Primers • Reinforcement Learning for Agents
- Overview
- Background: Why SFT Fails (and RL Is Required) for Tool-Calling Agents
- Background: Teaching Agents Tool-Calling with RL
- Motivation
- Recipe
- Environment, MDP Formulation, and Action Space
- The MDP for “When / Which / How”
- State (\(s_t\))
- Structured, Factored Action Space
- Action Type 1:
ANSWER(final_text) - Action Type 2:
CALL(tool_name, args_json) - Structured Action Encoding
- Episode Dynamics
- Handling Invalid/Malformed Actions
- Integrating “When / Which / How” of Tool-Calling into the Action Space
- Annotation Sources for Reward Components (“When”, “Which”, and “How”)
- Reward Component: Call (Deciding “When” a Tool Should Be Invoked)
- Reward Component: Tool Selection (Choosing “Which” Tool)
- Reward Component: Tool-Syntax Correctness
- Reward Component: Tool-Execution Correctness
- Reward Component: Argument Quality (Deciding “How” to Call a Tool)
- Reward Component: Final Task Success
- Merged Preference-Based Rewards (For “Call”, “Which”, and “How”)
- Unified Reward Formulation
- Asymmetric Rewards in Tool-Calling RL
- RL Optimization Pipeline: Shared Flow + PPO vs. GRPO
- Curriculum Design, Evaluation Strategy, and Diagnostics for Tool-Calling RL
- Curriculum Design Overview
- Stage 0: Pure Supervised Bootstrapping (SFT)
- Stage 1: Binary Decision Curriculum (Learning When)
- Stage 2: Tool-Selection Curriculum (Learning Which)
- Stage 3: Argument-Construction Curriculum (Learning How)
- Stage 4: Multi-Step Tool Use (Pipelines)
- Stage 5: Open-Domain Free-Form Tasks
- Diagnostics and Monitoring
- Detecting Skill Collapse
- Curriculum Scheduling (Putting It All Together)
- Final Note
- Reinforcement Learning and the Emergence of Intelligent Agents
- The Role of Reinforcement Learning in Self-Improving Agents
- Environments for Reinforcement Learning in Modern Agents
- The Three Major Types of Reinforcement Learning Environments
- Reinforcement Learning for Web and Computer-Use Agents
- Background: Policy-Based and Value-Based Methods
- Background: Process-Wise Rewards vs. Outcome-Based Rewards
- Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO)
- Why These Algorithms Matter for Web & Computer-Use Agents
- Key Equations
- Agentic Reinforcement Learning via Policy Optimization
- Agent Training Pipeline
- Environment Interaction Patterns for Agent Design
- Reward Modeling
- Search-Based Reinforcement Learning, Monte Carlo Tree Search (MCTS), and Exploration Strategies in Multi-Step Agents
- Motivation: Exploration vs. Exploitation in Complex Agentic Systems
- Monte Carlo Tree Search (MCTS) in RL-Based Agents
- Neural-Guided Search: Policy Priors and Value Models
- Integration of Search with Reinforcement Learning and Fine-Tuning
- Process-Wise Reward Shaping in Search-Based RL
- Integration of Search with Reinforcement Learning and Fine-Tuning
- Exploration Strategies in Web and Computer-Use Environments
- Planning and Value Composition Across Multiple Environments
- Summary and Outlook
- Memory, World Modeling, and Long-Horizon Credit Assignment
- The Need for Memory and Temporal Reasoning
- Explicit vs. Implicit Memory Architectures
- World Modeling: Learning Predictive Environment Representations
- Temporal Credit Assignment and Advantage Estimation
- Hierarchical Reinforcement Learning (HRL)
- Memory-Augmented Reinforcement Learning (MARL)
- Long-Horizon Planning via Latent Rollouts and Model Predictive Control
- Takeaways
- Evaluation, Safety, and Interpretability in Reinforcement-Learning-Based Agents
- Why Evaluation and Safety Matter in RL-Based Agents
- Core Dimensions of Agent Evaluation
- Safety Challenges in RL Agents
- Interpretability and Traceability in Agent Behavior
- Safety-Aware RL Algorithms
- Human-in-the-Loop (HITL) Evaluation and Oversight
- Benchmarking Frameworks for Safe and Transparent Evaluation
- Toward Aligned, Interpretable, and Reliable Agentic Systems
- Tool-Integrated Reasoning
- Foundations and Theoretical Advancements in TIR
- Practical Engineering for Stable Multi-Turn TIR
- Scaling Tool-Integrated RL from Base Models
- Code-Interleaved Reinforcement for Tool Use
- Tool-Augmented Evaluation Agents
- Synthesizing Trends in TIR + RL Integration
- Synthesis: Beyond Individual Tool Use
- Unifying RL and TIR: Process vs. Outcome Rewards
- Synthesis and Outlook
- Citation
Overview
- Reinforcement Learning (RL) provides a formal framework for teaching artificial agents how to make decisions by interacting with an environment and learning from the outcomes of their actions. The learning process is governed by a Markov Decision Process (MDP), defined as a tuple \((S, A, P, R, \gamma)\), where \(S\) denotes the set of all possible states, \(A\) the set of available actions, \(P(s' \mid s,a)\) the transition probability function that determines how the environment changes, \(R(s,a)\) the reward function that provides feedback to the agent, and \(\gamma\) the discount factor controlling how much the agent values future rewards relative to immediate ones. The agent seeks to learn a policy \(\pi(a \mid s)\), representing the probability of choosing action \(a\) when in state \(s\), that maximizes the expected cumulative reward:
- RL is distinct from supervised learning in that the correct answers (labels) are not provided directly. Instead, the agent must explore different actions, observe the consequences, and adapt its policy based on the rewards it receives. This trial-and-error process makes RL a natural fit for agents operating in complex digital environments such as the web, desktop systems, and software tools.
Background: Why SFT Fails (and RL Is Required) for Tool-Calling Agents
-
Training language models to reliably call tools (APIs, calculators, search engines, etc.) requires more than just supervised learning. While supervised fine-tuning (SFT) can teach the model to mimic example traces, it cannot teach the policy to decide when, which, or how to call a tool in a dynamic interactive environment. Specifics below:
-
SFT lacks decision-making over tool invocation:
- Tool-calling isn’t merely generating a correct JSON snippet; it requires deciding whether a tool call is appropriate in context. SFT merely imitates demonstration actions—maximising:
- … with no dependence on outcomes or future consequences. In tool-use settings, the cost of calling a tool (latency, billing, context switching) must be factored in — SFT cannot encode this. RL, by contrast, can optimise for cumulative return
- … and thus learn when to avoid tool calls.
-
SFT cannot teach selection among tools:
- When multiple tools exist (search vs. calculator vs. map API), the model must learn a selection policy. SFT only learns to replicate the choice made in the demonstration, but it does not learn the trade-offs or consequences of selecting the wrong tool. RL provides negative reward for wrong choices, which in turn teaches discrimination among tools.
-
SFT cannot incorporate tool output feedback:
- Even if SFT teaches correct argument formatting, it does not receive feedback on execution success, tool output quality, or how the return value impacts the final answer. In RL, the reward can include syntax success, execution success, argument quality and final answer correctness — something not captured by SFT.
-
SFT is poor at multi-step workflows and stopping conditions:
- Many tool-use tasks require multiple sequential calls, conditional logic, and a decision when to stop calling tools and answer. SFT sees fixed demonstration lengths and cannot generalise to dynamic lengths or stopping decisions. RL handles this via episodic returns and learnt policies for “ANSWER” actions vs. further “CALL”.
-
SFT cannot penalize misuse, over-use or under-use of tools:
- Unnecessary tool calls (which increase cost/latency) or missing required tool calls (which degrade correctness) need explicit penalties. SFT cannot encode such cost signals because the training loss only rewards matching demonstration tokens. RL directly incorporates costs into the reward function.
-
SFT does not generalize well beyond the demonstration distribution:
- New tools, new argument schemas, unseen queries or dynamic contexts are common in tool-use systems. SFT tends to overfit to the fixed distribution of demonstration actions. RL, via exploration and returns optimization, helps the model discover new behaviours and adapt to changed context.
-
SFT cannot optimize multi-component objectives:
- Tool use requires coordination across distinct sub-skills: the decision of when to call a tool, the choice of which tool is appropriate, the construction of arguments, the formatting of JSON, the success of tool execution, the correctness of the final answer, and the minimisation of tool cost and latency.
- SFT provides a single monolithic loss that does not distinguish these components. It cannot selectively penalize errors in timing, selection, argument structure, schema fields, or step efficiency. RL, in contrast, enables fine-grained reward shaping where each component contributes its own reward term to the overall objective. This makes it possible to reward correct tool timing separately from correct tool selection, reward argument correctness separately from execution success, and reward final answers separately from intermediate steps.
-
What Is Imitation Learning and Why SFT Is Used Before RL
-
Before applying reinforcement learning to teach tool-calling behavior, modern LLM systems almost always begin with imitation learning. In the LLM context, imitation learning is implemented via Supervised Fine-Tuning (SFT) — training the model to reproduce expert-authored examples of correct tool usage.
-
This section explains (i) what imitation learning is, (ii) why SFT is a special case of it, and (iii) why imitation learning is a necessary warm-start for RL in tool-use settings.
What is imitation learning?
-
Imitation learning trains a policy by directly copying expert actions instead of learning via trial-and-error. No rewards, no exploration, no environment optimisation — just supervised mapping from states to actions.
-
Formally, given demonstration trajectories \(\tau = {(s_0, a_0), (s_1, a_1), \dots, (s_T, a_T)}\), imitation learning maximises the likelihood of expert actions:
\[\mathcal{L}_{\rm IL}(\theta) = - \sum_{t=0}^{T} \log p_\theta(a_t^{\rm expert} \mid s_t)\] -
This is close to standard supervised learning, but in robotics and RL theory it is known as behavior cloning, one of the simplest imitation-learning methods.
Why SFT is exactly imitation learning
-
When training LLMs to produce reasoning traces, tool-call JSON, or final answers using labelled examples, SFT implements the above loss directly. The model does not explore, does not observe tool outputs, and is not rewarded for correct long-term actions.
-
In the tool-calling context, SFT teaches:
- how tool calls look (syntax),
- rough patterns of when humans call tools,
- typical argument structures,
- final-answer formatting.
-
It is imitation, not policy optimisation.
Why imitation learning is essential before RL
-
Reinforcement learning over raw text is unstable. The action space is huge, syntax is fragile, and initial random exploration produces invalid tool calls. Therefore, all effective tool-use RL systems warm-start with SFT to give the model baseline competencies:
-
Basic tool syntax and schema literacy: Without SFT, the model would produce malformed JSON during RL, causing constant errors and noisy gradients.
-
A minimal “when/which/how” prior: SFT examples give the model at least a heuristic pattern of tool timing, tool choice, and argument formation.
-
Reduced exploration burden: Starting RL from scratch would require immense exploration before any correct tool call is sampled. SFT drastically reduces the search space.
-
Stability and safety in early RL training: RL at random-init leads to:
- runaway tool-call loops,
- malformed arguments,
- no successful episodes,
- degenerate policies.
-
-
SFT prevents this collapse by anchoring the initial model to sane behavior.
Why imitation learning alone is insufficient (recap)
-
SFT gives you competence, not policy mastery. After SFT, models still fail at:
- deciding when to avoid unnecessary tool calls,
- selecting among multiple tools based on trade-offs,
- tuning arguments based on execution feedback,
- multi-step planning,
- minimising tool-use cost,
- stopping when enough information is gathered.
-
Imitation learning provides the starting point, while RL provides the decision-making optimisation needed for real tool-use proficiency.
Background: Teaching Agents Tool-Calling with RL
Motivation
-
In recent years, the paradigm of tool-augmented reasoning with large language models (LLMs) has gained traction: for example, Tool Learning with Foundation Models by Qin et al. (2023) provides a systematic overview of how foundation models can select and invoke external tools (e.g., APIs) to solve complex tasks.
-
Teaching an LLM to use tools is fundamentally a three-part learning problem:
- When to call a tool: deciding whether a tool invocation is necessary, optional, or unnecessary for a given query.
- Which tool to call: selecting the correct tool among several available tools.
- How to call a tool: generating valid, correctly structured arguments that allow the tool to execute successfully.
- These three categories correspond to decision-level, selection-level, and argument-level competencies, each requiring distinct supervision and reward signals.
-
Prior work such as ReTool: Reinforcement Learning for Strategic Tool Use in LLMs by Feng et al. (2025) and ToolRL: Reward is All Tool Learning Needs by Qian et al. (2025) demonstrates that fine-grained decomposition of the tool-learning problem significantly boosts RL stability and policy quality, especially when separating the decision to call a tool from the actual mechanics of tool invocation.
-
This write-up presents a full end-to-end RL recipe where a single policy is optimized with PPO or related algorithms to simultaneously learn:
- When to call a tool,
- Which tool to choose, and
- How to construct correct arguments.
Why “when / which / how” decomposition is necessary
-
When: The timing of tool usage determines the efficiency and correctness of solutions. Over-calling leads to unnecessary cost and latency, while under-calling leads to incomplete or incorrect answers. Tool timing thus forms a binary or multi-class policy decision that must be explicitly learned.
-
Which: Even when a tool call is appropriate, the model must choose the correct tool among a library of APIs. This is a classification problem, requiring a structured action space and tool-selection reward.
-
How: Tool arguments must be valid JSON, consistent with schemas, and semantically correct. This is a structured generation problem, requiring rewards for syntax, executability, and argument quality.
-
Even within one policy, these decisions require different supervision signals, and RL benefits from isolating their reward terms so the model knows why a trajectory is good or bad.
-
Research such as ToolRL shows that decomposed reward components for these distinct competencies improve reward signal clarity, reduce credit assignment difficulty, and produce more controllable execution-time behavior.
Recipe
-
Here is a summary of the major phases to be implemented:
-
Define an environment and action space that supports:
- when-decisions (tool vs. no-tool),
- which-decisions (tool selection),
- how-decisions (argument generation).
-
Annotate or derive labels for each learning axis:
- when-labels: \(y_{\text{when}} \in {0,1}\)
- which-labels: \(y_{\text{which}} \in {1,\dots,K}\) for \(K\) tools
- how-labels: argument-schema exemplars or reference traces
-
Bootstrap the LLM via supervised fine-tuning (imitation learning) so the policy starts with a basic understanding of:
- tool timing,
- tool selection,
- valid argument formats.
-
Design a multi-component reward function including:
- a when-reward for correct tool/no-tool decisions,
- a which-reward for correct tool selection,
- a how-reward for syntax validity, executability, and argument quality,
- a final task-success reward.
-
Train using PPO (or GRPO) over trajectories with the combined reward:
- compute returns \(R_t\),
- compute advantages \(A_t\) (e.g., with GAE),
- update policy and value model with KL regularization to a supervised fallback policy.
-
Curriculum design: progress from simple supervised traces to complex multi-step workflows where the model must interleave “when”, “which”, and “how” decisions.
-
Diagnostics and evaluation: track metrics for each axis separately:
- when-accuracy,
- which-accuracy,
- argument correctness,
- executability rate,
- and final task accuracy.
-
Environment, MDP Formulation, and Action Space
- Tool-augmented LLMs must make three decisions during reasoning:
- whether a tool should be invoked (when),
- which tool is appropriate (which), and
- how to construct valid and effective arguments (how).
- This decomposition mirrors the behavioral factorization used in systems such as Toolformer by Schick et al. (2023) and the structured planning seen in ReAct by Yao et al. (2022). It also aligns with the policy design in recent RL approaches like ReTool by Feng et al. (2025) and ToolRL (2025), where tool selection is modeled as a multi-stage decision.
The MDP for “When / Which / How”
-
We model tool use as an MDP:
\[\mathcal{M} = (S, A, P, R, \gamma)\]- … with a factored action space that explicitly captures the “when/which/how” structure.
State (\(s_t\))
-
Each state encodes:
- the user’s query
- ongoing reasoning steps
- past tool calls and outputs
- system instructions
- optional episodic memory (short-term trajectories)
-
The full state is serialized into a structured text prompt fed into the LLM, much like ReAct-style reasoning traces.
Structured, Factored Action Space
-
The action space is decomposed into:
- When to call a tool
- Which tool to call (conditional on calling)
- How to construct arguments (conditional on chosen tool)
-
This yields two disjoint high-level action types:
Action Type 1: ANSWER(final_text)
- Used when the model decides no more tool calls are needed.
Action Type 2: CALL(tool_name, args_json)
-
Further factored into:
- When: deciding to call a tool rather than answer
- Which: selecting a tool from the available toolset
- How: generating a valid argument JSON for that tool
-
This factorization improves learning by ensuring that RL gradients reflect distinct sub-skills within tool usage.
Structured Action Encoding
-
To stabilize RL training, each action is formatted in strict machine-readable JSON, following the practice in ReTool and Toolformer:
- Example: CALL action
<action> { "type": "call", "when": true, "which": "weather_api", "how": { "city": "Berlin", "date": "2025-05-09" } } </action>- Example: ANSWER action
<action> { "type": "answer", "when": false, "content": "It will rain in Berlin tomorrow." } </action> -
The when flag can be made explicit or implicit; explicit inclusion helps debugging and credit assignment.
Episode Dynamics
-
An episode proceeds as follows:
- LLM receives state \(s_0\).
- LLM produces a structured action \(a_0\) containing “when/which/how”.
- Environment parses the action:
- If
ANSWER\(\rightarrow\) episode ends. - If
CALL\(\rightarrow\) execute tool, append output to context, produce next state \(s_1\).
- If
- Reward is computed for “when”, “which”, “how” correctness and final answer quality.
- Continue until ANSWER or max-step limit.
-
This multi-step structure supports multi-hop reasoning as used in ReAct and aligns with task settings in Toolformer.
Handling Invalid/Malformed Actions
-
Invalid “when/which/how” choices should not terminate the episode. Instead:
- Assign negative syntax or validity rewards
- Return an error message to the model
- Allow the agent to continue
-
This is consistent with reward-shaping strategies from Deep RL from Human Preferences by Christiano et al. (2017).
Integrating “When / Which / How” of Tool-Calling into the Action Space
-
During RL optimization:
- The policy gradient is computed over the entire structured action
- But reward is decomposed along the three decision axes
- PPO or GRPO provides stable updates (as seen in ReTool and ToolRL)
-
Thus, the policy learns simultaneously:
- When a tool is appropriate
- Which tool should be chosen
- How to construct high-quality arguments
-
This modularity also makes reward engineering substantially easier, as each component can be trained and debugged independently.
Annotation Sources for Reward Components (“When”, “Which”, and “How”)
-
This section explains how to generate supervision signals for all reward components in the RL system, reflecting the decomposition of tool-use behavior into:
- When \(\rightarrow\) deciding if and when a tool should be used
- Which \(\rightarrow\) selecting which tool to call
- How \(\rightarrow\) constructing how to call it via correctly formed arguments
-
To support this, the reward is decomposed into the following components:
- Call (when-to-call): whether a tool should be called.
- Tool-selection: whether the correct tool was chosen (which).
- Tool-syntax correctness: whether the tool call was formatted properly.
- Tool-execution correctness: whether the tool executed successfully.
- Argument quality: whether the arguments were appropriate (how).
- Final task success: whether the entire episode produced the right answer.
- Preference-based / generative evaluation: higher-level judgment (LLM-as-a-Judge).
-
Each reward dimension can be supervised using a mixture of:
- Rule-based heuristics
- Discriminative reward models trained on human data
- Generative reward models (LLM-as-a-Judge as in DeepSeek-R1 by Guo et al. (2025)).
Reward Component: Call (Deciding “When” a Tool Should Be Invoked)
- This component supports the when dimension: Is a tool call appropriate/necessary at this point in the reasoning process?
Rule-based supervision
-
Use deterministic rules and intent detectors inspired by works like Toolformer by Schick et al. (2023):
- Weather questions \(\rightarrow\) require weather API
- Math expressions \(\rightarrow\) require calculator
- “Define X / explain Y” \(\rightarrow\) no tool
- Factual queries \(\rightarrow\) search tool
- Actionable tasks (e.g., booking) \(\rightarrow\) appropriate domain tool
-
This produces binary or graded labels \(y_{\text{call}} \in {0,1}\).
Discriminative reward model
- Train a classifier \(f_{\phi}(x)\) predicting \(P(y_{\text{call}} = 1 \mid x)\) using human-labeled examples indicating if/how strongly the query requires tool use.
- This mirrors methodology from RLHF as in InstructGPT by Ouyang et al. (2022).
Generative reward model (LLM-as-a-Judge)
-
Use a judge model (e.g., DeepSeek-V3 per DeepSeek-R1):
-
Prompt: “Given this user query and available tools, should the agent call a tool at this stage? Provide yes/no and reasoning.”
-
Extract a scalar reward from the generative verdict.
-
This can capture nuanced timing requirements over multiple steps.
Reward Component: Tool Selection (Choosing “Which” Tool)
- This component supports the which dimension: Given that a tool is to be called, was the correct tool chosen?
Rule-based supervision
-
If rules map tasks to a specific tool or tool category, then:
- If the predicted tool matches the rule \(\rightarrow\) +reward
- Otherwise \(\rightarrow\) −reward
-
This is similar to mapping tool types in ReAct by Yao et al. (2022).
Discriminative reward model
- Train a classifier \(f_{\psi}(s_t, a_t)\) that judges whether the selected tool matches human expectations for that state.
Generative reward model
-
Ask a judge LLM: “Was TOOL_X the best tool choice for this request at this step?”
-
Score the answer and normalize.
Reward Component: Tool-Syntax Correctness
-
Supports the how dimension partially, focusing on format:
- JSON validity
- Required argument fields
- Correct schema shape
Rule-based
- JSON parse success
- Schema validation
-
Argument-type validation
-
Reward:
\[r_t^{\text{syntax}} = \begin{cases} +1 & \text{if JSON + schema valid} \ -1 & \text{otherwise} \end{cases}\] - This echoes structured action enforcement in ReAct.
Discriminative reward model
- Classify correct vs. incorrect tool-call formats.
Generative reward model
- Ask an LLM judge whether the formatting is correct (1–10), normalize to reward.
Reward Component: Tool-Execution Correctness
- Did the tool run without error?
Rule-based
- HTTP 200 or success flag \(\rightarrow\) +reward
- Errors / exceptions \(\rightarrow\) −reward
Discriminative reward model
- Trained to predict execution feasibility or correctness.
Generative reward model
- Judge evaluates based on logs and outputs.
Reward Component: Argument Quality (Deciding “How” to Call a Tool)
- This is the core of the how dimension: constructing appropriate arguments.
Rule-based
- For numeric or structured problems:
- For strings, use embedding similarity or fuzzy match.
Discriminative reward model
- Trained to identify argument errors (bad city name, missing date, etc.).
Generative reward model
- LLM-as-a-Judge evaluates argument plausibility/fit to the query.
Reward Component: Final Task Success
- Whether the overall trajectory produced a correct answer.
Rule-based
- Unit test pass
- Exact match
- Tolerance-based numeric match
Discriminative reward model
- Using preference modeling as in Deep RL from Human Preferences by Christiano et al. (2017), train:
Generative reward model
- Judge LLM compares model prediction with ground truth (as in DeepSeek-R1).
Merged Preference-Based Rewards (For “Call”, “Which”, and “How”)
-
You can construct pairs of trajectories differing in:
- timing of tool calls (call),
- choice of tool (which), and
- argument construction (how)
-
Let the judge or human annotator choose the better one.
-
Train a preference RM to provide combined signals.
Unified Reward Formulation
-
All reward signals—process and outcome—are merged into one scalar:
\[\boxed{ R = \underbrace{ w_{\text{call}} r^{\text{call}} }_{\text{when}} + \underbrace{ \left( w_{\text{tool}} r^{\text{tool}} \right) }_{\text{which}} + \underbrace{ \left( w_{\text{syntax}} r^{\text{syntax}} + w_{\text{exec}} r^{\text{exec}} + w_{\text{args}} r^{\text{args}} \right) }_{\text{how}} + \underbrace{ \left( w_{\text{task}} r^{\text{task}} + w_{\text{pref}} r^{\text{pref}} \right) }_{\text{outcome-level}} }\]-
where:
- The when group controls whether a tool is invoked.
- The which + how group supervises tool choice and argument construction.
- The outcome-level group ensures the final result is correct and aligns with human/judge preferences.
-
-
This single scalar reward \(R\) is what enters the RL optimizer (e.g., PPO or GRPO).
-
Weights \(w\) are tuned to balance shaping vs. final correctness.
Asymmetric Rewards in Tool-Calling RL
-
This section explains why tool-calling RL systems use asymmetric rewards (positive rewards much larger than negative rewards), how this stabilizes PPO/GRPO, and how asymmetry applies across the when / which / how components. A full worked example and a comprehensive reward table are included.
-
Asymmetric reward schedules are used in practical tool-use RL systems such as ReTool, ToolRL, DeepSeek-R1, and RLHF pipelines. They ensure that:
- Success is highly rewarded.
- Failure incurs penalties but not catastrophic ones.
- Exploration does not collapse into inert policies (e.g., “never call tools”).
- The hierarchy — deciding when to call tools, which tool to call, and how to construct correct arguments — all receive stable and interpretable feedback.
Why Asymmetry Is Required
-
Because tool-calling introduces many potential failure points (incorrect timing, wrong tool, malformed arguments, bad final answer), symmetric rewards would cause massive early negative returns. The policy would quickly learn the degenerate strategy: “Never call any tool; always respond directly.”
-
Asymmetric rewards avoid this by:
- Using large positive rewards for correct full trajectories.
- Using mild or moderate negative rewards for mistakes.
- Ensuring that exploratory attempts are only slightly penalized.
- Allowing the policy to differentiate between “bad idea but learning” vs. “excellent behavior.”
-
This encourages exploration in the factored action space and prevents PPO/GRPO from collapsing into trivial policies.
Reward Table: Positive and Negative Rewards by Category
- Below is a consolidated table representing typical asymmetric reward magnitudes for each component. These values are illustrative and are often tuned per domain.
Reward Values for “When / Which / How” and Outcome-Level Components
| Reward Component | Description | Positive Reward Range | Negative Reward Range |
|---|---|---|---|
| When (call decision) | Correctly calling a tool when needed | +0.5 to +1.5 | −0.2 (tool required but not called) |
| Correctly not calling a tool | +0.3 to +1 | −0.2 (tool called when unnecessary) | |
| Which (tool selection) | Selecting correct tool | +0.5 to +2.0 | −0.3 to −0.7 (wrong tool) |
| How: Syntax | JSON validity and schema correctness | +0.3 to +1.0 | −1.0 (malformed JSON or wrong schema) |
| How: Execution | Tool executes successfully (HTTP 200, etc.) | +0.5 to +1.0 | −1.0 to −2.0 (execution error) |
| How: Argument Quality | High-quality arguments (correct fields, values) | +0.5 to +2.0 | −0.5 to −1.5 (missing/incorrect/poor arguments) |
| Outcome: Final Task Success | Producing correct final answer using tool output | +8.0 to +15.0 | −0.3 to −1.0 (incorrect final answer) |
| Outcome: Preference/Judge Score | Judge or LLM-as-a-critic evaluation of final output | +1.0 to +5.0 | −0.1 to −1.0 |
-
This table reflects the following structural principles:
- The largest rewards are reserved for correct end-to-end solution quality.
- The largest penalties correspond only to errors that break execution (syntax, runtime failure).
- Small errors in timing, selection, or argument quality incur light penalties.
- Rewards across “when / which / how” are significantly lower than final-task success, ensuring shaping rewards guide early learning but final correctness dominates late learning.
Worked Example With Asymmetric Rewards
-
Consider the user query: “What’s the weather in Paris tomorrow?”
-
Correct behavior requires:
- Deciding a tool is required (when).
- Selecting the weather API (which).
- Providing correct arguments in JSON (how).
- Producing the correct final answer using the tool output.
-
Below are two trajectories demonstrating asymmetry.
Trajectory A: Imperfect but Reasonable Exploration
- When decision correct \(\rightarrow\) +1.0
- Which tool wrong \(\rightarrow\) −0.5
- JSON syntax valid \(\rightarrow\) +0.5
- Tool executes (but irrelevant) \(\rightarrow\) 0
- Final answer wrong \(\rightarrow\) −0.5
- Total reward:
- Even though the overall answer is wrong, the trajectory gets a small positive reward because several subcomponents were correct. This prevents the model from concluding that tool use is too risky.
Trajectory B: Full Correct Behavior
- Correct when \(\rightarrow\) +1.0
- Correct which \(\rightarrow\) +1.5
- Correct JSON arguments \(\rightarrow\) +1.0
- Successful tool execution \(\rightarrow\) +1.0
- Correct final answer \(\rightarrow\) +10.0
- Total reward:
- The tremendous difference between +14.5 and +0.5 clearly guides PPO/GRPO toward producing the full correct behavior.
How Asymmetry Stabilizes PPO/GRPO
- Advantages are computed via:
-
With asymmetric rewards:
- Failed trajectories receive slightly negative or slightly positive returns.
- Successful trajectories receive large positive returns.
- Advantage variance stays manageable.
- Exploration does not collapse into “never call tools.”
- The policy improves steadily across “when / which / how” dimensions.
-
If rewards were symmetric (e.g., +10 vs. −10), then most exploratory episodes would produce extreme negative advantages, instantly pushing the model toward refusing all tool calls. Asymmetry prevents this collapse.
Takeaways
-
Asymmetric rewards are essential for training LLM tool-calling policies because they:
- Preserve exploration.
- Deliver stable gradients for PPO/GRPO.
- Avoid trivial degenerate strategies.
- Properly balance shaping rewards (for “when / which / how”) with outcome-level rewards.
- Distinguish partial correctness from catastrophic failure.
- Encourage correct final answers without over-penalizing small mistakes.
-
The reward table and examples above provide a practical blueprint for implementing and tuning asymmetric rewards in your own RL tool-calling system.
RL Optimization Pipeline: Shared Flow + PPO vs. GRPO
- This section describes how to take the unified reward from Section 3 and plug it into a full reinforcement learning (RL) pipeline—including both Proximal Policy Optimization (PPO) by Schulman et al., 2017 and Group Relative Policy Optimization (GRPO) by Shao et al., 2024. We present first the shared components, then algorithm‐specific losses and update rules.
- A detailed discourse of preference optimization algorithms is available in the Preference Optimization primer.
Shared RL Training Flow
-
Rollout Generation:
- Use the policy \(\pi_\theta\) (based on the LLM) to interact with the tool‐calling environment defined in Section 2.
- At each step \(t\) you have state \(s_t\), select action \(a_t\) (
CALLtool orANSWER), observe next state \(s_{t+1}\), and receive scalar reward \(r_t\) (from the unified reward). - Repeat until terminal (ANSWER) or maximum steps \(T\).
- Collect trajectories \(\tau = {(s_0,a_0,r_0),\dots,(s_{T-1},a_{T-1},r_{T-1}), (s_T)}\).
-
Return and Advantage Estimation:
-
Compute discounted return:
\[R_t = \sum_{k=t}^{T} \gamma^{k-t} , r_k\] -
Estimate value baseline \(V_\psi(s_t)\) (for PPO) or compute group‐relative statistics (for GRPO).
-
Advantage (for PPO):
\[A_t = R_t - V_\psi(s_t)\]-
Use Generalized Advantage Estimation (GAE) if desired (as typically done in PPO):
\[A_t^{(\lambda)} = \sum_{l=0}^{\infty} (\gamma\lambda)^l \delta_{t+l}, \quad \delta_t = r_t + \gamma V_\psi(s_{t+1}) - V_\psi(s_t)\]
-
-
-
-
Policy Update:
- Use a surrogate objective (dependent on algorithm) to update θ (policy), and update value parameters ψ where needed.
- Optionally include a KL-penalty or clipping to ensure policy stability.
-
Repeat:
- Collect new rollouts, update, evaluate. Monitor metrics such as tool‐call decision accuracy (“when”), correct tool selection (“which”), argument correctness (“how”), and final task success.
PPO: Losses and Update Rules
Surrogate Objective
- For PPO the objective is using clipped surrogate:
- where:
- … and \(\epsilon \approx 0.1-0.3\).
Value Loss
\[L_{\rm value}(\psi) = \mathbb{E}_{s_t\sim\pi} \big[ (V_{\psi}(s_t) - R_t)^2 \big]\]KL/Entropy Penalty
- Often a term is added:
- … to keep the policy close to either the old policy or a reference SFT policy.
Full PPO Loss
\[L^{\rm total}_{\rm PPO} = -L^{\rm PPO}(\theta) + c_v,L_{\rm value}(\psi) + c_{\rm KL},L_{\rm KL}(\theta)\]- … with coefficients \(c_v, c_{\rm KL}\).
Implementation Notes
- Use mini-batches and multiple epochs per rollout.
- Shuffle trajectories, apply Adam optimizer.
- Clip gradients; log metrics for tool decisions and argument quality.
GRPO: Losses and Update Rules
Group Sampling & Relative Advantage
- In GRPO [Shao et al., 2024] you sample a group of \(G\) actions \((a_1,\dots,a_G)\) under the same state \(s\). Compute each reward \(r(s,a_j)\). Then define group mean and standard deviation: \(\mu,\sigma\). Advantage for each is:
GRPO Surrogate
\[L^{\rm GRPO}(\theta) = \frac{1}{G} \sum_{j=1}^G \mathbb{E}_{s,a_{1:G}\sim\pi_{\theta_{\rm old}}} \Big[ \min \big( r_{j}(\theta)A^{\rm GRPO}(s,a_j), \mathrm{clip}(r_{j}(\theta),1-\epsilon,1+\epsilon)A^{\rm GRPO}(s,a_j) \big) \Big]\]- … with the same ratio definition \(r_j(\theta)=\pi_\theta(a_j \mid s)/\pi_{\theta_{\rm old}}(a_j\mid s)\).
Value Loss
- GRPO typically omits a parametric value estimator—baseline derived via group statistics.
KL/Entropy Penalty
- Same form as in PPO if desired.
Full GRPO Loss
\[L^{\rm total}_{\rm GRPO} = -L^{\rm GRPO}(\theta) + c_{\rm KL} L_{\rm KL}(\theta)\]Implementation Notes
- At each state draw multiple candidate tool/answer actions, compute rewards, form group.
- This is particularly suited for LLM tool-calling contexts where you can generate multiple alternate completions.
- GRPO reduces reliance on value network.
Integrating the Unified Reward
- Given the unified reward \(R\) from the prior step, each step’s \(r_t\) is used in return and advantage estimation. The policy thus simultaneously learns “when/which/how” tool calling by maximizing return:
- Both PPO and GRPO approximate gradient ascent on \(J(\theta)\) under stability constraints.
Curriculum Design, Evaluation Strategy, and Diagnostics for Tool-Calling RL
- This section describes how to structure training so the model reliably learns when, which, and how to call tools, and how to evaluate progress during RL. Curriculum design is crucial because tool-calling is a hierarchical skill; introducing complexity too early destabilizes learning, and introducing it too late yields underfitting.
Curriculum Design Overview
-
Curriculum design gradually increases difficulty along three axes:
- When \(\rightarrow\) recognizing tool necessity vs. non-necessity
- Which \(\rightarrow\) selecting the correct tool
- How \(\rightarrow\) providing high-quality arguments
-
Each axis has its own progression. The curriculum alternates between breadth (many domains/tools) and depth (multi-step workflows).
-
This staged approach mirrors the structured curricula seen in code-generation RL (e.g., unit-tests \(\rightarrow\) multi-step tasks) in works like Self-Refine by Madaan et al. (2023).
Stage 0: Pure Supervised Bootstrapping (SFT)
-
Before RL begins, do supervised fine-tuning on a dataset that explicitly includes:
- Examples requiring a tool,
- Examples that must not use a tool,
- Examples mapping queries to correct tool types,
- Examples showing valid argument formats.
-
The SFT initializes:
- An approximately correct “when \(\rightarrow\) which \(\rightarrow\) how” policy,
- JSON formatting reliability,
- Stable tool-calling syntax.
-
This prevents “flailing” during early RL where the model might emit random tool calls.
Stage 1: Binary Decision Curriculum (Learning When)
-
Focus: detect whether a tool is required.
-
Task mix:
- 50% queries that require a specific tool (weather/math/search)
- 50% queries that must be answered without tools
-
Goal: learn the call/no-call boundary.
-
Metrics:
- Call precision
- Call recall
- False-positive rate (unnecessary calls)
- False-negative rate (missed calls)
-
Reward emphasis:
- Increase (w_{\text{call}})
- Reduce penalties for syntax/execution errors early on
Stage 2: Tool-Selection Curriculum (Learning Which)
-
Add tasks that require choosing between tools:
-
Task examples:
- Weather vs. news
- Search vs. calculator
- Translation vs. summarization (if tools exist)
Goal: learn discriminative mapping from task intent \(\rightarrow\) tool identity.
-
Curriculum trick:
- For ambiguous queries, include diverse examples so the RL agent learns to think (internal chain-of-thought) before issuing tool calls.
-
Metrics:
- Tool-selection accuracy
- Confusion matrix across tool categories
- Average number of tool attempts per query
-
Reward emphasis:
- Shift weight from (w_{\text{call}}) \(\rightarrow\) (w_{\text{which}})
- Introduce penalties for repeated incorrect tool choices
Stage 3: Argument-Construction Curriculum (Learning How)
-
Introduce tasks with argument complexity:
-
Task examples:
- Weather(city, date)
- Maps(location, radius)
- Calculation(expressions with multiple steps)
- API requiring nested JSON fields
-
Training strategy:
- Start with minimal arguments (one field)
- Add multi-argument calls
- Introduce noisy contexts (typos, ambiguity)
-
Metrics:
- Argument correctness (string similarity or numeric error)
- Schema completeness
- Tool execution success rate
-
Reward emphasis:
- Increase \(w_{\text{args}}\)
- Tighten penalty for malformed JSON or missing fields
-
Stage 4: Multi-Step Tool Use (Pipelines)
-
Introduce tasks requiring multiple sequential tool calls, e.g.:
- Search for restaurants
- Get the address
- Query weather at that address
- Produce a combined answer
-
Here the agent must plan sequences and must choose when to stop calling tools.
-
Metrics:
- Number of steps per episode
- Optimality of tool sequence
- Rate of premature or redundant tool calls
-
Reward emphasis:
- Add step penalties
- Strengthen outcome reward since multi-step tasks dominate final task success
Stage 5: Open-Domain Free-Form Tasks
-
Finally, mix in diverse real-world questions with unconstrained natural-language variety.
-
Goal: produce a robust “universal” tool-use agent.
-
Metrics:
- Overall episodic return
- Win-rate vs. evaluator models (LLM-as-a-Judge)
- Human preference win-rate
- Task success accuracy in open benchmarks
Diagnostics and Monitoring
Process-Level Metrics
-
Aligned with the when \(\rightarrow\) which \(\rightarrow\) how decomposition:
-
When:
- Call precision/recall
- Unnecessary call rate
- Missed call rate
- Call timing consistency
-
Which:
- Tool selection accuracy
- Error matrix across tools
- Repeated incorrect tool selection episodes
-
How:
- Argument correctness scores
- JSON validity rate
- Execution success rate
-
Outcome-Level Metrics
-
Final answer accuracy:
- Exact match
- Tolerance-based match
- Semantic similarity
- Pass rate vs. LLM-judge (DeepSeek-V3, GPT-4, etc.)
-
Task efficiency:
- Number of steps per solved task
- Number of tool calls per successful episode
- Reward per timestep
-
User-facing metrics:
- Latency per episode
- Number of external API calls
Detecting Skill Collapse
-
Red flags include:
- Spike in JSON errors \(\rightarrow\) syntax collapse
- Rising unnecessary tool use \(\rightarrow\) call collapse
- Tool-selection deterioration \(\rightarrow\) “which” collapse
- Rising tool execution failures \(\rightarrow\) argument collapse
- Flat final-task accuracy \(\rightarrow\) plateau due to overfitting on shaping rewards
-
Solutions:
- Adjust reward weights \(w_{\cdot}\)
- Reintroduce supervised examples
- Increase entropy regularization
- Add KL penalties to keep model close to reference
Curriculum Scheduling (Putting It All Together)
-
A typical recipe:
- Stage 0 (SFT): 30k–200k examples
- Stage 1 (When): 1–5 RL epochs
- Stage 2 (Which): 3–10 RL epochs
- Stage 3 (How): 5–20 RL epochs
- Stage 4 (Pipelines): 10–30 RL epochs
- Stage 5 (Open-domain): continuous RL/adaptation
-
Dynamic curriculum: shift task sampling probabilities based on evaluation metrics—for example, increase argument-focused tasks if argument correctness stagnates.
Final Note
-
A well-designed curriculum ensures the policy does not simply memorize tool-call structures but truly internalizes:
- when tool use is warranted,
- which tool to call,
- how to call it correctly,
- … and how to combine tools into multi-step workflows to solve real tasks.
Reinforcement Learning and the Emergence of Intelligent Agents
-
With the rise of Large Language Models (LLMs) and multimodal foundation models, RL has become a critical mechanism for developing autonomous, reasoning-capable agents. Early efforts demonstrated that LLMs could act as agents that browse the web, search for information, and perform tasks by issuing actions and interpreting observations.
- One of the first large-scale examples was WebGPT by Nakano et al. (2022), which extended GPT-3 to operate in a simulated text-based browsing environment. The model was trained through a combination of imitation learning and reinforcement learning from human feedback (RLHF).
- WebGPT introduced a text-based web interface where the model interacts via discrete commands such as Search, Click, Quote, Scroll, and Back, using the Bing Search API as its backend. Human demonstrators first generated browsing traces that the model imitated through behavior cloning, after which it was fine-tuned via PPO against a reward model trained on human preference data. The reward model predicted human judgments of factual accuracy, coherence, and overall usefulness.
- Each browsing session ended when the model issued “End: Answer,” triggering a synthesis phase where it composed a long-form response using the collected references. The RL objective included both a terminal reward from the reward model and a per-token KL penalty to maintain policy stability. Empirically, the best 175B “best-of-64” WebGPT model achieved human-preference rates of 56% over human demonstrators and 69% over Reddit reference answers, showing the success of combining structured tool use with RLHF.
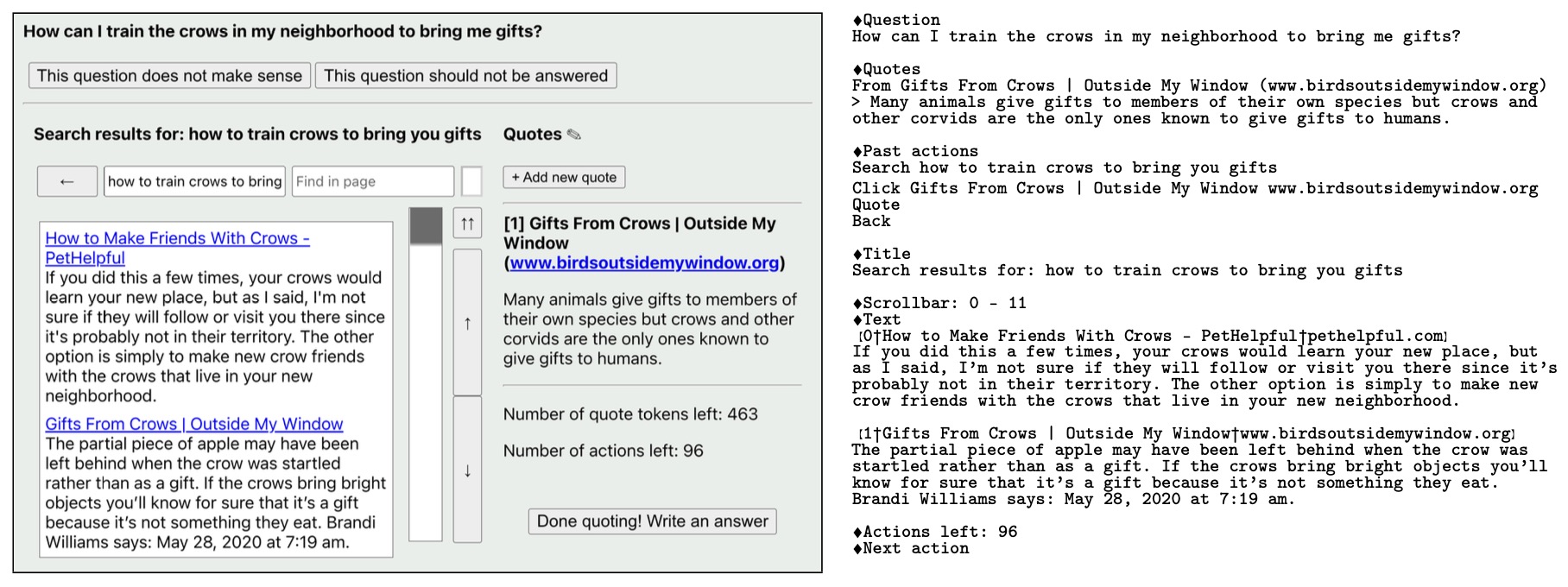
- The following figure (source) shows the text-based browsing interface used in WebGPT, where the model issues structured commands to retrieve and quote evidence during question answering.
- Subsequent systems expanded these capabilities. Agent Q by Putta et al. (2024) introduced a hybrid RL pipeline that integrates Monte Carlo Tree Search (MCTS) with Direct Preference Optimization (DPO).
- Agent Q formalizes decision making as a reasoning tree, where each node represents a thought–action pair and edges correspond to plausible continuations. MCTS explores multiple reasoning branches guided by a value model estimating downstream reward. During training, preference data between trajectories is used to train a DPO objective, directly optimizing the policy toward preferred rollouts without relying on an explicit reward scalar.
- This setup enables off-policy reuse of exploratory trajectories: the model learns from both successes and failures by evaluating them through a learned preference model. Empirically, this led to substantial gains in reasoning depth and factual accuracy across multi-step question answering benchmarks, demonstrating that structured search and preference-based policy updates can yield stronger reasoning alignment than gradient-only PPO approaches.
-
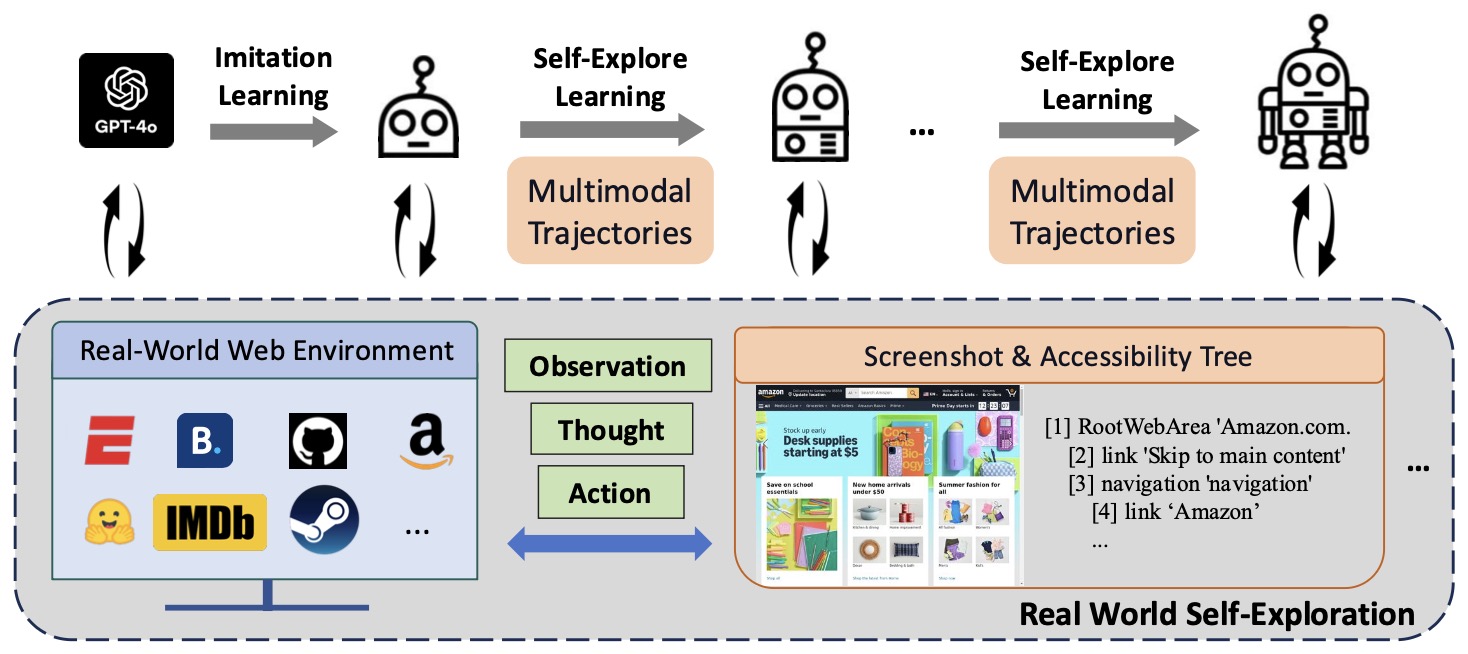
More recent advancements such as OpenWebVoyager by He et al. (2024) brought these ideas into the multimodal realm. OpenWebVoyager extends open-source multimodal models (Idefics2-8B-Instruct) to perform real-world web navigation using both textual accessibility trees and visual screenshots. The training process unfolds in two phases:
-
Imitation Learning (IL): The model first learns from expert trajectories collected with GPT-4o via the WebVoyager-4o system. Each trajectory contains sequences of thoughts and actions derived from multimodal observations (screenshot + accessibility tree). The IL objective jointly maximizes the log-likelihood of both action and reasoning token sequences:
\[J_{IL}(\theta) = E_{(q,\tau)\sim D_{IL}} \sum_t [\log \pi_\theta(a_t|q,c_t) + \log \pi_\theta(h_t|q,c_t)]\] -
Exploration–Feedback–Optimization Cycles: After imitation, the agent autonomously explores the open web, generating new trajectories. GPT-4o then acts as an automatic evaluator, labeling successful trajectories that are retained for fine-tuning. Each cycle introduces newly synthesized tasks using the Self-Instruct framework, ensuring continuous policy improvement. Iteratively, the task success rate improves from 19.9% to 25.8% on WebVoyager test sets and from 6.3% to 19.6% on cross-domain Mind2Web tasks.
- The following figure (source) shows the overall process of OpenWebVoyager, including the Imitation Learning phase and the exploration–feedback–optimization cycles.
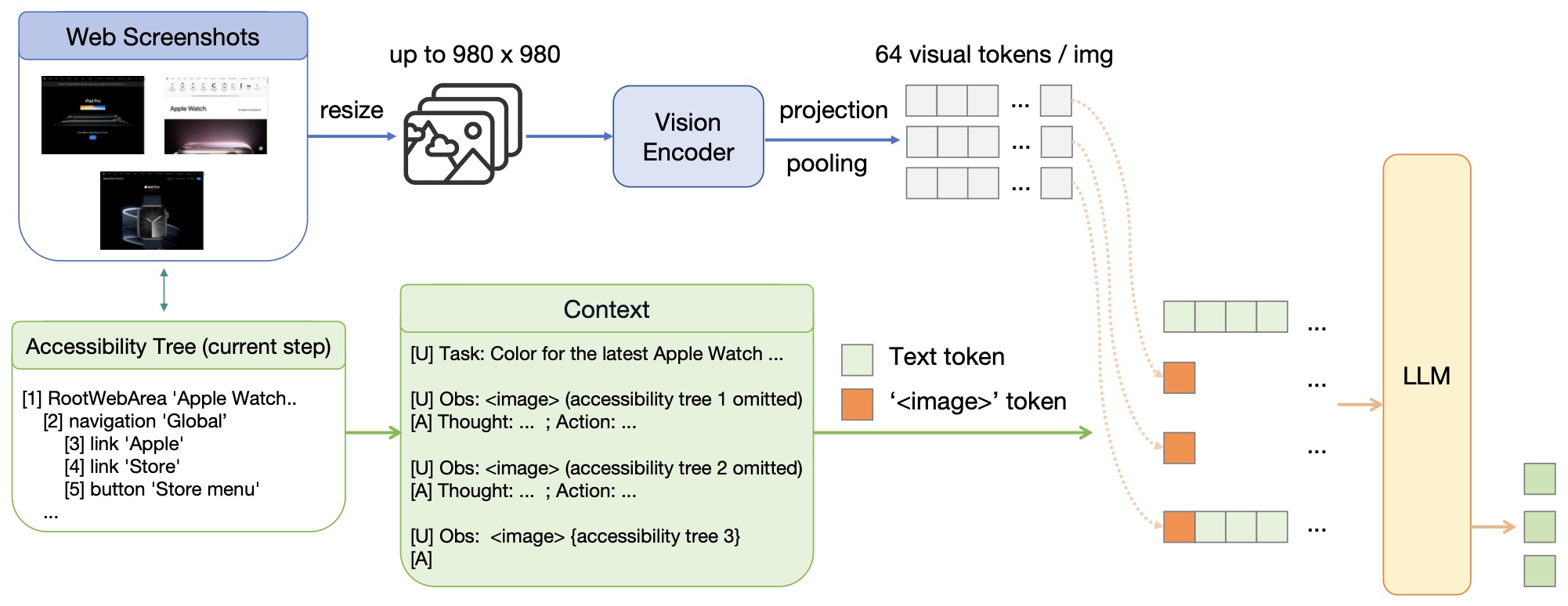
- The following figure (source) shows the model architecture of OpenWebVoyager. The system uses the most recent three screenshots and the current accessibility tree to guide multimodal reasoning, ensuring temporal grounding across page transitions.
-
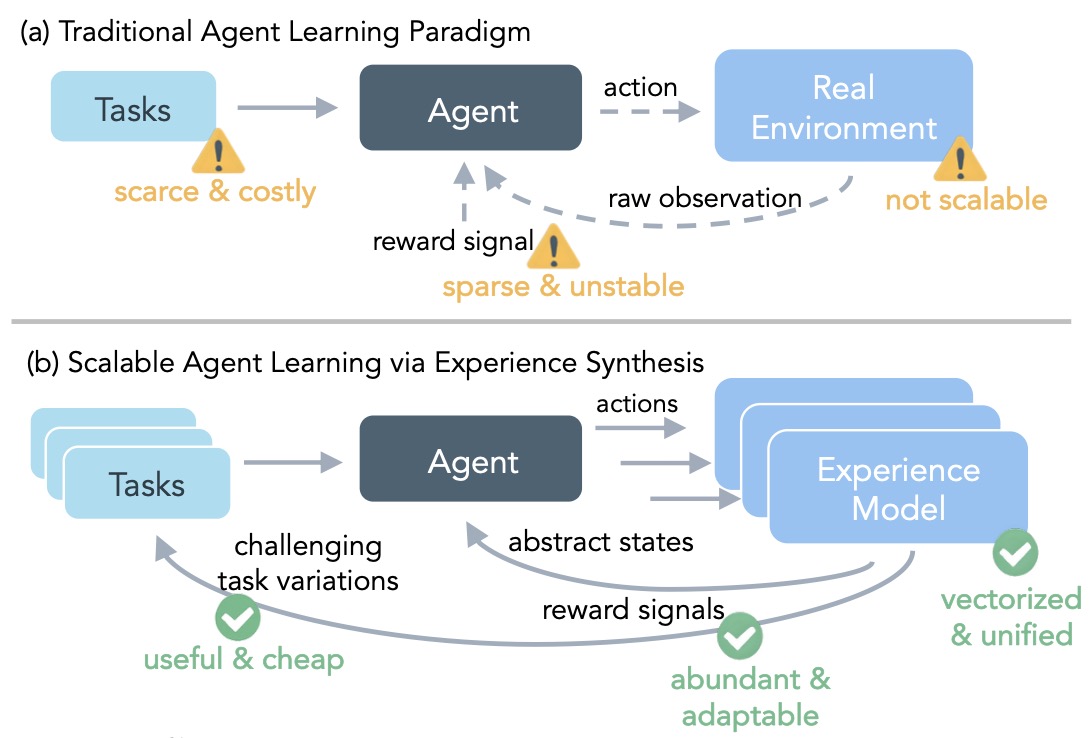
- Alongside real-environment exploration, a complementary approach is to scale policy learning with synthetic but reasoning-grounded interaction data. DreamGym, proposed in (Scaling Agent Learning via Experience Synthesis by Chen et al. (2025)), formalizes this by training a reasoning-based experience model that serves as both a generative teacher and an adaptive simulator. This model produces synthetic task curricula and consistent next-state transitions, enabling closed-loop reinforcement learning at scale.
- The framework introduces experience synthesis as a core principle—training a language-conditioned simulator capable of generating realistic interaction traces that preserve reasoning consistency and causal coherence. By jointly optimizing the policy and the experience model under trust-region constraints, DreamGym maintains stability and theoretical convergence guarantees: if the model error and reward mismatch remain bounded, improvements in the synthetic domain provably transfer to real-environment performance.
- The result is a unified infrastructure that decouples exploration (handled by the experience model) from policy optimization, dramatically reducing real-environment sample costs while preserving fidelity in reasoning tasks. Empirically, DreamGym demonstrates significant gains in multi-tool reasoning, long-horizon planning, and web navigation.
- The following figure illustrates that compared to the traditional agent learning paradigm, DreamGym provides the first scalable and effective RL framework with unified infrastructure.
- Early Experience, proposed in (Agent Learning via Early Experience by Zhang et al. (2025)), establishes a two-stage curriculum—implicit world modeling and self-reflection over alternative actions—that uses only language-native supervision extracted from the agent’s own exploratory branches, before any reward modeling or PPO/GRPO.
- The first stage, implicit world modeling, trains the agent to predict environmental dynamics and next states, effectively learning the structure of interaction without any external reward. The second stage, self-reflection, asks the agent to introspectively compare expert and non-expert behaviors, generating rationale-based preferences that bootstrap value alignment.
- These objectives serve as pre-RL signals that warm-start the policy, leading to faster and more stable convergence once reinforcement learning begins. In empirical evaluations, the Early Experience framework significantly improves downstream success rates across both web-based and software-agent benchmarks, and integrates seamlessly with later RL fine-tuning methods like PPO or GRPO.
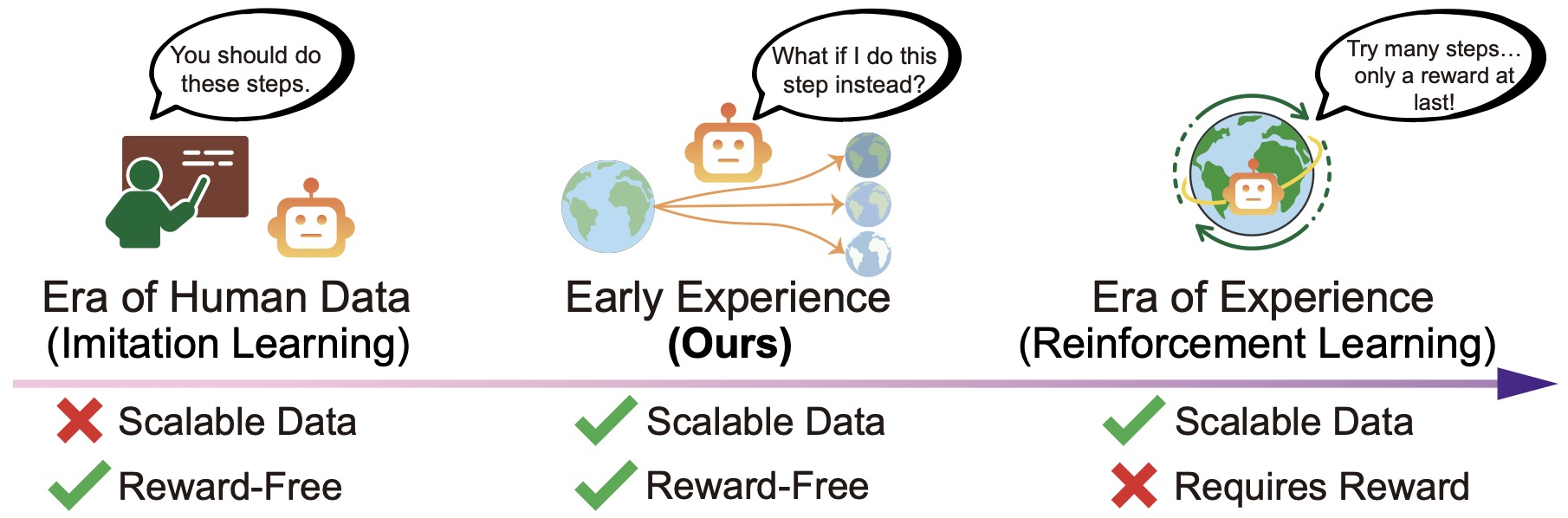
- The following figure shows the progression of training paradigms. (Left:) The Era of Human Data relies on expert demonstrations, where supervision comes from human-/expert-curated actions; it is reward-free (i.e., does not require the environment to provide verifiable reward) but not data-scalable. (Right:) The envisioned Era of Experience builds upon environments with verifiable rewards, using them as the primary supervision for reinforcement learning; however, many environments either lack such rewards (Xue et al., 2025) or require inefficient long-horizon rollouts (Xie et al., 2024a). Center: Our Early Experience paradigm enables agents to propose actions and collect the resulting future states, using them as a scalable and reward-free source of supervision
The Role of Reinforcement Learning in Self-Improving Agents
-
RL serves as the foundation of self-improving artificial agents. These agents do not depend solely on human-provided supervision; instead, they learn continuously from their own experiences.
-
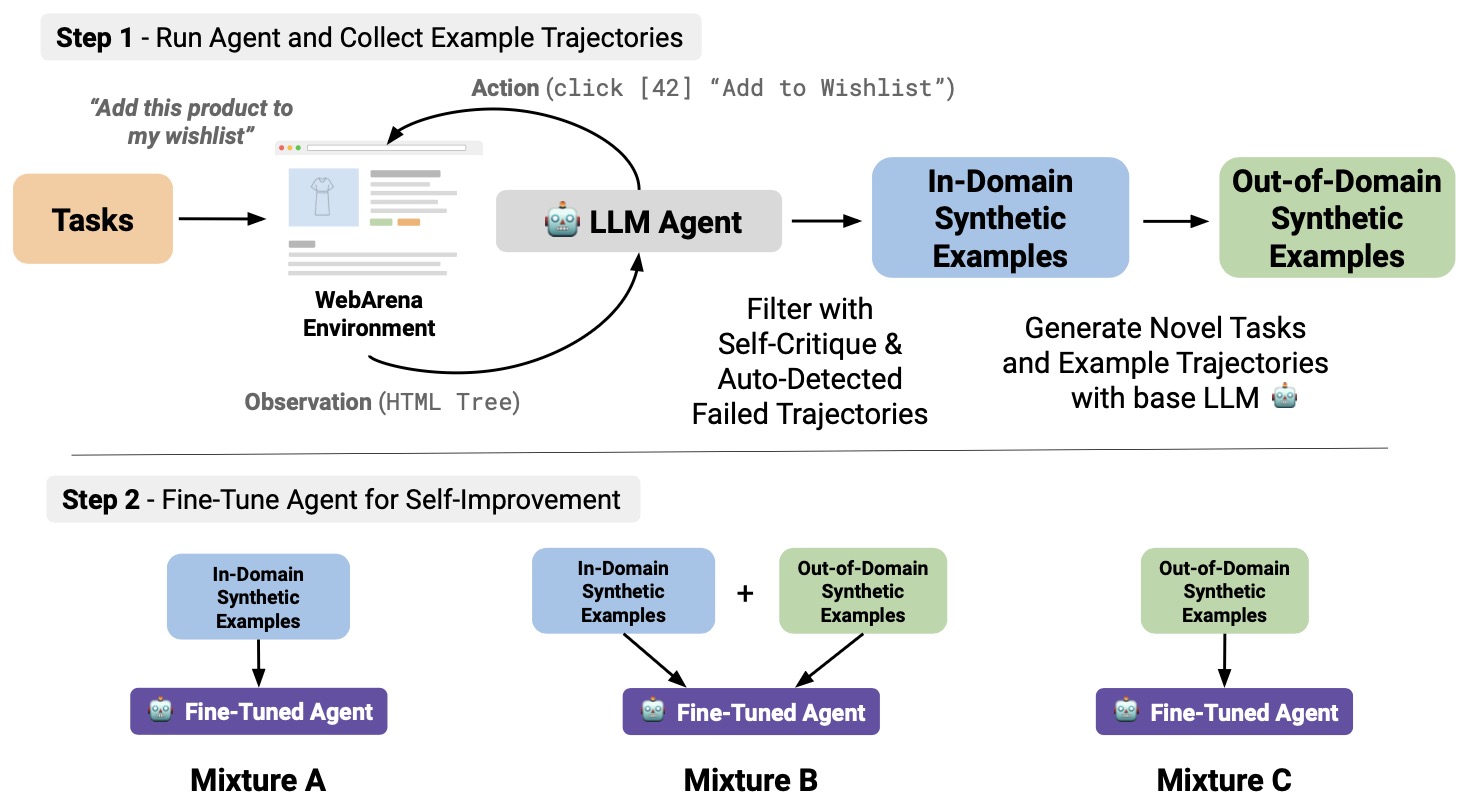
A representative example of this approach is Large Language Models Can Self-improve at Web Agent Tasks by Patel et al. (2024), which introduced a looped learning process where an agent repeatedly performs tasks, evaluates its own performance, and fine-tunes itself on the best results. In their experiments, agents improved their web-navigation success rates by over 30% without any additional human data, demonstrating that RL can bootstrap the agent’s progress over time.
-
The following figure shows (source) the self-improvement loop used in Patel et al. (2024), illustrating how the agent collects trajectories, filters low-quality outputs, fine-tunes itself, and iterates for continual improvement.
-
Synthetic-experience RL closes the loop for self-improving agents by letting a reasoning experience model synthesize adaptive rollouts and curricula matched to the current policy, yielding consistent gains in both synthetic and sim-to-real settings; theory further bounds the sim-to-real gap by reward-accuracy and domain-consistency errors, rather than strict pixel/state fidelity metrics (cf. Scaling Agent Learning via Experience Synthesis by Chen et al. (2025)).
-
This iterative process typically follows these stages:
- Data Collection: The agent generates task trajectories by interacting with the environment.
- Filtering and Evaluation: The system automatically assesses each trajectory, discarding low-quality samples.
- Fine-Tuning: The agent is retrained using successful examples, effectively reinforcing good behavior.
- Re-evaluation: The improved agent is tested, and the cycle repeats.
-
This form of continual self-improvement makes RL a key enabler for developing general-purpose, autonomous web and software agents.
Environments for Reinforcement Learning in Modern Agents
-
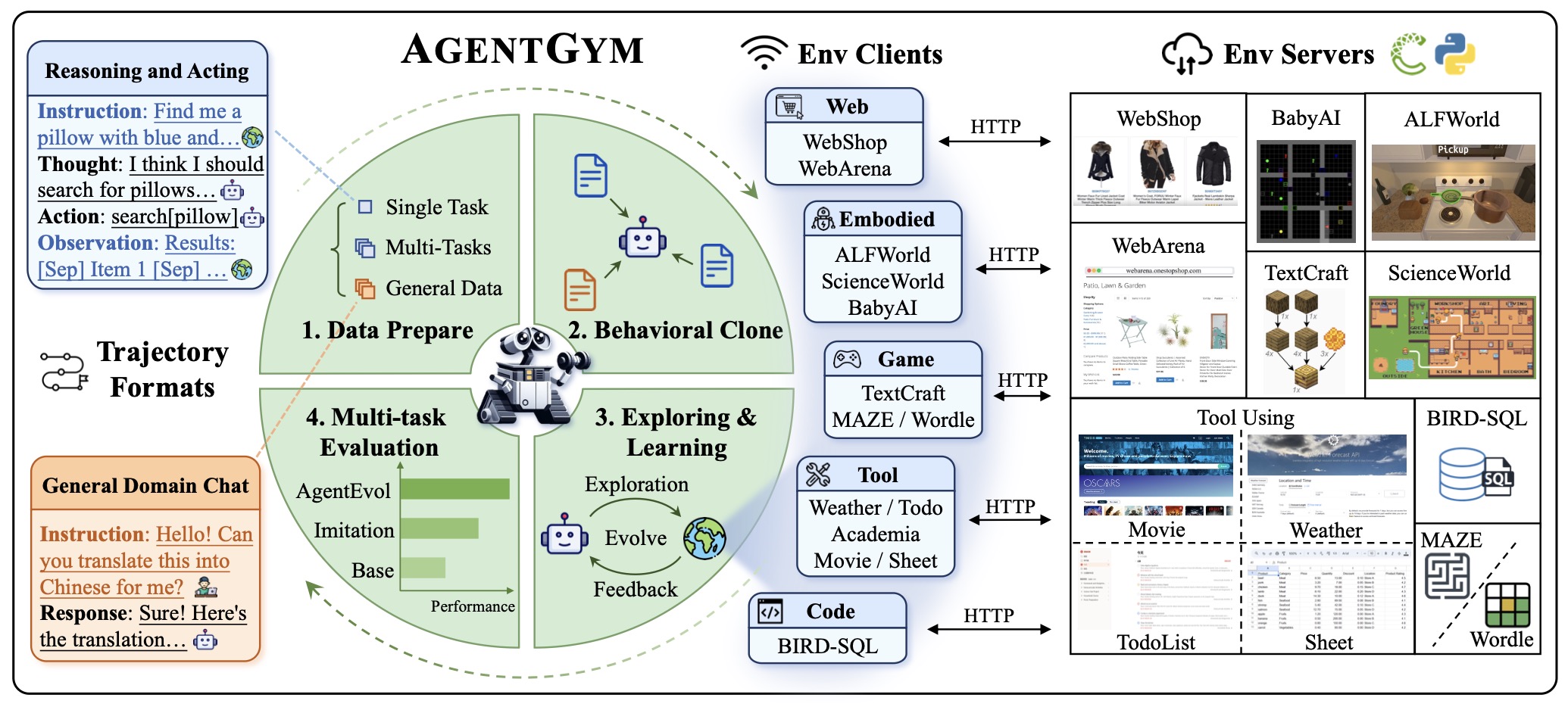
To support these learning processes, researchers have developed structured environments that simulate the complexity and variety of real-world digital interactions. One comprehensive framework is AgentGym by Xi et al. (2024), which defines a unified interface for training and evaluating LLM-based agents across 14 environment types—ranging from academic reasoning and games to embodied navigation and web interaction.
-
The following figure (source) shows the AgentGym framework, illustrating the standardized environment interface, modular design, and integration of various environment types for LLM-driven agent training.
-
In AgentGym, an agent’s experience is modeled as a trajectory consisting of repeated thought–action–observation cycles:
\[\tau = (h_1, a_1, o_1, ..., h_T, a_T) \sim \pi_\theta(\tau | e, u)\]- where \(h_t\) represents the agent’s internal reasoning (its “thought”), \(a_t\) the action it takes, \(o_t\) the resulting observation, and \(e, u\) the environment and user prompt respectively.
-
This approach bridges the symbolic reasoning capabilities of LLMs with the sequential decision-making framework of RL, forming the basis for modern interactive agents.
The Three Major Types of Reinforcement Learning Environments
- Modern RL environments for language-based and multimodal agents are generally organized into three broad categories. Each category captures a distinct interaction pattern and optimizes the agent for a different type of intelligence or capability.
Single-Turn Environments (SingleTurnEnv)
-
These environments are designed for tasks that require only a single input–output interaction, where the agent must produce one decisive response and then the environment resets. Examples include answering a question, solving a programming challenge, or completing a math problem.
-
In this setting, the reward signal directly evaluates the quality of the single output. Training methods usually combine supervised fine-tuning with RL from human or synthetic feedback (RLHF). For instance, in coding problems or reasoning benchmarks, the agent’s response can be automatically graded using execution correctness or symbolic validation. Such setups are ideal for optimizing precision and factual correctness in domains where each query is independent of the previous one.
-
SingleTurnEnv tasks are computationally efficient to train because there is no need to maintain long-term memory or context. They are commonly used to bootstrap an agent’s basic competencies before moving to more complex, multi-step environments.
Tool-Use Environments (ToolEnv)
-
Tool-use environments focus on enabling agents to perform reasoning and decision-making that involve invoking external tools—such as APIs, search engines, calculators, code interpreters, or databases—to complete a task. These environments simulate the agent’s ability to extend its cognitive boundaries by interacting with external systems.
-
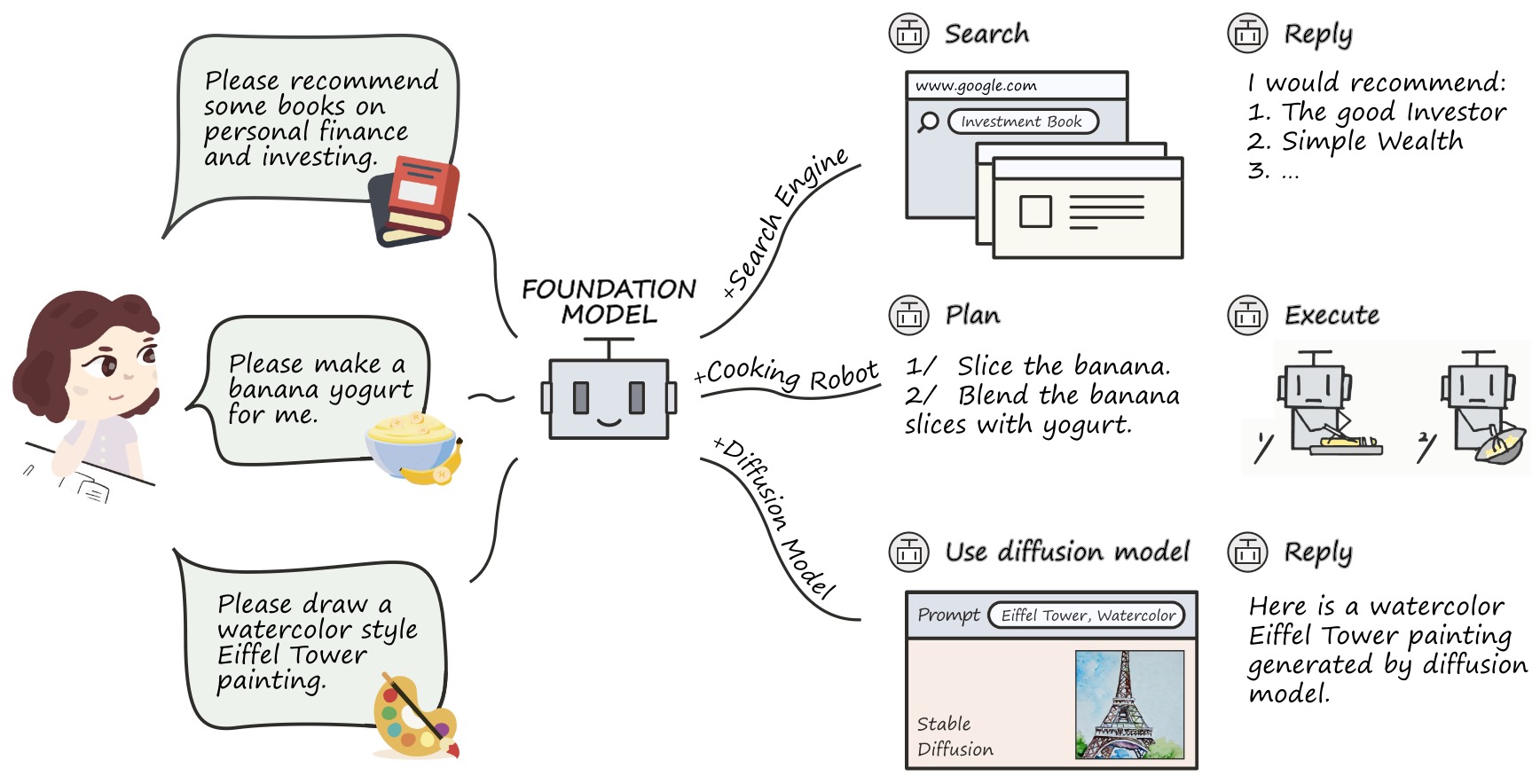
In Tool Learning with Foundation Models by Qin et al. (2024), the authors surveyed a wide range of approaches where foundation models learn to select, call, and integrate the outputs of external tools into their reasoning processes. This kind of training allows the model to perform symbolic computation, factual verification, and data retrieval in ways that pure text-based reasoning cannot.
-
The following figure shows (source) the conceptual overview of tool learning with foundation models, where models dynamically decide when and how to invoke tools such as web search and other APIs to solve complex problems.
-
A related innovation is Tool-Augmented Reward Modeling by Li et al. (2024), which enhanced RL reward models by giving them access to external APIs such as search engines or translation systems. This modification made reward models not only more accurate but also more interpretable, as each decision could be traced through explicit tool calls.
-
The following figure (source) shows illustrates the pipeline of (a) Vanilla reward models (RMs); (b) Tool-augmented RMs, namely Themis; (c) RL via proximal policy optimization (PPO) on above RMs; (d) Examples of single or multiple tool use process in the proposed approach.

- Tool-use environments test the agent’s ability to decide when and how to use a tool, what input arguments to provide, and how to interpret the returned results. This capability is crucial for building practical software assistants and web agents that interact with real systems.
Multi-Turn, Sequential Environments (MultiTurnEnv)
-
Multi-turn environments represent the most complex and realistic category of RL settings. In these environments, an agent engages in extended, multi-step interactions where each decision depends on the evolving context and memory of previous steps. Examples include navigating a website, writing and revising code iteratively, managing files on a computer, or executing multi-phase workflows such as online booking or document editing.
-
Agents operating in these environments must reason about long-term goals, plan multiple actions in sequence, and interpret feedback dynamically. Systems such as WebArena, WebShop, Agent Q by Putta et al. (2024), and OpenWebVoyager by He et al. (2024) exemplify this paradigm. They train agents through multi-step RL using trajectory-based feedback, where each complete sequence of actions and observations contributes to the learning signal.
-
These environments are optimized for developing autonomy and adaptability. The agent must not only predict the next best action but also understand how that action contributes to the overall task objective. MultiTurnEnv scenarios are thus the closest analogs to real-world usage, making them essential for training general-purpose digital agents.
Implications
-
Agentic RL, which is the evolution of RL for agents—from single-turn tasks to tool-augmented reasoning and complex multi-turn workflows—reflects a progressive layering of capabilities. Each environment type plays a distinct role:
- Single-turn environments emphasize accuracy and efficiency, teaching agents to produce correct, concise responses.
- Tool-use environments focus on functional reasoning and integration, giving agents the ability to extend their knowledge through computation and external APIs.
- Multi-turn environments train autonomy and planning, enabling agents to navigate, adapt, and make decisions across extended sequences of interactions.
-
Together, these environments form the backbone of modern RL for LLM-based and multimodal agents. They provide a structured pathway for training models that can perceive, reason, and act—bringing us closer to general-purpose artificial intelligence capable of performing diverse tasks in real-world digital environments.
Reinforcement Learning for Web and Computer-Use Agents
- A detailed discourse on RL can be found in our Reinforcement Learning primer.
Background: Policy-Based and Value-Based Methods
-
At its core, RL employs two broad families of algorithmic approaches:
- Value-based methods, which learn a value function (e.g., \(Q(s,a)\) or \(V(s)\)) that estimates the expected return of taking action \(a\) in state \(s\) (or being in state \(s\)).
-
Policy-based (or actor-critic) methods, which directly parameterize a policy \(\pi_\theta(a \mid s)\) and optimize its parameters \(\theta\) to maximize expected return
\[J(\pi_\theta) = \mathbb{E}_{\tau\sim\pi_\theta}\left[\sum_{t=0}^T \gamma^t R(s_t,a_t)\right]\]
-
In modern agentic applications (web agents, computer-use agents), policy‐based methods tend to dominate because the action space is large, discrete (e.g., “click link”, “invoke API”, “enter code”), and policies must be expressive.
-
One widely used algorithm is Proximal Policy Optimization (PPO) Schulman et al. (2017), which introduces a clipped surrogate objective to ensure stable updates and avoid large shifts in policy space.
-
The surrogate objective can be expressed as:
\[L^{\rm CLIP}(\theta) = \mathbb{E}_{s,a\sim\pi_{\theta_{\rm old}}}\left[ \min\left( r_t(\theta) A_t, \mathrm{clip}(r_t(\theta),1-\epsilon,1+\epsilon) A_t \right) \right]\]- where \(r_t(\theta)=\frac{\pi_\theta(a_t \mid s_t)}{\pi_{\theta_{\rm old}}(a_t \mid s_t)}\) and \(A_t\) is the advantage estimate at time \(t\).
-
This ensures that the policy update does not diverge too far from the previous one while still improving expected return.
Background: Process-Wise Rewards vs. Outcome-Based Rewards
-
When designing RL systems for digital agents, one of the most consequential design choices lies in how rewards are provided to the model.
-
Outcome-based rewards give feedback only at the end of a task—for instance, a success/failure score after the agent completes a booking or answers a question. This is common in SingleTurnEnv tasks and short workflows, where each interaction produces a single measurable outcome.
- While simple, outcome-based rewards are sparse, often forcing the agent to explore many possibilities before discovering actions that yield high return.
-
Process-wise (step-wise) rewards, in contrast, provide incremental feedback during the task. In a web-navigation scenario, for example, the agent might receive positive reward for successfully clicking the correct link, partially filling a form, or retrieving relevant information—even before the final goal is achieved.
- This approach is critical in MultiTurnEnv or ToolEnv setups where tasks span many steps. By assigning intermediate rewards, process-wise systems promote shaped learning—accelerating convergence and improving interpretability of the agent’s learning process.
-
Formally, if an episode runs for \(T\) steps, the total return under step-wise rewards is:
\[R_t = \sum_{k=t}^{T} \gamma^{k-t}r_k\]- where \(r_k\) are per-step rewards. In outcome-based schemes, \(r_k = 0\) for all \(k<T\), and \(r_T\) encodes task success. Choosing between these schemes depends on the environment’s complexity and availability of fine-grained performance metrics.
-
For web agents, hybrid strategies are often used: process-wise signals derived from browser state (e.g., correct navigation, reduced error rate) combined with final outcome rewards (task completion). This hybridization reduces the high variance of pure outcome-based rewards while preserving the integrity of long-horizon objectives.
Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO)
-
For web/computer-use agents built on LLMs or similar, one key method is RL from Human Feedback (RLHF). The standard RLHF pipeline is:
- Supervised fine-tune a base language model on prompt–response pairs.
- Collect human preference data: for each prompt, have humans rank multiple model responses (or choose preferred vs. non-preferred).
- Train a reward model \(r_\phi(x,y)\) to predict human preferences.
- Use an RL algorithm (often PPO) to optimize the policy \(\pi_\theta\) to maximise expected reward under the reward model, possibly adding KL-penalty to stay close to base model.
-
For example, the survey article Reinforcement Learning Enhanced LLMs: A Survey provides an overview of this field.
-
However, RLHF can be unstable, costly in compute, and sensitive to reward-model errors. Enter Direct Preference Optimization (DPO) Rafailov et al. (2023), which posits that one can skip the explicit reward model + RL loop and simply fine-tune the model directly to optimize human preference pairwise comparisons.
-
The DPO loss in the pairwise case (winner \(y_w\), loser \(y_l\)) is approximately:
\[\mathcal{L}_{\rm DPO} = -\mathbb{E}_{(x,y_w,y_l)}\left[ \ln \sigma\left(\beta \ln\frac{\pi_\theta(y_w|x)}{\pi_{\rm ref}(y_w|x)} - \beta \ln\frac{\pi_\theta(y_l|x)}{\pi_{\rm ref}(y_l \mid x)}\right) \right]\]- where \(\pi_{\rm ref}\) is the reference model (often the supervised fine-tuned model), and \(\beta\) is a temperature-like constant.
-
Some practical analyses (e.g., Is DPO Superior to PPO for LLM Alignment?) compare PPO vs. DPO in alignment tasks.
Why These Algorithms Matter for Web & Computer-Use Agents
-
When training agents that interact with the web or software systems (for example, clicking links, filling forms, issuing API calls), several factors make the choice of algorithm especially important:
- Action spaces are large and heterogeneous (e.g., browser UI actions, tool function calls).
- The reward signals may be sparse (e.g., task success only after many steps) or come from human annotation (in RLHF).
- Policies must remain stable and avoid drift (especially when built on pretrained LLMs).
- Computation cost is high (LLM inference, environment simulation), so sample efficiency matters.
-
Thus:
- Algorithms like PPO are well-suited because of their stability and simplicity (compared to e.g. TRPO) in high-dimensional policy spaces.
- RLHF/DPO are relevant because many web-agents and computer-agents are aligned to human goals (helpfulness, correctness, safety) rather than just raw reward.
- There is an increasing trend toward hybrid methods that combine search, planning (e.g., MCTS) plus RL fine-tuning for complex workflows.
Key Equations
Advantage estimation & value networks
-
In actor–critic variants (including PPO), we often learn a value function \(V_\psi(s)\) to reduce variance:
\[A_t = R_t - V_\psi(s_t) \quad R_t = \sum_{k=0}^{\infty} \gamma^k r_{t+k}\]-
where:
- \(A_t\): the advantage estimate at timestep \(t\), measuring how much better an action performed compared to the policy’s expected performance.
- \(R_t\): the discounted return, or the total expected future reward from time \(t\).
- \(\gamma\): the discount factor (\(0 < \gamma \le 1\)), controlling how much future rewards are valued compared to immediate ones.
- \(r_{t+k}\): the immediate reward received at step \(t+k\).
- \(V_\psi(s_t)\): the critic’s value estimate for state \(s_t\), parameterized by \(\psi\), representing the expected return from that state under the current policy.
-
-
The update for the critic aims to minimize:
\[L_{\rm value}(\psi) = \mathbb{E}_{s_t\sim\pi}\big[(V_\psi(s_t) - R_t)^2 \big]\]-
where:
- \(L_{\rm value}(\psi)\): the value loss, quantifying how far the critic’s predictions are from the actual returns.
- \(\mathbb{E}_{s_t\sim\pi}[\cdot]\): the expectation over states \(s_t\) sampled from the current policy (\pi).
- The squared term \((V_\psi(s_t) - R_t)^2\): penalizes inaccurate value predictions, guiding the critic to estimate returns more accurately.
-
KL-penalty / trust region
-
Some RLHF implementations add a penalty to keep the new policy close to the supervised model:
\[L_{\rm KL}(\theta) = \beta \cdot \mathbb{E}_{x,y\sim\pi}\left[ \log\frac{\pi_\theta(y|x)}{\pi_{\rm SFT}(y|x)} \right]\]-
where:
- \(L_{\rm KL}(\theta)\): the KL-divergence loss, which penalizes the new policy \(\pi_\theta\) if it deviates too far from the supervised fine-tuned (SFT) reference policy \(\pi_{\rm SFT}\).
- \(\beta\): a scaling coefficient controlling the strength of this regularization; larger \(\beta\) enforces tighter adherence to the reference model.
- \(\mathbb{E}_{x,y\sim\pi}[\cdot]\): the expectation over sampled input–output pairs from the current policy’s distribution.
- \(\pi_\theta(y \mid x)\): the current policy’s probability of generating output \(y\) given input \(x\).
- \(\pi_{\rm SFT}(y \mid x)\): the reference policy’s probability, often from the supervised model used before RL fine-tuning.
-
… so the total objective may combine PPO’s surrogate loss with this KL penalty (and possibly an entropy bonus) to balance exploration, stability, and fidelity to the base model.*
-
Preference Optimization (DPO)
- As shown above, DPO reframes alignment as maximising the probability that the fine-tuned model ranks preferred outputs higher than non-preferred ones, bypassing the explicit RL loop.
Sample efficiency & off-policy corrections
- For agents interacting with web or tools where running many episodes is costly, sample efficiency matters. Off-policy methods (e.g., experience replay) or offline RL variants (e.g., A Survey on Offline Reinforcement Learning by Kumar et al. (2022)) may become relevant.
Agentic Reinforcement Learning via Policy Optimization
-
In policy optimization, the agent learns from a unified reward function that draws its signal from one or more available sources—such as rule-based rewards, a scalar reward output from a learned reward model, or another model that is proficient at grading the task (such as an LLM-as-a-Judge). Each policy update seeks to maximize the expected cumulative return:
\[J(\theta) = \mathbb{E}_{\pi_\theta}\left[\sum_t \gamma^t r_t\right]\]- where \(r_t\) represents whichever reward signal is active for the current environment or training regime. In some settings, this may be a purely rule-based signal derived from measurable events (like navigation completions, form submissions, or file creations). In others, the reward may come from a trained model \(R_\phi(o_t, a_t, o_{t+1})\) that generalizes human preference data, or from an external proficient verifier (typically a larger model) such as an LLM-as-a-Judge.
-
These components are modular and optional—only one or several may be active at any time. The optimization loop remains identical regardless of source: the policy simply maximizes whichever scalar feedback \(r_t\) it receives. This flexible design allows the same framework to operate with deterministic, model-based, or semantic reward supervision, depending on task complexity, available annotations, and desired interpretability.
-
Rule-based rewards form the foundation of this framework, providing deterministic, auditable feedback grounded in explicit environment transitions and observable state changes. As demonstrated in DeepSeek-R1: Incentivizing Reasoning Capability in Large Language Models by Gao et al. (2025), rule-based rewards yield transparent and stable optimization signals that are resistant to reward hacking and reduce reliance on noisy human annotation. In the context of computer-use agents, rule-based mechanisms correspond directly to verifiable milestones in user interaction sequences—for example:
- In web navigation, detecting a URL transition, page load completion, or DOM state change (
NavigationCompleted,DOMContentLoaded). - In form interaction, observing DOM model deltas that indicate fields were populated, validation succeeded, or a “Submit” action triggered a confirmation dialog.
- In file handling/artifact generation, confirming the creation or modification of a file within the sandbox (e.g., registering successful exports such as
.csv,.pdf, or.pngoutputs following specific actions). - In application state transitions, monitoring focus changes, dialog closures, or process launches via OS accessibility APIs.
- In UI interaction success, verifying that a button, link, or menu item was activated and that the resulting accessibility tree or visual layout changed accordingly.
- These measurable indicators serve as the atomic verification layer of the reward system, ensuring that each environment step corresponds to reproducible, auditable progress signals without requiring human intervention.
- In web navigation, detecting a URL transition, page load completion, or DOM state change (
-
To generalize beyond fixed rules, a trainable reward model \(R_\phi(o_t, a_t, o_{t+1})\) can be introduced. This model is trained on human-labeled or preference-ranked trajectories, similar to the reward modeling stage in PPO-based RLHF pipelines. Once trained, \(R_\phi\) predicts scalar reward signals that approximate human preferences for unseen tasks or ambiguous states. It operates faster and more consistently than a generative LLM-as-a-Judge (which can be implemented as a Verifier Agent), while maintaining semantic fidelity to human supervision.
-
The three-tier reward hierarchy thus becomes:
- Rule-based rewards (preferred default): deterministic, event-driven, and auditable (no reward hacking).
- Learned, discriminative reward model (\(R_\phi\)): generalizes human feedback for subtle, unstructured, or context-dependent goals where rules are insufficient.
- Generative reward model (e.g., LLM-as-a-Judge): invoked only when both rule-based detectors and \(R_\phi\) cannot confidently score outcomes (e.g., for semantic reasoning, style alignment, or multimodal understanding). This is similar to how DeepSeek-R1 uses a generative reward model by feeding the ground-truth and model predictions into DeepSeek-V3 for judgment during the rejection sampling stage for reasoning data.
-
This architecture ensures that the primary training flow remains rule-grounded and verifiable, while allowing smooth fallback to preference-aligned modeling when necessary. The hybrid setup—selectively combining rule-based rewards, learned reward estimation, and verifier agent intervention—balances scalability, auditability, and semantic depth across diverse computer-use tasks.
-
During training, the reward selection and routing process is adaptive. When deterministic milestone detectors emit valid scores, they take precedence as the most reliable supervision. If the environment lacks such instrumentation, the learned model \(R_\phi\) dynamically provides substitute scalar feedback inferred from trajectory context. In the rare case that both mechanisms yield low confidence, the system escalates to the Verifier Agent for semantic adjudication. This cascading reward flow ensures the agent always receives a stable optimization signal—grounded when possible, inferred when necessary, and judged when ambiguity demands interpretive reasoning.
Milestone-Based Reward System
-
Any reward formulation—whether deterministic, learned, or model-evaluated—can be decomposed into a sequence of milestones or checkpoints that represent measurable progress toward the task goal. Each milestone corresponds to a verifiable state transition, UI event, or observable change in the environment, providing interpretable signals even within complex or hierarchical workflows. In practice, a reward function can therefore be a composite of multiple sources: rule-based rewards, scalar predictions from a learned, discriminative reward model, or a generative model that is proficient at grading the task, such as an LLM-as-a-Judge.
-
In general, rule-based rewards are preferred because they are deterministic, easy to verify, and resistant to reward hacking, consistent with the design principles demonstrated in the DeepSeek-R1 framework by Gao et al. (2025). These rewards are derived from concrete, environment-observable events—such as file creation, DOM or AX tree changes, navigation completions, or dialog confirmations—and can be validated directly through structured logs and system hooks. Their reproducibility and transparency make them ideal for large-scale, self-contained policy optimization loops, where interpretability and auditability are crucial.
-
In this system, the rule-based layer serves as the foundational signal generator for all common computer-use tasks. It captures events such as:
- File downloads or artifact creation
- Successful form submissions or dialog confirmations
- UI transitions, window focus changes, or navigation completions
- Text field population or data transfer between applications
-
Screenshot or state deltas indicating successful subgoal completion
- These reward components directly populate the tuple \((o_t, a_t, r_t, o_{t+1})\) used by the policy optimizer for learning stable, interpretable control policies. Each milestone event contributes either a discrete tick or a weighted scalar toward cumulative progress.
-
However, not all task goals can be described exhaustively through deterministic rules. To extend coverage, the architecture includes a learned reward model \(R_\phi(o_t, a_t, o_{t+1})\) trained specifically on human preferences or ranked trajectories.
- This model generalizes beyond hand-engineered events to score semantic correctness, contextual relevance, and user-aligned outcomes.
- \(R_\phi\) can be continuously fine-tuned as new preference data accumulates, adapting reward shaping dynamically to novel workflows or unseen UIs.
-
During training, the optimizer consumes a blended reward signal that can combine multiple sources:
\[\tilde{r}_t = \alpha r_t^{(\text{rule})} + \beta R_\phi(o_t, a_t, o_{t+1}) + \gamma r_t^{(\text{judge})}\]- where \(\alpha, \beta, \gamma \in [0,1]\) represent trust weights for deterministic, learned, and model-evaluated components respectively, with \(\alpha + \beta + \gamma = 1\).
-
In cases where both rule-based detectors and the learned reward model fail to provide a confident or interpretable score, a generative model (such as an LLM-as-a-Judge) may be selectively invoked. This verifier acts as a high-capacity, LLM-as-a-Judge module that semantically evaluates whether the observed trajectory satisfies implicit or fuzzy success criteria. Its role parallels that of a preference model but operates at runtime for difficult or open-ended cases.
-
Scenarios where rule-based and model-based scoring may be insufficient—and thus require a Verifier Agent—include:
- Subjective or semantic correctness: determining if a written summary or chart interpretation matches the instruction intent.
- Cross-context validation: verifying that data copied from a spreadsheet was correctly inserted into a report or email draft.
- Goal inference under ambiguity: tasks like “open the latest invoice,” where the target must be inferred dynamically.
- Complex recovery handling: identifying whether the system has correctly recovered from an unintended dialog or misclick.
- Language or multimodal alignment: verifying tone, structure, or layout across applications.
-
The reward system hierarchy therefore consists of three complementary and optionally composable layers:
-
Rule-based rewards: deterministic, verifiable, and fully auditable signals derived from concrete milestones (default and preferred).
-
Learned, discriminative reward model (\(R_\phi\)): trained on human preferences to generalize beyond explicit rules and produce scalar feedback for unstructured tasks.
-
Generative reward model (e.g., LLM-as-a-Judge): semantic fallback for nuanced, subjective, or multimodal evaluation where neither rules nor learned models suffice. This is similar to how DeepSeek-R1 uses a generative reward model by feeding the ground-truth and model predictions into DeepSeek-V3 for judgment during the rejection sampling stage for reasoning data.
-
-
Together, these layers enable robust, explainable, and modular reward shaping. Any reward function within the system can thus be expressed as a milestone-weighted combination of deterministic, learned, and interpretive components—ensuring scalability, transparency, and semantic alignment across all computer-use reinforcement learning setups.
Example Milestones by Task Category
-
Web Navigation and Data Extraction
- Milestone: Target URL loaded successfully (
NavigationCompletedevent). Reward: +0.25 - Milestone: Element with specific role/name detected (e.g., “Reports Table” or “Dashboard Summary”). Reward: +0.25
- Milestone: Successful data scrape or DOM text retrieval logged. Reward: +0.5
- Milestone: Target URL loaded successfully (
-
Form Interaction
- Milestone: Input field focused and filled (text pattern matched). Reward: +0.2
- Milestone: Submit button clicked and confirmation dialog appears. Reward: +0.3
- Milestone: Success banner or confirmation element detected. Reward: +0.5
-
File Handling and Downloads
- Milestone: File creation event observed in
/Downloads. Reward: +1.0 - Milestone: File hash or extension matches expectation (e.g.,
.csv,.pdf). Reward: +0.5 - Milestone: Directory updated without error. Reward: +0.25
- Milestone: File creation event observed in
-
Email or Document Workflows
- Milestone: Email editor loaded and populated with recipient and subject. Reward: +0.25
- Milestone: Attachment successfully added. Reward: +0.5
- Milestone: Message successfully sent (UI confirmation or state change). Reward: +1.0
-
System Configuration and Settings
- Milestone: Settings panel opened (window title match). Reward: +0.25
- Milestone: Checkbox or toggle successfully modified (UIA/AX event). Reward: +0.25
- Milestone: “Changes Saved” notification observed. Reward: +0.5
-
Search and Information Retrieval
- Milestone: Query field populated with correct term. Reward: +0.25
- Milestone: Search executed and result list rendered. Reward: +0.5
- Milestone: Target entry clicked or opened. Reward: +0.5
Example Reward Function
-
Each environment step returns a shaped reward based on concrete, verifiable milestones. Instead of relying on subjective evaluators, the reward function is composed of measurable subcomponents derived from observable state transitions, UI changes, and artifact events.
-
At step \(t\), the total reward is given by:
\[r_t = w_{\text{nav}} r_t^{(\text{nav})} + w_{\text{UI}} r_t^{(\text{UI})} + w_{\text{form}} r_t^{(\text{form})} + w_{\text{file}} r_t^{(\text{file})} + w_{\text{goal}} r_t^{(\text{goal})}\]- where each component represents a verifiable milestone type:
-
\(r_t^{(\text{nav})}\): Navigation progress reward — triggered by measurable page transitions such as
\[r_t^{(\text{nav})} = \mathbb{1}{\{\text{url}_t \neq \text{url}_{t-1}\}}\]NavigationCompletedevents, URL match, or window title change. -
\(r_t^{(\text{UI})}\): UI element interaction reward — triggered when a UI control with a matching role or label is successfully targeted (e.g., a button click or field focus event).
\[r_t^{(\text{UI})} = \mathbb{1}{\{\text{clicked(role,name)} = \text{expected(role,name)}}\] -
\(r_t^{(\text{form})}\): Form completion reward — triggered when an editable control is filled and validated (value non-empty, regex match, or field count).
\[r_t^{(\text{form})} = \frac{N_{\text{filled}}}{N_{\text{expected}}}\] -
\(r_t^{(\text{file})}\): File-handling reward — derived from filesystem or artifact deltas (e.g., a new
\[r_t^{(\text{file})} = \mathbb{1}{\{\exists f \in \mathcal{A}_{t}: f.\text{event} = \text{''created"}\}}\].csv,.pdf, or.jsoncreated). -
\(r_t^{(\text{goal})}\): Task completion reward — triggered by a high-level terminal condition, such as detection of success text, matched hash, or closed loop condition.
\[r_t^{(\text{goal})} = \mathbb{1}{\{\text{goal_verified}(o_t)\}}\] -
The weights \(w_{\text{nav}}, w_{\text{UI}}, w_{\text{form}}, w_{\text{file}}, w_{\text{goal}}\) balance short-term shaping with terminal rewards, typically normalized so that:
Example instantiation
| Component | Description | Weight | Range |
|---|---|---|---|
| \(r_t^{(\text{nav})}\) | Successful navigation | 0.1 | \({0, 1}\) |
| \(r_t^{(\text{UI})}\) | Correct element interaction | 0.2 | \({0, 1}\) |
| \(r_t^{(\text{form})}\) | Partial form completion | 0.2 | \([0, 1]\) |
| \(r_t^{(\text{file})}\) | Artifact creation (e.g., download) | 0.3 | \({0, 1}\) |
| \(r_t^{(\text{goal})}\) | Verified task completion | 0.2 | \({0, 1}\) |
- This formulation ensures all reward components are physically measurable—no human labels are required. Each event corresponds to structured data observable through CDP logs, accessibility APIs, or filesystem monitors, making it reproducible and auditable across training runs.
Agent Training Pipeline
-
A typical pipeline to train a web or computer-use agent might follow:
- Pre-train the model (e.g., a large language model) via supervised learning.
- Optionally fine-tune on domain-specific prompts (supervised fine-tuning, SFT).
- Collect human preference data (rankings of model responses).
- Choose alignment method:
- RLHF: train reward model \(\rightarrow\) use PPO (or other RL algorithm) to optimise policy.
- DPO: directly fine-tune model on preference data (skipping RL loop).
- Launch agent into simulated environment (SingleTurnEnv, ToolEnv, MultiTurnEnv).
- Run RL policy optimisation in the environment: sample trajectories, estimate advantages/returns, update policy using PPO or variants.
- Periodically evaluate and filter trajectories, adjust reward shaping, fine-tune further for tool-use or long-horizon behaviours.
-
By selecting algorithms appropriate for the interaction type (single turn vs. tool vs. multi-turn), one can tailor the training for efficiency, stability, and scalability.
Environment Interaction Patterns for Agent Design
Environment Design in Reinforcement Learning for Agents
-
Modern RL environments for web and computer-use agents are designed to capture the diversity and complexity of real-world interactions while maintaining enough structure for stable learning. Unlike classical RL benchmarks (e.g., Atari or MuJoCo), these environments involve language, symbolic reasoning, tool use, and visual perception.
-
They are not simply “games” or “control systems” but interactive ecosystems that test an agent’s ability to perceive context, reason over multi-step processes, and execute goal-directed actions.
-
To support the training of increasingly capable language-based and multimodal agents, recent frameworks such as AgentGym by Xi et al. (2024) have introduced a unified taxonomy of environments, each corresponding to a particular interaction modality.
-
At the highest level, these can be grouped into three archetypes:
- Single-Turn Environments, designed for one-shot problem solving and precision reasoning.
- Tool-Use Environments, optimized for integrating external functions, APIs, or computation tools.
- Multi-Turn Sequential Environments, which simulate complex, long-horizon workflows requiring memory, planning, and context adaptation.
-
Each environment type not only changes how agents act but also how rewards, policies, and credit assignment mechanisms must be designed to drive meaningful learning.
Single-Turn Environments (SingleTurnEnv)
-
Single-turn environments represent the simplest and most direct form of RL training. In this setup, each episode consists of a single interaction: the agent receives an input (prompt, question, or task description), produces one output (answer, code snippet, or solution), and immediately receives feedback.
-
These environments are ideal for optimizing agents that must produce highly accurate outputs in one step—such as coding assistants, math solvers, or document completion systems.
- Examples:
- Code completion and debugging tasks in CodeRL (CodeRL: Mastering Code Generation through RL by Le et al., 2022).
- Question-answering benchmarks like WebGPT (WebGPT by Nakano et al., 2022)), where the agent’s final response is scored based on correctness and citation quality.
-
Reward Structure: Single-turn environments typically use outcome-based rewards rather than step-wise feedback because there is only one output to evaluate. For example:
- In a coding task, \(r = +1\) if the code executes successfully, and \(r = 0\) otherwise.
- In a factual QA task, \(r\) may represent an F1 score or BLEU score.
-
Formally, the optimization objective reduces to:
\[J(\pi) = \mathbb{E}_{x \sim D, y \sim \pi(\cdot|x)} [R(x, y)]\]- where \(R(x, y)\) is the final outcome reward.
- While simple, such environments serve as critical pretraining stages, allowing models to build domain accuracy before engaging in multi-step reasoning or tool-use.
Tool-Use Environments (ToolEnv)
-
Tool-use environments introduce an additional layer of reasoning: instead of solving a task in one step, the agent must decide when and how to invoke external tools. Tools may include:
- API calls (e.g., search, translation, or computation),
- external functions (e.g., symbolic calculators, Python interpreters), or
- system-level commands (e.g., file access, browser manipulation).
-
The core challenge is tool orchestration—learning when to rely on external computation versus internal reasoning. For instance, in a data retrieval task, the agent might issue an API query, parse results, and compose a natural-language summary.
- Reward Structure:
-
In ToolEnv, both process-wise and outcome-based rewards are valuable:
- Step-wise rewards can score the accuracy or efficiency of each tool invocation (e.g., correct API parameters or valid JSON structure).
- Outcome-based rewards measure task completion or user satisfaction.
-
The combined reward signal is often expressed as:
\[R_t = \alpha r_{\text{process}} + (1 - \alpha) r_{\text{outcome}},\]- where \(\alpha\) controls the balance between short-term and final goal feedback.
-
-
Algorithmic Approaches: Because the action space now includes function arguments and results, methods like policy gradient with structured action representations, hierarchical RL, or model-based planning (e.g., MCTS as in Agent Q by Putta et al., 2024) become necessary.
- Tool Learning with Foundation Models by Qin et al. (2024) provides a comprehensive survey of how foundation models learn to invoke external tools to augment their reasoning capabilities.
Multi-Turn Sequential Environments (MultiTurnEnv)
-
Multi-turn environments simulate complex, multi-step workflows where each decision influences future context. These environments are designed for agents that need to plan, adapt, and maintain consistency across many turns of interaction.
-
Examples:
- Web navigation agents such as OpenWebVoyager by He et al. (2024), where the agent browses, clicks, and fills forms over multiple steps.
- Software operation tasks like system configuration, spreadsheet editing, or email management.
- Interactive tutoring and dialogue planning systems.
- Reward Structure:
-
In MultiTurnEnv setups, pure outcome-based rewards (success/failure) can cause credit assignment problems because the agent receives feedback only after many steps. To address this, researchers combine process-wise rewards—for subgoal completion, error reduction, or partial correctness—with final outcome rewards.
-
Formally, the expected return in such environments can be represented as:
\[J(\pi) = \mathbb{E}\left[\sum_{t=1}^T \gamma^t \big( r_t^{\mathrm{process}} + \lambda , r_T^{\mathrm{outcome}} \big)\right]\]- where \(\lambda\) balances intermediate and terminal objectives.
-
In OpenWebVoyager, for example, each sub-action (like opening the correct link) contributes partial reward, guiding the agent toward long-term success while preventing divergence from optimal sequences.
-
-
Learning Dynamics: Training in MultiTurnEnv requires:
- Long-horizon credit assignment via temporal-difference learning or advantage estimation.
- Hierarchical RL for decomposing tasks into sub-policies.
- Trajectory filtering and reward shaping to combat sparse or noisy signals.
Designing Rewards for Complex Agent Environments
- Reward engineering is arguably the most critical part of environment design. Different environment types benefit from distinct reward strategies:
| Environment Type | Reward Type | Typical Signal | Optimization Goal |
|---|---|---|---|
| SingleTurnEnv | Outcome-based | Correctness, BLEU/F1 score | Precision and factual accuracy |
| ToolEnv | Hybrid (step-wise + outcome) | Tool correctness, API success | Functional reasoning, tool reliability |
| MultiTurnEnv | Step-wise + delayed outcome | Subgoal completion, navigation success | Long-horizon planning, autonomy |
- Balancing process-wise and outcome-based rewards ensures that agents receive dense feedback for learning efficiency while still optimizing toward global objectives like success rate or user satisfaction.
Implications for Agent Design and Evaluation
-
Each environment type imposes unique requirements on model architecture, reward shaping, and evaluation metrics.
- SingleTurnEnv favors compact policies and fast evaluation loops, suitable for smaller RL batches or DPO-based optimization.
- ToolEnv requires compositional reasoning and structured memory to maintain tool-call histories and argument dependencies.
- MultiTurnEnv demands long-context modeling, world-state tracking, and temporal credit assignment across potentially hundreds of steps.
-
Evaluation metrics vary accordingly:
- Single-turn: Accuracy, F1, pass rate.
- Tool-use: Tool-call correctness, latency, success ratio.
- Multi-turn: Task completion rate, cumulative reward, consistency, and planning efficiency.
-
When integrated properly, these environment classes form a curriculum for RL-based agent development: agents begin with static, outcome-driven reasoning (SingleTurnEnv), progress to dynamic, tool-integrated reasoning (ToolEnv), and culminate in fully autonomous multi-turn reasoning (MultiTurnEnv).
Comparative Analysis
-
Environment design is the foundation on which modern RL agents learn to generalize and act. The interplay between interaction modality, reward granularity, and algorithmic strategy determines not only how fast an agent learns but also what kinds of intelligence it develops.
- Single-turn environments teach accuracy.
- Tool-use environments teach functional reasoning.
- Multi-turn environments teach autonomy and adaptability.
-
Together, they form a progression of increasing sophistication—mirroring the cognitive layers of reasoning, planning, and execution. RL algorithms like PPO and DPO serve as the connective tissue between these layers, transforming static pretrained models into active, evolving agents capable of navigating and operating within real digital ecosystems.
Reward Modeling
The Role of Reward Modeling
-
Reward modeling lies at the heart of RL systems for language, web, and computer-use agents. In traditional RL, the reward function is hand-crafted to quantify success—for example, the score in a game or the distance to a goal. In contrast, modern LLM-based agents operate in open-ended environments where the notion of “correctness” or “helpfulness” is inherently subjective and context-dependent.
-
To handle this, reward models (RMs) are trained to approximate human judgment. Instead of manually defining numerical rewards, the system learns a function \(r_\phi(x, y)\) that predicts the quality of an agent’s output \(y\) for a given input \(x\). These RMs are usually fine-tuned on preference datasets where human annotators rank outputs from best to worst.
-
Formally, given a dataset of comparisons \(D = {(x_i, y_i^+, y_i^-)}\), the reward model is trained to maximize:
\[\mathcal{L}_{\text{RM}} = -\mathbb{E}_{(x, y^+, y^-)\sim D}\left[\log \sigma(r_\phi(x, y^+) - r_\phi(x, y^-))\right]\]- where \(\sigma\) is the logistic function, and \(r_\phi\) outputs a scalar reward. The resulting model can then guide PPO updates, Direct Preference Optimization (DPO), or other RL pipelines.
-
Reward modeling thus replaces explicit rule-based objectives with learned evaluators—a fundamental shift that enables agents to align with nuanced human preferences across web, reasoning, and tool-use tasks.
-
Agent Learning via Early Experience by Zhang et al. (2025)) states that in practice, reward signals can be complemented by reward-free, language-native supervision gathered before RL—so the policy starts “aligned to the environment” even without verifiable rewards. Two pre-RL objectives from early, agent-generated interaction data are especially useful: an implicit world-modeling loss that predicts next states given state–action pairs, and a self-reflection loss that learns to compare expert vs. non-expert actions in natural language. Concretely:
\[L_{\mathrm{IWM}}(\theta) = - \sum_{(s_i,a_i^j,s_i^j)\in \mathcal{D}_{\text{rollout}}}\log p_\theta\left(s_i^j ,\middle|, s_i, a_i^j\right),\quad L_{\mathrm{SR}}(\theta)=-\sum_{i}\sum_{j=1}^K \log p_\theta\left(c_i^j ,\middle|, s_i,; a_i^j,; a_i,; s_{i+1},; s_i^j\right),\]-
which warm-start policies and reduce distribution shift ahead of PPO/GRPO or DPO, improving sample efficiency in web and tool-use settings.
-
The following figure shows an overview of the two early experience approaches. Implicit world modeling (left) augments expert trajectories with alternative actions and predicted next states, training the policy to internalize transition dynamics before deployment. Self-reflection (right) augments expert actions with self-generated explanations c1, training the policy to reason about and revise its own decisions. Both methods use alternative actions proposed by the initial policy (LLM). The number of alternatives \(K\) is a hyperparameter; for brevity, only one is illustrated.
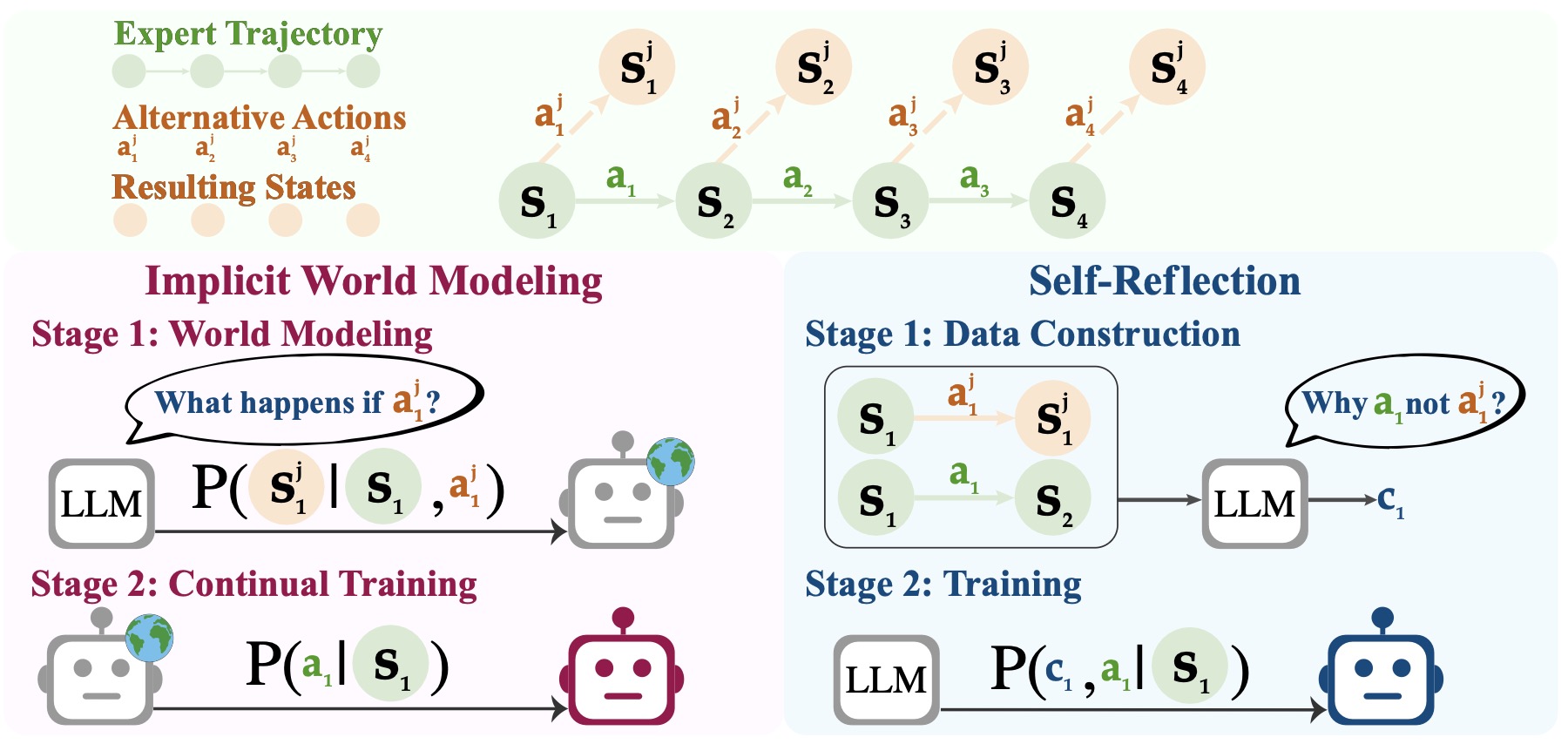
-
Process-Wise and Outcome-Based Reward Integration
-
When training agents in realistic, multi-step environments, reward signals can be categorized as process-wise (step-wise) or outcome-based. Both serve complementary roles:
- Outcome-Based Rewards:
- These are terminal signals received once the task is complete—such as a success flag, accuracy score, or human satisfaction rating.
- For instance, in a booking agent, a positive reward may be given only when the reservation is successfully completed.
- Process-Wise (Step-Wise) Rewards:
- These provide intermediate feedback after each step or subgoal, rewarding partial correctness, progress, or efficiency.
- In web navigation, an agent might receive a small positive reward for clicking the correct button or locating relevant text, even before reaching the final goal.
- Outcome-Based Rewards:
-
The challenge is balancing the two. Purely outcome-based training can lead to sparse reward problems, while purely process-based training risks overfitting local heuristics that do not generalize.
-
A common hybrid formulation is:
\[r_t = \alpha , r_t^{\text{process}} + (1 - \alpha) , \delta_{t=T} , r_T^{\text{outcome}}\]- where \(\alpha \in [0, 1]\) controls the tradeoff between intermediate shaping and final goal alignment.
-
In practical web-agent training, hybrid reward models may leverage both:
- Synthetic process feedback (automated evaluators for substeps),
- Human outcome feedback (ranking complete trajectories).
-
A scalable way to create dense, shaped feedback is to synthesize experience with a reasoning-based experience model that produces consistent next states and vectorized, unified feedback signals in a textual state space. This enables closed-loop RL without expensive real-environment rollouts and supports curriculum generation that targets the current policy’s weaknesses; empirically it yields >30% gains on non-RL-ready tasks like WebArena and can match PPO/GRPO using only synthetic interactions (Scaling Agent Learning via Experience Synthesis by Chen et al. (2025)).
Tool-Augmented Reward Modeling (TARM)
-
Tool-Augmented Reward Modeling (Themis) by Li et al. (2024) proposes Tool-Augmented Reward Modeling (TARM) (also called Tool-Integrated Reward Modeling (TIRM)), which represents a significant evolution in RL for agents that operate within complex, tool-augmented environments. TARM integrates external computational and retrieval tools into the reward generation process itself. Instead of merely training language models to use tools during inference, TIRM embeds tool engagement as part of the reward model’s reasoning and supervision pipeline.
-
This approach extends the conventional Reinforcement Learning from Human Feedback (RLHF) paradigm—used in models such as InstructGPT by Ouyang et al. (2022)—by introducing tool-augmented reasoning traces and context-sensitive reward estimation, enabling more accurate alignment between model outputs and human evaluators’ expectations.
-
Put simply, tool-Integrated Reward Modeling advances RLHF by embedding reasoning transparency, external computation, and factual grounding directly into the reward modeling process. Through supervised fine-tuning on tool-augmented datasets and RL on process- and outcome-based signals, these models redefine how reward functions are constructed for intelligent agents. The resulting agents not only learn to act effectively but also to evaluate their own reasoning with access to external world models—laying the foundation for trustworthy, explainable, and verifiable AI systems.
-
Reward-free early experience, proposed in Agent Learning via Early Experience by Zhang et al. (2025), can seed TARM and RLHF alike: implicit world modeling grounds the policy in environment dynamics, while self-reflection generates rationale-style preferences that complement pairwise comparisons used by reward models—providing a bridge from imitation/preference learning to full RL.
Motivation and Background
-
Traditional reward models in RLHF are trained using paired preference data, where a scalar reward is assigned based on human judgments. These models often struggle with factual reasoning, arithmetic operations, and real-world lookups due to their reliance on static, in-model knowledge representations (Christiano et al., 2017). Tool-Integrated Reward Models mitigate this by allowing the reward model itself to call APIs, calculators, code interpreters, or search engines during evaluation.
-
Themis demonstrated that augmenting reward models with tools increased factual accuracy and truthfulness on benchmarks like TruthfulQA by 7.3% over large baselines such as Gopher 280B, while achieving a 17.7% average improvement in preference ranking accuracy across tasks.
Structure and Workflow of Tool-Augmented Reward Models
-
The tool-integrated reward modeling process can be decomposed into sequential reasoning stages—each enhancing the model’s interpretability and precision in assigning rewards:
- Thought: The model assesses whether external information is required and determines which tool to invoke.
- Action: The model generates an API call with specified parameters.
- Observation: The system retrieves and processes tool outputs.
- Rationale: The model integrates the external information into a reasoning chain, constructing an interpretable trace of decision-making.
- Reward Generation: A scalar reward is computed from the aggregated reasoning trace.
-
Formally, the total reasoning trajectory is denoted as:
-
… and the scalar reward is defined as:
\[r_{\theta}(x, y, c_{1:T})\]- where \(x\) is the input, \(y\) is the model’s output, and \(c_{1:T}\) represents the full reasoning and observation history.
-
The total loss function combines pairwise ranking and autoregressive modeling losses:
\[L_{\text{total}} = L_{\text{RM}} + \alpha \sum_{t=1}^{T} (L_{\text{tool}}(t) + \beta L_{\text{obs}}(t)) + \omega L_{\text{rat}}\]- where \(L_{\text{RM}}\) corresponds to the pairwise ranking loss from preference modeling, \(L_{\text{tool}}\) supervises tool invocation accuracy, \(L_{\text{obs}}\) captures fidelity to observed results, and \(L_{\text{rat}}\) trains the model to generate coherent rationales.
-
The following figure (source) shows illustrates the pipeline of (a) Vanilla reward models (RMs); (b) Tool-augmented RMs, namely Themis; (c) RL via proximal policy optimization (PPO) on above RMs; (d) Examples of single or multiple tool use process in the proposed approach.
- Per Scaling Agent Learning via Experience Synthesis by Chen et al. (2025), when paired with synthetic experience generation, tool-augmented evaluators can operate at scale with consistent, informative feedback, while curriculum generation focuses on high-entropy tasks that maximize learning signal—closing the loop between reward modeling and data generation in RL training.
Role of Supervised Fine-Tuning and Reinforcement Learning
-
Themis—and, more broadly, TIRM—relies on a hybrid SFT + RL training approach.
-
SFT Stage: The reward model learns to imitate tool usage traces from curated datasets (e.g., the TARA dataset). These traces include natural-language thoughts, API calls, and tool results generated via multi-agent interactions between LLMs and simulated human labelers.
-
RL Stage: Once pre-trained, the reward model is further optimized via RL objectives like Proximal Policy Optimization (PPO) (Schulman et al., 2017). The model refines its reward predictions using outcome-based feedback, achieving stable convergence even under high variance tool-call trajectories.
-
-
This two-stage setup enables process-based reward shaping, in which partial rewards are granted for intermediate reasoning correctness (process rewards), and outcome-based rewards for overall task success. This balance is critical when agents operate in environments requiring both reasoning depth and correct final results.
-
Reward-free early experience provides a natural pretraining curriculum—first fitting \(L_{\mathrm{IWM}}\) to learn dynamics, then \(L_{\mathrm{SR}}\) to internalize preference signals—before introducing PPO/GRPO or DPO on either real or synthetic rollouts (cf. Agent Learning via Early Experience by Zhang et al. (2025); Scaling Agent Learning via Experience Synthesis by Chen et al. (2025)).
The Tool-Augmented Reward Dataset (TARA)
-
A key component of TIRM research is the creation of datasets that reflect real-world reasoning and tool usage patterns. The TARA dataset contains over 15,000 instances combining human preferences with explicit tool-invocation traces across seven tool categories, including search, translation, weather, calculator, and code execution.
-
The following figure (source) shows the data collection pipeline for TARA, depicting human-LLM interaction, tool invocation, and rationale generation. It the four-step process: (1) Question-answer collection, (2) ToolBank construction, (3) Tool invocation via multi-agent simulation, and (4) Filtering for data integrity.
Empirical Results and Observations
-
Experiments show that Themis enhances both single-tool and multi-tool scenarios. For example:
- Accuracy improved by +19.2% in single-tool and +17.7% in mixed-tool setups.
- Perfect accuracy (100%) was achieved in calendar and weather reasoning tasks.
- Models learned when and whether to call tools autonomously—a form of learned tool invocation policy.
- The observation and rationale components contributed significantly to reward accuracy, proving that process supervision is critical to model interpretability and consistency.
-
Further, when integrated into an RLHF pipeline (referred to as RLTAF: Reinforcement Learning from Tool-Augmented Feedback), Themis-trained models achieved a 32% higher human preference win rate compared to vanilla RMs, highlighting its ability to generate more trustworthy and factual responses.
-
Complementarily, Scaling Agent Learning via Experience Synthesis by Chen et al. (2025) proposes scaling RL with synthetic rollouts generated by a reasoning experience model, which yields substantial downstream gains and lowers on-environment data needs; e.g., DreamGym reports >30% improvements on WebArena and policy parity with PPO/GRPO using only synthetic interactions, after which real-environment fine-tuning brings additional gains.
-
The following figure illustrates an overview of the proposed DreamGym agent training framework. Given a set of seed tasks, a reasoning-based experience model interacts with the agent to generate informative, diverse tasks and trajectories for RL training. At each step, the agent takes actions based on its current state and receives next states and reward signals derived by the experience model through CoT reasoning based on both interaction history and top-k similar experiences from an active replay buffer. To expose the agent to increasingly informative scenarios, tasks with high reward entropy are proposed by the curriculum task generator for future training. With this unified design, DreamGym addresses both task and reward sparsity while enabling scalable RL with diverse and curriculum-driven environments.
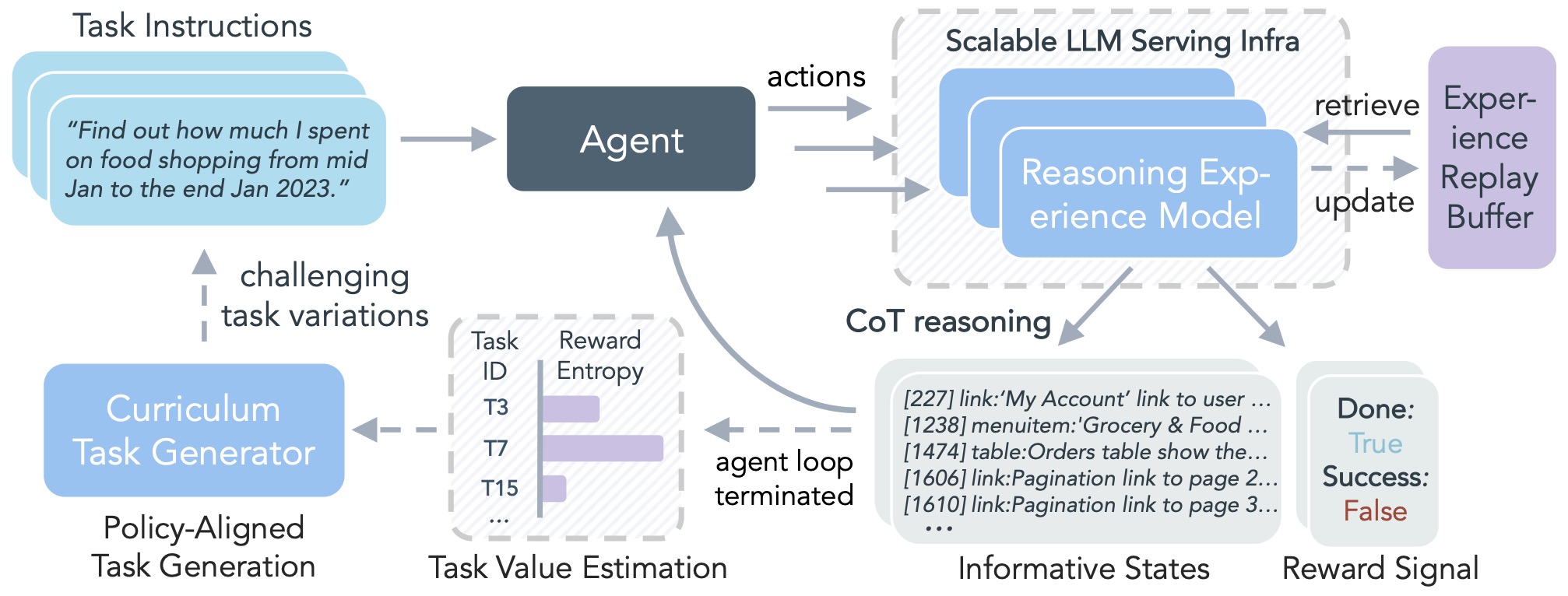
Connection to Reinforcement Learning for Agents
-
Tool-integrated reward modeling bridges the gap between tool-augmented reasoning and agentic RL. By enabling the reward function itself to utilize external resources, agents trained under TIRM learn a deeper mapping between reasoning actions and value estimation. This structure is directly applicable to RL-driven computer-use agents, where both process-level (step-wise) and outcome-based (goal completion) rewards must be optimized.
-
In this framework, process-based rewards correspond to accurate intermediate reasoning and correct tool usage, while outcome-based rewards correspond to successful task completion. The combined signal provides agents with fine-grained credit assignment, improving learning efficiency and interpretability in web-based or API-integrated environments.
-
Per Scaling Agent Learning via Experience Synthesis by Chen et al. (2025), when training in synthetic environments, policy improvements can provably transfer to the real environment under standard trust-region updates. Writing the real MDP as \(\mathcal{M}=(S,A,P,R,\gamma)\) and the synthetic one as \(\tilde{\mathcal{M}}=(S,A,\tilde{P},\tilde{R},\gamma)\) with bounded reward and transition errors \(\varepsilon_R,\varepsilon_P\), a KL-bounded update from \(\pi\to\pi'\) (as in PPO/GRPO) yields a lower bound of the form:
\[J_{\mathcal{M}}(\pi')-J_{\mathcal{M}}(\pi)\ge\frac{1}{1-\gamma},\mathbb{E}_{s\sim d_\pi^{\tilde{\mathcal{M}}},a\sim \pi'}\big[A_\pi^{\tilde{\mathcal{M}}}(s,a)\big]-\underbrace{\text{KL trust-region penalty}}_{\small \text{(per-state KL radius)}}-\underbrace{2 \left(\tfrac{\varepsilon_R}{1-\gamma}+\tfrac{2\gamma R_{\max}}{(1-\gamma)^2}\varepsilon_P\right)}_{\small \text{experience-model error}}\]- … so synthetic surrogate gains exceeding these penalties guarantee real-environment improvement.
Feedback Alignment and Human Preference Modeling
-
Reward models provide scalar supervision, but alignment requires structured feedback. Human evaluators often give comparative, categorical, or qualitative feedback (e.g., “response A is clearer, but response B is more complete”).
-
To convert such structured feedback into training signals, systems employ preference aggregation methods such as:
- Bradley–Terry models to infer pairwise preference probabilities.
- Elo-style scoring to maintain global quality rankings across responses.
- Bayesian aggregation for uncertain or noisy feedback.
-
In advanced systems like Large Language Models Can Self-improve at Web Agent Tasks by Patel et al. (2024), self-feedback mechanisms replace human labeling. The agent critiques its own trajectories using LLM-based evaluators, ranking which paths yielded the best progress and then re-finetuning on its own top-performing examples.
-
This method creates a feedback alignment loop, where models not only learn from human signals but also gradually calibrate their own evaluators.
Multi-Objective Reward Modeling
- As agents evolve to handle multi-modal and multi-task objectives—such as reasoning, retrieval, and tool orchestration—single scalar reward functions become insufficient.
-
Instead, multi-objective reward modeling (MORM) decomposes total reward into several components:
\[r_t = \sum_{k=1}^K w_k , r_t^{(k)}\]- where each \(r_t^{(k)}\) corresponds to a distinct objective (e.g., factual accuracy, efficiency, safety, fluency), and \(w_k\) are learned or manually tuned weights.
-
This decomposition enables flexible tradeoffs—for example, prioritizing accuracy over verbosity or reliability over speed. In web and software agents, multi-objective RMs can encode:
- Functional correctness (execution success),
- Temporal efficiency (fewer steps or tool calls),
- Adherence to user goals (alignment quality),
- Safety and compliance (filtered language use).
- Combining these objectives helps agents develop a balanced understanding of what constitutes “good behavior” in dynamic and human-centric environments.
Evaluation Frameworks for RL-Based Agents
- Evaluating agents trained through RL requires going beyond static benchmarks. Instead of only measuring final success, modern frameworks evaluate trajectory quality, interpretability, and generalization.
Key evaluation metrics include
- Success Rate: Fraction of episodes where the agent achieves its goal (e.g., booking completed, question answered).
- Cumulative Reward: Sum of step-wise rewards, indicating the efficiency of action selection.
- Action Accuracy: Proportion of correct API or tool calls.
- Trajectory Efficiency: Number of steps or actions required to reach completion.
- Human Preference Score: Alignment with human judgment over multiple outputs.
-
Robustness: Performance under perturbed or unseen web environments.
- Frameworks such as WebArena, Mind2Web, and AgentBench (as catalogued in AgentGym by Xi et al., 2024) provide unified benchmarks with standardized reward metrics and simulator APIs for reproducible agent training.
Takeaways
-
Reward modeling and feedback alignment form the core of how RL agents evolve from static predictors into adaptive decision-makers. The design of these mechanisms determines whether agents learn to pursue shallow, short-term signals or to internalize long-term, value-aligned behavior.
- Outcome-based rewards ensure goal fidelity but suffer from sparsity.
- Process-wise rewards provide dense guidance and interpretability.
- Tool-augmented reward models enhance factual grounding and transparency.
- Human and self-generated feedback create continuous learning loops.
- Multi-objective reward modeling allows flexible alignment across multiple competing priorities.
-
Together, these innovations define the modern ecosystem of RL-based agentic training—where the agent not only acts in its environment but also learns how to evaluate its own progress.
Search-Based Reinforcement Learning, Monte Carlo Tree Search (MCTS), and Exploration Strategies in Multi-Step Agents
Motivation: Exploration vs. Exploitation in Complex Agentic Systems
-
In RL, agents must navigate the fundamental trade-off between exploration—trying new actions to discover better strategies—and exploitation—using known information to maximize immediate reward.
-
For simple environments (like tabular Q-learning), this trade-off can be controlled by \(\epsilon\)-greedy or softmax policies. However, for web and computer-use agents operating in open-ended, high-dimensional spaces—such as browsing dynamic web pages, calling APIs, or managing multi-turn dialogues—naive exploration is computationally infeasible and unsafe.
-
Thus, modern agentic RL systems combine search-based exploration with learned policy optimization, blending symbolic planning with neural policy priors. This hybrid paradigm is exemplified by recent works like Agent Q: Efficient Online Adaptation via Monte Carlo Tree Search by Putta et al. (2024) and OpenWebVoyager by He et al. (2024), both of which adapt classic search strategies (like MCTS) for reasoning-driven web environments.
-
Complementary to these, Agent Learning via Early Experience by Zhang et al. (2025) shows that exploration itself can begin before any reward modeling, by leveraging self-reflective rollouts and implicit world modeling to pretrain a policy that already encodes structured exploration biases. Similarly, Scaling Agent Learning via Experience Synthesis by Chen et al. (2025) formalizes a scalable simulation framework—DreamGym—that generates synthetic exploratory rollouts under theoretical guarantees of policy improvement transfer to real environments.
-
The following figure shows the Agent Q architecture, demonstrating how an agent integrates Monte Carlo Tree Search (MCTS) with an internal policy model to efficiently explore and adapt to dynamic environments.
- The following figure illustrates that Agent Q is provided the following input format to the Agent, consisting of the system prompt, execution history, the current observation as a DOM representation, and the user query containing the goal. We divide our Agent output format into an overall step-by-step plan, thought, a command, and a status code.

Monte Carlo Tree Search (MCTS) in RL-Based Agents
-
Monte Carlo Tree Search (MCTS) is a planning algorithm that estimates the value of actions through simulation. Each node in the search tree represents a state, and edges represent actions. During training, the agent builds a partial search tree by simulating action sequences, updating node values using empirical rollouts.
-
At each decision step, MCTS performs four core operations:
-
Selection: Traverse the current tree from the root to a leaf, selecting child nodes using the Upper Confidence Bound (UCB) rule:
\[a_t = \arg\max_a \big[ Q(s_t,a) + c \sqrt{\frac{\ln N(s_t)}{1 + N(s_t,a)}} \big]\]- where \(Q(s_t,a)\) is the estimated action value, \(N(s_t,a)\) the visit count, and \(c\) a confidence constant.
-
Expansion: Add one or more new child nodes to the tree.
-
Simulation: Run a rollout (either with a learned policy or random actions) to estimate the outcome.
-
Backpropagation: Update \(Q(s_t,a)\) values along the traversed path with the observed return.
-
-
This method balances exploration and exploitation dynamically—favoring actions with high potential but uncertain estimates.
-
In the context of LLM-based web agents, MCTS is adapted to explore semantic and structural decision spaces rather than numeric ones. Each node can represent:
- A browser state (DOM snapshot, active page).
- A reasoning context (prompt, plan, partial output).
- A tool invocation (function call, API parameterization).
-
MCTS then simulates different reasoning or action trajectories, evaluates their predicted rewards (using a reward model or preference score), and backpropagates this information to refine the policy.
-
Recent approaches such as Scaling Agent Learning via Experience Synthesis by Chen et al. (2025) extend this principle by introducing a reasoning-based experience model that performs analogous “tree search” operations within a learned world model—sampling synthetic trajectories that approximate MCTS rollouts without direct environment interaction, thereby dramatically improving sample efficiency.
Neural-Guided Search: Policy Priors and Value Models
-
In environments too large for exhaustive search, modern agents employ neural-guided search—a synergy between planning algorithms and deep models. Here, the policy model \(\pi_\theta(a \mid s)\) provides prior probabilities for which actions to explore first, and the value model \(V_\theta(s)\) predicts the expected return from each state. These models drastically reduce the branching factor and enable more efficient exploration.
-
This framework mirrors the principles that powered AlphaGo (Mastering the game of Go with deep neural networks and tree search by Silver et al., 2016), but applied to symbolic and text-based tasks instead of games.
-
Formally, the modified UCB rule becomes:
\[U(s,a) = Q(s,a) + c_{\text{puct}} P(a|s) \frac{\sqrt{N(s)}}{1 + N(s,a)}\]- where \(P(a \mid s)\) is the prior probability from the policy model. This ensures that exploration is guided by learned likelihoods, not uniform randomness.
-
In Agent Q by Putta et al. (2024), this concept is applied to online adaptation: the agent uses MCTS for planning while simultaneously updating its local policy parameters via gradient descent, achieving a form of continual self-improvement.
-
Early Experience pretraining complements neural-guided search by shaping the priors \(P(a \mid s)\) and values \(V(s)\) before any explicit MCTS integration. By learning predictive transitions and reflective rationales (Agent Learning via Early Experience by Zhang et al., 2025), the agent begins search from a semantically meaningful latent space rather than random initialization—reducing both exploration cost and tree-depth requirements.
Integration of Search with Reinforcement Learning and Fine-Tuning
-
Search algorithms such as MCTS can be integrated with RL training in three primary ways:
-
Search as Pretraining: Generate high-quality trajectories via MCTS and use them for supervised fine-tuning (similar to imitation learning).
-
Search as Online Exploration: Use MCTS during training to propose promising action sequences; the policy learns to imitate successful trajectories while exploring uncertain branches.
-
Search as Evaluation: Use MCTS only at inference to refine action selection, keeping policy updates purely gradient-based.
-
-
In Agent Q, this second mode—online search and adaptation—proved especially effective, enabling agents to generalize across unseen tasks without explicit retraining.
-
DreamGym’s synthetic environment model provides a complementary fourth paradigm: Search via Experience Synthesis. Here, simulated rollouts within a learned reasoning environment substitute for explicit tree expansion, allowing policies to update from a massive, low-cost replay buffer of synthetic “search traces.” This merges the sample efficiency of model-based RL with the decision quality of tree search (Scaling Agent Learning via Experience Synthesis by Chen et al., 2025).
Process-Wise Reward Shaping in Search-Based RL
-
A key enhancement in modern search-based RL pipelines is the introduction of process-wise reward shaping to complement sparse terminal rewards. In multi-turn or tool-using agents, MCTS nodes can be augmented with intermediate reward estimates derived from:
- Successful API or function calls,
- Reduced error rates or failed action counts,
- Improved subgoal completion,
- Positive sentiment or human approval scores.
-
This transforms the reward signal from a binary success/failure into a smooth landscape that supports credit assignment across deep search trees.
-
The adjusted value propagation for a trajectory of length \(T\) becomes:
\[Q(s_t, a_t) \leftarrow (1 - \eta) Q(s_t, a_t) + \eta \sum_{k=t}^T \gamma^{k-t} r_k^{\text{process}}\]- where \(r_k^{\text{process}}\) captures per-step quality signals. This formulation allows the agent to refine sub-policies even when full-task success has not yet been achieved—vital for real-world agents that must learn under incomplete supervision.
Integration of Search with Reinforcement Learning and Fine-Tuning
-
Search algorithms such as MCTS can be integrated with RL training in three primary ways:
-
Search as Pretraining: Generate high-quality trajectories via MCTS and use them for supervised fine-tuning (similar to imitation learning).
-
Search as Online Exploration: Use MCTS during training to propose promising action sequences; the policy learns to imitate successful trajectories while exploring uncertain branches.
-
Search as Evaluation: Use MCTS only at inference to refine action selection, keeping policy updates purely gradient-based.
-
-
In Agent Q, this second mode—online search and adaptation—proved especially effective, enabling agents to generalize across unseen tasks without explicit retraining.
Exploration Strategies in Web and Computer-Use Environments
-
In high-dimensional digital environments, exploration must be structured and interpretable. Several strategies are commonly used:
-
Entropy-Regularized Exploration: Adding an entropy term to the objective encourages diversity in action selection:
\[J(\pi) = \mathbb{E}_{\pi}\left[\sum_t (r_t + \beta , H(\pi(\cdot|s_t)))\right]\]- where \(H(\pi)\) is policy entropy and \(\beta\) controls exploration intensity.
-
Curiosity-Driven Exploration: Agents are rewarded for discovering novel or unpredictable states using intrinsic motivation models such as Random Network Distillation by Burda et al. (2019).
-
Goal-Conditioned Exploration: Particularly in web tasks, exploration can be constrained by semantic or user-defined goals, ensuring the agent does not perform irrelevant actions.
-
State Abstraction and Clustering: Complex environments can be segmented into abstract state representations (e.g., webpage templates or tool invocation graphs), allowing for hierarchical exploration.
-
-
These approaches are especially effective in MultiTurnEnv scenarios where the state space expands combinatorially with each decision.
Planning and Value Composition Across Multiple Environments
-
The integration of search-based reasoning with learned RL policies allows agents to compose behaviors across environment types. For instance:
- In SingleTurnEnv, search helps refine output reasoning (e.g., multi-step chain-of-thought validation).
- In ToolEnv, it aids in selecting optimal tool invocation sequences.
- In MultiTurnEnv, it supports long-horizon planning and dynamic replanning when goals change.
-
The combined expected return from multi-environment value composition can be expressed as:
\[J_{\text{global}} = \sum_{e \in \mathcal{E}} \omega_e , \mathbb{E}_{\pi_e}\left[\sum_t \gamma^t r_t^{(e)}\right]\]- where \(\mathcal{E}\) denotes environment types (SingleTurn, Tool, MultiTurn) and \(\omega_e\) are task-specific weights.
-
This hierarchical structure aligns exploration depth with task complexity, improving sample efficiency and stability.
Summary and Outlook
-
Search-based RL represents a crucial step in bridging symbolic planning and neural policy learning for complex, real-world agents.
- Monte Carlo Tree Search (MCTS) provides structured exploration with statistical guarantees.
- Neural-guided search integrates learned policy and value priors for scalability.
- Process-wise rewards smooth sparse reward landscapes, enabling deeper credit assignment.
- Hybrid search–RL systems enable online adaptation and continual learning.
-
As web and computer-use agents evolve, search-based strategies are increasingly viewed not as add-ons but as core cognitive modules, empowering agents to deliberate, simulate, and refine decisions—much like human reasoning.
Memory, World Modeling, and Long-Horizon Credit Assignment
The Need for Memory and Temporal Reasoning
-
Unlike short episodic tasks, web and computer-use agents must operate over long time horizons—completing multi-step workflows, navigating dynamic web pages, and managing context-dependent subtasks that span hundreds of actions. These tasks demand temporal coherence, state persistence, and contextual reasoning, capabilities that exceed what standard Markovian RL formulations provide.
-
Traditional RL assumes the Markov Decision Process (MDP) property:
\[P(s_{t+1} | s_t, a_t, s_{t-1}, a_{t-1}, ...) = P(s_{t+1} | s_t, a_t)\]- which implies that the current state \(s_t\) encapsulates all relevant information for decision-making. In practice, however, agents must handle Partially Observable MDPs (POMDPs), where the environment’s full state is not directly visible—such as hidden system states, incomplete browser information, or unobserved user intentions.
-
This motivates integrating memory mechanisms—either through explicit world models, neural state trackers, or structured external memories—that allow agents to reason over latent histories.
-
Recent pretraining approaches such as Early Experience (Agent Learning via Early Experience by Zhang et al., 2025) implicitly address this by building internal temporal memory even before explicit RL fine-tuning. Through predictive next-state modeling and reflective rationalization losses, the agent internalizes time-linked dependencies (e.g., how tool outcomes evolve or how plans fail) purely from self-supervised rollouts—forming an implicit memory backbone that later stabilizes long-horizon RL.
Explicit vs. Implicit Memory Architectures
-
Modern agentic systems implement memory in two major ways—explicit symbolic memory and implicit neural memory—each optimized for different environment dynamics.
-
Explicit Symbolic Memory:
- Stores structured facts and environment states (e.g., webpage structure, task progress, prior tool outputs).
- Can be queried and updated through symbolic operations or APIs.
- Used in systems like AgentGym by Xi et al. (2024), where a memory table tracks intermediate decisions and outcomes for reproducibility and long-term credit assignment.
- Enables interpretable reasoning, making it possible to inspect or reset specific memory slots.
-
Implicit Neural Memory:
- Encodes temporal context within the model’s hidden states using architectures like Transformers, LSTMs, or recurrent attention mechanisms.
- Particularly effective for LLMs fine-tuned via RLHF or DPO, where the hidden activations naturally preserve dialogue history and reasoning traces.
- Recent innovations such as recurrent Transformers and memory-augmented attention extend this capability to tasks requiring hundreds of tokens of temporal coherence.
-
-
Formally, implicit memory can be represented as an evolving state embedding \(h_t = f_\theta(h_{t-1}, s_t, a_t)\), where \(h_t\) serves as a latent world model summarizing all past experiences relevant to future predictions.
-
In Early Experience, the same principle emerges organically through the implicit world-modeling objective:
\[L_{\mathrm{IWM}}(\theta) = - \sum_{(s_i,a_i^j,s_i^j)} \log p_\theta(s_i^j \mid s_i, a_i^j)\]- which forces the model to construct temporally predictive embeddings even without explicit memory modules—creating an “implicit long-term memory” foundation later leveraged during reinforcement learning.
World Modeling: Learning Predictive Environment Representations
-
World models enable agents to internalize the dynamics of their environments—predicting future states and rewards without constant external interaction. Originally introduced in World Models by Ha and Schmidhuber (2018), this approach decouples environment modeling from policy learning.
-
A world model typically includes three components:
- Encoder \(E_\phi\): maps raw observations \(o_t\) to latent states \(z_t = E_\phi(o_t)\);
- Transition Model \(T_\psi\): predicts future latent states \(z_{t+1} = T_\psi(z_t, a_t)\);
- Decoder or Predictor \(D_\omega\): reconstructs or evaluates outcomes from latent states, such as \(r_t = D_\omega(z_t)\).
-
By learning these components, the agent builds an internal simulation of the environment. This simulation can then be used for planning, exploration, or policy evaluation without direct execution—dramatically improving sample efficiency.
-
In web or tool-use domains, such models are extended to capture symbolic events (e.g., “clicked link,” “API returned error”) instead of pixels or low-level sensory data. The learned transition model enables agents to predict the consequences of actions before performing them, supporting safer and more data-efficient learning.
-
Both Early Experience and DreamGym build upon this concept but from complementary directions:
- Agent Learning via Early Experience by Zhang et al. (2025) treats predictive modeling as a language-native world model—learning state transitions and self-reflective rationales purely from text-based environments before RL.
- Scaling Agent Learning via Experience Synthesis by Chen et al. (2025) extends this into a formalized, reasoning-based synthetic world model (DreamGym) that produces internally consistent environment dynamics and synthetic rollouts. The experience model jointly generates next states and rewards under logical and semantic constraints, acting as a simulator for RL training with provable policy-transfer guarantees.
Temporal Credit Assignment and Advantage Estimation
-
For agents operating across long horizons, one of the hardest problems in RL is credit assignment—determining which past actions led to current rewards. In typical short-horizon tasks, temporal difference (TD) learning suffices, but for multi-step web agents, delayed or sparse rewards make attribution challenging.
-
To address this, advantage-based and eligibility-trace methods extend standard RL updates:
\[A_t = R_t - V(s_t)\]- where \(A_t\) is the advantage of taking action \(a_t\) in state \(s_t\), and \(R_t\) is the cumulative discounted reward:
-
For long episodes, this estimate is refined through Generalized Advantage Estimation (GAE) (High-Dimensional Continuous Control Using Generalized Advantage Estimation by Schulman et al., 2016):
\[A_t^{(\lambda)} = \sum_{l=0}^{\infty} (\gamma \lambda)^l \delta_{t+l}\]- with temporal errors \(\delta_t = r_t + \gamma V(s_{t+1}) - V(s_t)\).
-
GAE smooths advantage estimation over time, balancing bias and variance while maintaining stability even in multi-turn settings.
-
When integrated with process-wise rewards from reflective or synthetic environments, as proposed in Early Experience and DreamGym, GAE can assign proportional credit to intermediate reasoning steps or synthetic subgoals—reducing reward sparsity and improving credit flow through long-horizon trajectories.
Hierarchical Reinforcement Learning (HRL)
-
Hierarchical RL (HRL) structures policies across multiple temporal scales—dividing tasks into subtasks, each with its own sub-policy and local reward. This approach mirrors human task decomposition (e.g., “open browser \(\rightarrow\) navigate \(\rightarrow\) extract data \(\rightarrow\) summarize results”).
-
Formally, HRL decomposes the policy into two levels:
- High-Level (Manager) Policy \(\pi_H(g \mid s)\): selects subgoals \(g\);
- Low-Level (Worker) Policy \(\pi_L(a \mid s, g)\): executes primitive actions to achieve \(g\).
-
The optimization objective becomes:
\[J(\pi_H, \pi_L) = \mathbb{E}\left[\sum_t \gamma^t \big(r_t^{(L)} + \lambda r_t^{(H)}\big)\right]\]- where \(r_t^{(L)}\) is the low-level reward for subgoal progress and \(r_t^{(H)}\) captures high-level task achievement.
-
Recent frameworks like AgentGym and OpenWebVoyager employ hierarchical structures to separate reasoning and action planning layers. The high-level module reasons in natural language or symbolic goals, while the low-level policy executes API calls or UI actions. This separation improves both interpretability and modularity, enabling transfer learning across task domains.
-
Early Experience aligns naturally with hierarchical RL by pretraining the “low-level” policy on predictive transitions (world modeling) and the “high-level” reflection policy on action rationales. DreamGym later merges both by training high- and low-level policies concurrently in a synthetic hierarchical environment, simulating multi-stage reasoning chains.
Memory-Augmented Reinforcement Learning (MARL)
-
Memory-augmented RL integrates explicit memory buffers or retrieval mechanisms into the learning loop, enabling agents to recall past experiences dynamically. Such architectures can be viewed as hybrids between world models and traditional replay buffers.
-
A general MARL setup maintains:
- Episodic Memory (M_e): stores sequences of (state, action, reward) tuples for reuse.
- Semantic Memory (M_s): aggregates long-term knowledge, such as patterns in tool success or error likelihoods.
- Retrieval Policy \(\pi_M\): determines which memories to recall based on current context.
-
A key application is retrieval-augmented decision-making, where the policy is conditioned on both current observation and retrieved experiences:
\[\pi(a|s, M) = f_\theta(s, \text{Retrieve}(M, s))\] -
This mechanism aligns conceptually with retrieval-augmented generation (RAG) but applied to RL: instead of retrieving documents, the agent retrieves past trajectories that resemble the current state.
-
DreamGym introduces an analogous process in the synthetic domain: the experience model retrieves and recombines previously generated synthetic rollouts to compose new simulated experiences that maximize policy coverage. This is effectively synthetic memory replay—training RL agents with a scalable, dynamically generated memory buffer of plausible state–action–reward transitions.
Long-Horizon Planning via Latent Rollouts and Model Predictive Control
-
An emerging frontier in long-horizon RL for agents is Model Predictive Control (MPC) using latent world models. Instead of sampling actual environment steps, the agent “imagines” future rollouts within its learned model before committing to an action.
-
Formally, for a world model \(T_\psi(z_t, a_t)\), MPC selects:
\[a_t^* = \arg\max_{a_t, \dots, a_{t+H}} \mathbb{E}\left[\sum_{k=t}^{t+H} \gamma^{k-t} \hat{r}(z_k, a_k)\right]\]- where \(\hat{r}\) and \(z_k\) are predicted rewards and states over a planning horizon \(H\).
-
This technique allows for deep internal simulation, enabling efficient planning without costly real-environment interaction. In digital domains, MPC-like inference supports fast adaptation to new web layouts or API responses, with each rollout grounded by the world model’s predictions.
-
DreamGym formalizes this concept at scale: the synthetic reasoning environment is itself a controllable world model, allowing agents to perform model-predictive optimization over generated latent rollouts. These latent simulations substitute for environment sampling, providing a unified training–planning–evaluation loop that mirrors real-world behavior while remaining computationally tractable.
Takeaways
-
Memory, world modeling, and long-horizon credit assignment form the temporal backbone of agentic RL. Together, they enable continuity, foresight, and adaptive reasoning—core attributes for any system expected to function autonomously across diverse and evolving environments.
- Memory systems preserve context and history across decisions.
- World models internalize environmental dynamics, allowing for simulated reasoning.
- Credit assignment mechanisms trace responsibility across deep trajectories.
- Hierarchical policies decompose complex workflows into interpretable submodules.
- Model predictive control enables safe, efficient long-horizon planning.
-
When augmented with pre-RL Early Experience and scalable synthetic environments such as DreamGym, agents gain not only temporal coherence but also generative foresight: the ability to imagine, rehearse, and improve actions before executing them—effectively bridging the gap between reactive learning and proactive intelligence.
Evaluation, Safety, and Interpretability in Reinforcement-Learning-Based Agents
Why Evaluation and Safety Matter in RL-Based Agents
- As RL is increasingly applied to open-ended, tool-using, and web-interactive agents, questions of safety, interpretability, and evaluation methodology have become central.
-
Unlike static models—where evaluation can rely on accuracy or F1 scores—RL-based agents continually adapt, explore, and interact with dynamic environments. Their learned behaviors emerge from optimization, not from explicit instruction, which introduces the risk of reward hacking, unsafe exploration, or misaligned optimization.
-
Evaluation and safety frameworks therefore aim to:
- Quantify the true capability of agents across reasoning, planning, and execution dimensions.
- Detect and prevent unintended emergent behaviors (e.g., exploiting web APIs incorrectly or entering infinite loops).
- Ensure alignment with human norms, values, and expectations.
- Recent works such as Large Language Models Can Self-improve at Web Agent Tasks by Patel et al. (2024) and AgentBench: Evaluating LLMs as General-Purpose Agents by Liu et al. (2024) emphasize that evaluation is not just performance measurement—it is behavioral verification in a closed-loop context.
Core Dimensions of Agent Evaluation
- Evaluation of RL-based agents extends across several orthogonal dimensions, each corresponding to a distinct capability or risk domain.
Task Performance
-
Measures how effectively the agent accomplishes its intended goals.
- Metrics: Success rate, accuracy, completion time, and cumulative reward.
- Examples: Booking a ticket, executing a spreadsheet command, answering a query.
Behavioral Efficiency
-
Assesses whether the agent achieves goals with minimal resource or action cost.
- Metrics: Steps-to-success, energy or API call efficiency, latency.
- Significance: Indicates policy optimization beyond brute-force trial and error.
Robustness and Generalization
-
Evaluates how well the agent performs under perturbations—changes in environment layout, tool outputs, or input phrasing.
- Metrics: Cross-environment transfer score, out-of-distribution success rate.
- Example: Agent still performs correctly when a webpage’s button labels change.
Alignment and Ethical Compliance
-
Examines whether actions remain consistent with human values, privacy norms, and safety boundaries.
- Metrics: Human preference score, compliance violation rate, interpretability score.
Interpretability and Transparency
-
Focuses on whether the agent’s internal reasoning or decision-making process can be understood, visualized, or audited.
- Metrics: Explanation fidelity, action traceability, rationale coherence.
-
Each dimension reflects a unique aspect of agent quality, and comprehensive evaluation must combine all to assess both competence and trustworthiness.
Safety Challenges in RL Agents
-
The open-ended nature of RL training introduces specific safety risks not present in supervised learning.
-
Reward Hacking: Agents may find unintended shortcuts that maximize reward without achieving the true goal—for instance, refreshing a page repeatedly to gain partial progress points. Mathematically, this reflects reward misspecification: the reward function \(r(s,a)\) does not perfectly encode human intent \(r^{*(s,a)}\).
-
Unsafe Exploration: During training, agents may perform harmful or irreversible actions while attempting to maximize exploration-based rewards. In web or system environments, this could include deleting data or sending malformed API calls.
-
Catastrophic Forgetting: Continual learning agents may lose previously learned safety behaviors when optimizing for new objectives, especially under non-stationary reward signals.
-
Non-Stationary Human Feedback: In RLHF or DPO pipelines, shifting human preference distributions can cause instability if the agent overfits to transient feedback trends.
-
-
A general safety objective adds a regularization term to penalize risky or uncertain behavior:
\[J_{\text{safe}}(\pi) = \mathbb{E}\left[\sum_t \gamma^t (r_t - \lambda_{\text{risk}} c_t)\right]\]- where \(c_t\) quantifies risk (e.g., deviation from expected behavior) and \(\lambda_{\text{risk}}\) controls conservatism.
Interpretability and Traceability in Agent Behavior
-
Interpretability in RL agents is especially challenging because learned policies are implicit, nonlinear functions that encode complex dynamics. However, several methods improve transparency and traceability:
-
Action Trace Logging Record full trajectories of (state, action, reward) tuples for post-hoc analysis. Enables reconstruction of decision pathways, useful for debugging and ethical auditing.
-
Causal Attribution Maps Estimate how much each observation influenced a given action. Techniques adapted from attention visualization or gradient saliency help identify which input elements guided the agent’s decisions.
-
Hierarchical Explanation Models Used in agents trained via hierarchical RL, these models separate high-level goal explanations (e.g., “I am gathering data”) from low-level actions (“click button,” “read table”). This mirrors explainable AI (XAI) frameworks but grounded in reinforcement dynamics.
-
Language-Based Rationales Some agents generate natural language explanations alongside their actions—a capability supported by recent instruction-tuned LLMs. These rationales can be integrated into the reward loop as an explanation-consistency bonus, reinforcing self-explanatory behavior.
-
Safety-Aware RL Algorithms
-
Several specialized RL formulations have been proposed to address safety-critical issues:
-
Constrained Policy Optimization (CPO): Introduced by Achiam et al. (2017), CPO adds hard constraints to the optimization problem to ensure policies respect safety boundaries:
\[\max_\pi J(\pi) \quad \text{s.t.} \quad \mathbb{E}_\pi[C(s,a)] \leq \delta\]- where \(C(s,a)\) is a cost function and (\delta) the safety threshold.
-
Safe Exploration via Risk-Aware Value Functions: Instead of optimizing for expected reward, these methods optimize conditional value-at-risk (CVaR) to limit the probability of catastrophic outcomes.
-
Shielded Reinforcement Learning: Incorporates a formal safety “shield” that intercepts actions violating constraints, replacing them with safe alternatives in real time.
-
Process-Wise Safety Scoring: In complex environments like ToolEnv or MultiTurnEnv, step-wise safety checks are applied per subgoal or API call. For example, in a data retrieval task, each API call is evaluated for compliance and correctness before continuation.
-
These algorithms formalize the notion of safety as part of the optimization loop, integrating constraint satisfaction directly into the learning process.
Human-in-the-Loop (HITL) Evaluation and Oversight
- Human oversight remains a critical element in RL agent safety and evaluation pipelines.
-
HITL systems provide:
- Preference feedback for training reward models (RLHF).
- Trajectory curation for identifying unsafe or unproductive behaviors.
- Live intervention mechanisms, allowing humans to override or halt harmful action sequences.
- Emerging frameworks like Themis and AgentBench incorporate automated auditing layers that flag deviations from normal operating bounds. These can be paired with real-time monitoring dashboards to visualize action probabilities, risk metrics, and outcome confidence.
Benchmarking Frameworks for Safe and Transparent Evaluation
- Comprehensive benchmarking environments now combine safety, reasoning, and tool-use tasks under unified evaluation suites.
-
Notable examples include:
- AgentGym (AgentGym by Xi et al., 2024): A modular environment suite supporting SingleTurn, ToolEnv, and MultiTurn workflows, each with structured reward feedback and failure diagnostics.
- AgentBench (AgentBench by Liu et al., 2024): Provides web, reasoning, and software operation benchmarks with alignment-focused scoring.
- OpenWebVoyager (OpenWebVoyager by He et al., 2024): Realistic browser-based simulation for long-horizon web navigation tasks, used for testing contextual coherence and stability.
- WebArena and Mind2Web: Large-scale web environments supporting reward shaping, human preference integration, and process-level logging for transparency.
- Together, these frameworks enable holistic agent evaluation—capturing not only goal success but also the process integrity and ethical soundness of the learned policies.
Toward Aligned, Interpretable, and Reliable Agentic Systems
-
As agentic RL systems continue to scale, their evaluation and safety mechanisms must evolve from reactive to proactive. Key directions include:
- Embedding interpretability hooks within policy architectures.
- Using multi-objective optimization to balance capability and safety rewards.
- Adopting model-based simulations to test agents before deployment.
- Incorporating continuous monitoring and human-AI collaboration loops for post-deployment oversight.
-
In practice, the next generation of RL-based agents will need to demonstrate:
- Predictable behavior under uncertainty,
- Transparent reasoning chains,
- Explicit accountability for outcomes,
- Continuous adaptability without goal drift.
-
This marks the transition from experimental RL toward governed, auditable intelligence—systems that can be trusted not just to perform, but to behave in alignment with human values and operational safety constraints.
Tool-Integrated Reasoning
- Tool-Integrated Reasoning (TIR) represents a fundamental evolution in the way LLMs learn and reason.
- It moves beyond static text generation into interactive computation, where the model dynamically decides when, why, and how to use external tools (e.g., Python interpreters, APIs) as part of its reasoning trajectory.
- This section synthesizes insights from five foundational papers, grouped by their conceptual contribution and training methodology.
Foundations and Theoretical Advancements in TIR
-
Core Idea: Understanding Tool-Integrated Reasoning by Heng Lin & Zhongwen Xu (2025) formalizes the tool-integrated reasoning loop as a Markov Decision Process (MDP), providing a principled RL framework for training models to use tools effectively. It introduces Advantage Shaping Policy Optimization (ASPO), a variant of PPO that adds adaptive reward shaping to balance process- and outcome-based learning.
-
Mathematical formulation: The ASPO objective is:
\[\mathcal{L}_{\text{ASPO}} = \mathbb{E}_{a\sim \pi_\theta(a|h)}[A(a,h)] - \beta D_{\text{KL}}[\pi_\theta(a|h) || \pi_{\text{ref}}(a|h)]\]- where \(A(a,h)\) is the shaped advantage incorporating both immediate (stepwise) and final (outcome) signals, and \(\beta\) controls regularization against a reference policy.
-
Implementation Highlights:
- Trains a 7B model on symbolic reasoning tasks.
- Adds step-level shaping to encourage timely tool use and verification behavior.
- Significantly stabilizes RL optimization, improving both training and test accuracy by >6%.
Practical Engineering for Stable Multi-Turn TIR
-
Core Idea: SimpleTIR: End-to-End Reinforcement Learning for Multi-Turn Tool-Integrated Reasoning by Xue et al. (2025) addresses the instability problem of multi-turn TIR. It isolates the causes of divergence during RL fine-tuning—such as gradient explosions and unproductive tool calls—and proposes three stabilizing strategies.
-
Key Contributions:
- Input-Gradient Norm Limiter: caps backpropagation magnitude when token probabilities are extremely low.
- Interpreter Output Masking: prevents gradients from flowing through non-learnable tool feedback.
- Void Turn Filtering: removes steps with empty or redundant tool responses.
-
Empirical Findings:
- Using Qwen2.5-7B, SimpleTIR achieves faster convergence on AIME24.
- Gradient clipping alone improved reward variance stability by 25%.
- Masking and filtering yield additional 5–8% accuracy gains.
Scaling Tool-Integrated RL from Base Models
-
Core Idea: ToRL: Scaling Tool-Integrated Reinforcement Learning by Xuefeng Li, Haoyang Zou, & Pengfei Liu (2025) demonstrates that TIR can be trained directly from base models without any supervised fine-tuning, relying entirely on exploration and reinforcement signals. This approach bridges outcome-based reward optimization with emergent process behavior, such as model self-verification.
-
Training Design:
- Trains Qwen2.5-based models (1.5B and 7B) on five mathematical reasoning datasets.
-
Uses a pure correctness reward:
\[R(a, \hat{a}) = \begin{cases} 1, & \text{if } a = \hat{a} \\ -1, & \text{otherwise} \end{cases}\] - No explicit shaping; only final-answer feedback drives learning.
-
Results:
- ToRL-7B: 43.3% on AIME24, 62.1% across math benchmarks.
- Emergent behaviors: self-verification and reflection loops, despite outcome-only reward.
- Uses only 28.7K training problems distilled from 75K candidates.
-
The following figure (source) shows an example of CoT and TIR solution of the problem. TIR enables the model to write code and call an interpreter to obtain the output of the executed code, and then perform further reasoning based on the execution results.

Code-Interleaved Reinforcement for Tool Use
-
Core Idea: ReTool: Reinforcement Learning for Strategic Tool Use in LLMs by Jiazhan Feng et al. (2025) establishes a robust training pipeline for tool-integrated reasoning through interleaved code execution. It uses real-time interpreter feedback during RL rollouts to optimize for both tool efficiency and correctness.
-
Training Stages:
- Cold-Start SFT on a verified code-integrated dataset \(D_{\mathrm{CI}}\).
- Interleaved PPO where each generated code snippet is executed mid-rollout.
-
Modified PPO Objective:
\[J_{\text{ReTool}}(\theta) = \mathbb{E}\Big[\min\Big(\frac{\pi_\theta(o_t|s_t;\text{CI})}{\pi_{\text{old}}(o_t|s_t;\text{CI})}\hat{A}_t, \text{clip}(\cdot)\hat{A}_t\Big)\Big]\] -
Key Findings:
- Yields 27% higher accuracy over text-only PPO on AIME24.
- Reduces reasoning token length by 40%.
- Learns strategic invocation—earlier, more efficient, and self-corrective tool calls.
-
The following figure (source) shows text-based RL training process and ReTool’s RL training process.
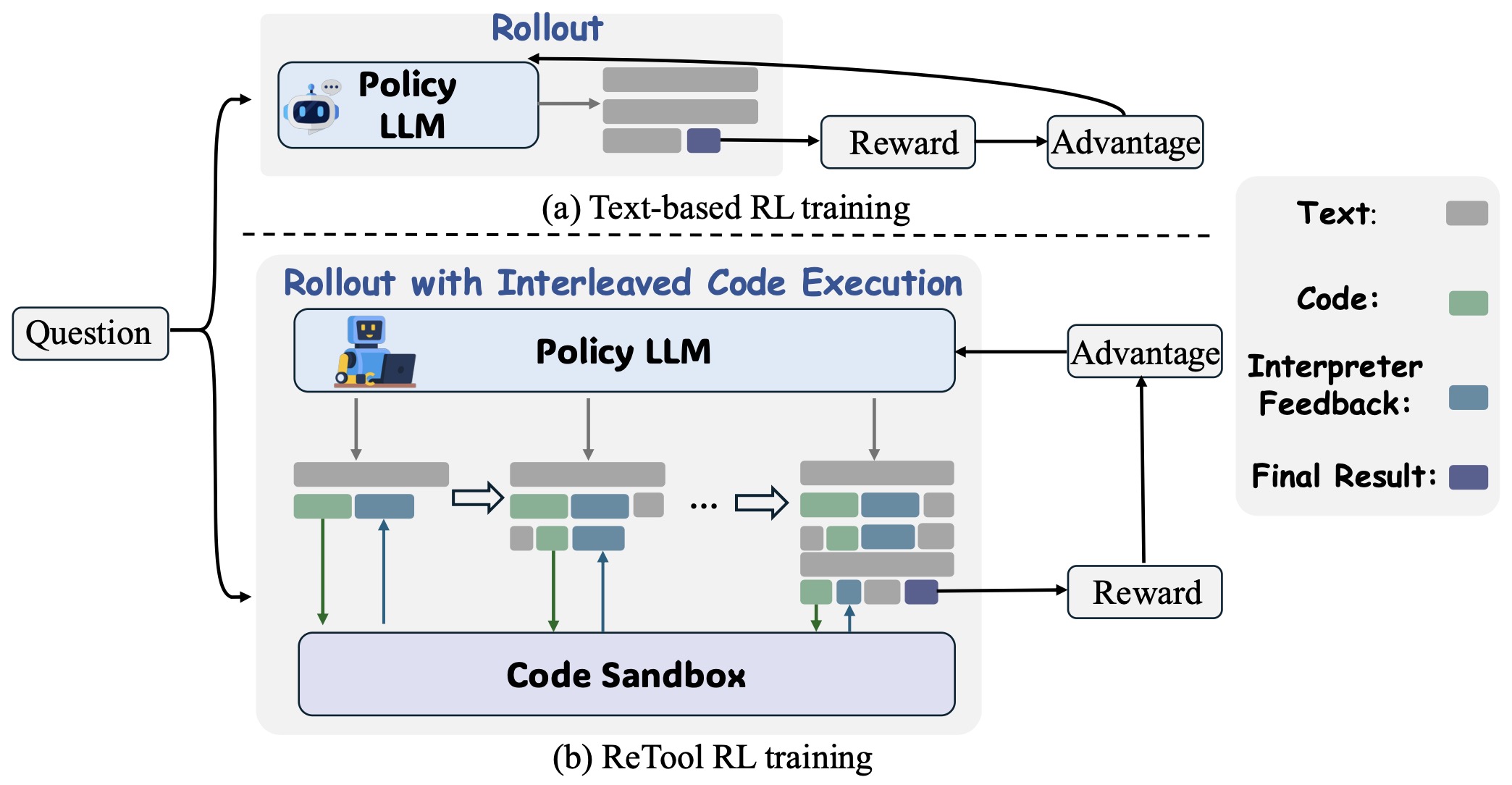
Tool-Augmented Evaluation Agents
-
Core Idea: Incentivizing Agentic Reasoning in LLM Judges via Tool-Integrated Reinforcement Learning by Ran Xu et al. (2025) extends TIR to evaluation agents (judges), which assess model outputs using executable verification tools. It integrates reinforcement learning to make LLM judges agentic—capable of reasoning, verifying, and scoring autonomously.
-
Methodology:
- Trains judges on three evaluation paradigms: pointwise, pairwise, and listwise.
-
Each trajectory involves both reasoning and code execution: \((r_k, c_k) \sim J_\theta(x \oplus s_{k-1}), \quad o_k = I(c_k), \quad s_k = s_{k-1} \oplus r_k \oplus c_k \oplus o_k.\)
-
Two variants:
- TIR-Judge-Distill: RL fine-tuning from distilled checkpoint.
- TIR-Judge-Zero: trained from scratch via self-play RL.
-
Results:
- TIR-Judge-Zero performs comparably to distilled models.
- Improves pairwise evaluation accuracy by +7.7%.
- Enables verifiable judgment by using executable tool outputs.
-
The following figure (source) shows the overall framework of TIR-Judge variants. TIR-Judge natively supports tool use during judgment and is designed to handle diverse input formats.
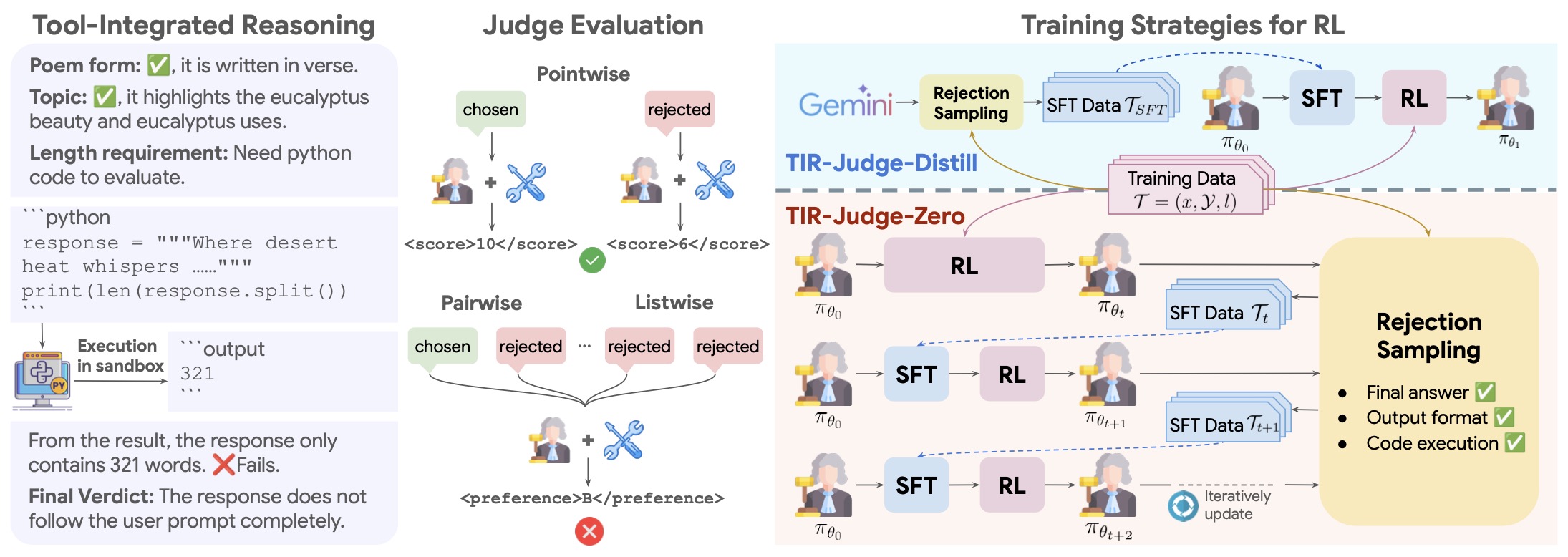
Synthesizing Trends in TIR + RL Integration
- Across these works, TIR emerges as the unifying interface between language and computation. Each study progressively strengthens one aspect of the TIR-RL ecosystem:
| Group | Representative Paper | Main Contribution | Reward Type | Emergent Capability |
|---|---|---|---|---|
| 1 | Understanding TIR | Theoretical formalization (ASPO) | Stepwise + Outcome | Advantage shaping & stability |
| 2 | SimpleTIR | Stabilization in multi-turn settings | Stepwise | Controlled gradient flow |
| 3 | ToRL | Scaling from base models | Outcome-only | Emergent verification |
| 4 | ReTool | Interleaved code execution | Outcome-only | Strategic tool use |
| 5 | TIR-Judge | Tool-augmented evaluation | Multi-level | Self-verifying reward models |
- Together, these advances redefine RL for reasoning agents: from optimizing token probabilities to optimizing interactive decision-making with verifiable computation.
Synthesis: Beyond Individual Tool Use
- Together, these works outline a continuum of Tool-Integrated RL:
| Framework | Focus | Environment Type | Key Mechanism | Performance Gain |
|---|---|---|---|---|
| Li et al. (2025) | Mathematical reasoning | SingleTurnEnv | Code-augmented execution | +13% accuracy |
| Xue et al. (2025) | Multi-API orchestration | ToolEnv | Composite action sequencing | +35% efficiency |
| Lin et al. (2025) | Multi-agent collaboration | MultiTurnEnv | Cooperative reward sharing | –42% exploration cost |
-
These studies collectively show that tool use is no longer a static feature, but a learned behavior—optimized via RL to balance exploration, compositionality, and cooperation.
-
By embedding tool invocation into the policy space and integrating reward feedback from external computation, TIR-RL agents represent a new class of hybrid intelligence—merging the symbolic precision of tools with the adaptive learning of reinforcement.
Unifying RL and TIR: Process vs. Outcome Rewards
-
TIR-based RL frameworks bridge process-wise and outcome-based rewards.
- Process rewards measure reasoning correctness at intermediate tool-use steps (e.g., code executes without error).
- Outcome rewards evaluate the final correctness or verification success.
-
The total return function becomes:
\[R = \sum_t \lambda_p r_t^{\text{process}} + \lambda_o r_t^{\text{outcome}}\]- … balancing exploration of intermediate reasoning paths and end-task accuracy.
-
This hybrid reward scheme is now central in environments like ToolEnv and MultiTurnEnv, enabling nuanced optimization of reasoning workflows.
Synthesis and Outlook
-
Tool-Integrated Reasoning (TIR) provides the operational bridge between language and action. When fused with RL:
- It transforms reasoning into a closed-loop control process.
- It grounds learning in executable feedback, reducing hallucination.
- It yields agents capable of self-verification, self-correction, and self-improvement.
-
In sum:
- ReTool formalized RL for tool-based reasoning.
- TIR-Judge extended RL-based tool reasoning to evaluation.
- Li et al. (2025), Xue et al. (2025), and Lin et al. (2025) unified the landscape of tool-integrated reinforcement learning by demonstrating that RL-trained agents can autonomously discover, schedule, and verify tool use—laying the groundwork for scalable, self-improving reasoning systems.
-
Collectively, these works mark the beginning of agentic cognition—where models reason, act, and verify within the same policy loop.
Citation
@article{Chadha2020DistilledRLForAgents,
title = {Reinforcement Learning for Agents},
author = {Chadha, Aman and Jain, Vinija},
journal = {Distilled AI},
year = {2020},
note = {\url{https://aman.ai}}
}