Models • CLIP
- Overview
- Contrastive Pretraining
- Architecture of CLIP
- Learning process
- Statistics on CLIP
- CLIP vs. Human
- CLIP Code walk-through
- CLIP Cons
- Parting Notes
- References
Overview
- OpenAI’s Contrastive Language Image Pretraining (CLIP) model was released in 2021 during a time when text-based transformer models such as GPT-3 were competitive on many tasks with little to no task-specific training.
- CLIP was the breakthrough vision model that proved that we could leverage the same methodology that GPT used for text (i.e., large-scale weak supervision), for vision and not need to train on task specific data.
- CLIP model is a zero-shot, multi-modal model that uses contrastive loss for pre-training.
- CLIP is able to predict the most relevant text/caption for an image without optimizing for any particular task.
- CLIP has been pretrained using 400 million (image, text) pairs for predicting the caption(s) that go with a particular image.
- It was also found that zero-shot CLIP model is often equivalent to fully supervised baseline models trained on ImageNet.
Contrastive Pretraining
- Contrastive learning is a method of training the AI model to tell the difference between similar things and dissimilar things, using a contrastive loss.
- More specifically, say you have a batch of $N$ (image, text) pairs, CLIP jointly trains an image encoder and a text encoder to predict which $N \times N$ possible (image, text) pairings are likely.
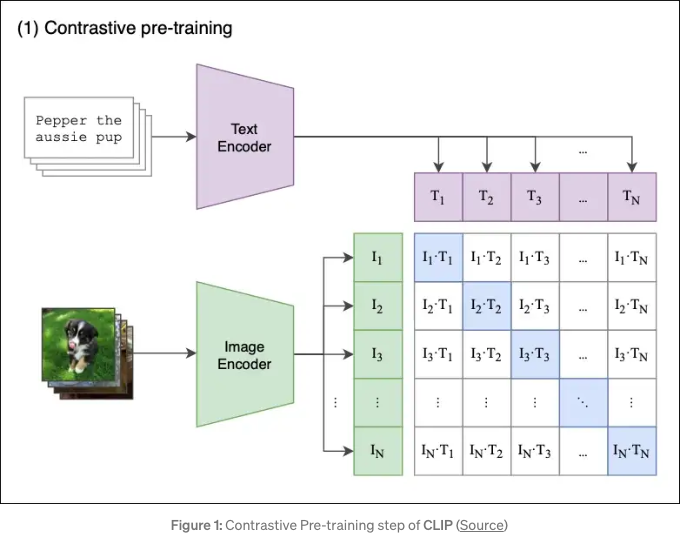
- As we see in the image above (source), you have a caption and a text encoding for that caption as well as an image and an image encoding for that image.
- In a multimodal way, you joint train both the image and the text together and try to maximize their pairwise cosine similarity (measure of closeness).
- In the image above, that translates to us wanting to maximize the diagonal in the matrix while minimizing all other elements.
- The loss used here is a cross entropy loss computed between logits and labels in the x, y direction and then averaged.
- “Contrastive Language: With this technique, CLIP is trained to understand that similar representations should be close to the latent space, while dissimilar ones should be far apart.” Towards Data science

Architecture of CLIP
- CLIP is architecture agnostic. You can use any models for the visual and text encoders.
- Now lets get into the architecture of CLIP.
- Image:
- The image encoder in CLIP computes the image embeddings using ResNet-50 or ResNet-101 or Vision Transformer (ViT).
- Text:
- For the text encoder, CLIP typically uses the Transformer architecture with the following configuration:
- 63 million parameters
- 12 layers
- 512 hidden layers
- 9 attention heads with masked self attention
- For the text encoder, CLIP typically uses the Transformer architecture with the following configuration:
- These models have been trained from scratch rather than with pretrained weights of say, ImageNet or text encoder with pre-trained weights.
Learning process
-
Here’s a step-by-step breakdown of how CLIP works:
- The model receives a batch of \((image, text)\) pairs.
- The text encoder is a standard Transformer model, say GPT2. The image encoder can be either a ResNet or a Vision Transformer.
- For every image in the batch, the Image Encoder computes an image vector. The first image corresponds to the
I1vector, the second toI2, and so on. Each vector is of sizede, wheredeis the size of the latent dimension. Hence, the output of this step is \(\mathrm{N} \times\)dematrix. - Similarly, the textual descriptions are squashed into text embeddings \([`T1`, `T2`, ..., `TN`]\), producing a \(N \times\)
dematrix. - Finally, we multiply those matrices and calculate the pairwise cosine similarities between every image and text description. This produces an \(N \times N\) matrix.
- The goal is to maximize the cosine similarity along the diagonal - these are the correct $(image, text)$ pairs. In a contrastive fashion, off-diagonal elements should have their similarities minimized (e.g.,
I1image is described byT1and not byT2,T3,T4, etc).
