Primers • Gemini
Overview
- Proposed in Gemini: A Family of Highly Capable Multimodal Models, Google’s Gemini series represents a milestone in AI development, featuring three models: Ultra, Pro, and Nano, each tailored for specific tasks ranging from complex problem-solving to on-device operations. Gemini Ultra, the flagship model, excels in demanding tasks and sets new benchmarks in AI performance. Gemini Pro is optimized for a wide range of tasks, while Nano is designed for efficiency in on-device applications. This suite of models, part of Google DeepMind’s vision, marks a significant scientific and engineering endeavor for the company.
- Gemini models are built with a transformative architecture that allows for a “deep fusion” of modalities, surpassing the capabilities of typical modular AI designs. This integration enables seamless concept transfer across various domains, such as vision and language. The models, trained on TPUs, support a 32k context length and are capable of handling diverse inputs and outputs, including text, vision, and audio. The visual encoder, inspired by Flamingo, and the comprehensive training data, comprising web documents, books, code, and multimedia, contribute to the models’ versatility.
- The figure below from the paper illustrates that Gemini supports interleaved sequences of text, image, audio, and video as inputs (illustrated by tokens of different colors in the input sequence). It can output responses with interleaved image and text.
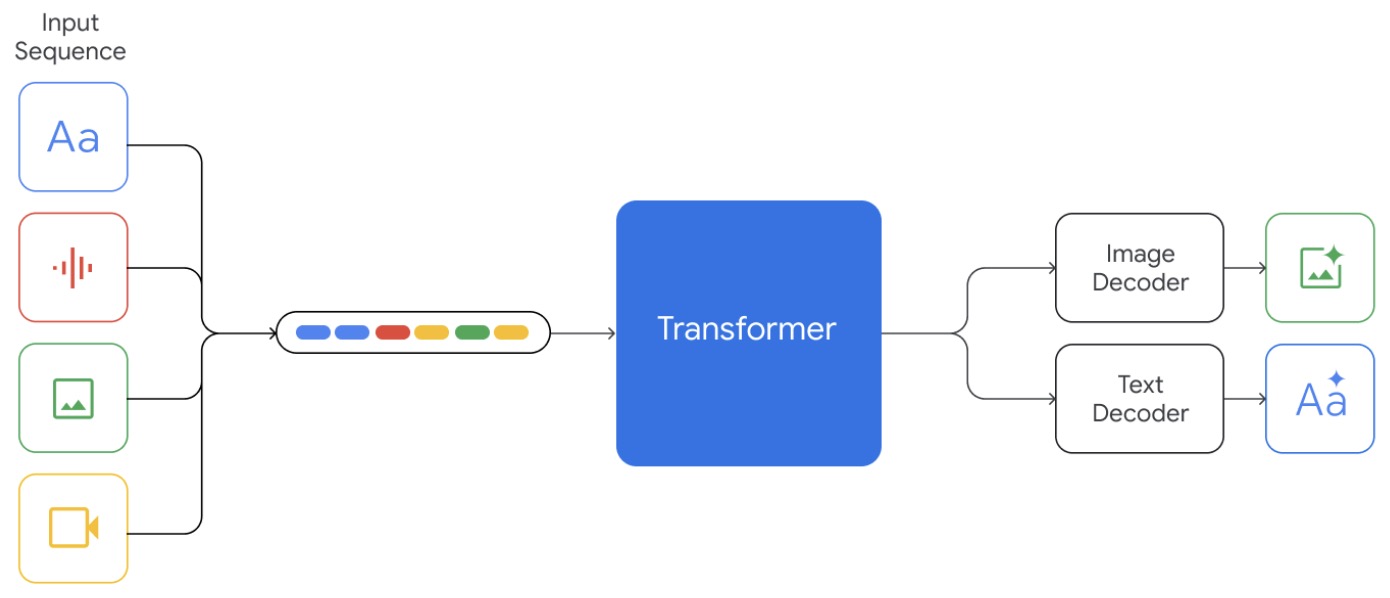
- The training infrastructure for Gemini utilizes Google’s latest TPU v4 and v5e accelerators, ensuring efficient scaling and reliable performance at an unprecedented scale. This advanced setup is integral to handling hardware failures and silent data corruption, ensuring high-quality training outcomes.
- The training dataset is multimodal and multilingual, with quality and safety filters to enhance model performance. The dataset mix is adjusted during training to emphasize domain-relevant data, contributing to the models’ high performance.
- Gemini Ultra showcases extraordinary capabilities across various benchmarks, surpassing GPT-4 in areas like coding and reasoning. Its performance in benchmarks like HumanEval and Natural2Code, as well as its superior reasoning capabilities in complex subjects like math and physics, demonstrate its state-of-the-art capabilities. For instance, the figure below from the paper shows solving a geometrical reasoning task. Gemini shows good understanding of the task and is able to provide meaningful reasoning steps despite slightly unclear instructions.

- Furthermore, in another instance, the figure below from the paper shows Gemini verifying a student’s solution to a physics problem. The model is able to correctly recognize all of the handwritten content and verify the reasoning. On top of understanding the text in the image, it needs to understand the problem setup and correctly follow instructions to generate LaTeX.

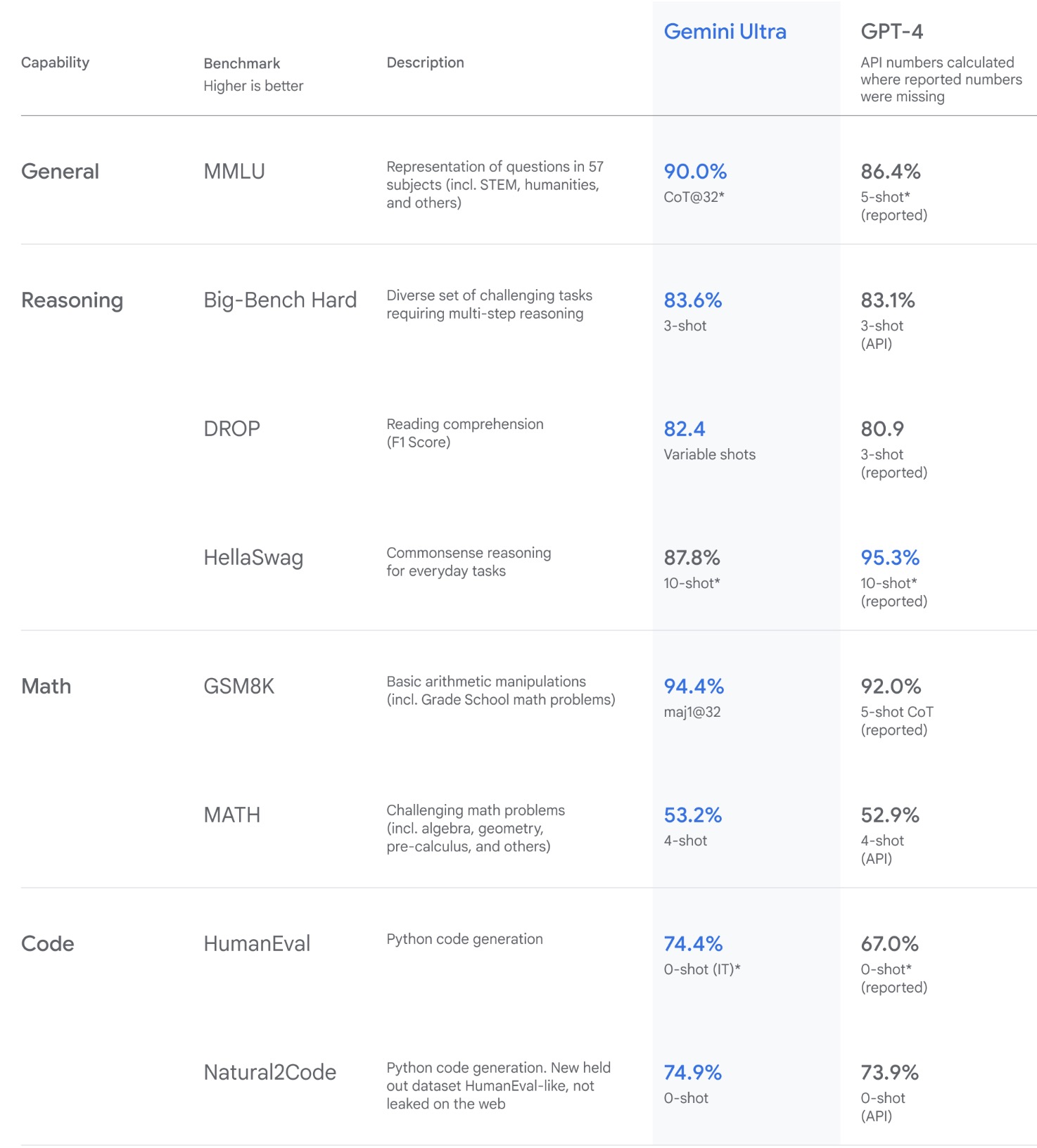
- Gemini outperforms OpenAI’s GPT-4 in 30 out of 32 benchmarks. Furthermore, it’s worth noting is that Gemini Ultra is the first model to outperform human experts on MMLU (massive multitask language understanding). The following table from Google’s blog Gemini surpasses state-of-the-art performance on a range of benchmarks including text and coding.
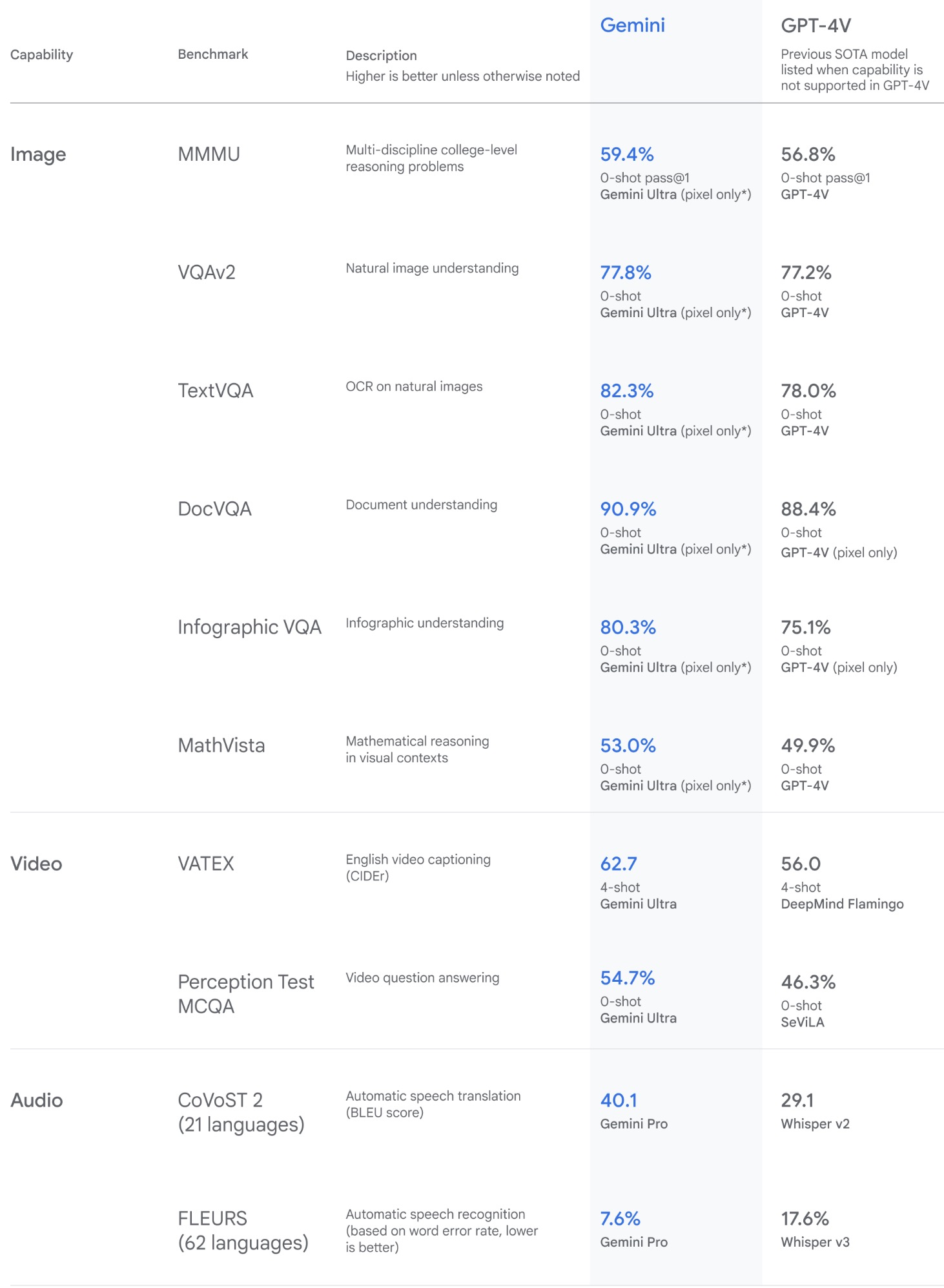
- For image understanding, Gemini Ultra sets new standards by outperforming existing models in zero-shot evaluations for OCR-related tasks. Its native multimodality and complex reasoning abilities enable it to excel in interpreting and reasoning with visual information. The following table from Google’s blog Gemini surpasses state-of-the-art performance on a range of multimodal benchmarks.
- Gemini’s training involves Reinforcement Learning from Human Feedback (RLHF), enhancing its performance and capabilities. This advanced training, combined with its innovative architecture and diverse dataset, contributes to its exceptional performance across various tasks.
- Despite its remarkable capabilities, specific details about Gemini’s architecture, training data, and the size of the Ultra and Pro models remain undisclosed. However, the models represent a significant leap in AI development, driven by the promise of AI to benefit humanity in diverse ways.
- Safety and responsibility are central to Gemini’s development, with comprehensive safety evaluations for bias and toxicity. Google is collaborating with external experts and partners to stress-test the models and ensure they adhere to robust safety policies, aligning with Google’s AI Principles.
- Gemini’s capabilities and its development approach reflect Google’s commitment to advancing AI responsibly and ethically, emphasizing safety and collaboration with the industry and broader ecosystem to define best practices and safety benchmarks.
- Blog.
Results
-
Google Gemini was marketed as the first legitimate OpenAI competitor. While model performance was embellished via selective prompting techniques, Gemini Pro performs comparably to GPT-3.5-Turbo in 3rd party evaluations and the multimodal capabilities of Gemini rival those of GPT-4V! Gemini distinguishes itself based on the following aspects:
-
Native multimodality: Gemini models are “natively multimodal”, meaning that multimodal data is used throughout the entire training process. The approach adopted by Gemini allows a deeper understanding of each data modality to be formed.
-
More data modalities: Most MLLMs focus upon two modalities of data—usually text and images—at most. The Gemini models are capable of ingesting text (and code), images, videos, and audio signals. Plus, Gemini models can produce both text and images as output!
-
Directly ingesting data: One can build a “multimodal” LLM by converting different data modalities into text before feeding it into the LLM. However, Gemini avoids such an approach, instead directly ingesting data from each modality to form a better representation.
-
Important benchmarks/evals: A variety of empirical evaluations are performed in the Gemini technical report, but two benchmarks were heavily marketed:
- MMLU: Gemini Ultra is the first model to achieve a score of >90% and surpass human-level accuracy.
- MMMU: Gemini Ultra outperforms prior work by 5% absolute when solving complex multimodal problems.
-
-
There is one important caveat in these results—the prompting strategy. Gemini is evaluated using different (specialized) prompting strategies that are not used by prior work in obtaining these evaluations. However, Gemini models still perform comparably to OpenAI models when prompting strategies are standardized!
-
3rd party evals: After its release, Gemini was evaluated by several (non-biased) groups of 3rd party researchers, such as Akter et al. (2023). The results of this analysis are:
- Gemini Pro is (slightly) worse than GPT-3.5-Turbo on text-based tasks.
- Gemini excels at generating non-English output.
- Gemini is better at handling longer and more complex reasoning chains.
- Gemini Pro and GPT-4V have comparable visual reasoning capabilities.
- Overall, the performance of Gemini seems to hold up in the face of 3rd party analysis, even if the performance is not quite as good as advertised.
-
Edge devices: Google released several sizes of Gemini—Ultra (biggest, for complex problems), Pro (medium sized model for scalable deployment), and Nano (1.8B and 3.25B models for on-device applications).
-
Multilinguality: Finally, Gemini has impressive multilingual capabilities. For example, Gemini can perform video captioning in Chinese, transcribe text from images in languages other than English, and perform automatic speech translation given an audio stream as input.
-
-
The following figure (source) summarizes the various aspects highlighted above:
