Introduction
- LLaMA (paper; blog) is a collection of language models released by Meta AI (FAIR).
- LLaMA is open source, unlike ChatGPT or GPT-4, available to the public on this Github repository.
- It’s important to note however that while the code is available for the public, the weights are only available once you confirm your use case does not involve commercial use.
- Inspired by Chinchilla’s scaling laws paper, the LLaMA paper proposes a set of “small” large language models that outperform GPT-3 (175B) with >10x fewer parameters (13B). And a larger 65B version outperforms PaLM-540B. In sum, the paper proposes smaller open-source models trained on public data that outperform some of the proprietary LLMs created in recent years.
- The LLaMA models, which outperform GPT-3, are a welcome alternative to previous open-source models like OPT and BLOOM, which are said to underperform GPT-3.
Architectural Design Decision
- Below are some of the architectural design decision LLaMA used to improve performance and outpace recent LLMs; the smallest (7B) model is on par with GPT-3 on many language tasks.
- The LLaMA architecture adopts four architectural modifications compared to the original Transformer:
- RMSNorm for pre-normalization
- Rotary embeddings
- SwiGLU activation function
- Attention optimizations
Pre-normalization
- To improve the training stability, LLaMA normalizes the input of each transformer sub-layer, instead of normalizing the output. LLaMA use the RMSNorm normalizing function.
- Pre-normalization is a technique that normalizes the input data before its fed into the neural network.
- The aim here is to improve the efficiency and stability of the training process by normalizing and reducing variation and correlation of the input features.
- Pre-normalization can take many forms, but the most common method is to subtract the mean and divide by the standard deviation of each feature across the training dataset.
- This ensures that the mean of each feature is zero and the standard deviation is one, which can make it easier for the neural network to learn the relationships between the features without being overly affected by their scales or magnitudes.
-Pre-normalization can be especially important when dealing with features that have vastly different scales or magnitudes, as this can cause the neural network to overemphasize some features and underemphasize others.
- By pre-normalizing the data, these differences are accounted for, and the neural network can better learn the underlying patterns and relationships in the data
SwiGLU activation function (Swish-Gated Linear Unit)
- LLaMA replaces the ReLU non-linearity by the SwiGLU activation function, introduced by Shazeer (2020) in Swish-Gated Linear Units for Neural Network Function Approximation to offer better performance.
- The SwiGLU activation function is based on the Swish activation function, which is a smooth and non-monotonic function that has been shown to outperform other commonly used activation functions such as ReLU and sigmoid in certain neural network architectures.
\[SwiGLU(x) = x * sigmoid(beta * x) + (1 - sigmoid(beta * x)) * x\]
- Experimental results have shown that SwiGLU can outperform other activation functions such as ReLU, Swish, and GELU (Gaussian Error Linear Units) on certain image classification and language modeling tasks.
- However, the effectiveness of SwiGLU can depend on the specific architecture and dataset used, so it may not always be the best choice for every application.
Rotary Positional Embeddings
- LLaMA does not utilize absolute positional embeddings to embed the notion of sequentiality of information as in the original Transformer, and instead, utilize Rotary Positional Embeddings (RoPE), introduced by Su et al. (2021) in Rotary Position Embedding, at each layer of the network.
- The basic idea behind rotary embeddings is to introduce additional structure into the position embeddings used in deep learning models. Position embeddings are used to encode the position of each element in a sequence (such as a word in a sentence) as a vector, which is then combined with the corresponding element embedding to form the input to the model.
- In traditional position embeddings, the vectors representing different positions are orthogonal to each other. However, this orthogonality can lead to certain symmetries in the model, which can limit its expressive power.
- Rotary embeddings address this issue by introducing a phase shift between the position embeddings for different dimensions. This phase shift is achieved using a matrix that has a special form based on the properties of rotations in high-dimensional space. The resulting embeddings are no longer orthogonal, but they preserve certain rotational symmetries that can make the model more expressive.
- Experimental results have shown that rotary embeddings can improve the performance of deep learning models on certain tasks, such as machine translation and language modeling.
Attention Optimizations
- LLaMA uses both memory efficient attention and FlashAttention, which offer an efficient implementation of the causal multi-head attention to reduce memory usage and runtime. The former present a very simple algorithm for attention that requires \(O(1)\) memory with respect to sequence length and an extension to self-attention that requires \(O(\log{n})\) memory.
- This is achieved by not storing the attention weights and not computing the key/query scores that are masked due to the causal nature of the language modeling task. This, in turn, helps improve the training efficiency and time-to-convergence.
- This also means that it would likely be possible to extend the context length to something much larger.

Visual Summary
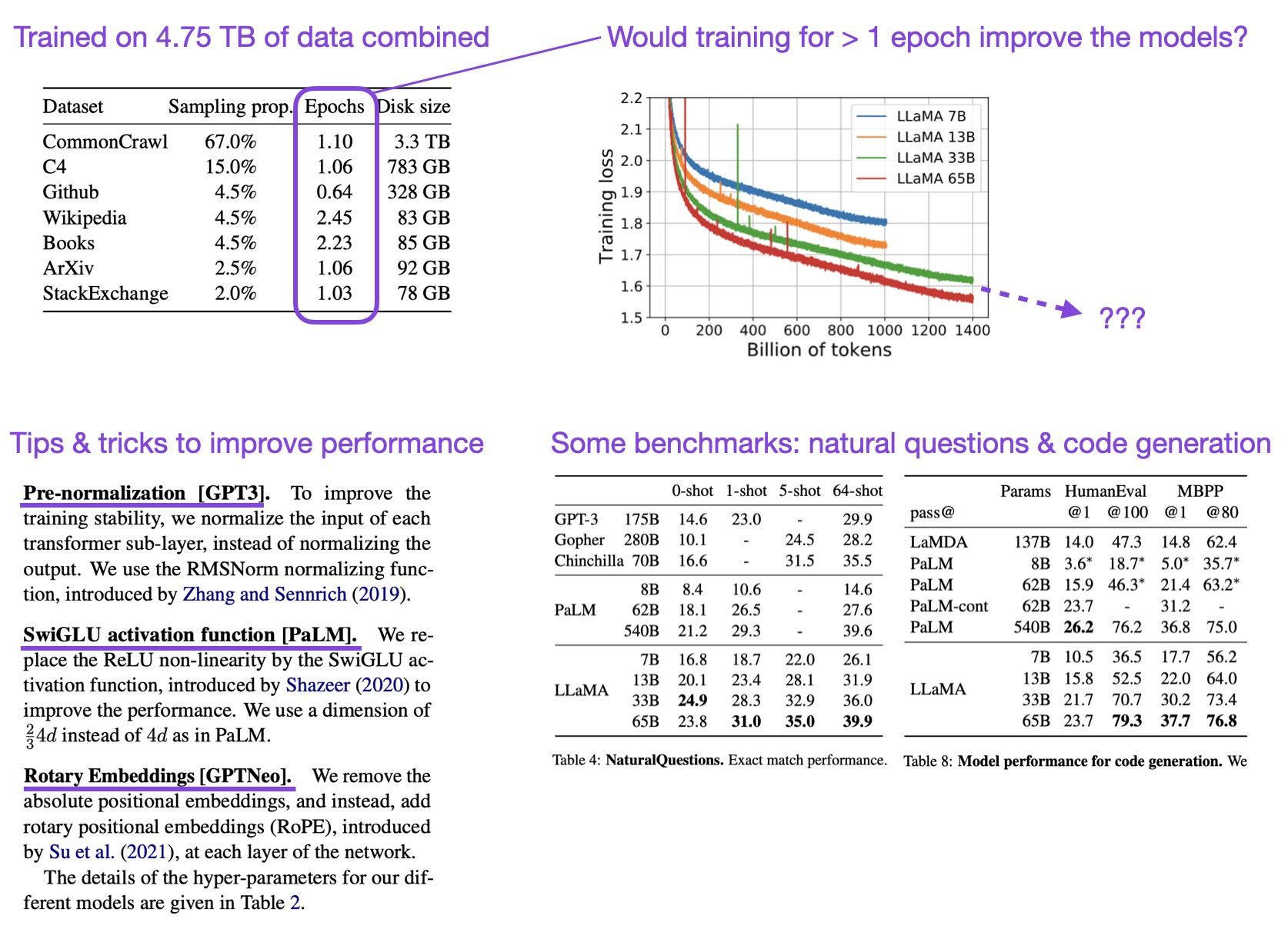
- The following visual summary by Sebastian Raschka details the methods LLaMA used to achieve this performance: pre-normalization, SwiGLU activations, and Rotary Embeddings. Sebastian Rashcka also points out that the plots show a steep negative slope when showing the training loss versus the number of training tokens, indicating that the authors should have trained the model for more than 1-2 epochs.
Model Variants
- LLaMA is available in several sizes (7B, 13B, 33B, and 65B parameters).
Training Protocol
- LLaMA 65B and LLaMA 33B are trained on 1.4 trillion tokens while LLaMA 7B, is trained on 1 trillion tokens.
- LLaMA was trained like most language models, it took an input of a sequence of words and worked on predicting the next word.
- It was trained on 20 different languages with a focus on Latin and Cyrillic alphabets.
Results
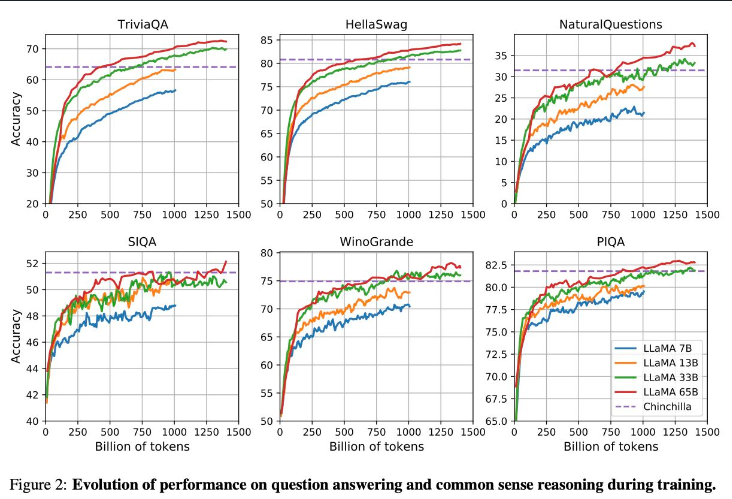
- LLaMA-13B outperforms GPT-3 (175B) on most benchmarks.
- LLaMA-65B is competitive with the best models, Chinchilla70B and PaLM-540B.
Llama 3
- Llama 3 by Meta offers substantial enhancements and novelties in the capabilities of the model. An analysis of its development illustrates a significant advance over its predecessors in multiple aspects, reflecting a sustained effort towards refining language model technology.
- Tokenizer Enhancements: Llama 3 has seen a notable expansion in its tokenizer capacity, increasing from 32,000 tokens in Llama 2 to 128,000 tokens. This enlargement allows for more efficient sequence compression, with a reduction in sequence length by approximately 15%, thus potentially enhancing downstream task performance due to a denser information representation.
- Architectural Developments: Despite no radical changes in the overall architecture from Llama 2, all variants of Llama 3 now incorporate Grouped Query Attention (GQA), a scheme previously reserved for larger models. GQA facilitates a more compact representation of the keys/values in the Attention mechanism, significantly reducing the footprint of the Key-Value (KV) cache during inference, thus optimizing computational efficiency.
- Sequence Length Capacity: The context window for Llama 3 has been increased to 8,192 tokens, up from 4,096 in Llama 2 and 2,048 in Llama 1. While this expansion is modest compared to the capabilities of models like GPT-4, which supports up to 128,000 tokens, it marks a progressive improvement, with potential future enhancements in subsequent versions.
- Training Data Scope: The training dataset size for Llama 3 has escalated dramatically to 15 trillion tokens, a substantial increment from the 2 trillion tokens used for Llama 2. This dataset not only focuses on English but also includes a 5% representation from over 30 different languages, incorporating a richer diversity in data, albeit still predominantly English-centric.
- Scaling Laws and Efficiency: The utilization of a 15 trillion token dataset to train a model with 8 billion parameters represents an unconventional approach by current standards, where such large datasets are typically reserved for much larger models. Meta’s approach indicates a shift towards maximizing model capability and efficiency beyond traditional compute-to-performance ratios, as indicated by scaling laws such as those outlined in the Chinchilla study.
- Systems and Infrastructure: Llama 3’s training was executed on a system of 16,000 GPUs, achieving an observed throughput of 400 TFLOPS. This figure suggests approximately 40% utilization of the peak theoretical output based on NVIDIA’s stated capabilities for the H100 GPUs at fp16 precision, acknowledging the adjustments required for realistic sparsity conditions.
- Model “Strength”: Incorporating insights from the model card for Llama 3, the performance comparison between the 8 billion parameter version (Llama 3 8B) and the larger 70 billion parameter version (Llama 2 70B) reveals intriguing nuances. Notably, Llama 3 8B, which was trained with a staggering 15 trillion tokens, exhibits comparable performance to Llama 2 70B, which was trained with just 2 trillion tokens. This discrepancy in training data volume underscores the significant impact of extensive training on model performance.
- Performance Metrics Based on Computational Training: The metrics defining the strength of Llama 3 8B highlight its computational intensity. The model accrued approximately \(1.8 \times 10^{24}\) floating point operations (FLOPs) over 1.3 million GPU hours, assuming a throughput of 400 TFLOPS. In contrast, an alternative calculation method estimating FLOPs as \(6ND\) (where \(N\) is the number of parameters and \(D\) is the number of tokens) yields approximately \(7.2 \times 10^{23}\) FLOPs, suggesting some variability in these estimates. Prioritizing the more comprehensive GPU hours calculation, Llama 3 8B’s total computational input stands around \(2 \times 10^{24}\) FLOPs.
- Comparative Analysis with Llama 3 70B and 400B Models: For Llama 3 70B, the computational input is substantially higher, reaching approximately \(9.2 \times 10^{24}\) FLOPs calculated over 6.4 million GPU hours, which aligns closely with the alternative method’s estimate of \(6.3 \times 10^{24}\) FLOPs. Should the 400 billion parameter model train on the same dataset, the expected computational investment would scale up to approximately \(4 \times 10^{25}\) FLOPs. This projection places it just below the threshold outlined in regulatory frameworks such as the recent Biden Executive Order, which sets a reporting requirement at \(1 \times 10^{26}\) FLOPs.
- The Significance of Data Quality and Comprehensive Model Evaluation: Beyond raw computational power, the quality of training data plays a critical role in shaping a model’s effectiveness. The integration of diverse and high-quality data can significantly enhance model performance, emphasizing the importance of not reducing the model’s capability to merely its computational input. However, when simplifying the comparison across models, total FLOPs provide a useful measure, amalgamating the scale of the model and the extent of its training into a singular metric indicative of its overall ‘strength.’
- In conclusion, Llama 3’s architecture and training regimen illustrate Meta’s strategic emphasis on maximizing model efficiency and performance through both scaled parameter counts and extensive training, setting new benchmarks in the landscape of language models. This approach not only boosts performance but also extends the model’s applicability and utility across a wider range of tasks and scenarios.
- Conclusion: The advancements in Llama 3 underscore Meta’s commitment to pushing the boundaries of what small yet powerfully trained models can achieve. This strategy not only enhances the capabilities of such models but also broadens their applicability in real-world scenarios, paving the way for future innovations in machine learning landscapes. Moreover, the anticipation surrounding the potential release of a 400 billion parameter model highlights the community’s eagerness for more robust, accessible AI tools, reflecting a growing trend towards democratizing high-performance computational models.
- Blog; Model Demo; Model Card; TorchTune