CS229 • Expectation Maximization Algorithms
- Expectation Maximization Algorithms
- The EM algorithm
- Mixture of Gaussians revisited
- Mixtures of Gaussians
- References
- Citation
Expectation Maximization Algorithms
- In the previous set of notes, we talked about the EM algorithm as applied to fitting a mixture of Gaussians. In this section, we give a broader view of the EM algorithm, and show how it can be applied to a large family of estimation problems with latent variables. We begin our discussion with a very useful result called Jensen’s inequality
Jensen’s inequality
- Let \(f\) be a function whose domain is the set of real numbers. Recall that \(f\) is a convex function if \(f^{\prime \prime}(x) \geq 0\) (for all \(\left.x \in \mathbb{R}\right)\). In the case of \(f\) taking vector-valued inputs, this is generalized to the condition that its hessian \(H\) is positive semi-definite \((H \geq 0)\). If \(f^{\prime \prime}(x)>0\) for all \(x\), then we say \(f\) is strictly convex (in the vector-valued case, the corresponding statement is that \(H\) must be positive definite, written \(H>0\)). Jensen’s inequality can then be stated as follows:
Theorem
- Let \(f\) be a convex function, and let \(X\) be a random variable. Then:
- Moreover, if \(f\) is strictly convex, then \(\mathrm{E}[f(X)]=f(\mathrm{E} X)\) holds true if and only if \(X=\mathrm{E}[X]\) with probability 1 (i.e., if \(X\) is a constant).
- Recall our convention of occasionally dropping the parentheses when writing expectations, so in the theorem above, \(f(\mathrm{E} X)=f(\mathrm{E}[X])\). For an interpretation of the theorem, consider the figure below.
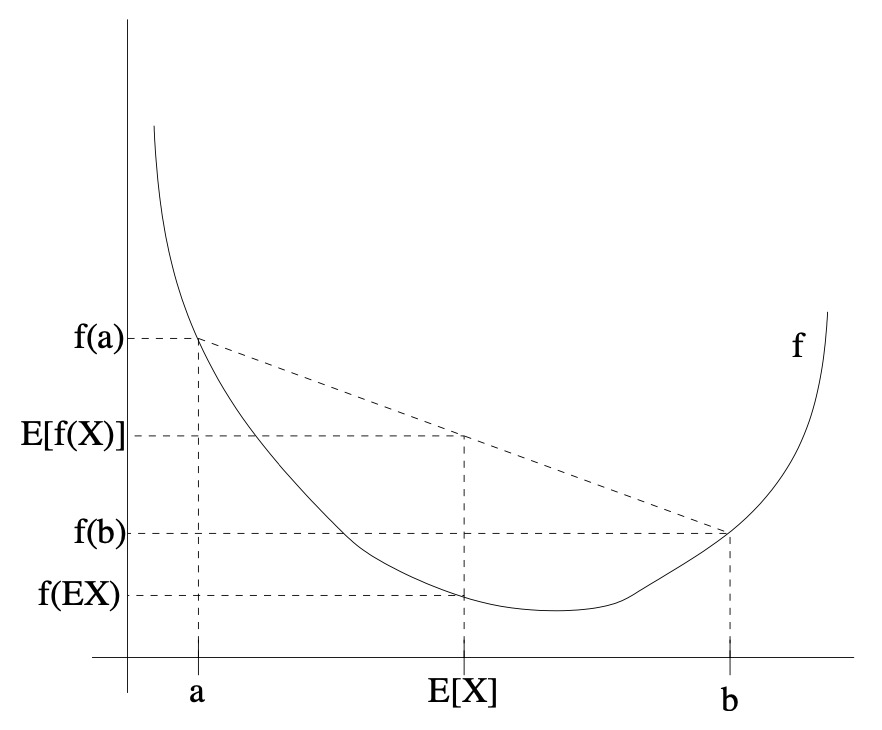
- Here, \(f\) is a convex function shown by the solid line. Also, \(X\) is a random variable that has a 0.5 chance of taking the value \(a\), and a 0.5 chance of taking the value \(b\) (indicated on the \(x\) -axis). Thus, the expected value of \(X\) is given by the midpoint between \(a\) and \(b\).
- We also see the values \(f(a), f(b)\) and \(f(\mathrm{E}[X])\) indicated on the \(y\) -axis. Morcover, the value \(\mathrm{E}[f(X)]\) is now the midpoint on the \(y\) -axis between \(f(a)\) and \(f(b)\). From our example, we see that because \(f\) is convex, it must be the case that \(\mathrm{E}[f(X)] \geq f(\mathrm{E} X)\).
- Incidentally, quite a lot of people have trouble remembering which way the inequality goes, and remembering a picture like this is a good way to quickly figure out the answer. Remark. Recall that \(f\) is strictly concave if and only if \(-f\) is strictly convex (i.e., \(f^{\prime \prime}(x) \leq 0\) or \(H \leq 0\)). Jensen’s inequality also holds for concave functions \(f\), but with the direction of all the inequalities reversed \((\mathrm{E}[f(X)] \leq\) \(f(\mathrm{E} X)\), etc.).
The EM algorithm
- Suppose we have an estimation problem in which we have a training set \(\left\{x^{(1)}, \ldots, x^{(m)}\right\}\) consisting of \(m\) independent examples. We wish to fit the parameters of a model \(P(x, z)\) to the data, where the likelihood is given by,
- But, explicitly finding the maximum likelihood estimates of the parameters \(\theta\) may be hard. Here, the \(z^{(i)}\)’s are the latent random variables; and it is often the case that if the \(z^{(i)}\)’s were observed, then maximum likelihood estimation would be easy.
- In such a setting, the EM algorithm gives an efficient method for maximum likelihood estimation. Maximizing \(\ell(\theta)\) explicitly might be difficult, and our strategy will be to instead repeatedly construct a lower-bound on \(\ell\) (E-step), and then optimize that lower-bound (M-step).
- For each \(i\), let \(Q_{i}\) be some distribution over the \(z\)’s \(\left(\sum_{z} Q_{i}(z)=1, Q_{i}(z) \geq 0 \right)\). Consider the following:
- Note that if \(z\) were continuous, then \(Q_{i}\) would be a density, and the summations over \(z\) in our discussion are replaced with integrals over \(z\).
- The last step of this derivation used Jensen’s inequality. Specifically, \(f(x)=\) \(\log x\) is a concave function, since \(f^{\prime \prime}(x)=-1 / x^{2}<0\) over its domain \(x \in \mathbb{R}^{+}\). Also, the term in the summation (below) is just an expectation of the quantity \(\left[\frac{P\left(x^{(i)}, z^{(i)} ; \theta\right)}{Q_{i}\left(z^{(i)}\right)}\right]\) with respect to \(z^{(i)}\) drawn according to the distribution given by \(Q_{i}\).
-
By Jensen’s inequality, we have,
\[f\left(\mathrm{E}_{z^{(i)} \sim Q_{i}}\left[\frac{P\left(x^{(i)}, z^{(i)} ; \theta\right)}{Q_{i}\left(z^{(i)}\right)}\right]\right) \geq \mathrm{E}_{z^{(i)} \sim Q_{i}}\left[f\left(\frac{P\left(x^{(i)}, z^{(i)} ; \theta\right)}{Q_{i}\left(z^{(i)}\right)}\right)\right]\]- where the \(“z^{(i)} \sim Q_{i}”\) subscripts above indicate that the expectations are with respect to \(z^{(i)}\) drawn from \(Q_{i}\). This allowed us to go from Equation \((2)\) to Equation \((3)\).
- Now, for any set of distributions \(Q_{i}\), the Equation \((3)\) gives a lower-bound on \(\ell(\theta)\). There are many possible choices for the \(Q_{i}\)’s. Which should we choose? Well, if we have some current guess \(\theta\) of the parameters, it seems natural to try to make the lower-bound tight at that value of \(\theta\), i.e., we’ll make the inequality above hold with equality at our particular value of \(\theta\). (We’ll see later how this enables us to prove that \(\ell(\theta)\) increases monotonically with successive iterations of EM.)
- To make the bound tight for a particular value of \(\theta\), we need for the step involving Jensen’s inequality in our derivation above to hold with equality. For this to be true, we know it is sufficient that that the expectation be taken over a “constant”-valued random variable, i.e., we require that,
- for some constant \(c\) that does not depend on \(z^{(i)}\). This is easily accomplished by choosing,
- Actually, since we know \(\sum_{z} Q_{i}\left(z^{(i)}\right)=1\) (because it is a distribution), this further tells us that,
- Thus, we simply set the \(Q_{i}\)’s to be the posterior distribution of the \(z^{(i)}\)’s given \(x^{(i)}\) and the setting of the parameters \(\theta\).
- Now, for this choice of the \(Q_{i}\)’s, Equation \((3)\) gives a lower-bound on the loglikelihood \(\ell\) that we’re trying to maximize. This is the E-step. In the M-step of the algorithm, we then maximize our formula in Equation \((3)\) with respect to the parameters to obtain a new setting of the \(\theta\)’s. Repeatedly carrying out these two steps gives us the EM algorithm, which is as follows:
- Repeat until convergence:
- (E-step) For each \(i\), set,
- (M-step) Set,
- Repeat until convergence:
- How we we know if this algorithm will converge? Well, suppose \(\theta^{(t)}\) and \(\theta^{(t+1)}\) are the parameters from two successive iterations of EM. We will now prove that \(\ell\left(\theta^{(t)}\right) \leq \ell\left(\theta^{(t+1)}\right)\), which shows EM always monotonically improves the log-likelihood. The key to showing this result lies in our choice of the \(Q_{i}\)’s. Specifically, on the iteration of \(\mathrm{EM}\) in which the parameters had started out as \(\theta^{(t)}\), we would have chosen \(Q_{i}^{(t)}\left(z^{(i)}\right):=P\left(z^{(i)} \mid x^{(i)} ; \theta^{(t)}\right)\). We saw earlier that this choice ensures that Jensen’s inequality, as applied to get Equation \((3)\), holds with equality, and hence,
- The parameters \(\theta^{(t+1)}\) are then obtained by maximizing the right hand side of the equation above. Thus,
- This first inequality comes from the fact that,
- holds for any values of \(Q_{i}\) and \(\theta\), and in particular holds for \(Q_{i}=Q_{i}^{(t)}\) \(\theta=\theta^{(t+1)}\). To get Equation \((5)\), we used the fact that \(\theta^{(t+1)}\) is chosen explicitly to be,
- and thus this formula evaluated at \(\theta^{(t+1)}\) must be equal to or larger than the same formula evaluated at \(\theta^{(t)}\). Finally, the step used to get Equation \((6)\) was shown earlier, and follows from \(Q_{i}^{(t)}\) having been chosen to make Jensen’s inequality hold with equality at \(\theta^{(t)}\).
- Hence, EM causes the likelihood to converge monotonically. In our description of the EM algorithm, we said we’d run it until convergence. Given the result that we just showed, one reasonable convergence test would be to check if the increase in \(\ell(\theta)\) between successive iterations is smaller than some tolerance parameter, and to declare convergence if \(\mathrm{EM}\) is improving \(\ell(\theta)\) too slowly.
Remarks
- If we define,
- then we know \(\ell(\theta) \geq J(Q, \theta)\) from our previous derivation. The EM can also be viewed a coordinate ascent on \(J\), in which the E-step maximizes it with respect to \(Q\) (check this yourself), and the M-step maximizes it with respect to \(\theta\).
Mixture of Gaussians revisited
- Armed with our general definition of the EM algorithm, let’s go back to our old example of fitting the parameters \(\phi, \mu\) and \(\Sigma\) in a mixture of Gaussians. For the sake of brevity, we carry out the derivations for the M-step updates only for \(\phi\) and \(\mu_{j}\), and leave the updates for \(\Sigma_{j}\) as an exercise for the reader. The E-step is easy. Following our algorithm derivation above, we simply calculate,
- Here, \(“Q_{i}\left(z^{(i)}=j\right)”\) denotes the probability of \(z^{(i)}\) taking the value \(j\) under the distribution \(Q_{i}\).
