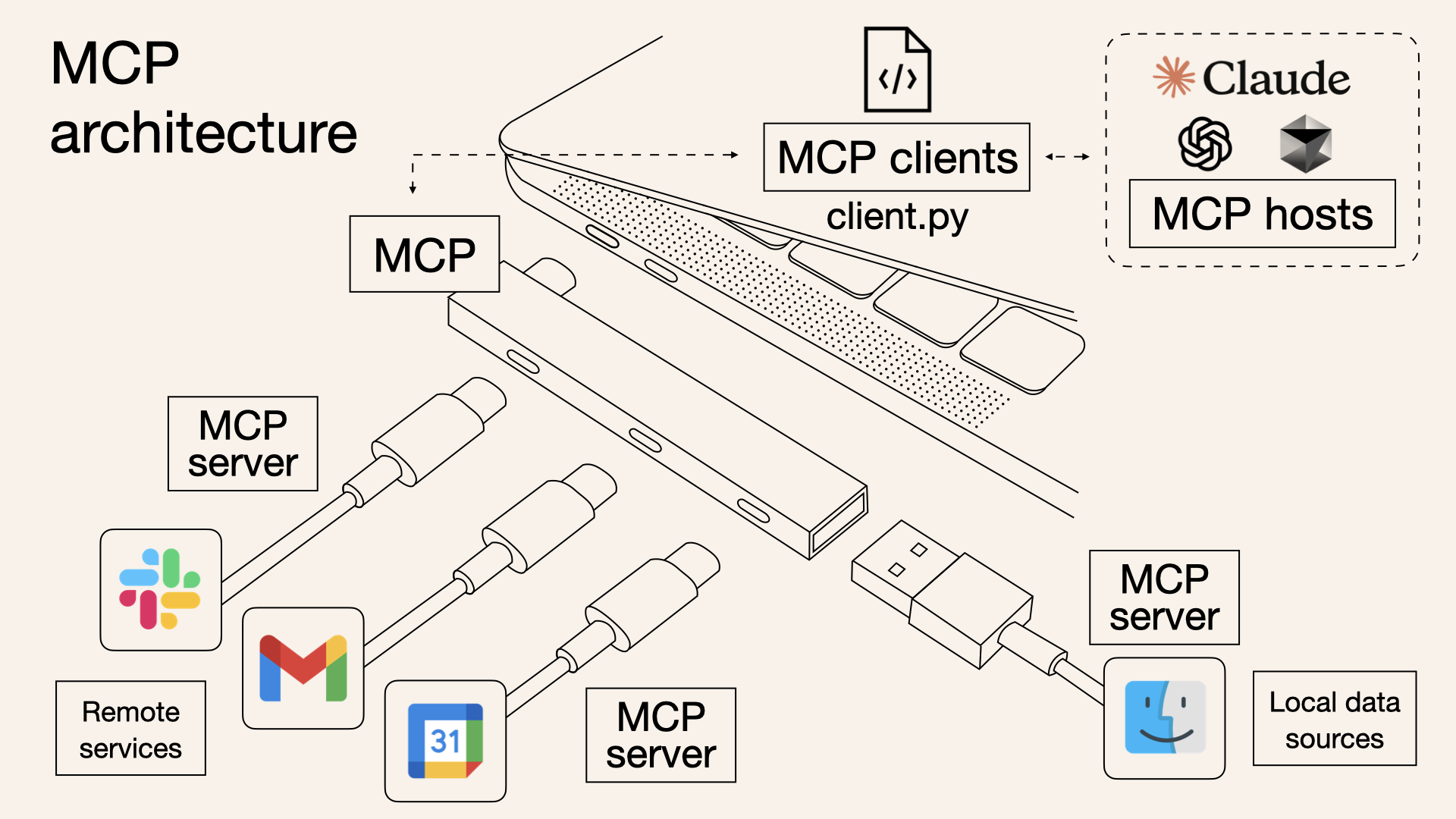
-
MCP has rapidly become the de facto standard for integrating LLMs with external tools and data sources. Its AI-native approach, strong industry backing, and pragmatic design choices have positioned it as the most viable open protocol for agent-based applications. As adoption continues to grow, MCP is likely to overtake existing standards like OpenAPI, solidifying its role in the future of AI-powered workflows.
-
The following figure (source) contrasts LLM tool integrations before and after MCP, highlighting how MCP simplifies interactions through a unified API layer.

Why MCP?
- MCP is essential for building AI-powered agents and complex workflows. LLMs often need access to external data and tools, and MCP facilitates this by offering:
- A growing library of pre-built integrations that LLMs can seamlessly interact with.
- Flexibility to switch between different LLM providers and vendors without reconfiguring integrations.
- Best practices for securing data while keeping it within a controlled infrastructure.
- Beyond these practical advantages, MCP has also emerged as the dominant open standard for AI agent integrations due to several key factors:
- MCP is an AI-Native adaptation of an existing idea: Unlike older interoperability standards such as OpenAPI, OData, and GraphQL, MCP was built specifically for LLM-based applications, making it more effective in AI-driven workflows.
- MCP is backed by a major player (Anthropic): Large organizations supporting a protocol significantly boost its chances of success, and Anthropic’s involvement has given MCP a strong foundation.
- Anthropic has a strong developer AI brand: The company’s focus on high-quality developer tooling has positioned MCP as the leading choice among AI engineers and application developers.
- MCP is built on the Language Server Protocol (LSP): By leveraging an already successful and widely adopted architecture, MCP avoids the pitfalls of entirely new protocol designs and benefits from proven best practices.
- MCP was dogfooded with complete tooling: From its launch, MCP was tested and refined with first-party clients like Claude Desktop, 19 reference server implementations, and essential development tools such as MCP Inspector and SDKs in Python and TypeScript.
General Architecture
- At its core, MCP follows a client-server architecture, enabling a host application to connect to multiple MCP servers. Below is an overview of the key components:
- MCP Hosts: Programs such as Claude Desktop, IDEs, and AI tools that need to access data through MCP.
- MCP Clients: Protocol clients that maintain one-to-one connections with MCP servers.
- MCP Servers: Lightweight programs that expose specific capabilities using the standardized MCP framework.
- Local Data Sources: Files, databases, and services on a user’s computer that MCP servers can securely access.
- Remote Services: External systems, such as APIs, that MCP servers can connect to over the internet.
- Client Example Using Python: The following code snippet (source) shows how to create a basic MCP client that initializes a session, lists available tools, and calls one of the server’s tools using standard I/O transport.
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
server_params = StdioServerParameters(
command="python", args=["example_server.py"]
)
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
await session.initialize()
tools = await session.list_tools()
result = await session.call_tool("tool-name", arguments={"arg1": "value"})
- Server Example Using FastMCP (Python): The following code snippet (source) illustrates how to create a simple MCP server using FastMCP, which exposes a tool, a data resource, and a reusable prompt template.
from fastmcp import FastMCP
mcp = FastMCP("Demo")
@mcp.tool()
def add(a: int, b: int) -> int:
return a + b
@mcp.resource("greeting://{name}")
def get_greeting(name: str) -> str:
return f"Hello, {name}!"
@mcp.prompt()
def review_code(code: str) -> str:
return f"Please review this code:\n\n{code}"
How MCP Works
- The following figure (source) provides an animated overview of the MCP Flow.
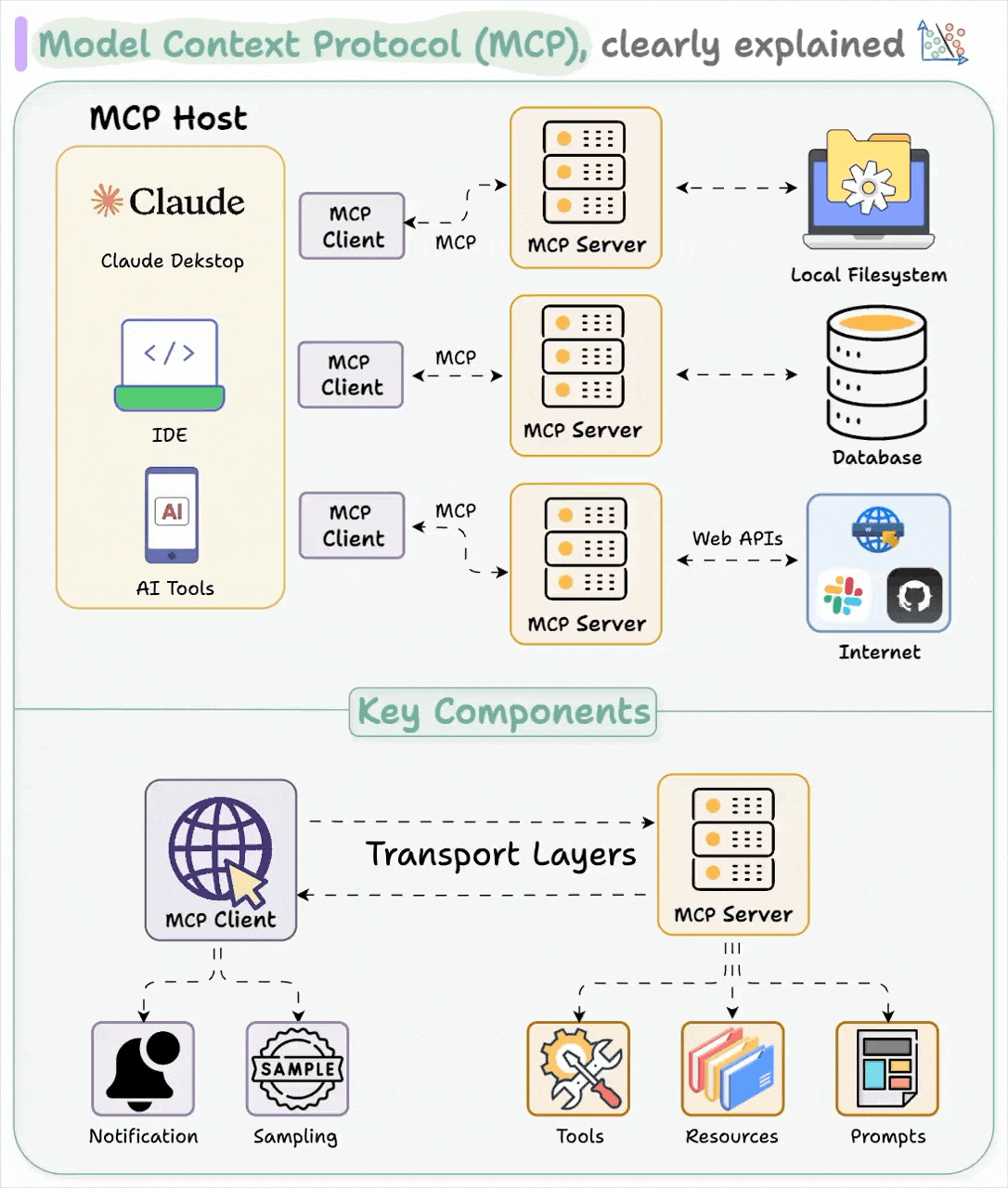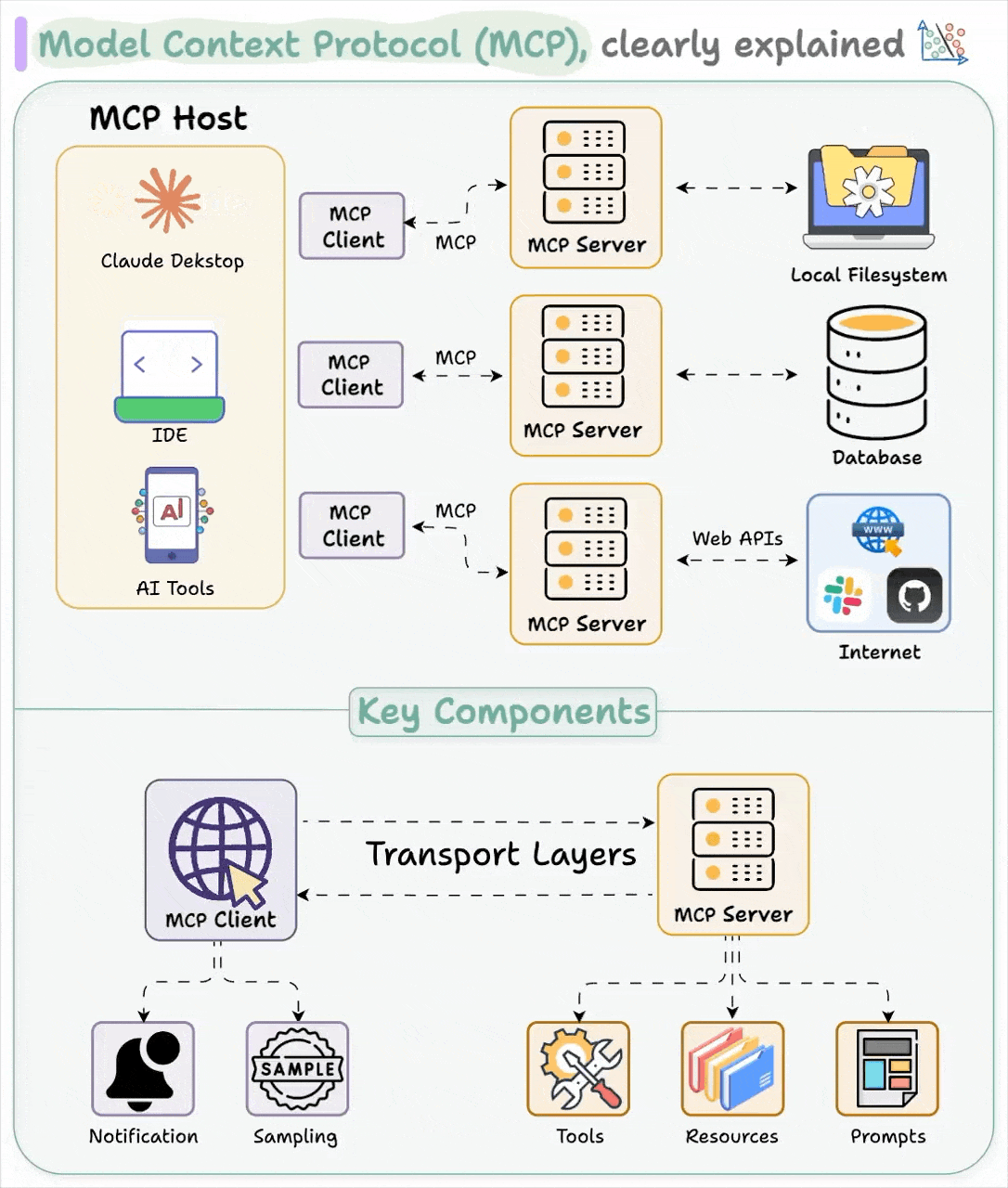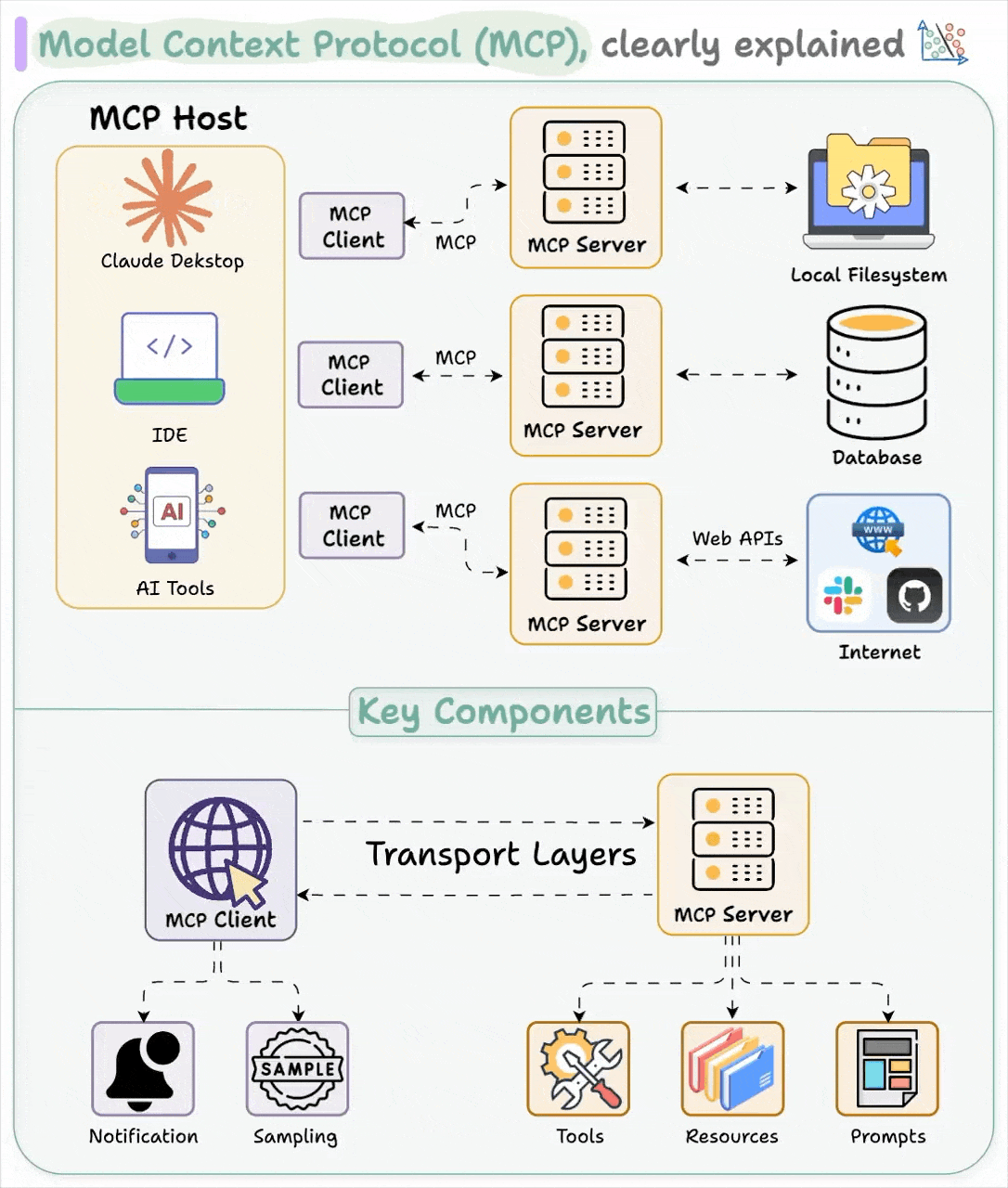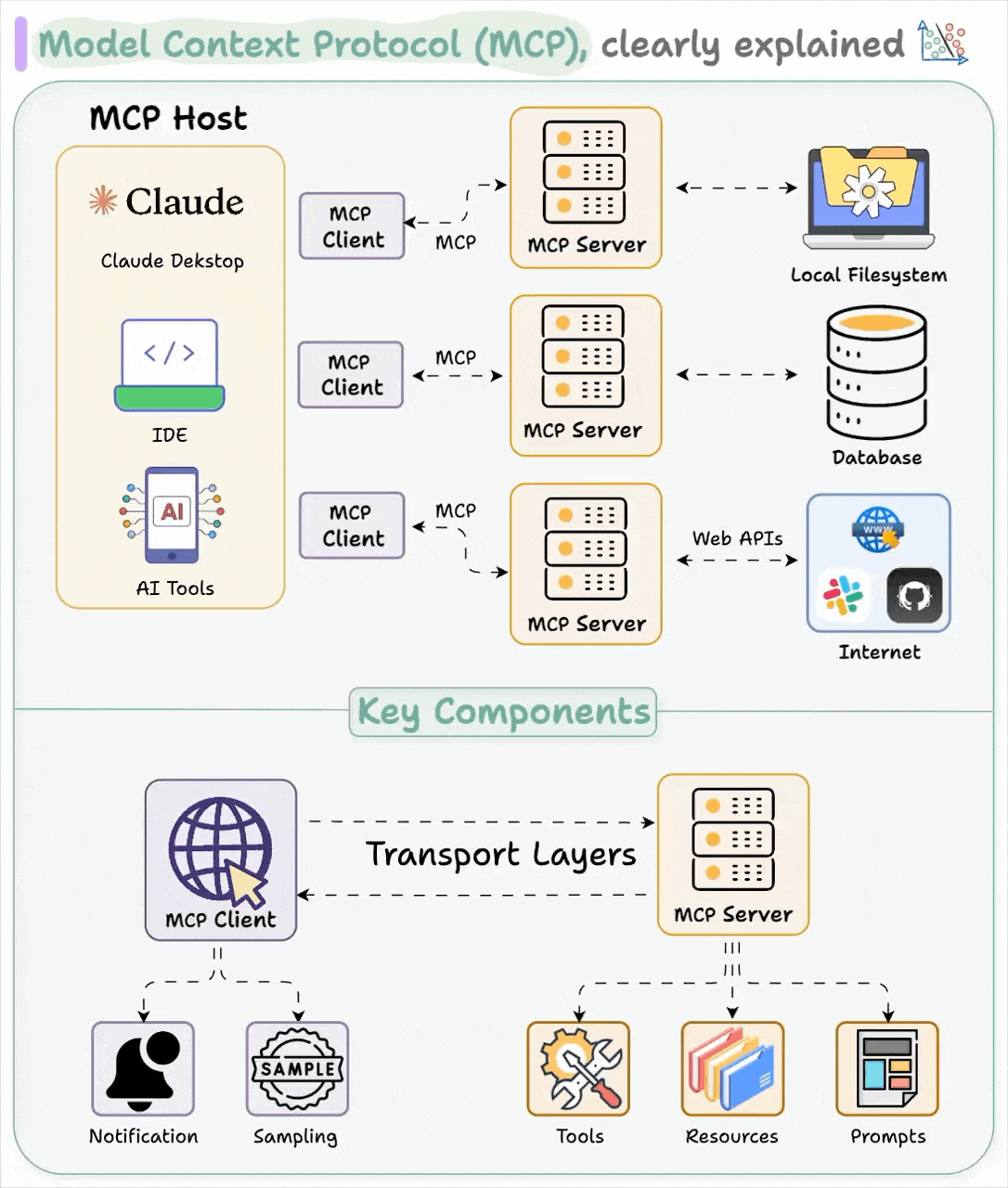
- MCP operates through a structured client-server interaction that involves capability exchange and bidirectional communication:
- Capability Exchange: The MCP client initializes a request to the server to learn about its available capabilities.
- Server Response: The server provides details about its available tools, resources, and prompts.
- Notification & Acknowledgment: The client acknowledges the connection and facilitates further communication.
- The following figure (source) the division of responsibilities between the MCP client and server, along with examples of Tools, Resources, and Prompts.

- Unlike traditional APIs, MCP communication is two-way, allowing:
- Servers to leverage client-side AI capabilities (such as LLM-based completions) without requiring API keys.
- Clients to maintain control over model access and permissions while enabling interoperability with various services.
- Practical Example with Gemini + MCP Client: The following code snippet (source) shows how an AI model like Gemini can dynamically discover available MCP tools and send function calls, making tool invocation seamless within natural language interactions.
from google import genai
from google.genai import types
# Assume session is an initialized MCP ClientSession
mcp_tools = await session.list_tools()
tools = types.Tool(function_declarations=[
{
"name": tool.name,
"description": tool.description,
"parameters": tool.inputSchema,
}
for tool in mcp_tools.tools
])
# Send tool schema to Gemini model
response = await client.aio.models.generate_content(
model="gemini-2.0-flash",
contents=[types.Content(role="user", parts=[types.Part(text="Show me available Airbnb listings in Paris.")])],
config=types.GenerateContentConfig(tools=[tools])
)
- Practical Example with Gemini and Python uSDK: The following end-to-end implementation (source) demonstrates an AI agent loop that connects to an MCP server via stdio, retrieves tool specs, sends them to Gemini 2.0 Flash, handles function calls from the model, and completes the interaction using the Google Python SDK.
from typing import List
from google import genai
from google.genai import types
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
import os
client = genai.Client(api_key=os.getenv("GEMINI_API_KEY"))
model = "gemini-2.0-flash"
server_params = StdioServerParameters(
command="npx",
args=["-y", "@openbnb/mcp-server-airbnb"],
env=None,
)
async def agent_loop(prompt: str, client: genai.Client, session: ClientSession):
contents = [types.Content(role="user", parts=[types.Part(text=prompt)])]
await session.initialize()
mcp_tools = await session.list_tools()
tools = types.Tool(function_declarations=[
{
"name": tool.name,
"description": tool.description,
"parameters": tool.inputSchema,
}
for tool in mcp_tools.tools
])
response = await client.aio.models.generate_content(
model=model,
contents=contents,
config=types.GenerateContentConfig(
temperature=0,
tools=[tools],
),
)
contents.append(response.candidates[0].content)
turn_count = 0
max_tool_turns = 5
while response.function_calls and turn_count < max_tool_turns:
turn_count += 1
tool_response_parts: List[types.Part] = []
for fc_part in response.function_calls:
tool_name = fc_part.name
args = fc_part.args or {}
try:
tool_result = await session.call_tool(tool_name, args)
if tool_result.isError:
tool_response = {"error": tool_result.content[0].text}
else:
tool_response = {"result": tool_result.content[0].text}
except Exception as e:
tool_response = {"error": f"Tool execution failed: {type(e).__name__}: {e}"}
tool_response_parts.append(
types.Part.from_function_response(
name=tool_name, response=tool_response
)
)
contents.append(types.Content(role="user", parts=tool_response_parts))
response = await client.aio.models.generate_content(
model=model,
contents=contents,
config=types.GenerateContentConfig(
temperature=1.0,
tools=[tools],
),
)
contents.append(response.candidates[0].content)
return response
async def run():
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
prompt = "I want to book an apartment in Paris for 2 nights. 03/28 - 03/30"
res = await agent_loop(prompt, client, session)
return res
res = await run()
print(res.text)
MCP vs. API
-
Single Protocol: Traditional APIs require distinct authentication and integration for each service, akin to managing multiple keys for different locks. This approach increases complexity, maintenance overhead, and integration effort for developers. MCP acts as a standardized “connector,” meaning integrating one MCP provides potential access to multiple tools and services.
-
The following figure (source) illustrates how traditional APIs require separate integrations for each tool, whereas MCP provides a unified, standardized connection for seamless interoperability.
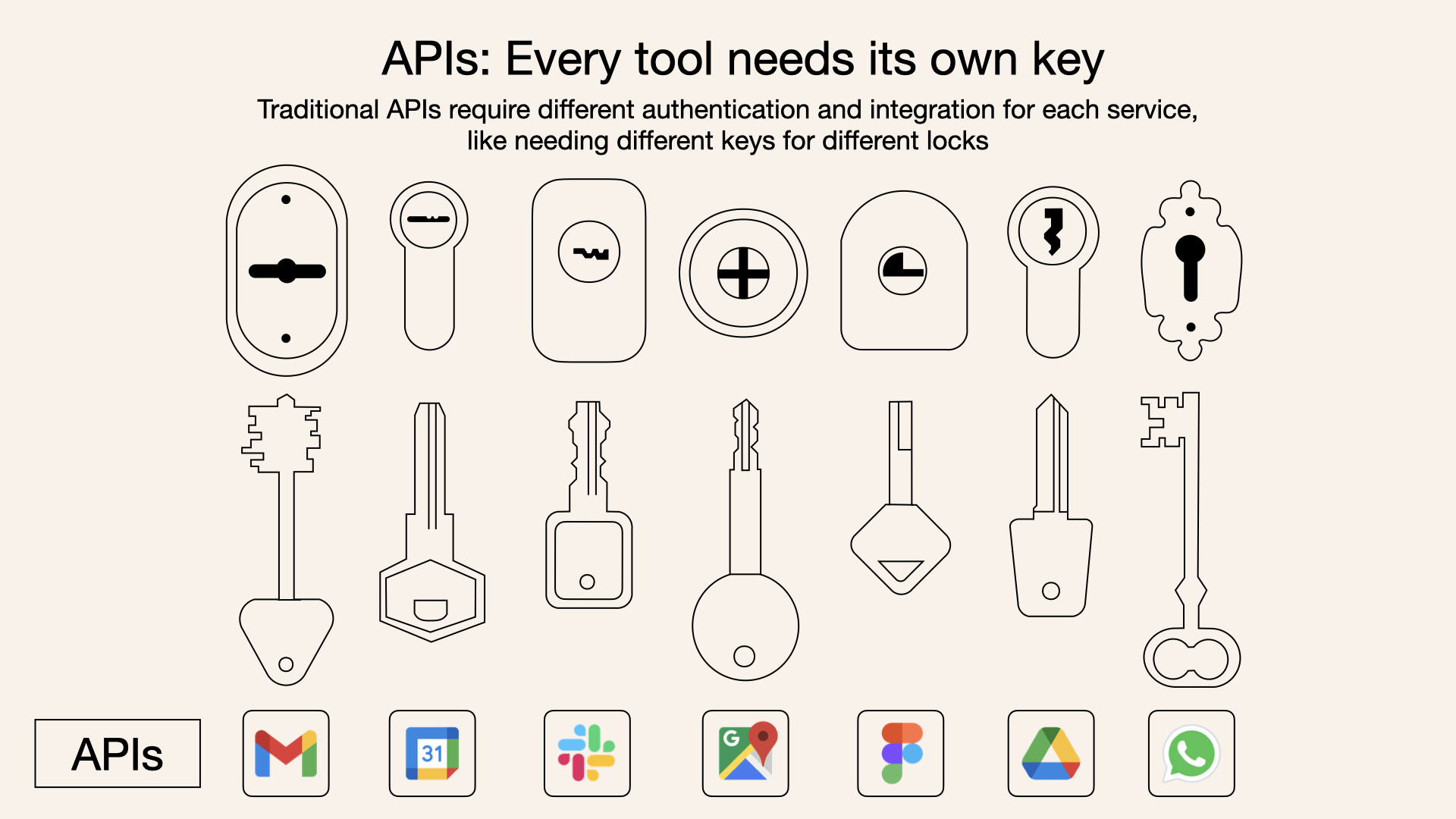
- Dynamic Discovery: MCP allows AI models to dynamically discover and interact with available tools without requiring hard-coded knowledge of each integration.
- Two-Way Communication: MCP supports persistent, real-time two-way communication, similar to WebSockets. The AI model can both retrieve information and trigger actions dynamically.
Comparative Analysis
| Feature | MCP | Traditional API |
|---|---|---|
| Integration Effort | Single, standardized integration | Separate integration per API |
| Real-Time Communication | ✅ Yes | ❌ No |
| Dynamic Discovery | ✅ Yes | ❌ No |
| Scalability | Easy (plug-and-play) | Requires additional integrations |
| Security & Control | Consistent across tools | Varies by API |
| Two-Way Communication | ✅ Yes | ❌ No |
When to Use MCP vs. Traditional APIs
- Use MCP when:
- You need flexible, AI-native integration with multiple tools and data sources.
- Your AI model benefits from real-time capability discovery.
- You want a scalable, standardized way to manage AI interactions.
- Stick with traditional APIs when:
- Your use case requires precise, deterministic behavior with strict limits.
- You need maximum predictability with minimal context autonomy.
- Fine-grained control over interactions is essential.
Security, Updates, and Authentication
- MCP is a living protocol, actively evolving. Key updates include:
- OAuth 2.1 Authentication: The protocol mandates OAuth 2.1 for secure HTTP server authentication.
- Transport Upgrades: A shift from SSE to Streamable HTTP improves efficiency and enables JSON-RPC batching.
- Richer Tool Metadata: Tools now support annotations such as side-effect classification (read-only vs. write operations), helping AI reason better about tool usage.
Getting Started with MCP: High-Level Steps
-
Integrating MCP into an AI-driven workflow involves several key steps:
- Define Capabilities: Clearly outline what your MCP server will offer, including available tools, data sources, and functionalities.
- Implement MCP Layer: Develop the MCP integration layer by adhering to the standardized MCP protocol specifications to ensure seamless interoperability.
- Choose Transport Method: Decide on the communication method between MCP clients and servers, using either local transport (stdio) or remote transport (Server-Sent Events/WebSockets) based on your requirements.
- Create Resources and Tools: Develop the specific data sources, services, and functionalities that your MCP server will expose for AI-driven applications.
- Set Up Clients: Establish secure and stable connections between MCP servers and clients, ensuring smooth data exchange and integration with AI agents.
-
By following these steps, developers can create powerful, flexible, and AI-enhanced systems that leverage MCP for dynamic and intelligent interactions with external tools and data sources.
Use-Cases of MCP in Real-World Development Scenarios
- Per this Reddit post, MCP is particularly powerful in software development workflows, where engineers often juggle multiple tasks beyond just writing code. From ticket retrieval to automated commits and intelligent pull request creation, MCP eliminates the friction of routine development tasks, allowing engineers to focus on coding rather than administrative overhead.
- In subsequent sections, we detail how MCP streamlines the entire development lifecycle.
Automating Feature Development from Ticket to Implementation
- When starting a new feature, developers typically need to reference multiple sources—project management tools for assigned tickets, design files for UI specifications, and documentation for technical requirements. MCP simplifies this process by:
- Fetching currently assigned tickets from Jira, GitHub Issues, or Linear, automatically understanding which ticket is being worked on.
- Extracting relevant requirements from the ticket without manual searching.
- Retrieving design specifications from Figma, analyzing images and text descriptions to provide necessary dimensions, fonts, and layouts.
- Allowing an AI-powered coding assistant like Cursor to immediately start implementing the feature based on all retrieved inputs.
Intelligent Ticket and Task Management
- During implementation, developers often discover inconsistencies or missing details in tickets. Instead of manually updating them, MCP-enabled servers allow:
- Cursor to update tickets dynamically, correct issues, and create new subtasks when necessary.
- Auto-detection of missing requirements and automatic messaging to the ticket’s author for clarifications.
- Seamless linking of related issues and tasks across different project management systems.
Automated Communication with Relevant Stakeholders
- If questions arise about the ticket or design, MCP servers determine the relevant author (e.g., a designer or product manager) and send automated messages via Slack or other communication tools. This eliminates delays caused by manually tracking down stakeholders.
Smart Staging, Commit Messages, and PR Creation
- Once development is complete, MCP enhances the process of committing code and opening pull requests by:
- Staging all modified files and generating an intelligent commit message based on the staged changes.
- Creating a pull request on platforms like GitHub or GitLab, automatically linking it to the corresponding Jira ticket.
- Adding necessary labels, titles, and descriptions to the PR, ensuring proper documentation without manual intervention.
Automated Debugging and Console Log Access
- Developers frequently encounter errors while testing their implementations in a browser. MCP can:
- Grant AI assistants real-time access to console logs, so they can analyze issues without requiring manual copy-pasting.
- Provide automated suggestions or fixes based on detected errors.
- Iterate on solutions in the background, accelerating the debugging process.
Integration with Personal Task Management Tools
- Many developers maintain personal to-do lists to track daily tasks. MCP allows seamless synchronization between personal task managers and project tracking tools:
- A local to-do app can be MCP-enabled, automatically pulling relevant tickets and work items.
- Developers can use natural language to prioritize tasks, delegate them, or get reminders.
Automated Project Announcements
- After completing a feature, developers often need to announce it to the team. MCP can:
- Automatically draft and send announcements in Slack, summarizing the completed work.
- Include links to the PR, Jira ticket, and relevant documentation.
- Ensure communication is structured, timely, and contains all necessary context.
MCP Servers List
- A curated list of ready-to-use and community-maintained servers:
Awesome MCP Servers
- A curated list of MCP servers that enable AI models to securely interact with local and remote resources through standardized implementations.
Model Context Protocol Servers
- A collection of reference implementations for the Model Context Protocol (MCP), showcasing how Large Language Models (LLMs) can securely access tools and data sources.
Composio MCP Servers
- Composio offers over 100 fully managed MCP server implementations with built-in authentication, facilitating seamless integration of AI agents and LLMs with various tools and services.
Smithery
- Smithery is a platform to help developers find and ship agentic services that follow the Model Context Protocols (MCP) specification.
- Smithery’s mission is to make agentic services accessible and accelerate the development of agentic AI.
Agent2Agent (A2A) Protocol
- Agent2Agent (A2A) is an open protocol introduced by Google to enable secure, interoperable communication between AI agents—regardless of their origin, framework, or vendor. Backed by contributions from over 50 leading technology and consulting partners, including Google Cloud, Atlassian, Salesforce, and Accenture, A2A establishes a universal mechanism for AI agents to discover one another, exchange information, and collaborate on tasks across diverse applications and platforms.
- Designed to break down the silos of traditional enterprise environments, A2A facilitates the creation of fluid, multi-agent ecosystems that support dynamic collaboration, long-running workflows, and rich user experiences. It empowers organizations to build intelligent, interoperable, and secure systems that span multiple enterprise platforms without requiring tight integration or risking vendor lock-in.
- At its core, A2A addresses a fundamental challenge in the evolution of agentic AI: enabling agents to interact across organizational and technological boundaries. Its open architecture promotes agent autonomy, enhances productivity, reduces duplication of effort, and fuels innovation in complex enterprise-grade environments.
-
A2A complements existing protocols like the Model Context Protocol (MCP)—which provides agents with external data and tool context—by enabling direct, structured, and semantically rich communication between agents themselves. Through A2A, agents can:
- Discover each other’s capabilities
- Manage long-running, collaborative tasks
- Exchange context and digital artifacts
- Negotiate outputs for user interfaces
- Built on familiar standards such as HTTP, Server-Sent Events (SSE), and JSON-RPC, the A2A protocol enforces robust security by default. Its open contribution model and growing industry adoption are laying the groundwork for a thriving ecosystem of intelligent, cooperative agents poised to transform enterprise automation at scale.
A2A Design Principles
-
The protocol’s architecture is grounded in five key principles:
- Embrace Agentic Capabilities
- A2A supports agents operating in unstructured, autonomous modes—even when agents do not share memory or toolsets. This enables robust, tool-agnostic agent collaboration that respects the diversity of agent implementations and modalities.
- Build on Existing Standards
- A2A leverages widely used, mature web technologies such as:
- HTTP for transport
- Server-Sent Events (SSE) for real-time messaging
- JSON-RPC for structured, language-agnostic function calls
- This alignment ensures compatibility with existing enterprise systems and lowers the barrier to adoption.
- A2A leverages widely used, mature web technologies such as:
- Secure by Default
- A2A supports enterprise-grade authentication and authorization protocols, achieving parity with OpenAPI authentication schemes (e.g., OAuth2, API keys, bearer tokens). This allows agents to authenticate both themselves and each other within secure, policy-governed environments.
- Support for Long-Running Tasks
- A2A is designed to support both ephemeral and extended workflows. Agents can initiate tasks that persist over hours or days, with real-time status updates, notifications, and progress messages shared throughout the lifecycle. This supports human-in-the-loop workflows, asynchronous task completion, and progressive state reporting.
- Modality Agnostic
- The protocol supports multiple modalities beyond text, including images, video, and audio. It accommodates multimodal data streams and user experiences by enabling agents to negotiate and exchange content in forms suited to downstream UI capabilities.
- Embrace Agentic Capabilities
How A2A Works
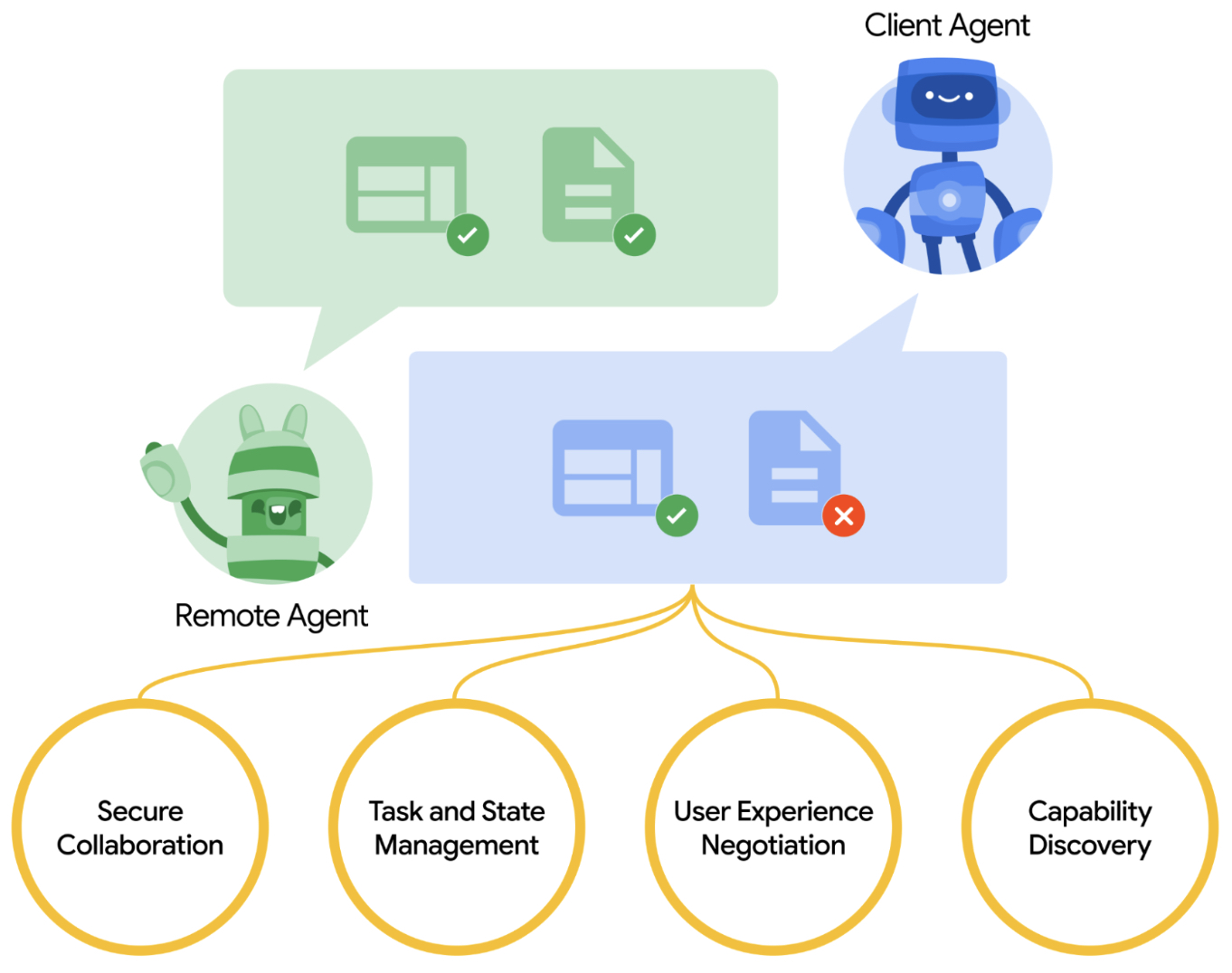
-
The illustration above (source) offers a visual overview of Agent2Agent communication and depicts the core dynamic between a client agent and a remote agent in an A2A-compliant system. It highlights the secure bidirectional exchange of structured tasks and content, and how mismatches or incompatibilities (like unsupported formats) are negotiated during collaboration.
-
A2A facilitates communication between two primary roles:
- Client Agent: Initiates the interaction, discovers the remote agent’s capabilities, and submits task requests.
- Remote Agent: Responds to the request, executes tasks, and delivers artifacts or messages back to the client.
-
This interaction is governed by four key capabilities:
- Secure Collaboration: All messages and artifacts exchanged are protected with enterprise-grade authentication and authorization mechanisms.
- Task and State Management: Tasks have lifecycle states and can be monitored or updated across long-running workflows.
- User Experience Negotiation: Agents can communicate about UI and modality expectations, ensuring compatibility across interfaces.
- Capability Discovery: Agents advertise their skills, tools, and modalities using Agent Cards, enabling intelligent routing of tasks.
Core Protocol Mechanics
Capability Discovery
- Every A2A-compliant agent publishes a JSON-based Agent Card, advertising its available capabilities, supported modalities, and service endpoints.