-
A few extra remarks:
- The model uses the symmetric cross-entropy loss as its optimization objective. This type of loss minimizes both the image-to-text direction as well as the text-to-image direction (remember, our contrastive loss matrix keeps both the (
I1,T2) and (I2,T1) cosine similarities). - Contrastive pre-training is not entirely new. It was introduced in previous models and was simply adapted by CLIP.
- The model uses the symmetric cross-entropy loss as its optimization objective. This type of loss minimizes both the image-to-text direction as well as the text-to-image direction (remember, our contrastive loss matrix keeps both the (
Zero-Shot CLIP
- Zero shot classification with CLIP seems to perform as well as supervised classifiers.
- CLIP uses the class names of the image as captions, for example, if the image is of a dog, it will use it’s breed as the caption.
- Zero shot essentially means CLIP can recognize and classify objects in new images even if it has not seen those objects during its pretraining (with both text and image) on the larger dataset.
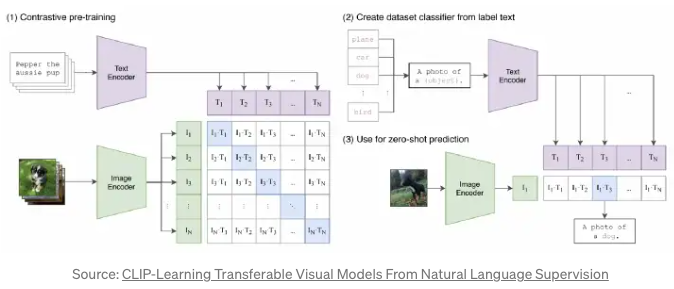
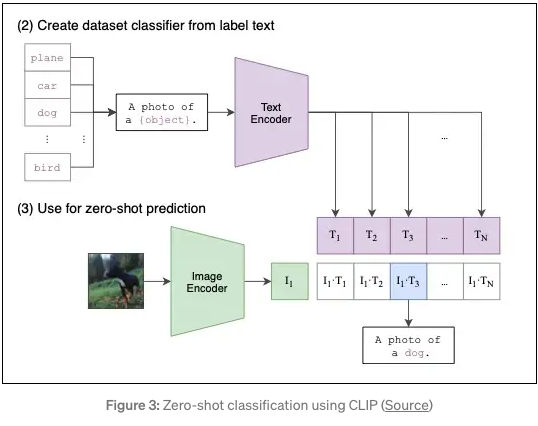
- The above image shows how CLIP works for zero-shot prediction:
- Per usual, we provide a text caption and an image that are encoded into text and image embeddings, respectively.
- CLIP will then compute the pairwise cosine similarities between the image and text embeddings and choose the text with the highest similarity as the prediction.
- CLIP also caches the input text embeddings as to save on compute for the rest of the input images.
Few-Shot CLIP
- Few-shot learning allows CLIP to classify new objects with only a small number of labeled examples.
- This is done by fine-tuning the pre-trained model on a small dataset of labeled images which allows it to learn to recognize the new objects with a small amount of data.
- Few-shot CLIP can be used in situations where there is limited labeled data available for a task or if the model needs to be quickly adapted to new classes.
Statistics on CLIP
- Below statistics on CLIP are provided by towards data science:
- CLIP is trained with 400 million image-text pairs. For comparison, the ImageNet dataset contains 1.2 million images. This is due to the fact that weak supervision typically requires a larger amount of data compared to full supervision (in other words, you are trading off data supervision for data volume).
- CLIP was trained on 256 V100 GPUs for two weeks. For on-demand training on AWS Sagemaker, this would cost at least $200k!
- CLIP uses a minibatch of 32,768 images for training.
- CLIP achieves the same accuracy as a SOTA ResNet model on ImageNet, even though CLIP is a zero-shot model.
CLIP vs. Human
- Let’s look at an interesting comparison of CLIP’s performance vs. humans.
- An experiment was run on the dataset Oxford IIT Pets and the task was to select which of the 37 cat or dog breed caption best matched the image.
- 5 humans ran this experiment along with CLIP.
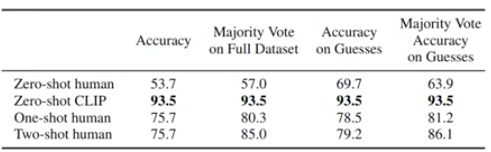
- As the results above show, zero-shot CLIP outperformed zero-shot human in 100% of the datasets they were tested with!
- Not only that, zero-shot CLIP further outperformed humans in one and two shot human tasks performed on all the datasets.
-
Albeit this experiment only ran on 5 human, CLIP was still able to outperform them and its astonishing.