- Next, in the M-step, we need to maximize, with respect to our parameters \(\phi, \mu, \Sigma\), the quantity,
- Let’s maximize this with respect to \(\mu_{l}\). If we take the derivative with respect to \(\mu_{l}\), we find,
- Setting this to zero and solving for \(\mu_{l}\) therefore yields the update rule,
- which was what we had in the previous set of notes. Let’s do one more example, and derive the M-step update for the parameters \(\phi_{j}\). Grouping together only the terms that depend on \(\phi_{j}\), we find that we need to maximize,
-
However, there is an additional constraint that the \(\phi_{j}\)’s sum to 1, since they represent the probabilities \(\phi_{j}=P\left(z^{(i)}=j ; \phi\right)\). To deal with the constraint that \(\sum_{j=1}^{k} \phi_{j}=1\), we construct the Lagrangian,
\[\mathcal{L}(\phi)=\sum_{i=1}^{m} \sum_{j=1}^{k} w_{j}^{(i)} \log \phi_{j}+\beta\left(\sum_{j=1}^{k} \phi_{j}-1\right)\]- where \(\beta\) is the Lagrange multiplier. We don’t need to worry about the constraint that \(\phi_{j} \geq 0\), because as we’ll shortly see, the solution we’ll find from this derivation will automatically satisfy that anyway.
-
Taking derivatives, we get,
- Setting this to zero and solving, we get,
- i.e., \(\phi_{j} \propto \sum_{i=1}^{m} w_{j}^{(i)}\). Using the constraint that \(\sum_{j} \phi_{j}=1\), we easily find that \(-\beta=\sum_{i=1}^{m} \sum_{j=1}^{k} w_{j}^{(i)}=\sum_{i=1}^{m} 1=m\). (This used the fact that \(w_{j}^{(i)}=\) \(Q_{i}\left(z^{(i)}=j\right)\), and since probabilities sum to \(1, \sum_{j} w_{j}^{(i)}=1\).) We therefore have our M-step updates for the parameters \(\phi_{j}\):
- The derivation for the M-step updates to \(\Sigma_{j}\) are also entirely straightforward.
Mixtures of Gaussians
- In this section, we discuss the EM (Expectation-Maximization) algorithm for density estimation, as applied to fitting a mixture of Gaussians.
- Suppose that we are given a training set \(\left\{x^{(1)}, \ldots, x^{(m)}\right\}\) as usual. Since we are in the unsupervised learning setting, these points do not come with any labels.
- We wish to model the data by specifying a joint distribution \(P\left(x^{(i)}, z^{(i)}\right)=\) \(P\left(x^{(i)} \mid z^{(i)}\right) P\left(z^{(i)}\right)\). Here, \(z^{(i)} \sim\) Multinomial \((\phi)\) (where \(\phi_{j} \geq 0, \sum_{j=1}^{k} \phi_{j}=1\). and the parameter \(\phi_{j}\) gives \(P\left(z^{(i)}=j\right)\), and \(x^{(i)} \mid z^{(i)}=j \sim \mathcal{N}\left(\mu_{j}, \Sigma_{j}\right)\). We let \(k\) denote the number of values that the \(z^{(i)}\)’s can take on. Thus, our model posits that each \(x^{(i)}\) was generated by randomly choosing \(z^{(i)}\) from \(\{1, \ldots, k\}\), and then \(x^{(i)}\) was drawn from one of \(k\) Gaussians depending on \(z^{(i)}\). This is called the mixture of Gaussians model. Also, note that the \(z^{(i)}\)’s are latent random variables, meaning that they’re hidden/unobserved. This is what will make our estimation problem difficult.
- The parameters of our model are thus \(\phi, \mu\) and \(\Sigma\). To estimate them, we can write down the likelihood of our data:
- However, if we set to zero the derivatives of this formula with respect to the parameters and try to solve, we’ll find that it is not possible to find the maximum likelihood estimates of the parameters in closed form. (Try this yourself at home.)
- The random variables \(z^{(i)}\) indicate which of the \(k\) Gaussians each \(x^{(i)}\) had come from. Note that if we knew what the \(z^{(i)}\)’s were, the maximum likelihood problem would have been easy. Specifically, we could then write down the likelihood as
- Maximizing this with respect to \(\phi, \mu\) and \(\Sigma\) gives the parameters:
- Indeed, we see that if the \(z^{(i)}\)’s were known, then maximum likelihood estimation becomes nearly identical to what we had when estimating the parameters of the Gaussian discriminant analysis model, except that here the \(z^{(i)}\)’s playing the role of the class labels.
- There are other minor differences in the formulas here from what we’d obtained in PS1 with Gaussian discriminant analysis, first because we’ve generalized the \(z^{(i)}\)’s to be multinomial rather than Bernoulli, and second because here we are using a different \(\Sigma_{j}\) for each Gaussian.
- However, in our density estimation problem, the \(z^{(i)}\)’s are not known. What can we do?
- The EM algorithm is an iterative algorithm that has two main steps. Applied to our problem, in the E-step, it tries to “guess” the values of the \(z^{(i)}\)’s. In the M-step, it updates the parameters of our model based on our guesses. since in the M-step we are pretending that the guesses in the first part were correct, the maximization becomes easy. Here’s the algorithm:
- Repeat until convergence:
- (E-step) For each \(i, j\), set,
- (M-step) Update the parameters:
- Repeat until convergence:
- In the E-step, we calculate the posterior probability of our parameters the \(z^{(i)}\)’s, given the \(x^{(i)}\) and using the current setting of our parameters, i.e.,, using Bayes rule, we obtain:
- Here, \(P\left(x^{(i)} \mid z^{(i)}=j ; \mu, \Sigma\right)\) is given by evaluating the density of a Gaussian with mean \(\mu_{j}\) and covariance \(\Sigma_{j}\) at \(x^{(i)} ; P\left(z^{(i)}=j ; \phi\right)\) is given by \(\phi_{j}\), and so on. The values \(w_{j}^{(i)}\) calculated in the E-step represent our “soft” guesses for the values of \(z^{(i)}\).
- The term “soft” refers to our guesses being probabilities and taking values in \([0,1]\); in contrast, a “hard” guess is one that represents a single best guess (such as taking values \(\operatorname{in}{0,1}\) or \({1, \ldots, k})\).
- Also, you should contrast the updates in the M-step with the formulas we had when the \(z^{(i)}\)’s were known exactly. They are identical, except that instead of the indicator functions \(“ 1\left\{z^{(i)}=j\right\} “\) indicating from which Gaussian each datapoint had come, we now instead have the \(w_{j}^{(i)}\)’s.
- The EM-algorithm is also reminiscent of the K-means clustering algorithm, except that instead of the “hard” cluster assignments \(c(i)\), we instead have the “soft” assignments \(w_{j}^{(i)}\). Similar to K-means, it is also susceptible to local optima, so reinitializing at several different initial parameters may be a good idea.
- It’s clear that the EM algorithm has a very natural interpretation of repeatedly trying to guess the unknown \(z^{(i)}\)’s; but how did it come about, and can we make any guarantees about it, such as regarding its convergence? In the next set of notes, we will describe a more general view of \(\mathrm{EM}\), one that will allow us to easily apply it to other estimation problems in which there are also latent variables, and which will allow us to give a convergence guarantee.
References
Citation
If you found our work useful, please cite it as:
@article{Chadha2020DistilledExpectationMaximizationAlgorithms,
title = {Expectation Maximization Algorithms},
author = {Chadha, Aman},
journal = {Distilled Notes for Stanford CS229: Machine Learning},
year = {2020},
note = {\url{https://aman.ai}}
}