Primers • VLM Architectures
- Overview
- Applications
- Architectural Challenges
- Architecture
- Training Process
- Fine-Tuning Process
- Leaderboards
- Popular VLMs
- VLMs for Generation
- GPT-4V
- LLaVA
- Frozen
- Flamingo
- OpenFlamingo
- Idefics
- PaLI
- PaLM-E
- Qwen-VL
- Fuyu-8B
- SPHINX
- MIRASOL3B
- BLIP
- BLIP-2
- InstructBLIP
- MiniGPT-4
- MiniGPT-v2
- LLaVA-Plus
- BakLLaVA
- LLaVA-1.5
- CogVLM
- FERRET
- KOSMOS-1
- KOSMOS-2
- OFAMultiInstruct
- LaVIN
- TinyGPT-V
- CoVLM
- FireLLaVA
- MoE-LLaVA
- BLIVA
- PALO
- DeepSeek-VL
- Grok-1.5 Vision
- LLaVA++
- LLaVA-NeXT
- InternVL
- Falcon 2
- PaliGemma
- Chameleon
- Phi-3.5-Vision
- Molmo
- Pixtral
- NVLM
- VLMs for Understanding
- Medical VLMs for Generation
- Indic VLMs for Generation
- VLMs for Generation
- Popular Video LLMs
- Any-to-Any VLMs
- Comparative Analysis
- Further Reading
- Citation
Overview
- Vision-Language Models (VLMs) integrate both visual (image) and textual (language) information processing. They are designed to understand and generate content that involves both images and text, enabling them to perform tasks like image captioning, visual question answering, and text-to-image generation.
- This primer offers an overview of their architecture and how they differ from Large Language Models (LLMs).
Applications
- Let’s look at a few VLM applications:
- Image Captioning: Generating descriptive text for images.
- Visual Question Answering: Answering questions based on visual content.
- Cross-modal Retrieval: Finding images based on text queries and vice versa.
Architectural Challenges
- Put succinctly, VLMs need to overcome the following challenges as part of their architectural definition and training:
- Data Alignment: Ensuring proper alignment between visual and textual data is challenging.
- Complexity: The integration of two modalities adds complexity to the model architecture and training process.
Architecture
- The architecture of VLMs is centered around the effective fusion of visual and linguistic modalities, a process that requires sophisticated mechanisms to align and integrate information from both text and images.
- Let’s delve deeper into this architecture, focusing on modality fusion and alignment, and then look at some examples of popular VLMs and their architectural choices.
Architecture of Vision-Language Models
- Modality Fusion:
- Early Fusion: In this approach, visual and textual inputs are combined at an early stage, often before any deep processing. This can mean simply concatenating features or embedding both modalities into a shared space early in the model.
- Intermediate Fusion: Here, fusion occurs after some independent processing of each modality. It allows each stream to develop an intermediate understanding before integration, often through cross-modal attention mechanisms.
- Late/Decision-Level Fusion: In late fusion, both modalities are processed independently through deep layers, and fusion occurs near the output. This method keeps the modalities separate for longer, allowing for more specialized processing before integration.
- Modality Alignment:
- Cross-Modal Attention: Models often use attention mechanisms, like transformers, to align elements of one modality (e.g., objects in an image) with elements of another (e.g., words in a sentence). This helps the model understand how specific parts of an image correlate with specific textual elements.
- Joint Embedding Space: Creating a joint/shared representation space where both visual and textual features are projected. This space is designed so that semantically similar concepts from both modalities are close to each other.
- Training Strategies:
- Contrastive Learning: Often used for alignment, this involves training the model to bring closer the representations of text and images that are semantically similar and push apart those that are not.
- Multi-Task Learning: Training the model on various tasks (e.g., image captioning, visual question answering) to improve its ability to understand and integrate both modalities.
Examples of Popular VLMs and Their Architectural Choices
- Each of the below models represents a unique approach to integrating and aligning text and image data, showcasing the diverse methodologies within the field of VLMs. The choice of architecture and fusion strategy depends largely on the specific application and the nature of the tasks the model is designed to perform.
- CLIP (Contrastive Language–Image Pretraining):
- Architecture: Uses a transformer for text and a ResNet (or a Vision Transformer) for images.
- Fusion Strategy: Late fusion, with a focus on learning a joint embedding space.
- Alignment Method: Trained using contrastive learning, where image-text pairs are aligned in a shared embedding space.
- DALL-E:
- Architecture: Based on the GPT-3 architecture, adapted to handle both text and image tokens.
- Fusion Strategy: Early to intermediate fusion, where text and image features are processed in an intertwined manner.
- Alignment Method: Uses an autoregressive model that understands text and image features in a sequential manner.
- VisualBERT:
- Architecture: A BERT-like model that processes both visual and textual information.
- Fusion Strategy: Intermediate fusion with cross-modal attention mechanisms.
- Alignment Method: Aligns text and image features using attention within a transformer framework.
- LXMERT (Learning Cross-Modality Encoder Representations from Transformers):
- Architecture: Specifically designed for vision-and-language tasks, uses separate encoders for language and vision, followed by a cross-modality encoder.
- Fusion Strategy: Intermediate fusion with a dedicated cross-modal encoder.
- Alignment Method: Employs cross-modal attention between language and vision encoders.
VLM: Differences from Large Language Models (LLMs)
- Input Modalities:
- VLMs: Handle both visual (images) and textual (language) inputs.
- LLMs: Primarily focused on processing and generating textual content.
- Task Versatility:
- VLMs: Capable of tasks that require understanding and correlating information from both visual and textual data, like image captioning, visual storytelling, etc.
- LLMs: Specialize in tasks that involve only text, such as language translation, text generation, question answering purely based on text, etc.
-
Complexity in Integration: VLMs involve a more complex architecture due to the need to integrate and correlate information from two different modalities (visual and textual), whereas LLMs deal with a single modality.
- Use Cases: VLMs are particularly useful in scenarios where both visual and textual understanding is crucial, such as in social media analysis, where both image and text content are prevalent. LLMs are more focused on applications like text summarization, chatbots, and content creation where the primary medium is text.
- In summary, while both VLMs and LLMs are advanced AI models leveraging deep learning, VLMs stand out for their ability to understand and synthesize information from both visual and textual data, offering a broader range of applications that require multimodal understanding.
Connecting Vision and Language via VLMs
- Vision-Language Models (VLMs) are designed to understand and generate content that combines both visual and textual data. To effectively integrate these two distinct modalities—vision and language—VLMs use specialized mechanisms, such as adapters and linear layers.
- This section details popular building blocks that various VLMs utilize to link visual and language input. Let’s delve into how these components work in the context of VLMs.
Adapters/MLPs/Fully Connected Layers in VLMs
-
Purpose of Adapters: Adapters are small neural network modules inserted into pre-existing models. In the context of VLMs, they facilitate the integration of visual and textual data by transforming the representations from one modality to be compatible with the other.
-
Functioning: Adapters typically consist of a few fully connected layers (put simply, a Multi-Layer Perceptron). They take the output from one type of encoder (say, a vision encoder) and transform it into a format that is suitable for processing by another type of encoder or decoder (like a language model).
-
Role of Linear Layers: Linear layers, or fully connected layers, are a fundamental component in neural networks. In VLMs, they are crucial for processing the output of vision encoders.
-
Processing Vision Encoder Output: After an image is processed through a vision encoder (like a CNN or a transformer-based vision model), the resulting feature representation needs to be adapted to be useful for language tasks. Linear layers can transform these vision features into a format that is compatible with the text modality.
-
Combining Modalities: In a VLM, after processing through adapters and linear layers, the transformed visual data can be combined with textual data. This combination typically occurs before or within the language model, allowing the VLM to generate responses or analyses that incorporate both visual and textual understanding.
-
End-to-End Training: In some advanced VLMs, the entire model, including vision encoders, linear layers, and language models, can be trained end-to-end. This approach allows the model to better learn how to integrate and interpret both visual and textual information.
-
Flexibility: Adapters offer flexibility in model training. They allow for fine-tuning a pre-trained model on a specific task without the need to retrain the entire model. This is particularly useful in VLMs where training from scratch is often computationally expensive.
- In summary, adapters and linear layers in VLMs serve as critical components for bridging the gap between visual and textual modalities, enabling these models to perform tasks that require an understanding of both images and text.
Q-Former
- The Querying Transformer (Q-Former) proposed in BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models is a critical component designed to carry out modality alignment and bridge the gap between a frozen image encoder and a frozen Large Language Model (LLM) in the BLIP-2 framework. Put simply, Q-Former is a trainable module designed to connect a frozen image encoder with a LLM.
- It features two transformer submodules: an image transformer for visual feature extraction from the image encoder, and a text transformer that serves as both text encoder and decoder. The module uses learnable query embeddings for the image transformer, facilitating interactions through self-attention and cross-attention layers with the frozen image features. The queries interact with each other through self-attention layers, and interact with frozen image features through cross-attention layers (inserted every other transformer block). These queries additionally interact with text via the same self-attention layers. The Q-Former is initialized with BERTbase pre-trained weights, while its cross-attention layers are randomly initialized. It comprises 188M parameters and employs 32 queries, each with a dimension of 768. The output query representation is significantly smaller than the frozen image features, allowing the architecture to focus on extracting visual information most relevant to the text.
- Here’s an overview of its structure and role.
Internal Architecture of Q-Former
- Two Transformer Submodules: The Q-Former is composed of two main parts:
- Image Transformer: This submodule interacts with the frozen image encoder. It is responsible for extracting visual features.
- Text Transformer: This part can function as both a text encoder and a text decoder. It deals with processing and generating text.
- Learnable Query Embeddings: Q-Former utilizes a set number of learnable query embeddings. These queries:
- Interact with each other through self-attention layers.
- Engage with frozen image features through cross-attention layers, which are inserted in alternate transformer blocks.
- Can also interact with text through the same self-attention layers.
-
Self-Attention Masking Strategy: Depending on the pre-training task, different self-attention masks are applied to control interactions between queries and text.
- Initialization and Parameters: The Q-Former is initialized with pre-trained weights of BERTbase, but its cross-attention layers are randomly initialized. The Q-Former contains a total of 188 million parameters, with the queries being considered as model parameters.
Q-Former: A Visual Summary
- The following figure from the paper shows an overview of BLIP-2’s framework. They pre-train a lightweight Querying Transformer following a two-stage strategy to bridge the modality gap. The first stage bootstraps vision-language representation learning from a frozen image encoder. The second stage bootstraps vision-to-language generative learning from a frozen LLM, which enables zero-shot instructed image-to-text generation.
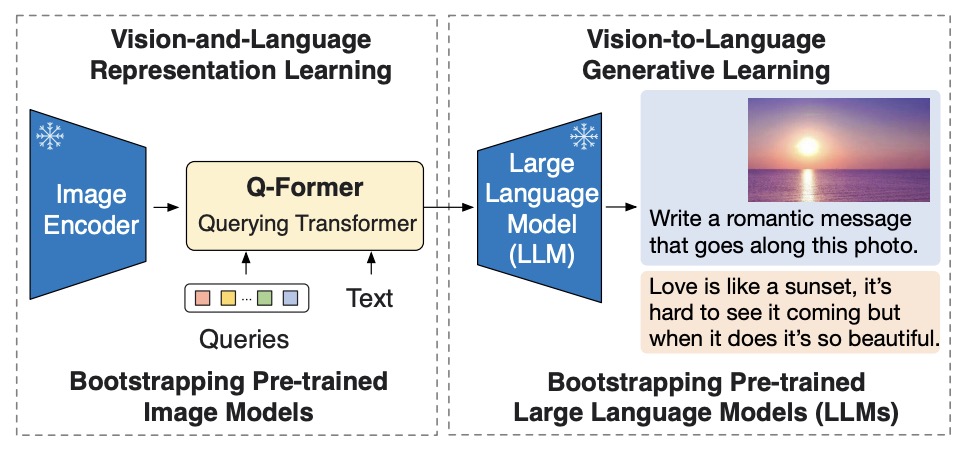
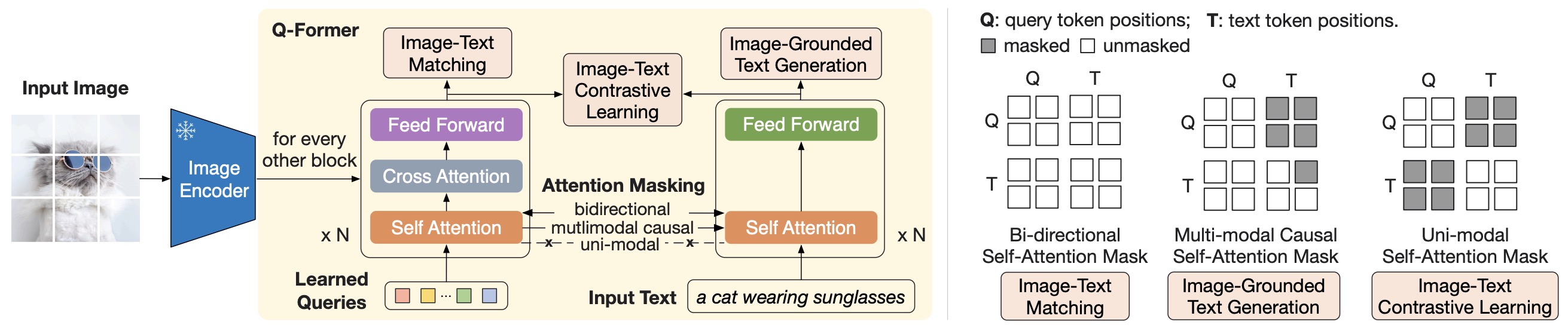
- The following figure from the paper shows: (Left) Model architecture of Q-Former and BLIP-2’s first-stage vision-language representation learning objectives. They jointly optimize three objectives which enforce the queries (a set of learnable embeddings) to extract visual representation most relevant to the text. (Right) The self-attention masking strategy for each objective to control query-text interaction.
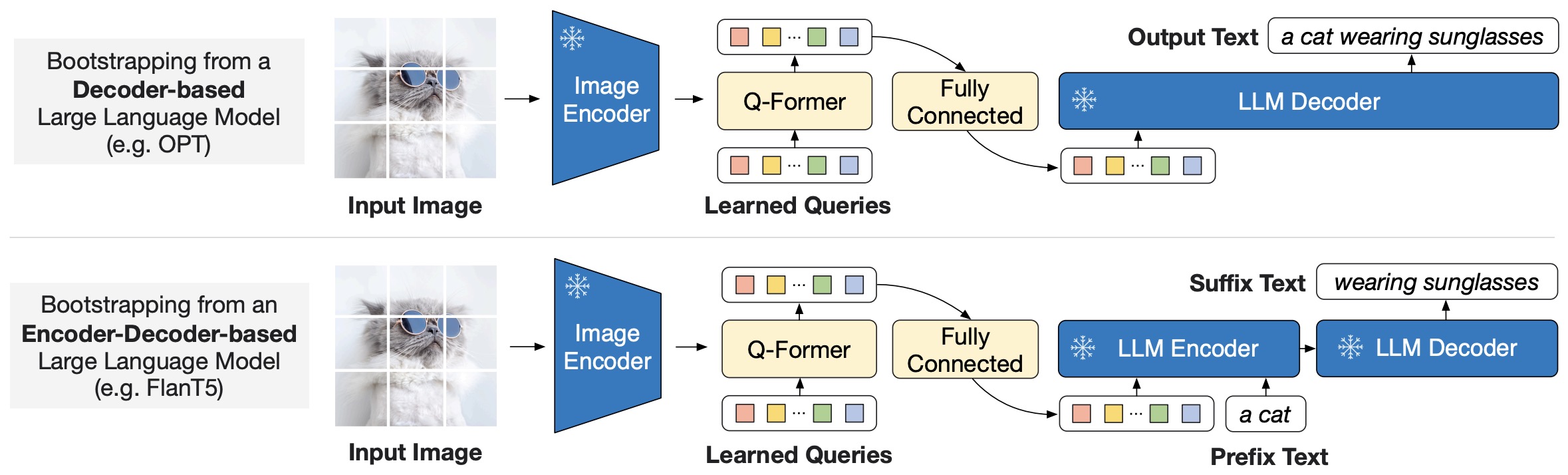
- The following figure from the paper shows BLIP-2’s second-stage vision-to-language generative pre-training, which bootstraps from frozen large language models (LLMs). (Top) Bootstrapping a decoder-based LLM (e.g., OPT). (Bottom) Bootstrapping an encoder-decoder-based LLM (e.g., FlanT5). The fully-connected layer adapts from the output dimension of the Q-Former to the input dimension of the chosen LLM.
Role of Q-Former
- Bridging Modalities: The primary function of the Q-Former is to serve as a trainable module that connects the visual information from the image encoder with the linguistic capabilities of the LLM.
- Feature Extraction and Interaction: It extracts a fixed number of output features from the image encoder, irrespective of the input image resolution, and enables interactions between these visual features and textual components.
- Adapting to Different Pre-training Tasks: Through its flexible architecture and self-attention masking strategy, the Q-Former can adapt to various pre-training tasks, effectively facilitating the integration of visual and textual data.
Summary
- To reiterate, the Q-Former in the BLIP-2 framework, as described in the document, comprises two transformer submodules - an image transformer and a text transformer. These submodules share self-attention layers. The image transformer interacts with the frozen image encoder for visual feature extraction, while the text transformer can function both as a text encoder and a text decoder. The Q-Former uses a set number of learnable query embeddings as input to the image transformer, which interacts with frozen image features through cross-attention layers (inserted in every other transformer block) and with the text through self-attention layers. The model applies different self-attention masks to control query-text interaction based on the pre-training task. The Q-Former is initialized with the pre-trained weights of BERTbase, and it contains a total of 188M parameters
- In summary, the Q-Former in the BLIP-2 framework plays a pivotal role in merging visual and textual information, making it a key element in enhancing the model’s ability to understand and generate contextually relevant responses in multimodal scenarios.
Perceiver Resampler
- The Perceiver Resampler, utilized in the Flamingo: a Visual Language Model for Few-Shot Learning is an integral component designed to efficiently bridge the gap between vision and language processing in the model. Here’s a breakdown of its composition and role:
Composition of Perceiver Resampler
- Function: The Perceiver Resampler’s primary function is to take a variable number of image or video features from the vision encoder and convert them into a fixed number of visual outputs.
- Output Generation: It produces 64 visual outputs regardless of the input size.
- Reducing Computational Complexity: By converting varying-size large feature maps into a few visual tokens, it significantly reduces the computational complexity involved in vision-text cross-attention.
- Latent Input Queries: Similar to the Perceiver and DETR models, it utilizes a predefined number of latent input queries. These queries are fed to a Transformer module.
- Cross-Attention Mechanism: The latent queries cross-attend to the visual features, facilitating the integration of visual information into the language processing workflow.
Flamingo: A Visual Summary
- The following figure from the paper shows the Flamingo architecture overview.
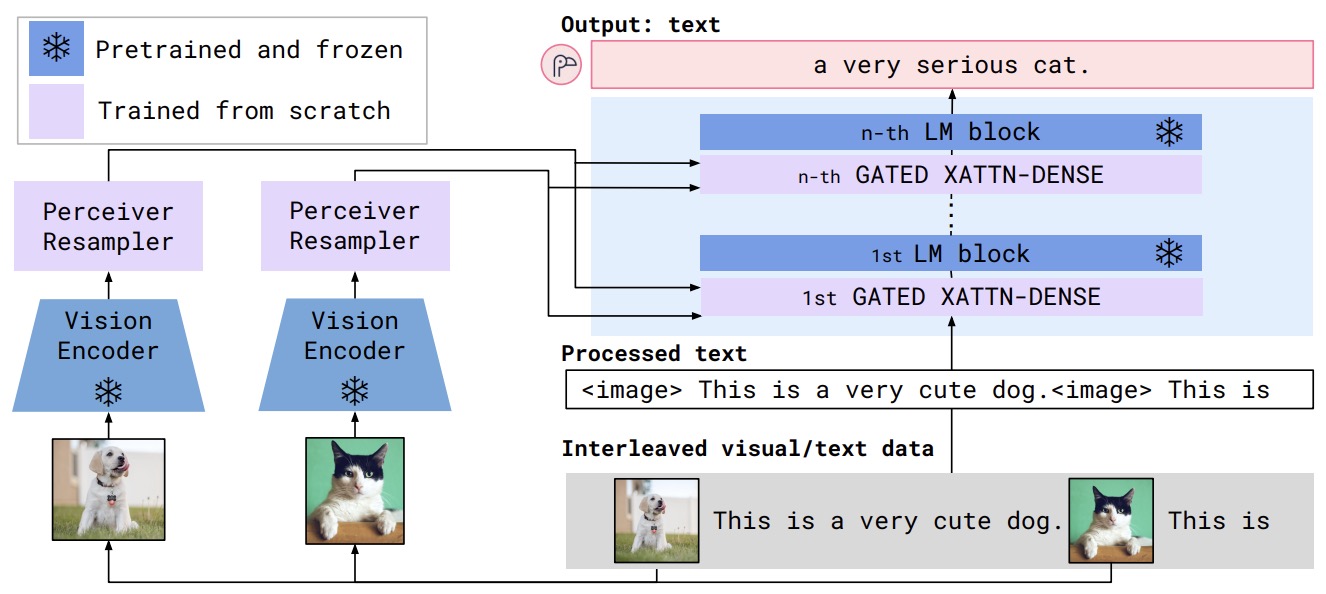
Role of Perceiver Resampler
- Connecting Vision and Language Models: It serves as a crucial link between the vision encoder and the frozen language model, enabling the model to process and integrate visual data efficiently.
- Efficiency and Performance: The Perceiver Resampler enhances the model’s ability to handle vision-language tasks more effectively compared to using a plain Transformer or a Multilayer Perceptron (MLP).
Summary
- To recap, the Perceiver Resampler is designed to convert varying-size large feature maps into a smaller number of visual tokens, thus reducing the computational complexity in vision-text cross-attention. It employs a set of latent input queries that interact with visual features through a Transformer, facilitating efficient integration of visual and textual data. In essence, the Perceiver Resampler plays a pivotal role in reducing the complexity of handling large visual data and efficiently integrating it with language processing, thereby enhancing the overall capability of the model in multimodal tasks.
Training Process
- The diagram below illustrates the structure of a typical vision language model, depicting its components during different phases: pre-training and fine-tuning.
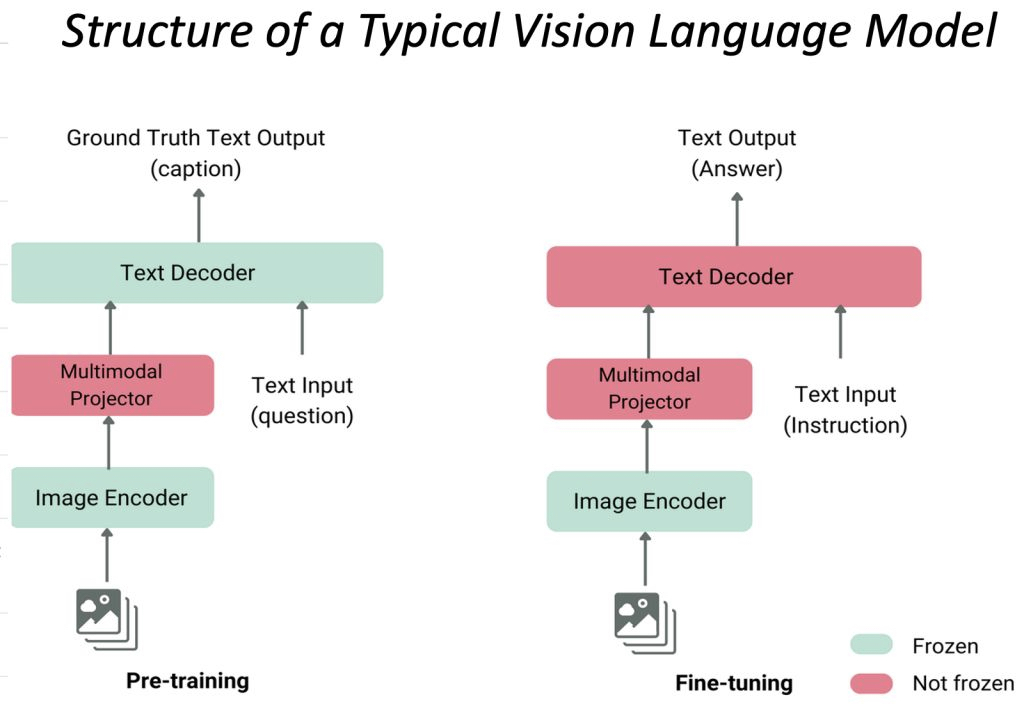
- Image Encoder:
- This component is responsible for processing the input image and encoding it into a feature-rich representation.
- In both the pre-training and fine-tuning phases, the Image Encoder is used to process the visual information.
- Multimodal Projector:
- This bridges the gap between the visual information encoded by the Image Encoder and the textual data processed or produced by the Text Decoder.
- It helps integrate or align the features from both modalities (text and image).
- Text Decoder (LLM):
- The Text Decoder generates text outputs based on the combined features provided by the Multimodal Projector.
- In the pre-training phase, the output is typically a caption that describes the image (Ground Truth Text Output), i.e., the data is in the form of
(image, text)pairs. In the fine-tuning phase, the output is an answer or a response to an instruction (Text Output).
- Text Input:
- In pre-training, the model might receive a question or some form of textual prompt to guide the generation of the image caption.
- In fine-tuning, the input text could be an instruction or specific question that guides the model to provide a more focused or contextual answer.
- Frozen vs. Not Frozen Components:
- The diagram indicates that certain parts of the model may be frozen (not updated) during the fine-tuning phase. Typically, this would be the Image Encoder to preserve the learned visual features.
- While the Multimodal Projector is fine-tuned during both the pre-training and fine-tuning phases, the Text Decoder (LLM) is fine-tuned only during the fine-tuning phase (and kept frozen during pre-training).
- This structure enables the model to leverage both visual and textual information effectively, adapting to various tasks by fine-tuning specific components.
Fine-Tuning Process
- When fine-tuning a VLM, the decision of which layers to fine-tune is guided by the model’s architecture and the specific objectives of the fine-tuning task. Here’s a detailed breakdown:
Vision Encoder Layers
- Role: These layers process and encode the visual input, such as images. They capture features from the visual data that are then used by the model to understand and integrate with text.
- When to Fine-Tune: Fine-tuning these layers is particularly beneficial if the visual data domain of your task differs from the domain on which the model was originally pre-trained. For example, if the model was pre-trained on general image datasets but your task involves medical images or satellite imagery, fine-tuning these layers can help the model better adapt to the new visual domain.
Language Model (LLM) Layers
- Role: These layers are responsible for processing and encoding textual input, such as captions or descriptions. They interpret and generate text based on the information received from the vision encoder and projection layers.
- When to Fine-Tune: Fine-tuning the LLM layers is crucial when the textual data in your task contains characteristics that differ significantly from the pre-training data. For instance, if your task involves domain-specific language, such as technical jargon or legal terminology, fine-tuning the LLM layers will enable the model to generate and understand text that is more accurate and relevant to that specific domain.
Projection/Cross-Attention Layers
- Role: In many VLM architectures, projection/cross-attention layers allow the model to integrate and align visual and textual inputs, facilitating the interaction between these modalities.
- When to Fine-Tune: Fine-tuning the projection layers is particularly important for tasks that require a strong correlation between visual and textual data, such as visual question answering, image captioning, or tasks involving multimodal reasoning. These layers help the model better understand and relate the visual content to the corresponding text, improving overall performance on such tasks.
Common Fine-Tuning Strategies
- Fine-Tuning the Entire Model: This involves fine-tuning all layers (vision encoder, LLM, and projection layers). While this approach is resource-intensive, it allows the model to fully adapt to the new task, making it the most comprehensive strategy.
- Partial Fine-Tuning: In this approach, some layers, often the lower layers, are kept frozen to retain the general features learned during pre-training, while others, typically the higher layers or projection layers, are fine-tuned. This reduces computational costs and is effective when the new task is similar to the original pre-training tasks.
- Adapter-Based Fine-Tuning: Instead of fine-tuning the main layers directly, small adapter layers are inserted into the model, and only these adapters are fine-tuned. This is a parameter-efficient approach that allows for task-specific tuning without modifying the original model weights extensively.
Use of LoRA (Low-Rank Adaptation)
- LoRA Application: LoRA can be applied to any of these layers (Vision Encoder, LLM, or Projection) to introduce efficient, lightweight fine-tuning. By adding trainable low-rank matrices to the existing model parameters, LoRA allows for fine-tuning with minimal additional computational overhead. This approach is particularly useful in scenarios where full model fine-tuning is impractical due to resource constraints.
Summary
In summary, whether you fine-tune the Vision Encoder layers, LLM layers, or Projection layers depends on the nature of your task:
- Fine-tune Vision Encoder Layers for tasks involving new or different visual domains.
- Fine-tune LLM Layers when dealing with domain-specific textual data.
- Fine-tune Projection Layers for tasks that require strong integration of visual and textual information.
- LoRA can be effectively used to fine-tune these layers in a resource-efficient manner, enabling the model to adapt to new tasks with minimal changes to its original structure.
Leaderboards
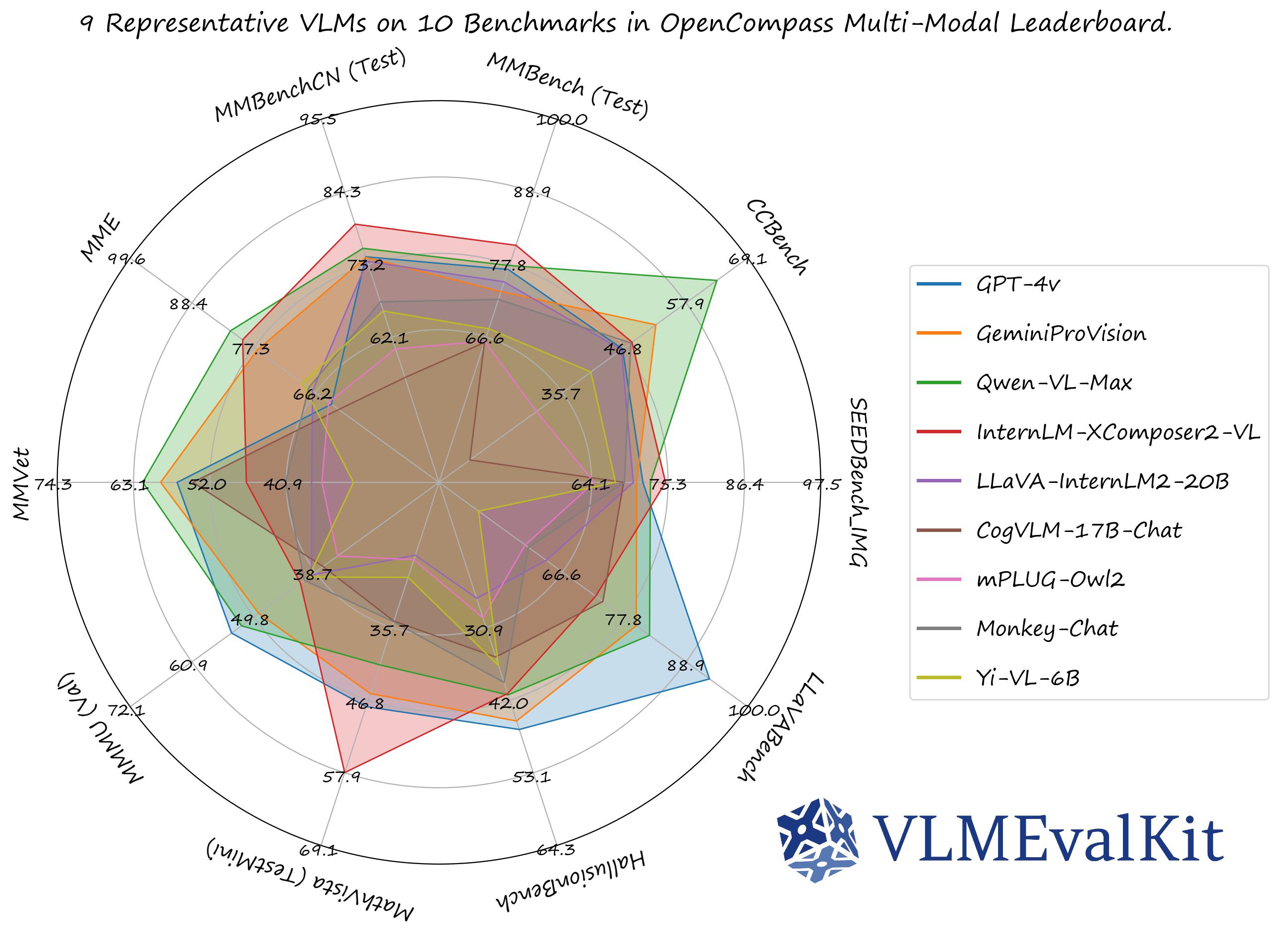
🤗 Open VLM Leaderboard
- Based on VLMEvalKit: A Toolkit for Evaluating Large Vision-Language Models which is an open-source evaluation toolkit for VLMs.
- As of this writing, the Open VLM Leaderboard covers 54 different VLMs (including GPT-4V, Gemini, QwenVL-Plus, LLaVA, etc.) and 22 different multi-modal benchmarks.
🤗 Open Object Detection Leaderboard
- The 🤗 Open Object Detection Leaderboard aims to track, rank and evaluate vision models available in the hub designed to detect objects in images.

Popular VLMs
VLMs for Generation
GPT-4V
- GPT-4 with vision (GPT-4V) enables users to instruct GPT-4 to analyze image inputs provided by the user.
- In the GPT-4V system card, OpenAI has analyzed the safety properties of GPT-4V.
LLaVA
- LLaVA is the most popular open-source multimodal framework.
- Proposed in Visual Instruction Tuning by Liu et al. from UW-Madison, Microsoft Research, and Columbia University.
- Instruction tuning large language models (LLMs) using machine-generated instruction-following data has improved zero-shot capabilities on new tasks, but the idea is less explored in the multimodal field.
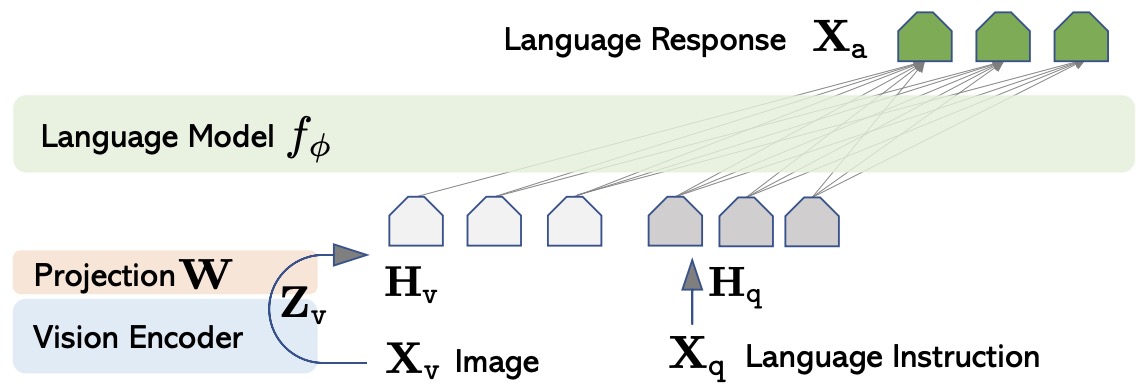
- The paper presents the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data. By instruction tuning on such generated data, they introduce Large Language-and-Vision Assistant (LLaVA), an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding.
- LLaVA is a minimal extension of the LLaMA series which conditions the model on visual inputs besides just text. The model leverages a pre-trained CLIP’s vision encoder to provide image features to the LLM, with a lightweight projection module in between.
- The model is first pre-trained on image-text pairs to align the features of the LLM and the CLIP encoder, keeping both frozen, and only training the projection layer. Next, the entire model is fine-tuned end-to-end, only keeping CLIP frozen, on visual instruction data to turn it into a multimodal chatbot.
- Their early experiments show that LLaVA demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%.
- The following figure from the paper shows the LLaVA network architecture.
- Project page; Demo; Code.
Frozen
- When trained at sufficient scale, auto-regressive language models exhibit the notable ability to learn a new language task after being prompted with just a few examples.
- Proposed in Multimodal Few-Shot Learning with Frozen Language Models, this paper by Tsimpoukelli et al. from DeepMind in NeurIPS 2021 presents Frozen – a simple, yet effective, approach for transferring this few-shot learning ability to a multimodal setting (vision and language).
- Using aligned image and caption data, they train a vision encoder to represent each image as a sequence of continuous embeddings, such that a pre-trained, frozen language model prompted with this prefix generates the appropriate caption.
- The resulting system is a multimodal few-shot learner, with the surprising ability to learn a variety of new tasks when conditioned on examples, represented as a sequence of multiple interleaved image and text embeddings.
- They demonstrate that it can rapidly learn words for new objects and novel visual categories, do visual question-answering with only a handful of examples, and make use of outside knowledge, by measuring a single model on a variety of established and new benchmarks.
- The following figure from the paper shows that gradients through a frozen language model’s self attention layers are used to train the vision encoder:
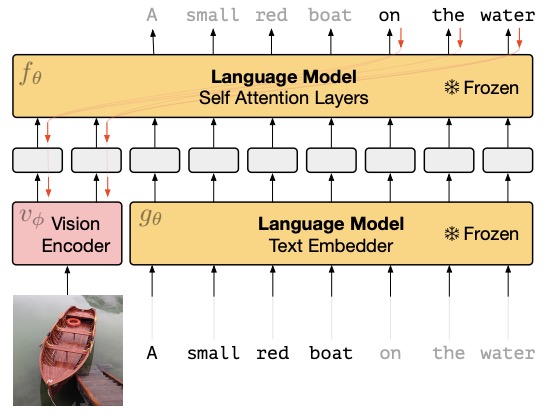
- Code.
Flamingo
- Introduced in Flamingo: a Visual Language Model for Few-Shot Learning, Flamingo models include key architectural innovations to: (i) bridge powerful pretrained vision-only and language-only models, (ii) handle sequences of arbitrarily interleaved visual and textual data, and (iii) seamlessly ingest images or videos as inputs.
- The key ideas behind Flamingo are:
- Interleave cross-attention layers with language-only self-attention layers (frozen).
- Perceiver-based architecture that transforms the input sequence data (videos) into a fixed number of visual tokens.
- Large-scale (web) multi-modal data by scraping webpages which has inter-leaved text and images.
- Thanks to their flexibility, Flamingo models can be trained on large-scale multimodal web corpora containing arbitrarily interleaved text and images, which is key to endow them with in-context few-shot learning capabilities.
- They perform a thorough evaluation of the proposed Flamingo models, exploring and measuring their ability to rapidly adapt to a variety of image and video understanding benchmarks. These include open-ended tasks such as visual question-answering, where the model is prompted with a question which it has to answer, captioning tasks, which evaluate the ability to describe a scene or an event, and close-ended tasks such as multiple choice visual question-answering.
- For tasks lying anywhere on this spectrum, they demonstrate that a single Flamingo model can achieve a new state of the art for few-shot learning, simply by prompting the model with task-specific examples. On many of these benchmarks, Flamingo actually surpasses the performance of models that are fine-tuned on thousands of times more task-specific data.

OpenFlamingo
- An open source version of DeepMind’s Flamingo model! They provide a PyTorch implementation for training and evaluating OpenFlamingo models as well as an initial OpenFlamingo 9B model trained on a new Multimodal C4 dataset.
Idefics
- IDEFICS (Image-aware Decoder Enhanced à la Flamingo with Interleaved Cross-attentionS) is an open-access reproduction of Flamingo, a closed-source visual language model developed by Deepmind. IDEFICS is an 80 billion parameter model of DeepMind’s Flamingo VLM model. Like GPT-4, the multimodal model accepts arbitrary sequences of image and text inputs and produces text outputs. IDEFICS is built solely on publicly available data and models.
- The model can answer questions about images, describe visual contents, create stories grounded on multiple images, or simply behave as a pure language model without visual inputs.
- IDEFICS is on par with the original closed-source model on various image-text benchmarks, including visual question answering (open-ended and multiple choice), image captioning, and image classification when evaluated with in-context few-shot learning. It comes into two variants: a large 80 billion parameters version and a 9 billion parameters version.
- HuggingFace has also fine-tuned the base models on a mixture of supervised and instruction fine-tuning datasets, which boosts the downstream performance while making the models more usable in conversational settings: idefics-80b-instruct and idefics-9b-instruct.
- The following screenshot is an example of interaction with the instructed model:

Knowledge sharing memo for IDEFICS, an open-source reproduction of Flamingo
- Notes/lessons by HuggingFace on training IDEFICS. They highlight the mistakes they’ve made and remaining open questions. Using an auxiliary Z-loss, Atlas for data filtering, and BF16 loss values were particularly enlightening.
- Related: Older knowledge memo which focused on lessons learned from stabilizing training at medium scale.