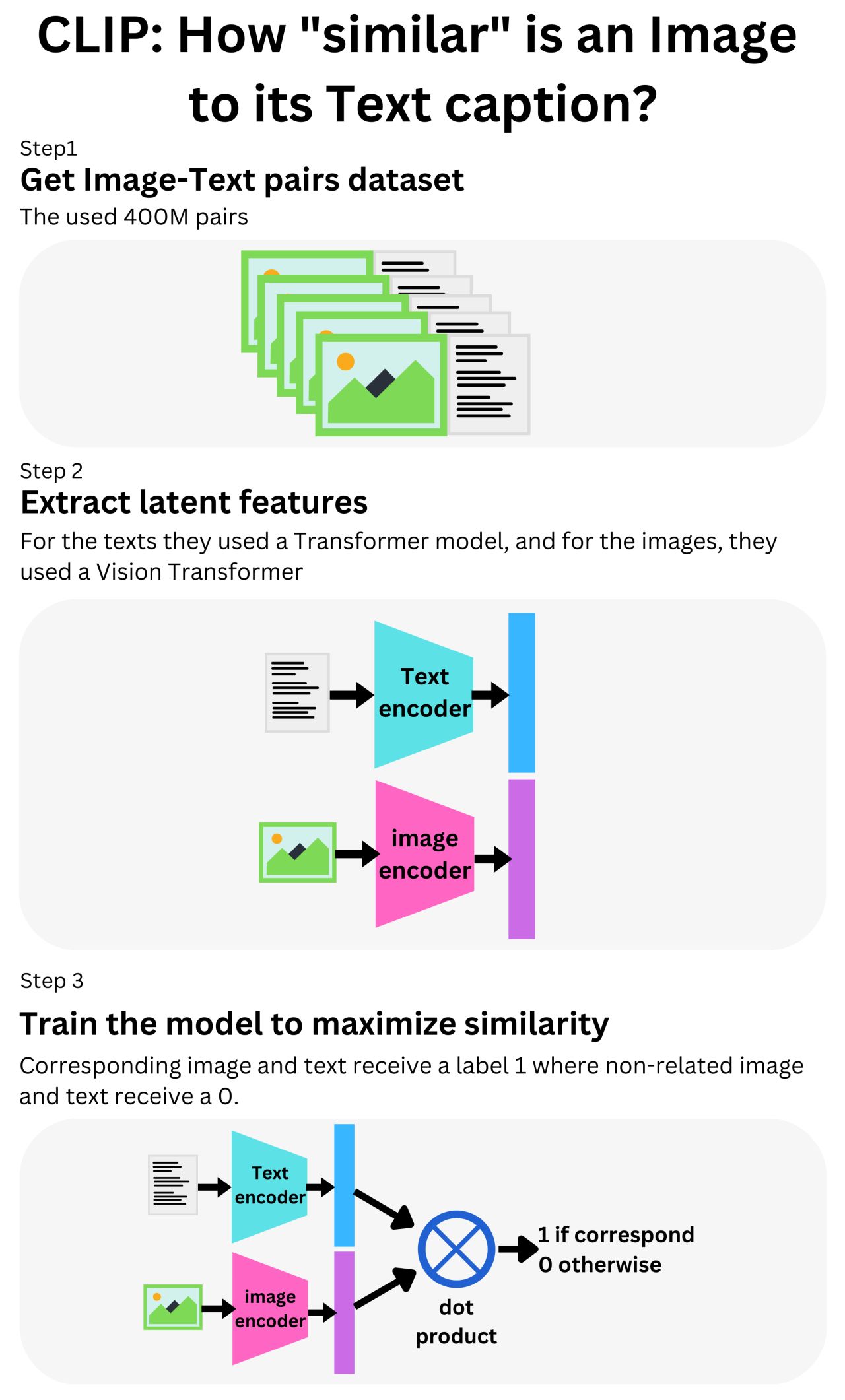
- The image below is by Damien Benveniste, PhD does a great job in visually explaining how CLIP internally works.
CLIP Code walk-through
- The entirety of the code walk-through below is from Nikos Kafritsas’s article linked here.
- First, Nikos picks 3 images and sends them as input to CLIP.

