Primers • Agent Skills
- Overview
- Skill Structure
- Triggering and Loading
- Writing Good Skills
- Add Missing Knowledge
- Start from Real Work
- Scope Tightly
- Write Procedures
- Output Contracts
- Explain the Reason behind the Rule
- Keep the Main Body Compact (and Push Depth into On-demand Files)
- Bundle Repeated Work into Scripts
- Describe User Intent
- Evaluate the Skill as a System
- Separate Trigger and Execution
- Writing Checklist
- Evaluation and Iteration
- Why Evaluation is Essential
- Two Evaluation Loops: Trigger Quality and Output Quality
- Realistic Evaluations
- Why Baselines Matter
- Assertions: Making Quality Testable
- Evidence-Based Grading
- Scripts and Judges
- Blind Comparison
- Aggregate Metrics
- Pattern Analysis
- Inner and Outside Validation Loops
- Trigger Evaluations
- Avoid Overfitting
- Codify Successful Runs
- Iteration Loop
- Workspace Bootstrap and Coordination
- Persistent Workspace Context
- Layered Bootstrap Architecture
- Relationship to Skills
- Multi-agent Coordination
AGENTS.md: Workspace-Level CoordinationSOUL.md: Personality and Behavioral ConstraintsTOOLS.md: Environment and Operational KnowledgeIDENTITY.md: Persistent Agent Identity and Role ContextUSER.md: Persistent User Preferences and Interaction ContextBOOTSTRAP.md: Runtime Initialization and Session StartupHEARTBEAT.md: Runtime State and Operational Continuity
- Implementation and Integration
- From Format to Runtime
- Startup Discovery
- Directory Conventions
- Scanning Rules
- Parsing
SKILL.md - Lenient Parsing
- Building the Catalog
- Catalog Placement
- Activation Paths
- Path Resolution
- Filtering and Permissions
- Precedence
- Trust and Injection Risk
- Runtime Environments
- Context Management
- Why It Works
- Key Implementation Lesson
- OpenClaw
- Advantages of Agent Skills: Knowledge Gaps and Domain Adaptation
- The Core Problem
- Skills: Domain Adaptation for Agents
- Why Procedural Knowledge Matters
- Skills Close the “Knowledge Half-life” Problem
- Skills as Organizational Memory
- Skills Reduce Always-on Context
- Skills Strengthen the Reasoning and Action Connection
- Skills Are a More Practical Unit of Sharing (than Agent Rewrites)
- Why Skills are Especially Valuable in Coding Workflows
- The Ecosystem Implication: Open Skill Infrastructure
- Limitations of Skills
- Key Significance
- Key Takeaways: When to Build a Skill (and When Not To)
- Example: A Complete Skill Workspace
- References
- Citation
Overview
Definition
- Agent Skills are best understood as small, portable capability packages for agents: each skill is a directory centered on a
SKILL.mdfile, with optional scripts, references, and assets that an agent can load when needed rather than carrying all of that guidance in context all the time. - Skills are described as open, file-based packages for reusable instructions, resources, and domain-specific know-how, making them auditable, versionable, and portable through ordinary developer workflows such as Git and shared folders.
- In other words, a skill is not a separate model, and not merely a tool call, but a structured packet of procedural knowledge that can include executable helpers and reference material.
Why Skills Exist
- The motivating problem is that strong models are often capable but underspecified: they can reason, code, and call tools, yet they still lack the task-local expertise, organizational conventions, and up-to-date procedural guidance needed for reliable work in real settings. This is exactly the gap that skills are designed to fill. In modern agent architectures, the model increasingly behaves like a general-purpose executor over code, files, and tools, while the missing ingredient is expert workflow knowledge that tells it what good execution looks like in a particular domain.
- The best way to understand agent skills is not as a trick for making models obey better, but as a disciplined way of packaging expertise so that agents can activate it only when it matters. Their power comes from a combination of simplicity and systems fit: they are just files, but they align with how real agent runtimes need to manage context, tools, procedure, and organizational knowledge.
- Closing the knowledge gap with agent skills frames this as the mismatch between static model knowledge and rapidly changing software practice, while Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Lewis et al. (2020) is relevant because it established the broader principle that parametric knowledge alone is often insufficient, and external context improves factual performance on knowledge-intensive tasks.
Procedural Memory
- A useful mental model is that tools provide actions, while skills provide situated procedure. A calculator API, shell, browser, or Python runtime tells the agent what it can do; a skill tells the agent when to do it, in what order, with what defaults, what edge cases to watch for, and what output standard to meet. This makes skills closer to procedural memory than to raw capability exposure. That framing fits naturally with Toolformer: Language Models Can Teach Themselves to Use Tools by Schick et al. (2023), which shows that language models benefit when they learn when and how to use tools, and with Gorilla: Large Language Model Connected with Massive APIs by Patil et al. (2023), which shows that access to tool documentation and retrieval improves API-call reliability under changing interfaces. Agent Skills occupy this layer of guidance between generic reasoning and concrete action execution.
Progressive Disclosure
- The defining systems idea behind Agent Skills is progressive disclosure. At startup, the agent loads only a compact catalog, typically just the skill name and description. It then activates the full
SKILL.mdonly when the current task matches that description, and it loads heavier resources such as scripts or reference docs only if the instructions point to them. This is essentially a three-tier loading strategy in which catalog, instructions, and resources are kept as separate context layers, which is what lets an agent have many installed skills without paying the full token cost upfront. - Conceptually, this selective loading aligns with the broader agent pattern in ReAct: Synergizing Reasoning and Acting in Language Models by Yao et al. (2022), where effective agents interleave reasoning and external action instead of front-loading all information into one monolithic prompt.
Context Efficiency
- The value proposition can be expressed as a simple context-budget argument. If an agent has \(n\) installed skills, and each full skill body would cost \(s_i\) tokens if loaded eagerly, then naive loading incurs
-
With progressive disclosure, the agent pays the catalog cost for all skills plus the full cost only for the activated subset \(A\):
\[C_{\text{progressive}} = \sum_{i=1}^{n} m_i + \sum_{j \in A} s_j + \sum_{k \in R} r_k\]- where \(m_i\) is compact metadata and \(r_k\) are only the resource files actually opened. Since typically \(m_i \ll s_i\) and \(\mid A \mid \ll n\), the expected context footprint is dramatically smaller, which is exactly why the format scales to large skill libraries while still allowing rich specialization on demand. The always-visible layer should be kept tiny, the loaded instruction body should be bounded, while
SKILL.mdshould be concise and pushing detailed material into on-demand references.
- where \(m_i\) is compact metadata and \(r_k\) are only the resource files actually opened. Since typically \(m_i \ll s_i\) and \(\mid A \mid \ll n\), the expected context footprint is dramatically smaller, which is exactly why the format scales to large skill libraries while still allowing rich specialization on demand. The always-visible layer should be kept tiny, the loaded instruction body should be bounded, while
Why It Matters
- The deeper significance of agent skills is architectural. They suggest that the path to better agents is not only bigger models or more tools, but cleaner separation between a general-purpose execution substrate and a portable layer of expert procedure. In that picture, one agent runtime can be reused across many domains, while skills encode the domain adaptation layer. That is why the format stresses portability, interoperability, and shareability across products and teams rather than binding knowledge to one vendor-specific harness. This matters more so in fast-moving domains where documentation and best practices change faster than model weights can.
Skill Structure
Directory Structure
- An agent skill is deliberately defined as a directory with a required
SKILL.mdfile and optional supporting folders such asscripts/,references/, andassets/. That design choice matters because it moves a skill away from being a single flat prompt and toward being a small, inspectable software package. In practice, this means a skill can combine instructions, executable helpers, and reference material in one portable unit that works with ordinary developer tooling such as version control and file sharing. This directory structure is the minimum contract for interoperability across compatible clients.
skill-name/
├── SKILL.md # Required: metadata + instructions
├── scripts/ # Optional: executable helpers
├── references/ # Optional: docs, notes, source material
├── assets/ # Optional: templates and static resources
└── ... # Optional: any additional files or folders
Why Files Matter
- The directory model solves a practical agent-design problem: good procedural knowledge is rarely just prose. Reliable execution often requires instructions plus examples, scripts, environment notes, and deeper references that should not all be loaded at once. By storing these as files, the skill becomes self-documenting, auditable, and incrementally loadable. This logic mirrors the broader tool-use literature, where language models become more dependable when they can combine reasoning with structured external artifacts rather than relying only on latent memory.
- Toolformer: Language Models Can Teach Themselves to Use Tools by Schick et al. (2023) is relevant because it shows that models improve when tool use is made explicit, while Gorilla: Large Language Model Connected with Massive APIs by Patil et al. (2023) matters here because it shows that attaching external specifications and API guidance improves performance under changing interfaces. The Agent Skills format applies that same principle at the workflow level.
SKILL.md: The Skill’s Control Plane
- The center of the skill is
SKILL.md, which contains YAML frontmatter followed by Markdown instructions. Conceptually, the frontmatter serves as the routing and compatibility layer, while the Markdown body serves as the operational layer. This separation is elegant because the agent can use the frontmatter for discovery and activation, but reserve the body for actual task execution. - The format specification explicitly requires YAML frontmatter plus Markdown content, making
SKILL.mdboth machine-readable enough for indexing and human-readable enough for review and editing.
---
name: skill-name
description: A description of what this skill does and when to use it.
license: Apache-2.0
compatibility: Requires Python 3.11+ and local file access.
metadata:
author: example-org
version: "1.0"
---
# Skill Title
## When to use this skill
Use this skill when...
## Steps
1. Inspect the input.
2. Run the preferred method.
3. Validate the result.
## Available scripts
- `scripts/validate.py` - checks output structure
Required Frontmatter Fields: name and description
-
Only two frontmatter fields are required, but they carry disproportionate architectural weight:
-
The
namefield is the stable identifier for the skill. It must be short, lowercase, hyphenated if needed, and constrained to a narrow format so clients can reliably discover, validate, and reference it. The specification states that the name must be at most 64 characters, use lowercase letters, numbers, and hyphens, avoid leading and trailing hyphens, and match the parent directory name. Those constraints are not cosmetic. They reduce ambiguity for discovery, activation, packaging, and filesystem interoperability. -
The
descriptionfield is even more consequential because it is the primary trigger surface for model-side activation. Agents typically see the description before they see anything else in the skill, and they use it to decide whether to load the full instructions. Description should explain both what the skill does and when to use it, with activation accuracy being given heavy emphasis. A poorly written description either fails to trigger when needed or triggers too often and wastes context.
-
Optional Frontmatter Fields
-
Beyond
nameanddescription, the format supports optional fields such aslicense,compatibility,metadata, andallowed-tools. Each exists to preserve portability without overcomplicating the core standard. -
licensesupports redistribution and governance, which matters once skills start being shared across teams or open ecosystems.compatibilityrecords environment requirements such as intended client, system dependencies, or network assumptions, which is especially useful when the same skill may be installed into different runtimes.metadataprovides extensibility for authors and tooling without bloating the core schema.allowed-tools, marked experimental, hints at a future in which skills may declare constrained tool envelopes rather than relying only on informal instruction. These fields let the format remain lightweight while still supporting operational realism.
Instruction Body
-
After frontmatter comes the Markdown body, which is where the actual expertise lives. Importantly, the format does not over-constrain this section. There is no mandatory section taxonomy, but the guidance consistently favors clear procedural writing: when to use the skill, what defaults to apply, what steps to execute, what output format to produce, and what exceptions or edge cases to handle. Skills typically work best when they encode what the agent would otherwise get wrong, especially project-specific conventions, fragile workflows, and non-obvious edge cases rather than generic background knowledge.
-
A useful way to think about the body is as an executable policy document. It does not execute directly, but it changes the policy by which the agent chooses tools, applies defaults, checks outputs, and handles ambiguity. That idea resonates with ReAct: Synergizing Reasoning and Acting in Language Models by Yao et al. (2022), which shows that agents work better when reasoning and action are interleaved, because a skill body effectively shapes that interleaving for a specific domain.
scripts/: Making Repeated Behavior Reusable
- The
scripts/directory is where a skill graduates from guidance only to guidance plus operational leverage. While not every action needs a bundled script, recurring, fragile, or verbose command sequences often benefit from one. This is especially true when the same helper logic would otherwise be rewritten across many runs. Bundled scripts reduce variance, speed up execution, and make behavior more testable. AgentSkills: Using scripts in skills presents this as a core authoring pattern and explicitly covers one-off commands, self-contained scripts, and agent-oriented script interfaces.
scripts/
├── validate.py # Checks output structure or schema
├── transform.sh # Runs a fixed transformation pipeline
└── report_template.py # Generates a standardized artifact
- The scripting guidance is notable because it is shaped around agent ergonomics rather than human convenience. Scripts should avoid interactive prompts, expose a clear
--help, return structured outputs such as JSON or CSV when possible, and emit helpful error messages that allow the agent to recover on the next attempt. Those recommendations are important because an agent reads stdout and stderr as part of its reasoning loop. In other words, script interface design becomes part of prompt design.
references/: Keeping Context off the Main Path
- The
references/directory exists to solve a context management problem. Some skills need detailed reference content such as API notes, failure catalogs, style guides, or specification extracts, but that material should not be injected into the mainSKILL.mdbody by default. Instead, the core instructions should tell the agent when to load a specific reference file. This preserves the economy of progressive disclosure while still allowing rich depth on demand. - The authoring guidance explicitly recommends keeping the main skill concise and moving detailed material into reference files with clear conditional loading instructions.
references/
├── api-notes.md # Current API constraints and examples
├── failure-modes.md # Common errors and recovery strategies
└── style-guide.md # Formatting and output conventions
- There is an implicit retrieval pattern here. Instead of performing external retrieval over an unbounded corpus, the agent is doing bounded retrieval over a curated local package. That makes the skill more predictable and easier to validate than open-ended browsing. This bounded-reference idea is closely related to the logic behind Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Lewis et al. (2020), where selectively consulting external documents improves task performance without requiring all knowledge to live in the model weights.
assets/: Templates, Exemplars, and Non-code resources
- The
assets/directory is the least discussed but still important part of the anatomy. It is the natural home for templates, example output skeletons, boilerplate files, or static resources that shape final deliverables. - While scripts help the agent do work, assets help the agent produce work in the expected form. This can be especially valuable for report generation, presentation building, code scaffolding, or any task where consistent output format matters as much as reasoning quality.
- The core format documentation lists assets alongside scripts and references as first-class optional skill resources, reinforcing that skills are intended to package not only know-how but also reusable artifacts.
assets/
├── report-template.md # Reusable report shell
├── slides-theme.json # Preset presentation styling
└── example-output.txt # Sample final artifact
Relative Paths
- An understated but important part of the specification is that file references inside a skill should use relative paths from the skill root. This is not merely a convenience. Relative addressing preserves portability across machines, projects, and compatible clients.
- A skill that depends on absolute paths is brittle; a skill that treats itself as a self-contained directory is portable by construction. The specification also recommends keeping reference chains shallow, which reduces both agent confusion and context sprawl.
Layered Design
-
Taken together, the anatomy of a skill can be viewed as a layered system:
-
At the top is the discovery layer, driven by
nameanddescription. -
In the middle is the procedural layer, driven by the Markdown body of
SKILL.md. -
Below that is the operational layer, driven by
scripts/,references/, andassets/.
-
-
This hierarchy is what makes the format economical. A large amount of expertise can be packaged in a skill without requiring all of it to be loaded at all times. The result is a design in which structure directly supports activation accuracy, context efficiency, and operational reliability.
Formal View
-
One concise way to model this is to treat a skill \(S\) as a tuple
\[S = \big(M, I, R\big)\]- where \(M\) is metadata, \(I\) is the main instruction body, and \(R\) is the set of auxiliary resources. Under progressive disclosure, activation is a staged loading process rather than a single prompt expansion:
- This is the core architectural idea behind the format: package richly, load selectively, and keep the always-on surface minimal.
Triggering and Loading
Triggering
- In a skills-based agent, the most important interface is not the script, nor the asset, nor even the detailed workflow in the body. It is the trigger boundary: the point at which the agent decides that a user request is better handled with specialized procedure than with its general-purpose tools alone.
- The
descriptionfield serves as the primary mechanism for determining whether a skill should be loaded for a task. In practical terms, it acts as the routing layer for procedural memory, signaling when specialized instructions should be brought into context. Through this mechanism, skills function as on-demand expertise packages rather than always-on prompts.
Three-Stage Loading
- The runtime lifecycle follows a three-stage progression: discovery, activation, and execution. During discovery, the agent loads only lightweight metadata, typically the skill name and description. During activation, it loads the full
SKILL.mdbody for the relevant skill. -
During execution, it may then open referenced files or run bundled scripts as required by those instructions. This staged structure is the operational meaning of progressive disclosure, and it is what allows a large skill library to remain cheap at session start while still making deep expertise available on demand. The implementation guidance quantifies this as a catalog tier, an instruction tier, and a resource tier, with only the first tier loaded universally at session start.
-
A compact formalization is:
\(\text{State}\)q\(= \begin{cases} \mathcal{C} & \text{before a relevant task is recognized} \\ \mathcal{C} \cup I_s & \text{after skill } s \text{ is activated} \\ \mathcal{C} \cup I_s \cup R_s' & \text{after execution loads needed resources} \end{cases}\)
- where \(\mathcal{C}\) is the catalog of available skills, \(I_s\) is the instruction body of skill \(s\), and \(R_s' \subseteq R_s\) is the subset of referenced resources actually needed for the task. The architectural point is that the agent pays only for the relevant suffix of this expansion, not for every installed skill up front.
Skill Discovery
- Skill discovery happens at session startup. A compatible client scans one or more skill directories, identifies subdirectories containing a file named exactly
SKILL.md, parses those files, and constructs an internal catalog. - At least two local-agent scopes are recommended: project-level skills associated with the current repository and user-level skills available across projects.
-
Cross-client interoperability can be obtained by recommending the
.agents/skills/convention, while noting that some clients also scan pragmatic compatibility locations. This skill discovery step is what turns a static filesystem into an agent-visible capability graph. More concretely, local agents typically scan both client-specific paths and cross-client paths within each scope, such as<project>/.<client>/skills/and<project>/.agents/skills/at the project level, plus~/.<client>/skills/and~/.agents/skills/at the user level. Some implementations also scan.claude/skills/for compatibility, may walk ancestor directories up to the git root for monorepos, and can additionally support XDG config directories or user-configured search paths. Within any of these roots, the agent should only treat subdirectories containing an exactSKILL.mdfile as skills, while ignoring unrelated files likeREADME.md. It is recommended to have practical scanning rules such as skipping directories like.git/andnode_modules/, optionally respecting.gitignore, and setting reasonable depth and directory-count bounds so discovery stays predictable even in large trees. - The design logic here is subtle but important. Skill discovery is not execution. The agent is not yet following the skill, and it has not consumed the skill’s detailed instructions. It has merely indexed a small set of capability descriptions so that later routing decisions become possible. In modern agent terms, this is closer to tool enumeration than to prompt expansion. That is why the catalog can remain compact even with dozens of installed skills. Discovery only loads lightweight metadata first, following the broader progressive-disclosure model in which the agent sees just the skill name and description at startup, reads the full
SKILL.mdonly when the skill is activated, and loads deeper resources such as scripts, references, or assets only if the instructions call for them. This is also why deterministic scanning and precedence rules matter: when two skills share a name, project-level skills conventionally override user-level ones, so the catalog reflects a stable, resolved view of what is actually available to the model rather than a noisy dump of everything on disk.
Parsing and Validation
- Once a candidate
SKILL.mdis found, the client must parse two things: frontmatter and body. The frontmatter yields thenameanddescription, plus any optional fields. The body yields the full instruction content to be loaded only at activation time or cached for faster later access. The implementation guidance also recommends lenient validation in practice: cosmetic issues such as a name mismatch or excessive length may warrant warnings rather than outright rejection, but missing or empty descriptions are serious because they break the disclosure mechanism itself. - AgentSkills: How to add skills support to your agent and AgentSkills: Specification both distinguish between strict schema expectations and practical compatibility behavior.
- This is one place where skills reveal themselves as infrastructure rather than prompt craft. Reliable activation depends on the client’s ability to normalize, parse, and store skill metadata consistently. If discovery is noisy or brittle, the skill library becomes operationally unstable even if the skills themselves are well written. That is why the deterministic precedence rules for collisions and diagnostics for malformed files.
Skill Catalog
- After discovery, the client discloses the catalog to the model in a structured form. The recommended catalog contains at least the skill
nameanddescription, and may also include a location or path hint if the model can later read the skill directly from disk. - The important point is that the model does not need the full instructions at this stage. It needs only enough information to answer the question, “Do I have a specialized procedure that matches the user’s intent?” This catalog may be inserted into the system prompt or attached to a dedicated activation-tool description, and the per-skill token cost can remain small enough for a reasonably sized library to stay economical.
-
AgentSkills: How to add skills support to your agent describes both placement patterns and the approximate token footprint of each entry. One way to express the decision rule is:
\[s^* = \arg\max_{s \in \mathcal{S}} \mathrm{Match}(q, d_s)\]- where \(q\) is the user request, \(\mathcal{S}\) is the set of discovered skills, and \(d_s\) is the description for skill \(s\). If no score exceeds an implicit threshold, the agent proceeds without activating a skill. The exact matching function is not standardized, but the design implication is clear: the quality of routing depends overwhelmingly on the informativeness and boundary precision of \(d_s\).
Why Descriptions Matter
-
The description carries the entire burden of triggering. That statement is more than rhetorical. At the moment of activation, the model has not yet seen the body of the skill, so it cannot rely on the later workflow, examples, or scripts to decide whether the skill is relevant. This is why descriptions must be written around user intent rather than implementation detail. A user says “my manager needs a chart from this data file,” not “invoke the CSV-analysis workflow.” Therefore a good description maps latent task intent to explicit procedural applicability.
-
Optimizing skill descriptions recommends imperative phrasing, focus on user intent, concise scope, and explicit mention of contexts where the skill applies even when the user does not name the domain directly.
-
This is tightly aligned with broader findings in agent research. ReAct by Yao et al. (2022) matters here because it shows that agent quality improves when reasoning and action are interleaved around task-relevant state rather than generated in a single undifferentiated pass, and Toolformer by Schick et al. (2023) matters because it shows that deciding when to call an external capability is itself a learned competency rather than a trivial side effect of general language modeling. Agent skills turn that decision into an explicit metadata design problem.
When Not to Trigger
-
An important nuance in that lexical match is not enough. Agents typically consult skills only when the task seems to require knowledge or procedure beyond what the base agent can already do. A simple one-step request may be answered directly even if it shares words with a description, because the skill would add little value. By contrast, tasks involving specialized workflows, unfamiliar APIs, domain constraints, or uncommon output formats are where a skill makes the largest difference. This means activation is not binary keyword matching but a judgment about whether specialized procedure is warranted.
-
That nuance can be written as a two-factor condition:
\(\text{Activate}(s, q) = 1 \quad \text{if and only if} \quad \mathrm{Match}(q, d_s) \ge \tau \land \mathrm{NeedSpecialization}\)q\(= 1\)
- The first term captures description match, and the second captures whether the task actually benefits from a specialized skill. This explains why over-broad descriptions are dangerous: they increase apparent match without guaranteeing true need.
Activation
-
Once the model determines that a skill is relevant, it loads the full
SKILL.mdbody into context. At this point, the skill changes from a latent option into active procedure. The model can now follow numbered steps, apply format constraints, consult in-skill references, and invoke bundled scripts exactly as instructed. This can be demonstrated cleanly with a dice-roll example: the agent first notices that “roll a d20” matches the dice-rolling description, then loads the short body that instructs it to run a terminal command and substitute the requested number of sides. -
This is where the design choice to keep
SKILL.mdunder a moderate size becomes operationally important. The body is not free once loaded. It enters the same context window that already contains the conversation, system instructions, tool descriptions, and any other active skill content. The best-practices guidance therefore recommends keeping the core instructions compact and moving detailed material into on-demand references. AgentSkills: Best practices for skill creators explicitly recommends a concise core body, roughly under 5,000 tokens, with deeper materials deferred to references.
Resource Loading
- Even activation is not the end of loading. A skill may instruct the agent to read a reference file only under certain conditions, or to run a script only after a validation step. This is the final stage of progressive disclosure: the agent loads resources conditionally, not preemptively. For example, a skill may say to consult
references/api-errors.mdonly if an API returns a non-200 error, or to runscripts/validate.pybefore finalizing output. This conditionality matters because it preserves context budget and sharpens operational control. AgentSkills: Best practices for skill creators and AgentSkills: Using scripts in skills both recommend explicit conditional loading and reusable validators rather than dumping every auxiliary detail into the main body. - This staged retrieval pattern is conceptually adjacent to Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Lewis et al. (2020), because both systems improve performance by consulting external, task-relevant context only when needed instead of expecting the model to carry all relevant knowledge in parameters or always-on prompt state. The difference is that agent skills perform bounded, curated retrieval over a local procedural package rather than over an open document corpus.
Cloud and Sandboxed Agents
- The loading logic is stable across deployment settings, but discovery changes when the agent does not have direct access to the user’s local filesystem. In a cloud-hosted or sandboxed environment, project-level skills may still travel with a cloned repository, but user-level or organization-level skills must usually be provisioned externally through a registry, uploaded package, bundled asset, or configuration repository.
- The key point is that once the skill becomes available to the runtime, the same parse-disclose-activate cycle applies. The implementation guidance is explicit on this separation between availability and lifecycle.
Trust and Precedence
- Triggering is not purely semantic. It is also shaped by precedence and trust. When two skills share the same name, deterministic precedence is recommended, with project-level skills conventionally overriding user-level skills. At the same time, project-level skills may come from untrusted repositories, so some clients may gate them behind explicit trust checks to avoid silently importing hostile instructions into context.
- This is a crucial reminder that skill loading is a security-sensitive form of prompt injection surface, just with better packaging.
Routing Quality
-
A skill can have excellent internal instructions and still be operationally weak if it does not trigger at the right times. Trigger performance should be evaluated empirically rather than only reasoned about intuitively. Sets of should-trigger and should-not-trigger queries should be maintained, running them multiple times because model behavior is nondeterministic, and measuring trigger rate rather than assuming one-off success is meaningful. It also recommends train-validation splits to avoid overfitting the description to a narrow prompt set. In other words, routing itself must be evaluated like a model component.
-
One useful metric is:
\[\mathrm{TriggerRate}(s, Q) = \frac{1}{|Q|} \sum_{q \in Q} \mathbf{1}{\{\text{skill } s \text{ activated on } q\}}\]- but in practice this should be tracked separately for positive and negative query sets, since the real goal is high recall on genuine matches and low false-positive activation on near misses. Should-trigger and should-not-trigger queries are effectively treated as separate evaluation targets.
Key Takeaway
- The central lesson of skill triggering is that metadata is not decoration. In a progressively disclosed system, metadata is policy. Discovery determines what exists, descriptions determine what routes, activation determines what becomes procedural law for the current task, and conditional resource loading determines how much depth is brought in afterward. The entire skill system therefore stands or falls on clean routing boundaries. The better the routing, the more skills can remain both numerous and lightweight.
Writing Good Skills
Add Missing Knowledge
-
A strong skill is not a generic explainer. It is a compact package of missing expertise. Broad, model-native advice such as “handle errors carefully” or “follow best practices” should be avoided because such phrasing consumes context without adding task-specific control; rather, what’s useful is the concrete sequence, defaults, failure cases, and project conventions that the base model would otherwise miss. That is why effective skills are typically extracted from real task execution or synthesized from project artifacts such as runbooks, issue history, reviewer comments, and failure reports rather than from generic documentation.
-
A good mental model is that a skill should maximize marginal information value per token. If \(K_m\) denotes what the model already handles reliably and \(K_s\) denotes the information included in the skill, then the useful part of the skill is not \(K_s\) itself but the difference:
- The higher the ratio of actionable novelty to total tokens, the more likely the skill is to improve execution rather than distract it. This principle is implicit in the guidance to “add what the agent lacks, omit what it knows,” and it also aligns with Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Lewis et al. (2020), which is relevant because it shows that supplementing model knowledge with targeted external context improves knowledge-intensive performance more than relying on parametric memory alone.
Start from Real Work
-
The most reliable way to author a skill is to perform a real task with an agent, observe where the process succeeds or fails, and then distill the reusable pattern. Only the parts that mattered during actual execution should be extracted: the successful step order, the corrections a human had to make, the input and output formats that mattered, and the domain context the model did not initially know. This matters because real tasks reveal friction points that synthetic “ideal” instructions often omit.
-
The aforementioned recommendation is consistent with the broader agent literature. ReAct by Yao et al. (2022) is relevant here because it demonstrates that strong agent behavior comes from the interplay between reasoning and action over a concrete task trajectory, not from static abstract advice alone. In practice, a real execution trace shows where the agent branches, retries, misinterprets an instruction, or wastes tool calls, and those are precisely the places where a skill should become more specific.
Scope Tightly
-
One of the clearest patterns in the documentation is that skills should be well-scoped. A skill should solve a coherent class of tasks with a shared procedure, not try to serve as a catch-all expert for an entire domain. Narrow scope improves three things at once: triggering precision, instruction clarity, and evaluation quality. When scope is too broad, the description becomes fuzzy, the body accumulates branches and exceptions, and the agent is more likely to activate the skill on tasks where it only partially applies. Precise descriptions should be emphasized, and instructions that do not help the current task class should be trimmed.
-
A simple way to formalize scoping is to think of a skill as defining a task family \(T_s\). As scope broadens, the variance of correct procedures inside that family tends to increase. If \(P(t)\) is the ideal procedure for task \(t\), then an overly broad skill is one for which:
\[\mathrm{Var}_{t \in T_s}[P(t)]\]- is too large for one concise instruction body to represent cleanly. In practice, when a skill body starts reading like a decision tree with many divergent branches, it is often a sign that the skill should be split into smaller skills. This interpretation is strongly supported by the recommendation to keep skills concise and to refine them through real execution rather than accumulate every possible edge case into one document.
Write Procedures
-
The body of a high-quality skill should read like a reliable operating procedure. That means it should specify when to inspect inputs, what default method to try first, what output format to produce, what sanity checks to run, and when to escalate to alternative paths. Vague advice such as “be robust,” “use best practices,” or “optimize performance” rarely helps because it does not reduce ambiguity at decision time. A common failure mode should be identified: several approaches may be attempted when instructions are too vague or option-heavy, so defaults should be clarified and irrelevant options should be trimmed.
-
This is closely related to the findings in Toolformer by Schick et al. (2023), which is relevant because it shows that model performance improves when the model learns not just that tools exist, but when to call them and how to incorporate results. A strong skill adds exactly that decision structure at the workflow level: it tells the agent which approach is first-line, which tool call pattern is preferred, and which outputs count as acceptable completion.
Output Contracts
-
A major difference between a merely helpful skill and a production-grade skill is whether it defines what success looks like in output space. Good skills tell the agent what artifact to produce, what structure it should have, what fields or sections it must include, and what validations should pass before the result is considered done. This is made concrete by having test cases define expected outputs in human-readable terms and by grading against assertions over those outcomes.
-
One can view a skill as defining a target output distribution \(p(y \mid x, s)\), where \(x\) is the task input and \(s\) is the skill. The more precisely the skill specifies output structure, the lower the entropy of acceptable completions:
- Reducing this entropy is often desirable in operational settings because it makes behavior more consistent across runs and easier to evaluate. That is exactly why the documentation encourages explicit expected outputs, realistic examples, and assertions instead of leaving “good output” implicit.
Explain the Reason behind the Rule
-
One especially valuable recommendation from the evaluation guidance is to prefer reasoning-based instructions over rigid imperatives when appropriate. Instead of saying only “always do X,” it is often better to say “do X because Y tends to cause Z,” since models frequently follow instructions more reliably when the underlying rationale is explicit. This is not a call for verbosity. It is a call for causal clarity. The purpose clause helps the model generalize the instruction to nearby cases rather than obey it mechanically only in the narrowest wording.
-
This design choice again echoes ReAct by Yao et al. (2022), where explicit intermediate reasoning improves action selection and exception handling. In a well-written skill, short rationale lines act as local control signals that help the model decide when a rule applies and when an apparent exception is actually consistent with the rule’s purpose. ReAct by Yao et al. (2022),
Keep the Main Body Compact (and Push Depth into On-demand Files)
-
The documentation consistently recommends keeping the core
SKILL.mdbody concise and using auxiliary files for deeper material. This is a direct consequence of progressive disclosure: once a skill activates, its main body sits inside the same context window as the conversation, the system instructions, and any other active material. Long skill bodies therefore compete for attention and context budget. The specification and implementation guidance recommend a compact main body, with larger details moved intoreferences/,assets/, or script help text that the agent can open only when relevant. -
A useful context-budget expression is:
- Because the total context \(C_{\text{active}}\) is finite, the marginal cost of an unnecessarily long skill body is not merely token expense; it is displaced attention from other task-relevant state. This is the core engineering reason to keep a skill body focused and to defer optional depth until needed.
Bundle Repeated Work into Scripts
-
A heuristic that can be relied on to identify when a script is needed: when the agent keeps recreating the same helper code or shell command pattern, that repeated work should often be turned into a bundled script. This improves consistency, reduces execution variance, and shortens the skill body because the skill can name the script and describe when to use it rather than restating the full command logic every time. The guide also recommends pinned versions for one-off command tools and self-contained script design for more complex flows.
-
For scripts to work well in agent settings, the documentation recommends several interface properties: avoid interactive prompts, support
--help, emit helpful error messages, and use structured output such as JSON when possible. These recommendations matter because the agent is effectively reading the script interface as part of its reasoning loop. A script with ambiguous flags or opaque failures becomes a source of agent confusion; a script with clear, machine-legible behavior becomes part of the skill’s reliability envelope.
Describe User Intent
-
Because the description is the trigger surface, its wording should match how users express needs, not how the author thinks about implementation. Imperative phrasing such as “Use this skill when…” should be used, and user intent should be prioritized rather than the skill’s internal mechanics. It also recommends being somewhat “pushy” about applicability by naming adjacent contexts where the skill should trigger even if the user does not explicitly mention the technical domain.
-
This can be viewed as a retrieval problem over intent language. If \(d_s\) is the description and \(q\) is a user request, then activation quality depends on maximizing semantic overlap between the latent intent expressed in \(q\) and the applicability boundary encoded in \(d_s\), not on maximizing overlap with the skill’s internal vocabulary. That is why “build a monthly revenue summary from this spreadsheet” is a better trigger target than “perform CSV statistical operations,” even if the latter sounds more technical.
Evaluate the Skill as a System
-
Skills should be treated as engineered artifacts that are tested systematically. It recommends building realistic test cases with prompts, expected outcomes, and optional input files; running each case with and without the skill; storing outputs, timing, and grading artifacts; and iterating across named evaluation rounds. The goal is not simply to ask whether the skill “works once,” but whether it improves reliability across varied prompts and edge cases relative to a baseline.
-
A simple improvement metric is:
\[\Delta = \mathrm{Score}_{\text{with skill}} - \mathrm{Score}_{\text{without skill}}\]- evaluated over a task set rather than a single run. The same guide also recommends reviewing full execution traces, not just final outputs, because a skill may arrive at a correct answer through wasteful or fragile steps that still indicate poor operational quality. That systems perspective is essential if the skill is meant for repeat use rather than a demo.
Separate Trigger and Execution
-
The framework distinguishes two different quality problems: whether the right skill activates, and whether the skill performs well after activation. Should-trigger and should-not-trigger query sets should be constructed, run multiple times because model behavior is nondeterministic, and split into train-validation splits to avoid overfitting the description to a narrow eval set. This is an important design lesson: a brilliant workflow hidden behind a weak description is still a weak skill in practice.
-
This distinction matches the layered architecture of the format itself. Trigger quality is primarily a metadata problem, while execution quality is primarily an instruction and tooling problem. Treating both as separate evaluation targets is one of the reasons the Agent Skills framework scales better than treating every failure as “the model wasn’t smart enough.”
Writing Checklist
- A reliable way to author high-quality skills is to follow a structured, end-to-end process that emphasizes precision, relevance, and validation.
- Begin by identifying a narrow, recurring task family and encoding only the missing expertise as a clear, step-by-step procedure.
- Specify concrete defaults, decision points, and an explicit output contract so the agent can execute reliably without ambiguity.
- Validate and refine the skill using realistic cases, comparing against a no-skill baseline and iterating based on execution traces rather than intuition.
Evaluation and Iteration
Why Evaluation is Essential
-
A skill that appears to work once is still an unvalidated hypothesis. The evaluation question should be framed more strictly: does the skill work reliably across varied prompts, edge cases, and realistic inputs, and does it outperform a baseline without the skill? Evaluating skill output quality is explicit that structured evals create the feedback loop that makes systematic improvement possible, while Optimizing skill descriptions makes the parallel point for triggering: a skill is only useful if it activates on the right requests and stays silent on the wrong ones.
-
The deeper reason is architectural. A skill has at least two separable failure modes:
- Routing failure means the skill did not trigger when it should have, or triggered when it should not have. Execution failure means the skill triggered but produced poor outputs, wasted steps, or inconsistent artifacts. Treating both as first-class evaluation targets is one of the most distinctive strengths of the Agent Skills framework.
Two Evaluation Loops: Trigger Quality and Output Quality
-
The framework separates evaluation into two loops:
-
The first loop evaluates triggering. Here the question is whether the description routes correctly. The recommended method is to build realistic queries labeled
should_triggerorshould_not_trigger, run them through the agent with the skill installed, observe whether the skill was actually invoked, and compute a trigger rate over multiple runs because model behavior is nondeterministic. Optimizing skill descriptions recommends three runs as a reasonable starting point and suggests a threshold around 0.5 for pass decisions on should-trigger and should-not-trigger cases. -
The second loop evaluates output quality. Here the question is whether the skill improves the end result once activated. The recommended pattern is to run each task twice, once with the skill and once without it or with a previous version, then compare outputs, timing, token usage, and grading results. Evaluating skill output quality presents this with-skill versus without-skill comparison as the core baseline design.
-
-
Together, these two loops form a minimal evaluation decomposition:
- A skill with excellent instructions but poor triggering still underperforms, and a skill that triggers perfectly but executes weakly is also not production-ready.
Realistic Evaluations
-
Each execution test case should contain three parts: a realistic prompt, a human-readable expected output, and optional input files needed for the run. Those cases live in
evals/evals.json, which becomes the authored source of truth for the evaluation set. It also recommends starting small, with only two or three test cases at first, then expanding once the first round of results reveals what actually matters. -
A good test set is deliberately varied. Prompts should differ in phrasing, detail, formality, and edge conditions. Realistic context such as file paths, messy personal phrasing, explicit column names, or partial ambiguity is encouraged because sterile prompts tend to overestimate skill quality. Casual language, typos, and indirect intent expressions should be included so routing evaluation reflects how users actually ask for help.
Why Baselines Matter
- The most important experimental design choice in the execution evaluation framework is the baseline. Every evaluation should be run both with the skill and without it, or against a previous version of the skill, so improvement is measured rather than assumed. This prevents a common mistake in prompt engineering: attributing to the skill behavior the base agent would have produced anyway.
- Evaluating skill output quality explicitly recommends paired runs for this reason.
- A simple performance delta is:
- But the guide makes clear that score alone is not enough. A skill can increase pass rate while also increasing tokens or runtime, so the real tradeoff is multidimensional. That is why the suggested
benchmark.jsonstructure records pass rate, time, tokens, and their deltas side by side.
Assertions: Making Quality Testable
- Once initial runs reveal the kinds of outputs being produced, the guide recommends adding assertions to each test case. Assertions should check concrete, objectively verifiable properties such as whether a chart file exists, whether exactly three items were selected, whether both axes were labeled, or whether a required section appears with sufficient substance. The guidance is careful here: strong assertions are specific enough to grade reliably, but not so brittle that harmless wording variation causes false failures.
-
AgentSkills: Evaluating skill output quality gives this contrast directly with in-line examples: a stronger assertion looks like “The report includes a ‘Summary’ section with at least 3 bullet points describing key trends,” while weaker assertions look like “The report is good” or “The report includes a ‘Summary’ section” because those are either too subjective or too shallow to verify reliably. The guidance is careful here: strong assertions are specific enough to grade reliably, but not so brittle that harmless wording variation causes false failures.
- This can be formalized as a set of checks \(A = {a_1, \dots, a_n}\) over an output \(y\). The per-run pass rate is then:
- The advantage of this formulation is that it decomposes “good output” into inspectable components. Instead of arguing abstractly that the result “felt better,” the evaluation can show exactly which output properties improved and which did not.
Evidence-Based Grading
- The grading guidance is unusually strong on one point: every PASS should be backed by concrete evidence from the actual output. A section titled “Summary” is not enough if the content is vague and does not satisfy the assertion. Likewise, grading should not merely mark pass or fail; it should record evidence so that later iteration is diagnostic rather than mysterious. Setting up a
grading.jsonfile that stores assertion results, evidence, and summary counts is recommended. - This is a key systems insight. The goal of grading is not only measurement but attribution. A bare fail signal says something went wrong. Evidence says what failed, where, and why, which is what lets the next revision target the actual problem rather than rewrite the skill blindly.
Scripts and Judges
- Two complementary graders are recommended. For mechanical properties such as valid JSON, correct row count, file existence, or dimensions, verification scripts are preferred because they are deterministic and reusable. For more qualitative judgments, an LLM judge can be used. This division of labor is practical: code handles objective checks better, while model judges can help compare organization, polish, or usability.
- This makes evaluation itself look like a skill-shaped pipeline:
- The benefit is that the eval stack becomes reusable across iterations rather than being re-created by hand each time.
Blind Comparison
- When comparing two versions of a skill, the guide recommends blind comparison as a complement to assertions. The two outputs are shown to a judging model without revealing which came from which version, and the judge scores them on holistic qualities like organization, formatting, polish, or usability. This matters because two outputs can both pass the same assertions and still differ substantially in overall quality.
- This is a reminder that not all quality dimensions decompose cleanly into binary checks. Assertions are excellent for objective contracts, but blind comparisons are often better for capturing the difference between merely acceptable and genuinely strong outputs.
Aggregate Metrics
-
Once every run in the iteration is graded, it is recommended to compute summary statistics per configuration, aggregate them, and save them into a benchmark file
benchmark.jsonalongside the eval directories. This benchmark should record summary statistics such as means and standard deviations for pass rate, time, and token use, along with the deltas betweenwith_skillandwithout_skillconfigurations. The practical question then becomes: what does the skill cost, and what does it buy? In other words, does the improvement in reliability justify the additional cost in time and tokens? -
AgentSkills: Evaluating skill output quality gives a concrete in-line example in which the
with_skillruns have a mean pass rate of0.83, mean time of45.0seconds, and mean token use of3800, while thewithout_skillruns have a mean pass rate of0.33, mean time of32.0seconds, and mean token use of2100, yielding a delta of+0.50pass rate,+13.0seconds, and+1700tokens. The practical question then becomes: what does the skill cost, and what does it buy? The guide’s interpretation is explicit: a skill that adds 13 seconds but improves pass rate by 50 percentage points is probably worth it, while a skill that doubles token usage for only a 2-point gain may not be. -
A useful compact score is a vector, not a scalar:
- This captures the fact that skill quality is operational, not merely semantic. A skill that doubles token usage for negligible gain may not be worth shipping, while one that modestly increases cost but dramatically improves reliability probably is.
Pattern Analysis
-
Aggregate statistics are useful, but the evaluation guidance stresses that the most actionable insights often come from inspecting recurring result patterns rather than relying only on headline averages. It therefore recommends examining specific patterns rather than stopping at a single benchmark summary. Here are several cases that are especially diagnostic:
-
Assertions that always pass with and without the skill are often too weak to be informative. They usually reflect behavior the base agent already handles reliably, so they do not help measure what the skill is adding. In these cases, the assertion should usually be removed, tightened, or replaced with one that probes a genuinely skill-dependent behavior.
-
Assertions that always fail in both conditions often point to a different kind of problem: a broken test, an overly strict or poorly specified assertion, an impossible requirement, or a task setup that is misaligned with what the skill is actually supposed to do. In some cases, they reveal that neither the baseline nor the skill can currently satisfy the requirement, which may mean the task setup, instructions, or expected output need revision before the eval can serve as a useful benchmark.
-
Assertions that pass with the skill but fail without it are usually the clearest evidence of value, because they isolate the specific behaviors or output qualities that the skill is improving beyond the baseline. These cases help answer the core evaluation question, which is not simply whether the output looks good, but whether the skill produces improvements that would not have happened anyway.
-
High variance across runs suggests ambiguity somewhere in the system, either in the eval prompt, the assertion itself, or the skill instructions. In practice, these cases often indicate the need for tighter guidance, stronger defaults, clearer output contracts, or more explicit examples inside the skill.
-
-
This pattern-based diagnosis is one of the most practically useful parts of the framework because it helps distinguish weak assertions from broken ones, and genuine skill gains from unstable behavior. It also helps identify which assertions are uninformative, which are broken, which capture real value, and which expose instability that still needs to be designed away.
-
In effect, evaluation becomes a search for error structure rather than a search for one headline number. The goal is not simply to know whether the skill is “good,” but to understand where its incremental value appears, which checks are uninformative, and where remaining ambiguity still needs to be designed away.
Inner and Outside Validation Loops
-
An important connection between authoring and evaluation is that good skills often contain their own validation loops. Patterns such as doing the work, running a validator, fixing issues, and repeating until validation passes are recommended. It also recommends plan-validate-execute for fragile or destructive operations, where an intermediate structured artifact is checked against a source of truth before the final action is taken. AgentSkills: Best practices for skill creators presents these as core design patterns.
-
This means there are really two levels of evaluation:
- The outer loop is the benchmark framework used by the skill author. The inner loop is the validator the skill instructs the agent to run during task execution. Strong skills often have both: the skill teaches the agent to self-check, and the author separately checks whether that self-checking actually improves outcomes.
Trigger Evaluations
-
A separate query set for routing quality should be built, with realistic should-trigger and should-not-trigger examples. The most valuable positive examples are often indirect requests where the skill would help even though the user does not name the domain explicitly. The most valuable negative examples are near misses that share vocabulary with the skill but actually require a different capability.
-
Because triggering is nondeterministic, it is recommended to carry out multiple runs and calculate the trigger rate as:
- A should-trigger query passes when this rate is high enough, and a should-not-trigger query passes when it stays low enough. The specific threshold can vary, but the important move is treating routing as a measurable probabilistic behavior rather than as a one-shot anecdote.
Avoid Overfitting
-
Train and validation splits should be used for trigger evaluation. If the description is repeatedly revised against the same set of queries, it can overfit to those exact phrasings and fail to generalize. The guide therefore recommends a roughly 60/40 split between train and validation queries, preserving the mix of positives and negatives in both sets, and choosing the best version by validation pass rate rather than by whichever iteration happens to be latest.
-
This is exactly the same logic that underlies generalization testing in machine learning. If \(Q_{\text{train}}\) is used to revise the description and \(Q_{\text{val}}\) is held out, then the goal is not to maximize \(\mathrm{PassRate}(Q_{\text{train}})\) alone, but to maximize \(\mathrm{PassRate}(Q_{\text{val}})\) because validation performance is the better proxy for how the description will behave on new user requests.
Codify Successful Runs
- A recurring theme across the broader skills material is that the best skills often come from successful real executions that are then distilled into a reusable artifact. That observation matters for evaluation because it changes what iteration is optimizing toward. The target is not an imagined ideal workflow but a demonstrated successful pattern that can be made more consistent over time. This is emphasized both in the official best-practices material and in broader discussions of skills as codified procedural knowledge derived from real runs rather than generic advice. AgentSkills: Best practices for skill creators and ReAct by Yao et al. (2022) are relevant together here, because both support the idea that robust agent behavior emerges from concrete task trajectories, not just abstract prompt intent.
Iteration Loop
-
A practical way to iterate on skills is to follow a structured, repeatable loop that treats improvement as a measurable system rather than an informal process:
-
Start by writing an initial version of the skill from a real workflow so the procedure reflects actual execution rather than an imagined ideal
-
Build a small but realistic evaluation set with varied prompts that resemble real user requests
-
Run each case in paired conditions, comparing with-skill and without-skill (or prior versions) to establish a baseline
-
Inspect the first outputs and convert informal judgments into explicit assertions that define what success looks like
-
Record grading evidence for each run so results are traceable and iteration targets specific failure modes
-
Aggregate key metrics such as pass rate, time, and token usage, and examine their deltas across conditions
-
Inspect failure patterns rather than relying only on summary averages to understand where the skill adds value or remains weak
-
Run separate trigger evaluations to test whether the description activates on the right queries and avoids false positives
-
Use train and validation splits when refining descriptions to prevent overfitting to a fixed set of prompts
-
Select the best iteration based on generalization performance rather than recency or subjective preference
-
Repeat the cycle as a disciplined loop of measurement, diagnosis, revision, and remeasurement rather than informal prompt tweaking
-
-
This reflects the Agent Skills approach to iteration: instead of informal cycles of prompting, inspecting, and tweaking by intuition, the process is grounded in measurement, diagnosis, targeted revision, and repeated evaluation. In practice, this makes skill development resemble model evaluation and software testing workflows, where changes are validated against structured evidence rather than subjective impressions, enabling the approach to scale reliably to more complex and production-oriented use cases.
Workspace Bootstrap and Coordination
-
Skills define reusable task-specific procedures, but agent systems also need persistent workspace-level context that governs how the agent behaves across tasks. This broader coordination layer is typically implemented through workspace bootstrap files such as
AGENTS.md,SOUL.md,TOOLS.md,IDENTITY.md,USER.md,HEARTBEAT.md, andBOOTSTRAP.md. Unlike skills, which are activated selectively through progressive disclosure, bootstrap files are generally loaded as part of the agent’s persistent operating environment. -
The broader significance of workspace bootstrap architecture is that it separates durable operational policy from transient procedural execution. Skills package reusable expertise, while bootstrap files package stable environmental assumptions and coordination behavior. This separation improves portability, maintainability, auditability, and organizational scalability. It also aligns with the broader trend in agent systems toward treating prompts, policies, procedures, and workflows as explicit software artifacts rather than hidden runtime state.
-
This distinction reflects an important architectural separation. Skills answer questions such as “how should this task be performed?”, while workspace bootstrap files answer questions such as “how should this agent behave inside this environment?” The former concerns procedural specialization; the latter concerns persistent execution policy, coordination, and environmental assumptions.
workspace/
├── AGENTS.md
├── SOUL.md
├── TOOLS.md
├── BOOTSTRAP.md
├── .agents/
│ └── skills/
│ ├── data-analysis/
│ │ └── SKILL.md
│ └── documentation/
│ └── SKILL.md
└── src/
Persistent Workspace Context
-
A major limitation of purely skill-based systems is that not all behavioral constraints are task-local. Some instructions should persist across all executions regardless of which skill is active. Examples include repository conventions, delegation rules, formatting expectations, coding standards, review requirements, safety constraints, communication style, environment assumptions, and organizational workflows.
-
Bootstrap files solve this by separating durable workspace policy from transient procedural activation. This layered structure prevents every skill from redundantly restating the same global assumptions and allows skills to remain narrowly scoped and composable.
-
Conceptually, the distinction can be expressed as:
\[\text{Agent Context} = \text{Workspace Policy} + \text{Active Skills} + \text{Conversation State} + \text{Tool State}\]- where workspace bootstrap files contribute primarily to the persistent policy layer, while skills contribute task-specific procedural knowledge loaded dynamically during execution.
Layered Bootstrap Architecture
-
OpenClaw-style systems organize bootstrap context as multiple specialized files rather than a single monolithic system prompt. Each file is intended to encode a distinct category of agent behavior or environment configuration.
-
AGENTS.mdtypically defines workspace coordination rules, delegation structure, execution expectations, and repository-level conventions. -
SOUL.mddefines personality, behavioral constraints, tone, and hard behavioral policies that should persist across all tasks. -
TOOLS.mdacts as an environment-specific operational reference, documenting available tools, infrastructure assumptions, workflows, and command conventions. -
Additional files such as
IDENTITY.md,USER.md,HEARTBEAT.md, andBOOTSTRAP.mdmay further separate identity, user preferences, runtime state, or initialization logic into independently maintainable layers. -
This layered decomposition is architecturally significant because it converts implicit runtime behavior into explicit, inspectable, version-controlled artifacts. Instead of burying coordination logic inside opaque prompts, workspace policy becomes modular, auditable, and independently evolvable.
Relationship to Skills
-
Bootstrap files and skills occupy different layers of the agent stack. Skills remain task-scoped capability packages activated only when relevant, while bootstrap files define stable environmental assumptions that persist regardless of which skills are active.
-
In practice, this separation improves composability. Skills can remain concise because they inherit workspace conventions implicitly from the bootstrap layer. At the same time, workspace policy can evolve independently without requiring every skill to be rewritten.
-
This layered model can be viewed as a hierarchy:
\[\text{Bootstrap Layer} \rightarrow \text{Skill Layer} \rightarrow \text{Execution Layer}\]- where bootstrap files establish persistent behavioral constraints, skills define specialized procedures, and execution consists of concrete tool use and reasoning during a task.
Multi-agent Coordination
-
Workspace bootstrap files become especially important in multi-agent or delegated execution environments. In these systems, coordination itself becomes part of the runtime policy. Files such as
AGENTS.mdmay define which agents handle particular responsibilities, how escalation should occur, when review is required, and how information should flow between specialized subagents. -
This transforms the agent runtime from a single isolated executor into a coordinated procedural system. Rather than encoding all coordination behavior dynamically inside prompts, the workspace bootstrap layer externalizes organizational structure into reusable policy artifacts.
AGENTS.md: Workspace-Level Coordination
- Among workspace bootstrap files,
AGENTS.mdis best understood as the file that makes workspace-level coordination concrete. The preceding section described the bootstrap layer as a whole; this section focuses specifically on the role ofAGENTS.mdwithin that layer. Its purpose is to define how work should be organized, delegated, reviewed, and constrained within a repository or agent workspace.
workspace/
├── AGENTS.md
├── .agents/
│ └── skills/
│ ├── code-review/
│ │ └── SKILL.md
│ └── testing/
│ └── SKILL.md
└── src/
-
The most useful way to distinguish
AGENTS.mdfromSKILL.mdis by asking what kind of knowledge each file contains.SKILL.mdcontains task-local procedure: the steps, defaults, checks, and resources needed to complete a specific class of work.AGENTS.mdcontains workspace-level operating policy: the standing rules that determine how tasks should be routed, how outputs should be reviewed, what conventions should be respected, and when additional agents or humans should be involved. -
In practice,
AGENTS.mdoften specifies repository-level conventions and coordination policies, including how work should be decomposed across agents or phases, which files or directories are authoritative for particular kinds of information, what validation or review gates should be applied before an output is considered complete, how agents should communicate intermediate state, what actions require escalation, and how tradeoffs between speed, safety, cost, and completeness should be handled.
Coordination Rather than Procedure
-
AGENTS.mdis primarily about coordination rather than task execution. For example, a reporting skill may describe the concrete steps for producing a benchmark report, whileAGENTS.mdmay specify that reports generated in this workspace must cite sources, preserve a particular document structure, pass validation checks, and be reviewed before publication. In this sense,AGENTS.mddoes not replace skills; it constrains and coordinates how skills and tools are used inside a specific environment. -
This separation prevents every skill from carrying the same workspace-specific rules. Instead of embedding citation policy, review requirements, escalation behavior, or repository conventions inside each individual skill, those standing expectations can live once in
AGENTS.md, while skills remain focused on the reusable procedures they are meant to encode. -
In practical terms,
AGENTS.mdshould focus on the standing coordination rules that apply before, during, and after skill activation. It should explain how tasks are routed, what review or validation is required, when escalation is needed, and how agents should preserve enough context for later audit or handoff.
Delegation and Review Policy
-
AGENTS.mdis especially useful when an agent runtime supports delegation or multiple specialized agents. It can define which agent should handle research, implementation, testing, documentation, review, or deployment; when a task should be split across roles; how one agent should hand off work to another; and what evidence should be preserved so later agents can verify the result. -
It can also define review boundaries. For instance, destructive operations may require explicit approval, code changes may require tests before completion, and generated documents may require source checks before publication. These policies are not individual task procedures; they are standing coordination constraints that shape many task procedures.
# AGENTS.md
## Delegation Rules
- Route literature review and citation checking to the research agent.
- Route code validation and regression testing to the testing agent.
- Escalate destructive operations or irreversible changes for human approval.
## Review Requirements
- Treat work as incomplete until required validation checks have passed.
- Preserve enough intermediate evidence for another agent or human to audit the result.
- Require documentation updates when implementation changes alter public behavior.
## Repository Conventions
- Prefer existing project structure over introducing new organization patterns.
- Treat files in `docs/` as user-facing documentation.
- Treat files in `tests/` as the source of truth for expected behavior.
Runtime Stability
-
A major benefit of
AGENTS.mdis that it gives the runtime a stable policy layer while skills remain dynamic. Skills may activate and deactivate depending on the task, but the coordination rules inAGENTS.mdremain available across the session. This gives the agent a consistent basis for routing, review, and escalation even as different skills are used. -
In effect,
AGENTS.mdestablishes the persistent coordination environment within which skills operate. Skills determine how particular tasks are executed, whileAGENTS.mddetermines the broader operational expectations under which those executions occur.
SOUL.md: Personality and Behavioral Constraints
- If
AGENTS.mddefines coordination policy,SOUL.mddefines behavioral identity. Its purpose is to establish persistent behavioral characteristics that should remain stable across all tasks, independent of which skills are active or which tools are being used. This matters because agent behavior can otherwise drift as different skills activate, contexts change, or workflows evolve. By externalizing behavioral policy into an explicit and inspectable artifact,SOUL.mdimproves transparency, maintainability, and organizational control while allowing personality and operational discipline to remain stable across the agent runtime.
workspace/
├── SOUL.md
├── AGENTS.md
├── TOOLS.md
└── .agents/
└── skills/
-
Unlike skills, which encode task procedures, or
AGENTS.md, which encodes workspace coordination,SOUL.mdencodes behavioral invariants. These may include tone, communication style, interaction philosophy, risk posture, response discipline, formatting expectations, escalation behavior, refusal policy, and other high-level constraints that should persist regardless of the current task. -
A useful distinction is that skills determine what procedure the agent follows, while
SOUL.mddetermines how the agent expresses and governs that behavior during execution.
Persistent Behavioral Identity
-
One of the main architectural motivations for
SOUL.mdis behavioral consistency. Without a persistent behavioral layer, agents tend to drift stylistically and operationally across tasks as different skills activate, different contexts are loaded, or different users interact with the system. -
SOUL.mdprovides a stable behavioral anchor. This can include instructions about how concise or verbose the agent should be, how uncertainty should be communicated, how strongly the agent should defer to human oversight, what kinds of assumptions are acceptable, how aggressively the agent should optimize for efficiency versus caution, and how the agent should prioritize clarity, correctness, or completeness during interaction. -
These policies are intentionally broader and more durable than task-specific instructions. A reporting skill may specify how to generate a benchmark report, but
SOUL.mdmay specify that the agent should avoid overstating conclusions, clearly separate observations from speculation, and explicitly acknowledge uncertainty when evidence is incomplete.
Hard Behavioral Constraints
-
In many systems,
SOUL.mdalso serves as the location for hard behavioral rules that should override local procedural behavior when conflicts arise. These constraints often concern safety, governance, or operational discipline rather than workflow mechanics. -
Examples may include rules about avoiding irreversible actions without confirmation, refusing to fabricate evidence, preserving auditability, avoiding hidden reasoning shortcuts, maintaining transparency about uncertainty, or preferring conservative execution paths when operating under ambiguity.
-
This separation is useful because hard behavioral rules should not be duplicated across every skill. Centralizing them inside
SOUL.mdallows skills to remain focused on reusable procedural knowledge while the behavioral layer remains globally consistent.
# SOUL.md
## Behavioral Principles
- Be explicit about uncertainty when evidence is incomplete.
- Prefer conservative execution for destructive or irreversible actions.
- Preserve enough reasoning trace for later audit or review.
## Communication Style
- Prioritize clarity over persuasion.
- Avoid overstating confidence or capability.
- Keep explanations concise unless additional depth is requested.
## Operational Constraints
- Do not fabricate citations, sources, or execution results.
- Escalate ambiguous high-risk operations for human approval.
- Preserve reproducibility whenever possible.
Relationship to Skills and Coordination
-
SOUL.mdoccupies a different layer of the runtime than either skills or workspace coordination files. Skills define procedural specialization.AGENTS.mddefines workspace organization and delegation.SOUL.mddefines behavioral consistency and execution philosophy. -
In practice, this layered separation reduces prompt entanglement. Behavioral policy, workspace coordination, and procedural execution can evolve independently rather than being merged into one large instruction block. This makes the system easier to maintain, audit, and reason about over time.
TOOLS.md: Environment and Operational Knowledge
- If
SOUL.mddefines behavioral identity andAGENTS.mddefines coordination policy,TOOLS.mddefines operational environment knowledge. Its purpose is to document the practical details the agent needs in order to interact effectively with a specific workspace, infrastructure setup, or execution environment. This matters because many agent failures are not caused by missing reasoning ability, but by missing operational context such as undocumented workflows, environment assumptions, command conventions, or infrastructure-specific constraints.
workspace/
├── TOOLS.md
├── AGENTS.md
├── SOUL.md
└── .agents/
└── skills/
-
Unlike skills, which encode reusable procedures,
TOOLS.mdacts as a workspace-specific operational reference. It typically contains concise information about available tools, preferred commands, local development conventions, deployment workflows, testing procedures, infrastructure assumptions, API locations, repository utilities, and other practical execution details that are expensive for the agent to rediscover repeatedly. -
In effect,
TOOLS.mdfunctions as an environment-specific cheat sheet that bridges the gap between generic tool capability and actual operational usage within a particular workspace.
Operational Context Rather than Procedure
-
A useful distinction is that skills describe how to perform a reusable task, while
TOOLS.mddescribes how the current environment is configured. For example, a deployment skill may explain the general deployment workflow, whileTOOLS.mdmay specify the actual deployment commands used in this repository, the location of configuration files, the preferred testing commands, the available package managers, or the conventions for interacting with internal infrastructure. -
This separation is important because environment knowledge changes more frequently and more locally than reusable procedures. Keeping operational assumptions inside
TOOLS.mdprevents individual skills from becoming tightly coupled to one repository, infrastructure stack, or developer workflow. -
In practice,
TOOLS.mdoften documents information such as which commands should be preferred over alternatives, where important scripts or utilities are located, how local services are started, what environment variables are required, which testing workflows are authoritative, how deployment is performed, what build systems are available, and which tools should be avoided because they are deprecated or unsafe in the current environment.
Reducing Operational Friction
-
One of the major benefits of
TOOLS.mdis that it reduces operational rediscovery. Without a persistent operational reference, agents repeatedly spend context and execution time rediscovering commands, probing repository structure, inspecting scripts, or inferring infrastructure conventions from incomplete evidence. -
TOOLS.mdcompresses this operational overhead into a stable reference layer. Instead of repeatedly reasoning from first principles about how the environment works, the agent can consult explicit workspace knowledge that has already been curated by the repository or organization. -
This also improves execution consistency. When multiple agents or users operate in the same environment,
TOOLS.mdhelps standardize command usage, testing workflows, deployment behavior, and operational assumptions across runs.
# TOOLS.md
## Development Commands
- Use `pnpm test` for the canonical test suite.
- Use `pnpm lint` before submitting changes.
- Use `scripts/dev.sh` to start local services.
## Infrastructure Notes
- Deployment configuration lives in `infra/`.
- Production secrets are managed externally and should never be written locally.
- The staging environment mirrors production behavior.
## Preferred Workflows
- Prefer existing helper scripts over ad hoc shell commands.
- Prefer incremental validation before running full benchmarks.
- Treat CI results as the authoritative validation source.
Relationship to Skills and Bootstrap Files
-
TOOLS.mdoccupies a different layer of the runtime than skills, coordination policy, or behavioral identity. Skills define reusable procedures.AGENTS.mddefines workspace coordination and delegation.SOUL.mddefines behavioral philosophy and operational discipline.TOOLS.mddefines the concrete operational environment in which all of those layers execute. -
In practice, this separation keeps skills portable while allowing environments to remain highly customized. A skill can remain reusable across repositories or organizations, while
TOOLS.mdadapts execution to the local infrastructure, tooling ecosystem, and workflow conventions of a particular workspace. -
This layered decomposition is one of the central architectural ideas behind bootstrap-oriented agent systems: reusable procedural knowledge, behavioral policy, coordination logic, and environment configuration remain separate but composable layers rather than collapsing into one large prompt.
IDENTITY.md: Persistent Agent Identity and Role Context
- If
TOOLS.mddefines operational environment knowledge,IDENTITY.mddefines who the agent is supposed to be within that environment. Its purpose is to establish stable role context, institutional positioning, domain specialization, and long-lived identity assumptions that persist independently of any individual task. This matters because agents often behave inconsistently when role context is implicit or reconstructed dynamically from conversation state alone.
workspace/
├── IDENTITY.md
├── TOOLS.md
├── AGENTS.md
├── SOUL.md
└── .agents/
└── skills/
-
Unlike skills, which define reusable procedures, or
SOUL.md, which defines behavioral philosophy,IDENTITY.mddefines persistent role and institutional framing. It answers questions such as what kind of agent this is, what responsibilities it is expected to prioritize, what domains it specializes in, what authority boundaries it operates under, and what perspective it should maintain while interacting with users or other agents. -
In practice,
IDENTITY.mdmay define whether the agent acts primarily as a researcher, engineer, analyst, reviewer, assistant, coordinator, educator, or domain specialist. It may also encode organizational context such as team ownership, project mission, reliability expectations, compliance posture, or operational priorities that should remain stable across tasks.
Stable Role Context
-
One of the primary motivations for
IDENTITY.mdis reducing role drift. Without a persistent identity layer, agents may implicitly shift persona, priorities, or authority assumptions depending on the active skill, the user’s phrasing, or the surrounding conversation context. -
IDENTITY.mdprovides a stable reference point that anchors execution behavior over long-running sessions and across heterogeneous tasks. This is especially important in systems where multiple specialized agents coexist and each one is expected to maintain a clearly differentiated role. -
For example, a research-oriented agent may prioritize completeness, sourcing, and uncertainty communication, while an operations-oriented agent may prioritize execution speed, stability, and operational safety. Those distinctions are broader than any one skill and therefore belong in a persistent identity layer rather than inside individual workflows.
Identity versus Personality
-
A useful distinction is that
IDENTITY.mddefines role and institutional positioning, whileSOUL.mddefines behavioral philosophy and personality constraints. For example,IDENTITY.mdmay specify that the agent is a security reviewer operating within an infrastructure team, whileSOUL.mdspecifies that the agent should communicate cautiously, avoid overstating confidence, and escalate ambiguous high-risk situations. -
This separation helps prevent prompt entanglement. Identity, personality, coordination policy, operational knowledge, and procedural execution remain independently maintainable layers rather than being merged into one monolithic instruction block.
-
In practice,
IDENTITY.mdoften contains information such as the agent’s primary mission, areas of specialization, operational scope, authority boundaries, preferred interaction model, institutional role, ownership context, and assumptions about the kinds of tasks the agent is expected to prioritize.
# IDENTITY.md
## Role
You are the infrastructure reliability agent for this workspace.
## Primary Responsibilities
- Maintain operational stability and deployment safety.
- Prioritize reproducibility and auditability.
- Support debugging, monitoring, and incident analysis workflows.
## Scope Boundaries
- Do not approve production-impacting changes without verification.
- Escalate ambiguous infrastructure risks for human review.
- Treat reliability and rollback safety as higher priority than execution speed.
## Operational Perspective
- Assume the repository is production-adjacent.
- Prefer conservative infrastructure changes.
- Preserve operational traceability whenever possible.
Relationship to the Bootstrap Layer
-
IDENTITY.mdoccupies a distinct layer within the bootstrap architecture. Skills define how particular tasks are executed.TOOLS.mddefines the operational environment.AGENTS.mddefines coordination and delegation policy.SOUL.mddefines behavioral philosophy.IDENTITY.mddefines the persistent role context within which all of those layers operate. -
Together, these layers allow agent systems to separate procedural knowledge, behavioral governance, workspace coordination, operational assumptions, and institutional role into modular and independently evolvable artifacts.
USER.md: Persistent User Preferences and Interaction Context
- If
IDENTITY.mddefines who the agent is,USER.mddefines who the agent is serving. Its purpose is to capture durable user-specific preferences, workflows, communication expectations, and recurring interaction patterns that should persist across tasks and sessions. This matters because many interaction failures arise not from missing procedural knowledge, but from repeatedly losing context about how a particular user prefers the agent to operate.
workspace/
├── USER.md
├── IDENTITY.md
├── TOOLS.md
├── AGENTS.md
├── SOUL.md
└── .agents/
└── skills/
-
Unlike skills, which encode reusable procedures, or
IDENTITY.md, which defines the agent’s institutional role,USER.mddefines stable assumptions about the user interacting with the system. These assumptions may include preferred communication style, formatting preferences, risk tolerance, recurring workflows, preferred tools, domain familiarity, review expectations, or long-running project context that should remain stable across conversations. -
In practice,
USER.mdacts as a persistent interaction-memory layer. Rather than forcing the agent to rediscover preferences repeatedly through conversational inference, the workspace can externalize durable user context into an explicit and inspectable artifact.
Persistent Interaction Preferences
-
One of the primary motivations for
USER.mdis reducing interaction inconsistency. Without a persistent user-context layer, agents tend to repeatedly relearn formatting expectations, communication preferences, workflow habits, and operational assumptions through ongoing conversation state alone. -
USER.mdprovides a stable reference for these recurring expectations. For example, it may specify whether the user prefers concise or highly detailed explanations, whether citations are expected by default, which programming languages or tools are preferred, how aggressively the agent should automate tasks, or how much intermediate reasoning should be surfaced during execution. -
These preferences are intentionally distinct from both procedural knowledge and behavioral policy. A reporting skill may define how to generate a benchmark report, while
USER.mdmay specify that the user prefers executive summaries first, detailed methodology second, and machine-readable output artifacts whenever possible.
Workflow Personalization
-
USER.mdalso enables workflow personalization without coupling those preferences to reusable skills. This is important because many user-specific expectations should not become part of portable procedural logic. -
For example, one user may prefer aggressive automation and minimal confirmation prompts, while another may prefer conservative execution with explicit review checkpoints. One workspace may prioritize exploratory analysis and iteration speed, while another may prioritize auditability and reproducibility. These differences are often user- or organization-specific rather than intrinsic to the underlying task procedure.
-
Centralizing these assumptions inside
USER.mdallows skills to remain portable and reusable while still adapting execution behavior to the expectations of a particular user or team.
# USER.md
## Communication Preferences
- Prefer concise explanations unless additional detail is requested.
- Include citations by default for research-oriented outputs.
- Surface uncertainty explicitly when confidence is low.
## Workflow Preferences
- Prefer incremental validation over large one-shot execution.
- Preserve intermediate artifacts for review when possible.
- Favor reproducibility over short-term execution speed.
## Tooling Preferences
- Prefer Python for structured data analysis.
- Prefer Markdown for generated reports.
- Prefer existing repository scripts over ad hoc shell commands.
Relationship to Other Bootstrap Files
-
USER.mdoccupies a distinct layer within the bootstrap architecture. Skills define reusable procedures.SOUL.mddefines behavioral philosophy.AGENTS.mddefines coordination policy.TOOLS.mddefines environment-specific operational knowledge.IDENTITY.mddefines the agent’s persistent institutional role.USER.mddefines the preferences and expectations of the human or organization interacting with the system. -
Together, these layers allow agent systems to separate reusable procedure, behavioral governance, operational assumptions, coordination logic, institutional identity, and user-specific preferences into independently maintainable artifacts rather than collapsing them into one large prompt.
BOOTSTRAP.md: Runtime Initialization and Session Startup
- If
USER.mddefines persistent user preferences,BOOTSTRAP.mddefines how the agent runtime should initialize itself at session startup. Its purpose is to establish the initialization sequence, startup assumptions, loading priorities, and early-session execution behavior that prepare the agent environment before normal task execution begins. This matters because many agent systems rely on implicit startup behavior that becomes difficult to audit, reproduce, or modify once the runtime grows more complex.
workspace/
├── BOOTSTRAP.md
├── USER.md
├── IDENTITY.md
├── TOOLS.md
├── AGENTS.md
├── SOUL.md
└── .agents/
└── skills/
-
Unlike skills, which define reusable task procedures, or
AGENTS.md, which defines persistent coordination policy,BOOTSTRAP.mdfocuses specifically on runtime initialization behavior. It describes what context should be loaded first, what assumptions should be established before execution, what environment checks should occur, and how the runtime should transition into its steady operating state. -
In practice,
BOOTSTRAP.mdoften functions as the initialization contract for the workspace. It may define which bootstrap files are mandatory, what order they should be processed in, which environment validations should occur at startup, how trust boundaries are established, what persistent state should be restored, and what operational invariants must hold before task execution begins.
Explicit Initialization Rather than Hidden Startup State
-
One of the main motivations for
BOOTSTRAP.mdis making startup behavior explicit. Without a dedicated initialization layer, many runtime assumptions become hidden inside system prompts, client implementations, or undocumented execution conventions. -
BOOTSTRAP.mdexternalizes those assumptions into a visible and version-controlled artifact. This improves reproducibility and operational transparency because the initialization sequence itself becomes inspectable and modifiable rather than implicitly embedded inside the runtime. -
For example,
BOOTSTRAP.mdmay specify that the runtime should load behavioral constraints before workspace coordination rules, validate tool availability before skill discovery, restore prior session state when available, or verify trust settings before loading repository-level bootstrap files.
Initialization Order and Dependency Structure
-
Bootstrap-oriented agent systems often rely on layered initialization because different categories of context have different scopes and stability properties. Behavioral constraints, workspace coordination policies, operational environment notes, user preferences, and skill catalogs may all need to be initialized in a consistent order.
-
BOOTSTRAP.mdprovides a centralized location for documenting and stabilizing this dependency structure. This becomes increasingly important as the number of bootstrap layers, skills, tools, and delegated agents grows. -
In practice,
BOOTSTRAP.mdmay define startup responsibilities such as which bootstrap files are loaded first, how conflicting policies are resolved, when skills become discoverable, what runtime diagnostics should execute, how cached context is restored, and which initialization failures should block execution entirely.
# BOOTSTRAP.md
## Initialization Order
1. Load behavioral constraints from `SOUL.md`
2. Load coordination policies from `AGENTS.md`
3. Load environment references from `TOOLS.md`
4. Load user preferences from `USER.md`
5. Discover and index available skills
## Startup Checks
- Verify required tools are available.
- Confirm repository trust before loading project-level bootstrap files.
- Restore prior workspace state if available.
## Runtime Invariants
- Treat bootstrap policies as higher priority than skill-local instructions.
- Preserve auditability during delegated execution.
- Require validation before destructive operations.
Relationship to the Bootstrap Architecture
-
BOOTSTRAP.mdoccupies a meta-coordination role within the bootstrap layer itself. Skills define reusable procedures.SOUL.mddefines behavioral philosophy.AGENTS.mddefines coordination policy.TOOLS.mddefines operational environment assumptions.IDENTITY.mddefines persistent institutional role.USER.mddefines user-specific preferences.BOOTSTRAP.mddefines how all of those layers are initialized and composed at runtime. -
This separation is architecturally useful because initialization logic evolves differently from behavioral policy, coordination rules, or procedural knowledge. By isolating startup behavior into its own artifact, the runtime becomes easier to reason about, debug, audit, and extend over time.
HEARTBEAT.md: Runtime State and Operational Continuity
- If
BOOTSTRAP.mddefines how the runtime initializes,HEARTBEAT.mddefines how the runtime maintains continuity over time. Its purpose is to capture lightweight persistent operational state that helps the agent preserve awareness across long-running sessions, delegated workflows, or iterative execution cycles. This matters because many agent systems lose coherence when execution spans multiple steps, multiple agents, or extended periods of interaction.
workspace/
├── HEARTBEAT.md
├── BOOTSTRAP.md
├── USER.md
├── IDENTITY.md
├── TOOLS.md
├── AGENTS.md
├── SOUL.md
└── .agents/
└── skills/
-
Unlike skills, which encode reusable procedures, or
BOOTSTRAP.md, which defines startup initialization,HEARTBEAT.mdfocuses on ongoing runtime continuity. It acts as a lightweight operational memory layer that tracks important session state, execution checkpoints, coordination status, or persistent runtime signals that should survive beyond a single conversational turn. -
In practice,
HEARTBEAT.mdmay contain information such as active tasks, pending reviews, unresolved issues, delegated work assignments, execution checkpoints, runtime health indicators, synchronization notes, or reminders about important operational constraints that remain relevant throughout the session.
Operational Continuity Rather than Long-term Knowledge
-
One of the primary motivations for
HEARTBEAT.mdis preserving operational continuity without overloading the permanent bootstrap layer. Some information is too transient to belong inAGENTS.mdorSOUL.md, but too important to rely entirely on ephemeral conversational context. -
HEARTBEAT.mdprovides a middle layer between durable policy and temporary conversation state. It allows the runtime to preserve lightweight execution continuity while avoiding the need to repeatedly reconstruct intermediate operational context from prior interactions. -
For example, a delegated multi-agent workflow may require tracking which subtasks are still pending, which outputs are awaiting review, which validation checks have completed, or which failures still require escalation. These are runtime-state concerns rather than reusable procedural knowledge.
Coordination Across Long-running Sessions
-
HEARTBEAT.mdbecomes especially useful in systems that support delegation, asynchronous workflows, background execution, or extended task lifecycles. In these environments, execution often spans multiple reasoning cycles and may involve several specialized agents operating over shared state. -
Rather than embedding transient coordination state directly into prompts, the runtime can externalize operational continuity into a dedicated artifact that remains inspectable and updateable over time.
-
In practice,
HEARTBEAT.mdmay track information such as which agent currently owns a task, what execution stage has completed, whether human review is pending, which validations have failed, or what contextual assumptions should remain active until the workflow finishes.
# HEARTBEAT.md
## Active Work
- Benchmark evaluation currently in validation phase.
- Documentation review pending for deployment workflow updates.
## Delegation State
- Research agent completed citation verification.
- Testing agent rerunning regression suite after fixes.
## Outstanding Issues
- Production rollback procedure requires confirmation.
- API compatibility validation still incomplete.
## Runtime Notes
- Preserve intermediate benchmark artifacts until review completes.
- Treat current workspace state as provisional until validation passes.
Relationship to the Bootstrap Architecture
-
HEARTBEAT.mdoccupies a distinct role within the bootstrap architecture. Skills define reusable procedures.SOUL.mddefines behavioral philosophy.AGENTS.mddefines coordination policy.TOOLS.mddefines environment assumptions.IDENTITY.mddefines persistent institutional role.USER.mddefines user-specific preferences.BOOTSTRAP.mddefines initialization behavior.HEARTBEAT.mddefines lightweight operational continuity during execution. -
This separation is useful because runtime state evolves at a much higher frequency than policy, identity, or procedural knowledge. By isolating operational continuity into its own layer, the runtime can preserve long-running execution coherence without constantly mutating the more stable bootstrap artifacts.
Implementation and Integration
From Format to Runtime
-
A skill format becomes useful only when an agent runtime can discover, expose, activate, and manage skills as part of its normal execution loop. In other words, implementation turns skills from files on disk into a live capability layer. The implementation guidance describes this lifecycle as discovery, disclosure to the model, activation, and ongoing context management, while the broader overview frames the goal as letting agents load procedural knowledge on demand rather than carrying every instruction up front.
-
A clean way to view the runtime is as a mapping
- Each component is simple in isolation, but the quality of the whole system depends on how well these parts fit together.
Startup Discovery
- The first implementation problem is discovery. A compatible client must scan one or more directories, find subdirectories containing a file named exactly
SKILL.md, and treat those directories as candidate skills. At least project-level and user-level scopes should be supported for locally running agents, with.agents/skills/being called out as a cross-client interoperability convention. It also notes that some clients scan compatibility locations such as.claude/skills/, and that additional search roots like ancestor directories, XDG config locations, or user-configured paths can be useful in practice.
Project scope
<project>/
├── .agents/
│ └── skills/
│ ├── pdf-processing/
│ │ ├── SKILL.md
│ │ └── scripts/
│ └── data-analysis/
│ └── SKILL.md
└── .claude/
└── skills/
└── compatibility-skill/
└── SKILL.md
User scope
~/
├── .agents/
│ └── skills/
│ ├── writing/
│ │ └── SKILL.md
│ └── research/
│ └── SKILL.md
└── .config/
└── <client>/
└── skills/
└── custom-skill/
└── SKILL.md
-
The discovery set can be written as:
\[\mathcal{S}_{\text{found}} = { d \in D \exists d/\texttt{SKILL.md} }\]- where \(D\) is the set of scanned directories. The point is not sophistication but determinism: discovery should be boring, predictable, and cheap enough to happen at session start.
Directory Conventions
-
The runtime guidance places unusual importance on path conventions because conventions are what make a file-based standard interoperable across clients. A skill can be portable only if different agents have a reasonable chance of finding it without vendor-specific setup. That is why
.agents/skills/matters so much: it is less a strict technical requirement than a coordination mechanism, and is a widely adopted cross-client convention since interoperability is one of the main benefits of the format. -
This design is part of a broader architectural idea: the runtime should be thin, while domain knowledge remains portable and file-based. That matches the argument in ReAct by Yao et al. (2022) that useful agents emerge from structured interaction between reasoning and external state, and it also fits the practical design stance that procedural knowledge should live in editable artifacts rather than only inside a vendor-specific prompt harness.
Scanning Rules
-
Path conventions should be treated as only one part of discovery, with additional operational safeguards applied during scanning. It also recommends operational safeguards for scanning itself: skip directories like
.git/andnode_modules/, optionally respect.gitignore, and set depth or directory-count limits to avoid runaway scans in large trees. These are small details, but they are exactly the kind of details that separate a clean integration from a fragile one. -
The principle is simple: discovery should scale sublinearly with repository mess. In practice, that means bounding search cost rather than treating the filesystem as a free index.
Parsing SKILL.md
-
After discovery, the runtime parses each
SKILL.mdinto frontmatter and body. At minimum, it needs thename,description, and a location pointer to the file. The guide recommends storing these in an in-memory map keyed by skill name for fast activation lookup. It also notes a practical implementation tradeoff: store the body at discovery time for faster activation, or read it from disk only at activation time to save memory and pick up file changes between activations. -
A minimal skill record is therefore:
\[r_s = (\text{name}, \text{description}, \text{location})\]- with optional cached fields for body, compatibility data, or other metadata. Everything else in the runtime depends on this record being clean and stable.
Lenient Parsing
-
One of the most practically important implementation recommendations is to parse leniently. The guide notes that skills authored for one client may contain technically invalid YAML that still works under that client’s parser, especially unquoted values containing colons. It therefore recommends fallback logic and warning-based validation: cosmetic issues such as directory-name mismatches or excessive name length can be logged while the skill is still loaded, whereas truly missing descriptions or fully unparseable YAML should cause the skill to be skipped.
-
This is an important lesson in standards design. Strict specifications are useful for interoperability, but runtimes often need tolerant readers to handle the real world. The implementation posture is therefore “accept broadly, diagnose clearly, reject only when disclosure would fail”.
-
That is exactly the right mindset for a format meant to move across heterogeneous agents.
Building the Catalog
-
Once skills are parsed, the runtime must disclose them to the model without loading the full instructions. A structured catalog containing at least name and description should be built, with an optional file location included when activation will happen through file reads. It also notes that the catalog can be represented as XML, JSON, or a simple list, because the central requirement is clarity, not one mandated serialization.
-
The catalog can be formalized as:
\[\mathcal{C} = {(n_s, d_s, \ell_s)}_{s \in \mathcal{S}}\]- where \(n_s\) is the name, \(d_s\) is the description, and \(\ell_s\) is an optional location. This catalog is the model’s entire prior over available skills until one is activated.
Catalog Placement
-
Two common catalog-placement strategies are recommended:
-
The first is to place the catalog directly in the system prompt with a short instruction block explaining how skills should be used.
-
The second is to embed the catalog in the description of a dedicated skill-activation tool, which keeps the system prompt cleaner and couples discovery with activation.
-
-
Both as valid, with system-prompt placement being simpler and tool-description embedding being cleaner when a dedicated activation tool exists.
-
This is a classic runtime tradeoff between universality and elegance. A system-prompt catalog works almost everywhere. A dedicated activation tool produces a tidier abstraction boundary.
Activation Paths
-
There are two main ways to activate a skill in practice:
-
If the model has file-reading access, activation can be model-driven: the model decides that a skill is relevant and reads the corresponding
SKILL.mddirectly from the disclosed location. -
If the model does not have direct file access, the runtime can provide a dedicated activation tool such as
activate_skill, which returns the skill body and related metadata in a structured wrapper.
-
-
Both activation patterns should be supported, with the final choice depending on the surrounding agent harness.
Catalog entry
└── pdf-processing
├── name: pdf-processing
├── description: Extract text, fill forms, merge PDFs
└── location: ~/.agents/skills/pdf-processing/SKILL.md
Activation path A: direct read
Model -> reads SKILL.md -> follows instructions
Activation path B: tool-based
Model -> calls activate_skill("pdf-processing") -> receives SKILL.md body
-
In either case, activation is logically the same transition:
\[\mathcal{C} \rightarrow \mathcal{C} \cup I_s\]- where \(I_s\) is the instruction body of the chosen skill. The mechanism changes, but the state transition does not.
Path Resolution
- Once a skill is activated, the runtime must support the next layer of progressive disclosure: references to scripts, assets, and documentation inside the skill directory. The skill base directory, usually the parent directory of SKILL.md, should be used as the anchor for resolving relative paths. That base path is needed whether the model reads files directly or receives wrapped skill contents from a tool.
pdf-processing/
├── SKILL.md
├── scripts/
│ └── extract_text.py
├── references/
│ └── form-fields.md
└── assets/
└── sample-output.txt
- This can be expressed as a simple resolution rule:
- That small rule is what turns a skill from a text blob into a structured local package.
Filtering and Permissions
-
Not every discovered skill should be shown to the model. It is recommended to filter out skills that the user has disabled, that permission systems deny, or that opt out of model-driven invocation. It also recommends hiding unavailable skills entirely rather than listing them and then blocking them at activation time, because exposing unusable skills wastes model turns and creates avoidable confusion.
-
This is an important design principle. A clean runtime presents only actionable affordances. In agent systems, misleading affordances are especially costly because the model will try to use them.
Precedence
-
When two skills share the same name, the guide recommends deterministic precedence, with project-level skills conventionally overriding user-level skills. Within the same scope, either first-found or last-found precedence is acceptable as long as the rule is consistent and collisions are logged. This matters because ambiguity in skill identity becomes ambiguity in model behavior.
-
A runtime can think of this as selecting
\[s^* = \arg\max_{s \in \mathcal{S}_{n}} \mathrm{Precedence}(s)\]- where \(\mathcal{S}_{n}\) is the set of skills sharing a name. The important part is not the exact precedence function but that it be deterministic and visible through diagnostics.
Trust and Injection Risk
-
One of the most valuable implementation recommendations is to treat project-level skills as potentially untrusted. A freshly cloned repository may contain a skill designed to manipulate the agent’s behavior in ways the user did not intend, so the guide recommends gating project-level skill loading behind an explicit trust decision for the project folder. This is a direct acknowledgement that skill loading is also a prompt-injection surface.
-
The policy can be written simply as:
- This is not merely a security hardening tweak. It is part of the correctness story for skills in real deployments.
Runtime Environments
-
The lifecycle of parsing, disclosure, and activation remains stable across deployment modes, but the discovery mechanism changes when the agent does not have direct access to the user’s local filesystem. In local environments, project and user skills can be scanned directly. In cloud or sandboxed agents, project-level skills may still arrive with a cloned repository, but user-level and organization-level skills must usually be provisioned externally, for example through uploaded packages, settings-based URLs, bundled assets, or configuration repositories.
-
This distinction is important because it shows that skills are transport-agnostic. What matters is not where the files originate, but whether the runtime can make them available before the disclosure phase begins.
Context Management
-
Implementation does not end at activation. Ongoing context management should be treated as part of the runtime contract: skill content should be protected from being lost in context compaction, duplicate activations should be avoided, and advanced clients may optionally use subagents to isolate specialized work. Those recommendations reinforce the central idea that skills are not single-shot prompt snippets but reusable context modules that must coexist with long-running agent state.
-
This yields a broader runtime state equation:
\[\text{Context}_t = \text{Conversation}_t + \text{System} + \text{Tools} + \sum_{s \in A_t} I_s + \sum_{r \in R_t} r\]- where \(A_t\) is the set of active skills and \(R_t\) is the set of loaded resources at time \(t\). Good implementations manage this state deliberately rather than letting it accrete arbitrarily.
Why It Works
- The reason the integration pattern is so effective is that it keeps the runtime general while letting expertise remain modular. The runtime only needs to know how to find skills, show a compact catalog, load one when appropriate, and resolve its local resources. Everything domain-specific stays in the skill package itself. That is the implementation counterpart to the larger architectural claim that better agents often come not from more scaffolding, but from cleaner separation between a general-purpose executor and portable procedural knowledge.
- AgentSkills: Overview, AgentSkills: How to add skills support to your agent, and Toolformer: Language Models Can Teach Themselves to Use Tools by Schick et al. (2023) all support this view from different angles, with Toolformer: Language Models Can Teach Themselves to Use Tools by Schick et al. (2023) being relevant because it shows that external capability use becomes more reliable when the model has explicit mechanisms for selecting and applying it.
Key Implementation Lesson
- The implementation lesson is that agent skills are not just a markdown authoring pattern. They are a runtime protocol for discovering portable expertise, exposing only the lightweight routing surface by default, activating detailed procedures only when needed, and doing so with deterministic precedence, explicit trust boundaries, and deployment-aware discovery paths.
OpenClaw
- OpenClaw is a useful real-world example of a skills-native runtime because it shows how Agent Skills, bootstrap files, routing, channels, approvals, and device nodes fit together inside one persistent control plane.
What OpenClaw Is
-
OpenClaw is an open-source, self-hosted agent gateway that connects AI agents to many chat surfaces, including Discord, Google Chat, iMessage, Matrix, Microsoft Teams, Signal, Slack, Telegram, WhatsApp, Zalo, and web chat, so the user can interact with one persistent assistant from the messaging channels they already use. It is described as a single Gateway process that becomes the control plane for sessions, routing, and channel connections, and it is positioned as a personal AI assistant with first-class tools, sessions, cron, and companion apps.
-
What makes OpenClaw especially relevant to a primer on Agent Skills is that it does not treat skills as an afterthought. Its skills system is explicitly AgentSkills-compatible, and the runtime loads bundled skills, local overrides, user-level skills, and workspace skills while filtering them at load time based on environment, configuration, binary availability, and allowlists. In other words, OpenClaw is a concrete example of a skills-native runtime rather than a general chatbot that merely tolerates skill folders.
Why It Matters
-
OpenClaw matters because it shows what Agent Skills look like when embedded inside a full runtime that must solve real systems problems: multi-channel ingress, session isolation, multi-agent routing, approvals, sandboxing, context injection, channel pairing, and skill precedence. It therefore turns the abstract format described earlier in the primer into an operational architecture. The generic lifecycle described in AgentSkills: How to add skills support to your agent starts with skill discovery across project and user scopes, continues with metadata parsing so the runtime can expose a lightweight catalog of names and descriptions to the model, then activates a skill only when the current task matches that catalog entry, and finally loads deeper resources such as scripts, references, or assets only when the instructions call for them.
-
OpenClaw’s skills implementation makes that lifecycle concrete by defining a strict load order across bundled, user, and workspace skill directories, supporting skill allowlists at both the global and per-agent level, auto-refreshing skill changes through a watcher, gating visibility based on environment and available binaries, and applying per-agent filtering so each agent sees only the skill subset relevant to its workspace and configuration.
-
This is exactly the kind of runtime layering anticipated by ReAct: Synergizing Reasoning and Acting in Language Models by Yao et al. (2022), which is relevant here because it argues that agents work best when reasoning is tightly coupled to actions in an environment, and by Toolformer: Language Models Can Teach Themselves to Use Tools by Schick et al. (2023), which is relevant because it shows that external capability use becomes more reliable when the model has explicit access patterns for tools and tool results. OpenClaw extends this pattern from isolated tool calls to a persistent, message-driven agent runtime.
Core Architecture
-
At a high level, OpenClaw separates the system into a Gateway layer, one or more agent workspaces, attached channels, apps and interfaces, and a tool and skills layer. The Gateway acts as the single source of truth for sessions, routing, and channel connections, while agent workspaces hold bootstrap files, memory, and skills that shape the behavior of a particular agent. The overview materials also highlight the surrounding surfaces that attach to this Gateway, including a Pi agent, CLI, Web Control UI, macOS companion app, and iOS and Android nodes. OpenClaw docs and Multi-Agent Routing describe this split directly, and the overview diagram in the OpenClaw materials visually shows chat apps and plugins flowing into the Gateway, then out to those control and device surfaces.
-
Put simply, OpenClaw works as a layered runtime: the Gateway manages traffic and routing, channels deliver messages in and out, each agent workspace defines the active persona and operating context, and tools plus skills determine what the agent can do and how it should do it. This matters because it makes clear that skills are only one layer in a broader runtime. They tell the agent what to do, but the Gateway decides where messages land, what session they join, which agent they target, and what tool surfaces are available.
-
The following figure (source) shows the OpenClaw Gateway architecture connecting chat apps and plugins to the central Gateway, which then fans out to agent and interface surfaces such as Pi agent, CLI, Web Control UI, macOS app, and iOS and Android nodes.
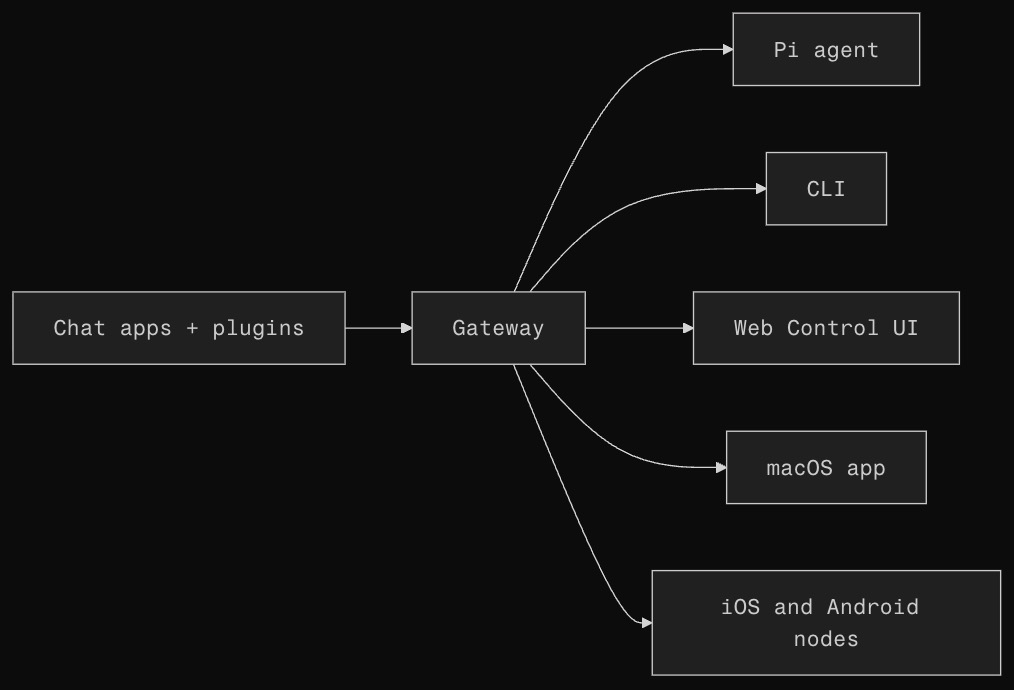
Bootstrap Files
-
A distinctive feature of OpenClaw is that it uses a family of workspace bootstrap files, not just skill folders. Workspace files such as
AGENTS.md,SOUL.md,TOOLS.md,IDENTITY.md,USER.md,HEARTBEAT.md, andBOOTSTRAP.mddefine layered agent context.SOUL.mdis used for personality and hard behavioral rules, whileTOOLS.mdserves as an environment-specific cheat sheet. Context - OpenClaw, SOUL.md Personality Guide, TOOLS.md Template, and Delegate Architecture all describe this layered bootstrap model. -
This is important for the primer because it shows a clean distinction between persistent bootstrap context, procedural context from skills, and live session context from ongoing conversations and memory. In OpenClaw, these layers complement one another rather than competing for the same purpose. Files like
SOUL.mdshape identity and behavior at a high level, skills encode reusable procedures, and sessions carry the current conversational state. OpenClaw’s architecture therefore complements, rather than replaces, the skills model developed earlier in the primer. -
A representative workspace looks like this:
workspace/
├── AGENTS.md
├── SOUL.md
├── TOOLS.md
├── USER.md
├── MEMORY.md
├── .agents/
│ └── skills/
│ ├── pdf-processing/
│ │ ├── SKILL.md
│ │ └── scripts/
│ └── inbox-triage/
│ ├── SKILL.md
│ └── references/
└── skills/
└── local-override-skill/
└── SKILL.md
- That structure matters because OpenClaw supports both standard
.agents/skillspaths and a workspace-localskills/directory with higher precedence, which gives the user an explicit way to install shared skills and override them locally when needed.
Skills and Precedence
-
OpenClaw’s skill system is significant because it adopts the broader Agent Skills format while adding a well-defined runtime policy for where skills come from and which version wins when names collide. The docs say OpenClaw loads skills from extra configured directories, bundled skills,
~/.openclaw/skills,~/.agents/skills,<workspace>/.agents/skills, and<workspace>/skills, with precedence running from<workspace>/skillsat the top down to extra configured directories at the bottom. In multi-agent setups, each agent also gets its own workspace skill view, and skills can be filtered by effective agent skill allowlists through settings such asagents.defaults.skillsandagents.list[].skills. -
In practical terms, the load-order facts mean that OpenClaw distinguishes between discovery and winner selection. It first discovers skills from all configured sources, then resolves same-named conflicts by giving highest priority to the workspace-local
skills/directory, followed by the workspace’s.agents/skills, then the user’s~/.agents/skills, then~/.openclaw/skills, then bundled skills, and finally any extra directories configured throughskills.load.extraDirs. This gives the user a predictable override ladder: a workspace can replace a personal or bundled skill simply by defining a skill with the same name in a higher-precedence location. -
The per-agent filtering facts are a separate control layer. Skill location and skill visibility are identified as different mechanisms: precedence decides which copy of a same-named skill wins, while agent allowlists decide which visible skills can be used. A shared baseline can be set through
agents.defaults.skills, and individual agents can either inherit that baseline, replace it with their own explicit list throughagents.list[].skills, or disable skills entirely by setting an empty list. The important detail is that a non-empty per-agent list replaces the defaults rather than merging with them, so allowlists are final agent-specific filters, not additive hints. -
This matters operationally because OpenClaw applies the effective per-agent skill set across prompt building, slash-command discovery, sandbox synchronization, and skill snapshots. That means filtering is not cosmetic. It changes what the model sees in its skill catalog, which slash commands are surfaced to the user, which skills are mirrored into sandboxed runs, and which skill state is retained for performance-sensitive session reuse. In other words, OpenClaw treats skills as part of the runtime contract for each agent, not just as a shared folder on disk.
-
So the combined picture is more precise than a simple “load order” rule. OpenClaw first discovers skills from multiple shared and workspace-specific roots, then resolves duplicate names by precedence, and only after that applies per-agent allowlists to decide the final visible skill set for each agent. That makes it possible for bundled defaults, user-level customizations, workspace-specific overrides, and tightly restricted specialist agents to coexist inside the same Gateway without ambiguity.
Multi-Agent Routing
-
A major reason OpenClaw stands out is that it is not only a single-agent shell. It supports multi-agent routing, where inbound traffic can be routed to different isolated agents with separate workspaces and sessions. The docs describe the goal as supporting multiple isolated agents plus multiple channel accounts inside one running Gateway, with routing determined by bindings. The attached overview materials further highlight that sessions can be isolated per workspace or sender, that direct chats can collapse into a shared
mainsession, and that groups can be isolated. -
This matters for a skills primer because it shows how skills become compositional at the agent level. Different agents can have different workspaces, different bootstrap files, different tool policies, and different effective skill sets, so the same Gateway can host specialized delegates for different roles or principals. That is a practical realization of the more general principle that agent capabilities can be adapted by swapping procedural packages rather than rewriting the runtime itself. Skills - OpenClaw notes that in multi-agent setups each agent has its own workspace, while Multi-Agent Routing explains the isolation goal.
-
Put simply, an incoming message is routed to a particular bound agent, and that routing decision determines which workspace, which bootstrap files, which memory, and which skill set become active for the conversation. That routing can be pinned by bindings for specific channels or accounts, which is why OpenClaw is especially useful as a case study in runtime-level specialization.
Tooling Surface
-
OpenClaw exposes a broad set of first-class tools, including browser, canvas, nodes, cron, sessions, message sending, and image generation, and it supports paired nodes for capabilities such as camera, screen, location, canvas, notifications, and shell execution. The overview materials add further detail: OpenClaw supports images, audio, video, and documents in and out, voice note transcription, text-to-speech, shared image and video generation surfaces, browser automation, exec, sandboxing, web search across multiple providers, cron jobs, heartbeat scheduling, and workflow pipelines such as Lobster. The docs and GitHub repo both emphasize that tool access is a first-class part of the runtime.
-
This is exactly why skills matter in OpenClaw. The richer the action space, the more important it becomes to provide procedural guidance over that action space. In a runtime with channels, browser control, node invocation, cron jobs, device pairing, rich media, and external messaging, a skill does more than add knowledge. It constrains and structures behavior over a large tool surface. This is closely aligned with Gorilla: Large Language Model Connected with Massive APIs by Patil et al. (2023), which is relevant because it shows that capability alone is not enough and that using external interfaces well depends heavily on good documentation and retrieval. OpenClaw operationalizes that insight through skills, bootstrap files, and approvals.
Security and Approvals
-
OpenClaw is unusually explicit about the risks of a powerful persistent agent, and that makes it a valuable case study for this primer. The security docs warn that “open” configurations with tools enabled should first be constrained by DM and group pairing rules, followed by tighter tool policy and sandboxing, and they caution strongly against unsafe public exposure and untrusted plugins. They also make a stronger systems point: one shared gateway is not a supported trust boundary for mutually untrusted users, and adversarial-user isolation should instead be handled by splitting gateways and credentials.
-
The system also has approval mechanisms for execution. The approvals CLI manages exec approvals for the local host, gateway host, or a node host, and the exec tool docs explicitly warn against treating
safeBinsas a generic allowlist or simply allowlisting interpreters likepython3,node, orbashwithout explicit profiles. DM safety with allowlists and mention-based activation in groups is recommended, reinforcing that message access and tool execution are both policy surfaces. -
For a skills primer, the key lesson is that a skills-native runtime must also be a trust-aware runtime. The more a skill can influence tool use and external actions, the more important approvals, allowlists, pairing, and environment-aware loading become. OpenClaw’s approach makes that explicit rather than assuming skill activation is harmless.
Context and Performance
-
Performance-oriented features such as load-time gating, skill allowlists, session snapshots, auto-refresh through a skills watcher, and token-impact awareness are recommended for the visible skills list. OpenClaw’s runtime supports streaming and chunking for long responses, per-sender sessions by default, embedded agent runtime behavior with tool streaming, and support for many providers, including hosted and self-hosted backends such as vLLM, SGLang, Ollama, and OpenAI-compatible or Anthropic-compatible endpoints. These features are not just operational conveniences. They show that, in a production runtime, skills are part of context budgeting and state management rather than merely part of authorship.
-
This is consistent with the broader finding from Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Lewis et al. (2020), which is relevant because it shows that external knowledge should be brought in selectively, not indiscriminately, and with the general long-context lesson that excess context can degrade practical agent behavior if not managed carefully. OpenClaw’s runtime-level gating of visible skills is therefore one practical answer to the context management problem discussed throughout the primer.
Ecosystem
-
Another reason to include OpenClaw in the primer is that it already has an ecosystem around it. The core repository is openclaw/openclaw, the official docs live at docs.openclaw.ai, the curated skill collection VoltAgent/awesome-openclaw-skills points to a large registry of categorized OpenClaw skills, and mergisi/awesome-openclaw-agents shows a parallel ecosystem of reusable
SOUL.md-based agent templates. These repositories are relevant because they show that OpenClaw is not only a runtime design, but also a growing packaging and sharing layer for both skills and agent personas. -
This ecosystem angle matters because it illustrates one of the central claims of the broader Agent Skills movement: once the unit of sharing becomes a folder or a small config package instead of a full custom agent product, expertise becomes easier to publish, version, remix, and reuse. OpenClaw demonstrates that this logic applies not only to skills but also to role and personality layers such as
SOUL.md.SOUL.mdPersonality Guide is relevant here because it shows how identity itself becomes a reusable, editable file-layer inside the broader runtime.
Deployment Model
-
OpenClaw is also useful as an example of the self-hosted agent model. It as a self-hosted gateway that runs on the user’s machine or server, and the AWS Lightsail blog frames it as a private autonomous agent that can connect to messaging apps and perform tasks like email management, web browsing, and file organization. Furthermore, OpenClaw can be deployed as a Lightsail blueprint and that Bedrock can serve as a preconfigured starting provider in that environment.
-
That deployment stance changes the meaning of skills slightly. In a hosted SaaS assistant, skills often feel like remote plugins. In OpenClaw, skills are local or workspace-level capability packages inside a runtime the user controls. That makes them closer to local infrastructure than to marketplace extensions, which is why path precedence, approvals, bootstrap files, and workspace isolation play such a large role.
Key Takeaways
-
The main lesson OpenClaw adds is that skills become most meaningful when they are embedded in a runtime that can route conversations, manage sessions, expose tools, isolate agents, connect to real channels and devices, and enforce trust boundaries. OpenClaw therefore serves as a useful bridge between the abstract Agent Skills specification and the real-world design of a persistent, message-driven agent system.
-
Put simply, OpenClaw combines a skills-native runtime, persistent messaging channels, a broad execution surface, app and node interfaces, and a trust-aware control plane. That is why it belongs in this primer, and why the best insertion point is immediately after the general implementation section.
Advantages of Agent Skills: Knowledge Gaps and Domain Adaptation
The Core Problem
- agent skills matter because strong models are still bounded systems: they are general, but not automatically current, local, or procedural enough for real work. In fast-moving domains such as software engineering, the central gap is not raw language ability but the absence of up-to-date workflows, organization-specific conventions, and reliable execution patterns.
-
Closing the knowledge gap with agent skills describes this directly: model weights are fixed at training time, while SDKs, libraries, and best practices keep changing, so lightweight skill packages can act as a practical bridge between static model knowledge and current procedural reality.
- This broader problem has been visible in the research literature for years. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Lewis et al. (2020) showed that external knowledge sources can improve factual and knowledge-intensive performance precisely because parametric memory alone is not enough, and agent skills can be understood as a specialized procedural version of that same idea: not just retrieve facts, but retrieve how to act.
Skills: Domain Adaptation for Agents
-
One of the most important implications of the skills model is architectural: it suggests that you do not always need a separate agent for every domain. Instead, a relatively general-purpose runtime can stay mostly fixed, while domain adaptation happens through portable skills that add expert procedure only when needed. In other words, skills are a way to give agents reusable expertise and capabilities across many task settings without rebuilding the agent itself.
-
This is a major shift in how one can think about adaptation. Instead of fine-tuning the base model or writing giant persistent instruction files, the system becomes layered:
- The advantage is that each layer changes at a different speed. Models improve on one timeline, tools evolve on another, and skills can be edited whenever a workflow changes. That separation is what makes the approach operationally attractive. Skills are hence lightweight, file-based packages of instructions and resources rather than heavyweight model modifications.
Why Procedural Knowledge Matters
- A recurring lesson across agent systems is that raw reasoning ability is not the same thing as dependable expertise. The difference between “a smart model” and “a useful agent” often lies in whether the system knows the right operating procedure for a specific domain, including defaults, failure modes, output standards, and validation loops. That is exactly the niche skills occupy.
-
Closing the knowledge gap with agent skills gives a concrete example from SDK usage, where a small, curated skill can guide an agent toward current APIs, current model choices, and authoritative documentation entry points.
- This is also where agent skills connect cleanly to the tool-use literature. Toolformer by Schick et al. (2023) is relevant because it showed that language models improve when they learn not only that tools exist, but when to call them, with what arguments, and how to incorporate results. Skills sit slightly above that layer: they encode not just tool choice, but task-level procedure over tools, files, and references.
Skills Close the “Knowledge Half-life” Problem
- A useful way to understand the value of skills is through knowledge half-life. Some knowledge remains stable for years, but other knowledge decays quickly. API surfaces, coding conventions, deployment steps, and product-specific workflows may drift in weeks or months. Since retraining a frontier model is expensive and infrequent relative to that pace, there is a mismatch between how often the world changes and how often the model’s internal knowledge updates.
-
Closing the knowledge gap with agent skills is directly about this mismatch and argues that skills are one lightweight way to address it without needing full retraining or elaborate infrastructure.
-
Formally, one can think of useful knowledge at time \(t\) as:
\[K_{\text{useful}}(t) = K_{\text{model}}(t_0) \cup K_{\text{external}}(t)\]- where \(t_0\) is training time and \(K_{\text{external}}(t)\) includes current instructions, references, and procedures. agent skills make that second term manageable by packaging it into bounded, local, reusable artifacts rather than requiring open-ended retrieval for every task. What are skills? provides the format-level basis for this view.
Skills as Organizational Memory
-
Another reason skills matter is that they provide a practical format for encoding organizational memory. Teams accumulate ways of doing things: review checklists, incident-response habits, data-cleaning defaults, file conventions, escalation rules, and output templates. Much of this knowledge is procedural and rarely lives cleanly in one place. Skills give that knowledge a portable container. Put simply, skills are a way for teams and enterprises to capture organization-specific knowledge in portable, version-controlled packages.
-
This is a subtle but important shift. Traditional documentation is usually written for humans first and agents second. Skills are written for agents first, but remain human-readable. That makes them a hybrid artifact: operational documentation that can also be executed indirectly through an agent’s reasoning and tool use.
SKILL.mdshould be easy to read, audit, and improve, which is why the format stays simple and file-based.
Skills Reduce Always-on Context
-
One of the most consequential systems benefits of skills is context discipline. Instead of injecting large instruction files into every turn, skills keep the always-visible layer small and load depth only when relevant. This is the essence of progressive disclosure, and it is what lets many skills coexist without collapsing the context window.
-
The context argument is simple:
\[C_{\text{progressive}} = \sum_i m_i + \sum_{j \in A} s_j + \sum_{k \in R} r_k\]- where \(m_i\) is per-skill metadata, \(A\) is the activated skill set, and \(R\) is the set of loaded resources. Since usually only a small subset of skills activates in any one conversation, this is much cheaper than eager loading of every instruction body. That efficiency is not incidental. It is what makes a skill ecosystem composable rather than merely possible.
Skills Strengthen the Reasoning and Action Connection
-
The intellectual fit between skills and agent research is especially clear in work on reason-action coupling. ReAct by Yao et al. (2022) is relevant because it showed that language models perform better when they interleave reasoning with actions that gather information or change the environment. Skills take that paradigm one step further by giving the model reusable task procedures that shape how those action sequences should unfold in a domain.
-
In that sense, a skill is not merely extra context. It is a structured bias over trajectories. If \(\tau\) is an execution trajectory, then a skill changes the distribution over likely trajectories from \(p(\tau \mid q)\) to \(p(\tau \mid q, s)\).
- where \(q\) is the user request and \(s\) is the activated skill. The point of the skill is to increase the probability of trajectories that are domain-correct, efficient, and verifiable. ReAct by Yao et al. (2022) and Toolformer by Schick et al. (2023) both help motivate this interpretation.
Skills Are a More Practical Unit of Sharing (than Agent Rewrites)
-
Skills also matter because they lower the unit cost of sharing expertise. Sharing an entire custom agent, harness, or orchestration stack is often heavy and vendor-specific. Sharing a small directory with a
SKILL.md, a script, and a few references is much easier. AgentSkills: Overview explicitly treats interoperability and reuse across compatible agents as a core benefit of the standard, and AgentSkills: Client Showcase reinforces that this is intended as a cross-client ecosystem rather than a single-product feature. -
This is strategically important because ecosystems grow faster when the transferable unit is small. A developer, team, or community member can contribute one good skill without needing to maintain a whole product. That creates a path toward layered marketplaces of procedural knowledge rather than monolithic agent platforms.
Why Skills are Especially Valuable in Coding Workflows
-
Although the general idea is broader, coding is a particularly natural fit for skills because software work changes quickly and already lives in file-based environments. The Google blog example is telling here: the Gemini API developer skill exists not because the base model is weak, but because current SDK guidance, current model choices, and current documentation paths are exactly the kinds of information that drift fast and benefit from explicit packaging. Closing the knowledge gap with agent skills reports that adding a developer skill measurably improved performance in their evaluation harness.
-
Coding also benefits because skills can bundle executable validators and helper scripts, which means the agent can not only know the desired workflow but also run the supporting machinery. Scripts and references should thus be first-class parts of the package rather than as afterthoughts.
The Ecosystem Implication: Open Skill Infrastructure
-
If the standard continues to spread, the long-term implication is that skills could become a kind of open procedural infrastructure for agents. Models may continue to improve, but many of the most useful differences between agent deployments could come from their installed skill libraries: domain packages, organization packages, task packages, and compliance packages layered over a relatively stable runtime. The format is positioned as an open standard adopted by multiple agent products, which is exactly the sort of condition needed for ecosystem effects to emerge.
-
This suggests a future in which the competitive frontier is not only model quality, but the quality of the surrounding skill layer. In that world, the best agent for a task may be the one with the best procedural package, not just the one with the largest base model. Toolformer by Schick et al. (2023) is relevant here because it underscores how much practical value comes from structured external capability use rather than raw language modeling alone.
Limitations of Skills
-
Skills are not a complete solution to every agent problem. They still depend on good triggering, careful authoring, and trustworthy runtime integration. A bad skill can misroute work, waste context, or encode brittle instructions. A hostile project skill can even act like a prompt injection payload if trust boundaries are weak. The official implementation and authoring guides both make these limits clear, especially around trust gating, narrow scope, and evaluation discipline.
-
That said, these limits do not weaken the case for skills. They clarify it. Skills are not a replacement for evaluation, retrieval, tools, or model progress. They are a coordination layer that makes those other components more usable in practice.
Key Significance
- The larger significance of agent skills is that they make expertise portable, incremental, and activatable. They let general agents stay general while giving them access to specific procedures exactly when those procedures matter, and they do so in a form that is simple enough to share, inspect, version, and improve.
Key Takeaways: When to Build a Skill (and When Not To)
Core Design Lesson
- The most important lesson of the agent skills model is that better agents do not come only from more intelligence. They come from better packaging of procedure.
- A strong base model can reason, code, and use tools, but reliable work usually depends on an intermediate layer that tells the system what sequence to follow, what defaults to prefer, what output standard to meet, and what edge cases to watch for – precisely the role skills play. In the research literature, this sits naturally beside ReAct by Yao et al. (2022), which shows that performance improves when reasoning is coupled to action, and Toolformer by Schick et al. (2023), which shows that explicit external capability use materially changes model behavior.
When to Build a Skill
-
A skill is warranted when the task is both recurring and procedural. Recurring means the same general task family keeps appearing. Procedural means there is a stable sequence, policy, template, validator, or output contract that should be reused. If the task is one-off, or if the model can already solve it reliably with its native tools and a short prompt, a skill is often unnecessary. This boundary is drawn by emphasizing that skills are for reusable expertise, specialized workflows, and missing context rather than every possible request.
-
A useful decision rule is:
- If any of those terms is near zero, a skill is often the wrong abstraction.
When a Prompt Is Enough
-
A short prompt is usually enough when the task is simple, local, and does not require persistent organizational knowledge. For example, if the agent can already read a file, summarize text, reformat JSON, or answer a straightforward coding question without special conventions, then building a skill often adds more overhead than value. Even a good description will not always cause activation if the request is simple enough for the base agent to handle alone.
-
This boundary matters because over-skillization is a real failure mode. A system overloaded with tiny or unnecessary skills can become harder to route, harder to evaluate, and more wasteful in context. Skills are powerful precisely because they are selective.
When Retrieval Fits
-
Retrieval is better than a skill when the central problem is not procedure but freshness or coverage over a changing body of source material. If the agent mainly needs current facts, a large set of documents, or answers that depend on open-ended reference lookup, then retrieval or web/document access should usually be the first mechanism, with a skill only adding procedure around how to use those sources. This is exactly the pattern described in Closing the knowledge gap with agent skills, where the skill does not replace authoritative docs but points the agent toward them and frames how they should be used. This also fits the broader lesson of Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Lewis et al. (2020), which showed that many knowledge-intensive tasks benefit from retrieval because the needed information is external and dynamic.
-
So the distinction is:
- Use retrieval when you need facts.
- Use a skill when you need procedure.
- Use both when the procedure tells you how to retrieve and apply the facts.
When Tools Are Enough
-
Tools expose actions. Skills expose policies for using those actions. If the problem is just “the agent needs a calculator, shell, browser, or Python runtime,” then a tool alone may be enough. But if the problem is “the agent keeps using the tool in inconsistent or wasteful ways,” then a skill becomes valuable because it narrows the space of acceptable action sequences. This distinction is strongly implied across AgentSkills: Using scripts in skills, AgentSkills: Best practices for skill creators, and AgentSkills: How to add skills support to your agent. Gorilla by Patil et al. (2023) is relevant here because it shows that connecting models to APIs improves capability, but dependable API use still benefits from documentation and structured external guidance.
-
In compact form: a tool defines what the agent is capable of doing, while a skill defines what the agent should do, when it should do it, and how it should be carried out in practice. Tools and skills are hence complementary rather than competing abstractions.
Traits of Good Skills
-
Across the material, strong skills share the same structural properties. They have a narrow, coherent scope. Their descriptions are written around user intent. Their bodies specify default procedures rather than vague aspirations. Their output contracts are explicit. Their repeated mechanical work is bundled into scripts when appropriate. Their deep reference material is deferred into on-demand files rather than dumped into the main body. And they are tested against realistic prompts with and without the skill.
-
A concise idealized representation is:
- If one of those terms is missing, reliability usually drops.
Common Failure Modes
-
A fairly consistent set of failure patterns explains why some skills fail to improve execution despite appearing well-written. In most cases, the issue is not the idea of using a skill, but how the expertise is packaged. Weak skills often add content without adding control, meaning they consume context but do not meaningfully guide decisions. Specifics below:
-
Vagueness: A skill may activate correctly but provide only high-level advice instead of concrete procedure. When instructions do not specify defaults, step order, or output expectations, the model continues to improvise, and the skill has little operational effect.
-
Overbreadth: When a skill tries to cover too many task families, its description becomes imprecise and its body accumulates branches and exceptions. This weakens both triggering and execution, since the agent cannot apply one clear procedure consistently.
-
Redundancy: Some skills restate general knowledge the model already handles well. This increases context usage without improving performance, and often crowds out the task-specific details that would actually help.
-
Overloaded main body (instead of using progressive disclosure): Packing all details into the core skill makes it harder for the model to identify what matters most, reduces clarity, and wastes context that could be reserved for task-relevant state.
-
Lack of evaluation: Without comparing performance against a no-skill baseline and reviewing execution traces, it is difficult to tell whether a skill genuinely improves reliability or simply appears to work in isolated cases.
-
-
Across these cases, the underlying issue is the same: ineffective skills add information but fail to reduce ambiguity. Strong skills, by contrast, make decisions clearer, defaults explicit, and outcomes more predictable.
Why Evaluation Matters
-
The biggest practical divider between a demo skill and a production skill is evaluation discipline. Skill quality is treated as measurable in two independent ways: triggering quality and execution quality. That means skills can be improved like engineered systems rather than treated like magical prompts. Evaluating skill output quality and Optimizing skill descriptions are the clearest expressions of this mindset.
-
A simple rubric is to track both:
- A skill with high \(Q_{\text{execution}}\) but low \(Q_{\text{trigger}}\) is invisible when needed. A skill with high \(Q_{\text{trigger}}\) but low \(Q_{\text{execution}}\) is noisy and disappointing. Only the combination produces durable value.
The architectural implication
-
The larger architectural implication is that skills make it plausible to keep the agent runtime relatively general while moving much of the domain adaptation burden into portable, inspectable, versionable procedural packages. That is why the format feels more like infrastructure than prompt craft. It provides a stable interface between a general model-and-tools layer and a changing domain-knowledge layer. This is the central systems idea running through AgentSkills: Overview, AgentSkills: Specification, and AgentSkills: How to add skills support to your agent.
-
In a compact decomposition:
\[\text{Effective Agent} = \text{General Model} + \text{Runtime} + \text{Portable Expertise}.\]- agent skills are a candidate standard for that last term.
A practical rubric: prompt, tool, retrieval, or skill?
-
A useful closing rubric is this:
-
Use a prompt when the task is simple, local, and not worth codifying.
-
Use a tool when the main gap is missing capability.
-
Use retrieval when the main gap is missing or changing knowledge.
-
Use a skill when the main gap is reusable procedure over capabilities and knowledge.
-
Use a skill plus retrieval when the task needs both a stable workflow and fresh sources of truth.
-
Example: A Complete Skill Workspace
- The following example shows how a skill can sit inside a broader bootstrap-oriented agent workspace. The skill itself remains centered on
SKILL.md, with optionalscripts/,references/, andassets/, while the surrounding Markdown files define persistent runtime context, coordination policy, tool knowledge, user preferences, identity, startup behavior, and operational continuity.
workspace/
├── BOOTSTRAP.md
├── SOUL.md
├── AGENTS.md
├── TOOLS.md
├── USER.md
├── IDENTITY.md
├── HEARTBEAT.md
└── .agents/
└── skills/
└── benchmark-report/
├── SKILL.md
├── scripts/
│ ├── validate_results.py
│ └── generate_summary.py
├── references/
│ ├── evaluation-methodology.md
│ └── reporting-style-guide.md
└── assets/
└── report-template.md
-
In this example,
BOOTSTRAP.mddefines the initialization sequence for the workspace, including which files are loaded first and what checks must pass before normal execution begins.SOUL.mddefines durable behavioral constraints, such as how the agent should communicate uncertainty or handle high-risk operations.AGENTS.mddefines workspace coordination rules, including delegation, review requirements, and escalation boundaries.TOOLS.mdrecords environment-specific operational knowledge, such as preferred commands, available scripts, testing conventions, and infrastructure notes. -
USER.mdcaptures persistent user preferences, such as preferred output format, citation expectations, verbosity, and review style.IDENTITY.mddefines the agent’s stable role within the workspace, such as whether it is acting as a research assistant, reliability engineer, coding agent, or documentation reviewer.HEARTBEAT.mdtracks lightweight runtime continuity, including active tasks, pending reviews, unresolved issues, and current execution state. -
The
benchmark-reportskill remains a portable procedural package. ItsSKILL.mddescribes when to use the skill and how to produce a benchmark report. Itsscripts/directory contains repeatable helpers for validation and summarization. Itsreferences/directory stores detailed methodology and style guidance that should be loaded only when needed. Itsassets/directory contains reusable templates that shape the final artifact. -
This example illustrates the central separation between workspace bootstrap files and skill files. Bootstrap files define the persistent operating environment, while the skill defines a task-specific procedure that can be activated on demand. The result is an agent workspace that can preserve stable policy and context while still supporting modular, selectively loaded skills.
SKILL.md Example
SKILL.mdis the procedural core of the skill. It defines when the skill should activate, what workflow the agent should follow, what defaults to apply, and which supporting resources should be used during execution.
---
name: benchmark-report
description: Generate structured benchmark evaluation reports with validation, citation, and standardized output formatting.
license: Apache-2.0
compatibility: Requires Python 3.11+ and local file access.
metadata:
author: example-org
version: "1.0"
---
# Benchmark Report Skill
## When to Use
Use this skill when generating benchmark summaries, evaluation reports, or comparative performance analyses.
## Workflow
1. Inspect the benchmark inputs and validation requirements.
2. Run the validation scripts before generating summaries.
3. Generate the report using the standard template.
4. Verify citations, metrics, and formatting consistency.
## Output Requirements
- Include methodology and evaluation context.
- Clearly separate observations from interpretation.
- Preserve reproducibility information where possible.
## Available Scripts
- `scripts/validate_results.py`
- `scripts/generate_summary.py`
## References
- `references/evaluation-methodology.md`
- `references/reporting-style-guide.md`
## Assets
- `assets/report-template.md`
BOOTSTRAP.md Example
BOOTSTRAP.mdshould make startup behavior explicit rather than leaving initialization order hidden inside the runtime. It defines which context files load first, what checks run at startup, and which assumptions govern normal execution.
# BOOTSTRAP.md
## Initialization Order
1. Load `SOUL.md` for behavioral constraints.
2. Load `IDENTITY.md` for role context.
3. Load `USER.md` for user preferences.
4. Load `AGENTS.md` for coordination and review policy.
5. Load `TOOLS.md` for environment-specific commands.
6. Discover available skills under `.agents/skills/`.
## Startup Checks
- Verify required tools and scripts are available.
- Confirm the workspace is trusted before loading local instructions.
- Treat bootstrap files as higher-priority context than skill-local guidance.
## Runtime Assumptions
- Skills are loaded only when relevant.
- Destructive or irreversible actions require explicit approval.
- Validation results should be preserved for audit or handoff.
SOUL.md Example
SOUL.mddefines persistent behavioral constraints that should remain stable regardless of which skills are active. It acts as the runtime’s behavioral and communication policy layer.
# SOUL.md
## Behavioral Principles
- Be explicit about uncertainty when evidence is incomplete.
- Prefer conservative execution for destructive operations.
- Preserve auditability during delegated workflows.
## Communication Style
- Prioritize clarity over persuasion.
- Avoid overstating confidence or capability.
- Keep explanations concise unless more depth is requested.
## Operational Constraints
- Do not fabricate citations or execution results.
- Escalate ambiguous high-risk actions for approval.
- Preserve reproducibility whenever possible.
AGENTS.md Example
AGENTS.mddefines workspace-level coordination policy. It specifies how work is delegated, reviewed, validated, and escalated across the runtime.
# AGENTS.md
## Delegation Rules
- Route literature review tasks to the research agent.
- Route validation and regression testing to the testing agent.
- Escalate destructive operations for human approval.
## Review Requirements
- Treat work as incomplete until validation checks pass.
- Preserve intermediate artifacts for audit or review.
- Require documentation updates for public API changes.
## Repository Conventions
- Prefer existing project structure over introducing new patterns.
- Treat `docs/` as user-facing documentation.
- Treat `tests/` as the source of truth for expected behavior.
TOOLS.md Example
TOOLS.mdacts as an operational reference for the workspace. It documents environment-specific commands, infrastructure assumptions, preferred workflows, and practical execution details that the agent should not repeatedly rediscover.
# TOOLS.md
## Development Commands
- Use `pnpm test` for the canonical test suite.
- Use `pnpm lint` before submitting changes.
- Use `scripts/dev.sh` to start local services.
## Infrastructure Notes
- Deployment configuration lives in `infra/`.
- Production secrets are managed externally.
- The staging environment mirrors production behavior.
## Preferred Workflows
- Prefer helper scripts over ad hoc shell commands.
- Prefer incremental validation before full benchmarks.
- Treat CI results as the authoritative validation source.
USER.md Example
USER.mdcaptures persistent user preferences and workflow expectations. It allows the runtime to adapt behavior to a particular user or team without embedding those assumptions into reusable skills.
# USER.md
## Communication Preferences
- Prefer concise explanations unless more detail is requested.
- Include citations by default for research-oriented outputs.
- Surface uncertainty explicitly when confidence is low.
## Workflow Preferences
- Prefer incremental validation over one-shot execution.
- Preserve intermediate artifacts for review.
- Favor reproducibility over execution speed.
## Tooling Preferences
- Prefer Python for structured data analysis.
- Prefer Markdown for generated reports.
- Prefer repository helper scripts over ad hoc commands.
IDENTITY.md Example
IDENTITY.mddefines the agent’s persistent role within the workspace. It establishes long-lived responsibilities, operational scope, and institutional context that remain stable across tasks.
# IDENTITY.md
## Role
You are the infrastructure reliability agent for this workspace.
## Primary Responsibilities
- Maintain deployment safety and operational stability.
- Prioritize reproducibility and auditability.
- Support debugging, monitoring, and incident analysis workflows.
## Scope Boundaries
- Do not approve production-impacting changes without verification.
- Escalate ambiguous infrastructure risks for human review.
- Treat rollback safety as higher priority than execution speed.
## Operational Perspective
- Assume the repository is production-adjacent.
- Prefer conservative infrastructure changes.
- Preserve operational traceability whenever possible.
HEARTBEAT.md Example
HEARTBEAT.mdtracks lightweight runtime continuity across long-running or delegated workflows. It preserves operational state that is too transient for persistent policy files but too important to leave entirely in conversational context.
# HEARTBEAT.md
## Active Work
- Benchmark evaluation currently in validation phase.
- Documentation review pending for deployment updates.
## Delegation State
- Research agent completed citation verification.
- Testing agent rerunning regression checks after fixes.
## Outstanding Issues
- Rollback procedure still requires approval.
- API compatibility validation remains incomplete.
## Runtime Notes
- Preserve benchmark artifacts until review completes.
- Treat current workspace state as provisional until validation passes.
References
Agent Skills core docs
- AgentSkills: Overview
- AgentSkills: What are skills?
- AgentSkills: Specification
- AgentSkills: Quickstart
- AgentSkills: Best practices for skill creators
- AgentSkills: Optimizing skill descriptions
- AgentSkills: Evaluating skill output quality
- AgentSkills: Using scripts in skills
- AgentSkills: How to add skills support to your agent
- AgentSkills: Client Showcase
Ecosystem articles and implementation guides
- Closing the knowledge gap with agent skills
- Building Effective AI Agents
- Writing effective tools for AI agents
- Effective context engineering for AI agents
- Effective harnesses for long-running agents
- Demystifying evals for AI agents
- Code execution with MCP: building more efficient AI agents
- Introducing advanced tool use on the Claude Developer Platform
Retrieval, tools, and execution papers
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Lewis et al. (2020)
- ReAct: Synergizing Reasoning and Acting in Language Models by Yao et al. (2022)
- Toolformer: Language Models Can Teach Themselves to Use Tools by Schick et al. (2023)
- Gorilla: Large Language Model Connected with Massive APIs by Patil et al. (2023)
Reflection, memory, and iterative improvement
- Reflexion: Language Agents with Verbal Reinforcement Learning by Shinn et al. (2023)
- Self-Refine: Iterative Refinement with Self-Feedback by Madaan et al. (2023)
- MemGPT: Towards LLMs as Operating Systems by Packer et al. (2023)
Agent architectures and long-horizon behavior
- Generative Agents: Interactive Simulacra of Human Behavior by Park et al. (2023)
- Voyager: An Open-Ended Embodied Agent with Large Language Models by Wang et al. (2023)
Citation
If you found our work useful, please cite it as:
@article{Chadha2020DistilledAgentSkills,
title = {Agent Skills},
author = {Chadha, Aman and Jain, Vinija},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}