Primers • Agentic Design Patterns
- Overview
- What makes an AI system an agent?
- Agentic Design Patterns
- Core Idea
- From linear prompts to execution graphs
- Functional roles
- Compositional structure
- When to use these patterns
- The unifying principle
- Prompt Chaining
- Routing
- Parallelization
- Reflection
- Tool Use
- Planning
- Prioritization
- Pattern Selection and Composition
- Multi-Agent Systems
- Single-Agent vs. Multi-Agent Systems
- Why this distinction matters
- Conceptual definitions
- Visual overview
- Architectural comparison
- Core tradeoffs
- When single-agent systems are usually better
- When multi-agent systems become competitive
- Architecture selection guidance
- Key takeaways
- State, Adaptation, and Control in Agentic Systems
- Core Idea
- Memory Management
- Learning and Adaptation
- Model Context Protocol (MCP)
- Goal Setting and Monitoring
- Exception Handling and Recovery
- Human-in-the-Loop
- Guardrails and Safety
- Evaluation
- References
- Citation
Overview
-
Agentic design patterns are reusable ways to structure systems in which a language model does more than generate text. The model becomes part of a larger loop that observes context, chooses actions, uses tools, manages state, and keeps moving toward a goal. That shift, from text generation to goal-directed orchestration, is the central idea behind modern agent engineering. In this view, the model is not the whole product. It is the reasoning core inside a system that must also handle memory, tool access, control flow, communication, and failure recovery.
-
A useful mental model is to treat an agent system as an operating canvas. The canvas is the runtime environment that holds prompts, state, tools, external APIs, memory stores, and the logic that routes information from one step to the next. The important design question is therefore not only “which model should I call?” but also “how should the system be structured so the model can act reliably under uncertainty?” That is exactly where design patterns matter.
-
The reason patterns are so important is that single-shot prompting breaks down quickly as tasks become multi-step, tool-dependent, or long-running. Once a system must decompose work, retrieve facts, call APIs, maintain conversational state, coordinate specialists, or recover from partial failure, the architecture matters at least as much as the prompt. This is the same lesson the broader agent literature has converged on: performance improves when reasoning is interleaved with action, when external tools can be invoked, and when retrieved evidence augments model-only memory. ReAct by Yao et al. (2022) showed that alternating reasoning and acting improves multi-step task solving by letting the model update plans from observations. Toolformer by Schick et al. (2023) showed that models can learn when and how to call tools, which is foundational for practical agents. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Lewis et al. (2020) established the now-standard idea that external retrieval can make generation more factual and updatable.
-
Each pattern in this primer is paired with hands-on implementations using LangChain, demonstrating how these concepts translate into real, executable systems. This bridges the gap between theory and practice by showing how agentic behaviors such as planning, tool use, memory, and coordination can be concretely realized in production-oriented frameworks.
-
At a high level, an agentic system can be described as a policy over actions conditioned on context. If we write the agent’s state at time \(t\) as \(s_t\), its chosen action as \(a_t\), and its objective as maximizing expected cumulative utility, then the design problem is often framed as:
- This is not saying every agent in practice is trained end-to-end with reinforcement learning. Most production agents are not. Rather, it gives a clean way to think about what the system is doing: at each step it selects the next best action given the current state, available tools, and long-term objective. For the introductory patterns in this primer, no special loss function is central yet, because the focus is system structure rather than model training.
Why are agentic systems needed?
-
Modern AI systems reached a point where generating high-quality text is no longer the bottleneck. The real limitation lies in reliably solving complex, multi-step, real-world problems. A standalone large language model can produce fluent answers, but it struggles when tasks require persistence, external interaction, or adaptive decision-making. This gap is precisely why agentic systems are needed.
-
At their core, real-world problems are not single-shot queries. They are processes. They involve gathering information, making intermediate decisions, interacting with external systems, and iteratively refining outcomes. A static prompt-response model cannot sustain this kind of workflow because it lacks continuity, structured control, and the ability to act.
-
Agentic systems address this by transforming the model into part of a loop rather than a terminal endpoint. Instead of producing a single output, the system continuously updates its understanding and actions:
-
This loop directly mirrors the five-step operational cycle described in the source material, where an agent gets a mission, gathers context, plans, acts, and improves over time.
-
The following figure illustrates that agentic AI functions as an intelligent assistant, continuously learning through experience. It operates via a straightforward five-step loop to accomplish tasks.
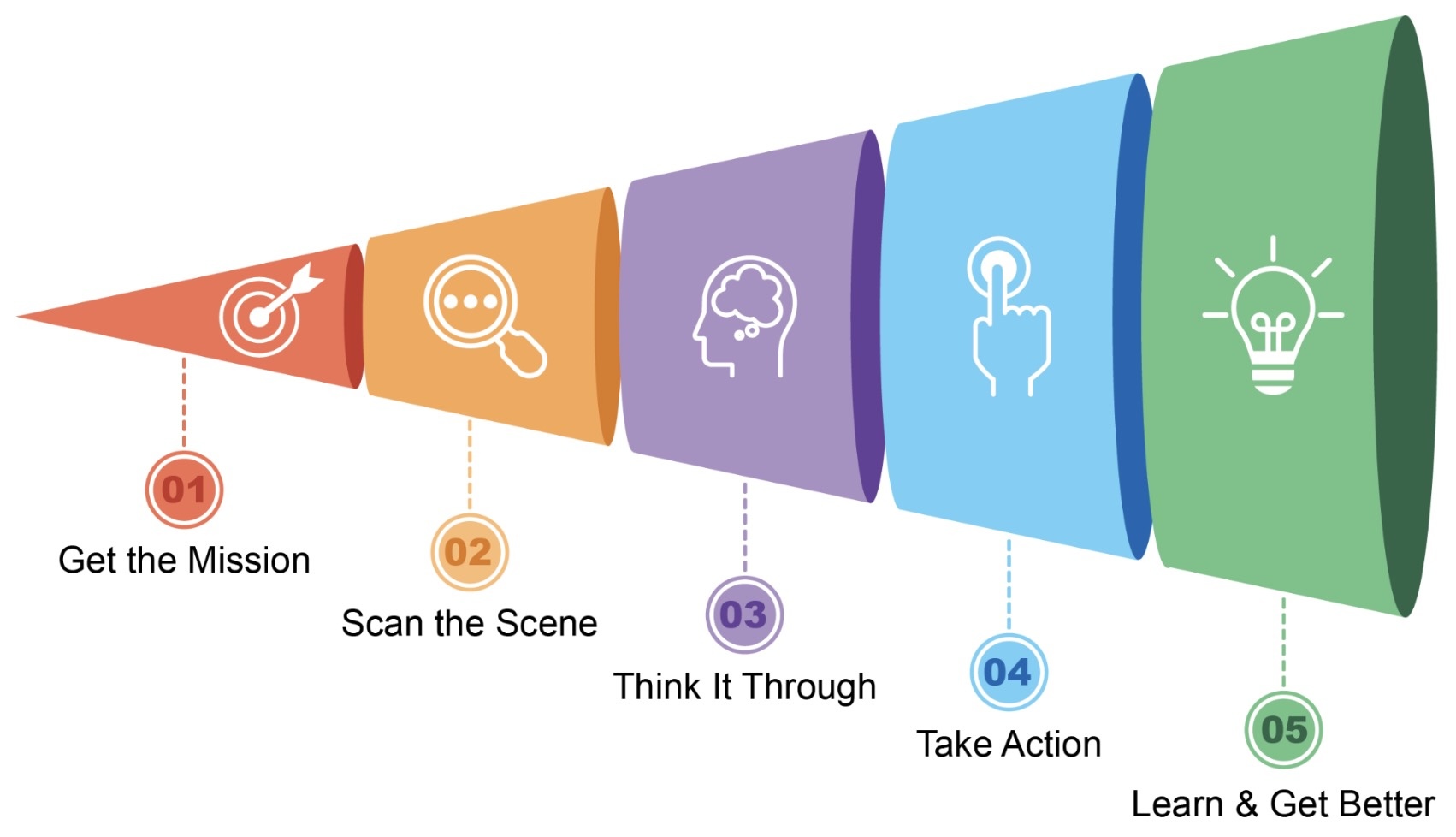
The limitations of non-agentic systems
-
Traditional LLM-based applications fail in predictable ways when pushed beyond simple tasks:
- They cannot maintain state across multiple steps without manual orchestration
- They lack access to real-time or external information unless explicitly integrated
- They do not inherently plan or decompose problems
- They cannot act in the environment (e.g., call APIs, update systems)
- They cannot improve through feedback within a task
-
This leads to brittle systems that perform well in demos but degrade quickly in production scenarios.
-
Research has consistently highlighted these gaps. For example, ReAct by Yao et al. (2022) demonstrated that combining reasoning with actions significantly improves performance on multi-step tasks by allowing models to update their strategy based on observations. Similarly, Toolformer by Schick et al. (2023) showed that models become far more capable when they can decide when to use external tools. These works reinforce a key idea: intelligence in practical systems emerges not just from reasoning, but from structured interaction with the environment.
The need for goal-directed behavior
-
Agentic systems are needed because real applications are goal-driven rather than query-driven. Instead of answering “What is X?”, systems must achieve objectives like:
- Resolve a customer issue end-to-end
- Plan and execute a workflow
- Monitor and react to changing conditions
- Coordinate multiple steps across systems
-
This shift requires systems that can operate autonomously toward a goal, rather than simply responding to inputs.
-
Formally, this aligns with decision-making under uncertainty, where the system must choose actions that maximize long-term success:
- Even when not explicitly trained with reinforcement learning, agentic systems implicitly approximate this process by iteratively selecting actions that move closer to a goal.
The need for interaction with the external world
-
Another critical limitation of standalone models is that they are closed systems. They rely entirely on pretraining data and cannot:
- Access up-to-date information
- Perform real operations (e.g., database queries, transactions)
- Verify outputs against external sources
-
Agentic systems solve this by incorporating tool use and retrieval. This is why approaches like Retrieval-Augmented Generation by Lewis et al. (2020) are foundational. They allow systems to ground their outputs in real data, reducing hallucinations and enabling dynamic knowledge access.
-
In practice, this turns the model into a coordinator rather than a knowledge container.
The need for adaptability and feedback
-
Real environments are dynamic. Requirements change, inputs are noisy, and intermediate steps often fail. Non-agentic systems lack mechanisms to adapt mid-execution.
-
Agentic systems introduce:
- Feedback loops that allow correction
- Reflection mechanisms that improve outputs
- Memory that accumulates knowledge across steps
-
This is essential for robustness. Without these capabilities, systems cannot recover from errors or improve performance within a task.
The need for scalable complexity
-
As tasks grow in complexity, a single monolithic reasoning step becomes inefficient and unreliable. Breaking problems into smaller steps, coordinating multiple components, and distributing responsibilities becomes necessary.
-
Agentic systems enable this by:
- Decomposing tasks into manageable units
- Coordinating multiple specialized components
- Supporting parallel and sequential execution
-
This naturally leads to more advanced architectures such as multi-agent systems, where different agents handle distinct roles and collaborate toward a shared goal.
Why patterns matter
-
Patterns matter because agent systems fail in recurring ways. They lose context, over-call tools, forget intermediate results, mis-handle branching logic, or produce brittle behavior when the environment changes. Reusable patterns help by decomposing these recurring problems into standard solutions: prompt chaining for staged reasoning, routing for specialization, parallelization for throughput, reflection for self-critique, tool use for external action, planning for long-horizon tasks, memory for continuity, guardrails for safety, and evaluation for observability.
-
This is also why frameworks matter. Frameworks are not the intelligence. They are the scaffolding that makes intelligence operational. LangChain overview - Docs by LangChain positions LangChain as an integration and agent framework, while LangGraph overview - Docs by LangChain emphasizes stateful, long-running workflows. That division is important: LangChain is convenient for composition, while LangGraph becomes especially useful once your agent needs explicit state transitions, branching, retries, or human checkpoints.
The architectural shift
-
The most important conceptual shift is that the model is no longer the application boundary. In earlier LLM applications, the prompt itself effectively defined the system. In agentic systems, the prompt becomes just one component within a broader orchestration layer that manages state, tools, and control flow.
-
Rather than relying on a single forward pass of reasoning, agentic systems operate as structured, iterative processes. The system continuously evaluates its current context, selects an action, executes it, and updates its internal state before proceeding. This introduces continuity and adaptability that static prompt-based systems fundamentally lack.
-
This shift enables several critical capabilities:
- Stateful execution: Intermediate outputs, decisions, and context are preserved across steps instead of being recomputed from scratch
- Adaptive decision-making: The system can revise its approach dynamically based on new observations or tool outputs
- Composability: Complex tasks can be decomposed into smaller, modular units that can be independently improved and reused
- Resilience: Failures are no longer terminal; the system can retry, branch, or escalate when needed
-
These capabilities align closely with how agentic systems are described in the source material, where an agent progresses through cycles of understanding, planning, acting, and refining its behavior over time.
-
From a systems perspective, this means that intelligence is no longer a single computation but an emergent property of coordinated interactions between components. The language model provides reasoning, but the surrounding system provides structure, memory, and execution.
-
This architectural framing also explains why many agentic patterns exist. Each pattern addresses a specific challenge introduced by this shift. For example:
- Prompt chaining structures multi-step reasoning
- Routing enables specialization across tasks
- Tool use connects reasoning to real-world actions
- Reflection introduces self-correction
- Planning supports long-horizon objectives
-
Instead of embedding all logic inside a single prompt, these patterns distribute responsibility across a controlled workflow. The result is a system that is easier to debug, extend, and scale.
-
The key takeaway is that once you move from single-step generation to iterative, goal-driven execution, architecture becomes the dominant factor in system performance. The model is still essential, but it is no longer sufficient on its own.
Practical implications for builders
-
For a practitioner, the immediate implication is that reliability comes more from architecture than from prompt cleverness alone. A strong system usually does four things well:
-
It controls context. The model should only see the information needed for the current decision. Too little context causes blind reasoning, while too much causes distraction and degraded instruction following.
-
It makes action explicit. A model should not merely suggest what to do when the system can safely do it through tools.
-
It stores state outside the model. Memory, checkpoints, and interaction history should live in structured state rather than being entrusted entirely to the context window.
-
It treats failures as expected events. Agents need retries, fallbacks, validation, and escalation paths.
-
-
Those principles are not isolated tricks. They are the connective tissue across the patterns that follow.
A LangChain sketch
- Even the simplest LangChain example already hints at the architectural idea. A plain chain is not yet a full agent, but it shows how you stop thinking in one giant prompt and begin thinking in composable steps.
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
prompt = ChatPromptTemplate.from_messages([
("system", "You are an assistant that turns vague goals into crisp task statements."),
("human", "Goal: {goal}")
])
goal_to_task = prompt | llm | StrOutputParser()
result = goal_to_task.invoke({
"goal": "Help me design an AI workflow that can answer support questions reliably."
})
print(result)
- This is only a starting point, but it captures the seed of the larger idea: the system translates a user goal into a machine-usable intermediate representation, which can later be routed into retrieval, planning, tool use, or evaluation. In other words, even the simplest useful agent begins by making hidden structure explicit.
What makes an AI system an agent?
-
An AI system becomes an agent when it transitions from passive response generation to active, goal-directed behavior. The defining shift is from generating outputs to driving outcomes. This happens when a system is embedded in a loop that enables it to perceive, reason, act, and adapt over time in pursuit of a goal.
-
At its simplest, an agent is a system that maps observations to actions in pursuit of a goal. However, modern agentic systems extend this classical definition by incorporating reasoning, tool use, memory, and iterative feedback loops. The result is a system that does not merely answer questions, but actively works toward outcomes.
The core agent loop
-
A practical way to understand what makes a system agentic is through its operational loop. An agent continuously cycles through a structured process:
- It receives a goal
- It gathers relevant context
- It reasons about possible actions
- It executes actions
- It observes outcomes and adapts
-
This can be formalized as a sequential decision process:
\[s_{t+1} = f(s_t, a_t, o_t), \quad a_t \sim \pi(a \mid s_t)\]- where \(s_t\) represents the system state, \(a_t\) the chosen action, and \(o_t\) the observation from the environment.
-
This loop is the minimal structure required for agency. Without it, a system cannot adapt, improve, or operate beyond a single interaction.
From models to agents
-
A large language model on its own does not qualify as an agent. It functions as a reasoning engine, capable of transforming input text into output text based on learned patterns. However, it lacks:
- Persistent state across interactions
- Direct access to external systems
- The ability to take real actions
- Feedback-driven adaptation within a task
-
This corresponds to what can be considered a baseline configuration, where intelligence is present but not operationalized.
-
An agent emerges when this reasoning capability is embedded within a system that provides:
- State management, allowing continuity across steps
- Tool interfaces, enabling interaction with external systems
- Control flow, determining how decisions unfold over time
- Feedback integration, enabling adaptation based on outcomes
-
This transformation aligns with the progression described in the source material, where systems evolve from isolated reasoning engines into connected, action-capable entities.
Levels of agent capability
-
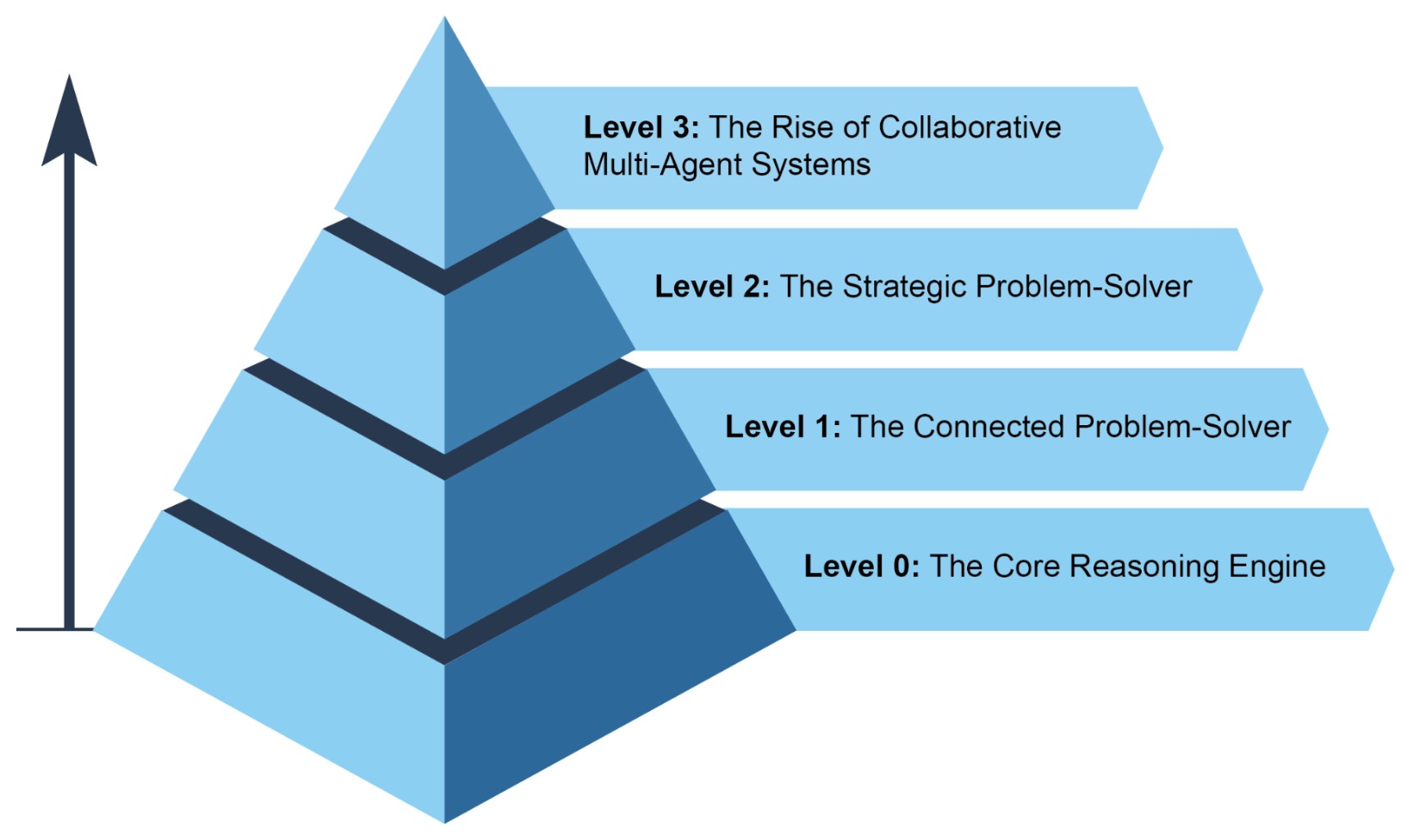
Agentic systems can be understood along a spectrum of increasing capability and autonomy.
-
Level 0: The reasoning core:
- At this level, the system consists solely of a language model. It can reason about problems but cannot interact with the environment or access external information beyond its training data.
-
Level 1: The connected problem-solver:
-
Here, the system gains access to tools and external data sources. It can retrieve information, call APIs, and execute multi-step actions, enabling it to solve real-world problems that require up-to-date or external knowledge.
-
This is closely related to the paradigm introduced in Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Lewis et al. (2020), where external retrieval enhances model capabilities by grounding outputs in factual data.
-
-
Level 2: The strategic problem-solver:
-
At this level, the agent can plan, manage context strategically, and handle complex, multi-step workflows. A key capability here is context engineering, which involves selecting and structuring the most relevant information for each step to maximize performance.
-
This is conceptually aligned with structured reasoning approaches such as Chain-of-Thought Prompting by Wei et al. (2022), where intermediate reasoning steps improve task performance by decomposing problems.
-
-
Level 3: Collaborative multi-agent systems:
-
The most advanced level involves multiple agents working together, each specializing in different roles. Instead of a single monolithic system, intelligence emerges from coordination among agents.
-
The following figure shows various instances demonstrating the spectrum of agent complexity.
-
-
This mirrors organizational structures in human systems, where specialized roles collaborate to achieve complex objectives. It also aligns with emerging research in distributed AI systems, where coordination and communication become central challenges.
-
Key properties of agentic systems
-
Several properties distinguish agents from traditional systems:
-
Autonomy: The ability to operate without constant human intervention
-
Proactiveness: The ability to initiate actions toward goals rather than waiting for instructions
-
Reactivity: The ability to respond dynamically to changes in the environment
-
Tool use: The ability to extend capabilities through interaction with external systems
-
Memory: The ability to retain and utilize information across time
-
Communication: The ability to interact with users or other agents
-
Prioritization: The ability to evaluate and rank tasks or actions based on criteria such as urgency, importance, dependencies, and resource constraints
-
Pattern selection and composition: The ability to combine multiple design patterns into a coherent system that aligns with task requirements and operational constraints
-
-
These properties are not independent. They reinforce each other to create systems that can operate effectively in complex, dynamic environments.
The role of reasoning and action
-
A defining feature of agentic systems is the tight coupling between reasoning and action. Instead of generating a complete solution upfront, the system iteratively refines its approach based on feedback.
-
This paradigm is exemplified by ReAct by Yao et al. (2022), which interleaves reasoning steps with actions, allowing the system to update its understanding as new information becomes available.
-
The key insight is that reasoning alone is insufficient. Effective problem-solving requires interaction with the environment, and that interaction must inform subsequent reasoning.
A minimal LangChain agent example
- The transition from a simple chain to an agent becomes clear when tools and decision-making are introduced.
from langchain.agents import initialize_agent, Tool
from langchain_openai import ChatOpenAI
# Define a simple tool
def search_tool(query: str) -> str:
return f"Search results for: {query}"
tools = [
Tool(
name="Search",
func=search_tool,
description="Useful for answering questions about current events"
)
]
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
agent = initialize_agent(
tools=tools,
llm=llm,
agent="zero-shot-react-description",
verbose=True
)
result = agent.run("What are recent developments in AI agents?")
print(result)
-
This example illustrates the essential ingredients of an agent:
- A reasoning model
- A set of tools
- A decision policy that determines when to use them
-
Even in this minimal form, the system is no longer just generating text. It is selecting actions based on context, which is the defining step toward agency.
The emerging paradigm
-
The progression from LLM workflows to fully agentic systems represents a broader shift in AI:
- From static pipelines to dynamic systems
- From isolated models to integrated environments
- From answering questions to achieving goals
-
The following figure shows transitioning from LLMs to RAG, then to Agentic RAG, and finally to Agentic AI.
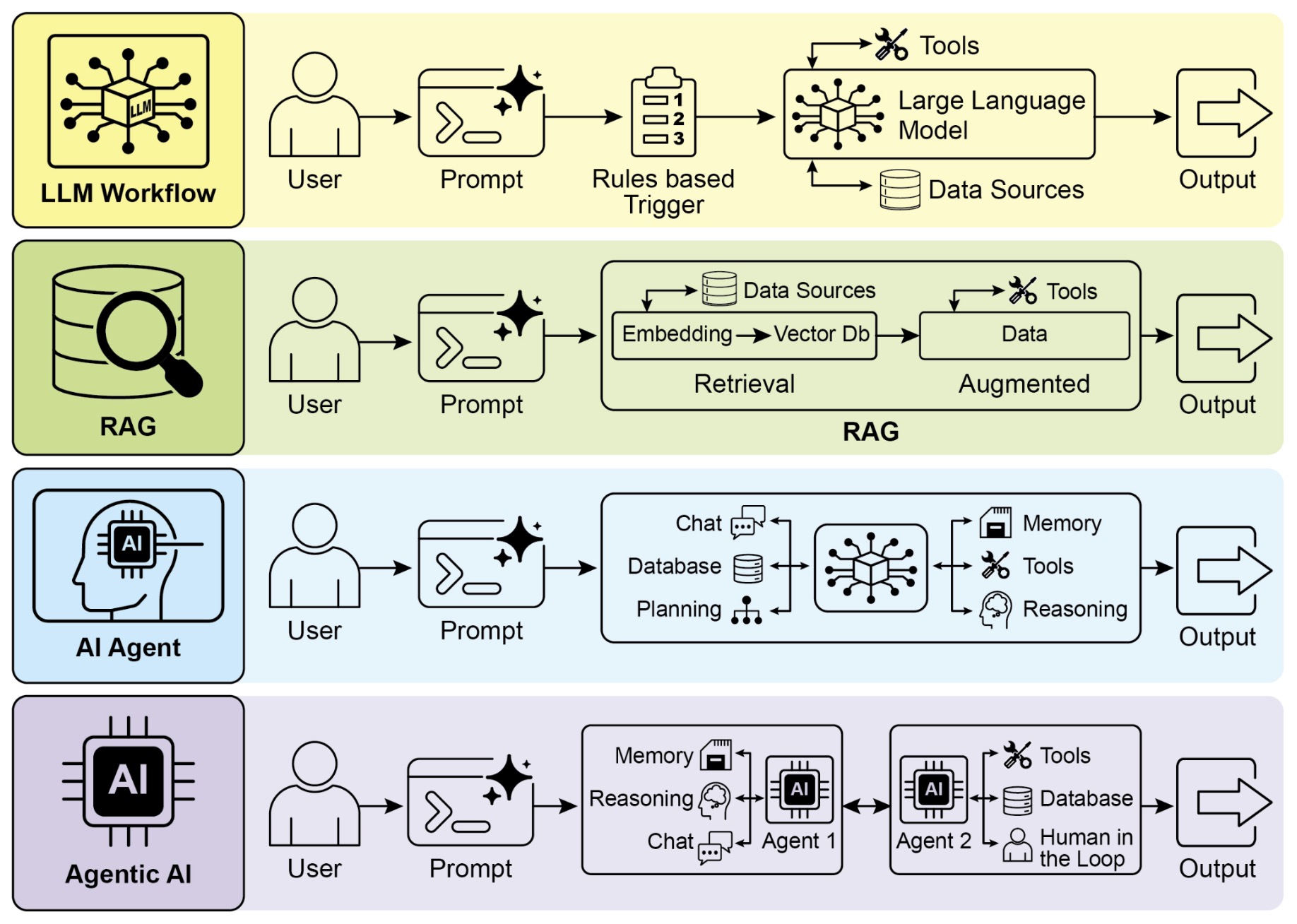
- This evolution reflects a growing recognition that intelligence is not just about knowledge or reasoning in isolation. It is about the ability to operate effectively in a world of uncertainty, constraints, and changing information.
Agentic Design Patterns
Core Idea
-
The agentic design patterns covered in this section form the operational backbone of agentic systems. Together, they define how an agent reasons, decides, acts, and improves while interacting with its environment. Rather than functioning as isolated techniques, these patterns compose into execution graphs that transform static model calls into dynamic, goal-directed systems.
-
At a high level, these patterns collectively implement a structured decision process:
- Each pattern contributes a specific capability within this flow, enabling agents to move from simple response generation to complex, adaptive behavior. Importantly, prioritization and pattern selection act as meta-level controls over this process, determining not only what actions are taken, but which patterns are invoked and in what order.
From linear prompts to execution graphs
-
Traditional LLM systems operate as linear pipelines: a prompt is constructed, a response is generated, and the process ends. In contrast, agentic systems organize computation as directed graphs of operations, where intermediate outputs are routed, transformed, validated, and reused.
-
The patterns in this section collectively enable this shift:
- Prompt chaining introduces structured decomposition
- Routing introduces conditional branching
- Parallelization introduces concurrent execution
- Reflection introduces iterative refinement
- Tool use introduces external interaction
- Planning introduces long-horizon structure
- Multi-agent systems introduce distributed specialization
- Prioritization introduces decision ordering under constraints
- Pattern selection and composition introduces system-level orchestration
-
Together, these transform a single inference into a coordinated, adaptive process.
Functional roles
-
Each pattern plays a distinct role in the execution lifecycle of an agent, as follows:
-
Prompt chaining as decomposition: Prompt chaining breaks complex tasks into smaller, sequential steps. It reduces cognitive load on the model and enables intermediate validation. This is the foundation upon which most other patterns build.
-
Routing as decision-making: Routing determines which path the system should take. It selects tools, models, or workflows based on input characteristics, enabling specialization and efficiency.
-
Parallelization as scaling mechanism: Parallelization allows independent tasks to be executed simultaneously. It improves latency and enables exploration of multiple reasoning paths or data sources.
-
Reflection as quality control: Reflection introduces feedback loops that allow the system to critique and refine its outputs. It improves reliability and correctness through iterative improvement.
-
Tool use as action interface: Tool use connects the agent to the external world. It enables retrieval, computation, and real-world actions, extending the system beyond its internal knowledge.
-
Planning as strategic coordination: Planning organizes actions over multiple steps. It enables the system to reason about dependencies, sequence tasks, and pursue long-term goals.
-
Multi-agent systems as distributed intelligence: Multi-agent systems distribute responsibilities across specialized agents. They enable modularity, scalability, and collaboration in complex workflows.
-
Prioritization as resource-aware decision control: Prioritization determines which tasks, goals, or actions should be executed first when multiple options compete. It incorporates criteria such as urgency, importance, dependencies, and resource constraints, ensuring that the agent focuses on high-impact actions under limited time or compute.
-
Pattern selection and composition as system orchestration: Pattern selection determines which combination of patterns should be applied for a given task, while composition defines how they are connected. This operates at a meta-level, shaping the overall execution graph rather than individual steps.
-
Compositional structure
- These patterns are rarely used in isolation. A typical execution flow may look like:
-
This structure highlights how patterns compose:
- Routing selects the workflow
- Planning defines the structure
- Prioritization orders tasks and allocates resources
- Parallelization executes independent steps
- Tool use provides capabilities
- Reflection ensures quality
-
At a higher level, pattern selection and composition determines whether this entire pipeline is even the right structure, or whether an alternative configuration (e.g., multi-agent orchestration or iterative loops) should be used instead.
-
In more advanced systems, multi-agent coordination may wrap around this entire process, with different agents handling planning, execution, validation, and prioritization.
When to use these patterns
-
These patterns become necessary as task complexity increases:
- Use prompt chaining when tasks require multiple reasoning steps
- Use routing when inputs vary significantly in type or complexity
- Use parallelization when tasks are independent and latency matters
- Use reflection when correctness and quality are critical
- Use tool use when external data or actions are required
- Use planning when tasks span multiple dependent steps
- Use multi-agent systems when specialization improves outcomes
- Use prioritization when multiple tasks compete under constraints (time, compute, dependencies)
- Use pattern selection and composition when designing full systems, especially when multiple patterns must be combined or adapted dynamically
-
The choice is not binary. Most real systems use a combination of these patterns, selected and orchestrated based on task requirements and constraints.
The unifying principle
-
The unifying idea across all these patterns is control. They introduce structure into how models are used, transforming them from passive generators into components of a controlled execution system.
-
Instead of asking “what should the model output?”, agentic systems ask “what should the system do next?”
-
Prioritization refines this further into “what should the system do next given constraints?”, while pattern selection elevates it to “what system should be constructed to solve this class of problems?”
-
This shift, from output generation to action selection and system design, is what enables the patterns in this primer to work together as a cohesive whole.
Prompt Chaining
-
Prompt chaining is a foundational agentic design pattern that transforms how complex problems are solved with language models. Rather than relying on a single, monolithic prompt, it decomposes a task into a sequence of smaller, structured steps, where each step feeds into the next. This approach shifts systems away from fragile one-shot reasoning toward controlled, multi-stage execution that is more reliable, interpretable, and scalable.
-
At its core, prompt chaining operationalizes the idea that complex reasoning is best handled incrementally. Each step focuses on a specific sub-problem, reducing the cognitive load on the model and improving overall performance. This principle is supported by findings from Chain-of-Thought Prompting (Wei et al., 2022), which demonstrate that breaking reasoning into intermediate steps significantly enhances accuracy on complex tasks.
-
More broadly, prompt chaining reflects a shift in how language models are conceptualized: not as monolithic problem solvers, but as components within a structured computation graph. In this paradigm, reasoning is distributed across multiple steps and can be integrated with external tools and persistent state, aligning with the evolution toward agentic systems.
-
Because it introduces structure and control while remaining relatively simple to implement, prompt chaining often serves as the entry point into agentic design.
Why prompt chaining is needed
-
Single-prompt approaches often fail when tasks become multi-step or require structured reasoning. These failures arise from several well-known limitations:
- Instruction overload: Large prompts with multiple constraints cause the model to ignore or misinterpret parts of the task
- Context dilution: Important details get lost as prompt length increases
- Error amplification: Mistakes in early reasoning cannot be corrected mid-process
- Lack of control: There is no way to inspect or guide intermediate steps
-
Prompt chaining addresses these issues by explicitly structuring the reasoning process into discrete stages. Each stage has a well-defined input and output, allowing the system to validate, transform, or enrich information before passing it forward.
The structure of a prompt chain
-
A prompt chain can be viewed as a directed sequence of transformations:
\[x_0 \rightarrow f_1(x_0) = x_1 \rightarrow f_2(x_1) = x_2 \rightarrow \cdots \rightarrow f_n(x_{n-1}) = x_n\]- where each \(f_i\) represents a prompt-driven transformation applied by the model.
-
This structure introduces modularity into the system:
- Each step can be independently designed and optimized
- Intermediate outputs can be inspected and debugged
- External tools can be inserted between steps
- Different models can be used for different stages
-
The result is a pipeline that behaves more like a program than a single inference call. The following figure illustrates the prompt chaining pattern, where agents receive a series of prompts from the user, with the output of each agent serving as the input for the next in the chain.
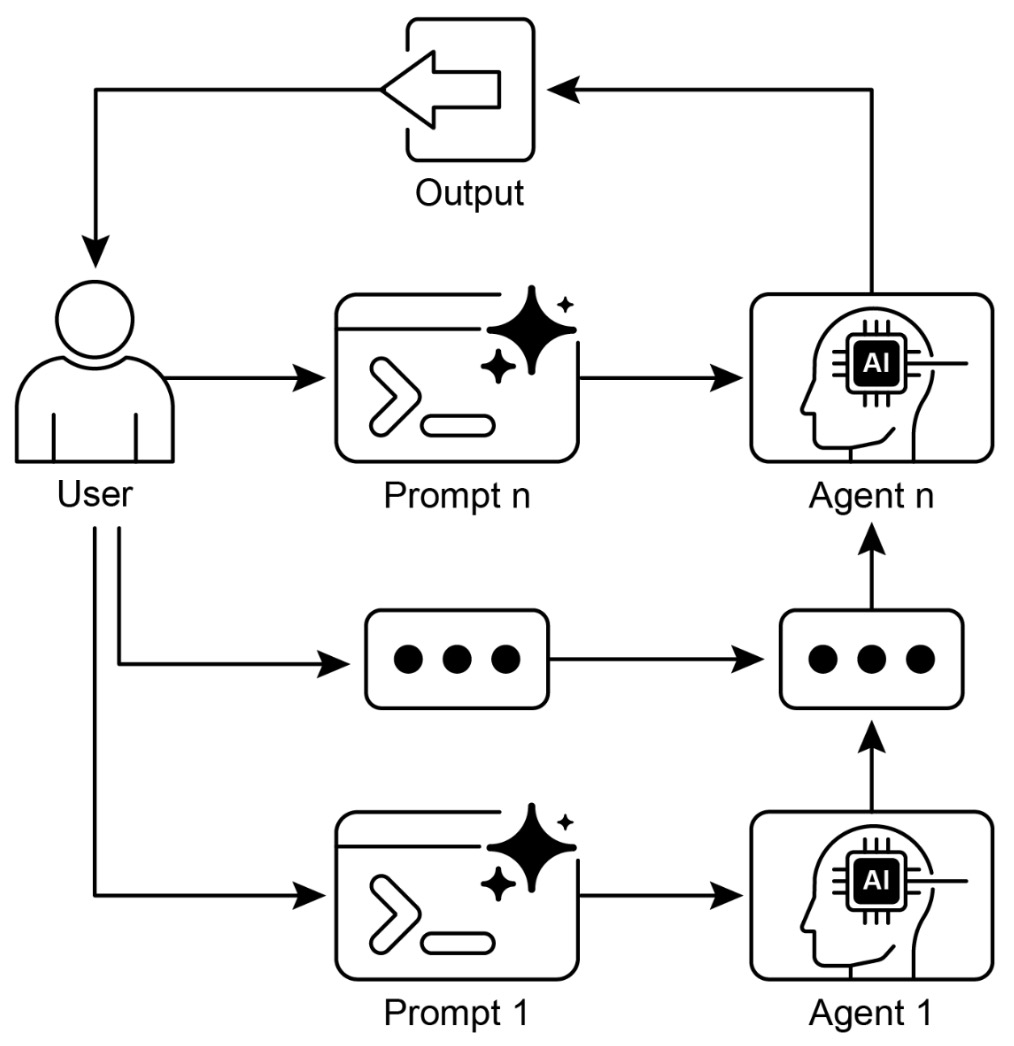
Example
-
Consider a task such as generating a research summary from raw documents. A single prompt might attempt to:
- Extract key points
- Organize them
- Generate a coherent summary
-
In a chained approach, this becomes:
- Extract key facts from the document
- Cluster facts into themes
- Generate a structured outline
- Produce the final summary
-
Each step reduces ambiguity and improves control over the output.
Implementation
- LangChain provides a natural abstraction for prompt chaining through composable chains. Each component in the chain transforms input into output, allowing pipelines to be constructed declaratively.
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Step 1: Extract key points
extract_prompt = ChatPromptTemplate.from_messages([
("system", "Extract key facts from the following text."),
("human", "{input_text}")
])
# Step 2: Organize into themes
organize_prompt = ChatPromptTemplate.from_messages([
("system", "Group the following facts into themes."),
("human", "{facts}")
])
# Step 3: Generate summary
summary_prompt = ChatPromptTemplate.from_messages([
("system", "Write a concise summary from these themes."),
("human", "{themes}")
])
extract_chain = extract_prompt | llm | StrOutputParser()
organize_chain = organize_prompt | llm | StrOutputParser()
summary_chain = summary_prompt | llm | StrOutputParser()
# Execute chain
text = "AI agents are systems that can reason, act, and adapt..."
facts = extract_chain.invoke({"input_text": text})
themes = organize_chain.invoke({"facts": facts})
summary = summary_chain.invoke({"themes": themes})
print(summary)
- This example demonstrates how each stage isolates a specific responsibility. The system becomes easier to debug and extend, since intermediate outputs can be inspected or modified.
Enhancing chains with tools
-
Prompt chains are not limited to model-only transformations. External tools can be inserted between steps to enrich the workflow.
-
For example:
- A retrieval step can fetch relevant documents
- A database query can validate extracted facts
- An API call can provide real-time data
-
This hybrid approach is closely related to Retrieval-Augmented Generation by Lewis et al. (2020), where retrieval is integrated into the generation pipeline to improve factual accuracy.
-
In practice, this turns a prompt chain into a flexible workflow that combines reasoning with external capabilities.
Prompt chaining as a building block for agents
-
Prompt chaining is more than a technique for structuring prompts. It is a foundational building block for agentic systems.
-
Many higher-level patterns rely on chaining:
- Planning uses chains to decompose tasks into subgoals
- Reflection uses chains to critique and refine outputs
- Routing uses chains to decide which path to take
- Tool use often involves chaining reasoning with action
-
In this sense, prompt chaining provides the scaffolding for more advanced behaviors. It enables systems to simulate structured thought processes and execute them reliably.
Failure modes
-
While powerful, prompt chaining introduces its own challenges:
- Latency: Multiple steps increase response time
- Cost: Each step requires an additional model call
- Error propagation: Incorrect outputs can cascade through the chain
- Over-fragmentation: Too many steps can make the system unnecessarily complex
-
These trade-offs must be carefully managed. In practice, effective chains strike a balance between decomposition and efficiency.
-
One common mitigation strategy is to validate intermediate outputs before passing them forward. Another is to selectively merge steps when they are tightly coupled.
Routing
-
Routing is an agentic design pattern that enables a system to dynamically select the most appropriate path, model, tool, or sub-agent based on the characteristics of the input. Instead of applying a single fixed workflow to every request, routing introduces conditional logic that directs tasks to specialized components, improving both performance and efficiency.
-
At a fundamental level, routing transforms an otherwise linear pipeline into a decision-driven system. This aligns with the broader principle that intelligence in complex systems often emerges not from uniform processing, but from specialization and selective execution.
Why routing is needed
-
As systems grow in complexity, a single model or workflow becomes insufficient for handling diverse inputs. Different tasks may require:
- Different reasoning strategies
- Different tools or APIs
- Different levels of computational cost
- Different domain expertise
-
Without routing, systems either overuse expensive resources or underperform on specialized tasks.
-
Routing addresses this by introducing a decision layer that determines how each input should be handled. This allows systems to:
- Improve accuracy by delegating to specialized components
- Reduce cost by using simpler models when appropriate
- Increase flexibility by supporting multiple workflows
-
This idea is closely related to modular AI systems and mixture-of-experts architectures. For example, Switch Transformers by Fedus et al. (2021) demonstrate how routing inputs to specialized subnetworks improves scalability and efficiency in large models.
The routing decision function
-
At its core, routing can be expressed as a decision function:
\[r(x) \rightarrow i\]- where \(x\) is the input and \(i\) is the selected route or component.
-
This decision can be implemented in several ways:
- A rule-based classifier
- A lightweight model
- A language model itself
- A hybrid of heuristics and learned signals
-
The output of the routing step determines which downstream process will handle the task.
-
The following figure shows the routing pattern where inputs are directed to different processing paths based on classification using an LLM as a router.
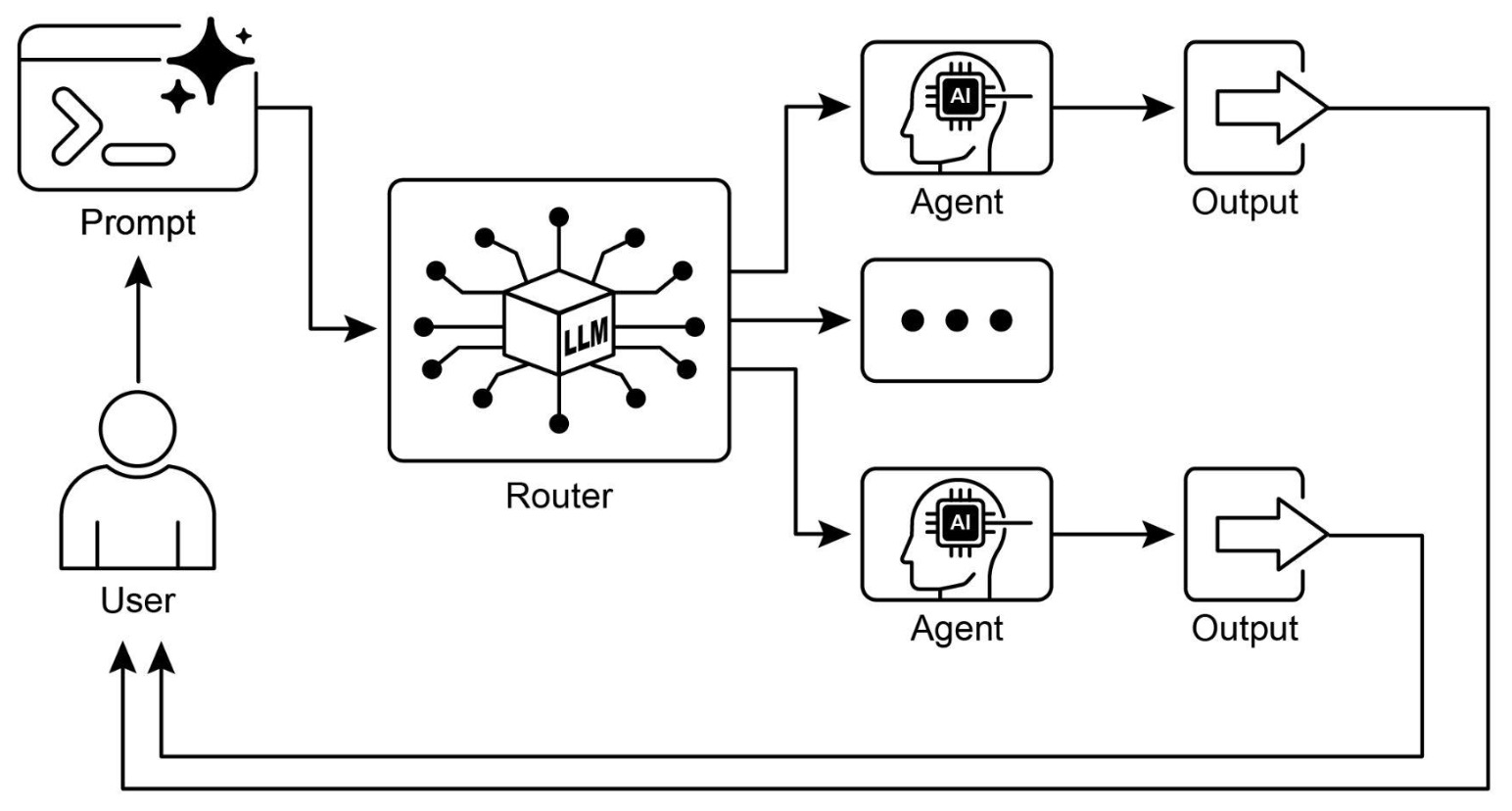
Types of routing
-
Routing can take several forms depending on the system design.
-
Input-based routing:
-
The system analyzes the input and decides which path to take. For example:
- Questions about math are routed to a symbolic solver
- Questions about current events are routed to a retrieval pipeline
- Creative writing tasks are routed to a generative model
-
-
Tool routing:
-
The system selects which tool or API to use based on the task. This is common in agent systems where multiple tools are available.
-
This behavior is closely related to the mechanisms explored in Toolformer by Schick et al. (2023), where models learn when to invoke external tools.
-
-
Model routing:
-
Different models are used depending on task complexity:
- Lightweight models for simple queries
- Larger models for complex reasoning
-
This enables cost-performance optimization in production systems.
-
-
Agent routing:
- Tasks are delegated to different agents, each with a specialized role. This becomes particularly important in multi-agent systems.
Example
-
Consider a system that handles customer support queries. Without routing, all queries are processed the same way. With routing:
- Billing issues are sent to a financial agent
- Technical issues are sent to a troubleshooting agent
- General inquiries are handled by a conversational agent
-
This improves both response quality and system efficiency.
Implementation
- LangChain supports routing through router chains and conditional logic. A common approach is to use a classification step to determine the route.
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Router prompt
router_prompt = ChatPromptTemplate.from_messages([
("system", "Classify the user query into one of: math, search, or general."),
("human", "{query}")
])
router_chain = router_prompt | llm | StrOutputParser()
def route(query):
route = router_chain.invoke({"query": query}).strip().lower()
return route
# Define handlers
def math_handler(query):
return f"Solving math problem: {query}"
def search_handler(query):
return f"Searching for: {query}"
def general_handler(query):
return f"General response: {query}"
# Routing logic
def handle_query(query):
route_type = route(query)
if "math" in route_type:
return math_handler(query)
elif "search" in route_type:
return search_handler(query)
else:
return general_handler(query)
print(handle_query("What is 25 * 17?"))
- This example demonstrates how a lightweight routing decision can direct queries to different handlers. In more advanced systems, each handler could itself be a complex chain or agent.
Routing with chains and tools
-
Routing becomes more powerful when combined with other patterns:
- With prompt chaining: Different chains can be selected dynamically
- With tool use: The system can choose the most appropriate tool
- With planning: Routing decisions can be made at multiple stages
- With multi-agent systems: Tasks can be distributed across agents
-
This composability makes routing a central mechanism in agent orchestration.
Failure modes
-
Routing introduces new challenges:
- Misclassification: Incorrect routing leads to poor results
- Ambiguity: Some inputs may not clearly map to a single route
- Overhead: The routing step adds latency and cost
- Fragmentation: Too many routes can make the system difficult to manage
-
To mitigate these issues:
- Use confidence thresholds and fallback paths
- Allow multiple routes for ambiguous inputs
- Continuously evaluate routing accuracy
- Keep routing logic interpretable when possible
Parallelization
-
Parallelization is an agentic design pattern that enables systems to execute multiple independent tasks simultaneously rather than sequentially. By distributing work across parallel branches, the system improves latency, throughput, and scalability while maintaining the ability to recombine results into a coherent output.
-
This pattern reflects a broader principle in intelligent systems: when tasks are independent or loosely coupled, executing them concurrently leads to significant efficiency gains. In agentic systems, where workflows often involve multiple sub-tasks such as retrieval, reasoning, validation, or generation, parallelization becomes a natural extension of prompt chaining and routing.
Why parallelization is needed
-
Sequential execution introduces unnecessary delays when tasks do not depend on each other. For example:
- Retrieving information from multiple sources
- Generating multiple candidate responses
- Evaluating outputs using different criteria
- Processing multiple inputs in batch
-
If these steps are executed one after another, total latency becomes the sum of all execution times. Parallelization reduces this to the maximum execution time among tasks:
\[T_{\text{parallel}} \approx \max(T_1, T_2, \dots, T_n)\]- instead of:
-
This reduction can be substantial in real-world systems, especially when individual steps involve network calls or model inference.
The following figure shows parallel execution of independent tasks using sub-agents and aggregation of their outputs.
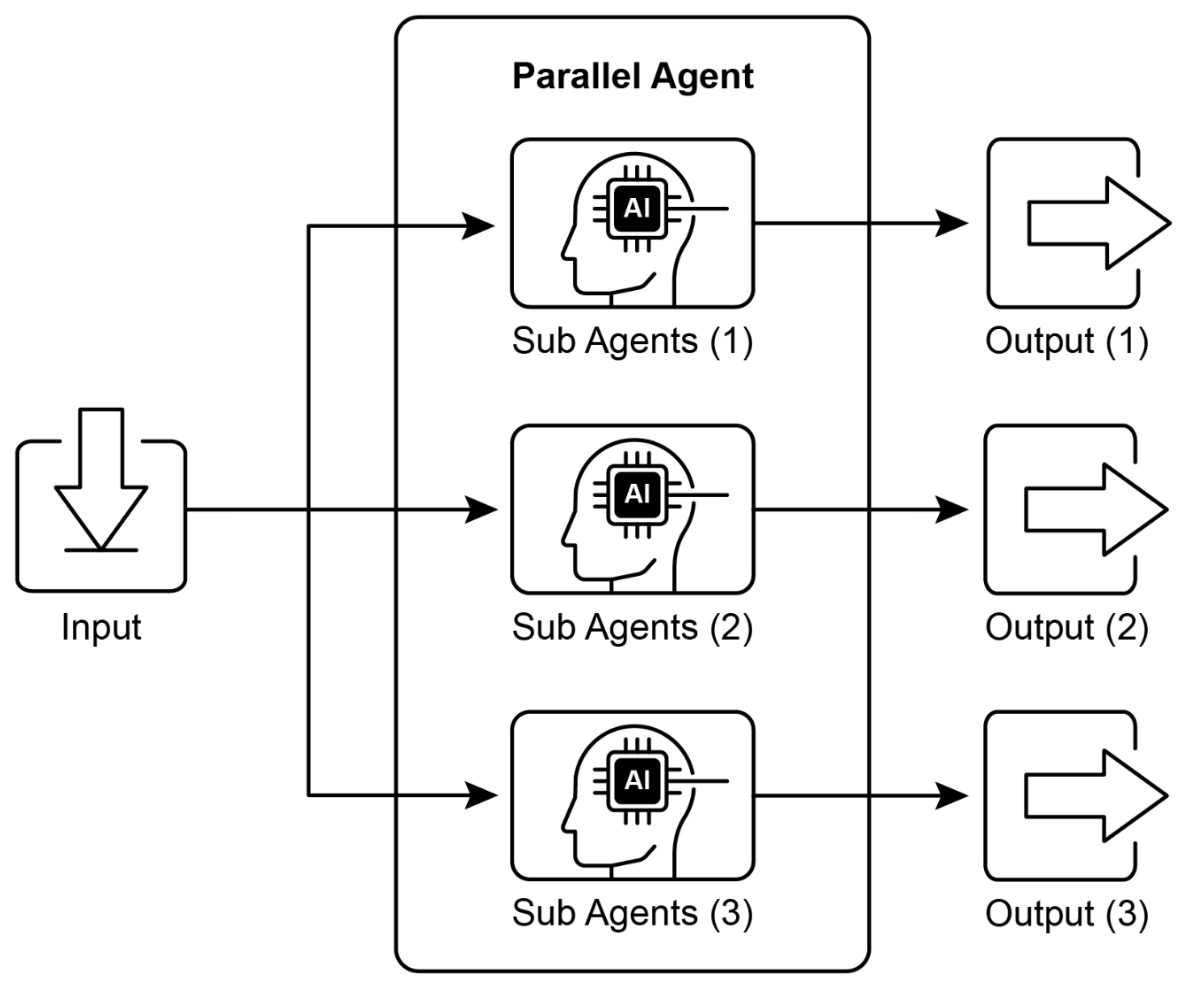
Forms of parallelization
-
Parallelization can be applied in several ways depending on the system design.
-
Task parallelism:
-
Different tasks are executed simultaneously. For example:
- Running multiple retrieval queries across different databases
- Generating answers using different prompts
- Evaluating outputs with multiple scoring functions
-
Each task operates independently and produces its own output.
-
-
Data parallelism:
-
The same operation is applied to multiple inputs in parallel. For example:
- Processing multiple documents simultaneously
- Running the same prompt across different data samples
-
This is useful for scaling workloads across large datasets.
-
-
Model parallelism:
-
Different models are used simultaneously to process the same input. This can improve robustness by combining diverse perspectives.
-
This idea connects to ensemble methods in machine learning, where combining multiple models often yields better performance. For example, Deep Ensembles by Lakshminarayanan et al. (2017) demonstrate improved predictive uncertainty and robustness by aggregating outputs from multiple models.
-
Example
-
Consider a system that generates multiple candidate answers to a question and then selects the best one. Instead of generating answers sequentially, the system can:
- Generate multiple responses in parallel
- Evaluate each response independently
- Select or combine the best outputs
-
This approach improves both speed and quality, as it allows exploration of multiple reasoning paths simultaneously.
Implementation
- LangChain supports parallel execution through constructs like RunnableParallel, which allows multiple chains to run concurrently.
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableParallel
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Define different reasoning strategies
prompt_1 = ChatPromptTemplate.from_messages([
("system", "Answer concisely."),
("human", "{question}")
])
prompt_2 = ChatPromptTemplate.from_messages([
("system", "Answer with detailed reasoning."),
("human", "{question}")
])
chain_1 = prompt_1 | llm | StrOutputParser()
chain_2 = prompt_2 | llm | StrOutputParser()
parallel_chain = RunnableParallel(
concise=chain_1,
detailed=chain_2
)
result = parallel_chain.invoke({"question": "What is reinforcement learning?"})
print(result)
- This example runs two different reasoning strategies in parallel and returns both outputs. A downstream step could then select or merge the best result.
Aggregation and synchronization
-
Parallelization requires a mechanism to combine results from multiple branches. This step is often referred to as aggregation.
-
Common aggregation strategies include:
- Selection: Choose the best output based on a scoring function
- Voting: Combine outputs using majority or weighted voting
- Synthesis: Merge outputs into a unified response
- Filtering: Remove low-quality or inconsistent results
-
This step is critical because parallelization without proper aggregation can lead to fragmented or inconsistent outputs.
Parallelization in agentic systems
-
Parallelization is particularly powerful when combined with other patterns:
- With prompt chaining: Multiple branches can process different aspects of a task
- With routing: Different routes can be executed concurrently
- With multi-agent systems: Multiple agents can work simultaneously on different subtasks
- With retrieval: Multiple sources can be queried in parallel
-
This enables systems to handle complex workflows efficiently while maintaining modularity.
Failure modes
-
While parallelization improves performance, it introduces additional complexity:
- Resource contention: Parallel tasks may compete for computational resources
- Synchronization overhead: Combining results adds complexity
- Inconsistent outputs: Different branches may produce conflicting results
- Cost increase: Running multiple tasks simultaneously increases usage
-
To mitigate these issues:
- Limit the number of parallel branches
- Use lightweight models for exploratory branches
- Apply strong aggregation and validation mechanisms
- Monitor system performance and resource usage
Reflection
-
Reflection is an agentic design pattern that enables a system to evaluate and improve its own outputs through iterative self-critique. Rather than treating an initial response as final, the system introduces a structured feedback loop in which outputs are analyzed, corrected, and refined. This transforms the system from a one-pass generator into an adaptive process capable of improving its performance within the scope of a single task.
-
At its core, reflection operationalizes a simple but powerful idea: reasoning improves when a system is given the opportunity to revisit and critique its own work. This mirrors human problem-solving, where first drafts are rarely final and iterative revision leads to stronger, more accurate outcomes. By incorporating this loop, systems can identify weaknesses, correct errors, and enhance clarity without external intervention.
-
More broadly, reflection represents a shift from static generation to iterative improvement. It serves as a built-in mechanism for quality control, increasing reliability and robustness by enabling systems to detect and address their own mistakes. In the context of agentic design patterns, this makes reflection a foundational capability—one that brings machine reasoning closer to human-like processes, where refinement and revision are essential.
-
Ultimately, reflection allows systems to “learn” within a task itself, even in the absence of explicit retraining. By continuously reassessing and improving their outputs, they become more adaptive, accurate, and effective problem-solvers.
Why reflection is needed
-
Even advanced models frequently produce outputs that are:
- Incomplete
- Inconsistent
- Hallucinated
-
Poorly structured
-
In a single-pass system, these issues persist because there is no mechanism for correction. Reflection introduces a second stage where the system evaluates its output against criteria such as correctness, completeness, and coherence.
- This idea is supported by research such as Self-Refine: Iterative Refinement with Self-Feedback by Madaan et al. (2023), which shows that iterative self-feedback significantly improves output quality across tasks.
The reflection loop
-
Reflection can be formalized as an iterative process:
\[y_0 = f(x), \quad y_{t+1} = g(y_t, x)\]-
where:
- \(f(x)\) generates an initial output
- \(g(y_t, x)\) evaluates and refines the output
-
-
This process can be repeated multiple times until a stopping condition is met, such as:
- A quality threshold
- A fixed number of iterations
- Convergence of outputs
-
The result is a progressively improved response.
-
The following figure shows the self-reflection design pattern which undergoes iterative self-refinement with outputs being critiqued and improved over multiple passes.
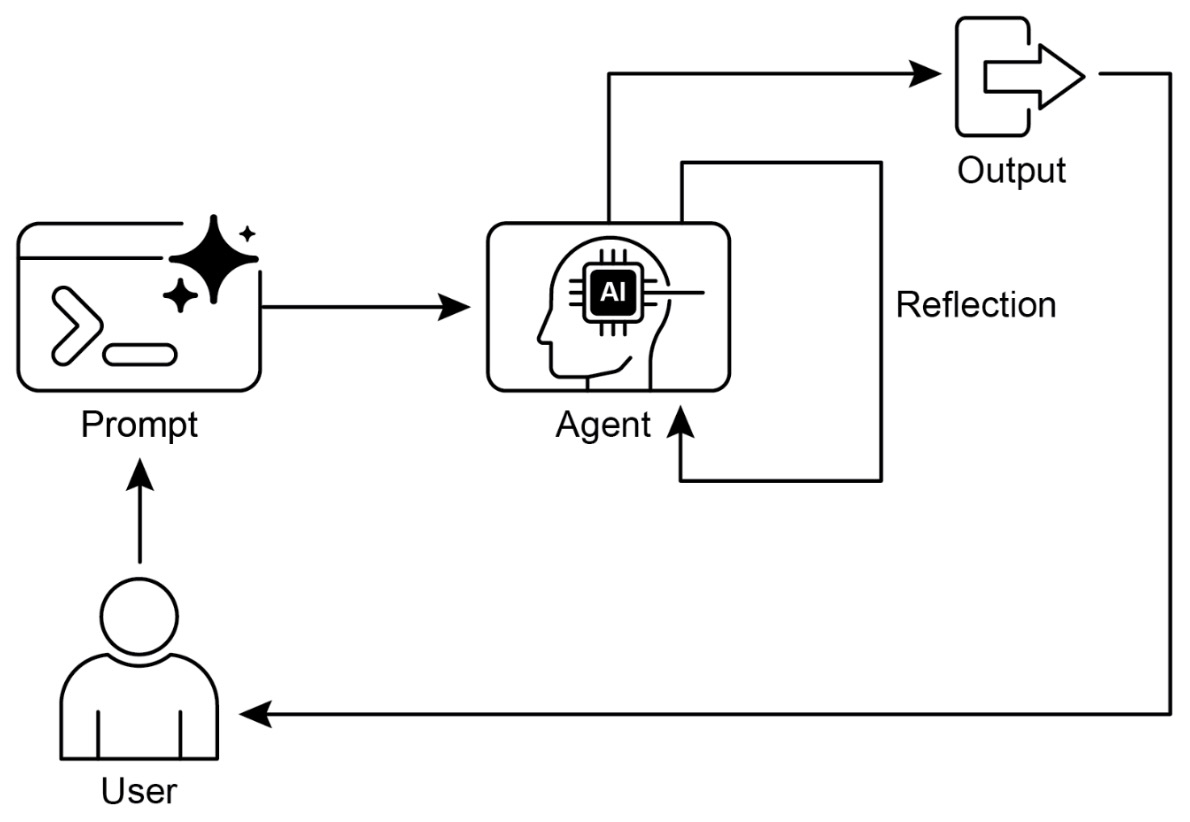
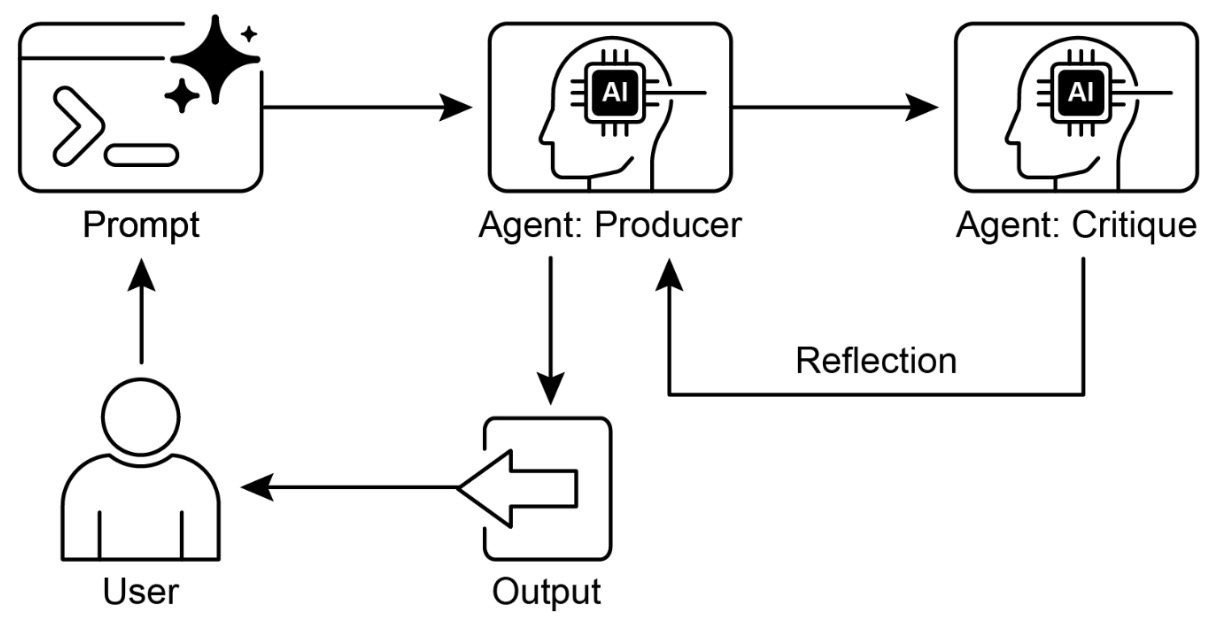
- The following figure shows the reflection design pattern with a producer and critique agent.
Types of reflection
-
Reflection can take several forms depending on how feedback is generated, as follows:
-
Self-critique:
-
The model evaluates its own output using a secondary prompt. For example:
- Identify errors in reasoning
- Check factual consistency
- Suggest improvements
-
-
External critique:
- A separate model or system evaluates the output. This can improve robustness by introducing diversity in evaluation.
-
Rule-based validation:
-
Outputs are checked against predefined constraints, such as:
- JSON schema validation
- Logical consistency checks
- Domain-specific rules
-
-
Human-in-the-loop reflection:
- A human provides feedback, which the system incorporates into subsequent iterations.
-
Example
-
Consider a system that generates code. A reflection-based workflow might:
- Generate initial code
- Analyze the code for errors or inefficiencies
- Revise the code based on feedback
- Repeat until the code meets quality criteria
-
This process significantly improves reliability compared to a single-pass generation.
Implementation
- LangChain can implement reflection by chaining generation and critique steps.
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Step 1: Generate initial answer
generate_prompt = ChatPromptTemplate.from_messages([
("system", "Answer the question."),
("human", "{question}")
])
# Step 2: Critique answer
critique_prompt = ChatPromptTemplate.from_messages([
("system", "Critique the following answer for correctness and completeness."),
("human", "{answer}")
])
# Step 3: Improve answer
improve_prompt = ChatPromptTemplate.from_messages([
("system", "Improve the answer based on the critique."),
("human", "Answer: {answer}\nCritique: {critique}")
])
generate_chain = generate_prompt | llm | StrOutputParser()
critique_chain = critique_prompt | llm | StrOutputParser()
improve_chain = improve_prompt | llm | StrOutputParser()
question = "Explain how neural networks learn."
initial = generate_chain.invoke({"question": question})
critique = critique_chain.invoke({"answer": initial})
improved = improve_chain.invoke({
"answer": initial,
"critique": critique
})
print(improved)
- This example demonstrates a single iteration of reflection. In practice, this loop can be repeated multiple times for further refinement.
Reflection in agentic systems
-
Reflection plays a critical role in enabling agents to improve their behavior dynamically. It is often used in:
- Planning: Refining task decomposition
- Tool use: Verifying correctness of tool outputs
- Reasoning: Correcting logical errors
- Multi-agent systems: Providing feedback between agents
-
This aligns with the paradigm introduced in ReAct by Yao et al. (2022), where reasoning is continuously updated based on observations and intermediate results.
Failure modes
-
While reflection improves quality, it introduces trade-offs:
- Increased latency: Multiple iterations require additional model calls
- Cost overhead: Each refinement step adds computational cost
- Over-correction: Excessive refinement can degrade outputs
- Bias reinforcement: The model may reinforce its own mistakes
-
To mitigate these issues:
- Limit the number of reflection iterations
- Use structured evaluation criteria
- Introduce diversity in critique (e.g., multiple evaluators)
- Combine reflection with external validation
Tool Use
-
Tool use is an agentic design pattern that extends a system’s capabilities beyond its internal knowledge by enabling interaction with external functions, APIs, databases, and real-world environments. It transforms a language model from a purely reasoning engine into an action-oriented system capable of operating in practical contexts.
-
At its core, tool use embodies the principle that intelligence is not just about understanding what needs to be done, but also about executing those actions—whether that involves retrieving information, performing computations, or triggering workflows.
-
By bridging the gap between reasoning and execution, tool use shifts the role of AI from a static source of knowledge to a dynamic coordinator of capabilities. In agentic systems, this pattern is what allows models to move beyond simulation and actively engage with the world. As such, it represents a fundamental step in the evolution of AI: the point at which intelligence becomes operational, turning insight into real-world execution.
Why tool use is needed
-
Language models are inherently constrained:
- Their knowledge is limited to training data
- They cannot access real-time or proprietary information
- They cannot perform deterministic computations reliably
- They cannot directly interact with external systems
-
Tool use addresses these limitations by allowing the system to delegate specific tasks to specialized components.
-
For example:
- Use a search API to retrieve current information
- Use a calculator for precise numerical computation
- Query a database for structured data
- Call a service to execute transactions
-
This paradigm is strongly supported by research such as Toolformer by Schick et al. (2023), which demonstrates that models can learn to decide when and how to use tools, significantly improving performance on real-world tasks.
-
The following figure shows the integration of external tools into the agentic reasoning loop for action execution.
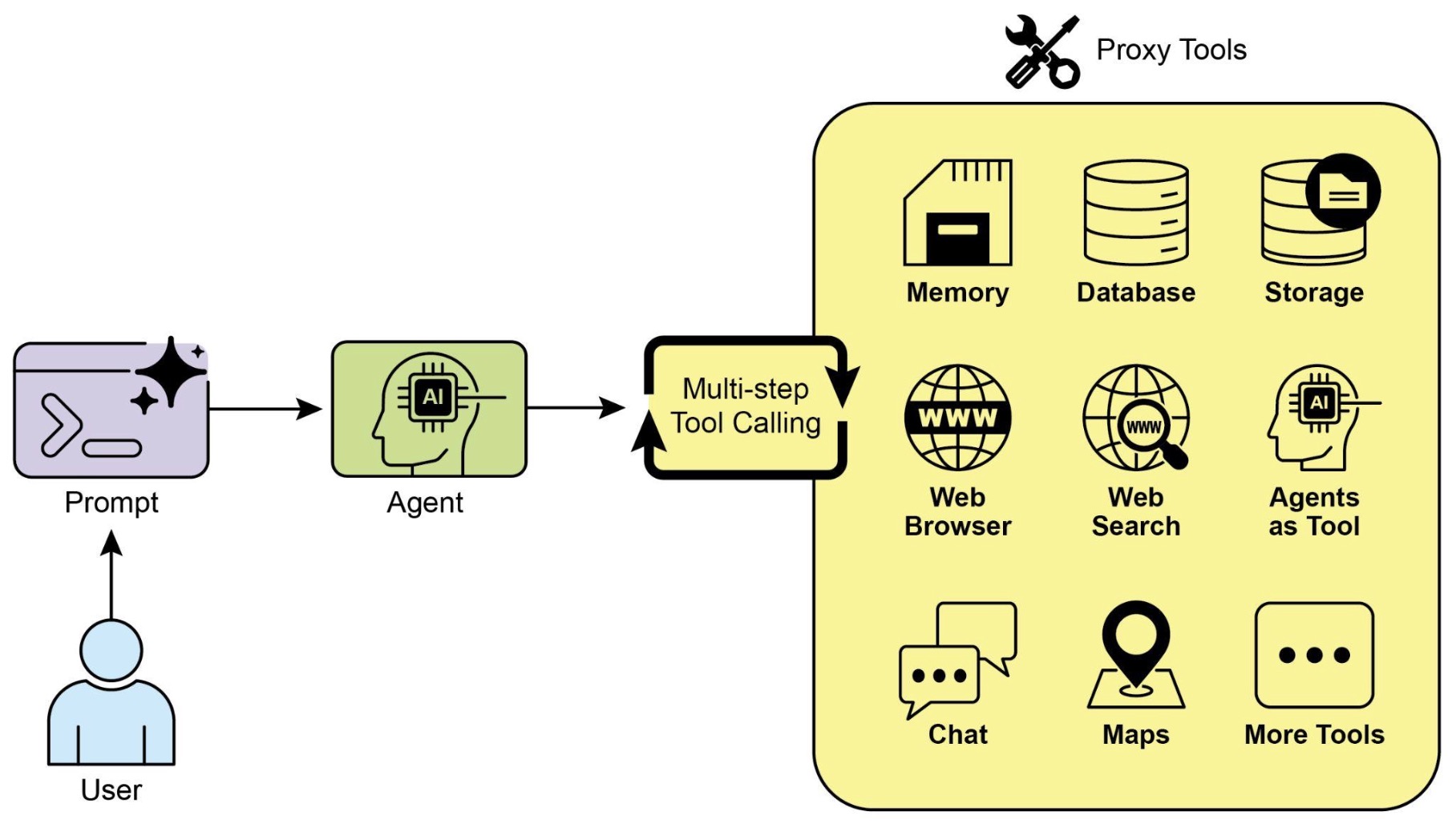
The tool interaction loop
- Tool use introduces an extended decision loop where the system must determine not only what to say, but what to do:
- After invoking a tool, the system observes the result and incorporates it into subsequent reasoning:
-
This creates a tight coupling between reasoning and execution, where actions directly influence future decisions.
-
This interaction pattern is central to modern agent frameworks and is exemplified by ReAct by Yao et al. (2022), where reasoning steps guide tool usage and observations refine subsequent reasoning.
-
The following figure shows the tool use design pattern.
Types of tools
-
Tools can take many forms depending on the application:
-
Information retrieval tools:
- Web search APIs
- Vector databases (RAG systems)
-
Knowledge bases
- These provide access to external knowledge and improve factual accuracy.
-
Computation tools:
- Calculators
- Code execution environments
-
Simulation engines
- These ensure correctness in tasks requiring precise computation.
-
Action tools:
- APIs for booking, payments, or transactions
- Workflow automation systems
-
Robotics interfaces
- These allow the system to affect the external world.
-
Validation tools:
- Schema validators
- Consistency checkers
-
Safety filters
- These ensure outputs meet required constraints.
-
Example
-
Consider a system tasked with answering a financial question: “What is the current stock price of AAPL, and how does it compare to last week?”
-
A tool-enabled system would:
- Recognize that real-time data is required
- Invoke a financial API to retrieve current and historical prices
- Compute the difference
- Generate a response
-
Without tool use, the model would either hallucinate or provide outdated information.
Implementation
- LangChain provides built-in abstractions for integrating tools into agent workflows.
from langchain.agents import initialize_agent, Tool
from langchain_openai import ChatOpenAI
# Define a simple calculator tool
def calculator(expression: str) -> str:
return str(eval(expression))
tools = [
Tool(
name="Calculator",
func=calculator,
description="Useful for solving math expressions"
)
]
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
agent = initialize_agent(
tools=tools,
llm=llm,
agent="zero-shot-react-description",
verbose=True
)
result = agent.run("What is (45 * 23) + 17?")
print(result)
- In this example, the agent decides when to invoke the calculator tool instead of attempting to compute the result internally. This improves both accuracy and reliability.
Tool selection and orchestration
-
A key challenge in tool use is deciding:
- Which tool to use
- When to use it
- How to interpret its output
-
This introduces a decision layer similar to routing, but focused specifically on action selection.
-
In more advanced systems, this can involve:
- Ranking multiple tools
- Composing multiple tool calls
- Handling tool failures and retries
-
This orchestration is central to building robust agentic systems.
Tool use in agentic systems
-
Tool use is deeply interconnected with other patterns:
- With routing: Selecting the appropriate tool
- With prompt chaining: Integrating tool outputs into multi-step workflows
- With reflection: Verifying and correcting tool results
- With planning: Sequencing multiple tool calls
-
This makes tool use one of the most critical enablers of real-world functionality.
Failure modes
-
Tool use introduces several challenges:
- Incorrect tool selection: The system may choose the wrong tool
- Tool misuse: Inputs to tools may be malformed
- Latency: External calls can be slow
- Error handling: Tools may fail or return unexpected results
-
To mitigate these issues:
- Provide clear tool descriptions
- Validate inputs and outputs
- Implement retries and fallbacks
- Monitor tool performance
Planning
-
Planning is an agentic design pattern that enables a system to break down a complex goal into a structured sequence of actions before execution. Instead of reacting myopically step by step, the system forms an explicit or implicit plan that guides its behavior across multiple steps, introducing foresight, coordination, and long-horizon reasoning.
-
At its core, planning shifts a system from reactive execution to goal-directed strategy. Rather than deciding only the immediate next action, the system reasons about how a sequence of actions can collectively achieve an objective. This marks a transition from local decision-making to a more global, strategic perspective.
-
By incorporating planning, agentic systems can anticipate dependencies, coordinate actions, and pursue goals with greater effectiveness. In this sense, planning is the pattern that transforms isolated actions into coherent strategy.
Why planning is needed
-
Reactive systems, even when combined with tools and reflection, often struggle with:
- Multi-step dependencies
- Long-horizon tasks
- Coordination across subtasks
- Efficient use of resources
-
Without planning, the system may:
- Take redundant or suboptimal actions
- Lose track of progress
- Fail to coordinate multiple steps effectively
-
Planning addresses these issues by introducing a structured representation of the task before execution begins.
-
This aligns with classical AI planning as well as modern LLM-based approaches. For example, Plan-and-Solve Prompting by Wang et al. (2023) shows that explicitly generating a plan before solving improves performance on complex reasoning tasks.
The planning process
-
Planning can be expressed as generating a sequence of actions:
\[\pi = (a_1, a_2, \dots, a_n)\]- where \(\pi\) is the plan and each \(a_i\) is an action or subtask.
-
Execution then follows:
-
The key distinction is that the sequence \(\pi\) is generated before or during execution, rather than emerging purely step-by-step.
-
The following figure shows the planning design pattern which involves task decomposition into a structured plan before execution.
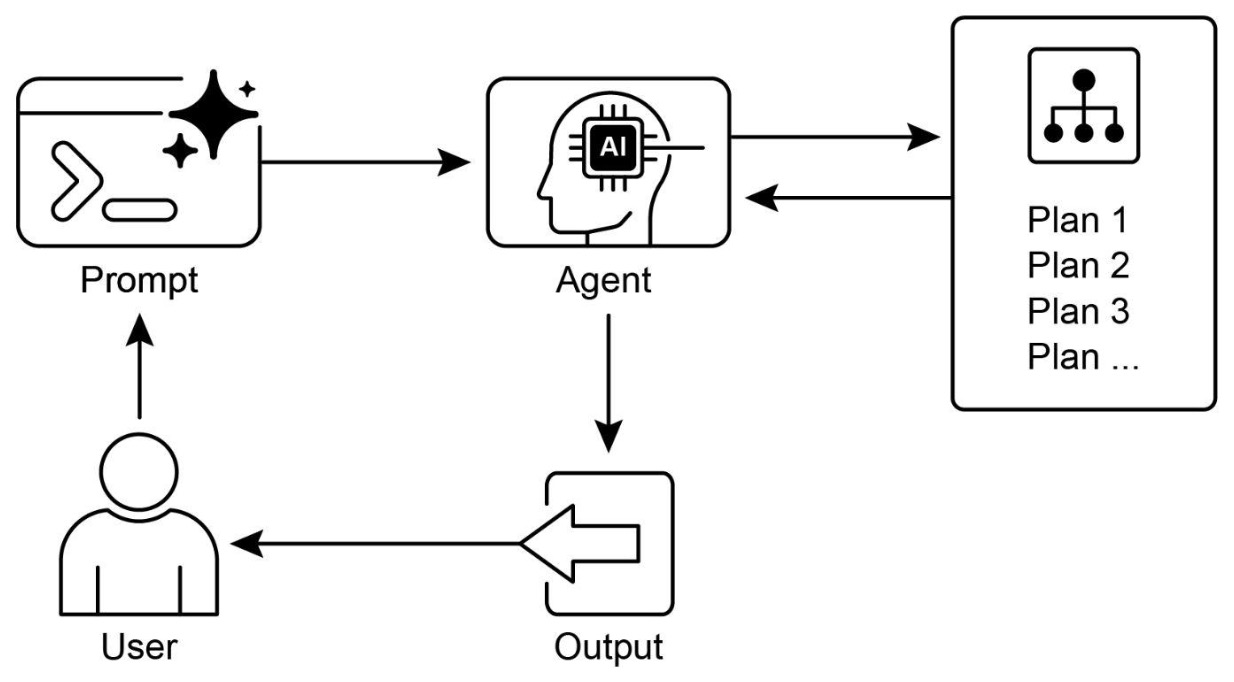
Types of planning
-
Planning can take several forms depending on how explicit and structured the plan is.
-
Static planning:
- The system generates a full plan upfront and executes it sequentially. This works well for well-defined tasks but can be brittle if conditions change.
-
Dynamic planning:
- The system updates its plan during execution based on new information. This introduces adaptability and resilience.
-
Hierarchical planning:
- Tasks are decomposed into subgoals and sub-subgoals, forming a tree structure. This is useful for complex problems with multiple layers of abstraction.
-
Iterative planning:
- The system alternates between planning and execution, refining its plan as it progresses.
-
These approaches reflect different trade-offs between structure and flexibility.
Example
-
Consider a task such as: “Plan a trip to Paris for three days.”
-
A planning-based system might:
- Identify key components: travel, accommodation, itinerary
- Break each component into subtasks
- Sequence the tasks logically
- Execute each step using tools (e.g., booking APIs, search)
-
Without planning, the system might jump between unrelated steps or miss important dependencies.
Implementation
- Planning can be implemented in LangChain by separating plan generation from execution.
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Step 1: Generate plan
plan_prompt = ChatPromptTemplate.from_messages([
("system", "Break the task into a sequence of steps."),
("human", "{task}")
])
# Step 2: Execute each step
execute_prompt = ChatPromptTemplate.from_messages([
("system", "Execute the following step."),
("human", "{step}")
])
plan_chain = plan_prompt | llm | StrOutputParser()
execute_chain = execute_prompt | llm | StrOutputParser()
task = "Prepare a report on renewable energy trends."
plan = plan_chain.invoke({"task": task})
steps = plan.split("\n")
results = []
for step in steps:
result = execute_chain.invoke({"step": step})
results.append(result)
print(results)
- This example demonstrates a simple two-phase approach: first generate a plan, then execute each step sequentially.
Planning with tools and feedback
-
Planning becomes more powerful when combined with other patterns:
- With tool use: Each step in the plan can invoke specific tools
- With reflection: The plan can be evaluated and refined
- With routing: Different steps can be assigned to specialized components
- With parallelization: Independent steps can be executed concurrently
-
This creates a flexible system where planning guides execution but does not rigidly constrain it.
Planning in agentic systems
-
Planning is a key enabler of advanced agent behavior:
- It allows agents to handle long-term objectives
- It improves coordination across multiple actions
- It reduces inefficiencies in execution
- It enables proactive behavior
-
In multi-agent systems, planning often involves coordination across agents, where different agents are assigned different parts of the plan.
Failure modes
-
Planning introduces its own challenges:
- Overplanning: Excessive detail can reduce flexibility
- Plan brittleness: Static plans may fail in dynamic environments
- Error propagation: Flawed plans lead to flawed execution
- Complexity: Managing plans adds overhead
-
To mitigate these issues:
- Use dynamic or iterative planning
- Incorporate feedback loops
- Validate plans before execution
- Allow replanning when conditions change
Prioritization
- In complex, dynamic environments, agentic systems constantly face multiple competing actions, conflicting goals, and limited resources. Without a structured way to decide what to do next, they risk inefficiency, delays, or even complete failure to achieve their objectives. The prioritization design pattern addresses this challenge by enabling agents to evaluate, rank, and select tasks according to well-defined criteria, ensuring that effort is directed toward the most impactful actions.
- At its core, prioritization transforms an agent from a reactive executor into a strategic decision-maker: rather than treating all tasks equally, the agent continuously determines what matters most and aligns its behavior with overarching goals and constraints. As a result, prioritization becomes a cornerstone of agentic intelligence, allowing agents not just to act, but to decide what is worth acting on. By continuously evaluating and reordering tasks, agents demonstrate a form of strategic reasoning that closely mirrors human decision-making, a capability that is essential for building systems that are not only functional, but truly effective in real-world, high-complexity environments.
Core idea
-
Prioritization introduces a decision function over a set of candidate tasks:
\[a^* = \arg\max_{a \in \mathcal{A}} \mathcal{S}(a)\]-
where:
- \(\mathcal{A}\) is the set of possible actions or tasks
- \(\mathcal{S}(a)\) is a scoring function based on prioritization criteria
- \(a^*\) is the selected highest-priority action
-
-
This formalization highlights that prioritization is fundamentally an optimization problem under constraints.
Key components of prioritization
-
Effective prioritization typically involves four key components:
-
Criteria definition:
-
Agents define evaluation criteria to assess tasks. Common criteria include:
- Urgency: how time-sensitive the task is
- Importance: impact on primary objectives
- Dependencies: whether other tasks rely on it
- Resource availability: readiness of tools or data
- Cost-benefit tradeoff: effort versus expected outcome
- User preferences: personalization signals
-
These criteria define the agent’s notion of “value”.
-
-
Task evaluation:
-
Each candidate task is evaluated against the defined criteria. This can range from:
- Rule-based scoring (e.g., priority levels P0, P1, P2)
- Heuristic functions
- LLM-based reasoning over task descriptions
-
This step transforms qualitative information into comparable scores.
-
-
Scheduling and selection:
-
Based on evaluations, the agent selects the next action or sequence of actions. This may involve:
- Priority queues
- Greedy selection
- Integration with planning systems
-
This is where prioritization connects directly with planning and execution.
-
-
Dynamic re-prioritization:
-
As new information arrives or conditions change, priorities must be updated. This enables:
- Responsiveness to new events
- Adaptation to deadlines
- Recovery from failures or delays
-
Dynamic re-prioritization is essential for real-world environments where conditions are non-static.
-
-
The following figure shows the prioritization design pattern and how tasks are evaluated and ordered based on defined criteria.
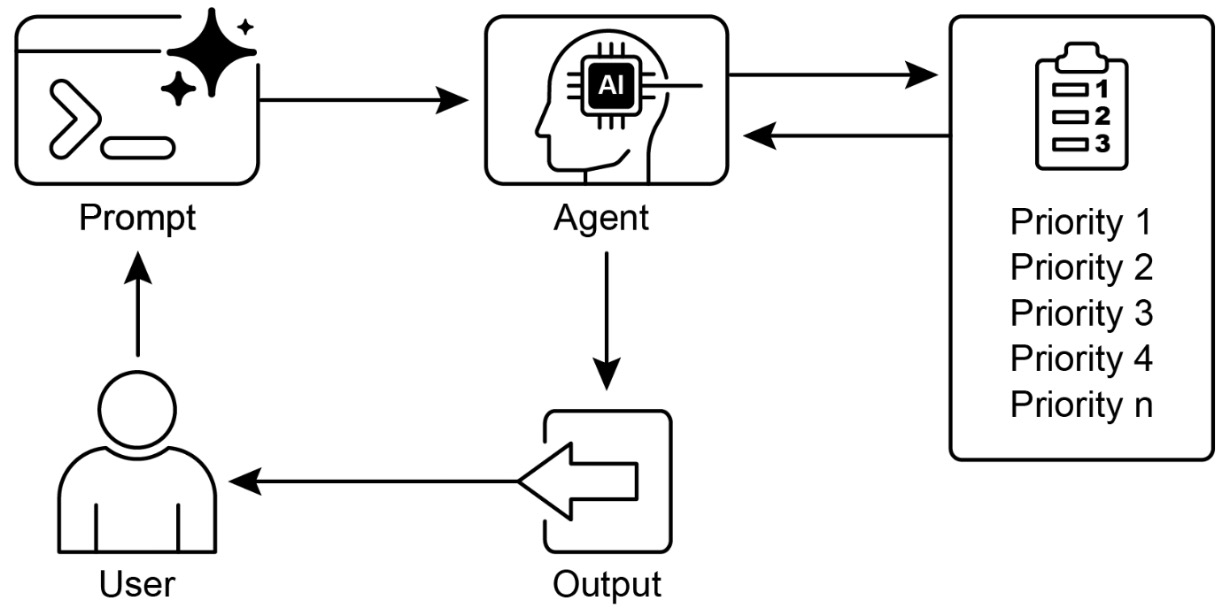
Levels of prioritization
-
Prioritization operates at multiple levels within an agentic system:
- Goal-level prioritization: selecting which high-level objective to pursue
- Plan-level prioritization: ordering sub-tasks within a plan
- Action-level prioritization: choosing the next immediate step
-
This multi-level structure mirrors hierarchical decision-making in human organizations.
Relationship to other patterns
-
Prioritization is deeply interconnected with other agentic design patterns:
- Planning: prioritization determines which plan steps execute first
- Routing: prioritization can influence which workflow or agent is selected
- Tool use: determines which tool invocation is most critical
- Goal monitoring: evaluates progress and adjusts focus
- Evaluation: provides signals that influence future prioritization
-
Together, these patterns form a decision-making backbone for the agent.
Real-world applications
-
Prioritization is fundamental across many domains:
- Customer support: urgent incidents (e.g., outages) are handled before routine requests
- Cloud computing: critical workloads receive resources before batch jobs
- Autonomous driving: collision avoidance overrides efficiency goals
- Financial trading: high-risk or high-reward trades are executed first
- Cybersecurity: severe threats are addressed before minor alerts
- Personal assistants: schedules and reminders are ordered by importance and timing
-
These examples demonstrate that prioritization is essential wherever decisions must be made under constraints.
Implementation
- The following example demonstrates a project manager agent that creates, prioritizes, and assigns tasks using tools.
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_react_agent
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.5)
prompt = ChatPromptTemplate.from_messages([
("system", """You are a Project Manager AI.
Always:
1. Create a task
2. Assign priority (P0 highest, P2 lowest)
3. Assign a worker
"""),
("human", "{input}")
])
agent = create_react_agent(llm, tools=[], prompt=prompt)
executor = AgentExecutor(agent=agent, tools=[], verbose=True)
executor.invoke({"input": "Create an urgent task to fix login issues"})
-
In practice, this system would integrate with:
- Task storage (memory layer)
- Tooling for updates and assignment
- Evaluation signals for reprioritization
Why prioritization matters
-
Without prioritization:
- Agents may waste resources on low-value tasks
- Critical deadlines may be missed
- Conflicting goals may cause indecision
- System behavior becomes unpredictable
-
With prioritization:
- Decision-making becomes structured and goal-aligned
- Resources are allocated efficiently
- Agents behave more intelligently and robustly
- Systems can scale to complex, multi-objective environments
Rule of thumb
- Use the prioritization pattern when an agent must autonomously manage multiple competing tasks or goals under constraints. It is especially critical in dynamic environments where conditions change and decisions must be made continuously.
Pattern Selection and Composition
Core Idea
-
Agentic systems are not constructed from a single model, prompt, or technique. Instead, they emerge from the deliberate integration of multiple design patterns, each contributing a distinct aspect of intelligence—reasoning, action, memory, control, and safety. While these patterns can be studied individually, real-world effectiveness depends on how they are brought together into a cohesive whole.
-
This marks an important shift in perspective: from understanding isolated capabilities to designing complete systems. At this stage, the emphasis is no longer on how each pattern works independently, but on how they interact, reinforce one another, and impose constraints within a unified architecture. The success of an agentic system is therefore defined not only by the strength of its individual components, but by the quality of their composition.
-
A central principle in this process is that pattern selection is inherently context-dependent. Different applications introduce varying requirements across dimensions such as latency, cost, reliability, risk tolerance, and task complexity. There is no single optimal configuration; instead, designing an effective system becomes an exercise in balancing trade-offs. The choice and arrangement of patterns must align with the specific constraints and goals of the problem being solved.
-
This is the transition from techniques to systems—from assembling capabilities to engineering architectures. Pattern selection and composition provide the mechanism for synthesis, enabling developers to combine discrete elements into cohesive, production-ready solutions that are robust, scalable, and aligned with real-world demands.
-
Ultimately, this is the layer where components become systems: where individual patterns, when thoughtfully composed, create something greater than the sum of their parts.
Why composition is needed
-
Real-world problems are inherently multi-dimensional. A single pattern cannot address all requirements:
- Prompt chaining handles structured reasoning
- Routing enables specialization
- Tool use enables external interaction
- Memory enables persistence
- Planning enables long-horizon execution
- Reflection enables refinement
- Guardrails ensure safety
-
Without composition, systems remain limited in capability. With composition, they become flexible and robust.
-
This reflects principles from software architecture, where modular components are combined to form complex systems. In agentic design, patterns serve as these modular building blocks.
The composition framework
-
Agentic systems can be viewed as compositions of patterns:
\[\mathcal{S} = \mathcal{P}_1 \circ \mathcal{P}_2 \circ \cdots \circ \mathcal{P}_n\]- where each \(\mathcal{P}_i\) represents a design pattern.
-
The challenge lies in determining:
- Which patterns to include
- How they interact
- In what order they are applied
-
This composition defines the system’s behavior.
Common composition strategies
-
Different strategies can be used to combine patterns effectively.
-
Linear composition:
- Patterns are applied sequentially
- Example: prompt chaining \(\rightarrow\) tool use \(\rightarrow\) reflection
-
Hierarchical composition:
- High-level patterns orchestrate lower-level ones
- Example: planning coordinating multiple chains
-
Parallel composition:
- Multiple patterns operate simultaneously
- Example: parallel retrieval + parallel evaluation
-
Conditional composition:
- Patterns are selected dynamically
- Example: routing between different workflows
-
-
These strategies can be combined to create complex architectures.
Example
-
Consider a research assistant agent:
- Routing determines the type of query
- Planning decomposes the task
- Tool use retrieves relevant information
- Prompt chaining processes the data
- Reflection improves the output
- Evaluation measures quality
- Memory stores results
-
This composition enables the system to handle complex tasks effectively.
Implementation
- LangChain enables composition through modular chains, agents, and workflows.
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableParallel
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Prompt chaining
prompt = ChatPromptTemplate.from_messages([
("system", "Summarize the input."),
("human", "{text}")
])
chain = prompt | llm
# Parallel evaluation
def evaluate(output):
return f"Evaluation of: {output}"
workflow = RunnableParallel(
summary=chain,
evaluation=lambda x: evaluate(x["text"])
)
result = workflow.invoke({"text": "Agentic systems combine reasoning and action."})
print(result)
- This example demonstrates how multiple components can be composed into a single workflow.
Design considerations
-
Effective composition requires careful consideration of:
-
Task complexity:
- Simple tasks may require only a few patterns
- Complex tasks require richer compositions
-
Performance constraints:
- Latency and cost must be balanced
- Parallelization and routing can optimize efficiency
-
Reliability requirements:
- Reflection, guardrails, and monitoring improve robustness
-
Scalability:
- Modular composition enables system growth
-
-
These factors guide pattern selection.
Failure modes
-
Poor composition can lead to:
- Over-engineering: Too many patterns increase complexity
- Under-engineering: Missing patterns limit capability
- Tight coupling: Reduces flexibility
- Unclear control flow: Makes debugging difficult
-
To mitigate these issues:
- Start simple and iterate
- Use modular designs
- Clearly define interfaces between patterns
- Continuously evaluate system performance
Multi-Agent Systems
-
Multi-agent systems represent an agentic design pattern in which multiple specialized agents collaborate to achieve a shared goal. Rather than relying on a single, monolithic agent to handle every aspect of a task, responsibilities are distributed across agents with clearly defined roles, expertise, and capabilities. This introduces modularity, scalability, and specialization into agentic architectures.
-
This approach reflects a fundamental shift in how complex problems are solved: moving away from a single generalist toward a coordinated team of specialists. Much like human organizations, where division of labor and collaboration drive effectiveness, multi-agent systems leverage structured cooperation to produce better outcomes.
-
At a deeper level, multi-agent systems embody the concept of distributed intelligence. Intelligence is no longer concentrated in a single entity but instead emerges from the interactions and coordination among agents. This enables systems to scale not only in size but also in capability and complexity, supporting parallelism, adaptability, and flexible coordination.
-
Ultimately, this pattern transforms individual intelligence into collective intelligence, making it a foundational approach for building sophisticated, real-world AI systems.
Motivation
-
As tasks grow in complexity, a single agent faces several limitations:
- Cognitive overload from handling multiple responsibilities
- Difficulty maintaining consistent context across diverse subtasks
- Inefficiency in switching between different types of reasoning
- Limited scalability for large workflows
-
Multi-agent systems address these challenges by decomposing the problem into roles and delegating tasks accordingly.
-
This idea aligns with distributed AI and cooperative systems, where coordination among multiple entities leads to emergent intelligence. For example, Generative Agents by Park et al. (2023) demonstrate how multiple agents interacting in a shared environment can produce complex, believable behaviors.
The multi-agent architecture
-
A multi-agent system can be viewed as a set of agents:
\[A = {a_1, a_2, \dots, a_n}\]- where each agent \(a_i\) is responsible for a specific function.
-
The system operates through communication and coordination:
-
A central coordinator or decentralized protocol manages how agents interact and share information.
-
The following figure shows an example of multi-agent system.
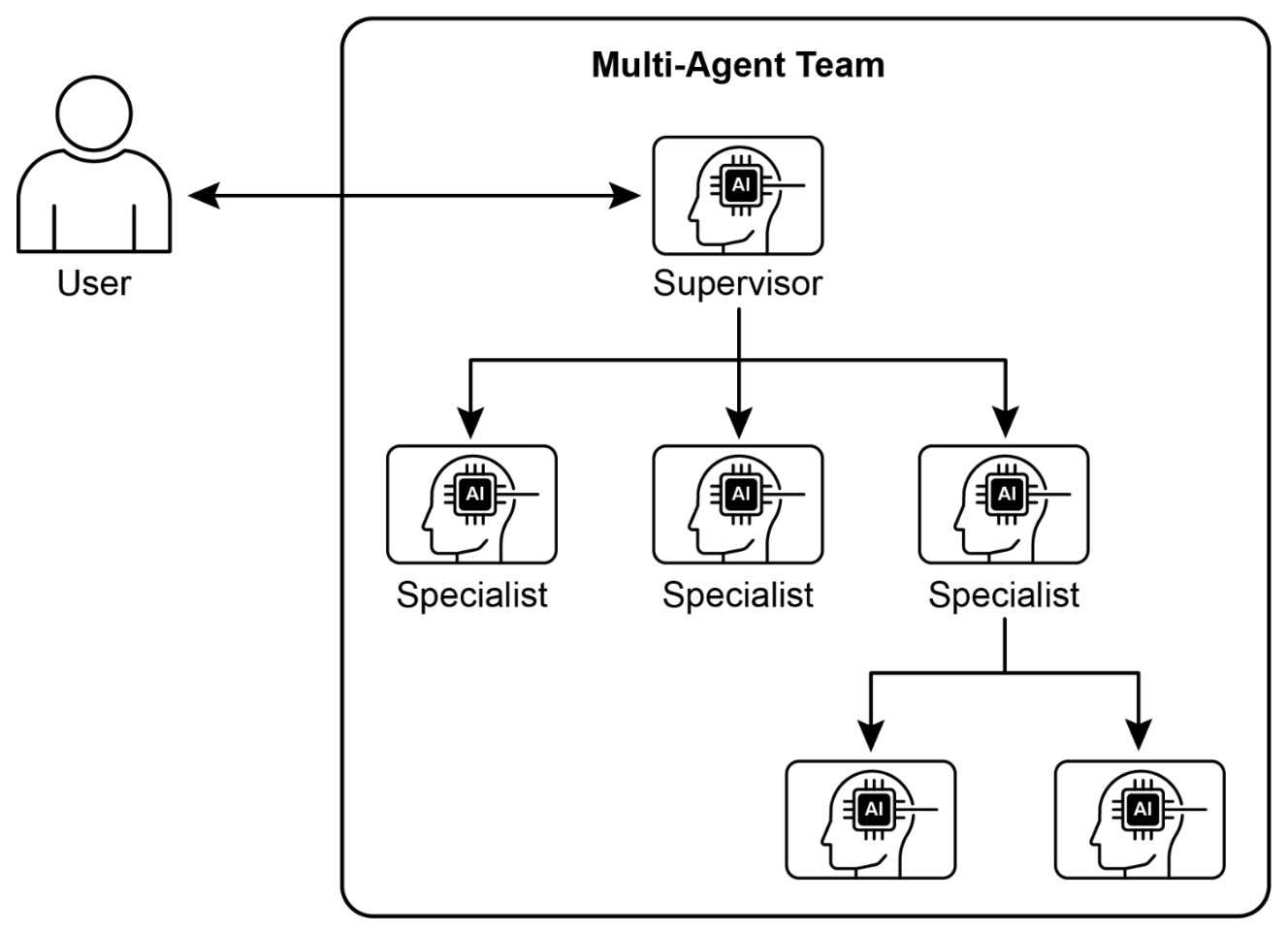
Multi-agent topologies
-
Multi-agent systems can be structured in different ways depending on how agents communicate, coordinate, and share responsibilities. These structures define the interrelationships between agents and directly impact system efficiency, robustness, scalability, and adaptability.
-
At a high level, multi-agent coordination spans a spectrum from fully independent agents to highly structured hierarchical and custom-designed systems. Each model introduces trade-offs between control, flexibility, communication overhead, and fault tolerance.
Single agent
- A single agent operates independently without interacting with others
- Simple to implement and manage
- Limited by the capabilities and resources of one agent
- This model is suitable when tasks can be solved in isolation and do not require collaboration.
Network (decentralized coordination)
- Multiple agents communicate directly in a peer-to-peer fashion
-
No central controller; agents share information, resources, and tasks
-
Advantages:
- High flexibility and scalability
- Resilient to individual agent failure
-
Challenges:
- Coordination complexity increases with scale
- Communication overhead can become significant
- Harder to ensure consistent global behavior
- This corresponds to decentralized coordination where autonomy is maximized but control is reduced.
Supervisor (centralized coordination)
-
A central “supervisor” agent manages a group of subordinate agents
-
The supervisor:
- Assigns tasks
- Aggregates results
- Maintains global context
- Resolves conflicts
-
Advantages:
- Clear control flow and coordination
- Easier to debug and manage
-
Challenges:
- Single point of failure
- Potential bottleneck under high load
-
This is the most common production pattern due to its simplicity and controllability.
Supervisor as a tool
- The supervisor provides capabilities rather than strict control
- Acts as a resource provider (e.g., tools, data, analysis)
-
Other agents retain autonomy in decision-making
-
Advantages:
- Balances guidance with flexibility
- Avoids rigid top-down control
- This model is useful when centralized expertise is needed without constraining agent autonomy.
Hierarchical systems
-
Agents are organized into multiple layers:
- High-level agents define goals
- Mid-level agents plan and coordinate
- Low-level agents execute actions
-
Advantages:
- Scales well for complex tasks
- Enables structured decomposition of problems
- Supports distributed decision-making
-
Challenges:
- Increased system complexity
- Requires careful coordination across layers
-
This mirrors real-world organizational hierarchies and is well-suited for large, multi-stage workflows.
Custom systems
- Tailored architectures combining elements of different models
-
May include hybrid coordination strategies or entirely novel designs
-
Advantages:
- Optimized for specific tasks, environments, or constraints
- Can balance trade-offs across control, flexibility, and efficiency
-
Challenges:
- More difficult to design and implement
- Requires deep understanding of agent interactions and communication protocols
-
Custom systems are typically used in advanced production settings where standard patterns are insufficient.
-
The choice of coordination model is a critical design decision. It depends on factors such as task complexity, number of agents, required autonomy, robustness needs, and acceptable communication overhead.
- The following figure shows how agents communicate and interact in various ways.
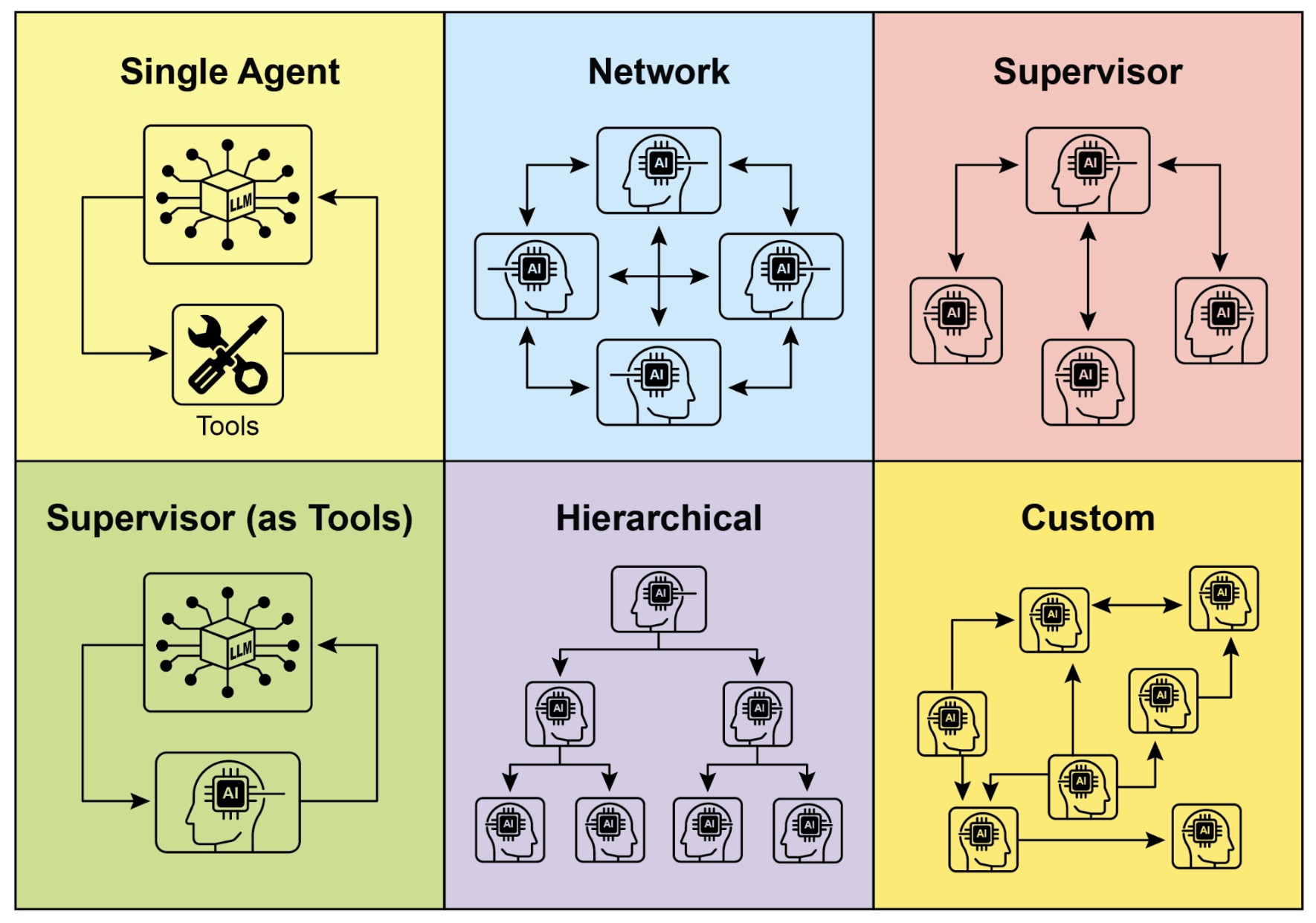
Example
-
Consider a product launch scenario. A multi-agent system might include:
- A Project Manager agent to coordinate tasks
- A Market Research agent to analyze trends
- A Design agent to create product concepts
- A Marketing agent to generate campaigns
-
The Project Manager agent assigns tasks, collects outputs, and ensures alignment across agents.
-
This example illustrates how specialization and coordination enable the system to handle complex, multi-faceted objectives.
Implementation
- LangChain and related frameworks support multi-agent orchestration through role-based agents and shared workflows.
from langchain_openai import ChatOpenAI
from langchain.agents import initialize_agent, Tool
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Define simple role-based tools (agents)
def research_agent(task: str) -> str:
return f"Research findings for: {task}"
def writing_agent(task: str) -> str:
return f"Written content for: {task}"
tools = [
Tool(name="ResearchAgent", func=research_agent, description="Performs research"),
Tool(name="WritingAgent", func=writing_agent, description="Writes content")
]
manager_agent = initialize_agent(
tools=tools,
llm=llm,
agent="zero-shot-react-description",
verbose=True
)
result = manager_agent.run("Create a blog post about AI agents.")
print(result)
- In this simplified example, the manager agent delegates tasks to specialized agents. In more advanced systems, each agent would have its own internal logic, memory, and tools.
Communication and coordination
-
Effective multi-agent systems depend on how agents communicate:
- Message passing: Agents exchange structured messages
- Shared memory: Agents read and write to a common state
- Task delegation: Agents assign subtasks to others
- Feedback loops: Agents critique and refine each other’s outputs
-
Communication protocols are critical for ensuring consistency and alignment across agents.
Multi-agent systems in practice
-
Multi-agent systems are most valuable in real-world settings where tasks are complex, multi-stage, and require coordination across different capabilities. In practice, these systems are implemented as orchestrated workflows of specialized agents, each responsible for a specific role within a larger pipeline.
-
A key advantage is specialization and parallelism. Different agents handle distinct subtasks such as retrieval, reasoning, planning, or execution, and can often operate concurrently. This improves both efficiency and quality compared to a single monolithic agent.
-
Multi-agent systems are particularly effective for:
-
Complex workflows with multiple stages:
- Example: Retrieval → summarization → synthesis → report generation
- Improves modularity and interpretability
-
Tasks requiring diverse expertise:
- Example: Software systems with agents for coding, testing, and debugging
- Each agent can use different tools or prompts
-
Large-scale automation pipelines:
- Example: Enterprise workflows for data processing and reporting
- Enables scalable and maintainable architectures
-
Collaborative problem-solving:
- Example: Multiple agents proposing and critiquing solutions
- Improves robustness through cross-verification
-
-
In production, most systems use a hybrid architecture:
- A central orchestrator handles task decomposition, coordination, and aggregation
- Specialized agents execute subtasks
- Shared memory and tools provide common context
-
Multi-agent systems are widely used across domains:
- Software engineering: Code generation, testing, deployment pipelines
- Research and analysis: Retrieval, summarization, and insight generation
- Business automation: Customer support, sales workflows
- Simulation: Interactive environments, inspired by Generative Agents by Park et al. (2023), which show how agent interactions produce emergent behavior
-
In practice, effectiveness depends less on the number of agents and more on clear role definition, efficient communication, and robust coordination.
Failure modes
-
Multi-agent systems introduce additional layers of complexity that can lead to subtle and emergent failure modes, especially as scale and interaction increase:
-
Coordination overhead: Increased communication and synchronization costs can lead to inefficiency, redundant work, or bottlenecks.
-
Inconsistency and conflict: Agents may produce contradictory or misaligned outputs due to partial context or differing reasoning paths.
-
Latency and cascading delays: Sequential dependencies can propagate delays across the system, increasing end-to-end execution time.
-
Debugging and observability challenges: Failures often emerge from interactions across agents, making root-cause analysis difficult without proper tracing.
-
Error amplification: Mistakes from one agent can propagate and compound through downstream agents.
-
Role ambiguity: Unclear responsibilities can lead to duplicated work or missed tasks.
-
Resource contention: Agents competing for shared tools or APIs can cause throttling or degraded performance.
-
Unbounded interaction loops: Agents may repeatedly interact without convergence if stopping criteria are not enforced.
-
-
To mitigate these issues:
- Define clear roles and responsibilities
- Use structured communication formats
- Add validation and aggregation mechanisms
- Implement observability and tracing
- Enforce execution bounds and timeouts
- Manage shared resource usage
-
Addressing these failure modes is critical for building reliable, production-grade multi-agent systems.
Single-Agent vs. Multi-Agent Systems
Why this distinction matters
Budget-aware comparison
- A useful primer on agentic systems should separate two ideas that are often conflated: reasoning quality and compute expenditure. A large share of the apparent advantage of MAS comes from comparing architectures that do not actually spend the same reasoning budget.
- Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026) makes this point especially clearly: under matched thinking-token budgets on multi-hop reasoning tasks, SAS often matches or outperforms MAS, suggesting that many reported gains from orchestration are better explained by additional test-time computation or context effects than by inherent architectural superiority.
System-level scaling perspective
- This distinction becomes even more important when combined with system-level evidence from Towards a Science of Scaling Agent Systems by Kim et al. (2025), which shows that architecture-task alignment matters more than simply adding more agents.
- The paper further demonstrates that coordination can either improve performance significantly or degrade it depending on how well the coordination pattern matches the task, reinforcing that multi-agent gains are conditional rather than universal.
Unified reasoning vs. distributed orchestration
- At a broader engineering level, the single-agent versus multi-agent distinction reflects a deeper tradeoff between unified reasoning and distributed orchestration. A single-agent system preserves a coherent internal reasoning trajectory over the full task state, which often makes it simpler, more maintainable, and more compute-efficient.
- A multi-agent system externalizes reasoning into multiple interacting components, which can be powerful when the task genuinely benefits from decomposition, specialization, verification, or parallel search, but also introduces communication overhead, message compression, orchestration complexity, and new failure modes.
Real-world applicability
- This explains why MAS is particularly useful in practice for complex workflows with multiple stages, tasks requiring diverse expertise, large-scale automation pipelines, and collaborative problem-solving environments.
- These characteristics naturally arise in domains such as software engineering, research and analysis, business process automation, and simulation or modeling, where multiple reasoning paths or roles must be coordinated, meaning success depends on structural alignment between the task and the coordination pattern.
Design principle
- This budget-aware framing is also consistent with Reasoning in Token Economies: Budget-Aware Evaluation of LLM Reasoning Strategies by Wang et al. (2024), which shows in one line that many complex reasoning strategies lose much of their claimed advantage once compute is normalized.
- Taken together, these works suggest a disciplined design principle: begin with a single coherent reasoning process, and only introduce additional agents when decomposition, modularity, verification, or parallel exploration provides a clear architectural benefit.
Conceptual definitions
Single-agent systems
-
Single-agent systems (SAS) solve the task within one model call over a unified context, where the model sees the full problem state and performs one continuous internal reasoning trajectory before emitting a final answer.
-
In the attached paper, this corresponds to allocating the entire thinking-token budget \(B\) to a single reasoning process, without externalizing intermediate steps or fragmenting the reasoning path.
-
This unified setup aligns closely with the idea of preserving full information flow throughout reasoning, which is one of the key advantages highlighted in Towards a Science of Scaling Agent Systems by Kim et al. (2025), where SAS maximize context integration by maintaining a single coherent memory stream.
-
Because all reasoning occurs within one locus, there is effectively no communication overhead, no need for message passing, and no risk of information loss due to serialization, making SAS both information-efficient and structurally simple.
Multi-agent systems
-
Multi-agent systems distribute reasoning across multiple model calls, often structured as planners, workers, critics, or aggregators that operate on different parts of the task.
-
Each component operates on partial views and communicates via generated messages, effectively transforming the original context \(C\) into intermediate representations \(M = g(C)\) that must be shared and reconciled.
-
Put simply, SAS keeps reasoning latent and unified, while MAS externalizes reasoning into explicit communication channels, introducing both structure and overhead.
-
This externalization is central to the coordination tradeoffs described in Towards a Science of Scaling Agent Systems by Kim et al. (2025), where MAS incurs a coordination tax due to message passing, synchronization, and context compression across agents.
Information flow and representation
-
The key conceptual difference between SAS and MAS lies in how information is represented and propagated through the system. In SAS, the full context \(C\) is directly available to the reasoning process at every step, enabling consistent access to all prior information.
-
In MAS, the context is repeatedly transformed into intermediate messages \(M\), which are necessarily lossy representations of the original state and can introduce fragmentation or divergence across agents.
-
This difference explains why SAS tends to perform well on tightly coupled reasoning tasks, where maintaining a consistent global state is critical, while MAS can be advantageous in settings where decomposition, specialization, or parallel exploration outweigh the cost of information loss.
-
It also directly connects to the broader architectural insight that coordination is not free: every additional agent introduces a boundary where information must be compressed, transmitted, and reconstructed, which fundamentally changes the dynamics of reasoning.
Visual overview
Architectural intuition
- The following figure shows a simplified comparison between single-agent and multi-agent LLM architectures under a fixed thinking token budget, emphasizing how information flows through the system and how compute is allocated.
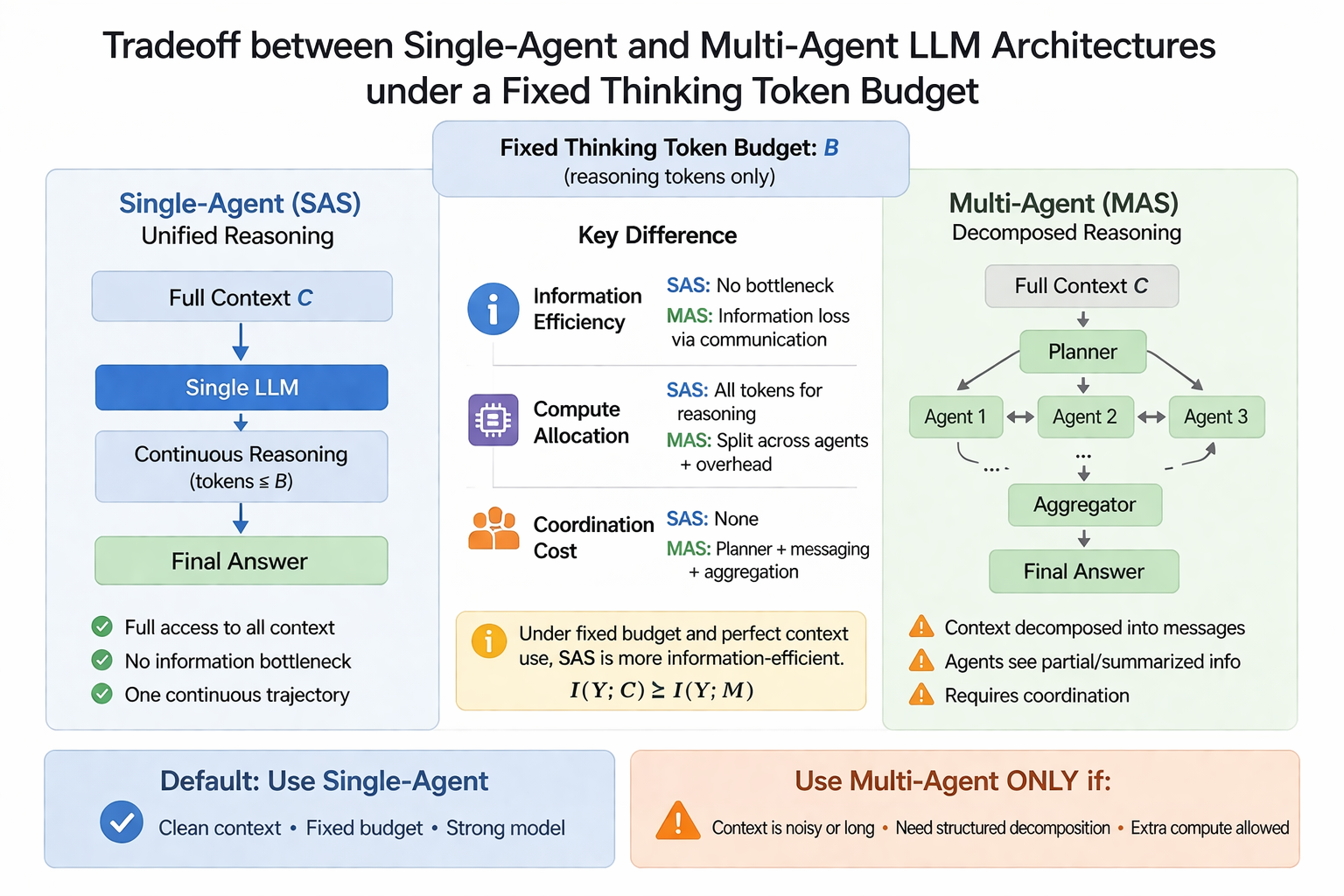
- In a single-agent setup, the full context is processed within a single reasoning trajectory, while in a multi-agent setup, that same context is split, transformed, and communicated across multiple interacting components.
Information flow differences
-
In the single-agent case, the model operates over a unified context \(C\), preserving all information internally and allowing each reasoning step to access the full history without any need for serialization or message passing.
-
In contrast, MAS transforms the context into intermediate messages \(M = g(C)\), which are passed between agents and can introduce compression, abstraction, or loss of detail at each step.
-
This distinction is closely related to the information bottleneck highlighted in both Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026) and Towards a Science of Scaling Agent Systems by Kim et al. (2025), where message passing reduces the effective information available for downstream reasoning.
-
In practical terms, every additional communication step in MAS introduces a transformation that can distort or omit useful signals, while SAS retains them natively.
Compute splitting and coordination
-
The figure also highlights how a fixed thinking-token budget \(B\) is used differently across architectures. In SAS, the entire budget is devoted to a single reasoning trajectory, maximizing depth and coherence.
-
In MAS, the same budget must be divided across multiple agents and coordination steps, reducing the effective reasoning depth available to each component.
-
This directly connects to the budget-controlled findings of Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026), which show that many MAS’ gains disappear when compute is normalized, and to the coordination overhead observed in Towards a Science of Scaling Agent Systems](https://arxiv.org/abs/2512.08296) by Kim et al. (2025), where additional agents introduce synchronization costs and increased total reasoning steps.
-
The visual intuition is that MAS trade depth for breadth, enabling parallel exploration or specialization at the cost of fragmentation and coordination complexity.
Architectural implication
- The key takeaway from this visual comparison is that architectural differences are not just about how many agents are used, but about how information and compute are structured across the system.
- SAS prioritizes coherence, depth, and simplicity, while MAS prioritize structure, modularity, and potential parallelism, making the choice between them fundamentally a question of how the task benefits from these tradeoffs.
Architectural comparison
Single-agent systems
Unified reasoning and context preservation
-
In a single-agent setup, the model has direct access to the full task context and spends the entire reasoning budget on one continuous chain of deliberation, allowing it to build and refine an internal representation without interruption.
-
This design is not only information-efficient but also structurally coherent, since all reasoning occurs within a shared latent space rather than being externalized into intermediate artifacts.
-
A key practical advantage is preservation of context. Because there is no need to serialize intermediate reasoning into messages, the system avoids context fragmentation and information loss.
-
In contrast, MAS must repeatedly summarize or transform intermediate outputs, which introduces subtle distortions and aligns with the information bottleneck described in Towards a Science of Scaling Agent Systems by Kim et al. (2025), where communication inherently compresses context.
Simplicity, maintainability, and flexibility
-
This unified reasoning structure also leads to improved simplicity and maintainability. A single-agent system requires fewer prompts, fewer coordination rules, and less orchestration logic, reducing both engineering overhead and system brittleness.
-
MAS, by comparison, introduce additional layers such as role definitions, routing policies, and aggregation mechanisms, each of which can fail independently and increase long-term maintenance complexity.
-
Another advantage is flexibility in problem solving. A well-configured single agent can dynamically shift strategies, tools, or reasoning styles within a single trajectory, adapting fluidly to task requirements.
-
This adaptability becomes especially important in real-world scenarios where tasks are not cleanly decomposable and require interleaving multiple capabilities such as retrieval, planning, and execution.
Scaling with modern LLM capabilities
-
Finally, advances in modern LLMs make SAS increasingly capable even for complex workflows. Longer context windows, improved reasoning capabilities, and better prompting techniques allow many tasks that previously required decomposition to be handled within a single coherent process.
-
This reinforces the empirical observation from Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026) that SAS is not only simpler but often more efficient under fixed compute budgets.
-
These observations are also consistent with Reasoning in Token Economies: Budget-Aware Evaluation of LLM Reasoning Strategies by Wang et al. (2024), which shows that many complex reasoning pipelines lose their advantage once compute is controlled.
-
Together with Towards a Science of Scaling Agent Systems by Kim et al. (2025), these results highlight that coordination overhead can offset the benefits of orchestration when the task does not require decomposition.
Multi-agent systems
Structured decomposition and coordination
-
In a multi-agent setup, the reasoning process is decomposed into interacting roles such as planners, workers, critics, or aggregators, each responsible for a subset of the overall task.
-
Towards a Science of Scaling Agent Systems by Kim et al. (2026) evaluates several such configurations, including sequential decomposition, subtask-parallel execution, role specialization, debate, and ensemble-style aggregation, all operating under a shared global token budget \(B\). This decomposition introduces structure, which can be beneficial in certain regimes. Parallel agents can explore different reasoning paths simultaneously, while specialized roles can focus on distinct aspects of the problem.
-
Put simply, MAS trades unified access for structured coordination, enabling breadth and modularity at the cost of coherence.
Real-world applicability and task alignment
-
These strengths are particularly relevant in real-world settings such as complex workflows with multiple stages, tasks requiring diverse expertise, and large-scale automation pipelines, where different components naturally operate on different parts of the problem. This is why MAS are increasingly used in domains like software engineering, research and analysis, business process automation, and simulation, where decomposition aligns with the underlying task structure.
-
This observation directly aligns with the architecture-task alignment principle from Towards a Science of Scaling Agent Systems by Kim et al. (2025), which shows that MAS succeeds when the task is inherently decomposable and fail when coordination is artificially imposed.
-
In practical terms, MAS work best when it mirrors real organizational structures where different roles contribute distinct, parallelizable value.
Coordination cost and failure modes
-
However, this structure comes at a cost. Each agent operates on partial or transformed context, and communication between agents introduces both overhead and opportunities for error.
-
The scaling analysis in Towards a Science of Scaling Agent Systems by Kim et al. (2025) shows that this coordination tax can dominate performance, especially in tasks that are sequential or tightly coupled.
-
MAS also tends to be more brittle from an engineering standpoint. Failures can arise not only from model reasoning errors but also from orchestration issues such as misaligned roles, incorrect aggregation, or communication breakdowns. This aligns with the findings of Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026), which highlights patterns such as over-exploration and incoherence in MAS compared to more focused reasoning in SAS.
-
The benefits of MAS are therefore highly context-dependent. For example, Improving Factuality and Reasoning in Language Models through Multiagent Debate by Du et al. (2023) shows that structured debate can improve reasoning in certain settings.
-
At the same time, real-world systems such as How we built our multi-agent research system demonstrate that multi-agent pipelines are most effective in open-ended exploration tasks where parallelism and role separation provide clear advantages.
Core tradeoffs
Information efficiency
Information bottleneck and message passing
- The central theoretical result from the attached paper is that MAS introduce an information bottleneck. Let \(Y\) denote the correct answer, \(C\) the full context, and \(M = g(C)\) the messages passed between agents.
- Then the following relationship holds due to the Data Processing Inequality:
- This inequality formalizes the idea that any transformation of the original context into intermediate messages cannot increase the information available about the correct answer.
- In practical terms, every step of message passing risks discarding useful signal, especially when intermediate outputs are summarized, abstracted, or truncated.
Entropy and uncertainty implications
- An equivalent formulation in terms of conditional entropy is:
- This means that conditioning on messages leaves more uncertainty about the correct answer than conditioning on the full context.
- In other words, MAS operates on noisier or less complete representations of the problem compared to SAS.
Practical impact on reasoning quality
-
The intuition behind context fragmentation can be formalized as: MAS must compress and transmit information, while SAS retains it natively within a unified reasoning process. This directly explains why SAS tends to perform better on tightly coupled reasoning tasks, while MAS can struggle when critical dependencies are lost across communication boundaries.
-
This observation also aligns with Towards a Science of Scaling Agent Systems by Kim et al. (2025), which describes how information fragmentation across agents increases coordination overhead and reduces effective reasoning quality.
-
Put simply, MAS introduces structural information loss, while SAS preserves full context fidelity.
Compute allocation
Token budget distribution
-
Another key tradeoff is how reasoning tokens are allocated. In SAS, the entire budget \(B\) is used for a single reasoning trajectory, maximizing depth and coherence.
-
In MAS, the same budget must be divided across multiple agents and coordination steps, reducing the effective reasoning depth available to each component. This split can be expressed conceptually as distributing \(B\) across agents and communication rounds, where each agent operates under a smaller effective budget than the single-agent baseline.
-
As a result, MAS often sacrifices depth of reasoning in exchange for breadth or parallelism.
Compute normalization and misleading gains
-
This creates an important confound: many reported gains from MAS arise because they implicitly use more compute rather than better structure.
-
When compute is normalized, as emphasized in both Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026) and Reasoning in Token Economies by Wang et al. (2024), these gains often disappear. This reinforces that fair comparisons must control for total reasoning tokens rather than number of agents.
-
Under equal budgets, SAS frequently matches or outperforms MAS because it uses all available compute for coherent reasoning rather than coordination.
Scaling and coordination overhead
- Beyond token splitting, MAS also introduces additional computational overhead due to coordination. The scaling analysis in Towards a Science of Scaling Agent Systems by Kim et al. (2025) presents a scaling law that shows that total reasoning steps grow superlinearly with the number of agents:
- The following table (source) shows architectural comparison of agent methods with objective complexity metrics.
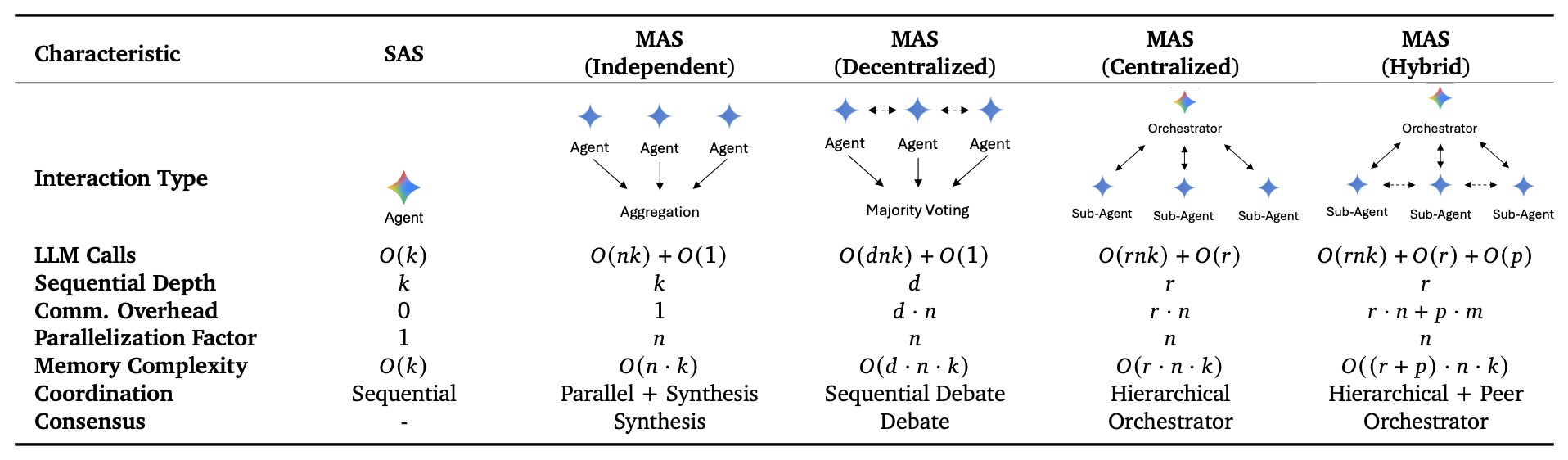
- This means that adding agents increases not just parallel work but also coordination cost, including synchronization, message passing, and aggregation. In practice, this can lead to higher latency and compute usage even when individual agents are operating on smaller budgets.
Coordination cost and failure modes
Coordination overhead and system complexity
-
MAS introduces additional layers of coordination, including planning, communication, and aggregation, each of which adds complexity to the system. These layers create overhead not present in SAS, both in terms of computation and engineering complexity.
-
The scaling results from Towards a Science of Scaling Agent Systems by Kim et al. (2025) quantify this overhead, showing that coordination can dominate performance costs, especially in hybrid or highly interactive architectures.
-
In one line, MAS trades reasoning simplicity for orchestration complexity.
Error propagation and amplification
-
These coordination layers also introduce new failure modes such as drift between agents, loss of critical information, or incorrect aggregation of intermediate results.
-
Errors are not isolated but can propagate across agents, leading to amplified failures in the final output.
-
Towards a Science of Scaling Agent Systems by Kim et al. (2026) reports that independent MAS can amplify trace-level errors by up to \(17.2\times\), while centralized systems reduce this to \(4.4\times\), highlighting how architecture choice directly affects reliability. This shows that coordination is not only a performance concern but also a safety and robustness concern.
Exploration vs. coherence tradeoff
-
The analysis in Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026) highlights patterns such as over-exploration in MAS versus more precise reasoning in SAS.
-
Put simply, MAS can broaden the search space but also increase the risk of incoherence or divergence across reasoning paths. This creates a fundamental tradeoff: MAS enables diversity and parallel exploration, while SAS maintains coherence and consistency.
-
The optimal choice depends on whether the task benefits more from exploring multiple hypotheses or from maintaining a tightly integrated reasoning trajectory.
When single-agent systems are usually better
Clean context and fixed budgets
Performance under equal compute
-
The empirical results in the attached paper show that under matched thinking-token budgets, SAS consistently matches or outperforms MAS across multiple models and datasets, including FRAMES and MuSiQue. This reinforces the central finding from Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026), where equal-budget comparisons remove the apparent advantage of orchestration. This result is particularly important because it isolates architecture from compute, showing that gains attributed to MAS are often driven by additional tokens rather than better reasoning structure.
-
Put simply, when compute is controlled, unified reasoning tends to dominate distributed coordination for many reasoning-heavy tasks.
Efficiency and coherence advantages
-
Because SAS preserves full context, avoids communication overhead, and uses all tokens for a single reasoning trajectory, it provides a strong baseline that many MAS fail to surpass. This efficiency is both computational and informational, since no intermediate compression or message passing is required. This aligns with the scaling insights from Towards a Science of Scaling Agent Systems by Kim et al. (2025), which show that coordination overhead can outweigh benefits when the task does not require decomposition.
-
In practice, SAS is often the most efficient choice when the problem can be solved through a coherent reasoning process over a well-defined context.
Strong base models
Diminishing returns from coordination
-
As model capability increases, the benefits of orchestration tend to diminish. Stronger models are better able to internally organize reasoning, reducing the need for explicit decomposition into multiple agents. This is consistent with the capability-saturation effect described in Towards a Science of Scaling Agent Systems by Kim et al. (2025), where coordination gains decrease as single-agent performance improves.
-
The paper identifies a practical threshold where tasks with sufficiently high single-agent baseline performance experience diminishing or even negative returns from additional agents. This reflects the idea that once a model can solve most of the task internally, coordination overhead becomes a net cost rather than a benefit.
Alignment with modern LLM trends
-
Advances in modern LLMs, including longer context windows and improved reasoning abilities, further reinforce this trend by making SAS more capable across a wide range of tasks.
-
Many workflows that previously required explicit decomposition can now be handled within a single reasoning trajectory, reducing the need for multi-agent orchestration. This trend also connects to broader findings in the literature that stronger base models reduce the marginal value of additional structure unless the task inherently requires it.
-
Put simply, as models improve, the default shifts increasingly toward SAS unless there is a clear structural reason to introduce MAS.
Tasks requiring global coherence
Sequential and tightly coupled tasks
-
Single-agent systems are particularly well-suited for tasks that require maintaining a consistent global state across multiple reasoning steps, such as sequential planning, constrained execution, or tightly coupled workflows.
-
In these settings, splitting reasoning across agents can fragment state and introduce inconsistencies.
-
The scaling analysis in Towards a Science of Scaling Agent Systems by Kim et al. (2025) shows that MAS can significantly degrade performance on sequential planning tasks, with large negative relative changes compared to single-agent baselines. This highlights that coordination is especially costly when reasoning steps are interdependent.
Avoiding context fragmentation
-
Because SAS operates over a unified context, it avoids the need to repeatedly serialize and reconstruct intermediate state, preserving consistency across the entire reasoning trajectory. This is critical for tasks where small errors or omissions can cascade into larger failures.
-
In contrast, MAS introduces boundaries where information must be compressed and transmitted, increasing the risk of losing important dependencies.
-
Put simply, SAS excels when coherence matters more than parallelism, making it the preferred choice for tightly integrated reasoning problems.
When multi-agent systems become competitive
Context degradation and noisy inputs
Limits of context utilization
-
A key nuance is that SAS assumes effective utilization of context, but in practice this assumption can break down due to long contexts, noise, distractors, or irrelevant information.
-
As context grows, models may fail to attend to the most relevant parts, reducing the effective information available for reasoning. Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026) models noisy inputs as \(\tilde{C}_\alpha\) where increasing \(\alpha\) corresponds to greater corruption or noise in the input.
-
As degradation increases, the available information decreases:
- This implies that the effectiveness of a single-agent system depends critically on its ability to utilize context efficiently, which is not guaranteed in long or noisy inputs.
Decomposition as filtering
-
In such regimes, a well-structured MAS can act as a filtering mechanism, breaking the problem into smaller subcontexts that are easier to process.
-
By distributing reasoning across agents, the system can isolate relevant signals and reduce the impact of noise or distraction. This connects directly to Lost in the Middle: How Language Models Use Long Contexts by Liu et al. (2023), which shows in one line that models often underutilize long contexts, and to Context Rot: How Increasing Input Tokens Impacts LLM Performance, which highlights performance degradation as context length grows.
-
Put simply, MAS can recover structure when raw context becomes too large or noisy for a single reasoning process.
Interaction with scaling behavior
- This also aligns with findings from Towards a Science of Scaling Agent Systems by Kim et al. (2025), where coordination can be beneficial in tasks involving partial observability, iterative information gathering, or high-entropy environments.
- In these cases, the ability to distribute reasoning across agents can compensate for limitations in context utilization.
Parallel search, specialization, and verification
Parallel exploration and diversity
-
MAS becomes advantageous when tasks benefit from exploring multiple reasoning paths in parallel, allowing different agents to pursue distinct hypotheses or strategies. This is particularly useful in open-ended or high-uncertainty tasks where no single reasoning trajectory is guaranteed to succeed.
-
Debate-style systems, for example, allow agents to challenge each other’s conclusions, surfacing alternative perspectives and improving robustness.
-
Improving Factuality and Reasoning in Language Models through Multiagent Debate by Du et al. (2023) shows in one line that structured debate can improve reasoning in certain settings.
Role specialization and modularity
-
MAS also enables role specialization, where different agents focus on distinct aspects of a task such as planning, execution, verification, or aggregation. This modularity can improve performance when tasks naturally decompose into separable components. This aligns with real-world system design, where complex workflows often involve multiple specialized roles working together.
-
In domains such as software engineering, research pipelines, and business automation, this mirrors how tasks are organized across teams and systems.
Verification and error correction
-
Another advantage of MAS is the ability to introduce explicit verification layers, where outputs from one agent are checked or refined by another.
-
Centralized architectures, in particular, can act as validation bottlenecks that reduce error propagation.
-
The scaling analysis in Towards a Science of Scaling Agent Systems by Kim et al. (2025) shows that centralized coordination significantly reduces error amplification compared to independent systems.
-
In one line, MAS can improve robustness when it introduces structured validation rather than uncoordinated parallelism.
Task structure and decomposability
Alignment with decomposable workflows
-
MAS is most effective when the task itself is inherently decomposable into semi-independent subproblems that can be solved in parallel or in loosely coupled stages. This includes workflows such as multi-stage analysis, distributed data processing, and collaborative problem-solving. These conditions are common in real-world applications such as software engineering pipelines, research and analysis, business process automation, and simulation environments.
-
In such settings, MAS aligns naturally with the structure of the work, making coordination beneficial rather than costly.
Architecture-task alignment principle
- This observation directly reflects the central finding from Towards a Science of Scaling Agent Systems by Kim et al. (2025), which shows that architecture-task alignment determines whether MAS succeeds or fails.
- Tasks that are decomposable benefit from coordination, while tasks that are sequential or tightly coupled tend to degrade under multi-agent architectures.
Limits of applicability
-
However, even in these favorable conditions, MAS is not universally superior. Gains depend heavily on implementation details, coordination mechanisms, and the specific structure of the task.
-
Put simply, MAS is most effective when decomposition is intrinsic to the problem rather than imposed by the system designer. This reinforces the broader design principle that MAS should be used selectively, as a targeted tool for handling complexity, noise, or structured exploration, rather than as a default architectural choice.
Architecture selection guidance
From heuristics to principled design
-
The combined evidence from Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets by Tran et al. (2026) and Towards a Science of Scaling Agent Systems by Kim et al. (2025) shifts architecture selection from heuristic design to principled reasoning.
-
Instead of assuming that more agents improve performance, these works show that architecture choice must be grounded in measurable tradeoffs involving information flow, compute allocation, coordination cost, and task structure.
-
Put simply, SAS maximizes information retention and reasoning coherence, while MAS introduces structure that can either help or harm depending on how it interacts with the task. This reframing emphasizes that architecture is not a matter of scaling complexity, but of aligning system structure with problem requirements.
Key Takeaways
-
At the highest level, the distinction between SAS and MAS can be understood as a tradeoff between coherence and coordination.
-
SAS emphasizes unified reasoning over a complete context, while MAS emphasizes modularity, parallelism, and structured interaction. This tradeoff manifests across all dimensions discussed earlier, including information efficiency, compute usage, error propagation, and system complexity.
-
Put simply, SAS prioritizes depth and consistency, while MAS prioritizes breadth and structure, and the correct choice depends on which dimension the task benefits from most.
Default design strategy
Start with a single-agent baseline
-
The strongest general recommendation is to begin with a single-agent system, since it provides a simpler, more maintainable, and often more efficient baseline.
-
By preserving full context, avoiding coordination overhead, and allocating the entire reasoning budget \(B\) to a single trajectory, SAS establishes a strong reference point for both performance and system design. This recommendation is directly supported by Tran et al. (2026), which shows that under equal compute budgets, SAS frequently matches or outperforms MAS on multi-hop reasoning tasks. It is further reinforced by Reasoning in Token Economies by Wang et al. (2024), which demonstrates that many complex reasoning pipelines lose their advantage once compute is normalized.
Treat multi-agent systems as a deliberate escalation
-
Rather than treating MAS as the default path to scaling, they should be introduced only when there is clear evidence that decomposition or coordination provides value. This reflects the architecture-task alignment principle from Kim et al. (2025), which shows that coordination can either help or harm depending on how well it matches the task.
-
Put simply, SAS should be the default for coherent reasoning, while MAS should be viewed as a targeted tool for handling complexity, noise, or structured workflows. This framing encourages disciplined system design by requiring explicit justification for additional architectural complexity.
Decision boundaries and escalation criteria
When single-agent systems dominate
-
Single-agent systems dominate in regimes where context is clean, reasoning is tightly coupled, and compute is constrained.
-
These include sequential planning, constrained execution, and tasks requiring global consistency across multiple steps.
-
Empirical results from Tran et al. (2026) show that under equal token budgets, SAS often outperforms MAS on multi-hop reasoning tasks.
-
Similarly, Kim et al. (2025) shows that when single-agent baseline performance is already high, additional coordination tends to yield diminishing or negative returns.
When multi-agent systems become beneficial
-
MAS become beneficial when tasks are inherently decomposable, require parallel exploration, or benefit from role specialization and verification.
-
These conditions arise in complex workflows, large-scale automation pipelines, collaborative problem-solving environments, and domains such as software engineering, research and analysis, business process automation, and simulation.
-
The architecture-task alignment principle from Kim et al. (2025) shows that MAS can produce significant gains when coordination matches task structure.
-
Put simply, MAS works best when decomposition is intrinsic to the problem rather than imposed by the system designer.
Boundary conditions and transitions
-
There is no sharp boundary between SAS and MAS, but rather a transition region where effectiveness depends on context quality, model capability, and task structure.
-
For example, as context becomes noisier or longer, MAS may become more competitive by filtering and structuring information across agents.
-
Conversely, as model capability increases, the need for explicit coordination decreases, shifting the optimal design toward SAS. This dynamic interplay highlights that architecture selection is not static but evolves with both task requirements and advances in model capabilities.
When to escalate to multi-agent systems in practice
Indicators for decomposition and structure
-
MAS should be introduced when tasks involve multiple independent or semi-independent components that can be processed in parallel or in loosely coupled stages. This includes scenarios with complex workflows, diverse expertise requirements, or pipelines that naturally map to multiple interacting roles. These conditions align with real-world systems such as software engineering pipelines, research workflows, business automation systems, and simulation environments.
-
In such settings, MAS mirrors the structure of the task, making coordination beneficial rather than wasteful.
Handling noise, scale, and context limitations
-
MAS is also appropriate when SAS struggles with long, noisy, or partially observable contexts where effective utilization of information breaks down.
-
By decomposing the problem, MAS can filter, restructure, or isolate relevant signals, improving robustness in degraded environments. This aligns with the earlier context degradation analysis, where breaking tasks into smaller subcontexts can recover useful information.
-
In one line, MAS acts as a structured filtering mechanism when raw context becomes too complex for unified reasoning.
Need for verification, robustness, and safety
-
Another important indicator for MAS is the need for explicit verification, validation, or redundancy in reasoning.
-
Multi-agent architectures can introduce critics, reviewers, or centralized aggregators that reduce error propagation and improve reliability.
-
The findings from Kim et al. (2025) show that centralized coordination significantly reduces error amplification compared to independent systems. This makes MAS particularly valuable in high-stakes or safety-critical workflows where correctness and robustness are more important than efficiency.
Integration with broader agentic patterns
Relationship to other design patterns
-
MAS should not be viewed in isolation but as one component within a broader set of agentic design patterns, including prompt chaining, routing, planning, tool use, and reflection.
-
In many cases, improvements attributed to MAS can instead be achieved by strengthening these underlying patterns within a single-agent system.
-
Prompt chaining exposes structure, routing enables specialization, planning organizes long-horizon reasoning, tool use connects to external systems, and reflection improves output quality.
-
Only when these patterns reveal a genuine need for multiple interacting roles should MAS be introduced.
Architecture as composition, not hierarchy
-
This perspective reframes architecture selection as a compositional problem rather than a linear progression from simple to complex systems.
-
SAS and MAS are alternative configurations that should be selected based on task requirements rather than viewed as stages in system maturity. This aligns with the broader architectural shift described in the primer, where intelligence emerges from structured interaction between components rather than from a single model invocation.
-
In one line, MAS is one possible composition of patterns, not the endpoint of system design.
Key takeaways
Architecture as a function of task structure
-
The central lesson is that architecture should be treated as a function of task structure rather than a fixed design choice.
-
The goal is to select the configuration that best aligns reasoning structure with the properties of the problem. This perspective integrates all prior observations, including information bottlenecks, compute allocation, coordination costs, and real-world applicability.
-
Put simply, the optimal architecture is the one that aligns system design with task structure.
Coordination as a scarce resource
-
Coordination is a scarce and expensive resource that introduces both capability and risk.
-
Every additional agent adds communication overhead, potential information loss, and new failure modes that must be justified by corresponding gains. This reinforces the principle that simplicity should be preferred unless complexity provides measurable benefits.
-
In practice, the most effective systems are those that use the simplest architecture capable of solving the problem reliably.
Design principle
-
Taken together, the evidence suggests a clear hierarchy of design decisions: begin with a single-agent system, strengthen internal structure through patterns such as planning, routing, and tool use, and only then introduce multi-agent coordination when the task demands it. This disciplined approach ensures that complexity is added incrementally and only when it provides real value.
-
Put simply, SAS is the default foundation, MAS is the specialized extension, and architecture selection is the process of deciding when to transition between them.
State, Adaptation, and Control in Agentic Systems
Core Idea
-
As agentic systems evolve from simple workflows into autonomous, goal-directed architectures, three foundational capabilities become critical: the ability to retain state, improve over time, and stay aligned with objectives. The patterns in this section, namely Memory Management, Learning and Adaptation, Model Context Protocol (MCP), and Goal Setting and Monitoring, collectively address these needs.
-
Together, they define how an agent persists information, updates its behavior, coordinates internal components, and ensures progress toward desired outcomes. Without these capabilities, even well-designed systems with strong reasoning, planning, and tool use remain fundamentally limited.
From stateless execution to persistent intelligence
-
Earlier patterns such as prompt chaining, routing, and tool use primarily operate within the scope of a single task or interaction. However, real-world systems require continuity across time. This introduces the need for stateful execution, where past interactions, intermediate results, and learned knowledge influence future behavior.
-
Formally, instead of treating each step independently:
\[a_t \sim \pi(a \mid x_t)\] -
agentic systems operate over accumulated state:
\[a_t \sim \pi(a \mid s_t), \quad s_t = f(s_{t-1}, o_{t-1})\]- where \(s_t\) captures memory, context, and prior outcomes.
-
This shift enables agents to maintain coherence, avoid redundant work, and build progressively richer representations of their environment.
Memory as the foundation of continuity
-
Memory management provides the infrastructure for storing and retrieving information across both short and long time horizons. It allows systems to:
- Maintain conversational and task continuity
- Personalize interactions
- Accumulate knowledge from prior executions
-
Without memory, agents behave like stateless functions. With memory, they begin to exhibit traits of persistence and experience.
Learning as the mechanism for improvement
-
While memory enables retention, learning enables transformation. Learning and adaptation allow agents to refine their behavior based on feedback, outcomes, and experience.
-
This introduces a feedback-driven optimization loop:
\[\pi_{t+1} = \pi_t + \Delta(\text{feedback}, \text{experience})\]- where the system updates its policy based on observed performance.
-
In practice, this may take the form of:
- Incorporating feedback into memory
- Adjusting prompts or workflows
- Improving routing and tool selection
-
Learning ensures that agents do not remain static, but evolve toward better performance over time.
Context as the glue of the system
-
As systems grow in complexity, multiple components such as tools, memory stores, and sub-agents must interact seamlessly. Model Context Protocol (MCP) provides the structure for this interaction.
-
It defines how information is represented and passed between components:
\[C = {u, s, m, t, r}\]- ensuring that all relevant context is consistently available.
-
Without structured context, systems become fragmented and difficult to scale. MCP ensures coherence across the entire architecture.
Goals as the anchor of behavior
-
Even with memory and learning, an agent requires a clear sense of direction. Goal setting and monitoring provide this by defining objectives and tracking progress.
-
This introduces a control loop:
\[\Delta_t = d(s_t, G)\]- where the system continuously measures its distance from the goal and adjusts accordingly.
-
This ensures that:
- Actions remain aligned with objectives
- Progress is measurable
- Deviations are detected and corrected
The combined effect
-
These four patterns are deeply interconnected:
- Memory stores experience
- Learning transforms experience into improved behavior
- MCP ensures experience and context flow correctly through the system
- Goals and monitoring ensure behavior remains aligned and purposeful
-
Together, they form the backbone of persistent, adaptive, and goal-driven agentic systems.
-
They mark the transition from systems that can act, to systems that can remember, improve, coordinate, and stay aligned over time.
Memory Management
-
Memory management is a foundational agentic design pattern that enables systems to retain, organize, and utilize information across interactions over time. At its core, it allows an agent to persist information beyond a single prompt or step - an essential capability, since real-world tasks often span multiple interactions, depend on historical context, and benefit from accumulated knowledge. Without memory, each interaction resets the system to a blank state, severely limiting its effectiveness.
-
By introducing persistence, memory transforms agents from stateless, reactive responders into stateful, adaptive systems. This shift enables continuity in interactions, supports personalization, and allows agents to incorporate past experiences into current decision-making. As a result, agents can learn, refine their behavior, and improve performance over time.
-
In agentic design, memory is the mechanism that turns isolated interactions into a coherent experience. It provides the structure for accumulating knowledge, maintaining context, and enabling long-term reasoning - making it a critical component for building capable, real-world AI systems.
-
Long-term conversational memory is especially important when systems must answer questions across many prior sessions, track user preferences, resolve temporal updates, and determine when information was never stated, as formalized in LongMemEval by Wu et al. (2024).
-
Memory effectiveness depends not only on what is stored, but also on how the agent searches, how retrieval tools are exposed, and how retrieved evidence is delivered back into the reasoning loop; Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) frames this as agentic search, where retrieval strategy, agent harness, and inline versus file-based tool delivery jointly affect long-memory QA accuracy even when the underlying corpus is fixed.
Why memory is needed
-
Stateless systems face fundamental limitations:
- They forget previous interactions
- They cannot build context over time
- They cannot personalize responses
- They struggle with long-horizon tasks
-
Memory addresses these issues by enabling the system to store and retrieve relevant information when needed.
-
Long-context models alone do not eliminate the need for memory, because relevant information can become harder to use as context grows; Lost in the Middle by Liu et al. (2023) shows that models may underuse information depending on where it appears in long inputs.
-
Memory therefore acts as both a persistence layer and a selection layer: it stores historical information, but it also decides which subset should be surfaced for the current decision.
Types of memory
-
Memory in agentic systems can be categorized along two complementary axes:
- Functional taxonomy (what kind of information is stored and why)
- Storage and retrieval mechanisms (how memory is implemented and accessed)
-
Together, these dimensions provide a more complete view of how memory operates in real-world systems.
Functional types of memory
-
These correspond to cognitive roles and are independent of how memory is physically stored.
-
Short-term memory (working memory):
-
Stores information relevant to the current task
-
Typically implemented within the model’s context window
-
Includes recent messages, intermediate outputs, and current execution state
-
Enables continuity within a single workflow
-
Often volatile and limited by context size
-
Short-term memory must be actively managed in tool-heavy agents, because tool outputs, intermediate reasoning state, and retrieved evidence compete for the same context budget; MemGPT by Packer et al. (2023) frames this as virtual context management across memory tiers.
-
-
Long-term memory:
-
Persists information across sessions
-
Stored externally, such as in databases, vector stores, file systems, logs, or versioned repositories
-
Includes user preferences, past interactions, accumulated knowledge, retrieved evidence, and historical tool outcomes
-
Enables personalization and learning over time
-
Long-term memory often requires structured temporal handling when facts evolve, and Chronos by Sen et al. (2026) represents dialogue as structured event and turn calendars to support time-aware retrieval over long interaction histories.
-
-
Episodic memory:
-
Stores specific past experiences or events
-
Often includes timestamps and contextual metadata
-
Allows the system to recall prior situations and outcomes
-
Particularly useful for temporal reasoning and history-aware behavior
-
Episodic memory becomes more useful when events are normalized into time-aware records, because the agent can distinguish earlier facts from later updates rather than treating all past statements as equally current.
-
-
Semantic memory:
-
Stores generalized knowledge extracted from experiences
-
Represents facts, abstractions, and patterns
-
Enables reasoning beyond specific past events
-
Semantic memory is commonly implemented with embedding-based retrieval, but lexical retrieval can remain competitive when the answer depends on literal evidence such as dates, names, counts, and exact user-stated preferences; Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) finds that grep-style lexical search often outperformed vector retrieval in long-memory conversational QA under inline tool delivery.
-
-
Storage and retrieval mechanisms
- In addition to functional types, memory can also be categorized by how it is implemented and accessed, because the same kind of memory can behave very differently depending on whether it is stored as embeddings, structured files, logs, metadata records, or tool-readable artifacts.
Vector memory (embedding-based memory)
-
Vector memory stores information as embeddings in vector databases, where each memory record is transformed into a high-dimensional numerical representation that captures semantic relationships between pieces of text.
-
Retrieval is based on semantic similarity search, meaning that the system retrieves memories whose embeddings are close to the query embedding even when the query and the stored memory do not use the same surface wording.
-
Vector memory is best suited for:
-
Semantic recall, where the agent needs to retrieve conceptually related information rather than exact keyword matches.
-
Paraphrase handling, where the user’s query may express the same meaning as a stored memory using different words.
-
Large-scale knowledge retrieval, where the memory store contains many documents, passages, or interaction records and approximate nearest-neighbor search is needed for efficient lookup.
-
-
Vector memory is commonly used in retrieval-augmented systems such as Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Lewis et al. (2020), where external memory improves generation by grounding the model in retrieved knowledge rather than relying only on parameters learned during pretraining.
-
Vector memory typically supports:
-
Long-term memory, because embeddings can be stored persistently and queried across sessions.
-
Semantic memory, because embeddings are designed to capture generalized meaning, conceptual similarity, and paraphrased relationships across stored information.
-
-
Vector retrieval can be formalized as nearest-neighbor search over embedded memories:
\[\text{retrieve}_{vec}(q) = \operatorname{topk}_{s_i \in \mathcal{M}} \ \text{sim}\bigl(f(q), f(s_i)\bigr)\]- where \(f(\cdot)\) is an embedding function that maps the query and stored memory records into a shared vector space, and \(\text{sim}(\cdot,\cdot)\) is often cosine similarity or another distance-based similarity function.
-
Dense retrieval is powerful when query phrasing differs from stored evidence, because it can retrieve memories that are semantically aligned with the user’s intent even without exact word overlap; however, it can also retrieve semantically nearby distractors in noisy long-memory settings where many records discuss related topics but only a small subset contains the correct evidence.
-
Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) reports that vector retrieval did not have a stable advantage as unrelated conversation history was added, which suggests that embedding-based memory should be evaluated inside the full agentic loop rather than treated as a universally superior default.
File-based memory (log-structured or document memory)
-
File-based memory stores information as structured files, such as markdown documents, JSON records, JSONL logs, conversation transcripts, event records, tool-result artifacts, or versioned project files that remain readable outside the model.
-
File-based memory is often versioned using systems like Git, where diffs, history, commits, and blame make it possible to inspect how memory changed over time and determine when a fact was added, edited, superseded, or removed.
-
Retrieval is keyword-based, structure-aware, metadata-aware, or temporally constrained, meaning that the agent can search by exact phrases, fields, timestamps, file paths, tags, source sessions, or explicit document structure.
-
File-based memory is best suited for:
-
Episodic memory with temporal tracking, because logs and files can preserve when an event occurred and how it relates to earlier or later events.
-
Auditable and human-readable memory, because the stored records can be inspected, corrected, diffed, and reviewed by developers, users, or other agents.
-
Reproducibility and debugging, because versioned files make it possible to reconstruct which memory state existed when a prior answer or action was produced.
-
Agentic search over raw interaction history, because the agent can actively search the stored record rather than passively receiving a fixed retrieved context.
-
Programmatic access to large result sets without immediately filling the model context, because search results can be written to files and inspected selectively only when needed.
-
-
Example implementations include Git-based memory systems such as DiffMem, where memory evolves through version-controlled commits and the history of changes becomes part of the memory substrate.
-
File-based memory naturally supports:
-
Episodic memory through time-stamped history, because individual experiences and events can be stored as ordered records.
-
Long-term memory through persistent logs, because files can survive beyond a single prompt, session, or workflow.
-
Agentic memory through searchable, revisable, and inspectable traces of prior interactions and tool outcomes, because the agent can treat memory as an environment it can query and navigate.
-
-
File-based memory is closely connected to agentic search, because the memory store is not merely a passive archive; it becomes a searchable environment that the agent can query, inspect, filter, and revisit through tools such as grep, regex search, file reads, structured metadata queries, and temporal filters.
-
In this framing, file-based memory may also be described as agentic memory when the stored files become part of an agent-controlled loop in which the agent decides what to search, which files to open, how much evidence to read, whether to refine the query, and when the evidence is sufficient to answer.
-
Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) explicitly studies this agentic search setting, distinguishing standalone retrieval from iterative, tool-mediated retrieval in which the model chooses search terms, issues multiple searches, consumes results, and decides whether more evidence is needed.
-
File-based retrieval also changes the context-management problem, because instead of injecting all retrieved evidence directly into the prompt, the system can write search results to files and expose them through paths, summaries, offsets, or metadata pointers, allowing the agent to inspect only the portions that are relevant to the current task.
-
This programmatic delivery pattern connects file-based memory to operating-system-like memory management; MemGPT by Packer et al. (2023) treats memory as a hierarchy in which limited context is managed through explicit read and write operations across different memory tiers.
-
In long-memory question answering, file-based routing can reduce immediate context pressure because large retrieval outputs do not have to be inserted into the model context all at once, but it also requires additional agent competence because the agent must open, scan, integrate, and sometimes re-search result files before producing an answer.
-
Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) shows that file-based delivery can reorder grep-versus-vector comparisons, because retrieval quality becomes inseparable from tool-use workflow quality, context delivery, result formatting, and harness behavior.
How these dimensions interact
-
These two categorizations are orthogonal and often combined in practice:
- Short-term memory \(\rightarrow\) usually context window
- Long-term memory \(\rightarrow\) vector store or file system
- Episodic memory \(\rightarrow\) often file-based logs, timelines, transcripts, or event stores
- Semantic memory \(\rightarrow\) often vector-based embeddings, sparse retrieval, or hybrid indexes
-
A unified view can be expressed as:
-
For example:
- A vector database may implement semantic long-term memory
- A Git-based system may implement episodic long-term memory
- A hybrid system may combine both
-
In agentic systems, this equation should also include the orchestration layer, because the same stored memory can produce different outcomes depending on the harness, tool descriptions, query policy, and result presentation format; Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) shows that harness choice shifted accuracy by margins comparable to changing retrievers.
-
When the memory store is exposed through tools, memory becomes part of an agentic search loop:
\[q_t \rightarrow \text{search}(\mathcal{M}, q_t) \rightarrow r_t \rightarrow \text{read}(r_t) \rightarrow q_{t+1} \ \text{or} \ a\]- where \(q_t\) is the agent’s current search query, \(\mathcal{M}\) is the memory store, \(r_t\) is the retrieved evidence, and \(a\) is the final answer or action.
Practical perspective
-
Modern agentic systems increasingly adopt hybrid memory architectures, where:
- Vector memory handles semantic retrieval
- File-based memory handles history, structure, and traceability
- Lexical search handles exact evidence recovery
- Metadata and temporal filters handle recency, validity, and evolving facts
-
This layered approach enables agents to:
- Retrieve relevant knowledge efficiently
- Track how knowledge evolves over time
- Maintain both performance and interpretability
- Separate storage from context delivery
- Audit why a memory was used in a particular answer
-
These distinctions mirror concepts from cognitive science, while also reflecting practical system design choices required for building robust, real-world agentic systems.
-
A practical memory architecture should therefore decide not only what to store, but also whether the agent should search memory semantically, lexically, temporally, or through a hybrid policy; BEIR by Thakur et al. (2021) motivates evaluating retrieval methods across heterogeneous tasks, while Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) shows that agentic retrieval must also be evaluated inside the full tool-using loop.
File-based vs. Vector Memory
-
As agentic systems evolve from simple reactive pipelines into stateful, adaptive systems, memory design becomes a first-class architectural decision. Modern agents are expected not only to retrieve relevant information, but also to reason about how that information changes over time, whether it remains valid, and how it should influence future decisions.
-
This introduces a fundamental design tension:
- Systems must optimize for recall and scale to handle large, diverse knowledge
- Systems must also ensure accuracy and interpretability to maintain trust and correctness
-
These competing requirements shape how memory systems are built in practice and lead to two dominant paradigms:
- Vector-based memory optimized for semantic recall and scalability
- File-based memory optimized for transparency, temporal tracking, and control
-
Rather than being interchangeable, these approaches reflect different philosophies of memory. Vector memory treats knowledge as a searchable semantic space, while file-based memory treats it as a structured, evolving record. As highlighted in the broader agentic design framework, managing state, context, and historical knowledge is central to building robust agents, and memory becomes the backbone of that capability.
-
In practice, no single approach is universally optimal. The choice depends on tradeoffs between scale, interpretability, semantic understanding, temporal reasoning, and system complexity. Increasingly, real-world systems adopt composable memory architectures that combine both paradigms to balance these tradeoffs effectively, enabling agents to be both scalable and trustworthy.
-
This distinction is also central to agentic search, where retrieval is not a single static lookup but an iterative tool-mediated process: the agent decides what to search, how many searches to issue, which results to inspect, and whether the evidence is sufficient. Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) defines retrieval in agentic systems as an agent-directed loop mediated by retrieval strategy, harness design, and result-delivery architecture, rather than as a fixed top-\(k\) retrieval pipeline.
-
When memory is exposed through tools such as grep, vector search, file reads, structured metadata filters, and temporal event stores, it can be understood as agentic memory: a memory substrate that the agent actively searches, updates, inspects, and reasons over while completing a task. Chronos: Temporal-Aware Conversational Agents with Structured Event Retrieval for Long-Term Memory by Sen et al. (2026) exemplifies this framing by decomposing long dialogue histories into event and turn calendars that agents query through an iterative tool-calling loop.
Vector memory (semantic retrieval)
-
Vector memory is the dominant paradigm in modern agentic systems and underpins retrieval-augmented architectures such as Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Lewis et al. (2020), which shows how external retrieval improves reasoning by grounding outputs in relevant knowledge.
-
In this approach:
- Text is converted into embeddings (high-dimensional vectors)
- Stored in a vector database (e.g., FAISS, Pinecone, Weaviate)
- Retrieved using similarity search
-
Formally, retrieval is defined as:
\[\text{retrieve}(q) = \arg\max_{s_i \in \mathcal{M}} \text{sim}(q, s_i)\]- where similarity is typically cosine similarity.
-
With an embedding function \(f(\cdot)\), cosine similarity is often written as:
-
Key characteristics:
- Semantic matching rather than exact matching
- Handles paraphrases and implicit meaning
- Scales efficiently to large datasets
- Retrieval is approximate but fast
-
In agentic search, vector memory gives the agent broad semantic reach, allowing it to recover information even when the current query does not share exact words with the stored memory. This is useful for conceptual recall, paraphrase-heavy corpora, and knowledge-intensive tasks, but it can also introduce semantically plausible distractors when the memory store contains many topically related but irrelevant records.
-
Dense retrieval is therefore not simply a memory storage choice; it also shapes the agent’s search behavior. If a vector search returns broad, semantically adjacent evidence, the agent must decide whether to refine the query, rerank results, or stop searching. Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) shows that vector retrieval effectiveness varies substantially with the agent harness and tool-calling style, indicating that dense memory must be evaluated inside the full agentic loop rather than only by standalone retrieval metrics.
File-based memory (log-structured memory)
-
File-based memory takes a fundamentally different approach by storing knowledge as structured documents, logs, or version-controlled files. Instead of embeddings, it relies on explicit representations of information.
-
A notable implementation is the Git-based memory approach in DiffMem GitHub Repository, where:
- Memories are stored as markdown files
- Each interaction is recorded as a commit
- Git history tracks how knowledge evolves
- Retrieval uses keyword-based methods like BM25
-
This approach treats memory as a versioned knowledge base, not just a retrieval index.
-
Key characteristics:
- Human-readable storage (markdown, logs)
- Native versioning (diff, history, blame)
- Deterministic retrieval (keyword or structured queries)
- Strong temporal awareness
-
A key capability is time-travel memory:
- Agents can inspect past states of knowledge
- Enables reproducibility and debugging
- Supports auditing and traceability
-
File-based memory connects directly to agentic search because it gives the agent an inspectable environment rather than a closed retrieval endpoint. The agent can issue lexical searches, open files, compare versions, follow timestamps, and decide which evidence to bring into context.
-
Lexical retrieval over file-based memory can be formalized using BM25-style scoring:
\[\text{score}(D, q) =\sum_{t \in q} \text{IDF}(t) \cdot \frac{f(t,D)(k_1+1)} {f(t,D)+k_1\left(1-b+b\frac{|D|}{\text{avgdl}}\right)}\]- where \(f(t,D)\) is the frequency of term \(t\) in document \(D\), \(\mid D \mid\) is document length, \(\text{avgdl}\) is average document length, and \(k_1,b\) control term-frequency saturation and length normalization.
-
In long-memory agents, file-based memory can function as agentic memory when it stores not only user facts but also tool traces, retrieved evidence, timestamps, event records, and revisions. This makes memory inspectable and corrigible: the agent or a human can determine when a fact was added, whether it was superseded, and which evidence supported a prior answer.
-
File-based delivery is also a context-engineering mechanism. Instead of returning all search results inline, a system can write results to files and let the agent selectively read them. MemGPT: Towards LLMs as Operating Systems by Packer et al. (2023) motivates this operating-system-like view by treating limited context as a managed resource with explicit memory operations.
-
In agentic search, however, file-based delivery is not automatically better. It trades context-window pressure for tool-use complexity: the agent must find the file, open it, inspect the relevant parts, and integrate the result into its reasoning. Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) finds that file-based delivery can change or even invert the relative performance of grep and vector retrieval because retrieval quality becomes coupled to the agent’s ability to complete this extra workflow.
Comparative Analysis
| Aspect | Vector Memory | File-based Memory |
|---|---|---|
| Retrieval type | Semantic similarity | Keyword / structured |
| Representation | Embeddings | Raw text / files |
| Interpretability | Low | High |
| Temporal awareness | Weak (unless added) | Strong (native) |
| Scalability | High | Moderate |
| Determinism | Approximate | Deterministic |
- From an agentic-search perspective, the comparison also depends on orchestration. Vector memory may produce a better candidate set for ambiguous natural-language queries, while file-based memory may provide better auditability, temporal precision, and exact evidence recovery. Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) shows that the same retrieval strategy can perform differently across Chronos, Claude Code, Codex, and Gemini CLI because the harness changes prompting, tool access, result formatting, and stopping behavior.
Strengths and weaknesses
Vector memory
-
Pros:
- Captures semantic meaning and paraphrases
- Scales to large datasets
- Efficient approximate search
- Strong for knowledge retrieval and QA
-
Cons:
- Weak temporal reasoning (evolving facts over time)
- Hard to debug or interpret
- Requires embedding infrastructure
- May retrieve semantically similar but irrelevant data
-
A known limitation is that embeddings capture surface similarity rather than true reasoning. For example, symbolic equivalences like “10 + 10” and “20” are not inherently aligned without additional processing.
-
In noisy long-memory settings, vector memory can surface topical false positives when irrelevant sessions share semantic overlap with the query. Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) reports that vector retrieval did not have a stable advantage as unrelated conversation history was progressively added, and that retrieval ordering depended on harness and model backbone.
File-based memory
-
Pros:
- Fully transparent and human-readable
- Native versioning and history tracking
- Strong temporal reasoning
- Easy manual correction and editing
- Deterministic and reproducible
-
Cons:
- Weak semantic understanding
- Limited scalability compared to vector systems
- Requires indexing (e.g., BM25)
- May miss relevant but differently phrased information
-
A key advantage is handling changing facts over time, such as: “My daughter is 10” \(\rightarrow\) later “11” \(\rightarrow\) later “12”
-
File-based systems preserve this evolution explicitly, whereas vector systems often treat outdated entries as noise unless additional filtering is applied.
-
File-based memory can be especially useful for temporal and episodic agentic memory because timestamps, diffs, commits, and structured event records make it possible to determine not only what was said, but when it was true.
-
Lexical retrieval over file-based memory can be surprisingly strong when the answer is licensed by exact evidence, such as dates, names, preferences, counts, or quoted user facts. Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) finds that inline grep exceeded inline vector retrieval for every evaluated harness-model pair on a 116-question LongMemEval subset, suggesting that exact evidence recovery can be a strong default for conversational memory QA.
When to use each approach
-
Use vector memory when:
-
You need semantic search across large corpora
-
Queries are ambiguous or paraphrased
-
Scale and latency are critical
-
Knowledge is relatively static
-
Examples:
- Enterprise knowledge assistants
- Document retrieval systems
- RAG-based copilots
-
-
Use file-based memory when:
-
You need strong temporal tracking and versioning
-
Interpretability and auditability are critical
-
Data scale is manageable
-
You require full control over stored knowledge
-
Examples:
- Personal assistants with long-term context
- Coding agents tracking project evolution
- Systems requiring reproducibility
- Research or journaling agents
-
-
Use agentic memory architectures when:
- The agent must decide how to search memory rather than receiving a fixed retrieval context
- The task requires iterative query refinement
- Retrieved evidence may need to be opened, filtered, compared, or temporally validated
- Memory includes both raw history and structured records
- Correctness depends on the interaction between retrieval, tool use, and context management
-
In this setting, the relevant unit of evaluation is not only the retriever but the full agentic search loop:
- This broader framing is important because long-memory failures can arise from storage, retrieval, result formatting, context overload, or tool-use mistakes. Lost in the Middle: How Language Models Use Long Contexts by Liu et al. (2023) shows that models may fail to use relevant information in long contexts depending on its position, while Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) shows that retrieval performance in agents also depends on how evidence is delivered and orchestrated.
Hybrid memory systems
-
In practice, most production systems combine both paradigms to balance tradeoffs:
\[\text{memory} = \text{vector store} + \text{file store} + \text{indexing layer}\]-
where:
- Vector store enables semantic retrieval
- File store maintains authoritative history
- Indexing layer bridges retrieval and structure
-
-
Example architecture:
- Store raw interactions in logs or Git
- Periodically generate embeddings from current state
- Use vector search for fast retrieval
- Fall back to file history for auditing and correctness
-
A stronger agentic-memory architecture also includes lexical search, temporal indexes, and tool-delivery policies:
-
In this design, the agent can begin with semantic recall, verify with exact lexical evidence, resolve recency through timestamps, and inspect file history when facts conflict.
-
Hybrid memory is therefore not just an implementation compromise. It is a way to separate complementary responsibilities: vector memory retrieves conceptually related evidence, file-based memory preserves authoritative and auditable state, lexical search recovers exact witnesses, and temporal metadata determines which facts remain valid.
