Introduction
- Multimodality is a new AI paradigm where various modalities (text, speech, videos, images) are combined with multiple intelligence processing algorithms to achieve higher performance.
- Multimodal applications currently include various discriminative tasks such as information retrieval, mapping and fusion.
Multimodal representations
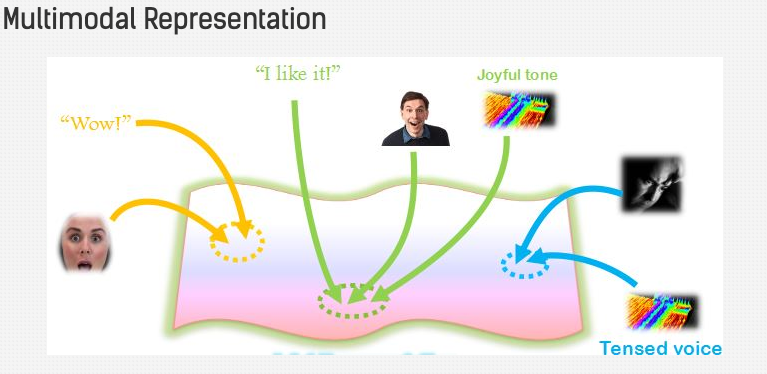
- There are several ways to achieve multi-modality in industry.
- Let’s start by first mentioning different uses of multi-modal representations:
- We want to make sure similarity in that space implies similarity in corresponding concepts
- We want them to be useful for various discriminative tasks such as: retrieval, mapping, and fusion etc.
- Fill in the missing modality, given the other modalities that are present
- The five core challenges in multimodal ML are – representation, translation, alignment, fusion, and co-learning. Let’s start looking through each of these individually.
- The greatest challenges of multimodal data is to summarize the information from multiple modalities (or views) in a way that complementary information is used as a conglomerate while filtering out the redundant parts of the modalities.
- Due to the heterogeneity of the data, some challenges naturally spring up including different kinds of noise, alignment of modalities (or views) and, techniques to handle missing data. (source)
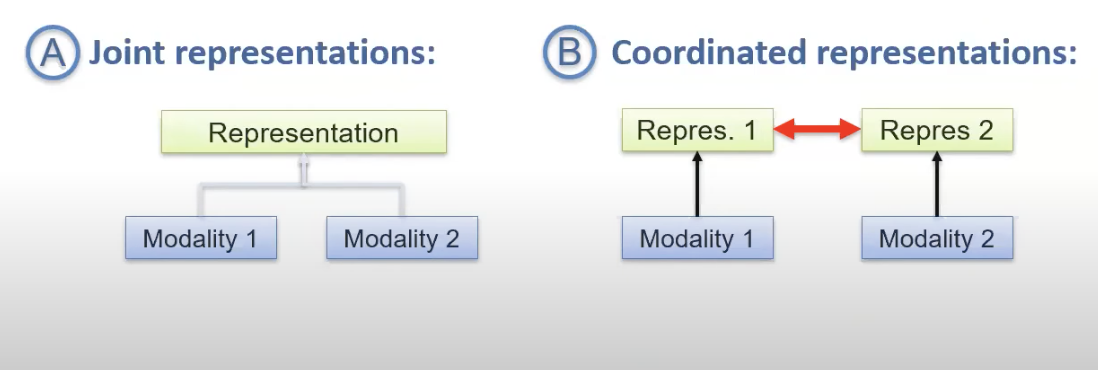
- We will continue to study multimodal representations using two broad approaches: Joint and Coordinated representations.
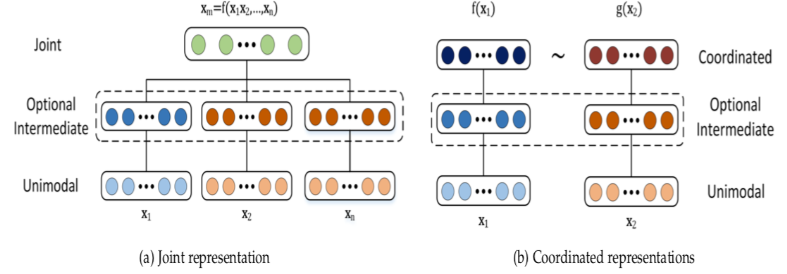
Coordinated representation
- Your modalities have to coordinate between very weak (where their spaces are not overlapped) or very strong (which ends up being joint representation).
- Structured coordinated embeddings:
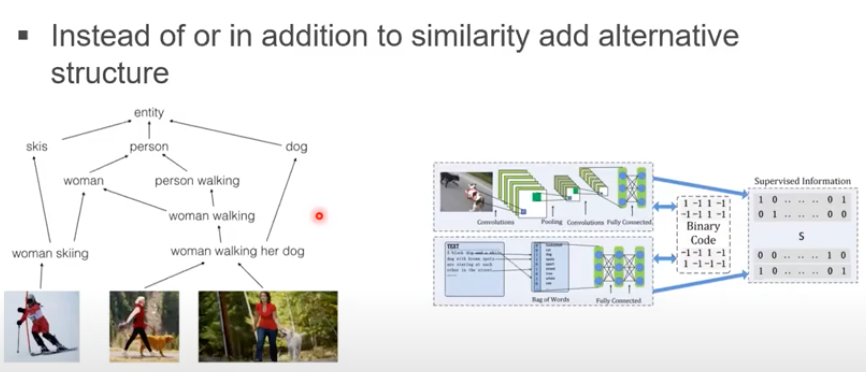
- Coordinated Representations involve projecting all the modalities to their space, but those spaces are coordinated using a constraint.
- This kind of an approach is more useful for modalities which are fundamentally very different and might not work well in a joint space.
- Due to the variety of modalities in nature, Coordinated Representations have a huge advantage over Joint Representations which gives us reason to believe that the coordination using constraints is the way to go in the field of multimodal representation.
Joint representation
- Joint Representations involve projecting all the modalities to a common space while preserving information from the given modalities.
- Data from all modalities is required at training and inference time which can potentially make dealing with missing data hard.
- In our study, we propose a recurrent model which can fuse different views of a modality at each time-step and finally use the joint representation to complete the task at hand (like classification, regression, etc.). (source)
Coordinated vs. Joint representation
- For the tasks in which all of the modalities are present at the inference time, the joint representation will be more suited.
- On the other hand, if one of the modalities is missing, coordinated representation is well suited.
Translation
- Multimodal machine translation involves drawing information from more than one modality, based on the assumption that the additional modalities will contain useful alternative views of the input data.
- The most prominent tasks in this area are spoken language translation, image-guided translation, and video-guided translation, which exploit audio and visual modalities, respectively.
- These tasks are distinguished from their monolingual counterparts of speech recognition, image captioning, and video captioning by the requirement of models to generate outputs in a different language. (source)
- Below we can see an image captioning example gone hilariously wrong:
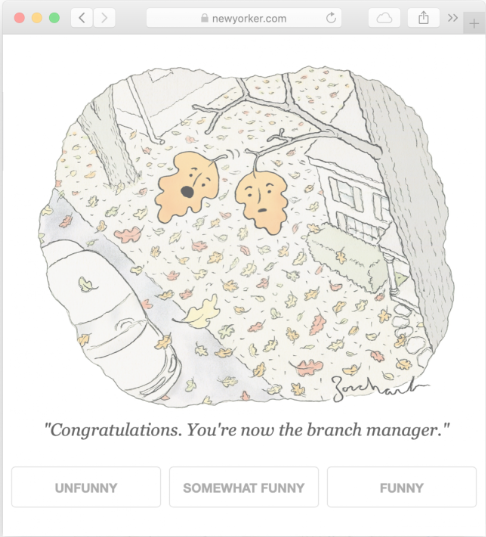
- As we can see, the model above is unable to understand the visual scene along with the grammatical scentence in sync. This is essential for a strong multimodal model.
- Multimodal translation models come in two flavors: example-based and generative:
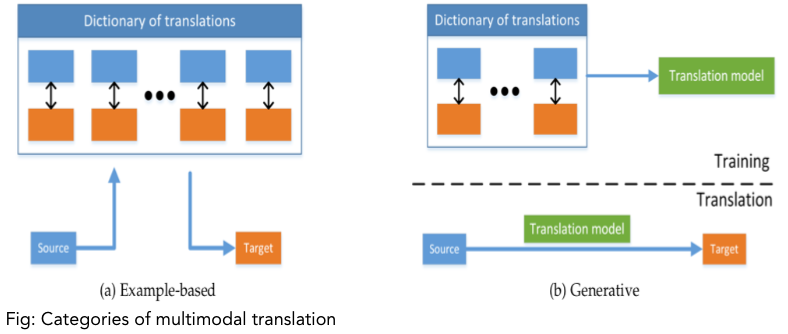
- Example -based models will store a dictionary of translations, as we see above, and maps that from one modality to another.
- During inference, the model will fetch the closest match from the dictionary or create the translation by inferring from what the dictionary provides.
- These models thus need to store a lot more information and are very slow to run.
- Generative models produce translations without referring to the training data at the time of inference.
- Generative models have 3 categories which are grammer-based, transformer model, and continuous generation.
Alignment
- Multimodal alignment is finding relationships and correspondences between two or more modalities.
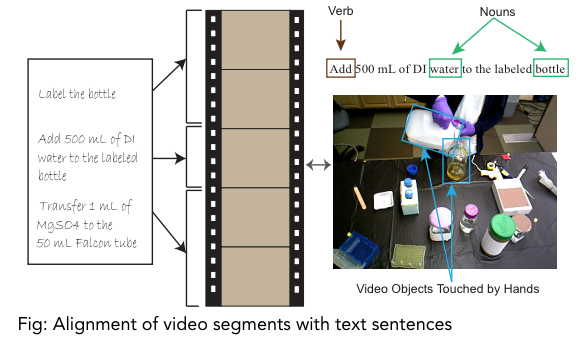
- To align different modalities, a model has to measure similarities between them and has to deal with long-range dependencies.
- Other difficulties involved in multimodal alignment include lack of annotated datasets, designing good similarity metrics between modalities, and the existence of multiple correct alignments.
- There are wo types of multimodal alignment:
- Explicit – whose goal is to find correspondences between modalities and to align data from different modalities of the same event.
- Eg: Aligning speech signal to a transcript
- Implicit – alignment helps when solving a different task (for example “Attention” models). Its a precursor to several downstream tasks like classification.
Fusion
- Multimodal fusion is probably one of the more important topics and challenges.
- Fusion is the practice of joining information from two or more modalities to solve a classification or regression problem.
- Using multiple modalities provides more robust predictions and allows us to capture complementary information.
- Multimodal fusion models could still be used even if one of the modalities is missing.
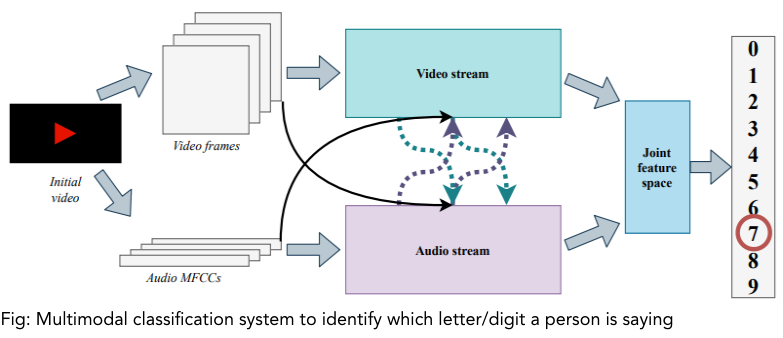
Co-learning
- Co-learning is the challenge of transferring learnings or knowledge from one modality to another.
- For building a model in a modality for which resources are limited – lack of annotated data, noisy input, and unreliable labels, transferring the knowledge from a resource-rich modality are quite useful.
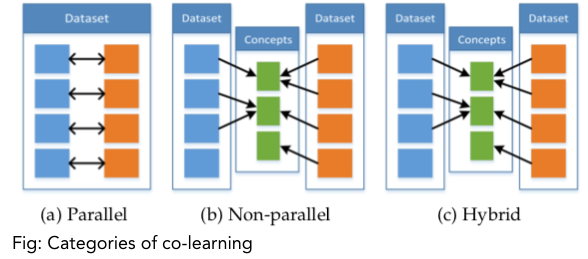
References