Idefics2: A Powerful 8B Vision-Language Model for the Community
- This article introduces Idefics2, a general multimodal model capable of processing arbitrary sequences of texts and images to generate text responses. It excels in various tasks such as answering questions about images, describing visual content, creating stories grounded in multiple images, extracting information from documents, and performing basic arithmetic operations. Idefics2 is an improved version of Idefics1, featuring 8 billion parameters, an open Apache 2.0 license, and enhanced OCR capabilities, positioning it as a strong foundation for the multimodality community.
- Idefics2’s architecture integrates images and text more efficiently than Idefics1 by moving away from gated cross-attentions and simplifying the integration of visual features into the language backbone. Images are processed through a vision encoder followed by Perceiver pooling and an MLP modality projection, which are then concatenated with text embeddings as shown in the figure below. This approach enables the model to handle images in their native resolutions and aspect ratios, eliminating the need for resizing.
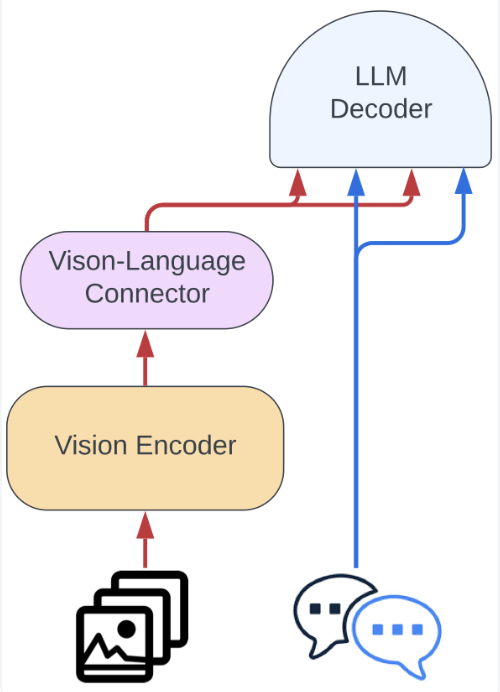
- Training data for Idefics2 included a mixture of openly available datasets such as Wikipedia, OBELICS, LAION-COCO, PDFA, IDL, Rendered-text, and WebSight. Additionally, Idefics2 was fine-tuned using “The Cauldron,” an open compilation of 50 manually-curated datasets formatted for multi-turn conversations. This comprehensive dataset compilation addresses the challenge of scattered and disparate task-oriented data formats in the community.
- Significant implementation details include the use of sub-image splitting to handle large-resolution images, following strategies from SPHINX and LLaVa-NeXT. The model’s OCR capabilities were significantly enhanced by integrating data requiring transcription of text in images and documents. Furthermore, Idefics2 demonstrates superior performance on various Visual Question Answering benchmarks, competing with much larger models like LLava-Next-34B and MM1-30B-chat.
- The article provides a code sample for users to get started with Idefics2 using the Hugging Face Hub. The sample illustrates how to load images, create inputs, and generate text responses using the model. The fine-tuning colab offered by the authors is intended to help users improve Idefics2 for specific use cases.
- Overall, Idefics2 represents a significant advancement in multimodal AI, offering improved performance, flexibility, and accessibility for a wide range of applications.
PaLI
- Introduced in PaLI: Scaling Language-Image Learning in 100+ Languages.
- Effective scaling and a flexible task interface enable large language models to excel at many tasks.
- This paper by Chen et al. from Google Research in ICLR 2023 presents PaLI (Pathways Language and Image model), a model that extends this approach to the joint modeling of language and vision.
- PaLI generates text based on visual and textual inputs, and with this interface performs many vision, language, and multimodal tasks, in many languages.
- To train PaLI, they make use of large pre-trained encoder-decoder language models and Vision Transformers (ViTs). This allows them to capitalize on their existing capabilities and leverage the substantial cost of training them. They find that joint scaling of the vision and language components is important.
- Since existing Transformers for language are much larger than their vision counterparts, we train a large, 4-billion parameter ViT (ViT-e) to quantify the benefits from even larger-capacity vision models.
- To train PaLI, they create a large multilingual mix of pretraining tasks, based on a new image-text training set containing 10B images and texts in over 100 languages. PaLI achieves state-of-the-art in multiple vision and language tasks (such as captioning, visual question-answering, scene-text understanding), while retaining a simple, modular, and scalable design.
- The PaLI main architecture is simple and scalable. It uses an encoder-decoder Transformer model, with a large-capacity ViT component for image processing.
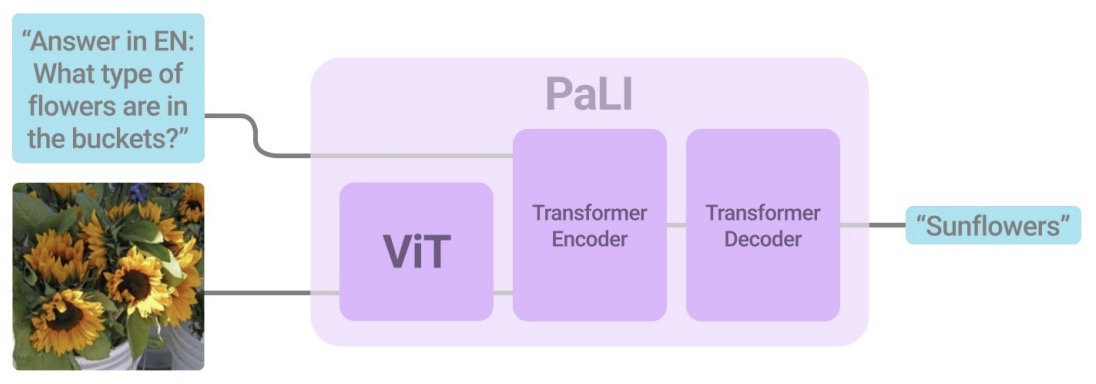
- Code.
PaLM-E
- Introduced in PaLM-E: An Embodied Multimodal Language Model.
- Large language models have been demonstrated to perform complex tasks. However, enabling general inference in the real world, e.g. for robotics problems, raises the challenge of grounding.
- This paper by Driess from Google, TU Berlin, and Google Research proposes PaLM-E, an embodied language models to directly incorporate real-world continuous sensor modalities into language models and thereby establish the link between words and percepts. Input to their embodied language model are multi-modal sentences that interleave visual, continuous state estimation, and textual input encodings.
- They train these encodings end-to-end, in conjunction with a pre-trained large language model, for multiple embodied tasks, including sequential robotic manipulation planning, visual question answering, and captioning.
- Their evaluations show that PaLM-E, a single large embodied multimodal model, can address a variety of embodied reasoning tasks, from a variety of observation modalities, on multiple embodiments, and further, exhibits positive transfer: the model benefits from diverse joint training across internet-scale language, vision, and visual-language domains.
- Their largest model, PaLM-E-562B with 562B parameters, in addition to being trained on robotics tasks, is a visual-language generalist with state-of-the-art performance on OK-VQA, and retains generalist language capabilities with increasing scale.
- The following figures from the paper shows PaLM-E, a single general-purpose multimodal language model for embodied reasoning tasks, visual-language tasks, and language tasks. - PaLM-E transfers knowledge from visual-language domains into embodied reasoning – from robot planning in environments with complex dynamics and physical constraints, to answering questions about the observable world. PaLM-E operates on multimodal sentences, i.e. sequences of tokens where inputs from arbitrary modalities (e.g. images, neural 3D representations, or states, in green and blue) are inserted alongside text tokens (in orange) as input to an LLM, trained end-to-end.
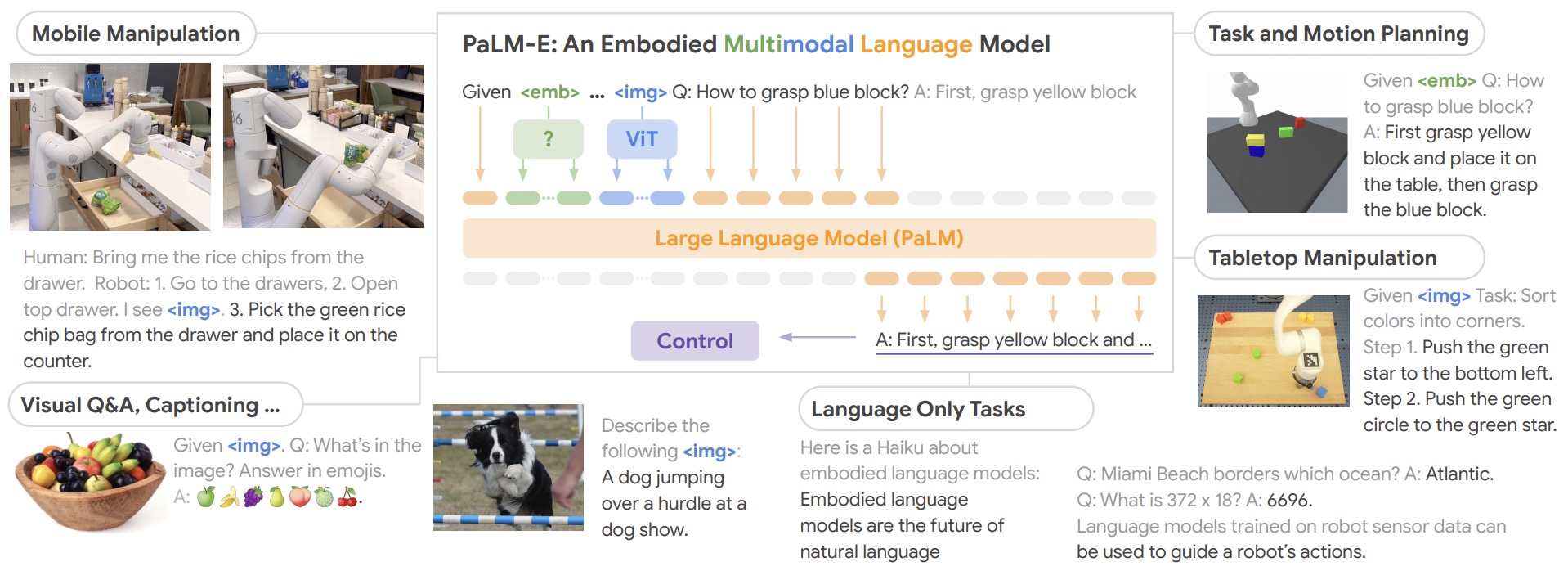
Qwen-VL
- Introduced in Qwen-VL: A Frontier Large Vision-Language Model with Versatile Abilities, the Qwen-VL series are a set of large-scale vision-language models designed to perceive and understand both text and images. Comprising Qwen-VL and Qwen-VL-Chat, these models exhibit remarkable performance in tasks like image captioning, question answering, visual localization, and flexible interaction.
- The evaluation covers a wide range of tasks including zero-shot captioning, visual or document visual question answering, and grounding. We demonstrate the Qwen-VL outperforms existing Large Vision Language Models (LVLMs).
- They present their architecture, training, capabilities, and performance, highlighting their contributions to advancing multimodal artificial intelligence.
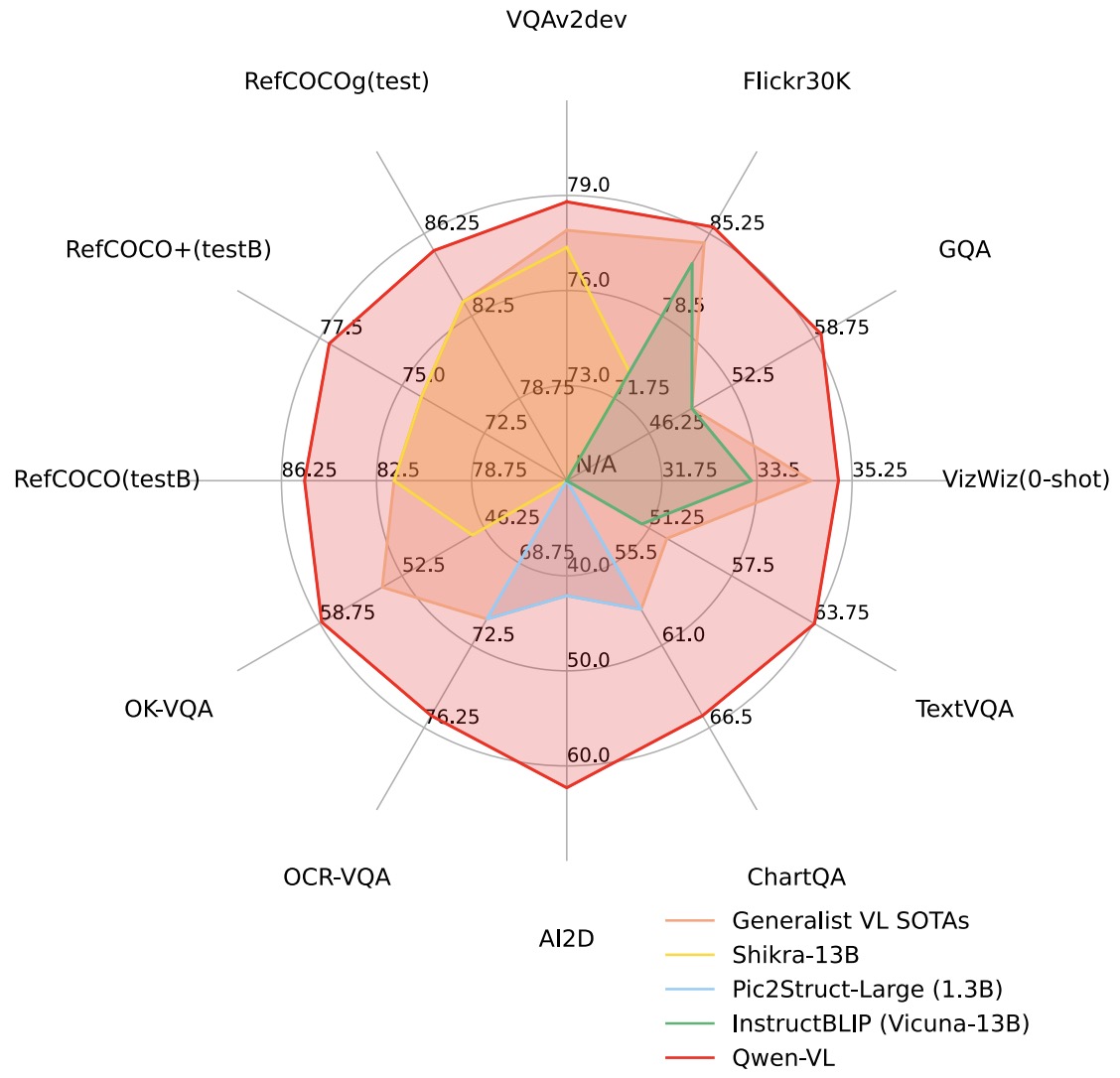
- The following figure from the paper shows that Qwen-VL achieves state-of-the-art performance on a broad range of tasks compared with other generalist models.
- The following figure from the paper shows some qualitative examples generated by Qwen-VL-Chat. Qwen-VL-Chat supports multiple image inputs, multi-round dialogue, multilingual conversation, and localization ability.

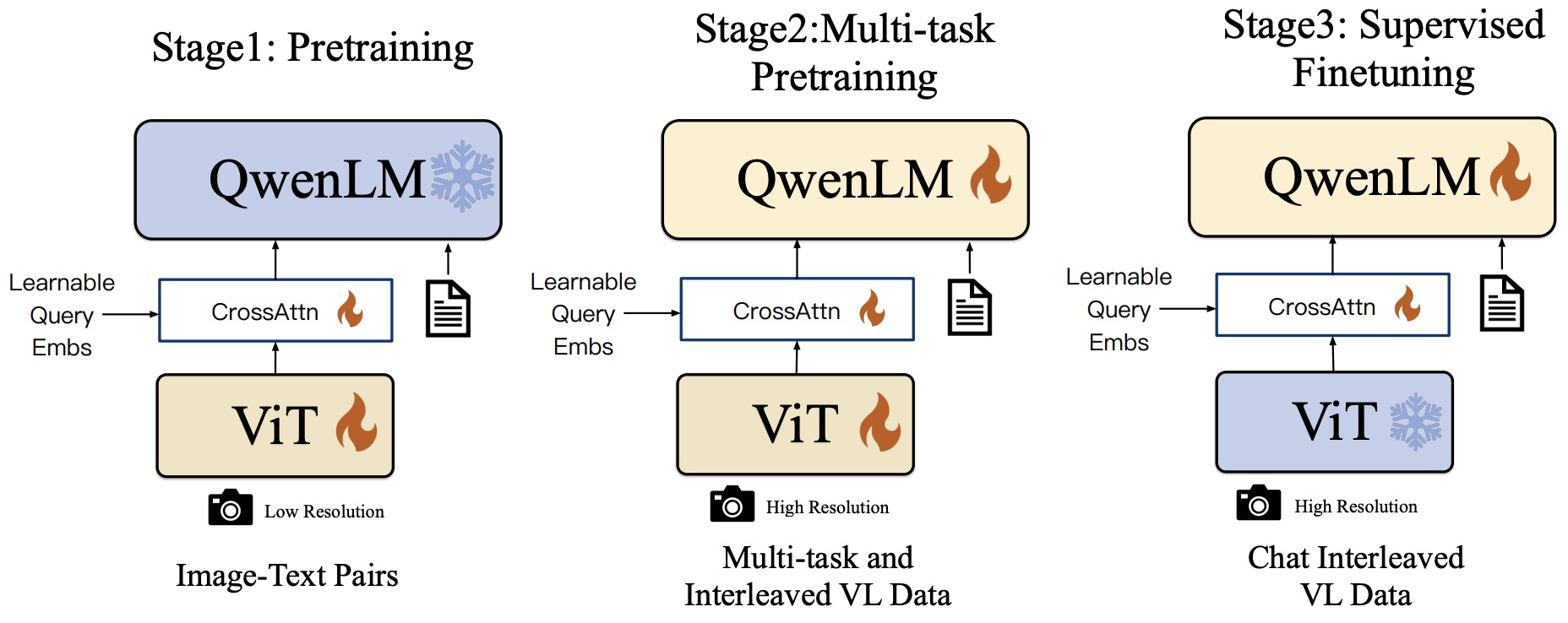
- The following figure from the paper shows the training pipeline of the Qwen-VL series.
QwenVL-Plus and Max
- Qwen-VL-Plus and Max are upgraded versions of Qwen-VL, developed by Alibaba Cloud.
Fuyu-8B
- Fuyu-8B is a multi-modal text and image transformer trained by Adept AI.
- Fuyu-8B is a small version of the multimodal model that powers our product. The model is available on HuggingFace. Fuyu-8B is exciting because:
- It has a much simpler architecture and training procedure than other multi-modal models, which makes it easier to understand, scale, and deploy.
- It’s designed from the ground up for digital agents, so it can support arbitrary image resolutions, answer questions about graphs and diagrams, answer UI-based questions, and do fine-grained localization on screen images.
- It’s fast – we can get responses for large images in less than 100 milliseconds.
- Despite being optimized for Adept’s use-case, it performs well at standard image understanding benchmarks such as visual question-answering and natural-image-captioning.
- Architecturally, Fuyu is a vanilla decoder-only transformer - there is no image encoder. Image patches are instead linearly projected into the first layer of the transformer, bypassing the embedding lookup. They simply treat the transformer decoder like an image transformer (albeit with no pooling and causal attention). See the below diagram for more details.

- This simplification allows us to support arbitrary image resolutions. To accomplish this, they treat the sequence of image tokens like the sequence of text tokens. they remove image-specific position embeddings and feed in as many image tokens as necessary in raster-scan order. To tell the model when a line has broken, they simply use a special image-newline character. The model can use its existing position embeddings to reason about different image sizes, and they can use images of arbitrary size at training time, removing the need for separate high and low-resolution training stages.
- Blog.
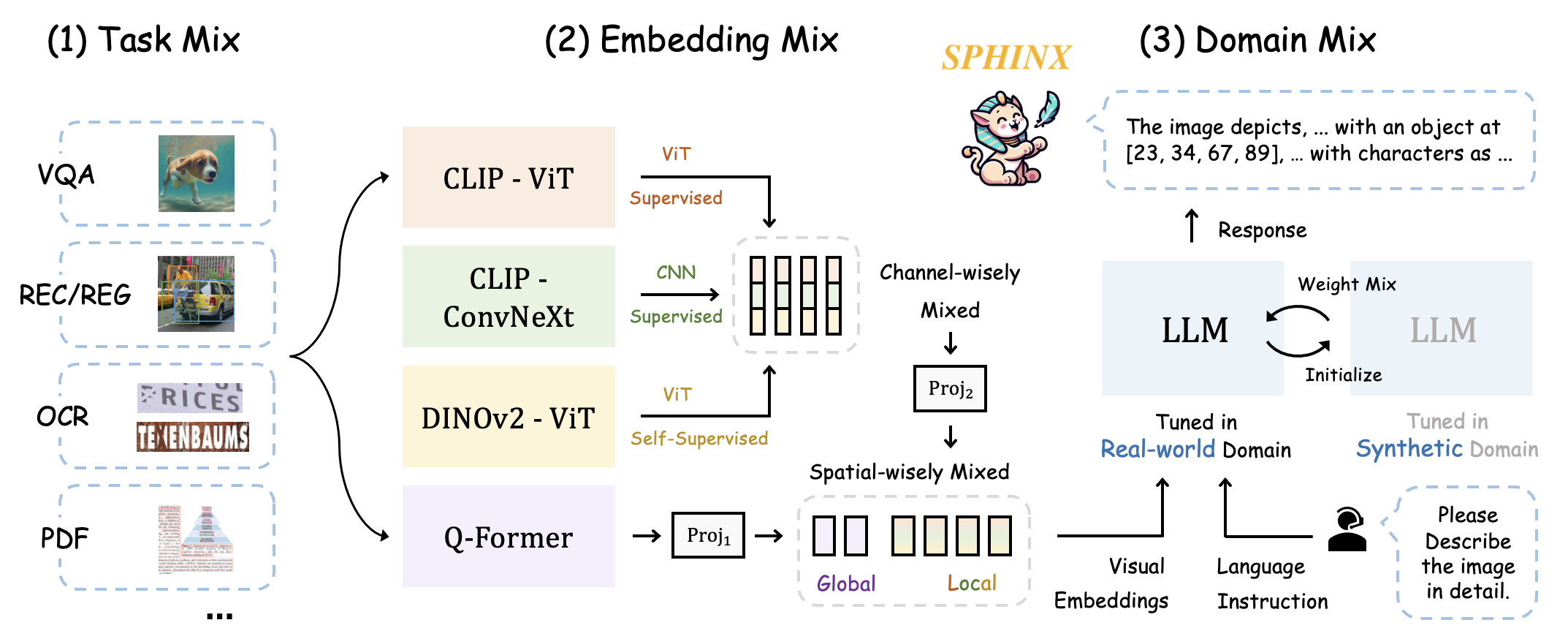
SPHINX
- SPHINX is a versatile multi-modal large language model (MLLM) with a mixer of training tasks, data domains, and visual embeddings.
- Task Mix: For all-purpose capabilities, they mix a variety of vision-language tasks for mutual improvement: VQA, REC, REG, OCR, etc.
- Embedding Mix: They capture robust visual representations by fusing distinct visual architectures, pre-training, and granularity.
- Domain Mix: For data from real-world and synthetic domains, they mix the weights of two domain-specific models for complementarity.
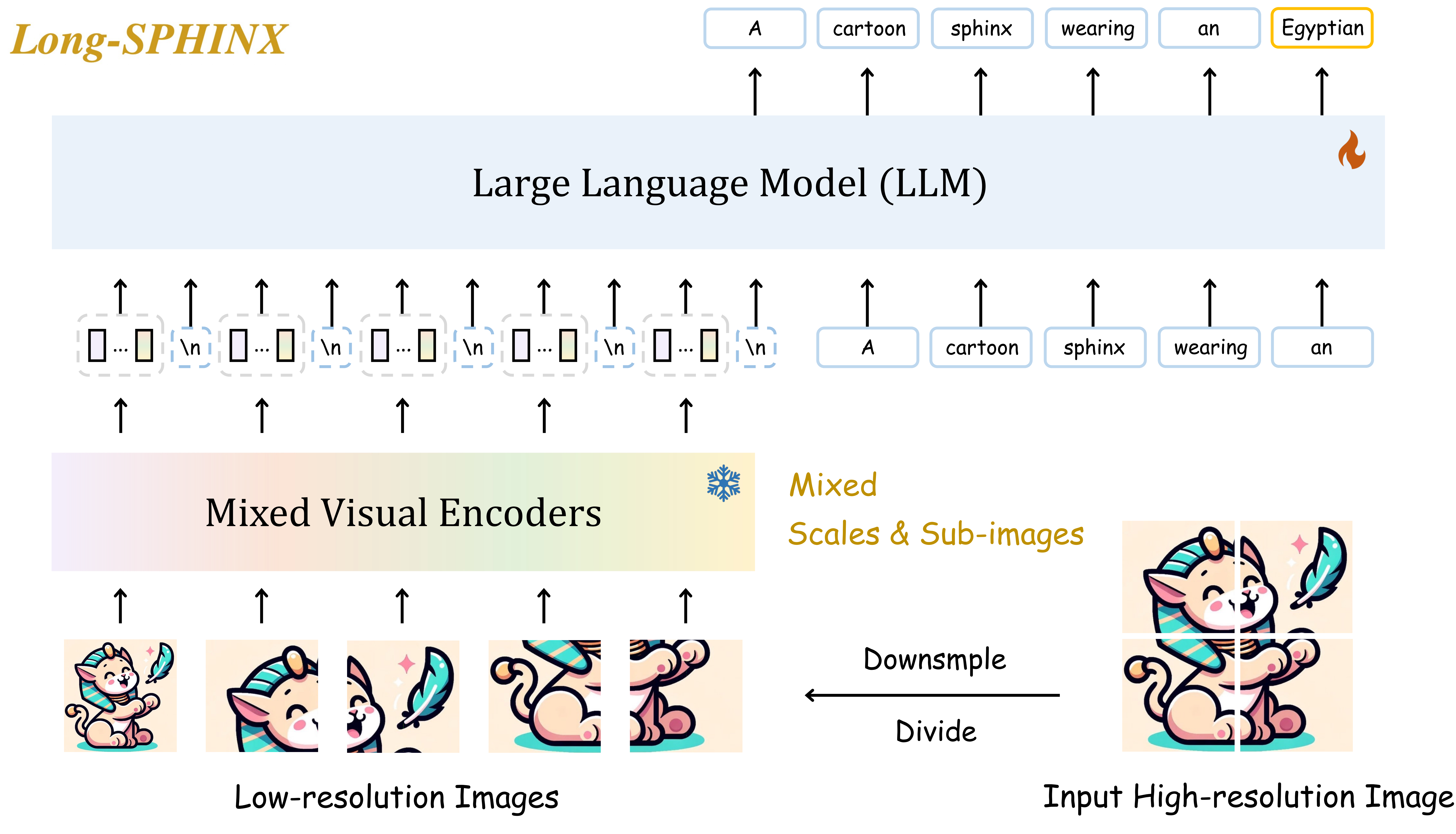
- On top of SPHINX, they propose to further mix visual scales and sub-images for better capture fine-grained semantics on high-resolution images, producing “LongSPHINX”.
MIRASOL3B
- Proposed in MIRASOL3B: A Multimodal Autoregressive Model for Time-Aligned and Contextual Modalities by Piergiovanni et al. from Google DeepMind and Google Research, MIRASOL3B is a multimodal autoregressive model adept at processing time-aligned modalities (audio and video) and non-time-aligned modality (text), to produce textual outputs.
- The model’s architecture uniquely handles the processing of audio and video. It starts by dividing long video-audio sequences, such as a 10-minute clip, into smaller, manageable chunks (e.g., 1-minute each). Each video chunk, containing \(V\) frames, is passed through a video encoder/temporal image encoder, while the corresponding audio chunk goes through an audio encoder.
- These processed chunks generate \(V\) video tokens and \(A\) audio tokens per chunk. These tokens are then sent to a Transformer block (\(T_VA\)), termed the Combiner. The Combiner effectively fuses video and audio features into a compressed representation of \(M\) tokens, each represented as a tensor of shape \((m, d)\), where \(d\) denotes the embedding size.
- MIRASOL3B’s autoregressive training involves predicting the next set of features \(X_t\) based on the preceding features \(X_0\) to \(X_{(t-1)}\), similar to how GPT predicts the next word in a sequence.
- For textual integration, prompts or questions are fed to a separate Transformer block that employs cross-attention on the hidden features produced by the Combiner. This cross-modal interaction allows the text to leverage audio-video features for richer contextual understanding.
- The following figure from the paper illustrates the Mirasol3B model architecture consists of an autoregressive model for the time-aligned modalities, such as audio and video, which are partitioned in chunks (left) and an autoregressive model for the unaligned context modalities, which are still sequential, e.g., text (right). This allows adequate computational capacity to the video/audio time-synchronized inputs, including processing them in time autoregressively, before fusing with the autoregressive decoder for unaligned text (right). Joint feature learning is conducted by the Combiner, balancing the need for compact representations and allowing sufficiently informative features to be processed in time.
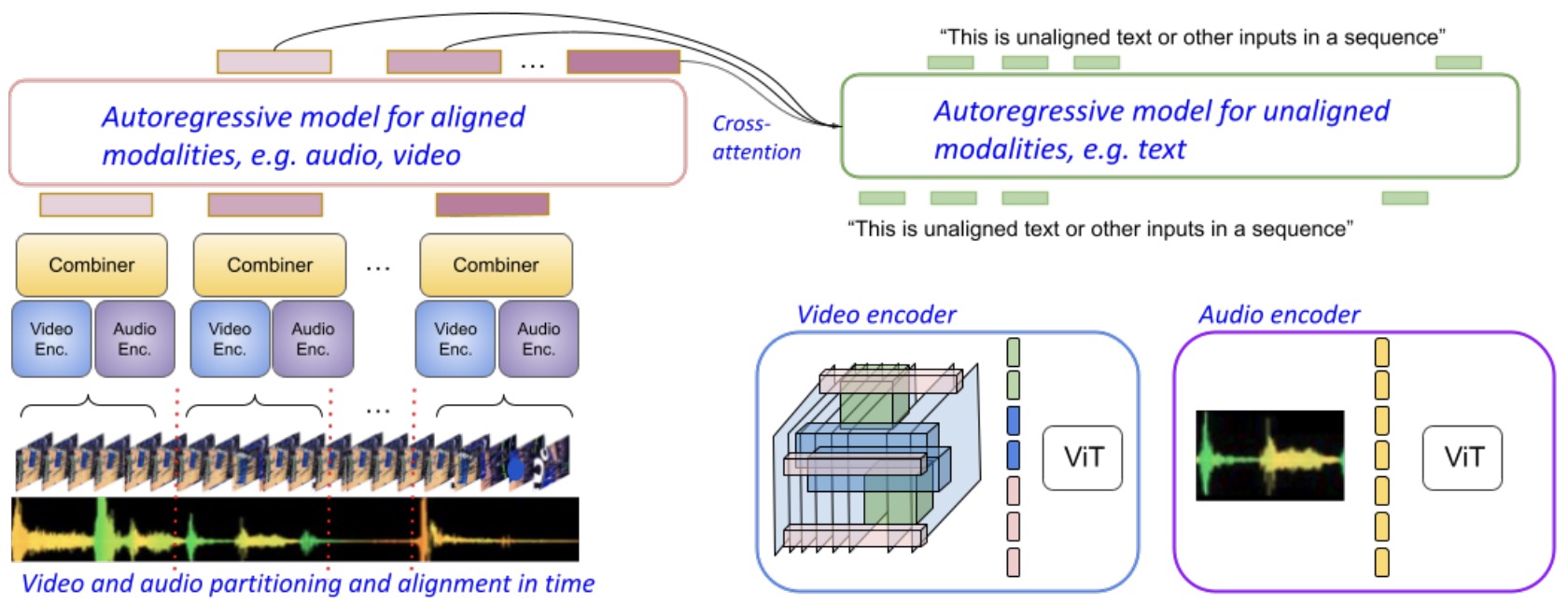
- With just 3 billion parameters, MIRASOL3B demonstrates state-of-the-art performance across various benchmarks. It excels in handling long-duration media inputs and shows versatility in integrating different modalities.
- The model was pretrained on the Video-Text Pairs (VTP) dataset using around 12% of the data. During pretraining, all losses were weighted equally, with the unaligned text loss increasing tenfold in the fine-tuning phase.
- Comprehensive ablation studies in the paper highlight the effects of different model components and configurations, emphasizing the model’s ability to maintain content consistency and capture dynamic changes in long video-audio sequences.
BLIP
- Proposed in BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation by Li et al. from Salesforce Research.
- They present a novel Vision-Language Pre-training (VLP) framework named BLIP. Unlike most existing pre-trained models, BLIP excels in both understanding-based and generation-based tasks. It addresses the limitations of relying on noisy web-based image-text pairs for training, demonstrating significant improvements in various vision-language tasks.
- Technical and Implementation Details: BLIP consists of two primary innovations:
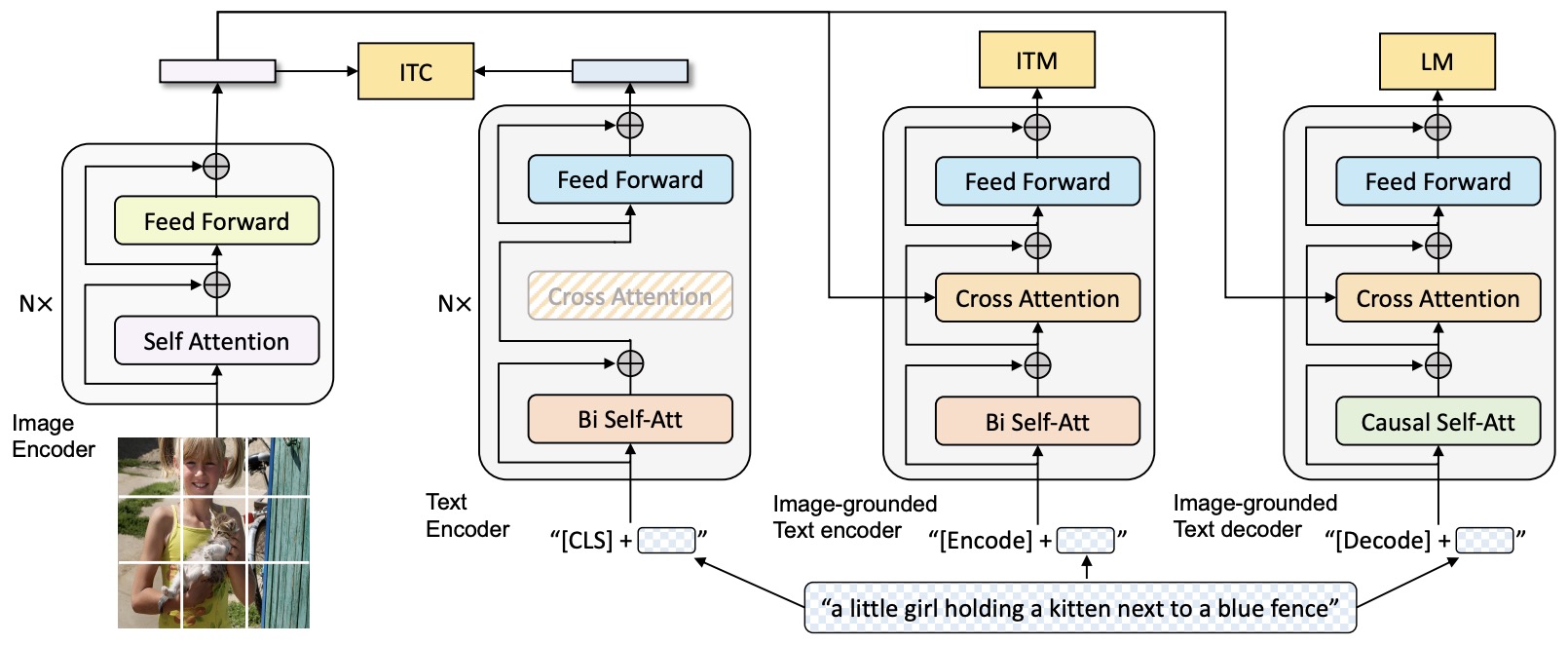
- Multimodal Mixture of Encoder-Decoder (MED): This new architecture effectively multitasks in pre-training and allows flexible transfer learning. It operates in three modes: as a unimodal encoder, an image-grounded text encoder, or an image-grounded text decoder. MED employs a visual transformer as an image encoder, dividing an input image into patches encoded into a sequence of embeddings. The text encoder and decoder share all parameters except for the self-attention layers to enhance efficiency. The model is pre-trained with three objectives: image-text contrastive learning (ITC), image-text matching (ITM), and image-conditioned language modeling (LM).
- Image-Text Contrastive Loss (ITC): This loss function focuses on aligning the feature spaces of visual and textual representations. The goal is to bring closer the embeddings of positive image-text pairs while distancing the embeddings of negative pairs. This objective is crucial for improving vision and language understanding. The equation is: \(ITC = -\log \frac{\exp(sim(v_i, t_i)/\tau)}{\sum_{j=1}^N \exp(sim(v_i, t_j)/\tau)}\) where \(v_i\) and \(t_i\) are the image and text embeddings of the \(i^{th}\) positive pair, \(sim\) is a similarity function, \(\tau\) is a temperature scaling parameter, and \(N\) is the number of negative samples.
- Image-Text Matching Loss (ITM): This objective is a more complex and nuanced task compared to ITC. It aims to learn a fine-grained, multimodal representation of image-text pairs, focusing on the alignment between visual and linguistic elements. ITM functions as a binary classification task, where the model predicts whether an image-text pair is correctly matched. This involves using an image-grounded text encoder that takes the multimodal representation and predicts the match/non-match status. The ITM loss is especially significant in training the model to understand the subtleties and nuances of how text and images relate, going beyond mere surface-level associations. To ensure informative training, a hard negative mining strategy is employed, selecting more challenging negative pairs based on their contrastive similarity, thereby enhancing the model’s discriminative ability. The loss function can be expressed as: \(ITM = -y \log(\sigma(f(v, t))) - (1 - y) \log(1 - \sigma(f(v, t)))\) where \(v\) and \(t\) are the visual and textual embeddings, \(y\) is the label indicating if the pair is a match (1) or not (0), \(\sigma\) denotes the sigmoid function, and \(f(v, t)\) represents the function that combines the embeddings to produce a match score.
- Language Modeling Loss (LM): This loss optimizes the generation of textual descriptions from images, used in the image-grounded text decoder. It aims to generate textual descriptions given an image, training the model to maximize the likelihood of the text in an autoregressive manner. It is typically formulated as a cross-entropy loss over the sequence of words in the text: \(LM = -\sum_{t=1}^{T} \log P(w_t | w_{\<t}, I)\) where \(w_t\) is the \(t^{th}\) word in the caption, \(w_{\<t}\) represents the sequence of words before \(w_t\), and \(I\) is the input image.
- Captioning and Filtering (CapFilt): This method improves the quality of training data from noisy web-based image-text pairs. It involves a captioner module, which generates synthetic captions for web images, and a filter module, which removes noisy captions from both web texts and synthetic texts. Both modules are derived from the pre-trained MED model and fine-tuned on the COCO dataset. CapFilt allows the model to learn from a refined dataset, leading to performance improvements in downstream tasks.
- Multimodal Mixture of Encoder-Decoder (MED): This new architecture effectively multitasks in pre-training and allows flexible transfer learning. It operates in three modes: as a unimodal encoder, an image-grounded text encoder, or an image-grounded text decoder. MED employs a visual transformer as an image encoder, dividing an input image into patches encoded into a sequence of embeddings. The text encoder and decoder share all parameters except for the self-attention layers to enhance efficiency. The model is pre-trained with three objectives: image-text contrastive learning (ITC), image-text matching (ITM), and image-conditioned language modeling (LM).
- The figure below from the paper shows the pre-training model architecture and objectives of BLIP (same parameters have the same color). We propose multimodal mixture of encoder-decoder, a unified vision-language model which can operate in one of the three functionalities: (1) Unimodal encoder is trained with an image-text contrastive (ITC) loss to align the vision and language representations. (2) Image-grounded text encoder uses additional cross-attention layers to model vision-language interactions, and is trained with a image-text matching (ITM) loss to distinguish between positive and negative image-text pairs. (3) Image-grounded text decoder replaces the bi-directional self-attention layers with causal self-attention layers, and shares the same cross-attention layers and feed forward networks as the encoder. The decoder is trained with a language modeling (LM) loss to generate captions given images.
- Experimentation and Results:
- BLIP’s models were implemented in PyTorch and pre-trained on a dataset including 14 million images, comprising both human-annotated and web-collected image-text pairs.
- The experiments showed that the captioner and filter, when used in conjunction, significantly improved performance in downstream tasks like image-text retrieval and image captioning.
- The CapFilt approach proved to be scalable with larger datasets and models, further boosting performance.
- The diversity introduced by nucleus sampling in generating synthetic captions was found to be key in achieving better results, outperforming deterministic methods like beam search.
- Parameter sharing strategies during pre-training were explored, with results indicating that sharing all layers except for self-attention layers provided the best performance.
- BLIP achieved substantial improvements over existing methods in image-text retrieval and image captioning tasks, outperforming the previous best models on standard datasets like COCO and Flickr30K.
- Conclusion:
- BLIP represents a significant advancement in unified vision-language understanding and generation tasks, effectively utilizing noisy web data and achieving state-of-the-art results in various benchmarks. The framework’s ability to adapt to both understanding and generation tasks, along with its robustness in handling web-collected noisy data, marks it as a notable contribution to the field of Vision-Language Pre-training.
- Code
BLIP-2
- Proposed in BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models by Li et al. from Salesforce Research.
- BLIP-2 utilizes a cost-effective pre-training strategy for vision-language models using off-the-shelf frozen image encoders and large language models (LLMs). The core component, the Querying Transformer (Q-Former), originally from the BLIP model, bridges the modality gap in a two-stage bootstrapping process, leading to state-of-the-art performance in vision-language tasks with significantly fewer trainable parameters. BLIP-2 leverages existing unimodal models from vision and language domains, utilizing Q-Former ti specifically address the challenge of interoperability between different modality embeddings, such as aligning visual and textual representations.
- Q-Former Architecture and Functionality””
- Q-Former Design: The Q-Former, central to BLIP-2, is a trainable BERT encoder with a causal language modeling head, akin to GPT. It integrates one cross-attention layer for every two layers of BERT and introduces a fixed number of 32 trainable query vectors, crucial for modality alignment.
- Embedding Alignment: The query vectors are designed to extract the most useful features from one of the frozen encoders, aligning embeddings across modalities, such as visual and textual spaces.
- Modality Handling: In BLIP-2, which is a vision-language model, the Q-Former uses cross-attention between query vectors and image patch embeddings to obtain image embeddings. For a hypothetical model with purely textual input, it functions like a normal BERT Model, bypassing cross-attention or query vectors.
- Methodology: BLIP-2 employs a two-stage bootstrapping method with the Q-Former:
- Vision-Language Representation Learning: Utilizes a frozen image encoder for vision-language representation learning. The Q-Former is trained to extract visual features most relevant to text, employing three pre-training objectives with different attention masking strategies: Image-Text Contrastive Learning (ITC), Image-grounded Text Generation (ITG), and Image-Text Matching (ITM).
- Vision-to-Language Generative Learning: Connects the Q-Former to a frozen LLM. The model uses a fully-connected layer to adapt the output query embeddings from the Q-Former to the LLM’s input dimension, functioning as soft visual prompts. This stage is compatible with both decoder-based and encoder-decoder-based LLMs.
- The following figure from the paper shows an overview of BLIP-2’s framework. They pre-train a lightweight Querying Transformer following a two-stage strategy to bridge the modality gap. The first stage bootstraps vision-language representation learning from a frozen image encoder. The second stage bootstraps vision-to-language generative learning from a frozen LLM, which enables zero-shot instructed image-to-text generation.
- The following figure from the paper shows: (Left) Model architecture of Q-Former and BLIP-2’s first-stage vision-language representation learning objectives. They jointly optimize three objectives which enforce the queries (a set of learnable embeddings) to extract visual representation most relevant to the text. (Right) The self-attention masking strategy for each objective to control query-text interaction.
- The following figure from the paper shows BLIP-2’s second-stage vision-to-language generative pre-training, which bootstraps from frozen large language models (LLMs). (Top) Bootstrapping a decoder-based LLM (e.g. OPT). (Bottom) Bootstrapping an encoder-decoder-based LLM (e.g. FlanT5). The fully-connected layer adapts from the output dimension of the Q-Former to the input dimension of the chosen LLM.
- Training: The Q-Former in BLIP-2 is trained on multiple tasks, including image captioning, image and text embedding alignment via contrastive learning, and classifying image-text pair matches, utilizing special attention masking schemes.
- Implementation Details:
- Pre-training Data: BLIP-2 is trained on a dataset comprising 129 million images from sources like COCO, Visual Genome, CC3M, CC12M, SBU, and LAION400M. Synthetic captions are generated using the CapFilt method and ranked based on image-text similarity.
- Image Encoder and LLMs: The method explores state-of-the-art vision transformer models like ViT-L/14 and ViT-g/14 for the image encoder, and OPT and FlanT5 models for the language model.
- Training Parameters: The model is pre-trained for 250k steps in the first stage and 80k steps in the second stage, using batch sizes tailored for each stage and model. Training utilizes AdamW optimizer, cosine learning rate decay, and images augmented with random resizing and horizontal flipping.
- Capabilities and Limitations: BLIP-2 enables effective zero-shot image-to-text generation, preserving the LLM’s ability to follow text prompts. It shows state-of-the-art results on the zero-shot visual question answering task on datasets like VQAv2 and GQA. However, the model’s performance does not improve with in-context learning using few-shot examples, attributed to the pre-training dataset’s structure. Additionally, BLIP-2 may inherit the risks of LLMs, such as outputting offensive language or propagating bias
- Applications: The Q-Former’s ability to align modalities makes it versatile for various models, including MiniGPT-4 and InstructBlip (Image + Text), and Video-LLaMA (image, video, audio, text). Its capability to produce a fixed sequence of high-information embeddings proves useful in different multimodal contexts.
- Code
InstructBLIP
- General-purpose language models that can solve various language-domain tasks have emerged driven by the pre-training and instruction-tuning pipeline. However, building general-purpose vision-language models is challenging due to the increased task discrepancy introduced by the additional visual input. Although vision-language pre-training has been widely studied, vision-language instruction tuning remains relatively less explored.
- InstructBLIP was proposed in InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning by Dai et al. from Salesforce Research, HKUST, and NTU Singapore in 2023.
- The paper conducts a systematic and comprehensive study on vision-language instruction tuning based on the pre-trained BLIP-2 models. They gather a wide variety of 26 publicly available datasets, transform them into instruction tuning format and categorize them into two clusters for held-in instruction tuning and held-out zero-shot evaluation. Additionally, they introduce instruction-aware visual feature extraction, a crucial method that enables the model to extract informative features tailored to the given instruction.
- The following figure from the paper shows the model architecture of InstructBLIP. The Q-Former extracts instruction-aware visual features from the output embeddings of the frozen image encoder, and feeds the visual features as soft prompt input to the frozen LLM. We instruction-tune the model with the language modeling loss to generate the response.
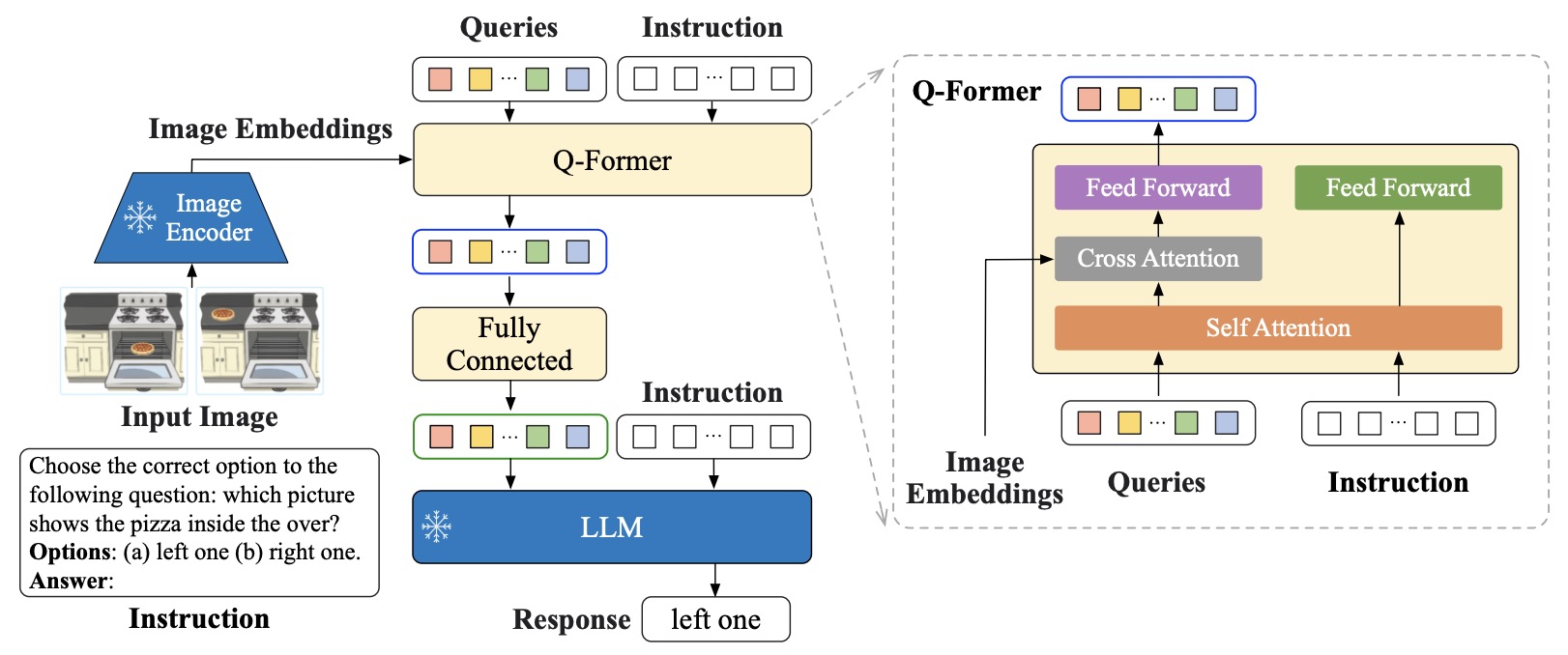
- The resulting InstructBLIP models achieve state-of-the-art zero-shot performance across all 13 held-out datasets, substantially outperforming BLIP-2 and the larger Flamingo.
- Their models also lead to state-of-the-art performance when finetuned on individual downstream tasks (e.g., 90.7% accuracy on ScienceQA IMG). Furthermore, they qualitatively demonstrate the advantages of InstructBLIP over concurrent multimodal models.
- The figure below from the paper shows a few qualitative examples generated by our InstructBLIP Vicuna model. Here, a range of its diverse capabilities are demonstrated, including complex visual scene understanding and reasoning, knowledge-grounded image description, multi-turn visual conversation, etc.

- Code.
MiniGPT-4
- Proposed in MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models by Zhu et al. from King Abdullah University of Science and Technology.
- The paper explores whether aligning visual features with advanced large language models (LLMs) like Vicuna can replicate the impressive vision-language capabilities exhibited by GPT-4.
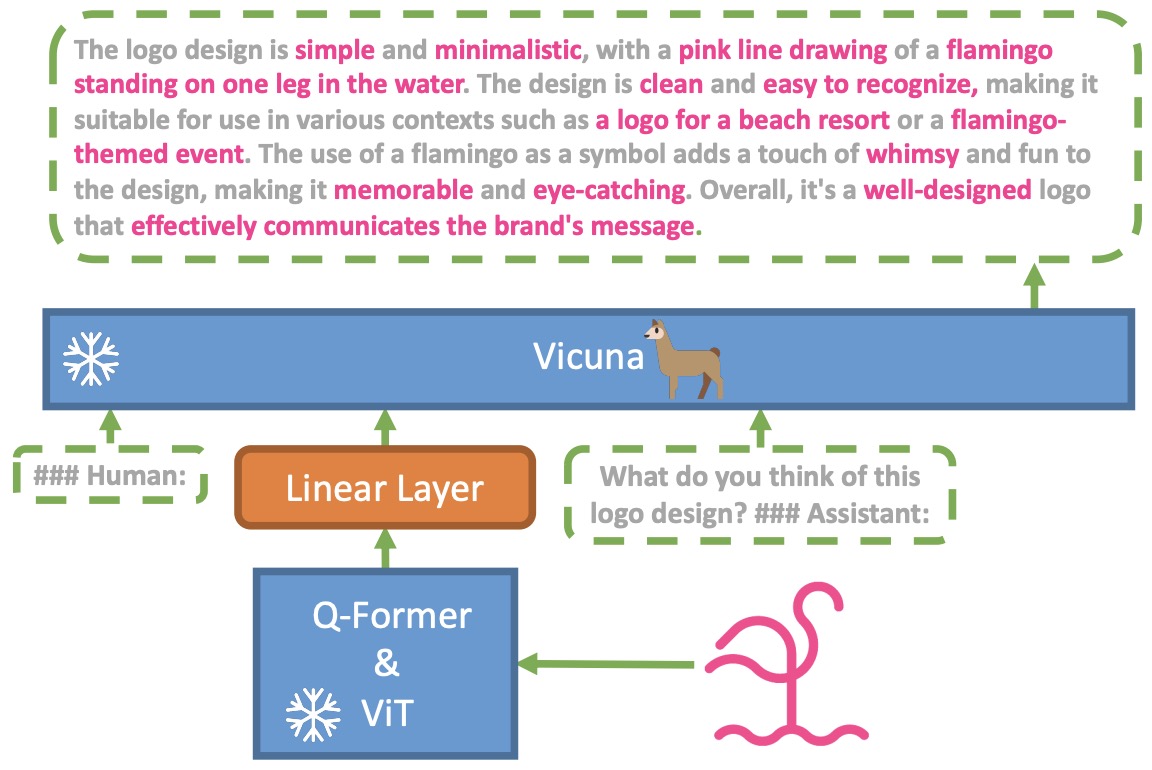
- The authors present MiniGPT-4 which combines a frozen visual encoder (ViT + Q-Former from BLIP-2) with a frozen Vicuna LLM using just a single trainable projection layer.
- The model undergoes a two-stage training process. The first stage involves pretraining on a large collection of aligned image-text pairs. The second stage involves finetuning with a smaller, detailed image description dataset to enhance generation reliability and usability. MiniGPT-4 was initially pretrained on 5M image-caption pairs, then finetuned on 3.5K detailed image descriptions to improve language quality.
- Without training the vision or language modules, MiniGPT-4 demonstrates abilities similar to GPT-4, such as generating intricate image descriptions, creating websites from handwritten text, and explaining unusual visual phenomena. Additionally, it showcases unique capabilities like generating detailed cooking recipes from food photos, writing stories or poems inspired by images, and diagnosing problems in photos with solutions. Quantitative analysis showed strong performance in tasks like meme interpretation, recipe generation, advertisement creation, and poem composition compared to BLIP-2.
- The finetuning process in the second stage significantly improved the naturalness and reliability of language outputs. This process was efficient, requiring only 400 training steps with a batch size of 12, and took around 7 minutes with a single A100 GPU.
- Additional emergent skills are observed like composing ads/poems from images, generating cooking recipes from food photos, retrieving facts from movie images etc. Aligning visual features with advanced LLMs appears critical for GPT-4-like capabilities, as evidenced by the absence of such skills in models like BLIP-2 with less powerful language models.
- The figure below from the paper shows the architecture of MiniGPT-4. It consists of a vision encoder with a pretrained ViT and Q-Former, a single linear projection layer, and an advanced Vicuna large language model. MiniGPT-4 only requires training the linear projection layer to align the visual features with the Vicuna.
- The simple methodology verifies that advanced vision-language abilities can emerge from properly aligning visual encoders with large language models, without necessarily needing huge datasets or model capacity.
- Despite its advancements, MiniGPT-4 faces limitations like hallucination of nonexistent knowledge and struggles with spatial localization. Future research could explore training on datasets designed for spatial information understanding to mitigate these issues.
- Project page; Code; HuggignFace Space; Video; Dataset.
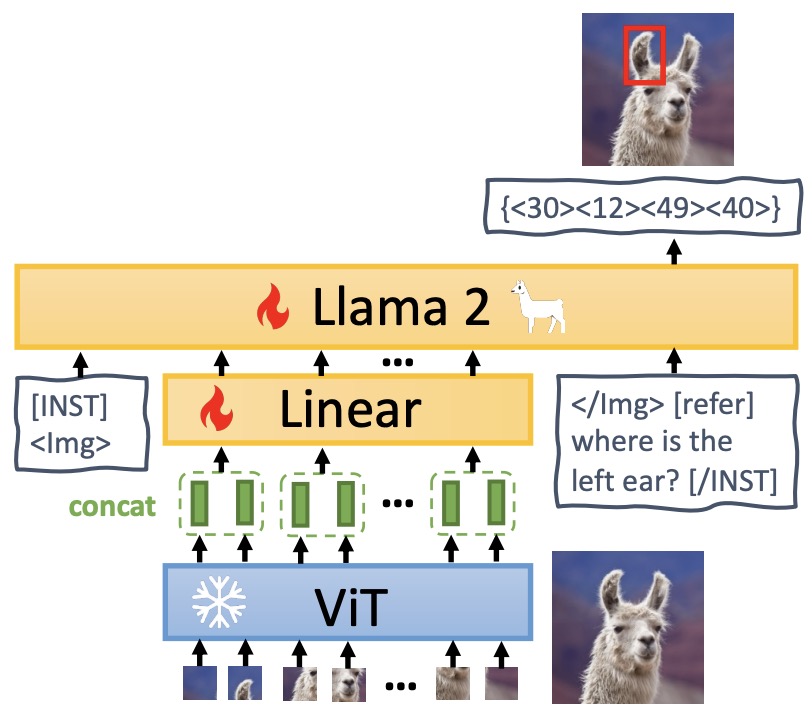
MiniGPT-v2
- Proposed in MiniGPT-v2: Large Language Model as a Unified Interface for Vision-Language Multi-task Learning by Chen et al. from King Abdullah University of Science and Technology and Meta AI Research.
- MiniGPT-v2 is a model designed to handle various vision-language tasks such as image description, visual question answering, and visual grounding.
- MiniGPT-v2 uniquely incorporates task-specific identifiers in training, allowing it to distinguish and effectively handle different task instructions. This is achieved by using a three-stage training strategy with a mix of weakly-labeled image-text datasets and multi-modal instructional datasets. The model architecture includes a visual backbone (adapted from EVA), a linear projection layer, and a large language model (LLaMA2-chat, 7B), trained with high-resolution images to process visual tokens efficiently.
- The figure below from the paper shows the architecture of MiniGPT-v2. The model takes a ViT visual backbone, which remains frozen during all training phases. We concatenate four adjacent visual output tokens from ViT backbone and project them into LLaMA-2 language model space via a linear projection layer.
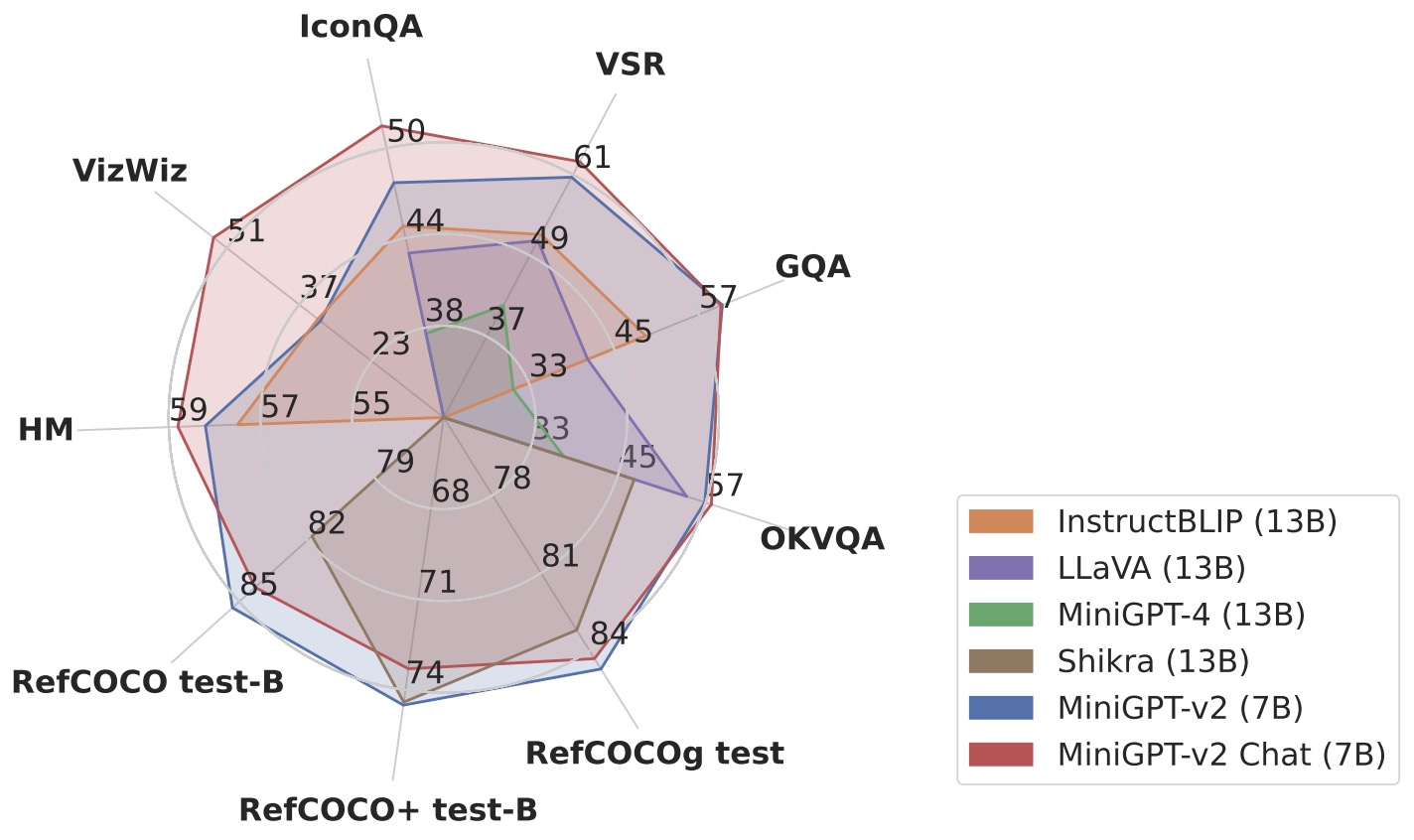
- In terms of performance, MiniGPT-v2 demonstrates superior results in various visual question-answering and visual grounding benchmarks, outperforming other generalist models like MiniGPT-4, InstructBLIP, LLaVA, and Shikra. It also shows a robust ability against hallucinations in image description tasks.
- The figure below from the paper shows that MiniGPT-v2 achieves state-of-the-art performances on a broad range of vision-language tasks compared with other generalist models.
- The paper highlights the importance of task identifier tokens, which significantly enhance the model’s efficiency in multi-task learning. These tokens have been shown to be crucial in the model’s strong performance across multiple tasks.
- Despite its capabilities, MiniGPT-v2 faces challenges like occasional hallucinations and the need for more high-quality image-text aligned data for improvement.
- The paper concludes that MiniGPT-v2, with its novel approach of task-specific identifiers and a unified interface, sets a new benchmark in multi-task vision-language learning. Its adaptability to new tasks underscores its potential in vision-language applications.
- Project page; Code; HuggignFace Space; Demo; Video
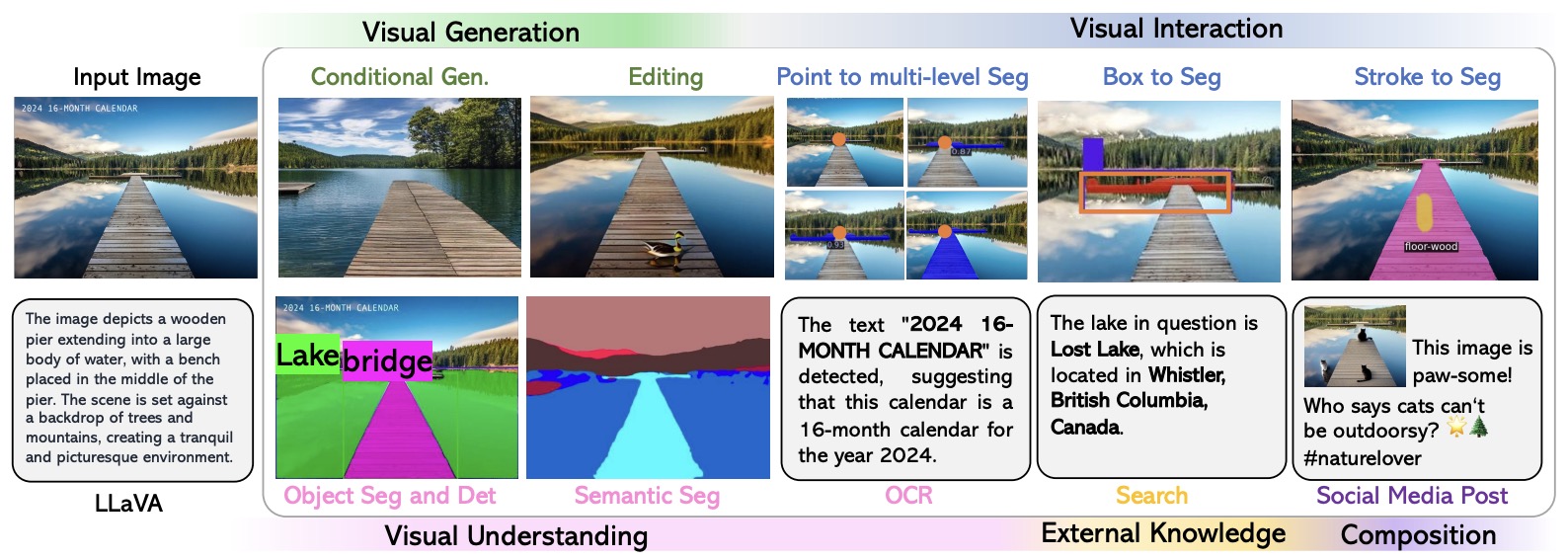
LLaVA-Plus
- Proposed in LLaVA-Plus: Learning to Use Tools for Creating Multimodal Agents by Liu et al. from Tsinghua University, Microsoft Research, University of Wisconsin-Madison, and HKUST IDEA Research.
- LLaVA-Plus is a general-purpose multimodal assistant that systematically expands the capabilities of large multimodal models (LMMs) through visual instruction tuning.
- LLaVA-Plus maintains a skill repository with a wide array of vision and vision-language pre-trained models, allowing it to activate relevant tools in response to user inputs and compose execution results for various tasks.
- The figure below from the paper offers a visual illustration of LLaVA-Plus’ capabilities enabled by learning to use skills.
- The model is trained on multimodal instruction-following data, covering examples of tool usage in visual understanding, generation, and external knowledge retrieval, demonstrating significant improvements over its predecessor, LLaVA, in both existing and new capabilities.
- The training approach includes using GPT-4 for generating instruction data and integrating new tools through instruction tuning, allowing continuous enhancement of the model’s abilities.
- The figure below from the paper shows the four-step LLaVA-Plus pipeline.
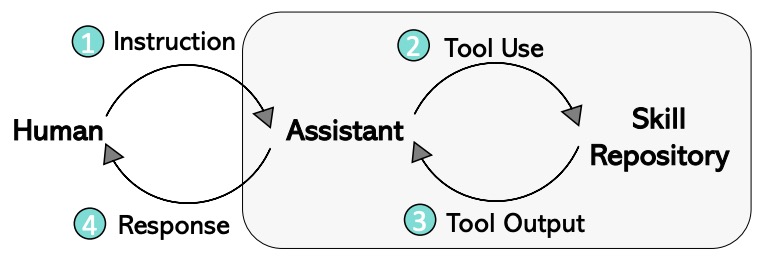
- Empirical results show that LLaVA-Plus achieves state-of-the-art performance on VisiT-Bench, a benchmark for evaluating multimodal agents in real-life tasks, and is more effective in tool use compared to other tool-augmented LLMs.
- The paper also highlights the model’s ability to adapt to various scenarios, such as external knowledge retrieval, image generation, and interactive segmentation, showcasing its versatility in handling real-world multimodal tasks.
- Project page; Code; Dataset; Demo; Model
BakLLaVA
- BakLLaVA is a VLM developed by LAION, Ontocord, and Skunkworks AI. BakLLaVA uses a Mistral 7B base augmented with the LLaVA 1.5 architecture. Used in combination with llama.cpp, a tool for running the LLaMA model in C++, you can use BakLLaVA on a laptop, provided you have enough GPU resources available.
- BakLLaVA is a faster and less resource-intensive alternative to GPT-4 with Vision.
LLaVA-1.5
- LLaVA-1.5 offers support for LLaMA-2, LoRA training with consumer GPUs, higher resolution (336x336), 4-/8- inference, etc.
- Introduced in Improved Baselines with Visual Instruction Tuning by Liu et al. from UW–Madison and MSR, LLaVA-1.5 focuses on enhancing multimodal models through visual instruction tuning.
- The paper presents improvements to the Large Multimodal Model (LMM) known as LLaVA, emphasizing its power and data efficiency. Simple modifications are proposed, including using CLIP-ViT-L-336px with an MLP projection and adding academic-task-oriented VQA data with simple response formatting prompts.
- A major achievement is establishing stronger baselines for LLaVA, which now achieves state-of-the-art performance across 11 benchmarks using only 1.2 million publicly available data points and completing training in about 1 day on a single 8-A100 node.
- The authors highlight two key improvements: an MLP cross-modal connector and incorporating academic task-related data like VQA. These are shown to be orthogonal to LLaVA’s framework and significantly enhance its multimodal understanding capabilities. LLaVA-1.5, the enhanced version, significantly outperforms the original LLaVA in a wide range of benchmarks, using a significantly smaller dataset for pretraining and instruction tuning compared to other methods.
- The figure below from the paper illustrates that LLaVA-1.5 achieves SoTA on a broad range of 11 tasks (Top), with high training sample efficiency (Left) and simple modifications to LLaVA (Right): an MLP connector and including academic-task-oriented data with response formatting prompts.
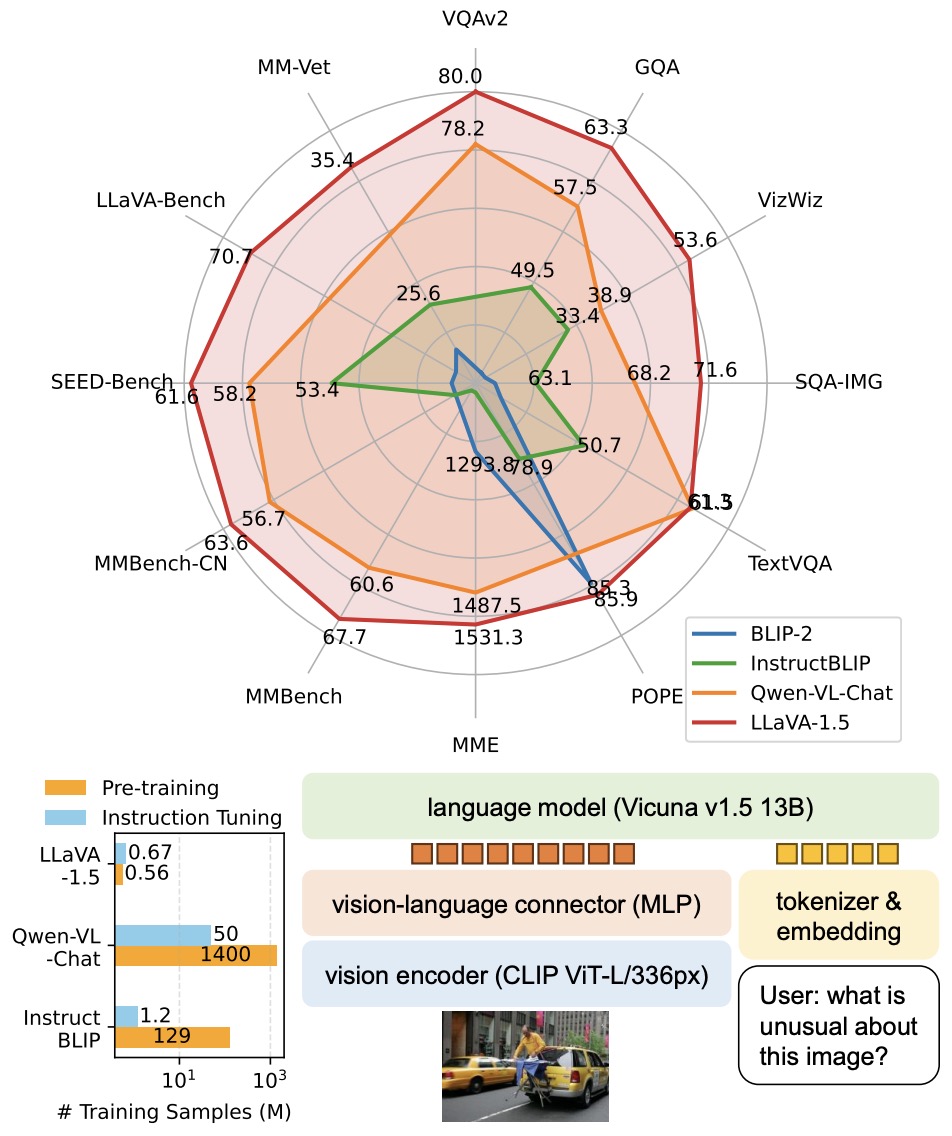
- The paper discusses limitations, including the use of full image patches in LLaVA, which may prolong training iterations. Despite its improved capability in following complex instructions, LLaVA-1.5 still has limitations in processing multiple images and certain domain-specific problem-solving tasks.
- Overall, the work demonstrates significant advancements in visual instruction tuning for multimodal models, making state-of-the-art research more accessible and providing a reference for future work in this field.
- Code.
CogVLM
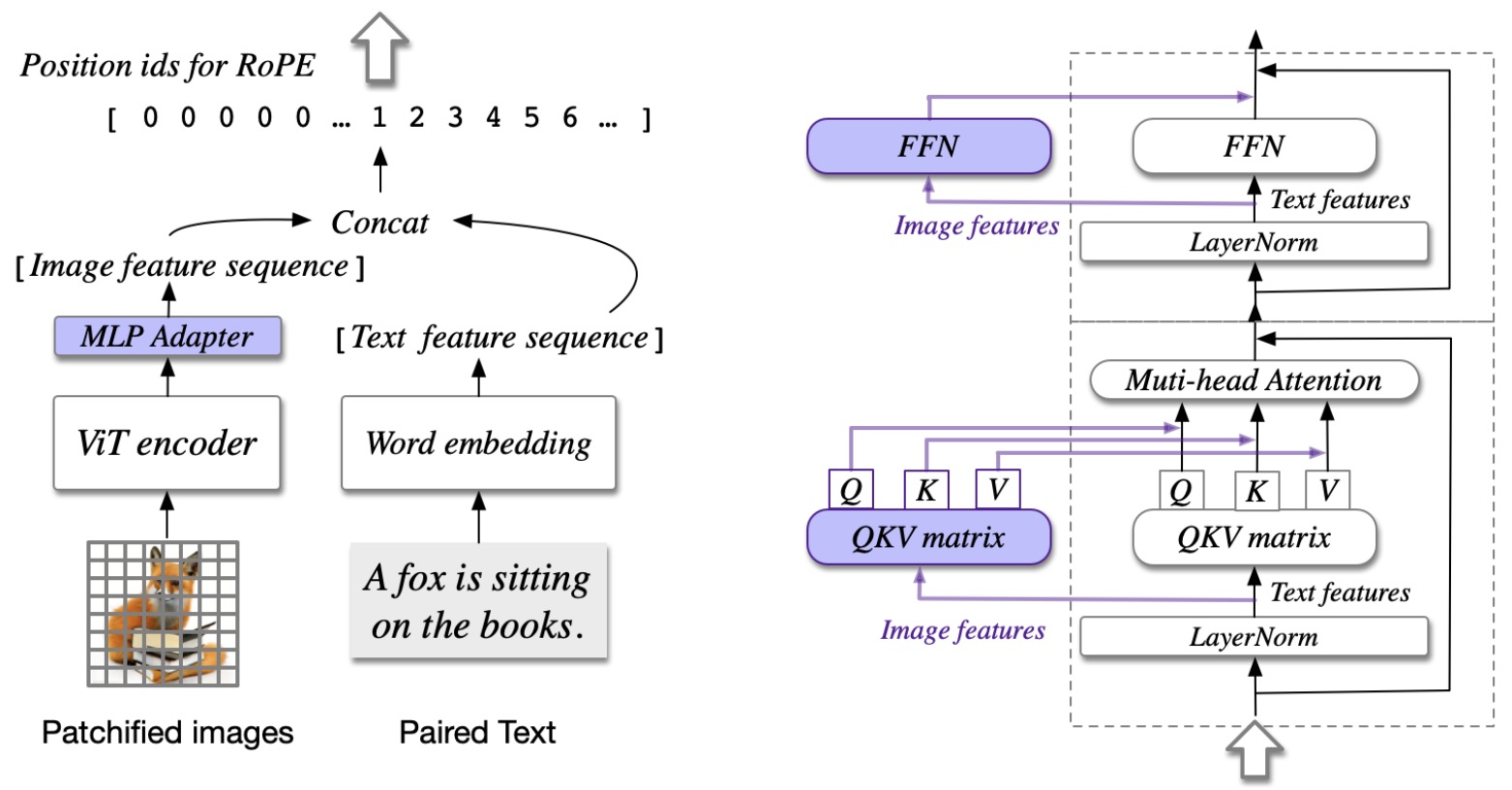
- This paper by Wang et al. from Zhipu AI and Tsinghua University introduces CogVLM, an open-source visual language foundation model. CogVLM offers an answer to the question: is it possible to retain the NLP capabilities of the large language model while adding top-notch visual understanding abilities? CogVLM is distinctive for integrating a trainable visual expert module with a pretrained language model, enabling deep fusion of visual and language features.
- The architecture of CogVLM comprises four main components: a vision transformer (ViT) encoder, an MLP adapter, a pretrained large language model (GPT-style), and a visual expert module. The ViT encoder, such as EVA2-CLIP-E, processes images, while the MLP adapter maps the output of ViT into the same space as the text features.
- The visual expert module, added to each layer of the model, consists of a QKV matrix and an MLP, both mirroring the structure in the pretrained language model. This setup allows for more effective integration of image and text data, enhancing the model’s capabilities in handling visual language tasks.
- Since all the parameters in the original language model are fixed, the behaviors are the same as in the original language model if the input sequence contains no image. This inspiration arises from the comparison between P-Tuning and LoRA in efficient finetuning, where p-tuning learns a task prefix embedding in the input while LoRA adapts the model weights in each layer via a low-rank matrix. As a result, LoRA performs better and more stable. A similar phenomenon might also exist in VLM, because in the shallow alignment methods, the image features act like the prefix embedding in P-Tuning.
- The figure below from the paper shows the architecture of CogVLM. (a) The illustration about the input, where an image is processed by a pretrained ViT and mapped into the same space as the text features. (b) The Transformer block in the language model. The image features have a different QKV matrix and FFN. Only the purple parts are trainable.
- CogVLM was pretrained on 1.5 billion image-text pairs, using a combination of image captioning loss and Referring Expression Comprehension (REC). It achieved state-of-the-art or second-best performance on 14 classic cross-modal benchmarks, demonstrating its effectiveness.
- The model was further fine-tuned on a range of tasks for alignment with free-form instructions, creating the CogVLM-Chat variant. This version showcased flexibility and adaptability to diverse user instructions, indicating the model’s robustness in real-world applications.
- The paper also includes an ablation study to evaluate the impact of different components and settings on the model’s performance, affirming the significance of the visual expert module and other architectural choices.
- The authors emphasize the model’s deep fusion approach as a major advancement over shallow alignment methods, leading to enhanced performance in multi-modal benchmarks. They anticipate that the open-sourcing of CogVLM will significantly contribute to research and industrial applications in visual understanding.
- The figure below from the paper shows the performance of CogVLM on a broad range of multi-modal tasks compared with existing models.
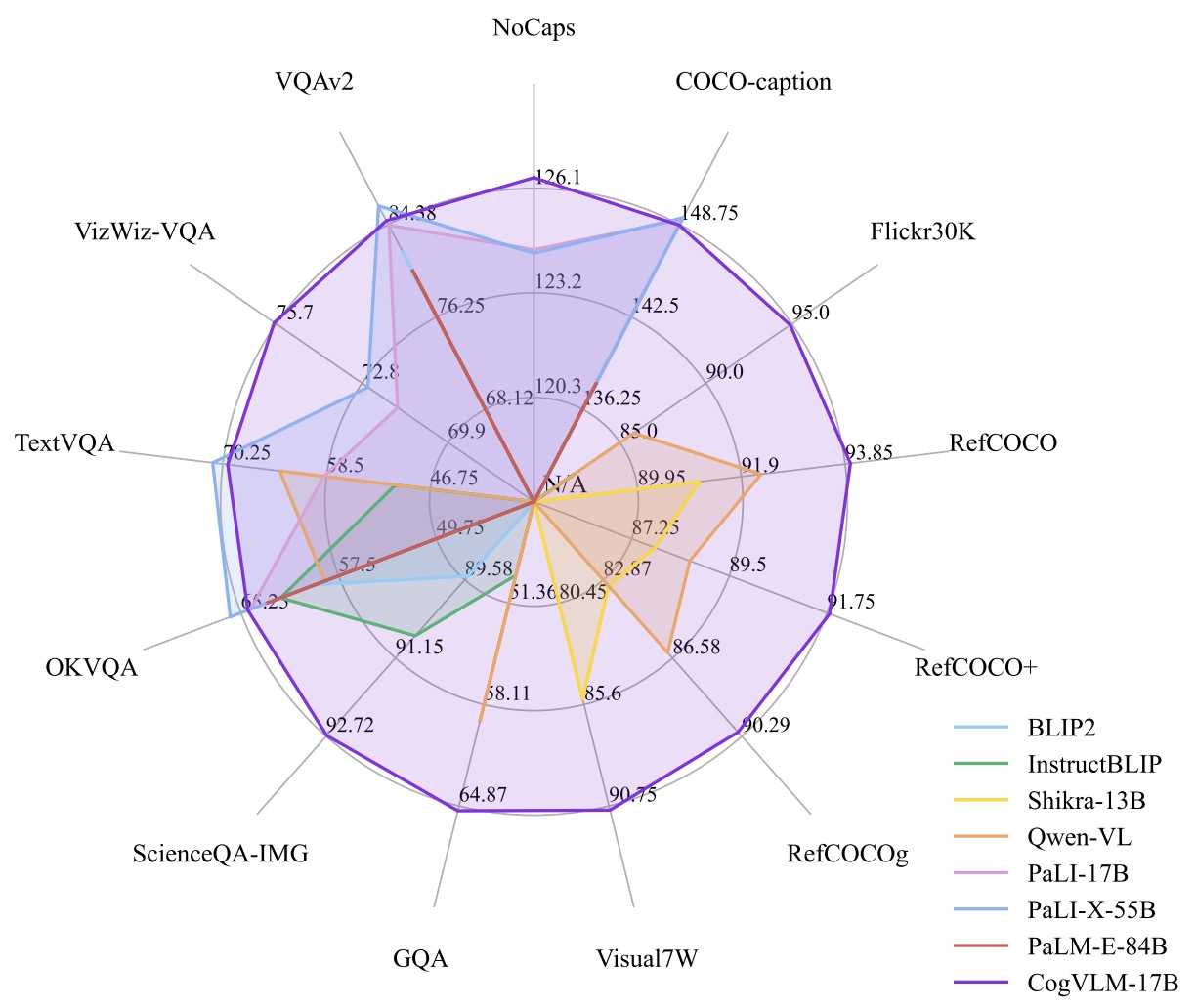
CogVLM 2
- CogVLM 2 beats GPT4-V, Gemini Pro on TextVQA, DocVQA and ChartQA by a decent margin.
- Specifics:
- 19B parameters
- Llama 3 8B (Instruct) text backbone
- Supports 8K context length
- Upto 1344 X 1344 resolution supported
- Works with both Chinese and English
- Open access with commercial use allowed!
- Hugging Face; Code
FERRET
- Proposed in FERRET: Refer and Ground Anything Anywhere at Any Granularity by You et al. from Columbia and Apple, Ferret is a novel Multimodal Large Language Model (MLLM) capable of spatial referring and grounding in images at various shapes and granularities.
- Ferret stands out in its ability to understand and localize open-vocabulary descriptions within images.
- Key Contributions:
- Hybrid Region Representation: Ferret employs a unique representation combining discrete coordinates and continuous visual features. This approach enables the processing of diverse region inputs like points, bounding boxes, and free-form shapes.
- Spatial-Aware Visual Sampler: To capture continuous features of various region shapes, Ferret uses a specialized sampler adept at handling different sparsity levels in shapes. This allows Ferret to deal with complex and irregular region inputs.
- GRIT Dataset: The Ground-and-Refer Instruction-Tuning (GRIT) dataset was curated for model training. It includes 1.1 million samples covering hierarchical spatial knowledge and contains 95k hard negative samples to enhance robustness.
- Ferret-Bench: A benchmark for evaluating MLLMs on tasks that require both referring and grounding abilities. Ferret excels in these tasks, demonstrating improved spatial understanding and commonsense reasoning capabilities.
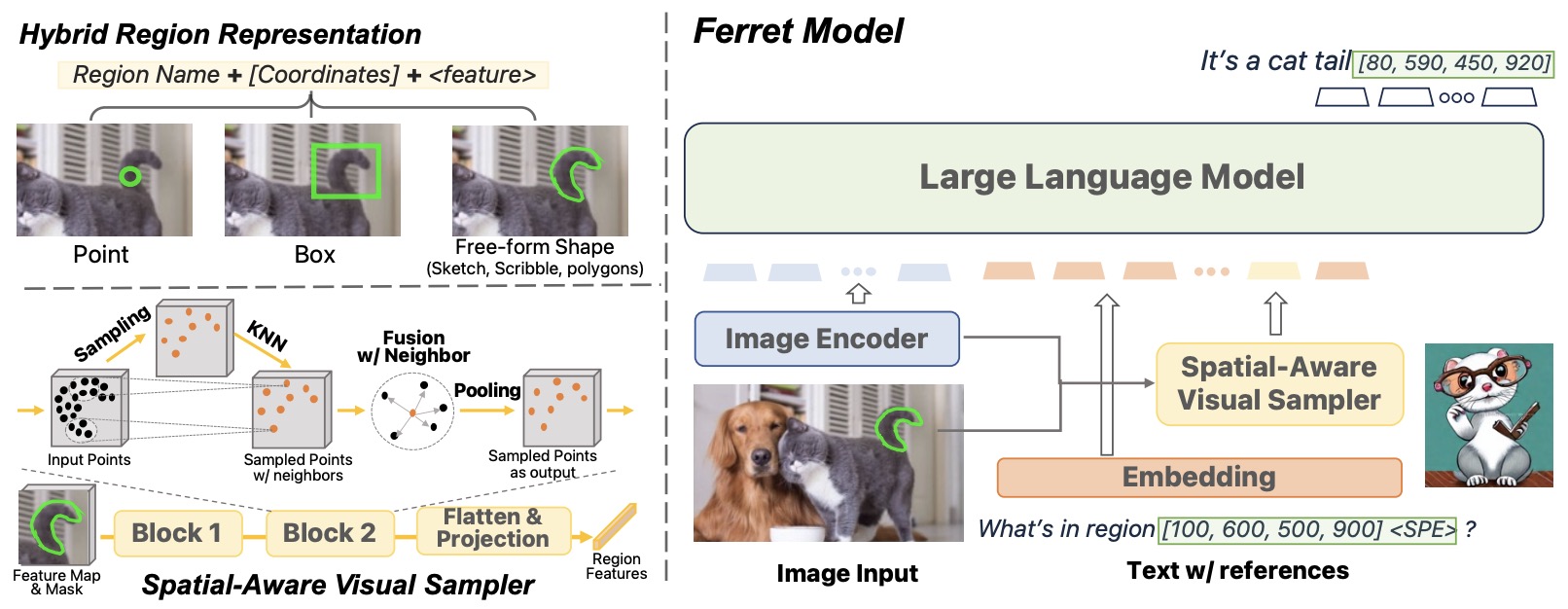
- The figure below from the paper shows that Ferret enables referring and grounding capabilities for MLLMs. In terms of referring, a user can refer to a region or an object in point, box, or any free-form shape. The regionN (green) in the input will be replaced by the proposed hybrid representation before being fed into the LLM. In terms of grounding, Ferret is able to accurately ground any open-vocabulary descriptions. The boxN (red) in the output denotes the predicted bounding box coordinates.
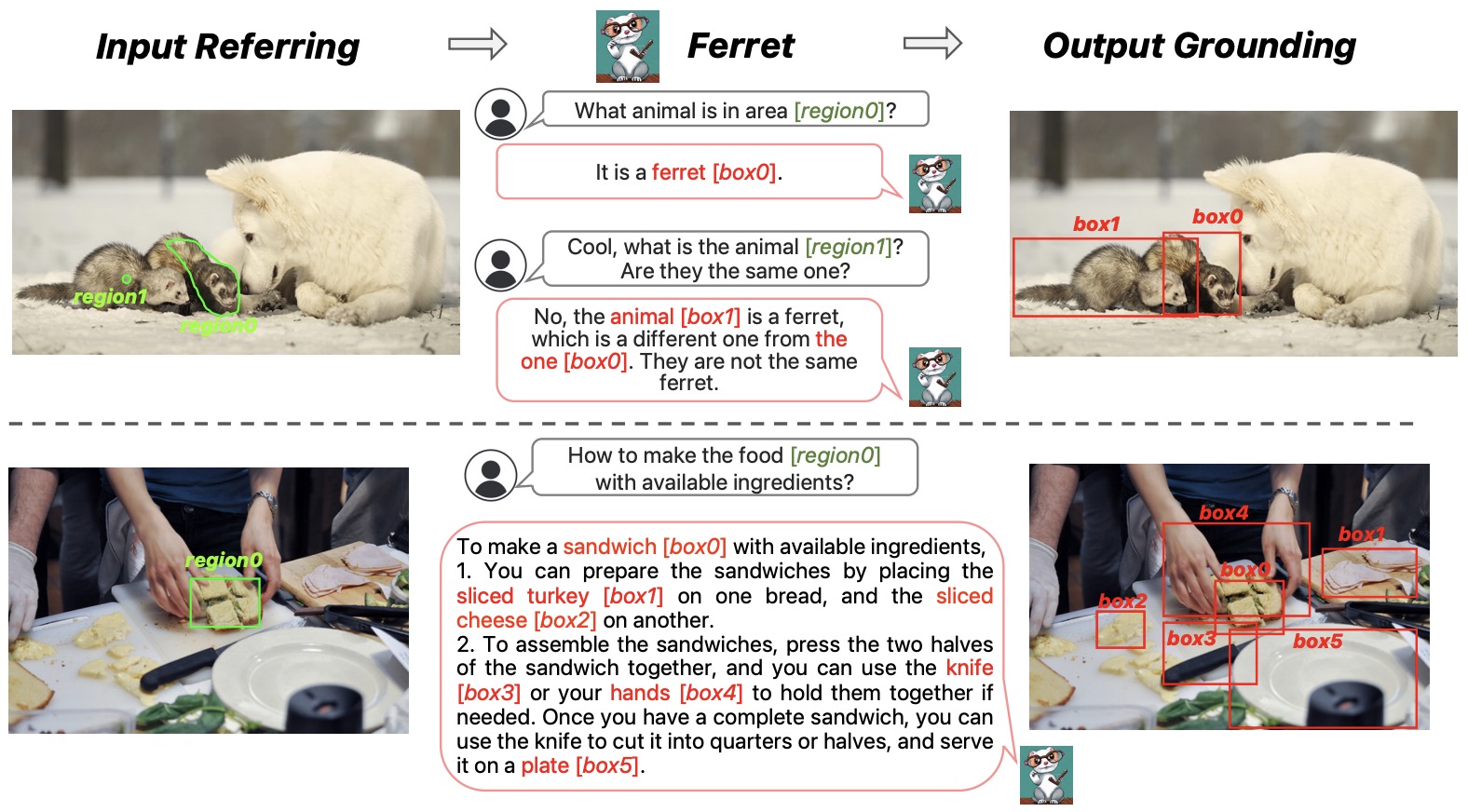
- Implementation Details:
- Model Architecture: Ferret’s architecture consists of an image encoder, a spatial-aware visual sampler, and an LLM to model image, text, and region features.
- Input Processing: The model uses a pre-trained visual encoder (CLIP-ViT-L/14) and LLM’s tokenizer for image and text embeddings. Referred regions are denoted using coordinates and a special token for continuous features.
- Output Grounding: Ferret generates box coordinates corresponding to the referred regions/nouns in its output.
- Language Model: Ferret utilizes Vicuna, a decoder-only LLM, instruction-tuned on LLaMA, for language modeling.
- Training: Ferret is trained on the GRIT dataset for three epochs. During training, the model randomly chooses between center points or bounding boxes to represent regions.
- The figure below from the paper shows an overview of the proposed Ferret model architecture. (Left) The proposed hybrid region representation and spatial-aware visual sampler. (Right) Overall model architecture. All parameters besides the image encoder are trainable.
- Evaluations and Findings:
- Performance on Standard Benchmarks: Ferret surpasses existing models in standard referring and grounding tasks.
- Capability in Multimodal Chatting: Ferret significantly improves performance in multimodal chatting tasks, integrating refer-and-ground capabilities.
- Ablation Studies: Studies indicate mutual benefits between grounding and referring data and demonstrate the effectiveness of the spatial-aware visual sampler.
- Reducing Object Hallucination: Notably, Ferret mitigates the issue of object hallucination, a common challenge in multimodal models.
- Ferret represents a significant advancement in MLLMs, offering robust and versatile spatial referring and grounding abilities. Its innovative approach and superior performance in various tasks mark it as a promising tool for practical applications in vision-language learning.
- Code
KOSMOS-1
- Proposed in Language Is Not All You Need: Aligning Perception with Language Models by Huang et al. from Microsoft, KOSMOS-1 is a Multimodal Large Language Model (MLLM) designed to perceive various modalities, learn in context (few-shot learning), and follow instructions (zero-shot learning). The model is trained from scratch on a web-scale multimodal corpus comprising interleaved text and images, image-caption pairs, and text data. KOSMOS-1 demonstrates remarkable performance in language understanding and generation, OCR-free NLP, perception-language tasks like multimodal dialogue and image captioning, and vision tasks such as image recognition with textual descriptions.
- KOSMOS-1, a Transformer-based causal language model, auto-regressively generates texts and handles multimodal input via a Transformer decoder. The input format includes special tokens to indicate the beginning and end of sequences and encoded image embeddings.
- The figure below from the paper shows that KOSMOS-1 is a multimodal large language model (MLLM) that is capable of perceiving multimodal input, following instructions, and performing in-context learning for not only language tasks but also multimodal tasks. In this work, we align vision with large language models (LLMs), advancing the trend of going from LLMs to MLLMs.
- Technical details of the implementation include using MAGNETO, a Transformer variant, as the backbone architecture, and XPOS for relative position encoding. MAGNETO offers training stability and improved performance across modalities, while XPOS enhances long-context modeling and attention resolution.
- The training involves web-scale multimodal corpora and focuses on next-token prediction to maximize log-likelihood of tokens. The data sources for training include The Pile, Common Crawl, LAION-2B, LAION-400M, COYO-700M, and Conceptual Captions. The model also undergoes language-only instruction tuning using the Unnatural Instructions and FLANv2 datasets to align better with human instructions.
- Evaluation of KOSMOS-1 covered a wide array of tasks:
- Language tasks: language understanding, generation, and OCR-free text classification.
- Cross-modal transfer and commonsense reasoning.
- Nonverbal reasoning using Raven’s Progressive Matrices.
- Perception-language tasks like image captioning and visual question answering.
- Vision tasks, including zero-shot image classification.
- In perception-language tasks, the model excels in image captioning and visual question answering. For image captioning, it was tested on MS COCO Caption and Flickr30k, achieving a CIDEr score of 67.1 on the Flickr30k dataset. In visual question answering, KOSMOS-1 showed higher accuracy and robustness on VQAv2 and VizWiz datasets compared to other models.
- OCR-free language understanding involved understanding text within images without OCR. WebSRC dataset was used for evaluating web page question answering, where KOSMOS-1 showed the ability to benefit from the layout and style information of web pages in images.
- Chain-of-thought prompting was also investigated, enabling KOSMOS-1 to generate a rationale first, then tackle complex question-answering and reasoning tasks. This approach showed better performance compared to standard prompting methods.
- For zero-shot image classification on ImageNet, KOSMOS-1 significantly outperformed GIT in both constrained and unconstrained settings. The approach involved prompting the model with an image and a corresponding natural language query to predict the category name of the image.
- Code
KOSMOS-2
- Proposed in KOSMOS-2: Grounding Multimodal Large Language Models to the World by Peng et al. from Microsoft Research, KOSMOS-2 is a groundbreaking Multimodal Large Language Model (MLLM). This model enhances traditional MLLMs by enabling new capabilities to perceive object descriptions, such as bounding boxes, and grounding text to the visual world.
- KOSMOS-2 uniquely represents refer expressions in a Markdown-like format,
[text span](bounding boxes), where object descriptions are sequences of location tokens. This approach allows the model to link text spans, such as noun phrases and referring expressions, to spatial locations in images. - The following figure from the paper illustrates KOSMOS-2’s new capabilities of multimodal grounding and referring. KOSMOS-2 can understand multimodal input, follow instructions, perceive object descriptions (e.g., bounding boxes), and ground language to the visual world.
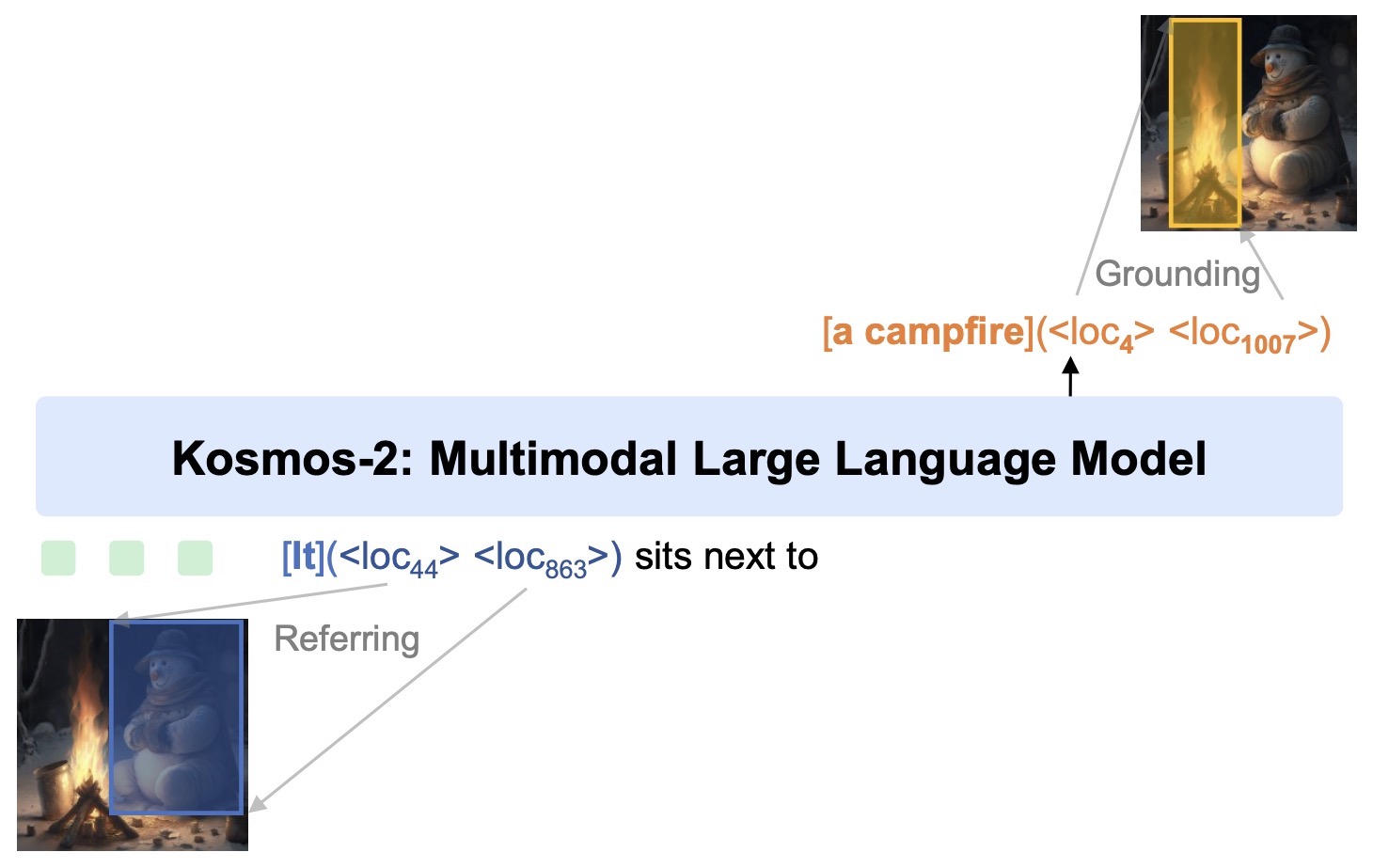
- For image input, KOSMOS-2 employs a sophisticated process. Images are first processed through a vision encoder, which generates embeddings for each image. These embeddings are then combined with the location tokens representing bounding boxes or specific areas of interest within the image. This combination enables the model to understand and relate specific parts of an image to corresponding textual descriptions.
- The large-scale dataset of grounded image-text pairs, named GRIT, is pivotal for training. Derived from subsets of the LAION-2B and COYO-700M datasets, it integrates grounding capability into downstream applications, alongside the existing capabilities of MLLMs like perceiving general modalities, following instructions, and performing in-context learning.
- The model’s architecture is built on KOSMOS-1, utilizing a Transformer-based causal language model for next-word prediction tasks. The vision encoder and multimodal large language model components process discrete tokens, including location tokens added to the word vocabulary for unified modeling with texts.
- KOSMOS-2 was rigorously trained with a mix of grounded image-text pairs, monomodal text corpora, and interleaved image-text data. The training involved 60k steps over 25 billion tokens, using the AdamW optimizer on 256 V100 GPUs.
- The evaluation of KOSMOS-2 covered a wide range of tasks: multimodal grounding (phrase grounding, referring expression comprehension), multimodal referring (referring expression generation), perception-language tasks (image captioning, visual question answering), and language understanding and generation. The results affirmed KOSMOS-2’s capacity to handle complex multimodal tasks and its effectiveness in grounding text descriptions to the visual world.
- This significant research lays the foundation for Embodiment AI and represents a vital step towards the convergence of language, multimodal perception, action, and world modeling. It marks a substantial advancement towards artificial general intelligence.
- The paper includes illustrative figures demonstrating KOSMOS-2’s capabilities in multimodal grounding and referring. These show how the model understands multimodal input, follows instructions, perceives object descriptions, and grounds language to the visual world.
- Code
OFAMultiInstruct
- Proposed in MultiInstruct: Improving Multi-Modal Zero-Shot Learning via Instruction Tuning by Xu et al. from Virginia Tech, MultiInstruct is a novel benchmark dataset for multimodal instruction tuning. The dataset, first of its kind, includes 62 diverse multimodal tasks in sequence-to-sequence format across 10 broad categories derived from 21 open-source datasets, each task accompanied by five expert-written instructions.
- The authors utilize OFA, a pre-trained multimodal language model, for instruction tuning. They focus on leveraging large-scale text-only instruction datasets like Natural Instructions for transfer learning, aiming to enhance zero-shot performance on various unseen multimodal tasks.
- Experimental results showcase strong zero-shot performance across different tasks, demonstrating the effectiveness of multimodal instruction tuning. The introduction of a new evaluation metric, ‘Sensitivity’, reveals that instruction tuning significantly reduces the model’s sensitivity to variations in instructions. The more diverse the tasks and instructions, the lower the sensitivity, enhancing model robustness.
- The study compares different transfer learning strategies, such as Mixed Instruction Tuning and Sequential Instruction Tuning, and examines their impact on zero-shot performance. Findings indicate that while transferring from a text-only instruction dataset (Natural Instructions) can sometimes reduce performance, it generally lowers model sensitivity across multimodal tasks.
- The figure below from the paper shows task groups included in MultiInstruct. The yellow boxes represent tasks used for evaluation, while the white boxes indicate tasks used for training.
- A key observation is that increasing the number of task clusters in the training process improves both the mean and maximum aggregated performance and decreases model sensitivity, supporting the efficacy of the MultiInstruct dataset. Moreover, the use of diverse instructions per task during tuning improves the model’s performance on unseen tasks and reduces instruction sensitivity.
- The paper also assesses the zero-shot performance on 20 natural language processing tasks from Natural Instructions, finding that multimodal instruction tuning can enhance performance in text-only tasks as well. OFAMultiInstruct, fine-tuned on MultiInstruct, generally outperforms other models, including the baseline OFA model.
- In conclusion, the authors highlight the significant improvements in zero-shot performance on various unseen multimodal tasks achieved through instruction tuning. They acknowledge limitations such as the dataset’s focus on English language tasks and vision-language tasks, suggesting future exploration into more diverse language settings and modalities.
LaVIN
- Proposed in Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models by Luo et al. from Xiamen University and Peng Cheng Laboratory, at NeurIPS 2023.
- LaVIN utilizes Mixture-of-Modality Adaptation (MMA), a novel and cost-effective approach, for adapting Large Language Models (LLMs) to vision-language (VL) tasks.
- MMA utilizes lightweight modules called adapters to bridge the gap between LLMs and VL tasks, enabling joint optimization of image and language models. This approach is distinct from existing solutions that either use large neural networks or require extensive pre-training.
- The authors developed a large vision-language instructed model, LaVIN, by applying MMA to the LLaMA model. LaVIN is designed to handle multimodal science question answering and multimodal dialogue tasks efficiently.
- Experimental results show that LaVIN, powered by MMA, achieves competitive performance and superior training efficiency compared to existing multimodal LLMs. It is also noted for its potential as a general-purpose chatbot.
- LaVIN’s training is notably efficient, requiring only 1.4 training hours and 3.8M trainable parameters. This efficiency is attributed to MMA’s design, which enables an automatic shift between single- and multi-modal instructions without compromising natural language understanding abilities.
- The figure below from the paper shows comparison of different multimodal adaptation schemes for LLMs. In the expert system, LLMs play a role of controller, while the ensemble of LLM and vision models is expensive in terms of computation and storage overhead. The modular training regime (b) requires an additional large neck branch and another large-scale pre-training for cross-modal alignment, which is inefficient in training and performs worse in previous NLP tasks. In contrast, the proposed Mixture-of-Modality Adaption (MMA) (c) is an end-to-end optimization scheme, which is cheap in training and superior in the automatic shift between text-only and image-text instructions.
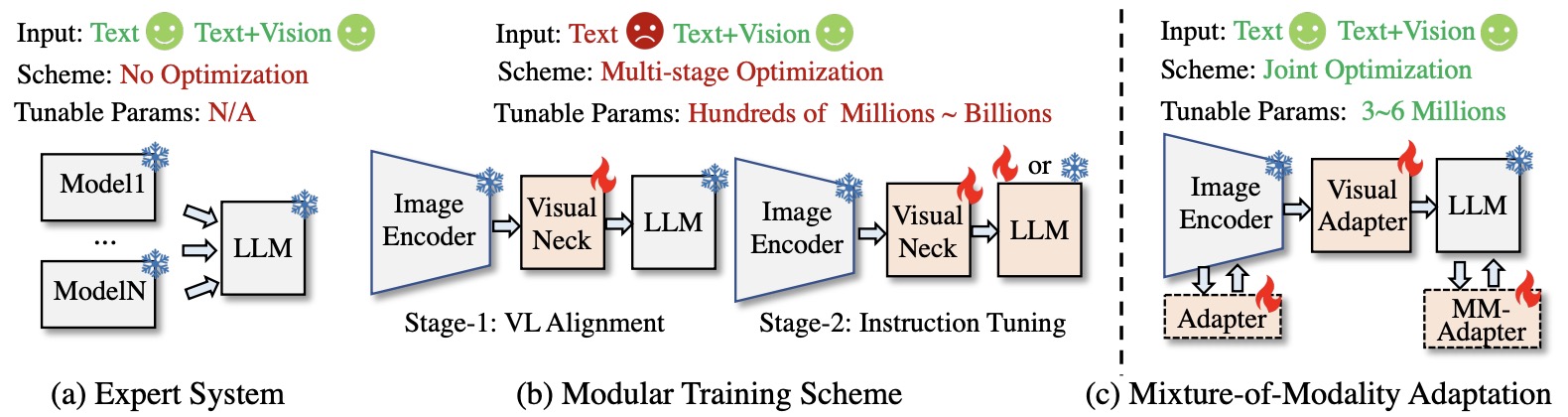
- The figure below from the paper shows the overview of the Mixture-of-Modality Adaptation (MMA) and the architecture of LaVIN. In LaVIN, the novel Mixture-of-Modality Adapters are employed to process the instructions of different modalities. During instruction tuning, LaVIN is optimized by Mixture of Modality Training (MMT) in an end-to-end manner.
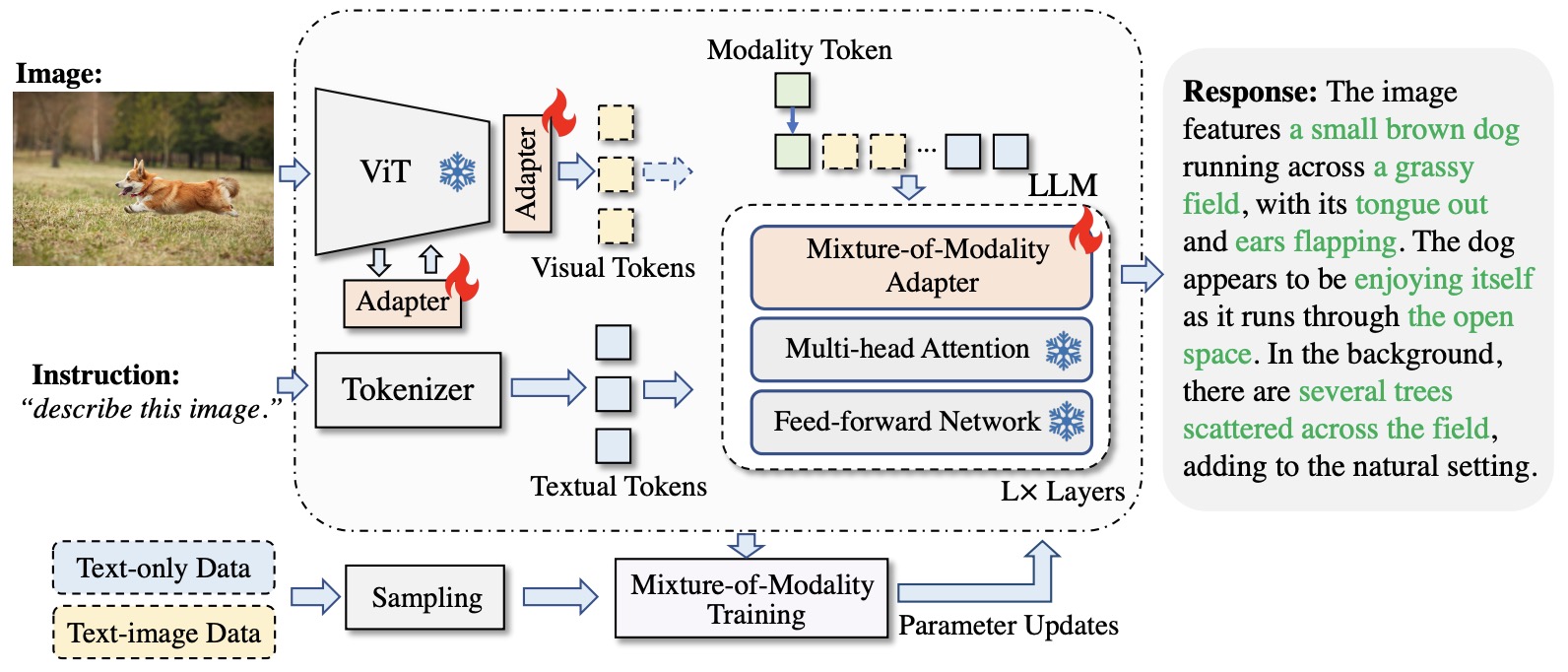
- The paper includes quantitative experiments on the ScienceQA dataset, where LaVIN shows comparable performance with advanced multimodal LLMs while significantly reducing training time and storage costs. Qualitative comparisons also demonstrate LaVIN’s effective execution of various types of human instructions, like coding, math, and image captioning, showcasing superior vision-language understanding.
- The authors highlight the cost-effectiveness of LaVIN, emphasizing its low training expenditure, which is much cheaper than existing methods like BLIP2 and LLaVA. LaVIN demonstrates significant reductions in training time, GPU memory, and storage cost, marking it as an efficient solution for VL instruction tuning.
- Limitations of LaVIN include its potential to generate incorrect or fabricated responses, similar to existing multimodal LLMs, and its inability to identify extremely fine-grained details in images.
- This research offers a breakthrough in efficiently adapting large language models to vision-language tasks, presenting a cost-effective and high-performance solution in the field of artificial intelligence.
- Code
TinyGPT-V
- Proposed in TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones by Yuan et al. from Anhui Polytechnic University, Nanyang Technological University, and Lehigh University.
- TinyGPT-V seeks to bridge the gap in multimodal learning due to the closed-source nature and high computational demand of models like GPT-4V. This model achieves high performance with lower computational requirements, requiring only a 24G GPU for training and an 8G GPU or CPU for inference.
- TinyGPT-V integrates Phi-2, a powerful language model, with pre-trained vision modules from BLIP-2 or CLIP, and employs a unique quantization process, making it suitable for deployment and inference tasks on various devices.
- The architecture involves a visual encoder (EVA of ViT), a linear projection layer, and the Phi-2 language model. The training process involves four stages: warm-up training with image-text pairs, pre-training the LoRA module, instruction fine-tuning with image-text pairs from MiniGPT4 or LLaVA, and multi-task learning to enhance conversational abilities.
- The figure below from the original paper shows the training process of TinyGPT-V, the first stage is warm-up training, the second stage is pre-training, the third stage is instruction finetuning, and the fourth stage is multi-task learning.
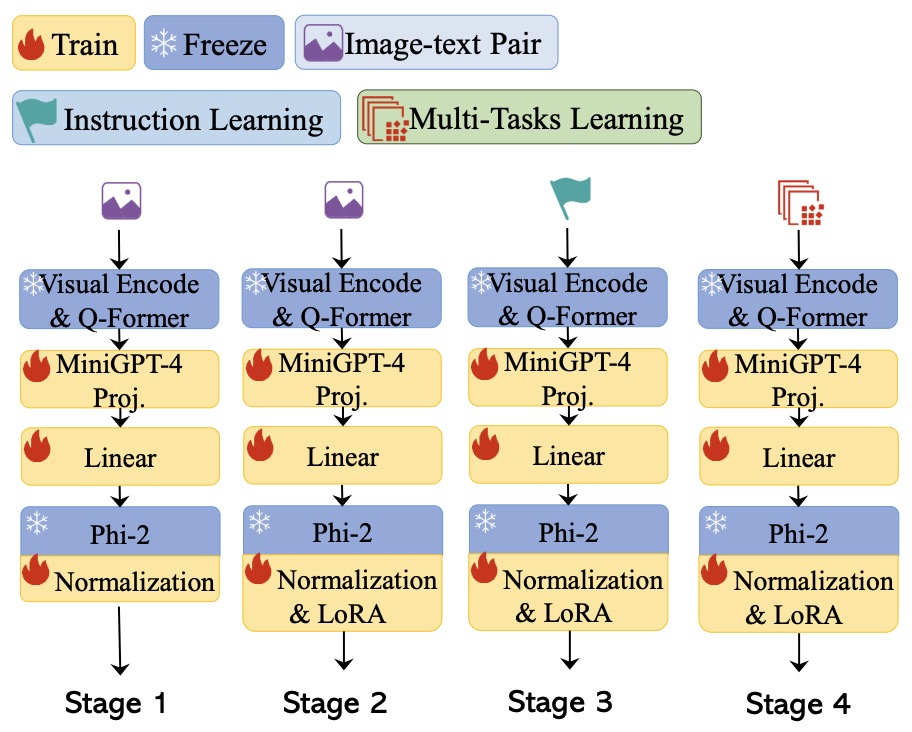
- The figure below from the paper shows: (a) represents the structure of LoRA, (b) represents how LoRA can efficiently fine-tune large language models (LLMs) in natural language processing, (c) represents the structure of LLMs for TinyGPT-V, and (d) represents the structure of QK Normalization.
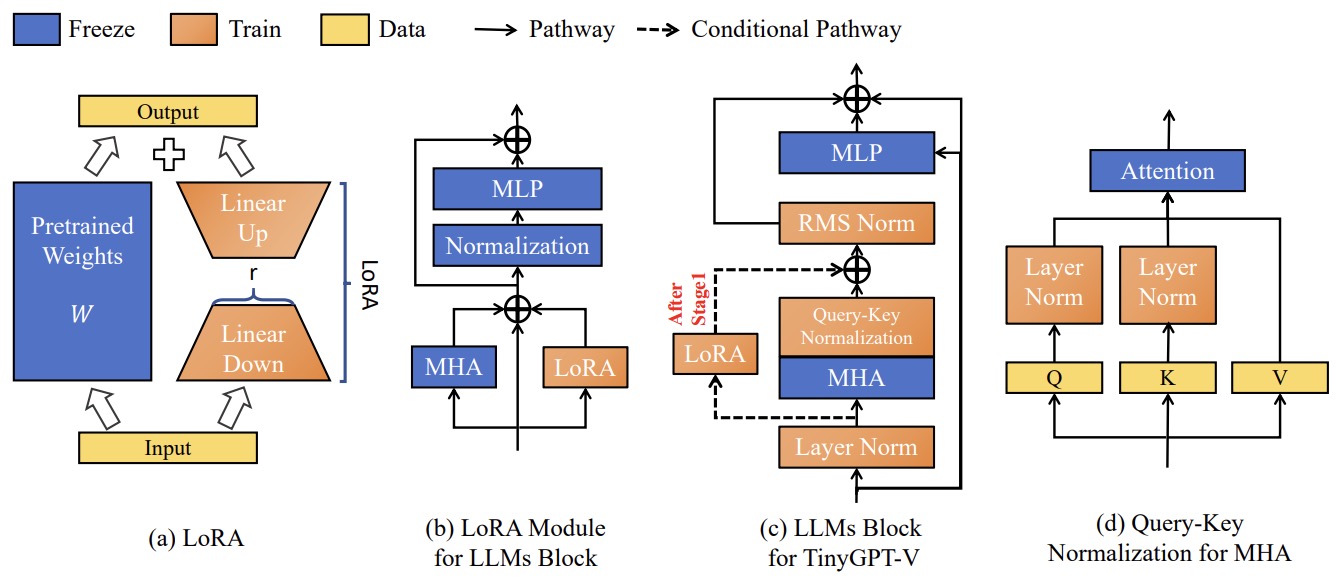
- The model excels in benchmarks like visual question-answering and referring expression comprehension. It showcases competitive performance against larger models in various benchmarks like GQA, VSR, IconVQ, VizWiz, and Hateful Memes.
- Ablation studies reveal the importance of modules like LoRA, Input Layer Norm, RMS Norm, and QK Norm in preventing gradient vanishing and maintaining low loss during training.
- TinyGPT-V’s compact and efficient design, combining a small backbone with large model capabilities, marks a significant step towards practical, high-performance multimodal language models for a broad range of applications.
- Code
CoVLM
- Proposed in CoVLM: Composing Visual Entities and Relationships in Large Language Models via Communicative Decoding by Li et al. from UMass Amherst, Wuhan University, UCLA, South China University of Technology, and MIT-IBM Watson AI Lab, CoVLM is a novel approach to enhance large language models’ (LLMs) compositional reasoning capabilities. This is achieved by integrating vision-language communicative decoding, enabling LLMs to dynamically compose visual entities and relationships in texts and communicate with vision encoders and detection networks.
- CoVLM introduces novel communication tokens that enable dynamic interaction between the visual detection system and the language system. After generating a sentence fragment involving a visual entity or relation, a communication token prompts the detection network to propose relevant regions of interest (ROIs). These ROIs are then fed back into the LLM, improving the language generation based on the relevant visual information. This iterative vision-to-language and language-to-vision communication significantly enhances the model’s performance on compositional reasoning tasks.
- The vision module in CoVLM uses the CLIP ViT-L model for image encoding and a YOLOX-like detection network. The language model component utilizes the pre-trained Pythia model, equipped with special communication tokens (
<obj>,<visual>,<box>,<previsual>,<prebox>) to facilitate vision-language modeling and communication. - The figure below from the paper shows a comparison with existing VLMs. Previous models take in a whole image as input, impairing the compositionality of VLMs. Our CoVLM inserts communication tokens into the LLM after visual entities / relationships to enable the language-to-vision and vision-to-language communication, improving compositionality to a large extent.
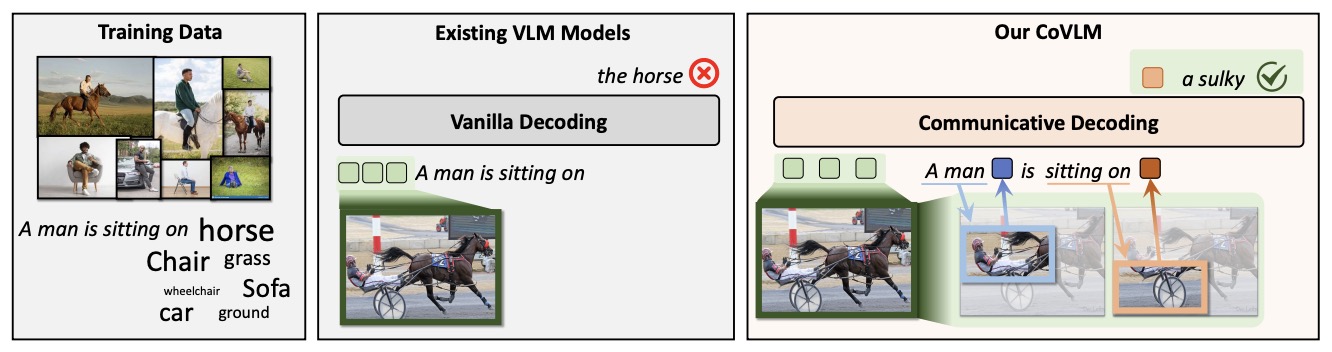
- The figure below from the paper shows an overview of CoVLM’s framework. Our vision module consists of a CLIP encoder to encode the image, and an object detector which takes in the image together with language inputs to generate relevant regions. For language modelling, we insert a set of communication tokens into the LLM, which can appear after a visual entity with a
<visual>token or after a relationship with a<previsual>token. The last hidden layer of the LLM is then sent to the object detector to propose regions relevant to the language inputs so far. This is termed as top down language-to-vision communication. Next, in vision-to-language communication, the features of the proposed regions are fed back to LLM via<box>or<prebox>token for further language generation.
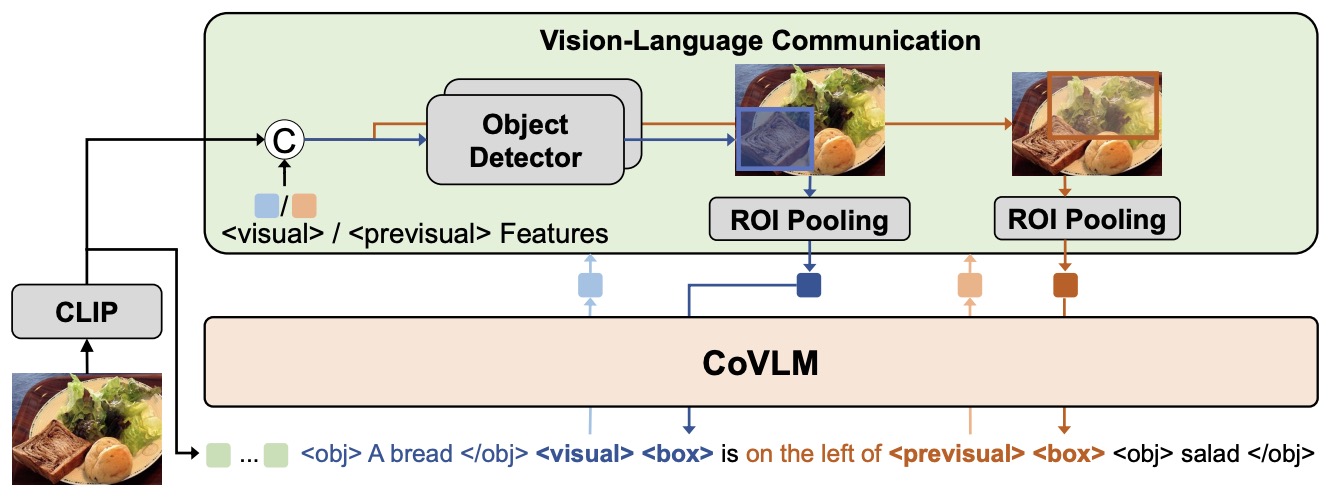
- CoVLM was trained on a large-scale dataset of over 97M image-text pairs from various sources, including COCO, CC3M, CC12M, Visual Genome, SBU, and a subset of LAION400M. The training process involved a grounding pipeline to link text spans in captions to corresponding visual entities in images, further enhancing the model’s grounding capabilities.
- The model significantly outperforms baseline vision-language models (VLMs) in compositional reasoning tasks on datasets like ARO, Cola, and HICO-DET, showing improvements of approximately 20% in HICO-DET mAP, 14% in Cola top-1 accuracy, and 3% in ARO top-1 accuracy. It also demonstrates competitive performance in vision-language tasks such as referring expression comprehension and visual question answering.
- CoVLM’s novel approach to integrating vision and language models marks a significant advancement in the field, though it acknowledges the need for future improvements in object-attribute compositionality and spatial event compositionality.
FireLLaVA
- Fireworks.ai’s FireLLaVA is the first commercially permissive OSS multi-modality model available under the Llama 2 Community License. FireLLaVA marks a significant advancement in handling diverse data sources, including images and text. FireLLaVA, available on Huggingface and via the playground, builds upon the foundation of VLMs like LLaVA, adept at processing and analyzing both visual content and text.
- LLaVA, a prominent VLM, excels in interpreting and responding to visual and textual inputs, setting benchmarks in the field. However, its commercial use was limited due to non-commercial licenses tied to its training with GPT4 generated data. FireLLaVA addresses this by leveraging open-source models for data generation, employing the CodeLlama 34B Instruct model for training. CodeLlama 34B Instruct model was picked to strike a balance between model quality and efficiency. The final mix of the data for the instruction fine-tuning stage consists of 588K lines of single and multi-turn visual question answering or conversation data, mixed from the permissive portion of the original LLaVA training data and Fireworks.ai generated training data. This approach thus maintains high-quality data generation while ensuring commercial usability.
- Despite its advancements, FireLLaVA shares a limitation with the original LLaVA model: it is optimized for conversations involving a single image. Multiple images can degrade its performance, and it may struggle with small texts in images.
- FireLLaVA’s performance has been benchmarked against the original LLaVA model (trained on GPT4 generated data), showing comparable, and in some cases even slightly beats the original LLaVA model on four of the seven benchmarks. This achievement underscores the feasibility and effectiveness of using language-only models to generate high-quality training data for VLMs. FireLLaVA, therefore, represents a significant stride in the development of versatile and sophisticated models capable of interpreting and responding to complex multi-modal data.
MoE-LLaVA
- Proposed in MoE-LLaVA: Mixture of Experts for Large Vision-Language Models by Lin et al. from Peking University, Sun Yat-sen University, FarReel Ai Lab, Tencent Data Platform, and Peng Cheng Laboratory.
- MoE-LLaVA is a novel training strategy for Large Vision-Language Models (LVLMs). The strategy, known as MoE-tuning, constructs a sparse model with a large number of parameters while maintaining constant computational costs and effectively addressing performance degradation in multi-modal learning and model sparsity.
- MoE-LLaVA uniquely activates only the top-k experts through routers during deployment, keeping the remaining experts inactive. This approach results in impressive visual understanding capabilities and reduces hallucinations in model outputs. Remarkably, with 3 billion sparsely activated parameters, MoE-LLaVA performs comparably to the LLaVA-1.5-7B and surpasses the LLaVA-1.5-13B in object hallucination benchmarks.
- The architecture of MoE-LLaVA includes a vision encoder, a visual projection layer (MLP), a word embedding layer, multiple stacked LLM blocks, and MoE blocks. The MoE-tuning process involves three stages: In Stage I, an MLP adapts visual tokens to the LLM. Stage II trains the whole LLM’s parameters except for the Vision Encoder (VE), and in Stage III, FFNs are used to initialize the experts in MoE, and only the MoE layers are trained.
- The following image from the paper illustrates MoE-tuning. The MoE-tuning consists of three stages. In stage I, only the MLP is trained. In stage II, all parameters are trained except for the Vision Encoder (VE). In stage III, FFNs are used to initialize the experts in MoE, and only the MoE layers are trained. For each MoE layer, only two experts are activated for each token, while the other experts remain silent.
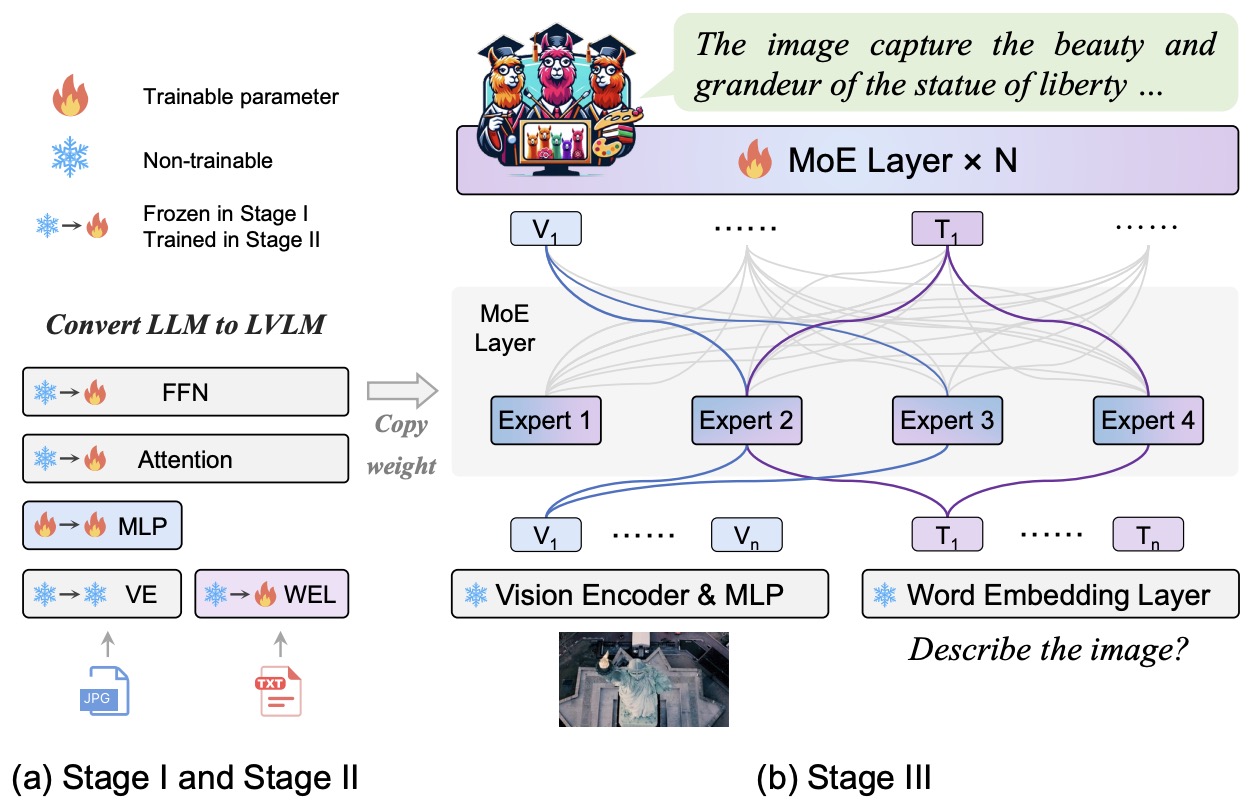
- The model was evaluated on various visual understanding datasets, demonstrating its efficiency and effectiveness. MoE-LLaVA’s performance was on par with or even superior to state-of-the-art models with fewer activated parameters. The paper also includes extensive ablation studies and visualizations to illustrate the effectiveness of the MoE-tuning strategy and the MoE-LLaVA architecture.
- The paper provides a significant contribution to the field of multi-modal learning systems, offering insights for future research in developing more efficient and effective systems.
- Code
BLIVA
- Proposed in BLIVA: A Simple Multimodal LLM for Better Handling of Text-Rich Visual Questions by Hu et al. from UC San Diego and Coinbase Global Inc., BLIVA is designed to improve handling of text-rich visual questions. It builds on the limitations of existing Vision Language Models (VLMs) like OpenAI’s GPT-4 and Flamingo, which struggle with images containing text.
- The model integrates InstructBLIP’s query embeddings and LLaVA-inspired encoded patch embeddings into an LLM. The approach uses a Q-Former to extract instruction-aware visual features and a fully connected projection layer to supplement the LLM with additional visual information.
- BLIVA’s two-stage training aligns the LLM with visual data using image-text pairs and fine-tunes it with instruction tuning data.
- The following image from the paper illustrates a comparison of various VLM approaches. Both (a) Flamingo (Alayrac et al. 2022) and (b) BLIP-2 / InstructBLIP (Li et al. 2023b; Dai et al. 2023) architecture utilize a fixed, small set of query embeddings. These are used to compress visual information for transfer to the LLM. In contrast, (c) LLaVA aligns the encoded patch embeddings directly with the LLM. (d) BLIVA builds upon these methods by merging learned query embeddings with additional encoded patch embeddings.

- The following image from the paper illustrates the model architecture of BLIVA. BLIVA uses a Q-Former to draw out instruction-aware visual features from the patch embeddings generated by a frozen image encoder. These learned query embeddings are then fed as soft prompt inputs into the frozen Language-Learning Model (LLM). Additionally, the system repurposes the originally encoded patch embeddings through a fully connected projection layer, serving as a supplementary source of visual information for the frozen LLM.

- BLIVA shows significant performance improvements in text-rich Visual Question Answering (VQA) benchmarks, including a 17.76% improvement in the OCR-VQA benchmark and 7.9% in the Visual Spatial Reasoning benchmark.
- The model also shows a 17.72% overall improvement in the multimodal LLM benchmark (MME) compared to baseline InstructBLIP. It demonstrates robust performance in real-world scenarios, including processing YouTube thumbnail question-answer pairs, indicating its wide applicability.
PALO
- Proposed in PALO: A Polyglot Large Multimodal Model for 5B People by Maaz et al. from MBZUAI, Australian National University, Aalto University, The University of Melbourne, and Linköping University.
- PALO is the first open-source Large Multimodal Model (LMM), which covers ten key languages (English, Chinese, Hindi, Spanish, French, Arabic, Bengali, Russian, Urdu, and Japanese), reaching 65% of the global population. It uses a semi-automated translation approach, employing a fine-tuned Large Language Model for dataset adaptation to ensure linguistic fidelity across languages, including less-resourced ones like Bengali, Hindi, Urdu, and Arabic.
- The model is scalable across three sizes (1.7B, 7B, 13B parameters), demonstrating significant performance improvements over existing baselines in both high-resource and low-resource languages, enhancing visual reasoning and content generation capabilities.
- The figure below from the paper shows PALO vs. English-VLMs. The plot compares PALO with corresponding Vision-Language Models (VLMs) across 10 different languages. These languages include English, Chinese, Hindi, Spanish, French, Arabic, Bengali, Russian, Urdu, and Japanese, collectively covering approximately 5B people and 65% of the global population. English-trained VLMs, such as LLaVA and MobileVLM, exhibit poor performance on low-resource languages including Hindi, Arabic, Bengali, and Urdu, due to the under-representation of these languages during their training phases. PALO, in contrast, is a unified model that can hold conversations simultaneously in all the ten languages, demonstrating consistent performance across the board.

- The figure below from the paper shows an architecture overview of PALO. (left) The model consists of a vision encoder that encodes the image, followed by a projector that projects the vision features into the input embedding space of the language model. The user’s text query is tokenized, and the tokens are concatenated with the vision tokens before being input into the causal language model to generate the response. For the PALO 7B and 13B variants, Vicuna is used as the Large Language Model while MobileLLaMA (Chu et al., 2023) is used as the Small Language Model in our MobilePALO-1.7B variant. CLIP ViT-L/336px is used as the vision encoder in all variants. (right) Projectors used in different variants of PALO are shown. For the PALO 7B and 13B, following (Liu et al., 2023b), they use a two-layer MLP projector with GELU activation. For our mobile version of PALO (MobilePALO-1.7B), they use a Lightweight Downsample Projector (LDP) from (Chu et al., 2023). It utilizes depth-wise separable convolutions to downsample the image tokens, making it faster than a standard MLP projector.

- Implementation utilizes CLIP ViT-L/336px as the vision encoder, with Vicuna or MobileLLaMA as the language model. A two-layer MLP projector or a Lightweight Downsample Projector (LDP) is used depending on the variant, aimed at efficiency and reduced training/inference time. PALO is pretrained on CC-595K, a subset of CC3M, and fine-tuned on a diverse multilingual instruction dataset.
- It introduces the first multilingual multimodal benchmark for evaluating future models’ vision-language reasoning across languages, showcasing PALO’s generalization and scalability. The model’s effectiveness is attributed to the refined multilingual multimodal dataset and the semi-automated translation pipeline, addressing the challenge of limited high-quality data for under-represented languages.
- Code
DeepSeek-VL
- Proposed in DeepSeek-VL: Towards Real-World Vision-Language Understanding.
- DeepSeek-VL, developed by DeepSeek-AI, is an open-source Vision-Language (VL) model designed to enhance real-world applications involving vision and language understanding. This model stands out due to its approach across three dimensions: comprehensive data construction, efficient model architecture, and an innovative training strategy.
- For data construction, DeepSeek-VL leverages diverse and scalable sources covering real-world scenarios extensively, including web screenshots, PDFs, OCR, charts, and knowledge-based content from expert knowledge and textbooks. The model also benefits from an instruction-tuning dataset derived from real user scenarios, enhancing its practical application.
- The model architecture features a hybrid vision encoder capable of efficiently processing high-resolution images (1024x1024) within a fixed token budget, striking a balance between semantic understanding and detailed visual information capture.
- The training strategy emphasizes the importance of language capabilities in VL models. By integrating LLM training from the onset and adjusting the modality ratio gradually, DeepSeek-VL maintains strong language abilities while incorporating vision capabilities. This strategy addresses the competitive dynamics between vision and language modalities, ensuring a balanced development of both.
- DeepSeek-VL’s training is divided into three stages: training the Vision-Language Adaptor, Joint Vision-Language pretraining, and Supervised Fine-tuning. These stages collectively ensure the model’s proficiency in handling both vision and language inputs effectively.
- DeepSeek-VL’s training pipelines consist of three stages. Stage 1 involves training the VisionLanguage (VL) adaptor while keeping the hybrid vision encoder and language model fixed. Stage 2 is the crucial part of the joint vision and language pretraining, where both VL adaptor and language model are trainable. Stage 3 is the supervised fine-tuning phase, during which the low-resolution vision encoder SigLIP-L, VL adaptor, and language model will be trained.
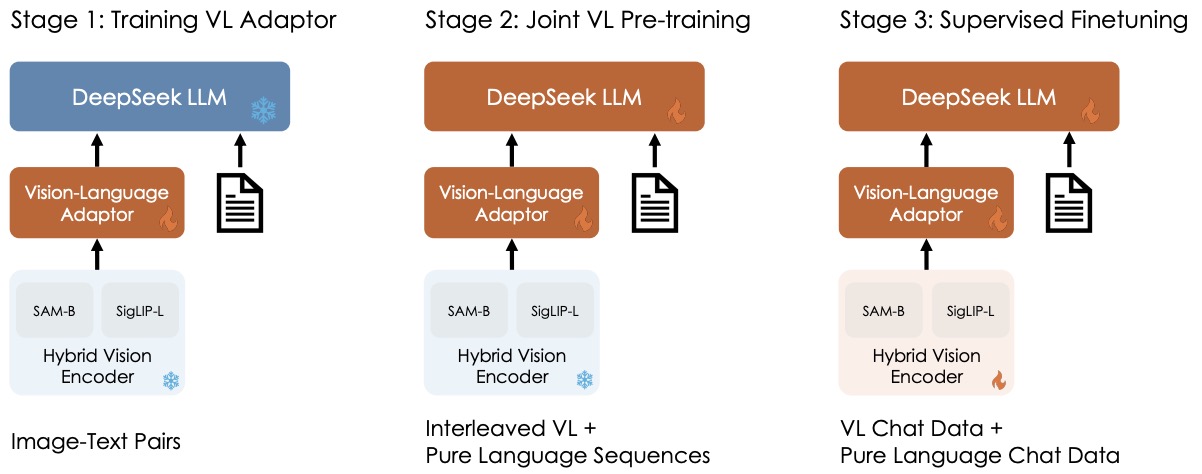
- Evaluation on public multimodal and language benchmarks shows that DeepSeek-VL achieves state-of-the-art or competitive performance, maintaining robust performance on language-centric benchmarks as well. The model’s effectiveness is further confirmed through human evaluation, where it demonstrates superior user experience in real-world applications.
- Code
Grok-1.5 Vision
- Grok-1.5V is a multimodal model from xAI that can process a wide variety of visual information, including documents, diagrams, charts, screenshots, and photographs.
- Grok outperforms its peers in their new RealWorldQA benchmark that measures real-world spatial understanding.
LLaVA++
- With a focus on exploring the potential of advanced language models such as Llama 3 and Phi-3 to enhance visual understanding tasks, MBZUAI carried out experiments by integrating the
Phi-3-Mini-3.8BandLLaMA-3-Instruct-8Bmodels within the LLaVA framework and conducted evaluations across a variety of vision-language contexts. - Impressively, the Phi-3-Mini model, equipped with merely 3.8 billion parameters, achieved performance that matched or exceeded that of the LLaVA-v1.5-13 billion parameters model. Similar trends were observed with LLaMA-3.
- These outcomes affirm that the recent enhancements in language models can be successfully extended to multimodal models, significantly improving their capabilities in visual reasoning.
- Code; Models
LLaVA-NeXT
- LLaVA-NeXT follows a cost-efficient recipe, supporting LLaMA3 (8B) and Qwen (72B &110B), catching up with GPT-V on selected benchmarks.
- Blog; Models; Demo; Code
InternVL
- InternVL 1.5 is an open-source multimodal large language model (MLLM) to bridge the capability gap between open-source and proprietary commercial models in multimodal understanding. We introduce three simple designs:
- Strong Vision Encoder: we explored a continuous learning strategy for the large-scale vision foundation model—InternViT-6B, boosting its visual understanding capabilities, and making it can be transferred and reused in different LLMs.
- Dynamic High-Resolution: we divide images into tiles ranging from 1 to 40 of 448 × 448 pixels according to the aspect ratio and resolution of the input images, which supports up to 4K resolution input.
- High-Quality Bilingual Dataset: we carefully collected a high-quality bilingual dataset that covers common scenes, document images, and annotated them with English and Chinese question-answer pairs, significantly enhancing performance in OCR- and Chinese-related tasks.
- Hugging Face; Code
Falcon 2
- Falcon2-11B-vlm is an 11B parameters causal decoder-only model built by TII and trained on over 5T tokens of RefinedWeb enhanced with curated corpora.
- To bring vision capabilities, they integrate the pretrained CLIP ViT-L/14 vision encoder with their Falcon2-11B chat-finetuned model and train with image-text data.
- For enhancing the VLM’s perception of fine-grained details w.r.t small objects in images, they employ a dynamic encoding mechanism at high-resolution for image inputs.
- The model is made available under the TII Falcon License 2.0, the permissive Apache 2.0-based software license which includes an acceptable use policy that promotes the responsible use of AI.
PaliGemma
- PaliGemma is a family of vision-language models with an architecture consisting of SigLIP-So400m as the image encoder and Gemma-2B as text decoder. SigLIP is a state-of-the-art model that can understand both images and text. Like CLIP, it consists of an image and text encoder trained jointly.
- Similar to PaLI-3, the combined PaliGemma model is pre-trained on image-text data and can then easily be fine-tuned on downstream tasks, such as captioning, or referring segmentation. Gemma is a decoder-only model for text generation. Combining the image encoder of SigLIP with Gemma using a linear adapter makes PaliGemma a powerful vision language model.
- Proposed in PaliGemma: A versatile 3B VLM for transfer, PaliGemma is an open VLM combining the 400M SigLIP vision encoder and the 2B Gemma language model to form a versatile and broadly knowledgeable base model. PaliGemma achieves strong performance across a wide variety of open-world tasks, evaluated on almost 40 diverse benchmarks, including standard VLM tasks and specialized areas like remote-sensing and segmentation.
- PaliGemma’s architecture consists of three main components: the SigLIP image encoder, the Gemma-2B decoder-only language model, and a linear projection layer. The SigLIP encoder, pretrained via sigmoid loss, turns images into a sequence of tokens. The text input is tokenized using Gemma’s SentencePiece tokenizer and embedded with Gemma’s vocabulary embedding layer. The linear projection maps SigLIP’s output tokens into the same dimensions as Gemma-2B’s vocab tokens, enabling seamless concatenation of image and text tokens.
- A key design decision in PaliGemma is the use of the SigLIP image encoder instead of a CLIP image encoder. SigLIP was chosen because it is a “shape optimized” ViT-So400m model, pretrained with a contrastive approach using the sigmoid loss. This optimization and training method provide state-of-the-art performance, especially for a model of its smaller size. The SigLIP encoder’s ability to effectively capture and represent visual information in a compact format was deemed more advantageous compared to the larger CLIP models, which, while powerful, require more computational resources. Additionally, the sigmoid loss training in SigLIP contributes to better spatial and relational understanding capabilities, which are crucial for complex vision-language tasks.
- The training process of PaliGemma follows a multi-stage procedure:
- Stage0: Unimodal Pretraining - Utilizes existing off-the-shelf components without custom unimodal pretraining.
- Stage1: Multimodal Pretraining - Involves long pretraining on a carefully chosen mixture of multimodal tasks, with nothing frozen, optimizing both vision and language components.
- Stage2: Resolution Increase - Short continued pretraining at higher resolution, increasing the text sequence length to accommodate tasks requiring detailed understanding.
- Stage3: Transfer - Fine-tuning the pretrained model on specific, specialized tasks like COCO Captions, Remote Sensing VQA, and more.
- The figure below from the paper illustrates PaliGemma’s architecture: a SigLIP image encoder feeds into a Gemma decoder LM.
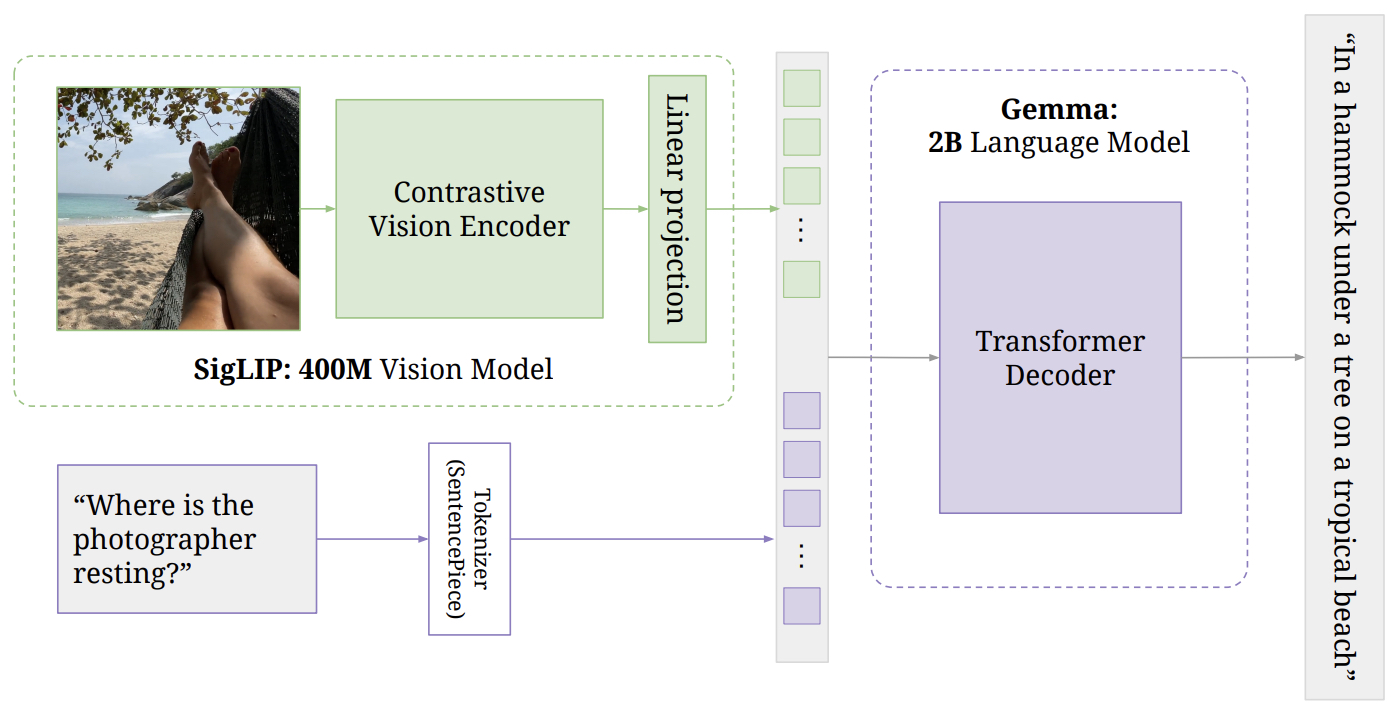
- Implementation details:
- Prefix-LM: PaliGemma employs a Prefix-LM masking strategy that allows full (bi-directional) attention on the “input” part of the data, which includes the image and prefix tokens. This means that during pretraining, the model uses a prefix-LM setup where the image tokens can attend to the prefix tokens representing the query, while the suffix tokens, which represent the output, are autoregressively masked. This approach allows more tokens to actively participate in the “thinking” process from the start, enhancing the model’s ability to understand and integrate information from both modalities effectively. The model’s input sequence thus looks like:
tokens = [image tokens..., BOS, prefix tokens..., SEP, suffix tokens..., EOS, PAD...]-
Freezing Components: The current common wisdom in VLMs is to keep the image encoder and sometimes the LLM frozen during multimodal pretraining. However, inspired by positive results from CapPa and LocCa, which show that pretraining an image encoder using captioning objectives solves contrastive’s blind spot to relation and localization, PaliGemma is pretrained with no frozen parts. Ablation studies demonstrate that not freezing any part of the model during Stage1 is advantageous. After transfers, there is no difference in performance when the image encoder is kept frozen, but the validation perplexity of tasks requiring spatial understanding is significantly improved. Freezing the language model or resetting any part of the model hurts performance dramatically, confirming that leveraging pre-trained components in Stage0 is crucial for good results.
-
Connector Design: Throughout experiments, a linear connector is used to map SigLIP output embeddings to the inputs of Gemma. Although an MLP connector is popular in VLM literature, ablation studies show that the linear connector performs better. When tuning all weights, the average transfer score is nearly identical for linear vs. MLP connectors, but in the “all-frozen” scenario, the linear connector achieves a slightly higher score.
-
Image Encoder: With or Without?: Most VLMs use an image encoder like CLIP/SigLIP or VQGAN to turn the image into soft tokens before passing them to the LLM. Removing the SigLIP encoder and passing raw image patches into a decoder-only LLM (similar to Fuyu) results in significantly lower performance. Despite re-tuning the learning-rate for this architecture, it still lags behind. This is noteworthy considering that the SigLIP encoder has seen 40B image-text pairs during Stage0 pretraining, while the raw patch model sees images for the first time in Stage1 pretraining. This ablation suggests that while decoder-only VLMs might be a promising future direction, they currently suffer in training efficiency due to not being able to reuse vision components.
-
Image Resolution: PaliGemma uses a simple approach: Stage1 is pretrained at a relatively low 224px resolution, and Stage2 “upcycles” this checkpoint to higher resolutions (448px and 896px). The final PaliGemma model thus comes with three different checkpoints for these resolutions, ensuring that it can handle tasks requiring different levels of detail effectively.
- Empirical results demonstrate PaliGemma’s ability to transfer effectively to over 30 academic benchmarks via fine-tuning, despite none of these tasks or datasets being part of the pretraining data. The study shows that PaliGemma achieves state-of-the-art results not only on standard benchmarks but also on more exotic tasks like Remote-Sensing VQA, TallyVQA, and several video captioning and QA tasks.
- Noteworthy findings include:
- Freezing Components: Ablation studies reveal that not freezing any part of the model during pretraining is advantageous, enhancing performance on tasks requiring spatial understanding.
- Connector Design: The linear connector outperforms MLP connectors in both fully tuned and frozen scenarios.
- Zero-shot Generalization: PaliGemma shows strong generalization to 3D renders from Objaverse without explicit training for this type of data.
- The training run of the final PaliGemma model on TPUv5e-256 takes slightly less than 3 days for Stage1 and 15 hours for each Stage2. The model’s performance demonstrates the feasibility of maintaining high performance with less than 3B total parameters, highlighting the potential for smaller models to achieve state-of-the-art results across a diverse range of benchmarks.
- In conclusion, PaliGemma serves as a robust and versatile base VLM that excels in transferability, offering a promising starting point for further research in instruction tuning and specific applications. The study encourages the exploration of smaller models for achieving broad and effective performance in vision-language tasks.
- Hugging Face; Code
Chameleon
- This paper presents Chameleon, a family of early-fusion, token-based mixed-modal models developed by the Chameleon Team at FAIR Meta. Chameleon models can understand and generate sequences of images and text, marking a significant advancement in unified multimodal document modeling.
- Chameleon employs a uniform transformer architecture, trained from scratch on a vast dataset containing interleaved images and text, allowing it to perform tasks such as visual question answering, image captioning, text generation, image generation, and long-form mixed-modal generation. The model’s architecture integrates images and text into a shared representational space from the start, unlike traditional models that use separate modality-specific encoders or decoders. This early-fusion approach facilitates seamless reasoning and generation across modalities.
- Key technical innovations include query-key normalization and revised layer norm placements within the transformer architecture, which address optimization stability challenges. Additionally, supervised finetuning approaches adapted from text-only LLMs are applied to the mixed-modal setting, enabling robust alignment and performance scaling.
- The figure below from the paper illustrates that Chameleon represents all modalities — images, text, and code, as discrete tokens and uses a uniform transformer-based architecture that is trained from scratch in an end-to-end fashion on ∼10T tokens of interleaved mixed-modal data. As a result, Chameleon can both reason over, as well as generate, arbitrary mixed-modal documents. Text tokens are represented in green and image tokens are represented in blue.
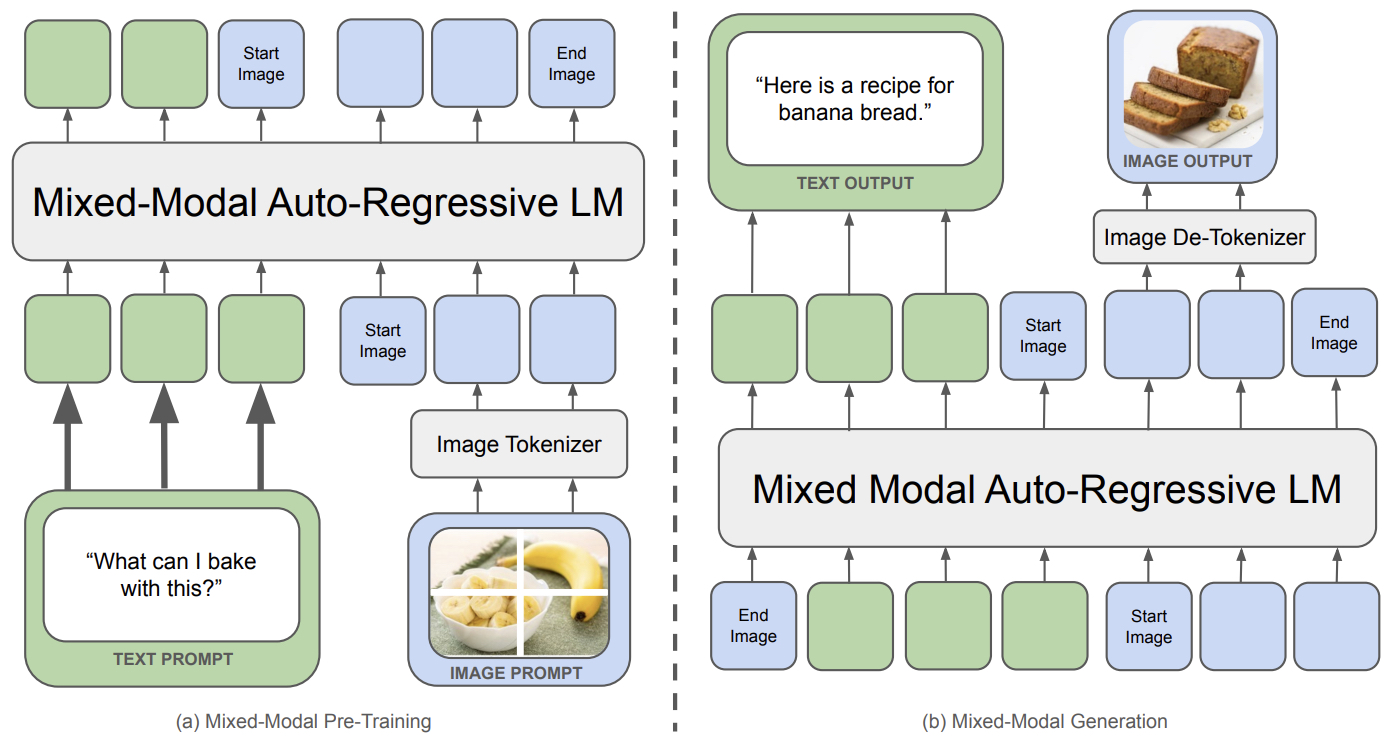
- Implementation Details:
- Architecture: Chameleon quantizes images into discrete tokens similar to words in text, using a uniform transformer architecture. The architecture modifications include query-key normalization and revised placement of layer norms for stable training.
- Tokenization: Images are tokenized using a new image tokenizer that encodes a 512×512 image into 1024 discrete tokens (thus every 16x16 patch is transformed into a token) from a codebook of size 8192. Text tokenization uses a BPE tokenizer with a vocabulary size of 65,536, including image codebook tokens.
- Training: Chameleon-34B was trained on approximately 10 trillion tokens of interleaved mixed-modal data. The training process includes two stages, with the second stage mixing higher quality datasets and applying 50% weight reduction from the first stage data.
- Optimization: The AdamW optimizer is used, with β1 set to 0.9 and β2 to 0.95, and ε = 10−5. A linear warm-up of 4000 steps with an exponential decay schedule is applied to the learning rate. Global gradient clipping is set at a threshold of 1.0.
- Stability Techniques: To maintain training stability, dropout is used after attention and feed-forward layers, along with query-key normalization. Norm reordering within the transformer blocks helps prevent divergence issues during training.
- Chameleon demonstrates strong performance across a wide range of vision-language tasks. It achieves state-of-the-art results in image captioning, surpassing models like Flamingo and IDEFICS, and competes well in text-only benchmarks against models such as Mixtral 8x7B and Gemini-Pro. Notably, Chameleon excels in new mixed-modal reasoning and generation tasks, outperforming larger models like Gemini Pro and GPT-4V according to human evaluations.
- In conclusion, Chameleon sets a new benchmark for open multimodal foundation models, capable of reasoning over and generating interleaved image-text documents. Its unified token-based architecture and innovative training techniques enable seamless integration and high performance across diverse tasks, pushing the boundaries of multimodal AI.
- Code; Models
Phi-3.5-Vision
- Phi-3.5-Vision-Instruct is a 4.2B model with an image encoder, connector, and projector, trained on 500B tokens (vision and text tokens), and is MIT-licensed.
- Only the instruct model were released; no base model.
- Long-context support up to 128k.
- Models are live on Azure AI Studio and Huggingface.
- Hugging Face
Molmo
- Proposed in Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models by Deitke et al. from Allen AI and UW, This paper introduces the Molmo family of vision-language models (VLMs), designed to be entirely open-weight and built using openly collected datasets, specifically focusing on PixMo, a novel dataset. The goal of the Molmo project is to develop high-performing multimodal models without relying on proprietary systems or synthetic data distilled from closed VLMs like GPT-4V. The research highlights the need for independent development of vision-language models to foster scientific exploration and create open resources for the community.
- Key Contributions:
-
Novel Dataset Collection: A significant innovation of this work is the development of PixMo, a highly detailed image caption dataset gathered from human annotators using speech-based descriptions rather than written inputs. This process was designed to ensure dense and rich image captions, avoiding synthetic data. Annotators were instructed to describe every aspect of the image, including spatial positioning and relationships, using 60-90 second speech prompts. This technique resulted in significantly more detailed captions than traditional methods.
- Model Architecture: The Molmo models follow a standard multimodal design that integrates a vision encoder with a language model. The architecture includes:
- Vision encoder: Using OpenAI’s ViT-L/14 336px CLIP model to encode images into vision tokens.
- Language model: Molmo offers models across different scales, such as OLMo-7B, OLMoE-1B-7B, and Qwen2-72B. The connector between the vision encoder and language model is a multi-layer perceptron (MLP) which processes and pools vision tokens before passing them to the language model.
- The models are fully trainable across both pre-training and fine-tuning stages, without freezing parts of the architecture.
- Training Pipeline:
- Stage 1: Caption Generation Pre-training: Using PixMo-Cap, a dataset of human-annotated captions, the models were trained to generate dense and detailed image descriptions. The PixMo-Cap dataset includes over 712,000 distinct images with approximately 1.3 million captions, thanks to naturalistic augmentation by combining human-generated captions with text processed by language-only LLMs.
- Stage 2: Supervised Fine-tuning: Following pre-training, the models are fine-tuned on a diverse set of tasks and datasets, including PixMo-AskModelAnything (a diverse Q&A dataset), PixMo-Points (which enables models to point to objects in images for visual explanations and counting), and PixMo-CapQA (Q&A pairs based on captions). Additional academic datasets like VQA v2, TextVQA, and DocVQA were also used to ensure wide applicability.
- Evaluation and Performance:
- The Molmo models were tested on 11 academic benchmarks and evaluated through human preference rankings. The top-performing model, Molmo-72B, outperformed many proprietary systems, including Gemini 1.5 Pro and Claude 3.5 Sonnet, achieving state-of-the-art results in its class of open models.
- A human evaluation was conducted, collecting over 325,000 preference ratings, with Molmo-72B scoring second in human preference rankings, just behind GPT-4o.
-
Model Comparison: The paper emphasizes the openness of Molmo compared to other VLMs. Unlike many contemporary models that rely on synthetic data from closed systems, Molmo is entirely open-weight and open-data, providing reproducible and transparent training processes.
- Practical Applications: Molmo’s ability to point at objects and explain visual content by grounding language in images opens up new directions for robotics, interactive agents, and web-based applications. The pointing mechanism is especially useful for visual explanations and counting tasks.
-
- The following figure from the paper shows the Molmo architecture follows the simple and standard design of combining a language model with a vision encoder. Its strong performance is the result of a well-tuned training pipeline and our new PixMo data.

- The Molmo family represents a significant step forward for open multimodal systems. The PixMo dataset, combined with an efficient and reproducible training pipeline, enables Molmo models to compete with proprietary systems while remaining entirely open. The research provides the broader community with open model weights, datasets, and code, encouraging further advancements in the field. Future releases will include additional datasets, model weights, and training code to enable widespread adoption and development.
- Blog
Pixtral
- Pixtral 12B is the first-ever multimodal model by Mistral AI, trained with interleaved image and text data, licensed under Apache 2.0.
- It excels in multimodal tasks (e.g., chart/figure understanding, document Q&A) while maintaining state-of-the-art performance on text-only benchmarks.
- Pixtral’s architecture includes a 400M parameter vision encoder and a 12B parameter multimodal decoder, supporting variable image sizes and multiple images, with a long context window of 128k tokens.
- Vision Encoder:
- Images are passed through the vision encoder at their native resolution and aspect ratio, converting them into image tokens for each 16x16 patch. These tokens are flattened into a sequence, with [IMG BREAK] and [IMG END] tokens added between rows and at the end. This process allows the model to distinguish between images of different aspect ratios with the same number of tokens. As a result, Pixtral can accurately process complex diagrams, charts, and documents in high resolution while also offering fast inference speeds for small images like icons and equations.
- A new vision encoder was trained from scratch that natively supports variable image sizes, contributing to Pixtral’s flexible image processing capabilities.
- Pixtral demonstrates superior instruction-following abilities, outperforming open models like Qwen2-VL, LLaVa-OneVision, and Phi-3.5 Vision by 20% on key benchmarks.
- On multimodal reasoning benchmarks, Pixtral outperforms larger models like LLaVa OneVision 72B and closed models such as Claude 3 Haiku, achieving best-in-class performance.
- Final architecture: Pixtral consists of a Vision Encoder, which tokenizes images, and a Multimodal Transformer Decoder, which predicts the next text token based on sequences of text and images. This design allows Pixtral to process any number of images of arbitrary sizes within its large context window of 128K tokens.
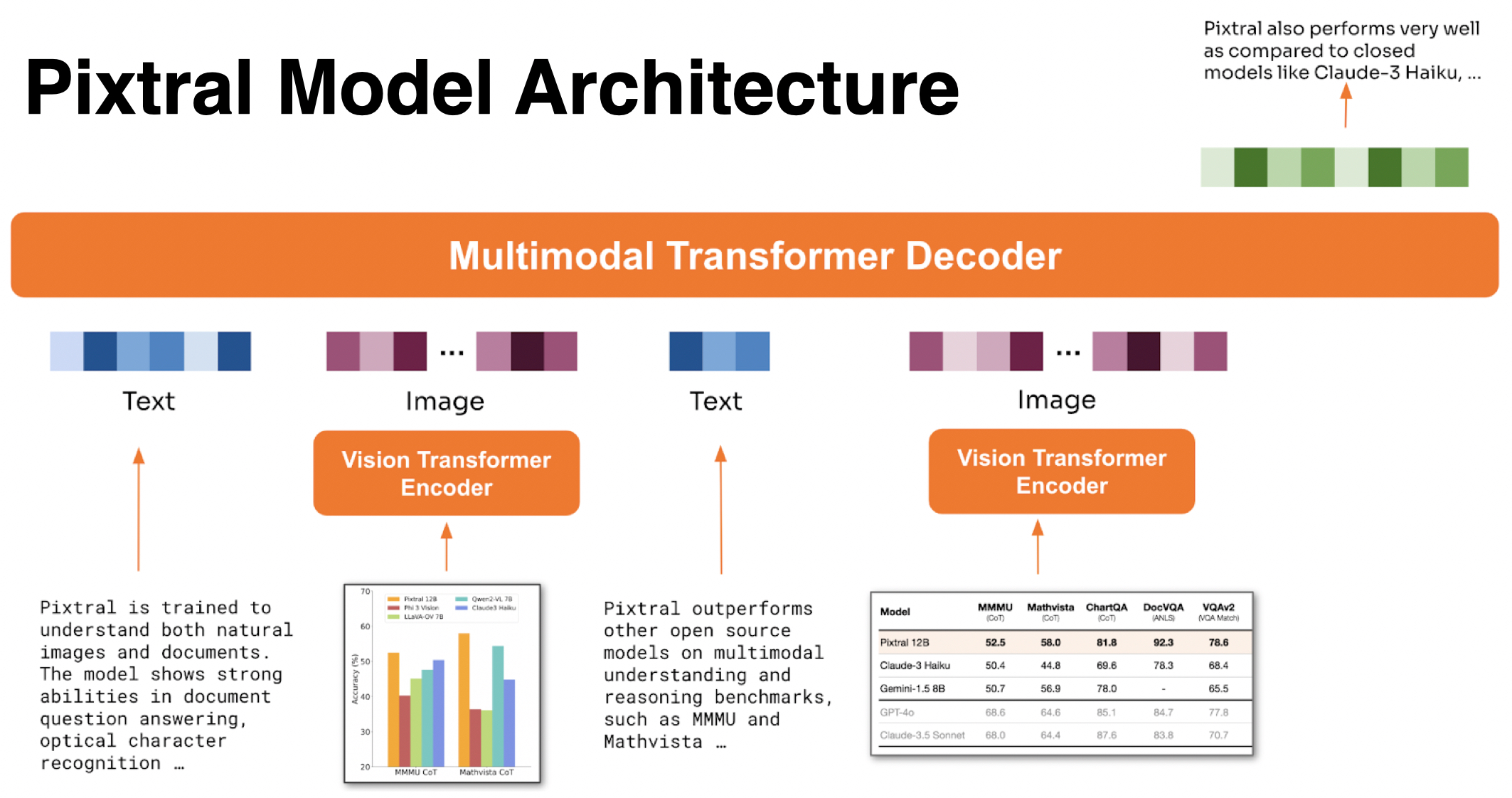
NVLM
- Proposed in NVLM: Open Frontier-Class Multimodal LLMs by Dai et al., NVLM 1.0 is a suite of frontier-class multimodal large language models (LLMs) designed to achieve state-of-the-art performance across vision-language tasks while maintaining strong performance on text-only tasks. The NVLM 1.0 models, developed by NVIDIA, are positioned to rival leading proprietary models like GPT-4V and open-access models such as Llama 3-V 405B and InternVL 2.
- Key Contributions:
-
Model Design: NVLM 1.0 is built on three architectural designs: decoder-only (NVLM-D), cross-attention-based (NVLM-X), and a novel hybrid model (NVLM-H). The paper offers a detailed comparison between the pros and cons of these architectures. NVLM-D performs well on OCR-related tasks, while NVLM-X is optimized for computational efficiency with high-resolution image inputs. NVLM-H integrates the advantages of both approaches to improve multimodal reasoning capabilities.
-
Training Data: NVLM’s performance is significantly enhanced by a meticulously curated pretraining dataset that prioritizes quality and task diversity over dataset size. This includes multimodal math and reasoning data, which notably improves NVLM’s math and coding abilities across modalities. The paper emphasizes that high-quality multimodal datasets are key to performance, particularly for improving models like LLaVA during the pretraining phase.
-
Multimodal Performance: NVLM 1.0 excels in tasks such as OCR, chart understanding, document VQA, and multimodal math reasoning, outperforming proprietary and open-access models in several benchmarks. The authors evaluated the model across various vision-language and text-only tasks, showing strong results without sacrificing text-only performance, a common issue in multimodal training.
-
- Implementation Details:
- Architectures: NVLM-D, the decoder-only model, connects a pretrained vision encoder to the LLM via a two-layer MLP. NVLM-X employs gated cross-attention layers to process image tokens, eliminating the need to unroll all image tokens in the LLM decoder. NVLM-H combines these approaches, processing global thumbnail tokens in the LLM decoder and using gated cross-attention for regular image tiles.
- Training Process: The models are trained in two stages: pretraining (where only the modality-alignment modules are trained) and supervised fine-tuning (SFT), during which both the LLM and the modality-alignment modules are trained. The vision encoder remains frozen during both stages. For multimodal SFT, a blend of multimodal and text-only datasets is used to preserve the LLM’s text-only capabilities.
- High-Resolution Handling: NVLM uses a dynamic high-resolution approach for image inputs, where images are split into tiles and processed individually. The paper introduces a 1-D tile-tagging method to inform the LLM about the structure of the tiled images, which significantly improves performance on OCR-related tasks.
- The following figure from the paper shows that NVLM-1.0 offers three architectural options: the cross-attention-based NVLM-X (top), the hybrid NVLM-H (middle), and the decoder-only NVLM-D (bottom). The dynamic high-resolution vision pathway is shared by all three models. However, different architectures process the image features from thumbnails and regular local tiles in distinct ways.
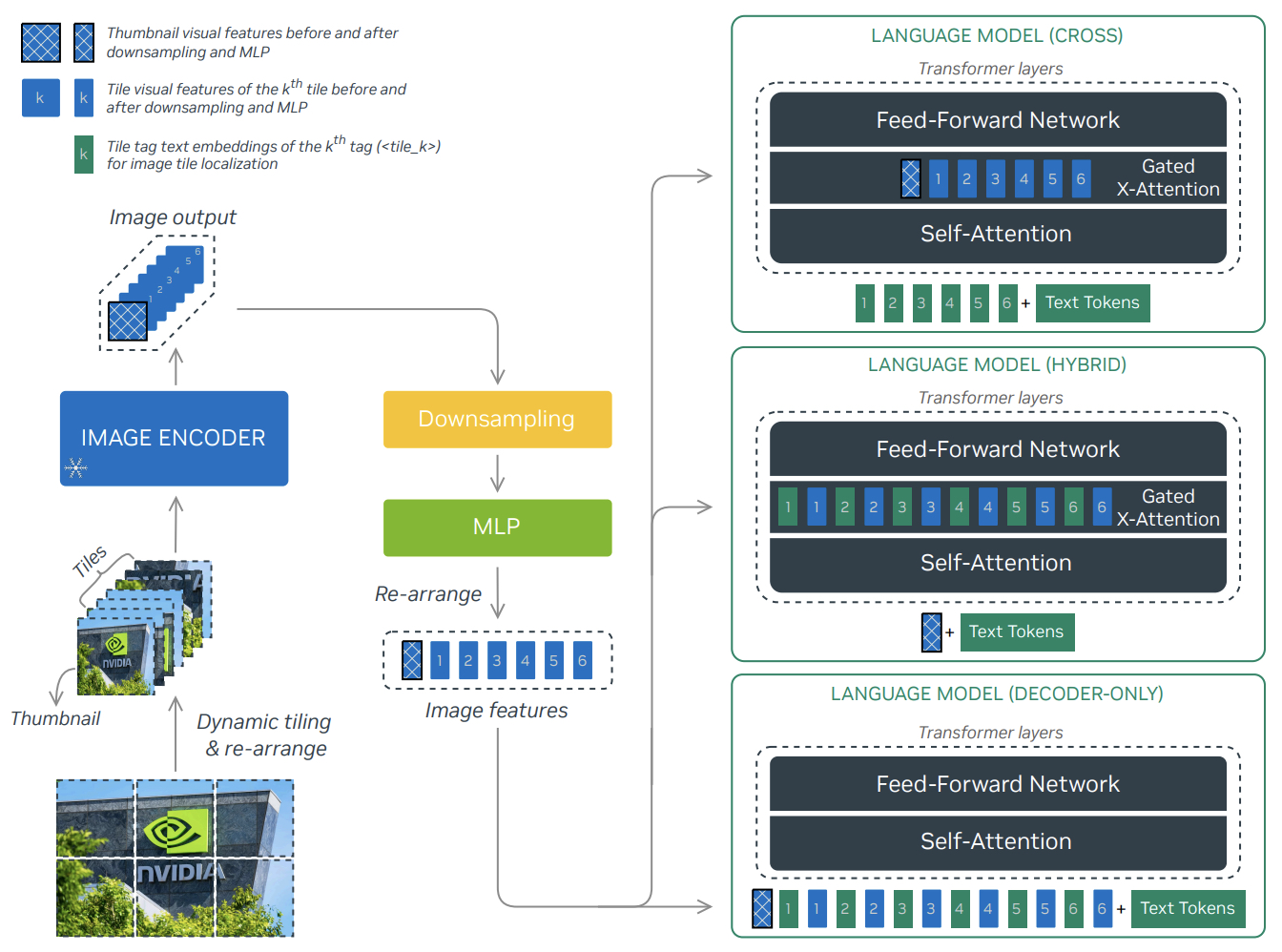
- NVLM 1.0 demonstrates significant improvements in vision-language tasks while maintaining or even enhancing text-only performance after multimodal training. The hybrid NVLM-H architecture particularly excels in multimodal reasoning and math tasks, while NVLM-D achieves top scores in OCR tasks. The authors will release model weights and code for community use.
VLMs for Understanding
CLIP
- Proposed in Learning Transferable Visual Models From Natural Language Supervision by Radford et al. from OpenAI, Contrastive Language-Image Pre-training (CLIP) is a pre-training task which efficiently learns visual concepts from natural language supervision. CLIP uses vision and language encoders trained in isolation and uses a contrastive loss to bring similar image-text pairs closer, while pulling apart dissimilar pairs as a part of pretaining. CLIP’s unique aspect is its departure from traditional models reliant on fixed object categories, instead utilizing a massive dataset of 400 million image-text pairs.
- CLIP’s core methodology revolves around a pre-training task using vision and language encoders, which are trained in isolation. These encoders are optimized using a contrastive loss, effectively narrowing the gap between similar image-text pairs while distancing dissimilar ones. This process is crucial for the model’s pretraining.
- The encoders in CLIP are designed to predict the pairing of images with corresponding texts in the dataset. This predictive capability is then harnessed to transform CLIP into a robust zero-shot classifier. For classification, CLIP utilizes captions (e.g., “a photo of a dog”) to predict the class of a given image, mirroring the zero-shot capabilities seen in models like GPT-2 and GPT-3.
- CLIP’s architecture consists of an image encoder and a text encoder, both fine-tuned to maximize the cosine similarity of embeddings from the correct pairs and minimize it for incorrect pairings. This structure enhances the efficiency of the model, enabling accurate prediction of pairings from a batch of training examples. The following figure from the paper offers an illustration of CLIP’s architecture. While standard image models jointly train an image feature extractor and a linear classifier to predict some label, CLIP jointly trains an image encoder and a text encoder to predict the correct pairings of a batch of
(image, text)training examples. At test time the learned text encoder synthesizes a zero-shot linear classifier by embedding the names or descriptions of the target dataset’s classes.
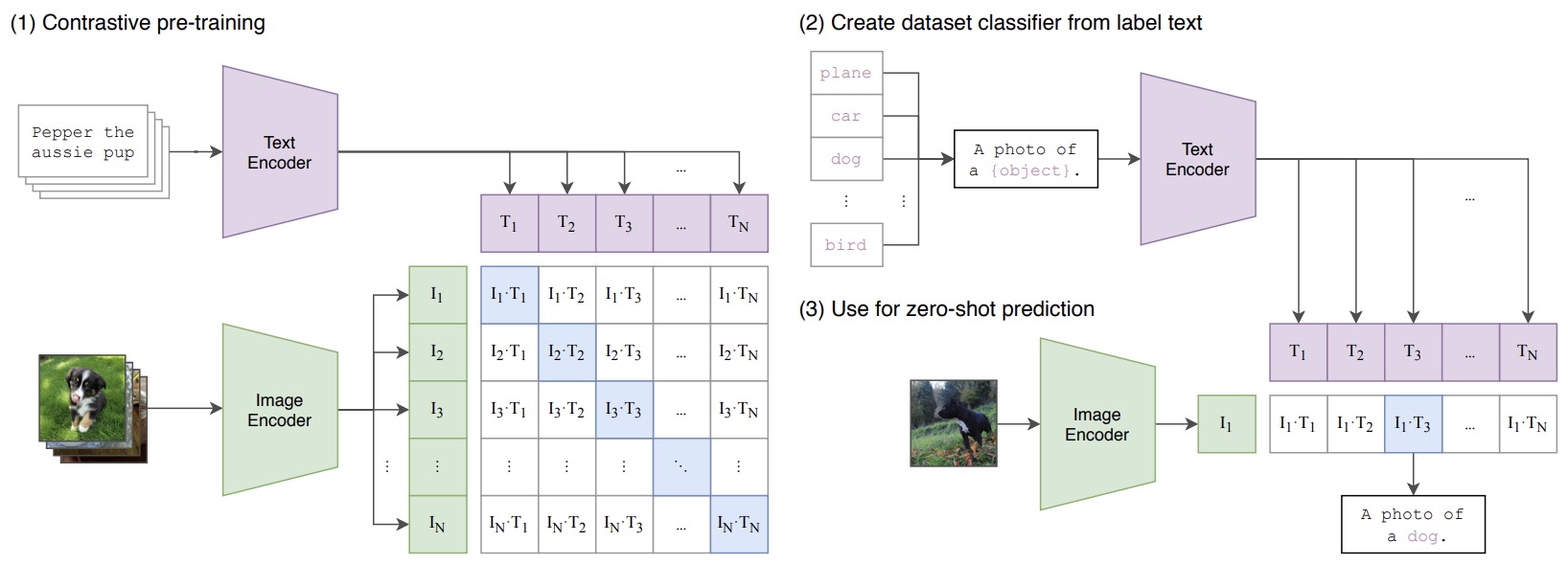
- The model exhibits exceptional zero-shot transfer capabilities, allowing it to classify images into categories it has never encountered during training, using only category names or descriptions.
- CLIP has been thoroughly evaluated on over 30 diverse datasets, encompassing tasks from OCR to object classification. It often matches or surpasses fully supervised baselines, despite not receiving dataset-specific training.
- The paper also explores the impact of prompt engineering and ensembling techniques on zero-shot classification performance. These techniques involve tailoring text prompts for each classification task, providing more context to the model.
- CLIP’s ability to rival the generalization of state-of-the-art ImageNet models is highlighted, thanks to its training on a diverse and extensive dataset. This versatility makes it particularly suitable for zero-shot image classification and cross-modal searches.
- The innovation of CLIP lies in its capacity to understand and learn from natural language supervision, a much more expansive and adaptable source than traditional methods. This feature positions CLIP as a pivotal tool in computer vision, capable of comprehending and categorizing a broad range of visual concepts with minimal specific training data.
- OpenAI article
MetaCLIP
- Proposed in Demystifying CLIP Data](https://arxiv.org/abs/2309.16671) by Xu et al. from FAIR Meta, NYU, and the University of Washington, MetaCLIP focuses on the Contrastive Language-Image Pre-training (CLIP) approach, which has significantly advanced research in computer vision. The authors believe the key to CLIP’s success lies in its data curation rather than its model architecture or pre-training objective.
- The paper introduces Metadata-Curated Language-Image Pre-training (MetaCLIP), which uses metadata derived from CLIP’s concepts to curate a balanced subset from a raw data pool. This method outperforms CLIP on multiple benchmarks, achieving 70.8% accuracy on zero-shot ImageNet classification with ViT-B models and even higher with larger data sets.
- MetaCLIP’s methodology involves creating a balanced subset from a raw data pool using metadata, focusing solely on data impact and excluding other factors. CLIP’s Per Radford et al. (2021), WIT400M is curated with an information retrieval method: “… we constructed a new dataset of 400 million (image, text) pairs collected from a variety of publicly available sources on the Internet. To attempt to cover as broad a set of visual concepts as possible, we search for (image, text) pairs as part of the construction process whose text includes one of a set of 500,000 queries We approximately class balance the results by including up to 20,000 (image, text) pairs per query.”
- They start by re-building CLIP’s 500,000-query metadata, similar to the procedure laid out in Radford et al. (2021): “The base query list is all words occurring at least 100 times in the English version of Wikipedia. This is augmented with bi-grams with high pointwise mutual information as well as the names of all Wikipedia articles above a certain search volume. Finally all WordNet synsets not already in the query list are added.”
- Experimentation was conducted on CommonCrawl with 400M image-text data pairs, showing significant performance improvements over CLIP’s data.
- The paper presents various model sizes and configurations, exemplified by ViT-H achieving 80.5% without additional modifications.
- Curation code and training data distribution on metadata are made available, marking a step towards transparency in data curation processes.
- The study isolates the model and training settings to concentrate on the impact of training data, making several observations about good data quality.
- MetaCLIP’s approach is particularly noted for its scalability and reduction in space complexity, making it adaptable to different data pools and not reliant on external model filters.
- The paper includes an empirical study on data curation with a frozen model architecture and training schedule, emphasizing the importance of the curation process.
- The authors’ contribution lies in revealing CLIP’s data curation approach and providing a more transparent and community-accessible version with MetaCLIP, which significantly outperforms CLIP’s data in terms of performance on various standard benchmarks.
Alpha-CLIP
- Proposed in Alpha-CLIP: A CLIP Model Focusing on Wherever You Want.
- This paper by Sun et al. from Shanghai Jiao Tong University, Fudan University, The Chinese University of Hong Kong, Shanghai AI Laboratory, University of Macau, and MThreads Inc., introduces Alpha-CLIP, an enhanced version of the CLIP model that focuses on specific image regions.
- Alpha-CLIP modifies the CLIP image encoder to accommodate an additional alpha channel along with the traditional RGB channels to suggest attentive regions, fine-tuned with millions of RGBA (Red, Green, Blue, Alpha) region-text pairs. This alpha channel is designed to highlight specific regions of interest in the image, guiding the model to focus on relevant parts. Alpha-CLIP incorporates This enables precise control over image contents and maintains the visual recognition ability of CLIP.
- The structure of the Alpha-CLIP Image Encoder involves integrating the alpha channel with the original CLIP’s image encoder. This integration allows the model to process RGBA images, with the alpha channel providing spatial information about the area of interest. Specifically:
- In the CLIP image encoder’s ViT structure, an RGB convolution is applied to the image in the first layer. As shown in the figure below, they introduce an additional Alpha Conv layer parallel to the RGB Conv layer, which enables the CLIP image encoder to accept an extra alpha channel as input. The alpha channel input is set to range from [0, 1], where 1 represents the foreground and 0 indicates the background. They initialize the Alpha Conv kernel weights to zero, ensuring that the initial Alpha-CLIP ignores the alpha channel as input. Both conv outputs are combined using element-wise addition as follows:
x = self.relu1(self.bn1(self.conv1(x) + self.conv1_alpha(alpha))) - During training, they keep the CLIP text encoder fixed and entirely train the Alpha-CLIP image encoder. Compared to the first convolution layer that processes the alpha channel input, they apply a lower learning rate to the subsequent transformer blocks. To preserve CLIP’s global recognition capability for full images, they adopt a specific data sampling strategy during training. They set the sample ratio, denoted as \(r_s\) = 0.1 to occasionally replace their generated RGBA-text pairs with the original image-text pairs and set the alpha channel to full 1.
- In the CLIP image encoder’s ViT structure, an RGB convolution is applied to the image in the first layer. As shown in the figure below, they introduce an additional Alpha Conv layer parallel to the RGB Conv layer, which enables the CLIP image encoder to accept an extra alpha channel as input. The alpha channel input is set to range from [0, 1], where 1 represents the foreground and 0 indicates the background. They initialize the Alpha Conv kernel weights to zero, ensuring that the initial Alpha-CLIP ignores the alpha channel as input. Both conv outputs are combined using element-wise addition as follows:
- For training, the Alpha-CLIP utilizes a loss function that combines the original CLIP loss, which is a contrastive loss measuring the alignment between image and text embeddings, with an additional term. This additional term ensures that the model pays more attention to regions highlighted by the alpha channel, thus enhancing its ability to focus on specified areas in the image. This could be achieved by applying a weighted loss mechanism where regions marked by the alpha channel contribute more to the loss calculation, encouraging the model to focus more on these areas.
- The figure below from the paper shows the pipeline of Alpha-CLIP’s data generation method and model architecture. (a) They generate millions of RGBA-region text pairs. (b) Alpha-CLIP modifies the CLIP image encoder to take an additional alpha channel along with RGB.
- The figure below from the paper shows the usage of Alpha-CLIP. Alpha-CLIP can seamlessly replace the original CLIP in a wide range of tasks to allow the whole system to focus on any specified region given by points, strokes or masks. Alpha-CLIP possesses the capability to focus on a specified region and controlled editing. Alpha-CLIP can enhance CLIP’s performance on various baselines in a plug-and-play fashion, across various downstream tasks like recognition, MLLM, and 2D/3D generation. Cases marked with are generated with the original CLIP. Cases marked with are generated with Alpha-CLIP. All cases shown here are made simply by replacing the original CLIP of the system with a plug-in Alpha-CLIP without further tuning.
- Experiments demonstrate Alpha-CLIP’s superior performance in zero-shot image classification, REC (Referring Expression Comprehension), and open vocabulary detection. It outperforms baselines like MaskCLIP, showing significant improvement in classification accuracy.
- The model showcases versatility in enhancing region-focused tasks while seamlessly replacing the original CLIP in multiple applications.
- Future work aims to address limitations like focusing on multiple objects and enhancing the model’s resolution for recognizing small objects.
- Code
GLIP
- Proposed in Grounded Language-Image Pre-training (GLIP).
- This paper by Li et al. from UCLA, Microsoft Research, University of Washington, University of Wisconsin-Madison, Microsoft Cloud and AI, International Digital Economy Academy, presents the GLIP model, a novel approach for learning object-level, language-aware, and semantic-rich visual representations.
- GLIP innovatively unifies object detection and phrase grounding for pre-training, leveraging 27M grounding data, including 3M human-annotated and 24M web-crawled image-text pairs. This unification allows GLIP to benefit from both data types, improving grounding models and learning from massive image-text pairs.
- A standout feature of GLIP is its reformulation of object detection as a phrase grounding task, which takes both an image and a text prompt as input. This approach leads to language-aware visual representations and superior transfer learning performance.
- The model introduces deep fusion between image and text encoders, enabling enhanced phrase grounding performance and making visual features language-aware. This deep fusion significantly contributes to the model’s ability to serve various downstream detection tasks.
- The figure below from the paper shows a unified framework for detection and grounding. Unlike a classical object detection model which predicts a categorical class for each detected object, we reformulate detection as a grounding task by aligning each region/box to phrases in a text prompt. GLIP jointly trains an image encoder and a language encoder to predict the correct pairings of regions and words. They further add the cross-modality deep fusion to early fuse information from two modalities and to learn a language-aware visual representation.
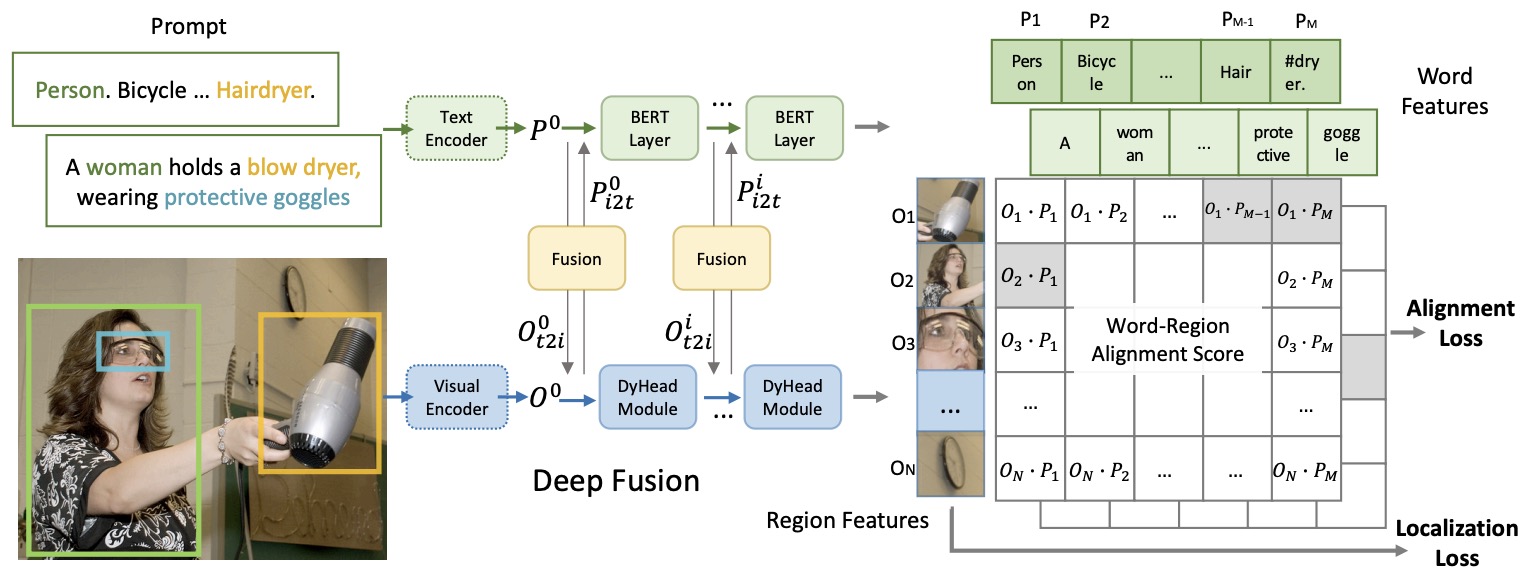
- Experimentally, GLIP demonstrates impressive zero-shot and few-shot transferability to multiple object-level recognition tasks, surpassing many supervised baselines on benchmarks like COCO and LVIS. The paper also explores the model’s robustness across 13 different object detection tasks, highlighting its versatility.
- The figure below from the paper shows that GLIP zero-shot transfers to various detection tasks, by writing the categories of interest into a text prompt.

- A key observation is that pre-training with both detection and grounding data is advantageous, enabling significant improvements in rare category detection and overall performance. The model’s data efficiency and ability to adapt to various tasks are also emphasized.
- The authors provide comprehensive implementation details, including model architecture, training strategies, and performance metrics across different datasets, offering valuable insights into the model’s practical applications and effectiveness.
- Code
ImageBind
- Proposed in ImageBind: One Embedding Space To Bind Them All by Girdhar et al. from Meta in CVPR 2023, ImageBind is an approach to learn a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data.
- They show that all combinations of paired data are not necessary to train such a joint embedding, and only image-paired data is sufficient to bind the modalities together.
- ImageBind can leverage recent large scale vision-language models, and extends their zero-shot capabilities to new modalities just by using their natural pairing with images. It enables novel emergent applications ‘out-of-the-box’ including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection, and generation.
- The emergent capabilities improve with the strength of the image encoder and we set a new state-of-the-art on emergent zero-shot recognition tasks across modalities, outperforming specialist supervised models. Finally, they show strong few-shot recognition results outperforming prior work, and that ImageBind serves as a new way to evaluate vision models for visual and non-visual tasks.
- This figure below from the paper shows ImageBind’s joint embedding space which enables novel multimodal capabilities. By aligning six modalities’ embedding into a common space, IMAGEBIND enables: (i) Cross-Modal Retrieval, which shows emergent alignment of modalities such as audio, depth or text, that aren’t observed together, (ii) Adding embeddings from different modalities naturally composes their semantics, and (iii) Audio-to-Image generation, by using their audio embeddings with a pre-trained DALLE-2 decoder designed to work with CLIP text embeddings.

SigLIP
- Proposed in Sigmoid Loss for Language Image Pre-Training by Zhai et al. from Google DeepMind, SigLIP (short for Sigmoid CLIP) is a novel approach to language-image pre-training, by proposing to replace the loss function used in CLIP by a simple pairwise Sigmoid loss. Put simply, SigLIP introduces a Sigmoid loss, contrasting with the softmax normalization used in OpenAI’s CLIP, a prior breakthrough in image-text understanding. The pairwise Sigmoid results in better performance in terms of zero-shot classification accuracy on ImageNet.
- Standard contrastive learning methods, as in CLIP, require softmax normalization, computing similarities across all pairs in a batch. Softmax normalization in standard contrastive learning, including in CLIP, involves calculating the exponential of a score for each image-text pair and dividing it by the sum of exponentials for all pairs in a batch. This process creates a probability distribution over the batch, helping the model to differentiate between correct and incorrect pairs. This approach, while effective, is computationally intensive and sensitive to batch size.
- SigLIP’s Sigmoid loss evaluates image-text pairs independently, allowing for larger batch sizes and better performance in smaller batches. This independence from global pairwise normalization enhances scaling and efficiency.
- The paper showcases Locked-image Tuning’s effectiveness on limited hardware, achieving 84.5% ImageNet zero-shot accuracy with minimal resources.
- SigLIP’s robustness is evident in its superior performance in zero-shot image classification and image-text retrieval tasks, outperforming the traditional softmax approach, especially under data noise and large-scale training.
- Extensive multilingual experiments involving over 100 languages demonstrate that a 32k batch size is optimal, challenging previous assumptions in large language models like CogVLM or Llava.
- The research contributes to advancements in multimodal large language models, including applications in generative models, text-based segmentation, object detection, and 3D understanding.
- Hugging Face; Models; Notebook
Medical VLMs for Generation
Med-Flamingo
- Proposed in Med-Flamingo: a Multimodal Medical Few-shot Learner.
- Medicine, by its nature, is a multifaceted domain that requires the synthesis of information across various modalities. Medical generative vision-language models (VLMs) make a first step in this direction and promise many exciting clinical applications. However, existing models typically have to be fine-tuned on sizeable down-stream datasets, which poses a significant limitation as in many medical applications data is scarce, necessitating models that are capable of learning from few examples in real-time.
- This paper by Moor et al. from Stanford University, Stanford Medicine, Hospital Israelita Albert Einstein, and Harvard Medical School proposes Med-Flamingo, a multimodal few-shot learner adapted to the medical domain. Based on OpenFlamingo-9B, they continue pre-training on paired and interleaved medical image-text data from publications and textbooks.
- The following figure from the paper shows an overview of the Med-Flamingo model using three steps. First, they pre-train their Med-Flamingo model using paired and interleaved image-text data from the general medical domain (sourced from publications and textbooks). They initialize their model at the OpenFlamingo checkpoint continue pre-training on medical image-text data. Second, we perform few-shot generative visual question answering (VQA). For this, we leverage two existing medical VQA datasets, and a new one, Visual USMLE. Third, we conduct a human rater study with clinicians to rate generations in the context of a given image, question and correct answer. The human evaluation was conducted with a dedicated app and results in a clinical evaluation score that serves as their main metric for evaluation.
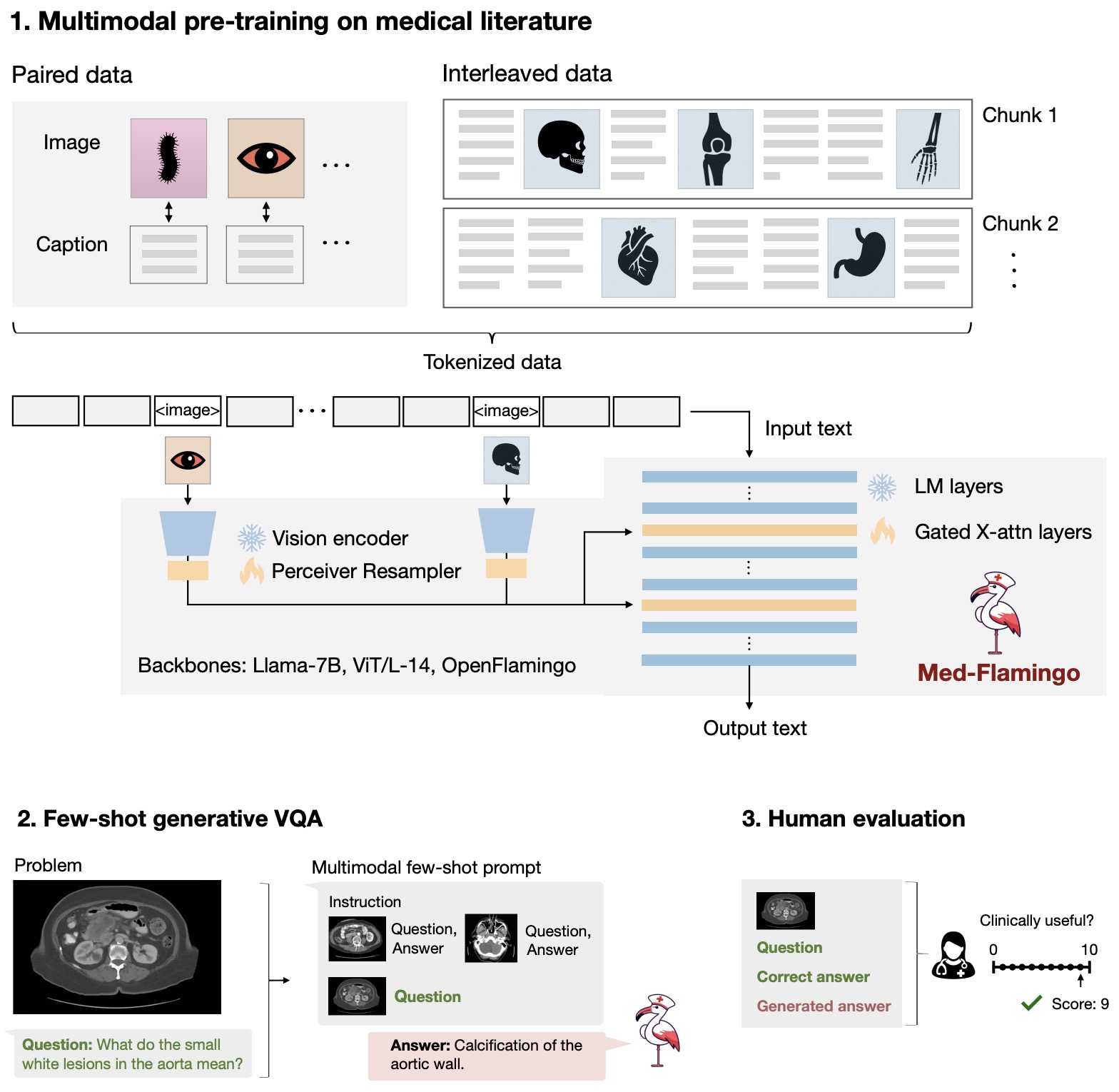
- Med-Flamingo unlocks few-shot generative medical visual question answering (VQA) abilities, which they evaluate on several datasets including a novel challenging open-ended VQA dataset of visual USMLE-style problems.
-
Furthermore, they conduct the first human evaluation for generative medical VQA where physicians review the problems and blinded generations in an interactive app. Med-Flamingo improves performance in generative medical VQA by up to 20% in clinician’s rating and firstly enables multimodal medical few-shot adaptations, such as rationale generation.
- Code
Med-PaLM M
- Medicine is inherently multimodal, with rich data modalities spanning text, imaging, genomics, and more. Generalist biomedical artificial intelligence (AI) systems that flexibly encode, integrate, and interpret this data at scale can potentially enable impactful applications ranging from scientific discovery to care delivery.
- Proposed in Towards Generalist Biomedical AI by Tu et al. from Google Research and Google DeepMind, the authors seek to enable the development of these models by first curating MultiMedBench, a new multimodal biomedical benchmark. MultiMedBench encompasses 14 diverse tasks such as medical question answering, mammography and dermatology image interpretation, radiology report generation and summarization, and genomic variant calling. They then introduce Med-PaLM Multimodal (Med-PaLM M), their proof of concept for a generalist biomedical AI system. Med-PaLM M is a large multimodal generative model that flexibly encodes and interprets biomedical data including clinical language, imaging, and genomics with the same set of model weights.
- Med-PaLM M reaches performance competitive with or exceeding the state of the art on all MultiMedBench tasks, often surpassing specialist models by a wide margin. They also report examples of zero-shot generalization to novel medical concepts and tasks, positive transfer learning across tasks, and emergent zero-shot medical reasoning.
- To further probe the capabilities and limitations of Med-PaLM M, they conduct a radiologist evaluation of model-generated (and human) chest X-ray reports and observe encouraging performance across model scales.
- In a side-by-side ranking on 246 retrospective chest X-rays, clinicians express a pairwise preference for Med-PaLM M reports over those produced by radiologists in up to 40.50% of cases, suggesting potential clinical utility.
- The following figure from the paper shows an overview of Med-PaLM M. A generalist biomedical AI system should be able to handle a diverse range of biomedical data modalities and tasks. To enable progress towards this overarching goal, they curate MultiMedBench, a benchmark spanning 14 diverse biomedical tasks including question answering, visual question answering, image classification, radiology report generation and summarization, and genomic variant calling. Med-PaLM Multimodal (Med-PaLM M), their proof of concept for such a generalist biomedical AI system (denoted by the shaded blue area) is competitive with or exceeds prior SOTA results from specialists models (denoted by dotted red lines) on all tasks in MultiMedBench. Notably, Med-PaLM M achieves this using a single set of model weights, without any task-specific customization.
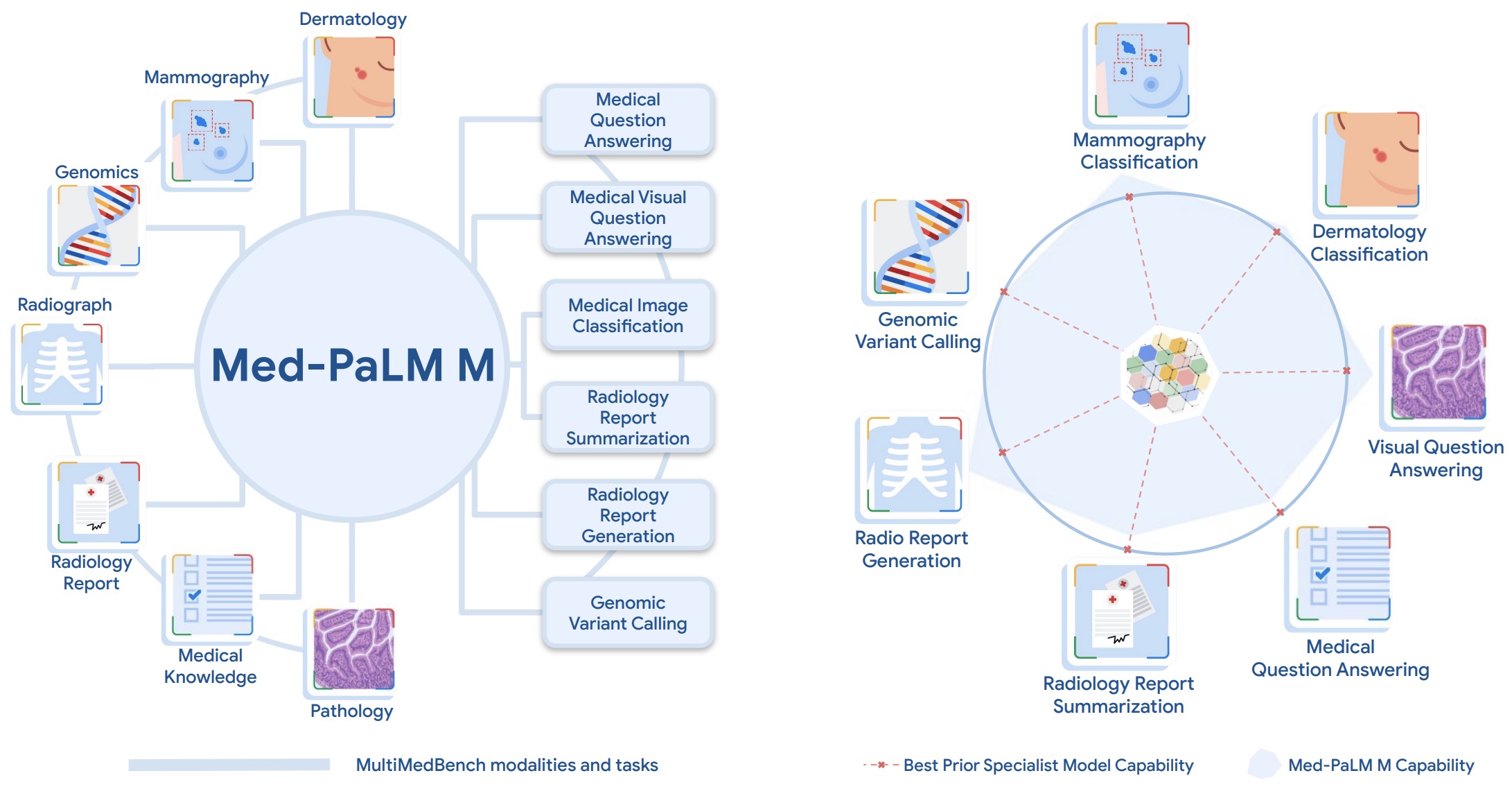
LLaVA-Med
- LLaVA-Med by Microsoft Research is a 7B biomedical vision-language model initialized from the general-domain LLaVA model and then trained on a large dataset of PubMed Central figure-captions.
- Code; Models
Med-Gemini
- Proposed in Capabilities of Gemini Models in Medicine.
- This paper introduces Med-Gemini, a specialized multimodal AI model for medical applications built upon the Gemini architecture. These models are enhanced for advanced reasoning with seamless web-search integration and are tailored for high performance in complex medical scenarios, utilizing self-training, and customized encoders for diverse medical modalities. They uniquely excel in processing complex multimodal data across over a million context tokens.
- Technical Details:
- Self-Training and Web Search Integration: Med-Gemini models employ an advanced reasoning approach that integrates web search during the training phase to improve factual accuracy and clinical reasoning. This involves generating multiple reasoning paths and an uncertainty-guided search strategy at inference time.
- Customized Encoders for Multimodal Data: The models are equipped with modality-specific encoders to handle varied medical data types effectively. This allows them to excel in multimodal understanding and processing of complex medical datasets such as text, images, surgical videos, EHRs, waveforms, and genomic data.
- Long-context Reasoning: The models are capable of processing extensive textual and multimodal data without losing context, critical for applications involving long medical records or detailed patient histories, which are currently beyond the capabilities of other popular models.
- The following figure from the paper illustrates self-training and search tool-use. The left panel illustrates the self-training with search framework used to fine-tune Med-Gemini-L 1.0 for advanced medical reasoning and use of web search. This framework iteratively generates reasoning responses (CoTs) with and without web search, improving the model’s ability to utilize external information for accurate answers. The right panel illustrates Med-Gemini-L 1.0’s uncertainty-guided search process at inference time. This iterative process involves generating multiple reasoning paths, filtering based on uncertainty, generating search queries to resolve ambiguity, and incorporating retrieved search results for more accurate responses.
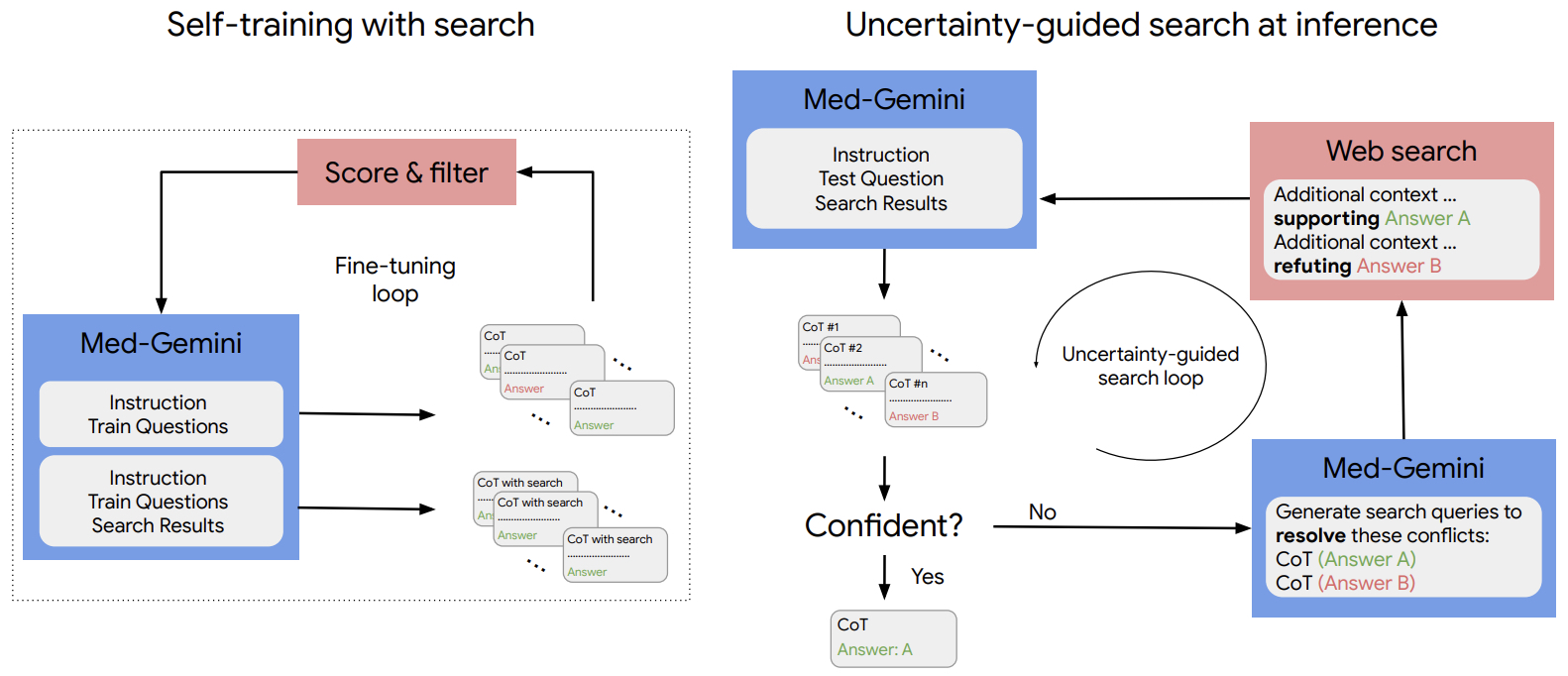
- Benchmark Performance:
- Med-Gemini models have established new state-of-the-art (SoTA) results on 10 out of 14 medical benchmarks, significantly outperforming the GPT-4 model family across these benchmarks. They demonstrate superior accuracy and efficiency in handling complex medical queries and data interpretation.
- In particular, the Med-Gemini model achieved a remarkable 91.1% accuracy on the MedQA (USMLE) benchmark using an uncertainty-guided search strategy, surpassing prior models like Med-PaLM 2 by 4.6%. On 7 multimodal medical benchmarks, Med-Gemini improves over GPT-4V by an average relative margin of 44.5%.
- Real-world Applications and Future Directions:
- The paper highlights potential real-world applications of Med-Gemini in medical text summarization, referral letter generation, and multimodal medical dialogue. These capabilities suggest that Med-Gemini can perform at or above the level of human experts in these tasks, supporting multimodal diagnostic conversations, facilitating improved clinician-EHR interactions, and accelerating biomedical research with the ability to summarize and generate insights from extensive research articles.
- Despite these promising results, the authors advocate for further rigorous evaluation before deployment in clinical settings, emphasizing the need for safety and reliability in medical AI applications. The capabilities of Med-Gemini are expected to be made available via Google Cloud MedLM APIs.
- This comprehensive summary presents a deep dive into the capabilities of the Med-Gemini models, emphasizing their advanced reasoning, multimodal understanding, and long-context capabilities across a broad range of medical benchmarks and potential real-world applications.
Indic VLMs for Generation
Dhenu
- KissanAI’s Dhenu is a series of fine-tuned agricultural VLMs for pest and disease detection and conversation over cure, symptoms, severity and prevention. The Dhenu-vision-lora-0.1 is fine-tuned Qwen-VL-chat, for 3 major crops and 10 diseases, giving 2x performance boost over the base.
- Tailored specifically for Indian agricultural practices and tackling farming challenges, this bilingual model is trained on 300k instruction sets in English and Hindi, to support English, Hindi, and Hinglish queries from farmers, a notable feature catering directly to farmers’ linguistic needs.
- Trained on synthetic data generated for around 9000 disease images for three major crops, Maize, Rice, and Wheat, for following common disease identifiable from leaves.
- Hugging Face
Popular Video LLMs
Video LLMs for Generation
VideoPoet
- Proposed in VideoPoet: A Large Language Model for Zero-Shot Video Generation.
- This paper by Kondratyuk et al. from Google Research introduces VideoPoet, a language model designed for synthesizing high-quality video with matching audio from a range of conditioning signals. It employs a decoder-only transformer architecture to process multimodal inputs like images, videos, text, and audio. The model follows a two-stage training protocol of pretraining and task-specific adaptation, incorporating multimodal generative objectives within an autoregressive Transformer framework. Empirical results highlight VideoPoet’s state-of-the-art capabilities in zero-shot video generation, particularly in generating high-fidelity motions.
- The figure below from the paper shows VideoPoet, a versatile video generator that conditions on multiple types of inputs and performs a variety of video generation tasks.
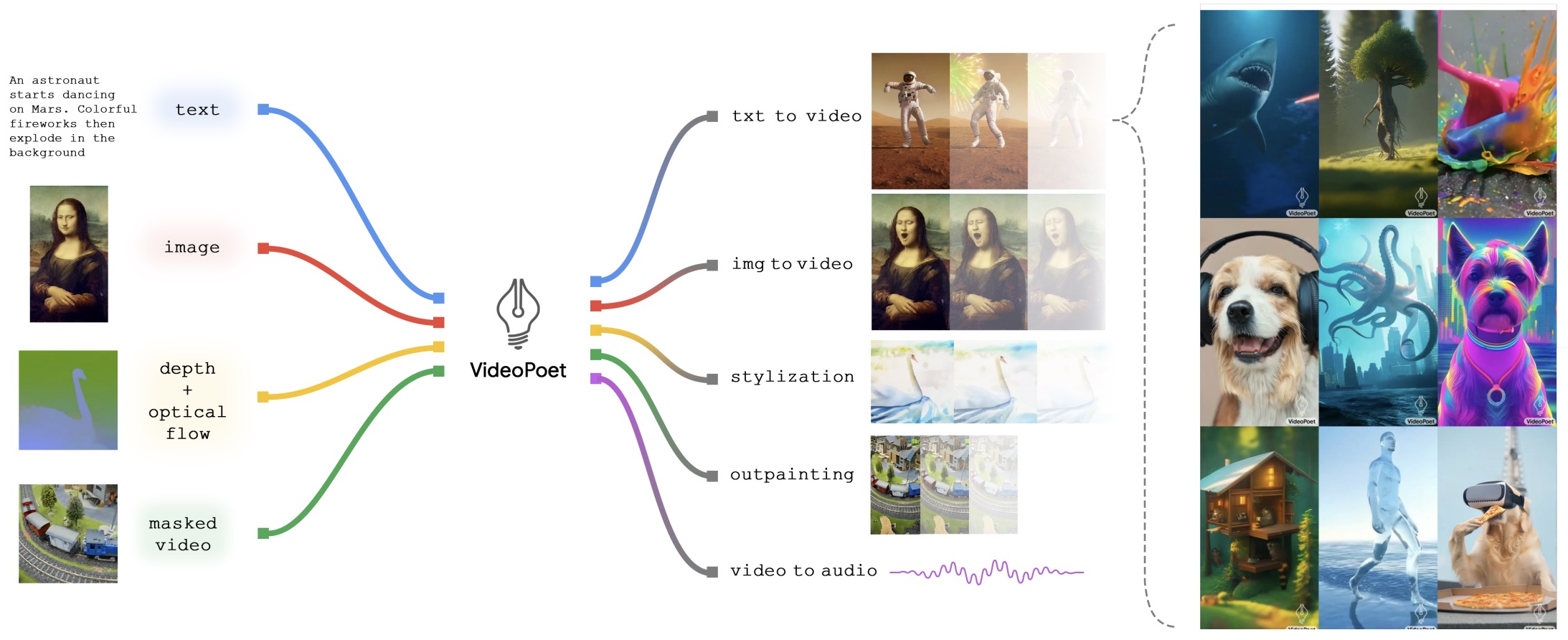
- Technical and Implementation Details:
- Tokenization: VideoPoet utilizes the MAGVIT-v2 tokenizer for joint image and video tokenization and the SoundStream tokenizer for audio. A unified vocabulary includes codes for special tokens, task prompts, image/video tokenization, and audio codes. Text modality is represented by text embeddings.
- Language Model Backbone: VideoPoet employs a Large Language Model (LLM) with a decoder-only transformer architecture. The model is a prefix language model that allows for control over task types by constructing different patterns of input tokens to output tokens. The shared multimodal vocabulary represents the generation of all modalities as a language modeling problem, totaling approximately 300,000 tokens. This approach effectively turns the task of generating videos and audios into a language modeling problem.
- Super-Resolution: For generating high-resolution videos, a custom spatial super-resolution (SR) non-autoregressive video transformer operates in token space atop the language model output, mitigating the computational demands of long sequences.
- LLM Pretraining for Generation: The model is trained with a large mixture of multimodal objectives, allowing individual tasks to be chained and demonstrating zero-shot capabilities beyond individual tasks.
- Task Prompt Design: A foundation model is produced through a mixture of tasks designed in pretraining, with defined prefix input and output for each task.
- Training Strategy: The training involves image-text pairs and videos with or without text or audio, covering approximately 2 trillion tokens across all modalities. A two-stage pretraining strategy is employed, initially focusing more on image data and then switching to video data. Post-pretraining, the model is fine-tuned to enhance performance on specific tasks or undertake new tasks.
- The figure below from the paper shows the sequence layout for VideoPoet. VideoPoet encode all modalities into the discrete token space, so that we can directly use large language model architectures for video generation. VideoPoet denote specital tokens in
<>. The modality agnostic tokens are in darker red; the text related components are in blue; the vision related components are in yellow; the audio related components are in green. The left portion of the layout on light yellow represents the bidirectional prefix inputs. The right portion on darker red represents the autoregressively generated outputs with causal attention.
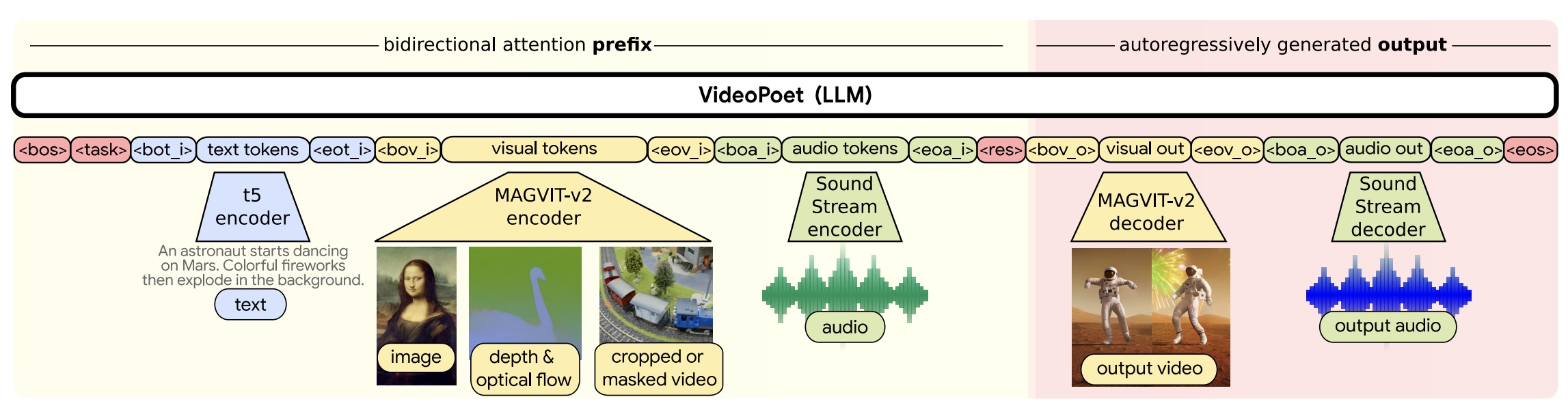
- Experiments and Evaluations:
- Experimental Setup: The model was trained on a mix of tasks like text-to-image, text-to-video, image-to-video, and video-to-video, including specialized tasks like outpainting, inpainting, stylization, and future frame prediction. The training dataset comprised 1 billion image-text pairs and around 270 million videos, with a focus on contextual and demographic diversity.
- Pretraining Task Analysis: Different combinations of pretraining tasks were analyzed using a 300 million parameter model. Incorporating all pretraining tasks resulted in the best overall performance across various evaluated tasks.
- Model Scaling: Scaling up the model size and training data showed significant improvements in video and audio generation quality. Larger models exhibited enhanced temporal consistency, prompt fidelity, and motion dynamics.
- Comparison to State-of-the-Art: VideoPoet demonstrated highly competitive performance in zero-shot text-to-video evaluation on MSR-VTT and UCF-101 datasets. The model, after fine-tuning, achieved even better performance in text-video pairings.
- Human Evaluations with Text-to-Video: VideoPoet outperformed other leading models in human evaluations across dimensions like text fidelity, video quality, motion interestingness, realism, and temporal consistency.
- Video Stylization: In video stylization tasks, VideoPoet significantly outperformed the Control-A-Video model. Human raters consistently preferred VideoPoet for text fidelity and video quality.
- Responsible AI and Fairness Analysis:
- The model was evaluated for fairness regarding attributes like perceived age, gender expression, and skin tone. It was observed that the model can be prompted to produce outputs with non-uniform distributions across these groups, but also has the capability to enhance uniformity through semantically unchanged prompts. This underscores the need for continued research to improve fairness in video generation.
- LLM’s Capabilities in Video Generation:
- VideoPoet demonstrates notable capabilities in video generation, including zero-shot video editing and task chaining. It can perform novel tasks by chaining multiple capabilities, such as image-to-video animation followed by stylization. The quality of outputs in each stage is sufficient to maintain in-distribution for subsequent stages without noticeable artifacts.
- Project page.
LLaMA-VID
- Proposed in LLaMA-VID: An Image is Worth 2 Tokens in Large Language Models.
- This paper by Li et al. from CUHK and SmartMore proposes LLaMA-VID, a novel approach designed to efficiently manage the token generation issue in long videos for Vision Language Models (VLMs). It addresses the computational challenges faced by traditional VLMs in processing long videos due to the requirement of excessive visual tokens. LLaMA-VID encodes each video frame using two distinct tokens - a context token and a content token - thus enabling support for hour-long videos with reduced computational burden.
- Architecture:
- Base Models: LLaMA-VID leverages the pre-trained LLM Vicuna for text processing and a Vision Transformer (ViT) model to generate image embeddings from video frames.
- Context-Attention Token \(E_t\): The Q-Former generates text embeddings (\(Q\)) from the user’s query. Attention is computed between \(Q\) and the visual tokens (\(X\)), and the resulting \(Q\) tokens are averaged to obtain the context-attention token \(E_t\). This token encapsulates visual features relevant to the query.
- Content Token \(E_v\): The visual tokens (\(X\)) undergo a 2D mean pooling operation to create the content token \(E_v\), summarizing all visual features of the frame.
- Integration with Vicuna Decoder: Both the context token and content token are appended to the input of the Vicuna decoder, which generates text responses to the user’s query.
- Token Generation Strategy:
- Dual-Token Generation: Each frame is represented with a context token and a content token. The context token is generated through interactive queries, while the content token captures frame details. This approach adapts to different settings, maintaining efficiency for videos and detail for single images.
- Training Framework and Strategy:
- Efficiency: Training can be completed within 2 days on a machine with 8xA100 GPUs. The model outperforms previous methods on most video- and image-based benchmarks.
- Stages: Training is divided into modality alignment, instruction tuning, and long video tuning. The modality alignment ensures that visual features align with the language space, instruction tuning enhances multi-modality understanding, and long video tuning focuses on extensive videos.
- Training Objectives: The model is trained on objectives of cross-modality embedding alignment, image/video captioning, and curated tasks for long video understanding.
- The figure below from the paper shows the framework of LLaMA-VID. With user directive, LLaMA-VID operates by taking either a single image or video frames as input, and generates responses from LLM. The process initiates with a visual encoder that transforms input frames into the visual embedding. Then, the text decoder produces text queries based on the user input. In context attention, the text query aggregates text-related visual cues from the visual embedding. For efficiency, an option is provided to downsample the visual embedding to various token sizes, or even to a single token. The text-guided context token and the visually-enriched content token are then formulated using a linear projector to represent each frame at time \(t\). Finally, the LLM takes the user directive and all visual tokens as input and gives responses.
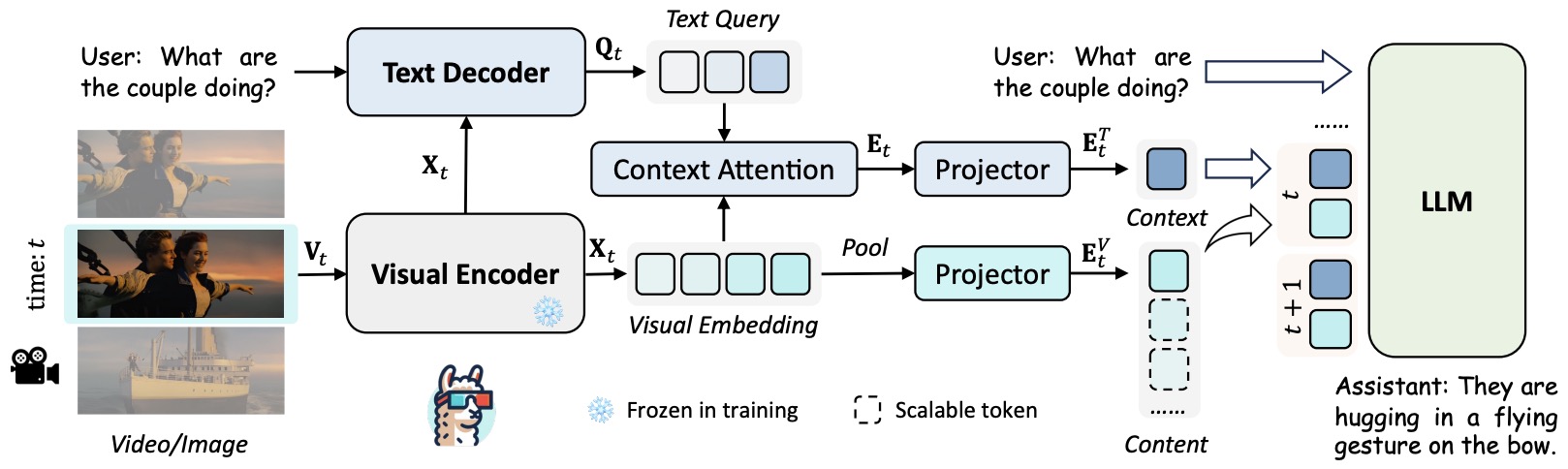
- Implementation Details:
- Experimental Setup: The model uses EVA-G for the visual encoder and QFormer for the text decoder. Training involves keeping the visual encoder fixed and optimizing other trainable parameters.
- Datasets: The training set is constructed from various sources, including image- and video-caption pairs, and the model is evaluated on numerous video- and image-based benchmarks.
- Performance and Analysis:
- Video-Based Benchmarks: LLaMA-VID demonstrates superior performance across various zero-shot video QA benchmarks, with notable accuracy using only two tokens per frame. Its efficiency in processing is evident from its performance with compressed content tokens and the effectiveness of the context token.
- Component Analysis: Different token types and numbers are analyzed to validate each part’s effectiveness. The instruction-guided context token significantly enhances performance across all datasets. Different text decoders show substantial gains, proving the effectiveness of the context token generation paradigm.
- Conclusion:
- LLaMA-VID introduces an efficient and effective method for token generation in VLMs. By representing images and video frames with just two tokens, it ensures detail preservation and efficient encoding. The model’s robust performance across diverse benchmarks and its capability to support hour-long videos affirm its potential as a benchmark for efficient visual representation.
Video-LLaMA
- Proposed in Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding.
- This paper by Zhang et al. from DAMO Academy, Alibaba Group, and Hupan Lab presents Video-LLaMA, a multi-modal framework for Large Language Models (LLMs) enabling understanding of both visual and auditory content in videos. Video-LLaMA integrates pre-trained visual and audio encoders with frozen LLMs for cross-modal training. It addresses two main challenges: capturing temporal changes in visual scenes and integrating audio-visual signals.
- The following figure from the paper shows a comparison with popular multi-modal large language models. Video-LLaMA has the unique ability to comprehend auditory and visual information simultaneously.
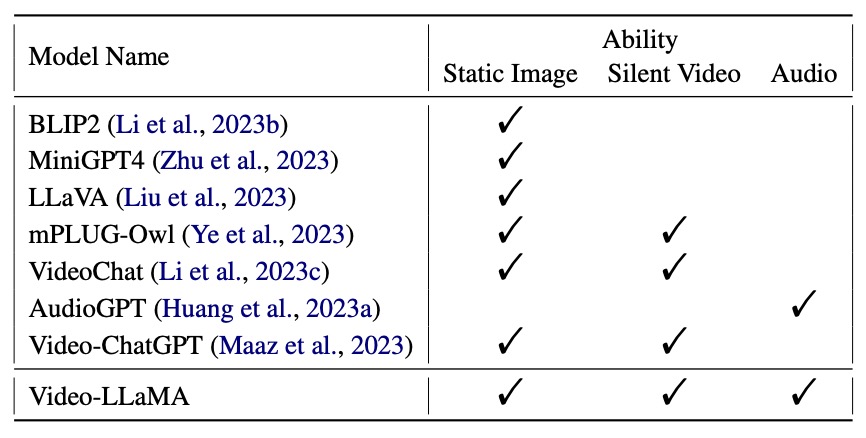
- The framework employs a Video Q-former, which assembles a pre-trained image encoder into the video encoder. The Video Q-former is designed to capture temporal information in videos by aggregating frame-level features into a video-level representation. It uses a self-attention mechanism, enabling the model to focus on relevant parts of the video across different frames. This process involves generating query embeddings for each frame, which are then fed into the LLM to create a holistic understanding of the video content.
- Additionally, it utilizes ImageBind as the pre-trained audio encoder, with an Audio Q-former to create auditory query embeddings for the LLM module. The Audio Q-former functions similarly, processing audio features to produce a concise representation that aligns with the LLM’s understanding of language and audio content. The output of visual and audio encoders aligns with the LLM’s embedding space. This alignment is crucial for the effective fusion of audio-visual data with textual information, ensuring that the LLM can interpret and respond to multi-modal inputs coherently.
- The training process of Video-LLaMA involves two stages: initial training on large video/image-caption pairs and fine-tuning with visual-instruction datasets. The framework aims to learn video-language correspondence and align audio and language modalities.
- The Vision-Language Branch, with a frozen image encoder, injects temporal information into frame representations and generates visual query tokens. The Audio-Language Branch employs ImageBind for audio encoding, adding positional embeddings to audio segments and creating fixed-length audio features.
- For vision-language correspondence, the framework pre-trains on a large-scale video caption dataset, including image-caption data, and then fine-tunes on a video-based conversation dataset. The audio-language alignment uses audio caption datasets and vision-text data due to limited availability of audio-text data.
- The following figure from the paper illustrates the overall architecture of Video-LLaMA.
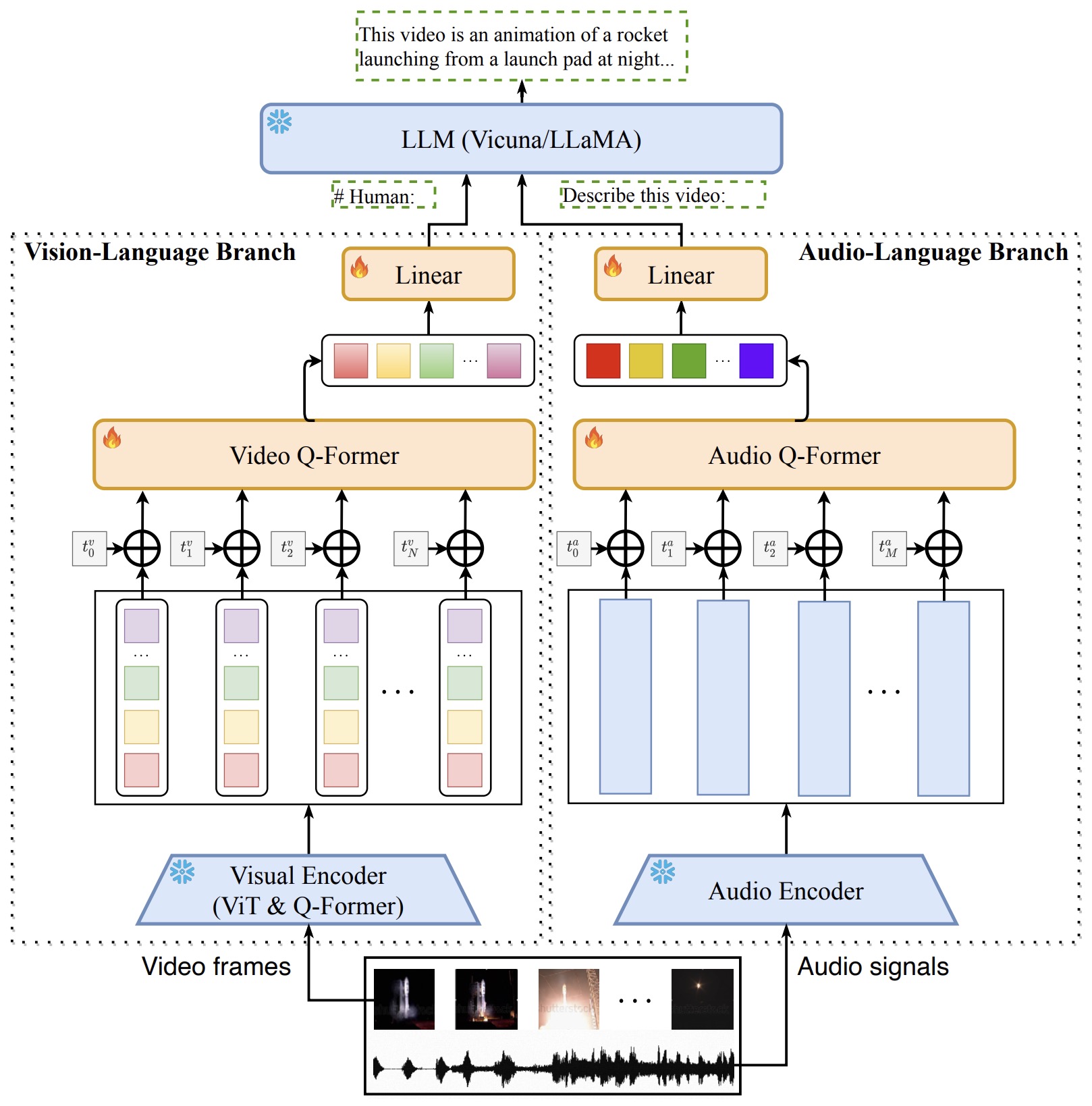
- Experimental results show that Video-LLaMA can effectively perceive and comprehend video content, generating meaningful responses grounded in the visual and auditory information presented in videos. It demonstrates abilities in audio and video-grounded conversations.
- The paper acknowledges limitations such as restricted perception capacities, challenges with long videos, and inherited hallucination issues from the frozen LLMs. Despite these, Video-LLaMA represents a significant advancement in audio-visual AI assistants. The authors have open-sourced the training code, model weights, and provided online demos for further development and exploration.
- Code.
VideoCoCa
- Proposed in VideoCoCa: Video-Text Modeling with Zero-Shot Transfer from Contrastive Captioners by Yan et al. from Google Research and The Ohio State University, VideoCoCa is an adaptation of the Contrastive Captioners (CoCa) model for video-text tasks, achieving minimal additional training.
- VideoCoCa utilizes the generative and contrastive attentional pooling layers from CoCa, applied to flattened frame embeddings, yielding state-of-the-art results in zero-shot video classification and text-to-video retrieval. It retains CoCa’s architecture but differs in processing image frames. While VideoCoCa is primarily a generative model due to its text generation capabilities, it also incorporates discriminative elements (through its contrastive training component) in its training and functioning.
- For data processing, VideoCoCa uniformly samples frames from videos. Each frame is then processed through CoCa’s image encoder, resulting in a tensor of shape \((B, T, N, D)\), where \(B\) is batch size, \(T\) is the number of frames, \(N\) is the number of visual tokens per frame, and \(D\) is the hidden dimension size. These tensors are concatenated along the time dimension.
- The process of how VideoCoCa handles video frames for subsequent processing through its attention pooling layers is as follows:
- Frame Sampling and Encoding: Initially, frames are uniformly sampled from a video. These frames are then individually processed through the image encoder of the CoCa model. This encoder converts each frame into a set of visual tokens, which are essentially high-dimensional representations capturing the key visual features of the frame.
- Tensor Formation: After encoding, for each frame, we get a tensor representing its visual tokens. The shape of this tensor for each frame is (B, N, D), where:
- B is the batch size, representing how many video sequences we are processing in parallel.
- N is the number of visual tokens generated by the image encoder for each frame.
- D is the dimensionality of each visual token, a fixed feature size.
- Concatenation Along Time Dimension: Now comes the critical part. Here, these tensors (representing individual frames) are concatenated along the time dimension. This step effectively aligns the visual tokens from all sampled frames in a sequential manner, forming a new tensor with shape \((B, T \times N, D)\), where T is the number of frames. This new tensor now represents the entire video sequence in a flattened format.
- Attention Pooling Layers: The concatenated tensor is then passed through two attention pooling layers:
- Generative Pooler: This pooler processes the tensor and outputs 256 tokens. These tokens are used by the model’s decoder to generate text, such as captions or answers in response to the video content.
- Contrastive Pooler: This pooler produces a single token from the tensor. This token is used in contrastive training, which involves learning to distinguish between matching and non-matching pairs of video and text, thus improving the model’s ability to associate the right text with a given video. - In summary, the VideoCoCa process is about transforming and aligning the encoded frames into a single, coherent representation that encapsulates the entire video sequence. This tensor (after concatenating along the time dimension) is passed through the poolers, with the generative pooler’s outputs used for text generation and the contrastive pooler’s for contrastive training. This representation is then used for both generative and contrastive modeling tasks, allowing the model to effectively generate text that corresponds to the video content.
- Various adaptation strategies were examined, including attentional poolers, a factorized encoder, a joint space-time encoder, and mean pooling. The attentional pooler method proved most effective, involving late fusion of temporal information without new learnable layers.
- The paper explores lightweight finetuning approaches on video-text data, such as Finetuning (FT), Frozen Encoder-Decoder Tuning, Frozen Tuning then Finetuning, and Frozen Encoder Tuning (LiT). The LiT approach, freezing the image encoder and tuning only the poolers and text decoder, was most efficient for task adaptation.
- VideoCoCa was trained on a joint contrastive loss and video captioning loss objective. The following figure from the paper shows: (Left) Overview of VideoCoCa. All weights of the pretrained CoCa model are reused, without the need of learning new modules. They compute frame token embeddings offline from the frozen CoCa image encoder. These tokens are then processed by a generative pooler and a contrastive pooler on all flattened frame tokens, yielding a strong zero-shot transfer video-text baseline. When continued pretraining on video-text data, the image encoder is frozen, while the attentional poolers and text decoders are jointly optimized with the contrastive loss and captioning loss, thereby saving heavy computation on frame embedding. (Right) An illustration of the attentional poolers and flattened frame token embeddings. They flatten \(N \times T\) token embeddings as a long sequence of frozen video representations.
- VideoCoCa was tested using datasets like HowTo100M, VideoCC3M, Kinetics, UCF101, HMDB51, Charades, MSR-VTT, ActivityNet Captions, Youcook2, and VATEX, showing significant improvements over the CoCa baseline in multiple tasks.
- The model scaling results demonstrate that VideoCoCa consistently outperforms the CoCa model with the same number of parameters across various scales and tasks.
Video-ChatGPT
- Proposed inVideo-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models by Maaz et al. from MBZUAI, Video-ChatGPT is a novel multimodal model that enhances video understanding through the integration of a video-adapted visual encoder with a Large Language Model (LLM).
- Video-ChatGPT’s architecture combines the representational strengths of a pretrained visual encoder, specifically CLIP ViT-L/14, adapted for spatiotemporal video representations, with the Vicuna-v1.1 language model. This model excels at understanding videos by capturing temporal dynamics and frame-to-frame consistency.
- A significant feature of Video-ChatGPT is the creation of a dataset comprising 100,000 video-instruction pairs, produced through a blend of human-assisted and semi-automatic annotation methods. This dataset enables the model to better understand and generate conversations about videos, focusing on temporal relationships and contextual understanding.
- The implementation details reveal that the model was fine-tuned on this video-instruction data for three epochs using a learning rate of 2e-5, with the training conducted on 8 A100 40GB GPUs. The model, which has 7 billion parameters, was trained for approximately 3 hours.
- The figure below from the paper shows the architecture of Video-ChatGPT. Video-ChatGPT leverages the CLIP-L/14 visual encoder to extract both spatial and temporal video features. This is accomplished by averaging frame-level features across temporal and spatial dimensions respectively. The computed spatiotemporal features are then fed into a learnable linear layer, which projects them into the LLMs input space. Video-ChatGPT utilizes the Vicuna-v1.1 model, comprised of 7B parameters, initialized it with weights from LLaVA.
- Quantitative evaluations of Video-ChatGPT used a custom framework assessing correctness, detail orientation, contextual and temporal understanding, and consistency. The model demonstrated competitive performance in these aspects, outperforming contemporary models in zero-shot question-answering tasks across multiple datasets.
-
Qualitatively, Video-ChatGPT showed proficiency in diverse video-based tasks, such as video reasoning, creative tasks, spatial understanding, and action recognition. However, it faced challenges in comprehending subtle temporal relationships and small visual details, indicating areas for future improvements.
- Code
Verbalize Videos
- Proposed in A Video Is Worth 4096 Tokens: Verbalize Videos To Understand Them In Zero Shot by Bhattacharyya et al. from Adobe Media and Data Science Research, IIIT-Delhi, and the State University of New York at Buffalo. The authors introduce a novel approach to video understanding by leveraging the capabilities of large language models (LLMs) for zero-shot performance on multimedia content.
- The core idea involves transforming long videos into concise textual narratives. This process, termed “video verbalization,” employs modules to extract unimodal information (like keyframes, audio, and text) from videos and prompts a generative language model (like GPT-3.5 or Flan-t5) to create a coherent story. Keyframes are identified using an optical flow-based heuristic for videos shorter than 120 seconds, selecting frames with higher optical flow values indicative of story transitions. For longer videos, frames are sampled at a uniform rate based on the video’s native frames-per-second. This method is designed to overcome the limitations of existing video understanding models that are generally trained on short, motion-centric videos and require extensive task-specific fine-tuning.
- The paper highlights two major contributions: firstly, the conversion of complex, multimodal videos into smaller, coherent textual stories, which outperform existing story generation methods. Secondly, the evaluation of the utility of these generated stories across fifteen different video understanding tasks on five benchmark datasets, demonstrating superior results compared to both fine-tuned and zero-shot baseline models.
- The figure below from the paper shows an overview of their framework to generate a story from a video and perform downstream video understanding tasks. First, they sample keyframes from the video which are verbalized using BLIP-2. They also extract OCR from all the frames. Next, using the channel name and ID, they query Wikidata to get company and product information. Next, they obtain automatically generated captions from Youtube videos using the Youtube API. All of these are concatenated as a single prompt and given as input to an LLM and ask it to generate the story of the advertisement. Using the generated story, they then perform the downstream tasks of emotion and topic classification and persuasion strategy identification.
- The datasets used include a video story dataset, a video advertisements dataset for assessing topics, emotions, actions, and reasons, a persuasion strategy dataset for understanding advertisement strategies, and the HVU dataset for a broad range of semantic elements in videos.
- Results showed that the proposed zero-shot model outperformed fine-tuned video-based baselines in most tasks. This indicates the efficacy of using generated stories for video content understanding, a method that bypasses the limitations of dataset size and annotation quality typically required in traditional video-based models.
Emu2
- Proposed in Generative Multimodal Models are In-Context Learners by Sun et al. from Beijing Academy of Artificial Intelligence, Tsinghua University, and Peking University, Emu2 is a 37 billion-parameter generative multimodal model. The model is trained on extensive multimodal sequences and exhibits strong multimodal in-context learning capabilities, setting new records on various multimodal understanding tasks in few-shot settings.
- Emu2 employs a unified autoregressive objective for predicting the next multimodal element, either visual embeddings or textual tokens, using large-scale multimodal sequences like text, image-text pairs, and interleaved image-text-video. The model architecture consists of a Visual Encoder, Multimodal Modeling, and a Visual Decoder. The Visual Encoder tokenizes each image into continuous embeddings, interleaved with text tokens for autoregressive Multimodal Modeling. The Visual Decoder is trained to decode visual embeddings back into images or videos.
- The “Multimodal Modeling” component of Emu2 is crucial for integrating and understanding the relationships between different modalities. This module is designed to process and synthesize information from both visual and textual embeddings, enabling the model to generate coherent outputs irrespective of the modality of the input. It leverages a transformer-based architecture, known for its efficacy in capturing long-range dependencies, to handle the complexities inherent in multimodal data. This module’s design allows it to seamlessly blend information from different sources, making it possible for the model to generate contextually relevant and accurate multimodal outputs, such as coherent text descriptions for images or generating images that match textual descriptions.
- Image generation in Emu2 is modeled as a regression task where the model learns to predict the features of the next portion of an image, given the previous context. This is achieved by training the Visual Decoder to reconstruct images from their encoded embeddings. The embeddings represent high-dimensional, continuous representations of the visual data, allowing the model to learn fine-grained details and nuances of the images. This regression-based approach enables Emu2 to generate high-quality, coherent images that are contextually aligned with the preceding text or visual inputs.
- The pretraining data includes datasets such as LAION-2B, CapsFusion-120M, WebVid-10M, Multimodal-C4, YT-Storyboard-1B, GRIT-20M, CapsFusion-grounded-100M, and language-only data from Pile. Emu2 is pretrained with a captioning loss on text tokens and image regression loss. The training uses the AdamW optimizer and involves different resolutions and batch sizes, spanning over 55,550 iterations.
- Emu2 demonstrates its proficiency in a few-shot setting on vision-language tasks, significantly improving as the number of examples in the context increases. The model also performs robustly in instruction tuning, where it is fine-tuned to follow specific instructions, leading to enhanced capabilities like controllable visual generation and instruction-following chat.
- Overview of Emu2 architecture. Emu2 learns with a predict-the-next-element objective in multimodality. Each image in the multimodal sequence is tokenized into embeddings via a visual encoder, and then interleaved with text tokens for autoregressive modeling. The regressed visual embeddings will be decoded into an image or a video by a visual decoder.
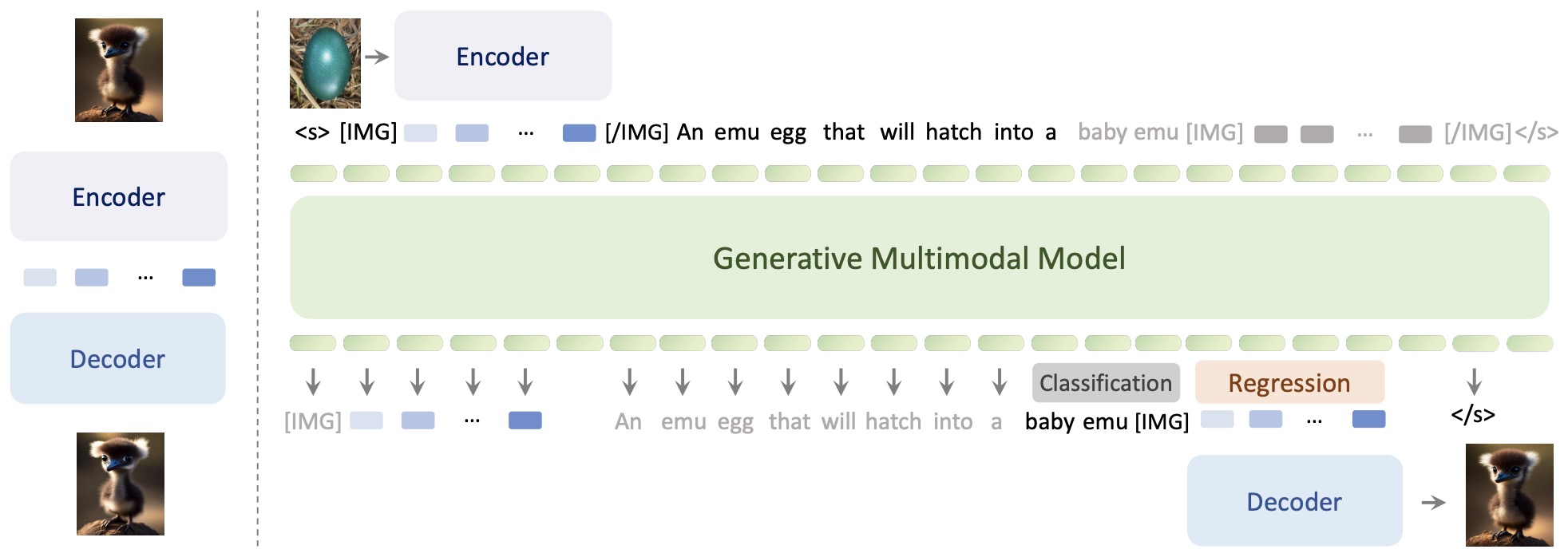
- The model’s performance is evaluated across various benchmarks and scenarios, showcasing remarkable abilities in both visual question answering and open-ended subject-driven generation. It outperforms other models in image question-answering tasks and shows notable improvements in tasks requiring external knowledge and video question-answering despite not using specific training data for these tasks.
- Emu2’s controllable visual generation abilities are demonstrated through zero-shot text-to-image generation and subject-driven generation, achieving state-of-the-art performance in comparison to other models. It excels in tasks like re-contextualization, stylization, modification, region-controllable generation, and multi-entity composition.
- The paper also discusses the broader impact and limitations of Emu2, emphasizing its potential applications and the need for responsible deployment, considering the challenges of hallucination, potential biases, and the gap in question-answering capabilities compared to closed multimodal systems.
LLaVA-NeXT (Video)
- The image-only-trained LLaVA-NeXT model is surprisingly strong on video tasks with zero-shot modality transfer. DPO training with AI feedback on videos can yield significant improvement.
- Blog; Models; Demo; Code
Video LLMs for Understanding
VideoCLIP
- Proposed in VideoCLIP: Contrastive Pre-training for Zero-shot Video-Text Understanding.
- This paper by Xu et al. from Facebook AI and CMU in EMNLP 2021 presents an innovative approach to pre-train a unified model for zero-shot video and text understanding without relying on labels for downstream tasks. The primary objective of VideoCLIP is to establish a fine-grained association between video and text to address the diverse requirements of end tasks. The method stands out by using contrastive learning with hard-retrieved negatives and overlapping positives for video-text pre-training.
- VideoCLIP aims for zero-shot video understanding via learning fine-grained association between video and text in a transformer using a contrastive objective with two key novelties: (1) for positive pairs, we use video and text clips that are loosely temporarily overlapping instead of enforcing strict start/end timestamp overlap; (2) for negative pairs, we employ a retrieval based sampling technique that uses video clusters to form batches with mutually harder videos.
- Key Technical and Implementation Details:
-
Video and Text Encoding: VideoCLIP uses pairs of video and text clips as inputs, employing a Transformer model for both video and text. The video features, extracted by a convolutional neural network (CNN), are projected to video tokens before being fed into a video transformer. Text tokens are obtained via embedding lookup as in BERT, and then both video and text tokens are processed by separate trainable Transformers to obtain hidden states. Average pooling is applied over these token sequences to encourage learning token-level representations for tasks like action localization and segmentation.
-
Contrastive Loss: The method utilizes the InfoNCE objective for contrastive loss, aiming to minimize the sum of two multimodal contrastive losses. This process involves contrasting positive video-text pairs with negative pairs within the same batch. This loss function is key to learning fine-grained correspondence between video and text by discriminating between positive and negative pairs. InfoNCE uses a softmax function over a dot product of video and text representations to estimate the mutual information between them. This process involves contrasting positive video-text pairs, where the positive pairs have high mutual information, with negative pairs within the same batch, which are assumed to have lower mutual information. The InfoNCE objective is crucial for the model to learn effective representations that distinguish relevant video-text pairs from irrelevant ones.
-
Overlapped Video-Text Clips: The approach samples text clips first to ensure nearby corresponding video clips, then grows a video clip with random duration from a center timestamp within the text clip. This method improves video-text association by focusing on higher relevance pairs, as opposed to strictly temporally aligned clips that may lack semantic closeness.
-
Retrieval Augmented Training: This component of training uses hard pairs for negatives, derived through retrieval-based sampling. The process involves building a dense index of videos’ global features and retrieving clusters of videos that are mutually closer to each other. This approach aims to model more fine-grained video-text similarity using difficult examples.
-
Zero-shot Transfer to End Tasks: VideoCLIP is evaluated on various end tasks without using any labels. These tasks include text-to-video retrieval, multiple-choice VideoQA, action segmentation, etc. Each of these tasks tests different aspects of the learned video-text representation, such as similarities between video and text, action labeling, and segmenting meaningful video portions.
-
- Pre-training and Implementation Details:
- The pre-training utilized HowTo100M, which contains instructional videos from YouTube. After filtering, 1.1 million videos were used, each averaging about 6.5 minutes with approximately 110 clip-text pairs.
- The video encoder used is a S3D, pre-trained on HowTo100M, and the video and text Transformers were initialized with weights from BERTBASE-uncased. The maximum number of video tokens was limited to 32, and 16 video/text pairs were sampled from each video to form batches of 512.
- Results and Impact:
- VideoCLIP showed state-of-the-art performance on a variety of tasks, often outperforming previous work and, in some cases, even supervised approaches. This was evident in its application to datasets like Youcook2, MSR-VTT, DiDeMo, COIN, and CrossTask.
- The method, by contrasting temporally overlapping positives with hard negatives from nearest neighbor retrieval, has been effective without supervision on downstream datasets. It also showed improvement upon fine-tuning.
- In summary, VideoCLIP demonstrates a significant advancement in zero-shot video-text understanding, offering a robust and versatile approach that effectively leverages the synergy between video and text data.
VideoMAE
- Proposed in VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training .
- This paper by Tong et al., from Nanjing University, Tencent AI Lab, and Shanghai AI Lab, presented at NeurIPS 2022, introduces VideoMAE, a novel approach for self-supervised video pre-training. VideoMAE demonstrates that video transformers can be effectively pre-trained on small datasets without external data, challenging the common belief of requiring large-scale datasets.
- VideoMAE adapts the masked autoencoder framework to videos, using a novel video tube masking strategy with an extremely high masking ratio (90-95%). This approach significantly differs from image models due to the temporal redundancy and correlation in videos.
- The authors found that VideoMAE is particularly data-efficient, achieving impressive results on datasets as small as 3k-4k videos, and showing that data quality is more crucial than quantity for self-supervised video pre-training (SSVP). Notably, VideoMAE achieves 87.4% on Kinetics-400 and 75.4% on Something-Something V2 without extra data.
- The figure below from the paper shows that VideoMAE performs the task of masking random cubes and reconstructing the missing ones with an asymmetric encoder-decoder architecture. Due to high redundancy and temporal correlation in videos, VideoMAE presents the customized design of tube masking with an extremely high ratio (90% to 95%). This simple design enables VideoMAE to create a more challenging and meaningful self-supervised task to make the learned representations capture more useful spatiotemporal structures.
- The method incorporates temporal downsampling and cube embedding to handle video data efficiently. It employs a vanilla Vision Transformer (ViT) with joint space-time attention, allowing interaction among all pair tokens in the multi-head self-attention layer.
- Extensive experiments and ablation studies reveal the importance of decoder design, masking strategy, and reconstruction targets in the effectiveness of VideoMAE. The high masking ratio helps mitigate information leakage during masked modeling, making the task more challenging and encouraging the learning of representative features.
- VideoMAE’s pre-training strategy outperforms traditional methods like training from scratch or contrastive learning models like MoCo v3. It demonstrates superior efficiency and effectiveness, requiring less training time due to its asymmetric encoder-decoder design and high masking ratio.
- The authors also highlight the strong transferability of VideoMAE, showing its effectiveness in downstream tasks like action detection. They note potential for future improvements by expanding to larger datasets, models, and integrating additional data streams like audio or text.
- The paper concludes by acknowledging potential negative societal impacts, mainly related to energy consumption during the pre-training phase. However, it emphasizes the practical value of VideoMAE in scenarios with limited data availability and its capacity to enhance video analysis using vanilla vision transformers.
- Code
Any-to-Any VLMs
CoDi
- Proposed in Any-to-Any Generation via Composable Diffusion by Tang et al. from UNCC and Microsoft, Composable Diffusion (CoDi) is a state-of-the-art generative model. CoDi uniquely generates any combination of output modalities (language, image, video, audio) from any combination of input modalities.
- CoDi stands out from existing generative AI systems by its ability to generate multiple modalities in parallel without being limited to specific input modalities. This is achieved by aligning modalities in both input and output space, allowing CoDi to condition on any input combination and generate any group of modalities, including those not present in the training data.
- The model employs a novel composable generation strategy. This involves building a shared multimodal space by bridging alignment in the diffusion process, enabling the synchronized generation of intertwined modalities, such as temporally aligned video and audio.
- The following figure from the paper shows CoDi’s architecture: (a) they first train individual diffusion models with aligned prompt encoder by “bridging alignments”; (b) diffusion models learn to attend with each other via “latent alignment”; (c) CoDi achieves any-to-any generation with a linear number of training objectives.
- The methodology includes two key stages: training a latent diffusion model (LDM) for each modality and enabling cross-modal generation through a cross-attention module in each diffuser and an environment encoder. These elements project the latent variables of different LDMs into a shared space.
- The model demonstrates exceptional performance in both single-modality synthesis and joint-modality generation, maintaining coherence and consistency across generated outputs. This includes high fidelity in generating images and videos from various inputs and strong joint-modality generation quality.
- The process that the model uses to output text tokens is as follows. CoDi involves the use of a Variational Autoencoder (VAE) within the Text Diffusion Model. Specifically:
- Text VAE Encoder and Decoder: The text Latent Diffusion Model (LDM) utilizes the OPTIMUS model as its VAE. The encoder and decoder for this text VAE are based on the architectures of BERT and GPT-2, respectively.
- Denoising UNet for Text: In the denoising process, the UNet architecture is employed. However, unlike in image diffusion where 2D convolutions are used in the residual blocks, the text diffusion model replaces these with 1D convolutions. This adjustment is essential for handling the one-dimensional nature of text data.
- Joint Multimodal Generation: The final step involves enabling cross-attention between the diffusion flows of different modalities. This is critical for joint generation, i.e., generating outputs that comprise two or more modalities simultaneously, including text.
- This process highlights the model’s ability to seamlessly integrate text generation within its broader multimodal generative framework, ensuring coherent and contextually aligned outputs across different modalities.
- The process for outputting image or speech tokens in the Composable Diffusion (CoDi) model is distinct from the process for text tokens:
- Image Tokens:
- Image VAE Encoder and Decoder: The image Latent Diffusion Model (LDM) uses a VAE architecture for encoding and decoding. The encoder projects the images into a compressed latent space, and the decoder maps the latent variables back to the image space.
- Image Diffusion Model: Similar to the text model, an image diffusion model is employed. The details of the specific architectures used for the encoder and decoder, however, differ from those used for text.
- Speech Tokens:
- Audio VAE Encoder and Decoder: For audio synthesis, the CoDi model employs a VAE encoder to encode the mel-spectrogram of the audio into a compressed latent space. A VAE decoder then maps the latent variable back to the mel-spectrogram.
- Vocoder for Audio Generation: After the mel-spectrogram is reconstructed, a vocoder generates the final audio sample from it. This step is crucial in converting the spectrogram representation back into audible sound.
- Image Tokens:
- In summary, while the process for all modalities involves encoding into and decoding from a latent space using a VAE, the specifics of the VAE architectures and the additional steps (like the use of a vocoder for audio) vary depending on whether the modality is text, image, or speech.
- CoDi is evaluated using datasets like Laion400M, AudioSet, and Webvid10M. The individual LDMs for text, image, video, and audio feature unique mechanisms; for instance, the video diffuser extends the image diffuser with temporal modules, and the audio diffuser uses a VAE encoder for mel-spectrogram encoding.
- The authors provide comprehensive quantitative and qualitative evaluations, showcasing CoDi’s potential for applications requiring simultaneous multimodal outputs.
- Code.
CoDi-2
- Proposed in CoDi-2: In-Context Interleaved and Interactive Any-to-Any Generation by Tang et al. from UC Berkeley, Microsoft Azure AI, Zoom, and UNC Chapel Hill, CoDi-2 is a groundbreaking Multi-modal Large Language Model (MLLM), which represents a paradigm shift in Large Language Model capabilities, extending beyond text to embrace a multimodal future.
- This advanced model excels in understanding and processing complex, interleaved instructions across multiple modalities, including text, images, and audio. By mapping these varied inputs to a language space, CoDi-2 can seamlessly interpret and generate content in any combination of these modalities.
- CoDi-2’s architecture features a multimodal encoder that transforms diverse data into a feature sequence, which the MLLM then processes. The model predicts the features of the output modality autoregressively, inputting these into synchronized diffusion models for generating high-quality multimodal outputs.
- The motivation of harnessing LLM is intuitively inspired by the observation that LLMs exhibit exceptional
ability such as chatting, zero-shot learning, instruction following, etc., in language-only domain. By leveraging projections from aligned multimodal encoders, they seamlessly empower the LLM to perceive modality-interleaved input sequence. Specifically, in processing the multimodal input sequence, they first use the multimodal encoder to project the multimodal data into a feature sequence. Special tokens are prepended and appended to the features sequence, e.g.
<audio> [audio feature sequence] </audio>. By such for instance, a modality-interleaved input sequence “A cat sitting on [image0:an image of a couch] is making the sound of [audio0:audio of cat purring]” is then transformed to “A cat sitting on<image> [image feature sequence] </image>is making the sound of<audio> [audio feature sequence] </audio>”, before inputting to the MLLM to process and generation - The model’s interactive capabilities have been demonstrated in a range of applications, such as zero-shot image generation from descriptive text, audio editing based on written commands, and dynamic video creation. These capabilities underscore CoDi-2’s ability to bridge the gap between different forms of input and output.
- The figure below from the paper shows multi-round conversation between humans and CoDi-2 offering in-context multimodal instructions for image editing.

- The figure below from the paper shows the model architecture of CoDi-2, which comprises a multimodal large language model that encompasses encoder and decoder for both audio and vision inputs, as well as a large language model. This architecture facilitates the decoding of image or audio inputs using diffusion models. In the training phase, CoDi-2 employs pixel loss obtained from the diffusion models alongside token loss, adhering to the standard causal generation loss.
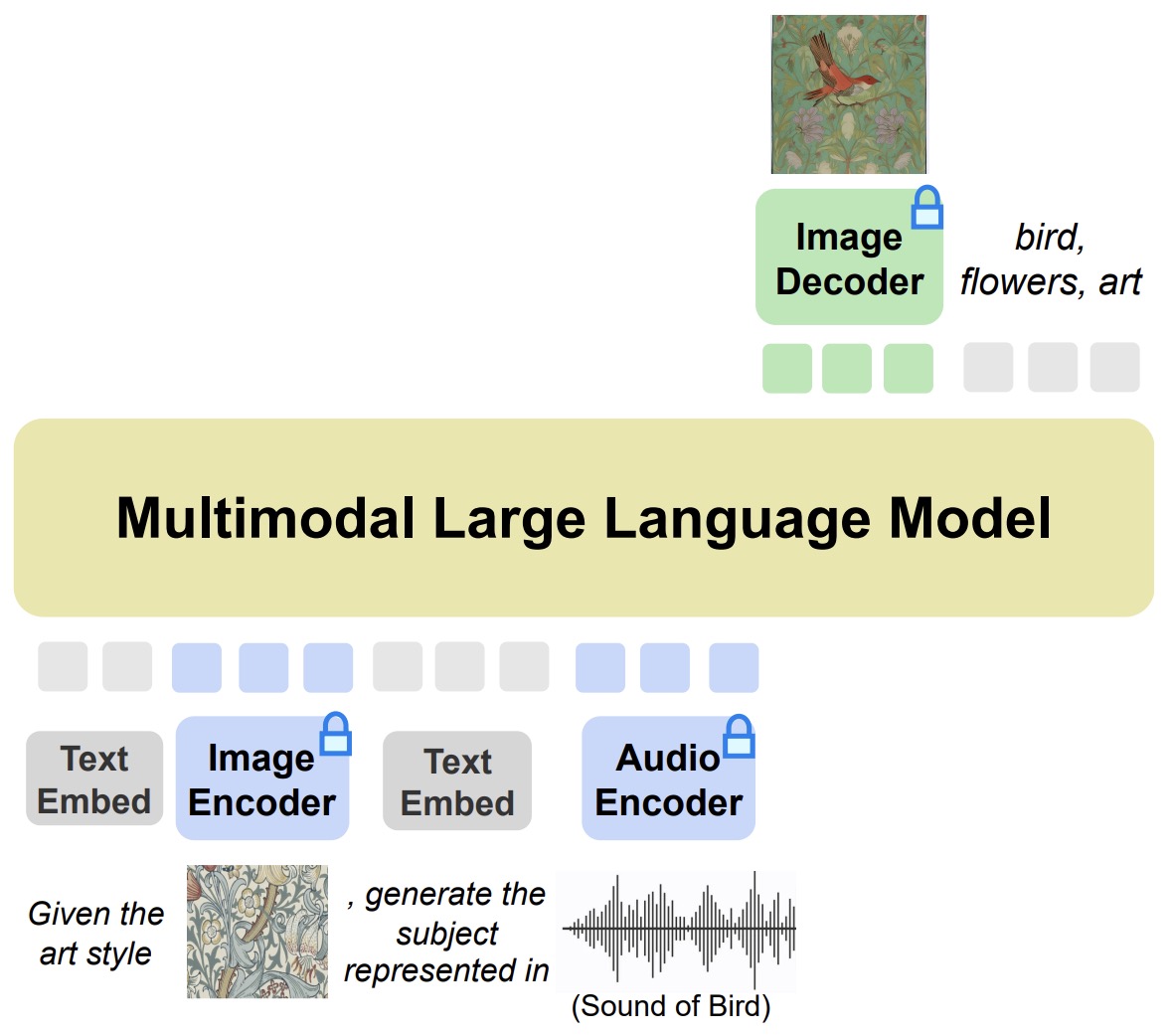
- CoDi-2 was trained on a large-scale generation dataset that includes multimodal in-context instructions. This dataset enables the model to exhibit impressive zero-shot and few-shot capabilities in multimodal generation, including in-context learning and multi-round interactive conversation.
- The process by which the CoDi-2 model outputs image tokens that are passed on to the image decoder to generate an image is described as follows:
- Text Generation by MLLM: For generating text, the Multimodal Large Language Model (MLLM) naturally generates text tokens autoregressively.
- Multimodal Generation Approach: When it comes to multimodal generation (like images), a common method in previous works was to transform the multimodal target (e.g., the ground-truth image) into discrete tokens, allowing them to be generated autoregressively like text. However, this approach is limited by the generation decoder’s quality, typically based on Variational Autoencoder (VAE) methodologies.
- Integration of Diffusion Models (DMs): To improve the generation quality, the CoDi-2 model integrates Diffusion Models into the MLLM. This enables the generation of multimodal outputs following detailed, modality-interleaved instructions and prompts.
- Training the MLLM for Conditional Feature Generation: The training involves configuring the MLLM to generate the conditional features that will be fed into the Diffusion Model to synthesize the target output. The generative loss of the DM is then used to train the MLLM.
- Retaining Perceptual Characteristics: To retain the perceptual characteristics inherent in the original input, it’s explicitly induced that the conditional features generated by the MLLM should match the features of the target modality.
- Final Training Loss: The final training loss comprises the mean squared error between the MLLM output feature and the target modality feature, the generative loss of the DM, and the text token prediction loss.
- Decoder: The image decoder used in the model described in the paper is based on StableDiffusion-2.1. This diffusion model is a key component in generating high-quality images, as it is specifically tailored to handle image features with high fidelity. The model employs the ImageBind framework for encoding image and audio features, which are then projected to the input dimension of the LLM (Large Language Model) using a multilayer perceptron (MLP). Once the LLM generates image or audio features, they are projected back to the ImageBind feature dimension using another MLP, ensuring that the generation process maintains high quality and fidelity.
- This approach enables the CoDi-2 model to conduct sophisticated reasoning for understanding and generating multiple modalities, allowing for diverse tasks like imitation, editing, and compositional creation. The integration of DMs with MLLM is a key aspect that allows the model to generate high-quality multimodal outputs.
- The CoDi-2 model, when generating multimodal outputs, does not solely rely on a traditional softmax over a vocabulary approach. For text generation, the MLLM within CoDi-2 generates text tokens autoregressively, which is a common method in language models. However, for multimodal generation (including images), the model diverges from the previous approach of transforming the target (like a ground-truth image) into discrete tokens for autoregressive generation. Instead of using a VAE-like generation decoder, CoDi-2 integrates Diffusion Models (DMs) into the MLLM. This integration allows for the generation of multimodal outputs following nuanced, modality-interleaved instructions and prompts. The diffusion models enable a different approach to generate outputs, focusing on the training objective of the model, which involves minimizing the mean squared error between the generated and target feature. This approach suggests that CoDi-2, particularly for its multimodal (non-text) outputs, relies on a more complex and integrated method than simply outputting over a vocabulary using softmax.
- An important to note is that even though that CoDi-2 uses two different mechanmisms to generate text and images respectively, it does not utilize two distinct, separate heads for each modality at the output – one for text and the other for image generation. Instead, CoDi-2 uses a unified framework for encoding and decoding different modalities, including text, images, and audio.
- CoDi-2 utilizes ImageBind, which has aligned encoders for multiple modalities like image, video, audio, text, depth, thermal, and IMU. These features are encoded and then projected to the input dimension of the LLM using a multilayer perceptron (MLP). When the LLM generates image or audio features, they are projected back to the ImageBind feature dimension with another MLP.
- The potential applications of CoDi-2 are vast, impacting industries like content creation, entertainment, and education. Its ability to engage in a dynamic interplay of multimodal inputs and responses opens up new possibilities, such as generating music that matches the mood of a photo or creating infographics to visualize complex ideas.
- CoDi-2 marks a significant advancement in multimodal generation technology. It integrates in-context learning within the realm of interleaved and interactive multimodal any-to-any generation, offering a glimpse into a future where AI can fluidly converse and create across multiple modalities.
- Code.
Gemini
- Proposed in Gemini: A Family of Highly Capable Multimodal Models, Google’s Gemini series represents a milestone in AI development, featuring three models: Ultra, Pro, and Nano, each tailored for specific tasks ranging from complex problem-solving to on-device operations. Gemini Ultra, the flagship model, excels in demanding tasks and sets new benchmarks in AI performance. Gemini Pro is optimized for a wide range of tasks, while Nano is designed for efficiency in on-device applications. This suite of models, part of Google DeepMind’s vision, marks a significant scientific and engineering endeavor for the company.
- Gemini models are built with a transformative architecture that allows for a “deep fusion” of modalities, surpassing the capabilities of typical modular AI designs. This integration enables seamless concept transfer across various domains, such as vision and language. The models, trained on TPUs, support a 32k context length and are capable of handling diverse inputs and outputs, including text, vision, and audio. The visual encoder, inspired by Flamingo, and the comprehensive training data, comprising web documents, books, code, and multimedia, contribute to the models’ versatility.
- The figure below from the paper illustrates that Gemini supports interleaved sequences of text, image, audio, and video as inputs (illustrated by tokens of different colors in the input sequence). It can output responses with interleaved image and text.
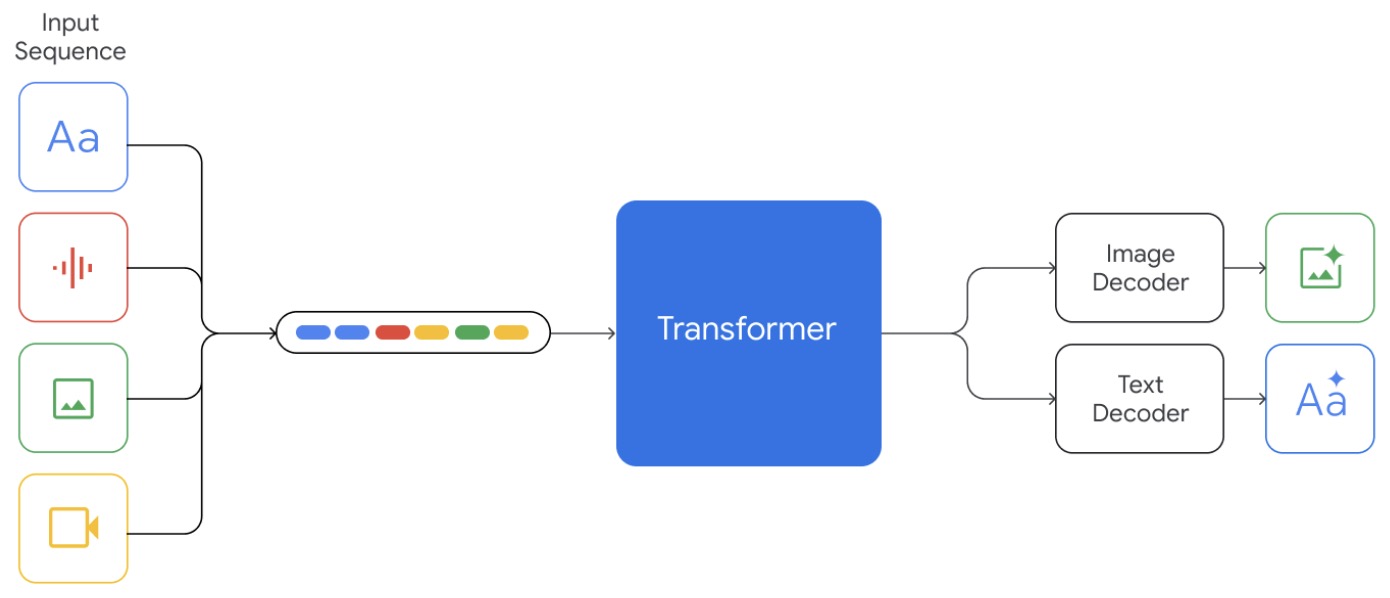
- The training infrastructure for Gemini utilizes Google’s latest TPU v4 and v5e accelerators, ensuring efficient scaling and reliable performance at an unprecedented scale. This advanced setup is integral to handling hardware failures and silent data corruption, ensuring high-quality training outcomes.
- The training dataset is multimodal and multilingual, with quality and safety filters to enhance model performance. The dataset mix is adjusted during training to emphasize domain-relevant data, contributing to the models’ high performance.
- Gemini Ultra showcases extraordinary capabilities across various benchmarks, surpassing GPT-4 in areas like coding and reasoning. Its performance in benchmarks like HumanEval and Natural2Code, as well as its superior reasoning capabilities in complex subjects like math and physics, demonstrate its state-of-the-art capabilities. For instance, the figure below from the paper shows solving a geometrical reasoning task. Gemini shows good understanding of the task and is able to provide meaningful reasoning steps despite slightly unclear instructions.

- Furthermore, in another instance, the figure below from the paper shows Gemini verifying a student’s solution to a physics problem. The model is able to correctly recognize all of the handwritten content and verify the reasoning. On top of understanding the text in the image, it needs to understand the problem setup and correctly follow instructions to generate LaTeX.

- Gemini outperforms OpenAI’s GPT-4 in 30 out of 32 benchmarks. Furthermore, it’s worth noting is that Gemini Ultra is the first model to outperform human experts on MMLU (massive multitask language understanding). The following table from Google’s blog Gemini surpasses state-of-the-art performance on a range of benchmarks including text and coding.
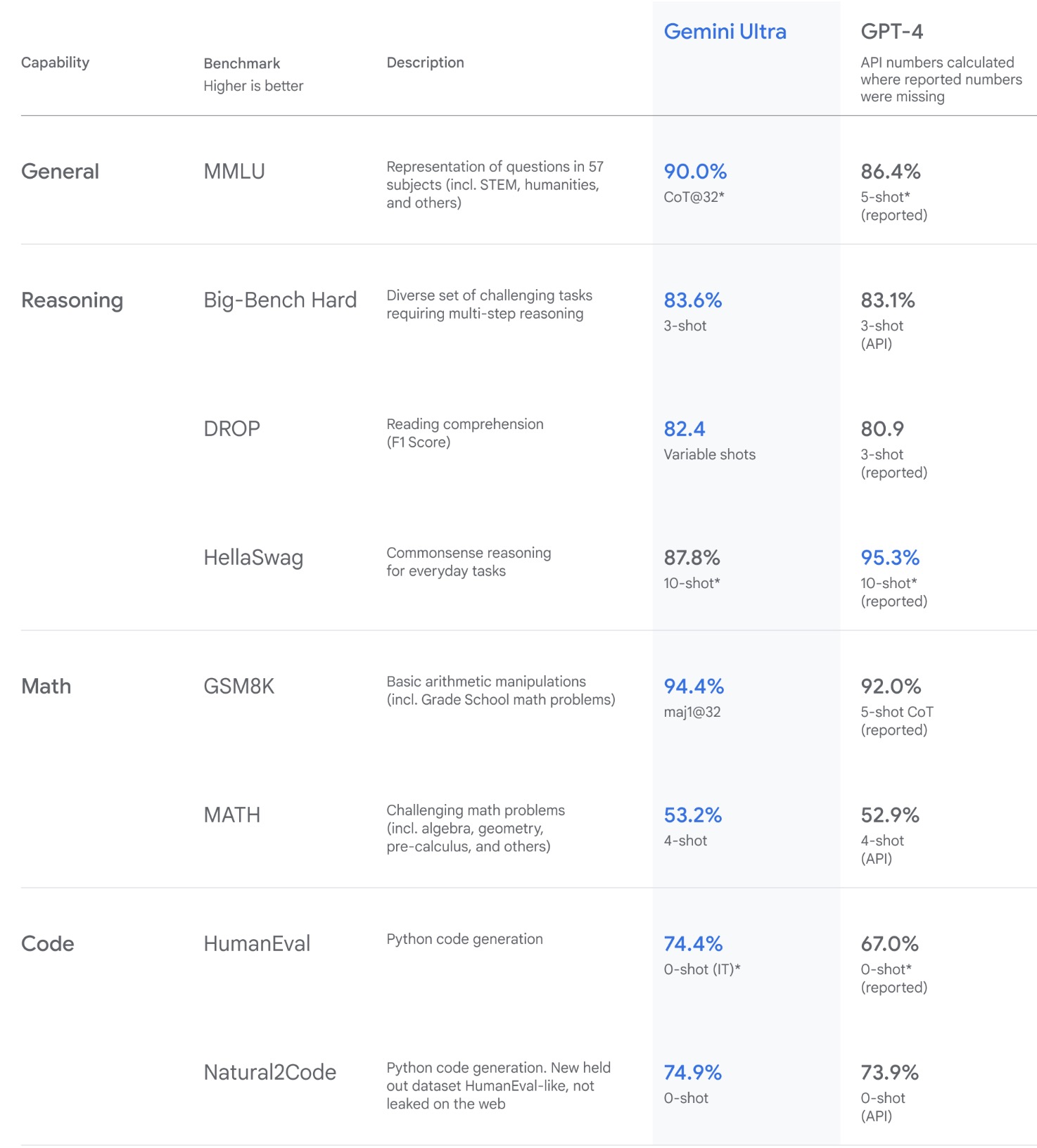
- For image understanding, Gemini Ultra sets new standards by outperforming existing models in zero-shot evaluations for OCR-related tasks. Its native multimodality and complex reasoning abilities enable it to excel in interpreting and reasoning with visual information. The following table from Google’s blog Gemini surpasses state-of-the-art performance on a range of multimodal benchmarks.
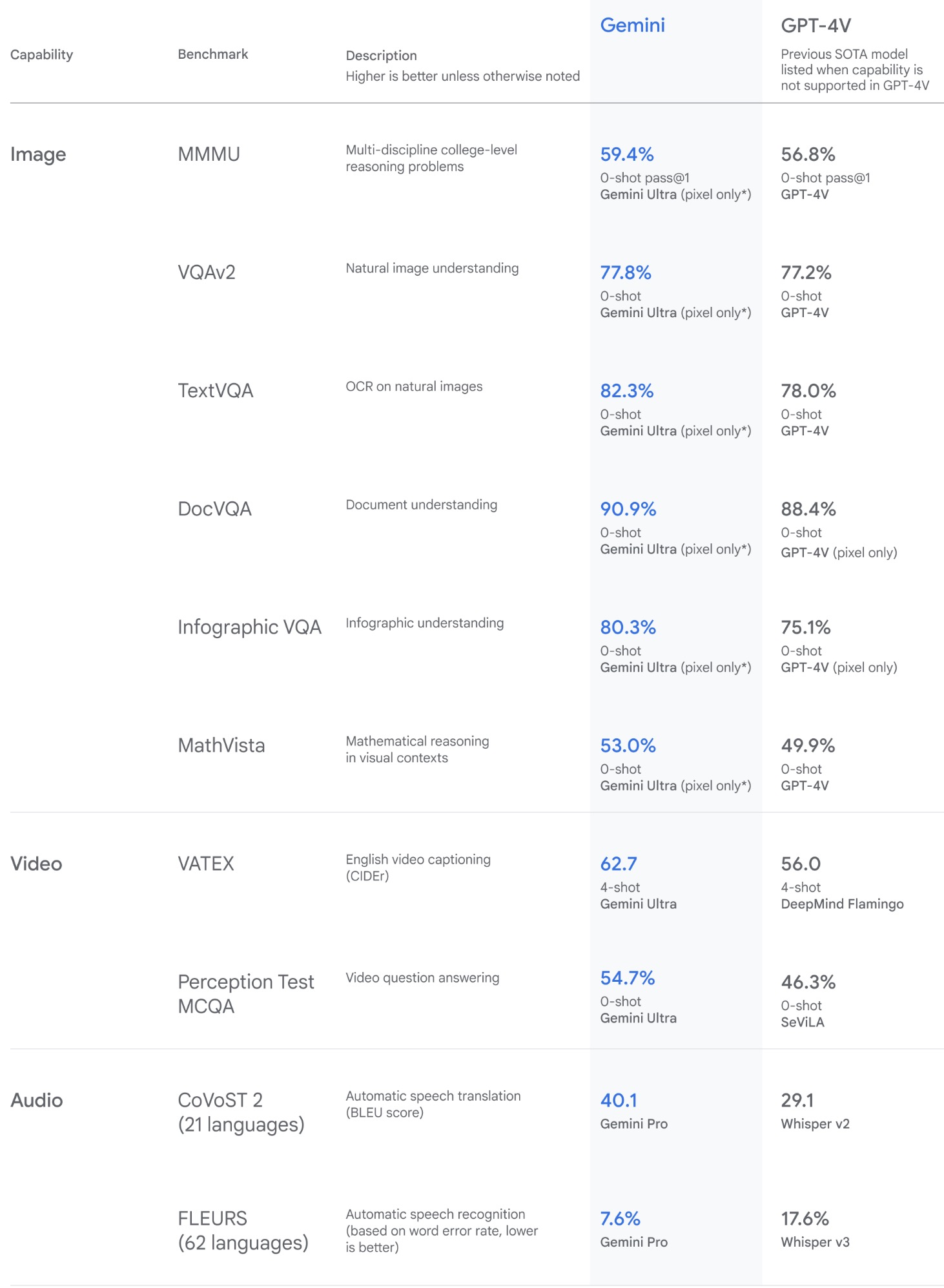
- Gemini’s training involves Reinforcement Learning from Human Feedback (RLHF), enhancing its performance and capabilities. This advanced training, combined with its innovative architecture and diverse dataset, contributes to its exceptional performance across various tasks.
- Despite its remarkable capabilities, specific details about Gemini’s architecture, training data, and the size of the Ultra and Pro models remain undisclosed. However, the models represent a significant leap in AI development, driven by the promise of AI to benefit humanity in diverse ways.
- Safety and responsibility are central to Gemini’s development, with comprehensive safety evaluations for bias and toxicity. Google is collaborating with external experts and partners to stress-test the models and ensure they adhere to robust safety policies, aligning with Google’s AI Principles.
- Gemini’s capabilities and its development approach reflect Google’s commitment to advancing AI responsibly and ethically, emphasizing safety and collaboration with the industry and broader ecosystem to define best practices and safety benchmarks.
- Blog.
NExT-GPT
- Proposed in NExT-GPT: Any-to-Any Multimodal LLM.
- Not all information can be efficiently captured and conveyed with text; as such, multimodal representations will lead to a deeper, more robust understanding of the world.
- While recently Multimodal Large Language Models (MM-LLMs) have made exciting strides, they mostly fall prey to the limitation of only input-side multimodal understanding, without the ability to produce content in multiple modalities. As they humans always perceive the world and communicate with people through various modalities, developing any-to-any MM-LLMs capable of accepting and delivering content in any modality becomes essential to human-level AI.
- This paper by Wu et al. from NExT++ at NUS seeks to address this gap and presents an end-to-end general-purpose any-to-any MM-LLM system, NExT-GPT.
- NExT-GPT is trained on four different modalities in parallel: text, image, audio and video. But more importantly, it can also output any of these modalities. NExT-GPT encompasses Vicuna, a Transformer-decoder LLM, and connects it to different Diffusion Models and Multimodal Adapter research. The former are well-known for their success in Stable Diffusion and Midjourney, the latter is one of the most promising techniques for adding any modality you want to your model. This enables NExT-GPT to perceive inputs and generate outputs in arbitrary combinations of text, images, videos, and audio.
- By leveraging the existing well-trained highly-performing encoders and decoders, NExT-GPT is tuned with only a small amount of parameter (1%) of certain projection layers, which not only benefits low-cost training and also facilitates convenient expansion to more potential modalities. Moreover, they introduce a modality-switching instruction tuning (MosIT) and manually curate a high-quality dataset for MosIT, based on which NExT-GPT is empowered with complex cross-modal semantic understanding and content generation.
- Overall, NExT-GPT showcases the promising possibility of building an AI agent capable of modeling universal modalities, paving the way for more human-like AI research in the community.
- Architecture:
- Multimodal Encoding Stage: Leveraging existing well-established models to encode inputs of various modalities. Here they adopt ImageBind, which is a unified high-performance encoder across six modalities. Then, via the linear projection layer, different input representations are mapped into language-like representations that are comprehensible to the LLM.
- LLM Understanding and Reasoning Stage: Vicuna, an LLM, is used as the core agent of NExT-GPT. LLM takes as input the representations from different modalities and carries out semantic understanding and reasoning over the inputs. It outputs 1) the textual responses directly, and 2) signal tokens of each modality that serve as instructions to dictate the decoding layers whether to generate multimodal contents, and what content to produce if yes.
- Multimodal Generation Stage: Receiving the multimodal signals with specific instructions from LLM (if any), the Transformer-based output projection layers map the signal token representations into the ones that are understandable to following multimodal decoders. Technically, they employ the current off-the-shelf latent conditioned diffusion models of different modal generations, i.e., Stable Diffusion (SD) for image synthesis, Zeroscope for video synthesis, and AudioLDM for audio synthesis.
- The following figure from the paper illustrates the fact that by connecting LLM with multimodal adapters and diffusion decoders, NExT-GPT achieves universal multimodal understanding and any-to-any modality input and output.
- System Inference:
- The figure below from the paper illustrates the inference procedure of NExT-GPT (grey colors denote the deactivation of the modules). Given certain user inputs of any combination of modalities, the corresponding modal encoders and projectors transform them into feature representations and passed to LLM (except the text inputs, which will be directly fed into LLM). Then, LLM decides what content to generate, i.e., textual tokens, and modality signal tokens. If LLM identifies a certain modality content (except language) to be produced, a special type of token will be output indicating the activation of that modality; otherwise, no special token output means deactivation of that modality. Technically, they design the
'<IMGi>'(i=0,…,4) as image signal tokens;'<AUDi>'(i=0,…,8) as audio signal tokens; and'<VIDi>'(i=0,…,24) as video signal tokens. After LLM, the text responses are output to the user; while the representations of the signal tokens of certain activated modalities are passed to the corresponding diffusion decoders for content generation.
- The figure below from the paper illustrates the inference procedure of NExT-GPT (grey colors denote the deactivation of the modules). Given certain user inputs of any combination of modalities, the corresponding modal encoders and projectors transform them into feature representations and passed to LLM (except the text inputs, which will be directly fed into LLM). Then, LLM decides what content to generate, i.e., textual tokens, and modality signal tokens. If LLM identifies a certain modality content (except language) to be produced, a special type of token will be output indicating the activation of that modality; otherwise, no special token output means deactivation of that modality. Technically, they design the
- Lightweight Multimodal Alignment Learning:
- They design the system with mainly three tiers in loose coupling, and they only need to update the two projection layers at encoding side and decoding side.
- Encoding-side LLM-centric Multimodal Alignment: They align different inputting multimodal features with the text feature space, the representations that are understandable to the core LLM.
- Decoding-side Instruction-following Alignment: They minimize the distance between the LLM’s modal signal token representations (after each Transformer-based project layer) and the conditional text representations of the diffusion models. Since only the textual condition encoders are used (with the diffusion backbone frozen), the learning is merely based on the purely captioning texts, i.e., without any visual or audio inputs.
- The figure below from the paper offers an illustrates of the lightweight multimodal alignment learning of encoding and decoding.
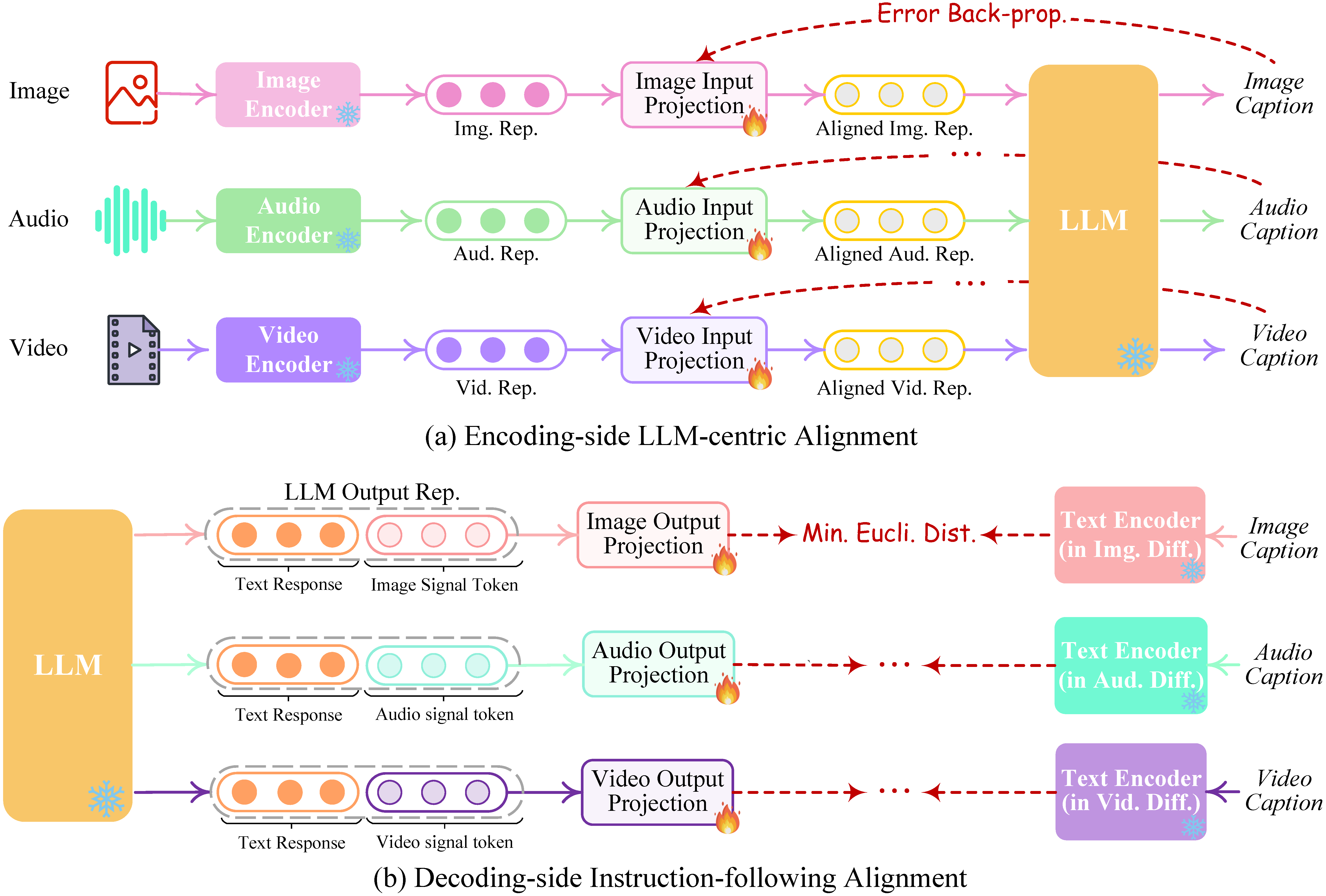
- They design the system with mainly three tiers in loose coupling, and they only need to update the two projection layers at encoding side and decoding side.
- Modality-switching Instruction Tuning (MosIT):
- Further instruction tuning (IT) is necessary to enhance the capabilities and controllability of LLM. To facilitate the development of any-to-any MM-LLM, they propose a novel Modality-switching Instruction Tuning (MosIT). As illustrated in Figure 4, when an IT dialogue sample is fed into the system, the LLM reconstructs and generates the textual content of input (and represents the multimodal content with the multimodal signal tokens). The optimization is imposed based on gold annotations and LLM’s outputs. In addition to the LLM tuning, they also fine-tune the decoding end of NExT-GPT. they align the modal signal token representation encoded by the output projection with the gold multimodal caption representation encoded by the diffusion condition encoder. Thereby, the comprehensive tuning process brings closer to the goal of faithful and effective interaction with users.
- MosIT Data:
- All the existing IT datasets fail to meet the requirements for our any-to-any MM-LLM scenario. They thus construct the MosIT dataset of high quality. The data encompasses a wide range of multimodal inputs and outputs, offering the necessary complexity and variability to facilitate the training of MM-LLMs that can handle diverse user interactions and deliver desired responses accurately.
- The figure below from the paper offers a summary and comparison of existing datasets for multimodal instruction tuning. T: text, I: image, V: video, A: audio, B: bounding box, PC: point cloud, Tab: table, Web: web page.
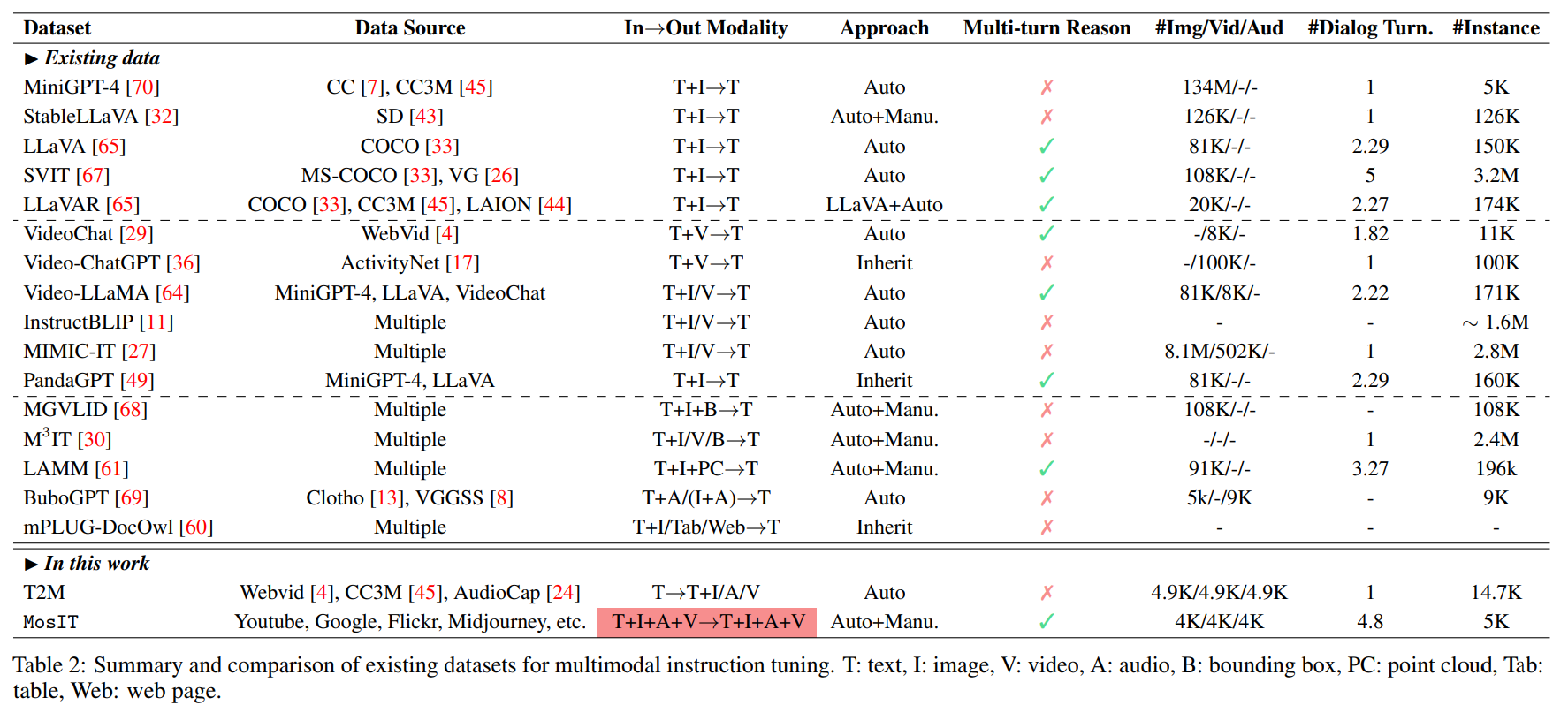
- While NExT-GPT isn’t the first project that went in this direction, it’s arguably the first one that provides a convincing demo and workflow heralding the future of Generative AI.
- Code; Demo; Dataset; YouTube.
Comparative Analysis
- A comparative analysis (source) of some popular VLMs across the areas of (i) single image reasoning, (ii) multiple images reasoning, (iii) image embeddings, and (iv) simple query engine is as follows:
Further Reading
- Lilian Weng’s blog on Generalized Visual Language Models
- Vision Language models: towards multi-modal deep learning
- CVPR2023 Tutorial Talk: Large Multimodal Models – Towards Building and Surpassing Multimodal GPT-4; Slides: Large Multimodal Models
- CMU course: 11-777 MMML
- Salesforce’s LAVIS
Citation
If you found our work useful, please cite it as:
@article{Chadha2020DistilledVLMs,
title = {Overview of Vision-Language Models},
author = {Chadha, Aman},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}