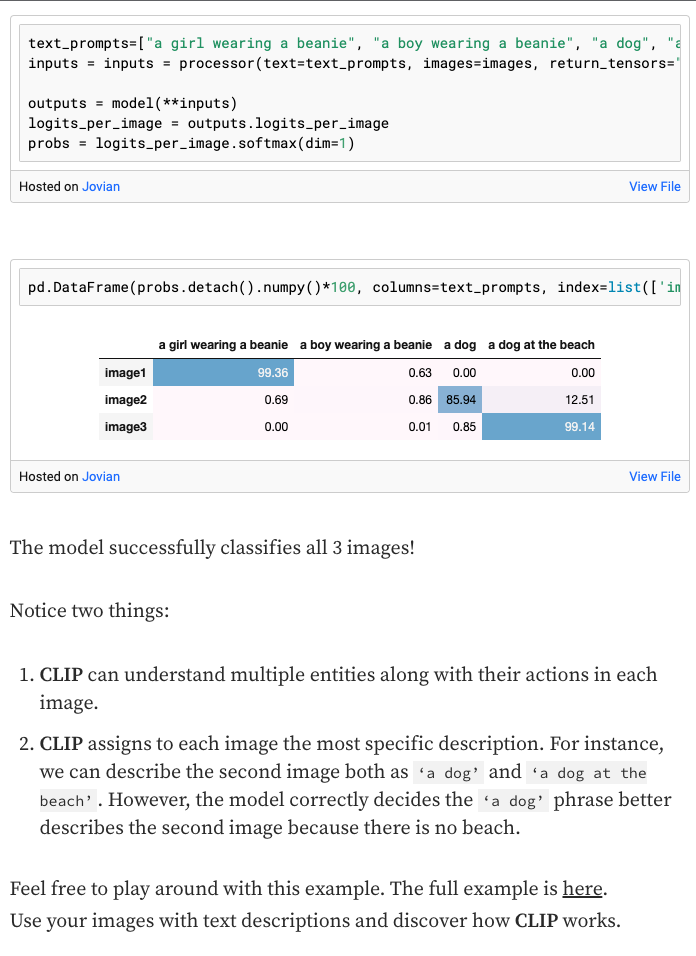
CLIP Cons
- The authors of the paper claim that CLIP suffers from polysemy, which means that the model can not differentiate between two words due to lack of context.
- For example, the word ‘boxer’ can appear as a dog breed or an athlete. Perhaps a better set of data could help here.
- Additionally, while CLIP is excellent at understanding complex images, it still struggles with a few tasks such as handwriting detection (especially handwritten digits).
- This can be due to lack of sufficient data and not having the model see enough handwritten numbers during training.
Parting Notes
- Let’s summarize CLIP’s key contributions:
- Pre-Training $(image, text)$ pairs together.
- Zero-shot performance which is on par with supervised models with the caveat of CLIP not needing the task specific dataset.
- Open source model and weights.
- CLIP has been one of OpenAI’s breakthrough models and is used by both DALL-E and Stable Diffusion.
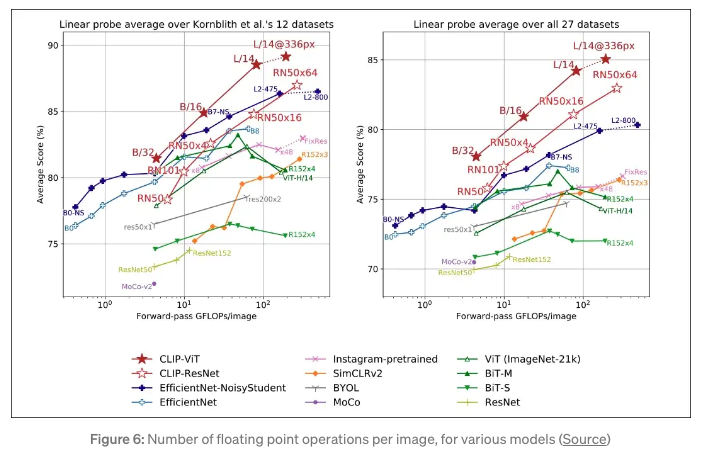
- Below, we can see how zero-shot CLIP really took its competitors by storm:
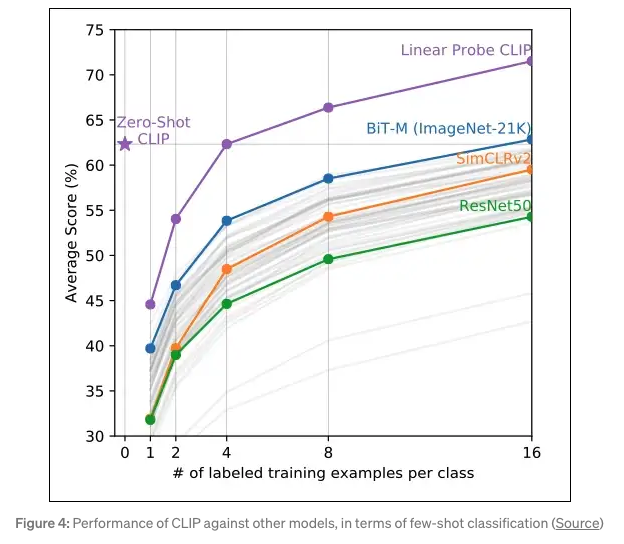
- In addition, CLIP is also very computationally-friendly in its architecture, the results are below: