CS229 • Neural Networks
Overview
- We now begin our study of deep learning. In this section, we give an overview of neural networks, discuss vectorization and discuss training neural networks with backpropagation.
Neural Networks
- We will start small and slowly build up a neural network, step by step. Recall the housing price prediction problem from before: given the size of the house, we want to predict the price.
- Previously, we fitted a straight line to the graph. Now, instead of fitting a straight line, we wish prevent negative housing prices by setting the absolute minimum price as zero. This produces a “kink” in the graph as shown in the below figure.
- Our goal is to input some input \(x\) into a function \(f(x)\) that outputs the price of the house \(y\). Formally, \(f: x \rightarrow y\). One of the simplest possible neural networks is to define \(f(x)\) as a single “neuron” in the network where \(f(x)=\max (a x+b, 0)\), for some coefficients \(a, b\). What \(f(x)\) does is return a single value: \(x\) or zero, whichever is greater. In the context of neural networks, this function is called a ReLU (pronounced “ray-lu”), or rectified linear unit. A more complex neural network may take the single neuron described above and “stack” them together such that one neuron passes its output as input into the next neuron, resulting in a more complex function. Let us now deepen the housing prediction example. In addition to the size of the house, suppose that you know the number of bedrooms, the zip code and the wealth of the neighborhood.
- The figure below shows the plot of housing prices vs. square feet with a “kink” in the graph.
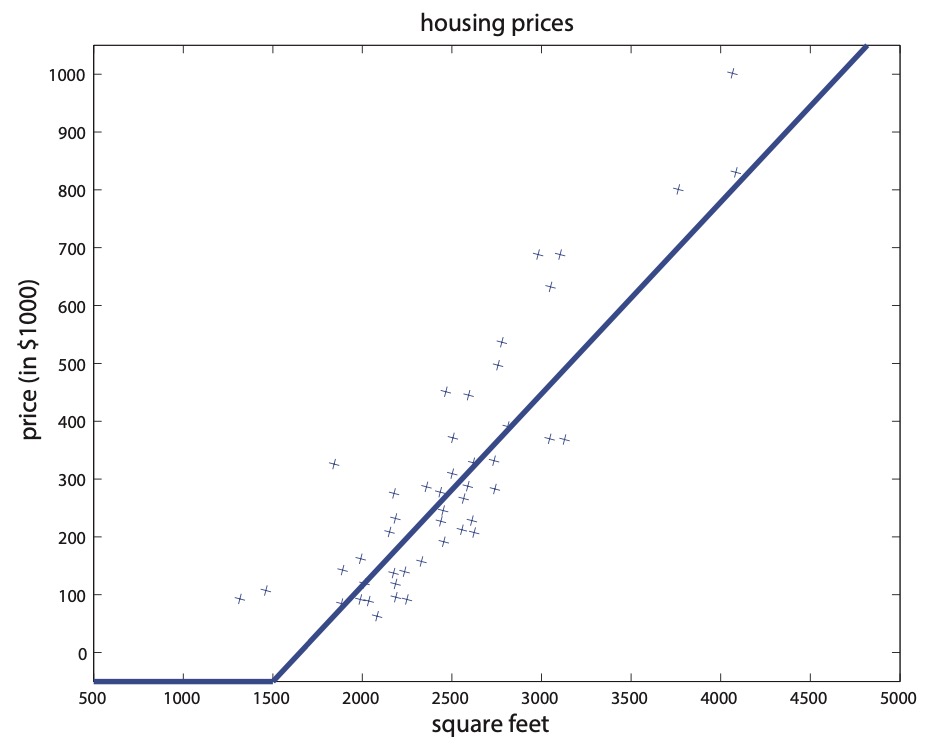
- Building neural networks is analogous to Lego bricks: you take individual bricks and stack them together to build complex structures. The same applies to neural networks: we take individual neurons and stack them together to create complex neural networks.
- Given these features (size, number of bedrooms, zip code, and wealth), we might then decide that the price of the house depends on the maximum family size it can accommodate. Suppose the family size is a function of the size of the house and number of bedrooms (cf. figure below). The zip code may provide additional information such as how walkable the neighborhood is (i.e., can you walk to the grocery store or do you need to drive everywhere). Combining the zip code with the wealth of the neighborhood may predict the quality of the local elementary school. Given these three derived features (family size, walkable, school quality), we may conclude that the price of the home ultimately depends on these three features. The following figure shows a diagram of a small neural network for predicting housing prices.
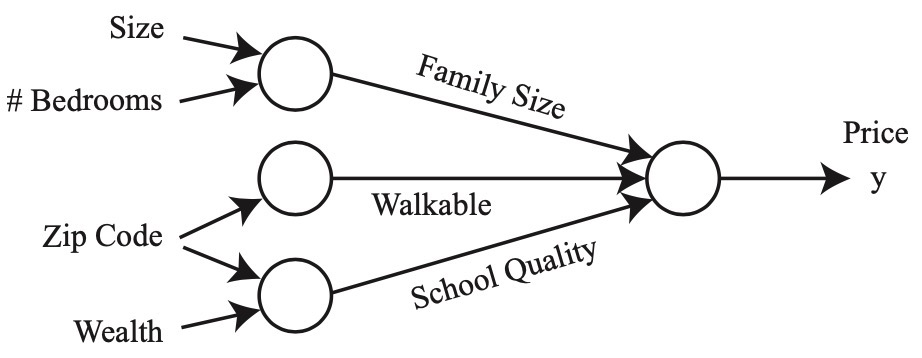
- We have described this neural network as if you (the reader) already have the insight to determine these three factors ultimately affect the housing price. Part of the magic of a neural network is that all you need are the input features \(x\) and the output \(y\) while the neural network will figure out everything in the middle by itself. The process of a neural network learning the intermediate features is called end-to-end learning.
- Following the housing example, formally, the input to a neural network is a set of input features \(x_{1}, x_{2}, x_{3}, x_{4}\). We connect these four features to three neurons. These three “internal” neurons are called hidden units. The goal for the neural network is to automatically determine three relevant features such that the three features predict the price of a house. The only thing we must provide to the neural network is a sufficient number of training examples \((x^{(i)}, y^{(i)})\). Often times, the neural network will discover complex features which are very useful for predicting the output but may be difficult for a human to understand since it does not have a “common” meaning. This is why some people refer to neural networks as a black box, as it can be difficult to understand the features it has invented.
- Let us formalize this neural network representation. Suppose we have three input features \(x_{1}, x_{2}, x_{3}\) which are collectively called the input layer, four hidden units which are collectively called the hidden layer and one output neuron called the output layer. The term hidden layer is called “hidden” because we do not have the ground truth/training value for the hidden units. This is in contrast to the input and output layers, both of which we know the ground truth values from \((x^{(i)}, y^{(i)})\).
- The first hidden unit requires the input \(x_{1}, x_{2}, x_{3}\) and outputs a value denoted by \(a_{1}\). We use the letter \(a\) since it refers to the neuron’s “activation” value. In this particular example, we have a single hidden layer but it is possible to have multiple hidden layers. Let \(a_{1}^{[1]}\) denote the output value of the first hidden unit in the first hidden layer. We use zero-indexing to refer to the layer numbers. That is, the input layer is layer 0, the first hidden layer is layer 1 and the output layer is layer 2. Again, more complex neural networks may have more hidden layers. Given this mathematical notation, the output of layer 2 is \(a_{1}^{[2]}\). We can unify our notation:
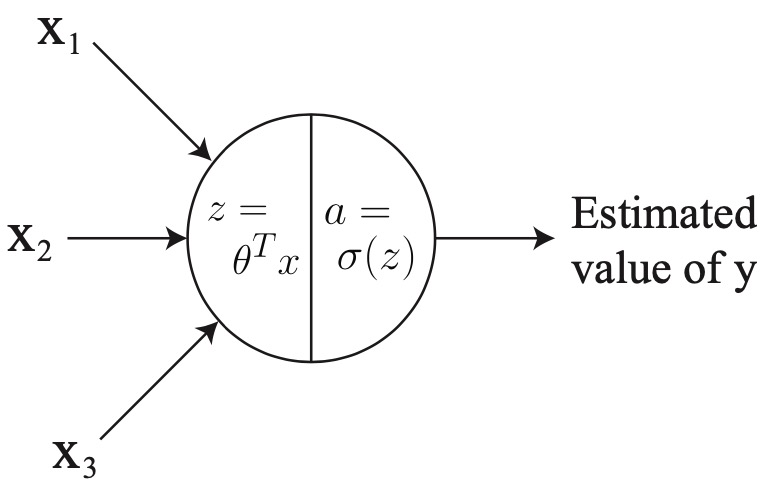
- To clarify, foo \(^{[1]}\) with brackets denotes anything associated with layer \(1, x^{(i)}\) with parenthesis refers to the \(i^{t h}\) training example, and \(a_{j}^{[\ell]}\) refers to the activation of the \(j^{t h}\) unit in layer \(\ell\). If we look at logistic regression \(g(x)\) as a single neuron (see the below figure):
-
The input to the logistic regression \(g(x)\) is three features \(x_{1}, x_{2}\) and \(x_{3}\) and it outputs an estimated value of \(y\). We can represent \(g(x)\) with a single neuron in the neural network. We can break \(g(x)\) into two distinct computations:
- \(z=w^{T} x+b\) and,
- \(a=\sigma(z)\) where \(\sigma(z)=\frac{1}{\left(1+e^{-z}\right)}\).
-
Note the notational difference: previously we used \(z=\theta^{T} x\) but now we are using \(z=w^{T} x+b\), where \(w\) is a vector. Later in these notes you will see capital \(W\) to denote a matrix. The reasoning for this notational difference is conform with standard neural network notation. More generally, \(a=g(z)\) where \(g(z)\) is some activation function. Example activation functions include:
- In general, \(g(z)\) is a non-linear function.
-
Returning to our neural network from before, the first hidden unit in the first hidden layer will perform the following computation:
\[z_{1}^{[1]}=W_{1}^{[1]^{T}} x+b_{1}^{[1]} \quad \text { and } \quad a_{1}^{[1]}=g\left(z_{1}^{[1]}\right)\]- where \(W\) is a matrix of parameters and \(W_{1}\) refers to the first row of this matrix.
-
The parameters associated with the first hidden unit is the vector \(W_{1}^{[1]} \in \mathbb{R}^{3}\) and the scalar \(b_{1}^{[1]} \in \mathbb{R}\). For the second and third hidden units in the first hidden layer, the computation is defined as:
\[\begin{array}{lll} z_{2}^{[1]}=W_{2}^{[1]^{T}} x+b_{2}^{[1]} & \text { and } & a_{2}^{[1]}=g\left(z_{2}^{[1]}\right) \\ z_{3}^{[1]}=W_{3}^{[1]^{T}} x+b_{3}^{[1]} & \text { and } & a_{3}^{[1]}=g\left(z_{3}^{[1]}\right) \end{array}\]- where each hidden unit has its corresponding parameters \(W\) and \(b\).
-
Moving on, the output layer performs the computation:
\[z_{1}^{[2]}=W_{1}^{[2]^{T}} a^{[1]}+b_{1}^{[2]} \quad \text { and } \quad a_{1}^{[2]}=g\left(z_{1}^{[2]}\right)\]- where \(a^{[1]}\) is defined as the concatenation of all first layer activations:
- The activation \(a_{1}^{[2]}\) from the second layer, which is a single scalar as defined by \(a_{1}^{[2]}=g(z_{1}^{[2]})\), represents the neural network’s final output prediction. Note that for regression tasks, one typically does not apply a non-linear function which is strictly positive (i.e., ReLU or sigmoid) because for some tasks, the ground truth \(y\) value may in fact be negative.
Vectorization
- In order to implement a neural network at a reasonable speed, one must be careful when using for loops. In order to compute the hidden unit activations in the first layer, we must compute \(z_{1}, \ldots, z_{4}\) and \(a_{1}, \ldots, a_{4}\)
- The most natural way to implement this in code is to use a for loop. One of the treasures that deep learning has given to the field of machine learning is that deep learning algorithms have high computational requirements. As a result, code will run very slowly if you use for loops.
- This gave rise to vectorization. Instead of using for loops, vectorization takes advantage of matrix algebra and highly optimized numerical linear algebra packages (e.g., BLAS) to make neural network computations run quickly. Before the deep learning era, a for loop may have been sufficient on smaller datasets, but modern deep networks and state-of-the-art datasets will be infeasible to run with for loops.
Vectorizing the Output Computation
- We now present a method for computing \(z_{1}, \ldots, z_{4}\) without a for loop. Using our matrix algebra, we can compute the activations:
- Where the \(\mathbb{R}^{n \times m}\) beneath each matrix indicates the dimensions. Expressing this in matrix notation: \(z^{[1]}=W^{[1]} x+b^{[1]}\). To compute \(a^{[1]}\) without a for loop, we can leverage vectorized libraries in Matlab, Octave, or Python which compute \(a^{[1]}=g(z^{[1]})\) very fast by performing parallel element-wise operations. Mathematically, we defined the sigmoid function \(g(z)\) as:
-
However, the sigmoid function can be defined not only for scalars but also vectors. In a Matlab/Octave-like pseudocode, we can define the sigmoid as:
\[g(z)=1 . /(1+\exp (-z)) \quad \text { where } z \in \mathbb{R}^{n}\]- where \(. /\) denotes element-wise division. With this vectorized implementation, \(a^{[1]}=g(z^{[1]})\) can be computed quickly.
-
To summarize the neural network so far, given an input \(x \in \mathbb{R}^{3}\), we compute the hidden layer’s activations with \(z^{[1]}=W^{[1]} x+b^{[1]}\) and \(a^{[1]}=g(z^{[1]})\). To compute the output layer’s activations (i.e., neural network output):
- Why do we not use the identity function for \(g(z)\)? That is, why not use \(g(z)=z\)? Assume for sake of argument that \(b^{[1]}\) and \(b^{[2]}\) are zeros. Using Equation 2, we have:
- Notice how \(W^{[2]} W^{[1]}\) collapsed into \(\tilde{W}\). This is because applying a linear function to another linear function will result in a linear function over the original input (i.e., you can construct a \(\tilde{W}\) such that \(\left.\tilde{W} x=W^{[2]} W^{[1]} x\right)\). This loses much of the representational power of the neural network as often times the output we are trying to predict has a non-linear relationship with the inputs. Without non-linear activation functions, the neural network will simply perform linear regression.
Vectorization Over Training Examples
- Suppose you have a training set with three examples. The activations for each example are as follows:
- Note the difference between square brackets \([\cdot]\), which refer to the layer number, and parenthesis \((\cdot)\), which refer to the training example number. Intuitively, one would implement this using a for loop. It turns out, we can vectorize these operations as well. First, define:
- Note that we are stacking training examples in columns and not rows. We can then combine this into a single unified formulation:
- Putting it together: Suppose we have a training set \(\left(x^{(1)}, y^{(1)}\right), \ldots,\left(x^{(m)}, y^{(m)}\right)\) where \(x^{(i)}\) is a picture and \(y^{(i)}\) is a binary label for whether the picture contains a cat or not (i.e., \(1=\) contains a cat).
- First, we initialize the parameters \(W^{[1]}, b^{[1]}, W^{[2]}, b^{[2]}\) to small random numbers. For each example, we compute the output “probability” from the sigmoid function \(a^{[2](i)}\). Using the logistic regression log likelihood:
- We maximize this function using gradient ascent. This maximization procedure corresponds to training the neural network.
Backpropagation
- Instead of the housing example, we now have a new problem. Suppose we wish to detect whether there is a soccer ball in an image or not. Given an input image \(x^{(i)}\), we wish to output a binary prediction 1 if there is a ball in the image and 0 otherwise.
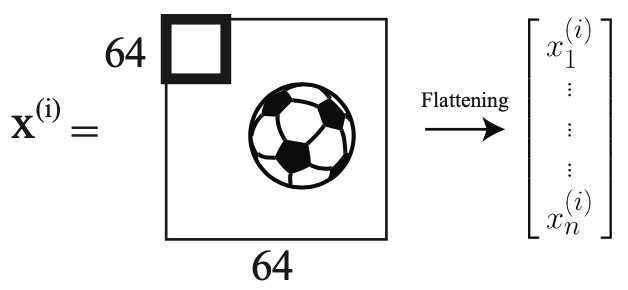
- Aside: Images can be represented as a matrix with number of elements equal to the number of pixels. However, color images are digitally represented as a volume (i.e., three-channels; or three matrices stacked on each other). The number three is used because colors are represented as red-green-blue (RGB) values. In the diagram below, we have a \(64 \times 64 \times 3\) image containing a soccer ball. It is flattened into a single vector containing \(12,288\) elements.
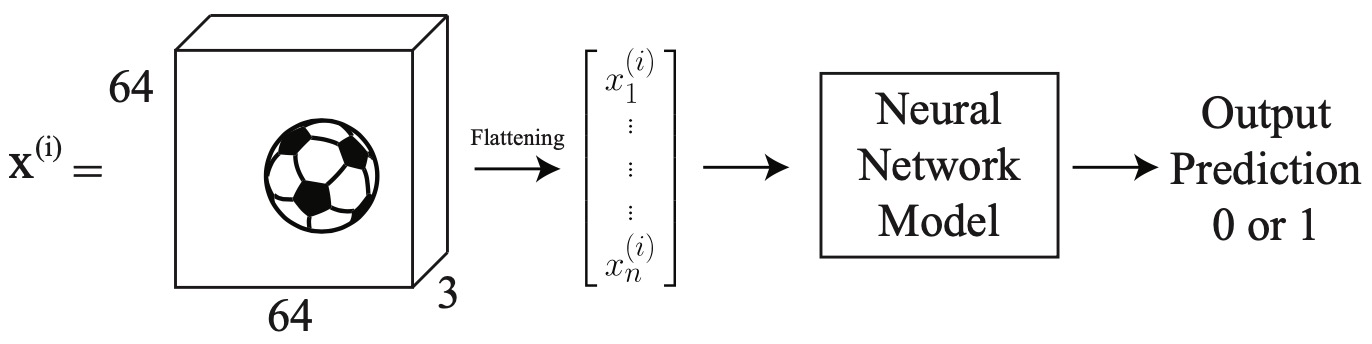
- A neural network model consists of two components:
- The network architecture, which defines how many layers, how many neurons, and how the neurons are connected and,
- The parameters (values; also known as weights). In this section, we will talk about how to learn the parameters. First we will talk about parameter initialization, optimization and analyzing these parameters.
Parameter Initialization
- Consider a two layer neural network. On the left, the input is a flattened image vector \(x^{(1)}, \ldots, x_{n}^{(i)}\). In the first hidden layer, notice how all inputs are connected to all neurons in the next layer. This is called a fully connected layer.
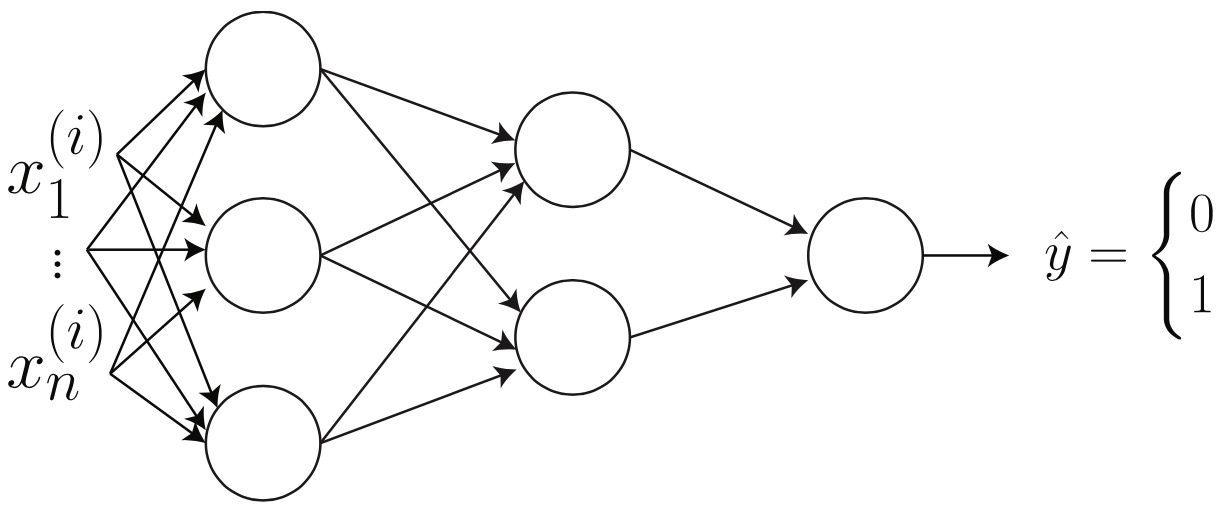
- The next step is to compute how many parameters are in this network. One way of doing this is to compute the forward propagation by hand.
- We know that \(z^{[1]}, a^{[1]} \in \mathbb{R}^{3 \times 1}\) and \(z^{[2]}, a^{[2]} \in \mathbb{R}^{2 \times 1}\) and \(z^{[3]}, a^{[3]} \in \mathbb{R}^{1 \times 1}\). As of now, we do not know the size of \(W^{[1]}\). However, we can compute its size. We know that \(x \in \mathbb{R}^{n \times 1}\). This leads us to the following:
- Using matrix multiplication, we conclude that \(? \times\)? must be \(3 \times n\). We also conclude that the bias is of size \(3 \times 1\) because its size must match \(W^{[1]} x^{(i)}\) We repeat this process for each hidden layer. This gives us:
- In total, we have \(3 n+3\) in the first layer, \(2 \times 3+2\) in the second layer and \(2+1\) in the third layer. This gives us a total of \(3 n+14\) parameters.
- Before we start training the neural network, we must select an initial value for these parameters. We do not use the value zero as the initial value. This is because the output of the first layer will always be the same since \(W^{[1]} x^{(i)}+b^{[1]}=0^{3 \times 1} x^{(i)}+0^{3 \times 1}\) where \(0^{n \times m}\) denotes a matrix of size \(n \times m\) filled with zeros. This will cause problems later on when we try to update these parameters (i.e., the gradients will all be the same). The solution is to randomly initialize the parameters to small values (e.g., normally distributed around zero; \(\mathcal{N}(0,0.1)\)). Once the parameters have been initialized, we can begin training the neural network with gradient descent.
- The next step of the training process is to update the parameters. After a single forward pass through the neural network, the output will be a predicted value \(\hat{y}\). We can then compute the loss \(\mathcal{L}\), in our case the log loss:
-
The loss function \(\mathcal{L}(\hat{y}, y)\) produces a single scalar value. For short, we will refer to the loss value as \(\mathcal{L}\). Given this value, we now must update all parameters in layers of the neural network. For any given layer index \(\ell\), we update them:
\[W^{[\ell]} =W^{[\ell]}-\alpha \frac{\partial \mathcal{L}}{\partial W^{[\ell]}} \\ \tag{5}\] \[b^{[\ell]} =b^{[\ell]}-\alpha \frac{\partial \mathcal{L}}{\partial b^{[\ell]}} \tag{6}\]- where \(\alpha\) is the learning rate. To proceed, we must compute the gradient with respect to the parameters: \(\frac{\partial \mathcal{L}}{\partial W^{[\ell]}}\) and \(\frac{\partial \mathcal{L}}{\partial b^{[\ell]}}\).
- Remember, we made a decision to not set all parameters to zero. What if we had initialized all parameters to be zero? We know that \(z^{[3]}=W^{[3]} a^{[2]}+b^{[3]}\) will evaluate to zero, because \(W^{[3]}\) and \(b^{[3]}\) are all zero. However, the output of the neural network is defined as \(a^{[3]}=g\left(z^{[3]}\right)\). Recall that \(g(\cdot)\) is defined as the sigmoid function. This means \(a^{[3]}=g(0)=0.5\). Thus, no matter what value of \(x^{(i)}\) we provide, the network will output \(\hat{y}=0.5\).
- What if we had initialized all parameters to be the same non-zero value? In this case, consider the activations of the first layer:
- Each element of the activation vector \(a^{[1]}\) will be the same (because \(W^{[1]}\) contains all the same values). This behavior will occur at all layers of the neural network. As a result, when we compute the gradient, all neurons in a layer will be equally responsible for anything contributed to the final loss. We call this property symmetry. This means each neuron (within a layer) will receive the exact same gradient update value (i.e., all neurons will learn the same thing).
-
In practice, it turns out there is something better than random initialization, called Xavier/He initialization which initializes the weights as:
\[w^{[\ell]} \sim \mathcal{N}\left(0, \sqrt{\frac{2}{n^{[\ell]}+n^{[\ell-1]}}}\right)\]- where \(n^{[\ell]}\) is the number of neurons in layer \(\ell\). This acts as a mini-normalization technique. For a single layer, consider the variance of the input to the layer as \(\sigma^{(i n)}\) and the variance of the output (i.e., activations) of a layer to be \(\sigma^{(o u t)}\). Xavier/He initialization encourages \(\sigma^{(i n)}\) to be similar to \(\sigma^{(o u t)}\)
Optimization
- Recall our neural network parameters: \(W^{[1]}, b^{[1]}, W^{[2]}, b^{[2]}, W^{[3]}, b^{[3]}\). To update them, we use stochastic gradient descent (SGD) using the update rules in Equations \((5)\) and \((6)\). We will first compute the gradient with respect to \(W^{[3]}\). The reason for this is that the influence of \(W^{[1]}\) on the loss is more complex than that of \(W^{[3]}\). This is because \(W^{[3]}\) is “closer” to the output \(\hat{y}\), in terms of number of computations.
- Note that we are using sigmoid for \(g(\cdot)\). The derivative of the sigmoid function: \(g^{\prime}=\sigma^{\prime}=\sigma(1-\sigma)\). Additionally \(a^{[3]}=\sigma\left(W^{[3]} a^{[2]}+b^{[3]}\right)\). At this point, we have finished computing the gradient for one parameter, \(W^{[3]}\) We will now compute the gradient for \(W^{[2]}\). Instead of deriving \(\frac{\partial \mathcal{L}}{\partial W^{[2]}}\) we can use the chain rule of calculus. We know that \(\mathcal{L}\) depends on \(\hat{y}=a^{[3]}\).
- If we look at the forward propagation, we know that loss \(\mathcal{L}\) depends on \(\hat{y}=a^{[3]}\). Using the chain rule, we can insert \(\frac{\partial a^{[3]}}{\partial a^{[3]}}\):
- We know that \(a^{[3]}\) is directly related to \(z^{[3]}\).
- Furthermore we know that \(z^{[3]}\) is directly related to \(a^{[2]}\). Note that we cannot use \(W^{[2]}\) or \(b^{[2]}\) because \(a^{[2]}\) is the only common element between Equations \((3)\) and \((4)\). A common element is required for backpropagation.
- Again, \(a^{[2]}\) depends on \(z^{[2]}\), which \(z^{[2]}\) directly depends on \(W^{[2]}\), which allows us to complete the chain:
- Recall \(\frac{\partial \mathcal{L}}{\partial W^{[3]}}\)
- since we computed \(\frac{\partial \mathcal{L}}{\partial W^{[3]}}\) first, we know that \(\frac{a^{[2]}=\partial z^{[3]}}{\partial W^{[3]}}\). Similarly we have \(\left(a^{[3]}-y\right)=\frac{\partial \mathcal{L}}{\partial z^{[3]}}\). These can help us compute \(\frac{\partial \mathcal{L}}{\partial W^{[2]}}\). We substitute these values into Equation \((7)\). This gives us:
- While we have greatly simplified the process, we are not done yet. Because we are computing derivatives in higher dimensions, the exact order of matrix multiplication required to compute Equation \((8)\) is not clear. We must reorder the terms in Equation \((8)\) such that the dimensions align. First, we note the dimensions of all the terms:
- Notice how the terms do not align their shapes properly. We must rearrange the terms by using properties of matrix algebra such that the matrix operations produce a result with the correct output shape. The correct ordering is below:
-
We leave the remaining gradients as an exercise to the reader. In calculating the gradients for the remaining parameters, it is important to use the intermediate results we have computed for \(\frac{\partial \mathcal{L}}{\partial W^{[2]}}\) and \(\frac{\partial \mathcal{L}}{\partial W^{[3]}}\), as these will me directly useful for computing the gradient.
-
Returning to optimization, we previously discussed stochastic gradient descent. Now we will talk about gradient descent. For any single layer \(\ell\), the update rule is defined as:
\[W^{[\ell]}=W^{[\ell]}-\alpha \frac{\partial J}{\partial W^{[\ell]}}\]- where \(J\) is the cost function \(J=\frac{1}{m} \sum_{i=1}^{m} \mathcal{L}^{(i)}\) and \(\mathcal{L}^{(i)}\) is the loss for a single example.
- The difference between the gradient descent update versus the stochastic gradient descent version is that the cost function \(J\) gives more accurate gradients whereas \(\mathcal{L}^{(i)}\) may be noisy. Stochastic gradient descent attempts to approximate the gradient from (full) gradient descent. The disadvantage of gradient descent is that it can be difficult to compute all activations for all examples in a single forward or backwards propagation phase. In practice, research and applications use mini-batch gradient descent.
-
This is a compromise between gradient descent and stochastic gradient descent. In the case mini-batch gradient descent, the cost function \(J_{\mathrm{mb}}\) is defined as follows:
\[J_{\mathrm{mb}}=\frac{1}{\mathrm{B}} \sum_{i=1}^{\mathrm{B}} \mathcal{L}^{(i)}\]- where \(B\) is the number of examples in the mini-batch.
- There is another optimization method called momentum. Consider minibatch stochastic gradient. For any single layer \(\ell\), the update rule is as follows:
- Notice how there are now two stages instead of a single stage. The weight update now depends on the cost \(J\) at this update step and the velocity \(v_{d W^{[\ell]}}\) The relative importance is controlled by \(\beta\). Consider the analogy to a human driving a car. While in motion, the car has momentum. If the car were to use the brakes (or not push accelerator throttle), the car would continue moving due to its momentum. Returning to optimization, the velocity \(v_{d W^{[\ell]}}\) will keep track of the gradient over time. This technique has significantly helped neural networks during the training phase.
Analyzing the Parameters
- At this point, we have initialized the parameters and have optimized the parameters. Suppose we evaluate the trained model and observe that it achieves \(96 \%\) accuracy on the training set but only \(64 \%\) on the testing set. Some solutions include: collecting more data, employing regularization, or making the model shallower. Let us briefly look at regularization techniques.
L2 Regularization
-
Let \(W\) below denote all the parameters in a model. In the case of neural networks, you may think of applying the 2 nd term to all layer weights \(W^{[\ell]}\) For convenience, we simply write \(W\). The L2 regularization adds another term to the cost function:
\[J_{L 2}=J+\frac{\lambda}{2}\|W\|^{2} \tag{9}\] \[\quad=J+\frac{\lambda}{2} \sum_{i j}\left|W_{i j}\right|^{2} \tag{10}\] \[\quad=J+\frac{\lambda}{2} W^{T} W \tag{11}\]- where \(J\) is the standard cost function from before, \(\lambda\) is an arbitrary value with a larger value indicating more regularization and \(W\) contains all the weight matrices, and where Equations \((9)\), \((10)\) and \((11)\) are equivalent.
-
The update rule with L2 regularization becomes:
- When we were updating our parameters using gradient descent, we did not have the \((1-\alpha \lambda) W\) term. This means with L2 regularization, every update will include some penalization, depending on \(W\). This penalization increases the cost \(J(\cdot)\), which encourages individual parameters to be small in magnitude, which is a way to reduce overfitting.
Parameter Sharing
- Recall logistic regression. It can be represented as a neural network, as shown in the section on neural networks. The parameter vector \(\theta=\left(\theta_{1}, \ldots, \theta_{n}\right)\) must have the same number of elements as the input vector \(x=\left(x_{1}, \ldots, x_{n}\right)\). In our image soccer ball example, this means \(\theta_{1}\) always looks at the top left pixel of the image no matter what. However, we know that a soccer ball might appear in any region of the image and not always the center. It is possible that \(\theta_{1}\) was never trained on a soccer ball in the top left of the image. As a result, during test time, if an image of a soccer ball in the top left appears, the logistic regression will likely predict no soccer ball. This is a problem.
- This leads us to convolutional neural networks. Suppose \(\theta\) is no longer a vector but instead is a matrix. For our soccer ball example, suppose \(\theta=\mathbb{R}^{4 \times 4}\) For simplicity, we show the image as \(64 \times 64\) but recall it is actually three-dimensional and contains 3 channels. We now take our matrix of parameters \(\theta\) and slide it over the image. This is shown by the figure below by the thick square in the upper left of the image.
- To compute the activation \(a\), we compute the element-wise product between \(\theta\) and \(x_{1: 4,1: 4}\), where the subscripts for \(x\) indicate we are taking the top left \(4 \times 4\) region in the image \(x\). We then collapse the matrix into a single scalar by summing all the elements resulting from the element-wise product. Formally:
- We then move this window slightly to the right in the image and repeat this process. Once we have reached the end of the row, we start at the beginning of the second row.
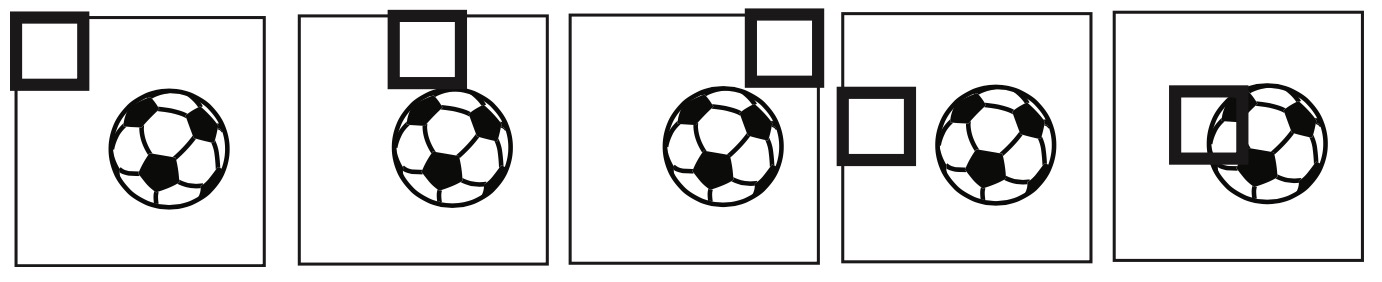
- Once we have reached the end of the image, the parameters \(\theta\) have “seen” all pixels of the image: \(\theta_{1}\) is no longer related to only the top left pixel. As a result, whether the soccer ball appears in the bottom right or top left of the image, the neural network will successfully detect the soccer ball.
References
Citation
If you found our work useful, please cite it as:
@article{Chadha2020DistilledNeuralNetworks,
title = {Neural Networks},
author = {Chadha, Aman},
journal = {Distilled Notes for Stanford CS229: Machine Learning},
year = {2020},
note = {\url{https://aman.ai}}
}