-
This directly aligns with agentic search: the agent does not merely consume a prebuilt context, but actively chooses among retrieval tools and memory representations. Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) highlights that retrieval mechanics, harness orchestration, and result-delivery path should be evaluated jointly because each can change end-to-end long-memory QA accuracy.
Memory operations
-
Memory usage involves two key operations:
\[\text{store}(s_t) \quad \text{and} \quad \text{retrieve}(q)\]-
where:
- \(s_t\) is the state or information to store
- \(q\) is a query used to retrieve relevant memory
-
-
In practice, the retrieval mechanism depends on how memory is implemented:
-
Vector-based retrieval:
- Uses embeddings and similarity search
- Retrieves items based on semantic closeness
-
-
File-based retrieval:
- Uses keyword search (e.g., BM25), metadata filtering, or structured queries
- Retrieves items based on exact matches, timestamps, or document structure
-
The core challenge is not just storing information, but retrieving the most relevant subset at the right time.
- Vector memory excels at semantic recall, finding conceptually similar information
- File-based memory excels at temporal and structural recall, finding the most recent, authoritative, or exact record
-
In agentic systems, memory operations are better understood as an agentic search loop rather than a single retrieval call. The agent does not merely receive a fixed top-\(k\) context; it chooses search terms, invokes tools, reads results, decides whether the evidence is sufficient, and may issue follow-up searches before answering.
\[q_t \rightarrow \text{search}(\mathcal{M}, q_t) \rightarrow r_t \rightarrow \text{inspect}(r_t) \rightarrow q_{t+1} \quad \text{or} \quad a\]- where \(q_t\) is the current search query, \(\mathcal{M}\) is the memory store, \(r_t\) is the retrieved result set, and \(a\) is the final answer or action.
-
This is the operational meaning of agentic memory: memory is not only a passive persistence layer, but an active substrate that the agent can search, inspect, revise, and reason over through tools.
-
Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) characterizes retrieval in agentic systems as iterative and agent-directed, where the model decides what to search, how many queries to issue, and whether retrieved results are sufficient, making retrieval strategy inseparable from tool use and harness design.
-
Retrieval quality in this setting depends on both the search operator and the delivery path. Inline delivery injects search results directly into the conversation context, while programmatic file-based delivery writes results to disk and requires the agent to explicitly read or search the resulting artifact.
-
This distinction matters because inline delivery optimizes for immediate evidence visibility, while file-based delivery optimizes for context control and selective inspection. MemGPT: Towards LLMs as Operating Systems by Packer et al. (2023) formalizes a related memory-management view in which limited context is treated as a scarce resource managed through explicit memory operations.
-
The following figure shows memory storage and retrieval flow in an agentic system, including short-term and long-term memory components.
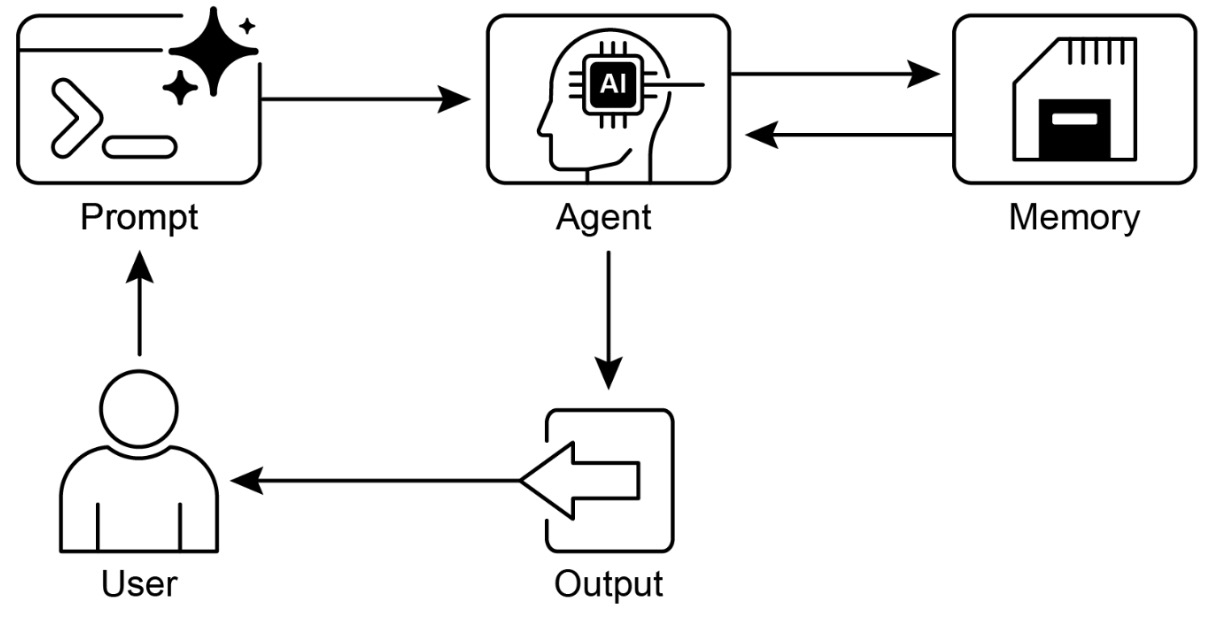
Store operation
-
The store operation determines what information should be persisted after an interaction, tool call, or workflow step.
\[\mathcal{M}_{t+1} =\mathcal{M}_t \cup \phi(s_t)\]- where \(\mathcal{M}_t\) is the memory store at time \(t\), \(s_t\) is the current state, and \(\phi(\cdot)\) is a transformation that converts raw state into a memory record.
-
The transformation \(\phi(\cdot)\) may include:
- Summarization
- Entity extraction
- Timestamping
- Embedding generation
- File serialization
- Event extraction
- Deduplication
- Privacy filtering
-
In conversational agents, raw transcripts are often insufficient because facts evolve over time. A robust store operation should therefore preserve both the original evidence and structured metadata such as speaker, timestamp, source session, event date, and validity period.
-
Chronos: Temporal-Aware Conversational Agents with Structured Event Retrieval for Long-Term Memory by Sen et al. (2026) operationalizes this idea by representing long dialogue history through structured event and turn calendars, so that temporal facts can be retrieved and reasoned over separately from raw utterance history.
Retrieve operation
-
The retrieve operation selects memory records relevant to a current query or task.
\[R_t =\operatorname{topk}_{s_i \in \mathcal{M}} \ \text{score}(q_t, s_i)\]- where \(R_t\) is the retrieved set and \(\text{score}(q_t, s_i)\) depends on the retrieval mechanism.
-
For vector memory:
- For lexical or file-based memory:
-
For temporally aware memory, retrieval may include a recency or validity term:
\[\text{score}(q, s_i) =\lambda_1 \text{relevance}(q,s_i) +\lambda_2 \text{recency}(s_i) +\lambda_3 \text{validity}(s_i)\]- where \(\lambda_1,\lambda_2,\lambda_3\) control the relative importance of semantic relevance, recency, and whether the memory remains valid.
-
This is important when memory contains changing facts. A query such as “What meeting time does Alice prefer?” should not retrieve all historical preferences equally; it should prefer the current or most recently valid preference unless the user asks for history.
Inspect operation
-
In agentic memory, retrieval is often followed by inspection. The agent may need to open a file, scan a result list, compare several snippets, or search within retrieved artifacts before deciding whether the evidence is sufficient.
\[e_t =\text{inspect}(r_t, c_t)\]- where \(e_t\) is the evidence actually read by the model and \(c_t\) is the current context budget.
-
This step is especially important for file-based memory, where retrieved results may be too large to place directly into context. The system may return only paths, summaries, offsets, or metadata, leaving the agent to decide what to read.
-
Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) shows that this delivery choice matters: programmatic file-based delivery changes the task from “read the tool message” to “locate, open, and integrate an artifact,” so retrieval accuracy becomes coupled to tool-use reliability.
Update and consolidation operation
-
Memory systems should also update, merge, or prune stored records over time.
\[\mathcal{M}_{t+1} =\psi(\mathcal{M}_t, s_t, R_t)\]- where \(\psi(\cdot)\) represents consolidation, correction, forgetting, or versioning.
-
Update operations include:
- Adding new facts
- Superseding outdated facts
- Merging duplicate memories
- Summarizing repeated patterns
- Archiving low-value details
- Preserving evidence for auditability
- Removing sensitive or expired information
-
In file-based systems, updates can be represented as commits or diffs, making memory evolution explicit. In vector systems, updates often require embedding new records, deleting stale vectors, or maintaining metadata filters so outdated facts do not dominate retrieval.
-
A temporally aware update can mark old memories as superseded rather than deleting them:
- This preserves historical traceability while allowing the retrieval layer to prioritize active facts.
Stopping operation
- Agentic search also requires a stopping policy: the agent must decide when retrieved evidence is sufficient to answer.
-
A robust stopping policy may consider:
- Whether the retrieved evidence directly answers the question
- Whether there are conflicting memories
- Whether the answer depends on recency or temporal ordering
- Whether additional retrieval is likely to change the answer
- Whether the context budget is being exhausted
-
Poor stopping behavior can cause failures even when the memory store contains the correct information. The agent may stop too early after reading a plausible distractor, or search too long and overload the context with irrelevant evidence.
-
Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) emphasizes this point by showing that retrieval outcomes depend strongly on the harness and tool-calling architecture, because these components shape how the agent schedules queries and decides when enough evidence has been gathered.
Practical operation flow
-
A typical memory-enabled agentic system follows this workflow:
- Store the current interaction, tool outputs, and relevant state
- Transform raw state into structured records, summaries, embeddings, or files
- Retrieve candidate memories using lexical, vector, temporal, or hybrid search
- Inspect retrieved evidence through inline context or file-based tools
- Resolve conflicts using recency, authority, and source metadata
- Answer or act using the selected evidence
- Update memory with new facts, outcomes, and corrections
-
In compact form:
-
The design goal is not simply to maximize retrieval volume, but to surface the smallest sufficient set of accurate, current, and task-relevant memories.
-
This is why hybrid retrieval is often preferred in production:
\[R_t =R_{vec} \cup R_{lex} \cup R_{time}\]- where \(R_{vec}\) captures semantic similarity, \(R_{lex}\) captures exact evidence, and \(R_{time}\) captures recency or temporal validity.
-
The agent can then rerank or filter the union:
- Hybrid memory operations connect naturally to agentic search because the agent may choose different tools for different subproblems: vector search for broad recall, grep for exact witnesses, file reads for auditability, and temporal filters for current validity.
Example
-
Consider a personal assistant agent. Memory enables it to remember user preferences (e.g., preferred meeting times), recall past conversations, adapt responses based on historical context, and use different memory types depending on whether the task requires short-term continuity, long-term persistence, semantic recall, or temporal tracking. Specifics below:
-
Vector memory:
- Retrieves semantically relevant preferences
- Example: “When does Alice like meetings?” \(\rightarrow\) retrieves “morning meetings”
- This is useful when the user’s query is phrased differently from the stored memory, such as asking “What time does Alice usually prefer for scheduling?” when the stored memory says “Alice prefers morning meetings.”
- In an agentic search setting, the agent may issue a broad semantic query first, inspect the retrieved candidates, and refine the query if the evidence is incomplete.
-
File-based memory:
- Tracks how preferences evolve over time
-
Example:
- 2023: “Alice prefers morning meetings”
- 2025: “Alice now prefers afternoons”
- Enables selecting the most recent or valid fact
- This is especially useful when the agent must distinguish historical facts from current facts, because the memory record can preserve timestamps, session boundaries, source files, and update history.
- In an agentic memory setting, the agent can search the stored history, inspect the relevant log entries, compare timestamps, and determine that the 2025 preference supersedes the 2023 preference.
-
Without memory, the assistant would treat each interaction independently, leading to repetitive and less useful behavior.
Agentic search example
-
Suppose a user asks:
- “When does Alice prefer meetings now?”
-
A non-agentic retrieval system might perform a single lookup and return a fixed top-\(k\) set of results. An agentic memory system instead performs an iterative search process:
-
The agent’s final answer should depend not only on whether it found a relevant memory, but also on whether it found the current memory rather than an outdated one.
-
In this example, vector retrieval may surface both “morning meetings” and “afternoon meetings” because they are semantically related, while file-based or lexical retrieval may help verify exact timestamps, source sessions, and supersession relationships.
-
This illustrates why memory and agentic search are tightly connected: memory provides the persistent substrate, while agentic search determines how the agent queries, filters, validates, and applies that substrate during reasoning.
Inline versus file-based delivery example
-
Consider two ways the assistant might receive retrieved memories:
-
Inline delivery:
- The retrieval tool returns snippets directly into the model context.
- The model immediately sees both “Alice prefers morning meetings” and “Alice now prefers afternoon meetings.”
- This is simple and fast, but too many retrieved snippets can crowd the context window.
-
File-based delivery:
- The retrieval tool writes results to a file and returns a path.
- The agent must open, search, or read the file before answering.
- This can reduce context pressure, but it introduces an additional tool-use step.
-
-
Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) shows that this distinction is practically important: inline grep exceeded inline vector retrieval for every evaluated harness-model pair in one long-memory QA experiment, while file-based delivery sometimes changed or inverted the relative ordering because the agent had to locate, open, and integrate retrieval artifacts before answering.
Putting the pieces together
-
A robust personal assistant may combine several memory mechanisms:
- Short-term memory keeps the current conversation coherent
- Vector memory retrieves semantically related facts and preferences
- File-based memory preserves exact history, timestamps, and updates
- Lexical search finds literal evidence such as names, dates, and exact preference statements
- Temporal metadata determines which memory is current
- Agentic search coordinates the retrieval process across these tools
-
A simplified execution flow is:
-
For the question “When does Alice prefer meetings now?”, the assistant might:
- Retrieve semantically related memories about Alice and meetings
- Use lexical search for exact preference statements
- Compare timestamps or version history
- Select the most recent active preference
- Answer: “Alice currently prefers afternoon meetings.”
- Store the interaction as evidence that this preference was used in the current decision
-
This example demonstrates that memory is not only about storing facts. In agentic systems, memory also includes the search process, tool interface, evidence delivery path, and update policy that determine whether the right fact is used at the right time.
Implementation
-
LangChain provides built-in support for memory across multiple dimensions, with native integrations for vector-based memory (e.g., FAISS, Pinecone, Chroma) and extensibility that allows integration of file-based or custom storage systems via tools, retrievers, or custom memory implementations.
-
In current LangChain and LangGraph terminology, short-term memory is commonly treated as thread-scoped agent state that is persisted through a checkpointer, while long-term memory is stored across sessions in external stores that can organize memories by namespace and key. Memory overview and Long-term memory describe this split as short-term state for an ongoing thread and long-term JSON memories stored in a searchable external store.
-
To better reflect real-world agent design, these examples can be categorized along two axes:
- Duration: short-term vs. long-term
- Mechanism: vector-based vs. file-based
-
In agentic systems, implementation should also account for a third axis:
- Orchestration: whether memory is retrieved by a fixed retrieval pipeline or through an agentic search loop in which the agent chooses search terms, invokes tools, inspects evidence, and decides whether to continue searching
-
This third axis is important because memory quality is not determined only by the memory store. It also depends on the harness, tool interface, result formatting, and delivery path. Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) shows that grep and vector retrieval can produce different end-to-end outcomes depending on whether evidence is delivered inline or through files, and depending on the agent harness used.
Short-term memory (working memory)
- Context-based buffer memory (LangChain native)
from langchain_openai import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
memory = ConversationBufferMemory()
conversation = ConversationChain(
llm=llm,
memory=memory
)
conversation.predict(input="Hi, my name is Alice.")
conversation.predict(input="What is my name?")
-
Mechanism: in-context (no external storage)
-
Duration: short-term
-
Use case: conversational continuity within a session
-
This demonstrates how recent interactions are retained in the context window to maintain coherence.
-
In newer LangChain and LangGraph patterns, short-term memory is commonly implemented as persisted agent state rather than as a standalone buffer object; Short-term memory describes short-term memory as state that updates when the agent is invoked or completes a step, such as a tool call.
-
A modern short-term memory implementation can therefore be represented as graph state plus a checkpointer:
from langgraph.checkpoint.memory import InMemorySaver
from langchain.agents import create_agent
checkpointer = InMemorySaver()
agent = create_agent(
model="openai:gpt-4o-mini",
tools=[],
checkpointer=checkpointer
)
config = {
"configurable": {
"thread_id": "alice-thread"
}
}
agent.invoke(
{"messages": [{"role": "user", "content": "Hi, my name is Alice."}]},
config=config
)
agent.invoke(
{"messages": [{"role": "user", "content": "What is my name?"}]},
config=config
)
-
Mechanism: persisted thread state
-
Duration: short-term across steps within a thread
-
Use case: maintaining continuity across tool calls and multi-step agent workflows
-
This implementation is closely related to agentic search because tool results, retrieved snippets, and intermediate decisions are stored in the running state. If too many results are injected inline, the context can become crowded, so practical agents often trim, summarize, or selectively retrieve state before the next model call.
Long-term memory (persistent storage)
-
Long-term memory in LangChain is typically implemented using vector stores, while file-based approaches can be integrated depending on system requirements.
-
In LangGraph-style systems, long-term memory may also be stored as structured JSON documents under namespaces and keys, making it possible to organize memories by user, organization, project, task, or domain. Long-term memory describes this as a store abstraction in which each memory is organized under a namespace and distinct key.
Vector-based long-term memory (semantic retrieval)
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
vector_store = FAISS.from_texts(
["Alice prefers morning meetings.", "Alice works in AI research."],
embeddings
)
query = "What does Alice prefer?"
docs = vector_store.similarity_search(query)
print(docs)
-
Mechanism: embeddings + similarity search
-
Duration: long-term
-
Strength: semantic recall
-
Best suited for:
- Knowledge bases
- Retrieval-augmented generation (RAG) systems
- Large-scale memory
-
This is the primary memory abstraction supported natively by LangChain.
-
Vector memory implements retrieval as semantic search over embedded records:
\[R_{vec} =\operatorname{topk}_{s_i \in \mathcal{M}} \text{sim}\bigl(f(q), f(s_i)\bigr)\]- where \(q\) is the query, \(s_i\) is a stored memory record, \(f(\cdot)\) is an embedding function, and \(\text{sim}(\cdot,\cdot)\) is commonly cosine similarity.
-
In an agentic memory system, vector retrieval is usually not the final step. The agent may inspect retrieved records, issue a narrower query, verify facts with lexical search, or use temporal metadata to decide whether a retrieved fact is current.
-
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Lewis et al. (2020) establishes the retrieval-augmented generation pattern in which external retrieved knowledge conditions generation, while Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) highlights that in agentic search, the retriever is embedded inside a broader tool-calling loop rather than used as a fixed prompt-construction step.
File-based long-term memory (structured logs)
- Simple file-based memory (custom integration):
import json
memory_file = "memory.json"
def store_memory(entry):
try:
data = json.load(open(memory_file))
except:
data = []
data.append(entry)
json.dump(data, open(memory_file, "w"))
def retrieve_memory(query):
data = json.load(open(memory_file))
return [m for m in data if query.lower() in m.lower()]
store_memory("Alice prefers morning meetings.")
store_memory("Alice now prefers afternoon meetings.")
print(retrieve_memory("Alice"))
-
Mechanism: file storage + keyword search
-
Duration: long-term
-
Strength: transparency and control
-
This is not a native LangChain memory abstraction, but can be integrated via custom tools or retrievers.
-
File-based memory is particularly useful when memory must be inspectable, auditable, and temporally precise. Instead of turning every record into an opaque vector, the system preserves the original text, metadata, and update history.
-
A more structured implementation stores each memory as an object:
import json
import datetime
from pathlib import Path
memory_file = Path("memory.jsonl")
def store_memory(text, memory_type="episodic", source="conversation"):
record = {
"timestamp": datetime.datetime.now().isoformat(),
"type": memory_type,
"source": source,
"text": text,
"status": "active"
}
with memory_file.open("a", encoding="utf-8") as f:
f.write(json.dumps(record) + "\n")
def retrieve_memory(keyword):
results = []
if not memory_file.exists():
return results
with memory_file.open("r", encoding="utf-8") as f:
for line in f:
record = json.loads(line)
if keyword.lower() in record["text"].lower():
results.append(record)
return results
store_memory("Alice prefers morning meetings.", memory_type="preference")
store_memory("Alice now prefers afternoon meetings.", memory_type="preference")
print(retrieve_memory("Alice"))
-
Mechanism: append-only JSONL files + keyword search
-
Duration: long-term
-
Strength: auditability, manual correction, and temporal inspection
-
In agentic search terms, this file is not just storage. It becomes a searchable environment that the agent can query through tools such as grep, exact-match search, timestamp filters, or structured reads.
File-based long-term memory (temporal / versioned)
import datetime
log = []
def store_event(text):
log.append({
"timestamp": str(datetime.datetime.now()),
"text": text
})
def retrieve_latest(keyword):
results = [e for e in log if keyword.lower() in e["text"].lower()]
return sorted(results, key=lambda x: x["timestamp"], reverse=True)[0]
store_event("Alice prefers morning meetings.")
store_event("Alice now prefers afternoon meetings.")
print(retrieve_latest("Alice"))
-
Mechanism: timestamped logs
-
Duration: long-term
-
Strength: temporal reasoning and recency awareness
-
This approach is particularly useful for tracking evolving state and can be layered alongside vector memory.
-
A temporal memory implementation should generally distinguish between old facts and active facts:
-
This allows the agent to preserve historical evidence while prioritizing the current valid fact during retrieval.
-
Chronos: Temporal-Aware Conversational Agents with Structured Event Retrieval for Long-Term Memory by Sen et al. (2026) follows this broader design principle by structuring long conversational memory around event and turn calendars, making temporal evidence easier for agents to retrieve and reason over.
Agentic search over memory tools
- A practical agentic memory system exposes memory through tools rather than through a single hidden retrieval call.
import re
import json
from pathlib import Path
memory_file = Path("memory.jsonl")
def grep_memory(pattern):
matches = []
regex = re.compile(pattern, flags=re.IGNORECASE)
if not memory_file.exists():
return matches
with memory_file.open("r", encoding="utf-8") as f:
for line_number, line in enumerate(f, start=1):
record = json.loads(line)
if regex.search(record["text"]):
matches.append({
"line": line_number,
"timestamp": record["timestamp"],
"text": record["text"],
"status": record.get("status", "active")
})
return matches
def get_latest_active_memory(pattern):
matches = [
m for m in grep_memory(pattern)
if m["status"] == "active"
]
return sorted(matches, key=lambda x: x["timestamp"], reverse=True)[0]
-
Mechanism: lexical search over structured memory files
-
Duration: long-term
-
Strength: exact evidence recovery and temporal validation
-
This form of memory is closely aligned with the agentic search framing: the agent can choose a pattern, inspect matches, refine the pattern, and select the latest active result.
-
The agentic loop can be summarized as:
\[q_t \rightarrow \text{tool}(q_t) \rightarrow r_t \rightarrow \text{inspect}(r_t) \rightarrow q_{t+1} \ \text{or} \ a\]- where \(q_t\) is the agent’s current memory query, \(r_t\) is the returned evidence, and \(a\) is the final answer or action.
-
Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) shows why this implementation detail matters: retrieval mode, harness behavior, and result delivery are jointly responsible for accuracy in long-memory QA.
Programmatic file-based delivery
- File-based delivery can be implemented by writing retrieval results to disk and returning only a path to the agent.
import json
from pathlib import Path
results_dir = Path("search_results")
results_dir.mkdir(exist_ok=True)
def search_memory_to_file(query, output_name="results.json"):
results = retrieve_memory(query)
output_path = results_dir / output_name
with output_path.open("w", encoding="utf-8") as f:
json.dump(results, f, indent=2)
return {
"path": str(output_path),
"count": len(results),
"message": "Search results were written to file."
}
-
Mechanism: file-based result delivery
-
Duration: retrieval artifact persists beyond the immediate tool call
-
Strength: reduces immediate context pressure and supports selective inspection
-
This design is useful when search results are large, but it turns retrieval into a multi-step workflow. The agent must read, search within, or summarize the file before answering.
-
In formal terms, file-based delivery separates retrieval from inspection:
\[R_t = \text{retrieve}(q_t, \mathcal{M})\] \[p_t = \text{write}(R_t)\] \[e_t = \text{inspect}(p_t, c_t)\]- where \(p_t\) is the path to the retrieval artifact and \(c_t\) is the available context budget.
-
This is why file-based delivery belongs in a memory primer rather than only in a retrieval primer: it is a memory-management strategy for controlling what enters the model context.
Comparative Analysis
| Type | Mechanism | Duration | LangChain Support | Strength |
|---|---|---|---|---|
| Buffer memory | Context window | Short-term | Native / legacy pattern | Conversational continuity |
| Thread-scoped state | Agent state + checkpointer | Short-term across steps | Native in LangGraph-style agents | Continuity across tool calls |
| Vector memory | Embeddings | Long-term | Native via vector stores | Semantic retrieval |
| Structured store memory | JSON documents + namespace/key | Long-term | Native store abstraction | Persistent user or task memory |
| File memory (simple) | Files + keyword | Long-term | Custom | Interpretability |
| File memory (temporal) | Logs + timestamps | Long-term | Custom | Temporal reasoning |
| Agentic memory | Memory tools + search loop | Short-term and long-term | Custom or framework-integrated | Iterative evidence discovery |
Key takeaways
-
LangChain natively supports vector-based memory for scalable semantic retrieval
-
File-based memory must be integrated manually, but provides strong benefits for traceability and temporal reasoning
-
Buffer memory provides short-term conversational continuity
-
In practice, production systems combine all three into a layered memory architecture.
-
Modern LangChain and LangGraph implementations increasingly separate short-term thread state from long-term stores, making it possible to resume conversations while also maintaining persistent memories across sessions. Memory overview describes this distinction between thread-scoped short-term memory and persistent long-term memory.
-
Agentic memory extends the implementation problem beyond storage. The system must also expose memory through tools, define when the agent should search or write memory, decide whether results enter context inline or through files, and specify how outdated facts are superseded.
-
For robust implementations, memory should usually include:
- A short-term state layer for the current thread
- A long-term semantic layer for paraphrase-friendly recall
- A file or structured-store layer for authoritative records
- A lexical search layer for exact evidence
- Temporal metadata for recency and validity
- A tool policy for when the agent should search, inspect, update, or stop
-
A practical hybrid implementation can be summarized as:
- The implementation lesson from agentic search is that memory should be evaluated as an end-to-end tool-using system. A retriever that performs well in isolation may fail if the agent receives results in an inconvenient format, stops too early, overlooks a file, or fails to distinguish an outdated memory from a current one.
Memory in agentic systems
-
Memory is deeply integrated with other agentic design patterns:
- With planning: tracks goals, subgoals, intermediate states, and unresolved tasks
- With reflection: stores feedback, critiques, corrections, and improved strategies
- With tool use: records tool calls, tool outputs, evidence traces, and execution outcomes
- With multi-agent systems: enables shared context, coordination history, and task handoff across agents
-
Different memory types serve different roles:
- Vector memory \(\rightarrow\) shared semantic knowledge
- File-based memory \(\rightarrow\) shared logs, history, and traceability
- Short-term memory \(\rightarrow\) current task state and working context
- Episodic memory \(\rightarrow\) prior experiences, events, and outcomes
- Temporal memory \(\rightarrow\) ordering, recency, validity, and supersession of facts
-
This makes memory a foundational and multi-layered component of any sophisticated agentic system.
-
In agentic systems, memory is closely connected to agentic search. Memory provides the persistent substrate, while agentic search describes the process by which the agent actively queries, inspects, filters, and applies that substrate during reasoning.
-
The distinction is important: a conventional retrieval pipeline usually takes a fixed query, returns top-\(k\) results, and inserts them into a prompt, while agentic search is iterative and model-directed. The agent chooses what to search, how many searches to run, whether to refine the query, and whether the retrieved evidence is sufficient.
-
Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) uses the term agentic search for this tool-mediated retrieval loop, emphasizing that retrieval effectiveness depends on the retriever, the harness, and the result-delivery architecture rather than on the search method alone.
-
When the same idea is discussed from the memory side, it can be described as agentic memory: a memory system whose contents are not merely injected into the prompt, but are exposed through tools that the agent can search, read, update, summarize, and validate.
-
A compact view is:
\[\text{Agentic Memory} =\text{Persistent Memory} +\text{Agentic Search} +\text{Update Policy}\]- where persistent memory stores state across time, agentic search retrieves and inspects the right evidence, and the update policy determines how new information is written, superseded, or consolidated.
Memory as part of the agent loop
-
A basic agent loop can be written as:
\[o_t \rightarrow m_t \rightarrow a_t \rightarrow o_{t+1}\]- where \(o_t\) is the current observation, \(m_t\) is the agent’s memory state, and \(a_t\) is the action selected by the agent.
-
In a memory-enabled agent, the model does not rely only on the current prompt. It can retrieve memories before acting, store new outcomes after acting, and refine its future behavior based on both retrieved evidence and new observations.
\[m_t =\text{retrieve}(\mathcal{M}, q_t)\] \[a_t =\pi(o_t, m_t)\] \[\mathcal{M}_{t+1} =\text{update}(\mathcal{M}_t, o_t, a_t, o_{t+1})\]- where \(\mathcal{M}\) is the persistent memory store, \(q_t\) is a memory query, \(\pi\) is the agent policy, and \(\mathcal{M}_{t+1}\) is the updated memory after the step.
-
ReAct by Yao et al. (2022) introduced a reasoning-and-acting pattern in which language models interleave reasoning traces with actions against external environments, making memory retrieval and tool use natural parts of the same control loop.
-
Toolformer by Schick et al. (2023) shows that models can learn when to call external tools, what arguments to pass, and how to incorporate returned results, which is directly relevant to memory tools such as search, read, summarize, and write operations.
Memory and planning
-
Planning agents decompose goals into steps, maintain progress, and revise plans when new information appears.
-
Memory supports planning by storing:
- The current plan
- Completed and pending steps
- Intermediate observations
- Constraints and user preferences
- Failed attempts and recovery strategies
-
Without memory, planning becomes brittle because the agent must keep all state in the immediate context window.
-
With memory, the agent can resume long-horizon tasks, recover from interruptions, and avoid repeating failed actions.
\[P_{t+1} =\text{revise}(P_t, o_t, m_t)\]- where \(P_t\) is the current plan, \(o_t\) is the latest observation, and \(m_t\) is retrieved memory relevant to the plan.
-
In agentic search terms, planning often determines what memory should be retrieved next. For example, if a plan step requires confirming a user preference, the agent may search preference memory; if a step requires verifying a past tool result, it may search logs or files.
Memory and reflection
-
Reflection agents evaluate their own behavior, identify errors, and store lessons for future use.
-
Memory supports reflection by storing:
- Mistakes and corrections
- Feedback from users or evaluators
- Successful strategies
- Failed strategies
- Post-task summaries
- Critiques of prior decisions
-
Reflection turns memory into a learning substrate. Instead of only recording what happened, the system records what should change next time.
\[r_t =\text{reflect}(o_t, a_t, y_t)\] \[\mathcal{M}_{t+1} =\mathcal{M}_t \cup r_t\]- where \(r_t\) is a reflection record and \(y_t\) is the observed outcome or feedback.
-
Self-RAG by Asai et al. (2023) connects retrieval with self-reflection by training a model to decide when to retrieve, generate with retrieved evidence, and critique its own generations, illustrating how memory access and reflection can be coupled inside the generation process.
Memory and tool use
-
Tool-using agents rely on external functions, APIs, files, databases, browsers, terminals, and retrieval systems.
-
Memory supports tool use by storing:
- Which tools were called
- Tool arguments
- Tool outputs
- Errors and retries
- Result files or artifacts
- Evidence used in final answers
-
This is especially important when tool outputs are large or when the agent must preserve an audit trail.
-
Tool outputs may enter memory in two ways:
- Inline: the output is appended directly to the conversation context
- Programmatic: the output is written to an artifact, such as a file, and the agent receives a pointer
-
Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) finds that inline and file-based tool-result delivery can produce different accuracy outcomes, because file-based delivery changes retrieval from immediate reading into a multi-step workflow of locating, opening, and integrating artifacts.
-
The operational pattern is:
\[\text{tool}(x_t) \rightarrow r_t \rightarrow \text{store}(r_t) \rightarrow \text{retrieve}(r_t \mid q_{t+k})\]- where \(x_t\) is a tool input, \(r_t\) is the tool result, and \(q_{t+k}\) is a later query that may reuse the result.
Memory and multi-agent systems
-
In multi-agent systems, memory can be private, shared, or hierarchical.
-
Private memory stores agent-specific history, preferences, and local reasoning state.
-
Shared memory stores task-level facts, environment state, decisions, and artifacts that multiple agents need to coordinate around.
-
Hierarchical memory allows specialized agents to maintain local working state while writing important outcomes to a shared long-term store.
-
This structure helps agents coordinate without forcing every detail into a single shared context.
-
Cognitive Architectures for Language Agents by Sumers et al. (2023) describes language agents as systems with modular memory components, a structured action space for interacting with internal memory and external environments, and a decision process for choosing actions.
Memory as a control surface
-
Memory is not only a storage component. It is also a control surface that shapes what the agent can know, what it can verify, and how it can recover from mistakes.
-
Important control decisions include:
- What should be written to memory
- What should be excluded for privacy or safety
- Which retriever should be used
- Whether retrieval should be semantic, lexical, temporal, or hybrid
- Whether results should be injected inline or exposed through files
- When outdated facts should be superseded
- When the agent should stop searching
-
These decisions affect both performance and trust.
-
A useful abstraction is:
- Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) shows that harness choice can shift accuracy by margins comparable to changing retrievers, which means memory behavior must be evaluated as part of the full agentic stack rather than as an isolated database or index.
Practical design implications
-
In practice, memory-enabled agents should be designed around several principles:
- Store raw evidence when auditability matters
- Store summaries when context efficiency matters
- Store embeddings when semantic recall matters
- Store timestamps and validity markers when facts evolve
- Use lexical search when exact witnesses are likely to matter
- Use vector search when paraphrase and conceptual matching are likely to matter
- Use file-based artifacts when results are too large for direct context injection
- Use inline delivery when immediate visibility is more important than context conservation
-
A robust agentic memory system therefore combines:
-
This design makes memory useful not only for personalization, but also for evidence-grounded reasoning, long-horizon task execution, debugging, reproducibility, and multi-agent coordination.
-
The key lesson is that memory in agentic systems is not a passive cache. It is an active, tool-mediated reasoning layer that connects storage, retrieval, inspection, action, and update into one continuous loop.
Failure modes
-
Memory introduces several challenges:
-
Irrelevant retrieval:
- Vector memory may return semantically similar but incorrect data
- File-based memory may return keyword matches without context
-
Context overload:
- Too much retrieved memory degrades model performance
-
Staleness:
- Vector memory may surface outdated embeddings
- File-based memory may accumulate obsolete entries
-
Semantic gaps:
- Vector memory may miss exact or symbolic relationships
- File-based memory may miss semantically relevant matches
-
Privacy concerns:
- Storing sensitive data requires safeguards regardless of storage type
-
-
To mitigate these issues:
- Use hybrid retrieval (semantic + keyword)
- Apply recency and relevance ranking
- Implement memory consolidation and pruning
- Add metadata (timestamps, entities, summaries)
- Use access controls and encryption
-
In practice, robust systems combine both approaches:
- Vector memory for semantic recall at scale
- File-based memory for accuracy, history, and control
-
This hybrid design enables agents to retrieve the right information while understanding its context and evolution.
Irrelevant retrieval
-
Irrelevant retrieval occurs when the memory system returns records that appear related to the query but do not actually support the current answer.
-
In vector memory, this often happens because semantic similarity is not the same as evidential relevance. A memory may discuss the same topic, person, or task while still being outdated, contradicted, incomplete, or irrelevant to the specific question.
-
In file-based memory, irrelevant retrieval often occurs through overly broad lexical matches. A keyword search for “Alice meetings” may return every meeting-related memory, even if only one entry states Alice’s current preference.
-
This failure mode becomes more visible in agentic search because the agent may issue multiple underspecified queries, inspect partial evidence, and stop after reading a plausible but incorrect result.
-
Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) shows that dense retrieval can surface semantically nearby distractors in long-memory QA, while lexical retrieval can miss evidence when the agent fails to generate the right exact search pattern.
-
A useful mitigation is hybrid retrieval followed by evidence validation:
\[R = R_{vec} \cup R_{lex} \cup R_{time}\] \[R^{*} =\operatorname{filter}(R,\text{relevance},\text{recency},\text{authority})\]- where \(R_{vec}\) captures semantic candidates, \(R_{lex}\) captures exact witnesses, and \(R_{time}\) captures temporally valid records.
Context overload
-
Context overload occurs when too much memory is injected into the model context, causing relevant evidence to be diluted by irrelevant or redundant information.
-
This can happen when retrieval returns too many snippets, when tool outputs are appended repeatedly, or when long conversation history is passed directly into the model.
-
Long-context capacity does not guarantee reliable use of long-context information. Lost in the Middle: How Language Models Use Long Contexts by Liu et al. (2023) shows that model performance can degrade depending on the position of relevant information in long inputs, especially when it must be retrieved from the middle of the context.
-
In memory systems, context overload can be formalized as a budgeted selection problem:
\[E^{*} =\arg\max_{E \subseteq R} \sum_{e_i \in E} \text{utility}(e_i) \quad \text{s.t.} \quad \sum_{e_i \in E} \text{tokens}(e_i) \leq B\]- where \(E^{*}\) is the selected evidence set, \(R\) is the retrieved candidate set, and \(B\) is the context budget.
-
MemGPT: Towards LLMs as Operating Systems by Packer et al. (2023) addresses this class of failure by treating context as a limited memory tier and using explicit memory operations to move information between fast in-context memory and slower external storage.
-
In agentic search, file-based delivery can mitigate context overload by writing large result sets to disk and letting the agent inspect only selected parts, but it introduces a new dependency on the agent’s ability to locate, read, and integrate those files.
Staleness and supersession
-
Staleness occurs when memory contains facts that were once correct but are no longer valid.
-
This is common in long-term personalization, where preferences, projects, relationships, schedules, and goals evolve over time.
-
A typical staleness pattern is:
\[s_1 = \text{``Alice prefers morning meetings''}\] \[s_2 = \text{``Alice now prefers afternoon meetings''}\] \[s_1 \prec s_2\]- where \(s_1 \prec s_2\) means that \(s_2\) is the later and currently authoritative memory.
-
Vector memory may retrieve both records because they are semantically similar, while file-based memory may preserve both records unless the system explicitly marks the old fact as superseded.
-
A safer update rule is:
- Temporal metadata should therefore be part of the memory schema:
- Chronos: Temporal-Aware Conversational Agents with Structured Event Retrieval for Long-Term Memory by Sen et al. (2026) addresses this kind of temporal-memory problem by decomposing long dialogue into event and turn calendars with resolved datetime ranges, making temporally grounded facts easier to retrieve and reason over.
Semantic gaps
-
Semantic gaps occur when the retrieval mechanism fails to capture the kind of relationship needed by the task.
-
Vector retrieval may fail on exact symbolic relationships, identifiers, numbers, code fragments, names, dates, or literal phrases if those details are not well represented in the embedding space.
-
File-based lexical retrieval may fail when the query and memory use different wording. For example, a search for “preferred schedule” may miss “Alice likes calls after lunch.”
-
This creates a practical design rule:
- Use vector retrieval for paraphrase and conceptual similarity
- Use lexical retrieval for exact evidence, identifiers, and literal spans
- Use temporal retrieval for recency and validity
- Use structured retrieval for fields such as entities, dates, status, and source
-
In agentic search, the agent may choose among these retrieval modes dynamically:
- Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) reports that inline grep exceeded inline vector retrieval across evaluated harness-model pairs in a long-memory QA setting, suggesting that exact evidence recovery can be especially strong when answers depend on literal spans such as preferences, dates, counts, and time expressions.
Harness and delivery failures
-
In agentic memory, retrieval quality is inseparable from the agent harness and result-delivery path.
-
Harness failures include:
- Poor tool descriptions that lead to weak queries
- Bad result formatting that hides relevant evidence
- Premature stopping after partial retrieval
- Excessive repeated searches that fill the context window
- Failure to inspect result artifacts
- Weak coordination between short-term state and long-term memory
-
Delivery failures include:
- Inline results overloading context
- File-based results being ignored or only partially read
- Search artifacts being too large or poorly structured
- Relevant evidence being hidden behind an additional tool call
- The agent losing track of which file or result set contains the answer
-
Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) finds that overall scores depend strongly on harness and tool-calling style even when the underlying corpus is fixed, and that file-based delivery can reorder grep-versus-vector comparisons because the agent must locate, open, and integrate artifacts before answering.
-
This means memory failures can occur even when the correct memory exists and the retriever is capable of finding it.
Privacy, security, and governance failures
-
Memory systems may store sensitive personal information, business context, credentials, internal documents, or user preferences.
-
Privacy failures include:
- Storing information that should not be retained
- Retrieving private memories in unrelated contexts
- Exposing one user’s memory to another user or agent
- Keeping obsolete sensitive records indefinitely
- Logging tool outputs that contain secrets
-
Security failures include:
- Prompt injection embedded inside stored memory
- Malicious tool outputs written into long-term logs
- Retrieval of untrusted instructions as if they were facts
- Cross-agent contamination through shared memory
-
A safer memory schema should separate facts from instructions:
- Access control should be enforced at retrieval time:
- Memory pruning should also be treated as a first-class operation:
Evaluation failures
-
Memory systems are often evaluated as isolated retrievers, but agentic memory requires end-to-end evaluation.
-
A retriever can score well on static top-\(k\) metrics while still failing inside an agent because:
- The agent asks the wrong query
- The correct result is returned but not inspected
- The result is delivered in a format the agent does not use effectively
- The model stops before resolving conflicts
- The answer requires temporal reasoning rather than topical similarity
- The memory is correct but stale
-
Agentic memory should therefore be evaluated over the full loop:
- Is Grep All You Need? How Agent Harnesses Reshape Agentic Search by Sen et al. (2026) explicitly motivates this evaluation framing by comparing retrieval strategies across multiple harnesses and tool-delivery styles, showing that retrieval effectiveness is not stable across architecturally distinct agent stacks.
Practical mitigations
-
A robust memory system should include:
- Hybrid retrieval to combine semantic, lexical, temporal, and structured signals
- Metadata filters for time, source, permissions, trust, and status
- Recency-aware ranking for evolving facts
- Supersession markers for outdated memories
- Evidence validation before answering
- Context budgeting to avoid overloading the model
- File-based delivery when result sets are large
- Inline delivery when immediate evidence visibility is important
- Audit logs for memory writes, retrievals, and tool outputs
- Pruning and expiration policies for low-value or sensitive records
- Access controls for user-specific, project-specific, or agent-specific memories
-
A practical ranking function may combine several signals:
\[\text{score}(q,s_i) =\lambda_1 \text{semantic}(q,s_i) +\lambda_2 \text{lexical}(q,s_i) +\lambda_3 \text{recency}(s_i) +\lambda_4 \text{authority}(s_i) -\lambda_5 \text{risk}(s_i)\]- where \(\lambda_1,\ldots,\lambda_5\) control how strongly the system weights semantic similarity, literal match, recency, source authority, and privacy or safety risk.
-
The safest high-level design is a layered memory architecture:
- The central lesson is that memory failures are rarely isolated to storage. In agentic systems, they emerge from the interaction between what is stored, how it is searched, how it is delivered, how it is inspected, and how it is updated.
Learning and Adaptation
-
Learning and adaptation represent the shift from static intelligence to evolving intelligence. Rather than simply executing tasks, systems that incorporate this pattern continuously improve, adapting to new environments and refining their behavior over time. This marks a fundamental transition: intelligence is no longer fixed at design, but shaped through experience.
-
In agentic design, learning introduces the concept of growth. Agents are no longer limited to acting and reasoning within a single task—they develop across tasks and over time. While patterns like reflection enable short-term corrections within a given interaction, learning extends this capability, allowing agents to carry insights forward and apply them in future situations.
-
At its core, learning and adaptation turn experience into improvement. By leveraging feedback, interaction outcomes, and accumulated knowledge, agents refine their internal policies and decision-making processes. This creates a compounding effect, where each interaction contributes to a more capable system.
-
Ultimately, this pattern defines the evolution from systems that merely execute and correct to systems that continuously improve. It lays the foundation for building agents that do not just perform tasks, but become progressively better at performing them.
Why learning is needed
-
Even with planning, tool use, and memory, an agent without learning remains fundamentally static:
- It repeats the same mistakes across tasks
- It cannot generalize from past experiences
- It does not improve efficiency over time
- It lacks adaptation to changing environments
-
Learning enables agents to:
- Optimize decision-making strategies
- Improve task performance
- Adapt to new conditions
- Personalize behavior
-
This aligns with reinforcement learning principles, where agents improve through interaction with an environment. For example, Deep Reinforcement Learning by Mnih et al. (2015) demonstrates how agents can learn optimal policies through reward-driven interaction, showing that iterative feedback improves long-term outcomes.
The learning process
-
Learning can be formalized as updating a policy based on experience:
\[\pi_{\theta'} = \pi_{\theta} + \alpha \nabla J(\theta)\]-
where:
- \(\pi_{\theta}\) is the current policy
- \(\theta\) are the parameters
- \(J(\theta)\) is the objective function
- \(\alpha\) is the learning rate
-
-
The objective often involves maximizing expected reward:
- This formulation underpins many adaptive agent systems, even when implemented implicitly through prompt updates or memory adjustments.
Types of learning in agentic systems
-
Learning can occur in multiple ways depending on how feedback is obtained and applied, as follows:
-
Supervised learning from feedback:
- Uses labeled examples or corrections
- Often implemented via human feedback
-
Improves specific behaviors
- This is closely related to approaches like InstructGPT by Ouyang et al. (2022), where models are fine-tuned using human preferences to improve alignment.
-
Reinforcement learning:
- Uses reward signals from the environment
- Optimizes long-term performance
- Suitable for sequential decision-making
-
Self-improvement (bootstrapped learning):
- Uses the agent’s own outputs and reflections
- Iteratively improves without external labels
- Often combined with reflection and memory
-
Online adaptation:
- Continuously updates behavior during deployment
- Adapts to dynamic environments
-
These approaches are often combined in practical systems.
Example
-
Consider a customer support agent:
- Initially, it provides generic responses
- Over time, it learns which responses resolve issues faster
- It adapts to user preferences and common queries
- It improves its routing and tool usage decisions
-
Without learning, the system remains static. With learning, it becomes progressively more effective.
Implementation
- While LangChain does not directly implement reinforcement learning, learning can be approximated through feedback loops and memory updates.
from langchain_openai import ChatOpenAI
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
memory = ConversationBufferMemory()
def update_memory_with_feedback(input_text, response, feedback):
memory.save_context(
{"input": input_text},
{"output": f"{response}\nFeedback: {feedback}"}
)
# Simulated interaction
user_input = "Explain quantum computing simply."
response = llm.invoke(user_input)
# Simulated feedback
feedback = "Too complex, simplify further."
update_memory_with_feedback(user_input, response.content, feedback)
- This example demonstrates how feedback can be incorporated into memory, influencing future responses.
Learning through evaluation loops
-
Learning in agentic systems often emerges from repeated evaluation cycles, where performance is continuously measured and used to drive improvement. Rather than relying on static behavior, agents iteratively refine their outputs based on feedback signals.
-
A typical loop follows:
- Generate output
- Evaluate output (via metrics, rules, or humans)
- Update system behavior
- Repeat
-
This creates a feedback loop that gradually improves performance over time and mirrors reinforcement learning pipelines such as Deep Reinforcement Learning by Mnih et al. (2015), which shows how iterative reward-driven updates improve policies over time.
-
The following figure shows the learning and adapting pattern, which features feedback-driven learning where agent outputs are evaluated and used to improve future behavior.
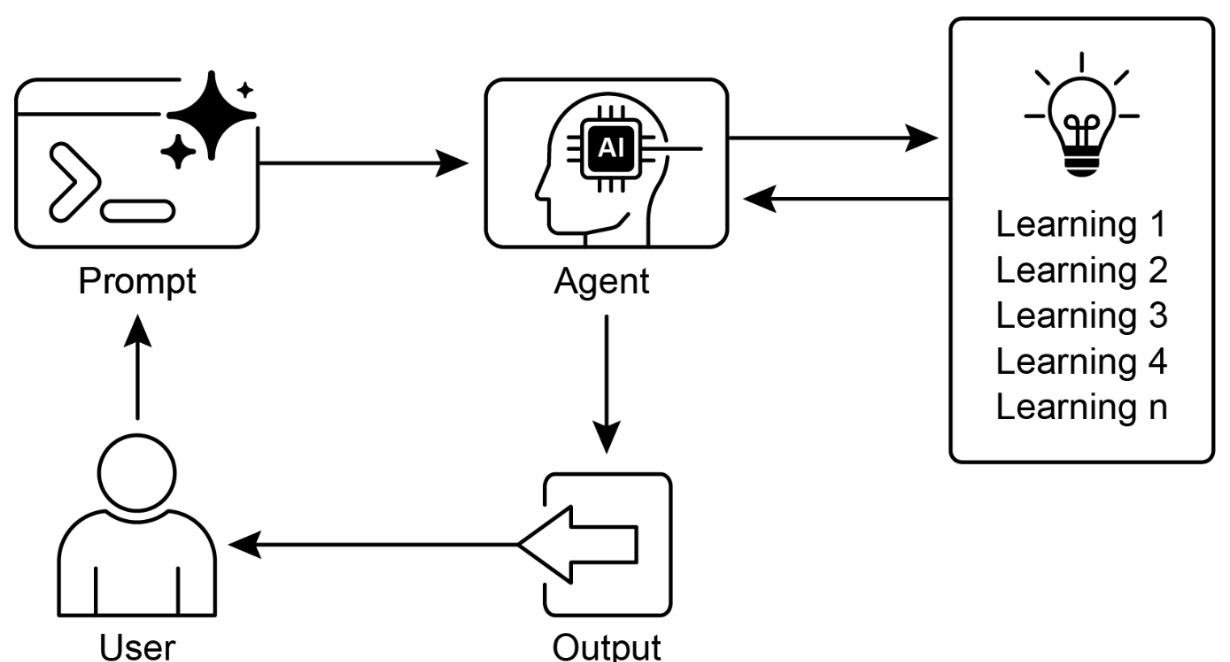
- This loop forms the foundation for more advanced self-improving systems, including agents that can modify their own behavior, architecture, or even code.
Learning in agentic systems
-
Learning interacts deeply with other patterns:
- With memory: Stores learned knowledge
- With reflection: Provides signals for improvement
- With planning: Refines strategies over time
- With tool use: Improves tool selection and usage
-
This integration enables agents to evolve holistically rather than in isolated components.
Failure modes
-
Learning introduces new risks:
- Overfitting: Adapting too strongly to specific cases
- Feedback bias: Learning from incorrect or biased signals
- Instability: Frequent updates may degrade performance
- Catastrophic forgetting: Losing previously learned knowledge
-
To mitigate these issues:
- Use balanced and diverse feedback
- Regularize updates
- Maintain stable baseline behaviors
- Monitor performance over time
Self-Improving Coding Agent (SICA)
-
The Self-Improving Coding Agent GitHub Repository represents a significant step beyond standard evaluation loops by enabling an agent to directly modify its own source code. Instead of learning indirectly through parameter updates or prompt adjustments, SICA performs explicit self-modification, making it both the learner and the subject of learning.
-
SICA operates through an iterative self-improvement cycle:
- It maintains an archive of past agent versions and their benchmark performance
- It selects the best-performing version using a weighted scoring function (considering success, time, and computational cost)
- It analyzes past performance to identify improvements
- It modifies its own codebase
- The new version is evaluated and added back to the archive
-
This creates a closed-loop system where learning is driven entirely by past performance, enabling continuous evolution without traditional retraining.
-
The following figure shows SICA’s self-improvement flow, learning and adapting based on its past versions.
-
Over time, SICA demonstrated meaningful architectural evolution:
- Transitioned from simple file overwrites to a Smart Editor
- Introduced Diff-Enhanced editing for targeted code changes
- Implemented AST-based reasoning for efficient navigation
- Developed hybrid search mechanisms combining fast lookup and structural parsing
-
The following figure shows performance across iterations with key improvements annotated with their corresponding tool or agent modifications.
-
SICA’s architecture also highlights several production-relevant design patterns:
- Multi-agent decomposition: coding, reasoning, and problem-solving sub-agents
- Memory and context structuring: organized prompts and execution traces
- Tool use: file operations, command execution, and AST parsing
- Exception handling and monitoring: an asynchronous overseer agent detects loops, stagnation, and inefficiencies
-
A particularly important innovation is the overseer agent, which acts as a meta-controller:
- Monitors execution via callgraphs and logs
- Detects pathological behavior (e.g., repeated work)
- Can intervene or terminate execution
-
This introduces a form of self-regulation and aligns closely with guardrails and monitoring patterns in production systems.
AlphaEvolve
-
AlphaEvolve extends the idea of learning through evaluation into the domain of algorithm discovery. Developed by Google, it combines large language models with evolutionary algorithms and automated evaluation systems to iteratively generate and optimize solutions.
-
The system operates through a structured evolutionary loop:
- Generate candidate algorithms using LLMs
- Evaluate them using predefined metrics
- Select high-performing candidates
- Refine and recombine them
- Repeat
-
A key design feature is the use of LLM ensembles:
- Gemini Flash generates diverse candidate solutions
- Gemini Pro performs deeper analysis and refinement
-
This division of labor improves both exploration and exploitation in the search space.
-
AlphaEvolve has demonstrated strong real-world impact:
- Reduced data center compute usage by 0.7%
- Improved TPU hardware design via Verilog optimization
- Achieved up to 32.5% performance gains in GPU kernels
- Discovered new matrix multiplication algorithms
- Solved or improved a large fraction of open mathematical problems
-
Conceptually, AlphaEvolve represents the convergence of:
- Learning through evaluation loops
- Parallelization (multiple candidates evaluated simultaneously)
- Planning and search (evolutionary optimization)
- Tool use (evaluation systems and computational pipelines)
-
It shows that agentic systems can move beyond task execution into knowledge and algorithm discovery.
OpenEvolve
-
OpenEvolve builds on similar principles but focuses specifically on evolving code through an LLM-driven pipeline. It generalizes the evolutionary approach into a flexible, production-ready system for optimizing programs.
-
Its architecture is centered around a controller that orchestrates multiple components:
- Program sampler
- Program database
- Evaluator pool
- LLM ensemble
-
The following figure shows the OpenEvolve internal architecture and how these components interact.
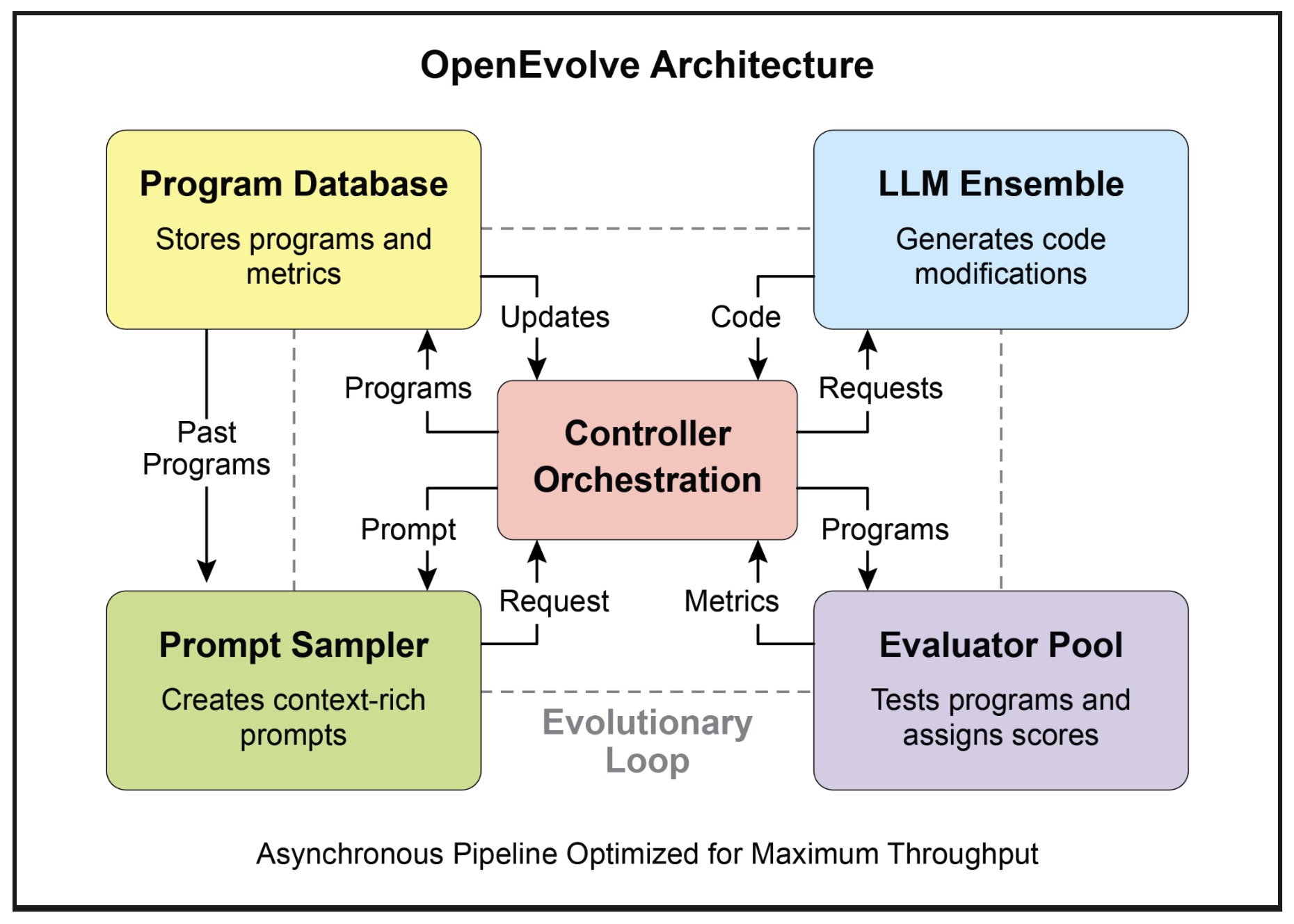
-
The system operates through an iterative loop:
- Generate candidate programs using LLMs
- Evaluate them using custom evaluators
- Store results in a database
- Select and refine high-performing programs
- Repeat
-
Key capabilities include:
- Evolution of entire codebases, not just functions
- Multi-objective optimization (e.g., performance, efficiency)
- Support for multiple programming languages
- Distributed evaluation for scalability
- Flexible prompt and configuration control
-
A typical usage pattern:
from openevolve import OpenEvolve
evolve = OpenEvolve(
initial_program_path="path/to/initial_program.py",
evaluation_file="path/to/evaluator.py",
config_path="path/to/config.yaml",
)
best_program = await evolve.run(iterations=1000)
print("Best program metrics:")
for name, value in best_program.metrics.items():
print(f"{name}: {value:.4f}")
-
OpenEvolve highlights how learning through evaluation can be operationalized in production systems:
- Evaluation becomes the central driver of improvement
- Memory is externalized via program databases
- Parallelization enables large-scale search
- Composition integrates LLMs, evaluators, and storage systems
Learning and Adaptation Loop
- Across SICA, AlphaEvolve, and OpenEvolve, a common pattern emerges:
-
This loop generalizes learning beyond traditional training into continuous system evolution.
-
These systems demonstrate that:
- Evaluation is not just for measurement, but for driving improvement
-
Agents can evolve at multiple levels:
- Outputs (reflection)
- strategies (planning)
- architectures (multi-agent composition)
- code itself (self-modification)
-
The boundary between execution and learning is increasingly blurred
- This pattern becomes essential when building agents that must operate in dynamic, uncertain, or evolving environments, where static behavior is insufficient.
Model Context Protocol (MCP)
-
Model Context Protocol (MCP) is an agentic design pattern that standardizes how context is structured, transmitted, and consumed across the components of an agentic system. It defines a consistent interface for passing information between models, tools, memory systems, and agents, enabling interoperability and composability.
-
As agentic systems grow in complexity, context becomes the central medium through which all components interact. MCP introduces discipline into this process by formalizing how context is represented and exchanged, preventing fragmentation, inconsistency, and misalignment between system parts. By doing so, it ensures that every component operates on a shared understanding of the system state.
-
More than just a technical convention, MCP represents the standardization of information flow in agentic systems. It is the pattern that enables coherence—allowing complex systems to function as unified wholes rather than disconnected parts. In this sense, MCP transforms context from passive data into an active mechanism for coordination, turning information into aligned, system-wide behavior.
Why MCP is needed
-
Without a structured protocol for context, systems encounter several challenges:
- Inconsistent data formats across components
- Loss of critical information during transitions
- Difficulty integrating multiple tools and agents
- Poor scalability due to ad-hoc interfaces
-
MCP addresses these issues by defining a shared schema for context, enabling seamless communication across system boundaries.
-
This aligns with broader system design principles seen in distributed systems and APIs, where standardization enables interoperability. In agentic systems, context plays the role of both data and control signal, making its structure even more critical.
-
The following figure shows structured context flowing between components in an agentic system, ensuring consistent data exchange and interoperability. This visualization highlights how MCP acts as the connective tissue of the system.
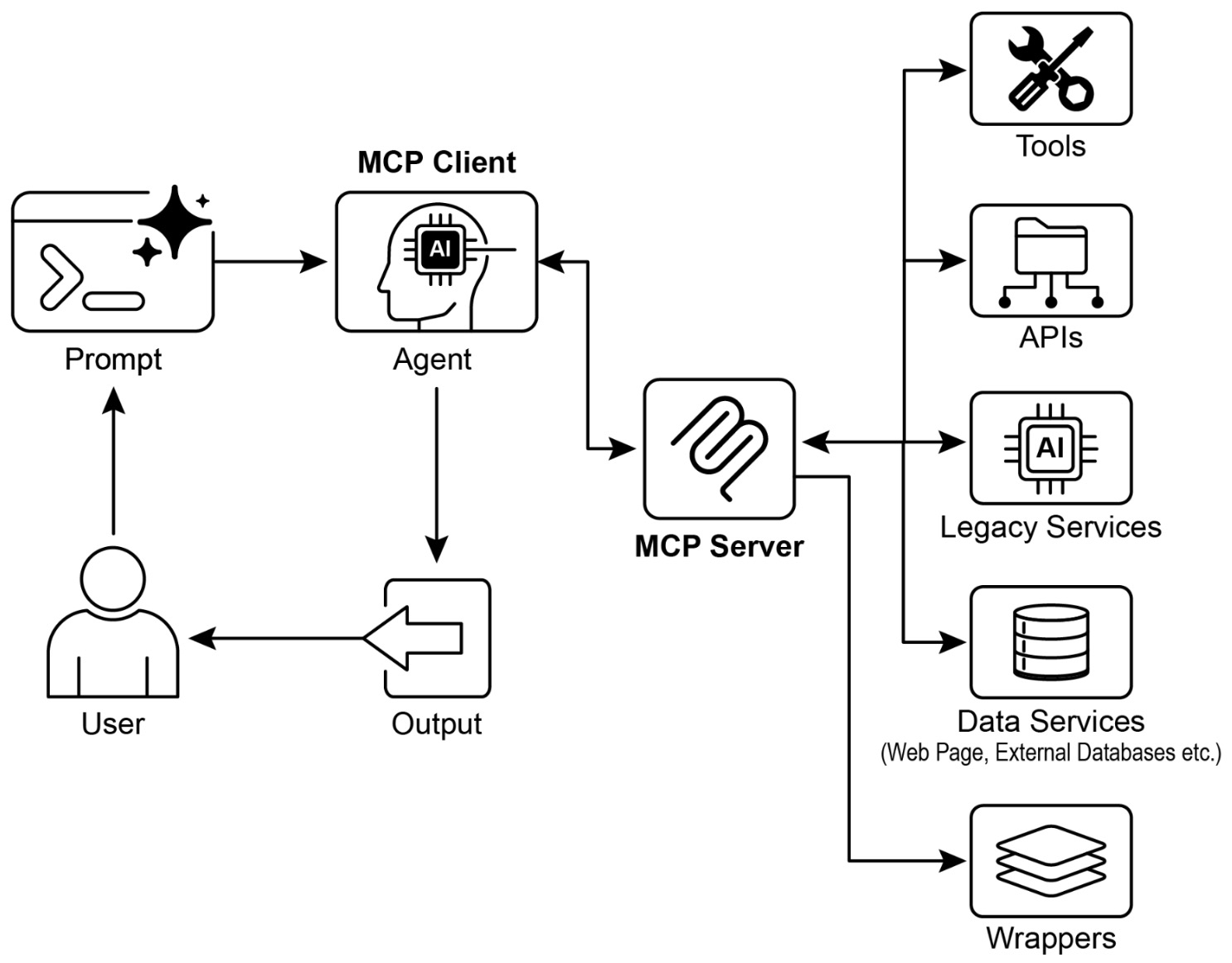
The structure of context
-
Context in an agentic system typically includes:
- User input
- System state
- Memory retrievals
- Tool outputs
- Intermediate reasoning steps
-
MCP organizes these elements into a structured representation:
\[C = {u, s, m, t, r}\]-
where:
- \(u\) = user input
- \(s\) = system state
- \(m\) = memory
- \(t\) = tool outputs
- \(r\) = reasoning traces
-
-
This structured context is passed between components, ensuring that all relevant information is preserved.
Context transformation
-
As context flows through the system, it is transformed:
\[C_{t+1} = f(C_t, a_t)\]-
where:
- \(C_t\) is the current context
- \(a_t\) is the action taken
- \(f\) is the transformation function
-
-
Each component consumes context, modifies it, and passes it forward. MCP ensures that this transformation remains consistent and interpretable.
Example
-
Consider a multi-step agent handling a customer request:
- Receives user query
- Retrieves relevant memory
- Calls a tool (e.g., database query)
- Updates state with results
- Generates response
-
Without MCP, each step might use different formats, leading to integration issues. With MCP, all steps operate on a shared context structure, enabling smooth transitions.
Implementation
- LangChain implicitly supports MCP-like behavior through structured inputs and outputs.
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
prompt = ChatPromptTemplate.from_messages([
("system", "You are an assistant that uses structured context."),
("human", "User input: {input}\nMemory: {memory}\nTool Output: {tool_output}")
])
context = {
"input": "What is my order status?",
"memory": "User has order #1234",
"tool_output": "Order #1234 is shipped"
}
response = llm.invoke(prompt.format(**context))
print(response.content)
- This example demonstrates how structured context can be passed into a model, ensuring that all relevant information is included.
MCP in multi-component systems
-
MCP becomes especially important in systems involving:
- Multiple agents
- Multiple tools
- Distributed execution
- Complex workflows
-
In such systems, context must be:
- Consistent: Same structure across components
- Complete: Includes all necessary information
- Efficient: Avoids unnecessary duplication
- Traceable: Supports debugging and monitoring
MCP and other patterns
-
MCP integrates tightly with other agentic patterns:
- With memory: Defines how memory is injected into context
- With tool use: Standardizes tool input and output formats
- With multi-agent systems: Enables communication between agents
- With planning: Represents plans and intermediate states
-
This makes MCP a foundational infrastructure pattern rather than a standalone capability.
Failure modes
-
Improper context management can lead to:
- Context fragmentation: Missing or inconsistent data
- Overloaded context: Excessive information degrading performance
- Ambiguity: Unclear structure leading to misinterpretation
- Latency: Large context sizes slowing down processing
-
To mitigate these issues:
- Define clear schemas for context
- Limit context to relevant information
- Use structured formats (e.g., JSON-like representations)
- Monitor context size and flow
Goal Setting and Monitoring
-
Goal setting and monitoring enables systems to define objectives explicitly, track progress toward them, and adjust behavior based on deviations or outcomes. It introduces a control layer that ensures the agent remains aligned with its intended purpose over time.
-
While planning determines how a task will be executed, goal setting defines what success looks like, and monitoring ensures that execution remains on track. Together, they transform agent behavior from open-ended activity into directed, measurable progress.
Motivation
-
Without explicit goals and monitoring mechanisms, agentic systems face several risks:
- Drift from the original objective
- Inefficient or redundant actions
- Lack of termination criteria
- Inability to detect failure or suboptimal performance
-
Goal setting provides direction, while monitoring provides feedback. This mirrors control systems in engineering, where a system continuously compares its current state to a desired target.
-
This concept aligns with optimization frameworks where systems aim to minimize or maximize an objective function:
\[\min_{\pi} L(\pi, G)\]-
where:
- \(\pi\) is the policy or behavior
- \(G\) is the goal
- \(L\) is a loss function measuring deviation from the goal
-
-
Monitoring ensures that this loss is evaluated continuously and used to guide behavior.
-
The following figure shows continuous monitoring of agent progress against defined goals, enabling dynamic adjustments and termination decisions. This loop ensures that the system remains aligned with its objectives.
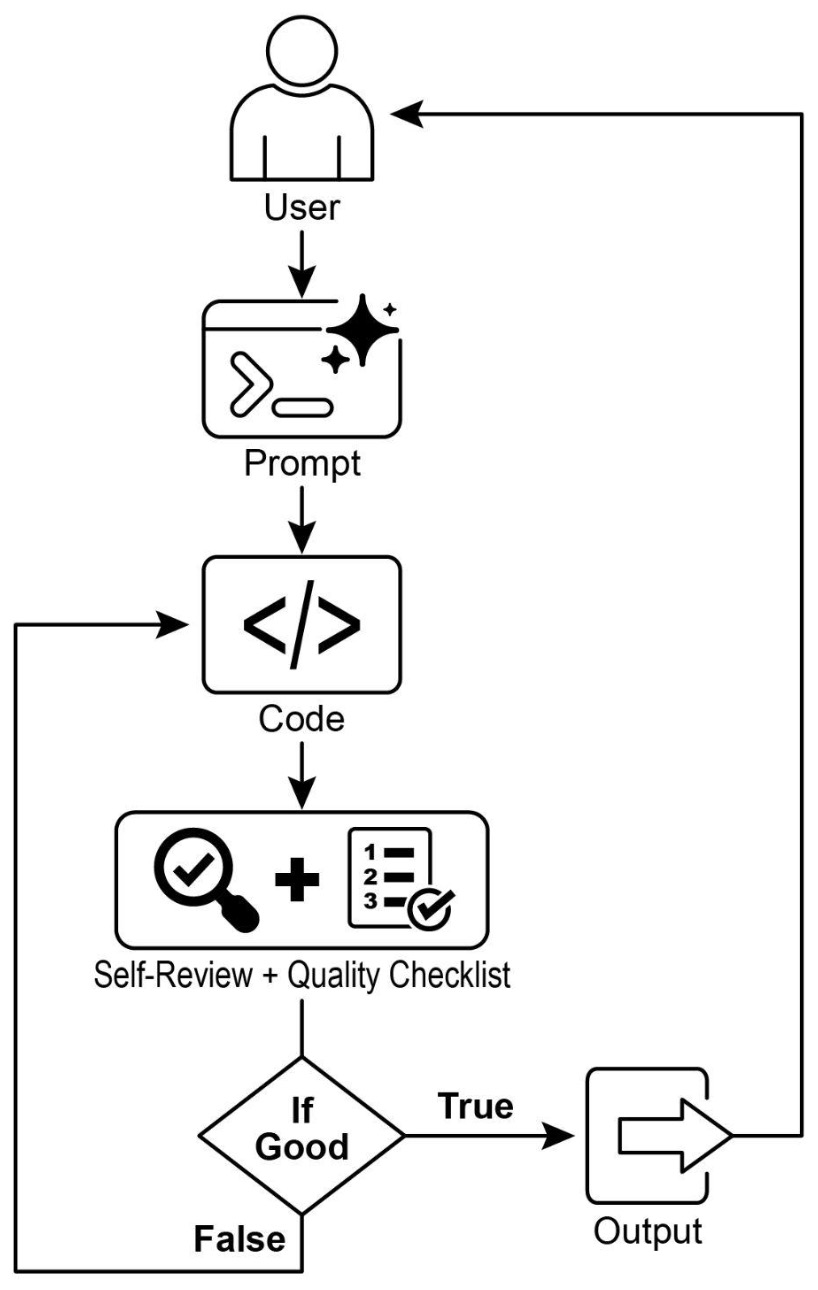
Defining goals
-
Goals in agentic systems can take different forms depending on the task, as follows:
-
Explicit goals:
- Clearly defined objectives (e.g., “summarize this document”)
- Often provided by the user or system
-
Implicit goals:
- Derived from context or system design
- Not directly specified but inferred
-
Hierarchical goals:
- High-level goals decomposed into subgoals
- Enables complex task execution
-
-
Goals can also include constraints, such as time limits, resource usage, or quality thresholds.
Monitoring progress
-
Monitoring involves tracking the agent’s state relative to its goal:
\[\Delta_t = d(s_t, G)\]-
where:
- \(s_t\) is the current state
- \(G\) is the goal
- \(d\) is a distance or discrepancy function
-
-
The system uses \(\Delta_t\) to decide whether to continue execution, adjust strategy, or terminate.
Example
-
Consider an agent tasked with: “Write a research report on climate change.”
-
Goal setting defines:
- Completion criteria (e.g., structured report with sections)
- Quality requirements (e.g., factual accuracy, citations)
-
Monitoring tracks:
- Progress through sections
- Coverage of required topics
- Consistency and coherence
-
If the system detects missing sections or poor quality, it can trigger corrective actions such as re-planning or reflection.
Implementation
- Goal tracking can be implemented by maintaining a state object and evaluating progress at each step.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
goal = "Write a 3-section report on renewable energy."
state = {"sections_completed": 0}
def check_progress(state, goal):
return state["sections_completed"] >= 3
while not check_progress(state, goal):
response = llm.invoke("Write next section of report.")
print(response.content)
state["sections_completed"] += 1
print("Goal achieved!")
- This example demonstrates a simple monitoring loop where progress is tracked and used to determine termination.
Feedback-driven monitoring
-
Monitoring often involves evaluating outputs against criteria:
- Completeness
- Accuracy
- Consistency
- Efficiency
-
This creates a feedback loop:
- Generate output
- Evaluate against goal
- Update state
- Adjust behavior
Goal management in complex systems
-
In advanced agentic systems, goal management can involve:
- Multiple concurrent goals
- Dynamic goal updates
- Conflict resolution between goals
- Prioritization of objectives
-
This requires a more sophisticated control layer that can balance competing demands.
Integration with other patterns
-
Goal setting and monitoring interact with multiple patterns:
- With planning: Defines what the plan aims to achieve
- With reflection: Identifies deviations and triggers corrections
- With memory: Stores progress and past outcomes
- With learning: Refines goal achievement strategies
-
This integration ensures that goals are not static, but actively influence system behavior.
Failure modes
-
Common challenges include:
- Poorly defined goals: Ambiguity leads to inconsistent behavior
- Over-constrained goals: Limits flexibility
- Insufficient monitoring: Failures go undetected
- Metric misalignment: Optimizing the wrong objective
-
To mitigate these issues:
- Define clear and measurable goals
- Use appropriate evaluation metrics
- Monitor continuously
- Allow adaptive goal refinement
Exception Handling and Recovery
-
Exception handling and recovery enables systems to detect failures, handle unexpected conditions, and recover gracefully without derailing the overall task. It introduces robustness into agentic systems, ensuring that errors are not terminal but manageable events.
-
In real-world environments, uncertainty and failure are inevitable. APIs fail, tools return incorrect outputs, plans break, and environments change. This pattern ensures that agents can continue operating despite these disruptions.
Why exception handling is needed
-
Without structured exception handling, agentic systems suffer from:
- Fragility in the presence of errors
- Cascading failures across steps
- Inability to recover from unexpected conditions
- Poor user experience due to abrupt failures
-
Exception handling transforms failure from a stopping condition into a recoverable event.
-
This aligns with resilience principles in distributed systems, where systems are designed to tolerate faults rather than avoid them entirely.
Types of exceptions
-
Agentic systems encounter different categories of failures:
-
Execution errors:
- Tool failures (e.g., API timeouts, invalid responses)
- Code execution errors
- Resource constraints
-
Reasoning errors:
- Incorrect assumptions
- Logical inconsistencies
- Misinterpretation of inputs
-
Planning errors:
- Invalid or incomplete plans
- Missing dependencies
-
Environmental errors:
- Changes in external systems
- Unavailable resources
-
-
Each type requires different handling strategies.
The exception handling process
-
Exception handling can be modeled as:
\[s_{t+1} = \begin{cases} f(s_t, a_t) & \text{if no error} \ g(s_t, e_t) & \text{if error occurs} \end{cases}\]-
where:
- \(e_t\) is the detected error
- \(g\) is the recovery function
-
-
The system must detect the error, classify it, and apply an appropriate recovery strategy.
Recovery strategies
-
Different strategies can be applied depending on the nature of the failure,as follows:
-
Retry mechanisms:
- Re-execute the failed action
- Useful for transient errors
-
Fallback strategies:
- Use alternative tools or methods
- Provide degraded but functional output
-
Replanning:
- Adjust the plan to account for failure
- Often used in dynamic environments
-
Human escalation:
- Request human intervention for critical failures
-
Graceful degradation:
- Continue operation with reduced capability
-
-
These strategies ensure that the system remains functional even under adverse conditions.
Example
-
Consider an agent that queries a weather API:
- The API fails due to a timeout
- The agent retries the request
- If failure persists, it switches to an alternative API
- If no data is available, it informs the user gracefully
-
Without exception handling, the system would simply fail. With it, the system adapts and continues.
Implementation
- LangChain supports exception handling through standard Python constructs combined with agent logic.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
def safe_invoke(prompt):
try:
return llm.invoke(prompt).content
except Exception as e:
return f"Error occurred: {str(e)}. Retrying..."
response = safe_invoke("Explain black holes.")
print(response)
- This example demonstrates a simple retry mechanism for handling failures.
Exception handling loop
-
Exception handling often operates as a loop and ensures that failures are managed systematically. The core components of the loop are as below:
- Attempt action
- Detect error
- Classify error
- Apply recovery strategy
- Continue execution
Exception handling in agentic systems
-
This pattern integrates with other patterns:
- With planning: Enables replanning after failure
- With tool use: Handles tool-related errors
- With reflection: Diagnoses reasoning failures
- With monitoring: Detects deviations from expected behavior
-
This interconnectedness ensures that recovery is not isolated but part of the overall system behavior.
Failure modes
-
Even exception handling can fail if not designed properly:
- Silent failures: Errors go undetected
- Infinite retries: System gets stuck retrying
- Incorrect recovery: Wrong strategy applied
- Overhead: Excessive handling slows down execution
-
To mitigate these issues:
- Implement clear error detection mechanisms
- Limit retries and define thresholds
- Use appropriate recovery strategies
- Monitor system behavior
Human-in-the-Loop
Core Idea
-
As agentic systems evolve from simple workflows into autonomous, goal-driven architectures, a fundamental tension emerges between capability and control. The more autonomy an agent is given through patterns such as planning, tool use, and multi-agent collaboration, the greater the need for mechanisms that ensure reliability, correctness, and alignment with human intent. This is where human-in-the-loop (HITL) becomes essential.
-
Agentic systems operate in environments that are inherently uncertain, dynamic, and often high-stakes. While models can reason, act, and adapt, they do not possess true judgment, accountability, or contextual awareness in the way humans do. This creates a gap between what systems can do and what they should be allowed to do autonomously. HITL bridges this gap by embedding human oversight directly into the system’s execution loop.
-
Rather than viewing autonomy as an all-or-nothing property, modern agentic design treats it as a spectrum. At one end are fully automated workflows with minimal intervention, and at the other are tightly controlled systems where humans validate every step. Human-in-the-loop enables systems to operate flexibly along this spectrum, introducing checkpoints, approvals, and feedback mechanisms exactly where they are needed.
-
This pattern is particularly critical in scenarios involving ambiguity, ethical considerations, or irreversible actions. In such cases, purely automated decision-making can lead to compounding errors or unintended consequences. By incorporating human judgment at key points, systems gain an additional layer of robustness and accountability without sacrificing the efficiency benefits of automation.
-
More broadly, HITL reflects a shift toward hybrid intelligence systems, where humans and AI collaborate rather than compete. The agent handles scale, speed, and pattern recognition, while the human provides oversight, intuition, and contextual grounding. Together, they form a system that is more reliable and adaptable than either could achieve alone.
-
This section explores how human-in-the-loop is implemented as a design pattern within agentic systems, and how it integrates with other patterns such as reflection, evaluation, and guardrails to enable safe and effective real-world deployment.
Why human-in-the-loop is needed
-
Fully autonomous systems face inherent limitations:
- They may produce incorrect or unsafe outputs
- They lack contextual understanding in ambiguous situations
- They may misinterpret goals or constraints
- They cannot always be trusted for high-stakes decisions
-
Human-in-the-loop addresses these limitations by introducing checkpoints where human input can:
- Validate decisions
- Correct errors
- Provide additional context
- Override system behavior
-
This aligns with approaches such as Deep Reinforcement Learning from Human Preferences by Christiano et al. (2017), where human feedback is used to guide agent behavior toward desired outcomes.
-
The following figure shows the integration of human checkpoints within the agent workflow, enabling validation, correction, and control at different stages. This illustrates how human input is interleaved with automated processes.
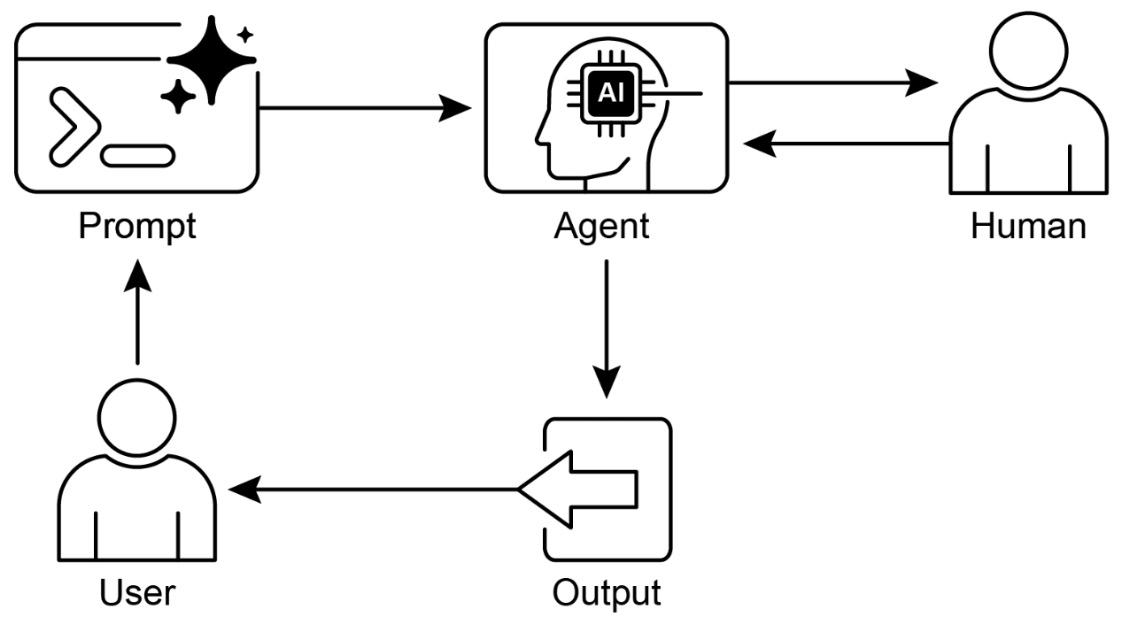
Modes of human involvement
-
Human interaction can occur at different stages of the agent workflow, as follows:
-
Pre-execution guidance:
- Humans define goals, constraints, or plans
- Ensures correct initial setup
-
Mid-execution intervention:
- Humans review intermediate outputs
- Can approve, modify, or redirect actions
-
Post-execution validation:
- Humans evaluate final outputs
- Provide feedback for improvement
-
Continuous supervision:
- Humans monitor system behavior in real time
-
-
Each mode offers different trade-offs between autonomy and control.
The HITL interaction loop
-
Human-in-the-loop can be modeled as an augmented decision process:
\[a_t = \begin{cases} \pi(s_t) & \text{if autonomous} \ \pi_h(s_t) & \text{if human intervention} \end{cases}\]-
where:
- \(\pi\) is the agent policy
- \(\pi_h\) is the human-influenced decision
-
-
This introduces an external control signal that can override or guide the agent.
Example
-
Consider an AI system assisting with legal document drafting:
- The agent generates a draft
- A human reviews and edits the content
- The agent incorporates feedback
- The process repeats until approval
-
Without HITL, errors could propagate into critical outputs. With HITL, quality and accountability are significantly improved.
Implementation
- LangChain supports human-in-the-loop patterns through interactive workflows and checkpoints.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
def human_review(output):
print("Model output:", output)
feedback = input("Approve? (yes/edit): ")
return feedback
response = llm.invoke("Draft a business email.")
decision = human_review(response.content)
if decision == "yes":
final_output = response.content
else:
final_output = llm.invoke("Revise based on feedback.").content
print(final_output)
- This example demonstrates a simple human approval step before finalizing output.
HITL in agentic systems
-
Human-in-the-loop integrates with multiple patterns:
- With reflection: Humans provide higher-quality critiques
- With learning: Human feedback improves future performance
- With planning: Humans validate or refine plans
- With monitoring: Humans detect anomalies and intervene
-
This makes HITL a key mechanism for ensuring alignment and reliability.
Failure modes
-
While beneficial, HITL introduces challenges:
- Latency: Human intervention slows down execution
- Scalability: Human involvement does not scale easily
- Inconsistency: Different humans may provide different feedback
- Over-reliance: Excessive dependence on humans reduces autonomy
-
To mitigate these issues:
- Use HITL selectively for high-risk or ambiguous tasks
- Define clear guidelines for human intervention
- Combine with automated validation where possible
- Optimize workflows to minimize delays
Guardrails and Safety
Core Idea
-
Guardrails and safety represent a critical control layer in agentic systems, ensuring that increasing autonomy does not lead to uncontrolled or harmful behavior. As agents become more capable through patterns like planning, tool use, memory, and learning, they transition from passive assistants to systems that can take actions, make decisions, and influence real-world outcomes. This increased capability introduces corresponding risks, making safety mechanisms not optional but foundational.
-
At a systems level, guardrails can be understood as constraint-enforcing functions applied throughout the agent lifecycle:
-
Rather than being a single checkpoint, guardrails operate as a layered system across the entire architecture. They are applied at input ingestion, during reasoning and planning, before tool execution, and after output generation. This layered enforcement ensures that safety is maintained continuously, not just validated at the end.
-
In production architectures, guardrails serve multiple roles:
- They act as policy enforcement mechanisms, ensuring compliance with business rules and regulations
- They function as risk mitigation systems, preventing unsafe or unintended actions
- They provide trust boundaries, especially when agents interact with external systems or sensitive data
- They enable controlled autonomy, allowing systems to act independently within safe limits
-
This pattern is closely related to alignment research such as Constitutional AI by Bai et al. (2022), which shows that embedding explicit principles into system behavior can guide outputs toward safer and more aligned responses.
-
Importantly, guardrails are not meant to replace other patterns but to complement them. They work in conjunction with:
- Tool use, by restricting what actions can be executed
- Planning, by ensuring generated plans adhere to constraints
- Reflection, by validating and correcting unsafe outputs
- Human-in-the-loop, by escalating high-risk decisions
-
From a design perspective, guardrails introduce a shift from “can the system do this?” to “should the system do this?” This distinction is essential for building reliable, production-grade agentic systems.
-
Ultimately, guardrails and safety transform agentic systems from powerful but potentially unpredictable entities into controlled, trustworthy systems capable of operating in real-world environments.
Motivation
-
Without safety mechanisms, agentic systems may:
- Generate harmful or unsafe outputs
- Execute unintended or dangerous actions
- Violate constraints or policies
- Amplify biases or hallucinations
-
Guardrails mitigate these risks by enforcing rules and validating outputs at different stages of execution.
-
This aligns with alignment research such as Constitutional AI by Bai et al. (2022), which demonstrates how predefined principles can guide model behavior toward safer outputs without constant human supervision.
Types of guardrails
-
Guardrails can be applied at multiple levels within an agentic system.
-
Input guardrails:
- Validate and sanitize user inputs
- Prevent prompt injection or malicious inputs
-
Output guardrails:
- Filter or modify generated outputs
- Ensure compliance with policies
-
Tool guardrails:
- Restrict which tools can be used
- Validate tool inputs and outputs
-
Execution guardrails:
- Enforce constraints during workflow execution
- Prevent unsafe sequences of actions
-
-
These layers collectively ensure system safety.
The guardrail enforcement process
-
Guardrails can be modeled as constraint functions applied to actions and outputs:
\[a_t' = \mathcal{G}(a_t)\]-
where:
- \(a_t\) is the original action
- \(\mathcal{G}\) is the guardrail function
- \(a_t'\) is the validated or modified action
-
-
If an action violates constraints, it can be blocked, modified, or escalated. This ensures that only safe actions are executed.
Example
-
Consider an agent with access to a payment API:
- The agent attempts to execute a transaction
- A guardrail checks if the transaction exceeds a threshold
- If it does, the action is blocked or requires human approval
-
Without guardrails, the system could perform unsafe operations. With guardrails, constraints are enforced.
Implementation
- Guardrails can be implemented using validation layers and conditional logic. The following example demonstrates a simple output filtering mechanism.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
def output_guardrail(response):
if "harmful" in response.lower():
return "Output blocked due to safety concerns."
return response
response = llm.invoke("Generate a response.")
safe_response = output_guardrail(response.content)
print(safe_response)
Guardrails in agentic workflows
-
Guardrails are typically applied at multiple points:
- Before processing input
- During reasoning and planning
- Before executing actions
- After generating outputs
-
The following figure illustrates guardrail design, with enforcement of safety constraints at multiple stages of the agent workflow, including input validation, action filtering, and output moderation.
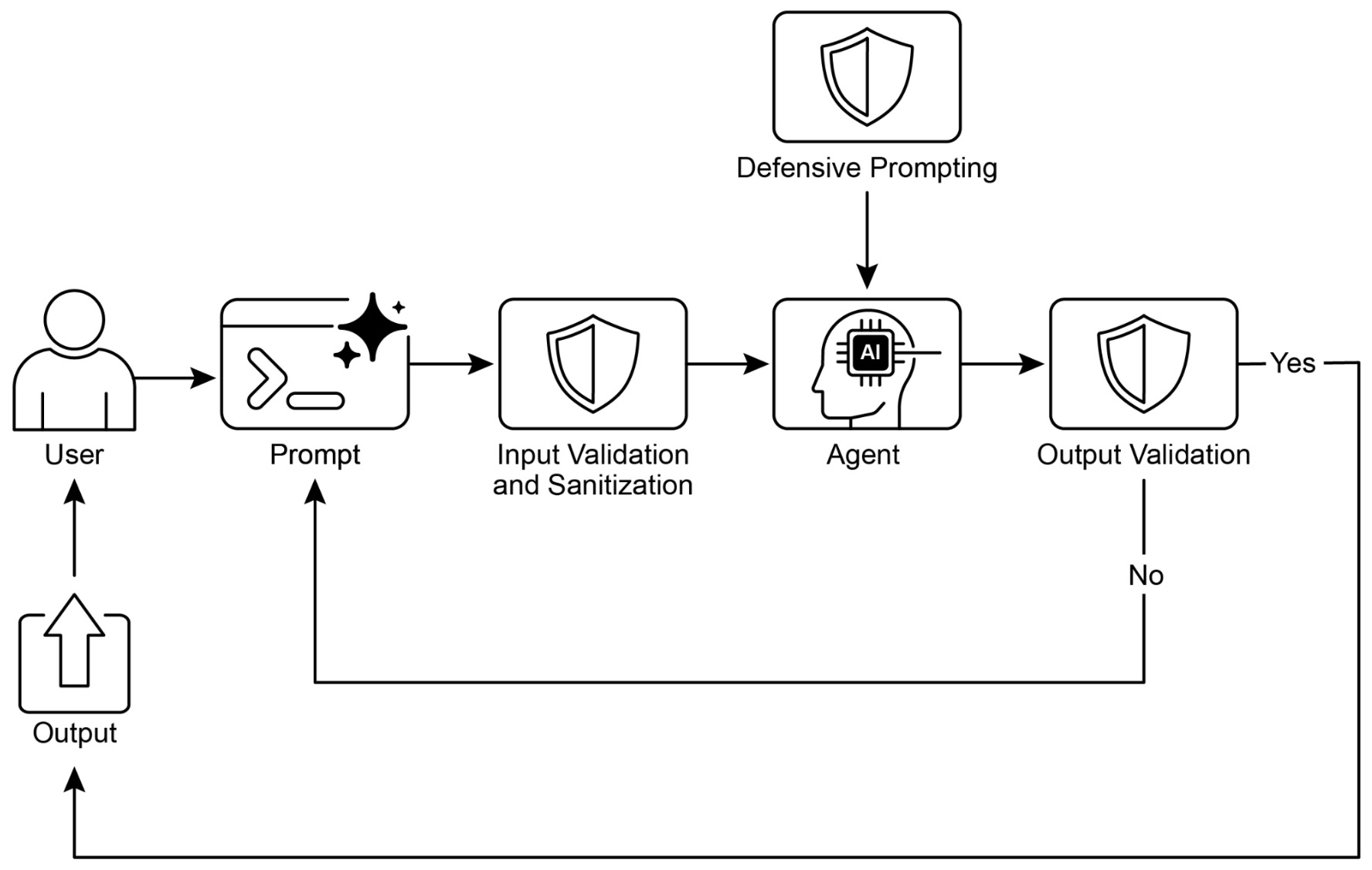
- This layered approach ensures comprehensive safety coverage.
Guardrails and other patterns
-
Guardrails interact with several other patterns:
- With tool use: Restricts unsafe tool interactions
- With planning: Ensures plans adhere to constraints
- With monitoring: Detects violations in real time
- With human-in-the-loop: Escalates critical decisions
-
This integration ensures that safety is embedded throughout the system.
Failure modes
-
Improperly designed guardrails can introduce issues:
- Over-restriction: Blocking useful or valid actions
- Under-restriction: Failing to prevent harmful behavior
- False positives/negatives: Incorrect validation decisions
-
Latency: Additional checks slow down execution
-
To mitigate these challenges:
- Define clear and balanced constraints
- Use layered guardrails for redundancy
- Continuously evaluate and refine rules
- Combine automated checks with human oversight
Evaluation
Core Idea
-
Evaluation is the foundational layer that transforms agentic systems from experimental prototypes into reliable, production-ready systems. As these systems evolve from simple prompt-response interactions into complex, multi-step architectures capable of reasoning, planning, acting, and adapting, the need for structured and quantitative assessment becomes essential. Without evaluation, there is no reliable way to determine whether these increasingly sophisticated behaviors are effective, correct, or aligned with intended goals.
-
At its core, evaluation provides the mechanism for turning agent behavior into measurable signals. It enables developers to validate correctness, detect failure modes, and systematically improve performance. Rather than relying on intuition or manual inspection—which quickly becomes infeasible as system complexity grows—evaluation introduces a structured framework for assessing outputs across key dimensions such as accuracy, quality, efficiency, and robustness.
-
From a systems perspective, evaluation acts as the feedback backbone that connects execution to learning. It creates visibility into how an agent behaves across different stages of its operation, making it possible to trace decisions, identify breakdowns, and understand outcomes. This visibility also enables comparability between different system designs, prompts, or models, allowing teams to make informed decisions about trade-offs and optimizations. In turn, this supports continuous improvement through iterative refinement and reinforces accountability in production environments where reliability and correctness are critical.
-
Importantly, evaluation is not just diagnostic—it is operational. The signals it generates can feed directly into monitoring systems, trigger corrective actions, and inform future updates. In this way, evaluation becomes deeply integrated into the lifecycle of an agentic system, guiding reflection, validating planning, informing learning, and enforcing guardrails.
-
As a cross-cutting concern, evaluation touches nearly every aspect of agent design. It is the mechanism that provides visibility, turns performance into insight, and enables systems to be measured, compared, and optimized systematically. Without it, agentic systems lack the ability to understand or improve their own behavior, making evaluation not just a supporting component, but a fundamental requirement for building robust, scalable, and trustworthy intelligent systems.
Why evaluation is needed
-
Without proper evaluation, agentic systems face several issues:
- Inability to measure progress or success
- Difficulty identifying failure modes
- Lack of feedback for learning and adaptation
- Poor comparability between system versions
-
Evaluation transforms system behavior into measurable outcomes, enabling continuous improvement.
-
This aligns with empirical evaluation practices in machine learning, where models are assessed using defined metrics. For example, benchmarks in NLP have been critical for tracking progress across models and techniques.
Defining evaluation metrics
-
Metrics depend on the task and system goals. Common categories include:
-
Accuracy metrics:
- Correctness of outputs
- Factual consistency
- Task completion rate
-
Quality metrics:
- Coherence and clarity
- Relevance
- Completeness
-
Efficiency metrics:
- Latency
- Resource usage
- Cost
-
Robustness metrics:
- Performance under noisy or adversarial inputs
- Stability across different scenarios
-
-
These metrics provide a multi-dimensional view of system performance.
The evaluation function
-
Evaluation can be formalized as:
\[M = \mathcal{E}(y, y^*)\]-
where:
- \(y\) is the system output
- \(y^*\) is the ground truth or expected output
- \(\mathcal{E}\) is the evaluation function
-
-
In cases where ground truth is unavailable, proxy metrics or human evaluation may be used.
Types of evaluation
-
Evaluation can be performed at different stages and levels, as follows:
-
Offline evaluation:
- Conducted using predefined datasets
- Useful for benchmarking
-
Online evaluation:
- Conducted during deployment
- Reflects real-world performance
-
Human evaluation:
- Involves human judgment
- Useful for subjective criteria
-
Automated evaluation:
- Uses metrics or models to score outputs
- Scalable and consistent
-
-
These approaches are often combined for comprehensive assessment.
Example
-
Consider an agent generating summaries:
- Accuracy is measured by comparing against reference summaries
- Quality is evaluated using coherence and readability metrics
- Efficiency is measured by latency and cost
-
By tracking these metrics, the system can be improved iteratively.
Implementation
- Evaluation can be integrated into workflows using scoring functions.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
def evaluate_response(response, reference):
return "correct" if response.strip() == reference.strip() else "incorrect"
response = llm.invoke("What is 2 + 2?")
score = evaluate_response(response.content, "4")
print("Score:", score)
- This example demonstrates a simple evaluation mechanism.
Evaluation loop
-
Evaluation is often part of a continuous loop:
- Generate output
- Measure performance
- Analyze results
- Improve system
-
The following figure shows evaluation and monitoring of agents, with an continuous evaluation loop where outputs are measured against metrics and used to guide system improvements.
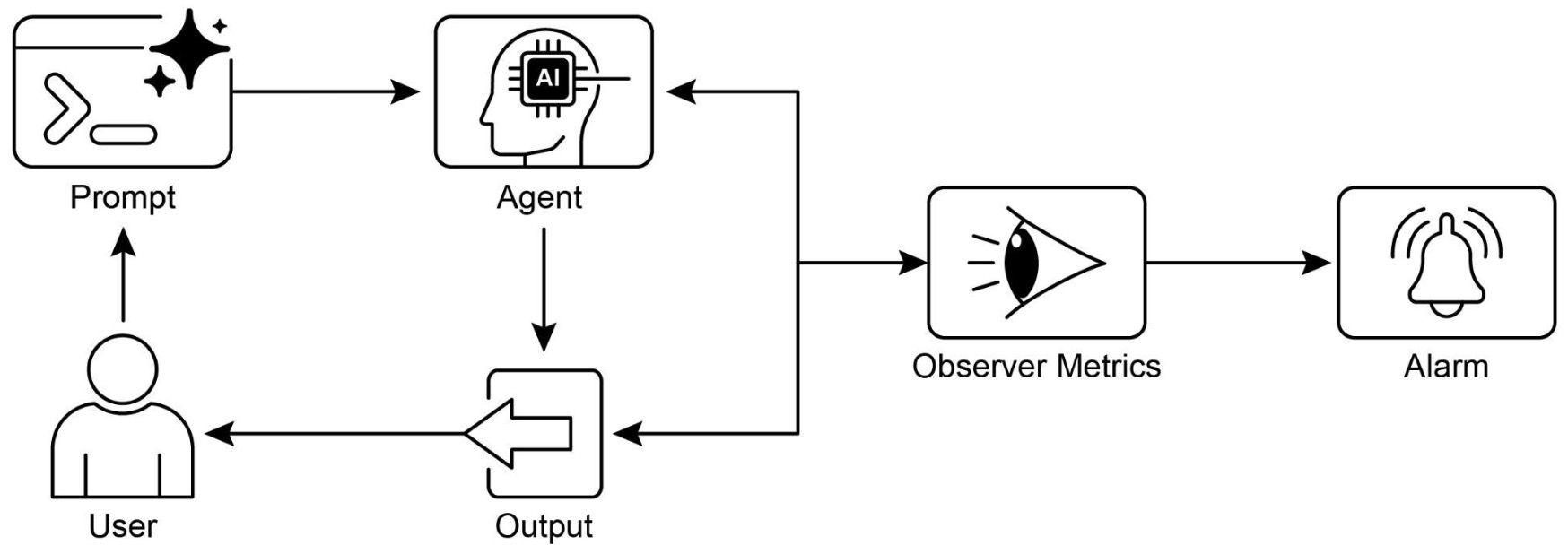
- This loop is central to maintaining and improving system quality.
Evaluation in agentic systems
-
Evaluation interacts with multiple patterns:
- With learning: Provides signals for updating behavior
- With monitoring: Tracks real-time performance
- With guardrails: Ensures compliance with constraints
- With planning: Evaluates plan effectiveness
-
This integration ensures that evaluation is not isolated but embedded throughout the system lifecycle.
Failure modes
-
Evaluation introduces its own challenges:
- Metric misalignment: Metrics may not reflect true objectives
- Incomplete coverage: Not all scenarios are evaluated
- Bias in evaluation: Metrics may favor certain outputs
- Over-optimization: System may optimize for metrics rather than goals
-
To mitigate these issues:
- Use multiple complementary metrics
- Include human evaluation where needed
- Continuously update evaluation criteria
- Monitor for unintended consequences
References
Foundational Techniques
- ReAct: Synergizing Reasoning and Acting in Language Models by Yao et al. (2022)
- Toolformer: Language Models Can Teach Themselves to Use Tools by Schick et al. (2023)
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Lewis et al. (2020)
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models by Wei et al. (2022)
- Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Wang et al. (2023)
Reflection, Self-Improvement, and Learning
- Self-Refine: Iterative Refinement with Self-Feedback by Madaan et al. (2023)
- Deep Reinforcement Learning by Mnih et al. (2015)
- Training Language Models to Follow Instructions with Human Feedback (InstructGPT) by Ouyang et al. (2022)
- Deep Reinforcement Learning from Human Preferences by Christiano et al. (2017)
Agentic Design Patterns Blogs/Books
- Agentic Design Patterns: A Hands-On Guide to Building Intelligent Systems by Antonio Gullí
- The Different Agentic Patterns by Damien Benveniste
Multi-Agent Systems
- Generative Agents: Interactive Simulacra of Human Behavior by Park et al. (2023)
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity by Fedus et al. (2021)
- Deep Ensembles: A Loss Landscape Perspective by Lakshminarayanan et al. (2017)
Safety, Alignment, and Guardrails
- Constitutional AI: Harmlessness from AI Feedback by Bai et al. (2022)
Developer Frameworks and Agent Infrastructure
Production Agent Architectures and Design Guidance
- Building Agents - OpenAI Developers Guide
- Evaluation Best Practices - OpenAI API
- A Practical Guide to Building AI Agents - OpenAI
- Choose a Design Pattern for Your Agentic AI System - Google Cloud
- Choose Your Agentic AI Architecture Components - Google Cloud
Enterprise and Platform Implementations
Citation
If you found our work useful, please cite it as:
@article{Chadha2020DistilledAgenticDesignPatterns,
title = {Agentic Design Patterns},
author = {Chadha, Aman},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}