- This enables the client agent to:
- Programmatically discover agents relevant to a given task
- Select remote agents based on advertised functions, tools, or domain expertise
- Agent Cards may include metadata such as:
- Versioning info
- Contact or fallback methods
- Supported content types (e.g.,
text/plain,image/png,video/webm) - Trust level or authentication requirements
Task Management
- The core of the A2A interaction is the task object, a structured entity that captures:
- Task description and parameters
- Required capabilities or desired outputs
- Task lifecycle state (created, in-progress, completed, failed)
- Timestamps, identifiers, and optional user metadata
- Agents coordinate on task status updates through SSE or HTTP polling, ensuring synchronized task execution over long durations.
- Upon task completion, the remote agent emits one or more artifacts, which are structured outputs (e.g., a file, message, API call result).
Collaboration and Messaging
- Agents exchange context, interim results, clarifications, and feedback via message objects. These messages may contain:
- Plain or rich content (e.g., structured JSON, UI-renderable components)
- Contextual replies or updates (e.g., clarification requests, validation errors)
- User or agent instructions
- All messages are delivered using SSE or HTTP endpoints, ensuring timely delivery and minimal overhead.
User Experience (UX) Negotiation
- Each message can contain multiple parts, each with a specified content type.
- Example parts might include:
- A generated image (
image/png) - A previewable webpage (
text/html) - An embeddable iframe (
application/vnd.ui.iframe)
- A generated image (
- Client and remote agents negotiate these parts to align with UI capabilities of the requesting environment, ensuring that output is rendered in a format compatible with the user interface—whether it’s a chat window, dashboard, or mobile device.
Content Routing and Privacy
- A2A supports fine-grained control over which agents receive what content. This is essential for:
- Multi-agent task orchestration
- Privacy-preserving collaboration
- Compliance with enterprise data protection rules
- Payloads may be routed through secure proxies, or encrypted per agent-to-agent key exchange.
Real-World Scenario: Candidate Sourcing
- In a hiring workflow, a hiring manager tasks an agent to find suitable engineering candidates. This agent:
- Consults the job description and location
- Uses A2A to identify and query remote agents specialized in resume parsing, candidate databases, or social graph insights
- Aggregates candidate artifacts and presents them via a unified UI
- Further agents handle interview scheduling, background checks, or onboarding
- This coordinated agent ecosystem—built atop A2A—enables seamless, scalable execution of complex enterprise workflows, combining capabilities from multiple vendors and systems.
Implementation Architecture
-
A2A-compliant agents are typically composed of the following components:
- Agent Card Endpoint
GET /agent/card- Returns metadata about the agent, capabilities, and supported modalities
- Task Endpoint
POST /agent/tasks- Accepts new task requests from a client agent
- Task State Endpoint
GET /agent/tasks/{task_id}- Returns current status of a task (e.g., “in_progress”, “completed”)
- Artifact Retrieval Endpoint
GET /agent/tasks/{task_id}/artifact- Downloads final output(s) for the task
- Message Stream Endpoint
GET /agent/messages/stream- Uses SSE to deliver messages (contextual updates, feedback, etc.)
- Authentication
- OAuth 2.0 Bearer Tokens or API keys passed in headers
- Supports mutual TLS or signed requests for sensitive data exchange
- Agent Card Endpoint
Integration and Future Roadmap
- A2A is being released as open source, with contributions from major cloud vendors, enterprise software providers, and consulting firms.
- A full draft specification is available online, with example implementations using:
- Python and FastAPI
- Node.js and Express
- Langchain-based agents
- Development kits, validators, and sandbox agents are available to accelerate adoption and testing.
- A production-ready version of the protocol is scheduled for release later this year, with backward compatibility and feature expansion focused on:
- Peer discovery
- Intent routing
- Secure agent marketplaces
- UI auto-generation from message part schemas
Agentic Retrieval-Augmented Generation (RAG)
-
Agent-based Retrieval-Augmented Generation (RAG), or Agentic RAG, represents an advanced approach in AI that enhances the traditional RAG pipeline with intelligent agents. In conventional RAG systems, an AI model queries a knowledge base to retrieve relevant information and generate responses. However, Agentic RAG extends beyond this by employing AI agents capable of orchestrating multi-step retrieval processes, utilizing external tools, and dynamically adapting to the query. This added layer of autonomy enables advanced reasoning, decision-making, and adaptability, allowing the system to handle complex queries and diverse data sources with greater precision and responsiveness.
-
By integrating AI agents, Agentic RAG transforms traditional RAG, providing a flexible, intelligent solution for nuanced, real-world inquiries. This shift enables organizations to deploy AI systems with a higher degree of accuracy, flexibility, and intelligence, allowing them to tackle intricate tasks and deliver more precise results across a wide range of applications.
How Agentic RAG Works
-
In an agentic RAG system, AI agents play key roles in the retrieval process, using specialized tools to retrieve context-sensitive information. Unlike traditional RAG, where retrieval functions are static, agentic RAG allows dynamic selection and operation of tools based on query requirements. Retrieval agents may utilize tools such as:
- Vector Search Engines: Retrieve information from vectorized data in databases.
- Web Search Tools: Access live web data for up-to-date, contextually relevant information.
- Calculators: Perform computations for queries that require accurate calculation.
- APIs for Software Programs: Programmatically retrieve information from applications like email or chat programs to access user-specific data.
-
In the context of Agentic RAG, the retrieval process is “agentic,” meaning agents are capable of reasoning and decision-making regarding which sources and tools to use, based on the specific requirements of the query. This flexibility elevates their tool usage beyond simple retrieval, allowing for a more dynamic and adaptive response.
Agentic Decision-Making in Retrieval
-
The decision-making process of retrieval agents encompasses several key actions, including:
- Deciding Whether to Retrieve: Assessing if additional information is necessary for the query.
- Choosing the Appropriate Tool: Selecting the most suitable tool (e.g., a vector search engine or web search) based on the query.
- Query Formulation: Refining or rephrasing the query to enhance retrieval accuracy.
- Evaluating Retrieved Results: Reviewing the retrieved information to determine sufficiency, and whether further retrieval is needed.
Agentic RAG Architectures: Single-Agent vs. Multi-Agent Systems
- Agentic RAG can be implemented with a single agent or multiple agents, each offering unique strengths.
Single-Agent RAG (Router)
- The simplest implementation of agentic RAG involves a single agent functioning as a “router.” This agent determines the appropriate source or tool for retrieving information based on the query. The single agent toggles between different options, such as a vector database, web search, or an API. This setup provides a versatile retrieval process, enabling access to multiple data sources beyond a single vector search tool.
- As shown in the figure below (source), the single-Agent RAG system (router) architecture involves a single agent serving as a “router,” dynamically selecting the best tool or source based on the query, enabling efficient information retrieval across multiple data channels.
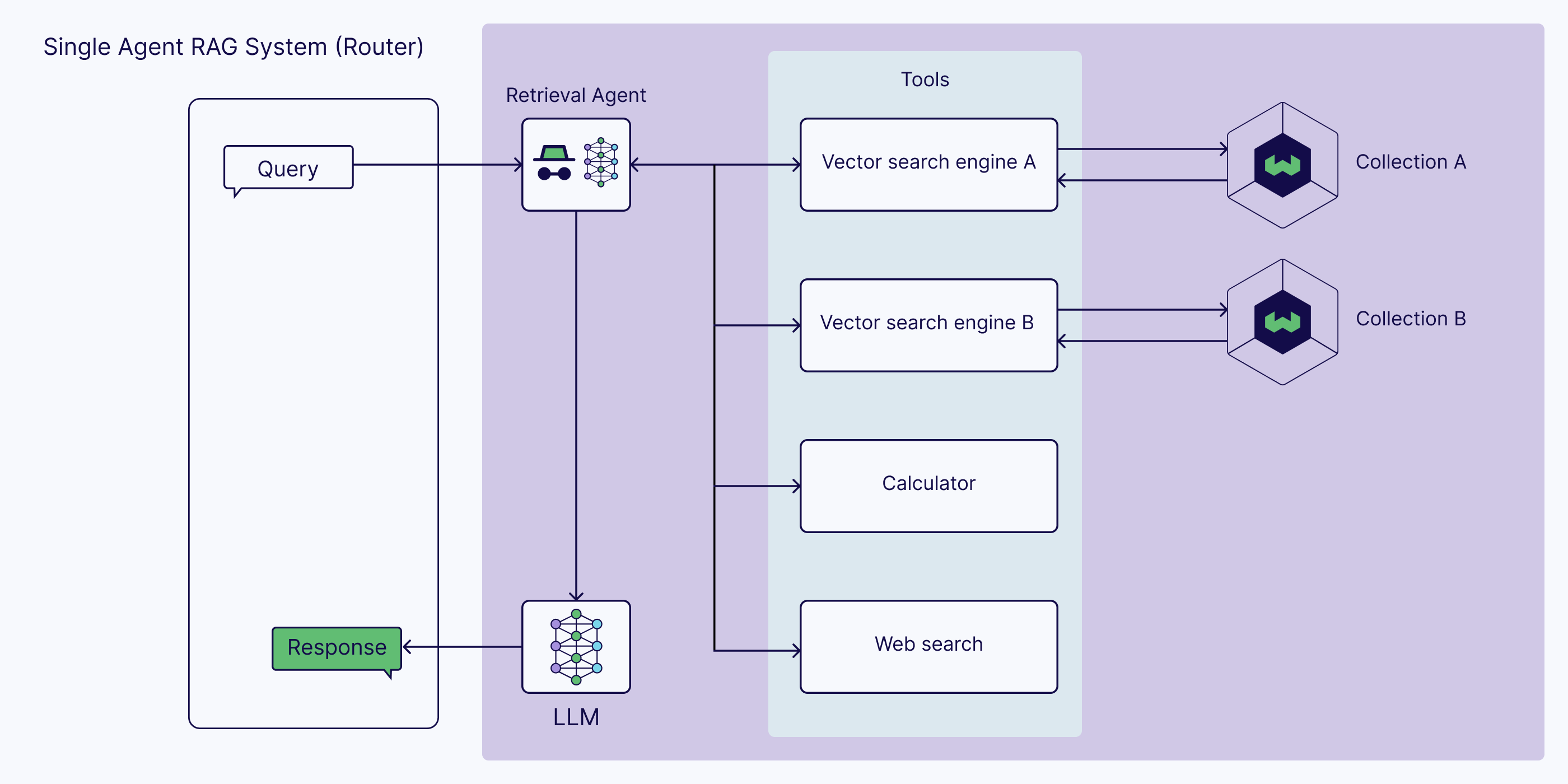
Multi-Agent RAG Systems
-
For more complex queries, multi-agent RAG systems provide additional flexibility. These systems feature a “master agent” that coordinates several specialized retrieval agents, such as:
- Internal Data Retrieval Agent: Retrieves information from proprietary, internal databases.
- Personal Data Retrieval Agent: Accesses user-specific information, such as emails or chat history.
- Public Data Retrieval Agent: Conducts web searches for up-to-date public information.
-
By utilizing multiple agents tailored to specific sources or tasks, multi-agent RAG systems can deliver comprehensive, accurate responses across diverse channels.
-
As shown in the figure below (source), the multi-agent RAG system architecture utilizes multiple specialized retrieval agents to access different sources and tools, offering a flexible and comprehensive approach to complex queries.
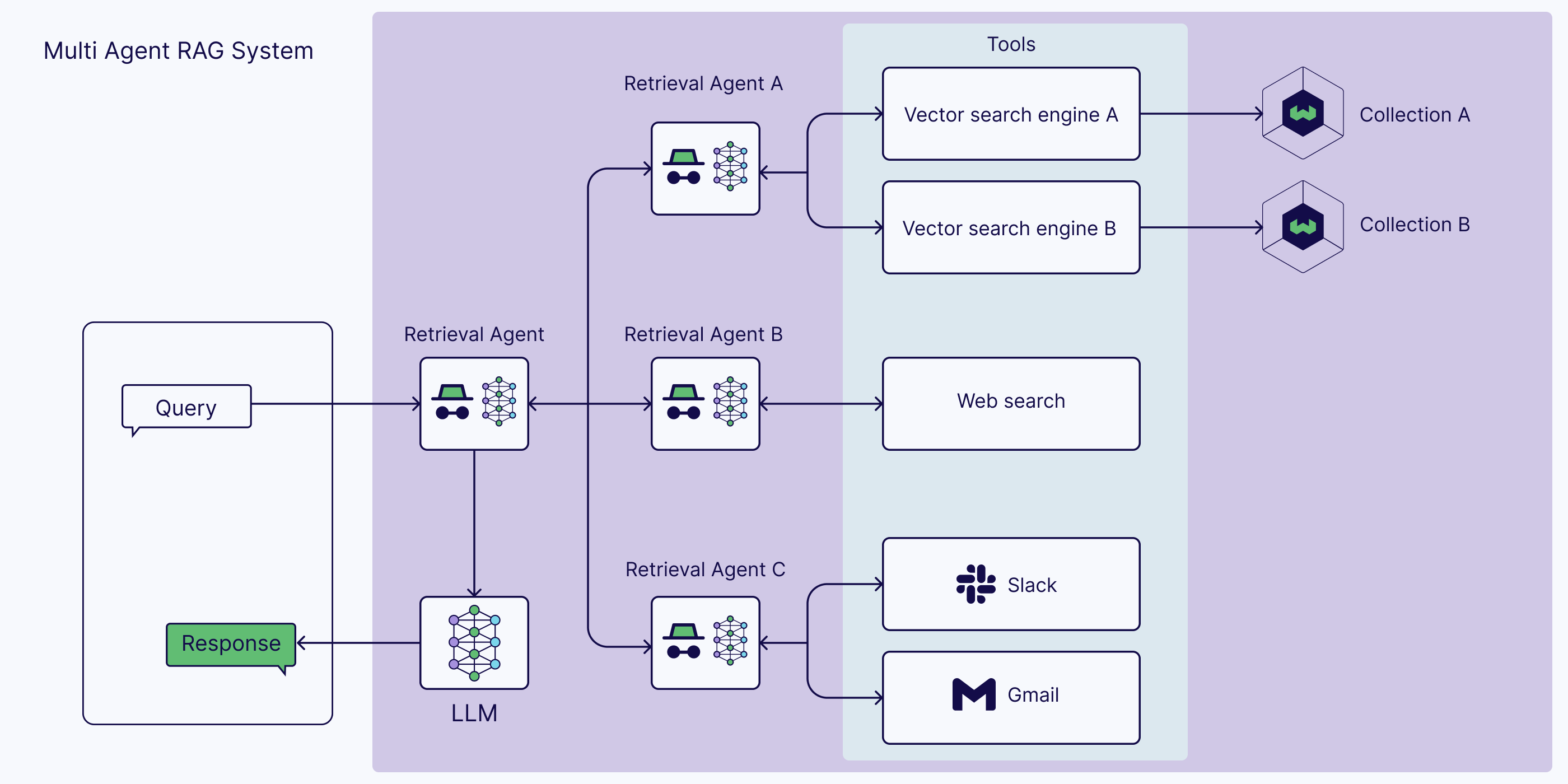
Beyond Retrieval: Expanding Agentic RAG’s Capabilities
-
Agentic RAG systems can incorporate agents for tasks beyond retrieval, including:
- Validating Information: Cross-referencing data across sources to ensure accuracy.
- Performing Multi-step Reasoning: Following logical steps to address complex queries before generating responses.
- Updating System Memory: Tracking and retaining user-specific preferences or past queries, enabling personalized and context-aware responses.
-
By expanding its capabilities beyond simple retrieval, Agentic RAG delivers a powerful, context-sensitive AI solution capable of handling intricate, real-world applications.
Agentic RAG vs. Vanilla RAG: Key Differences
- While both vanilla and agentic RAG systems aim to retrieve information and generate responses, agentic RAG introduces several significant enhancements:
| Feature | Vanilla RAG | Agentic RAG |
|---|---|---|
| Access to External Tools | No | Yes – Utilizes external tools like vector search engines, web search tools, calculators, and APIs. |
| Query Pre-processing | No | Yes – Agents dynamically refine, rephrase, and adapt queries for optimized retrieval. |
| Decision-making in Retrieval | Limited to direct retrieval from knowledge base | Agents autonomously decide if retrieval is needed, select tools, and adapt based on query complexity and source type. |
| Multi-step Retrieval Process | No | Yes – Agents perform multi-step, adaptive retrieval processes involving various sources or tool combinations. |
| Data Validation | No | Yes – Information is cross-referenced across sources to validate accuracy, supporting complex, real-world responses. |
| Dynamic Tool Selection | Static retrieval tools only | Dynamic – Agents choose specific tools (e.g., vector search, APIs) based on query needs. |
| Adaptability to Query | Limited | Highly adaptive – Agents select and operate tools based on real-time assessment of query requirements. |
| Types of Agents | Not applicable | Multiple specialized agents, such as internal data retrieval, personal data retrieval, public data retrieval. |
| Single-Agent vs. Multi-Agent System | Not applicable | Single-agent router or multi-agent systems, with “master” and specialized agents for complex queries. |
| Reasoning and Logic Capability | No | Yes – Supports multi-step reasoning, allowing logical sequence handling before generating responses. |
| Memory and Personalization | Limited to immediate query | Yes – Capable of updating memory to retain user preferences or history, allowing personalized responses. |
| Real-world Applications | Primarily static responses from a fixed database | Supports a wide range of real-world applications by responding to complex, nuanced inquiries with context sensitivity. |
- Drawing a parallel with problem-solving, agentic RAG offers capabilities akin to having a smartphone in hand—equipped with multiple apps and tools to help answer a question—whereas vanilla RAG is akin to being in a library with limited resources.
Implementing Agentic RAG: Key Approaches
- To implement agentic RAG, developers can use either language models with function calling or agent frameworks, each providing specific advantages in terms of flexibility and control.
- Both methods—function calling in language models and agent frameworks—enable agentic RAG, though each has unique benefits:
- Function Calling provides control over each tool interaction, suitable for cases with specific tool chains or simple agent setups.
- Agent Frameworks offer pre-built integrations and routing logic, ideal for larger, multi-agent architectures.
- Using these implementations, developers can build flexible and adaptive agentic RAG pipelines, enhancing retrieval, reasoning, and response generation capabilities for AI-driven applications.
Language Models with Function Calling
- Function calling allows language models to interact directly with external tools. For example, OpenAI’s function calling for GPT-4 or Cohere’s connectors API lets developers connect language models to databases, calculators, and other services. This interaction involves defining a function (such as querying a database), passing it to the model via a schema, and routing the model’s queries through the defined functions. This approach enables the model to leverage specific tools as needed, based on the query.
Agent Frameworks
- Several agent frameworks—such as LangChain, LlamaIndex, CrewAI—simplify agentic RAG implementation by providing pre-built templates and tool integrations. Key features include:
- LangChain: Offers support for language model tools, and its LCEL and LangGraph frameworks integrate these tools seamlessly.
- LlamaIndex: Provides a QueryEngineTool to streamline retrieval tasks.
- CrewAI: A leading framework for multi-agent setups, which supports shared tool access among agents.
Enterprise-driven Adoption
- Organizations are increasingly transitioning to agentic RAG to gain more autonomous and accurate AI-driven systems. Enterprises such as Microsoft and Replit have introduced agents to enhance task completion and software development assistance. With agentic RAG, companies can build AI applications capable of handling diverse, real-time data sources, providing robust and adaptable responses for complex queries and tasks.
Benefits
- The primary benefits of agentic RAG include:
- Enhanced Retrieval Accuracy: By routing queries through specialized agents, agentic RAG can provide more accurate responses.
- Autonomous Task Performance: Agents can perform multi-step reasoning, independently solving complex problems.
- Improved Collaboration: These systems can better assist users by handling more varied and personalized queries.
Limitations
- Agentic RAG does present challenges, such as:
- Increased Latency: Running multiple agents and interacting with tools can add delays to the response.
- Reliability of Agents: Depending on the LLM’s reasoning capabilities, agents may fail to complete certain tasks accurately.
- Complexity in Error Handling: Systems need robust fallback mechanisms to recover if an agent fails to retrieve or process data.
Code
- Implementing agentic RAG requires setting up an agent framework capable of handling tool integrations and coordinating retrieval processes. This section walks through an example code setup, demonstrating both language models with function calling and agent frameworks for building an agentic RAG pipeline.
Implementing Agentic RAG with Function Calling
-
Function calling in language models allows them to interact with tools by defining functions that retrieve data from external sources. This method leverages API calls, database queries, and computation tools to enrich the response with dynamic data.
-
Here’s an example implementation using a function for retrieval from a database via the Weaviate vector search API.
Define the Function for Retrieval
- To start, we define a function that uses Weaviate’s hybrid search to query a database and retrieve relevant results.
def get_search_results(query: str) -> str:
"""Sends a query to Weaviate's Hybrid Search. Parses the response into a formatted string."""
response = blogs.query.hybrid(query, limit=5) # Retrieve top 5 results based on the query
stringified_response = ""
for idx, o in enumerate(response.objects):
stringified_response += f"Search Result {idx+1}:\n"
for prop in o.properties:
stringified_response += f"{prop}: {o.properties[prop]}\n"
stringified_response += "\n"
return stringified_response
Define the Tools Schema
- Next, we define a tools schema that connects the function to the language model. This schema tells the model how to use the function for retrieving data.
tools_schema = [{
'type': 'function',
'function': {
'name': 'get_search_results',
'description': 'Get search results for a provided query.',
'parameters': {
'type': 'object',
'properties': {
'query': {
'type': 'string',
'description': 'The search query.',
},
},
'required': ['query'],
},
},
}]
Setting Up the Interaction Loop
- To ensure the model can call the tool multiple times (if needed), we set up a loop that enables the model to interact with tools and retrieve data iteratively until it has all necessary information.
def ollama_generation_with_tools(user_message: str, tools_schema: list, tool_mapping: dict, model_name: str = "llama3.1") -> str:
messages = [{"role": "user", "content": user_message}]
response = ollama.chat(model=model_name, messages=messages, tools=tools_schema)
# Check if the model needs to use a tool
if not response["message"].get("tool_calls"):
return response["message"]["content"]
# Handle tool calls and retrieve information
for tool in response["message"]["tool_calls"]:
function_to_call = tool_mapping[tool["function"]["name"]]
function_response = function_to_call(tool["function"]["arguments"]["query"])
messages.append({"role": "tool", "content": function_response})
# Generate final response after tool calls
final_response = ollama.chat(model=model_name, messages=messages)
return final_response["message"]["content"]
Executing the Agentic RAG Query
- Finally, we run the function, allowing the language model to interact with the
get_search_resultstool.
tool_mapping = {"get_search_results": get_search_results} # Maps tool name to function
response = ollama_generation_with_tools(
"How is HNSW different from DiskANN?",
tools_schema=tools_schema,
tool_mapping=tool_mapping
)
print(response)
- This setup enables the language model to retrieve dynamic information and perform tool-based retrievals as needed.
Implementing Agentic RAG with Agent Frameworks
- Using agent frameworks streamlines the implementation process by providing templates and pre-built modules for multi-agent orchestration. Here’s how to set up an agentic RAG pipeline using LangChain as an example.
Step 1: Define Agents and Tools
- LangChain simplifies agentic RAG by managing tools and routing tasks. First, define the agents and register the tools they will use.
from langchain.tools import WebSearchTool, DatabaseTool, CalculatorTool
from langchain.agents import Agent
# Define tools for retrieval
web_search_tool = WebSearchTool(api_key="YOUR_WEB_SEARCH_API_KEY")
database_tool = DatabaseTool(db_client="your_database_client")
calculator_tool = CalculatorTool()
# Set up an agent with a routing function
retrieval_agent = Agent(
tools=[web_search_tool, database_tool, calculator_tool],
routing_function="retrieve_and_select_tool"
)
Step 2: Configure Agent Routing
- Set up the routing function to let the agent decide which tool to use based on the input query.
def retrieve_and_select_tool(query):
if "calculate" in query:
return calculator_tool
elif "web" in query:
return web_search_tool
else:
return database_tool
Step 3: Chain Agents for Multi-Agent RAG
- In multi-agent RAG, you might have a “master agent” that routes queries to specialized agents based on query type. Here’s how to set up a master agent to coordinate multiple agents.
from langchain.agents import MultiAgent
# Define specialized agents
internal_agent = Agent(tools=[database_tool], routing_function="database_retrieval")
public_agent = Agent(tools=[web_search_tool], routing_function="web_retrieval")
# Create a master agent to coordinate retrieval
master_agent = MultiAgent(agents=[internal_agent, public_agent])
# Function to handle a query using master agent
def handle_query_with_master_agent(query):
return master_agent.handle_query(query)
Running the Multi-Agent Query
- Finally, to test the system, input a query and let the master agent route it appropriately:
response = handle_query_with_master_agent("Find recent studies on neural networks")
print(response)
Disadvantages of Agentic RAG
-
Despite its advantages, agentic RAG comes with several limitations that should be carefully considered, particularly for time-sensitive applications:
-
Increased Latency: The inherent complexity of agentic RAG often translates to longer response times. Each query may require multiple tool interactions and sequential retrieval steps, which increase the latency significantly. This can hinder the system’s usability in environments where quick responses are crucial, such as real-time support systems or conversational interfaces.
-
Higher Computational Cost: Agentic RAG systems often involve multiple calls to LLMs and other external tools. These calls cumulatively drive up computational costs, making it less efficient and potentially prohibitive for high-traffic applications. This expense adds to operational concerns, especially if the system must process large volumes of queries.
-
Production Feasibility: Due to the latency and cost concerns, agentic RAG may not be ideal for production applications requiring rapid and continuous output. In such cases, vanilla RAG, which offers more direct and faster response generation, might be more suitable.
-
-
While these drawbacks limit agentic RAG’s use in certain scenarios, its capability to generate high-quality, well-researched responses can make it worthwhile in contexts where response time is less critical and information accuracy is paramount.
Summary
- Agentic RAG refers to an agent-based implementation of RAG. AI agents are entities tasked with accomplishing specific objectives. These agents are often equipped with memory and tools, which they can utilize to carry out their tasks effectively. Among these tools, one significant capability is the ability to retrieve information from various sources, such as web searches or internal documents.
- In the context of agentic RAG, the “retrieval becomes agentic.” This implies that the AI agent is capable of reasoning and making decisions regarding which sources are most appropriate for retrieving the required information. The agent’s tool usage evolves beyond simple information retrieval, becoming more flexible and dynamic.
- The distinction between standard and agentic RAG can be summarized as follows:
- Common RAG: The user input prompts a single call to a database, retrieving additional information in response to the query.
- Agentic RAG: The agent is able to deliberate on which source is the most suitable for retrieving information based on the query, providing a more sophisticated and adaptable approach.
- The following figure (source) offers a visual summary of Agentic RAG:
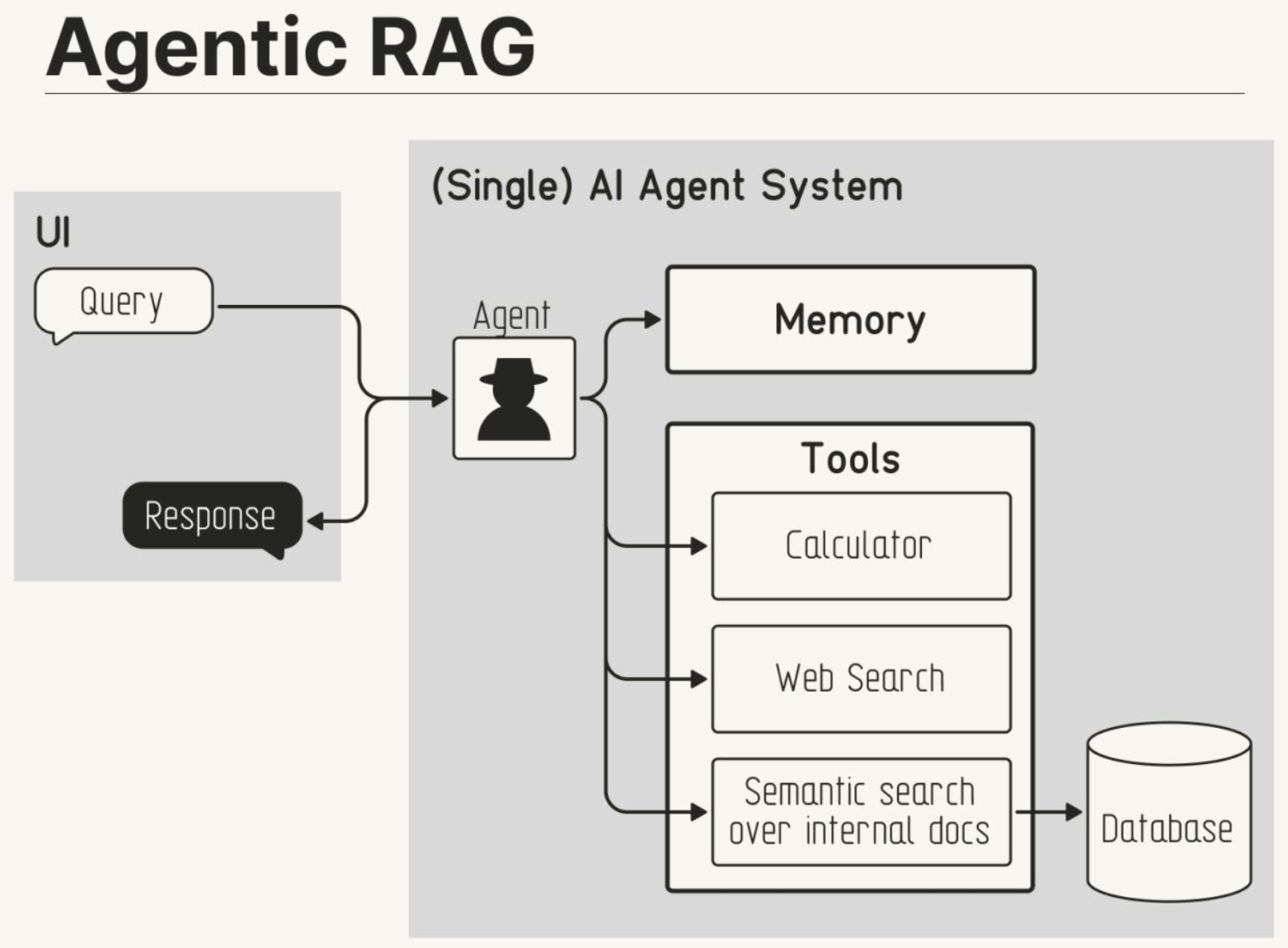
Reinforcement Learning for Agents
- For a detailed discourse on Reinforcement Learning for Agents please refer our Reinforcement Learning for Agents primer.
Benchmarks
- Evaluating LLM-based agents requires specialized benchmarks that go beyond static NLP tasks and assess the agent’s ability to reason, plan, execute actions, and adapt to dynamic environments.
-
These benchmarks measure an agent’s capability in real-world-like simulations, web interaction, tool use, and multi-step decision-making, which are critical for developing autonomous AI systems. Benchmarks designed to evaluate LLM agents include:
-
OSWorld: OSWorld evaluates LLM-based agents in a simulated open-ended world where they interact with diverse environments. It tests reasoning, planning, and multi-step task execution, emphasizing adaptability to dynamic conditions.
-
WebArena: WebArena assesses LLM agents’ ability to navigate and interact with realistic web environments, covering tasks like browsing, searching, and form-filling. It provides a high-fidelity, human-like internet experience for testing generalization and real-world usability.
-
Mind2Web: Mind2Web introduces a large-scale dataset for building and evaluating generalist web agents on real-world websites rather than simulations. It includes over 2,000 tasks across 137 websites in 31 domains, testing agents on their ability to interpret high-level natural language goals, plan multi-step interactions, and generalize to unseen websites and domains. The benchmark emphasizes real-world complexity, multi-domain generalization, and autonomy in executing diverse web-based tasks without step-by-step supervision.
-
WebVoyager: WebVoyager focuses on evaluating LLM agents in autonomous web exploration. It measures how well agents adapt to unseen websites, perform goal-oriented browsing, and extract relevant information with minimal human intervention.
-
OpenWebVoyager: OpenWebVoyager extends the WebVoyager framework by introducing a self-improving, multimodal web agent that iteratively explores, receives feedback, and optimizes its policy based on real-world web interactions. It evaluates agents’ abilities to perform multimodal reasoning and navigation using both visual and textual inputs. The benchmark emphasizes self-improvement through imitation learning followed by exploration-feedback-optimization cycles, enabling continuous adaptation to complex, dynamic web environments.
-
SWE-Bench: SWE-Bench is tailored for evaluating LLM-based software engineering agents. It includes real-world GitHub issues and codebases, testing agents on debugging, pull request generation, and code improvement tasks with automated correctness verification.
-
GAIA: General AI Agent Benchmark (GAIA) evaluates the robustness and general intelligence of AI agents across multiple domains, including gaming, web interaction, and decision-making. It emphasizes long-horizon planning and adaptability.
-
AgentBench: AgentBench is a large-scale benchmark for multi-agent collaboration and LLM-based decision-making. It covers a wide range of tasks, from coordination and negotiation to strategic planning and problem-solving.
-
IGLU: Interactive Grounded Language Understanding (IGLU) tests LLM agents in interactive 3D environments where they must understand natural language commands and manipulate objects accordingly. It measures spatial reasoning and task execution in multimodal settings.
-
ClemBench: ClemBench benchmarks the performance of LLM agents in structured dialogue and task automation. It includes real-world chatbot use cases, emphasizing context retention, instruction-following, and multi-turn reasoning.
-
ToolBench: ToolBench evaluates LLM agents’ ability to use external tools and APIs to complete tasks. It assesses tool integration, multi-step reasoning, and adaptability in using calculators, databases, and search engines.
-
GentBench: GentBench focuses on generative reasoning and task execution, testing LLM agents on creative and logical problem-solving. It includes challenges in writing, planning, and structured data manipulation.
-
MLAgentBench: MLAgentBench is designed to evaluate reinforcement learning agents powered by LLMs. It provides a set of standard environments to measure agent learning, adaptability, and decision-making efficiency across different problem spaces.
-
- Evaluation dimensions include:
- Utility: Task completion effectiveness and efficiency, measured by success rate and task outcomes.
- Sociability: Language communication proficiency, cooperation, negotiation abilities, and role-playing capability.
- Values: Adherence to moral and ethical guidelines, honesty, harmlessness, and contextual appropriateness.
- Ability to Evolve Continually: Continual learning, autotelic learning ability, and adaptability to new environments.
- Adversarial Robustness: Susceptibility to adversarial attacks, with techniques like adversarial training and human-in-the-loop supervision employed.
- Trustworthiness: Calibration problems and biases in training data affect trustworthiness. Efforts are made to guide models to exhibit thought processes or explanations to enhance credibility.
Common Use-cases
-
Agentic systems can be employed in various domains to enable AI systems to operate autonomously, making decisions, executing tasks, and adapting to changing circumstances without constant human intervention.
-
Customer Support: AI-driven virtual assistants such as Conversational AI Agents can manage customer inquiries, troubleshoot common issues, and escalate complex cases to human representatives when necessary. Examples include AI chatbots for e-commerce support (e.g., Amazon’s Alexa for customer service) and automated call center agents handling telecom support.
-
Content Creation: AI Content Generators like GPT-based writing agents can craft blog posts, marketing copy, and social media updates. They can optimize content for SEO, personalize messaging for different audiences, and even generate video scripts. Examples include AI-driven copywriting assistants like Jasper or OpenAI’s ChatGPT for content strategy.
-
Education: AI Tutoring Agents can personalize learning experiences, provide step-by-step explanations, and assess student progress. These include virtual math tutors like Photomath, AI-powered language learning assistants like Duolingo’s chatbots, and generative AI for personalized essay feedback.
-
Coding Assistance: Autonomous Coding Agents can provide real-time code suggestions, detect and fix bugs, and even generate complete functions based on prompts. These include tools like GitHub Copilot, Tabnine, and OpenAI’s Codex, which help developers streamline their coding workflows.
-
Healthcare: AI Medical Assistants can analyze medical literature, provide diagnostic insights based on patient symptoms, and support mental health through AI therapy chatbots. Examples include IBM Watson Health for medical research, AI symptom checkers like Ada Health, and AI therapy agents like Woebot.
-
Accessibility: AI Accessibility Agents can convert text into speech, describe images for visually impaired users, and generate captions in real-time for hearing-impaired individuals. Notable examples include screen readers like NVDA, Microsoft’s Seeing AI, and AI-powered live captioning tools like Google’s Live Transcribe.
-
Case Studies
- Two particularly promising applications for AI agents that demonstrate the practical value include customer support and software development (i.e., coding agents). Both applications illustrate how agents add the most value for tasks that require both conversation and action, have clear success criteria, enable feedback loops, and integrate meaningful human oversight. Below, we cover them in detail.
Customer Support
-
Customer support combines familiar chatbot interfaces with enhanced capabilities through tool integration. This is a natural fit for more open-ended agents because:
- Support interactions naturally follow a conversation flow while requiring access to external information and actions;
- Tools can be integrated to pull customer data, order history, and knowledge base articles;
- Actions such as issuing refunds or updating tickets can be handled programmatically; and
- Success can be clearly measured through user-defined resolutions.
-
Several companies have demonstrated the viability of this approach through usage-based pricing models that charge only for successful resolutions, showing confidence in their agents’ effectiveness.
Software Development
-
The software development space has shown remarkable potential for LLM features, with capabilities evolving from code completion to autonomous problem-solving. Agents are particularly effective because:
- Code solutions are verifiable through automated tests;
- Agents can iterate on solutions using test results as feedback;
- The problem space is well-defined and structured; and
- Output quality can be measured objectively.
-
Agentic workflows demonstrate significant performance improvements in programming tasks. The figure below (source) offers an analysis of various AI models’ coding capabilities on the HumanEval benchmark revealed stark differences when using iterative agentic approaches. Zero-shot attempts by GPT-3.5 and GPT-4 achieved correctness rates of 48.1% and 67.0%, respectively. However, when GPT-3.5 was embedded within an agent loop, it achieved up to 95.1% accuracy, highlighting the profound impact of iterative processing.
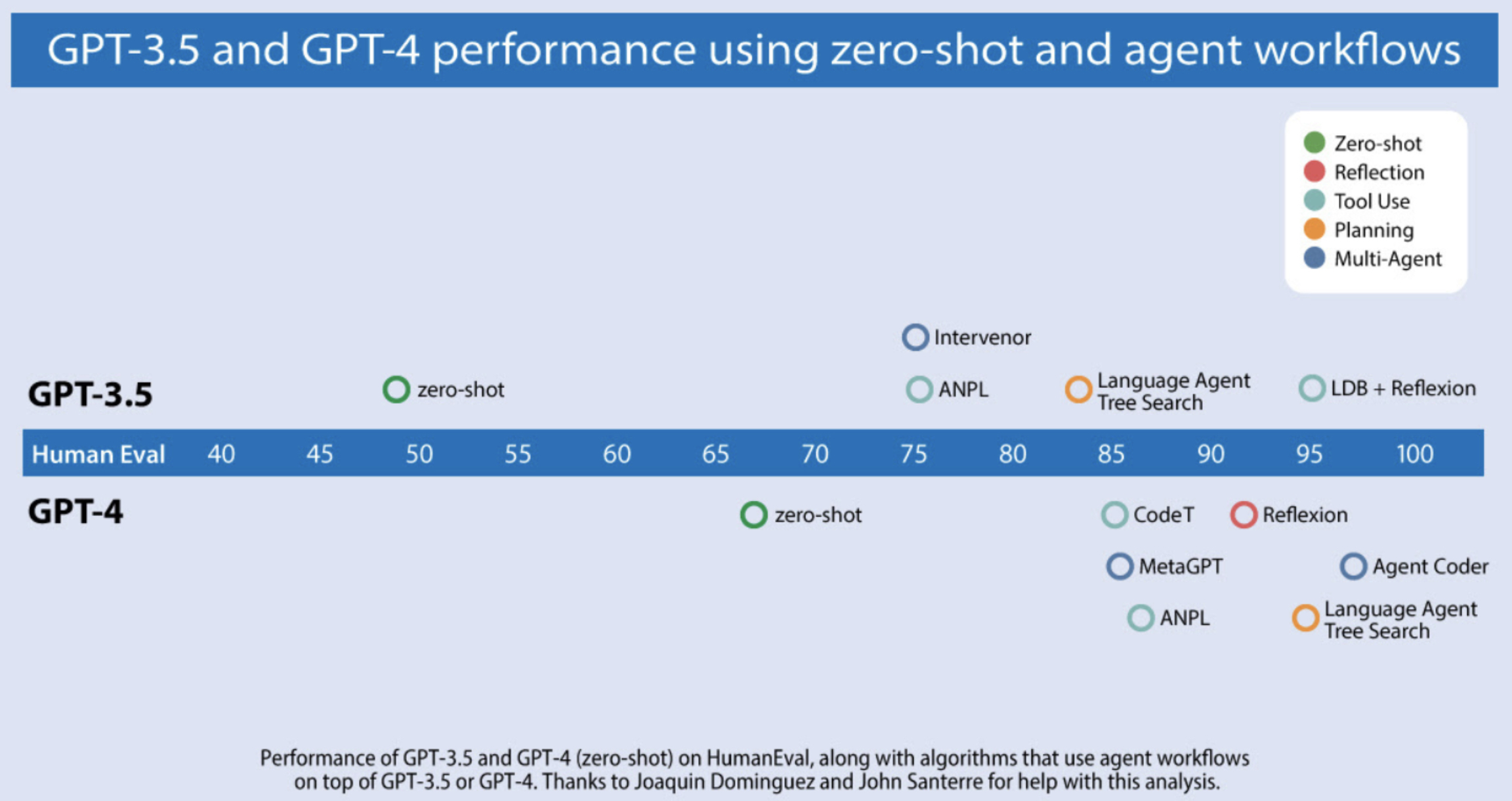
-
In summary, the integration of agentic and iterative workflows marks a significant evolution in AI design patterns, enhancing the ability of LLM-powered agents to handle increasingly sophisticated tasks. As these frameworks and tools continue to mature, they are poised to become essential components in AI-driven task management and automation, offering unparalleled efficiency and adaptability.
-
In our own implementation, agents can now solve real GitHub issues in the SWE-bench Verified benchmark based on the pull request description alone. However, whereas automated testing helps verify functionality, human review remains crucial for ensuring solutions align with broader system requirements.
Devin
- A notable example of an agentic approach applied to software development is Devin, an autonomous agent optimized for software engineering tasks. Devin exemplifies the effectiveness of agentic workflows, achieving state-of-the-art results on the SWE-Bench coding benchmark, passing rigorous practical engineering interviews at top AI firms, and successfully executing real-world assignments on platforms like Upwork. Devin operates by leveraging its own shell, code editor, and web browser, enabling it to autonomously solve engineering problems and refine its work iteratively.
Frameworks/Libraries
- The below frameworks facilitate the initial development process of agents by streamlining fundamental low-level tasks such as invoking LLMs, defining and interpreting tools, and managing sequential function calls. However, they often introduce additional layers of abstraction that can obscure the underlying prompts and responses, making debugging more challenging. Furthermore, they may encourage unnecessary complexity when a simpler approach would be sufficient. Beginning by working directly with LLM APIs (rather than frameworks) is ideal, as many patterns can be implemented with minimal code.
- Anthropic’s cookbook offers some sample implementations.
AutoGen Studio
- Microsoft Research’s AutoGen Studio is a low-code interface for rapidly prototyping AI agents. It’s built on top of the AutoGen framework and can also be used for debugging and evaluating multi-agent workflows.
AutoGen
- AutoGen is an open-source framework by Microsoft for building AI agent systems. It simplifies the creation of event-driven, distributed, scalable, and resilient agentic applications.
- Github; Docs; Examples
Swarm
- Swarm by OpenAI’s is a framework exploring ergonomic, lightweight multi-agent orchestration.
- Github
CrewAI
- Cutting-edge framework for orchestrating role-playing, autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks.
- Github; Docs; Examples
Letta
- Letta is an open source framework for building stateful LLM applications powered by agents with advanced reasoning capabilities and transparent long-term memory.
- Github; Docs; Examples
Llama Stack
- Llama Stack from Meta defines and standardizes the building blocks needed to bring generative AI applications to market. These blocks span the entire development lifecycle: from model training and fine-tuning, through product evaluation, to building and running AI agents in production.
- Github; Docs; Examples
AutoRAG
- AutoRAG is a tool for finding the optimal RAG pipeline for “your data”, including Agentic RAG approaches. You can evaluate various RAG modules automatically with your own evaluation data and find the best RAG pipeline for your own use-case.
- Github; Docs; Examples
Beam
- Beam is the leading platform for Agentic Process Automation.
AutoAgents
- AutoAgents is a novel framework designed for dynamic multi-agent generation and coordination, enabling language models to construct adaptive AI teams for a wide range of tasks. Unlike traditional systems that rely on static, predefined agents, AutoAgents generates task-specific agents autonomously, allowing for flexible collaboration across varied domains. The framework introduces a drafting and execution stage to handle complex task environments and facilitate effective role assignment and solution planning.
Amazon Bedrock’s AI Agent framework
- Amazon Bedrock Agents automate complex tasks by integrating with company systems, using foundation models for reasoning, memory retention, and secure execution. They support multi-agent collaboration, retrieval-augmented generation, code execution, and customizable prompt engineering for efficient workflows.
Rivet
- Rivet is a drag and drop GUI LLM workflow builder.
Vellum
- Vellum is a GUI tool for building and testing complex workflows.
BabyAGI
- BabyAGI is a widely used, task-driven autonomous agent built to tackle a variety of tasks across multiple domains. It leverages advanced technologies, including OpenAI’s GPT-4 language model, the Pinecone vector search platform, and the LangChain framework. A breakdown of its core components is here and code is here.
-
BabyAGI’s workflow involves the following operational steps:
- Task Completion: The system processes the task at the forefront of the task list, utilizing GPT-4 in conjunction with LangChain’s chain and agent functionalities to produce a result. This result is subsequently refined, if necessary, and stored in Pinecone for future reference.
- Task Generation: Following the completion of a task, the system leverages GPT-4 to create new tasks, ensuring that these do not duplicate any existing tasks.
- Task Prioritization: The system reprioritizes the task list by evaluating the newly generated tasks and their relative importance, with GPT-4 facilitating the prioritization process.
- The following figure (source) illustrates the workflow of an AI agent system comprising multiple GPT-4-based agents. The user initiates the process by providing an objective and task, which is added to the Task Queue. The Execution Agent completes the task and sends the result back, which is stored in Memory for future context. The Task Creation Agent can create additional tasks based on the task results, and the Task Prioritization Agent organizes the Task Queue by prioritizing tasks to ensure an optimized flow. Memory is accessed throughout to maintain contextual relevance.
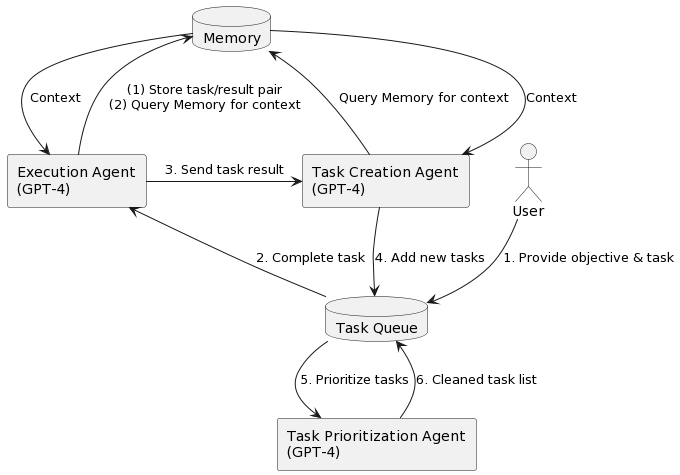
smolagents
- smolagents by Hugging Face is a simple library to build powerful agents. The main logic for agents fits in ~1000 lines of code. So it’s really dead simple.
- The main agent class is
CodeAgent, an agent that writes its actions in code. That means, contrary to the standard set by OpenAI of writing JSON blobs that call tools, this agent writes code blobs. It’s much more natural for LLMs to write actions this way, and as a result performance is much better. - Code
Agent S2
- Agent S2 is an open source, autonomous AI framework that offers improved performance, modularity, and scalability by combining frontier and specialized models.
- Code
Open Operator
- Open Operator is inspired by OpenAI’s Operator feature and builds upon various open source technologies such as Browserbase powers the core browser automation and interaction capabilities and Stagehand which handles precise DOM manipulation and state management
Example Flow Chart for an LLM Agent: Handling a Customer Inquiry
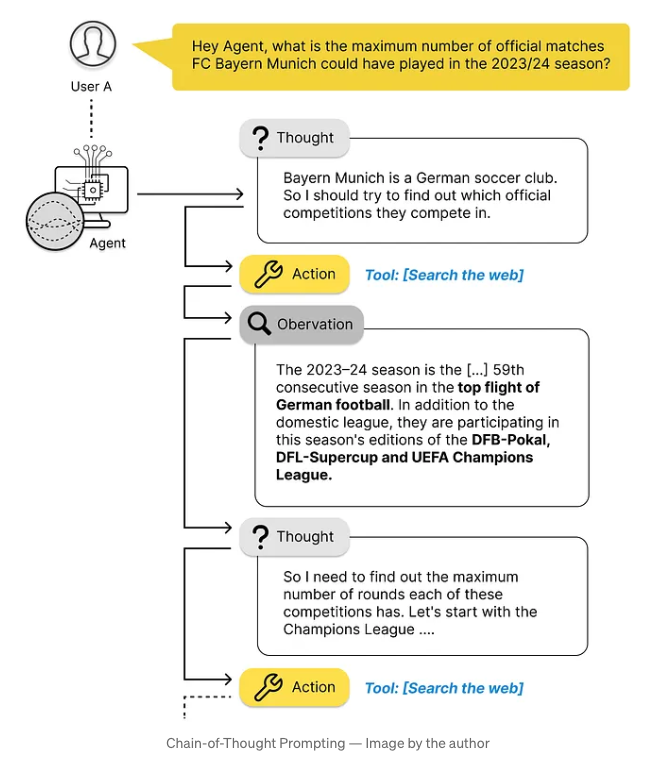
-
The image above (source) shows an example of AI Agent flow.
- Customer Interaction
- Input: “Is the new XYZ smartphone available, and what are its features?”
- Action: Customer types the query into the e-commerce platform’s chat interface.
- Query Reception and Parsing
- Agent Core Reception: Receive text input.
- Natural Language Understanding: Parse the text to extract intent and relevant entities.
- Intent Classification and Information Retrieval
- Intent Classification: Classify the query intent.
- Memory Access: Retrieve stored data on product inventory and specifications.
- External API Calls: Fetch additional data if not available in memory.
- Data Processing and Response Planning
- Planning Module: Split the query into “check availability” and “retrieve features”.
- Data Synthesis: Combine information from memory.
- Customer Interaction
Use Cases
- Let’s look at a few agent use cases below:
Data Agent for Data Analysis
-
The image above (source) visually illustrates the flow we will use below.
- Identify the Use Case:
- Define specific data analysis tasks, such as querying databases or analyzing financial reports.
- Select the Appropriate LLM:
- Choose an LLM that handles the complexity of data queries and analysis.
- Agent Components:
- Develop the agent with tools for data handling, a memory module for tracking interactions, and a planning module for strategic execution of tasks.
- Design the Data Interaction Tools:
- Implement tools for interacting with databases or other data sources.
- Identify the Use Case:
Tools Setup
class SQLExecutor:
def __init__(self, database_url):
self.database_url = database_url
def execute_query(self, query):
print(f"Executing SQL query: {query}")
return "Query results"
class Calculator:
@staticmethod
def perform_calculation(data):
print(f"Performing calculation on data: {data}")
return "Calculation results"
Agent Core Logic
class DataAgent:
def __init__(self, sql_executor, calculator):
self.sql_executor = sql_executor
self.calculator = calculator
self.memory = []
def analyze_data(self, query, calculation_needed=True):
results = self.sql_executor.execute_query(query)
self.memory.append(results)
if calculation_needed:
calculation_results = self.calculator.perform_calculation(results)
self.memory.append(calculation_results)
return calculation_results
return results
database_url = "your_database_url_here"
sql_executor = SQLExecutor(database_url)
calculator = Calculator()
agent = DataAgent(sql_executor, calculator)
query = "SELECT * FROM sales_data WHERE year = 2021"
print(agent.analyze_data(query))
LLM-Powered API Agent for Task Execution
- Choose an LLM:
- Select a suitable LLM for handling task execution.
- Select a Use Case:
- Define the tasks the agent will execute.
- Build the Agent:
- Develop the components required for the API agent: tools, planning module, and agent core.
- Define API Functions:
- Create classes for each API call to the models.
Python Code Example
class ImageGenerator:
def __init__(self, api_key):
self.api_key = api_key
def generate_image(self, description, negative_prompt=""):
print(f"Generating image with description: {description}")
return "Image URL or data"
class TextGenerator:
def __init__(self, api_key):
self.api_key = api_key
def generate_text(self, text_prompt):
print(f"Generating text with prompt: {text_prompt}")
return "Generated text"
class CodeGenerator:
def __init__(self, api_key):
self.api_key = api_key
def generate_code(self, problem_description):
print(f"Generating code for: {problem_description}")
return "Generated code"
Plan-and-Execute Approach
def plan_and_execute(question):
if 'marketing' in question:
plan = [
{
"function": "ImageGenerator",
"arguments": {
"description": "A bright and clean laundry room with a large bottle of WishyWash detergent, featuring the new UltraClean formula and softener, placed prominently.",
"negative_prompt": "No clutter, no other brands, only WishyWash."
}
},
{
"function": "TextGenerator",
"arguments": {
"text_prompt": "Compose a tweet to promote the new WishyWash detergent with the UltraClean formula and softener at $4.99. Highlight its benefits and competitive pricing."
}
},
{
"function": "TextGenerator",
"arguments": {
"text_prompt": "Generate ideas for marketing campaigns to increase WishyWash detergent sales, focusing on the new UltraClean formula and softener."
}
}
]
return plan
else:
pass
def execute_plan(plan):
results = []
for step in plan:
if step["function"] == "ImageGenerator":
generator = ImageGenerator(api_key="your_api_key")
result = generator.generate_image(**step["arguments"])
results.append(result)
elif step["function"] == "TextGenerator":
generator = TextGenerator(api_key="your_api_key")
result = generator.generate_text(**step["arguments"])
results.append(result)
elif step["function"] == "CodeGenerator":
generator = CodeGenerator(api_key="your_api_key")
result = generator.generate_code(**step["arguments"])
results.append(result)
return results
question = "How can we create a marketing campaign for our new detergent?"
plan = plan_and_execute(question)
results = execute_plan(plan)
for result in results:
print(result)
Build your own LLM Agent
- Here’s a detailed explanation including some Python code examples as outlined in the NVIDIA blog for building a question-answering LLM agent:
- Set Up the Agent’s Components:
- Tools: Include tools like a Retrieval-Augmented Generation (RAG) pipeline and mathematical tools necessary for data analysis.
- Planning Module: A module to decompose complex questions into simpler parts for easier processing.
- Memory Module: A system to track and remember previous interactions and solutions.
- Agent Core: The central processing unit of the agent that uses the other components to solve user queries.
- Python Code Example for the Memory Module:
class Ledger: def __init__(self): self.question_trace = [] self.answer_trace = [] def add_question(self, question): self.question_trace.append(question) def add_answer(self, answer): self.answer_trace.append(answer) - Python Code Example for the Agent Core:
- This part of the code defines how the agent processes questions, interacts with the planning module, and retrieves or computes answers.
def agent_core(question, context): # Assume a function LLM is defined to handle LLM processing action = LLM(context + question) if action == "Decomposition": sub_questions = LLM(question) for sub_question in sub_questions: agent_core(sub_question, context) elif action == "Search Tool": answer = RAG_Pipeline(question) context += answer agent_core(question, context) elif action == "Generate Final Answer": return LLM(context) elif action == "<Another Tool>": # Execute another specific tool pass
- This part of the code defines how the agent processes questions, interacts with the planning module, and retrieves or computes answers.
- Execution Flow:
- The agent receives a question, and based on the context and internal logic, decides if it needs to decompose the question, search for information, or directly generate an answer.
- The agent can recursively handle sub-questions until a final answer is generated.
- Using the Components Together:
- All the components are used in tandem to manage the flow of data and information processing within the agent. The memory module keeps track of all queries and responses, which aids in contextual understanding for the agent.
- Deploying and Testing the Agent:
- Once all components are integrated, the agent is tested with sample queries to ensure it functions correctly and efficiently handles real-world questions.
Responsible AI Agents
- As AI agents increasingly operate with greater autonomy, designing them responsibly has become a fundamental priority. Responsible AI agent development encompasses dimensions like safety, alignment, reliability, oversight, fairness, and privacy. Recent work by Lu et al. (2024) and Shavit et al. (2024) provides detailed frameworks and implementation practices to guide the creation of safe, aligned, and governable agentic systems.
Core Dimensions of Responsible AI Agents
- Safety: Agents must avoid harmful actions, even under adversarial inputs or environmental changes.
- Alignment: Agent behaviors must reflect human intentions and values, especially as agents pursue independent goals.
- Reliability: Agents must perform predictably across diverse conditions and handle uncertainty gracefully.
- Oversight and Accountability: There must be clear mechanisms for monitoring, auditing, and intervening in agent behavior.
- Fairness: Agents should avoid perpetuating biases and should treat users equitably.
- Privacy and Data Protection: Agents must process user data securely and comply with privacy standards.
Responsible Architectures for Agentic Systems
-
Lu et al. (2024) propose a modular architecture for responsible agent design, emphasizing the need for built-in constraints, safe memory structures, planning checks, and execution controls.
-
The image below (source) illustrates the architecture of a responsible agent-based ecosystem proposed by Lu et al. (2024), highlighting key components like interaction engineering, memory safety, planning constraints, and RAI plugins.
-
Their architecture includes:
- Interaction Engineering: Designing goal creation mechanisms that limit dangerous autonomy, such as using passive goal generators or human-in-the-loop goal acceptance.
- Memory Systems: Structuring memory with safe retrieval mechanisms, separating working memory from permanent storage to minimize risky hallucinations.
- Planning Module Constraints: Enabling multi-agent planning through voting-based, debate-based, or role-based cooperation, improving robustness before critical actions.
- Execution Engines with Guardrails: Adding middleware between the planner and actuators, incorporating filters like RAG-based retrieval, multimodal validation, and affordance estimation to screen unsafe actions.
- Responsible AI (RAI) Plugins: Plug-and-play modules such as black-box recorders, explainers, ethical rule checkers, and self-critique evaluators, integrated into every agent cycle.
Governance Practices for Agentic AI Systems
-
Shavit et al. (2024) outline a full life-cycle governance model for agentic AI systems, covering developers, deployers, users, and regulators. Key practices include:
- Evaluate Task Suitability: Assess if an agentic system is appropriate for a given use case or if simpler automation would be safer.
- Constrain Action Spaces: Strictly limit the agent’s available actions and tool access by default, only expanding capabilities based on demonstrated safety.
- Default Safe Behaviors: Configure safe fallback plans, such as agent shutdown or user escalation, when agents encounter uncertainty.
- Ensure Legibility: Design agents to generate explanations, self-reports, or summaries of their goals, plans, and actions to enhance transparency for users and overseers.
- Continuous Monitoring and Logging: Implement robust observability frameworks to track agent reasoning steps, tool calls, and environmental interactions.
- Establish Accountability Mechanisms: Assign responsibility for agent actions through contracts, insurance, and internal auditing systems.
Implementation Details for Responsible Agents
-
Based on Lu et al. (2024) and Shavit et al. (2024), responsible agent development can be operationalized through the following techniques:
- Goal Creation Interfaces: Implement passive goal creators that require explicit user approval before initiating complex workflows.
- Memory Safety Filters: Deploy retrieval guards to prevent the agent from inserting unverified external information into planning stages.
- Constrained Planning Algorithms: Restrict planning algorithms to verifiable tool chains and avoid open-ended execution flows unless carefully sandboxed.
- Pre-Execution Checks: Use RAI Plugins like ethics checkers or adversarial simulators to validate plans before critical execution steps.
- Post-Hoc Auditing Tools: Record entire agent trajectories using black-box recorders for external auditors to review and investigate.
- Adjustable Autonomy Levels: Enable dynamic risk scaling, where agents can operate semi-autonomously during low-risk tasks but require human approval for high-risk operations.
- Feedback Loops: Incorporate human feedback in deployment via reinforcement learning or preference modeling to refine agent behaviors over time.
Challenges and Open Research Questions
-
Shavit et al. (2024) note that agentic systems introduce novel governance challenges compared to traditional software, including:
- Scaling Oversight: How to supervise agents operating faster and more broadly than human monitors.
- Value Drift: How to ensure agents’ goals remain aligned over long timescales and diverse environments.
- Emergent Cooperation: How to prevent networks of agents from colluding or misbehaving in unintended ways.
- Cross-Organizational Accountability: How to allocate liability between developers, deployers, and users when harms occur.
-
Addressing these issues will require deeper collaboration between AI developers, ethicists, regulators, and society at large to build safe and trustworthy agentic ecosystems.
Related Papers
Reflection
Self-Refine: Iterative Refinement with Self-Feedback
- Like humans, large language models (LLMs) do not always generate the best output on their first try.
- This paper by Madaan et al. from CMU, Allen AI, UW, NVIDIA, UC San Diego, and Google Research introduces a novel approach for enhancing outputs from large language models (LLMs) like GPT-3.5 and GPT-4 through self-generated iterative feedback and refinement, without the need for additional training data or supervised learning – similar to how humans refine their written text.
- Put simply, the main idea is to generate an initial output using an LLM; then, the same LLM provides feedback for its output and uses it to refine itself, iteratively. This process repeats until a predefined condition is met. Self-Refine does not require any supervised training data, additional training, or reinforcement learning, and instead uses a single LLM as the generator, refiner and the feedback provider.
- The figure below from the paper shows that given an input (step 0), Self-Refine starts by generating an output and passing it back to the same model M to get feedback (step 1). The feedback is passed back to M, which refines the previously generated output (step 2). Steps (step 1) and (step 2) iterate until a stopping condition is met. SELF-REFINE is instantiated with a language model such as GPT-3.5 and does not involve human assistance.
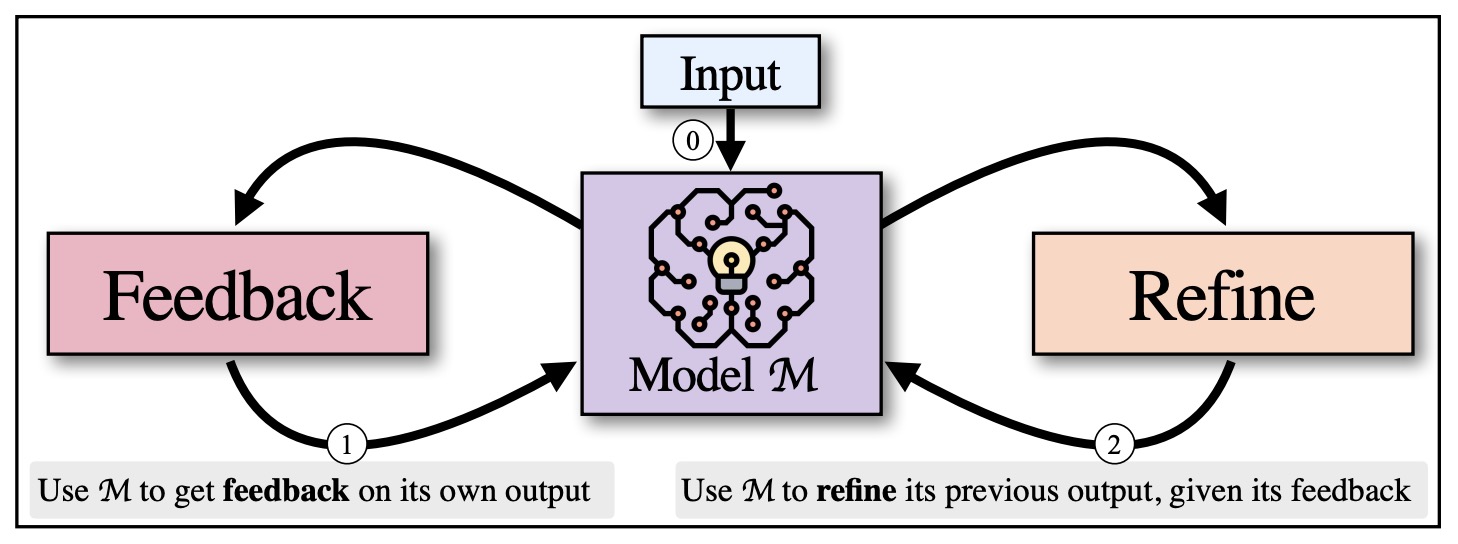
- The approach is evaluated across seven diverse tasks, including dialogue response and code optimization, demonstrating significant improvements over conventional one-step generation methods. This method leverages few-shot prompting for guiding the LLM to generate feedback and incorporate it for output refinement.
- The results show that Self-Refine significantly enhances output quality in terms of human preference and task-specific metrics, indicating its potential to improve LLM-generated content across a range of applications.
- Code
Reflexion: Language Agents with Verbal Reinforcement Learning
- This paper by Shinn et al. from Northeastern University, MIT, and Princeton University introduces Reflexion, a reinforcement learning framework for large language model (LLM)-based agents, enabling them to improve task performance using self-reflective verbal feedback instead of traditional weight updates. Reflexion processes external feedback, transforming it into actionable self-reflections stored in episodic memory, enhancing agents’ decision-making over successive trials in tasks such as sequential action selection, reasoning, and code generation.
- Framework Overview: Reflexion involves three models: an Actor (task action generation), an Evaluator (performance assessment), and a Self-Reflection model (produces verbal guidance for improvement). The Actor, built on LLMs, generates actions based on both state observations and past experiences. The Evaluator assigns task-specific rewards, and the Self-Reflection model formulates verbal feedback based on task failures, guiding future attempts.
- Memory Structure: Reflexion employs short-term memory (trajectory history) and long-term memory (aggregated self-reflections), which the Actor consults during action generation. This structure allows the agent to remember specific past mistakes while retaining broader learnings across episodes, which aids in complex decision-making tasks.
- The following figure from the paper shows that Reflexion works on decision-making, programming, and reasoning tasks.

- Experimentation and Results:
- Decision-Making in AlfWorld: Reflexion significantly improved performance on multi-step tasks in AlfWorld by 22%, using heuristics to detect repetitive failures and adapt action choices based on memory. Reflexion enables effective backtracking and context recall, with a notable reduction in inefficient planning errors compared to baseline.
- Reasoning with HotPotQA: Reflexion enhanced reasoning on HotPotQA, achieving a 20% improvement by refining answers through Chain-of-Thought and episodic memory. Reflexion agents retained task-specific strategies across trials, outpacing baseline approaches in correctly navigating long contextual questions.
- Programming in HumanEval and LeetcodeHardGym: Reflexion set new state-of-the-art scores, achieving 91% on HumanEval, aided by self-generated test suites and continuous error-checking through self-reflection. This iterative testing allowed Reflexion agents to refine code output by addressing both syntactical and logical errors.
- Implementation Details:
- Reflexion agents use Chain-of-Thought and ReAct generation techniques, with self-reflective prompts implemented through few-shot examples tailored for each task type. For programming, Reflexion employs syntactically validated test suites, filtered to retain only valid abstract syntax tree representations, ensuring comprehensive error handling in code generation.
- Self-reflection feedback is stored in memory limited to the last three experiences to maintain efficiency within LLM context limits. Reflexion’s feedback loop iterates until the Evaluator confirms task success, effectively combining reinforcement with natural language memory for performance gains.
- Ablation Studies and Analysis: Tests on compromised versions of Reflexion, such as without test generation or self-reflection, showed marked performance drops, underscoring the importance of verbal self-reflection in driving task success. This highlights Reflexion’s effectiveness in environments requiring high interpretability and actionable feedback.
- Reflexion exemplifies a low-compute yet adaptive approach to reinforcement learning for LLM agents, showing potential for expansive applications in autonomous decision-making where interpretable and incremental learning are essential.
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing
- The paper by Gou et al. from Tsinghua University, Microsoft Research Asia, and Microsoft Azure AI, published in ICLR 2024, introduces a novel framework called CRITIC, designed to enhance the reliability of LLM outputs by allowing the models to interact with external tools to critique and amend their own responses.
- CRITIC’s approach diverges from traditional model fine-tuning, focusing instead on a verify-and-correct process where LLMs generate initial outputs and subsequently engage with tools such as search engines, code interpreters, and calculators to verify aspects of these outputs, like truthfulness or accuracy. Based on feedback from these tools, the model then refines its response, iteratively improving until a specified condition (e.g., sufficient accuracy) is achieved. This method sidesteps the need for extensive additional training or data annotation and is structured to work with black-box LLMs through in-context learning and few-shot demonstrations.
- In terms of implementation, CRITIC operates in two main phases: verification and correction. An initial output is generated using a few-shot prompt-based approach. This output is then scrutinized with tools tailored to the task at hand. For instance, for fact-checking in question answering, CRITIC uses a Google-based search API to retrieve relevant web snippets, while for mathematical problem-solving, a Python interpreter verifies code execution and provides debugging information if errors occur. The verification feedback, structured as critiques, is appended to the prompt, enabling the LLM to correct its initial output. This verify-then-correct cycle is repeated iteratively, with the maximum number of interactions set per task or until stability in the output is observed.
- The following figure from the paper shows that the CRITIC framework consists of two steps: (1) verifying the output by interacting with external tools to generate critiques and (2) correcting the output based on the received critiques. We can iterate over such verify-then-correct process to enable continuous improvements.
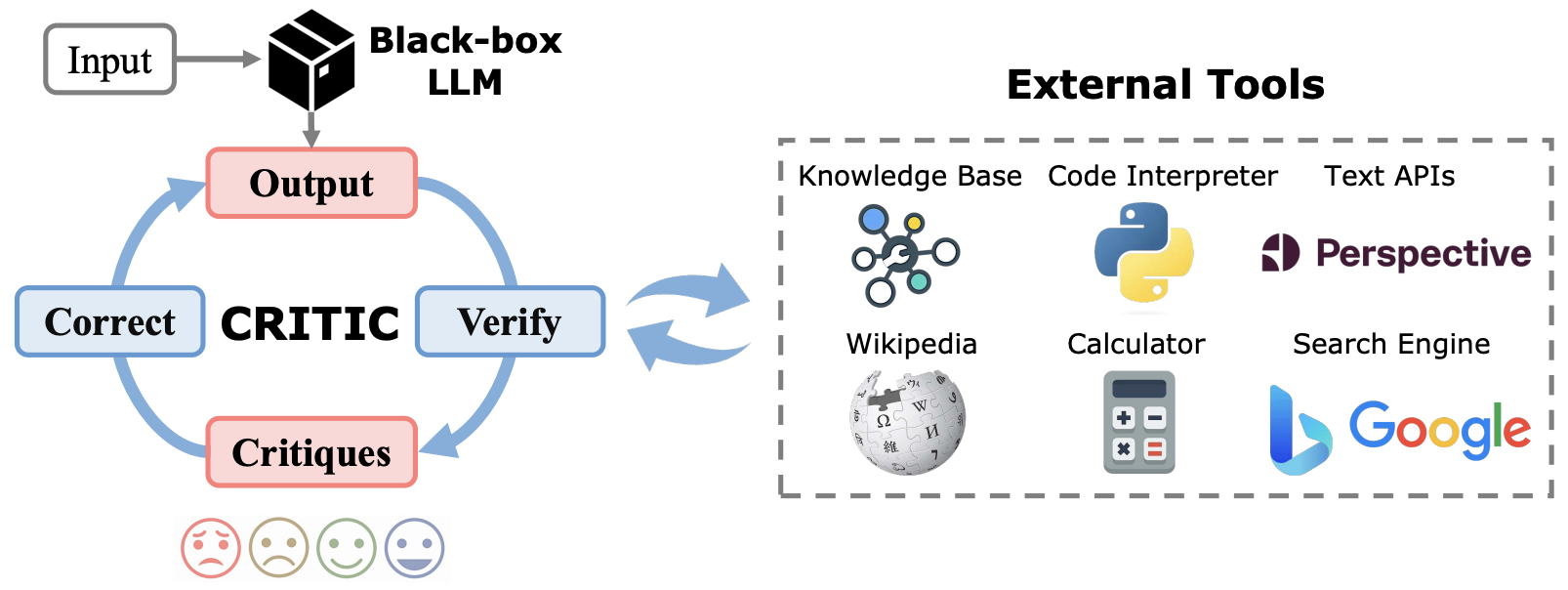
- CRITIC’s performance evaluation demonstrates its effectiveness across three types of tasks:
- Free-form Question Answering: Here, CRITIC leverages web search to validate answers, achieving notable improvements in F1 scores over baseline methods, such as chain-of-thought (CoT) prompting and retrieval-augmented techniques.
- Mathematical Program Synthesis: By utilizing an interpreter for mathematical validation, CRITIC substantially enhances solve rates for datasets like GSM8k, surpassing program-of-thought (PoT) strategies.
- Toxicity Reduction: CRITIC employs the PERSPECTIVE API to monitor and reduce toxic content, achieving higher fluency and diversity in outputs while significantly reducing toxicity probabilities.
- Experimental results indicate that CRITIC consistently improves model performance, especially in cases requiring high factual accuracy or computational precision. The paper concludes by emphasizing that the inclusion of external feedback mechanisms allows LLMs to perform self-corrections that would be challenging through self-refinement alone.
- Code
Tool Calling
Gorilla: Large Language Model Connected with Massive APIs
- Large Language Models (LLMs) have seen an impressive wave of advances recently, with models now excelling in a variety of tasks, such as mathematical reasoning and program synthesis. However, their potential to effectively use tools via API calls remains unfulfilled. This is a challenging task even for today’s state-of-the-art LLMs such as GPT-4, largely due to their inability to generate accurate input arguments and their tendency to hallucinate the wrong usage of an API call.
- This paper by Patil et al. from UC Berkeley and Microsoft Research in 2023 introduces Gorilla, a finetuned LLaMA-based model that generates APIs to complete tasks by interacting with external tools and surpasses the performance of GPT-4 while writing API calls. When combined with a document retriever, Gorilla demonstrates a strong capability to adapt to test-time document changes, enabling flexible user updates or version changes. It also substantially mitigates the issue of hallucination, commonly encountered when prompting LLMs directly.
- To evaluate the model’s ability, they introduce APIBench, a comprehensive dataset consisting of Weights, TorchHub, and TensorHub APIs. The successful integration of the retrieval system with Gorilla demonstrates the potential for LLMs to use tools more accurately, keep up with frequently updated documentation, and consequently increase the reliability and applicability of their outputs.
- The following figure from the paper shows (top) the training procedure for Gorilla using the most exhaustive API dataset for ML to the best of their knowledge; (bottom) during inference Gorilla supports two modes - with retrieval, and zero-shot. In this example, it is able to suggest the right API call for generating the image from the user’s natural language query.
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
- This paper by Yang et al. from proposes MM-REACT, a system paradigm that integrates ChatGPT with a pool of vision experts to achieve multimodal reasoning and action.
- They define and explore a comprehensive list of advanced vision tasks that are intriguing to solve, but may exceed the capabilities of existing vision and vision-language models. To achieve such advanced visual intelligence, MM-REACT introduces a textual prompt design that can represent text descriptions, textualized spatial coordinates, and aligned file names for dense visual signals such as images and videos.
- MM-REACT’s prompt design allows language models to accept, associate, and process multimodal information, thereby facilitating the synergetic combination of ChatGPT and various vision experts. Zero-shot experiments demonstrate MM-REACT’s effectiveness in addressing the specified capabilities of interests and its wide application in different scenarios that require advanced visual understanding.
- Furthermore, they discuss and compare MM-REACT’s system paradigm with an alternative approach that extends language models for multimodal scenarios through joint finetuning.
- The following figure from the paper shows that MM-REACT allocates specialized vision experts with ChatGPT to solve challenging visual understanding tasks through multimodal reasoning and action. For example, the system could associate information from multiple uploaded receipts and calculate the total travel cost (“Multi-Image Reasoning”).
- The following figure from the paper shows the flowchart of MM-REACT for enhanced visual understanding with ChatGPT. The user input can be in the form of text, images, or videos, with the latter two represented as file path strings. ChatGPT is instructed to say specific watchwords in action request if a vision expert is required to interpret the visual inputs. Regular expression matching is applied to parse the expert’s name and the file path, which are then used to call the vision expert (action execution). The expert’s output (observation) is serialized as text and combined with the history to further activate ChatGPT. If no extra experts are needed, MM-REACT would return the final response to the user. The right figure shows a single-round vision expert execution, which is the component that constructs the full execution flow.
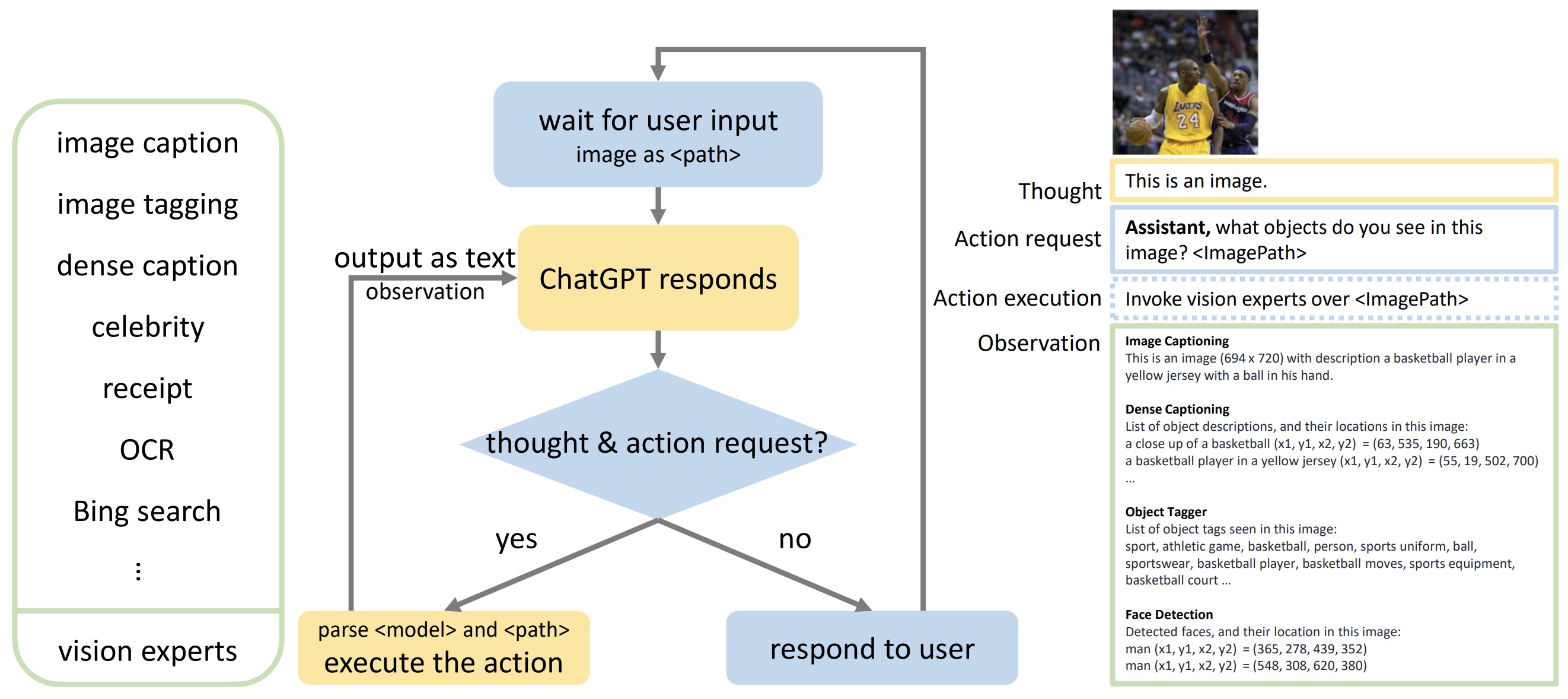
Efficient Tool Use with Chain-of-Abstraction Reasoning
-
This paper by Gao et al. from EPFL and FAIR introduces a novel method called Chain-of-Abstraction (CoA) reasoning, which optimizes LLMs for multi-step reasoning by using tools to access external knowledge. CoA decouples general reasoning from domain-specific information, which is later retrieved using specialized tools, enhancing LLM accuracy and efficiency in domains that require complex reasoning chains, such as mathematics and Wikipedia-based question answering (Wiki QA). The CoA method trains LLMs to generate reasoning chains with placeholders for domain knowledge, allowing parallel tool usage and reducing the lag introduced by interleaving LLM outputs with tool responses.
-
Implementation of CoA reasoning involves a two-stage fine-tuning process: first, LLMs are trained to produce abstract reasoning chains that include placeholders for required operations or knowledge, such as calculations or article references. Then, these chains are reified by filling placeholders with actual knowledge retrieved from tools like an equation solver or a Wikipedia search engine. This approach enables parallel processing, as tools fill in specific information after generating the complete reasoning chain, speeding up inference significantly compared to sequential tool-augmented approaches.
- For the training pipeline, the authors fine-tune LLMs by re-writing gold-standard answers into abstract reasoning chains labeled with placeholders (e.g., “[20 + 35 = y1]”) for mathematical derivations or search queries for Wiki QA. Verification with domain-specific tools ensures that placeholders align with expected outcomes. For instance, in math, an equation solver calculates final results for placeholders. For Wiki QA, a combination of Wikipedia search (BM25 retriever) and NER extracts relevant articles and entities, which are then matched against gold references.
- The following figure from the paper shows an overview of chain-of-abstraction reasoning with tools. Given a domain question (green scroll), a LLM is fine-tuned to first generate an abstract multi-step reasoning chain (blue bubble), and then call external tools to reify the chain with domain-specific knowledge (orange label). The final answer (yellow bubble) is obtained based on the reified chain of reasoning.
- Evaluation on GSM8K and HotpotQA datasets showed CoA’s significant improvements in both accuracy and inference speed, outperforming baselines such as Toolformer and traditional chain-of-thought (CoT) methods by 6-7.5% accuracy in mathematics and Wiki QA. Additionally, CoA demonstrated robust generalization in zero-shot settings on other datasets like SVAMP and Natural Questions, with human evaluations confirming reduced reasoning and arithmetic errors.
Planning
Chain of Thought Prompting Elicits Reasoning in Large Language Models
- Although scaling up language model size has reliably improved performance on a range of NLP tasks, even the largest models currently struggle with certain reasoning tasks such as arithmetic reasoning, math word problems, symbolic manipulation, and commonsense reasoning.
- This paper by Wei et al. from Google in 2022 explores the ability of language models to generate a coherent chain of thought – a series of short sentences that mimic the reasoning process a person might have when responding to a question. The idea is strikingly simple: instead of being terse while prompting show the model a few examples of a multi-step reasoning process (the like of which a human would use). Couple this with LLMs (the larger the better) and magic happens! Check out the below image from the paper.
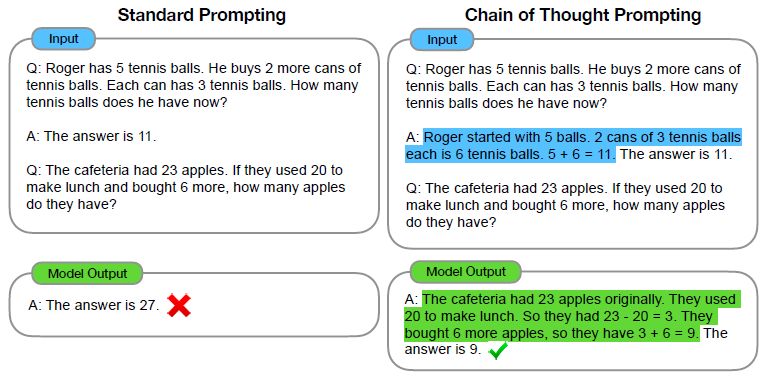
- They have explored chain of thought prompting as a simple and broadly applicable method for enhancing reasoning in language models. The superb results you can elucidate via this method are an emergent property of model scale (surprise surprise) - bigger models benefit more from this, and the conclusion holds across models (LaMDA, GPT, PaLM).
- Interestingly enough, the more complex the task of interest is (in the sense of requiring multi-step reasoning approach), the bigger the boost from the chain of thought prompting!
- In order to make sure that the performance boost comes from this multi-step approach and not simply because of e.g. more compute, the authors have done a couple of ablations: (i) outputting a terse equation instead of a multi-step reasoning description, (ii) outputting the answer and only then the chain of thought, etc. None of these experiments yielded good results.
- The method also proved to be fairly robust (always outperforms standard prompting) to the choice of exact few shot exemplars. Despite different annotators, different styles, etc. the method is always better than standard prompting.
- Through experiments on arithmetic, symbolic, and commonsense reasoning, they find that chain of thought processing is an emergent property of model scale that can be induced via prompting and can enable sufficiently large language models to better perform reasoning tasks that otherwise have flat scaling curves.
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace
- Solving complicated AI tasks with different domains and modalities is a key step toward advanced artificial intelligence. While there are abundant AI models available for different domains and modalities, they cannot handle complicated AI tasks.
- This paper by Shen et al. from Zhejiang University and Microsoft Research Asia in 2023 advocates that LLMs could act as a controller to manage existing AI models to solve complicated AI tasks and language could be a generic interface to empower this, considering the exceptional ability large language models (LLMs) have exhibited in language understanding, generation, interaction, and reasoning, etc. Based on this philosophy, they present HuggingGPT, a framework that leverages LLMs (e.g., ChatGPT) to connect various AI models in machine learning communities (e.g., Weights) to solve AI tasks.
- Specifically, they use ChatGPT to conduct task planning when receiving a user request, select models according to their function descriptions available in Weights, execute each subtask with the selected AI model, and summarize the response according to the execution results. By leveraging the strong language capability of ChatGPT and abundant AI models in Weights, HuggingGPT is able to cover numerous sophisticated AI tasks in different modalities and domains and achieve impressive results in language, vision, speech, and other challenging tasks, which paves a new way towards advanced artificial intelligence.
- Summary:
- HuggingGPT is recently introduced as a suitable middleware to bridge the connections between Large Language Models (LLMs) and AI models. The workflow goes as follows.
- Users can send a request (multimodal for sure) which will be processed by an LLM controller. The LLM analyzes the request, understands the intention of the user, and generates possible solvable sub-tasks.
- ChatGPT selects and invokes the corresponding models hosted on Weights to solve each subtask.
- Once tasks are executed, the invoked model returns the results to the ChatGPT controller.
- Finally, ChatGPT integrates the prediction of all models and generates the response.
- It is amazing how HuggingGPT can show its reasoning and point to its in-context task-model assignment as intermediary steps before generating the output.
- The following figure from the paper shows that language serves as an interface for LLMs (e.g., ChatGPT) to connect numerous AI models (e.g., those in Weights) for solving complicated AI tasks. In this concept, an LLM acts as a controller, managing and organizing the cooperation of expert models. The LLM first plans a list of tasks based on the user request and then assigns expert models to each task. After the experts execute the tasks, the LLM collects the results and responds to the user.
Understanding the Planning of LLM Agents: A Survey
- This paper by Xu Huang et al. from the USTC and Huawei Noah’s Ark Lab presents a comprehensive survey of the planning capabilities of Large Language Model (LLM)-based agents, systematically categorizing recent approaches and identifying challenges in leveraging LLMs as planning modules. The authors define a taxonomy that classifies existing LLM-agent planning methods into five main categories: Task Decomposition, Multi-Plan Selection, External Planner-Aided Planning, Reflection and Refinement, and Memory-Augmented Planning. This taxonomy serves as a framework for understanding how various methods address the complexity of planning tasks in autonomous agents and highlights key developments in each category.
- The paper explores Task Decomposition, where complex tasks are divided into manageable sub-tasks, categorized further into Decomposition-First and Interleaved Decomposition. Techniques like Chain-of-Thought (CoT) and ReAct are examined for their methods in guiding LLMs to sequentially reason through tasks, emphasizing the benefits of sub-task correlation while noting limitations in handling lengthy planning sequences due to memory constraints. Multi-Plan Selection is detailed with methods like Tree-of-Thought (ToT) and Graph-of-Thought (GoT), where LLMs generate multiple candidate plans and then employ search algorithms (e.g., Monte Carlo Tree Search) to choose optimal paths, addressing the stochastic nature of LLM planning but also noting challenges with computational overhead.
- External Planner-Aided Planning is reviewed, dividing approaches into symbolic and neural planners, where LLMs act primarily as intermediaries, structuring tasks for external systems like PDDL or reinforcement learning-based neural planners. The symbolic planners enhance task formalization, while neural planners like DRRN model LLM-aided planning as Markov decision processes, showing efficiency in domain-specific scenarios. Reflection and Refinement strategies, such as Self-Refine and Reflexion, use iterative planning and feedback mechanisms to allow LLM agents to self-correct based on previous errors, resembling reinforcement learning updates but emphasizing textual feedback over parameter adjustments.
- This paper by Xu Huang et al. from the USTC and Huawei Noah’s Ark Lab presents a comprehensive survey of the planning capabilities of Large Language Model (LLM)-based agents, systematically categorizing recent approaches and identifying challenges in leveraging LLMs as planning modules. The authors define a taxonomy that classifies existing LLM-agent planning methods into five main categories: Task Decomposition, Multi-Plan Selection, External Planner-Aided Planning, Reflection and Refinement, and Memory-Augmented Planning. This taxonomy serves as a framework for understanding how various methods address the complexity of planning tasks in autonomous agents and highlights key developments in each category.
- Memory-Augmented Planning is discussed through RAG-based memory, which retrieves task-relevant information to support planning, and embodied memory, where agents fine-tune on experiential data, embedding learned knowledge into model parameters. Examples like MemGPT and TDT illustrate how different memory types enhance planning capabilities, balancing between update costs and memorization capacity.
- The following figure from the paper shows a taxonomy on LLM-Agent planning.

- The paper evaluates the effectiveness of these approaches on four benchmarks, demonstrating that strategies involving task decomposition, multi-path selection, and reflection significantly improve performance, albeit at higher computational costs. Challenges identified include LLM hallucinations, plan feasibility under complex constraints, efficiency, and limitations in handling multi-modal feedback. Future directions suggested include incorporating symbolic models for constraint handling, optimizing for planning efficiency, and developing realistic evaluation environments to more closely simulate real-world agent interactions. This survey provides a foundational overview of LLM planning, guiding future work toward robust and adaptable planning agents.
Multi-Agent Collaboration
ChatDev: Communicative Agents for Software Development
- The paper by Qian et al. from Tsinghua, The University of Sydney, BUPT, and Modelbest Inc., published in ACL 2024, presents ChatDev, a software development framework using multiple agents powered by large language models (LLMs) to facilitate collaborative tasks within the software development lifecycle, including design, coding, and testing. The framework is designed to streamline multi-agent communication for more coherent, effective problem-solving across these phases. Key innovations include a structured “chat chain” approach and a “communicative dehallucination” mechanism, both aimed at enhancing the quality and executability of the generated code.
- ChatDev’s chat chain organizes the workflow into sequential phases—design, coding (subdivided into code writing and completion), and testing (split between code review and system testing)—with each phase containing sequential subtasks. Each subtask is addressed by an “instructor” and an “assistant” agent, who engage in multi-turn dialogues to collaboratively develop solutions, making it easier to handle complex requirements through natural language exchanges in design and programming dialogues in development. The framework thus maintains a coherent flow across phases, facilitating effective transitions and linking subtasks while offering transparency for monitoring intermediate solutions and issues.
- The communicative dehallucination mechanism addresses the problem of LLM-induced hallucinations in code by prompting agents to seek additional details from the instructor before finalizing responses. This enables agents to achieve more precise task outcomes, reducing instances of incomplete or unexecutable code. In this pattern, the assistant initially requests further guidance, which the instructor then clarifies, allowing the assistant to proceed with an optimized response. This iterative approach helps minimize errors and increases the quality and reliability of the generated code.
- The following figure from the paper shows that upon receiving a preliminary task requirement (e.g., “develop a Gomoku game”), these software agents engage in multi-turn communication and perform instruction-following along a chain-structured workflow, collaborating to execute a series of subtasks autonomously to craft a comprehensive solution.
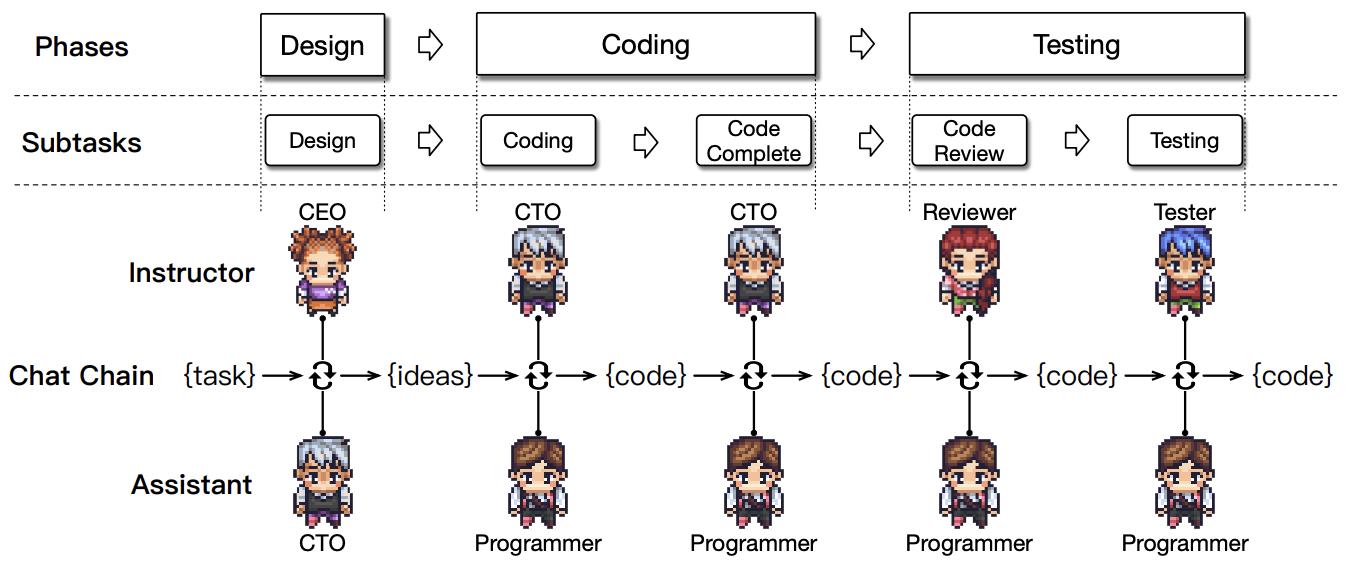
- Implementation Details:
- Role Assignment and Memory Management: Each agent is assigned a specific role tailored to different stages in the workflow, like CEO, CTO, programmer, reviewer, and tester. These roles ensure that agents contribute specialized insights at each phase. ChatDev employs short-term memory to maintain contextual continuity within a phase and long-term memory for cross-phase coherence, selectively transmitting only key solutions rather than entire dialogues to avoid memory overload.
- Subtask Termination Criteria: To streamline communication, a subtask concludes after two consecutive unchanged code updates or after 10 rounds of communication. This rule optimizes resource use and prevents redundant iterations.
- Prompt Engineering and LLM Integration: In each subtask, prompt engineering is applied at the onset, followed by automated exchanges. ChatGPT-3.5, with a low temperature of 0.2, supports task-specific response generation, while Python-3.11.4 integration enables real-time feedback on executable code.
- Evaluation:
- ChatDev was evaluated against baseline models GPT-Engineer and MetaGPT using metrics including completeness, executability, consistency, and overall quality. Results show ChatDev’s significant improvements in generating more executable and complete code, largely due to its structured chat chain and communicative dehallucination mechanisms. An ablation study highlights the importance of specific roles and the dehallucination mechanism in boosting software quality.
- Code
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
- This paper by Wu et al. from Microsoft Research, Pennsylvania State University, University of Washington, and Xidian University, introduces AutoGen, an open-source framework designed to facilitate the development of multi-agent large language model (LLM) applications. The framework allows the creation of customizable, conversable agents that can operate in various modes combining LLMs, human inputs, and tools.
- AutoGen agents can be easily programmed using both natural language and computer code to define flexible conversation patterns for different applications. The framework supports hierarchical chat, joint chat, and other conversation patterns, enabling agents to converse and cooperate to solve tasks. The agents can hold multiple-turn conversations with other agents or solicit human inputs, enhancing their ability to solve complex tasks.
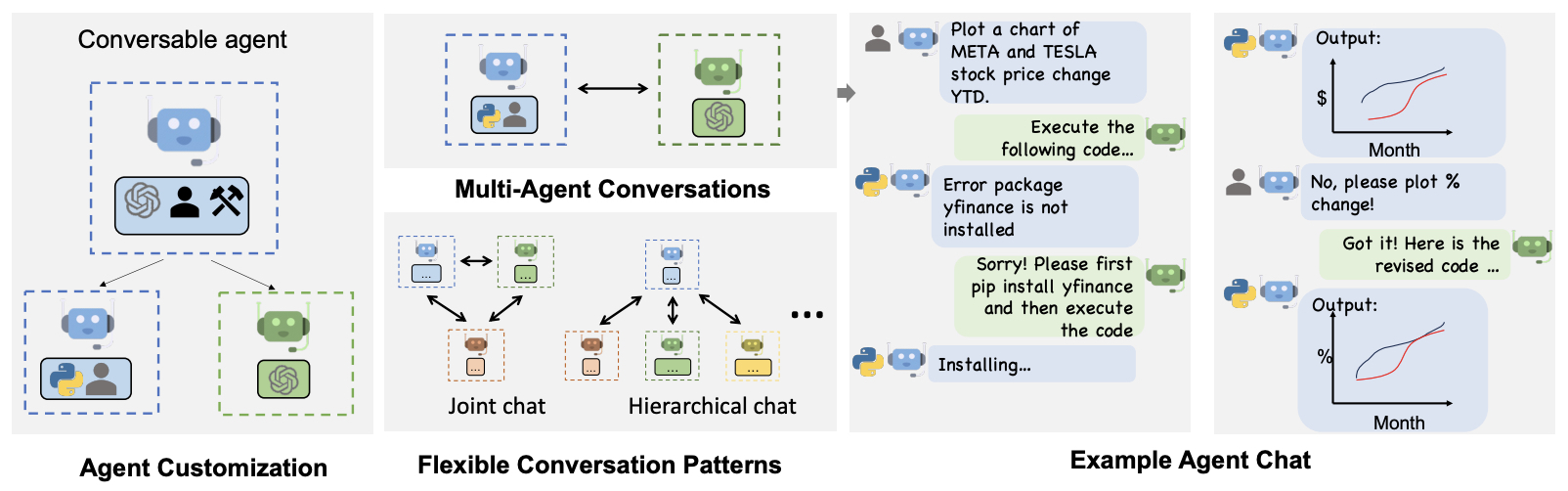
- Key technical details include the design of conversable agents and conversation programming. Conversable agents can send and receive messages, maintain internal context, and be configured with various capabilities such as LLMs, human inputs, and tools. These agents can also be extended to include more custom behaviors. Conversation programming involves defining agent roles and capabilities and programming their interactions using a combination of natural and programming languages. This approach simplifies complex workflows into intuitive multi-agent conversations.
- Implementation details:
- Conversable Agents: AutoGen provides a generic design for agents, enabling them to leverage LLMs, human inputs, tools, or a combination. The agents can autonomously hold conversations and solicit human inputs at certain stages. Developers can easily create specialized agents with different roles by configuring built-in capabilities and extending agent backends.
- Conversation Programming: AutoGen adopts a conversation programming paradigm to streamline LLM application workflows. This involves defining conversable agents and programming their interactions via conversation-centric computation and control. The framework supports various conversation patterns, including static and dynamic flows, allowing for flexible agent interactions.
- Unified Interfaces and Auto-Reply Mechanisms: Agents in AutoGen have unified interfaces for sending, receiving, and generating replies. An auto-reply mechanism enables conversation-driven control, where agents automatically generate and send replies based on received messages unless a termination condition is met. Custom reply functions can also be registered to define specific behavior patterns.
- Control Flow: AutoGen allows control over conversations using both natural language and programming languages. Natural language prompts guide LLM-backed agents, while Python code specifies conditions for human input, tool execution, and termination. This flexibility supports diverse multi-agent conversation patterns, including dynamic group chats managed by the
GroupChatManagerclass.
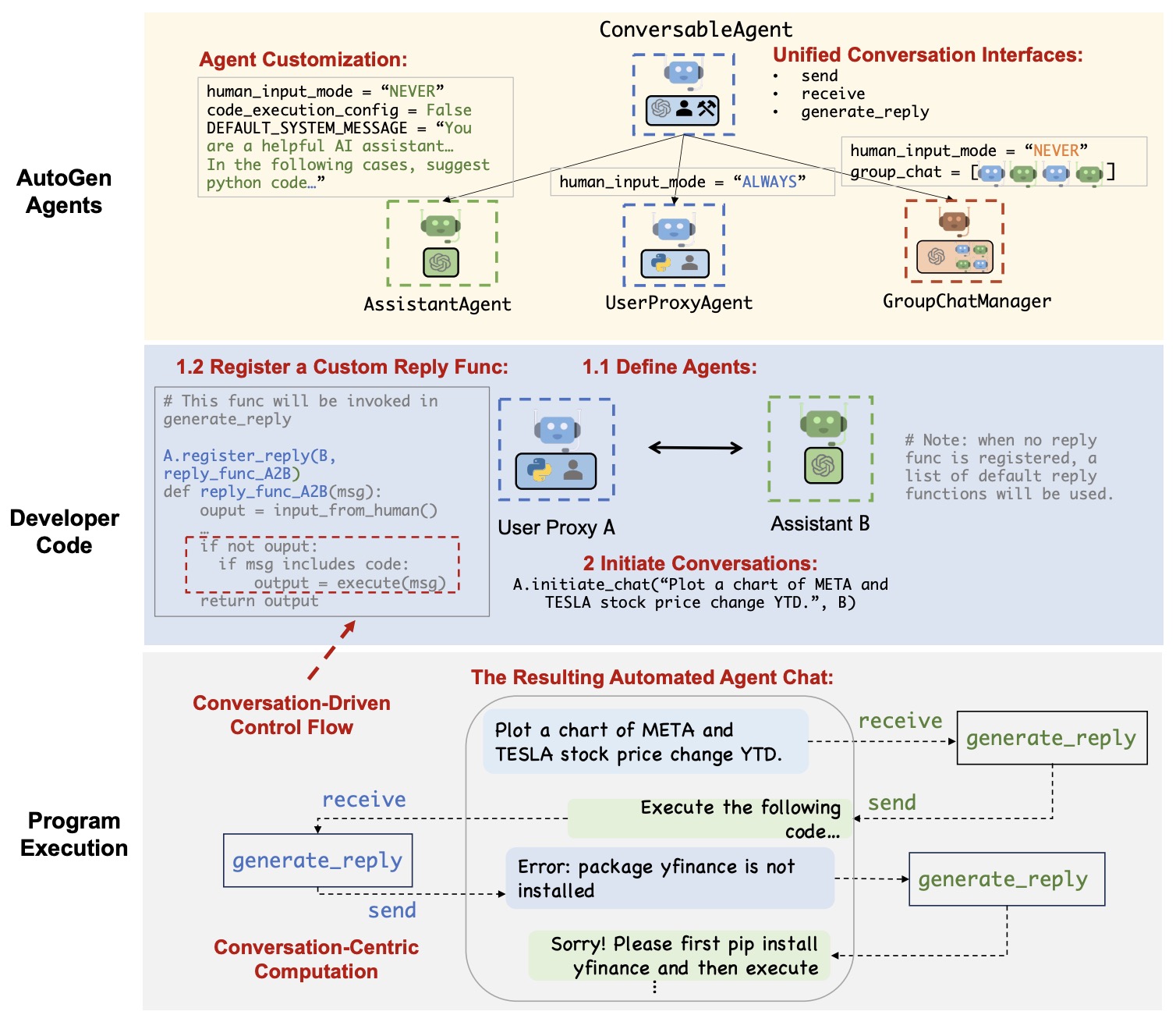
- The framework’s architecture defines agents with specific roles and capabilities, interacting through structured conversations to process tasks efficiently. This approach improves task performance, reduces development effort, and enhances application flexibility. Key technical aspects include using a unified interface for agent interaction, conversation-centric computation for defining agent behaviors, and conversation-driven control flows that manage interactions among agents.
- Applications demonstrate AutoGen’s capabilities in various domains:
- Math Problem Solving: AutoGen builds systems for autonomous and human-in-the-loop math problem solving, outperforming other approaches on the MATH dataset.
- Retrieval-Augmented Code Generation and Question Answering: The framework enhances retrieval-augmented generation systems, improving performance on question-answering tasks through interactive retrieval mechanisms.
- Decision Making in Text World Environments: AutoGen implements effective interactive decision-making applications using benchmarks like ALFWorld.
- Multi-Agent Coding: The framework simplifies coding tasks by dividing responsibilities among agents, improving code safety and efficiency.
- Dynamic Group Chat: AutoGen supports dynamic group chats, enabling collaborative problem-solving without predefined communication orders.
- Conversational Chess: The framework creates engaging chess games with natural language interfaces, ensuring valid moves through a board agent.
- The empirical results indicate that AutoGen significantly outperforms existing single-agent and some MAS in complex task environments by effectively integrating and managing multiple agents’ capabilities. The paper includes a figure illustrating the use of AutoGen to program a multi-agent conversation, showing built-in agents, a two-agent system with a custom reply function, and the resulting automated agent chat.
- The authors highlight the potential for AutoGen to improve LLM applications by reducing development effort, enhancing performance, and enabling innovative uses of LLMs. Future work will explore optimal multi-agent workflows, agent capabilities, scaling, safety, and human involvement in multi-agent conversations. The open-source library invites contributions from the broader community to further develop and refine AutoGen.
APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets
- This paper introduces APIGen, a novel automated data generation pipeline designed by Salesforce AI Research to create reliable and diverse datasets specifically for function-calling applications in LLMs. The APIGen framework addresses challenges in training function-calling agents by producing a large-scale dataset with high-quality, verified function calls. The authors leverage a structured, multi-stage verification approach to generate a dataset that enables fine-tuning LLMs, which demonstrates significant improvements in performance on the Berkeley Function-Calling Benchmark (BFCL).
- APIGen includes a dataset of 60,000 entries across 3,673 APIs from 21 categories, encompassing different query styles (simple, multiple, parallel, and parallel multiple). Notably, APIGen-trained models, even with relatively fewer parameters, achieved strong results in function-calling benchmarks, surpassing larger LLMs such as GPT-4 and Claude-3.
- APIGen Framework and Data Generation: The APIGen framework generates query-answer pairs through a structured pipeline, involving:
- Sampling: APIs and QA pairs are sampled from a comprehensive library and formatted in a unified JSON schema.
- Prompting: LLMs are prompted using diverse templates to generate function-call responses in JSON format, promoting response variability across different real-world scenarios.
- Multi-Stage Verification:
- Format Checker: Ensures generated data follows JSON specifications and filters poorly formatted entries.
- Execution Checker: Executes function calls to verify correctness against backend APIs, discarding calls with errors.
- Semantic Checker: A second LLM verifies alignment between generated answers and query intent, further refining data quality.
- This pipeline allows APIGen to create a dataset that supports diverse function-calling scenarios, enhancing model generalization and robustness. The figure below from the paper illustrates the post-process filters.
