Models • Toolformer
- Overview
- Toolformer: Language Models Can Teach Themselves to Use Tools
- Approach
- Tools
- Experimental Results
- Limitations
- References
Overview
- LLMs perform incredibly at solving new tasks from limited textual data.
- That being said however, they have limitations as well in other areas such as:
- Inability to access up-to-date information
- Tendency to hallucinate facts
- Difficulty with low-resource languages
- Lack mathematical skills to perform accurate calculations
- Meta’s new model, Toolformer, is able to solve problems that require leveraging API’s such as a calculator, Wikipedia search, dictionary lookups, etc.
- Toolformer is able to recognize that it has to use a tool, able to determine which tool to use, as well as how to use that tool.
- The use cases for Toolformers will be endless, from having instant search results for any questions, to situational information, such as the best restaurants in town.
Toolformer: Language Models Can Teach Themselves to Use Tools
- Toolformer is based on a pre-trained GPT-J model with 6.7 billion parameters.
-
Toolformer was trained using a self-supervised learning approach that involves sampling and filtering API calls to augment an existing dataset of text.
- Toolformer looks to fulfill its task of LLMs teaching themselves how to use tools via the following two requirements:
- “The use of tools should be learned in a self-supervised way without requiring large amounts of human annotations.”
- “The LM should not lose any of its generality and should be able to decide for itself when and how to use which tool.” (source)
- The figure below (source) shows the predictions of the Toolformer (i.e., the embedded API calls within the data samples):

Approach
- Now, lets segue into the approach and architecture of Toolformer.
- As we’ve mentioned, Toolformer is a large language model with the ability to use different tools by the means of API calls.
- The input and outputs of each API call need to be formatted to a text/dialogue sequence to flow naturally in the conversation.
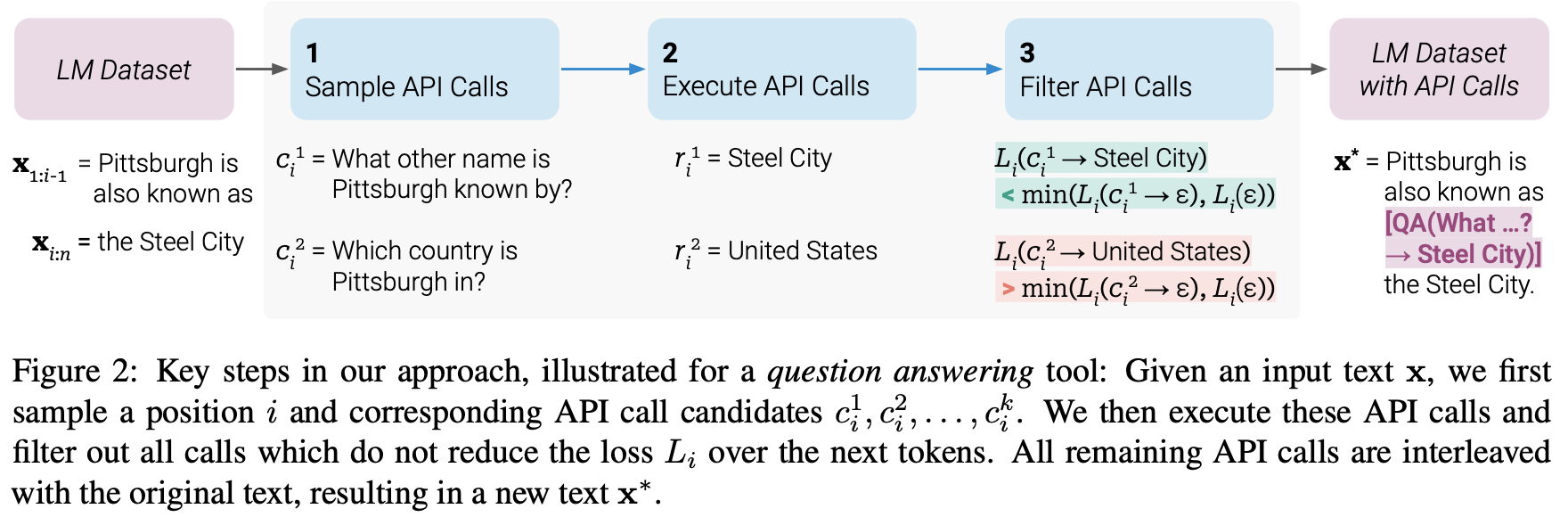
- As we can see from the image above (source), Toolformer starts by exploiting the in-context learning ability of the model to sample a large number of potential API calls.
- These API calls are executed and the obtained responses are checked if they are helpful for predicting future tokens; this is used as a filtering criterion.
- After filtering, the API calls for different tools are embedded within the original data sample, resulting in the augmented dataset which the model is finetuned on.
- Let’s walk through the example again in deeper detail.
- The image shows the model using the question-answering tool for this task.
- The LM dataset has the sample text: “Pittsburgh is also known as the Steel City” for the input prompt of, “Pittsburgh is also known as”.
- To find the correct answer, the model needs to make an API call and do so correctly.
- A few API calls are sampled, particularly, “What other name is Pittsburgh known by?” and “Which country is Pittsburgh in?”.
- The corresponding answers are, “Steel City” and “United States”.
- Since the first answer is better, its included into a new LM dataset with API calls as: “Pittsburgh is also known as [QA(”What other name is Pittsburgh known by?”) -> Steel City] the Steel City.”
- This contains the expected API call along with the answer. This step is repeated to generate a new LM dataset with each kind of tool (i.e., API call).
- Thus, the LM annotates a large corpus of data with API calls embedded in text, which then it uses to finetune the LM to make helpful API calls.
- This is how it is trained in a self-supervised way and there are a lot of benefits to this approach including:
- Less need for human annotators.
- Embedding API calls into the text allows LM to use multiple external tools with room to add more.
- Toolformer then learned to predict which tool was to be used for each task.
- In the sections below, we will go over these in a bit more detail.
Sampling API calls

- The image above (source) shows examples of the prompts Toolformer uses to make APIs calls given the user input.
- Toolformer uses
and to indicate the start and end of the API call. - A prompt is written for each API, which encourages the Toolformer to annotate an example with relevant API calls.
- Toolformer assigns a probability to each token as a possible continuation of a given sequence.
- The method involves sampling up to k candidate positions for API calls by computing the probability that the Toolformer assigns to starting an API call at each position in the sequence.
- Positions with probabilities greater than a given threshold are kept, and for each position, up to m API calls are obtained by sampling from the Toolformer using the sequence with the API call as a prefix and the end-of-sequence token as the suffix.
Executing API Calls
- The next step in the architecture is to actually make the API calls.
- This is entirely dependent on the client we are calling, whether it be another neural network, a Python script, or a retrieval system that searches over a large corpus.
- The thing to note is that the response here needs to be in a singular text sequence.
Filtering API Calls
- During filtering, Toolformer calculates a weighted cross-entropy loss for Toolformer over the tokens following the API call.
- Then, two different loss calculations are compared: one with the API call and its result given as input to Toolformer, and one with no API call or with the API call but not providing the result.
- API calls are considered useful if providing them with both input and output makes it easier for Toolformer to predict future tokens.
- A filtering threshold is applied to keep only API calls for which the difference between the two losses is greater than or equal to the threshold.
Model Finetuning
- Finally, Toolformer merges the remaining API calls with the original inputs and creates a new dataset augmented with API calls.
- The new dataset is then used to finetune Toolformer using a standard language modeling objective.
- Note: the augmented dataset contains the same texts as the original dataset, with only inserted API calls.
- This is because this ensures that finetuning the model on the augmented dataset exposes it to the same content as finetuning on the original dataset.
- By inserting API calls in the exact positions and with the inputs that help the model predict future tokens, finetuning on the augmented data enables the language model to learn when and how to use the API calls based on its own feedback.
Inference
- During inference, the decoding process is interrupted when the language model produces the “→” token, indicating the next expected response for an API call.
- The appropriate API is then called to get the response, and decoding continues after inserting both the response and the “</API>” token.
Tools
- Now lets look at the five tools Toolformer is currently exploring.
- One thing to note are the two requirement it requires from all of these tools which are:
- Both the input/outputs need to be represented as a text sequence.
- There should be available demos of how these tools can be used.
- Now lets get back to seeing which tools are currently being leveraged:
- Question Answering: this is another LM that can answer simple factoid questions.
- Calculator: currently only 4 basic arithmetic operations are supported and rounded to two decimal places.
- Wiki search: search engine that returns a short text snipped from Wikipedia.
- Machine Translation System: an LM that can translate a phrase from any language to English.
- Calendar: API call to a calendar that returns the current date without taking any input.
- The following figure (source) shows examples of inputs and outputs for all APIs used:

Experimental Results
- Before we talk about the experiments, lets look at the models used leveraged from here:
- GPT-J: used without any finetuning
- GPT-J + CC: GPT-J finetuned on our subset of CCNet without any API calls
- Toolformer: GPT-J finetuned on our subset of CCNet augmented with API calls
- Toolformer (disabled): Simmilar to Toolformer but API calls are disabled during decoding
- Now let’s break down the experiment by task.
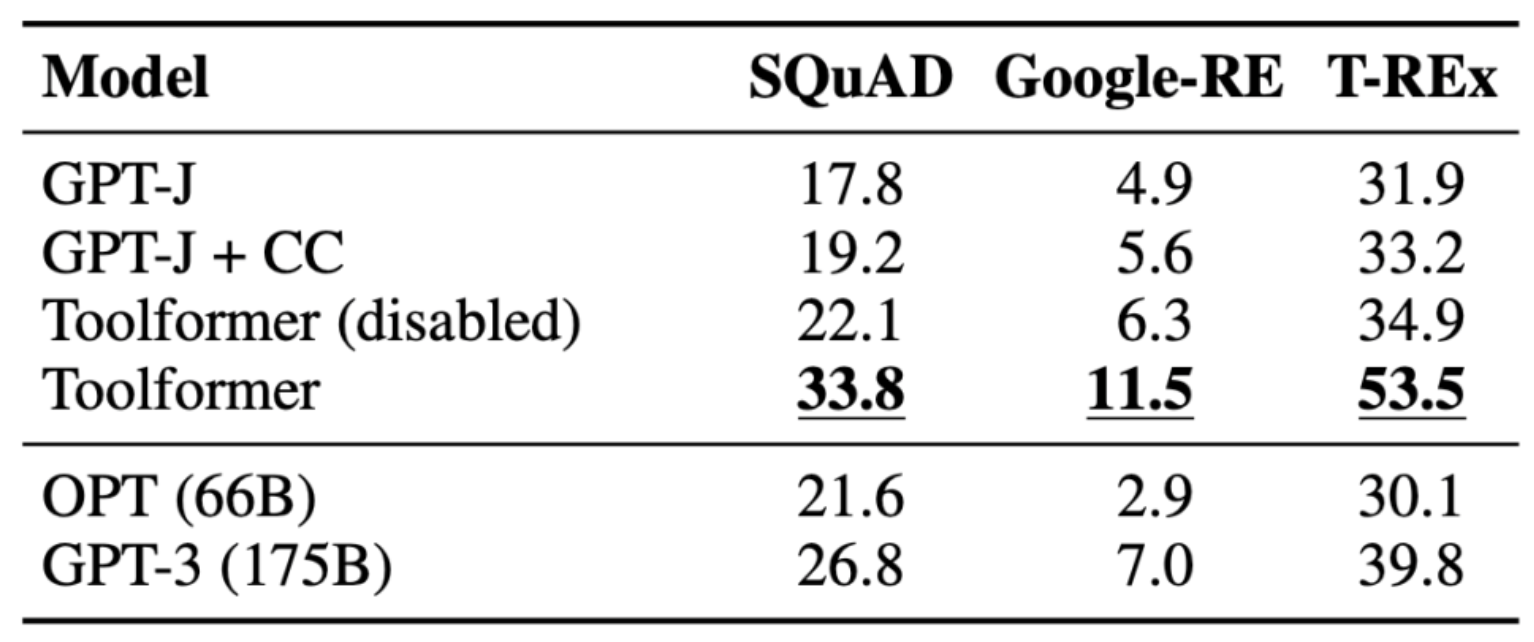
LAMA
- Here, the task is to complete a statement with a missing fact.
- Toolformer outperforms baseline models and even larger models such as GPT-3.
- The authors also prevent Toolformer from using the Wikipedia Search API to avoid an unfair advantage.
- The following table (source) encapsulates the results obtained with LAMA API calls:
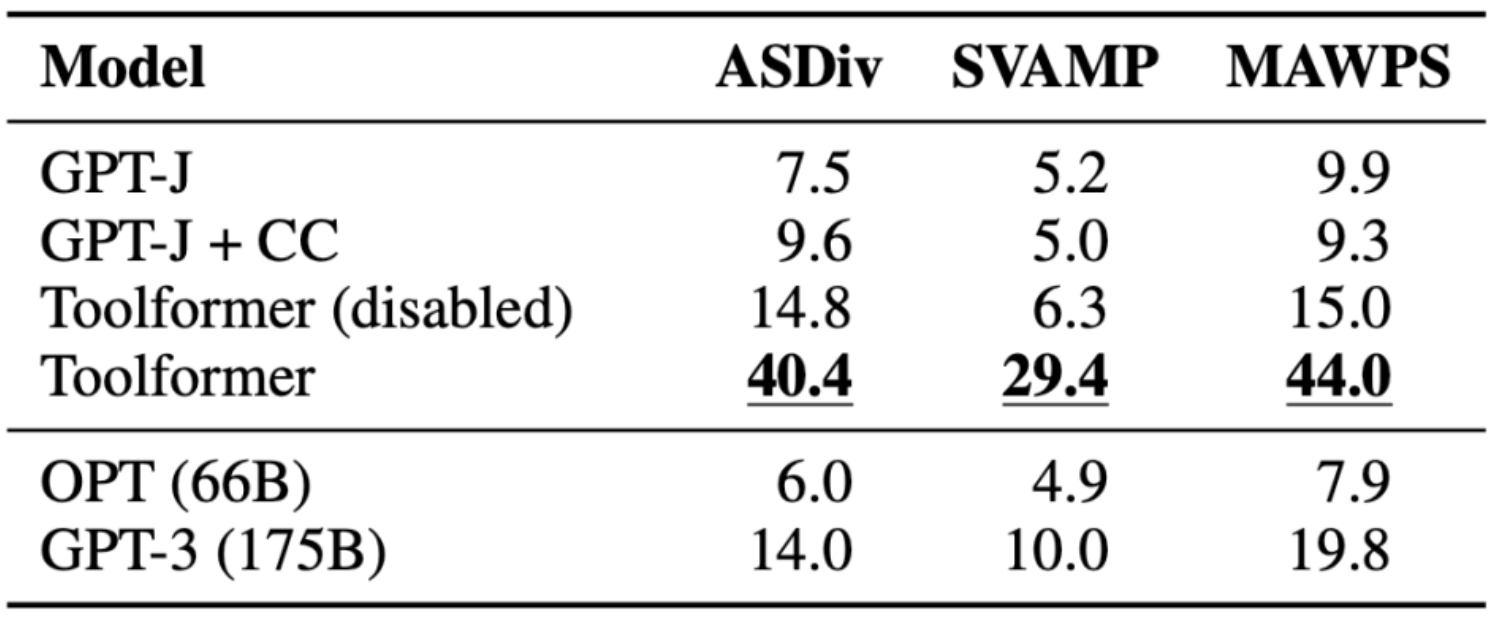
Math Datasets
- The task here was to evaluate the mathematical reasoning abilities of Toolformer against various baseline models.
- Toolformer performs better than the other models, possibly due to its fine-tuning on examples of API calls.
- Allowing the model to make API calls significantly improves performance for all tasks and outperforms larger models like OPT and GPT-3.
- In almost all cases, the model decides to ask the calculator tool for help.
- The following table (source) encapsulates the results obtained with Calculator API calls:
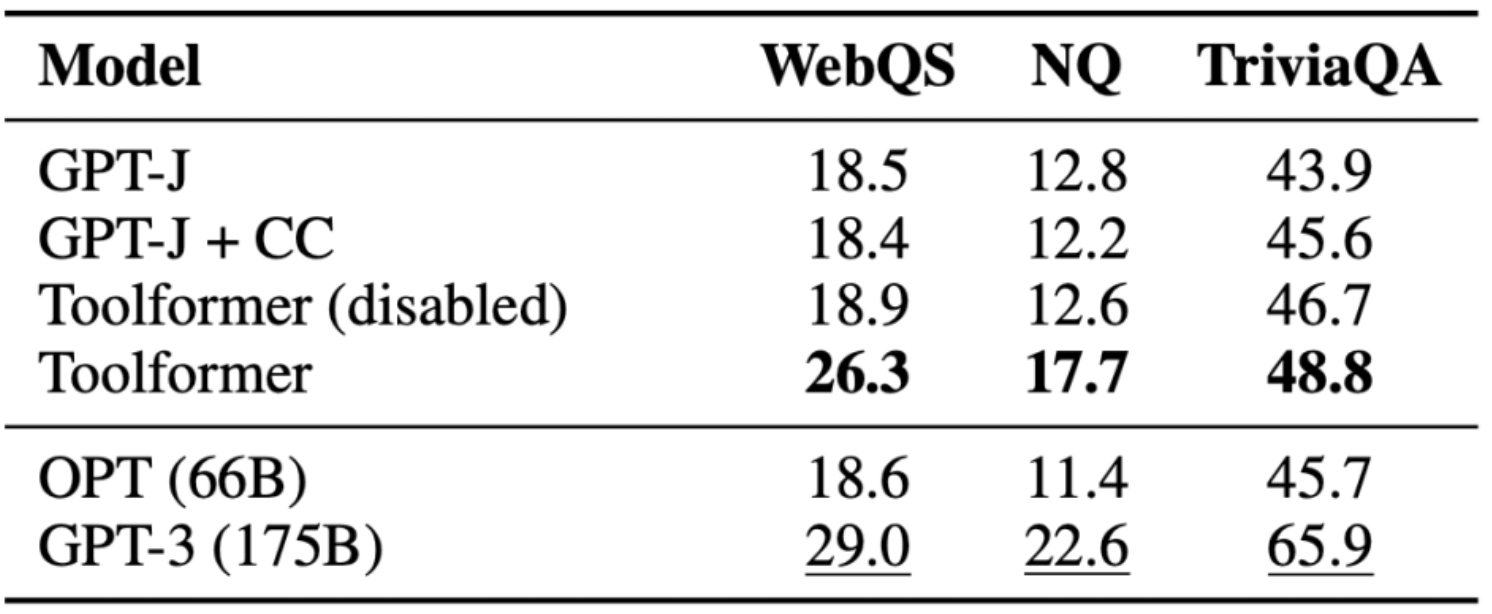
Question Answering
- Here, the model was tasked with question-answering.
- We can see that Toolformer outperformed the baseline models of the same size but was outperformed by GPT-3 (175B).
- Toolformer leveraged Wikipedia’s search tool for most of the examples in this task.
- The authors attribute the pitfall here due to the lack of quality of their search engine.
- The following table (source) encapsulates the results obtained with the Wikipedia search tool API calls:
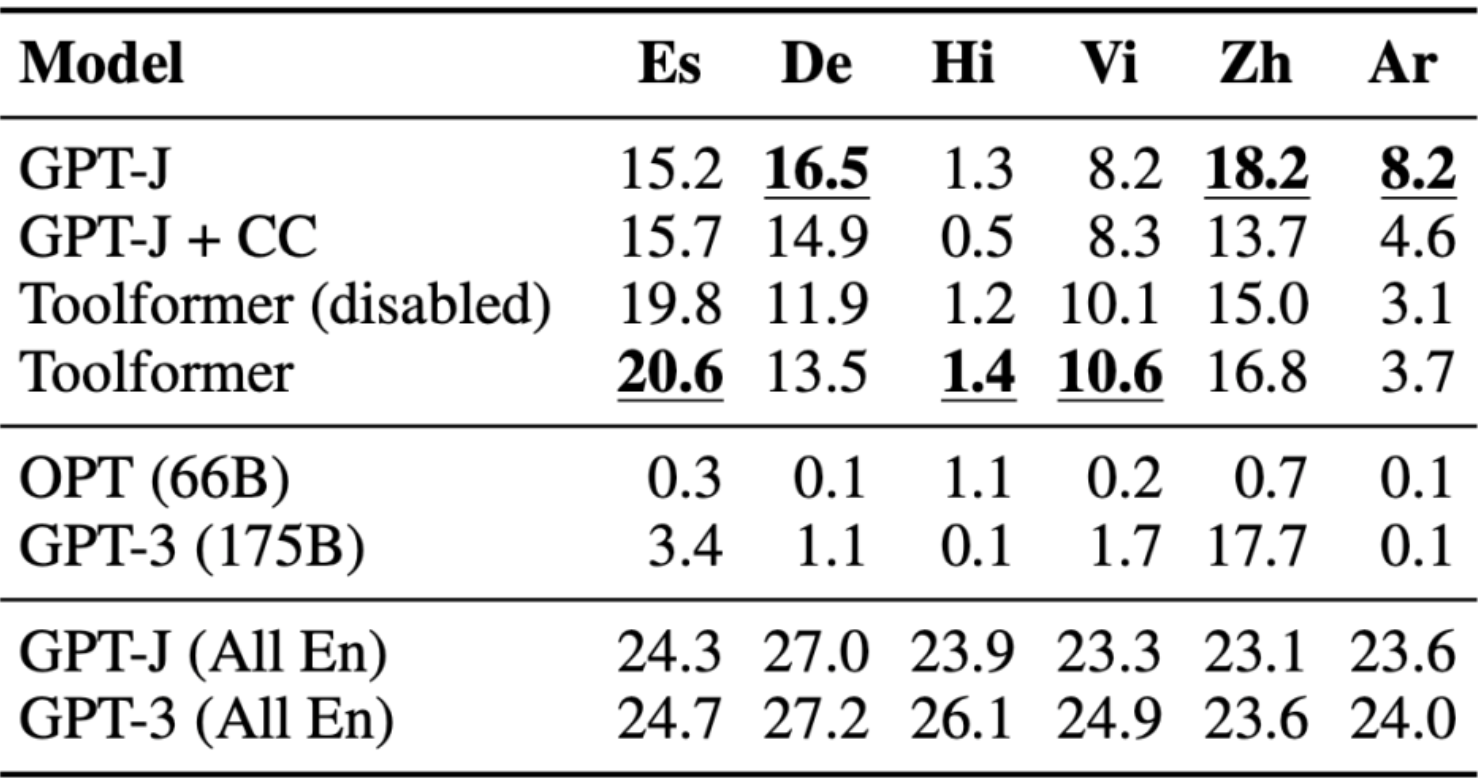
Multilingual Question Answering
- The question answering dataset was used for the multilingual question-answering benchmark, MLQA, with a context paragraph in English and questions in Arabic, German, Spanish, Hindi, Vietnamese, or Simplified Chinese.
- Toolformer does not come out here as the strongest performer, perhaps due to the lack of CCNet being finetuned on all the languages.
- The following table (source) encapsulates the results obtained with the Wikipedia search tool API calls:
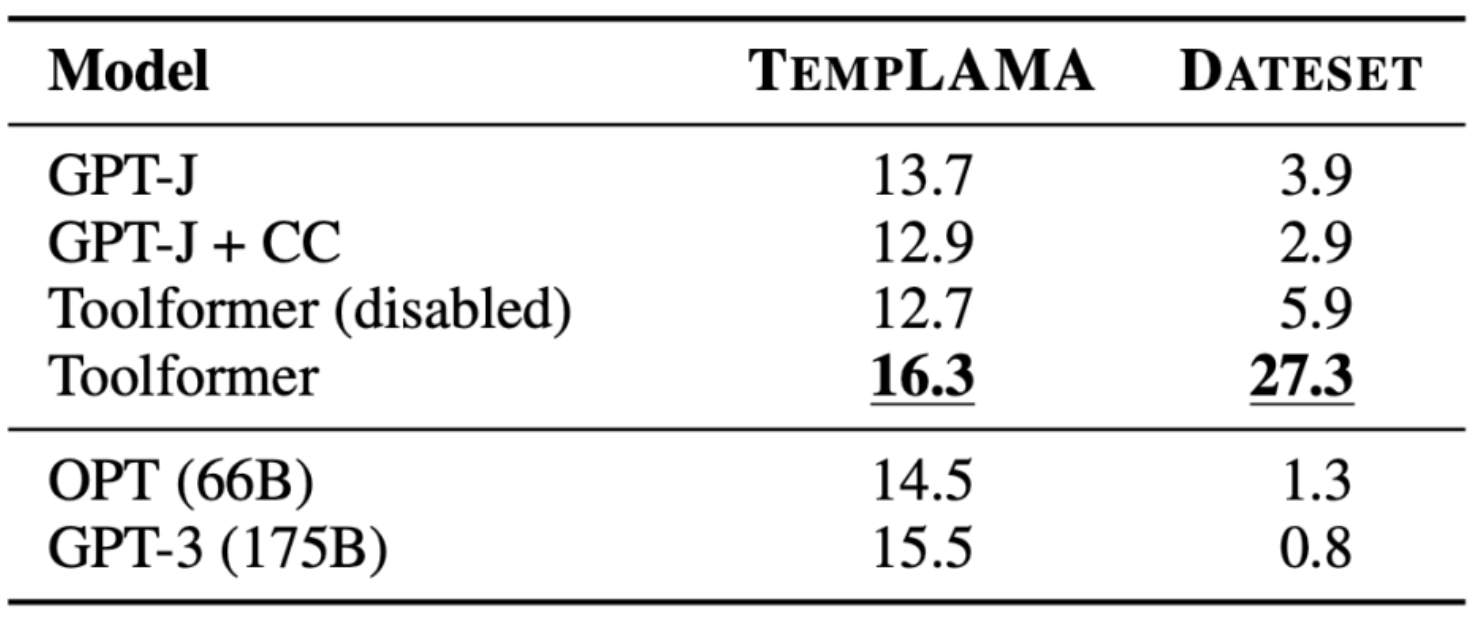
Temporal Datasets
- This is where knowing the current date is crucial to answering the question.
- Toolformer was able to outperform the baseline, however, apparently it was not utilizing the calendar tool 100% of the time. Instead, it was using Wikipedia’s search.
- The following table (source) encapsulates the results obtained with the Wikipedia search tool API calls:
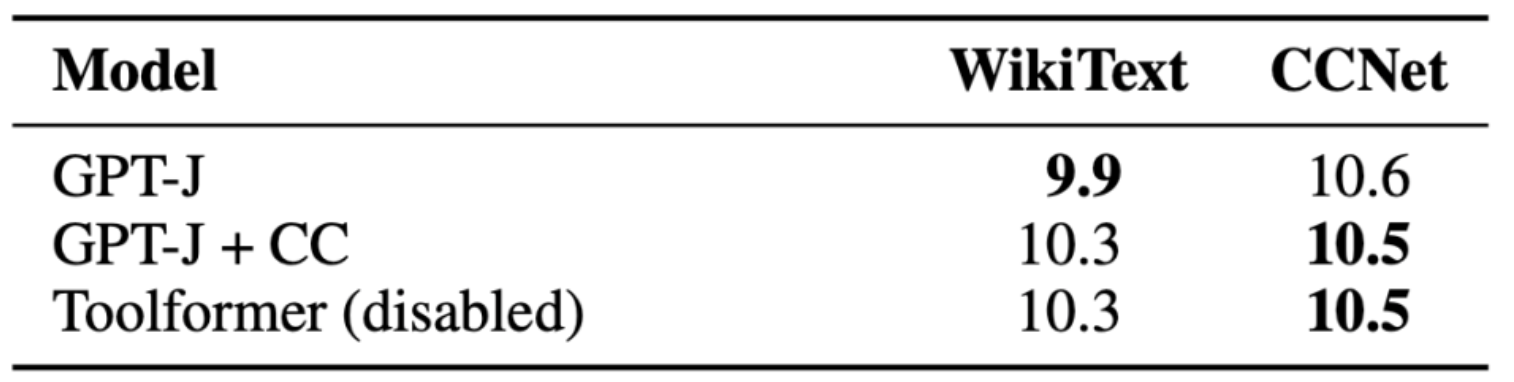
Language Modeling
- The study evaluates Toolformer on two language modeling datasets: WikiText and a subset of 10,000 randomly selected documents from CCNet.
- The goal is to ensure that finetuning with API calls does not degrade the language modeling performance of Toolformer.
- The models are evaluated based on their perplexity on the two datasets, with lower perplexity indicating better performance.
- Toolformer, GPT-J, and GPT-J + CC perform similarly on both datasets, indicating that Toolformer does not degrade the language modeling performance of GPT-J.
- The following table (source) encapsulates the results obtained:
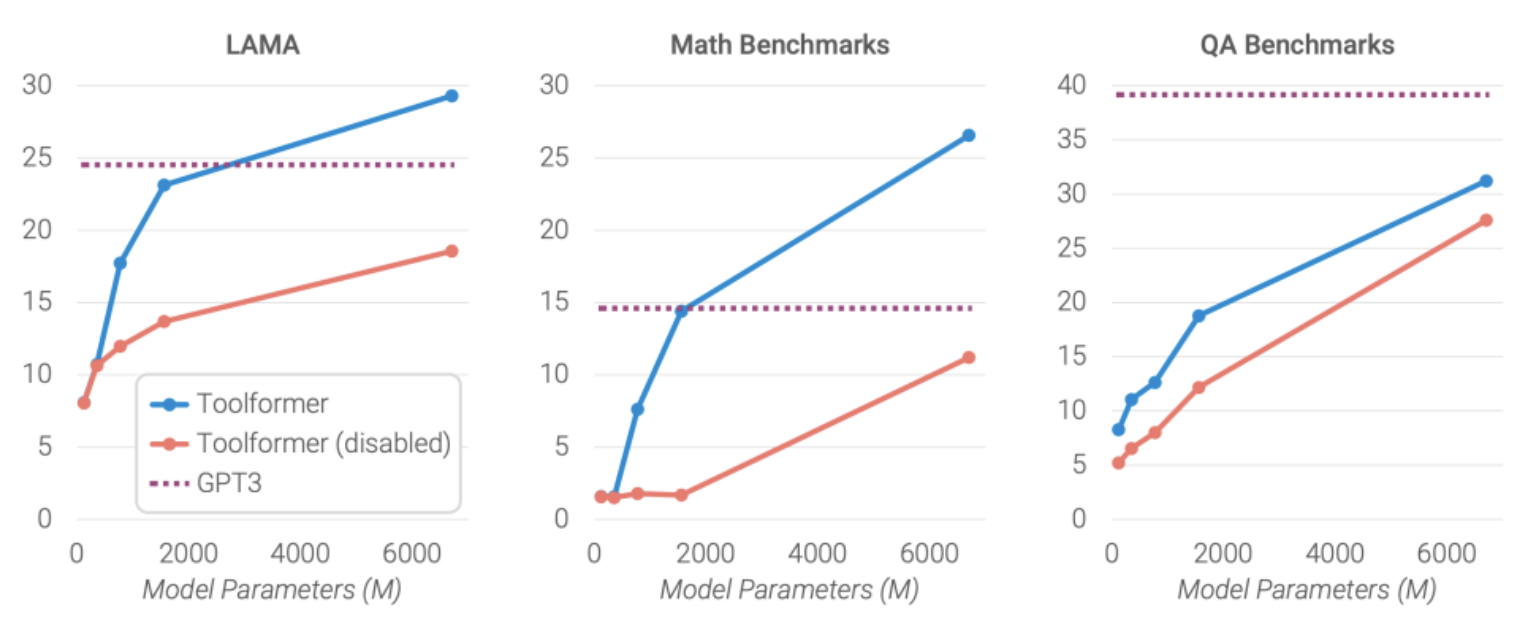
Scaling Law
- The study evaluates the performance of four smaller models from the GPT-2 family (with 124M, 355M, 775M, and 1.6B parameters, respectively) using the Toolformer approach.
- Only a subset of three tools are used: the question-answering system, the calculator, and the Wikipedia search engine.
- The goal is to see how the Toolformer approach scales with the model size.
- The following table (source) encapsulates the results:
Limitations
- There are still yet quite a few limitations of Toolformer:
- Firstly, Toolformer cannot use tools in a chain because API calls for each tool are generated independently.
- Also, it cannot use tools in an interactive way, especially for tools like search engines that could potentially return hundreds of different results.
- Models trained with Toolformer are sensitive to the exact wording of their input when deciding whether or not to call an API.
- The method is sample-inefficient for some tools, requiring a large number of documents to generate a small number of useful API calls.
- Lastly, the cost of using each tool is not taken into account while deciding to use it, thus resulting in possible high computational cost.