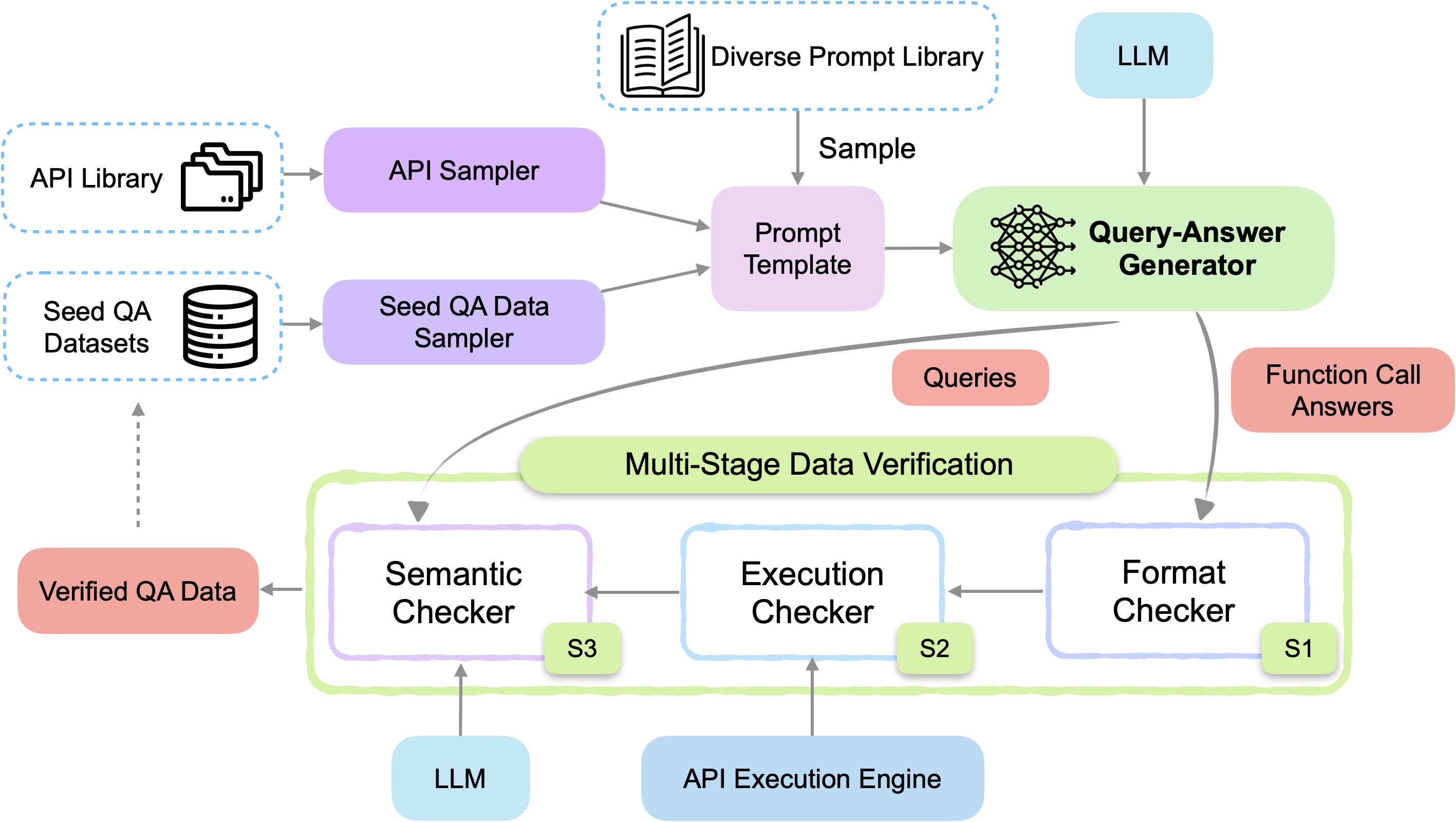
- The figure below from the paper illustrates JSON data format examples.

- Diversity and Scalability: APIGen emphasizes diversity by categorizing queries and sampling API descriptions from different sources. It includes four query types:
- Simple: A single API call per query.
- Multiple: Requires selecting the appropriate function from various APIs.
- Parallel: Executes multiple API calls in one response.
- Parallel Multiple: Combines both parallel and multiple query types, calling for intricate function handling.
- To ensure scalability, APIGen processes data from multiple API formats, such as REST and Python functions, adapting them into its JSON format. This modular approach accommodates a variety of API sources with minimal adjustments.
- Dataset and Implementation: The dataset generation involves filtering APIs for quality, executing requests to ensure validity, and regenerating API descriptions where necessary. The resulting dataset spans diverse categories, ensuring comprehensive coverage across fields like finance, technology, and social sciences.
- Training experiments involved two model versions, xLAM-1B (FC) and xLAM-7B (FC), demonstrating APIGen’s dataset’s efficacy. Models trained with APIGen data achieved remarkable accuracy on the BFCL, particularly in scenarios involving complex, parallel, and multi-call queries. The xLAM-7B model notably ranked 6th on the BFCL leaderboard, surpassing models like GPT-4 and Llama3.
- Human Evaluation and Future Work: APIGen’s effectiveness was validated through human evaluation, with over 95% of samples passing quality checks. The authors plan to extend APIGen to support more API types and incorporate multi-turn interaction capabilities for function-calling agents.
- By providing a structured and scalable approach to high-quality dataset generation, APIGen sets a new standard for training robust function-calling LLMs, addressing gaps in current datasets and enhancing LLMs’ real-world applicability.
- Hugging Face; Project page
AutoAgents: A Framework for Automatic Agent Generation
- This paper from Chen et al. published in IJCAI 2024 presents AutoAgents, a novel framework designed for dynamic multi-agent generation and coordination, enabling language models to construct adaptive AI teams for a wide range of tasks. Unlike traditional systems that rely on static, predefined agents, AutoAgents generates task-specific agents autonomously, allowing for flexible collaboration across varied domains. The framework introduces a drafting and execution stage to handle complex task environments and facilitate effective role assignment and solution planning.
- In the drafting stage, three primary agents—Planner, Agent Observer, and Plan Observer—collaborate to define and refine an agent team and execution plan. The Planner generates specialized agents, each described by prompts detailing roles, objectives, constraints, and toolsets. The Agent Observer evaluates agents for task suitability, ensuring they are adequately diverse and relevant. Simultaneously, the Plan Observer assesses the execution plan, refining it to address any gaps and optimize agent collaboration.
- The execution stage leverages two mechanisms for task completion: self-refinement and collaborative refinement. In self-refinement, individual agents iterate on their tasks, improving their outputs through cycles of reasoning and self-evaluation. Collaborative refinement allows agents to pool expertise, enhancing task execution through interdisciplinary dialogue. A predefined Action Observer oversees coordination, adjusting task allocations and managing memory across agents to maintain efficiency and coherence.
- To enhance adaptability in complex tasks, AutoAgents incorporates three types of memory—short-term, long-term, and dynamic—to manage historical data and context for each action. Dynamic memory, in particular, facilitates the Action Observer’s access to essential prior actions, optimizing task-related decisions.
-
- The figure below from the paper illustrates a schematic diagram of AutoAgents. The system takes the user input as a starting point and generates a set of specialized agents for novel writing, along with a corresponding execution plan. The agents collaboratively carry out the tasks according to the plan and produce the final novel. Meanwhile, an observer monitors the generation and execution of the Agents and the plan, ensuring the quality and coherence of the process.
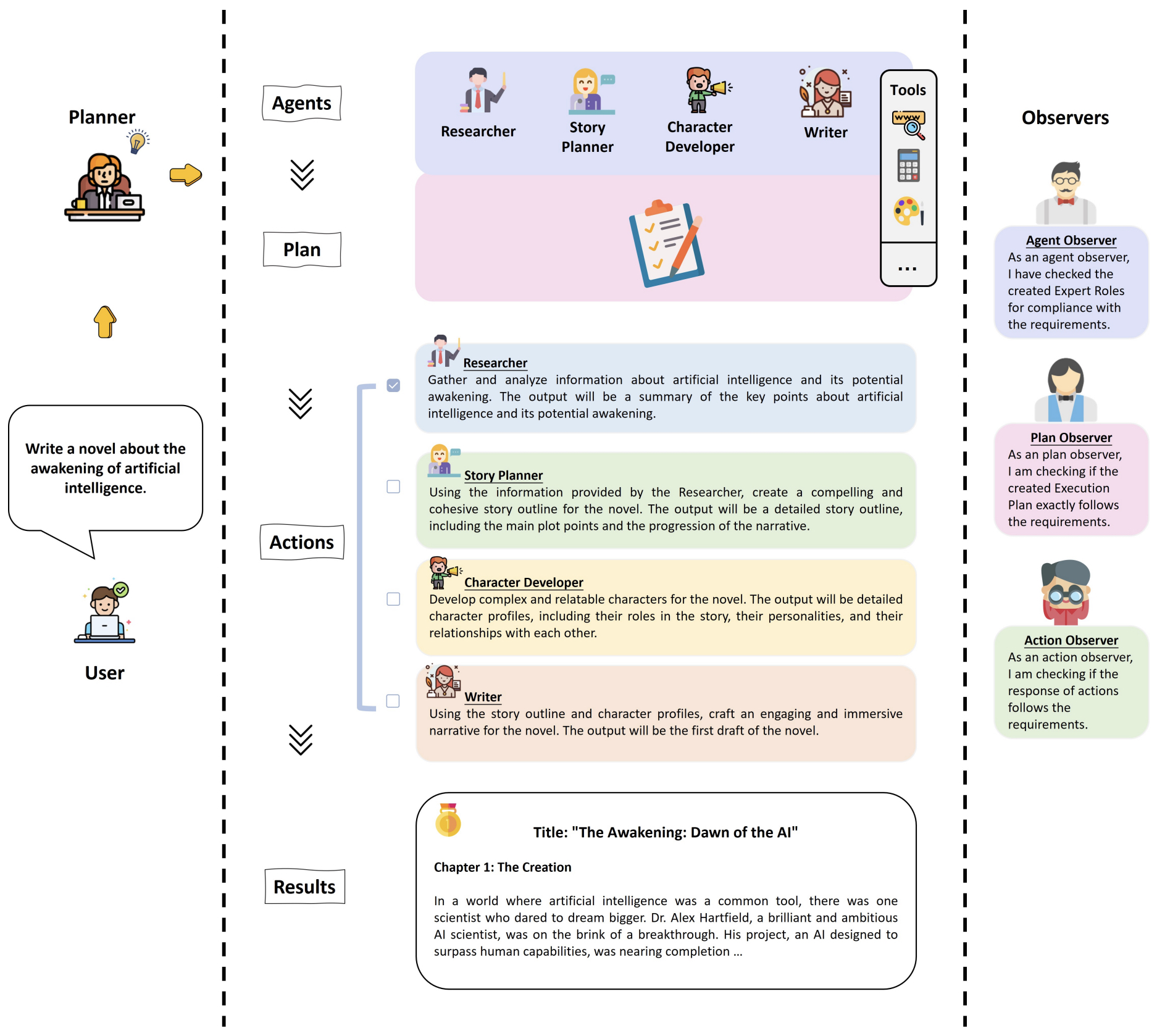
- Experiments across open-ended question-answering and trivia creative writing tasks validate AutoAgents’ superior performance. AutoAgents surpasses traditional models, including GPT-4, in both knowledge acquisition and reasoning quality. The system demonstrates a significant increase in knowledge integration, especially when handling tasks demanding extensive domain-specific information. A case study in software development shows how AutoAgents generates diverse expert roles (e.g., game designer, programmer, tester) for developing a Python-based Tetris game, highlighting the versatility of the agent team composition.
- Implementation-wise, AutoAgents utilizes GPT-4 API with a controlled temperature setting for reproducibility. Experiment parameters include a maximum of three drafting discussions and five execution refinements, with dynamic prompts designed to guide each agent’s expertise and actions.
- In summary, AutoAgents offers a significant advancement in adaptive, collaborative AI systems by automating agent generation and task planning, reinforcing the capabilities of LLMs in handling complex, domain-spanning tasks through self-organizing, expert-driven agent teams.
- Code
MetaGPT: Meta Programming for Multi-Agent Collaborative Framework
- Recently, remarkable progress has been made in automated task-solving through the use of multi-agents driven by large language models (LLMs). However, existing works primarily focuses on simple tasks lacking exploration and investigation in complicated tasks mainly due to the hallucination problem. This kind of hallucination gets amplified infinitely as multiple intelligent agents interact with each other, resulting in failures when tackling complicated problems.
- This paper by Hong et al. from DeepWisdom, Xiamen University, CUHK, Shenzhen, Nanjing University, UPenn, Berkeley introduces MetaGPT, an innovative framework that infuses effective human workflows as a meta programming approach into LLM-driven multi-agent collaboration. In particular, MetaGPT first encodes Standardized Operating Procedures (SOPs) into prompts, fostering structured coordination. And then, it further mandates modular outputs, bestowing agents with domain expertise paralleling human professionals to validate outputs and reduce compounded errors.
- In this way, MetaGPT leverages the assembly line work model to assign diverse roles to various agents, thus establishing a framework that can effectively and cohesively deconstruct complex multi-agent collaborative problems.
- Their experiments conducted on collaborative software engineering tasks illustrate MetaGPT’s capability in producing comprehensive solutions with higher coherence relative to existing conversational and chat-based MAS. This underscores the potential of incorporating human domain knowledge into multi-agents, thus opening up novel avenues for grappling with intricate real-world challenges.
- The following figure from the paper shows a comparative depiction of the software development SOP between MetaGPT and real-world human team. The MetaGPT approach showcases its ability to decompose high-level tasks into detailed actionable components handled by distinct roles (ProductManager, Architect, ProjectManager, Engineer), thereby facilitating role-specific expertise and coordination. This methodology mirrors human software development teams, but with the advantage of improved efficiency, precision, and consistency. The diagram illustrates how MetaGPT is designed to handle task complexity and promote clear role delineations, making it a valuable tool for complex software development scenarios.
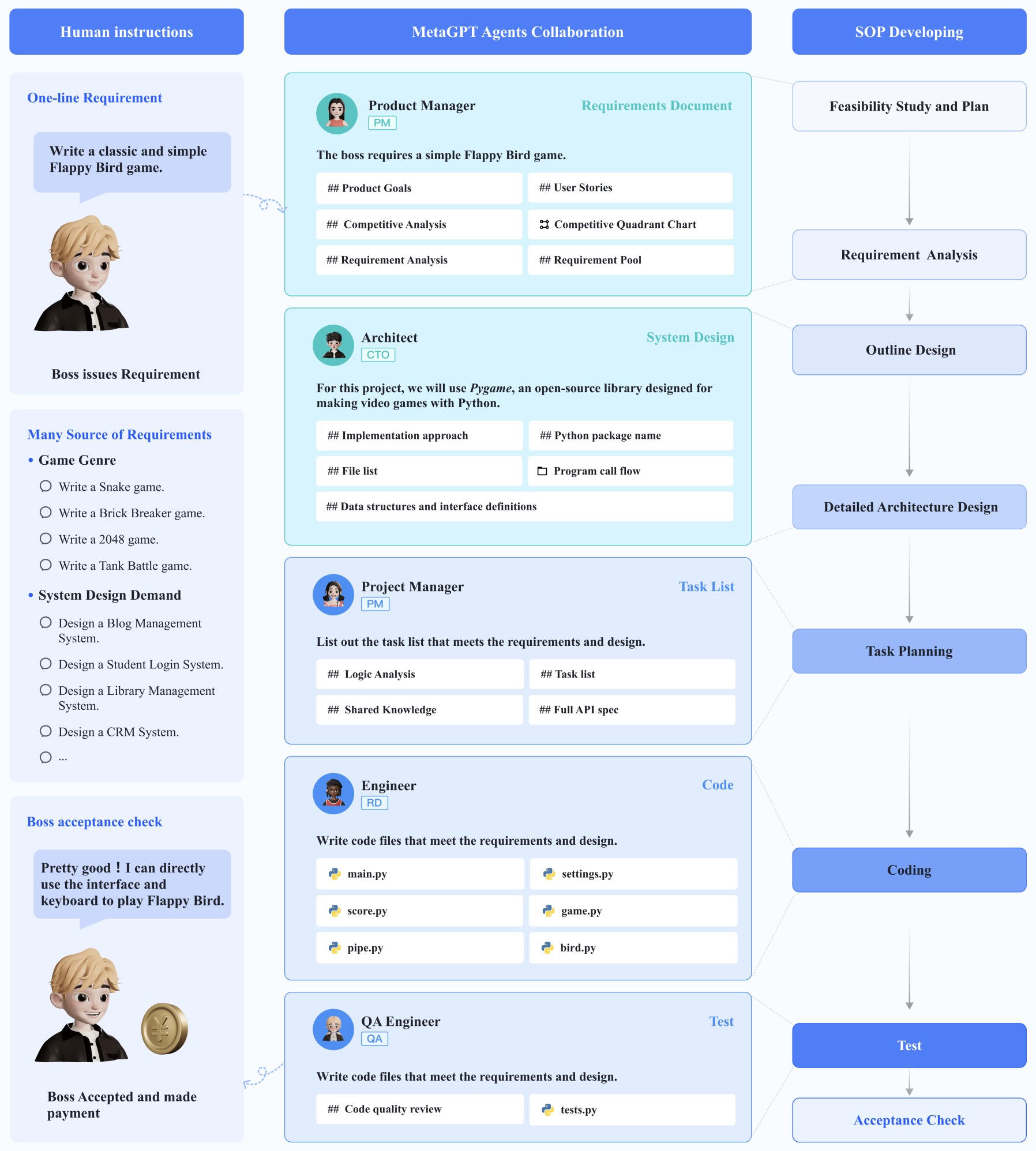
Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models
- Large language models (LLMs) have achieved remarkable progress in solving various natural language processing tasks due to emergent reasoning abilities. However, LLMs have inherent limitations as they are incapable of accessing up-to-date information (stored on the Web or in task-specific knowledge bases), using external tools, and performing precise mathematical and logical reasoning.
- This paper by Lu et al. from UCLA and Microsoft Research presents Chameleon, an AI system that mitigates these limitations by augmenting LLMs with plug-and-play modules for compositional reasoning. Chameleon synthesizes programs by composing various tools (e.g., LLMs, off-the-shelf vision models, web search engines, Python functions, and heuristic-based modules) for accomplishing complex reasoning tasks.
- At the heart of Chameleon is an LLM-based planner that assembles a sequence of tools to execute to generate the final response.
- They showcase the effectiveness of Chameleon on two multi-modal knowledge-intensive reasoning tasks: ScienceQA and TabMWP. Chameleon, powered by GPT-4, achieves an 86.54% overall accuracy on ScienceQA, improving the best published few-shot result by 11.37%. On TabMWP, GPT-4-powered Chameleon improves the accuracy by 17.0%, lifting the state of the art to 98.78%.
- Their analysis also shows that the GPT-4-powered planner exhibits more consistent and rational tool selection via inferring potential constraints from instructions, compared to a ChatGPT-powered planner.
- The following figures from the paper shows two examples from their Chameleon with GPT-4 on TabMWP, a mathematical reasoning benchmark with tabular contexts. Chameleon demonstrates flexibility and efficiency in adapting to different queries that require various reasoning abilities.
OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning
- This paper by Lu et al. from Stanford introduces OctoTools, a training-free, extensible agentic framework designed to enhance large language models (LLMs) with external tools for complex reasoning. Unlike prior approaches, OctoTools does not require additional training data or domain-specific tool constraints, making it adaptable across diverse reasoning tasks.
- Key contributions:
- Tool cards: Standardized tool wrappers encapsulate various functionalities, enabling seamless integration and execution without framework modifications.
- Planner-executor framework: Separates high-level task planning from tool execution. The planner formulates a structured problem-solving strategy, while the executor generates and executes tool commands dynamically.
- Task-specific toolset optimization: A lightweight algorithm selects the most beneficial subset of tools for each task, improving both accuracy and efficiency.
- Comprehensive benchmarking: OctoTools was evaluated on 16 reasoning benchmarks (MathVista, MMLU-Pro, MedQA, GAIA-Text, etc.), achieving a 9.3% accuracy improvement over GPT-4o and up to 10.6% over existing agent frameworks like AutoGen, GPT-Functions, and LangChain.
- The following figures from the paper shows the framework of OctoTools. (1) Tool cards define tool-usage metadata and encapsulate tools, enabling training-free integration of new tools without additional training or framework refinement. (2) The planner governs both high-level and low-level planning to address the global objective and refine actions step by step. (3) The executor instantiates tool calls by generating executable commands and save structured results in the context. The final answer is summarized from the full trajectory in the context. Furthermore, the task-specific toolset optimization algorithm learns to select a beneficial subset of tools for downstream tasks.
- Implementation details:
- The system operates through three core modules:
- Tool cards: Define metadata for each tool, including input-output formats, constraints, and best-use cases (e.g., Image Captioner, Object Detector, Python Calculator).
- Planner: Determines which tools to invoke and structures problem decomposition into sub-goals.
- Executor: Converts planner instructions into executable commands, runs tools, and updates context iteratively.
- Uses structured reasoning pipelines, where each step refines prior results to enhance multi-step problem-solving.
- The optimization algorithm iteratively selects tools based on validation accuracy, ensuring efficiency without introducing unnecessary complexity.
- The system operates through three core modules:
- Experimental results:
- Achieved 58.5% accuracy across 16 diverse benchmarks, outperforming GPT-4o (49.2%), LangChain (51.2%), and AutoGen (47.9%).
- Demonstrated superior multi-step reasoning and tool utilization, particularly in math, science, and medical domains.
- Ablation studies confirmed that task planning, external tool calling, and multi-step problem solving each contribute significantly to performance improvements.
- Conclusion:
- OctoTools is a scalable, modular, and effective solution for enhancing LLMs with external tool integration.
- It bridges the gap between generic LLM reasoning and domain-specific problem solving, making it a powerful alternative to traditional AI agent frameworks.
- Future work includes real-time query-based tool selection, multi-agent collaboration, and expanding domain-specific functionalities.
- Website; GitHub Repository; Hugging Face Demo
Further Reading
- Communicative Agents for Software Development by Qian et al. (2023): Discusses the application of communicative agents in software development by introducing ChatDev, an open-source virtual software company run by agents.
- AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation by Wu et al. (2023): Explores how multi-agent conversations can enhance LLM applications.
- MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework by Hong et al. (2023): Provides insights into meta programming within a multi-agent framework.
- Task-driven Autonomous Agent Utilizing GPT-4, Pinecone, and LangChain for Diverse Applications
- Anthropic’s blog on building effective agents
- Model Context Protocol (MCP): Specifications
- What is Model Context Protocol (MCP)? How it simplifies AI integrations compared to APIs
- Don’t Sleep on Single-agent Systems
References
- The Batch – Weekly Issues: Issue 245
- The Batch – Agentic Design Patterns
- AWS: What are AI Agents
- LLM Agents by Prompt Engineering Guide
- Introduction to LLM Agents, Nvidia Blog
- Aishwarya Reganti’s Agents 101 Guide
- Nvidia Introduction to LLM Agents
- Deepchecks
- Weaviate Blog: What is Agentic RAG?
- Agentic RAG with VoyageAI, Gemini and LangGraph
- Why MCP Won
- Philipp Schmid: Model Context Protocol (MCP) an overview
- What Is MCP, and Why Is Everyone – Suddenly!– Talking About It?
- What is MCP
- I gave Claude root access to my server… Model Context Protocol explained
- Building Agents with Model Context Protocol - Full Workshop with Mahesh Murag of Anthropic
Citation
If you found our work useful, please cite it as:
@article{Chadha2020DistilledAgents,
title = {Agents},
author = {Chadha, Aman and Jain, Vinija},
journal = {Distilled AI},
year = {2020},
note = {\url{https://vinija.ai}}
}